[jira] [Updated] (DRILL-6989) Upgrade to SqlLine 1.7.0
[
https://issues.apache.org/jira/browse/DRILL-6989?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Bridget Bevens updated DRILL-6989:
--
Labels: doc-complete ready-to-commit (was: doc-impacting ready-to-commit)
> Upgrade to SqlLine 1.7.0
>
>
> Key: DRILL-6989
> URL: https://issues.apache.org/jira/browse/DRILL-6989
> Project: Apache Drill
> Issue Type: Task
>Affects Versions: 1.15.0
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: doc-complete, ready-to-commit
> Fix For: 1.16.0
>
> Attachments: sqliine.JPG
>
>
> Upgrade to SqlLine 1.7.0 after its officially released.
> Major improvements is that Drill Sqlline prom will change from the default
> {{0: jdbc:drill:zk=local>}} to {{apache drill>}} if schema is unset. If
> schema was set (ex: {{use dfs.tmp}}), prompt will look the following way:
> {{apache drill (dfs.tmp)>}}.
> To return to previous prompt display, user can modify
> {{drill-sqlline-override.conf}} and set {{drill.sqlline.prompt.with_schema}}
> to false.
> To set custom prompt user can use one of the SqlLine properties: prompt,
> promptScript, rightPrompt.
> This can be achieved using set command, example: {{!set prompt my_prompt)}},
> or these properties can be overridden in {{drill-sqlline-override.conf}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (DRILL-6989) Upgrade to SqlLine 1.7.0
[
https://issues.apache.org/jira/browse/DRILL-6989?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16832062#comment-16832062
]
Bridget Bevens commented on DRILL-6989:
---
Hi [~arina],
Doc is updated with this info here:
https://drill.apache.org/docs/configuring-the-drill-shell/
Thanks,
Bridget
> Upgrade to SqlLine 1.7.0
>
>
> Key: DRILL-6989
> URL: https://issues.apache.org/jira/browse/DRILL-6989
> Project: Apache Drill
> Issue Type: Task
>Affects Versions: 1.15.0
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: doc-impacting, ready-to-commit
> Fix For: 1.16.0
>
> Attachments: sqliine.JPG
>
>
> Upgrade to SqlLine 1.7.0 after its officially released.
> Major improvements is that Drill Sqlline prom will change from the default
> {{0: jdbc:drill:zk=local>}} to {{apache drill>}} if schema is unset. If
> schema was set (ex: {{use dfs.tmp}}), prompt will look the following way:
> {{apache drill (dfs.tmp)>}}.
> To return to previous prompt display, user can modify
> {{drill-sqlline-override.conf}} and set {{drill.sqlline.prompt.with_schema}}
> to false.
> To set custom prompt user can use one of the SqlLine properties: prompt,
> promptScript, rightPrompt.
> This can be achieved using set command, example: {{!set prompt my_prompt)}},
> or these properties can be overridden in {{drill-sqlline-override.conf}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-7058) Refresh command to support subset of columns
[ https://issues.apache.org/jira/browse/DRILL-7058?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Bridget Bevens updated DRILL-7058: -- Labels: doc-complete ready-to-commit (was: doc-impacting ready-to-commit) > Refresh command to support subset of columns > > > Key: DRILL-7058 > URL: https://issues.apache.org/jira/browse/DRILL-7058 > Project: Apache Drill > Issue Type: Sub-task > Components: Metadata >Reporter: Venkata Jyothsna Donapati >Assignee: Venkata Jyothsna Donapati >Priority: Major > Labels: doc-complete, ready-to-commit > Fix For: 1.16.0 > > Original Estimate: 72h > Remaining Estimate: 72h > > Modify the REFRESH TABLE METADATA command to specify selected columns which > are deemed interesting in some form - either sorted/partitioned/clustered by > and column metadata will be stored only for those columns. The proposed > syntax is > REFRESH TABLE METADATA *_[ COLUMNS (list of columns) / NONE ]_* path> > For example, REFRESH TABLE METADATA COLUMNS (age, salary) `/tmp/employee` > stores column metadata only for the age and salary columns. REFRESH TABLE > METADATA COLUMNS NONE `/tmp/employee` will not store column metadata for any > column. > By default, if the optional 'COLUMNS' clause is omitted, column metadata is > collected for all the columns. > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-7058) Refresh command to support subset of columns
