[spark] branch master updated: [SPARK-41112][SQL] RuntimeFilter should apply ColumnPruning eagerly with in-subquery filter
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new bd29ca78905 [SPARK-41112][SQL] RuntimeFilter should apply
ColumnPruning eagerly with in-subquery filter
bd29ca78905 is described below
commit bd29ca7890554ac8932be59097e6345505a36c4c
Author: ulysses-you
AuthorDate: Tue Nov 15 16:47:29 2022 +0800
[SPARK-41112][SQL] RuntimeFilter should apply ColumnPruning eagerly with
in-subquery filter
### What changes were proposed in this pull request?
Apply ColumnPruning for in subquery filter.
Note that, the bloom filter side has already fixed by
https://github.com/apache/spark/pull/36047
### Why are the changes needed?
The inferred in-subquery filter should apply ColumnPruning before get plan
statistics and check if can be broadcasted. Otherwise, the final physical plan
will be different from expected.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
add test
Closes #38619 from ulysses-you/SPARK-41112.
Authored-by: ulysses-you
Signed-off-by: Wenchen Fan
---
.../apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala | 2 +-
.../test/scala/org/apache/spark/sql/InjectRuntimeFilterSuite.scala | 7 ++-
2 files changed, 7 insertions(+), 2 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala
index 62782f6051b..efcf607b589 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InjectRuntimeFilter.scala
@@ -99,7 +99,7 @@ object InjectRuntimeFilter extends Rule[LogicalPlan] with
PredicateHelper with J
require(filterApplicationSideExp.dataType ==
filterCreationSideExp.dataType)
val actualFilterKeyExpr = mayWrapWithHash(filterCreationSideExp)
val alias = Alias(actualFilterKeyExpr, actualFilterKeyExpr.toString)()
-val aggregate = Aggregate(Seq(alias), Seq(alias), filterCreationSidePlan)
+val aggregate = ColumnPruning(Aggregate(Seq(alias), Seq(alias),
filterCreationSidePlan))
if (!canBroadcastBySize(aggregate, conf)) {
// Skip the InSubquery filter if the size of `aggregate` is beyond
broadcast join threshold,
// i.e., the semi-join will be a shuffled join, which is not worthwhile.
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/InjectRuntimeFilterSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/InjectRuntimeFilterSuite.scala
index 0e016e19a62..fda442eeef0 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/InjectRuntimeFilterSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/InjectRuntimeFilterSuite.scala
@@ -19,7 +19,7 @@ package org.apache.spark.sql
import org.apache.spark.sql.catalyst.expressions.{Alias,
BloomFilterMightContain, Literal}
import
org.apache.spark.sql.catalyst.expressions.aggregate.{AggregateExpression,
BloomFilterAggregate}
-import org.apache.spark.sql.catalyst.optimizer.MergeScalarSubqueries
+import org.apache.spark.sql.catalyst.optimizer.{ColumnPruning,
MergeScalarSubqueries}
import org.apache.spark.sql.catalyst.plans.LeftSemi
import org.apache.spark.sql.catalyst.plans.logical.{Aggregate, Filter, Join,
LogicalPlan}
import org.apache.spark.sql.execution.{ReusedSubqueryExec, SubqueryExec}
@@ -257,6 +257,11 @@ class InjectRuntimeFilterSuite extends QueryTest with
SQLTestUtils with SharedSp
val normalizedDisabled = normalizePlan(normalizeExprIds(planDisabled))
ensureLeftSemiJoinExists(planEnabled)
assert(normalizedEnabled != normalizedDisabled)
+val agg = planEnabled.collect {
+ case Join(_, agg: Aggregate, LeftSemi, _, _) => agg
+}
+assert(agg.size == 1)
+assert(agg.head.fastEquals(ColumnPruning(agg.head)))
} else {
comparePlans(planDisabled, planEnabled)
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (bd29ca78905 -> a9bf5d2b3f5)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from bd29ca78905 [SPARK-41112][SQL] RuntimeFilter should apply ColumnPruning eagerly with in-subquery filter add a9bf5d2b3f5 [SPARK-41144][SQL] Unresolved hint should not cause query failure No new revisions were added by this update. Summary of changes: .../scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala | 1 + sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala | 8 2 files changed, 9 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-41144][SQL] Unresolved hint should not cause query failure
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 29dee664dd0 [SPARK-41144][SQL] Unresolved hint should not cause query
failure
29dee664dd0 is described below
commit 29dee664dd0d3296318d3551577c868320cbbf78
Author: ulysses-you
AuthorDate: Tue Nov 15 16:49:03 2022 +0800
[SPARK-41144][SQL] Unresolved hint should not cause query failure
Skip `UnresolvedHint` in rule `AddMetadataColumns` to avoid call exprId on
`UnresolvedAttribute`.
