[GitHub] zeppelin issue #3240: [ZEPPELIN-3840] Zeppelin on Kubernetes
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3240 Would be great to cut 0.9 release with this and all other great improvements that are currently only available in master. So more folks can take leverage of those features, and provide feedback sooner. Thank you! ---
[GitHub] zeppelin issue #3145: [ZEPPELIN-2572] multiple paragraphs actions
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3145 @Leemoonsoo please help reviewing this I personally think that color palette of selected paragraphs can be better something else, but functionally it's a great improvement to core Zeppelin UI. Thanks. ---
[GitHub] zeppelin issue #3113: [ZEPPELIN-3616] fix editor sections auto-collapse
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3113 cc @zjffdu @Leemoonsoo @prabhjyotsingh can you please merge this? Thank you. ---
[GitHub] zeppelin issue #3199: ZEPPELIN-3792. Support Kerberos Realm
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3199 Thanks @zjffdu ! Would be nice to have documentation as a reference on how to setup Kerberos realm for Zeppelin authentication. Or at least documentation that it's supported with perhaps links to Shiro with examples of shiro.ini. ---
[GitHub] zeppelin issue #3150: ZEPPELIN-3734. Remove runtimeinfo from note.json
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3150 Thanks On Tue, Aug 21, 2018 at 7:17 PM Jeff Zhang wrote: > Will merge if no more comments > > â > You are receiving this because you were mentioned. > Reply to this email directly, view it on GitHub > <https://github.com/apache/zeppelin/pull/3150#issuecomment-414873963>, or mute > the thread > <https://github.com/notifications/unsubscribe-auth/AC37KqePZ4i0cug16kym6wK_WOJnAWOrks5uTLEjgaJpZM4WDWHq> > . > ---
[GitHub] zeppelin issue #3150: ZEPPELIN-3734. Remove runtimeinfo from note.json
Github user Tagar commented on the issue:
https://github.com/apache/zeppelin/pull/3150
Yep, what I meant are fields like
"dateCreated": "2018-07-12 13:53:34.479",
"dateStarted": "2018-07-23 16:27:18.751",
"dateFinished": "2018-07-23 16:27:55.416",
under "results"
And also
"user": "rdautkha...@corp.epsilon.com",
"dateUpdated": "2018-07-23 16:27:18.714",
at the root of paragraph json data.
This information is used to render the string `Took {runtime} sec. Last
updated by {user} at {dateUpdated}.` at the end of each paragraph, correct? I
thought this PR removes persisting some of this information, so after zeppelin
restart this information will get lost, isn't it?
Thanks
---
[GitHub] zeppelin issue #3150: ZEPPELIN-3734. Remove runtimeinfo from note.json
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3150 Can this be an option? Perhaps that's on by default to make it compatible with current Zeppelin release. Our users find it useful to compare paragraph runtimes and who ran it from last time. Thanks. ---
[GitHub] zeppelin issue #3045: ZEPPELIN-3570. Fix for doing user search for LDAPRealm
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3045 Can you guys please have a look at https://issues.apache.org/jira/browse/ZEPPELIN-3719 in case if this change caused that problem ? ---
[GitHub] zeppelin issue #2923: ZEPPELIN-3312 Add option to convert username to lower ...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2923 Can you guys please have a look at https://issues.apache.org/jira/browse/ZEPPELIN-3719 in case if this change caused that problem ? ---
[GitHub] zeppelin issue #3103: ZEPPELIN-3666. Use zeppelin.interpreter.default to rep...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3103 As discussed in https://github.com/apache/zeppelin/pull/3059 it seems a good idea to have a **default interpreter group** set globally, and **default interpreter set at note level**. What do you think? Thanks! ---
[GitHub] zeppelin issue #3059: ZEPPELIN-3595. Remove interpreter binding in backend
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3059 @jongyoul I like the idea of having a default interpreter (and not a default interpreter group ) **per note**. +1 ---
[GitHub] zeppelin issue #3103: ZEPPELIN-3666. Use zeppelin.interpreter.default to rep...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3103 Thanks @zjffdu - that's a great improvement as ordering wasn't used in zeppelin. Would it be possible to introduce a similar knob to choose a default interpreter, not just default interpreter group? ---
[GitHub] zeppelin issue #3084: [zeppelin-3639] Add Ipython interpreter prerequisite c...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3084 that makes sense. thanks @khalidhuseynov ---
[GitHub] zeppelin issue #3103: ZEPPELIN-3666. Use zeppelin.interpreter.default to rep...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3103 @zjffdu, do I understand correctly that `zeppelin.interpreter.default` would choose default interpreter, and not just interpreter group? If so, it would also resolve https://issues.apache.org/jira/browse/ZEPPELIN-3282 Thanks! ---
[GitHub] zeppelin issue #3101: [ZEPPELIN-3667] [Improvement] Large CVS download.
