[jira] [Commented] (DRILL-6353) Upgrade Parquet MR dependencies
[
https://issues.apache.org/jira/browse/DRILL-6353?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16490118#comment-16490118
]
ASF GitHub Bot commented on DRILL-6353:
---
vrozov commented on a change in pull request #1259: DRILL-6353: Upgrade Parquet
MR dependencies
URL: https://github.com/apache/drill/pull/1259#discussion_r190774252
##
File path:
exec/java-exec/src/test/java/org/apache/drill/exec/store/parquet/TestParquetMetadataCache.java
##
@@ -737,6 +738,7 @@ public void testBooleanPartitionPruning() throws Exception
{
}
}
+ @Ignore
Review comment:
It will be good if you can point to JIRA with the fix that Drill uses to
correct statistics. Without JIRA it is not clear what particular fix is used by
Drill to workaround bugs in how parquet library handles statistics and for what
data types.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Upgrade Parquet MR dependencies
> ---
>
> Key: DRILL-6353
> URL: https://issues.apache.org/jira/browse/DRILL-6353
> Project: Apache Drill
> Issue Type: Task
>Reporter: Vlad Rozov
>Assignee: Vlad Rozov
>Priority: Major
> Fix For: 1.14.0
>
>
> Upgrade from a custom build {{1.8.1-drill-r0}} to Apache release {{1.10.0}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6443) Search feature for profiles is available only for running OR completed queries, but not both
[
https://issues.apache.org/jira/browse/DRILL-6443?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16490017#comment-16490017
]
ASF GitHub Bot commented on DRILL-6443:
---
Ben-Zvi closed pull request #1287: DRILL-6443: Enable Search for both running
AND completed queries
URL: https://github.com/apache/drill/pull/1287
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/exec/java-exec/src/main/resources/rest/profile/list.ftl
b/exec/java-exec/src/main/resources/rest/profile/list.ftl
index 6a8b51dc72..f9334b891f 100644
--- a/exec/java-exec/src/main/resources/rest/profile/list.ftl
+++ b/exec/java-exec/src/main/resources/rest/profile/list.ftl
@@ -23,26 +23,28 @@
$(document).ready(function() {
- $("#profileList").DataTable( {
-//Preserve order
-"ordering": false,
-"searching": true,
-"paging": true,
-"pagingType": "first_last_numbers",
-"lengthMenu": [[10, 25, 50, -1], [10, 25, 50, "All"]],
-"lengthChange": true,
-"info": true,
-//Ref: https://legacy.datatables.net/ref#sDom
-"sDom": '<"top"lftip><"bottom"><"clear">',
-//Customized info labels
-"language": {
-"lengthMenu": "Display _MENU_ profiles per page",
-"zeroRecords": "No matching profiles found!",
-"info": "Showing page _PAGE_ of _PAGES_ ",
-"infoEmpty": "No profiles available",
-"infoFiltered": "(filtered _TOTAL_ from _MAX_)",
-"search": "Search Profiles "
-}
+ $.each(["running","completed"], function(i, key) {
+$("#profileList_"+key).DataTable( {
+ //Preserve order
+ "ordering": false,
+ "searching": true,
+ "paging": true,
+ "pagingType": "full_numbers",
+ "lengthMenu": [[10, 25, 50, -1], [10, 25, 50, "All"]],
+ "lengthChange": true,
+ "info": true,
+ //Ref: https://legacy.datatables.net/ref#sDom
+ "sDom": '<"top"lftip><"bottom"><"clear">',
+ //Customized info labels
+ "language": {
+ "lengthMenu": "Display _MENU_ profiles per page",
+ "zeroRecords": "No matching profiles found!",
+ "info": "Showing page _PAGE_ of _PAGES_ ",
+ "infoEmpty": "No profiles available",
+ "infoFiltered": "(filtered _TOTAL_ from _MAX_)",
+ "search": "Search Profiles "
+ }
+} );
} );
} );
@@ -94,7 +96,7 @@
<#if (model.getRunningQueries()?size > 0) >
Running Queries
-<@list_queries queries=model.getRunningQueries()/>
+<@list_queries queries=model.getRunningQueries() stateList="running" />
<#else>
@@ -139,12 +141,12 @@
$("#fetchMax").val(maxFetched);
});
- <@list_queries queries=model.getFinishedQueries()/>
+ <@list_queries queries=model.getFinishedQueries() stateList="completed" />
-<#macro list_queries queries>
+<#macro list_queries queries stateList>
-
+
Time
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Search feature for profiles is available only for running OR completed
> queries, but not both
>
>
> Key: DRILL-6443
> URL: https://issues.apache.org/jira/browse/DRILL-6443
> Project: Apache Drill
> Issue Type: Bug
> Components: Web Server
>Affects Versions: 1.13.0
>Reporter: Kunal Khatua
>Assignee: Kunal Khatua
>Priority: Major
> Labels: ready-to-commit
> Fix For: 1.14.0
>
> Original Estimate: 48h
> Remaining Estimate: 48h
>
> When running a query in Drill, the {{/profiles}} page will show the search
> (and pagination) capabilities only for the top most visible table (i.e.
> _Running Queries_ ).
> The _Completed Queries_ table will show the search feature only when there
> are no running queries. This is because the backend uses a generalized
> freemarker macro to define the seach capabilities for the tables being
> rendered. With running queries, both, _running_ and _completed queries_
> tables
[jira] [Commented] (DRILL-6353) Upgrade Parquet MR dependencies
[
https://issues.apache.org/jira/browse/DRILL-6353?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489988#comment-16489988
]
ASF GitHub Bot commented on DRILL-6353:
---
parthchandra commented on a change in pull request #1259: DRILL-6353: Upgrade
Parquet MR dependencies
URL: https://github.com/apache/drill/pull/1259#discussion_r190758787
##
File path:
exec/java-exec/src/test/java/org/apache/drill/exec/store/parquet/TestParquetMetadataCache.java
##
@@ -737,6 +738,7 @@ public void testBooleanPartitionPruning() throws Exception
{
}
}
+ @Ignore
Review comment:
Hmm, we need to take a look at this. For a period of two years, files
written by tools using Parquet libraries were writing incorrect statistics, but
because Drill had its own build where we had fixed the issue (we found the
issue in the first place), files written by Drill were correct. A very large
number of Drill users use the Parquet files produced by Drill and it was
decided that we cannot penalize them. We provided a migration tool to users to
tag files produced by Drill. The tool added information in the extra metadata
in Parquet files to indicate the file was written by Drill and stats from these
files should be allowed.
AFAIK, this should be in the current build of Drill Parquet as well as in
the Parquet library v 1.8.2 and above.
Do you know if the stats corruption that affects these tests is something
that was fixed in a version after 1.8.2?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Upgrade Parquet MR dependencies
> ---
>
> Key: DRILL-6353
> URL: https://issues.apache.org/jira/browse/DRILL-6353
> Project: Apache Drill
> Issue Type: Task
>Reporter: Vlad Rozov
>Assignee: Vlad Rozov
>Priority: Major
> Fix For: 1.14.0
>
>
> Upgrade from a custom build {{1.8.1-drill-r0}} to Apache release {{1.10.0}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6445) Fix existing test cases in TestScripts.java and add new test case for DRILLBIT_CONTEXT variable
[ https://issues.apache.org/jira/browse/DRILL-6445?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Pritesh Maker updated DRILL-6445: - Reviewer: Timothy Farkas > Fix existing test cases in TestScripts.java and add new test case for > DRILLBIT_CONTEXT variable > --- > > Key: DRILL-6445 > URL: https://issues.apache.org/jira/browse/DRILL-6445 > Project: Apache Drill > Issue Type: Task >Reporter: Sorabh Hamirwasia >Assignee: Sorabh Hamirwasia >Priority: Major > Fix For: 1.14.0 > > > Under drill-yarn module there is [TestScripts.java > file|https://github.com/apache/drill/blob/master/drill-yarn/src/test/java/org/apache/drill/yarn/scripts/TestScripts.java] > created for testing the scripts provided by Drill to setup the environment. > Currently those tests are failing. This Jira is to make sure all the tests > are passing and few new tests are added for DRILLBIT_CONTEXT variable inside > the script. > Also currently these tests are ignored and meant to be run in Developer > environment. May be we can investigate in future to provide support for it to > be run as regular tests by using DirTestWatcher -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6435) MappingSet is stateful, so it can't be shared between threads
[
https://issues.apache.org/jira/browse/DRILL-6435?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489869#comment-16489869
]
ASF GitHub Bot commented on DRILL-6435:
---
Ben-Zvi closed pull request #1286: DRILL-6435: MappingSet is stateful, so it
can't be shared between threads
URL: https://github.com/apache/drill/pull/1286
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/TopN/TopNBatch.java
b/exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/TopN/TopNBatch.java
index 39297144cd..366e4e 100644
---
a/exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/TopN/TopNBatch.java
+++
b/exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/TopN/TopNBatch.java
@@ -72,9 +72,9 @@
public class TopNBatch extends AbstractRecordBatch {
static final org.slf4j.Logger logger =
org.slf4j.LoggerFactory.getLogger(TopNBatch.class);
- public final MappingSet mainMapping = createMainMappingSet();
- public final MappingSet leftMapping = createLeftMappingSet();
- public final MappingSet rightMapping = createRightMappingSet();
+ private final MappingSet mainMapping = createMainMappingSet();
+ private final MappingSet leftMapping = createLeftMappingSet();
+ private final MappingSet rightMapping = createRightMappingSet();
private final int batchPurgeThreshold;
private final boolean codegenDump;
diff --git
a/exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/join/MergeJoinBatch.java
b/exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/join/MergeJoinBatch.java
index 9713b70d29..a5c2ae7318 100644
---
a/exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/join/MergeJoinBatch.java
+++
b/exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/join/MergeJoinBatch.java
@@ -73,23 +73,23 @@
private static final org.slf4j.Logger logger =
