[spark] branch master updated: [SPARK-41346][CONNECT][TESTS][FOLLOWUP] Fix `test_connect_function` to import `PandasOnSparkTestCase` properly
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new b6ec1ce41d8 [SPARK-41346][CONNECT][TESTS][FOLLOWUP] Fix `test_connect_function` to import `PandasOnSparkTestCase` properly b6ec1ce41d8 is described below commit b6ec1ce41d8c35a3e9d3ab74c026a7419ded2eae Author: Dongjoon Hyun AuthorDate: Mon Dec 5 22:58:23 2022 -0800 [SPARK-41346][CONNECT][TESTS][FOLLOWUP] Fix `test_connect_function` to import `PandasOnSparkTestCase` properly ### What changes were proposed in this pull request? This PR aims to fix `test_connect_function` to import `PandasOnSparkTestCase` properly. If we handle `import` properly, the test cases are ignored properly because `should_test_connect` assumes `have_pandas` https://github.com/apache/spark/blob/97976a5cc915597fd2606602d18c52c075a03bf6/python/pyspark/testing/connectutils.py#L49 ### Why are the changes needed? SPARK-41346 imported `PandasOnSparkTestCase` outside of `if have_pandas:`. https://github.com/apache/spark/blob/97976a5cc915597fd2606602d18c52c075a03bf6/python/pyspark/sql/tests/connect/test_connect_function.py#L25-L29 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? **BEFORE** ``` $ python/run-tests --testnames pyspark.sql.tests.connect.test_connect_function ... ModuleNotFoundError: No module named 'pandas' ``` **AFTER** ``` $ python/run-tests --testnames pyspark.sql.tests.connect.test_connect_function ... Skipped tests in pyspark.sql.tests.connect.test_connect_function with python3.9: test_aggregation_functions (pyspark.sql.tests.connect.test_connect_function.SparkConnectFunctionTests) ... skip (0.004s) test_math_functions (pyspark.sql.tests.connect.test_connect_function.SparkConnectFunctionTests) ... skip (0.004s) test_normal_functions (pyspark.sql.tests.connect.test_connect_function.SparkConnectFunctionTests) ... skip (0.002s) test_sort_with_nulls_order (pyspark.sql.tests.connect.test_connect_function.SparkConnectFunctionTests) ... skip (0.001s) test_sorting_functions_with_column (pyspark.sql.tests.connect.test_connect_function.SparkConnectFunctionTests) ... skip (0.001s) ``` Closes #38929 from dongjoon-hyun/SPARK-41346. Authored-by: Dongjoon Hyun Signed-off-by: Dongjoon Hyun --- python/pyspark/sql/tests/connect/test_connect_function.py | 4 +++- 1 file changed, 3 insertions(+), 1 deletion(-) diff --git a/python/pyspark/sql/tests/connect/test_connect_function.py b/python/pyspark/sql/tests/connect/test_connect_function.py index 83d27235bdb..6d06421d084 100644 --- a/python/pyspark/sql/tests/connect/test_connect_function.py +++ b/python/pyspark/sql/tests/connect/test_connect_function.py @@ -24,9 +24,11 @@ from pyspark.sql import SparkSession if have_pandas: from pyspark.sql.connect.session import SparkSession as RemoteSparkSession +from pyspark.testing.pandasutils import PandasOnSparkTestCase +else: +from pyspark.testing.sqlutils import ReusedSQLTestCase as PandasOnSparkTestCase from pyspark.sql.dataframe import DataFrame from pyspark.testing.connectutils import should_test_connect, connect_requirement_message -from pyspark.testing.pandasutils import PandasOnSparkTestCase from pyspark.testing.utils import ReusedPySparkTestCase - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41034][CONNECT][TESTS][FOLLOWUP] `connectutils` should be skipped when pandas is not installed
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 97976a5cc91 [SPARK-41034][CONNECT][TESTS][FOLLOWUP] `connectutils` should be skipped when pandas is not installed 97976a5cc91 is described below commit 97976a5cc915597fd2606602d18c52c075a03bf6 Author: Dongjoon Hyun AuthorDate: Mon Dec 5 22:35:25 2022 -0800 [SPARK-41034][CONNECT][TESTS][FOLLOWUP] `connectutils` should be skipped when pandas is not installed ### What changes were proposed in this pull request? This PR aims to fix two errors. ``` $ python/run-tests --testnames pyspark.sql.tests.connect.test_connect_column_expressions ... NameError: name 'SparkSession' is not defined ... NameError: name 'LogicalPlan' is not defined ``` ### Why are the changes needed? Previously, `connect` tests are ignored when `pandas` is not available. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manually. ``` $ python/run-tests --testnames pyspark.sql.tests.connect.test_connect_column_expressions ... Finished test(python3): pyspark.sql.tests.connect.test_connect_column_expressions (0s) ... 9 tests were skipped Tests passed in 0 seconds Skipped tests in pyspark.sql.tests.connect.test_connect_column_expressions with python3: test_binary_literal (pyspark.sql.tests.connect.test_connect_column_expressions.SparkConnectColumnExpressionSuite) ... skip (0.002s) test_column_alias (pyspark.sql.tests.connect.test_connect_column_expressions.SparkConnectColumnExpressionSuite) ... skip (0.000s) test_column_literals (pyspark.sql.tests.connect.test_connect_column_expressions.SparkConnectColumnExpressionSuite) ... skip (0.000s) test_float_nan_inf (pyspark.sql.tests.connect.test_connect_column_expressions.SparkConnectColumnExpressionSuite) ... skip (0.000s) test_map_literal (pyspark.sql.tests.connect.test_connect_column_expressions.SparkConnectColumnExpressionSuite) ... skip (0.000s) test_null_literal (pyspark.sql.tests.connect.test_connect_column_expressions.SparkConnectColumnExpressionSuite) ... skip (0.000s) test_numeric_literal_types (pyspark.sql.tests.connect.test_connect_column_expressions.SparkConnectColumnExpressionSuite) ... skip (0.000s) test_simple_column_expressions (pyspark.sql.tests.connect.test_connect_column_expressions.SparkConnectColumnExpressionSuite) ... skip (0.000s) test_uuid_literal (pyspark.sql.tests.connect.test_connect_column_expressions.SparkConnectColumnExpressionSuite) ... skip (0.000s) ``` Closes #38928 from dongjoon-hyun/SPARK-41034. Authored-by: Dongjoon Hyun Signed-off-by: Dongjoon Hyun --- python/pyspark/testing/connectutils.py | 10 ++ 1 file changed, 6 insertions(+), 4 deletions(-) diff --git a/python/pyspark/testing/connectutils.py b/python/pyspark/testing/connectutils.py index feca9e9f825..05df6b02e67 100644 --- a/python/pyspark/testing/connectutils.py +++ b/python/pyspark/testing/connectutils.py @@ -69,7 +69,8 @@ class MockRemoteSession: class PlanOnlyTestFixture(unittest.TestCase): connect: "MockRemoteSession" -session: SparkSession +if have_pandas: +session: SparkSession @classmethod def _read_table(cls, table_name: str) -> "DataFrame": @@ -95,9 +96,10 @@ class PlanOnlyTestFixture(unittest.TestCase): def _session_sql(cls, query: str) -> "DataFrame": return DataFrame.withPlan(SQL(query), cls.connect) # type: ignore -@classmethod -def _with_plan(cls, plan: LogicalPlan) -> "DataFrame": -return DataFrame.withPlan(plan, cls.connect) # type: ignore +if have_pandas: +@classmethod +def _with_plan(cls, plan: LogicalPlan) -> "DataFrame": +return DataFrame.withPlan(plan, cls.connect) # type: ignore @classmethod def setUpClass(cls: Any) -> None: - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (78532fd7c6d -> 324d0909623)
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a change to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
from 78532fd7c6d [SPARK-41244][UI] Introducing a Protobuf serializer for UI
data on KV store
add 324d0909623 Revert "[SPARK-41369][CONNECT][BUILD] Split connect
project into common and server projects"
No new revisions were added by this update.
