[jira] [Commented] (HDFS-16456) EC: Decommission a rack with only on dn will fail when the rack number is equal with replication
[
https://issues.apache.org/jira/browse/HDFS-16456?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17492423#comment-17492423
]
caozhiqiang commented on HDFS-16456:
[~ebadger], please help to review this issue.
> EC: Decommission a rack with only on dn will fail when the rack number is
> equal with replication
>
>
> Key: HDFS-16456
> URL: https://issues.apache.org/jira/browse/HDFS-16456
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: ec, namenode
>Affects Versions: 3.4.0
>Reporter: caozhiqiang
>Priority: Critical
> Attachments: HDFS-16456.001.patch
>
>
> In below scenario, decommission will fail by TOO_MANY_NODES_ON_RACK reason:
> # Enable EC policy, such as RS-6-3-1024k.
> # The rack number in this cluster is equal with the replication number(9)
> # A rack only has one DN, and decommission this DN.
> The root cause is in
> BlockPlacementPolicyRackFaultTolerant::getMaxNodesPerRack() function, it will
> give a limit parameter maxNodesPerRack for choose targets. In this scenario,
> the maxNodesPerRack is 1, which means each rack can only be chosen one
> datanode.
> {code:java}
> protected int[] getMaxNodesPerRack(int numOfChosen, int numOfReplicas) {
>...
> // If more replicas than racks, evenly spread the replicas.
> // This calculation rounds up.
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> return new int[] {numOfReplicas, maxNodesPerRack};
> } {code}
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> here will be called, where totalNumOfReplicas=9 and numOfRacks=9
> When we decommission one dn which is only one node in its rack, the
> chooseOnce() in BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder()
> will throw NotEnoughReplicasException, but the exception will not be caught
> and fail to fallback to chooseEvenlyFromRemainingRacks() function.
> When decommission, after choose targets, verifyBlockPlacement() function will
> return the total rack number contains the invalid rack, and
> BlockPlacementStatusDefault::isPlacementPolicySatisfied() will return false
> and it will also cause decommission fail.
> {code:java}
> public BlockPlacementStatus verifyBlockPlacement(DatanodeInfo[] locs,
> int numberOfReplicas) {
> if (locs == null)
> locs = DatanodeDescriptor.EMPTY_ARRAY;
> if (!clusterMap.hasClusterEverBeenMultiRack()) {
> // only one rack
> return new BlockPlacementStatusDefault(1, 1, 1);
> }
> // Count locations on different racks.
> Set racks = new HashSet<>();
> for (DatanodeInfo dn : locs) {
> racks.add(dn.getNetworkLocation());
> }
> return new BlockPlacementStatusDefault(racks.size(), numberOfReplicas,
> clusterMap.getNumOfRacks());
> } {code}
> {code:java}
> public boolean isPlacementPolicySatisfied() {
> return requiredRacks <= currentRacks || currentRacks >= totalRacks;
> }{code}
> According to the above description, we should make the below modify to fix it:
> # In startDecommission() or stopDecommission(), we should also change the
> numOfRacks in class NetworkTopology. Or choose targets may fail for the
> maxNodesPerRack is too small. And even choose targets success,
> isPlacementPolicySatisfied will also return false cause decommission fail.
> # In BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder(), the first
> chooseOnce() function should also be put in try..catch..., or it will not
> fallback to call chooseEvenlyFromRemainingRacks() when throw exception.
> # In chooseEvenlyFromRemainingRacks(), this numResultsOflastChoose =
> results.size(); code should be move to after chooseOnce(), or it will throw
> lastException and make choose targets failed.
>
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work started] (HDFS-16450) Give priority to releasing DNs with less free space
[
https://issues.apache.org/jira/browse/HDFS-16450?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Work on HDFS-16450 started by yanbin.zhang.
---
> Give priority to releasing DNs with less free space
> ---
>
> Key: HDFS-16450
> URL: https://issues.apache.org/jira/browse/HDFS-16450
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: hdfs
>Affects Versions: 3.3.0
>Reporter: yanbin.zhang
>Assignee: yanbin.zhang
>Priority: Major
> Attachments: HDFS-16450.001.patch
>
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> When deleting redundant replicas, the one with the least free space should be
> prioritized.
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else {
> return null;
> }
> excessTypes.remove(storage.getStorageType());
> return storage; {code}
> Change the above logic to the following:
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else {
> return null;
> } {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Reopened] (HDFS-16450) Give priority to releasing DNs with less free space
[
https://issues.apache.org/jira/browse/HDFS-16450?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
yanbin.zhang reopened HDFS-16450:
-
> Give priority to releasing DNs with less free space
> ---
>
> Key: HDFS-16450
> URL: https://issues.apache.org/jira/browse/HDFS-16450
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: hdfs
>Affects Versions: 3.3.0
>Reporter: yanbin.zhang
>Assignee: yanbin.zhang
>Priority: Major
> Attachments: HDFS-16450.001.patch
>
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> When deleting redundant replicas, the one with the least free space should be
> prioritized.
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else {
> return null;
> }
> excessTypes.remove(storage.getStorageType());
> return storage; {code}
> Change the above logic to the following:
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else {
> return null;
> } {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16450) Give priority to releasing DNs with less free space
[
https://issues.apache.org/jira/browse/HDFS-16450?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
yanbin.zhang updated HDFS-16450:
Labels: (was: 无)
> Give priority to releasing DNs with less free space
> ---
>
> Key: HDFS-16450
> URL: https://issues.apache.org/jira/browse/HDFS-16450
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: hdfs
>Affects Versions: 3.3.0
>Reporter: yanbin.zhang
>Assignee: yanbin.zhang
>Priority: Major
> Attachments: HDFS-16450.001.patch
>
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> When deleting redundant replicas, the one with the least free space should be
> prioritized.
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else {
> return null;
> }
> excessTypes.remove(storage.getStorageType());
> return storage; {code}
> Change the above logic to the following:
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else {
> return null;
> } {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16450) Give priority to releasing DNs with less free space
[
https://issues.apache.org/jira/browse/HDFS-16450?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
yanbin.zhang updated HDFS-16450:
Fix Version/s: 3.3.2
> Give priority to releasing DNs with less free space
> ---
>
> Key: HDFS-16450
> URL: https://issues.apache.org/jira/browse/HDFS-16450
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: hdfs
>Affects Versions: 3.3.0
>Reporter: yanbin.zhang
>Assignee: yanbin.zhang
>Priority: Major
> Labels: 无
> Fix For: 3.3.2
>
> Attachments: HDFS-16450.001.patch
>
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> When deleting redundant replicas, the one with the least free space should be
> prioritized.
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else {
> return null;
> }
> excessTypes.remove(storage.getStorageType());
> return storage; {code}
> Change the above logic to the following:
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else {
> return null;
> } {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16450) Give priority to releasing DNs with less free space
[
https://issues.apache.org/jira/browse/HDFS-16450?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
yanbin.zhang updated HDFS-16450:
Fix Version/s: (was: 3.3.2)
> Give priority to releasing DNs with less free space
> ---
>
> Key: HDFS-16450
> URL: https://issues.apache.org/jira/browse/HDFS-16450
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: hdfs
>Affects Versions: 3.3.0
>Reporter: yanbin.zhang
>Assignee: yanbin.zhang
>Priority: Major
> Labels: 无
> Attachments: HDFS-16450.001.patch
>
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> When deleting redundant replicas, the one with the least free space should be
> prioritized.
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else {
> return null;
> }
> excessTypes.remove(storage.getStorageType());
> return storage; {code}
> Change the above logic to the following:
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else {
> return null;
> } {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-14920) Erasure Coding: Decommission may hang If one or more datanodes are out of service during decommission
[
https://issues.apache.org/jira/browse/HDFS-14920?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
yanbin.zhang updated HDFS-14920:
Labels: (was: 无)
> Erasure Coding: Decommission may hang If one or more datanodes are out of
> service during decommission
> ---
>
> Key: HDFS-14920
> URL: https://issues.apache.org/jira/browse/HDFS-14920
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: ec
>Affects Versions: 3.0.3, 3.2.1, 3.1.3
>Reporter: Hui Fei
>Assignee: Hui Fei
>Priority: Major
> Fix For: 3.3.0, 3.1.4, 3.2.2
>
> Attachments: HDFS-14920.001.patch, HDFS-14920.002.patch,
> HDFS-14920.003.patch, HDFS-14920.004.patch, HDFS-14920.005.patch
>
>
> Decommission test hangs in our clusters.
> Have seen the messages as follow
> {quote}
> 2019-10-22 15:58:51,514 TRACE
> org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminManager: Block
> blk_-9223372035600425840_372987973 numExpected=9, numLive=5
> 2019-10-22 15:58:51,514 INFO BlockStateChange: Block:
> blk_-9223372035600425840_372987973, Expected Replicas: 9, live replicas: 5,
> corrupt replicas: 0, decommissioned replicas: 0, decommissioning replicas: 4,
> maintenance replicas: 0, live entering maintenance replicas: 0, excess
> replicas: 0, Is Open File: false, Datanodes having this block:
> 10.255.43.57:50010 10.255.53.12:50010 10.255.63.12:50010 10.255.62.39:50010
> 10.255.37.36:50010 10.255.33.15:50010 10.255.69.29:50010 10.255.51.13:50010
> 10.255.64.15:50010 , Current Datanode: 10.255.69.29:50010, Is current
> datanode decommissioning: true, Is current datanode entering maintenance:
> false
> 2019-10-22 15:58:51,514 DEBUG
> org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminManager: Node
> 10.255.69.29:50010 still has 1 blocks to replicate before it is a candidate
> to finish Decommission In Progress
> {quote}
> After digging the source code and cluster log, guess it happens as follow
> steps.
> # Storage strategy is RS-6-3-1024k.
> # EC block b consists of b0, b1, b2, b3, b4, b5, b6, b7, b8. b0 is from
> datanode dn0, b1 is from datanode dn1, ...etc
> # At the beginning dn0 is in decommission progress, b0 is replicated
> successfully, and dn0 is still in decommission progress.
> # Later b1, b2, b3 in decommission progress, and dn4 containing b4 is out of
> service, so need to reconstruct, and create ErasureCodingWork to do it, in
> the ErasureCodingWork, additionalReplRequired is 4
> # Because hasAllInternalBlocks is false, Will call
> ErasureCodingWork#addTaskToDatanode ->
> DatanodeDescriptor#addBlockToBeErasureCoded, and send
> BlockECReconstructionInfo task to Datanode
> # DataNode can not reconstruction the block because targets is 4, greater
> than 3( parity number).
> There is a problem as follow, from BlockManager.java#scheduleReconstruction
> {code}
> // should reconstruct all the internal blocks before scheduling
> // replication task for decommissioning node(s).
> if (additionalReplRequired - numReplicas.decommissioning() -
> numReplicas.liveEnteringMaintenanceReplicas() > 0) {
> additionalReplRequired = additionalReplRequired -
> numReplicas.decommissioning() -
> numReplicas.liveEnteringMaintenanceReplicas();
> }
> {code}
> Should reconstruction firstly and then replicate for decommissioning. Because
> numReplicas.decommissioning() is 4, and additionalReplRequired is 4, that's
> wrong,
> numReplicas.decommissioning() should be 3, it should exclude live replica.
