This is an automated email from the ASF dual-hosted git repository.
wenchen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c234c5b [SPARK-34575][SQL] Push down limit through window when
partitionSpec is empty
c234c5b is described below
commit c234c5b5f1676fbb9a79dc865534fec566425326
Author: Yuming Wang <yumw...@ebay.com>
AuthorDate: Wed Mar 17 07:16:10 2021 +0000
[SPARK-34575][SQL] Push down limit through window when partitionSpec is
empty
### What changes were proposed in this pull request?
Push down limit through `Window` when the partitionSpec of all window
functions is empty and the same order is used. This is a real case from
production:

This pr support 2 cases:
1. All window functions have same orderSpec:
```sql
SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rn, RANK() OVER(ORDER BY a)
AS rk FROM t1 LIMIT 5;
== Optimized Logical Plan ==
Window [row_number() windowspecdefinition(a#9L ASC NULLS FIRST,
specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$()))
AS rn#4, rank(a#9L) windowspecdefinition(a#9L ASC NULLS FIRST,
specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#5],
[a#9L ASC NULLS FIRST]
+- GlobalLimit 5
+- LocalLimit 5
+- Sort [a#9L ASC NULLS FIRST], true
+- Relation default.t1[A#9L,B#10L,C#11L] parquet
```
2. There is a window function with a different orderSpec:
```sql
SELECT a, ROW_NUMBER() OVER(ORDER BY a) AS rn, RANK() OVER(ORDER BY b
DESC) AS rk FROM t1 LIMIT 5;
== Optimized Logical Plan ==
Project [a#9L, rn#4, rk#5]
+- Window [rank(b#10L) windowspecdefinition(b#10L DESC NULLS LAST,
specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS rk#5],
[b#10L DESC NULLS LAST]
+- GlobalLimit 5
+- LocalLimit 5
+- Sort [b#10L DESC NULLS LAST], true
+- Window [row_number() windowspecdefinition(a#9L ASC NULLS
FIRST, specifiedwindowframe(RowFrame, unboundedpreceding$(), currentrow$())) AS
rn#4], [a#9L ASC NULLS FIRST]
+- Project [a#9L, b#10L]
+- Relation default.t1[A#9L,B#10L,C#11L] parquet
```
### Why are the changes needed?
Improve query performance.
```scala
spark.range(500000000L).selectExpr("id AS a", "id AS
b").write.saveAsTable("t1")
spark.sql("SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rowId FROM t1 LIMIT
5").show
```
Before this pr | After this pr
-- | --
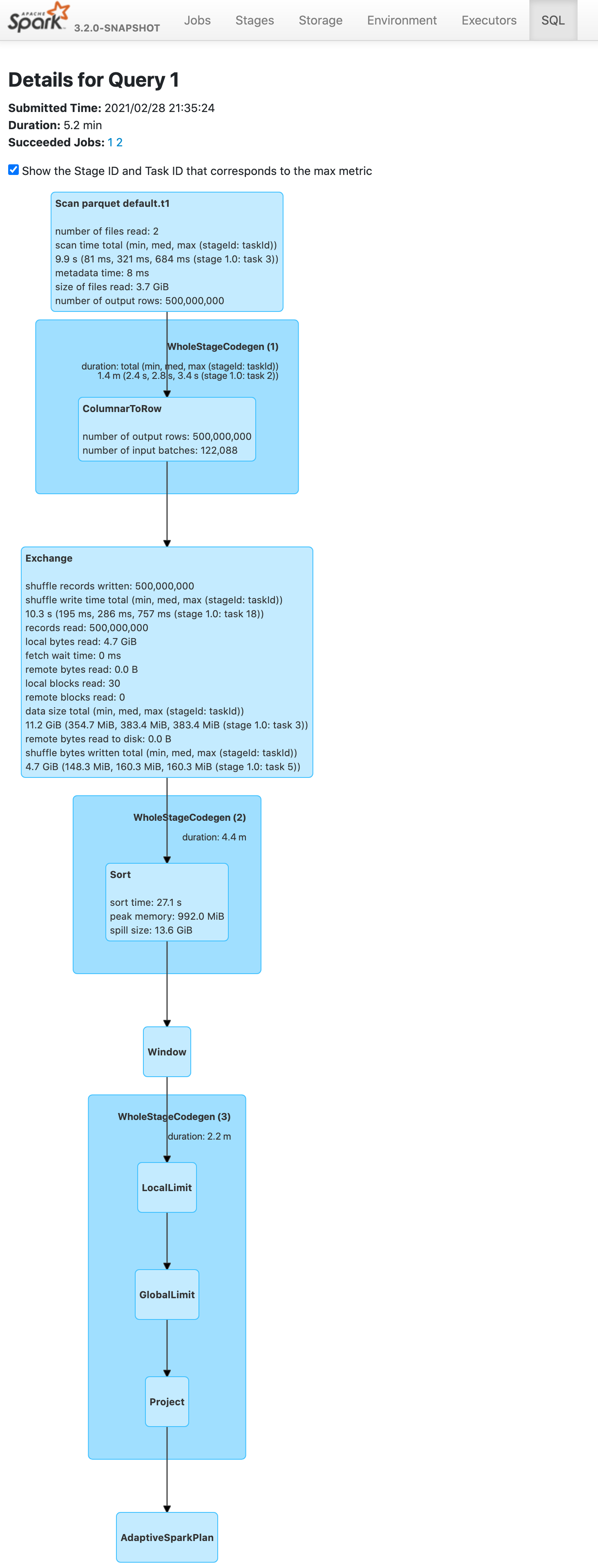
|
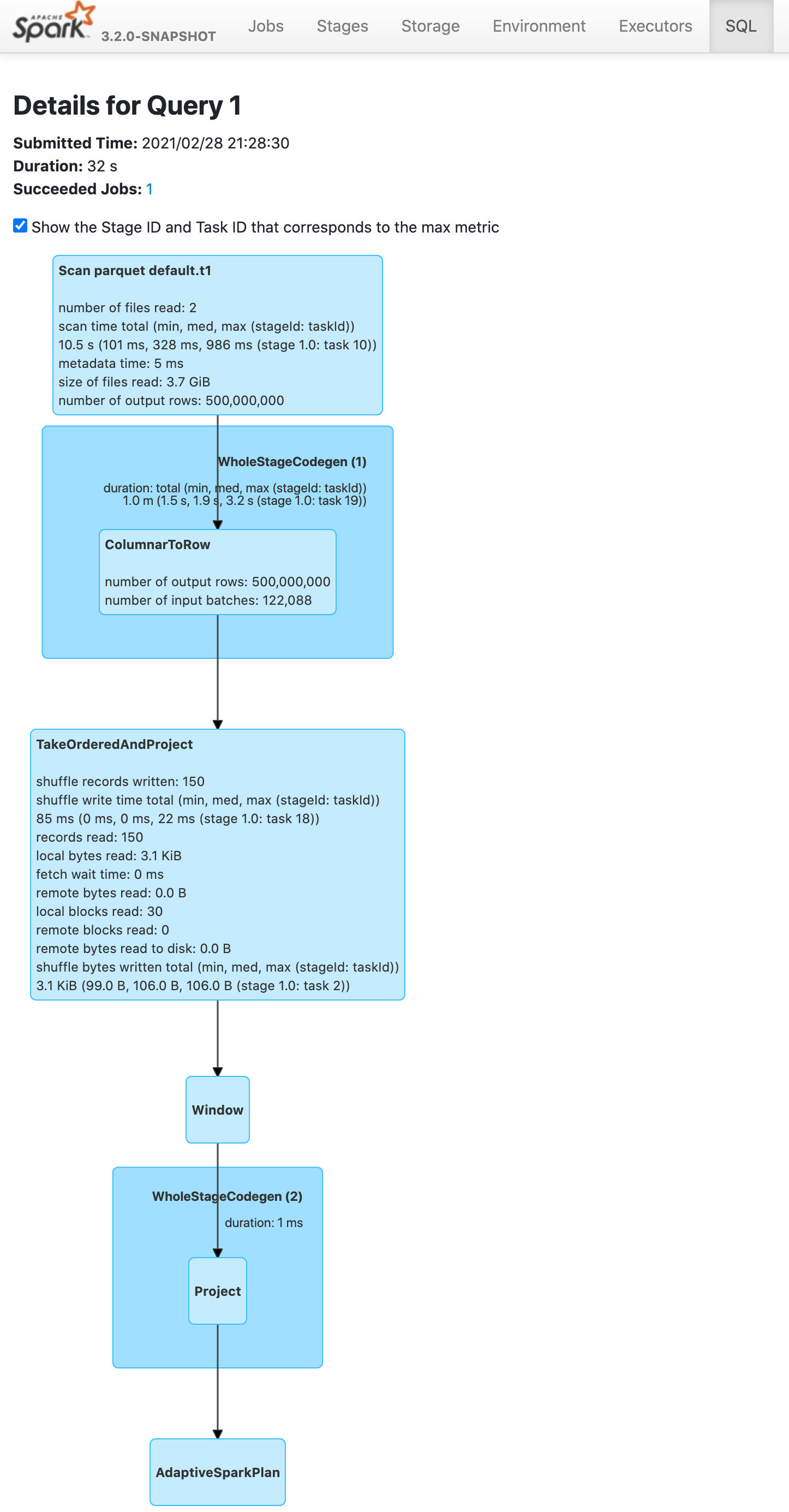
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
Closes #31691 from wangyum/SPARK-34575.
