[jira] [Created] (CARBONDATA-3761) Remove redundant conversion for complex type insert
Ajantha Bhat created CARBONDATA-3761:
Summary: Remove redundant conversion for complex type insert
Key: CARBONDATA-3761
URL: https://issues.apache.org/jira/browse/CARBONDATA-3761
Project: CarbonData
Issue Type: Improvement
Reporter: Ajantha Bhat
Assignee: Ajantha Bhat
h3. Problem
# In {{PrimitiveDataType#writeByteArray}}
{{DataTypeUtil.parseValue(**input.toString()**, carbonDimension)}}
Here we convert every complex child element to string and then parse as an
object to handle bad records. Which leads to heavy GC
# {{DatatypeUtil#getBytesDataDataTypeForNoDictionaryColumn}} -> double,float,
byte, decimal case is missing. so we convert them to string and then convert to
bytes. which create more redundant objects
h3. Solution
# For new Insert into flow, no need to handle bad records for complex types as
it is already validated in source table. So, use object directly. This can
decrease the memory foot print for complex type insert
# Add a case for double,float, byte, decimal data type.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert
CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert URL: https://github.com/apache/carbondata/pull/3687#issuecomment-607619932 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/907/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert
CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert URL: https://github.com/apache/carbondata/pull/3687#issuecomment-607616961 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2616/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on issue #3687: [WIP] Remove redundant conversion for complex type insert
ajantha-bhat commented on issue #3687: [WIP] Remove redundant conversion for complex type insert URL: https://github.com/apache/carbondata/pull/3687#issuecomment-607583473 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document
CarbonDataQA1 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#issuecomment-607468373 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2615/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document
CarbonDataQA1 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#issuecomment-607466069 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/906/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3690: [WIP] Block creating materilaized view with duplicate column
CarbonDataQA1 commented on issue #3690: [WIP] Block creating materilaized view with duplicate column URL: https://github.com/apache/carbondata/pull/3690#issuecomment-607416194 Build Failed with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2614/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3690: [WIP] Block creating materilaized view with duplicate column
CarbonDataQA1 commented on issue #3690: [WIP] Block creating materilaized view with duplicate column URL: https://github.com/apache/carbondata/pull/3690#issuecomment-607415544 Build Failed with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/905/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert
CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert URL: https://github.com/apache/carbondata/pull/3687#issuecomment-607396547 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2612/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#issuecomment-607391866 @ajantha-bhat handled all comments, please check This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert
CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert URL: https://github.com/apache/carbondata/pull/3687#issuecomment-607391335 Build Failed with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/904/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3691: [CARBONDATA-3760]Enable prefetch in presto to improve query performance
CarbonDataQA1 commented on issue #3691: [CARBONDATA-3760]Enable prefetch in presto to improve query performance URL: https://github.com/apache/carbondata/pull/3691#issuecomment-607385939 Build Failed with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/903/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3691: [CARBONDATA-3760]Enable prefetch in presto to improve query performance
CarbonDataQA1 commented on issue #3691: [CARBONDATA-3760]Enable prefetch in presto to improve query performance URL: https://github.com/apache/carbondata/pull/3691#issuecomment-607374347 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2611/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401755706
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,192 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [DDLs on Secondary Index](#DDLs-on-Secondary-Index)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ Secondary Index table can be create with below syntax
+
+ ```
+ CREATE INDEX [IF NOT EXISTS] index_name
+ [ON TABLE maintable](index_column)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored in
HiveSERDEPROPERTIES as json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user executes a filter query, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checks if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property. The subsequent main table load will load the old failed loads along
with current load and
+ makes the SI table enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
+
+
+## Compacting SI table
+
+### Compacting SI table table through Main Table compaction
+Running
[GitHub] [carbondata] ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401754918 ## File path: docs/index/secondary-index-guide.md ## @@ -0,0 +1,192 @@ + + +# CarbonData Secondary Index + +* [Quick Example](#quick-example) +* [Secondary Index Table](#Secondary-Index-Introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-SI-table) +* [DDLs on Secondary Index](#DDLs-on-Secondary-Index) + +## Quick example + +Start spark-sql in terminal and run the following queries, +``` +CREATE TABLE maintable(a int, b string, c string) stored as carbondata; +insert into maintable select 1, 'ab', 'cd'; +CREATE index inex1 on table maintable(c) AS 'carbondata'; +SELECT a from maintable where c = 'cd'; +// NOTE: run explain query and check if query hits the SI table from the plan +EXPLAIN SELECT a from maintable where c = 'cd'; +``` + +## Secondary Index Introduction + Sencondary index tables are created as a indexes and managed as child tables internally by + Carbondata. Users can create secondary index based on the column position in main table(Recommended + for right columns) and the queries should have filter on that column to improve the filter query + performance. + + SI tables will always be loaded non-lazy way. Once SI table is created, Carbondata's + CarbonOptimizer with the help of CarbonSITransformationRule, transforms the query plan to hit the + SI table based on the filter condition or set of filter conditions present in the query. + So first level of pruning will be done on SI table as it stores blocklets and main table/parent + table pruning will be based on the SI output, which helps in giving the faster query results with + better pruning. + + Secondary Index table can be create with below syntax + + ``` + CREATE INDEX [IF NOT EXISTS] index_name + [ON TABLE maintable](index_column) Review comment: on table is not optional, don't use it in [] This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401753444
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,192 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [DDLs on Secondary Index](#DDLs-on-Secondary-Index)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ Secondary Index table can be create with below syntax
+
+ ```
+ CREATE INDEX [IF NOT EXISTS] index_name
+ [ON TABLE maintable](index_column)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
Review comment:
can you make table properties also optional [] ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401749949
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,192 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [DDLs on Secondary Index](#DDLs-on-Secondary-Index)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ Secondary Index table can be create with below syntax
+
+ ```
+ CREATE INDEX [IF NOT EXISTS] index_name
+ [ON TABLE maintable](index_column)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored in
HiveSERDEPROPERTIES as json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
Review comment:
as user will not register it manually, this information is irrelevant ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401748755
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,192 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [DDLs on Secondary Index](#DDLs-on-Secondary-Index)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ Secondary Index table can be create with below syntax
+
+ ```
+ CREATE INDEX [IF NOT EXISTS] index_name
+ [ON TABLE maintable](index_column)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored in
