[tvm] branch main updated (9396a66 -> 0d38a92)
This is an automated email from the ASF dual-hosted git repository. masahi pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from 9396a66 [Vulkan][Codegen] Added spvValidate check after vulkan shader generation (#8098) add 0d38a92 [Relay, ONNX] Support gather_nd batch_dims attribute for TF/ONNX (#8084) No new revisions were added by this update. Summary of changes: include/tvm/relay/attrs/transform.h| 7 include/tvm/topi/transform.h | 10 -- python/tvm/relay/frontend/onnx.py | 15 ++-- python/tvm/relay/op/transform.py | 11 -- src/relay/op/tensor/transform.cc | 38 - tests/python/frontend/onnx/test_forward.py | 25 -- tests/python/relay/test_op_level3.py | 55 -- 7 files changed, 140 insertions(+), 21 deletions(-)
[GitHub] [tvm] masahi edited a comment on pull request #8084: [Relay, ONNX] Support gather_nd batch_dims attribute for TF/ONNX
masahi edited a comment on pull request #8084: URL: https://github.com/apache/tvm/pull/8084#issuecomment-845650904 thanks @mbrookhart @comaniac @tkonolige -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi commented on pull request #8084: [Relay, ONNX] Support gather_nd batch_dims attribute for TF/ONNX
masahi commented on pull request #8084: URL: https://github.com/apache/tvm/pull/8084#issuecomment-845650904 @mbrookhart @comaniac @tkonolige -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi merged pull request #8084: [Relay, ONNX] Support gather_nd batch_dims attribute for TF/ONNX
masahi merged pull request #8084: URL: https://github.com/apache/tvm/pull/8084 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated (e438a73 -> 9396a66)
This is an automated email from the ASF dual-hosted git repository. masahi pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from e438a73 [Relay][PRNG] Add uniform distribution generator wrt threefry PRNG (#8041) add 9396a66 [Vulkan][Codegen] Added spvValidate check after vulkan shader generation (#8098) No new revisions were added by this update. Summary of changes: src/target/spirv/build_vulkan.cc | 20 +--- 1 file changed, 17 insertions(+), 3 deletions(-)
[GitHub] [tvm] masahi merged pull request #8098: [Vulkan][Codegen] Added spvValidate check after vulkan shader generation
masahi merged pull request #8098: URL: https://github.com/apache/tvm/pull/8098 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi commented on pull request #8098: [Vulkan][Codegen] Added spvValidate check after vulkan shader generation
masahi commented on pull request #8098: URL: https://github.com/apache/tvm/pull/8098#issuecomment-845650817 Thanks @Lunderberg -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] lmxyy opened a new pull request #8101: Fix some typos
lmxyy opened a new pull request #8101: URL: https://github.com/apache/tvm/pull/8101 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] beautyGril100 opened a new issue #8100: [device] set tvm.cpu(1), error occurred when run
beautyGril100 opened a new issue #8100: URL: https://github.com/apache/tvm/issues/8100 I have two physical CPUs. Each CPU has 32 cores. When I set tvm.cpu (0), the program can run normally. When I set tvm.cpu (1), the program will run with an error. Why? The error is as follows: 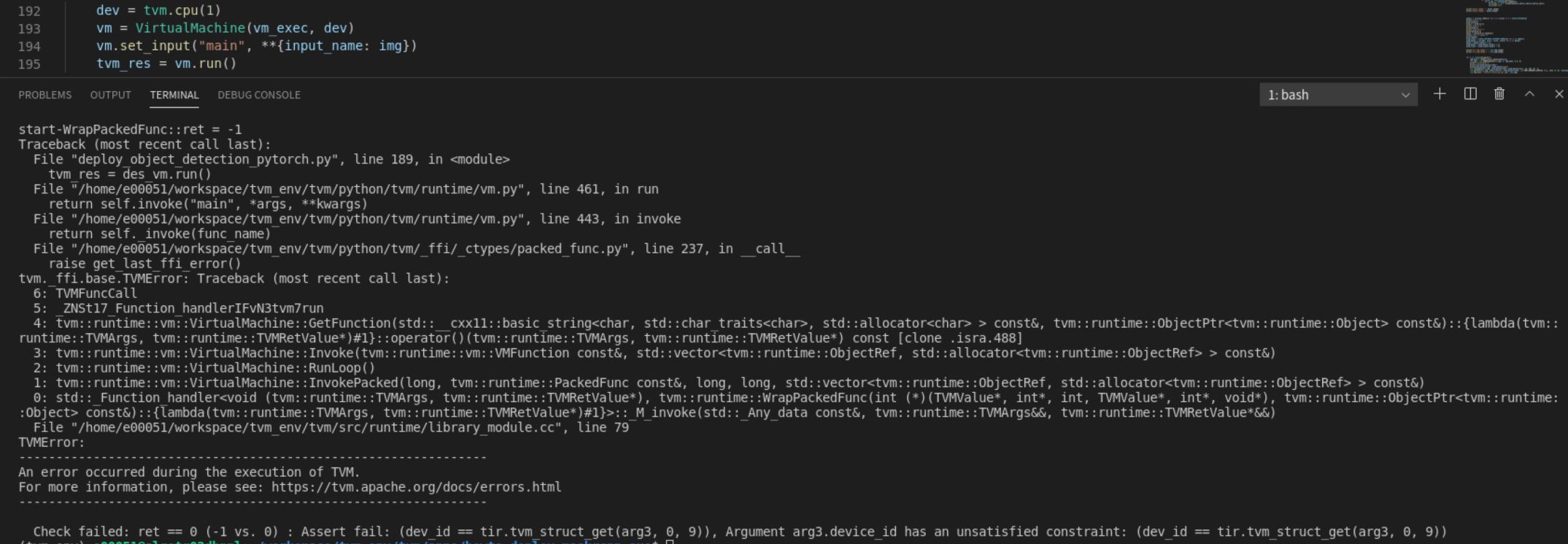 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] FrozenGene commented on pull request #8041: [Relay][PRNG] Add uniform distribution generator wrt threefry PRNG
FrozenGene commented on pull request #8041: URL: https://github.com/apache/tvm/pull/8041#issuecomment-845621917 Thanks @zhuzilin @altanh @tkonolige merged now -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated (aba2806 -> e438a73)
This is an automated email from the ASF dual-hosted git repository. zhaowu pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from aba2806 [CI][Docker] set environment variables for UTF-8, to prevent errors when running `black` (#8089) add e438a73 [Relay][PRNG] Add uniform distribution generator wrt threefry PRNG (#8041) No new revisions were added by this update. Summary of changes: include/tvm/relay/attrs/random.h | 12 ++ python/tvm/relay/op/op_attrs.py| 5 +++ python/tvm/relay/op/random/_kernel.py | 4 ++ python/tvm/relay/op/random/kernel.py | 54 +++- python/tvm/relay/op/strategy/generic.py| 22 ++ python/tvm/topi/random/kernel.py | 66 ++ src/relay/op/random/kernel.cc | 47 + tests/python/relay/test_prng.py| 15 +++ tests/python/topi/python/test_topi_prng.py | 34 +++ 9 files changed, 258 insertions(+), 1 deletion(-)
[GitHub] [tvm] FrozenGene merged pull request #8041: [Relay][PRNG] Add uniform distribution generator wrt threefry PRNG
FrozenGene merged pull request #8041: URL: https://github.com/apache/tvm/pull/8041 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] gromero commented on pull request #8086: [TVMC] Add support for the MLF to 'compile' command
gromero commented on pull request #8086: URL: https://github.com/apache/tvm/pull/8086#issuecomment-845617096 @leandron @areusch Thanks a lot for the reviews. @leandron I'm addressing the test case and I'll push it soon, thanks for pointing it out. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] gromero commented on a change in pull request #8086: [TVMC] Add support for the MLF to 'compile' command
gromero commented on a change in pull request #8086:
URL: https://github.com/apache/tvm/pull/8086#discussion_r636602209
##
File path: python/tvm/driver/tvmc/compiler.py
##
@@ -40,35 +40,42 @@
def add_compile_parser(subparsers):
""" Include parser for 'compile' subcommand """
-parser = subparsers.add_parser("compile", help="compile a model")
+parser = subparsers.add_parser("compile", help="compile a model.")
parser.set_defaults(func=drive_compile)
parser.add_argument(
"--cross-compiler",
default="",
-help="the cross compiler to generate target libraries, e.g.
'aarch64-linux-gnu-gcc'",
+help="the cross compiler to generate target libraries, e.g.
