[jira] [Work logged] (BEAM-3072) Improve error handling at staging time time for DataflowRunner
[ https://issues.apache.org/jira/browse/BEAM-3072?focusedWorklogId=220422&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220422 ] ASF GitHub Bot logged work on BEAM-3072: Author: ASF GitHub Bot Created on: 29/Mar/19 07:22 Start Date: 29/Mar/19 07:22 Worklog Time Spent: 10m Work Description: NikeNano commented on issue #8158: [BEAM-3072] updates to that the error handling and collected the fail… URL: https://github.com/apache/beam/pull/8158#issuecomment-477895867 @aaltay after thinking about it a bit more, could you elaborate on how "hat errors are captured as expected" and i will add some tests for it. I have set it up so that errors ar captured both if the command is not present compare to default "No such file or director" [1]. If the command is valid but the arguments are incorrect an error is rased giving the command stating that the arguments are wrong. @pabloem I have resolved the error in the build concerning the formatting. [1] https://stackoverflow.com/questions/24306205/file-not-found-error-when-launching-a-subprocess-containing-piped-commands This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220422) Time Spent: 2.5h (was: 2h 20m) > Improve error handling at staging time time for DataflowRunner > -- > > Key: BEAM-3072 > URL: https://issues.apache.org/jira/browse/BEAM-3072 > Project: Beam > Issue Type: Bug > Components: sdk-py-core >Reporter: Ahmet Altay >Assignee: niklas Hansson >Priority: Minor > Labels: starter, triaged > Time Spent: 2.5h > Remaining Estimate: 0h > > dependency.py calls out to external process to collect dependencies: > https://github.com/apache/beam/blob/de7cc05cc67d1aa6331cddc17c2e02ed0efbe37d/sdks/python/apache_beam/runners/dataflow/internal/dependency.py#L263 > If these calls fails, the error is not clear. The error only tells what > failed but does not show the actual error message, and is not helpful for > users. > As a general fix processes.py should have general better output collection > from failed processes. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-3072) Improve error handling at staging time time for DataflowRunner
[ https://issues.apache.org/jira/browse/BEAM-3072?focusedWorklogId=220423&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220423 ] ASF GitHub Bot logged work on BEAM-3072: Author: ASF GitHub Bot Created on: 29/Mar/19 07:23 Start Date: 29/Mar/19 07:23 Worklog Time Spent: 10m Work Description: NikeNano commented on issue #8158: [BEAM-3072] updates to that the error handling and collected the fail… URL: https://github.com/apache/beam/pull/8158#issuecomment-477895867 @aaltay after thinking about it a bit more, could you elaborate on "errors are captured as expected" and I will add some tests for it. I have set it up so that errors are captured both if the command is not present and raise a more meaningful error, compare to default "No such file or director" [1]. If the command is valid but the arguments are incorrect an error is rased giving the command stating that the arguments are wrong. @pabloem I have resolved the error in the build concerning the formatting. [1] https://stackoverflow.com/questions/24306205/file-not-found-error-when-launching-a-subprocess-containing-piped-commands This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220423) Time Spent: 2h 40m (was: 2.5h) > Improve error handling at staging time time for DataflowRunner > -- > > Key: BEAM-3072 > URL: https://issues.apache.org/jira/browse/BEAM-3072 > Project: Beam > Issue Type: Bug > Components: sdk-py-core >Reporter: Ahmet Altay >Assignee: niklas Hansson >Priority: Minor > Labels: starter, triaged > Time Spent: 2h 40m > Remaining Estimate: 0h > > dependency.py calls out to external process to collect dependencies: > https://github.com/apache/beam/blob/de7cc05cc67d1aa6331cddc17c2e02ed0efbe37d/sdks/python/apache_beam/runners/dataflow/internal/dependency.py#L263 > If these calls fails, the error is not clear. The error only tells what > failed but does not show the actual error message, and is not helpful for > users. > As a general fix processes.py should have general better output collection > from failed processes. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Closed] (BEAM-6703) Support Java 11 in Jenkins
[ https://issues.apache.org/jira/browse/BEAM-6703?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Michal Walenia closed BEAM-6703. Resolution: Done Fix Version/s: Not applicable > Support Java 11 in Jenkins > -- > > Key: BEAM-6703 > URL: https://issues.apache.org/jira/browse/BEAM-6703 > Project: Beam > Issue Type: Sub-task > Components: runner-dataflow, runner-direct >Reporter: Michal Walenia >Assignee: Michal Walenia >Priority: Minor > Fix For: Not applicable > > Time Spent: 15h 40m > Remaining Estimate: 0h > > In this issue I'll create a Jenkins job that compiles Dataflow and Direct > runners with tests using Java 8 and runs Validates Runner suites with Java 11 > Runtime. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (BEAM-6936) Add a Jenkins job running Java examples on Java 11 Dataflow
Michal Walenia created BEAM-6936: Summary: Add a Jenkins job running Java examples on Java 11 Dataflow Key: BEAM-6936 URL: https://issues.apache.org/jira/browse/BEAM-6936 Project: Beam Issue Type: Sub-task Components: examples-java, testing Reporter: Michal Walenia Assignee: Michal Walenia -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BEAM-6910) Beam does not consider BigQuery's processing location when getting query results
[
https://issues.apache.org/jira/browse/BEAM-6910?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16804669#comment-16804669
]
niklas Hansson commented on BEAM-6910:
--
As far as I understand this issue is solved in BEAM-6909. I will leave this
task. Let me know if there is anything that needs to be done.
> Beam does not consider BigQuery's processing location when getting query
> results
>
>
> Key: BEAM-6910
> URL: https://issues.apache.org/jira/browse/BEAM-6910
> Project: Beam
> Issue Type: Bug
> Components: dependencies, runner-dataflow, sdk-py-core
>Affects Versions: 2.11.0
> Environment: Python
>Reporter: Graham Polley
>Assignee: niklas Hansson
>Priority: Major
>
> When using the BigQuery source with a SQL query in a pipeline, the
> "processing location" is not taken into consideration and the pipeline fails.
> For example, consider the following which uses {{BigQuerySource}} to read
> from BigQuery using some SQL. The BigQuery dataset and tables are located in
> {{australia-southeast1}}. The query is submitted successfully ([Beam works
> out the processing location by examining the first table referenced in the
> query and sets it
> accordingly|https://github.com/apache/beam/blob/master/sdks/python/apache_beam/io/gcp/bigquery_tools.py#L221]),
> but when Beam attempts to poll for the job status after it has been
> submitted, it fails because it doesn't set the {{location}} to be
> {{australia-southeast1}}, which is required by BigQuery:
>
> {code:java}
> p | 'read' >> beam.io.Read(beam.io.BigQuerySource(use_standard_sql=True,
> query='SELECT * from
> `a_project_id.dataset_in_australia.table_in_australia`'){code}
>
> {code:java}
> HttpNotFoundError: HttpError accessing
> :
> response: <{'status': '404', 'content-length': '328', 'x-xss-protection':
> '1; mode=block', 'x-content-type-options': 'nosniff', 'transfer-encoding':
> 'chunked', 'vary': 'Origin, X-Origin, Referer', 'server': 'ESF',
> '-content-encoding': 'gzip', 'cache-control': 'private', 'date': 'Tue, 26 Mar
> 2019 03:11:32 GMT', 'x-frame-options': 'SAMEORIGIN', 'alt-svc': 'quic=":443";
> ma=2592000; v="46,44,43,39"', 'content-type': 'application/json;
> charset=UTF-8'}>, content <{
> "error": {
> "code": 404,
> "message": "Not found: Job a_project_id:5ad9cc803baa432290b6cd0203f556d9",
> "errors": [
> {
> "message": "Not found: Job
> a_project_id:5ad9cc803baa432290b6cd0203f556d9",
> "domain": "global",
> "reason": "notFound"
> }
> ],
> "status": "NOT_FOUND"
> }
> }
> {code}
>
> The problem can be seen/found here:
> [https://github.com/apache/beam/blob/v2.11.0/sdks/python/apache_beam/io/gcp/bigquery_tools.py#L571]
> [https://github.com/apache/beam/blob/master/sdks/python/apache_beam/io/gcp/bigquery_tools.py#L357]
> The location of the job (in this case {{australia-southeast1}}) needs to
> set/inferred (or exposed via the API), otherwise its fails.
> For reference, Airflow had the same bug/problem:
> [https://github.com/apache/airflow/pull/4695]
>
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Work logged] (BEAM-5995) Create Jenkins jobs to run the load tests
[ https://issues.apache.org/jira/browse/BEAM-5995?focusedWorklogId=220431&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220431 ] ASF GitHub Bot logged work on BEAM-5995: Author: ASF GitHub Bot Created on: 29/Mar/19 08:30 Start Date: 29/Mar/19 08:30 Worklog Time Spent: 10m Work Description: kkucharc commented on issue #8151: [BEAM-5995] add Jenkins job with GBK Python load tests URL: https://github.com/apache/beam/pull/8151#issuecomment-477912806 run seed job This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220431) Time Spent: 16.5h (was: 16h 20m) > Create Jenkins jobs to run the load tests > - > > Key: BEAM-5995 > URL: https://issues.apache.org/jira/browse/BEAM-5995 > Project: Beam > Issue Type: Sub-task > Components: testing >Reporter: Kasia Kucharczyk >Assignee: Kasia Kucharczyk >Priority: Major > Labels: triaged > Time Spent: 16.5h > Remaining Estimate: 0h > > (/) Add SMOKE test > Add GBK load tests. > Add CoGBK load tests. > Add Pardo load tests. > Add SideInput tests. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-5995) Create Jenkins jobs to run the load tests
[ https://issues.apache.org/jira/browse/BEAM-5995?focusedWorklogId=220432&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220432 ] ASF GitHub Bot logged work on BEAM-5995: Author: ASF GitHub Bot Created on: 29/Mar/19 08:30 Start Date: 29/Mar/19 08:30 Worklog Time Spent: 10m Work Description: kkucharc commented on issue #8151: [BEAM-5995] add Jenkins job with GBK Python load tests URL: https://github.com/apache/beam/pull/8151#issuecomment-477676995 run seed job This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220432) Time Spent: 16h 40m (was: 16.5h) > Create Jenkins jobs to run the load tests > - > > Key: BEAM-5995 > URL: https://issues.apache.org/jira/browse/BEAM-5995 > Project: Beam > Issue Type: Sub-task > Components: testing >Reporter: Kasia Kucharczyk >Assignee: Kasia Kucharczyk >Priority: Major > Labels: triaged > Time Spent: 16h 40m > Remaining Estimate: 0h > > (/) Add SMOKE test > Add GBK load tests. > Add CoGBK load tests. > Add Pardo load tests. > Add SideInput tests. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6922) Remove LGPL test library dependency in cassandraio-test
[ https://issues.apache.org/jira/browse/BEAM-6922?focusedWorklogId=220433&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220433 ] ASF GitHub Bot logged work on BEAM-6922: Author: ASF GitHub Bot Created on: 29/Mar/19 08:35 Start Date: 29/Mar/19 08:35 Worklog Time Spent: 10m Work Description: echauchot commented on issue #8160: [BEAM-6922] do not deliver cassandra-io test jar and test-sources jar URL: https://github.com/apache/beam/pull/8160#issuecomment-477914123 @apilloud as you which. Let's see with the upcoming Achilles release maybe this week end This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220433) Time Spent: 40m (was: 0.5h) > Remove LGPL test library dependency in cassandraio-test > --- > > Key: BEAM-6922 > URL: https://issues.apache.org/jira/browse/BEAM-6922 > Project: Beam > Issue Type: Bug > Components: io-java-cassandra >Reporter: Etienne Chauchot >Assignee: Etienne Chauchot >Priority: Blocker > Fix For: 2.12.0 > > Time Spent: 40m > Remaining Estimate: 0h > > cassandra-io tests use cassandra-unit test library that has LGPLV3 ASF > category X licence , we cannot deliver test jars that depend on LGPL licence. > A similar discussion at > https://issues.apache.org/jira/browse/LEGAL-153?focusedCommentId=13548819 -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-5995) Create Jenkins jobs to run the load tests
[ https://issues.apache.org/jira/browse/BEAM-5995?focusedWorklogId=220436&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220436 ] ASF GitHub Bot logged work on BEAM-5995: Author: ASF GitHub Bot Created on: 29/Mar/19 08:54 Start Date: 29/Mar/19 08:54 Worklog Time Spent: 10m Work Description: kkucharc commented on issue #8151: [BEAM-5995] add Jenkins job with GBK Python load tests URL: https://github.com/apache/beam/pull/8151#issuecomment-477919548 Run Java Load Tests Smoke This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220436) Time Spent: 17h (was: 16h 50m) > Create Jenkins jobs to run the load tests > - > > Key: BEAM-5995 > URL: https://issues.apache.org/jira/browse/BEAM-5995 > Project: Beam > Issue Type: Sub-task > Components: testing >Reporter: Kasia Kucharczyk >Assignee: Kasia Kucharczyk >Priority: Major > Labels: triaged > Time Spent: 17h > Remaining Estimate: 0h > > (/) Add SMOKE test > Add GBK load tests. > Add CoGBK load tests. > Add Pardo load tests. > Add SideInput tests. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-5995) Create Jenkins jobs to run the load tests
[ https://issues.apache.org/jira/browse/BEAM-5995?focusedWorklogId=220435&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220435 ] ASF GitHub Bot logged work on BEAM-5995: Author: ASF GitHub Bot Created on: 29/Mar/19 08:54 Start Date: 29/Mar/19 08:54 Worklog Time Spent: 10m Work Description: kkucharc commented on issue #8151: [BEAM-5995] add Jenkins job with GBK Python load tests URL: https://github.com/apache/beam/pull/8151#issuecomment-477919504 Run Python Load Tests Smoke This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220435) Time Spent: 16h 50m (was: 16h 40m) > Create Jenkins jobs to run the load tests > - > > Key: BEAM-5995 > URL: https://issues.apache.org/jira/browse/BEAM-5995 > Project: Beam > Issue Type: Sub-task > Components: testing >Reporter: Kasia Kucharczyk >Assignee: Kasia Kucharczyk >Priority: Major > Labels: triaged > Time Spent: 16h 50m > Remaining Estimate: 0h > > (/) Add SMOKE test > Add GBK load tests. > Add CoGBK load tests. > Add Pardo load tests. > Add SideInput tests. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-5995) Create Jenkins jobs to run the load tests
[ https://issues.apache.org/jira/browse/BEAM-5995?focusedWorklogId=220440&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220440 ] ASF GitHub Bot logged work on BEAM-5995: Author: ASF GitHub Bot Created on: 29/Mar/19 08:55 Start Date: 29/Mar/19 08:55 Worklog Time Spent: 10m Work Description: kkucharc commented on issue #8151: [BEAM-5995] add Jenkins job with GBK Python load tests URL: https://github.com/apache/beam/pull/8151#issuecomment-477161668 Run Java Load Tests Smoke This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220440) Time Spent: 17.5h (was: 17h 20m) > Create Jenkins jobs to run the load tests > - > > Key: BEAM-5995 > URL: https://issues.apache.org/jira/browse/BEAM-5995 > Project: Beam > Issue Type: Sub-task > Components: testing >Reporter: Kasia Kucharczyk >Assignee: Kasia Kucharczyk >Priority: Major > Labels: triaged > Time Spent: 17.5h > Remaining Estimate: 0h > > (/) Add SMOKE test > Add GBK load tests. > Add CoGBK load tests. > Add Pardo load tests. > Add SideInput tests. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-5995) Create Jenkins jobs to run the load tests
[ https://issues.apache.org/jira/browse/BEAM-5995?focusedWorklogId=220438&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220438 ] ASF GitHub Bot logged work on BEAM-5995: Author: ASF GitHub Bot Created on: 29/Mar/19 08:55 Start Date: 29/Mar/19 08:55 Worklog Time Spent: 10m Work Description: kkucharc commented on issue #8151: [BEAM-5995] add Jenkins job with GBK Python load tests URL: https://github.com/apache/beam/pull/8151#issuecomment-477919844 Run Load Tests Java GBK Dataflow Batch This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220438) Time Spent: 17h 10m (was: 17h) > Create Jenkins jobs to run the load tests > - > > Key: BEAM-5995 > URL: https://issues.apache.org/jira/browse/BEAM-5995 > Project: Beam > Issue Type: Sub-task > Components: testing >Reporter: Kasia Kucharczyk >Assignee: Kasia Kucharczyk >Priority: Major > Labels: triaged > Time Spent: 17h 10m > Remaining Estimate: 0h > > (/) Add SMOKE test > Add GBK load tests. > Add CoGBK load tests. > Add Pardo load tests. > Add SideInput tests. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-5995) Create Jenkins jobs to run the load tests
[ https://issues.apache.org/jira/browse/BEAM-5995?focusedWorklogId=220441&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220441 ] ASF GitHub Bot logged work on BEAM-5995: Author: ASF GitHub Bot Created on: 29/Mar/19 08:55 Start Date: 29/Mar/19 08:55 Worklog Time Spent: 10m Work Description: kkucharc commented on issue #8151: [BEAM-5995] add Jenkins job with GBK Python load tests URL: https://github.com/apache/beam/pull/8151#issuecomment-477164083 Run Python Load Tests Smoke This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220441) Time Spent: 17h 40m (was: 17.5h) > Create Jenkins jobs to run the load tests > - > > Key: BEAM-5995 > URL: https://issues.apache.org/jira/browse/BEAM-5995 > Project: Beam > Issue Type: Sub-task > Components: testing >Reporter: Kasia Kucharczyk >Assignee: Kasia Kucharczyk >Priority: Major > Labels: triaged > Time Spent: 17h 40m > Remaining Estimate: 0h > > (/) Add SMOKE test > Add GBK load tests. > Add CoGBK load tests. > Add Pardo load tests. > Add SideInput tests. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-5995) Create Jenkins jobs to run the load tests
[ https://issues.apache.org/jira/browse/BEAM-5995?focusedWorklogId=220439&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220439 ] ASF GitHub Bot logged work on BEAM-5995: Author: ASF GitHub Bot Created on: 29/Mar/19 08:55 Start Date: 29/Mar/19 08:55 Worklog Time Spent: 10m Work Description: kkucharc commented on issue #8151: [BEAM-5995] add Jenkins job with GBK Python load tests URL: https://github.com/apache/beam/pull/8151#issuecomment-477919896 Run Python Load Tests GBK Dataflow Batch This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220439) Time Spent: 17h 20m (was: 17h 10m) > Create Jenkins jobs to run the load tests > - > > Key: BEAM-5995 > URL: https://issues.apache.org/jira/browse/BEAM-5995 > Project: Beam > Issue Type: Sub-task > Components: testing >Reporter: Kasia Kucharczyk >Assignee: Kasia Kucharczyk >Priority: Major > Labels: triaged > Time Spent: 17h 20m > Remaining Estimate: 0h > > (/) Add SMOKE test > Add GBK load tests. > Add CoGBK load tests. > Add Pardo load tests. > Add SideInput tests. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-1893) Add IO module for Couchbase
[
https://issues.apache.org/jira/browse/BEAM-1893?focusedWorklogId=220465&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220465
]
ASF GitHub Bot logged work on BEAM-1893:
Author: ASF GitHub Bot
Created on: 29/Mar/19 09:57
Start Date: 29/Mar/19 09:57
Worklog Time Spent: 10m
Work Description: aromanenko-dev commented on issue #8152:
[DoNotMerge][BEAM-1893] Implementation of CouchbaseIO
URL: https://github.com/apache/beam/pull/8152#issuecomment-477938700
@iemejia This mappings are on low level and this API is not supposed to be
exposed to users, as @EdgarLGB said. So, I think we need to follow an approach
based on splitting by number of records and offset, and implement it using
`ParDo`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220465)
Time Spent: 2h 20m (was: 2h 10m)
> Add IO module for Couchbase
> ---
>
> Key: BEAM-1893
> URL: https://issues.apache.org/jira/browse/BEAM-1893
> Project: Beam
> Issue Type: New Feature
> Components: io-ideas
>Reporter: Xu Mingmin
>Assignee: LI Guobao
>Priority: Major
> Labels: Couchbase, IO, features, triaged
> Time Spent: 2h 20m
> Remaining Estimate: 0h
>
> Create a {{CouchbaseIO}} for Couchbase database.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Work logged] (BEAM-1893) Add IO module for Couchbase
[
https://issues.apache.org/jira/browse/BEAM-1893?focusedWorklogId=220467&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220467
]
ASF GitHub Bot logged work on BEAM-1893:
Author: ASF GitHub Bot
Created on: 29/Mar/19 09:57
Start Date: 29/Mar/19 09:57
Worklog Time Spent: 10m
Work Description: aromanenko-dev commented on issue #8152:
[DoNotMerge][BEAM-1893] Implementation of CouchbaseIO
URL: https://github.com/apache/beam/pull/8152#issuecomment-477938700
@iemejia These mappings are on low level and this API is not supposed to be
exposed to users, as @EdgarLGB said. So, I think we need to follow an approach
based on splitting by number of records and offset, and implement it using
`ParDo`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220467)
Time Spent: 2.5h (was: 2h 20m)
> Add IO module for Couchbase
> ---
>
> Key: BEAM-1893
> URL: https://issues.apache.org/jira/browse/BEAM-1893
> Project: Beam
> Issue Type: New Feature
> Components: io-ideas
>Reporter: Xu Mingmin
>Assignee: LI Guobao
>Priority: Major
> Labels: Couchbase, IO, features, triaged
> Time Spent: 2.5h
> Remaining Estimate: 0h
>
> Create a {{CouchbaseIO}} for Couchbase database.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Work logged] (BEAM-6929) Session Windows with lateness cause NullPointerException in Flink Runner
[
https://issues.apache.org/jira/browse/BEAM-6929?focusedWorklogId=220470&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220470
]
ASF GitHub Bot logged work on BEAM-6929:
Author: ASF GitHub Bot
Created on: 29/Mar/19 10:08
Start Date: 29/Mar/19 10:08
Worklog Time Spent: 10m
Work Description: mxm commented on issue #8162: [BEAM-6929] Prevent
NullPointerException in Flink's CombiningState
URL: https://github.com/apache/beam/pull/8162#issuecomment-477942111
>Is it a release blocker though? This bug has existed presumably for many
releases.
I'd say yes because it is reported as a blocker for session windows by a
user on the mailing list. I've verified that it prevents merging session
windows when late data arrives.
The bug in Spark's state internals was easy to fix. It assumed that
accumulators are always modified in place, which does not have to be the case
(though it usually is for performance reasons).
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220470)
Time Spent: 50m (was: 40m)
> Session Windows with lateness cause NullPointerException in Flink Runner
>
>
> Key: BEAM-6929
> URL: https://issues.apache.org/jira/browse/BEAM-6929
> Project: Beam
> Issue Type: Bug
> Components: runner-flink
>Reporter: Maximilian Michels
>Assignee: Maximilian Michels
>Priority: Major
> Fix For: 2.12.0
>
> Time Spent: 50m
> Remaining Estimate: 0h
>
> Reported on the mailing list:
> {noformat}
> I am using Beam 2.11.0, Runner - beam-runners-flink-1.7, Flink Cluster -
> 1.7.2.
> I have this flow in my pipeline:
> KafkaSource(withCreateTime()) --> ApplyWindow(SessionWindow with
> gapDuration=1 Minute, lateness=3 Minutes, AccumulatingFiredPanes, default
> trigger) --> BeamSQL(GroupBy query) --> Window.remerge() --> Enrichment
> --> KafkaSink
> I am generating data in such a way that the first two records belong to two
> different sessions. And, generating the third record before the first session
> expires with the timestamp for the third record in such a way that the two
> sessions will be merged to become a single session.
> For Example, These are the sample input and output obtained when I ran the
> same pipeline in DirectRunner.
> Sample Input:
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-27-44"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-51"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-26"}}
> Sample Output:
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-28-44"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-28-51"},"WET":{"string":"2019-03-27 15-29-51"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":3},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-29-51"}}
> Where "NumberOfRecords" is the count, "WST" is the Avro field Name which
> indicates the window start time for the session window. Similarly "WET"
> indicates the window End time of the session window. I am getting "WST" and
> "WET" after remerging and applying ParDo(Enrichment stage of the pipeline).
