[GitHub] zeppelin issue #3000: [ZEPPELIN-3467] two-step, atomic configuration file
Github user sanjaydasgupta commented on the issue: https://github.com/apache/zeppelin/pull/3000 I've fixed the style issues pointed out. One test still fails on travis--despite a rebase and restart. But the failure seems unrelated to the changes made in this PR. ---
[GitHub] zeppelin issue #3056: [ZEPPELIN-3567] fix InterpreterContext convert(...) me...
Github user zjffdu commented on the issue: https://github.com/apache/zeppelin/pull/3056 LGTM ---
[GitHub] zeppelin issue #2231: ZEPPELIN-2150. NoSuchMethodError: org.apache.spark.ui....
Github user SivaKaviyappa commented on the issue: https://github.com/apache/zeppelin/pull/2231 @yywwd - Few things to check What are your zeppelin-env.sh and livy intrepreter settings 1.have you set the PYTHONPATH in the zeppelin-env.sh 2. zeppelin.livy.url=http://localhost:8998 - have set this value in your livy intrepreter? 3. you have installed python libraries in all the core nodes? I am using emr 5.11.0 and everything works fine. ---
[GitHub] zeppelin issue #3000: [ZEPPELIN-3467] two-step, atomic configuration file
Github user sanjaydasgupta commented on the issue: https://github.com/apache/zeppelin/pull/3000 Have fixed the style issues @felixcheung. One of the tests is failing--despite rebase and restart--but appears to be unrelated to the code change. ---
[GitHub] zeppelin issue #3047: [ZEPPELIN-3574] fix large number rendering issue
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3047 wow. that's pretty serious issue. thanks for fixing this. LGTM. ---
[GitHub] zeppelin pull request #3057: [Zeppelin 3582] Add type data to result of quer...
GitHub user oxygen311 opened a pull request: https://github.com/apache/zeppelin/pull/3057 [Zeppelin 3582] Add type data to result of query from SQL ### What is this PR for? JDBCInterpreter knows type information for every SQL Query. We could save this info to pool and use it. There are three types of table column: - Number; - String; - Date. ### What type of PR is it? Improvement ### What is the Jira issue? [Zeppelin 3582](https://issues.apache.org/jira/projects/ZEPPELIN/issues/ZEPPELIN-3582) ### Screenshots 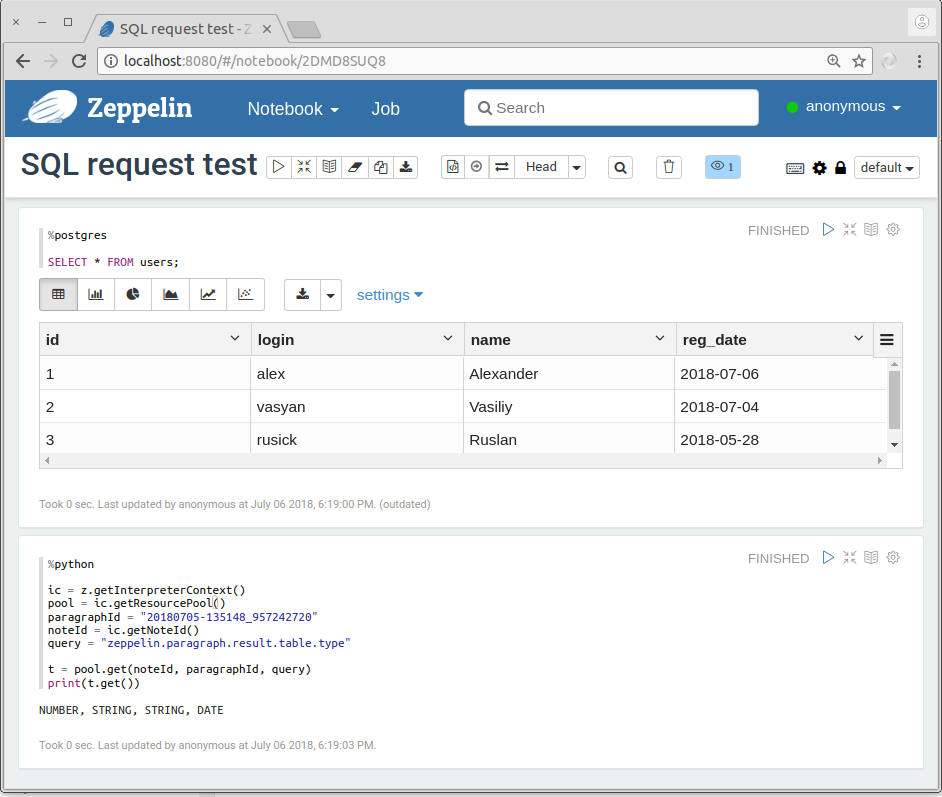 ### Questions: * Does the licenses files need update? No * Is there breaking changes for older versions? No * Does this needs documentation? No You can merge this pull request into a Git repository by running: $ git pull https://github.com/TinkoffCreditSystems/zeppelin ZEPPELIN-3582 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/zeppelin/pull/3057.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #3057 ---
[jira] [Created] (ZEPPELIN-3591) Some values of "args" property in interpreter settings for Spark ruin UDF execution
Denis Efarov created ZEPPELIN-3591:
--