```
CREATE TABLE t1(c1 bigint) USING PARQUET;
CREATE TABLE t2(c2 bigint) USING PARQUET;
SELECT /*+ hash(t2) */ * FROM t1 join t2 on c1 = c2;
```
failed with msg:
```
org.apache.spark.sql.catalyst.analysis.UnresolvedException: Invalid call to
exprId on unresolved object
at
org.apache.spark.sql.catalyst.analysis.UnresolvedAttribute.exprId(unresolved.scala:147)
at
org.apache.spark.sql.catalyst.analysis.Analyzer$AddMetadataColumns$.$anonfun$hasMetadataCol$4(Analyzer.scala:1005)
at
org.apache.spark.sql.catalyst.analysis.Analyzer$AddMetadataColumns$.$anonfun$hasMetadataCol$4$adapted(Analyzer.scala:1005)
at scala.collection.Iterator.exists(Iterator.scala:969)
at scala.collection.Iterator.exists$(Iterator.scala:967)
at scala.collection.AbstractIterator.exists(Iterator.scala:1431)
at scala.collection.IterableLike.exists(IterableLike.scala:79)
at scala.collection.IterableLike.exists$(IterableLike.scala:78)
at scala.collection.AbstractIterable.exists(Iterable.scala:56)
at
org.apache.spark.sql.catalyst.analysis.Analyzer$AddMetadataColumns$.$anonfun$hasMetadataCol$3(Analyzer.scala:1005)
at
org.apache.spark.sql.catalyst.analysis.Analyzer$AddMetadataColumns$.$anonfun$hasMetadataCol$3$adapted(Analyzer.scala:1005)
```
But before just a warning: `WARN HintErrorLogger: Unrecognized hint:
hash(t2)`
yes, fix regression from 3.3.1.
Note, the root reason is we mark `UnresolvedHint` is resolved if child is
resolved since https://github.com/apache/spark/pull/32841, then
https://github.com/apache/spark/pull/37758 trigger this bug.
add test
Closes #38662 from ulysses-you/hint.
