[GitHub] lamber-ken commented on issue #6647: [hotfix][docs] Fix error html tag in batch index documentatition
lamber-ken commented on issue #6647: [hotfix][docs] Fix error html tag in batch index documentatition URL: https://github.com/apache/flink/pull/6647#issuecomment-418008209 Old `DataSet Transformations documents` has some error html tag. [flink-1.4-dataset-transformations-scala](https://ci.apache.org/projects/flink/flink-docs-release-1.4/dev/batch/) [flink-1.5-dataset-transformations-scala](https://ci.apache.org/projects/flink/flink-docs-release-1.5/dev/batch/) [flink-1.6-dataset-transformations-scala](https://ci.apache.org/projects/flink/flink-docs-release-1.6/dev/batch/) 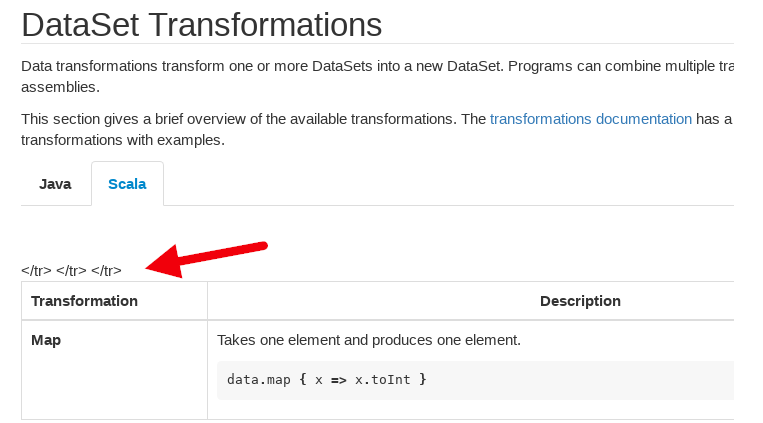  This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] lamber-ken opened a new pull request #6647: [hotfix][docs] Fix error html tag in batch index documentatition
lamber-ken opened a new pull request #6647: [hotfix][docs] Fix error html tag in batch index documentatition URL: https://github.com/apache/flink/pull/6647 ## What is the purpose of the change Fix error html tag in batch index documentatition ## Brief change log - *Change `` to ``* - *`` and `` appear in pairs* This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-10245) Add DataStream HBase Sink
[ https://issues.apache.org/jira/browse/FLINK-10245?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Shimin Yang updated FLINK-10245: Description: Design documentation: [https://docs.google.com/document/d/1of0cYd73CtKGPt-UL3WVFTTBsVEre-TNRzoAt5u2PdQ/edit?usp=sharing] > Add DataStream HBase Sink > - > > Key: FLINK-10245 > URL: https://issues.apache.org/jira/browse/FLINK-10245 > Project: Flink > Issue Type: Sub-task > Components: Streaming Connectors >Reporter: Shimin Yang >Assignee: Shimin Yang >Priority: Major > Labels: pull-request-available > > Design documentation: > [https://docs.google.com/document/d/1of0cYd73CtKGPt-UL3WVFTTBsVEre-TNRzoAt5u2PdQ/edit?usp=sharing] -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (FLINK-10277) Add AppendStreamTableSink and UpsertStreamTableSink
Shimin Yang created FLINK-10277: --- Summary: Add AppendStreamTableSink and UpsertStreamTableSink Key: FLINK-10277 URL: https://issues.apache.org/jira/browse/FLINK-10277 Project: Flink Issue Type: Sub-task Components: Streaming Connectors Reporter: Shimin Yang Assignee: Shimin Yang -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-10245) Add DataStream HBase Sink
[ https://issues.apache.org/jira/browse/FLINK-10245?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601755#comment-16601755 ] ASF GitHub Bot commented on FLINK-10245: Clark commented on issue #6628: [FLINK-10245] [Streaming Connector] Add Pojo, Tuple, Row and Scala Product DataStream Sink for HBase URL: https://github.com/apache/flink/pull/6628#issuecomment-417989650 Hi @twalthr @hequn8128 , I have added the link of design document in the PR. Hope you guys could review my code soon. Best, Shimin Yang This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Add DataStream HBase Sink > - > > Key: FLINK-10245 > URL: https://issues.apache.org/jira/browse/FLINK-10245 > Project: Flink > Issue Type: Sub-task > Components: Streaming Connectors >Reporter: Shimin Yang >Assignee: Shimin Yang >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] Clarkkkkk commented on issue #6628: [FLINK-10245] [Streaming Connector] Add Pojo, Tuple, Row and Scala Product DataStream Sink for HBase
Clark commented on issue #6628: [FLINK-10245] [Streaming Connector] Add Pojo, Tuple, Row and Scala Product DataStream Sink for HBase URL: https://github.com/apache/flink/pull/6628#issuecomment-417989650 Hi @twalthr @hequn8128 , I have added the link of design document in the PR. Hope you guys could review my code soon. Best, Shimin Yang This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] maqingxiang commented on a change in pull request #6645: [hotfix] Update deprecated parameters in WebOptions
maqingxiang commented on a change in pull request #6645: [hotfix] Update deprecated parameters in WebOptions URL: https://github.com/apache/flink/pull/6645#discussion_r214565332 ## File path: flink-jepsen/src/jepsen/flink/db.clj ## @@ -51,7 +51,7 @@ :high-availability.zookeeper.quorum (zookeeper-quorum test) :high-availability.storageDir (str (:ha-storage-dir test) "/ha") :state.savepoints.dir (str (:ha-storage-dir test) "/savepoints") - :web.port 8081 + :rest.port 8081 Review comment: ok, It's been changed. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] maqingxiang commented on a change in pull request #6645: [hotfix] Update deprecated parameters in WebOptions
maqingxiang commented on a change in pull request #6645: [hotfix] Update
deprecated parameters in WebOptions
URL: https://github.com/apache/flink/pull/6645#discussion_r214565291
##
File path:
flink-core/src/test/java/org/apache/flink/configuration/RestOptionsTest.java
##
@@ -46,7 +46,7 @@ public void testBindAddressFirstDeprecatedKey() {
public void testBindAddressSecondDeprecatedKey() {
final Configuration configuration = new Configuration();
final String expectedAddress = "foobar";
- configuration.setString("jobmanager.web.address",
expectedAddress);
Review comment:
Sorry, I was careless. It's been recovered.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Comment Edited] (FLINK-9172) Support external catalog factory that comes default with SQL-Client
[
https://issues.apache.org/jira/browse/FLINK-9172?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601690#comment-16601690
]
Rong Rong edited comment on FLINK-9172 at 9/2/18 10:41 PM:
---
Hi folks. Sorry for not taking this task for so long. I think [~twalthr] had
put int a very nice unification on external catalog by merging the change in
[https://github.com/apache/flink/pull/6343] for FLINK-9852.
As of now I think there are several things missing:
1. how the external catalogs can be configured in SQL-client. I am thinking
adding the following in sql-client yaml config:
{code}
#==
# Data Catalogs
#==
catalogs: [] # empty list
# A typical data catalog definition looks like:
# - name: ...
# catalog-type: [? extends ExternalCatalog.class] # such as HCatalog,
AvroCatalog
# datastore-type: [batch, streaming]
# connection: [? extends ConnectorDescriptor]
{code}
since ExternalCatalogTable only requires (1) a concrete implementation class
and (2) ConnectorDescriptor for instantiate the connection
2. how to use the ExternalCatalog
We definitely by default register all {{ExternalCatalog}} implementations into
{{TableEnvironment}}. I tried with a POC and it can be easily put into use by
simply invoking the external catalog tables with
{code}
SELECT cols FROM catalog_name.subschema_name.table_name
{code}
I haven't put too much thought in to the {{TableSink}} part, maybe this is
already supported by
{code}
INSERT INTO catalog_name.table_sink_name SELECT * FROM
catalog_name.table_source_name
{code}
[~eronwright] what do you think about the config YAML change. anything else we
can add? I was thinking about credential / security but they can probably be
put in as part of the ConnectorDescriptor
was (Author: walterddr):
Hi folks. Sorry for not taking this task for so long. I think [~twalthr] had
put int a very nice unification on external catalog by merging the change in
[https://github.com/apache/flink/pull/6343] for FLLINK-9852.