'aarch64-linux-gnu-gcc'.",
)
parser.add_argument(
"--desired-layout",
choices=["NCHW", "NHWC"],
default=None,
-help="change the data layout of the whole graph",
+help="change the data layout of the whole graph.",
)
parser.add_argument(
"--dump-code",
metavar="FORMAT",
default="",
-help="comma separarated list of formats to export, e.g. 'asm,ll,relay'
",
+help="comma separated list of possible formats to export the input
model, e.g. 'asm,ll,relay'.",
)
parser.add_argument(
"--model-format",
choices=frontends.get_frontend_names(),
-help="specify input model format",
+help="specify input model format.",
+)
+parser.add_argument(
+"-f",
+"--output-format",
+choices=["so", "mlf"],
+default="so",
+help="output format. Use 'so' for shared object or 'mlf' for Model
Library Format (only for µTVM targets).",
Review comment:
Done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] gromero commented on a change in pull request #8086: [TVMC] Add support for the MLF to 'compile' command
gromero commented on a change in pull request #8086:
URL: https://github.com/apache/tvm/pull/8086#discussion_r636601965
##
File path: python/tvm/driver/tvmc/model.py
##
@@ -53,6 +53,7 @@
from tvm import relay
from tvm.contrib import utils
from tvm.relay.backend.executor_factory import GraphExecutorFactoryModule
+from tvm.micro import export_model_library_format
Review comment:
@leandron fwiw if `USE_MICRO OFF` an error is already generated:
```
raise ImportError("micro tvm is not enabled. Set USE_MICRO to ON in
config.cmake")
ImportError: micro tvm is not enabled. Set USE_MICRO to ON in config.cmake
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] gromero commented on a change in pull request #8086: [TVMC] Add support for the MLF to 'compile' command
gromero commented on a change in pull request #8086:
URL: https://github.com/apache/tvm/pull/8086#discussion_r636601079
##
File path: python/tvm/driver/tvmc/model.py
##
@@ -233,6 +232,43 @@ def export_package(
return package_path
+def export_package(
+self,
+executor_factory: GraphExecutorFactoryModule,
+package_path: Optional[str] = None,
+cross: Optional[Union[str, Callable]] = None,
+output_format: str = "so",
+):
+"""Save this TVMCModel to file.
+Parameters
+--
+executor_factory : GraphExecutorFactoryModule
+The factory containing compiled the compiled artifacts needed to
run this model.
+package_path : str, None
+Where the model should be saved. Note that it will be packaged as
a .tar file.
+If not provided, the package will be saved to a generically named
file in tmp.
+cross : str or callable object, optional
+Function that performs the actual compilation.
+output_format : str
+How to save the modules function library. Must be one of "so" and
"tar" to save
+using the classic format or "mlf" to save using the Model Library
Format.
+
+Returns
+---
+package_path : str
+The path that the package was saved to.
+"""
+if output_format not in ["so", "tar", "mlf"]:
+raise TVMCException("Only 'so', 'tar', and 'mlf' output formats
are supported.")
+
+if output_format == "mlf" and cross:
+raise TVMCException("Specifying the MLF output and a cross
compiler is not supported.")
+
+if output_format in ["so", "tar"]:
+return self.export_classic_format(executor_factory, package_path,
cross, output_format)
+else:
Review comment:
sure! done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] zhuzilin commented on pull request #8041: [Relay][PRNG] Add uniform distribution generator wrt threefry PRNG
zhuzilin commented on pull request #8041: URL: https://github.com/apache/tvm/pull/8041#issuecomment-845608860 @FrozenGene Could you have another look at this PR? Thank you! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] zhuzilin edited a comment on pull request #8056: [Relay, TOPI] Add negative log likelihood loss (nll_loss) op
zhuzilin edited a comment on pull request #8056: URL: https://github.com/apache/tvm/pull/8056#issuecomment-845607944 @altanh Thanks. I'll add the test soon. Could you also check the comments above relate to the optional weight, Diagnostics and the tag? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] zhuzilin commented on pull request #8056: [Relay, TOPI] Add negative log likelihood loss (nll_loss) op
zhuzilin commented on pull request #8056: URL: https://github.com/apache/tvm/pull/8056#issuecomment-845607944 @altanh Thanks. I'll add the test soon. Could you also check the comments above relates to the optional weight, Diagnostics and the tag? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] zhuzilin commented on pull request #8085: [Relay][PRNG] Support generating data of any shape in threefry_generate
zhuzilin commented on pull request #8085: URL: https://github.com/apache/tvm/pull/8085#issuecomment-845597364 @tkonolige Thank you for your review~ I've updated the code based on them. Could you take a second look? As for the incorrect part of the update, I have some different opinion, see the comment above. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] zhuzilin commented on a change in pull request #8085: [Relay][PRNG] Support generating data of any shape in threefry_generate
zhuzilin commented on a change in pull request #8085: URL: https://github.com/apache/tvm/pull/8085#discussion_r636583911 ## File path: python/tvm/topi/random/kernel.py ## @@ -306,7 +309,10 @@ def gen_ir(gen_ptr, out_gen_ptr, out_array_ptr): out_gen[4] = tmp[4] # path stays the same out_gen[5] = tmp[5] out_gen[6] = tir.const(0, dtype=gen.dtype) # unused, leave it as 0 -out_gen[7] = tmp[7] + tir.Cast(gen.dtype, out_len) # increment counter +with irb.if_scope(out_len % 4 != 0): +out_gen[7] = tmp[7] + tir.Cast(gen.dtype, out_len % 4) +with irb.else_scope(): +out_gen[7] = tmp[7] + tir.Cast(gen.dtype, out_len) # increment counter Review comment: @tkonolige I changed the increment to `out_len % 4` here because I already update the `tmp[7]` above with: ```python tmp[7] = tmp[7] + tir.Cast(gen.dtype, out_len // 4 * 4) ``` The reason for the separate update is that I think we need to update the key before the second `threefry`. However, I update the second update from `tir.Cast(gen.dtype, out_len % 4)` to `tir.Cast(gen.dtype, 4)`, because 4 random numbers are actually generated (though partially discarded). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] mehrdadh commented on pull request #8075: [microTVM] AOT Demo
mehrdadh commented on pull request #8075: URL: https://github.com/apache/tvm/pull/8075#issuecomment-845583368 @areusch tested this on NRF board, however, the model doesn't fit on Nucleo board. So I removed the boards that has not been tested so far in the aot_demo. PTAL. Thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] electriclilies opened a new pull request #8099: [ONNX] [Relay] Update unique operator to match ONNX output (1D only)
electriclilies opened a new pull request #8099: URL: https://github.com/apache/tvm/pull/8099 The unique operator in TVM did not match the ONNX output. In this PR, I make changes to Unique so that the 1D ONNX unit tests passes. The changes are: - Adding indices to the output of unique - Correcting the documentation and order of return values in Relay code, topi code and in testing code. The documentation currently says that TVM's unique op returns indices, which is "A 1-D tensor. The same size as output. For each entry in output, it contains the index of its first occurance in the input data. The end of the tensor is padded with the length of the input data". However, the op was actually returning inverse_indices, which is "A 1-D tensor. For each entry in data, it contains the index of that data element in the unique array." To fix this, I renamed indices as inverse_indices and updated the documentation. - Adding Unique to the ONNX importer - Fixing a bug in the ONNX importer which caused ops with multiple optional outputs to not import @mbrookhart Please take a look! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated (28ea03c -> aba2806)
This is an automated email from the ASF dual-hosted git repository. areusch pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from 28ea03c [TOPI] Custom schedule for standalone transpose in cuda (#8030) add aba2806 [CI][Docker] set environment variables for UTF-8, to prevent errors when running `black` (#8089) No new revisions were added by this update. Summary of changes: docker/Dockerfile.ci_lint | 4 1 file changed, 4 insertions(+)
[GitHub] [tvm] areusch merged pull request #8089: [CI][Docker] set environment variables for UTF-8, to prevent errors when running `black`
areusch merged pull request #8089: URL: https://github.com/apache/tvm/pull/8089 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated (71ff875 -> 28ea03c)
This is an automated email from the ASF dual-hosted git repository. areusch pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from 71ff875 [AOT] Remove lookup parameter function in AOT (#7988) add 28ea03c [TOPI] Custom schedule for standalone transpose in cuda (#8030) No new revisions were added by this update. Summary of changes: python/tvm/relay/op/_transform.py | 4 +- python/tvm/relay/op/strategy/cuda.py| 22 python/tvm/relay/op/strategy/generic.py | 7 +++ python/tvm/topi/cuda/__init__.py| 1 + python/tvm/topi/cuda/sparse.py | 39 +- python/tvm/topi/cuda/transform.py | 67 + tests/python/topi/python/test_topi_transform.py | 26 ++ vta/tutorials/autotvm/tune_relay_vta.py | 2 +- 8 files changed, 129 insertions(+), 39 deletions(-) create mode 100644 python/tvm/topi/cuda/transform.py
[GitHub] [tvm] areusch merged pull request #8030: [TOPI] Custom schedule for standalone transpose in cuda
areusch merged pull request #8030: URL: https://github.com/apache/tvm/pull/8030 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] tkonolige commented on pull request #8089: [CI][Docker] set environment variables for UTF-8, to prevent errors when running `black`
tkonolige commented on pull request #8089: URL: https://github.com/apache/tvm/pull/8089#issuecomment-845550374 This should be an easy rebuild. Let's merge. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] areusch commented on pull request #8089: [CI][Docker] set environment variables for UTF-8, to prevent errors when running `black`
