[spark] branch master updated: [SPARK-38032][INFRA] Upgrade Arrow version < 7.0.0 for Python UDF tests in SQL and documentation generation
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 6e64e92 [SPARK-38032][INFRA] Upgrade Arrow version < 7.0.0 for Python
UDF tests in SQL and documentation generation
6e64e92 is described below
commit 6e64e9252a821651a8984babfac79a9ea433
Author: Hyukjin Kwon
AuthorDate: Wed Jan 26 15:55:12 2022 +0900
[SPARK-38032][INFRA] Upgrade Arrow version < 7.0.0 for Python UDF tests in
SQL and documentation generation
### What changes were proposed in this pull request?
This PR proposes to use Arrow < 7.0.0 (6.0.1 latest) for
[IntegratedUDFTestUtils](https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/IntegratedUDFTestUtils.scala),
e.g.,
https://github.com/apache/spark/tree/master/sql/core/src/test/resources/sql-tests/inputs/udf
for pandas UDFs.
Note that this PR does not change the PyArrow and pandas used for PySpark
test base because they are installed in the base image
(https://github.com/apache/spark/blob/master/.github/workflows/build_and_test.yml#L290),
and they are already using almost latest version (PyArrow 6.0.0, and pandas
1.3.3) so I think it's fine.
### Why are the changes needed?
It's better to test latest versions as they are likely more used by end
users.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Existing test cases should cover.
Closes #35331 from HyukjinKwon/arrow-version-sql-test.
Authored-by: Hyukjin Kwon
Signed-off-by: Hyukjin Kwon
---
.github/workflows/build_and_test.yml | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/.github/workflows/build_and_test.yml
b/.github/workflows/build_and_test.yml
index 32f46d3..4529cd9 100644
--- a/.github/workflows/build_and_test.yml
+++ b/.github/workflows/build_and_test.yml
@@ -252,7 +252,7 @@ jobs:
- name: Install Python packages (Python 3.8)
if: (contains(matrix.modules, 'sql') && !contains(matrix.modules,
'sql-'))
run: |
-python3.8 -m pip install 'numpy>=1.20.0' 'pyarrow<5.0.0' pandas scipy
xmlrunner
+python3.8 -m pip install 'numpy>=1.20.0' 'pyarrow<7.0.0' pandas scipy
xmlrunner
python3.8 -m pip list
# Run the tests.
- name: Run tests
@@ -530,7 +530,7 @@ jobs:
# Jinja2 3.0.0+ causes error when building with Sphinx.
# See also https://issues.apache.org/jira/browse/SPARK-35375.
python3.9 -m pip install 'sphinx<3.1.0' mkdocs pydata_sphinx_theme
ipython nbsphinx numpydoc 'jinja2<3.0.0'
-python3.9 -m pip install sphinx_plotly_directive 'numpy>=1.20.0'
'pyarrow<5.0.0' pandas 'plotly>=4.8'
+python3.9 -m pip install sphinx_plotly_directive 'numpy>=1.20.0'
'pyarrow<7.0.0' pandas 'plotly>=4.8'
apt-get update -y
apt-get install -y ruby ruby-dev
Rscript -e "install.packages(c('devtools', 'testthat', 'knitr',
'rmarkdown', 'roxygen2'), repos='https://cloud.r-project.org/')"
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (e4b1984 -> a765a4dc)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from e4b1984 [SPARK-37929][SQL][FOLLOWUP] Support cascade mode for JDBC V2 add a765a4dc [SPARK-38031][PYTHON][DOCS] Update document type conversion for Pandas UDFs (pyarrow 6.0.1, pandas 1.4.0, Python 3.9) No new revisions were added by this update. Summary of changes: python/pyspark/sql/pandas/functions.py | 6 +++--- 1 file changed, 3 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r52282 - in /dev/spark: v3.1.2-rc1-docs/ v3.2.0-rc1-bin/ v3.2.0-rc1-docs/ v3.2.0-rc2-bin/ v3.2.0-rc2-docs/ v3.2.0-rc3-bin/ v3.2.0-rc3-docs/ v3.2.0-rc4-bin/ v3.2.0-rc4-docs/ v3.2.0-rc5-bin/
Author: gurwls223 Date: Wed Jan 26 06:31:48 2022 New Revision: 52282 Log: Removing RC artifacts. Removed: dev/spark/v3.1.2-rc1-docs/ dev/spark/v3.2.0-rc1-bin/ dev/spark/v3.2.0-rc1-docs/ dev/spark/v3.2.0-rc2-bin/ dev/spark/v3.2.0-rc2-docs/ dev/spark/v3.2.0-rc3-bin/ dev/spark/v3.2.0-rc3-docs/ dev/spark/v3.2.0-rc4-bin/ dev/spark/v3.2.0-rc4-docs/ dev/spark/v3.2.0-rc5-bin/ dev/spark/v3.2.0-rc5-docs/ dev/spark/v3.2.0-rc6-bin/ dev/spark/v3.2.0-rc6-docs/ dev/spark/v3.2.1-rc1-bin/ dev/spark/v3.2.1-rc1-docs/ - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r52281 - /release/spark/spark-3.2.0/
Author: gurwls223 Date: Wed Jan 26 06:24:26 2022 New Revision: 52281 Log: Keep the latest 3.2.1 Removed: release/spark/spark-3.2.0/ - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] dongjoon-hyun commented on pull request #374: Add Test coverage section at developer-tools page
dongjoon-hyun commented on pull request #374: URL: https://github.com/apache/spark-website/pull/374#issuecomment-1021894942 Hi, All. I addressed the review comments and attached the generate HTML image into the PR description. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r52280 - /release/spark/KEYS
Author: gurwls223 Date: Wed Jan 26 06:02:24 2022 New Revision: 52280 Log: Update KEYS Modified: release/spark/KEYS Modified: release/spark/KEYS == --- release/spark/KEYS (original) +++ release/spark/KEYS Wed Jan 26 06:02:24 2022 @@ -1679,3 +1679,60 @@ atzKlpZxTel4xO9ZPRdngxTrtAxbcOY4C9R017/q KSJjUZyL1f+EufpF7lRzqRVVRzc= =kgaF -END PGP PUBLIC KEY BLOCK- + +pub rsa4096 2021-12-07 [SC] + CEA888BDB32D983C7F094564AC01E6E9139F610C +uid [ultimate] Huaxin Gao (CODE SIGNING KEY) +sub rsa4096 2021-12-07 [E] +-BEGIN PGP PUBLIC KEY BLOCK- + +mQINBGGutG0BEADV+VY+DciBLfD1iZDrDKs/hND4K4q9rE7qHgXoWdzF2JlvbSmn +EM26aTySuvsH8Y02a/g/GwAmHVyjSOHd69/kdvtzUS04W3yBToZbS9ZZ1M4NXVe5 +Apl5WlfF5CSW28CcbB8X67YDAkjc3qAviSWhGYn+V19wUx5gBE3QhmhPgGvnTpzw +je7TmtU6HMbfI+Nt2gNyQ5YWMFqIgKBH70F+cvy5Cs4mEJ8llLRqt600vOPLITCd +Wi9SpyEcftxWyTopfxuMDiuyw7quKsx5pfnOMbaGqN9YpCmK1/KuYkIXOS0i84Nr +1iNCZJjRxt/inPRH9kZZtRzTpr5MEmYooE5sfwZUGSo+EI+4eQV950p8x9eUsrx1 +X7BiEyDjTnBJU1qSr0f+CvTgjhcCBGMH2eV+r2/Vl/u+WzRfXOiBdh5EUQd5BW9+ +3zB8YwHp7cFFNhD/oF1IPWPhEiqEs+KsNYbKcqkjipakAyu/SQppTXCLgLFf2fGT +fa57S/uablQfsIL0Em3pl+mkpidxZ0st/ZhBtFBjVQ8vCnrYIKuswUd6XMI85kEt +YdaUYqaT+riLXX96SdTLiq4IGJypo1ERgF7epYWTH7XCIO1IZ8K/HoK2+wiOc3jA ++6ydOHAxruncBl8glM+Ffi6c/g0cULYBxJV010rm7L5NyUl9iktkXtl6EwARAQAB +tDZIdWF4aW4gR2FvIChDT0RFIFNJR05JTkcgS0VZKSA8aHVheGluLmdhbzExQGdt +YWlsLmNvbT6JAlIEEwEIADwWIQTOqIi9sy2YPH8JRWSsAebpE59hDAUCYa60bQIb +AwULCQgHAgMiAgEGFQoJCAsCBBYCAwECHgcCF4AACgkQrAHm6ROfYQwMPxAApjub +YoZK9/2Y7XlbWwIRDkcXA2ktMGlka/gISBfOw0aXkjeRTwuq7fG6YwK4BRlsuZVF +ALtGRvNiz+UMsPemR/NRaCQY+z4onIvwMbotQ+4ow6vmxZMPhyeCkhL50NPWX2M7 +XkZWRm1r4P9+jJaQiqL6XKcfUb8W9bK6xQ9+SABEh7Nwp8vf8+A9Ab8jXMjYqhmj +yAITsBW7y8xCdJ26xhWNIQbTwnoKsT6X5pDD/mQpXvTnqRXK1//IO0c5jHtswKgx +qEe3nMM4GFFaCLghI5DBoXKJPTgIdb+XEyaBJzuw3tI+ZClxi7P82GOE85m/xiwh +KO3VDpInp81cnHB1aDNh4QLd2F89KYsNUbWlnA6lgLJA+T4Ljg8A4ps5jf0VSP1Y +KJ/G4C999WD03EZzi1XbIdN2JujsdLpvJzxkyL0civaKbYD/Rn/cWuvQ9JMR3hna +0qE2w5NSsxRTvCt2svo/8KSr09fUZvqakkUhJWd5q/TJd6ysgXZ1qIeLqy4zkilp +sopHYFPfsuccVze7wblCIkZPT6bXK9cLBKddiaSCX8iIP57xDrktutrtTGmKmkf/ +9BPHYVK3sM4yiWFkmBn8gyFT52wTY1Hoq8k4SIsA1uG14EK8OYZsGudOAP3sGjZr +5K+1EWxFk2E976IryZ/jqI5wArbYyeJL+w9nIUa5Ag0EYa60bQEQAKvEMF4C/MR8 +X5YPkWFVaiQJL7WW4Rxc9dMV1wzUm7xexWvSnkglN1QtVJ9MFUoBUJsCBtcS5GaJ +u4Vv9W/gA9nkk3EG5h8AMIa9XrPQvv1VudLx8I4VAI33XW83bDCxh0jo4Fq9TZt1 +Wa/jcbIPxIiV1Z18VXaaMgS/N/SL+zO2IuMsj1mctlZ2AvR6e2j3M30l4ZfbJ8fO +PvyG9FiPiVCikmoI92eOFl06AfEQTrCbwsB1/i5ugKZleHalS46tynkCgzUtxJCk +z6q1xgJtbF164lL8TCPHzTr3bfEZCAw0LgJuRTHK/qloPGVcCheYnaijeMExtYY2 +Q/VM36q5adDegEZOhGIzcJ9mbTDpl8euvRuvAAn5bQOqO/v0aKE00sNlfIGiU6wu +B0K3QtxHgO48lhZ4agU489fyPGNBrHR+/goKPSNthMa+Pp0/B3FGdG5US9BiIe1O +cLTllvofeEwjrlqetZna0687peImiu3FWBG5JUzXTFjfEckXqsxsMcQe8715y8tz +unW8fEmHkGxK9vRljFTy15ug2cgAIdl8WF9h6zReKyVmvQPaROhN6+H0CIanDnzB +xt3hhfIhY7LP0E1baCrVxPWslugcEVTO93mmzRFEgV599BojbO7XUr7nziMNPYJL +/WwGnQHQ9wMTIE4iBK5mtbvTKTxzq0kvABEBAAGJAjYEGAEIACAWIQTOqIi9sy2Y +PH8JRWSsAebpE59hDAUCYa60bQIbDAAKCRCsAebpE59hDINOD/9muHui2A2BgiO0 +PE4cpzLw0AvHvilFF1Cnd6pwy9SyXKUXCHBAKbo3Z0PRBXw24BgwUiAsbFakPc60 +cD8IgcGKyvDeFNat1cYtIzw+ZFFtLdedzlUbaAnMCB+c7CncKhjNfPxJl7AgNn6r +bG7kQ0n1By7VMEcN7x9jpg5b5IzWi7nOWbPL1XTTg5f8JknB63eWFqvjivdCL08m +uTIR76frsvnlkhdxgnBvdAw/iPc43/EAM1IPvsm45Bpa7kZShU+HslLT5BXg2f3x +/BGCwX2DI4Aoww452iwqYlKbZES8bVROk1BFmaRSzqjz8qN3PRbd1rNJK1IgzmlZ +LFLHhOnCwTO79/cNn3u47he6h1PPvBZsacWGlCHJlXYi51z8Wdq8k31LaczNpk1u +MBR4ngBnW7QqXVE4LlSqISBczpTaYuTTvx93d5SjBLi8woWTZHH4GAyRTuFXK3lu +DR+P2FH3Gqvb1dRbmh5R4w1WuuepzU46rANYthRDaiaGTn5npkplEzMr3fscACDU +q52TUoULJ0ztpnejklwULzpyD8QzR/TKKjdjpKepX5ykIcRuhsriJ3CiVTnXBfLA +QzSNDZqk1/XFpio3lgqBgt6UuZyJfb24mnMUvghiYBxPhf2AT2XR9YVYlQJmZ3YN +NStvKoQzc2ERXMW50A6DhyYI1UGQVw== +=rMlG +-END PGP PUBLIC KEY BLOCK- - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r52279 - /dev/spark/v3.2.1-rc2-bin/ /release/spark/spark-3.2.1/
Author: gurwls223 Date: Wed Jan 26 06:01:34 2022 New Revision: 52279 Log: Apache Spark 3.2.1 Added: release/spark/spark-3.2.1/ - copied from r52278, dev/spark/v3.2.1-rc2-bin/ Removed: dev/spark/v3.2.1-rc2-bin/ - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r52278 - /dev/spark/v3.2.1-rc2-docs/
Author: huaxingao Date: Wed Jan 26 05:52:38 2022 New Revision: 52278 Log: Remove RC artifacts Removed: dev/spark/v3.2.1-rc2-docs/ - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (a4e2bf9 -> e4b1984)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from a4e2bf9 [SPARK-37636][SQL][FOLLOW-UP] Move handling Hive exceptions for create/drop database to HiveClientImpl add e4b1984 [SPARK-37929][SQL][FOLLOWUP] Support cascade mode for JDBC V2 No new revisions were added by this update. Summary of changes: .../spark/sql/jdbc/v2/V2JDBCNamespaceTest.scala| 34 +- .../sql/execution/datasources/jdbc/JdbcUtils.scala | 10 +-- .../datasources/v2/jdbc/JDBCTableCatalog.scala | 5 +--- .../apache/spark/sql/jdbc/PostgresDialect.scala| 3 +- 4 files changed, 44 insertions(+), 8 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (543e008 -> a4e2bf9)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 543e008 [SPARK-37896][SQL][FOLLOWUP] Fix NPE in ConstantColumnVector.close() add a4e2bf9 [SPARK-37636][SQL][FOLLOW-UP] Move handling Hive exceptions for create/drop database to HiveClientImpl No new revisions were added by this update. Summary of changes: .../spark/sql/hive/HiveExternalCatalog.scala | 47 -- .../spark/sql/hive/client/HiveClientImpl.scala | 16 ++-- .../spark/sql/hive/client/VersionsSuite.scala | 18 + 3 files changed, 30 insertions(+), 51 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (660d2ab -> 543e008)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 660d2ab [SPARK-38003][SQL] LookupFunctions rule should only look up functions from the scalar function registry add 543e008 [SPARK-37896][SQL][FOLLOWUP] Fix NPE in ConstantColumnVector.close() No new revisions were added by this update. Summary of changes: .../sql/execution/vectorized/ConstantColumnVector.java | 13 + .../execution/vectorized/ConstantColumnVectorSuite.scala| 4 +++- 2 files changed, 12 insertions(+), 5 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] tag v3.2.1 created (now 4f25b3f)
This is an automated email from the ASF dual-hosted git repository. huaxingao pushed a change to tag v3.2.1 in repository https://gitbox.apache.org/repos/asf/spark.git. at 4f25b3f (commit) No new revisions were added by this update. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (7e5c3b2 -> 660d2ab)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7e5c3b2 [SPARK-30062][SQL] Add the IMMEDIATE statement to the DB2 dialect truncate implementation add 660d2ab [SPARK-38003][SQL] LookupFunctions rule should only look up functions from the scalar function registry No new revisions were added by this update. Summary of changes: .../spark/sql/catalyst/analysis/Analyzer.scala | 11 ++- .../sql/catalyst/catalog/SessionCatalog.scala | 22 +++--- .../results/postgreSQL/window_part3.sql.out| 2 +- 3 files changed, 26 insertions(+), 9 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-30062][SQL] Add the IMMEDIATE statement to the DB2 dialect truncate implementation
This is an automated email from the ASF dual-hosted git repository.
huaxingao pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new cd7a3c2 [SPARK-30062][SQL] Add the IMMEDIATE statement to the DB2
dialect truncate implementation
cd7a3c2 is described below
commit cd7a3c2e667600c722c86b3914d487394f711916
Author: Ivan Karol
AuthorDate: Tue Jan 25 19:14:24 2022 -0800
[SPARK-30062][SQL] Add the IMMEDIATE statement to the DB2 dialect truncate
implementation
### What changes were proposed in this pull request?
I've added a DB2 specific truncate implementation that adds an IMMEDIATE
statement at the end of the query.