As of now I think there are several things missing:
1. how the external catalogs can be configured in SQL-client. I am thinking
adding the following in sql-client yaml config:
{code}
#==
# Data Catalogs
#==
catalogs: [] # empty list
# A typical data catalog definition looks like:
# - name: ...
# catalog-type: [? extends ExternalCatalog.class] # such as HCatalog,
AvroCatalog
# datastore-type: [batch, streaming]
# connection: [? extends ConnectorDescriptor]
{code}
since ExternalCatalogTable only requires (1) a concrete implementation class
and (2) ConnectorDescriptor for instantiate the connection
2. how to use the ExternalCatalog
We definitely by default register all {{ExternalCatalog}} implementations into
{{TableEnvironment}}. I tried with a POC and it can be easily put into use by
simply invoking the external catalog tables with
{code}
SELECT cols FROM catalog_name.subschema_name.table_name
{code}
I haven't put too much thought in to the {{TableSink}} part, maybe this is
already supported by
{code}
INSERT INTO catalog_name.table_sink_name SELECT * FROM
catalog_name.table_source_name
{code}
[~eronwright] what do you think about the config YAML change. anything else we
can add? I was thinking about credential / security but they can probably be
put in as part of the ConnectorDescriptor
> Support external catalog factory that comes default with SQL-Client
> ---
>
> Key: FLINK-9172
> URL: https://issues.apache.org/jira/browse/FLINK-9172
> Project: Flink
> Issue Type: Sub-task
>Reporter: Rong Rong
>Assignee: Rong Rong
>Priority: Major
>
> It will be great to have SQL-Client to support some external catalogs
> out-of-the-box for SQL users to configure and utilize easily. I am currently
> think of having an external catalog factory that spins up both streaming and
> batch external catalog table sources and sinks. This could greatly unify and
> provide easy access for SQL users.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-9172) Support external catalog factory that comes default with SQL-Client
[
https://issues.apache.org/jira/browse/FLINK-9172?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601690#comment-16601690
]
Rong Rong commented on FLINK-9172:
--
Hi folks. Sorry for not taking this task for so long. I think [~twalthr] had
put int a very nice unification on external catalog by merging the change in
[https://github.com/apache/flink/pull/6343] for FLLINK-9852.
As of now I think there are several things missing:
1. how the external catalogs can be configured in SQL-client. I am thinking
adding the following in sql-client yaml config:
{code}
#==
# Data Catalogs
#==
catalogs: [] # empty list
# A typical data catalog definition looks like:
# - name: ...
# catalog-type: [? extends ExternalCatalog.class] # such as HCatalog,
AvroCatalog
# datastore-type: [batch, streaming]
# connection: [? extends ConnectorDescriptor]
{code}
since ExternalCatalogTable only requires (1) a concrete implementation class
and (2) ConnectorDescriptor for instantiate the connection
2. how to use the ExternalCatalog
We definitely by default register all {{ExternalCatalog}} implementations into
{{TableEnvironment}}. I tried with a POC and it can be easily put into use by
simply invoking the external catalog tables with
{code}
SELECT cols FROM catalog_name.subschema_name.table_name
{code}
I haven't put too much thought in to the {{TableSink}} part, maybe this is
already supported by
{code}
INSERT INTO catalog_name.table_sink_name SELECT * FROM
catalog_name.table_source_name
{code}
[~eronwright] what do you think about the config YAML change. anything else we
can add? I was thinking about credential / security but they can probably be
put in as part of the ConnectorDescriptor
> Support external catalog factory that comes default with SQL-Client
> ---
>
> Key: FLINK-9172
> URL: https://issues.apache.org/jira/browse/FLINK-9172
> Project: Flink
> Issue Type: Sub-task
>Reporter: Rong Rong
>Assignee: Rong Rong
>Priority: Major
>
> It will be great to have SQL-Client to support some external catalogs
> out-of-the-box for SQL users to configure and utilize easily. I am currently
> think of having an external catalog factory that spins up both streaming and
> batch external catalog table sources and sinks. This could greatly unify and
> provide easy access for SQL users.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] zentol commented on a change in pull request #6645: [hotfix] Update deprecated parameters in WebOptions
zentol commented on a change in pull request #6645: [hotfix] Update deprecated parameters in WebOptions URL: https://github.com/apache/flink/pull/6645#discussion_r214549713 ## File path: flink-jepsen/src/jepsen/flink/db.clj ## @@ -51,7 +51,7 @@ :high-availability.zookeeper.quorum (zookeeper-quorum test) :high-availability.storageDir (str (:ha-storage-dir test) "/ha") :state.savepoints.dir (str (:ha-storage-dir test) "/savepoints") - :web.port 8081 + :rest.port 8081 Review comment: values are no longer aligned properly This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] zentol commented on a change in pull request #6645: [hotfix] Update deprecated parameters in WebOptions
zentol commented on a change in pull request #6645: [hotfix] Update deprecated
parameters in WebOptions
URL: https://github.com/apache/flink/pull/6645#discussion_r214549705
##
File path:
flink-core/src/test/java/org/apache/flink/configuration/RestOptionsTest.java
##
@@ -46,7 +46,7 @@ public void testBindAddressFirstDeprecatedKey() {
public void testBindAddressSecondDeprecatedKey() {
final Configuration configuration = new Configuration();
final String expectedAddress = "foobar";
- configuration.setString("jobmanager.web.address",
expectedAddress);
Review comment:
this specifically tests that the deprecated key remains functional and must
be revert.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Comment Edited] (FLINK-10206) Add hbase sink connector
[ https://issues.apache.org/jira/browse/FLINK-10206?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601241#comment-16601241 ] Hequn Cheng edited comment on FLINK-10206 at 9/2/18 3:39 PM: - [~dangdangdang] Cool~ You can start from the datastream sink first. Another new jira for streaming table sink is ok. As for the design doc, you can add the link to [FLINK-10245|https://issues.apache.org/jira/browse/FLINK-10245] if you intended to solve the datastream sink. It might be useful to have a design document first before making a PR. Thanks. was (Author: hequn8128): [~dangdangdang] Cool~ You can start from the datastream sink first. Another new jira for streaming table sink is ok. As for the design doc, you can add the link to [FLINK-10245|https://issues.apache.org/jira/browse/FLINK-10245]. Thanks. > Add hbase sink connector > > > Key: FLINK-10206 > URL: https://issues.apache.org/jira/browse/FLINK-10206 > Project: Flink > Issue Type: New Feature > Components: Streaming Connectors >Affects Versions: 1.6.0 >Reporter: Igloo >Assignee: Shimin Yang >Priority: Major > Original Estimate: 336h > Remaining Estimate: 336h > > Now, there is a hbase source connector for batch operation. > > In some cases, we need to save Streaming/Batch results into hbase. Just like > cassandra streaming/Batch sink implementations. > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-10206) Add hbase sink connector
[ https://issues.apache.org/jira/browse/FLINK-10206?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601241#comment-16601241 ] Hequn Cheng commented on FLINK-10206: - [~dangdangdang] Cool~ You can start from the datastream sink first. Another new jira for streaming table sink is ok. As for the design doc, you can add the link to [FLINK-10245|https://issues.apache.org/jira/browse/FLINK-10245]. Thanks. > Add hbase sink connector > > > Key: FLINK-10206 > URL: https://issues.apache.org/jira/browse/FLINK-10206 > Project: Flink > Issue Type: New Feature > Components: Streaming Connectors >Affects Versions: 1.6.0 >Reporter: Igloo >Assignee: Shimin Yang >Priority: Major > Original Estimate: 336h > Remaining Estimate: 336h > > Now, there is a hbase source connector for batch operation. > > In some cases, we need to save Streaming/Batch results into hbase. Just like > cassandra streaming/Batch sink implementations. > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-10259) Key validation for GroupWindowAggregate is broken
[
https://issues.apache.org/jira/browse/FLINK-10259?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601236#comment-16601236
]
ASF GitHub Bot commented on FLINK-10259:
hequn8128 commented on a change in pull request #6641: [FLINK-10259] Fix key
extraction for GroupWindows.