> The program ran successfully in DirectRunner. But, in FlinkRunner, I am
> getting this exception when the third record arrives:
> 2019-03-27 15:31:00,442 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph- Source:
> DfleKafkaSource/KafkaIO.Read/Read(KafkaUnboundedSource) -> Flat Map ->
> DfleKafkaSource/ParDo(ConvertKafkaRecordtoRow)/ParMultiDo(ConvertKafkaRecordtoRow)
> -> (Window.Into()/Window.Assign.out ->
> DfleSql/SqlTransform/BeamIOSourceRel_4/Convert.ConvertTransform/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/Group
> by fields/ParMultiDo(Anonymous) -> ToKeyedWorkItem,
> DfleKafkaSink/ParDo(RowToGenericRecordConverter)/ParMultiDo(RowToGenericRecordConverter)
> -> DfleKafkaSink/KafkaIO.KafkaValueWrite/Kafka values with default
> key/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/Kafka
> ProducerRecord/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/KafkaIO.WriteRecords/ParDo(KafkaWriter)/ParMultiDo(KafkaWriter))
> (1/1) (d00be62e110c
[jira] [Updated] (BEAM-6929) Session Windows with lateness cause NullPointerException in Flink Runner
[
https://issues.apache.org/jira/browse/BEAM-6929?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Maximilian Michels updated BEAM-6929:
-
Priority: Critical (was: Major)
> Session Windows with lateness cause NullPointerException in Flink Runner
>
>
> Key: BEAM-6929
> URL: https://issues.apache.org/jira/browse/BEAM-6929
> Project: Beam
> Issue Type: Bug
> Components: runner-flink
>Reporter: Maximilian Michels
>Assignee: Maximilian Michels
>Priority: Critical
> Fix For: 2.12.0
>
> Time Spent: 1h
> Remaining Estimate: 0h
>
> Reported on the mailing list:
> {noformat}
> I am using Beam 2.11.0, Runner - beam-runners-flink-1.7, Flink Cluster -
> 1.7.2.
> I have this flow in my pipeline:
> KafkaSource(withCreateTime()) --> ApplyWindow(SessionWindow with
> gapDuration=1 Minute, lateness=3 Minutes, AccumulatingFiredPanes, default
> trigger) --> BeamSQL(GroupBy query) --> Window.remerge() --> Enrichment
> --> KafkaSink
> I am generating data in such a way that the first two records belong to two
> different sessions. And, generating the third record before the first session
> expires with the timestamp for the third record in such a way that the two
> sessions will be merged to become a single session.
> For Example, These are the sample input and output obtained when I ran the
> same pipeline in DirectRunner.
> Sample Input:
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-27-44"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-51"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-26"}}
> Sample Output:
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-28-44"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-28-51"},"WET":{"string":"2019-03-27 15-29-51"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":3},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-29-51"}}
> Where "NumberOfRecords" is the count, "WST" is the Avro field Name which
> indicates the window start time for the session window. Similarly "WET"
> indicates the window End time of the session window. I am getting "WST" and
> "WET" after remerging and applying ParDo(Enrichment stage of the pipeline).
> The program ran successfully in DirectRunner. But, in FlinkRunner, I am
> getting this exception when the third record arrives:
> 2019-03-27 15:31:00,442 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph- Source:
> DfleKafkaSource/KafkaIO.Read/Read(KafkaUnboundedSource) -> Flat Map ->
> DfleKafkaSource/ParDo(ConvertKafkaRecordtoRow)/ParMultiDo(ConvertKafkaRecordtoRow)
> -> (Window.Into()/Window.Assign.out ->
> DfleSql/SqlTransform/BeamIOSourceRel_4/Convert.ConvertTransform/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/Group
> by fields/ParMultiDo(Anonymous) -> ToKeyedWorkItem,
> DfleKafkaSink/ParDo(RowToGenericRecordConverter)/ParMultiDo(RowToGenericRecordConverter)
> -> DfleKafkaSink/KafkaIO.KafkaValueWrite/Kafka values with default
> key/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/Kafka
> ProducerRecord/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/KafkaIO.WriteRecords/ParDo(KafkaWriter)/ParMultiDo(KafkaWriter))
> (1/1) (d00be62e110cef00d9d772042f4b87a9) switched from DEPLOYING to RUNNING.
> 2019-03-27 15:33:25,427 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph-
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/GroupByKey
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Combine.GroupedValues/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/mergeRecord/ParMultiDo(Anonymous)
> -> DfleSql/SqlTransform/BeamCalcRel_46/ParDo(Calc)/ParMultiDo(Calc) ->
> DfleSql/Window.Remerge/Identity/Map/ParMultiDo(Anonymous) ->
> DfleSql/ParDo(EnrichRecordWithWindowTimeInfo)/ParMultiDo(EnrichRecordWithWindowTimeInfo)
> ->
> DfleKafkaSink2/ParDo(RowToGenericRecordConverter)/ParMultiDo(RowToGenericRecordConverter)
> -> DfleKafkaSink2/KafkaIO.KafkaValueWrite/Kafka values with default
> key/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink2/KafkaIO.KafkaValueWrite/KafkaIO.Write/Kafka
> ProducerRecord/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink2/KafkaIO.KafkaValueWrite/KafkaIO.Write/KafkaIO.WriteRecords/ParDo(KafkaWriter)/ParMultiDo(KafkaWriter)
> (1/1) (d95af17b7457443c13bd327b46b282e6) switched from RUNNING to FAILED.
> org.apache.beam.sdk.util.UserCode
[jira] [Work logged] (BEAM-6929) Session Windows with lateness cause NullPointerException in Flink Runner
[
https://issues.apache.org/jira/browse/BEAM-6929?focusedWorklogId=220472&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220472
]
ASF GitHub Bot logged work on BEAM-6929:
Author: ASF GitHub Bot
Created on: 29/Mar/19 10:11
Start Date: 29/Mar/19 10:11
Worklog Time Spent: 10m
Work Description: mxm commented on pull request #8162: [BEAM-6929]
Prevent NullPointerException in Flink's CombiningState
URL: https://github.com/apache/beam/pull/8162#discussion_r270347525
##
File path:
runners/spark/src/main/java/org/apache/beam/runners/spark/stateful/SparkStateInternals.java
##
@@ -297,8 +297,7 @@ public OutputT read() {
@Override
public void add(InputT input) {
- AccumT accum = getAccum();
- combineFn.addInput(accum, input);
+ AccumT accum = combineFn.addInput(getAccum(), input);
Review comment:
CC @iemejia FYI
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220472)
Time Spent: 1h (was: 50m)
> Session Windows with lateness cause NullPointerException in Flink Runner
>
>
> Key: BEAM-6929
> URL: https://issues.apache.org/jira/browse/BEAM-6929
> Project: Beam
> Issue Type: Bug
> Components: runner-flink
>Reporter: Maximilian Michels
>Assignee: Maximilian Michels
>Priority: Major
> Fix For: 2.12.0
>
> Time Spent: 1h
> Remaining Estimate: 0h
>
> Reported on the mailing list:
> {noformat}
> I am using Beam 2.11.0, Runner - beam-runners-flink-1.7, Flink Cluster -
> 1.7.2.
> I have this flow in my pipeline:
> KafkaSource(withCreateTime()) --> ApplyWindow(SessionWindow with
> gapDuration=1 Minute, lateness=3 Minutes, AccumulatingFiredPanes, default
> trigger) --> BeamSQL(GroupBy query) --> Window.remerge() --> Enrichment
> --> KafkaSink
> I am generating data in such a way that the first two records belong to two
> different sessions. And, generating the third record before the first session
> expires with the timestamp for the third record in such a way that the two
> sessions will be merged to become a single session.
> For Example, These are the sample input and output obtained when I ran the
> same pipeline in DirectRunner.
> Sample Input:
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-27-44"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-51"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-26"}}
> Sample Output:
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-28-44"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-28-51"},"WET":{"string":"2019-03-27 15-29-51"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":3},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-29-51"}}
> Where "NumberOfRecords" is the count, "WST" is the Avro field Name which
> indicates the window start time for the session window. Similarly "WET"
> indicates the window End time of the session window. I am getting "WST" and
> "WET" after remerging and applying ParDo(Enrichment stage of the pipeline).
> The program ran successfully in DirectRunner. But, in FlinkRunner, I am
> getting this exception when the third record arrives:
> 2019-03-27 15:31:00,442 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph- Source:
> DfleKafkaSource/KafkaIO.Read/Read(KafkaUnboundedSource) -> Flat Map ->
> DfleKafkaSource/ParDo(ConvertKafkaRecordtoRow)/ParMultiDo(ConvertKafkaRecordtoRow)
> -> (Window.Into()/Window.Assign.out ->
> DfleSql/SqlTransform/BeamIOSourceRel_4/Convert.ConvertTransform/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/Group
> by fields/ParMultiDo(Anonymous) -> ToKeyedWorkItem,
> DfleKafkaSink/ParDo(RowToGenericRecordConverter)/ParMultiDo(RowToGenericRecordConverter)
> -> DfleKafkaSink/KafkaIO.KafkaValueWrite/Kafka values with default
> key/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/Kafka
> ProducerRecord/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/KafkaIO.WriteRecords/ParDo(KafkaWriter)/ParMultiDo(KafkaWriter))
> (1/1) (d00be62e110cef00d9d772042f4b87a9) switched from DEPLOYING to RUNNING.
> 2019-03-27
[jira] [Commented] (BEAM-3312) Add IO convenient "with" methods
[
https://issues.apache.org/jira/browse/BEAM-3312?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16804770#comment-16804770
]
Ismaël Mejía commented on BEAM-3312:
We need to add the methods to the `ConnectionConfiguration` object not to the
Read/Write transforms, this is simpler and keeps the nice builder style, only
difference is that the connection building stays in one place so it is less
error-prone.
> Add IO convenient "with" methods
>
>
> Key: BEAM-3312
> URL: https://issues.apache.org/jira/browse/BEAM-3312
> Project: Beam
> Issue Type: Improvement
> Components: io-java-mqtt
>Reporter: Jean-Baptiste Onofré
>Assignee: Jean-Baptiste Onofré
>Priority: Major
> Labels: triaged
>
> Now, for instance, {{MqttIO}} requires a {{ConnectionConfiguration}} object
> to pass the URL and topic name. It means, the user has to do something like:
> {code}
> MqttIO.read()
> .withConnectionConfiguration(MqttIO.ConnectionConfiguration.create("tcp://localhost:1883",
> "CAR"))
> {code}
> It's pretty verbose and long. I think it makes sense to provide convenient
> "direct" method allowing to do:
> {code}
> MqttIO.read().withUrl().withTopic()
> {code}
> or even:
> {code}
> MqttIO.read().withConnection("url", "topic")
> {code}
> The same apply for some other IOs (JMS, ...).
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Reopened] (BEAM-3604) MqttIOTest testReadNoClientId failure timeout
[
https://issues.apache.org/jira/browse/BEAM-3604?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Ismaël Mejía reopened BEAM-3604:
The test was disabled but it has not been fixed yet.
> MqttIOTest testReadNoClientId failure timeout
> -
>
> Key: BEAM-3604
> URL: https://issues.apache.org/jira/browse/BEAM-3604
> Project: Beam
> Issue Type: Bug
> Components: io-java-mqtt
>Reporter: Kenneth Knowles
>Assignee: Ismaël Mejía
>Priority: Critical
> Labels: flake
> Fix For: Not applicable
>
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> I've seen failures a bit today. Here is one:
> [https://builds.apache.org/job/beam_PreCommit_Java_GradleBuild/1758/testReport/junit/org.apache.beam.sdk.io.mqtt/MqttIOTest/testReadNoClientId/]
> Filing all flakes as "Critical" priority so we can sickbay or fix.
> Since that build will get GC'd, here is the Standard Error. It looks like
> from that perspective everything went as planned, but perhaps the test has a
> race condition or something?
> {code}
> Feb 01, 2018 11:28:01 PM org.apache.beam.sdk.io.mqtt.MqttIOTest startBroker
> INFO: Finding free network port
> Feb 01, 2018 11:28:01 PM org.apache.beam.sdk.io.mqtt.MqttIOTest startBroker
> INFO: Starting ActiveMQ brokerService on 57986
> Feb 01, 2018 11:28:03 PM org.apache.activemq.broker.BrokerService
> doStartPersistenceAdapter
> INFO: Using Persistence Adapter: MemoryPersistenceAdapter
> Feb 01, 2018 11:28:04 PM org.apache.activemq.broker.BrokerService
> doStartBroker
> INFO: Apache ActiveMQ 5.13.1 (localhost,
> ID:115.98.154.104.bc.googleusercontent.com-38646-1517527683931-0:1) is
> starting
> Feb 01, 2018 11:28:04 PM
> org.apache.activemq.transport.TransportServerThreadSupport doStart
> INFO: Listening for connections at: mqtt://localhost:57986
> Feb 01, 2018 11:28:04 PM org.apache.activemq.broker.TransportConnector start
> INFO: Connector mqtt://localhost:57986 started
> Feb 01, 2018 11:28:04 PM org.apache.activemq.broker.BrokerService
> doStartBroker
> INFO: Apache ActiveMQ 5.13.1 (localhost,
> ID:115.98.154.104.bc.googleusercontent.com-38646-1517527683931-0:1) started
> Feb 01, 2018 11:28:04 PM org.apache.activemq.broker.BrokerService
> doStartBroker
> INFO: For help or more information please see: http://activemq.apache.org
> Feb 01, 2018 11:28:26 PM org.apache.activemq.broker.BrokerService stop
> INFO: Apache ActiveMQ 5.13.1 (localhost,
> ID:115.98.154.104.bc.googleusercontent.com-38646-1517527683931-0:1) is
> shutting down
> Feb 01, 2018 11:28:26 PM org.apache.activemq.broker.TransportConnector stop
> INFO: Connector mqtt://localhost:57986 stopped
> Feb 01, 2018 11:28:26 PM org.apache.activemq.broker.BrokerService stop
> INFO: Apache ActiveMQ 5.13.1 (localhost,
> ID:115.98.154.104.bc.googleusercontent.com-38646-1517527683931-0:1) uptime
> 24.039 seconds
> Feb 01, 2018 11:28:26 PM org.apache.activemq.broker.BrokerService stop
> INFO: Apache ActiveMQ 5.13.1 (localhost,
> ID:115.98.154.104.bc.googleusercontent.com-38646-1517527683931-0:1) is
> shutdown
> Feb 01, 2018 11:28:26 PM org.apache.beam.sdk.io.mqtt.MqttIOTest startBroker
> INFO: Finding free network port
> Feb 01, 2018 11:28:26 PM org.apache.beam.sdk.io.mqtt.MqttIOTest startBroker
> INFO: Starting ActiveMQ brokerService on 46799
> Feb 01, 2018 11:28:26 PM org.apache.activemq.broker.BrokerService
> doStartPersistenceAdapter
> INFO: Using Persistence Adapter: MemoryPersistenceAdapter
> Feb 01, 2018 11:28:26 PM org.apache.activemq.broker.BrokerService
> doStartBroker
> INFO: Apache ActiveMQ 5.13.1 (localhost,
> ID:115.98.154.104.bc.googleusercontent.com-38646-1517527683931-0:2) is
> starting
> Feb 01, 2018 11:28:26 PM
> org.apache.activemq.transport.TransportServerThreadSupport doStart
> INFO: Listening for connections at: mqtt://localhost:46799
> Feb 01, 2018 11:28:26 PM org.apache.activemq.broker.TransportConnector start
> INFO: Connector mqtt://localhost:46799 started
> Feb 01, 2018 11:28:26 PM org.apache.activemq.broker.BrokerService
> doStartBroker
> INFO: Apache ActiveMQ 5.13.1 (localhost,
> ID:115.98.154.104.bc.googleusercontent.com-38646-1517527683931-0:2) started
> Feb 01, 2018 11:28:26 PM org.apache.activemq.broker.BrokerService
> doStartBroker
> INFO: For help or more information please see: http://activemq.apache.org
> Feb 01, 2018 11:28:28 PM org.apache.beam.sdk.io.mqtt.MqttIOTest
> lambda$testRead$1
> INFO: Waiting pipeline connected to the MQTT broker before sending messages
> ...
> Feb 01, 2018 11:28:35 PM org.apache.activemq.broker.BrokerService stop
> INFO: Apache ActiveMQ 5.13.1 (localhost,
> ID:115.98.154.104.bc.googleusercontent.com-38646-1517527683931-0:2) is
> shutting down
> Feb 01, 2018 11:28:35 PM org.apache.activemq.broker.TransportConnector stop
> INFO: Connector mqtt://local
[jira] [Work logged] (BEAM-2939) Fn API streaming SDF support
[
https://issues.apache.org/jira/browse/BEAM-2939?focusedWorklogId=220479&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220479
]
ASF GitHub Bot logged work on BEAM-2939:
Author: ASF GitHub Bot
Created on: 29/Mar/19 10:25
Start Date: 29/Mar/19 10:25
Worklog Time Spent: 10m
Work Description: robertwb commented on pull request #8088: [BEAM-2939]
SDF sizing in FnAPI and Python SDK/runner.
URL: https://github.com/apache/beam/pull/8088#discussion_r270352238
##
File path: model/pipeline/src/main/proto/beam_runner_api.proto
##
@@ -301,8 +301,15 @@ message StandardPTransforms {
// Like PROCESS_KEYED_ELEMENTS, but without the unique key - just elements
// and restrictions.
-// Input: KV(element, restriction); output: DoFn's output.
+// Input: KV(KV(element, restriction), weight); output: DoFn's output.
PROCESS_ELEMENTS = 3 [(beam_urn) =
"beam:transform:sdf_process_elements:v1"];
Review comment:
Incomplete find-and-replace. Fixed.
I updated the URNs as per our discussion. "with weights" was ambiguous
(producing vs. consuming) so I went with "split_and_size" and
"process_weighted."
https://github.com/apache/beam/pull/8166 for the double coder.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220479)
Time Spent: 14h 10m (was: 14h)
> Fn API streaming SDF support
>
>
> Key: BEAM-2939
> URL: https://issues.apache.org/jira/browse/BEAM-2939
> Project: Beam
> Issue Type: Improvement
> Components: beam-model
>Reporter: Henning Rohde
>Assignee: Luke Cwik
>Priority: Major
> Labels: portability, triaged
> Time Spent: 14h 10m
> Remaining Estimate: 0h
>
> The Fn API should support streaming SDF. Detailed design TBD.
> Once design is ready, expand subtasks similarly to BEAM-2822.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Assigned] (BEAM-3312) Add IO convenient "with" methods
[
https://issues.apache.org/jira/browse/BEAM-3312?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
LI Guobao reassigned BEAM-3312:
---
Assignee: LI Guobao (was: Jean-Baptiste Onofré)
> Add IO convenient "with" methods
>
>
> Key: BEAM-3312
> URL: https://issues.apache.org/jira/browse/BEAM-3312
> Project: Beam
> Issue Type: Improvement
> Components: io-java-mqtt
>Reporter: Jean-Baptiste Onofré
>Assignee: LI Guobao
>Priority: Major
> Labels: triaged
>
> Now, for instance, {{MqttIO}} requires a {{ConnectionConfiguration}} object
> to pass the URL and topic name. It means, the user has to do something like:
> {code}
> MqttIO.read()
> .withConnectionConfiguration(MqttIO.ConnectionConfiguration.create("tcp://localhost:1883",
> "CAR"))
> {code}
> It's pretty verbose and long. I think it makes sense to provide convenient
> "direct" method allowing to do:
> {code}
> MqttIO.read().withUrl().withTopic()
> {code}
> or even:
> {code}
> MqttIO.read().withConnection("url", "topic")
> {code}
> The same apply for some other IOs (JMS, ...).
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (BEAM-3312) Add convenient "with" to MqttIO.ConnectionConfiguration
[
https://issues.apache.org/jira/browse/BEAM-3312?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Ismaël Mejía updated BEAM-3312:
---
Summary: Add convenient "with" to MqttIO.ConnectionConfiguration (was: Add
IO convenient "with" methods)
> Add convenient "with" to MqttIO.ConnectionConfiguration
> ---
>
> Key: BEAM-3312
> URL: https://issues.apache.org/jira/browse/BEAM-3312
> Project: Beam
> Issue Type: Improvement
> Components: io-java-mqtt
>Reporter: Jean-Baptiste Onofré
>Assignee: LI Guobao
>Priority: Major
> Labels: triaged
>
> Now, for instance, {{MqttIO}} requires a {{ConnectionConfiguration}} object
> to pass the URL and topic name. It means, the user has to do something like:
> {code}
> MqttIO.read()
> .withConnectionConfiguration(MqttIO.ConnectionConfiguration.create("tcp://localhost:1883",
> "CAR"))
> {code}
> It's pretty verbose and long. I think it makes sense to provide convenient
> "direct" method allowing to do:
> {code}
> MqttIO.read().withUrl().withTopic()
> {code}
> or even:
> {code}
> MqttIO.read().withConnection("url", "topic")
> {code}
> The same apply for some other IOs (JMS, ...).
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BEAM-3312) Add convenient "with" to MqttIO.ConnectionConfiguration
[
https://issues.apache.org/jira/browse/BEAM-3312?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16804794#comment-16804794
]
LI Guobao commented on BEAM-3312:
-
So let us just extend the `ConnectionConfiguration` currently and probably we
might just delegate the connection construction to the users.
> Add convenient "with" to MqttIO.ConnectionConfiguration
> ---
>
> Key: BEAM-3312
> URL: https://issues.apache.org/jira/browse/BEAM-3312
> Project: Beam
> Issue Type: Improvement
> Components: io-java-mqtt
>Reporter: Jean-Baptiste Onofré
>Assignee: LI Guobao
>Priority: Major
> Labels: triaged
>
> Now, for instance, {{MqttIO}} requires a {{ConnectionConfiguration}} object
> to pass the URL and topic name. It means, the user has to do something like:
> {code}
> MqttIO.read()
> .withConnectionConfiguration(MqttIO.ConnectionConfiguration.create("tcp://localhost:1883",
> "CAR"))
> {code}
> It's pretty verbose and long. I think it makes sense to provide convenient
> "direct" method allowing to do:
> {code}
> MqttIO.read().withUrl().withTopic()
> {code}
> or even:
> {code}
> MqttIO.read().withConnection("url", "topic")
> {code}
> The same apply for some other IOs (JMS, ...).
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Work logged] (BEAM-6929) Session Windows with lateness cause NullPointerException in Flink Runner
[
https://issues.apache.org/jira/browse/BEAM-6929?focusedWorklogId=220487&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220487
]
ASF GitHub Bot logged work on BEAM-6929:
Author: ASF GitHub Bot
Created on: 29/Mar/19 11:13
Start Date: 29/Mar/19 11:13
Worklog Time Spent: 10m
Work Description: mxm commented on issue #8162: [BEAM-6929] Prevent
NullPointerException in Flink's CombiningState
URL: https://github.com/apache/beam/pull/8162#issuecomment-477960940
Run Java PreCommit
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220487)
Time Spent: 1h 10m (was: 1h)
> Session Windows with lateness cause NullPointerException in Flink Runner
>
>
> Key: BEAM-6929
> URL: https://issues.apache.org/jira/browse/BEAM-6929
> Project: Beam
> Issue Type: Bug
> Components: runner-flink
>Reporter: Maximilian Michels
>Assignee: Maximilian Michels
>Priority: Critical
> Fix For: 2.12.0
>
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> Reported on the mailing list:
> {noformat}
> I am using Beam 2.11.0, Runner - beam-runners-flink-1.7, Flink Cluster -
> 1.7.2.
> I have this flow in my pipeline:
> KafkaSource(withCreateTime()) --> ApplyWindow(SessionWindow with
> gapDuration=1 Minute, lateness=3 Minutes, AccumulatingFiredPanes, default
> trigger) --> BeamSQL(GroupBy query) --> Window.remerge() --> Enrichment
> --> KafkaSink
> I am generating data in such a way that the first two records belong to two
> different sessions. And, generating the third record before the first session
> expires with the timestamp for the third record in such a way that the two
> sessions will be merged to become a single session.
> For Example, These are the sample input and output obtained when I ran the
> same pipeline in DirectRunner.
> Sample Input:
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-27-44"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-51"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-26"}}
> Sample Output:
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-28-44"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-28-51"},"WET":{"string":"2019-03-27 15-29-51"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":3},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-29-51"}}
> Where "NumberOfRecords" is the count, "WST" is the Avro field Name which
> indicates the window start time for the session window. Similarly "WET"
> indicates the window End time of the session window. I am getting "WST" and
> "WET" after remerging and applying ParDo(Enrichment stage of the pipeline).
> The program ran successfully in DirectRunner. But, in FlinkRunner, I am
> getting this exception when the third record arrives:
> 2019-03-27 15:31:00,442 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph- Source:
> DfleKafkaSource/KafkaIO.Read/Read(KafkaUnboundedSource) -> Flat Map ->
> DfleKafkaSource/ParDo(ConvertKafkaRecordtoRow)/ParMultiDo(ConvertKafkaRecordtoRow)
> -> (Window.Into()/Window.Assign.out ->
> DfleSql/SqlTransform/BeamIOSourceRel_4/Convert.ConvertTransform/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/Group
> by fields/ParMultiDo(Anonymous) -> ToKeyedWorkItem,
> DfleKafkaSink/ParDo(RowToGenericRecordConverter)/ParMultiDo(RowToGenericRecordConverter)
> -> DfleKafkaSink/KafkaIO.KafkaValueWrite/Kafka values with default
> key/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/Kafka
> ProducerRecord/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/KafkaIO.WriteRecords/ParDo(KafkaWriter)/ParMultiDo(KafkaWriter))
> (1/1) (d00be62e110cef00d9d772042f4b87a9) switched from DEPLOYING to RUNNING.