### Why are the changes needed?
I've encountered this issue myself while working with DB2 and trying to use
truncate functionality.
A quick google search shows that some people have also encountered this
issue before:
https://stackoverflow.com/questions/70027567/overwrite-mode-does-not-work-in-spark-sql-while-adding-data-in-db2
https://issues.apache.org/jira/browse/SPARK-30062
By looking into DB2 docs it becomes apparent that the IMMEDIATE statement
is only optional if the table is column organized(though I'm not sure if it
applies to all DB2 versions). So for the cases(such as mine) where the table is
not column organized adding an IMMEDIATE statement becomes essential for the
query to work.
https://www.ibm.com/support/knowledgecenter/en/SSEPGG_11.5.0/com.ibm.db2.luw.sql.ref.doc/doc/r0053474.html
Also, that might not be the best example, but I've found that DbVisualizer
does add an IMMEDIATE statement at the end of the truncate command. Though,
does it only for versions that are >=9.7
https://fossies.org/linux/dbvis/resources/profiles/db2.xml (please look at
line number 473)
### Does this PR introduce _any_ user-facing change?
It should not, as even though the docs mention that if the TRUNCATE
statement is executed in conjunction with IMMEDIATE, it has to be the first
statement in the transaction, the JDBC connection that is established to
execute the TRUNCATE statement has the auto-commit mode turned on. This means
that there won't be any other query/statement executed prior within the same
transaction.
https://www.ibm.com/docs/en/db2/11.5?topic=statements-truncate (see the
description for IMMEDIATE)
https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JdbcRelationProvider.scala#L49
https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JdbcRelationProvider.scala#L57
https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JdbcUtils.scala#L108
### How was this patch tested?
Existing test case with slightly adjusted logic.
Closes #35283 from ikarol/SPARK-30062.
Authored-by: Ivan Karol
Signed-off-by: huaxingao
(cherry picked from commit 7e5c3b216431b6a5e9a0786bf7cded694228cdee)
Signed-off-by: huaxingao
---
.../apache/spark/sql/jdbc/DB2IntegrationSuite.scala | 21 -
.../org/apache/spark/sql/jdbc/DB2Dialect.scala | 9 +
.../scala/org/apache/spark/sql/jdbc/JDBCSuite.scala | 8 ++--
3 files changed, 35 insertions(+), 3 deletions(-)
diff --git
a/external/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/DB2IntegrationSuite.scala
b/external/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/DB2IntegrationSuite.scala
index 77d7254..fd4f2aa 100644
---
a/external/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/DB2IntegrationSuite.scala
+++
b/external/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/DB2IntegrationSuite.scala
@@ -23,7 +23,7 @@ import java.util.Properties
import org.scalatest.time.SpanSugar._
-import org.apache.spark.sql.Row
+import org.apache.spark.sql.{Row, SaveMode}
import org.apache.spark.sql.catalyst.util.DateTimeTestUtils._
import org.apache.spark.sql.types.{BooleanType, ByteType, ShortType,
StructType}
import org.apache.spark.tags.DockerTest
@@ -198,4 +198,23 @@ class DB2IntegrationSuite extends
DockerJDBCIntegrationSuite {
""".stripMargin.replaceAll("\n", " "))
assert(sql("select x, y from queryOption").collect.toSet == expectedResult)
}
+
+ test("SPARK-30062") {
+val expectedResult = Set(
+ (42, "fred"),
+ (17, "dave")
+).map { case (x, y) =>
+ Row(Integer.valueOf(x), String.valueOf(y))
+}
+val df = sqlContext.read.jdbc(jdbcUrl, "tbl", new Properties)
+for (_ <- 0 to 2) {
+ df.write.mode(SaveMode.Append).jdbc(jdbcUrl, "tblcopy", new Properties)
+}
+assert(sqlContext.read.jdbc(jdbcUrl, "tblcopy", new Properties).count ===
6)
+
[spark] branch master updated (94df0d5 -> 7e5c3b2)
This is an automated email from the ASF dual-hosted git repository. huaxingao pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 94df0d5 [SPARK-38028][SQL] Expose Arrow Vector from ArrowColumnVector add 7e5c3b2 [SPARK-30062][SQL] Add the IMMEDIATE statement to the DB2 dialect truncate implementation No new revisions were added by this update. Summary of changes: .../apache/spark/sql/jdbc/DB2IntegrationSuite.scala | 21 - .../org/apache/spark/sql/jdbc/DB2Dialect.scala | 9 + .../scala/org/apache/spark/sql/jdbc/JDBCSuite.scala | 8 ++-- 3 files changed, 35 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (69c213d -> 94df0d5)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 69c213d [SPARK-38029][K8S][TESTS] Support K8S integration test in SBT add 94df0d5 [SPARK-38028][SQL] Expose Arrow Vector from ArrowColumnVector No new revisions were added by this update. Summary of changes: .../main/java/org/apache/spark/sql/vectorized/ArrowColumnVector.java| 2 ++ 1 file changed, 2 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (cff6921 -> 69c213d)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from cff6921 [SPARK-38015][CORE] Mark legacy file naming functions as deprecated in FileCommitProtocol add 69c213d [SPARK-38029][K8S][TESTS] Support K8S integration test in SBT No new revisions were added by this update. Summary of changes: project/SparkBuild.scala | 10 ++ 1 file changed, 6 insertions(+), 4 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (a722c6d -> cff6921)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from a722c6d [MINOR][ML][TESTS] Increase timeout for mllib streaming test add cff6921 [SPARK-38015][CORE] Mark legacy file naming functions as deprecated in FileCommitProtocol No new revisions were added by this update. Summary of changes: .../main/scala/org/apache/spark/internal/io/FileCommitProtocol.scala| 2 ++ 1 file changed, 2 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (9887d0f -> a722c6d)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 9887d0f [SPARK-38023][CORE] `ExecutorMonitor.onExecutorRemoved` should handle `ExecutorDecommission` as finished add a722c6d [MINOR][ML][TESTS] Increase timeout for mllib streaming test No new revisions were added by this update. Summary of changes: .../scala/org/apache/spark/mllib/clustering/StreamingKMeansSuite.scala | 2 +- .../apache/spark/mllib/regression/StreamingLinearRegressionSuite.scala | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] dongjoon-hyun commented on a change in pull request #374: Add Test coverage section at developer-tools page
dongjoon-hyun commented on a change in pull request #374: URL: https://github.com/apache/spark-website/pull/374#discussion_r792205923 ## File path: developer-tools.md ## @@ -7,6 +7,30 @@ navigation: show: true --- +Test coverage + +Apache Spark community uses various resources to maintain the community test coverage. + +[GitHub Action](https://github.com/apache/spark/actions) + +GitHub Action provides the following on Ubuntu 20.04. +- Scala 2.12/2.13 SBT build with Java 8 +- Scala 2.12 Maven build with Java 11/17 +- TPCDS ScaleFactor=1 Benchmark +- JDBC docker tests +- Java/Scala/Python/R unit tests with Java 8 + +[AppVeyor](https://ci.appveyor.com/project/ApacheSoftwareFoundation/spark) + +AppVeyor provides the following on Windows. +- Java/Scala/R unit tests with Java 8/Scala 2.12/SBT + +[Scaleway](https://www.scaleway.com) Review comment: Oops. Thank you! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: Revert "[SPARK-38022][K8S][TESTS] Use relativePath for K8s remote file test in `BasicTestsSuite`"
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 87ab955 Revert "[SPARK-38022][K8S][TESTS] Use relativePath for K8s
remote file test in `BasicTestsSuite`"
87ab955 is described below
commit 87ab9550b1933a425590126c34072bb74364bf18
Author: Dongjoon Hyun
AuthorDate: Tue Jan 25 15:07:03 2022 -0800
Revert "[SPARK-38022][K8S][TESTS] Use relativePath for K8s remote file test
in `BasicTestsSuite`"
This reverts commit 727dbe35f468e6e5cf0ba6abbd83676a19046a60.