Authored-by: ulysses-you
Signed-off-by: Wenchen Fan
(cherry picked from commit a9bf5d2b3f5b3331e3b024a3ad631fcbe88a9d18)
Signed-off-by: Wenchen Fan
---
.../scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala | 1 +
sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala | 8
2 files changed, 9 insertions(+)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
index ad40f924ef8..2a2fe6f2957 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
@@ -923,6 +923,7 @@ class Analyzer(override val catalogManager: CatalogManager)
def apply(plan: LogicalPlan): LogicalPlan =
plan.resolveOperatorsDownWithPruning(
AlwaysProcess.fn, ruleId) {
+ case hint: UnresolvedHint => hint
// Add metadata output to all node types
case node if node.children.nonEmpty && node.resolved &&
hasMetadataCol(node) =>
val inputAttrs = AttributeSet(node.children.flatMap(_.output))
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
index 0a3107cdff6..5b42d05c237 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
@@ -4564,6 +4564,14 @@ class SQLQuerySuite extends QueryTest with
SharedSparkSession with AdaptiveSpark
}
}
}
+
+ test("SPARK-41144: Unresolved hint should not cause query failure") {
+withTable("t1", "t2") {
+ sql("CREATE TABLE t1(c1 bigint) USING PARQUET")
+ sql("CREATE TABLE t2(c2 bigint) USING PARQUET")
+ sql("SELECT /*+ hash(t2) */ * FROM t1 join t2 on c1 = c2")
+}
+ }
}
case class Foo(bar: Option[String])
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-40956] SQL Equivalent for Dataframe overwrite command
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 5c43da68587 [SPARK-40956] SQL Equivalent for Dataframe overwrite
command
5c43da68587 is described below
commit 5c43da6858721664318c3cdbcb051231b0e98175
Author: carlfu-db
AuthorDate: Tue Nov 15 16:56:49 2022 +0800
[SPARK-40956] SQL Equivalent for Dataframe overwrite command
### What changes were proposed in this pull request?
Proposing syntax
INSERT INTO tbl REPLACE whereClause identifierList
to the spark SQL, as the equivalent of
[dataframe.overwrite()](https://github.com/apache/spark/blob/35d00df9bba7238ad4f40617fae4d04ddbfd/sql/core/src/main/scala/org/apache/spark/sql/DataFrameWriterV2.scala#L163)
command.
For Example
INSERT INTO table1 REPLACE WHERE key = 3 SELECT * FROM table2
will, in an atomic operation, 1) delete rows with key = 3 and 2) insert
rows from table2
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Add Unit Test in
[DataSourceV2SQLSuite.scala](https://github.com/apache/spark/pull/38404/commits/9429a6c3430e00f273406e755e27f2066e6d352c#diff-eeb429a8e3eb55228451c8dbc2fccca044836be608d62e9166561b005030c940)
Closes #38404 from carlfu-db/replacewhere.
Lead-authored-by: carlfu-db
Co-authored-by: Wenchen Fan
Signed-off-by: Wenchen Fan
---
.../spark/sql/catalyst/parser/SqlBaseParser.g4 | 1 +
.../spark/sql/catalyst/parser/AstBuilder.scala | 6 +++
.../spark/sql/connector/DataSourceV2SQLSuite.scala | 46 ++
3 files changed, 53 insertions(+)
diff --git
a/sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBaseParser.g4
b/sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBaseParser.g4
index 7b673870af8..a3c5f4a7b07 100644
---
a/sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBaseParser.g4
+++
b/sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBaseParser.g4
@@ -319,6 +319,7 @@ query
insertInto
: INSERT OVERWRITE TABLE? multipartIdentifier (partitionSpec (IF NOT
EXISTS)?)? identifierList?#insertOverwriteTable
| INSERT INTO TABLE? multipartIdentifier partitionSpec? (IF NOT EXISTS)?
identifierList?#insertIntoTable
+| INSERT INTO TABLE? multipartIdentifier REPLACE whereClause
#insertIntoReplaceWhere
| INSERT OVERWRITE LOCAL? DIRECTORY path=stringLit rowFormat?
createFileFormat?#insertOverwriteHiveDir
| INSERT OVERWRITE LOCAL? DIRECTORY (path=stringLit)? tableProvider
(OPTIONS options=propertyList)?#insertOverwriteDir
;
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
index 8edb1702028..af2097b5d0f 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
@@ -261,6 +261,7 @@ class AstBuilder extends SqlBaseParserBaseVisitor[AnyRef]
with SQLConfHelper wit
* {{{
* INSERT OVERWRITE TABLE tableIdentifier [partitionSpec [IF NOT EXISTS]]?
