[GitHub] [flink] lirui-apache commented on pull request #14203: [FLINK-20241][hive] Improve exception message when hive deps are miss…
lirui-apache commented on pull request #14203: URL: https://github.com/apache/flink/pull/14203#issuecomment-734138103 @StephanEwen @JingsongLi Would you mind have a look at the PR? Thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-20365) The native k8s cluster could not be unregistered when executing Python DataStream application attachedly.
[ https://issues.apache.org/jira/browse/FLINK-20365?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Dian Fu reassigned FLINK-20365: --- Assignee: Shuiqiang Chen > The native k8s cluster could not be unregistered when executing Python > DataStream application attachedly. > - > > Key: FLINK-20365 > URL: https://issues.apache.org/jira/browse/FLINK-20365 > Project: Flink > Issue Type: Bug > Components: API / Python >Reporter: Shuiqiang Chen >Assignee: Shuiqiang Chen >Priority: Major > Fix For: 1.12.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-20345) Adds an Expand node only if there are multiple distinct aggregate functions in an Aggregate when executes SplitAggregateRule
[
https://issues.apache.org/jira/browse/FLINK-20345?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239107#comment-17239107
]
Jingsong Lee commented on FLINK-20345:
--
[~qingru zhang] Assigned to u
> Adds an Expand node only if there are multiple distinct aggregate functions
> in an Aggregate when executes SplitAggregateRule
>
>
> Key: FLINK-20345
> URL: https://issues.apache.org/jira/browse/FLINK-20345
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / Planner
>Affects Versions: 1.11.2
>Reporter: Andy
>Assignee: Andy
>Priority: Major
> Fix For: 1.11.3
>
>
> As mentioned in [Flink
> Document|https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/tuning/streaming_aggregation_optimization.html],
> we could split distinct aggregation to solve skew data on distinct keys
> which is a very good optimization. However, an unnecessary `Expand` node will
> be generated under some special cases, like the following sql.
> {code:java}
> SELECT COUNT(c) AS pv, COUNT(DISTINCT c) AS uv FROM T GROUP BY a
> {code}
> Which plan is like the following text, the Expand and filter condition in
> aggregate functions could be removed.
> {code:java}
> Sink(name=[DataStreamTableSink], fields=[pv, uv])
> +- Calc(select=[pv, uv])
>+- GroupAggregate(groupBy=[a], partialFinalType=[FINAL], select=[a,
> $SUM0_RETRACT($f2_0) AS $f1, $SUM0_RETRACT($f3) AS $f2])
> +- Exchange(distribution=[hash[a]])
> +- GroupAggregate(groupBy=[a, $f2], partialFinalType=[PARTIAL],
> select=[a, $f2, COUNT(c) FILTER $g_1 AS $f2_0, COUNT(DISTINCT c) FILTER $g_0
> AS $f3])
> +- Exchange(distribution=[hash[a, $f2]])
>+- Calc(select=[a, c, $f2, =($e, 1) AS $g_1, =($e, 0) AS $g_0])
> +- Expand(projects=[{a=[$0], c=[$1], $f2=[$2], $e=[0]},
> {a=[$0], c=[$1], $f2=[null], $e=[1]}])
> +- Calc(select=[a, c, MOD(HASH_CODE(c), 1024) AS $f2])
> +- MiniBatchAssigner(interval=[1000ms],
> mode=[ProcTime])
>+- DataStreamScan(table=[[default_catalog,
> default_database, T]], fields=[a, b, c]){code}
> An `Expand` node is only necessary when multiple aggregate function with
> different distinct keys appear in an Aggregate.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-20345) Adds an Expand node only if there are multiple distinct aggregate functions in an Aggregate when executes SplitAggregateRule
[
https://issues.apache.org/jira/browse/FLINK-20345?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jingsong Lee updated FLINK-20345:
-
Fix Version/s: (was: 1.11.3)
1.13.0
> Adds an Expand node only if there are multiple distinct aggregate functions
> in an Aggregate when executes SplitAggregateRule
>
>
> Key: FLINK-20345
> URL: https://issues.apache.org/jira/browse/FLINK-20345
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / Planner
>Affects Versions: 1.11.2
>Reporter: Andy
>Assignee: Andy
>Priority: Major
> Fix For: 1.13.0
>
>
> As mentioned in [Flink
> Document|https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/tuning/streaming_aggregation_optimization.html],
> we could split distinct aggregation to solve skew data on distinct keys
> which is a very good optimization. However, an unnecessary `Expand` node will
> be generated under some special cases, like the following sql.
> {code:java}
> SELECT COUNT(c) AS pv, COUNT(DISTINCT c) AS uv FROM T GROUP BY a
> {code}
> Which plan is like the following text, the Expand and filter condition in
> aggregate functions could be removed.
> {code:java}
> Sink(name=[DataStreamTableSink], fields=[pv, uv])
> +- Calc(select=[pv, uv])
>+- GroupAggregate(groupBy=[a], partialFinalType=[FINAL], select=[a,
> $SUM0_RETRACT($f2_0) AS $f1, $SUM0_RETRACT($f3) AS $f2])
> +- Exchange(distribution=[hash[a]])
> +- GroupAggregate(groupBy=[a, $f2], partialFinalType=[PARTIAL],
> select=[a, $f2, COUNT(c) FILTER $g_1 AS $f2_0, COUNT(DISTINCT c) FILTER $g_0
> AS $f3])
> +- Exchange(distribution=[hash[a, $f2]])
>+- Calc(select=[a, c, $f2, =($e, 1) AS $g_1, =($e, 0) AS $g_0])
> +- Expand(projects=[{a=[$0], c=[$1], $f2=[$2], $e=[0]},
> {a=[$0], c=[$1], $f2=[null], $e=[1]}])
> +- Calc(select=[a, c, MOD(HASH_CODE(c), 1024) AS $f2])
> +- MiniBatchAssigner(interval=[1000ms],
> mode=[ProcTime])
>+- DataStreamScan(table=[[default_catalog,
> default_database, T]], fields=[a, b, c]){code}
> An `Expand` node is only necessary when multiple aggregate function with
> different distinct keys appear in an Aggregate.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Assigned] (FLINK-20345) Adds an Expand node only if there are multiple distinct aggregate functions in an Aggregate when executes SplitAggregateRule
[
https://issues.apache.org/jira/browse/FLINK-20345?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jingsong Lee reassigned FLINK-20345:
Assignee: Andy
> Adds an Expand node only if there are multiple distinct aggregate functions
> in an Aggregate when executes SplitAggregateRule
>
>
> Key: FLINK-20345
> URL: https://issues.apache.org/jira/browse/FLINK-20345
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / Planner
>Affects Versions: 1.11.2
>Reporter: Andy
>Assignee: Andy
>Priority: Major
> Fix For: 1.11.3
>
>
> As mentioned in [Flink
> Document|https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/tuning/streaming_aggregation_optimization.html],
> we could split distinct aggregation to solve skew data on distinct keys
> which is a very good optimization. However, an unnecessary `Expand` node will
> be generated under some special cases, like the following sql.
> {code:java}
> SELECT COUNT(c) AS pv, COUNT(DISTINCT c) AS uv FROM T GROUP BY a
> {code}
> Which plan is like the following text, the Expand and filter condition in
> aggregate functions could be removed.
> {code:java}
> Sink(name=[DataStreamTableSink], fields=[pv, uv])
> +- Calc(select=[pv, uv])
>+- GroupAggregate(groupBy=[a], partialFinalType=[FINAL], select=[a,
> $SUM0_RETRACT($f2_0) AS $f1, $SUM0_RETRACT($f3) AS $f2])
> +- Exchange(distribution=[hash[a]])
> +- GroupAggregate(groupBy=[a, $f2], partialFinalType=[PARTIAL],
> select=[a, $f2, COUNT(c) FILTER $g_1 AS $f2_0, COUNT(DISTINCT c) FILTER $g_0
> AS $f3])
> +- Exchange(distribution=[hash[a, $f2]])
>+- Calc(select=[a, c, $f2, =($e, 1) AS $g_1, =($e, 0) AS $g_0])
> +- Expand(projects=[{a=[$0], c=[$1], $f2=[$2], $e=[0]},
> {a=[$0], c=[$1], $f2=[null], $e=[1]}])
> +- Calc(select=[a, c, MOD(HASH_CODE(c), 1024) AS $f2])
> +- MiniBatchAssigner(interval=[1000ms],
> mode=[ProcTime])
>+- DataStreamScan(table=[[default_catalog,
> default_database, T]], fields=[a, b, c]){code}
> An `Expand` node is only necessary when multiple aggregate function with
> different distinct keys appear in an Aggregate.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot commented on pull request #14228: [FLINK-20349][table-planner-blink] Fix checking for deadlock caused by exchange
flinkbot commented on pull request #14228: URL: https://github.com/apache/flink/pull/14228#issuecomment-734132510 ## CI report: * 523a5b439481c59e89ed2c548b36cc0ae8df69c9 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] AHeise commented on pull request #13885: [FLINK-19911] add read buffer for input stream
AHeise commented on pull request #13885: URL: https://github.com/apache/flink/pull/13885#issuecomment-734129526 > > > > `LocalFileSystem` > > > > > > > > > Yes, it looks like `LocalFileSystem` should also be a good candidate. In particular `#open(Path, int)` currently ignores the buffer size... > > > I'm wondering if it makes more sense to create two PRs though. Even though the solution is pretty much the same, the underlying issues are different imho. The smaller a PR, the faster we can usually go. However, since they are so related, I wouldn't mind both issues being resolved in the same PR. > > > > > > Hi @AHeise , thanks for your quick reply. > > I think it is okay to create two PRs. The current PR developed `FsDataBuefferedInputStream` and applied it to `HadoopFileSysytem`. > > The next PR considers whether other FileSystem are profitable. > > Hi @AHeise , > > Do you think this plan is OK? If ok, I will develop the code of the current PR when I have time. Yes @1996fanrui , please go ahead. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-20345) Adds an Expand node only if there are multiple distinct aggregate functions in an Aggregate when executes SplitAggregateRule
[
https://issues.apache.org/jira/browse/FLINK-20345?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239105#comment-17239105
]
Andy commented on FLINK-20345:
--
[~lzljs3620320] I agree with you. Could I take this issue?
> Adds an Expand node only if there are multiple distinct aggregate functions
> in an Aggregate when executes SplitAggregateRule
>
>
> Key: FLINK-20345
> URL: https://issues.apache.org/jira/browse/FLINK-20345
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / Planner
>Affects Versions: 1.11.2
>Reporter: Andy
>Priority: Major
> Fix For: 1.11.3
>
>
> As mentioned in [Flink
> Document|https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/tuning/streaming_aggregation_optimization.html],
> we could split distinct aggregation to solve skew data on distinct keys
> which is a very good optimization. However, an unnecessary `Expand` node will
> be generated under some special cases, like the following sql.
> {code:java}
> SELECT COUNT(c) AS pv, COUNT(DISTINCT c) AS uv FROM T GROUP BY a
> {code}
> Which plan is like the following text, the Expand and filter condition in
> aggregate functions could be removed.
> {code:java}
> Sink(name=[DataStreamTableSink], fields=[pv, uv])
> +- Calc(select=[pv, uv])
>+- GroupAggregate(groupBy=[a], partialFinalType=[FINAL], select=[a,
> $SUM0_RETRACT($f2_0) AS $f1, $SUM0_RETRACT($f3) AS $f2])
> +- Exchange(distribution=[hash[a]])
> +- GroupAggregate(groupBy=[a, $f2], partialFinalType=[PARTIAL],
> select=[a, $f2, COUNT(c) FILTER $g_1 AS $f2_0, COUNT(DISTINCT c) FILTER $g_0
> AS $f3])
> +- Exchange(distribution=[hash[a, $f2]])
>+- Calc(select=[a, c, $f2, =($e, 1) AS $g_1, =($e, 0) AS $g_0])
> +- Expand(projects=[{a=[$0], c=[$1], $f2=[$2], $e=[0]},
> {a=[$0], c=[$1], $f2=[null], $e=[1]}])
> +- Calc(select=[a, c, MOD(HASH_CODE(c), 1024) AS $f2])
> +- MiniBatchAssigner(interval=[1000ms],
> mode=[ProcTime])
>+- DataStreamScan(table=[[default_catalog,
> default_database, T]], fields=[a, b, c]){code}
> An `Expand` node is only necessary when multiple aggregate function with
> different distinct keys appear in an Aggregate.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Closed] (FLINK-20362) Broken Link in dev/table/sourceSinks.zh.md
[
https://issues.apache.org/jira/browse/FLINK-20362?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Dian Fu closed FLINK-20362.
---
Resolution: Fixed
Fixed in
- master via 47d81ce1328fb5979e237048bdfc8bae5d88d283
- release-1.12 via 3ebeb6c8f5ab6791e32a4f98210a4b8fd8e45cd8
> Broken Link in dev/table/sourceSinks.zh.md
> --
>
> Key: FLINK-20362
> URL: https://issues.apache.org/jira/browse/FLINK-20362
> Project: Flink
> Issue Type: Bug
> Components: Documentation, Table SQL / API
>Affects Versions: 1.12.0
>Reporter: Huang Xingbo
>Assignee: Shengkai Fang
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.12.0
>
>
> When executing the script build_docs.sh, it will throw the following
> exception:
> {code:java}
> Liquid Exception: Could not find document 'dev/table/legacySourceSinks.md' in
> tag 'link'. Make sure the document exists and the path is correct. in
> dev/table/sourceSinks.zh.md Could not find document
> 'dev/table/legacySourceSinks.md' in tag 'link'.
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #14227: [FLINK-20245][hive][docs] Document how to create a Hive catalog from DDL
flinkbot edited a comment on pull request #14227: URL: https://github.com/apache/flink/pull/14227#issuecomment-734118464 ## CI report: * 22f1148159795b2c6e292bc018df4292fd0692a8 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=10152) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] dianfu closed pull request #14226: [FLINK-20362][doc] Fix broken link in sourceSinks.zh.md
dianfu closed pull request #14226: URL: https://github.com/apache/flink/pull/14226 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #14228: [FLINK-20349][table-planner-blink] Fix checking for deadlock caused by exchange
flinkbot commented on pull request #14228: URL: https://github.com/apache/flink/pull/14228#issuecomment-734123858 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit 523a5b439481c59e89ed2c548b36cc0ae8df69c9 (Thu Nov 26 07:23:59 UTC 2020) **Warnings:** * No documentation files were touched! Remember to keep the Flink docs up to date! Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-20349) Query fails with "A conflict is detected. This is unexpected."
[
https://issues.apache.org/jira/browse/FLINK-20349?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-20349:
---
Labels: pull-request-available (was: )
> Query fails with "A conflict is detected. This is unexpected."
