[jira] [Commented] (DRILL-7368) Query from Iceberg Metastore fails if filter column contains null
[ https://issues.apache.org/jira/browse/DRILL-7368?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16927390#comment-16927390 ] ASF GitHub Bot commented on DRILL-7368: --- arina-ielchiieva commented on pull request #1853: DRILL-7368: Fix Iceberg Metastore failure when filter column contains nulls URL: https://github.com/apache/drill/pull/1853 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Query from Iceberg Metastore fails if filter column contains null > - > > Key: DRILL-7368 > URL: https://issues.apache.org/jira/browse/DRILL-7368 > Project: Apache Drill > Issue Type: Bug >Reporter: Arina Ielchiieva >Assignee: Arina Ielchiieva >Priority: Major > Labels: ready-to-commit > Fix For: 1.17.0 > > > When querying data from Drill Iceberg Metastore query fails if filter column > contains null. > Problem is in Iceberg implementation - > https://github.com/apache/incubator-iceberg/pull/443 > Fix steps: > upgrade to latest Iceberg commit which includes appropriate fix. -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Created] (DRILL-7371) DST/UTC problem
benj created DRILL-7371:
---
Summary: DST/UTC problem
Key: DRILL-7371
URL: https://issues.apache.org/jira/browse/DRILL-7371
Project: Apache Drill
Issue Type: Bug
Components: Functions - Drill
Affects Versions: 1.16.0
Reporter: benj
With LC_TIME=fr_FR.UTF-8 and +drillbits configured in UTC+ (like specified in
[http://www.openkb.info/2015/05/understanding-drills-timestamp-and.html#.VUzhotpVhHw]
find from [https://drill.apache.org/docs/data-type-conversion/#to_timestamp])
{code:sql}
SELECT TIMEOFDAY();
+-+
| EXPR$0|
+-+
| 2019-09-11 08:20:12.247 UTC |
+-+
{code}
Problems appears when _cast/to_timestamp_ date (date related to the DST
(Daylight Save Time) of some countries).
To illustrate, all the next requests give the same +wrong+ results:
{code:sql}
SELECT to_timestamp('2018-03-25 02:22:40 UTC','-MM-dd HH:mm:ss z');
SELECT to_timestamp('2018-03-25 02:22:40','-MM-dd HH:mm:ss');
SELECT cast('2018-03-25 02:22:40' as timestamp);
SELECT cast('2018-03-25 02:22:40 +' as timestamp);
+---+
|EXPR$0 |
+---+
| 2018-03-25 03:22:40.0 |
+---+
{code}
while the result should be "2018-03-25 +02+:22:40.0"
An UTC date and time in string shouldn't change when casting to UTC timestamp.
To illustrate, the next requests produce +good+ results:
{code:java}
SELECT to_timestamp('2018-03-26 02:22:40 UTC','-MM-dd HH:mm:ss z');
+---+
|EXPR$0 |
+---+
| 2018-03-26 02:22:40.0 |
+---+
SELECT CAST('2018-03-24 02:22:40' AS timestamp);
+---+
|EXPR$0 |
+---+
| 2018-03-24 02:22:40.0 |
+---+
{code}
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Updated] (DRILL-7371) DST/UTC cast/to_timestamp problem
[
https://issues.apache.org/jira/browse/DRILL-7371?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
benj updated DRILL-7371:
Summary: DST/UTC cast/to_timestamp problem (was: DST/UTC problem)
> DST/UTC cast/to_timestamp problem
> -
>
> Key: DRILL-7371
> URL: https://issues.apache.org/jira/browse/DRILL-7371
> Project: Apache Drill
> Issue Type: Bug
> Components: Functions - Drill
>Affects Versions: 1.16.0
>Reporter: benj
>Priority: Major
>
> With LC_TIME=fr_FR.UTF-8 and +drillbits configured in UTC+ (like specified in
> [http://www.openkb.info/2015/05/understanding-drills-timestamp-and.html#.VUzhotpVhHw]
> find from [https://drill.apache.org/docs/data-type-conversion/#to_timestamp])
> {code:sql}
> SELECT TIMEOFDAY();
> +-+
> | EXPR$0|
> +-+
> | 2019-09-11 08:20:12.247 UTC |
> +-+
> {code}
> Problems appears when _cast/to_timestamp_ date (date related to the DST
> (Daylight Save Time) of some countries).
