[GitHub] commons-lang issue #353: WIP: LANG-1416: Update tests to JUnit5 via @boyarsk...
Github user kinow commented on the issue: https://github.com/apache/commons-lang/pull/353 >In general it's hard to review gigantic change sets which have been created automatically, so I'd welcome an approach where we migrate one test case after another. +1, and bonus points if we refactor some of the old test code, or maybe even cover extra parts of the code :-) :tada ---
[jira] [Commented] (LANG-1416) Update to JUnit 5
[ https://issues.apache.org/jira/browse/LANG-1416?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16604052#comment-16604052 ] ASF GitHub Bot commented on LANG-1416: -- Github user kinow commented on the issue: https://github.com/apache/commons-lang/pull/353 >In general it's hard to review gigantic change sets which have been created automatically, so I'd welcome an approach where we migrate one test case after another. +1, and bonus points if we refactor some of the old test code, or maybe even cover extra parts of the code :-) :tada > Update to JUnit 5 > - > > Key: LANG-1416 > URL: https://issues.apache.org/jira/browse/LANG-1416 > Project: Commons Lang > Issue Type: Task >Reporter: Benedikt Ritter >Assignee: Benedikt Ritter >Priority: Major > Fix For: 3.9 > > > Once LANG-1415 is resolved we can start using the latest and greatest JUnit > version. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] commons-lang issue #353: WIP: LANG-1416: Update tests to JUnit5 via @boyarsk...
Github user smoyer64 commented on the issue: https://github.com/apache/commons-lang/pull/353 Sounds like the vote is to close this PR then? I certainly don''t disagree that it's hard (impossible?) to review the conversion of the entire test "set". ---
[jira] [Commented] (LANG-1416) Update to JUnit 5
[ https://issues.apache.org/jira/browse/LANG-1416?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16604223#comment-16604223 ] ASF GitHub Bot commented on LANG-1416: -- Github user smoyer64 commented on the issue: https://github.com/apache/commons-lang/pull/353 Sounds like the vote is to close this PR then? I certainly don''t disagree that it's hard (impossible?) to review the conversion of the entire test "set". > Update to JUnit 5 > - > > Key: LANG-1416 > URL: https://issues.apache.org/jira/browse/LANG-1416 > Project: Commons Lang > Issue Type: Task >Reporter: Benedikt Ritter >Assignee: Benedikt Ritter >Priority: Major > Fix For: 3.9 > > > Once LANG-1415 is resolved we can start using the latest and greatest JUnit > version. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] commons-lang issue #353: WIP: LANG-1416: Update tests to JUnit5 via @boyarsk...
Github user kinow commented on the issue: https://github.com/apache/commons-lang/pull/353 I think so @smoyer64 , but not meaning giving up on the task, just split it into smaller changes, or a complete change but with less distractions from the main work. Alternatively, you can update the PR with some base work that you think might be useful for the next iterations. Up to you :-) ---
[jira] [Commented] (LANG-1416) Update to JUnit 5
[ https://issues.apache.org/jira/browse/LANG-1416?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16604235#comment-16604235 ] ASF GitHub Bot commented on LANG-1416: -- Github user kinow commented on the issue: https://github.com/apache/commons-lang/pull/353 I think so @smoyer64 , but not meaning giving up on the task, just split it into smaller changes, or a complete change but with less distractions from the main work. Alternatively, you can update the PR with some base work that you think might be useful for the next iterations. Up to you :-) > Update to JUnit 5 > - > > Key: LANG-1416 > URL: https://issues.apache.org/jira/browse/LANG-1416 > Project: Commons Lang > Issue Type: Task >Reporter: Benedikt Ritter >Assignee: Benedikt Ritter >Priority: Major > Fix For: 3.9 > > > Once LANG-1415 is resolved we can start using the latest and greatest JUnit > version. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] commons-lang issue #353: WIP: LANG-1416: Update tests to JUnit5 via @boyarsk...
