[jira] [Work logged] (HDFS-16394) RPCMetrics increases the number of handlers in processing
[ https://issues.apache.org/jira/browse/HDFS-16394?focusedWorklogId=699817&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699817 ] ASF GitHub Bot logged work on HDFS-16394: - Author: ASF GitHub Bot Created on: 22/Dec/21 06:34 Start Date: 22/Dec/21 06:34 Worklog Time Spent: 10m Work Description: jianghuazhu commented on pull request #3822: URL: https://github.com/apache/hadoop/pull/3822#issuecomment-999323118 Here are some data that has been verified. 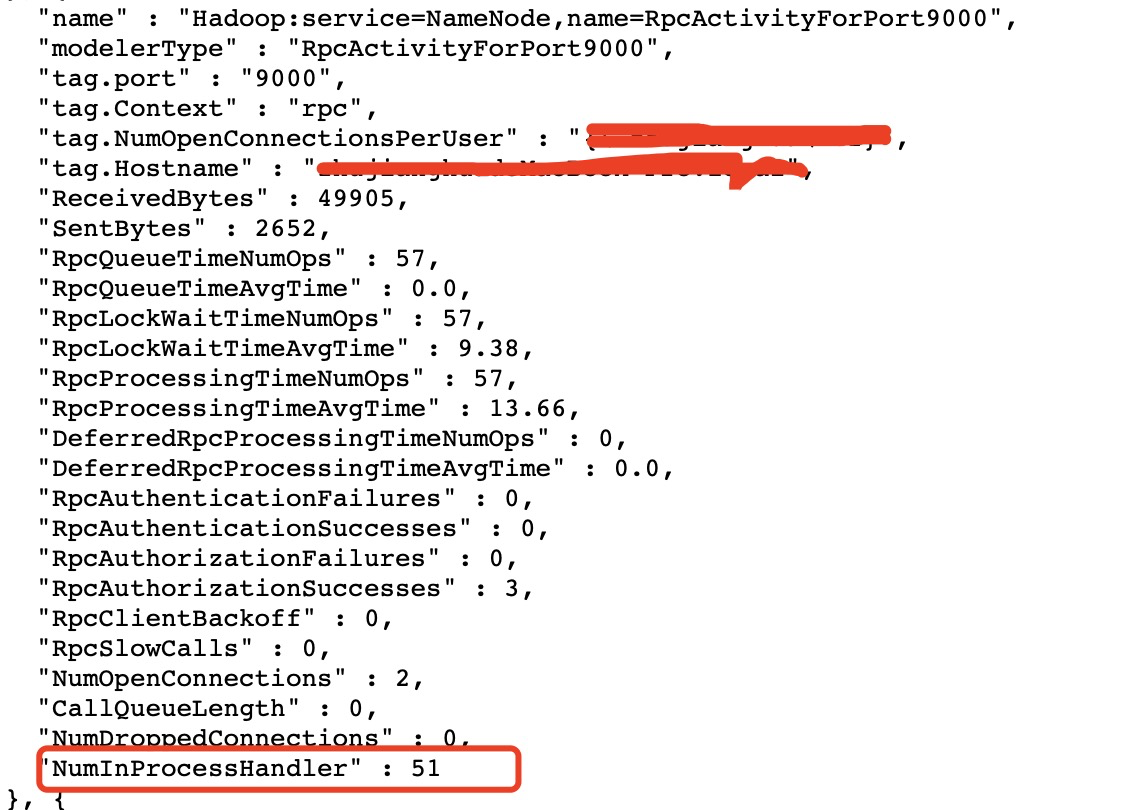 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 699817) Time Spent: 20m (was: 10m) > RPCMetrics increases the number of handlers in processing > - > > Key: HDFS-16394 > URL: https://issues.apache.org/jira/browse/HDFS-16394 > Project: Hadoop HDFS > Issue Type: Improvement > Components: namenode >Affects Versions: 2.9.2 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Labels: pull-request-available > Time Spent: 20m > Remaining Estimate: 0h > > When using RPC, we recorded a lot of useful information, such as Queue time, > Processing time. These are very helpful. > But we can't know how many handlers are actually working now (only those that > handle Call), especially when the Call Queue is very high. This is also not > conducive to us optimizing the cluster. > It would be very helpful if we can see the number of handlers being processed > in RPCMetrics. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work started] (HDFS-16394) RPCMetrics increases the number of handlers in processing
[ https://issues.apache.org/jira/browse/HDFS-16394?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Work on HDFS-16394 started by JiangHua Zhu. --- > RPCMetrics increases the number of handlers in processing > - > > Key: HDFS-16394 > URL: https://issues.apache.org/jira/browse/HDFS-16394 > Project: Hadoop HDFS > Issue Type: Improvement > Components: namenode >Affects Versions: 2.9.2 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > When using RPC, we recorded a lot of useful information, such as Queue time, > Processing time. These are very helpful. > But we can't know how many handlers are actually working now (only those that > handle Call), especially when the Call Queue is very high. This is also not > conducive to us optimizing the cluster. > It would be very helpful if we can see the number of handlers being processed > in RPCMetrics. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16394) RPCMetrics increases the number of handlers in processing
[ https://issues.apache.org/jira/browse/HDFS-16394?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDFS-16394: -- Labels: pull-request-available (was: ) > RPCMetrics increases the number of handlers in processing > - > > Key: HDFS-16394 > URL: https://issues.apache.org/jira/browse/HDFS-16394 > Project: Hadoop HDFS > Issue Type: Improvement > Components: namenode >Affects Versions: 2.9.2 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > When using RPC, we recorded a lot of useful information, such as Queue time, > Processing time. These are very helpful. > But we can't know how many handlers are actually working now (only those that > handle Call), especially when the Call Queue is very high. This is also not > conducive to us optimizing the cluster. > It would be very helpful if we can see the number of handlers being processed > in RPCMetrics. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16394) RPCMetrics increases the number of handlers in processing
[ https://issues.apache.org/jira/browse/HDFS-16394?focusedWorklogId=699816&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699816 ] ASF GitHub Bot logged work on HDFS-16394: - Author: ASF GitHub Bot Created on: 22/Dec/21 06:30 Start Date: 22/Dec/21 06:30 Worklog Time Spent: 10m Work Description: jianghuazhu opened a new pull request #3822: URL: https://github.com/apache/hadoop/pull/3822 ### Description of PR Now we can't see how many Handlers in RPC are actually being used. It would be very helpful to see this information directly through RPCMetrics. The purpose of this pr is to solve this problem. Details: HDFS-16394 ### How was this patch tested? This needs to be tested. When accessing RPC, you need to know how many handlers are being used based on RPCMetrics. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 699816) Remaining Estimate: 0h Time Spent: 10m > RPCMetrics increases the number of handlers in processing > - > > Key: HDFS-16394 > URL: https://issues.apache.org/jira/browse/HDFS-16394 > Project: Hadoop HDFS > Issue Type: Improvement > Components: namenode >Affects Versions: 2.9.2 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > When using RPC, we recorded a lot of useful information, such as Queue time, > Processing time. These are very helpful. > But we can't know how many handlers are actually working now (only those that > handle Call), especially when the Call Queue is very high. This is also not > conducive to us optimizing the cluster. > It would be very helpful if we can see the number of handlers being processed > in RPCMetrics. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16389) Improve NNThroughputBenchmark test mkdirs
[
https://issues.apache.org/jira/browse/HDFS-16389?focusedWorklogId=699811&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699811
]
ASF GitHub Bot logged work on HDFS-16389:
-
Author: ASF GitHub Bot
Created on: 22/Dec/21 05:57
Start Date: 22/Dec/21 05:57
Worklog Time Spent: 10m
Work Description: jianghuazhu commented on a change in pull request #3819:
URL: https://github.com/apache/hadoop/pull/3819#discussion_r773618967
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/test/java/org/apache/hadoop/hdfs/server/namenode/NNThroughputBenchmark.java
##
@@ -265,6 +265,11 @@ void benchmark() throws IOException {
LOG.info("Starting " + numOpsRequired + " " + getOpName() + "(s).");
for(StatsDaemon d : daemons)
d.start();
+ } catch (Exception e) {
+if (e instanceof ArrayIndexOutOfBoundsException) {
+ LOG.error("The -dirsPerDir or -filesPerDir parameter set is
incorrect.");
Review comment:
Thanks @jojochuang for the comment and review.
