[spark] branch master updated: [SPARK-43169][INFRA][FOLLOWUP] Add more memory for mima check
This is an automated email from the ASF dual-hosted git repository. ruifengz pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 6c9153b206c [SPARK-43169][INFRA][FOLLOWUP] Add more memory for mima check 6c9153b206c is described below commit 6c9153b206c4a7cbd3f8b81c4840cdcfd4a14412 Author: yangjie01 AuthorDate: Mon Apr 24 16:12:07 2023 +0800 [SPARK-43169][INFRA][FOLLOWUP] Add more memory for mima check ### What changes were proposed in this pull request? This pr aims to change `-Xmx` from `4196` to `120` for dev/mima to avoid `GC overhead limit exceeded`. ### Why are the changes needed? Make `dev/mina` stable on GitHub Action. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually check that `GC overhead limit exceeded` no longer exists Closes #40862 from LuciferYang/SPARK-43169-FOLLOWUP. Lead-authored-by: yangjie01 Co-authored-by: YangJie Signed-off-by: Ruifeng Zheng --- dev/mima | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/dev/mima b/dev/mima index 06d6dba201b..4a9e343b0a7 100755 --- a/dev/mima +++ b/dev/mima @@ -42,7 +42,7 @@ $JAVA_CMD \ -cp "$TOOLS_CLASSPATH:$OLD_DEPS_CLASSPATH" \ org.apache.spark.tools.GenerateMIMAIgnore -echo -e "q\n" | build/sbt -mem 4196 -DcopyDependencies=false "$@" mimaReportBinaryIssues | grep -v -e "info.*Resolving" +echo -e "q\n" | build/sbt -mem 5120 -DcopyDependencies=false "$@" mimaReportBinaryIssues | grep -v -e "info.*Resolving" ret_val=$? if [ $ret_val != 0 ]; then - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42317][SQL] Assign name to _LEGACY_ERROR_TEMP_2247: CANNOT_MERGE_SCHEMAS
This is an automated email from the ASF dual-hosted git repository.
maxgekk pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 69946bb5c70 [SPARK-42317][SQL] Assign name to _LEGACY_ERROR_TEMP_2247:
CANNOT_MERGE_SCHEMAS
69946bb5c70 is described below
commit 69946bb5c707657bf0840b21356fbe95b8524ab9
Author: Koray Beyaz
AuthorDate: Mon Apr 24 11:30:11 2023 +0300
[SPARK-42317][SQL] Assign name to _LEGACY_ERROR_TEMP_2247:
CANNOT_MERGE_SCHEMAS
### What changes were proposed in this pull request?
This PR proposes to assign name to _LEGACY_ERROR_TEMP_2247 as
"CANNOT_MERGE_SCHEMAS".
Also proposes to display both left and right schemas in the exception so
that one can compare them. Please let me know if you prefer the old error
message with a single schema.
This is the stack trace after the changes:
```
scala> spark.read.option("mergeSchema", "true").parquet(path)
org.apache.spark.SparkException: [CANNOT_MERGE_SCHEMAS] Failed merging
schemas:
Initial schema:
"STRUCT"
Schema that cannot be merged with the initial schema:
"STRUCT".
at
org.apache.spark.sql.errors.QueryExecutionErrors$.failedMergingSchemaError(QueryExecutionErrors.scala:2355)
at
org.apache.spark.sql.execution.datasources.SchemaMergeUtils$.$anonfun$mergeSchemasInParallel$5(SchemaMergeUtils.scala:104)
at
org.apache.spark.sql.execution.datasources.SchemaMergeUtils$.$anonfun$mergeSchemasInParallel$5$adapted(SchemaMergeUtils.scala:100)
at
scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
at
scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198)
at
org.apache.spark.sql.execution.datasources.SchemaMergeUtils$.mergeSchemasInParallel(SchemaMergeUtils.scala:100)
at
org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat$.mergeSchemasInParallel(ParquetFileFormat.scala:496)
at
org.apache.spark.sql.execution.datasources.parquet.ParquetUtils$.inferSchema(ParquetUtils.scala:132)
at
org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat.inferSchema(ParquetFileFormat.scala:78)
at
org.apache.spark.sql.execution.datasources.DataSource.$anonfun$getOrInferFileFormatSchema$11(DataSource.scala:208)
at scala.Option.orElse(Option.scala:447)
at
org.apache.spark.sql.execution.datasources.DataSource.getOrInferFileFormatSchema(DataSource.scala:205)
at
org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:407)
at
org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:229)
at
org.apache.spark.sql.DataFrameReader.$anonfun$load$2(DataFrameReader.scala:211)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:211)
at org.apache.spark.sql.DataFrameReader.parquet(DataFrameReader.scala:563)
at org.apache.spark.sql.DataFrameReader.parquet(DataFrameReader.scala:548)
... 49 elided
Caused by: org.apache.spark.SparkException:
[CANNOT_MERGE_INCOMPATIBLE_DATA_TYPE] Failed to merge incompatible data types
"BIGINT" and "INT".
at
org.apache.spark.sql.errors.QueryExecutionErrors$.cannotMergeIncompatibleDataTypesError(QueryExecutionErrors.scala:1326)
at
org.apache.spark.sql.types.StructType$.$anonfun$merge$3(StructType.scala:610)
at scala.Option.map(Option.scala:230)
at
org.apache.spark.sql.types.StructType$.$anonfun$merge$2(StructType.scala:602)
at
org.apache.spark.sql.types.StructType$.$anonfun$merge$2$adapted(StructType.scala:599)
at
scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
at
scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198)
at
org.apache.spark.sql.types.StructType$.$anonfun$merge$1(StructType.scala:599)
at
org.apache.spark.sql.types.StructType$.mergeInternal(StructType.scala:647)
at org.apache.spark.sql.types.StructType$.merge(StructType.scala:593)
at org.apache.spark.sql.types.StructType.merge(StructType.scala:498)
at
org.apache.spark.sql.execution.datasources.SchemaMergeUtils$.$anonfun$mergeSchemasInParallel$5(SchemaMergeUtils.scala:102)
... 67 more
```
### Why are the changes needed?
We should assign proper name to LEGACY_ERROR_TEMP*
### Does this PR introduce _any_ user-facing change?
Yes, the users will see an improved error message.
### How was this patch tested?
Changed an existing test case to test the new error class with `checkError`
utility.
