[jira] [Commented] (FLINK-7378) Create a fix size (non rebalancing) buffer pool type for the floating buffers
[
https://issues.apache.org/jira/browse/FLINK-7378?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143416#comment-16143416
]
ASF GitHub Bot commented on FLINK-7378:
---
Github user zhijiangW commented on the issue:
https://github.com/apache/flink/pull/4485
@NicoK , thank you for giving this discussion and comments!
Actually I proposed the same way of using fixed-size `LocalBufferPool` for
managing exclusive buffers for per `RemoteInputChannel` with stephan before
implementation. I attached the dialogue below:
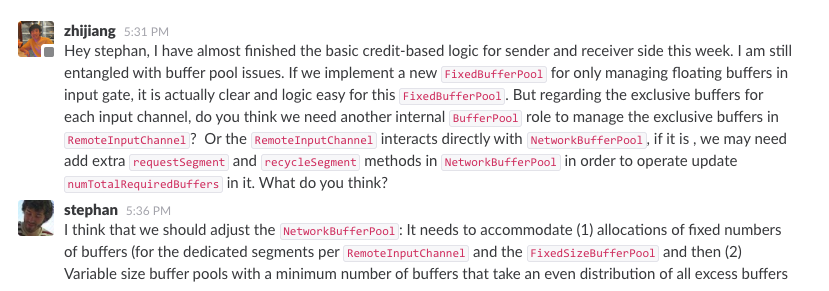
Maybe I did not catch stephan's meaning from the above dialogue and took
the current way to implement. I also agree with the way you mentioned and the
fixed-size buffer pool for `RemoteInputChannel` can be submitted in an separate
PR.
> Create a fix size (non rebalancing) buffer pool type for the floating buffers
> -
>
> Key: FLINK-7378
> URL: https://issues.apache.org/jira/browse/FLINK-7378
> Project: Flink
> Issue Type: Sub-task
> Components: Core
>Reporter: zhijiang
>Assignee: zhijiang
> Fix For: 1.4.0
>
>
> Currently the number of network buffers in {{LocalBufferPool}} for
> {{SingleInputGate}} is limited by {{a * + b}}, where a
> is the number of exclusive buffers for each channel and b is the number of
> floating buffers shared by all channels.
> Considering the credit-based flow control feature, we want to create a fix
> size buffer pool used to manage the floating buffers for {{SingleInputGate}}.
> And the exclusive buffers are assigned to {{InputChannel}}s directly.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[GitHub] flink issue #4485: [FLINK-7378][core]Create a fix size (non rebalancing) buf...
Github user zhijiangW commented on the issue: https://github.com/apache/flink/pull/4485 @NicoK , thank you for giving this discussion and comments! Actually I proposed the same way of using fixed-size `LocalBufferPool` for managing exclusive buffers for per `RemoteInputChannel` with stephan before implementation. I attached the dialogue below:  Maybe I did not catch stephan's meaning from the above dialogue and took the current way to implement. I also agree with the way you mentioned and the fixed-size buffer pool for `RemoteInputChannel` can be submitted in an separate PR. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] flink issue #4513: [FLINK-6938] [cep] IterativeCondition should support Rich...
Github user dianfu commented on the issue: https://github.com/apache/flink/pull/4513 @dawidwys It would be great if you could take a look. Very appreciated! --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[jira] [Commented] (FLINK-6938) IterativeCondition should support RichFunction interface
[
https://issues.apache.org/jira/browse/FLINK-6938?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143403#comment-16143403
]
ASF GitHub Bot commented on FLINK-6938:
---
Github user dianfu commented on the issue:
https://github.com/apache/flink/pull/4513
@dawidwys It would be great if you could take a look. Very appreciated!
> IterativeCondition should support RichFunction interface
>
>
> Key: FLINK-6938
> URL: https://issues.apache.org/jira/browse/FLINK-6938
> Project: Flink
> Issue Type: Sub-task
> Components: CEP
>Reporter: Jark Wu
>Assignee: Jark Wu
> Fix For: 1.4.0
>
>
> In FLIP-20, we need IterativeCondition to support an {{open()}} method to
> compile the generated code once. We do not want to insert a if condition in
> the {{filter()}} method. So I suggest make IterativeCondition support
> {{RichFunction}} interface.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[GitHub] flink pull request #4296: [FLINK-7147] [cep] Support greedy quantifier in CE...
Github user dianfu commented on a diff in the pull request:
https://github.com/apache/flink/pull/4296#discussion_r135441351
--- Diff:
flink-libraries/flink-cep/src/main/java/org/apache/flink/cep/nfa/compiler/NFACompiler.java
---
@@ -421,6 +437,15 @@ private void addStopStateToLooping(final State
loopingState) {
untilCondition,
true);
+ if
(currentPattern.getQuantifier().hasProperty(Quantifier.QuantifierProperty.GREEDY)
&&
+ times.getFrom() != times.getTo()) {
+ if (untilCondition != null) {
+ State sinkStateCopy =
copy(sinkState);
+
originalStateMap.put(sinkState.getName(), sinkStateCopy);
--- End diff --
originalStateMap is used when compiling the NFA and it will be collected
after NFA is created and so I think it's unnecessary to clear the entries.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[jira] [Commented] (FLINK-7147) Support greedy quantifier in CEP
[
https://issues.apache.org/jira/browse/FLINK-7147?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143367#comment-16143367
]
ASF GitHub Bot commented on FLINK-7147:
---
Github user dianfu commented on a diff in the pull request:
https://github.com/apache/flink/pull/4296#discussion_r135441351
--- Diff:
flink-libraries/flink-cep/src/main/java/org/apache/flink/cep/nfa/compiler/NFACompiler.java
---
@@ -421,6 +437,15 @@ private void addStopStateToLooping(final State
loopingState) {
untilCondition,
true);
+ if
(currentPattern.getQuantifier().hasProperty(Quantifier.QuantifierProperty.GREEDY)
&&
+ times.getFrom() != times.getTo()) {
+ if (untilCondition != null) {
+ State sinkStateCopy =
copy(sinkState);
+
originalStateMap.put(sinkState.getName(), sinkStateCopy);
--- End diff --
originalStateMap is used when compiling the NFA and it will be collected
after NFA is created and so I think it's unnecessary to clear the entries.
> Support greedy quantifier in CEP
>
>
> Key: FLINK-7147
> URL: https://issues.apache.org/jira/browse/FLINK-7147
> Project: Flink
> Issue Type: Sub-task
> Components: CEP, Table API & SQL
>Reporter: Dian Fu
>Assignee: Dian Fu
>
> Greedy quantifier will try to match the token as many times as possible. For
> example, for pattern {{a b* c}} (skip till next is used) and inputs {{a b1 b2
> c}}, if the quantifier for {{b}} is greedy, it will only output {{a b1 b2 c}}.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (FLINK-7147) Support greedy quantifier in CEP
[
https://issues.apache.org/jira/browse/FLINK-7147?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143360#comment-16143360
]
ASF GitHub Bot commented on FLINK-7147:
---
Github user dianfu commented on a diff in the pull request:
https://github.com/apache/flink/pull/4296#discussion_r135440842
--- Diff:
flink-libraries/flink-cep/src/main/java/org/apache/flink/cep/nfa/compiler/NFACompiler.java
---
@@ -526,18 +551,32 @@ private boolean isPatternOptional(Pattern
pattern) {
return createGroupPatternState((GroupPattern)
currentPattern, sinkState, proceedState, isOptional);
}
- final IterativeCondition trueFunction =
getTrueFunction();
-
final State singletonState =
createState(currentPattern.getName(), State.StateType.Normal);
// if event is accepted then all notPatterns previous
to the optional states are no longer valid
final State sink =
copyWithoutTransitiveNots(sinkState);
singletonState.addTake(sink, takeCondition);
+ // if no element accepted the previous nots are still
valid.