I agree with your suggestion, and I will update it later.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 699811)
Time Spent: 50m (was: 40m)
> Improve NNThroughputBenchmark test mkdirs
> -
>
> Key: HDFS-16389
> URL: https://issues.apache.org/jira/browse/HDFS-16389
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: benchmarks, namenode
>Affects Versions: 2.9.2
>Reporter: JiangHua Zhu
>Assignee: JiangHua Zhu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 50m
> Remaining Estimate: 0h
>
> When using the NNThroughputBenchmark test to create a large number of
> directories, some abnormal information will be prompted.
> Here is the command:
> ./bin/hadoop org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark -fs
> hdfs:// -op mkdirs -threads 30 -dirs 500
> There are some exceptions here, such as:
> 21/12/20 10:25:00 INFO namenode.NNThroughputBenchmark: Starting benchmark:
> mkdirs
> 21/12/20 10:25:01 INFO namenode.NNThroughputBenchmark: Generate 500
> inputs for mkdirs
> 21/12/20 10:25:08 ERROR namenode.NNThroughputBenchmark:
> java.lang.ArrayIndexOutOfBoundsException: 20
> at
> org.apache.hadoop.hdfs.server.namenode.FileNameGenerator.getNextDirName(FileNameGenerator.java:65)
> at
> org.apache.hadoop.hdfs.server.namenode.FileNameGenerator.getNextFileName(FileNameGenerator.java:73)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark$MkdirsStats.generateInputs(NNThroughputBenchmark.java:668)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark$OperationStatsBase.benchmark(NNThroughputBenchmark.java:257)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark.run(NNThroughputBenchmark.java:1528)
> at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
> at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:90)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark.runBenchmark(NNThroughputBenchmark.java:1430)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark.main(NNThroughputBenchmark.java:1550)
> Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 20
> at
> org.apache.hadoop.hdfs.server.namenode.FileNameGenerator.getNextDirName(FileNameGenerator.java:65)
> at
> org.apache.hadoop.hdfs.server.namenode.FileNameGenerator.getNextFileName(FileNameGenerator.java:73)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark$MkdirsStats.generateInputs(NNThroughputBenchmark.java:668)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark$OperationStatsBase.benchmark(NNThroughputBenchmark.java:257)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark.run(NNThroughputBenchmark.java:1528)
> at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
> at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:90)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark.runBenchmark(NNThroughputBenchmark.java:1430)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark.main(NNThroughputBenchmark.java:1550)
> These messages appear because some parameters are incorrectly set, such as
> dirsPerDir or filesPerDir.
> When we see this log, this will make us have
[jira] [Work logged] (HDFS-16355) Improve block scanner desc
[
https://issues.apache.org/jira/browse/HDFS-16355?focusedWorklogId=699806&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699806
]
ASF GitHub Bot logged work on HDFS-16355:
-
Author: ASF GitHub Bot
Created on: 22/Dec/21 05:35
Start Date: 22/Dec/21 05:35
Worklog Time Spent: 10m
Work Description: jojochuang commented on a change in pull request #3724:
URL: https://github.com/apache/hadoop/pull/3724#discussion_r773611386
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/test/java/org/apache/hadoop/hdfs/server/datanode/TestBlockScanner.java
##
@@ -290,6 +290,18 @@ public void testDisableVolumeScanner() throws Exception {
}
}
+ @Test(timeout=6)
+ public void testDisableVolumeScanner2() throws Exception {
+Configuration conf = new Configuration();
+conf.setLong(DFS_BLOCK_SCANNER_VOLUME_BYTES_PER_SECOND, -1L);
+TestContext ctx = new TestContext(conf, 1);
+try {
+ Assert.assertFalse(ctx.datanode.getBlockScanner().isEnabled());
Review comment:
seems it's still not updated.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 699806)
Time Spent: 1h 40m (was: 1.5h)
> Improve block scanner desc
> --
>
> Key: HDFS-16355
> URL: https://issues.apache.org/jira/browse/HDFS-16355
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: hdfs
>Affects Versions: 3.3.1
>Reporter: guophilipse
>Priority: Minor
> Labels: pull-request-available
> Time Spent: 1h 40m
> Remaining Estimate: 0h
>
> datanode block scanner will be disabled if
> `dfs.block.scanner.volume.bytes.per.second` is configured less then or equal
> to zero, we can improve the desciption
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDFS-16317) Backport HDFS-14729 for branch-3.2
[ https://issues.apache.org/jira/browse/HDFS-16317?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Wei-Chiu Chuang resolved HDFS-16317. Fix Version/s: 3.2.3 Resolution: Fixed Merged the commit into branch-3.2 and branch-3.2.3. > Backport HDFS-14729 for branch-3.2 > -- > > Key: HDFS-16317 > URL: https://issues.apache.org/jira/browse/HDFS-16317 > Project: Hadoop HDFS > Issue Type: Bug > Components: security >Affects Versions: 3.2.2 >Reporter: Ananya Singh >Assignee: Ananya Singh >Priority: Major > Labels: pull-request-available > Fix For: 3.2.3 > > Time Spent: 2.5h > Remaining Estimate: 0h > > Our security tool raised the following security flaw on Hadoop 3.2.2: > +[CVE-2015-9251 : > |http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2015-9251] > [https://nvd.nist.gov/vuln/detail/|https://nvd.nist.gov/vuln/detail/CVE-2021-29425] > > [CVE-2015-9251|http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2015-9251]+ > +[CVE-2019-11358|http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2019-11358] > : > [https://nvd.nist.gov/vuln/detail/|https://nvd.nist.gov/vuln/detail/CVE-2021-29425] > > [CVE-2019-11358|http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2019-11358]+ > +[CVE-2020-11022 > |http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2020-11022] : > [https://nvd.nist.gov/vuln/detail/|https://nvd.nist.gov/vuln/detail/CVE-2021-29425] > > [CVE-2020-11022|http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2020-11022]+ > > +[CVE-2020-11023 > |http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2020-11023] [ > |http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2020-11022] : > [https://nvd.nist.gov/vuln/detail/|https://nvd.nist.gov/vuln/detail/CVE-2021-29425] > > [CVE-2020-11023|http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2020-11023]+ > > > > -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16317) Backport HDFS-14729 for branch-3.2
[ https://issues.apache.org/jira/browse/HDFS-16317?focusedWorklogId=699805&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699805 ] ASF GitHub Bot logged work on HDFS-16317: - Author: ASF GitHub Bot Created on: 22/Dec/21 05:32 Start Date: 22/Dec/21 05:32 Worklog Time Spent: 10m Work Description: jojochuang merged pull request #3780: URL: https://github.com/apache/hadoop/pull/3780 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 699805) Time Spent: 2.5h (was: 2h 20m) > Backport HDFS-14729 for branch-3.2 > -- > > Key: HDFS-16317 > URL: https://issues.apache.org/jira/browse/HDFS-16317 > Project: Hadoop HDFS > Issue Type: Bug > Components: security >Affects Versions: 3.2.2 >Reporter: Ananya Singh >Assignee: Ananya Singh >Priority: Major > Labels: pull-request-available > Time Spent: 2.5h > Remaining Estimate: 0h > > Our security tool raised the following security flaw on Hadoop 3.2.2: > +[CVE-2015-9251 : > |http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2015-9251] > [https://nvd.nist.gov/vuln/detail/|https://nvd.nist.gov/vuln/detail/CVE-2021-29425] > > [CVE-2015-9251|http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2015-9251]+ > +[CVE-2019-11358|http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2019-11358] > : > [https://nvd.nist.gov/vuln/detail/|https://nvd.nist.gov/vuln/detail/CVE-2021-29425] > > [CVE-2019-11358|http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2019-11358]+ > +[CVE-2020-11022 > |http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2020-11022] : > [https://nvd.nist.gov/vuln/detail/|https://nvd.nist.gov/vuln/detail/CVE-2021-29425] > > [CVE-2020-11022|http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2020-11022]+ > > +[CVE-2020-11023 > |http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2020-11023] [ > |http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2020-11022] : > [https://nvd.nist.gov/vuln/detail/|https://nvd.nist.gov/vuln/detail/CVE-2021-29425] > > [CVE-2020-11023|http://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2020-11023]+ > > > > -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16389) Improve NNThroughputBenchmark test mkdirs
