[spark-docker] branch master created (now c5b015a)
This is an automated email from the ASF dual-hosted git repository. yikun pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark-docker.git at c5b015a [SPARK-40723][INFRA] Add .asf.yaml to spark-docker This branch includes the following new commits: new c5b015a [SPARK-40723][INFRA] Add .asf.yaml to spark-docker The 1 revisions listed above as "new" are entirely new to this repository and will be described in separate emails. The revisions listed as "add" were already present in the repository and have only been added to this reference. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-docker] 01/01: [SPARK-40723][INFRA] Add .asf.yaml to spark-docker
This is an automated email from the ASF dual-hosted git repository. yikun pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark-docker.git commit c5b015ac2014bfeb47daafd454b610ae9633f676 Author: Yikun Jiang AuthorDate: Mon Oct 10 16:40:34 2022 +0800 [SPARK-40723][INFRA] Add .asf.yaml to spark-docker ### What changes were proposed in this pull request? This change add the .asf.yaml as first commit. ### Why are the changes needed? Initialize the repo setting. ### Does this PR introduce _any_ user-facing change? No, dev only ### How was this patch tested? See result after merged Authored-by: Yikun Jiang Signed-off-by: Yikun Jiang --- .asf.yaml | 39 +++ 1 file changed, 39 insertions(+) diff --git a/.asf.yaml b/.asf.yaml new file mode 100644 index 000..cc7385f --- /dev/null +++ b/.asf.yaml @@ -0,0 +1,39 @@ +# Licensed to the Apache Software Foundation (ASF) under one or more +# contributor license agreements. See the NOTICE file distributed with +# this work for additional information regarding copyright ownership. +# The ASF licenses this file to You under the Apache License, Version 2.0 +# (the "License"); you may not use this file except in compliance with +# the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +# https://cwiki.apache.org/confluence/display/INFRA/git+-+.asf.yaml+features +--- +github: + description: "Official Dockerfile for Apache Spark" + homepage: https://spark.apache.org/ + labels: +- python +- scala +- r +- java +- big-data +- jdbc +- sql +- spark + enabled_merge_buttons: +merge: false +squash: true +rebase: true + +notifications: + pullrequests: revi...@spark.apache.org + issues: revi...@spark.apache.org + commits: commits@spark.apache.org + - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (d323fa8fc07 -> 76a7c5a3625)
This is an automated email from the ASF dual-hosted git repository. ruifengz pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from d323fa8fc07 [SPARK-40448][CONNECT][FOLLOWUP] Use more suitable variable name and fix code style add 76a7c5a3625 [SPARK-40724][PS] Simplify `corr` with method `inline` No new revisions were added by this update. Summary of changes: python/pyspark/pandas/frame.py | 23 +++ 1 file changed, 7 insertions(+), 16 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-40725][INFRA] Add `mypy-protobuf` to dev/requirements
This is an automated email from the ASF dual-hosted git repository.
yikun pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 3fa958af326 [SPARK-40725][INFRA] Add `mypy-protobuf` to
dev/requirements
3fa958af326 is described below
commit 3fa958af326582d8638f36f90b91fe7045f396bf
Author: Ruifeng Zheng
AuthorDate: Mon Oct 10 17:30:12 2022 +0800
[SPARK-40725][INFRA] Add `mypy-protobuf` to dev/requirements
### What changes were proposed in this pull request?
Add `mypy-protobuf` to dev/requirements
### Why are the changes needed?
`connector/connect/dev/generate_protos.sh` requires this package:
```
DEBUG /buf.alpha.registry.v1alpha1.GenerateService/GeneratePlugins
{"duration": "14.25µs", "http.path":
"/buf.alpha.registry.v1alpha1.GenerateService/GeneratePlugins", "http.url":
"https://api.buf.build/buf.alpha.registry.v1alpha1.GenerateService/GeneratePlugins";,
"http.host": "api.buf.build", "http.method": "POST", "http.user_agent":
"connect-go/0.4.0-dev (go1.19.2)"}
DEBUG command {"duration": "9.238333ms"}
Failure: plugin mypy: could not find protoc plugin for name mypy
```
### Does this PR introduce _any_ user-facing change?
No, only for contributors
### How was this patch tested?
manually check
Closes #38186 from zhengruifeng/add_mypy-protobuf_to_requirements.
Authored-by: Ruifeng Zheng
Signed-off-by: Yikun Jiang
---
dev/requirements.txt | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git a/dev/requirements.txt b/dev/requirements.txt
index c610d84c11a..4b47c1f6e83 100644
--- a/dev/requirements.txt
+++ b/dev/requirements.txt
@@ -48,4 +48,5 @@ black==22.6.0
# Spark Connect
grpcio==1.48.1
-protobuf==4.21.6
\ No newline at end of file
+protobuf==4.21.6
+mypy-protobuf
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (3fa958af326 -> 81d8aa5b416)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 3fa958af326 [SPARK-40725][INFRA] Add `mypy-protobuf` to dev/requirements add 81d8aa5b416 [SPARK-40665][CONNECT][FOLLOW-UP] Fix `connector/connect/dev/generate_protos.sh` No new revisions were added by this update. Summary of changes: connector/connect/dev/generate_protos.sh | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (81d8aa5b416 -> 52a66c9f7b3)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 81d8aa5b416 [SPARK-40665][CONNECT][FOLLOW-UP] Fix `connector/connect/dev/generate_protos.sh` add 52a66c9f7b3 [SPARK-40718][BUILD][CONNECT][FOLLOWUP] Explicitly add Netty related dependencies for the `connect` module No new revisions were added by this update. Summary of changes: connector/connect/pom.xml | 18 ++ dev/deps/spark-deps-hadoop-2-hive-2.3 | 4 dev/deps/spark-deps-hadoop-3-hive-2.3 | 4 pom.xml | 16 4 files changed, 26 insertions(+), 16 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-docker] branch master updated: [SPARK-40727][INFRA] Add merge_spark_docker_pr.py
This is an automated email from the ASF dual-hosted git repository.
yikun pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark-docker.git
The following commit(s) were added to refs/heads/master by this push:
new fa2d1a5 [SPARK-40727][INFRA] Add merge_spark_docker_pr.py
fa2d1a5 is described below
commit fa2d1a59b6e47b1e4072154de0b1f215780af595
Author: Yikun Jiang
AuthorDate: Mon Oct 10 20:34:43 2022 +0800
[SPARK-40727][INFRA] Add merge_spark_docker_pr.py
### What changes were proposed in this pull request?
This patch add the merge_spark_docker_pr.py to help to merge `spark-docker`
commits and resolve spark JIRA issue.