Closes #40810 from kori73/assign-name-2247.
Lead-authored-by: K
[spark] branch master updated: [SPARK-43249][CONNECT] Fix missing stats for SQL Command
This is an automated email from the ASF dual-hosted git repository.
ruifengz pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 9d050539bed [SPARK-43249][CONNECT] Fix missing stats for SQL Command
9d050539bed is described below
commit 9d050539bed10e5089c3c125887a9995693733c6
Author: Martin Grund
AuthorDate: Mon Apr 24 16:33:32 2023 +0800
[SPARK-43249][CONNECT] Fix missing stats for SQL Command
### What changes were proposed in this pull request?
This patch fixes a minor issue in the code where for SQL Commands the plan
metrics are not sent to the client. In addition, it renames a method to make
clear that the method does not actually send anything but only creates the
response object.
### Why are the changes needed?
Clarity
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes #40899 from grundprinzip/fix_sql_stats.
Authored-by: Martin Grund
Signed-off-by: Ruifeng Zheng
---
.../org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala| 2 +-
.../apache/spark/sql/connect/service/SparkConnectStreamHandler.scala | 4 ++--
2 files changed, 3 insertions(+), 3 deletions(-)
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
index 7bc67f8c398..59c407c8eea 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
@@ -1829,7 +1829,7 @@ class SparkConnectPlanner(val session: SparkSession) {
.build())
// Send Metrics
-SparkConnectStreamHandler.sendMetricsToResponse(sessionId, df)
+
responseObserver.onNext(SparkConnectStreamHandler.createMetricsResponse(sessionId,
df))
}
private def handleRegisterUserDefinedFunction(
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectStreamHandler.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectStreamHandler.scala
index 845eb084598..f08dfba5e28 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectStreamHandler.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectStreamHandler.scala
@@ -87,7 +87,7 @@ class SparkConnectStreamHandler(responseObserver:
StreamObserver[ExecutePlanResp
SparkConnectStreamHandler.sendSchemaToResponse(request.getSessionId,
dataframe.schema))
processAsArrowBatches(request.getSessionId, dataframe, responseObserver)
responseObserver.onNext(
- SparkConnectStreamHandler.sendMetricsToResponse(request.getSessionId,
dataframe))
+ SparkConnectStreamHandler.createMetricsResponse(request.getSessionId,
dataframe))
if (dataframe.queryExecution.observedMetrics.nonEmpty) {
responseObserver.onNext(
SparkConnectStreamHandler.sendObservedMetricsToResponse(request.getSessionId,
dataframe))
@@ -271,7 +271,7 @@ object SparkConnectStreamHandler {
.build()
}
- def sendMetricsToResponse(sessionId: String, rows: DataFrame):
ExecutePlanResponse = {
+ def createMetricsResponse(sessionId: String, rows: DataFrame):
ExecutePlanResponse = {
// Send a last batch with the metrics
ExecutePlanResponse
.newBuilder()
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-43249][CONNECT] Fix missing stats for SQL Command
This is an automated email from the ASF dual-hosted git repository.
ruifengz pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new 1c28ec7d9b5 [SPARK-43249][CONNECT] Fix missing stats for SQL Command
1c28ec7d9b5 is described below
commit 1c28ec7d9b50933107b2d2f56dd57aeeb9ec4e53
Author: Martin Grund
AuthorDate: Mon Apr 24 16:33:32 2023 +0800
[SPARK-43249][CONNECT] Fix missing stats for SQL Command
### What changes were proposed in this pull request?
This patch fixes a minor issue in the code where for SQL Commands the plan
metrics are not sent to the client. In addition, it renames a method to make
clear that the method does not actually send anything but only creates the
response object.
### Why are the changes needed?
Clarity
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes #40899 from grundprinzip/fix_sql_stats.
Authored-by: Martin Grund
Signed-off-by: Ruifeng Zheng
(cherry picked from commit 9d050539bed10e5089c3c125887a9995693733c6)
Signed-off-by: Ruifeng Zheng
---
.../org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala| 2 +-
.../apache/spark/sql/connect/service/SparkConnectStreamHandler.scala | 4 ++--
2 files changed, 3 insertions(+), 3 deletions(-)
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
index 7650532fcf9..0f3189e6013 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
@@ -1667,7 +1667,7 @@ class SparkConnectPlanner(val session: SparkSession) {
.build())
// Send Metrics
-SparkConnectStreamHandler.sendMetricsToResponse(sessionId, df)
+
responseObserver.onNext(SparkConnectStreamHandler.createMetricsResponse(sessionId,
df))
}
private def handleRegisterUserDefinedFunction(
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectStreamHandler.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectStreamHandler.scala
index 335b871d499..760ff8a64b4 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectStreamHandler.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectStreamHandler.scala
@@ -65,7 +65,7 @@ class SparkConnectStreamHandler(responseObserver:
StreamObserver[ExecutePlanResp
SparkConnectStreamHandler.sendSchemaToResponse(request.getSessionId,
dataframe.schema))
processAsArrowBatches(request.getSessionId, dataframe, responseObserver)
responseObserver.onNext(
- SparkConnectStreamHandler.sendMetricsToResponse(request.getSessionId,
dataframe))
+ SparkConnectStreamHandler.createMetricsResponse(request.getSessionId,
dataframe))
if (dataframe.queryExecution.observedMetrics.nonEmpty) {
responseObserver.onNext(
SparkConnectStreamHandler.sendObservedMetricsToResponse(request.getSessionId,
dataframe))
@@ -215,7 +215,7 @@ object SparkConnectStreamHandler {
.build()
}
- def sendMetricsToResponse(sessionId: String, rows: DataFrame):
ExecutePlanResponse = {
+ def createMetricsResponse(sessionId: String, rows: DataFrame):
ExecutePlanResponse = {
// Send a last batch with the metrics
ExecutePlanResponse
.newBuilder()
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-43178][CONNECT][PYTHON] Migrate UDF errors into PySpark error framework
This is an automated email from the ASF dual-hosted git repository.
ruifengz pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 8ae9c512a55 [SPARK-43178][CONNECT][PYTHON] Migrate UDF errors into
PySpark error framework
8ae9c512a55 is described below
commit 8ae9c512a55df1651508dc0de468fd6826955344
Author: itholic
AuthorDate: Mon Apr 24 18:17:52 2023 +0800
[SPARK-43178][CONNECT][PYTHON] Migrate UDF errors into PySpark error
framework
### What changes were proposed in this pull request?
This PR proposes to migrate UDF errors into PySpark error framework.