[
https://issues.apache.org/jira/browse/HDFS-16389?focusedWorklogId=699796&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699796
]
ASF GitHub Bot logged work on HDFS-16389:
-
Author: ASF GitHub Bot
Created on: 22/Dec/21 05:01
Start Date: 22/Dec/21 05:01
Worklog Time Spent: 10m
Work Description: jojochuang commented on a change in pull request #3819:
URL: https://github.com/apache/hadoop/pull/3819#discussion_r773600232
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/test/java/org/apache/hadoop/hdfs/server/namenode/NNThroughputBenchmark.java
##
@@ -265,6 +265,11 @@ void benchmark() throws IOException {
LOG.info("Starting " + numOpsRequired + " " + getOpName() + "(s).");
for(StatsDaemon d : daemons)
d.start();
+ } catch (Exception e) {
+if (e instanceof ArrayIndexOutOfBoundsException) {
+ LOG.error("The -dirsPerDir or -filesPerDir parameter set is
incorrect.");
Review comment:
It would be really nice to suggest a valid range of number of
directories or files. For example, up to 1 million directories?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 699796)
Time Spent: 40m (was: 0.5h)
> Improve NNThroughputBenchmark test mkdirs
> -
>
> Key: HDFS-16389
> URL: https://issues.apache.org/jira/browse/HDFS-16389
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: benchmarks, namenode
>Affects Versions: 2.9.2
>Reporter: JiangHua Zhu
>Assignee: JiangHua Zhu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 40m
> Remaining Estimate: 0h
>
> When using the NNThroughputBenchmark test to create a large number of
> directories, some abnormal information will be prompted.
> Here is the command:
> ./bin/hadoop org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark -fs
> hdfs:// -op mkdirs -threads 30 -dirs 500
> There are some exceptions here, such as:
> 21/12/20 10:25:00 INFO namenode.NNThroughputBenchmark: Starting benchmark:
> mkdirs
> 21/12/20 10:25:01 INFO namenode.NNThroughputBenchmark: Generate 500
> inputs for mkdirs
> 21/12/20 10:25:08 ERROR namenode.NNThroughputBenchmark:
> java.lang.ArrayIndexOutOfBoundsException: 20
> at
> org.apache.hadoop.hdfs.server.namenode.FileNameGenerator.getNextDirName(FileNameGenerator.java:65)
> at
> org.apache.hadoop.hdfs.server.namenode.FileNameGenerator.getNextFileName(FileNameGenerator.java:73)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark$MkdirsStats.generateInputs(NNThroughputBenchmark.java:668)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark$OperationStatsBase.benchmark(NNThroughputBenchmark.java:257)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark.run(NNThroughputBenchmark.java:1528)
> at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
> at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:90)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark.runBenchmark(NNThroughputBenchmark.java:1430)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark.main(NNThroughputBenchmark.java:1550)
> Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 20
> at
> org.apache.hadoop.hdfs.server.namenode.FileNameGenerator.getNextDirName(FileNameGenerator.java:65)
> at
> org.apache.hadoop.hdfs.server.namenode.FileNameGenerator.getNextFileName(FileNameGenerator.java:73)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark$MkdirsStats.generateInputs(NNThroughputBenchmark.java:668)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark$OperationStatsBase.benchmark(NNThroughputBenchmark.java:257)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark.run(NNThroughputBenchmark.java:1528)
> at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
> at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:90)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark.runBenchmark(NNThroughputBenchmark.java:1430)
> at
> org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark.main(NNThroughputBenchmark.java:1550)
> These messages appear because some parameters are incorrectly set, such as
> dirsPerDir or filesPerDir.
> When we see this log, this
[jira] [Assigned] (HDFS-16394) RPCMetrics increases the number of handlers in processing
[ https://issues.apache.org/jira/browse/HDFS-16394?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] JiangHua Zhu reassigned HDFS-16394: --- Assignee: JiangHua Zhu > RPCMetrics increases the number of handlers in processing > - > > Key: HDFS-16394 > URL: https://issues.apache.org/jira/browse/HDFS-16394 > Project: Hadoop HDFS > Issue Type: Improvement > Components: namenode >Affects Versions: 2.9.2 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > > When using RPC, we recorded a lot of useful information, such as Queue time, > Processing time. These are very helpful. > But we can't know how many handlers are actually working now (only those that > handle Call), especially when the Call Queue is very high. This is also not > conducive to us optimizing the cluster. > It would be very helpful if we can see the number of handlers being processed > in RPCMetrics. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Created] (HDFS-16394) RPCMetrics increases the number of handlers in processing
JiangHua Zhu created HDFS-16394: --- Summary: RPCMetrics increases the number of handlers in processing Key: HDFS-16394 URL: https://issues.apache.org/jira/browse/HDFS-16394 Project: Hadoop HDFS Issue Type: Improvement Components: namenode Affects Versions: 2.9.2 Reporter: JiangHua Zhu When using RPC, we recorded a lot of useful information, such as Queue time, Processing time. These are very helpful. But we can't know how many handlers are actually working now (only those that handle Call), especially when the Call Queue is very high. This is also not conducive to us optimizing the cluster. It would be very helpful if we can see the number of handlers being processed in RPCMetrics. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-7928) Scanning blocks from disk during rolling upgrade startup takes a lot of time if disks are busy
[ https://issues.apache.org/jira/browse/HDFS-7928?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17463566#comment-17463566 ] hu xiaodong commented on HDFS-7928: --- [~shahrs87], hello, this patch is for rolling upgrade datanode. But we use start-stop script to shutdown or start datanode. And we face the same problem. How to use this patch when using the start-stop script? > Scanning blocks from disk during rolling upgrade startup takes a lot of time > if disks are busy > -- > > Key: HDFS-7928 > URL: https://issues.apache.org/jira/browse/HDFS-7928 > Project: Hadoop HDFS > Issue Type: Improvement > Components: datanode >Affects Versions: 2.6.0 >Reporter: Rushabh Shah >Assignee: Rushabh Shah >Priority: Major > Fix For: 2.8.0, 3.0.0-alpha1 > > Attachments: HDFS-7928-v1.patch, HDFS-7928-v2.patch, HDFS-7928.patch > > > We observed this issue in rolling upgrade to 2.6.x on one of our cluster. > One of the disks was very busy and it took long time to scan that disk > compared to other disks. > Seeing the sar (System Activity Reporter) data we saw that the particular > disk was very busy performing IO operations. > Requesting for an improvement during datanode rolling upgrade. > During shutdown, we can persist the whole volume map on the disk and let the > datanode read that file and create the volume map during startup after > rolling upgrade. > This will not require the datanode process to scan all the disk and read the > block. > This will significantly improve the datanode startup time. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16371) Exclude slow disks when choosing volume
[
https://issues.apache.org/jira/browse/HDFS-16371?focusedWorklogId=699762&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699762
]
ASF GitHub Bot logged work on HDFS-16371:
-
Author: ASF GitHub Bot
Created on: 22/Dec/21 03:17
Start Date: 22/Dec/21 03:17
Worklog Time Spent: 10m
Work Description: tomscut commented on a change in pull request #3753:
URL: https://github.com/apache/hadoop/pull/3753#discussion_r773573177
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/metrics/DataNodeDiskMetrics.java
##
@@ -127,6 +143,16 @@ public void run() {
detectAndUpdateDiskOutliers(metadataOpStats, readIoStats,
writeIoStats);
+
+// Sort the slow disks by latency.