The script is from
https://github.com/apache/spark/blob/ef837ca71020950b841f9891c70dc4b29d968bf1/dev/merge_spark_pr.py
And change `spark` to `spark-docker`:
https://github.com/apache/spark-docker/commit/e4107a74d348656041612ff68a647c6051894240
### Why are the changes needed?
Help to merge spark-docker commits.
### Does this PR introduce _any_ user-facing change?
No, dev only
### How was this patch tested?
will merge it by using itself
Closes #1 from Yikun/merge_script.
Authored-by: Yikun Jiang
Signed-off-by: Yikun Jiang
---
merge_spark_docker_pr.py | 571 +++
1 file changed, 571 insertions(+)
diff --git a/merge_spark_docker_pr.py b/merge_spark_docker_pr.py
new file mode 100755
index 000..578a280
--- /dev/null
+++ b/merge_spark_docker_pr.py
@@ -0,0 +1,571 @@
+#!/usr/bin/env python3
+
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+# Utility for creating well-formed pull request merges and pushing them to
Apache
+# Spark.
+# usage: ./merge_spark_docker_pr.py(see config env vars below)
+#
+# This utility assumes you already have a local Spark git folder and that you
+# have added remotes corresponding to both (i) the github apache Spark
+# mirror and (ii) the apache git repo.
+
+import json
+import os
+import re
+import subprocess
+import sys
+import traceback
+from urllib.request import urlopen
+from urllib.request import Request
+from urllib.error import HTTPError
+
+try:
+import jira.client
+
+JIRA_IMPORTED = True
+except ImportError:
+JIRA_IMPORTED = False
+
+# Location of your Spark git development area
+SPARK_DOCKER_HOME = os.environ.get("SPARK_DOCKER_HOME", os.getcwd())
+# Remote name which points to the Gihub site
+PR_REMOTE_NAME = os.environ.get("PR_REMOTE_NAME", "apache-github")
+# Remote name which points to Apache git
+PUSH_REMOTE_NAME = os.environ.get("PUSH_REMOTE_NAME", "apache")
+# ASF JIRA username
+JIRA_USERNAME = os.environ.get("JIRA_USERNAME", "")
+# ASF JIRA password
+JIRA_PASSWORD = os.environ.get("JIRA_PASSWORD", "")
+# OAuth key used for issuing requests against the GitHub API. If this is not
defined, then requests
+# will be unauthenticated. You should only need to configure this if you find
yourself regularly
+# exceeding your IP's unauthenticated request rate limit. You can create an
OAuth key at
+# https://github.com/settings/tokens. This script only requires the
"public_repo" scope.
+GITHUB_OAUTH_KEY = os.environ.get("GITHUB_OAUTH_KEY")
+
+
+GITHUB_BASE = "https://github.com/apache/spark-docker/pull";
+GITHUB_API_BASE = "https://api.github.com/repos/apache/spark-docker";
+JIRA_BASE = "https://issues.apache.org/jira/browse";
+JIRA_API_BASE = "https://issues.apache.org/jira";
+# Prefix added to temporary branches
+BRANCH_PREFIX = "PR_TOOL"
+
+
+def get_json(url):
+try:
+request = Request(url)
+if GITHUB_OAUTH_KEY:
+request.add_header("Authorization", "token %s" % GITHUB_OAUTH_KEY)
+return json.load(urlopen(request))
+except HTTPError as e:
+if "X-RateLimit-Remaining" in e.headers and
e.headers["X-RateLimit-Remaining"] == "0":
+print(
+"Exceeded the GitHub API rate limit; see the instructions in "
++ "dev/merge_spark_docker_pr.py to configure an OAuth token
for making authenticated "
++ "GitHub requests."