### Why are the changes needed?
To leverage the PySpark error framework so that we can provide more
actionable and consistent errors for users.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
The existing CI should pass.
Closes #40866 from itholic/udf_errors.
Authored-by: itholic
Signed-off-by: Ruifeng Zheng
---
python/pyspark/errors/error_classes.py | 15 ++
python/pyspark/sql/connect/udf.py | 33 +++-
.../sql/tests/pandas/test_pandas_grouped_map.py| 13 +++--
python/pyspark/sql/tests/pandas/test_pandas_udf.py | 22 ++--
python/pyspark/sql/tests/test_udf.py | 11 +++-
python/pyspark/sql/udf.py | 62 +-
6 files changed, 108 insertions(+), 48 deletions(-)
diff --git a/python/pyspark/errors/error_classes.py
b/python/pyspark/errors/error_classes.py
index 2b41f54def9..e3742441fe4 100644
--- a/python/pyspark/errors/error_classes.py
+++ b/python/pyspark/errors/error_classes.py
@@ -74,6 +74,11 @@ ERROR_CLASSES_JSON = """
" should not be set together."
]
},
+ "CANNOT_SPECIFY_RETURN_TYPE_FOR_UDF": {
+"message": [
+ "returnType can not be specified when `` is a user-defined
function, but got ."
+]
+ },
"COLUMN_IN_LIST": {
"message": [
"`` does not allow a Column in a list."
@@ -99,11 +104,21 @@ ERROR_CLASSES_JSON = """
"All items in `` should be in , got
."
]
},
+ "INVALID_RETURN_TYPE_FOR_PANDAS_UDF": {
+"message": [
+ "Pandas UDF should return StructType for , got ."
+]
+ },
"INVALID_TIMEOUT_TIMESTAMP" : {
"message" : [
"Timeout timestamp () cannot be earlier than the current
watermark ()."
]
},
+ "INVALID_UDF_EVAL_TYPE" : {
+"message" : [
+ "Eval type for UDF must be SQL_BATCHED_UDF, SQL_SCALAR_PANDAS_UDF,
SQL_SCALAR_PANDAS_ITER_UDF or SQL_GROUPED_AGG_PANDAS_UDF."
+]
+ },
"INVALID_WHEN_USAGE": {
"message": [
"when() can only be applied on a Column previously generated by when()
function, and cannot be applied once otherwise() is applied."
diff --git a/python/pyspark/sql/connect/udf.py
b/python/pyspark/sql/connect/udf.py
index aab7bb3c0d3..89d126e43d1 100644
--- a/python/pyspark/sql/connect/udf.py
+++ b/python/pyspark/sql/connect/udf.py
@@ -37,6 +37,7 @@ from pyspark.sql.connect.column import Column
from pyspark.sql.connect.types import UnparsedDataType
from pyspark.sql.types import ArrayType, DataType, MapType, StringType,
StructType
from pyspark.sql.udf import UDFRegistration as PySparkUDFRegistration
+from pyspark.errors import PySparkTypeError
if TYPE_CHECKING:
@@ -125,20 +126,24 @@ class UserDefinedFunction:
deterministic: bool = True,
):
if not callable(func):
-raise TypeError(
-"Invalid function: not a function or callable (__call__ is not
defined): "
-"{0}".format(type(func))
+raise PySparkTypeError(
+error_class="NOT_CALLABLE",
+message_parameters={"arg_name": "func", "arg_type":
type(func).__name__},
)
if not isinstance(returnType, (DataType, str)):
-raise TypeError(
-"Invalid return type: returnType should be DataType or str "
-"but is {}".format(returnType)
+raise PySparkTypeError(
+error_class="NOT_DATATYPE_OR_STR",
+message_parameters={
+"arg_name": "returnType",
+"arg_type": type(returnType).__name__,
+},
)
if not isinstance(evalType, int):
-raise TypeError(
-"Invalid evaluation type: evalType should be an int but is
{}".format(evalType)
+raise PySparkTypeError(
+error_class="NOT_INT",
+message_parameters={"arg_name": "evalType", "arg_type":
type(evalType).__name__},
)
self.func = func
@@ -241,9 +246,9 @@ class UDFRegistration:
# Python function.
if hasattr(f, "asNondeterministic"):
if returnType is not None:
-
[spark] branch master updated: [SPARK-41233][FOLLOWUP] Refactor `array_prepend` with `RuntimeReplaceable`
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 3e4a32d1d4a [SPARK-41233][FOLLOWUP] Refactor `array_prepend` with
`RuntimeReplaceable`
3e4a32d1d4a is described below
commit 3e4a32d1d4a0bace21651a80203cda2c3f2f3b68
Author: jiaan Geng
AuthorDate: Mon Apr 24 18:30:03 2023 +0800
[SPARK-41233][FOLLOWUP] Refactor `array_prepend` with `RuntimeReplaceable`
### What changes were proposed in this pull request?
Recently, Spark SQL supported `array_insert` and `array_prepend`. All
implementations are individual.
In fact, `array_prepend` is special case of `array_insert` and we can reuse
the `array_insert` by extends `RuntimeReplaceable`.
### Why are the changes needed?
Simplify the implementation of `array_prepend`.
### Does this PR introduce _any_ user-facing change?
'No'.
Just update the inner implementation.
### How was this patch tested?
Exists test case.
Closes #40563 from beliefer/SPARK-41232_SPARK-41233_followup.