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3101 FYI. That download button will be removed by https://github.com/apache/zeppelin/pull/3013 ---
[GitHub] zeppelin issue #3090: [ZEPPELIN-3645] Add LSP Protocol completion support
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3090 Very interesting improvements. Thanks for working on this. Shouldn't LSP server be embedded into Python / PySpark interpreter itself and not be a separate process? This would address both security concerns and ability to grasp code across paragraphs like in the above example. ---
[GitHub] zeppelin issue #3099: [ZEPPELIN-3665] fix notebook name
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3099 If there is a very long "folder/subfolder1/subfolder" part, wouldn't this change always to display only "folder/subfolder1/subfolder..." and not a notebook name? ---
[GitHub] zeppelin issue #3074: [ZEPPELIN-3610] Cluster Raft module design
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3074 Just out of curiosity, why Raft Protocol? Have you considered alternatives, for example, Zookeeper could do here, I guess. I think what the design document is missing is some sort of pros and cons compared to alternatives. Thanks! ---
[GitHub] zeppelin issue #3084: [zeppelin-3639] Add Ipython interpreter prerequisite c...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3084 Would be nice to check freeze output for tornado version. tornado 5.x is broken for Zeppelin. https://issues.apache.org/jira/browse/ZEPPELIN-3505 ---
[GitHub] zeppelin issue #3047: [ZEPPELIN-3574] fix large number rendering issue
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3047 wow. that's pretty serious issue. thanks for fixing this. LGTM. ---
[GitHub] zeppelin issue #3044: ZEPPELIN-3563. Add pool to paragraph property that use...
Github user Tagar commented on the issue:
https://github.com/apache/zeppelin/pull/3044
Thanks @zjffdu - that looks good to me. What about {username} instead of
{name} ?
---
[GitHub] zeppelin issue #3044: ZEPPELIN-3563. Add pool to paragraph property that use...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3044 > We could do that but it depends on the farischeduler.xml that user specified. If user didn't specify the user name as pool name in fairscheduler.xml, then it doesn't make sense to do that in zeppelin side. Yep, I understand that. They have to specify a pool name in `farischeduler.xml` either way - if it's given manually through paragraph property as proposed in this PR, or if it's taken from authenticated username as proposed in https://issues.apache.org/jira/browse/ZEPPELIN-3334 . Thanks. ---
[GitHub] zeppelin issue #3044: ZEPPELIN-3563. Add pool to paragraph property that use...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3044 I meant Zeppelin would set `spark.scheduler.pool` to username of the user that was used to authenticate into Zeppelin. ---
[GitHub] zeppelin issue #3044: ZEPPELIN-3563. Add pool to paragraph property that use...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3044 Would it be possible to set `spark.scheduler.pool` to authenticated user name as well, as described in https://issues.apache.org/jira/browse/ZEPPELIN-3334 I think it's a much better default than setting it manually in each paragraph. (still a great feature of having ability to set pool at a paragraph level too) ---
[GitHub] zeppelin issue #3013: [ZEPPELIN-3511] remove old button "Download Data as CS...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3013 my 2 cents: 1. yes. 2,3. yes. except that `grid-ui` doesn't have native `tsv` export, right? I thought `grid-ui` only allows to export as `csv` and as `xlsx`, is this correct? If it is, we might just drop `tsv` export. I personally never used it. `csv` and `xlsx` exports through `grid-ui` should be enough. ---
[GitHub] zeppelin issue #3013: [ZEPPELIN-3511] remove old button "Download Data as CS...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3013 @sanjaydasgupta I agree with what you're saying but what I was suggesting is just hook up **old button** to **ui-grid** ---
[GitHub] zeppelin issue #3013: [ZEPPELIN-3511] remove old button "Download Data as CS...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3013 Was thinking of another solution.. is it possible to *move* grid-ui's - Export all/visible data as csv/xls four options to that old Download menu? So grid-ui would only have more rare-used "Columns: .. " items, and export items will be moves completely to that older button that users got used to. So old button would exposes newer angular-ui-grid export functionality. Thoughts? ---
[GitHub] zeppelin issue #3000: [ZEPPELIN-3467] two-step, atomic configuration file
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/3000 > The orphaned file will not be automatically overwritten later because File.createTempFile(...) will always attempt to create a new filename that is unused in the directory. That makes now. Thanks for the detailed response. ---
[GitHub] zeppelin issue #2952: [Zeppelin-2572] multiple paragraphs actions
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2952 We were using PR this in prod for a couple of weeks. Works great. Left one additional comment based on users feedback. "Select a paragraph" tooltip change to "Add this paragraph to selection" would be better, as it selects that particular paragraph and based on tooltip users can see that it talks about multi-paragraph selection. ---
[GitHub] zeppelin issue #2978: [ZEPPELIN-3467] two-step, atomic configuration file wr...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2978 @sanjaydasgupta, `writeFile` in `FileSystemStorage` drops file first, and then renames temp file. It's not an atomic write, and also leaves a chance to loosing file that is being written. I'd say approach in this PR is more formalized and a better way to go. https://github.com/apache/zeppelin/blob/master/zeppelin-zengine/src/main/java/org/apache/zeppelin/notebook/FileSystemStorage.java#L155 ---
[GitHub] zeppelin issue #2601: [ZEPPELIN-2956] [font-end] Downloaded CSV/TSV data wil...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2601 > I believe one could remove old button "Download Data as CSV". filed https://issues.apache.org/jira/browse/ZEPPELIN-3511 to remove old export csv/tsv This idea was also briefly discussed on [PR-2971](https://github.com/apache/zeppelin/pull/2971#issuecomment-391219166) ---
[GitHub] zeppelin issue #2971: [ZEPPELIN-3466] Table export to excel is not working d...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2971 Thanks @prabhjyotsingh - filed https://issues.apache.org/jira/browse/ZEPPELIN-3511 to consider removing old export csv/tsv which is broken in some other ways (like when data has double quotes and commas) . ---
