[jira] [Updated] (FLINK-15421) GroupAggsHandler throws java.time.LocalDateTime cannot be cast to java.sql.Timestamp
[
https://issues.apache.org/jira/browse/FLINK-15421?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Benchao Li updated FLINK-15421:
---
Description:
`TimestmapType` has two types of physical representation: `Timestamp` and
`LocalDateTime`. When we use following SQL, it will conflict each other:
{quote}SELECT
SUM(cnt) as s,
MAX(ts)
FROM
SELECT
`string`,
`int`,
COUNT * AS cnt,
MAX(rowtime) as ts
FROM T1
GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
GROUP BY `string`
{quote}
with 'table.exec.emit.early-fire.enabled' = true.
The exceptions is below:
{quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime cannot
be cast to java.sql.Timestamp
at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
at
org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
at
org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
at
org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
at
org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527)
at java.lang.Thread.run(Thread.java:748)
{quote}
I also create a UT to quickly reproduce this bug in `WindowAggregateITCase`:
```scala
@Test
def testEarlyFireWithTumblingWindow(): Unit = {
val stream = failingDataSource(data)
.assignTimestampsAndWatermarks(
new TimestampAndWatermarkWithOffset
[(Long, Int, Double, Float, BigDecimal, String, String)](10L))
val table = stream.toTable(tEnv,
'rowtime.rowtime, 'int, 'double, 'float, 'bigdec, 'string, 'name)
tEnv.registerTable("T1", table)
tEnv.getConfig.getConfiguration.setBoolean("table.exec.emit.early-fire.enabled",
true)
tEnv.getConfig.getConfiguration.setString("table.exec.emit.early-fire.delay",
"1000 ms")
val sql =
"""
|SELECT
| SUM(cnt) as s,
| MAX(ts)
|FROM
| (SELECT
| `string`,
| `int`,
| COUNT(*) AS cnt,
| MAX(rowtime) as ts
| FROM T1
| GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND))
|GROUP BY `string`
|""".stripMargin
tEnv.sqlQuery(sql).toRetractStream[Row].print()
env.execute()
}
```
was:
`TimestmapType` has two types of physical representation: `Timestamp` and
`LocalDateTime`. When we use following SQL, it will conflict each other:
{quote}SELECT
SUM(cnt) as s,
MAX(ts)
FROM
SELECT
`string`,
`int`,
COUNT * AS cnt,
MAX(rowtime) as ts
FROM T1
GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
GROUP BY `string`
{quote}
with 'table.exec.emit.early-fire.enabled' = true.
The exceptions is below:
{quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime cannot
be cast to java.sql.Timestamp
at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
at
org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
at
org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
at
org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
at
org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
at org.apache.flink.runtime.taskmanager.
[jira] [Commented] (FLINK-15418) StreamExecMatchRule not set FlinkRelDistribution
[ https://issues.apache.org/jira/browse/FLINK-15418?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003976#comment-17003976 ] Benchao Li commented on FLINK-15418: [~jark] I've fixed this bug, could you help to verify and assign this issue to me? I'd like to contribute it to the community. > StreamExecMatchRule not set FlinkRelDistribution > > > Key: FLINK-15418 > URL: https://issues.apache.org/jira/browse/FLINK-15418 > Project: Flink > Issue Type: Bug >Affects Versions: 1.9.1, 1.10.0 >Reporter: Benchao Li >Priority: Major > > StreamExecMatchRule forgets to set FlinkRelDistribution. When match clause > with `partition by`, and parallelism > 1, will result in following exception: > ``` > Caused by: java.lang.NullPointerException > at > org.apache.flink.runtime.state.heap.StateTable.put(StateTable.java:336) > at > org.apache.flink.runtime.state.heap.StateTable.put(StateTable.java:159) > at > org.apache.flink.runtime.state.heap.HeapMapState.put(HeapMapState.java:100) > at > org.apache.flink.runtime.state.UserFacingMapState.put(UserFacingMapState.java:52) > at > org.apache.flink.cep.nfa.sharedbuffer.SharedBuffer.registerEvent(SharedBuffer.java:141) > at > org.apache.flink.cep.nfa.sharedbuffer.SharedBufferAccessor.registerEvent(SharedBufferAccessor.java:74) > at org.apache.flink.cep.nfa.NFA$EventWrapper.getEventId(NFA.java:483) > at org.apache.flink.cep.nfa.NFA.computeNextStates(NFA.java:605) > at org.apache.flink.cep.nfa.NFA.doProcess(NFA.java:292) > at org.apache.flink.cep.nfa.NFA.process(NFA.java:228) > at > org.apache.flink.cep.operator.CepOperator.processEvent(CepOperator.java:420) > at > org.apache.flink.cep.operator.CepOperator.processElement(CepOperator.java:242) > at > org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173) > at > org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151) > at > org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128) > at > org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69) > at > org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311) > at > org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187) > at > org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488) > at > org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470) > at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702) > at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527) > at java.lang.Thread.run(Thread.java:748) > ``` -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot commented on issue #10702: [FLINK-15412][hive] LocalExecutorITCase#testParameterizedTypes failed…
flinkbot commented on issue #10702: [FLINK-15412][hive] LocalExecutorITCase#testParameterizedTypes failed… URL: https://github.com/apache/flink/pull/10702#issuecomment-569214736 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit c0a381f057e721c85e693a280e7be30a62163475 (Fri Dec 27 07:54:23 UTC 2019) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! * **This pull request references an unassigned [Jira ticket](https://issues.apache.org/jira/browse/FLINK-15412).** According to the [code contribution guide](https://flink.apache.org/contributing/contribute-code.html), tickets need to be assigned before starting with the implementation work. Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-15412) LocalExecutorITCase#testParameterizedTypes failed in travis
[
https://issues.apache.org/jira/browse/FLINK-15412?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-15412:
---
Labels: pull-request-available (was: )
> LocalExecutorITCase#testParameterizedTypes failed in travis
> ---
>
> Key: FLINK-15412
> URL: https://issues.apache.org/jira/browse/FLINK-15412
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Client
>Reporter: Dian Fu
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.10.0
>
>
> The travis of release-1.9 failed with the following error:
> {code:java}
> 14:43:17.916 [INFO] Running
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase
> 14:44:47.388 [ERROR] Tests run: 34, Failures: 0, Errors: 1, Skipped: 1, Time
> elapsed: 89.468 s <<< FAILURE! - in
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase
> 14:44:47.388 [ERROR] testParameterizedTypes[Planner:
> blink](org.apache.flink.table.client.gateway.local.LocalExecutorITCase) Time
> elapsed: 7.88 s <<< ERROR!
> org.apache.flink.table.client.gateway.SqlExecutionException: Invalid SQL
> statement at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:557)
> Caused by: org.apache.flink.table.api.ValidationException: SQL validation
> failed. findAndCreateTableSource failed
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:557)
> Caused by: org.apache.flink.table.api.TableException:
> findAndCreateTableSource failed
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:557)
> Caused by: org.apache.flink.table.api.NoMatchingTableFactoryException:
> Could not find a suitable table factory for
> 'org.apache.flink.table.factories.TableSourceFactory' in
> the classpath.
> Reason: No context matches.
> {code}
> instance: [https://api.travis-ci.org/v3/job/629636106/log.txt]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-15421) GroupAggsHandler throws java.time.LocalDateTime cannot be cast to java.sql.Timestamp
[
https://issues.apache.org/jira/browse/FLINK-15421?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003974#comment-17003974
]
Benchao Li commented on FLINK-15421:
[~lzljs3620320] Sorry about the format of the code. Could you tell me how to
write a code block correctly in issue description ?
> GroupAggsHandler throws java.time.LocalDateTime cannot be cast to
> java.sql.Timestamp
>
>
> Key: FLINK-15421
> URL: https://issues.apache.org/jira/browse/FLINK-15421
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.9.1, 1.10.0
>Reporter: Benchao Li
>Priority: Major
> Fix For: 1.9.2, 1.10.0
>
>
> `TimestmapType` has two types of physical representation: `Timestamp` and
> `LocalDateTime`. When we use following SQL, it will conflict each other:
> {quote}SELECT
> SUM(cnt) as s,
> MAX(ts)
> FROM
> SELECT
> `string`,
> `int`,
> COUNT * AS cnt,
> MAX(rowtime) as ts
> FROM T1
> GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
> GROUP BY `string`
> {quote}
> with 'table.exec.emit.early-fire.enabled' = true.
> The exceptions is below:
> {quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime
> cannot be cast to java.sql.Timestamp
> at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
> at
> org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
> at
> org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
> at
> org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
> at
> org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527)
> at java.lang.Thread.run(Thread.java:748)
> {quote}
> I also create a UT to quickly reproduce this bug in `WindowAggregateITCase`:
> {quote}@Test
> def testEarlyFireWithTumblingWindow(): Unit = {
> val stream = failingDataSource(data)
> .assignTimestampsAndWatermarks(
> new TimestampAndWatermarkWithOffset
> [(Long, Int, Double, Float, BigDecimal, String, String)](10L))
> val table = stream.toTable(tEnv,
> 'rowtime.rowtime, 'int, 'double, 'float, 'bigdec, 'string, 'name)
> tEnv.registerTable("T1", table)
>
> tEnv.getConfig.getConfiguration.setBoolean("table.exec.emit.early-fire.enabled",
> true)
>
> tEnv.getConfig.getConfiguration.setString("table.exec.emit.early-fire.delay",
> "1000 ms")
> val sql =
> """
> |SELECT
> | SUM(cnt) as s,
> | MAX(ts)
> |FROM
> | (SELECT
> | `string`,
> | `int`,
> | COUNT(*) AS cnt,
> | MAX(rowtime) as ts
> | FROM T1
> | GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND))
> |GROUP BY `string`
> |""".stripMargin
> tEnv.sqlQuery(sql).toRetractStream[Row].print()
> env.execute()
> }
>
>
> {quote}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] lirui-apache commented on issue #10702: [FLINK-15412][hive] LocalExecutorITCase#testParameterizedTypes failed…
lirui-apache commented on issue #10702: [FLINK-15412][hive] LocalExecutorITCase#testParameterizedTypes failed… URL: https://github.com/apache/flink/pull/10702#issuecomment-569214511 I'm just back porting FLINK-15240. cc @KurtYoung @bowenli86 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-15421) GroupAggsHandler throws java.time.LocalDateTime cannot be cast to java.sql.Timestamp
[
https://issues.apache.org/jira/browse/FLINK-15421?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003973#comment-17003973
]
Jingsong Lee commented on FLINK-15421:
--
Thanks [~libenchao] for reporting. Can you format the code in description?
> GroupAggsHandler throws java.time.LocalDateTime cannot be cast to
> java.sql.Timestamp
>
>
> Key: FLINK-15421
> URL: https://issues.apache.org/jira/browse/FLINK-15421
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.9.1, 1.10.0
>Reporter: Benchao Li
>Priority: Major
> Fix For: 1.9.2, 1.10.0
>
>
> `TimestmapType` has two types of physical representation: `Timestamp` and
> `LocalDateTime`. When we use following SQL, it will conflict each other:
> {quote}SELECT
> SUM(cnt) as s,
> MAX(ts)
> FROM
> SELECT
> `string`,
> `int`,
> COUNT * AS cnt,
> MAX(rowtime) as ts
> FROM T1
> GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
> GROUP BY `string`
> {quote}
> with 'table.exec.emit.early-fire.enabled' = true.
> The exceptions is below:
> {quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime
> cannot be cast to java.sql.Timestamp
> at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
> at
> org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
> at
> org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
> at
> org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
> at
> org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527)
> at java.lang.Thread.run(Thread.java:748)
> {quote}
> I also create a UT to quickly reproduce this bug in `WindowAggregateITCase`:
> {quote}@Test
> def testEarlyFireWithTumblingWindow(): Unit = {
> val stream = failingDataSource(data)
> .assignTimestampsAndWatermarks(
> new TimestampAndWatermarkWithOffset
> [(Long, Int, Double, Float, BigDecimal, String, String)](10L))
> val table = stream.toTable(tEnv,
> 'rowtime.rowtime, 'int, 'double, 'float, 'bigdec, 'string, 'name)
> tEnv.registerTable("T1", table)
>
> tEnv.getConfig.getConfiguration.setBoolean("table.exec.emit.early-fire.enabled",
> true)
>
> tEnv.getConfig.getConfiguration.setString("table.exec.emit.early-fire.delay",
> "1000 ms")
> val sql =
> """
> |SELECT
> | SUM(cnt) as s,
> | MAX(ts)
> |FROM
> | (SELECT
> | `string`,
> | `int`,
> | COUNT(*) AS cnt,
> | MAX(rowtime) as ts
> | FROM T1
> | GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND))
> |GROUP BY `string`
> |""".stripMargin
> tEnv.sqlQuery(sql).toRetractStream[Row].print()
> env.execute()
> }
>
>
> {quote}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] lirui-apache opened a new pull request #10702: [FLINK-15412][hive] LocalExecutorITCase#testParameterizedTypes failed…
lirui-apache opened a new pull request #10702: [FLINK-15412][hive] LocalExecutorITCase#testParameterizedTypes failed… URL: https://github.com/apache/flink/pull/10702 … in travis ## What is the purpose of the change Fix LocalExecutorITCase#testParameterizedTypes in release-1.9 ## Brief change log - Back port the changes in FLINK-15240. ## Verifying this change Covered by existing tests ## Does this pull request potentially affect one of the following parts: NA ## Documentation NA This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-15421) GroupAggsHandler throws java.time.LocalDateTime cannot be cast to java.sql.Timestamp
[
https://issues.apache.org/jira/browse/FLINK-15421?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Benchao Li updated FLINK-15421:
---
Description:
`TimestmapType` has two types of physical representation: `Timestamp` and
`LocalDateTime`. When we use following SQL, it will conflict each other:
{quote}SELECT
SUM(cnt) as s,
MAX(ts)
FROM
SELECT
`string`,
`int`,
COUNT * AS cnt,
MAX(rowtime) as ts
FROM T1
GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
GROUP BY `string`
{quote}
with 'table.exec.emit.early-fire.enabled' = true.
The exceptions is below:
{quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime cannot
be cast to java.sql.Timestamp
at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
at
org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
at
org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
at
org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
at
org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527)
at java.lang.Thread.run(Thread.java:748)
{quote}
I also create a UT to quickly reproduce this bug in `WindowAggregateITCase`:
{quote}@Test
def testEarlyFireWithTumblingWindow(): Unit = {
val stream = failingDataSource(data)
.assignTimestampsAndWatermarks(
new TimestampAndWatermarkWithOffset
[(Long, Int, Double, Float, BigDecimal, String, String)](10L))
val table = stream.toTable(tEnv,
'rowtime.rowtime, 'int, 'double, 'float, 'bigdec, 'string, 'name)
tEnv.registerTable("T1", table)
tEnv.getConfig.getConfiguration.setBoolean("table.exec.emit.early-fire.enabled",
true)
tEnv.getConfig.getConfiguration.setString("table.exec.emit.early-fire.delay",
"1000 ms")
val sql =
"""
|SELECT
| SUM(cnt) as s,
| MAX(ts)
|FROM
| (SELECT
| `string`,
| `int`,
| COUNT(*) AS cnt,
| MAX(rowtime) as ts
| FROM T1
| GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND))
|GROUP BY `string`
|""".stripMargin
tEnv.sqlQuery(sql).toRetractStream[Row].print()
env.execute()
}
{quote}
was:
`TimestmapType` has two types of physical representation: `Timestamp` and
`LocalDateTime`. When we use following SQL, it will conflict each other:
{quote}SELECT
SUM(cnt) as s,
MAX(ts)
FROM
SELECT
`string`,
`int`,
COUNT * AS cnt,
MAX(rowtime) as ts
FROM T1
GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
GROUP BY `string`
{quote}
with 'table.exec.emit.early-fire.enabled' = true.
The exceptions is below:
{quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime cannot
be cast to java.sql.Timestamp
at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
at
org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
at
org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
at
org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
at
org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
at org.apache.flink.runtime.taskmanager
[jira] [Updated] (FLINK-15421) GroupAggsHandler throws java.time.LocalDateTime cannot be cast to java.sql.Timestamp
[
https://issues.apache.org/jira/browse/FLINK-15421?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jingsong Lee updated FLINK-15421:
-
Component/s: Table SQL / Planner
> GroupAggsHandler throws java.time.LocalDateTime cannot be cast to
> java.sql.Timestamp
>
>
> Key: FLINK-15421
> URL: https://issues.apache.org/jira/browse/FLINK-15421
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.9.1, 1.10.0
>Reporter: Benchao Li
>Priority: Major
> Fix For: 1.9.2, 1.10.0
>
>
> `TimestmapType` has two types of physical representation: `Timestamp` and
> `LocalDateTime`. When we use following SQL, it will conflict each other:
> {quote}SELECT
> SUM(cnt) as s,
> MAX(ts)
> FROM
> SELECT
> `string`,
> `int`,
> COUNT * AS cnt,
> MAX(rowtime) as ts
> FROM T1
> GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
> GROUP BY `string`
> {quote}
> with 'table.exec.emit.early-fire.enabled' = true.
> The exceptions is below:
> {quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime
> cannot be cast to java.sql.Timestamp
> at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
> at
> org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
> at
> org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
> at
> org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
> at
> org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527)
> at java.lang.Thread.run(Thread.java:748)
> {quote}
> I also create a UT to quickly reproduce this bug in `WindowAggregateITCase`:
>
> @Test
> def testEarlyFireWithTumblingWindow(): Unit = {
> val stream = failingDataSource(data)
> .assignTimestampsAndWatermarks(
> new TimestampAndWatermarkWithOffset
> [(Long, Int, Double, Float, BigDecimal, String, String)](10L))
> val table = stream.toTable(tEnv,
> 'rowtime.rowtime, 'int, 'double, 'float, 'bigdec, 'string, 'name)
> tEnv.registerTable("T1", table)
>
> tEnv.getConfig.getConfiguration.setBoolean("table.exec.emit.early-fire.enabled",
> true)
>
> tEnv.getConfig.getConfiguration.setString("table.exec.emit.early-fire.delay",
> "1000 ms")
> val sql =
> """
> |SELECT
> | SUM(cnt) as s,
> | MAX(ts)
> |FROM
> | (SELECT
> | `string`,
> | `int`,
> | COUNT(*) AS cnt,
> | MAX(rowtime) as ts
> | FROM T1
> | GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND))
> |GROUP BY `string`
> |""".stripMargin
> tEnv.sqlQuery(sql).toRetractStream[Row].print()
> env.execute()
> }
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-15421) GroupAggsHandler throws java.time.LocalDateTime cannot be cast to java.sql.Timestamp
[
https://issues.apache.org/jira/browse/FLINK-15421?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Benchao Li updated FLINK-15421:
---
Description:
`TimestmapType` has two types of physical representation: `Timestamp` and
`LocalDateTime`. When we use following SQL, it will conflict each other:
{quote}SELECT
SUM(cnt) as s,
MAX(ts)
FROM
SELECT
`string`,
`int`,
COUNT * AS cnt,
MAX(rowtime) as ts
FROM T1
GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
GROUP BY `string`
{quote}
with 'table.exec.emit.early-fire.enabled' = true.
