(spark) branch master updated (ee2a87b4642c -> 8fa794b13195)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from ee2a87b4642c [SPARK-40876][SQL][TESTS][FOLLOW-UP] Remove invalid decimal test case when ANSI mode is on add 8fa794b13195 [SPARK-46627][SS][UI] Fix timeline tooltip content on streaming ui No new revisions were added by this update. Summary of changes: core/src/main/resources/org/apache/spark/ui/static/streaming-page.js | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-44490][WEBUI] Remove unused `TaskPagedTable` in StagePage
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 546e39c5dab [SPARK-44490][WEBUI] Remove unused `TaskPagedTable` in
StagePage
546e39c5dab is described below
commit 546e39c5dabc243ab81b6238dc893d9993e0
Author: sychen
AuthorDate: Tue Aug 1 15:37:27 2023 +0900
[SPARK-44490][WEBUI] Remove unused `TaskPagedTable` in StagePage
### What changes were proposed in this pull request?
Remove `TaskPagedTable`
### Why are the changes needed?
In [SPARK-21809](https://issues.apache.org/jira/browse/SPARK-21809), we
introduced `stagespage-template.html` to show the running status of Stage.
`TaskPagedTable` is no longer effective, but there are still many PRs
updating related codes.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
local test
Closes #42085 from cxzl25/SPARK-44490.
Authored-by: sychen
Signed-off-by: Kousuke Saruta
---
.../scala/org/apache/spark/ui/jobs/StagePage.scala | 301 +
.../scala/org/apache/spark/ui/StagePageSuite.scala | 12 +-
2 files changed, 13 insertions(+), 300 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
index 02aece6e50a..d50ccdadff5 100644
--- a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
+++ b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
@@ -17,17 +17,12 @@
package org.apache.spark.ui.jobs
-import java.net.URLEncoder
-import java.nio.charset.StandardCharsets.UTF_8
import java.util.Date
-import java.util.concurrent.TimeUnit
import javax.servlet.http.HttpServletRequest
-import scala.collection.mutable.{HashMap, HashSet}
+import scala.collection.mutable.HashSet
import scala.xml.{Node, Unparsed}
-import org.apache.commons.text.StringEscapeUtils
-
import org.apache.spark.internal.config.UI._
import org.apache.spark.scheduler.TaskLocality
import org.apache.spark.status._
@@ -209,32 +204,20 @@ private[ui] class StagePage(parent: StagesTab, store:
AppStatusStore) extends We
val dagViz = UIUtils.showDagVizForStage(stageId, stageGraph)
val currentTime = System.currentTimeMillis()
-val taskTable = try {
- val _taskTable = new TaskPagedTable(
-stageData,
-UIUtils.prependBaseUri(request, parent.basePath) +
- s"/stages/stage/?id=${stageId}&attempt=${stageAttemptId}",
-pageSize = taskPageSize,
-sortColumn = taskSortColumn,
-desc = taskSortDesc,
-store = parent.store
- )
- _taskTable
-} catch {
- case e @ (_ : IllegalArgumentException | _ : IndexOutOfBoundsException)
=>
-null
-}
val content =
summary ++
dagViz ++ ++
makeTimeline(
// Only show the tasks in the table
-Option(taskTable).map({ taskPagedTable =>
+() => {
val from = (eventTimelineTaskPage - 1) * eventTimelineTaskPageSize
- val to = taskPagedTable.dataSource.dataSize.min(
-eventTimelineTaskPage * eventTimelineTaskPageSize)
- taskPagedTable.dataSource.sliceData(from, to)}).getOrElse(Nil),
currentTime,
+ val dataSize = store.taskCount(stageData.stageId,
stageData.attemptId).toInt
+ val to = dataSize.min(eventTimelineTaskPage *
eventTimelineTaskPageSize)
+ val sliceData = store.taskList(stageData.stageId,
stageData.attemptId, from, to - from,
+indexName(taskSortColumn), !taskSortDesc)
+ sliceData
+}, currentTime,
eventTimelineTaskPage, eventTimelineTaskPageSize,
eventTimelineTotalPages, stageId,
stageAttemptId, totalTasks) ++
@@ -246,8 +229,8 @@ private[ui] class StagePage(parent: StagesTab, store:
AppStatusStore) extends We
}
- def makeTimeline(
- tasks: Seq[TaskData],
+ private def makeTimeline(
+ tasksFunc: () => Seq[TaskData],
currentTime: Long,
page: Int,
pageSize: Int,
@@ -258,6 +241,8 @@ private[ui] class StagePage(parent: StagesTab, store:
AppStatusStore) extends We
if (!TIMELINE_ENABLED) return Seq.empty[Node]
+val tasks = tasksFunc()
+
val executorsSet = new HashSet[(String, String)]
var minLaunchTime = Long.MaxValue
var maxFinishTime = Long.MinValue
@@ -453,268 +438,6 @@ private[ui] class StagePage(parent: StagesTab, store:
AppStatusStore) extends We
}
-private[ui] class TaskDataSource(
-stage: StageData,
-pageSize: Int,
-sortColumn: String,
-desc: Boolean,
-store: AppStatusStore) extends PagedDataSource[TaskData](pageSize) {
- import ApiHelper._
-
- // Keep an internal cache of executor log maps so that long task lists
ren
[spark] branch master updated: [MINOR][UI] Simplify columnDefs in stagepage.js
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 46440a4a542 [MINOR][UI] Simplify columnDefs in stagepage.js
46440a4a542 is described below
commit 46440a4a542148bc05b8c0f80d1860e6380efdb6
Author: Kent Yao
AuthorDate: Sat Jul 22 17:12:07 2023 +0900
[MINOR][UI] Simplify columnDefs in stagepage.js
### What changes were proposed in this pull request?
Simplify `columnDefs` in stagepage.js
### Why are the changes needed?
Reduce hardcode in stagepage.js and potential inconsistency for hidden/show
in future changes.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
Locally verified.
https://github.com/apache/spark/assets/8326978/3b3595a4-7825-47d5-8c28-30ec916321e6";>
Closes #42101 from yaooqinn/m.
Authored-by: Kent Yao
Signed-off-by: Kousuke Saruta
---
.../org/apache/spark/ui/static/stagepage.js| 35 ++
1 file changed, 9 insertions(+), 26 deletions(-)
diff --git a/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
b/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
index 50bf959d3aa..a8792593bf2 100644
--- a/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
+++ b/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
@@ -235,11 +235,7 @@ function
createDataTableForTaskSummaryMetricsTable(taskSummaryMetricsTable) {
}
],
"columnDefs": [
-{ "type": "duration", "targets": 1 },
-{ "type": "duration", "targets": 2 },
-{ "type": "duration", "targets": 3 },
-{ "type": "duration", "targets": 4 },
-{ "type": "duration", "targets": 5 }
+{ "type": "duration", "targets": [1, 2, 3, 4, 5] }
],
"paging": false,
"info": false,
@@ -592,22 +588,16 @@ $(document).ready(function () {
// The targets: $id represents column id which comes from
stagespage-template.html
// #summary-executor-table.If the relative position of the
columns in the table
// #summary-executor-table has changed,please be careful to
adjust the column index here
-// Input Size / Records
-{"type": "size", "targets": 9},
-// Output Size / Records
-{"type": "size", "targets": 10},
-// Shuffle Read Size / Records
-{"type": "size", "targets": 11},
-// Shuffle Write Size / Records
-{"type": "size", "targets": 12},
+// Input Size / Records - 9
+// Output Size / Records - 10
+// Shuffle Read Size / Records - 11
+// Shuffle Write Size / Records - 12
+{"type": "size", "targets": [9, 10, 11, 12]},
// Peak JVM Memory OnHeap / OffHeap
-{"visible": false, "targets": 15},
// Peak Execution Memory OnHeap / OffHeap
-{"visible": false, "targets": 16},
// Peak Storage Memory OnHeap / OffHeap
-{"visible": false, "targets": 17},
// Peak Pool Memory Direct / Mapped
-{"visible": false, "targets": 18}
+{"visible": false, "targets": executorOptionalColumns},
],
"deferRender": true,
"order": [[0, "asc"]],
@@ -1079,15 +1069,8 @@ $(document).ready(function () {
}
],
"columnDefs": [
-{ "visible": false, "targets": 11 },
-{ "visible": false, "targets": 12 },
-{ "visible": false, "targets": 13 },
-{ "visible": false, "targets": 14 },
-{ "visible": false, "targets": 15 },
-{ "visible": false, "targets": 16 },
-{ "visible": false, "targets": 17 },
-{ "visible": false, "targets": 18 },
-{ "visible": false, "targets": 21 }
+{ "visible": false, "targets": optionalColumns },
+{ "visible": false, "targets": 18 }, // accumulators
],
"deferRender": true
};
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-44279][BUILD] Upgrade `optionator` to ^0.9.3
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new d35fda69e49 [SPARK-44279][BUILD] Upgrade `optionator` to ^0.9.3
d35fda69e49 is described below
commit d35fda69e49b06cda316ecd664acb22cb8c12266
Author: Bjørn Jørgensen
AuthorDate: Fri Jul 14 03:26:56 2023 +0900
[SPARK-44279][BUILD] Upgrade `optionator` to ^0.9.3
### What changes were proposed in this pull request?
This PR proposes a change in the package.json file to update the resolution
for the `optionator` package to ^0.9.3.
I've added a resolutions field to package.json and specified the
`optionator` package version as ^0.9.3.
This will ensure that our project uses `optionator` version 0.9.3 or the
latest minor or patch version (due to the caret ^), regardless of any other
version that may be specified in the dependencies or nested dependencies of our
project.
### Why are the changes needed?
[CVE-2023-26115](https://nvd.nist.gov/vuln/detail/CVE-2023-26115)
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA
Closes #41955 from bjornjorgensen/word-wrap.
Authored-by: Bjørn Jørgensen
Signed-off-by: Kousuke Saruta
---
dev/package-lock.json | 774 ++
dev/package.json | 3 +
2 files changed, 350 insertions(+), 427 deletions(-)
diff --git a/dev/package-lock.json b/dev/package-lock.json
index 104a3fb7854..f676b9cec07 100644
--- a/dev/package-lock.json
+++ b/dev/package-lock.json
@@ -10,6 +10,15 @@
"minimatch": "^3.1.2"
}
},
+"node_modules/@aashutoshrathi/word-wrap": {
+ "version": "1.2.6",
+ "resolved":
"https://registry.npmjs.org/@aashutoshrathi/word-wrap/-/word-wrap-1.2.6.tgz";,
+ "integrity":
"sha512-1Yjs2SvM8TflER/OD3cOjhWWOZb58A2t7wpE2S9XfBYTiIl+XFhQG2bjy4Pu1I+EAlCNUzRDYDdFwFYUKvXcIA==",
+ "dev": true,
+ "engines": {
+"node": ">=0.10.0"
+ }
+},
"node_modules/@babel/code-frame": {
"version": "7.12.11",
"resolved":
"https://registry.npmjs.org/@babel/code-frame/-/code-frame-7.12.11.tgz";,
@@ -20,20 +29,38 @@
}
},
"node_modules/@babel/helper-validator-identifier": {
- "version": "7.14.0",
- "resolved":
"https://registry.npmjs.org/@babel/helper-validator-identifier/-/helper-validator-identifier-7.14.0.tgz";,
- "integrity":
"sha512-V3ts7zMSu5lfiwWDVWzRDGIN+lnCEUdaXgtVHJgLb1rGaA6jMrtB9EmE7L18foXJIE8Un/A/h6NJfGQp/e1J4A==",
- "dev": true
+ "version": "7.22.5",
+ "resolved":
"https://registry.npmjs.org/@babel/helper-validator-identifier/-/helper-validator-identifier-7.22.5.tgz";,
+ "integrity":
"sha512-aJXu+6lErq8ltp+JhkJUfk1MTGyuA4v7f3pA+BJ5HLfNC6nAQ0Cpi9uOquUj8Hehg0aUiHzWQbOVJGao6ztBAQ==",
+ "dev": true,
+ "engines": {
+"node": ">=6.9.0"
+ }
},
"node_modules/@babel/highlight": {
- "version": "7.14.0",
- "resolved":
"https://registry.npmjs.org/@babel/highlight/-/highlight-7.14.0.tgz";,
- "integrity":
"sha512-YSCOwxvTYEIMSGaBQb5kDDsCopDdiUGsqpatp3fOlI4+2HQSkTmEVWnVuySdAC5EWCqSWWTv0ib63RjR7dTBdg==",
+ "version": "7.22.5",
+ "resolved":
"https://registry.npmjs.org/@babel/highlight/-/highlight-7.22.5.tgz";,
+ "integrity":
"sha512-BSKlD1hgnedS5XRnGOljZawtag7H1yPfQp0tdNJCHoH6AZ+Pcm9VvkrK59/Yy593Ypg0zMxH2BxD1VPYUQ7UIw==",
"dev": true,
"dependencies": {
-"@babel/helper-validator-identifier": "^7.14.0",
+"@babel/helper-validator-identifier": "^7.22.5",
"chalk": "^2.0.0",
"js-tokens": "^4.0.0"
+ },
+ "engines": {
+"node": ">=6.9.0"
+ }
+},
+"node_modules/@babel/highlight/node_modules/ansi-styles": {
+ "version": "3.2.1",
+ "resolved":
"https://registry.npmjs.org/ansi-styles/-/ansi-styles-3.2.1.tgz";,
+ "integrity":
"sha512-VT0ZI6kZRdTh8YyJw3SMbYm/u+NqfsAxEpWO0Pf9sq8/e94WxxOpPKx9FR1FlyCtOVDNOQ+8ntlqFxiRc+r5qA==",
+ "dev": true,
+ "dependencies": {
+
[spark] branch master updated: [SPARK-41634][BUILD] Upgrade `minimatch` to 3.1.2
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 4539260f4ac [SPARK-41634][BUILD] Upgrade `minimatch` to 3.1.2
4539260f4ac is described below
commit 4539260f4ac346f22ce1a47ca9e94e3181803490
Author: Bjørn
AuthorDate: Wed Dec 21 13:49:45 2022 +0900
[SPARK-41634][BUILD] Upgrade `minimatch` to 3.1.2
### What changes were proposed in this pull request?
Upgrade `minimatch` to 3.1.2
$ npm -v
9.1.2
$ npm install
added 118 packages, and audited 119 packages in 2s
15 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
### Why are the changes needed?
[CVE-2022-3517](https://nvd.nist.gov/vuln/detail/CVE-2022-3517)
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA
Closes #39143 from bjornjorgensen/upgrade-minimatch.
Authored-by: Bjørn
Signed-off-by: Kousuke Saruta
---
dev/package-lock.json | 15 ---
dev/package.json | 3 ++-
2 files changed, 10 insertions(+), 8 deletions(-)
diff --git a/dev/package-lock.json b/dev/package-lock.json
index c2a61b389ac..104a3fb7854 100644
--- a/dev/package-lock.json
+++ b/dev/package-lock.json
@@ -6,7 +6,8 @@
"": {
"devDependencies": {
"ansi-regex": "^5.0.1",
-"eslint": "^7.25.0"
+"eslint": "^7.25.0",
+"minimatch": "^3.1.2"
}
},
"node_modules/@babel/code-frame": {
@@ -853,9 +854,9 @@
}
},
"node_modules/minimatch": {
- "version": "3.0.4",
- "resolved": "https://registry.npmjs.org/minimatch/-/minimatch-3.0.4.tgz";,
- "integrity":
"sha512-yJHVQEhyqPLUTgt9B83PXu6W3rx4MvvHvSUvToogpwoGDOUQ+yDrR0HRot+yOCdCO7u4hX3pWft6kWBBcqh0UA==",
+ "version": "3.1.2",
+ "resolved": "https://registry.npmjs.org/minimatch/-/minimatch-3.1.2.tgz";,
+ "integrity":
"sha512-J7p63hRiAjw1NDEww1W7i37+ByIrOWO5XQQAzZ3VOcL0PNybwpfmV/N05zFAzwQ9USyEcX6t3UO+K5aqBQOIHw==",
"dev": true,
"dependencies": {
"brace-expansion": "^1.1.7"
@@ -1931,9 +1932,9 @@
}
},
"minimatch": {
- "version": "3.0.4",
- "resolved": "https://registry.npmjs.org/minimatch/-/minimatch-3.0.4.tgz";,
- "integrity":
"sha512-yJHVQEhyqPLUTgt9B83PXu6W3rx4MvvHvSUvToogpwoGDOUQ+yDrR0HRot+yOCdCO7u4hX3pWft6kWBBcqh0UA==",
+ "version": "3.1.2",
+ "resolved": "https://registry.npmjs.org/minimatch/-/minimatch-3.1.2.tgz";,
+ "integrity":
"sha512-J7p63hRiAjw1NDEww1W7i37+ByIrOWO5XQQAzZ3VOcL0PNybwpfmV/N05zFAzwQ9USyEcX6t3UO+K5aqBQOIHw==",
"dev": true,
"requires": {
"brace-expansion": "^1.1.7"
diff --git a/dev/package.json b/dev/package.json
index f975bdde831..4e4a4bf1bca 100644
--- a/dev/package.json
+++ b/dev/package.json
@@ -1,6 +1,7 @@
{
"devDependencies": {
"eslint": "^7.25.0",
-"ansi-regex": "^5.0.1"
+"ansi-regex": "^5.0.1",
+"minimatch": "^3.1.2"
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-41587][BUILD] Upgrade `org.scalatestplus:selenium-4-4` to `org.scalatestplus:selenium-4-7`
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new ee2e582ff19 [SPARK-41587][BUILD] Upgrade
`org.scalatestplus:selenium-4-4` to `org.scalatestplus:selenium-4-7`
ee2e582ff19 is described below
commit ee2e582ff195fa11047545f43d1cb0ebd20a7091
Author: yangjie01
AuthorDate: Wed Dec 21 13:40:40 2022 +0900
[SPARK-41587][BUILD] Upgrade `org.scalatestplus:selenium-4-4` to
`org.scalatestplus:selenium-4-7`
### What changes were proposed in this pull request?
This pr aims upgrade `org.scalatestplus:selenium-4-4` to
`org.scalatestplus:selenium-4-7`:
- `org.scalatestplus:selenium-4-4` -> `org.scalatestplus:selenium-4-7`
- `selenium-java`: 4.4.0 -> 4.7.1
- `htmlunit-driver`: 3.64.0 -> 4.7.0
- `htmlunit` -> 2.64.0 -> 2.67.0
And all upgraded dependencies versions are matched.
### Why are the changes needed?
The release notes as follows:
-
https://github.com/scalatest/scalatestplus-selenium/releases/tag/release-3.2.14.0-for-selenium-4.7
### Does this PR introduce _any_ user-facing change?
No, just for test
### How was this patch tested?
- Pass Github Actions
- Manual test:
- ChromeUISeleniumSuite
```
build/sbt -Dguava.version=31.1-jre
-Dspark.test.webdriver.chrome.driver=/path/to/chromedriver
-Dtest.default.exclude.tags="" -Phive -Phive-thriftserver "core/testOnly
org.apache.spark.ui.ChromeUISeleniumSuite"
```
```
[info] ChromeUISeleniumSuite:
Starting ChromeDriver 108.0.5359.71
(1e0e3868ee06e91ad636a874420e3ca3ae3756ac-refs/branch-heads/5359{#1016}) on
port 13600
Only local connections are allowed.
Please see https://chromedriver.chromium.org/security-considerations for
suggestions on keeping ChromeDriver safe.
ChromeDriver was started successfully.
[info] - SPARK-31534: text for tooltip should be escaped (2 seconds, 702
milliseconds)
[info] - SPARK-31882: Link URL for Stage DAGs should not depend on paged
table. (824 milliseconds)
[info] - SPARK-31886: Color barrier execution mode RDD correctly (313
milliseconds)
[info] - Search text for paged tables should not be saved (1 second, 745
milliseconds)
[info] Run completed in 10 seconds, 266 milliseconds.
[info] Total number of tests run: 4
[info] Suites: completed 1, aborted 0
[info] Tests: succeeded 4, failed 0, canceled 0, ignored 0, pending 0
[info] All tests passed.
[success] Total time: 23 s, completed 2022-12-19 19:41:26
```
- RocksDBBackendChromeUIHistoryServerSuite
```
build/sbt -Dguava.version=31.1-jre
-Dspark.test.webdriver.chrome.driver=/path/to/chromedriver
-Dtest.default.exclude.tags="" -Phive -Phive-thriftserver "core/testOnly
org.apache.spark.deploy.history.RocksDBBackendChromeUIHistoryServerSuite"
```
```
[info] RocksDBBackendChromeUIHistoryServerSuite:
Starting ChromeDriver 108.0.5359.71
(1e0e3868ee06e91ad636a874420e3ca3ae3756ac-refs/branch-heads/5359{#1016}) on
port 2201
Only local connections are allowed.
Please see https://chromedriver.chromium.org/security-considerations for
suggestions on keeping ChromeDriver safe.
ChromeDriver was started successfully.
[info] - ajax rendered relative links are prefixed with uiRoot
(spark.ui.proxyBase) (2 seconds, 362 milliseconds)
[info] Run completed in 10 seconds, 254 milliseconds.
[info] Total number of tests run: 1
[info] Suites: completed 1, aborted 0
[info] Tests: succeeded 1, failed 0, canceled 0, ignored 0, pending 0
[info] All tests passed.
[success] Total time: 24 s, completed 2022-12-19 19:40:42
```
Closes #39129 from LuciferYang/selenium-47.
Authored-by: yangjie01
Signed-off-by: Kousuke Saruta
---
pom.xml | 10 +-
1 file changed, 5 insertions(+), 5 deletions(-)
diff --git a/pom.xml b/pom.xml
index 5ae26570e2d..f09207c660f 100644
--- a/pom.xml
+++ b/pom.xml
@@ -205,9 +205,9 @@
4.9.3
1.1
-4.4.0
-3.64.0
-2.64.0
+4.7.1
+4.7.0
+2.67.0
1.8
1.1.0
1.5.0
@@ -416,7 +416,7 @@
org.scalatestplus
- selenium-4-4_${scala.binary.version}
+ selenium-4-7_${scala.binary.version}
test
@@ -1144,7 +1144,7 @@
org.scalatestplus
-selenium-4-4_${scala.binary.version}
+selenium-4-7_${scala.binary.version}
3.2.14.0
test
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (12e48527846 -> 40590e6d911)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 12e48527846 [SPARK-40423][K8S][TESTS] Add explicit YuniKorn queue submission test coverage add 40590e6d911 [SPARK-40397][BUILD] Upgrade `org.scalatestplus:selenium` to 3.12.13 No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2-hive-2.3 | 2 +- dev/deps/spark-deps-hadoop-3-hive-2.3 | 2 +- pom.xml | 18 +++--- 3 files changed, 13 insertions(+), 9 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [MINOR][INFRA] Add ANTLR generated files to .gitignore
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 46ccc22 [MINOR][INFRA] Add ANTLR generated files to .gitignore 46ccc22 is described below commit 46ccc22ee40c780f6ae4a9af4562fb1ad10ccd9f Author: Yuto Akutsu AuthorDate: Thu Mar 17 18:12:13 2022 +0900 [MINOR][INFRA] Add ANTLR generated files to .gitignore ### What changes were proposed in this pull request? Add git ignore entries for files created by ANTLR. ### Why are the changes needed? To avoid developers from accidentally adding those files when working on parser/lexer. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? To make sure those files are ignored by `git status` when they exist. Closes #35838 from yutoacts/minor_gitignore. Authored-by: Yuto Akutsu Signed-off-by: Kousuke Saruta --- .gitignore | 5 + 1 file changed, 5 insertions(+) diff --git a/.gitignore b/.gitignore index b758781..0e2f59f 100644 --- a/.gitignore +++ b/.gitignore @@ -117,3 +117,8 @@ spark-warehouse/ # For Node.js node_modules + +# For Antlr +sql/catalyst/gen/ +sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBaseLexer.tokens +sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/gen/ - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-38303][BUILD] Upgrade `ansi-regex` from 5.0.0 to 5.0.1 in /dev
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 637a69f [SPARK-38303][BUILD] Upgrade `ansi-regex` from 5.0.0 to 5.0.1
in /dev
637a69f is described below
commit 637a69f349d01199db8af7331a22d2b9154cb50e
Author: bjornjorgensen
AuthorDate: Fri Feb 25 11:43:36 2022 +0900
[SPARK-38303][BUILD] Upgrade `ansi-regex` from 5.0.0 to 5.0.1 in /dev
### What changes were proposed in this pull request?
Upgrade ansi-regex from 5.0.0 to 5.0.1 in /dev
### Why are the changes needed?
[CVE-2021-3807](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-3807)
[Releases notes at github](https://github.com/chalk/ansi-regex/releases)
By upgrading ansi-regex from 5.0.0 to 5.0.1 we will resolve this issue.
### Does this PR introduce _any_ user-facing change?
Some users use remote security scanners and this is one of the issues that
comes up. How this can do some damage with spark is highly uncertain. but let's
remove the uncertainty that any user may have.
### How was this patch tested?
All test must pass.
Closes #35628 from bjornjorgensen/ansi-regex-from-5.0.0-to-5.0.1.
Authored-by: bjornjorgensen
Signed-off-by: Kousuke Saruta
(cherry picked from commit 9758d55918dfec236e8ac9f1655a9ff0acd7156e)
Signed-off-by: Kousuke Saruta
---
dev/package-lock.json | 3189 ++---
dev/package.json |3 +-
2 files changed, 2229 insertions(+), 963 deletions(-)
diff --git a/dev/package-lock.json b/dev/package-lock.json
index a57f45b..c2a61b3 100644
--- a/dev/package-lock.json
+++ b/dev/package-lock.json
@@ -1,979 +1,2244 @@
{
-"requires": true,
-"lockfileVersion": 1,
-"dependencies": {
-"@babel/code-frame": {
-"version": "7.12.11",
-"resolved":
"https://registry.npmjs.org/@babel/code-frame/-/code-frame-7.12.11.tgz";,
-"integrity":
"sha512-Zt1yodBx1UcyiePMSkWnU4hPqhwq7hGi2nFL1LeA3EUl+q2LQx16MISgJ0+z7dnmgvP9QtIleuETGOiOH1RcIw==",
-"dev": true,
-"requires": {
-"@babel/highlight": "^7.10.4"
-}
-},
-"@babel/helper-validator-identifier": {
-"version": "7.14.0",
-"resolved":
"https://registry.npmjs.org/@babel/helper-validator-identifier/-/helper-validator-identifier-7.14.0.tgz";,
-"integrity":
"sha512-V3ts7zMSu5lfiwWDVWzRDGIN+lnCEUdaXgtVHJgLb1rGaA6jMrtB9EmE7L18foXJIE8Un/A/h6NJfGQp/e1J4A==",
-"dev": true
-},
-"@babel/highlight": {
-"version": "7.14.0",
-"resolved":
"https://registry.npmjs.org/@babel/highlight/-/highlight-7.14.0.tgz";,
-"integrity":
"sha512-YSCOwxvTYEIMSGaBQb5kDDsCopDdiUGsqpatp3fOlI4+2HQSkTmEVWnVuySdAC5EWCqSWWTv0ib63RjR7dTBdg==",
-"dev": true,
-"requires": {
-"@babel/helper-validator-identifier": "^7.14.0",
-"chalk": "^2.0.0",
-"js-tokens": "^4.0.0"
-},
-"dependencies": {
-"chalk": {
-"version": "2.4.2",
-"resolved":
"https://registry.npmjs.org/chalk/-/chalk-2.4.2.tgz";,
-"integrity":
"sha512-Mti+f9lpJNcwF4tWV8/OrTTtF1gZi+f8FqlyAdouralcFWFQWF2+NgCHShjkCb+IFBLq9buZwE1xckQU4peSuQ==",
-"dev": true,
-"requires": {
-"ansi-styles": "^3.2.1",
-"escape-string-regexp": "^1.0.5",
-"supports-color": "^5.3.0"
-}
-}
-}
-},
-"@eslint/eslintrc": {
-"version": "0.4.0",
-"resolved":
"https://registry.npmjs.org/@eslint/eslintrc/-/eslintrc-0.4.0.tgz";,
-"integrity":
"sha512-2ZPCc+uNbjV5ERJr+aKSPRwZgKd2z11x0EgLvb1PURmUrn9QNRXFqje0Ldq454PfAVyaJYyrDvvIKSFP4NnBog==",
-"dev": true,
-"requires": {
-"ajv": "^6.12.4",
-"debug": "^4.1.1",
-"espree&
[spark] branch master updated: [SPARK-38303][BUILD] Upgrade `ansi-regex` from 5.0.0 to 5.0.1 in /dev
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 9758d55 [SPARK-38303][BUILD] Upgrade `ansi-regex` from 5.0.0 to 5.0.1
in /dev
9758d55 is described below
commit 9758d55918dfec236e8ac9f1655a9ff0acd7156e
Author: bjornjorgensen
AuthorDate: Fri Feb 25 11:43:36 2022 +0900
[SPARK-38303][BUILD] Upgrade `ansi-regex` from 5.0.0 to 5.0.1 in /dev
### What changes were proposed in this pull request?
Upgrade ansi-regex from 5.0.0 to 5.0.1 in /dev
### Why are the changes needed?
[CVE-2021-3807](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-3807)
[Releases notes at github](https://github.com/chalk/ansi-regex/releases)
By upgrading ansi-regex from 5.0.0 to 5.0.1 we will resolve this issue.
### Does this PR introduce _any_ user-facing change?
Some users use remote security scanners and this is one of the issues that
comes up. How this can do some damage with spark is highly uncertain. but let's
remove the uncertainty that any user may have.
### How was this patch tested?
All test must pass.
Closes #35628 from bjornjorgensen/ansi-regex-from-5.0.0-to-5.0.1.
Authored-by: bjornjorgensen
Signed-off-by: Kousuke Saruta
---
dev/package-lock.json | 3189 ++---
dev/package.json |3 +-
2 files changed, 2229 insertions(+), 963 deletions(-)
diff --git a/dev/package-lock.json b/dev/package-lock.json
index a57f45b..c2a61b3 100644
--- a/dev/package-lock.json
+++ b/dev/package-lock.json
@@ -1,979 +1,2244 @@
{
-"requires": true,
-"lockfileVersion": 1,
-"dependencies": {
-"@babel/code-frame": {
-"version": "7.12.11",
-"resolved":
"https://registry.npmjs.org/@babel/code-frame/-/code-frame-7.12.11.tgz";,
-"integrity":
"sha512-Zt1yodBx1UcyiePMSkWnU4hPqhwq7hGi2nFL1LeA3EUl+q2LQx16MISgJ0+z7dnmgvP9QtIleuETGOiOH1RcIw==",
-"dev": true,
-"requires": {
-"@babel/highlight": "^7.10.4"
-}
-},
-"@babel/helper-validator-identifier": {
-"version": "7.14.0",
-"resolved":
"https://registry.npmjs.org/@babel/helper-validator-identifier/-/helper-validator-identifier-7.14.0.tgz";,
-"integrity":
"sha512-V3ts7zMSu5lfiwWDVWzRDGIN+lnCEUdaXgtVHJgLb1rGaA6jMrtB9EmE7L18foXJIE8Un/A/h6NJfGQp/e1J4A==",
-"dev": true
-},
-"@babel/highlight": {
-"version": "7.14.0",
-"resolved":
"https://registry.npmjs.org/@babel/highlight/-/highlight-7.14.0.tgz";,
-"integrity":
"sha512-YSCOwxvTYEIMSGaBQb5kDDsCopDdiUGsqpatp3fOlI4+2HQSkTmEVWnVuySdAC5EWCqSWWTv0ib63RjR7dTBdg==",
-"dev": true,
-"requires": {
-"@babel/helper-validator-identifier": "^7.14.0",
-"chalk": "^2.0.0",
-"js-tokens": "^4.0.0"
-},
-"dependencies": {
-"chalk": {
-"version": "2.4.2",
-"resolved":
"https://registry.npmjs.org/chalk/-/chalk-2.4.2.tgz";,
-"integrity":
"sha512-Mti+f9lpJNcwF4tWV8/OrTTtF1gZi+f8FqlyAdouralcFWFQWF2+NgCHShjkCb+IFBLq9buZwE1xckQU4peSuQ==",
-"dev": true,
-"requires": {
-"ansi-styles": "^3.2.1",
-"escape-string-regexp": "^1.0.5",
-"supports-color": "^5.3.0"
-}
-}
-}
-},
-"@eslint/eslintrc": {
-"version": "0.4.0",
-"resolved":
"https://registry.npmjs.org/@eslint/eslintrc/-/eslintrc-0.4.0.tgz";,
-"integrity":
"sha512-2ZPCc+uNbjV5ERJr+aKSPRwZgKd2z11x0EgLvb1PURmUrn9QNRXFqje0Ldq454PfAVyaJYyrDvvIKSFP4NnBog==",
-"dev": true,
-"requires": {
-"ajv": "^6.12.4",
-"debug": "^4.1.1",
-"espree": "^7.3.0",
-"
[spark] branch master updated (a103a49 -> 48b56c0)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from a103a49 [SPARK-38279][TESTS][3.2] Pin MarkupSafe to 2.0.1 fix linter failure add 48b56c0 [SPARK-38278][PYTHON] Add SparkContext.addArchive in PySpark No new revisions were added by this update. Summary of changes: python/docs/source/reference/pyspark.rst | 1 + python/pyspark/context.py| 44 2 files changed, 45 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated (3dea6c4 -> 0dde12f)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git. from 3dea6c4 [SPARK-38211][SQL][DOCS] Add SQL migration guide on restoring loose upcast from string to other types add 0dde12f [SPARK-36808][BUILD][3.2] Upgrade Kafka to 2.8.1 No new revisions were added by this update. Summary of changes: pom.xml | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-37934][BUILD][3.2] Upgrade Jetty version to 9.4.44
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new adba516 [SPARK-37934][BUILD][3.2] Upgrade Jetty version to 9.4.44 adba516 is described below commit adba5165a56bd4e7a71fcad77c568c0cbc2e7f97 Author: Jack Richard Buggins AuthorDate: Wed Feb 9 02:28:03 2022 +0900 [SPARK-37934][BUILD][3.2] Upgrade Jetty version to 9.4.44 ### What changes were proposed in this pull request? This pull request updates provides a minor update to the Jetty version from `9.4.43.v20210629` to `9.4.44.v20210927` which is required against branch-3.2 to fully resolve https://issues.apache.org/jira/browse/SPARK-37934 ### Why are the changes needed? As discussed in https://github.com/apache/spark/pull/35338, DoS vector is available even within a private or restricted network. The below result is the output of a twistlock scan, which also detects this vulnerability. ``` Source: https://github.com/eclipse/jetty.project/issues/6973 CVE: PRISMA-2021-0182 Sev.: medium Package Name: org.eclipse.jetty_jetty-server Package Ver.: 9.4.43.v20210629 Status: fixed in 9.4.44 Description: org.eclipse.jetty_jetty-server package versions before 9.4.44 are vulnerable to DoS (Denial of Service). Logback-access calls Request.getParameterNames() for request logging. That will force a request body read (if it hasn't been read before) per the servlet. This will now consume resources to read the request body content, which could easily be malicious (in size? in keys? etc), even though the application intentionally didn't read the request body. ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? * Core local ``` $ build/sbt > project core > test ``` * CI Closes #35442 from JackBuggins/branch-3.2. Authored-by: Jack Richard Buggins Signed-off-by: Kousuke Saruta --- pom.xml | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/pom.xml b/pom.xml index bc3f925..8af3d6a 100644 --- a/pom.xml +++ b/pom.xml @@ -138,7 +138,7 @@ 10.14.2.0 1.12.2 1.6.13 -9.4.43.v20210629 +9.4.44.v20210927 4.0.3 0.10.0 2.5.0 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (3d736d9 -> 6115f58)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 3d736d9 [SPARK-37412][PYTHON][ML] Inline typehints for pyspark.ml.stat add 6115f58 [MINOR][SQL] Remove redundant array creation in UnsafeRow No new revisions were added by this update. Summary of changes: .../java/org/apache/spark/sql/catalyst/expressions/UnsafeRow.java | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38021][BUILD] Upgrade dropwizard metrics from 4.2.2 to 4.2.7
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new a1b061d [SPARK-38021][BUILD] Upgrade dropwizard metrics from 4.2.2 to 4.2.7 a1b061d is described below commit a1b061d7fc5427138bfaa9fe68d2748f8bf3907c Author: yangjie01 AuthorDate: Tue Jan 25 20:57:16 2022 +0900 [SPARK-38021][BUILD] Upgrade dropwizard metrics from 4.2.2 to 4.2.7 ### What changes were proposed in this pull request? This pr upgrade dropwizard metrics from 4.2.2 to 4.2.7. ### Why are the changes needed? There are 5 versions after 4.2.2, the release notes as follows: - https://github.com/dropwizard/metrics/releases/tag/v4.2.3 - https://github.com/dropwizard/metrics/releases/tag/v4.2.4 - https://github.com/dropwizard/metrics/releases/tag/v4.2.5 - https://github.com/dropwizard/metrics/releases/tag/v4.2.6 - https://github.com/dropwizard/metrics/releases/tag/v4.2.7 And after 4.2.5, dropwizard metrics supports [build with JDK 17](https://github.com/dropwizard/metrics/pull/2180). ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GA Closes #35317 from LuciferYang/upgrade-metrics. Authored-by: yangjie01 Signed-off-by: Kousuke Saruta --- dev/deps/spark-deps-hadoop-2-hive-2.3 | 10 +- dev/deps/spark-deps-hadoop-3-hive-2.3 | 10 +- pom.xml | 2 +- 3 files changed, 11 insertions(+), 11 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-2-hive-2.3 b/dev/deps/spark-deps-hadoop-2-hive-2.3 index 5efdca9..8284237 100644 --- a/dev/deps/spark-deps-hadoop-2-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-2-hive-2.3 @@ -195,11 +195,11 @@ logging-interceptor/3.12.12//logging-interceptor-3.12.12.jar lz4-java/1.8.0//lz4-java-1.8.0.jar macro-compat_2.12/1.1.1//macro-compat_2.12-1.1.1.jar mesos/1.4.3/shaded-protobuf/mesos-1.4.3-shaded-protobuf.jar -metrics-core/4.2.2//metrics-core-4.2.2.jar -metrics-graphite/4.2.2//metrics-graphite-4.2.2.jar -metrics-jmx/4.2.2//metrics-jmx-4.2.2.jar -metrics-json/4.2.2//metrics-json-4.2.2.jar -metrics-jvm/4.2.2//metrics-jvm-4.2.2.jar +metrics-core/4.2.7//metrics-core-4.2.7.jar +metrics-graphite/4.2.7//metrics-graphite-4.2.7.jar +metrics-jmx/4.2.7//metrics-jmx-4.2.7.jar +metrics-json/4.2.7//metrics-json-4.2.7.jar +metrics-jvm/4.2.7//metrics-jvm-4.2.7.jar minlog/1.3.0//minlog-1.3.0.jar netty-all/4.1.73.Final//netty-all-4.1.73.Final.jar netty-buffer/4.1.73.Final//netty-buffer-4.1.73.Final.jar diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3 b/dev/deps/spark-deps-hadoop-3-hive-2.3 index a79a71b..f169277 100644 --- a/dev/deps/spark-deps-hadoop-3-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-3-hive-2.3 @@ -181,11 +181,11 @@ logging-interceptor/3.12.12//logging-interceptor-3.12.12.jar lz4-java/1.8.0//lz4-java-1.8.0.jar macro-compat_2.12/1.1.1//macro-compat_2.12-1.1.1.jar mesos/1.4.3/shaded-protobuf/mesos-1.4.3-shaded-protobuf.jar -metrics-core/4.2.2//metrics-core-4.2.2.jar -metrics-graphite/4.2.2//metrics-graphite-4.2.2.jar -metrics-jmx/4.2.2//metrics-jmx-4.2.2.jar -metrics-json/4.2.2//metrics-json-4.2.2.jar -metrics-jvm/4.2.2//metrics-jvm-4.2.2.jar +metrics-core/4.2.7//metrics-core-4.2.7.jar +metrics-graphite/4.2.7//metrics-graphite-4.2.7.jar +metrics-jmx/4.2.7//metrics-jmx-4.2.7.jar +metrics-json/4.2.7//metrics-json-4.2.7.jar +metrics-jvm/4.2.7//metrics-jvm-4.2.7.jar minlog/1.3.0//minlog-1.3.0.jar netty-all/4.1.73.Final//netty-all-4.1.73.Final.jar netty-buffer/4.1.73.Final//netty-buffer-4.1.73.Final.jar diff --git a/pom.xml b/pom.xml index 5bae4d2..09577f2 100644 --- a/pom.xml +++ b/pom.xml @@ -147,7 +147,7 @@ If you changes codahale.metrics.version, you also need to change the link to metrics.dropwizard.io in docs/monitoring.md. --> -4.2.2 +4.2.7 1.11.0 1.12.0 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-38017][SQL][DOCS] Fix the API doc for window to say it supports TimestampNTZType too as timeColumn
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 263fe44 [SPARK-38017][SQL][DOCS] Fix the API doc for window to say it
supports TimestampNTZType too as timeColumn
263fe44 is described below
commit 263fe44f8a9738fc8d7dcfbcc1c0c10c942146e3
Author: Kousuke Saruta
AuthorDate: Tue Jan 25 20:44:06 2022 +0900
[SPARK-38017][SQL][DOCS] Fix the API doc for window to say it supports
TimestampNTZType too as timeColumn
### What changes were proposed in this pull request?
This PR fixes the API docs for `window` to say it supports
`TimestampNTZType` too as `timeColumn`.
### Why are the changes needed?
`window` function supports not only `TimestampType` but also
`TimestampNTZType`.
### Does this PR introduce _any_ user-facing change?
Yes, but I don't think this change affects existing users.
### How was this patch tested?
Built the docs with the following commands.
```
bundle install
SKIP_RDOC=1 SKIP_SQLDOC=1 bundle exec jekyll build
```
Then, confirmed the built doc.