Github user smoyer64 commented on the issue: https://github.com/apache/commons-lang/pull/353 @kinow > Alternatively, you can update the PR with some base work that you think might be useful for the next iterations. Up to you If the intention is to use the conversion as an opportunity to review all the test classes, then completing the automatic conversion is probably a bad idea. Once the tests are running again, nobody's going to look at them right? Most of the changes made by the converter were boilerplate ... greater than 80% of the test classes only had changes to their imports. I could create a branch that was nothing more than the conversion if you're interested and people could pick off a class, optimize/update it and submit a single class as a PR. The conversion tool needs a little work but it's also capable of converting a single file at a time. Or I can drop the whole idea of automation. ---
[GitHub] commons-lang pull request #353: WIP: LANG-1416: Update tests to JUnit5 via @...
Github user smoyer64 closed the pull request at: https://github.com/apache/commons-lang/pull/353 ---
[jira] [Commented] (LANG-1416) Update to JUnit 5
[ https://issues.apache.org/jira/browse/LANG-1416?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16604269#comment-16604269 ] ASF GitHub Bot commented on LANG-1416: -- Github user smoyer64 commented on the issue: https://github.com/apache/commons-lang/pull/353 @kinow > Alternatively, you can update the PR with some base work that you think might be useful for the next iterations. Up to you If the intention is to use the conversion as an opportunity to review all the test classes, then completing the automatic conversion is probably a bad idea. Once the tests are running again, nobody's going to look at them right? Most of the changes made by the converter were boilerplate ... greater than 80% of the test classes only had changes to their imports. I could create a branch that was nothing more than the conversion if you're interested and people could pick off a class, optimize/update it and submit a single class as a PR. The conversion tool needs a little work but it's also capable of converting a single file at a time. Or I can drop the whole idea of automation. > Update to JUnit 5 > - > > Key: LANG-1416 > URL: https://issues.apache.org/jira/browse/LANG-1416 > Project: Commons Lang > Issue Type: Task >Reporter: Benedikt Ritter >Assignee: Benedikt Ritter >Priority: Major > Fix For: 3.9 > > > Once LANG-1415 is resolved we can start using the latest and greatest JUnit > version. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (LANG-1416) Update to JUnit 5
[ https://issues.apache.org/jira/browse/LANG-1416?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16604270#comment-16604270 ] ASF GitHub Bot commented on LANG-1416: -- Github user smoyer64 closed the pull request at: https://github.com/apache/commons-lang/pull/353 > Update to JUnit 5 > - > > Key: LANG-1416 > URL: https://issues.apache.org/jira/browse/LANG-1416 > Project: Commons Lang > Issue Type: Task >Reporter: Benedikt Ritter >Assignee: Benedikt Ritter >Priority: Major > Fix For: 3.9 > > > Once LANG-1415 is resolved we can start using the latest and greatest JUnit > version. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] commons-lang pull request #354: Convert tests for Validate.isTrue overloads ...
GitHub user britter opened a pull request: https://github.com/apache/commons-lang/pull/354 Convert tests for Validate.isTrue overloads to @Nested test Proposal for a better structure of tests using `@Nested`. Each method should have it's own `@Nested` container which is called like the method. Inside that container each overload has it's own `@Nested` container. I did this for `Validate.isTrue` to show the approach. You can merge this pull request into a Git repository by running: $ git pull https://github.com/britter/commons-lang nested-validate-test Alternatively you can review and apply these changes as the patch at: https://github.com/apache/commons-lang/pull/354.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #354 commit aad2db8b12b8c61556df9df7de4fadc927633504 Author: Benedikt Ritter Date: 2018-09-05T12:26:25Z Convert tests for Validate.isTrue overloads to @Nested test ---
[GitHub] commons-lang issue #354: Convert tests for Validate.isTrue overloads to @Nes...
Github user britter commented on the issue: https://github.com/apache/commons-lang/pull/354 @kinow @PascalSchumacher @chtompki WDYT? ---
[GitHub] commons-lang issue #354: Convert tests for Validate.isTrue overloads to @Nes...
Github user coveralls commented on the issue: https://github.com/apache/commons-lang/pull/354 [](https://coveralls.io/builds/18838060) Coverage remained the same at 95.253% when pulling **aad2db8b12b8c61556df9df7de4fadc927633504 on britter:nested-validate-test** into **bce28f99f383051b419510ef72531e0f6fa67352 on apache:master**. ---
[GitHub] commons-lang pull request #355: Use @ParameterizedTest to iterate over avail...