+if (maxSlowDisksToBeExcluded > 0) {
+ ArrayList diskLatencies = new ArrayList<>();
+ for (Map.Entry> diskStats :
+ diskOutliersStats.entrySet()) {
+diskLatencies.add(new DiskLatency(diskStats.getKey(),
diskStats.getValue()));
+ }
+ sortSlowDisks(diskLatencies);
Review comment:
Thank you @tasanuma very much for your review and comments. I think your
suggestions are very good. I will revise ASAP.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 699762)
Time Spent: 1h 50m (was: 1h 40m)
> Exclude slow disks when choosing volume
> ---
>
> Key: HDFS-16371
> URL: https://issues.apache.org/jira/browse/HDFS-16371
> Project: Hadoop HDFS
> Issue Type: New Feature
>Reporter: tomscut
>Assignee: tomscut
>Priority: Major
> Labels: pull-request-available
> Time Spent: 1h 50m
> Remaining Estimate: 0h
>
> Currently, the datanode can detect slow disks. See HDFS-11461.
> And after HDFS-16311, the slow disk information we collected is more accurate.
> So we can exclude these slow disks according to some rules when choosing
> volume. This will prevents some slow disks from affecting the throughput of
> the whole datanode.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16371) Exclude slow disks when choosing volume
[
https://issues.apache.org/jira/browse/HDFS-16371?focusedWorklogId=699757&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699757
]
ASF GitHub Bot logged work on HDFS-16371:
-
Author: ASF GitHub Bot
Created on: 22/Dec/21 02:53
Start Date: 22/Dec/21 02:53
Worklog Time Spent: 10m
Work Description: tasanuma commented on a change in pull request #3753:
URL: https://github.com/apache/hadoop/pull/3753#discussion_r773564004
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/metrics/DataNodeDiskMetrics.java
##
@@ -127,6 +143,16 @@ public void run() {
detectAndUpdateDiskOutliers(metadataOpStats, readIoStats,
writeIoStats);
+
+// Sort the slow disks by latency.
+if (maxSlowDisksToBeExcluded > 0) {
+ ArrayList diskLatencies = new ArrayList<>();
+ for (Map.Entry> diskStats :
+ diskOutliersStats.entrySet()) {
+diskLatencies.add(new DiskLatency(diskStats.getKey(),
diskStats.getValue()));
+ }
+ sortSlowDisks(diskLatencies);
Review comment:
You could use `Collections.sort` to make it more concise.
```suggestion
Collections.sort(diskLatencies, (o1, o2)
-> Double.compare(o2.getMaxLatency(), o1.getMaxLatency()));
slowDisksToBeExcluded =
diskLatencies.stream().limit(maxSlowDisksToBeExcluded)
.map(DiskLatency::getSlowDisk).collect(Collectors.toList());
```
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/metrics/DataNodeDiskMetrics.java
##
@@ -127,6 +143,16 @@ public void run() {
detectAndUpdateDiskOutliers(metadataOpStats, readIoStats,
writeIoStats);
+
+// Sort the slow disks by latency.
+if (maxSlowDisksToBeExcluded > 0) {
+ ArrayList diskLatencies = new ArrayList<>();
+ for (Map.Entry> diskStats :
+ diskOutliersStats.entrySet()) {
+diskLatencies.add(new DiskLatency(diskStats.getKey(),
diskStats.getValue()));
+ }
+ sortSlowDisks(diskLatencies);
Review comment:
`sortSlowDisks` seems to do more than just sort slow disks, it also
limits them with `maxSlowDisksToBeExcluded` and sets them to
`slowDisksToBeExcluded`. It would be better to give this method a more
appropriate name.
##
File path: hadoop-hdfs-project/hadoop-hdfs/src/main/resources/hdfs-default.xml
##
@@ -2483,6 +2483,15 @@
+
+ dfs.datanode.max.slowdisks.to.be.excluded
Review comment:
IMHO, the passive voice is a bit wordy for configurations. I prefer the
active voice, like `dfs.datanode.max.slowdisks.to.exclude`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 699757)
Time Spent: 1h 40m (was: 1.5h)
> Exclude slow disks when choosing volume
> ---
>
> Key: HDFS-16371
> URL: https://issues.apache.org/jira/browse/HDFS-16371
> Project: Hadoop HDFS
> Issue Type: New Feature
>Reporter: tomscut
>Assignee: tomscut
>Priority: Major
> Labels: pull-request-available
> Time Spent: 1h 40m
> Remaining Estimate: 0h
>
> Currently, the datanode can detect slow disks. See HDFS-11461.
> And after HDFS-16311, the slow disk information we collected is more accurate.
> So we can exclude these slow disks according to some rules when choosing
> volume. This will prevents some slow disks from affecting the throughput of
> the whole datanode.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDFS-16392) TestWebHdfsFileSystemContract#testResponseCode fails
[
https://issues.apache.org/jira/browse/HDFS-16392?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Hui Fei resolved HDFS-16392.
Fix Version/s: 3.4.0
Resolution: Fixed
> TestWebHdfsFileSystemContract#testResponseCode fails
>
>
> Key: HDFS-16392
> URL: https://issues.apache.org/jira/browse/HDFS-16392
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: test
>Affects Versions: 3.4.0
>Reporter: secfree
>Assignee: secfree
>Priority: Major
> Labels: pull-request-available
> Fix For: 3.4.0
>
> Time Spent: 40m
> Remaining Estimate: 0h
>
> We can find a lot of failed cases with searching
> "TestWebHdfsFileSystemContract" in "pull requests"
> (https://github.com/apache/hadoop/pulls?q=is%3Apr+is%3Aopen+TestWebHdfsFileSystemContract)
> And they all have the following exception log
> {code}
> [ERROR]
> testResponseCode(org.apache.hadoop.hdfs.web.TestWebHdfsFileSystemContract)
> Time elapsed: 30.019 s <<< ERROR!