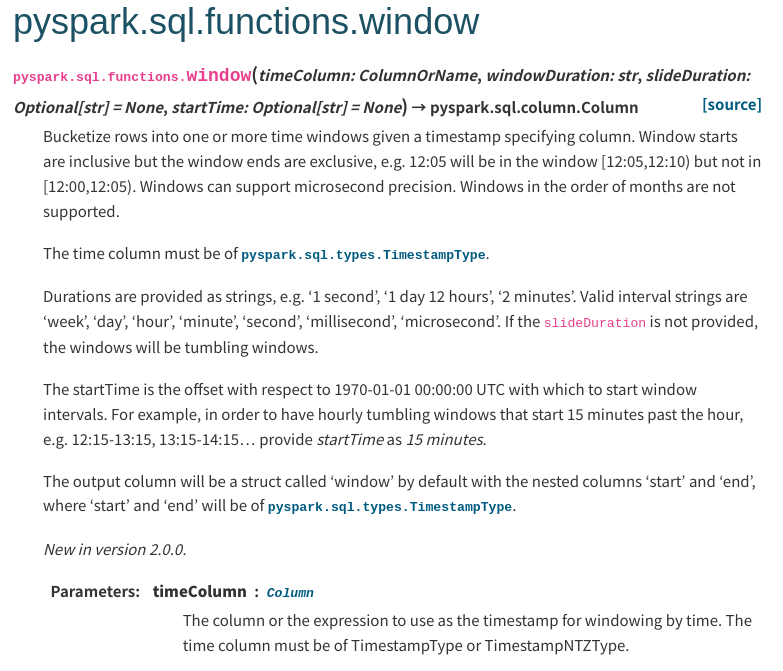
Closes #35313 from sarutak/window-timestampntz-doc.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit 76f685d26dc1f0f4d92293cd370e58ee2fa68452)
Signed-off-by: Kousuke Saruta
---
python/pyspark/sql/functions.py | 2 +-
sql/core/src/main/scala/org/apache/spark/sql/functions.scala | 6 +++---
2 files changed, 4 insertions(+), 4 deletions(-)
diff --git a/python/pyspark/sql/functions.py b/python/pyspark/sql/functions.py
index c7bc581..acde817 100644
--- a/python/pyspark/sql/functions.py
+++ b/python/pyspark/sql/functions.py
@@ -2304,7 +2304,7 @@ def window(timeColumn, windowDuration,
slideDuration=None, startTime=None):
--
timeColumn : :class:`~pyspark.sql.Column`
The column or the expression to use as the timestamp for windowing by
time.
-The time column must be of TimestampType.
+The time column must be of TimestampType or TimestampNTZType.
windowDuration : str
A string specifying the width of the window, e.g. `10 minutes`,
`1 second`. Check `org.apache.spark.unsafe.types.CalendarInterval` for
diff --git a/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
b/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
index a4c77b2..f4801ee 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
@@ -3517,7 +3517,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param windowDuration A string specifying the width of the window, e.g.
`10 minutes`,
* `1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
* valid duration identifiers. Note that the duration
is a fixed length of
@@ -3573,7 +3573,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param windowDuration A string specifying the width of the window, e.g.
`10 minutes`,
* `1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
* valid duration identifiers. Note that the duration
is a fixed length of
@@ -3618,7 +3618,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param windowDuration A string specifying the width of the window, e.g.
`10 minutes`,
* `1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
* valid duration identifiers.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e
[spark] branch master updated: [SPARK-38017][SQL][DOCS] Fix the API doc for window to say it supports TimestampNTZType too as timeColumn
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 76f685d [SPARK-38017][SQL][DOCS] Fix the API doc for window to say it
supports TimestampNTZType too as timeColumn
76f685d is described below
commit 76f685d26dc1f0f4d92293cd370e58ee2fa68452
Author: Kousuke Saruta
AuthorDate: Tue Jan 25 20:44:06 2022 +0900
[SPARK-38017][SQL][DOCS] Fix the API doc for window to say it supports
TimestampNTZType too as timeColumn
### What changes were proposed in this pull request?
This PR fixes the API docs for `window` to say it supports
`TimestampNTZType` too as `timeColumn`.
### Why are the changes needed?
`window` function supports not only `TimestampType` but also
`TimestampNTZType`.
### Does this PR introduce _any_ user-facing change?
Yes, but I don't think this change affects existing users.
### How was this patch tested?
Built the docs with the following commands.
```
bundle install
SKIP_RDOC=1 SKIP_SQLDOC=1 bundle exec jekyll build
```
Then, confirmed the built doc.


Closes #35313 from sarutak/window-timestampntz-doc.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
python/pyspark/sql/functions.py | 2 +-
sql/core/src/main/scala/org/apache/spark/sql/functions.scala | 6 +++---
2 files changed, 4 insertions(+), 4 deletions(-)
diff --git a/python/pyspark/sql/functions.py b/python/pyspark/sql/functions.py
index bfee994..2dfaec8 100644
--- a/python/pyspark/sql/functions.py
+++ b/python/pyspark/sql/functions.py
@@ -2551,7 +2551,7 @@ def window(
--
timeColumn : :class:`~pyspark.sql.Column`
The column or the expression to use as the timestamp for windowing by
time.
-The time column must be of TimestampType.
+The time column must be of TimestampType or TimestampNTZType.
windowDuration : str
A string specifying the width of the window, e.g. `10 minutes`,
`1 second`. Check `org.apache.spark.unsafe.types.CalendarInterval` for
diff --git a/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
b/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
index f217dad..0db12a2 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
@@ -3621,7 +3621,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param windowDuration A string specifying the width of the window, e.g.
`10 minutes`,
* `1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
* valid duration identifiers. Note that the duration
is a fixed length of
@@ -3677,7 +3677,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param windowDuration A string specifying the width of the window, e.g.
`10 minutes`,
* `1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
* valid duration identifiers. Note that the duration
is a fixed length of
@@ -3722,7 +3722,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param windowDuration A string specifying the width of the window, e.g.
`10 minutes`,
* `1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
* valid duration identifiers.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-38016][SQL][DOCS] Fix the API doc for session_window to say it supports TimestampNTZType too as timeColumn
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 48a440f [SPARK-38016][SQL][DOCS] Fix the API doc for session_window
to say it supports TimestampNTZType too as timeColumn
48a440f is described below
commit 48a440fe1fc334134f42a726cc6fb3d98802e0fd
Author: Kousuke Saruta
AuthorDate: Tue Jan 25 20:41:38 2022 +0900
[SPARK-38016][SQL][DOCS] Fix the API doc for session_window to say it
supports TimestampNTZType too as timeColumn
### What changes were proposed in this pull request?
This PR fixes the API docs for `session_window` to say it supports
`TimestampNTZType` too as `timeColumn`.
### Why are the changes needed?
As of Spark 3.3.0 (e858cd568a74123f7fd8fe4c3d2917a), `session_window`
supports not only `TimestampType` but also `TimestampNTZType`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Built the docs with the following commands.
```
bundle install
SKIP_RDOC=1 SKIP_SQLDOC=1 bundle exec jekyll build
```
Then, confirmed the built doc.