+ final IterativeCondition proceedCondition =
getTrueFunction();
+
// for the first state of a group pattern, its PROCEED
edge should point to the following state of
// that group pattern and the edge will be added at the
end of creating the NFA for that group pattern
if (isOptional && !headOfGroup(currentPattern)) {
- // if no element accepted the previous nots are
still valid.
- singletonState.addProceed(proceedState,
trueFunction);
+ if
(currentPattern.getQuantifier().hasProperty(Quantifier.QuantifierProperty.GREEDY))
{
+ final IterativeCondition
untilCondition =
+ (IterativeCondition)
currentPattern.getUntilCondition();
+ if (untilCondition != null) {
+ singletonState.addProceed(
+
originalStateMap.get(proceedState.getName()),
+ new
AndCondition<>(proceedCondition, untilCondition));
--- End diff --
When untilCondition holds, the loop should break and the state should
proceed to the next state. This is covered by the test case
GreedyITCase#testGreedyUntilWithDummyEventsBeforeQuantifier.
> Support greedy quantifier in CEP
>
>
> Key: FLINK-7147
> URL: https://issues.apache.org/jira/browse/FLINK-7147
> Project: Flink
> Issue Type: Sub-task
> Components: CEP, Table API & SQL
>Reporter: Dian Fu
>Assignee: Dian Fu
>
> Greedy quantifier will try to match the token as many times as possible. For
> example, for pattern {{a b* c}} (skip till next is used) and inputs {{a b1 b2
> c}}, if the quantifier for {{b}} is greedy, it will only output {{a b1 b2 c}}.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[GitHub] flink pull request #4296: [FLINK-7147] [cep] Support greedy quantifier in CE...
Github user dianfu commented on a diff in the pull request:
https://github.com/apache/flink/pull/4296#discussion_r135440842
--- Diff:
flink-libraries/flink-cep/src/main/java/org/apache/flink/cep/nfa/compiler/NFACompiler.java
---
@@ -526,18 +551,32 @@ private boolean isPatternOptional(Pattern
pattern) {
return createGroupPatternState((GroupPattern)
currentPattern, sinkState, proceedState, isOptional);
}
- final IterativeCondition trueFunction =
getTrueFunction();
-
final State singletonState =
createState(currentPattern.getName(), State.StateType.Normal);
// if event is accepted then all notPatterns previous
to the optional states are no longer valid
final State sink =
copyWithoutTransitiveNots(sinkState);
singletonState.addTake(sink, takeCondition);
+ // if no element accepted the previous nots are still
valid.
+ final IterativeCondition proceedCondition =
getTrueFunction();
+
// for the first state of a group pattern, its PROCEED
edge should point to the following state of
// that group pattern and the edge will be added at the
end of creating the NFA for that group pattern
if (isOptional && !headOfGroup(currentPattern)) {
- // if no element accepted the previous nots are
still valid.
- singletonState.addProceed(proceedState,
trueFunction);
+ if
(currentPattern.getQuantifier().hasProperty(Quantifier.QuantifierProperty.GREEDY))
{
+ final IterativeCondition
untilCondition =
+ (IterativeCondition)
currentPattern.getUntilCondition();
+ if (untilCondition != null) {
+ singletonState.addProceed(
+
originalStateMap.get(proceedState.getName()),
+ new
AndCondition<>(proceedCondition, untilCondition));
--- End diff --
When untilCondition holds, the loop should break and the state should
proceed to the next state. This is covered by the test case
GreedyITCase#testGreedyUntilWithDummyEventsBeforeQuantifier.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
issues@flink.apache.org
[
https://issues.apache.org/jira/browse/FLINK-7465?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143342#comment-16143342
]
sunjincheng commented on FLINK-7465:
Hi [~jparkie]When we deal with a [Dynamic
table|http://flink.apache.org/news/2017/04/04/dynamic-tables.html] retract
record will generate when record is updated. [Retract
stream|https://ci.apache.org/projects/flink/flink-docs-release-1.4/dev/table/streaming.html]
contains retract record. i.e.: A retract stream is a stream with two types of
messages, add messages and retract messages. A dynamic table is converted into
an retract stream by encoding an INSERT change as add message, a DELETE change
as retract message, and an UPDATE change as a retract message for the updated
(previous) row and an add message for the updating (new) row. The following
figure visualizes the conversion of a dynamic table into a retract stream.
!https://ci.apache.org/projects/flink/flink-docs-release-1.4/fig/table-streaming/undo-redo-mode.png!
So, the core issue of traditional {{HyperLogLog}} is not to support delete. To
be honest HyperLogLog is (approximately) count the number of distinct
values,maybe we can ignore the retract recode.
> Add build-in BloomFilterCount on TableAPI&SQL
> -
>
> Key: FLINK-7465
> URL: https://issues.apache.org/jira/browse/FLINK-7465
> Project: Flink
> Issue Type: Sub-task
> Components: Table API & SQL
>Reporter: sunjincheng
>Assignee: sunjincheng
> Attachments: bloomfilter.png
>
>
> In this JIRA. use BloomFilter to implement counting functions.
> BloomFilter Algorithm description:
> An empty Bloom filter is a bit array of m bits, all set to 0. There must also
> be k different hash functions defined, each of which maps or hashes some set
> element to one of the m array positions, generating a uniform random
> distribution. Typically, k is a constant, much smaller than m, which is
> proportional to the number of elements to be added; the precise choice of k
> and the constant of proportionality of m are determined by the intended false
> positive rate of the filter.
> To add an element, feed it to each of the k hash functions to get k array
> positions. Set the bits at all these positions to 1.
> To query for an element (test whether it is in the set), feed it to each of
> the k hash functions to get k array positions. If any of the bits at these
> positions is 0, the element is definitely not in the set – if it were, then
> all the bits would have been set to 1 when it was inserted. If all are 1,
> then either the element is in the set, or the bits have by chance been set to
> 1 during the insertion of other elements, resulting in a false positive.
> An example of a Bloom filter, representing the set {x, y, z}. The colored
> arrows show the positions in the bit array that each set element is mapped
> to. The element w is not in the set {x, y, z}, because it hashes to one
> bit-array position containing 0. For this figure, m = 18 and k = 3. The
> sketch as follows:
> !bloomfilter.png!
> Reference:
> 1. https://en.wikipedia.org/wiki/Bloom_filter
> 2.
> https://github.com/apache/hive/blob/master/storage-api/src/java/org/apache/hive/common/util/BloomFilter.java
> Hi [~fhueske] [~twalthr] I appreciated if you can give me some advice. :-)
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[GitHub] flink pull request #4536: [FLINK-7439] [table] Support variable arguments fo...