> org.junit.runners.model.TestTimedOutException: test timed out after 3
> milliseconds
> at java.net.SocketInputStream.socketRead0(Native Method)
> at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
> ...
> [ERROR]
> org.apache.hadoop.hdfs.web.TestWebHdfsFileSystemContract.testResponseCode(org.apache.hadoop.hdfs.web.TestWebHdfsFileSystemContract)
> [ERROR] Run 1: TestWebHdfsFileSystemContract.testResponseCode:473 »
> TestTimedOut test timed o...
> [ERROR] Run 2: TestWebHdfsFileSystemContract.testResponseCode:473 »
> TestTimedOut test timed o...
> [ERROR] Run 3: TestWebHdfsFileSystemContract.testResponseCode:473 »
> TestTimedOut test timed o...
> {code}
> This issue has the same root cause as HDFS-16168
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16392) TestWebHdfsFileSystemContract#testResponseCode fails
[
https://issues.apache.org/jira/browse/HDFS-16392?focusedWorklogId=699753&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699753
]
ASF GitHub Bot logged work on HDFS-16392:
-
Author: ASF GitHub Bot
Created on: 22/Dec/21 02:44
Start Date: 22/Dec/21 02:44
Worklog Time Spent: 10m
Work Description: ferhui merged pull request #3821:
URL: https://github.com/apache/hadoop/pull/3821
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 699753)
Time Spent: 0.5h (was: 20m)
> TestWebHdfsFileSystemContract#testResponseCode fails
>
>
> Key: HDFS-16392
> URL: https://issues.apache.org/jira/browse/HDFS-16392
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: test
>Affects Versions: 3.4.0
>Reporter: secfree
>Assignee: secfree
>Priority: Major
> Labels: pull-request-available
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> We can find a lot of failed cases with searching
> "TestWebHdfsFileSystemContract" in "pull requests"
> (https://github.com/apache/hadoop/pulls?q=is%3Apr+is%3Aopen+TestWebHdfsFileSystemContract)
> And they all have the following exception log
> {code}
> [ERROR]
> testResponseCode(org.apache.hadoop.hdfs.web.TestWebHdfsFileSystemContract)
> Time elapsed: 30.019 s <<< ERROR!
> org.junit.runners.model.TestTimedOutException: test timed out after 3
> milliseconds
> at java.net.SocketInputStream.socketRead0(Native Method)
> at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
> ...
> [ERROR]
> org.apache.hadoop.hdfs.web.TestWebHdfsFileSystemContract.testResponseCode(org.apache.hadoop.hdfs.web.TestWebHdfsFileSystemContract)
> [ERROR] Run 1: TestWebHdfsFileSystemContract.testResponseCode:473 »
> TestTimedOut test timed o...
> [ERROR] Run 2: TestWebHdfsFileSystemContract.testResponseCode:473 »
> TestTimedOut test timed o...
> [ERROR] Run 3: TestWebHdfsFileSystemContract.testResponseCode:473 »
> TestTimedOut test timed o...
> {code}
> This issue has the same root cause as HDFS-16168
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16392) TestWebHdfsFileSystemContract#testResponseCode fails
[
https://issues.apache.org/jira/browse/HDFS-16392?focusedWorklogId=699754&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699754
]
ASF GitHub Bot logged work on HDFS-16392:
-
Author: ASF GitHub Bot
Created on: 22/Dec/21 02:44
Start Date: 22/Dec/21 02:44
Worklog Time Spent: 10m
Work Description: ferhui commented on pull request #3821:
URL: https://github.com/apache/hadoop/pull/3821#issuecomment-999241338
@secfree Thanks for your contribution. @ayushtkn @tomscut Thanks for your
review!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 699754)
Time Spent: 40m (was: 0.5h)
> TestWebHdfsFileSystemContract#testResponseCode fails
>
>
> Key: HDFS-16392
> URL: https://issues.apache.org/jira/browse/HDFS-16392
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: test
>Affects Versions: 3.4.0
>Reporter: secfree
>Assignee: secfree
>Priority: Major
> Labels: pull-request-available
> Time Spent: 40m
> Remaining Estimate: 0h
>
> We can find a lot of failed cases with searching
> "TestWebHdfsFileSystemContract" in "pull requests"
> (https://github.com/apache/hadoop/pulls?q=is%3Apr+is%3Aopen+TestWebHdfsFileSystemContract)
> And they all have the following exception log
> {code}
> [ERROR]
> testResponseCode(org.apache.hadoop.hdfs.web.TestWebHdfsFileSystemContract)
> Time elapsed: 30.019 s <<< ERROR!
> org.junit.runners.model.TestTimedOutException: test timed out after 3
> milliseconds
> at java.net.SocketInputStream.socketRead0(Native Method)
> at java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
> ...
> [ERROR]
> org.apache.hadoop.hdfs.web.TestWebHdfsFileSystemContract.testResponseCode(org.apache.hadoop.hdfs.web.TestWebHdfsFileSystemContract)
> [ERROR] Run 1: TestWebHdfsFileSystemContract.testResponseCode:473 »
> TestTimedOut test timed o...
> [ERROR] Run 2: TestWebHdfsFileSystemContract.testResponseCode:473 »
> TestTimedOut test timed o...
> [ERROR] Run 3: TestWebHdfsFileSystemContract.testResponseCode:473 »
> TestTimedOut test timed o...