Closes #35312 from sarutak/sessionwindow-timestampntz-doc.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
python/pyspark/sql/functions.py | 2 +-
sql/core/src/main/scala/org/apache/spark/sql/functions.scala | 4 ++--
2 files changed, 3 insertions(+), 3 deletions(-)
diff --git a/python/pyspark/sql/functions.py b/python/pyspark/sql/functions.py
index e69c37d..bfee994 100644
--- a/python/pyspark/sql/functions.py
+++ b/python/pyspark/sql/functions.py
@@ -2623,7 +2623,7 @@ def session_window(timeColumn: "ColumnOrName",
gapDuration: Union[Column, str])
--
timeColumn : :class:`~pyspark.sql.Column` or str
The column name or column to use as the timestamp for windowing by
time.
-The time column must be of TimestampType.
+The time column must be of TimestampType or TimestampNTZType.
gapDuration : :class:`~pyspark.sql.Column` or str
A Python string literal or column specifying the timeout of the
session. It could be
static value, e.g. `10 minutes`, `1 second`, or an expression/UDF that
specifies gap
diff --git a/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
b/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
index ec28d8d..f217dad 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/functions.scala
@@ -3750,7 +3750,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param gapDuration A string specifying the timeout of the session, e.g.
`10 minutes`,
*`1 second`. Check
`org.apache.spark.unsafe.types.CalendarInterval` for
*valid duration identifiers.
@@ -3787,7 +3787,7 @@ object functions {
* processing time.
*
* @param timeColumn The column or the expression to use as the timestamp
for windowing by time.
- * The time column must be of TimestampType.
+ * The time column must be of TimestampType or
TimestampNTZType.
* @param gapDuration A column specifying the timeout of the session. It
could be static value,
*e.g. `10 minutes`, `1 second`, or an expression/UDF
that specifies gap
*duration dynamically based on the input row.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-37860][UI] Fix taskindex in the stage page task event timeline
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.0
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.0 by this push:
new 755d11d [SPARK-37860][UI] Fix taskindex in the stage page task event
timeline
755d11d is described below
commit 755d11d0d1479f5441c6ead2cc6142bab45d6e16
Author: stczwd
AuthorDate: Tue Jan 11 15:23:12 2022 +0900
[SPARK-37860][UI] Fix taskindex in the stage page task event timeline
### What changes were proposed in this pull request?
This reverts commit 450b415028c3b00f3a002126cd11318d3932e28f.
### Why are the changes needed?
In #32888, shahidki31 change taskInfo.index to taskInfo.taskId. However, we
generally use `index.attempt` or `taskId` to distinguish tasks within a stage,
not `taskId.attempt`.
Thus #32888 was a wrong fix issue, we should revert it.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
origin test suites
Closes #35160 from stczwd/SPARK-37860.
Authored-by: stczwd
Signed-off-by: Kousuke Saruta
(cherry picked from commit 3d2fde5242c8989688c176b8ed5eb0bff5e1f17f)
Signed-off-by: Kousuke Saruta
---
core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
index e9eb62e..ccaa70b 100644
--- a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
+++ b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
@@ -352,7 +352,7 @@ private[ui] class StagePage(parent: StagesTab, store:
AppStatusStore) extends We
|'content': '
+ |data-title="${s"Task " + index + " (attempt " + attempt +
")"}
|Status: ${taskInfo.status}
|Launch Time: ${UIUtils.formatDate(new Date(launchTime))}
|${
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-37860][UI] Fix taskindex in the stage page task event timeline
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 830d5b6 [SPARK-37860][UI] Fix taskindex in the stage page task event
timeline
830d5b6 is described below
commit 830d5b650ce9ac00f2a64bbf3e7fe9d31b02e51d
Author: stczwd
AuthorDate: Tue Jan 11 15:23:12 2022 +0900
[SPARK-37860][UI] Fix taskindex in the stage page task event timeline
### What changes were proposed in this pull request?
This reverts commit 450b415028c3b00f3a002126cd11318d3932e28f.
### Why are the changes needed?
In #32888, shahidki31 change taskInfo.index to taskInfo.taskId. However, we
generally use `index.attempt` or `taskId` to distinguish tasks within a stage,
not `taskId.attempt`.
Thus #32888 was a wrong fix issue, we should revert it.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
origin test suites
Closes #35160 from stczwd/SPARK-37860.
Authored-by: stczwd
Signed-off-by: Kousuke Saruta
(cherry picked from commit 3d2fde5242c8989688c176b8ed5eb0bff5e1f17f)
Signed-off-by: Kousuke Saruta
---
core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
index 459e09a..47ba951 100644
--- a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
+++ b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
@@ -355,7 +355,7 @@ private[ui] class StagePage(parent: StagesTab, store:
AppStatusStore) extends We
|'content': '
+ |data-title="${s"Task " + index + " (attempt " + attempt +
")"}
|Status: ${taskInfo.status}
|Launch Time: ${UIUtils.formatDate(new Date(launchTime))}
|${
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-37860][UI] Fix taskindex in the stage page task event timeline
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new db1023c [SPARK-37860][UI] Fix taskindex in the stage page task event
timeline
db1023c is described below
commit db1023c728c5e0bdcd4ef457cf5f7ba4f13cb79d
Author: stczwd
AuthorDate: Tue Jan 11 15:23:12 2022 +0900
[SPARK-37860][UI] Fix taskindex in the stage page task event timeline
### What changes were proposed in this pull request?
This reverts commit 450b415028c3b00f3a002126cd11318d3932e28f.
### Why are the changes needed?
In #32888, shahidki31 change taskInfo.index to taskInfo.taskId. However, we
generally use `index.attempt` or `taskId` to distinguish tasks within a stage,
not `taskId.attempt`.
Thus #32888 was a wrong fix issue, we should revert it.
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
origin test suites
Closes #35160 from stczwd/SPARK-37860.
Authored-by: stczwd
Signed-off-by: Kousuke Saruta
(cherry picked from commit 3d2fde5242c8989688c176b8ed5eb0bff5e1f17f)
Signed-off-by: Kousuke Saruta
---
core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
index 81dfe83..777a6b0 100644
--- a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
+++ b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
@@ -355,7 +355,7 @@ private[ui] class StagePage(parent: StagesTab, store:
AppStatusStore) extends We
|'content': '
+ |data-title="${s"Task " + index + " (attempt " + attempt +
")"}
|Status: ${taskInfo.status}
|Launch Time: ${UIUtils.formatDate(new Date(launchTime))}
|${
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (7463564 -> 3d2fde5)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7463564 [SPARK-37847][CORE][SHUFFLE] PushBlockStreamCallback#isStale should check null to avoid NPE add 3d2fde5 [SPARK-37860][UI] Fix taskindex in the stage page task event timeline No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (98e1c77 -> 3b88bc8)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 98e1c77 [SPARK-37803][SQL] Add ORC read benchmarks for structs add 3b88bc8 [SPARK-37792][CORE] Fix the check of custom configuration in SparkShellLoggingFilter No new revisions were added by this update. Summary of changes: .../scala/org/apache/spark/internal/Logging.scala | 19 -- .../org/apache/spark/internal/LoggingSuite.scala | 23 +++--- .../scala/org/apache/spark/repl/ReplSuite.scala| 19 -- 3 files changed, 42 insertions(+), 19 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-37302][BUILD][FOLLOWUP] Extract the versions of dependencies accurately
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 0888622 [SPARK-37302][BUILD][FOLLOWUP] Extract the versions of
dependencies accurately
0888622 is described below
commit 08886223c6373cc7c7e132bfb58f1536e70286ef
Author: Kousuke Saruta
AuthorDate: Fri Dec 24 11:29:37 2021 +0900
[SPARK-37302][BUILD][FOLLOWUP] Extract the versions of dependencies
accurately
### What changes were proposed in this pull request?
This PR changes `dev/test-dependencies.sh` to extract the versions of
dependencies accurately.
In the current implementation, the versions are extracted like as follows.
```
GUAVA_VERSION=`build/mvn help:evaluate -Dexpression=guava.version -q
-DforceStdout`
```
But, if the output of the `mvn` command includes not only the version but
also other messages like warnings, a following command referring the version
will fail.
```
build/mvn dependency:get -Dartifact=com.google.guava:guava:${GUAVA_VERSION}
-q
...
[ERROR] Failed to execute goal
org.apache.maven.plugins:maven-dependency-plugin:3.1.1:get (default-cli) on
project spark-parent_2.12: Couldn't download artifact:
org.eclipse.aether.resolution.DependencyResolutionException:
com.google.guava:guava:jar:Falling was not found in
https://maven-central.storage-download.googleapis.com/maven2/ during a previous
attempt. This failure was cached in the local repository and resolution is not
reattempted until the update interval of gcs-maven-cent [...]
```
Actually, this causes the recent linter failure.
https://github.com/apache/spark/runs/4623297663?check_suite_focus=true
### Why are the changes needed?
To recover the CI.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually run `dev/test-dependencies.sh`.
Closes #35006 from sarutak/followup-SPARK-37302.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit dd0decff5f1e95cedd8fe83de7e4449be57cb31c)
Signed-off-by: Kousuke Saruta
---
dev/test-dependencies.sh | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/dev/test-dependencies.sh b/dev/test-dependencies.sh
index 363ba1a..39a11e7 100755
--- a/dev/test-dependencies.sh
+++ b/dev/test-dependencies.sh
@@ -48,9 +48,9 @@ OLD_VERSION=$($MVN -q \
--non-recursive \
org.codehaus.mojo:exec-maven-plugin:1.6.0:exec | grep -E
'[0-9]+\.[0-9]+\.[0-9]+')
# dependency:get for guava and jetty-io are workaround for SPARK-37302.
-GUAVA_VERSION=`build/mvn help:evaluate -Dexpression=guava.version -q
-DforceStdout`
+GUAVA_VERSION=$(build/mvn help:evaluate -Dexpression=guava.version -q
-DforceStdout | grep -E "^[0-9.]+$")
build/mvn dependency:get -Dartifact=com.google.guava:guava:${GUAVA_VERSION} -q
-JETTY_VERSION=`build/mvn help:evaluate -Dexpression=jetty.version -q
-DforceStdout`
+JETTY_VERSION=$(build/mvn help:evaluate -Dexpression=jetty.version -q
-DforceStdout | grep -E "^[0-9.]+v[0-9]+")
build/mvn dependency:get
-Dartifact=org.eclipse.jetty:jetty-io:${JETTY_VERSION} -q
if [ $? != 0 ]; then
echo -e "Error while getting version string from Maven:\n$OLD_VERSION"
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37302][BUILD][FOLLOWUP] Extract the versions of dependencies accurately
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new dd0decf [SPARK-37302][BUILD][FOLLOWUP] Extract the versions of
dependencies accurately
dd0decf is described below
commit dd0decff5f1e95cedd8fe83de7e4449be57cb31c
Author: Kousuke Saruta
AuthorDate: Fri Dec 24 11:29:37 2021 +0900
[SPARK-37302][BUILD][FOLLOWUP] Extract the versions of dependencies
accurately
### What changes were proposed in this pull request?
This PR changes `dev/test-dependencies.sh` to extract the versions of
dependencies accurately.
In the current implementation, the versions are extracted like as follows.
```
GUAVA_VERSION=`build/mvn help:evaluate -Dexpression=guava.version -q
-DforceStdout`
```
But, if the output of the `mvn` command includes not only the version but
also other messages like warnings, a following command referring the version
will fail.
```
build/mvn dependency:get -Dartifact=com.google.guava:guava:${GUAVA_VERSION}
-q
...
[ERROR] Failed to execute goal
org.apache.maven.plugins:maven-dependency-plugin:3.1.1:get (default-cli) on
project spark-parent_2.12: Couldn't download artifact:
org.eclipse.aether.resolution.DependencyResolutionException:
com.google.guava:guava:jar:Falling was not found in
https://maven-central.storage-download.googleapis.com/maven2/ during a previous
attempt. This failure was cached in the local repository and resolution is not
reattempted until the update interval of gcs-maven-cent [...]
```
Actually, this causes the recent linter failure.
https://github.com/apache/spark/runs/4623297663?check_suite_focus=true
### Why are the changes needed?
To recover the CI.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually run `dev/test-dependencies.sh`.
Closes #35006 from sarutak/followup-SPARK-37302.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
dev/test-dependencies.sh | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/dev/test-dependencies.sh b/dev/test-dependencies.sh
index cf05126..2268a26 100755
--- a/dev/test-dependencies.sh
+++ b/dev/test-dependencies.sh
@@ -50,9 +50,9 @@ OLD_VERSION=$($MVN -q \
--non-recursive \
org.codehaus.mojo:exec-maven-plugin:1.6.0:exec | grep -E
'[0-9]+\.[0-9]+\.[0-9]+')
# dependency:get for guava and jetty-io are workaround for SPARK-37302.
-GUAVA_VERSION=`build/mvn help:evaluate -Dexpression=guava.version -q
-DforceStdout`
+GUAVA_VERSION=$(build/mvn help:evaluate -Dexpression=guava.version -q
-DforceStdout | grep -E "^[0-9.]+$")
build/mvn dependency:get -Dartifact=com.google.guava:guava:${GUAVA_VERSION} -q
-JETTY_VERSION=`build/mvn help:evaluate -Dexpression=jetty.version -q
-DforceStdout`
+JETTY_VERSION=$(build/mvn help:evaluate -Dexpression=jetty.version -q
-DforceStdout | grep -E "^[0-9.]+v[0-9]+")
build/mvn dependency:get
-Dartifact=org.eclipse.jetty:jetty-io:${JETTY_VERSION} -q
if [ $? != 0 ]; then
echo -e "Error while getting version string from Maven:\n$OLD_VERSION"
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37391][SQL] JdbcConnectionProvider tells if it modifies security context
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 6cc4c90 [SPARK-37391][SQL] JdbcConnectionProvider tells if it
modifies security context
6cc4c90 is described below
commit 6cc4c90cbc09a7729f9c40f440fcdda83e3d8648
Author: Danny Guinther
AuthorDate: Fri Dec 24 10:07:16 2021 +0900
[SPARK-37391][SQL] JdbcConnectionProvider tells if it modifies security
context
Augments the JdbcConnectionProvider API such that a provider can indicate
that it will need to modify the global security configuration when establishing
a connection, and as such, if access to the global security configuration
should be synchronized to prevent races.
### What changes were proposed in this pull request?
As suggested by gaborgsomogyi
[here](https://github.com/apache/spark/pull/29024/files#r755788709), augments
the `JdbcConnectionProvider` API to include a `modifiesSecurityContext` method
that can be used by `ConnectionProvider` to determine when
`SecurityConfigurationLock.synchronized` is required to avoid race conditions
when establishing a JDBC connection.
### Why are the changes needed?
Provides a path forward for working around a significant bottleneck
introduced by synchronizing `SecurityConfigurationLock` every time a connection
is established. The synchronization isn't always needed and it should be at the
discretion of the `JdbcConnectionProvider` to determine when locking is
necessary. See [SPARK-37391](https://issues.apache.org/jira/browse/SPARK-37391)
or [this thread](https://github.com/apache/spark/pull/29024/files#r754441783).
### Does this PR introduce _any_ user-facing change?
Any existing implementations of `JdbcConnectionProvider` will need to add a
definition of `modifiesSecurityContext`. I'm also open to adding a default
implementation, but it seemed to me that requiring an explicit implementation
of the method was preferable.
A drop-in implementation that would continue the existing behavior is:
```scala
override def modifiesSecurityContext(
driver: Driver,
options: Map[String, String]
): Boolean = true
```
### How was this patch tested?
Unit tests, but I also plan to run a real workflow once I get the initial
thumbs up on this implementation.
Closes #34745 from tdg5/SPARK-37391-opt-in-security-configuration-sync.
Authored-by: Danny Guinther
Signed-off-by: Kousuke Saruta
---
.../sql/jdbc/ExampleJdbcConnectionProvider.scala | 5 ++
project/MimaExcludes.scala | 5 +-
.../jdbc/connection/BasicConnectionProvider.scala | 8
.../jdbc/connection/ConnectionProvider.scala | 22 +
.../spark/sql/jdbc/JdbcConnectionProvider.scala| 19 +++-
.../main/scala/org/apache/spark/sql/jdbc/README.md | 5 +-
.../jdbc/connection/ConnectionProviderSuite.scala | 55 ++
.../IntentionallyFaultyConnectionProvider.scala| 4 ++
8 files changed, 109 insertions(+), 14 deletions(-)
diff --git
a/examples/src/main/scala/org/apache/spark/examples/sql/jdbc/ExampleJdbcConnectionProvider.scala
b/examples/src/main/scala/org/apache/spark/examples/sql/jdbc/ExampleJdbcConnectionProvider.scala
index 6d275d4..c63467d 100644
---
a/examples/src/main/scala/org/apache/spark/examples/sql/jdbc/ExampleJdbcConnectionProvider.scala
+++
b/examples/src/main/scala/org/apache/spark/examples/sql/jdbc/ExampleJdbcConnectionProvider.scala
@@ -30,4 +30,9 @@ class ExampleJdbcConnectionProvider extends
JdbcConnectionProvider with Logging
override def canHandle(driver: Driver, options: Map[String, String]):
Boolean = false
override def getConnection(driver: Driver, options: Map[String, String]):
Connection = null
+
+ override def modifiesSecurityContext(
+driver: Driver,
+options: Map[String, String]
+ ): Boolean = false
}
diff --git a/project/MimaExcludes.scala b/project/MimaExcludes.scala
index 75fa001..6cf639f 100644
--- a/project/MimaExcludes.scala
+++ b/project/MimaExcludes.scala
@@ -40,7 +40,10 @@ object MimaExcludes {
// The followings are necessary for Scala 2.13.
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend#Arguments.*"),
ProblemFilters.exclude[IncompatibleResultTypeProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend#Arguments.*"),
-
ProblemFilters.exclude[MissingTypesProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend$Arguments$")
+
ProblemFilters.exclude[MissingTypesProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend$Arguments$"),
+
+// [SPARK-37391][SQL] JdbcConnectionProvider tells if it modifies security
context
+
P
[spark] branch master updated (ae8940c -> d270d40)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from ae8940c [SPARK-37310][SQL] Migrate ALTER NAMESPACE ... SET PROPERTIES to use V2 command by default add d270d40 [SPARK-37635][SQL] SHOW TBLPROPERTIES should print the fully qualified table name No new revisions were added by this update. Summary of changes: .../spark/sql/execution/datasources/v2/DataSourceV2Strategy.scala | 2 +- .../spark/sql/execution/datasources/v2/ShowTablePropertiesExec.scala | 3 ++- .../src/test/resources/sql-tests/results/show-tblproperties.sql.out| 2 +- 3 files changed, 4 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (6a59fba -> ae8940c)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 6a59fba [SPARK-37575][SQL] null values should be saved as nothing rather than quoted empty Strings "" by default settings add ae8940c [SPARK-37310][SQL] Migrate ALTER NAMESPACE ... SET PROPERTIES to use V2 command by default No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/catalyst/analysis/ResolveSessionCatalog.scala | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36038][CORE] Speculation metrics summary at stage level
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 4158d35 [SPARK-36038][CORE] Speculation metrics summary at stage level
4158d35 is described below
commit 4158d3544030058a23c7741d4283213a56ae7cc7
Author: Thejdeep Gudivada
AuthorDate: Mon Dec 13 09:58:27 2021 +0900
[SPARK-36038][CORE] Speculation metrics summary at stage level
### What changes were proposed in this pull request?
Currently there are no speculation metrics available for Spark either at
application/job/stage level. This PR is to add some basic speculation metrics
for a stage when speculation execution is enabled.
This is similar to the existing stage level metrics tracking numTotal
(total number of speculated tasks), numCompleted (total number of successful
speculated tasks), numFailed (total number of failed speculated tasks),
numKilled (total number of killed speculated tasks) etc.
With this new set of metrics, it helps further understanding speculative
execution feature in the context of the application and also helps in further
tuning the speculative execution config knobs.
### Why are the changes needed?
Additional metrics for speculative execution.
### Does this PR introduce _any_ user-facing change?
Yes, Stages Page in SHS UI will have an additional table for speculation
metrics, if present.
### How was this patch tested?
Unit tests added and also tested on our internal platform.
Absence of speculation metrics :
Presence of speculation metrics :