The exceptions is below:
{quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime cannot
be cast to java.sql.Timestamp
at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
at
org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
at
org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
at
org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
at
org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527)
at java.lang.Thread.run(Thread.java:748)
{quote}
I also create a UT to quickly reproduce this bug in `WindowAggregateITCase`:
@Test
def testEarlyFireWithTumblingWindow(): Unit = {
val stream = failingDataSource(data)
.assignTimestampsAndWatermarks(
new TimestampAndWatermarkWithOffset
[(Long, Int, Double, Float, BigDecimal, String, String)](10L))
val table = stream.toTable(tEnv,
'rowtime.rowtime, 'int, 'double, 'float, 'bigdec, 'string, 'name)
tEnv.registerTable("T1", table)
tEnv.getConfig.getConfiguration.setBoolean("table.exec.emit.early-fire.enabled",
true)
tEnv.getConfig.getConfiguration.setString("table.exec.emit.early-fire.delay",
"1000 ms")
val sql =
"""
|SELECT
| SUM(cnt) as s,
| MAX(ts)
|FROM
| (SELECT
| `string`,
| `int`,
| COUNT(*) AS cnt,
| MAX(rowtime) as ts
| FROM T1
| GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND))
|GROUP BY `string`
|""".stripMargin
tEnv.sqlQuery(sql).toRetractStream[Row].print()
env.execute()
}
was:
`TimestmapType` has two types of physical representation: `Timestamp` and
`LocalDateTime`. When we use following SQL, it will conflict each other:
{quote}SELECT
SUM(cnt) as s,
MAX(ts)
FROM
SELECT
`string`,
`int`,
COUNT * AS cnt,
MAX(rowtime) as ts
FROM T1
GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
GROUP BY `string`
{quote}
with 'table.exec.emit.early-fire.enabled' = true.
The exceptions is below:
{quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime cannot
be cast to java.sql.Timestamp
at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
at
org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
at
org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
at
org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
at
org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
at org.apache.flink.runtime.taskmanager.Task.doRun
[jira] [Updated] (FLINK-15421) GroupAggsHandler throws java.time.LocalDateTime cannot be cast to java.sql.Timestamp
[
https://issues.apache.org/jira/browse/FLINK-15421?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jingsong Lee updated FLINK-15421:
-
Fix Version/s: 1.10.0
1.9.2
> GroupAggsHandler throws java.time.LocalDateTime cannot be cast to
> java.sql.Timestamp
>
>
> Key: FLINK-15421
> URL: https://issues.apache.org/jira/browse/FLINK-15421
> Project: Flink
> Issue Type: Bug
>Affects Versions: 1.9.1, 1.10.0
>Reporter: Benchao Li
>Priority: Major
> Fix For: 1.9.2, 1.10.0
>
>
> `TimestmapType` has two types of physical representation: `Timestamp` and
> `LocalDateTime`. When we use following SQL, it will conflict each other:
> {quote}SELECT
> SUM(cnt) as s,
> MAX(ts)
> FROM
> SELECT
> `string`,
> `int`,
> COUNT * AS cnt,
> MAX(rowtime) as ts
> FROM T1
> GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
> GROUP BY `string`
> {quote}
> with 'table.exec.emit.early-fire.enabled' = true.
> The exceptions is below:
> {quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime
> cannot be cast to java.sql.Timestamp
> at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
> at
> org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
> at
> org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
> at
> org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
> at
> org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527)
> at java.lang.Thread.run(Thread.java:748)
> {quote}
> I also create a UT to quickly reproduce this bug in `WindowAggregateITCase`:
>
> @Test
> def testEarlyFireWithTumblingWindow(): Unit = {
> val stream = failingDataSource(data)
> .assignTimestampsAndWatermarks(
> new TimestampAndWatermarkWithOffset
> [(Long, Int, Double, Float, BigDecimal, String, String)](10L))
> val table = stream.toTable(tEnv,
> 'rowtime.rowtime, 'int, 'double, 'float, 'bigdec, 'string, 'name)
> tEnv.registerTable("T1", table)
>
> tEnv.getConfig.getConfiguration.setBoolean("table.exec.emit.early-fire.enabled",
> true)
>
> tEnv.getConfig.getConfiguration.setString("table.exec.emit.early-fire.delay",
> "1000 ms")
> val sql =
> """
> |SELECT
> | SUM(cnt) as s,
> | MAX(ts)
> |FROM
> | (SELECT
> | `string`,
> | `int`,
> | COUNT(*) AS cnt,
> | MAX(rowtime) as ts
> | FROM T1
> | GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND))
> |GROUP BY `string`
> |""".stripMargin
> tEnv.sqlQuery(sql).toRetractStream[Row].print()
> env.execute()
> }
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-15420) Cast string to timestamp will loose precision
[
https://issues.apache.org/jira/browse/FLINK-15420?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003950#comment-17003950
]
Jingsong Lee commented on FLINK-15420:
--
CC: [~docete]
> Cast string to timestamp will loose precision
> -
>
> Key: FLINK-15420
> URL: https://issues.apache.org/jira/browse/FLINK-15420
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Reporter: Jingsong Lee
>Priority: Blocker
> Fix For: 1.10.0
>
>
> {code:java}
> cast('2010-10-14 12:22:22.123456' as timestamp(9))
> {code}
> Will produce "2010-10-14 12:22:22.123" in blink planner, this should not
> happen.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-15421) GroupAggsHandler throws java.time.LocalDateTime cannot be cast to java.sql.Timestamp
[
https://issues.apache.org/jira/browse/FLINK-15421?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003951#comment-17003951
]
Jingsong Lee commented on FLINK-15421:
--
CC: [~docete]
> GroupAggsHandler throws java.time.LocalDateTime cannot be cast to
> java.sql.Timestamp
>
>
> Key: FLINK-15421
> URL: https://issues.apache.org/jira/browse/FLINK-15421
> Project: Flink
> Issue Type: Bug
>Affects Versions: 1.9.1, 1.10.0
>Reporter: Benchao Li
>Priority: Major
>
> `TimestmapType` has two types of physical representation: `Timestamp` and
> `LocalDateTime`. When we use following SQL, it will conflict each other:
> {quote}SELECT
> SUM(cnt) as s,
> MAX(ts)
> FROM
> SELECT
> `string`,
> `int`,
> COUNT * AS cnt,
> MAX(rowtime) as ts
> FROM T1
> GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
> GROUP BY `string`
> {quote}
> with 'table.exec.emit.early-fire.enabled' = true.
> The exceptions is below:
> {quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime
> cannot be cast to java.sql.Timestamp
> at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
> at
> org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
> at
> org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
> at
> org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
> at
> org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527)
> at java.lang.Thread.run(Thread.java:748)
> {quote}
> I also create a UT to quickly reproduce this bug in `WindowAggregateITCase`:
> @Test
> def testEarlyFireWithTumblingWindow(): Unit = {
> val stream = failingDataSource(data)
> .assignTimestampsAndWatermarks(
> new TimestampAndWatermarkWithOffset
> [(Long, Int, Double, Float, BigDecimal, String, String)](10L))
> val table = stream.toTable(tEnv,
> 'rowtime.rowtime, 'int, 'double, 'float, 'bigdec, 'string, 'name)
> tEnv.registerTable("T1", table)
>
> tEnv.getConfig.getConfiguration.setBoolean("table.exec.emit.early-fire.enabled",
> true)
>
> tEnv.getConfig.getConfiguration.setString("table.exec.emit.early-fire.delay",
> "1000 ms")
> val sql =
> """
> |SELECT
> | SUM(cnt) as s,
> | MAX(ts)
> |FROM
> | (SELECT
> | `string`,
> | `int`,
> | COUNT(*) AS cnt,
> | MAX(rowtime) as ts
> | FROM T1
> | GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND))
> |GROUP BY `string`
> |""".stripMargin
> tEnv.sqlQuery(sql).toRetractStream[Row].print()
> env.execute()
> }
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-15421) GroupAggsHandler throws java.time.LocalDateTime cannot be cast to java.sql.Timestamp
[
https://issues.apache.org/jira/browse/FLINK-15421?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Benchao Li updated FLINK-15421:
---
Description:
`TimestmapType` has two types of physical representation: `Timestamp` and
`LocalDateTime`. When we use following SQL, it will conflict each other:
{quote}SELECT
SUM(cnt) as s,
MAX(ts)
FROM
SELECT
`string`,
`int`,
COUNT * AS cnt,
MAX(rowtime) as ts
FROM T1
GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
GROUP BY `string`
{quote}
with 'table.exec.emit.early-fire.enabled' = true.
The exceptions is below:
{quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime cannot
be cast to java.sql.Timestamp
at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
at
org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
at
org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
at
org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
at
org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527)
at java.lang.Thread.run(Thread.java:748)
{quote}
I also create a UT to quickly reproduce this bug in `WindowAggregateITCase`:
@Test
def testEarlyFireWithTumblingWindow(): Unit = {
val stream = failingDataSource(data)
.assignTimestampsAndWatermarks(
new TimestampAndWatermarkWithOffset
[(Long, Int, Double, Float, BigDecimal, String, String)](10L))
val table = stream.toTable(tEnv,
'rowtime.rowtime, 'int, 'double, 'float, 'bigdec, 'string, 'name)
tEnv.registerTable("T1", table)
tEnv.getConfig.getConfiguration.setBoolean("table.exec.emit.early-fire.enabled",
true)
tEnv.getConfig.getConfiguration.setString("table.exec.emit.early-fire.delay",
"1000 ms")
val sql =
"""
|SELECT
| SUM(cnt) as s,
| MAX(ts)
|FROM
| (SELECT
| `string`,
| `int`,
| COUNT(*) AS cnt,
| MAX(rowtime) as ts
| FROM T1
| GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND))
|GROUP BY `string`
|""".stripMargin
tEnv.sqlQuery(sql).toRetractStream[Row].print()
env.execute()
}
was:
`TimestmapType` has two types of physical representation: `Timestamp` and
`LocalDateTime`. When we use following SQL, it will conflict each other:
{quote}SELECT
SUM(cnt) as s,
MAX(ts)
FROM
SELECT
`string`,
`int`,
COUNT * AS cnt,
MAX(rowtime) as ts
FROM T1
GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
GROUP BY `string`
{quote}
with 'table.exec.emit.early-fire.enabled' = true.
The exceptions is below:
{quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime cannot
be cast to java.sql.Timestamp
at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
at
org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
at
org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
at
org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
at
org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
at org.apache.flink.runtime.taskmanager.Task.doRun(Ta
[jira] [Updated] (FLINK-15421) GroupAggsHandler throws java.time.LocalDateTime cannot be cast to java.sql.Timestamp
[
https://issues.apache.org/jira/browse/FLINK-15421?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Benchao Li updated FLINK-15421:
---
Description:
`TimestmapType` has two types of physical representation: `Timestamp` and
`LocalDateTime`. When we use following SQL, it will conflict each other:
{quote}SELECT
SUM(cnt) as s,
MAX(ts)
FROM
SELECT
`string`,
`int`,
COUNT * AS cnt,
MAX(rowtime) as ts
FROM T1
GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
GROUP BY `string`
{quote}
with 'table.exec.emit.early-fire.enabled' = true.
The exceptions is below:
{quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime cannot
be cast to java.sql.Timestamp
at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
at
org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
at
org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
at
org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
at
org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527)
at java.lang.Thread.run(Thread.java:748)
{quote}
I also create a UT to quickly reproduce this bug in `WindowAggregateITCase`:
{{@Test}}
{{ def testEarlyFireWithTumblingWindow(): Unit = {}}
{{ val stream = failingDataSource(data)}}
{{ .assignTimestampsAndWatermarks(}}
{{ new TimestampAndWatermarkWithOffset}}
{{ [(Long, Int, Double, Float, BigDecimal, String, String)](10L))}}
{{ val table = stream.toTable(tEnv,}}
{{ 'rowtime.rowtime, 'int, 'double, 'float, 'bigdec, 'string, 'name)}}
{{ tEnv.registerTable("T1", table)}}
{{
tEnv.getConfig.getConfiguration.setBoolean("table.exec.emit.early-fire.enabled",
true)}}
{{
tEnv.getConfig.getConfiguration.setString("table.exec.emit.early-fire.delay",
"1000 ms")}}{{val sql =}}
{{ """}}
{{ |SELECT}}
{{ | SUM(cnt) as s,}}
{{ | MAX(ts)}}
{{ |FROM}}
{{ | (SELECT}}
{{ | `string`,}}
{{ | `int`,}}
{{ | COUNT(*) AS cnt,}}
{{ | MAX(rowtime) as ts}}
{{ | FROM T1}}
{{ | GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND))}}
{{ |GROUP BY `string`}}
{{ |""".stripMargin}}{{tEnv.sqlQuery(sql).toRetractStream[Row].print()}}
{{ env.execute()}}
{{ }}}
was:
`TimestmapType` has two types of physical representation: `Timestamp` and
`LocalDateTime`. When we use following SQL, it will conflict each other:
{quote}SELECT
SUM(cnt) as s,
MAX(ts)
FROM
SELECT
`string`,
`int`,
COUNT(*) AS cnt,
MAX(rowtime) as ts
FROM T1
GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
GROUP BY `string`
{quote}
with 'table.exec.emit.early-fire.enabled' = true.
The exceptions is below:
{quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime cannot
be cast to java.sql.Timestamp
at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
at
org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
at
org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
at
org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
at
org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
at
org.apache.flink.stre
[GitHub] [flink] wuchong commented on issue #10669: [FLINK-15192][docs][table] Restructure "SQL" pages for better readability
wuchong commented on issue #10669: [FLINK-15192][docs][table] Restructure "SQL" pages for better readability URL: https://github.com/apache/flink/pull/10669#issuecomment-569213420 Hi @danny0405 , thanks for the suggestion. I agree with you. Many users don't understand what is DML and DDL, and they do not need to know that at all. I restructured the pages again to `SELECT`, `CREATE`, `DROP`, `ALTER` pages, so that users can find what they need from the title quickly. Please have a look again @danny0405 , @bowenli86 , @JingsongLi . 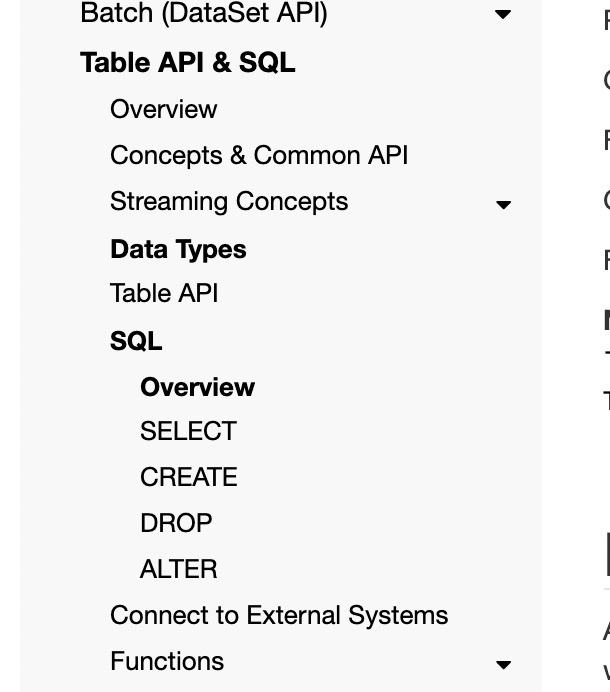 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (FLINK-15421) GroupAggsHandler throws java.time.LocalDateTime cannot be cast to java.sql.Timestamp
Benchao Li created FLINK-15421:
--
Summary: GroupAggsHandler throws java.time.LocalDateTime cannot be
cast to java.sql.Timestamp
Key: FLINK-15421
URL: https://issues.apache.org/jira/browse/FLINK-15421
Project: Flink
Issue Type: Bug
Affects Versions: 1.9.1, 1.10.0
Reporter: Benchao Li
`TimestmapType` has two types of physical representation: `Timestamp` and
`LocalDateTime`. When we use following SQL, it will conflict each other:
{quote}SELECT
SUM(cnt) as s,
MAX(ts)
FROM
SELECT
`string`,
`int`,
COUNT(*) AS cnt,
MAX(rowtime) as ts
FROM T1
GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND)
GROUP BY `string`
{quote}
with 'table.exec.emit.early-fire.enabled' = true.
The exceptions is below:
{quote}Caused by: java.lang.ClassCastException: java.time.LocalDateTime cannot
be cast to java.sql.Timestamp
at GroupAggsHandler$83.getValue(GroupAggsHandler$83.java:529)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:164)
at
org.apache.flink.table.runtime.operators.aggregate.GroupAggFunction.processElement(GroupAggFunction.java:43)
at
org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)
at
org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151)
at
org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128)
at
org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311)
at
org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488)
at
org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527)
at java.lang.Thread.run(Thread.java:748)
{quote}
I also create a UT to quickly reproduce this bug in `WindowAggregateITCase`:
{quote} @Test
def testEarlyFireWithTumblingWindow(): Unit = {
val stream = failingDataSource(data)
.assignTimestampsAndWatermarks(
new TimestampAndWatermarkWithOffset
[(Long, Int, Double, Float, BigDecimal, String, String)](10L))
val table = stream.toTable(tEnv,
'rowtime.rowtime, 'int, 'double, 'float, 'bigdec, 'string, 'name)
tEnv.registerTable("T1", table)
tEnv.getConfig.getConfiguration.setBoolean("table.exec.emit.early-fire.enabled",
true)
tEnv.getConfig.getConfiguration.setString("table.exec.emit.early-fire.delay",
"1000 ms")
val sql =
"""
|SELECT
| SUM(cnt) as s,
| MAX(ts)
|FROM
| (SELECT
|`string`,
|`int`,
|COUNT(*) AS cnt,
|MAX(rowtime) as ts
| FROM T1
| GROUP BY `string`, `int`, TUMBLE(rowtime, INTERVAL '10' SECOND))
|GROUP BY `string`
|""".stripMargin
tEnv.sqlQuery(sql).toRetractStream[Row].print()
env.execute()
}{quote}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (FLINK-15420) Cast string to timestamp will loose precision
Jingsong Lee created FLINK-15420:
Summary: Cast string to timestamp will loose precision
Key: FLINK-15420
URL: https://issues.apache.org/jira/browse/FLINK-15420
Project: Flink
Issue Type: Bug
Components: Table SQL / Planner
Reporter: Jingsong Lee
Fix For: 1.10.0
{code:java}
cast('2010-10-14 12:22:22.123456' as timestamp(9))
{code}
Will produce "2010-10-14 12:22:22.123" in blink planner, this should not happen.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #10695: [FLINK-15377] Remove the useless stage in Mesos dockerfile
flinkbot edited a comment on issue #10695: [FLINK-15377] Remove the useless stage in Mesos dockerfile URL: https://github.com/apache/flink/pull/10695#issuecomment-569014612 ## CI report: * 97ac65498d207e34e891dcd59c87b6a44f04bead Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142361209) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3927) * e58625466acbbf46aeb41b14561f2c63ba075297 Travis: [SUCCESS](https://travis-ci.com/flink-ci/flink/builds/142364869) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3930) * cb283afa0c2f0cf95a6628d9b4cb6b53a52fb019 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142421957) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3945) * 12e322af2d7393cfb8d17432147c930ce7143841 Travis: [PENDING](https://travis-ci.com/flink-ci/flink/builds/142432715) Azure: [PENDING](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3948) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #10681: [FLINK-14849][hive][doc] Fix documentation about Hive dependencies
flinkbot edited a comment on issue #10681: [FLINK-14849][hive][doc] Fix documentation about Hive dependencies URL: https://github.com/apache/flink/pull/10681#issuecomment-568831538 ## CI report: * 4347bedaf5a20884347af39baf197932238c6d24 Travis: [SUCCESS](https://travis-ci.com/flink-ci/flink/builds/142300202) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3900) * b940b474f8617f292159ef85d675e62890e3c222 Travis: [SUCCESS](https://travis-ci.com/flink-ci/flink/builds/142308230) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3905) * 0379fb44aa182467b12c6647c0c2f1d1ba0a25fc Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142348340) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3922) * ab0da875807ef1e178167f2683826879a3a82f74 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (FLINK-15419) Validate SQL syntax not need to depend on connector jar
Kaibo Zhou created FLINK-15419:
--
Summary: Validate SQL syntax not need to depend on connector jar
Key: FLINK-15419
URL: https://issues.apache.org/jira/browse/FLINK-15419
Project: Flink
Issue Type: Improvement
Components: Table SQL / API
Reporter: Kaibo Zhou
Fix For: 1.11.0
As a platform user, I want to integrate Flink SQL in my platform.