GitHub user britter opened a pull request: https://github.com/apache/commons-lang/pull/355 Use @ParameterizedTest to iterate over available locales You can merge this pull request into a Git repository by running: $ git pull https://github.com/britter/commons-lang parameterized-FastDateParser_TimeZoneStrategyTest Alternatively you can review and apply these changes as the patch at: https://github.com/apache/commons-lang/pull/355.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #355 commit 7e440785d9ccdafc84ae7a50022097dc3dd422e8 Author: Benedikt Ritter Date: 2018-09-05T13:58:27Z Use @ParameterizedTest to iterate over available locales ---
[GitHub] commons-lang issue #355: Use @ParameterizedTest to iterate over available lo...
Github user coveralls commented on the issue: https://github.com/apache/commons-lang/pull/355 [](https://coveralls.io/builds/18840189) Coverage remained the same at 95.253% when pulling **7e440785d9ccdafc84ae7a50022097dc3dd422e8 on britter:parameterized-FastDateParser_TimeZoneStrategyTest** into **bce28f99f383051b419510ef72531e0f6fa67352 on apache:master**. ---
[jira] [Resolved] (CONFIGURATION-713) Add conversion to Regex patterns
[ https://issues.apache.org/jira/browse/CONFIGURATION-713?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Oliver Heger resolved CONFIGURATION-713. Resolution: Fixed Fix Version/s: 2.4 Patch applied in SVN revision 1840138. Many thanks! > Add conversion to Regex patterns > > > Key: CONFIGURATION-713 > URL: https://issues.apache.org/jira/browse/CONFIGURATION-713 > Project: Commons Configuration > Issue Type: Improvement > Components: Type conversion >Reporter: Lars W >Priority: Major > Fix For: 2.4 > > Attachments: pattern.patch > > > Attached patch adds conversion to regex pattern from string to > PropertyConverter.java. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] commons-lang issue #340: [LANG-1406] StringIndexOutOfBoundsException in Stri...
Github user HiuKwok commented on the issue: https://github.com/apache/commons-lang/pull/340 To whom who interested in this issue, here is some founding that I discovered throughout this month of issue solving. Problem: - The exception would happened when any String object passed in with unicode character. In order to achieve ignore case replacement, the internal logic would first transform both `text` and `SearchString` to lowerCase( ) for comparaition. - However if anyone passion enough to digger deeper into the src logic of `.toLowerCase( )`. Certain unicode character would be denormalized. In this way the result String length would tend to longer than original length(). Example like: 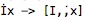 So making use of the transformed String, Out bound exception would happen when trying to access the index that doesn't access at all (3 in this case vs 2 in length before lowerCase). Flow: - So the first thought into my mind is, why dun just normalize both `text` and `searchString` before performing ignore case comparation? In this way the String length would always stay consistence no matter `toLowerCase( )` or `toUpperCase( )` 3 -> 3. However the another problem would emerged, as you may noticed, while the String mentioned above denormalize, it would turn into a UpperCase I and a dot sign. - But what happen if the search pattern emerge into searchText in decompose form. In this case let say I am trying to match a upper [I]. Then mismatch would happen and this is certain not the desire behavior of this method I believe. BTW I Drafted a simple main method to demonstrate how mismatch would happen in here. https://github.com/HiuKwok/commons-lang/blob/master/src/main/java/com/hiukwok/test.java#L10-L20 ---
[jira] [Commented] (LANG-1406) StringIndexOutOfBoundsException in StringUtils.replaceIgnoreCase
[
https://issues.apache.org/jira/browse/LANG-1406?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16604572#comment-16604572
]
ASF GitHub Bot commented on LANG-1406:
--
Github user HiuKwok commented on the issue:
https://github.com/apache/commons-lang/pull/340
To whom who interested in this issue, here is some founding that I
discovered throughout this month of issue solving.
Problem:
- The exception would happened when any String object passed in with
unicode character. In order to achieve ignore case replacement, the internal
logic would first transform both `text` and `SearchString` to lowerCase( ) for
comparaition.
- However if anyone passion enough to digger deeper into the src logic of
`.toLowerCase( )`. Certain unicode character would be denormalized. In this way
the result String length would tend to longer than original length(). Example
like:
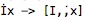
So making use of the transformed String, Out bound exception would happen
when trying to access the index that doesn't access at all (3 in this case vs 2
in length before lowerCase).