[ https://issues.apache.org/jira/browse/DRILL-7058?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16832061#comment-16832061 ] Bridget Bevens commented on DRILL-7058: --- Hi [~vdonapati], Doc is posted here: https://drill.apache.org/docs/refresh-table-metadata/ Thanks, Bridget > Refresh command to support subset of columns > > > Key: DRILL-7058 > URL: https://issues.apache.org/jira/browse/DRILL-7058 > Project: Apache Drill > Issue Type: Sub-task > Components: Metadata >Reporter: Venkata Jyothsna Donapati >Assignee: Venkata Jyothsna Donapati >Priority: Major > Labels: doc-impacting, ready-to-commit > Fix For: 1.16.0 > > Original Estimate: 72h > Remaining Estimate: 72h > > Modify the REFRESH TABLE METADATA command to specify selected columns which > are deemed interesting in some form - either sorted/partitioned/clustered by > and column metadata will be stored only for those columns. The proposed > syntax is > REFRESH TABLE METADATA *_[ COLUMNS (list of columns) / NONE ]_* path> > For example, REFRESH TABLE METADATA COLUMNS (age, salary) `/tmp/employee` > stores column metadata only for the age and salary columns. REFRESH TABLE > METADATA COLUMNS NONE `/tmp/employee` will not store column metadata for any > column. > By default, if the optional 'COLUMNS' clause is omitted, column metadata is > collected for all the columns. > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (DRILL-1328) Support table statistics
[ https://issues.apache.org/jira/browse/DRILL-1328?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Bridget Bevens updated DRILL-1328: -- Labels: doc-complete (was: doc-impacting) > Support table statistics > > > Key: DRILL-1328 > URL: https://issues.apache.org/jira/browse/DRILL-1328 > Project: Apache Drill > Issue Type: Improvement >Reporter: Cliff Buchanan >Assignee: Gautam Parai >Priority: Major > Labels: doc-complete > Fix For: 1.16.0 > > Attachments: 0001-PRE-Set-value-count-in-splitAndTransfer.patch > > > This consists of several subtasks > * implement operators to generate statistics > * add "analyze table" support to parser/planner > * create a metadata provider to allow statistics to be used by optiq in > planning optimization > * implement statistics functions > Right now, the bulk of this functionality is implemented, but it hasn't been > rigorously tested and needs to have some definite answers for some of the > parts "around the edges" (how analyze table figures out where the table > statistics are located, how a table "append" should work in a read only file > system) > Also, here are a few known caveats: > * table statistics are collected by creating a sql query based on the string > path of the table. This should probably be done with a Table reference. > * Case sensitivity for column statistics is probably iffy > * Math for combining two column NDVs into a joint NDV should be checked. > * Schema changes aren't really being considered yet. > * adding getDrillTable is probably unnecessary; it might be better to do > getTable().unwrap(DrillTable.class) -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-1328) Support table statistics
[ https://issues.apache.org/jira/browse/DRILL-1328?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16832059#comment-16832059 ] Bridget Bevens commented on DRILL-1328: --- Hi [~gparai], The doc is posted here: https://drill.apache.org/docs/analyze-table/ Thanks, Bridget > Support table statistics > > > Key: DRILL-1328 > URL: https://issues.apache.org/jira/browse/DRILL-1328 > Project: Apache Drill > Issue Type: Improvement >Reporter: Cliff Buchanan >Assignee: Gautam Parai >Priority: Major > Labels: doc-impacting > Fix For: 1.16.0 > > Attachments: 0001-PRE-Set-value-count-in-splitAndTransfer.patch > > > This consists of several subtasks > * implement operators to generate statistics > * add "analyze table" support to parser/planner > * create a metadata provider to allow statistics to be used by optiq in > planning optimization > * implement statistics functions > Right now, the bulk of this functionality is implemented, but it hasn't been > rigorously tested and needs to have some definite answers for some of the > parts "around the edges" (how analyze table figures out where the table > statistics are located, how a table "append" should work in a read only file > system) > Also, here are a few known caveats: > * table statistics are collected by creating a sql query based on the string > path of the table. This should probably be done with a Table reference. > * Case sensitivity for column statistics is probably iffy > * Math for combining two column NDVs into a joint NDV should be checked. > * Schema changes aren't really being considered yet. > * adding getDrillTable is probably unnecessary; it might be better to do > getTable().unwrap(DrillTable.class) -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-7222) Visualize estimated and actual row counts for a query
[ https://issues.apache.org/jira/browse/DRILL-7222?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16832055#comment-16832055 ] ASF GitHub Bot commented on DRILL-7222: --- kkhatua commented on issue #1779: DRILL-7222: Visualize estimated and actual row counts for a query URL: https://github.com/apache/drill/pull/1779#issuecomment-488857904 No. Why do you think it'll increase query execution time? It's just a visual aid to understand if the stats were way off. Users who rely on using sampling to generate stats can see if their sample size is too small. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Visualize estimated and actual row counts for a query > - > > Key: DRILL-7222 > URL: https://issues.apache.org/jira/browse/DRILL-7222 > Project: Apache Drill > Issue Type: Improvement > Components: Web Server >Affects Versions: 1.16.0 >Reporter: Kunal Khatua >Assignee: Kunal Khatua >Priority: Major > Labels: user-experience > Fix For: 1.17.0 > > > With statistics in place, it would be useful to have the *estimated* rowcount > along side the *actual* rowcount query profile's operator overview. > We can extract this from the Physical Plan section of the profile. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-7222) Visualize estimated and actual row counts for a query