> --
>
> Key: FLINK-20349
> URL: https://issues.apache.org/jira/browse/FLINK-20349
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.12.0
>Reporter: Rui Li
>Assignee: Caizhi Weng
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.12.0
>
>
> The test case to reproduce:
> {code}
> @Test
> public void test() throws Exception {
> tableEnv.executeSql("create table src(key string,val string)");
> tableEnv.executeSql("SELECT sum(char_length(src5.src1_value))
> FROM " +
> "(SELECT src3.*, src4.val as src4_value,
> src4.key as src4_key FROM src src4 JOIN " +
> "(SELECT src2.*, src1.key as src1_key, src1.val
> as src1_value FROM src src1 JOIN src src2 ON src1.key = src2.key) src3 " +
> "ON src3.src1_key = src4.key) src5").collect();
> }
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] TsReaper opened a new pull request #14228: [FLINK-20349][table-planner-blink] Fix checking for deadlock caused by exchange
TsReaper opened a new pull request #14228: URL: https://github.com/apache/flink/pull/14228 ## What is the purpose of the change This is the bug fix for FLINK-20349, where the checking for deadlock caused by exchange in the deadlock break-up algorithm does not work for some cases. ## Brief change log - Fix checking for deadlock caused by exchange ## Verifying this change This change added tests and can be verified by running the added tests. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn/Mesos, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-20331) UnalignedCheckpointITCase.execute failed with "Sequence number for checkpoint 20 is not known (it was likely been overwritten by a newer checkpoint 21)"
[
https://issues.apache.org/jira/browse/FLINK-20331?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239097#comment-17239097
]
Arvid Heise edited comment on FLINK-20331 at 11/26/20, 7:18 AM:
Not a real bug but a too strict assumption.
Merged a fix as
[50af0b161b1962d9db5c692aa965b310a4000da9|https://github.com/apache/flink/commit/50af0b161b1962d9db5c692aa965b310a4000da9]
in master.
Merged as 2c77c38d55 into release-1.12.
was (Author: aheise):
Not a real bug but a too strict assumption.
Merged a fix as
[50af0b161b1962d9db5c692aa965b310a4000da9|https://github.com/apache/flink/commit/50af0b161b1962d9db5c692aa965b310a4000da9]
in master.
> UnalignedCheckpointITCase.execute failed with "Sequence number for checkpoint
> 20 is not known (it was likely been overwritten by a newer checkpoint 21)"
>
>
> Key: FLINK-20331
> URL: https://issues.apache.org/jira/browse/FLINK-20331
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Checkpointing
>Affects Versions: 1.12.0
>Reporter: Dian Fu
>Assignee: Roman Khachatryan
>Priority: Blocker
> Labels: pull-request-available, test-stability
> Fix For: 1.12.0
>
>
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=10059&view=logs&j=119bbba7-f5e3-5e08-e72d-09f1529665de&t=7dc1f5a9-54e1-502e-8b02-c7df69073cfc
> {code}
> 2020-11-24T22:42:17.6704402Z [ERROR] execute[parallel pipeline with mixed
> channels, p =
> 20](org.apache.flink.test.checkpointing.UnalignedCheckpointITCase) Time
> elapsed: 7.901 s <<< ERROR!
> 2020-11-24T22:42:17.6706095Z
> org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
> 2020-11-24T22:42:17.6707450Z at
> org.apache.flink.runtime.jobmaster.JobResult.toJobExecutionResult(JobResult.java:147)
> 2020-11-24T22:42:17.6708569Z at
> org.apache.flink.runtime.minicluster.MiniClusterJobClient.lambda$getJobExecutionResult$2(MiniClusterJobClient.java:119)
> 2020-11-24T22:42:17.6709626Z at
> java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:616)
> 2020-11-24T22:42:17.6710452Z at
> java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591)
> 2020-11-24T22:42:17.6711271Z at
> java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
> 2020-11-24T22:42:17.6713170Z at
> java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975)
> 2020-11-24T22:42:17.6713974Z at
> org.apache.flink.runtime.rpc.akka.AkkaInvocationHandler.lambda$invokeRpc$0(AkkaInvocationHandler.java:229)
> 2020-11-24T22:42:17.6714517Z at
> java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774)
> 2020-11-24T22:42:17.6715372Z at
> java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750)
> 2020-11-24T22:42:17.6715871Z at
> java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
> 2020-11-24T22:42:17.6716514Z at
> java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975)
> 2020-11-24T22:42:17.6718475Z at
> org.apache.flink.runtime.concurrent.FutureUtils$1.onComplete(FutureUtils.java:996)
> 2020-11-24T22:42:17.6719322Z at
> akka.dispatch.OnComplete.internal(Future.scala:264)
> 2020-11-24T22:42:17.6719887Z at
> akka.dispatch.OnComplete.internal(Future.scala:261)
> 2020-11-24T22:42:17.6720271Z at
> akka.dispatch.japi$CallbackBridge.apply(Future.scala:191)
> 2020-11-24T22:42:17.6720645Z at
> akka.dispatch.japi$CallbackBridge.apply(Future.scala:188)
> 2020-11-24T22:42:17.6721114Z at
> scala.concurrent.impl.CallbackRunnable.run(Promise.scala:36)
> 2020-11-24T22:42:17.6721585Z at
> org.apache.flink.runtime.concurrent.Executors$DirectExecutionContext.execute(Executors.java:74)
> 2020-11-24T22:42:17.6722078Z at
> scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:44)
> 2020-11-24T22:42:17.6722738Z at
> scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:252)
> 2020-11-24T22:42:17.6723183Z at
> akka.pattern.PromiseActorRef.$bang(AskSupport.scala:572)
> 2020-11-24T22:42:17.6723862Z at
> akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:22)
> 2020-11-24T22:42:17.6724435Z at
> akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:21)
> 2020-11-24T22:42:17.6724914Z at
> scala.concurrent.Future$$anonfun$andThen$1.apply(Future.scala:436)
> 2020-11-24T22:42:17.6725323Z at
> scala.concurrent.Future$$anonfun$andThen$1.apply(Future.scala:435)
> 2020-11-24T22:42:17.6725866Z at
> scala.concurrent.impl.CallbackRunnable.run(Prom
[jira] [Commented] (FLINK-20327) The Hive's read/write page should redirect to SQL Fileystem connector
[ https://issues.apache.org/jira/browse/FLINK-20327?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239100#comment-17239100 ] Leonard Xu commented on FLINK-20327: I'd like to take this, could you help assign this to me ? [~dwysakowicz] > The Hive's read/write page should redirect to SQL Fileystem connector > - > > Key: FLINK-20327 > URL: https://issues.apache.org/jira/browse/FLINK-20327 > Project: Flink > Issue Type: Improvement > Components: Connectors / Hive, Documentation >Reporter: Dawid Wysakowicz >Priority: Critical > Fix For: 1.12.0 > > > Right now the Hive's read/write page redirects to SQL filesystem connector > with a note: ??Please see the StreamingFileSink for a full list of available > configurations.?? but this page actually has no configuration options. We > should link to > https://ci.apache.org/projects/flink/flink-docs-master/dev/table/connectors/filesystem.html > instead which cover the SQL related configuration. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Closed] (FLINK-20339) `FileWriter` support to load StreamingFileSink's state.
[ https://issues.apache.org/jira/browse/FLINK-20339?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Guowei Ma closed FLINK-20339. - Resolution: Won't Fix > `FileWriter` support to load StreamingFileSink's state. > --- > > Key: FLINK-20339 > URL: https://issues.apache.org/jira/browse/FLINK-20339 > Project: Flink > Issue Type: Sub-task > Components: API / DataStream >Affects Versions: 1.12.0 >Reporter: Guowei Ma >Priority: Critical > Fix For: 1.12.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Closed] (FLINK-20338) Make the `StatefulSinkWriterOperator` load `StreamingFileSink`'s state.
[ https://issues.apache.org/jira/browse/FLINK-20338?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Guowei Ma closed FLINK-20338. - Resolution: Won't Fix > Make the `StatefulSinkWriterOperator` load `StreamingFileSink`'s state. > --- > > Key: FLINK-20338 > URL: https://issues.apache.org/jira/browse/FLINK-20338 > Project: Flink > Issue Type: Sub-task > Components: API / DataStream >Affects Versions: 1.12.0 >Reporter: Guowei Ma >Priority: Critical > Labels: pull-request-available > Fix For: 1.12.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-20337) Make migrate `StreamingFileSink` to `FileSink` possible
[ https://issues.apache.org/jira/browse/FLINK-20337?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239098#comment-17239098 ] Guowei Ma commented on FLINK-20337: --- Sorry [~kkl0u] for responsing so late. I think it is good for other to follow what is happen if we merge the two tasks together. So I would close the two sub tasks. > Make migrate `StreamingFileSink` to `FileSink` possible > --- > > Key: FLINK-20337 > URL: https://issues.apache.org/jira/browse/FLINK-20337 > Project: Flink > Issue Type: Improvement > Components: API / DataStream >Affects Versions: 1.12.0 >Reporter: Guowei Ma >Assignee: Guowei Ma >Priority: Critical > Fix For: 1.12.0 > > > Flink-1.12 introduces the `FileSink` in FLINK-19510, which can guarantee the > exactly once semantics both in the streaming and batch execution mode. We > need to provide a way for the user who uses `StreamingFileSink` to migrate > from `StreamingFileSink` to `FileSink`. > For this purpose we propose to let the new sink writer operator could load > the previous StreamingFileSink's state and then the `SinkWriter` could have > the opertunity to handle the old state. > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot commented on pull request #14227: [FLINK-20245][hive][docs] Document how to create a Hive catalog from DDL
flinkbot commented on pull request #14227: URL: https://github.com/apache/flink/pull/14227#issuecomment-734118464 ## CI report: * 22f1148159795b2c6e292bc018df4292fd0692a8 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Resolved] (FLINK-20331) UnalignedCheckpointITCase.execute failed with "Sequence number for checkpoint 20 is not known (it was likely been overwritten by a newer checkpoint 21)"
[
https://issues.apache.org/jira/browse/FLINK-20331?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Arvid Heise resolved FLINK-20331.
-
Resolution: Fixed
> UnalignedCheckpointITCase.execute failed with "Sequence number for checkpoint
> 20 is not known (it was likely been overwritten by a newer checkpoint 21)"
>
>
> Key: FLINK-20331
> URL: https://issues.apache.org/jira/browse/FLINK-20331
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Checkpointing
>Affects Versions: 1.12.0
>Reporter: Dian Fu
>Assignee: Roman Khachatryan
>Priority: Blocker
> Labels: pull-request-available, test-stability
> Fix For: 1.12.0
>
>
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=10059&view=logs&j=119bbba7-f5e3-5e08-e72d-09f1529665de&t=7dc1f5a9-54e1-502e-8b02-c7df69073cfc
> {code}
> 2020-11-24T22:42:17.6704402Z [ERROR] execute[parallel pipeline with mixed
> channels, p =
> 20](org.apache.flink.test.checkpointing.UnalignedCheckpointITCase) Time
> elapsed: 7.901 s <<< ERROR!
> 2020-11-24T22:42:17.6706095Z
> org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
> 2020-11-24T22:42:17.6707450Z at
> org.apache.flink.runtime.jobmaster.JobResult.toJobExecutionResult(JobResult.java:147)
> 2020-11-24T22:42:17.6708569Z at
> org.apache.flink.runtime.minicluster.MiniClusterJobClient.lambda$getJobExecutionResult$2(MiniClusterJobClient.java:119)
> 2020-11-24T22:42:17.6709626Z at
> java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:616)
> 2020-11-24T22:42:17.6710452Z at
> java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591)
> 2020-11-24T22:42:17.6711271Z at
> java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
> 2020-11-24T22:42:17.6713170Z at
> java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975)
> 2020-11-24T22:42:17.6713974Z at
> org.apache.flink.runtime.rpc.akka.AkkaInvocationHandler.lambda$invokeRpc$0(AkkaInvocationHandler.java:229)
> 2020-11-24T22:42:17.6714517Z at
> java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774)
> 2020-11-24T22:42:17.6715372Z at
> java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750)
> 2020-11-24T22:42:17.6715871Z at
> java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
> 2020-11-24T22:42:17.6716514Z at
> java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975)
> 2020-11-24T22:42:17.6718475Z at
> org.apache.flink.runtime.concurrent.FutureUtils$1.onComplete(FutureUtils.java:996)
> 2020-11-24T22:42:17.6719322Z at
> akka.dispatch.OnComplete.internal(Future.scala:264)
> 2020-11-24T22:42:17.6719887Z at
> akka.dispatch.OnComplete.internal(Future.scala:261)
> 2020-11-24T22:42:17.6720271Z at
> akka.dispatch.japi$CallbackBridge.apply(Future.scala:191)
> 2020-11-24T22:42:17.6720645Z at
> akka.dispatch.japi$CallbackBridge.apply(Future.scala:188)
> 2020-11-24T22:42:17.6721114Z at
> scala.concurrent.impl.CallbackRunnable.run(Promise.scala:36)
> 2020-11-24T22:42:17.6721585Z at
> org.apache.flink.runtime.concurrent.Executors$DirectExecutionContext.execute(Executors.java:74)
> 2020-11-24T22:42:17.6722078Z at
> scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:44)
> 2020-11-24T22:42:17.6722738Z at
> scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:252)
> 2020-11-24T22:42:17.6723183Z at
> akka.pattern.PromiseActorRef.$bang(AskSupport.scala:572)
> 2020-11-24T22:42:17.6723862Z at
> akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:22)
> 2020-11-24T22:42:17.6724435Z at
> akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:21)
> 2020-11-24T22:42:17.6724914Z at
> scala.concurrent.Future$$anonfun$andThen$1.apply(Future.scala:436)
> 2020-11-24T22:42:17.6725323Z at
> scala.concurrent.Future$$anonfun$andThen$1.apply(Future.scala:435)
> 2020-11-24T22:42:17.6725866Z at
> scala.concurrent.impl.CallbackRunnable.run(Promise.scala:36)
> 2020-11-24T22:42:17.6726313Z at
> akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:55)
> 2020-11-24T22:42:17.6726829Z at
> akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply$mcV$sp(BatchingExecutor.scala:91)
> 2020-11-24T22:42:17.6727376Z at
> akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply(BatchingExecutor.scala:91)
> 2020-11-24T22:42:17.6727891Z at
> akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply(BatchingExecutor.scala:91)
> 2020
[jira] [Commented] (FLINK-20331) UnalignedCheckpointITCase.execute failed with "Sequence number for checkpoint 20 is not known (it was likely been overwritten by a newer checkpoint 21)"
[
https://issues.apache.org/jira/browse/FLINK-20331?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239097#comment-17239097
]
Arvid Heise commented on FLINK-20331:
-
Not a real bug but a too strict assumption.