> {code}
> This issue has the same root cause as HDFS-16168
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16371) Exclude slow disks when choosing volume
[ https://issues.apache.org/jira/browse/HDFS-16371?focusedWorklogId=699709&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699709 ] ASF GitHub Bot logged work on HDFS-16371: - Author: ASF GitHub Bot Created on: 21/Dec/21 23:57 Start Date: 21/Dec/21 23:57 Worklog Time Spent: 10m Work Description: tomscut commented on pull request #3753: URL: https://github.com/apache/hadoop/pull/3753#issuecomment-999173476 Hi @sodonnel , could you please also take a look at this? Thanks. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 699709) Time Spent: 1.5h (was: 1h 20m) > Exclude slow disks when choosing volume > --- > > Key: HDFS-16371 > URL: https://issues.apache.org/jira/browse/HDFS-16371 > Project: Hadoop HDFS > Issue Type: New Feature >Reporter: tomscut >Assignee: tomscut >Priority: Major > Labels: pull-request-available > Time Spent: 1.5h > Remaining Estimate: 0h > > Currently, the datanode can detect slow disks. See HDFS-11461. > And after HDFS-16311, the slow disk information we collected is more accurate. > So we can exclude these slow disks according to some rules when choosing > volume. This will prevents some slow disks from affecting the throughput of > the whole datanode. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16348) Mark slownode as badnode to recover pipeline
[
https://issues.apache.org/jira/browse/HDFS-16348?focusedWorklogId=699658&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699658
]
ASF GitHub Bot logged work on HDFS-16348:
-
Author: ASF GitHub Bot
Created on: 21/Dec/21 21:15
Start Date: 21/Dec/21 21:15
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on pull request #3704:
URL: https://github.com/apache/hadoop/pull/3704#issuecomment-999099036
:confetti_ball: **+1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 49s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 1s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 2 new or modified test files. |
_ trunk Compile Tests _ |
| +0 :ok: | mvndep | 12m 32s | | Maven dependency ordering for branch |
| +1 :green_heart: | mvninstall | 24m 29s | | trunk passed |
| +1 :green_heart: | compile | 6m 6s | | trunk passed with JDK
Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04 |
| +1 :green_heart: | compile | 5m 32s | | trunk passed with JDK
Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| +1 :green_heart: | checkstyle | 1m 16s | | trunk passed |
| +1 :green_heart: | mvnsite | 2m 20s | | trunk passed |
| +1 :green_heart: | javadoc | 1m 40s | | trunk passed with JDK
Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04 |
| +1 :green_heart: | javadoc | 2m 6s | | trunk passed with JDK
Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| +1 :green_heart: | spotbugs | 5m 55s | | trunk passed |
| +1 :green_heart: | shadedclient | 25m 27s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +0 :ok: | mvndep | 0m 22s | | Maven dependency ordering for patch |
| +1 :green_heart: | mvninstall | 2m 8s | | the patch passed |
| +1 :green_heart: | compile | 5m 54s | | the patch passed with JDK
Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04 |
| +1 :green_heart: | javac | 5m 54s | | the patch passed |
| +1 :green_heart: | compile | 5m 26s | | the patch passed with JDK
Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| +1 :green_heart: | javac | 5m 26s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 1m 12s | | hadoop-hdfs-project: The
patch generated 0 new + 528 unchanged - 1 fixed = 528 total (was 529) |
| +1 :green_heart: | mvnsite | 2m 11s | | the patch passed |
| +1 :green_heart: | xml | 0m 1s | | The patch has no ill-formed XML
file. |
| +1 :green_heart: | javadoc | 1m 27s | | the patch passed with JDK
Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04 |
| +1 :green_heart: | javadoc | 1m 57s | | the patch passed with JDK
Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| +1 :green_heart: | spotbugs | 6m 6s | | the patch passed |
| +1 :green_heart: | shadedclient | 25m 52s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 2m 17s | | hadoop-hdfs-client in the patch
passed. |
| +1 :green_heart: | unit | 313m 54s | | hadoop-hdfs in the patch
passed. |
| +1 :green_heart: | asflicense | 0m 39s | | The patch does not
generate ASF License warnings. |
| | | 455m 2s | | |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3704/8/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/3704 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell xml |
| uname | Linux 180c2a1af2dc 4.15.0-163-generic #171-Ubuntu SMP Fri Nov 5
11:55:11 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 97485b93f414733d024e567489315b91582e9096 |
| Default Java | Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| Multi-JDK versions |
/usr/lib/jvm/java-11-openjdk-amd64:Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04
/usr/lib/jvm/java-8-openjdk-amd64:Private
Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| Test Results |
https://ci-hadoop.apache.org/job/hadoop-multibranc
[jira] [Work logged] (HDFS-16348) Mark slownode as badnode to recover pipeline
[
https://issues.apache.org/jira/browse/HDFS-16348?focusedWorklogId=699350&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699350
]
ASF GitHub Bot logged work on HDFS-16348:
-
Author: ASF GitHub Bot
Created on: 21/Dec/21 13:16
Start Date: 21/Dec/21 13:16
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on pull request #3704:
URL: https://github.com/apache/hadoop/pull/3704#issuecomment-998770725
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 51s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 1s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 2 new or modified test files. |
_ trunk Compile Tests _ |
| +0 :ok: | mvndep | 12m 42s | | Maven dependency ordering for branch |
| +1 :green_heart: | mvninstall | 24m 52s | | trunk passed |
| +1 :green_heart: | compile | 5m 59s | | trunk passed with JDK
Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04 |
| +1 :green_heart: | compile | 5m 39s | | trunk passed with JDK
Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| +1 :green_heart: | checkstyle | 1m 15s | | trunk passed |
| +1 :green_heart: | mvnsite | 2m 22s | | trunk passed |
| +1 :green_heart: | javadoc | 1m 40s | | trunk passed with JDK
Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04 |
| +1 :green_heart: | javadoc | 2m 2s | | trunk passed with JDK
Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| +1 :green_heart: | spotbugs | 5m 53s | | trunk passed |
| +1 :green_heart: | shadedclient | 25m 26s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +0 :ok: | mvndep | 0m 24s | | Maven dependency ordering for patch |
| +1 :green_heart: | mvninstall | 2m 7s | | the patch passed |
| +1 :green_heart: | compile | 5m 53s | | the patch passed with JDK
Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04 |
| +1 :green_heart: | javac | 5m 53s | | the patch passed |
| +1 :green_heart: | compile | 5m 27s | | the patch passed with JDK
Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| +1 :green_heart: | javac | 5m 27s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 1m 9s | | hadoop-hdfs-project: The
patch generated 0 new + 528 unchanged - 1 fixed = 528 total (was 529) |
| +1 :green_heart: | mvnsite | 2m 10s | | the patch passed |
| +1 :green_heart: | xml | 0m 1s | | The patch has no ill-formed XML
file. |
| +1 :green_heart: | javadoc | 1m 26s | | the patch passed with JDK
Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04 |
| +1 :green_heart: | javadoc | 1m 53s | | the patch passed with JDK
Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| +1 :green_heart: | spotbugs | 6m 9s | | the patch passed |
| +1 :green_heart: | shadedclient | 25m 50s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 2m 18s | | hadoop-hdfs-client in the patch
passed. |
| -1 :x: | unit | 320m 50s |
[/patch-unit-hadoop-hdfs-project_hadoop-hdfs.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3704/7/artifact/out/patch-unit-hadoop-hdfs-project_hadoop-hdfs.txt)
| hadoop-hdfs in the patch passed. |
| +1 :green_heart: | asflicense | 0m 40s | | The patch does not
generate ASF License warnings. |
| | | 462m 26s | | |
| Reason | Tests |
|---:|:--|
| Failed junit tests | hadoop.hdfs.server.balancer.TestBalancer |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3704/7/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/3704 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell xml |
| uname | Linux dd4f5befacaf 4.15.0-163-generic #171-Ubuntu SMP Fri Nov 5
11:55:11 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 6a6875d588bd3aab072a48409376c29c45b85c80 |
| Default Java | Private Build-1.8.0_292-8u292-b1
[jira] [Resolved] (HDFS-16391) Avoid evaluation of LOG.debug statement in NameNodeHeartbeatService
[ https://issues.apache.org/jira/browse/HDFS-16391?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Stephen O'Donnell resolved HDFS-16391. -- Resolution: Fixed > Avoid evaluation of LOG.debug statement in NameNodeHeartbeatService > --- > > Key: HDFS-16391 > URL: https://issues.apache.org/jira/browse/HDFS-16391 > Project: Hadoop HDFS > Issue Type: Improvement >Reporter: wangzhaohui >Assignee: wangzhaohui >Priority: Trivial > Labels: pull-request-available > Fix For: 3.4.0, 3.2.4, 3.3.3 > > Time Spent: 1.5h > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Assigned] (HDFS-16391) Avoid evaluation of LOG.debug statement in NameNodeHeartbeatService