> 2019-03-27 15:33:25,427 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph-
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/GroupByKey
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Combine.GroupedValues/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_4
[jira] [Work logged] (BEAM-3312) Add convenient "with" to MqttIO.ConnectionConfiguration
[ https://issues.apache.org/jira/browse/BEAM-3312?focusedWorklogId=220491&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220491 ] ASF GitHub Bot logged work on BEAM-3312: Author: ASF GitHub Bot Created on: 29/Mar/19 11:22 Start Date: 29/Mar/19 11:22 Worklog Time Spent: 10m Work Description: EdgarLGB commented on pull request #8167: [BEAM-3312] Improve the builder to MqttIO connection URL: https://github.com/apache/beam/pull/8167 Hi all, Here is the PR to add the builder methods allowing to configure the MqttIO connection. The idea is to stick to the builder style instead of putting the arguments directly in the constructor. Thanks in advance for the review. (R @iemejia ) Regards, Guobao Post-Commit Tests Status (on master branch) Lang | SDK | Apex | Dataflow | Flink | Gearpump | Samza | Spark --- | --- | --- | --- | --- | --- | --- | --- Go | [](https://builds.apache.org/job/beam_PostCommit_Go/lastCompletedBuild/) | --- | --- | --- | --- | --- | --- Java | [](https://builds.apache.org/job/beam_PostCommit_Java/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Apex/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Dataflow/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Flink/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Java_PVR_Flink_Batch/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Java_PVR_Flink_Streaming/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Gearpump/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Samza/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Spark/lastCompletedBuild/) Python | [](https://builds.apache.org/job/beam_PostCommit_Python_Verify/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Python3_Verify/lastCompletedBuild/) | --- | [](https://builds.apache.org/job/beam_PostCommit_Py_VR_Dataflow/lastCompletedBuild/) [](https://builds.apache.org/job/beam_PostCommit_Py_ValCont/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PreCommit_Python_PVR_Flink_Cron/lastCompletedBuild/) | --- | --- | --- Pre-Commit Tests Status (on master branch) --- |Java | Python | Go | Website --- | --- | --- | --- | --- Non-portable | [](https://builds.apache.org/job/beam_PreCommit_Java_Cron/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PreCommit_Python_Cron/lastCompletedBuild/) | [ Streaming FlinkTransformOverrides are not applied without explicit streaming mode
Maximilian Michels created BEAM-6937:
Summary: Streaming FlinkTransformOverrides are not applied without
explicit streaming mode
Key: BEAM-6937
URL: https://issues.apache.org/jira/browse/BEAM-6937
Project: Beam
Issue Type: Bug
Components: runner-flink
Reporter: Maximilian Michels
Assignee: Maximilian Michels
Fix For: 2.12.0
When streaming is set to false the streaming mode will be switched to true if
the pipeline contains unbounded sources. There is a regression which prevents
PipelineOverrides to be applied correctly in this case.
As reported on the mailing list:
{noformat}
I just upgraded to Flink 1.7.2 from 1.6.2 with my dev cluster and from Beam
2.10 to 2.11 and I am seeing this error when starting my pipelines:
org.apache.flink.client.program.ProgramInvocationException: The main method
caused an error.
at
org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:546)
at
org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:421)
at
org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:427)
at
org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:813)
at
org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:287)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
at
org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
at
org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
at
org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
Caused by: java.lang.UnsupportedOperationException: The transform
beam:transform:create_view:v1 is currently not supported.
at
org.apache.beam.runners.flink.FlinkStreamingPipelineTranslator.visitPrimitiveTransform(FlinkStreamingPipelineTranslator.java:113)
at
org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:665)
at
org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
at
org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
at
org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
at
org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
at
org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
at
org.apache.beam.sdk.runners.TransformHierarchy$Node.access$600(TransformHierarchy.java:317)
at
org.apache.beam.sdk.runners.TransformHierarchy.visit(TransformHierarchy.java:251)
at org.apache.beam.sdk.Pipeline.traverseTopologically(Pipeline.java:458)
at
org.apache.beam.runners.flink.FlinkPipelineTranslator.translate(FlinkPipelineTranslator.java:38)
at
org.apache.beam.runners.flink.FlinkStreamingPipelineTranslator.translate(FlinkStreamingPipelineTranslator.java:68)
at
org.apache.beam.runners.flink.FlinkPipelineExecutionEnvironment.translate(FlinkPipelineExecutionEnvironment.java:111)
at org.apache.beam.runners.flink.FlinkRunner.run(FlinkRunner.java:108)
at org.apache.beam.sdk.Pipeline.run(Pipeline.java:313)
at org.apache.beam.sdk.Pipeline.run(Pipeline.java:299)
at ch.ricardo.di.beam.KafkaToBigQuery.main(KafkaToBigQuery.java:175)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:529)
... 9 more
{noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Work logged] (BEAM-6937) Streaming FlinkTransformOverrides are not applied without explicit streaming mode
[ https://issues.apache.org/jira/browse/BEAM-6937?focusedWorklogId=220511&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220511 ] ASF GitHub Bot logged work on BEAM-6937: Author: ASF GitHub Bot Created on: 29/Mar/19 12:42 Start Date: 29/Mar/19 12:42 Worklog Time Spent: 10m Work Description: mxm commented on pull request #8168: [BEAM-6937] Apply FlinkTransformOverrides correctly with inferred streaming mode URL: https://github.com/apache/beam/pull/8168 When streaming is set to false the streaming mode will be switched to true if the pipeline contains unbounded sources. There is a regression which prevents PipelineOverrides to be applied correctly in this case. CC @tweise @angoenka Post-Commit Tests Status (on master branch) Lang | SDK | Apex | Dataflow | Flink | Gearpump | Samza | Spark --- | --- | --- | --- | --- | --- | --- | --- Go | [](https://builds.apache.org/job/beam_PostCommit_Go/lastCompletedBuild/) | --- | --- | --- | --- | --- | --- Java | [](https://builds.apache.org/job/beam_PostCommit_Java/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Apex/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Dataflow/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Flink/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Java_PVR_Flink_Batch/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Java_PVR_Flink_Streaming/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Gearpump/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Samza/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Spark/lastCompletedBuild/) Python | [](https://builds.apache.org/job/beam_PostCommit_Python_Verify/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Python3_Verify/lastCompletedBuild/) | --- | [](https://builds.apache.org/job/beam_PostCommit_Py_VR_Dataflow/lastCompletedBuild/) [](https://builds.apache.org/job/beam_PostCommit_Py_ValCont/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PreCommit_Python_PVR_Flink_Cron/lastCompletedBuild/) | --- | --- | --- Pre-Commit Tests Status (on master branch) --- |Java | Python | Go | Website --- | --- | --- | --- | --- Non-portable | [](https://builds.apache.org/job/beam_PreCommit_Java_Cron/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PreCommit_Python_Cron/lastCompletedBuild/) | [](https://b
[jira] [Work started] (BEAM-3312) Add convenient "with" to MqttIO.ConnectionConfiguration
[
https://issues.apache.org/jira/browse/BEAM-3312?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Work on BEAM-3312 started by LI Guobao.
---
> Add convenient "with" to MqttIO.ConnectionConfiguration
> ---
>
> Key: BEAM-3312
> URL: https://issues.apache.org/jira/browse/BEAM-3312
> Project: Beam
> Issue Type: Improvement
> Components: io-java-mqtt
>Reporter: Jean-Baptiste Onofré
>Assignee: LI Guobao
>Priority: Major
> Labels: triaged
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Now, for instance, {{MqttIO}} requires a {{ConnectionConfiguration}} object
> to pass the URL and topic name. It means, the user has to do something like:
> {code}
> MqttIO.read()
> .withConnectionConfiguration(MqttIO.ConnectionConfiguration.create("tcp://localhost:1883",
> "CAR"))
> {code}
> It's pretty verbose and long. I think it makes sense to provide convenient
> "direct" method allowing to do:
> {code}
> MqttIO.read().withUrl().withTopic()
> {code}
> or even:
> {code}
> MqttIO.read().withConnection("url", "topic")
> {code}
> The same apply for some other IOs (JMS, ...).
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Work logged] (BEAM-6876) User state cleanup in portable Flink runner
[
https://issues.apache.org/jira/browse/BEAM-6876?focusedWorklogId=220520&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220520
]
ASF GitHub Bot logged work on BEAM-6876:
Author: ASF GitHub Bot
Created on: 29/Mar/19 13:20
Start Date: 29/Mar/19 13:20
Worklog Time Spent: 10m
Work Description: tweise commented on pull request #8118: [BEAM-6876]
Cleanup user state in portable Flink Runner
URL: https://github.com/apache/beam/pull/8118#discussion_r270404554
##
File path:
runners/flink/src/test/java/org/apache/beam/runners/flink/translation/wrappers/streaming/ExecutableStageDoFnOperatorTest.java
##
@@ -340,6 +359,101 @@ public void testStageBundleClosed() throws Exception {
verifyNoMoreInteractions(bundle);
}
+ @Test
+ @SuppressWarnings("unchecked")
+ public void testEnsureStateCleanupWithKeyedInput() throws Exception {
+TupleTag mainOutput = new TupleTag<>("main-output");
+DoFnOperator.MultiOutputOutputManagerFactory outputManagerFactory
=
+new DoFnOperator.MultiOutputOutputManagerFactory(mainOutput,
VarIntCoder.of());
+VarIntCoder keyCoder = VarIntCoder.of();
+ExecutableStageDoFnOperator operator =
+getOperator(mainOutput, Collections.emptyList(), outputManagerFactory,
keyCoder);
+
+KeyedOneInputStreamOperatorTestHarness,
WindowedValue>
+testHarness =
+new KeyedOneInputStreamOperatorTestHarness(
+operator, val -> val, new CoderTypeInformation<>(keyCoder));
+
+RemoteBundle bundle = Mockito.mock(RemoteBundle.class);
+when(bundle.getInputReceivers())
+.thenReturn(
+ImmutableMap.>builder()
+.put("input", Mockito.mock(FnDataReceiver.class))
+.build());
+when(stageBundleFactory.getBundle(any(), any(), any())).thenReturn(bundle);
+
+testHarness.open();
+
+Object doFnRunner = Whitebox.getInternalState(operator, "doFnRunner");
+assertThat(doFnRunner, instanceOf(DoFnRunnerWithMetricsUpdate.class));
+
+// There should be a StatefulDoFnRunner installed which takes care of
clearing state
+Object statefulDoFnRunner = Whitebox.getInternalState(doFnRunner,
"delegate");
+assertThat(statefulDoFnRunner, instanceOf(StatefulDoFnRunner.class));
+ }
+
+ @Test
+ public void testEnsureStateCleanupWithKeyedInputCleanupTimer() throws
Exception {
+InMemoryTimerInternals inMemoryTimerInternals = new
InMemoryTimerInternals();
+Consumer keyConsumer = Mockito.mock(Consumer.class);
+KeyedStateBackend keyedStateBackend =
Mockito.mock(KeyedStateBackend.class);
+Lock stateBackendLock = Mockito.mock(Lock.class);
+StringUtf8Coder keyCoder = StringUtf8Coder.of();
+GlobalWindow window = GlobalWindow.INSTANCE;
+GlobalWindow.Coder windowCoder = GlobalWindow.Coder.INSTANCE;
+
+// Test that cleanup timer is set correctly
+ExecutableStageDoFnOperator.CleanupTimer cleanupTimer =
+new ExecutableStageDoFnOperator.CleanupTimer<>(
+inMemoryTimerInternals,
+stateBackendLock,
+WindowingStrategy.globalDefault(),
+keyCoder,
+windowCoder,
+keyConsumer,
+keyedStateBackend);
+cleanupTimer.setForWindow(KV.of("key", "string"), window);
+
+Mockito.verify(stateBackendLock).lock();
+ByteBuffer key = ByteBuffer.wrap(CoderUtils.encodeToByteArray(keyCoder,
"key"));
+Mockito.verify(keyConsumer).accept(key);
+Mockito.verify(keyedStateBackend).setCurrentKey(key);
+assertThat(
+inMemoryTimerInternals.getNextTimer(TimeDomain.EVENT_TIME),
+is(window.maxTimestamp().plus(1)));
+Mockito.verify(stateBackendLock).unlock();
+ }
+
+ @Test
+ public void testEnsureStateCleanupWithKeyedInputStateCleaner() throws
Exception {
+GlobalWindow.Coder windowCoder = GlobalWindow.Coder.INSTANCE;
+InMemoryStateInternals stateInternals =
InMemoryStateInternals.forKey("key");
+List userStateNames = ImmutableList.of("state1", "state2");
+ImmutableList.Builder> bagStateBuilder =
ImmutableList.builder();
+for (String userStateName : userStateNames) {
+ BagState state =
+ stateInternals.state(
+ StateNamespaces.window(windowCoder, GlobalWindow.INSTANCE),
+ StateTags.bag(userStateName, StringUtf8Coder.of()));
+ bagStateBuilder.add(state);
+ state.add("this should be cleaned");
+}
+ImmutableList> bagStates = bagStateBuilder.build();
+
+// Test that state is cleanup up correctly
Review comment:
```suggestion
// Test that state is cleaned up correctly
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about
[jira] [Work logged] (BEAM-6876) User state cleanup in portable Flink runner
[ https://issues.apache.org/jira/browse/BEAM-6876?focusedWorklogId=220521&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220521 ] ASF GitHub Bot logged work on BEAM-6876: Author: ASF GitHub Bot Created on: 29/Mar/19 13:24 Start Date: 29/Mar/19 13:24 Worklog Time Spent: 10m Work Description: tweise commented on issue #8118: [BEAM-6876] Cleanup user state in portable Flink Runner URL: https://github.com/apache/beam/pull/8118#issuecomment-477996082 The effect of cleanup is clearly visible when monitoring the checkpoint size. Without the fix, checkpoint size is climbing fast: 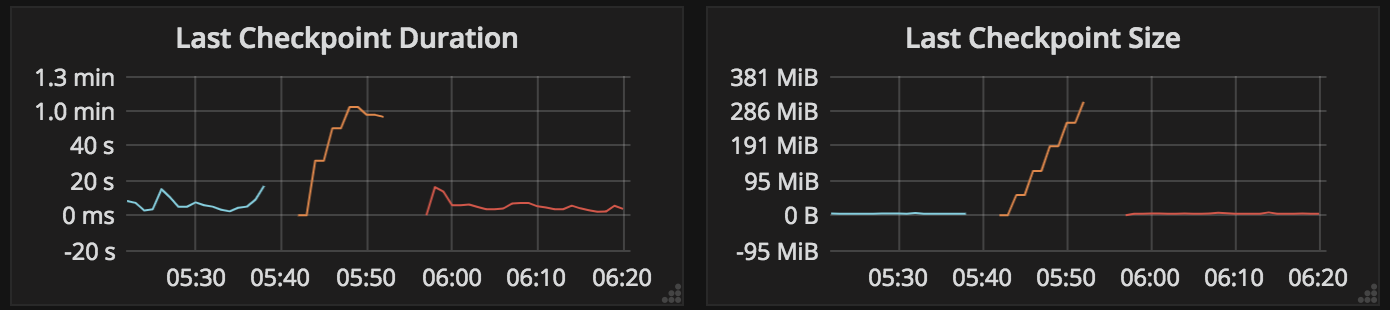 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220521) Time Spent: 2h 40m (was: 2.5h) > User state cleanup in portable Flink runner > --- > > Key: BEAM-6876 > URL: https://issues.apache.org/jira/browse/BEAM-6876 > Project: Beam > Issue Type: Bug > Components: runner-flink >Affects Versions: 2.11.0 >Reporter: Thomas Weise >Assignee: Maximilian Michels >Priority: Major > Labels: portability-flink, triaged > Time Spent: 2h 40m > Remaining Estimate: 0h > > State is currently not being cleaned up by the runner. > [https://lists.apache.org/thread.html/86f0809fbfa3da873051287b9ff249d6dd5a896b45409db1e484cf38@%3Cdev.beam.apache.org%3E] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6876) User state cleanup in portable Flink runner
[ https://issues.apache.org/jira/browse/BEAM-6876?focusedWorklogId=220526&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220526 ] ASF GitHub Bot logged work on BEAM-6876: Author: ASF GitHub Bot Created on: 29/Mar/19 13:33 Start Date: 29/Mar/19 13:33 Worklog Time Spent: 10m Work Description: mxm commented on issue #8118: [BEAM-6876] Cleanup user state in portable Flink Runner URL: https://github.com/apache/beam/pull/8118#issuecomment-477998910 @tweise Great. Do you have these graphs also with the fix applied? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220526) Time Spent: 2h 50m (was: 2h 40m) > User state cleanup in portable Flink runner > --- > > Key: BEAM-6876 > URL: https://issues.apache.org/jira/browse/BEAM-6876 > Project: Beam > Issue Type: Bug > Components: runner-flink >Affects Versions: 2.11.0 >Reporter: Thomas Weise >Assignee: Maximilian Michels >Priority: Major > Labels: portability-flink, triaged > Time Spent: 2h 50m > Remaining Estimate: 0h > > State is currently not being cleaned up by the runner. > [https://lists.apache.org/thread.html/86f0809fbfa3da873051287b9ff249d6dd5a896b45409db1e484cf38@%3Cdev.beam.apache.org%3E] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (BEAM-6938) Add support for dynamic destinations when writing to MQTT
Ismaël Mejía created BEAM-6938: -- Summary: Add support for dynamic destinations when writing to MQTT Key: BEAM-6938 URL: https://issues.apache.org/jira/browse/BEAM-6938 Project: Beam Issue Type: Improvement Components: io-java-mqtt Reporter: Ismaël Mejía -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6876) User state cleanup in portable Flink runner
[ https://issues.apache.org/jira/browse/BEAM-6876?focusedWorklogId=220529&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220529 ] ASF GitHub Bot logged work on BEAM-6876: Author: ASF GitHub Bot Created on: 29/Mar/19 13:35 Start Date: 29/Mar/19 13:35 Worklog Time Spent: 10m Work Description: tweise commented on issue #8118: [BEAM-6876] Cleanup user state in portable Flink Runner URL: https://github.com/apache/beam/pull/8118#issuecomment-477999636 @mxm it's the same graph (job in the middle is without cleanup). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220529) Time Spent: 3h (was: 2h 50m) > User state cleanup in portable Flink runner > --- > > Key: BEAM-6876 > URL: https://issues.apache.org/jira/browse/BEAM-6876 > Project: Beam > Issue Type: Bug > Components: runner-flink >Affects Versions: 2.11.0 >Reporter: Thomas Weise >Assignee: Maximilian Michels >Priority: Major > Labels: portability-flink, triaged > Time Spent: 3h > Remaining Estimate: 0h > > State is currently not being cleaned up by the runner. > [https://lists.apache.org/thread.html/86f0809fbfa3da873051287b9ff249d6dd5a896b45409db1e484cf38@%3Cdev.beam.apache.org%3E] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6876) User state cleanup in portable Flink runner
[ https://issues.apache.org/jira/browse/BEAM-6876?focusedWorklogId=220536&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220536 ] ASF GitHub Bot logged work on BEAM-6876: Author: ASF GitHub Bot Created on: 29/Mar/19 13:38 Start Date: 29/Mar/19 13:38 Worklog Time Spent: 10m Work Description: mxm commented on issue #8118: [BEAM-6876] Cleanup user state in portable Flink Runner URL: https://github.com/apache/beam/pull/8118#issuecomment-478000424 @tweise Ah, that looks perfect then. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220536) Time Spent: 3h 10m (was: 3h) > User state cleanup in portable Flink runner > --- > > Key: BEAM-6876 > URL: https://issues.apache.org/jira/browse/BEAM-6876 > Project: Beam > Issue Type: Bug > Components: runner-flink >Affects Versions: 2.11.0 >Reporter: Thomas Weise >Assignee: Maximilian Michels >Priority: Major > Labels: portability-flink, triaged > Time Spent: 3h 10m > Remaining Estimate: 0h > > State is currently not being cleaned up by the runner. > [https://lists.apache.org/thread.html/86f0809fbfa3da873051287b9ff249d6dd5a896b45409db1e484cf38@%3Cdev.beam.apache.org%3E] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Assigned] (BEAM-6938) Add support for dynamic destinations when writing to MQTT
[ https://issues.apache.org/jira/browse/BEAM-6938?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ismaël Mejía reassigned BEAM-6938: -- Assignee: LI Guobao > Add support for dynamic destinations when writing to MQTT > - > > Key: BEAM-6938 > URL: https://issues.apache.org/jira/browse/BEAM-6938 > Project: Beam > Issue Type: Improvement > Components: io-java-mqtt >Reporter: Ismaël Mejía >Assignee: LI Guobao >Priority: Minor > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-2939) Fn API streaming SDF support
[ https://issues.apache.org/jira/browse/BEAM-2939?focusedWorklogId=220546&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220546 ] ASF GitHub Bot logged work on BEAM-2939: Author: ASF GitHub Bot Created on: 29/Mar/19 14:13 Start Date: 29/Mar/19 14:13 Worklog Time Spent: 10m Work Description: robertwb commented on issue #8088: [BEAM-2939] SDF sizing in FnAPI and Python SDK/runner. URL: https://github.com/apache/beam/pull/8088#issuecomment-478012591 Run Python PreCommit This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220546) Time Spent: 14h 20m (was: 14h 10m) > Fn API streaming SDF support > > > Key: BEAM-2939 > URL: https://issues.apache.org/jira/browse/BEAM-2939 > Project: Beam > Issue Type: Improvement > Components: beam-model >Reporter: Henning Rohde >Assignee: Luke Cwik >Priority: Major > Labels: portability, triaged > Time Spent: 14h 20m > Remaining Estimate: 0h > > The Fn API should support streaming SDF. Detailed design TBD. > Once design is ready, expand subtasks similarly to BEAM-2822. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6929) Session Windows with lateness cause NullPointerException in Flink Runner
[
https://issues.apache.org/jira/browse/BEAM-6929?focusedWorklogId=220556&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220556
]
ASF GitHub Bot logged work on BEAM-6929:
Author: ASF GitHub Bot
Created on: 29/Mar/19 14:41
Start Date: 29/Mar/19 14:41
Worklog Time Spent: 10m
Work Description: iemejia commented on pull request #8162: [BEAM-6929]
Prevent NullPointerException in Flink's CombiningState
URL: https://github.com/apache/beam/pull/8162
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220556)
Time Spent: 1h 20m (was: 1h 10m)
> Session Windows with lateness cause NullPointerException in Flink Runner
>
>
> Key: BEAM-6929
> URL: https://issues.apache.org/jira/browse/BEAM-6929
> Project: Beam
> Issue Type: Bug
> Components: runner-flink
>Reporter: Maximilian Michels
>Assignee: Maximilian Michels
>Priority: Critical
> Fix For: 2.12.0
>
> Time Spent: 1h 20m
> Remaining Estimate: 0h
>
> Reported on the mailing list:
> {noformat}
> I am using Beam 2.11.0, Runner - beam-runners-flink-1.7, Flink Cluster -
> 1.7.2.
> I have this flow in my pipeline:
> KafkaSource(withCreateTime()) --> ApplyWindow(SessionWindow with
> gapDuration=1 Minute, lateness=3 Minutes, AccumulatingFiredPanes, default
> trigger) --> BeamSQL(GroupBy query) --> Window.remerge() --> Enrichment
> --> KafkaSink
> I am generating data in such a way that the first two records belong to two
> different sessions. And, generating the third record before the first session
> expires with the timestamp for the third record in such a way that the two
> sessions will be merged to become a single session.
> For Example, These are the sample input and output obtained when I ran the
> same pipeline in DirectRunner.
> Sample Input:
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-27-44"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-51"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-26"}}
> Sample Output:
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-28-44"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-28-51"},"WET":{"string":"2019-03-27 15-29-51"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":3},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-29-51"}}
> Where "NumberOfRecords" is the count, "WST" is the Avro field Name which
> indicates the window start time for the session window. Similarly "WET"
> indicates the window End time of the session window. I am getting "WST" and
> "WET" after remerging and applying ParDo(Enrichment stage of the pipeline).
> The program ran successfully in DirectRunner. But, in FlinkRunner, I am
> getting this exception when the third record arrives:
> 2019-03-27 15:31:00,442 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph- Source:
> DfleKafkaSource/KafkaIO.Read/Read(KafkaUnboundedSource) -> Flat Map ->
> DfleKafkaSource/ParDo(ConvertKafkaRecordtoRow)/ParMultiDo(ConvertKafkaRecordtoRow)
> -> (Window.Into()/Window.Assign.out ->
> DfleSql/SqlTransform/BeamIOSourceRel_4/Convert.ConvertTransform/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/Group
> by fields/ParMultiDo(Anonymous) -> ToKeyedWorkItem,
> DfleKafkaSink/ParDo(RowToGenericRecordConverter)/ParMultiDo(RowToGenericRecordConverter)
> -> DfleKafkaSink/KafkaIO.KafkaValueWrite/Kafka values with default
> key/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/Kafka
> ProducerRecord/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/KafkaIO.WriteRecords/ParDo(KafkaWriter)/ParMultiDo(KafkaWriter))
> (1/1) (d00be62e110cef00d9d772042f4b87a9) switched from DEPLOYING to RUNNING.