+)
+else:
+print("Unable to fetch URL, exiting: %s" % url)
+
[spark] branch master updated: [SPARK-40726][DOCS] Supplement undocumented orc configurations in documentation
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 9e8198d3115 [SPARK-40726][DOCS] Supplement undocumented orc configurations in documentation 9e8198d3115 is described below commit 9e8198d3115848ba87b4c71b43fd7212a1b729c3 Author: Qian.Sun AuthorDate: Mon Oct 10 09:59:37 2022 -0500 [SPARK-40726][DOCS] Supplement undocumented orc configurations in documentation ### What changes were proposed in this pull request? This PR aims to supplement undocumented orc configurations in documentation. ### Why are the changes needed? Help users to confirm configurations through documentation instead of code. ### Does this PR introduce _any_ user-facing change? Yes, more configurations in documentations. ### How was this patch tested? Pass the GA. Closes #38188 from dcoliversun/SPARK-40726. Authored-by: Qian.Sun Signed-off-by: Sean Owen --- docs/sql-data-sources-orc.md | 37 + 1 file changed, 37 insertions(+) diff --git a/docs/sql-data-sources-orc.md b/docs/sql-data-sources-orc.md index 28e237a382d..200037a7dea 100644 --- a/docs/sql-data-sources-orc.md +++ b/docs/sql-data-sources-orc.md @@ -153,6 +153,24 @@ When reading from Hive metastore ORC tables and inserting to Hive metastore ORC 2.3.0 + +spark.sql.orc.columnarReaderBatchSize +4096 + + The number of rows to include in an orc vectorized reader batch. The number should + be carefully chosen to minimize overhead and avoid OOMs in reading data. + +2.4.0 + + +spark.sql.orc.columnarWriterBatchSize +1024 + + The number of rows to include in an orc vectorized writer batch. The number should + be carefully chosen to minimize overhead and avoid OOMs in writing data. + +3.4.0 + spark.sql.orc.enableNestedColumnVectorizedReader false @@ -163,6 +181,25 @@ When reading from Hive metastore ORC tables and inserting to Hive metastore ORC 3.2.0 + +spark.sql.orc.filterPushdown +true + + When true, enable filter pushdown for ORC files. + +1.4.0 + + +spark.sql.orc.aggregatePushdown +false + + If true, aggregates will be pushed down to ORC for optimization. Support MIN, MAX and + COUNT as aggregate expression. For MIN/MAX, support boolean, integer, float and date + type. For COUNT, support all data types. If statistics is missing from any ORC file + footer, exception would be thrown. + +3.3.0 + spark.sql.orc.mergeSchema false - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (9e8198d3115 -> 9a97f8c62bc)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 9e8198d3115 [SPARK-40726][DOCS] Supplement undocumented orc configurations in documentation add 9a97f8c62bc [SPARK-40705][SQL] Handle case of using mutable array when converting Row to JSON for Scala 2.13 No new revisions were added by this update. Summary of changes: sql/catalyst/src/main/scala/org/apache/spark/sql/Row.scala| 2 ++ .../src/test/scala/org/apache/spark/sql/RowTest.scala | 11 +++ 2 files changed, 13 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-40705][SQL] Handle case of using mutable array when converting Row to JSON for Scala 2.13
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new fdc51c73fb0 [SPARK-40705][SQL] Handle case of using mutable array when
converting Row to JSON for Scala 2.13
fdc51c73fb0 is described below
commit fdc51c73fb08eb2cd234cdaf1032a4e54ff0b1a4
Author: Ait Zeouay Amrane
AuthorDate: Mon Oct 10 10:18:51 2022 -0500
[SPARK-40705][SQL] Handle case of using mutable array when converting Row
to JSON for Scala 2.13
### What changes were proposed in this pull request?
I encountered an issue using Spark while reading JSON files based on a
schema it throws every time an exception related to conversion of types.
>Note: This issue can be reproduced only with Scala `2.13`, I'm not having
this issue with `2.12`
Failed to convert value ArraySeq(1, 2, 3) (class of class
scala.collection.mutable.ArraySeq$ofRef}) with the type of
ArrayType(StringType,true) to JSON.
java.lang.IllegalArgumentException: Failed to convert value ArraySeq(1, 2,
3) (class of class scala.collection.mutable.ArraySeq$ofRef}) with the type of
ArrayType(StringType,true) to JSON.
If I add ArraySeq to the matching cases, the test that I added passed
successfully
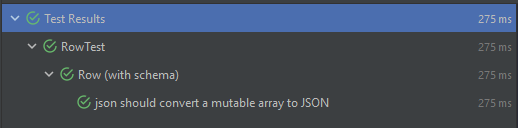
With the current code source, the test fails and we have this following
error

### Why are the changes needed?
If the person is using Scala 2.13, they can't parse an array. Which means
they need to fallback to 2.12 to keep the project functioning
### How was this patch tested?
I added a sample unit test for the case, but I can add more if you want to.
Closes #38154 from Amraneze/fix/spark_40705.
Authored-by: Ait Zeouay Amrane
Signed-off-by: Sean Owen
(cherry picked from commit 9a97f8c62bcd1ad9f34c6318792ae443af46ea85)
Signed-off-by: Sean Owen
---
sql/catalyst/src/main/scala/org/apache/spark/sql/Row.scala| 2 ++
.../src/test/scala/org/apache/spark/sql/RowTest.scala | 11 +++
2 files changed, 13 insertions(+)
diff --git a/sql/catalyst/src/main/scala/org/apache/spark/sql/Row.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/Row.scala
index 4f6c9a8c703..72e1dd94c94 100644
--- a/sql/catalyst/src/main/scala/org/apache/spark/sql/Row.scala
+++ b/sql/catalyst/src/main/scala/org/apache/spark/sql/Row.scala
@@ -584,6 +584,8 @@ trait Row extends Serializable {
case (i: CalendarInterval, _) => JString(i.toString)
case (a: Array[_], ArrayType(elementType, _)) =>
iteratorToJsonArray(a.iterator, elementType)
+ case (a: mutable.ArraySeq[_], ArrayType(elementType, _)) =>
+iteratorToJsonArray(a.iterator, elementType)
case (s: Seq[_], ArrayType(elementType, _)) =>
iteratorToJsonArray(s.iterator, elementType)
case (m: Map[String @unchecked, _], MapType(StringType, valueType, _)) =>
diff --git a/sql/catalyst/src/test/scala/org/apache/spark/sql/RowTest.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/RowTest.scala
index 385f7497368..82731cdb220 100644
--- a/sql/catalyst/src/test/scala/org/apache/spark/sql/RowTest.scala
+++ b/sql/catalyst/src/test/scala/org/apache/spark/sql/RowTest.scala
@@ -17,6 +17,9 @@
package org.apache.spark.sql
+import scala.collection.mutable.ArraySeq
+
+import org.json4s.JsonAST.{JArray, JObject, JString}
import org.scalatest.funspec.AnyFunSpec
import org.scalatest.matchers.must.Matchers
import org.scalatest.matchers.should.Matchers._
@@ -91,6 +94,14 @@ class RowTest extends AnyFunSpec with Matchers {
it("getAs() on type extending AnyVal does not throw exception when value
is null") {
sampleRowWithoutCol3.getAs[String](sampleRowWithoutCol3.fieldIndex("col1"))
shouldBe null
}
+
+it("json should convert a mutable array to JSON") {
+ val schema = new StructType().add(StructField("list",
ArrayType(StringType)))
+ val values = ArraySeq("1", "2", "3")
+ val row = new GenericRowWithSchema(Array(values), schema)
+ val expectedList = JArray(JString("1") :: JString("2") :: JString("3")
:: Nil)
+ row.jsonValue shouldBe new JObject(("list", expectedList) :: Nil)
+}
}
describe("row equals") {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-40714][SQL] Remove `PartitionAlreadyExistsException`
This is an automated email from the ASF dual-hosted git repository.
