[jira] [Commented] (JENA-1630) store literals only once in lucene docs for jena-text w/ multilingual configs
[ https://issues.apache.org/jira/browse/JENA-1630?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16689910#comment-16689910 ] ASF GitHub Bot commented on JENA-1630: -- Github user xristy commented on the issue: https://github.com/apache/jena/pull/489 Odd. Here's what I see on this page: 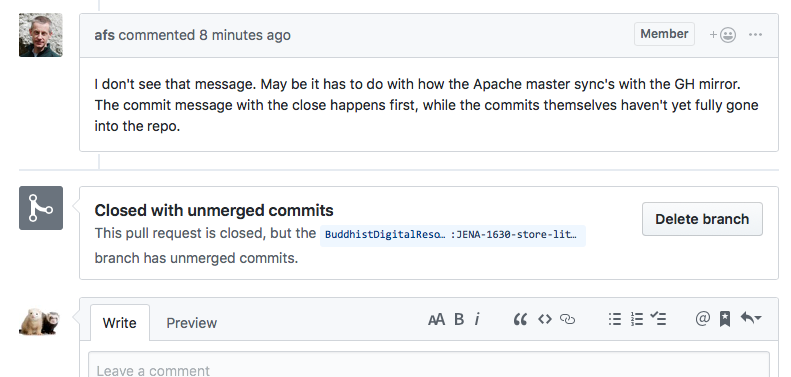 In any event I went through the procedure for PR #491 and realized that after the ``git merge --squash`` I should have done a commit. I'm pretty sure that's why the the unmerged commits. indication. > store literals only once in lucene docs for jena-text w/ multilingual configs > - > > Key: JENA-1630 > URL: https://issues.apache.org/jira/browse/JENA-1630 > Project: Apache Jena > Issue Type: Improvement > Components: Text >Affects Versions: Jena 3.9.0 >Reporter: Code Ferret >Assignee: Code Ferret >Priority: Major > Labels: easyfix, performance, pull-request-available > Fix For: Jena 3.10.0 > > > We can save some space in the Lucene db for jena-text when using multilingual > configurations by only storing the incoming literal once rather than for each > field's language tag variant. > A PR is ready -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] jena issue #489: Merged store literals once for JENA-1630
Github user xristy commented on the issue: https://github.com/apache/jena/pull/489 Odd. Here's what I see on this page:  In any event I went through the procedure for PR #491 and realized that after the ``git merge --squash`` I should have done a commit. I'm pretty sure that's why the the unmerged commits. indication. ---
[jira] [Commented] (JENA-1630) store literals only once in lucene docs for jena-text w/ multilingual configs
[ https://issues.apache.org/jira/browse/JENA-1630?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16689897#comment-16689897 ] ASF GitHub Bot commented on JENA-1630: -- Github user afs commented on the issue: https://github.com/apache/jena/pull/489 I don't see that message. May be it has to do with how the Apache master sync's with the GH mirror. The commit message with the close happens first, while the commits themselves haven't yet fully gone into the repo. > store literals only once in lucene docs for jena-text w/ multilingual configs > - > > Key: JENA-1630 > URL: https://issues.apache.org/jira/browse/JENA-1630 > Project: Apache Jena > Issue Type: Improvement > Components: Text >Affects Versions: Jena 3.9.0 >Reporter: Code Ferret >Assignee: Code Ferret >Priority: Major > Labels: easyfix, performance, pull-request-available > Fix For: Jena 3.10.0 > > > We can save some space in the Lucene db for jena-text when using multilingual > configurations by only storing the incoming literal once rather than for each > field's language tag variant. > A PR is ready -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] jena issue #489: Merged store literals once for JENA-1630
Github user afs commented on the issue: https://github.com/apache/jena/pull/489 I don't see that message. May be it has to do with how the Apache master sync's with the GH mirror. The commit message with the close happens first, while the commits themselves haven't yet fully gone into the repo. ---
[GitHub] jena issue #491: merge of IndexErrorOption
Github user xristy commented on the issue: https://github.com/apache/jena/pull/491 I think I see why I was getting unmerged commits. I was needed to do a commit after the ``merge --squash`` ---
[GitHub] jena pull request #491: merge of IndexErrorOption
GitHub user xristy opened a pull request: https://github.com/apache/jena/pull/491 merge of IndexErrorOption PR for JENA #1636 You can merge this pull request into a Git repository by running: $ git pull https://github.com/BuddhistDigitalResourceCenter/jena JENA-1636-IgnoreIndexErrors Alternatively you can review and apply these changes as the patch at: https://github.com/apache/jena/pull/491.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #491 commit dd3527ddbf0d1b82565ecd00bc1b2900b065731c Author: Code Ferret Date: 2018-11-16T18:37:17Z merge of IndexErrorOption ---