HiveSERDEPROPERTIES as json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user executes a filter query, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checks if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
Review comment:
for class names use code style presentation
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401747847
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,192 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [DDLs on Secondary Index](#DDLs-on-Secondary-Index)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ Secondary Index table can be create with below syntax
+
+ ```
+ CREATE INDEX [IF NOT EXISTS] index_name
+ [ON TABLE maintable](index_column)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored in
HiveSERDEPROPERTIES as json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user executes a filter query, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checks if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
Review comment:
```suggestion
* In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
```
If data loading fails for SI table,
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3688: [WIP] Refactor Index Metadata
CarbonDataQA1 commented on issue #3688: [WIP] Refactor Index Metadata URL: https://github.com/apache/carbondata/pull/3688#issuecomment-607353473 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/902/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401745203
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,192 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [DDLs on Secondary Index](#DDLs-on-Secondary-Index)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ Secondary Index table can be create with below syntax
+
+ ```
+ CREATE INDEX [IF NOT EXISTS] index_name
+ [ON TABLE maintable](index_column)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored in
HiveSERDEPROPERTIES as json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user executes a filter query, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checks if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property. The subsequent main table load will load the old failed loads along
with current load and
+ makes the SI table enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
+
+
+## Compacting SI table
+
+### Compacting SI table table through Main Table compaction
+Running
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3675: [CARBONDATA-3744] Fix select query failure issue when warehouse directory is default (not configured) in cluster
CarbonDataQA1 commented on issue #3675: [CARBONDATA-3744] Fix select query failure issue when warehouse directory is default (not configured) in cluster URL: https://github.com/apache/carbondata/pull/3675#issuecomment-607350487 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2610/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3688: [WIP] Refactor Index Metadata
CarbonDataQA1 commented on issue #3688: [WIP] Refactor Index Metadata URL: https://github.com/apache/carbondata/pull/3688#issuecomment-607348609 Build Failed with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2609/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3675: [CARBONDATA-3744] Fix select query failure issue when warehouse directory is default (not configured) in cluster
CarbonDataQA1 commented on issue #3675: [CARBONDATA-3744] Fix select query failure issue when warehouse directory is default (not configured) in cluster URL: https://github.com/apache/carbondata/pull/3675#issuecomment-607348598 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/901/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401741063 ## File path: docs/configuration-parameters.md ## @@ -147,6 +148,8 @@ This section provides the details of all the configurations required for the Car | carbon.query.stage.input.enable | false | Stage input files are data files written by external applications (such as Flink), but have not been loaded into carbon table. Enabling this configuration makes query to include these files, thus makes query on latest data. However, since these files are not indexed, query maybe slower as full scan is required for these files. | | carbon.driver.pruning.multi.thread.enable.files.count | 10 | To prune in multi-thread when total number of segment files for a query increases beyond the configured value. | | carbon.load.all.segment.indexes.to.cache | true | Setting this configuration to false, will prune and load only matched segment indexes to cache using segment metadata information such as columnid and it's minmax values, which decreases the usage of driver memory. | +| carbon.secondary.index.creation.threads | 1 | Specifies the number of threads to concurrently process segments during secondary index creation. This property helps fine tuning the system when there are a lot of segments in a table. The value range is 1 to 50. | Review comment: I see, IDE it was showing grey. Indexing problem may be This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401720641 ## File path: docs/configuration-parameters.md ## @@ -147,6 +148,8 @@ This section provides the details of all the configurations required for the Car | carbon.query.stage.input.enable | false | Stage input files are data files written by external applications (such as Flink), but have not been loaded into carbon table. Enabling this configuration makes query to include these files, thus makes query on latest data. However, since these files are not indexed, query maybe slower as full scan is required for these files. | | carbon.driver.pruning.multi.thread.enable.files.count | 10 | To prune in multi-thread when total number of segment files for a query increases beyond the configured value. | | carbon.load.all.segment.indexes.to.cache | true | Setting this configuration to false, will prune and load only matched segment indexes to cache using segment metadata information such as columnid and it's minmax values, which decreases the usage of driver memory. | +| carbon.secondary.index.creation.threads | 1 | Specifies the number of threads to concurrently process segments during secondary index creation. This property helps fine tuning the system when there are a lot of segments in a table. The value range is 1 to 50. | Review comment: its used, please refer org.apache.spark.sql.secondaryindex.rdd.SecondaryIndexCreator#getThreadPoolSize This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
ajantha-bhat commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401714678 ## File path: docs/configuration-parameters.md ## @@ -147,6 +148,8 @@ This section provides the details of all the configurations required for the Car | carbon.query.stage.input.enable | false | Stage input files are data files written by external applications (such as Flink), but have not been loaded into carbon table. Enabling this configuration makes query to include these files, thus makes query on latest data. However, since these files are not indexed, query maybe slower as full scan is required for these files. | | carbon.driver.pruning.multi.thread.enable.files.count | 10 | To prune in multi-thread when total number of segment files for a query increases beyond the configured value. | | carbon.load.all.segment.indexes.to.cache | true | Setting this configuration to false, will prune and load only matched segment indexes to cache using segment metadata information such as columnid and it's minmax values, which decreases the usage of driver memory. | +| carbon.secondary.index.creation.threads | 1 | Specifies the number of threads to concurrently process segments during secondary index creation. This property helps fine tuning the system when there are a lot of segments in a table. The value range is 1 to 50. | Review comment: looks like this is unused property, couldn't find usage. can we remove it from code also ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3690: [WIP] Block creating materilaized view with duplicate column
CarbonDataQA1 commented on issue #3690: [WIP] Block creating materilaized view with duplicate column URL: https://github.com/apache/carbondata/pull/3690#issuecomment-607312723 Build Failed with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/900/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on a change in pull request #3691: [CARBONDATA-3760]Enable prefetch in presto to improve query performance
ajantha-bhat commented on a change in pull request #3691:
[CARBONDATA-3760]Enable prefetch in presto to improve query performance
URL: https://github.com/apache/carbondata/pull/3691#discussion_r401695885
##
File path:
integration/presto/src/main/prestosql/org/apache/carbondata/presto/CarbondataPageSource.java
##
@@ -356,7 +356,6 @@ private PrestoCarbonVectorizedRecordReader
createReaderForColumnar(HiveSplit car
QueryModel queryModel = createQueryModel(carbonSplit, tableHandle,
columns, conf);
if (isDirectVectorFill) {
queryModel.setDirectVectorFill(true);
- queryModel.setPreFetchData(false);
Review comment:
@QiangCai : During streaming support for presto [#3001]
you made prefetch as false.