Github user wuchong commented on a diff in the pull request: https://github.com/apache/flink/pull/4536#discussion_r135430307 --- Diff: flink-libraries/flink-table/src/main/scala/org/apache/flink/table/plan/schema/FlinkTableFunctionImpl.scala --- @@ -71,6 +69,9 @@ class FlinkTableFunctionImpl[T]( override def getElementType(arguments: util.List[AnyRef]): Type = classOf[Array[Object]] + // we do never use the FunctionParameters, so return an empty list + override def getParameters: util.List[FunctionParameter] = Collections.emptyList() --- End diff -- `ReflectiveFunctionBase#getParameters` is used to create `SqlOperandTypeChecker` in the previous implementation. But with the new implementation, we don't need the `ReflectiveFunctionBase#getParameters` to create `SqlOperandTypeChecker`. So I think we can just return an empty list. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[jira] [Commented] (FLINK-7439) Support variable arguments for UDTF in SQL
[ https://issues.apache.org/jira/browse/FLINK-7439?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143299#comment-16143299 ] ASF GitHub Bot commented on FLINK-7439: --- Github user wuchong commented on a diff in the pull request: https://github.com/apache/flink/pull/4536#discussion_r135430307 --- Diff: flink-libraries/flink-table/src/main/scala/org/apache/flink/table/plan/schema/FlinkTableFunctionImpl.scala --- @@ -71,6 +69,9 @@ class FlinkTableFunctionImpl[T]( override def getElementType(arguments: util.List[AnyRef]): Type = classOf[Array[Object]] + // we do never use the FunctionParameters, so return an empty list + override def getParameters: util.List[FunctionParameter] = Collections.emptyList() --- End diff -- `ReflectiveFunctionBase#getParameters` is used to create `SqlOperandTypeChecker` in the previous implementation. But with the new implementation, we don't need the `ReflectiveFunctionBase#getParameters` to create `SqlOperandTypeChecker`. So I think we can just return an empty list. > Support variable arguments for UDTF in SQL > -- > > Key: FLINK-7439 > URL: https://issues.apache.org/jira/browse/FLINK-7439 > Project: Flink > Issue Type: Improvement > Components: Table API & SQL >Reporter: Jark Wu >Assignee: Jark Wu > > Currently, both UDF and UDAF support variable parameters, but UDTF not. > FLINK-5882 supports variable UDTF for Table API only, but missed SQL. -- This message was sent by Atlassian JIRA (v6.4.14#64029)
[jira] [Commented] (FLINK-7439) Support variable arguments for UDTF in SQL
[ https://issues.apache.org/jira/browse/FLINK-7439?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143297#comment-16143297 ] ASF GitHub Bot commented on FLINK-7439: --- Github user wuchong commented on a diff in the pull request: https://github.com/apache/flink/pull/4536#discussion_r135430161 --- Diff: flink-libraries/flink-table/src/main/scala/org/apache/flink/table/plan/schema/FlinkTableFunctionImpl.scala --- @@ -36,10 +36,8 @@ import org.apache.flink.table.calcite.FlinkTypeFactory class FlinkTableFunctionImpl[T]( val typeInfo: TypeInformation[T], val fieldIndexes: Array[Int], -val fieldNames: Array[String], -val evalMethod: Method) - extends ReflectiveFunctionBase(evalMethod) --- End diff -- In the first implementation of UDTF, we use `ReflectiveFunctionBase` to infer the operand types. But with the new approach in this PR, we customize a `SqlOperandTypeChecker` to check operands which means we don't need the `ReflectiveFunctionBase` anymore. If we extends `ReflectiveFunctionBase` we have to register every `eval` method as a UDTF. But with the new approach in this PR, we only need to register once. > Support variable arguments for UDTF in SQL > -- > > Key: FLINK-7439 > URL: https://issues.apache.org/jira/browse/FLINK-7439 > Project: Flink > Issue Type: Improvement > Components: Table API & SQL >Reporter: Jark Wu >Assignee: Jark Wu > > Currently, both UDF and UDAF support variable parameters, but UDTF not. > FLINK-5882 supports variable UDTF for Table API only, but missed SQL. -- This message was sent by Atlassian JIRA (v6.4.14#64029)
[GitHub] flink pull request #4536: [FLINK-7439] [table] Support variable arguments fo...
Github user wuchong commented on a diff in the pull request: https://github.com/apache/flink/pull/4536#discussion_r135430161 --- Diff: flink-libraries/flink-table/src/main/scala/org/apache/flink/table/plan/schema/FlinkTableFunctionImpl.scala --- @@ -36,10 +36,8 @@ import org.apache.flink.table.calcite.FlinkTypeFactory class FlinkTableFunctionImpl[T]( val typeInfo: TypeInformation[T], val fieldIndexes: Array[Int], -val fieldNames: Array[String], -val evalMethod: Method) - extends ReflectiveFunctionBase(evalMethod) --- End diff -- In the first implementation of UDTF, we use `ReflectiveFunctionBase` to infer the operand types. But with the new approach in this PR, we customize a `SqlOperandTypeChecker` to check operands which means we don't need the `ReflectiveFunctionBase` anymore. If we extends `ReflectiveFunctionBase` we have to register every `eval` method as a UDTF. But with the new approach in this PR, we only need to register once. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[jira] [Commented] (FLINK-7439) Support variable arguments for UDTF in SQL
[
https://issues.apache.org/jira/browse/FLINK-7439?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143282#comment-16143282
]
ASF GitHub Bot commented on FLINK-7439:
---
Github user sunjincheng121 commented on a diff in the pull request:
https://github.com/apache/flink/pull/4536#discussion_r135425816
--- Diff:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/functions/utils/TableSqlFunction.scala
---
@@ -74,48 +75,102 @@ class TableSqlFunction(
object TableSqlFunction {
- /**
-* Util function to create a [[TableSqlFunction]].
-*
-* @param name function name (used by SQL parser)
-* @param udtf user-defined table function to be called
-* @param rowTypeInfo the row type information generated by the table
function
-* @param typeFactory type factory for converting Flink's between
Calcite's types
-* @param functionImpl Calcite table function schema
-* @return [[TableSqlFunction]]
-*/
- def apply(
+ private[flink] def createOperandTypeInference(
name: String,
udtf: TableFunction[_],
-rowTypeInfo: TypeInformation[_],
-typeFactory: FlinkTypeFactory,
-functionImpl: FlinkTableFunctionImpl[_]): TableSqlFunction = {
-
-val argTypes: util.List[RelDataType] = new util.ArrayList[RelDataType]
-val typeFamilies: util.List[SqlTypeFamily] = new
util.ArrayList[SqlTypeFamily]
-// derives operands' data types and type families
-functionImpl.getParameters.asScala.foreach{ o =>
- val relType: RelDataType = o.getType(typeFactory)
- argTypes.add(relType)
- typeFamilies.add(Util.first(relType.getSqlTypeName.getFamily,
SqlTypeFamily.ANY))
+typeFactory: FlinkTypeFactory)
+ : SqlOperandTypeInference = {
+/**
+ * Operand type inference based on [[TableFunction]] given
information.