Summary of changes:
connector/connect/common/pom.xml | 225 -
connector/connect/dev/generate_protos.sh | 2 +-
connector/connect/{server => }/pom.xml | 85 ++--
.../connect/{common => }/src/main/buf.gen.yaml | 0
.../connect/{common => }/src/main/buf.work.yaml| 0
.../{common => }/src/main/protobuf/buf.yaml| 0
.../src/main/protobuf/spark/connect/base.proto | 0
.../src/main/protobuf/spark/connect/commands.proto | 0
.../main/protobuf/spark/connect/expressions.proto | 0
.../main/protobuf/spark/connect/relations.proto| 0
.../src/main/protobuf/spark/connect/types.proto| 0
.../spark/sql/connect/SparkConnectPlugin.scala | 0
.../apache/spark/sql/connect/config/Connect.scala | 0
.../org/apache/spark/sql/connect/dsl/package.scala | 0
.../connect/planner/DataTypeProtoConverter.scala | 0
.../sql/connect/planner/SparkConnectPlanner.scala | 0
.../service/SparkConnectInterceptorRegistry.scala | 0
.../sql/connect/service/SparkConnectService.scala | 0
.../service/SparkConnectStreamHandler.scala| 0
.../src/test/resources/log4j2.properties | 0
.../messages/ConnectProtoMessagesSuite.scala | 0
.../connect/planner/SparkConnectPlannerSuite.scala | 0
.../connect/planner/SparkConnectProtoSuite.scala | 0
.../connect/planner/SparkConnectServiceSuite.scala | 0
.../connect/service/InterceptorRegistrySuite.scala | 0
pom.xml| 3 +-
project/SparkBuild.scala | 114 +++
27 files changed, 98 insertions(+), 331 deletions(-)
delete mode 100644 connector/connect/common/pom.xml
rename connector/connect/{server => }/pom.xml (83%)
rename connector/connect/{common => }/src/main/buf.gen.yaml (100%)
rename connector/connect/{common => }/src/main/buf.work.yaml (100%)
rename connector/connect/{common => }/src/main/protobuf/buf.yaml (100%)
rename connector/connect/{common =>
}/src/main/protobuf/spark/connect/base.proto (100%)
rename connector/connect/{common =>
}/src/main/protobuf/spark/connect/commands.proto (100%)
rename connector/connect/{common =>
}/src/main/protobuf/spark/connect/expressions.proto (100%)
rename connector/connect/{common =>
}/src/main/protobuf/spark/connect/relations.proto (100%)
rename connector/connect/{common =>
}/src/main/protobuf/spark/connect/types.proto (100%)
rename connector/connect/{server =>
}/src/main/scala/org/apache/spark/sql/connect/SparkConnectPlugin.scala (100%)
rename connector/connect/{server =>
}/src/main/scala/org/apache/spark/sql/connect/config/Connect.scala (100%)
rename connector/connect/{server =>
}/src/main/scala/org/apache/spark/sql/connect/dsl/package.scala (100%)
rename connector/connect/{server =>
}/src/main/scala/org/apache/spark/sql/connect/planner/DataTypeProtoConverter.scala
(100%)
rename connector/connect/{server =>
}/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
(100%)
rename connector/connect/{server =>
}/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectInterceptorRegistry.scala
(100%)
rename connector/connect/{server =>
}/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectService.scala
(100%)
rename connector/connect/{server =>
}/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectStreamHandler.scala
(100%)
rename connector/connect/{server => }/src/test/resources/log4j2.properties
(100%)
rename connector/connect/{server =>
}/src/test/scala/org/apache/spark/sql/connect/messages/ConnectProtoMessagesSuite.scala
(100%)
rename connector/connect/{server =>
}/src/test/scala/org/apache/spark/sql/connect/planner/SparkConnectPlannerSuite.scala
(100%)
rename connector/connect/{server =>
}/src/test/scala/org/apache/spark/sql/connect/planner/SparkConnectProtoSuite.scala
(100%)
rename connector/connect/{server =>
}/src/test/scala/org/apache/spark/sql/connect/planner/SparkConnectServiceSuite.scala
(100%)
rename connector/connect/{server =>
}/src/test/scala/org/apache/spark/sql/connect/service/InterceptorRegistrySuite.scala
(100%)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41244][UI] Introducing a Protobuf serializer for UI data on KV store
This is an automated email from the ASF dual-hosted git repository.
gengliang pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 78532fd7c6d [SPARK-41244][UI] Introducing a Protobuf serializer for UI
data on KV store
78532fd7c6d is described below
commit 78532fd7c6d741d501fcc7d375471917d0f79328
Author: Gengliang Wang
AuthorDate: Mon Dec 5 21:46:31 2022 -0800
[SPARK-41244][UI] Introducing a Protobuf serializer for UI data on KV store
### What changes were proposed in this pull request?
Introducing Protobuf serializer for KV store, which is 3 times as fast as
the default serializer according to end-to-end benchmark against RocksDB.
| Serializer | Avg Write time(μs) | Avg Read time(μs)
| RocksDB File Total Size(MB) | Result total size in memory(MB) |
|--||---|-|-|
| Spark’s KV Serializer(JSON+gzip) | 352.2 | 119.26
| 837 | 868 |
| Protobuf | 109.9 | 34.3
| 858 | 2105|
To move fast and make PR review easier, this PR will:
* Cover the class `JobDataWrapper` only. We can handle more UI data later.
* Not adding configuration for setting serializer in SHS. We will have it
as a follow-up.
### Why are the changes needed?
A faster serializer for KV store. It supports schema evolution so that in
the future SHS can leverage it as well.
More details in the SPIP:
https://docs.google.com/document/d/1cuKnFwlTodyVhUQPMuakq2YDaLH05jaY9FRu_aD1zMo/edit
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Closes #38779 from gengliangwang/protobuf.
Authored-by: Gengliang Wang
Signed-off-by: Gengliang Wang
---
.../spark/util/kvstore/KVStoreSerializer.java | 4 +-
connector/protobuf/pom.xml | 2 +-
core/pom.xml | 49 -
.../apache/spark/status/protobuf/store_types.proto | 57 ++
.../spark/deploy/history/FsHistoryProvider.scala | 2 +-
.../org/apache/spark/status/AppStatusStore.scala | 6 +-
.../scala/org/apache/spark/status/KVUtils.scala| 34 --
.../status/protobuf/JobDataWrapperSerializer.scala | 119 +
.../protobuf/KVStoreProtobufSerializer.scala | 34 ++
.../spark/status/AppStatusListenerSuite.scala | 14 ++-
.../protobuf/KVStoreProtobufSerializerSuite.scala | 81 ++
pom.xml| 1 +
project/SparkBuild.scala | 14 +++
13 files changed, 398 insertions(+), 19 deletions(-)
diff --git
a/common/kvstore/src/main/java/org/apache/spark/util/kvstore/KVStoreSerializer.java
b/common/kvstore/src/main/java/org/apache/spark/util/kvstore/KVStoreSerializer.java
index ff99d052cf7..02dd73e1a2f 100644
---
a/common/kvstore/src/main/java/org/apache/spark/util/kvstore/KVStoreSerializer.java
+++
b/common/kvstore/src/main/java/org/apache/spark/util/kvstore/KVStoreSerializer.java
@@ -49,7 +49,7 @@ public class KVStoreSerializer {
this.mapper = new ObjectMapper();
}
- public final byte[] serialize(Object o) throws Exception {
+ public byte[] serialize(Object o) throws Exception {
if (o instanceof String) {
return ((String) o).getBytes(UTF_8);
} else {
@@ -62,7 +62,7 @@ public class KVStoreSerializer {
}
@SuppressWarnings("unchecked")
- public final T deserialize(byte[] data, Class klass) throws Exception
{
+ public T deserialize(byte[] data, Class klass) throws Exception {
if (klass.equals(String.class)) {
return (T) new String(data, UTF_8);
} else {
diff --git a/connector/protobuf/pom.xml b/connector/protobuf/pom.xml
index 7057e6148d4..3036fcbf256 100644
--- a/connector/protobuf/pom.xml
+++ b/connector/protobuf/pom.xml
@@ -122,7 +122,7 @@
com.github.os72
protoc-jar-maven-plugin
-3.11.4
+${protoc-jar-maven-plugin.version}
diff --git a/core/pom.xml b/core/pom.xml
index 182cab90427..a9b40acf5a3 100644
--- a/core/pom.xml
+++ b/core/pom.xml
@@ -532,7 +532,12 @@
org.apache.commons
commons-crypto
-
+
+ com.google.protobuf
+ protobuf-java
+ ${protobuf.version}
+ compile
+
target/scala-${scala.binary.version}/classes
@@ -616,6 +621,48 @@
+
+org.apache.maven.plugins
+maven-shade-plugin
+
+ false
+ true
+
+
[spark] branch branch-3.3 updated: [SPARK-41350][SQL] Allow simple name access of join hidden columns after subquery alias
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 398948ef51c [SPARK-41350][SQL] Allow simple name access of join hidden
columns after subquery alias
398948ef51c is described below
commit 398948ef51ca9dd81be70f0ce02b1b5cebfd02e6
Author: Wenchen Fan
AuthorDate: Mon Dec 5 10:24:25 2022 +0900
[SPARK-41350][SQL] Allow simple name access of join hidden columns after
subquery alias
### What changes were proposed in this pull request?
This fixes a regression caused by
https://github.com/apache/spark/pull/37758 . In
https://github.com/apache/spark/pull/37758 , we decided to only allow qualified
name access for using/natural join hidden columns, to fix other problems around
hidden columns.
We thought that is not a breaking change, as you can only access the join
hidden columns by qualified names to disambiguate. However, one case is missed:
when we wrap the join with a subquery alias, the ambiguity is gone and we
should allow simple name access.
This PR fixes this bug by removing the qualified access only restriction in
`SubqueryAlias.output`.