Merged a fix as
[50af0b161b1962d9db5c692aa965b310a4000da9|https://github.com/apache/flink/commit/50af0b161b1962d9db5c692aa965b310a4000da9]
in master.
> UnalignedCheckpointITCase.execute failed with "Sequence number for checkpoint
> 20 is not known (it was likely been overwritten by a newer checkpoint 21)"
>
>
> Key: FLINK-20331
> URL: https://issues.apache.org/jira/browse/FLINK-20331
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Checkpointing
>Affects Versions: 1.12.0
>Reporter: Dian Fu
>Assignee: Roman Khachatryan
>Priority: Blocker
> Labels: pull-request-available, test-stability
> Fix For: 1.12.0
>
>
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=10059&view=logs&j=119bbba7-f5e3-5e08-e72d-09f1529665de&t=7dc1f5a9-54e1-502e-8b02-c7df69073cfc
> {code}
> 2020-11-24T22:42:17.6704402Z [ERROR] execute[parallel pipeline with mixed
> channels, p =
> 20](org.apache.flink.test.checkpointing.UnalignedCheckpointITCase) Time
> elapsed: 7.901 s <<< ERROR!
> 2020-11-24T22:42:17.6706095Z
> org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
> 2020-11-24T22:42:17.6707450Z at
> org.apache.flink.runtime.jobmaster.JobResult.toJobExecutionResult(JobResult.java:147)
> 2020-11-24T22:42:17.6708569Z at
> org.apache.flink.runtime.minicluster.MiniClusterJobClient.lambda$getJobExecutionResult$2(MiniClusterJobClient.java:119)
> 2020-11-24T22:42:17.6709626Z at
> java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:616)
> 2020-11-24T22:42:17.6710452Z at
> java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591)
> 2020-11-24T22:42:17.6711271Z at
> java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
> 2020-11-24T22:42:17.6713170Z at
> java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975)
> 2020-11-24T22:42:17.6713974Z at
> org.apache.flink.runtime.rpc.akka.AkkaInvocationHandler.lambda$invokeRpc$0(AkkaInvocationHandler.java:229)
> 2020-11-24T22:42:17.6714517Z at
> java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774)
> 2020-11-24T22:42:17.6715372Z at
> java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750)
> 2020-11-24T22:42:17.6715871Z at
> java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
> 2020-11-24T22:42:17.6716514Z at
> java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975)
> 2020-11-24T22:42:17.6718475Z at
> org.apache.flink.runtime.concurrent.FutureUtils$1.onComplete(FutureUtils.java:996)
> 2020-11-24T22:42:17.6719322Z at
> akka.dispatch.OnComplete.internal(Future.scala:264)
> 2020-11-24T22:42:17.6719887Z at
> akka.dispatch.OnComplete.internal(Future.scala:261)
> 2020-11-24T22:42:17.6720271Z at
> akka.dispatch.japi$CallbackBridge.apply(Future.scala:191)
> 2020-11-24T22:42:17.6720645Z at
> akka.dispatch.japi$CallbackBridge.apply(Future.scala:188)
> 2020-11-24T22:42:17.6721114Z at
> scala.concurrent.impl.CallbackRunnable.run(Promise.scala:36)
> 2020-11-24T22:42:17.6721585Z at
> org.apache.flink.runtime.concurrent.Executors$DirectExecutionContext.execute(Executors.java:74)
> 2020-11-24T22:42:17.6722078Z at
> scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:44)
> 2020-11-24T22:42:17.6722738Z at
> scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:252)
> 2020-11-24T22:42:17.6723183Z at
> akka.pattern.PromiseActorRef.$bang(AskSupport.scala:572)
> 2020-11-24T22:42:17.6723862Z at
> akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:22)
> 2020-11-24T22:42:17.6724435Z at
> akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:21)
> 2020-11-24T22:42:17.6724914Z at
> scala.concurrent.Future$$anonfun$andThen$1.apply(Future.scala:436)
> 2020-11-24T22:42:17.6725323Z at
> scala.concurrent.Future$$anonfun$andThen$1.apply(Future.scala:435)
> 2020-11-24T22:42:17.6725866Z at
> scala.concurrent.impl.CallbackRunnable.run(Promise.scala:36)
> 2020-11-24T22:42:17.6726313Z at
> akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:55)
> 2020-11-24T22:42:17.6726829Z at
> akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply$mcV$sp(BatchingExecutor.scala:91)
> 2020-11-24T22:42:17.6727376Z at
> a
[GitHub] [flink] flinkbot edited a comment on pull request #13983: [FLINK-19989][python] Add collect operation in Python DataStream API
flinkbot edited a comment on pull request #13983: URL: https://github.com/apache/flink/pull/13983#issuecomment-723574143 ## CI report: * fe0505f91d71c3a5947bdac49a8b3fb91983d5c5 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=9922) * 5ed0db74dfc9f605365d6cbf811b5092b3eca062 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=10150) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] 1996fanrui commented on pull request #13885: [FLINK-19911] add read buffer for input stream
1996fanrui commented on pull request #13885: URL: https://github.com/apache/flink/pull/13885#issuecomment-734116774 > > > `LocalFileSystem` > > > > > > Yes, it looks like `LocalFileSystem` should also be a good candidate. In particular `#open(Path, int)` currently ignores the buffer size... > > I'm wondering if it makes more sense to create two PRs though. Even though the solution is pretty much the same, the underlying issues are different imho. The smaller a PR, the faster we can usually go. However, since they are so related, I wouldn't mind both issues being resolved in the same PR. > > Hi @AHeise , thanks for your quick reply. > > I think it is okay to create two PRs. The current PR developed `FsDataBuefferedInputStream` and applied it to `HadoopFileSysytem`. > > The next PR considers whether other FileSystem are profitable. Hi @AHeise , Do you think this plan is OK? If ok, I will develop the code of the current PR when I have time. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] AHeise merged pull request #14218: [FLINK-20331][checkpointing][task] Don't fail the task if unaligned checkpoint was subsumed
AHeise merged pull request #14218: URL: https://github.com/apache/flink/pull/14218 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-20213) Partition commit is delayed when records keep coming
[ https://issues.apache.org/jira/browse/FLINK-20213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239096#comment-17239096 ] zouyunhe commented on FLINK-20213: -- [~lzljs3620320] OK > Partition commit is delayed when records keep coming > > > Key: FLINK-20213 > URL: https://issues.apache.org/jira/browse/FLINK-20213 > Project: Flink > Issue Type: Bug > Components: Connectors / FileSystem, Table SQL / Ecosystem >Affects Versions: 1.11.2 >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0, 1.11.3 > > Attachments: image-2020-11-26-12-00-23-542.png, > image-2020-11-26-12-00-55-829.png > > > When set partition-commit.delay=0, Users expect partitions to be committed > immediately. > However, if the record of this partition continues to flow in, the bucket for > the partition will be activated, and no inactive bucket will appear. > We need to consider listening to bucket created. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (FLINK-20367) Show the in-use config of job to users
zlzhang0122 created FLINK-20367: --- Summary: Show the in-use config of job to users Key: FLINK-20367 URL: https://issues.apache.org/jira/browse/FLINK-20367 Project: Flink Issue Type: Improvement Reporter: zlzhang0122 Now the config can be set from global cluster configuration and single job code , since we can't absolutely sure that which config is in-use except we check it in the start-up log. I think maybe we can show the in-use config of job to users and this can be helpful! -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Closed] (FLINK-20316) update the deduplication section of query page
[ https://issues.apache.org/jira/browse/FLINK-20316?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu closed FLINK-20316. --- Resolution: Fixed Fixed in - master (1.13.0): 54ac81a4b2acc8239f9ff809e4b2c7d090740e1b - 1.12.0: 4c8a71b6b6f590520051ccb6ef9f47633f533916 > update the deduplication section of query page > -- > > Key: FLINK-20316 > URL: https://issues.apache.org/jira/browse/FLINK-20316 > Project: Flink > Issue Type: Task > Components: Documentation, Table SQL / API >Affects Versions: 1.12.0 >Reporter: Leonard Xu >Assignee: Leonard Xu >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0 > > > We have supported deduplication in row time and deduplicate in mini-batch > mode, but the document did not update, we need to update the doc. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] lirui-apache commented on pull request #14227: [FLINK-20245][hive][docs] Document how to create a Hive catalog from DDL
lirui-apache commented on pull request #14227: URL: https://github.com/apache/flink/pull/14227#issuecomment-734106437 @dawidwys @JingsongLi Could you take a look at the PR? It only updates the eng page, I'll sync the changes to zh page once we think it's good enough. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #14227: [FLINK-20245][hive][docs] Document how to create a Hive catalog from DDL
flinkbot commented on pull request #14227: URL: https://github.com/apache/flink/pull/14227#issuecomment-734106347 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit 22f1148159795b2c6e292bc018df4292fd0692a8 (Thu Nov 26 06:40:27 UTC 2020) **Warnings:** * Documentation files were touched, but no `.zh.md` files: Update Chinese documentation or file Jira ticket. Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #13983: [FLINK-19989][python] Add collect operation in Python DataStream API
flinkbot edited a comment on pull request #13983: URL: https://github.com/apache/flink/pull/13983#issuecomment-723574143 ## CI report: * fe0505f91d71c3a5947bdac49a8b3fb91983d5c5 Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=9922) * 5ed0db74dfc9f605365d6cbf811b5092b3eca062 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] lirui-apache commented on pull request #14227: [FLINK-20245][hive][docs] Document how to create a Hive catalog from DDL
lirui-apache commented on pull request #14227: URL: https://github.com/apache/flink/pull/14227#issuecomment-734105833 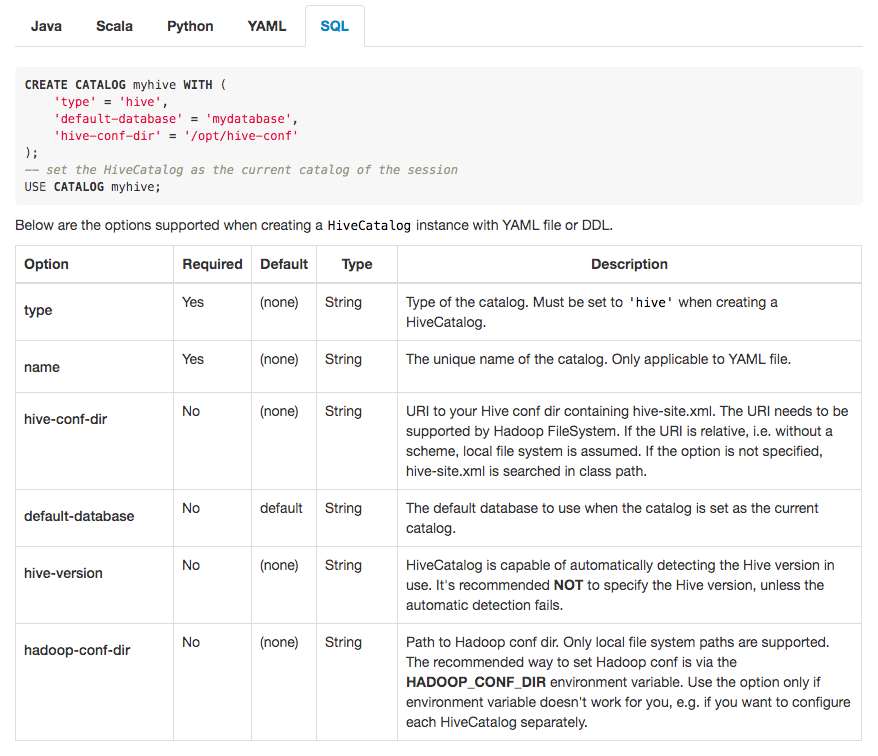 Attached is a screenshot of the updated page. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-20245) Document how to create a Hive catalog from DDL
[ https://issues.apache.org/jira/browse/FLINK-20245?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-20245: --- Labels: pull-request-available (was: ) > Document how to create a Hive catalog from DDL > -- > > Key: FLINK-20245 > URL: https://issues.apache.org/jira/browse/FLINK-20245 > Project: Flink > Issue Type: Improvement > Components: Connectors / Hive, Documentation >Reporter: Dawid Wysakowicz >Assignee: Rui Li >Priority: Critical > Labels: pull-request-available > Fix For: 1.12.0 > > > I'd appreciate if the documentation contained a description how to create the > hive catalog from DDL. What I am missing especially are the options that > HiveCatalog expects (type, conf-dir). We should have a table somewhere with a > description possible values etc. the same way as we have such tables for > other connectors and formats. See e.g. > https://ci.apache.org/projects/flink/flink-docs-master/dev/table/connectors/kafka.html#connector-options -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] lirui-apache opened a new pull request #14227: [FLINK-20245][hive][docs] Document how to create a Hive catalog from DDL
lirui-apache opened a new pull request #14227: URL: https://github.com/apache/flink/pull/14227 ## What is the purpose of the change Document how to create `HiveCatalog` with DDL and add table of supported options. ## Brief change log - Document how to create `HiveCatalog` with DDL and add table of supported options. ## Verifying this change NA ## Does this pull request potentially affect one of the following parts: NA ## Documentation NA This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-20366) ColumnIntervalUtil#getColumnIntervalWithFilter does not consider the case when the predicate is a false constant
[
https://issues.apache.org/jira/browse/FLINK-20366?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239086#comment-17239086
]
godfrey he commented on FLINK-20366:
good catch [~TsReaper], I will fix it
> ColumnIntervalUtil#getColumnIntervalWithFilter does not consider the case
> when the predicate is a false constant
>
>
> Key: FLINK-20366
> URL: https://issues.apache.org/jira/browse/FLINK-20366
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Reporter: Caizhi Weng
>Priority: Major
> Fix For: 1.12.0
>
>
> To reproduce this bug, add the following test case to
> {{DeadlockBreakupTest.scala}}
> {code:scala}
> @Test
> def testSubplanReuse_DeadlockCausedByReusingExchangeInAncestor(): Unit = {
> util.tableEnv.getConfig.getConfiguration.setBoolean(
> OptimizerConfigOptions.TABLE_OPTIMIZER_REUSE_SUB_PLAN_ENABLED, true)
> util.tableEnv.getConfig.getConfiguration.setBoolean(
> OptimizerConfigOptions.TABLE_OPTIMIZER_MULTIPLE_INPUT_ENABLED, false)
> util.tableEnv.getConfig.getConfiguration.setString(
> ExecutionConfigOptions.TABLE_EXEC_DISABLED_OPERATORS,
> "NestedLoopJoin,SortMergeJoin")
> val sqlQuery =
> """
> |WITH T1 AS (SELECT x1.*, x2.a AS k, x2.b AS v FROM x x1 LEFT JOIN x x2
> ON x1.a = x2.a WHERE x2.b > 0)
> |SELECT x.a, T1.* FROM x LEFT JOIN T1 ON x.a = T1.k WHERE x.b > 0 AND
> T1.v = 0
> |""".stripMargin
> util.verifyPlan(sqlQuery)
> }
> {code}
> And we'll get the exception stack
> {code}
> java.lang.RuntimeException: Error while applying rule
> FlinkLogicalJoinConverter(in:NONE,out:LOGICAL), args
> [rel#414:LogicalJoin.NONE.any.[](left=RelSubset#406,right=RelSubset#413,condition==($0,
> $4),joinType=inner)]
> at
> org.apache.calcite.plan.volcano.VolcanoRuleCall.onMatch(VolcanoRuleCall.java:256)
> at
> org.apache.calcite.plan.volcano.IterativeRuleDriver.drive(IterativeRuleDriver.java:58)
> at
> org.apache.calcite.plan.volcano.VolcanoPlanner.findBestExp(VolcanoPlanner.java:510)