+ */
+new SqlOperandTypeInference {
+ override def inferOperandTypes(
+ callBinding: SqlCallBinding,
+ returnType: RelDataType,
+ operandTypes: Array[RelDataType]): Unit = {
+
+val operandTypeInfo = getOperandTypeInfo(callBinding)
+
+val foundSignature = getEvalMethodSignature(udtf, operandTypeInfo)
+ .getOrElse(throw new ValidationException(
+s"Given parameters of function '$name' do not match any
signature. \n" +
+ s"Actual: ${signatureToString(operandTypeInfo)} \n" +
+ s"Expected: ${signaturesToString(udtf, "eval")}"))
+
+val inferredTypes = foundSignature
+ .map(TypeExtractor.getForClass(_))
+ .map(typeFactory.createTypeFromTypeInfo(_, isNullable = true))
+
+for (i <- operandTypes.indices) {
+ if (i < inferredTypes.length - 1) {
+operandTypes(i) = inferredTypes(i)
+ } else if (null != inferredTypes.last.getComponentType) {
+// last argument is a collection, the array type
+operandTypes(i) = inferredTypes.last.getComponentType
+ } else {
+operandTypes(i) = inferredTypes.last
+ }
+}
+ }
}
-// derives whether the 'input'th parameter of a method is optional.
-val optional: Predicate[Integer] = new Predicate[Integer]() {
- def apply(input: Integer): Boolean = {
-functionImpl.getParameters.get(input).isOptional
+ }
+
+ private[flink] def createOperandTypeChecker(
--- End diff --
Can we share the methods of `SqlOperandTypeInference` and
`createOperandTypeChecker` with `ScalarSqlFunction``TableSqlFunction` and
`AggSqlFunction`, Because all of the UDX need them, and the logic of these
method are same or similar. May be we can move them into
`UserDefinedFunctionUtils`. What do you think?
> Support variable arguments for UDTF in SQL
> --
>
> Key: FLINK-7439
> URL: https://issues.apache.org/jira/browse/FLINK-7439
> Project: Flink
> Issue Type: Improvement
> Components: Table API & SQL
>Reporter: Jark Wu
>Assignee: Jark Wu
>
> Currently, both UDF and UDAF support variable parameters, but UDTF not.
> FLINK-5882 supports variable UDTF for Table API only, but missed SQL.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (FLINK-7439) Support variable arguments for UDTF in SQL
[
https://issues.apache.org/jira/browse/FLINK-7439?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143278#comment-16143278
]
ASF GitHub Bot commented on FLINK-7439:
---
Github user sunjincheng121 commented on a diff in the pull request:
https://github.com/apache/flink/pull/4536#discussion_r135426250
--- Diff:
flink-libraries/flink-table/src/test/java/org/apache/flink/table/runtime/utils/JavaUserDefinedTableFunctions.java
---
@@ -35,4 +35,15 @@ public void eval(Integer a, Long b, Long c) {
collect(c);
}
}
+
+ /**
+* Emit every input string.
+*/
+ public static class JavaVarsArgTableFunc0 extends TableFunction
{
+ public void eval(String... strs) {
+ for (String s : strs) {
+ collect(s);
+ }
+ }
--- End diff --
Add an other eval for method match check.(only a suggestion).
{code}
public void eval(int ival, String sVal) {
while (ival-- > 0) {
collect(sVal);
}
}
{code}
> Support variable arguments for UDTF in SQL
> --
>
> Key: FLINK-7439
> URL: https://issues.apache.org/jira/browse/FLINK-7439
> Project: Flink
> Issue Type: Improvement
> Components: Table API & SQL
>Reporter: Jark Wu
>Assignee: Jark Wu
>
> Currently, both UDF and UDAF support variable parameters, but UDTF not.
> FLINK-5882 supports variable UDTF for Table API only, but missed SQL.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (FLINK-7439) Support variable arguments for UDTF in SQL
[
https://issues.apache.org/jira/browse/FLINK-7439?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143280#comment-16143280
]
ASF GitHub Bot commented on FLINK-7439:
---
Github user sunjincheng121 commented on a diff in the pull request:
https://github.com/apache/flink/pull/4536#discussion_r135425261
--- Diff:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/functions/utils/TableSqlFunction.scala
---
@@ -18,39 +18,40 @@
package org.apache.flink.table.functions.utils
-import com.google.common.base.Predicate
import org.apache.calcite.rel.`type`.RelDataType
import org.apache.calcite.sql._
import org.apache.calcite.sql.`type`._
import org.apache.calcite.sql.parser.SqlParserPos
import org.apache.calcite.sql.validate.SqlUserDefinedTableFunction
-import org.apache.calcite.util.Util
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.table.calcite.FlinkTypeFactory
-import org.apache.flink.table.functions.TableFunction
+import org.apache.flink.table.functions.{ScalarFunction, TableFunction}
--- End diff --
remove useless import.
> Support variable arguments for UDTF in SQL
> --
>
> Key: FLINK-7439
> URL: https://issues.apache.org/jira/browse/FLINK-7439
> Project: Flink
> Issue Type: Improvement
> Components: Table API & SQL
>Reporter: Jark Wu
>Assignee: Jark Wu
>
> Currently, both UDF and UDAF support variable parameters, but UDTF not.
> FLINK-5882 supports variable UDTF for Table API only, but missed SQL.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (FLINK-7439) Support variable arguments for UDTF in SQL
[
https://issues.apache.org/jira/browse/FLINK-7439?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143276#comment-16143276
]
ASF GitHub Bot commented on FLINK-7439:
---
Github user sunjincheng121 commented on a diff in the pull request:
https://github.com/apache/flink/pull/4536#discussion_r135425060
--- Diff:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/api/TableEnvironment.scala
---
@@ -350,8 +350,8 @@ abstract class TableEnvironment(val config:
TableConfig) {
functionCatalog.registerFunction(name, function.getClass)
// register in SQL API
-val sqlFunctions = createTableSqlFunctions(name, function, typeInfo,
typeFactory)
-functionCatalog.registerSqlFunctions(sqlFunctions)
+val sqlFunctions = createTableSqlFunction(name, function, typeInfo,
typeFactory)
--- End diff --
sqlFunctions -> sqlFunction
> Support variable arguments for UDTF in SQL
> --
>
> Key: FLINK-7439
> URL: https://issues.apache.org/jira/browse/FLINK-7439
> Project: Flink
> Issue Type: Improvement
> Components: Table API & SQL
>Reporter: Jark Wu
>Assignee: Jark Wu
>
> Currently, both UDF and UDAF support variable parameters, but UDTF not.
> FLINK-5882 supports variable UDTF for Table API only, but missed SQL.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[GitHub] flink pull request #4536: [FLINK-7439] [table] Support variable arguments fo...
Github user sunjincheng121 commented on a diff in the pull request:
https://github.com/apache/flink/pull/4536#discussion_r135425816
--- Diff:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/functions/utils/TableSqlFunction.scala
---
@@ -74,48 +75,102 @@ class TableSqlFunction(
object TableSqlFunction {
- /**
-* Util function to create a [[TableSqlFunction]].