> To illustrate, all the next requests give the same +wrong+ results:
> {code:sql}
> SELECT to_timestamp('2018-03-25 02:22:40 UTC','-MM-dd HH:mm:ss z');
> SELECT to_timestamp('2018-03-25 02:22:40','-MM-dd HH:mm:ss');
> SELECT cast('2018-03-25 02:22:40' as timestamp);
> SELECT cast('2018-03-25 02:22:40 +' as timestamp);
> +---+
> |EXPR$0 |
> +---+
> | 2018-03-25 03:22:40.0 |
> +---+
> {code}
> while the result should be "2018-03-25 +02+:22:40.0"
> An UTC date and time in string shouldn't change when casting to UTC timestamp.
> To illustrate, the next requests produce +good+ results:
> {code:java}
> SELECT to_timestamp('2018-03-26 02:22:40 UTC','-MM-dd HH:mm:ss z');
> +---+
> |EXPR$0 |
> +---+
> | 2018-03-26 02:22:40.0 |
> +---+
> SELECT CAST('2018-03-24 02:22:40' AS timestamp);
> +---+
> |EXPR$0 |
> +---+
> | 2018-03-24 02:22:40.0 |
> +---+
> {code}
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (DRILL-7371) DST/UTC cast/to_timestamp problem
[
https://issues.apache.org/jira/browse/DRILL-7371?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16927480#comment-16927480
]
Volodymyr Vysotskyi commented on DRILL-7371:
[~benj641], I tried to reproduce this issue, but Drill returns correct results
for queries you have specified.
The locale was set as you have recommended:
{noformat}
localectl
System Locale: LC_TIME=fr_FR.UTF-8
{noformat}
And Drill was configured in UTC.
Could you please provide more info? Is it possible that this issue is
reproduced for specific date ranges? In this case, please provide a date which
should be set on the system.
> DST/UTC cast/to_timestamp problem
> -
>
> Key: DRILL-7371
> URL: https://issues.apache.org/jira/browse/DRILL-7371
> Project: Apache Drill
> Issue Type: Bug
> Components: Functions - Drill
>Affects Versions: 1.16.0
>Reporter: benj
>Priority: Major
>
> With LC_TIME=fr_FR.UTF-8 and +drillbits configured in UTC+ (like specified in
> [http://www.openkb.info/2015/05/understanding-drills-timestamp-and.html#.VUzhotpVhHw]
> find from [https://drill.apache.org/docs/data-type-conversion/#to_timestamp])
> {code:sql}
> SELECT TIMEOFDAY();
> +-+
> | EXPR$0|
> +-+
> | 2019-09-11 08:20:12.247 UTC |
> +-+
> {code}
> Problems appears when _cast/to_timestamp_ date (date related to the DST
> (Daylight Save Time) of some countries).
> To illustrate, all the next requests give the same +wrong+ results:
> {code:sql}
> SELECT to_timestamp('2018-03-25 02:22:40 UTC','-MM-dd HH:mm:ss z');
> SELECT to_timestamp('2018-03-25 02:22:40','-MM-dd HH:mm:ss');
> SELECT cast('2018-03-25 02:22:40' as timestamp);
> SELECT cast('2018-03-25 02:22:40 +' as timestamp);
> +---+
> |EXPR$0 |
> +---+
> | 2018-03-25 03:22:40.0 |
> +---+
> {code}
> while the result should be "2018-03-25 +02+:22:40.0"
> An UTC date and time in string shouldn't change when casting to UTC timestamp.
> To illustrate, the next requests produce +good+ results:
> {code:java}
> SELECT to_timestamp('2018-03-26 02:22:40 UTC','-MM-dd HH:mm:ss z');
> +---+
> |EXPR$0 |
> +---+
> | 2018-03-26 02:22:40.0 |
> +---+
> SELECT CAST('2018-03-24 02:22:40' AS timestamp);
> +---+
> |EXPR$0 |
> +---+
> | 2018-03-24 02:22:40.0 |
> +---+
> {code}
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (DRILL-7371) DST/UTC cast/to_timestamp problem
[
https://issues.apache.org/jira/browse/DRILL-7371?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16927527#comment-16927527
]
benj commented on DRILL-7371:
-
[~vvysotskyi], the problem occurs on all Daylight Saving Time of Europe (Paris).