Any particular reason or issue you found with that?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3690: [WIP] Block creating materilaized view with duplicate column
CarbonDataQA1 commented on issue #3690: [WIP] Block creating materilaized view with duplicate column URL: https://github.com/apache/carbondata/pull/3690#issuecomment-607309184 Build Failed with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2608/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 opened a new pull request #3691: [CARBONDATA-3760]Enable prefetch in presto to improve query performance
akashrn5 opened a new pull request #3691: [CARBONDATA-3760]Enable prefetch in presto to improve query performance URL: https://github.com/apache/carbondata/pull/3691 ### Why is this PR needed? Prefetch was set to false explicitly. ### What changes were proposed in this PR? Improve the query performance with prefetch enabled ### Does this PR introduce any user interface change? - No ### Is any new testcase added? - No TPCDS queries executed and some queries time was improved by almost 50% This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (CARBONDATA-3760) Improve presto query performance
Akash R Nilugal created CARBONDATA-3760: --- Summary: Improve presto query performance Key: CARBONDATA-3760 URL: https://issues.apache.org/jira/browse/CARBONDATA-3760 Project: CarbonData Issue Type: Bug Reporter: Akash R Nilugal Assignee: Akash R Nilugal Improve presto query performance -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document
CarbonDataQA1 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#issuecomment-607266226 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2606/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 opened a new pull request #3690: [WIP] Block creating materilaized view with duplicate column
Indhumathi27 opened a new pull request #3690: [WIP] Block creating materilaized view with duplicate column URL: https://github.com/apache/carbondata/pull/3690 ### Why is this PR needed? ### What changes were proposed in this PR? ### Does this PR introduce any user interface change? - No - Yes. (please explain the change and update document) ### Is any new testcase added? - No - Yes This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert
CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert URL: https://github.com/apache/carbondata/pull/3687#issuecomment-607253777 Build Failed with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2607/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert
CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert URL: https://github.com/apache/carbondata/pull/3687#issuecomment-607249603 Build Failed with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/899/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document
CarbonDataQA1 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#issuecomment-607232094 Build Failed with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/898/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] dependabot[bot] commented on issue #3447: Bump dep.jackson.version from 2.6.5 to 2.10.1 in /store/sdk
dependabot[bot] commented on issue #3447: Bump dep.jackson.version from 2.6.5 to 2.10.1 in /store/sdk URL: https://github.com/apache/carbondata/pull/3447#issuecomment-607226580 Dependabot tried to update this pull request, but something went wrong. We're looking into it, but in the meantime you can retry the update by commenting `@dependabot rebase`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (CARBONDATA-3705) Support create and load MV for spark datasource table
[ https://issues.apache.org/jira/browse/CARBONDATA-3705?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kunal Kapoor updated CARBONDATA-3705: - Fix Version/s: 2.0.0 > Support create and load MV for spark datasource table > - > > Key: CARBONDATA-3705 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3705 > Project: CarbonData > Issue Type: Sub-task >Reporter: Jacky Li >Priority: Major > Fix For: 2.0.0 > > Time Spent: 4.5h > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [carbondata] niuge01 commented on issue #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant.
niuge01 commented on issue #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant. URL: https://github.com/apache/carbondata/pull/3661#issuecomment-607202895 > many examples has create datamap Yes, we will clean all 'datamap' word in new pr. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on issue #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant.
ajantha-bhat commented on issue #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant. URL: https://github.com/apache/carbondata/pull/3661#issuecomment-607197936 @niuge01 : Look for datamap in *.md file. Still many exmaples has create datamap syntax. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat edited a comment on issue #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant.
ajantha-bhat edited a comment on issue #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant. URL: https://github.com/apache/carbondata/pull/3661#issuecomment-607197936 @niuge01 : Look for datamap in *.md file. Still, many examples has create datamap syntax. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401547146 ## File path: docs/index/secondary-index-guide.md ## @@ -0,0 +1,182 @@ + + +# CarbonData Secondary Index + +* [Quick Example](#quick-example) +* [Secondary Index Table](#Secondary-Index-Introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-SI-table) + +## Quick example + +Start spark-sql in terminal and run the following queries, +``` +CREATE TABLE maintable(a int, b string, c string) stored as carbondata; +insert into maintable select 1, 'ab', 'cd'; +CREATE index inex1 on table maintable(c) AS 'carbondata'; +SELECT a from maintable where c = 'cd'; +// NOTE: run explain query and check if query hits the SI table from the plan +EXPLAIN SELECT a from maintable where c = 'cd'; +``` + +## Secondary Index Introduction + Sencondary index tables are created as a indexes and managed as child tables internally by + Carbondata. Users can create secondary index based on the column position in main table(Recommended + for right columns) and the queries should have filter on that column to improve the filter query + performance. + + SI tables will always be loaded non-lazy way. Once SI table is created, Carbondata's + CarbonOptimizer with the help of CarbonSITransformationRule, transforms the query plan to hit the + SI table based on the filter condition or set of filter conditions present in the query. + So first level of pruning will be done on SI table as it stores blocklets and main table/parent + table pruning will be based on the SI output, which helps in giving the faster query results with + better pruning. + + For instance, main table called **sales** which is defined as + + ``` + CREATE TABLE sales ( +order_time timestamp, +user_id string, +sex string, +country string, +quantity int, +price bigint) + STORED AS carbondata + ``` + Review comment: added This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] QiangCai commented on issue #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant.