### Why are the changes needed?
fix a regression.
### Does this PR introduce _any_ user-facing change?
Yes, certain querys that failed with `UNRESOLVED_COLUMN` before this PR can
work now.
### How was this patch tested?
new tests
Closes #38862 from cloud-fan/join.
Authored-by: Wenchen Fan
Signed-off-by: Hyukjin Kwon
---
.../plans/logical/basicLogicalOperators.scala | 10 -
.../apache/spark/sql/catalyst/util/package.scala | 7
.../resources/sql-tests/inputs/natural-join.sql| 2 +
.../test/resources/sql-tests/inputs/using-join.sql | 8
.../sql-tests/results/natural-join.sql.out | 10 +
.../resources/sql-tests/results/using-join.sql.out | 44 ++
6 files changed, 80 insertions(+), 1 deletion(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala
index bdc6e48d08a..69fd825a086 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala
@@ -1329,7 +1329,15 @@ case class SubqueryAlias(
override def output: Seq[Attribute] = {
val qualifierList = identifier.qualifier :+ alias
-child.output.map(_.withQualifier(qualifierList))
+child.output.map { attr =>
+ // `SubqueryAlias` sets a new qualifier for its output columns. It
doesn't make sense to still
+ // restrict the hidden columns of natural/using join to be accessed by
qualified name only.
+ if (attr.qualifiedAccessOnly) {
+attr.markAsAllowAnyAccess().withQualifier(qualifierList)
+ } else {
+attr.withQualifier(qualifierList)
+ }
+}
}
override def metadataOutput: Seq[Attribute] = {
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/package.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/package.scala
index 257749ed6d0..c6374a20c46 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/package.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/package.scala
@@ -208,5 +208,12 @@ package object util extends Logging {
.putBoolean(QUALIFIED_ACCESS_ONLY, true)
.build()
)
+
+def markAsAllowAnyAccess(): Attribute = attr.withMetadata(
+ new MetadataBuilder()
+.withMetadata(attr.metadata)
+.remove(QUALIFIED_ACCESS_ONLY)
+.build()
+)
}
}
diff --git a/sql/core/src/test/resources/sql-tests/inputs/natural-join.sql
b/sql/core/src/test/resources/sql-tests/inputs/natural-join.sql
index 060f15e3d2e..9c9ce6c37ba 100644
--- a/sql/core/src/test/resources/sql-tests/inputs/natural-join.sql
+++ b/sql/core/src/test/resources/sql-tests/inputs/natural-join.sql
@@ -50,6 +50,8 @@ SELECT *, nt2.k FROM nt1 natural join nt2;
SELECT nt1.k, nt2.k FROM nt1 natural join nt2;
+SELECT k FROM (SELECT nt2.k FROM nt1 natural join nt2);
+
SELECT nt1.k, nt2.k FROM nt1 natural join nt2 where k = "one";
SELECT * FROM (SELECT * FROM nt1 natural join nt2);
diff --git a/sql/core/src/test/resources/sql-tests/inputs/using-join.sql
b/sql/core/src/test/resources/sql-tests/inputs/using-join.sql
index 87390b38876..414221e5b71 100644
--- a/sql/core/src/test/resources/sql-tests/inputs/using-join.sql
+++ b/sql/core/src/test/resources/sql-tests/inputs/using-join.sql
@@ -19,6 +19,8 @@ SELECT nt1.*, nt2.* FROM nt1 left outer joi
[spark] branch master updated: [SPARK-41399][CONNECT] Refactor column related tests to test_connect_column
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 889c08b4fe4 [SPARK-41399][CONNECT] Refactor column related tests to
test_connect_column
889c08b4fe4 is described below
commit 889c08b4fe4fb58157a68af5ecd50ec1df10d127
Author: Rui Wang
AuthorDate: Mon Dec 5 19:11:06 2022 -0800
[SPARK-41399][CONNECT] Refactor column related tests to test_connect_column
### What changes were proposed in this pull request?
Given there is a dedicated `test_connect_column.py` now, we should move
those column API tests to this place.
### Why are the changes needed?
Codebase refactoring
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Existing UT
Closes #38925 from amaliujia/move_all_column_tests_to_right_place.
Authored-by: Rui Wang
Signed-off-by: Dongjoon Hyun
---
.../sql/tests/connect/test_connect_basic.py| 51 -
.../sql/tests/connect/test_connect_column.py | 52 ++
2 files changed, 52 insertions(+), 51 deletions(-)
diff --git a/python/pyspark/sql/tests/connect/test_connect_basic.py
b/python/pyspark/sql/tests/connect/test_connect_basic.py
index 22ee98558de..1f67f4c49de 100644
--- a/python/pyspark/sql/tests/connect/test_connect_basic.py
+++ b/python/pyspark/sql/tests/connect/test_connect_basic.py
@@ -146,48 +146,6 @@ class SparkConnectTests(SparkConnectSQLTestCase):
)
self.assert_eq(joined_plan3.toPandas(), joined_plan4.toPandas())
-def test_columns(self):
-# SPARK-41036: test `columns` API for python client.
-df = self.connect.read.table(self.tbl_name)
-df2 = self.spark.read.table(self.tbl_name)
-self.assertEqual(["id", "name"], df.columns)
-
-self.assert_eq(
-df.filter(df.name.rlike("20")).toPandas(),
df2.filter(df2.name.rlike("20")).toPandas()
-)
-self.assert_eq(
-df.filter(df.name.like("20")).toPandas(),
df2.filter(df2.name.like("20")).toPandas()
-)
-self.assert_eq(
-df.filter(df.name.ilike("20")).toPandas(),
df2.filter(df2.name.ilike("20")).toPandas()
-)
-self.assert_eq(
-df.filter(df.name.contains("20")).toPandas(),
-df2.filter(df2.name.contains("20")).toPandas(),
-)
-self.assert_eq(
-df.filter(df.name.startswith("2")).toPandas(),
-df2.filter(df2.name.startswith("2")).toPandas(),
-)
-self.assert_eq(
-df.filter(df.name.endswith("0")).toPandas(),
-df2.filter(df2.name.endswith("0")).toPandas(),
-)
-self.assert_eq(
-df.select(df.name.substr(0, 1).alias("col")).toPandas(),
-df2.select(df2.name.substr(0, 1).alias("col")).toPandas(),
-)
-df3 = self.connect.sql("SELECT cast(null as int) as name")
-df4 = self.spark.sql("SELECT cast(null as int) as name")
-self.assert_eq(
-df3.filter(df3.name.isNull()).toPandas(),
-df4.filter(df4.name.isNull()).toPandas(),
-)
-self.assert_eq(
-df3.filter(df3.name.isNotNull()).toPandas(),
-df4.filter(df4.name.isNotNull()).toPandas(),
-)
-
def test_collect(self):
df = self.connect.read.table(self.tbl_name)
data = df.limit(10).collect()
@@ -369,15 +327,6 @@ class SparkConnectTests(SparkConnectSQLTestCase):
finally:
shutil.rmtree(tmpPath)
-def test_simple_binary_expressions(self):
-"""Test complex expression"""
-df = self.connect.read.table(self.tbl_name)
-pd = df.select(df.id).where(df.id % lit(30) ==
lit(0)).sort(df.id.asc()).toPandas()
-self.assertEqual(len(pd.index), 4)
-
-res = pandas.DataFrame(data={"id": [0, 30, 60, 90]})
-self.assert_(pd.equals(res), f"{pd.to_string()} != {res.to_string()}")
-
def test_limit_offset(self):
df = self.connect.read.table(self.tbl_name)
pd = df.limit(10).offset(1).toPandas()
diff --git a/python/pyspark/sql/tests/connect/test_connect_column.py
b/python/pyspark/sql/tests/connect/test_connect_column.py
index 803481508e5..106ab609bfa 100644
--- a/python/pyspark/sql/tests/connect/test_connect_column.py
+++ b/python/pyspark/sql/tests/connect/test_connect_column.py
@@ -20,6 +20,7 @@ from pyspark.testing.sqlutils import have_pandas
if have_pandas:
from pyspark.sql.connect.functions import lit
+import pandas
class SparkConnectTests(SparkConnectSQLTestCase):
@@ -28,6 +29,57 @@ class SparkConnectTests(SparkConnectSQLTestCase):
df = self.connect.range(10)
self.assertEqual(9, len(df.filter(df.id != lit(1)).collect()))
+def test_colum
[spark] branch master updated (37f1fae3514 -> d34c95161ce)
This is an automated email from the ASF dual-hosted git repository.
hvanhovell pushed a change to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
from 37f1fae3514 [SPARK-41394][PYTHON][TESTS] Skip `MemoryProfilerTests`
when pandas is not installed
add d34c95161ce [SPARK-41369][CONNECT][BUILD] Split connect project into
common and server projects
No new revisions were added by this update.