[identifierList]
* INSERT INTO [TABLE] tableIdentifier [partitionSpec] [identifierList]
+ * INSERT INTO [TABLE] tableIdentifier REPLACE whereClause
* INSERT OVERWRITE [LOCAL] DIRECTORY STRING [rowFormat] [createFileFormat]
* INSERT OVERWRITE [LOCAL] DIRECTORY [STRING] tableProvider [OPTIONS
tablePropertyList]
* }}}
@@ -288,6 +289,11 @@ class AstBuilder extends SqlBaseParserBaseVisitor[AnyRef]
with SQLConfHelper wit
query,
overwrite = true,
ifPartitionNotExists)
+ case ctx: InsertIntoReplaceWhereContext =>
+OverwriteByExpression.byPosition(
+ createUnresolvedRelation(ctx.multipartIdentifier),
+ query,
+ expression(ctx.whereClause().booleanExpression()))
case dir: InsertOverwriteDirContext =>
val (isLocal, storage, provider) = visitInsertOverwriteDir(dir)
InsertIntoDir(isLocal, storage, provider, query, overwrite = true)
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/connector/DataSourceV2SQLSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/connector/DataSourceV2SQLSuite.scala
index 25faa34b697..de8612c3348 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/connector/DataSourceV2SQLSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/connector/DataSourceV2SQLSuite.scala
@@ -2729,6 +2729,52 @@ class DataSourceV2SQLSuiteV1Filter extends
DataSourceV2SQLSui
[spark] branch master updated (5c43da68587 -> 8806086b952)
This is an automated email from the ASF dual-hosted git repository. ruifengz pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 5c43da68587 [SPARK-40956] SQL Equivalent for Dataframe overwrite command add 8806086b952 [SPARK-41128][CONNECT][PYTHON] Implement `DataFrame.fillna ` and `DataFrame.na.fill ` No new revisions were added by this update. Summary of changes: .../main/protobuf/spark/connect/relations.proto| 26 .../org/apache/spark/sql/connect/dsl/package.scala | 54 + .../sql/connect/planner/SparkConnectPlanner.scala | 64 ++ .../connect/planner/SparkConnectProtoSuite.scala | 15 +++ python/pyspark/sql/connect/dataframe.py| 109 - python/pyspark/sql/connect/plan.py | 58 + python/pyspark/sql/connect/proto/relations_pb2.py | 134 +++-- python/pyspark/sql/connect/proto/relations_pb2.pyi | 68 +++ python/pyspark/sql/connect/typing/__init__.pyi | 4 + .../sql/tests/connect/test_connect_basic.py| 40 ++ .../sql/tests/connect/test_connect_plan_only.py| 32 + 11 files changed, 537 insertions(+), 67 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (8806086b952 -> 8b5fee7ea03)
This is an automated email from the ASF dual-hosted git repository. maxgekk pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 8806086b952 [SPARK-41128][CONNECT][PYTHON] Implement `DataFrame.fillna ` and `DataFrame.na.fill ` add 8b5fee7ea03 [SPARK-41140][SQL] Rename the error class `_LEGACY_ERROR_TEMP_2440` to `INVALID_WHERE_CONDITION` No new revisions were added by this update. Summary of changes: core/src/main/resources/error/error-classes.json | 13 ++-- .../sql/catalyst/analysis/CheckAnalysis.scala | 6 +++--- .../sql/catalyst/analysis/AnalysisErrorSuite.scala | 7 +-- .../resources/sql-tests/results/group-by.sql.out | 24 +++--- .../sql-tests/results/udf/udf-group-by.sql.out | 18 5 files changed, 35 insertions(+), 33 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (8b5fee7ea03 -> f3400e4fdac)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 8b5fee7ea03 [SPARK-41140][SQL] Rename the error class `_LEGACY_ERROR_TEMP_2440` to `INVALID_WHERE_CONDITION` add f3400e4fdac [SPARK-40875][CONNECT][FOLLOW] Retain Group expressions in aggregate No new revisions were added by this update. Summary of changes: .../sql/connect/planner/SparkConnectPlanner.scala | 7 ++-- .../connect/planner/SparkConnectProtoSuite.scala | 37 ++ 2 files changed, 21 insertions(+), 23 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-docker] branch master updated: [SPARK-40519] Add "Publish" workflow to help release apache/spark image
This is an automated email from the ASF dual-hosted git repository.