areusch commented on pull request #8089: URL: https://github.com/apache/tvm/pull/8089#issuecomment-845525468 @tkonolige wdyt? i'm holding most changes, but this one a) only affects ci-lint and b) is pretty low-impact -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] Lunderberg commented on pull request #8098: [Vulkan][Codegen] Added spvValidate check after vulkan shader generation
Lunderberg commented on pull request #8098: URL: https://github.com/apache/tvm/pull/8098#issuecomment-845516473 Potential reviewer: @masahi -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] Lunderberg opened a new pull request #8098: [Vulkan][Codegen] Added spvValidate check after vulkan shader generation
Lunderberg opened a new pull request #8098: URL: https://github.com/apache/tvm/pull/8098 spvValidate found the bug that was fixed in #7966, along with a few other issues on missing capability/extension declarations. Now that all unit tests checked by the CI pass with it enabled, would like to enable by default. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leandron commented on pull request #8089: [CI][Docker] set environment variables for UTF-8, to prevent errors when running `black`
leandron commented on pull request #8089: URL: https://github.com/apache/tvm/pull/8089#issuecomment-845515921 > @leandron if it's ok, i'd like to hold this change until we finish #7995. i think it's likely not going to affect it, but we have a few CUDA changes to make in order to make any progress on updating the images and i'd like to not mix future changes. that said, if it's pressing, i don't think this one will affect much. It would be good to merge as it is very low impact - if possible, so that I can keep validating the images overnight. In case you want to keep this to organise #7995 - I also support it -, I’ll manage with some local change on my CI jobs. Let me know. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] areusch commented on pull request #8089: [CI][Docker] set environment variables for UTF-8, to prevent errors when running `black`
areusch commented on pull request #8089: URL: https://github.com/apache/tvm/pull/8089#issuecomment-845500964 @leandron if it's ok, i'd like to hold this change until we finish #7995. i think it's likely not going to affect it, but we have a few CUDA changes to make in order to make any progress on updating the images and i'd like to not mix future changes. that said, if it's pressing, i don't think this one will affect much. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leandron commented on pull request #8089: [CI][Docker] set environment variables for UTF-8, to prevent errors when running `black`
leandron commented on pull request #8089: URL: https://github.com/apache/tvm/pull/8089#issuecomment-845492727 @areusch if you have a minute, can you review? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] comaniac commented on pull request #8088: [BYOC][NNAPI]: Add testing package to ci_cpu image
comaniac commented on pull request #8088: URL: https://github.com/apache/tvm/pull/8088#issuecomment-845471519 Accordingly, we will put this PR on hold for now, and @areusch will merge it when the issues of updating container images are resolved. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi commented on pull request #8084: [Relay, ONNX] Support gather_nd batch_dims attribute for TF/ONNX
masahi commented on pull request #8084: URL: https://github.com/apache/tvm/pull/8084#issuecomment-845467697 > I'd use the expanded definition with X_0... because I think it is clearer for users Ok since the definition with X_0... only applies when B > 0, I added output shape descriptions for two cases (B > 0 and B == 0). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated (ec3b160 -> 71ff875)
This is an automated email from the ASF dual-hosted git repository. areusch pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from ec3b160 Add support for the quantized TANH operator to relay TFLite frontend (#8024) add 71ff875 [AOT] Remove lookup parameter function in AOT (#7988) No new revisions were added by this update. Summary of changes: include/tvm/tir/builtin.h | 8 +++ src/relay/backend/aot_executor_codegen.cc | 25 src/target/source/codegen_c.cc| 5 src/target/source/codegen_c_host.cc | 39 ++- src/target/source/codegen_c_host.h| 1 + src/tir/op/builtin.cc | 4 6 files changed, 45 insertions(+), 37 deletions(-)
[GitHub] [tvm] areusch merged pull request #7988: [AOT] Remove lookup parameter function in AOT
areusch merged pull request #7988: URL: https://github.com/apache/tvm/pull/7988 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] tkonolige commented on pull request #8084: [Relay, ONNX] Support gather_nd batch_dims attribute for TF/ONNX
tkonolige commented on pull request #8084: URL: https://github.com/apache/tvm/pull/8084#issuecomment-845461487 Ah thats what I was missing. I'd use the expanded definition with X_0... because I think it is clearer for users. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi edited a comment on pull request #8084: [Relay, ONNX] Support gather_nd batch_dims attribute for TF/ONNX
masahi edited a comment on pull request #8084:
URL: https://github.com/apache/tvm/pull/8084#issuecomment-845460104
As the onnx doc says,
https://github.com/onnx/onnx/blob/master/docs/Operators.md#GatherND, `the
leading B number of dimensions of data tensor and indices are representing the
batches`, so there is a constraint `X_0, ... X_{B-1} == Y_0, ... Y_{B-1}`.
When I wrote the output shape as `(Y_0, ..., Y_{K-1}, X_{M+B}, ...,
X_{N-1})`, more precisely it means `(Y_0, ..., Y_{B-1}, ... Y_{K-1}, X_{M+B},
..., X_{N-1})`, which is equivalent to `(X_0, ..., X_{B-1}, ... Y_{K-1},
X_{M+B}, ..., X_{N-1})`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] masahi commented on pull request #8084: [Relay, ONNX] Support gather_nd batch_dims attribute for TF/ONNX
masahi commented on pull request #8084:
URL: https://github.com/apache/tvm/pull/8084#issuecomment-845460104
As the onnx doc says,
https://github.com/onnx/onnx/blob/master/docs/Operators.md#GatherND, `the
leading B number of dimensions of data tensor and indices are representing the
batches`, so there is a constraint `X_0, ... X_{B-1} == Y_0, ... Y_{B-1}`.
When I wrote the output shape as `(Y_0, ..., Y_{K-1}, X_{M+B}, ...,
X_{N-1})`, more precisely it means `(Y_0, ...,Y_{B-1}, ... Y_{K-1}, X_{M+B},
..., X_{N-1})`, which is equivalent to `(X_0, ...,X_{B-1}, ... Y_{K-1},
X_{M+B}, ..., X_{N-1})`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] altanh commented on pull request #7952: [IR][Pass][Instrument] Pass instrument framework
altanh commented on pull request #7952: URL: https://github.com/apache/tvm/pull/7952#issuecomment-845458234 > For the reason not to overload superclass, I don't know, but I have a guess, maybe need someone to confirm: Currently, only FunctionPass, ModulePass, SequentialPass and PrimFuncPass extends Pass. FunctionPass calls InferType at the end (see the comments for detail) while SequentialPass is just like a wrapper. > > In these cases, InterType and SequentialPass maybe not want to be traced/instrumented. I disagree with this, mainly because some (perhaps not so) surprising results I got with my initial pass profiling implementation is that `InferType` is called **a lot** and often due to the `FunctionPass`/`SequentialPass` design, leading to quite a bit of compilation slowdown. This information would not have been obtained if we didn't include all passes that are run in the profiling. Now, I wonder if we should introduce a "universal" pass context which *every* PassNode must respect and has access to (perhaps a thread local one)? I definitely want to make sure the timing instrument can time all passes that are run. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] altanh commented on pull request #8056: [Relay, TOPI] Add negative log likelihood loss (nll_loss) op
altanh commented on pull request #8056: URL: https://github.com/apache/tvm/pull/8056#issuecomment-845452140 > Could you tell me how to decide to level of an op? And I could add the test to the correct place. Yep, sorry that the documentation of support level is lacking! We do have a doc at (https://tvm.apache.org/docs/langref/relay_op.html#overview-of-operators) but it seems outdated and missing quite a bit, so this needs to be improved. For this op, I think we can go with level 10 which matches the existing `nn.cross_entropy` op. I think we might want to remove this operator in the future since NLLLoss seems to be more general and subsumes it in my opinion, but that will be a separate PR :) Thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] tkonolige commented on pull request #8084: [Relay, ONNX] Support gather_nd batch_dims attribute for TF/ONNX
tkonolige commented on pull request #8084:
URL: https://github.com/apache/tvm/pull/8084#issuecomment-845448819
Shouldn't the batch size appear in the output shape? I think it should be
`(X_0, ..., X_{B-1}, Y_0, ..., Y_{K-1}, X_{M+B}, .. X_{N-1})`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] rohanmukh closed pull request #8097: Simple Test
rohanmukh closed pull request #8097: URL: https://github.com/apache/tvm/pull/8097 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] rohanmukh opened a new pull request #8097: Simple Test
rohanmukh opened a new pull request #8097: URL: https://github.com/apache/tvm/pull/8097 Co-authored-by: David Huang davh...@amazon.com Co-authored-by: Rohan Mukherjee mukro...@amazon.com Co-authored-by: Wei Xiao w...@amazon.com -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] masahi edited a comment on pull request #8084: [Relay, ONNX] Support gather_nd batch_dims attribute for TF/ONNX
masahi edited a comment on pull request #8084:
URL: https://github.com/apache/tvm/pull/8084#issuecomment-845414090
> X_M, ..., X_{N-1} is the implicit batch dimension
I don't get what you meant by "implicit batch dimension". X_M, ..., X_{N-1}
are axes of the input that are not indexed and thus simply copied. `batch_dims`
tells from which axis the indexing starts.
