[spark] branch master updated: [SPARK-41413][FOLLOWUP][SQL][TESTS] More test coverage in KeyGroupedPartitioningSuite
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 8547046e634 [SPARK-41413][FOLLOWUP][SQL][TESTS] More test coverage in
KeyGroupedPartitioningSuite
8547046e634 is described below
commit 8547046e63430c6bab747efd1c33888c18e97d86
Author: Chao Sun
AuthorDate: Mon Jan 23 23:51:03 2023 -0800
[SPARK-41413][FOLLOWUP][SQL][TESTS] More test coverage in
KeyGroupedPartitioningSuite
### What changes were proposed in this pull request?
This is a follow-up of https://github.com/apache/spark/pull/38950, to make
sure we run all tests in the suite with
`spark.sql.sources.v2.bucketing.pushPartValues.enabled` on and off.
### Why are the changes needed?
To increase test coverage. As the config
`spark.sql.sources.v2.bucketing.pushPartValues.enabled` changes, the test
results would change accordingly, so we should make sure the suite covers both
cases.
### Does this PR introduce _any_ user-facing change?
No, this is just test related change.
### How was this patch tested?
N/A
Closes #39708 from sunchao/SPARK-41413-follow-up.
Authored-by: Chao Sun
Signed-off-by: Dongjoon Hyun
---
.../connector/KeyGroupedPartitioningSuite.scala| 183 +
1 file changed, 117 insertions(+), 66 deletions(-)
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/connector/KeyGroupedPartitioningSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/connector/KeyGroupedPartitioningSuite.scala
index b75574a4e77..6cb2313f487 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/connector/KeyGroupedPartitioningSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/connector/KeyGroupedPartitioningSuite.scala
@@ -45,15 +45,12 @@ class KeyGroupedPartitioningSuite extends
DistributionAndOrderingSuiteBase {
UnboundTruncateFunction)
private var originalV2BucketingEnabled: Boolean = false
- private var originalV2BucketingPushPartKeysEnabled: Boolean = false
private var originalAutoBroadcastJoinThreshold: Long = -1
override def beforeAll(): Unit = {
super.beforeAll()
originalV2BucketingEnabled = conf.getConf(V2_BUCKETING_ENABLED)
-originalV2BucketingPushPartKeysEnabled =
conf.getConf(V2_BUCKETING_PUSH_PART_VALUES_ENABLED)
conf.setConf(V2_BUCKETING_ENABLED, true)
-conf.setConf(V2_BUCKETING_PUSH_PART_VALUES_ENABLED, true)
originalAutoBroadcastJoinThreshold =
conf.getConf(AUTO_BROADCASTJOIN_THRESHOLD)
conf.setConf(AUTO_BROADCASTJOIN_THRESHOLD, -1L)
}
@@ -63,7 +60,6 @@ class KeyGroupedPartitioningSuite extends
DistributionAndOrderingSuiteBase {
super.afterAll()
} finally {
conf.setConf(V2_BUCKETING_ENABLED, originalV2BucketingEnabled)
- conf.setConf(V2_BUCKETING_PUSH_PART_VALUES_ENABLED,
originalV2BucketingPushPartKeysEnabled)
conf.setConf(AUTO_BROADCASTJOIN_THRESHOLD,
originalAutoBroadcastJoinThreshold)
}
}
@@ -346,16 +342,21 @@ class KeyGroupedPartitioningSuite extends
DistributionAndOrderingSuiteBase {
s"(2, 11.0, cast('2020-01-01' as timestamp)), " +
s"(3, 19.5, cast('2020-02-01' as timestamp))")
-val df = sql("SELECT id, name, i.price as purchase_price, p.price as
sale_price " +
-s"FROM testcat.ns.$items i JOIN testcat.ns.$purchases p " +
-"ON i.id = p.item_id AND i.arrive_time = p.time ORDER BY id,
purchase_price, sale_price")
-
-val shuffles = collectShuffles(df.queryExecution.executedPlan)
-assert(shuffles.isEmpty, "should not add shuffle for both sides of the
join")
-checkAnswer(df,
- Seq(Row(1, "aa", 40.0, 42.0), Row(1, "aa", 41.0, 44.0), Row(1, "aa",
41.0, 45.0),
-Row(2, "bb", 10.0, 11.0), Row(2, "bb", 10.5, 11.0), Row(3, "cc", 15.5,
19.5))
-)
+Seq(true, false).foreach { pushDownValues =>
+ withSQLConf(SQLConf.V2_BUCKETING_PUSH_PART_VALUES_ENABLED.key ->
pushDownValues.toString) {
+val df = sql("SELECT id, name, i.price as purchase_price, p.price as
sale_price " +
+s"FROM testcat.ns.$items i JOIN testcat.ns.$purchases p " +
+"ON i.id = p.item_id AND i.arrive_time = p.time " +
+"ORDER BY id, purchase_price, sale_price")
+
+val shuffles = collectShuffles(df.queryExecution.executedPlan)
+assert(shuffles.isEmpty, "should not add shuffle for both sides of the
join")
+checkAnswer(df,
+ Seq(Row(1, "aa", 40.0, 42.0), Row(1, "aa", 41.0, 44.0), Row(1, "aa",
41.0, 45.0),
+Row(2, "bb", 10.0, 11.0), Row(2, "bb", 10.5, 11.0), Row(3, "cc",
15.5, 19.5))
+)
+ }
+}
}
test("partitioned join: join with two partition keys and unsorted
partitions") {
@@ -377,16 +378,21 @@ class KeyGroupedPartitioningSuite extends
[spark] branch branch-3.2 updated: [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 35023e81f29 [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should
