[GitHub] [tvm] masahi edited a comment on pull request #7123: Parallelize cumsum in get_valid_counts
masahi edited a comment on pull request #7123: URL: https://github.com/apache/tvm/pull/7123#issuecomment-752856182 @Laurawly The plan is after we merge this first, we will generalize the cumsum IR in this PR into a reusable, exclusive scan primitive. After that, we can update our CUDA `argwhere` implementation to use ex scan + compaction, and introduce numpy style `cumsum` operator. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated (c6b766a -> c02c9c5)
This is an automated email from the ASF dual-hosted git repository. laurawly pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from c6b766a [Relay][Op] Remove reverse attribute from reshape and reverse_reshape operators. (#7086) add c02c9c5 Parallelize cumsum in get_valid_counts (#7123) No new revisions were added by this update. Summary of changes: python/tvm/topi/cuda/nms.py | 134 --- python/tvm/topi/vision/nms.py| 2 +- tests/python/relay/test_op_level5.py | 4 +- tests/python/topi/python/test_topi_vision.py | 21 ++--- 4 files changed, 109 insertions(+), 52 deletions(-)
[GitHub] [tvm] Laurawly commented on pull request #7123: Parallelize cumsum in get_valid_counts
Laurawly commented on pull request #7123: URL: https://github.com/apache/tvm/pull/7123#issuecomment-752856716 > @Laurawly The plan is after we merge this first, we will generaliz the cumsum IR in this PR into a reusable, exclusive scan primitive. After that, we can update our CUDA `argwhere` implementation to use ex scan + compaction, and introduce numpy style `cumsum` operator. Sure, I can merge this first. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] Laurawly merged pull request #7123: Parallelize cumsum in get_valid_counts
Laurawly merged pull request #7123: URL: https://github.com/apache/tvm/pull/7123 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi edited a comment on pull request #7123: Parallelize cumsum in get_valid_counts
masahi edited a comment on pull request #7123: URL: https://github.com/apache/tvm/pull/7123#issuecomment-752856182 @Laurawly The plan is after we merge this first, we will generaliz the cumsum IR in this PR into a reusable, exclusive scan primitive. After that, we can update our CUDA `argwhere` implementation to use ex scan + compaction, and introduce numpy style `cumsum` operator. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi commented on pull request #7123: Parallelize cumsum in get_valid_counts
masahi commented on pull request #7123: URL: https://github.com/apache/tvm/pull/7123#issuecomment-752856182 @Laurawly The plan is after we merge this first, we will generalized the cumsum IR in this PR into a reusable, exclusive scan primitive. After that, we can update our CUDA `argwhere` implementation to use ex scan + compaction, and introduce numpy style `cumsum` operator. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi commented on a change in pull request #7123: Parallelize cumsum in get_valid_counts
masahi commented on a change in pull request #7123: URL: https://github.com/apache/tvm/pull/7123#discussion_r550404065 ## File path: python/tvm/topi/vision/nms.py ## @@ -213,7 +213,7 @@ def get_valid_counts(data, score_threshold=0, id_index=0, score_index=1): out_indices: tvm.te.Tensor or numpy NDArray Related index in input data. """ -if isinstance(score_threshold, float): +if isinstance(score_threshold, (float, int)): Review comment: I remember a funny error message from hybridscript. This is from https://github.com/apache/tvm/blob/3144cec7fac88707f0a5e338a5157435be070d6b/tests/python/topi/python/test_topi_vision.py#L131 It is only for passing this test. We can also change `0` to `0.0` instead. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi commented on a change in pull request #7123: Parallelize cumsum in get_valid_counts
masahi commented on a change in pull request #7123: URL: https://github.com/apache/tvm/pull/7123#discussion_r550404065 ## File path: python/tvm/topi/vision/nms.py ## @@ -213,7 +213,7 @@ def get_valid_counts(data, score_threshold=0, id_index=0, score_index=1): out_indices: tvm.te.Tensor or numpy NDArray Related index in input data. """ -if isinstance(score_threshold, float): +if isinstance(score_threshold, (float, int)): Review comment: I remember it is from https://github.com/apache/tvm/blob/3144cec7fac88707f0a5e338a5157435be070d6b/tests/python/topi/python/test_topi_vision.py#L131 It is only for passing this test. We can also change `0` to `0.0` instead. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] Laurawly commented on a change in pull request #7123: Parallelize cumsum in get_valid_counts
Laurawly commented on a change in pull request #7123: URL: https://github.com/apache/tvm/pull/7123#discussion_r550403082 ## File path: python/tvm/topi/vision/nms.py ## @@ -213,7 +213,7 @@ def get_valid_counts(data, score_threshold=0, id_index=0, score_index=1): out_indices: tvm.te.Tensor or numpy NDArray Related index in input data. """ -if isinstance(score_threshold, float): +if isinstance(score_threshold, (float, int)): Review comment: Just curious what's the scenario for score_threshold to be an int. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] areusch commented on a change in pull request #7164: [µTVM] Add documentation
areusch commented on a change in pull request #7164: URL: https://github.com/apache/tvm/pull/7164#discussion_r550402038 ## File path: docs/dev/index.rst ## @@ -396,3 +396,11 @@ Security :maxdepth: 1 security + + +microTVM +- +.. toctree:: Review comment: why's that? these are text figures and making people upload to an external repository sort of discourages figures. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] Laurawly opened a new pull request #7187: [Fix] Tensor core type issue for dense
Laurawly opened a new pull request #7187: URL: https://github.com/apache/tvm/pull/7187 As mentioned in PR #7146, previous tensor core code lacks type check and this PR is trying to fix that. cc @jcf94 @merrymercy @Meteorix This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] Laurawly commented on a change in pull request #7146: [CUDA]batch_matmul tensorcore schedule
Laurawly commented on a change in pull request #7146: URL: https://github.com/apache/tvm/pull/7146#discussion_r550363118 ## File path: python/tvm/relay/op/strategy/cuda.py ## @@ -657,6 +657,23 @@ def batch_matmul_strategy_cuda(attrs, inputs, out_type, target): name="batch_matmul_cublas.cuda", plevel=15, ) +if target.kind.name == "cuda" and nvcc.have_tensorcore(tvm.gpu(0).compute_version): Review comment: It's better to use `nvcc.have_tensorcore(target=target)` here since `tvm.gpu(0)` might not exist. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] FrozenGene commented on a change in pull request #7185: [AutoScheduler] Add custom build function
FrozenGene commented on a change in pull request #7185: URL: https://github.com/apache/tvm/pull/7185#discussion_r550388292 ## File path: python/tvm/auto_scheduler/measure.py ## @@ -303,11 +306,16 @@ class LocalBuilder(ProgramBuilder): This is used in a wrapper of the multiprocessing.Process.join(). n_parallel : int = multiprocessing.cpu_count() Number of threads used to build in parallel. -build_func : str = 'default' -The name of registered build function. +build_func: callable or str Review comment: add the default value in the comment ## File path: python/tvm/auto_scheduler/measure.py ## @@ -628,6 +636,8 @@ def local_build_worker(args): build_func = tar.tar elif build_func == "ndk": build_func = ndk.create_shared +elif build_func == "custom": Review comment: if so, we could use BuildFunc.build_func for all conditions ## File path: python/tvm/auto_scheduler/measure.py ## @@ -63,6 +63,9 @@ # We use 1e10 instead of sys.float_info.max for better readability in log MAX_FLOAT = 1e10 +class CustomBuildFunc: Review comment: Suggest we use one class BuildFunc, which could store default / ndk / custom and so on. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] Meteorix closed issue #7008: [RELAY][BUG]type inference is slow