> at
> org.apache.calcite.tools.Programs$RuleSetProgram.run(Programs.java:312)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkVolcanoProgram.optimize(FlinkVolcanoProgram.scala:64)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram$$anonfun$optimize$1.apply(FlinkChainedProgram.scala:62)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram$$anonfun$optimize$1.apply(FlinkChainedProgram.scala:58)
> at
> scala.collection.TraversableOnce$$anonfun$foldLeft$1.apply(TraversableOnce.scala:157)
> at
> scala.collection.TraversableOnce$$anonfun$foldLeft$1.apply(TraversableOnce.scala:157)
> at scala.collection.Iterator$class.foreach(Iterator.scala:891)
> at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
> at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
> at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
> at
> scala.collection.TraversableOnce$class.foldLeft(TraversableOnce.scala:157)
> at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:104)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram.optimize(FlinkChainedProgram.scala:57)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer.optimizeTree(BatchCommonSubGraphBasedOptimizer.scala:86)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer.org$apache$flink$table$planner$plan$optimize$BatchCommonSubGraphBasedOptimizer$$optimizeBlock(BatchCommonSubGraphBasedOptimizer.scala:57)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer$$anonfun$doOptimize$1.apply(BatchCommonSubGraphBasedOptimizer.scala:45)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer$$anonfun$doOptimize$1.apply(BatchCommonSubGraphBasedOptimizer.scala:45)
> at scala.collection.immutable.List.foreach(List.scala:392)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer.doOptimize(BatchCommonSubGraphBasedOptimizer.scala:45)
> at
> org.apache.flink.table.planner.plan.optimize.CommonSubGraphBasedOptimizer.optimize(CommonSubGraphBasedOptimizer.scala:77)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.optimize(PlannerBase.scala:286)
> at
> org.apache.flink.table.planner.utils.TableTestUtilBase.getOptimizedPlan(TableTestBase.scala:431)
> at
> org.apache.flink.table.planner.utils.TableTestUtilBase.doVerifyPlan(TableTestBase.scala:348)
> at
> org.apache.fl
[GitHub] [flink] wuchong merged pull request #14214: [FLINK-20316][doc] update the deduplication section of query page
wuchong merged pull request #14214: URL: https://github.com/apache/flink/pull/14214 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-20366) ColumnIntervalUtil#getColumnIntervalWithFilter does not consider the case when the predicate is a false constant
[
https://issues.apache.org/jira/browse/FLINK-20366?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
godfrey he reassigned FLINK-20366:
--
Assignee: godfrey he
> ColumnIntervalUtil#getColumnIntervalWithFilter does not consider the case
> when the predicate is a false constant
>
>
> Key: FLINK-20366
> URL: https://issues.apache.org/jira/browse/FLINK-20366
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Reporter: Caizhi Weng
>Assignee: godfrey he
>Priority: Major
> Fix For: 1.12.0
>
>
> To reproduce this bug, add the following test case to
> {{DeadlockBreakupTest.scala}}
> {code:scala}
> @Test
> def testSubplanReuse_DeadlockCausedByReusingExchangeInAncestor(): Unit = {
> util.tableEnv.getConfig.getConfiguration.setBoolean(
> OptimizerConfigOptions.TABLE_OPTIMIZER_REUSE_SUB_PLAN_ENABLED, true)
> util.tableEnv.getConfig.getConfiguration.setBoolean(
> OptimizerConfigOptions.TABLE_OPTIMIZER_MULTIPLE_INPUT_ENABLED, false)
> util.tableEnv.getConfig.getConfiguration.setString(
> ExecutionConfigOptions.TABLE_EXEC_DISABLED_OPERATORS,
> "NestedLoopJoin,SortMergeJoin")
> val sqlQuery =
> """
> |WITH T1 AS (SELECT x1.*, x2.a AS k, x2.b AS v FROM x x1 LEFT JOIN x x2
> ON x1.a = x2.a WHERE x2.b > 0)
> |SELECT x.a, T1.* FROM x LEFT JOIN T1 ON x.a = T1.k WHERE x.b > 0 AND
> T1.v = 0
> |""".stripMargin
> util.verifyPlan(sqlQuery)
> }
> {code}
> And we'll get the exception stack
> {code}
> java.lang.RuntimeException: Error while applying rule
> FlinkLogicalJoinConverter(in:NONE,out:LOGICAL), args
> [rel#414:LogicalJoin.NONE.any.[](left=RelSubset#406,right=RelSubset#413,condition==($0,
> $4),joinType=inner)]
> at
> org.apache.calcite.plan.volcano.VolcanoRuleCall.onMatch(VolcanoRuleCall.java:256)
> at
> org.apache.calcite.plan.volcano.IterativeRuleDriver.drive(IterativeRuleDriver.java:58)
> at
> org.apache.calcite.plan.volcano.VolcanoPlanner.findBestExp(VolcanoPlanner.java:510)
> at
> org.apache.calcite.tools.Programs$RuleSetProgram.run(Programs.java:312)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkVolcanoProgram.optimize(FlinkVolcanoProgram.scala:64)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram$$anonfun$optimize$1.apply(FlinkChainedProgram.scala:62)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram$$anonfun$optimize$1.apply(FlinkChainedProgram.scala:58)
> at
> scala.collection.TraversableOnce$$anonfun$foldLeft$1.apply(TraversableOnce.scala:157)
> at
> scala.collection.TraversableOnce$$anonfun$foldLeft$1.apply(TraversableOnce.scala:157)
> at scala.collection.Iterator$class.foreach(Iterator.scala:891)
> at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
> at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
> at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
> at
> scala.collection.TraversableOnce$class.foldLeft(TraversableOnce.scala:157)
> at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:104)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram.optimize(FlinkChainedProgram.scala:57)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer.optimizeTree(BatchCommonSubGraphBasedOptimizer.scala:86)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer.org$apache$flink$table$planner$plan$optimize$BatchCommonSubGraphBasedOptimizer$$optimizeBlock(BatchCommonSubGraphBasedOptimizer.scala:57)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer$$anonfun$doOptimize$1.apply(BatchCommonSubGraphBasedOptimizer.scala:45)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer$$anonfun$doOptimize$1.apply(BatchCommonSubGraphBasedOptimizer.scala:45)
> at scala.collection.immutable.List.foreach(List.scala:392)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer.doOptimize(BatchCommonSubGraphBasedOptimizer.scala:45)
> at
> org.apache.flink.table.planner.plan.optimize.CommonSubGraphBasedOptimizer.optimize(CommonSubGraphBasedOptimizer.scala:77)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.optimize(PlannerBase.scala:286)
> at
> org.apache.flink.table.planner.utils.TableTestUtilBase.getOptimizedPlan(TableTestBase.scala:431)
> at
> org.apache.flink.table.planner.utils.TableTestUtilBase.doVerifyPlan(TableTestBase.scala:348)
> at
> org.apache.flink.table.planner.utils.TableT
[jira] [Closed] (FLINK-20184) update hive streaming read and temporal table documents
[ https://issues.apache.org/jira/browse/FLINK-20184?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee closed FLINK-20184. Resolution: Fixed master (1.13): 47ae3341b5f5796e397ff255baadc95d4426e15d release-1.12: f051510709c05f63ae1708caa266a6f192e29aa0 > update hive streaming read and temporal table documents > --- > > Key: FLINK-20184 > URL: https://issues.apache.org/jira/browse/FLINK-20184 > Project: Flink > Issue Type: Task > Components: Connectors / Hive, Documentation >Reporter: Leonard Xu >Assignee: Leonard Xu >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0 > > > The hive streaming read and temporal table document has been out of style, we > need to update it. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-20366) ColumnIntervalUtil#getColumnIntervalWithFilter does not consider the case when the predicate is a false constant
[
https://issues.apache.org/jira/browse/FLINK-20366?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239084#comment-17239084
]
Caizhi Weng commented on FLINK-20366:
-
[~godfreyhe] please take a look.
> ColumnIntervalUtil#getColumnIntervalWithFilter does not consider the case
> when the predicate is a false constant
>
>
> Key: FLINK-20366
> URL: https://issues.apache.org/jira/browse/FLINK-20366
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Reporter: Caizhi Weng
>Priority: Major
> Fix For: 1.12.0
>
>
> To reproduce this bug, add the following test case to
> {{DeadlockBreakupTest.scala}}
> {code:scala}
> @Test
> def testSubplanReuse_DeadlockCausedByReusingExchangeInAncestor(): Unit = {
> util.tableEnv.getConfig.getConfiguration.setBoolean(
> OptimizerConfigOptions.TABLE_OPTIMIZER_REUSE_SUB_PLAN_ENABLED, true)
> util.tableEnv.getConfig.getConfiguration.setBoolean(
> OptimizerConfigOptions.TABLE_OPTIMIZER_MULTIPLE_INPUT_ENABLED, false)
> util.tableEnv.getConfig.getConfiguration.setString(
> ExecutionConfigOptions.TABLE_EXEC_DISABLED_OPERATORS,
> "NestedLoopJoin,SortMergeJoin")
> val sqlQuery =
> """
> |WITH T1 AS (SELECT x1.*, x2.a AS k, x2.b AS v FROM x x1 LEFT JOIN x x2
> ON x1.a = x2.a WHERE x2.b > 0)
> |SELECT x.a, T1.* FROM x LEFT JOIN T1 ON x.a = T1.k WHERE x.b > 0 AND
> T1.v = 0
> |""".stripMargin
> util.verifyPlan(sqlQuery)
> }
> {code}
> And we'll get the exception stack
> {code}
> java.lang.RuntimeException: Error while applying rule
> FlinkLogicalJoinConverter(in:NONE,out:LOGICAL), args
> [rel#414:LogicalJoin.NONE.any.[](left=RelSubset#406,right=RelSubset#413,condition==($0,
> $4),joinType=inner)]
> at
> org.apache.calcite.plan.volcano.VolcanoRuleCall.onMatch(VolcanoRuleCall.java:256)
> at
> org.apache.calcite.plan.volcano.IterativeRuleDriver.drive(IterativeRuleDriver.java:58)
> at
> org.apache.calcite.plan.volcano.VolcanoPlanner.findBestExp(VolcanoPlanner.java:510)
> at
> org.apache.calcite.tools.Programs$RuleSetProgram.run(Programs.java:312)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkVolcanoProgram.optimize(FlinkVolcanoProgram.scala:64)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram$$anonfun$optimize$1.apply(FlinkChainedProgram.scala:62)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram$$anonfun$optimize$1.apply(FlinkChainedProgram.scala:58)
> at
> scala.collection.TraversableOnce$$anonfun$foldLeft$1.apply(TraversableOnce.scala:157)
> at
> scala.collection.TraversableOnce$$anonfun$foldLeft$1.apply(TraversableOnce.scala:157)
> at scala.collection.Iterator$class.foreach(Iterator.scala:891)
> at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
> at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
> at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
> at
> scala.collection.TraversableOnce$class.foldLeft(TraversableOnce.scala:157)
> at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:104)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram.optimize(FlinkChainedProgram.scala:57)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer.optimizeTree(BatchCommonSubGraphBasedOptimizer.scala:86)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer.org$apache$flink$table$planner$plan$optimize$BatchCommonSubGraphBasedOptimizer$$optimizeBlock(BatchCommonSubGraphBasedOptimizer.scala:57)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer$$anonfun$doOptimize$1.apply(BatchCommonSubGraphBasedOptimizer.scala:45)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer$$anonfun$doOptimize$1.apply(BatchCommonSubGraphBasedOptimizer.scala:45)
> at scala.collection.immutable.List.foreach(List.scala:392)
> at
> org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer.doOptimize(BatchCommonSubGraphBasedOptimizer.scala:45)
> at
> org.apache.flink.table.planner.plan.optimize.CommonSubGraphBasedOptimizer.optimize(CommonSubGraphBasedOptimizer.scala:77)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.optimize(PlannerBase.scala:286)
> at
> org.apache.flink.table.planner.utils.TableTestUtilBase.getOptimizedPlan(TableTestBase.scala:431)
> at
> org.apache.flink.table.planner.utils.TableTestUtilBase.doVerifyPlan(TableTestBase.scala:348)
> at
> org.apache.flink
[jira] [Created] (FLINK-20366) ColumnIntervalUtil#getColumnIntervalWithFilter does not consider the case when the predicate is a false constant
Caizhi Weng created FLINK-20366:
---
Summary: ColumnIntervalUtil#getColumnIntervalWithFilter does not
consider the case when the predicate is a false constant
Key: FLINK-20366
URL: https://issues.apache.org/jira/browse/FLINK-20366
Project: Flink
Issue Type: Bug
Components: Table SQL / Planner
Reporter: Caizhi Weng
Fix For: 1.12.0
To reproduce this bug, add the following test case to
{{DeadlockBreakupTest.scala}}
{code:scala}
@Test
def testSubplanReuse_DeadlockCausedByReusingExchangeInAncestor(): Unit = {
util.tableEnv.getConfig.getConfiguration.setBoolean(
OptimizerConfigOptions.TABLE_OPTIMIZER_REUSE_SUB_PLAN_ENABLED, true)
util.tableEnv.getConfig.getConfiguration.setBoolean(
OptimizerConfigOptions.TABLE_OPTIMIZER_MULTIPLE_INPUT_ENABLED, false)
util.tableEnv.getConfig.getConfiguration.setString(
ExecutionConfigOptions.TABLE_EXEC_DISABLED_OPERATORS,
"NestedLoopJoin,SortMergeJoin")
val sqlQuery =
"""
|WITH T1 AS (SELECT x1.*, x2.a AS k, x2.b AS v FROM x x1 LEFT JOIN x x2
ON x1.a = x2.a WHERE x2.b > 0)
|SELECT x.a, T1.* FROM x LEFT JOIN T1 ON x.a = T1.k WHERE x.b > 0 AND
T1.v = 0
|""".stripMargin
util.verifyPlan(sqlQuery)
}
{code}
And we'll get the exception stack
{code}
java.lang.RuntimeException: Error while applying rule
FlinkLogicalJoinConverter(in:NONE,out:LOGICAL), args
[rel#414:LogicalJoin.NONE.any.[](left=RelSubset#406,right=RelSubset#413,condition==($0,
$4),joinType=inner)]
at
org.apache.calcite.plan.volcano.VolcanoRuleCall.onMatch(VolcanoRuleCall.java:256)
at
org.apache.calcite.plan.volcano.IterativeRuleDriver.drive(IterativeRuleDriver.java:58)
at
org.apache.calcite.plan.volcano.VolcanoPlanner.findBestExp(VolcanoPlanner.java:510)
at
org.apache.calcite.tools.Programs$RuleSetProgram.run(Programs.java:312)
at