[jira] [Commented] (JENA-1630) store literals only once in lucene docs for jena-text w/ multilingual configs
[ https://issues.apache.org/jira/browse/JENA-1630?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16689814#comment-16689814 ] ASF GitHub Bot commented on JENA-1630: -- Github user xristy commented on the issue: https://github.com/apache/jena/pull/489 Thanks Andy. I see now that I haven't been pulling the PR from github. I just need to replace steps 11-12 & 14 above by: 11) ``git pull github-jena pull/489/head --no-ff`` w/ the appropriate comment info and then continue w/ testing and the push to ``apache-jena``. The [Commit Workflow page](https://cwiki.apache.org/confluence/display/JENA/Commit+Workflow+for+Github-ASF) is silent about what _local_ branch should be used, but it seems that master would be appropriate. I was referring to the _Closed message_ at the bottom of the PR page just below the last comment > store literals only once in lucene docs for jena-text w/ multilingual configs > - > > Key: JENA-1630 > URL: https://issues.apache.org/jira/browse/JENA-1630 > Project: Apache Jena > Issue Type: Improvement > Components: Text >Affects Versions: Jena 3.9.0 >Reporter: Code Ferret >Assignee: Code Ferret >Priority: Major > Labels: easyfix, performance, pull-request-available > Fix For: Jena 3.10.0 > > > We can save some space in the Lucene db for jena-text when using multilingual > configurations by only storing the incoming literal once rather than for each > field's language tag variant. > A PR is ready -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] jena issue #489: Merged store literals once for JENA-1630
Github user xristy commented on the issue: https://github.com/apache/jena/pull/489 Thanks Andy. I see now that I haven't been pulling the PR from github. I just need to replace steps 11-12 & 14 above by: 11) ``git pull github-jena pull/489/head --no-ff`` w/ the appropriate comment info and then continue w/ testing and the push to ``apache-jena``. The [Commit Workflow page](https://cwiki.apache.org/confluence/display/JENA/Commit+Workflow+for+Github-ASF) is silent about what _local_ branch should be used, but it seems that master would be appropriate. I was referring to the _Closed message_ at the bottom of the PR page just below the last comment ---
[jira] [Commented] (JENA-1635) Invalid Automatic-Module-Names in fuseki2 modules
[ https://issues.apache.org/jira/browse/JENA-1635?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16689771#comment-16689771 ] ASF GitHub Bot commented on JENA-1635: -- Github user acoburn commented on the issue: https://github.com/apache/jena/pull/490 @afs feel free to pull this into #486. I used `fuseki2` because that's what was used [here](https://github.com/apache/jena/blob/master/jena-fuseki2/pom.xml#L57), but I'd also prefer just `fuseki`, as you suggest. > Invalid Automatic-Module-Names in fuseki2 modules > - > > Key: JENA-1635 > URL: https://issues.apache.org/jira/browse/JENA-1635 > Project: Apache Jena > Issue Type: Improvement > Components: Fuseki >Affects Versions: Jena 3.9.0 >Reporter: Aaron Coburn >Assignee: Aaron Coburn >Priority: Major > Fix For: Jena 3.10.0 > > > The maven configuration for some of the fuseki2 modules produces > syntactically invalid Automatic-Module-Name values (dashes are not permitted). > For instance, org.apache.jena.jena-fuseki-main would need to be changed to > org.apache.jena.fuseki2.main -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] jena issue #490: JENA-1635 Fix invalid Automatic-Module-Name values
Github user acoburn commented on the issue: https://github.com/apache/jena/pull/490 @afs feel free to pull this into #486. I used `fuseki2` because that's what was used [here](https://github.com/apache/jena/blob/master/jena-fuseki2/pom.xml#L57), but I'd also prefer just `fuseki`, as you suggest. ---