> If so, additionalReplRequired will be 1, reconstruction will schedule as
> expected. After that, decommission goes on.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-14920) Erasure Coding: Decommission may hang If one or more datanodes are out of service during decommission
[
https://issues.apache.org/jira/browse/HDFS-14920?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
yanbin.zhang updated HDFS-14920:
Labels: 无 (was: pull)
> Erasure Coding: Decommission may hang If one or more datanodes are out of
> service during decommission
> ---
>
> Key: HDFS-14920
> URL: https://issues.apache.org/jira/browse/HDFS-14920
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: ec
>Affects Versions: 3.0.3, 3.2.1, 3.1.3
>Reporter: Hui Fei
>Assignee: Hui Fei
>Priority: Major
> Labels: 无
> Fix For: 3.3.0, 3.1.4, 3.2.2
>
> Attachments: HDFS-14920.001.patch, HDFS-14920.002.patch,
> HDFS-14920.003.patch, HDFS-14920.004.patch, HDFS-14920.005.patch
>
>
> Decommission test hangs in our clusters.
> Have seen the messages as follow
> {quote}
> 2019-10-22 15:58:51,514 TRACE
> org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminManager: Block
> blk_-9223372035600425840_372987973 numExpected=9, numLive=5
> 2019-10-22 15:58:51,514 INFO BlockStateChange: Block:
> blk_-9223372035600425840_372987973, Expected Replicas: 9, live replicas: 5,
> corrupt replicas: 0, decommissioned replicas: 0, decommissioning replicas: 4,
> maintenance replicas: 0, live entering maintenance replicas: 0, excess
> replicas: 0, Is Open File: false, Datanodes having this block:
> 10.255.43.57:50010 10.255.53.12:50010 10.255.63.12:50010 10.255.62.39:50010
> 10.255.37.36:50010 10.255.33.15:50010 10.255.69.29:50010 10.255.51.13:50010
> 10.255.64.15:50010 , Current Datanode: 10.255.69.29:50010, Is current
> datanode decommissioning: true, Is current datanode entering maintenance:
> false
> 2019-10-22 15:58:51,514 DEBUG
> org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminManager: Node
> 10.255.69.29:50010 still has 1 blocks to replicate before it is a candidate
> to finish Decommission In Progress
> {quote}
> After digging the source code and cluster log, guess it happens as follow
> steps.
> # Storage strategy is RS-6-3-1024k.
> # EC block b consists of b0, b1, b2, b3, b4, b5, b6, b7, b8. b0 is from
> datanode dn0, b1 is from datanode dn1, ...etc
> # At the beginning dn0 is in decommission progress, b0 is replicated
> successfully, and dn0 is still in decommission progress.
> # Later b1, b2, b3 in decommission progress, and dn4 containing b4 is out of
> service, so need to reconstruct, and create ErasureCodingWork to do it, in
> the ErasureCodingWork, additionalReplRequired is 4
> # Because hasAllInternalBlocks is false, Will call
> ErasureCodingWork#addTaskToDatanode ->
> DatanodeDescriptor#addBlockToBeErasureCoded, and send
> BlockECReconstructionInfo task to Datanode
> # DataNode can not reconstruction the block because targets is 4, greater
> than 3( parity number).
> There is a problem as follow, from BlockManager.java#scheduleReconstruction
> {code}
> // should reconstruct all the internal blocks before scheduling
> // replication task for decommissioning node(s).
> if (additionalReplRequired - numReplicas.decommissioning() -
> numReplicas.liveEnteringMaintenanceReplicas() > 0) {
> additionalReplRequired = additionalReplRequired -
> numReplicas.decommissioning() -
> numReplicas.liveEnteringMaintenanceReplicas();
> }
> {code}
> Should reconstruction firstly and then replicate for decommissioning. Because
> numReplicas.decommissioning() is 4, and additionalReplRequired is 4, that's
> wrong,
> numReplicas.decommissioning() should be 3, it should exclude live replica.
> If so, additionalReplRequired will be 1, reconstruction will schedule as
> expected. After that, decommission goes on.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-14920) Erasure Coding: Decommission may hang If one or more datanodes are out of service during decommission
[
https://issues.apache.org/jira/browse/HDFS-14920?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
yanbin.zhang updated HDFS-14920:
Labels: pull (was: )
> Erasure Coding: Decommission may hang If one or more datanodes are out of
> service during decommission
> ---
>
> Key: HDFS-14920
> URL: https://issues.apache.org/jira/browse/HDFS-14920
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: ec
>Affects Versions: 3.0.3, 3.2.1, 3.1.3
>Reporter: Hui Fei
>Assignee: Hui Fei
>Priority: Major
> Labels: pull
> Fix For: 3.3.0, 3.1.4, 3.2.2
>
> Attachments: HDFS-14920.001.patch, HDFS-14920.002.patch,
> HDFS-14920.003.patch, HDFS-14920.004.patch, HDFS-14920.005.patch
>
>
> Decommission test hangs in our clusters.
> Have seen the messages as follow
> {quote}
> 2019-10-22 15:58:51,514 TRACE
> org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminManager: Block
> blk_-9223372035600425840_372987973 numExpected=9, numLive=5
> 2019-10-22 15:58:51,514 INFO BlockStateChange: Block:
> blk_-9223372035600425840_372987973, Expected Replicas: 9, live replicas: 5,
> corrupt replicas: 0, decommissioned replicas: 0, decommissioning replicas: 4,
> maintenance replicas: 0, live entering maintenance replicas: 0, excess
> replicas: 0, Is Open File: false, Datanodes having this block:
> 10.255.43.57:50010 10.255.53.12:50010 10.255.63.12:50010 10.255.62.39:50010
> 10.255.37.36:50010 10.255.33.15:50010 10.255.69.29:50010 10.255.51.13:50010
> 10.255.64.15:50010 , Current Datanode: 10.255.69.29:50010, Is current
> datanode decommissioning: true, Is current datanode entering maintenance:
> false
> 2019-10-22 15:58:51,514 DEBUG
> org.apache.hadoop.hdfs.server.blockmanagement.DatanodeAdminManager: Node
> 10.255.69.29:50010 still has 1 blocks to replicate before it is a candidate
> to finish Decommission In Progress
> {quote}
> After digging the source code and cluster log, guess it happens as follow
> steps.
> # Storage strategy is RS-6-3-1024k.
> # EC block b consists of b0, b1, b2, b3, b4, b5, b6, b7, b8. b0 is from
> datanode dn0, b1 is from datanode dn1, ...etc
> # At the beginning dn0 is in decommission progress, b0 is replicated
> successfully, and dn0 is still in decommission progress.
> # Later b1, b2, b3 in decommission progress, and dn4 containing b4 is out of
> service, so need to reconstruct, and create ErasureCodingWork to do it, in
> the ErasureCodingWork, additionalReplRequired is 4
> # Because hasAllInternalBlocks is false, Will call
> ErasureCodingWork#addTaskToDatanode ->
> DatanodeDescriptor#addBlockToBeErasureCoded, and send
> BlockECReconstructionInfo task to Datanode
> # DataNode can not reconstruction the block because targets is 4, greater
> than 3( parity number).
> There is a problem as follow, from BlockManager.java#scheduleReconstruction
> {code}
> // should reconstruct all the internal blocks before scheduling
> // replication task for decommissioning node(s).
> if (additionalReplRequired - numReplicas.decommissioning() -
> numReplicas.liveEnteringMaintenanceReplicas() > 0) {
> additionalReplRequired = additionalReplRequired -
> numReplicas.decommissioning() -
> numReplicas.liveEnteringMaintenanceReplicas();
> }
> {code}
> Should reconstruction firstly and then replicate for decommissioning. Because
> numReplicas.decommissioning() is 4, and additionalReplRequired is 4, that's
> wrong,
> numReplicas.decommissioning() should be 3, it should exclude live replica.
> If so, additionalReplRequired will be 1, reconstruction will schedule as
> expected. After that, decommission goes on.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16450) Give priority to releasing DNs with less free space
[
https://issues.apache.org/jira/browse/HDFS-16450?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
yanbin.zhang updated HDFS-16450:
Labels: 无 (was: patch)
> Give priority to releasing DNs with less free space
> ---
>
> Key: HDFS-16450
> URL: https://issues.apache.org/jira/browse/HDFS-16450
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: hdfs
>Affects Versions: 3.3.0
>Reporter: yanbin.zhang
>Assignee: yanbin.zhang
>Priority: Major
> Labels: 无
> Attachments: HDFS-16450.001.patch
>
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> When deleting redundant replicas, the one with the least free space should be
> prioritized.
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else {
> return null;
> }
> excessTypes.remove(storage.getStorageType());
> return storage; {code}
> Change the above logic to the following:
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else {
> return null;
> } {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16450) Give priority to releasing DNs with less free space
[
https://issues.apache.org/jira/browse/HDFS-16450?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
yanbin.zhang updated HDFS-16450:
Labels: patch (was: pull-request-available)
> Give priority to releasing DNs with less free space
> ---
>
> Key: HDFS-16450
> URL: https://issues.apache.org/jira/browse/HDFS-16450
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: hdfs
>Affects Versions: 3.3.0
>Reporter: yanbin.zhang
>Assignee: yanbin.zhang
>Priority: Major
> Labels: patch
> Attachments: HDFS-16450.001.patch
>
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> When deleting redundant replicas, the one with the least free space should be
> prioritized.
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else {
> return null;
> }
> excessTypes.remove(storage.getStorageType());
> return storage; {code}
> Change the above logic to the following:
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else {
> return null;
> } {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDFS-16450) Give priority to releasing DNs with less free space
[
https://issues.apache.org/jira/browse/HDFS-16450?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
yanbin.zhang resolved HDFS-16450.
-
Resolution: Done
> Give priority to releasing DNs with less free space
> ---
>
> Key: HDFS-16450
> URL: https://issues.apache.org/jira/browse/HDFS-16450
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: hdfs
>Affects Versions: 3.3.0
>Reporter: yanbin.zhang
>Assignee: yanbin.zhang
>Priority: Major
> Labels: pull-request-available
> Attachments: HDFS-16450.001.patch
>
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> When deleting redundant replicas, the one with the least free space should be
> prioritized.