[ https://issues.apache.org/jira/browse/DRILL-7222?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16832051#comment-16832051 ] ASF GitHub Bot commented on DRILL-7222: --- khurram-faraaz commented on issue #1779: DRILL-7222: Visualize estimated and actual row counts for a query URL: https://github.com/apache/drill/pull/1779#issuecomment-488856988 @kkhatua Will this increase the total query execution time in any way ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Visualize estimated and actual row counts for a query > - > > Key: DRILL-7222 > URL: https://issues.apache.org/jira/browse/DRILL-7222 > Project: Apache Drill > Issue Type: Improvement > Components: Web Server >Affects Versions: 1.16.0 >Reporter: Kunal Khatua >Assignee: Kunal Khatua >Priority: Major > Labels: user-experience > Fix For: 1.17.0 > > > With statistics in place, it would be useful to have the *estimated* rowcount > along side the *actual* rowcount query profile's operator overview. > We can extract this from the Physical Plan section of the profile. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-7222) Visualize estimated and actual row counts for a query
[ https://issues.apache.org/jira/browse/DRILL-7222?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16831970#comment-16831970 ] ASF GitHub Bot commented on DRILL-7222: --- kkhatua commented on pull request #1779: DRILL-7222: Visualize estimated and actual row counts for a query URL: https://github.com/apache/drill/pull/1779 With statistics in place, it is useful to have the estimated rowcount along side the actual rowcount query profile's operator overview. We extract this from the Physical Plan section of the profile and show it in parenthesis with a toggle button to have the estimates hidden by default. 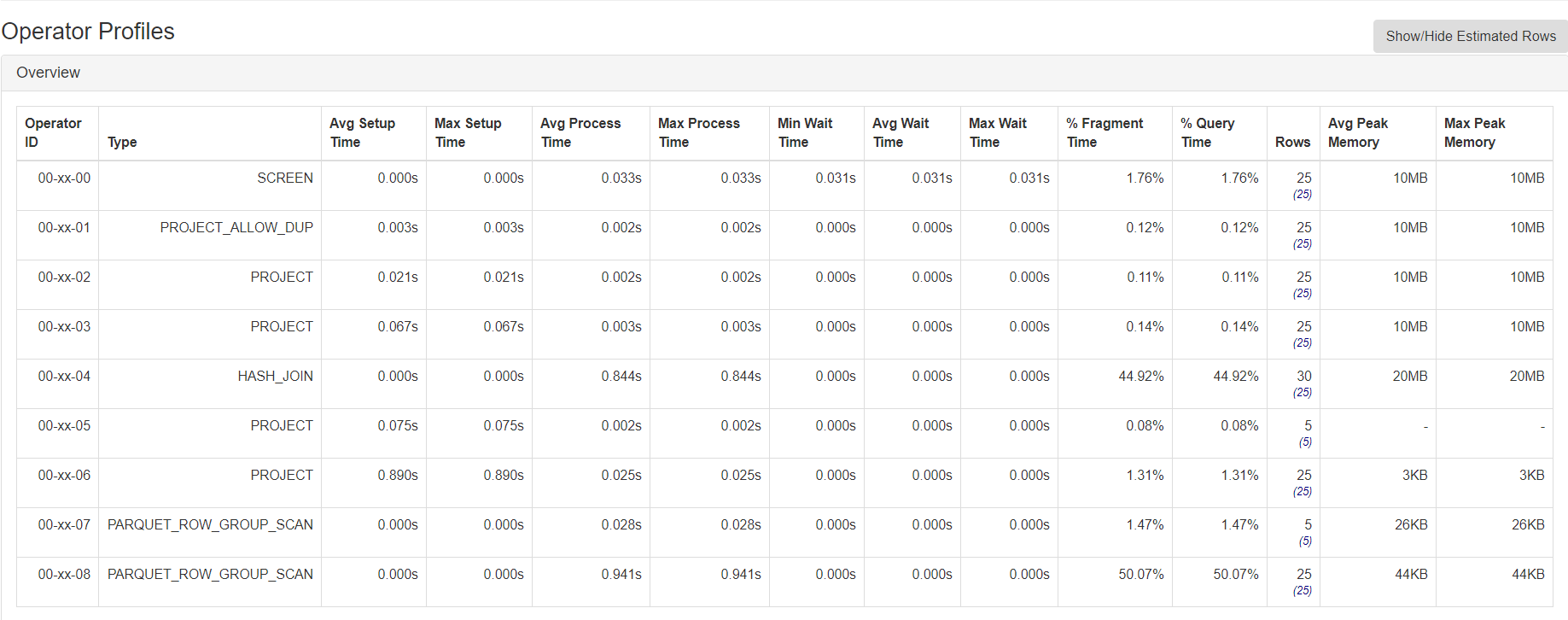 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Visualize estimated and actual row counts for a query > - > > Key: DRILL-7222 > URL: https://issues.apache.org/jira/browse/DRILL-7222 > Project: Apache Drill > Issue Type: Improvement > Components: Web Server >Affects Versions: 1.16.0 >Reporter: Kunal Khatua >Assignee: Kunal Khatua >Priority: Major > Labels: user-experience > Fix For: 1.17.0 > > > With statistics in place, it would be useful to have the *estimated* rowcount > along side the *actual* rowcount query profile's operator overview. > We can extract this from the Physical Plan section of the profile. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (DRILL-6965) Adjust table function usage for all storage plugins and implement schema parameter
[
https://issues.apache.org/jira/browse/DRILL-6965?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16831894#comment-16831894
]
ASF GitHub Bot commented on DRILL-6965:
---
vvysotskyi commented on pull request #1777: DRILL-6965: Implement schema table
function parameter
URL: https://github.com/apache/drill/pull/1777#discussion_r280560701
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/record/metadata/schema/SchemaProviderFactory.java
##
@@ -0,0 +1,87 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.drill.exec.record.metadata.schema;
+
+import org.apache.drill.exec.planner.sql.handlers.SchemaHandler;
+import org.apache.drill.exec.planner.sql.parser.SqlSchema;
+import org.apache.drill.exec.store.dfs.WorkspaceSchemaFactory;
+import org.apache.hadoop.fs.Path;
+
+import java.io.IOException;
+
+/**
+ * Factory class responsible for creating different instances of schema
provider based on given parameters.
+ */
+public class SchemaProviderFactory {
+
+ /**
+ * Creates schema provider for sql schema commands.
+ *
+ * @param sqlSchema sql schema call
+ * @param schemaHandler schema handler
+ * @return schema provider instance
+ * @throws IOException if unable to init schema provider
+ */
+ public static SchemaProvider create(SqlSchema sqlSchema, SchemaHandler
schemaHandler) throws IOException {
+if (sqlSchema.hasTable()) {
+ String tableName = sqlSchema.getTableName();
+ WorkspaceSchemaFactory.WorkspaceSchema wsSchema =
schemaHandler.getWorkspaceSchema(sqlSchema.getSchemaPath(), tableName);
+ return new FsMetastoreSchemaProvider(wsSchema, tableName);
+} else {
+ return new PathSchemaProvider(new Path(sqlSchema.getPath()));
+}
+ }
+
+ /**
+ * Creates schema provider based table function schema parameter.