[GitHub] zeppelin issue #2978: [ZEPPELIN-3467] two-step, atomic configuration file wr...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2978 @sanjaydasgupta > do you recommend similar treatment for FileSystemConfigStorage also? yep, HDFS although is not a posix filesystem, but renaming a file is still implemented as an atomic operation. might want to consider moving atomicWriteToFile() to ConfigStorage so both LocalConfigStorage and FileSystemConfigStorage can use it. ---
[GitHub] zeppelin issue #2952: [Zeppelin-2572] multiple paragraphs actions
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2952 thank you @Savalek @zjffdu would it be possible to merge this to master? (and not to 0.8) thanks! ---
[GitHub] zeppelin issue #2978: [ZEPPELIN-3467] two-step, atomic configuration file wr...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2978 What's difference between LocalConfigStorage and FileSystemConfigStorage? I don't know Zeppelin internals that well. Wonder if this has to be fixed FileSystemConfigStorage.java as well? https://github.com/sanjaydasgupta/zeppelin/blob/36698a9a6a45610b409fa456f94255b32b746db8/zeppelin-zengine/src/main/java/org/apache/zeppelin/storage/FileSystemConfigStorage.java#L66 ---
[GitHub] zeppelin issue #2945: [ZEPPELIN-3430] fix logic of loading githubnotebookrep...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2945 got it, thanks @zjffdu ---
[GitHub] zeppelin issue #2979: ZEPPELIN-3484. sc.setJobGroup() shows up in error stac...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2979 works as expected. thanks for quick turnaround! LGTM. ---
[GitHub] zeppelin issue #2975: ZEPPELIN-3475: Bump up version of Apache Thrift
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2975 When I build Zeppelin, I see in maven build log > [INFO] Including org.apache.thrift:libthrift:jar:0.9.3 in the shaded jar. > [INFO] Including org.apache.thrift:libfb303:jar:0.9.3 in the shaded jar. Does this mean it's already shaded? cc @zjffdu ---
[GitHub] zeppelin issue #2945: [ZEPPELIN-3430] fix logic of loading githubnotebookrep...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2945 @zjffdu, is it possible to commit this into the 0.8 branch? thanks. ---
[GitHub] zeppelin issue #2978: [ZEPPELIN-3467] two-step, atomic configuration file wr...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2978 Thanks @sanjaydasgupta. I will give this a try today. ---
[GitHub] zeppelin issue #2979: ZEPPELIN-3484. sc.setJobGroup() shows up in error stac...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2979 Thanks @zjffdu - I will test this today. ---
[GitHub] zeppelin issue #2971: [ZEPPELIN-3466] Table export to excel is not working d...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2971 Got it @prabhjyotsingh - thanks. So there are two separate ways to export data now - [1] is the newer way and [2] is the older way. What's advantage of having two export options? Should we leave just [1] if this newer export through Angular-ui-grid seems to be better? For example, I think it might be a little bit confusing to users to have two different ways to exprot csv. Thanks. [1]  [2]  ---
[GitHub] zeppelin issue #2963: [ZEPPELIN-3450] Number sorting issue
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2963 @sameer79 I refreshed my Zeppelin to latest master snapshot. Can't reproduce any longer the issue I specified on the screenshot above. Please disregard my earlier comment. LGTM. This would be great if this fix can make into 0.8 release. ---
[GitHub] zeppelin issue #2976: [ZEPPELIN-3478] Download Data as CSV downloads data as...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2976 LGTM Verified manually - this patch fixes the issue. Thanks a lot @prabhjyotsingh ---
[GitHub] zeppelin issue #2975: ZEPPELIN-3475: Bump up version of Apache Thrift
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2975 thanks @prabhjyotsingh bumping up 0.9.3 seems a good idea to me, but I'd like somebody else to review this too. my 2 cents - It might be also good to shade Thrift to avoid future conflicts with older/newer versions of Spark/Hive that could be relying on? ---
[GitHub] zeppelin issue #2975: ZEPPELIN-3475: Bump up version of Apache Thrift
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2975 @prabhjyotsingh yes, seems that way. It might be more specific for Cloudera or more generic. I know that Cloudera packages CDH with a specific version of Thrift. It used to be 0.9.2 in earlier CDH 5 versions - now it is 0.9.3 as I mentioned above. Thanks. ---
[GitHub] zeppelin issue #2971: [ZEPPELIN-3466] Table export to excel is not working d...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2971 How to activate XLS/XLSX download option? It doesn't show up for me with this PR applied.  ---
[GitHub] zeppelin issue #2976: [ZEPPELIN-3478] Download Data as CSV downloads data as...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2976 thanks for prompt response @prabhjyotsingh I will give this a try today. ---
[GitHub] zeppelin issue #2975: ZEPPELIN-3475: Bump up version of Apache Thrift
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2975 @felixcheung as an example, I've seen NoSuchMethodError exceptions like one below when working with Spark interpreter reading Hive tables and Thrift version had a version mismatch .. so it may not be as internal as it looks at first. > Caused by: java.lang.NoSuchMethodError: com.facebook.fb303.FacebookService$Client.sendBaseOneway(Ljava/lang/String;Lorg/apache/thrift/TBase;)V > at com.facebook.fb303.FacebookService$Client.send_shutdown(FacebookService.java:436) > at com.facebook.fb303.FacebookService$Client.shutdown(FacebookService.java:430) > ---
[GitHub] zeppelin issue #2971: [ZEPPELIN-3466] Table export to excel is not working d...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2971 Could you please also have a look at https://issues.apache.org/jira/browse/ZEPPELIN-3478 CSV/TSV exports seem to be broken too. ---
[GitHub] zeppelin issue #2974: ZEPPELIN-3472 No interpreter status is shown after res...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2974 I think it's a great idea to add something like this to also show status if an interpreter is running. so show a green icon if interpreter is running/ or had been restarted successfully. no icon - if it wasn't started. red icon - if interpreter had issues restarting, or if it was terminated / killed through Lifecycle management.. what do you think? ---
[GitHub] zeppelin issue #2975: ZEPPELIN-3475: Bump up version of Apache Thrift
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2975 checked a few newer CDH 5 versions and they're packaged with 0.9.3. older CDH 5 version come with 0.9.2. CDH 6 will be shipped with 0.9.3 too. my two cents: +1 from me. thanks. ---
[GitHub] zeppelin issue #2963: [ZEPPELIN-3450] Number sorting issue
Github user Tagar commented on the issue:
https://github.com/apache/zeppelin/pull/2963
@sameer79 I was using latest Zeppelin from master snapshot. Chrome browser.