org.slf4j.LoggerFactory.getLogger(MergeJoinBatch.class);
- public final MappingSet setupMapping =
+ private final MappingSet setupMapping =
new MappingSet("null", "null",
GM("doSetup", "doSetup", null, null),
GM("doSetup", "doSetup", null, null));
- public final MappingSet copyLeftMapping =
+ private final MappingSet copyLeftMapping =
new MappingSet("leftIndex", "outIndex",
GM("doSetup", "doSetup", null, null),
GM("doSetup", "doCopyLeft", null, null));
- public final MappingSet copyRightMappping =
+ private final MappingSet copyRightMappping =
new MappingSet("rightIndex", "outIndex",
GM("doSetup", "doSetup", null, null),
GM("doSetup", "doCopyRight", null, null));
- public final MappingSet compareMapping =
+ private final MappingSet compareMapping =
new MappingSet("leftIndex", "rightIndex",
GM("doSetup", "doSetup", null, null),
GM("doSetup", "doCompare", null, null));
- public final MappingSet compareRightMapping =
+ private final MappingSet compareRightMapping =
new MappingSet("rightIndex", "null",
GM("doSetup", "doSetup", null, null),
GM("doSetup", "doCompare", null, null));
diff --git
a/exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/join/NestedLoopJoinBatch.java
b/exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/join/NestedLoopJoinBatch.java
index 03bf58b36b..ae14fb3ec9 100644
---
a/exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/join/NestedLoopJoinBatch.java
+++
b/exec/java-exec/src/main/java/org/apache/drill/exec/physical/impl/join/NestedLoopJoinBatch.java
@@ -111,17 +111,17 @@
// Mapping set for the right side
- private static final MappingSet emitRightMapping =
+ private final MappingSet emitRightMapping =
new MappingSet("rightCompositeIndex" /* read index */, "outIndex" /*
write index */, "rightContainer" /* read container */,
"outgoing" /* write container */, EMIT_RIGHT_CONSTANT, EMIT_RIGHT);
// Mapping set for the left side
- private static final MappingSet emitLeftMapping = new MappingSet("leftIndex"
/* read index */, "outIndex" /* write index */,
+ private final MappingSet emitLeftMapping = new MappingSet("leftIndex" /*
read index */, "outIndex" /* write index */,
"leftBatch" /* read container */,
"outgoing" /* write container */,
EMIT_LEFT_CONSTANT, EMIT_LEFT);
- private static final MappingSet SETUP_LEFT_MAPPING = new
MappingSet("leftIndex" /* read index */, "outIndex" /* write index */,
+ private final MappingSet SETUP_LEFT_MAPPING = new MappingSet("leftIndex" /*
read index */, "outIndex" /* write index */,
"leftBatch" /* read container */,
"outgoing" /* write
[jira] [Commented] (DRILL-6445) Fix existing test cases in TestScripts.java and add new test case for DRILLBIT_CONTEXT variable
[ https://issues.apache.org/jira/browse/DRILL-6445?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489706#comment-16489706 ] ASF GitHub Bot commented on DRILL-6445: --- sohami opened a new pull request #1289: DRILL-6445: Fix existing test cases in TestScripts.java and add new t… URL: https://github.com/apache/drill/pull/1289 …est case for DRILLBIT_CONTEXT variable This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Fix existing test cases in TestScripts.java and add new test case for > DRILLBIT_CONTEXT variable > --- > > Key: DRILL-6445 > URL: https://issues.apache.org/jira/browse/DRILL-6445 > Project: Apache Drill > Issue Type: Task >Reporter: Sorabh Hamirwasia >Assignee: Sorabh Hamirwasia >Priority: Major > Fix For: 1.14.0 > > > Under drill-yarn module there is [TestScripts.java > file|https://github.com/apache/drill/blob/master/drill-yarn/src/test/java/org/apache/drill/yarn/scripts/TestScripts.java] > created for testing the scripts provided by Drill to setup the environment. > Currently those tests are failing. This Jira is to make sure all the tests > are passing and few new tests are added for DRILLBIT_CONTEXT variable inside > the script. > Also currently these tests are ignored and meant to be run in Developer > environment. May be we can investigate in future to provide support for it to > be run as regular tests by using DirTestWatcher -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6353) Upgrade Parquet MR dependencies
[
https://issues.apache.org/jira/browse/DRILL-6353?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489703#comment-16489703
]
ASF GitHub Bot commented on DRILL-6353:
---
vrozov commented on a change in pull request #1259: DRILL-6353: Upgrade Parquet
MR dependencies
URL: https://github.com/apache/drill/pull/1259#discussion_r190715129
##
File path:
exec/java-exec/src/test/java/org/apache/drill/exec/store/parquet/TestParquetMetadataCache.java
##
@@ -737,6 +738,7 @@ public void testBooleanPartitionPruning() throws Exception
{
}
}
+ @Ignore
Review comment:
The tests fail during plan validation as the new version of the parquet
library ignores wrong statistics for the data types used by queries. Even if
statistics is wrong for a small portion of parquet files and for the parquet
files used by the tests it is correct, Drill can't rely on wrong statistics as
it leads to the wrong query results. Basically, there is a bug in the version
of the parquet library that Drill currently uses that may cause query result to
be wrong and this bug is fixed in the new version causing 2 unit tests
failures. IMO, it is better to upgrade to the new library sooner than later
even if it will cause slowdown for some queries.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Upgrade Parquet MR dependencies
> ---
>
> Key: DRILL-6353
> URL: https://issues.apache.org/jira/browse/DRILL-6353
> Project: Apache Drill
> Issue Type: Task
>Reporter: Vlad Rozov
>Assignee: Vlad Rozov
>Priority: Major
> Fix For: 1.14.0
>
>
> Upgrade from a custom build {{1.8.1-drill-r0}} to Apache release {{1.10.0}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6445) Fix existing test cases in TestScripts.java and add new test case for DRILLBIT_CONTEXT variable
[ https://issues.apache.org/jira/browse/DRILL-6445?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sorabh Hamirwasia updated DRILL-6445: - Description: Under drill-yarn module there is [TestScripts.java file|https://github.com/apache/drill/blob/master/drill-yarn/src/test/java/org/apache/drill/yarn/scripts/TestScripts.java] created for testing the scripts provided by Drill to setup the environment. Currently those tests are failing. This Jira is to make sure all the tests are passing and few new tests are added for DRILLBIT_CONTEXT variable inside the script. Also currently these tests are ignored and meant to be run in Developer environment. May be we can investigate in future to provide support for it to be run as regular tests by using DirTestWatcher was:Under drill-yarn module there is [TestScripts.java file|https://github.com/apache/drill/blob/master/drill-yarn/src/test/java/org/apache/drill/yarn/scripts/TestScripts.java] created for testing the scripts provided by Drill to setup the environment. Currently those tests are failing. This Jira is to make sure all the tests are passing and few new tests are added for DRILLBIT_CONTEXT variable inside the script. > Fix existing test cases in TestScripts.java and add new test case for > DRILLBIT_CONTEXT variable > --- > > Key: DRILL-6445 > URL: https://issues.apache.org/jira/browse/DRILL-6445 > Project: Apache Drill > Issue Type: Task >Reporter: Sorabh Hamirwasia >Assignee: Sorabh Hamirwasia >Priority: Major > Fix For: 1.14.0 > > > Under drill-yarn module there is [TestScripts.java > file|https://github.com/apache/drill/blob/master/drill-yarn/src/test/java/org/apache/drill/yarn/scripts/TestScripts.java] > created for testing the scripts provided by Drill to setup the environment. > Currently those tests are failing. This Jira is to make sure all the tests > are passing and few new tests are added for DRILLBIT_CONTEXT variable inside > the script. > Also currently these tests are ignored and meant to be run in Developer > environment. May be we can investigate in future to provide support for it to > be run as regular tests by using DirTestWatcher -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (DRILL-6445) Fix existing test cases in TestScripts.java and add new test case for DRILLBIT_CONTEXT variable
Sorabh Hamirwasia created DRILL-6445: Summary: Fix existing test cases in TestScripts.java and add new test case for DRILLBIT_CONTEXT variable Key: DRILL-6445 URL: https://issues.apache.org/jira/browse/DRILL-6445 Project: Apache Drill Issue Type: Task Reporter: Sorabh Hamirwasia Assignee: Sorabh Hamirwasia Fix For: 1.14.0 Under drill-yarn module there is [TestScripts.java file|https://github.com/apache/drill/blob/master/drill-yarn/src/test/java/org/apache/drill/yarn/scripts/TestScripts.java] created for testing the scripts provided by Drill to setup the environment. Currently those tests are failing. This Jira is to make sure all the tests are passing and few new tests are added for DRILLBIT_CONTEXT variable inside the script. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6438) Remove excess logging from tests
[
https://issues.apache.org/jira/browse/DRILL-6438?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489545#comment-16489545
]
ASF GitHub Bot commented on DRILL-6438:
---
ilooner commented on issue #1284: DRILL-6438: Remove excess logging form some
tests.
URL: https://github.com/apache/drill/pull/1284#issuecomment-391815016
Sure I'll try to remove them from the other tests as well. Some of the extra
logging I might not be able to remove. For example a lot of the MongoDB logging
comes from separate MongoDB server processes the test launches with the
flapadoodle library.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Remove excess logging from tests
>
>
> Key: DRILL-6438
> URL: https://issues.apache.org/jira/browse/DRILL-6438
> Project: Apache Drill
> Issue Type: Improvement
>Reporter: Timothy Farkas
>Assignee: Timothy Farkas
>Priority: Major
> Fix For: 1.14.0
>
>
> TestLocalExchange and TestLoad have this issue.