+ *
+ * @param parameterValue schema parameter value
+ * @return schema provider instance
+ * @throws IOException if unable to init schema provider
+ */
+ public static SchemaProvider create(String parameterValue) throws
IOException {
+String[] split = parameterValue.split("=", 2);
+if (split.length != 2) {
+ throw new IOException("Incorrect parameter value format: " +
parameterValue);
+}
+ProviderType providerType =
ProviderType.valueOf(split[0].trim().toUpperCase());
+String value = split[1].trim();
+switch (providerType) {
+ case INLINE:
+return new InlineSchemaProvider(value);
+ case PATH:
+char c = value.charAt(0);
+// if path starts with any type of quotes, strip them and remove
escape characters if any
+if (c == '\'' || c == '"' || c == '`') {
+ value = value.substring(1, value.length() - 1).replaceAll("(.)",
"$1");
Review comment:
I'm not sure that `replaceAll("(.)", "$1")` is needed. For the case, if
`value` is not escaped and windows path is specified, it may cause problems.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Adjust table function usage for all storage plugins and implement schema
> parameter
> --
>
> Key: DRILL-6965
> URL: https://issues.apache.org/jira/browse/DRILL-6965
> Project: Apache Drill
> Issue Type: Sub-task
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: doc-impacting
> Fix For: 1.17.0
>
>
> Schema can be used while reading the table into two ways:
> a. schema is created in the table root folder using CREATE SCHEMA command
> and schema usage command is enabled;
> b. schema indicated in table function.
> This Jira implements point b.
> Schema indication using table function is useful when user does not want to
> pers
[jira] [Commented] (DRILL-6965) Adjust table function usage for all storage plugins and implement schema parameter
[
https://issues.apache.org/jira/browse/DRILL-6965?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16831893#comment-16831893
]
ASF GitHub Bot commented on DRILL-6965:
---
vvysotskyi commented on pull request #1777: DRILL-6965: Implement schema table
function parameter
URL: https://github.com/apache/drill/pull/1777#discussion_r280474815
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/record/metadata/schema/SchemaProviderFactory.java
##
@@ -0,0 +1,87 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.drill.exec.record.metadata.schema;
+
+import org.apache.drill.exec.planner.sql.handlers.SchemaHandler;
+import org.apache.drill.exec.planner.sql.parser.SqlSchema;
+import org.apache.drill.exec.store.dfs.WorkspaceSchemaFactory;
+import org.apache.hadoop.fs.Path;
+
+import java.io.IOException;
+
+/**
+ * Factory class responsible for creating different instances of schema
provider based on given parameters.
+ */
+public class SchemaProviderFactory {
+
+ /**
+ * Creates schema provider for sql schema commands.
+ *
+ * @param sqlSchema sql schema call
+ * @param schemaHandler schema handler
+ * @return schema provider instance
+ * @throws IOException if unable to init schema provider
+ */
+ public static SchemaProvider create(SqlSchema sqlSchema, SchemaHandler
schemaHandler) throws IOException {
+if (sqlSchema.hasTable()) {
+ String tableName = sqlSchema.getTableName();
+ WorkspaceSchemaFactory.WorkspaceSchema wsSchema =
schemaHandler.getWorkspaceSchema(sqlSchema.getSchemaPath(), tableName);
+ return new FsMetastoreSchemaProvider(wsSchema, tableName);
+} else {
+ return new PathSchemaProvider(new Path(sqlSchema.getPath()));
+}
+ }
+
+ /**
+ * Creates schema provider based table function schema parameter.
+ *
+ * @param parameterValue schema parameter value
+ * @return schema provider instance
+ * @throws IOException if unable to init schema provider
+ */
+ public static SchemaProvider create(String parameterValue) throws
IOException {
+String[] split = parameterValue.split("=", 2);
+if (split.length != 2) {
Review comment:
Is it makes sense to change this check to something like `split.length < 2`
since `split` length cannot be greater than 2?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Adjust table function usage for all storage plugins and implement schema
> parameter
> --
>
> Key: DRILL-6965
> URL: https://issues.apache.org/jira/browse/DRILL-6965
> Project: Apache Drill
> Issue Type: Sub-task
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: doc-impacting
> Fix For: 1.17.0
>
>
> Schema can be used while reading the table into two ways:
> a. schema is created in the table root folder using CREATE SCHEMA command
> and schema usage command is enabled;
> b. schema indicated in table function.
> This Jira implements point b.
> Schema indication using table function is useful when user does not want to
> persist schema in table root location or when reading from file, not folder.
> Schema parameter can be used as individual unit or in together with for
> format plugin table properties.
> Usage examples:
> Pre-requisites:
> V3 reader must be enabled: {{set `exec.storage.enable_v3_text_reader` =
> true;}}
> Query examples:
> 1. There is folder with files or just one file (ex: dfs.tmp.text_table) and
> user wants to apply schema to them:
> a. indicate schema inline:
> {noformat}
> select * from table(dfs.tmp.`text_table`(
> schema => 'inline=(col1 date properties {`drill.format` = `-MM-dd`})
> properties {`drill.strict` = `f
[jira] [Commented] (DRILL-6965) Adjust table function usage for all storage plugins and implement schema parameter
[
https://issues.apache.org/jira/browse/DRILL-6965?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16831895#comment-16831895
]
ASF GitHub Bot commented on DRILL-6965:
---
vvysotskyi commented on pull request #1777: DRILL-6965: Implement schema table
function parameter
URL: https://github.com/apache/drill/pull/1777#discussion_r280561180
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/store/table/function/TableSignature.java
##
@@ -0,0 +1,98 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.drill.exec.store.table.function;
+
+import java.util.Collection;
+import java.util.Collections;
+import java.util.List;
+import java.util.Objects;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+/**
+ * Describes table and parameters that can be used during table initialization
and usage.