>From investigation after your message, it's appears that the problem appears
>in console mode (/bin/sqlline -u jdbc:drill:zk=...:2181;schema=myhdfs).
The result is almost wrong with an execution via zeppelin (jdbc too).
But there is no problem with the request launched directly in the Apache Drill
web interface ([http://...:8047/query).]
So it's seems that the problem probably comes with JDBC.
> DST/UTC cast/to_timestamp problem
> -
>
> Key: DRILL-7371
> URL: https://issues.apache.org/jira/browse/DRILL-7371
> Project: Apache Drill
> Issue Type: Bug
> Components: Functions - Drill
>Affects Versions: 1.16.0
>Reporter: benj
>Priority: Major
>
> With LC_TIME=fr_FR.UTF-8 and +drillbits configured in UTC+ (like specified in
> [http://www.openkb.info/2015/05/understanding-drills-timestamp-and.html#.VUzhotpVhHw]
> find from [https://drill.apache.org/docs/data-type-conversion/#to_timestamp])
> {code:sql}
> SELECT TIMEOFDAY();
> +-+
> | EXPR$0|
> +-+
> | 2019-09-11 08:20:12.247 UTC |
> +-+
> {code}
> Problems appears when _cast/to_timestamp_ date (date related to the DST
> (Daylight Save Time) of some countries).
> To illustrate, all the next requests give the same +wrong+ results:
> {code:sql}
> SELECT to_timestamp('2018-03-25 02:22:40 UTC','-MM-dd HH:mm:ss z');
> SELECT to_timestamp('2018-03-25 02:22:40','-MM-dd HH:mm:ss');
> SELECT cast('2018-03-25 02:22:40' as timestamp);
> SELECT cast('2018-03-25 02:22:40 +' as timestamp);
> +---+
> |EXPR$0 |
> +---+
> | 2018-03-25 03:22:40.0 |
> +---+
> {code}
> while the result should be "2018-03-25 +02+:22:40.0"
> An UTC date and time in string shouldn't change when casting to UTC timestamp.
> To illustrate, the next requests produce +good+ results:
> {code:java}
> SELECT to_timestamp('2018-03-26 02:22:40 UTC','-MM-dd HH:mm:ss z');
> +---+
> |EXPR$0 |
> +---+
> | 2018-03-26 02:22:40.0 |
> +---+
> SELECT CAST('2018-03-24 02:22:40' AS timestamp);
> +---+
> |EXPR$0 |
> +---+
> | 2018-03-24 02:22:40.0 |
> +---+
> {code}
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Updated] (DRILL-7371) DST/UTC cast/to_timestamp problem
[
https://issues.apache.org/jira/browse/DRILL-7371?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
benj updated DRILL-7371:
Component/s: Client - JDBC
> DST/UTC cast/to_timestamp problem
> -
>
> Key: DRILL-7371
> URL: https://issues.apache.org/jira/browse/DRILL-7371
> Project: Apache Drill
> Issue Type: Bug
> Components: Client - JDBC, Functions - Drill
>Affects Versions: 1.16.0
>Reporter: benj
>Priority: Major
>
> With LC_TIME=fr_FR.UTF-8 and +drillbits configured in UTC+ (like specified in
> [http://www.openkb.info/2015/05/understanding-drills-timestamp-and.html#.VUzhotpVhHw]
> find from [https://drill.apache.org/docs/data-type-conversion/#to_timestamp])
> {code:sql}
> SELECT TIMEOFDAY();
> +-+
> | EXPR$0|
> +-+
> | 2019-09-11 08:20:12.247 UTC |
> +-+
> {code}
> Problems appears when _cast/to_timestamp_ date (date related to the DST
> (Daylight Save Time) of some countries).
> To illustrate, all the next requests give the same +wrong+ results:
> {code:sql}
> SELECT to_timestamp('2018-03-25 02:22:40 UTC','-MM-dd HH:mm:ss z');
> SELECT to_timestamp('2018-03-25 02:22:40','-MM-dd HH:mm:ss');
> SELECT cast('2018-03-25 02:22:40' as timestamp);
> SELECT cast('2018-03-25 02:22:40 +' as timestamp);
> +---+
> |EXPR$0 |
> +---+
> | 2018-03-25 03:22:40.0 |
> +---+
> {code}
> while the result should be "2018-03-25 +02+:22:40.0"
> An UTC date and time in string shouldn't change when casting to UTC timestamp.