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else {
> return null;
> }
> excessTypes.remove(storage.getStorageType());
> return storage; {code}
> Change the above logic to the following:
> {code:java}
> //BlockPlacementPolicyDefault#chooseReplicaToDelete
> final DatanodeStorageInfo storage;
> if (minSpaceStorage != null) {
> storage = minSpaceStorage;
> } else if (oldestHeartbeatStorage != null) {
> storage = oldestHeartbeatStorage;
> } else {
> return null;
> } {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16440) RBF: Support router get HAServiceStatus with Lifeline RPC address
[ https://issues.apache.org/jira/browse/HDFS-16440?focusedWorklogId=726851=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726851 ] ASF GitHub Bot logged work on HDFS-16440: - Author: ASF GitHub Bot Created on: 15/Feb/22 05:56 Start Date: 15/Feb/22 05:56 Worklog Time Spent: 10m Work Description: yulongz commented on pull request #3971: URL: https://github.com/apache/hadoop/pull/3971#issuecomment-1039887623 @goiri This failed unit test is unrelated to my change. All tests work fine locally. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 726851) Time Spent: 1.5h (was: 1h 20m) > RBF: Support router get HAServiceStatus with Lifeline RPC address > - > > Key: HDFS-16440 > URL: https://issues.apache.org/jira/browse/HDFS-16440 > Project: Hadoop HDFS > Issue Type: Improvement > Components: rbf >Reporter: YulongZ >Assignee: YulongZ >Priority: Minor > Labels: pull-request-available > Attachments: HDFS-16440.001.patch, HDFS-16440.003.patch, > HDFS-16440.004.patch > > Time Spent: 1.5h > Remaining Estimate: 0h > > NamenodeHeartbeatService gets HAServiceStatus using > NNHAServiceTarget.getProxy. When we set a special > dfs.namenode.lifeline.rpc-address , NamenodeHeartbeatService may get > HAServiceStatus using NNHAServiceTarget.getHealthMonitorProxy. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16455) RBF: Router should explicitly specify the value of `jute.maxbuffer` in hadoop configuration files like core-site.xml
[
https://issues.apache.org/jira/browse/HDFS-16455?focusedWorklogId=726849=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726849
]
ASF GitHub Bot logged work on HDFS-16455:
-
Author: ASF GitHub Bot
Created on: 15/Feb/22 05:51
Start Date: 15/Feb/22 05:51
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on pull request #3983:
URL: https://github.com/apache/hadoop/pull/3983#issuecomment-1039885118
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 1m 14s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 1s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| -1 :x: | test4tests | 0m 0s | | The patch doesn't appear to include
any new or modified tests. Please justify why no new tests are needed for this
patch. Also please list what manual steps were performed to verify this patch.
|
_ trunk Compile Tests _ |
| +1 :green_heart: | mvninstall | 38m 22s | | trunk passed |
| +1 :green_heart: | compile | 25m 38s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | compile | 21m 14s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 1m 0s | | trunk passed |
| +1 :green_heart: | mvnsite | 1m 43s | | trunk passed |
| +1 :green_heart: | javadoc | 1m 8s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 1m 41s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 2m 34s | | trunk passed |
| +1 :green_heart: | shadedclient | 25m 54s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 1m 5s | | the patch passed |
| +1 :green_heart: | compile | 24m 13s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javac | 24m 13s | | the patch passed |
| +1 :green_heart: | compile | 21m 21s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 21m 21s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 0m 59s | | the patch passed |
| +1 :green_heart: | mvnsite | 1m 36s | | the patch passed |
| +1 :green_heart: | javadoc | 1m 5s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 1m 38s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 2m 41s | | the patch passed |
| +1 :green_heart: | shadedclient | 25m 35s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 18m 4s | | hadoop-common in the patch
passed. |
| +1 :green_heart: | asflicense | 0m 49s | | The patch does not
generate ASF License warnings. |
| | | 219m 11s | | |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3983/2/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/3983 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell |
| uname | Linux 378f1572afc2 4.15.0-153-generic #160-Ubuntu SMP Thu Jul 29
06:54:29 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / e898cb2a0668e54069b1ba26401e570ad33f3302 |
| Default Java | Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Multi-JDK versions |
/usr/lib/jvm/java-11-openjdk-amd64:Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04
/usr/lib/jvm/java-8-openjdk-amd64:Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Test Results |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3983/2/testReport/ |
| Max. process+thread count | 3059 (vs. ulimit of 5500) |
| modules | C: hadoop-common-project/hadoop-common U:
hadoop-common-project/hadoop-common |
| Console output |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3983/2/console |
| versions
[jira] [Work logged] (HDFS-16316) Improve DirectoryScanner: add regular file check related block
[
https://issues.apache.org/jira/browse/HDFS-16316?focusedWorklogId=726848=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726848
]
ASF GitHub Bot logged work on HDFS-16316:
-
Author: ASF GitHub Bot
Created on: 15/Feb/22 05:51
Start Date: 15/Feb/22 05:51
Worklog Time Spent: 10m
Work Description: jianghuazhu commented on a change in pull request #3861:
URL: https://github.com/apache/hadoop/pull/3861#discussion_r806465949
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/test/java/org/apache/hadoop/hdfs/server/datanode/TestDirectoryScanner.java
##
@@ -507,6 +509,71 @@ public void testDeleteBlockOnTransientStorage() throws
Exception {
}
}
+ @Test(timeout = 60)
+ public void testRegularBlock() throws Exception {
+// add a logger stream to check what has printed to log
+ByteArrayOutputStream loggerStream = new ByteArrayOutputStream();
Review comment:
Yes, it was my mistake.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 726848)
Time Spent: 2.5h (was: 2h 20m)
> Improve DirectoryScanner: add regular file check related block
> --
>
> Key: HDFS-16316
> URL: https://issues.apache.org/jira/browse/HDFS-16316
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: datanode
>Affects Versions: 2.9.2
>Reporter: JiangHua Zhu
>Assignee: JiangHua Zhu
>Priority: Major
> Labels: pull-request-available
> Attachments: screenshot-1.png, screenshot-2.png, screenshot-3.png,
> screenshot-4.png
>
> Time Spent: 2.5h
> Remaining Estimate: 0h
>
> Something unusual happened in the online environment.
> The DataNode is configured with 11 disks (${dfs.datanode.data.dir}). It is
> normal for 10 disks to calculate the used capacity, and the calculated value
> for the other 1 disk is much larger, which is very strange.
> This is about the live view on the NameNode:
> !screenshot-1.png!
> This is about the live view on the DataNode:
> !screenshot-2.png!
> We can look at the view on linux:
> !screenshot-3.png!
> There is a big gap here, regarding'/mnt/dfs/11/data'. This situation should
> be prohibited from happening.
> I found that there are some abnormal block files.
> There are wrong blk_.meta in some subdir directories, causing abnormal
> computing space.
> Here are some abnormal block files:
> !screenshot-4.png!
> Such files should not be used as normal blocks. They should be actively
> identified and filtered, which is good for cluster stability.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16455) RBF: Router should explicitly specify the value of `jute.maxbuffer` in hadoop configuration files like core-site.xml
[
https://issues.apache.org/jira/browse/HDFS-16455?focusedWorklogId=726844=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726844
]
ASF GitHub Bot logged work on HDFS-16455:
-
Author: ASF GitHub Bot
Created on: 15/Feb/22 05:29
Start Date: 15/Feb/22 05:29
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on pull request #3983:
URL: https://github.com/apache/hadoop/pull/3983#issuecomment-1039875071
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 36s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 0s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| -1 :x: | test4tests | 0m 0s | | The patch doesn't appear to include
any new or modified tests. Please justify why no new tests are needed for this
patch. Also please list what manual steps were performed to verify this patch.
|
_ trunk Compile Tests _ |
| +1 :green_heart: | mvninstall | 32m 1s | | trunk passed |
| +1 :green_heart: | compile | 22m 9s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | compile | 19m 39s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 1m 7s | | trunk passed |
| +1 :green_heart: | mvnsite | 1m 43s | | trunk passed |
| +1 :green_heart: | javadoc | 1m 15s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 1m 42s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 2m 26s | | trunk passed |
| +1 :green_heart: | shadedclient | 21m 53s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 0m 59s | | the patch passed |
| +1 :green_heart: | compile | 21m 31s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javac | 21m 31s | | the patch passed |
| +1 :green_heart: | compile | 19m 39s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 19m 39s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 1m 5s | | the patch passed |
| +1 :green_heart: | mvnsite | 1m 39s | | the patch passed |
| +1 :green_heart: | javadoc | 1m 9s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 1m 44s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 2m 36s | | the patch passed |
| +1 :green_heart: | shadedclient | 22m 14s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 17m 37s | | hadoop-common in the patch
passed. |
| +1 :green_heart: | asflicense | 0m 59s | | The patch does not
generate ASF License warnings. |
| | | 196m 3s | | |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3983/3/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/3983 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell |
| uname | Linux 5991516568fc 4.15.0-161-generic #169-Ubuntu SMP Fri Oct 15
13:41:54 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / e898cb2a0668e54069b1ba26401e570ad33f3302 |
| Default Java | Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Multi-JDK versions |
/usr/lib/jvm/java-11-openjdk-amd64:Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04
/usr/lib/jvm/java-8-openjdk-amd64:Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Test Results |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3983/3/testReport/ |
| Max. process+thread count | 1289 (vs. ulimit of 5500) |
| modules | C: hadoop-common-project/hadoop-common U:
hadoop-common-project/hadoop-common |
| Console output |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3983/3/console |
| versions
[jira] [Resolved] (HDFS-16396) Reconfig slow peer parameters for datanode
[ https://issues.apache.org/jira/browse/HDFS-16396?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Takanobu Asanuma resolved HDFS-16396. - Fix Version/s: 3.4.0 Resolution: Fixed > Reconfig slow peer parameters for datanode > -- > > Key: HDFS-16396 > URL: https://issues.apache.org/jira/browse/HDFS-16396 > Project: Hadoop HDFS > Issue Type: New Feature >Reporter: tomscut >Assignee: tomscut >Priority: Major > Labels: pull-request-available > Fix For: 3.4.0 > > Time Spent: 4h 40m > Remaining Estimate: 0h > > In large clusters, rolling restart datanodes takes a long time. We can make > slow peers parameters and slow disks parameters in datanode reconfigurable to > facilitate cluster operation and maintenance. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16316) Improve DirectoryScanner: add regular file check related block
[
https://issues.apache.org/jira/browse/HDFS-16316?focusedWorklogId=726843=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726843
]
ASF GitHub Bot logged work on HDFS-16316:
-
Author: ASF GitHub Bot
Created on: 15/Feb/22 05:03
Start Date: 15/Feb/22 05:03
Worklog Time Spent: 10m
Work Description: jojochuang commented on a change in pull request #3861:
URL: https://github.com/apache/hadoop/pull/3861#discussion_r806448723
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/test/java/org/apache/hadoop/hdfs/server/datanode/TestDirectoryScanner.java
##
@@ -507,6 +509,71 @@ public void testDeleteBlockOnTransientStorage() throws
Exception {
}
}
+ @Test(timeout = 60)
+ public void testRegularBlock() throws Exception {
+// add a logger stream to check what has printed to log
+ByteArrayOutputStream loggerStream = new ByteArrayOutputStream();
Review comment:
Can you use the Hadoop utility class LogCapturer
https://github.com/apache/hadoop/blob/6342d5e523941622a140fd877f06e9b59f48c48b/hadoop-common-project/hadoop-common/src/test/java/org/apache/hadoop/test/GenericTestUtils.java#L533
for this purpose?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 726843)
Time Spent: 2h 20m (was: 2h 10m)
> Improve DirectoryScanner: add regular file check related block
> --
>
> Key: HDFS-16316
> URL: https://issues.apache.org/jira/browse/HDFS-16316
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: datanode
>Affects Versions: 2.9.2
>Reporter: JiangHua Zhu
>Assignee: JiangHua Zhu
>Priority: Major
> Labels: pull-request-available
> Attachments: screenshot-1.png, screenshot-2.png, screenshot-3.png,
> screenshot-4.png
>
> Time Spent: 2h 20m
> Remaining Estimate: 0h
>
> Something unusual happened in the online environment.