maxgekk pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 288bdd28635 [SPARK-40714][SQL] Remove `PartitionAlreadyExistsException`
288bdd28635 is described below
commit 288bdd28635d71623dfc6fe82dc1e3aab5fa6c63
Author: Max Gekk
AuthorDate: Mon Oct 10 19:54:17 2022 +0300
[SPARK-40714][SQL] Remove `PartitionAlreadyExistsException`
### What changes were proposed in this pull request?
In the PR, I propose to remove `PartitionAlreadyExistsException` and use
`PartitionsAlreadyExistException` instead of it.
### Why are the changes needed?
1. To simplify user apps. After the changes, users don't need to catch both
exceptions `PartitionsAlreadyExistException` as well as
`PartitionAlreadyExistsException `.
2. To improve code maintenance since don't need to support almost the same
code.
3. To avoid errors like the PR https://github.com/apache/spark/pull/38152
fixed `PartitionsAlreadyExistException` but not
`PartitionAlreadyExistsException`.
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
By running the affected test suites:
```
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly
*SupportsPartitionManagementSuite"
$ build/sbt -Phive-2.3 -Phive-thriftserver "test:testOnly
*.AlterTableAddPartitionSuite"
```
Closes #38161 from MaxGekk/remove-PartitionAlreadyExistsException.
Authored-by: Max Gekk
Signed-off-by: Max Gekk
---
docs/sql-migration-guide.md| 1 +
.../catalog/SupportsAtomicPartitionManagement.java | 5 ++---
.../catalog/SupportsPartitionManagement.java | 10 +-
.../catalyst/analysis/AlreadyExistException.scala | 22 --
.../sql/catalyst/catalog/InMemoryCatalog.scala | 2 +-
.../catalog/InMemoryAtomicPartitionTable.scala | 4 ++--
.../connector/catalog/InMemoryPartitionTable.scala | 6 +++---
.../catalog/SupportsPartitionManagementSuite.scala | 6 +++---
.../AlterTableRenamePartitionSuiteBase.scala | 8
.../command/v1/AlterTableAddPartitionSuite.scala | 2 +-
.../command/v2/AlterTableAddPartitionSuite.scala | 2 +-
.../spark/sql/hive/client/HiveClientImpl.scala | 4 ++--
.../spark/sql/hive/client/HiveClientSuite.scala| 2 +-
13 files changed, 34 insertions(+), 40 deletions(-)
diff --git a/docs/sql-migration-guide.md b/docs/sql-migration-guide.md
index bc7f17fd5cb..18cc579e4f9 100644
--- a/docs/sql-migration-guide.md
+++ b/docs/sql-migration-guide.md
@@ -33,6 +33,7 @@ license: |
- Valid Base64 string should include symbols from in base64 alphabet
(A-Za-z0-9+/), optional padding (`=`), and optional whitespaces. Whitespaces
are skipped in conversion except when they are preceded by padding symbol(s).
If padding is present it should conclude the string and follow rules described
in RFC 4648 § 4.
- Valid hexadecimal strings should include only allowed symbols
(0-9A-Fa-f).
- Valid values for `fmt` are case-insensitive `hex`, `base64`, `utf-8`,
`utf8`.
+ - Since Spark 3.4, Spark throws only `PartitionsAlreadyExistException` when
it creates partitions but some of them exist already. In Spark 3.3 or earlier,
Spark can throw either `PartitionsAlreadyExistException` or
`PartitionAlreadyExistsException`.
## Upgrading from Spark SQL 3.2 to 3.3
diff --git
a/sql/catalyst/src/main/java/org/apache/spark/sql/connector/catalog/SupportsAtomicPartitionManagement.java
b/sql/catalyst/src/main/java/org/apache/spark/sql/connector/catalog/SupportsAtomicPartitionManagement.java
index e2c693f2d0a..09b26d8f793 100644
---
a/sql/catalyst/src/main/java/org/apache/spark/sql/connector/catalog/SupportsAtomicPartitionManagement.java
+++
b/sql/catalyst/src/main/java/org/apache/spark/sql/connector/catalog/SupportsAtomicPartitionManagement.java
@@ -22,7 +22,6 @@ import java.util.Map;
import org.apache.spark.annotation.Experimental;
import org.apache.spark.sql.catalyst.InternalRow;
import org.apache.spark.sql.catalyst.analysis.NoSuchPartitionException;
-import org.apache.spark.sql.catalyst.analysis.PartitionAlreadyExistsException;
import org.apache.spark.sql.catalyst.analysis.PartitionsAlreadyExistException;
/**
@@ -50,11 +49,11 @@ public interface SupportsAtomicPartitionManagement extends
SupportsPartitionMana
default void createPartition(
InternalRow ident,
Map properties)
- throws PartitionAlreadyExistsException, UnsupportedOperationException {
+ throws PartitionsAlreadyExistException, UnsupportedOperationException {
try {
createPartitions(new InternalRow[]{ident}, new Map[]{properties});
} catch (PartitionsAlreadyExistException e) {
- throw new PartitionAlreadyExistsException(e.getMessage());
+ throw ne
[spark] branch master updated (288bdd28635 -> 67c6408f133)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 288bdd28635 [SPARK-40714][SQL] Remove `PartitionAlreadyExistsException` add 67c6408f133 [SPARK-40534][CONNECT] Extend the support for Join with different join types No new revisions were added by this update. Summary of changes: .../main/protobuf/spark/connect/relations.proto| 9 +++--- .../org/apache/spark/sql/connect/dsl/package.scala | 16 ++ .../sql/connect/planner/SparkConnectPlanner.scala | 25 --- .../connect/planner/SparkConnectPlannerSuite.scala | 9 -- .../connect/planner/SparkConnectProtoSuite.scala | 37 +- 5 files changed, 84 insertions(+), 12 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (67c6408f133 -> f8d68b00071)
This is an automated email from the ASF dual-hosted git repository. ruifengz pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 67c6408f133 [SPARK-40534][CONNECT] Extend the support for Join with different join types add f8d68b00071 [SPARK-40725][INFRA][FOLLOWUP] Mark mypy-protobuf as an optional dependency for Spark Connect No new revisions were added by this update. Summary of changes: dev/requirements.txt | 4 +++- 1 file changed, 3 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-40596][CORE] Populate ExecutorDecommission with messages in ExecutorDecommissionInfo
This is an automated email from the ASF dual-hosted git repository.