Closes #34607 from thejdeep/SPARK-36038.
Lead-authored-by: Thejdeep Gudivada
Co-authored-by: Ron Hu
Co-authored-by: Venkata krishnan Sowrirajan
Signed-off-by: Kousuke Saruta
---
.../org/apache/spark/ui/static/stagepage.js| 32 ++
.../spark/ui/static/stagespage-template.html | 15 +
.../resources/org/apache/spark/ui/static/webui.css | 10 +
.../apache/spark/status/AppStatusListener.scala| 14 +
.../org/apache/spark/status/AppStatusStore.scala | 11 +
.../scala/org/apache/spark/status/LiveEntity.scala | 26 ++
.../scala/org/apache/spark/status/api/v1/api.scala | 8 +
.../scala/org/apache/spark/status/storeTypes.scala | 12 +
.../scala/org/apache/spark/ui/jobs/JobPage.scala | 1 +
.../application_list_json_expectation.json | 15 +
.../completed_app_list_json_expectation.json | 15 +
.../limit_app_list_json_expectation.json | 30 +-
.../minDate_app_list_json_expectation.json | 15 +
.../minEndDate_app_list_json_expectation.json | 15 +
...stage_with_speculation_summary_expectation.json | 507 +
.../spark-events/application_1628109047826_1317105 | 52 +++
.../spark/deploy/history/HistoryServerSuite.scala | 5 +-
.../spark/status/AppStatusListenerSuite.scala | 10 +
.../apache/spark/status/AppStatusStoreSuite.scala | 51 ++-
.../scala/org/apache/spark/ui/StagePageSuite.scala | 1 +
dev/.rat-excludes | 3 +-
21 files changed, 830 insertions(+), 18 deletions(-)
diff --git a/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
b/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
index 584e1a7..a5955f3 100644
--- a/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
+++ b/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
@@ -652,6 +652,38 @@ $(document).ready(function () {
executorSummaryTableSelector.column(14).visible(dataToShow.showBytesSpilledData);
});
+// Prepare data for speculation metrics
+$("#speculationSummaryTitle").hide();
+$("#speculationSummary").hide();
+var speculationSummaryInfo = responseBody.speculationSummary;
+var speculationData;
+if(speculationSummaryInfo) {
+ speculationData = [[
+speculationSummaryInfo.numTasks,
+speculationSummaryInfo.numActiveTasks,
+speculationSummaryInfo.numCompletedTasks,
+speculationSummaryInfo.numFailedTasks,
+speculationSummaryInfo.numKilledTasks
+ ]];
+ if (speculationSummaryInfo.numTasks > 0) {
+// Show speculationSummary if there is atleast one speculated task
that ran
+$("#speculationSummaryTitle").show();
+$("#speculationSummary").show();
+ }
+}
+var specu
[spark] branch master updated (119da4e -> 7692773)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 119da4e [SPARK-37615][BUILD] Upgrade SBT to 1.5.6 add 7692773 [SPARK-37615][BUILD][FOLLOWUP] Upgrade SBT to 1.5.6 in AppVeyor No new revisions were added by this update. Summary of changes: dev/appveyor-install-dependencies.ps1 | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37586][SQL] Add the `mode` and `padding` args to `aes_encrypt()`/`aes_decrypt()`
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 8f6e439 [SPARK-37586][SQL] Add the `mode` and `padding` args to
`aes_encrypt()`/`aes_decrypt()`
8f6e439 is described below
commit 8f6e439068281633acefb895f8c4bd9203868c24
Author: Max Gekk
AuthorDate: Thu Dec 9 14:36:47 2021 +0900
[SPARK-37586][SQL] Add the `mode` and `padding` args to
`aes_encrypt()`/`aes_decrypt()`
### What changes were proposed in this pull request?
In the PR, I propose to add new optional arguments to the `aes_encrypt()`
and `aes_decrypt()` functions with default values:
1. `mode` - specifies which block cipher mode should be used to
encrypt/decrypt messages. Only one valid value is `ECB` at the moment.
2. `padding` - specifies how to pad messages whose length is not a multiple
of the block size. Currently, only `PKCS` is supported.
In this way, when an user doesn't pass `mode`/`padding` to the functions,
the functions apply AES encryption/decryption in the `ECB` mode with the
`PKCS5Padding` padding.
### Why are the changes needed?
1. For now, `aes_encrypt()` and `aes_decrypt()` rely on the jvm's
configuration regarding which cipher mode to support, this is problematic as it
is not fixed across versions and systems. By using default constants for new
arguments, we can guarantee the same behaviour across all supported platforms.
2. We can consider new arguments as new point of extension in the current
implementation of AES algorithm in Spark SQL. In the future in OSS or in a
private Spark fork, devs can implement other modes (and paddings) like GCM.
Other systems have already supported different AES modes, see:
1. Snowflake:
https://docs.snowflake.com/en/sql-reference/functions/encrypt.html
2. BigQuery:
https://cloud.google.com/bigquery/docs/reference/standard-sql/aead-encryption-concepts#block_cipher_modes
3. MySQL:
https://dev.mysql.com/doc/refman/8.0/en/encryption-functions.html#function_aes-encrypt
4. Hive:
https://cwiki.apache.org/confluence/display/hive/languagemanual+udf
5. PostgreSQL:
https://www.postgresql.org/docs/12/pgcrypto.html#id-1.11.7.34.8
### Does this PR introduce _any_ user-facing change?
No. This PR just extends existing APIs.
### How was this patch tested?
By running new checks:
```
$ build/sbt "test:testOnly org.apache.spark.sql.DataFrameFunctionsSuite"
$ build/sbt "sql/test:testOnly
org.apache.spark.sql.expressions.ExpressionInfoSuite"
$ build/sbt "sql/testOnly *ExpressionsSchemaSuite"
```
Closes #34837 from MaxGekk/aes-gsm-mode.
Authored-by: Max Gekk
Signed-off-by: Kousuke Saruta
---
.../catalyst/expressions/ExpressionImplUtils.java | 24 +--
.../spark/sql/catalyst/expressions/misc.scala | 78 +-
.../spark/sql/errors/QueryExecutionErrors.scala| 10 ++-
.../sql-functions/sql-expression-schema.md | 2 +-
.../apache/spark/sql/DataFrameFunctionsSuite.scala | 16 +
5 files changed, 104 insertions(+), 26 deletions(-)
diff --git
a/sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/ExpressionImplUtils.java
b/sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/ExpressionImplUtils.java
index 9afa5a6..83205c1 100644
---
a/sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/ExpressionImplUtils.java
+++
b/sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/ExpressionImplUtils.java
@@ -18,6 +18,7 @@
package org.apache.spark.sql.catalyst.expressions;
import org.apache.spark.sql.errors.QueryExecutionErrors;
+import org.apache.spark.unsafe.types.UTF8String;
import javax.crypto.Cipher;
import javax.crypto.spec.SecretKeySpec;
@@ -27,19 +28,28 @@ import java.security.GeneralSecurityException;
* An utility class for constructing expressions.
*/
public class ExpressionImplUtils {
- public static byte[] aesEncrypt(byte[] input, byte[] key) {
-return aesInternal(input, key, Cipher.ENCRYPT_MODE);
+ public static byte[] aesEncrypt(byte[] input, byte[] key, UTF8String mode,
UTF8String padding) {
+return aesInternal(input, key, mode.toString(), padding.toString(),
Cipher.ENCRYPT_MODE);
}
- public static byte[] aesDecrypt(byte[] input, byte[] key) {
-return aesInternal(input, key, Cipher.DECRYPT_MODE);
+ public static byte[] aesDecrypt(byte[] input, byte[] key, UTF8String mode,
UTF8String padding) {
+return aesInternal(input, key, mode.toString(), padding.toString(),
Cipher.DECRYPT_MODE);
}
- private static byte[] aesInternal(byte[] input, byte[] key, int mode) {
+ private static byte[] aesInternal(
+ byte[] input,
+ byte[] key,
+ String mode,
[spark] branch master updated (d50d464 -> cd4476f)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from d50d464 [SPARK-37555][SQL] spark-sql should pass last unclosed comment to backend add cd4476f [SPARK-37469][WEBUI] unified shuffle read block time to shuffle read fetch wait time in StagePage No new revisions were added by this update. Summary of changes: .../org/apache/spark/ui/static/stagepage.js| 16 .../spark/ui/static/stagespage-template.html | 2 +- .../resources/org/apache/spark/ui/static/webui.css | 4 ++-- .../org/apache/spark/status/AppStatusStore.scala | 2 +- .../scala/org/apache/spark/status/storeTypes.scala | 5 +++-- .../main/scala/org/apache/spark/ui/ToolTips.scala | 2 +- .../scala/org/apache/spark/ui/jobs/StagePage.scala | 9 + .../spark/ui/jobs/TaskDetailsClassNames.scala | 2 +- docs/img/AllStagesPageDetail6.png | Bin 106909 -> 163423 bytes docs/web-ui.md | 2 +- 10 files changed, 23 insertions(+), 21 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (406455d -> a85c51f)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 406455d Revert "[SPARK-36231][PYTHON] Support arithmetic operations of decimal(nan) series" add a85c51f [SPARK-37354][K8S][TESTS] Make the Java version installed on the container image used by the K8s integration tests with SBT configurable No new revisions were added by this update. Summary of changes: project/SparkBuild.scala | 1 + 1 file changed, 1 insertion(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-35672][FOLLOWUP][TESTS] Add more exclusion rules to MimaExcludes.scala for Scala 2.13
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 4f20898 [SPARK-35672][FOLLOWUP][TESTS] Add more exclusion rules to
MimaExcludes.scala for Scala 2.13
4f20898 is described below
commit 4f2089899dd7f21ba41c9ccfc0453a93afa1e7eb
Author: Kousuke Saruta
AuthorDate: Fri Nov 19 20:33:23 2021 +0900
[SPARK-35672][FOLLOWUP][TESTS] Add more exclusion rules to
MimaExcludes.scala for Scala 2.13
### What changes were proposed in this pull request?
This PR adds more MiMa exclusion rules for Scala 2.13.
#34649 partially resolved the compatibility issue but additional 3
compatibility problems are raised.
```
$ build/sbt clean
$ dev/change-scala-version.sh 2.13
$ build/sbt -Pscala-2.13 clean
$ dev/mima
...
[error] spark-core: Failed binary compatibility check against
org.apache.spark:spark-core_2.13:3.2.0! Found 3 potential problems (filtered
910)
[error] * synthetic method
copy$default$8()scala.collection.mutable.ListBuffer in class
org.apache.spark.executor.CoarseGrainedExecutorBackend#Arguments has a
different result type in current version, where it is scala.Option rather than
scala.collection.mutable.ListBuffer
[error]filter with:
ProblemFilters.exclude[IncompatibleResultTypeProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend#Arguments.copy$default$8")
[error] * synthetic method copy$default$9()scala.Option in class
org.apache.spark.executor.CoarseGrainedExecutorBackend#Arguments has a
different result type in current version, where it is Int rather than
scala.Option
[error]filter with:
ProblemFilters.exclude[IncompatibleResultTypeProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend#Arguments.copy$default$9")
[error] * the type hierarchy of object
org.apache.spark.executor.CoarseGrainedExecutorBackend#Arguments is different
in current version. Missing types {scala.runtime.AbstractFunction10}
[error]filter with:
ProblemFilters.exclude[MissingTypesProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend$Arguments$")
...
```
### Why are the changes needed?
To keep the build stable.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Confirmed MiMa passed.
```
$ build/sbt clean
$ dev/change-scala-version.sh 2.13
$ build/sbt -Pscala-2.13 clean
$ dev/mima
Closes #34664 from sarutak/followup-SPARK-35672-mima-take2.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
project/MimaExcludes.scala | 4 +++-
1 file changed, 3 insertions(+), 1 deletion(-)
diff --git a/project/MimaExcludes.scala b/project/MimaExcludes.scala
index 15df3d4..75fa001 100644
--- a/project/MimaExcludes.scala
+++ b/project/MimaExcludes.scala
@@ -37,8 +37,10 @@ object MimaExcludes {
// Exclude rules for 3.3.x from 3.2.0
lazy val v33excludes = v32excludes ++ Seq(
// [SPARK-35672][CORE][YARN] Pass user classpath entries to executors
using config instead of command line
-// This is necessary for Scala 2.13.
+// The followings are necessary for Scala 2.13.
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend#Arguments.*"),
+
ProblemFilters.exclude[IncompatibleResultTypeProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend#Arguments.*"),
+
ProblemFilters.exclude[MissingTypesProblem]("org.apache.spark.executor.CoarseGrainedExecutorBackend$Arguments$")
)
// Exclude rules for 3.2.x from 3.1.1
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (edbc7cf -> bb9e1d9)
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a change to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git.
from edbc7cf [SPARK-36533][SS][FOLLOWUP] Support Trigger.AvailableNow in
PySpark
add bb9e1d9 [SPARK-37319][K8S] Support K8s image building with Java 17
No new revisions were added by this update.
Summary of changes:
bin/docker-image-tool.sh | 11 ---
.../main/dockerfiles/spark/{Dockerfile => Dockerfile.java17} | 9 -
2 files changed, 12 insertions(+), 8 deletions(-)
copy
resource-managers/kubernetes/docker/src/main/dockerfiles/spark/{Dockerfile =>
Dockerfile.java17} (92%)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37282][TESTS][FOLLOWUP] Mark `YarnShuffleServiceSuite` as ExtendedLevelDBTest
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 8b45a08 [SPARK-37282][TESTS][FOLLOWUP] Mark `YarnShuffleServiceSuite`
as ExtendedLevelDBTest
8b45a08 is described below
commit 8b45a08b763e9ee6c75b039893af3de5e5167643
Author: Dongjoon Hyun
AuthorDate: Sat Nov 13 15:21:59 2021 +0900
[SPARK-37282][TESTS][FOLLOWUP] Mark `YarnShuffleServiceSuite` as
ExtendedLevelDBTest
### What changes were proposed in this pull request?
This PR is a follow-up of #34548. This is missed due to `-Pyarn` profile.
### Why are the changes needed?
This is required to pass `yarn` module on Apple Silicon.
**BEFORE**
```
$ build/sbt "yarn/test"
...
[info] YarnShuffleServiceSuite:
[info] org.apache.spark.network.yarn.YarnShuffleServiceSuite *** ABORTED
*** (20 milliseconds)
[info] java.lang.UnsatisfiedLinkError: Could not load library. Reasons:
[no leveldbjni64-1.8
...
```
**AFTER**
```
$ build/sbt "yarn/test" -Pyarn
-Dtest.exclude.tags=org.apache.spark.tags.ExtendedLevelDBTest
...
[info] Run completed in 4 minutes, 57 seconds.
[info] Total number of tests run: 135
[info] Suites: completed 18, aborted 0
[info] Tests: succeeded 135, failed 0, canceled 1, ignored 0, pending 0
[info] All tests passed.
[success] Total time: 319 s (05:19), completed Nov 12, 2021, 4:53:14 PM
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
A manual test on Apple Silicon.
```
$ build/sbt "yarn/test" -Pyarn
-Dtest.exclude.tags=org.apache.spark.tags.ExtendedLevelDBTest
```
Closes #34576 from dongjoon-hyun/SPARK-37282-2.
Authored-by: Dongjoon Hyun
Signed-off-by: Kousuke Saruta
---
.../scala/org/apache/spark/network/yarn/YarnShuffleServiceSuite.scala | 2 ++
1 file changed, 2 insertions(+)
diff --git
a/resource-managers/yarn/src/test/scala/org/apache/spark/network/yarn/YarnShuffleServiceSuite.scala
b/resource-managers/yarn/src/test/scala/org/apache/spark/network/yarn/YarnShuffleServiceSuite.scala
index b2025aa..38d2247 100644
---
a/resource-managers/yarn/src/test/scala/org/apache/spark/network/yarn/YarnShuffleServiceSuite.scala
+++
b/resource-managers/yarn/src/test/scala/org/apache/spark/network/yarn/YarnShuffleServiceSuite.scala
@@ -46,8 +46,10 @@ import org.apache.spark.internal.config._
import org.apache.spark.network.shuffle.{NoOpMergedShuffleFileManager,
RemoteBlockPushResolver, ShuffleTestAccessor}
import org.apache.spark.network.shuffle.protocol.ExecutorShuffleInfo
import org.apache.spark.network.util.TransportConf
+import org.apache.spark.tags.ExtendedLevelDBTest
import org.apache.spark.util.Utils
+@ExtendedLevelDBTest
class YarnShuffleServiceSuite extends SparkFunSuite with Matchers with
BeforeAndAfterEach {
private[yarn] var yarnConfig: YarnConfiguration = null
private[yarn] val SORT_MANAGER =
"org.apache.spark.shuffle.sort.SortShuffleManager"
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37312][TESTS] Add `.java-version` to `.gitignore` and `.rat-excludes`
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new d0eb621 [SPARK-37312][TESTS] Add `.java-version` to `.gitignore` and `.rat-excludes` d0eb621 is described below commit d0eb62179822c82596c4feaa412f2fdf5b83c02a Author: Dongjoon Hyun AuthorDate: Sat Nov 13 14:43:52 2021 +0900 [SPARK-37312][TESTS] Add `.java-version` to `.gitignore` and `.rat-excludes` ### What changes were proposed in this pull request? To support Java 8/11/17 test more easily, this PR aims to add `.java-version` to `.gitignore` and `.rat-excludes`. ### Why are the changes needed? When we use `jenv`, `dev/check-license` and `dev/run-tests` fails. ``` Running Apache RAT checks Could not find Apache license headers in the following files: !? /Users/dongjoon/APACHE/spark-merge/.java-version [error] running /Users/dongjoon/APACHE/spark-merge/dev/check-license ; received return code 1 ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? ``` $ jenv local 17 $ dev/check-license ``` Closes #34577 from dongjoon-hyun/SPARK-37312. Authored-by: Dongjoon Hyun Signed-off-by: Kousuke Saruta --- .gitignore| 1 + dev/.rat-excludes | 1 + 2 files changed, 2 insertions(+) diff --git a/.gitignore b/.gitignore index 1a7881a..560265e 100644 --- a/.gitignore +++ b/.gitignore @@ -7,6 +7,7 @@ *.pyo *.swp *~ +.java-version .DS_Store .bsp/ .cache diff --git a/dev/.rat-excludes b/dev/.rat-excludes index a35d4ce..7932c5d 100644 --- a/dev/.rat-excludes +++ b/dev/.rat-excludes @@ -10,6 +10,7 @@ cache .generated-mima-member-excludes .rat-excludes .*md +.java-version derby.log licenses/* licenses-binary/* - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (bc80c84 -> b89f415)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from bc80c84 [SPARK-36575][CORE] Should ignore task finished event if its task set is gone in TaskSchedulerImpl.handleSuccessfulTask add b89f415 [SPARK-37264][BUILD] Exclude `hadoop-client-api` transitive dependency from `orc-core` No new revisions were added by this update. Summary of changes: pom.xml | 4 1 file changed, 4 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [MINOR][DOCS] Fix typos in python user guide and "the the" in the whole codebase
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b6ac331 [MINOR][DOCS] Fix typos in python user guide and "the the" in
the whole codebase
b6ac331 is described below
commit b6ac3311b70d7fdb373e88b8617c74dda63e1c8f
Author: sudoliyang
AuthorDate: Tue Nov 9 13:54:27 2021 +0900
[MINOR][DOCS] Fix typos in python user guide and "the the" in the whole
codebase
### What changes were proposed in this pull request?
Fix typos in python user guide and "the the" in the whole codebase.
### Why are the changes needed?
Improve readability.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Tested by checking dictionary.
Closes #34524 from sudoliyang/master.
Authored-by: sudoliyang
Signed-off-by: Kousuke Saruta
---
core/src/main/scala/org/apache/spark/scheduler/TaskSchedulerImpl.scala | 2 +-
python/docs/source/user_guide/pandas_on_spark/typehints.rst | 2 +-
python/docs/source/user_guide/python_packaging.rst | 2 +-
python/pyspark/rdd.py | 2 +-
.../sql/execution/datasources/BasicWriteTaskStatsTrackerSuite.scala | 2 +-
.../test/scala/org/apache/spark/sql/hive/thriftserver/CliSuite.scala| 2 +-
6 files changed, 6 insertions(+), 6 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/scheduler/TaskSchedulerImpl.scala
b/core/src/main/scala/org/apache/spark/scheduler/TaskSchedulerImpl.scala
index ae50a45..55db73a 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/TaskSchedulerImpl.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/TaskSchedulerImpl.scala
@@ -610,7 +610,7 @@ private[spark] class TaskSchedulerImpl(
taskSet.getCompletelyExcludedTaskIfAny(hostToExecutors).foreach {
taskIndex =>
// If the taskSet is unschedulable we try to find an existing
idle excluded
// executor and kill the idle executor and kick off an
abortTimer which if it doesn't
- // schedule a task within the the timeout will abort the taskSet
if we were unable to
+ // schedule a task within the timeout will abort the taskSet if
we were unable to
// schedule any task from the taskSet.
// Note 1: We keep track of schedulability on a per taskSet
basis rather than on a per
// task basis.
diff --git a/python/docs/source/user_guide/pandas_on_spark/typehints.rst
b/python/docs/source/user_guide/pandas_on_spark/typehints.rst
index 72519fc..fda400d 100644
--- a/python/docs/source/user_guide/pandas_on_spark/typehints.rst
+++ b/python/docs/source/user_guide/pandas_on_spark/typehints.rst
@@ -91,7 +91,7 @@ plans to move gradually towards using pandas instances only
as the stability bec
Type Hinting with Names
---
-This apporach is to overcome the limitations in the existing type
+This approach is to overcome the limitations in the existing type
hinting especially for DataFrame. When you use a DataFrame as the return type
hint, for example,
``DataFrame[int, int]``, there is no way to specify the names of each Series.
In the old way, pandas API on Spark just generates
the column names as ``c#`` and this easily leads users to lose or forgot the
Series mappings. See the example below:
diff --git a/python/docs/source/user_guide/python_packaging.rst
b/python/docs/source/user_guide/python_packaging.rst
index 6409c5f..8a60177 100644
--- a/python/docs/source/user_guide/python_packaging.rst
+++ b/python/docs/source/user_guide/python_packaging.rst
@@ -249,5 +249,5 @@ For the interactive pyspark shell, the commands are almost
the same:
An end-to-end Docker example for deploying a standalone PySpark with
``SparkSession.builder`` and PEX
can be found `here
<https://github.com/criteo/cluster-pack/blob/master/examples/spark-with-S3/README.md>`_
-- it uses cluster-pack, a library on top of PEX that automatizes the the
intermediate step of having
+- it uses cluster-pack, a library on top of PEX that automatizes the
intermediate step of having
to create & upload the PEX manually.
diff --git a/python/pyspark/rdd.py b/python/pyspark/rdd.py
index 2f0db7f..6942634 100644
--- a/python/pyspark/rdd.py
+++ b/python/pyspark/rdd.py
@@ -2797,7 +2797,7 @@ class RDD(object):
Returns
---
:py:class:`pyspark.resource.ResourceProfile`
-The the user specified profile or None if none were specified
+The user specified profile or None if none were specified
Notes
-
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/BasicWriteTaskSta
[spark] branch master updated: [SPARK-36895][SQL][FOLLOWUP] Use property to specify index type
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new d8a4a8c [SPARK-36895][SQL][FOLLOWUP] Use property to specify index
type
d8a4a8c is described below
commit d8a4a8c629db6ae8081477e58fdbf20983b48a39
Author: Huaxin Gao
AuthorDate: Tue Nov 9 04:21:29 2021 +0900
[SPARK-36895][SQL][FOLLOWUP] Use property to specify index type
### What changes were proposed in this pull request?
use property to specify index type
### Why are the changes needed?
fix scala doc in https://github.com/apache/spark/pull/34486 and resubmit
### Does this PR introduce _any_ user-facing change?
Yes
```
void createIndex(String indexName,
String indexType,
NamedReference[] columns,
Map> columnsProperties,
Map properties)
```
changed to
```
createIndex(String indexName,
NamedReference[] columns,
Map> columnsProperties,
Map properties
```
### How was this patch tested?
new test
Closes #34523 from huaxingao/newDelete.
Authored-by: Huaxin Gao
Signed-off-by: Kousuke Saruta
---
.../spark/sql/jdbc/v2/MySQLIntegrationSuite.scala | 67 --
.../org/apache/spark/sql/jdbc/v2/V2JDBCTest.scala | 82 +-
.../sql/connector/catalog/index/SupportsIndex.java | 8 ++-
.../sql/execution/datasources/jdbc/JdbcUtils.scala | 3 +-
.../execution/datasources/v2/CreateIndexExec.scala | 9 ++-
.../execution/datasources/v2/jdbc/JDBCTable.scala | 3 +-
.../org/apache/spark/sql/jdbc/JdbcDialects.scala | 2 -
.../org/apache/spark/sql/jdbc/MySQLDialect.scala | 27 ---
8 files changed, 45 insertions(+), 156 deletions(-)
diff --git
a/external/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/v2/MySQLIntegrationSuite.scala
b/external/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/v2/MySQLIntegrationSuite.scala
index d77dcb4..592f7d6 100644
---
a/external/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/v2/MySQLIntegrationSuite.scala
+++
b/external/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/v2/MySQLIntegrationSuite.scala
@@ -18,16 +18,11 @@
package org.apache.spark.sql.jdbc.v2
import java.sql.{Connection, SQLFeatureNotSupportedException}
-import java.util
import org.scalatest.time.SpanSugar._
import org.apache.spark.SparkConf
import org.apache.spark.sql.AnalysisException
-import org.apache.spark.sql.catalyst.analysis.{IndexAlreadyExistsException,
NoSuchIndexException}
-import org.apache.spark.sql.connector.catalog.{Catalogs, Identifier,
TableCatalog}
-import org.apache.spark.sql.connector.catalog.index.SupportsIndex
-import org.apache.spark.sql.connector.expressions.{FieldReference,
NamedReference}
import org.apache.spark.sql.execution.datasources.v2.jdbc.JDBCTableCatalog
import org.apache.spark.sql.jdbc.{DatabaseOnDocker, DockerJDBCIntegrationSuite}
import org.apache.spark.sql.types._
@@ -122,66 +117,4 @@ class MySQLIntegrationSuite extends
DockerJDBCIntegrationSuite with V2JDBCTest {
}
override def supportsIndex: Boolean = true
-
- override def testIndexProperties(jdbcTable: SupportsIndex): Unit = {
-val properties = new util.HashMap[String, String]();
-properties.put("KEY_BLOCK_SIZE", "10")
-properties.put("COMMENT", "'this is a comment'")
-// MySQL doesn't allow property set on individual column, so use empty
Array for
-// column properties
-jdbcTable.createIndex("i1", "BTREE", Array(FieldReference("col1")),
- new util.HashMap[NamedReference, util.Map[String, String]](), properties)
-
-var index = jdbcTable.listIndexes()
-// The index property size is actually 1. Even though the index is created
-// with properties "KEY_BLOCK_SIZE", "10" and "COMMENT", "'this is a
comment'", when
-// retrieving index using `SHOW INDEXES`, MySQL only returns `COMMENT`.
-assert(index(0).properties.size == 1)
-assert(index(0).properties.get("COMMENT").equals("this is a comment"))
- }
-
- override def testIndexUsingSQL(tbl: String): Unit = {
-val loaded = Catalogs.load("mysql", conf)
-val jdbcTable = loaded.asInstanceOf[TableCatalog]
- .loadTable(Identifier.of(Array.empty[String], "new_table"))
- .asInstanceOf[SupportsIndex]
-assert(jdbcTable.indexExists("i1") == false)
-assert(jdbcTable.indexExists("i2") == false)
-
-val indexType = "DUMMY"
-var m = intercept[UnsupportedOperationException] {
- sql(s"CREATE index i1 ON $catalogName.new_table USING DUMM
[spark] branch master updated (a47d380 -> 61e9789)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from a47d380 [SPARK-37241][BUILD] Upgrade Jackson to 2.13.0 add 61e9789 [SPARK-37240][SQL] Handle ANSI intervals by `ColumnVectorUtils.populate()` No new revisions were added by this update. Summary of changes: .../execution/vectorized/ColumnVectorUtils.java| 5 ++- .../spark/sql/sources/PartitionedWriteSuite.scala | 43 -- 2 files changed, 26 insertions(+), 22 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (06bdea0 -> 597cee6)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 06bdea0 [MINOR][INFRA] Explicitly specify Java version for lint test on GA add 597cee6 Revert "[SPARK-36895][SQL][FOLLOWUP] Use property to specify index type" No new revisions were added by this update. Summary of changes: .../spark/sql/jdbc/v2/MySQLIntegrationSuite.scala | 67 ++ .../org/apache/spark/sql/jdbc/v2/V2JDBCTest.scala | 82 +- .../sql/connector/catalog/index/SupportsIndex.java | 8 +-- .../sql/execution/datasources/jdbc/JdbcUtils.scala | 3 +- .../execution/datasources/v2/CreateIndexExec.scala | 9 +-- .../execution/datasources/v2/jdbc/JDBCTable.scala | 3 +- .../org/apache/spark/sql/jdbc/JdbcDialects.scala | 1 + .../org/apache/spark/sql/jdbc/MySQLDialect.scala | 27 +++ 8 files changed, 155 insertions(+), 45 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: Revert "[SPARK-36038][CORE] Speculation metrics summary at stage level"