QiangCai commented on issue #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant. URL: https://github.com/apache/carbondata/pull/3661#issuecomment-607194573 LGTM This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401528603 ## File path: docs/index/secondary-index-guide.md ## @@ -0,0 +1,182 @@ + + +# CarbonData Secondary Index + +* [Quick Example](#quick-example) +* [Secondary Index Table](#Secondary-Index-Introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-SI-table) + +## Quick example + +Start spark-sql in terminal and run the following queries, +``` +CREATE TABLE maintable(a int, b string, c string) stored as carbondata; +insert into maintable select 1, 'ab', 'cd'; +CREATE index inex1 on table maintable(c) AS 'carbondata'; +SELECT a from maintable where c = 'cd'; +// NOTE: run explain query and check if query hits the SI table from the plan +EXPLAIN SELECT a from maintable where c = 'cd'; +``` + +## Secondary Index Introduction + Sencondary index tables are created as a indexes and managed as child tables internally by + Carbondata. Users can create secondary index based on the column position in main table(Recommended + for right columns) and the queries should have filter on that column to improve the filter query + performance. + + SI tables will always be loaded non-lazy way. Once SI table is created, Carbondata's + CarbonOptimizer with the help of CarbonSITransformationRule, transforms the query plan to hit the + SI table based on the filter condition or set of filter conditions present in the query. + So first level of pruning will be done on SI table as it stores blocklets and main table/parent + table pruning will be based on the SI output, which helps in giving the faster query results with + better pruning. + + For instance, main table called **sales** which is defined as + + ``` + CREATE TABLE sales ( +order_time timestamp, +user_id string, +sex string, +country string, +quantity int, +price bigint) + STORED AS carbondata + ``` + Review comment: NO. We have added syntax as well. For MV,BLOOM,LUCENE, create syntax can be found in [https://github.com/apache/carbondata/blob/master/docs/index/index-management.md](https://github.com/apache/carbondata/blob/master/docs/index/index-management.md) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#issuecomment-607179217 @Indhumathi27 handled all This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401526296
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,182 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES as json formatted
Review comment:
these will be thrown as exceptions right, code validations no need to
mention, if there are any thing which not handled in code can be mentioned i
think
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401524898 ## File path: docs/index/secondary-index-guide.md ## @@ -0,0 +1,182 @@ + + +# CarbonData Secondary Index + +* [Quick Example](#quick-example) +* [Secondary Index Table](#Secondary-Index-Introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-SI-table) + +## Quick example + +Start spark-sql in terminal and run the following queries, +``` +CREATE TABLE maintable(a int, b string, c string) stored as carbondata; +insert into maintable select 1, 'ab', 'cd'; +CREATE index inex1 on table maintable(c) AS 'carbondata'; +SELECT a from maintable where c = 'cd'; +// NOTE: run explain query and check if query hits the SI table from the plan +EXPLAIN SELECT a from maintable where c = 'cd'; +``` + +## Secondary Index Introduction + Sencondary index tables are created as a indexes and managed as child tables internally by + Carbondata. Users can create secondary index based on the column position in main table(Recommended + for right columns) and the queries should have filter on that column to improve the filter query + performance. + + SI tables will always be loaded non-lazy way. Once SI table is created, Carbondata's + CarbonOptimizer with the help of CarbonSITransformationRule, transforms the query plan to hit the + SI table based on the filter condition or set of filter conditions present in the query. + So first level of pruning will be done on SI table as it stores blocklets and main table/parent + table pruning will be based on the SI output, which helps in giving the faster query results with + better pruning. + + For instance, main table called **sales** which is defined as + + ``` + CREATE TABLE sales ( +order_time timestamp, +user_id string, +sex string, +country string, +quantity int, +price bigint) + STORED AS carbondata + ``` + Review comment: we followed same for all docs, so lets keep same i think This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401523505
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,182 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES as json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user executes a filter query is submitted, during query planning phase,
CarbonData with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property. The subsequent main table load will load the old failed loads along
with current load and
+ makes the SI table enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
+
+
+## Compacting SI table
+
+### Compacting SI table table through Main Table compaction
+Running Compaction command (`ALTER TABLE COMPACT`)[COMPACTION TYPE->
MINOR/MAJOR] on main table will
+automatically delete all the old segments of SI and creates a new segment with
same name as main
+table compacted segmet and loads data to it.
+
+### Compacting SI table's
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401523505
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,182 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES as json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user executes a filter query is submitted, during query planning phase,
CarbonData with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property. The subsequent main table load will load the old failed loads along
with current load and
+ makes the SI table enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
+
+
+## Compacting SI table
+
+### Compacting SI table table through Main Table compaction
+Running Compaction command (`ALTER TABLE COMPACT`)[COMPACTION TYPE->
MINOR/MAJOR] on main table will
+automatically delete all the old segments of SI and creates a new segment with
same name as main
+table compacted segmet and loads data to it.
+
+### Compacting SI table's
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant.
CarbonDataQA1 commented on issue #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant. URL: https://github.com/apache/carbondata/pull/3661#issuecomment-607165296 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/896/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant.
CarbonDataQA1 commented on issue #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant. URL: https://github.com/apache/carbondata/pull/3661#issuecomment-607158608 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2603/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document
CarbonDataQA1 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#issuecomment-607154752 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2604/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document
CarbonDataQA1 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#issuecomment-607154069 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/895/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Resolved] (CARBONDATA-3726) Add example for CDC and data dedup
[ https://issues.apache.org/jira/browse/CARBONDATA-3726?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kunal Kapoor resolved CARBONDATA-3726. -- Resolution: Fixed > Add example for CDC and data dedup > -- > > Key: CARBONDATA-3726 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3726 > Project: CarbonData > Issue Type: New Feature >Reporter: Jacky Li >Assignee: Jacky Li >Priority: Major > Fix For: 2.0.0 > > Time Spent: 2.5h > Remaining Estimate: 0h > > Change Data Capture and Data Duplication is common tasks for data management, > we should add examples for user to reference > We can leverage CarbonData's Merge API to implement these use cases -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Resolved] (CARBONDATA-3735) Avoid listing all tables in metastore
[ https://issues.apache.org/jira/browse/CARBONDATA-3735?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kunal Kapoor resolved CARBONDATA-3735. -- Resolution: Fixed > Avoid listing all tables in metastore > - > > Key: CARBONDATA-3735 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3735 > Project: CarbonData > Issue Type: Improvement >Reporter: Jacky Li >Assignee: Jacky Li >Priority: Major > Fix For: 2.0.0 > > Time Spent: 1h > Remaining Estimate: 0h > > In CarbonCreateDataSourceTableCommand.scala, RegisterIndexTableCommand.scala, > carbon is trying to list all tables in a database. > It will be slow if there are many tables in the db, thus should be avoided. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Resolved] (CARBONDATA-3578) Reduce size of table status file