+ * Common parameters are those that are common for all tables (ex: schema).
+ * Specific parameters are those that are specific to the schema table belongs
to.
+ */
+public final class TableSignature {
+
+ private final String name;
+ private final List commonParams;
+ private final List specificParams;
+ private final List params;
+
+ public static TableSignature of(String name) {
+return new TableSignature(name, Collections.emptyList(),
Collections.emptyList());
+ }
+
+ public static TableSignature of(String name, List
primaryParams) {
Review comment:
Could you please rename arguments here and in the method below?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Adjust table function usage for all storage plugins and implement schema
> parameter
> --
>
> Key: DRILL-6965
> URL: https://issues.apache.org/jira/browse/DRILL-6965
> Project: Apache Drill
> Issue Type: Sub-task
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: doc-impacting
> Fix For: 1.17.0
>
>
> Schema can be used while reading the table into two ways:
> a. schema is created in the table root folder using CREATE SCHEMA command
> and schema usage command is enabled;
> b. schema indicated in table function.
> This Jira implements point b.
> Schema indication using table function is useful when user does not want to
> persist schema in table root location or when reading from file, not folder.
> Schema parameter can be used as individual unit or in together with for
> format plugin table properties.
> Usage examples:
> Pre-requisites:
> V3 reader must be enabled: {{set `exec.storage.enable_v3_text_reader` =
> true;}}
> Query examples:
> 1. There is folder with files or just one file (ex: dfs.tmp.text_table) and
> user wants to apply schema to them:
> a. indicate schema inline:
> {noformat}
> select * from table(dfs.tmp.`text_table`(
> schema => 'inline=(col1 date properties {`drill.format` = `-MM-dd`})
> properties {`drill.strict` = `false`}'))
> {noformat}
> To indicate only table properties use the following syntax:
> {noformat}
> select * from table(dfs.tmp.`text_table`(
> schema => 'inline=()
> properties {`drill.strict` = `false`}'))
> {noformat}
> b. indicate schema using path:
> First schema was created in some location using CREATE SCHEMA command. For
> example:
> {noformat}
> create schema
> (col int)
> path '/tmp/my_schema'
> {noformat}
> Now user wants to apply this schema in table function:
> {noformat}
> select * from table(dfs.tmp.`text_table`(schema => 'path=`/tmp/my_schema`'))
> {noformat}
> 2. User wants to apply schema along side with format plugin table function
> parameters.
> Assuming that user has CSV file with headers with extension that does not
> comply to default text file with headers
[jira] [Commented] (DRILL-6965) Adjust table function usage for all storage plugins and implement schema parameter
[
https://issues.apache.org/jira/browse/DRILL-6965?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16831892#comment-16831892
]
ASF GitHub Bot commented on DRILL-6965:
---
vvysotskyi commented on pull request #1777: DRILL-6965: Implement schema table
function parameter
URL: https://github.com/apache/drill/pull/1777#discussion_r280473490
##
File path:
exec/java-exec/src/main/java/org/apache/drill/exec/record/metadata/TupleSchema.java
##
@@ -56,7 +56,9 @@ public TupleSchema() { }
@JsonCreator
public TupleSchema(@JsonProperty("columns") List
columns,
@JsonProperty("properties") Map
properties) {
-columns.forEach(this::addColumn);
+if (columns != null && !columns.isEmpty()) {
Review comment:
Looks like `!columns.isEmpty()` check is redundant.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Adjust table function usage for all storage plugins and implement schema
> parameter
> --
>
> Key: DRILL-6965
> URL: https://issues.apache.org/jira/browse/DRILL-6965
> Project: Apache Drill
> Issue Type: Sub-task
>Reporter: Arina Ielchiieva
>Assignee: Arina Ielchiieva
>Priority: Major
> Labels: doc-impacting
> Fix For: 1.17.0
>
>
> Schema can be used while reading the table into two ways:
> a. schema is created in the table root folder using CREATE SCHEMA command
> and schema usage command is enabled;
> b. schema indicated in table function.
> This Jira implements point b.
> Schema indication using table function is useful when user does not want to
> persist schema in table root location or when reading from file, not folder.
> Schema parameter can be used as individual unit or in together with for
> format plugin table properties.
> Usage examples:
> Pre-requisites:
> V3 reader must be enabled: {{set `exec.storage.enable_v3_text_reader` =
> true;}}
> Query examples:
> 1. There is folder with files or just one file (ex: dfs.tmp.text_table) and
> user wants to apply schema to them:
> a. indicate schema inline:
> {noformat}
> select * from table(dfs.tmp.`text_table`(
> schema => 'inline=(col1 date properties {`drill.format` = `-MM-dd`})
> properties {`drill.strict` = `false`}'))
> {noformat}
> To indicate only table properties use the following syntax:
> {noformat}
> select * from table(dfs.tmp.`text_table`(
> schema => 'inline=()
> properties {`drill.strict` = `false`}'))
> {noformat}
> b. indicate schema using path:
> First schema was created in some location using CREATE SCHEMA command. For
> example:
> {noformat}
> create schema
> (col int)
> path '/tmp/my_schema'
> {noformat}
> Now user wants to apply this schema in table function:
> {noformat}
> select * from table(dfs.tmp.`text_table`(schema => 'path=`/tmp/my_schema`'))
> {noformat}
> 2. User wants to apply schema along side with format plugin table function
> parameters.