The users will register Source/Sink Tables and Functions to catalog service
through UI, and write SQL scripts on Web SQLEditor. I want to validate the SQL
syntax and validate that all catalog objects exist (table, fields, UDFs).
After some investigation, I decided to use the `tEnv.sqlUpdate/sqlQuery` API to
do this.`SqlParser` and`FlinkSqlParserImpl` is not a good choice, as it will
not read the catalog.
The users have registered *Kafka* source/sink table in the catalog, so the
validation logic will be:
{code:java}
TableEnvironment tableEnv =
tEnv.registerCatalog(CATALOG_NAME, catalog);
tEnv.useCatalog(CATALOG_NAME);
tEnv.useDatabase(DB_NAME);
tEnv.sqlUpdate("INSERT INTO sinkTable SELECT f1,f2 FROM sourceTable");
or
tEnv.sqlQuery("SELECT * FROM tableName")
{code}
It will through exception on Flink 1.9.0 because I do not have
`flink-connector-kafka_2.11-1.9.0.jar` in my classpath.
{code:java}
org.apache.flink.table.api.ValidationException: SQL validation failed.
findAndCreateTableSource failed.org.apache.flink.table.api.ValidationException:
SQL validation failed. findAndCreateTableSource failed. at
org.apache.flink.table.planner.calcite.FlinkPlannerImpl.validate(FlinkPlannerImpl.scala:125)
at
org.apache.flink.table.planner.operations.SqlToOperationConverter.convert(SqlToOperationConverter.java:82)
at
org.apache.flink.table.planner.delegation.PlannerBase.parse(PlannerBase.scala:132)
at
org.apache.flink.table.api.internal.TableEnvironmentImpl.sqlUpdate(TableEnvironmentImpl.java:335)
The following factories have been considered:
org.apache.flink.formats.json.JsonRowFormatFactory
org.apache.flink.table.planner.delegation.BlinkPlannerFactory
org.apache.flink.table.planner.delegation.BlinkExecutorFactory
org.apache.flink.table.catalog.GenericInMemoryCatalogFactory
org.apache.flink.table.sources.CsvBatchTableSourceFactory
org.apache.flink.table.sources.CsvAppendTableSourceFactory
org.apache.flink.table.sinks.CsvBatchTableSinkFactory
org.apache.flink.table.sinks.CsvAppendTableSinkFactory
at
org.apache.flink.table.factories.TableFactoryService.filterByContext(TableFactoryService.java:283)
at
org.apache.flink.table.factories.TableFactoryService.filter(TableFactoryService.java:191)
at
org.apache.flink.table.factories.TableFactoryService.findSingleInternal(TableFactoryService.java:144)
at
org.apache.flink.table.factories.TableFactoryService.find(TableFactoryService.java:97)
at
org.apache.flink.table.factories.TableFactoryUtil.findAndCreateTableSource(TableFactoryUtil.java:64)
{code}
For a platform provider, the user's SQL may depend on *ANY* connector or even a
custom connector. It is complicated to do dynamic loading connector jar after
parser the connector type in SQL. And this requires the users must upload their
custom connector jar before doing a syntax check.
I hope that Flink can provide a friendly way to verify the syntax of SQL whose
tables/functions are already registered in the catalog, *NOT* need to depend on
the jar of the connector. This makes it easier for SQL to be integrated by
external platforms.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-15412) LocalExecutorITCase#testParameterizedTypes failed in travis
[
https://issues.apache.org/jira/browse/FLINK-15412?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003944#comment-17003944
]
Rui Li commented on FLINK-15412:
The failure was introduced since FLINK-15240 was not properly ported to
release-1.9. I'll submit a fix for it.
> LocalExecutorITCase#testParameterizedTypes failed in travis
> ---
>
> Key: FLINK-15412
> URL: https://issues.apache.org/jira/browse/FLINK-15412
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Client
>Reporter: Dian Fu
>Priority: Major
> Fix For: 1.10.0
>
>
> The travis of release-1.9 failed with the following error:
> {code:java}
> 14:43:17.916 [INFO] Running
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase
> 14:44:47.388 [ERROR] Tests run: 34, Failures: 0, Errors: 1, Skipped: 1, Time
> elapsed: 89.468 s <<< FAILURE! - in
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase
> 14:44:47.388 [ERROR] testParameterizedTypes[Planner:
> blink](org.apache.flink.table.client.gateway.local.LocalExecutorITCase) Time
> elapsed: 7.88 s <<< ERROR!
> org.apache.flink.table.client.gateway.SqlExecutionException: Invalid SQL
> statement at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:557)
> Caused by: org.apache.flink.table.api.ValidationException: SQL validation
> failed. findAndCreateTableSource failed
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:557)
> Caused by: org.apache.flink.table.api.TableException:
> findAndCreateTableSource failed
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:557)
> Caused by: org.apache.flink.table.api.NoMatchingTableFactoryException:
> Could not find a suitable table factory for
> 'org.apache.flink.table.factories.TableSourceFactory' in
> the classpath.
> Reason: No context matches.
> {code}
> instance: [https://api.travis-ci.org/v3/job/629636106/log.txt]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] zjuwangg commented on issue #9919: [FLINK-13303][hive]add hive e2e connector test
zjuwangg commented on issue #9919: [FLINK-13303][hive]add hive e2e connector test URL: https://github.com/apache/flink/pull/9919#issuecomment-569210087 I'll close this PR and open a new PR FLINK-13437 to cover this based on new Java based test framework. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] zjuwangg closed pull request #9919: [FLINK-13303][hive]add hive e2e connector test
zjuwangg closed pull request #9919: [FLINK-13303][hive]add hive e2e connector test URL: https://github.com/apache/flink/pull/9919 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Comment Edited] (FLINK-15388) The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
[
https://issues.apache.org/jira/browse/FLINK-15388?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003934#comment-17003934
]
Xintong Song edited comment on FLINK-15388 at 12/27/19 7:13 AM:
One thing draw my attention, it seems there are quite some error messages like
"Exception occurred in REST handler: Job 9bf1a8b3b40ddccb5aa258f150a750b1 not
found". This indicates something that monitoring other jobs are accessing the
wrong rest server address.
I tried to print out the time and amount of such error message, and find that
the timepoints with lots of such error messages quite match the timepoints when
there are high prometheus scrape duration.
!屏幕快照 2019-12-27 下午3.05.36.png!
This might be the reason that affects the heartbeats, because rest server need
to access the rpc main thread.
I would suggest to first find out where the rest queries come from and try to
eliminate them, see if the problem still exist after that.
was (Author: xintongsong):
One thing draw my attention, it seems there are quite some error messages like
"Exception occurred in REST handler: Job 9bf1a8b3b40ddccb5aa258f150a750b1 not
found". This indicates something that monitoring other jobs are accessing the
wrong rest server address.
I tried to print out the time and amount of such error message, and find that
the timepoints with lots of such error messages quite match the timepoints when
there are high prometheus scrape duration.
This might be the reason that affects the heartbeats, because rest server need
to access the rpc main thread.
!屏幕快照 2019-12-27 下午3.05.36.png!
I would suggest to first find out where the rest queries come from and try to
eliminate them, see if the problem still exist after that.
> The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
> --
>
> Key: FLINK-15388
> URL: https://issues.apache.org/jira/browse/FLINK-15388
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Task
>Affects Versions: 1.8.0
> Environment: model : standalone,not yarn
> version : flink 1.8.0
> configration :
> jobmanager.heap.size: 4096m
> taskmanager.heap.size: 144gb
> taskmanager.numberOfTaskSlots: 48
> taskmanager.memory.fraction: 0.7
> taskmanager.memory.off-heap: false
> parallelism.default: 1
>
>Reporter: hiliuxg
>Priority: Major
> Attachments: 236log.7z, 236log.7z, metrics.png, metrics.png, 屏幕快照
> 2019-12-27 下午3.05.36.png
>
>
> the taskmanager's slot was removed , there was not full gc or oom , what's
> the problem ? the error bellow
> {code:java}
> org.apache.flink.util.FlinkException: The assigned slot
> bae00218c818157649eb9e3c533b86af_32 was removed.
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlot(SlotManager.java:893)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlots(SlotManager.java:863)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.internalUnregisterTaskManager(SlotManager.java:1058)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.unregisterTaskManager(SlotManager.java:385)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager.closeTaskManagerConnection(ResourceManager.java:847)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener$1.run(ResourceManager.java:1161)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:392)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:185)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:147)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.onReceive(FencedAkkaRpcActor.java:40)
> at
> akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:165)
> at akka.actor.Actor$class.aroundReceive(Actor.scala:502)
> at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:95)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:526)
> at akka.actor.ActorCell.invoke(ActorCell.scala:495)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:257)
> at akka.dispatch.Mailbox.run(Mailbox.scala:224)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:234)
> at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
> at
> scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
> at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
> at
> scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#8
[jira] [Comment Edited] (FLINK-15388) The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
[
https://issues.apache.org/jira/browse/FLINK-15388?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003934#comment-17003934
]
Xintong Song edited comment on FLINK-15388 at 12/27/19 7:12 AM:
One thing draw my attention, it seems there are quite some error messages like
"Exception occurred in REST handler: Job 9bf1a8b3b40ddccb5aa258f150a750b1 not
found". This indicates something that monitoring other jobs are accessing the
wrong rest server address.
I tried to print out the time and amount of such error message, and find that
the timepoints with lots of such error messages quite match the timepoints when
there are high prometheus scrape duration.
This might be the reason that affects the heartbeats, because rest server need
to access the rpc main thread.
!屏幕快照 2019-12-27 下午3.05.36.png!
I would suggest to first find out where the rest queries come from and try to
eliminate them, see if the problem still exist after that.
was (Author: xintongsong):
One thing draw my attention, it seems there are quite some error messages like
"Exception occurred in REST handler: Job 9bf1a8b3b40ddccb5aa258f150a750b1 not
found". This indicates something that monitoring other jobs are accessing the
wrong rest server address.
I tried to print out the time and amount of such error message, and find that
the timepoints with lots of such error messages quite match the timepoints when
there are high prometheus scrape duration. This might be the reason that
affects the heartbeats, because rest server need to access the rpc main thread.
I would suggest to first find out where the rest queries come from and try to
eliminate them, see if the problem still exist after that.
> The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
> --
>
> Key: FLINK-15388
> URL: https://issues.apache.org/jira/browse/FLINK-15388
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Task
>Affects Versions: 1.8.0
> Environment: model : standalone,not yarn
> version : flink 1.8.0
> configration :
> jobmanager.heap.size: 4096m
> taskmanager.heap.size: 144gb
> taskmanager.numberOfTaskSlots: 48
> taskmanager.memory.fraction: 0.7
> taskmanager.memory.off-heap: false
> parallelism.default: 1
>
>Reporter: hiliuxg
>Priority: Major
> Attachments: 236log.7z, 236log.7z, metrics.png, metrics.png, 屏幕快照
> 2019-12-27 下午3.05.36.png
>
>
> the taskmanager's slot was removed , there was not full gc or oom , what's
> the problem ? the error bellow
> {code:java}
> org.apache.flink.util.FlinkException: The assigned slot
> bae00218c818157649eb9e3c533b86af_32 was removed.
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlot(SlotManager.java:893)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlots(SlotManager.java:863)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.internalUnregisterTaskManager(SlotManager.java:1058)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.unregisterTaskManager(SlotManager.java:385)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager.closeTaskManagerConnection(ResourceManager.java:847)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener$1.run(ResourceManager.java:1161)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:392)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:185)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:147)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.onReceive(FencedAkkaRpcActor.java:40)
> at
> akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:165)
> at akka.actor.Actor$class.aroundReceive(Actor.scala:502)
> at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:95)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:526)
> at akka.actor.ActorCell.invoke(ActorCell.scala:495)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:257)
> at akka.dispatch.Mailbox.run(Mailbox.scala:224)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:234)
> at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
> at
> scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
> at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
> at
> scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-15388) The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
[
https://issues.apache.org/jira/browse/FLINK-15388?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003934#comment-17003934
]
Xintong Song commented on FLINK-15388:
--
One thing draw my attention, it seems there are quite some error messages like
"Exception occurred in REST handler: Job 9bf1a8b3b40ddccb5aa258f150a750b1 not
found". This indicates something that monitoring other jobs are accessing the
wrong rest server address.
I tried to print out the time and amount of such error message, and find that
the timepoints with lots of such error messages quite match the timepoints when
there are high prometheus scrape duration. This might be the reason that
affects the heartbeats, because rest server need to access the rpc main thread.
I would suggest to first find out where the rest queries come from and try to
eliminate them, see if the problem still exist after that.
> The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
> --
>
> Key: FLINK-15388
> URL: https://issues.apache.org/jira/browse/FLINK-15388
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Task
>Affects Versions: 1.8.0
> Environment: model : standalone,not yarn
> version : flink 1.8.0
> configration :
> jobmanager.heap.size: 4096m
> taskmanager.heap.size: 144gb
> taskmanager.numberOfTaskSlots: 48
> taskmanager.memory.fraction: 0.7
> taskmanager.memory.off-heap: false
> parallelism.default: 1
>
>Reporter: hiliuxg
>Priority: Major
> Attachments: 236log.7z, 236log.7z, metrics.png, metrics.png
>
>
> the taskmanager's slot was removed , there was not full gc or oom , what's
> the problem ? the error bellow
> {code:java}
> org.apache.flink.util.FlinkException: The assigned slot
> bae00218c818157649eb9e3c533b86af_32 was removed.
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlot(SlotManager.java:893)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlots(SlotManager.java:863)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.internalUnregisterTaskManager(SlotManager.java:1058)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.unregisterTaskManager(SlotManager.java:385)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager.closeTaskManagerConnection(ResourceManager.java:847)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener$1.run(ResourceManager.java:1161)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:392)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:185)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:147)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.onReceive(FencedAkkaRpcActor.java:40)
> at
> akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:165)
> at akka.actor.Actor$class.aroundReceive(Actor.scala:502)
> at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:95)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:526)
> at akka.actor.ActorCell.invoke(ActorCell.scala:495)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:257)
> at akka.dispatch.Mailbox.run(Mailbox.scala:224)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:234)
> at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
> at
> scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
> at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
> at
> scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #10695: [FLINK-15377] Remove the useless stage in Mesos dockerfile
flinkbot edited a comment on issue #10695: [FLINK-15377] Remove the useless stage in Mesos dockerfile URL: https://github.com/apache/flink/pull/10695#issuecomment-569014612 ## CI report: * 97ac65498d207e34e891dcd59c87b6a44f04bead Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142361209) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3927) * e58625466acbbf46aeb41b14561f2c63ba075297 Travis: [SUCCESS](https://travis-ci.com/flink-ci/flink/builds/142364869) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3930) * cb283afa0c2f0cf95a6628d9b4cb6b53a52fb019 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142421957) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3945) * 12e322af2d7393cfb8d17432147c930ce7143841 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (FLINK-15418) StreamExecMatchRule not set FlinkRelDistribution
Benchao Li created FLINK-15418: -- Summary: StreamExecMatchRule not set FlinkRelDistribution Key: FLINK-15418 URL: https://issues.apache.org/jira/browse/FLINK-15418 Project: Flink Issue Type: Bug Affects Versions: 1.9.1, 1.10.0 Reporter: Benchao Li StreamExecMatchRule forgets to set FlinkRelDistribution. When match clause with `partition by`, and parallelism > 1, will result in following exception: ``` Caused by: java.lang.NullPointerException at org.apache.flink.runtime.state.heap.StateTable.put(StateTable.java:336) at org.apache.flink.runtime.state.heap.StateTable.put(StateTable.java:159) at org.apache.flink.runtime.state.heap.HeapMapState.put(HeapMapState.java:100) at org.apache.flink.runtime.state.UserFacingMapState.put(UserFacingMapState.java:52) at org.apache.flink.cep.nfa.sharedbuffer.SharedBuffer.registerEvent(SharedBuffer.java:141) at org.apache.flink.cep.nfa.sharedbuffer.SharedBufferAccessor.registerEvent(SharedBufferAccessor.java:74) at org.apache.flink.cep.nfa.NFA$EventWrapper.getEventId(NFA.java:483) at org.apache.flink.cep.nfa.NFA.computeNextStates(NFA.java:605) at org.apache.flink.cep.nfa.NFA.doProcess(NFA.java:292) at org.apache.flink.cep.nfa.NFA.process(NFA.java:228) at org.apache.flink.cep.operator.CepOperator.processEvent(CepOperator.java:420) at org.apache.flink.cep.operator.CepOperator.processElement(CepOperator.java:242) at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:173) at org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:151) at org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:128) at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:69) at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:311) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:187) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:488) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:470) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:702) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:527) at java.lang.Thread.run(Thread.java:748) ``` -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-15414) KafkaITCase#prepare failed in travis
[
https://issues.apache.org/jira/browse/FLINK-15414?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Dian Fu updated FLINK-15414:
Fix Version/s: 1.9.2
> KafkaITCase#prepare failed in travis
>
>
> Key: FLINK-15414
> URL: https://issues.apache.org/jira/browse/FLINK-15414
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Reporter: Dian Fu
>Priority: Major
> Fix For: 1.9.2
>
>
> The travis for release-1.9 failed with the following error:
> {code:java}
> 15:43:24.454 [ERROR] Errors: 809815:43:24.455 [ERROR]
> KafkaITCase.prepare:58->KafkaTestBase.prepare:92->KafkaTestBase.prepare:100->KafkaTestBase.startClusters:134->KafkaTestBase.startClusters:145
> » Kafka
> {code}
> instance: [https://api.travis-ci.org/v3/job/629636116/log.txt]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] lirui-apache commented on issue #10681: [FLINK-14849][hive][doc] Fix documentation about Hive dependencies
lirui-apache commented on issue #10681: [FLINK-14849][hive][doc] Fix documentation about Hive dependencies URL: https://github.com/apache/flink/pull/10681#issuecomment-569205043 @bowenli86 PR updated to add the explanations. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] JingsongLi commented on a change in pull request #10620: [FLINK-15239][table-planner-blink] CompileUtils::COMPILED_CACHE leaks class loaders
JingsongLi commented on a change in pull request #10620:
[FLINK-15239][table-planner-blink] CompileUtils::COMPILED_CACHE leaks class
loaders
URL: https://github.com/apache/flink/pull/10620#discussion_r361594049
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/runtime/generated/CompileUtils.java
##
@@ -59,14 +62,16 @@
* @return the compiled class
*/
public static Class compile(ClassLoader cl, String name, String
code) {
- Tuple2 cacheKey = Tuple2.of(cl, name);
- Class clazz = COMPILED_CACHE.getIfPresent(cacheKey);
- if (clazz == null) {
- clazz = doCompile(cl, name, code);
- COMPILED_CACHE.put(cacheKey, clazz);
+ try {
+ Cache compiledClasses =
COMPILED_CACHE.get(name,
+ () ->
CacheBuilder.newBuilder().maximumSize(5).weakKeys().softValues().build());
+ return compiledClasses.get(cl, () -> doCompile(cl,
name, code));
+ } catch (ExecutionException | UncheckedExecutionException e) {
Review comment:
It is just nit suggestion.