Lead-authored-by: jiaan Geng
Co-authored-by: Jiaan Geng
Signed-off-by: Wenchen Fan
---
.../explain-results/function_array_prepend.explain | 2 +-
.../expressions/collectionOperations.scala | 118 -
.../expressions/CollectionExpressionsSuite.scala | 44
.../apache/spark/sql/DataFrameFunctionsSuite.scala | 16 +++
4 files changed, 36 insertions(+), 144 deletions(-)
diff --git
a/connector/connect/common/src/test/resources/query-tests/explain-results/function_array_prepend.explain
b/connector/connect/common/src/test/resources/query-tests/explain-results/function_array_prepend.explain
index 539e1eaf767..4c3e7c85d64 100644
---
a/connector/connect/common/src/test/resources/query-tests/explain-results/function_array_prepend.explain
+++
b/connector/connect/common/src/test/resources/query-tests/explain-results/function_array_prepend.explain
@@ -1,2 +1,2 @@
-Project [array_prepend(e#0, 1) AS array_prepend(e, 1)#0]
+Project [array_insert(e#0, 1, 1) AS array_prepend(e, 1)#0]
+- LocalRelation , [id#0L, a#0, b#0, d#0, e#0, f#0, g#0]
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
index beed5a6e365..63060e61d56 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
@@ -1397,7 +1397,6 @@ case class ArrayContains(left: Expression, right:
Expression)
copy(left = newLeft, right = newRight)
}
-// scalastyle:off line.size.limit
@ExpressionDescription(
usage = """
_FUNC_(array, element) - Add the element at the beginning of the array
passed as first
@@ -1416,101 +1415,26 @@ case class ArrayContains(left: Expression, right:
Expression)
""",
group = "array_funcs",
since = "3.5.0")
-case class ArrayPrepend(left: Expression, right: Expression)
- extends BinaryExpression
-with ImplicitCastInputTypes
-with ComplexTypeMergingExpression
-with QueryErrorsBase {
+case class ArrayPrepend(left: Expression, right: Expression) extends
RuntimeReplaceable
+ with ImplicitCastInputTypes with BinaryLike[Expression] with QueryErrorsBase
{
- override def nullable: Boolean = left.nullable
+ override lazy val replacement: Expression = ArrayInsert(left, Literal(1),
right)
- @transient protected lazy val elementType: DataType =
-inputTypes.head.asInstanceOf[ArrayType].elementType
-
- override def eval(input: InternalRow): Any = {
-val value1 = left.eval(input)
-if (value1 == null) {
- null
-} else {
- val value2 = right.eval(input)
- nullSafeEval(value1, value2)
-}
- }
- override def nullSafeEval(arr: Any, elementData: Any): Any = {
-val arrayData = arr.asInstanceOf[ArrayData]
-val numberOfElements = arrayData.numElements() + 1
-if (numberOfElements > ByteArrayMethods.MAX_ROUNDED_ARRAY_LENGTH) {
- throw
QueryExecutionErrors.concatArraysWithElementsExceedLimitError(numberOfElements)
-}
-val finalData = new Array[Any](numberOfElements)
-finalData.update(0, elementData)
-arrayData.foreach(elementType, (i: Int, v: Any) => finalData.update(i + 1,
v))
-new GenericArrayData(finalData)
- }
- override protected def doGenCode(ctx: CodegenContext, ev: ExprCode):
ExprCode = {
-val leftGen = left.genCode(ctx)
-val rightGen = right.genCode(ctx)
-val f = (arr: String, value: String) => {
- val newArraySize = s"$arr.numElements() + 1"
- val newArray = ctx.freshName("newArray")
- val i = ctx.freshName("i")
- val iPlus1 = s"$i+1"
- va
[spark] branch master updated: [SPARK-43214][SQL] Post driver-side metrics for LocalTableScanExec/CommandResultExec
This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 8704f6bcaf1 [SPARK-43214][SQL] Post driver-side metrics for
LocalTableScanExec/CommandResultExec
8704f6bcaf1 is described below
commit 8704f6bcaf135247348599119723bb2cd84f6c63
Author: Fu Chen
AuthorDate: Mon Apr 24 18:48:04 2023 +0800
[SPARK-43214][SQL] Post driver-side metrics for
LocalTableScanExec/CommandResultExec
### What changes were proposed in this pull request?
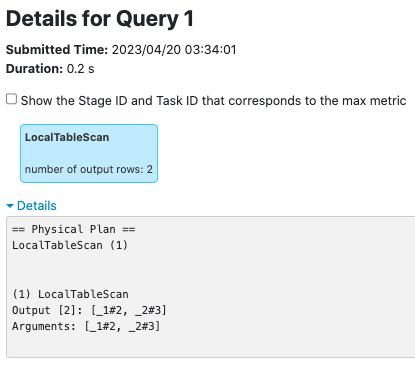
Since `LocalTableScan`/`CommandResultExec` may not trigger a Spark job,
post the driver-side metrics even in scenarios where a Spark job is not
triggered, so that we can track the metrics in the SQL UI tab.
**LocalTableScanExec**
before this PR:
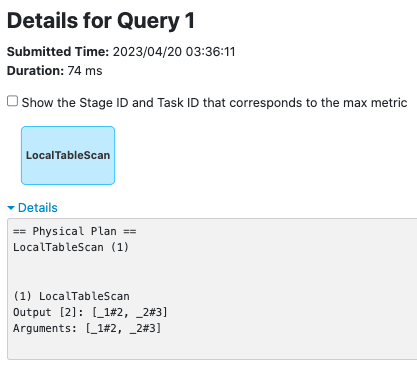
after this PR:
**CommandResultExec**
before this PR:
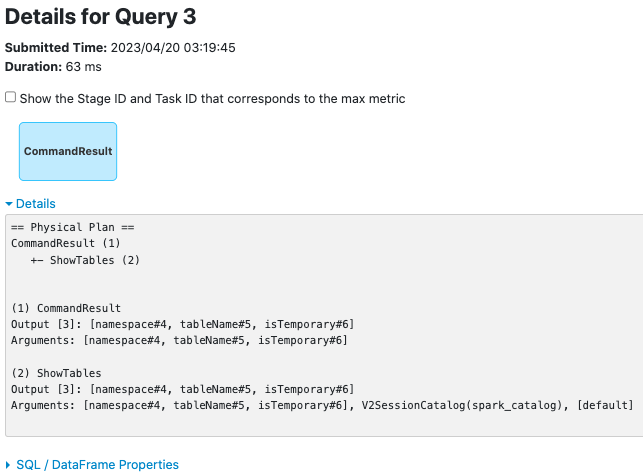
after this PR:
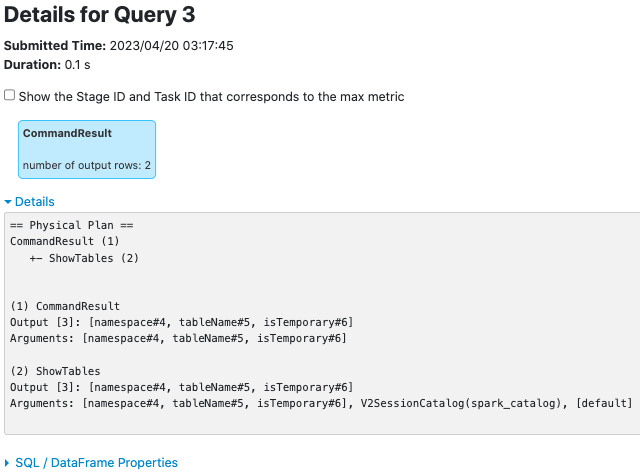
### Why are the changes needed?
makes metrics of `LocalTableScanExec`/`CommandResultExec` trackable on the
SQL UI tab
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
new UT.