> To illustrate, the next requests produce +good+ results:
> {code:java}
> SELECT to_timestamp('2018-03-26 02:22:40 UTC','-MM-dd HH:mm:ss z');
> +---+
> |EXPR$0 |
> +---+
> | 2018-03-26 02:22:40.0 |
> +---+
> SELECT CAST('2018-03-24 02:22:40' AS timestamp);
> +---+
> |EXPR$0 |
> +---+
> | 2018-03-24 02:22:40.0 |
> +---+
> {code}
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Created] (DRILL-7372) MethodAnalyzer consumes too many memory
Volodymyr Vysotskyi created DRILL-7372:
--
Summary: MethodAnalyzer consumes too many memory
Key: DRILL-7372
URL: https://issues.apache.org/jira/browse/DRILL-7372
Project: Apache Drill
Issue Type: Bug
Affects Versions: 1.16.0
Reporter: Volodymyr Vysotskyi
Assignee: Volodymyr Vysotskyi
Fix For: 1.17.0
In the scope of DRILL-6524 was added logic for determining whether a variable
is assigned in conditional block to prevent incorrect scalar replacement for
such cases.
But for some queries, this logic consumes too many memory, for example, for the
following query:
{code:sql}
SELECT *
FROM cp.`employee.json`
WHERE employee_id+0 < employee_id
OR employee_id+1 < employee_id
AND employee_id+2 < employee_id
OR employee_id+3 < employee_id
AND employee_id+4 < employee_id
OR employee_id+5 < employee_id
AND employee_id+6 < employee_id
OR employee_id+7 < employee_id
AND employee_id+8 < employee_id
OR employee_id+9 < employee_id
AND employee_id+10 < employee_id
OR employee_id+11 < employee_id
AND employee_id+12 < employee_id
OR employee_id+13 < employee_id
AND employee_id+14 < employee_id
OR employee_id+15 < employee_id
AND employee_id+16 < employee_id
OR employee_id+17 < employee_id
AND employee_id+18 < employee_id
OR employee_id+19 < employee_id
AND employee_id+20 < employee_id
OR employee_id+21 < employee_id
AND employee_id+22 < employee_id
OR employee_id+23 < employee_id
AND employee_id+24 < employee_id
OR employee_id+25 < employee_id
AND employee_id+26 < employee_id
OR employee_id+27 < employee_id
AND employee_id+28 < employee_id
OR employee_id+29 < employee_id
AND employee_id+30 < employee_id
OR employee_id+31 < employee_id
AND employee_id+32 < employee_id
OR employee_id+33 < employee_id
AND employee_id+34 < employee_id
OR employee_id+35 < employee_id
AND employee_id+36 < employee_id
OR employee_id+37 < employee_id
AND employee_id+38 < employee_id
OR employee_id+39 < employee_id
AND employee_id+40 < employee_id
OR employee_id+41 < employee_id
AND employee_id+42 < employee_id
OR employee_id+43 < employee_id
AND employee_id+44 < employee_id
OR employee_id+45 < employee_id
AND employee_id+46 < employee_id
OR employee_id+47 < employee_id
AND employee_id+48 < employee_id
OR employee_id+49 < employee_id
AND TRUE;
{code}
Drill consumes more than 6 GB memory.
One of the issues to fix is to replace {{Deque>
localVariablesSet;}} with {{Deque}}, it will reduce memory usage
significantly.
Additionally should be investigated why these objects cannot be collected by GC.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (DRILL-7174) Expose complex to Json control in the Drill C++ Client
[ https://issues.apache.org/jira/browse/DRILL-7174?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16927638#comment-16927638 ] ASF GitHub Bot commented on DRILL-7174: --- arina-ielchiieva commented on issue #1814: DRILL-7174: Expose complex to Json control in the Drill C++ Client URL: https://github.com/apache/drill/pull/1814#issuecomment-530423627 @arjuntheprogrammer is there any update? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Expose complex to Json control in the Drill C++ Client > -- > > Key: DRILL-7174 > URL: https://issues.apache.org/jira/browse/DRILL-7174 > Project: Apache Drill > Issue Type: Task >Reporter: Rob Wu >Priority: Minor > Fix For: 1.17.0 > > > Arjun Gupta will be supplying a patch for this > -- This message was sent by Atlassian Jira (v8.3.2#803003)
[jira] [Assigned] (DRILL-5550) SELECT non-existent column produces empty required VARCHAR
[
https://issues.apache.org/jira/browse/DRILL-5550?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arina Ielchiieva reassigned DRILL-5550:
---
Assignee: (was: Prasad Nagaraj Subramanya)
> SELECT non-existent column produces empty required VARCHAR
> --
>
> Key: DRILL-5550
> URL: https://issues.apache.org/jira/browse/DRILL-5550
> Project: Apache Drill
> Issue Type: Bug
> Components: Storage - Text & CSV
>Affects Versions: 1.10.0
>Reporter: Paul Rogers
>Priority: Minor
> Fix For: Future
>
>
> Drill's CSV column reader supports two forms of files:
> * Files with column headers as the first line of the file.