Because `ExecutionException` is an invalid exception, and it could/should be
threw. This can simplify exception stack.
You can take a look to:
https://github.com/apache/flink/blob/4adf23d3b93c301b53f11f1c05a1aa6d37112d46/flink-runtime/src/main/java/org/apache/flink/runtime/rest/handler/taskmanager/AbstractTaskManagerFileHandler.java#L125
It is an example. And there are some examples in Spark too.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (FLINK-15415) Flink machine node memory is consumed quickly, but the heap has not changed
[ https://issues.apache.org/jira/browse/FLINK-15415?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003926#comment-17003926 ] hiliuxg commented on FLINK-15415: - Hi [~yunta]: Sorry, I don’t know if you can create a new question directly on jira like this, I will pay attention, next time I use email . Thanks . > Flink machine node memory is consumed quickly, but the heap has not changed > --- > > Key: FLINK-15415 > URL: https://issues.apache.org/jira/browse/FLINK-15415 > Project: Flink > Issue Type: Bug > Components: Runtime / State Backends >Affects Versions: 1.8.0 > Environment: machine : 256G memory , SSD , 32 CORE CPU > config : > jobmanager.heap.size: 4096m > taskmanager.heap.size: 144gb > taskmanager.numberOfTaskSlots: 48 > taskmanager.memory.fraction: 0.7 > taskmanager.memory.off-heap: false > parallelism.default: 1 > > > > > >Reporter: hiliuxg >Priority: Major > Attachments: flink-3.png, flink-pid-2.png, flink-pid.png > > > The Flink node has been running for 1 month, and it is found that the > machine's memory is getting higher and higher, even exceeding the memory > configured by the heap. Through top -c, it is found that the machine's memory > and virtual memory are very high. It may be an off-heap memory leak. What is > the collection mechanism of flink's off-heap memory? It need to start FULL GC > to recycle off-heap memory? > In addition, does flink disable off-heap memory by default? > taskmanager.memory.off-heap: false, why is the memory still increasing slowly > . > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (FLINK-15417) Remove the docker volume or mount when starting Mesos e2e cluster
Yangze Guo created FLINK-15417: -- Summary: Remove the docker volume or mount when starting Mesos e2e cluster Key: FLINK-15417 URL: https://issues.apache.org/jira/browse/FLINK-15417 Project: Flink Issue Type: Test Reporter: Yangze Guo Fix For: 1.10.0 As discussed [here|https://github.com/apache/flink/pull/10695#discussion_r361574394], there is a potential risk of permission problems when cleanup logs and output. We could found another way to let containers get the input and output file. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (FLINK-15411) Planner can't prune partition on DATE/TIMESTAMP columns
[ https://issues.apache.org/jira/browse/FLINK-15411?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kurt Young reassigned FLINK-15411: -- Assignee: Jingsong Lee (was: Rui Li) > Planner can't prune partition on DATE/TIMESTAMP columns > --- > > Key: FLINK-15411 > URL: https://issues.apache.org/jira/browse/FLINK-15411 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive, Table SQL / Planner >Affects Versions: 1.10.0 >Reporter: Bowen Li >Assignee: Jingsong Lee >Priority: Major > Fix For: 1.10.0 > > > Hive should work after planner fixed due to: > [https://github.com/apache/flink/pull/10690#issuecomment-569021089] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe…
flinkbot edited a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe… URL: https://github.com/apache/flink/pull/10651#issuecomment-567927075 ## CI report: * 5945e5e8f373215b0dfe051c7f91f7b91e6b0928 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/141917314) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3825) * 2393b32572b49bf430ddb0e001de1b79501894b9 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142345451) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3918) * d58e89c10722afd2626fbc0b864bf6545479ae30 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142423087) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3946) * 5f7d5b1038646012781f8a2cbcd9c256eef7e79a Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142426426) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3947) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Comment Edited] (FLINK-15411) Planner can't prune partition on DATE/TIMESTAMP columns
[ https://issues.apache.org/jira/browse/FLINK-15411?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003924#comment-17003924 ] Kurt Young edited comment on FLINK-15411 at 12/27/19 6:32 AM: -- Yeah, that might also be true. Even if users want to partition the data by date, they could still choose STRING as field type. was (Author: ykt836): Yeah, that might also be true. Even if the want to partition the data by date, they could still choose STRING as field type. > Planner can't prune partition on DATE/TIMESTAMP columns > --- > > Key: FLINK-15411 > URL: https://issues.apache.org/jira/browse/FLINK-15411 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive, Table SQL / Planner >Affects Versions: 1.10.0 >Reporter: Bowen Li >Assignee: Rui Li >Priority: Major > Fix For: 1.10.0 > > > Hive should work after planner fixed due to: > [https://github.com/apache/flink/pull/10690#issuecomment-569021089] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-15411) Planner can't prune partition on DATE/TIMESTAMP columns
[ https://issues.apache.org/jira/browse/FLINK-15411?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003924#comment-17003924 ] Kurt Young commented on FLINK-15411: Yeah, that might also be true. Even if the want to partition the data by date, they could still choose STRING as field type. > Planner can't prune partition on DATE/TIMESTAMP columns > --- > > Key: FLINK-15411 > URL: https://issues.apache.org/jira/browse/FLINK-15411 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive, Table SQL / Planner >Affects Versions: 1.10.0 >Reporter: Bowen Li >Assignee: Rui Li >Priority: Major > Fix For: 1.10.0 > > > Hive should work after planner fixed due to: > [https://github.com/apache/flink/pull/10690#issuecomment-569021089] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] wuchong commented on a change in pull request #10620: [FLINK-15239][table-planner-blink] CompileUtils::COMPILED_CACHE leaks class loaders
wuchong commented on a change in pull request #10620:
[FLINK-15239][table-planner-blink] CompileUtils::COMPILED_CACHE leaks class
loaders
URL: https://github.com/apache/flink/pull/10620#discussion_r361592411
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/runtime/generated/CompileUtils.java
##
@@ -59,14 +62,16 @@
* @return the compiled class
*/
public static Class compile(ClassLoader cl, String name, String
code) {
- Tuple2 cacheKey = Tuple2.of(cl, name);
- Class clazz = COMPILED_CACHE.getIfPresent(cacheKey);
- if (clazz == null) {
- clazz = doCompile(cl, name, code);
- COMPILED_CACHE.put(cacheKey, clazz);
+ try {
+ Cache compiledClasses =
COMPILED_CACHE.get(name,
+ () ->
CacheBuilder.newBuilder().maximumSize(5).weakKeys().softValues().build());
+ return compiledClasses.get(cl, () -> doCompile(cl,
name, code));
+ } catch (ExecutionException | UncheckedExecutionException e) {
Review comment:
What's the benefit? From my point of view, it will introduce some complex
codes.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Created] (FLINK-15416) Add Retry Mechanism for PartitionRequestClientFactory.ConnectingChannel
Zhenqiu Huang created FLINK-15416: - Summary: Add Retry Mechanism for PartitionRequestClientFactory.ConnectingChannel Key: FLINK-15416 URL: https://issues.apache.org/jira/browse/FLINK-15416 Project: Flink Issue Type: Wish Components: Runtime / Network Affects Versions: 1.10.0 Reporter: Zhenqiu Huang We run a flink with 256 TMs in production. The job internally has keyby logic. Thus, it builds a 256 * 256 communication channels. An outage happened when there is a chip internal link of one of the network switchs broken that connecting these machines. During the outage, the flink can't restart successfully as there is always an exception like "Connecting the channel failed: Connecting to remote task manager + '/10.14.139.6:41300' has failed. This might indicate that the remote task manager has been lost. After deep investigation with the network infrastructure team, we found there are 6 switchs connecting with these machines. Each switch has 32 physcal links. Every socket is round-robin assigned to each of links for load balances. Thus, there is always average 256 * 256 / 6 * 32 * 2 = 170 channels will be assigned to the broken link. The issue lasted for 4 hours until we found the broken link and restart the problematic switch. Given this, we found that the retry of creating channel will help to resolve this issue. For our networking topology, we can set retry to 2. As 170 / (132 * 132) < 1, which means after retry twice no channel in 170 channels will be assigned to the broken link in the average case. I think it is valuable fix for this kind of partial network partition. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-15415) Flink machine node memory is consumed quickly, but the heap has not changed
[ https://issues.apache.org/jira/browse/FLINK-15415?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003922#comment-17003922 ] Yun Tang commented on FLINK-15415: -- [~hiliuxg], generally speaking, it's not recommend to directly open a bug issue which is complex due to many possible causes and unclear without an explicit exception stack but a comprehensive unexpected behavior. The better place is to ask in user mail list. Especially you have asked a general problem of removed assigned slot in FLINK-15388. Flink community is really active and glad to answer your question in mail list. If we finally figure out this is a real bug, that's the time to create a issue here. > Flink machine node memory is consumed quickly, but the heap has not changed > --- > > Key: FLINK-15415 > URL: https://issues.apache.org/jira/browse/FLINK-15415 > Project: Flink > Issue Type: Bug > Components: Runtime / State Backends >Affects Versions: 1.8.0 > Environment: machine : 256G memory , SSD , 32 CORE CPU > config : > jobmanager.heap.size: 4096m > taskmanager.heap.size: 144gb > taskmanager.numberOfTaskSlots: 48 > taskmanager.memory.fraction: 0.7 > taskmanager.memory.off-heap: false > parallelism.default: 1 > > > > > >Reporter: hiliuxg >Priority: Major > Attachments: flink-3.png, flink-pid-2.png, flink-pid.png > > > The Flink node has been running for 1 month, and it is found that the > machine's memory is getting higher and higher, even exceeding the memory > configured by the heap. Through top -c, it is found that the machine's memory > and virtual memory are very high. It may be an off-heap memory leak. What is > the collection mechanism of flink's off-heap memory? It need to start FULL GC > to recycle off-heap memory? > In addition, does flink disable off-heap memory by default? > taskmanager.memory.off-heap: false, why is the memory still increasing slowly > . > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-15411) Planner can't prune partition on DATE/TIMESTAMP columns
[ https://issues.apache.org/jira/browse/FLINK-15411?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003920#comment-17003920 ] Rui Li commented on FLINK-15411: I find a lot of users using string partition columns to represent the date. So IMO while it's good if we can implement this in 1.10, it doesn't have to be a blocker. > Planner can't prune partition on DATE/TIMESTAMP columns > --- > > Key: FLINK-15411 > URL: https://issues.apache.org/jira/browse/FLINK-15411 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive, Table SQL / Planner >Affects Versions: 1.10.0 >Reporter: Bowen Li >Assignee: Rui Li >Priority: Major > Fix For: 1.10.0 > > > Hive should work after planner fixed due to: > [https://github.com/apache/flink/pull/10690#issuecomment-569021089] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-15411) Planner can't prune partition on DATE/TIMESTAMP columns
[ https://issues.apache.org/jira/browse/FLINK-15411?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003919#comment-17003919 ] Jingsong Lee commented on FLINK-15411: -- We did a simple survey. Most users use string to represent date to be a partition field. But we also need fix this ticket. > Planner can't prune partition on DATE/TIMESTAMP columns > --- > > Key: FLINK-15411 > URL: https://issues.apache.org/jira/browse/FLINK-15411 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive, Table SQL / Planner >Affects Versions: 1.10.0 >Reporter: Bowen Li >Assignee: Rui Li >Priority: Major > Fix For: 1.10.0 > > > Hive should work after planner fixed due to: > [https://github.com/apache/flink/pull/10690#issuecomment-569021089] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-15411) Planner can't prune partition on DATE/TIMESTAMP columns
[ https://issues.apache.org/jira/browse/FLINK-15411?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee updated FLINK-15411: - Description: Hive should work after planner fixed due to: [https://github.com/apache/flink/pull/10690#issuecomment-569021089] > Planner can't prune partition on DATE/TIMESTAMP columns > --- > > Key: FLINK-15411 > URL: https://issues.apache.org/jira/browse/FLINK-15411 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive, Table SQL / Planner >Affects Versions: 1.10.0 >Reporter: Bowen Li >Assignee: Rui Li >Priority: Major > Fix For: 1.10.0 > > > Hive should work after planner fixed due to: > [https://github.com/apache/flink/pull/10690#issuecomment-569021089] -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-15415) Flink machine node memory is consumed quickly, but the heap has not changed
[ https://issues.apache.org/jira/browse/FLINK-15415?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003916#comment-17003916 ] hiliuxg commented on FLINK-15415: - Hi [~Benchao Li]: Thank you for following my question . I used the flink default configration, it is -XX:MaxDirectMemorySize=8388607T . You can see the picture i parsed . I don't understand why flink is set so large . > Flink machine node memory is consumed quickly, but the heap has not changed > --- > > Key: FLINK-15415 > URL: https://issues.apache.org/jira/browse/FLINK-15415 > Project: Flink > Issue Type: Bug > Components: Runtime / State Backends >Affects Versions: 1.8.0 > Environment: machine : 256G memory , SSD , 32 CORE CPU > config : > jobmanager.heap.size: 4096m > taskmanager.heap.size: 144gb > taskmanager.numberOfTaskSlots: 48 > taskmanager.memory.fraction: 0.7 > taskmanager.memory.off-heap: false > parallelism.default: 1 > > > > > >Reporter: hiliuxg >Priority: Major > Attachments: flink-3.png, flink-pid-2.png, flink-pid.png > > > The Flink node has been running for 1 month, and it is found that the > machine's memory is getting higher and higher, even exceeding the memory > configured by the heap. Through top -c, it is found that the machine's memory > and virtual memory are very high. It may be an off-heap memory leak. What is > the collection mechanism of flink's off-heap memory? It need to start FULL GC > to recycle off-heap memory? > In addition, does flink disable off-heap memory by default? > taskmanager.memory.off-heap: false, why is the memory still increasing slowly > . > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-15411) Planner can't prune partition on DATE/TIMESTAMP columns
[ https://issues.apache.org/jira/browse/FLINK-15411?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003913#comment-17003913 ] Jingsong Lee commented on FLINK-15411: -- [~ykt836] Can you assign this to me? > Planner can't prune partition on DATE/TIMESTAMP columns > --- > > Key: FLINK-15411 > URL: https://issues.apache.org/jira/browse/FLINK-15411 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive, Table SQL / Planner >Affects Versions: 1.10.0 >Reporter: Bowen Li >Assignee: Rui Li >Priority: Major > Fix For: 1.10.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-15415) Flink machine node memory is consumed quickly, but the heap has not changed
[ https://issues.apache.org/jira/browse/FLINK-15415?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003912#comment-17003912 ] Yang Wang commented on FLINK-15415: --- Maybe it is a same case with [FLINK-11205|https://issues.apache.org/jira/browse/FLINK-11205]. > Flink machine node memory is consumed quickly, but the heap has not changed > --- > > Key: FLINK-15415 > URL: https://issues.apache.org/jira/browse/FLINK-15415 > Project: Flink > Issue Type: Bug > Components: Runtime / State Backends >Affects Versions: 1.8.0 > Environment: machine : 256G memory , SSD , 32 CORE CPU > config : > jobmanager.heap.size: 4096m > taskmanager.heap.size: 144gb > taskmanager.numberOfTaskSlots: 48 > taskmanager.memory.fraction: 0.7 > taskmanager.memory.off-heap: false > parallelism.default: 1 > > > > > >Reporter: hiliuxg >Priority: Major > Attachments: flink-3.png, flink-pid-2.png, flink-pid.png > > > The Flink node has been running for 1 month, and it is found that the > machine's memory is getting higher and higher, even exceeding the memory > configured by the heap. Through top -c, it is found that the machine's memory > and virtual memory are very high. It may be an off-heap memory leak. What is > the collection mechanism of flink's off-heap memory? It need to start FULL GC > to recycle off-heap memory? > In addition, does flink disable off-heap memory by default? > taskmanager.memory.off-heap: false, why is the memory still increasing slowly > . > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-15388) The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
[
https://issues.apache.org/jira/browse/FLINK-15388?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
hiliuxg updated FLINK-15388:
Attachment: 236log.7z
> The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
> --
>
> Key: FLINK-15388
> URL: https://issues.apache.org/jira/browse/FLINK-15388
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Task
>Affects Versions: 1.8.0
> Environment: model : standalone,not yarn
> version : flink 1.8.0
> configration :
> jobmanager.heap.size: 4096m
> taskmanager.heap.size: 144gb
> taskmanager.numberOfTaskSlots: 48
> taskmanager.memory.fraction: 0.7
> taskmanager.memory.off-heap: false
> parallelism.default: 1
>
>Reporter: hiliuxg
>Priority: Major
> Attachments: 236log.7z, 236log.7z, metrics.png, metrics.png
>
>
> the taskmanager's slot was removed , there was not full gc or oom , what's
> the problem ? the error bellow
> {code:java}
> org.apache.flink.util.FlinkException: The assigned slot
> bae00218c818157649eb9e3c533b86af_32 was removed.
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlot(SlotManager.java:893)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlots(SlotManager.java:863)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.internalUnregisterTaskManager(SlotManager.java:1058)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.unregisterTaskManager(SlotManager.java:385)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager.closeTaskManagerConnection(ResourceManager.java:847)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener$1.run(ResourceManager.java:1161)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:392)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:185)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:147)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.onReceive(FencedAkkaRpcActor.java:40)
> at
> akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:165)
> at akka.actor.Actor$class.aroundReceive(Actor.scala:502)
> at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:95)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:526)
> at akka.actor.ActorCell.invoke(ActorCell.scala:495)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:257)
> at akka.dispatch.Mailbox.run(Mailbox.scala:224)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:234)
> at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
> at
> scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
> at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
> at
> scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-15388) The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
[
https://issues.apache.org/jira/browse/FLINK-15388?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
hiliuxg updated FLINK-15388:
Attachment: 236log.7z
> The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
> --
>
> Key: FLINK-15388
> URL: https://issues.apache.org/jira/browse/FLINK-15388
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Task
>Affects Versions: 1.8.0
> Environment: model : standalone,not yarn
> version : flink 1.8.0
> configration :
> jobmanager.heap.size: 4096m
> taskmanager.heap.size: 144gb
> taskmanager.numberOfTaskSlots: 48
> taskmanager.memory.fraction: 0.7
> taskmanager.memory.off-heap: false
> parallelism.default: 1
>
>Reporter: hiliuxg
>Priority: Major
> Attachments: 236log.7z, metrics.png, metrics.png
>
>
> the taskmanager's slot was removed , there was not full gc or oom , what's
> the problem ? the error bellow
> {code:java}
> org.apache.flink.util.FlinkException: The assigned slot
> bae00218c818157649eb9e3c533b86af_32 was removed.