---
.../org/apache/spark/deploy/k8s/integrationtest/BasicTestsSuite.scala | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git
a/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/BasicTestsSuite.scala
b/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/BasicTestsSuite.scala
index 8c753ea..1c12123 100644
---
a/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/BasicTestsSuite.scala
+++
b/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/BasicTestsSuite.scala
@@ -102,8 +102,8 @@ private[spark] trait BasicTestsSuite { k8sSuite:
KubernetesSuite =>
test("Run SparkRemoteFileTest using a remote data file", k8sTestTag) {
assert(sys.props.contains("spark.test.home"), "spark.test.home is not
set!")
TestUtils.withHttpServer(sys.props("spark.test.home")) { baseURL =>
- sparkAppConf.set("spark.files", baseURL.toString +
- REMOTE_PAGE_RANK_DATA_FILE.replace(sys.props("spark.test.home"),
"").substring(1))
+ sparkAppConf
+.set("spark.files", baseURL.toString + REMOTE_PAGE_RANK_DATA_FILE)
runSparkRemoteCheckAndVerifyCompletion(appArgs =
Array(REMOTE_PAGE_RANK_FILE_NAME))
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] viirya commented on a change in pull request #374: Add Test coverage section at developer-tools page
viirya commented on a change in pull request #374: URL: https://github.com/apache/spark-website/pull/374#discussion_r792191729 ## File path: developer-tools.md ## @@ -7,6 +7,30 @@ navigation: show: true --- +Test coverage + +Apache Spark community uses various resources to maintain the community test coverage. + +[GitHub Action](https://github.com/apache/spark/actions) + +GitHub Action provides the following on Ubuntu 20.04. +- Scala 2.12/2.13 SBT build with Java 8 +- Scala 2.12 Maven build with Java 11/17 +- TPCDS ScaleFactor=1 Benchmark +- JDBC docker tests +- Java/Scala/Python/R unit tests with Java 8 + +[AppVeyor](https://ci.appveyor.com/project/ApacheSoftwareFoundation/spark) + +AppVeyor provides the following on Windows. +- Java/Scala/R unit tests with Java 8/Scala 2.12/SBT + +[Scaleway](https://www.scaleway.com) Review comment: The html `id` is correct? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-38023][CORE] `ExecutorMonitor.onExecutorRemoved` should handle `ExecutorDecommission` as finished
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 1d8b556 [SPARK-38023][CORE] `ExecutorMonitor.onExecutorRemoved`
should handle `ExecutorDecommission` as finished
1d8b556 is described below
commit 1d8b556bd600baaed23fe700b60bddb2bf7cfc5f
Author: Dongjoon Hyun
AuthorDate: Tue Jan 25 14:34:56 2022 -0800
[SPARK-38023][CORE] `ExecutorMonitor.onExecutorRemoved` should handle
`ExecutorDecommission` as finished
Although SPARK-36614 (https://github.com/apache/spark/pull/33868) fixed the
UI issue, it made a regression where the `K8s integration test` has been broken
and shows a wrong metrics and message to the users. After `Finished
decommissioning`, it's still counted it as `unfinished`. This PR aims to fix
this bug.
**BEFORE**
```
22/01/25 13:05:16 DEBUG
KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint:
Asked to remove executor 1 with reason Finished decommissioning
...
22/01/25 13:05:16 INFO ExecutorMonitor: Executor 1 is removed.
Remove reason statistics: (gracefully decommissioned: 0, decommision
unfinished: 1, driver killed: 0, unexpectedly exited: 0).
```
**AFTER**
```
Remove reason statistics: (gracefully decommissioned: 1, decommision
unfinished: 0, driver killed: 0, unexpectedly exited: 0).
```
```
$ build/sbt -Pkubernetes -Pkubernetes-integration-tests
-Dspark.kubernetes.test.dockerFile=resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile.java17
-Dtest.exclude.tags=minikube,r "kubernetes-integration-tests/test"
```
**BEFORE**
The corresponding test case hangs and fails.
```
[info] KubernetesSuite:
...
[info] *** Test still running after 2 minutes, 13 seconds: suite name:
KubernetesSuite, test name: Test decommissioning with dynamic allocation &
shuffle cleanups.
// Eventually fails
...
```
**AFTER**
```
[info] KubernetesSuite:
...
[info] - Test decommissioning with dynamic allocation & shuffle cleanups (2
minutes, 41 seconds)
...
```
Yes, this is a regression bug fix.
Manually because this should be verified via the K8s integration test
```
$ build/sbt -Pkubernetes -Pkubernetes-integration-tests
-Dspark.kubernetes.test.dockerFile=resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile.java17
-Dtest.exclude.tags=minikube,r "kubernetes-integration-tests/test"
```
Closes #35321 from dongjoon-hyun/SPARK-38023.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
(cherry picked from commit 9887d0f7f55157da1b9f55d7053cc6c78ea3cdc5)
Signed-off-by: Dongjoon Hyun
---
.../scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala| 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git
a/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
b/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
index acdfaa5..8ce24aa 100644
---
a/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
+++
b/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
@@ -355,7 +355,8 @@ private[spark] class ExecutorMonitor(
if (removed != null) {
decrementExecResourceProfileCount(removed.resourceProfileId)
if (removed.decommissioning) {
-if (event.reason == ExecutorLossMessage.decommissionFinished) {
+if (event.reason == ExecutorLossMessage.decommissionFinished ||
+event.reason == ExecutorDecommission().message) {
metrics.gracefullyDecommissioned.inc()
} else {
metrics.decommissionUnfinished.inc()
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] dongjoon-hyun commented on pull request #374: Add Test coverage section at developer-tools page
dongjoon-hyun commented on pull request #374: URL: https://github.com/apache/spark-website/pull/374#issuecomment-1021675746 Thank you, @srowen . Sure! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38023][CORE] `ExecutorMonitor.onExecutorRemoved` should handle `ExecutorDecommission` as finished
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 9887d0f [SPARK-38023][CORE] `ExecutorMonitor.onExecutorRemoved`
should handle `ExecutorDecommission` as finished
9887d0f is described below
commit 9887d0f7f55157da1b9f55d7053cc6c78ea3cdc5
Author: Dongjoon Hyun
AuthorDate: Tue Jan 25 14:34:56 2022 -0800
[SPARK-38023][CORE] `ExecutorMonitor.onExecutorRemoved` should handle
`ExecutorDecommission` as finished
### What changes were proposed in this pull request?
Although SPARK-36614 (https://github.com/apache/spark/pull/33868) fixed the
UI issue, it made a regression where the `K8s integration test` has been broken
and shows a wrong metrics and message to the users. After `Finished
decommissioning`, it's still counted it as `unfinished`. This PR aims to fix
this bug.
**BEFORE**
```
22/01/25 13:05:16 DEBUG
KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint:
Asked to remove executor 1 with reason Finished decommissioning
...
22/01/25 13:05:16 INFO ExecutorMonitor: Executor 1 is removed.
Remove reason statistics: (gracefully decommissioned: 0, decommision
unfinished: 1, driver killed: 0, unexpectedly exited: 0).
```
**AFTER**
```
Remove reason statistics: (gracefully decommissioned: 1, decommision
unfinished: 0, driver killed: 0, unexpectedly exited: 0).
```
### Why are the changes needed?
```
$ build/sbt -Pkubernetes -Pkubernetes-integration-tests
-Dspark.kubernetes.test.dockerFile=resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile.java17
-Dtest.exclude.tags=minikube,r "kubernetes-integration-tests/test"
```
**BEFORE**
The corresponding test case hangs and fails.
```
[info] KubernetesSuite:
...
[info] *** Test still running after 2 minutes, 13 seconds: suite name:
KubernetesSuite, test name: Test decommissioning with dynamic allocation &
shuffle cleanups.