org.apache.flink.table.planner.plan.optimize.program.FlinkVolcanoProgram.optimize(FlinkVolcanoProgram.scala:64)
at
org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram$$anonfun$optimize$1.apply(FlinkChainedProgram.scala:62)
at
org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram$$anonfun$optimize$1.apply(FlinkChainedProgram.scala:58)
at
scala.collection.TraversableOnce$$anonfun$foldLeft$1.apply(TraversableOnce.scala:157)
at
scala.collection.TraversableOnce$$anonfun$foldLeft$1.apply(TraversableOnce.scala:157)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at
scala.collection.TraversableOnce$class.foldLeft(TraversableOnce.scala:157)
at scala.collection.AbstractTraversable.foldLeft(Traversable.scala:104)
at
org.apache.flink.table.planner.plan.optimize.program.FlinkChainedProgram.optimize(FlinkChainedProgram.scala:57)
at
org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer.optimizeTree(BatchCommonSubGraphBasedOptimizer.scala:86)
at
org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer.org$apache$flink$table$planner$plan$optimize$BatchCommonSubGraphBasedOptimizer$$optimizeBlock(BatchCommonSubGraphBasedOptimizer.scala:57)
at
org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer$$anonfun$doOptimize$1.apply(BatchCommonSubGraphBasedOptimizer.scala:45)
at
org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer$$anonfun$doOptimize$1.apply(BatchCommonSubGraphBasedOptimizer.scala:45)
at scala.collection.immutable.List.foreach(List.scala:392)
at
org.apache.flink.table.planner.plan.optimize.BatchCommonSubGraphBasedOptimizer.doOptimize(BatchCommonSubGraphBasedOptimizer.scala:45)
at
org.apache.flink.table.planner.plan.optimize.CommonSubGraphBasedOptimizer.optimize(CommonSubGraphBasedOptimizer.scala:77)
at
org.apache.flink.table.planner.delegation.PlannerBase.optimize(PlannerBase.scala:286)
at
org.apache.flink.table.planner.utils.TableTestUtilBase.getOptimizedPlan(TableTestBase.scala:431)
at
org.apache.flink.table.planner.utils.TableTestUtilBase.doVerifyPlan(TableTestBase.scala:348)
at
org.apache.flink.table.planner.utils.TableTestUtilBase.verifyPlan(TableTestBase.scala:271)
at
org.apache.flink.table.planner.plan.batch.sql.DeadlockBreakupTest.testSubplanReuse_DeadlockCausedByReusingExchangeInAncestor(DeadlockBreakupTest.scala:248)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccess
[GitHub] [flink] JingsongLi merged pull request #14182: [FLINK-20184][doc] update hive streaming read and temporal table document
JingsongLi merged pull request #14182: URL: https://github.com/apache/flink/pull/14182 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14204: [FLINK-20325][build] Move docs_404_check to CI stage
flinkbot edited a comment on pull request #14204: URL: https://github.com/apache/flink/pull/14204#issuecomment-733048767 ## CI report: * 6550d3e1b01af94d4f652f993834b75272da1020 UNKNOWN * 595ab82c651f8c225193eeeba90d6366fdff341d Azure: [CANCELED](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=10145) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14103: [FLINK-18545] Introduce `pipeline.name` to allow users to specify job name by configuration
flinkbot edited a comment on pull request #14103: URL: https://github.com/apache/flink/pull/14103#issuecomment-729030820 ## CI report: * cda47b16b8fa216fefb5399249026c2a54e907ed Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=10146) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-20213) Partition commit is delayed when records keep coming
[ https://issues.apache.org/jira/browse/FLINK-20213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239080#comment-17239080 ] Jingsong Lee commented on FLINK-20213: -- Hi [~zouyunhe], I think your correct commit delay should be 1 hour plus 1min > Partition commit is delayed when records keep coming > > > Key: FLINK-20213 > URL: https://issues.apache.org/jira/browse/FLINK-20213 > Project: Flink > Issue Type: Bug > Components: Connectors / FileSystem, Table SQL / Ecosystem >Affects Versions: 1.11.2 >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0, 1.11.3 > > Attachments: image-2020-11-26-12-00-23-542.png, > image-2020-11-26-12-00-55-829.png > > > When set partition-commit.delay=0, Users expect partitions to be committed > immediately. > However, if the record of this partition continues to flow in, the bucket for > the partition will be activated, and no inactive bucket will appear. > We need to consider listening to bucket created. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-20213) Partition commit is delayed when records keep coming
[ https://issues.apache.org/jira/browse/FLINK-20213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239075#comment-17239075 ] zouyunhe commented on FLINK-20213: -- [~lzljs3620320] the commit delay is 1 min, the tblproperties 'partition.time-extractor.timestamp-pattern'='$day $hour:00:00', 'sink.partition-commit.delay'='1 min', 'sink.partition-commit.policy.kind'='metastore,success-file', 'sink.partition-commit.trigger'='partition-time', > Partition commit is delayed when records keep coming > > > Key: FLINK-20213 > URL: https://issues.apache.org/jira/browse/FLINK-20213 > Project: Flink > Issue Type: Bug > Components: Connectors / FileSystem, Table SQL / Ecosystem >Affects Versions: 1.11.2 >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0, 1.11.3 > > Attachments: image-2020-11-26-12-00-23-542.png, > image-2020-11-26-12-00-55-829.png > > > When set partition-commit.delay=0, Users expect partitions to be committed > immediately. > However, if the record of this partition continues to flow in, the bucket for > the partition will be activated, and no inactive bucket will appear. > We need to consider listening to bucket created. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-20213) Partition commit is delayed when records keep coming
[ https://issues.apache.org/jira/browse/FLINK-20213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239073#comment-17239073 ] Jingsong Lee commented on FLINK-20213: -- [~zouyunhe] What is the delay? > Partition commit is delayed when records keep coming > > > Key: FLINK-20213 > URL: https://issues.apache.org/jira/browse/FLINK-20213 > Project: Flink > Issue Type: Bug > Components: Connectors / FileSystem, Table SQL / Ecosystem >Affects Versions: 1.11.2 >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0, 1.11.3 > > Attachments: image-2020-11-26-12-00-23-542.png, > image-2020-11-26-12-00-55-829.png > > > When set partition-commit.delay=0, Users expect partitions to be committed > immediately. > However, if the record of this partition continues to flow in, the bucket for > the partition will be activated, and no inactive bucket will appear. > We need to consider listening to bucket created. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] wuchong merged pull request #14211: [hotfix] Fix typo `dispatcherResourceManagreComponentRpcServiceFactory`
wuchong merged pull request #14211: URL: https://github.com/apache/flink/pull/14211 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-20123) Test native support of PyFlink on Kubernetes
[ https://issues.apache.org/jira/browse/FLINK-20123?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239070#comment-17239070 ] Shuiqiang Chen edited comment on FLINK-20123 at 11/26/20, 5:27 AM: --- Hi [~rmetzger] I found that the native k8s cluster could not be unregistered when executing Python DataStream application in attach mode during test. I have created a [JIRA|https://issues.apache.org/jira/browse/FLINK-20365] for it and will fix it today. was (Author: csq): Hi [~rmetzger] I found that the native k8s cluster could not be unregistered when executing Python DataStream application in attach mode during test. I have created a [JIRA|https://issues.apache.org/jira/browse/FLINK-20365] for it and will fixed it today. > Test native support of PyFlink on Kubernetes > > > Key: FLINK-20123 > URL: https://issues.apache.org/jira/browse/FLINK-20123 > Project: Flink > Issue Type: Sub-task > Components: API / Python >Affects Versions: 1.12.0 >Reporter: Robert Metzger >Assignee: Shuiqiang Chen >Priority: Critical > Fix For: 1.12.0 > > > > [General Information about the Flink 1.12 release > testing|https://cwiki.apache.org/confluence/display/FLINK/1.12+Release+-+Community+Testing] > When testing a feature, consider the following aspects: > - Is the documentation easy to understand > - Are the error messages, log messages, APIs etc. easy to understand > - Is the feature working as expected under normal conditions > - Is the feature working / failing as expected with invalid input, induced > errors etc. > If you find a problem during testing, please file a ticket > (Priority=Critical; Fix Version = 1.12.0), and link it in this testing ticket. > During the testing keep us updated on tests conducted, or please write a > short summary of all things you have tested in the end. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Comment Edited] (FLINK-20123) Test native support of PyFlink on Kubernetes
[ https://issues.apache.org/jira/browse/FLINK-20123?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239070#comment-17239070 ] Shuiqiang Chen edited comment on FLINK-20123 at 11/26/20, 5:27 AM: --- Hi [~rmetzger] I found that the native k8s cluster could not be unregistered when executing Python DataStream application in attach mode during test. I have created a [JIRA|https://issues.apache.org/jira/browse/FLINK-20365] for it and will fixed it today. was (Author: csq): Hi [~rmetzger] I found that the native k8s cluster could not be unregistered when executing Python DataStream application in attach mode during test. I have created a [JIRA|https://issues.apache.org/jira/browse/FLINK-20365] for and will fixed it today. > Test native support of PyFlink on Kubernetes > > > Key: FLINK-20123 > URL: https://issues.apache.org/jira/browse/FLINK-20123 > Project: Flink > Issue Type: Sub-task > Components: API / Python >Affects Versions: 1.12.0 >Reporter: Robert Metzger >Assignee: Shuiqiang Chen >Priority: Critical > Fix For: 1.12.0 > > > > [General Information about the Flink 1.12 release > testing|https://cwiki.apache.org/confluence/display/FLINK/1.12+Release+-+Community+Testing] > When testing a feature, consider the following aspects: > - Is the documentation easy to understand > - Are the error messages, log messages, APIs etc. easy to understand > - Is the feature working as expected under normal conditions > - Is the feature working / failing as expected with invalid input, induced > errors etc. > If you find a problem during testing, please file a ticket > (Priority=Critical; Fix Version = 1.12.0), and link it in this testing ticket. > During the testing keep us updated on tests conducted, or please write a > short summary of all things you have tested in the end. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-20365) The native k8s cluster could not be unregistered when executing Python DataStream application attachedly.
[ https://issues.apache.org/jira/browse/FLINK-20365?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Shuiqiang Chen updated FLINK-20365: --- Affects Version/s: (was: 1.12.0) > The native k8s cluster could not be unregistered when executing Python > DataStream application attachedly. > - > > Key: FLINK-20365 > URL: https://issues.apache.org/jira/browse/FLINK-20365 > Project: Flink > Issue Type: Bug > Components: API / Python >Reporter: Shuiqiang Chen >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-20365) The native k8s cluster could not be unregistered when executing Python DataStream application attachedly.
[ https://issues.apache.org/jira/browse/FLINK-20365?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Shuiqiang Chen updated FLINK-20365: --- Fix Version/s: 1.12.0 > The native k8s cluster could not be unregistered when executing Python > DataStream application attachedly. > - > > Key: FLINK-20365 > URL: https://issues.apache.org/jira/browse/FLINK-20365 > Project: Flink > Issue Type: Bug > Components: API / Python >Reporter: Shuiqiang Chen >Priority: Major > Fix For: 1.12.0 > > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-20123) Test native support of PyFlink on Kubernetes
[ https://issues.apache.org/jira/browse/FLINK-20123?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239070#comment-17239070 ] Shuiqiang Chen commented on FLINK-20123: Hi [~rmetzger] I found that the native k8s cluster could not be unregistered when executing Python DataStream application in attach mode during test. I have created a [JIRA|https://issues.apache.org/jira/browse/FLINK-20365] for and will fixed it today. > Test native support of PyFlink on Kubernetes > > > Key: FLINK-20123 > URL: https://issues.apache.org/jira/browse/FLINK-20123 > Project: Flink > Issue Type: Sub-task > Components: API / Python >Affects Versions: 1.12.0 >Reporter: Robert Metzger >Assignee: Shuiqiang Chen >Priority: Critical > Fix For: 1.12.0 > > > > [General Information about the Flink 1.12 release > testing|https://cwiki.apache.org/confluence/display/FLINK/1.12+Release+-+Community+Testing] > When testing a feature, consider the following aspects: > - Is the documentation easy to understand > - Are the error messages, log messages, APIs etc. easy to understand > - Is the feature working as expected under normal conditions > - Is the feature working / failing as expected with invalid input, induced > errors etc. > If you find a problem during testing, please file a ticket > (Priority=Critical; Fix Version = 1.12.0), and link it in this testing ticket. > During the testing keep us updated on tests conducted, or please write a > short summary of all things you have tested in the end. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (FLINK-20365) The native k8s cluster could not be unregistered when executing Python DataStream application attachedly.