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlot(SlotManager.java:893)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlots(SlotManager.java:863)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.internalUnregisterTaskManager(SlotManager.java:1058)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.unregisterTaskManager(SlotManager.java:385)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager.closeTaskManagerConnection(ResourceManager.java:847)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener$1.run(ResourceManager.java:1161)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:392)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:185)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:147)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.onReceive(FencedAkkaRpcActor.java:40)
> at
> akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:165)
> at akka.actor.Actor$class.aroundReceive(Actor.scala:502)
> at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:95)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:526)
> at akka.actor.ActorCell.invoke(ActorCell.scala:495)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:257)
> at akka.dispatch.Mailbox.run(Mailbox.scala:224)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:234)
> at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
> at
> scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
> at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
> at
> scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-15388) The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
[
https://issues.apache.org/jira/browse/FLINK-15388?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003911#comment-17003911
]
hiliuxg commented on FLINK-15388:
-
Hi [~xintongsong]:
I ping taskmanager on the machine where the jobmanager is located, and then
write the data to a file every 5 seconds. I found that the latest delay did not
exceed 5 milliseconds.Also , I jstat the TM gc to a file every 5 seconds.
I have packaged all the related logs and monitoring files, please help me to
look at it. In addition, is there a problem with the way I locate the network?
Very gratefully !
[^236log.7z]
> The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
> --
>
> Key: FLINK-15388
> URL: https://issues.apache.org/jira/browse/FLINK-15388
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Task
>Affects Versions: 1.8.0
> Environment: model : standalone,not yarn
> version : flink 1.8.0
> configration :
> jobmanager.heap.size: 4096m
> taskmanager.heap.size: 144gb
> taskmanager.numberOfTaskSlots: 48
> taskmanager.memory.fraction: 0.7
> taskmanager.memory.off-heap: false
> parallelism.default: 1
>
>Reporter: hiliuxg
>Priority: Major
> Attachments: 236log.7z, metrics.png, metrics.png
>
>
> the taskmanager's slot was removed , there was not full gc or oom , what's
> the problem ? the error bellow
> {code:java}
> org.apache.flink.util.FlinkException: The assigned slot
> bae00218c818157649eb9e3c533b86af_32 was removed.
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlot(SlotManager.java:893)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlots(SlotManager.java:863)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.internalUnregisterTaskManager(SlotManager.java:1058)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.unregisterTaskManager(SlotManager.java:385)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager.closeTaskManagerConnection(ResourceManager.java:847)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener$1.run(ResourceManager.java:1161)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:392)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:185)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:147)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.onReceive(FencedAkkaRpcActor.java:40)
> at
> akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:165)
> at akka.actor.Actor$class.aroundReceive(Actor.scala:502)
> at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:95)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:526)
> at akka.actor.ActorCell.invoke(ActorCell.scala:495)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:257)
> at akka.dispatch.Mailbox.run(Mailbox.scala:224)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:234)
> at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
> at
> scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
> at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
> at
> scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] wangyang0918 commented on a change in pull request #10695: [hotfix] Remove the useless stage in Mesos dockerfile
wangyang0918 commented on a change in pull request #10695: [hotfix] Remove the
useless stage in Mesos dockerfile
URL: https://github.com/apache/flink/pull/10695#discussion_r361574394
##
File path:
flink-end-to-end-tests/test-scripts/docker-mesos-cluster/docker-compose.yml
##
@@ -53,7 +53,6 @@ services:
networks:
- docker-mesos-cluster-network
volumes:
- - /var/run/docker.sock:/var/run/docker.sock
- ${END_TO_END_DIR}:${END_TO_END_DIR}
Review comment:
I suggest to use `docker cp` to get the output to local and then verify.
Using docker volume and mount may cause permission problems when cleanup logs
and output.
However, it is out of the scope of this PR. Maybe you could create another
ticket to track this potential problem.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (FLINK-15412) LocalExecutorITCase#testParameterizedTypes failed in travis
[
https://issues.apache.org/jira/browse/FLINK-15412?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003909#comment-17003909
]
Kurt Young commented on FLINK-15412:
cc [~lirui]
> LocalExecutorITCase#testParameterizedTypes failed in travis
> ---
>
> Key: FLINK-15412
> URL: https://issues.apache.org/jira/browse/FLINK-15412
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Client
>Reporter: Dian Fu
>Priority: Major
> Fix For: 1.10.0
>
>
> The travis of release-1.9 failed with the following error:
> {code:java}
> 14:43:17.916 [INFO] Running
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase
> 14:44:47.388 [ERROR] Tests run: 34, Failures: 0, Errors: 1, Skipped: 1, Time
> elapsed: 89.468 s <<< FAILURE! - in
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase
> 14:44:47.388 [ERROR] testParameterizedTypes[Planner:
> blink](org.apache.flink.table.client.gateway.local.LocalExecutorITCase) Time
> elapsed: 7.88 s <<< ERROR!
> org.apache.flink.table.client.gateway.SqlExecutionException: Invalid SQL
> statement at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:557)
> Caused by: org.apache.flink.table.api.ValidationException: SQL validation
> failed. findAndCreateTableSource failed
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:557)
> Caused by: org.apache.flink.table.api.TableException:
> findAndCreateTableSource failed
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:557)
> Caused by: org.apache.flink.table.api.NoMatchingTableFactoryException:
> Could not find a suitable table factory for
> 'org.apache.flink.table.factories.TableSourceFactory' in
> the classpath.
> Reason: No context matches.
> {code}
> instance: [https://api.travis-ci.org/v3/job/629636106/log.txt]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-15412) LocalExecutorITCase#testParameterizedTypes failed in travis
[
https://issues.apache.org/jira/browse/FLINK-15412?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-15412:
---
Fix Version/s: 1.10.0
> LocalExecutorITCase#testParameterizedTypes failed in travis
> ---
>
> Key: FLINK-15412
> URL: https://issues.apache.org/jira/browse/FLINK-15412
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Client
>Reporter: Dian Fu
>Priority: Major
> Fix For: 1.10.0
>
>
> The travis of release-1.9 failed with the following error:
> {code:java}
> 14:43:17.916 [INFO] Running
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase
> 14:44:47.388 [ERROR] Tests run: 34, Failures: 0, Errors: 1, Skipped: 1, Time
> elapsed: 89.468 s <<< FAILURE! - in
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase
> 14:44:47.388 [ERROR] testParameterizedTypes[Planner:
> blink](org.apache.flink.table.client.gateway.local.LocalExecutorITCase) Time
> elapsed: 7.88 s <<< ERROR!
> org.apache.flink.table.client.gateway.SqlExecutionException: Invalid SQL
> statement at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:557)
> Caused by: org.apache.flink.table.api.ValidationException: SQL validation
> failed. findAndCreateTableSource failed
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:557)
> Caused by: org.apache.flink.table.api.TableException:
> findAndCreateTableSource failed
> at
> org.apache.flink.table.client.gateway.local.LocalExecutorITCase.testParameterizedTypes(LocalExecutorITCase.java:557)
> Caused by: org.apache.flink.table.api.NoMatchingTableFactoryException:
> Could not find a suitable table factory for
> 'org.apache.flink.table.factories.TableSourceFactory' in
> the classpath.
> Reason: No context matches.
> {code}
> instance: [https://api.travis-ci.org/v3/job/629636106/log.txt]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-15409) Add semicolon to WindowJoinUtil#generateJoinFunction '$collectorTerm.collect($joinedRow)' statement
[
https://issues.apache.org/jira/browse/FLINK-15409?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003907#comment-17003907
]
Kurt Young commented on FLINK-15409:
cc [~jark] [~jinyu.zj]
> Add semicolon to WindowJoinUtil#generateJoinFunction
> '$collectorTerm.collect($joinedRow)' statement
> ---
>
> Key: FLINK-15409
> URL: https://issues.apache.org/jira/browse/FLINK-15409
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Runtime
>Affects Versions: 1.9.1
>Reporter: hailong wang
>Priority: Major
> Fix For: 1.9.2, 1.10.0
>
>
> In WindowJoinUtil#generateJoinFunction, When otherCondition is none, it will
> go into statement:
> {code:java}
> case None =>
> s"""
> |$buildJoinedRow
> |$collectorTerm.collect($joinedRow)
> |""".stripMargin
> {code}
> And it miss a semicolon after collet($joinedRow). This will cause compile
> fail:
> {code:java}
> Caused by: org.apache.flink.api.common.InvalidProgramException: Table program
> cannot be compiled. This is a bug. Please file an issue.Caused by:
> org.apache.flink.api.common.InvalidProgramException: Table program cannot be
> compiled. This is a bug. Please file an issue. at
> org.apache.flink.table.runtime.generated.CompileUtils.doCompile(CompileUtils.java:81)
> at
> org.apache.flink.table.runtime.generated.CompileUtils.compile(CompileUtils.java:65)
> at
> org.apache.flink.table.runtime.generated.GeneratedClass.compile(GeneratedClass.java:78)
> at
> org.apache.flink.table.runtime.generated.GeneratedClass.newInstance(GeneratedClass.java:52)
> ... 26 moreCaused by: org.codehaus.commons.compiler.CompileException: Line
> 28, Column 21: Expression "c.collect(joinedRow)" is not a type
> {code}
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-15409) Add semicolon to WindowJoinUtil#generateJoinFunction '$collectorTerm.collect($joinedRow)' statement
[
https://issues.apache.org/jira/browse/FLINK-15409?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-15409:
---
Affects Version/s: (was: 1.10.0)
1.9.1
> Add semicolon to WindowJoinUtil#generateJoinFunction
> '$collectorTerm.collect($joinedRow)' statement
> ---
>
> Key: FLINK-15409
> URL: https://issues.apache.org/jira/browse/FLINK-15409
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Runtime
>Affects Versions: 1.9.1
>Reporter: hailong wang
>Priority: Major
> Fix For: 1.9.2, 1.10.0
>
>
> In WindowJoinUtil#generateJoinFunction, When otherCondition is none, it will
> go into statement:
> {code:java}
> case None =>
> s"""
> |$buildJoinedRow
> |$collectorTerm.collect($joinedRow)
> |""".stripMargin
> {code}
> And it miss a semicolon after collet($joinedRow). This will cause compile
> fail:
> {code:java}
> Caused by: org.apache.flink.api.common.InvalidProgramException: Table program
> cannot be compiled. This is a bug. Please file an issue.Caused by:
> org.apache.flink.api.common.InvalidProgramException: Table program cannot be
> compiled. This is a bug. Please file an issue. at
> org.apache.flink.table.runtime.generated.CompileUtils.doCompile(CompileUtils.java:81)
> at
> org.apache.flink.table.runtime.generated.CompileUtils.compile(CompileUtils.java:65)
> at
> org.apache.flink.table.runtime.generated.GeneratedClass.compile(GeneratedClass.java:78)
> at
> org.apache.flink.table.runtime.generated.GeneratedClass.newInstance(GeneratedClass.java:52)
> ... 26 moreCaused by: org.codehaus.commons.compiler.CompileException: Line
> 28, Column 21: Expression "c.collect(joinedRow)" is not a type
> {code}
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-15409) Add semicolon to WindowJoinUtil#generateJoinFunction '$collectorTerm.collect($joinedRow)' statement
[
https://issues.apache.org/jira/browse/FLINK-15409?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-15409:
---
Fix Version/s: (was: 1.11.0)
1.10.0
1.9.2
> Add semicolon to WindowJoinUtil#generateJoinFunction
> '$collectorTerm.collect($joinedRow)' statement
> ---
>
> Key: FLINK-15409
> URL: https://issues.apache.org/jira/browse/FLINK-15409
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Runtime
>Affects Versions: 1.10.0
>Reporter: hailong wang
>Priority: Major
> Fix For: 1.9.2, 1.10.0
>
>
> In WindowJoinUtil#generateJoinFunction, When otherCondition is none, it will
> go into statement:
> {code:java}
> case None =>
> s"""
> |$buildJoinedRow
> |$collectorTerm.collect($joinedRow)
> |""".stripMargin
> {code}
> And it miss a semicolon after collet($joinedRow). This will cause compile
> fail:
> {code:java}
> Caused by: org.apache.flink.api.common.InvalidProgramException: Table program
> cannot be compiled. This is a bug. Please file an issue.Caused by:
> org.apache.flink.api.common.InvalidProgramException: Table program cannot be
> compiled. This is a bug. Please file an issue. at
> org.apache.flink.table.runtime.generated.CompileUtils.doCompile(CompileUtils.java:81)
> at
> org.apache.flink.table.runtime.generated.CompileUtils.compile(CompileUtils.java:65)
> at
> org.apache.flink.table.runtime.generated.GeneratedClass.compile(GeneratedClass.java:78)
> at
> org.apache.flink.table.runtime.generated.GeneratedClass.newInstance(GeneratedClass.java:52)
> ... 26 moreCaused by: org.codehaus.commons.compiler.CompileException: Line
> 28, Column 21: Expression "c.collect(joinedRow)" is not a type
> {code}
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-15411) Planner can't prune partition on DATE/TIMESTAMP columns
[ https://issues.apache.org/jira/browse/FLINK-15411?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kurt Young updated FLINK-15411: --- Affects Version/s: (was: 1.11.0) > Planner can't prune partition on DATE/TIMESTAMP columns > --- > > Key: FLINK-15411 > URL: https://issues.apache.org/jira/browse/FLINK-15411 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive, Table SQL / Planner >Affects Versions: 1.10.0 >Reporter: Bowen Li >Assignee: Rui Li >Priority: Major > Fix For: 1.10.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-15411) Planner can't prune partition on DATE/TIMESTAMP columns
[ https://issues.apache.org/jira/browse/FLINK-15411?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kurt Young updated FLINK-15411: --- Fix Version/s: (was: 1.11.0) > Planner can't prune partition on DATE/TIMESTAMP columns > --- > > Key: FLINK-15411 > URL: https://issues.apache.org/jira/browse/FLINK-15411 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive, Table SQL / Planner >Affects Versions: 1.10.0, 1.11.0 >Reporter: Bowen Li >Assignee: Rui Li >Priority: Major > Fix For: 1.10.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-15411) Planner can't prune partition on DATE/TIMESTAMP columns
[ https://issues.apache.org/jira/browse/FLINK-15411?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003905#comment-17003905 ] Kurt Young commented on FLINK-15411: IMO partition with DATE field maybe the most widely used in hive data warehouse. > Planner can't prune partition on DATE/TIMESTAMP columns > --- > > Key: FLINK-15411 > URL: https://issues.apache.org/jira/browse/FLINK-15411 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive, Table SQL / Planner >Affects Versions: 1.10.0, 1.11.0 >Reporter: Bowen Li >Assignee: Rui Li >Priority: Major > Fix For: 1.10.0, 1.11.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-15413) ScalarOperatorsTest failed in travis
[
https://issues.apache.org/jira/browse/FLINK-15413?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kurt Young updated FLINK-15413:
---
Fix Version/s: 1.9.2
> ScalarOperatorsTest failed in travis
>
>
> Key: FLINK-15413
> URL: https://issues.apache.org/jira/browse/FLINK-15413
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Reporter: Dian Fu
>Priority: Major
> Fix For: 1.9.2
>
>
> The travis of release-1.9 failed with the following error:
> {code:java}
> 14:50:19.796 [ERROR] ScalarOperatorsTest>ExpressionTestBase.evaluateExprs:161
> Wrong result for: [CASE WHEN (CASE WHEN f2 = 1 THEN CAST('' as INT) ELSE 0
> END) is null THEN 'null' ELSE 'not null' END] optimized to: [_UTF-16LE'not
> null':VARCHAR(8) CHARACTER SET "UTF-16LE"] expected: but was: n]ull>
> {code}
> instance: [https://api.travis-ci.org/v3/job/629636107/log.txt]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] JingsongLi commented on a change in pull request #10620: [FLINK-15239][table-planner-blink] CompileUtils::COMPILED_CACHE leaks class loaders
JingsongLi commented on a change in pull request #10620:
[FLINK-15239][table-planner-blink] CompileUtils::COMPILED_CACHE leaks class
loaders
URL: https://github.com/apache/flink/pull/10620#discussion_r361588690
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/runtime/generated/CompileUtils.java
##
@@ -59,14 +62,16 @@
* @return the compiled class
*/
public static Class compile(ClassLoader cl, String name, String
code) {
- Tuple2 cacheKey = Tuple2.of(cl, name);
- Class clazz = COMPILED_CACHE.getIfPresent(cacheKey);
- if (clazz == null) {
- clazz = doCompile(cl, name, code);
- COMPILED_CACHE.put(cacheKey, clazz);
+ try {
+ Cache compiledClasses =
COMPILED_CACHE.get(name,
+ () ->
CacheBuilder.newBuilder().maximumSize(5).weakKeys().softValues().build());
+ return compiledClasses.get(cl, () -> doCompile(cl,
name, code));
+ } catch (ExecutionException | UncheckedExecutionException e) {
Review comment:
I mean removing guava wrapped exceptions in the stack as you previous did.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] JingsongLi commented on a change in pull request #10620: [FLINK-15239][table-planner-blink] CompileUtils::COMPILED_CACHE leaks class loaders
JingsongLi commented on a change in pull request #10620:
[FLINK-15239][table-planner-blink] CompileUtils::COMPILED_CACHE leaks class
loaders
URL: https://github.com/apache/flink/pull/10620#discussion_r361588690
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/runtime/generated/CompileUtils.java
##
@@ -59,14 +62,16 @@
* @return the compiled class
*/
public static Class compile(ClassLoader cl, String name, String
code) {
- Tuple2 cacheKey = Tuple2.of(cl, name);
- Class clazz = COMPILED_CACHE.getIfPresent(cacheKey);
- if (clazz == null) {
- clazz = doCompile(cl, name, code);
- COMPILED_CACHE.put(cacheKey, clazz);
+ try {
+ Cache compiledClasses =
COMPILED_CACHE.get(name,
+ () ->
CacheBuilder.newBuilder().maximumSize(5).weakKeys().softValues().build());
+ return compiledClasses.get(cl, () -> doCompile(cl,
name, code));
+ } catch (ExecutionException | UncheckedExecutionException e) {
Review comment:
I mean remove guava wrapped exceptions in the stack as you previous did.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe…
flinkbot edited a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe… URL: https://github.com/apache/flink/pull/10651#issuecomment-567927075 ## CI report: * 5945e5e8f373215b0dfe051c7f91f7b91e6b0928 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/141917314) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3825) * 2393b32572b49bf430ddb0e001de1b79501894b9 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142345451) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3918) * d58e89c10722afd2626fbc0b864bf6545479ae30 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142423087) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3946) * 5f7d5b1038646012781f8a2cbcd9c256eef7e79a Travis: [PENDING](https://travis-ci.com/flink-ci/flink/builds/142426426) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3947) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] lirui-apache commented on a change in pull request #10620: [FLINK-15239][table-planner-blink] CompileUtils::COMPILED_CACHE leaks class loaders
lirui-apache commented on a change in pull request #10620:
[FLINK-15239][table-planner-blink] CompileUtils::COMPILED_CACHE leaks class
loaders
URL: https://github.com/apache/flink/pull/10620#discussion_r361588220
##
File path:
flink-table/flink-table-runtime-blink/src/main/java/org/apache/flink/table/runtime/generated/CompileUtils.java
##
@@ -59,14 +62,16 @@
* @return the compiled class
*/
public static Class compile(ClassLoader cl, String name, String
code) {
- Tuple2 cacheKey = Tuple2.of(cl, name);
- Class clazz = COMPILED_CACHE.getIfPresent(cacheKey);
- if (clazz == null) {
- clazz = doCompile(cl, name, code);
- COMPILED_CACHE.put(cacheKey, clazz);
+ try {
+ Cache compiledClasses =
COMPILED_CACHE.get(name,
+ () ->
CacheBuilder.newBuilder().maximumSize(5).weakKeys().softValues().build());
+ return compiledClasses.get(cl, () -> doCompile(cl,
name, code));
+ } catch (ExecutionException | UncheckedExecutionException e) {
Review comment:
@JingsongLi We're catching `Exception` now
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (FLINK-15343) Add Watermarks options for TwoInputStreamOperator
[ https://issues.apache.org/jira/browse/FLINK-15343?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003898#comment-17003898 ] jocean.shi commented on FLINK-15343: [~aljoscha] As you're the author of method "processWatermark1" "processWatermark2" of the "AbstractStreamOperator.java", what do you think about this, if this is valid, could you please assign this ticket to me? > Add Watermarks options for TwoInputStreamOperator > - > > Key: FLINK-15343 > URL: https://issues.apache.org/jira/browse/FLINK-15343 > Project: Flink > Issue Type: Improvement >Reporter: jocean.shi >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > Currently, The "TwoInputStreamOperator" such as > "CoBroadcastWithKeyedOperator" "KeyedCoProcessOperator" and the > (Co)stream such as "ConnectedStreams" "BroadcastConnectedStream" only > support compute watermark by two stream. > but user just need one stream to compute watermark in some case. > For example: one stream is only rule data or control command, it > don't hava event time. > I think user has right to choose which stream to compute watermark. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-15404) How to insert hive table for different catalog
[
https://issues.apache.org/jira/browse/FLINK-15404?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003899#comment-17003899
]
hehuiyuan commented on FLINK-15404:
---
Hi [~lzljs3620320] , thanks , I ingore to invoke the `tableEnv.execute` .