URL: https://github.com/apache/flink/pull/6641#discussion_r214543970
##
File path:
flink-libraries/flink-table/src/test/scala/org/apache/flink/table/runtime/stream/sql/InsertIntoITCase.scala
##
@@ -0,0 +1,406 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.runtime.stream.sql
+
+import org.apache.flink.api.common.typeinfo.TypeInformation
+import org.apache.flink.streaming.api.TimeCharacteristic
+import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
+import org.apache.flink.table.api.scala._
+import org.apache.flink.table.api.{TableEnvironment, Types}
+import org.apache.flink.table.runtime.stream.table.{RowCollector,
TestRetractSink, TestUpsertSink}
+import org.apache.flink.table.runtime.utils.StreamTestData
+import org.apache.flink.table.utils.MemoryTableSourceSinkUtil
+import org.apache.flink.test.util.{AbstractTestBase, TestBaseUtils}
+import org.junit.Assert._
+import org.junit.Test
+
+import scala.collection.JavaConverters._
+
+class InsertIntoITCase extends AbstractTestBase {
Review comment:
extends StreamingWithStateTestBase?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Key validation for GroupWindowAggregate is broken
> -
>
> Key: FLINK-10259
> URL: https://issues.apache.org/jira/browse/FLINK-10259
> Project: Flink
> Issue Type: Bug
> Components: Table API SQL
>Reporter: Fabian Hueske
>Assignee: Fabian Hueske
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.6.1, 1.7.0, 1.5.4
>
>
> WindowGroups have multiple equivalent keys (start, end) that should be
> handled differently from other keys. The {{UpdatingPlanChecker}} uses
> equivalence groups to identify equivalent keys but the keys of WindowGroups
> are not correctly assigned to groups.
> This means that we cannot correctly extract keys from queries that use group
> windows.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-10259) Key validation for GroupWindowAggregate is broken
[
https://issues.apache.org/jira/browse/FLINK-10259?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601237#comment-16601237
]
ASF GitHub Bot commented on FLINK-10259:
hequn8128 commented on a change in pull request #6641: [FLINK-10259] Fix key
extraction for GroupWindows.
URL: https://github.com/apache/flink/pull/6641#discussion_r214544003
##
File path:
flink-libraries/flink-table/src/test/scala/org/apache/flink/table/runtime/stream/sql/InsertIntoITCase.scala
##
@@ -0,0 +1,406 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.runtime.stream.sql
+
+import org.apache.flink.api.common.typeinfo.TypeInformation
+import org.apache.flink.streaming.api.TimeCharacteristic
+import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
+import org.apache.flink.table.api.scala._
+import org.apache.flink.table.api.{TableEnvironment, Types}
+import org.apache.flink.table.runtime.stream.table.{RowCollector,
TestRetractSink, TestUpsertSink}
+import org.apache.flink.table.runtime.utils.StreamTestData
+import org.apache.flink.table.utils.MemoryTableSourceSinkUtil
+import org.apache.flink.test.util.{AbstractTestBase, TestBaseUtils}
+import org.junit.Assert._
+import org.junit.Test
+
+import scala.collection.JavaConverters._
+
+class InsertIntoITCase extends AbstractTestBase {
+
+ @Test
+ def testInsertIntoAppendStreamToTableSink(): Unit = {
+val env = StreamExecutionEnvironment.getExecutionEnvironment
+env.getConfig.enableObjectReuse()
+env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
+
+val tEnv = TableEnvironment.getTableEnvironment(env)
+MemoryTableSourceSinkUtil.clear()
+
+val input = StreamTestData.get3TupleDataStream(env)
+ .assignAscendingTimestamps(r => r._2)
+
+tEnv.registerDataStream("sourceTable", input, 'a, 'b, 'c, 't.rowtime)
+
+val fieldNames = Array("d", "e", "t")
+val fieldTypes: Array[TypeInformation[_]] = Array(Types.STRING,
Types.SQL_TIMESTAMP, Types.LONG)
+val sink = new MemoryTableSourceSinkUtil.UnsafeMemoryAppendTableSink
+
+tEnv.registerTableSink("targetTable", fieldNames, fieldTypes, sink)
+
+tEnv.sqlUpdate(
+ s"""INSERT INTO targetTable
+ |SELECT c, t, b
+ |FROM sourceTable
+ |WHERE a < 3 OR a > 19
+ """.stripMargin)
+
+env.execute()
+
+val expected = Seq(
+ "Hi,1970-01-01 00:00:00.001,1",
+ "Hello,1970-01-01 00:00:00.002,2",
+ "Comment#14,1970-01-01 00:00:00.006,6",
+ "Comment#15,1970-01-01 00:00:00.006,6").mkString("\n")
+
+
TestBaseUtils.compareResultAsText(MemoryTableSourceSinkUtil.tableData.asJava,
expected)
+ }
+
+ @Test
+ def testInsertIntoUpdatingTableToRetractSink(): Unit = {
+val env = StreamExecutionEnvironment.getExecutionEnvironment
+env.getConfig.enableObjectReuse()
+env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
+val tEnv = TableEnvironment.getTableEnvironment(env)
+
+val t = StreamTestData.get3TupleDataStream(env)
+ .assignAscendingTimestamps(_._1.toLong)
+
+tEnv.registerDataStream("sourceTable", t, 'id, 'num, 'text)
+tEnv.registerTableSink(
+ "targetTable",
+ Array("len", "cntid", "sumnum"),
+ Array(Types.INT, Types.LONG, Types.LONG),
+ new TestRetractSink)
+
+tEnv.sqlUpdate(
+ s"""INSERT INTO targetTable
+ |SELECT len, COUNT(id) AS cntid, SUM(num) AS sumnum
+ |FROM (SELECT id, num, CHAR_LENGTH(text) AS len FROM sourceTable)
+ |GROUP BY len
+ """.stripMargin)
+
+env.execute()
+val results = RowCollector.getAndClearValues
+
+val retracted = RowCollector.retractResults(results).sorted
+val expected = List(
+ "2,1,1",
+ "5,1,2",
+ "11,1,2",
+ "25,1,3",
+ "10,7,39",
+ "14,1,3",
+ "9,9,41").sorted
+assertEquals(expected, retracted)
+
+ }
+
+ @Test
+ def testInsertIntoAppendTableToRetractSink(): Unit = {
+val env = StreamExecutionEnvironment.getExecutionEnvironment
+env.getConfig.enableObjectReuse()
+env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
+val
[jira] [Commented] (FLINK-10259) Key validation for GroupWindowAggregate is broken
[
https://issues.apache.org/jira/browse/FLINK-10259?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601235#comment-16601235
]
ASF GitHub Bot commented on FLINK-10259:
hequn8128 commented on a change in pull request #6641: [FLINK-10259] Fix key
extraction for GroupWindows.