> Assuming that user has CSV file with headers with extension that does not
> comply to default text file with headers extension (ex: cars.csvh-test):
> {noformat}
> select * from table(dfs.tmp.`cars.csvh-test`(type => 'text',
> fieldDelimiter => ',', extractHeader => true,
> schema => 'inline=(col1 date)'))
> {noformat}
> More details about syntax can be found in design document:
>
> [https://docs.google.com/document/d/1mp4egSbNs8jFYRbPVbm_l0Y5GjH3HnoqCmOpMTR_g4w/edit]
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Created] (DRILL-7234) Allow support for using Drill WebU through a Reverse Proxy server
Kunal Khatua created DRILL-7234:
---
Summary: Allow support for using Drill WebU through a Reverse
Proxy server
Key: DRILL-7234
URL: https://issues.apache.org/jira/browse/DRILL-7234
Project: Apache Drill
Issue Type: Improvement
Components: Web Server
Affects Versions: 1.16.0
Reporter: Kunal Khatua
Assignee: Kunal Khatua
Fix For: 1.17.0
Currently, Drill's WebUI has a lot of links and references going through the
root of the URL.
i.e. to access the profiles listing or submitting a query, we'd need to access
the following URL format:
{code}
http://localhost:8047/profiles
http://localhost:8047/query
{code}
With a reverse proxy, these pages need to be accessed by:
{code}
http://localhost:8047/x/y/z/profiles
http://localhost:8047/x/y/z/query
{code}
However, the links within these page do not include the *{{x/y/z/}}* part, as a
result of which the visiting those links will fail.
The WebServer should implement a mechanism that can detect this additional
layer and modify the links within the webpage accordingly.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (DRILL-7222) Visualize estimated and actual row counts for a query
[ https://issues.apache.org/jira/browse/DRILL-7222?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kunal Khatua updated DRILL-7222: Reviewer: Aman Sinha > Visualize estimated and actual row counts for a query > - > > Key: DRILL-7222 > URL: https://issues.apache.org/jira/browse/DRILL-7222 > Project: Apache Drill > Issue Type: Improvement > Components: Web Server >Affects Versions: 1.16.0 >Reporter: Kunal Khatua >Assignee: Kunal Khatua >Priority: Major > Labels: user-experience > Fix For: 1.17.0 > > > With statistics in place, it would be useful to have the *estimated* rowcount > along side the *actual* rowcount query profile's operator overview. > We can extract this from the Physical Plan section of the profile. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (DRILL-7030) Make format plugins fully pluggable
[
https://issues.apache.org/jira/browse/DRILL-7030?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Anton Gozhiy updated DRILL-7030:
Summary: Make format plugins fully pluggable (was: Make format plugins
fully plugable)
> Make format plugins fully pluggable
> ---
>
> Key: DRILL-7030
> URL: https://issues.apache.org/jira/browse/DRILL-7030
> Project: Apache Drill
> Issue Type: Improvement
>Affects Versions: 1.15.0
>Reporter: Arina Ielchiieva
>Assignee: Anton Gozhiy
>Priority: Major
> Labels: doc-impacting
> Fix For: 1.17.0
>
>
> Discussion on the mailing list -
> [https://lists.apache.org/thread.html/0c7de9c23ee9a8e18f8548ae0a323284cf1311b9570bd77ba544f63d@%3Cdev.drill.apache.org%3E]
> {noformat}
> Before we were adding new formats / plugins into the exec module. Eventually
> we came up to the point that exec package size is growing and adding plugin
> and format contributions is better to separate out in the different module.
> Now we have contrib module where we add such contributions. Plugins are
> pluggable, there are added automatically by means of having drill-module.conf
> file which points to the scanning packages.
> Format plugins are using the same approach, the only problem is that they are
> not added into bootstrap-storage-plugins.json. So when adding new format
> plugin, in order for it to automatically appear in Drill Web UI, developer
> has to update bootstrap file which is in the exec module.
> My suggestion we implement some functionality that would merge format config
> with the bootstrap one. For example, each plugin would have to have
> bootstrap-format.json file with the information to which plugin format should
> be added (structure the same as in bootstrap-storage-plugins.json):
> Example:
> {
> "storage":{
> dfs: {
> formats: {
> "psv" : {
> type: "msgpack",
> extensions: [ "mp" ]
> }
> }
> }
> }
> }
> Then during Drill start up such bootstrap-format.json files will be merged
> with bootstrap-storage-plugins.json.{noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Assigned] (DRILL-416) Make Drill work with SELECT without FROM
[
https://issues.apache.org/jira/browse/DRILL-416?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sorabh Hamirwasia reassigned DRILL-416:
---
Assignee: Volodymyr Vysotskyi
> Make Drill work with SELECT without FROM
>
>
> Key: DRILL-416
> URL: https://issues.apache.org/jira/browse/DRILL-416
> Project: Apache Drill
> Issue Type: Improvement
>Affects Versions: 0.4.0
>Reporter: Chun Chang
>Assignee: Volodymyr Vysotskyi
>Priority: Major
> Fix For: 1.16.0
>
>
> This works with postgres:
> [root@qa-node120 ~]# sudo -u postgres psql foodmart
> foodmart=# select 1+1.1;
> ?column?
> --
> 2.1
> (1 row)
> But does not work with Drill:
> 0: jdbc:drill:> select 1+1.1;
> Query failed: org.apache.drill.exec.rpc.RpcException: Remote failure while
> running query.[error_id: "100f4d4c-1ee1-495e-9c2f-547aae75473d"
> endpoint {
> address: "qa-node118.qa.lab"
> user_port: 31010
> control_port: 31011
> data_port: 31012
> }
> error_type: 0
> message: "Failure while parsing sql. < SqlParseException:[ Encountered
> \"\" at line 1, column 12.\nWas expecting one of:
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Assigned] (DRILL-912) Project push down tests rely on JSON pushdown but JSON reader no longer supports pushdown.