> See example
> {code}
> Running
> org.apache.drill.exec.physical.impl.TestLocalExchange#testGroupByMultiFields
> Plan: {
> "head" : {
> "version" : 1,
> "generator" : {
> "type" : "ExplainHandler",
> "info" : ""
> },
> "type" : "APACHE_DRILL_PHYSICAL",
> "options" : [ {
> "kind" : "LONG",
> "accessibleScopes" : "ALL",
> "name" : "planner.width.max_per_node",
> "num_val" : 2,
> "scope" : "SESSION"
> }, {
> "kind" : "BOOLEAN",
> "accessibleScopes" : "ALL",
> "name" : "planner.enable_mux_exchange",
> "bool_val" : true,
> "scope" : "SESSION"
> }, {
> "kind" : "BOOLEAN",
> "accessibleScopes" : "ALL",
> "name" : "planner.enable_demux_exchange",
> "bool_val" : false,
> "scope" : "SESSION"
> }, {
> "kind" : "LONG",
> "accessibleScopes" : "ALL",
> "name" : "planner.slice_target",
> "num_val" : 1,
> "scope" : "SESSION"
> } ],
> "queue" : 0,
> "hasResourcePlan" : false,
> "resultMode" : "EXEC"
> },
> "graph" : [ {
> "pop" : "fs-scan",
> "@id" : 196611,
> "userName" : "travis",
> "files" : [
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/6.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/9.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/3.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/1.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/2.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/7.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/0.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/5.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/4.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/8.json"
> ],
> "storage" : {
> "type" : "file",
> "enabled" : true,
> "connection" : "file:///",
> "config" : null,
> "workspaces" : {
> "root" : {
> "location" :
> "/home/travis/build/apache/drill/exec/java-exec/./target/org.apache.drill.exec.physical.impl.TestLocalExchange/root",
> "writable" : true,
> "defaultInputFormat" : null,
> "allowAccessOutsideWorkspace" : false
> },
> "tmp" : {
> "location" :
> "/home/travis/build/apache/drill/exec/java-exec/./target/org.apache.drill.exec.physical.impl.TestLocalExchange/dfsTestTmp/1527026062606-0",
> "writable" : true,
> "defaultInputFormat" : null,
> "allowAccessOutsideWorkspace" : false
> },
> "default" : {
> "location" :
> "/home/travis/build/apache/drill/exec/java-exec/./target/org.apache.drill.exec.physical.impl.TestLocalExchange/root",
>
[jira] [Commented] (DRILL-6444) Hash Join: Avoid partitioning when memory is sufficient
[ https://issues.apache.org/jira/browse/DRILL-6444?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489495#comment-16489495 ] Timothy Farkas commented on DRILL-6444: --- This would be a good feature. It would be good to see a design doc of how you plan on introducing this optimization and testing it. Specifically I'm concerned that we'll follow the convention of adding more and more code to the same file, and not adding proper abstractions and unit testing. Could you post a google doc with some of your thoughts on how you plan to implement this? > Hash Join: Avoid partitioning when memory is sufficient > > > Key: DRILL-6444 > URL: https://issues.apache.org/jira/browse/DRILL-6444 > Project: Apache Drill > Issue Type: Improvement > Components: Execution - Relational Operators >Reporter: Boaz Ben-Zvi >Assignee: Boaz Ben-Zvi >Priority: Minor > > The Hash Join Spilling feature introduced partitioning (of the incoming build > side) which adds some overhead (copying the incoming data, row by row). That > happens even when no spilling is needed. > Suggested optimization: Try reading the incoming build data without > partitioning, while checking that enough memory is available. In case the > whole build side (plus hash table) fits in memory - then continue like a > "single partition". In case not, then need to partition the data read so far > and continue as usual (with partitions). > (See optimization 8.1 in the Hash Join Spill design document: > [https://docs.google.com/document/d/1-c_oGQY4E5d58qJYv_zc7ka834hSaB3wDQwqKcMoSAI/edit] > ) > This is currently implemented only for the case of num_partitions = 1 (i.e, > no spilling, and no memory checking). > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6432) Allow to print the visualized query plan only
[ https://issues.apache.org/jira/browse/DRILL-6432?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489435#comment-16489435 ] ASF GitHub Bot commented on DRILL-6432: --- kkhatua commented on issue #1278: DRILL-6432: Show Button to print visualized query plan URL: https://github.com/apache/drill/pull/1278#issuecomment-391794757 Screenshot of Print Dialog. THe printer provides scaling capabilities which would allow users to choose the zoom level as well as the page orientation. On closing the print dialog, the popup window remains open with only the plan available as a popup. 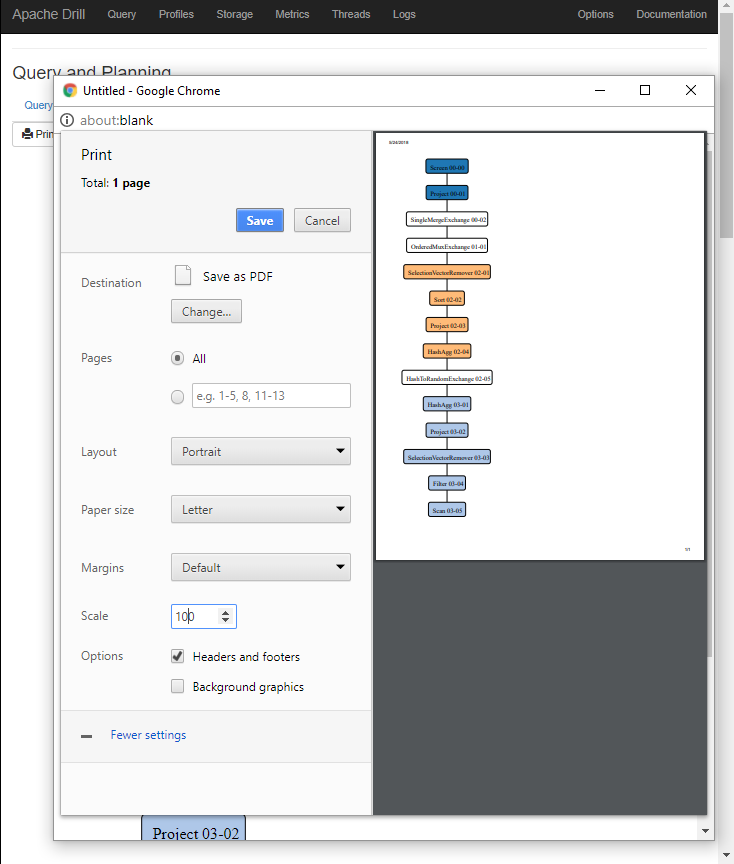 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Allow to print the visualized query plan only > - > > Key: DRILL-6432 > URL: https://issues.apache.org/jira/browse/DRILL-6432 > Project: Apache Drill > Issue Type: New Feature > Components: Web Server >Reporter: Kunal Khatua >Assignee: Kunal Khatua >Priority: Minor > Fix For: 1.14.0 > > > Provide a convenient way to printing the Visual Query Plan only, instead of > the entire profile page. > This allows for capability in specifying the zoom level when printing large > complex plans that might span multiple pages. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6432) Allow to print the visualized query plan only
[ https://issues.apache.org/jira/browse/DRILL-6432?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489431#comment-16489431 ] ASF GitHub Bot commented on DRILL-6432: --- kkhatua commented on issue #1278: DRILL-6432: Show Button to print visualized query plan URL: https://github.com/apache/drill/pull/1278#issuecomment-391794236 Screenshot of the button's appearance:  This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Allow to print the visualized query plan only > - > > Key: DRILL-6432 > URL: https://issues.apache.org/jira/browse/DRILL-6432 > Project: Apache Drill > Issue Type: New Feature > Components: Web Server >Reporter: Kunal Khatua >Assignee: Kunal Khatua >Priority: Minor > Fix For: 1.14.0 > > > Provide a convenient way to printing the Visual Query Plan only, instead of > the entire profile page. > This allows for capability in specifying the zoom level when printing large > complex plans that might span multiple pages. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (DRILL-6444) Hash Join: Avoid partitioning when memory is sufficient
Boaz Ben-Zvi created DRILL-6444: --- Summary: Hash Join: Avoid partitioning when memory is sufficient Key: DRILL-6444 URL: https://issues.apache.org/jira/browse/DRILL-6444 Project: Apache Drill Issue Type: Improvement Components: Execution - Relational Operators Reporter: Boaz Ben-Zvi Assignee: Boaz Ben-Zvi The Hash Join Spilling feature introduced partitioning (of the incoming build side) which adds some overhead (copying the incoming data, row by row). That happens even when no spilling is needed. Suggested optimization: Try reading the incoming build data without partitioning, while checking that enough memory is available. In case the whole build side (plus hash table) fits in memory - then continue like a "single partition". In case not, then need to partition the data read so far and continue as usual (with partitions). (See optimization 8.1 in the Hash Join Spill design document: [https://docs.google.com/document/d/1-c_oGQY4E5d58qJYv_zc7ka834hSaB3wDQwqKcMoSAI/edit] ) This is currently implemented only for the case of num_partitions = 1 (i.e, no spilling, and no memory checking). -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6353) Upgrade Parquet MR dependencies
[
https://issues.apache.org/jira/browse/DRILL-6353?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489332#comment-16489332
]
ASF GitHub Bot commented on DRILL-6353:
---
vrozov commented on a change in pull request #1259: DRILL-6353: Upgrade Parquet
MR dependencies
URL: https://github.com/apache/drill/pull/1259#discussion_r190652287
##
File path:
exec/java-exec/src/test/java/org/apache/drill/exec/store/parquet/TestParquetMetadataCache.java
##
@@ -737,6 +738,7 @@ public void testBooleanPartitionPruning() throws Exception
{
}
}
+ @Ignore
Review comment:
The test needs to be fixed as part of a separate JIRA/PR (another option is
to remove the check for the filter, but IMO it is even less desirable).
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Upgrade Parquet MR dependencies
> ---
>
> Key: DRILL-6353
> URL: https://issues.apache.org/jira/browse/DRILL-6353
> Project: Apache Drill
> Issue Type: Task
>Reporter: Vlad Rozov
>Assignee: Vlad Rozov
>Priority: Major
> Fix For: 1.14.0
>
>
> Upgrade from a custom build {{1.8.1-drill-r0}} to Apache release {{1.10.0}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6332) DrillbitStartupException: Failure while initializing values in Drillbit
[
https://issues.apache.org/jira/browse/DRILL-6332?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489327#comment-16489327
]
Hari Sekhon commented on DRILL-6332:
Yes we have found you need to leave Plain auth enabled for username + password
form login. Otherwise you would have to use Kerberos SpNego.
> DrillbitStartupException: Failure while initializing values in Drillbit
> ---
>
> Key: DRILL-6332
> URL: https://issues.apache.org/jira/browse/DRILL-6332
> Project: Apache Drill
> Issue Type: Improvement
> Components: Server
>Affects Versions: 1.10.0
>Reporter: Hari Sekhon
>Priority: Major
>
> Improvement request to make this error more specific so we can tell what is
> causing it:
> {code:java}
> ==> /opt/mapr/drill/drill-1.10.0/logs/drillbit.out <==
> Exception in thread "main"
> org.apache.drill.exec.exception.DrillbitStartupException: Failure while
> initializing values in Drillbit.