Our current `gather_nd` is identical with mxnet one in
https://mxnet.apache.org/versions/1.6/api/r/docs/api/mx.symbol.gather_nd.html,
which is the same as TF `gather_nd` and ONNX `GatherND` except that
* indexing M tuples are in the first axis rather than the last.
* batch dims is always 0
(There is an open request to add `batch_dims` support to the mxnet op
https://github.com/apache/incubator-mxnet/issues/9998)
So right now the output is
```
output[y_0, ..., y_{K-1}, x_M, ..., x_{N-1}] = data[indices[0, y_0, ...,
y_{K-1}],
...,
indices[M-1, y_0, ..., y_{K-1}],
x_M, ..., x_{N-1}]
```
With `batch_dims` B, it becomes (I hope it is correct but didn't check
deeply)
```
output[y_0, ..., y_{K-1}, x_M, ..., x_{N-1}] = data[y_0, ..., y_{B-1},
indices[0, y_0, ..., y_{K-1}],
...,
indices[M-1, y_0, ..., y_{K-1}],
x_{M+B}, ..., x_{N-1}]
```
I'm going to update the doc to the following if this makes sense @tkonolige
```
Optionally, batch_dims, the number of batch dimensions, can be given, whose
default value is 0.
Let B denote batch_dims, and data, indices shape be (X_0, X_1, ..., X_{N-1}),
(M, Y_0, ..., Y_{K-1}) respectively. When B > 0, indexing will start from
the B-th axis,
and it must be the case that X_0, ... X_{B-1} == Y_0, ... Y_{B-1}.
The output will have shape
(Y_0, ..., Y_{K-1}, X_{M+B}, ..., X_{N-1}), where M + B <= N. If M + B == N,
output shape will simply be (Y_0, ..., Y_{K-1}).
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] masahi commented on pull request #8084: [Relay, ONNX] Support gather_nd batch_dims attribute for TF/ONNX
masahi commented on pull request #8084:
URL: https://github.com/apache/tvm/pull/8084#issuecomment-845414090
> X_M, ..., X_{N-1} is the implicit batch dimension
I don't get what you meant by "implicit batch dimension". X_M, ..., X_{N-1}
are axes of the input that are not indexed and thus simply copied. `batch_dims`
tells from which axis the indexing starts.
Our current `gather_nd` is identical with mxnet one in
https://mxnet.apache.org/versions/1.6/api/r/docs/api/mx.symbol.gather_nd.html,
which is the same as TF `gather_nd` and ONNX `GatherND` except that indexing M
tuples are in the first axis rather than the last. (There is an open request to
add `batch_dims` support to the mxnet op
https://github.com/apache/incubator-mxnet/issues/9998)
So right now the output is
```
output[y_0, ..., y_{K-1}, x_M, ..., x_{N-1}] = data[indices[0, y_0, ...,
y_{K-1}],
...,
indices[M-1, y_0, ..., y_{K-1}],
x_M, ..., x_{N-1}]
```
With `batch_dims` B, it becomes (I hope it is correct but didn't check
deeply)
```
output[y_0, ..., y_{K-1}, x_M, ..., x_{N-1}] = data[y_0, ..., y_{B-1},
indices[0, y_0, ..., y_{K-1}],
...,
indices[M-1, y_0, ..., y_{K-1}],
x_{M+B}, ..., x_{N-1}]
```
I'm going to update the doc to the following if this makes sense @tkonolige
```
Optionally, batch_dims, the number of batch dimensions, can be given, whose
default value is 0.
Let B denote batch_dims, and data, indices shape be (X_0, X_1, ..., X_{N-1}),
(M, Y_0, ..., Y_{K-1}) respectively. When B > 0, indexing will start from
the B-th axis,
and it must be the case that X_0, ... X_{B-1} == Y_0, ... Y_{B-1}.
The output will have shape
(Y_0, ..., Y_{K-1}, X_{M+B}, ..., X_{N-1}), where M + B <= N. If M + B == N,
output shape will simply be (Y_0, ..., Y_{K-1}).
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] areusch commented on pull request #6953: Add retry to sockets on EINTR error
areusch commented on pull request #6953: URL: https://github.com/apache/tvm/pull/6953#issuecomment-845409988 superseded by #7919 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] areusch closed pull request #6953: Add retry to sockets on EINTR error
areusch closed pull request #6953: URL: https://github.com/apache/tvm/pull/6953 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] areusch commented on a change in pull request #8086: [TVMC] Add support for the MLF to 'compile' command
areusch commented on a change in pull request #8086:
URL: https://github.com/apache/tvm/pull/8086#discussion_r636401574
##
File path: python/tvm/driver/tvmc/model.py
##
@@ -233,6 +232,43 @@ def export_package(
return package_path
+def export_package(
+self,
+executor_factory: GraphExecutorFactoryModule,
+package_path: Optional[str] = None,
+cross: Optional[Union[str, Callable]] = None,
+output_format: str = "so",
+):
+"""Save this TVMCModel to file.
+Parameters
+--
+executor_factory : GraphExecutorFactoryModule
+The factory containing compiled the compiled artifacts needed to
run this model.
+package_path : str, None
+Where the model should be saved. Note that it will be packaged as
a .tar file.
+If not provided, the package will be saved to a generically named
file in tmp.
+cross : str or callable object, optional
+Function that performs the actual compilation.
+output_format : str
+How to save the modules function library. Must be one of "so" and
"tar" to save
+using the classic format or "mlf" to save using the Model Library
Format.
+
+Returns
+---
+package_path : str
+The path that the package was saved to.
+"""
+if output_format not in ["so", "tar", "mlf"]:
+raise TVMCException("Only 'so', 'tar', and 'mlf' output formats
are supported.")
+
+if output_format == "mlf" and cross:
+raise TVMCException("Specifying the MLF output and a cross
compiler is not supported.")