[ https://issues.apache.org/jira/browse/DRILL-912?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sorabh Hamirwasia reassigned DRILL-912: --- Assignee: Volodymyr Vysotskyi > Project push down tests rely on JSON pushdown but JSON reader no longer > supports pushdown. > -- > > Key: DRILL-912 > URL: https://issues.apache.org/jira/browse/DRILL-912 > Project: Apache Drill > Issue Type: Improvement > Components: Query Planning & Optimization >Reporter: Jacques Nadeau >Assignee: Volodymyr Vysotskyi >Priority: Major > Fix For: 1.16.0 > > > We need to either add back pushdown or update the tests so that they use a > reader that supports pushdown. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (DRILL-7232) Error while writing parquet by Drill Docker container Drill version 1.15
[ https://issues.apache.org/jira/browse/DRILL-7232?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Manoj Singh updated DRILL-7232: --- Priority: Critical (was: Minor) > Error while writing parquet by Drill Docker container Drill version 1.15 > > > Key: DRILL-7232 > URL: https://issues.apache.org/jira/browse/DRILL-7232 > Project: Apache Drill > Issue Type: Bug >Reporter: Manoj Singh >Priority: Critical > > We are getting the below error in our application logs. We are running > drill1.15 as a docker container. > The Parquet location /opt/data/parquet-location has all the rights and > permissions. > > Please advise what i am doing wrong here. > 2019-05-02 07:29:02 [WARN ] [] @ Log : warn : 182 - could not write summary > file for > file:/opt/data/parquet-location/72AB79EC-D841-4D7D-8FEE-2FCEC6D089A7-Online_Search__Snapshot_Data.parquet > java.lang.NullPointerException > at > org.apache.parquet.hadoop.ParquetFileWriter.mergeFooters(ParquetFileWriter.java:456) > at > org.apache.parquet.hadoop.ParquetFileWriter.writeMetadataFile(ParquetFileWriter.java:420) > at > org.apache.parquet.hadoop.ParquetOutputCommitter.writeMetaDataFile(ParquetOutputCommitter.java:58) > at > org.apache.parquet.hadoop.ParquetOutputCommitter.commitJob(ParquetOutputCommitter.java:48) > at > org.apache.spark.sql.execution.datasources.BaseWriterContainer.commitJob(WriterContainer.scala:208) > at > org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelation$$anonfun$run$1.apply$mcV$sp(InsertIntoHadoopFsRelation.scala:151) > at > org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelation$$anonfun$run$1.apply(InsertIntoHadoopFsRelation.scala:108) > at > org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelation$$anonfun$run$1.apply(Inse -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (DRILL-7177) Format Plugin for Excel Files
[ https://issues.apache.org/jira/browse/DRILL-7177?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Charles Givre updated DRILL-7177: - Affects Version/s: 1.17.0 > Format Plugin for Excel Files > - > > Key: DRILL-7177 > URL: https://issues.apache.org/jira/browse/DRILL-7177 > Project: Apache Drill > Issue Type: Improvement >Affects Versions: 1.17.0 >Reporter: Charles Givre >Assignee: Charles Givre >Priority: Major > Labels: doc-impacting > Fix For: 1.17.0 > > > This pull request adds the functionality which enables Drill to query > Microsoft Excel files. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (DRILL-7233) Format Plugin for HDF5
Charles Givre created DRILL-7233:
Summary: Format Plugin for HDF5
Key: DRILL-7233
URL: https://issues.apache.org/jira/browse/DRILL-7233
Project: Apache Drill
Issue Type: New Feature
Affects Versions: 1.17.0
Reporter: Charles Givre
Assignee: Charles Givre
Fix For: 1.17.0
h2. Drill HDF5 Format Plugin
h2.
Per wikipedia, Hierarchical Data Format (HDF) is a set of file formats designed
to store and organize large amounts of data. Originally developed at the
National Center for Supercomputing Applications, it is supported by The HDF
Group, a non-profit corporation whose mission is to ensure continued
development of HDF5 technologies and the continued accessibility of data stored
in HDF.
This plugin enables Apache Drill to query HDF5 files.
h3. Configuration
There are three configuration variables in this plugin:
type: This should be set to hdf5.
extensions: This is a list of the file extensions used to identify HDF5 files.
Typically HDF5 uses .h5 or .hdf5 as file extensions. This defaults to .h5.
defaultPath:
h3. Example Configuration
h3.
For most uses, the configuration below will suffice to enable Drill to query
HDF5 files.
{{"hdf5": {
"type": "hdf5",
"extensions": [
"h5"
],
"defaultPath": null
}}}
h3. Usage
Since HDF5 can be viewed as a file system within a file, a single file can
contain many datasets. For instance, if you have a simple HDF5 file, a star
query will produce the following result:
{{apache drill> select * from dfs.test.`dset.h5`;
+---+---+---+--+
| path | data_type | file_name | int_data
|
+---+---+---+--+
| /dset | DATASET | dset.h5 |
[[1,2,3,4,5,6],[7,8,9,10,11,12],[13,14,15,16,17,18],[19,20,21,22,23,24]] |
+---+---+---+--+}}
The actual data in this file is mapped to a column called int_data. In order to
effectively access the data, you should use Drill's FLATTEN() function on the
int_data column, which produces the following result.
{{apache drill> select flatten(int_data) as int_data from dfs.test.`dset.h5`;
+-+
| int_data |
+-+
| [1,2,3,4,5,6] |
| [7,8,9,10,11,12]|
| [13,14,15,16,17,18] |
| [19,20,21,22,23,24] |
+-+}}
Once you have the data in this form, you can access it similarly to how you
might access nested data in JSON or other files.