> at org.apache.drill.exec.server.Drillbit.start(Drillbit.java:287)
> at org.apache.drill.exec.server.Drillbit.start(Drillbit.java:271)
> at org.apache.drill.exec.server.Drillbit.main(Drillbit.java:267)
> Caused by: java.lang.IllegalStateException
> at com.google.common.base.Preconditions.checkState(Preconditions.java:158)
> at
> org.apache.drill.common.KerberosUtil.splitPrincipalIntoParts(KerberosUtil.java:59)
> at
> org.apache.drill.exec.server.BootStrapContext.login(BootStrapContext.java:130)
> at
> org.apache.drill.exec.server.BootStrapContext.(BootStrapContext.java:77)
> at org.apache.drill.exec.server.Drillbit.(Drillbit.java:94)
> at org.apache.drill.exec.server.Drillbit.start(Drillbit.java:285)
> ... 2 more
> {code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Assigned] (DRILL-4517) Reading emtpy Parquet file failes with java.lang.IllegalArgumentException
[
https://issues.apache.org/jira/browse/DRILL-4517?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Pritesh Maker reassigned DRILL-4517:
Assignee: salim achouche
> Reading emtpy Parquet file failes with java.lang.IllegalArgumentException
> -
>
> Key: DRILL-4517
> URL: https://issues.apache.org/jira/browse/DRILL-4517
> Project: Apache Drill
> Issue Type: Bug
> Components: Server
>Reporter: Tobias
>Assignee: salim achouche
>Priority: Major
> Attachments: empty.parquet, no_rows.parquet
>
>
> When querying a Parquet file that has a schema but no rows the Drill Server
> will fail with the below
> This looks similar to DRILL-3557
> {noformat}
> {{ParquetMetaData{FileMetaData{schema: message TRANSACTION_REPORT {
> required int64 MEMBER_ACCOUNT_ID;
> required int64 TIMESTAMP_IN_HOUR;
> optional int64 APPLICATION_ID;
> }
> , metadata: {}}}, blocks: []}
> {noformat}
> {noformat}
> Caused by: java.lang.IllegalArgumentException: MinorFragmentId 0 has no read
> entries assigned
> at
> com.google.common.base.Preconditions.checkArgument(Preconditions.java:92)
> ~[guava-14.0.1.jar:na]
> at
> org.apache.drill.exec.store.parquet.ParquetGroupScan.getSpecificScan(ParquetGroupScan.java:707)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.store.parquet.ParquetGroupScan.getSpecificScan(ParquetGroupScan.java:105)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitGroupScan(Materializer.java:68)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitGroupScan(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractGroupScan.accept(AbstractGroupScan.java:60)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitOp(Materializer.java:102)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitOp(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractPhysicalVisitor.visitProject(AbstractPhysicalVisitor.java:77)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.config.Project.accept(Project.java:51)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitStore(Materializer.java:82)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitStore(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractPhysicalVisitor.visitScreen(AbstractPhysicalVisitor.java:195)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.config.Screen.accept(Screen.java:97)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.SimpleParallelizer.generateWorkUnit(SimpleParallelizer.java:355)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.SimpleParallelizer.getFragments(SimpleParallelizer.java:134)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.getQueryWorkUnit(Foreman.java:518)
> [drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.runPhysicalPlan(Foreman.java:405)
> [drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.runSQL(Foreman.java:926)
> [drill-java-exec-1.5.0.jar:1.5.0]
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Assigned] (DRILL-4517) Reading emtpy Parquet file failes with java.lang.IllegalArgumentException
[
https://issues.apache.org/jira/browse/DRILL-4517?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Pritesh Maker reassigned DRILL-4517:
Assignee: (was: salim achouche)
> Reading emtpy Parquet file failes with java.lang.IllegalArgumentException
> -
>
> Key: DRILL-4517
> URL: https://issues.apache.org/jira/browse/DRILL-4517
> Project: Apache Drill
> Issue Type: Bug
> Components: Server
>Reporter: Tobias
>Priority: Major
> Attachments: empty.parquet, no_rows.parquet
>
>
> When querying a Parquet file that has a schema but no rows the Drill Server
> will fail with the below
> This looks similar to DRILL-3557
> {noformat}
> {{ParquetMetaData{FileMetaData{schema: message TRANSACTION_REPORT {
> required int64 MEMBER_ACCOUNT_ID;
> required int64 TIMESTAMP_IN_HOUR;
> optional int64 APPLICATION_ID;
> }
> , metadata: {}}}, blocks: []}
> {noformat}
> {noformat}
> Caused by: java.lang.IllegalArgumentException: MinorFragmentId 0 has no read
> entries assigned
> at
> com.google.common.base.Preconditions.checkArgument(Preconditions.java:92)
> ~[guava-14.0.1.jar:na]
> at
> org.apache.drill.exec.store.parquet.ParquetGroupScan.getSpecificScan(ParquetGroupScan.java:707)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.store.parquet.ParquetGroupScan.getSpecificScan(ParquetGroupScan.java:105)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitGroupScan(Materializer.java:68)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitGroupScan(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractGroupScan.accept(AbstractGroupScan.java:60)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitOp(Materializer.java:102)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitOp(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractPhysicalVisitor.visitProject(AbstractPhysicalVisitor.java:77)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.config.Project.accept(Project.java:51)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitStore(Materializer.java:82)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitStore(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractPhysicalVisitor.visitScreen(AbstractPhysicalVisitor.java:195)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.config.Screen.accept(Screen.java:97)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.SimpleParallelizer.generateWorkUnit(SimpleParallelizer.java:355)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.SimpleParallelizer.getFragments(SimpleParallelizer.java:134)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.getQueryWorkUnit(Foreman.java:518)
> [drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.runPhysicalPlan(Foreman.java:405)
> [drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.runSQL(Foreman.java:926)
> [drill-java-exec-1.5.0.jar:1.5.0]
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6353) Upgrade Parquet MR dependencies
[
https://issues.apache.org/jira/browse/DRILL-6353?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489308#comment-16489308
]
ASF GitHub Bot commented on DRILL-6353:
---
arina-ielchiieva commented on a change in pull request #1259: DRILL-6353:
Upgrade Parquet MR dependencies
URL: https://github.com/apache/drill/pull/1259#discussion_r190648363
##
File path:
exec/java-exec/src/test/java/org/apache/drill/exec/store/parquet/TestParquetMetadataCache.java
##
@@ -737,6 +738,7 @@ public void testBooleanPartitionPruning() throws Exception
{
}
}
+ @Ignore
Review comment:
In this case, I don't think it's a good idea to disable unit tests. You can
consider asking for help to resolve unit tests failures but not disable them.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Upgrade Parquet MR dependencies
> ---
>
> Key: DRILL-6353
> URL: https://issues.apache.org/jira/browse/DRILL-6353
> Project: Apache Drill
> Issue Type: Task
>Reporter: Vlad Rozov
>Assignee: Vlad Rozov
>Priority: Major
> Fix For: 1.14.0
>
>
> Upgrade from a custom build {{1.8.1-drill-r0}} to Apache release {{1.10.0}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6353) Upgrade Parquet MR dependencies
[
https://issues.apache.org/jira/browse/DRILL-6353?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489281#comment-16489281
]
ASF GitHub Bot commented on DRILL-6353:
---
vrozov commented on a change in pull request #1259: DRILL-6353: Upgrade Parquet
MR dependencies
URL: https://github.com/apache/drill/pull/1259#discussion_r190642661
##
File path:
exec/java-exec/src/test/java/org/apache/drill/exec/store/parquet/TestParquetMetadataCache.java
##
@@ -737,6 +738,7 @@ public void testBooleanPartitionPruning() throws Exception
{
}
}
+ @Ignore
Review comment:
I do not plan to enable the tests back as part of the PR. The test relies on
wrong statistics and needs to be fixed/modified for the new parquet library. As
I am not familiar with the functionality it tests, I'll file JIRA to work on
enabling those tests.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Upgrade Parquet MR dependencies
> ---
>
> Key: DRILL-6353
> URL: https://issues.apache.org/jira/browse/DRILL-6353
> Project: Apache Drill
> Issue Type: Task
>Reporter: Vlad Rozov
>Assignee: Vlad Rozov
>Priority: Major
> Fix For: 1.14.0
>
>
> Upgrade from a custom build {{1.8.1-drill-r0}} to Apache release {{1.10.0}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-4517) Reading emtpy Parquet file failes with java.lang.IllegalArgumentException
[
https://issues.apache.org/jira/browse/DRILL-4517?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489176#comment-16489176
]
Dave Challis commented on DRILL-4517:
-
I've also attached a Parquet file containing no rows (generated from PyArrow)
in case it helps:
[^no_rows.parquet]
> Reading emtpy Parquet file failes with java.lang.IllegalArgumentException
> -
>
> Key: DRILL-4517
> URL: https://issues.apache.org/jira/browse/DRILL-4517
> Project: Apache Drill
> Issue Type: Bug
> Components: Server
>Reporter: Tobias
>Priority: Major
> Attachments: empty.parquet, no_rows.parquet
>
>
> When querying a Parquet file that has a schema but no rows the Drill Server
> will fail with the below
> This looks similar to DRILL-3557
> {noformat}
> {{ParquetMetaData{FileMetaData{schema: message TRANSACTION_REPORT {
> required int64 MEMBER_ACCOUNT_ID;
> required int64 TIMESTAMP_IN_HOUR;
> optional int64 APPLICATION_ID;
> }
> , metadata: {}}}, blocks: []}
> {noformat}
> {noformat}
> Caused by: java.lang.IllegalArgumentException: MinorFragmentId 0 has no read
> entries assigned
> at
> com.google.common.base.Preconditions.checkArgument(Preconditions.java:92)
> ~[guava-14.0.1.jar:na]
> at
> org.apache.drill.exec.store.parquet.ParquetGroupScan.getSpecificScan(ParquetGroupScan.java:707)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.store.parquet.ParquetGroupScan.getSpecificScan(ParquetGroupScan.java:105)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitGroupScan(Materializer.java:68)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitGroupScan(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractGroupScan.accept(AbstractGroupScan.java:60)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitOp(Materializer.java:102)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitOp(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractPhysicalVisitor.visitProject(AbstractPhysicalVisitor.java:77)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.config.Project.accept(Project.java:51)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitStore(Materializer.java:82)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitStore(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractPhysicalVisitor.visitScreen(AbstractPhysicalVisitor.java:195)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.config.Screen.accept(Screen.java:97)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.SimpleParallelizer.generateWorkUnit(SimpleParallelizer.java:355)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.SimpleParallelizer.getFragments(SimpleParallelizer.java:134)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.getQueryWorkUnit(Foreman.java:518)
> [drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.runPhysicalPlan(Foreman.java:405)
> [drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.runSQL(Foreman.java:926)
> [drill-java-exec-1.5.0.jar:1.5.0]
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-4517) Reading emtpy Parquet file failes with java.lang.IllegalArgumentException
[
https://issues.apache.org/jira/browse/DRILL-4517?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16489125#comment-16489125
]
Arina Ielchiieva commented on DRILL-4517:
-