Flow:
- So the first thought into my mind is, why dun just normalize both `text`
and `searchString` before performing ignore case comparation? In this way the
String length would always stay consistence no matter `toLowerCase( )` or
`toUpperCase( )` 3 -> 3. However the another problem would emerged, as you may
noticed, while the String mentioned above denormalize, it would turn into a
UpperCase I and a dot sign.
- But what happen if the search pattern emerge into searchText in decompose
form. In this case let say I am trying to match a upper [I]. Then mismatch
would happen and this is certain not the desire behavior of this method I
believe.
BTW I Drafted a simple main method to demonstrate how mismatch would happen
in here.
https://github.com/HiuKwok/commons-lang/blob/master/src/main/java/com/hiukwok/test.java#L10-L20
> StringIndexOutOfBoundsException in StringUtils.replaceIgnoreCase
>
>
> Key: LANG-1406
> URL: https://issues.apache.org/jira/browse/LANG-1406
> Project: Commons Lang
> Issue Type: Bug
> Components: lang.*
>Reporter: Michael Ryan
>Priority: Major
>
> STEPS TO REPRODUCE:
> {code}
> StringUtils.replaceIgnoreCase("\u0130x", "x", "")
> {code}
> EXPECTED: "\u0130" is returned.
> ACTUAL: StringIndexOutOfBoundsException
> This happens because the replace method is assuming that text.length() ==
> text.toLowerCase().length(), which is not true for certain characters.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (GEOMETRY-9) New Euclidean Vector Methods
[
https://issues.apache.org/jira/browse/GEOMETRY-9?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16604607#comment-16604607
]
Gilles commented on GEOMETRY-9:
---
Sorry I missed that a PR was available...
There are some design issues:
# Wherever {{IllegalStateException}} is used, I think that
{{IllegalArgumentException}} would convey the right meaning.
# Class {{Vectors}} is a a so-called "utility" class, which is viewed as an
[anti-pattern|https://www.yegor256.com/2014/05/05/oop-alternative-to-utility-classes.html].
Without having looked at the implications, I'd suggest to rethink its
necessity. If it's just syntactic sugar to speed development, please consider
putting it in an "internal" package so that the "bad" API is not public and can
be replaced without notice.
# Why is a {{static}} version needed, since as the comment says "it simply
calls" the other method?
> New Euclidean Vector Methods
>
>
> Key: GEOMETRY-9
> URL: https://issues.apache.org/jira/browse/GEOMETRY-9
> Project: Apache Commons Geometry
> Issue Type: Wish
>Reporter: Matt Juntunen
>Priority: Minor
>
> We should add some more methods to the Euclidean vector classes for user
> convenience and algorithm clarity.
> # length() – more intuitive alias for getNorm()
> # project(Vector) – returns the current vector projected onto the given
> vector
> # static project(Vector, Vector) – static version of project
> # reject(Vector) – returns the current vector projected onto the plane whose
> normal is passed to the method (vec equals vec.project(v) + vec.reject(v))
> # static reject(Vector, Vector) – static version of reject
> # lerp(Vector, double) – linear interpolation between the current vector and
> the given one
> # static lerp(Vector, Vector, double) – static version of lerp
> # withLength(double) – returns the current vector with the given length.
> This is equivalent to vector.normalize().scalarMultiply(x) but without the
> intermediate vector.
>
> Pull request: [https://github.com/apache/commons-geometry/pull/8]
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (LANG-1406) StringIndexOutOfBoundsException in StringUtils.replaceIgnoreCase
[
https://issues.apache.org/jira/browse/LANG-1406?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16604694#comment-16604694
]
Michael Ryan commented on LANG-1406:
I've been thinking - how do case-insensitive regular expressions handle this?
Theoretically these should do the same thing:
{code}
StringUtils.replaceIgnoreCase("\u0130x", "x", "");
Pattern.compile("x",
Pattern.CASE_INSENSITIVE).matcher("\u0130x").replaceAll("");
{code}
The Matcher.replaceAll(String) method does not throw an exception.
So what is the difference? The Pattern.newSingle(int) method is the key thing
to look at. It uses Character.toUpperCase(char) and
Character.toLowerCase(char), which do not have the same behavior as
String.toUpperCase() and String.toLowerCase(). The Character class produce a
single character.