+
+if output_format in ["so", "tar"]:
+return self.export_classic_format(executor_factory, package_path,
cross, output_format)
+else:
Review comment:
could we be explicit here (`elif output_format == "mlf"`) rather than as
a fallback?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] leandron commented on a change in pull request #8086: [TVMC] Add support for the MLF to 'compile' command
leandron commented on a change in pull request #8086: URL: https://github.com/apache/tvm/pull/8086#discussion_r636397101 ## File path: python/tvm/driver/tvmc/model.py ## @@ -53,6 +53,7 @@ from tvm import relay from tvm.contrib import utils from tvm.relay.backend.executor_factory import GraphExecutorFactoryModule +from tvm.micro import export_model_library_format Review comment: I would be in favour of removing it, meaning it is always built without the need for a flag. Happy to support such proposal on Discuss. Alternatively we could change the default to ON, leaving the door open for people to disable it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leandron commented on a change in pull request #8086: [TVMC] Add support for the MLF to 'compile' command
leandron commented on a change in pull request #8086: URL: https://github.com/apache/tvm/pull/8086#discussion_r636397101 ## File path: python/tvm/driver/tvmc/model.py ## @@ -53,6 +53,7 @@ from tvm import relay from tvm.contrib import utils from tvm.relay.backend.executor_factory import GraphExecutorFactoryModule +from tvm.micro import export_model_library_format Review comment: I would be in favour of removing it, meaning it is always built without the need for a flag. Happy to support such proposal on Discuss. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] areusch commented on a change in pull request #8086: [TVMC] Add support for the MLF to 'compile' command
areusch commented on a change in pull request #8086: URL: https://github.com/apache/tvm/pull/8086#discussion_r636394228 ## File path: python/tvm/driver/tvmc/model.py ## @@ -53,6 +53,7 @@ from tvm import relay from tvm.contrib import utils from tvm.relay.backend.executor_factory import GraphExecutorFactoryModule +from tvm.micro import export_model_library_format Review comment: i'm wondering if it makes sense to keep `USE_MICRO`. i may propose removing it on Discuss. Currently, `USE_MICRO` means to build the utvm_rpc_common library from the CRT into `libtvm_runtime.so`. I don't know that adding this is a huge burden, but on the other hand I do want to be sensitive to people trying to compile for smaller runtime environments. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] mehrdadh commented on issue #8062: AOT C Codegen Type Issue
mehrdadh commented on issue #8062: URL: https://github.com/apache/tvm/issues/8062#issuecomment-845373215 will be solved by this PR: https://github.com/apache/tvm/pull/8096 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] mehrdadh closed issue #8062: AOT C Codegen Type Issue
mehrdadh closed issue #8062: URL: https://github.com/apache/tvm/issues/8062 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] mehrdadh commented on pull request #8096: Decoupling AOT from graph memory planner
mehrdadh commented on pull request #8096: URL: https://github.com/apache/tvm/pull/8096#issuecomment-845372478 thanks @giuseros for working on this! I tested it and it solves the issue that I had. So I close the issue assuming this will merge sometimes soon. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] areusch commented on pull request #8088: [BYOC][NNAPI]: Add testing package to ci_cpu image
areusch commented on pull request #8088: URL: https://github.com/apache/tvm/pull/8088#issuecomment-845369330 hi all, i added some updates on #7995 to let you know where we are. given the complexity there, i'd prefer if we could keep this PR out of it and then we can update again after that. The CUDA issues encountered on 18.04 are making this container update more challenging than normal. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] areusch commented on issue #7995: Update all ci- containers to reflect main
areusch commented on issue #7995: URL: https://github.com/apache/tvm/issues/7995#issuecomment-845368725 apologies for the light updates here. we determined that the "Frontend : GPU" tests get into a state where either the GPU hardware is inaccessible after a while or TVM's existence check is wrong. Since we didn't change the CUDA version used here--we just updated to 18.04--the theory is that there is some interoperability problem between CUDA running in the containers (at 10.0) and the CUDA driver loaded on the docker host side (either 10.2 or 11.0, depending which CI node you hit). @tkonolige and I have spent the last couple days running on a test TVM CI cluster using the same AMI (which has only CUDA 11.0). With CUDA 10.0 (ci-gpu) and 11.0 (host), we ran into another similar-looking bug during the GPU unit tests: ``` [ RUN ] BuildModule.Heterogeneous [22:11:58] /workspace/src/target/opt/build_cuda_on.cc:89: Warning: cannot detect compute capability from your device, fall back to compute_30. unknown file: Failure C++ exception with description "[22:11:58] /workspace/src/runtime/cuda/cuda_device_api.cc:117: --- An error occurred during the execution of TVM. For more information, please see: https://tvm.apache.org/docs/errors.html --- Check failed: (e == cudaSuccess || e == cudaErrorCudartUnloading) is false: CUDA: no CUDA-capable device is detected ``` We then upgraded ci-gpu to use CUDA 11.0, and this test seemed to pass all the way to the end of the GPU integration tests, modulo a tolerance issue: ``` tests/python/contrib/test_cublas.py::test_batch_matmul FAILED // ... > np.testing.assert_allclose(actual, desired, rtol=rtol, atol=atol, verbose=True) E AssertionError: E Not equal to tolerance rtol=1e-05, atol=1e-07 E E Mismatched elements: 2875175 / 3866624 (74.4%) E Max absolute difference: 0.00541687 E Max relative difference: 0.00015383 Ex: array([[[29.647408, 31.88966 , 33.90233 , ..., 34.673954, 32.908764, E31.219051], E [30.993076, 30.78019 , 33.67124 , ..., 36.1395 , 29.176218,... Ey: array([[[29.646427, 31.889557, 33.900528, ..., 34.673126, 32.90791 , E31.21726 ], E [30.991737, 30.780437, 33.67001 , ..., 36.139397, 29.174744,... ``` we'll try and push this CUDA 11.0 ci-gpu container through the test CI cluster to see how far we can get. feel free to comment if there are concerns updating to CUDA 11.0. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] vegaluisjose commented on a change in pull request #8094: [BYOC][Verilator] Skip mobilenet test if Verilator is not available
vegaluisjose commented on a change in pull request #8094: URL: https://github.com/apache/tvm/pull/8094#discussion_r636328724 ## File path: tests/python/contrib/test_verilator/test_mobilenet.py ## @@ -220,6 +221,8 @@ def tmobilenet(lanes): lanes : Int The number of vector lanes. """ +if skip_test(): Review comment: Fixed! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leandron commented on a change in pull request #8094: [BYOC][Verilator] Skip mobilenet test if Verilator is not available
leandron commented on a change in pull request #8094: URL: https://github.com/apache/tvm/pull/8094#discussion_r636323804 ## File path: tests/python/contrib/test_verilator/test_mobilenet.py ## @@ -220,6 +221,8 @@ def tmobilenet(lanes): lanes : Int The number of vector lanes. """ +if skip_test(): Review comment: One small note about this approach, when compared to the `skipIf` is that if you have no Verilator and you run these tests, once you reach the `return`, you'll see `PASSED` in the report, which might give the illusion that the test ran and passed. The `skipIf` will be a bit more precise and report `SKIPPED`, so it is clear that the test was not run. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] hogepodge commented on pull request #8082: [Docs] Added developer documentation for DeviceAPI and Target.
hogepodge commented on pull request #8082: URL: https://github.com/apache/tvm/pull/8082#issuecomment-845308930 Just gave it a read-through. I'm not an expert in this part of the code, but the documentation looks clear and really well organized. Thank you for writing it up! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leandron commented on pull request #8086: [TVMC] Add support for the MLF to 'compile' command
leandron commented on pull request #8086: URL: https://github.com/apache/tvm/pull/8086#issuecomment-845299445 Also just to report, I tested it locally and it works. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] mehrdadh commented on issue #8062: AOT C Codegen Type Issue
mehrdadh commented on issue #8062: URL: https://github.com/apache/tvm/issues/8062#issuecomment-845298021 Thanks @giuseros! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leandron commented on a change in pull request #8086: [TVMC] Add support for the MLF to 'compile' command
leandron commented on a change in pull request #8086:
URL: https://github.com/apache/tvm/pull/8086#discussion_r636280545
##
File path: python/tvm/driver/tvmc/compiler.py
##
@@ -40,35 +40,42 @@
def add_compile_parser(subparsers):
""" Include parser for 'compile' subcommand """
-parser = subparsers.add_parser("compile", help="compile a model")
+parser = subparsers.add_parser("compile", help="compile a model.")
parser.set_defaults(func=drive_compile)
parser.add_argument(
"--cross-compiler",
default="",
-help="the cross compiler to generate target libraries, e.g.
'aarch64-linux-gnu-gcc'",
+help="the cross compiler to generate target libraries, e.g.
'aarch64-linux-gnu-gcc'.",
)
parser.add_argument(
"--desired-layout",
choices=["NCHW", "NHWC"],
default=None,
-help="change the data layout of the whole graph",
+help="change the data layout of the whole graph.",
)
parser.add_argument(
"--dump-code",
metavar="FORMAT",
default="",
-help="comma separarated list of formats to export, e.g. 'asm,ll,relay'
",
+help="comma separated list of possible formats to export the input
model, e.g. 'asm,ll,relay'.",
)
parser.add_argument(
"--model-format",
choices=frontends.get_frontend_names(),
-help="specify input model format",
+help="specify input model format.",
+)
+parser.add_argument(
+"-f",
+"--output-format",
+choices=["so", "mlf"],
+default="so",
+help="output format. Use 'so' for shared object or 'mlf' for Model
Library Format (only for µTVM targets).",
Review comment:
```suggestion
help="output format. Use 'so' for shared object or 'mlf' for Model
Library Format (only for µTVM targets). Defaults to 'so'",
```
##
File path: python/tvm/driver/tvmc/model.py
##
@@ -53,6 +53,7 @@
from tvm import relay
from tvm.contrib import utils
from tvm.relay.backend.executor_factory import GraphExecutorFactoryModule
+from tvm.micro import export_model_library_format
Review comment:
It seems this is the only hard dependency on micro. In case the
developer build their TVM with `USE_MICRO OFF`, this throws an error.
I **suggest** we lazy load that just before line 270 and throw a message in
case the import fails, such as "TVM was build without MicroTVM support. Please
make sure TVM was build with `USE_MICRO ON`.".