To reproduce the issue attached empty parquet with the following schema:
{noformat}
message test {
required int32 int_field_1;
required int32 int_field_2;
required binary bin_field;
}
{noformat}
> Reading emtpy Parquet file failes with java.lang.IllegalArgumentException
> -
>
> Key: DRILL-4517
> URL: https://issues.apache.org/jira/browse/DRILL-4517
> Project: Apache Drill
> Issue Type: Bug
> Components: Server
>Reporter: Tobias
>Priority: Major
> Attachments: empty.parquet
>
>
> When querying a Parquet file that has a schema but no rows the Drill Server
> will fail with the below
> This looks similar to DRILL-3557
> {noformat}
> {{ParquetMetaData{FileMetaData{schema: message TRANSACTION_REPORT {
> required int64 MEMBER_ACCOUNT_ID;
> required int64 TIMESTAMP_IN_HOUR;
> optional int64 APPLICATION_ID;
> }
> , metadata: {}}}, blocks: []}
> {noformat}
> {noformat}
> Caused by: java.lang.IllegalArgumentException: MinorFragmentId 0 has no read
> entries assigned
> at
> com.google.common.base.Preconditions.checkArgument(Preconditions.java:92)
> ~[guava-14.0.1.jar:na]
> at
> org.apache.drill.exec.store.parquet.ParquetGroupScan.getSpecificScan(ParquetGroupScan.java:707)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.store.parquet.ParquetGroupScan.getSpecificScan(ParquetGroupScan.java:105)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitGroupScan(Materializer.java:68)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitGroupScan(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractGroupScan.accept(AbstractGroupScan.java:60)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitOp(Materializer.java:102)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitOp(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractPhysicalVisitor.visitProject(AbstractPhysicalVisitor.java:77)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.config.Project.accept(Project.java:51)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitStore(Materializer.java:82)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitStore(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractPhysicalVisitor.visitScreen(AbstractPhysicalVisitor.java:195)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.config.Screen.accept(Screen.java:97)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.SimpleParallelizer.generateWorkUnit(SimpleParallelizer.java:355)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.SimpleParallelizer.getFragments(SimpleParallelizer.java:134)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.getQueryWorkUnit(Foreman.java:518)
> [drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.runPhysicalPlan(Foreman.java:405)
> [drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.runSQL(Foreman.java:926)
> [drill-java-exec-1.5.0.jar:1.5.0]
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-4517) Reading emtpy Parquet file failes with java.lang.IllegalArgumentException
[
https://issues.apache.org/jira/browse/DRILL-4517?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arina Ielchiieva updated DRILL-4517:
Attachment: empty.parquet
> Reading emtpy Parquet file failes with java.lang.IllegalArgumentException
> -
>
> Key: DRILL-4517
> URL: https://issues.apache.org/jira/browse/DRILL-4517
> Project: Apache Drill
> Issue Type: Bug
> Components: Server
>Reporter: Tobias
>Priority: Major
> Attachments: empty.parquet
>
>
> When querying a Parquet file that has a schema but no rows the Drill Server
> will fail with the below
> This looks similar to DRILL-3557
> {noformat}
> {{ParquetMetaData{FileMetaData{schema: message TRANSACTION_REPORT {
> required int64 MEMBER_ACCOUNT_ID;
> required int64 TIMESTAMP_IN_HOUR;
> optional int64 APPLICATION_ID;
> }
> , metadata: {}}}, blocks: []}
> {noformat}
> {noformat}
> Caused by: java.lang.IllegalArgumentException: MinorFragmentId 0 has no read
> entries assigned
> at
> com.google.common.base.Preconditions.checkArgument(Preconditions.java:92)
> ~[guava-14.0.1.jar:na]
> at
> org.apache.drill.exec.store.parquet.ParquetGroupScan.getSpecificScan(ParquetGroupScan.java:707)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.store.parquet.ParquetGroupScan.getSpecificScan(ParquetGroupScan.java:105)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitGroupScan(Materializer.java:68)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitGroupScan(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractGroupScan.accept(AbstractGroupScan.java:60)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitOp(Materializer.java:102)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitOp(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractPhysicalVisitor.visitProject(AbstractPhysicalVisitor.java:77)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.config.Project.accept(Project.java:51)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitStore(Materializer.java:82)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.Materializer.visitStore(Materializer.java:35)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.base.AbstractPhysicalVisitor.visitScreen(AbstractPhysicalVisitor.java:195)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.physical.config.Screen.accept(Screen.java:97)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.SimpleParallelizer.generateWorkUnit(SimpleParallelizer.java:355)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.planner.fragment.SimpleParallelizer.getFragments(SimpleParallelizer.java:134)
> ~[drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.getQueryWorkUnit(Foreman.java:518)
> [drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.runPhysicalPlan(Foreman.java:405)
> [drill-java-exec-1.5.0.jar:1.5.0]
> at
> org.apache.drill.exec.work.foreman.Foreman.runSQL(Foreman.java:926)
> [drill-java-exec-1.5.0.jar:1.5.0]
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6442) Adjust Hbase disk cost & row count estimation when filter push down is applied
[
https://issues.apache.org/jira/browse/DRILL-6442?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Volodymyr Vysotskyi updated DRILL-6442:
---
Labels: ready-to-commit (was: )
> Adjust Hbase disk cost & row count estimation when filter push down is applied
> --
>
> Key: DRILL-6442
> URL: https://issues.apache.org/jira/browse/DRILL-6442
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.13.0
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: ready-to-commit
> Fix For: 1.14.0
>
>
> Disk cost for Hbase scan is calculated based on scan size in bytes.
> {noformat}
> float diskCost = scanSizeInBytes * ((columns == null || columns.isEmpty()) ?
> 1 : columns.size() / statsCalculator.getColsPerRow());
> {noformat}
> Scan size is bytes is estimated using {{TableStatsCalculator}} with the help
> of sampling.
> When we estimate size for the first time (before applying filter push down),
> for sampling we use random rows. When estimating rows after filter push down,
> for sampling we use rows that qualify filter condition. It can happen that
> average row size can be higher after filter push down
> than before. Unfortunately since disk cost depends on these calculations,
> plan with filter push down can give higher cost then without it.
> Possible enhancements:
> 1. Currently default row count is 1 million but if during sampling we return
> less rows then expected, it means that our query will return not more rows
> then this number. We can use this number instead of default row count to
> achieve better cost estimations.
> 2. When filter push down was applied, row number was reduced by half in order
> to ensure plan with filter push down will have less cost. Then same should be
> done for disk cost as well.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6442) Adjust Hbase disk cost & row count estimation when filter push down is applied
[
https://issues.apache.org/jira/browse/DRILL-6442?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16488994#comment-16488994
]
ASF GitHub Bot commented on DRILL-6442:
---
arina-ielchiieva opened a new pull request #1288: DRILL-6442: Adjust Hbase disk
cost & row count estimation when filter push down is applied
URL: https://github.com/apache/drill/pull/1288
Details in [DRILL-6442](https://issues.apache.org/jira/browse/DRILL-6442).
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Adjust Hbase disk cost & row count estimation when filter push down is applied
> --
>
> Key: DRILL-6442
> URL: https://issues.apache.org/jira/browse/DRILL-6442
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.13.0
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Fix For: 1.14.0
>
>
> Disk cost for Hbase scan is calculated based on scan size in bytes.
> {noformat}
> float diskCost = scanSizeInBytes * ((columns == null || columns.isEmpty()) ?
> 1 : columns.size() / statsCalculator.getColsPerRow());
> {noformat}
> Scan size is bytes is estimated using {{TableStatsCalculator}} with the help
> of sampling.
> When we estimate size for the first time (before applying filter push down),
> for sampling we use random rows. When estimating rows after filter push down,
> for sampling we use rows that qualify filter condition. It can happen that
> average row size can be higher after filter push down
> than before. Unfortunately since disk cost depends on these calculations,
> plan with filter push down can give higher cost then without it.
> Possible enhancements:
> 1. Currently default row count is 1 million but if during sampling we return
> less rows then expected, it means that our query will return not more rows
> then this number. We can use this number instead of default row count to
> achieve better cost estimations.
> 2. When filter push down was applied, row number was reduced by half in order
> to ensure plan with filter push down will have less cost. Then same should be
> done for disk cost as well.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6442) Adjust Hbase disk cost & row count estimation when filter push down is applied
[
https://issues.apache.org/jira/browse/DRILL-6442?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16488995#comment-16488995
]
ASF GitHub Bot commented on DRILL-6442:
---
arina-ielchiieva commented on issue #1288: DRILL-6442: Adjust Hbase disk cost &
row count estimation when filter push down is applied
URL: https://github.com/apache/drill/pull/1288#issuecomment-391717281
@vvysotskyi please review.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Adjust Hbase disk cost & row count estimation when filter push down is applied
> --
>
> Key: DRILL-6442
> URL: https://issues.apache.org/jira/browse/DRILL-6442
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.13.0
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Fix For: 1.14.0
>
>
> Disk cost for Hbase scan is calculated based on scan size in bytes.
> {noformat}
> float diskCost = scanSizeInBytes * ((columns == null || columns.isEmpty()) ?
> 1 : columns.size() / statsCalculator.getColsPerRow());
> {noformat}
> Scan size is bytes is estimated using {{TableStatsCalculator}} with the help
> of sampling.
> When we estimate size for the first time (before applying filter push down),
> for sampling we use random rows. When estimating rows after filter push down,
> for sampling we use rows that qualify filter condition. It can happen that
> average row size can be higher after filter push down
> than before. Unfortunately since disk cost depends on these calculations,
> plan with filter push down can give higher cost then without it.
> Possible enhancements:
> 1. Currently default row count is 1 million but if during sampling we return
> less rows then expected, it means that our query will return not more rows
> then this number. We can use this number instead of default row count to
> achieve better cost estimations.
> 2. When filter push down was applied, row number was reduced by half in order
> to ensure plan with filter push down will have less cost. Then same should be
> done for disk cost as well.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6332) DrillbitStartupException: Failure while initializing values in Drillbit
[
https://issues.apache.org/jira/browse/DRILL-6332?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16488866#comment-16488866
]
Thomas commented on DRILL-6332:
---
Funny. I figuered the same thing yesterday and was about to write something
here.
The reason is the the following piece of code that rigidly insists on the
respective principal construction...