So I think a possible naive solution to this would be to call
Character.toLowerCase() on each character in the String and then append the
characters together into a new String.
{code}
String text = "foo";
char[] chars = text.toCharArray();
for (int i = 0; i < chars.length; i++) {
chars[i] = Character.toLowerCase(chars[i]);
}
String lowerText = new String(chars);
{code}
> StringIndexOutOfBoundsException in StringUtils.replaceIgnoreCase
>
>
> Key: LANG-1406
> URL: https://issues.apache.org/jira/browse/LANG-1406
> Project: Commons Lang
> Issue Type: Bug
> Components: lang.*
>Reporter: Michael Ryan
>Priority: Major
>
> STEPS TO REPRODUCE:
> {code}
> StringUtils.replaceIgnoreCase("\u0130x", "x", "")
> {code}
> EXPECTED: "\u0130" is returned.
> ACTUAL: StringIndexOutOfBoundsException
> This happens because the replace method is assuming that text.length() ==
> text.toLowerCase().length(), which is not true for certain characters.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Comment Edited] (LANG-1406) StringIndexOutOfBoundsException in StringUtils.replaceIgnoreCase
[
https://issues.apache.org/jira/browse/LANG-1406?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16604694#comment-16604694
]
Michael Ryan edited comment on LANG-1406 at 9/5/18 5:30 PM:
I've been thinking - how do case-insensitive regular expressions handle this?
Theoretically these should do the same thing:
{code}
StringUtils.replaceIgnoreCase("\u0130x", "x", "");
Pattern.compile("x",
Pattern.CASE_INSENSITIVE).matcher("\u0130x").replaceAll("");
{code}
The Matcher.replaceAll(String) method does not throw an exception.
So what is the difference? The Pattern.newSingle(int) method is the key thing
to look at. It uses Character.toUpperCase(char) and
Character.toLowerCase(char), which do not have the same behavior as
String.toUpperCase() and String.toLowerCase(). The Character class produces a
single character.
So I think a possible naive solution to this would be to call
Character.toLowerCase() on each character in the String and then append the
characters together into a new String.
{code}
String text = "foo";
char[] chars = text.toCharArray();
for (int i = 0; i < chars.length; i++) {
chars[i] = Character.toLowerCase(chars[i]);
}
String lowerText = new String(chars);
{code}
was (Author: michaelryan):
I've been thinking - how do case-insensitive regular expressions handle this?
Theoretically these should do the same thing:
{code}
StringUtils.replaceIgnoreCase("\u0130x", "x", "");
Pattern.compile("x",
Pattern.CASE_INSENSITIVE).matcher("\u0130x").replaceAll("");
{code}
The Matcher.replaceAll(String) method does not throw an exception.
So what is the difference? The Pattern.newSingle(int) method is the key thing
to look at. It uses Character.toUpperCase(char) and
Character.toLowerCase(char), which do not have the same behavior as
String.toUpperCase() and String.toLowerCase(). The Character class produce a
single character.
So I think a possible naive solution to this would be to call
Character.toLowerCase() on each character in the String and then append the
characters together into a new String.
{code}
String text = "foo";
char[] chars = text.toCharArray();
for (int i = 0; i < chars.length; i++) {
chars[i] = Character.toLowerCase(chars[i]);
}
String lowerText = new String(chars);
{code}
> StringIndexOutOfBoundsException in StringUtils.replaceIgnoreCase
>
>
> Key: LANG-1406
> URL: https://issues.apache.org/jira/browse/LANG-1406
> Project: Commons Lang
> Issue Type: Bug
> Components: lang.*
>Reporter: Michael Ryan
>Priority: Major
>
> STEPS TO REPRODUCE:
> {code}
> StringUtils.replaceIgnoreCase("\u0130x", "x", "")
> {code}
> EXPECTED: "\u0130" is returned.
> ACTUAL: StringIndexOutOfBoundsException
> This happens because the replace method is assuming that text.length() ==
> text.toLowerCase().length(), which is not true for certain characters.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] commons-lang issue #340: [LANG-1406] StringIndexOutOfBoundsException in Stri...