[ https://issues.apache.org/jira/browse/HDFS-16391?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Stephen O'Donnell reassigned HDFS-16391: Assignee: wangzhaohui > Avoid evaluation of LOG.debug statement in NameNodeHeartbeatService > --- > > Key: HDFS-16391 > URL: https://issues.apache.org/jira/browse/HDFS-16391 > Project: Hadoop HDFS > Issue Type: Improvement >Reporter: wangzhaohui >Assignee: wangzhaohui >Priority: Trivial > Labels: pull-request-available > Fix For: 3.4.0, 3.2.4, 3.3.3 > > Time Spent: 1.5h > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16391) Avoid evaluation of LOG.debug statement in NameNodeHeartbeatService
[ https://issues.apache.org/jira/browse/HDFS-16391?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Stephen O'Donnell updated HDFS-16391: - Fix Version/s: 3.4.0 3.2.4 3.3.3 > Avoid evaluation of LOG.debug statement in NameNodeHeartbeatService > --- > > Key: HDFS-16391 > URL: https://issues.apache.org/jira/browse/HDFS-16391 > Project: Hadoop HDFS > Issue Type: Improvement >Reporter: wangzhaohui >Priority: Trivial > Labels: pull-request-available > Fix For: 3.4.0, 3.2.4, 3.3.3 > > Time Spent: 1.5h > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16386) Reduce DataNode load when FsDatasetAsyncDiskService is working
[ https://issues.apache.org/jira/browse/HDFS-16386?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Stephen O'Donnell updated HDFS-16386: - Fix Version/s: 3.2.3 > Reduce DataNode load when FsDatasetAsyncDiskService is working > -- > > Key: HDFS-16386 > URL: https://issues.apache.org/jira/browse/HDFS-16386 > Project: Hadoop HDFS > Issue Type: Improvement > Components: datanode >Affects Versions: 2.9.2 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Labels: pull-request-available > Fix For: 3.4.0, 3.2.3, 3.2.4, 3.3.3 > > Attachments: monitor.png > > Time Spent: 3h 10m > Remaining Estimate: 0h > > Our DataNode node has 36 disks. When FsDatasetAsyncDiskService is working, it > will cause a high load on the DataNode. > Here are some monitoring related to memory: > !monitor.png! > Since each disk deletes the block asynchronously, and each thread allows 4 > threads to work, > This will cause some troubles to the DataNode, such as increased cpu and > increased memory. > We should appropriately reduce the number of jobs of the total thread so that > the DataNode can work better. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16386) Reduce DataNode load when FsDatasetAsyncDiskService is working
[ https://issues.apache.org/jira/browse/HDFS-16386?focusedWorklogId=699314&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699314 ] ASF GitHub Bot logged work on HDFS-16386: - Author: ASF GitHub Bot Created on: 21/Dec/21 11:45 Start Date: 21/Dec/21 11:45 Worklog Time Spent: 10m Work Description: sodonnel commented on pull request #3806: URL: https://github.com/apache/hadoop/pull/3806#issuecomment-998712304 This will not go onto branch-3.2 cleanly due to HADOOP-17126 (new Preconditions class), however it is a trivial change in the import statement, so I have went ahead and made it and committed to 3.2.3 too. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 699314) Time Spent: 3h 10m (was: 3h) > Reduce DataNode load when FsDatasetAsyncDiskService is working > -- > > Key: HDFS-16386 > URL: https://issues.apache.org/jira/browse/HDFS-16386 > Project: Hadoop HDFS > Issue Type: Improvement > Components: datanode >Affects Versions: 2.9.2 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Labels: pull-request-available > Fix For: 3.4.0, 3.2.4, 3.3.3 > > Attachments: monitor.png > > Time Spent: 3h 10m > Remaining Estimate: 0h > > Our DataNode node has 36 disks. When FsDatasetAsyncDiskService is working, it > will cause a high load on the DataNode. > Here are some monitoring related to memory: > !monitor.png! > Since each disk deletes the block asynchronously, and each thread allows 4 > threads to work, > This will cause some troubles to the DataNode, such as increased cpu and > increased memory. > We should appropriately reduce the number of jobs of the total thread so that > the DataNode can work better. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16391) Avoid evaluation of LOG.debug statement in NameNodeHeartbeatService
[ https://issues.apache.org/jira/browse/HDFS-16391?focusedWorklogId=699308&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699308 ] ASF GitHub Bot logged work on HDFS-16391: - Author: ASF GitHub Bot Created on: 21/Dec/21 11:29 Start Date: 21/Dec/21 11:29 Worklog Time Spent: 10m Work Description: sodonnel merged pull request #3820: URL: https://github.com/apache/hadoop/pull/3820 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 699308) Time Spent: 1.5h (was: 1h 20m) > Avoid evaluation of LOG.debug statement in NameNodeHeartbeatService > --- > > Key: HDFS-16391 > URL: https://issues.apache.org/jira/browse/HDFS-16391 > Project: Hadoop HDFS > Issue Type: Improvement >Reporter: wangzhaohui >Priority: Trivial > Labels: pull-request-available > Time Spent: 1.5h > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16391) Avoid evaluation of LOG.debug statement in NameNodeHeartbeatService
[
https://issues.apache.org/jira/browse/HDFS-16391?focusedWorklogId=699294&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699294
]
ASF GitHub Bot logged work on HDFS-16391:
-
Author: ASF GitHub Bot
Created on: 21/Dec/21 10:37
Start Date: 21/Dec/21 10:37
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on pull request #3820:
URL: https://github.com/apache/hadoop/pull/3820#issuecomment-998667402
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 53s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 0s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| -1 :x: | test4tests | 0m 0s | | The patch doesn't appear to include
any new or modified tests. Please justify why no new tests are needed for this
patch. Also please list what manual steps were performed to verify this patch.
|
_ trunk Compile Tests _ |
| +1 :green_heart: | mvninstall | 39m 56s | | trunk passed |
| +1 :green_heart: | compile | 0m 49s | | trunk passed with JDK
Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04 |
| +1 :green_heart: | compile | 0m 43s | | trunk passed with JDK
Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| +1 :green_heart: | checkstyle | 0m 29s | | trunk passed |
| +1 :green_heart: | mvnsite | 0m 49s | | trunk passed |
| +1 :green_heart: | javadoc | 0m 54s | | trunk passed with JDK
Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04 |
| +1 :green_heart: | javadoc | 1m 13s | | trunk passed with JDK
Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| +1 :green_heart: | spotbugs | 1m 39s | | trunk passed |
| +1 :green_heart: | shadedclient | 27m 9s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 0m 38s | | the patch passed |
| +1 :green_heart: | compile | 0m 36s | | the patch passed with JDK
Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04 |
| +1 :green_heart: | javac | 0m 36s | | the patch passed |
| +1 :green_heart: | compile | 0m 33s | | the patch passed with JDK
Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| +1 :green_heart: | javac | 0m 33s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 0m 18s | | the patch passed |
| +1 :green_heart: | mvnsite | 0m 35s | | the patch passed |
| +1 :green_heart: | javadoc | 0m 33s | | the patch passed with JDK
Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04 |
| +1 :green_heart: | javadoc | 0m 47s | | the patch passed with JDK
Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| +1 :green_heart: | spotbugs | 1m 17s | | the patch passed |
| +1 :green_heart: | shadedclient | 20m 6s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| -1 :x: | unit | 20m 57s |
[/patch-unit-hadoop-hdfs-project_hadoop-hdfs-rbf.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3820/3/artifact/out/patch-unit-hadoop-hdfs-project_hadoop-hdfs-rbf.txt)
| hadoop-hdfs-rbf in the patch passed. |
| +1 :green_heart: | asflicense | 0m 35s | | The patch does not
generate ASF License warnings. |
| | | 123m 6s | | |
| Reason | Tests |
|---:|:--|
| Failed junit tests |
hadoop.hdfs.server.federation.router.TestRouterRPCMultipleDestinationMountTableResolver
|
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3820/3/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/3820 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell |
| uname | Linux 8da299d2bf37 4.15.0-156-generic #163-Ubuntu SMP Thu Aug 19
23:31:58 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 91c089285a1ce0f0ec9f3b2b8db89b676f4fc9c4 |
| Default Java | Private Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| Multi-JDK versions |
/usr/lib/jvm/java-11-openjdk-amd64:Ubuntu-11.0.11+9-Ubuntu-0ubuntu2.20.04
/usr/lib/jvm/java-8-openjdk-amd64:Private
Build-1.8.0_292-8u292-b10-0ubuntu1~20.04-b10 |
| Test Results |
[jira] [Commented] (HDFS-16356) JournalNode short name missmatch
[
https://issues.apache.org/jira/browse/HDFS-16356?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17463092#comment-17463092
]
FliegenKLATSCH commented on HDFS-16356:
---
HADOOP-16314 actually introduced this behaviour, before this endpoint was
always protected by kerberos auth.