Summary: Some values of "args" property in interpreter settings
for Spark ruin UDF execution
Key: ZEPPELIN-3591
URL: https://issues.apache.org/jira/browse/ZEPPELIN-3591
Project: Zeppelin
Issue Type: Bug
Components: zeppelin-interpreter
Affects Versions: 0.7.2
Environment: CentOS Linux 7.3.1611
Java 1.8.0_60
Scala 2.11.8
Spark 2.1.1
Hadoop 2.6.0
Zeppelin 0.7.2
Reporter: Denis Efarov
In "args" interpreter configuration property, any value which starts with "-"
(minus) sign prevents correct UDF execution in Spark running on YARN. Text
after "-" doesn't matter, it fails anyway. All the other properties do not
affect this.
Steps to reproduce:
* On the interpreter settings page, find Spark interpreter
* For "args" property, put any value starting with "-", for example "-test"
* Make sure spark starts on yarn (master=yarn-client)
* Save settings and restart the interpreter
* In any notebook, write and execute the following code:
** %spark
val udfDemo = (i: Int) => i + 10;
sqlContext.udf.register("demoUdf", (i: Int) => i);
sqlContext.sql("select demoUdf(1) val").show
Stacktrace:
{{java.lang.ClassCastException: cannot assign instance of
scala.collection.immutable.List$SerializationProxy to field
org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type
scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD}}{{at
java.io.ObjectStreamClass$FieldReflector.setObjFieldValues(ObjectStreamClass.java:2083)}}{{at
java.io.ObjectStreamClass.setObjFieldValues(ObjectStreamClass.java:1261)}}{{at
java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1996)}}{{at
java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)}}{{at
java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)}}{{at
java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)}}{{at
java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:1990)}}{{at
java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:1915)}}{{at
java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:1798)}}{{at
java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1350)}}{{at
java.io.ObjectInputStream.readObject(ObjectInputStream.java:370)}}{{at
org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:75)}}{{at
org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:114)}}{{at
org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:80)}}{{at
org.apache.spark.scheduler.Task.run(Task.scala:99)}}{{at
org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322)}}{{at
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)}}{{at
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)}}{{at
java.lang.Thread.run(Thread.java:744)}}
Making the same UDF declaration in, for example, %pyspark interpreter, helps,
even if one executes it in %spark.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] zeppelin pull request #3056: [ZEPPELIN-3567] fix InterpreterContext convert(...