Meteorix closed issue #7008: URL: https://github.com/apache/tvm/issues/7008 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] sxjscience closed issue #6721: [FRONTEND][MXNET 2.0] Support three missing operators: _npi_subtract_scalar, _npi_stack, _npi_advanced_indexing_multiple
sxjscience closed issue #6721: URL: https://github.com/apache/tvm/issues/6721 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] sxjscience commented on issue #6721: [FRONTEND][MXNET 2.0] Support three missing operators: _npi_subtract_scalar, _npi_stack, _npi_advanced_indexing_multiple
sxjscience commented on issue #6721: URL: https://github.com/apache/tvm/issues/6721#issuecomment-752828593 Move to https://github.com/apache/tvm/issues/7186 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] sxjscience commented on issue #7186: [Frontend][MXNet] Importer Missing Operators
sxjscience commented on issue #7186: URL: https://github.com/apache/tvm/issues/7186#issuecomment-752828553 @junrushao1994 I created this new issue. Also, I just figured out that I cannot attach the "help wanted" label so would you help with that? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] sxjscience opened a new issue #7186: [Frontend][MXNet] Importer Missing Operators
sxjscience opened a new issue #7186: URL: https://github.com/apache/tvm/issues/7186 # Feature Request Recently, TVM has supported the incoming MXNet 2.0 frontend via a series of PRs: https://github.com/apache/incubator-tvm/pull/6054, https://github.com/apache/incubator-tvm/pull/6699. This enables the new GluonNLP 1.0, which has been upgraded from MXNet 1.x to MXNet 2.0 to convert to TVM graph (as added in https://github.com/dmlc/gluon-nlp/pull/1390). However, not all operators in MXNet support conversion to TVM. The following is the list of operators that need to be supported. - [ ] _npi_subtract_scalar [BART model](https://github.com/dmlc/gluon-nlp/blob/master/src/gluonnlp/models/bart.py) - [ ] _npi_stack, [BART model](https://github.com/dmlc/gluon-nlp/blob/master/src/gluonnlp/models/bart.py) - [ ] _npi_advanced_indexing_multiple, [BART model](https://github.com/dmlc/gluon-nlp/blob/master/src/gluonnlp/models/bart.py). This is triggered when we call `a[idx1, idx2]`. Also see the [MXNet-side implementation](https://github.com/apache/incubator-mxnet/blob/6bbd53107aa16fc41e8d462cf5dc46fb70d592df/src/operator/numpy/np_indexing_op.cc#L479-L491). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 commented on issue #6721: [FRONTEND][MXNET 2.0] Support three missing operators: _npi_subtract_scalar, _npi_stack, _npi_advanced_indexing_multiple
junrushao1994 commented on issue #6721: URL: https://github.com/apache/tvm/issues/6721#issuecomment-752823550 What about creating a new one, categorizing operators like #1799 does This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] sxjscience commented on issue #6721: [FRONTEND][MXNET 2.0] Support three missing operators: _npi_subtract_scalar, _npi_stack, _npi_advanced_indexing_multiple
sxjscience commented on issue #6721: URL: https://github.com/apache/tvm/issues/6721#issuecomment-752823206 Sounds good to me. Should I change the title of this issue so we may reuse that? (Or create a new one?) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leowang1225 commented on pull request #7185: [AutoScheduler] Add custom build function
leowang1225 commented on pull request #7185: URL: https://github.com/apache/tvm/pull/7185#issuecomment-752822165 > Signed-off-by: leowang1225 [810916...@qq.com](mailto:810916...@qq.com) > > Thanks for contributing to TVM! Please refer to guideline https://tvm.apache.org/docs/contribute/ for useful information and tips. After the pull request is submitted, please request code reviews from [Reviewers](https://github.com/apache/incubator-tvm/blob/master/CONTRIBUTORS.md#reviewers) by @ them in the pull request thread. @merrymercy @FrozenGene please help to review! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leowang1225 opened a new pull request #7185: [AutoScheduler] Add custom build function
leowang1225 opened a new pull request #7185: URL: https://github.com/apache/tvm/pull/7185 Signed-off-by: leowang1225 <810916...@qq.com> Thanks for contributing to TVM! Please refer to guideline https://tvm.apache.org/docs/contribute/ for useful information and tips. After the pull request is submitted, please request code reviews from [Reviewers](https://github.com/apache/incubator-tvm/blob/master/CONTRIBUTORS.md#reviewers) by @ them in the pull request thread. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 commented on issue #6721: [FRONTEND][MXNET 2.0] Support three missing operators: _npi_subtract_scalar, _npi_stack, _npi_advanced_indexing_multiple
junrushao1994 commented on issue #6721: URL: https://github.com/apache/tvm/issues/6721#issuecomment-752817334 Yeah we can have a consolidated "[Frontend][MXNet] Importer Missing Operators" thread and mark it as "help wanted". What do you think? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 commented on issue #6817: [WASM] apps/wasm-standalone is broken
junrushao1994 commented on issue #6817: URL: https://github.com/apache/tvm/issues/6817#issuecomment-752816644 Closed via #6862. Please feel free to reopen if the bug still exists. Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 closed issue #6817: [WASM] apps/wasm-standalone is broken
junrushao1994 closed issue #6817: URL: https://github.com/apache/tvm/issues/6817 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] comaniac opened a new pull request #7184: [ConvertLayout] slice_like support
comaniac opened a new pull request #7184: URL: https://github.com/apache/tvm/pull/7184 Add support to convert layouts for `slice_like` operator. The current limitation is that we require the layout of both inputs to perform the layout inference. It means if one of the inputs is input tensor or constant tensor which has no layout information, then the inference will fail. cc @anijain2305 @yzhliu This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] sxjscience commented on issue #6721: [FRONTEND][MXNET 2.0] Support three missing operators: _npi_subtract_scalar, _npi_stack, _npi_advanced_indexing_multiple
sxjscience commented on issue #6721: URL: https://github.com/apache/tvm/issues/6721#issuecomment-752811662 I think we can create a thread about that. Do you think that we should create a new one? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 commented on issue #6721: [FRONTEND][MXNET 2.0] Support three missing operators: _npi_subtract_scalar, _npi_stack, _npi_advanced_indexing_multiple
junrushao1994 commented on issue #6721: URL: https://github.com/apache/tvm/issues/6721#issuecomment-752811499 Hey Xingjian, thanks for bringing this up! It is certainly more than welcome for future contribution. Shall we put up a list of MXNet operators to be supported and consolidate them into a single thread instead? If there is no actionable item, shall we close this issue? Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 commented on issue #7008: [RELAY][BUG]type inference is slow
junrushao1994 commented on issue #7008: URL: https://github.com/apache/tvm/issues/7008#issuecomment-752811155 If there is no actionable item, I suggest we merge this particular issue to relay improvements, and close this thread. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated: [Relay][Op] Remove reverse attribute from reshape and reverse_reshape operators. (#7086)
This is an automated email from the ASF dual-hosted git repository.