URL: https://github.com/apache/flink/pull/6641#discussion_r214543996
##
File path:
flink-libraries/flink-table/src/test/scala/org/apache/flink/table/runtime/stream/sql/InsertIntoITCase.scala
##
@@ -0,0 +1,406 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.runtime.stream.sql
+
+import org.apache.flink.api.common.typeinfo.TypeInformation
+import org.apache.flink.streaming.api.TimeCharacteristic
+import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
+import org.apache.flink.table.api.scala._
+import org.apache.flink.table.api.{TableEnvironment, Types}
+import org.apache.flink.table.runtime.stream.table.{RowCollector,
TestRetractSink, TestUpsertSink}
+import org.apache.flink.table.runtime.utils.StreamTestData
+import org.apache.flink.table.utils.MemoryTableSourceSinkUtil
+import org.apache.flink.test.util.{AbstractTestBase, TestBaseUtils}
+import org.junit.Assert._
+import org.junit.Test
+
+import scala.collection.JavaConverters._
+
+class InsertIntoITCase extends AbstractTestBase {
+
+ @Test
+ def testInsertIntoAppendStreamToTableSink(): Unit = {
Review comment:
Since we have this test case, should we remove the
`testInsertIntoMemoryTable` in `SqlITCase` ? It seems the two test cases are
same.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Key validation for GroupWindowAggregate is broken
> -
>
> Key: FLINK-10259
> URL: https://issues.apache.org/jira/browse/FLINK-10259
> Project: Flink
> Issue Type: Bug
> Components: Table API SQL
>Reporter: Fabian Hueske
>Assignee: Fabian Hueske
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.6.1, 1.7.0, 1.5.4
>
>
> WindowGroups have multiple equivalent keys (start, end) that should be
> handled differently from other keys. The {{UpdatingPlanChecker}} uses
> equivalence groups to identify equivalent keys but the keys of WindowGroups
> are not correctly assigned to groups.
> This means that we cannot correctly extract keys from queries that use group
> windows.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-10259) Key validation for GroupWindowAggregate is broken
[
https://issues.apache.org/jira/browse/FLINK-10259?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601238#comment-16601238
]
ASF GitHub Bot commented on FLINK-10259:
hequn8128 commented on a change in pull request #6641: [FLINK-10259] Fix key
extraction for GroupWindows.
URL: https://github.com/apache/flink/pull/6641#discussion_r214543996
##
File path:
flink-libraries/flink-table/src/test/scala/org/apache/flink/table/runtime/stream/sql/InsertIntoITCase.scala
##
@@ -0,0 +1,406 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.runtime.stream.sql
+
+import org.apache.flink.api.common.typeinfo.TypeInformation
+import org.apache.flink.streaming.api.TimeCharacteristic
+import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
+import org.apache.flink.table.api.scala._
+import org.apache.flink.table.api.{TableEnvironment, Types}
+import org.apache.flink.table.runtime.stream.table.{RowCollector,
TestRetractSink, TestUpsertSink}
+import org.apache.flink.table.runtime.utils.StreamTestData
+import org.apache.flink.table.utils.MemoryTableSourceSinkUtil
+import org.apache.flink.test.util.{AbstractTestBase, TestBaseUtils}
+import org.junit.Assert._
+import org.junit.Test
+
+import scala.collection.JavaConverters._
+
+class InsertIntoITCase extends AbstractTestBase {
+
+ @Test
+ def testInsertIntoAppendStreamToTableSink(): Unit = {
Review comment:
Since we have this test case, should we remove the
`testInsertIntoMemoryTable` in `SqlITCase` ? It seems the two test cases are
very similar.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Key validation for GroupWindowAggregate is broken
> -
>
> Key: FLINK-10259
> URL: https://issues.apache.org/jira/browse/FLINK-10259
> Project: Flink
> Issue Type: Bug
> Components: Table API SQL
>Reporter: Fabian Hueske
>Assignee: Fabian Hueske
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.6.1, 1.7.0, 1.5.4
>
>
> WindowGroups have multiple equivalent keys (start, end) that should be
> handled differently from other keys. The {{UpdatingPlanChecker}} uses
> equivalence groups to identify equivalent keys but the keys of WindowGroups
> are not correctly assigned to groups.
> This means that we cannot correctly extract keys from queries that use group
> windows.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] hequn8128 commented on a change in pull request #6641: [FLINK-10259] Fix key extraction for GroupWindows.
hequn8128 commented on a change in pull request #6641: [FLINK-10259] Fix key
extraction for GroupWindows.
URL: https://github.com/apache/flink/pull/6641#discussion_r214543996
##
File path:
flink-libraries/flink-table/src/test/scala/org/apache/flink/table/runtime/stream/sql/InsertIntoITCase.scala
##
@@ -0,0 +1,406 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.runtime.stream.sql
+
+import org.apache.flink.api.common.typeinfo.TypeInformation
+import org.apache.flink.streaming.api.TimeCharacteristic
+import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
+import org.apache.flink.table.api.scala._
+import org.apache.flink.table.api.{TableEnvironment, Types}
+import org.apache.flink.table.runtime.stream.table.{RowCollector,
TestRetractSink, TestUpsertSink}
+import org.apache.flink.table.runtime.utils.StreamTestData
+import org.apache.flink.table.utils.MemoryTableSourceSinkUtil
+import org.apache.flink.test.util.{AbstractTestBase, TestBaseUtils}
+import org.junit.Assert._
+import org.junit.Test
+
+import scala.collection.JavaConverters._
+
+class InsertIntoITCase extends AbstractTestBase {
+
+ @Test
+ def testInsertIntoAppendStreamToTableSink(): Unit = {
Review comment:
Since we have this test case, should we remove the
`testInsertIntoMemoryTable` in `SqlITCase` ? It seems the two test cases are
very similar.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] hequn8128 commented on a change in pull request #6641: [FLINK-10259] Fix key extraction for GroupWindows.
hequn8128 commented on a change in pull request #6641: [FLINK-10259] Fix key
extraction for GroupWindows.
URL: https://github.com/apache/flink/pull/6641#discussion_r214543970
##
File path:
flink-libraries/flink-table/src/test/scala/org/apache/flink/table/runtime/stream/sql/InsertIntoITCase.scala
##
@@ -0,0 +1,406 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.runtime.stream.sql
+
+import org.apache.flink.api.common.typeinfo.TypeInformation
+import org.apache.flink.streaming.api.TimeCharacteristic
+import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
+import org.apache.flink.table.api.scala._
+import org.apache.flink.table.api.{TableEnvironment, Types}
+import org.apache.flink.table.runtime.stream.table.{RowCollector,
TestRetractSink, TestUpsertSink}
+import org.apache.flink.table.runtime.utils.StreamTestData
+import org.apache.flink.table.utils.MemoryTableSourceSinkUtil
+import org.apache.flink.test.util.{AbstractTestBase, TestBaseUtils}
+import org.junit.Assert._
+import org.junit.Test
+
+import scala.collection.JavaConverters._
+
+class InsertIntoITCase extends AbstractTestBase {
Review comment:
extends StreamingWithStateTestBase?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] hequn8128 commented on a change in pull request #6641: [FLINK-10259] Fix key extraction for GroupWindows.
hequn8128 commented on a change in pull request #6641: [FLINK-10259] Fix key
extraction for GroupWindows.