yikun pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark-docker.git
The following commit(s) were added to refs/heads/master by this push:
new f488d73 [SPARK-40519] Add "Publish" workflow to help release
apache/spark image
f488d73 is described below
commit f488d732d254caa78c1e1a2ef74958e6c867dad6
Author: Yikun Jiang
AuthorDate: Tue Nov 15 21:32:30 2022 +0800
[SPARK-40519] Add "Publish" workflow to help release apache/spark image
### What changes were proposed in this pull request?
The publish step will include 3 steps:
1. First build the local image.
2. Pass related test (K8s test / Standalone test) using image of first step.
3. After pass all test, will publish to `ghcr` (This might help RC test) or
`dockerhub`
It's about 30-40 mins to publish all images.
Add "Publish" workflow to help release apache/spark image.
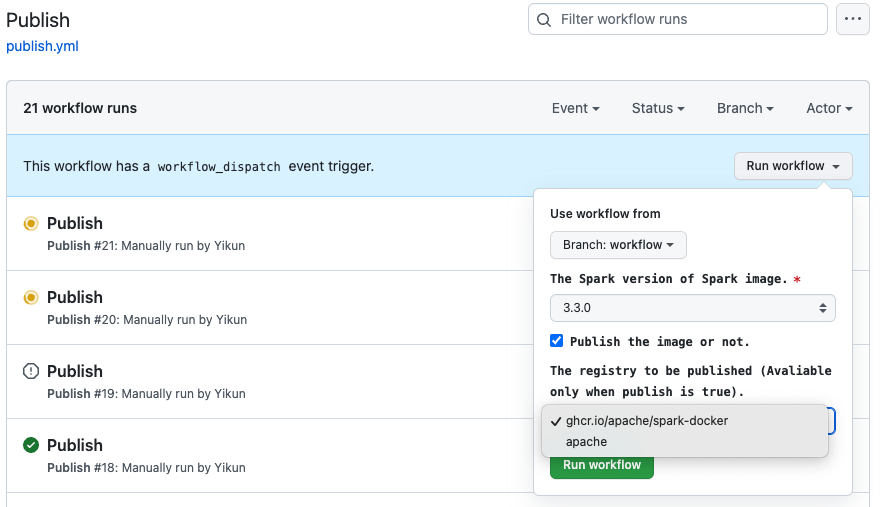
### Why are the changes needed?
One click to create the `apche/spark` image.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
1. Set default branch in my fork repo
2. Run workflow manually,
https://github.com/Yikun/spark-docker/actions/workflows/publish.yml?query=is%3Asuccess
Closes #23 from Yikun/workflow.
Authored-by: Yikun Jiang
Signed-off-by: Yikun Jiang
---
.github/workflows/main.yml| 43 +++
.github/workflows/publish.yml | 66 ++
tools/manifest.py | 82 +++
versions.json | 64 +
4 files changed, 255 insertions(+)
diff --git a/.github/workflows/main.yml b/.github/workflows/main.yml
index accf8ae..dfb99e9 100644
--- a/.github/workflows/main.yml
+++ b/.github/workflows/main.yml
@@ -37,6 +37,16 @@ on:
required: true
type: string
default: 11
+ publish:
+description: Publish the image or not.
+required: false
+type: boolean
+default: false
+ repository:
+description: The registry to be published (Avaliable only when publish
is selected).