-*
-* @param name function name (used by SQL parser)
-* @param udtf user-defined table function to be called
-* @param rowTypeInfo the row type information generated by the table
function
-* @param typeFactory type factory for converting Flink's between
Calcite's types
-* @param functionImpl Calcite table function schema
-* @return [[TableSqlFunction]]
-*/
- def apply(
+ private[flink] def createOperandTypeInference(
name: String,
udtf: TableFunction[_],
-rowTypeInfo: TypeInformation[_],
-typeFactory: FlinkTypeFactory,
-functionImpl: FlinkTableFunctionImpl[_]): TableSqlFunction = {
-
-val argTypes: util.List[RelDataType] = new util.ArrayList[RelDataType]
-val typeFamilies: util.List[SqlTypeFamily] = new
util.ArrayList[SqlTypeFamily]
-// derives operands' data types and type families
-functionImpl.getParameters.asScala.foreach{ o =>
- val relType: RelDataType = o.getType(typeFactory)
- argTypes.add(relType)
- typeFamilies.add(Util.first(relType.getSqlTypeName.getFamily,
SqlTypeFamily.ANY))
+typeFactory: FlinkTypeFactory)
+ : SqlOperandTypeInference = {
+/**
+ * Operand type inference based on [[TableFunction]] given
information.
+ */
+new SqlOperandTypeInference {
+ override def inferOperandTypes(
+ callBinding: SqlCallBinding,
+ returnType: RelDataType,
+ operandTypes: Array[RelDataType]): Unit = {
+
+val operandTypeInfo = getOperandTypeInfo(callBinding)
+
+val foundSignature = getEvalMethodSignature(udtf, operandTypeInfo)
+ .getOrElse(throw new ValidationException(
+s"Given parameters of function '$name' do not match any
signature. \n" +
+ s"Actual: ${signatureToString(operandTypeInfo)} \n" +
+ s"Expected: ${signaturesToString(udtf, "eval")}"))
+
+val inferredTypes = foundSignature
+ .map(TypeExtractor.getForClass(_))
+ .map(typeFactory.createTypeFromTypeInfo(_, isNullable = true))
+
+for (i <- operandTypes.indices) {
+ if (i < inferredTypes.length - 1) {
+operandTypes(i) = inferredTypes(i)
+ } else if (null != inferredTypes.last.getComponentType) {
+// last argument is a collection, the array type
+operandTypes(i) = inferredTypes.last.getComponentType
+ } else {
+operandTypes(i) = inferredTypes.last
+ }
+}
+ }
}
-// derives whether the 'input'th parameter of a method is optional.
-val optional: Predicate[Integer] = new Predicate[Integer]() {
- def apply(input: Integer): Boolean = {
-functionImpl.getParameters.get(input).isOptional
+ }
+
+ private[flink] def createOperandTypeChecker(
--- End diff --
Can we share the methods of `SqlOperandTypeInference` and
`createOperandTypeChecker` with `ScalarSqlFunction``TableSqlFunction` and
`AggSqlFunction`, Because all of the UDX need them, and the logic of these
method are same or similar. May be we can move them into
`UserDefinedFunctionUtils`. What do you think?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] flink pull request #4536: [FLINK-7439] [table] Support variable arguments fo...
Github user sunjincheng121 commented on a diff in the pull request:
https://github.com/apache/flink/pull/4536#discussion_r135425060
--- Diff:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/api/TableEnvironment.scala
---
@@ -350,8 +350,8 @@ abstract class TableEnvironment(val config:
TableConfig) {
functionCatalog.registerFunction(name, function.getClass)
// register in SQL API
-val sqlFunctions = createTableSqlFunctions(name, function, typeInfo,
typeFactory)
-functionCatalog.registerSqlFunctions(sqlFunctions)
+val sqlFunctions = createTableSqlFunction(name, function, typeInfo,
typeFactory)
--- End diff --
sqlFunctions -> sqlFunction
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] flink pull request #4536: [FLINK-7439] [table] Support variable arguments fo...
Github user sunjincheng121 commented on a diff in the pull request:
https://github.com/apache/flink/pull/4536#discussion_r135425261
--- Diff:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/functions/utils/TableSqlFunction.scala
---
@@ -18,39 +18,40 @@
package org.apache.flink.table.functions.utils
-import com.google.common.base.Predicate
import org.apache.calcite.rel.`type`.RelDataType
import org.apache.calcite.sql._
import org.apache.calcite.sql.`type`._
import org.apache.calcite.sql.parser.SqlParserPos
import org.apache.calcite.sql.validate.SqlUserDefinedTableFunction
-import org.apache.calcite.util.Util
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.table.calcite.FlinkTypeFactory
-import org.apache.flink.table.functions.TableFunction
+import org.apache.flink.table.functions.{ScalarFunction, TableFunction}
--- End diff --
remove useless import.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[jira] [Commented] (FLINK-7439) Support variable arguments for UDTF in SQL
[
https://issues.apache.org/jira/browse/FLINK-7439?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143279#comment-16143279
]
ASF GitHub Bot commented on FLINK-7439:
---
Github user sunjincheng121 commented on a diff in the pull request:
https://github.com/apache/flink/pull/4536#discussion_r135425326
--- Diff:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/functions/utils/TableSqlFunction.scala
---
@@ -18,39 +18,40 @@
package org.apache.flink.table.functions.utils
-import com.google.common.base.Predicate
import org.apache.calcite.rel.`type`.RelDataType
import org.apache.calcite.sql._
import org.apache.calcite.sql.`type`._
import org.apache.calcite.sql.parser.SqlParserPos
import org.apache.calcite.sql.validate.SqlUserDefinedTableFunction
-import org.apache.calcite.util.Util
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.table.calcite.FlinkTypeFactory
-import org.apache.flink.table.functions.TableFunction
+import org.apache.flink.table.functions.{ScalarFunction, TableFunction}
import org.apache.flink.table.plan.schema.FlinkTableFunctionImpl
import scala.collection.JavaConverters._
import java.util
+import org.apache.calcite.sql.`type`.SqlOperandTypeChecker.Consistency
+import org.apache.flink.api.java.typeutils.TypeExtractor
--- End diff --
I suggest that format the import order, i.e.:
**calcite**
**calcite**
**flink.api**
**flink.api**
**flink.table**
**flink.talbe**
What do you think?
> Support variable arguments for UDTF in SQL
> --
>
> Key: FLINK-7439
> URL: https://issues.apache.org/jira/browse/FLINK-7439
> Project: Flink
> Issue Type: Improvement
> Components: Table API & SQL
>Reporter: Jark Wu
>Assignee: Jark Wu
>
> Currently, both UDF and UDAF support variable parameters, but UDTF not.