wuyi pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 4eb0edf5382 [SPARK-40596][CORE] Populate ExecutorDecommission with
messages in ExecutorDecommissionInfo
4eb0edf5382 is described below
commit 4eb0edf538266a8f7085fe57255a6870b2c13769
Author: Bo Zhang
AuthorDate: Tue Oct 11 09:50:06 2022 +0800
[SPARK-40596][CORE] Populate ExecutorDecommission with messages in
ExecutorDecommissionInfo
### What changes were proposed in this pull request?
This change populates `ExecutorDecommission` with messages in
`ExecutorDecommissionInfo`.
### Why are the changes needed?
Currently the message in `ExecutorDecommission` is a fixed value ("Executor
decommission."), so it is the same for all cases, e.g. spot instance
interruptions and auto-scaling down. With this change we can better
differentiate those cases.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Added a unit test.
Closes #38030 from bozhang2820/spark-40596.
Authored-by: Bo Zhang
Signed-off-by: Yi Wu
---
.../scala/org/apache/spark/scheduler/DAGScheduler.scala| 2 +-
.../org/apache/spark/scheduler/ExecutorLossReason.scala| 11 +--
.../scala/org/apache/spark/scheduler/TaskSetManager.scala | 2 +-
.../scheduler/cluster/CoarseGrainedSchedulerBackend.scala | 13 +++--
.../apache/spark/scheduler/dynalloc/ExecutorMonitor.scala | 2 +-
.../storage/BlockManagerDecommissionIntegrationSuite.scala | 14 +++---
6 files changed, 30 insertions(+), 14 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
b/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
index c5529851382..7ad53b8f9f8 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
@@ -2949,7 +2949,7 @@ private[scheduler] class
DAGSchedulerEventProcessLoop(dagScheduler: DAGScheduler
case ExecutorLost(execId, reason) =>
val workerHost = reason match {
case ExecutorProcessLost(_, workerHost, _) => workerHost
-case ExecutorDecommission(workerHost) => workerHost
+case ExecutorDecommission(workerHost, _) => workerHost
case _ => None
}
dagScheduler.handleExecutorLost(execId, workerHost)
diff --git
a/core/src/main/scala/org/apache/spark/scheduler/ExecutorLossReason.scala
b/core/src/main/scala/org/apache/spark/scheduler/ExecutorLossReason.scala
index f333c01bb89..fb6a62551fa 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/ExecutorLossReason.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/ExecutorLossReason.scala
@@ -77,6 +77,13 @@ case class ExecutorProcessLost(
* If you update this code make sure to re-run the K8s integration tests.
*
* @param workerHost it is defined when the worker is decommissioned too
+ * @param reason detailed decommission message
*/
-private [spark] case class ExecutorDecommission(workerHost: Option[String] =
None)
- extends ExecutorLossReason("Executor decommission.")
+private [spark] case class ExecutorDecommission(
+workerHost: Option[String] = None,
+reason: String = "")
+ extends ExecutorLossReason(ExecutorDecommission.msgPrefix + reason)
+
+private[spark] object ExecutorDecommission {
+ val msgPrefix = "Executor decommission: "
+}
diff --git
a/core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala
b/core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala
index 1d157f51fe6..943d1e53df4 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala
@@ -1071,7 +1071,7 @@ private[spark] class TaskSetManager(
for ((tid, info) <- taskInfos if info.running && info.executorId ==
execId) {
val exitCausedByApp: Boolean = reason match {
case ExecutorExited(_, false, _) => false
-case ExecutorKilled | ExecutorDecommission(_) => false
+case ExecutorKilled | ExecutorDecommission(_, _) => false
case ExecutorProcessLost(_, _, false) => false
// If the task is launching, this indicates that Driver has sent
LaunchTask to Executor,
// but Executor has not sent StatusUpdate(TaskState.RUNNING) to
Driver. Hence, we assume
diff --git
a/core/src/main/scala/org/apache/spark/scheduler/cluster/CoarseGrainedSchedulerBackend.scala
b/core/src/main/scala/org/apache/spark/scheduler/cluster/CoarseGrainedSchedulerBackend.scala
index e37abd76296..225dd1d75bf 100644
---
a/core/src/main/scala/org/apache/spark/scheduler/cluster/CoarseGrainedSchedulerBackend.scala
+++
b/core/src/main/scala/org/apache/spark/scheduler/cluster
[spark] branch master updated (4eb0edf5382 -> e927a7edad4)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 4eb0edf5382 [SPARK-40596][CORE] Populate ExecutorDecommission with messages in ExecutorDecommissionInfo add e927a7edad4 [SPARK-40677][CONNECT][FOLLOWUP] Refactor shade `relocation/rename` rules No new revisions were added by this update. Summary of changes: connector/connect/pom.xml | 66 +-- project/SparkBuild.scala | 30 - 2 files changed, 82 insertions(+), 14 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-40698][PS][SQL] Improve the precision of `product` for integral inputs
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new d59f71c627b [SPARK-40698][PS][SQL] Improve the precision of `product`