+required: false
+type: string
+default: ghcr.io/apache/spark-docker
jobs:
main:
@@ -83,6 +93,9 @@ jobs:
UNIQUE_IMAGE_TAG=${{ matrix.spark_version }}-$TAG
IMAGE_URL=$TEST_REPO/$IMAGE_NAME:$UNIQUE_IMAGE_TAG
+ PUBLISH_REPO=${{ inputs.repository }}
+ PUBLISH_IMAGE_URL=`tools/manifest.py tags -i
${PUBLISH_REPO}/${IMAGE_NAME} -p ${{ matrix.spark_version }}/${TAG}`
+
# Unique image tag in each version:
3.3.0-scala2.12-java11-python3-ubuntu
echo "UNIQUE_IMAGE_TAG=${UNIQUE_IMAGE_TAG}" >> $GITHUB_ENV
# Test repo: ghcr.io/apache/spark-docker
@@ -94,6 +107,9 @@ jobs:
# Image URL:
ghcr.io/apache/spark-docker/spark:3.3.0-scala2.12-java11-python3-ubuntu
echo "IMAGE_URL=${IMAGE_URL}" >> $GITHUB_ENV
+ echo "PUBLISH_REPO=${PUBLISH_REPO}" >> $GITHUB_ENV
+ echo "PUBLISH_IMAGE_URL=${PUBLISH_IMAGE_URL}" >> $GITHUB_ENV
+
- name: Print Image tags
run: |
echo "UNIQUE_IMAGE_TAG: "${UNIQUE_IMAGE_TAG}
@@ -102,6 +118,9 @@ jobs:
echo "IMAGE_PATH: "${IMAGE_PATH}
echo "IMAGE_URL: "${IMAGE_URL}
+ echo "PUBLISH_REPO:"${PUBLISH_REPO}
+ echo "PUBLISH_IMAGE_URL:"${PUBLISH_IMAGE_URL}
+
- name: Build and push test image
uses: docker/build-push-action@v2
with:
@@ -221,3 +240,27 @@ jobs:
with:
name: spark-on-kubernetes-it-log
path: "**/target/integration-tests.log"
+
+ - name: Publish - Login to GitHub Container Registry
+if: ${{ inputs.publish }}
+uses: docker/login-action@v2
+with:
+ registry: ghcr.io
+ username: ${{ github.actor }}
+ password: ${{ secrets.GITHUB_TOKEN }}
+
+ - name: Publish - Login to Dockerhub Registry
+if: ${{ inputs.publish }}
+uses: docker/login-action@v2
+with:
+ username: ${{ secrets.DOCKERHUB_USER }}
+ password: ${{ secrets.DOCKERHUB_TOKEN }}
+
+ - name: Publish - Push Image
+if: ${{ inputs.publish }}
+uses: docker/build-push-action@v2
+with:
+ context: ${{ env.IMAGE_PATH }}
+ push: true
+ tags: ${{ env.PUBLISH_IMAGE_URL }}
+ platforms: linux/amd64,linux/arm64
diff --git a/.github/workflows/publish.yml b/.github/workflows/publish.yml
new file mode 100644
index 000..a44153b
--- /dev/null
+++ b/.github/workflows/publish.yml
@@ -0,0 +1,66 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor
[spark] branch master updated (f3400e4fdac -> b8b90ad5880)
This is an automated email from the ASF dual-hosted git repository. maxgekk pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from f3400e4fdac [SPARK-40875][CONNECT][FOLLOW] Retain Group expressions in aggregate add b8b90ad5880 [SPARK-40755][SQL] Migrate type check failures of number formatting onto error classes No new revisions were added by this update. Summary of changes: core/src/main/resources/error/error-classes.json | 40 .../expressions/numberFormatExpressions.scala | 24 ++- .../spark/sql/catalyst/util/ToNumberParser.scala | 82 + .../expressions/StringExpressionsSuite.scala | 202 - .../sql-tests/results/postgreSQL/numeric.sql.out | 14 +- 5 files changed, 275 insertions(+), 87 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41113][BUILD] Upgrade sbt to 1.8.0
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 953ef9e70fb [SPARK-41113][BUILD] Upgrade sbt to 1.8.0