provide FAIR scheduler
35023e81f29 is described below
commit 35023e81f2938e496bdc90214e239c2e136652ac
Author: Dongjoon Hyun
AuthorDate: Mon Jan 23 23:47:26 2023 -0800
[SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR
scheduler
### What changes were proposed in this pull request?
Like our documentation, `spark.sheduler.mode=FAIR` should provide a `FAIR
Scheduling Within an Application`.
https://spark.apache.org/docs/latest/job-scheduling.html#scheduling-within-an-application

This bug is hidden in our CI because we have `fairscheduler.xml` always as
one of test resources.
-
https://github.com/apache/spark/blob/master/core/src/test/resources/fairscheduler.xml
### Why are the changes needed?
Currently, when `spark.scheduler.mode=FAIR` is given without scheduler
allocation file, Spark creates `Fair Scheduler Pools` with `FIFO` scheduler
which is wrong. We need to switch the mode to `FAIR` from `FIFO`.
**BEFORE**
```
$ bin/spark-shell -c spark.scheduler.mode=FAIR
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use
setLogLevel(newLevel).
23/01/22 14:47:37 WARN NativeCodeLoader: Unable to load native-hadoop
library for your platform... using builtin-java classes where applicable
23/01/22 14:47:38 WARN FairSchedulableBuilder: Fair Scheduler configuration
file not found so jobs will be scheduled in FIFO order. To use fair scheduling,
configure pools in fairscheduler.xml or set spark.scheduler.allocation.file to
a file that contains the configuration.
Spark context Web UI available at http://localhost:4040
```
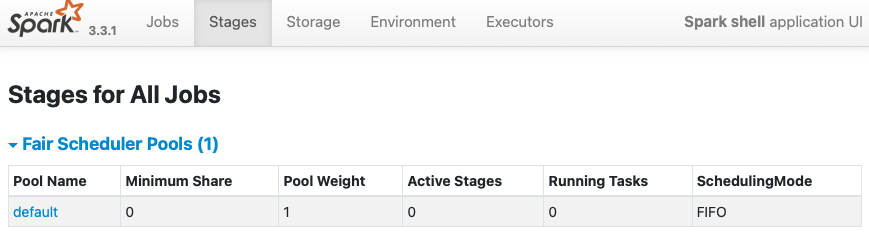
**AFTER**
```
$ bin/spark-shell -c spark.scheduler.mode=FAIR
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use
setLogLevel(newLevel).
23/01/22 14:48:18 WARN NativeCodeLoader: Unable to load native-hadoop
library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://localhost:4040
```
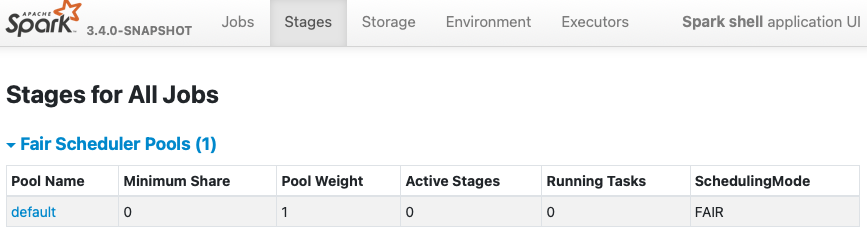
### Does this PR introduce _any_ user-facing change?
Yes, but this is a bug fix to match with Apache Spark official
documentation.
### How was this patch tested?
Pass the CIs.
Closes #39703 from dongjoon-hyun/SPARK-42157.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
(cherry picked from commit 4d51bfa725c26996641f566e42ae392195d639c5)
Signed-off-by: Dongjoon Hyun
---
.../scala/org/apache/spark/scheduler/SchedulableBuilder.scala | 11 +++
1 file changed, 7 insertions(+), 4 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
b/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
index e7c45a9faa1..a30744da9ee 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
@@ -27,7 +27,7 @@ import org.apache.hadoop.fs.Path
import org.apache.spark.SparkContext
import org.apache.spark.internal.Logging
-import org.apache.spark.internal.config.SCHEDULER_ALLOCATION_FILE
+import org.apache.spark.internal.config.{SCHEDULER_ALLOCATION_FILE,
SCHEDULER_MODE}
import org.apache.spark.scheduler.SchedulingMode.SchedulingMode
import org.apache.spark.util.Utils
@@ -86,9 +86,12 @@ private[spark] class FairSchedulableBuilder(val rootPool:
Pool, sc: SparkContext
logInfo(s"Creating Fair Scheduler pools from default file:
$DEFAULT_SCHEDULER_FILE")
Some((is, DEFAULT_SCHEDULER_FILE))
} else {
- logWarning("Fair Scheduler configuration file not found so jobs will
be scheduled in " +
-s"FIFO order. To use fair scheduling, configure pools in
$DEFAULT_SCHEDULER_FILE or " +
-s"set ${SCHEDULER_ALLOCATION_FILE.key} to a file that contains the
configuration.")