[https://github.com/apache/hadoop/commit/294695dd57cb75f2756a31a54264bdd37b32bb01#diff-4e9d7dccc4530205e71b54fe7f967135aeca170cff5ace98b5b7f04304153813L872]
[~eyang]/[~prabhujoseph] What's the proposed solution for this? I actually do
not want kerberos authentication for the webinterfaces.
> JournalNode short name missmatch
>
>
> Key: HDFS-16356
> URL: https://issues.apache.org/jira/browse/HDFS-16356
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: journal-node
>Affects Versions: 3.3.0
>Reporter: FliegenKLATSCH
>Priority: Major
> Labels: pull-request-available
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> I see the following issue in one of 3 JournalNodes:
> "Only Namenode and another JournalNode may access this servlet".
> The journalnode wants to download an edit log (shortly after startup) from
> another journalnode, but in the request the short username equals the (long)
> principal name and thus the request gets denied.
> I'll add a PR which trims the principal to the actual short name, but I am
> not sure why in the first place the request token contains the full principal
> name and what the desired name actually is. Maybe I have a misconfiguration
> on my end?
> "Server" side (scn1):
> {code:bash}
> 2021-11-26 09:02:04,609 DEBUG
> org.apache.hadoop.security.authentication.server.AuthenticationFilter:
> Request [https://scn1:8481/getJournal?jid=backups&segmentTxId=136002159
> 98&storageInfo=-65%3A1807091115%3A1522842919075%3ACID-661a9237-3a5d-4895-8257-1a2cc3642e98&inProgressOk=false]
> user [jn/s...@example.com] authenticated
> 2021-11-26 09:02:04,610 DEBUG org.eclipse.jetty.servlet.ServletHandler: call
> servlet
> getJournal@e931eb01==org.apache.hadoop.hdfs.qjournal.server.GetJournalEditServlet,jsp=null,ord
> er=-1,inst=true,async=true
> 2021-11-26 09:02:04,610 DEBUG
> org.apache.hadoop.hdfs.qjournal.server.GetJournalEditServlet: Validating
> request made by jn/s...@example.com / jn/s...@example.com. This user is:
> jn/s...@example.com (auth:KERBEROS)
> 2021-11-26 09:02:04,610 DEBUG
> org.apache.hadoop.hdfs.server.namenode.NameNode: Setting fs.defaultFS to
> hdfs://scn1:8020
> 2021-11-26 09:02:04,610 DEBUG
> org.apache.hadoop.hdfs.server.namenode.NameNode: Setting fs.defaultFS to
> hdfs://scn3:8020
> 2021-11-26 09:02:04,610 DEBUG
> org.apache.hadoop.hdfs.qjournal.server.GetJournalEditServlet:
> isValidRequestor is comparing to valid requestor: nn/s...@example.com
> 2021-11-26 09:02:04,610 DEBUG
> org.apache.hadoop.hdfs.qjournal.server.GetJournalEditServlet:
> isValidRequestor is comparing to valid requestor: nn/s...@example.com
> 2021-11-26 09:02:04,610 DEBUG
> org.apache.hadoop.hdfs.qjournal.server.GetJournalEditServlet:
> isValidRequestor is rejecting: jn/s...@example.com
> {code}
> "Client" side (scn2):
> {code:bash}
> 2021-11-26 08:56:03,377 INFO
> org.apache.hadoop.hdfs.qjournal.server.JournalNodeSyncer: Syncing Journal
> /0.0.0.0:8485 with scn1/1.2.6.9:8485, journal id: backups
> 2021-11-26 08:56:03,397 INFO
> org.apache.hadoop.hdfs.qjournal.server.JournalNodeSyncer: Downloading missing
> Edit Log from
> https://scn1:8481/getJournal?jid=backups&segmentTxId=13600215998&storageInfo=-65%3A1807091115%3A1522842919075%3ACID-661a9237-3a5d-4895-8257-1a2cc3642e98&inProgressOk=false
> to /hdfs/journal/backups
> 2021-11-26 08:56:03,412 ERROR
> org.apache.hadoop.hdfs.qjournal.server.JournalNodeSyncer: Download of Edit
> Log file for Syncing failed. Deleting temp file:
> /hdfs/journal/backups/edits.sync/edits_13600215998-13600227922
> org.apache.hadoop.hdfs.server.common.HttpGetFailedException: Image transfer
> servlet at
> https://scn1:8481/getJournal?jid=backups&segmentTxId=13600215998&storageInfo=-65%3A1807091115%3A152242919075%3ACID-661a9237-3a5d-4895-8257-1a2cc3642e98&inProgressOk=false
> failed with status code 403
> Response message:
> Only Namenode and another JournalNode may access this servlet
> at org.apache.hadoop.hdfs.server.common.Util.doGetUrl(Util.java:168)
> at
> org.apache.hadoop.hdfs.qjournal.server.JournalNodeSyncer.lambda$downloadMissingLogSegment$1(JournalNodeSyncer.java:448)
> at java.base/java.security.AccessController.doPrivileged(Native
> Method)
> at java.base/javax.security.auth.Subject.doAs(Subject.java:423)
> at
> org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845)
> at
> org.apache.hadoop.security.SecurityUtil.doAsUser(Securi
[jira] [Work logged] (HDFS-16348) Mark slownode as badnode to recover pipeline
[ https://issues.apache.org/jira/browse/HDFS-16348?focusedWorklogId=699267&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-699267 ] ASF GitHub Bot logged work on HDFS-16348: - Author: ASF GitHub Bot Created on: 21/Dec/21 09:16 Start Date: 21/Dec/21 09:16 Worklog Time Spent: 10m Work Description: tasanuma commented on pull request #3704: URL: https://github.com/apache/hadoop/pull/3704#issuecomment-998605177 Thanks for updating PR, @symious. +1 from me, pending Jenkins. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 699267) Time Spent: 3.5h (was: 3h 20m) > Mark slownode as badnode to recover pipeline > > > Key: HDFS-16348 > URL: https://issues.apache.org/jira/browse/HDFS-16348 > Project: Hadoop HDFS > Issue Type: Improvement >Reporter: Janus Chow >Assignee: Janus Chow >Priority: Major > Labels: pull-request-available > Time Spent: 3.5h > Remaining Estimate: 0h > > In HDFS-16320, the DataNode can retrieve the SLOW status from each NameNode. > This ticket is to send this information back to Clients who are writing > blocks. If a Clients noticed the pipeline is build on a slownode, he/she can > choose to mark the slownode as a badnode to exclude the node or rebuild a > pipeline. > In order to avoid the false positives, we added a config of "threshold", only > clients continuously receives slownode reply from the same node will the node > be marked as SLOW. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org