Github user kinow commented on the issue: https://github.com/apache/commons-lang/pull/340 Good progress so far @HiuKwok . Understanding the problem well is a good first step to solve it ð my next development cycle for Apache will probably be for a release for Apache Commons Imaging, then after that Lang+Text. So will try to help here if you haven't found a way to solve it yet. ---
[jira] [Commented] (LANG-1406) StringIndexOutOfBoundsException in StringUtils.replaceIgnoreCase
[
https://issues.apache.org/jira/browse/LANG-1406?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16604916#comment-16604916
]
ASF GitHub Bot commented on LANG-1406:
--
Github user kinow commented on the issue:
https://github.com/apache/commons-lang/pull/340
Good progress so far @HiuKwok . Understanding the problem well is a good
first step to solve it 👍 my next development cycle for Apache will probably be
for a release for Apache Commons Imaging, then after that Lang+Text. So will
try to help here if you haven't found a way to solve it yet.
> StringIndexOutOfBoundsException in StringUtils.replaceIgnoreCase
>
>
> Key: LANG-1406
> URL: https://issues.apache.org/jira/browse/LANG-1406
> Project: Commons Lang
> Issue Type: Bug
> Components: lang.*
>Reporter: Michael Ryan
>Priority: Major
>
> STEPS TO REPRODUCE:
> {code}
> StringUtils.replaceIgnoreCase("\u0130x", "x", "")
> {code}
> EXPECTED: "\u0130" is returned.
> ACTUAL: StringIndexOutOfBoundsException
> This happens because the replace method is assuming that text.length() ==
> text.toLowerCase().length(), which is not true for certain characters.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] commons-lang issue #354: Convert tests for Validate.isTrue overloads to @Nes...
Github user PascalSchumacher commented on the issue: https://github.com/apache/commons-lang/pull/354 +1 ---
[jira] [Resolved] (DBCP-520) BasicManagedDataSource needs to pass the TSR with creating DataSourceXAConnectionFactory
[ https://issues.apache.org/jira/browse/DBCP-520?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gary Gregory resolved DBCP-520. --- Resolution: Fixed Fix Version/s: 2.6.0 [~zhfeng], Thank you for your patch. This is in git master. Please verify and close. Gary > BasicManagedDataSource needs to pass the TSR with creating > DataSourceXAConnectionFactory > > > Key: DBCP-520 > URL: https://issues.apache.org/jira/browse/DBCP-520 > Project: Commons DBCP > Issue Type: Improvement >Affects Versions: 2.5.0 >Reporter: Zheng Feng >Priority: Major > Fix For: 2.6.0 > > > As the TransactionSynchronizationRegistry has been introduced in the 2.5.0, > it needs to pass the transactionSynchronizationRegistry to create the > DataSourceXAConnectionFactory. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (GEOMETRY-9) New Euclidean Vector Methods
[ https://issues.apache.org/jira/browse/GEOMETRY-9?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16605168#comment-16605168 ] Matt Juntunen commented on GEOMETRY-9: -- # This is something I've been going back and forth on. We throw exceptions in several methods when we encounter vectors with zero norms, however the circumstances of the method call vary and makes the actual type of exception hard to decide on. For example, the Vector3D.angle(Vector3D) method requires that both vectors have zero norms. So, should we throw an IllegalStateException if the calling vector has a zero norm and an IllegalArgumentException if the argument does? If a user wants to catch a zero norm in this situation, would they then need to catch both exception types? I've been trying to avoid this by using an IllegalStateException for all zero norm situations but this doesn't quite feel right. I know we've talked about this before, but I'd really like to go back to having a general GeometryException class with a ZeroNormException subclass. That would be the most useful to me as a user of the library, since I could catch a single exception hierarchy for geometric errors. # I see what you're saying, but I think that Vectors is legitimate as a utility class. It contains only well-defined mathematical equations and saves us from having to duplicate the code in other places. For example, Vectors.norm(double, double, double) is used in Point3D.distance(), Vector3D.distance(), Vector3D.getNorm(), and one more place that I added for GEOMETRY-10. # I did this partly because there were already several existing methods