[https://github.com/apache/drill/blob/master/common/src/main/java/org/apache/drill/common/KerberosUtil.java]
{code:java|borderStyle=solid}
public static String[] splitPrincipalIntoParts(final String principal) {
final String[] components = principal.split("[/@]");
checkState(components.length == 3);
checkNotNull(components[0]);
checkNotNull(components[1]);
checkNotNull(components[2]);
return components;
}
{code}
However, now, I am facing an authentication problem with the webserver
component:
2018-05-24 13:57:54,003 [main] WARN
o.a.d.e.s.r.a.DrillHttpSecurityHandlerProvider - Failed to create
DrillHttpConstra$
org.apache.drill.common.exceptions.DrillException: FORM mechanism was
configured but PLAIN mechanism is not enabled to $
at
org.apache.drill.exec.server.rest.auth.FormSecurityHanlder.doSetup(FormSecurityHanlder.java:40)
~[drill-java$
at
org.apache.drill.exec.server.rest.auth.DrillHttpSecurityHandlerProvider.(DrillHttpSecurityHandlerProvi$
at
org.apache.drill.exec.server.rest.WebServer.createServletContextHandler(WebServer.java:213)
[drill-java-exec$
at
org.apache.drill.exec.server.rest.WebServer.start(WebServer.java:161)
[drill-java-exec-1.13.0.jar:1.13.0]
at org.apache.drill.exec.server.Drillbit.run(Drillbit.java:193)
[drill-java-exec-1.13.0.jar:1.13.0]
at org.apache.drill.exec.server.Drillbit.start(Drillbit.java:398)
[drill-java-exec-1.13.0.jar:1.13.0]
at org.apache.drill.exec.server.Drillbit.start(Drillbit.java:372)
[drill-java-exec-1.13.0.jar:1.13.0]
at org.apache.drill.exec.server.Drillbit.main(Drillbit.java:368)
[drill-java-exec-1.13.0.jar:1.13.0]
2018-05-24 13:57:54,003 [main] ERROR o.apache.drill.exec.server.Drillbit -
Failure during initial startup of Drillbit.
org.apache.drill.exec.exception.DrillbitStartupException: Authentication is
enabled for WebServer but none of the secur$
at
org.apache.drill.exec.server.rest.auth.DrillHttpSecurityHandlerProvider.(DrillHttpSecurityHandlerProvi$
at
org.apache.drill.exec.server.rest.WebServer.createServletContextHandler(WebServer.java:213)
~[drill-java-exe$
at
org.apache.drill.exec.server.rest.WebServer.start(WebServer.java:161)
~[drill-java-exec-1.13.0.jar:1.13.0]
at org.apache.drill.exec.server.Drillbit.run(Drillbit.java:193)
[drill-java-exec-1.13.0.jar:1.13.0]
at org.apache.drill.exec.server.Drillbit.start(Drillbit.java:398)
[drill-java-exec-1.13.0.jar:1.13.0]
I could avoid it by disabling the web interface in the conf like:
{code:java}
http: {
enabled: false
},
{code}
Anny suggestions how to fix the web interface appreciated.
I guess you would also enable "Plain" authentication and require a user to log
in ...?
> DrillbitStartupException: Failure while initializing values in Drillbit
> ---
>
> Key: DRILL-6332
> URL: https://issues.apache.org/jira/browse/DRILL-6332
> Project: Apache Drill
> Issue Type: Improvement
> Components: Server
>Affects Versions: 1.10.0
>Reporter: Hari Sekhon
>Priority: Major
>
> Improvement request to make this error more specific so we can tell what is
> causing it:
> {code:java}
> ==> /opt/mapr/drill/drill-1.10.0/logs/drillbit.out <==
> Exception in thread "main"
> org.apache.drill.exec.exception.DrillbitStartupException: Failure while
> initializing values in Drillbit.
> at org.apache.drill.exec.server.Drillbit.start(Drillbit.java:287)
> at org.apache.drill.exec.server.Drillbit.start(Drillbit.java:271)
> at org.apache.drill.exec.server.Drillbit.main(Drillbit.java:267)
> Caused by: java.lang.IllegalStateException
> at com.google.common.base.Preconditions.checkState(Preconditions.java:158)
> at
> org.apache.drill.common.KerberosUtil.splitPrincipalIntoParts(KerberosUtil.java:59)
> at
> org.apache.drill.exec.server.BootStrapContext.login(BootStrapContext.java:130)
> at
> org.apache.drill.exec.server.BootStrapContext.(BootStrapContext.java:77)
> at org.apache.drill.exec.server.Drillbit.(Drillbit.java:94)
> at org.apache.drill.exec.server.Drillbit.start(Drillbit.java:285)
> ... 2 more
> {code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6332) DrillbitStartupException: Failure while initializing values in Drillbit
[
https://issues.apache.org/jira/browse/DRILL-6332?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16488822#comment-16488822
]
Hari Sekhon commented on DRILL-6332:
In my case this was caused by auth.principal not having a hostname component eg:
{code:java}
mapr/@REALM{code}
rather than
{code:java}
mapr@REALM{code}
> DrillbitStartupException: Failure while initializing values in Drillbit
> ---
>
> Key: DRILL-6332
> URL: https://issues.apache.org/jira/browse/DRILL-6332
> Project: Apache Drill
> Issue Type: Improvement
> Components: Server
>Affects Versions: 1.10.0
>Reporter: Hari Sekhon
>Priority: Major
>
> Improvement request to make this error more specific so we can tell what is
> causing it:
> {code:java}
> ==> /opt/mapr/drill/drill-1.10.0/logs/drillbit.out <==
> Exception in thread "main"
> org.apache.drill.exec.exception.DrillbitStartupException: Failure while
> initializing values in Drillbit.
> at org.apache.drill.exec.server.Drillbit.start(Drillbit.java:287)
> at org.apache.drill.exec.server.Drillbit.start(Drillbit.java:271)
> at org.apache.drill.exec.server.Drillbit.main(Drillbit.java:267)
> Caused by: java.lang.IllegalStateException
> at com.google.common.base.Preconditions.checkState(Preconditions.java:158)
> at
> org.apache.drill.common.KerberosUtil.splitPrincipalIntoParts(KerberosUtil.java:59)
> at
> org.apache.drill.exec.server.BootStrapContext.login(BootStrapContext.java:130)
> at
> org.apache.drill.exec.server.BootStrapContext.(BootStrapContext.java:77)
> at org.apache.drill.exec.server.Drillbit.(Drillbit.java:94)
> at org.apache.drill.exec.server.Drillbit.start(Drillbit.java:285)
> ... 2 more
> {code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6438) Remove excess logging from tests
[
https://issues.apache.org/jira/browse/DRILL-6438?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16488752#comment-16488752
]
ASF GitHub Bot commented on DRILL-6438:
---
vvysotskyi commented on issue #1284: DRILL-6438: Remove excess logging form
some tests.
URL: https://github.com/apache/drill/pull/1284#issuecomment-391652009
@ilooner, could you please remove other places in tests where results are
printed using `System.out.println()`. For example, in `TestHiveUDFs`,
`ExpressionTest`, `TestPartitionSender`, `TestSimpleProjection`,
`TestConvertFunctions`, `TestFragmentChecker`, `JdbcTestActionBase`,
`ITTestShadedJar` it also may be removed; for every HBase test its result is
printed for now.
Mongo and hive tests have a large output, it would be fine to reduce it.
Also, may be changed value of the option `drill.test.query.printing.silent`
to reduce output.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Remove excess logging from tests
>
>
> Key: DRILL-6438
> URL: https://issues.apache.org/jira/browse/DRILL-6438
> Project: Apache Drill
> Issue Type: Improvement
>Reporter: Timothy Farkas
>Assignee: Timothy Farkas
>Priority: Major
> Fix For: 1.14.0
>
>
> TestLocalExchange and TestLoad have this issue.
> See example
> {code}
> Running
> org.apache.drill.exec.physical.impl.TestLocalExchange#testGroupByMultiFields
> Plan: {
> "head" : {
> "version" : 1,
> "generator" : {
> "type" : "ExplainHandler",
> "info" : ""
> },
> "type" : "APACHE_DRILL_PHYSICAL",
> "options" : [ {
> "kind" : "LONG",
> "accessibleScopes" : "ALL",
> "name" : "planner.width.max_per_node",
> "num_val" : 2,
> "scope" : "SESSION"
> }, {
> "kind" : "BOOLEAN",
> "accessibleScopes" : "ALL",
> "name" : "planner.enable_mux_exchange",
> "bool_val" : true,
> "scope" : "SESSION"
> }, {
> "kind" : "BOOLEAN",
> "accessibleScopes" : "ALL",
> "name" : "planner.enable_demux_exchange",
> "bool_val" : false,
> "scope" : "SESSION"
> }, {
> "kind" : "LONG",
> "accessibleScopes" : "ALL",
> "name" : "planner.slice_target",
> "num_val" : 1,
> "scope" : "SESSION"
> } ],
> "queue" : 0,
> "hasResourcePlan" : false,
> "resultMode" : "EXEC"
> },
> "graph" : [ {
> "pop" : "fs-scan",
> "@id" : 196611,
> "userName" : "travis",
> "files" : [
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/6.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/9.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/3.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/1.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/2.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/7.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/0.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/5.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/4.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/8.json"
> ],
> "storage" : {
> "type" : "file",
> "enabled" : true,
> "connection" : "file:///",
> "config" : null,
> "workspaces" : {
> "root" : {
> "location" :
> "/home/travis/build/apache/drill/exec/java-exec/./target/org.apache.drill.exec.physical.impl.TestLocalExchange/root",
> "writable" : true,
> "defaultInputFormat" : null,
> "allowAccessOutsideWorkspace" : false
> },
> "tmp" : {
> "location" :
> "/home/travis/build/apache/drill/exec/java-exec/./target/org.apache.drill.exec.physical.impl.TestLocalExchange/dfsTestTmp/1527026062606-0",
>
[jira] [Updated] (DRILL-6442) Adjust Hbase disk cost & row count estimation when filter push down is applied
[
https://issues.apache.org/jira/browse/DRILL-6442?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arina Ielchiieva updated DRILL-6442:
Description:
Disk cost for Hbase scan is calculated based on scan size in bytes.
{noformat}
float diskCost = scanSizeInBytes * ((columns == null || columns.isEmpty()) ? 1
: columns.size() / statsCalculator.getColsPerRow());
{noformat}
Scan size is bytes is estimated using {{TableStatsCalculator}} with the help of
sampling.
When we estimate size for the first time (before applying filter push down),
for sampling we use random rows. When estimating rows after filter push down,
for sampling we use rows that qualify filter condition. It can happen that
average row size can be higher after filter push down
than before. Unfortunately since disk cost depends on these calculations, plan
with filter push down can give higher cost then without it.
Possible enhancements:
1. Currently default row count is 1 million but if during sampling we return
less rows then expected, it means that our query will return not more rows then
this number. We can use this number instead of default row count to achieve
better cost estimations.
2. When filter push down was applied, row number was reduced by half in order
to ensure plan with filter push down will have less cost. Then same should be
done for disk cost as well.
was:
Disk cost for Hbase scan is calculated based on scan size in bytes.
{noformat}
float diskCost = scanSizeInBytes * ((columns == null || columns.isEmpty()) ? 1
: columns.size() / statsCalculator.getColsPerRow());
{noformat}
Scan size is bytes is estimated using {{TableStatsCalculator}} with the help of
sampling.
When we estimate size for the first time (before applying filter push down),
for sampling we use random rows. When estimating rows after filter push down,
for sampling we use rows that qualify filter condition. It can happen that
average row size can be higher after filter push down
than before. Unfortunately since disk cost depends on these calculations, plan
with filter push down can give higher cost then without it.
Possible enhancements:
1. Currently default row count is 1 million but if during sampling we return
less rows then expected, it means that our query will return not more rows then
this number. We can use this number instead of default row count to achieve
better cost estimations.