> How to insert hive table for different catalog
> ---
>
> Key: FLINK-15404
> URL: https://issues.apache.org/jira/browse/FLINK-15404
> Project: Flink
> Issue Type: Wish
> Components: Table SQL / Planner
>Reporter: hehuiyuan
>Priority: Major
>
> I have a hive catalog :
>
> {code:java}
> catalog name : myhive
> database : default
> {code}
>
> and the flink has a default catalog :
>
> {code:java}
> catalog name : default_catalog
> database : default_database
> {code}
>
> For example :
> I have a source table 'source_table' that's from kafka which is register to
> default_catalog,
> I want to insert hive table 'hive_table' that is from myhive catalog.
> SQL:
> insert into hive_table select * from source_table;
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-15343) Add Watermarks options for TwoInputStreamOperator
[ https://issues.apache.org/jira/browse/FLINK-15343?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] jocean.shi updated FLINK-15343: --- Description: Currently, The "TwoInputStreamOperator" such as "CoBroadcastWithKeyedOperator" "KeyedCoProcessOperator" and the (Co)stream such as "ConnectedStreams" "BroadcastConnectedStream" only support compute watermark by two stream. but user just need one stream to compute watermark in some case. For example: one stream is only rule data or control command, it don't hava event time. I think user has right to choose which stream to compute watermark. was: Currently, The "TwoInputStreamOperator" such as "CoBroadcastWithKeyedOperator" "KeyedCoProcessOperator" and the (Co)stream such as "ConnectedStreams" "BroadcastConnectedStream" only support compute watermark by two stream. but user just need one stream to compute watermark in some case. For example: one stream is only rule data or control command, it don't hava event time. I think user has right to choose which stream to compute watermark. > Add Watermarks options for TwoInputStreamOperator > - > > Key: FLINK-15343 > URL: https://issues.apache.org/jira/browse/FLINK-15343 > Project: Flink > Issue Type: Improvement >Reporter: jocean.shi >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > Currently, The "TwoInputStreamOperator" such as > "CoBroadcastWithKeyedOperator" "KeyedCoProcessOperator" and the > (Co)stream such as "ConnectedStreams" "BroadcastConnectedStream" only > support compute watermark by two stream. > but user just need one stream to compute watermark in some case. > For example: one stream is only rule data or control command, it > don't hava event time. > I think user has right to choose which stream to compute watermark. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-15343) Add Watermarks options for TwoInputStreamOperator
[ https://issues.apache.org/jira/browse/FLINK-15343?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] jocean.shi updated FLINK-15343: --- Description: Currently, The "TwoInputStreamOperator" such as "CoBroadcastWithKeyedOperator" "KeyedCoProcessOperator" and the (Co)stream such as "ConnectedStreams" "BroadcastConnectedStream" only support compute watermark by two stream. but user just need one stream to compute watermark in some case. For example: one stream is only rule data or control command, it don't hava event time. I think user has right to choose which stream to compute watermark. was:Currently, TwoInputStreamOperator use two Watermark default. but often one stream dont't have Watermark at some case. > Add Watermarks options for TwoInputStreamOperator > - > > Key: FLINK-15343 > URL: https://issues.apache.org/jira/browse/FLINK-15343 > Project: Flink > Issue Type: Improvement >Reporter: jocean.shi >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > Currently, The "TwoInputStreamOperator" such as > "CoBroadcastWithKeyedOperator" "KeyedCoProcessOperator" and the > (Co)stream such as "ConnectedStreams" "BroadcastConnectedStream" only support > compute watermark by two stream. > but user just need one stream to compute watermark in some case. > For example: one stream is only rule data or control command, it > don't hava event time. > I think user has right to choose which stream to compute watermark. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Comment Edited] (FLINK-15388) The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
[
https://issues.apache.org/jira/browse/FLINK-15388?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003869#comment-17003869
]
hiliuxg edited comment on FLINK-15388 at 12/27/19 5:42 AM:
---
Hi [~xintongsong]:
The problem reappears, the network is ok, the CPU is not high, and there is no
full gc, but heartbeat timeout, the zk response timeout, the promethues get the
metric point timeout. Is it possible that a certain operator of a job is
blocked, such as the sink operator, causing the TM response to time out? Is it
possible that my configuration is not reasonable, 32 core cpu is configured
with 48 slots, and heap 144G.
was (Author: hiliuxg):
Hi [~xintongsong]:
The problem reappears, the network is ok, the CPU is not high, and there is no
full gc, but heartbeat timeout, the zk response timeout, the promethues get the
metric point timeout. Is it possible that a certain operator of a job is
blocked, such as the sink operator, causing the TM response to time out? Is it
possible that my configuration is not reasonable, 32 core cpu is configured
with 48 slots, and heap 144G. !metrics.png!
> The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
> --
>
> Key: FLINK-15388
> URL: https://issues.apache.org/jira/browse/FLINK-15388
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Task
>Affects Versions: 1.8.0
> Environment: model : standalone,not yarn
> version : flink 1.8.0
> configration :
> jobmanager.heap.size: 4096m
> taskmanager.heap.size: 144gb
> taskmanager.numberOfTaskSlots: 48
> taskmanager.memory.fraction: 0.7
> taskmanager.memory.off-heap: false
> parallelism.default: 1
>
>Reporter: hiliuxg
>Priority: Major
> Attachments: metrics.png, metrics.png
>
>
> the taskmanager's slot was removed , there was not full gc or oom , what's
> the problem ? the error bellow
> {code:java}
> org.apache.flink.util.FlinkException: The assigned slot
> bae00218c818157649eb9e3c533b86af_32 was removed.
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlot(SlotManager.java:893)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlots(SlotManager.java:863)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.internalUnregisterTaskManager(SlotManager.java:1058)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.unregisterTaskManager(SlotManager.java:385)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager.closeTaskManagerConnection(ResourceManager.java:847)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener$1.run(ResourceManager.java:1161)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:392)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:185)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:147)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.onReceive(FencedAkkaRpcActor.java:40)
> at
> akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:165)
> at akka.actor.Actor$class.aroundReceive(Actor.scala:502)
> at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:95)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:526)
> at akka.actor.ActorCell.invoke(ActorCell.scala:495)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:257)
> at akka.dispatch.Mailbox.run(Mailbox.scala:224)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:234)
> at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
> at
> scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
> at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
> at
> scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #10695: [hotfix] Remove the useless stage in Mesos dockerfile
flinkbot edited a comment on issue #10695: [hotfix] Remove the useless stage in Mesos dockerfile URL: https://github.com/apache/flink/pull/10695#issuecomment-569014612 ## CI report: * 97ac65498d207e34e891dcd59c87b6a44f04bead Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142361209) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3927) * e58625466acbbf46aeb41b14561f2c63ba075297 Travis: [SUCCESS](https://travis-ci.com/flink-ci/flink/builds/142364869) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3930) * cb283afa0c2f0cf95a6628d9b4cb6b53a52fb019 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142421957) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3945) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe…
flinkbot edited a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe… URL: https://github.com/apache/flink/pull/10651#issuecomment-567927075 ## CI report: * 5945e5e8f373215b0dfe051c7f91f7b91e6b0928 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/141917314) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3825) * 2393b32572b49bf430ddb0e001de1b79501894b9 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142345451) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3918) * d58e89c10722afd2626fbc0b864bf6545479ae30 Travis: [PENDING](https://travis-ci.com/flink-ci/flink/builds/142423087) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3946) * 5f7d5b1038646012781f8a2cbcd9c256eef7e79a UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] shidayang removed a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe…
shidayang removed a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe… URL: https://github.com/apache/flink/pull/10651#issuecomment-569178934 @flinkbot run travis This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] shidayang removed a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe…
shidayang removed a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe… URL: https://github.com/apache/flink/pull/10651#issuecomment-569186927 @flinkbot run travis This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe…
flinkbot edited a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe… URL: https://github.com/apache/flink/pull/10651#issuecomment-567927075 ## CI report: * 5945e5e8f373215b0dfe051c7f91f7b91e6b0928 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/141917314) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3825) * 2393b32572b49bf430ddb0e001de1b79501894b9 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142345451) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3918) * d58e89c10722afd2626fbc0b864bf6545479ae30 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142423087) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3946) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] shidayang commented on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe…
shidayang commented on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe… URL: https://github.com/apache/flink/pull/10651#issuecomment-569186927 @flinkbot run travis This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Updated] (FLINK-15391) DATE and TIMESTAMP partition columns don't work
[ https://issues.apache.org/jira/browse/FLINK-15391?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kurt Young updated FLINK-15391: --- Fix Version/s: (was: 1.11.0) > DATE and TIMESTAMP partition columns don't work > --- > > Key: FLINK-15391 > URL: https://issues.apache.org/jira/browse/FLINK-15391 > Project: Flink > Issue Type: Bug > Components: Connectors / Hive >Reporter: Rui Li >Assignee: Rui Li >Priority: Blocker > Labels: pull-request-available > Fix For: 1.10.0 > > Time Spent: 20m > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] danny0405 commented on a change in pull request #10669: [FLINK-15192][docs][table] Restructure "SQL" pages for better readability
danny0405 commented on a change in pull request #10669:
[FLINK-15192][docs][table] Restructure "SQL" pages for better readability
URL: https://github.com/apache/flink/pull/10669#discussion_r361579192
##
File path: docs/dev/table/sql/ddl.md
##
@@ -0,0 +1,297 @@
+---
+title: "Data Definition Language (DDL)"
+nav-title: "Data Definition Language"
+nav-parent_id: sql
+nav-pos: 1
+---
+
+
+* This will be replaced by the TOC
+{:toc}
+
+DDLs are specified with the `sqlUpdate()` method of the `TableEnvironment`.
The method returns nothing for a success create/drop/alter database or table
operation. A catalog table will be registered into the [Catalog]({{
site.baseurl }}/dev/table/catalogs.html) with a `CREATE TABLE` statement, then
can be referenced in SQL queries.
+
+Flink SQL DDL statements are documented here, including:
+
+- CREATE TABLE, VIEW, DATABASE, FUNCTION
+- DROP TABLE, VIEW, DATABASE, FUNCTION
+- ALTER TABLE, DATABASE
+
+## Run a DDL
+
+The following examples show how to run a SQL DDL in `TableEnvironment`.
+
+
+
+{% highlight java %}
+EnvironmentSettings settings = EnvironmentSettings.newInstance()...
+TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+// SQL query with a registered table
+// register a table named "Orders"
+tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR,
amount INT) WITH (...)");
+// run a SQL query on the Table and retrieve the result as a new Table
+Table result = tableEnv.sqlQuery(
+ "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
+
+// SQL update with a registered table
+// register a TableSink
+tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
WITH (...)");
+// run a SQL update query on the Table and emit the result to the TableSink
+tableEnv.sqlUpdate(
+ "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product
LIKE '%Rubber%'");
+{% endhighlight %}
+
+
+
+{% highlight scala %}
+val settings = EnvironmentSettings.newInstance()...
+val tableEnv = TableEnvironment.create(settings)
+
+// SQL query with a registered table
+// register a table named "Orders"
+tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR,
amount INT) WITH (...)");
+// run a SQL query on the Table and retrieve the result as a new Table
+val result = tableEnv.sqlQuery(
+ "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
+
+// SQL update with a registered table
+// register a TableSink
+tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
WITH ('connector.path'='/path/to/file' ...)");
+// run a SQL update query on the Table and emit the result to the TableSink
+tableEnv.sqlUpdate(
+ "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product
LIKE '%Rubber%'")
+{% endhighlight %}
+
+
+
+{% highlight python %}
+settings = EnvironmentSettings.newInstance()...
+table_env = TableEnvironment.create(settings)
+
+# SQL update with a registered table
+# register a TableSink
+table_env.sql_update("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
with (...)")
+# run a SQL update query on the Table and emit the result to the TableSink
+table_env \
+.sql_update("INSERT INTO RubberOrders SELECT product, amount FROM Orders
WHERE product LIKE '%Rubber%'")
+{% endhighlight %}
+
+
+
+{% top %}
+
+## Table DDL
+
+### CREATE TABLE
+
+{% highlight sql %}
+CREATE TABLE [catalog_name.][db_name.]table_name
+ (
+{ | }[ , ...n]
+[ ]
+ )
+ [COMMENT table_comment]
+ [PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
+ WITH (key1=val1, key2=val2, ...)
+
+:
+ column_name column_type [COMMENT column_comment]
+
+:
+ column_name AS computed_column_expression [COMMENT column_comment]
+
+:
+ WATERMARK FOR rowtime_column_name AS watermark_strategy_expression
+
+{% endhighlight %}
+
+Creates a table with the given name. If a table with the same name already
exists in the catalog, an exception is thrown.
+
+**COMPUTED COLUMN**
+
+Column declared with syntax "`column_name AS computed_column_expression`" is a
computed column. A computed column is a virtual column that is not physically
stored in the table. The column is computed from an non-query expression that
uses other columns in the same table. For example, a computed column can have
the definition: `cost AS price * qty`. The expression can be a noncomputed
column name, constant, (user-defined/system) function, variable, and any
combination of these connected by one or more operators. The expression cannot
be a subquery.
+
+Computed column is introduced to Flink for defining [time attributes]({{
site.baseurl}}/dev/table/streaming/time_attributes.html) in CREATE TABLE DDL.
+A [processing time attribute]({{
site.baseurl}}/dev/table/streaming/time_attributes.html#processing-time) can be
defined easily via `proc AS PROCTIME()` using the system `PROCTIME()` function.
+On the other hand, computed column can be used to derive e
[GitHub] [flink] wuchong commented on a change in pull request #10669: [FLINK-15192][docs][table] Restructure "SQL" pages for better readability
wuchong commented on a change in pull request #10669:
[FLINK-15192][docs][table] Restructure "SQL" pages for better readability
URL: https://github.com/apache/flink/pull/10669#discussion_r361579079
##
File path: docs/dev/table/sql/ddl.md
##
@@ -0,0 +1,297 @@
+---
+title: "Data Definition Language (DDL)"
+nav-title: "Data Definition Language"
+nav-parent_id: sql
+nav-pos: 1
+---
+
+
+* This will be replaced by the TOC
+{:toc}
+
+DDLs are specified with the `sqlUpdate()` method of the `TableEnvironment`.
The method returns nothing for a success create/drop/alter database or table
operation. A catalog table will be registered into the [Catalog]({{
site.baseurl }}/dev/table/catalogs.html) with a `CREATE TABLE` statement, then
can be referenced in SQL queries.
+
+Flink SQL DDL statements are documented here, including:
+
+- CREATE TABLE, VIEW, DATABASE, FUNCTION
+- DROP TABLE, VIEW, DATABASE, FUNCTION
+- ALTER TABLE, DATABASE
+
+## Run a DDL
+
+The following examples show how to run a SQL DDL in `TableEnvironment`.
+
+
+
+{% highlight java %}
+EnvironmentSettings settings = EnvironmentSettings.newInstance()...
+TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+// SQL query with a registered table
+// register a table named "Orders"
+tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR,
amount INT) WITH (...)");
+// run a SQL query on the Table and retrieve the result as a new Table
+Table result = tableEnv.sqlQuery(
+ "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
+
+// SQL update with a registered table
+// register a TableSink
+tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
WITH (...)");
+// run a SQL update query on the Table and emit the result to the TableSink
+tableEnv.sqlUpdate(
+ "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product
LIKE '%Rubber%'");
+{% endhighlight %}
+
+
+
+{% highlight scala %}
+val settings = EnvironmentSettings.newInstance()...
+val tableEnv = TableEnvironment.create(settings)
+
+// SQL query with a registered table
+// register a table named "Orders"
+tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR,
amount INT) WITH (...)");
+// run a SQL query on the Table and retrieve the result as a new Table
+val result = tableEnv.sqlQuery(
+ "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
+
+// SQL update with a registered table
+// register a TableSink
+tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
WITH ('connector.path'='/path/to/file' ...)");
+// run a SQL update query on the Table and emit the result to the TableSink
+tableEnv.sqlUpdate(
+ "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product
LIKE '%Rubber%'")
+{% endhighlight %}
+
+
+
+{% highlight python %}
+settings = EnvironmentSettings.newInstance()...
+table_env = TableEnvironment.create(settings)
+
+# SQL update with a registered table
+# register a TableSink
+table_env.sql_update("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
with (...)")
+# run a SQL update query on the Table and emit the result to the TableSink
+table_env \
+.sql_update("INSERT INTO RubberOrders SELECT product, amount FROM Orders
WHERE product LIKE '%Rubber%'")
+{% endhighlight %}
+
+
+
+{% top %}
+
+## Table DDL
+
+### CREATE TABLE
+
+{% highlight sql %}
+CREATE TABLE [catalog_name.][db_name.]table_name
+ (
+{ | }[ , ...n]
+[ ]
+ )
+ [COMMENT table_comment]
+ [PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
+ WITH (key1=val1, key2=val2, ...)