> 2019-03-27 15:33:25,427 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph-
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/GroupByKey
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Combine.GroupedValues/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/mergeRecord/ParMultiDo(A
[jira] [Work logged] (BEAM-6929) Session Windows with lateness cause NullPointerException in Flink Runner
[
https://issues.apache.org/jira/browse/BEAM-6929?focusedWorklogId=220559&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220559
]
ASF GitHub Bot logged work on BEAM-6929:
Author: ASF GitHub Bot
Created on: 29/Mar/19 14:42
Start Date: 29/Mar/19 14:42
Worklog Time Spent: 10m
Work Description: iemejia commented on issue #8162: [BEAM-6929] Prevent
NullPointerException in Flink's CombiningState
URL: https://github.com/apache/beam/pull/8162#issuecomment-478023184
Two extra questions @mxm:
1. Does this mean that if they are not calculated in place we can have a
future consistency issue for spark?
2. Did you check in other runners too?
This is worth the cherry-pick indeed.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220559)
Time Spent: 1.5h (was: 1h 20m)
> Session Windows with lateness cause NullPointerException in Flink Runner
>
>
> Key: BEAM-6929
> URL: https://issues.apache.org/jira/browse/BEAM-6929
> Project: Beam
> Issue Type: Bug
> Components: runner-flink
>Reporter: Maximilian Michels
>Assignee: Maximilian Michels
>Priority: Critical
> Fix For: 2.12.0
>
> Time Spent: 1.5h
> Remaining Estimate: 0h
>
> Reported on the mailing list:
> {noformat}
> I am using Beam 2.11.0, Runner - beam-runners-flink-1.7, Flink Cluster -
> 1.7.2.
> I have this flow in my pipeline:
> KafkaSource(withCreateTime()) --> ApplyWindow(SessionWindow with
> gapDuration=1 Minute, lateness=3 Minutes, AccumulatingFiredPanes, default
> trigger) --> BeamSQL(GroupBy query) --> Window.remerge() --> Enrichment
> --> KafkaSink
> I am generating data in such a way that the first two records belong to two
> different sessions. And, generating the third record before the first session
> expires with the timestamp for the third record in such a way that the two
> sessions will be merged to become a single session.
> For Example, These are the sample input and output obtained when I ran the
> same pipeline in DirectRunner.
> Sample Input:
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-27-44"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-51"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-26"}}
> Sample Output:
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-28-44"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-28-51"},"WET":{"string":"2019-03-27 15-29-51"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":3},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-29-51"}}
> Where "NumberOfRecords" is the count, "WST" is the Avro field Name which
> indicates the window start time for the session window. Similarly "WET"
> indicates the window End time of the session window. I am getting "WST" and
> "WET" after remerging and applying ParDo(Enrichment stage of the pipeline).
> The program ran successfully in DirectRunner. But, in FlinkRunner, I am
> getting this exception when the third record arrives:
> 2019-03-27 15:31:00,442 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph- Source:
> DfleKafkaSource/KafkaIO.Read/Read(KafkaUnboundedSource) -> Flat Map ->
> DfleKafkaSource/ParDo(ConvertKafkaRecordtoRow)/ParMultiDo(ConvertKafkaRecordtoRow)
> -> (Window.Into()/Window.Assign.out ->
> DfleSql/SqlTransform/BeamIOSourceRel_4/Convert.ConvertTransform/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/Group
> by fields/ParMultiDo(Anonymous) -> ToKeyedWorkItem,
> DfleKafkaSink/ParDo(RowToGenericRecordConverter)/ParMultiDo(RowToGenericRecordConverter)
> -> DfleKafkaSink/KafkaIO.KafkaValueWrite/Kafka values with default
> key/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/Kafka
> ProducerRecord/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/KafkaIO.WriteRecords/ParDo(KafkaWriter)/ParMultiDo(KafkaWriter))
> (1/1) (d00be62e110cef00d9d772042f4b87a9) switched from DEPLOYING to RUNNING.
> 2019-03-27 15:33:25,427 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph-
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFi
[jira] [Work logged] (BEAM-6929) Session Windows with lateness cause NullPointerException in Flink Runner
[
https://issues.apache.org/jira/browse/BEAM-6929?focusedWorklogId=220560&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220560
]
ASF GitHub Bot logged work on BEAM-6929:
Author: ASF GitHub Bot
Created on: 29/Mar/19 14:43
Start Date: 29/Mar/19 14:43
Worklog Time Spent: 10m
Work Description: iemejia commented on issue #8162: [BEAM-6929] Prevent
NullPointerException in Flink's CombiningState
URL: https://github.com/apache/beam/pull/8162#issuecomment-478023184
Two extra questions @mxm:
1. Does this mean that if they are not calculated in place we can have a
future consistency issue for spark?
2. Did you check in other runners too?
I think this is worth to be cherry picked and pushed into the 2.12.x branch
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220560)
Time Spent: 1h 40m (was: 1.5h)
> Session Windows with lateness cause NullPointerException in Flink Runner
>
>
> Key: BEAM-6929
> URL: https://issues.apache.org/jira/browse/BEAM-6929
> Project: Beam
> Issue Type: Bug
> Components: runner-flink
>Reporter: Maximilian Michels
>Assignee: Maximilian Michels
>Priority: Critical
> Fix For: 2.12.0
>
> Time Spent: 1h 40m
> Remaining Estimate: 0h
>
> Reported on the mailing list:
> {noformat}
> I am using Beam 2.11.0, Runner - beam-runners-flink-1.7, Flink Cluster -
> 1.7.2.
> I have this flow in my pipeline:
> KafkaSource(withCreateTime()) --> ApplyWindow(SessionWindow with
> gapDuration=1 Minute, lateness=3 Minutes, AccumulatingFiredPanes, default
> trigger) --> BeamSQL(GroupBy query) --> Window.remerge() --> Enrichment
> --> KafkaSink
> I am generating data in such a way that the first two records belong to two
> different sessions. And, generating the third record before the first session
> expires with the timestamp for the third record in such a way that the two
> sessions will be merged to become a single session.
> For Example, These are the sample input and output obtained when I ran the
> same pipeline in DirectRunner.
> Sample Input:
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-27-44"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-51"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-26"}}
> Sample Output:
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-28-44"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-28-51"},"WET":{"string":"2019-03-27 15-29-51"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":3},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-29-51"}}
> Where "NumberOfRecords" is the count, "WST" is the Avro field Name which
> indicates the window start time for the session window. Similarly "WET"
> indicates the window End time of the session window. I am getting "WST" and
> "WET" after remerging and applying ParDo(Enrichment stage of the pipeline).
> The program ran successfully in DirectRunner. But, in FlinkRunner, I am
> getting this exception when the third record arrives:
> 2019-03-27 15:31:00,442 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph- Source:
> DfleKafkaSource/KafkaIO.Read/Read(KafkaUnboundedSource) -> Flat Map ->
> DfleKafkaSource/ParDo(ConvertKafkaRecordtoRow)/ParMultiDo(ConvertKafkaRecordtoRow)
> -> (Window.Into()/Window.Assign.out ->
> DfleSql/SqlTransform/BeamIOSourceRel_4/Convert.ConvertTransform/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/Group
> by fields/ParMultiDo(Anonymous) -> ToKeyedWorkItem,
> DfleKafkaSink/ParDo(RowToGenericRecordConverter)/ParMultiDo(RowToGenericRecordConverter)
> -> DfleKafkaSink/KafkaIO.KafkaValueWrite/Kafka values with default
> key/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/Kafka
> ProducerRecord/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/KafkaIO.WriteRecords/ParDo(KafkaWriter)/ParMultiDo(KafkaWriter))
> (1/1) (d00be62e110cef00d9d772042f4b87a9) switched from DEPLOYING to RUNNING.
> 2019-03-27 15:33:25,427 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph-
> DfleSql/SqlTransform/BeamAggregation
[jira] [Work logged] (BEAM-4610) RedisIO should allow to configure SSL
[ https://issues.apache.org/jira/browse/BEAM-4610?focusedWorklogId=220561&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220561 ] ASF GitHub Bot logged work on BEAM-4610: Author: ASF GitHub Bot Created on: 29/Mar/19 14:48 Start Date: 29/Mar/19 14:48 Worklog Time Spent: 10m Work Description: iemejia commented on issue #8161: [BEAM-4610] Add SSL support for RedisIO URL: https://github.com/apache/beam/pull/8161#issuecomment-478025175 Run Java PreCommit This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220561) Time Spent: 1h 10m (was: 1h) > RedisIO should allow to configure SSL > - > > Key: BEAM-4610 > URL: https://issues.apache.org/jira/browse/BEAM-4610 > Project: Beam > Issue Type: Improvement > Components: io-java-redis >Reporter: Ismaël Mejía >Assignee: LI Guobao >Priority: Minor > Time Spent: 1h 10m > Remaining Estimate: 0h > > Current version of RedisIO does not support SSL connection, this could be > easily added by enabling the flag as a configuration option in the IO. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (BEAM-6939) Simon Poortman
Simon Poortman created BEAM-6939: Summary: Simon Poortman Key: BEAM-6939 URL: https://issues.apache.org/jira/browse/BEAM-6939 Project: Beam Issue Type: New Feature Components: dependencies Reporter: Simon Poortman -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6876) User state cleanup in portable Flink runner
[ https://issues.apache.org/jira/browse/BEAM-6876?focusedWorklogId=220568&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220568 ] ASF GitHub Bot logged work on BEAM-6876: Author: ASF GitHub Bot Created on: 29/Mar/19 14:58 Start Date: 29/Mar/19 14:58 Worklog Time Spent: 10m Work Description: tweise commented on issue #8118: [BEAM-6876] Cleanup user state in portable Flink Runner URL: https://github.com/apache/beam/pull/8118#issuecomment-478029117 Run Python PreCommit This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220568) Time Spent: 3.5h (was: 3h 20m) > User state cleanup in portable Flink runner > --- > > Key: BEAM-6876 > URL: https://issues.apache.org/jira/browse/BEAM-6876 > Project: Beam > Issue Type: Bug > Components: runner-flink >Affects Versions: 2.11.0 >Reporter: Thomas Weise >Assignee: Maximilian Michels >Priority: Major > Labels: portability-flink, triaged > Time Spent: 3.5h > Remaining Estimate: 0h > > State is currently not being cleaned up by the runner. > [https://lists.apache.org/thread.html/86f0809fbfa3da873051287b9ff249d6dd5a896b45409db1e484cf38@%3Cdev.beam.apache.org%3E] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6876) User state cleanup in portable Flink runner
[ https://issues.apache.org/jira/browse/BEAM-6876?focusedWorklogId=220567&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220567 ] ASF GitHub Bot logged work on BEAM-6876: Author: ASF GitHub Bot Created on: 29/Mar/19 14:58 Start Date: 29/Mar/19 14:58 Worklog Time Spent: 10m Work Description: tweise commented on issue #8118: [BEAM-6876] Cleanup user state in portable Flink Runner URL: https://github.com/apache/beam/pull/8118#issuecomment-478028919 Run Java PreCommit This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220567) Time Spent: 3h 20m (was: 3h 10m) > User state cleanup in portable Flink runner > --- > > Key: BEAM-6876 > URL: https://issues.apache.org/jira/browse/BEAM-6876 > Project: Beam > Issue Type: Bug > Components: runner-flink >Affects Versions: 2.11.0 >Reporter: Thomas Weise >Assignee: Maximilian Michels >Priority: Major > Labels: portability-flink, triaged > Time Spent: 3h 20m > Remaining Estimate: 0h > > State is currently not being cleaned up by the runner. > [https://lists.apache.org/thread.html/86f0809fbfa3da873051287b9ff249d6dd5a896b45409db1e484cf38@%3Cdev.beam.apache.org%3E] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6929) Session Windows with lateness cause NullPointerException in Flink Runner
[
https://issues.apache.org/jira/browse/BEAM-6929?focusedWorklogId=220569&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220569
]
ASF GitHub Bot logged work on BEAM-6929:
Author: ASF GitHub Bot
Created on: 29/Mar/19 15:00
Start Date: 29/Mar/19 15:00
Worklog Time Spent: 10m
Work Description: mxm commented on issue #8162: [BEAM-6929] Prevent
NullPointerException in Flink's CombiningState
URL: https://github.com/apache/beam/pull/8162#issuecomment-478029736
Thanks for merging!
>Does this mean that if they are not calculated in place we can have a
future consistency issue for spark?
Yes, combiners which do not work in-place but on a new accumulator produced
wrong results for combining state. That said, I think almost all combiners work
in-place.
>Did you check in other runners too?
I adjusted the `StateInternalsTest` which Flink, Spark, Apex, and the
InMemoryStateInternals use.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220569)
Time Spent: 1h 50m (was: 1h 40m)
> Session Windows with lateness cause NullPointerException in Flink Runner
>
>
> Key: BEAM-6929
> URL: https://issues.apache.org/jira/browse/BEAM-6929
> Project: Beam
> Issue Type: Bug
> Components: runner-flink
>Reporter: Maximilian Michels
>Assignee: Maximilian Michels
>Priority: Critical
> Fix For: 2.12.0
>
> Time Spent: 1h 50m
> Remaining Estimate: 0h
>
> Reported on the mailing list:
> {noformat}
> I am using Beam 2.11.0, Runner - beam-runners-flink-1.7, Flink Cluster -
> 1.7.2.
> I have this flow in my pipeline:
> KafkaSource(withCreateTime()) --> ApplyWindow(SessionWindow with
> gapDuration=1 Minute, lateness=3 Minutes, AccumulatingFiredPanes, default
> trigger) --> BeamSQL(GroupBy query) --> Window.remerge() --> Enrichment
> --> KafkaSink
> I am generating data in such a way that the first two records belong to two
> different sessions. And, generating the third record before the first session
> expires with the timestamp for the third record in such a way that the two
> sessions will be merged to become a single session.
> For Example, These are the sample input and output obtained when I ran the
> same pipeline in DirectRunner.
> Sample Input:
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-27-44"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-51"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-26"}}
> Sample Output:
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-28-44"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-28-51"},"WET":{"string":"2019-03-27 15-29-51"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":3},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-29-51"}}
> Where "NumberOfRecords" is the count, "WST" is the Avro field Name which
> indicates the window start time for the session window. Similarly "WET"
> indicates the window End time of the session window. I am getting "WST" and
> "WET" after remerging and applying ParDo(Enrichment stage of the pipeline).
> The program ran successfully in DirectRunner. But, in FlinkRunner, I am
> getting this exception when the third record arrives:
> 2019-03-27 15:31:00,442 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph- Source:
> DfleKafkaSource/KafkaIO.Read/Read(KafkaUnboundedSource) -> Flat Map ->
> DfleKafkaSource/ParDo(ConvertKafkaRecordtoRow)/ParMultiDo(ConvertKafkaRecordtoRow)
> -> (Window.Into()/Window.Assign.out ->
> DfleSql/SqlTransform/BeamIOSourceRel_4/Convert.ConvertTransform/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/Group
> by fields/ParMultiDo(Anonymous) -> ToKeyedWorkItem,
> DfleKafkaSink/ParDo(RowToGenericRecordConverter)/ParMultiDo(RowToGenericRecordConverter)
> -> DfleKafkaSink/KafkaIO.KafkaValueWrite/Kafka values with default
> key/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/Kafka
> ProducerRecord/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/KafkaIO.WriteRecords/ParDo(KafkaWriter)/ParMultiDo(KafkaWriter))
> (1/1) (d00be62e110cef0
[jira] [Work logged] (BEAM-6937) Streaming FlinkTransformOverrides are not applied without explicit streaming mode
[
https://issues.apache.org/jira/browse/BEAM-6937?focusedWorklogId=220570&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220570
]
ASF GitHub Bot logged work on BEAM-6937:
Author: ASF GitHub Bot
Created on: 29/Mar/19 15:02
Start Date: 29/Mar/19 15:02
Worklog Time Spent: 10m
Work Description: iemejia commented on pull request #8168: [BEAM-6937]
Apply FlinkTransformOverrides correctly with inferred streaming mode
URL: https://github.com/apache/beam/pull/8168
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220570)
Time Spent: 20m (was: 10m)
> Streaming FlinkTransformOverrides are not applied without explicit streaming
> mode
> -
>
> Key: BEAM-6937
> URL: https://issues.apache.org/jira/browse/BEAM-6937
> Project: Beam
> Issue Type: Bug
> Components: runner-flink
>Reporter: Maximilian Michels
>Assignee: Maximilian Michels
>Priority: Critical
> Fix For: 2.12.0
>
> Time Spent: 20m
> Remaining Estimate: 0h
>
> When streaming is set to false the streaming mode will be switched to true if
> the pipeline contains unbounded sources. There is a regression which prevents
> PipelineOverrides to be applied correctly in this case.
> As reported on the mailing list:
> {noformat}
> I just upgraded to Flink 1.7.2 from 1.6.2 with my dev cluster and from Beam
> 2.10 to 2.11 and I am seeing this error when starting my pipelines:
> org.apache.flink.client.program.ProgramInvocationException: The main method
> caused an error.
> at
> org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:546)
> at
> org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:421)
> at
> org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:427)
> at
> org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:813)
> at
> org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:287)
> at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
> at
> org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
> at
> org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
> at
> org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
> at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
> Caused by: java.lang.UnsupportedOperationException: The transform
> beam:transform:create_view:v1 is currently not supported.
>
>
> at
> org.apache.beam.runners.flink.FlinkStreamingPipelineTranslator.visitPrimitiveTransform(FlinkStreamingPipelineTranslator.java:113)
>
>
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:665)
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.access$600(TransformHierarchy.java:317)
> at
> org.apache.beam.sdk.runners.TransformHierarchy.visit(TransformHierarchy.java:251)
> at
> org.apache.beam.sdk.Pipeline.traverseTopologically(Pipeline.java:458)
> at
> org.apache.beam.runners.flink.FlinkPipelineTranslator.translate(FlinkPipelineTranslator.java:38)
> at
> org.apache.beam.runners.flink.FlinkStreamingPipelineTranslator.translate(FlinkStreamingPipelineTranslator.java:68)
>
>
> at
> org.apache.beam.runners.flink.FlinkPipelineExecutionEnvironment.translate(FlinkPipelineExecutionEnvironment.java:111)
>
[jira] [Created] (BEAM-6940) Validate that namespace and table are part of the query in CassandraIO
Ismaël Mejía created BEAM-6940: -- Summary: Validate that namespace and table are part of the query in CassandraIO Key: BEAM-6940 URL: https://issues.apache.org/jira/browse/BEAM-6940 Project: Beam Issue Type: Improvement Components: io-java-cassandra Reporter: Ismaël Mejía If the user sets a different namespace or table than the ones provided in `withQuery`. CassandraIO may throw an exception, or get invalid size estimation (so invalid splitting). To fix this, if the query is set (not null) we should validate that the namespace and table should be part of the query expression. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Reopened] (BEAM-5723) CassandraIO is broken because of use of bad relocation of guava
[
https://issues.apache.org/jira/browse/BEAM-5723?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Ismaël Mejía reopened BEAM-5723:
Assignee: (was: Max Charas)
> CassandraIO is broken because of use of bad relocation of guava
> ---
>
> Key: BEAM-5723
> URL: https://issues.apache.org/jira/browse/BEAM-5723
> Project: Beam
> Issue Type: Bug
> Components: io-java-cassandra
>Affects Versions: 2.5.0, 2.6.0, 2.7.0, 2.8.0, 2.9.0, 2.10.0, 2.11.0
>Reporter: Arun sethia
>Priority: Major
> Fix For: 2.12.0
>
> Time Spent: 8h 20m
> Remaining Estimate: 0h
>
> While using apache beam to run dataflow job to read data from BigQuery and
> Store/Write to Cassandra with following libaries:
> # beam-sdks-java-io-cassandra - 2.6.0
> # beam-sdks-java-io-jdbc - 2.6.0
> # beam-sdks-java-io-google-cloud-platform - 2.6.0
> # beam-sdks-java-core - 2.6.0
> # google-cloud-dataflow-java-sdk-all - 2.5.0
> # google-api-client -1.25.0
>
> I am getting following error at the time insert/save data to Cassandra.
> {code:java}
> [error] (run-main-0) org.apache.beam.sdk.Pipeline$PipelineExecutionException:
> java.lang.NoSuchMethodError:
> com.datastax.driver.mapping.Mapper.saveAsync(Ljava/lang/Object;)Lorg/apache/beam/repackaged/beam_sdks_java_io_cassandra/com/google/common/util/concurrent/ListenableFuture;
> org.apache.beam.sdk.Pipeline$PipelineExecutionException:
> java.lang.NoSuchMethodError:
> com.datastax.driver.mapping.Mapper.saveAsync(Ljava/lang/Object;)Lorg/apache/beam/repackaged/beam_sdks_java_io_cassandra/com/google/common/util/concurrent/ListenableFuture;
> at
> org.apache.beam.runners.direct.DirectRunner$DirectPipelineResult.waitUntilFinish(DirectRunner.java:332)
> at
> org.apache.beam.runners.direct.DirectRunner$DirectPipelineResult.waitUntilFinish(DirectRunner.java:302)
> at org.apache.beam.runners.direct.DirectRunner.run(DirectRunner.java:197)
> at org.apache.beam.runners.direct.DirectRunner.run(DirectRunner.java:64)
> at org.apache.beam.sdk.Pipeline.run(Pipeline.java:313)
> at org.apache.beam.sdk.Pipeline.run(Pipeline.java:299){code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BEAM-6324) CassandraIO.Read - Add the ability to provide a filter to the query
[ https://issues.apache.org/jira/browse/BEAM-6324?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16805143#comment-16805143 ] Ismaël Mejía commented on BEAM-6324: You are right, this is error prone but a consequence of earlier API design mistakes. We could add a validation that detects that if the user set the query then the tablespace and the table name should be part of the query to fail eagerly. Would you be up to work on that fix? I created BEAM-6940 feel free to sel assign if you can help us to fix it and thanks for reporting. Notice that the we need the keyspace and table to be explicit to find the token ranges, otherwise we should extract that from the query and that's a way trickier problem. > CassandraIO.Read - Add the ability to provide a filter to the query > --- > > Key: BEAM-6324 > URL: https://issues.apache.org/jira/browse/BEAM-6324 > Project: Beam > Issue Type: Improvement > Components: io-java-cassandra >Reporter: Shahar Frank >Assignee: Shahar Frank >Priority: Major > Labels: performance, pull-request-available, triaged > Fix For: Not applicable > > Time Spent: 12h 50m > Remaining Estimate: 0h > > CassandraIO.Read doesn't support using WHERE to filter the input at the > source (In Cassandra) which might provide great performance boost. > Already implemented by: > https://github.com/apache/beam/pull/7340 -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BEAM-5723) CassandraIO is broken because of use of bad relocation of guava
[
https://issues.apache.org/jira/browse/BEAM-5723?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16805153#comment-16805153
]
Ismaël Mejía commented on BEAM-5723:
@srfrnk thanks for confirming this. So it is not as I expected sadly. It seems
that even if the IO now does not use the relocated paths, the relocation plugin
is rewriting the 'Cassandra' classes.
[~kenn] is there an 'easy' way to exclude CassandraIO from relocating guava? I
can try to tackle it just to get this fixed for 2.12.0 ?
> CassandraIO is broken because of use of bad relocation of guava
> ---
>
> Key: BEAM-5723
> URL: https://issues.apache.org/jira/browse/BEAM-5723
> Project: Beam
> Issue Type: Bug
> Components: io-java-cassandra
>Affects Versions: 2.5.0, 2.6.0, 2.7.0, 2.8.0, 2.9.0, 2.10.0, 2.11.0
>Reporter: Arun sethia
>Priority: Major
> Fix For: 2.12.0
>
> Time Spent: 8h 20m
> Remaining Estimate: 0h
>
> While using apache beam to run dataflow job to read data from BigQuery and
> Store/Write to Cassandra with following libaries:
> # beam-sdks-java-io-cassandra - 2.6.0
> # beam-sdks-java-io-jdbc - 2.6.0
> # beam-sdks-java-io-google-cloud-platform - 2.6.0
> # beam-sdks-java-core - 2.6.0
> # google-cloud-dataflow-java-sdk-all - 2.5.0
> # google-api-client -1.25.0
>
> I am getting following error at the time insert/save data to Cassandra.