following the same pattern and partly because I think in some situations, using a static method can make code slightly easier to read. For example, I usually picture the dot product as an operator in its own right and not as something that a vector does, so I may want to write Vector3D.dotProduct(v1, v2) as opposed to v1.dotProduct(v2) when coding an algorithm. Those are really the only reasons. > New Euclidean Vector Methods > > > Key: GEOMETRY-9 > URL: https://issues.apache.org/jira/browse/GEOMETRY-9 > Project: Apache Commons Geometry > Issue Type: Wish >Reporter: Matt Juntunen >Priority: Minor > > We should add some more methods to the Euclidean vector classes for user > convenience and algorithm clarity. > # length() – more intuitive alias for getNorm() > # project(Vector) – returns the current vector projected onto the given > vector > # static project(Vector, Vector) – static version of project > # reject(Vector) – returns the current vector projected onto the plane whose > normal is passed to the method (vec equals vec.project(v) + vec.reject(v)) > # static reject(Vector, Vector) – static version of reject > # lerp(Vector, double) – linear interpolation between the current vector and > the given one > # static lerp(Vector, Vector, double) – static version of lerp > # withLength(double) – returns the current vector with the given length. > This is equivalent to vector.normalize().scalarMultiply(x) but without the > intermediate vector. > > Pull request: [https://github.com/apache/commons-geometry/pull/8] -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (LANG-1418) Incorrect Javadoc for StringUtils.isAnyBlank(null)
Andrei created LANG-1418: Summary: Incorrect Javadoc for StringUtils.isAnyBlank(null) Key: LANG-1418 URL: https://issues.apache.org/jira/browse/LANG-1418 Project: Commons Lang Issue Type: Bug Components: lang.* Affects Versions: 3.8 Reporter: Andrei Attachments: apache-common.isAnyBlank(null).png As of [https://commons.apache.org/proper/commons-lang/apidocs/org/apache/commons/lang3/StringUtils.html#isAnyBlank-java.lang.CharSequence...-] isAnyBlank((String) null) -> true But test isAnyBlank((String) null) -> false. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (LANG-1418) Incorrect Javadoc for StringUtils.isAnyBlank(null)
[ https://issues.apache.org/jira/browse/LANG-1418?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Andrei updated LANG-1418: - Description: As of [https://commons.apache.org/proper/commons-lang/apidocs/org/apache/commons/lang3/StringUtils.html#isAnyBlank-java.lang.CharSequence...-] isAnyBlank((String) null) -> true But test isAnyBlank((String) null) -> false. As the result incorrect description for the other methods that used isAnyBlank was: As of [https://commons.apache.org/proper/commons-lang/apidocs/org/apache/commons/lang3/StringUtils.html#isAnyBlank-java.lang.CharSequence...-] isAnyBlank((String) null) -> true But test isAnyBlank((String) null) -> false. > Incorrect Javadoc for StringUtils.isAnyBlank(null) > -- > > Key: LANG-1418 > URL: https://issues.apache.org/jira/browse/LANG-1418 > Project: Commons Lang > Issue Type: Bug > Components: lang.* >Affects Versions: 3.8 >Reporter: Andrei >Priority: Major > Attachments: apache-common.isAnyBlank(null).png > > > As of > [https://commons.apache.org/proper/commons-lang/apidocs/org/apache/commons/lang3/StringUtils.html#isAnyBlank-java.lang.CharSequence...-] > isAnyBlank((String) null) -> true > But test isAnyBlank((String) null) -> false. > As the result incorrect description for the other methods that used isAnyBlank -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Closed] (DBCP-520) BasicManagedDataSource needs to pass the TSR with creating DataSourceXAConnectionFactory
[ https://issues.apache.org/jira/browse/DBCP-520?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Zheng Feng closed DBCP-520. --- > BasicManagedDataSource needs to pass the TSR with creating > DataSourceXAConnectionFactory > > > Key: DBCP-520 > URL: https://issues.apache.org/jira/browse/DBCP-520 > Project: Commons DBCP > Issue Type: Improvement >Affects Versions: 2.5.0 >Reporter: Zheng Feng >Priority: Major > Fix For: 2.6.0 > > > As the TransactionSynchronizationRegistry has been introduced in the 2.5.0, > it needs to pass the transactionSynchronizationRegistry to create the > DataSourceXAConnectionFactory. -- This message was sent by Atlassian JIRA (v7.6.3#76005)