for integral inputs
d59f71c627b is described below
commit d59f71c627b4a1499a25c1c53e1e73447d31bbbc
Author: Ruifeng Zheng
AuthorDate: Tue Oct 11 11:32:36 2022 +0900
[SPARK-40698][PS][SQL] Improve the precision of `product` for integral
inputs
### What changes were proposed in this pull request?
add a dedicated expression for `product`:
1. for integral inputs, directly use `LongType` to avoid the rounding error:
2. when `ignoreNA` is true, skip following values when meet a `zero`;
3. when `ignoreNA` is false, skip following values when meet a `zero` or
`null`;
### Why are the changes needed?
1. existing computation logic is too complex in the PySpark side, with a
dedicated expression, we can simplify the PySpark side and apply it in more
cases.
2. existing computation of `product` is likely to introduce rounding error
for integral inputs, for example `55108 x 55108 x 55108 x 55108` in the
following case:
before:
```
In [14]: df = pd.DataFrame({"a": [55108, 55108, 55108, 55108], "b":
[55108.0, 55108.0, 55108.0, 55108.0], "c": [1, 2, 3, 4]})
In [15]: df.a.prod()
Out[15]: 9222710978872688896
In [16]: type(df.a.prod())
Out[16]: numpy.int64
In [17]: df.b.prod()
Out[17]: 9.222710978872689e+18
In [18]: type(df.b.prod())
Out[18]: numpy.float64
In [19]:
In [19]: psdf = ps.from_pandas(df)
In [20]: psdf.a.prod()
Out[20]: 9222710978872658944
In [21]: type(psdf.a.prod())
Out[21]: int
In [22]: psdf.b.prod()
Out[22]: 9.222710978872659e+18
In [23]: type(psdf.b.prod())
Out[23]: float
In [24]: df.a.prod() - psdf.a.prod()
Out[24]: 29952
```
after:
```
In [1]: import pyspark.pandas as ps
In [2]: import pandas as pd
In [3]: df = pd.DataFrame({"a": [55108, 55108, 55108, 55108], "b":
[55108.0, 55108.0, 55108.0, 55108.0], "c": [1, 2, 3, 4]})
In [4]: df.a.prod()
Out[4]: 9222710978872688896
In [5]: psdf = ps.from_pandas(df)
In [6]: psdf.a.prod()
Out[6]: 9222710978872688896
In [7]: df.a.prod() - psdf.a.prod()
Out[7]: 0
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing UT & added UT
Closes #38148 from zhengruifeng/ps_new_prod.
Authored-by: Ruifeng Zheng
Signed-off-by: Hyukjin Kwon
---
python/pyspark/pandas/generic.py | 23 +
python/pyspark/pandas/groupby.py | 53 +++---
python/pyspark/pandas/spark/functions.py | 5 +
.../pyspark/pandas/tests/test_generic_functions.py | 16 +++
python/pyspark/pandas/tests/test_groupby.py| 28 -
.../catalyst/expressions/aggregate/Product.scala | 115 -
.../spark/sql/api/python/PythonSQLUtils.scala | 4 +
7 files changed, 180 insertions(+), 64 deletions(-)
diff --git a/python/pyspark/pandas/generic.py b/python/pyspark/pandas/generic.py
index 5b94da44125..9db688d9134 100644
--- a/python/pyspark/pandas/generic.py
+++ b/python/pyspark/pandas/generic.py
@@ -45,7 +45,6 @@ from pyspark.sql import Column, functions as F
from pyspark.sql.types import (
BooleanType,
DoubleType,
-IntegralType,
LongType,
NumericType,
)
@@ -1421,32 +1420,16 @@ class Frame(object, metaclass=ABCMeta):
def prod(psser: "Series") -> Column:
spark_type = psser.spark.data_type
spark_column = psser.spark.column
-
-if not skipna:
-spark_column = F.when(spark_column.isNull(),
np.nan).otherwise(spark_column)
-
if isinstance(spark_type, BooleanType):
-scol = F.min(F.coalesce(spark_column,
F.lit(True))).cast(LongType())
-elif isinstance(spark_type, NumericType):
-num_zeros = F.sum(F.when(spark_column == 0, 1).otherwise(0))
-sign = F.when(
-F.sum(F.when(spark_column < 0, 1).otherwise(0)) % 2 == 0, 1
-).otherwise(-1)
-
-scol = F.when(num_zeros > 0, 0).otherwise(
-sign * F.exp(F.sum(F.log(F.abs(spark_column
-)
-
-if isinstance(spark_type, IntegralType):
-scol = F.round(scol).cast(LongType())
-else:
+spark_column = spark_column.cast(LongType())
+elif not isinstance(spark_type, NumericType):
raise TypeError(
"Could not convert {} ({}) to numeric".format(
[spark-docker] branch master updated: [SPARK-40516] Add Apache Spark 3.3.0 Dockerfile
This is an automated email from the ASF dual-hosted git repository. yikun pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark-docker.git The following commit(s) were added to refs/heads/master by this push: new e61aba1 [SPARK-40516] Add Apache Spark 3.3.0 Dockerfile e61aba1 is described below commit e61aba1ed4ca8e747f38cae5f6bd72a3a50f57cd Author: Yikun Jiang AuthorDate: Tue Oct 11 10:45:57 2022 +0800 [SPARK-40516] Add Apache Spark 3.3.0 Dockerfile ### What changes were proposed in this pull request? This patch adds Apache Spark 3.3.0 Dockerfile: - 3.3.0-scala2.12-java11-python3-ubuntu: pyspark + scala - 3.3.0-scala2.12-java11-ubuntu: scala - 3.3.0-scala2.12-java11-r-ubuntu: sparkr + scala - 3.3.0-scala2.12-java11-python3-r-ubuntu: All in one image ### Why are the changes needed? This is needed by Docker Official Image See also in: https://docs.google.com/document/d/1nN-pKuvt-amUcrkTvYAQ-bJBgtsWb9nAkNoVNRM2S2o ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? **The action won't be triggered until