tqchen pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/tvm.git
The following commit(s) were added to refs/heads/main by this push:
new c6b766a [Relay][Op] Remove reverse attribute from reshape and
reverse_reshape operators. (#7086)
c6b766a is described below
commit c6b766a4cea4e59384c2606deecdc5321ac3d41c
Author: Josh Fromm
AuthorDate: Wed Dec 30 17:29:06 2020 -0800
[Relay][Op] Remove reverse attribute from reshape and reverse_reshape
operators. (#7086)
---
include/tvm/relay/attrs/transform.h| 4 --
src/relay/op/dyn/tensor/transform.cc | 1 -
src/relay/op/tensor/transform.cc | 76 +-
src/relay/op/tensor/transform.h| 2 +-
.../contrib/test_arm_compute_lib/test_reshape.py | 1 -
5 files changed, 59 insertions(+), 25 deletions(-)
diff --git a/include/tvm/relay/attrs/transform.h
b/include/tvm/relay/attrs/transform.h
index cbe989f..efa44e0 100644
--- a/include/tvm/relay/attrs/transform.h
+++ b/include/tvm/relay/attrs/transform.h
@@ -83,13 +83,9 @@ struct TransposeAttrs : public
tvm::AttrsNode {
/*! \brief Attributes used in reshape operators */
struct ReshapeAttrs : public tvm::AttrsNode {
Array newshape;
- bool reverse;
TVM_DECLARE_ATTRS(ReshapeAttrs, "relay.attrs.ReshapeAttrs") {
TVM_ATTR_FIELD(newshape).describe(
"The new shape. Should be compatible with the original shape.");
-TVM_ATTR_FIELD(reverse)
-.describe("Infer the special values from right to left if true")
-.set_default(false);
}
}; // struct ReshapeAttrs
diff --git a/src/relay/op/dyn/tensor/transform.cc
b/src/relay/op/dyn/tensor/transform.cc
index 815f24b..e4e81e3 100644
--- a/src/relay/op/dyn/tensor/transform.cc
+++ b/src/relay/op/dyn/tensor/transform.cc
@@ -90,7 +90,6 @@ Array ReshapeCompute(const Attrs& attrs, const
Array& in
Expr MakeReshape(Expr data, Expr newshape) {
auto attrs = make_object();
- attrs->reverse = false;
static const Op& op = Op::Get("dyn.reshape");
return Call(op, {data, newshape}, Attrs(attrs), {});
}
diff --git a/src/relay/op/tensor/transform.cc b/src/relay/op/tensor/transform.cc
index 6819ea9..19ca612 100644
--- a/src/relay/op/tensor/transform.cc
+++ b/src/relay/op/tensor/transform.cc
@@ -455,13 +455,14 @@ RELAY_REGISTER_OP("transpose")
TVM_REGISTER_NODE_TYPE(ReshapeAttrs);
TVM_REGISTER_NODE_TYPE(ReshapeLikeAttrs);
-Array infer_newshape(const Array& data_shape, const
Attrs& attrs) {
+Array InferNewShape(const Array& data_shape, const
Attrs& attrs,
+ bool reverse) {
const auto* param = attrs.as();
Array oshape;
Array ishape;
Array newshape;
- if (param->reverse) {
+ if (reverse) {
ishape.Assign(data_shape.rbegin(), data_shape.rend());
newshape.Assign(param->newshape.rbegin(), param->newshape.rend());
} else {
@@ -584,7 +585,6 @@ Array infer_newshape(const Array&
data_shape, const Attrs&
bool ReshapeRel(const Array& types, int num_inputs, const Attrs& attrs,
const TypeReporter& reporter) {
- const auto* param = attrs.as();
// types: [data, result]
ICHECK_EQ(types.size(), 2);
const auto* data = types[0].as();
@@ -594,16 +594,12 @@ bool ReshapeRel(const Array& types, int num_inputs,
const Attrs& attrs,
return false;
}
- const auto& oshape = infer_newshape(data->shape, attrs);
+ const auto& oshape = InferNewShape(data->shape, attrs, false);
// Verify that the sum of dimensions in the output shape is the sum of
// dimensions in the input shape
Array data_shape;
- if (param->reverse) {
-data_shape.Assign(data->shape.rbegin(), data->shape.rend());
- } else {
-data_shape = data->shape;
- }
+ data_shape = data->shape;
bool found_dynamic = false;
int64_t oshape_sum = 1;
@@ -633,12 +629,58 @@ bool ReshapeRel(const Array& types, int num_inputs,
const Attrs& attrs,
<< "Input tensor shape and reshaped shape are not compatible";
}
- if (param->reverse) {
-reporter->Assign(types[1],
- TensorType(Array(oshape.rbegin(),
oshape.rend()), data->dtype));
- } else {
-reporter->Assign(types[1], TensorType(oshape, data->dtype));
+ reporter->Assign(types[1], TensorType(oshape, data->dtype));
+ return true;
+}
+
+bool ReverseReshapeRel(const Array& types, int num_inputs, const Attrs&
attrs,
+ const TypeReporter& reporter) {
+ // types: [data, result]
+ ICHECK_EQ(types.size(), 2);
+ const auto* data = types[0].as();
+ if (data == nullptr) {
+ICHECK(types[0].as())
+<< "reshape: expect input type to be TensorType but get " << types[0];
+return false;
+ }
+
+ const auto& oshape = InferNewShape(data->shape, attrs, true);
+
+ // Verify that the sum of dimensions in the output shape is the sum of
+ // dimensions in the input shape
+ Array data_sha
[GitHub] [tvm] tqchen merged pull request #7086: [Relay][Op] Remove reverse attribute from reshape and reverse_reshape operators.