Can you reproduce the same sorting issue for strings?
Here's the code I used:
```python
%pyspark
print sorted(['abba2','abba','abba','Abba','abba','aBBa' ])
z.show(spark.sql("""
select 1,2,0, '2014-05-01', 'abba2'
union all select 1,3,-1, '2014-05-01', 'abba'
union all select 1,5,3, '2014-12-01', 'abba'
union all select 1,9,-3, '2014-05-01', 'Abba'
union all select 1,2,-10, '2014-05-01', 'abba'
union all select 2,7,3, '2014-05-01', 'aBBa'
"""))
```
---
[GitHub] zeppelin issue #2963: [ZEPPELIN-3450] Number sorting issue
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2963 Thanks for fixing this - I just had a chance to test and confirm it fixes number sorting. PR title reads "Number sorting issue", but code change seems tries to address String and Date sorting issues too? I see String sorting is still not correct even with this PR applied: 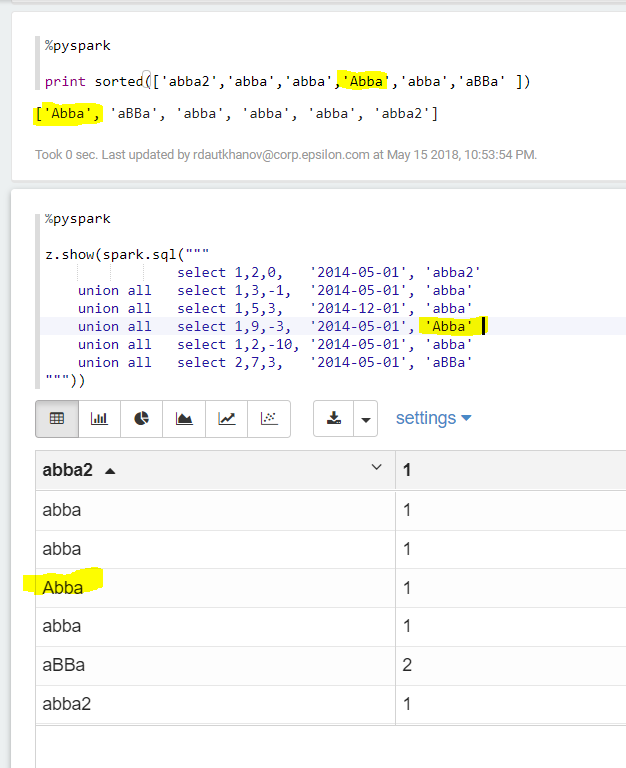 'Abba' should be at the top. It seems sort strings while ignoring their case? ---
[GitHub] zeppelin issue #2945: [ZEPPELIN-3430] fix logic of loading githubnotebookrep...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2945 This PR fixes the issue I described in https://github.com/apache/zeppelin/pull/2760#issuecomment-386148566 Now the git/versioning subpanel is back! Thanks. ---
[GitHub] zeppelin issue #2760: ZEPPELIN-3196. Plugin framework for Zeppelin Engine
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2760 I wonder if https://github.com/apache/zeppelin/pull/2945 fixes issue I described in my earlier comment. cc @cvaliente @myuwono ---
[GitHub] zeppelin issue #2760: ZEPPELIN-3196. Plugin framework for Zeppelin Engine
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2760 @zjffdu, just updated to master, and noticed versioning toolbar is missing... I think it's because of this PR. We have `zeppelin.notebook.storage`=`org.apache.zeppelin.notebook.repo.GitNotebookRepo` in `zeppelin-site.xml` .. is there is some additional setting required now, or perhaps Zeppelin now has to be build differently? Thanks! ---
[GitHub] zeppelin issue #2742: [ZEPPELIN-3168] Interpreter Settings Authorization
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2742 @necosta thanks for this great feature. It makes a lot of sense for Zeppelin instance shared with different set of users. Would it be possible to do this interpreter settings authorization for LDAP groups too, not just for users? ---
[GitHub] zeppelin issue #2923: ZEPPELIN-3312 Add option to convert username to lower ...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2923 I was thinking we should also lower-case usernames that are stored in `notebook-authorization.json`, when doing authorization. Otherwise users wouldn't be able to see their own notebooks when this option is enabled and they used case inconsistently when were logging into Zeppelin before. ---
[GitHub] zeppelin issue #2923: ZEPPELIN-3312 Add option to convert username to lower ...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2923 Great idea.. I had a similar jira https://issues.apache.org/jira/browse/ZEPPELIN-2886 Thanks! ---
[GitHub] zeppelin issue #2894: ZEPPELIN-3364. Followup of ZEPPELIN-3362, improve Zepp...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2894 Thanks @zjffdu cc @prabhjyotsingh - you were saying in [a comment for ZEPPELIN-3292](https://issues.apache.org/jira/browse/ZEPPELIN-3292?focusedCommentId=16387420=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-16387420) there is some issue in the backend that have caused data duplication and you made a workaround in the [frontend here](https://github.com/apache/zeppelin/pull/2835) Can you please help review if this PR also hopefully fixes that data duplication in the backend? Not sure if we need a separate PR for that? IPython/IPySpark is newer in Zeppelin and may have some issues so would be great to make it rock-solid as I know there are more PySpark users than Spark users using Scala API.. ---
[GitHub] zeppelin issue #2834: [ZEPPELIN-1967] Passing Z variables to Shell and SQL I...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2834 @zjffdu, @felixcheung would be exciting to have this feature be part of the 0.8.0 release. Since there is a way to maintain backward compatibility, it seems to be a low hanging fruit as it's a great improvement in Zeppelin functionality. Thanks @sanjaydasgupta and everyone! ---