953ef9e70fb is described below
commit 953ef9e70fb1afcdabf400637c3a702b87eb8a56
Author: YangJie
AuthorDate: Tue Nov 15 13:28:03 2022 -0800
[SPARK-41113][BUILD] Upgrade sbt to 1.8.0
### What changes were proposed in this pull request?
This pr aims to upgrade sbt from 1.7.3 to 1.8.0
### Why are the changes needed?
This version fix 2 CVE:
- Updates to Coursier 2.1.0-RC1 to address
https://github.com/advisories/GHSA-wv7w-rj2x-556x
- Updates to Ivy 2.3.0-sbt-a8f9eb5bf09d0539ea3658a2c2d4e09755b5133e to
address https://github.com/advisories/GHSA-wv7w-rj2x-556x
The full release notes as follows:
- https://github.com/sbt/sbt/releases/tag/v1.8.0
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Pass GitHub Actions
- Run ` dev/sbt-checkstyle` passed
Closes #38620 from LuciferYang/sbt-180.
Lead-authored-by: YangJie
Co-authored-by: yangjie01
Signed-off-by: Dongjoon Hyun
---
dev/appveyor-install-dependencies.ps1 | 2 +-
project/build.properties | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/dev/appveyor-install-dependencies.ps1
b/dev/appveyor-install-dependencies.ps1
index 1c36e76fb0f..caa281d5c9c 100644
--- a/dev/appveyor-install-dependencies.ps1
+++ b/dev/appveyor-install-dependencies.ps1
@@ -97,7 +97,7 @@ if (!(Test-Path $tools)) {
# == SBT
Push-Location $tools
-$sbtVer = "1.7.3"
+$sbtVer = "1.8.0"
Start-FileDownload
"https://github.com/sbt/sbt/releases/download/v$sbtVer/sbt-$sbtVer.zip";
"sbt.zip"
# extract
diff --git a/project/build.properties b/project/build.properties
index f5c34287a4d..33236b9f48d 100644
--- a/project/build.properties
+++ b/project/build.properties
@@ -15,4 +15,4 @@
# limitations under the License.
#
# Please update the version in appveyor-install-dependencies.ps1 together.
-sbt.version=1.7.3
+sbt.version=1.8.0
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-40622][SQL][CORE] Remove the limitation that single task result must fit in 2GB
This is an automated email from the ASF dual-hosted git repository.
mridulm80 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c23245d78e2 [SPARK-40622][SQL][CORE] Remove the limitation that single
task result must fit in 2GB
c23245d78e2 is described below
commit c23245d78e25497ac6e8848ca400a920fed62144
Author: Ziqi Liu
AuthorDate: Tue Nov 15 20:54:20 2022 -0600
[SPARK-40622][SQL][CORE] Remove the limitation that single task result must
fit in 2GB
### What changes were proposed in this pull request?
Single task result must fit in 2GB, because we're using byte array or
`ByteBuffer`(which is backed by byte array as well), and thus has a limit of
2GB(java array size limit on `byte[]`).
This PR is trying to fix this by replacing byte array with
`ChunkedByteBuffer`.
### Why are the changes needed?
To overcome the 2GB limit for single task.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes #38064 from liuzqt/SPARK-40622.