As a side effect of this PR, I think it makes sense to adjust the TVM
packaging project to build TVM with USE_MICRO ON, as we expect `tvmc` users are
likely to also install TVM using the package.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] tkonolige commented on pull request #8084: [Relay, ONNX] Support gather_nd batch_dims attribute for TF/ONNX
tkonolige commented on pull request #8084:
URL: https://github.com/apache/tvm/pull/8084#issuecomment-845274248
Our implementation already has an implicit batch dimension. The current
implementation is "Given data with shape (X_0, X_1, …, X_{N-1}) and indices
with shape (M, Y_0, …, Y_{K-1}), the output will have shape (Y_0, …, Y_{K-1},
X_M, …, X_{N-1}), where M <= N. If M == N, output shape will simply be (Y_0, …,
Y_{K-1})." X_M, ..., X_{N-1} is the implicit batch dimension. How does the
explicit batch size differ from this. And should we consider unifying the two?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [tvm] zackcquic commented on pull request #7952: [IR][Pass][Instrument] Pass instrument framework
zackcquic commented on pull request #7952: URL: https://github.com/apache/tvm/pull/7952#issuecomment-845250654 Hi @areusch: Could you elaborate more on "after_pass with a result notation"? What kind of result and use scenario you expected? That will be very helpful for me. Thanks a lot. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] giuseros commented on issue #8062: AOT C Codegen Type Issue
giuseros commented on issue #8062: URL: https://github.com/apache/tvm/issues/8062#issuecomment-845249393 Hi all, The main problem is that the Graph Memory Planner( in Relay ) sees the output of the graph as a further temporary variable. When using the graph executor this temporary area is then copied to the user real output, but in AOT that *is* the real output. Why is this a problem? Because GMP can expand temporaries to that they can be shared. Thinking the output is a temporary it expands the output as well, but the output is not expandable in AOT (since it is provided by the user). We were able to reproduce this with mobilenet quantized. The fix we come up with in #8096 is to remove the dependency from the GMP and use the TIR StorageRewrite pass on the runner function, which does not suffer of this problem. The memory foot print is the same, so we basically got two birds with one stone. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] giuseros commented on pull request #8096: Decoupling AOT from graph memory planner
giuseros commented on pull request #8096: URL: https://github.com/apache/tvm/pull/8096#issuecomment-845244133 cc: @manupa-arm @MatthewARM @mehrdadh @areusch -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] giuseros opened a new pull request #8096: Decoupling AOT from graph memory planner
giuseros opened a new pull request #8096: URL: https://github.com/apache/tvm/pull/8096 In this PR we are decoupling AOT from the Graph Memory Planner. Since AOT has the runner expressed in TIR we can get rid of the GMP in relay and use the Storage Rewrite Pass to do memory planning on the runner function. This also sorts out the issue mentioned in #8062 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] tkonolige commented on a change in pull request #8085: [Relay][PRNG] Support generating data of any shape in threefry_generate
tkonolige commented on a change in pull request #8085: URL: https://github.com/apache/tvm/pull/8085#discussion_r636230174 ## File path: python/tvm/topi/random/kernel.py ## @@ -297,6 +294,12 @@ def gen_ir(gen_ptr, out_gen_ptr, out_array_ptr): # Compute random values _threefry(irb, tmp, 0, tmp, 4, out_array, 0, out_len // 4) +with irb.if_scope(out_len % 4 != 0): Review comment: This should be `if out_len.value % 4 != 0:` ## File path: python/tvm/topi/random/kernel.py ## @@ -306,7 +309,10 @@ def gen_ir(gen_ptr, out_gen_ptr, out_array_ptr): out_gen[4] = tmp[4] # path stays the same out_gen[5] = tmp[5] out_gen[6] = tir.const(0, dtype=gen.dtype) # unused, leave it as 0 -out_gen[7] = tmp[7] + tir.Cast(gen.dtype, out_len) # increment counter +with irb.if_scope(out_len % 4 != 0): +out_gen[7] = tmp[7] + tir.Cast(gen.dtype, out_len % 4) +with irb.else_scope(): +out_gen[7] = tmp[7] + tir.Cast(gen.dtype, out_len) # increment counter Review comment: This is incorrect. It should just be `out_gen[7] = tmp[7] + tir.Cast(gen.dtype, out_len)` because we used `out_len` values from the counter. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] rafzi opened a new pull request #8095: doc: fix description of stop_fusion annotation
rafzi opened a new pull request #8095: URL: https://github.com/apache/tvm/pull/8095 The annotation causes the fuse_ops pass to stop fusing once it encounteres the annotation: https://github.com/apache/tvm/blob/b2c4f1c2cbd4c4b7ac27ac853dbad7c48978/src/relay/transforms/fuse_ops.cc#L878 Therefore, the correct documentation should state that it stops fusing with the calls that follow, not the previous ones. @vinx13 @tqchen -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] vegaluisjose commented on issue #8092: [verilator] test_mobilenet needs to skip in case TVM is built without verilator support
vegaluisjose commented on issue #8092: URL: https://github.com/apache/tvm/issues/8092#issuecomment-845224361 Fixed here #8094 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] vegaluisjose opened a new pull request #8094: [BYOC][Verilator] Skip mobilenet test if Verilator is not available
vegaluisjose opened a new pull request #8094: URL: https://github.com/apache/tvm/pull/8094 @leandron @tmoreau89 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] vegaluisjose commented on issue #8092: [verilator] test_mobilenet needs to skip in case TVM is built without verilator support
vegaluisjose commented on issue #8092: URL: https://github.com/apache/tvm/issues/8092#issuecomment-845215331 Hi Leandro, You are right, when I was refactoring the code I missed adding the `skip_test()` function back. I will add it right away. Thanks for catching this up, -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] Johnson9009 commented on pull request #8090: [WIP] Just want use official CI to verify idea.
Johnson9009 commented on pull request #8090: URL: https://github.com/apache/tvm/pull/8090#issuecomment-845192858 Sorry for occupation of CI resources, this idea actually come from a real bug of "ElemOffset", the current mul mod merging logic and simplifier prefer to simplify the most inner expression first, so #8093 will happen. After I know how to fix it, I strange whether we still need the code of mul mod merging, because as you said know the simplifiers of analyzer is very strong, so I have a doubt that we need the code of mul mod merging because we haven't the strong simplifier at that time. Finally I simple delete the code of mul mod merging and want use official CI to see which case will fail, sorry for that because our internal CI haven't be set up. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leandron commented on issue #8092: [verilator] test_mobilenet needs to skip in case TVM is built without verilator support
leandron commented on issue #8092: URL: https://github.com/apache/tvm/issues/8092#issuecomment-845191982 Just to add a bit more of the specifics, I think this can be solved with something similar to this: https://github.com/apache/tvm/blob/813136401a11a49d6c15e6013c34dd822a5c4ff6/tests/python/contrib/test_bnns/test_conv2d.py#L86 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] Johnson9009 opened a new issue #8093: Bug in StorageFlatten Cause Mussy Index
Johnson9009 opened a new issue #8093:
URL: https://github.com/apache/tvm/issues/8093
Below simple case can reproduce the issue.
```python
import tvm
from tvm import te, nd
_dtype = tvm.DataType("int8")
dshape = (1, 14, 14, 1024)
A = te.placeholder(dshape, name="A", dtype=_dtype)
C = te.compute(dshape, lambda *i: A(*i) + 3, name="C")
s = te.create_schedule(C.op)
c_axis = s[C].fuse(*C.op.axis)
outer, inner = s[C].split(c_axis, nparts=4)
outer, inner = s[C].split(inner, 28*1024)
ir_mod = tvm.lower(s, [A, C], name='fadd')
```
The IR before and after pass "StorageFlatten" is something like below.
```
PrintIR(Before StorageFlatten):
primfn(A_1: handle, C_1: handle) -> ()
attr = {"global_symbol": "fadd", "tir.noalias": True}
buffers = {C: Buffer(C_2: Pointer(int32), int32, [1, 14, 14, 1024], []),
A: Buffer(A_2: Pointer(int8), int8, [1, 14, 14, 1024], [])}
buffer_map = {A_1: A, C_1: C} {
attr [C] "realize_scope" = "";
realize(C, [0:1, 0:14, 0:14, 0:1024], True {
for (i0.i1.fused.i2.fused.i3.fused.outer: int32, 0, 4) {
for (i0.i1.fused.i2.fused.i3.fused.inner.outer: int32, 0, 2) {
for (i0.i1.fused.i2.fused.i3.fused.inner.inner: int32, 0, 28672) {
if
@tir.likely((floordiv(floordiv(floordiv(((i0.i1.fused.i2.fused.i3.fused.inner.inner
+ (i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024), 14), 14) < 1), dtype=bool)
{
if
@tir.likely((floordiv(floordiv(((i0.i1.fused.i2.fused.i3.fused.inner.inner +
(i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024), 14) < 14), dtype=bool) {
if
@tir.likely((floordiv(((i0.i1.fused.i2.fused.i3.fused.inner.inner +
(i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024) < 196), dtype=bool) {
if @tir.likelyi0.i1.fused.i2.fused.i3.fused.inner.inner
+ (i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)) < 200704), dtype=bool) {
if @tir.likely(((i0.i1.fused.i2.fused.i3.fused.inner.inner
+ (i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) < 50176), dtype=bool) {
C[floordiv(floordiv(floordiv(((i0.i1.fused.i2.fused.i3.fused.inner.inner +
(i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024), 14), 14),
floormod(floordiv(floordiv(((i0.i1.fused.i2.fused.i3.fused.inner.inner +
(i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024), 14), 14),
floormod(floordiv(((i0.i1.fused.i2.fused.i3.fused.inner.inner +
(i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024), 14),
floormod(((i0.i1.fused.i2.fused.i3.fused.inner.inner +
(i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024)] = (cast(int32,
A[floordiv(floordiv(floordiv(((i0.i1.fused.i2.fused.i3.fused.inner.inner +
(i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024), 14), 14),
floormod(floordiv(floordiv(((i0.i1.fused.i2.fused.i3.