// Eventually fails
...
```
**AFTER**
```
[info] KubernetesSuite:
...
[info] - Test decommissioning with dynamic allocation & shuffle cleanups (2
minutes, 41 seconds)
...
```
### Does this PR introduce _any_ user-facing change?
Yes, this is a regression bug fix.
### How was this patch tested?
Manually because this should be verified via the K8s integration test
```
$ build/sbt -Pkubernetes -Pkubernetes-integration-tests
-Dspark.kubernetes.test.dockerFile=resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile.java17
-Dtest.exclude.tags=minikube,r "kubernetes-integration-tests/test"
```
Closes #35321 from dongjoon-hyun/SPARK-38023.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
---
.../scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala| 3 ++-
.../apache/spark/deploy/k8s/integrationtest/DecommissionSuite.scala| 2 +-
2 files changed, 3 insertions(+), 2 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
b/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
index 3dea64c..def63b9 100644
---
a/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
+++
b/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
@@ -356,7 +356,8 @@ private[spark] class ExecutorMonitor(
if (removed != null) {
decrementExecResourceProfileCount(removed.resourceProfileId)
if (removed.decommissioning) {
-if (event.reason == ExecutorLossMessage.decommissionFinished) {
+if (event.reason == ExecutorLossMessage.decommissionFinished ||
+event.reason == ExecutorDecommission().message) {
metrics.gracefullyDecommissioned.inc()
} else {
metrics.decommissionUnfinished.inc()
diff --git
a/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/DecommissionSuite.scala
b/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/DecommissionSuite.scala
index 9605f6c..ca6108d 100644
---
a/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/DecommissionSuite.scala
+++
b/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/DecommissionSuite.scala
@@ -151,7 +151,7 @@ private[spark] trait DecommissionSuite { k8sSuite:
KubernetesSuite =>
val client = kubernetesTestComponents.kubernetesClient
// The label will be added eventually, but k8s objects don't refresh.
Eventually.eventually(
-PatienceConfiguration.Timeout(Sp
[GitHub] [spark-website] srowen commented on pull request #374: Add Test coverage section at developer-tools page
srowen commented on pull request #374: URL: https://github.com/apache/spark-website/pull/374#issuecomment-1021649598 Just generate the html when done, yes. Looks ok -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] dongjoon-hyun commented on pull request #374: Add Test coverage section at developer-tools page
dongjoon-hyun commented on pull request #374: URL: https://github.com/apache/spark-website/pull/374#issuecomment-1021646253 Hi, @HyukjinKwon . Could you add some about the additional Python coverage tools which we are currently using? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] dongjoon-hyun commented on pull request #374: Add Test Infra Section at developer-tools page
dongjoon-hyun commented on pull request #374: URL: https://github.com/apache/spark-website/pull/374#issuecomment-1021644450 This is a draft which I'm working on now in order to give a summary of our infra. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-38022][K8S][TESTS] Use relativePath for K8s remote file test in `BasicTestsSuite`
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 727dbe3 [SPARK-38022][K8S][TESTS] Use relativePath for K8s remote
file test in `BasicTestsSuite`
727dbe3 is described below
commit 727dbe35f468e6e5cf0ba6abbd83676a19046a60
Author: Dongjoon Hyun
AuthorDate: Tue Jan 25 09:29:57 2022 -0800
[SPARK-38022][K8S][TESTS] Use relativePath for K8s remote file test in
`BasicTestsSuite`
### What changes were proposed in this pull request?
This PR aims to use `relativePath` for K8s remote file test in
`BasicTestsSuite`.
### Why are the changes needed?
To make `Run SparkRemoteFileTest using a remote data file` test pass.
**BEFORE**
```
$ build/sbt -Pkubernetes -Pkubernetes-integration-tests
-Dspark.kubernetes.test.dockerFile=resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile.java17
-Dtest.exclude.tags=minikube,r "kubernetes-integration-tests/test"
...
[info] KubernetesSuite:
...
[info] - Run SparkRemoteFileTest using a remote data file *** FAILED *** (3
minutes, 3 seconds)
[info] The code passed to eventually never returned normally. Attempted
190 times over 3.01226506667 minutes. Last failure message: false was not
true. (KubernetesSuite.scala:452)
...
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
```
$ build/sbt -Pkubernetes -Pkubernetes-integration-tests
-Dspark.kubernetes.test.dockerFile=resource-managers/kubernetes/docker/src/main/dockerfiles/spark/Dockerfile.java17
-Dtest.exclude.tags=minikube,r "kubernetes-integration-tests/test"
...
[info] KubernetesSuite:
...
[info] - Run SparkRemoteFileTest using a remote data file (8 seconds, 608
milliseconds)
...
```
Closes #35318 from dongjoon-hyun/SPARK-38022.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
(cherry picked from commit 277322851f3c96f812c7da115f00f66bb6f11f6b)
Signed-off-by: Dongjoon Hyun
---
.../org/apache/spark/deploy/k8s/integrationtest/BasicTestsSuite.scala | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git
a/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/BasicTestsSuite.scala
b/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/BasicTestsSuite.scala
index 1c12123..8c753ea 100644
---
a/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/BasicTestsSuite.scala
+++
b/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/BasicTestsSuite.scala
@@ -102,8 +102,8 @@ private[spark] trait BasicTestsSuite { k8sSuite:
KubernetesSuite =>
test("Run SparkRemoteFileTest using a remote data file", k8sTestTag) {
assert(sys.props.contains("spark.test.home"), "spark.test.home is not
set!")
TestUtils.withHttpServer(sys.props("spark.test.home")) { baseURL =>
- sparkAppConf
-.set("spark.files", baseURL.toString + REMOTE_PAGE_RANK_DATA_FILE)
+ sparkAppConf.set("spark.files", baseURL.toString +
+ REMOTE_PAGE_RANK_DATA_FILE.replace(sys.props("spark.test.home"),
"").substring(1))
runSparkRemoteCheckAndVerifyCompletion(appArgs =
Array(REMOTE_PAGE_RANK_FILE_NAME))
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (a13f79a -> 2773228)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from a13f79a [SPARK-37479][SQL] Migrate DROP NAMESPACE to use V2 command by default add 2773228 [SPARK-38022][K8S][TESTS] Use relativePath for K8s remote file test in `BasicTestsSuite` No new revisions were added by this update. Summary of changes: .../org/apache/spark/deploy/k8s/integrationtest/BasicTestsSuite.scala | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37479][SQL] Migrate DROP NAMESPACE to use V2 command by default
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new a13f79a [SPARK-37479][SQL] Migrate DROP NAMESPACE to use V2 command
by default
a13f79a is described below
commit a13f79a49fb77dc3c876f551c2c712f2fc69675c
Author: dch nguyen
AuthorDate: Tue Jan 25 22:13:52 2022 +0800
[SPARK-37479][SQL] Migrate DROP NAMESPACE to use V2 command by default
### What changes were proposed in this pull request?
This PR migrates `DROP NAMESPACE` to use V2 command by default.
### Why are the changes needed?
It's been a while since we introduced the v2 commands, and it seems
reasonable to use v2 commands by default even for the session catalog, with a
legacy config to fall back to the v1 commands.
### Does this PR introduce _any_ user-facing change?
The error message will be different if drop database containing tables with
RESTRICT mode when v2 command is run against v1 catalog and Hive Catalog:
Before: `Cannot drop a non-empty database`
vs.
After: `Cannot drop a non-empty namespace`
### How was this patch tested?
Existing *DropNamespaceSuite tests
Closes #35202 from dchvn/migrate_dropnamespace_v2_command_default.