Closes #40875 from cfmcgrady/SPARK-43214.
Authored-by: Fu Chen
Signed-off-by: Wenchen Fan
---
.../spark/sql/execution/CommandResultExec.scala| 8 +++
.../spark/sql/execution/LocalTableScanExec.scala | 8 +++
.../sql/execution/metric/SQLMetricsSuite.scala | 27 ++
3 files changed, 43 insertions(+)
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/CommandResultExec.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/CommandResultExec.scala
index 21d1c97db98..5f38278d2dc 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/CommandResultExec.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/CommandResultExec.scala
@@ -77,18 +77,21 @@ case class CommandResultExec(
override def executeCollect(): Array[InternalRow] = {
longMetric("numOutputRows").add(unsafeRows.size)
+sendDriverMetrics()
unsafeRows
}
override def executeTake(limit: Int): Array[InternalRow] = {
val taken = unsafeRows.take(limit)
longMetric("numOutputRows").add(taken.size)
+sendDriverMetrics()
taken
}
override def executeTail(limit: Int): Array[InternalRow] = {
val taken: Seq[InternalRow] = unsafeRows.takeRight(limit)
longMetric("numOutputRows").add(taken.size)
+sendDriverMetrics()
taken.toArray
}
@@ -96,4 +99,9 @@ case class CommandResultExec(
override protected val createUnsafeProjection: Boolean = false
override def inputRDD: RDD[InternalRow] = rdd
+
+ private def sendDriverMetrics(): Unit = {
+val executionId =
sparkContext.getLocalProperty(SQLExecution.EXECUTION_ID_KEY)
+SQLMetrics.postDriverMetricUpdates(sparkContext, executionId,
metrics.values.toSeq)
+ }
}
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/LocalTableScanExec.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/LocalTableScanExec.scala
index 1a79c08dabd..f178cd63dfe 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/LocalTableScanExec.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/LocalTableScanExec.scala
@@ -73,18 +73,21 @@ case class LocalTableScanExec(
override def executeCollect(): Array[InternalRow] = {
longMetric("numOutputRows").add(unsafeRows.size)
+sendDriverMetrics()
unsafeRows
}
override def executeTake(limit: Int): Array[InternalRow] = {
val taken = unsafeRows.take(limit)
longMetric("numOutputRows").add(taken.size)
+sendDriverMetrics()
taken
}
override def executeTail(limit: Int): Array[InternalRow] = {
val taken: Seq[InternalRow] = unsafeRows.takeRight(limit)
longMetric("numOutputRows").add(taken.size)
+sendDriverMetrics()
taken.toArray
}
@@ -92,4 +95,9 @@ case class LocalTableScanExec(
override protected val createUnsafeProjection: Boolean = false
override def inputRDD: RDD[InternalRow] = rdd
+
+ private def sendDriverMetrics(): Unit = {
+val executionId =
sparkContext.getLocalProperty(SQLExecution.EXECUTION_ID_KEY)
+SQLMetrics.postDriverMetricUpdates(sparkContext, e
[spark] branch master updated (8704f6bcaf1 -> 31aba5bef92)
This is an automated email from the ASF dual-hosted git repository. wenchen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 8704f6bcaf1 [SPARK-43214][SQL] Post driver-side metrics for LocalTableScanExec/CommandResultExec add 31aba5bef92 [SPARK-43217] Correctly recurse in nested maps/arrays in findNestedField No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/types/StructType.scala| 69 ++ .../apache/spark/sql/types/StructTypeSuite.scala | 105 + 2 files changed, 117 insertions(+), 57 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (31aba5bef92 -> 35f0d8e9a2d)
This is an automated email from the ASF dual-hosted git repository. sunchao pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 31aba5bef92 [SPARK-43217] Correctly recurse in nested maps/arrays in findNestedField add 35f0d8e9a2d [SPARK-43268][SQL] Use proper error classes when exceptions are constructed with a message No new revisions were added by this update. Summary of changes: .../catalyst/analysis/AlreadyExistException.scala | 27 + .../catalyst/analysis/NoSuchItemException.scala| 34 ++ 2 files changed, 50 insertions(+), 11 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-43233][SS] Add logging for Kafka Batch Reading for topic partition, offset range and task ID
This is an automated email from the ASF dual-hosted git repository.
kabhwan pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 82138f4b430 [SPARK-43233][SS] Add logging for Kafka Batch Reading for
topic partition, offset range and task ID
82138f4b430 is described below
commit 82138f4b430089766af4e457ba052f0d252f9f75
Author: Siying Dong
AuthorDate: Tue Apr 25 09:33:03 2023 +0900
[SPARK-43233][SS] Add logging for Kafka Batch Reading for topic partition,
offset range and task ID
### What changes were proposed in this pull request?
We add a logging when creating the batch reader with task ID, topic,
partition and offset range included.
The log line looks like following:
23/04/18 22:35:38 INFO KafkaBatchReaderFactory: Creating Kafka reader
partitionId=1
partition=StreamingDustTest-KafkaToKafkaTopic-4ccf8662-c3ca-4f3b-871e-1853c0e61765-source-2
fromOffset=0 untilOffset=3 queryId=b5b806c3-ebf3-432e-a9a7-d882d474c0f5
batchId=0 taskId=1
### Why are the changes needed?
Right now, for structure streaming from Kafka, it's hard to finding which
task handling which topic/partition and offset range.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Run KafkaMicroBatchV2SourceSuite and watch logging outputs contain
information needed. Also does a small cluster test and observe logs.
Closes #40905 from siying/kafka_logging.