fused.inner.inner + (i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024), 14), 14),
floormod(floordiv(((i0.i1.fused.i2.fused.i3.fused.inner.inner +
(i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024), 14),
floormod(((i0.i1.fused.i2.fused.i3.fused.inner.inner +
(i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024)]) + 3)
}
}
}
}
}
}
}
}
})
}
PrintIR(After StorageFlatten):
primfn(A_1: handle, C_1: handle) -> ()
attr = {"global_symbol": "fadd", "tir.noalias": True}
buffers = {C: Buffer(C_2: Pointer(int32), int32, [1, 14, 14, 1024], []),
A: Buffer(A_2: Pointer(int8), int8, [1, 14, 14, 1024], [])}
buffer_map = {A_1: A, C_1: C} {
for (i0.i1.fused.i2.fused.i3.fused.outer: int32, 0, 4) {
for (i0.i1.fused.i2.fused.i3.fused.inner.outer: int32, 0, 2) {
for (i0.i1.fused.i2.fused.i3.fused.inner.inner: int32, 0, 28672) {
if
@tir.likely((floordiv(floordiv(floordiv(((i0.i1.fused.i2.fused.i3.fused.inner.inner
+ (i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024), 14), 14) < 1), dtype=bool)
{
if
@tir.likely((floordiv(floordiv(((i0.i1.fused.i2.fused.i3.fused.inner.inner +
(i0.i1.fused.i2.fused.i3.fused.inner.outer*28672)) +
(i0.i1.fused.i2.fused.i3.fused.outer*50176)), 1024), 14) < 14), dtype=boo
[GitHub] [tvm] vinceab commented on pull request #7922: [TVMC] add the support of the cross compiler options
vinceab commented on pull request #7922: URL: https://github.com/apache/tvm/pull/7922#issuecomment-845169388 @leandron formatting/linter fixed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] hogepodge commented on pull request #7767: [docs] Getting Started with TVM: Auto Tuning with Python
hogepodge commented on pull request #7767: URL: https://github.com/apache/tvm/pull/7767#issuecomment-845140808 I can push some updates later today after the community meeting. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leandron opened a new issue #8092: [verilator] test_mobilenet needs to skip in case TVM is built without verilator support
leandron opened a new issue #8092:
URL: https://github.com/apache/tvm/issues/8092
Since #7972 was merged, it is impossible to run tests without having
`USE_VERILATOR ON`.
I understand this is enabled in our upstream CI, but I think that It would
be good to have tests dependant on verilator support to be skipped, if I'm
testing a TVM build without verilator, such as we have for many other tests.
The error I see, in case you run tests without Verilator support is:
```
=== FAILURES
===
test_mobilenet
def test_mobilenet():
"""Mobilenet tests."""
> tmobilenet(4)
tests/python/contrib/test_verilator/test_mobilenet.py:239:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
_ _
tests/python/contrib/test_verilator/test_mobilenet.py:231: in tmobilenet
res = run_model(mod, params, opts)
tests/python/contrib/test_verilator/test_mobilenet.py:152: in run_model
with transform.PassContext(opt_level=3,
config={"relay.ext.verilator.options": opts}):
python/tvm/ir/transform.py:85: in __init__
_ffi_transform_api.PassContext, opt_level, required, disabled, trace,
config
python/tvm/_ffi/_ctypes/object.py:136: in __init_handle_by_constructor__
handle = __init_by_constructor__(fconstructor, args)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
_ _
fconstructor =
args = (3, [], [], None, {'relay.ext.verilator.options': {'lib_path':
'/workspace/tests/python/contrib/test_verilator/../../../../3rdparty/vta-hw/apps/verilator/add/libverilator_4.so',
'profiler_cycle_counter_id': 0, 'profiler_enable': True}})
def __init_handle_by_constructor__(fconstructor, args):
"""Initialize handle by constructor"""
temp_args = []
values, tcodes, num_args = _make_tvm_args(args, temp_args)
ret_val = TVMValue()
ret_tcode = ctypes.c_int()
if (
_LIB.TVMFuncCall(
fconstructor.handle,
values,
tcodes,
ctypes.c_int(num_args),
ctypes.byref(ret_val),
ctypes.byref(ret_tcode),
)
!= 0
):
> raise get_last_ffi_error()
E AttributeError: Traceback (most recent call last):
E 12: TVMFuncCall
E at /workspace/src/runtime/c_runtime_api.cc:474
E 11:
tvm::runtime::PackedFunc::CallPacked(tvm::runtime::TVMArgs,
tvm::runtime::TVMRetValue*) const
E at /workspace/include/tvm/runtime/packed_func.h:1150
E 10: std::function::operator()(tvm::runtime::TVMArgs,
tvm::runtime::TVMRetValue*) const
E at /usr/include/c++/7/bits/std_function.h:706
E 9: operator()
E at /workspace/include/tvm/runtime/packed_func.h:1479
E 8: unpack_call,
tvm::runtime::Array, tvm::transform::TraceFunc,
tvm::runtime::Optional >)> >
E at /workspace/include/tvm/runtime/packed_func.h:1420
E 7: run<>
E at /workspace/include/tvm/runtime/packed_func.h:1381
E 6: run
E at /workspace/include/tvm/runtime/packed_func.h:1381
E 5: run
E at /workspace/include/tvm/runtime/packed_func.h:1381
E 4: run
E at /workspace/include/tvm/runtime/packed_func.h:1381
E 3: run
E at /workspace/include/tvm/runtime/packed_func.h:1381
E 2: run
E at /workspace/include/tvm/runtime/packed_func.h:1396
E 1: operator()
E at /workspace/src/ir/transform.cc:634
E 0:
tvm::transform::PassConfigManager::Legalize(tvm::runtime::Map*)
E at /workspace/src/ir/transform.cc:125
E File "/workspace/src/ir/transform.cc", line 125
E AttributeError: Invalid config option
'relay.ext.verilator.options' candidates are:
relay.ext.vitis_ai.options.load_runtime_module
,relay.ext.vitis_ai.options.export_runtime_module
,relay.ext.vitis_ai.options.work_dir ,relay.ext.vitis_ai.options.build_dir
,relay.ext.vitis_ai.options.target ,tir.detect_global_barrier
,tir.InjectDoubleBuffer ,tir.HoistIfThenElse ,relay.FuseOps.max_depth
,tir.instrument_bound_checkers ,tir.disable_vectorize ,tir.add_lower_pass
,tir.noalias ,tir.UnrollLoop ,relay.backend.use_auto_scheduler
,relay.backend.disable_compile_engine_cache ,tir.LoopPartition
,relay.fallback_device_type ,tir.disable_assert ,relay.ext.vitis_ai.options
,relay.ext.ethos-n.options
```
cc @vegaluisjose @tmoreau89
--
This is an automated mess
[GitHub] [tvm] leandron commented on pull request #8089: [CI][Docker] set environment variables for UTF-8, to prevent errors when running `black`
leandron commented on pull request #8089: URL: https://github.com/apache/tvm/pull/8089#issuecomment-845107591 That's just a problem not seen yet, before we implement our image rebuilds. cc @tqchen @areusch for reviews. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] hzshao0131 opened a new pull request #8091: [Relay][TOPI] Fix compute and schedule bugs for conv2d_winograd_nhwc on mali device.
hzshao0131 opened a new pull request #8091: URL: https://github.com/apache/tvm/pull/8091 This PR fix the schedule and compute bugs when running AutoScheduler om mali device. 1. add argument `auto_scheduler_rewritten_layout=""` in conv2d_winograd_nhwc_mali; 2. add `need_auto_scheduler_layout=True` for conv2d_strategy_mali and conv2d_winograd_without_weight_transfrom_strategy_mali. Thank you for your time on reviewing this PR :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated (1203d73 -> ec3b160)
This is an automated email from the ASF dual-hosted git repository. mbaret pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from 1203d73 [TensorIR] change IntRV to ExprRV (#8077) add ec3b160 Add support for the quantized TANH operator to relay TFLite frontend (#8024) No new revisions were added by this update. Summary of changes: python/tvm/relay/frontend/tflite.py | 11 +-- tests/python/frontend/tflite/test_forward.py | 25 +++-- 2 files changed, 28 insertions(+), 8 deletions(-)
[GitHub] [tvm] mbaret commented on pull request #8024: Quantized TANH operator support in TF Lite Frontend
mbaret commented on pull request #8024: URL: https://github.com/apache/tvm/pull/8024#issuecomment-845100285 Thanks @NicolaLancellotti @manupa-arm @d-smirnov this is now merged. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] mbaret merged pull request #8024: Quantized TANH operator support in TF Lite Frontend
mbaret merged pull request #8024: URL: https://github.com/apache/tvm/pull/8024 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] tqchen commented on pull request #8090: [WIP] Just want use official CI to verify idea.