> The DataNode is configured with 11 disks (${dfs.datanode.data.dir}). It is
> normal for 10 disks to calculate the used capacity, and the calculated value
> for the other 1 disk is much larger, which is very strange.
> This is about the live view on the NameNode:
> !screenshot-1.png!
> This is about the live view on the DataNode:
> !screenshot-2.png!
> We can look at the view on linux:
> !screenshot-3.png!
> There is a big gap here, regarding'/mnt/dfs/11/data'. This situation should
> be prohibited from happening.
> I found that there are some abnormal block files.
> There are wrong blk_.meta in some subdir directories, causing abnormal
> computing space.
> Here are some abnormal block files:
> !screenshot-4.png!
> Such files should not be used as normal blocks. They should be actively
> identified and filtered, which is good for cluster stability.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16396) Reconfig slow peer parameters for datanode
[ https://issues.apache.org/jira/browse/HDFS-16396?focusedWorklogId=726835=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726835 ] ASF GitHub Bot logged work on HDFS-16396: - Author: ASF GitHub Bot Created on: 15/Feb/22 04:41 Start Date: 15/Feb/22 04:41 Worklog Time Spent: 10m Work Description: tasanuma merged pull request #3827: URL: https://github.com/apache/hadoop/pull/3827 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 726835) Time Spent: 4.5h (was: 4h 20m) > Reconfig slow peer parameters for datanode > -- > > Key: HDFS-16396 > URL: https://issues.apache.org/jira/browse/HDFS-16396 > Project: Hadoop HDFS > Issue Type: New Feature >Reporter: tomscut >Assignee: tomscut >Priority: Major > Labels: pull-request-available > Time Spent: 4.5h > Remaining Estimate: 0h > > In large clusters, rolling restart datanodes takes a long time. We can make > slow peers parameters and slow disks parameters in datanode reconfigurable to > facilitate cluster operation and maintenance. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16396) Reconfig slow peer parameters for datanode
[ https://issues.apache.org/jira/browse/HDFS-16396?focusedWorklogId=726836=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726836 ] ASF GitHub Bot logged work on HDFS-16396: - Author: ASF GitHub Bot Created on: 15/Feb/22 04:41 Start Date: 15/Feb/22 04:41 Worklog Time Spent: 10m Work Description: tasanuma commented on pull request #3827: URL: https://github.com/apache/hadoop/pull/3827#issuecomment-1039851634 Merged it. Thanks for your contribution, @tomscut, and thanks for your review, @ayushtkn! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 726836) Time Spent: 4h 40m (was: 4.5h) > Reconfig slow peer parameters for datanode > -- > > Key: HDFS-16396 > URL: https://issues.apache.org/jira/browse/HDFS-16396 > Project: Hadoop HDFS > Issue Type: New Feature >Reporter: tomscut >Assignee: tomscut >Priority: Major > Labels: pull-request-available > Time Spent: 4h 40m > Remaining Estimate: 0h > > In large clusters, rolling restart datanodes takes a long time. We can make > slow peers parameters and slow disks parameters in datanode reconfigurable to > facilitate cluster operation and maintenance. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16316) Improve DirectoryScanner: add regular file check related block
[
https://issues.apache.org/jira/browse/HDFS-16316?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17492356#comment-17492356
]
JiangHua Zhu commented on HDFS-16316:
-
Sorry I'm late. Thanks to [~aajisaka] and [~weichiu] for your attention.
Yes, this happens occasionally, I've been monitoring it for a long time and
still can't find a specific cause.
But I think this situation may be related to the linux environment, when the
normal data flow works, there is no exception. (I will continue to monitor this
situation)
When this happens, we can do some work, such as doing more standardized checks
on Blocks. Because for Block, it should be a standard file.
> Improve DirectoryScanner: add regular file check related block
> --
>
> Key: HDFS-16316
> URL: https://issues.apache.org/jira/browse/HDFS-16316
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: datanode
>Affects Versions: 2.9.2
>Reporter: JiangHua Zhu
>Assignee: JiangHua Zhu
>Priority: Major
> Labels: pull-request-available
> Attachments: screenshot-1.png, screenshot-2.png, screenshot-3.png,
> screenshot-4.png
>
> Time Spent: 2h 10m
> Remaining Estimate: 0h
>
> Something unusual happened in the online environment.
> The DataNode is configured with 11 disks (${dfs.datanode.data.dir}). It is
> normal for 10 disks to calculate the used capacity, and the calculated value
> for the other 1 disk is much larger, which is very strange.
> This is about the live view on the NameNode:
> !screenshot-1.png!
> This is about the live view on the DataNode:
> !screenshot-2.png!
> We can look at the view on linux:
> !screenshot-3.png!
> There is a big gap here, regarding'/mnt/dfs/11/data'. This situation should
> be prohibited from happening.
> I found that there are some abnormal block files.
> There are wrong blk_.meta in some subdir directories, causing abnormal
> computing space.
> Here are some abnormal block files:
> !screenshot-4.png!
> Such files should not be used as normal blocks. They should be actively
> identified and filtered, which is good for cluster stability.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16316) Improve DirectoryScanner: add regular file check related block
[
https://issues.apache.org/jira/browse/HDFS-16316?focusedWorklogId=726826=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726826
]
ASF GitHub Bot logged work on HDFS-16316:
-
Author: ASF GitHub Bot
Created on: 15/Feb/22 03:55
Start Date: 15/Feb/22 03:55
Worklog Time Spent: 10m
Work Description: jianghuazhu commented on pull request #3861:
URL: https://github.com/apache/hadoop/pull/3861#issuecomment-1039827275
Here are some examples of online clusters.
We construct a block device file such as:
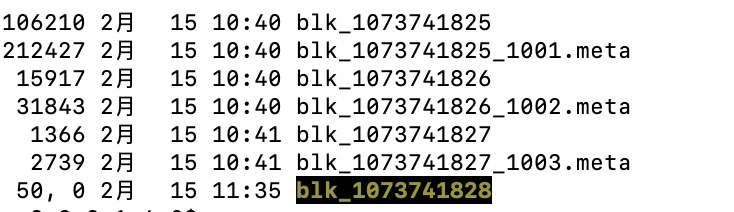
This file is non-standard.
This kind of file is found when DirectoryScanner is working.
log:
`
2022-02-15 11:24:10,286 WARN
org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl:
Block:1073741828 is not a regular file.
`
`
2022-02-15 11:24:10,286 WARN
org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Reporting
the block blk_1073741828_0 as corrupt due to length mismatch
`
Then DataNode will tell NameNode that there are some unqualified blocks
through NameNodeRpcServer#reportBadBlocks(). After the NameNode gets the data,
it will process it further.
After a period of time, the DataNode will automatically clean up these
unqualified replica data.
Can you help review this pr again, @jojochuang .
Thank you so much.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 726826)
Time Spent: 2h 10m (was: 2h)
> Improve DirectoryScanner: add regular file check related block
> --
>
> Key: HDFS-16316
> URL: https://issues.apache.org/jira/browse/HDFS-16316
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: datanode
>Affects Versions: 2.9.2
>Reporter: JiangHua Zhu
>Assignee: JiangHua Zhu
>Priority: Major
> Labels: pull-request-available
> Attachments: screenshot-1.png, screenshot-2.png, screenshot-3.png,
> screenshot-4.png
>
> Time Spent: 2h 10m
> Remaining Estimate: 0h
>
> Something unusual happened in the online environment.
> The DataNode is configured with 11 disks (${dfs.datanode.data.dir}). It is
> normal for 10 disks to calculate the used capacity, and the calculated value
> for the other 1 disk is much larger, which is very strange.
> This is about the live view on the NameNode:
> !screenshot-1.png!
> This is about the live view on the DataNode:
> !screenshot-2.png!
> We can look at the view on linux:
> !screenshot-3.png!
> There is a big gap here, regarding'/mnt/dfs/11/data'. This situation should
> be prohibited from happening.
> I found that there are some abnormal block files.
> There are wrong blk_.meta in some subdir directories, causing abnormal
> computing space.
> Here are some abnormal block files:
> !screenshot-4.png!
> Such files should not be used as normal blocks. They should be actively
> identified and filtered, which is good for cluster stability.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16316) Improve DirectoryScanner: add regular file check related block
[
https://issues.apache.org/jira/browse/HDFS-16316?focusedWorklogId=726825=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726825
]
ASF GitHub Bot logged work on HDFS-16316:
-
Author: ASF GitHub Bot
Created on: 15/Feb/22 03:53
Start Date: 15/Feb/22 03:53
Worklog Time Spent: 10m
Work Description: jianghuazhu removed a comment on pull request #3861:
URL: https://github.com/apache/hadoop/pull/3861#issuecomment-1039826045
Here are some examples of online clusters.
We construct a block device file such as:

This file is non-standard.
This kind of file is found when DirectoryScanner is working.
log:
`
2022-02-15 11:24:10,286 WARN
org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl:
Block:1073741828 is not a regular file.
`
`
2022-02-15 11:24:10,286 WARN
org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Reporting
the block blk_1073741828_0 as corrupt due to length mismatch
`
Then DataNode will tell NameNode that there are some unqualified blocks
through NameNodeRpcServer#reportBadBlocks(). After the NameNode gets the data,
it will process it further.
After a period of time, the DataNode will automatically clean up these
unqualified replica data.

Can you help review this pr again, @jojochuang .
Thank you so much.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 726825)
Time Spent: 2h (was: 1h 50m)
> Improve DirectoryScanner: add regular file check related block
> --
>
> Key: HDFS-16316
> URL: https://issues.apache.org/jira/browse/HDFS-16316
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: datanode
>Affects Versions: 2.9.2
>Reporter: JiangHua Zhu
>Assignee: JiangHua Zhu
>Priority: Major
> Labels: pull-request-available
> Attachments: screenshot-1.png, screenshot-2.png, screenshot-3.png,
> screenshot-4.png
>
> Time Spent: 2h
> Remaining Estimate: 0h
>
> Something unusual happened in the online environment.
> The DataNode is configured with 11 disks (${dfs.datanode.data.dir}). It is
> normal for 10 disks to calculate the used capacity, and the calculated value
> for the other 1 disk is much larger, which is very strange.
> This is about the live view on the NameNode:
> !screenshot-1.png!
> This is about the live view on the DataNode:
> !screenshot-2.png!
> We can look at the view on linux:
> !screenshot-3.png!
> There is a big gap here, regarding'/mnt/dfs/11/data'. This situation should
> be prohibited from happening.
> I found that there are some abnormal block files.
> There are wrong blk_.meta in some subdir directories, causing abnormal
> computing space.