> {code:java}
> [error] (run-main-0) org.apache.beam.sdk.Pipeline$PipelineExecutionException:
> java.lang.NoSuchMethodError:
> com.datastax.driver.mapping.Mapper.saveAsync(Ljava/lang/Object;)Lorg/apache/beam/repackaged/beam_sdks_java_io_cassandra/com/google/common/util/concurrent/ListenableFuture;
> org.apache.beam.sdk.Pipeline$PipelineExecutionException:
> java.lang.NoSuchMethodError:
> com.datastax.driver.mapping.Mapper.saveAsync(Ljava/lang/Object;)Lorg/apache/beam/repackaged/beam_sdks_java_io_cassandra/com/google/common/util/concurrent/ListenableFuture;
> at
> org.apache.beam.runners.direct.DirectRunner$DirectPipelineResult.waitUntilFinish(DirectRunner.java:332)
> at
> org.apache.beam.runners.direct.DirectRunner$DirectPipelineResult.waitUntilFinish(DirectRunner.java:302)
> at org.apache.beam.runners.direct.DirectRunner.run(DirectRunner.java:197)
> at org.apache.beam.runners.direct.DirectRunner.run(DirectRunner.java:64)
> at org.apache.beam.sdk.Pipeline.run(Pipeline.java:313)
> at org.apache.beam.sdk.Pipeline.run(Pipeline.java:299){code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Work logged] (BEAM-3072) Improve error handling at staging time time for DataflowRunner
[ https://issues.apache.org/jira/browse/BEAM-3072?focusedWorklogId=220589&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220589 ] ASF GitHub Bot logged work on BEAM-3072: Author: ASF GitHub Bot Created on: 29/Mar/19 16:07 Start Date: 29/Mar/19 16:07 Worklog Time Spent: 10m Work Description: aaltay commented on issue #8158: [BEAM-3072] updates to that the error handling and collected the fail… URL: https://github.com/apache/beam/pull/8158#issuecomment-478055779 @NikeNano According to JIRA if a command fails we only log that such a thing happened but do not log why. Let's say, we are calling out "pip install a-package-that-does-not-exist", In the error log we would like to see the actual pip error saying that this is an non existent package, in addition to the current error message of a process failed with a non-zero return code. This output will be very likely in stderr. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220589) Time Spent: 2h 50m (was: 2h 40m) > Improve error handling at staging time time for DataflowRunner > -- > > Key: BEAM-3072 > URL: https://issues.apache.org/jira/browse/BEAM-3072 > Project: Beam > Issue Type: Bug > Components: sdk-py-core >Reporter: Ahmet Altay >Assignee: niklas Hansson >Priority: Minor > Labels: starter, triaged > Time Spent: 2h 50m > Remaining Estimate: 0h > > dependency.py calls out to external process to collect dependencies: > https://github.com/apache/beam/blob/de7cc05cc67d1aa6331cddc17c2e02ed0efbe37d/sdks/python/apache_beam/runners/dataflow/internal/dependency.py#L263 > If these calls fails, the error is not clear. The error only tells what > failed but does not show the actual error message, and is not helpful for > users. > As a general fix processes.py should have general better output collection > from failed processes. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6932) SamzaRunner: migrate to use new Samza 1.1.0 liraries
[
https://issues.apache.org/jira/browse/BEAM-6932?focusedWorklogId=220588&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220588
]
ASF GitHub Bot logged work on BEAM-6932:
Author: ASF GitHub Bot
Created on: 29/Mar/19 16:07
Start Date: 29/Mar/19 16:07
Worklog Time Spent: 10m
Work Description: lhaiesp commented on pull request #8163: [BEAM-6932]
SamzaRunner: migrate to use new Samza 1.1.0 liraries
URL: https://github.com/apache/beam/pull/8163#discussion_r270477306
##
File path:
runners/samza/src/main/java/org/apache/beam/runners/samza/container/BeamContainerRunner.java
##
@@ -18,34 +18,67 @@
package org.apache.beam.runners.samza.container;
import java.time.Duration;
-import org.apache.samza.application.StreamApplication;
+import org.apache.samza.application.SamzaApplication;
+import org.apache.samza.application.descriptors.ApplicationDescriptor;
+import org.apache.samza.application.descriptors.ApplicationDescriptorImpl;
+import org.apache.samza.application.descriptors.ApplicationDescriptorUtil;
import org.apache.samza.config.Config;
import org.apache.samza.config.ShellCommandConfig;
+import org.apache.samza.context.ExternalContext;
import org.apache.samza.job.ApplicationStatus;
-import org.apache.samza.runtime.LocalContainerRunner;
+import org.apache.samza.runtime.ApplicationRunner;
+import org.apache.samza.runtime.ContainerLaunchUtil;
+import org.apache.samza.util.SamzaUncaughtExceptionHandler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/** Runs the beam Yarn container, using the static global job model. */
-public class BeamContainerRunner extends LocalContainerRunner {
+public class BeamContainerRunner implements ApplicationRunner {
private static final Logger LOG =
LoggerFactory.getLogger(ContainerCfgFactory.class);
- public BeamContainerRunner(Config config) {
-super(ContainerCfgFactory.jobModel,
System.getenv(ShellCommandConfig.ENV_CONTAINER_ID()));
+ private final ApplicationDescriptorImpl
appDesc;
+
+ public BeamContainerRunner(SamzaApplication app, Config config) {
+this.appDesc = ApplicationDescriptorUtil.getAppDescriptor(app, config);
+ }
+
+ @Override
+ public void run(ExternalContext externalContext) {
+Thread.setDefaultUncaughtExceptionHandler(
+new SamzaUncaughtExceptionHandler(
+() -> {
+ LOG.info("Exiting process now.");
Review comment:
this is exiting after exception, is "error" maybe more appropriate?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220588)
Time Spent: 50m (was: 40m)
> SamzaRunner: migrate to use new Samza 1.1.0 liraries
>
>
> Key: BEAM-6932
> URL: https://issues.apache.org/jira/browse/BEAM-6932
> Project: Beam
> Issue Type: Improvement
> Components: runner-samza
>Reporter: Xinyu Liu
>Assignee: Xinyu Liu
>Priority: Major
> Time Spent: 50m
> Remaining Estimate: 0h
>
> Update SamzaRunner to use the latest Samza release libraries (1.1.0).
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (BEAM-6939) Simon Poortman
[ https://issues.apache.org/jira/browse/BEAM-6939?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16805158#comment-16805158 ] Ismaël Mejía commented on BEAM-6939: [~Klootviool] it seems you forgot to put the title (and the description in this issue) > Simon Poortman > -- > > Key: BEAM-6939 > URL: https://issues.apache.org/jira/browse/BEAM-6939 > Project: Beam > Issue Type: New Feature > Components: dependencies >Reporter: Simon Poortman >Priority: Major > Labels: Happy > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BEAM-6886) Change batch handling in ElasticsearchIO to avoid necessity for GroupIntoBatches
[ https://issues.apache.org/jira/browse/BEAM-6886?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16805162#comment-16805162 ] Etienne Chauchot commented on BEAM-6886: [~MadEgg]: - upgrading GroupIntoBatches for keying/unkeying is a very simple task. - when you said that you would like a batching mechanism in ESIO you meant like BigQueryIO#write()#withTriggeringFrequency() ? Such a thing could be included to ESIO I guess Unfortunately I don't have time to do those 2 things. [~MadEgg] or [~timrobertson100] do you want to contribute them ? > Change batch handling in ElasticsearchIO to avoid necessity for > GroupIntoBatches > > > Key: BEAM-6886 > URL: https://issues.apache.org/jira/browse/BEAM-6886 > Project: Beam > Issue Type: Improvement > Components: io-java-elasticsearch >Affects Versions: 2.11.0 >Reporter: Egbert >Priority: Major > > I have a streaming job inserting records into an Elasticsearch cluster. I set > the batch size appropriately big, but I found out this is not causing any > effect at all: I found that all elements are inserted in batches of 1 or 2 > elements. > The reason seems to be that this is a streaming pipeline, which may result in > tiny bundles. Since ElasticsearchIO uses `@FinishBundle` to flush a batch, > this will result in equally small batches. > This results in a huge amount of bulk requests with just one element, > grinding the Elasticsearch cluster to a halt. > I have now been able to work around this by using a `GroupIntoBatches` > operation before the insert, but this results in 3 steps (mapping to a key, > applying GroupIntoBatches, stripping key and outputting all collected > elements), making the process quite awkward. > A much better approach would be to internalize this into the ElasticsearchIO > write transform.. Use a timer that flushes the batch at batch size or end of > window, not at the end of a bundle. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6932) SamzaRunner: migrate to use new Samza 1.1.0 liraries
[
https://issues.apache.org/jira/browse/BEAM-6932?focusedWorklogId=220594&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220594
]
ASF GitHub Bot logged work on BEAM-6932:
Author: ASF GitHub Bot
Created on: 29/Mar/19 16:13
Start Date: 29/Mar/19 16:13
Worklog Time Spent: 10m
Work Description: xinyuiscool commented on pull request #8163:
[BEAM-6932] SamzaRunner: migrate to use new Samza 1.1.0 liraries
URL: https://github.com/apache/beam/pull/8163#discussion_r270479355
##
File path:
runners/samza/src/main/java/org/apache/beam/runners/samza/container/BeamContainerRunner.java
##
@@ -18,34 +18,67 @@
package org.apache.beam.runners.samza.container;
import java.time.Duration;
-import org.apache.samza.application.StreamApplication;
+import org.apache.samza.application.SamzaApplication;
+import org.apache.samza.application.descriptors.ApplicationDescriptor;
+import org.apache.samza.application.descriptors.ApplicationDescriptorImpl;
+import org.apache.samza.application.descriptors.ApplicationDescriptorUtil;
import org.apache.samza.config.Config;
import org.apache.samza.config.ShellCommandConfig;
+import org.apache.samza.context.ExternalContext;
import org.apache.samza.job.ApplicationStatus;
-import org.apache.samza.runtime.LocalContainerRunner;
+import org.apache.samza.runtime.ApplicationRunner;
+import org.apache.samza.runtime.ContainerLaunchUtil;
+import org.apache.samza.util.SamzaUncaughtExceptionHandler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/** Runs the beam Yarn container, using the static global job model. */
-public class BeamContainerRunner extends LocalContainerRunner {
+public class BeamContainerRunner implements ApplicationRunner {
private static final Logger LOG =
LoggerFactory.getLogger(ContainerCfgFactory.class);
- public BeamContainerRunner(Config config) {
-super(ContainerCfgFactory.jobModel,
System.getenv(ShellCommandConfig.ENV_CONTAINER_ID()));
+ private final ApplicationDescriptorImpl
appDesc;
+
+ public BeamContainerRunner(SamzaApplication app, Config config) {
+this.appDesc = ApplicationDescriptorUtil.getAppDescriptor(app, config);
+ }
+
+ @Override
+ public void run(ExternalContext externalContext) {
+Thread.setDefaultUncaughtExceptionHandler(
+new SamzaUncaughtExceptionHandler(
+() -> {
+ LOG.info("Exiting process now.");
Review comment:
Makes sense. Let me put our another pr for this given how hard it is to get
all the checks passed :).
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220594)
Time Spent: 1h (was: 50m)
> SamzaRunner: migrate to use new Samza 1.1.0 liraries
>
>
> Key: BEAM-6932
> URL: https://issues.apache.org/jira/browse/BEAM-6932
> Project: Beam
> Issue Type: Improvement
> Components: runner-samza
>Reporter: Xinyu Liu
>Assignee: Xinyu Liu
>Priority: Major
> Time Spent: 1h
> Remaining Estimate: 0h
>
> Update SamzaRunner to use the latest Samza release libraries (1.1.0).
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Work logged] (BEAM-6932) SamzaRunner: migrate to use new Samza 1.1.0 liraries
[ https://issues.apache.org/jira/browse/BEAM-6932?focusedWorklogId=220595&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220595 ] ASF GitHub Bot logged work on BEAM-6932: Author: ASF GitHub Bot Created on: 29/Mar/19 16:15 Start Date: 29/Mar/19 16:15 Worklog Time Spent: 10m Work Description: xinyuiscool commented on pull request #8163: [BEAM-6932] SamzaRunner: migrate to use new Samza 1.1.0 liraries URL: https://github.com/apache/beam/pull/8163 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220595) Time Spent: 1h 10m (was: 1h) > SamzaRunner: migrate to use new Samza 1.1.0 liraries > > > Key: BEAM-6932 > URL: https://issues.apache.org/jira/browse/BEAM-6932 > Project: Beam > Issue Type: Improvement > Components: runner-samza >Reporter: Xinyu Liu >Assignee: Xinyu Liu >Priority: Major > Time Spent: 1h 10m > Remaining Estimate: 0h > > Update SamzaRunner to use the latest Samza release libraries (1.1.0). -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6929) Session Windows with lateness cause NullPointerException in Flink Runner
[
https://issues.apache.org/jira/browse/BEAM-6929?focusedWorklogId=220596&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220596
]
ASF GitHub Bot logged work on BEAM-6929:
Author: ASF GitHub Bot
Created on: 29/Mar/19 16:19
Start Date: 29/Mar/19 16:19
Worklog Time Spent: 10m
Work Description: iemejia commented on pull request #8169:
[release-2.12.0] Cherry pick fixes for BEAM-6929 and BEAM-6937
URL: https://github.com/apache/beam/pull/8169
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220596)
Time Spent: 2h (was: 1h 50m)
> Session Windows with lateness cause NullPointerException in Flink Runner
>
>
> Key: BEAM-6929
> URL: https://issues.apache.org/jira/browse/BEAM-6929
> Project: Beam
> Issue Type: Bug
> Components: runner-flink
>Reporter: Maximilian Michels
>Assignee: Maximilian Michels
>Priority: Critical
> Fix For: 2.12.0
>
> Time Spent: 2h
> Remaining Estimate: 0h
>
> Reported on the mailing list:
> {noformat}
> I am using Beam 2.11.0, Runner - beam-runners-flink-1.7, Flink Cluster -
> 1.7.2.
> I have this flow in my pipeline:
> KafkaSource(withCreateTime()) --> ApplyWindow(SessionWindow with
> gapDuration=1 Minute, lateness=3 Minutes, AccumulatingFiredPanes, default
> trigger) --> BeamSQL(GroupBy query) --> Window.remerge() --> Enrichment
> --> KafkaSink
> I am generating data in such a way that the first two records belong to two
> different sessions. And, generating the third record before the first session
> expires with the timestamp for the third record in such a way that the two
> sessions will be merged to become a single session.
> For Example, These are the sample input and output obtained when I ran the
> same pipeline in DirectRunner.
> Sample Input:
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-27-44"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-51"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-26"}}
> Sample Output:
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-28-44"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-28-51"},"WET":{"string":"2019-03-27 15-29-51"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":3},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-29-51"}}
> Where "NumberOfRecords" is the count, "WST" is the Avro field Name which
> indicates the window start time for the session window. Similarly "WET"
> indicates the window End time of the session window. I am getting "WST" and
> "WET" after remerging and applying ParDo(Enrichment stage of the pipeline).
> The program ran successfully in DirectRunner. But, in FlinkRunner, I am
> getting this exception when the third record arrives:
> 2019-03-27 15:31:00,442 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph- Source:
> DfleKafkaSource/KafkaIO.Read/Read(KafkaUnboundedSource) -> Flat Map ->
> DfleKafkaSource/ParDo(ConvertKafkaRecordtoRow)/ParMultiDo(ConvertKafkaRecordtoRow)
> -> (Window.Into()/Window.Assign.out ->
> DfleSql/SqlTransform/BeamIOSourceRel_4/Convert.ConvertTransform/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/Group
> by fields/ParMultiDo(Anonymous) -> ToKeyedWorkItem,
> DfleKafkaSink/ParDo(RowToGenericRecordConverter)/ParMultiDo(RowToGenericRecordConverter)
> -> DfleKafkaSink/KafkaIO.KafkaValueWrite/Kafka values with default
> key/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/Kafka
> ProducerRecord/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/KafkaIO.WriteRecords/ParDo(KafkaWriter)/ParMultiDo(KafkaWriter))
> (1/1) (d00be62e110cef00d9d772042f4b87a9) switched from DEPLOYING to RUNNING.
> 2019-03-27 15:33:25,427 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph-
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/GroupByKey
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Combine.GroupedValues/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/mergeRecord/ParMultiDo(Anonymous)
>
[jira] [Resolved] (BEAM-6929) Session Windows with lateness cause NullPointerException in Flink Runner
[
https://issues.apache.org/jira/browse/BEAM-6929?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Ismaël Mejía resolved BEAM-6929.
Resolution: Fixed
> Session Windows with lateness cause NullPointerException in Flink Runner
>
>
> Key: BEAM-6929
> URL: https://issues.apache.org/jira/browse/BEAM-6929
> Project: Beam
> Issue Type: Bug
> Components: runner-flink
>Reporter: Maximilian Michels
>Assignee: Maximilian Michels
>Priority: Critical
> Fix For: 2.12.0
>
> Time Spent: 2h
> Remaining Estimate: 0h
>
> Reported on the mailing list:
> {noformat}
> I am using Beam 2.11.0, Runner - beam-runners-flink-1.7, Flink Cluster -
> 1.7.2.
> I have this flow in my pipeline:
> KafkaSource(withCreateTime()) --> ApplyWindow(SessionWindow with
> gapDuration=1 Minute, lateness=3 Minutes, AccumulatingFiredPanes, default
> trigger) --> BeamSQL(GroupBy query) --> Window.remerge() --> Enrichment
> --> KafkaSink
> I am generating data in such a way that the first two records belong to two
> different sessions. And, generating the third record before the first session
> expires with the timestamp for the third record in such a way that the two
> sessions will be merged to become a single session.
> For Example, These are the sample input and output obtained when I ran the
> same pipeline in DirectRunner.
> Sample Input:
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-27-44"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-51"}}
> {"Col1":{"string":"str1"}, "Timestamp":{"string":"2019-03-27 15-28-26"}}
> Sample Output:
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-28-44"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":1},"WST":{"string":"2019-03-27
> 15-28-51"},"WET":{"string":"2019-03-27 15-29-51"}}
> {"Col1":{"string":"str1"},"NumberOfRecords":{"long":3},"WST":{"string":"2019-03-27
> 15-27-44"},"WET":{"string":"2019-03-27 15-29-51"}}
> Where "NumberOfRecords" is the count, "WST" is the Avro field Name which
> indicates the window start time for the session window. Similarly "WET"
> indicates the window End time of the session window. I am getting "WST" and
> "WET" after remerging and applying ParDo(Enrichment stage of the pipeline).
> The program ran successfully in DirectRunner. But, in FlinkRunner, I am
> getting this exception when the third record arrives:
> 2019-03-27 15:31:00,442 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph- Source:
> DfleKafkaSource/KafkaIO.Read/Read(KafkaUnboundedSource) -> Flat Map ->
> DfleKafkaSource/ParDo(ConvertKafkaRecordtoRow)/ParMultiDo(ConvertKafkaRecordtoRow)
> -> (Window.Into()/Window.Assign.out ->
> DfleSql/SqlTransform/BeamIOSourceRel_4/Convert.ConvertTransform/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/Group
> by fields/ParMultiDo(Anonymous) -> ToKeyedWorkItem,
> DfleKafkaSink/ParDo(RowToGenericRecordConverter)/ParMultiDo(RowToGenericRecordConverter)
> -> DfleKafkaSink/KafkaIO.KafkaValueWrite/Kafka values with default
> key/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/Kafka
> ProducerRecord/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink/KafkaIO.KafkaValueWrite/KafkaIO.Write/KafkaIO.WriteRecords/ParDo(KafkaWriter)/ParMultiDo(KafkaWriter))
> (1/1) (d00be62e110cef00d9d772042f4b87a9) switched from DEPLOYING to RUNNING.
> 2019-03-27 15:33:25,427 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph-
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Group.ByFields/GroupByKey
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/Group.CombineFieldsByFields/Combine.GroupedValues/ParDo(Anonymous)/ParMultiDo(Anonymous)
> ->
> DfleSql/SqlTransform/BeamAggregationRel_45/mergeRecord/ParMultiDo(Anonymous)
> -> DfleSql/SqlTransform/BeamCalcRel_46/ParDo(Calc)/ParMultiDo(Calc) ->
> DfleSql/Window.Remerge/Identity/Map/ParMultiDo(Anonymous) ->
> DfleSql/ParDo(EnrichRecordWithWindowTimeInfo)/ParMultiDo(EnrichRecordWithWindowTimeInfo)
> ->
> DfleKafkaSink2/ParDo(RowToGenericRecordConverter)/ParMultiDo(RowToGenericRecordConverter)
> -> DfleKafkaSink2/KafkaIO.KafkaValueWrite/Kafka values with default
> key/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink2/KafkaIO.KafkaValueWrite/KafkaIO.Write/Kafka
> ProducerRecord/Map/ParMultiDo(Anonymous) ->
> DfleKafkaSink2/KafkaIO.KafkaValueWrite/KafkaIO.Write/KafkaIO.WriteRecords/ParDo(KafkaWriter)/ParMultiDo(KafkaWriter)
> (1/1) (d95af17b7457443c13bd327b46b282e6) switched from RUNNING to FAILED.
> org.apache.beam.sdk.util.UserCodeException: java.lang.Null
[jira] [Resolved] (BEAM-6937) Streaming FlinkTransformOverrides are not applied without explicit streaming mode
[
https://issues.apache.org/jira/browse/BEAM-6937?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Ismaël Mejía resolved BEAM-6937.
Resolution: Fixed
> Streaming FlinkTransformOverrides are not applied without explicit streaming
> mode
> -
>
> Key: BEAM-6937
> URL: https://issues.apache.org/jira/browse/BEAM-6937
> Project: Beam
> Issue Type: Bug
> Components: runner-flink
>Reporter: Maximilian Michels
>Assignee: Maximilian Michels
>Priority: Critical
> Fix For: 2.12.0
>
> Time Spent: 20m
> Remaining Estimate: 0h
>
> When streaming is set to false the streaming mode will be switched to true if
> the pipeline contains unbounded sources. There is a regression which prevents
> PipelineOverrides to be applied correctly in this case.
> As reported on the mailing list:
> {noformat}
> I just upgraded to Flink 1.7.2 from 1.6.2 with my dev cluster and from Beam
> 2.10 to 2.11 and I am seeing this error when starting my pipelines:
> org.apache.flink.client.program.ProgramInvocationException: The main method
> caused an error.
> at
> org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:546)
> at
> org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:421)
> at
> org.apache.flink.client.program.ClusterClient.run(ClusterClient.java:427)
> at
> org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:813)
> at
> org.apache.flink.client.cli.CliFrontend.runProgram(CliFrontend.java:287)
> at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:213)
> at
> org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:1050)
> at
> org.apache.flink.client.cli.CliFrontend.lambda$main$11(CliFrontend.java:1126)
> at
> org.apache.flink.runtime.security.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)
> at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1126)
> Caused by: java.lang.UnsupportedOperationException: The transform
> beam:transform:create_view:v1 is currently not supported.
>
>
> at
> org.apache.beam.runners.flink.FlinkStreamingPipelineTranslator.visitPrimitiveTransform(FlinkStreamingPipelineTranslator.java:113)
>
>
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:665)
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.visit(TransformHierarchy.java:657)
> at
> org.apache.beam.sdk.runners.TransformHierarchy$Node.access$600(TransformHierarchy.java:317)
> at
> org.apache.beam.sdk.runners.TransformHierarchy.visit(TransformHierarchy.java:251)
> at
> org.apache.beam.sdk.Pipeline.traverseTopologically(Pipeline.java:458)
> at
> org.apache.beam.runners.flink.FlinkPipelineTranslator.translate(FlinkPipelineTranslator.java:38)
> at
> org.apache.beam.runners.flink.FlinkStreamingPipelineTranslator.translate(FlinkStreamingPipelineTranslator.java:68)
>
>
> at
> org.apache.beam.runners.flink.FlinkPipelineExecutionEnvironment.translate(FlinkPipelineExecutionEnvironment.java:111)
>
>
> at org.apache.beam.runners.flink.FlinkRunner.run(FlinkRunner.java:108)
> at org.apache.beam.sdk.Pipeline.run(Pipeline.java:313)
> at org.apache.beam.sdk.Pipeline.run(Pipeline.java:299)
> at ch.ricardo.di.beam.KafkaToBigQuery.main(KafkaToBigQuery.java:175)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.j
[jira] [Assigned] (BEAM-5723) CassandraIO is broken because of use of bad relocation of guava
[
https://issues.apache.org/jira/browse/BEAM-5723?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Andrew Pilloud reassigned BEAM-5723:
Assignee: Ismaël Mejía
> CassandraIO is broken because of use of bad relocation of guava
> ---
>
> Key: BEAM-5723
> URL: https://issues.apache.org/jira/browse/BEAM-5723
> Project: Beam
> Issue Type: Bug
> Components: io-java-cassandra
>Affects Versions: 2.5.0, 2.6.0, 2.7.0, 2.8.0, 2.9.0, 2.10.0, 2.11.0
>Reporter: Arun sethia
>Assignee: Ismaël Mejía
>Priority: Major
> Fix For: 2.12.0
>
> Time Spent: 8h 20m
> Remaining Estimate: 0h
>
> While using apache beam to run dataflow job to read data from BigQuery and
> Store/Write to Cassandra with following libaries:
> # beam-sdks-java-io-cassandra - 2.6.0
> # beam-sdks-java-io-jdbc - 2.6.0
> # beam-sdks-java-io-google-cloud-platform - 2.6.0
> # beam-sdks-java-core - 2.6.0
> # google-cloud-dataflow-java-sdk-all - 2.5.0
> # google-api-client -1.25.0
>
> I am getting following error at the time insert/save data to Cassandra.