Shuiqiang Chen created FLINK-20365: -- Summary: The native k8s cluster could not be unregistered when executing Python DataStream application attachedly. Key: FLINK-20365 URL: https://issues.apache.org/jira/browse/FLINK-20365 Project: Flink Issue Type: Bug Components: API / Python Affects Versions: 1.12.0 Reporter: Shuiqiang Chen -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (FLINK-20119) Test Temporal Table DDL and Temporal Table Join
[ https://issues.apache.org/jira/browse/FLINK-20119?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239064#comment-17239064 ] Leonard Xu commented on FLINK-20119: I've finished the test, let me update the comment and close this ticket. *Environment:* Flink standalone cluster, version: 1.12-SNAPSHOT Kafka cluster version 2.11_0.10 *Test case:* (1)Test kafka append-only stream temporal join a changelog stream( also test FLIP-107 META read) (a) test extract meta from debezium format data and using as watermark (b) test different watermark interval, the result is as expected (2)Test kafka append-only stream temporal join a upsert kafka connector (a) test read/write data to upsert kafka table in sql client (b) test an append-only stream join the upsert topic, the result is as expected (3)Test kafka append-only stream temporal join a view from append-only stream, the view from a deduplication query can be used as versioned table, and the result is as expected. (4) Test write/ read from/to a versioned table in sql client, do a processing time temporal join with the regular table, the result is as expected > Test Temporal Table DDL and Temporal Table Join > --- > > Key: FLINK-20119 > URL: https://issues.apache.org/jira/browse/FLINK-20119 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / API >Affects Versions: 1.12.0 >Reporter: Robert Metzger >Assignee: Leonard Xu >Priority: Critical > Fix For: 1.12.0 > > > > [General Information about the Flink 1.12 release > testing|https://cwiki.apache.org/confluence/display/FLINK/1.12+Release+-+Community+Testing] > When testing a feature, consider the following aspects: > - Is the documentation easy to understand > - Are the error messages, log messages, APIs etc. easy to understand > - Is the feature working as expected under normal conditions > - Is the feature working / failing as expected with invalid input, induced > errors etc. > If you find a problem during testing, please file a ticket > (Priority=Critical; Fix Version = 1.12.0), and link it in this testing ticket. > During the testing keep us updated on tests conducted, or please write a > short summary of all things you have tested in the end. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Resolved] (FLINK-20119) Test Temporal Table DDL and Temporal Table Join
[ https://issues.apache.org/jira/browse/FLINK-20119?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Leonard Xu resolved FLINK-20119. Resolution: Resolved > Test Temporal Table DDL and Temporal Table Join > --- > > Key: FLINK-20119 > URL: https://issues.apache.org/jira/browse/FLINK-20119 > Project: Flink > Issue Type: Sub-task > Components: Table SQL / API >Affects Versions: 1.12.0 >Reporter: Robert Metzger >Assignee: Leonard Xu >Priority: Critical > Fix For: 1.12.0 > > > > [General Information about the Flink 1.12 release > testing|https://cwiki.apache.org/confluence/display/FLINK/1.12+Release+-+Community+Testing] > When testing a feature, consider the following aspects: > - Is the documentation easy to understand > - Are the error messages, log messages, APIs etc. easy to understand > - Is the feature working as expected under normal conditions > - Is the feature working / failing as expected with invalid input, induced > errors etc. > If you find a problem during testing, please file a ticket > (Priority=Critical; Fix Version = 1.12.0), and link it in this testing ticket. > During the testing keep us updated on tests conducted, or please write a > short summary of all things you have tested in the end. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #14226: [FLINK-20362][doc] Fix broken link in sourceSinks.zh.md
flinkbot edited a comment on pull request #14226: URL: https://github.com/apache/flink/pull/14226#issuecomment-734044273 ## CI report: * e0e112b0a92a02a62de739fa37a98f2d132e5a46 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=10143) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14103: [FLINK-18545] Introduce `pipeline.name` to allow users to specify job name by configuration
flinkbot edited a comment on pull request #14103: URL: https://github.com/apache/flink/pull/14103#issuecomment-729030820 ## CI report: * 938cbb403a01e6d31cbc605a49f9baf7b3b9bf31 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=9714) * cda47b16b8fa216fefb5399249026c2a54e907ed Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=10146) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-20364) Add support for scheduling with slot sharing
[
https://issues.apache.org/jira/browse/FLINK-20364?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239059#comment-17239059
]
Guruh Fajar Samudra commented on FLINK-20364:
-
Github user GJL commented on a diff in the pull request:
https://github.com/apache/flink/pull/5091#discussion_r155754738
— Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/jobmaster/slotpool/SlotPool.java
—
@@ -266,104 +279,367 @@ public void disconnectResourceManager() {
//
@Override
public CompletableFuture allocateSlot(
SlotRequestID requestId,
ScheduledUnit task,
ResourceProfile resources,
Iterable locationPreferences,
+ public CompletableFuture allocateSlot(
+ SlotRequestId slotRequestId,
+ ScheduledUnit scheduledUnit,
+ ResourceProfile resourceProfile,
+ Collection locationPreferences,
+ boolean allowQueuedScheduling,
Time timeout) { - return internalAllocateSlot(requestId, task, resources,
locationPreferences); + return internalAllocateSlot( + slotRequestId, +
scheduledUnit, + resourceProfile, + locationPreferences, +
allowQueuedScheduling); }
@Override
public void returnAllocatedSlot(Slot slot) {
internalReturnAllocatedSlot(slot);
+ private CompletableFuture internalAllocateSlot(
+ SlotRequestId slotRequestId,
+ ScheduledUnit task,
+ ResourceProfile resourceProfile,
+ Collection locationPreferences,
+ boolean allowQueuedScheduling) {
+
+ final SlotSharingGroupId slotSharingGroupId = task.getSlotSharingGroupId();
+
+ if (slotSharingGroupId != null) {
+ // allocate slot with slot sharing
+ final SlotSharingManager multiTaskSlotManager =
slotSharingManagers.computeIfAbsent(
+ slotSharingGroupId,
+ id -> new SlotSharingManager(
+ id,
+ this,
+ providerAndOwner));
+
+ final SlotSharingManager.MultiTaskSlotLocality multiTaskSlotFuture;
+
+ try
Unknown macro: { + if (task.getCoLocationConstraint() != null) { +
multiTaskSlotFuture = allocateCoLocatedMultiTaskSlot( +
task.getCoLocationConstraint(), + multiTaskSlotManager, + resourceProfile, +
locationPreferences, + allowQueuedScheduling); + } else { + multiTaskSlotFuture
= allocateMultiTaskSlot( + task.getJobVertexId(), multiTaskSlotManager, +
resourceProfile, + locationPreferences, + allowQueuedScheduling); + } + }
catch (NoResourceAvailableException noResourceException)
{ + return FutureUtils.completedExceptionally(noResourceException); + }
+
+ // sanity check
+
Preconditions.checkState(!multiTaskSlotFuture.getMultiTaskSlot().contains(task.getJobVertexId()));
+
+ final SlotSharingManager.SingleTaskSlot leave =
multiTaskSlotFuture.getMultiTaskSlot().allocateSingleTaskSlot(
+ slotRequestId,
+ task.getJobVertexId(),
+ multiTaskSlotFuture.getLocality());
+
+ return leave.getLogicalSlotFuture();
+ } else {
+ // request an allocated slot to assign a single logical slot to
+ CompletableFuture slotAndLocalityFuture =
requestAllocatedSlot(
+ slotRequestId,
+ resourceProfile,
+ locationPreferences,
+ allowQueuedScheduling);
+
+ return slotAndLocalityFuture.thenApply(
+ (SlotAndLocality slotAndLocality) ->
Unknown macro: { + final AllocatedSlot allocatedSlot =
slotAndLocality.getSlot(); + + final SingleLogicalSlot singleTaskSlot = new
SingleLogicalSlot( + slotRequestId, + allocatedSlot, + null, +
slotAndLocality.getLocality(), + providerAndOwner); + + if
(allocatedSlot.tryAssignPayload(singleTaskSlot)) { + return singleTaskSlot; + }
else { + final FlinkException flinkException = new FlinkException("Could not
assign payload to allocated slot " + allocatedSlot.getAllocationId() + '.'); +
releaseSlot(slotRequestId, null, flinkException); + throw new
CompletionException(flinkException); + } + }
);
+ }
}
@Override
public CompletableFuture cancelSlotAllocation(SlotRequestID
requestId) {
final PendingRequest pendingRequest = removePendingRequest(requestId);
+ /**
+ * Allocates a co-located {@link SlotSharingManager.MultiTaskSlot} for the
given {@link CoLocationConstraint}.
+ *
+ * If allowQueuedScheduling is true, then the returned {@link
SlotSharingManager.MultiTaskSlot}
can be
+ * uncompleted.
+ *
+ * @param coLocationConstraint for which to allocate a
{@link SlotSharingManager.MultiTaskSlot}
+ * @param multiTaskSlotManager responsible for the slot sharing group for
which to allocate the slot
+ * @param resourceProfile specifying the requirements for the requested slot
+ * @param locationPreferences containing preferred TaskExecutors on which to
allocate the slot
+ * @param allowQueuedScheduling true if queued scheduling (the returned task
slot must not be completed yet) is allowed, otherwise false
+ * @return A {@link SlotSharingManager.MultiTaskSlotLocality} which contains
the allocated{@link SlotSharingManager.MultiTaskSlot}
+ * and its locality wrt the given location preferences
+ * @throws NoResourceAvailableException if no task slot could be allocated
+ */
+ private SlotSharingManag
[jira] [Commented] (FLINK-20364) Add support for scheduling with slot sharing
[
https://issues.apache.org/jira/browse/FLINK-20364?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239058#comment-17239058
]
Guruh Fajar Samudra commented on FLINK-20364:
-
Github user GJL commented on a diff in the pull request:
https://github.com/apache/flink/pull/5091#discussion_r155751694
— Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/jobmaster/slotpool/SlotPool.java
—
@@ -266,104 +279,367 @@ public void disconnectResourceManager() {
//
@Override
public CompletableFuture allocateSlot(
SlotRequestID requestId,
ScheduledUnit task,
ResourceProfile resources,
Iterable locationPreferences,
+ public CompletableFuture allocateSlot(
+ SlotRequestId slotRequestId,
+ ScheduledUnit scheduledUnit,
+ ResourceProfile resourceProfile,
+ Collection locationPreferences,
+ boolean allowQueuedScheduling,
Time timeout) { - return internalAllocateSlot(requestId, task, resources,
locationPreferences); + return internalAllocateSlot( + slotRequestId, +
scheduledUnit, + resourceProfile, + locationPreferences, +
allowQueuedScheduling); }
@Override
public void returnAllocatedSlot(Slot slot) {
internalReturnAllocatedSlot(slot);
+ private CompletableFuture internalAllocateSlot(
+ SlotRequestId slotRequestId,
+ ScheduledUnit task,
+ ResourceProfile resourceProfile,
+ Collection locationPreferences,
+ boolean allowQueuedScheduling) {
+
+ final SlotSharingGroupId slotSharingGroupId = task.getSlotSharingGroupId();
+
+ if (slotSharingGroupId != null) {
+ // allocate slot with slot sharing
+ final SlotSharingManager multiTaskSlotManager =
slotSharingManagers.computeIfAbsent(
+ slotSharingGroupId,
+ id -> new SlotSharingManager(
+ id,
+ this,
+ providerAndOwner));
+
+ final SlotSharingManager.MultiTaskSlotLocality multiTaskSlotFuture;
+
+ try
Unknown macro: { + if (task.getCoLocationConstraint() != null) { +
multiTaskSlotFuture = allocateCoLocatedMultiTaskSlot( +
task.getCoLocationConstraint(), + multiTaskSlotManager, + resourceProfile, +
locationPreferences, + allowQueuedScheduling); + } else { + multiTaskSlotFuture
= allocateMultiTaskSlot( + task.getJobVertexId(), multiTaskSlotManager, +
resourceProfile, + locationPreferences, + allowQueuedScheduling); + } + }
catch (NoResourceAvailableException noResourceException)
{ + return FutureUtils.completedExceptionally(noResourceException); + }
+
+ // sanity check
+
Preconditions.checkState(!multiTaskSlotFuture.getMultiTaskSlot().contains(task.getJobVertexId()));
+
+ final SlotSharingManager.SingleTaskSlot leave =
multiTaskSlotFuture.getMultiTaskSlot().allocateSingleTaskSlot(
+ slotRequestId,
+ task.getJobVertexId(),
+ multiTaskSlotFuture.getLocality());
+
+ return leave.getLogicalSlotFuture();
+ } else {
+ // request an allocated slot to assign a single logical slot to
+ CompletableFuture slotAndLocalityFuture =
requestAllocatedSlot(
+ slotRequestId,
+ resourceProfile,
+ locationPreferences,
+ allowQueuedScheduling);
+
+ return slotAndLocalityFuture.thenApply(
+ (SlotAndLocality slotAndLocality) ->
Unknown macro: { + final AllocatedSlot allocatedSlot =
slotAndLocality.getSlot(); + + final SingleLogicalSlot singleTaskSlot = new
SingleLogicalSlot( + slotRequestId, + allocatedSlot, + null, +
slotAndLocality.getLocality(), + providerAndOwner); + + if
(allocatedSlot.tryAssignPayload(singleTaskSlot)) { + return singleTaskSlot; + }
else { + final FlinkException flinkException = new FlinkException("Could not
assign payload to allocated slot " + allocatedSlot.getAllocationId() + '.'); +
releaseSlot(slotRequestId, null, flinkException); + throw new
CompletionException(flinkException); + } + }
);
+ }
}
@Override
public CompletableFuture cancelSlotAllocation(SlotRequestID
requestId) {
final PendingRequest pendingRequest = removePendingRequest(requestId);
+ /**
+ * Allocates a co-located {@link SlotSharingManager.MultiTaskSlot} for the
given {@link CoLocationConstraint}.
+ *
+ * If allowQueuedScheduling is true, then the returned {@link
SlotSharingManager.MultiTaskSlot}
can be
+ * uncompleted.