> FLINK-5882 supports variable UDTF for Table API only, but missed SQL.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (FLINK-7439) Support variable arguments for UDTF in SQL
[ https://issues.apache.org/jira/browse/FLINK-7439?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143283#comment-16143283 ] ASF GitHub Bot commented on FLINK-7439: --- Github user sunjincheng121 commented on a diff in the pull request: https://github.com/apache/flink/pull/4536#discussion_r135426183 --- Diff: flink-libraries/flink-table/src/main/scala/org/apache/flink/table/plan/schema/FlinkTableFunctionImpl.scala --- @@ -71,6 +69,9 @@ class FlinkTableFunctionImpl[T]( override def getElementType(arguments: util.List[AnyRef]): Type = classOf[Array[Object]] + // we do never use the FunctionParameters, so return an empty list + override def getParameters: util.List[FunctionParameter] = Collections.emptyList() --- End diff -- I think we can keep using `ReflectiveFunctionBase#getParameters`. > Support variable arguments for UDTF in SQL > -- > > Key: FLINK-7439 > URL: https://issues.apache.org/jira/browse/FLINK-7439 > Project: Flink > Issue Type: Improvement > Components: Table API & SQL >Reporter: Jark Wu >Assignee: Jark Wu > > Currently, both UDF and UDAF support variable parameters, but UDTF not. > FLINK-5882 supports variable UDTF for Table API only, but missed SQL. -- This message was sent by Atlassian JIRA (v6.4.14#64029)
[jira] [Commented] (FLINK-7439) Support variable arguments for UDTF in SQL
[ https://issues.apache.org/jira/browse/FLINK-7439?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143281#comment-16143281 ] ASF GitHub Bot commented on FLINK-7439: --- Github user sunjincheng121 commented on a diff in the pull request: https://github.com/apache/flink/pull/4536#discussion_r135426134 --- Diff: flink-libraries/flink-table/src/main/scala/org/apache/flink/table/plan/schema/FlinkTableFunctionImpl.scala --- @@ -36,10 +36,8 @@ import org.apache.flink.table.calcite.FlinkTypeFactory class FlinkTableFunctionImpl[T]( val typeInfo: TypeInformation[T], val fieldIndexes: Array[Int], -val fieldNames: Array[String], -val evalMethod: Method) - extends ReflectiveFunctionBase(evalMethod) --- End diff -- I suggest keep extends `ReflectiveFunctionBase` for keep consistent with calcite. > Support variable arguments for UDTF in SQL > -- > > Key: FLINK-7439 > URL: https://issues.apache.org/jira/browse/FLINK-7439 > Project: Flink > Issue Type: Improvement > Components: Table API & SQL >Reporter: Jark Wu >Assignee: Jark Wu > > Currently, both UDF and UDAF support variable parameters, but UDTF not. > FLINK-5882 supports variable UDTF for Table API only, but missed SQL. -- This message was sent by Atlassian JIRA (v6.4.14#64029)
[jira] [Commented] (FLINK-7439) Support variable arguments for UDTF in SQL
[
https://issues.apache.org/jira/browse/FLINK-7439?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143277#comment-16143277
]
ASF GitHub Bot commented on FLINK-7439:
---
Github user sunjincheng121 commented on a diff in the pull request:
https://github.com/apache/flink/pull/4536#discussion_r135425277
--- Diff:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/functions/utils/TableSqlFunction.scala
---
@@ -18,39 +18,40 @@
package org.apache.flink.table.functions.utils
-import com.google.common.base.Predicate
import org.apache.calcite.rel.`type`.RelDataType
import org.apache.calcite.sql._
import org.apache.calcite.sql.`type`._
import org.apache.calcite.sql.parser.SqlParserPos
import org.apache.calcite.sql.validate.SqlUserDefinedTableFunction
-import org.apache.calcite.util.Util
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.table.calcite.FlinkTypeFactory
-import org.apache.flink.table.functions.TableFunction
+import org.apache.flink.table.functions.{ScalarFunction, TableFunction}
import org.apache.flink.table.plan.schema.FlinkTableFunctionImpl
import scala.collection.JavaConverters._
import java.util
--- End diff --
remove useless import.
> Support variable arguments for UDTF in SQL
> --
>
> Key: FLINK-7439
> URL: https://issues.apache.org/jira/browse/FLINK-7439
> Project: Flink
> Issue Type: Improvement
> Components: Table API & SQL
>Reporter: Jark Wu
>Assignee: Jark Wu
>
> Currently, both UDF and UDAF support variable parameters, but UDTF not.
> FLINK-5882 supports variable UDTF for Table API only, but missed SQL.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[GitHub] flink pull request #4536: [FLINK-7439] [table] Support variable arguments fo...
Github user sunjincheng121 commented on a diff in the pull request:
https://github.com/apache/flink/pull/4536#discussion_r135425326
--- Diff:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/functions/utils/TableSqlFunction.scala
---
@@ -18,39 +18,40 @@
package org.apache.flink.table.functions.utils
-import com.google.common.base.Predicate
import org.apache.calcite.rel.`type`.RelDataType
import org.apache.calcite.sql._
import org.apache.calcite.sql.`type`._
import org.apache.calcite.sql.parser.SqlParserPos
import org.apache.calcite.sql.validate.SqlUserDefinedTableFunction
-import org.apache.calcite.util.Util
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.table.calcite.FlinkTypeFactory
-import org.apache.flink.table.functions.TableFunction
+import org.apache.flink.table.functions.{ScalarFunction, TableFunction}
import org.apache.flink.table.plan.schema.FlinkTableFunctionImpl
import scala.collection.JavaConverters._
import java.util
+import org.apache.calcite.sql.`type`.SqlOperandTypeChecker.Consistency
+import org.apache.flink.api.java.typeutils.TypeExtractor
--- End diff --
I suggest that format the import order, i.e.:
**calcite**
**calcite**
**flink.api**
**flink.api**
**flink.table**
**flink.talbe**
What do you think?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] flink pull request #4536: [FLINK-7439] [table] Support variable arguments fo...
Github user sunjincheng121 commented on a diff in the pull request:
https://github.com/apache/flink/pull/4536#discussion_r135425277
--- Diff:
flink-libraries/flink-table/src/main/scala/org/apache/flink/table/functions/utils/TableSqlFunction.scala
---
@@ -18,39 +18,40 @@
package org.apache.flink.table.functions.utils
-import com.google.common.base.Predicate
import org.apache.calcite.rel.`type`.RelDataType
import org.apache.calcite.sql._
import org.apache.calcite.sql.`type`._
import org.apache.calcite.sql.parser.SqlParserPos
import org.apache.calcite.sql.validate.SqlUserDefinedTableFunction
-import org.apache.calcite.util.Util
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.table.calcite.FlinkTypeFactory
-import org.apache.flink.table.functions.TableFunction
+import org.apache.flink.table.functions.{ScalarFunction, TableFunction}
import org.apache.flink.table.plan.schema.FlinkTableFunctionImpl
import scala.collection.JavaConverters._
import java.util
--- End diff --
remove useless import.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] flink pull request #4536: [FLINK-7439] [table] Support variable arguments fo...
Github user sunjincheng121 commented on a diff in the pull request: https://github.com/apache/flink/pull/4536#discussion_r135426183 --- Diff: flink-libraries/flink-table/src/main/scala/org/apache/flink/table/plan/schema/FlinkTableFunctionImpl.scala --- @@ -71,6 +69,9 @@ class FlinkTableFunctionImpl[T]( override def getElementType(arguments: util.List[AnyRef]): Type = classOf[Array[Object]] + // we do never use the FunctionParameters, so return an empty list + override def getParameters: util.List[FunctionParameter] = Collections.emptyList() --- End diff -- I think we can keep using `ReflectiveFunctionBase#getParameters`. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] flink pull request #4536: [FLINK-7439] [table] Support variable arguments fo...