tqchen merged pull request #7086: URL: https://github.com/apache/tvm/pull/7086 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 commented on issue #7079: [CUDA] argmax in tvm.tir.scan operation
junrushao1994 commented on issue #7079: URL: https://github.com/apache/tvm/issues/7079#issuecomment-752810786 Thanks for your interests in TVM. Please create a thread at the discuss forum (https://discuss.tvm.apache.org/) and ask general usability issues. Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 closed issue #7079: [CUDA] argmax in tvm.tir.scan operation
junrushao1994 closed issue #7079: URL: https://github.com/apache/tvm/issues/7079 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 commented on issue #6990: Try gradient with relay.build() failed
junrushao1994 commented on issue #6990: URL: https://github.com/apache/tvm/issues/6990#issuecomment-752810735 Thanks for your interests in TVM. Please create a thread at the discuss forum (https://discuss.tvm.apache.org/) and ask general usability issues. Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 closed issue #6990: Try gradient with relay.build() failed
junrushao1994 closed issue #6990: URL: https://github.com/apache/tvm/issues/6990 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] Laurawly commented on a change in pull request #7146: [CUDA]batch_matmul tensorcore schedule
Laurawly commented on a change in pull request #7146: URL: https://github.com/apache/tvm/pull/7146#discussion_r550363118 ## File path: python/tvm/relay/op/strategy/cuda.py ## @@ -657,6 +657,23 @@ def batch_matmul_strategy_cuda(attrs, inputs, out_type, target): name="batch_matmul_cublas.cuda", plevel=15, ) +if target.kind.name == "cuda" and nvcc.have_tensorcore(tvm.gpu(0).compute_version): Review comment: Maybe it's better to use `nvcc.have_tensorcore(target=target)` here since `tvm.gpu(0)` might not exist? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] jwfromm commented on pull request #7086: [Relay][Op] Remove reverse attribute from reshape and reverse_reshape operators.
jwfromm commented on pull request #7086: URL: https://github.com/apache/tvm/pull/7086#issuecomment-752792218 @icemelon9, I made the change recommended by TQ. This should now be ready to merge. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 closed issue #7155: Potential bug for SearchSpace length
junrushao1994 closed issue #7155: URL: https://github.com/apache/tvm/issues/7155 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 commented on issue #7155: Potential bug for SearchSpace length
junrushao1994 commented on issue #7155: URL: https://github.com/apache/tvm/issues/7155#issuecomment-752770806 Closed via #7175 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 commented on issue #7176: OpNotImplemented: The following operators are not supported for frontend ONNX: Softplus
junrushao1994 commented on issue #7176: URL: https://github.com/apache/tvm/issues/7176#issuecomment-752770671 Thanks for your interests in TVM. Please create a thread at the discuss forum (https://discuss.tvm.apache.org/) since it is not a bug. Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 closed issue #7176: OpNotImplemented: The following operators are not supported for frontend ONNX: Softplus
junrushao1994 closed issue #7176: URL: https://github.com/apache/tvm/issues/7176 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 edited a comment on issue #7176: OpNotImplemented: The following operators are not supported for frontend ONNX: Softplus
junrushao1994 edited a comment on issue #7176: URL: https://github.com/apache/tvm/issues/7176#issuecomment-752254454 Looks like softplus is not implemented yet, so a PR is more than welcomed :-) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 commented on issue #7178: CPU core number setting
junrushao1994 commented on issue #7178: URL: https://github.com/apache/tvm/issues/7178#issuecomment-752770468 Thanks for your interests in TVM. Please create a thread at the discuss forum (https://discuss.tvm.apache.org/) and ask general usability issues. Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 closed issue #7178: CPU core number setting
junrushao1994 closed issue #7178: URL: https://github.com/apache/tvm/issues/7178 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 commented on issue #7179: [Auto Scheduler] Add custom build func support
junrushao1994 commented on issue #7179: URL: https://github.com/apache/tvm/issues/7179#issuecomment-752770377 Thanks for your interests in TVM. Please create a thread at the discuss forum (https://discuss.tvm.apache.org/) and ask general usability issues. Thanks! BTW, I agree with a custom build func is a good feature to have, and your contribution is definitely more than welcome. To workaround your issue temporarily, you might be interested in hacking those lines: https://github.com/apache/tvm/blob/main/python/tvm/auto_scheduler/measure.py#L627-L630 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 closed issue #7179: [Auto Scheduler] Add custom build func support