> {code:java}
> [error] (run-main-0) org.apache.beam.sdk.Pipeline$PipelineExecutionException:
> java.lang.NoSuchMethodError:
> com.datastax.driver.mapping.Mapper.saveAsync(Ljava/lang/Object;)Lorg/apache/beam/repackaged/beam_sdks_java_io_cassandra/com/google/common/util/concurrent/ListenableFuture;
> org.apache.beam.sdk.Pipeline$PipelineExecutionException:
> java.lang.NoSuchMethodError:
> com.datastax.driver.mapping.Mapper.saveAsync(Ljava/lang/Object;)Lorg/apache/beam/repackaged/beam_sdks_java_io_cassandra/com/google/common/util/concurrent/ListenableFuture;
> at
> org.apache.beam.runners.direct.DirectRunner$DirectPipelineResult.waitUntilFinish(DirectRunner.java:332)
> at
> org.apache.beam.runners.direct.DirectRunner$DirectPipelineResult.waitUntilFinish(DirectRunner.java:302)
> at org.apache.beam.runners.direct.DirectRunner.run(DirectRunner.java:197)
> at org.apache.beam.runners.direct.DirectRunner.run(DirectRunner.java:64)
> at org.apache.beam.sdk.Pipeline.run(Pipeline.java:313)
> at org.apache.beam.sdk.Pipeline.run(Pipeline.java:299){code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Work logged] (BEAM-6914) Use BigQuerySink as default for 2.12.
[ https://issues.apache.org/jira/browse/BEAM-6914?focusedWorklogId=220615&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220615 ] ASF GitHub Bot logged work on BEAM-6914: Author: ASF GitHub Bot Created on: 29/Mar/19 16:42 Start Date: 29/Mar/19 16:42 Worklog Time Spent: 10m Work Description: pabloem commented on pull request #8170: [release-2.12.0][BEAM-6914] Reverting behavior of Native BQ sink in Python (#8143) URL: https://github.com/apache/beam/pull/8170 Backporting https://github.com/apache/beam/pull/8143 * Reverting normal behavior of BQ sink in Python * Addressing comments **Please** add a meaningful description for your change here r: @apilloud cc: @tvalentyn @chamikaramj Thank you for your contribution! Follow this checklist to help us incorporate your contribution quickly and easily: - [ ] [**Choose reviewer(s)**](https://beam.apache.org/contribute/#make-your-change) and mention them in a comment (`R: @username`). - [ ] Format the pull request title like `[BEAM-XXX] Fixes bug in ApproximateQuantiles`, where you replace `BEAM-XXX` with the appropriate JIRA issue, if applicable. This will automatically link the pull request to the issue. - [ ] If this contribution is large, please file an Apache [Individual Contributor License Agreement](https://www.apache.org/licenses/icla.pdf). Post-Commit Tests Status (on master branch) Lang | SDK | Apex | Dataflow | Flink | Gearpump | Samza | Spark --- | --- | --- | --- | --- | --- | --- | --- Go | [](https://builds.apache.org/job/beam_PostCommit_Go/lastCompletedBuild/) | --- | --- | --- | --- | --- | --- Java | [](https://builds.apache.org/job/beam_PostCommit_Java/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Apex/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Dataflow/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Flink/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Java_PVR_Flink_Batch/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Java_PVR_Flink_Streaming/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Gearpump/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Samza/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Spark/lastCompletedBuild/) Python | [](https://builds.apache.org/job/beam_PostCommit_Python_Verify/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Python3_Verify/lastCompletedBuild/) | --- | [](https://builds.apache.org/job/beam_PostCommit_Py_VR_Dataflow/lastCompletedBuild/) [](https://builds.apache.org/job/beam_PostCommit_Py_ValCont/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PreCommit_Python_PVR_Flink_Cron/lastCompletedBuild/) | --- | --- | --- Pre-Commit Tests
[jira] [Work logged] (BEAM-6914) Use BigQuerySink as default for 2.12.
[ https://issues.apache.org/jira/browse/BEAM-6914?focusedWorklogId=220617&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220617 ] ASF GitHub Bot logged work on BEAM-6914: Author: ASF GitHub Bot Created on: 29/Mar/19 17:01 Start Date: 29/Mar/19 17:01 Worklog Time Spent: 10m Work Description: apilloud commented on issue #8170: [release-2.12.0][BEAM-6914] Reverting behavior of Native BQ sink in Python (#8143) URL: https://github.com/apache/beam/pull/8170#issuecomment-478074349 LGTM This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220617) Time Spent: 4h 50m (was: 4h 40m) > Use BigQuerySink as default for 2.12. > - > > Key: BEAM-6914 > URL: https://issues.apache.org/jira/browse/BEAM-6914 > Project: Beam > Issue Type: Improvement > Components: sdk-py-core >Reporter: Pablo Estrada >Assignee: Pablo Estrada >Priority: Blocker > Fix For: 2.12.0 > > Time Spent: 4h 50m > Remaining Estimate: 0h > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (BEAM-6941) Logs include exception="None\n" when there is no exception
Eric Roshan Eisner created BEAM-6941:
Summary: Logs include exception="None\n" when there is no exception
Key: BEAM-6941
URL: https://issues.apache.org/jira/browse/BEAM-6941
Project: Beam
Issue Type: Bug
Components: sdk-py-core
Reporter: Eric Roshan Eisner
All python SDK logs emit an exception field even when there is no exception.
Weirdly, the field is "None\n" with a trailing newline that does not appear in
any other field. This field should be omitted when there is no exception, so
that searches for "exception" will not return so many spurious results
Example from stackdriver logging in a python job using dataflow runner:
jsonPayload: {
exception: "None
"
job: "2019-03-28_18_01_16-4563580283031363654"
logger: "root:cloud_logging.py:EmitLogMessages"
message: "baz"
stage: "s01"
step: "EmitLogs"
thread: "132:139730156779264"
worker: "df2-cloud-logging-python--03281801-ilme-harness-7sw5"
}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Work logged] (BEAM-6909) Add location support for BigQueryWrapper._get_query_results()
[ https://issues.apache.org/jira/browse/BEAM-6909?focusedWorklogId=220620&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220620 ] ASF GitHub Bot logged work on BEAM-6909: Author: ASF GitHub Bot Created on: 29/Mar/19 17:13 Start Date: 29/Mar/19 17:13 Worklog Time Spent: 10m Work Description: pabloem commented on issue #8139: [BEAM-6909] Add location support for BigQueryWrapper._get_query_resul… URL: https://github.com/apache/beam/pull/8139#issuecomment-478078488 Oddly, this change is causing trouble in PostCommit tests, so we will need to review what's going on. I'll look into this next week. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220620) Time Spent: 3h 20m (was: 3h 10m) > Add location support for BigQueryWrapper._get_query_results() > - > > Key: BEAM-6909 > URL: https://issues.apache.org/jira/browse/BEAM-6909 > Project: Beam > Issue Type: Bug > Components: sdk-py-core >Reporter: Ryan Yuan >Priority: Critical > Time Spent: 3h 20m > Remaining Estimate: 0h > > When a BQ Job is created outside US or EU, the _get_query_results() in > bigquery_tools.py always return 404. > > This is to patch the _get_query_results() so that it can support location as > parameter. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (BEAM-6942) Pipeline options to experiment propagation is not working in Dataflow runner.
Valentyn Tymofieiev created BEAM-6942: - Summary: Pipeline options to experiment propagation is not working in Dataflow runner. Key: BEAM-6942 URL: https://issues.apache.org/jira/browse/BEAM-6942 Project: Beam Issue Type: Bug Components: sdk-py-core Reporter: Valentyn Tymofieiev Fix For: 2.12.0 Relevant code: [https://github.com/apache/beam/blob/master/sdks/python/apache_beam/runners/dataflow/dataflow_runner.py#L356-L388] 3 experiments/options are affected. We need to fix it in 2.12.0 cc: [~altay] [~apilloud] -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Assigned] (BEAM-6942) Pipeline options to experiment propagation is not working in Dataflow runner.
[ https://issues.apache.org/jira/browse/BEAM-6942?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Andrew Pilloud reassigned BEAM-6942: Assignee: Valentyn Tymofieiev > Pipeline options to experiment propagation is not working in Dataflow runner. > - > > Key: BEAM-6942 > URL: https://issues.apache.org/jira/browse/BEAM-6942 > Project: Beam > Issue Type: Bug > Components: sdk-py-core >Reporter: Valentyn Tymofieiev >Assignee: Valentyn Tymofieiev >Priority: Blocker > Fix For: 2.12.0 > > > Relevant code: > [https://github.com/apache/beam/blob/master/sdks/python/apache_beam/runners/dataflow/dataflow_runner.py#L356-L388] > 3 experiments/options are affected. We need to fix it in 2.12.0 > cc: [~altay] [~apilloud] -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BEAM-6942) Pipeline options to experiment propagation is not working in Dataflow runner.
[ https://issues.apache.org/jira/browse/BEAM-6942?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16805220#comment-16805220 ] Valentyn Tymofieiev commented on BEAM-6942: --- Clean up on the way. > Pipeline options to experiment propagation is not working in Dataflow runner. > - > > Key: BEAM-6942 > URL: https://issues.apache.org/jira/browse/BEAM-6942 > Project: Beam > Issue Type: Bug > Components: sdk-py-core >Reporter: Valentyn Tymofieiev >Assignee: Valentyn Tymofieiev >Priority: Blocker > Fix For: 2.12.0 > > > Relevant code: > [https://github.com/apache/beam/blob/master/sdks/python/apache_beam/runners/dataflow/dataflow_runner.py#L356-L388] > 3 experiments/options are affected. We need to fix it in 2.12.0 > cc: [~altay] [~apilloud] -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6894) ExternalTransform.expand() does not create the proper AppliedPTransform sub-graph
[ https://issues.apache.org/jira/browse/BEAM-6894?focusedWorklogId=220626&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220626 ] ASF GitHub Bot logged work on BEAM-6894: Author: ASF GitHub Bot Created on: 29/Mar/19 17:21 Start Date: 29/Mar/19 17:21 Worklog Time Spent: 10m Work Description: chamikaramj commented on issue #8165: [BEAM-6894] Fixes a bug in external transform and adds tests URL: https://github.com/apache/beam/pull/8165#issuecomment-478081258 Run Python PostCommit This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220626) Time Spent: 40m (was: 0.5h) > ExternalTransform.expand() does not create the proper AppliedPTransform > sub-graph > - > > Key: BEAM-6894 > URL: https://issues.apache.org/jira/browse/BEAM-6894 > Project: Beam > Issue Type: Bug > Components: sdk-py-core >Reporter: Chamikara Jayalath >Assignee: Chamikara Jayalath >Priority: Major > Time Spent: 40m > Remaining Estimate: 0h > > 'ExternalTransform.expand()' can be used to expand a remote transform and > build the correct runner-api subgraph for that transform. However currently > we do not modify the AppliedPTransform sub-graph correctly during this > process. Relevant code location here. > [https://github.com/apache/beam/blob/master/sdks/python/apache_beam/transforms/external.py#L135] > > Without this, DataflowRunner that relies in this object graph (not just the > runner API proto) to build the job submission request to Dataflow service > cannot construct this request properly. > > cc: [~robertwb] -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BEAM-5865) Auto sharding of streaming sinks in FlinkRunner
[ https://issues.apache.org/jira/browse/BEAM-5865?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16805234#comment-16805234 ] Jozef Vilcek commented on BEAM-5865: Hello, I wanted to post update earlier but got swamped with other things. I did put together a git commit to illustrate changes required for the feature of auto-balancing keys from write files to Flink workers. This should guarantee an even spread of keys among workers. I did not create a PR because this is nowhere near finish line but really just an illustration of the landscape which will need to be hit somehow. [https://github.com/JozoVilcek/beam/commit/afc7fe949b543604cead529171774153b6caa433] My main questions and concern is about changes required at SDK level around WriteFiles and ShardedKey. An am not sure if this is possible to do in a backward compatible manner. I would prefer Flink to replace ShardedKey with it's own alternative, but I am not sure what does it mean at the level of operators and coders (not just swapping logic inside DoFn). What I would like to get from this is: * how does such change feels conceptually, does it still make sense and we can continue? * how should we incorporate it into the SDK and FlinkRunner > Auto sharding of streaming sinks in FlinkRunner > --- > > Key: BEAM-5865 > URL: https://issues.apache.org/jira/browse/BEAM-5865 > Project: Beam > Issue Type: Improvement > Components: runner-flink >Reporter: Maximilian Michels >Priority: Major > > The Flink Runner should do auto-sharding of streaming sinks, similar to > BEAM-1438. That way, the user doesn't have to set shards manually which > introduces additional shuffling and might cause skew in the distribution of > data. > As per discussion: > https://lists.apache.org/thread.html/7b92145dd9ae68da1866f1047445479f51d31f103d6407316bb4114c@%3Cuser.beam.apache.org%3E -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6841) Support reading query results with the BigQuery storage API
[ https://issues.apache.org/jira/browse/BEAM-6841?focusedWorklogId=220635&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220635 ] ASF GitHub Bot logged work on BEAM-6841: Author: ASF GitHub Bot Created on: 29/Mar/19 17:53 Start Date: 29/Mar/19 17:53 Worklog Time Spent: 10m Work Description: kmjung commented on issue #8061: [BEAM-6841] Add support for reading query results using the BigQuery storage API. URL: https://github.com/apache/beam/pull/8061#issuecomment-478091641 Run Java PostCommit This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220635) Time Spent: 5h 10m (was: 5h) > Support reading query results with the BigQuery storage API > --- > > Key: BEAM-6841 > URL: https://issues.apache.org/jira/browse/BEAM-6841 > Project: Beam > Issue Type: New Feature > Components: io-java-gcp >Reporter: Kenneth Jung >Assignee: Kenneth Jung >Priority: Minor > Time Spent: 5h 10m > Remaining Estimate: 0h > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6841) Support reading query results with the BigQuery storage API
[ https://issues.apache.org/jira/browse/BEAM-6841?focusedWorklogId=220636&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220636 ] ASF GitHub Bot logged work on BEAM-6841: Author: ASF GitHub Bot Created on: 29/Mar/19 17:53 Start Date: 29/Mar/19 17:53 Worklog Time Spent: 10m Work Description: kmjung commented on issue #8061: [BEAM-6841] Add support for reading query results using the BigQuery storage API. URL: https://github.com/apache/beam/pull/8061#issuecomment-478091684 Run Dataflow ValidatesRunner This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220636) Time Spent: 5h 20m (was: 5h 10m) > Support reading query results with the BigQuery storage API > --- > > Key: BEAM-6841 > URL: https://issues.apache.org/jira/browse/BEAM-6841 > Project: Beam > Issue Type: New Feature > Components: io-java-gcp >Reporter: Kenneth Jung >Assignee: Kenneth Jung >Priority: Minor > Time Spent: 5h 20m > Remaining Estimate: 0h > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6876) User state cleanup in portable Flink runner
[ https://issues.apache.org/jira/browse/BEAM-6876?focusedWorklogId=220642&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220642 ] ASF GitHub Bot logged work on BEAM-6876: Author: ASF GitHub Bot Created on: 29/Mar/19 17:55 Start Date: 29/Mar/19 17:55 Worklog Time Spent: 10m Work Description: tweise commented on issue #8118: [BEAM-6876] Cleanup user state in portable Flink Runner URL: https://github.com/apache/beam/pull/8118#issuecomment-478092457 Run Java PreCommit This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220642) Time Spent: 3h 40m (was: 3.5h) > User state cleanup in portable Flink runner > --- > > Key: BEAM-6876 > URL: https://issues.apache.org/jira/browse/BEAM-6876 > Project: Beam > Issue Type: Bug > Components: runner-flink >Affects Versions: 2.11.0 >Reporter: Thomas Weise >Assignee: Maximilian Michels >Priority: Major > Labels: portability-flink, triaged > Time Spent: 3h 40m > Remaining Estimate: 0h > > State is currently not being cleaned up by the runner. > [https://lists.apache.org/thread.html/86f0809fbfa3da873051287b9ff249d6dd5a896b45409db1e484cf38@%3Cdev.beam.apache.org%3E] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (BEAM-6943) DataInputOperation object has no attribute 'needs_finalization'
Boyuan Zhang created BEAM-6943: -- Summary: DataInputOperation object has no attribute 'needs_finalization' Key: BEAM-6943 URL: https://issues.apache.org/jira/browse/BEAM-6943 Project: Beam Issue Type: Bug Components: sdk-py-core Affects Versions: 2.12.0 Reporter: Boyuan Zhang Assignee: Boyuan Zhang Fix For: 2.12.0 -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6876) User state cleanup in portable Flink runner
[ https://issues.apache.org/jira/browse/BEAM-6876?focusedWorklogId=220643&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220643 ] ASF GitHub Bot logged work on BEAM-6876: Author: ASF GitHub Bot Created on: 29/Mar/19 17:57 Start Date: 29/Mar/19 17:57 Worklog Time Spent: 10m Work Description: tweise commented on issue #8118: [BEAM-6876] Cleanup user state in portable Flink Runner URL: https://github.com/apache/beam/pull/8118#issuecomment-478093108 Run Java PreCommit This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220643) Time Spent: 3h 50m (was: 3h 40m) > User state cleanup in portable Flink runner > --- > > Key: BEAM-6876 > URL: https://issues.apache.org/jira/browse/BEAM-6876 > Project: Beam > Issue Type: Bug > Components: runner-flink >Affects Versions: 2.11.0 >Reporter: Thomas Weise >Assignee: Maximilian Michels >Priority: Major > Labels: portability-flink, triaged > Time Spent: 3h 50m > Remaining Estimate: 0h > > State is currently not being cleaned up by the runner. > [https://lists.apache.org/thread.html/86f0809fbfa3da873051287b9ff249d6dd5a896b45409db1e484cf38@%3Cdev.beam.apache.org%3E] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (BEAM-6943) DataInputOperation object has no attribute 'needs_finalization' in Jupyter
[ https://issues.apache.org/jira/browse/BEAM-6943?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Boyuan Zhang updated BEAM-6943: --- Summary: DataInputOperation object has no attribute 'needs_finalization' in Jupyter (was: DataInputOperation object has no attribute 'needs_finalization') > DataInputOperation object has no attribute 'needs_finalization' in Jupyter > --- > > Key: BEAM-6943 > URL: https://issues.apache.org/jira/browse/BEAM-6943 > Project: Beam > Issue Type: Bug > Components: sdk-py-core >Affects Versions: 2.12.0 >Reporter: Boyuan Zhang >Assignee: Boyuan Zhang >Priority: Blocker > Fix For: 2.12.0 > > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BEAM-5061) Invisible parameter type exception in JDK 10
[
https://issues.apache.org/jira/browse/BEAM-5061?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16805314#comment-16805314
]
Pablo Estrada commented on BEAM-5061:
-
Is this still happening? We have SDK tests running now with all PreCommits and
ValidatesRunner tests...
> Invisible parameter type exception in JDK 10
>
>
> Key: BEAM-5061
> URL: https://issues.apache.org/jira/browse/BEAM-5061
> Project: Beam
> Issue Type: Sub-task
> Components: sdk-java-core
>Affects Versions: 2.5.0
>Reporter: Mike Pedersen
>Priority: Major
>
> When using JDK 10, using a ParDo after a CoGroupByKey seems to create the
> following exception when executed on local runner:
> {noformat}
> Exception in thread "main"
> org.apache.beam.repackaged.beam_runners_direct_java.com.google.common.util.concurrent.UncheckedExecutionException:
> java.lang.IllegalStateException: Invisible parameter type of Main$1 arg0 for
> public Main$1$DoFnInvoker(Main$1)
> at
> org.apache.beam.repackaged.beam_runners_direct_java.com.google.common.cache.LocalCache$Segment.get(LocalCache.java:2214)
> at
> org.apache.beam.repackaged.beam_runners_direct_java.com.google.common.cache.LocalCache.get(LocalCache.java:4053)
> at
> org.apache.beam.repackaged.beam_runners_direct_java.com.google.common.cache.LocalCache.getOrLoad(LocalCache.java:4057)
> ...
> Caused by: java.lang.IllegalStateException: Invisible parameter type of
> Main$1 arg0 for public Main$1$DoFnInvoker(Main$1)
> at
> org.apache.beam.repackaged.beam_sdks_java_core.net.bytebuddy.dynamic.scaffold.InstrumentedType$Default.validated(InstrumentedType.java:925)
> at
> org.apache.beam.repackaged.beam_sdks_java_core.net.bytebuddy.dynamic.scaffold.MethodRegistry$Default.prepare(MethodRegistry.java:465)
> at
> org.apache.beam.repackaged.beam_sdks_java_core.net.bytebuddy.dynamic.scaffold.subclass.SubclassDynamicTypeBuilder.make(SubclassDynamicTypeBuilder.java:170)
> ...
> {noformat}
> This error disappears completely when using JDK 8. Here is a minimal example
> to reproduce it:
> {code:java}
> import org.apache.beam.sdk.Pipeline;
> import org.apache.beam.sdk.options.PipelineOptions;
> import org.apache.beam.sdk.options.PipelineOptionsFactory;
> import org.apache.beam.sdk.transforms.Create;
> import org.apache.beam.sdk.transforms.DoFn;
> import org.apache.beam.sdk.transforms.ParDo;
> import org.apache.beam.sdk.transforms.join.CoGbkResult;
> import org.apache.beam.sdk.transforms.join.CoGroupByKey;
> import org.apache.beam.sdk.transforms.join.KeyedPCollectionTuple;
> import org.apache.beam.sdk.values.KV;
> import org.apache.beam.sdk.values.PCollection;
> import org.apache.beam.sdk.values.TupleTag;
> import java.util.Arrays;
> import java.util.List;
> public class Main {
> public static void main(String[] args) {
> PipelineOptions options = PipelineOptionsFactory.create();
> Pipeline p = Pipeline.create(options);
> final TupleTag emailsTag = new TupleTag<>();
> final TupleTag phonesTag = new TupleTag<>();
> final List> emailsList =
> Arrays.asList(
> KV.of("amy", "a...@example.com"),
> KV.of("carl", "c...@example.com"),
> KV.of("julia", "ju...@example.com"),
> KV.of("carl", "c...@email.com"));
> final List> phonesList =
> Arrays.asList(
> KV.of("amy", "111-222-"),
> KV.of("james", "222-333-"),
> KV.of("amy", "333-444-"),
> KV.of("carl", "444-555-"));
> PCollection> emails = p.apply("CreateEmails",
> Create.of(emailsList));
> PCollection> phones = p.apply("CreatePhones",
> Create.of(phonesList));
> PCollection> results =
> KeyedPCollectionTuple.of(emailsTag, emails)
> .and(phonesTag, phones)
> .apply(CoGroupByKey.create());
> PCollection contactLines =
> results.apply(
> ParDo.of(
> new DoFn, String>() {
> @ProcessElement
> public void processElement(ProcessContext
> c) {
> KV e =
> c.element();
> String name = e.getKey();
> Iterable emailsIter =
> e.getValue().getAll(emailsTag);
> Iterable phonesIter =
> e.getValue().getAll(phonesTag);
> String formattedResult = "";
> c.output(formattedResul
[jira] [Commented] (BEAM-6668) use add experiment methods (Java and Python)
[ https://issues.apache.org/jira/browse/BEAM-6668?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16805335#comment-16805335 ] Udi Meiri commented on BEAM-6668: - [~tvalentyn] > use add experiment methods (Java and Python) > > > Key: BEAM-6668 > URL: https://issues.apache.org/jira/browse/BEAM-6668 > Project: Beam > Issue Type: Improvement > Components: io-java-gcp, sdk-py-core >Reporter: Udi Meiri >Priority: Minor > Labels: beginner, easyfix, newbie > > Python: > Convert instances of experiments.append(...) > to debug_options.add_experiment(...) > Java: > Use ExperimentalOptions.addExperiment(...) > instead of getExperiments(), modify, setExperiments() pattern. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6914) Use BigQuerySink as default for 2.12.