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 4f16d38 Revert "[SPARK-36038][CORE] Speculation metrics summary at
stage level"
4f16d38 is described below
commit 4f16d3844532d9434d93c817e4fae15d10378af7
Author: Kousuke Saruta
AuthorDate: Mon Nov 8 17:26:00 2021 +0900
Revert "[SPARK-36038][CORE] Speculation metrics summary at stage level"
This reverts commit 73747ecb970595d49c478b0eb65f5132c8b0bf02.
See the
[comment](https://github.com/apache/spark/pull/33253#issuecomment-962913353).
Closes #34518 from sarutak/revert-SPARK-36038.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
.../org/apache/spark/ui/static/stagepage.js| 29 --
.../spark/ui/static/stagespage-template.html | 15 -
.../resources/org/apache/spark/ui/static/webui.css | 10 -
.../apache/spark/status/AppStatusListener.scala| 19 -
.../org/apache/spark/status/AppStatusStore.scala | 11 -
.../scala/org/apache/spark/status/LiveEntity.scala | 26 --
.../scala/org/apache/spark/status/api/v1/api.scala | 8 -
.../scala/org/apache/spark/status/storeTypes.scala | 14 -
.../scala/org/apache/spark/ui/jobs/JobPage.scala | 1 -
.../application_list_json_expectation.json | 15 -
.../completed_app_list_json_expectation.json | 15 -
.../limit_app_list_json_expectation.json | 30 +-
.../minDate_app_list_json_expectation.json | 15 -
.../minEndDate_app_list_json_expectation.json | 15 -
...stage_with_speculation_summary_expectation.json | 507 -
.../spark-events/application_1628109047826_1317105 | 52 ---
.../spark/deploy/history/HistoryServerSuite.scala | 5 +-
.../spark/status/AppStatusListenerSuite.scala | 10 -
.../apache/spark/status/AppStatusStoreSuite.scala | 57 +--
.../scala/org/apache/spark/ui/StagePageSuite.scala | 1 -
dev/.rat-excludes | 3 +-
21 files changed, 18 insertions(+), 840 deletions(-)
diff --git a/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
b/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
index 595635a..db1a148 100644
--- a/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
+++ b/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
@@ -652,35 +652,6 @@ $(document).ready(function () {
executorSummaryTableSelector.column(14).visible(dataToShow.showBytesSpilledData);
});
-// Prepare data for speculation metrics
-$("#speculationSummaryTitle").hide()
-$("#speculationSummary").hide()
-var speculationSummaryInfo = responseBody.speculationSummary;
-var speculationData = [[
- speculationSummaryInfo.numTasks,
- speculationSummaryInfo.numActiveTasks,
- speculationSummaryInfo.numCompletedTasks,
- speculationSummaryInfo.numFailedTasks,
- speculationSummaryInfo.numKilledTasks
-]];
-if (speculationSummaryInfo.numTasks > 0) {
- // Show speculationSummary if there is atleast one speculated task
ran
- $("#speculationSummaryTitle").show()
- $("#speculationSummary").show()
-}
-var speculationMetricsTableConf = {
- "data": speculationData,
- "paging": false,
- "searching": false,
- "order": [[0, "asc"]],
- "bSort": false,
- "bAutoWidth": false,
- "oLanguage": {
-"sEmptyTable": "No speculation metrics yet"
- }
-}
-$("#speculation-metrics-table").DataTable(speculationMetricsTableConf);
-
// prepare data for accumulatorUpdates
var accumulatorTable =
responseBody.accumulatorUpdates.filter(accumUpdate =>
!(accumUpdate.name).toString().includes("internal."));
diff --git
a/core/src/main/resources/org/apache/spark/ui/static/stagespage-template.html
b/core/src/main/resources/org/apache/spark/ui/static/stagespage-template.html
index 8c47e5a..98e714f 100644
---
a/core/src/main/resources/org/apache/spark/ui/static/stagespage-template.html
+++
b/core/src/main/resources/org/apache/spark/ui/static/stagespage-template.html
@@ -31,21 +31,6 @@ limitations under the License.
-Speculation
Summary
-
-
-
-Total
-Active
-Complete
-Failed
-Killed
-
-
-
-
-
-
Aggregated Metrics by Executor
diff --git a/core/src/main/resources/org/apache/spark/
[spark] branch branch-3.2 updated (e55bab5 -> 90b7ee0)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git. from e55bab5 [SPARK-37214][SQL] Fail query analysis earlier with invalid identifiers add 90b7ee0 [SPARK-37238][BUILD][3.2] Upgrade ORC to 1.6.12 No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2.7-hive-2.3 | 6 +++--- dev/deps/spark-deps-hadoop-3.2-hive-2.3 | 6 +++--- pom.xml | 2 +- 3 files changed, 7 insertions(+), 7 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (7ef6a2e -> e29c4e1)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7ef6a2e [SPARK-37231][SQL] Dynamic writes/reads of ANSI interval partitions add e29c4e1 [SPARK-37211][INFRA] Added descriptions and an image to the guide for enabling GitHub Actions in notify_test_workflow.yml No new revisions were added by this update. Summary of changes: .github/workflows/images/workflow-enable-button.png | Bin 0 -> 79807 bytes .github/workflows/notify_test_workflow.yml | 10 -- 2 files changed, 8 insertions(+), 2 deletions(-) create mode 100644 .github/workflows/images/workflow-enable-button.png - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (8ab9d63 -> 7ef6a2e)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 8ab9d63 [SPARK-37214][SQL] Fail query analysis earlier with invalid identifiers add 7ef6a2e [SPARK-37231][SQL] Dynamic writes/reads of ANSI interval partitions No new revisions were added by this update. Summary of changes: .../execution/datasources/PartitioningUtils.scala | 2 ++ .../spark/sql/sources/PartitionedWriteSuite.scala | 40 ++ 2 files changed, 36 insertions(+), 6 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-37108][R] Expose make_date expression in R
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 5f997c7 [SPARK-37108][R] Expose make_date expression in R
5f997c7 is described below
commit 5f997c78c83551942b6c5a8ec6344547b86ae68a
Author: Leona Yoda
AuthorDate: Thu Nov 4 12:25:12 2021 +0900
[SPARK-37108][R] Expose make_date expression in R
### What changes were proposed in this pull request?
Expose `make_date` API on SparkR
### Why are the changes needed?
`make_date` APIs on Scala and PySpark were added by
[SPARK-34356](https://github.com/apache/spark/pull/34356), this PR aims to
cover the API on SparkR.
### Does this PR introduce _any_ user-facing change?
Yes, users can call the API by SparkR
### How was this patch tested?
unit tests.
Closes #34480 from yoda-mon/make-date-r.
Authored-by: Leona Yoda
Signed-off-by: Kousuke Saruta
---
R/pkg/NAMESPACE | 1 +
R/pkg/R/functions.R | 26 ++
R/pkg/R/generics.R| 4
R/pkg/tests/fulltests/test_sparkSQL.R | 14 ++
4 files changed, 45 insertions(+)
diff --git a/R/pkg/NAMESPACE b/R/pkg/NAMESPACE
index 10bb02a..6e0557c 100644
--- a/R/pkg/NAMESPACE
+++ b/R/pkg/NAMESPACE
@@ -343,6 +343,7 @@ exportMethods("%<=>%",
"lower",
"lpad",
"ltrim",
+ "make_date",
"map_concat",
"map_entries",
"map_filter",
diff --git a/R/pkg/R/functions.R b/R/pkg/R/functions.R
index fdbf48b..48d4fe8 100644
--- a/R/pkg/R/functions.R
+++ b/R/pkg/R/functions.R
@@ -41,6 +41,8 @@ NULL
#' @param x Column to compute on. In \code{window}, it must be a time Column of
#' \code{TimestampType}. This is not used with \code{current_date} and
#' \code{current_timestamp}
+#' @param y Column to compute on.
+#' @param z Column to compute on.
#' @param format The format for the given dates or timestamps in Column
\code{x}. See the
#' format used in the following methods:
#' \itemize{
@@ -1467,6 +1469,30 @@ setMethod("ltrim",
})
#' @details
+#' \code{make_date}: Create date from year, month and day fields.
+#'
+#' @rdname column_datetime_functions
+#' @aliases make_date make_date,Column-method
+#' @note make_date since 3.3.0
+#' @examples
+#'
+#' \dontrun{
+#' df <- createDataFrame(
+#' list(list(2021, 10, 22), list(2021, 13, 1),
+#'list(2021, 2, 29), list(2020, 2, 29)),
+#' list("year", "month", "day")
+#' )
+#' tmp <- head(select(df, make_date(df$year, df$month, df$day)))
+#' head(tmp)}
+setMethod("make_date",
+ signature(x = "Column", y = "Column", z = "Column"),
+ function(x, y, z) {
+jc <- callJStatic("org.apache.spark.sql.functions", "make_date",
+ x@jc, y@jc, z@jc)
+column(jc)
+ })
+
+#' @details
#' \code{max}: Returns the maximum value of the expression in a group.
#'
#' @rdname column_aggregate_functions
diff --git a/R/pkg/R/generics.R b/R/pkg/R/generics.R
index af19e72..5fe2ec6 100644
--- a/R/pkg/R/generics.R
+++ b/R/pkg/R/generics.R
@@ -1158,6 +1158,10 @@ setGeneric("lpad", function(x, len, pad) {
standardGeneric("lpad") })
#' @name NULL
setGeneric("ltrim", function(x, trimString) { standardGeneric("ltrim") })
+#' @rdname column_datetime_functions
+#' @name NULL
+setGeneric("make_date", function(x, y, z) { standardGeneric("make_date") })
+
#' @rdname column_collection_functions
#' @name NULL
setGeneric("map_concat", function(x, ...) { standardGeneric("map_concat") })
diff --git a/R/pkg/tests/fulltests/test_sparkSQL.R
b/R/pkg/tests/fulltests/test_sparkSQL.R
index b6e02bb..0e46324e 100644
--- a/R/pkg/tests/fulltests/test_sparkSQL.R
+++ b/R/pkg/tests/fulltests/test_sparkSQL.R
@@ -2050,6 +2050,20 @@ test_that("date functions on a DataFrame", {
Sys.setenv(TZ = .originalTimeZone)
})
+test_that("SPARK-37108: expose make_date expression in R", {
+ df <- createDataFrame(
+list(list(2021, 10, 22), list(2021, 13, 1),
+ list(2021, 2, 29), list(2020, 2, 29)),
+list("year", "month", "day")
+ )
+ expect <- createDataFrame(
+list(list(as.Date("2021-10-22")), NA, N
[spark] branch master updated: [SPARK-36894][SPARK-37077][PYTHON] Synchronize RDD.toDF annotations with SparkSession and SQLContext .createDataFrame variants
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b874bf5 [SPARK-36894][SPARK-37077][PYTHON] Synchronize RDD.toDF
annotations with SparkSession and SQLContext .createDataFrame variants
b874bf5 is described below
commit b874bf5dca4f1b7272f458350eb153e7b272f8c8
Author: zero323
AuthorDate: Thu Nov 4 02:06:48 2021 +0900
[SPARK-36894][SPARK-37077][PYTHON] Synchronize RDD.toDF annotations with
SparkSession and SQLContext .createDataFrame variants
### What changes were proposed in this pull request?
This pull request synchronizes `RDD.toDF` annotations with
`SparkSession.createDataFrame` and `SQLContext.createDataFrame` variants.
Additionally, it fixes recent regression in `SQLContext.createDataFrame`
(SPARK-37077), where `RDD` is no longer consider a valid input.
### Why are the changes needed?
- Adds support for providing `str` schema.
- Add supports for converting `RDDs` of "atomic" values, if schema is
provided.
Additionally it introduces a `TypeVar` representing supported "atomic"
values. This was done to avoid issue with manual data tests, where the following
```python
sc.parallelize([1]).toDF(schema=IntegerType())
```
results in
```
error: No overload variant of "toDF" of "RDD" matches argument type
"IntegerType" [call-overload]
note: Possible overload variants:
note: def toDF(self, schema: Union[List[str], Tuple[str, ...], None] =
..., sampleRatio: Optional[float] = ...) -> DataFrame
note: def toDF(self, schema: Union[StructType, str, None] = ...) ->
DataFrame
```
when `Union` type is used (this problem doesn't surface when non-self bound
is used).
### Does this PR introduce _any_ user-facing change?
Type checker only.
Please note, that these annotations serve primarily to support
documentation, as checks on `self` types are still very limited.
### How was this patch tested?
Existing tests and manual data tests.
__Note__:
Updated data tests to reflect new expected traceback, after reversal in
#34477
Closes #34478 from zero323/SPARK-36894.
Authored-by: zero323
Signed-off-by: Kousuke Saruta
---
python/pyspark/rdd.pyi | 15 ++---
python/pyspark/sql/_typing.pyi | 11 +++
python/pyspark/sql/context.py| 38 ++
python/pyspark/sql/session.py| 40 +---
python/pyspark/sql/tests/typing/test_session.yml | 8 ++---
5 files changed, 71 insertions(+), 41 deletions(-)
diff --git a/python/pyspark/rdd.pyi b/python/pyspark/rdd.pyi
index a810a2c..84481d3 100644
--- a/python/pyspark/rdd.pyi
+++ b/python/pyspark/rdd.pyi
@@ -55,8 +55,8 @@ from pyspark.resource.requests import ( # noqa: F401
from pyspark.resource.profile import ResourceProfile
from pyspark.statcounter import StatCounter
from pyspark.sql.dataframe import DataFrame
-from pyspark.sql.types import StructType
-from pyspark.sql._typing import RowLike
+from pyspark.sql.types import AtomicType, StructType
+from pyspark.sql._typing import AtomicValue, RowLike
from py4j.java_gateway import JavaObject # type: ignore[import]
T = TypeVar("T")
@@ -445,11 +445,18 @@ class RDD(Generic[T]):
@overload
def toDF(
self: RDD[RowLike],
-schema: Optional[List[str]] = ...,
+schema: Optional[Union[List[str], Tuple[str, ...]]] = ...,
sampleRatio: Optional[float] = ...,
) -> DataFrame: ...
@overload
-def toDF(self: RDD[RowLike], schema: Optional[StructType] = ...) ->
DataFrame: ...
+def toDF(
+self: RDD[RowLike], schema: Optional[Union[StructType, str]] = ...
+) -> DataFrame: ...
+@overload
+def toDF(
+self: RDD[AtomicValue],
+schema: Union[AtomicType, str],
+) -> DataFrame: ...
class RDDBarrier(Generic[T]):
rdd: RDD[T]
diff --git a/python/pyspark/sql/_typing.pyi b/python/pyspark/sql/_typing.pyi
index 1a3bd8f..b6b4606 100644
--- a/python/pyspark/sql/_typing.pyi
+++ b/python/pyspark/sql/_typing.pyi
@@ -42,6 +42,17 @@ AtomicDataTypeOrString = Union[pyspark.sql.types.AtomicType,
str]
DataTypeOrString = Union[pyspark.sql.types.DataType, str]
OptionalPrimitiveType = Optional[PrimitiveType]
+AtomicValue = TypeVar(
+"AtomicValue",
+datetime.datetime,
+datetime.date,
+decimal.Decimal,
+bool,
+str,
+int,
+float,
+)
+
RowLike = TypeVar("RowLike", List[Any], Tuple[Any, ...], pyspark.sql.types.Row)
class SupportsOpen(Protocol):
diff --git a/python/pyspark/sql/context.py b/pytho
[spark] branch master updated: Revert "[SPARK-36894][SPARK-37077][PYTHON] Synchronize RDD.toDF annotations with SparkSession and SQLContext .createDataFrame variants."
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 8687138 Revert "[SPARK-36894][SPARK-37077][PYTHON] Synchronize
RDD.toDF annotations with SparkSession and SQLContext .createDataFrame
variants."
8687138 is described below
commit 86871386b063d8f7a8b5b42eb327a3900525af58
Author: Kousuke Saruta
AuthorDate: Wed Nov 3 23:01:38 2021 +0900
Revert "[SPARK-36894][SPARK-37077][PYTHON] Synchronize RDD.toDF annotations
with SparkSession and SQLContext .createDataFrame variants."
This reverts commit 855da09f02f3007a2c36e7a738d4dc81fd95569a.
See [this
comment](https://github.com/apache/spark/pull/34146#issuecomment-959136935).
Closes #34477 from sarutak/revert-SPARK-37077.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
python/pyspark/rdd.pyi | 15 ---
python/pyspark/sql/_typing.pyi | 11 ---
python/pyspark/sql/context.py | 38 ++
python/pyspark/sql/session.py | 40 +++-
4 files changed, 37 insertions(+), 67 deletions(-)
diff --git a/python/pyspark/rdd.pyi b/python/pyspark/rdd.pyi
index 84481d3..a810a2c 100644
--- a/python/pyspark/rdd.pyi
+++ b/python/pyspark/rdd.pyi
@@ -55,8 +55,8 @@ from pyspark.resource.requests import ( # noqa: F401
from pyspark.resource.profile import ResourceProfile
from pyspark.statcounter import StatCounter
from pyspark.sql.dataframe import DataFrame
-from pyspark.sql.types import AtomicType, StructType
-from pyspark.sql._typing import AtomicValue, RowLike
+from pyspark.sql.types import StructType
+from pyspark.sql._typing import RowLike
from py4j.java_gateway import JavaObject # type: ignore[import]
T = TypeVar("T")
@@ -445,18 +445,11 @@ class RDD(Generic[T]):
@overload
def toDF(
self: RDD[RowLike],
-schema: Optional[Union[List[str], Tuple[str, ...]]] = ...,
+schema: Optional[List[str]] = ...,
sampleRatio: Optional[float] = ...,
) -> DataFrame: ...
@overload
-def toDF(
-self: RDD[RowLike], schema: Optional[Union[StructType, str]] = ...
-) -> DataFrame: ...
-@overload
-def toDF(
-self: RDD[AtomicValue],
-schema: Union[AtomicType, str],
-) -> DataFrame: ...
+def toDF(self: RDD[RowLike], schema: Optional[StructType] = ...) ->
DataFrame: ...
class RDDBarrier(Generic[T]):
rdd: RDD[T]
diff --git a/python/pyspark/sql/_typing.pyi b/python/pyspark/sql/_typing.pyi
index b6b4606..1a3bd8f 100644
--- a/python/pyspark/sql/_typing.pyi
+++ b/python/pyspark/sql/_typing.pyi
@@ -42,17 +42,6 @@ AtomicDataTypeOrString = Union[pyspark.sql.types.AtomicType,
str]
DataTypeOrString = Union[pyspark.sql.types.DataType, str]
OptionalPrimitiveType = Optional[PrimitiveType]
-AtomicValue = TypeVar(
-"AtomicValue",
-datetime.datetime,
-datetime.date,
-decimal.Decimal,
-bool,
-str,
-int,
-float,
-)
-
RowLike = TypeVar("RowLike", List[Any], Tuple[Any, ...], pyspark.sql.types.Row)
class SupportsOpen(Protocol):
diff --git a/python/pyspark/sql/context.py b/python/pyspark/sql/context.py
index eba2087..7d27c55 100644
--- a/python/pyspark/sql/context.py
+++ b/python/pyspark/sql/context.py
@@ -48,11 +48,13 @@ from pyspark.conf import SparkConf
if TYPE_CHECKING:
from pyspark.sql._typing import (
-AtomicValue,
-RowLike,
UserDefinedFunctionLike,
+RowLike,
+DateTimeLiteral,
+LiteralType,
+DecimalLiteral
)
-from pyspark.sql.pandas._typing import DataFrameLike as PandasDataFrameLike
+from pyspark.sql.pandas._typing import DataFrameLike
__all__ = ["SQLContext", "HiveContext"]
@@ -321,8 +323,7 @@ class SQLContext(object):
@overload
def createDataFrame(
self,
-data: Union["RDD[RowLike]", Iterable["RowLike"]],
-schema: Union[List[str], Tuple[str, ...]] = ...,
+data: Iterable["RowLike"],
samplingRatio: Optional[float] = ...,
) -> DataFrame:
...
@@ -330,9 +331,8 @@ class SQLContext(object):
@overload
def createDataFrame(
self,
-data: Union["RDD[RowLike]", Iterable["RowLike"]],
-schema: Union[StructType, str],
-*,
+data: Iterable["RowLike"],
+schema: Union[List[str], Tuple[str, ...]] = ...,
verifySchema: bool = ...,
) -> DataFrame:
...
@@ -340,10 +340,7 @@ class SQLContext(object):
@overload
def createDataFrame(
self,
-data: Union[
-"RDD[AtomicValue]",
-Iterable["AtomicValue"
[spark] branch branch-3.2 updated: [MINOR][PYTHON][DOCS] Fix broken link in legacy Apache Arrow in PySpark page
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new c2f147e [MINOR][PYTHON][DOCS] Fix broken link in legacy Apache Arrow in PySpark page c2f147e is described below commit c2f147eff8e3e353cfb43f5d45f19f174fb26773 Author: Hyukjin Kwon AuthorDate: Wed Nov 3 20:54:50 2021 +0900 [MINOR][PYTHON][DOCS] Fix broken link in legacy Apache Arrow in PySpark page ### What changes were proposed in this pull request? This PR proposes to fix the broken link in the legacy page. Currently it links to:   It should link to:   ### Why are the changes needed? For users to easily navigate from legacy page to newer page. ### Does this PR introduce _any_ user-facing change? Yes, it fixes a bug in documentation. ### How was this patch tested? Manually built the side and checked the link Closes #34475 from HyukjinKwon/minor-doc-fix-py. Authored-by: Hyukjin Kwon Signed-off-by: Kousuke Saruta (cherry picked from commit ab7e5030b23ccb8ef6aa43645e909457f9d68ffa) Signed-off-by: Kousuke Saruta --- python/docs/source/user_guide/arrow_pandas.rst | 2 +- python/docs/source/user_guide/sql/arrow_pandas.rst | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) diff --git a/python/docs/source/user_guide/arrow_pandas.rst b/python/docs/source/user_guide/arrow_pandas.rst index c1b68a6..60c11b7 100644 --- a/python/docs/source/user_guide/arrow_pandas.rst +++ b/python/docs/source/user_guide/arrow_pandas.rst @@ -21,4 +21,4 @@ Apache Arrow in PySpark === -This page has been moved to `Apache Arrow in PySpark <../sql/arrow_pandas.rst>`_. +This page has been moved to `Apache Arrow in PySpark `_. diff --git a/python/docs/source/user_guide/sql/arrow_pandas.rst b/python/docs/source/user_guide/sql/arrow_pandas.rst index 1767624..78d3e7a 100644 --- a/python/docs/source/user_guide/sql/arrow_pandas.rst +++ b/python/docs/source/user_guide/sql/arrow_pandas.rst @@ -343,7 +343,7 @@ Supported SQL Types Currently, all Spark SQL data types are supported by Arrow-based conversion except :class:`ArrayType` of :class:`TimestampType`, and nested :class:`StructType`. -:class: `MapType` is only supported when using PyArrow 2.0.0 and above. +:class:`MapType` is only supported when using PyArrow 2.0.0 and above. Setting Arrow Batch Size - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (9babf9a -> ab7e503)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 9babf9a [SPARK-37200][SQL] Support drop index for Data Source V2 add ab7e503 [MINOR][PYTHON][DOCS] Fix broken link in legacy Apache Arrow in PySpark page No new revisions were added by this update. Summary of changes: python/docs/source/user_guide/arrow_pandas.rst | 2 +- python/docs/source/user_guide/sql/arrow_pandas.rst | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (675071a -> 320fa07)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 675071a [MINOR][DOCS] Corrected spacing in structured streaming programming add 320fa07 [SPARK-37159][SQL][TESTS] Change HiveExternalCatalogVersionsSuite to be able to test with Java 17 No new revisions were added by this update. Summary of changes: .../apache/spark/sql/hive/HiveExternalCatalogVersionsSuite.scala | 8 +++- 1 file changed, 7 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (11de0fd -> cf7fbc1)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 11de0fd [MINOR][DOCS] Add import for MultivariateGaussian to Docs add cf7fbc1 [SPARK-36554][SQL][PYTHON] Expose make_date expression in functions.scala No new revisions were added by this update. Summary of changes: python/docs/source/reference/pyspark.sql.rst | 1 + python/pyspark/sql/functions.py| 29 ++ python/pyspark/sql/tests/test_functions.py | 10 +++- .../scala/org/apache/spark/sql/functions.scala | 9 +++ 4 files changed, 48 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (40f1494 -> 81aa514)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 40f1494 [SPARK-37041][SQL] Backport HIVE-15025: Secure-Socket-Layer (SSL) support for HMS add 81aa514 [SPARK-37059][PYTHON][TESTS] Ensure the sort order of the output in the PySpark doctests No new revisions were added by this update. Summary of changes: python/pyspark/ml/fpm.py| 20 ++-- python/pyspark/sql/functions.py | 4 ++-- python/run-tests.py | 2 +- 3 files changed, 13 insertions(+), 13 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (1c61d90 -> 838a9d9)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 1c61d90 [SPARK-35973][SQL] Add command `SHOW CATALOGS` add 838a9d9 [SPARK-36922][SQL] The SIGN/SIGNUM functions should support ANSI intervals No new revisions were added by this update. Summary of changes: .../sql/catalyst/expressions/mathExpressions.scala | 7 +++ .../expressions/MathExpressionsSuite.scala | 21 + .../test/resources/sql-tests/inputs/interval.sql | 6 +++ .../sql-tests/results/ansi/interval.sql.out| 50 +- .../resources/sql-tests/results/interval.sql.out | 50 +- 5 files changed, 132 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36981][BUILD] Upgrade joda-time to 2.10.12
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 3a91b9a [SPARK-36981][BUILD] Upgrade joda-time to 2.10.12 3a91b9a is described below commit 3a91b9ac598abcb69703d2cd0247b5e378be58c0 Author: Kousuke Saruta AuthorDate: Wed Oct 13 09:18:22 2021 +0900 [SPARK-36981][BUILD] Upgrade joda-time to 2.10.12 ### What changes were proposed in this pull request? This PR upgrades `joda-time` from `2.10.10` to `2.10.12`. ### Why are the changes needed? `2.10.12` supports an updated TZDB. [diff](https://github.com/JodaOrg/joda-time/compare/v2.10.10...v2.10.12#diff-9c5fb3d1b7e3b0f54bc5c4182965c4fe1f9023d449017cece3005d3f90e8e4d8R1037) https://github.com/JodaOrg/joda-time/issues/566#issuecomment-930207547 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? CIs. Closes #34253 from sarutak/upgrade-joda-2.10.12. Authored-by: Kousuke Saruta Signed-off-by: Kousuke Saruta --- dev/deps/spark-deps-hadoop-2.7-hive-2.3 | 2 +- dev/deps/spark-deps-hadoop-3.2-hive-2.3 | 2 +- pom.xml | 2 +- 3 files changed, 3 insertions(+), 3 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-2.7-hive-2.3 b/dev/deps/spark-deps-hadoop-2.7-hive-2.3 index 94a4758..d37b38b 100644 --- a/dev/deps/spark-deps-hadoop-2.7-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-2.7-hive-2.3 @@ -148,7 +148,7 @@ jetty-util/6.1.26//jetty-util-6.1.26.jar jetty-util/9.4.43.v20210629//jetty-util-9.4.43.v20210629.jar jetty/6.1.26//jetty-6.1.26.jar jline/2.14.6//jline-2.14.6.jar -joda-time/2.10.10//joda-time-2.10.10.jar +joda-time/2.10.12//joda-time-2.10.12.jar jodd-core/3.5.2//jodd-core-3.5.2.jar jpam/1.1//jpam-1.1.jar json/1.8//json-1.8.jar diff --git a/dev/deps/spark-deps-hadoop-3.2-hive-2.3 b/dev/deps/spark-deps-hadoop-3.2-hive-2.3 index 091f399..3040ffe 100644 --- a/dev/deps/spark-deps-hadoop-3.2-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-3.2-hive-2.3 @@ -136,7 +136,7 @@ jettison/1.1//jettison-1.1.jar jetty-util-ajax/9.4.43.v20210629//jetty-util-ajax-9.4.43.v20210629.jar jetty-util/9.4.43.v20210629//jetty-util-9.4.43.v20210629.jar jline/2.14.6//jline-2.14.6.jar -joda-time/2.10.10//joda-time-2.10.10.jar +joda-time/2.10.12//joda-time-2.10.12.jar jodd-core/3.5.2//jodd-core-3.5.2.jar jpam/1.1//jpam-1.1.jar json/1.8//json-1.8.jar diff --git a/pom.xml b/pom.xml index 6225fc0..2c46c52 100644 --- a/pom.xml +++ b/pom.xml @@ -184,7 +184,7 @@ 14.0.1 3.0.16 2.34 -2.10.10 +2.10.12 3.5.2 3.0.0 0.12.0 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (36b3bbc0 -> b9a8165)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 36b3bbc0 [SPARK-36979][SQL] Add RewriteLateralSubquery rule into nonExcludableRules add b9a8165 [SPARK-36972][PYTHON] Add max_by/min_by API to PySpark No new revisions were added by this update. Summary of changes: python/docs/source/reference/pyspark.sql.rst | 2 + python/pyspark/sql/functions.py | 72 2 files changed, 74 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (aed977c -> 2953d4f)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from aed977c [SPARK-36919][SQL] Make BadRecordException fields transient add 2953d4f [SPARK-36751][PYTHON][DOCS][FOLLOW-UP] Fix unexpected section title for Examples in docstring No new revisions were added by this update. Summary of changes: python/pyspark/sql/functions.py | 12 ++-- 1 file changed, 6 insertions(+), 6 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36038][CORE] Speculation metrics summary at stage level
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 73747ec [SPARK-36038][CORE] Speculation metrics summary at stage level
73747ec is described below
commit 73747ecb970595d49c478b0eb65f5132c8b0bf02
Author: Venkata krishnan Sowrirajan
AuthorDate: Fri Oct 1 16:59:29 2021 +0900
[SPARK-36038][CORE] Speculation metrics summary at stage level
### What changes were proposed in this pull request?
Currently there are no speculation metrics available for Spark either at
application/job/stage level. This PR is to add some basic speculation metrics
for a stage when speculation execution is enabled.
This is similar to the existing stage level metrics tracking numTotal
(total number of speculated tasks), numCompleted (total number of successful
speculated tasks), numFailed (total number of failed speculated tasks),
numKilled (total number of killed speculated tasks) etc.
With this new set of metrics, it helps further understanding speculative
execution feature in the context of the application and also helps in further
tuning the speculative execution config knobs.
Screenshot of Spark UI with speculation summary:

Screenshot of Spark UI with API output:

### Why are the changes needed?
Additional metrics for speculative execution.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit tests added and also deployed in our internal platform for quite some
time now.
Lead-authored by: Venkata krishnan Sowrirajan
Co-authored by: Ron Hu
Co-authored by: Thejdeep Gudivada
Closes #33253 from venkata91/speculation-metrics.
Authored-by: Venkata krishnan Sowrirajan
Signed-off-by: Kousuke Saruta
---
.../org/apache/spark/ui/static/stagepage.js| 29 ++
.../spark/ui/static/stagespage-template.html | 15 +
.../resources/org/apache/spark/ui/static/webui.css | 10 +
.../apache/spark/status/AppStatusListener.scala| 19 +
.../org/apache/spark/status/AppStatusStore.scala | 11 +
.../scala/org/apache/spark/status/LiveEntity.scala | 26 ++
.../scala/org/apache/spark/status/api/v1/api.scala | 8 +
.../scala/org/apache/spark/status/storeTypes.scala | 14 +
.../scala/org/apache/spark/ui/jobs/JobPage.scala | 1 +
.../application_list_json_expectation.json | 15 +
.../completed_app_list_json_expectation.json | 15 +
.../limit_app_list_json_expectation.json | 30 +-
.../minDate_app_list_json_expectation.json | 15 +
.../minEndDate_app_list_json_expectation.json | 15 +
...stage_with_speculation_summary_expectation.json | 507 +
.../spark-events/application_1628109047826_1317105 | 52 +++
.../spark/deploy/history/HistoryServerSuite.scala | 5 +-
.../spark/status/AppStatusListenerSuite.scala | 10 +
.../apache/spark/status/AppStatusStoreSuite.scala | 57 ++-
.../scala/org/apache/spark/ui/StagePageSuite.scala | 1 +
dev/.rat-excludes | 3 +-
21 files changed, 840 insertions(+), 18 deletions(-)
diff --git a/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
b/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
index db1a148..595635a 100644
--- a/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
+++ b/core/src/main/resources/org/apache/spark/ui/static/stagepage.js
@@ -652,6 +652,35 @@ $(document).ready(function () {
executorSummaryTableSelector.column(14).visible(dataToShow.showBytesSpilledData);
});
+// Prepare data for speculation metrics
+$("#speculationSummaryTitle").hide()
+$("#speculationSummary").hide()
+var speculationSummaryInfo = responseBody.speculationSummary;
+var speculationData = [[
+ speculationSummaryInfo.numTasks,
+ speculationSummaryInfo.numActiveTasks,
+ speculationSummaryInfo.numCompletedTasks,
+ speculationSummaryInfo.numFailedTasks,
+ speculationSummaryInfo.numKilledTasks
+]];
+if (speculationSummaryInfo.numTasks > 0) {
+ // Show speculationSummary if there is atleast one speculated task
ran
+ $("#speculationSummaryTitle").show()
+ $("#speculationSummary").show()
+}
+var speculationMetricsTableConf = {
+ "data": speculationData,
+
[spark] branch master updated: [SPARK-36899][R] Support ILIKE API on R
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 17e3ca6 [SPARK-36899][R] Support ILIKE API on R
17e3ca6 is described below
commit 17e3ca6df5eb4b7b74cd8d04868da39eb0137826
Author: Leona Yoda
AuthorDate: Thu Sep 30 14:43:09 2021 +0900
[SPARK-36899][R] Support ILIKE API on R
### What changes were proposed in this pull request?
Support ILIKE (case insensitive LIKE) API on R.
### Why are the changes needed?
ILIKE statement on SQL interface is supported by SPARK-36674.
This PR will support R API for it.
### Does this PR introduce _any_ user-facing change?
Yes. Users can call ilike from R.
### How was this patch tested?
Unit tests.
Closes #34152 from yoda-mon/r-ilike.
Authored-by: Leona Yoda
Signed-off-by: Kousuke Saruta
---
R/pkg/NAMESPACE | 1 +
R/pkg/R/column.R | 2 +-
R/pkg/R/generics.R| 3 +++
R/pkg/tests/fulltests/test_sparkSQL.R | 2 ++
4 files changed, 7 insertions(+), 1 deletion(-)
diff --git a/R/pkg/NAMESPACE b/R/pkg/NAMESPACE
index 5de7aeb..11403f6 100644
--- a/R/pkg/NAMESPACE
+++ b/R/pkg/NAMESPACE
@@ -316,6 +316,7 @@ exportMethods("%<=>%",
"hour",
"hypot",
"ifelse",
+ "ilike",
"initcap",
"input_file_name",
"instr",
diff --git a/R/pkg/R/column.R b/R/pkg/R/column.R
index 9fa117c..f1fd30e 100644
--- a/R/pkg/R/column.R
+++ b/R/pkg/R/column.R
@@ -72,7 +72,7 @@ column_functions1 <- c(
"desc", "desc_nulls_first", "desc_nulls_last",
"isNaN", "isNull", "isNotNull"
)
-column_functions2 <- c("like", "rlike", "getField", "getItem", "contains")
+column_functions2 <- c("like", "rlike", "ilike", "getField", "getItem",
"contains")
createOperator <- function(op) {
setMethod(op,
diff --git a/R/pkg/R/generics.R b/R/pkg/R/generics.R
index 9da818b..ad29a70 100644
--- a/R/pkg/R/generics.R
+++ b/R/pkg/R/generics.R
@@ -725,6 +725,9 @@ setGeneric("like", function(x, ...) {
standardGeneric("like") })
#' @rdname columnfunctions
setGeneric("rlike", function(x, ...) { standardGeneric("rlike") })
+#' @rdname columnfunctions
+setGeneric("ilike", function(x, ...) { standardGeneric("ilike") })
+
#' @rdname startsWith
setGeneric("startsWith", function(x, prefix) { standardGeneric("startsWith") })
diff --git a/R/pkg/tests/fulltests/test_sparkSQL.R
b/R/pkg/tests/fulltests/test_sparkSQL.R
index bd5c250..1d8ac2b 100644
--- a/R/pkg/tests/fulltests/test_sparkSQL.R
+++ b/R/pkg/tests/fulltests/test_sparkSQL.R
@@ -2130,6 +2130,8 @@ test_that("higher order functions", {
expr("transform(xs, (x, i) -> CASE WHEN ((i % 2.0) = 0.0) THEN x ELSE (-
x) END)"),
array_exists("vs", function(v) rlike(v, "FAILED")) ==
expr("exists(vs, v -> (v RLIKE 'FAILED'))"),
+array_exists("vs", function(v) ilike(v, "failed")) ==
+ expr("exists(vs, v -> (v ILIKE 'failed'))"),
array_forall("xs", function(x) x > 0) ==
expr("forall(xs, x -> x > 0)"),
array_filter("xs", function(x, i) x > 0 | i %% 2 == 0) ==
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36882][PYTHON] Support ILIKE API on Python
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new ca1c09d [SPARK-36882][PYTHON] Support ILIKE API on Python
ca1c09d is described below
commit ca1c09d88c21d0f8664df8e852778f864f130d94
Author: Leona Yoda
AuthorDate: Wed Sep 29 15:04:03 2021 +0900
[SPARK-36882][PYTHON] Support ILIKE API on Python
### What changes were proposed in this pull request?
Support ILIKE (case insensitive LIKE) API on Python.
### Why are the changes needed?
ILIKE statement on SQL interface is supported by SPARK-36674.
This PR will support Python API for it.
### Does this PR introduce _any_ user-facing change?
Yes. Users can call `ilike` from Python.
### How was this patch tested?
Unit tests.
Closes #34135 from yoda-mon/python-ilike.
Authored-by: Leona Yoda
Signed-off-by: Kousuke Saruta
---
python/docs/source/reference/pyspark.sql.rst | 1 +
python/pyspark/sql/column.py | 21 +
python/pyspark/sql/tests/test_column.py | 2 +-
3 files changed, 23 insertions(+), 1 deletion(-)
diff --git a/python/docs/source/reference/pyspark.sql.rst
b/python/docs/source/reference/pyspark.sql.rst
index f5a8357..0fd2c4d 100644
--- a/python/docs/source/reference/pyspark.sql.rst
+++ b/python/docs/source/reference/pyspark.sql.rst
@@ -259,6 +259,7 @@ Column APIs
Column.eqNullSafe
Column.getField
Column.getItem
+Column.ilike
Column.isNotNull
Column.isNull
Column.isin
diff --git a/python/pyspark/sql/column.py b/python/pyspark/sql/column.py
index 9046e7f..c46b0eb 100644
--- a/python/pyspark/sql/column.py
+++ b/python/pyspark/sql/column.py
@@ -507,6 +507,26 @@ class Column(object):
>>> df.filter(df.name.like('Al%')).collect()
[Row(age=2, name='Alice')]
"""
+_ilike_doc = """
+SQL ILIKE expression (case insensitive LIKE). Returns a boolean
:class:`Column`
+based on a case insensitive match.
+
+.. versionadded:: 3.3.0
+
+Parameters
+--
+other : str
+a SQL LIKE pattern
+
+See Also
+
+pyspark.sql.Column.rlike
+
+Examples
+
+>>> df.filter(df.name.ilike('%Ice')).collect()
+[Row(age=2, name='Alice')]
+"""
_startswith_doc = """
String starts with. Returns a boolean :class:`Column` based on a string
match.
@@ -541,6 +561,7 @@ class Column(object):
contains = _bin_op("contains", _contains_doc)
rlike = _bin_op("rlike", _rlike_doc)
like = _bin_op("like", _like_doc)
+ilike = _bin_op("ilike", _ilike_doc)
startswith = _bin_op("startsWith", _startswith_doc)
endswith = _bin_op("endsWith", _endswith_doc)
diff --git a/python/pyspark/sql/tests/test_column.py
b/python/pyspark/sql/tests/test_column.py
index c2530b2..9a918c2 100644
--- a/python/pyspark/sql/tests/test_column.py
+++ b/python/pyspark/sql/tests/test_column.py
@@ -75,7 +75,7 @@ class ColumnTests(ReusedSQLTestCase):
self.assertTrue(all(isinstance(c, Column) for c in cb))
cbool = (ci & ci), (ci | ci), (~ci)
self.assertTrue(all(isinstance(c, Column) for c in cbool))
-css = cs.contains('a'), cs.like('a'), cs.rlike('a'), cs.asc(),
cs.desc(),\
+css = cs.contains('a'), cs.like('a'), cs.rlike('a'), cs.ilike('A'),
cs.asc(), cs.desc(),\
cs.startswith('a'), cs.endswith('a'), ci.eqNullSafe(cs)
self.assertTrue(all(isinstance(c, Column) for c in css))
self.assertTrue(isinstance(ci.cast(LongType()), Column))
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (6e815da -> 0b65daa)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 6e815da [SPARK-36760][SQL][FOLLOWUP] Add interface SupportsPushDownV2Filters add 0b65daa [SPARK-36760][DOCS][FOLLOWUP] Fix wrong JavaDoc style No new revisions were added by this update. Summary of changes: .../org/apache/spark/sql/connector/read/SupportsPushDownV2Filters.java | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (4cc39cf -> 30d17b6)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 4cc39cf [SPARK-36101][CORE] Grouping exception in core/api add 30d17b6 [SPARK-36683][SQL] Add new built-in SQL functions: SEC and CSC No new revisions were added by this update. Summary of changes: python/docs/source/reference/pyspark.sql.rst | 2 + python/pyspark/sql/functions.py| 58 python/pyspark/sql/functions.pyi | 2 + python/pyspark/sql/tests/test_functions.py | 78 -- python/pyspark/testing/sqlutils.py | 8 +++ .../sql/catalyst/analysis/FunctionRegistry.scala | 2 + .../sql/catalyst/expressions/mathExpressions.scala | 46 + .../expressions/MathExpressionsSuite.scala | 28 .../scala/org/apache/spark/sql/functions.scala | 18 + .../sql-functions/sql-expression-schema.md | 4 +- .../test/resources/sql-tests/inputs/operators.sql | 8 +++ .../resources/sql-tests/results/operators.sql.out | 66 +- .../org/apache/spark/sql/MathFunctionsSuite.scala | 15 + 13 files changed, 299 insertions(+), 36 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36751][SQL][PYTHON][R] Add bit/octet_length APIs to Scala, Python and R
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 0666f5c [SPARK-36751][SQL][PYTHON][R] Add bit/octet_length APIs to
Scala, Python and R
0666f5c is described below
commit 0666f5c00393acccecdd82d3794e5a2b88f3210b
Author: Leona Yoda
AuthorDate: Wed Sep 15 16:27:13 2021 +0900
[SPARK-36751][SQL][PYTHON][R] Add bit/octet_length APIs to Scala, Python
and R
### What changes were proposed in this pull request?
octet_length: caliculate the byte length of strings
bit_length: caliculate the bit length of strings
Those two string related functions are only implemented on SparkSQL, not on
Scala, Python and R.
### Why are the changes needed?
Those functions would be useful for multi-bytes character users, who mainly
working with Scala, Python or R.
### Does this PR introduce _any_ user-facing change?
Yes. Users can call octet_length/bit_length APIs on Scala(Dataframe),
Python, and R.
### How was this patch tested?
unit tests
Closes #33992 from yoda-mon/add-bit-octet-length.
Authored-by: Leona Yoda
Signed-off-by: Kousuke Saruta
---
R/pkg/NAMESPACE| 2 +
R/pkg/R/functions.R| 26 +++
R/pkg/R/generics.R | 8
R/pkg/tests/fulltests/test_sparkSQL.R | 11 +
python/docs/source/reference/pyspark.sql.rst | 2 +
python/pyspark/sql/functions.py| 52 ++
python/pyspark/sql/functions.pyi | 2 +
python/pyspark/sql/tests/test_functions.py | 14 +-
.../scala/org/apache/spark/sql/functions.scala | 16 +++
.../apache/spark/sql/StringFunctionsSuite.scala| 52 ++
10 files changed, 184 insertions(+), 1 deletion(-)
diff --git a/R/pkg/NAMESPACE b/R/pkg/NAMESPACE
index 7fa8085..686a49e 100644
--- a/R/pkg/NAMESPACE
+++ b/R/pkg/NAMESPACE
@@ -243,6 +243,7 @@ exportMethods("%<=>%",
"base64",
"between",
"bin",
+ "bit_length",
"bitwise_not",
"bitwiseNOT",
"bround",
@@ -364,6 +365,7 @@ exportMethods("%<=>%",
"not",
"nth_value",
"ntile",
+ "octet_length",
"otherwise",
"over",
"overlay",
diff --git a/R/pkg/R/functions.R b/R/pkg/R/functions.R
index 62066da1..f0768c7 100644
--- a/R/pkg/R/functions.R
+++ b/R/pkg/R/functions.R
@@ -647,6 +647,19 @@ setMethod("bin",
})
#' @details
+#' \code{bit_length}: Calculates the bit length for the specified string
column.
+#'
+#' @rdname column_string_functions
+#' @aliases bit_length bit_length,Column-method
+#' @note length since 3.3.0
+setMethod("bit_length",
+ signature(x = "Column"),
+ function(x) {
+jc <- callJStatic("org.apache.spark.sql.functions", "bit_length",
x@jc)
+column(jc)
+ })
+
+#' @details
#' \code{bitwise_not}: Computes bitwise NOT.
#'
#' @rdname column_nonaggregate_functions
@@ -1570,6 +1583,19 @@ setMethod("negate",
})
#' @details
+#' \code{octet_length}: Calculates the byte length for the specified string
column.
+#'
+#' @rdname column_string_functions
+#' @aliases octet_length octet_length,Column-method
+#' @note length since 3.3.0
+setMethod("octet_length",
+ signature(x = "Column"),
+ function(x) {
+jc <- callJStatic("org.apache.spark.sql.functions",
"octet_length", x@jc)
+column(jc)
+ })
+
+#' @details
#' \code{overlay}: Overlay the specified portion of \code{x} with
\code{replace},
#' starting from byte position \code{pos} of \code{src} and proceeding for
#' \code{len} bytes.
diff --git a/R/pkg/R/generics.R b/R/pkg/R/generics.R
index 9ebea3f..1abde65 100644
--- a/R/pkg/R/generics.R
+++ b/R/pkg/R/generics.R
@@ -884,6 +884,10 @@ setGeneric("base64", function(x) {
standardGeneric("base64") })
#' @name NULL
setGeneric("bin", function(x) { standardGeneric("bin") })
+#' @rdname column_string_functions
+#' @name NULL
+setGeneric("bit_length", function(x, ...) { standardGeneric("bit_length") })
+
#' @rdname column_nonaggregate_functions
#&
[spark] branch branch-3.1 updated: [SPARK-36639][SQL] Fix an issue that sequence builtin function causes ArrayIndexOutOfBoundsException if the arguments are under the condition of start == stop && ste
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new c1f8d75 [SPARK-36639][SQL] Fix an issue that sequence builtin
function causes ArrayIndexOutOfBoundsException if the arguments are under the
condition of start == stop && step < 0
c1f8d75 is described below
commit c1f8d759a3d75885e694e8c468ee6beea70131a3
Author: Kousuke Saruta
AuthorDate: Fri Sep 3 23:25:18 2021 +0900
[SPARK-36639][SQL] Fix an issue that sequence builtin function causes
ArrayIndexOutOfBoundsException if the arguments are under the condition of
start == stop && step < 0
### What changes were proposed in this pull request?
This PR fixes an issue that `sequence` builtin function causes
`ArrayIndexOutOfBoundsException` if the arguments are under the condition of
`start == stop && step < 0`.
This is an example.
```
SELECT sequence(timestamp'2021-08-31', timestamp'2021-08-31', -INTERVAL 1
month);
21/09/02 04:14:42 ERROR SparkSQLDriver: Failed in [SELECT
sequence(timestamp'2021-08-31', timestamp'2021-08-31', -INTERVAL 1 month)]
java.lang.ArrayIndexOutOfBoundsException: 1
```
Actually, this example succeeded before SPARK-31980 (#28819) was merged.
### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New tests.
Closes #33895 from sarutak/fix-sequence-issue.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit cf3bc65e69dcb0f8ba3dee89642d082265edab31)
Signed-off-by: Kousuke Saruta
---
.../catalyst/expressions/collectionOperations.scala| 4 ++--
.../expressions/CollectionExpressionsSuite.scala | 18 ++
2 files changed, 20 insertions(+), 2 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
index b341895..bb2163c 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
@@ -2711,7 +2711,7 @@ object Sequence {
val maxEstimatedArrayLength =
getSequenceLength(startMicros, stopMicros, intervalStepInMicros)
-val stepSign = if (stopMicros >= startMicros) +1 else -1
+val stepSign = if (intervalStepInMicros > 0) +1 else -1
val exclusiveItem = stopMicros + stepSign
val arr = new Array[T](maxEstimatedArrayLength)
var t = startMicros
@@ -2786,7 +2786,7 @@ object Sequence {
|
| $sequenceLengthCode
|
- | final int $stepSign = $stopMicros >= $startMicros ? +1 : -1;
+ | final int $stepSign = $intervalInMicros > 0 ? +1 : -1;
| final long $exclusiveItem = $stopMicros + $stepSign;
|
| $arr = new $elemType[$arrLength];
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CollectionExpressionsSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CollectionExpressionsSuite.scala
index 095894b..d79f06f 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CollectionExpressionsSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CollectionExpressionsSuite.scala
@@ -1888,6 +1888,24 @@ class CollectionExpressionsSuite extends SparkFunSuite
with ExpressionEvalHelper
Seq(Date.valueOf("2018-01-01")))
}
+ test("SPARK-36639: Start and end equal in month range with a negative step")
{
+checkEvaluation(new Sequence(
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(stringToInterval("interval -1 day"))),
+ Seq(Date.valueOf("2018-01-01")))
+checkEvaluation(new Sequence(
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(stringToInterval("interval -1 month"))),
+ Seq(Date.valueOf("2018-01-01")))
+checkEvaluation(new Sequence(
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(stringToInterval("interval -1 year"))),
+ Seq(Date.valueOf("2018-01-01")))
+ }
+
test("SPARK-33386: element_at ArrayIndexOutOfBoundsException") {
Seq(true, false).foreach { ansiEnabled =>
[spark] branch branch-3.2 updated: [SPARK-36639][SQL] Fix an issue that sequence builtin function causes ArrayIndexOutOfBoundsException if the arguments are under the condition of start == stop && ste
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new a3901ed [SPARK-36639][SQL] Fix an issue that sequence builtin
function causes ArrayIndexOutOfBoundsException if the arguments are under the
condition of start == stop && step < 0
a3901ed is described below
commit a3901ed3848d21fd36bb5aa265ef8e8d74d8e324
Author: Kousuke Saruta
AuthorDate: Fri Sep 3 23:25:18 2021 +0900
[SPARK-36639][SQL] Fix an issue that sequence builtin function causes
ArrayIndexOutOfBoundsException if the arguments are under the condition of
start == stop && step < 0
### What changes were proposed in this pull request?
This PR fixes an issue that `sequence` builtin function causes
`ArrayIndexOutOfBoundsException` if the arguments are under the condition of
`start == stop && step < 0`.
This is an example.
```
SELECT sequence(timestamp'2021-08-31', timestamp'2021-08-31', -INTERVAL 1
month);
21/09/02 04:14:42 ERROR SparkSQLDriver: Failed in [SELECT
sequence(timestamp'2021-08-31', timestamp'2021-08-31', -INTERVAL 1 month)]
java.lang.ArrayIndexOutOfBoundsException: 1
```
Actually, this example succeeded before SPARK-31980 (#28819) was merged.
### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New tests.
Closes #33895 from sarutak/fix-sequence-issue.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit cf3bc65e69dcb0f8ba3dee89642d082265edab31)
Signed-off-by: Kousuke Saruta
---
.../catalyst/expressions/collectionOperations.scala| 4 ++--
.../expressions/CollectionExpressionsSuite.scala | 18 ++
2 files changed, 20 insertions(+), 2 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
index 6cbab86..ce17231 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
@@ -2903,7 +2903,7 @@ object Sequence {
val maxEstimatedArrayLength =
getSequenceLength(startMicros, stopMicros, input3,
intervalStepInMicros)
-val stepSign = if (stopMicros >= startMicros) +1 else -1
+val stepSign = if (intervalStepInMicros > 0) +1 else -1
val exclusiveItem = stopMicros + stepSign
val arr = new Array[T](maxEstimatedArrayLength)
var t = startMicros
@@ -2989,7 +2989,7 @@ object Sequence {
|
| $sequenceLengthCode
|
- | final int $stepSign = $stopMicros >= $startMicros ? +1 : -1;
+ | final int $stepSign = $intervalInMicros > 0 ? +1 : -1;
| final long $exclusiveItem = $stopMicros + $stepSign;
|
| $arr = new $elemType[$arrLength];
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CollectionExpressionsSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CollectionExpressionsSuite.scala
index caa5e96..e8f5f07 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CollectionExpressionsSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CollectionExpressionsSuite.scala
@@ -2232,6 +2232,24 @@ class CollectionExpressionsSuite extends SparkFunSuite
with ExpressionEvalHelper
Seq(Date.valueOf("2018-01-01")))
}
+ test("SPARK-36639: Start and end equal in month range with a negative step")
{
+checkEvaluation(new Sequence(
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(stringToInterval("interval -1 day"))),
+ Seq(Date.valueOf("2018-01-01")))
+checkEvaluation(new Sequence(
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(stringToInterval("interval -1 month"))),
+ Seq(Date.valueOf("2018-01-01")))
+checkEvaluation(new Sequence(
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(stringToInterval("interval -1 year"))),
+ Seq(Date.valueOf("2018-01-01")))
+ }
+
test("SPARK-33386: element_at ArrayIndexOutOfBoundsException") {
Seq(true, false).foreach { ansiEnabled =&
[spark] branch master updated: [SPARK-36639][SQL] Fix an issue that sequence builtin function causes ArrayIndexOutOfBoundsException if the arguments are under the condition of start == stop && step <
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new cf3bc65 [SPARK-36639][SQL] Fix an issue that sequence builtin
function causes ArrayIndexOutOfBoundsException if the arguments are under the
condition of start == stop && step < 0
cf3bc65 is described below
commit cf3bc65e69dcb0f8ba3dee89642d082265edab31
Author: Kousuke Saruta
AuthorDate: Fri Sep 3 23:25:18 2021 +0900
[SPARK-36639][SQL] Fix an issue that sequence builtin function causes
ArrayIndexOutOfBoundsException if the arguments are under the condition of
start == stop && step < 0
### What changes were proposed in this pull request?
This PR fixes an issue that `sequence` builtin function causes
`ArrayIndexOutOfBoundsException` if the arguments are under the condition of
`start == stop && step < 0`.
This is an example.
```
SELECT sequence(timestamp'2021-08-31', timestamp'2021-08-31', -INTERVAL 1
month);
21/09/02 04:14:42 ERROR SparkSQLDriver: Failed in [SELECT
sequence(timestamp'2021-08-31', timestamp'2021-08-31', -INTERVAL 1 month)]
java.lang.ArrayIndexOutOfBoundsException: 1
```
Actually, this example succeeded before SPARK-31980 (#28819) was merged.
### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New tests.
Closes #33895 from sarutak/fix-sequence-issue.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
.../catalyst/expressions/collectionOperations.scala| 4 ++--
.../expressions/CollectionExpressionsSuite.scala | 18 ++
2 files changed, 20 insertions(+), 2 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
index 6cbab86..ce17231 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
@@ -2903,7 +2903,7 @@ object Sequence {
val maxEstimatedArrayLength =
getSequenceLength(startMicros, stopMicros, input3,
intervalStepInMicros)
-val stepSign = if (stopMicros >= startMicros) +1 else -1
+val stepSign = if (intervalStepInMicros > 0) +1 else -1
val exclusiveItem = stopMicros + stepSign
val arr = new Array[T](maxEstimatedArrayLength)
var t = startMicros
@@ -2989,7 +2989,7 @@ object Sequence {
|
| $sequenceLengthCode
|
- | final int $stepSign = $stopMicros >= $startMicros ? +1 : -1;
+ | final int $stepSign = $intervalInMicros > 0 ? +1 : -1;
| final long $exclusiveItem = $stopMicros + $stepSign;
|
| $arr = new $elemType[$arrLength];
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CollectionExpressionsSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CollectionExpressionsSuite.scala
index 8f35cf3..688ee61 100644
---
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CollectionExpressionsSuite.scala
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/expressions/CollectionExpressionsSuite.scala
@@ -2249,6 +2249,24 @@ class CollectionExpressionsSuite extends SparkFunSuite
with ExpressionEvalHelper
Seq(Date.valueOf("2018-01-01")))
}
+ test("SPARK-36639: Start and end equal in month range with a negative step")
{
+checkEvaluation(new Sequence(
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(stringToInterval("interval -1 day"))),
+ Seq(Date.valueOf("2018-01-01")))
+checkEvaluation(new Sequence(
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(stringToInterval("interval -1 month"))),
+ Seq(Date.valueOf("2018-01-01")))
+checkEvaluation(new Sequence(
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(Date.valueOf("2018-01-01")),
+ Literal(stringToInterval("interval -1 year"))),
+ Seq(Date.valueOf("2018-01-01")))
+ }
+
test("SPARK-33386: element_at ArrayIndexOutOfBoundsException") {
Seq(true, false).foreach { ansiEnabled =>
withSQLConf(SQLConf.ANSI_ENABLED.key -> ansiEnabled.toString) {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (9c5bcac -> 94c3062)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 9c5bcac [SPARK-36626][PYTHON] Support TimestampNTZ in createDataFrame/toPandas and Python UDFs add 94c3062 [SPARK-36400][TEST][FOLLOWUP] Add test for redacting sensitive information in UI by config No new revisions were added by this update. Summary of changes: .../sql/hive/thriftserver/UISeleniumSuite.scala| 45 ++ 1 file changed, 45 insertions(+) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated (c420149 -> 068465d)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch branch-3.0 in repository https://gitbox.apache.org/repos/asf/spark.git. from c420149 [SPARK-36352][SQL][3.0] Spark should check result plan's output schema name add 068465d [SPARK-36509][CORE] Fix the issue that executors are never re-scheduled if the worker stops with standalone cluster No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/deploy/master/Master.scala | 1 + core/src/main/scala/org/apache/spark/deploy/worker/ExecutorRunner.scala | 2 +- 2 files changed, 2 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-36509][CORE] Fix the issue that executors are never re-scheduled if the worker stops with standalone cluster
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 0af666a [SPARK-36509][CORE] Fix the issue that executors are never
re-scheduled if the worker stops with standalone cluster
0af666a is described below
commit 0af666a310590367a80439000d74975526064c87
Author: Kousuke Saruta
AuthorDate: Sat Aug 28 18:01:55 2021 +0900
[SPARK-36509][CORE] Fix the issue that executors are never re-scheduled if
the worker stops with standalone cluster
### What changes were proposed in this pull request?
This PR fixes an issue that executors are never re-scheduled if the worker
which the executors run on stops.
As a result, the application stucks.
You can easily reproduce this issue by the following procedures.
```
# Run master
$ sbin/start-master.sh
# Run worker 1
$ SPARK_LOG_DIR=/tmp/worker1 SPARK_PID_DIR=/tmp/worker1/
sbin/start-worker.sh -c 1 -h localhost -d /tmp/worker1 --webui-port 8081
spark://:7077
# Run worker 2
$ SPARK_LOG_DIR=/tmp/worker2 SPARK_PID_DIR=/tmp/worker2/
sbin/start-worker.sh -c 1 -h localhost -d /tmp/worker2 --webui-port 8082
spark://:7077
# Run Spark Shell
$ bin/spark-shell --master spark://:7077 --executor-cores 1
--total-executor-cores 1
# Check which worker the executor runs on and then kill the worker.
$ kill
```
With the procedure above, we will expect that the executor is re-scheduled
on the other worker but it won't.
The reason seems that `Master.schedule` cannot be called after the worker
is marked as `WorkerState.DEAD`.
So, the solution this PR proposes is to call `Master.schedule` whenever
`Master.removeWorker` is called.
This PR also fixes an issue that `ExecutorRunner` can send
`ExecutorStateChanged` message without changing its state.
This issue causes assertion error.
```
2021-08-13 14:05:37,991 [dispatcher-event-loop-9] ERROR: Ignoring
errorjava.lang.AssertionError: assertion failed: executor 0 state transfer from
RUNNING to RUNNING is illegal
```
### Why are the changes needed?
It's a critical bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually tested with the procedure shown above and confirmed the executor
is re-scheduled.
Closes #33818 from sarutak/fix-scheduling-stuck.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit ea8c31e5ea233da4407f6821b2d6dd7f3c88f8d9)
Signed-off-by: Kousuke Saruta
---
core/src/main/scala/org/apache/spark/deploy/master/Master.scala | 1 +
core/src/main/scala/org/apache/spark/deploy/worker/ExecutorRunner.scala | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
diff --git a/core/src/main/scala/org/apache/spark/deploy/master/Master.scala
b/core/src/main/scala/org/apache/spark/deploy/master/Master.scala
index 9f1b36a..1cbeacf 100644
--- a/core/src/main/scala/org/apache/spark/deploy/master/Master.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/master/Master.scala
@@ -964,6 +964,7 @@ private[deploy] class Master(
app.driver.send(WorkerRemoved(worker.id, worker.host, msg))
}
persistenceEngine.removeWorker(worker)
+schedule()
}
private def relaunchDriver(driver: DriverInfo): Unit = {
diff --git
a/core/src/main/scala/org/apache/spark/deploy/worker/ExecutorRunner.scala
b/core/src/main/scala/org/apache/spark/deploy/worker/ExecutorRunner.scala
index 974c2d6..40d9407 100644
--- a/core/src/main/scala/org/apache/spark/deploy/worker/ExecutorRunner.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/worker/ExecutorRunner.scala
@@ -83,7 +83,7 @@ private[deploy] class ExecutorRunner(
shutdownHook = ShutdownHookManager.addShutdownHook { () =>
// It's possible that we arrive here before calling
`fetchAndRunExecutor`, then `state` will
// be `ExecutorState.LAUNCHING`. In this case, we should set `state` to
`FAILED`.
- if (state == ExecutorState.LAUNCHING) {
+ if (state == ExecutorState.LAUNCHING || state == ExecutorState.RUNNING) {
state = ExecutorState.FAILED
}
killProcess(Some("Worker shutting down")) }
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-36509][CORE] Fix the issue that executors are never re-scheduled if the worker stops with standalone cluster
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 93f2b00 [SPARK-36509][CORE] Fix the issue that executors are never
re-scheduled if the worker stops with standalone cluster
93f2b00 is described below
commit 93f2b00501c7fad20fb6bc130b548cb87e9f91f1
Author: Kousuke Saruta
AuthorDate: Sat Aug 28 18:01:55 2021 +0900
[SPARK-36509][CORE] Fix the issue that executors are never re-scheduled if
the worker stops with standalone cluster
### What changes were proposed in this pull request?
This PR fixes an issue that executors are never re-scheduled if the worker
which the executors run on stops.
As a result, the application stucks.
You can easily reproduce this issue by the following procedures.
```
# Run master
$ sbin/start-master.sh
# Run worker 1
$ SPARK_LOG_DIR=/tmp/worker1 SPARK_PID_DIR=/tmp/worker1/
sbin/start-worker.sh -c 1 -h localhost -d /tmp/worker1 --webui-port 8081
spark://:7077
# Run worker 2
$ SPARK_LOG_DIR=/tmp/worker2 SPARK_PID_DIR=/tmp/worker2/
sbin/start-worker.sh -c 1 -h localhost -d /tmp/worker2 --webui-port 8082
spark://:7077
# Run Spark Shell
$ bin/spark-shell --master spark://:7077 --executor-cores 1
--total-executor-cores 1
# Check which worker the executor runs on and then kill the worker.
$ kill
```
With the procedure above, we will expect that the executor is re-scheduled
on the other worker but it won't.
The reason seems that `Master.schedule` cannot be called after the worker
is marked as `WorkerState.DEAD`.
So, the solution this PR proposes is to call `Master.schedule` whenever
`Master.removeWorker` is called.
This PR also fixes an issue that `ExecutorRunner` can send
`ExecutorStateChanged` message without changing its state.
This issue causes assertion error.
```
2021-08-13 14:05:37,991 [dispatcher-event-loop-9] ERROR: Ignoring
errorjava.lang.AssertionError: assertion failed: executor 0 state transfer from
RUNNING to RUNNING is illegal
```
### Why are the changes needed?
It's a critical bug.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually tested with the procedure shown above and confirmed the executor
is re-scheduled.
Closes #33818 from sarutak/fix-scheduling-stuck.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit ea8c31e5ea233da4407f6821b2d6dd7f3c88f8d9)
Signed-off-by: Kousuke Saruta
---
core/src/main/scala/org/apache/spark/deploy/master/Master.scala | 1 +
core/src/main/scala/org/apache/spark/deploy/worker/ExecutorRunner.scala | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
diff --git a/core/src/main/scala/org/apache/spark/deploy/master/Master.scala
b/core/src/main/scala/org/apache/spark/deploy/master/Master.scala
index c964e34..7dbf6b9 100644
--- a/core/src/main/scala/org/apache/spark/deploy/master/Master.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/master/Master.scala
@@ -965,6 +965,7 @@ private[deploy] class Master(
app.driver.send(WorkerRemoved(worker.id, worker.host, msg))
}
persistenceEngine.removeWorker(worker)
+schedule()
}
private def relaunchDriver(driver: DriverInfo): Unit = {
diff --git
a/core/src/main/scala/org/apache/spark/deploy/worker/ExecutorRunner.scala
b/core/src/main/scala/org/apache/spark/deploy/worker/ExecutorRunner.scala
index 974c2d6..40d9407 100644
--- a/core/src/main/scala/org/apache/spark/deploy/worker/ExecutorRunner.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/worker/ExecutorRunner.scala
@@ -83,7 +83,7 @@ private[deploy] class ExecutorRunner(
shutdownHook = ShutdownHookManager.addShutdownHook { () =>
// It's possible that we arrive here before calling
`fetchAndRunExecutor`, then `state` will
// be `ExecutorState.LAUNCHING`. In this case, we should set `state` to
`FAILED`.
- if (state == ExecutorState.LAUNCHING) {
+ if (state == ExecutorState.LAUNCHING || state == ExecutorState.RUNNING) {
state = ExecutorState.FAILED
}
killProcess(Some("Worker shutting down")) }
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (fe7bf5f -> ea8c31e)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from fe7bf5f [SPARK-36327][SQL] Spark sql creates staging dir inside database directory rather than creating inside table directory add ea8c31e [SPARK-36509][CORE] Fix the issue that executors are never re-scheduled if the worker stops with standalone cluster No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/deploy/master/Master.scala | 1 + core/src/main/scala/org/apache/spark/deploy/worker/ExecutorRunner.scala | 2 +- 2 files changed, 2 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-36398][SQL] Redact sensitive information in Spark Thrift Server log
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 8c0852c [SPARK-36398][SQL] Redact sensitive information in Spark
Thrift Server log
8c0852c is described below
commit 8c0852ca805a918cebe9f22166887128a03b3222
Author: Kousuke Saruta
AuthorDate: Wed Aug 25 21:30:43 2021 +0900
[SPARK-36398][SQL] Redact sensitive information in Spark Thrift Server log
### What changes were proposed in this pull request?
This PR fixes an issue that there is no way to redact sensitive information
in Spark Thrift Server log.
For example, JDBC password can be exposed in the log.
```
21/08/25 18:52:37 INFO SparkExecuteStatementOperation: Submitting query
'CREATE TABLE mytbl2(a int) OPTIONS(url="jdbc:mysql//example.com:3306",
driver="com.mysql.jdbc.Driver", dbtable="test_tbl", user="test_usr",
password="abcde")' with ca14ae38-1aaf-4bf4-a099-06b8e5337613
```
### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Ran ThriftServer, connect to it and execute `CREATE TABLE mytbl2(a int)
OPTIONS(url="jdbc:mysql//example.com:3306", driver="com.mysql.jdbc.Driver",
dbtable="test_tbl", user="test_usr", password="abcde");` with
`spark.sql.redaction.string.regex=((?i)(?<=password=))(".*")|('.*')`
Then, confirmed the log.
```
21/08/25 18:54:11 INFO SparkExecuteStatementOperation: Submitting query
'CREATE TABLE mytbl2(a int) OPTIONS(url="jdbc:mysql//example.com:3306",
driver="com.mysql.jdbc.Driver", dbtable="test_tbl", user="test_usr",
password=*(redacted))' with ffc627e2-b1a8-4d83-ab6d-d819b3ccd909
```
Closes #33832 from sarutak/fix-SPARK-36398.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit b2ff01608f5ecdba19630e12478bd370f9766f7b)
Signed-off-by: Kousuke Saruta
---
.../spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala| 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
index acb00e4..bb55bb0 100644
---
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
+++
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
@@ -219,8 +219,8 @@ private[hive] class SparkExecuteStatementOperation(
override def runInternal(): Unit = {
setState(OperationState.PENDING)
-logInfo(s"Submitting query '$statement' with $statementId")
val redactedStatement =
SparkUtils.redact(sqlContext.conf.stringRedactionPattern, statement)
+logInfo(s"Submitting query '$redactedStatement' with $statementId")
HiveThriftServer2.eventManager.onStatementStart(
statementId,
parentSession.getSessionHandle.getSessionId.toString,
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-36398][SQL] Redact sensitive information in Spark Thrift Server log
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new fb38887 [SPARK-36398][SQL] Redact sensitive information in Spark
Thrift Server log
fb38887 is described below
commit fb38887e001d33adef519d0288bd0844dcfe2bd5
Author: Kousuke Saruta
AuthorDate: Wed Aug 25 21:30:43 2021 +0900
[SPARK-36398][SQL] Redact sensitive information in Spark Thrift Server log
### What changes were proposed in this pull request?
This PR fixes an issue that there is no way to redact sensitive information
in Spark Thrift Server log.
For example, JDBC password can be exposed in the log.
```
21/08/25 18:52:37 INFO SparkExecuteStatementOperation: Submitting query
'CREATE TABLE mytbl2(a int) OPTIONS(url="jdbc:mysql//example.com:3306",
driver="com.mysql.jdbc.Driver", dbtable="test_tbl", user="test_usr",
password="abcde")' with ca14ae38-1aaf-4bf4-a099-06b8e5337613
```
### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Ran ThriftServer, connect to it and execute `CREATE TABLE mytbl2(a int)
OPTIONS(url="jdbc:mysql//example.com:3306", driver="com.mysql.jdbc.Driver",
dbtable="test_tbl", user="test_usr", password="abcde");` with
`spark.sql.redaction.string.regex=((?i)(?<=password=))(".*")|('.*')`
Then, confirmed the log.
```
21/08/25 18:54:11 INFO SparkExecuteStatementOperation: Submitting query
'CREATE TABLE mytbl2(a int) OPTIONS(url="jdbc:mysql//example.com:3306",
driver="com.mysql.jdbc.Driver", dbtable="test_tbl", user="test_usr",
password=*(redacted))' with ffc627e2-b1a8-4d83-ab6d-d819b3ccd909
```
Closes #33832 from sarutak/fix-SPARK-36398.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit b2ff01608f5ecdba19630e12478bd370f9766f7b)
Signed-off-by: Kousuke Saruta
---
.../spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala| 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
index 0df5885..4f40889 100644
---
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
+++
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
@@ -185,8 +185,8 @@ private[hive] class SparkExecuteStatementOperation(
override def runInternal(): Unit = {
setState(OperationState.PENDING)
-logInfo(s"Submitting query '$statement' with $statementId")
val redactedStatement =
SparkUtils.redact(sqlContext.conf.stringRedactionPattern, statement)
+logInfo(s"Submitting query '$redactedStatement' with $statementId")
HiveThriftServer2.eventManager.onStatementStart(
statementId,
parentSession.getSessionHandle.getSessionId.toString,
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36398][SQL] Redact sensitive information in Spark Thrift Server log
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b2ff016 [SPARK-36398][SQL] Redact sensitive information in Spark
Thrift Server log
b2ff016 is described below
commit b2ff01608f5ecdba19630e12478bd370f9766f7b
Author: Kousuke Saruta
AuthorDate: Wed Aug 25 21:30:43 2021 +0900
[SPARK-36398][SQL] Redact sensitive information in Spark Thrift Server log
### What changes were proposed in this pull request?
This PR fixes an issue that there is no way to redact sensitive information
in Spark Thrift Server log.
For example, JDBC password can be exposed in the log.
```
21/08/25 18:52:37 INFO SparkExecuteStatementOperation: Submitting query
'CREATE TABLE mytbl2(a int) OPTIONS(url="jdbc:mysql//example.com:3306",
driver="com.mysql.jdbc.Driver", dbtable="test_tbl", user="test_usr",
password="abcde")' with ca14ae38-1aaf-4bf4-a099-06b8e5337613
```
### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Ran ThriftServer, connect to it and execute `CREATE TABLE mytbl2(a int)
OPTIONS(url="jdbc:mysql//example.com:3306", driver="com.mysql.jdbc.Driver",
dbtable="test_tbl", user="test_usr", password="abcde");` with
`spark.sql.redaction.string.regex=((?i)(?<=password=))(".*")|('.*')`
Then, confirmed the log.
```
21/08/25 18:54:11 INFO SparkExecuteStatementOperation: Submitting query
'CREATE TABLE mytbl2(a int) OPTIONS(url="jdbc:mysql//example.com:3306",
driver="com.mysql.jdbc.Driver", dbtable="test_tbl", user="test_usr",
password=*(redacted))' with ffc627e2-b1a8-4d83-ab6d-d819b3ccd909
```
Closes #33832 from sarutak/fix-SPARK-36398.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
.../spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala| 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
index 0df5885..4f40889 100644
---
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
+++
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
@@ -185,8 +185,8 @@ private[hive] class SparkExecuteStatementOperation(
override def runInternal(): Unit = {
setState(OperationState.PENDING)
-logInfo(s"Submitting query '$statement' with $statementId")
val redactedStatement =
SparkUtils.redact(sqlContext.conf.stringRedactionPattern, statement)
+logInfo(s"Submitting query '$redactedStatement' with $statementId")
HiveThriftServer2.eventManager.onStatementStart(
statementId,
parentSession.getSessionHandle.getSessionId.toString,
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (0b6af46 -> adc485a)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 0b6af46 [SPARK-36470][PYTHON] Implement `CategoricalIndex.map` and `DatetimeIndex.map` add adc485a [MINOR][DOCS] Mention Hadoop 3 in YARN introduction on cluster-overview.md No new revisions were added by this update. Summary of changes: docs/cluster-overview.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-34309][BUILD][FOLLOWUP] Upgrade Caffeine to 2.9.2
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 281b00a [SPARK-34309][BUILD][FOLLOWUP] Upgrade Caffeine to 2.9.2 281b00a is described below commit 281b00ab5b3dd3f21dd6af020ad5455f35498b79 Author: Kousuke Saruta AuthorDate: Wed Aug 18 13:40:52 2021 +0900 [SPARK-34309][BUILD][FOLLOWUP] Upgrade Caffeine to 2.9.2 ### What changes were proposed in this pull request? This PR upgrades Caffeine to `2.9.2`. Caffeine was introduced in SPARK-34309 (#31517). At the time that PR was opened, the latest version of caffeine was `2.9.1` but now `2.9.2` is available. ### Why are the changes needed? `2.9.2` have the following improvements (https://github.com/ben-manes/caffeine/releases/tag/v2.9.2). * Fixed reading an intermittent null weak/soft value during a concurrent write * Fixed extraneous eviction when concurrently removing a collected entry after a writer resurrects it with a new mapping * Fixed excessive retries of discarding an expired entry when the fixed duration period is extended, thereby resurrecting it ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? CIs. Closes #33772 from sarutak/upgrade-caffeine-2.9.2. Authored-by: Kousuke Saruta Signed-off-by: Kousuke Saruta --- dev/deps/spark-deps-hadoop-2.7-hive-2.3 | 2 +- dev/deps/spark-deps-hadoop-3.2-hive-2.3 | 2 +- pom.xml | 2 +- 3 files changed, 3 insertions(+), 3 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-2.7-hive-2.3 b/dev/deps/spark-deps-hadoop-2.7-hive-2.3 index 1dc01b5..31dd02f 100644 --- a/dev/deps/spark-deps-hadoop-2.7-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-2.7-hive-2.3 @@ -30,7 +30,7 @@ blas/2.2.0//blas-2.2.0.jar bonecp/0.8.0.RELEASE//bonecp-0.8.0.RELEASE.jar breeze-macros_2.12/1.2//breeze-macros_2.12-1.2.jar breeze_2.12/1.2//breeze_2.12-1.2.jar -caffeine/2.9.1//caffeine-2.9.1.jar +caffeine/2.9.2//caffeine-2.9.2.jar cats-kernel_2.12/2.1.1//cats-kernel_2.12-2.1.1.jar checker-qual/3.10.0//checker-qual-3.10.0.jar chill-java/0.10.0//chill-java-0.10.0.jar diff --git a/dev/deps/spark-deps-hadoop-3.2-hive-2.3 b/dev/deps/spark-deps-hadoop-3.2-hive-2.3 index 698a03c..5b27680 100644 --- a/dev/deps/spark-deps-hadoop-3.2-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-3.2-hive-2.3 @@ -25,7 +25,7 @@ blas/2.2.0//blas-2.2.0.jar bonecp/0.8.0.RELEASE//bonecp-0.8.0.RELEASE.jar breeze-macros_2.12/1.2//breeze-macros_2.12-1.2.jar breeze_2.12/1.2//breeze_2.12-1.2.jar -caffeine/2.9.1//caffeine-2.9.1.jar +caffeine/2.9.2//caffeine-2.9.2.jar cats-kernel_2.12/2.1.1//cats-kernel_2.12-2.1.1.jar checker-qual/3.10.0//checker-qual-3.10.0.jar chill-java/0.10.0//chill-java-0.10.0.jar diff --git a/pom.xml b/pom.xml index bd1722f..1452b0b 100644 --- a/pom.xml +++ b/pom.xml @@ -182,7 +182,7 @@ 2.6.2 4.1.17 14.0.1 -2.9.1 +2.9.2 3.0.16 2.34 2.10.10 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-36400][SPARK-36398][SQL][WEBUI] Make ThriftServer recognize spark.sql.redaction.string.regex
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 31d771d [SPARK-36400][SPARK-36398][SQL][WEBUI] Make ThriftServer
recognize spark.sql.redaction.string.regex
31d771d is described below
commit 31d771dcf242cfa477b04f28950526bf87b7e90a
Author: Kousuke Saruta
AuthorDate: Wed Aug 18 13:31:22 2021 +0900
[SPARK-36400][SPARK-36398][SQL][WEBUI] Make ThriftServer recognize
spark.sql.redaction.string.regex
### What changes were proposed in this pull request?
This PR fixes an issue that ThriftServer doesn't recognize
`spark.sql.redaction.string.regex`.
The problem is that sensitive information included in queries can be
exposed.


### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Ran ThriftServer, connect to it and execute `CREATE TABLE mytbl2(a int)
OPTIONS(url="jdbc:mysql//example.com:3306", driver="com.mysql.jdbc.Driver",
dbtable="test_tbl", user="test_usr", password="abcde");` with
`spark.sql.redaction.string.regex=((?i)(?<=password=))(".*")|('.*')`
Then, confirmed UI.


Closes #33743 from sarutak/thrift-redact.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit b914ff7d54bd7c07e7313bb06a1fa22c36b628d2)
Signed-off-by: Kousuke Saruta
---
.../spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
index f7a4be9..acb00e4 100644
---
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
+++
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
@@ -220,10 +220,11 @@ private[hive] class SparkExecuteStatementOperation(
override def runInternal(): Unit = {
setState(OperationState.PENDING)
logInfo(s"Submitting query '$statement' with $statementId")
+val redactedStatement =
SparkUtils.redact(sqlContext.conf.stringRedactionPattern, statement)
HiveThriftServer2.eventManager.onStatementStart(
statementId,
parentSession.getSessionHandle.getSessionId.toString,
- statement,
+ redactedStatement,
statementId,
parentSession.getUsername)
setHasResultSet(true) // avoid no resultset for async run
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-36400][SPARK-36398][SQL][WEBUI] Make ThriftServer recognize spark.sql.redaction.string.regex
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new b749b49 [SPARK-36400][SPARK-36398][SQL][WEBUI] Make ThriftServer
recognize spark.sql.redaction.string.regex
b749b49 is described below
commit b749b49a283800d3e12455a00a23da24bf6cd333
Author: Kousuke Saruta
AuthorDate: Wed Aug 18 13:31:22 2021 +0900
[SPARK-36400][SPARK-36398][SQL][WEBUI] Make ThriftServer recognize
spark.sql.redaction.string.regex
### What changes were proposed in this pull request?
This PR fixes an issue that ThriftServer doesn't recognize
`spark.sql.redaction.string.regex`.
The problem is that sensitive information included in queries can be
exposed.


### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Ran ThriftServer, connect to it and execute `CREATE TABLE mytbl2(a int)
OPTIONS(url="jdbc:mysql//example.com:3306", driver="com.mysql.jdbc.Driver",
dbtable="test_tbl", user="test_usr", password="abcde");` with
`spark.sql.redaction.string.regex=((?i)(?<=password=))(".*")|('.*')`
Then, confirmed UI.


Closes #33743 from sarutak/thrift-redact.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit b914ff7d54bd7c07e7313bb06a1fa22c36b628d2)
Signed-off-by: Kousuke Saruta
---
.../spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
index f43f8e7..0df5885 100644
---
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
+++
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
@@ -186,10 +186,11 @@ private[hive] class SparkExecuteStatementOperation(
override def runInternal(): Unit = {
setState(OperationState.PENDING)
logInfo(s"Submitting query '$statement' with $statementId")
+val redactedStatement =
SparkUtils.redact(sqlContext.conf.stringRedactionPattern, statement)
HiveThriftServer2.eventManager.onStatementStart(
statementId,
parentSession.getSessionHandle.getSessionId.toString,
- statement,
+ redactedStatement,
statementId,
parentSession.getUsername)
setHasResultSet(true) // avoid no resultset for async run
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-36400][SPARK-36398][SQL][WEBUI] Make ThriftServer recognize spark.sql.redaction.string.regex
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b914ff7 [SPARK-36400][SPARK-36398][SQL][WEBUI] Make ThriftServer
recognize spark.sql.redaction.string.regex
b914ff7 is described below
commit b914ff7d54bd7c07e7313bb06a1fa22c36b628d2
Author: Kousuke Saruta
AuthorDate: Wed Aug 18 13:31:22 2021 +0900
[SPARK-36400][SPARK-36398][SQL][WEBUI] Make ThriftServer recognize
spark.sql.redaction.string.regex
### What changes were proposed in this pull request?
This PR fixes an issue that ThriftServer doesn't recognize
`spark.sql.redaction.string.regex`.
The problem is that sensitive information included in queries can be
exposed.


### Why are the changes needed?
Bug fix.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Ran ThriftServer, connect to it and execute `CREATE TABLE mytbl2(a int)
OPTIONS(url="jdbc:mysql//example.com:3306", driver="com.mysql.jdbc.Driver",
dbtable="test_tbl", user="test_usr", password="abcde");` with
`spark.sql.redaction.string.regex=((?i)(?<=password=))(".*")|('.*')`
Then, confirmed UI.