Authored-by: Ziqi Liu
Signed-off-by: Mridul gmail.com>
---
.../scala/org/apache/spark/executor/Executor.scala | 19 ---
.../org/apache/spark/internal/config/package.scala | 2 +
.../org/apache/spark/scheduler/TaskResult.scala| 27 ++
.../apache/spark/scheduler/TaskResultGetter.scala | 14 ++---
.../apache/spark/serializer/SerializerHelper.scala | 54 +++
.../main/scala/org/apache/spark/util/Utils.scala | 45 ++--
.../apache/spark/util/io/ChunkedByteBuffer.scala | 62 --
.../apache/spark/io/ChunkedByteBufferSuite.scala | 50 +
.../scheduler/SchedulerIntegrationSuite.scala | 3 +-
.../spark/scheduler/TaskResultGetterSuite.scala| 2 +-
.../spark/scheduler/TaskSchedulerImplSuite.scala | 8 +--
.../spark/scheduler/TaskSetManagerSuite.scala | 2 +-
.../KryoSerializerResizableOutputSuite.scala | 16 +++---
project/SparkBuild.scala | 1 +
.../spark/sql/catalyst/expressions/Cast.scala | 6 +--
.../org/apache/spark/sql/execution/SparkPlan.scala | 22
.../scala/org/apache/spark/sql/DatasetSuite.scala | 30 ++-
17 files changed, 289 insertions(+), 74 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/executor/Executor.scala
b/core/src/main/scala/org/apache/spark/executor/Executor.scala
index db507bd176b..8d8a4592a3e 100644
--- a/core/src/main/scala/org/apache/spark/executor/Executor.scala
+++ b/core/src/main/scala/org/apache/spark/executor/Executor.scala
@@ -48,10 +48,10 @@ import org.apache.spark.metrics.source.JVMCPUSource
import org.apache.spark.resource.ResourceInformation
import org.apache.spark.rpc.RpcTimeout
import org.apache.spark.scheduler._
+import org.apache.spark.serializer.SerializerHelper
import org.apache.spark.shuffle.{FetchFailedException, ShuffleBlockPusher}
import org.apache.spark.storage.{StorageLevel, TaskResultBlockId}
import org.apache.spark.util._
-import org.apache.spark.util.io.ChunkedByteBuffer
/**
* Spark executor, backed by a threadpool to run tasks.
@@ -172,7 +172,7 @@ private[spark] class Executor(
env.serializerManager.setDefaultClassLoader(replClassLoader)
// Max size of direct result. If task result is bigger than this, we use the
block manager
- // to send the result back.
+ // to send the result back. This is guaranteed to be smaller than array
bytes limit (2GB)
private val maxDirectResultSize = Math.min(
conf.get(TASK_MAX_DIRECT_RESULT_SIZE),
RpcUtils.maxMessageSizeBytes(conf))
@@ -596,7 +596,7 @@ private[spark] class Executor(
val resultSer = env.serializer.newInstance()
val beforeSerializationNs = System.nanoTime()
-val valueBytes = resultSer.serialize(value)
+val valueByteBuffer =
SerializerHelper.serializeToChunkedBuffer(resultSer, value)
val afterSerializationNs = System.nanoTime()
// Deserialization happens in two parts: first, we deserialize a Task
object, which
@@ -659,9 +659,11 @@ private[spark] class Executor(
val accumUpdates = task.collectAccumulatorUpdates()
val metricPeaks = metricsPoller.getTaskMetricPeaks(taskId)
// TODO: do not serialize value twice
-val directResult = new DirectTaskResult(valueBytes, accumUpdates,
metricPeaks)
-val serializedDirectResult = ser.serialize(directResult)
-val resultSize = serializedDirectResult.limit()
+val directResult = new DirectTaskResult(valueByteBuffer, accumUpdates,
metricPeaks)
+// try to estimate a reasonable upper bound of DirectTaskResult
serialization
+val serializedDirectResult =
SerializerHelper.serializeToChunkedBuffer(ser, directResult,
+ valueByteBuffer.size + accumUpdate
[spark] branch master updated (c23245d78e2 -> 96211202d76)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from c23245d78e2 [SPARK-40622][SQL][CORE] Remove the limitation that single task result must fit in 2GB add 96211202d76 [SPARK-40798][DOCS][FOLLOW-UP] Fix a typo in the configuration name at migration guide No new revisions were added by this update. Summary of changes: docs/sql-migration-guide.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org