junrushao1994 closed issue #7179: URL: https://github.com/apache/tvm/issues/7179 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 commented on issue #7182: VTA test fail while running the 2D convolution testbench on Pynq
junrushao1994 commented on issue #7182: URL: https://github.com/apache/tvm/issues/7182#issuecomment-752769933 Thanks for your interests in TVM. Please create a thread at the discuss forum (https://discuss.tvm.apache.org/) and ask general usability issues. Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] junrushao1994 closed issue #7182: VTA test fail while running the 2D convolution testbench on Pynq
junrushao1994 closed issue #7182: URL: https://github.com/apache/tvm/issues/7182 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] codeislife99 opened a new issue #7183: test_arith_solve_linear_inequality.py fails due to non-deterministic test
codeislife99 opened a new issue #7183: URL: https://github.com/apache/tvm/issues/7183 tests/python/unittest/test_arith_solve_linear_inequality.py:73: fails with seed 3858162330384474861 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] codeislife99 commented on pull request #7126: Sparse fill empty rows op
codeislife99 commented on pull request #7126: URL: https://github.com/apache/tvm/pull/7126#issuecomment-752721781 @tkonolige @mbrookhart This PR is ready for re-review as well whenever you are back from vacation. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] codeislife99 commented on a change in pull request #7126: Sparse fill empty rows op
codeislife99 commented on a change in pull request #7126:
URL: https://github.com/apache/tvm/pull/7126#discussion_r550291956
##
File path: src/relay/op/tensor/transform.cc
##
@@ -1553,6 +1553,65 @@ RELAY_REGISTER_OP("meshgrid")
.set_attr("FTVMCompute", MeshgridCompute)
.set_attr("TOpPattern", kInjective);
+TVM_REGISTER_NODE_TYPE(SparseFillEmptyRowsAttrs);
+
+bool SparseFillEmptyRowsRel(const Array& types, int num_inputs, const
Attrs& attrs,
+const TypeReporter& reporter) {
+ // types: [ sparse_indices, sparse_values, default_values, result]
+ ICHECK_EQ(types.size(), 4) << "SparseFillEmptyRowsRel expects 4 arguments
but provided "
+ << types.size();
+ std::vector fields;
+ auto sparse_indices = types[0].as();
+ auto default_value = types[2].as();
+ const auto* param = attrs.as();
+ ICHECK(param != nullptr);
+
+ Array sp_ordered_output_shape;
+ sp_ordered_output_shape.push_back(param->dense_shape[0] +
sparse_indices->shape[0]);
+ if (sparse_indices->shape.size() > 1) {
+sp_ordered_output_shape.push_back(sparse_indices->shape[1]);
+ }
+ fields.push_back(TensorType(sp_ordered_output_shape, sparse_indices->dtype));
+ fields.push_back(TensorType(Array{param->dense_shape[0]},
tvm::DataType::Bool()));
+ fields.push_back(TensorType(Array{sp_ordered_output_shape[0]},
default_value->dtype));
+ fields.push_back(TensorType(Array{1}, tvm::DataType::Int(32)));
+ reporter->Assign(types[3], TupleType(Array(fields)));
+ return true;
+}
+
+Array SparseFillEmptyRowsCompute(const Attrs& attrs, const
Array& inputs,
+ const Type& out_type) {
+ ICHECK_EQ(inputs.size(), 3) << "SparseFillEmptyRowsCompute expects 3
arguments but provided "
+ << inputs.size();
+ const auto* param = attrs.as();
+ ICHECK(param != nullptr);
+ return {topi::SparseFillEmptyRows(inputs[0], inputs[1], inputs[2],
param->dense_shape)};
+}
+
+Expr MakeSparseFillEmptyRows(Expr sparse_indices, Expr sparse_values, Expr
default_value,
+ Array dense_shape) {
+ auto attrs = make_object();
+ attrs->dense_shape = std::move(dense_shape);
+ static const Op& op = Op::Get("sparse_fill_empty_rows");
+ return Call(op, {sparse_indices, sparse_values, default_value},
Attrs(attrs), {});
+}
+
+TVM_REGISTER_GLOBAL("relay.op._make.sparse_fill_empty_rows")
+.set_body_typed(MakeSparseFillEmptyRows);
+
+RELAY_REGISTER_OP("sparse_fill_empty_rows")
+.describe(R"code(Return representation of a sparse tensor with empty rows
filled with default
+value.)code" TVM_ADD_FILELINE)
+.set_num_inputs(3)
+.set_attrs_type()
+.add_argument("sparse_indices", "Tensor", "The first tensor")
Review comment:
Done.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] codeislife99 commented on a change in pull request #7126: Sparse fill empty rows op
codeislife99 commented on a change in pull request #7126: URL: https://github.com/apache/tvm/pull/7126#discussion_r550279440 ## File path: python/tvm/relay/op/transform.py ## @@ -1320,3 +1320,83 @@ def adv_index(inputs): Output tensor. """ return _make.adv_index(Tuple(inputs)) + + +def sparse_fill_empty_rows(sparse_indices, sparse_values, dense_shape, default_value): +""" +Fill first column of the empty rows with default values for a sparse array. +It returns a TupleWrapper with four outputs + +Parameters +-- +sparse_indices : relay.Expr +A 2-D tensor[N, n_dim] of integers containing location of sparse values, where N is the +number of sparse values and n_dim is the number of dimensions of the dense_shape + +sparse_values : relay.Expr +A 1-D tensor[N] containing the sparse values for the sparse indices. + +dense_shape : relay.Expr +A list of integers. Shape of the dense output tensor. + +default_value : relay.Expr +A 0-D tensor containing the default value for the remaining locations. +Defaults to 0. + +Returns +--- +new_sparse_indices : relay.Expr +A 2-D tensor[N + dense_shape[0], n_dim] of integers containing location of new sparse +indices where N is the number of sparse values. It is filled with -1 at irrelevant indices +which will be sliced in a future op discarding non-useful elements. This is done since the +real rows of new_sparse_indices depends on the input. + +empty_row_indicator : relay.Expr +A 1-D Boolean tensor[dense_shape[0]] indicating whether the particular row is empty + +new_sparse_values : relay.Expr +A 1-D tensor[dense_shape[0]] containing the sparse values for the sparse indices. It is +filled with -1 at to_be_discarded indices Review comment: Done. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] juannzou commented on pull request #6012: [VTA] Move compiler related registry items to vta/build_module.py
juannzou commented on pull request #6012: URL: https://github.com/apache/tvm/pull/6012#issuecomment-752647032 Hi @lhf1997 I had the same issue. Have you tried with [Pynq bitstream 0.0.2](https://github.com/uwsampl/vta-distro/tree/master/bitstreams/pynq/0.0.2)? It worked for me! But then I got another error. I have opened new issue #7182 on that. Hope this helps. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] juannzou opened a new issue #7182: VTA test fail while running the 2D convolution testbench on Pynq
juannzou opened a new issue #7182: URL: https://github.com/apache/tvm/issues/7182 I am getting an error while following [Testing Pynq-based Hardware Setup](https://tvm.apache.org/docs/vta/install.html#testing-your-pynq-based-hardware-setup). First I used [Pynq 0.0.1 bitstream](https://github.com/uwsampl/vta-distro/tree/master/bitstreams/pynq/0.0.1), and ran the following on host/PC, while RPC server is running on the Pynq board: > python3 /vta/tests/python/integration/test_benchmark_topi_conv2d.py Which resulted in RecursionError. See @lhf1997 comment under: https://github.com/apache/tvm/pull/6012#issuecomment-656022147. See also: https://discuss.tvm.apache.org/t/vta-recursion-error/7271. Then I tried with [Pynq 0.0.2 bitstream](https://github.com/uwsampl/vta-distro/tree/master/bitstreams/pynq/0.0.2), and got the following output: VTA CONV2D TEST FAILED, as shown in the picture below (the one on the right is the host/PC output and the one on the left is the board output): 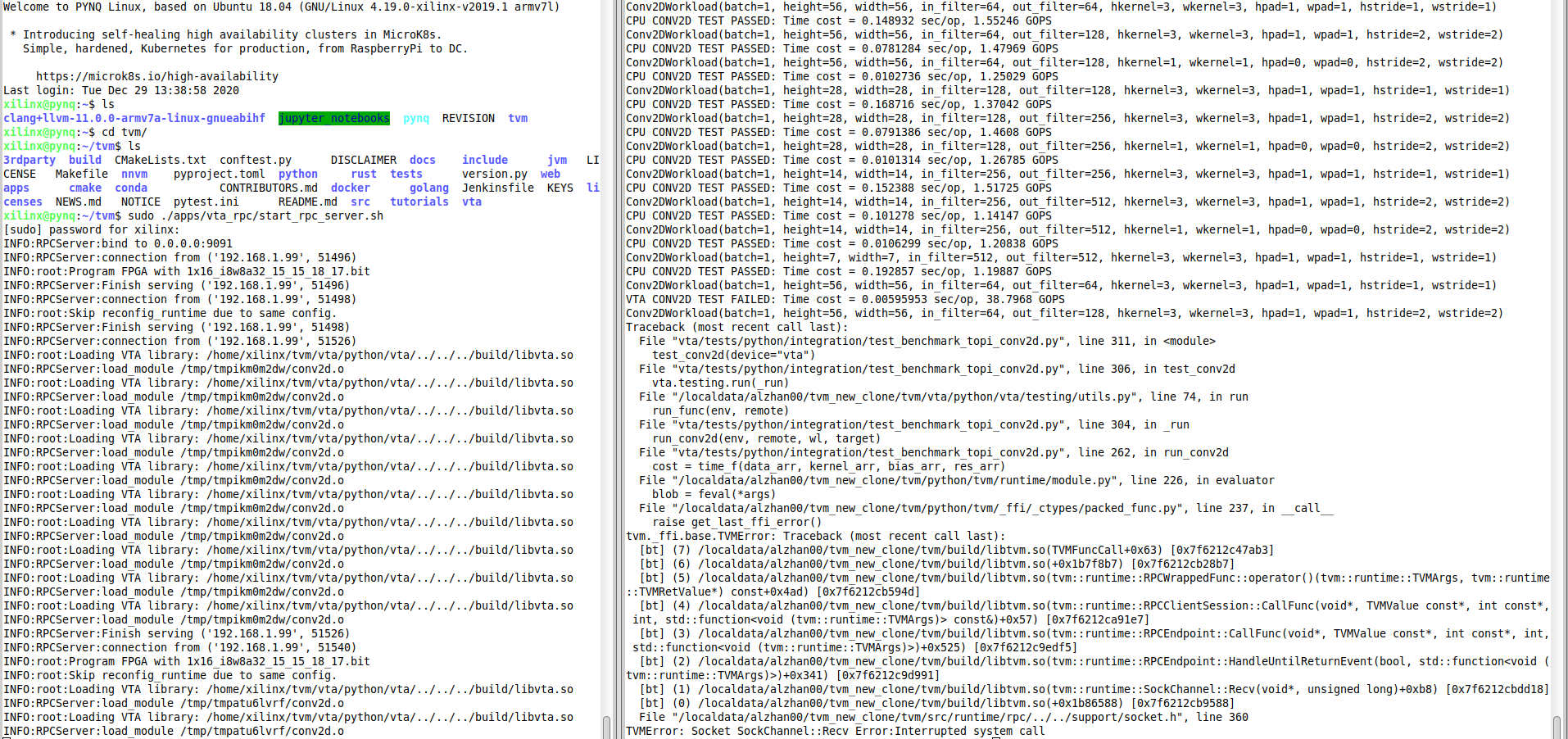 I tried to run again and got some other error, as shown in the picture below: 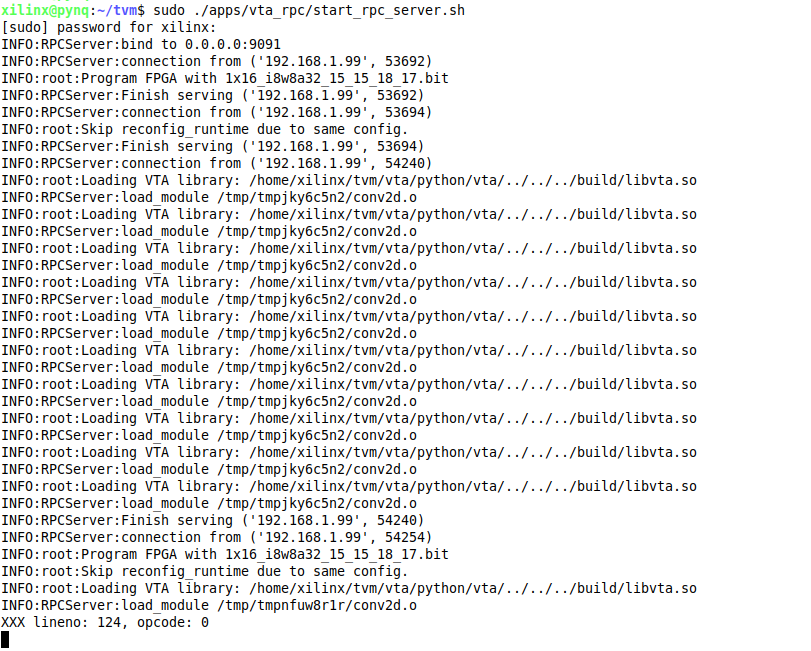 The error in both cases seems to be related to loading VTA library libvta.so and conv2d.o! Any idea? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] FrozenGene commented on pull request #7181: [Auto Scheduler][fix] Add dense strategy for mali
FrozenGene commented on pull request #7181: URL: https://github.com/apache/tvm/pull/7181#issuecomment-752526322 It is merged now, thanks @leowang1225 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated: [Auto Scheduler][fix] Add dense strategy for mali (#7181)
This is an automated email from the ASF dual-hosted git repository. zhaowu pushed a commit to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git The following commit(s) were added to refs/heads/main by this push: new 712b4a5 [Auto Scheduler][fix] Add dense strategy for mali (#7181) 712b4a5 is described below commit 712b4a553fb417b743407be9194c0c4a545978d9 Author: leowang1225 <810916...@qq.com> AuthorDate: Wed Dec 30 20:32:43 2020 +0800 [Auto Scheduler][fix] Add dense strategy for mali (#7181) Signed-off-by: leowang1225 <810916...@qq.com> --- python/tvm/relay/op/strategy/mali.py | 17 - 1 file changed, 12 insertions(+), 5 deletions(-) diff --git a/python/tvm/relay/op/strategy/mali.py b/python/tvm/relay/op/strategy/mali.py index c4cb4a1..fc47bd6 100644 --- a/python/tvm/relay/op/strategy/mali.py +++ b/python/tvm/relay/op/strategy/mali.py @@ -171,9 +171,16 @@ def conv2d_winograd_without_weight_transfrom_strategy_mali(attrs, inputs, out_ty def dense_strategy_mali(attrs, inputs, out_type, target): """dense mali strategy""" strategy = _op.OpStrategy() -strategy.add_implementation( -wrap_compute_dense(topi.mali.dense), -wrap_topi_schedule(topi.mali.schedule_dense), -name="dense.mali", -) +if not is_auto_scheduler_enabled(): +strategy.add_implementation( +wrap_compute_dense(topi.mali.dense), +wrap_topi_schedule(topi.mali.schedule_dense), +name="dense.mali", +) +else: +strategy.add_implementation( +wrap_compute_dense(topi.nn.dense, need_auto_scheduler_layout=True), +naive_schedule, +name="dense.mali", +) return strategy
[GitHub] [tvm] FrozenGene merged pull request #7181: [Auto Scheduler][fix] Add dense strategy for mali
FrozenGene merged pull request #7181: URL: https://github.com/apache/tvm/pull/7181 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] merrymercy merged pull request #7180: [AutoScheduler] Fix for zero-rank output
merrymercy merged pull request #7180: URL: https://github.com/apache/tvm/pull/7180 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated: [AutoScheduler] Fix policy for zero-rank output (#7180)
This is an automated email from the ASF dual-hosted git repository.