URL: https://github.com/apache/flink/pull/6641#discussion_r214544003
##
File path:
flink-libraries/flink-table/src/test/scala/org/apache/flink/table/runtime/stream/sql/InsertIntoITCase.scala
##
@@ -0,0 +1,406 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.runtime.stream.sql
+
+import org.apache.flink.api.common.typeinfo.TypeInformation
+import org.apache.flink.streaming.api.TimeCharacteristic
+import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
+import org.apache.flink.table.api.scala._
+import org.apache.flink.table.api.{TableEnvironment, Types}
+import org.apache.flink.table.runtime.stream.table.{RowCollector,
TestRetractSink, TestUpsertSink}
+import org.apache.flink.table.runtime.utils.StreamTestData
+import org.apache.flink.table.utils.MemoryTableSourceSinkUtil
+import org.apache.flink.test.util.{AbstractTestBase, TestBaseUtils}
+import org.junit.Assert._
+import org.junit.Test
+
+import scala.collection.JavaConverters._
+
+class InsertIntoITCase extends AbstractTestBase {
+
+ @Test
+ def testInsertIntoAppendStreamToTableSink(): Unit = {
+val env = StreamExecutionEnvironment.getExecutionEnvironment
+env.getConfig.enableObjectReuse()
+env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
+
+val tEnv = TableEnvironment.getTableEnvironment(env)
+MemoryTableSourceSinkUtil.clear()
+
+val input = StreamTestData.get3TupleDataStream(env)
+ .assignAscendingTimestamps(r => r._2)
+
+tEnv.registerDataStream("sourceTable", input, 'a, 'b, 'c, 't.rowtime)
+
+val fieldNames = Array("d", "e", "t")
+val fieldTypes: Array[TypeInformation[_]] = Array(Types.STRING,
Types.SQL_TIMESTAMP, Types.LONG)
+val sink = new MemoryTableSourceSinkUtil.UnsafeMemoryAppendTableSink
+
+tEnv.registerTableSink("targetTable", fieldNames, fieldTypes, sink)
+
+tEnv.sqlUpdate(
+ s"""INSERT INTO targetTable
+ |SELECT c, t, b
+ |FROM sourceTable
+ |WHERE a < 3 OR a > 19
+ """.stripMargin)
+
+env.execute()
+
+val expected = Seq(
+ "Hi,1970-01-01 00:00:00.001,1",
+ "Hello,1970-01-01 00:00:00.002,2",
+ "Comment#14,1970-01-01 00:00:00.006,6",
+ "Comment#15,1970-01-01 00:00:00.006,6").mkString("\n")
+
+
TestBaseUtils.compareResultAsText(MemoryTableSourceSinkUtil.tableData.asJava,
expected)
+ }
+
+ @Test
+ def testInsertIntoUpdatingTableToRetractSink(): Unit = {
+val env = StreamExecutionEnvironment.getExecutionEnvironment
+env.getConfig.enableObjectReuse()
+env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
+val tEnv = TableEnvironment.getTableEnvironment(env)
+
+val t = StreamTestData.get3TupleDataStream(env)
+ .assignAscendingTimestamps(_._1.toLong)
+
+tEnv.registerDataStream("sourceTable", t, 'id, 'num, 'text)
+tEnv.registerTableSink(
+ "targetTable",
+ Array("len", "cntid", "sumnum"),
+ Array(Types.INT, Types.LONG, Types.LONG),
+ new TestRetractSink)
+
+tEnv.sqlUpdate(
+ s"""INSERT INTO targetTable
+ |SELECT len, COUNT(id) AS cntid, SUM(num) AS sumnum
+ |FROM (SELECT id, num, CHAR_LENGTH(text) AS len FROM sourceTable)
+ |GROUP BY len
+ """.stripMargin)
+
+env.execute()
+val results = RowCollector.getAndClearValues
+
+val retracted = RowCollector.retractResults(results).sorted
+val expected = List(
+ "2,1,1",
+ "5,1,2",
+ "11,1,2",
+ "25,1,3",
+ "10,7,39",
+ "14,1,3",
+ "9,9,41").sorted
+assertEquals(expected, retracted)
+
+ }
+
+ @Test
+ def testInsertIntoAppendTableToRetractSink(): Unit = {
+val env = StreamExecutionEnvironment.getExecutionEnvironment
+env.getConfig.enableObjectReuse()
+env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
+val tEnv = TableEnvironment.getTableEnvironment(env)
+
+val t = StreamTestData.get3TupleDataStream(env)
+ .assignAscendingTimestamps(_._1.toLong)
+
+tEnv.registerDataStream("sourceTable", t, 'id, 'num, 'text,
'rowtime.rowtime)
+
[GitHub] hequn8128 commented on a change in pull request #6641: [FLINK-10259] Fix key extraction for GroupWindows.
hequn8128 commented on a change in pull request #6641: [FLINK-10259] Fix key
extraction for GroupWindows.
URL: https://github.com/apache/flink/pull/6641#discussion_r214543996
##
File path:
flink-libraries/flink-table/src/test/scala/org/apache/flink/table/runtime/stream/sql/InsertIntoITCase.scala
##
@@ -0,0 +1,406 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.runtime.stream.sql
+
+import org.apache.flink.api.common.typeinfo.TypeInformation
+import org.apache.flink.streaming.api.TimeCharacteristic
+import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
+import org.apache.flink.table.api.scala._
+import org.apache.flink.table.api.{TableEnvironment, Types}
+import org.apache.flink.table.runtime.stream.table.{RowCollector,
TestRetractSink, TestUpsertSink}
+import org.apache.flink.table.runtime.utils.StreamTestData
+import org.apache.flink.table.utils.MemoryTableSourceSinkUtil
+import org.apache.flink.test.util.{AbstractTestBase, TestBaseUtils}
+import org.junit.Assert._
+import org.junit.Test
+
+import scala.collection.JavaConverters._
+
+class InsertIntoITCase extends AbstractTestBase {
+
+ @Test
+ def testInsertIntoAppendStreamToTableSink(): Unit = {
Review comment:
Since we have this test case, should we remove the
`testInsertIntoMemoryTable` in `SqlITCase` ? It seems the two test cases are
same.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] TisonKun commented on issue #6644: [hotfix] check correct parameter
TisonKun commented on issue #6644: [hotfix] check correct parameter URL: https://github.com/apache/flink/pull/6644#issuecomment-417934845 cc @zentol This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-8660) Enable the user to provide custom HAServices implementation
[
https://issues.apache.org/jira/browse/FLINK-8660?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601212#comment-16601212
]
ASF GitHub Bot commented on FLINK-8660:
---
Xeli commented on issue #5530: [FLINK-8660] Enable the user to provide custom
HAServices implementation
URL: https://github.com/apache/flink/pull/5530#issuecomment-417931651
I am in the process of building a HAService for our kubernetes set up
without having to use zookeeper (https://stackoverflow.com/q/52104759/988324)
and this PR would be very helpful.
Would it be possible to merge this into 1.7? (or 1.6.1? :D)
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Enable the user to provide custom HAServices implementation
>
>
> Key: FLINK-8660
> URL: https://issues.apache.org/jira/browse/FLINK-8660
> Project: Flink
> Issue Type: Improvement
> Components: Cluster Management, Configuration, Distributed
> Coordination
>Affects Versions: 1.4.0, 1.5.0
>Reporter: Krzysztof Białek
>Assignee: Krzysztof Białek
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.7.0
>
>
> At the moment Flink uses ZooKeeper as HA backend.
> The goal of this improvement is to make Flink supporting more HA backends,
> also maintained as independent projects.
> The following changes are required to achieve it:
> # Add {{HighAvailabilityServicesFactory}} interface
> # Add new option {{HighAvailabilityMode.CUSTOM}}
> # Add new configuration property {{high-availability.factoryClass}}
> # Use the factory in {{HighAvailabilityServicesUtils}} to instantiate
> {{HighAvailabilityServices}}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-8660) Enable the user to provide custom HAServices implementation
[
https://issues.apache.org/jira/browse/FLINK-8660?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-8660:
--
Labels: pull-request-available (was: )
> Enable the user to provide custom HAServices implementation
>
>
> Key: FLINK-8660
> URL: https://issues.apache.org/jira/browse/FLINK-8660
> Project: Flink
> Issue Type: Improvement
> Components: Cluster Management, Configuration, Distributed
> Coordination
>Affects Versions: 1.4.0, 1.5.0
>Reporter: Krzysztof Białek
>Assignee: Krzysztof Białek
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.7.0
>
>
> At the moment Flink uses ZooKeeper as HA backend.
> The goal of this improvement is to make Flink supporting more HA backends,
> also maintained as independent projects.