[ https://issues.apache.org/jira/browse/CARBONDATA-3578?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kunal Kapoor resolved CARBONDATA-3578. -- Resolution: Fixed > Reduce size of table status file > > > Key: CARBONDATA-3578 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3578 > Project: CarbonData > Issue Type: Improvement >Reporter: Jacky Li >Priority: Major > Fix For: 2.0.0 > > Time Spent: 5h 50m > Remaining Estimate: 0h > > Currently, each segment entry in the table status file occupies 347 Bytes, if > one has 1 segments, the file becomes 3.47MB. > Since carbondata relies on this file heavily, it is better to reduce its size > to improve IO. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Resolved] (CARBONDATA-3514) Support integration with spark 2.4.4
[ https://issues.apache.org/jira/browse/CARBONDATA-3514?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kunal Kapoor resolved CARBONDATA-3514. -- Resolution: Fixed > Support integration with spark 2.4.4 > > > Key: CARBONDATA-3514 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3514 > Project: CarbonData > Issue Type: Improvement >Reporter: Jacky Li >Priority: Major > Fix For: 2.0.0 > > Time Spent: 20h > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (CARBONDATA-3756) the query of stage files only read the first blocklet of each carbondata file
[ https://issues.apache.org/jira/browse/CARBONDATA-3756?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kunal Kapoor updated CARBONDATA-3756: - Fix Version/s: (was: 2.0.0) > the query of stage files only read the first blocklet of each carbondata file > - > > Key: CARBONDATA-3756 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3756 > Project: CarbonData > Issue Type: Improvement >Reporter: David Cai >Priority: Major > Time Spent: 50m > Remaining Estimate: 0h > > the query of stage files only read the first blocklet of each carbondata file. > if the file contains multiple blocklets, the query result will be wrong. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (CARBONDATA-3756) the query of stage files only read the first blocklet of each carbondata file
[ https://issues.apache.org/jira/browse/CARBONDATA-3756?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kunal Kapoor updated CARBONDATA-3756: - Fix Version/s: 2.0.0 > the query of stage files only read the first blocklet of each carbondata file > - > > Key: CARBONDATA-3756 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3756 > Project: CarbonData > Issue Type: Improvement >Reporter: David Cai >Priority: Major > Fix For: 2.0.0 > > Time Spent: 50m > Remaining Estimate: 0h > > the query of stage files only read the first blocklet of each carbondata file. > if the file contains multiple blocklets, the query result will be wrong. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Resolved] (CARBONDATA-3700) Optimize prune performance when prunning with multi-threads
[ https://issues.apache.org/jira/browse/CARBONDATA-3700?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kunal Kapoor resolved CARBONDATA-3700. -- Fix Version/s: 2.0.0 Resolution: Fixed > Optimize prune performance when prunning with multi-threads > --- > > Key: CARBONDATA-3700 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3700 > Project: CarbonData > Issue Type: Bug > Components: data-query >Affects Versions: 2.0.0 >Reporter: Xingjun Hao >Priority: Major > Fix For: 2.0.0 > > Time Spent: 11h 20m > Remaining Estimate: 0h > > When pruning with multi-threads, there is a bug hambers the prunning > performance heavily. > When the datamap pruning results in no blocklet to map filter, The > getExtendblocklet function aims to get the extend blocklet metadata, when the > Input is a empty blocklet list, this function should return a extend blocklet > list directyly , but now there is a bug leading to a hashset add operation > overhead. > Meanwhile ,When pruning with multi-threads, the getExtendblocklet function > will be triggerd for each blocklet. This should avoided by trgger this > function for each segment. > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert
CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert URL: https://github.com/apache/carbondata/pull/3687#issuecomment-607139937 Build Failed with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/894/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert
CarbonDataQA1 commented on issue #3687: [WIP] Remove redundant conversion for complex type insert URL: https://github.com/apache/carbondata/pull/3687#issuecomment-607130786 Build Failed with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2602/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401449799
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,182 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES as json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user executes a filter query is submitted, during query planning phase,
CarbonData with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property. The subsequent main table load will load the old failed loads along
with current load and
+ makes the SI table enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
+
+
+## Compacting SI table
+
+### Compacting SI table table through Main Table compaction
+Running Compaction command (`ALTER TABLE COMPACT`)[COMPACTION TYPE->
MINOR/MAJOR] on main table will
+automatically delete all the old segments of SI and creates a new segment with
same name as main
+table compacted segmet and loads data to it.
+
+### Compacting SI
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401451711
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,182 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES as json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user executes a filter query is submitted, during query planning phase,
CarbonData with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property. The subsequent main table load will load the old failed loads along
with current load and
+ makes the SI table enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
+
+
+## Compacting SI table
+
+### Compacting SI table table through Main Table compaction
+Running Compaction command (`ALTER TABLE COMPACT`)[COMPACTION TYPE->
MINOR/MAJOR] on main table will
+automatically delete all the old segments of SI and creates a new segment with
same name as main
+table compacted segmet and loads data to it.
+
+### Compacting SI
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401452823 ## File path: docs/index/secondary-index-guide.md ## @@ -0,0 +1,182 @@ + + +# CarbonData Secondary Index + +* [Quick Example](#quick-example) +* [Secondary Index Table](#Secondary-Index-Introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-SI-table) + +## Quick example + +Start spark-sql in terminal and run the following queries, +``` +CREATE TABLE maintable(a int, b string, c string) stored as carbondata; +insert into maintable select 1, 'ab', 'cd'; +CREATE index inex1 on table maintable(c) AS 'carbondata'; +SELECT a from maintable where c = 'cd'; +// NOTE: run explain query and check if query hits the SI table from the plan +EXPLAIN SELECT a from maintable where c = 'cd'; +``` + +## Secondary Index Introduction + Sencondary index tables are created as a indexes and managed as child tables internally by + Carbondata. Users can create secondary index based on the column position in main table(Recommended + for right columns) and the queries should have filter on that column to improve the filter query + performance. + + SI tables will always be loaded non-lazy way. Once SI table is created, Carbondata's + CarbonOptimizer with the help of CarbonSITransformationRule, transforms the query plan to hit the + SI table based on the filter condition or set of filter conditions present in the query. + So first level of pruning will be done on SI table as it stores blocklets and main table/parent + table pruning will be based on the SI output, which helps in giving the faster query results with + better pruning. + + For instance, main table called **sales** which is defined as + + ``` + CREATE TABLE sales ( +order_time timestamp, +user_id string, +sex string, +country string, +quantity int, +price bigint) + STORED AS carbondata + ``` + Review comment: Can add syntax for create index command and can keep example as below code This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401447490 ## File path: docs/configuration-parameters.md ## @@ -147,6 +148,8 @@ This section provides the details of all the configurations required for the Car | carbon.query.stage.input.enable | false | Stage input files are data files written by external applications (such as Flink), but have not been loaded into carbon table. Enabling this configuration makes query to include these files, thus makes query on latest data. However, since these files are not indexed, query maybe slower as full scan is required for these files. | | carbon.driver.pruning.multi.thread.enable.files.count | 10 | To prune in multi-thread when total number of segment files for a query increases beyond the configured value. | | carbon.load.all.segment.indexes.to.cache | true | Setting this configuration to false, will prune and load only matched segment indexes to cache using segment metadata information such as columnid and it's minmax values, which decreases the usage of driver memory. | +| carbon.secondary.index.creation.threads | 1 | Specifies the number of threads to concurrently process segments during secondary index creation. This property helps fine tuning the system when there are a lot of segments in a table. The value range is 1 to 50. | +| carbon.si.lookup.partialstring | true | When true, it includes starts with, ends with and contains. When false, it includes only starts with secondary indexex. | Review comment: ```suggestion | carbon.si.lookup.partialstring | true | When true, it includes starts with, ends with and contains. When false, it includes only starts with secondary indexes. | ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401458116