GitHub user Savalek opened a pull request: https://github.com/apache/zeppelin/pull/3056 [ZEPPELIN-3567] fix InterpreterContext convert(...) method ### What is this PR for? After commit [7af861...](https://github.com/apache/zeppelin/commit/7af86168254e0ad08234c57043e18179fca8d04c) will be lost convert of `config`. This PR returning it back. Because of this, the status of the autocomplete was lost after the run of the paragraph.  ### What type of PR is it? Bug Fix JIRA: [ZEPPELIN-3567](https://issues.apache.org/jira/browse/ZEPPELIN-3567) ### Questions: * Does the licenses files need update? no * Is there breaking changes for older versions? no * Does this needs documentation? no You can merge this pull request into a Git repository by running: $ git pull https://github.com/TinkoffCreditSystems/zeppelin ZEPPELIN-3567 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/zeppelin/pull/3056.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #3056 commit 05f2659779ca0d606cd4d44408b15fa032d5e558 Author: Savalek Date: 2018-07-06T13:48:39Z [ZEPPELIN-3567] fix InterpreterContext convert(...) method ---
[GitHub] zeppelin issue #3053: [ZEPPELIN-3583] Add function getNoteName() in Interpre...
Github user egorklimov commented on the issue: https://github.com/apache/zeppelin/pull/3053 Look again please: * Thrift file updated * CI is green: https://travis-ci.org/TinkoffCreditSystems/zeppelin/builds/400831400 ---
[GitHub] zeppelin pull request #3035: [ZEPPELIN-3553] Fix URLs on "Multi-user Support...
Github user asfgit closed the pull request at: https://github.com/apache/zeppelin/pull/3035 ---
[GitHub] zeppelin issue #2848: [Zeppelin-3307] - Improved shared browsing/editing for...
Github user jongyoul commented on the issue: https://github.com/apache/zeppelin/pull/2848 Git it. Thanks. I thought it might not be useful. but I might be wrong. Thank you. ---
[GitHub] zeppelin issue #2848: [Zeppelin-3307] - Improved shared browsing/editing for...
Github user mebelousov commented on the issue: https://github.com/apache/zeppelin/pull/2848 @jongyoul I see next usecase. 10 users open the note, put client ID in dynamic form, refresh note, get and process data result. In this case getting of default note view is OK. That is in personal mode we may not save note updates. ---
[jira] [Created] (ZEPPELIN-3590) Add test for spark streaming
Jeff Zhang created ZEPPELIN-3590: Summary: Add test for spark streaming Key: ZEPPELIN-3590 URL: https://issues.apache.org/jira/browse/ZEPPELIN-3590 Project: Zeppelin Issue Type: Improvement Reporter: Jeff Zhang -- This message was sent by Atlassian JIRA (v7.6.3#76005)
zeppelin 0.8.0-rc2 pyspark error
Hi All,
I am running the streaming pyspark programme from pyspark interpreter by using
zeppelin-0.8.0-rc2 code .
When pyspark streaming programme is being submitted, it is giving following
error message, When we see the driver logs.
ERROR [2018-07-06 06:35:14,026] ({JobScheduler} Logging.scala[logError]:91) -
Error generating jobs for time 1530858914000 ms
org.apache.zeppelin.py4j.Py4JException: Command Part is unknown: yro464
and following is the pyspark programme
%spark.pyspark
import time
from pyspark.streaming import StreamingContext
ssc = StreamingContext(sc, 1)
rddQueue = []
for i in range(5):
rddQueue += [ssc.sparkContext.parallelize([j for j in range(1, 1001)], 10)]
print rddQueue
#Create the QueueInputDStream and use it do some processing
inputStream = ssc.queueStream(rddQueue)
mappedStream = inputStream.map(lambda x: (x % 10, 1))
reducedStream = mappedStream.reduceByKey(lambda a, b: a + b)
reducedStream.pprint()
ssc.start()
time.sleep(6)
ssc.stop(stopSparkContext=True, stopGraceFully=True)
any idea what we can do for this.