Authored-by: dch nguyen
Signed-off-by: Wenchen Fan
---
.../apache/spark/sql/catalyst/analysis/ResolveSessionCatalog.scala | 2 +-
.../apache/spark/sql/execution/command/v1/DropNamespaceSuite.scala | 7 +--
.../spark/sql/hive/execution/command/DropNamespaceSuite.scala | 1 +
3 files changed, 7 insertions(+), 3 deletions(-)
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveSessionCatalog.scala
b/sql/core/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveSessionCatalog.scala
index 3dde998..6df94f3 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveSessionCatalog.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveSessionCatalog.scala
@@ -221,7 +221,7 @@ class ResolveSessionCatalog(val catalogManager:
CatalogManager)
val newProperties = c.properties --
CatalogV2Util.NAMESPACE_RESERVED_PROPERTIES
CreateDatabaseCommand(name, c.ifNotExists, location, comment,
newProperties)
-case d @ DropNamespace(DatabaseInSessionCatalog(db), _, _) =>
+case d @ DropNamespace(DatabaseInSessionCatalog(db), _, _) if
conf.useV1Command =>
DropDatabaseCommand(db, d.ifExists, d.cascade)
case ShowTables(DatabaseInSessionCatalog(db), pattern, output) if
conf.useV1Command =>
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/DropNamespaceSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/DropNamespaceSuite.scala
index 24e5131..174ac97 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/DropNamespaceSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/DropNamespaceSuite.scala
@@ -28,7 +28,8 @@ import org.apache.spark.sql.execution.command
* - V1 In-Memory catalog:
`org.apache.spark.sql.execution.command.v1.DropNamespaceSuite`
* - V1 Hive External catalog:
`org.apache.spark.sql.hive.execution.command.DropNamespaceSuite`
*/
-trait DropNamespaceSuiteBase extends command.DropNamespaceSuiteBase {
+trait DropNamespaceSuiteBase extends command.DropNamespaceSuiteBase
+ with command.TestsV1AndV2Commands {
override protected def builtinTopNamespaces: Seq[String] = Seq("default")
override protected def namespaceAlias(): String = "database"
@@ -41,4 +42,6 @@ trait DropNamespaceSuiteBase extends
command.DropNamespaceSuiteBase {
}
}
-class DropNamespaceSuite extends DropNamespaceSuiteBase with CommandSuiteBase
+class DropNamespaceSuite extends DropNamespaceSuiteBase with CommandSuiteBase {
+ override def commandVersion: String =
super[DropNamespaceSuiteBase].commandVersion
+}
diff --git
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/command/DropNamespaceSuite.scala
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/command/DropNamespaceSuite.scala
index cabebb9..955fe33 100644
---
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/command/DropNamespaceSuite.scala
+++
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/command/DropNamespaceSuite.scala
@@ -25,4 +25,5 @@ import org.apache.spark.sql.execution.command.v1
*/
class DropNamespaceSuite extends v1.DropNamespaceSuiteBase with
CommandSuiteBase {
override def isCasePreserving: Boolean = false
+ override def commandVersion: String =
super[DropNamespaceSuiteBase].commandVersion
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h..
[spark] branch master updated: [SPARK-38021][BUILD] Upgrade dropwizard metrics from 4.2.2 to 4.2.7
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new a1b061d [SPARK-38021][BUILD] Upgrade dropwizard metrics from 4.2.2 to 4.2.7 a1b061d is described below commit a1b061d7fc5427138bfaa9fe68d2748f8bf3907c Author: yangjie01 AuthorDate: Tue Jan 25 20:57:16 2022 +0900 [SPARK-38021][BUILD] Upgrade dropwizard metrics from 4.2.2 to 4.2.7 ### What changes were proposed in this pull request? This pr upgrade dropwizard metrics from 4.2.2 to 4.2.7. ### Why are the changes needed? There are 5 versions after 4.2.2, the release notes as follows: - https://github.com/dropwizard/metrics/releases/tag/v4.2.3 - https://github.com/dropwizard/metrics/releases/tag/v4.2.4 - https://github.com/dropwizard/metrics/releases/tag/v4.2.5 - https://github.com/dropwizard/metrics/releases/tag/v4.2.6 - https://github.com/dropwizard/metrics/releases/tag/v4.2.7 And after 4.2.5, dropwizard metrics supports [build with JDK 17](https://github.com/dropwizard/metrics/pull/2180). ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GA Closes #35317 from LuciferYang/upgrade-metrics. Authored-by: yangjie01 Signed-off-by: Kousuke Saruta --- dev/deps/spark-deps-hadoop-2-hive-2.3 | 10 +- dev/deps/spark-deps-hadoop-3-hive-2.3 | 10 +- pom.xml | 2 +- 3 files changed, 11 insertions(+), 11 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-2-hive-2.3 b/dev/deps/spark-deps-hadoop-2-hive-2.3 index 5efdca9..8284237 100644 --- a/dev/deps/spark-deps-hadoop-2-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-2-hive-2.3 @@ -195,11 +195,11 @@ logging-interceptor/3.12.12//logging-interceptor-3.12.12.jar lz4-java/1.8.0//lz4-java-1.8.0.jar macro-compat_2.12/1.1.1//macro-compat_2.12-1.1.1.jar mesos/1.4.3/shaded-protobuf/mesos-1.4.3-shaded-protobuf.jar -metrics-core/4.2.2//metrics-core-4.2.2.jar -metrics-graphite/4.2.2//metrics-graphite-4.2.2.jar -metrics-jmx/4.2.2//metrics-jmx-4.2.2.jar -metrics-json/4.2.2//metrics-json-4.2.2.jar -metrics-jvm/4.2.2//metrics-jvm-4.2.2.jar +metrics-core/4.2.7//metrics-core-4.2.7.jar +metrics-graphite/4.2.7//metrics-graphite-4.2.7.jar +metrics-jmx/4.2.7//metrics-jmx-4.2.7.jar +metrics-json/4.2.7//metrics-json-4.2.7.jar +metrics-jvm/4.2.7//metrics-jvm-4.2.7.jar minlog/1.3.0//minlog-1.3.0.jar netty-all/4.1.73.Final//netty-all-4.1.73.Final.jar netty-buffer/4.1.73.Final//netty-buffer-4.1.73.Final.jar diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3 b/dev/deps/spark-deps-hadoop-3-hive-2.3 index a79a71b..f169277 100644 --- a/dev/deps/spark-deps-hadoop-3-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-3-hive-2.3 @@ -181,11 +181,11 @@ logging-interceptor/3.12.12//logging-interceptor-3.12.12.jar lz4-java/1.8.0//lz4-java-1.8.0.jar macro-compat_2.12/1.1.1//macro-compat_2.12-1.1.1.jar mesos/1.4.3/shaded-protobuf/mesos-1.4.3-shaded-protobuf.jar -metrics-core/4.2.2//metrics-core-4.2.2.jar -metrics-graphite/4.2.2//metrics-graphite-4.2.2.jar -metrics-jmx/4.2.2//metrics-jmx-4.2.2.jar -metrics-json/4.2.2//metrics-json-4.2.2.jar -metrics-jvm/4.2.2//metrics-jvm-4.2.2.jar +metrics-core/4.2.7//metrics-core-4.2.7.jar +metrics-graphite/4.2.7//metrics-graphite-4.2.7.jar +metrics-jmx/4.2.7//metrics-jmx-4.2.7.jar +metrics-json/4.2.7//metrics-json-4.2.7.jar +metrics-jvm/4.2.7//metrics-jvm-4.2.7.jar minlog/1.3.0//minlog-1.3.0.jar netty-all/4.1.73.Final//netty-all-4.1.73.Final.jar netty-buffer/4.1.73.Final//netty-buffer-4.1.73.Final.jar diff --git a/pom.xml b/pom.xml index 5bae4d2..09577f2 100644 --- a/pom.xml +++ b/pom.xml @@ -147,7 +147,7 @@ If you changes codahale.metrics.version, you also need to change the link to metrics.dropwizard.io in docs/monitoring.md. --> -4.2.2 +4.2.7 1.11.0 1.12.0 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-38017][SQL][DOCS] Fix the API doc for window to say it supports TimestampNTZType too as timeColumn
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 263fe44 [SPARK-38017][SQL][DOCS] Fix the API doc for window to say it
supports TimestampNTZType too as timeColumn
263fe44 is described below
commit 263fe44f8a9738fc8d7dcfbcc1c0c10c942146e3
Author: Kousuke Saruta
AuthorDate: Tue Jan 25 20:44:06 2022 +0900
[SPARK-38017][SQL][DOCS] Fix the API doc for window to say it supports
TimestampNTZType too as timeColumn
### What changes were proposed in this pull request?
This PR fixes the API docs for `window` to say it supports
`TimestampNTZType` too as `timeColumn`.
### Why are the changes needed?
`window` function supports not only `TimestampType` but also
`TimestampNTZType`.
### Does this PR introduce _any_ user-facing change?
Yes, but I don't think this change affects existing users.
### How was this patch tested?
Built the docs with the following commands.
```
bundle install
SKIP_RDOC=1 SKIP_SQLDOC=1 bundle exec jekyll build
```
Then, confirmed the built doc.