Summary of changes:
connector/connect/common/pom.xml | 225 +
.../connect/{ => common}/src/main/buf.gen.yaml | 0
.../connect/{ => common}/src/main/buf.work.yaml| 0
.../{ => common}/src/main/protobuf/buf.yaml| 0
.../src/main/protobuf/spark/connect/base.proto | 0
.../src/main/protobuf/spark/connect/commands.proto | 0
.../main/protobuf/spark/connect/expressions.proto | 0
.../main/protobuf/spark/connect/relations.proto| 0
.../src/main/protobuf/spark/connect/types.proto| 0
connector/connect/dev/generate_protos.sh | 2 +-
connector/connect/{ => server}/pom.xml | 85 ++--
.../spark/sql/connect/SparkConnectPlugin.scala | 0
.../apache/spark/sql/connect/config/Connect.scala | 0
.../org/apache/spark/sql/connect/dsl/package.scala | 0
.../connect/planner/DataTypeProtoConverter.scala | 0
.../sql/connect/planner/SparkConnectPlanner.scala | 0
.../service/SparkConnectInterceptorRegistry.scala | 0
.../sql/connect/service/SparkConnectService.scala | 0
.../service/SparkConnectStreamHandler.scala| 0
.../src/test/resources/log4j2.properties | 0
.../messages/ConnectProtoMessagesSuite.scala | 0
.../connect/planner/SparkConnectPlannerSuite.scala | 0
.../connect/planner/SparkConnectProtoSuite.scala | 0
.../connect/planner/SparkConnectServiceSuite.scala | 0
.../connect/service/InterceptorRegistrySuite.scala | 0
pom.xml| 3 +-
project/SparkBuild.scala | 114 ---
27 files changed, 331 insertions(+), 98 deletions(-)
create mode 100644 connector/connect/common/pom.xml
rename connector/connect/{ => common}/src/main/buf.gen.yaml (100%)
rename connector/connect/{ => common}/src/main/buf.work.yaml (100%)
rename connector/connect/{ => common}/src/main/protobuf/buf.yaml (100%)
rename connector/connect/{ =>
common}/src/main/protobuf/spark/connect/base.proto (100%)
rename connector/connect/{ =>
common}/src/main/protobuf/spark/connect/commands.proto (100%)
rename connector/connect/{ =>
common}/src/main/protobuf/spark/connect/expressions.proto (100%)
rename connector/connect/{ =>
common}/src/main/protobuf/spark/connect/relations.proto (100%)
rename connector/connect/{ =>
common}/src/main/protobuf/spark/connect/types.proto (100%)
rename connector/connect/{ => server}/pom.xml (83%)
rename connector/connect/{ =>
server}/src/main/scala/org/apache/spark/sql/connect/SparkConnectPlugin.scala
(100%)
rename connector/connect/{ =>
server}/src/main/scala/org/apache/spark/sql/connect/config/Connect.scala (100%)
rename connector/connect/{ =>
server}/src/main/scala/org/apache/spark/sql/connect/dsl/package.scala (100%)
rename connector/connect/{ =>
server}/src/main/scala/org/apache/spark/sql/connect/planner/DataTypeProtoConverter.scala
(100%)
rename connector/connect/{ =>
server}/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
(100%)
rename connector/connect/{ =>
server}/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectInterceptorRegistry.scala
(100%)
rename connector/connect/{ =>
server}/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectService.scala
(100%)
rename connector/connect/{ =>
server}/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectStreamHandler.scala
(100%)
rename connector/connect/{ => server}/src/test/resources/log4j2.properties
(100%)
rename connector/connect/{ =>
server}/src/test/scala/org/apache/spark/sql/connect/messages/ConnectProtoMessagesSuite.scala
(100%)
rename connector/connect/{ =>
server}/src/test/scala/org/apache/spark/sql/connect/planner/SparkConnectPlannerSuite.scala
(100%)
rename connector/connect/{ =>
server}/src/test/scala/org/apache/spark/sql/connect/planner/SparkConnectProtoSuite.scala
(100%)
rename connector/connect/{ =>
server}/src/test/scala/org/apache/spark/sql/connect/planner/SparkConnectServiceSuite.scala
(100%)
rename connector/connect/{ =>
server}/src/test/scala/org/apache/spark/sql/connect/service/InterceptorRegistrySuite.scala
(100%)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-41151][FOLLOW-UP][SQL][3.3] Keep built-in file _metadata fields nullable value consistent
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new e8a4fb8fad1 [SPARK-41151][FOLLOW-UP][SQL][3.3] Keep built-in file
_metadata fields nullable value consistent
e8a4fb8fad1 is described below
commit e8a4fb8fad1e203720ee54a5250425b4d71a0bd7
Author: yaohua
AuthorDate: Mon Dec 5 16:23:07 2022 -0800
[SPARK-41151][FOLLOW-UP][SQL][3.3] Keep built-in file _metadata fields
nullable value consistent
### What changes were proposed in this pull request?
Cherry-pick https://github.com/apache/spark/pull/38777. Resolved conflicts
in
https://github.com/apache/spark/commit/ac2d027a768f50e279a1785ebf4dae1a37b7d3f4
### Why are the changes needed?
N/A
### Does this PR introduce _any_ user-facing change?
N/A
### How was this patch tested?
N/A
Closes #38910 from Yaohua628/spark-41151-follow-up-3-3.
Authored-by: yaohua
Signed-off-by: Dongjoon Hyun
---
.../spark/sql/execution/datasources/FileFormat.scala | 13 -
.../execution/datasources/FileMetadataStructSuite.scala | 16
2 files changed, 20 insertions(+), 9 deletions(-)
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileFormat.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileFormat.scala
index 0263de8525f..941d2cffe21 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileFormat.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileFormat.scala
@@ -197,12 +197,15 @@ object FileFormat {
*/
val OPTION_RETURNING_BATCH = "returning_batch"
- // supported metadata struct fields for hadoop fs relation
+ /**
+ * Schema of metadata struct that can be produced by every file format,
+ * metadata fields for every file format must be *not* nullable.
+ * */
val METADATA_STRUCT: StructType = new StructType()
-.add(StructField(FILE_PATH, StringType))
-.add(StructField(FILE_NAME, StringType))
-.add(StructField(FILE_SIZE, LongType))
-.add(StructField(FILE_MODIFICATION_TIME, TimestampType))
+.add(StructField(FILE_PATH, StringType, nullable = false))
+.add(StructField(FILE_NAME, StringType, nullable = false))
+.add(StructField(FILE_SIZE, LongType, nullable = false))
+.add(StructField(FILE_MODIFICATION_TIME, TimestampType, nullable = false))
// create a file metadata struct col
def createFileMetadataCol: AttributeReference =
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/FileMetadataStructSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/FileMetadataStructSuite.scala
index 37016b58431..b53ac3a838f 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/FileMetadataStructSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/FileMetadataStructSuite.scala
@@ -267,8 +267,8 @@ class FileMetadataStructSuite extends QueryTest with
SharedSparkSession {
val expectedSchema = new StructType()
.add(StructField("myName", StringType))
.add(StructField("myAge", IntegerType))
- .add(StructField("myFileName", StringType))
- .add(StructField("myFileSize", LongType))
+ .add(StructField("myFileName", StringType, nullable = false))
+ .add(StructField("myFileSize", LongType, nullable = false))
assert(aliasDF.schema.fields.toSet == expectedSchema.fields.toSet)
@@ -654,13 +654,21 @@ class FileMetadataStructSuite extends QueryTest with
SharedSparkSession {
val queryExecution = df.select("_metadata").queryExecution
val analyzedSchema = queryExecution.analyzed.schema
val executedSchema = queryExecution.executedPlan.schema
-assert(analyzedSchema.fields.head.name == "_metadata")
-assert(executedSchema.fields.head.name == "_metadata")
// For stateful streaming, we store the schema in the state store
// and check consistency across batches.
// To avoid state schema compatibility mismatched,
// we should keep nullability consistent for _metadata struct
+assert(analyzedSchema.fields.head.name == "_metadata")
+assert(executedSchema.fields.head.name == "_metadata")
+
+// Metadata struct is not nullable
assert(!analyzedSchema.fields.head.nullable)
assert(analyzedSchema.fields.head.nullable ==
executedSchema.fields.head.nullable)
+
+// All sub-fields all not nullable
+val analyzedStruct =
analyzedSchema.fields.head.dataType.asInstanceOf[StructType]
+val executedStruct =
executedSchema.fields.head.dataType.asInstanceOf[StructType]
+assert(analyzedStruct.fields.forall(!_.nullable))
+assert(executedStruct.fields.forall(!_.nullable))
}
}
--
[spark] branch master updated: [SPARK-41394][PYTHON][TESTS] Skip `MemoryProfilerTests` when pandas is not installed
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 37f1fae3514 [SPARK-41394][PYTHON][TESTS] Skip `MemoryProfilerTests`
when pandas is not installed
37f1fae3514 is described below
commit 37f1fae35149391db80c7b33b6716ab97e0b46a2
Author: Dongjoon Hyun
AuthorDate: Mon Dec 5 14:29:54 2022 -0800
[SPARK-41394][PYTHON][TESTS] Skip `MemoryProfilerTests` when pandas is not
installed
### What changes were proposed in this pull request?
This PR aims to skip `pandas`-related tests of `MemoryProfilerTests` when
`pandas` is not installed.