> Here are some abnormal block files:
> !screenshot-4.png!
> Such files should not be used as normal blocks. They should be actively
> identified and filtered, which is good for cluster stability.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16396) Reconfig slow peer parameters for datanode
[ https://issues.apache.org/jira/browse/HDFS-16396?focusedWorklogId=726824=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726824 ] ASF GitHub Bot logged work on HDFS-16396: - Author: ASF GitHub Bot Created on: 15/Feb/22 03:52 Start Date: 15/Feb/22 03:52 Worklog Time Spent: 10m Work Description: tomscut commented on pull request #3827: URL: https://github.com/apache/hadoop/pull/3827#issuecomment-1039826206 Thanks @tasanuma and @ayushtkn for the review and confirming this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 726824) Time Spent: 4h 20m (was: 4h 10m) > Reconfig slow peer parameters for datanode > -- > > Key: HDFS-16396 > URL: https://issues.apache.org/jira/browse/HDFS-16396 > Project: Hadoop HDFS > Issue Type: New Feature >Reporter: tomscut >Assignee: tomscut >Priority: Major > Labels: pull-request-available > Time Spent: 4h 20m > Remaining Estimate: 0h > > In large clusters, rolling restart datanodes takes a long time. We can make > slow peers parameters and slow disks parameters in datanode reconfigurable to > facilitate cluster operation and maintenance. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16316) Improve DirectoryScanner: add regular file check related block
[
https://issues.apache.org/jira/browse/HDFS-16316?focusedWorklogId=726823=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726823
]
ASF GitHub Bot logged work on HDFS-16316:
-
Author: ASF GitHub Bot
Created on: 15/Feb/22 03:52
Start Date: 15/Feb/22 03:52
Worklog Time Spent: 10m
Work Description: jianghuazhu commented on pull request #3861:
URL: https://github.com/apache/hadoop/pull/3861#issuecomment-1039826045
Here are some examples of online clusters.
We construct a block device file such as:

This file is non-standard.
This kind of file is found when DirectoryScanner is working.
log:
`
2022-02-15 11:24:10,286 WARN
org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl:
Block:1073741828 is not a regular file.
`
`
2022-02-15 11:24:10,286 WARN
org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Reporting
the block blk_1073741828_0 as corrupt due to length mismatch
`
Then DataNode will tell NameNode that there are some unqualified blocks
through NameNodeRpcServer#reportBadBlocks(). After the NameNode gets the data,
it will process it further.
After a period of time, the DataNode will automatically clean up these
unqualified replica data.

Can you help review this pr again, @jojochuang .
Thank you so much.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 726823)
Time Spent: 1h 50m (was: 1h 40m)
> Improve DirectoryScanner: add regular file check related block
> --
>
> Key: HDFS-16316
> URL: https://issues.apache.org/jira/browse/HDFS-16316
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: datanode
>Affects Versions: 2.9.2
>Reporter: JiangHua Zhu
>Assignee: JiangHua Zhu
>Priority: Major
> Labels: pull-request-available
> Attachments: screenshot-1.png, screenshot-2.png, screenshot-3.png,
> screenshot-4.png
>
> Time Spent: 1h 50m
> Remaining Estimate: 0h
>
> Something unusual happened in the online environment.
> The DataNode is configured with 11 disks (${dfs.datanode.data.dir}). It is
> normal for 10 disks to calculate the used capacity, and the calculated value
> for the other 1 disk is much larger, which is very strange.
> This is about the live view on the NameNode:
> !screenshot-1.png!
> This is about the live view on the DataNode:
> !screenshot-2.png!
> We can look at the view on linux:
> !screenshot-3.png!
> There is a big gap here, regarding'/mnt/dfs/11/data'. This situation should
> be prohibited from happening.
> I found that there are some abnormal block files.
> There are wrong blk_.meta in some subdir directories, causing abnormal
> computing space.
> Here are some abnormal block files:
> !screenshot-4.png!
> Such files should not be used as normal blocks. They should be actively
> identified and filtered, which is good for cluster stability.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16455) RBF: Router should explicitly specify the value of `jute.maxbuffer` in hadoop configuration files like core-site.xml
[
https://issues.apache.org/jira/browse/HDFS-16455?focusedWorklogId=726787=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726787
]
ASF GitHub Bot logged work on HDFS-16455:
-
Author: ASF GitHub Bot
Created on: 15/Feb/22 02:11
Start Date: 15/Feb/22 02:11
Worklog Time Spent: 10m
Work Description: Neilxzn commented on a change in pull request #3983:
URL: https://github.com/apache/hadoop/pull/3983#discussion_r806389802
##
File path:
hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/security/token/delegation/ZKDelegationTokenSecretManager.java
##
@@ -199,6 +202,10 @@ public ZKDelegationTokenSecretManager(Configuration conf) {
ZK_DTSM_ZK_SESSION_TIMEOUT_DEFAULT);
int numRetries =
conf.getInt(ZK_DTSM_ZK_NUM_RETRIES,
ZK_DTSM_ZK_NUM_RETRIES_DEFAULT);
+String juteMaxBuffer =
+conf.get(ZK_DTSM_ZK_JUTE_MAXBUFFER,
ZK_DTSM_ZK_JUTE_MAXBUFFER_DEFAULT);
Review comment:
Thank you for your review. fix it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 726787)
Time Spent: 1h (was: 50m)
> RBF: Router should explicitly specify the value of `jute.maxbuffer` in hadoop
> configuration files like core-site.xml
>
>
> Key: HDFS-16455
> URL: https://issues.apache.org/jira/browse/HDFS-16455
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: rbf
>Affects Versions: 3.3.0, 3.4.0
>Reporter: Max Xie
>Assignee: Max Xie
>Priority: Minor
> Labels: pull-request-available
> Time Spent: 1h
> Remaining Estimate: 0h
>
> Based on the current design for delegation token in secure Router, the total
> number of tokens store and update in zookeeper using
> ZKDelegationTokenManager.
> But the default value of system property `jute.maxbuffer` is just 4MB, if
> Router store too many tokens in zk, it will throw IOException `{{{}Packet
> lenxx is out of range{}}}` and all Router will crash.
>
> In our cluster, Routers crashed because of it. The crash logs are below
> {code:java}
> 2022-02-09 02:15:51,607 INFO
> org.apache.hadoop.security.token.delegation.AbstractDelegationTokenSecretManager:
> Token renewal for identifier: (token for xxx: HDFS_DELEGATION_TOKEN
> owner=xxx/scheduler, renewer=hadoop, realUser=, issueDate=1644344146305,
> maxDate=1644948946305, sequenceNumbe
> r=27136070, masterKeyId=1107); total currentTokens 279548 2022-02-09
> 02:16:07,632 WARN org.apache.zookeeper.ClientCnxn: Session 0x1000172775a0012
> for server zkurl:2181, unexpected e
> rror, closing socket connection and attempting reconnect
> java.io.IOException: Packet len4194553 is out of range!
> at org.apache.zookeeper.ClientCnxnSocket.readLength(ClientCnxnSocket.java:113)
> at org.apache.zookeeper.ClientCnxnSocketNIO.doIO(ClientCnxnSocketNIO.java:79)
> at
> org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:366)
> at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1145)
> 2022-02-09 02:16:07,733 WARN org.apache.hadoop.ipc.Server: IPC Server handler
> 1254 on default port 9001, call Call#144 Retry#0
> org.apache.hadoop.hdfs.protocol.ClientProtocol.getDelegationToken from
> ip:46534
> java.lang.RuntimeException: Could not increment shared counter !!
> at
> org.apache.hadoop.security.token.delegation.ZKDelegationTokenSecretManager.incrementDelegationTokenSeqNum(ZKDelegationTokenSecretManager.java:582)
> {code}
> When we restart a Router, it crashed again
> {code:java}
> 2022-02-09 03:14:17,308 INFO
> org.apache.hadoop.security.token.delegation.ZKDelegationTokenSecretManager:
> Starting to load key cache.
> 2022-02-09 03:14:17,310 INFO
> org.apache.hadoop.security.token.delegation.ZKDelegationTokenSecretManager:
> Loaded key cache.
> 2022-02-09 03:14:32,930 WARN org.apache.zookeeper.ClientCnxn: Session
> 0x205584be35b0001 for server zkurl:2181, unexpected
> error, closing socket connection and attempting reconnect
> java.io.IOException: Packet len4194478 is out of range!
> at
> org.apache.zookeeper.ClientCnxnSocket.readLength(ClientCnxnSocket.java:113)
> at
> org.apache.zookeeper.ClientCnxnSocketNIO.doIO(ClientCnxnSocketNIO.java:79)
> at
> org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:366)
> at
>
[jira] [Work logged] (HDFS-16316) Improve DirectoryScanner: add regular file check related block
[
https://issues.apache.org/jira/browse/HDFS-16316?focusedWorklogId=726752=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726752
]
ASF GitHub Bot logged work on HDFS-16316:
-
Author: ASF GitHub Bot
Created on: 15/Feb/22 00:53
Start Date: 15/Feb/22 00:53
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on pull request #3861:
URL: https://github.com/apache/hadoop/pull/3861#issuecomment-1039731742
:confetti_ball: **+1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 47s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 0s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 1s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 2 new or modified test files. |
_ trunk Compile Tests _ |
| +0 :ok: | mvndep | 12m 38s | | Maven dependency ordering for branch |
| +1 :green_heart: | mvninstall | 22m 42s | | trunk passed |
| +1 :green_heart: | compile | 25m 0s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | compile | 21m 33s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 3m 40s | | trunk passed |
| +1 :green_heart: | mvnsite | 3m 21s | | trunk passed |
| +1 :green_heart: | javadoc | 2m 30s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 3m 25s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 5m 54s | | trunk passed |
| +1 :green_heart: | shadedclient | 22m 58s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +0 :ok: | mvndep | 0m 27s | | Maven dependency ordering for patch |
| +1 :green_heart: | mvninstall | 2m 24s | | the patch passed |
| +1 :green_heart: | compile | 24m 30s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javac | 24m 30s | | the patch passed |
| +1 :green_heart: | compile | 21m 38s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 21m 38s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 3m 59s | | the patch passed |
| +1 :green_heart: | mvnsite | 3m 32s | | the patch passed |
| +1 :green_heart: | javadoc | 2m 23s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 3m 26s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 6m 17s | | the patch passed |
| +1 :green_heart: | shadedclient | 23m 31s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 18m 8s | | hadoop-common in the patch
passed. |
| +1 :green_heart: | unit | 244m 31s | | hadoop-hdfs in the patch
passed. |
| +1 :green_heart: | asflicense | 1m 11s | | The patch does not
generate ASF License warnings. |
| | | 479m 39s | | |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3861/5/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/3861 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell |
| uname | Linux f5704bbd2c85 4.15.0-58-generic #64-Ubuntu SMP Tue Aug 6
11:12:41 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 39177f5f70296fc117b6f5e5bdf01a6acf52e040 |
| Default Java | Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Multi-JDK versions |
/usr/lib/jvm/java-11-openjdk-amd64:Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04
/usr/lib/jvm/java-8-openjdk-amd64:Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Test Results |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3861/5/testReport/ |
| Max. process+thread count | 3458 (vs. ulimit of 5500) |
| modules | C: hadoop-common-project/hadoop-common
hadoop-hdfs-project/hadoop-hdfs U: .