[jira] [Commented] (JENA-1630) store literals only once in lucene docs for jena-text w/ multilingual configs
[ https://issues.apache.org/jira/browse/JENA-1630?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16689762#comment-16689762 ] ASF GitHub Bot commented on JENA-1630: -- Github user afs commented on the issue: https://github.com/apache/jena/pull/489 Where do you get "unmerged commits"? Just specualtion: The workflow at https://cwiki.apache.org/confluence/display/JENA/Commit+Workflow+for+Github-ASF has the PR pulled from the github PR. Is that happening in the sequence above? > store literals only once in lucene docs for jena-text w/ multilingual configs > - > > Key: JENA-1630 > URL: https://issues.apache.org/jira/browse/JENA-1630 > Project: Apache Jena > Issue Type: Improvement > Components: Text >Affects Versions: Jena 3.9.0 >Reporter: Code Ferret >Assignee: Code Ferret >Priority: Major > Labels: easyfix, performance, pull-request-available > Fix For: Jena 3.10.0 > > > We can save some space in the Lucene db for jena-text when using multilingual > configurations by only storing the incoming literal once rather than for each > field's language tag variant. > A PR is ready -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] jena issue #489: Merged store literals once for JENA-1630
Github user afs commented on the issue: https://github.com/apache/jena/pull/489 Where do you get "unmerged commits"? Just specualtion: The workflow at https://cwiki.apache.org/confluence/display/JENA/Commit+Workflow+for+Github-ASF has the PR pulled from the github PR. Is that happening in the sequence above? ---
[jira] [Commented] (JENA-1635) Invalid Automatic-Module-Names in fuseki2 modules
[ https://issues.apache.org/jira/browse/JENA-1635?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16689705#comment-16689705 ] ASF GitHub Bot commented on JENA-1635: -- Github user afs commented on the issue: https://github.com/apache/jena/pull/490 PR #473 touches on these modules. Do you mind if I merge this PR into PR #473? And "fuseki", not "fuseki2" as Fuseki1 is now well and truly legacy only? > Invalid Automatic-Module-Names in fuseki2 modules > - > > Key: JENA-1635 > URL: https://issues.apache.org/jira/browse/JENA-1635 > Project: Apache Jena > Issue Type: Improvement > Components: Fuseki >Affects Versions: Jena 3.9.0 >Reporter: Aaron Coburn >Assignee: Aaron Coburn >Priority: Major > Fix For: Jena 3.10.0 > > > The maven configuration for some of the fuseki2 modules produces > syntactically invalid Automatic-Module-Name values (dashes are not permitted). > For instance, org.apache.jena.jena-fuseki-main would need to be changed to > org.apache.jena.fuseki2.main -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] jena issue #490: JENA-1635 Fix invalid Automatic-Module-Name values
Github user afs commented on the issue: https://github.com/apache/jena/pull/490 PR #473 touches on these modules. Do you mind if I merge this PR into PR #473? And "fuseki", not "fuseki2" as Fuseki1 is now well and truly legacy only? ---
[jira] [Created] (JENA-1636) Log indexing errors and optionally ignore them
Code Ferret created JENA-1636:
-
Summary: Log indexing errors and optionally ignore them
Key: JENA-1636
URL: https://issues.apache.org/jira/browse/JENA-1636
Project: Apache Jena
Issue Type: Improvement
Components: Text
Affects Versions: Jena 3.9.0
Reporter: Code Ferret
Assignee: Code Ferret
Fix For: Jena 3.10.0
If Lucene signals an error during indexing, the current jena-text does not log
any useful information about the triple that was being indexed so as to aid in
finding and fixing the error. Further, during development and production an
input may lead to an error and an upload of triples may be aborted which in
practice could be continued as long as the error is logged.