{{apache drill> SELECT int_data[0] as col_0,
. .semicolon> int_data[1] as col_1,
. .semicolon> int_data[2] as col_2
. .semicolon> FROM ( SELECT flatten(int_data) AS int_data
. . . . . .)> FROM dfs.test.`dset.h5`
. . . . . .)> );
+---+---+---+
| col_0 | col_1 | col_2 |
+---+---+---+
| 1 | 2 | 3 |
| 7 | 8 | 9 |
| 13| 14| 15|
| 19| 20| 21|
+---+---+---+}}
Alternatively, a better way to query the actual data in an HDF5 file is to use
the defaultPath field in your query. If the defaultPath field is defined in the
query, or via the plugin configuration, Drill will only return the data, rather
than the file metadata.
** Note: Once you have determined which data set you are querying, it is
advisable to use this method to query HDF5 data. **
You can set the defaultPath variable in either the plugin configuration, or at
query time using the table() function as shown in the example below:
{{SELECT *
FROM table(dfs.test.`dset.h5` (type => 'hdf5', defaultPath => '/dset'))}}
This query will return the result below:
{{apache drill> SELECT * FROM table(dfs.test.`dset.h5` (type => 'hdf5',
defaultPath => '/dset'));
+---+---+---+---+---+---+
| int_col_0 | int_col_1 | int_col_2 | int_col_3 | int_col_4 | int_col_5 |
+---+---+---+---+---+---+
| 1 | 2 | 3 | 4 | 5 | 6 |
| 7 | 8 | 9 | 10| 11| 12|
| 13| 14| 15| 16| 17| 18|
| 19| 20| 21| 22| 23| 24|
+---+---+---+---+---+---+
4 rows selected (0.223 seconds)}}
If the data in defaultPath is a column, the column name will be the last part
of the path. If the data is multidimensional, the columns will get a name of
_col_n . Therefore a column of integers will be called int_col_1.
h3. Attributes
Occasionally, HDF5 paths will contain attributes. Drill will map these to a map
data st
[jira] [Created] (DRILL-7232) Error while writing parquet by Drill Docker container Drill version 1.15
Manoj Singh created DRILL-7232: -- Summary: Error while writing parquet by Drill Docker container Drill version 1.15 Key: DRILL-7232 URL: https://issues.apache.org/jira/browse/DRILL-7232 Project: Apache Drill Issue Type: Bug Reporter: Manoj Singh We are getting the below error in our application logs. We are running drill1.15 as a docker container. The Parquet location /opt/data/parquet-location has all the rights and permissions. Please advise what i am doing wrong here. 2019-05-02 07:29:02 [WARN ] [] @ Log : warn : 182 - could not write summary file for file:/opt/data/parquet-location/72AB79EC-D841-4D7D-8FEE-2FCEC6D089A7-Online_Search__Snapshot_Data.parquet java.lang.NullPointerException at org.apache.parquet.hadoop.ParquetFileWriter.mergeFooters(ParquetFileWriter.java:456) at org.apache.parquet.hadoop.ParquetFileWriter.writeMetadataFile(ParquetFileWriter.java:420) at org.apache.parquet.hadoop.ParquetOutputCommitter.writeMetaDataFile(ParquetOutputCommitter.java:58) at org.apache.parquet.hadoop.ParquetOutputCommitter.commitJob(ParquetOutputCommitter.java:48) at org.apache.spark.sql.execution.datasources.BaseWriterContainer.commitJob(WriterContainer.scala:208) at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelation$$anonfun$run$1.apply$mcV$sp(InsertIntoHadoopFsRelation.scala:151) at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelation$$anonfun$run$1.apply(InsertIntoHadoopFsRelation.scala:108) at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelation$$anonfun$run$1.apply(Inse -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (DRILL-7098) File Metadata Metastore Plugin
[ https://issues.apache.org/jira/browse/DRILL-7098?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Volodymyr Vysotskyi updated DRILL-7098: --- Reviewer: Volodymyr Vysotskyi (was: Aman Sinha) > File Metadata Metastore Plugin > -- > > Key: DRILL-7098 > URL: https://issues.apache.org/jira/browse/DRILL-7098 > Project: Apache Drill > Issue Type: Sub-task > Components: Server, Metadata >Reporter: Vitalii Diravka >Assignee: Vitalii Diravka >Priority: Major > Labels: Metastore, ready-to-commit > Fix For: 2.0.0 > > > DRILL-6852 introduces Drill Metastore API. > The second step is to create internal Drill Metastore mechanism (and File > Metastore Plugin), which will involve Metastore API and can be extended for > using by other Storage Plugins. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (DRILL-7098) File Metadata Metastore Plugin
[ https://issues.apache.org/jira/browse/DRILL-7098?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Volodymyr Vysotskyi updated DRILL-7098: --- Labels: Metastore ready-to-commit (was: Metastore) > File Metadata Metastore Plugin > -- > > Key: DRILL-7098 > URL: https://issues.apache.org/jira/browse/DRILL-7098 > Project: Apache Drill > Issue Type: Sub-task > Components: Server, Metadata >Reporter: Vitalii Diravka >Assignee: Vitalii Diravka >Priority: Major > Labels: Metastore, ready-to-commit > Fix For: 2.0.0 > > > DRILL-6852 introduces Drill Metastore API. > The second step is to create internal Drill Metastore mechanism (and File > Metastore Plugin), which will involve Metastore API and can be extended for > using by other Storage Plugins. -- This message was sent by Atlassian JIRA (v7.6.3#76005)