lmzheng pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/tvm.git
The following commit(s) were added to refs/heads/main by this push:
new f904d4f [AutoScheduler] Fix policy for zero-rank output (#7180)
f904d4f is described below
commit f904d4fe95b16044a8d46edeea0b7b7792e0ef3c
Author: Lianmin Zheng
AuthorDate: Wed Dec 30 04:18:41 2020 -0800
[AutoScheduler] Fix policy for zero-rank output (#7180)
---
src/auto_scheduler/search_policy/sketch_policy.cc | 15 ++--
src/auto_scheduler/search_policy/sketch_policy.h | 7 ++
src/auto_scheduler/search_policy/utils.h | 7 +-
src/auto_scheduler/transform_step.cc | 35 ++---
.../python/unittest/test_auto_scheduler_common.py | 17 +
.../unittest/test_auto_scheduler_search_policy.py | 83 --
.../test_auto_scheduler_sketch_generation.py | 16 +
7 files changed, 136 insertions(+), 44 deletions(-)
diff --git a/src/auto_scheduler/search_policy/sketch_policy.cc
b/src/auto_scheduler/search_policy/sketch_policy.cc
index e267837..1e20b0f 100644
--- a/src/auto_scheduler/search_policy/sketch_policy.cc
+++ b/src/auto_scheduler/search_policy/sketch_policy.cc
@@ -78,6 +78,8 @@ SketchPolicy::SketchPolicy(SearchTask task, CostModel
program_cost_model,
node->rand_gen = std::mt19937(seed);
node->params = std::move(params);
node->verbose = verbose;
+ node->sample_init_min_pop_ =
+ GetIntParam(node->params,
SketchParamKey::SampleInitPopulation::min_population);
if (init_search_callbacks) {
PrintTitle("Call init-search callbacks", verbose);
@@ -382,8 +384,6 @@ Array SketchPolicyNode::GenerateSketches() {
Array SketchPolicyNode::SampleInitPopulation(const Array&
sketches) {
// Use this population as the parallel degree to do sampling
int population = GetIntParam(params,
SketchParamKey::EvolutionarySearch::population);
- // At least we should sample this number of valid programs
- int min_population = GetIntParam(params,
SketchParamKey::SampleInitPopulation::min_population);
auto tic_begin = std::chrono::high_resolution_clock::now();
@@ -397,9 +397,8 @@ Array SketchPolicyNode::SampleInitPopulation(const
Array& sketches
std::unordered_set explored_state_strs;
size_t iter = 1;
- size_t target_size = min_population;
size_t unchange_cnt = 0;
- while (out_states.size() < target_size) {
+ while (static_cast(out_states.size()) < sample_init_min_pop_) {
std::vector temp_states(population);
// Sample a batch of states randomly
@@ -458,7 +457,7 @@ Array SketchPolicyNode::SampleInitPopulation(const
Array& sketches
std::chrono::high_resolution_clock::now() -
tic_begin)
.count();
StdCout(verbose) << "Sample Iter: " << iter << std::fixed <<
std::setprecision(4)
- << "\t#Pop: " << out_states.size() << "\t#Target: " <<
target_size
+ << "\t#Pop: " << out_states.size() << "\t#Target: " <<
sample_init_min_pop_
<< "\tfail_ct: " << fail_ct << "\tTime elapsed: " <<
std::fixed
<< std::setprecision(2) << duration << std::endl;
}
@@ -466,9 +465,9 @@ Array SketchPolicyNode::SampleInitPopulation(const
Array& sketches
if (unchange_cnt == 5) {
// Reduce the target size to avoid too-long time in this phase if no
valid state was found
// in the past iterations
- if (target_size > 1) {
-target_size /= 2;
-StdCout(verbose) << "#Target has been reduced to " << target_size
+ if (sample_init_min_pop_ > 1) {
+sample_init_min_pop_ /= 2;
+StdCout(verbose) << "#Target has been reduced to " <<
sample_init_min_pop_
<< " due to too many failures or duplications" <<
std::endl;
}
unchange_cnt = 0;
diff --git a/src/auto_scheduler/search_policy/sketch_policy.h
b/src/auto_scheduler/search_policy/sketch_policy.h
index 3d135d1..4886349 100644
--- a/src/auto_scheduler/search_policy/sketch_policy.h
+++ b/src/auto_scheduler/search_policy/sketch_policy.h
@@ -87,6 +87,8 @@ struct SketchParamKey {
static constexpr const char* disable_change_compute_location =
"disable_change_compute_location";
};
+class SketchPolicy;
+
/*!
* \brief The search policy that searches in a hierarchical search space
defined by sketches.
* The policy randomly samples programs from the space defined by sketches
@@ -166,6 +168,11 @@ class SketchPolicyNode : public SearchPolicyNode {
/*! \brief The cached sketches */
Array sketch_cache_;
+
+ /*! \brief The minimul output population of SampleInitPopulation */
+ int sample_init_min_pop_;
+
+ friend class SketchPolicy;
};
/*!
diff --git a/src/auto_scheduler/search_policy/utils.h
b/src/auto_scheduler/search_policy/utils.h
index d59a6ca..eb2cd69 100644
--- a/src/auto_scheduler/s
[GitHub] [tvm] codeislife99 commented on a change in pull request #7126: Sparse fill empty rows op
codeislife99 commented on a change in pull request #7126: URL: https://github.com/apache/tvm/pull/7126#discussion_r550161068 ## File path: python/tvm/relay/op/transform.py ## @@ -1320,3 +1320,84 @@ def adv_index(inputs): Output tensor. """ return _make.adv_index(Tuple(inputs)) + + +def sparsefillemptyrows(sparse_indices, sparse_values, dense_shape, default_value): +""" +Fill first column of the empty rows with default values for a sparse array. + +Parameters +-- +sparse_indices : relay.Expr +A 2-D tensor[N, n_dim] of integers containing location of sparse values, where N is the +number of sparse values and n_dim is the number of dimensions of the dense_shape + +sparse_values : relay.Expr +A 1-D tensor[N] containing the sparse values for the sparse indices. + +dense_shape : relay.Expr +A list of integers. Shape of the dense output tensor. + +default_value : relay.Expr +A 0-D tensor containing the default value for the remaining locations. +Defaults to 0. + +Returns +--- +TupleWrapper with the following four outputs + +new_sparse_indices : relay.Expr +A 2-D tensor[N + dense_shape[0], n_dim] of integers containing location of new sparse +indices where N is the number of sparse values. It is filled with -1 at to_be_discarded +indices. + +empty_row_indicator : relay.Expr +A 1-D Boolean tensor[dense_shape[0]] indicating whether the particular row is empty + +new_sparse_values : relay.Expr +A 1-D tensor[dense_shape[0]] containing the sparse values for the sparse indices. It is +filled with -1 at to_be_discarded indices. + +slice_element_index : relay.Expr +A 1-D tensor containing the amount of elements in the sparse_indices and new_sparse_values +expression to be sliced in a future op discarding non-useful elements in new_sparse_indices +and new_sparse_values + +Examples +--- + +.. code-block:: python + +sparse_indices = [[0, 1], + [0, 3], + [2, 0], + [3, 1]] +sparse_values = [1, 2, 3, 4] +default_value = [10] +dense_shape = [5, 6] +new_sparse_indices, empty_row_indicator, new_sparse_values, slice_element_index = +relay.sparsereshape( +sparse_indices, +sparse_values, +prev_shape, +new_shape) +new_sparse_indices = [[0, 1], + [0, 3], + [2, 0], + [3, 1], + [1, 0], + [4, 0], + [-1, -1], Review comment: Resolving this conversation since based on our offline discussion, we will start off with static shape This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] codeislife99 commented on pull request #7125: Sparse reshape op
codeislife99 commented on pull request #7125: URL: https://github.com/apache/tvm/pull/7125#issuecomment-752427169 Thats understandable ofcourse, I can wait for the full review. In the meantime I will create a branch with all the three Ops and E2E testing. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated (66e123f -> 6a4c51e)
This is an automated email from the ASF dual-hosted git repository. masahi pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from 66e123f [TOPI] Parallelize GPU NMS inner loop (#7172) add 6a4c51e [AutoScheduler] Use VM to extract tasks for dynamic models (#7173) No new revisions were added by this update. Summary of changes: python/tvm/auto_scheduler/relay_integration.py | 58 python/tvm/auto_scheduler/utils.py | 13 +++- src/auto_scheduler/compute_dag.cc | 2 +- src/relay/backend/compile_engine.cc| 3 +- .../relay/test_auto_scheduler_task_extraction.py | 80 +- 5 files changed, 103 insertions(+), 53 deletions(-)
[GitHub] [tvm] masahi commented on pull request #7173: [AutoScheduler] Use VM to extract tasks for dynamic models
masahi commented on pull request #7173: URL: https://github.com/apache/tvm/pull/7173#issuecomment-752417084 thanks @comaniac @jcf94 @merrymercy This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi merged pull request #7173: [AutoScheduler] Use VM to extract tasks for dynamic models
masahi merged pull request #7173: URL: https://github.com/apache/tvm/pull/7173 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi merged pull request #7172: [TOPI] Parallelize GPU NMS inner loop
masahi merged pull request #7172: URL: https://github.com/apache/tvm/pull/7172 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi commented on pull request #7172: [TOPI] Parallelize GPU NMS inner loop
masahi commented on pull request #7172: URL: https://github.com/apache/tvm/pull/7172#issuecomment-752381473 thanks @Laurawly This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated: [TOPI] Parallelize GPU NMS inner loop (#7172)
This is an automated email from the ASF dual-hosted git repository.