### Why are the changes needed?
For Apache Spark 3.4, to recover the module (like `pyspark-core`) tests
pass like before SPARK-40281 (#38584).
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Run individual test.
```
python/run-tests --testnames pyspark.tests.test_memory_profiler
--python-executables python3
```
Closes #38920 from dongjoon-hyun/SPARK-41394.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
---
python/pyspark/tests/test_memory_profiler.py | 14 --
1 file changed, 12 insertions(+), 2 deletions(-)
diff --git a/python/pyspark/tests/test_memory_profiler.py
b/python/pyspark/tests/test_memory_profiler.py
index 3dc8ce4ce22..cdb75e5b6aa 100644
--- a/python/pyspark/tests/test_memory_profiler.py
+++ b/python/pyspark/tests/test_memory_profiler.py
@@ -24,16 +24,16 @@ from io import StringIO
from typing import Iterator
from unittest import mock
-import pandas as pd
-
from pyspark import SparkConf, SparkContext
from pyspark.profiler import has_memory_profiler
from pyspark.sql import SparkSession
from pyspark.sql.functions import pandas_udf, udf
+from pyspark.testing.sqlutils import have_pandas, pandas_requirement_message
from pyspark.testing.utils import PySparkTestCase
@unittest.skipIf(not has_memory_profiler, "Must have memory-profiler
installed.")
+@unittest.skipIf(not have_pandas, pandas_requirement_message) # type: ignore
class MemoryProfilerTests(PySparkTestCase):
def setUp(self):
self._old_sys_path = list(sys.path)
@@ -103,6 +103,8 @@ class MemoryProfilerTests(PySparkTestCase):
self.spark.range(10).select(plus_one("id")).collect()
def exec_pandas_udf_ser_to_ser(self):
+import pandas as pd
+
@pandas_udf("int")
def ser_to_ser(ser: pd.Series) -> pd.Series:
return ser + 1
@@ -110,6 +112,8 @@ class MemoryProfilerTests(PySparkTestCase):
self.spark.range(10).select(ser_to_ser("id")).collect()
def exec_pandas_udf_ser_to_scalar(self):
+import pandas as pd
+
@pandas_udf("int")
def ser_to_scalar(ser: pd.Series) -> float:
return ser.median()
@@ -118,6 +122,8 @@ class MemoryProfilerTests(PySparkTestCase):
# Unsupported
def exec_pandas_udf_iter_to_iter(self):
+import pandas as pd
+
@pandas_udf("int")
def iter_to_iter(batch_ser: Iterator[pd.Series]) ->
Iterator[pd.Series]:
for ser in batch_ser:
@@ -126,6 +132,8 @@ class MemoryProfilerTests(PySparkTestCase):
self.spark.range(10).select(iter_to_iter("id")).collect()
def exec_grouped_map(self):
+import pandas as pd
+
def grouped_map(pdf: pd.DataFrame) -> pd.DataFrame:
return pdf.assign(v=pdf.v - pdf.v.mean())
@@ -134,6 +142,8 @@ class MemoryProfilerTests(PySparkTestCase):
# Unsupported
def exec_map(self):
+import pandas as pd
+
def map(pdfs: Iterator[pd.DataFrame]) -> Iterator[pd.DataFrame]:
for pdf in pdfs:
yield pdf[pdf.id == 1]
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41390][SQL] Update the script used to generate `register` function in `UDFRegistration`
This is an automated email from the ASF dual-hosted git repository.
maxgekk pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 11cebdbdd0e [SPARK-41390][SQL] Update the script used to generate
`register` function in `UDFRegistration`
11cebdbdd0e is described below
commit 11cebdbdd0e6d83cbde5f1cb5e4802a7dd5ada48
Author: yangjie01
AuthorDate: Mon Dec 5 23:11:23 2022 +0300
[SPARK-41390][SQL] Update the script used to generate `register` function
in `UDFRegistration`
### What changes were proposed in this pull request?
SPARK-35065 use `QueryCompilationErrors.invalidFunctionArgumentsError`
instead of `throw new AnalysisException(...)` for `register` function in
`UDFRegistration`, but the script used to generate `register` function has not
been updated, so this pr update the script.
### Why are the changes needed?
Update the script used to generate `register` function in `UDFRegistration`
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually checked the results of the script.
Closes #38916 from LuciferYang/register-func-script.
Authored-by: yangjie01
Signed-off-by: Max Gekk
---
sql/core/src/main/scala/org/apache/spark/sql/UDFRegistration.scala | 6 ++
1 file changed, 2 insertions(+), 4 deletions(-)
diff --git a/sql/core/src/main/scala/org/apache/spark/sql/UDFRegistration.scala
b/sql/core/src/main/scala/org/apache/spark/sql/UDFRegistration.scala
index 99820336477..80550dc21d2 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/UDFRegistration.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/UDFRegistration.scala
@@ -145,8 +145,7 @@ class UDFRegistration private[sql] (functionRegistry:
FunctionRegistry) extends
| def builder(e: Seq[Expression]) = if (e.length == $x) {
|finalUdf.createScalaUDF(e)
| } else {
-|throw new AnalysisException("Invalid number of arguments for
function " + name +
-| ". Expected: $x; Found: " + e.length)
+|throw QueryCompilationErrors.invalidFunctionArgumentsError(name,
"$x", e.length)
| }
| functionRegistry.createOrReplaceTempFunction(name, builder,
"scala_udf")
| finalUdf
@@ -171,8 +170,7 @@ class UDFRegistration private[sql] (functionRegistry:
FunctionRegistry) extends
| def builder(e: Seq[Expression]) = if (e.length == $i) {
|ScalaUDF(func, replaced, e, Nil, udfName = Some(name))
| } else {
-|throw new AnalysisException("Invalid number of arguments for
function " + name +
-| ". Expected: $i; Found: " + e.length)
+|throw QueryCompilationErrors.invalidFunctionArgumentsError(name,
"$i", e.length)
| }
| functionRegistry.createOrReplaceTempFunction(name, builder,
"java_udf")
|}""".stripMargin)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (d2d1b50bfac -> d0a73f80e25)
This is an automated email from the ASF dual-hosted git repository. dongjoon pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from d2d1b50bfac [SPARK-41372][CONNECT][PYTHON] Implement DataFrame TempView add d0a73f80e25 [SPARK-40419][SQL][TESTS][FOLLOWUP] Remove results/udaf.sql.out No new revisions were added by this update. Summary of changes: .../test/resources/sql-tests/results/udaf.sql.out | 67 -- 1 file changed, 67 deletions(-) delete mode 100644 sql/core/src/test/resources/sql-tests/results/udaf.sql.out - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41372][CONNECT][PYTHON] Implement DataFrame TempView
This is an automated email from the ASF dual-hosted git repository.
xinrong pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new d2d1b50bfac [SPARK-41372][CONNECT][PYTHON] Implement DataFrame TempView
d2d1b50bfac is described below
commit d2d1b50bfacf1c5bdcf56f150ae44d1b7e5cb5a6
Author: Rui Wang
AuthorDate: Mon Dec 5 09:20:10 2022 -0800
[SPARK-41372][CONNECT][PYTHON] Implement DataFrame TempView
### What changes were proposed in this pull request?
Implement DataFrame TempView (which is createTemView and
createOrReplaceTempView). This is a session local temp view which is different
from the global temp view.
### Why are the changes needed?
API coverage.
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
UT
Closes #38891 from amaliujia/createTempView.
Authored-by: Rui Wang
Signed-off-by: Xinrong Meng
---
python/pyspark/sql/connect/dataframe.py| 38 ++
.../sql/tests/connect/test_connect_basic.py| 14 +++-
2 files changed, 51 insertions(+), 1 deletion(-)
diff --git a/python/pyspark/sql/connect/dataframe.py
b/python/pyspark/sql/connect/dataframe.py
index 8e8a5f4d318..026b7e6099f 100644
--- a/python/pyspark/sql/connect/dataframe.py
+++ b/python/pyspark/sql/connect/dataframe.py
@@ -1554,6 +1554,44 @@ class DataFrame(object):
"""
print(self._explain_string(extended=extended, mode=mode))
+def createTempView(self, name: str) -> None:
+"""Creates a local temporary view with this :class:`DataFrame`.
+
+The lifetime of this temporary table is tied to the
:class:`SparkSession`
+that was used to create this :class:`DataFrame`.
+throws :class:`TempTableAlreadyExistsException`, if the view name
already exists in the
+catalog.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+name : str
+Name of the view.
+"""
+command = plan.CreateView(
+child=self._plan, name=name, is_global=False, replace=False
+).command(session=self._session.client)
+self._session.client.execute_command(command)
+
+def createOrReplaceTempView(self, name: str) -> None:
+"""Creates or replaces a local temporary view with this
:class:`DataFrame`.