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,182 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES as json formatted
Review comment:
can add limitations for si in Notes section:
1. not supported for measure column and complex column
2. cannot be created on streaming/partition/non transaction table
3. Index table column indexing order cannot be same as Parent table column
start order
4. TableProperties like
TABLE_BLOCKSIZE,COLUMN_META_CACHE,CACHE_LEVEL,COMPRESSOR are supported in
create index
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401458549
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,182 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES as json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user executes a filter query is submitted, during query planning phase,
CarbonData with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
Review comment:
```suggestion
CarbonSITransformationRule, checks if there are any index tables present on
the filter column of
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401460400 ## File path: docs/index/secondary-index-guide.md ## @@ -0,0 +1,182 @@ + + +# CarbonData Secondary Index + +* [Quick Example](#quick-example) +* [Secondary Index Table](#Secondary-Index-Introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-SI-table) Review comment: Add DDLs on Secondary Index This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401453741
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,182 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES as json formatted
Review comment:
```suggestion
* Secondary Index tables are registered with hive and stored in
HiveSERDEPROPERTIES as json formatted
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401450107
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,182 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES as json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user executes a filter query is submitted, during query planning phase,
CarbonData with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property. The subsequent main table load will load the old failed loads along
with current load and
+ makes the SI table enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
+
+
+## Compacting SI table
+
+### Compacting SI table table through Main Table compaction
+Running Compaction command (`ALTER TABLE COMPACT`)[COMPACTION TYPE->
MINOR/MAJOR] on main table will
+automatically delete all the old segments of SI and creates a new segment with
same name as main
+table compacted segmet and loads data to it.
+
+### Compacting SI
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401458439
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,182 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a indexes and managed as child tables
internally by
+ Carbondata. Users can create secondary index based on the column position in
main table(Recommended
+ for right columns) and the queries should have filter on that column to
improve the filter query
+ performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES as json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user executes a filter query is submitted, during query planning phase,
CarbonData with help of
Review comment:
```suggestion
When a user executes a filter query, during query planning phase, CarbonData
with help of
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] ajantha-bhat edited a comment on issue #3675: [CARBONDATA-3744] Fix select query failure issue when warehouse directory is default (not configured) in cluster
ajantha-bhat edited a comment on issue #3675: [CARBONDATA-3744] Fix select query failure issue when warehouse directory is default (not configured) in cluster URL: https://github.com/apache/carbondata/pull/3675#issuecomment-607099805 Yes, If we set "spark.sql.warehouse.dir" to /home/root1/temp; table is created with hdfs scheme (because cluster is hdfs) 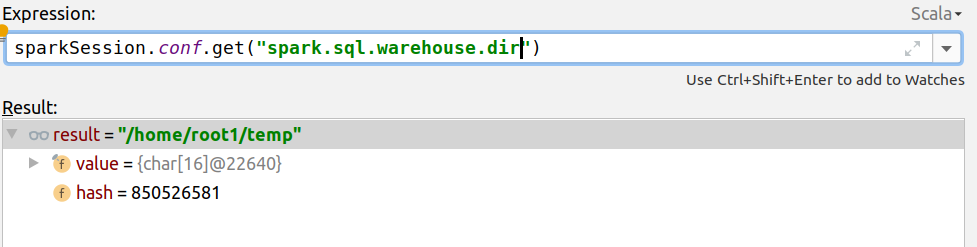  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on issue #3675: [CARBONDATA-3744] Fix select query failure issue when warehouse directory is default (not configured) in cluster
ajantha-bhat commented on issue #3675: [CARBONDATA-3744] Fix select query failure issue when warehouse directory is default (not configured) in cluster URL: https://github.com/apache/carbondata/pull/3675#issuecomment-607099805 Yes, If we set "spark.sql.warehouse.dir" to /home/root1/temp; table is created with hdfs scheme (because cluster is hdfs)   This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on issue #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#issuecomment-607091132 @Indhumathi27 handled all comments, please check.Thanks for the review. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401417882
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user filter query is submitted, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property and subsequent load to main table will also load to SI with failed
load data also and
+ make it enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
Review comment:
i think, we have many things like that like, filter combinations of or , and
so, better to avoid these kind in user documents , it will be better to mention
in developer document
This is an automated message from the Apache Git Service.
To respond to the message,
[GitHub] [carbondata] niuge01 commented on a change in pull request #3661: [CARBONDATA-3704] Support create materialized view on all type table, and make mv support mutil-tenant.
niuge01 commented on a change in pull request #3661: [CARBONDATA-3704] Support
create materialized view on all type table, and make mv support mutil-tenant.
URL: https://github.com/apache/carbondata/pull/3661#discussion_r401415307
##
File path:
integration/spark/src/main/scala/org/apache/spark/sql/secondaryindex/command/SIRebuildSegmentRunner.scala
##
@@ -35,32 +34,24 @@ import
org.apache.carbondata.common.exceptions.sql.MalformedCarbonCommandExcepti
import org.apache.carbondata.common.logging.LogServiceFactory
import org.apache.carbondata.core.locks.{CarbonLockFactory, LockUsage}
import org.apache.carbondata.core.metadata.{CarbonTableIdentifier,
ColumnarFormatVersion}
-import org.apache.carbondata.core.metadata.schema.table.{CarbonTable,
TableInfo}
+import org.apache.carbondata.core.metadata.schema.table.CarbonTable
import org.apache.carbondata.core.statusmanager.{LoadMetadataDetails,
SegmentStatus, SegmentStatusManager}
import org.apache.carbondata.core.util.CarbonUtil
import org.apache.carbondata.events.{OperationContext, OperationListenerBus}
-case class SIRebuildSegmentCommand(
- alterTableModel: AlterTableModel,
- tableInfoOp: Option[TableInfo] = None,
- operationContext: OperationContext = new OperationContext)
- extends AtomicRunnableCommand {
+case class SIRebuildSegmentRunner(
Review comment:
we will do it in a new pr.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401411591
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user filter query is submitted, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property and subsequent load to main table will also load to SI with failed
load data also and
+ make it enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
Review comment:
with filter on SI and donotPushToSI. For expressions like NOT, ISNOTNULL
etc. Can list those expressions
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401412761
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user filter query is submitted, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property and subsequent load to main table will also load to SI with failed
load data also and
+ make it enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
+
+
+## Compacting SI table
+
+### Compacting SI table table through Main Table compaction
+Running Compaction command (`ALTER TABLE COMPACT`)[COMPACTION TYPE->
MINOR/MAJOR] on main table will
+automatically delete all the old segments of SI and creates a new segment with
same name as main
+table compacted segmet and loads data to it.