masahi pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/tvm.git
The following commit(s) were added to refs/heads/main by this push:
new 66e123f [TOPI] Parallelize GPU NMS inner loop (#7172)
66e123f is described below
commit 66e123ff7ce4f5524b3f51ccd95bd4010b7af2c6
Author: masahi
AuthorDate: Wed Dec 30 18:00:22 2020 +0900
[TOPI] Parallelize GPU NMS inner loop (#7172)
* make NMS inner loop parallel
* use one block two avoid global sync issue
* temp disable write by only thread 0
* leave a TODO on write by only one thread
* add some comments, remove check the check on negative class id
* minor improvement when topk is available
* fix write by a single thread
---
python/tvm/topi/cuda/nms.py | 50 +
1 file changed, 32 insertions(+), 18 deletions(-)
diff --git a/python/tvm/topi/cuda/nms.py b/python/tvm/topi/cuda/nms.py
index 020cf9b..dd9d3f8 100644
--- a/python/tvm/topi/cuda/nms.py
+++ b/python/tvm/topi/cuda/nms.py
@@ -512,26 +512,44 @@ def nms_ir(
with ib.new_scope():
nthread_by = batch_size
+nthread_tx = max_threads
+
by = te.thread_axis("blockIdx.y")
+tx = te.thread_axis("threadIdx.x")
ib.scope_attr(by, "thread_extent", nthread_by)
+ib.scope_attr(tx, "thread_extent", nthread_tx)
+
i = by
+
base_idx = i * num_anchors * box_data_length
num_valid_boxes_local = ib.allocate(
"int32", (1,), name="num_valid_boxes_local", scope="local"
)
num_valid_boxes_local[0] = 0
+nkeep = if_then_else(tvm.tir.all(top_k > 0, top_k < valid_count[i]),
top_k, valid_count[i])
def nms_inner_loop(ib, j):
+# The box j is valid, invalidate other boxes that overlap with j
above iou_threshold
+
+# When return_indices is False, no need to populate box_indices
+if return_indices:
+with ib.if_scope(tx + 0 == 0):
+orig_idx = sorted_index[i * num_anchors + j]
+box_indices[i, num_valid_boxes_local[0]] = indices[i,
orig_idx]
+
+num_valid_boxes_local[0] += 1
+
offset_j = j * box_data_length
+num_iter_per_thread = ceil_div(nkeep - (j + 1), nthread_tx)
-with ib.for_range(0, j) as k:
+with ib.for_range(0, num_iter_per_thread) as _k:
+k = j + 1 + _k * nthread_tx + tx
offset_k = k * box_data_length
with ib.if_scope(
tvm.tir.all(
-out[base_idx + offset_j + score_index] > -1.0, # if
already surpressed
-out[base_idx + offset_k + score_index] > 0,
-tvm.tir.any(id_index < 0, out[base_idx + offset_k +
id_index] >= 0),
+k < nkeep,
+out[base_idx + offset_k + score_index] > 0, # is the
box k still valid?
tvm.tir.any(
force_suppress > 0,
id_index < 0,
@@ -546,27 +564,22 @@ def nms_ir(
base_idx + offset_k + coord_start,
)
with ib.if_scope(iou >= iou_threshold):
-out[base_idx + offset_j + score_index] = -1.0
+# invalidate the box k
+out[base_idx + offset_k + score_index] = -1.0
with ib.if_scope(id_index >= 0):
-out[base_idx + offset_j + id_index] = -1.0
+out[base_idx + offset_k + id_index] = -1.0
-# Has the box j survived IOU tests?
-with ib.if_scope(out[base_idx + offset_j + score_index] > -1.0):
-# When return_indices is False, no need to populate box_indices
-if return_indices:
-orig_idx = sorted_index[i * num_anchors + j]
-box_indices[i, num_valid_boxes_local[0]] = indices[i,
orig_idx]
-num_valid_boxes_local[0] += 1
+# Make sure to do the next loop in a lock step
+ib.emit(tvm.tir.Call(None, "tir.tvm_storage_sync",
tvm.runtime.convert(["shared"])))
if isinstance(max_output_size, int):
max_output_size = tvm.tir.const(max_output_size)
with ib.if_scope(tvm.tir.all(iou_threshold > 0, valid_count[i] > 0)):
# Apply nms
-with ib.for_range(0, valid_count[i]) as j:
-with ib.if_scope(
-tvm.tir.any(id_index < 0, out[base_idx + j *
box_data_length + id_index] >= 0)
-):
+with ib.for_range(0, nkeep) as j:
+# Proceed to the inner loop if the box j is still valid
+with ib.if_scope
[GitHub] [tvm] leowang1225 commented on pull request #7181: [Auto Scheduler][fix] Add dense strategy for mali
leowang1225 commented on pull request #7181: URL: https://github.com/apache/tvm/pull/7181#issuecomment-752374930 > Signed-off-by: leowang1225 [810916...@qq.com](mailto:810916...@qq.com) > > Thanks for contributing to TVM! Please refer to guideline https://tvm.apache.org/docs/contribute/ for useful information and tips. After the pull request is submitted, please request code reviews from [Reviewers](https://github.com/apache/incubator-tvm/blob/master/CONTRIBUTORS.md#reviewers) by @ them in the pull request thread. @FrozenGene please help to check This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leowang1225 opened a new pull request #7181: [Auto Scheduler][fix] Add dense strategy for mali
leowang1225 opened a new pull request #7181: URL: https://github.com/apache/tvm/pull/7181 Signed-off-by: leowang1225 <810916...@qq.com> Thanks for contributing to TVM! Please refer to guideline https://tvm.apache.org/docs/contribute/ for useful information and tips. After the pull request is submitted, please request code reviews from [Reviewers](https://github.com/apache/incubator-tvm/blob/master/CONTRIBUTORS.md#reviewers) by @ them in the pull request thread. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org