+
+The lifetime of this temporary table is tied to the
:class:`SparkSession`
+that was used to create this :class:`DataFrame`.
+
+.. versionadded:: 3.4.0
+
+Parameters
+--
+name : str
+Name of the view.
+"""
+command = plan.CreateView(
+child=self._plan, name=name, is_global=False, replace=True
+).command(session=self._session.client)
+self._session.client.execute_command(command)
+
def createGlobalTempView(self, name: str) -> None:
"""Creates a global temporary view with this :class:`DataFrame`.
diff --git a/python/pyspark/sql/tests/connect/test_connect_basic.py
b/python/pyspark/sql/tests/connect/test_connect_basic.py
index abab47b36bf..22ee98558de 100644
--- a/python/pyspark/sql/tests/connect/test_connect_basic.py
+++ b/python/pyspark/sql/tests/connect/test_connect_basic.py
@@ -530,11 +530,23 @@ class SparkConnectTests(SparkConnectSQLTestCase):
self.connect.sql("SELECT 2 AS X LIMIT
1").createOrReplaceGlobalTempView("view_1")
self.assertTrue(self.spark.catalog.tableExists("global_temp.view_1"))
-# Test when creating a view which is alreayd exists but
+# Test when creating a view which is already exists but
self.assertTrue(self.spark.catalog.tableExists("global_temp.view_1"))
with self.assertRaises(grpc.RpcError):
self.connect.sql("SELECT 1 AS X LIMIT
0").createGlobalTempView("view_1")
+def test_create_session_local_temp_view(self):
+# SPARK-41372: test session local temp view creation.
+with self.tempView("view_local_temp"):
+self.connect.sql("SELECT 1 AS X").createTempView("view_local_temp")
+self.assertEqual(self.connect.sql("SELECT * FROM
view_local_temp").count(), 1)
+self.connect.sql("SELECT 1 AS X LIMIT
0").createOrReplaceTempView("view_local_temp")
+self.assertEqual(self.connect.sql("SELECT * FROM
view_local_temp").count(), 0)
+
+# Test when creating a view which is already exists but
+with self.assertRaises(grpc.RpcError):
+self.connect.sql("SELECT 1 AS X LIMIT
0").createTempView("view_local_temp")
+
def test_to_pandas(self):
# SPARK-41005: Test to pandas
query = """
-
To unsubscribe, e-mail: commits-unsubscr.
[spark] branch master updated: [SPARK-41389][CORE][SQL] Reuse `WRONG_NUM_ARGS` instead of `_LEGACY_ERROR_TEMP_1044`
This is an automated email from the ASF dual-hosted git repository.
maxgekk pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 1996a94b09f [SPARK-41389][CORE][SQL] Reuse `WRONG_NUM_ARGS` instead of
`_LEGACY_ERROR_TEMP_1044`
1996a94b09f is described below
commit 1996a94b09fe1f450eb33ddb23b16af090bc4d1b
Author: yangjie01
AuthorDate: Mon Dec 5 18:04:51 2022 +0300
[SPARK-41389][CORE][SQL] Reuse `WRONG_NUM_ARGS` instead of
`_LEGACY_ERROR_TEMP_1044`
### What changes were proposed in this pull request?
This pr aims to reuse error class `WRONG_NUM_ARGS` instead of
`_LEGACY_ERROR_TEMP_1044`.
### Why are the changes needed?
Proper names of error classes to improve user experience with Spark SQL.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass Github Actions.
Closes #38913 from LuciferYang/SPARK-41389.
Authored-by: yangjie01
Signed-off-by: Max Gekk
---
core/src/main/resources/error/error-classes.json| 5 -
.../org/apache/spark/sql/catalyst/analysis/FunctionRegistry.scala | 5 +++--
.../scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala | 6 --
.../resources/sql-tests/results/sql-compatibility-functions.sql.out | 6 --
4 files changed, 7 insertions(+), 15 deletions(-)
diff --git a/core/src/main/resources/error/error-classes.json
b/core/src/main/resources/error/error-classes.json
index 7d5c272a77f..19ab5ada2b5 100644
--- a/core/src/main/resources/error/error-classes.json
+++ b/core/src/main/resources/error/error-classes.json
@@ -2011,11 +2011,6 @@
"Invalid arguments for function ."
]
},
- "_LEGACY_ERROR_TEMP_1044" : {
-"message" : [
- "Function accepts only one argument."
-]
- },
"_LEGACY_ERROR_TEMP_1045" : {
"message" : [
"ALTER TABLE SET LOCATION does not support partition for v2 tables."
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/FunctionRegistry.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/FunctionRegistry.scala
index 3817f00d09d..be16eaec6ac 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/FunctionRegistry.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/FunctionRegistry.scala
@@ -896,8 +896,9 @@ object FunctionRegistry {
name: String,
dataType: DataType): (String, (ExpressionInfo, FunctionBuilder)) = {
val builder = (args: Seq[Expression]) => {
- if (args.size != 1) {
-throw QueryCompilationErrors.functionAcceptsOnlyOneArgumentError(name)
+ val argSize = args.size
+ if (argSize != 1) {
+throw QueryCompilationErrors.invalidFunctionArgumentsError(name, "1",
argSize)
}
Cast(args.head, dataType)
}
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala
index 2e20d7aec8d..ed08e33829e 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala
@@ -663,12 +663,6 @@ private[sql] object QueryCompilationErrors extends
QueryErrorsBase {
}
}
- def functionAcceptsOnlyOneArgumentError(name: String): Throwable = {
-new AnalysisException(
- errorClass = "_LEGACY_ERROR_TEMP_1044",
- messageParameters = Map("name" -> name))
- }
-
def alterV2TableSetLocationWithPartitionNotSupportedError(): Throwable = {
new AnalysisException(
errorClass = "_LEGACY_ERROR_TEMP_1045",
diff --git
a/sql/core/src/test/resources/sql-tests/results/sql-compatibility-functions.sql.out
b/sql/core/src/test/resources/sql-tests/results/sql-compatibility-functions.sql.out
index e0d5874d058..319ac059385 100644
---
a/sql/core/src/test/resources/sql-tests/results/sql-compatibility-functions.sql.out
+++
b/sql/core/src/test/resources/sql-tests/results/sql-compatibility-functions.sql.out
@@ -94,9 +94,11 @@ struct<>
-- !query output
org.apache.spark.sql.AnalysisException
{
- "errorClass" : "_LEGACY_ERROR_TEMP_1044",
+ "errorClass" : "WRONG_NUM_ARGS",
"messageParameters" : {
-"name" : "string"
+"actualNum" : "2",
+"expectedNum" : "1",
+"functionName" : "`string`"
},
"queryContext" : [ {
"objectType" : "",
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] srowen commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
srowen commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1337440852 Right, but this change is affecting both. Maybe just say "Hadoop 3" -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (e234cd8276a -> 986cf2c7a7a)
This is an automated email from the ASF dual-hosted git repository. yumwang pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from e234cd8276a [SPARK-41388][K8S] `getReusablePVCs` should ignore recently created PVCs in the previous batch add 986cf2c7a7a [SPARK-41167][SQL] Improve multi like performance by creating a balanced expression tree predicate No new revisions were added by this update. Summary of changes: .../apache/spark/sql/catalyst/optimizer/expressions.scala | 10 +- .../sql/catalyst/optimizer/LikeSimplificationSuite.scala | 14 +++--- 2 files changed, 12 insertions(+), 12 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] bjornjorgensen commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
bjornjorgensen commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1337390183 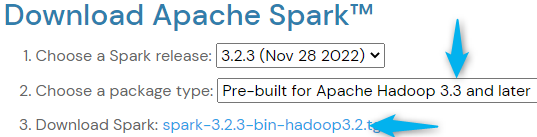  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] bjornjorgensen commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
bjornjorgensen commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1337373595 spark-3.2.3-bin-hadoop3.2.tgz Spark 3.2.3 hadoop 3.2 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] srowen commented on pull request #429: Change download text for spark 3.2.3. from Apache Hadoop 3.3 to Apache Hadoop 3.2
srowen commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1337337921 Yeah this changes the name for Spark 3.2 and 3.3. To be clear what is the correct/desired display here - Hadoop 3.2 with Spark 3.2 ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] bjornjorgensen commented on pull request #429: Change Apache Hadoop 3.3 to Apache Hadoop 3.2
bjornjorgensen commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1337038144 @dongjoon-hyun Its only for 3.2.3. Spark 3.2.3 have hadoop3.2 not 3.3 as the dropdown are telling. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-41388][K8S] `getReusablePVCs` should ignore recently created PVCs in the previous batch
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new aac8d0a7e1d [SPARK-41388][K8S] `getReusablePVCs` should ignore
recently created PVCs in the previous batch
aac8d0a7e1d is described below
commit aac8d0a7e1d20d9fd9fbabcbd80ea1df2aa40225
Author: Dongjoon Hyun
AuthorDate: Mon Dec 5 01:09:50 2022 -0800
[SPARK-41388][K8S] `getReusablePVCs` should ignore recently created PVCs in
the previous batch
This PR aims to prevent `getReusablePVCs` from choosing recently created
PVCs in the very previous batch by excluding newly created PVCs whose creation
time is within `spark.kubernetes.allocation.batch.delay`.