Regards
Naveen
[GitHub] zeppelin issue #2848: [Zeppelin-3307] - Improved shared browsing/editing for...
Github user jongyoul commented on the issue: https://github.com/apache/zeppelin/pull/2848 @mebelousov The main purpose of "personalized mode" is to keep the current user's view. But if the user refreshes the browser, it changes the newest one. Do you think it's enough? ---
[GitHub] zeppelin issue #2848: [Zeppelin-3307] - Improved shared browsing/editing for...
Github user mebelousov commented on the issue: https://github.com/apache/zeppelin/pull/2848 @jongyoul As I understand personal mode allows users run paragraphs and have different views and different results due user chosen values in dynamic forms. I'm against the removal of personal mode. ---
[GitHub] zeppelin issue #3055: ZEPPELIN-3587. Interpret paragarph text as whole code ...
Github user zjffdu commented on the issue: https://github.com/apache/zeppelin/pull/3055 oops, please ignore my last comment. Actually we could interpreter paragraph text as whole ---
Re: [DISCUSS] Is interpreter binding necessary ?
We already allow setting default interpreter when creating note. Another way to set default interpreter is to reorder the interpreter setting binding in note page. But personally I don't recommend user to use short interpreter name because of default interpreter. 2 Reaons: 1. It introduce in-accurate info. e.g. In our product, we have 2 spark interpreters (`spark`: for spark 1.x & `spark2` for spark 2.x). Then user often specify `%spark` for spark interpreter. But it could mean both `%spark.spark` and `%spark2.spark`, So usually it is very hard to tell what's wrong when user expect to work spark2 but actually he still use spark 1.x. So usually we would recommend user to specify the full qualified interpreter name. Just type several more characters which just cost 2 seconds but make it more clear and readable. 2. Another issue is that interpreter binding is stored in interpreter.json, that means if they export this note to another zeppelin instance, the default interpreter won't work. So I don't think setting default interpreter via interpreter binding is valuable for users. If user really want to do that, I would suggest to store it in note.json instead of interpreter.json Jongyoul Lee 于2018年7月6日周五 下午3:36写道: > There are two purposes of interpreter binding. One is what you mentioned > and another one is to manage a default interpreter. If we provide a new way > to set default interpreter, I think we can remove them :-) We could set > permissions in other ways. > > Overall, +1 > > On Fri, Jul 6, 2018 at 4:24 PM, Jeff Zhang wrote: > >> Hi Folks, >> >> I raise this thread to discuss whether we need the interpreter binding. >> Currently when user create notes, they have to bind interpreters to their >> notes in note page. Otherwise they will hit interpreter not found issue. >> Besides that in zeppelin server side, we maintain the interpreter binding >> info in memory as well as in interpreter.json. >> >> IMHO, it is not necessary to do interpreter binding. Because it just add >> extra burden to maintain the interpreter binding info in zeppelin server >> side, and doesn't introduce any benefits. The only benefit is that we will >> check whether user have permission to use this interpreter, but actually >> zeppelin will check the permission when running paragraph, so I don't think >> we need to introduce interpreter binding just for this kind of permission >> check that we will do later. >> >> So overall, I would suggest to remove interpreter binding feature. What >> do you think ? >> > > > > -- > 이종열, Jongyoul Lee, 李宗烈 > http://madeng.net >
Re: [DISCUSS] Is interpreter binding necessary ?