2. When filter push down was applied, row number was reduced by half in order
to ensure plan with filter push down will have less cost. Then same should be
done foe disk cost as well.
> Adjust Hbase disk cost & row count estimation when filter push down is applied
> --
>
> Key: DRILL-6442
> URL: https://issues.apache.org/jira/browse/DRILL-6442
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.13.0
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Fix For: 1.14.0
>
>
> Disk cost for Hbase scan is calculated based on scan size in bytes.
> {noformat}
> float diskCost = scanSizeInBytes * ((columns == null || columns.isEmpty()) ?
> 1 : columns.size() / statsCalculator.getColsPerRow());
> {noformat}
> Scan size is bytes is estimated using {{TableStatsCalculator}} with the help
> of sampling.
> When we estimate size for the first time (before applying filter push down),
> for sampling we use random rows. When estimating rows after filter push down,
> for sampling we use rows that qualify filter condition. It can happen that
> average row size can be higher after filter push down
> than before. Unfortunately since disk cost depends on these calculations,
> plan with filter push down can give higher cost then without it.
> Possible enhancements:
> 1. Currently default row count is 1 million but if during sampling we return
> less rows then expected, it means that our query will return not more rows
> then this number. We can use this number instead of default row count to
> achieve better cost estimations.
> 2. When filter push down was applied, row number was reduced by half in order
> to ensure plan with filter push down will have less cost. Then same should be
> done for disk cost as well.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6442) Adjust Hbase disk cost & row count estimation when filter push down is applied
[
https://issues.apache.org/jira/browse/DRILL-6442?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arina Ielchiieva updated DRILL-6442:
Description:
Disk cost for Hbase scan is calculated based on scan size in bytes.
{noformat}
float diskCost = scanSizeInBytes * ((columns == null || columns.isEmpty()) ? 1
: columns.size() / statsCalculator.getColsPerRow());
{noformat}
Scan size is bytes is estimated using {{TableStatsCalculator}} with the help of
sampling.
When we estimate size for the first time (before applying filter push down),
for sampling we use random rows. When estimating rows after filter push down,
for sampling we use rows that qualify filter condition. It can happen that
average row size can be higher after filter push down
than before. Unfortunately since disk cost depends on these calculations, plan
with filter push down can give higher cost then without it.
Possible enhancements:
1. Currently default row count is 1 million but if during sampling we return
less rows then expected, it means that our query will return not more rows then
this number. We can use this number instead of default row count to achieve
better cost estimations.
2. When filter push down was applied, row number was reduced by half in order
to ensure plan with filter push down will have less cost. Then same should be
done foe disk cost as well.
was:
Disk cost for Hbase scan is calculated based on scan size in bytes.
{noformat}
float diskCost = scanSizeInBytes * ((columns == null || columns.isEmpty()) ? 1
: columns.size() / statsCalculator.getColsPerRow());
{noformat}
Scan size is bytes is estimated using {{TableStatsCalculator}} with the help of
sampling.
When we estimate size for the first time (before applying filter push down),
for sampling we use random rows. When estimating rows after filter push down,
for sampling we use rows that qualify filter condition. It can happen that
average row size can be higher after filter push down
than before. Unfortunately since disk cost depends on these calculations, plan
with filter push down can give higher cost then without it.
> Adjust Hbase disk cost & row count estimation when filter push down is applied
> --
>
> Key: DRILL-6442
> URL: https://issues.apache.org/jira/browse/DRILL-6442
> Project: Apache Drill
> Issue Type: Bug
>Affects Versions: 1.13.0
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Fix For: 1.14.0
>
>
> Disk cost for Hbase scan is calculated based on scan size in bytes.
> {noformat}
> float diskCost = scanSizeInBytes * ((columns == null || columns.isEmpty()) ?
> 1 : columns.size() / statsCalculator.getColsPerRow());
> {noformat}
> Scan size is bytes is estimated using {{TableStatsCalculator}} with the help
> of sampling.
> When we estimate size for the first time (before applying filter push down),
> for sampling we use random rows. When estimating rows after filter push down,
> for sampling we use rows that qualify filter condition. It can happen that
> average row size can be higher after filter push down
> than before. Unfortunately since disk cost depends on these calculations,
> plan with filter push down can give higher cost then without it.
> Possible enhancements:
> 1. Currently default row count is 1 million but if during sampling we return
> less rows then expected, it means that our query will return not more rows
> then this number. We can use this number instead of default row count to
> achieve better cost estimations.
> 2. When filter push down was applied, row number was reduced by half in order
> to ensure plan with filter push down will have less cost. Then same should be
> done foe disk cost as well.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6353) Upgrade Parquet MR dependencies
[
https://issues.apache.org/jira/browse/DRILL-6353?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16488724#comment-16488724
]
ASF GitHub Bot commented on DRILL-6353:
---
arina-ielchiieva commented on a change in pull request #1259: DRILL-6353:
Upgrade Parquet MR dependencies
URL: https://github.com/apache/drill/pull/1259#discussion_r190524422
##
File path:
exec/java-exec/src/test/java/org/apache/drill/exec/store/parquet/TestParquetMetadataCache.java
##
@@ -737,6 +738,7 @@ public void testBooleanPartitionPruning() throws Exception
{
}
}
+ @Ignore
Review comment:
@vvysotskyi no worries, work is still in progress.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Upgrade Parquet MR dependencies
> ---
>
> Key: DRILL-6353
> URL: https://issues.apache.org/jira/browse/DRILL-6353
> Project: Apache Drill
> Issue Type: Task
>Reporter: Vlad Rozov
>Assignee: Vlad Rozov
>Priority: Major
> Fix For: 1.14.0
>
>
> Upgrade from a custom build {{1.8.1-drill-r0}} to Apache release {{1.10.0}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6438) Remove excess logging from tests
[
https://issues.apache.org/jira/browse/DRILL-6438?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16488719#comment-16488719
]
ASF GitHub Bot commented on DRILL-6438:
---
vvysotskyi commented on issue #1284: DRILL-6438: Remove excess logging form
some tests.
URL: https://github.com/apache/drill/pull/1284#issuecomment-391652009
@ilooner, could you please remove other places in tests where results are
printed using `System.out.println()`. For example, in TestHiveUDFs it also may
be removed; for every HBase test its result is printed for now.
Also, may be changed value of the option `drill.test.query.printing.silent`
to reduce output.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Remove excess logging from tests
>
>
> Key: DRILL-6438
> URL: https://issues.apache.org/jira/browse/DRILL-6438
> Project: Apache Drill
> Issue Type: Improvement
>Reporter: Timothy Farkas
>Assignee: Timothy Farkas
>Priority: Major
> Fix For: 1.14.0
>
>
> TestLocalExchange and TestLoad have this issue.
> See example
> {code}
> Running
> org.apache.drill.exec.physical.impl.TestLocalExchange#testGroupByMultiFields
> Plan: {
> "head" : {
> "version" : 1,
> "generator" : {
> "type" : "ExplainHandler",
> "info" : ""
> },
> "type" : "APACHE_DRILL_PHYSICAL",
> "options" : [ {
> "kind" : "LONG",
> "accessibleScopes" : "ALL",
> "name" : "planner.width.max_per_node",
> "num_val" : 2,
> "scope" : "SESSION"
> }, {
> "kind" : "BOOLEAN",
> "accessibleScopes" : "ALL",
> "name" : "planner.enable_mux_exchange",
> "bool_val" : true,
> "scope" : "SESSION"
> }, {
> "kind" : "BOOLEAN",
> "accessibleScopes" : "ALL",
> "name" : "planner.enable_demux_exchange",
> "bool_val" : false,
> "scope" : "SESSION"
> }, {
> "kind" : "LONG",
> "accessibleScopes" : "ALL",
> "name" : "planner.slice_target",
> "num_val" : 1,
> "scope" : "SESSION"
> } ],
> "queue" : 0,
> "hasResourcePlan" : false,
> "resultMode" : "EXEC"
> },
> "graph" : [ {
> "pop" : "fs-scan",
> "@id" : 196611,
> "userName" : "travis",
> "files" : [
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/6.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/9.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/3.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/1.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/2.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/7.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/0.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/5.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/4.json",
>
> "file:/home/travis/build/apache/drill/exec/java-exec/target/org.apache.drill.exec.physical.impl.TestLocalExchange/root/empTable/8.json"
> ],
> "storage" : {
> "type" : "file",
> "enabled" : true,
> "connection" : "file:///",
> "config" : null,
> "workspaces" : {
> "root" : {
> "location" :
> "/home/travis/build/apache/drill/exec/java-exec/./target/org.apache.drill.exec.physical.impl.TestLocalExchange/root",
> "writable" : true,
> "defaultInputFormat" : null,
> "allowAccessOutsideWorkspace" : false
> },
> "tmp" : {
> "location" :
> "/home/travis/build/apache/drill/exec/java-exec/./target/org.apache.drill.exec.physical.impl.TestLocalExchange/dfsTestTmp/1527026062606-0",
> "writable" : true,
> "defaultInputFormat" : null,
> "allowAccessOutsideWorkspace" : false
> },
> "default" : {
> "location" :
>
[jira] [Updated] (DRILL-6443) Search feature for profiles is available only for running OR completed queries, but not both
[
https://issues.apache.org/jira/browse/DRILL-6443?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arina Ielchiieva updated DRILL-6443:
Labels: ready-to-commit (was: )
> Search feature for profiles is available only for running OR completed
> queries, but not both
>
>
> Key: DRILL-6443
> URL: https://issues.apache.org/jira/browse/DRILL-6443
> Project: Apache Drill
> Issue Type: Bug
> Components: Web Server
>Affects Versions: 1.13.0
>Reporter: Kunal Khatua
>Assignee: Kunal Khatua
>Priority: Major
> Labels: ready-to-commit
> Fix For: 1.14.0
>
> Original Estimate: 48h
> Remaining Estimate: 48h
>
> When running a query in Drill, the {{/profiles}} page will show the search
> (and pagination) capabilities only for the top most visible table (i.e.
> _Running Queries_ ).