+ val schedulingMode =
SchedulingMode.withName(sc.conf.get(SCHEDULER_MODE))
+ rootPool.addSchedulable(new Pool(
+DEFAULT_POOL_NAME, schedulingMode,
[spark] branch branch-3.3 updated: [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 41e6875613c [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should
provide FAIR scheduler
41e6875613c is described below
commit 41e6875613c13fefaa504130c8e63c5eebb2394d
Author: Dongjoon Hyun
AuthorDate: Mon Jan 23 23:47:26 2023 -0800
[SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR
scheduler
### What changes were proposed in this pull request?
Like our documentation, `spark.sheduler.mode=FAIR` should provide a `FAIR
Scheduling Within an Application`.
https://spark.apache.org/docs/latest/job-scheduling.html#scheduling-within-an-application

This bug is hidden in our CI because we have `fairscheduler.xml` always as
one of test resources.
-
https://github.com/apache/spark/blob/master/core/src/test/resources/fairscheduler.xml
### Why are the changes needed?
Currently, when `spark.scheduler.mode=FAIR` is given without scheduler
allocation file, Spark creates `Fair Scheduler Pools` with `FIFO` scheduler
which is wrong. We need to switch the mode to `FAIR` from `FIFO`.
**BEFORE**
```
$ bin/spark-shell -c spark.scheduler.mode=FAIR
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use
setLogLevel(newLevel).
23/01/22 14:47:37 WARN NativeCodeLoader: Unable to load native-hadoop
library for your platform... using builtin-java classes where applicable
23/01/22 14:47:38 WARN FairSchedulableBuilder: Fair Scheduler configuration
file not found so jobs will be scheduled in FIFO order. To use fair scheduling,
configure pools in fairscheduler.xml or set spark.scheduler.allocation.file to
a file that contains the configuration.
Spark context Web UI available at http://localhost:4040
```

**AFTER**
```
$ bin/spark-shell -c spark.scheduler.mode=FAIR
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use
setLogLevel(newLevel).
23/01/22 14:48:18 WARN NativeCodeLoader: Unable to load native-hadoop
library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://localhost:4040
```

### Does this PR introduce _any_ user-facing change?
Yes, but this is a bug fix to match with Apache Spark official
documentation.
### How was this patch tested?
Pass the CIs.
Closes #39703 from dongjoon-hyun/SPARK-42157.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
(cherry picked from commit 4d51bfa725c26996641f566e42ae392195d639c5)
Signed-off-by: Dongjoon Hyun
---
.../scala/org/apache/spark/scheduler/SchedulableBuilder.scala | 11 +++
1 file changed, 7 insertions(+), 4 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
b/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
index e7c45a9faa1..a30744da9ee 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
@@ -27,7 +27,7 @@ import org.apache.hadoop.fs.Path
import org.apache.spark.SparkContext
import org.apache.spark.internal.Logging
-import org.apache.spark.internal.config.SCHEDULER_ALLOCATION_FILE
+import org.apache.spark.internal.config.{SCHEDULER_ALLOCATION_FILE,
SCHEDULER_MODE}
import org.apache.spark.scheduler.SchedulingMode.SchedulingMode
import org.apache.spark.util.Utils
@@ -86,9 +86,12 @@ private[spark] class FairSchedulableBuilder(val rootPool:
Pool, sc: SparkContext
logInfo(s"Creating Fair Scheduler pools from default file:
$DEFAULT_SCHEDULER_FILE")
Some((is, DEFAULT_SCHEDULER_FILE))
} else {
- logWarning("Fair Scheduler configuration file not found so jobs will
be scheduled in " +
-s"FIFO order. To use fair scheduling, configure pools in
$DEFAULT_SCHEDULER_FILE or " +
-s"set ${SCHEDULER_ALLOCATION_FILE.key} to a file that contains the
configuration.")
+ val schedulingMode =
SchedulingMode.withName(sc.conf.get(SCHEDULER_MODE))
+ rootPool.addSchedulable(new Pool(
+DEFAULT_POOL_NAME, schedulingMode,
[spark] branch master updated: [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 4d51bfa725c [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should
provide FAIR scheduler
4d51bfa725c is described below
commit 4d51bfa725c26996641f566e42ae392195d639c5
Author: Dongjoon Hyun
AuthorDate: Mon Jan 23 23:47:26 2023 -0800
[SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR
scheduler
### What changes were proposed in this pull request?
Like our documentation, `spark.sheduler.mode=FAIR` should provide a `FAIR
Scheduling Within an Application`.
https://spark.apache.org/docs/latest/job-scheduling.html#scheduling-within-an-application

This bug is hidden in our CI because we have `fairscheduler.xml` always as
one of test resources.