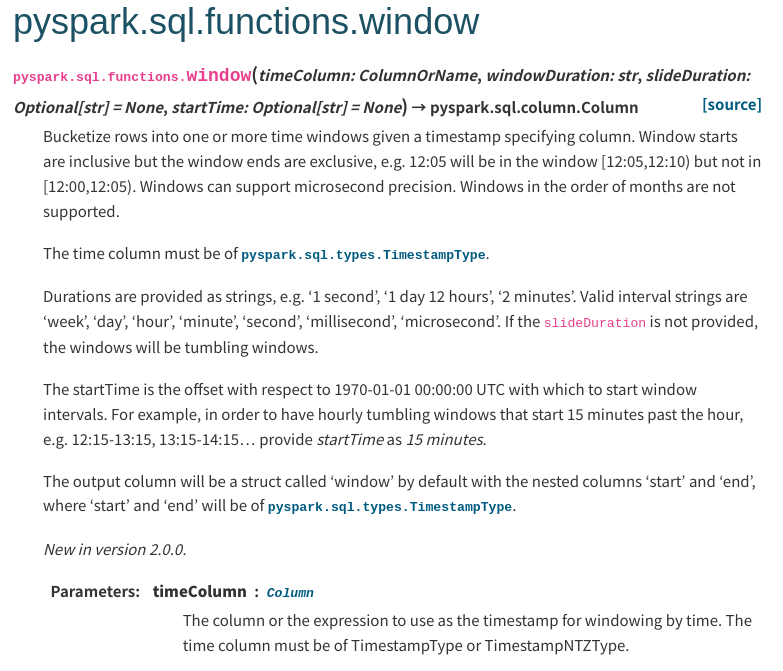
Closes #35313 from sarutak/window-timestampntz-doc.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit 76f685d26dc1f0f4d92293cd370e58ee2fa68452)
Signed-off-by: Kousuke Saruta
---
python/pyspark/sql/functions.py | 2 +-
sql/core/src/main/scala/org/apache/spark/sql/functions.scala | 6 +++---
2 files changed, 4 insertions(+), 4 deletions(-)
diff --git a/python/pyspark/sql/functions.py b/python/pyspark/sql/functions.py
index c7bc581..acde817 100644
--- a/python/pyspark/sql/functions.py
+++ b/python/pyspark/sql/functions.py
@@ -2304,7 +2304,7 @@ def window(timeColumn, windowDuration,
slideDuration=None, startTime=None):
--
timeColumn : :class:`~pyspark.sql.Column`
The column or the expression to use as the timestamp for windowing by
time.
-The time column must be of TimestampType.
+The time column must be of TimestampType or TimestampNTZType.
windowDuration : str
A string specifying the width of the window, e.g. `10 minutes`,
`1 second`. Check `org.apache.spark.unsafe.types.CalendarInterval` for
diff --git a/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
b/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
index a4c77b2..f4801ee 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
@@ -3517,7 +3517,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param windowDuration A string specifying the width of the window, e.g.
`10 minutes`,
* `1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
* valid duration identifiers. Note that the duration
is a fixed length of
@@ -3573,7 +3573,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param windowDuration A string specifying the width of the window, e.g.
`10 minutes`,
* `1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
* valid duration identifiers. Note that the duration
is a fixed length of
@@ -3618,7 +3618,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param windowDuration A string specifying the width of the window, e.g.
`10 minutes`,
* `1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
* valid duration identifiers.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: co
[spark] branch master updated: [SPARK-38017][SQL][DOCS] Fix the API doc for window to say it supports TimestampNTZType too as timeColumn
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 76f685d [SPARK-38017][SQL][DOCS] Fix the API doc for window to say it
supports TimestampNTZType too as timeColumn
76f685d is described below
commit 76f685d26dc1f0f4d92293cd370e58ee2fa68452
Author: Kousuke Saruta
AuthorDate: Tue Jan 25 20:44:06 2022 +0900
[SPARK-38017][SQL][DOCS] Fix the API doc for window to say it supports
TimestampNTZType too as timeColumn
### What changes were proposed in this pull request?
This PR fixes the API docs for `window` to say it supports
`TimestampNTZType` too as `timeColumn`.
### Why are the changes needed?
`window` function supports not only `TimestampType` but also
`TimestampNTZType`.
### Does this PR introduce _any_ user-facing change?
Yes, but I don't think this change affects existing users.
### How was this patch tested?
Built the docs with the following commands.
```
bundle install
SKIP_RDOC=1 SKIP_SQLDOC=1 bundle exec jekyll build
```
Then, confirmed the built doc.


Closes #35313 from sarutak/window-timestampntz-doc.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
python/pyspark/sql/functions.py | 2 +-
sql/core/src/main/scala/org/apache/spark/sql/functions.scala | 6 +++---
2 files changed, 4 insertions(+), 4 deletions(-)
diff --git a/python/pyspark/sql/functions.py b/python/pyspark/sql/functions.py
index bfee994..2dfaec8 100644
--- a/python/pyspark/sql/functions.py
+++ b/python/pyspark/sql/functions.py
@@ -2551,7 +2551,7 @@ def window(
--
timeColumn : :class:`~pyspark.sql.Column`
The column or the expression to use as the timestamp for windowing by
time.
-The time column must be of TimestampType.
+The time column must be of TimestampType or TimestampNTZType.
windowDuration : str
A string specifying the width of the window, e.g. `10 minutes`,
`1 second`. Check `org.apache.spark.unsafe.types.CalendarInterval` for
diff --git a/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
b/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
index f217dad..0db12a2 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
@@ -3621,7 +3621,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param windowDuration A string specifying the width of the window, e.g.
`10 minutes`,
* `1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
* valid duration identifiers. Note that the duration
is a fixed length of
@@ -3677,7 +3677,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param windowDuration A string specifying the width of the window, e.g.
`10 minutes`,
* `1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
* valid duration identifiers. Note that the duration
is a fixed length of
@@ -3722,7 +3722,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param windowDuration A string specifying the width of the window, e.g.
`10 minutes`,
* `1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
* valid duration identifiers.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38016][SQL][DOCS] Fix the API doc for session_window to say it supports TimestampNTZType too as timeColumn
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 48a440f [SPARK-38016][SQL][DOCS] Fix the API doc for session_window
to say it supports TimestampNTZType too as timeColumn
48a440f is described below
commit 48a440fe1fc334134f42a726cc6fb3d98802e0fd
Author: Kousuke Saruta
AuthorDate: Tue Jan 25 20:41:38 2022 +0900
[SPARK-38016][SQL][DOCS] Fix the API doc for session_window to say it
supports TimestampNTZType too as timeColumn
### What changes were proposed in this pull request?
This PR fixes the API docs for `session_window` to say it supports
`TimestampNTZType` too as `timeColumn`.
### Why are the changes needed?
As of Spark 3.3.0 (e858cd568a74123f7fd8fe4c3d2917a), `session_window`
supports not only `TimestampType` but also `TimestampNTZType`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Built the docs with the following commands.
```
bundle install
SKIP_RDOC=1 SKIP_SQLDOC=1 bundle exec jekyll build
```
Then, confirmed the built doc.


Closes #35312 from sarutak/sessionwindow-timestampntz-doc.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
python/pyspark/sql/functions.py | 2 +-
sql/core/src/main/scala/org/apache/spark/sql/functions.scala | 4 ++--
2 files changed, 3 insertions(+), 3 deletions(-)
diff --git a/python/pyspark/sql/functions.py b/python/pyspark/sql/functions.py
index e69c37d..bfee994 100644
--- a/python/pyspark/sql/functions.py
+++ b/python/pyspark/sql/functions.py
@@ -2623,7 +2623,7 @@ def session_window(timeColumn: "ColumnOrName",
gapDuration: Union[Column, str])
--
timeColumn : :class:`~pyspark.sql.Column` or str
The column name or column to use as the timestamp for windowing by
time.
-The time column must be of TimestampType.
+The time column must be of TimestampType or TimestampNTZType.
gapDuration : :class:`~pyspark.sql.Column` or str
A Python string literal or column specifying the timeout of the
session. It could be
static value, e.g. `10 minutes`, `1 second`, or an expression/UDF that
specifies gap
diff --git a/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
b/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
index ec28d8d..f217dad 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
@@ -3750,7 +3750,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param gapDuration A string specifying the timeout of the session, e.g.