> * Files without column headers.
> The CSV storage plugin specifies which format to use for files accessed via
> that storage plugin config.
> Suppose we have a CSV file with headers:
> {code}
> a,b,c
> 10,foo,bar
> {code}
> Suppose we configure a storage plugin to use headers:
> {code}
> TextFormatConfig csvFormat = new TextFormatConfig();
> csvFormat.fieldDelimiter = ',';
> csvFormat.skipFirstLine = false;
> csvFormat.extractHeader = true;
> {code}
> (The above can also be done using JSON when running Drill as a server.)
> Execute the following query:
> {code}
> SELECT a, c, d FROM `dfs.data.example.csv`
> {code}
> Results:
> {code}
> a,c,d
> 10,bar,
> {code}
> The actual type of column {{d}} is non-nullable VARCHAR.
> This is inconsistent with other parts of Drill in two ways, one may be a bug.
> Most other parts of Drill use a nullable INT for "missing" columns.
> 1. For CSV it makes sense for the data type to be VARCHAR, since all CSV
> columns are of that type.
> 2. It may *not* make sense for the column to be non-nullable and blank rather
> than nullable and NULL. In SQL, NULL means that the data is unknown, which is
> the case here.
> In the future, we may want to use some other indication for a missing column.
> Until then, the requested change is to make the type of a missing CSV column
> a nullable VARCHAR set to value NULL.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (DRILL-5550) SELECT non-existent column produces empty required VARCHAR
[
https://issues.apache.org/jira/browse/DRILL-5550?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16927655#comment-16927655
]
ASF GitHub Bot commented on DRILL-5550:
---
arina-ielchiieva commented on issue #939: DRILL-5550: Missing CSV column value
set to null
URL: https://github.com/apache/drill/pull/939#issuecomment-530428270
Closing PR since it's no longer valid due to new text reader introduction.
Keeping the Jira open though since issue still persists.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> SELECT non-existent column produces empty required VARCHAR
> --
>
> Key: DRILL-5550
> URL: https://issues.apache.org/jira/browse/DRILL-5550
> Project: Apache Drill
> Issue Type: Bug
> Components: Storage - Text & CSV
>Affects Versions: 1.10.0
>Reporter: Paul Rogers
>Priority: Minor
> Fix For: Future
>
>
> Drill's CSV column reader supports two forms of files:
> * Files with column headers as the first line of the file.
> * Files without column headers.
> The CSV storage plugin specifies which format to use for files accessed via
> that storage plugin config.
> Suppose we have a CSV file with headers:
> {code}
> a,b,c
> 10,foo,bar
> {code}
> Suppose we configure a storage plugin to use headers:
> {code}
> TextFormatConfig csvFormat = new TextFormatConfig();
> csvFormat.fieldDelimiter = ',';
> csvFormat.skipFirstLine = false;
> csvFormat.extractHeader = true;
> {code}
> (The above can also be done using JSON when running Drill as a server.)
> Execute the following query:
> {code}
> SELECT a, c, d FROM `dfs.data.example.csv`
> {code}
> Results:
> {code}
> a,c,d
> 10,bar,
> {code}
> The actual type of column {{d}} is non-nullable VARCHAR.
> This is inconsistent with other parts of Drill in two ways, one may be a bug.
> Most other parts of Drill use a nullable INT for "missing" columns.
> 1. For CSV it makes sense for the data type to be VARCHAR, since all CSV
> columns are of that type.
> 2. It may *not* make sense for the column to be non-nullable and blank rather
> than nullable and NULL. In SQL, NULL means that the data is unknown, which is
> the case here.
> In the future, we may want to use some other indication for a missing column.