-
https://github.com/apache/spark/blob/master/core/src/test/resources/fairscheduler.xml
### Why are the changes needed?
Currently, when `spark.scheduler.mode=FAIR` is given without scheduler
allocation file, Spark creates `Fair Scheduler Pools` with `FIFO` scheduler
which is wrong. We need to switch the mode to `FAIR` from `FIFO`.
**BEFORE**
```
$ bin/spark-shell -c spark.scheduler.mode=FAIR
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use
setLogLevel(newLevel).
23/01/22 14:47:37 WARN NativeCodeLoader: Unable to load native-hadoop
library for your platform... using builtin-java classes where applicable
23/01/22 14:47:38 WARN FairSchedulableBuilder: Fair Scheduler configuration
file not found so jobs will be scheduled in FIFO order. To use fair scheduling,
configure pools in fairscheduler.xml or set spark.scheduler.allocation.file to
a file that contains the configuration.
Spark context Web UI available at http://localhost:4040
```

**AFTER**
```
$ bin/spark-shell -c spark.scheduler.mode=FAIR
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use
setLogLevel(newLevel).
23/01/22 14:48:18 WARN NativeCodeLoader: Unable to load native-hadoop
library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://localhost:4040
```

### Does this PR introduce _any_ user-facing change?
Yes, but this is a bug fix to match with Apache Spark official
documentation.
### How was this patch tested?
Pass the CIs.
Closes #39703 from dongjoon-hyun/SPARK-42157.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
---
.../scala/org/apache/spark/scheduler/SchedulableBuilder.scala | 11 +++
1 file changed, 7 insertions(+), 4 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
b/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
index e7c45a9faa1..a30744da9ee 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala
@@ -27,7 +27,7 @@ import org.apache.hadoop.fs.Path
import org.apache.spark.SparkContext
import org.apache.spark.internal.Logging
-import org.apache.spark.internal.config.SCHEDULER_ALLOCATION_FILE
+import org.apache.spark.internal.config.{SCHEDULER_ALLOCATION_FILE,
SCHEDULER_MODE}
import org.apache.spark.scheduler.SchedulingMode.SchedulingMode
import org.apache.spark.util.Utils
@@ -86,9 +86,12 @@ private[spark] class FairSchedulableBuilder(val rootPool:
Pool, sc: SparkContext
logInfo(s"Creating Fair Scheduler pools from default file:
$DEFAULT_SCHEDULER_FILE")
Some((is, DEFAULT_SCHEDULER_FILE))
} else {
- logWarning("Fair Scheduler configuration file not found so jobs will
be scheduled in " +
-s"FIFO order. To use fair scheduling, configure pools in
$DEFAULT_SCHEDULER_FILE or " +
-s"set ${SCHEDULER_ALLOCATION_FILE.key} to a file that contains the
configuration.")
+ val schedulingMode =
SchedulingMode.withName(sc.conf.get(SCHEDULER_MODE))
+ rootPool.addSchedulable(new Pool(
+DEFAULT_POOL_NAME, schedulingMode, DEFAULT_MINIMUM_SHARE,
DEFAULT_WEIGHT))
+ logInfo("Fair scheduler configuration not found, created default
pool: " +
[spark] branch master updated: [SPARK-42164][CORE] Register partitioned-table-related classes to KryoSerializer
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 7546b4405d5 [SPARK-42164][CORE] Register partitioned-table-related
classes to KryoSerializer
7546b4405d5 is described below
commit 7546b4405d5b35626e98b28bfc8031d2100172d1
Author: Dongjoon Hyun
AuthorDate: Mon Jan 23 21:39:30 2023 -0800
[SPARK-42164][CORE] Register partitioned-table-related classes to
KryoSerializer
### What changes were proposed in this pull request?
This PR aims to register partitioned-table-related classes to
`KryoSerializer`.
Specifically, `CREATE TABLE` and `MSCK REPAIR TABLE` uses this classes.
### Why are the changes needed?
To support partitioned-tables more easily with `KryoSerializer`.
Previously, it fails like the following.
```
java.lang.IllegalArgumentException: Class is not registered:
org.apache.spark.util.HadoopFSUtils$SerializableBlockLocation
```
```
java.lang.IllegalArgumentException: Class is not registered:
org.apache.spark.util.HadoopFSUtils$SerializableFileStatus
```
```
java.lang.IllegalArgumentException: Class is not registered:
org.apache.spark.sql.execution.command.PartitionStatistics
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the CIs and manually tests.