Lead-authored-by: Siying Dong
Co-authored-by: Ubuntu
Signed-off-by: Jungtaek Lim
---
.../spark/sql/kafka010/KafkaBatchPartitionReader.scala | 13 -
1 file changed, 12 insertions(+), 1 deletion(-)
diff --git
a/connector/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaBatchPartitionReader.scala
b/connector/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaBatchPartitionReader.scala
index b6d64c79b1d..508f5c7036b 100644
---
a/connector/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaBatchPartitionReader.scala
+++
b/connector/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaBatchPartitionReader.scala
@@ -19,11 +19,13 @@ package org.apache.spark.sql.kafka010
import java.{util => ju}
+import org.apache.spark.TaskContext
import org.apache.spark.internal.Logging
import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.catalyst.expressions.UnsafeRow
import org.apache.spark.sql.connector.metric.CustomTaskMetric
import org.apache.spark.sql.connector.read.{InputPartition, PartitionReader,
PartitionReaderFactory}
+import org.apache.spark.sql.execution.streaming.{MicroBatchExecution,
StreamExecution}
import org.apache.spark.sql.kafka010.consumer.KafkaDataConsumer
/** A [[InputPartition]] for reading Kafka data in a batch based streaming
query. */
@@ -34,9 +36,18 @@ private[kafka010] case class KafkaBatchInputPartition(
failOnDataLoss: Boolean,
includeHeaders: Boolean) extends InputPartition
-private[kafka010] object KafkaBatchReaderFactory extends
PartitionReaderFactory {
+private[kafka010] object KafkaBatchReaderFactory extends
PartitionReaderFactory with Logging {
override def createReader(partition: InputPartition):
PartitionReader[InternalRow] = {
val p = partition.asInstanceOf[KafkaBatchInputPartition]
+
+val taskCtx = TaskContext.get()
+val queryId = taskCtx.getLocalProperty(StreamExecution.QUERY_ID_KEY)
+val batchId = taskCtx.getLocalProperty(MicroBatchExecution.BATCH_ID_KEY)
+logInfo(s"Creating Kafka reader
topicPartition=${p.offsetRange.topicPartition} " +
+ s"fromOffset=${p.offsetRange.fromOffset}
untilOffset=${p.offsetRange.untilOffset}, " +
+ s"for query queryId=$queryId batchId=$batchId
taskId=${TaskContext.get().taskAttemptId()} " +
+ s"partitionId=${TaskContext.get().partitionId()}")
+
KafkaBatchPartitionReader(p.offsetRange, p.executorKafkaParams,
p.pollTimeoutMs,
p.failOnDataLoss, p.includeHeaders)
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-43262][CONNECT][SS][PYTHON] Migrate Spark Connect Structured Streaming errors into error class
This is an automated email from the ASF dual-hosted git repository.
ruifengz pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c1359567f21 [SPARK-43262][CONNECT][SS][PYTHON] Migrate Spark Connect
Structured Streaming errors into error class
c1359567f21 is described below
commit c1359567f217b78f59a0a754b6448f942a132855
Author: itholic
AuthorDate: Tue Apr 25 09:37:21 2023 +0800
[SPARK-43262][CONNECT][SS][PYTHON] Migrate Spark Connect Structured
Streaming errors into error class
### What changes were proposed in this pull request?
This PR proposes to migrate built-in `TypeError` and `ValueError` from
Spark Connect Structured Streaming into PySpark error framework.
### Why are the changes needed?
To leverage the PySpark error framework for Spark Connect Structured
Streaming
### Does this PR introduce _any_ user-facing change?
No API changes, only error improvements.
### How was this patch tested?
The existing CI should pass.
Closes #40928 from itholic/error_streaming_connect.
Authored-by: itholic
Signed-off-by: Ruifeng Zheng
---
python/pyspark/sql/connect/streaming/query.py | 7 ++-
python/pyspark/sql/connect/streaming/readwriter.py | 70 --
2 files changed, 58 insertions(+), 19 deletions(-)
diff --git a/python/pyspark/sql/connect/streaming/query.py
b/python/pyspark/sql/connect/streaming/query.py
index a2b2e81357e..eb196971985 100644
--- a/python/pyspark/sql/connect/streaming/query.py
+++ b/python/pyspark/sql/connect/streaming/query.py
@@ -19,7 +19,7 @@ import json
import sys
from typing import TYPE_CHECKING, Any, cast, Dict, List, Optional
-from pyspark.errors import StreamingQueryException
+from pyspark.errors import StreamingQueryException, PySparkValueError
import pyspark.sql.connect.proto as pb2
from pyspark.sql.streaming.query import (
StreamingQuery as PySparkStreamingQuery,
@@ -73,7 +73,10 @@ class StreamingQuery:
cmd = pb2.StreamingQueryCommand()
if timeout is not None:
if not isinstance(timeout, (int, float)) or timeout <= 0:
-raise ValueError("timeout must be a positive integer or float.
Got %s" % timeout)
+raise PySparkValueError(
+error_class="VALUE_NOT_POSITIVE",
+message_parameters={"arg_name": "timeout", "arg_value":
type(timeout).__name__},
+)
cmd.await_termination.timeout_ms = int(timeout * 1000)
terminated =
self._execute_streaming_query_cmd(cmd).await_termination.terminated
return terminated
diff --git a/python/pyspark/sql/connect/streaming/readwriter.py
b/python/pyspark/sql/connect/streaming/readwriter.py
index 0775c1ab4a3..df336a932cb 100644
--- a/python/pyspark/sql/connect/streaming/readwriter.py
+++ b/python/pyspark/sql/connect/streaming/readwriter.py
@@ -30,6 +30,7 @@ from pyspark.sql.streaming.readwriter import (
DataStreamWriter as PySparkDataStreamWriter,
)
from pyspark.sql.types import Row, StructType
+from pyspark.errors import PySparkTypeError, PySparkValueError
if TYPE_CHECKING:
from pyspark.sql.connect.session import SparkSession
@@ -64,7 +65,10 @@ class DataStreamReader(OptionUtils):
elif isinstance(schema, str):
self._schema = schema
else:
-raise TypeError("schema should be StructType or string")
+raise PySparkTypeError(
+error_class="NOT_STR_OR_STRUCT",
+message_parameters={"arg_name": "schema", "arg_type":
type(schema).__name__},
+)
return self
schema.__doc__ = PySparkDataStreamReader.schema.__doc__
@@ -95,9 +99,9 @@ class DataStreamReader(OptionUtils):
self.schema(schema)
self.options(**options)
if path is not None and (type(path) != str or len(path.strip()) == 0):
-raise ValueError(
-"If the path is provided for stream, it needs to be a "
-+ "non-empty string. List of paths are not supported."