This improvement adds appropriate logging for {{TextIndexLucene.addDocument}}
and {{TextIndexLucene.updateDocument}} and adds a {{text:TextIndexLucene}}
option {{text:ignoreIndexErrors}} that simply ignores the error and continues.
There is a PR available.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Assigned] (JENA-1635) Invalid Automatic-Module-Names in fuseki2 modules
[ https://issues.apache.org/jira/browse/JENA-1635?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Aaron Coburn reassigned JENA-1635: -- Assignee: Aaron Coburn > Invalid Automatic-Module-Names in fuseki2 modules > - > > Key: JENA-1635 > URL: https://issues.apache.org/jira/browse/JENA-1635 > Project: Apache Jena > Issue Type: Improvement > Components: Fuseki >Affects Versions: Jena 3.9.0 >Reporter: Aaron Coburn >Assignee: Aaron Coburn >Priority: Major > Fix For: Jena 3.10.0 > > > The maven configuration for some of the fuseki2 modules produces > syntactically invalid Automatic-Module-Name values (dashes are not permitted). > For instance, org.apache.jena.jena-fuseki-main would need to be changed to > org.apache.jena.fuseki2.main -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (JENA-1635) Invalid Automatic-Module-Names in fuseki2 modules
[ https://issues.apache.org/jira/browse/JENA-1635?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16689655#comment-16689655 ] ASF GitHub Bot commented on JENA-1635: -- GitHub user acoburn opened a pull request: https://github.com/apache/jena/pull/490 JENA-1635 Fix invalid Automatic-Module-Name values The jena-fuseki-access, jena-fuseki-core and jena-fuseki-main modules have invalid data for Automatic-Module-Name. This aligns the data from those modules with the existing fuseki2 module. You can merge this pull request into a Git repository by running: $ git pull https://github.com/acoburn/jena JENA-1635 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/jena/pull/490.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #490 commit 24742db2d697def1057b27a0d3f29300185bac84 Author: Aaron Coburn Date: 2018-11-16T16:43:40Z JENA-1635 Fix invalid Automatic-Module-Name values The jena-fuseki-access, jena-fuseki-core and jena-fuseki-main modules have invalid data for Automatic-Module-Name. This aligns the data from those modules with the existing fuseki2 module. > Invalid Automatic-Module-Names in fuseki2 modules > - > > Key: JENA-1635 > URL: https://issues.apache.org/jira/browse/JENA-1635 > Project: Apache Jena > Issue Type: Improvement > Components: Fuseki >Affects Versions: Jena 3.9.0 >Reporter: Aaron Coburn >Priority: Major > Fix For: Jena 3.10.0 > > > The maven configuration for some of the fuseki2 modules produces > syntactically invalid Automatic-Module-Name values (dashes are not permitted). > For instance, org.apache.jena.jena-fuseki-main would need to be changed to > org.apache.jena.fuseki2.main -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] jena pull request #490: JENA-1635 Fix invalid Automatic-Module-Name values
GitHub user acoburn opened a pull request: https://github.com/apache/jena/pull/490 JENA-1635 Fix invalid Automatic-Module-Name values The jena-fuseki-access, jena-fuseki-core and jena-fuseki-main modules have invalid data for Automatic-Module-Name. This aligns the data from those modules with the existing fuseki2 module. You can merge this pull request into a Git repository by running: $ git pull https://github.com/acoburn/jena JENA-1635 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/jena/pull/490.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #490 commit 24742db2d697def1057b27a0d3f29300185bac84 Author: Aaron Coburn Date: 2018-11-16T16:43:40Z JENA-1635 Fix invalid Automatic-Module-Name values The jena-fuseki-access, jena-fuseki-core and jena-fuseki-main modules have invalid data for Automatic-Module-Name. This aligns the data from those modules with the existing fuseki2 module. ---
[jira] [Created] (JENA-1635) Invalid Automatic-Module-Names in fuseki2 modules
Aaron Coburn created JENA-1635: -- Summary: Invalid Automatic-Module-Names in fuseki2 modules Key: JENA-1635 URL: https://issues.apache.org/jira/browse/JENA-1635 Project: Apache Jena Issue Type: Improvement Components: Fuseki Affects Versions: Jena 3.9.0 Reporter: Aaron Coburn Fix For: Jena 3.10.0 The maven configuration for some of the fuseki2 modules produces syntactically invalid Automatic-Module-Name values (dashes are not permitted). For instance, org.apache.jena.jena-fuseki-main would need to be changed to org.apache.jena.fuseki2.main -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Comment Edited] (JENA-1634) StreamRDFWriter doesn't work with Lang or RDFFormat default instances.