[jira] [Work logged] (HDFS-16316) Improve DirectoryScanner: add regular file check related block
[
https://issues.apache.org/jira/browse/HDFS-16316?focusedWorklogId=726750=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726750
]
ASF GitHub Bot logged work on HDFS-16316:
-
Author: ASF GitHub Bot
Created on: 15/Feb/22 00:48
Start Date: 15/Feb/22 00:48
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on pull request #3861:
URL: https://github.com/apache/hadoop/pull/3861#issuecomment-1039728159
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 36s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 1s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 2 new or modified test files. |
_ trunk Compile Tests _ |
| +0 :ok: | mvndep | 12m 49s | | Maven dependency ordering for branch |
| +1 :green_heart: | mvninstall | 23m 3s | | trunk passed |
| +1 :green_heart: | compile | 24m 37s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | compile | 21m 51s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 4m 3s | | trunk passed |
| +1 :green_heart: | mvnsite | 3m 18s | | trunk passed |
| +1 :green_heart: | javadoc | 2m 24s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 3m 36s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 6m 12s | | trunk passed |
| +1 :green_heart: | shadedclient | 23m 10s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +0 :ok: | mvndep | 0m 27s | | Maven dependency ordering for patch |
| +1 :green_heart: | mvninstall | 2m 16s | | the patch passed |
| +1 :green_heart: | compile | 24m 18s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javac | 24m 18s | | the patch passed |
| +1 :green_heart: | compile | 22m 1s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 22m 1s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 3m 52s | | the patch passed |
| +1 :green_heart: | mvnsite | 3m 18s | | the patch passed |
| +1 :green_heart: | javadoc | 2m 26s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 3m 34s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 6m 40s | | the patch passed |
| +1 :green_heart: | shadedclient | 23m 20s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 18m 3s | | hadoop-common in the patch
passed. |
| -1 :x: | unit | 243m 20s |
[/patch-unit-hadoop-hdfs-project_hadoop-hdfs.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3861/4/artifact/out/patch-unit-hadoop-hdfs-project_hadoop-hdfs.txt)
| hadoop-hdfs in the patch passed. |
| +1 :green_heart: | asflicense | 1m 7s | | The patch does not
generate ASF License warnings. |
| | | 479m 3s | | |
| Reason | Tests |
|---:|:--|
| Failed junit tests | hadoop.hdfs.TestRollingUpgrade |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3861/4/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/3861 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell |
| uname | Linux 63415c0a5ad9 4.15.0-58-generic #64-Ubuntu SMP Tue Aug 6
11:12:41 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / adede8620292339919f23c457164b573e0c73aee |
| Default Java | Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Multi-JDK versions |
/usr/lib/jvm/java-11-openjdk-amd64:Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04
/usr/lib/jvm/java-8-openjdk-amd64:Private
[jira] [Updated] (HDFS-16271) RBF: NullPointerException when setQuota through routers with quota disabled
[ https://issues.apache.org/jira/browse/HDFS-16271?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Chao Sun updated HDFS-16271: Fix Version/s: 3.3.2 (was: 3.3.1) > RBF: NullPointerException when setQuota through routers with quota disabled > --- > > Key: HDFS-16271 > URL: https://issues.apache.org/jira/browse/HDFS-16271 > Project: Hadoop HDFS > Issue Type: Bug >Affects Versions: 3.3.1 >Reporter: Chengwei Wang >Assignee: Chengwei Wang >Priority: Major > Fix For: 3.4.0, 3.3.2 > > Attachments: HDFS-16271.001.patch, HDFS-16271.002.patch > > > When we started routers with *dfs.federation.router.quota.enable=false*, and > try to setQuota through them, NullPointerException caught. > The cuase of NPE is that the Router#quotaManager not initialized when > dfs.federation.router.quota.enable=false, > but when executing setQuota rpc request inside router, we wolud use it in > method Quota#isMountEntry without null check . > I think it's better to check whether Router#isQuotaEnabled is true before use > Router#quotaManager, and throw an IOException with readable message if need. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16344) Improve DirectoryScanner.Stats#toString
[ https://issues.apache.org/jira/browse/HDFS-16344?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Chao Sun updated HDFS-16344: Fix Version/s: 3.3.2 (was: 3.3.3) > Improve DirectoryScanner.Stats#toString > --- > > Key: HDFS-16344 > URL: https://issues.apache.org/jira/browse/HDFS-16344 > Project: Hadoop HDFS > Issue Type: Improvement >Reporter: tomscut >Assignee: tomscut >Priority: Major > Labels: pull-request-available > Fix For: 3.4.0, 3.3.2 > > Attachments: image-2021-11-21-19-35-16-838.png > > Time Spent: 1h 40m > Remaining Estimate: 0h > > Improve DirectoryScanner.Stats#toString. > !image-2021-11-21-19-35-16-838.png|width=1019,height=71! -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16332) Expired block token causes slow read due to missing handling in sasl handshake
[
https://issues.apache.org/jira/browse/HDFS-16332?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Chao Sun updated HDFS-16332:
Fix Version/s: 3.3.2
(was: 3.3.3)
> Expired block token causes slow read due to missing handling in sasl handshake
> --
>
> Key: HDFS-16332
> URL: https://issues.apache.org/jira/browse/HDFS-16332
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: datanode, dfs, dfsclient
>Affects Versions: 2.8.5, 3.3.1
>Reporter: Shinya Yoshida
>Assignee: Shinya Yoshida
>Priority: Major
> Labels: pull-request-available
> Fix For: 3.4.0, 3.3.2, 3.2.4
>
> Attachments: Screenshot from 2021-11-18 12-11-34.png, Screenshot from
> 2021-11-18 12-14-29.png, Screenshot from 2021-11-18 13-31-35.png
>
> Time Spent: 5h 40m
> Remaining Estimate: 0h
>
> We're operating the HBase 1.4.x cluster on Hadoop 2.8.5.
> We're recently evaluating Kerberos secured HBase and Hadoop cluster with
> production load and we observed HBase's response slows >= several seconds,
> and about several minutes for worst-case (about once~three times a month).
> The following image is a scatter plot of HBase's response slow, each circle
> is each base's slow response log.
> The X-axis is the date time of the log occurred, the Y-axis is the response
> slow time.
> !Screenshot from 2021-11-18 12-14-29.png!
> We could reproduce this issue by reducing "dfs.block.access.token.lifetime"
> and we could figure out the cause.
> (We used dfs.block.access.token.lifetime=60, i.e. 1 hour)
> When hedged read enabled:
> !Screenshot from 2021-11-18 12-11-34.png!
> When hedged read disabled:
> !Screenshot from 2021-11-18 13-31-35.png!
> As you can see, it's worst if the hedged read is enabled. However, it happens
> whether the hedged read is enabled or not.
> This impacts our 99%tile response time.
> This happens when the block token is expired and the root cause is the wrong
> handling of the InvalidToken exception in sasl handshake in
> SaslDataTransferServer.
> I propose to add a new response code for DataTransferEncryptorStatus to
> request the client to update the block token like DataTransferProtos does.
> The test code and patch is available in
> https://github.com/apache/hadoop/pull/3677
> We could reproduce this issue by the following test code in 2.8.5 branch and
> trunk as I tested
> {code:java}
> // HDFS is configured as secure cluster
> try (FileSystem fs = newFileSystem();
> FSDataInputStream in = fs.open(PATH)) {
> waitBlockTokenExpired(in);
> in.read(0, bytes, 0, bytes.length)
> }
> private void waitBlockTokenExpired(FSDataInputStream in1) throws Exception {
> DFSInputStream innerStream = (DFSInputStream) in1.getWrappedStream();
> for (LocatedBlock block : innerStream.getAllBlocks()) {
> while (!SecurityTestUtil.isBlockTokenExpired(block.getBlockToken())) {
> Thread.sleep(100);
> }
> }
> }
> {code}
> Here is the log we got, we added a custom log before and after the block
> token refresh:
> https://github.com/bitterfox/hadoop/commit/173a9f876f2264b76af01d658f624197936fd79c
> {code}
> 2021-11-16 09:40:20,330 WARN [hedgedRead-247] impl.BlockReaderFactory: I/O
> error constructing remote block reader.
> java.io.IOException: DIGEST-MD5: IO error acquiring password
> at
> org.apache.hadoop.hdfs.protocol.datatransfer.sasl.DataTransferSaslUtil.readSaslMessageAndNegotiatedCipherOption(DataTransferSaslUtil.java:420)
> at
> org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.doSaslHandshake(SaslDataTransferClient.java:475)
> at
> org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.getSaslStreams(SaslDataTransferClient.java:389)
> at
> org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.send(SaslDataTransferClient.java:263)
> at
> org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.checkTrustAndSend(SaslDataTransferClient.java:211)
> at
> org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.peerSend(SaslDataTransferClient.java:160)
> at
> org.apache.hadoop.hdfs.DFSUtilClient.peerFromSocketAndKey(DFSUtilClient.java:568)
> at
> org.apache.hadoop.hdfs.DFSClient.newConnectedPeer(DFSClient.java:2880)
> at
> org.apache.hadoop.hdfs.client.impl.BlockReaderFactory.nextTcpPeer(BlockReaderFactory.java:815)
> at
> org.apache.hadoop.hdfs.client.impl.BlockReaderFactory.getRemoteBlockReaderFromTcp(BlockReaderFactory.java:740)
> at
> org.apache.hadoop.hdfs.client.impl.BlockReaderFactory.build(BlockReaderFactory.java:385)
> at
>
[jira] [Updated] (HDFS-16350) Datanode start time should be set after RPC server starts successfully
[ https://issues.apache.org/jira/browse/HDFS-16350?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Chao Sun updated HDFS-16350: Fix Version/s: 3.3.2 (was: 3.3.3) > Datanode start time should be set after RPC server starts successfully > -- > > Key: HDFS-16350 > URL: https://issues.apache.org/jira/browse/HDFS-16350 > Project: Hadoop HDFS > Issue Type: Bug >Reporter: Viraj Jasani >Assignee: Viraj Jasani >Priority: Minor > Labels: pull-request-available > Fix For: 3.4.0, 3.2.3, 3.3.2 > > Attachments: Screenshot 2021-11-23 at 4.32.04 PM.png > > Time Spent: 2.5h > Remaining Estimate: 0h > > We set start time of Datanode when the class is instantiated but it should be > ideally set only after RPC server starts and RPC handlers are initialized to > serve client requests. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16336) De-flake TestRollingUpgrade#testRollback
[
https://issues.apache.org/jira/browse/HDFS-16336?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Chao Sun updated HDFS-16336:
Fix Version/s: 3.3.2
(was: 3.3.3)
> De-flake TestRollingUpgrade#testRollback
>
>
> Key: HDFS-16336
> URL: https://issues.apache.org/jira/browse/HDFS-16336
> Project: Hadoop HDFS
> Issue Type: Sub-task
> Components: hdfs, test
>Affects Versions: 3.4.0
>Reporter: Kevin Wikant
>Assignee: Viraj Jasani
>Priority: Minor
> Labels: pull-request-available
> Fix For: 3.4.0, 3.3.2, 3.2.4
>
> Time Spent: 2h 10m
> Remaining Estimate: 0h
>
> This pull request: [https://github.com/apache/hadoop/pull/3675]
> Failed Jenkins pre-commit job due to an unrelated unit test failure:
> [https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3675/1/artifact/out/patch-unit-hadoop-hdfs-project_hadoop-hdfs.txt]
> {code:java}
> [ERROR] Failures:
> [ERROR]
> org.apache.hadoop.hdfs.TestRollingUpgrade.testRollback(org.apache.hadoop.hdfs.TestRollingUpgrade)
> [ERROR] Run 1: TestRollingUpgrade.testRollback:328->checkMxBeanIsNull:299
> expected null, but
> was: createdRollbackImages=true, finalizeTime=0, startTime=1637204448659})>
> [ERROR] Run 2: TestRollingUpgrade.testRollback:328->checkMxBeanIsNull:299
> expected null, but
> was: createdRollbackImages=true, finalizeTime=0, startTime=1637204448659})>
> [ERROR] Run 3: TestRollingUpgrade.testRollback:328->checkMxBeanIsNull:299
> expected null, but
> was: createdRollbackImages=true, finalizeTime=0, startTime=1637204448659})> {code}
> Seems that perhaps "TestRollingUpgrade.testRollback" is a flaky unit test
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16171) De-flake testDecommissionStatus
[
https://issues.apache.org/jira/browse/HDFS-16171?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Chao Sun updated HDFS-16171:
Fix Version/s: 3.3.2
(was: 3.3.3)
> De-flake testDecommissionStatus
> ---
>
> Key: HDFS-16171
> URL: https://issues.apache.org/jira/browse/HDFS-16171
> Project: Hadoop HDFS
> Issue Type: Sub-task
>Reporter: Viraj Jasani
>Assignee: Viraj Jasani
>Priority: Major
> Labels: pull-request-available
> Fix For: 3.4.0, 3.3.2, 3.2.4
>
> Time Spent: 2h 40m
> Remaining Estimate: 0h
>
> testDecommissionStatus keeps failing intermittently.