[ https://issues.apache.org/jira/browse/BEAM-6914?focusedWorklogId=220665&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220665 ] ASF GitHub Bot logged work on BEAM-6914: Author: ASF GitHub Bot Created on: 29/Mar/19 19:01 Start Date: 29/Mar/19 19:01 Worklog Time Spent: 10m Work Description: pabloem commented on issue #8170: [release-2.12.0][BEAM-6914] Reverting behavior of Native BQ sink in Python (#8143) URL: https://github.com/apache/beam/pull/8170#issuecomment-478113721 Run Python PreCommit This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220665) Time Spent: 5h (was: 4h 50m) > Use BigQuerySink as default for 2.12. > - > > Key: BEAM-6914 > URL: https://issues.apache.org/jira/browse/BEAM-6914 > Project: Beam > Issue Type: Improvement > Components: sdk-py-core >Reporter: Pablo Estrada >Assignee: Pablo Estrada >Priority: Blocker > Fix For: 2.12.0 > > Time Spent: 5h > Remaining Estimate: 0h > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6841) Support reading query results with the BigQuery storage API
[
https://issues.apache.org/jira/browse/BEAM-6841?focusedWorklogId=220672&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220672
]
ASF GitHub Bot logged work on BEAM-6841:
Author: ASF GitHub Bot
Created on: 29/Mar/19 19:07
Start Date: 29/Mar/19 19:07
Worklog Time Spent: 10m
Work Description: chamikaramj commented on pull request #8061:
[BEAM-6841] Add support for reading query results using the BigQuery storage
API.
URL: https://github.com/apache/beam/pull/8061#discussion_r270524751
##
File path:
sdks/java/io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/bigquery/BigQueryIO.java
##
@@ -914,6 +933,181 @@ void cleanup(PassThroughThenCleanup.ContextContainer c)
throws Exception {
return rows.apply(new PassThroughThenCleanup<>(cleanupOperation,
jobIdTokenView));
}
+private PCollection expandForDirectRead(PBegin input, Coder
outputCoder) {
+ ValueProvider tableProvider = getTableProvider();
+ Pipeline p = input.getPipeline();
+ if (tableProvider != null) {
+// No job ID is required. Read directly from BigQuery storage.
+return p.apply(
+org.apache.beam.sdk.io.Read.from(
+BigQueryStorageTableSource.create(
+tableProvider,
+getReadOptions(),
+getParseFn(),
+outputCoder,
+getBigQueryServices(;
+ }
+
+ checkArgument(
+ getReadOptions() == null,
+ "Invalid BigQueryIO.Read: Specifies table read options, "
+ + "which only applies when reading from a table");
+
+ //
+ // N.B. All of the code below exists because the BigQuery storage API
can't (yet) read from
+ // all anonymous tables, so we need the job ID to reason about the name
of the destination
+ // table for the query to read the data and subsequently delete the
table and dataset. Once
+ // the storage API can handle anonymous tables, the storage source
should be modified to use
+ // anonymous tables and all of the code related to job ID generation and
table and dataset
+ // cleanup can be removed.
+ //
+
+ PCollectionView jobIdTokenView;
+ PCollection rows;
+
+ if (!getWithTemplateCompatibility()) {
+// Create a singleton job ID token at pipeline construction time.
+String staticJobUuid = BigQueryHelpers.randomUUIDString();
+jobIdTokenView =
+p.apply("TriggerIdCreation", Create.of(staticJobUuid))
+.apply("ViewId", View.asSingleton());
+// Apply the traditional Source model.
+rows =
+p.apply(
+org.apache.beam.sdk.io.Read.from(
+createStorageQuerySource(staticJobUuid, outputCoder)));
+ } else {
+// Create a singleton job ID token at pipeline execution time.
+PCollection jobIdTokenCollection =
+p.apply("TriggerIdCreation", Create.of("ignored"))
+.apply(
+"CreateJobId",
+MapElements.via(
+new SimpleFunction() {
+ @Override
+ public String apply(String input) {
+return BigQueryHelpers.randomUUIDString();
+ }
+}));
+
+jobIdTokenView = jobIdTokenCollection.apply("ViewId",
View.asSingleton());
+
+TupleTag streamsTag = new TupleTag<>();
+TupleTag readSessionTag = new TupleTag<>();
+TupleTag tableSchemaTag = new TupleTag<>();
+
+PCollectionTuple tuple =
+jobIdTokenCollection.apply(
+"RunQueryJob",
+ParDo.of(
+new DoFn() {
+ @ProcessElement
+ public void processElement(ProcessContext c) throws
Exception {
+BigQueryOptions options =
+
c.getPipelineOptions().as(BigQueryOptions.class);
+String jobUuid = c.element();
+// Execute the query and get the destination table
holding the results.
+BigQueryStorageQuerySource querySource =
+createStorageQuerySource(jobUuid, outputCoder);
+Table queryResultTable =
querySource.getTargetTable(options);
+
+// Create a read session without specifying a
desired stream count and
+// let the BigQuery storage server pick the number
of streams.
+CreateReadSessionRequest request =
+CreateReadSessionRequest.newBuilder()
+.setParent("pr
[jira] [Work logged] (BEAM-6841) Support reading query results with the BigQuery storage API
[
https://issues.apache.org/jira/browse/BEAM-6841?focusedWorklogId=220668&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220668
]
ASF GitHub Bot logged work on BEAM-6841:
Author: ASF GitHub Bot
Created on: 29/Mar/19 19:07
Start Date: 29/Mar/19 19:07
Worklog Time Spent: 10m
Work Description: chamikaramj commented on pull request #8061:
[BEAM-6841] Add support for reading query results using the BigQuery storage
API.
URL: https://github.com/apache/beam/pull/8061#discussion_r270517951
##
File path:
sdks/java/io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/bigquery/BigQueryIO.java
##
@@ -914,6 +933,181 @@ void cleanup(PassThroughThenCleanup.ContextContainer c)
throws Exception {
return rows.apply(new PassThroughThenCleanup<>(cleanupOperation,
jobIdTokenView));
}
+private PCollection expandForDirectRead(PBegin input, Coder
outputCoder) {
+ ValueProvider tableProvider = getTableProvider();
+ Pipeline p = input.getPipeline();
+ if (tableProvider != null) {
+// No job ID is required. Read directly from BigQuery storage.
+return p.apply(
+org.apache.beam.sdk.io.Read.from(
+BigQueryStorageTableSource.create(
+tableProvider,
+getReadOptions(),
+getParseFn(),
+outputCoder,
+getBigQueryServices(;
+ }
+
+ checkArgument(
+ getReadOptions() == null,
+ "Invalid BigQueryIO.Read: Specifies table read options, "
+ + "which only applies when reading from a table");
+
+ //
+ // N.B. All of the code below exists because the BigQuery storage API
can't (yet) read from
+ // all anonymous tables, so we need the job ID to reason about the name
of the destination
+ // table for the query to read the data and subsequently delete the
table and dataset. Once
+ // the storage API can handle anonymous tables, the storage source
should be modified to use
+ // anonymous tables and all of the code related to job ID generation and
table and dataset
+ // cleanup can be removed.
+ //
+
+ PCollectionView jobIdTokenView;
+ PCollection rows;
+
+ if (!getWithTemplateCompatibility()) {
+// Create a singleton job ID token at pipeline construction time.
+String staticJobUuid = BigQueryHelpers.randomUUIDString();
+jobIdTokenView =
+p.apply("TriggerIdCreation", Create.of(staticJobUuid))
+.apply("ViewId", View.asSingleton());
+// Apply the traditional Source model.
+rows =
+p.apply(
+org.apache.beam.sdk.io.Read.from(
+createStorageQuerySource(staticJobUuid, outputCoder)));
+ } else {
+// Create a singleton job ID token at pipeline execution time.
+PCollection jobIdTokenCollection =
+p.apply("TriggerIdCreation", Create.of("ignored"))
+.apply(
+"CreateJobId",
+MapElements.via(
+new SimpleFunction() {
+ @Override
+ public String apply(String input) {
+return BigQueryHelpers.randomUUIDString();
+ }
+}));
+
+jobIdTokenView = jobIdTokenCollection.apply("ViewId",
View.asSingleton());
+
+TupleTag streamsTag = new TupleTag<>();
+TupleTag readSessionTag = new TupleTag<>();
+TupleTag tableSchemaTag = new TupleTag<>();
+
+PCollectionTuple tuple =
+jobIdTokenCollection.apply(
+"RunQueryJob",
+ParDo.of(
+new DoFn() {
+ @ProcessElement
+ public void processElement(ProcessContext c) throws
Exception {
+BigQueryOptions options =
+
c.getPipelineOptions().as(BigQueryOptions.class);
+String jobUuid = c.element();
+// Execute the query and get the destination table
holding the results.
+BigQueryStorageQuerySource querySource =
+createStorageQuerySource(jobUuid, outputCoder);
+Table queryResultTable =
querySource.getTargetTable(options);
Review comment:
Can you please add a comment here since that's not clear from the code.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastruc
[jira] [Work logged] (BEAM-6841) Support reading query results with the BigQuery storage API
[
https://issues.apache.org/jira/browse/BEAM-6841?focusedWorklogId=220670&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220670
]
ASF GitHub Bot logged work on BEAM-6841:
Author: ASF GitHub Bot
Created on: 29/Mar/19 19:07
Start Date: 29/Mar/19 19:07
Worklog Time Spent: 10m
Work Description: chamikaramj commented on pull request #8061:
[BEAM-6841] Add support for reading query results using the BigQuery storage
API.
URL: https://github.com/apache/beam/pull/8061#discussion_r270537891
##
File path:
sdks/java/io/google-cloud-platform/src/test/java/org/apache/beam/sdk/io/gcp/bigquery/BigQueryIOReadTest.java
##
@@ -617,22 +614,17 @@ public void testEstimatedSizeWithStreamingBuffer()
throws Exception {
@Test
public void testBigQueryQuerySourceEstimatedSize() throws Exception {
-List data =
-ImmutableList.of(
-new TableRow().set("name", "A").set("number", 10L),
-new TableRow().set("name", "B").set("number", 11L),
Review comment:
Changes here does not look that significant. So it should be fine.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 220670)
Time Spent: 5h 50m (was: 5h 40m)
> Support reading query results with the BigQuery storage API
> ---
>
> Key: BEAM-6841
> URL: https://issues.apache.org/jira/browse/BEAM-6841
> Project: Beam
> Issue Type: New Feature
> Components: io-java-gcp
>Reporter: Kenneth Jung
>Assignee: Kenneth Jung
>Priority: Minor
> Time Spent: 5h 50m
> Remaining Estimate: 0h
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Work logged] (BEAM-6841) Support reading query results with the BigQuery storage API
[ https://issues.apache.org/jira/browse/BEAM-6841?focusedWorklogId=220671&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220671 ] ASF GitHub Bot logged work on BEAM-6841: Author: ASF GitHub Bot Created on: 29/Mar/19 19:07 Start Date: 29/Mar/19 19:07 Worklog Time Spent: 10m Work Description: chamikaramj commented on pull request #8061: [BEAM-6841] Add support for reading query results using the BigQuery storage API. URL: https://github.com/apache/beam/pull/8061#discussion_r270540092 ## File path: sdks/java/io/google-cloud-platform/src/test/java/org/apache/beam/sdk/io/gcp/bigquery/BigQueryIOStorageQueryTest.java ## @@ -0,0 +1,712 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ +package org.apache.beam.sdk.io.gcp.bigquery; + +import static org.apache.beam.sdk.io.gcp.bigquery.BigQueryHelpers.createJobIdToken; +import static org.apache.beam.sdk.io.gcp.bigquery.BigQueryHelpers.createTempTableReference; +import static org.apache.beam.sdk.transforms.display.DisplayDataMatchers.hasDisplayItem; +import static org.hamcrest.MatcherAssert.assertThat; +import static org.hamcrest.Matchers.hasItem; +import static org.junit.Assert.assertEquals; +import static org.junit.Assert.assertNull; +import static org.junit.Assert.assertTrue; +import static org.mockito.Matchers.any; +import static org.mockito.Mockito.mock; +import static org.mockito.Mockito.when; +import static org.mockito.Mockito.withSettings; +import static org.testng.Assert.assertFalse; + +import com.google.api.services.bigquery.model.JobStatistics; +import com.google.api.services.bigquery.model.JobStatistics2; +import com.google.api.services.bigquery.model.Table; +import com.google.api.services.bigquery.model.TableFieldSchema; +import com.google.api.services.bigquery.model.TableReference; +import com.google.api.services.bigquery.model.TableRow; +import com.google.api.services.bigquery.model.TableSchema; +import com.google.cloud.bigquery.storage.v1beta1.AvroProto.AvroRows; +import com.google.cloud.bigquery.storage.v1beta1.AvroProto.AvroSchema; +import com.google.cloud.bigquery.storage.v1beta1.ReadOptions.TableReadOptions; +import com.google.cloud.bigquery.storage.v1beta1.Storage.CreateReadSessionRequest; +import com.google.cloud.bigquery.storage.v1beta1.Storage.ReadRowsRequest; +import com.google.cloud.bigquery.storage.v1beta1.Storage.ReadRowsResponse; +import com.google.cloud.bigquery.storage.v1beta1.Storage.ReadSession; +import com.google.cloud.bigquery.storage.v1beta1.Storage.Stream; +import com.google.cloud.bigquery.storage.v1beta1.Storage.StreamPosition; +import com.google.protobuf.ByteString; +import java.io.ByteArrayOutputStream; +import java.util.Collection; +import java.util.List; +import java.util.Set; +import org.apache.avro.Schema; +import org.apache.avro.generic.GenericData.Record; +import org.apache.avro.generic.GenericDatumWriter; +import org.apache.avro.generic.GenericRecord; +import org.apache.avro.io.Encoder; +import org.apache.avro.io.EncoderFactory; +import org.apache.beam.sdk.coders.CoderRegistry; +import org.apache.beam.sdk.coders.KvCoder; +import org.apache.beam.sdk.extensions.protobuf.ByteStringCoder; +import org.apache.beam.sdk.extensions.protobuf.ProtoCoder; +import org.apache.beam.sdk.io.BoundedSource; +import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO.TableRowParser; +import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO.TypedRead; +import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO.TypedRead.Method; +import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO.TypedRead.QueryPriority; +import org.apache.beam.sdk.io.gcp.bigquery.BigQueryServices.StorageClient; +import org.apache.beam.sdk.options.ValueProvider; +import org.apache.beam.sdk.testing.PAssert; +import org.apache.beam.sdk.testing.TestPipeline; +import org.apache.beam.sdk.transforms.SerializableFunction; +import org.apache.beam.sdk.transforms.display.DisplayData; +import org.apache.beam.sdk.transforms.display.DisplayDataEvaluator; +import org.apache.beam.sdk.values.KV; +import org.apache.beam.sdk.values.PCollection; +import org.apache.beam.vendor.guava
[jira] [Work logged] (BEAM-6841) Support reading query results with the BigQuery storage API
[
https://issues.apache.org/jira/browse/BEAM-6841?focusedWorklogId=220669&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220669
]
ASF GitHub Bot logged work on BEAM-6841:
Author: ASF GitHub Bot
Created on: 29/Mar/19 19:07
Start Date: 29/Mar/19 19:07
Worklog Time Spent: 10m
Work Description: chamikaramj commented on pull request #8061:
[BEAM-6841] Add support for reading query results using the BigQuery storage
API.
URL: https://github.com/apache/beam/pull/8061#discussion_r270521373
##
File path:
sdks/java/io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/bigquery/BigQueryIO.java
##
@@ -914,6 +933,181 @@ void cleanup(PassThroughThenCleanup.ContextContainer c)
throws Exception {
return rows.apply(new PassThroughThenCleanup<>(cleanupOperation,
jobIdTokenView));
}
+private PCollection expandForDirectRead(PBegin input, Coder
outputCoder) {
+ ValueProvider tableProvider = getTableProvider();
+ Pipeline p = input.getPipeline();
+ if (tableProvider != null) {
+// No job ID is required. Read directly from BigQuery storage.
+return p.apply(
+org.apache.beam.sdk.io.Read.from(
+BigQueryStorageTableSource.create(
+tableProvider,
+getReadOptions(),
+getParseFn(),
+outputCoder,
+getBigQueryServices(;
+ }
+
+ checkArgument(
+ getReadOptions() == null,
+ "Invalid BigQueryIO.Read: Specifies table read options, "
+ + "which only applies when reading from a table");
+
+ //
+ // N.B. All of the code below exists because the BigQuery storage API
can't (yet) read from
+ // all anonymous tables, so we need the job ID to reason about the name
of the destination
+ // table for the query to read the data and subsequently delete the
table and dataset. Once
+ // the storage API can handle anonymous tables, the storage source
should be modified to use
+ // anonymous tables and all of the code related to job ID generation and
table and dataset
+ // cleanup can be removed.
+ //
+
+ PCollectionView jobIdTokenView;
+ PCollection rows;
+
+ if (!getWithTemplateCompatibility()) {
+// Create a singleton job ID token at pipeline construction time.
+String staticJobUuid = BigQueryHelpers.randomUUIDString();
+jobIdTokenView =
+p.apply("TriggerIdCreation", Create.of(staticJobUuid))
+.apply("ViewId", View.asSingleton());
+// Apply the traditional Source model.
+rows =
+p.apply(
+org.apache.beam.sdk.io.Read.from(
+createStorageQuerySource(staticJobUuid, outputCoder)));
+ } else {
+// Create a singleton job ID token at pipeline execution time.
+PCollection jobIdTokenCollection =
+p.apply("TriggerIdCreation", Create.of("ignored"))
+.apply(
+"CreateJobId",
+MapElements.via(
+new SimpleFunction() {
+ @Override
+ public String apply(String input) {
+return BigQueryHelpers.randomUUIDString();
+ }
+}));
+
+jobIdTokenView = jobIdTokenCollection.apply("ViewId",
View.asSingleton());
+
+TupleTag streamsTag = new TupleTag<>();
+TupleTag readSessionTag = new TupleTag<>();
+TupleTag tableSchemaTag = new TupleTag<>();
+
+PCollectionTuple tuple =
+jobIdTokenCollection.apply(
+"RunQueryJob",
+ParDo.of(
+new DoFn() {
+ @ProcessElement
+ public void processElement(ProcessContext c) throws
Exception {
+BigQueryOptions options =
+
c.getPipelineOptions().as(BigQueryOptions.class);
+String jobUuid = c.element();
+// Execute the query and get the destination table
holding the results.
+BigQueryStorageQuerySource querySource =
+createStorageQuerySource(jobUuid, outputCoder);
+Table queryResultTable =
querySource.getTargetTable(options);
+
+// Create a read session without specifying a
desired stream count and
+// let the BigQuery storage server pick the number
of streams.