**TEST TABLE**
```
$ tree /tmp/t
/tmp/t
├── p=1
│ └── users.orc
├── p=10
│ └── users.orc
├── p=11
│ └── users.orc
├── p=2
│ └── users.orc
├── p=3
│ └── users.orc
├── p=4
│ └── users.orc
├── p=5
│ └── users.orc
├── p=6
│ └── users.orc
├── p=7
│ └── users.orc
├── p=8
│ └── users.orc
└── p=9
└── users.orc
```
**CREATE PARTITIONED TABLES AND RECOVER PARTITIONS**
```
$ bin/spark-shell -c spark.kryo.registrationRequired=true -c
spark.serializer=org.apache.spark.serializer.KryoSerializer -c
spark.sql.sources.parallelPartitionDiscovery.threshold=1
scala> sql("CREATE TABLE t USING ORC LOCATION '/tmp/t'").show()
++
||
++
++
scala> sql("MSCK REPAIR TABLE t").show()
++
||
++
++
```
Closes #39713 from dongjoon-hyun/SPARK-42164.
Authored-by: Dongjoon Hyun
Signed-off-by: Dongjoon Hyun
---
core/src/main/scala/org/apache/spark/serializer/KryoSerializer.scala | 5 +
1 file changed, 5 insertions(+)
diff --git
a/core/src/main/scala/org/apache/spark/serializer/KryoSerializer.scala
b/core/src/main/scala/org/apache/spark/serializer/KryoSerializer.scala
index b7035feba84..5499732660b 100644
--- a/core/src/main/scala/org/apache/spark/serializer/KryoSerializer.scala
+++ b/core/src/main/scala/org/apache/spark/serializer/KryoSerializer.scala
@@ -510,6 +510,10 @@ private[serializer] object KryoSerializer {
// SQL / ML / MLlib classes once and then re-use that filtered list in
newInstance() calls.
private lazy val loadableSparkClasses: Seq[Class[_]] = {
Seq(
+ "org.apache.spark.util.HadoopFSUtils$SerializableBlockLocation",
+ "[Lorg.apache.spark.util.HadoopFSUtils$SerializableBlockLocation;",
+ "org.apache.spark.util.HadoopFSUtils$SerializableFileStatus",
+
"org.apache.spark.sql.catalyst.expressions.BoundReference",
"org.apache.spark.sql.catalyst.expressions.SortOrder",
"[Lorg.apache.spark.sql.catalyst.expressions.SortOrder;",
@@ -536,6 +540,7 @@ private[serializer] object KryoSerializer {
"org.apache.spark.sql.types.DecimalType",
"org.apache.spark.sql.types.Decimal$DecimalAsIfIntegral$",
"org.apache.spark.sql.types.Decimal$DecimalIsFractional$",
+ "org.apache.spark.sql.execution.command.PartitionStatistics",
"org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTaskResult",
"org.apache.spark.sql.execution.joins.EmptyHashedRelation$",
"org.apache.spark.sql.execution.joins.LongHashedRelation",
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42133] Add basic Dataset API methods to Spark Connect Scala Client
This is an automated email from the ASF dual-hosted git repository.
hvanhovell pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 934d14d73c1 [SPARK-42133] Add basic Dataset API methods to Spark
Connect Scala Client
934d14d73c1 is described below
commit 934d14d73c14406242ccd11ba67e64fde1f3b955
Author: vicennial
AuthorDate: Mon Jan 23 22:10:02 2023 -0400
[SPARK-42133] Add basic Dataset API methods to Spark Connect Scala Client
### What changes were proposed in this pull request?
Adds the following methods:
- Dataset API methods
- project
- filter
- limit
- SparkSession
- range (and its variations)
This PR also introduces `Column` and `functions` to support the above
changes.
### Why are the changes needed?
Incremental development of Spark Connect Scala Client.
### Does this PR introduce _any_ user-facing change?
Yes, users may now use the proposed API methods.
Example: `val df = sparkSession.range(5).limit(3)`
### How was this patch tested?
Unit tests + simple E2E test.
Closes #39672 from vicennial/SPARK-42133.
Authored-by: vicennial
Signed-off-by: Herman van Hovell
---
.../main/scala/org/apache/spark/sql/Column.scala | 107 ++
.../main/scala/org/apache/spark/sql/Dataset.scala | 50 +
.../scala/org/apache/spark/sql/SparkSession.scala | 51 +
.../sql/connect/client/SparkConnectClient.scala| 22
.../client/package.scala} | 14 ++-
.../scala/org/apache/spark/sql/functions.scala | 83 ++
.../org/apache/spark/sql/ClientE2ETestSuite.scala | 10 ++
.../scala/org/apache/spark/sql/DatasetSuite.scala | 114
.../org/apache/spark/sql/SparkSessionSuite.scala | 120 +
.../connect/client/SparkConnectClientSuite.scala | 10 ++
10 files changed, 576 insertions(+), 5 deletions(-)
diff --git
a/connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/Column.scala
b/connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/Column.scala
new file mode 100644
index 000..f25d579d5c3
--- /dev/null
+++
b/connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/Column.scala
@@ -0,0 +1,107 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql
+
+import scala.collection.JavaConverters._
+
+import org.apache.spark.connect.proto
+import org.apache.spark.sql.Column.fn
+import org.apache.spark.sql.connect.client.unsupported
+import org.apache.spark.sql.functions.lit
+
+/**
+ * A column that will be computed based on the data in a `DataFrame`.