the workflow is merged to the default branch**, so I can only test it in my local repo: - local test: https://github.com/Yikun/spark-docker/pull/1  - Dockerfile E2E K8S Local test: https://github.com/Yikun/spark-docker-bak/pull/7  Closes #2 from Yikun/SPARK-40516. Authored-by: Yikun Jiang Signed-off-by: Yikun Jiang --- .github/workflows/build_3.3.0.yaml | 38 .github/workflows/main.yml | 105 3.3.0/scala2.12-java11-python3-r-ubuntu/Dockerfile | 84 .../entrypoint.sh | 107 + 3.3.0/scala2.12-java11-python3-ubuntu/Dockerfile | 81 .../scala2.12-java11-python3-ubuntu/entrypoint.sh | 107 + 3.3.0/scala2.12-java11-r-ubuntu/Dockerfile | 79 +++ 3.3.0/scala2.12-java11-r-ubuntu/entrypoint.sh | 107 + 3.3.0/scala2.12-java11-ubuntu/Dockerfile | 76 +++ 3.3.0/scala2.12-java11-ubuntu/entrypoint.sh| 107 + 10 files changed, 891 insertions(+) diff --git a/.github/workflows/build_3.3.0.yaml b/.github/workflows/build_3.3.0.yaml new file mode 100644 index 000..63b1ab3 --- /dev/null +++ b/.github/workflows/build_3.3.0.yaml @@ -0,0 +1,38 @@ +# +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, +# software distributed under the License is distributed on an +# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +# KIND, either express or implied. See the License for the +# specific language governing permissions and limitations +# under the License. +# + +name: "Build and Test (3.3.0)" + +on: + pull_request: +branches: + - 'master' +paths: + - '3.3.0/' + - '.github/workflows/main.yml' + +jobs: + run-build: +name: Run +secrets: inherit +uses: ./.github/workflows/main.yml +with: + spark: 3.3.0 + scala: 2.12 + java: 11 diff --git a/.github/workflows/main.yml b/.github/workflows/main.yml new file mode 100644 index 000..90bd706 --- /dev/null +++ b/.github/workflows/main.yml @@ -0,0 +1,105 @@ +# +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, +# software distributed under the License is distributed on an +# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +# KIND, either express or implied. See the License for the +# specific language governing permissions and limitations +# under the License. +# + +name: Main (Build/Test/Publish) + +on: + workflow_call: +inputs: + spark: +description:
[spark] branch master updated: [SPARK-40707][CONNECT] Add groupby to connect DSL and test more than one grouping expressions
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 4e4a848c275 [SPARK-40707][CONNECT] Add groupby to connect DSL and test
more than one grouping expressions
4e4a848c275 is described below
commit 4e4a848c2759577464f4c11c4ea938c7d931f214
Author: Rui Wang
AuthorDate: Tue Oct 11 12:35:08 2022 +0800
[SPARK-40707][CONNECT] Add groupby to connect DSL and test more than one
grouping expressions
### What changes were proposed in this pull request?
1. Add `groupby` to connect DSL and test more than one grouping expressions
2. Pass limited data types through connect proto for LocalRelation's
attributes.
3. Cleanup unused `Trait` in the testing code.
### Why are the changes needed?
Enhance connect's support for GROUP BY.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
UT
Closes #38155 from amaliujia/support_more_than_one_grouping_set.
Authored-by: Rui Wang
Signed-off-by: Wenchen Fan
---
.../src/main/protobuf/spark/connect/commands.proto | 4 +-
.../main/protobuf/spark/connect/expressions.proto | 7 ++--
.../main/protobuf/spark/connect/relations.proto| 18 +
.../src/main/protobuf/spark/connect/types.proto| 12 +++---
.../org/apache/spark/sql/connect/dsl/package.scala | 13 ++
.../connect/planner/DataTypeProtoConverter.scala | 46 ++
.../sql/connect/planner/SparkConnectPlanner.scala | 19 -
.../connect/planner/SparkConnectPlannerSuite.scala | 20 +++---
.../connect/planner/SparkConnectProtoSuite.scala | 19 +++--
9 files changed, 101 insertions(+), 57 deletions(-)
diff --git a/connector/connect/src/main/protobuf/spark/connect/commands.proto
b/connector/connect/src/main/protobuf/spark/connect/commands.proto
index 425857b842e..0a83e4543f5 100644
--- a/connector/connect/src/main/protobuf/spark/connect/commands.proto
+++ b/connector/connect/src/main/protobuf/spark/connect/commands.proto
@@ -44,8 +44,8 @@ message CreateScalarFunction {
repeated string parts = 1;
FunctionLanguage language = 2;
bool temporary = 3;
- repeated Type argument_types = 4;
- Type return_type = 5;
+ repeated DataType argument_types = 4;
+ DataType return_type = 5;
// How the function body is defined:
oneof function_definition {
diff --git
a/connector/connect/src/main/protobuf/spark/connect/expressions.proto
b/connector/connect/src/main/protobuf/spark/connect/expressions.proto
index 9b3029a32b0..791b1b5887b 100644
--- a/connector/connect/src/main/protobuf/spark/connect/expressions.proto
+++ b/connector/connect/src/main/protobuf/spark/connect/expressions.proto
@@ -65,10 +65,10 @@ message Expression {
// Timestamp in units of microseconds since the UNIX epoch.