Authored-by: Yuming Wang <yumw...@ebay.com>
Signed-off-by: Wenchen Fan <wenc...@databricks.com>
---
.../optimizer/LimitPushDownThroughWindow.scala | 56 ++++++
.../spark/sql/catalyst/optimizer/Optimizer.scala | 1 +
.../LimitPushdownThroughWindowSuite.scala | 190 +++++++++++++++++++++
.../scala/org/apache/spark/sql/SQLQuerySuite.scala | 34 +++-
4 files changed, 280 insertions(+), 1 deletion(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/LimitPushDownThroughWindow.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/LimitPushDownThroughWindow.scala
new file mode 100644
index 0000000..0e89e4a
--- /dev/null
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/LimitPushDownThroughWindow.scala
@@ -0,0 +1,56 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, CurrentRow,
IntegerLiteral, NamedExpression, RankLike, RowFrame, RowNumberLike,
SpecifiedWindowFrame, UnboundedPreceding, WindowExpression,
WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Limit, LocalLimit,
LogicalPlan, Project, Sort, Window}
+import org.apache.spark.sql.catalyst.rules.Rule
+
+/**
+ * Pushes down [[LocalLimit]] beneath WINDOW. This rule optimizes the
following case:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rn FROM Tab1 LIMIT 5 ==>
+ * SELECT *, ROW_NUMBER() OVER(ORDER BY a) AS rn FROM (SELECT * FROM Tab1
ORDER BY a LIMIT 5) t
+ * }}}
+ */
+object LimitPushDownThroughWindow extends Rule[LogicalPlan] {
+ // The window frame of RankLike and RowNumberLike can only be UNBOUNDED
PRECEDING to CURRENT ROW.
+ private def supportsPushdownThroughWindow(
+ windowExpressions: Seq[NamedExpression]): Boolean =
windowExpressions.forall {
+ case Alias(WindowExpression(_: RankLike | _: RowNumberLike,
WindowSpecDefinition(Nil, _,
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _)
=> true
+ case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = plan transform {
+ // Adding an extra Limit below WINDOW when the partitionSpec of all window
functions is empty.
+ case LocalLimit(limitExpr @ IntegerLiteral(limit),
+ window @ Window(windowExpressions, Nil, orderSpec, child))
+ if supportsPushdownThroughWindow(windowExpressions) &&
child.maxRows.forall(_ > limit) &&
+ limit < conf.topKSortFallbackThreshold =>
+ // Sort is needed here because we need global sort.
+ window.copy(child = Limit(limitExpr, Sort(orderSpec, true, child)))
+ // There is a Project between LocalLimit and Window if they do not have
the same output.
+ case LocalLimit(limitExpr @ IntegerLiteral(limit), project @ Project(_,
+ window @ Window(windowExpressions, Nil, orderSpec, child)))
+ if supportsPushdownThroughWindow(windowExpressions) &&
child.maxRows.forall(_ > limit) &&
+ limit < conf.topKSortFallbackThreshold =>
+ // Sort is needed here because we need global sort.
+ project.copy(child = window.copy(child = Limit(limitExpr,
Sort(orderSpec, true, child))))
+ }
+}
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
index 9a12ca1..d54f4ba 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
@@ -78,6 +78,7 @@ abstract class Optimizer(catalogManager: CatalogManager)
PushDownLeftSemiAntiJoin,
PushLeftSemiLeftAntiThroughJoin,
LimitPushDown,
+ LimitPushDownThroughWindow,
ColumnPruning,
// Operator combine
CollapseRepartition,
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/LimitPushdownThroughWindowSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/LimitPushdownThroughWindowSuite.scala
new file mode 100644
index 0000000..f2c1f45
--- /dev/null
+++
b/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/LimitPushdownThroughWindowSuite.scala
@@ -0,0 +1,190 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.catalyst.dsl.expressions._
+import org.apache.spark.sql.catalyst.dsl.plans._
+import org.apache.spark.sql.catalyst.expressions.{CurrentRow, Rank, RowFrame,
RowNumber, SpecifiedWindowFrame, UnboundedPreceding}
+import org.apache.spark.sql.catalyst.plans._
+import org.apache.spark.sql.catalyst.plans.logical._
+import org.apache.spark.sql.catalyst.rules._
+import org.apache.spark.sql.internal.SQLConf
+
+class LimitPushdownThroughWindowSuite extends PlanTest {
+ // CollapseProject and RemoveNoopOperators is needed because we need it to
collapse project.