[GitHub] zeppelin issue #2834: [ZEPPELIN-1967] Passing Z variables to Shell and SQL I...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2834 @zjffdu Great idea on paragraph-level properties! There are so many possible uses for this feature like ones you explained below. For interpolation I think there should be a way to do it globally too, to match Jupyter's behavior. And it could be also optionally enabled at paragraph level like you're describing. Not sure I understood on overhead though - since it will be only applied to code in the paragraphs. @sanjaydasgupta > I am thinking if we need (2) at all, since (1) alone is enough for allowing users to start using the new feature in a safe and controlled way. I agree, thank you. @zjffdu, what @sanjaydasgupta is saying allows to switch this feature off at global level, so we can maintain compatibility with previous version, and only switch interpolation when users choose to enable it. It looks like a good idea to me. We could add enabling this at paragraph-level as part of another PR later, when this new facility to have paragraph-level properties will be available. What do you guys think? ---
[GitHub] zeppelin issue #2834: [ZEPPELIN-1967] Passing Z variables to Shell and SQL I...
Github user Tagar commented on the issue:
https://github.com/apache/zeppelin/pull/2834
What happens when a notebook had code {something} and "something" doesn't
exist as a 'z' variable?
Would it be possible to review that comment I left earlier in
https://github.com/apache/zeppelin/pull/2502#issuecomment-324095161
Should we have a Zeppelin option that controls this behavior?
> Option 1 if used - it'll completely follow Jupyter bahavior (no error,
{..} block return unchanged).
> Option 2 - fail explicitly if variable in curly braces can't be found.
> That being said, I think most of folks may actually prefer option 1, as
introduction of { .. } may be a breaking change for some notebooks' code. So I
think Option 1 should be default.
Because this change may break code in some users' notebooks (if they had
curly braces), it would be nice to let users choose if they want to use Option
1 (so their code will be compatible / not broken by this PR), or Option 2 which
would tell them explicitly that variable isn't found.
---
[GitHub] zeppelin issue #2684: [Zeppelin-2572] multiple paragraphs actions
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2684 Just noticed this.. I think it's a great feature! In Jupyter we can also select multiple paragraphs. Although it is made more seamless.. I believe you could Ctrl+click anywhere on a cell to select it. So no separate UI element was necessary (like a checkbox that you have). Selected cells are just slightly highlighted then. Two pros for this approach: - easier to select multiple cells as you could click anywhere on a cell to add it to a selection; - no additional UI elements - easier to find what cells were selected. ---
[GitHub] zeppelin issue #2782: [ZEPPELIN-2729] Paragraph numbering
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2782 I think it's a good improvement. As an example, Databricks spark notebooks also have paragraph numbering across whole notebook. Thanks. ---
[GitHub] zeppelin issue #2833: ZEPPELIN-3286. Run All Paragraphs stops if there is a ...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2833 Tested manually - this patch fixes issue described in ZEPPELIN-3286 Thank you @zjffdu ---
[GitHub] zeppelin issue #2835: [ZEPPELIN-3289] Table not using full height after para...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2835 @weand I just logged in https://issues.apache.org/jira/browse/ZEPPELIN-3292 for data duplication ) I don't think it's related to this PR? ---
[GitHub] zeppelin issue #2833: ZEPPELIN-3286. Run All Paragraphs stops if there is a ...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2833 thanks Jeff! will validate a bit later today. ---
[GitHub] zeppelin issue #2817: [ZEPPELIN-3264] Notebook Snapshot feature.