[
https://issues.apache.org/jira/browse/JENA-1634?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16689538#comment-16689538
]
Andy Seaborne edited comment on JENA-1634 at 11/16/18 4:09 PM:
---
"Stream" refers to the fact that these writers do not need to analysis the
whole of the RDF data before writing. "Pretty" formats need to analysis in
order to build datastructures to guide the output process before starting to
generate thrie output.
{{RDFWriterRegistry}} holds all the registered writers; {{StreamRDFWriter}}
gives a stronger guarantee about a subset of these - that the output streams.
The default RDFFormat for RDF/XML does not stream; RDFFormat.RDFXML_PLAIN does.
{{RDFDataMgr}} uses {{RDFWriterRegistry}}.
If you want a fallback, then check with {{StreamRDFWriter.registered}} and if
it returns null, use {{RDFWriterRegistry}}.
Or just lookup in {{RDFWriterRegistry}}. For a streaming format, like
RDFFormat.TURTLE_BLOCKS, you will get a streaming writer (in fact the same
writer code).
See {{ModLangOutput}} and how it handles {{argOutput}}.
On reading all RDF formats stream.
was (Author: andy.seaborne):
{{RDFWriterRegistry}} holds all the registered writers; {{StreamRDFWriter}}
gives a stronger guarantee about a subset of these - that the output streams.
The default RDFFormat for RDF/XML does not stream; RDFFormat.RDFXML_PLAIN does.
{{RDFDataMgr}} uses {{RDFWriterRegistry}}.
If you want a fallback, then check with {{StreamRDFWriter.registered}} and if
it returns null, use {{RDFWriterRegistry}}.
Or just lookup in {{RDFWriterRegistry}}. For a streaming format, like
RDFFormat.TURTLE_BLOCKS, you will get a streaming writer (in fact the same
writer code).
See {{ModLangOutput}} and how it handles {{argOutput}}.
On reading all RDF formats stream.
> StreamRDFWriter doesn't work with Lang or RDFFormat default instances.
> --
>
> Key: JENA-1634
> URL: https://issues.apache.org/jira/browse/JENA-1634
> Project: Apache Jena
> Issue Type: New Feature
> Components: RIOT
>Affects Versions: Jena 3.9.0
>Reporter: Marco Brandizi
>Priority: Major
>
> I have [some
> code|https://github.com/Rothamsted/ondex-knet-builder/blob/master/modules/rdf-export-2/src/main/java/net/sourceforge/ondex/rdf/export/RDFFileExporter.java]
> that writes RDF to a file, starting from a Model. This is invoked many times
> over the same FileOutput stream, by many threads that are producing RDF in
> parallel.
> The output type can be selected by the invoker, by passing Lang or RDFFormat
> instances. Because of the way it works, that output will be
> RDFFormat.TURTLE_BLOCKS most of times. However, there might be cases of small
> output, where the user might want to send in formats like Lang.RDFXML.