+ private val limitPushdownRules = Seq(
+ CollapseProject,
+ RemoveNoopOperators,
+ LimitPushDownThroughWindow,
+ EliminateLimits,
+ ConstantFolding,
+ BooleanSimplification)
+
+ private object Optimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Limit pushdown through window", FixedPoint(100),
+ limitPushdownRules: _*) :: Nil
+ }
+
+ private object WithoutOptimize extends RuleExecutor[LogicalPlan] {
+ val batches =
+ Batch("Without limit pushdown through window", FixedPoint(100),
+ limitPushdownRules
+ .filterNot(_.ruleName.equals(LimitPushDownThroughWindow.ruleName)):
_*) :: Nil
+ }
+
+ private val testRelation = LocalRelation.fromExternalRows(
+ Seq("a".attr.int, "b".attr.int, "c".attr.int),
+ 1.to(6).map(_ => Row(1, 2, 3)))
+
+ private val a = testRelation.output(0)
+ private val b = testRelation.output(1)
+ private val c = testRelation.output(2)
+ private val windowFrame = SpecifiedWindowFrame(RowFrame, UnboundedPreceding,
CurrentRow)
+
+ test("Push down limit through window when partitionSpec is empty") {
+ val originalQuery = testRelation
+ .select(a, b, c,
+ windowExpr(RowNumber(), windowSpec(Nil, c.desc :: Nil,
windowFrame)).as("rn"))
+ .limit(2)
+ val correctAnswer = testRelation
+ .select(a, b, c)
+ .orderBy(c.desc)
+ .limit(2)
+ .select(a, b, c,
+ windowExpr(RowNumber(), windowSpec(Nil, c.desc :: Nil,
windowFrame)).as("rn"))
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(correctAnswer.analyze))
+ }
+
+ test("Push down limit through window for multiple window functions") {
+ val originalQuery = testRelation
+ .select(a, b, c,
+ windowExpr(RowNumber(), windowSpec(Nil, c.desc :: Nil,
windowFrame)).as("rn"),
+ windowExpr(new Rank(), windowSpec(Nil, c.desc :: Nil,
windowFrame)).as("rk"))
+ .limit(2)
+ val correctAnswer = testRelation
+ .select(a, b, c)
+ .orderBy(c.desc)
+ .limit(2)
+ .select(a, b, c,
+ windowExpr(RowNumber(), windowSpec(Nil, c.desc :: Nil,
windowFrame)).as("rn"),
+ windowExpr(new Rank(), windowSpec(Nil, c.desc :: Nil,
windowFrame)).as("rk"))
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(correctAnswer.analyze))
+ }
+
+ test("Push down limit through window respect
spark.sql.execution.topKSortFallbackThreshold") {
+ Seq(1, 100).foreach { threshold =>
+ withSQLConf(SQLConf.TOP_K_SORT_FALLBACK_THRESHOLD.key ->
threshold.toString) {
+ val originalQuery = testRelation
+ .select(a, b, c,
+ windowExpr(RowNumber(), windowSpec(Nil, c.desc :: Nil,
windowFrame)).as("rn"))
+ .limit(2)
+ val correctAnswer = if (threshold == 1) {
+ originalQuery
+ } else {
+ testRelation
+ .select(a, b, c)
+ .orderBy(c.desc)
+ .limit(2)
+ .select(a, b, c,
+ windowExpr(RowNumber(), windowSpec(Nil, c.desc :: Nil,
windowFrame)).as("rn"))
+ }
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(correctAnswer.analyze))
+ }
+ }
+ }
+
+ test("Push down to first window if order column is different") {
+ val originalQuery = testRelation
+ .select(a, b, c,
+ windowExpr(RowNumber(), windowSpec(Nil, b.desc :: Nil,
windowFrame)).as("rn"),
+ windowExpr(new Rank(), windowSpec(Nil, c.asc :: Nil,
windowFrame)).as("rk"))
+ .limit(2)
+ val correctAnswer = testRelation
+ .select(a, b, c,
+ windowExpr(RowNumber(), windowSpec(Nil, b.desc :: Nil,
windowFrame)).as("rn"))
+ .orderBy(c.asc)
+ .limit(2)
+ .select(a, b, c, $"rn".attr,
+ windowExpr(new Rank(), windowSpec(Nil, c.asc :: Nil,
windowFrame)).as("rk"))
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(correctAnswer.analyze))
+ }
+