Closes #33743 from sarutak/thrift-redact.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
.../spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
index f43f8e7..0df5885 100644
---
a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
+++
b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkExecuteStatementOperation.scala
@@ -186,10 +186,11 @@ private[hive] class SparkExecuteStatementOperation(
override def runInternal(): Unit = {
setState(OperationState.PENDING)
logInfo(s"Submitting query '$statement' with $statementId")
+val redactedStatement =
SparkUtils.redact(sqlContext.conf.stringRedactionPattern, statement)
HiveThriftServer2.eventManager.onStatementStart(
statementId,
parentSession.getSessionHandle.getSessionId.toString,
- statement,
+ redactedStatement,
statementId,
parentSession.getUsername)
setHasResultSet(true) // avoid no resultset for async run
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: Revert "[SPARK-36429][SQL] JacksonParser should throw exception when data type unsupported"
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 586eb5d Revert "[SPARK-36429][SQL] JacksonParser should throw
exception when data type unsupported"
586eb5d is described below
commit 586eb5d4c6b01b008cb0ace076f94f49580201de
Author: Kousuke Saruta
AuthorDate: Fri Aug 6 20:56:24 2021 +0900
Revert "[SPARK-36429][SQL] JacksonParser should throw exception when data
type unsupported"
### What changes were proposed in this pull request?
This PR reverts the change in SPARK-36429 (#33654).
See
[conversation](https://github.com/apache/spark/pull/33654#issuecomment-894160037).
### Why are the changes needed?
To recover CIs.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
N/A
Closes #33670 from sarutak/revert-SPARK-36429.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
(cherry picked from commit e17612d0bfa1b1dc719f6f2c202e2a4ea7870ff1)
Signed-off-by: Kousuke Saruta
---
.../scala/org/apache/spark/sql/catalyst/json/JacksonParser.scala | 8 ++--
.../sql-tests/results/timestampNTZ/timestamp-ansi.sql.out | 5 ++---
.../resources/sql-tests/results/timestampNTZ/timestamp.sql.out| 5 ++---
3 files changed, 10 insertions(+), 8 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JacksonParser.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JacksonParser.scala
index 2761c52..04a0f1a 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JacksonParser.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JacksonParser.scala
@@ -330,8 +330,12 @@ class JacksonParser(
case udt: UserDefinedType[_] =>
makeConverter(udt.sqlType)
-// We don't actually hit this exception though, we keep it for
understandability
-case _ => throw QueryExecutionErrors.unsupportedTypeError(dataType)
+case _ =>
+ (parser: JsonParser) =>
+// Here, we pass empty `PartialFunction` so that this case can be
+// handled as a failed conversion. It will throw an exception as
+// long as the value is not null.
+parseJsonToken[AnyRef](parser,
dataType)(PartialFunction.empty[JsonToken, AnyRef])
}
/**
diff --git
a/sql/core/src/test/resources/sql-tests/results/timestampNTZ/timestamp-ansi.sql.out
b/sql/core/src/test/resources/sql-tests/results/timestampNTZ/timestamp-ansi.sql.out
index fae7721..fe83675 100644
---
a/sql/core/src/test/resources/sql-tests/results/timestampNTZ/timestamp-ansi.sql.out
+++
b/sql/core/src/test/resources/sql-tests/results/timestampNTZ/timestamp-ansi.sql.out
@@ -661,10 +661,9 @@ You may get a different result due to the upgrading of
Spark 3.0: Fail to recogn
-- !query
select from_json('{"t":"26/October/2015"}', 't Timestamp',
map('timestampFormat', 'dd/M/'))
-- !query schema
-struct<>
+struct>
-- !query output
-java.lang.Exception
-Unsupported type: timestamp_ntz
+{"t":null}
-- !query
diff --git
a/sql/core/src/test/resources/sql-tests/results/timestampNTZ/timestamp.sql.out
b/sql/core/src/test/resources/sql-tests/results/timestampNTZ/timestamp.sql.out
index c6de535..b8a6800 100644
---
a/sql/core/src/test/resources/sql-tests/results/timestampNTZ/timestamp.sql.out
+++
b/sql/core/src/test/resources/sql-tests/results/timestampNTZ/timestamp.sql.out
@@ -642,10 +642,9 @@ You may get a different result due to the upgrading of
Spark 3.0: Fail to recogn
-- !query
select from_json('{"t":"26/October/2015"}', 't Timestamp',
map('timestampFormat', 'dd/M/'))
-- !query schema
-struct<>
+struct>
-- !query output
-java.lang.Exception
-Unsupported type: timestamp_ntz
+{"t":null}
-- !query
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (888f8f0 -> e17612d)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 888f8f0 [SPARK-36339][SQL] References to grouping that not part of aggregation should be replaced add e17612d Revert "[SPARK-36429][SQL] JacksonParser should throw exception when data type unsupported" No new revisions were added by this update. Summary of changes: .../scala/org/apache/spark/sql/catalyst/json/JacksonParser.scala | 8 ++-- .../sql-tests/results/timestampNTZ/timestamp-ansi.sql.out | 5 ++--- .../resources/sql-tests/results/timestampNTZ/timestamp.sql.out| 5 ++--- 3 files changed, 10 insertions(+), 8 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-36318][SQL][DOCS] Update docs about mapping of ANSI interval types to Java/Scala/SQL types
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new 56f1ee4 [SPARK-36318][SQL][DOCS] Update docs about mapping of ANSI interval types to Java/Scala/SQL types 56f1ee4 is described below commit 56f1ee4b066ca5123c207acd91f27ee80a3bb07b Author: Max Gekk AuthorDate: Wed Jul 28 13:42:35 2021 +0900 [SPARK-36318][SQL][DOCS] Update docs about mapping of ANSI interval types to Java/Scala/SQL types ### What changes were proposed in this pull request? 1. Update the tables at https://spark.apache.org/docs/latest/sql-ref-datatypes.html about mapping ANSI interval types to Java/Scala/SQL types. 2. Remove `CalendarIntervalType` from the table of mapping Catalyst types to SQL types. https://user-images.githubusercontent.com/1580697/127204790-7ccb9c64-daf2-427d-963e-b7367aaa3439.png";> https://user-images.githubusercontent.com/1580697/127204806-a0a51950-3c2d-4198-8a22-0f6614bb1487.png";> ### Why are the changes needed? To inform users which types from language APIs should be used as ANSI interval types. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manually checking by building the docs: ``` $ SKIP_RDOC=1 SKIP_API=1 SKIP_PYTHONDOC=1 bundle exec jekyll build ``` Closes #33543 from MaxGekk/doc-interval-type-lang-api. Authored-by: Max Gekk Signed-off-by: Kousuke Saruta (cherry picked from commit 1614d004174c1aeda0c1511d3cba92cf55fc14b0) Signed-off-by: Kousuke Saruta --- docs/sql-ref-datatypes.md | 7 ++- 1 file changed, 6 insertions(+), 1 deletion(-) diff --git a/docs/sql-ref-datatypes.md b/docs/sql-ref-datatypes.md index 89ffa34..d699bfe 100644 --- a/docs/sql-ref-datatypes.md +++ b/docs/sql-ref-datatypes.md @@ -125,6 +125,8 @@ You can access them by doing |**BooleanType**|Boolean|BooleanType| |**TimestampType**|java.sql.Timestamp|TimestampType| |**DateType**|java.sql.Date|DateType| +|**YearMonthIntervalType**|java.time.Period|YearMonthIntervalType| +|**DayTimeIntervalType**|java.time.Duration|DayTimeIntervalType| |**ArrayType**|scala.collection.Seq|ArrayType(*elementType*, [*containsNull]*)**Note:** The default value of *containsNull* is true.| |**MapType**|scala.collection.Map|MapType(*keyType*, *valueType*, [*valueContainsNull]*)**Note:** The default value of *valueContainsNull* is true.| |**StructType**|org.apache.spark.sql.Row|StructType(*fields*)**Note:** *fields* is a Seq of StructFields. Also, two fields with the same name are not allowed.| @@ -153,6 +155,8 @@ please use factory methods provided in |**BooleanType**|boolean or Boolean|DataTypes.BooleanType| |**TimestampType**|java.sql.Timestamp|DataTypes.TimestampType| |**DateType**|java.sql.Date|DataTypes.DateType| +|**YearMonthIntervalType**|java.time.Period|YearMonthIntervalType| +|**DayTimeIntervalType**|java.time.Duration|DayTimeIntervalType| |**ArrayType**|java.util.List|DataTypes.createArrayType(*elementType*)**Note:** The value of *containsNull* will be true.DataTypes.createArrayType(*elementType*, *containsNull*).| |**MapType**|java.util.Map|DataTypes.createMapType(*keyType*, *valueType*)**Note:** The value of *valueContainsNull* will be true.DataTypes.createMapType(*keyType*, *valueType*, *valueContainsNull*)| |**StructType**|org.apache.spark.sql.Row|DataTypes.createStructType(*fields*)**Note:** *fields* is a List or an array of StructFields.Also, two fields with the same name are not allowed.| @@ -230,7 +234,8 @@ The following table shows the type names as well as aliases used in Spark SQL pa |**StringType**|STRING| |**BinaryType**|BINARY| |**DecimalType**|DECIMAL, DEC, NUMERIC| -|**CalendarIntervalType**|INTERVAL| +|**YearMonthIntervalType**|INTERVAL YEAR, INTERVAL YEAR TO MONTH, INTERVAL MONTH| +|**DayTimeIntervalType**|INTERVAL DAY, INTERVAL DAY TO HOUR, INTERVAL DAY TO MINUTE, INTERVAL DAY TO SECOND, INTERVAL HOUR, INTERVAL HOUR TO MINUTE, INTERVAL HOUR TO SECOND, INTERVAL MINUTE, INTERVAL MINUTE TO SECOND, INTERVAL SECOND| |**ArrayType**|ARRAY\| |**StructType**|STRUCT **Note:** ':' is optional.| |**MapType**|MAP| - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (1fafa8e -> 1614d00)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 1fafa8e [SPARK-36314][SS] Update Sessionization examples to use native support of session window add 1614d00 [SPARK-36318][SQL][DOCS] Update docs about mapping of ANSI interval types to Java/Scala/SQL types No new revisions were added by this update. Summary of changes: docs/sql-ref-datatypes.md | 7 ++- 1 file changed, 6 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-34619][SQL][DOCS] Describe ANSI interval types at the `Data types` page of the SQL reference
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new f483796 [SPARK-34619][SQL][DOCS] Describe ANSI interval types at the `Data types` page of the SQL reference f483796 is described below commit f4837961a9c4c35eaf71406c22874984b454e8fd Author: Max Gekk AuthorDate: Tue Jul 27 19:05:39 2021 +0900 [SPARK-34619][SQL][DOCS] Describe ANSI interval types at the `Data types` page of the SQL reference ### What changes were proposed in this pull request? In the PR, I propose to update the page https://spark.apache.org/docs/latest/sql-ref-datatypes.html and add information about the year-month and day-time interval types introduced by SPARK-27790. https://user-images.githubusercontent.com/1580697/127115289-e633ca3a-2c18-49a0-a7c0-22421ae5c363.png";> ### Why are the changes needed? To inform users about new ANSI interval types, and improve UX with Spark SQL. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Should be tested by a GitHub action. Closes #33518 from MaxGekk/doc-interval-types. Authored-by: Max Gekk Signed-off-by: Kousuke Saruta --- docs/sql-ref-datatypes.md | 38 ++ 1 file changed, 38 insertions(+) diff --git a/docs/sql-ref-datatypes.md b/docs/sql-ref-datatypes.md index ce22d92..89ffa34 100644 --- a/docs/sql-ref-datatypes.md +++ b/docs/sql-ref-datatypes.md @@ -49,6 +49,44 @@ Spark SQL and DataFrames support the following data types: absolute point in time. - `DateType`: Represents values comprising values of fields year, month and day, without a time-zone. +* Interval types + - `YearMonthIntervalType(startField, endField)`: Represents a year-month interval which is made up of a contiguous subset of the following fields: +- MONTH, months within years `[0..11]`, +- YEAR, years in the range `[0..178956970]`. + +Individual interval fields are non-negative, but an interval itself can have a sign, and be negative. + +`startField` is the leftmost field, and `endField` is the rightmost field of the type. Valid values of `startField` and `endField` are 0(MONTH) and 1(YEAR). Supported year-month interval types are: + +|Year-Month Interval Type|SQL type|An instance of the type| +|-||---| +|`YearMonthIntervalType(YEAR, YEAR)` or `YearMonthIntervalType(YEAR)`|INTERVAL YEAR|`INTERVAL '2021' YEAR`| +|`YearMonthIntervalType(YEAR, MONTH)`|INTERVAL YEAR TO MONTH|`INTERVAL '2021-07' YEAR TO MONTH`| +|`YearMonthIntervalType(MONTH, MONTH)` or `YearMonthIntervalType(MONTH)`|INTERVAL MONTH|`INTERVAL '10' MONTH`| + + - `DayTimeIntervalType(startField, endField)`: Represents a day-time interval which is made up of a contiguous subset of the following fields: +- SECOND, seconds within minutes and possibly fractions of a second `[0..59.99]`, +- MINUTE, minutes within hours `[0..59]`, +- HOUR, hours within days `[0..23]`, +- DAY, days in the range `[0..106751991]`. + +Individual interval fields are non-negative, but an interval itself can have a sign, and be negative. + +`startField` is the leftmost field, and `endField` is the rightmost field of the type. Valid values of `startField` and `endField` are 0 (DAY), 1 (HOUR), 2 (MINUTE), 3 (SECOND). Supported day-time interval types are: + +|Day-Time Interval Type|SQL type|An instance of the type| +|-||---| +|`DayTimeIntervalType(DAY, DAY)` or `DayTimeIntervalType(DAY)`|INTERVAL DAY|`INTERVAL '100' DAY`| +|`DayTimeIntervalType(DAY, HOUR)`|INTERVAL DAY TO HOUR|`INTERVAL '100 10' DAY TO HOUR`| +|`DayTimeIntervalType(DAY, MINUTE)`|INTERVAL DAY TO MINUTE|`INTERVAL '100 10:30' DAY TO MINUTE`| +|`DayTimeIntervalType(DAY, SECOND)`|INTERVAL DAY TO SECOND|`INTERVAL '100 10:30:40.99' DAY TO SECOND`| +|`DayTimeIntervalType(HOUR, HOUR)` or `DayTimeIntervalType(HOUR)`|INTERVAL HOUR|`INTERVAL '123' HOUR`| +|`DayTimeIntervalType(HOUR, MINUTE)`|INTERVAL HOUR TO MINUTE|`INTERVAL '123:10' HOUR TO MINUTE`| +|`DayTimeIntervalType(HOUR, SECOND)`|INTERVAL HOUR TO SECOND|`INTERVAL '123:10:59' HOUR TO SECOND`| +|`DayTimeIntervalType(MINUTE, MINUTE)` or `DayTimeIntervalType(MINUTE)`|INTERVAL MINUTE|`INTERVAL '1000' MINUTE`| +|`DayTimeIntervalType(MINUTE, SECOND)`|INTERVAL MINUTE TO SECOND|`INTERVAL '1000:01.001' MINUTE TO SECOND`| +|`DayTimeIntervalType(SECOND, SECOND)` or `DayTimeIntervalType(SECOND)`|INTERVAL SECOND|`INTERVAL '1000.01' SECOND`| + * Complex types - `ArrayType(elementType, cont
[spark] branch master updated (6474226 -> 554d5fe)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 6474226 [SPARK-35982][SQL] Allow from_json/to_json for map types where value types are year-month intervals add 554d5fe [SPARK-36010][BUILD] Upgrade sbt-antlr4 from 0.8.2 to 0.8.3 No new revisions were added by this update. Summary of changes: project/plugins.sbt | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (59ec7a2 -> c562c16)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 59ec7a2 [SPARK-35885][K8S][R] Use keyserver.ubuntu.com as a keyserver for CRAN add c562c16 [SPARK-34320][SQL][FOLLOWUP] Modify V2JDBCTest to follow the change of the error message No new revisions were added by this update. Summary of changes: .../src/test/scala/org/apache/spark/sql/jdbc/v2/V2JDBCTest.scala | 3 ++- 1 file changed, 2 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-35870][BUILD] Upgrade Jetty to 9.4.42
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 7b78d56 [SPARK-35870][BUILD] Upgrade Jetty to 9.4.42 7b78d56 is described below commit 7b78d56f34a30148374c68141a3adb3a0c432a1b Author: Kousuke Saruta AuthorDate: Fri Jun 25 03:32:32 2021 +0900 [SPARK-35870][BUILD] Upgrade Jetty to 9.4.42 ### What changes were proposed in this pull request? This PR upgrades Jetty to `9.4.42`. In the current master, `9.4.40` is used. `9.4.41` and `9.4.42` include the following updates. https://github.com/eclipse/jetty.project/releases/tag/jetty-9.4.41.v20210516 https://github.com/eclipse/jetty.project/releases/tag/jetty-9.4.42.v20210604 ### Why are the changes needed? Mainly for CVE-2021-28169. https://nvd.nist.gov/vuln/detail/CVE-2021-28169 This CVE might little affect Spark, but just in case. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? CI. Closes #33053 from sarutak/upgrade-jetty-9.4.42. Authored-by: Kousuke Saruta Signed-off-by: Kousuke Saruta --- pom.xml | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/pom.xml b/pom.xml index a53aae3..16fe9e6 100644 --- a/pom.xml +++ b/pom.xml @@ -138,7 +138,7 @@ 10.14.2.0 1.12.0 1.6.8 -9.4.40.v20210413 +9.4.42.v20210604 4.0.3 0.9.5 2.4.0 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-35593][K8S][TESTS][FOLLOWUP] Increase timeout in KubernetesLocalDiskShuffleDataIOSuite
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b9d6473 [SPARK-35593][K8S][TESTS][FOLLOWUP] Increase timeout in
KubernetesLocalDiskShuffleDataIOSuite
b9d6473 is described below
commit b9d6473e898cea255bbbc27f657e2958fd4c011b
Author: Dongjoon Hyun
AuthorDate: Sat Jun 19 15:22:29 2021 +0900
[SPARK-35593][K8S][TESTS][FOLLOWUP] Increase timeout in
KubernetesLocalDiskShuffleDataIOSuite
### What changes were proposed in this pull request?
This increases the timeout from 10 seconds to 60 seconds in
KubernetesLocalDiskShuffleDataIOSuite to reduce the flakiness.
### Why are the changes needed?
-
https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/140003/testReport/
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass the CIs
Closes #32967 from dongjoon-hyun/SPARK-35593-2.
Authored-by: Dongjoon Hyun
Signed-off-by: Kousuke Saruta
---
.../apache/spark/shuffle/KubernetesLocalDiskShuffleDataIOSuite.scala| 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git
a/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/shuffle/KubernetesLocalDiskShuffleDataIOSuite.scala
b/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/shuffle/KubernetesLocalDiskShuffleDataIOSuite.scala
index e94e8dd..eca38a8 100644
---
a/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/shuffle/KubernetesLocalDiskShuffleDataIOSuite.scala
+++
b/resource-managers/kubernetes/core/src/test/scala/org/apache/spark/shuffle/KubernetesLocalDiskShuffleDataIOSuite.scala
@@ -210,7 +210,7 @@ class KubernetesLocalDiskShuffleDataIOSuite extends
SparkFunSuite with LocalSpar
assert(master.shuffleStatuses(1).mapStatuses.forall(_ == null))
}
sc.parallelize(Seq((1, 1)), 2).groupByKey().collect()
- eventually(timeout(10.second), interval(1.seconds)) {
+ eventually(timeout(60.second), interval(1.seconds)) {
assert(master.shuffleStatuses(0).mapStatuses.map(_.mapId).toSet ==
Set(0, 1, 2))
assert(master.shuffleStatuses(1).mapStatuses.map(_.mapId).toSet ==
Set(6, 7, 8))
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (9709ee5 -> ac228d4)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 9709ee5 [SPARK-35760][SQL] Fix the max rows check for broadcast exchange add ac228d4 [SPARK-35691][CORE] addFile/addJar/addDirectory should put CanonicalFile No new revisions were added by this update. Summary of changes: .../main/scala/org/apache/spark/rpc/RpcEnv.scala | 3 +- .../spark/rpc/netty/NettyStreamManager.scala | 12 .../main/scala/org/apache/spark/util/Utils.scala | 2 +- .../scala/org/apache/spark/SparkContextSuite.scala | 32 ++ .../scala/org/apache/spark/rpc/RpcEnvSuite.scala | 9 ++ 5 files changed, 51 insertions(+), 7 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.0 updated: [SPARK-35746][UI] Fix taskid in the stage page task event timeline
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.0
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.0 by this push:
new 6597c3b [SPARK-35746][UI] Fix taskid in the stage page task event
timeline
6597c3b is described below
commit 6597c3bd5e91040dc53576c912c85d84f630bb17
Author: shahid
AuthorDate: Sat Jun 12 15:38:41 2021 +0900
[SPARK-35746][UI] Fix taskid in the stage page task event timeline
### What changes were proposed in this pull request?
Task id is given incorrect in the timeline plot in Stage Page
### Why are the changes needed?
Map event timeline plots to correct task
**Before:**

**After**

### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually tested
Closes #32888 from shahidki31/shahid/fixtaskid.
Authored-by: shahid
Signed-off-by: Kousuke Saruta
(cherry picked from commit 450b415028c3b00f3a002126cd11318d3932e28f)
Signed-off-by: Kousuke Saruta
---
core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
index ccaa70b..e9eb62e 100644
--- a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
+++ b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
@@ -352,7 +352,7 @@ private[ui] class StagePage(parent: StagesTab, store:
AppStatusStore) extends We
|'content': '
+ |data-title="${s"Task " + taskInfo.taskId + " (attempt " +
attempt + ")"}
|Status: ${taskInfo.status}
|Launch Time: ${UIUtils.formatDate(new Date(launchTime))}
|${
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.1 updated: [SPARK-35746][UI] Fix taskid in the stage page task event timeline
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch branch-3.1
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.1 by this push:
new 78d3d0f [SPARK-35746][UI] Fix taskid in the stage page task event
timeline
78d3d0f is described below
commit 78d3d0f0a562743bb9a36854c2302b242f4d9309
Author: shahid
AuthorDate: Sat Jun 12 15:38:41 2021 +0900
[SPARK-35746][UI] Fix taskid in the stage page task event timeline
### What changes were proposed in this pull request?
Task id is given incorrect in the timeline plot in Stage Page
### Why are the changes needed?
Map event timeline plots to correct task
**Before:**

**After**

### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually tested
Closes #32888 from shahidki31/shahid/fixtaskid.
Authored-by: shahid
Signed-off-by: Kousuke Saruta
(cherry picked from commit 450b415028c3b00f3a002126cd11318d3932e28f)
Signed-off-by: Kousuke Saruta
---
core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
index 47ba951..459e09a 100644
--- a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
+++ b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
@@ -355,7 +355,7 @@ private[ui] class StagePage(parent: StagesTab, store:
AppStatusStore) extends We
|'content': '
+ |data-title="${s"Task " + taskInfo.taskId + " (attempt " +
attempt + ")"}
|Status: ${taskInfo.status}
|Launch Time: ${UIUtils.formatDate(new Date(launchTime))}
|${
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-35746][UI] Fix taskid in the stage page task event timeline
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 450b415 [SPARK-35746][UI] Fix taskid in the stage page task event
timeline
450b415 is described below
commit 450b415028c3b00f3a002126cd11318d3932e28f
Author: shahid
AuthorDate: Sat Jun 12 15:38:41 2021 +0900
[SPARK-35746][UI] Fix taskid in the stage page task event timeline
### What changes were proposed in this pull request?
Task id is given incorrect in the timeline plot in Stage Page
### Why are the changes needed?
Map event timeline plots to correct task
**Before:**

**After**

### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually tested
Closes #32888 from shahidki31/shahid/fixtaskid.
Authored-by: shahid
Signed-off-by: Kousuke Saruta
---
core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
index 777a6b0..81dfe83 100644
--- a/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
+++ b/core/src/main/scala/org/apache/spark/ui/jobs/StagePage.scala
@@ -355,7 +355,7 @@ private[ui] class StagePage(parent: StagesTab, store:
AppStatusStore) extends We
|'content': '
+ |data-title="${s"Task " + taskInfo.taskId + " (attempt " +
attempt + ")"}
|Status: ${taskInfo.status}
|Launch Time: ${UIUtils.formatDate(new Date(launchTime))}
|${
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-35609][BUILD] Add style rules to prohibit to use a Guava's API which is incompatible with newer versions
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c532f82 [SPARK-35609][BUILD] Add style rules to prohibit to use a
Guava's API which is incompatible with newer versions
c532f82 is described below
commit c532f8260ee2f2f4170dc50f7e890fafab438b76
Author: Kousuke Saruta
AuthorDate: Thu Jun 3 21:52:41 2021 +0900
[SPARK-35609][BUILD] Add style rules to prohibit to use a Guava's API which
is incompatible with newer versions
### What changes were proposed in this pull request?
This PR adds rules to `checkstyle.xml` and `scalastyle-config.xml` to avoid
introducing `Objects.toStringHelper` a Guava's API which is no longer present
in newer Guava.
### Why are the changes needed?
SPARK-30272 (#26911) replaced `Objects.toStringHelper` which is an APIs
Guava 14 provides with `commons.lang3` API because `Objects.toStringHelper` is
no longer present in newer Guava.
But toStringHelper was introduced into Spark again and replaced them in
SPARK-35420 (#32567).
I think it's better to have a style rule to avoid such repetition.
SPARK-30272 replaced some APIs aside from `Objects.toStringHelper` but
`Objects.toStringHelper` seems to affect Spark for now so I add rules only for
it.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
I confirmed that `lint-java` and `lint-scala` detect the usage of
`toStringHelper` and let the lint check fail.
```
$ dev/lint-java
exec: curl --silent --show-error -L
https://downloads.lightbend.com/scala/2.12.14/scala-2.12.14.tgz
Using `mvn` from path: /opt/maven/3.6.3//bin/mvn
Checkstyle checks failed at following occurrences:
[ERROR]
src/main/java/org/apache/spark/network/protocol/OneWayMessage.java:[78]
(regexp) RegexpSinglelineJava: Avoid using Object.toStringHelper. Use
ToStringBuilder instead.
$ dev/lint-scala
Scalastyle checks failed at following occurrences:
[error]
/home/kou/work/oss/spark/core/src/main/scala/org/apache/spark/rdd/RDD.scala:93:25:
Avoid using Object.toStringHelper. Use ToStringBuilder instead.
[error] Total time: 25 s, completed 2021/06/02 16:18:25
```
Closes #32740 from sarutak/style-rule-for-guava.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
dev/checkstyle.xml| 5 -
scalastyle-config.xml | 4
2 files changed, 8 insertions(+), 1 deletion(-)
diff --git a/dev/checkstyle.xml b/dev/checkstyle.xml
index 483fc7c..06c79a9 100644
--- a/dev/checkstyle.xml
+++ b/dev/checkstyle.xml
@@ -185,6 +185,9 @@
-
+
+
+
+
diff --git a/scalastyle-config.xml b/scalastyle-config.xml
index c1dc57b..c06b4ab 100644
--- a/scalastyle-config.xml
+++ b/scalastyle-config.xml
@@ -397,4 +397,8 @@ This file is divided into 3 sections:
-1,0,1,2,3
+
+Objects.toStringHelper
+Avoid using Object.toStringHelper. Use ToStringBuilder
instead.
+
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (d773373 -> b7dd4b3)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from d773373 [SPARK-35584][CORE][TESTS] Increase the timeout in FallbackStorageSuite add b7dd4b3 [SPARK-35516][WEBUI] Storage UI tab Storage Level tool tip correction No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/ui/storage/ToolTips.scala | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-35194][SQL][FOLLOWUP] Recover build error with Scala 2.13 on GA
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b763db3 [SPARK-35194][SQL][FOLLOWUP] Recover build error with Scala
2.13 on GA
b763db3 is described below
commit b763db3efdd6a58e34c136b03426371400afefd1
Author: Kousuke Saruta
AuthorDate: Sat May 29 00:11:16 2021 +0900
[SPARK-35194][SQL][FOLLOWUP] Recover build error with Scala 2.13 on GA
### What changes were proposed in this pull request?
This PR fixes a build error with Scala 2.13 on GA.
#32301 seems to bring this error.
### Why are the changes needed?
To recover CI.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
GA
Closes #32696 from sarutak/followup-SPARK-35194.
Authored-by: Kousuke Saruta
Signed-off-by: Kousuke Saruta
---
.../org/apache/spark/sql/catalyst/optimizer/NestedColumnAliasing.scala | 3 ++-
1 file changed, 2 insertions(+), 1 deletion(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/NestedColumnAliasing.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/NestedColumnAliasing.scala
index cd7032d..e0e8f92 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/NestedColumnAliasing.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/NestedColumnAliasing.scala
@@ -146,7 +146,8 @@ object NestedColumnAliasing {
val nestedFieldToAlias =
attributeToExtractValuesAndAliases.values.flatten.toMap
// A reference attribute can have multiple aliases for nested fields.
-val attrToAliases =
AttributeMap(attributeToExtractValuesAndAliases.mapValues(_.map(_._2)))
+val attrToAliases =
+
AttributeMap(attributeToExtractValuesAndAliases.mapValues(_.map(_._2)).toSeq)
plan match {
case Project(projectList, child) =>
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (0549caf -> 003294c)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 0549caf [MINOR][SQL] Change the script name for creating oracle docker image add 003294c [SPARK-35488][BUILD] Upgrade ASM to 7.3.1 No new revisions were added by this update. Summary of changes: dev/deps/spark-deps-hadoop-2.7-hive-2.3 | 2 +- dev/deps/spark-deps-hadoop-3.2-hive-2.3 | 2 +- pom.xml | 6 +++--- project/plugins.sbt | 4 ++-- 4 files changed, 7 insertions(+), 7 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (46f7d78 -> 9283beb)
This is an automated email from the ASF dual-hosted git repository.
sarutak pushed a change to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git.
from 46f7d78 [SPARK-35368][SQL] Update histogram statistics for RANGE
operator for stats estimation
add 9283beb [SPARK-35418][SQL] Add sentences function to
functions.{scala,py}
No new revisions were added by this update.
Summary of changes:
python/docs/source/reference/pyspark.sql.rst | 1 +
python/pyspark/sql/functions.py| 39 ++
python/pyspark/sql/functions.pyi | 5 +++
.../scala/org/apache/spark/sql/functions.scala | 19 +++
.../apache/spark/sql/StringFunctionsSuite.scala| 7
5 files changed, 71 insertions(+)
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (3b859a1 -> 7b942d5)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 3b859a1 [SPARK-35431][SQL][TESTS] Sort elements generated by collect_set in SQLQueryTestSuite add 7b942d5 [SPARK-35425][BUILD] Pin jinja2 in `spark-rm/Dockerfile` and add as a required dependency in the release README.md No new revisions were added by this update. Summary of changes: dev/create-release/spark-rm/Dockerfile | 4 +++- docs/README.md | 5 - 2 files changed, 7 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (7c13636 -> b4348b7)
This is an automated email from the ASF dual-hosted git repository. sarutak pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git. from 7c13636 [SPARK-34888][SS] Introduce UpdatingSessionIterator adjusting session window on elements add b4348b7 [SPARK-35420][BUILD] Replace the usage of toStringHelper with ToStringBuilder No new revisions were added by this update. Summary of changes: .../spark/network/shuffle/RemoteBlockPushResolver.java | 8 +--- .../network/shuffle/protocol/FinalizeShuffleMerge.java | 8 +--- .../spark/network/shuffle/protocol/MergeStatuses.java | 8 +--- .../spark/network/shuffle/protocol/PushBlockStream.java| 14 -- 4 files changed, 23 insertions(+), 15 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org