There are two purposes of interpreter binding. One is what you mentioned and another one is to manage a default interpreter. If we provide a new way to set default interpreter, I think we can remove them :-) We could set permissions in other ways. Overall, +1 On Fri, Jul 6, 2018 at 4:24 PM, Jeff Zhang wrote: > Hi Folks, > > I raise this thread to discuss whether we need the interpreter binding. > Currently when user create notes, they have to bind interpreters to their > notes in note page. Otherwise they will hit interpreter not found issue. > Besides that in zeppelin server side, we maintain the interpreter binding > info in memory as well as in interpreter.json. > > IMHO, it is not necessary to do interpreter binding. Because it just add > extra burden to maintain the interpreter binding info in zeppelin server > side, and doesn't introduce any benefits. The only benefit is that we will > check whether user have permission to use this interpreter, but actually > zeppelin will check the permission when running paragraph, so I don't think > we need to introduce interpreter binding just for this kind of permission > check that we will do later. > > So overall, I would suggest to remove interpreter binding feature. What > do you think ? > -- 이종열, Jongyoul Lee, 李宗烈 http://madeng.net
[GitHub] zeppelin issue #2231: ZEPPELIN-2150. NoSuchMethodError: org.apache.spark.ui....
Github user yywwd commented on the issue: https://github.com/apache/zeppelin/pull/2231 @zjffdu NoSuchMethodError: org.apache.spark.ui.SparkUI.appUIAddress() My AWS cluster is EMR-5.14.0, Application: Ganglia 3.7.2, Spark 2.3.0, Zeppelin 0.7.3, Livy 0.4.0 ---
[GitHub] zeppelin issue #3054: [WIP] ZEPPELIN-3569. Improvement of FlinkInterpreter
Github user zjffdu commented on the issue: https://github.com/apache/zeppelin/pull/3054 There's one critical issue in flink 1.5.0 FLINK-9554 ---
[GitHub] zeppelin issue #2231: ZEPPELIN-2150. NoSuchMethodError: org.apache.spark.ui....
Github user zjffdu commented on the issue: https://github.com/apache/zeppelin/pull/2231 What kind of error you see in zeppelin when using livy.spark.master yarn mode ---
[GitHub] zeppelin issue #3055: ZEPPELIN-3587. Don't stop to interpret when the next l...
Github user zjffdu commented on the issue: https://github.com/apache/zeppelin/pull/3055 @felixcheung I am afraid we have to break paragraph text. Zeppelin interpreter is different from scala shell. scala shell will execute the code when user type a complete code, while in zeppelin there may be multiple complete scala code. e.g. If we type the following code in scala-shell, it will execute `sc.version`, then you can type `1+1`. While in zeppelin spark interpreter, we submit the whole code to spark interpreter which will break it and execute it via scala repl api. ``` sc.version 1+1 ``` ---
[DISCUSS] Is interpreter binding necessary ?
Hi Folks, I raise this thread to discuss whether we need the interpreter binding. Currently when user create notes, they have to bind interpreters to their notes in note page. Otherwise they will hit interpreter not found issue. Besides that in zeppelin server side, we maintain the interpreter binding info in memory as well as in interpreter.json. IMHO, it is not necessary to do interpreter binding. Because it just add extra burden to maintain the interpreter binding info in zeppelin server side, and doesn't introduce any benefits. The only benefit is that we will check whether user have permission to use this interpreter, but actually zeppelin will check the permission when running paragraph, so I don't think we need to introduce interpreter binding just for this kind of permission check that we will do later. So overall, I would suggest to remove interpreter binding feature. What do you think ?
[GitHub] zeppelin issue #3055: ZEPPELIN-3587. Don't stop to interpret when the next l...
Github user jongyoul commented on the issue: https://github.com/apache/zeppelin/pull/3055 I think the most simple solution is to copy from the old interpret method. We discussed several times and fixed several times as well. ---
[GitHub] zeppelin issue #2231: ZEPPELIN-2150. NoSuchMethodError: org.apache.spark.ui....
Github user yywwd commented on the issue: https://github.com/apache/zeppelin/pull/2231 @zjffdu This issue is not related to the codes run in zeppelin. I mean, I cannot guarantee âUsing Livy interpreter in Zeppelinâ and "Using Programmatic API" work well at the same time. Using Zeppelin, I just write codes like this: ``` %livy.pyspark sc.version ``` just test whether it works. Using Programmatic API, I just use official examples: https://github.com/apache/incubator-livy/blob/master/examples/src/main/python/pi_app.py **BUT!!!** In **livy.spark.master yarn-cluster** mode zeppelin works, programmatic API cannot work In **livy.spark.master yarn** mode (the default mode), programmatic API works, zeppelin cannot work ---
[GitHub] zeppelin issue #2231: ZEPPELIN-2150. NoSuchMethodError: org.apache.spark.ui....