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2817 @SleepyThread - great feature! Building on @felixcheung's comment, it would be good if Snapshot feature would use org.apache.zeppelin.notebook.repo.GitNotebookRepo to store a snapshot/revision, so then you could compare revisions etc. ps. Looks like commits should be slashed? It shows unrelated commits in this PR. ---
[GitHub] zeppelin issue #2822: ZEPPELIN-3242. Listener threw an exception java.lang.N...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2822 Manually tested. Works as expected. This PR fixes: - Spark job progress bar - ability to cancel as spark job from paragraph - Spark Driver web UI link. Thanks a lot @zjffdu ---
[GitHub] zeppelin issue #2822: ZEPPELIN-3242. Listener threw an exception java.lang.N...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2822 thank you @zjffdu - I will give this a try today ---
[GitHub] zeppelin issue #2812: disable tab completion
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2812 One way to fix [ZEPPELIN-3253](https://issues.apache.org/jira/browse/ZEPPELIN-3253?focusedCommentId=16373706=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-16373706 ) - this is just proof of concept ---
[GitHub] zeppelin pull request #2812: disable tab completion
Github user Tagar closed the pull request at: https://github.com/apache/zeppelin/pull/2812 ---
[GitHub] zeppelin pull request #2812: disable tab completion
GitHub user Tagar opened a pull request: https://github.com/apache/zeppelin/pull/2812 disable tab completion ### What is this PR for? A few sentences describing the overall goals of the pull request's commits. First time? Check out the contributing guide - https://zeppelin.apache.org/contribution/contributions.html ### What type of PR is it? [Bug Fix | Improvement | Feature | Documentation | Hot Fix | Refactoring] ### Todos * [ ] - Task ### What is the Jira issue? * Open an issue on Jira https://issues.apache.org/jira/browse/ZEPPELIN/ * Put link here, and add [ZEPPELIN-*Jira number*] in PR title, eg. [ZEPPELIN-533] ### How should this be tested? * First time? Setup Travis CI as described on https://zeppelin.apache.org/contribution/contributions.html#continuous-integration * Strongly recommended: add automated unit tests for any new or changed behavior * Outline any manual steps to test the PR here. ### Screenshots (if appropriate) ### Questions: * Does the licenses files need update? * Is there breaking changes for older versions? * Does this needs documentation? You can merge this pull request into a Git repository by running: $ git pull https://github.com/Tagar/zeppelin master Alternatively you can review and apply these changes as the patch at: https://github.com/apache/zeppelin/pull/2812.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2812 commit 0ecc35233a68844c0c388edefaec34ab61209d16 Author: Ruslan Dautkhanov <tagar@...> Date: 2018-02-22T23:25:35Z disable tab completion ---
[GitHub] zeppelin issue #2624: [ZEPPELIN-2965] Add code completion for livy interpret...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2624 This commit seems broke Tab to indent text behavior. https://issues.apache.org/jira/browse/ZEPPELIN-3253 ---
[GitHub] zeppelin issue #2809: [ZEPPELIN-3249] Add support for streaming table
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2809 I think as a nice side effect, this PR also fixes https://issues.apache.org/jira/browse/ZEPPELIN-3238 - see comments there ---
[GitHub] zeppelin issue #2323: [ZEPPELIN-2411] Improve Table
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2323 Great improvement. Submitted https://issues.apache.org/jira/browse/ZEPPELIN-3251 to consider showing rows/columns lazily on scrolling events as otherwise ui-grid has a significant overhead for wide datasets so it randers much slower too. Other ideas? ---
[GitHub] zeppelin issue #2649: [ZEPPELIN-3033] IPYNB import/export
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2649 Would be great to have this functionality part of core Zeppelin. Any plans to move this PR forward? Thanks! ---
[GitHub] zeppelin issue #2802: ZEPPELIN-3236. Make grpc framesize configurable
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2802 @zjffdu I just verified this new commit and it works great. Glad to see exceptions in ipython backend are now being captured correctly. I wasn't able to actually test frame size problem, as it's hard to reproduce. As @ejona86 said today in https://github.com/grpc/grpc-java/issues/4086#issuecomment-367053465 > Note that something else is broken if you're seeing that error. You should not be receiving a frame that large. (Chances are it's not actually a frame length and we're seeing garbage.) So I think that frame size error might be caused by some other problem. But it's great we can make frame size configurable now. ---
[GitHub] zeppelin issue #2802: ZEPPELIN-3236. Make grpc framesize configurable
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2802 LGTM thanks a lot @zjffdu ---
[GitHub] zeppelin issue #2810: ZEPPELIN-3239. unicode characters in an iPython paragr...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2810 Verified manually. Works as expected. Thanks a lot @zjffdu ---
[GitHub] zeppelin issue #2782: [ZEPPELIN-2729] Paragraph numbering
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2782 I think a low-hanging fruit here might be if Zeppelin would treat paragraph titles as mark down code? So if you added leading `#` it would mean a high-level section of the notebook, `##` would mean a sub-section etc. So then it should be more straight-forward to implement something like above mentioned floating ToC with automatic section numbering from Jupyter natively in Zeppelin. I've seen zeppelin-toc-spell but haven't tried to use it. What do you guys think? ---
[GitHub] zeppelin issue #2802: ZEPPELIN-3236. Make grpc framesize configurable
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2802 thank you @zjffdu - I will check this today. ---
[GitHub] zeppelin issue #2810: ZEPPELIN-3239. unicode characters in an iPython paragr...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2810 thanks @zjffdu! will give this a try today. ---
[GitHub] zeppelin issue #2808: [ZEPPELIN-3243] fix IndexOutOfBoundsException when 'No...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2808 I think I've seen this behavior too. Thanks for fixing this. ---
[GitHub] zeppelin issue #2802: ZEPPELIN-3236. Make grpc framesize configurable
Github user Tagar commented on the issue:
https://github.com/apache/zeppelin/pull/2802
> ERROR [2018-02-14 10:39:10,922] ({grpc-default-executor-3}
IPythonClient.java[onError]:138) - Fail to call IPython grpc
> io.grpc.StatusRuntimeException: RESOURCE_EXHAUSTED:
io.grpc.netty.NettyClientTransport$3: Frame size 216695976 exceeds maximum:
4194304.