> The following changes are required to achieve it:
> # Add {{HighAvailabilityServicesFactory}} interface
> # Add new option {{HighAvailabilityMode.CUSTOM}}
> # Add new configuration property {{high-availability.factoryClass}}
> # Use the factory in {{HighAvailabilityServicesUtils}} to instantiate
> {{HighAvailabilityServices}}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] Xeli commented on issue #5530: [FLINK-8660] Enable the user to provide custom HAServices implementation
Xeli commented on issue #5530: [FLINK-8660] Enable the user to provide custom HAServices implementation URL: https://github.com/apache/flink/pull/5530#issuecomment-417931651 I am in the process of building a HAService for our kubernetes set up without having to use zookeeper (https://stackoverflow.com/q/52104759/988324) and this PR would be very helpful. Would it be possible to merge this into 1.7? (or 1.6.1? :D) This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Comment Edited] (FLINK-10050) Support 'allowedLateness' in CoGroupedStreams
[ https://issues.apache.org/jira/browse/FLINK-10050?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601172#comment-16601172 ] eugen yushin edited comment on FLINK-10050 at 9/2/18 10:28 AM: --- [~aljoscha], [~till.rohrmann] Guys, please can you take a look at PR? I didn't add unit tests because of: a. there're no mock tests for referenced files in master branch to cover such kind of delegates as evictor/trigger/... b. 'allowedLateness' is a feature of WindowedStream, and proposed fix simply delegates all the work to WindowedStream logic Regards was (Author: eyushin): [~aljoscha], [~till.rohrmann] Guys, please can you take a look at PR? I didn't add unit tests because of: a. there're no mock tests for referenced files in master branch to cover such kind of delegates as evictor/trigger/... b. 'allowedLateness' is an feature of WindowedStream, and proposed fix simply delegates all the work to WindowedStream logic Regards > Support 'allowedLateness' in CoGroupedStreams > - > > Key: FLINK-10050 > URL: https://issues.apache.org/jira/browse/FLINK-10050 > Project: Flink > Issue Type: Improvement > Components: Streaming >Affects Versions: 1.5.1, 1.6.0 >Reporter: eugen yushin >Priority: Major > Labels: pull-request-available, ready-to-commit, windows > > WindowedStream has a support of 'allowedLateness' feature, while > CoGroupedStreams are not. At the mean time, WindowedStream is an inner part > of CoGroupedStreams and all main functionality (like evictor/trigger/...) is > simply delegated to WindowedStream. > There's no chance to operate with late arriving data from previous steps in > cogroups (and joins). Consider the following flow: > a. read data from source1 -> aggregate data with allowed lateness > b. read data from source2 -> aggregate data with allowed lateness > c. cogroup/join streams a and b, and compare aggregated values > Step c doesn't accept any late data from steps a/b due to lack of > `allowedLateness` API call in CoGroupedStreams.java. > Scope: add method `WithWindow.allowedLateness` to Java API > (flink-streaming-java) and extend scala API (flink-streaming-scala). -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-10050) Support 'allowedLateness' in CoGroupedStreams
[ https://issues.apache.org/jira/browse/FLINK-10050?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601172#comment-16601172 ] eugen yushin commented on FLINK-10050: -- [~aljoscha], [~till.rohrmann] Guys, please can you take a look at PR? I didn't add unit tests because of: a. there're no mock tests for referenced files in master branch to cover such kind of delegates as evictor/trigger/... b. 'allowedLateness' is an feature of WindowedStream, and proposed fix simply delegates all the work to WindowedStream logic Regards > Support 'allowedLateness' in CoGroupedStreams > - > > Key: FLINK-10050 > URL: https://issues.apache.org/jira/browse/FLINK-10050 > Project: Flink > Issue Type: Improvement > Components: Streaming >Affects Versions: 1.5.1, 1.6.0 >Reporter: eugen yushin >Priority: Major > Labels: pull-request-available, ready-to-commit, windows > > WindowedStream has a support of 'allowedLateness' feature, while > CoGroupedStreams are not. At the mean time, WindowedStream is an inner part > of CoGroupedStreams and all main functionality (like evictor/trigger/...) is > simply delegated to WindowedStream. > There's no chance to operate with late arriving data from previous steps in > cogroups (and joins). Consider the following flow: > a. read data from source1 -> aggregate data with allowed lateness > b. read data from source2 -> aggregate data with allowed lateness > c. cogroup/join streams a and b, and compare aggregated values > Step c doesn't accept any late data from steps a/b due to lack of > `allowedLateness` API call in CoGroupedStreams.java. > Scope: add method `WithWindow.allowedLateness` to Java API > (flink-streaming-java) and extend scala API (flink-streaming-scala). -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-10229) Support listing of views
[
https://issues.apache.org/jira/browse/FLINK-10229?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601170#comment-16601170
]
ASF GitHub Bot commented on FLINK-10229:
hequn8128 commented on a change in pull request #6631: [FLINK-10229]
[sql-client] Support listing of views
URL: https://github.com/apache/flink/pull/6631#discussion_r214535531
##
File path:
flink-libraries/flink-sql-client/src/test/java/org/apache/flink/table/client/gateway/local/LocalExecutorITCase.java
##
@@ -148,6 +148,28 @@ public void testValidateSession() throws Exception {
assertEquals(expectedTables, actualTables);
}
+ @Test
+ public void testListViews() throws Exception {
+ final Executor executor = createDefaultExecutor(clusterClient);
+ final SessionContext session = new
SessionContext("test-session", new Environment());
+
+ executor.validateSession(session);
+
+ assertEquals(session.getViews().size(), 0);
Review comment:
Use executor to test list views(similar to `testListTables` and
`testListUserDefinedFunctions`). There are 2 views in the default environment.
Executor will merge environments.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Support listing of views
>
>
> Key: FLINK-10229
> URL: https://issues.apache.org/jira/browse/FLINK-10229
> Project: Flink
> Issue Type: New Feature
> Components: SQL Client
>Reporter: Timo Walther
>Assignee: vinoyang
>Priority: Major
> Labels: pull-request-available
>
> FLINK-10163 added initial support of views for the SQL Client. According to
> other database vendors, views are listed in the \{{SHOW TABLES}}. However,
> there should be a way of listing only the views. We can support the \{{SHOW
> VIEWS}} command.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-10229) Support listing of views
[
https://issues.apache.org/jira/browse/FLINK-10229?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601167#comment-16601167
]
ASF GitHub Bot commented on FLINK-10229:
hequn8128 commented on a change in pull request #6631: [FLINK-10229]
[sql-client] Support listing of views
URL: https://github.com/apache/flink/pull/6631#discussion_r214535527
##
File path:
flink-libraries/flink-sql-client/src/main/java/org/apache/flink/table/client/cli/CliClient.java
##
@@ -332,6 +336,17 @@ private void callShowTables() {
terminal.flush();
}
+ private void callShowViews() {
+ final Set views = context.getViews().keySet();
Review comment:
Get views from `Executor` like `listTables` so that to provide listViews for
external systems and gateway mode.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Support listing of views
>
>
> Key: FLINK-10229
> URL: https://issues.apache.org/jira/browse/FLINK-10229
> Project: Flink
> Issue Type: New Feature
> Components: SQL Client
>Reporter: Timo Walther
>Assignee: vinoyang
>Priority: Major
> Labels: pull-request-available
>
> FLINK-10163 added initial support of views for the SQL Client. According to
> other database vendors, views are listed in the \{{SHOW TABLES}}. However,
> there should be a way of listing only the views. We can support the \{{SHOW
> VIEWS}} command.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-10229) Support listing of views
[
https://issues.apache.org/jira/browse/FLINK-10229?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601169#comment-16601169
]
ASF GitHub Bot commented on FLINK-10229:
hequn8128 commented on a change in pull request #6631: [FLINK-10229]
[sql-client] Support listing of views
URL: https://github.com/apache/flink/pull/6631#discussion_r214535530
##
File path:
flink-libraries/flink-sql-client/src/main/java/org/apache/flink/table/client/cli/CliClient.java
##
@@ -332,6 +336,17 @@ private void callShowTables() {
terminal.flush();
}
+ private void callShowViews() {
+ final Set views = context.getViews().keySet();
+
+ if (views.isEmpty()) {
+
terminal.writer().println(CliStrings.messageInfo(CliStrings.MESSAGE_EMPTY).toAnsi());
+ } else {
+ views.forEach((v) -> terminal.writer().println(v));
Review comment:
Would it better to sort views in alphabetical order(also for show
functions)? Show tables did in this way as table names stored in a TreeSet in
table environment.