+raise PySparkValueError(
+error_class="VALUE_NOT_NON_EMPTY_STR",
+message_parameters={"arg_name": "path", "arg_value":
str(path)},
)
plan = DataSource(
@@ -163,7 +167,10 @@ class DataStreamReader(OptionUtils):
if isinstance(path, str):
return self.load(path=path, format="json")
else:
-raise TypeError("path can be only a single string")
+raise PySparkTypeError(
+error_class="NOT_STR",
+message_parameters={"arg_name": "path", "arg_type":
type(path).__name__},
+)
json.__doc__ = PySparkDataStreamReader.json.__doc__
@@ -182,7 +189,10 @@ class DataStreamReader(OptionUtils):
if
[spark] branch master updated: [MINOR][CONNECT] Remove unnecessary creation of `planner` in `handleWriteOperation` and `handleWriteOperationV2`
This is an automated email from the ASF dual-hosted git repository.
ruifengz pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 7a347c60dae [MINOR][CONNECT] Remove unnecessary creation of `planner`
in `handleWriteOperation` and `handleWriteOperationV2`
7a347c60dae is described below
commit 7a347c60dae0412087856756714feb6c80a2acb1
Author: Ruifeng Zheng
AuthorDate: Tue Apr 25 11:26:05 2023 +0800
[MINOR][CONNECT] Remove unnecessary creation of `planner` in
`handleWriteOperation` and `handleWriteOperationV2`
### What changes were proposed in this pull request?
Remove unnecessary creation of `planner` in `handleWriteOperation` and
`handleWriteOperationV2`
### Why are the changes needed?
`handleWriteOperation` and `handleWriteOperationV2` themselves are the
methods of planner, no need to create another planner to call
`transformRelation`
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing UTs
Closes #40936 from zhengruifeng/connect_write_remove_planner.
Authored-by: Ruifeng Zheng
Signed-off-by: Ruifeng Zheng
---
.../org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala | 6 ++
1 file changed, 2 insertions(+), 4 deletions(-)
diff --git
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
index 59c407c8eea..9c37aba32d3 100644
---
a/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
+++
b/connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala
@@ -1920,8 +1920,7 @@ class SparkConnectPlanner(val session: SparkSession) {
*/
private def handleWriteOperation(writeOperation: proto.WriteOperation): Unit
= {
// Transform the input plan into the logical plan.
-val planner = new SparkConnectPlanner(session)
-val plan = planner.transformRelation(writeOperation.getInput)
+val plan = transformRelation(writeOperation.getInput)
// And create a Dataset from the plan.
val dataset = Dataset.ofRows(session, logicalPlan = plan)
@@ -1991,8 +1990,7 @@ class SparkConnectPlanner(val session: SparkSession) {
*/
def handleWriteOperationV2(writeOperation: proto.WriteOperationV2): Unit = {
// Transform the input plan into the logical plan.
-val planner = new SparkConnectPlanner(session)
-val plan = planner.transformRelation(writeOperation.getInput)
+val plan = transformRelation(writeOperation.getInput)
// And create a Dataset from the plan.
val dataset = Dataset.ofRows(session, logicalPlan = plan)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-43144] Scala Client DataStreamReader table() API
This is an automated email from the ASF dual-hosted git repository.
ruifengz pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new adc4a3dd600 [SPARK-43144] Scala Client DataStreamReader table() API
adc4a3dd600 is described below
commit adc4a3dd600f83283f67f32f7bf9de21c2b51593
Author: Wei Liu
AuthorDate: Tue Apr 25 14:20:50 2023 +0800
[SPARK-43144] Scala Client DataStreamReader table() API
### What changes were proposed in this pull request?
Add the table() API for scala client.
### Why are the changes needed?
Continuation of SS Connect development.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
Unit test
I also changed `ProtoToParsedPlanTestSuite` a little to remove the memory
addresses, before the change the test for streaming table would fail with:
```
- streaming_table_API_with_options *** FAILED *** (8 milliseconds)
[info] Expected and actual plans do not match:
[info]
[info] === Expected Plan ===
[info] SubqueryAlias primary.tempdb.myStreamingTable
[info] +- StreamingRelationV2 primary.tempdb.myStreamingTable,
org.apache.spark.sql.connector.catalog.InMemoryTable752725d9, [p1=v1, p2=v2],
[id#0L], org.apache.spark.sql.connector.catalog.InMemoryCatalog347d8e2a,
tempdb.myStreamingTable
[info]
[info]
[info] === Actual Plan ===
[info] SubqueryAlias primary.tempdb.myStreamingTable
[info] +- StreamingRelationV2 primary.tempdb.myStreamingTable,
org.apache.spark.sql.connector.catalog.InMemoryTablea88a5db, [p1=v1, p2=v2],
[id#0L], org.apache.spark.sql.connector.catalog.InMemoryCatalog2c6b362e,
tempdb.myStreamingTable
```
Because the memory address (`InMemoryTable752725d9`) is different every
time it runs. I removed these in the test suite.
And verified that memory addresses doesn't exist in existing explain files:
```
wei.liu:~/oss-spark$ cat
connector/connect/common/src/test/resources/query-tests/explain-results/* | grep
wei.liu:~/oss-spark$
```
Closes #40887 from WweiL/SPARK-43144-scala-table-api.
Authored-by: Wei Liu
Signed-off-by: Ruifeng Zheng
---
.../spark/sql/streaming/DataStreamReader.scala | 18 +++
.../apache/spark/sql/PlanGenerationTestSuite.scala | 5 +++
.../spark/sql/streaming/StreamingQuerySuite.scala | 36 +
.../streaming_table_API_with_options.explain | 2 ++
.../queries/streaming_table_API_with_options.json | 14
.../streaming_table_API_with_options.proto.bin | Bin 0 -> 55 bytes
.../sql/connect/ProtoToParsedPlanTestSuite.scala | 14 ++--
7 files changed, 87 insertions(+), 2 deletions(-)
diff --git
a/connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/streaming/DataStreamReader.scala
b/connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/streaming/DataStreamReader.scala
index f6f41257417..4b0b99dd787 100644
---
a/connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/streaming/DataStreamReader.scala
+++
b/connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/streaming/DataStreamReader.scala
@@ -217,6 +217,24 @@ final class DataStreamReader private[sql] (sparkSession:
SparkSession) extends L
*/
def parquet(path: String): DataFrame = format("parquet").load(path)
+ /**
+ * Define a Streaming DataFrame on a Table. The DataSource corresponding to
the table should
+ * support streaming mode.