> Now, the problem is in the latter case the StreamRDFWriter.getWriterStream()
> doesn't work. I've isolated the issue
> [here|https://github.com/marco-brandizi/jena-stream-writer-issue/blob/master/src/test/java/info/marcobrandizi/rdf/test/JenaWritersTest.java]:
> I get messages like _"No serialization for language Lang:RDF/XML"_ and,
> looking at the sources, it seems that StreamRDFWriter recognises only
> Lang/RDFFormat instances set in its own registry.
> The same languages/variants work fine when I use the RDFDataMgr approach.
> This makes me guess/hope that data manager is able to work in a stream
> fashion, when the received RDF variants supports it.
> Whatever it is, I think this is wrong, or at least should be documented
> better, in particular, the documentation should say what to do in a situation
> like mine, where it's not known in advance if we're going to deal with
> streaming or not. Ideally, StreamRDFWriter should fallback to non-streaming,
> or trigger a specific exception when dealing with a streaming-incompatible
> format, so that the invoker can take fallback actions.
> I'm using the whole apache-jena-libs as Jena dependency.
> I suppose this applies to reading too.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] jena pull request #489: Merged store literals once for JENA-1630
Github user asfgit closed the pull request at: https://github.com/apache/jena/pull/489 ---
[jira] [Commented] (JENA-1630) store literals only once in lucene docs for jena-text w/ multilingual configs
[ https://issues.apache.org/jira/browse/JENA-1630?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16689553#comment-16689553 ] ASF GitHub Bot commented on JENA-1630: -- Github user asfgit closed the pull request at: https://github.com/apache/jena/pull/489 > store literals only once in lucene docs for jena-text w/ multilingual configs > - > > Key: JENA-1630 > URL: https://issues.apache.org/jira/browse/JENA-1630 > Project: Apache Jena > Issue Type: Improvement > Components: Text >Affects Versions: Jena 3.9.0 >Reporter: Code Ferret >Assignee: Code Ferret >Priority: Major > Labels: easyfix, performance, pull-request-available > Fix For: Jena 3.10.0 > > > We can save some space in the Lucene db for jena-text when using multilingual > configurations by only storing the incoming literal once rather than for each > field's language tag variant. > A PR is ready -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (JENA-1634) StreamRDFWriter doesn't work with Lang or RDFFormat default instances.
[
https://issues.apache.org/jira/browse/JENA-1634?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16689538#comment-16689538
]
Andy Seaborne commented on JENA-1634:
-
{{RDFWriterRegistry}} holds all the registered writers; {{StreamRDFWriter}}
gives a stronger guarantee about a subset of these - that the output streams.
The default RDFFormat for RDF/XML does not stream; RDFFormat.RDFXML_PLAIN does.
{{RDFDataMgr}} uses {{RDFWriterRegistry}}.
If you want a fallback, then check with {{StreamRDFWriter.registered}} and if
it returns null, use {{RDFWriterRegistry}}.
Or just lookup in {{RDFWriterRegistry}}. For a streaming format, like
RDFFormat.TURTLE_BLOCKS, you will get a streaming writer (in fact the same
writer code).
See {{ModLangOutput}} and how it handles {{argOutput}}.
On reading all RDF formats stream.
> StreamRDFWriter doesn't work with Lang or RDFFormat default instances.
> --
>
> Key: JENA-1634
> URL: https://issues.apache.org/jira/browse/JENA-1634
> Project: Apache Jena
> Issue Type: New Feature
> Components: RIOT
>Affects Versions: Jena 3.9.0
>Reporter: Marco Brandizi
>Priority: Major
>
> I have [some
> code|https://github.com/Rothamsted/ondex-knet-builder/blob/master/modules/rdf-export-2/src/main/java/net/sourceforge/ondex/rdf/export/RDFFileExporter.java]
> that writes RDF to a file, starting from a Model. This is invoked many times
> over the same FileOutput stream, by many threads that are producing RDF in
> parallel.