> The _Completed Queries_ table will show the search feature only when there
> are no running queries. This is because the backend uses a generalized
> freemarker macro to define the seach capabilities for the tables being
> rendered. With running queries, both, _running_ and _completed queries_
> tables have the same element ID, resulting in the search capability only
> being applied to the first table.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6443) Search feature for profiles is available only for running OR completed queries, but not both
[
https://issues.apache.org/jira/browse/DRILL-6443?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16488702#comment-16488702
]
ASF GitHub Bot commented on DRILL-6443:
---
arina-ielchiieva commented on issue #1287: DRILL-6443: Enable Search for both
running AND completed queries
URL: https://github.com/apache/drill/pull/1287#issuecomment-391647031
+1
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Search feature for profiles is available only for running OR completed
> queries, but not both
>
>
> Key: DRILL-6443
> URL: https://issues.apache.org/jira/browse/DRILL-6443
> Project: Apache Drill
> Issue Type: Bug
> Components: Web Server
>Affects Versions: 1.13.0
>Reporter: Kunal Khatua
>Assignee: Kunal Khatua
>Priority: Major
> Fix For: 1.14.0
>
> Original Estimate: 48h
> Remaining Estimate: 48h
>
> When running a query in Drill, the {{/profiles}} page will show the search
> (and pagination) capabilities only for the top most visible table (i.e.
> _Running Queries_ ).
> The _Completed Queries_ table will show the search feature only when there
> are no running queries. This is because the backend uses a generalized
> freemarker macro to define the seach capabilities for the tables being
> rendered. With running queries, both, _running_ and _completed queries_
> tables have the same element ID, resulting in the search capability only
> being applied to the first table.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6432) Allow to print the visualized query plan only
[ https://issues.apache.org/jira/browse/DRILL-6432?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16488700#comment-16488700 ] ASF GitHub Bot commented on DRILL-6432: --- arina-ielchiieva commented on issue #1278: DRILL-6432: Show Button to print visualized query plan URL: https://github.com/apache/drill/pull/1278#issuecomment-391646697 @kkhatua please add screenshots. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Allow to print the visualized query plan only > - > > Key: DRILL-6432 > URL: https://issues.apache.org/jira/browse/DRILL-6432 > Project: Apache Drill > Issue Type: New Feature > Components: Web Server >Reporter: Kunal Khatua >Assignee: Kunal Khatua >Priority: Minor > Fix For: 1.14.0 > > > Provide a convenient way to printing the Visual Query Plan only, instead of > the entire profile page. > This allows for capability in specifying the zoom level when printing large > complex plans that might span multiple pages. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6353) Upgrade Parquet MR dependencies
[
https://issues.apache.org/jira/browse/DRILL-6353?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16488546#comment-16488546
]
ASF GitHub Bot commented on DRILL-6353:
---
vvysotskyi commented on a change in pull request #1259: DRILL-6353: Upgrade
Parquet MR dependencies
URL: https://github.com/apache/drill/pull/1259#discussion_r190483417
##
File path:
exec/java-exec/src/test/java/org/apache/drill/exec/store/parquet/TestParquetMetadataCache.java
##
@@ -737,6 +738,7 @@ public void testBooleanPartitionPruning() throws Exception
{
}
}
+ @Ignore
Review comment:
Could you please explain the reason why these tests should be ignored?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Upgrade Parquet MR dependencies
> ---
>
> Key: DRILL-6353
> URL: https://issues.apache.org/jira/browse/DRILL-6353
> Project: Apache Drill
> Issue Type: Task
>Reporter: Vlad Rozov
>Assignee: Vlad Rozov
>Priority: Major
> Fix For: 1.14.0
>
>
> Upgrade from a custom build {{1.8.1-drill-r0}} to Apache release {{1.10.0}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6373) Refactor the Result Set Loader to prepare for Union, List support
[
https://issues.apache.org/jira/browse/DRILL-6373?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Paul Rogers updated DRILL-6373:
---
Labels: ready-to-commit (was: )
> Refactor the Result Set Loader to prepare for Union, List support
> -
>
> Key: DRILL-6373
> URL: https://issues.apache.org/jira/browse/DRILL-6373
> Project: Apache Drill
> Issue Type: Improvement
>Affects Versions: 1.13.0
>Reporter: Paul Rogers
>Assignee: Paul Rogers
>Priority: Major
> Labels: ready-to-commit
> Fix For: 1.14.0
>
>
> As the next step in merging the "batch sizing" enhancements, refactor the
> {{ResultSetLoader}} and related classes to prepare for Union and List
> support. This fix follows the refactoring of the column accessors for the
> same purpose. Actual Union and List support is to follow in a separate PR.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6373) Refactor the Result Set Loader to prepare for Union, List support
[
https://issues.apache.org/jira/browse/DRILL-6373?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16488534#comment-16488534
]
ASF GitHub Bot commented on DRILL-6373:
---
paul-rogers commented on issue #1244: DRILL-6373: Refactor Result Set Loader
for Union, List support
URL: https://github.com/apache/drill/pull/1244#issuecomment-391610102
Rebased onto latest master. Fixed check style issues due to new rules.
This one is ready to commit; can someone merge it and run the tests?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Refactor the Result Set Loader to prepare for Union, List support
> -
>
> Key: DRILL-6373
> URL: https://issues.apache.org/jira/browse/DRILL-6373
> Project: Apache Drill
> Issue Type: Improvement
>Affects Versions: 1.13.0
>Reporter: Paul Rogers
>Assignee: Paul Rogers
>Priority: Major
> Fix For: 1.14.0
>
>
> As the next step in merging the "batch sizing" enhancements, refactor the
> {{ResultSetLoader}} and related classes to prepare for Union and List
> support. This fix follows the refactoring of the column accessors for the
> same purpose. Actual Union and List support is to follow in a separate PR.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6435) MappingSet is stateful, so it can't be shared between threads
[
https://issues.apache.org/jira/browse/DRILL-6435?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Pritesh Maker updated DRILL-6435:
-
Labels: ready-to-commit (was: )
> MappingSet is stateful, so it can't be shared between threads
> -
>
> Key: DRILL-6435
> URL: https://issues.apache.org/jira/browse/DRILL-6435
> Project: Apache Drill
> Issue Type: Bug
>Reporter: Vlad Rozov
>Assignee: Vlad Rozov
>Priority: Major
> Labels: ready-to-commit
> Fix For: 1.14.0
>
>
> There are several instances where static {{MappingSet}} instances are used
> (for example {{NestedLoopJoinBatch}} and {{BaseSortWrapper}}). This causes
> instance reuse across threads when queries are executed concurrently. As
> {{MappingSet}} is a stateful class with visitor design pattern, such reuse
> causes invalid state.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-6436) Store context and name in AbstractStoragePlugin instead of replicating fields in each StoragePlugin
[ https://issues.apache.org/jira/browse/DRILL-6436?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Pritesh Maker updated DRILL-6436: - Labels: ready-to-commit (was: ) > Store context and name in AbstractStoragePlugin instead of replicating fields > in each StoragePlugin > --- > > Key: DRILL-6436 > URL: https://issues.apache.org/jira/browse/DRILL-6436 > Project: Apache Drill > Issue Type: Improvement >Reporter: Timothy Farkas >Assignee: Timothy Farkas >Priority: Major > Labels: ready-to-commit > Fix For: 1.14.0 > > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-5977) predicate pushdown support kafkaMsgOffset
[
https://issues.apache.org/jira/browse/DRILL-5977?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16488501#comment-16488501
]
ASF GitHub Bot commented on DRILL-5977:
---
akumarb2010 commented on issue #1272: DRILL-5977: Filter Pushdown in
Drill-Kafka plugin
URL: https://github.com/apache/drill/pull/1272#issuecomment-391601936
>> Did you mean that we do not apply predicate pushdown for such conditions?
Yes, IMO the users who is applying these predicates on offsets, should be
aware of offset scope per partition. So, in such cases where offset predicates
without partitionId can be ignored and let it be full scan as these are in
valid queries in kafka perspective. Please let me know your thoughts.
>> If we do not pushdown, all partitions will be scanned from startOffset to
endOffset.
Yes, but actually this kind queries itself are in valid except for topics
with one partition. So better to not consider them.
>> Are there any drawbacks of applying pushdown on such conditions?
These are not drawbacks, but my point is let's not handle this invalid
queries.
>> we can use this predicate pushdown feature for external checkpointing
mechanism.
Mostly timestamp based predicates will be useful for the users. Only use
case which i can see , for offset based predicates will be for checkpointing
and all the check pointing strategies used in various systems like Storm/Spark
streaming/Camus etc will be checkpointing on offset per partition.
>> Even with pushdown we will return empty results. Pushdown is applied to
each of the predicates
independently and merged. The implementation is such that it ensures
offsetsForTimes is called only for valid partitions (i.e., partitions returned
by partitionsFor). Hence we will not run into the situation where
offsetsForTimes blocks infinitely.
Thanks for clarifying it. Good to know that you are already handling these
cases.
>> I will add test case for this situation. (I have already added cases for
predicates with invalid offsets and timestamps.)
Thanks @aravi5
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> predicate pushdown support kafkaMsgOffset
> -
>
> Key: DRILL-5977
> URL: https://issues.apache.org/jira/browse/DRILL-5977
> Project: Apache Drill
> Issue Type: Improvement
>Reporter: B Anil Kumar
>Assignee: Abhishek Ravi
>Priority: Major
> Fix For: 1.14.0
>
>
> As part of Kafka storage plugin review, below is the suggestion from Paul.
> {noformat}
> Does it make sense to provide a way to select a range of messages: a starting
> point or a count? Perhaps I want to run my query every five minutes, scanning
> only those messages since the previous scan. Or, I want to limit my take to,
> say, the next 1000 messages. Could we use a pseudo-column such as
> "kafkaMsgOffset" for that purpose? Maybe
> SELECT * FROM WHERE kafkaMsgOffset > 12345
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-5990) Apache Drill /status API returns OK ('Running') even with JRE while queries will not work - make status API reflect the fact that Drill is broken on JRE or stop Drill sta
[
https://issues.apache.org/jira/browse/DRILL-5990?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kunal Khatua updated DRILL-5990:
Labels: ready-to-commit (was: )
> Apache Drill /status API returns OK ('Running') even with JRE while queries
> will not work - make status API reflect the fact that Drill is broken on JRE
> or stop Drill starting up with JRE
> ---
>
> Key: DRILL-5990
> URL: https://issues.apache.org/jira/browse/DRILL-5990
> Project: Apache Drill
> Issue Type: Bug
> Components: Server
>Affects Versions: 1.10.0, 1.11.0
> Environment: Docker
>Reporter: Hari Sekhon
>Assignee: Kunal Khatua
>Priority: Major
> Labels: ready-to-commit
> Fix For: 1.14.0
>
>
> If running Apache Drill on versions 1.10 / 1.11 on JRE it appears that
> queries no longer run without JDK, but the /status monitoring API endpoint
> does not reflect the fact the Apache Drill will not work and still returns
> 'Running'.
> While 'Running' is technically true the process is up, it's effectively
> broken and Apache Drill should either reflect this in /status that is is
> broken or refuse to start up on JRE altogether.
> See this ticket for more information:
> https://github.com/HariSekhon/Dockerfiles/pull/15
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)