+
+###
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401411591
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user filter query is submitted, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property and subsequent load to main table will also load to SI with failed
load data also and
+ make it enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
Review comment:
with filter on SI and donotPushToSI. For expressions like NOT, ISNOTNULL etc
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401383769
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user filter query is submitted, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property and subsequent load to main table will also load to SI with failed
load data also and
+ make it enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
+
+
+## Compacting SI table
+
+### Compacting SI table table through Main Table compaction
+Running Compaction command (`ALTER TABLE COMPACT`)[COMPACTION TYPE->
MINOR/MAJOR] on main table will
+automatically delete all the old segments of SI and creates a new segment with
same name as main
+table compacted segmet and loads data to it.
+
+###
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401380164 ## File path: docs/index/secondary-index-guide.md ## @@ -0,0 +1,155 @@ + + +# CarbonData Secondary Index + +* [Quick Example](#quick-example) +* [Secondary Index Table](#Secondary-Index-Introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-SI-table) +* [Data Management](#data-management-with-SI-tables) Review comment: Can add document for REGISTER INDEX, SHOW INDEX, DROP INDEX commands also This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401408219
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user filter query is submitted, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property and subsequent load to main table will also load to SI with failed
load data also and
+ make it enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
+
+
+## Compacting SI table
+
+### Compacting SI table table through Main Table compaction
+Running Compaction command (`ALTER TABLE COMPACT`)[COMPACTION TYPE->
MINOR/MAJOR] on main table will
+automatically delete all the old segments of SI and creates a new segment with
same name as main
+table compacted segmet and loads data to it.
+
+### Compacting
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401407346
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user filter query is submitted, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property and subsequent load to main table will also load to SI with failed
load data also and
+ make it enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
Review comment:
thats already explained right, if no filester on SI, then it will not push
down no need to add more queries as eamples
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
akashrn5 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401407346
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user filter query is submitted, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property and subsequent load to main table will also load to SI with failed
load data also and
+ make it enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
Review comment:
thats already explained right, if no filter on SI, then it will not push
down no need to add more queries as eamples
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the
[jira] [Resolved] (CARBONDATA-3740) During loading, if '\r' appears before the first '\n', line separator detection will treat '\r' as line separator, lead to line mismatch
[ https://issues.apache.org/jira/browse/CARBONDATA-3740?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ajantha Bhat resolved CARBONDATA-3740. -- Fix Version/s: 2.0.0 Resolution: Fixed > During loading, if '\r' appears before the first '\n', line separator > detection will treat '\r' as line separator, lead to line mismatch > > > Key: CARBONDATA-3740 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3740 > Project: CarbonData > Issue Type: Bug > Components: data-load >Affects Versions: 2.0.0 >Reporter: Yahui Liu >Priority: Minor > Fix For: 2.0.0 > > Attachments: image-2020-03-07-14-22-44-111.png, > image-2020-03-07-14-32-18-961.png > > Time Spent: 8h 10m > Remaining Estimate: 0h > > During loading, if in the first line, there is one field has a '\r' character > and this '\r' appears before the first '\n', line separator detection will > treat '\r' as line separator. This is not the intention. > !image-2020-03-07-14-22-44-111.png! > This will lead to line mismatch. The result of loading will be like this: > !image-2020-03-07-14-32-18-961.png! -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [carbondata] asfgit closed pull request #3664: [CARBONDATA-3740] Add line separator option to load command to configure the line separator during csv parsing.
asfgit closed pull request #3664: [CARBONDATA-3740] Add line separator option to load command to configure the line separator during csv parsing. URL: https://github.com/apache/carbondata/pull/3664 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3688: [WIP] Refactor Index Metadata
CarbonDataQA1 commented on issue #3688: [WIP] Refactor Index Metadata URL: https://github.com/apache/carbondata/pull/3688#issuecomment-607074142 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/892/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on issue #3664: [CARBONDATA-3740] Add line separator option to load command to configure the line separator during csv parsing.
ajantha-bhat commented on issue #3664: [CARBONDATA-3740] Add line separator option to load command to configure the line separator during csv parsing. URL: https://github.com/apache/carbondata/pull/3664#issuecomment-607073170 LGTM. Thanks for the contribution. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA1 commented on issue #3688: [WIP] Refactor Index Metadata
CarbonDataQA1 commented on issue #3688: [WIP] Refactor Index Metadata URL: https://github.com/apache/carbondata/pull/3688#issuecomment-607068826 Build Failed with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/2600/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401379282
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user filter query is submitted, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property and subsequent load to main table will also load to SI with failed
load data also and
Review comment:
```suggestion
property. Users can fire REFRESH INDEX command to sync or else the
subsequent main table load will load the old failed loads along with current
load and makes the SI table enable and available for query
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401371348 ## File path: docs/index/secondary-index-guide.md ## @@ -0,0 +1,155 @@ + + +# CarbonData Secondary Index + +* [Quick Example](#quick-example) +* [Secondary Index Table](#Secondary-Index-Introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-SI-table) +* [Data Management](#data-management-with-SI-tables) + +## Quick example + +Start spark-sql in terminal and run the following queries, +``` +CREATE TABLE maintable(a int, b string, c string) stored as carbondata; +insert into maintable select 1, 'ab', 'cd'; +CREATE index inex1 on table maintable(c) AS 'carbondata'; +SELECT a from maintable where c = 'cd'; +// NOTE: run explain query and check if query hits the SI table from the plan +EXPLAIN SELECT a from maintable where c = 'cd'; +``` + +## Secondary Index Introduction + Sencondary index tables are created as a child table and manager as tables internally by Carbondata. Review comment: ```suggestion Secondary index tables are created as indexes and managed as child tables internally by Carbondata. ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401381166
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user filter query is submitted, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property and subsequent load to main table will also load to SI with failed
load data also and
+ make it enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
Review comment:
Can add documentation for queries which do not push down to SI
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service,
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401374771
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user filter query is submitted, during query planning phase, CarbonData
with help of
Review comment:
```suggestion
When a user executes a filter query, during query planning phase, CarbonData
with help of
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401379775 ## File path: docs/index/secondary-index-guide.md ## @@ -0,0 +1,155 @@ + + +# CarbonData Secondary Index + +* [Quick Example](#quick-example) +* [Secondary Index Table](#Secondary-Index-Introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-SI-table) +* [Data Management](#data-management-with-SI-tables) Review comment: Please remove Data Management This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401380164 ## File path: docs/index/secondary-index-guide.md ## @@ -0,0 +1,155 @@ + + +# CarbonData Secondary Index + +* [Quick Example](#quick-example) +* [Secondary Index Table](#Secondary-Index-Introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-SI-table) +* [Data Management](#data-management-with-SI-tables) Review comment: Can add document for REFRESH INDEX, REGISTER INDEX, SHOW INDEX, DROP INDEX commands also This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401383769
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
+ value. Maximum characters supported for SERDEPROPERTIES by hive is 4000
characters which cannot be
+ changed.