> The output type can be selected by the invoker, by passing Lang or RDFFormat
> instances. Because of the way it works, that output will be
> RDFFormat.TURTLE_BLOCKS most of times. However, there might be cases of small
> output, where the user might want to send in formats like Lang.RDFXML.
> Now, the problem is in the latter case the StreamRDFWriter.getWriterStream()
> doesn't work. I've isolated the issue
> [here|https://github.com/marco-brandizi/jena-stream-writer-issue/blob/master/src/test/java/info/marcobrandizi/rdf/test/JenaWritersTest.java]:
> I get messages like _"No serialization for language Lang:RDF/XML"_ and,
> looking at the sources, it seems that StreamRDFWriter recognises only
> Lang/RDFFormat instances set in its own registry.
> The same languages/variants work fine when I use the RDFDataMgr approach.
> This makes me guess/hope that data manager is able to work in a stream
> fashion, when the received RDF variants supports it.
> Whatever it is, I think this is wrong, or at least should be documented
> better, in particular, the documentation should say what to do in a situation
> like mine, where it's not known in advance if we're going to deal with
> streaming or not. Ideally, StreamRDFWriter should fallback to non-streaming,
> or trigger a specific exception when dealing with a streaming-incompatible
> format, so that the invoker can take fallback actions.
> I'm using the whole apache-jena-libs as Jena dependency.
> I suppose this applies to reading too.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (JENA-1634) StreamRDFWriter doesn't work with Lang or RDFFormat default instances.
[ https://issues.apache.org/jira/browse/JENA-1634?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Marco Brandizi updated JENA-1634: - Description: I have [some code|https://github.com/Rothamsted/ondex-knet-builder/blob/master/modules/rdf-export-2/src/main/java/net/sourceforge/ondex/rdf/export/RDFFileExporter.java] that writes RDF to a file, starting from a Model. This is invoked many times over the same FileOutput stream, by many threads that are producing RDF in parallel. The output type can be selected by the invoker, by passing Lang or RDFFormat instances. Because of the way it works, that output will be RDFFormat.TURTLE_BLOCKS most of times. However, there might be cases of small output, where the user might want to send in formats like Lang.RDFXML. Now, the problem is in the latter case the StreamRDFWriter.getWriterStream() doesn't work. I've isolated the issue [here|https://github.com/marco-brandizi/jena-stream-writer-issue/blob/master/src/test/java/info/marcobrandizi/rdf/test/JenaWritersTest.java]: I get messages like _"No serialization for language Lang:RDF/XML"_ and, looking at the sources, it seems that StreamRDFWriter recognises only Lang/RDFFormat instances set in its own registry. The same languages/variants work fine when I use the RDFDataMgr approach. This makes me guess/hope that data manager is able to work in a stream fashion, when the received RDF variants supports it. Whatever it is, I think this is wrong, or at least should be documented better, in particular, the documentation should say what to do in a situation like mine, where it's not known in advance if we're going to deal with streaming or not. Ideally, StreamRDFWriter should fallback to non-streaming, or trigger a specific exception when dealing with a streaming-incompatible format, so that the invoker can take fallback actions. I'm using the whole apache-jena-libs as Jena dependency. I suppose this applies to reading too. was: I have [some code|https://github.com/Rothamsted/ondex-knet-builder/blob/master/modules/rdf-export-2/src/main/java/net/sourceforge/ondex/rdf/export/RDFFileExporter.java] that writes RDF to a file, starting from a Model. This is invoked many times over the same FileOutput stream, by many threads that are producing RDF in parallel. The output type can be selected by the invoker, by passing Lang or RDFFormat instances. Because of the way it works, that output will be RDFFormat.TURTLE_BLOCKS most of times. However, there might be cases of small output, where the user might want to send in formats like Lang.RDFXML. Now, the problem is in the latter case the StreamRDFWriter.getWriterStream() doesn't