> at io.grpc.Status.asRuntimeException(Status.java:543)
> at
io.grpc.stub.ClientCalls$StreamObserverToCallListenerAdapter.onClose(ClientCalls.java:395)
> at
io.grpc.internal.ClientCallImpl.closeObserver(ClientCallImpl.java:426)
> at
io.grpc.internal.ClientCallImpl.access$100(ClientCallImpl.java:76)
> at
io.grpc.internal.ClientCallImpl$ClientStreamListenerImpl.close(ClientCallImpl.java:512)
> at
io.grpc.internal.ClientCallImpl$ClientStreamListenerImpl.access$700(ClientCallImpl.java:429)
> at
io.grpc.internal.ClientCallImpl$ClientStreamListenerImpl$1StreamClosed.runInContext(ClientCallImpl.java:544)
> at io.grpc.internal.ContextRunnable.run(ContextRunnable.java:52)
> at
io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:117)
> at
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> INFO [2018-02-14 10:39:10,923] ({grpc-default-worker-ELG-1-2}
AbstractClientStream2.java[inboundDataReceived]:249) - Received data on closed
stream
> INFO [2018-02-14 10:39:10,924] ({grpc-default-worker-ELG-1-2}
AbstractClientStream2.java[inboundDataReceived]:249) - Received data on closed
stream
> INFO [2018-02-14 10:39:10,925] ({grpc-default-worker-ELG-1-2}
AbstractClientStream2.java[inboundDataReceived]:249) - Received data on closed
stream
>
@zjffdu that's what I have.. is this helpful? It seems contain full
exception stack.
---
[GitHub] zeppelin issue #2805: [ZEPPELIN-3240] Zeppelin server fail to start if inter...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2805 Are those kind of properties mix in interpreter could happen because of Zeppelin upgrade? I.e. old properties and new properties mix? ---
[GitHub] zeppelin issue #2802: ZEPPELIN-3236. Make grpc framesize configurable
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2802 @zjffdu I don't have a reproducible case yet. This error hasn't been very consistent for me so it might be also a side effect of another problem. That's why I asked above if we could capture exceptions in grpc better. Also check what you think of the suggestion made in grpc/grpc-java#4086 to make a new grpc stream for each call? ---
[GitHub] zeppelin issue #2802: ZEPPELIN-3236. Make grpc framesize configurable
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2802 1) My main point was that this exception should be thrown to the user, so he or she has a chance to increase this limit. Currently if it breaks, only way to find out about this limitation is to enable debugging and not a lot of users can do that. 2) You're right .. it's 200M not sure how that user got that much data. That wasn't from my code, but from a colleague of mine. I guess it was a larger table of data. Would you mine making default somewhere in the range 16-32M? I think a lot of folks would run into the 4M limit. 3) Also, it would be great if IPythonInterpreter would catch exceptions better. Found another problem - https://issues.apache.org/jira/browse/ZEPPELIN-3239 - unrelated to this one, but it also shows the same symptoms to the user - Spark interpreter just becomes irresponsive. ---
[GitHub] zeppelin issue #2802: ZEPPELIN-3236. Make grpc framesize configurable