+ test("Push down if there is a Project between LocalLimit and Window") {
+ val originalQuery = testRelation
+ .select(a, b,
+ windowExpr(RowNumber(), windowSpec(Nil, b.desc :: Nil,
windowFrame)).as("rn"))
+ .select(a, $"rn".attr)
+ .limit(2)
+ val correctAnswer = testRelation
+ .select(a, b)
+ .orderBy(b.desc)
+ .limit(2)
+ .select(a, windowExpr(RowNumber(), windowSpec(Nil, b.desc :: Nil,
windowFrame)).as("rn"))
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(correctAnswer.analyze))
+ }
+
+ test("Should not push down if partitionSpec is not empty") {
+ val originalQuery = testRelation
+ .select(a, b, c,
+ windowExpr(RowNumber(), windowSpec(a :: Nil, c.desc :: Nil,
windowFrame)).as("rn"))
+ .limit(2)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+
+ test("Should not push down when child's maxRows smaller than limit value") {
+ val originalQuery = testRelation
+ .select(a, b, c,
+ windowExpr(RowNumber(), windowSpec(Nil, c.desc :: Nil,
windowFrame)).as("rn"))
+ .limit(20)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+
+ test("Should not push down if it is not RankLike/RowNumberLike window
function") {
+ val originalQuery = testRelation
+ .select(a, b, c,
+ windowExpr(count(b), windowSpec(Nil, c.desc :: Nil,
windowFrame)).as("rn"))
+ .limit(2)
+
+ comparePlans(
+ Optimize.execute(originalQuery.analyze),
+ WithoutOptimize.execute(originalQuery.analyze))
+ }
+}
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
index 3865952..f709d803 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
@@ -29,7 +29,7 @@ import org.apache.spark.scheduler.{SparkListener,
SparkListenerJobStart}
import org.apache.spark.sql.catalyst.expressions.GenericRow
import org.apache.spark.sql.catalyst.expressions.aggregate.{Complete, Partial}
import org.apache.spark.sql.catalyst.optimizer.{ConvertToLocalRelation,
NestedColumnAliasingSuite}
-import org.apache.spark.sql.catalyst.plans.logical.{LocalLimit, Project,
RepartitionByExpression}
+import org.apache.spark.sql.catalyst.plans.logical.{LocalLimit, Project,
RepartitionByExpression, Sort}
import org.apache.spark.sql.catalyst.util.StringUtils
import org.apache.spark.sql.execution.UnionExec
import org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanHelper
@@ -4065,6 +4065,38 @@ class SQLQuerySuite extends QueryTest with
SharedSparkSession with AdaptiveSpark
}
}
}
+
+ test("SPARK-34575 Push down limit through window when partitionSpec is
empty") {
+ withTable("t1") {
+ val numRows = 10
+ spark.range(numRows)
+ .selectExpr("if (id % 2 = 0, null, id) AS a", s"$numRows - id AS b")
+ .write
+ .saveAsTable("t1")
+
+ val df1 = spark.sql(
+ """
+ |SELECT a, b, ROW_NUMBER() OVER(ORDER BY a, b) AS rn
+ |FROM t1 LIMIT 3
+ |""".stripMargin)
+ val pushedLocalLimits1 = df1.queryExecution.optimizedPlan.collect {
+ case l @ LocalLimit(_, _: Sort) => l
+ }
+ assert(pushedLocalLimits1.length === 1)
+ checkAnswer(df1, Seq(Row(null, 2, 1), Row(null, 4, 2), Row(null, 6, 3)))
+
+ val df2 = spark.sql(
+ """
+ |SELECT b, RANK() OVER(ORDER BY a, b) AS rk, DENSE_RANK(b)
OVER(ORDER BY a, b) AS s
+ |FROM t1 LIMIT 2
+ |""".stripMargin)
+ val pushedLocalLimits2 = df2.queryExecution.optimizedPlan.collect {
+ case l @ LocalLimit(_, _: Sort) => l
+ }
+ assert(pushedLocalLimits2.length === 1)
+ checkAnswer(df2, Seq(Row(2, 1, 1), Row(4, 2, 2)))
+ }
+ }
}
case class Foo(bar: Option[String])
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
{kind=link}
{kind=link}
{kind=link}