> {code:java}
> [ERROR]
> testDecommissionStatus(org.apache.hadoop.hdfs.server.namenode.TestDecommissioningStatusWithBackoffMonitor)
> Time elapsed: 3.299 s <<< FAILURE!
> java.lang.AssertionError: Unexpected num under-replicated blocks expected:<4>
> but was:<3>
> at org.junit.Assert.fail(Assert.java:89)
> at org.junit.Assert.failNotEquals(Assert.java:835)
> at org.junit.Assert.assertEquals(Assert.java:647)
> at
> org.apache.hadoop.hdfs.server.namenode.TestDecommissioningStatus.checkDecommissionStatus(TestDecommissioningStatus.java:169)
> at
> org.apache.hadoop.hdfs.server.namenode.TestDecommissioningStatusWithBackoffMonitor.testDecommissionStatus(TestDecommissioningStatusWithBackoffMonitor.java:136)
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16339) Show the threshold when mover threads quota is exceeded
[ https://issues.apache.org/jira/browse/HDFS-16339?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Chao Sun updated HDFS-16339: Fix Version/s: 3.3.2 (was: 3.3.3) > Show the threshold when mover threads quota is exceeded > --- > > Key: HDFS-16339 > URL: https://issues.apache.org/jira/browse/HDFS-16339 > Project: Hadoop HDFS > Issue Type: Wish >Reporter: tomscut >Assignee: tomscut >Priority: Minor > Labels: pull-request-available > Fix For: 3.4.0, 3.3.2, 3.2.4 > > Attachments: image-2021-11-20-17-23-04-924.png > > Time Spent: 1.5h > Remaining Estimate: 0h > > Show the threshold when mover threads quota is exceeded in > DataXceiver#replaceBlock and DataXceiver#copyBlock. > !image-2021-11-20-17-23-04-924.png|width=1233,height=124! -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16455) RBF: Router should explicitly specify the value of `jute.maxbuffer` in hadoop configuration files like core-site.xml
[
https://issues.apache.org/jira/browse/HDFS-16455?focusedWorklogId=726430=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726430
]
ASF GitHub Bot logged work on HDFS-16455:
-
Author: ASF GitHub Bot
Created on: 14/Feb/22 17:27
Start Date: 14/Feb/22 17:27
Worklog Time Spent: 10m
Work Description: goiri commented on a change in pull request #3983:
URL: https://github.com/apache/hadoop/pull/3983#discussion_r806077863
##
File path:
hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/security/token/delegation/ZKDelegationTokenSecretManager.java
##
@@ -98,6 +98,8 @@
+ "kerberos.keytab";
public static final String ZK_DTSM_ZK_KERBEROS_PRINCIPAL = ZK_CONF_PREFIX
+ "kerberos.principal";
+ public static final String ZK_DTSM_ZK_JUTE_MAXBUFFER = ZK_CONF_PREFIX
+ + "jute.maxbuffer";
Review comment:
The indentation is not correct. Check the checkstyle.
##
File path:
hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/security/token/delegation/ZKDelegationTokenSecretManager.java
##
@@ -199,6 +202,10 @@ public ZKDelegationTokenSecretManager(Configuration conf) {
ZK_DTSM_ZK_SESSION_TIMEOUT_DEFAULT);
int numRetries =
conf.getInt(ZK_DTSM_ZK_NUM_RETRIES,
ZK_DTSM_ZK_NUM_RETRIES_DEFAULT);
+String juteMaxBuffer =
+conf.get(ZK_DTSM_ZK_JUTE_MAXBUFFER,
ZK_DTSM_ZK_JUTE_MAXBUFFER_DEFAULT);
Review comment:
Indentation fix.
##
File path:
hadoop-common-project/hadoop-common/src/main/java/org/apache/hadoop/security/token/delegation/ZKDelegationTokenSecretManager.java
##
@@ -199,6 +202,10 @@ public ZKDelegationTokenSecretManager(Configuration conf) {
ZK_DTSM_ZK_SESSION_TIMEOUT_DEFAULT);
int numRetries =
conf.getInt(ZK_DTSM_ZK_NUM_RETRIES,
ZK_DTSM_ZK_NUM_RETRIES_DEFAULT);
+String juteMaxBuffer =
+conf.get(ZK_DTSM_ZK_JUTE_MAXBUFFER,
ZK_DTSM_ZK_JUTE_MAXBUFFER_DEFAULT);
+System.setProperty(ZKClientConfig.JUTE_MAXBUFFER,
+ juteMaxBuffer);
Review comment:
This could go to the previous line.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 726430)
Time Spent: 50m (was: 40m)
> RBF: Router should explicitly specify the value of `jute.maxbuffer` in hadoop
> configuration files like core-site.xml
>
>
> Key: HDFS-16455
> URL: https://issues.apache.org/jira/browse/HDFS-16455
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: rbf
>Affects Versions: 3.3.0, 3.4.0
>Reporter: Max Xie
>Assignee: Max Xie
>Priority: Minor
> Labels: pull-request-available
> Time Spent: 50m
> Remaining Estimate: 0h
>
> Based on the current design for delegation token in secure Router, the total
> number of tokens store and update in zookeeper using
> ZKDelegationTokenManager.
> But the default value of system property `jute.maxbuffer` is just 4MB, if
> Router store too many tokens in zk, it will throw IOException `{{{}Packet
> lenxx is out of range{}}}` and all Router will crash.
>
> In our cluster, Routers crashed because of it. The crash logs are below
> {code:java}
> 2022-02-09 02:15:51,607 INFO
> org.apache.hadoop.security.token.delegation.AbstractDelegationTokenSecretManager:
> Token renewal for identifier: (token for xxx: HDFS_DELEGATION_TOKEN
> owner=xxx/scheduler, renewer=hadoop, realUser=, issueDate=1644344146305,
> maxDate=1644948946305, sequenceNumbe
> r=27136070, masterKeyId=1107); total currentTokens 279548 2022-02-09
> 02:16:07,632 WARN org.apache.zookeeper.ClientCnxn: Session 0x1000172775a0012
> for server zkurl:2181, unexpected e
> rror, closing socket connection and attempting reconnect
> java.io.IOException: Packet len4194553 is out of range!