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2802 Thanks for the heads up, yep I figured out that I have to tune up zeppelin.ipython.grpc.framesize to a large number. I looked over the PR. Two quick suggestions 1) Would it be possible to make spark interpreter keep and not close the stream if such an exception happens? We can see a higher limit, but I am sure users will have cases when they will try to go higher. The Spark interpreter is then in a bad state and only way to fix this is to try increase a limit again.. Not sure if this problem belongs to Zeppelin or to grpc, so provisionally opened an issue in grpc too - https://github.com/grpc/grpc-java/issues/4086 2) Should we increase the default? .. 4Mb isn't that hard to hit when ipython returns a mid-size dataset / table. ---
[GitHub] zeppelin issue #2782: [ZEPPELIN-2729] Paragraph numbering
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2782 Since we migrated from Jupyter to Zeppelin, I miss a lot floating ToC menu Jupyter extension. Super useful for larger notebooks - navigation becomes very transparent. http://jupyter-contrib-nbextensions.readthedocs.io/en/latest/nbextensions/toc2/README.html 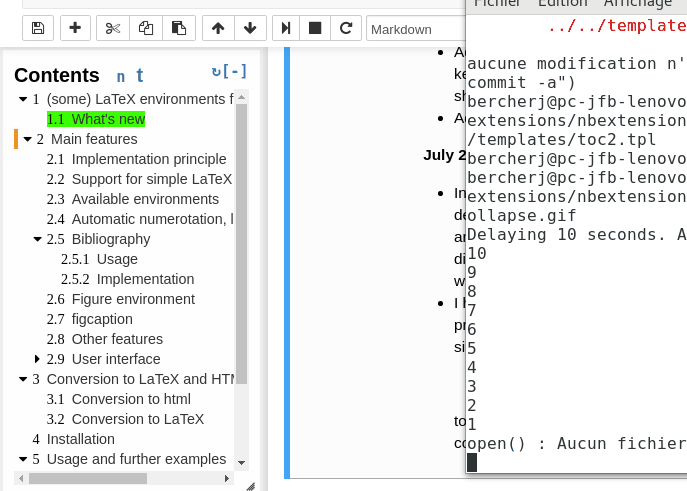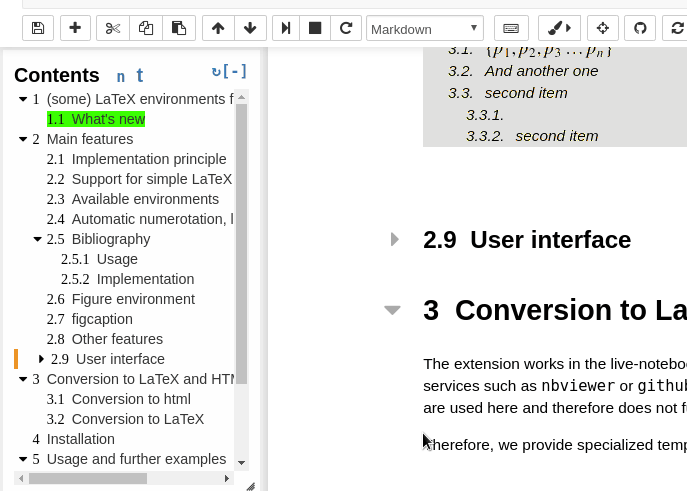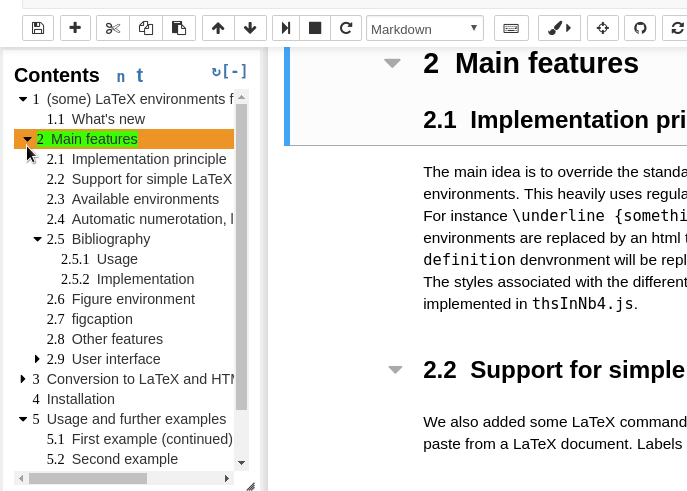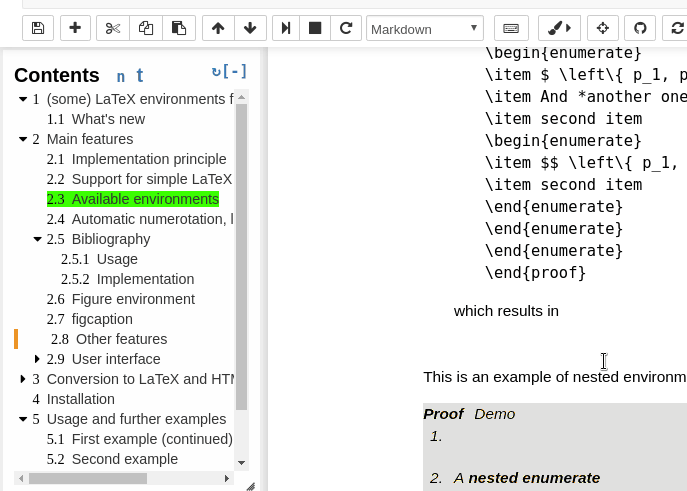   Hope to see something like this in Zeppelin one day. ---
[GitHub] zeppelin issue #2790: ZEPPELIN-3222. Shade libfb303 in SparkInterpreter
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2790 Manually tested master with this PR when using CDH 5.12 and it solves NPE issue when starting Spark interpreter. Thanks @zjffdu ! ---
[GitHub] zeppelin issue #2744: ZEPPELIN-3184. Use hadoop-azure to replace azure-stora...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2744 Do you mean compile without option like > -Dhadoop.version=2.6.0-cdh5.12.1 ? It compiles fine but I was getting runtime errors (like some non-existent method etc). Can't find details now. But I will give it a try again. Thanks. ---
[GitHub] zeppelin issue #2744: ZEPPELIN-3184. Use hadoop-azure to replace azure-stora...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2744 This commit broke build for CDH (maven convergence error on dependencies). Should there be a automated test to check if a commit breaks compatibility with Cloudera distro of Hadoop? ---
[GitHub] zeppelin issue #2723: ZEPPELIN-3119. Build issue with CDH
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2723 thank you @zjffdu ---
[GitHub] zeppelin issue #2555: [ZEPPELIN-2885] Have Logger subclass StringIO and over...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2555 FYI This Zeppelin issue will be worked around in Sparkling Water in following PR - https://github.com/h2oai/h2o-3/pull/1705 ---
[GitHub] zeppelin issue #2555: [ZEPPELIN-2885] Have Logger subclass StringIO and over...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2555 Found this works around the issue on Python 2.. will test more. ``` import sys sys.stdout.isatty = lambda : False sys.stdout.encoding = None ``` ---
[GitHub] zeppelin issue #2555: [ZEPPELIN-2885] Have Logger subclass StringIO and over...
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2555 @sctincman Did you find a workaround for this issue ? Thanks ---
[GitHub] zeppelin issue #2631: ZEPPELIN-2197. Interpreter Lifecycle Manager
Github user Tagar commented on the issue: https://github.com/apache/zeppelin/pull/2631 One last thing - from user experience it would be convenient to know when their interpreters timed out. Something like a popup or just some sort of a graphical flag would do, I guess? Not sure how hard it'll be add this at this point. ---