+ *
+ * A new column can be constructed based on the input columns present in a
DataFrame:
+ *
+ * {{{
+ * df("columnName")// On a specific `df` DataFrame.
+ * col("columnName") // A generic column not yet associated with a
DataFrame.
+ * col("columnName.field") // Extracting a struct field
+ * col("`a.column.with.dots`") // Escape `.` in column names.
+ * $"columnName" // Scala short hand for a named column.
+ * }}}
+ *
+ * [[Column]] objects can be composed to form complex expressions:
+ *
+ * {{{
+ * $"a" + 1
+ * }}}
+ *
+ * @since 3.4.0
+ */
+class Column private[sql] (private[sql] val expr: proto.Expression) {
+
+ /**
+ * Sum of this expression and another expression.
+ * {{{
+ * // Scala: The following selects the sum of a person's height and weight.
+ * people.select( people("height") + people("weight") )
+ *
+ * // Java:
+ * people.select( people.col("height").plus(people.col("weight")) );
+ * }}}
+ *
+ * @group expr_ops
+ * @since 3.4.0
+ */
+ def +(other: Any): Column = fn("+", this, lit(other))
+
+ /**
+ * Gives the column a name (alias).
+ * {{{
+ * // Renames colA to colB in select output.
+ * df.select($"colA".name("colB"))
+ * }}}
+ *
+ * If the current column has metadata associated with it, this metadata will
be propagated to
+ * the new column. If this not
[GitHub] [spark-website] gaborgsomogyi commented on pull request #432: Change Gabor Somogyi company
gaborgsomogyi commented on PR #432: URL: https://github.com/apache/spark-website/pull/432#issuecomment-1400360251 Thanks guys for taking care -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[GitHub] [spark-website] srowen closed pull request #432: Change Gabor Somogyi company
srowen closed pull request #432: Change Gabor Somogyi company URL: https://github.com/apache/spark-website/pull/432 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Change Gabor Somogyi company
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 2f766afbc Change Gabor Somogyi company 2f766afbc is described below commit 2f766afbcb77e495f0e5e7e6a81458075e6ade96 Author: Gabor Somogyi AuthorDate: Mon Jan 23 07:12:20 2023 -0600 Change Gabor Somogyi company Author: Gabor Somogyi Closes #432 from gaborgsomogyi/company. --- committers.md| 2 +- site/committers.html | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) diff --git a/committers.md b/committers.md index a16b33d31..827073a0d 100644 --- a/committers.md +++ b/committers.md @@ -74,7 +74,7 @@ navigation: |Kousuke Saruta|NTT Data| |Saisai Shao|Tencent| |Prashant Sharma|IBM| -|Gabor Somogyi|Cloudera| +|Gabor Somogyi|Apple| |Ram Sriharsha|Databricks| |Chao Sun|Apple| |Maciej Szymkiewicz|| diff --git a/site/committers.html b/site/committers.html index 5ac86d8db..c0543233b 100644 --- a/site/committers.html +++ b/site/committers.html @@ -390,7 +390,7 @@ Gabor Somogyi - Cloudera + Apple Ram Sriharsha - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41948][SQL] Fix NPE for error classes: CANNOT_PARSE_JSON_FIELD
This is an automated email from the ASF dual-hosted git repository.
maxgekk pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new cc1674d66ef [SPARK-41948][SQL] Fix NPE for error classes:
CANNOT_PARSE_JSON_FIELD
cc1674d66ef is described below
commit cc1674d66ef34f540aa7bd5c7e465605e264e040
Author: panbingkun
AuthorDate: Mon Jan 23 15:15:59 2023 +0300
[SPARK-41948][SQL] Fix NPE for error classes: CANNOT_PARSE_JSON_FIELD
### What changes were proposed in this pull request?
The pr aims to fix NPE for error classes: CANNOT_PARSE_JSON_FIELD.
### Why are the changes needed?
1. When I want to delete redundant 'toString()' in code block as follow
https://user-images.githubusercontent.com/15246973/211269145-0f087bb1-dc93-480c-9f9d-afde5ac1c8de.png;>
I found the UT("select from_json('[1, \"2\", 3]', 'array')") failed.
Why can it succeed before deletion?
`parse.getCurrentName.toString()` => null.toString() => throw NPE, but
follow logical can cover it,
https://github.com/apache/spark/blob/15a0f55246bee7b043bd6081f53744fbf74403eb/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JacksonParser.scala#L569-L573
But obviously this is not our original intention.
After deletion, The IllegalArgumentException will be thrown.