+ * @param tableName
+ * The name of the table
+ * @since 3.5.0
+ */
+ def table(tableName: String): DataFrame = {
+require(tableName != null, "The table name can't be null")
+sparkSession.newDataFrame { builder =>
+ builder.getReadBuilder
+.setIsStreaming(true)
+.getNamedTableBuilder
+.setUnparsedIdentifier(tableName)
+.putAllOptions(sourceBuilder.getOptionsMap)
+}
+ }
+
/**
* Loads text files and returns a `DataFrame` whose schema starts with a
string column named
* "value", and followed by partitioned columns if there are any. The text
files must be encoded
diff --git
a/connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/PlanGenerationTestSuite.scala
b/connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/PlanGenerationTestSuite.scala
index 3b1537ce755..36ef3a8dbf8 100644
---
a/connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/PlanGenerationTestSuite.scala
+++
b/connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/PlanGenerationTestSuite.scala
@@ -2170,6 +2170,11 @@ class PlanGenerationTestSuite
session.read.options(Map("p1" -> "v1", "p2" ->
"v2")).table("tempdb.myTable")
}
+ /* Stream Reader API */
+ test("streaming table API with options") {
+session.readStr
[spark] branch master updated: [SPARK-43260][PYTHON] Migrate the Spark SQL pandas arrow type errors into error class
This is an automated email from the ASF dual-hosted git repository.
ruifengz pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 15111a05e92 [SPARK-43260][PYTHON] Migrate the Spark SQL pandas arrow
type errors into error class
15111a05e92 is described below
commit 15111a05e925c0f25949908a9407c3b71e332e5f
Author: itholic
AuthorDate: Tue Apr 25 14:22:13 2023 +0800
[SPARK-43260][PYTHON] Migrate the Spark SQL pandas arrow type errors into
error class
### What changes were proposed in this pull request?
This PR proposes to migrate the Spark SQL pandas arrow type errors into
error class.
### Why are the changes needed?
Leveraging the PySpark error framework.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
The existing CI should pass
Closes #40924 from itholic/error_pandas_types.
Authored-by: itholic
Signed-off-by: Ruifeng Zheng
---
python/pyspark/errors/error_classes.py | 10 ++
python/pyspark/sql/pandas/types.py | 61 ++
python/pyspark/sql/tests/test_arrow.py | 17 --
3 files changed, 73 insertions(+), 15 deletions(-)
diff --git a/python/pyspark/errors/error_classes.py
b/python/pyspark/errors/error_classes.py
index e3742441fe4..f6fd0f24a35 100644
--- a/python/pyspark/errors/error_classes.py
+++ b/python/pyspark/errors/error_classes.py
@@ -354,6 +354,16 @@ ERROR_CLASSES_JSON = """
"Unsupported DataType ``."
]
},
+ "UNSUPPORTED_DATA_TYPE_FOR_ARROW_CONVERSION" : {
+"message" : [
+ " is not supported in conversion to Arrow."
+]
+ },
+ "UNSUPPORTED_DATA_TYPE_FOR_ARROW_VERSION" : {
+"message" : [
+ " is only supported with pyarrow 2.0.0 and above."
+]
+ },
"UNSUPPORTED_LITERAL" : {
"message" : [
"Unsupported Literal ''."
diff --git a/python/pyspark/sql/pandas/types.py
b/python/pyspark/sql/pandas/types.py
index 67efdae2b87..70d50ca6e95 100644
--- a/python/pyspark/sql/pandas/types.py
+++ b/python/pyspark/sql/pandas/types.py
@@ -44,6 +44,7 @@ from pyspark.sql.types import (
NullType,
DataType,
)
+from pyspark.errors import PySparkTypeError
if TYPE_CHECKING:
import pyarrow as pa
@@ -87,27 +88,43 @@ def to_arrow_type(dt: DataType) -> "pa.DataType":
arrow_type = pa.duration("us")
elif type(dt) == ArrayType:
if type(dt.elementType) == TimestampType:
-raise TypeError("Unsupported type in conversion to Arrow: " +
str(dt))
+raise PySparkTypeError(
+error_class="UNSUPPORTED_DATA_TYPE",
+message_parameters={"data_type": str(dt)},
+)
elif type(dt.elementType) == StructType:
if LooseVersion(pa.__version__) < LooseVersion("2.0.0"):
-raise TypeError(
-"Array of StructType is only supported with pyarrow 2.0.0
and above"
+raise PySparkTypeError(
+error_class="UNSUPPORTED_DATA_TYPE_FOR_ARROW_VERSION",
+message_parameters={"data_type": "Array of StructType"},
)
if any(type(field.dataType) == StructType for field in
dt.elementType):
-raise TypeError("Nested StructType not supported in conversion
to Arrow")
+raise PySparkTypeError(
+error_class="UNSUPPORTED_DATA_TYPE_FOR_ARROW_CONVERSION",
+message_parameters={"data_type": "Nested StructType"},
+)
arrow_type = pa.list_(to_arrow_type(dt.elementType))
elif type(dt) == MapType:
if LooseVersion(pa.__version__) < LooseVersion("2.0.0"):
-raise TypeError("MapType is only supported with pyarrow 2.0.0 and
above")
+raise PySparkTypeError(
+error_class="UNSUPPORTED_DATA_TYPE_FOR_ARROW_VERSION",
+message_parameters={"data_type": "MapType"},
+)
if type(dt.keyType) in [StructType, TimestampType] or
type(dt.valueType) in [
StructType,
TimestampType,
]:
-raise TypeError("Unsupported type in conversion to Arrow: " +
str(dt))
+raise PySparkTypeError(
+error_class="UNSUPPORTED_DATA_TYPE_FOR_ARROW_CONVERSION",
+message_parameters={"data_type": str(dt)},
+)
arrow_type = pa.map_(to_arrow_type(dt.keyType),
to_arrow_type(dt.valueType))
elif type(dt) == StructType:
if any(type(field.dataType) == StructType for field in dt):
-raise TypeError("Nested StructType not supported in conversion to
Arrow")
+raise PySparkTypeError(
+error_class="UNSUPPORTED_DATA_TYPE_FOR_ARROW_CONVERSION",
+message_parameters={"data_type": "Nest