> at org.apache.zookeeper.ClientCnxnSocket.readLength(ClientCnxnSocket.java:113)
> at org.apache.zookeeper.ClientCnxnSocketNIO.doIO(ClientCnxnSocketNIO.java:79)
> at
> org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:366)
> at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1145)
> 2022-02-09 02:16:07,733 WARN org.apache.hadoop.ipc.Server: IPC Server handler
> 1254 on default port 9001, call Call#144 Retry#0
>
[jira] [Work logged] (HDFS-16440) RBF: Support router get HAServiceStatus with Lifeline RPC address
[ https://issues.apache.org/jira/browse/HDFS-16440?focusedWorklogId=726427=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726427 ] ASF GitHub Bot logged work on HDFS-16440: - Author: ASF GitHub Bot Created on: 14/Feb/22 17:27 Start Date: 14/Feb/22 17:27 Worklog Time Spent: 10m Work Description: goiri commented on pull request #3971: URL: https://github.com/apache/hadoop/pull/3971#issuecomment-1039354689 It would be nice to have a full Yetus run, not sure what happened with the previous one. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 726427) Time Spent: 1h 20m (was: 1h 10m) > RBF: Support router get HAServiceStatus with Lifeline RPC address > - > > Key: HDFS-16440 > URL: https://issues.apache.org/jira/browse/HDFS-16440 > Project: Hadoop HDFS > Issue Type: Improvement > Components: rbf >Reporter: YulongZ >Assignee: YulongZ >Priority: Minor > Labels: pull-request-available > Attachments: HDFS-16440.001.patch, HDFS-16440.003.patch, > HDFS-16440.004.patch > > Time Spent: 1h 20m > Remaining Estimate: 0h > > NamenodeHeartbeatService gets HAServiceStatus using > NNHAServiceTarget.getProxy. When we set a special > dfs.namenode.lifeline.rpc-address , NamenodeHeartbeatService may get > HAServiceStatus using NNHAServiceTarget.getHealthMonitorProxy. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Assigned] (HDFS-16440) RBF: Support router get HAServiceStatus with Lifeline RPC address
[ https://issues.apache.org/jira/browse/HDFS-16440?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Íñigo Goiri reassigned HDFS-16440: -- Assignee: YulongZ > RBF: Support router get HAServiceStatus with Lifeline RPC address > - > > Key: HDFS-16440 > URL: https://issues.apache.org/jira/browse/HDFS-16440 > Project: Hadoop HDFS > Issue Type: Improvement > Components: rbf >Reporter: YulongZ >Assignee: YulongZ >Priority: Minor > Labels: pull-request-available > Attachments: HDFS-16440.001.patch, HDFS-16440.003.patch, > HDFS-16440.004.patch > > Time Spent: 1h 10m > Remaining Estimate: 0h > > NamenodeHeartbeatService gets HAServiceStatus using > NNHAServiceTarget.getProxy. When we set a special > dfs.namenode.lifeline.rpc-address , NamenodeHeartbeatService may get > HAServiceStatus using NNHAServiceTarget.getHealthMonitorProxy. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-15273) CacheReplicationMonitor hold lock for long time and lead to NN out of service
[
https://issues.apache.org/jira/browse/HDFS-15273?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17491957#comment-17491957
]
Hadoop QA commented on HDFS-15273:
--
| (x) *{color:red}-1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Logfile || Comment ||
| {color:blue}0{color} | {color:blue} reexec {color} | {color:blue} 0m
38s{color} | {color:blue}{color} | {color:blue} Docker mode activated. {color} |
|| || || || {color:brown} Prechecks {color} || ||
| {color:green}+1{color} | {color:green} dupname {color} | {color:green} 0m
0s{color} | {color:green}{color} | {color:green} No case conflicting files
found. {color} |
| {color:red}-1{color} | {color:red} test4tests {color} | {color:red} 0m
0s{color} | {color:red}{color} | {color:red} The patch doesn't appear to
include any new or modified tests. Please justify why no new tests are needed
for this patch. Also please list what manual steps were performed to verify
this patch. {color} |
|| || || || {color:brown} trunk Compile Tests {color} || ||
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 20m
53s{color} | {color:green}{color} | {color:green} trunk passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
27s{color} | {color:green}{color} | {color:green} trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
21s{color} | {color:green}{color} | {color:green} trunk passed with JDK Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 1m
3s{color} | {color:green}{color} | {color:green} trunk passed {color} |
| {color:green}+1{color} | {color:green} mvnsite {color} | {color:green} 1m
26s{color} | {color:green}{color} | {color:green} trunk passed {color} |
| {color:green}+1{color} | {color:green} shadedclient {color} | {color:green}
21m 25s{color} | {color:green}{color} | {color:green} branch has no errors when
building and testing our client artifacts. {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
57s{color} | {color:green}{color} | {color:green} trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 1m
29s{color} | {color:green}{color} | {color:green} trunk passed with JDK Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 {color} |
| {color:blue}0{color} | {color:blue} spotbugs {color} | {color:blue} 27m
0s{color} | {color:blue}{color} | {color:blue} Both FindBugs and SpotBugs are
enabled, using SpotBugs. {color} |
| {color:green}+1{color} | {color:green} spotbugs {color} | {color:green} 3m
8s{color} | {color:green}{color} | {color:green} trunk passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} || ||
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 1m
15s{color} | {color:green}{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
18s{color} | {color:green}{color} | {color:green} the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 1m
18s{color} | {color:green}{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 1m
12s{color} | {color:green}{color} | {color:green} the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 1m
12s{color} | {color:green}{color} | {color:green} the patch passed {color} |
| {color:orange}-0{color} | {color:orange} checkstyle {color} | {color:orange}
0m 55s{color} |
{color:orange}https://ci-hadoop.apache.org/job/PreCommit-HDFS-Build/755/artifact/out/diff-checkstyle-hadoop-hdfs-project_hadoop-hdfs.txt{color}
| {color:orange} hadoop-hdfs-project/hadoop-hdfs: The patch generated 1 new +
230 unchanged - 0 fixed = 231 total (was 230) {color} |
| {color:green}+1{color} | {color:green} mvnsite {color} | {color:green} 1m
19s{color} | {color:green}{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green}{color} | {color:green} The patch has no whitespace
issues. {color} |
| {color:green}+1{color} | {color:green} shadedclient {color} | {color:green}
18m 46s{color} | {color:green}{color} | {color:green} patch has no errors when
building and testing our client artifacts. {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 0m
51s{color} | {color:green}{color} | {color:green} the patch passed with JDK
[jira] [Work logged] (HDFS-16396) Reconfig slow peer parameters for datanode
[
https://issues.apache.org/jira/browse/HDFS-16396?focusedWorklogId=726224=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726224
]
ASF GitHub Bot logged work on HDFS-16396:
-
Author: ASF GitHub Bot
Created on: 14/Feb/22 10:37
Start Date: 14/Feb/22 10:37
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on pull request #3827:
URL: https://github.com/apache/hadoop/pull/3827#issuecomment-1038924634
:confetti_ball: **+1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 17m 16s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 0s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 2 new or modified test files. |
_ trunk Compile Tests _ |
| +1 :green_heart: | mvninstall | 34m 47s | | trunk passed |
| +1 :green_heart: | compile | 1m 30s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | compile | 1m 19s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 0m 59s | | trunk passed |
| +1 :green_heart: | mvnsite | 1m 26s | | trunk passed |
| +1 :green_heart: | javadoc | 1m 1s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 1m 31s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 3m 23s | | trunk passed |
| +1 :green_heart: | shadedclient | 25m 38s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 1m 20s | | the patch passed |
| +1 :green_heart: | compile | 1m 23s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javac | 1m 23s | | the patch passed |
| +1 :green_heart: | compile | 1m 13s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 1m 13s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| -0 :warning: | checkstyle | 0m 51s |
[/results-checkstyle-hadoop-hdfs-project_hadoop-hdfs.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3827/8/artifact/out/results-checkstyle-hadoop-hdfs-project_hadoop-hdfs.txt)
| hadoop-hdfs-project/hadoop-hdfs: The patch generated 1 new + 209 unchanged
- 1 fixed = 210 total (was 210) |
| +1 :green_heart: | mvnsite | 1m 22s | | the patch passed |
| +1 :green_heart: | javadoc | 0m 53s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 1m 23s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 3m 26s | | the patch passed |
| +1 :green_heart: | shadedclient | 25m 24s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 345m 5s | | hadoop-hdfs in the patch
passed. |
| +1 :green_heart: | asflicense | 0m 38s | | The patch does not
generate ASF License warnings. |
| | | 468m 53s | | |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3827/8/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/3827 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell |
| uname | Linux eb298760596d 4.15.0-163-generic #171-Ubuntu SMP Fri Nov 5
11:55:11 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 1b9155e5cb920beab40e352a0b00dbd8b5178af9 |
| Default Java | Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Multi-JDK versions |
/usr/lib/jvm/java-11-openjdk-amd64:Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04
/usr/lib/jvm/java-8-openjdk-amd64:Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Test Results |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-3827/8/testReport/ |
| Max. process+thread count | 2343 (vs. ulimit of 5500) |
| modules | C: hadoop-hdfs-project/hadoop-hdfs U:
[jira] [Work logged] (HDFS-16455) RBF: Router should explicitly specify the value of `jute.maxbuffer` in hadoop configuration files like core-site.xml
[
https://issues.apache.org/jira/browse/HDFS-16455?focusedWorklogId=726213=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-726213
]
ASF GitHub Bot logged work on HDFS-16455:
-
Author: ASF GitHub Bot
Created on: 14/Feb/22 10:16
Start Date: 14/Feb/22 10:16
Worklog Time Spent: 10m
Work Description: Neilxzn commented on pull request #3983:
URL: https://github.com/apache/hadoop/pull/3983#issuecomment-1038902823
> The patch itself looks good. I think one of the problem today is there's
no documentation around the zkdt usage unless you dig into the code. We should
add a better doc as a follow-up jira.
@jojochuang Thank you for your review. We should add a better doc around
the zkdt usage. +1
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 726213)
Time Spent: 40m (was: 0.5h)
> RBF: Router should explicitly specify the value of `jute.maxbuffer` in hadoop
> configuration files like core-site.xml
>
>
> Key: HDFS-16455
> URL: https://issues.apache.org/jira/browse/HDFS-16455
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: rbf
>Affects Versions: 3.3.0, 3.4.0
>Reporter: Max Xie
>Assignee: Max Xie
>Priority: Minor
> Labels: pull-request-available
> Time Spent: 40m
> Remaining Estimate: 0h
>
> Based on the current design for delegation token in secure Router, the total
> number of tokens store and update in zookeeper using
> ZKDelegationTokenManager.
> But the default value of system property `jute.maxbuffer` is just 4MB, if
> Router store too many tokens in zk, it will throw IOException `{{{}Packet
> lenxx is out of range{}}}` and all Router will crash.
>
> In our cluster, Routers crashed because of it. The crash logs are below
> {code:java}
> 2022-02-09 02:15:51,607 INFO
> org.apache.hadoop.security.token.delegation.AbstractDelegationTokenSecretManager:
> Token renewal for identifier: (token for xxx: HDFS_DELEGATION_TOKEN
> owner=xxx/scheduler, renewer=hadoop, realUser=, issueDate=1644344146305,
> maxDate=1644948946305, sequenceNumbe
> r=27136070, masterKeyId=1107); total currentTokens 279548 2022-02-09
> 02:16:07,632 WARN org.apache.zookeeper.ClientCnxn: Session 0x1000172775a0012
> for server zkurl:2181, unexpected e
> rror, closing socket connection and attempting reconnect
> java.io.IOException: Packet len4194553 is out of range!
> at org.apache.zookeeper.ClientCnxnSocket.readLength(ClientCnxnSocket.java:113)
> at org.apache.zookeeper.ClientCnxnSocketNIO.doIO(ClientCnxnSocketNIO.java:79)
> at
> org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:366)
> at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1145)
> 2022-02-09 02:16:07,733 WARN org.apache.hadoop.ipc.Server: IPC Server handler
> 1254 on default port 9001, call Call#144 Retry#0
> org.apache.hadoop.hdfs.protocol.ClientProtocol.getDelegationToken from
> ip:46534
> java.lang.RuntimeException: Could not increment shared counter !!
> at
> org.apache.hadoop.security.token.delegation.ZKDelegationTokenSecretManager.incrementDelegationTokenSeqNum(ZKDelegationTokenSecretManager.java:582)
> {code}
> When we restart a Router, it crashed again
> {code:java}
> 2022-02-09 03:14:17,308 INFO
> org.apache.hadoop.security.token.delegation.ZKDelegationTokenSecretManager:
> Starting to load key cache.
> 2022-02-09 03:14:17,310 INFO
> org.apache.hadoop.security.token.delegation.ZKDelegationTokenSecretManager:
> Loaded key cache.
> 2022-02-09 03:14:32,930 WARN org.apache.zookeeper.ClientCnxn: Session
> 0x205584be35b0001 for server zkurl:2181, unexpected
> error, closing socket connection and attempting reconnect
> java.io.IOException: Packet len4194478 is out of range!
> at
> org.apache.zookeeper.ClientCnxnSocket.readLength(ClientCnxnSocket.java:113)
> at
> org.apache.zookeeper.ClientCnxnSocketNIO.doIO(ClientCnxnSocketNIO.java:79)
> at
> org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:366)
> at
> org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1145)
> 2022-02-09 03:14:33,030 ERROR
> org.apache.hadoop.hdfs.server.federation.router.security.token.ZKDelegationTokenSecretManagerImpl:
> Error starting threads for z
> kDelegationTokens
> java.io.IOException: Could not start PathChildrenCache for