In case of slow K8s control plane situation where
`spark.kubernetes.allocation.batch.delay` is too short relatively or
`spark.kubernetes.executor.enablePollingWithResourceVersion=true` is used,
`onNewSnapshots` may not return the full list of executor pods created by the
previous batch. This sometimes makes Spark driver think the PVCs in the
previous batch are reusable for the next batch.
No.
Pass the CIs with the newly created test case.
Closes #38912 from dongjoon-hyun/SPARK-41388.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
(cherry picked from commit e234cd8276a603ab8a191dd078b11c605b22a50c)
Signed-off-by: Dongjoon Hyun
(cherry picked from commit 651f5da7d58554ebd4b15c5b0204acf2d08ca439)
Signed-off-by: Dongjoon Hyun
---
.../cluster/k8s/ExecutorPodsAllocator.scala| 6 +-
.../cluster/k8s/ExecutorPodsAllocatorSuite.scala | 23 --
2 files changed, 26 insertions(+), 3 deletions(-)
diff --git
a/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
b/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
index dc79f2205d5..72bdaed89c9 100644
---
a/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
+++
b/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
@@ -364,7 +364,11 @@ private[spark] class ExecutorPodsAllocator(
.getItems
.asScala
- val reusablePVCs = createdPVCs.filterNot(pvc =>
pvcsInUse.contains(pvc.getMetadata.getName))
+ val now = Instant.now().toEpochMilli
+ val reusablePVCs = createdPVCs
+.filterNot(pvc => pvcsInUse.contains(pvc.getMetadata.getName))
+.filter(pvc => now -
Instant.parse(pvc.getMetadata.getCreationTimestamp).toEpochMilli
+ > podAllocationDelay)
logInfo(s"Found ${reusablePVCs.size} reusable PVCs from
${createdPVCs.size} PVCs")
reusablePVCs
} else {
diff --git
a/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
b/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
index 5b33da6d2b5..6dbf45ddd61 100644
---
a/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
+++
b/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
@@ -17,9 +17,11 @@
package org.apache.spark.scheduler.cluster.k8s
import java.time.Instant
+import java.time.temporal.ChronoUnit.MILLIS
import java.util.concurrent.atomic.AtomicInteger
import scala.collection.JavaConverters._
+import scala.collection.mutable
import io.fabric8.kubernetes.api.model._
import io.fabric8.kubernetes.client.KubernetesClient
@@ -678,8 +680,10 @@ class ExecutorPodsAllocatorSuite extends SparkFunSuite
with BeforeAndAfter {
when(kubernetesClient.persistentVolumeClaims()).thenReturn(persistentVolumeClaims)
when(persistentVolumeClaims.withLabel(any(),
any())).thenReturn(labeledPersistentVolumeClaims)
when(labeledPersistentVolumeClaims.list()).thenReturn(persistentVolumeClaimList)
-when(persistentVolumeClaimList.getItems)
- .thenReturn(Seq(persistentVolumeClaim("pvc-0", "gp2", "200Gi")).asJava)
+val pvc = persistentVolumeClaim("pvc-0", "gp2", "200Gi")
+pvc.getMetadata
+ .setCreationTimestamp(Instant.now().minus(podAllocationDelay + 1,
MILLIS).toString)
+when(persistentVolumeClaimList.getItems).thenReturn(Seq(pvc).asJava)
when(executorBuilder.buildFromFeatures(any(classOf[KubernetesExecutorConf]),
meq(secMgr),
meq(kubernetesClient), any(classOf[ResourceProfile])))
.thenAnswer((invocation: InvocationOnMock) => {
@@ -742,6 +746,21 @@ class ExecutorPodsAllocatorSuite extends SparkFunSuite
with BeforeAndAfter {
" namespace
[GitHub] [spark-website] bjornjorgensen commented on pull request #429: Change Apache Hadoop 3.3 to Apache Hadoop 3.2
bjornjorgensen commented on PR #429: URL: https://github.com/apache/spark-website/pull/429#issuecomment-1337018346  @srowen Can you fix this? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] bjornjorgensen opened a new pull request, #429: Change Apache Hadoop 3.3 to Apache Hadoop 3.2
bjornjorgensen opened a new pull request, #429: URL: https://github.com/apache/spark-website/pull/429 Change Apache Hadoop 3.3 to Apache Hadoop 3.2 I have not Make sure that you generate site HTML with `bundle exec jekyll build`, and include the changes to the HTML in your pull request. See README.md for more information. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-41388][K8S] `getReusablePVCs` should ignore recently created PVCs in the previous batch
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 651f5da7d58 [SPARK-41388][K8S] `getReusablePVCs` should ignore
recently created PVCs in the previous batch
651f5da7d58 is described below
commit 651f5da7d58554ebd4b15c5b0204acf2d08ca439
Author: Dongjoon Hyun
AuthorDate: Mon Dec 5 01:09:50 2022 -0800
[SPARK-41388][K8S] `getReusablePVCs` should ignore recently created PVCs in
the previous batch
This PR aims to prevent `getReusablePVCs` from choosing recently created
PVCs in the very previous batch by excluding newly created PVCs whose creation
time is within `spark.kubernetes.allocation.batch.delay`.
In case of slow K8s control plane situation where
`spark.kubernetes.allocation.batch.delay` is too short relatively or
`spark.kubernetes.executor.enablePollingWithResourceVersion=true` is used,
`onNewSnapshots` may not return the full list of executor pods created by the
previous batch. This sometimes makes Spark driver think the PVCs in the
previous batch are reusable for the next batch.
No.
Pass the CIs with the newly created test case.
Closes #38912 from dongjoon-hyun/SPARK-41388.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
(cherry picked from commit e234cd8276a603ab8a191dd078b11c605b22a50c)
Signed-off-by: Dongjoon Hyun
---
.../cluster/k8s/ExecutorPodsAllocator.scala| 6 +-
.../cluster/k8s/ExecutorPodsAllocatorSuite.scala | 23 --
2 files changed, 26 insertions(+), 3 deletions(-)
diff --git
a/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
b/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
index 3519efd3fcb..86fe61077bf 100644
---
a/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
+++
b/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
@@ -367,7 +367,11 @@ class ExecutorPodsAllocator(
.getItems
.asScala
- val reusablePVCs = createdPVCs.filterNot(pvc =>
pvcsInUse.contains(pvc.getMetadata.getName))
+ val now = Instant.now().toEpochMilli
+ val reusablePVCs = createdPVCs
+.filterNot(pvc => pvcsInUse.contains(pvc.getMetadata.getName))
+.filter(pvc => now -
Instant.parse(pvc.getMetadata.getCreationTimestamp).toEpochMilli
+ > podAllocationDelay)
logInfo(s"Found ${reusablePVCs.size} reusable PVCs from
${createdPVCs.size} PVCs")
reusablePVCs
} else {
diff --git
a/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
b/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
index d263bd00731..856ee7031c2 100644
---
a/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
+++
b/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
@@ -17,9 +17,11 @@
package org.apache.spark.scheduler.cluster.k8s
import java.time.Instant
+import java.time.temporal.ChronoUnit.MILLIS
import java.util.concurrent.atomic.AtomicInteger
import scala.collection.JavaConverters._
+import scala.collection.mutable
import io.fabric8.kubernetes.api.model._
import io.fabric8.kubernetes.client.KubernetesClient
@@ -697,8 +699,10 @@ class ExecutorPodsAllocatorSuite extends SparkFunSuite
with BeforeAndAfter {
when(kubernetesClient.persistentVolumeClaims()).thenReturn(persistentVolumeClaims)
when(persistentVolumeClaims.withLabel(any(),
any())).thenReturn(labeledPersistentVolumeClaims)
when(labeledPersistentVolumeClaims.list()).thenReturn(persistentVolumeClaimList)
-when(persistentVolumeClaimList.getItems)
- .thenReturn(Seq(persistentVolumeClaim("pvc-0", "gp2", "200Gi")).asJava)
+val pvc = persistentVolumeClaim("pvc-0", "gp2", "200Gi")
+pvc.getMetadata
+ .setCreationTimestamp(Instant.now().minus(podAllocationDelay + 1,
MILLIS).toString)
+when(persistentVolumeClaimList.getItems).thenReturn(Seq(pvc).asJava)
when(executorBuilder.buildFromFeatures(any(classOf[KubernetesExecutorConf]),
meq(secMgr),
meq(kubernetesClient), any(classOf[ResourceProfile])))
.thenAnswer((invocation: InvocationOnMock) => {
@@ -761,6 +765,21 @@ class ExecutorPodsAllocatorSuite extends SparkFunSuite
with BeforeAndAfter {
" namespace default"))
}
+ test("SPARK-41388: getReusablePVCs should ignore recently created PVCs in
the previous batch") {
+
[spark] branch master updated: [SPARK-41388][K8S] `getReusablePVCs` should ignore recently created PVCs in the previous batch
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new e234cd8276a [SPARK-41388][K8S] `getReusablePVCs` should ignore
recently created PVCs in the previous batch
e234cd8276a is described below
commit e234cd8276a603ab8a191dd078b11c605b22a50c
Author: Dongjoon Hyun
AuthorDate: Mon Dec 5 01:09:50 2022 -0800
[SPARK-41388][K8S] `getReusablePVCs` should ignore recently created PVCs in
the previous batch
### What changes were proposed in this pull request?
This PR aims to prevent `getReusablePVCs` from choosing recently created
PVCs in the very previous batch by excluding newly created PVCs whose creation
time is within `spark.kubernetes.allocation.batch.delay`.