Github user zjffdu commented on the issue: https://github.com/apache/zeppelin/pull/2231 Sorry, I still not sure what code you run in zeppelin. If it is livy related issue, you need to ask question in livy mail list. ---
[GitHub] zeppelin issue #2231: ZEPPELIN-2150. NoSuchMethodError: org.apache.spark.ui....
Github user yywwd commented on the issue: https://github.com/apache/zeppelin/pull/2231 @zjffdu I'm sorry to response slowly, because I tried to reproduce the bugs. I thought it may caused by my codes, so I tried to use official PySpark examples, the bugs still occurred. This is the code I used. https://github.com/apache/incubator-livy/blob/master/examples/src/main/python/pi_app.py **Note:** I comment the last line # client.stop(True), cause I won't want to close the session after submitting just one job. The details about this bug are as follows: 1. When I use default yarn mode, that is "yarn", official PySpark examples and programmatic API work well. Using Livy interpreter in Zeppelin will throw exception:` NoSuchMethodError: org.apache.spark.ui.SparkUI.appUIAddress()` for the spark master. 2. ThenI change the yarn mode into "yarn-cluster" as SivaKaviyappa suggested, Zeppelin works well. But the logs of this statement will hav a warning: `"Warning: Master yarn-cluster is deprecated since 2.0. Please use master \"yarn\" with specified deploy mode instead.` However, Using programmatic API will have such bug: 2.1 I delete all Livy sessions, and run pi_app.py. It throw such exception: ``` ReadTimeout: HTTPConnectionPool(host='172.31.5.251', port=8998): Read timed out. (read timeout=10) Traceback (most recent call last): File "/home/ec2-user/wandongwu/livy_test_9/pi_app.py", line 35, in pi = client.submit(pi_job).result() File "/usr/local/lib/python2.7/site-packages/concurrent/futures/_base.py", line 462, in result return self.__get_result() File "/usr/local/lib/python2.7/site-packages/concurrent/futures/_base.py", line 414, in __get_result raise exception_type, self._exception, self._traceback TypeError: raise: arg 3 must be a traceback or None ``` But I find It has started a new Livy session. So I edit configuration parameter into `'http://:8998/sessions/0' 2`. It will throw another exception: ``` Traceback (most recent call last): File "/home/ec2-user/wandongwu/livy_test_9/pi_app.py", line 35, in pi = client.submit(pi_job).result() File "/usr/local/lib/python2.7/site-packages/concurrent/futures/_base.py", line 462, in result return self.__get_result() File "/usr/local/lib/python2.7/site-packages/concurrent/futures/_base.py", line 414, in __get_result raise exception_type, self._exception, self._traceback Exception: org.apache.livy.repl.PythonJobException: Client job error:Traceback (most recent call last): File "/mnt/yarn/usercache/livy/appcache/application_1528945006613_0302/container_1528945006613_0302_01_01/tmp/4991895008696585180", line 159, in processBypassJob deserialized_job = pickle.loads(serialized_job) File "/usr/lib64/python2.7/pickle.py", line 1388, in loads return Unpickler(file).load() File "/usr/lib64/python2.7/pickle.py", line 864, in load dispatch[key](self) File "/usr/lib64/python2.7/pickle.py", line 1096, in load_global klass = self.find_class(module, name) File "/usr/lib64/python2.7/pickle.py", line 1130, in find_class __import__(module) ImportError: No module named cloudpickle.cloudpickle ``` 3. Then I change yarn mode into default mode, that is "yarn", programmatic API can work well, but Zeppelin still cannot work. ---