tqchen commented on pull request #8090: URL: https://github.com/apache/tvm/pull/8090#issuecomment-845098489 Please avoid using CI for just verifications purposes, since CI is a resource shared by the community for code contribution gatting, since we always recommend testing things locally before sending the PR and write unit-test cases for the related change. I can see the proposed set of changes, the particular logic of mul mod merging can likely be removed in most settings where the offset are constant(as in your case), because canonical simplifier covers that. It is a bit unclear whether we can safely remove in settings when shape are symbolic. Constructing unit-test cases would be a good way to explore the problem Thank you! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] tqchen closed pull request #8090: [WIP] Just want use official CI to verify idea.
tqchen closed pull request #8090: URL: https://github.com/apache/tvm/pull/8090 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[tvm] branch main updated (7c732af -> 1203d73)
This is an automated email from the ASF dual-hosted git repository. tqchen pushed a change to branch main in repository https://gitbox.apache.org/repos/asf/tvm.git. from 7c732af [VM] add removeUnusedFunctions pass in vm memoryopt (#8040) add 1203d73 [TensorIR] change IntRV to ExprRV (#8077) No new revisions were added by this update. Summary of changes: include/tvm/tir/schedule/schedule.h | 20 +++ python/tvm/tir/schedule/__init__.py | 2 +- python/tvm/tir/schedule/schedule.py | 12 - src/tir/schedule/concrete_schedule.h | 48 ++-- src/tir/schedule/schedule.cc | 9 +++ 5 files changed, 45 insertions(+), 46 deletions(-)
[GitHub] [tvm] tqchen merged pull request #8077: [TensorIR] change IntRV to ExprRV
tqchen merged pull request #8077: URL: https://github.com/apache/tvm/pull/8077 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] Johnson9009 opened a new pull request #8090: [WIP] Just want use official CI to verify idea.
Johnson9009 opened a new pull request #8090: URL: https://github.com/apache/tvm/pull/8090 Just want use official CI to verify idea. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] leandron opened a new pull request #8089: [CI][Docker] set environment variables for UTF-8, to prevent errors when running `black`
leandron opened a new pull request #8089: URL: https://github.com/apache/tvm/pull/8089 Updates ci_lint image to use UTF-8 encoding. * Sets environment shell encoding to UTF-8 * This prevents the black formatting tool to exit with the following error: "RuntimeError: Click will abort further execution because Python was configured to use ASCII as encoding for the environment" -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] melsonlai commented on pull request #8088: [BYOC][NNAPI]: Add testing package to ci_cpu image
melsonlai commented on pull request #8088: URL: https://github.com/apache/tvm/pull/8088#issuecomment-844936205 cc @comaniac @zhiics -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] melsonlai opened a new pull request #8088: [BYOC][NNAPI]: Add testing package to ci_cpu image
melsonlai opened a new pull request #8088: URL: https://github.com/apache/tvm/pull/8088 This commit adds Android SDK to the ci_cpu image for supporting tests of Android NNAPI BYOC. See also: + [\[RFC\]\[BYOC\] Android NNAPI Integration](https://discuss.tvm.apache.org/t/rfc-byoc-android-nnapi-integration/9072) + PR #8076 Thanks for contributing to TVM! Please refer to guideline https://tvm.apache.org/docs/contribute/ for useful information and tips. After the pull request is submitted, please request code reviews from [Reviewers](https://github.com/apache/incubator-tvm/blob/master/CONTRIBUTORS.md#reviewers) by @ them in the pull request thread. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] manupa-arm commented on issue #8062: AOT C Codegen Type Issue
manupa-arm commented on issue #8062: URL: https://github.com/apache/tvm/issues/8062#issuecomment-844883325 Ack, Yes its not what I thought. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] rohanmukh commented on a change in pull request #8074: [Frontend] [Tensorflow2] Added test infrastructure for TF2 frozen models
rohanmukh commented on a change in pull request #8074: URL: https://github.com/apache/tvm/pull/8074#discussion_r635878452 ## File path: tests/python/frontend/tensorflow2/common.py ## @@ -0,0 +1,120 @@ +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, +# software distributed under the License is distributed on an +# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +# KIND, either express or implied. See the License for the +# specific language governing permissions and limitations +# under the License. +# pylint: disable=import-self, invalid-name, unused-argument, too-many-lines, len-as-condition, broad-except +# pylint: disable=import-outside-toplevel, redefined-builtin +"""TF2 to relay converter test utilities""" + +import tvm +from tvm import relay + +from tvm.runtime.vm import VirtualMachine +import tvm.contrib.graph_executor as runtime +from tvm.relay.frontend.tensorflow import from_tensorflow +import tvm.testing + +import tensorflow as tf +from tensorflow.python.eager.def_function import Function + + +def vmobj_to_list(o): Review comment: Thanks @yongwww for the comments. I addressed them in the new commits. In this commit I do not introduce a new frontend code for TF2 models. That I will address in a new PR that is designed to handle TF2 style control flows and will also inherit some code from TF1 frontend code, mostly the ops. The structure of the PRs should follow the pattern as discussed in this thread, especially in this comment as below: https://github.com/apache/tvm/issues/4102#issuecomment-784456088 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] rohanmukh commented on a change in pull request #8074: [Frontend] [Tensorflow2] Added test infrastructure for TF2 frozen models
rohanmukh commented on a change in pull request #8074: URL: https://github.com/apache/tvm/pull/8074#discussion_r635875512 ## File path: tests/python/frontend/tensorflow2/test_sequential_models.py ## @@ -0,0 +1,118 @@ +# Licensed to the Apache Software Foundation (ASF) under one +# or more contributor license agreements. See the NOTICE file +# distributed with this work for additional information +# regarding copyright ownership. The ASF licenses this file +# to you under the Apache License, Version 2.0 (the +# "License"); you may not use this file except in compliance +# with the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, +# software distributed under the License is distributed on an +# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +# KIND, either express or implied. See the License for the +# specific language governing permissions and limitations +# under the License. +# pylint: disable=import-self, invalid-name, unused-argument, too-many-lines, len-as-condition, broad-except +# pylint: disable=import-outside-toplevel, redefined-builtin +"""TF2 to relay converter test: testing models built with tf.keras.Sequential()""" + +import tempfile +import numpy as np +import pytest +import tensorflow as tf +from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2 + +from common import compare_tf_tvm +from common import run_tf_code + + +def run_sequential_model(model_fn, input_shape): +def get_input(shape): +_input = np.random.uniform(0, 1, shape).astype(dtype="float32") +return _input + +def save_and_reload(_model): +with tempfile.TemporaryDirectory() as model_path: +tf.saved_model.save(_model, model_path) +loaded = tf.saved_model.load(model_path) +func = loaded.signatures["serving_default"] +frozen_func = convert_variables_to_constants_v2(func) +return frozen_func + +def model_graph(model, input_shape): +_input = get_input(input_shape) +f = save_and_reload(model(input_shape)) +_output = run_tf_code(f, _input) +gdef = f.graph.as_graph_def(add_shapes=True) +return gdef, _input, _output + +compare_tf_tvm(*model_graph(model_fn, input_shape), vm=True, output_sig=None) + + +def dense_model(input_shape, num_units=128): Review comment: Thanks @trevor-m I addressed the comments in the new commits. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] xqdan edited a comment on pull request #8079: Complete register op from python
xqdan edited a comment on pull request #8079: URL: https://github.com/apache/tvm/pull/8079#issuecomment-844692104 > @xqdan Thanks a lot for this PR. > > I'd really like to complete registering ops from python. > Some discussions are in [RFC 9903](https://discuss.tvm.apache.org/t/rfc-register-ops-from-python-site-and-followup/9903/4). > > The major problem (why I didn't complete it at once) is that the `TypeRelation` currently is pure C++ with very limited FFI. > Also, need to think about how to use TypeReporter while `InferType` from python? 1, We may need to expose some basic TypeRelation function without TypeReporter . 2, We apply infer result by TypeReporter in ir.OpAddTypeRel, which is c++ side. we rewrite the relation function here. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [tvm] xqdan edited a comment on pull request #8079: Complete register op from python
xqdan edited a comment on pull request #8079: URL: https://github.com/apache/tvm/pull/8079#issuecomment-844692104 > @xqdan Thanks a lot for this PR. > > I'd really like to complete registering ops from python. > Some discussions are in [RFC 9903](https://discuss.tvm.apache.org/t/rfc-register-ops-from-python-site-and-followup/9903/4). > > The major problem (why I didn't complete it at once) is that the `TypeRelation` currently is pure C++ with very limited FFI. > Also, need to think about how to use TypeReporter while `InferType` from python? 1, We may need to expose some basic TypeRelation function without TypeReporter . 2, We apply infer result by TypeReporter in ir.OpAddTypeRel, which is c++ side. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org