### Why are the changes needed?
In case of slow K8s control plane situation where
`spark.kubernetes.allocation.batch.delay` is too short relatively or
`spark.kubernetes.executor.enablePollingWithResourceVersion=true` is used,
`onNewSnapshots` may not return the full list of executor pods created by the
previous batch. This sometimes makes Spark driver think the PVCs in the
previous batch are reusable for the next batch.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the CIs with the newly created test case.
Closes #38912 from dongjoon-hyun/SPARK-41388.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
---
.../cluster/k8s/ExecutorPodsAllocator.scala| 6 +-
.../cluster/k8s/ExecutorPodsAllocatorSuite.scala | 22 --
2 files changed, 25 insertions(+), 3 deletions(-)
diff --git
a/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
b/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
index 524ab0c845c..d8ae910b1ae 100644
---
a/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
+++
b/resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocator.scala
@@ -373,7 +373,11 @@ class ExecutorPodsAllocator(
.getItems
.asScala
-val reusablePVCs = createdPVCs.filterNot(pvc =>
pvcsInUse.contains(pvc.getMetadata.getName))
+val now = Instant.now().toEpochMilli
+val reusablePVCs = createdPVCs
+ .filterNot(pvc => pvcsInUse.contains(pvc.getMetadata.getName))
+ .filter(pvc => now -
Instant.parse(pvc.getMetadata.getCreationTimestamp).toEpochMilli
+> podAllocationDelay)
logInfo(s"Found ${reusablePVCs.size} reusable PVCs from
${createdPVCs.size} PVCs")
reusablePVCs
} catch {
diff --git
a/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
b/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
index caec9ef9201..c526bf0968e 100644
---
a/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
+++
b/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala
@@ -17,6 +17,7 @@
package org.apache.spark.scheduler.cluster.k8s
import java.time.Instant
+import java.time.temporal.ChronoUnit.MILLIS
import java.util.concurrent.atomic.AtomicInteger
import scala.collection.JavaConverters._
@@ -721,8 +722,10 @@ class ExecutorPodsAllocatorSuite extends SparkFunSuite
with BeforeAndAfter {
.set(s"$prefix.option.sizeLimit", "200Gi")
.set(s"$prefix.option.storageClass", "gp2")
-when(persistentVolumeClaimList.getItems)
- .thenReturn(Seq(persistentVolumeClaim("pvc-0", "gp2", "200Gi")).asJava)
+val pvc = persistentVolumeClaim("pvc-0", "gp2", "200Gi")
+pvc.getMetadata
+ .setCreationTimestamp(Instant.now().minus(podAllocationDelay + 1,
MILLIS).toString)
+when(persistentVolumeClaimList.getItems).thenReturn(Seq(pvc).asJava)
when(executorBuilder.buildFromFeatures(any(classOf[KubernetesExecutorConf]),
meq(secMgr),
meq(kubernetesClient), any(classOf[ResourceProfile])))
.thenAnswer((invocation: InvocationOnMock) => {
@@ -791,6 +794,21 @@ class ExecutorPodsAllocatorSuite extends SparkFunSuite
with BeforeAndAfter {
podsAllocatorUnderTest invokePrivate getReusablePVCs("appId",
Seq.empty[String])
}
+ test("SPARK-41388: getReusablePVCs should ignore recently created PVCs in
the previous batch") {
+val getReusablePVCs =
+
PrivateMethod[mutable.Buffer[PersistentVolumeClaim]](Symbol("getReusablePVCs"))
+
+val pvc1 = persi
[spark] branch master updated: [SPARK-41355][SQL] Workaround hive table name validation issue
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 8319cec9869 [SPARK-41355][SQL] Workaround hive table name validation
issue
8319cec9869 is described below
commit 8319cec9869ffece624ad4117fea31d452c45e5b
Author: Kun Wan
AuthorDate: Mon Dec 5 16:19:21 2022 +0800
[SPARK-41355][SQL] Workaround hive table name validation issue
### What changes were proposed in this pull request?
Restore dbName and tableName in `HiveShim.getTable()` method.
When we create a hive table, hive will convert the dbName and tableName in
lower case:
https://github.com/apache/hive/blob/release-2.3.9-rc0/metastore/src/java/org/apache/hadoop/hive/metastore/ObjectStore.java#L1446-L1482
And then throw an exception in `Hive.alterTable()`:
https://github.com/apache/hive/blob/release-2.3.9-rc0/ql/src/java/org/apache/hadoop/hive/ql/metadata/Hive.java#L623
For example:
* We want to create a table called `tAb_I`
* Hive metastore will check if the table name is valid by
`MetaStoreUtils.validateName(tbl.getTableName())`
* Hive will call `HiveStringUtils.normalizeIdentifier(tbl.getTableName())`
and then save the save the table name to lower case, **but after setting the
local to "tr", it will be `tab_ı` which is not a valid table name**
* When we run alter table command, we will first get the hive table from
hive metastore which is not a valid table name.
* Update some properties or other, and then try to save it to hive
metastore.
* Hive metastore will check if the table name is valid and then throw
exception `org.apache.hadoop.hive.ql.metadata.HiveException: [tab_ı]: is not a
valid table name`
### Why are the changes needed?
Bug fix for alter table command.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Add UT
Closes #38765 from wankunde/write_stats_directly2.
Authored-by: Kun Wan
Signed-off-by: Wenchen Fan
---
.../apache/spark/sql/execution/command/DDLSuite.scala | 19 +++
.../org/apache/spark/sql/hive/client/HiveShim.scala | 7 ++-
.../org/apache/spark/sql/hive/StatisticsSuite.scala | 2 +-
3 files changed, 26 insertions(+), 2 deletions(-)
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/command/DDLSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/command/DDLSuite.scala
index 6d4e907835e..1e12340d983 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/command/DDLSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/execution/command/DDLSuite.scala
@@ -1963,6 +1963,25 @@ abstract class DDLSuite extends QueryTest with
DDLSuiteBase {
}
}
+ test(s"Support alter table command with CASE_SENSITIVE is true") {
+withSQLConf(SQLConf.CASE_SENSITIVE.key -> s"true") {
+ withLocale("tr") {
+val dbName = "DaTaBaSe_I"
+withDatabase(dbName) {
+ sql(s"CREATE DATABASE $dbName")
+ sql(s"USE $dbName")
+
+ val tabName = "tAb_I"
+ withTable(tabName) {
+sql(s"CREATE TABLE $tabName(col_I int) USING PARQUET")
+sql(s"ALTER TABLE $tabName SET TBLPROPERTIES ('foo' = 'a')")
+checkAnswer(sql(s"SELECT col_I FROM $tabName"), Nil)
+ }
+}
+ }
+}
+ }
+
test("set command rejects SparkConf entries") {
val ex = intercept[AnalysisException] {
sql(s"SET ${config.CPUS_PER_TASK.key} = 4")
diff --git
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
index 95e5582cb8c..5e5d2757e9d 100644
--- a/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
+++ b/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
@@ -620,7 +620,12 @@ private[client] class Shim_v0_12 extends Shim with Logging
{
tableName: String,
throwException: Boolean): Table = {
recordHiveCall()
-hive.getTable(dbName, tableName, throwException)
+val table = hive.getTable(dbName, tableName, throwException)
+if (table != null) {
+ table.getTTable.setTableName(tableName)
+ table.getTTable.setDbName(dbName)
+}
+table
}
override def getTablesByPattern(hive: Hive, dbName: String, pattern:
String): Seq[String] = {
diff --git
a/sql/hive/src/test/scala/org/apache/spark/sql/hive/StatisticsSuite.scala
b/sql/hive/src/test/scala/org/apache/spark/sql/hive/StatisticsSuite.scala
index a1f34945868..4b69a01834d 100644
--- a/sql/hive/src/test/scala/org/apache/spark/sql/hive/StatisticsSuite.scala
+++ b/sql/hive/src/test/scala/org/apache/spark/sql/hive/StatisticsSuite.scala
@@ -537,7 +537,7 @@ class Statist