> Until then, the requested change is to make the type of a missing CSV column
> a nullable VARCHAR set to value NULL.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (DRILL-5550) SELECT non-existent column produces empty required VARCHAR
[
https://issues.apache.org/jira/browse/DRILL-5550?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16927654#comment-16927654
]
ASF GitHub Bot commented on DRILL-5550:
---
arina-ielchiieva commented on pull request #939: DRILL-5550: Missing CSV column
value set to null
URL: https://github.com/apache/drill/pull/939
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> SELECT non-existent column produces empty required VARCHAR
> --
>
> Key: DRILL-5550
> URL: https://issues.apache.org/jira/browse/DRILL-5550
> Project: Apache Drill
> Issue Type: Bug
> Components: Storage - Text & CSV
>Affects Versions: 1.10.0
>Reporter: Paul Rogers
>Priority: Minor
> Fix For: Future
>
>
> Drill's CSV column reader supports two forms of files:
> * Files with column headers as the first line of the file.
> * Files without column headers.
> The CSV storage plugin specifies which format to use for files accessed via
> that storage plugin config.
> Suppose we have a CSV file with headers:
> {code}
> a,b,c
> 10,foo,bar
> {code}
> Suppose we configure a storage plugin to use headers:
> {code}
> TextFormatConfig csvFormat = new TextFormatConfig();
> csvFormat.fieldDelimiter = ',';
> csvFormat.skipFirstLine = false;
> csvFormat.extractHeader = true;
> {code}
> (The above can also be done using JSON when running Drill as a server.)
> Execute the following query:
> {code}
> SELECT a, c, d FROM `dfs.data.example.csv`
> {code}
> Results:
> {code}
> a,c,d
> 10,bar,
> {code}
> The actual type of column {{d}} is non-nullable VARCHAR.
> This is inconsistent with other parts of Drill in two ways, one may be a bug.
> Most other parts of Drill use a nullable INT for "missing" columns.
> 1. For CSV it makes sense for the data type to be VARCHAR, since all CSV
> columns are of that type.
> 2. It may *not* make sense for the column to be non-nullable and blank rather
> than nullable and NULL. In SQL, NULL means that the data is unknown, which is
> the case here.
> In the future, we may want to use some other indication for a missing column.
> Until then, the requested change is to make the type of a missing CSV column
> a nullable VARCHAR set to value NULL.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (DRILL-5550) SELECT non-existent column produces empty required VARCHAR
[
https://issues.apache.org/jira/browse/DRILL-5550?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16927653#comment-16927653
]
ASF GitHub Bot commented on DRILL-5550:
---
arina-ielchiieva commented on issue #939: DRILL-5550: Missing CSV column value
set to null
URL: https://github.com/apache/drill/pull/939#issuecomment-530428270
Closing PR since it's no longer valid to to new text reader introduction.
Keeping the Jira open though since issue still persists.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> SELECT non-existent column produces empty required VARCHAR
> --
>
> Key: DRILL-5550
> URL: https://issues.apache.org/jira/browse/DRILL-5550
> Project: Apache Drill
> Issue Type: Bug
> Components: Storage - Text & CSV
>Affects Versions: 1.10.0
>Reporter: Paul Rogers
>Priority: Minor
> Fix For: Future
>
>
> Drill's CSV column reader supports two forms of files:
> * Files with column headers as the first line of the file.
> * Files without column headers.
> The CSV storage plugin specifies which format to use for files accessed via
> that storage plugin config.
> Suppose we have a CSV file with headers:
> {code}
> a,b,c
> 10,foo,bar
> {code}
> Suppose we configure a storage plugin to use headers:
> {code}
> TextFormatConfig csvFormat = new TextFormatConfig();
> csvFormat.fieldDelimiter = ',';
> csvFormat.skipFirstLine = false;
> csvFormat.extractHeader = true;
> {code}
> (The above can also be done using JSON when running Drill as a server.)
> Execute the following query:
> {code}
> SELECT a, c, d FROM `dfs.data.example.csv`
> {code}
> Results:
> {code}
> a,c,d
> 10,bar,
> {code}
> The actual type of column {{d}} is non-nullable VARCHAR.
> This is inconsistent with other parts of Drill in two ways, one may be a bug.
> Most other parts of Drill use a nullable INT for "missing" columns.
> 1. For CSV it makes sense for the data type to be VARCHAR, since all CSV
> columns are of that type.