What do you think? @twalthr @yanghua
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Support listing of views
>
>
> Key: FLINK-10229
> URL: https://issues.apache.org/jira/browse/FLINK-10229
> Project: Flink
> Issue Type: New Feature
> Components: SQL Client
>Reporter: Timo Walther
>Assignee: vinoyang
>Priority: Major
> Labels: pull-request-available
>
> FLINK-10163 added initial support of views for the SQL Client. According to
> other database vendors, views are listed in the \{{SHOW TABLES}}. However,
> there should be a way of listing only the views. We can support the \{{SHOW
> VIEWS}} command.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-10229) Support listing of views
[
https://issues.apache.org/jira/browse/FLINK-10229?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601168#comment-16601168
]
ASF GitHub Bot commented on FLINK-10229:
hequn8128 commented on a change in pull request #6631: [FLINK-10229]
[sql-client] Support listing of views
URL: https://github.com/apache/flink/pull/6631#discussion_r214535526
##
File path: docs/dev/table/sqlClient.md
##
@@ -503,6 +503,12 @@ Views created within a CLI session can also be removed
again using the `DROP VIE
DROP VIEW MyNewView
{% endhighlight %}
+Views created within a CLI session can also be shown again using the `SHOW
VIEWS` statement:
Review comment:
Views created in a session environment file can also be listed, so change
the description to:
Displays all of the views in the current session using the \`SHOW VIEWS\`
statement:
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Support listing of views
>
>
> Key: FLINK-10229
> URL: https://issues.apache.org/jira/browse/FLINK-10229
> Project: Flink
> Issue Type: New Feature
> Components: SQL Client
>Reporter: Timo Walther
>Assignee: vinoyang
>Priority: Major
> Labels: pull-request-available
>
> FLINK-10163 added initial support of views for the SQL Client. According to
> other database vendors, views are listed in the \{{SHOW TABLES}}. However,
> there should be a way of listing only the views. We can support the \{{SHOW
> VIEWS}} command.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] hequn8128 commented on a change in pull request #6631: [FLINK-10229] [sql-client] Support listing of views
hequn8128 commented on a change in pull request #6631: [FLINK-10229]
[sql-client] Support listing of views
URL: https://github.com/apache/flink/pull/6631#discussion_r214535531
##
File path:
flink-libraries/flink-sql-client/src/test/java/org/apache/flink/table/client/gateway/local/LocalExecutorITCase.java
##
@@ -148,6 +148,28 @@ public void testValidateSession() throws Exception {
assertEquals(expectedTables, actualTables);
}
+ @Test
+ public void testListViews() throws Exception {
+ final Executor executor = createDefaultExecutor(clusterClient);
+ final SessionContext session = new
SessionContext("test-session", new Environment());
+
+ executor.validateSession(session);
+
+ assertEquals(session.getViews().size(), 0);
Review comment:
Use executor to test list views(similar to `testListTables` and
`testListUserDefinedFunctions`). There are 2 views in the default environment.
Executor will merge environments.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] hequn8128 commented on a change in pull request #6631: [FLINK-10229] [sql-client] Support listing of views
hequn8128 commented on a change in pull request #6631: [FLINK-10229]
[sql-client] Support listing of views
URL: https://github.com/apache/flink/pull/6631#discussion_r214535527
##
File path:
flink-libraries/flink-sql-client/src/main/java/org/apache/flink/table/client/cli/CliClient.java
##
@@ -332,6 +336,17 @@ private void callShowTables() {
terminal.flush();
}
+ private void callShowViews() {
+ final Set views = context.getViews().keySet();
Review comment:
Get views from `Executor` like `listTables` so that to provide listViews for
external systems and gateway mode.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Updated] (FLINK-10274) The stop-cluster.sh cannot stop cluster properly when there are multiple clusters running
[ https://issues.apache.org/jira/browse/FLINK-10274?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] YuFeng Shen updated FLINK-10274: Description: When you are preparing to do a Flink framework version upgrading by using the strategy [shadow copy|https://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/upgrading.html#upgrading-the-flink-framework-version] , you have to run multiple clusters concurrently, however when you are ready to stop the old version cluster after upgrading, you would find the stop-cluster.sh wouldn't work as you expected, the following is the steps to duplicate the issue: # There is already a running Flink 1.5.x cluster instance; # Installing another Flink 1.6.x cluster instance at the same cluster machines; # Migrating the jobs from Flink 1.5.x to Flink 1.6.x ; # go to the bin dir of the Flink 1.5.x cluster instance and run stop-cluster.sh ; You would expect the old Flink 1.5.x cluster instance be stopped ,right? Unfortunately the stopped cluster is the new installed Flink 1.6.x cluster instance instead! was: When you are prepare to do a Flink framework version upgrading by using the strategy [shadow copy|https://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/upgrading.html#upgrading-the-flink-framework-version] , you have to run multiple clusters concurrently, however when you are ready to stop the old version cluster after upgrading, you would find the stop-cluster.sh wouldn't work as you expected, the following is the steps to duplicate the issue: # There is already a running Flink 1.5.x cluster instance; # Installing another Flink 1.6.x cluster instance at the same cluster machines; # Migrating the jobs from Flink 1.5.x to Flink 1.6.x ; # go to the bin dir of the Flink 1.5.x cluster instance and run stop-cluster.sh ; You would expect the old Flink 1.5.x cluster instance be stopped ,right? Unfortunately the stopped cluster is the new installed Flink 1.6.x cluster instance instead! > The stop-cluster.sh cannot stop cluster properly when there are multiple > clusters running > - > > Key: FLINK-10274 > URL: https://issues.apache.org/jira/browse/FLINK-10274 > Project: Flink > Issue Type: Bug > Components: Configuration >Affects Versions: 1.5.1, 1.5.2, 1.5.3, 1.6.0 >Reporter: YuFeng Shen >Assignee: YuFeng Shen >Priority: Major > Time Spent: 1h > Remaining Estimate: 0h > > When you are preparing to do a Flink framework version upgrading by using the > strategy [shadow > copy|https://ci.apache.org/projects/flink/flink-docs-release-1.6/ops/upgrading.html#upgrading-the-flink-framework-version] > , you have to run multiple clusters concurrently, however when you are > ready to stop the old version cluster after upgrading, you would find the > stop-cluster.sh wouldn't work as you expected, the following is the steps to > duplicate the issue: > # There is already a running Flink 1.5.x cluster instance; > # Installing another Flink 1.6.x cluster instance at the same cluster > machines; > # Migrating the jobs from Flink 1.5.x to Flink 1.6.x ; > # go to the bin dir of the Flink 1.5.x cluster instance and run > stop-cluster.sh ; > You would expect the old Flink 1.5.x cluster instance be stopped ,right? > Unfortunately the stopped cluster is the new installed Flink 1.6.x cluster > instance instead! -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] hequn8128 commented on a change in pull request #6631: [FLINK-10229] [sql-client] Support listing of views
hequn8128 commented on a change in pull request #6631: [FLINK-10229]
[sql-client] Support listing of views
URL: https://github.com/apache/flink/pull/6631#discussion_r214535530
##
File path:
flink-libraries/flink-sql-client/src/main/java/org/apache/flink/table/client/cli/CliClient.java
##
@@ -332,6 +336,17 @@ private void callShowTables() {
terminal.flush();
}
+ private void callShowViews() {
+ final Set views = context.getViews().keySet();
+
+ if (views.isEmpty()) {
+
terminal.writer().println(CliStrings.messageInfo(CliStrings.MESSAGE_EMPTY).toAnsi());
+ } else {
+ views.forEach((v) -> terminal.writer().println(v));
Review comment:
Would it better to sort views in alphabetical order(also for show
functions)? Show tables did in this way as table names stored in a TreeSet in
table environment.