+CreateReadSessionRequest request =
+CreateReadSessionRequest.newBuilder()
+.setParent("pr
[jira] [Work logged] (BEAM-5732) expose runner mode to user through samza pipeline option
[ https://issues.apache.org/jira/browse/BEAM-5732?focusedWorklogId=220674&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220674 ] ASF GitHub Bot logged work on BEAM-5732: Author: ASF GitHub Bot Created on: 29/Mar/19 19:08 Start Date: 29/Mar/19 19:08 Worklog Time Spent: 10m Work Description: dxichen commented on pull request #8172: BEAM-5732: Expose Samza runner mode through samza pipeline option URL: https://github.com/apache/beam/pull/8172 R: @xinyuiscool @lhaiesp - Exposed runner mode(`SamzaExecutionEnvironment`) to user through `SamzaPipelineOptions` so that user can decide whether to start samza job as local mode(`LOCAL`), clustered mode (`YARN`) or standalone mode ( `STANDALONE`). - Made `SamzaRunner` ctor to be private. Thank you for your contribution! Follow this checklist to help us incorporate your contribution quickly and easily: - [X] [**Choose reviewer(s)**](https://beam.apache.org/contribute/#make-your-change) and mention them in a comment (`R: @username`). - [X] Format the pull request title like `[BEAM-XXX] Fixes bug in ApproximateQuantiles`, where you replace `BEAM-XXX` with the appropriate JIRA issue, if applicable. This will automatically link the pull request to the issue. - [X] If this contribution is large, please file an Apache [Individual Contributor License Agreement](https://www.apache.org/licenses/icla.pdf). Post-Commit Tests Status (on master branch) Lang | SDK | Apex | Dataflow | Flink | Gearpump | Samza | Spark --- | --- | --- | --- | --- | --- | --- | --- Go | [](https://builds.apache.org/job/beam_PostCommit_Go/lastCompletedBuild/) | --- | --- | --- | --- | --- | --- Java | [](https://builds.apache.org/job/beam_PostCommit_Java/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Apex/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Dataflow/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Flink/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Java_PVR_Flink_Batch/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Java_PVR_Flink_Streaming/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Gearpump/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Samza/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Spark/lastCompletedBuild/) Python | [](https://builds.apache.org/job/beam_PostCommit_Python_Verify/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Python3_Verify/lastCompletedBuild/) | --- | [](https://builds.apache.org/job/beam_PostCommit_Py_VR_Dataflow/lastCompletedBuild/) [](https://builds.apache.org/job/beam_PostCommit_Py_ValCont/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PreCommit_Python_PVR_Flink_Cron/lastCompletedBuild/) | --- | --- | --
[jira] [Work logged] (BEAM-6876) User state cleanup in portable Flink runner
[ https://issues.apache.org/jira/browse/BEAM-6876?focusedWorklogId=220684&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220684 ] ASF GitHub Bot logged work on BEAM-6876: Author: ASF GitHub Bot Created on: 29/Mar/19 19:37 Start Date: 29/Mar/19 19:37 Worklog Time Spent: 10m Work Description: tweise commented on pull request #8118: [BEAM-6876] Cleanup user state in portable Flink Runner URL: https://github.com/apache/beam/pull/8118 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220684) Time Spent: 4h (was: 3h 50m) > User state cleanup in portable Flink runner > --- > > Key: BEAM-6876 > URL: https://issues.apache.org/jira/browse/BEAM-6876 > Project: Beam > Issue Type: Bug > Components: runner-flink >Affects Versions: 2.11.0 >Reporter: Thomas Weise >Assignee: Maximilian Michels >Priority: Major > Labels: portability-flink, triaged > Time Spent: 4h > Remaining Estimate: 0h > > State is currently not being cleaned up by the runner. > [https://lists.apache.org/thread.html/86f0809fbfa3da873051287b9ff249d6dd5a896b45409db1e484cf38@%3Cdev.beam.apache.org%3E] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6853) Make Java and python portable options same
[ https://issues.apache.org/jira/browse/BEAM-6853?focusedWorklogId=220685&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220685 ] ASF GitHub Bot logged work on BEAM-6853: Author: ASF GitHub Bot Created on: 29/Mar/19 19:38 Start Date: 29/Mar/19 19:38 Worklog Time Spent: 10m Work Description: angoenka commented on pull request #8082: [BEAM-6853] Add sdk-worker-parallelism and environment-cache-millis to python sdk URL: https://github.com/apache/beam/pull/8082 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220685) Time Spent: 40m (was: 0.5h) > Make Java and python portable options same > -- > > Key: BEAM-6853 > URL: https://issues.apache.org/jira/browse/BEAM-6853 > Project: Beam > Issue Type: Task > Components: sdk-py-core >Reporter: Ankur Goenka >Assignee: Ankur Goenka >Priority: Major > Time Spent: 40m > Remaining Estimate: 0h > > Java > [PortableRunnerOptions|https://github.com/apache/beam/blob/f21cfaefd54afb798103dc90ab57290739e81e81/sdks/java/core/src/main/java/org/apache/beam/sdk/options/PortablePipelineOptions.java#L80] > and [Python Portable > options|https://github.com/apache/beam/blob/f21cfaefd54afb798103dc90ab57290739e81e81/sdks/python/apache_beam/options/pipeline_options.py#L719] > don't have the same values limiting the use of sdk-worker-parallelism and > environment-cache-millis in python sdk. > > Add these options to the python sdk. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (BEAM-6876) User state cleanup in portable Flink runner
[ https://issues.apache.org/jira/browse/BEAM-6876?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Thomas Weise updated BEAM-6876: --- Fix Version/s: 2.12.0 > User state cleanup in portable Flink runner > --- > > Key: BEAM-6876 > URL: https://issues.apache.org/jira/browse/BEAM-6876 > Project: Beam > Issue Type: Bug > Components: runner-flink >Affects Versions: 2.11.0 >Reporter: Thomas Weise >Assignee: Maximilian Michels >Priority: Major > Labels: portability-flink, triaged > Fix For: 2.12.0 > > Time Spent: 4h > Remaining Estimate: 0h > > State is currently not being cleaned up by the runner. > [https://lists.apache.org/thread.html/86f0809fbfa3da873051287b9ff249d6dd5a896b45409db1e484cf38@%3Cdev.beam.apache.org%3E] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6876) User state cleanup in portable Flink runner
[ https://issues.apache.org/jira/browse/BEAM-6876?focusedWorklogId=220692&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220692 ] ASF GitHub Bot logged work on BEAM-6876: Author: ASF GitHub Bot Created on: 29/Mar/19 19:48 Start Date: 29/Mar/19 19:48 Worklog Time Spent: 10m Work Description: tweise commented on pull request #8173: [release-2.12] [BEAM-6876] Cleanup user state in portable Flink Runner URL: https://github.com/apache/beam/pull/8173 State had to be explicitly cleaned up in user state using timers which fire at the end of a window. This uses the StatefulDoFnRunner to set timers to clean up user state at the end of each window. **Please** add a meaningful description for your change here Thank you for your contribution! Follow this checklist to help us incorporate your contribution quickly and easily: - [ ] [**Choose reviewer(s)**](https://beam.apache.org/contribute/#make-your-change) and mention them in a comment (`R: @username`). - [ ] Format the pull request title like `[BEAM-XXX] Fixes bug in ApproximateQuantiles`, where you replace `BEAM-XXX` with the appropriate JIRA issue, if applicable. This will automatically link the pull request to the issue. - [ ] If this contribution is large, please file an Apache [Individual Contributor License Agreement](https://www.apache.org/licenses/icla.pdf). Post-Commit Tests Status (on master branch) Lang | SDK | Apex | Dataflow | Flink | Gearpump | Samza | Spark --- | --- | --- | --- | --- | --- | --- | --- Go | [](https://builds.apache.org/job/beam_PostCommit_Go/lastCompletedBuild/) | --- | --- | --- | --- | --- | --- Java | [](https://builds.apache.org/job/beam_PostCommit_Java/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Apex/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Dataflow/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Flink/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Java_PVR_Flink_Batch/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Java_PVR_Flink_Streaming/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Gearpump/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Samza/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PostCommit_Java_ValidatesRunner_Spark/lastCompletedBuild/) Python | [](https://builds.apache.org/job/beam_PostCommit_Python_Verify/lastCompletedBuild/)[](https://builds.apache.org/job/beam_PostCommit_Python3_Verify/lastCompletedBuild/) | --- | [](https://builds.apache.org/job/beam_PostCommit_Py_VR_Dataflow/lastCompletedBuild/) [](https://builds.apache.org/job/beam_PostCommit_Py_ValCont/lastCompletedBuild/) | [](https://builds.apache.org/job/beam_PreCommit_Python_PVR_Flink_Cron/lastCompletedBuild/) | --- | --- | --- Pre-Commit Tests
[jira] [Updated] (BEAM-6944) Add support for MeanByteCount metric for Python Streaming to Java DF Runner
[ https://issues.apache.org/jira/browse/BEAM-6944?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Mikhail Gryzykhin updated BEAM-6944: Description: (was: # Add new UserDistributionCounter urn to metrics.proto # Report UserDistribution metric in python SDK # Plumb User Distribution metric in Dataflow runner.) > Add support for MeanByteCount metric for Python Streaming to Java DF Runner > --- > > Key: BEAM-6944 > URL: https://issues.apache.org/jira/browse/BEAM-6944 > Project: Beam > Issue Type: Bug > Components: runner-dataflow, sdk-py-harness >Reporter: Mikhail Gryzykhin >Assignee: Mikhail Gryzykhin >Priority: Major > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (BEAM-6944) Add support for MeanByteCount metric for Python Streaming to Java DF Runner
Mikhail Gryzykhin created BEAM-6944: --- Summary: Add support for MeanByteCount metric for Python Streaming to Java DF Runner Key: BEAM-6944 URL: https://issues.apache.org/jira/browse/BEAM-6944 Project: Beam Issue Type: Bug Components: runner-dataflow, sdk-py-harness Reporter: Mikhail Gryzykhin Assignee: Mikhail Gryzykhin # Add new UserDistributionCounter urn to metrics.proto # Report UserDistribution metric in python SDK # Plumb User Distribution metric in Dataflow runner. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6944) Add support for MeanByteCount metric for Python Streaming to Java DF Runner
[ https://issues.apache.org/jira/browse/BEAM-6944?focusedWorklogId=220705&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220705 ] ASF GitHub Bot logged work on BEAM-6944: Author: ASF GitHub Bot Created on: 29/Mar/19 20:06 Start Date: 29/Mar/19 20:06 Worklog Time Spent: 10m Work Description: Ardagan commented on issue #8171: [BEAM-6944] Add MeanByteCountMonitoringInfoToCounterUpdateTransformer URL: https://github.com/apache/beam/pull/8171#issuecomment-478132916 @ajamato @pabloem @kennknowles This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220705) Time Spent: 10m Remaining Estimate: 0h > Add support for MeanByteCount metric for Python Streaming to Java DF Runner > --- > > Key: BEAM-6944 > URL: https://issues.apache.org/jira/browse/BEAM-6944 > Project: Beam > Issue Type: Bug > Components: runner-dataflow, sdk-py-harness >Reporter: Mikhail Gryzykhin >Assignee: Mikhail Gryzykhin >Priority: Major > Time Spent: 10m > Remaining Estimate: 0h > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6918) Github link requires login and example link is broken
[ https://issues.apache.org/jira/browse/BEAM-6918?focusedWorklogId=220715&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220715 ] ASF GitHub Bot logged work on BEAM-6918: Author: ASF GitHub Bot Created on: 29/Mar/19 20:25 Start Date: 29/Mar/19 20:25 Worklog Time Spent: 10m Work Description: tweise commented on pull request #8156: [BEAM-6918] Fixed broken Flink example link URL: https://github.com/apache/beam/pull/8156 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220715) Time Spent: 2h (was: 1h 50m) > Github link requires login and example link is broken > - > > Key: BEAM-6918 > URL: https://issues.apache.org/jira/browse/BEAM-6918 > Project: Beam > Issue Type: Improvement > Components: examples-python >Reporter: David Yan >Priority: Minor > Time Spent: 2h > Remaining Estimate: 0h > > Two minor issues in > [https://github.com/apache/beam/blob/master/sdks/python/apache_beam/runners/interactive/README.md] > 1. git clone g...@github.com:apache/beam.git requires the user to be logged > in, while https://github.com/apache/beam does not. > 2. Spaces in the example link need to be escaped. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6918) Github link requires login and example link is broken
[ https://issues.apache.org/jira/browse/BEAM-6918?focusedWorklogId=220714&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220714 ] ASF GitHub Bot logged work on BEAM-6918: Author: ASF GitHub Bot Created on: 29/Mar/19 20:25 Start Date: 29/Mar/19 20:25 Worklog Time Spent: 10m Work Description: tweise commented on issue #8156: [BEAM-6918] Fixed broken Flink example link URL: https://github.com/apache/beam/pull/8156#issuecomment-478138164 @davidyan74 good to see you here! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 220714) Time Spent: 1h 50m (was: 1h 40m) > Github link requires login and example link is broken > - > > Key: BEAM-6918 > URL: https://issues.apache.org/jira/browse/BEAM-6918 > Project: Beam > Issue Type: Improvement > Components: examples-python >Reporter: David Yan >Priority: Minor > Time Spent: 1h 50m > Remaining Estimate: 0h > > Two minor issues in > [https://github.com/apache/beam/blob/master/sdks/python/apache_beam/runners/interactive/README.md] > 1. git clone g...@github.com:apache/beam.git requires the user to be logged > in, while https://github.com/apache/beam does not. > 2. Spaces in the example link need to be escaped. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (BEAM-2530) Make Beam compatible with next Java LTS version (Java 11)
[ https://issues.apache.org/jira/browse/BEAM-2530?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16805422#comment-16805422 ] Pablo Estrada commented on BEAM-2530: - The Beam 2.12.0 release has been tested by building with Java 8, and running with Java 11. We have good test coverage now (thanks to work by [~mwalenia] and [~ŁukaszG]). So Beam 2.12.0 will have basic, experimental support for Java 11. > Make Beam compatible with next Java LTS version (Java 11) > - > > Key: BEAM-2530 > URL: https://issues.apache.org/jira/browse/BEAM-2530 > Project: Beam > Issue Type: Improvement > Components: build-system >Affects Versions: Not applicable >Reporter: Ismaël Mejía >Priority: Minor > Labels: java9 > Fix For: Not applicable > > Time Spent: 4.5h > Remaining Estimate: 0h > > The goal of this task is to validate that the Java SDK and the Java Direct > Runner (and its tests) work as intended on the next Java LTS version (Java 11 > /18.9). For this we will base the compilation on the java.base profile and > include other core Java modules when needed. > *Notes:* > - Ideally validation of the IOs/extensions will be included but if serious > issues are found they will be tracked independently. > - The goal of using the Java Platform module system is out of the scope of > this work. > - Support for other runners will be a tracked as a separate effort because > other runners depend strongly in the support of the native runner ecosystems. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Work logged] (BEAM-6841) Support reading query results with the BigQuery storage API
[
https://issues.apache.org/jira/browse/BEAM-6841?focusedWorklogId=220722&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220722
]
ASF GitHub Bot logged work on BEAM-6841:
Author: ASF GitHub Bot
Created on: 29/Mar/19 20:40
Start Date: 29/Mar/19 20:40
Worklog Time Spent: 10m
Work Description: kmjung commented on pull request #8061: [BEAM-6841] Add
support for reading query results using the BigQuery storage API.
URL: https://github.com/apache/beam/pull/8061#discussion_r270566398
##
File path:
sdks/java/io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/bigquery/BigQueryIO.java
##
@@ -914,6 +933,181 @@ void cleanup(PassThroughThenCleanup.ContextContainer c)
throws Exception {
return rows.apply(new PassThroughThenCleanup<>(cleanupOperation,
jobIdTokenView));
}
+private PCollection expandForDirectRead(PBegin input, Coder
outputCoder) {
+ ValueProvider tableProvider = getTableProvider();
+ Pipeline p = input.getPipeline();
+ if (tableProvider != null) {
+// No job ID is required. Read directly from BigQuery storage.
+return p.apply(
+org.apache.beam.sdk.io.Read.from(
+BigQueryStorageTableSource.create(
+tableProvider,
+getReadOptions(),
+getParseFn(),
+outputCoder,
+getBigQueryServices(;
+ }
+
+ checkArgument(
+ getReadOptions() == null,
+ "Invalid BigQueryIO.Read: Specifies table read options, "
+ + "which only applies when reading from a table");
+
+ //
+ // N.B. All of the code below exists because the BigQuery storage API
can't (yet) read from
+ // all anonymous tables, so we need the job ID to reason about the name
of the destination
+ // table for the query to read the data and subsequently delete the
table and dataset. Once
+ // the storage API can handle anonymous tables, the storage source
should be modified to use
+ // anonymous tables and all of the code related to job ID generation and
table and dataset
+ // cleanup can be removed.
+ //
+
+ PCollectionView jobIdTokenView;
+ PCollection rows;
+
+ if (!getWithTemplateCompatibility()) {
+// Create a singleton job ID token at pipeline construction time.
+String staticJobUuid = BigQueryHelpers.randomUUIDString();
+jobIdTokenView =
+p.apply("TriggerIdCreation", Create.of(staticJobUuid))
+.apply("ViewId", View.asSingleton());
+// Apply the traditional Source model.
+rows =
+p.apply(
+org.apache.beam.sdk.io.Read.from(
+createStorageQuerySource(staticJobUuid, outputCoder)));
+ } else {
+// Create a singleton job ID token at pipeline execution time.
+PCollection jobIdTokenCollection =
+p.apply("TriggerIdCreation", Create.of("ignored"))
+.apply(
+"CreateJobId",
+MapElements.via(
+new SimpleFunction() {
+ @Override
+ public String apply(String input) {
+return BigQueryHelpers.randomUUIDString();
+ }
+}));
+
+jobIdTokenView = jobIdTokenCollection.apply("ViewId",
View.asSingleton());
+
+TupleTag streamsTag = new TupleTag<>();
+TupleTag readSessionTag = new TupleTag<>();
+TupleTag tableSchemaTag = new TupleTag<>();
+
+PCollectionTuple tuple =
+jobIdTokenCollection.apply(
+"RunQueryJob",
+ParDo.of(
+new DoFn() {
+ @ProcessElement
+ public void processElement(ProcessContext c) throws
Exception {
+BigQueryOptions options =
+
c.getPipelineOptions().as(BigQueryOptions.class);
+String jobUuid = c.element();
+// Execute the query and get the destination table
holding the results.
+BigQueryStorageQuerySource querySource =
+createStorageQuerySource(jobUuid, outputCoder);
+Table queryResultTable =
querySource.getTargetTable(options);
+
+// Create a read session without specifying a
desired stream count and
+// let the BigQuery storage server pick the number
of streams.
+CreateReadSessionRequest request =
+CreateReadSessionRequest.newBuilder()
+.setParent("projects
[jira] [Work logged] (BEAM-6841) Support reading query results with the BigQuery storage API
[
https://issues.apache.org/jira/browse/BEAM-6841?focusedWorklogId=220726&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220726
]
ASF GitHub Bot logged work on BEAM-6841:
Author: ASF GitHub Bot
Created on: 29/Mar/19 20:43
Start Date: 29/Mar/19 20:43
Worklog Time Spent: 10m
Work Description: kmjung commented on pull request #8061: [BEAM-6841] Add
support for reading query results using the BigQuery storage API.
URL: https://github.com/apache/beam/pull/8061#discussion_r270567317
##
File path:
sdks/java/io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/bigquery/BigQueryIO.java
##
@@ -914,6 +933,181 @@ void cleanup(PassThroughThenCleanup.ContextContainer c)
throws Exception {
return rows.apply(new PassThroughThenCleanup<>(cleanupOperation,
jobIdTokenView));
}
+private PCollection expandForDirectRead(PBegin input, Coder
outputCoder) {
+ ValueProvider tableProvider = getTableProvider();
+ Pipeline p = input.getPipeline();
+ if (tableProvider != null) {
+// No job ID is required. Read directly from BigQuery storage.
+return p.apply(
+org.apache.beam.sdk.io.Read.from(
+BigQueryStorageTableSource.create(
+tableProvider,
+getReadOptions(),
+getParseFn(),
+outputCoder,
+getBigQueryServices(;
+ }
+
+ checkArgument(
+ getReadOptions() == null,
+ "Invalid BigQueryIO.Read: Specifies table read options, "
+ + "which only applies when reading from a table");
+
+ //
+ // N.B. All of the code below exists because the BigQuery storage API
can't (yet) read from
+ // all anonymous tables, so we need the job ID to reason about the name
of the destination
+ // table for the query to read the data and subsequently delete the
table and dataset. Once
+ // the storage API can handle anonymous tables, the storage source
should be modified to use
+ // anonymous tables and all of the code related to job ID generation and
table and dataset
+ // cleanup can be removed.
+ //
+
+ PCollectionView jobIdTokenView;
+ PCollection rows;
+
+ if (!getWithTemplateCompatibility()) {
+// Create a singleton job ID token at pipeline construction time.
+String staticJobUuid = BigQueryHelpers.randomUUIDString();
+jobIdTokenView =
+p.apply("TriggerIdCreation", Create.of(staticJobUuid))
+.apply("ViewId", View.asSingleton());
+// Apply the traditional Source model.
+rows =
+p.apply(
+org.apache.beam.sdk.io.Read.from(
+createStorageQuerySource(staticJobUuid, outputCoder)));
+ } else {
+// Create a singleton job ID token at pipeline execution time.
+PCollection jobIdTokenCollection =
+p.apply("TriggerIdCreation", Create.of("ignored"))
+.apply(
+"CreateJobId",
+MapElements.via(
+new SimpleFunction() {
+ @Override
+ public String apply(String input) {
+return BigQueryHelpers.randomUUIDString();
+ }
+}));
+
+jobIdTokenView = jobIdTokenCollection.apply("ViewId",
View.asSingleton());
+
+TupleTag streamsTag = new TupleTag<>();
+TupleTag readSessionTag = new TupleTag<>();
+TupleTag tableSchemaTag = new TupleTag<>();
+
+PCollectionTuple tuple =
+jobIdTokenCollection.apply(
+"RunQueryJob",
+ParDo.of(
+new DoFn() {
+ @ProcessElement
+ public void processElement(ProcessContext c) throws
Exception {
+BigQueryOptions options =
+
c.getPipelineOptions().as(BigQueryOptions.class);
+String jobUuid = c.element();
+// Execute the query and get the destination table
holding the results.
+BigQueryStorageQuerySource querySource =
+createStorageQuerySource(jobUuid, outputCoder);
+Table queryResultTable =
querySource.getTargetTable(options);
+
+// Create a read session without specifying a
desired stream count and
+// let the BigQuery storage server pick the number
of streams.
+CreateReadSessionRequest request =
+CreateReadSessionRequest.newBuilder()
+.setParent("projects
[jira] [Work logged] (BEAM-6841) Support reading query results with the BigQuery storage API
[
https://issues.apache.org/jira/browse/BEAM-6841?focusedWorklogId=220725&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220725
]
ASF GitHub Bot logged work on BEAM-6841:
Author: ASF GitHub Bot
Created on: 29/Mar/19 20:43
Start Date: 29/Mar/19 20:43
Worklog Time Spent: 10m
Work Description: kmjung commented on pull request #8061: [BEAM-6841] Add
support for reading query results using the BigQuery storage API.
URL: https://github.com/apache/beam/pull/8061#discussion_r270567254
##
File path:
sdks/java/io/google-cloud-platform/src/main/java/org/apache/beam/sdk/io/gcp/bigquery/BigQueryIO.java
##
@@ -914,6 +933,181 @@ void cleanup(PassThroughThenCleanup.ContextContainer c)
throws Exception {
return rows.apply(new PassThroughThenCleanup<>(cleanupOperation,
jobIdTokenView));
}
+private PCollection expandForDirectRead(PBegin input, Coder
outputCoder) {
+ ValueProvider tableProvider = getTableProvider();
+ Pipeline p = input.getPipeline();
+ if (tableProvider != null) {
+// No job ID is required. Read directly from BigQuery storage.
+return p.apply(
+org.apache.beam.sdk.io.Read.from(
+BigQueryStorageTableSource.create(
+tableProvider,
+getReadOptions(),
+getParseFn(),
+outputCoder,
+getBigQueryServices(;
+ }
+
+ checkArgument(
+ getReadOptions() == null,
+ "Invalid BigQueryIO.Read: Specifies table read options, "
+ + "which only applies when reading from a table");
+
+ //
+ // N.B. All of the code below exists because the BigQuery storage API
can't (yet) read from
+ // all anonymous tables, so we need the job ID to reason about the name
of the destination
+ // table for the query to read the data and subsequently delete the
table and dataset. Once
+ // the storage API can handle anonymous tables, the storage source
should be modified to use
+ // anonymous tables and all of the code related to job ID generation and
table and dataset
+ // cleanup can be removed.
+ //
+
+ PCollectionView jobIdTokenView;
+ PCollection rows;
+
+ if (!getWithTemplateCompatibility()) {
+// Create a singleton job ID token at pipeline construction time.
+String staticJobUuid = BigQueryHelpers.randomUUIDString();
+jobIdTokenView =
+p.apply("TriggerIdCreation", Create.of(staticJobUuid))
+.apply("ViewId", View.asSingleton());
+// Apply the traditional Source model.
+rows =
+p.apply(
+org.apache.beam.sdk.io.Read.from(
+createStorageQuerySource(staticJobUuid, outputCoder)));
+ } else {
+// Create a singleton job ID token at pipeline execution time.
+PCollection jobIdTokenCollection =
+p.apply("TriggerIdCreation", Create.of("ignored"))
+.apply(
+"CreateJobId",
+MapElements.via(
+new SimpleFunction() {
+ @Override
+ public String apply(String input) {
+return BigQueryHelpers.randomUUIDString();
+ }
+}));
+
+jobIdTokenView = jobIdTokenCollection.apply("ViewId",
View.asSingleton());
+
+TupleTag streamsTag = new TupleTag<>();
+TupleTag readSessionTag = new TupleTag<>();
+TupleTag tableSchemaTag = new TupleTag<>();
+
+PCollectionTuple tuple =
+jobIdTokenCollection.apply(
+"RunQueryJob",
+ParDo.of(
+new DoFn() {
+ @ProcessElement
+ public void processElement(ProcessContext c) throws
Exception {
+BigQueryOptions options =
+
c.getPipelineOptions().as(BigQueryOptions.class);
+String jobUuid = c.element();
+// Execute the query and get the destination table
holding the results.
+BigQueryStorageQuerySource querySource =
+createStorageQuerySource(jobUuid, outputCoder);
+Table queryResultTable =
querySource.getTargetTable(options);
Review comment:
Done.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
--
[jira] [Work logged] (BEAM-6841) Support reading query results with the BigQuery storage API
[ https://issues.apache.org/jira/browse/BEAM-6841?focusedWorklogId=220728&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-220728 ] ASF GitHub Bot logged work on BEAM-6841: Author: ASF GitHub Bot Created on: 29/Mar/19 20:44 Start Date: 29/Mar/19 20:44 Worklog Time Spent: 10m Work Description: kmjung commented on pull request #8061: [BEAM-6841] Add support for reading query results using the BigQuery storage API. URL: https://github.com/apache/beam/pull/8061#discussion_r270567487 ## File path: sdks/java/io/google-cloud-platform/src/test/java/org/apache/beam/sdk/io/gcp/bigquery/BigQueryIOStorageQueryTest.java ## @@ -0,0 +1,712 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ +package org.apache.beam.sdk.io.gcp.bigquery; + +import static org.apache.beam.sdk.io.gcp.bigquery.BigQueryHelpers.createJobIdToken; +import static org.apache.beam.sdk.io.gcp.bigquery.BigQueryHelpers.createTempTableReference; +import static org.apache.beam.sdk.transforms.display.DisplayDataMatchers.hasDisplayItem; +import static org.hamcrest.MatcherAssert.assertThat; +import static org.hamcrest.Matchers.hasItem; +import static org.junit.Assert.assertEquals; +import static org.junit.Assert.assertNull; +import static org.junit.Assert.assertTrue; +import static org.mockito.Matchers.any; +import static org.mockito.Mockito.mock; +import static org.mockito.Mockito.when; +import static org.mockito.Mockito.withSettings; +import static org.testng.Assert.assertFalse; + +import com.google.api.services.bigquery.model.JobStatistics; +import com.google.api.services.bigquery.model.JobStatistics2; +import com.google.api.services.bigquery.model.Table; +import com.google.api.services.bigquery.model.TableFieldSchema; +import com.google.api.services.bigquery.model.TableReference; +import com.google.api.services.bigquery.model.TableRow; +import com.google.api.services.bigquery.model.TableSchema; +import com.google.cloud.bigquery.storage.v1beta1.AvroProto.AvroRows; +import com.google.cloud.bigquery.storage.v1beta1.AvroProto.AvroSchema; +import com.google.cloud.bigquery.storage.v1beta1.ReadOptions.TableReadOptions; +import com.google.cloud.bigquery.storage.v1beta1.Storage.CreateReadSessionRequest; +import com.google.cloud.bigquery.storage.v1beta1.Storage.ReadRowsRequest; +import com.google.cloud.bigquery.storage.v1beta1.Storage.ReadRowsResponse; +import com.google.cloud.bigquery.storage.v1beta1.Storage.ReadSession; +import com.google.cloud.bigquery.storage.v1beta1.Storage.Stream; +import com.google.cloud.bigquery.storage.v1beta1.Storage.StreamPosition; +import com.google.protobuf.ByteString; +import java.io.ByteArrayOutputStream; +import java.util.Collection; +import java.util.List; +import java.util.Set; +import org.apache.avro.Schema; +import org.apache.avro.generic.GenericData.Record; +import org.apache.avro.generic.GenericDatumWriter; +import org.apache.avro.generic.GenericRecord; +import org.apache.avro.io.Encoder; +import org.apache.avro.io.EncoderFactory; +import org.apache.beam.sdk.coders.CoderRegistry; +import org.apache.beam.sdk.coders.KvCoder; +import org.apache.beam.sdk.extensions.protobuf.ByteStringCoder; +import org.apache.beam.sdk.extensions.protobuf.ProtoCoder; +import org.apache.beam.sdk.io.BoundedSource; +import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO.TableRowParser; +import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO.TypedRead; +import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO.TypedRead.Method; +import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO.TypedRead.QueryPriority; +import org.apache.beam.sdk.io.gcp.bigquery.BigQueryServices.StorageClient; +import org.apache.beam.sdk.options.ValueProvider; +import org.apache.beam.sdk.testing.PAssert; +import org.apache.beam.sdk.testing.TestPipeline; +import org.apache.beam.sdk.transforms.SerializableFunction; +import org.apache.beam.sdk.transforms.display.DisplayData; +import org.apache.beam.sdk.transforms.display.DisplayDataEvaluator; +import org.apache.beam.sdk.values.KV; +import org.apache.beam.sdk.values.PCollection; +import org.apache.beam.vendor.guava.v20_0
[jira] [Deleted] (BEAM-6939) Simon Poortman
[ https://issues.apache.org/jira/browse/BEAM-6939?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Chris Thistlethwaite deleted BEAM-6939: --- > Simon Poortman > -- > > Key: BEAM-6939 > URL: https://issues.apache.org/jira/browse/BEAM-6939 > Project: Beam > Issue Type: New Feature >Reporter: Simon Poortman >Priority: Major > Labels: Happy > -- This message was sent by Atlassian JIRA (v7.6.3#76005)