Github user sunjincheng121 commented on a diff in the pull request: https://github.com/apache/flink/pull/4536#discussion_r135426134 --- Diff: flink-libraries/flink-table/src/main/scala/org/apache/flink/table/plan/schema/FlinkTableFunctionImpl.scala --- @@ -36,10 +36,8 @@ import org.apache.flink.table.calcite.FlinkTypeFactory class FlinkTableFunctionImpl[T]( val typeInfo: TypeInformation[T], val fieldIndexes: Array[Int], -val fieldNames: Array[String], -val evalMethod: Method) - extends ReflectiveFunctionBase(evalMethod) --- End diff -- I suggest keep extends `ReflectiveFunctionBase` for keep consistent with calcite. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] flink pull request #4536: [FLINK-7439] [table] Support variable arguments fo...
Github user sunjincheng121 commented on a diff in the pull request:
https://github.com/apache/flink/pull/4536#discussion_r135426250
--- Diff:
flink-libraries/flink-table/src/test/java/org/apache/flink/table/runtime/utils/JavaUserDefinedTableFunctions.java
---
@@ -35,4 +35,15 @@ public void eval(Integer a, Long b, Long c) {
collect(c);
}
}
+
+ /**
+* Emit every input string.
+*/
+ public static class JavaVarsArgTableFunc0 extends TableFunction
{
+ public void eval(String... strs) {
+ for (String s : strs) {
+ collect(s);
+ }
+ }
--- End diff --
Add an other eval for method match check.(only a suggestion).
{code}
public void eval(int ival, String sVal) {
while (ival-- > 0) {
collect(sVal);
}
}
{code}
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[jira] [Commented] (FLINK-6306) Sink for eventually consistent file systems
[ https://issues.apache.org/jira/browse/FLINK-6306?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143246#comment-16143246 ] ASF GitHub Bot commented on FLINK-6306: --- Github user sjwiesman commented on the issue: https://github.com/apache/flink/pull/4607 CC: @aljoscha I screwed up the rebase so I cherry picked the updates into a new branch and re-opened the pr. > Sink for eventually consistent file systems > --- > > Key: FLINK-6306 > URL: https://issues.apache.org/jira/browse/FLINK-6306 > Project: Flink > Issue Type: New Feature > Components: filesystem-connector >Reporter: Seth Wiesman >Assignee: Seth Wiesman > Attachments: eventually-consistent-sink > > > Currently Flink provides the BucketingSink as an exactly once method for > writing out to a file system. It provides these guarantees by moving files > through several stages and deleting or truncating files that get into a bad > state. While this is a powerful abstraction, it causes issues with eventually > consistent file systems such as Amazon's S3 where most operations (ie rename, > delete, truncate) are not guaranteed to become consistent within a reasonable > amount of time. Flink should provide a sink that provides exactly once writes > to a file system where only PUT operations are considered consistent. -- This message was sent by Atlassian JIRA (v6.4.14#64029)
[GitHub] flink issue #4607: [FLINK-6306][connectors] Sink for eventually consistent f...
Github user sjwiesman commented on the issue: https://github.com/apache/flink/pull/4607 CC: @aljoscha I screwed up the rebase so I cherry picked the updates into a new branch and re-opened the pr. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[jira] [Commented] (FLINK-6306) Sink for eventually consistent file systems
[ https://issues.apache.org/jira/browse/FLINK-6306?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143244#comment-16143244 ] ASF GitHub Bot commented on FLINK-6306: --- GitHub user sjwiesman opened a pull request: https://github.com/apache/flink/pull/4607 [FLINK-6306][connectors] Sink for eventually consistent file systems ## What is the purpose of the change This pull request implements a sink for writing out to an eventually consistent filesystem, such as Amazon S3, with exactly once semantics. ## Brief change log - The sink stages files on a consistent filesystem (local, hdfs, etc) . - Once per checkpoint, files are copied to the eventually consistent filesystem. - When a checkpoint completion notification is sent, the files are marked consistent. Otherwise, they are left because delete is not a consistent operation. - It is up to consumers to choose their semantics; at least once by reading all files, or exactly once by only reading files marked consistent. ## Verifying this change This change added tests and can be verified as follows: - Added tests based on the existing BucketingSink test suite. - Added tests that verify semantics based on different checkpointing combinations (successful, concurrent, timed out, and failed). - Added integration test that verifies exactly once holds during failure. - Manually verified by having run in production for several months. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper:no ## Documentation - Does this pull request introduce a new feature? yes - If yes, how is the feature documented? JavaDocs You can merge this pull request into a Git repository by running: $ git pull https://github.com/sjwiesman/flink FLINK-6306 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/4607.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #4607 commit 347ea767195d74efc39964c02ace1bbe10d8aa0a Author: Seth Wiesman Date: 2017-08-27T21:36:04Z [FLINK-6306][connectors] Sink for eventually consistent file systems > Sink for eventually consistent file systems > --- > > Key: FLINK-6306 > URL: https://issues.apache.org/jira/browse/FLINK-6306 > Project: Flink > Issue Type: New Feature > Components: filesystem-connector >Reporter: Seth Wiesman >Assignee: Seth Wiesman > Attachments: eventually-consistent-sink > > > Currently Flink provides the BucketingSink as an exactly once method for > writing out to a file system. It provides these guarantees by moving files > through several stages and deleting or truncating files that get into a bad > state. While this is a powerful abstraction, it causes issues with eventually > consistent file systems such as Amazon's S3 where most operations (ie rename, > delete, truncate) are not guaranteed to become consistent within a reasonable > amount of time. Flink should provide a sink that provides exactly once writes > to a file system where only PUT operations are considered consistent. -- This message was sent by Atlassian JIRA (v6.4.14#64029)
[GitHub] flink pull request #4607: [FLINK-6306][connectors] Sink for eventually consi...
GitHub user sjwiesman opened a pull request: https://github.com/apache/flink/pull/4607 [FLINK-6306][connectors] Sink for eventually consistent file systems ## What is the purpose of the change This pull request implements a sink for writing out to an eventually consistent filesystem, such as Amazon S3, with exactly once semantics. ## Brief change log - The sink stages files on a consistent filesystem (local, hdfs, etc) . - Once per checkpoint, files are copied to the eventually consistent filesystem. - When a checkpoint completion notification is sent, the files are marked consistent. Otherwise, they are left because delete is not a consistent operation. - It is up to consumers to choose their semantics; at least once by reading all files, or exactly once by only reading files marked consistent. ## Verifying this change This change added tests and can be verified as follows: - Added tests based on the existing BucketingSink test suite. - Added tests that verify semantics based on different checkpointing combinations (successful, concurrent, timed out, and failed). - Added integration test that verifies exactly once holds during failure. - Manually verified by having run in production for several months. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper:no ## Documentation - Does this pull request introduce a new feature? yes - If yes, how is the feature documented? JavaDocs You can merge this pull request into a Git repository by running: $ git pull https://github.com/sjwiesman/flink FLINK-6306 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/4607.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #4607 commit 347ea767195d74efc39964c02ace1bbe10d8aa0a Author: Seth Wiesman Date: 2017-08-27T21:36:04Z [FLINK-6306][connectors] Sink for eventually consistent file systems --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[jira] [Commented] (FLINK-6306) Sink for eventually consistent file systems
[ https://issues.apache.org/jira/browse/FLINK-6306?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143229#comment-16143229 ] ASF GitHub Bot commented on FLINK-6306: --- Github user sjwiesman closed the pull request at: https://github.com/apache/flink/pull/3752 > Sink for eventually consistent file systems > --- > > Key: FLINK-6306 > URL: https://issues.apache.org/jira/browse/FLINK-6306 > Project: Flink > Issue Type: New Feature > Components: filesystem-connector >Reporter: Seth Wiesman >Assignee: Seth Wiesman > Attachments: eventually-consistent-sink > > > Currently Flink provides the BucketingSink as an exactly once method for > writing out to a file system. It provides these guarantees by moving files > through several stages and deleting or truncating files that get into a bad > state. While this is a powerful abstraction, it causes issues with eventually > consistent file systems such as Amazon's S3 where most operations (ie rename, > delete, truncate) are not guaranteed to become consistent within a reasonable > amount of time. Flink should provide a sink that provides exactly once writes > to a file system where only PUT operations are considered consistent. -- This message was sent by Atlassian JIRA (v6.4.14#64029)
[GitHub] flink pull request #3752: [FLINK-6306] [filesystem-connectors] Sink for even...