+
+:
+ column_name column_type [COMMENT column_comment]
+
+:
+ column_name AS computed_column_expression [COMMENT column_comment]
+
+:
+ WATERMARK FOR rowtime_column_name AS watermark_strategy_expression
+
+{% endhighlight %}
+
+Creates a table with the given name. If a table with the same name already
exists in the catalog, an exception is thrown.
+
+**COMPUTED COLUMN**
+
+Column declared with syntax "`column_name AS computed_column_expression`" is a
computed column. A computed column is a virtual column that is not physically
stored in the table. The column is computed from an non-query expression that
uses other columns in the same table. For example, a computed column can have
the definition: `cost AS price * qty`. The expression can be a noncomputed
column name, constant, (user-defined/system) function, variable, and any
combination of these connected by one or more operators. The expression cannot
be a subquery.
+
+Computed column is introduced to Flink for defining [time attributes]({{
site.baseurl}}/dev/table/streaming/time_attributes.html) in CREATE TABLE DDL.
+A [processing time attribute]({{
site.baseurl}}/dev/table/streaming/time_attributes.html#processing-time) can be
defined easily via `proc AS PROCTIME()` using the system `PROCTIME()` function.
+On the other hand, computed column can be used to derive eve
[GitHub] [flink] danny0405 commented on issue #10669: [FLINK-15192][docs][table] Restructure "SQL" pages for better readability
danny0405 commented on issue #10669: [FLINK-15192][docs][table] Restructure "SQL" pages for better readability URL: https://github.com/apache/flink/pull/10669#issuecomment-569184987 Thanks for refactoring this, the page looks much better now, i would suggest to split the page by specific clause, i.e. `select` be a page and `insert` be a page and there is navigate button on the left side for each of them. We do not really need the `DML` or `DDL` terminology which is hard to understand. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] flinkbot edited a comment on issue #10695: [hotfix] Remove the useless stage in Mesos dockerfile
flinkbot edited a comment on issue #10695: [hotfix] Remove the useless stage in Mesos dockerfile URL: https://github.com/apache/flink/pull/10695#issuecomment-569014612 ## CI report: * 97ac65498d207e34e891dcd59c87b6a44f04bead Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142361209) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3927) * e58625466acbbf46aeb41b14561f2c63ba075297 Travis: [SUCCESS](https://travis-ci.com/flink-ci/flink/builds/142364869) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3930) * cb283afa0c2f0cf95a6628d9b4cb6b53a52fb019 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142421957) Azure: [PENDING](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3945) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] wuchong commented on a change in pull request #10669: [FLINK-15192][docs][table] Restructure "SQL" pages for better readability
wuchong commented on a change in pull request #10669:
[FLINK-15192][docs][table] Restructure "SQL" pages for better readability
URL: https://github.com/apache/flink/pull/10669#discussion_r361578824
##
File path: docs/dev/table/sql/ddl.md
##
@@ -0,0 +1,297 @@
+---
+title: "Data Definition Language (DDL)"
+nav-title: "Data Definition Language"
+nav-parent_id: sql
+nav-pos: 1
+---
+
+
+* This will be replaced by the TOC
+{:toc}
+
+DDLs are specified with the `sqlUpdate()` method of the `TableEnvironment`.
The method returns nothing for a success create/drop/alter database or table
operation. A catalog table will be registered into the [Catalog]({{
site.baseurl }}/dev/table/catalogs.html) with a `CREATE TABLE` statement, then
can be referenced in SQL queries.
+
+Flink SQL DDL statements are documented here, including:
+
+- CREATE TABLE, VIEW, DATABASE, FUNCTION
+- DROP TABLE, VIEW, DATABASE, FUNCTION
+- ALTER TABLE, DATABASE
+
+## Run a DDL
+
+The following examples show how to run a SQL DDL in `TableEnvironment`.
+
+
+
+{% highlight java %}
+EnvironmentSettings settings = EnvironmentSettings.newInstance()...
+TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+// SQL query with a registered table
+// register a table named "Orders"
+tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR,
amount INT) WITH (...)");
+// run a SQL query on the Table and retrieve the result as a new Table
+Table result = tableEnv.sqlQuery(
+ "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
+
+// SQL update with a registered table
+// register a TableSink
+tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
WITH (...)");
+// run a SQL update query on the Table and emit the result to the TableSink
+tableEnv.sqlUpdate(
+ "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product
LIKE '%Rubber%'");
+{% endhighlight %}
+
+
+
+{% highlight scala %}
+val settings = EnvironmentSettings.newInstance()...
+val tableEnv = TableEnvironment.create(settings)
+
+// SQL query with a registered table
+// register a table named "Orders"
+tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR,
amount INT) WITH (...)");
+// run a SQL query on the Table and retrieve the result as a new Table
+val result = tableEnv.sqlQuery(
+ "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
+
+// SQL update with a registered table
+// register a TableSink
+tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
WITH ('connector.path'='/path/to/file' ...)");
+// run a SQL update query on the Table and emit the result to the TableSink
+tableEnv.sqlUpdate(
+ "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product
LIKE '%Rubber%'")
+{% endhighlight %}
+
+
+
+{% highlight python %}
+settings = EnvironmentSettings.newInstance()...
+table_env = TableEnvironment.create(settings)
+
+# SQL update with a registered table
+# register a TableSink
+table_env.sql_update("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
with (...)")
+# run a SQL update query on the Table and emit the result to the TableSink
+table_env \
+.sql_update("INSERT INTO RubberOrders SELECT product, amount FROM Orders
WHERE product LIKE '%Rubber%'")
+{% endhighlight %}
+
+
+
+{% top %}
+
+## Table DDL
+
+### CREATE TABLE
+
+{% highlight sql %}
+CREATE TABLE [catalog_name.][db_name.]table_name
+ (
+{ | }[ , ...n]
+[ ]
+ )
+ [COMMENT table_comment]
+ [PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
+ WITH (key1=val1, key2=val2, ...)
+
+:
+ column_name column_type [COMMENT column_comment]
+
+:
+ column_name AS computed_column_expression [COMMENT column_comment]
+
+:
+ WATERMARK FOR rowtime_column_name AS watermark_strategy_expression
+
+{% endhighlight %}
+
+Creates a table with the given name. If a table with the same name already
exists in the catalog, an exception is thrown.
+
+**COMPUTED COLUMN**
+
+Column declared with syntax "`column_name AS computed_column_expression`" is a
computed column. A computed column is a virtual column that is not physically
stored in the table. The column is computed from an non-query expression that
uses other columns in the same table. For example, a computed column can have
the definition: `cost AS price * qty`. The expression can be a noncomputed
column name, constant, (user-defined/system) function, variable, and any
combination of these connected by one or more operators. The expression cannot
be a subquery.
+
Review comment:
I refered the description from sql server:
https://docs.microsoft.com/en-us/sql/t-sql/statements/create-table-transact-sql?view=sql-server-ver15#arguments
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
Fo
[GitHub] [flink] danny0405 commented on a change in pull request #10669: [FLINK-15192][docs][table] Restructure "SQL" pages for better readability
danny0405 commented on a change in pull request #10669:
[FLINK-15192][docs][table] Restructure "SQL" pages for better readability
URL: https://github.com/apache/flink/pull/10669#discussion_r361578634
##
File path: docs/dev/table/sql/ddl.md
##
@@ -0,0 +1,297 @@
+---
+title: "Data Definition Language (DDL)"
+nav-title: "Data Definition Language"
+nav-parent_id: sql
+nav-pos: 1
+---
+
+
+* This will be replaced by the TOC
+{:toc}
+
+DDLs are specified with the `sqlUpdate()` method of the `TableEnvironment`.
The method returns nothing for a success create/drop/alter database or table
operation. A catalog table will be registered into the [Catalog]({{
site.baseurl }}/dev/table/catalogs.html) with a `CREATE TABLE` statement, then
can be referenced in SQL queries.
+
+Flink SQL DDL statements are documented here, including:
+
+- CREATE TABLE, VIEW, DATABASE, FUNCTION
+- DROP TABLE, VIEW, DATABASE, FUNCTION
+- ALTER TABLE, DATABASE
+
+## Run a DDL
+
+The following examples show how to run a SQL DDL in `TableEnvironment`.
+
+
+
+{% highlight java %}
+EnvironmentSettings settings = EnvironmentSettings.newInstance()...
+TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+// SQL query with a registered table
+// register a table named "Orders"
+tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR,
amount INT) WITH (...)");
+// run a SQL query on the Table and retrieve the result as a new Table
+Table result = tableEnv.sqlQuery(
+ "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
+
+// SQL update with a registered table
+// register a TableSink
+tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
WITH (...)");
+// run a SQL update query on the Table and emit the result to the TableSink
+tableEnv.sqlUpdate(
+ "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product
LIKE '%Rubber%'");
+{% endhighlight %}
+
+
+
+{% highlight scala %}
+val settings = EnvironmentSettings.newInstance()...
+val tableEnv = TableEnvironment.create(settings)
+
+// SQL query with a registered table
+// register a table named "Orders"
+tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR,
amount INT) WITH (...)");
+// run a SQL query on the Table and retrieve the result as a new Table
+val result = tableEnv.sqlQuery(
+ "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
+
+// SQL update with a registered table
+// register a TableSink
+tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
WITH ('connector.path'='/path/to/file' ...)");
+// run a SQL update query on the Table and emit the result to the TableSink
+tableEnv.sqlUpdate(
+ "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product
LIKE '%Rubber%'")
+{% endhighlight %}
+
+
+
+{% highlight python %}
+settings = EnvironmentSettings.newInstance()...
+table_env = TableEnvironment.create(settings)
+
+# SQL update with a registered table
+# register a TableSink
+table_env.sql_update("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
with (...)")
+# run a SQL update query on the Table and emit the result to the TableSink
+table_env \
+.sql_update("INSERT INTO RubberOrders SELECT product, amount FROM Orders
WHERE product LIKE '%Rubber%'")
+{% endhighlight %}
+
+
+
+{% top %}
+
+## Table DDL
+
+### CREATE TABLE
+
+{% highlight sql %}
+CREATE TABLE [catalog_name.][db_name.]table_name
+ (
+{ | }[ , ...n]
+[ ]
+ )
+ [COMMENT table_comment]
+ [PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
+ WITH (key1=val1, key2=val2, ...)
+
+:
+ column_name column_type [COMMENT column_comment]
+
+:
+ column_name AS computed_column_expression [COMMENT column_comment]
+
+:
+ WATERMARK FOR rowtime_column_name AS watermark_strategy_expression
+
+{% endhighlight %}
+
+Creates a table with the given name. If a table with the same name already
exists in the catalog, an exception is thrown.
+
+**COMPUTED COLUMN**
+
+Column declared with syntax "`column_name AS computed_column_expression`" is a
computed column. A computed column is a virtual column that is not physically
stored in the table. The column is computed from an non-query expression that
uses other columns in the same table. For example, a computed column can have
the definition: `cost AS price * qty`. The expression can be a noncomputed
column name, constant, (user-defined/system) function, variable, and any
combination of these connected by one or more operators. The expression cannot
be a subquery.
+
+Computed column is introduced to Flink for defining [time attributes]({{
site.baseurl}}/dev/table/streaming/time_attributes.html) in CREATE TABLE DDL.
+A [processing time attribute]({{
site.baseurl}}/dev/table/streaming/time_attributes.html#processing-time) can be
defined easily via `proc AS PROCTIME()` using the system `PROCTIME()` function.
+On the other hand, computed column can be used to derive e
[GitHub] [flink] flinkbot edited a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe…
flinkbot edited a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe… URL: https://github.com/apache/flink/pull/10651#issuecomment-567927075 ## CI report: * 5945e5e8f373215b0dfe051c7f91f7b91e6b0928 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/141917314) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3825) * 2393b32572b49bf430ddb0e001de1b79501894b9 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142345451) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3918) * d58e89c10722afd2626fbc0b864bf6545479ae30 Travis: [PENDING](https://travis-ci.com/flink-ci/flink/builds/142423087) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3946) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] danny0405 commented on a change in pull request #10669: [FLINK-15192][docs][table] Restructure "SQL" pages for better readability
danny0405 commented on a change in pull request #10669:
[FLINK-15192][docs][table] Restructure "SQL" pages for better readability
URL: https://github.com/apache/flink/pull/10669#discussion_r361578477
##
File path: docs/dev/table/sql/ddl.md
##
@@ -0,0 +1,297 @@
+---
+title: "Data Definition Language (DDL)"
+nav-title: "Data Definition Language"
+nav-parent_id: sql
+nav-pos: 1
+---
+
+
+* This will be replaced by the TOC
+{:toc}
+
+DDLs are specified with the `sqlUpdate()` method of the `TableEnvironment`.
The method returns nothing for a success create/drop/alter database or table
operation. A catalog table will be registered into the [Catalog]({{
site.baseurl }}/dev/table/catalogs.html) with a `CREATE TABLE` statement, then
can be referenced in SQL queries.
+
+Flink SQL DDL statements are documented here, including:
+
+- CREATE TABLE, VIEW, DATABASE, FUNCTION
+- DROP TABLE, VIEW, DATABASE, FUNCTION
+- ALTER TABLE, DATABASE
+
+## Run a DDL
+
+The following examples show how to run a SQL DDL in `TableEnvironment`.
+
+
+
+{% highlight java %}
+EnvironmentSettings settings = EnvironmentSettings.newInstance()...
+TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+// SQL query with a registered table
+// register a table named "Orders"
+tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR,
amount INT) WITH (...)");
+// run a SQL query on the Table and retrieve the result as a new Table
+Table result = tableEnv.sqlQuery(
+ "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
+
+// SQL update with a registered table
+// register a TableSink
+tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
WITH (...)");
+// run a SQL update query on the Table and emit the result to the TableSink
+tableEnv.sqlUpdate(
+ "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product
LIKE '%Rubber%'");
+{% endhighlight %}
+
+
+
+{% highlight scala %}
+val settings = EnvironmentSettings.newInstance()...
+val tableEnv = TableEnvironment.create(settings)
+
+// SQL query with a registered table
+// register a table named "Orders"
+tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR,
amount INT) WITH (...)");
+// run a SQL query on the Table and retrieve the result as a new Table
+val result = tableEnv.sqlQuery(
+ "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
+
+// SQL update with a registered table
+// register a TableSink
+tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
WITH ('connector.path'='/path/to/file' ...)");
+// run a SQL update query on the Table and emit the result to the TableSink
+tableEnv.sqlUpdate(
+ "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product
LIKE '%Rubber%'")
+{% endhighlight %}
+
+
+
+{% highlight python %}
+settings = EnvironmentSettings.newInstance()...
+table_env = TableEnvironment.create(settings)
+
+# SQL update with a registered table
+# register a TableSink
+table_env.sql_update("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
with (...)")
+# run a SQL update query on the Table and emit the result to the TableSink
+table_env \
+.sql_update("INSERT INTO RubberOrders SELECT product, amount FROM Orders
WHERE product LIKE '%Rubber%'")
+{% endhighlight %}
+
+
+
+{% top %}
+
+## Table DDL
+
+### CREATE TABLE
+
+{% highlight sql %}
+CREATE TABLE [catalog_name.][db_name.]table_name
+ (
+{ | }[ , ...n]
+[ ]
+ )
+ [COMMENT table_comment]
+ [PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
+ WITH (key1=val1, key2=val2, ...)
+
+:
+ column_name column_type [COMMENT column_comment]
+
+:
+ column_name AS computed_column_expression [COMMENT column_comment]
+
+:
+ WATERMARK FOR rowtime_column_name AS watermark_strategy_expression
+
+{% endhighlight %}
+
+Creates a table with the given name. If a table with the same name already
exists in the catalog, an exception is thrown.
+
+**COMPUTED COLUMN**
+
+Column declared with syntax "`column_name AS computed_column_expression`" is a
computed column. A computed column is a virtual column that is not physically
stored in the table. The column is computed from an non-query expression that
uses other columns in the same table. For example, a computed column can have
the definition: `cost AS price * qty`. The expression can be a noncomputed
column name, constant, (user-defined/system) function, variable, and any
combination of these connected by one or more operators. The expression cannot
be a subquery.
+
+Computed column is introduced to Flink for defining [time attributes]({{
site.baseurl}}/dev/table/streaming/time_attributes.html) in CREATE TABLE DDL.
+A [processing time attribute]({{
site.baseurl}}/dev/table/streaming/time_attributes.html#processing-time) can be
defined easily via `proc AS PROCTIME()` using the system `PROCTIME()` function.
+On the other hand, computed column can be used to derive e
[GitHub] [flink] danny0405 commented on a change in pull request #10669: [FLINK-15192][docs][table] Restructure "SQL" pages for better readability
danny0405 commented on a change in pull request #10669:
[FLINK-15192][docs][table] Restructure "SQL" pages for better readability
URL: https://github.com/apache/flink/pull/10669#discussion_r361578392
##
File path: docs/dev/table/sql/ddl.md
##
@@ -0,0 +1,297 @@
+---
+title: "Data Definition Language (DDL)"
+nav-title: "Data Definition Language"
+nav-parent_id: sql
+nav-pos: 1
+---
+
+
+* This will be replaced by the TOC
+{:toc}
+
+DDLs are specified with the `sqlUpdate()` method of the `TableEnvironment`.
The method returns nothing for a success create/drop/alter database or table
operation. A catalog table will be registered into the [Catalog]({{
site.baseurl }}/dev/table/catalogs.html) with a `CREATE TABLE` statement, then
can be referenced in SQL queries.
+
+Flink SQL DDL statements are documented here, including:
+
+- CREATE TABLE, VIEW, DATABASE, FUNCTION
+- DROP TABLE, VIEW, DATABASE, FUNCTION
+- ALTER TABLE, DATABASE
+
+## Run a DDL
+
+The following examples show how to run a SQL DDL in `TableEnvironment`.
+
+
+
+{% highlight java %}
+EnvironmentSettings settings = EnvironmentSettings.newInstance()...
+TableEnvironment tableEnv = TableEnvironment.create(settings);
+
+// SQL query with a registered table
+// register a table named "Orders"
+tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR,
amount INT) WITH (...)");
+// run a SQL query on the Table and retrieve the result as a new Table
+Table result = tableEnv.sqlQuery(
+ "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
+
+// SQL update with a registered table
+// register a TableSink
+tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
WITH (...)");
+// run a SQL update query on the Table and emit the result to the TableSink
+tableEnv.sqlUpdate(
+ "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product
LIKE '%Rubber%'");
+{% endhighlight %}
+
+
+
+{% highlight scala %}
+val settings = EnvironmentSettings.newInstance()...
+val tableEnv = TableEnvironment.create(settings)
+
+// SQL query with a registered table
+// register a table named "Orders"
+tableEnv.sqlUpdate("CREATE TABLE Orders (`user` BIGINT, product VARCHAR,
amount INT) WITH (...)");
+// run a SQL query on the Table and retrieve the result as a new Table
+val result = tableEnv.sqlQuery(
+ "SELECT product, amount FROM Orders WHERE product LIKE '%Rubber%'");
+
+// SQL update with a registered table
+// register a TableSink
+tableEnv.sqlUpdate("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
WITH ('connector.path'='/path/to/file' ...)");
+// run a SQL update query on the Table and emit the result to the TableSink
+tableEnv.sqlUpdate(
+ "INSERT INTO RubberOrders SELECT product, amount FROM Orders WHERE product
LIKE '%Rubber%'")
+{% endhighlight %}
+
+
+
+{% highlight python %}
+settings = EnvironmentSettings.newInstance()...