+ *
+ * @param coLocationConstraint for which to allocate a
{@link SlotSharingManager.MultiTaskSlot}
+ * @param multiTaskSlotManager responsible for the slot sharing group for
which to allocate the slot
+ * @param resourceProfile specifying the requirements for the requested slot
+ * @param locationPreferences containing preferred TaskExecutors on which to
allocate the slot
+ * @param allowQueuedScheduling true if queued scheduling (the returned task
slot must not be completed yet) is allowed, otherwise false
+ * @return A {@link SlotSharingManager.MultiTaskSlotLocality} which contains
the allocated{@link SlotSharingManager.MultiTaskSlot}
+ * and its locality wrt the given location preferences
+ * @throws NoResourceAvailableException if no task slot could be allocated
+ */
+ private SlotSharingManag
[jira] [Commented] (FLINK-20364) Add support for scheduling with slot sharing
[
https://issues.apache.org/jira/browse/FLINK-20364?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239056#comment-17239056
]
Guruh Fajar Samudra commented on FLINK-20364:
-
Github user GJL commented on a diff in the pull request:
[https://github.com/apache/flink/pull/5091#discussion_r155590317]
— Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/jobmaster/slotpool/SlotPool.java
—
@@ -266,104 +279,367 @@ public void disconnectResourceManager() {
//
@Override
- public CompletableFuture allocateSlot(
- SlotRequestID requestId,
- ScheduledUnit task,
- ResourceProfile resources,
- Iterable locationPreferences,
+ public CompletableFuture allocateSlot(
+ SlotRequestId slotRequestId,
+ ScheduledUnit scheduledUnit,
+ ResourceProfile resourceProfile,
+ Collection locationPreferences,
+ boolean allowQueuedScheduling,
Time timeout) \{ - return internalAllocateSlot(requestId, task, resources,
locationPreferences); + return internalAllocateSlot( + slotRequestId, +
scheduledUnit, + resourceProfile, + locationPreferences, +
allowQueuedScheduling); }
- @Override
- public void returnAllocatedSlot(Slot slot) {
- internalReturnAllocatedSlot(slot);
+ private CompletableFuture internalAllocateSlot(
+ SlotRequestId slotRequestId,
+ ScheduledUnit task,
+ ResourceProfile resourceProfile,
+ Collection locationPreferences,
+ boolean allowQueuedScheduling) {
+
+ final SlotSharingGroupId slotSharingGroupId = task.getSlotSharingGroupId();
+
+ if (slotSharingGroupId != null) {
+ // allocate slot with slot sharing
+ final SlotSharingManager multiTaskSlotManager =
slotSharingManagers.computeIfAbsent(
+ slotSharingGroupId,
+ id -> new SlotSharingManager(
+ id,
+ this,
+ providerAndOwner));
+
+ final SlotSharingManager.MultiTaskSlotLocality multiTaskSlotFuture;
+
+ try
Unknown macro: \{ + if (task.getCoLocationConstraint() != null) { +
multiTaskSlotFuture = allocateCoLocatedMultiTaskSlot( +
task.getCoLocationConstraint(), + multiTaskSlotManager, + resourceProfile, +
locationPreferences, + allowQueuedScheduling); + } else \{ +
multiTaskSlotFuture = allocateMultiTaskSlot( + task.getJobVertexId(),
multiTaskSlotManager, + resourceProfile, + locationPreferences, +
allowQueuedScheduling); + } + }
catch (NoResourceAvailableException noResourceException)
{ + return FutureUtils.completedExceptionally(noResourceException); + }
+
+ // sanity check
+
Preconditions.checkState(!multiTaskSlotFuture.getMultiTaskSlot().contains(task.getJobVertexId()));
+
+ final SlotSharingManager.SingleTaskSlot leave =
multiTaskSlotFuture.getMultiTaskSlot().allocateSingleTaskSlot(
--
--- End diff –
nit: variable name should be *pin*
[https://travelingpin.com/|https://travelingpin.com/]
> Add support for scheduling with slot sharing
>
>
> Key: FLINK-20364
> URL: https://issues.apache.org/jira/browse/FLINK-20364
> Project: Flink
> Issue Type: Test
> Components: Runtime / Coordination
>Affects Versions: statefun-2.2.1
>Reporter: Guruh Fajar Samudra
>Priority: Major
> Fix For: statefun-2.2.2
>
>
> In order to reach feature equivalence with the old code base, we should add
> support for scheduling with slot sharing to the SlotPool. This will also
> allow us to run all the IT cases based on the {{AbstractTestBase}} on the
> Flip-6 {{MiniCluster}}.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-20364) Add support for scheduling with slot sharing
[
https://issues.apache.org/jira/browse/FLINK-20364?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239057#comment-17239057
]
Guruh Fajar Samudra commented on FLINK-20364:
-
Github user GJL commented on a diff in the pull request:
https://github.com/apache/flink/pull/5091#discussion_r155604499
— Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/jobmaster/slotpool/SlotPool.java
—
@@ -266,104 +279,367 @@ public void disconnectResourceManager() {
//
@Override
public CompletableFuture allocateSlot(
SlotRequestID requestId,
ScheduledUnit task,
ResourceProfile resources,
Iterable locationPreferences,
+ public CompletableFuture allocateSlot(
+ SlotRequestId slotRequestId,
+ ScheduledUnit scheduledUnit,
+ ResourceProfile resourceProfile,
+ Collection locationPreferences,
+ boolean allowQueuedScheduling,
Time timeout) { - return internalAllocateSlot(requestId, task, resources,
locationPreferences); + return internalAllocateSlot( + slotRequestId, +
scheduledUnit, + resourceProfile, + locationPreferences, +
allowQueuedScheduling); }
@Override
public void returnAllocatedSlot(Slot slot) {
internalReturnAllocatedSlot(slot);
+ private CompletableFuture internalAllocateSlot(
+ SlotRequestId slotRequestId,
+ ScheduledUnit task,
+ ResourceProfile resourceProfile,
+ Collection locationPreferences,
+ boolean allowQueuedScheduling) {
+
+ final SlotSharingGroupId slotSharingGroupId = task.getSlotSharingGroupId();
+
+ if (slotSharingGroupId != null) {
+ // allocate slot with slot sharing
+ final SlotSharingManager multiTaskSlotManager =
slotSharingManagers.computeIfAbsent(
+ slotSharingGroupId,
+ id -> new SlotSharingManager(
+ id,
+ this,
+ providerAndOwner));
+
+ final SlotSharingManager.MultiTaskSlotLocality multiTaskSlotFuture;
End diff –
The variable name is confusing. `multiTaskSlotFuture` is not of type `Future`.
Permalink
githubbot
ASF GitHub Bot added a comment - 07/Dec/17 18:39
Github user GJL commented on a diff in the pull request:
https://github.com/apache/flink/pull/5091#discussion_r155605251
— Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/jobmaster/LogicalSlot.java
—
@@ -0,0 +1,165 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.jobmaster;
+
+import org.apache.flink.runtime.clusterframework.types.AllocationID;
+import org.apache.flink.runtime.instance.SlotSharingGroupId;
+import org.apache.flink.runtime.jobmanager.scheduler.Locality;
+import org.apache.flink.runtime.jobmanager.slots.TaskManagerGateway;
+import org.apache.flink.runtime.taskmanager.TaskManagerLocation;
+
+import javax.annotation.Nullable;
+
+import java.util.concurrent.CompletableFuture;
+
+/**
+ * A logical slot represents a resource on a TaskManager into
+ * which a single task can be deployed.
+ */
+public interface LogicalSlot {
+
+ Payload TERMINATED_PAYLOAD = new Payload() {
+
+ private final CompletableFuture COMPLETED_TERMINATION_FUTURE =
CompletableFuture.completedFuture(null);
— End diff –
nit: `COMPLETED_TERMINATION_FUTURE` should be camel cased because is not
actually a constant (not static).
> Add support for scheduling with slot sharing
>
>
> Key: FLINK-20364
> URL: https://issues.apache.org/jira/browse/FLINK-20364
> Project: Flink
> Issue Type: Test
> Components: Runtime / Coordination
>Affects Versions: statefun-2.2.1
>Reporter: Guruh Fajar Samudra
>Priority: Major
> Fix For: statefun-2.2.2
>
>
> In order to reach feature equivalence with the old code base, we should add
> support for scheduling with slot sharing to the SlotPool. This will also
> allow us to run all the IT cases based on the {{AbstractTestBase}} on the
> Flip-6 {{MiniCluster}}.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-20364) Add support for scheduling with slot sharing
[
https://issues.apache.org/jira/browse/FLINK-20364?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239055#comment-17239055
]
Guruh Fajar Samudra commented on FLINK-20364:
-
Github user GJL commented on a diff in the pull request:
[https://github.com/apache/flink/pull/5091#discussion_r155520946]
— Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/jobmaster/slotpool/SlotSharingManager.java
—
@@ -0,0 +1,722 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * [http://www.apache.org/licenses/LICENSE-2.0]
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.jobmaster.slotpool;
+
+import org.apache.flink.annotation.VisibleForTesting;
+import org.apache.flink.runtime.jobmaster.LogicalSlot;
+import org.apache.flink.runtime.jobmaster.SlotContext;
+import org.apache.flink.runtime.jobmaster.SlotOwner;
+import org.apache.flink.runtime.jobmaster.SlotRequestId;
+import org.apache.flink.runtime.instance.SlotSharingGroupId;
+import org.apache.flink.runtime.jobmanager.scheduler.Locality;
+import org.apache.flink.runtime.taskmanager.TaskManagerLocation;
+import org.apache.flink.util.AbstractID;
+import org.apache.flink.util.FlinkException;
+import org.apache.flink.util.Preconditions;
+
+import javax.annotation.Nullable;
+
+import java.util.AbstractCollection;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.Map;
+import java.util.Objects;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+
+/**
+ * Manager which is responsible for slot sharing. Slot sharing allows to run
different
+ * tasks in the same slot and to realize co-location constraints.
+ *
+ * The SlotSharingManager allows to create a hierarchy of
{@link TaskSlot} such that
+ * every \{@link TaskSlot}
is uniquely identified by a
{@link SlotRequestId}
identifying
+ * the request for the TaskSlot and a
{@link AbstractID} identifying the task or the
+ * co-location constraint running in this slot.
+ *
+ * The \{@link TaskSlot} hierarchy is implemented by \{@link MultiTaskSlot}
and
+ * \{@link SingleTaskSlot}. The former class represents inner nodes which can
contain
+ * a number of other \{@link TaskSlot} and the latter class represents the
leave nodes.
+ * The hierarchy starts with a root \{@link MultiTaskSlot} which is a future
+ * \{@link SlotContext} assigned. The \{@link SlotContext} represents the
allocated slot
+ * on the TaskExecutor in which all slots of this hierarchy run. A \{@link
MultiTaskSlot}
+ * can be assigned multiple \{@link SingleTaskSlot} or \{@link MultiTaskSlot}
if and only if
+ * the task slot does not yet contain another child with the same \{@link
AbstractID}
identifying
+ * the actual task or the co-location constraint.
+ *
+ * Normal slot sharing is represented by a root
{@link MultiTaskSlot} which contains a set
+ * of \{@link SingleTaskSlot} on the second layer. Each \{@link
SingleTaskSlot} represents a different
+ * task.
+ *
+ * Co-location constraints are modeled by adding a \{@link MultiTaskSlot}
to the root node. The co-location
+ * constraint is uniquely identified by a
{@link AbstractID}
such that we cannot add a second co-located
+ *
{@link MultiTaskSlot}
to the same root node. Now all co-located tasks will be added to co-located
+ * multi task slot.
+ */
+public class SlotSharingManager {
+
+ private final SlotSharingGroupId slotSharingGroupId;
+
+ // needed to release allocated slots after a complete multi task slot
hierarchy has been released
— End diff –
nit: All fields are commented with non-javadoc comments. Normally comments on
fields are also done in Javadoc style, e.g., `SlotPool`. Javadoc comments on
fields are displayed by IntelliJ (`Ctrl + J`).
Permalink
added a comment - 07/Dec/17 15:17
Github user GJL commented on a diff in the pull request:
[https://github.com/apache/flink/pull/5091#discussion_r155549755]
— Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/jobmaster/LogicalSlot.java
—
@@ -32,6 +34,20 @@
*/
public interface LogicalSlot {
+ Payload TERMINATED_PAYLOAD = new Payload() {
+
+ private final CompletableFuture COMPLETED_TERMINATION_FUTURE =
Comple
[jira] [Commented] (FLINK-20364) Add support for scheduling with slot sharing
[
https://issues.apache.org/jira/browse/FLINK-20364?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239054#comment-17239054
]
Guruh Fajar Samudra commented on FLINK-20364:
-
Github user GJL commented on a diff in the pull request:
[https://github.com/apache/flink/pull/5091#discussion_r155503866]
— Diff:
flink-runtime/src/test/java/org/apache/flink/runtime/jobmanager/scheduler/SchedulerTest.java
—
@@ -0,0 +1,97 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * [http://www.apache.org/licenses/LICENSE-2.0]
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.jobmanager.scheduler;
+
+import org.apache.flink.runtime.instance.Instance;
+import org.apache.flink.runtime.testingUtils.TestingUtils;
+import org.apache.flink.util.TestLogger;
+
+import org.junit.Test;
+
+import static
org.apache.flink.runtime.jobmanager.scheduler.SchedulerTestUtils.getRandomInstance;
+import static org.junit.Assert.assertEquals;
+import static org.junit.Assert.assertFalse;
+import static org.junit.Assert.fail;
+
+public class SchedulerTest extends TestLogger {
+
+ @Test
+ public void testAddAndRemoveInstance() {
+ try {
+ Scheduler scheduler = new Scheduler(TestingUtils.defaultExecutionContext());
+
+ Instance i1 = getRandomInstance(2);
+ Instance i2 = getRandomInstance(2);
+ Instance i3 = getRandomInstance(2);
+
+ assertEquals(0, scheduler.getNumberOfAvailableInstances());
+ assertEquals(0, scheduler.getNumberOfAvailableSlots());
+ scheduler.newInstanceAvailable(i1);
+ assertEquals(1, scheduler.getNumberOfAvailableInstances());
+ assertEquals(2, scheduler.getNumberOfAvailableSlots());
+ scheduler.newInstanceAvailable(i2);
+ assertEquals(2, scheduler.getNumberOfAvailableInstances());
+ assertEquals(4, scheduler.getNumberOfAvailableSlots());
+ scheduler.newInstanceAvailable(i3);
+ assertEquals(3, scheduler.getNumberOfAvailableInstances());
+ assertEquals(6, scheduler.getNumberOfAvailableSlots());
+
+ // cannot add available instance again
+ try
{ + scheduler.newInstanceAvailable(i2); + fail("Scheduler accepted instance
twice"); + }
+ catch (IllegalArgumentException e)
{ + // bueno! + }
+
+ // some instances die
+ assertEquals(3, scheduler.getNumberOfAvailableInstances());
+ assertEquals(6, scheduler.getNumberOfAvailableSlots());
+ scheduler.instanceDied(i2);
+ assertEquals(2, scheduler.getNumberOfAvailableInstances());
+ assertEquals(4, scheduler.getNumberOfAvailableSlots());
+
+ // try to add a dead instance
+ try
{ + scheduler.newInstanceAvailable(i2); + fail("Scheduler accepted dead
instance"); + }
+ catch (IllegalArgumentException e) {
+ // stimmt
— End diff –
😃
Permalink
[~githubbot] added a comment - 07/Dec/17 12:10
Github user GJL commented on a diff in the pull request:
[https://github.com/apache/flink/pull/5091#discussion_r155503994]
— Diff:
flink-runtime/src/test/java/org/apache/flink/runtime/jobmanager/scheduler/SchedulerTest.java
—
@@ -0,0 +1,97 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * [http://www.apache.org/licenses/LICENSE-2.0]
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.jobmanager.scheduler;
+
+import org.apache.flink.runtime.instance.Instance;
+import org.apache.flink.runtime.testingUtils.TestingUtils;
+import org.apache.flink.util.TestLogger;
+
+import org.junit.Test;
+
+import static
org.apache.flink.runtime.jobmanager.scheduler.SchedulerTestUtils.getRandomInstance;
+import static org.junit.Assert.assertEquals;
+import static org.junit.Assert.assertFalse;
+import static org.junit.Assert.fail;
+
+public c
[jira] [Commented] (FLINK-20364) Add support for scheduling with slot sharing
[
https://issues.apache.org/jira/browse/FLINK-20364?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239053#comment-17239053
]
Guruh Fajar Samudra commented on FLINK-20364:
-
Github user GJL commented on a diff in the pull request:
[https://github.com/apache/flink/pull/5091#discussion_r155502971]
— Diff:
flink-runtime/src/test/java/org/apache/flink/runtime/jobmaster/slotpool/TestingAllocatedSlotActions.java
—
@@ -0,0 +1,53 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * [http://www.apache.org/licenses/LICENSE-2.0]
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.jobmaster.slotpool;
+
+import org.apache.flink.api.java.tuple.Tuple3;
+import org.apache.flink.runtime.instance.SlotSharingGroupId;
+import org.apache.flink.runtime.jobmaster.SlotRequestId;
+import org.apache.flink.runtime.messages.Acknowledge;
+import org.apache.flink.util.Preconditions;
+
+import javax.annotation.Nullable;
+
+import java.util.concurrent.CompletableFuture;
+import java.util.function.Consumer;
+
+/**
+ * Simple
{@link AllocatedSlotActions}
implementations for testing purposes.