Github user sjwiesman closed the pull request at: https://github.com/apache/flink/pull/3752 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] flink issue #3511: [Flink-5734] code generation for normalizedkey sorter
Github user ggevay commented on the issue: https://github.com/apache/flink/pull/3511 Thank @heytitle , I'll try to do the code generation for `FixedLengthRecordSorter` tomorrow, and I will also take a look at the failing tests. Btw. you can force push (`git push -f`) the rebased version to the branch of the PR. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[jira] [Commented] (FLINK-7539) Make AvroOutputFormat default codec configurable
[ https://issues.apache.org/jira/browse/FLINK-7539?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143139#comment-16143139 ] ASF GitHub Bot commented on FLINK-7539: --- GitHub user packet23 opened a pull request: https://github.com/apache/flink/pull/4606 [FLINK-7539] Made AvroOutputFormat default codec configurable. Implement site-wide codec defaults. ## Brief change log - Added connect.avro.output.codec option ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: yes - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: no ## Documentation - Does this pull request introduce a new feature? yes - If yes, how is the feature documented? docs and JavaDocs You can merge this pull request into a Git repository by running: $ git pull https://github.com/packet23/flink FLINK-7539 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/4606.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #4606 commit cf59242ce09c0c01c22539b772abb8b78dbd632c Author: Sebastian Klemke Date: 2017-08-27T15:25:35Z [FLINK-7539] Made AvroOutputFormat default codec configurable. > Make AvroOutputFormat default codec configurable > > > Key: FLINK-7539 > URL: https://issues.apache.org/jira/browse/FLINK-7539 > Project: Flink > Issue Type: Improvement >Reporter: Sebastian Klemke > > In my organization there is a requirement that all avro datasets stored on > HDFS should be compressed. Currently, this requires invoking setCodec() > manually on all AvroOutputFormat instances. To ease setting up > AvroOutputFormat instances, we'd like to be able to configure default codec > site-wide, ideally via flink-conf.yaml -- This message was sent by Atlassian JIRA (v6.4.14#64029)
[GitHub] flink pull request #4606: [FLINK-7539] Made AvroOutputFormat default codec c...
GitHub user packet23 opened a pull request: https://github.com/apache/flink/pull/4606 [FLINK-7539] Made AvroOutputFormat default codec configurable. Implement site-wide codec defaults. ## Brief change log - Added connect.avro.output.codec option ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: yes - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: no ## Documentation - Does this pull request introduce a new feature? yes - If yes, how is the feature documented? docs and JavaDocs You can merge this pull request into a Git repository by running: $ git pull https://github.com/packet23/flink FLINK-7539 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/4606.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #4606 commit cf59242ce09c0c01c22539b772abb8b78dbd632c Author: Sebastian Klemke Date: 2017-08-27T15:25:35Z [FLINK-7539] Made AvroOutputFormat default codec configurable. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[jira] [Created] (FLINK-7539) Make AvroOutputFormat default codec configurable
Sebastian Klemke created FLINK-7539: --- Summary: Make AvroOutputFormat default codec configurable Key: FLINK-7539 URL: https://issues.apache.org/jira/browse/FLINK-7539 Project: Flink Issue Type: Improvement Reporter: Sebastian Klemke In my organization there is a requirement that all avro datasets stored on HDFS should be compressed. Currently, this requires invoking setCodec() manually on all AvroOutputFormat instances. To ease setting up AvroOutputFormat instances, we'd like to be able to configure default codec site-wide, ideally via flink-conf.yaml -- This message was sent by Atlassian JIRA (v6.4.14#64029)
[jira] [Commented] (FLINK-7410) Add getName method to UserDefinedFunction
[
https://issues.apache.org/jira/browse/FLINK-7410?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143111#comment-16143111
]
Jark Wu commented on FLINK-7410:
Hi [~hequn8128] do you mean users may use {{toString}} for other purpose?
AFAIK, {{toString}} of UserDefinedFunction is not used in Flink, please correct
me if I missed something [~twalthr] [~fhueske]
> Add getName method to UserDefinedFunction
> -
>
> Key: FLINK-7410
> URL: https://issues.apache.org/jira/browse/FLINK-7410
> Project: Flink
> Issue Type: Improvement
> Components: Table API & SQL
>Affects Versions: 1.4.0
>Reporter: Hequn Cheng
>Assignee: Hequn Cheng
>
> *Motivation*
> Operator names setted in table-api are used by visualization and logging, it
> is import to make these names simple and readable. Currently,
> UserDefinedFunction’s name contains class CanonicalName and md5 value making
> the name too long and unfriendly to users.
> As shown in the following example,
> {quote}
> select: (a, b, c,
> org$apache$flink$table$expressions$utils$RichFunc1$281f7e61ec5d8da894f5783e2e17a4f5(a)
> AS _c3,
> org$apache$flink$table$expressions$utils$RichFunc2$fb99077e565685ebc5f48b27edc14d98(c)
> AS _c4)
> {quote}
> *Changes:*
>
> Provide getName method for UserDefinedFunction. The method will return class
> name by default. Users can also override the method to return whatever he
> wants.
> What do you think [~fhueske] ?
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
[jira] [Commented] (FLINK-7491) Support COLLECT Aggregate function in Flink SQL
[
https://issues.apache.org/jira/browse/FLINK-7491?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143104#comment-16143104
]
Jark Wu commented on FLINK-7491:
Hi [~suez1224] , what I mean use {{Array}} instead of {{AbstractMultiSet}} is
the runtime type, not sql type. For sql type, of course we should use the
{{MultisetSqlType}}. But for the runtime type, you are using a guava
{{AbstractMultiSet}} (collect elements into the AbstractMultiSet) which I think
is poor performance, and I think maybe a Java array is enough for this. Calcite
MultisetSqlType doesn't force us to use which Java type in runtime.
> Support COLLECT Aggregate function in Flink SQL
> ---
>
> Key: FLINK-7491
> URL: https://issues.apache.org/jira/browse/FLINK-7491
> Project: Flink
> Issue Type: New Feature
> Components: Table API & SQL
>Reporter: Shuyi Chen
>Assignee: Shuyi Chen
>
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)