`parse.getCurrentName` => throw java.lang.IllegalArgumentException as
follow:
`Caused by: java.lang.IllegalArgumentException: Cannot resolve variable
'fieldName' (enableSubstitutionInVariables=false).
at
org.apache.commons.text.StringSubstitutor.substitute(StringSubstitutor.java:1532)
at
org.apache.commons.text.StringSubstitutor.substitute(StringSubstitutor.java:1389)
at
org.apache.commons.text.StringSubstitutor.replace(StringSubstitutor.java:893)
at
org.apache.spark.ErrorClassesJsonReader.getErrorMessage(ErrorClassesJSONReader.scala:51)
... 140 more
`
Above code can't handle IllegalArgumentException, so the UT failed.
So, we should consider the case where `parse.getCurrentName` is null.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA.
Existed UT.
Closes #39466 from panbingkun/SPARK-41948.
Authored-by: panbingkun
Signed-off-by: Max Gekk
---
.../main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala | 4 ++--
sql/core/src/test/scala/org/apache/spark/sql/JsonFunctionsSuite.scala | 3 ++-
2 files changed, 4 insertions(+), 3 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala
index 8128c460602..9c8c764cf92 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala
@@ -1443,8 +1443,8 @@ private[sql] object QueryExecutionErrors extends
QueryErrorsBase {
new SparkRuntimeException(
errorClass = "CANNOT_PARSE_JSON_FIELD",
messageParameters = Map(
-"fieldName" -> parser.getCurrentName.toString(),
-"fieldValue" -> parser.getText.toString(),
+"fieldName" -> toSQLValue(parser.getCurrentName, StringType),
+"fieldValue" -> parser.getText,
"jsonType" -> jsonType.toString(),
"dataType" -> toSQLType(dataType)))
}
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/JsonFunctionsSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/JsonFunctionsSuite.scala
index 6e16533eb30..57c54e88229 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/JsonFunctionsSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/JsonFunctionsSuite.scala
@@ -27,6 +27,7 @@ import org.apache.commons.lang3.exception.ExceptionUtils
import org.apache.spark.{SparkException, SparkRuntimeException}
import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.catalyst.expressions.{Literal, StructsToJson}
+import org.apache.spark.sql.catalyst.expressions.Cast._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.test.SharedSparkSession
@@ -785,7 +786,7 @@ class JsonFunctionsSuite extends QueryTest with
SharedSparkSession {
exception =
ExceptionUtils.getRootCause(exception).asInstanceOf[SparkRuntimeException],
errorClass = "CANNOT_PARSE_JSON_FIELD",
parameters = Map(
- "fieldName" -> "a",
+ "fieldName" -> toSQLValue("a", StringType),
"fieldValue" -> "1",
"jsonType" -> "VALUE_STRING",
"dataType" -> "\"INT\"")
-
To unsubscribe, e-mail:
[GitHub] [spark-website] gaborgsomogyi commented on pull request #432: Change Gabor Somogyi company
gaborgsomogyi commented on PR #432: URL: https://github.com/apache/spark-website/pull/432#issuecomment-1400034321 cc @dongjoon-hyun -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41979][SQL] Add missing dots for error messages in error classes
This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 04d72659a88 [SPARK-41979][SQL] Add missing dots for error messages in
error classes
04d72659a88 is described below
commit 04d72659a88c3e94ff97f27e5481bc130b824b0a
Author: itholic
AuthorDate: Mon Jan 23 17:17:06 2023 +0900
[SPARK-41979][SQL] Add missing dots for error messages in error classes
### What changes were proposed in this pull request?
This PR proposes to add missing dots for error messages in error classes.
This PR also fixes related tests, and includes a minor error message fix.
### Why are the changes needed?
To keep consistency across all error messages. Error messages should end
with a dot.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
`./build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite*`
Closes #39505 from itholic/missing_dots.
Authored-by: itholic
Signed-off-by: Hyukjin Kwon
---
core/src/main/resources/error/error-classes.json | 614 ++---
.../org/apache/spark/SparkThrowableSuite.scala | 4 +-
.../spark/metrics/sink/GraphiteSinkSuite.scala | 13 +-
.../org/apache/spark/sql/types/DataTypeSuite.scala | 15 +-
.../results/ansi/datetime-parsing-invalid.sql.out | 6 +-
.../org/apache/spark/sql/DataFrameSuite.scala | 24 +-
.../spark/sql/execution/SQLViewTestSuite.scala | 13 +-
.../sql/execution/datasources/FileIndexSuite.scala | 13 +-
.../datasources/parquet/ParquetSchemaSuite.scala | 24 +-
.../sql/execution/joins/HashedRelationSuite.scala | 11 +-
.../streaming/sources/ForeachWriterSuite.scala | 10 +-
.../spark/sql/hive/thriftserver/CliSuite.scala | 2 +-
12 files changed, 399 insertions(+), 350 deletions(-)
diff --git a/core/src/main/resources/error/error-classes.json
b/core/src/main/resources/error/error-classes.json
index 5340ba2abc2..08ce9fe1021 100644
--- a/core/src/main/resources/error/error-classes.json
+++ b/core/src/main/resources/error/error-classes.json
@@ -31,7 +31,7 @@
},
"CANNOT_CONSTRUCT_PROTOBUF_DESCRIPTOR" : {
"message" : [
- "Error constructing FileDescriptor for "
+ "Error constructing FileDescriptor for ."