int64 timestamp_tz = 27;
bytes uuid = 28;
- Type null = 29; // a typed null literal
+ DataType null = 29; // a typed null literal
List list = 30;
- Type.List empty_list = 31;
- Type.Map empty_map = 32;
+ DataType.List empty_list = 31;
+ DataType.Map empty_map = 32;
UserDefined user_defined = 33;
}
@@ -164,5 +164,6 @@ message Expression {
// by the analyzer.
message QualifiedAttribute {
string name = 1;
+DataType type = 2;
}
}
diff --git a/connector/connect/src/main/protobuf/spark/connect/relations.proto
b/connector/connect/src/main/protobuf/spark/connect/relations.proto
index 25bc4e8a16b..30f36fa6ceb 100644
--- a/connector/connect/src/main/protobuf/spark/connect/relations.proto
+++ b/connector/connect/src/main/protobuf/spark/connect/relations.proto
@@ -130,22 +130,8 @@ message Fetch {
// Relation of type [[Aggregate]].
message Aggregate {
Relation input = 1;
-
- // Grouping sets are used in rollups
- repeated GroupingSet grouping_sets = 2;
-
- // Measures
- repeated Measure measures = 3;
-
- message GroupingSet {
-repeated Expression aggregate_expressions = 1;
- }
-
- message Measure {
-AggregateFunction function = 1;
-// Conditional filter for SUM(x FILTER WHERE x < 10)
-Expression filter = 2;
- }
+ repeated Expression grouping_expressions = 2;
+ repeated AggregateFunction result_expressions = 3;
message AggregateFunction {
string name = 1;
diff --git a/connector/connect/src/main/protobuf/spark/connect/types.proto
b/connector/connect/src/main/protobuf/spark/connect/types.proto
index c46afa2afc6..98b0c48b1e0 100644
--- a/connector/connect/src/main/protobuf/spark/connect/types.proto
+++ b/connector/connect/src/main/protobuf/spark/connect/types.proto
@@ -22,9 +22,9 @@ package spark.connect;
option java_multiple_files = true;
option java_package = "org.apache.spark.connect.proto";
-// This message describes the logical [[Type]] of
[spark] branch master updated (4e4a848c275 -> 47d119dfc1a)
This is an automated email from the ASF dual-hosted git repository. maxgekk pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 4e4a848c275 [SPARK-40707][CONNECT] Add groupby to connect DSL and test more than one grouping expressions add 47d119dfc1a [SPARK-40358][SQL] Migrate collection type check failures onto error classes No new revisions were added by this update. Summary of changes: core/src/main/resources/error/error-classes.json | 40 + .../expressions/collectionOperations.scala | 53 +-- .../apache/spark/sql/catalyst/util/TypeUtils.scala | 28 +++- .../sql/catalyst/analysis/AnalysisErrorSuite.scala | 12 +- .../analysis/ExpressionTypeCheckingSuite.scala | 175 - .../expressions/CollectionExpressionsSuite.scala | 10 +- .../catalyst/expressions/ComplexTypeSuite.scala| 10 +- .../expressions/HigherOrderFunctionsSuite.scala| 5 +- .../sql/catalyst/expressions/PredicateSuite.scala | 5 +- .../spark/sql/catalyst/util/TypeUtilsSuite.scala | 5 +- .../sql-tests/results/ansi/interval.sql.out| 32 +++- .../resources/sql-tests/results/ansi/map.sql.out | 36 - .../resources/sql-tests/results/interval.sql.out | 32 +++- .../test/resources/sql-tests/results/map.sql.out | 36 - .../results/typeCoercion/native/mapconcat.sql.out | 81 +- .../apache/spark/sql/DataFrameAggregateSuite.scala | 26 ++- .../apache/spark/sql/DataFrameFunctionsSuite.scala | 86 +++--- 17 files changed, 564 insertions(+), 108 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (47d119dfc1a -> 9ddd7344464)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 47d119dfc1a [SPARK-40358][SQL] Migrate collection type check failures onto error classes add 9ddd7344464 [SPARK-40740][SQL] Improve listFunctions in SessionCatalog No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala| 8 1 file changed, 4 insertions(+), 4 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (9ddd7344464 -> 8e853933ba6)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 9ddd7344464 [SPARK-40740][SQL] Improve listFunctions in SessionCatalog add 8e853933ba6 [SPARK-40667][SQL] Refactor File Data Source Options No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/avro/AvroOptions.scala| 36 +++--- .../org/apache/spark/sql/avro/AvroUtils.scala | 6 +- .../org/apache/spark/sql/avro/AvroSuite.scala | 18 ++- .../spark/sql/catalyst/DataSourceOptions.scala | 66 ++ .../apache/spark/sql/catalyst/csv/CSVOptions.scala | 133 ++--- .../spark/sql/catalyst/json/JSONOptions.scala | 99 ++- .../execution/datasources/FileIndexOptions.scala | 18 +-- .../datasources/PartitioningAwareFileIndex.scala | 16 +-- .../sql/execution/datasources/orc/OrcOptions.scala | 12 +- .../datasources/parquet/ParquetOptions.scala | 18 +-- .../sql/execution/datasources/pathFilters.scala| 16 +-- .../execution/datasources/text/TextOptions.scala | 16 +-- .../execution/streaming/FileStreamOptions.scala| 4 +- .../sql/execution/datasources/FileIndexSuite.scala | 12 ++ .../sql/execution/datasources/csv/CSVSuite.scala | 52 .../sql/execution/datasources/json/JsonSuite.scala | 37 ++ .../execution/datasources/orc/OrcSourceSuite.scala | 8 ++ .../datasources/parquet/ParquetIOSuite.scala | 10 ++ .../sql/execution/datasources/text/TextSuite.scala | 9 ++ 19 files changed, 440 insertions(+), 146 deletions(-) create mode 100644 sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/DataSourceOptions.scala copy connector/avro/src/test/scala/org/apache/spark/sql/execution/datasources/AvroReadSchemaSuite.scala => sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileIndexOptions.scala (59%) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org