+table_env = TableEnvironment.create(settings)
+
+# SQL update with a registered table
+# register a TableSink
+table_env.sql_update("CREATE TABLE RubberOrders(product VARCHAR, amount INT)
with (...)")
+# run a SQL update query on the Table and emit the result to the TableSink
+table_env \
+.sql_update("INSERT INTO RubberOrders SELECT product, amount FROM Orders
WHERE product LIKE '%Rubber%'")
+{% endhighlight %}
+
+
+
+{% top %}
+
+## Table DDL
+
+### CREATE TABLE
+
+{% highlight sql %}
+CREATE TABLE [catalog_name.][db_name.]table_name
+ (
+{ | }[ , ...n]
+[ ]
+ )
+ [COMMENT table_comment]
+ [PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
+ WITH (key1=val1, key2=val2, ...)
+
+:
+ column_name column_type [COMMENT column_comment]
+
+:
+ column_name AS computed_column_expression [COMMENT column_comment]
+
+:
+ WATERMARK FOR rowtime_column_name AS watermark_strategy_expression
+
+{% endhighlight %}
+
+Creates a table with the given name. If a table with the same name already
exists in the catalog, an exception is thrown.
+
+**COMPUTED COLUMN**
+
+Column declared with syntax "`column_name AS computed_column_expression`" is a
computed column. A computed column is a virtual column that is not physically
stored in the table. The column is computed from an non-query expression that
uses other columns in the same table. For example, a computed column can have
the definition: `cost AS price * qty`. The expression can be a noncomputed
column name, constant, (user-defined/system) function, variable, and any
combination of these connected by one or more operators. The expression cannot
be a subquery.
+
Review comment:
`connected by` -> `combinated by` ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Serv
[jira] [Commented] (FLINK-15404) How to insert hive table for different catalog
[
https://issues.apache.org/jira/browse/FLINK-15404?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003879#comment-17003879
]
Jingsong Lee commented on FLINK-15404:
--
[~hehuiyuan] You need invoke "tableEnv.execute"
> How to insert hive table for different catalog
> ---
>
> Key: FLINK-15404
> URL: https://issues.apache.org/jira/browse/FLINK-15404
> Project: Flink
> Issue Type: Wish
> Components: Table SQL / Planner
>Reporter: hehuiyuan
>Priority: Major
>
> I have a hive catalog :
>
> {code:java}
> catalog name : myhive
> database : default
> {code}
>
> and the flink has a default catalog :
>
> {code:java}
> catalog name : default_catalog
> database : default_database
> {code}
>
> For example :
> I have a source table 'source_table' that's from kafka which is register to
> default_catalog,
> I want to insert hive table 'hive_table' that is from myhive catalog.
> SQL:
> insert into hive_table select * from source_table;
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-15388) The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
[
https://issues.apache.org/jira/browse/FLINK-15388?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003877#comment-17003877
]
Xintong Song commented on FLINK-15388:
--
If you look at the log file, there are quite some activities before the timeout
happen, which indicates that the task manager is probably not blocked. Also the
job operators does not operates on the taskmanager rpc main thread, thus should
not block the heartbeats.
>From what you described, it still sounds like network problem to me. How do
>you know the network is ok?
For the configuration, usually we would avoid having such large containers. But
I'm not sure whether that is relevant to this heartbeat timeout problem.
> The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
> --
>
> Key: FLINK-15388
> URL: https://issues.apache.org/jira/browse/FLINK-15388
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Task
>Affects Versions: 1.8.0
> Environment: model : standalone,not yarn
> version : flink 1.8.0
> configration :
> jobmanager.heap.size: 4096m
> taskmanager.heap.size: 144gb
> taskmanager.numberOfTaskSlots: 48
> taskmanager.memory.fraction: 0.7
> taskmanager.memory.off-heap: false
> parallelism.default: 1
>
>Reporter: hiliuxg
>Priority: Major
> Attachments: metrics.png, metrics.png
>
>
> the taskmanager's slot was removed , there was not full gc or oom , what's
> the problem ? the error bellow
> {code:java}
> org.apache.flink.util.FlinkException: The assigned slot
> bae00218c818157649eb9e3c533b86af_32 was removed.
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlot(SlotManager.java:893)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlots(SlotManager.java:863)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.internalUnregisterTaskManager(SlotManager.java:1058)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.unregisterTaskManager(SlotManager.java:385)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager.closeTaskManagerConnection(ResourceManager.java:847)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener$1.run(ResourceManager.java:1161)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:392)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:185)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:147)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.onReceive(FencedAkkaRpcActor.java:40)
> at
> akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:165)
> at akka.actor.Actor$class.aroundReceive(Actor.scala:502)
> at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:95)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:526)
> at akka.actor.ActorCell.invoke(ActorCell.scala:495)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:257)
> at akka.dispatch.Mailbox.run(Mailbox.scala:224)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:234)
> at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
> at
> scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
> at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
> at
> scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-15404) How to insert hive table for different catalog
[
https://issues.apache.org/jira/browse/FLINK-15404?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003873#comment-17003873
]
hehuiyuan commented on FLINK-15404:
---
Hi [~lzljs3620320] , that is not ok. My usage may be wrong.
I use table-planner , that is ok for select and insert.
{code:java}
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tableEnv = BatchTableEnvironment.create(env);
//增加hive支持
String name= "myhive";
String defaultDatabase = "default";
String hiveConfDir =
"/Users/hehuiyuan/softs/hive/apache-hive-2.3.4-bin/conf";
String version = "2.3.4"; // or 1.2.1
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version);
tableEnv.registerCatalog("myhive", hive);
tableEnv.useCatalog("myhive");
tableEnv.useDatabase("default");
Table staff = tableEnv.sqlQuery("select * from staff");
//tableEnv.sqlUpdate("INSERT INTO staff (name, age, sex) VALUES
('hehuiyuan5',11,'m')");
DataSet dataSet = tableEnv.toDataSet(staff, Row.class);
try {
dataSet.print();
} catch (Exception e) {
e.printStackTrace();
}
{code}
But i use table planner blink ,that is not ok ! That do not insert
{code:java}
EnvironmentSettings settings =
EnvironmentSettings.newInstance().inBatchMode().useBlinkPlanner().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//增加hive支持
String name= "myhive";
String defaultDatabase = "default";
String hiveConfDir =
"/Users/hehuiyuan/softs/hive/apache-hive-2.3.4-bin/conf";
String version = "2.3.4"; // or 1.2.1
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version);
tableEnv.registerCatalog("myhive", hive);
tableEnv.useCatalog("myhive");
tableEnv.useDatabase("default");
Table staff = tableEnv.sqlQuery("select * from staff");
staff.printSchema();
tableEnv.sqlUpdate("INSERT INTO staff (name, age, sex) VALUES
('hehuiyuan6',11,'m')");
Table stafftest = tableEnv.sqlQuery("select * from stafftest");
stafftest.printSchema();
tableEnv.sqlUpdate("insert into myhive.`default`.stafftest select * from
staff");
{code}
> How to insert hive table for different catalog
> ---
>
> Key: FLINK-15404
> URL: https://issues.apache.org/jira/browse/FLINK-15404
> Project: Flink
> Issue Type: Wish
> Components: Table SQL / Planner
>Reporter: hehuiyuan
>Priority: Major
>
> I have a hive catalog :
>
> {code:java}
> catalog name : myhive
> database : default
> {code}
>
> and the flink has a default catalog :
>
> {code:java}
> catalog name : default_catalog
> database : default_database
> {code}
>
> For example :
> I have a source table 'source_table' that's from kafka which is register to
> default_catalog,
> I want to insert hive table 'hive_table' that is from myhive catalog.
> SQL:
> insert into hive_table select * from source_table;
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] wangyang0918 commented on a change in pull request #10695: [hotfix] Remove the useless stage in Mesos dockerfile
wangyang0918 commented on a change in pull request #10695: [hotfix] Remove the
useless stage in Mesos dockerfile
URL: https://github.com/apache/flink/pull/10695#discussion_r361574795
##
File path:
flink-end-to-end-tests/test-scripts/docker-mesos-cluster/docker-compose.yml
##
@@ -53,7 +53,6 @@ services:
networks:
- docker-mesos-cluster-network
volumes:
- - /var/run/docker.sock:/var/run/docker.sock
- ${END_TO_END_DIR}:${END_TO_END_DIR}
Review comment:
I think we need to avoid `privileged container` as much as possible too.
Since it may cause the same problem.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[jira] [Commented] (FLINK-15415) Flink machine node memory is consumed quickly, but the heap has not changed
[ https://issues.apache.org/jira/browse/FLINK-15415?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003870#comment-17003870 ] Benchao Li commented on FLINK-15415: what's your `-XX:MaxDirectMemory`'s value? and you can check the metaspace size of your TM. I encountered similar issue as before, which result that metaspace increases heavily after a lot of failover. > Flink machine node memory is consumed quickly, but the heap has not changed > --- > > Key: FLINK-15415 > URL: https://issues.apache.org/jira/browse/FLINK-15415 > Project: Flink > Issue Type: Bug > Components: Runtime / State Backends >Affects Versions: 1.8.0 > Environment: machine : 256G memory , SSD , 32 CORE CPU > config : > jobmanager.heap.size: 4096m > taskmanager.heap.size: 144gb > taskmanager.numberOfTaskSlots: 48 > taskmanager.memory.fraction: 0.7 > taskmanager.memory.off-heap: false > parallelism.default: 1 > > > > > >Reporter: hiliuxg >Priority: Major > Attachments: flink-3.png, flink-pid-2.png, flink-pid.png > > > The Flink node has been running for 1 month, and it is found that the > machine's memory is getting higher and higher, even exceeding the memory > configured by the heap. Through top -c, it is found that the machine's memory > and virtual memory are very high. It may be an off-heap memory leak. What is > the collection mechanism of flink's off-heap memory? It need to start FULL GC > to recycle off-heap memory? > In addition, does flink disable off-heap memory by default? > taskmanager.memory.off-heap: false, why is the memory still increasing slowly > . > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #10695: [hotfix] Remove the useless stage in Mesos dockerfile
flinkbot edited a comment on issue #10695: [hotfix] Remove the useless stage in Mesos dockerfile URL: https://github.com/apache/flink/pull/10695#issuecomment-569014612 ## CI report: * 97ac65498d207e34e891dcd59c87b6a44f04bead Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142361209) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3927) * e58625466acbbf46aeb41b14561f2c63ba075297 Travis: [SUCCESS](https://travis-ci.com/flink-ci/flink/builds/142364869) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3930) * cb283afa0c2f0cf95a6628d9b4cb6b53a52fb019 Travis: [PENDING](https://travis-ci.com/flink-ci/flink/builds/142421957) Azure: [PENDING](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3945) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-15388) The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
[
https://issues.apache.org/jira/browse/FLINK-15388?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003869#comment-17003869
]
hiliuxg commented on FLINK-15388:
-
Hi [~xintongsong]:
The problem reappears, the network is ok, the CPU is not high, and there is no
full gc, but heartbeat timeout, the zk response timeout, the promethues get the
metric point timeout. Is it possible that a certain operator of a job is
blocked, such as the sink operator, causing the TM response to time out? Is it
possible that my configuration is not reasonable, 32 core cpu is configured
with 48 slots, and heap 144G. !metrics.png!
> The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
> --
>
> Key: FLINK-15388
> URL: https://issues.apache.org/jira/browse/FLINK-15388
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Task
>Affects Versions: 1.8.0
> Environment: model : standalone,not yarn
> version : flink 1.8.0
> configration :
> jobmanager.heap.size: 4096m
> taskmanager.heap.size: 144gb
> taskmanager.numberOfTaskSlots: 48
> taskmanager.memory.fraction: 0.7
> taskmanager.memory.off-heap: false
> parallelism.default: 1
>
>Reporter: hiliuxg
>Priority: Major
> Attachments: metrics.png, metrics.png
>
>
> the taskmanager's slot was removed , there was not full gc or oom , what's
> the problem ? the error bellow
> {code:java}
> org.apache.flink.util.FlinkException: The assigned slot
> bae00218c818157649eb9e3c533b86af_32 was removed.
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlot(SlotManager.java:893)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlots(SlotManager.java:863)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.internalUnregisterTaskManager(SlotManager.java:1058)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.unregisterTaskManager(SlotManager.java:385)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager.closeTaskManagerConnection(ResourceManager.java:847)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener$1.run(ResourceManager.java:1161)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:392)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:185)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:147)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.onReceive(FencedAkkaRpcActor.java:40)
> at
> akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:165)
> at akka.actor.Actor$class.aroundReceive(Actor.scala:502)
> at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:95)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:526)
> at akka.actor.ActorCell.invoke(ActorCell.scala:495)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:257)
> at akka.dispatch.Mailbox.run(Mailbox.scala:224)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:234)
> at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
> at
> scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
> at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
> at
> scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-15388) The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
[
https://issues.apache.org/jira/browse/FLINK-15388?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
hiliuxg updated FLINK-15388:
Attachment: metrics.png
> The assigned slot bae00218c818157649eb9e3c533b86af_32 was removed.
> --
>
> Key: FLINK-15388
> URL: https://issues.apache.org/jira/browse/FLINK-15388
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Task
>Affects Versions: 1.8.0
> Environment: model : standalone,not yarn
> version : flink 1.8.0
> configration :
> jobmanager.heap.size: 4096m
> taskmanager.heap.size: 144gb
> taskmanager.numberOfTaskSlots: 48
> taskmanager.memory.fraction: 0.7
> taskmanager.memory.off-heap: false
> parallelism.default: 1
>
>Reporter: hiliuxg
>Priority: Major
> Attachments: metrics.png, metrics.png
>
>
> the taskmanager's slot was removed , there was not full gc or oom , what's
> the problem ? the error bellow
> {code:java}
> org.apache.flink.util.FlinkException: The assigned slot
> bae00218c818157649eb9e3c533b86af_32 was removed.
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlot(SlotManager.java:893)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.removeSlots(SlotManager.java:863)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.internalUnregisterTaskManager(SlotManager.java:1058)
> at
> org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager.unregisterTaskManager(SlotManager.java:385)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager.closeTaskManagerConnection(ResourceManager.java:847)
> at
> org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener$1.run(ResourceManager.java:1161)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:392)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:185)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.onReceive(AkkaRpcActor.java:147)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.onReceive(FencedAkkaRpcActor.java:40)
> at
> akka.actor.UntypedActor$$anonfun$receive$1.applyOrElse(UntypedActor.scala:165)
> at akka.actor.Actor$class.aroundReceive(Actor.scala:502)
> at akka.actor.UntypedActor.aroundReceive(UntypedActor.scala:95)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:526)
> at akka.actor.ActorCell.invoke(ActorCell.scala:495)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:257)
> at akka.dispatch.Mailbox.run(Mailbox.scala:224)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:234)
> at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
> at
> scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
> at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
> at
> scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe…
flinkbot edited a comment on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe… URL: https://github.com/apache/flink/pull/10651#issuecomment-567927075 ## CI report: * 5945e5e8f373215b0dfe051c7f91f7b91e6b0928 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/141917314) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3825) * 2393b32572b49bf430ddb0e001de1b79501894b9 Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142345451) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3918) * d58e89c10722afd2626fbc0b864bf6545479ae30 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [flink] wangyang0918 commented on a change in pull request #10695: [hotfix] Remove the useless stage in Mesos dockerfile
wangyang0918 commented on a change in pull request #10695: [hotfix] Remove the
useless stage in Mesos dockerfile
URL: https://github.com/apache/flink/pull/10695#discussion_r361574795
##
File path:
flink-end-to-end-tests/test-scripts/docker-mesos-cluster/docker-compose.yml
##
@@ -53,7 +53,6 @@ services:
networks:
- docker-mesos-cluster-network
volumes:
- - /var/run/docker.sock:/var/run/docker.sock
- ${END_TO_END_DIR}:${END_TO_END_DIR}
Review comment:
I think we need to avoid `privileged container` as much as possible too.
Since it may cause the same problem.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] wangyang0918 commented on a change in pull request #10695: [hotfix] Remove the useless stage in Mesos dockerfile
wangyang0918 commented on a change in pull request #10695: [hotfix] Remove the
useless stage in Mesos dockerfile
URL: https://github.com/apache/flink/pull/10695#discussion_r361574394
##
File path:
flink-end-to-end-tests/test-scripts/docker-mesos-cluster/docker-compose.yml
##
@@ -53,7 +53,6 @@ services:
networks:
- docker-mesos-cluster-network
volumes:
- - /var/run/docker.sock:/var/run/docker.sock
- ${END_TO_END_DIR}:${END_TO_END_DIR}
Review comment:
I suggest to use `docker cp` to get the output to local and then verify.
Using docker volume and mount may cause permission problems when cleanup logs
and output.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [flink] shidayang commented on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe…
shidayang commented on issue #10651: [FLINK-15343][API/DataStream] Add Watermarks options for TwoInputStreamOpe… URL: https://github.com/apache/flink/pull/10651#issuecomment-569178934 @flinkbot run travis This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (FLINK-15407) Add document to explain how to write a table with PK
[
https://issues.apache.org/jira/browse/FLINK-15407?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17003858#comment-17003858
]
Jingsong Lee commented on FLINK-15407:
--
cc: [~jark] [~ykt836]
> Add document to explain how to write a table with PK
>
>
> Key: FLINK-15407
> URL: https://issues.apache.org/jira/browse/FLINK-15407
> Project: Flink
> Issue Type: Bug
> Components: Documentation, Table SQL / API
>Reporter: Jingsong Lee
>Priority: Major
> Fix For: 1.10.0
>
>
> I have had several user problems:
> Why is an error reported when writing the upsertsink: TableException:
> UpsertStreamTableSink requires that Table has a full primary keys if it is
> updated.
> Users are confused.
> I think we can consider writing a document to describe it.
> User need careful like:
>
> {code:java}
> insert into result_table select pk1, if(pk2 is null, '', pk2) as pk2,
> count(*), sum(f3) from source group by pk1, pk2; {code}
> This will failed.
>
> {code:java}
> insert into result_table select pk1, pk2, count(*), sum(f1) from (select pk1,
> if(pk2 is null, '', pk2) as pk2, f1 from source) group by pk1, pk2;
> {code}
> This can work.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on issue #10695: [hotfix] Remove the useless stage in Mesos dockerfile
flinkbot edited a comment on issue #10695: [hotfix] Remove the useless stage in Mesos dockerfile URL: https://github.com/apache/flink/pull/10695#issuecomment-569014612 ## CI report: * 97ac65498d207e34e891dcd59c87b6a44f04bead Travis: [FAILURE](https://travis-ci.com/flink-ci/flink/builds/142361209) Azure: [FAILURE](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3927) * e58625466acbbf46aeb41b14561f2c63ba075297 Travis: [SUCCESS](https://travis-ci.com/flink-ci/flink/builds/142364869) Azure: [SUCCESS](https://dev.azure.com/rmetzger/5bd3ef0a-4359-41af-abca-811b04098d2e/_build/results?buildId=3930) * cb283afa0c2f0cf95a6628d9b4cb6b53a52fb019 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services