`10 minutes`,
*`1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
*valid duration identifiers.
@@ -3787,7 +3787,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param gapDuration A column specifying the timeout of the session. It
could be static value,
*e.g. `10 minutes`, `1 second`, or an expression/UDF
that specifies gap
*duration dynamically based on the input row.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (e2c4913 -> 1bda48b)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from e2c4913 [SPARK-38019][CORE] Make `ExecutorMonitor.timedOutExecutors` deterministic add 1bda48b [SPARK-38018][SQL] Fix ColumnVectorUtils.populate to handle CalendarIntervalType correctly No new revisions were added by this update. Summary of changes: .../spark/sql/execution/vectorized/ColumnVectorUtils.java | 3 ++- .../spark/sql/execution/vectorized/ColumnVectorSuite.scala| 11 ++- 2 files changed, 12 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-38019][CORE] Make `ExecutorMonitor.timedOutExecutors` deterministic
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 0bc4a37 [SPARK-38019][CORE] Make `ExecutorMonitor.timedOutExecutors`
deterministic
0bc4a37 is described below
commit 0bc4a370e144008d3c687e687714cb31873792e6
Author: Dongjoon Hyun
AuthorDate: Tue Jan 25 03:00:34 2022 -0800
[SPARK-38019][CORE] Make `ExecutorMonitor.timedOutExecutors` deterministic
### What changes were proposed in this pull request?
This PR aims to make `ExecutorMonitor.timedOutExecutors` method
deterministic.
### Why are the changes needed?
Since the AS-IS `timedOutExecutors` returns the result indeterministic, it
kills the executors in a random order at Dynamic Allocation setting.
https://github.com/apache/spark/blob/18f9e7efac5100744f255b6c8ae267579cd8d9ce/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala#L58
https://github.com/apache/spark/blob/18f9e7efac5100744f255b6c8ae267579cd8d9ce/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala#L119
This random behavior not only makes the users confusing but also causes a
K8s decommission tests flaky like the following case in Java 17 on Apple
Silicon environment. The K8s test expects the decommission of executor 1 while
the executor 2 is chosen at this time.
```
22/01/25 06:11:16 DEBUG ExecutorMonitor: Executors 1,2 do not have active
shuffle data after job 0 finished.
22/01/25 06:11:16 DEBUG ExecutorAllocationManager: max needed for rpId: 0
numpending: 0, tasksperexecutor: 1
22/01/25 06:11:16 DEBUG ExecutorAllocationManager: No change in number of
executors
22/01/25 06:11:16 DEBUG ExecutorAllocationManager: Request to remove
executorIds: (2,0), (1,0)
22/01/25 06:11:16 DEBUG ExecutorAllocationManager: Not removing idle
executor 1 because there are only 1 executor(s) left (minimum number of
executor limit 1)
22/01/25 06:11:16 INFO KubernetesClusterSchedulerBackend: Decommission
executors: 2
```
### Does this PR introduce _any_ user-facing change?
No because the previous behavior was a random list and new behavior is now
deterministic.
### How was this patch tested?
Pass the CIs with the newly added test case.
Closes #35315 from dongjoon-hyun/SPARK-38019.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
(cherry picked from commit e2c4913c2e43481d1a12e5a2f307ed8a8d913311)
Signed-off-by: Dongjoon Hyun
---
.../apache/spark/scheduler/dynalloc/ExecutorMonitor.scala | 2 +-
.../spark/scheduler/dynalloc/ExecutorMonitorSuite.scala | 15 +++
2 files changed, 16 insertions(+), 1 deletion(-)
diff --git
a/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
b/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
index cecd4b0..acdfaa5 100644
---
a/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
+++
b/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
@@ -133,7 +133,7 @@ private[spark] class ExecutorMonitor(
.toSeq
updateNextTimeout(newNextTimeout)
}
-timedOutExecs
+timedOutExecs.sortBy(_._1)
}
/**
diff --git
a/core/src/test/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitorSuite.scala
b/core/src/test/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitorSuite.scala
index 69afdb5..6fb89b8 100644
---
a/core/src/test/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitorSuite.scala
+++
b/core/src/test/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitorSuite.scala
@@ -233,6 +233,21 @@ class ExecutorMonitorSuite extends SparkFunSuite {
assert(monitor.timedOutExecutors(clock.nanoTime()).toSet === Set("1", "2",
"3"))
}
+ test("SPARK-38019: timedOutExecutors should be deterministic") {
+knownExecs ++= Set("1", "2", "3")
+
+// start exec 1, 2, 3 at 0s (should idle time out at 60s)
+monitor.onExecutorAdded(SparkListenerExecutorAdded(clock.getTimeMillis(),
"1", execInfo))
+assert(monitor.isExecutorIdle("1"))
+monitor.onExecutorAdded(SparkListenerExecutorAdded(clock.getTimeMillis(),
"2", execInfo))
+assert(monitor.isExecutorIdle("2"))
+monitor.onExecutorAdded(SparkListenerExecutorAdded(clock.getTimeMillis(),
"3", execInfo))
+assert(monitor.isExecutorIdle("3"))
+
+clock.setTime(TimeUnit.SECONDS.toMillis(150))
+assert(monitor.timedOutExecutors().map(_._1) === Seq("1", "2", "3"))
+ }
+
test("SPARK-27677: don't track blocks stored on disk when using shuffle
service") {
// First make sure that blocks on disk are counted when no shuffle service
is available.
monitor.onExecutorAdded(SparkListenerExecutorAdded(clock.get
[spark] branch master updated (7148980 -> e2c4913)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7148980 [SPARK-37867][SQL] Compile aggregate functions of build-in JDBC dialect add e2c4913 [SPARK-38019][CORE] Make `ExecutorMonitor.timedOutExecutors` deterministic No new revisions were added by this update. Summary of changes: .../apache/spark/scheduler/dynalloc/ExecutorMonitor.scala | 2 +- .../spark/scheduler/dynalloc/ExecutorMonitorSuite.scala | 15 +++ 2 files changed, 16 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (ac2b0df -> 7148980)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from ac2b0df [SPARK-37915][SQL] Combine unions if there is a project between them add 7148980 [SPARK-37867][SQL] Compile aggregate functions of build-in JDBC dialect No new revisions were added by this update. Summary of changes: .../spark/sql/jdbc/v2/DB2IntegrationSuite.scala| 17 +- .../sql/jdbc/v2/DockerJDBCIntegrationV2Suite.scala | 44 + .../sql/jdbc/v2/MsSqlServerIntegrationSuite.scala | 16 +- .../spark/sql/jdbc/v2/MySQLIntegrationSuite.scala | 17 +- .../spark/sql/jdbc/v2/OracleIntegrationSuite.scala | 24 ++- .../sql/jdbc/v2/PostgresIntegrationSuite.scala | 19 +- .../org/apache/spark/sql/jdbc/v2/V2JDBCTest.scala | 198 ++--- .../org/apache/spark/sql/jdbc/DB2Dialect.scala | 13 ++ .../org/apache/spark/sql/jdbc/DerbyDialect.scala | 25 +++ .../apache/spark/sql/jdbc/MsSqlServerDialect.scala | 25 +++ .../org/apache/spark/sql/jdbc/MySQLDialect.scala | 25 +++ .../org/apache/spark/sql/jdbc/OracleDialect.scala | 37 .../apache/spark/sql/jdbc/PostgresDialect.scala| 37 .../apache/spark/sql/jdbc/TeradataDialect.scala| 37 14 files changed, 493 insertions(+), 41 deletions(-) create mode 100644 external/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/v2/DockerJDBCIntegrationV2Suite.scala - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (18f9e7e -> ac2b0df)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 18f9e7e [SPARK-37258][K8S][BUILD] Upgrade kubernetes-client to 5.12.0 add ac2b0df [SPARK-37915][SQL] Combine unions if there is a project between them No new revisions were added by this update. Summary of changes: .../spark/sql/catalyst/optimizer/Optimizer.scala | 47 +++- .../sql/catalyst/optimizer/SetOperationSuite.scala | 64 +- 2 files changed, 97 insertions(+), 14 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r52259 - in /dev/spark/v3.1.3-rc2-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _site/api/java/org/apache/parqu
Author: holden Date: Tue Jan 25 08:02:31 2022 New Revision: 52259 Log: Apache Spark v3.1.3-rc2 docs [This commit notification would consist of 2264 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org