]
},
"CANNOT_CONVERT_PROTOBUF_FIELD_TYPE_TO_SQL_TYPE" : {
@@ -46,7 +46,7 @@
},
"CANNOT_CONVERT_SQL_TYPE_TO_PROTOBUF_ENUM_TYPE" : {
"message" : [
- "Cannot convert SQL to Protobuf because
cannot be written since it's not defined in ENUM "
+ "Cannot convert SQL to Protobuf because
cannot be written since it's not defined in ENUM ."
]
},
"CANNOT_CONVERT_SQL_TYPE_TO_PROTOBUF_FIELD_TYPE" : {
@@ -72,7 +72,7 @@
},
"CANNOT_PARSE_DECIMAL" : {
"message" : [
- "Cannot parse decimal"
+ "Cannot parse decimal."
],
"sqlState" : "22018"
},
@@ -84,7 +84,7 @@
},
"CANNOT_PARSE_PROTOBUF_DESCRIPTOR" : {
"message" : [
- "Error parsing file descriptor byte[] into Descriptor
object"
+ "Error parsing file descriptor byte[] into Descriptor
object."
]
},
"CANNOT_PARSE_TIMESTAMP" : {
@@ -179,7 +179,7 @@
},
"CREATE_TABLE_COLUMN_OPTION_DUPLICATE" : {
"message" : [
- "CREATE TABLE column specifies option \"\" more
than once, which is invalid"
+ "CREATE TABLE column specifies option \"\" more
than once, which is invalid."
],
"sqlState" : "42710"
},
@@ -272,7 +272,7 @@
},
"INPUT_SIZE_NOT_ONE" : {
"message" : [
- "Length of should be 1"
+ "Length of should be 1."
]
},
"INVALID_ARG_VALUE" : {
@@ -342,7 +342,7 @@
},
"PARAMETER_CONSTRAINT_VIOLATION" : {
"message" : [
- "The () must be the
()"
+ "The () must be the
()."
]
},
"RANGE_FRAME_INVALID_TYPE" : {
@@ -364,7 +364,7 @@
"message" : [
" uses the wrong parameter type. The parameter type
must conform to:",
"1. The start and stop expressions must resolve to the same type.",
- "2. If start and stop expressions resolve to the type,
then the step expression must resolve to the type",
+ "2. If start and stop expressions resolve to the type,
then the step expression must resolve to the type.",
"3. Otherwise, if start and stop expressions resolve to the
type, then the step expression must resolve to the same type."
]
},
@@ -400,7 +400,7 @@
},
"UNEXPECTED_CLASS_TYPE" : {
"message" : [
- "class not found"
+ "class not found."
]
},
"UNEXPECTED_INPUT_TYPE" : {
@@ -410,7 +410,7 @@
},
"UNEXPECTED_NULL" : {
[spark] branch master updated (5b9ec43a611 -> 57d06f85727)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 5b9ec43a611 [SPARK-42152][BUILD][CORE][SQL][PYTHON][PROTOBUF] Use `_` instead of `-` for relocation package name add 57d06f85727 [SPARK-41712][PYTHON][CONNECT] Migrate the Spark Connect errors into PySpark error framework No new revisions were added by this update. Summary of changes: python/docs/source/reference/pyspark.errors.rst| 5 ++ python/pyspark/errors/__init__.py | 10 +++ python/pyspark/errors/exceptions.py| 73 +- python/pyspark/sql/connect/client.py | 54 +++- .../sql/tests/connect/test_connect_basic.py| 25 +--- .../sql/tests/connect/test_connect_column.py | 2 +- .../sql/tests/connect/test_connect_function.py | 16 ++--- 7 files changed, 134 insertions(+), 51 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (ea5be383105 -> 5b9ec43a611)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from ea5be383105 [SPARK-41775][PYTHON][ML] Adding support for PyTorch functions add 5b9ec43a611 [SPARK-42152][BUILD][CORE][SQL][PYTHON][PROTOBUF] Use `_` instead of `-` for relocation package name No new revisions were added by this update. Summary of changes: connector/protobuf/pom.xml| 2 +- .../src/main/scala/org/apache/spark/sql/protobuf/functions.scala | 8 core/pom.xml | 2 +- project/SparkBuild.scala | 2 +- python/pyspark/sql/protobuf/functions.py | 8 5 files changed, 11 insertions(+), 11 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (041883f6b90 -> ea5be383105)
This is an automated email from the ASF dual-hosted git repository. gurwls223 pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 041883f6b90 [SPARK-42154][K8S][TESTS] Enable `Volcano` unit and integration tests in GitHub Action add ea5be383105 [SPARK-41775][PYTHON][ML] Adding support for PyTorch functions No new revisions were added by this update. Summary of changes: python/pyspark/ml/torch/distributor.py| 154 +- python/pyspark/ml/torch/tests/test_distributor.py | 117 ++-- 2 files changed, 224 insertions(+), 47 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org