work. I've isolated the issue [here|https://github.com/marco-brandizi/jena-stream-writer-issue/blob/master/src/test/java/info/marcobrandizi/rdf/test/JenaWritersTest.java]: I get messages like _"No serialization for language Lang:RDF/XML"_ and, looking at the sources, it seems that StreamRDFWriter recognises only Lang/RDFFormat instances set in its own registry. The same languages/variants work fine when I use the RDFDataMgr approach. This makes me guess/hope that data manager is able to work in a stream fashion, when the received RDF variants supports it. Whatever it is, I think this is wrong, or at least should be documented better, in particular, the documentation should say what to do in a situation like mine, where it's not known in advance if we're going to deal with streaming or not. Ideally, StreamRDFWriter should fallback to non-streaming, or trigger a specific exception when dealing with a streaming-incompatible format, so that the invoker can take fallback actions. I suppose this applies to reading too. > StreamRDFWriter doesn't work with Lang or RDFFormat default instances. > -- > > Key: JENA-1634 > URL: https://issues.apache.org/jira/browse/JENA-1634 > Project: Apache Jena > Issue Type: New Feature > Components: RIOT >Affects Versions: Jena 3.9.0 >Reporter: Marco Brandizi >Priority: Major > > I have [some > code|https://github.com/Rothamsted/ondex-knet-builder/blob/master/modules/rdf-export-2/src/main/java/net/sourceforge/ondex/rdf/export/RDFFileExporter.java] > that writes RDF to a file, starting from a Model. This is invoked many times > over the same FileOutput stream, by many threads that are producing RDF in > parallel. > The output type can be selected by the invoker, by passing Lang or RDFFormat > instances. Because of the way it works, that output will be > RDFFormat.TURTLE_BLOCKS most of times. However, there might be cases of small > output, where the user might want to send in formats like Lang.RDFXML. > Now, the problem is in the latter case the StreamRDFWriter.getWriterStream() > doesn't work. I've isolated t
[jira] [Created] (JENA-1634) StreamRDFWriter doesn't work with Lang or RDFFormat default instances.
Marco Brandizi created JENA-1634: Summary: StreamRDFWriter doesn't work with Lang or RDFFormat default instances. Key: JENA-1634 URL: https://issues.apache.org/jira/browse/JENA-1634 Project: Apache Jena Issue Type: New Feature Components: RIOT Affects Versions: Jena 3.9.0 Reporter: Marco Brandizi I have [some code|https://github.com/Rothamsted/ondex-knet-builder/blob/master/modules/rdf-export-2/src/main/java/net/sourceforge/ondex/rdf/export/RDFFileExporter.java] that writes RDF to a file, starting from a Model. This is invoked many times over the same FileOutput stream, by many threads that are producing RDF in parallel. The output type can be selected by the invoker, by passing Lang or RDFFormat instances. Because of the way it works, that output will be RDFFormat.TURTLE_BLOCKS most of times. However, there might be cases of small output, where the user might want to send in formats like Lang.RDFXML. Now, the problem is in the latter case the StreamRDFWriter.getWriterStream() doesn't work. I've isolated the issue [here|https://github.com/marco-brandizi/jena-stream-writer-issue/blob/master/src/test/java/info/marcobrandizi/rdf/test/JenaWritersTest.java]: I get messages like _"No serialization for language Lang:RDF/XML"_ and, looking at the sources, it seems that StreamRDFWriter recognises only Lang/RDFFormat instances set in its own registry. The same languages/variants work fine when I use the RDFDataMgr approach. This makes me guess/hope that data manager is able to work in a stream fashion, when the received RDF variants supports it. Whatever it is, I think this is wrong, or at least should be documented better, in particular, the documentation should say what to do in a situation like mine, where it's not known in advance if we're going to deal with streaming or not. Ideally, StreamRDFWriter should fallback to non-streaming, or trigger a specific exception when dealing with a streaming-incompatible format, so that the invoker can take fallback actions. I suppose this applies to reading too. -- This message was sent by Atlassian JIRA (v7.6.3#76005)