> 2. It may *not* make sense for the column to be non-nullable and blank rather
> than nullable and NULL. In SQL, NULL means that the data is unknown, which is
> the case here.
> In the future, we may want to use some other indication for a missing column.
> Until then, the requested change is to make the type of a missing CSV column
> a nullable VARCHAR set to value NULL.
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Updated] (DRILL-6975) TO_CHAR does not seems work well depends on LOCALE
[
https://issues.apache.org/jira/browse/DRILL-6975?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
benj updated DRILL-6975:
Affects Version/s: 1.14.0
1.16.0
> TO_CHAR does not seems work well depends on LOCALE
> --
>
> Key: DRILL-6975
> URL: https://issues.apache.org/jira/browse/DRILL-6975
> Project: Apache Drill
> Issue Type: Bug
> Components: Functions - Drill
>Affects Versions: 1.14.0, 1.15.0, 1.16.0
>Reporter: benj
>Priority: Major
>
> Strange results from TO_CHAR function when using different LOCALE.
> {code:java}
> SELECT TO_CHAR((CAST('2008-2-23' AS DATE)), '-MMM-dd') FROM (VALUES(1));
> 2008-Feb-23 (in documentation (en_US.UTF-8))
> 2008-févr.-2 (fr_FR.UTF-8)
> {code}
> surprisingly by adding a space ('-MMM-dd ') (or any character) at the end
> of the format the result becomes correct (so there is no problem when format
> a timestamp with ' MMM dd HH:mm:ss')
> {code:java}
> SELECT TO_CHAR(1256.789383, '#,###.###') FROM (VALUES(1));
> 1,256.789 (in documentation (en_US.UTF-8))
> 1 256,78 (fr_FR.UTF-8)
> {code}
> Even worse results can be achieved
> {code:java}
> SELECT TO_CHAR(12567,'#,###.###');
> 12,567 (en_US.UTF-8)
> 12 56 (fr_FR.UTF-8)
> {code}
> Again, with the add of a space/char at the end we get a better result.
> I don't have tested all the locale, but for the last example, the result is
> right with de_DE.UTF-8 : 12.567
> The situation is identical in 1.14
>
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Created] (DRILL-7373) Fix problems involving reading from DICT type
Bohdan Kazydub created DRILL-7373:
-
Summary: Fix problems involving reading from DICT type
Key: DRILL-7373
URL: https://issues.apache.org/jira/browse/DRILL-7373
Project: Apache Drill
Issue Type: Bug
Reporter: Bohdan Kazydub
Assignee: Bohdan Kazydub
Add better support for different key types ({{boolean}}, {{decimal}},
{{float}}, {{double}} etc.) when retrieving values by key from {{DICT}} column
when querying data source with known (during query validation phase) field
types (such as Hive table), so that actual key object instance is created in
generated code and is passed to given {{DICT}} reader instead of generating its
value for every row based on {{int}} ({{ArraySegment}}) or {{String}}
({{NamedSegment}}) value.
This may be achieved by storing original literal value of passed key (as
{{Object}}) in {{PathSegment}} and its type (as {{MajorType}}) and using it
during code generation when reading {{DICT}}'s values by key in
{{EvaluationVisitor}}.
Also, fix NPE when reading some cases involving reading values from {{DICT}}
and fix wrong result when reading complex structures using many ITEM operators
(i.e. , [] brackets), e.g.