+
+
+ How SI tables are selected
+
+When a user filter query is submitted, during query planning phase, CarbonData
with help of
+CarbonSITransformationRule, checkes if there are any index tables present on
the filter column of
+query. If there are any, then filter query plan will be transformed such a way
that, execution will
+first hit the corresponding SI table and give input to main table for further
pruning.
+
+
+For the main table **sales** and SI table **index_sales** created above,
following queries
+```
+SELECT country, sex from sales where user_id = 'xxx'
+
+SELECT country, sex from sales where user_id = 'xxx' and country = 'INDIA'
+```
+
+will be transformed by CarbonData's CarbonSITransformationRule to query
against SI table
+**index_sales** first which will be input to the main table **sales**
+
+
+## Loading data
+
+### Loading data to Secondary Index table(s).
+
+*case1:* When SI table is created and the main table does not have any data.
In this case every
+consecutive load will load to SI table once main table data load is finished.
+
+*case2:* When SI table is created and main table already contains some data,
then SI creation will
+also load to SI table with same number of segments as main table. There after,
consecutive load to
+main table will load to SI table also.
+
+ **NOTE**:
+ * In case of any failure to SI table, then we make the SI table disable by
setting a hive serde
+ property and subsequent load to main table will also load to SI with failed
load data also and
+ make it enable and available for query.
+
+## Querying data
+Direct query can be made on SI tables to see the data present in position
reference columns.
+When a filter query is fired, if the filter column is a secondary index
column, then plan is
+transformed accordingly to hit SI table first to make better pruning with main
table and in turn
+helps for faster query results.
+
+User can verify whether a query can leverage SI table or not by executing
`EXPLAIN`
+command, which will show the transformed logical plan, and thus user can check
whether SI table
+table is selected.
+
+
+## Compacting SI table
+
+### Compacting SI table table through Main Table compaction
+Running Compaction command (`ALTER TABLE COMPACT`)[COMPACTION TYPE->
MINOR/MAJOR] on main table will
+automatically delete all the old segments of SI and creates a new segment with
same name as main
+table compacted segmet and loads data to it.
+
+###
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add
Secondary Index Document
URL: https://github.com/apache/carbondata/pull/3689#discussion_r401373694
##
File path: docs/index/secondary-index-guide.md
##
@@ -0,0 +1,155 @@
+
+
+# CarbonData Secondary Index
+
+* [Quick Example](#quick-example)
+* [Secondary Index Table](#Secondary-Index-Introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-SI-table)
+* [Data Management](#data-management-with-SI-tables)
+
+## Quick example
+
+Start spark-sql in terminal and run the following queries,
+```
+CREATE TABLE maintable(a int, b string, c string) stored as carbondata;
+insert into maintable select 1, 'ab', 'cd';
+CREATE index inex1 on table maintable(c) AS 'carbondata';
+SELECT a from maintable where c = 'cd';
+// NOTE: run explain query and check if query hits the SI table from the plan
+EXPLAIN SELECT a from maintable where c = 'cd';
+```
+
+## Secondary Index Introduction
+ Sencondary index tables are created as a child table and manager as tables
internally by Carbondata.
+ User can create the SI tables based on the column position in
table(Recommended for right columns)
+ and the queries should have filter on that column to improve the filter
query performance.
+
+ SI tables will always be loaded non-lazy way. Once SI table is created,
Carbondata's
+ CarbonOptimizer with the help of CarbonSITransformationRule, transforms the
query plan to hit the
+ SI table based on the filter condition or set of filter conditions present
in the query.
+ So first level of pruning will be done on SI table as it stores blocklets
and main table/parent
+ table pruning will be based on the SI output, which helps in giving the
faster query results with
+ better pruning.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create SI table using the Create Index DDL
+
+ ```
+ CREATE INDEX index_sales
+ ON TABLE sales(user_id)
+ AS
+ 'carbondata'
+ TBLPROPERTIES('table_blocksize'='1')
+ ```
+**NOTE**:
+ * Secondary Index tables are registered with hive and stored n
HiveSERDEPROPERTIES s json formatted
Review comment:
Please check and correct the spelling
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document
Indhumathi27 commented on a change in pull request #3689: [CARBONDATA-3680]Add Secondary Index Document URL: https://github.com/apache/carbondata/pull/3689#discussion_r401371348 ## File path: docs/index/secondary-index-guide.md ## @@ -0,0 +1,155 @@ + + +# CarbonData Secondary Index + +* [Quick Example](#quick-example) +* [Secondary Index Table](#Secondary-Index-Introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-SI-table) +* [Data Management](#data-management-with-SI-tables) + +## Quick example + +Start spark-sql in terminal and run the following queries, +``` +CREATE TABLE maintable(a int, b string, c string) stored as carbondata; +insert into maintable select 1, 'ab', 'cd'; +CREATE index inex1 on table maintable(c) AS 'carbondata'; +SELECT a from maintable where c = 'cd'; +// NOTE: run explain query and check if query hits the SI table from the plan +EXPLAIN SELECT a from maintable where c = 'cd'; +``` + +## Secondary Index Introduction + Sencondary index tables are created as a child table and manager as tables internally by Carbondata. Review comment: ```suggestion Sencondary index tables are created as indexes and managed as child tables internally by Carbondata. ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services