What do you think? @twalthr @yanghua
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] hequn8128 commented on a change in pull request #6631: [FLINK-10229] [sql-client] Support listing of views
hequn8128 commented on a change in pull request #6631: [FLINK-10229]
[sql-client] Support listing of views
URL: https://github.com/apache/flink/pull/6631#discussion_r214535526
##
File path: docs/dev/table/sqlClient.md
##
@@ -503,6 +503,12 @@ Views created within a CLI session can also be removed
again using the `DROP VIE
DROP VIEW MyNewView
{% endhighlight %}
+Views created within a CLI session can also be shown again using the `SHOW
VIEWS` statement:
Review comment:
Views created in a session environment file can also be listed, so change
the description to:
Displays all of the views in the current session using the \`SHOW VIEWS\`
statement:
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (FLINK-10050) Support 'allowedLateness' in CoGroupedStreams
[ https://issues.apache.org/jira/browse/FLINK-10050?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601166#comment-16601166 ] ASF GitHub Bot commented on FLINK-10050: EugeneYushin opened a new pull request #6646: [FLINK-10050] Support allowedLateness in CoGroupedStreams URL: https://github.com/apache/flink/pull/6646 ## What is the purpose of the change [https://issues.apache.org/jira/browse/FLINK-10050](https://issues.apache.org/jira/browse/FLINK-10050) Add 'allowedLateness' method to coGroup and join streams API. ## Brief change log - add 'allowedLateness' for CoGroupedStreams/JoinedStreams java and scala API - delegate calls to underlying WindowedStream (as for Trigger/Evictor scenario) ## Verifying this change This change is a trivial rework. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: yes - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Support 'allowedLateness' in CoGroupedStreams > - > > Key: FLINK-10050 > URL: https://issues.apache.org/jira/browse/FLINK-10050 > Project: Flink > Issue Type: Improvement > Components: Streaming >Affects Versions: 1.5.1, 1.6.0 >Reporter: eugen yushin >Priority: Major > Labels: pull-request-available, ready-to-commit, windows > > WindowedStream has a support of 'allowedLateness' feature, while > CoGroupedStreams are not. At the mean time, WindowedStream is an inner part > of CoGroupedStreams and all main functionality (like evictor/trigger/...) is > simply delegated to WindowedStream. > There's no chance to operate with late arriving data from previous steps in > cogroups (and joins). Consider the following flow: > a. read data from source1 -> aggregate data with allowed lateness > b. read data from source2 -> aggregate data with allowed lateness > c. cogroup/join streams a and b, and compare aggregated values > Step c doesn't accept any late data from steps a/b due to lack of > `allowedLateness` API call in CoGroupedStreams.java. > Scope: add method `WithWindow.allowedLateness` to Java API > (flink-streaming-java) and extend scala API (flink-streaming-scala). -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-10050) Support 'allowedLateness' in CoGroupedStreams
[ https://issues.apache.org/jira/browse/FLINK-10050?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-10050: --- Labels: pull-request-available ready-to-commit windows (was: ready-to-commit windows) > Support 'allowedLateness' in CoGroupedStreams > - > > Key: FLINK-10050 > URL: https://issues.apache.org/jira/browse/FLINK-10050 > Project: Flink > Issue Type: Improvement > Components: Streaming >Affects Versions: 1.5.1, 1.6.0 >Reporter: eugen yushin >Priority: Major > Labels: pull-request-available, ready-to-commit, windows > > WindowedStream has a support of 'allowedLateness' feature, while > CoGroupedStreams are not. At the mean time, WindowedStream is an inner part > of CoGroupedStreams and all main functionality (like evictor/trigger/...) is > simply delegated to WindowedStream. > There's no chance to operate with late arriving data from previous steps in > cogroups (and joins). Consider the following flow: > a. read data from source1 -> aggregate data with allowed lateness > b. read data from source2 -> aggregate data with allowed lateness > c. cogroup/join streams a and b, and compare aggregated values > Step c doesn't accept any late data from steps a/b due to lack of > `allowedLateness` API call in CoGroupedStreams.java. > Scope: add method `WithWindow.allowedLateness` to Java API > (flink-streaming-java) and extend scala API (flink-streaming-scala). -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] EugeneYushin opened a new pull request #6646: [FLINK-10050] Support allowedLateness in CoGroupedStreams
EugeneYushin opened a new pull request #6646: [FLINK-10050] Support allowedLateness in CoGroupedStreams URL: https://github.com/apache/flink/pull/6646 ## What is the purpose of the change [https://issues.apache.org/jira/browse/FLINK-10050](https://issues.apache.org/jira/browse/FLINK-10050) Add 'allowedLateness' method to coGroup and join streams API. ## Brief change log - add 'allowedLateness' for CoGroupedStreams/JoinedStreams java and scala API - delegate calls to underlying WindowedStream (as for Trigger/Evictor scenario) ## Verifying this change This change is a trivial rework. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: yes - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-10212) REST API for listing all the available save points
[ https://issues.apache.org/jira/browse/FLINK-10212?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16601131#comment-16601131 ] Marc Rooding commented on FLINK-10212: -- Hi Chesnay, You understand correctly. I do agree with you that it's not a monitoring feature and that it would only make it easier to integrate with Flink without third-party tooling. > REST API for listing all the available save points > -- > > Key: FLINK-10212 > URL: https://issues.apache.org/jira/browse/FLINK-10212 > Project: Flink > Issue Type: New Feature >Reporter: Marc Rooding >Priority: Major > > *Background* > I'm one of the authors of the open-source Flink job deployer > ([https://github.com/ing-bank/flink-deployer)]. Recently, I rewrote our > implementation to use the Flink REST API instead of the native CLI. > In our use case, we store the job savepoints in a Kubernetes persistent > volume. For our deployer, we mount the persistent volume to our deployer > container so that we can find and use the savepoints. > In the rewrite to the REST API, I saw that the API to monitor savepoint > creation returns the complete path to the created savepoint, and we can use > this one in the job deployer to start the new job with the latest save point. > However, we also allow users to deploy a job with a recovered state by > specifying only the directory savepoints are stored in. In this scenario we > will look for the latest savepoint created for this job ourselves inside the > given directory. To find this path, we're still relying on the mounted volume > and listing directory content to discover savepoints. > *Feature* > I was thinking that it might be a good addition if the native Flink REST API > offers the ability to retrieve savepoints. Seeing that the API doesn't > inherently know where savepoints are stored, it could take a path as one of > the arguments. It could even allow the user to provide a job ID as an > argument so that the API would be able to search for savepoints for a > specific job ID in the specified directory. > As the API would require the path as an argument, and providing a path > containing forward slashes in the URL isn't ideal, I'm eager to discuss what > a proper solution would look like. > A POST request to /jobs/:jobid/savepoints with the path as a body parameter > would make sense if the API were to offer to list all save points in a > specific path but this request is already being used for creating new > savepoints. > An alternative could be a POST to /savepoints with the path and job ID in the > request body. > A POST request to retrieve data is obviously not the most straightforward > approach but in my opinion still preferable over a GET to, for example, > /jobs/:jobid/savepoints/:targetDirectory > I'm willing to help out on this one by submitting a pull request. > Looking forward to your thoughts! -- This message was sent by Atlassian JIRA (v7.6.3#76005)