{code}
SELECT rid, mc.map_arr_map['key01'][1]['key01.1'] p16 FROM hive.map_complex_tbl
mc
{code}
where {{map_arr_map}} is of following type: {{MAP>>}}
--
This message was sent by Atlassian Jira
(v8.3.2#803003)
[jira] [Commented] (DRILL-7174) Expose complex to Json control in the Drill C++ Client
[ https://issues.apache.org/jira/browse/DRILL-7174?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16927739#comment-16927739 ] ASF GitHub Bot commented on DRILL-7174: --- arjuntheprogrammer commented on issue #1814: DRILL-7174: Expose complex to Json control in the Drill C++ Client URL: https://github.com/apache/drill/pull/1814#issuecomment-530455926 Hi @arina-ielchiieva - I have already written the unit test but I am getting some linker error: 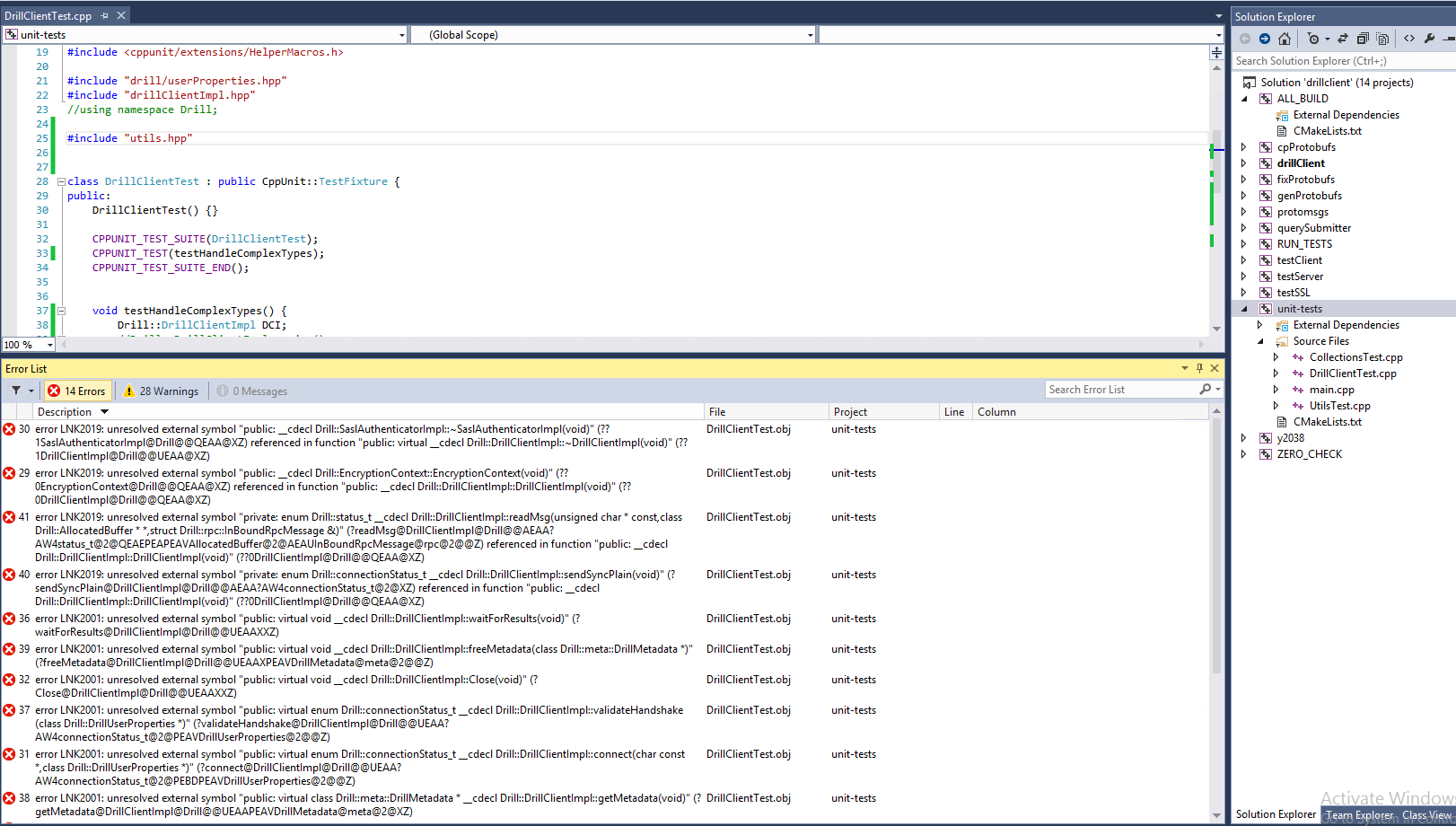 If you get any idea looking at the error in the image, please let me know. Otherwise by end of this week I will try to resolve that error and update the PR request. By the way may I know what is the planned release date? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Expose complex to Json control in the Drill C++ Client > -- > > Key: DRILL-7174 > URL: https://issues.apache.org/jira/browse/DRILL-7174 > Project: Apache Drill > Issue Type: Task >Reporter: Rob Wu >Priority: Minor > Fix For: 1.17.0 > > > Arjun Gupta will be supplying a patch for this > -- This message was sent by Atlassian Jira (v8.3.2#803003)