+ */
+public class TestingAllocatedSlotActions implements AllocatedSlotActions {
+
+ private volatile Consumer> releaseSlotConsumer;
+
+ public void setReleaseSlotConsumer(Consumer> releaseSlotConsumer)
{ + this.releaseSlotConsumer = Preconditions.checkNotNull(releaseSlotConsumer);
+ }
+
+ @Override
+ public CompletableFuture releaseSlot(SlotRequestId
slotRequestId, @Nullable SlotSharingGroupId slotSharingGroupId, @Nullable
Throwable cause) {
+ Consumer>
currentReleaseSlotConsumer = this.releaseSlotConsumer;
+
+ if (currentReleaseSlotConsumer != null) {
+ currentReleaseSlotConsumer.accept(Tuple3.of(slotRequestId,
slotSharingGroupId, cause ));
— End diff –
nit: whitespace after `cause`
```
... cause ));
```
> Add support for scheduling with slot sharing
>
>
> Key: FLINK-20364
> URL: https://issues.apache.org/jira/browse/FLINK-20364
> Project: Flink
> Issue Type: Test
> Components: Runtime / Coordination
>Affects Versions: statefun-2.2.1
>Reporter: Guruh Fajar Samudra
>Priority: Major
> Fix For: statefun-2.2.2
>
>
> In order to reach feature equivalence with the old code base, we should add
> support for scheduling with slot sharing to the SlotPool. This will also
> allow us to run all the IT cases based on the {{AbstractTestBase}} on the
> Flip-6 {{MiniCluster}}.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-20364) Add support for scheduling with slot sharing
[ https://issues.apache.org/jira/browse/FLINK-20364?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239052#comment-17239052 ] Guruh Fajar Samudra commented on FLINK-20364: - GitHub user tillrohrmann opened a pull request: [https://github.com/apache/flink/pull/5091] FLINK-7956 [flip6] Add support for queued scheduling with slot sharing to SlotPool # ## What is the purpose of the change This commit adds support for queued scheduling with slot sharing to the SlotPool. The idea of slot sharing is that multiple tasks can run in the same slot. Moreover, queued scheduling means that a slot request must not be completed right away but at a later point in time. This allows to start new TaskExecutors in case that there are no more slots left. The main component responsible for the management of shared slots is the SlotSharingManager. The SlotSharingManager maintains internally a tree-like structure which stores the SlotContext future of the underlying AllocatedSlot. Whenever this future is completed potentially pending LogicalSlot instantiations are executed and sent to the slot requester. A shared slot is represented by a MultiTaskSlot which can harbour multiple TaskSlots. A TaskSlot can either be a MultiTaskSlot or a SingleTaskSlot. In order to represent co-location constraints, we first obtain a root MultiTaskSlot and then allocate a nested MultiTaskSlot in which the co-located tasks are allocated. The corresponding SlotRequestID is assigned to the CoLocationConstraint in order to make the TaskSlot retrievable for other tasks assigned to the same CoLocationConstraint. This PR also moves the `SlotPool` components to `o.a.f.runtime.jobmaster.slotpool`. This PR is based on #5090 # ## Brief change log - Add `SlotSharingManager` to manage shared slots - Rework `SlotPool` to use `SlotSharingManager` - Add `SlotPool#allocateMultiTaskSlot` to allocate a shared slot - Add `SlotPool#allocateCoLocatedMultiTaskSlot` to allocate a co-located slot - Move `SlotPool` components to `o.a.f.runtime.jobmaster.slotpool` # ## Verifying this change - Port `SchedulerSlotSharingTest`, `SchedulerIsolatedTasksTest` and `ScheduleWithCoLocationHintTest` to run with `SlotPool` - Add `SlotSharingManagerTest`, `SlotPoolSlotSharingTest` and `SlotPoolCoLocationTest` # ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (yes) - The S3 file system connector: (no) # ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (not applicable) CC: @GJL You can merge this pull request into a Git repository by running: $ git pull [https://github.com/tillrohrmann/flink] slotPoolSlots Alternatively you can review and apply these changes as the patch at: [https://github.com/apache/flink/pull/5091.patch] To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5091 commit d30dde83548dbeff4249f3b57b67cdb6247af510 Author: Till Rohrmann Date: 2017-11-14T22:50:52Z FLINK-8078 Introduce LogicalSlot interface The LogicalSlot interface decouples the task deployment from the actual slot implementation which at the moment is Slot, SimpleSlot and SharedSlot. This is a helpful step to introduce a different slot implementation for Flip-6. commit e5da9566a6fc8a36ac8b06bae911c0dff5554e5d Author: Till Rohrmann Date: 2017-11-15T13:20:27Z FLINK-8085 Thin out LogicalSlot interface Remove isCanceled, isReleased method and decouple logical slot from Execution by introducing a Payload interface which is set for a LogicalSlot. The Payload interface is implemented by the Execution and allows to fail an implementation and obtaining a termination future. Introduce proper Execution#releaseFuture which is completed once the Execution's assigned resource has been released. commit 84d86bebe2f9f8395430e7c71dd2393ba117b44f Author: Till Rohrmann Date: 2017-11-24T17:03:49Z FLINK-8087 Decouple Slot from AllocatedSlot This commit introduces the SlotContext which is an abstraction for the SimpleSlot to obtain the relevant slot information to do the communication with the TaskManager without relying on the AllocatedSlot which is now only used by the SlotPool. commit 80a3cc848a0c724a2bc09b1b967cc9e6ccec5942 Author: Till Rohrmann Date: 2017-11-24T17:06:10Z FLINK-8088 Associate logical slots with the slot request id Before logical slots like the SimpleSlot and SharedSlot where associated to the actually allocated slot via the A
[jira] [Closed] (FLINK-20364) Add support for scheduling with slot sharing
[
https://issues.apache.org/jira/browse/FLINK-20364?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Guruh Fajar Samudra closed FLINK-20364.
---
Resolution: Fixed
> Add support for scheduling with slot sharing
>
>
> Key: FLINK-20364
> URL: https://issues.apache.org/jira/browse/FLINK-20364
> Project: Flink
> Issue Type: Test
> Components: Runtime / Coordination
>Affects Versions: statefun-2.2.1
>Reporter: Guruh Fajar Samudra
>Priority: Major
> Fix For: statefun-2.2.2
>
>
> In order to reach feature equivalence with the old code base, we should add
> support for scheduling with slot sharing to the SlotPool. This will also
> allow us to run all the IT cases based on the {{AbstractTestBase}} on the
> Flip-6 {{MiniCluster}}.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #14204: [FLINK-20325][build] Move docs_404_check to CI stage
flinkbot edited a comment on pull request #14204: URL: https://github.com/apache/flink/pull/14204#issuecomment-733048767 ## CI report: * 6550d3e1b01af94d4f652f993834b75272da1020 UNKNOWN * c460e22339284c6817e5aad3ea947e87743272e7 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=10128) * 595ab82c651f8c225193eeeba90d6366fdff341d Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=10145) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14103: [FLINK-18545] Introduce `pipeline.name` to allow users to specify job name by configuration
flinkbot edited a comment on pull request #14103: URL: https://github.com/apache/flink/pull/14103#issuecomment-729030820 ## CI report: * 938cbb403a01e6d31cbc605a49f9baf7b3b9bf31 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=9714) * cda47b16b8fa216fefb5399249026c2a54e907ed UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-20213) Partition commit is delayed when records keep coming
[ https://issues.apache.org/jira/browse/FLINK-20213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239051#comment-17239051 ] zouyunhe commented on FLINK-20213: -- [~lzljs3620320] We found the watermark as below, the time is about 2020-11-25 21:53:02 !image-2020-11-26-12-00-23-542.png! And we see the data write in hive partition , the _SUCCESS file has been writeen finished. !image-2020-11-26-12-00-55-829.png! But Some in-progress file was not finished, which mean this paritition is not finished. > Partition commit is delayed when records keep coming > > > Key: FLINK-20213 > URL: https://issues.apache.org/jira/browse/FLINK-20213 > Project: Flink > Issue Type: Bug > Components: Connectors / FileSystem, Table SQL / Ecosystem >Affects Versions: 1.11.2 >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0, 1.11.3 > > Attachments: image-2020-11-26-12-00-23-542.png, > image-2020-11-26-12-00-55-829.png > > > When set partition-commit.delay=0, Users expect partitions to be committed > immediately. > However, if the record of this partition continues to flow in, the bucket for > the partition will be activated, and no inactive bucket will appear. > We need to consider listening to bucket created. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-20364) Add support for scheduling with slot sharing
[
https://issues.apache.org/jira/browse/FLINK-20364?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Guruh Fajar Samudra updated FLINK-20364:
External issue URL: https://github.com/apache/flink/pull/5091
> Add support for scheduling with slot sharing
>
>
> Key: FLINK-20364
> URL: https://issues.apache.org/jira/browse/FLINK-20364
> Project: Flink
> Issue Type: Test
> Components: Runtime / Coordination
>Affects Versions: statefun-2.2.1
>Reporter: Guruh Fajar Samudra
>Priority: Major
> Fix For: statefun-2.2.2
>
>
> In order to reach feature equivalence with the old code base, we should add
> support for scheduling with slot sharing to the SlotPool. This will also
> allow us to run all the IT cases based on the {{AbstractTestBase}} on the
> Flip-6 {{MiniCluster}}.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-20213) Partition commit is delayed when records keep coming
[ https://issues.apache.org/jira/browse/FLINK-20213?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] zouyunhe updated FLINK-20213: - Attachment: image-2020-11-26-12-00-23-542.png > Partition commit is delayed when records keep coming > > > Key: FLINK-20213 > URL: https://issues.apache.org/jira/browse/FLINK-20213 > Project: Flink > Issue Type: Bug > Components: Connectors / FileSystem, Table SQL / Ecosystem >Affects Versions: 1.11.2 >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0, 1.11.3 > > Attachments: image-2020-11-26-12-00-23-542.png, > image-2020-11-26-12-00-55-829.png > > > When set partition-commit.delay=0, Users expect partitions to be committed > immediately. > However, if the record of this partition continues to flow in, the bucket for > the partition will be activated, and no inactive bucket will appear. > We need to consider listening to bucket created. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-20213) Partition commit is delayed when records keep coming
[ https://issues.apache.org/jira/browse/FLINK-20213?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] zouyunhe updated FLINK-20213: - Attachment: image-2020-11-26-12-00-55-829.png > Partition commit is delayed when records keep coming > > > Key: FLINK-20213 > URL: https://issues.apache.org/jira/browse/FLINK-20213 > Project: Flink > Issue Type: Bug > Components: Connectors / FileSystem, Table SQL / Ecosystem >Affects Versions: 1.11.2 >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0, 1.11.3 > > Attachments: image-2020-11-26-12-00-23-542.png, > image-2020-11-26-12-00-55-829.png > > > When set partition-commit.delay=0, Users expect partitions to be committed > immediately. > However, if the record of this partition continues to flow in, the bucket for > the partition will be activated, and no inactive bucket will appear. > We need to consider listening to bucket created. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (FLINK-20364) Add support for scheduling with slot sharing
Guruh Fajar Samudra created FLINK-20364:
---
Summary: Add support for scheduling with slot sharing
Key: FLINK-20364
URL: https://issues.apache.org/jira/browse/FLINK-20364
Project: Flink
Issue Type: Test
Components: Runtime / Coordination
Affects Versions: statefun-2.2.1
Reporter: Guruh Fajar Samudra
Fix For: statefun-2.2.2
In order to reach feature equivalence with the old code base, we should add
support for scheduling with slot sharing to the SlotPool. This will also allow
us to run all the IT cases based on the {{AbstractTestBase}} on the Flip-6
{{MiniCluster}}.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #13580: [hotfix][flink-runtime-web] modify checkpoint time format
flinkbot edited a comment on pull request #13580: URL: https://github.com/apache/flink/pull/13580#issuecomment-706475658 ## CI report: * c8adc676db1403b4a2eef7f9898970f2051dea1f Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=9583) * c40d308eb442e992ea6b2808a2af3f9265665af9 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=10144) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-20213) Partition commit is delayed when records keep coming
[ https://issues.apache.org/jira/browse/FLINK-20213?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239050#comment-17239050 ] Jingsong Lee commented on FLINK-20213: -- [~zouyunhe] Thanks for you feedback, Can you check the watermark is correct? > Partition commit is delayed when records keep coming > > > Key: FLINK-20213 > URL: https://issues.apache.org/jira/browse/FLINK-20213 > Project: Flink > Issue Type: Bug > Components: Connectors / FileSystem, Table SQL / Ecosystem >Affects Versions: 1.11.2 >Reporter: Jingsong Lee >Assignee: Jingsong Lee >Priority: Major > Labels: pull-request-available > Fix For: 1.12.0, 1.11.3 > > > When set partition-commit.delay=0, Users expect partitions to be committed > immediately. > However, if the record of this partition continues to flow in, the bucket for > the partition will be activated, and no inactive bucket will appear. > We need to consider listening to bucket created. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #13580: [hotfix][flink-runtime-web] modify checkpoint time format
flinkbot edited a comment on pull request #13580: URL: https://github.com/apache/flink/pull/13580#issuecomment-706475658 ## CI report: * c8adc676db1403b4a2eef7f9898970f2051dea1f Azure: [FAILURE](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=9583) * c40d308eb442e992ea6b2808a2af3f9265665af9 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-20289) Computed columns can be calculated after ChangelogNormalize to reduce shuffle
[
https://issues.apache.org/jira/browse/FLINK-20289?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu updated FLINK-20289:
Description:
In FLINK-19878, we improved that the ChangelogNormalize is applied after
WatermarkAssigner to make the watermark to be close to the source. This helps
the watermark to be more fine-grained.
However, in some cases, this may shuffle more data, because we may apply all
computed column expressions before ChangelogNormalize. As follows, {{a+1}} can
be applied after ChangelogNormalize to reduce the shuffles.
{code:sql}
CREATE TABLE src (
id STRING,
a INT,
b AS a + 1,
c STRING,
ts as to_timestamp(c),
PRIMARY KEY (id) NOT ENFORCED,
WATERMARK FOR ts AS ts - INTERVAL '1' SECOND
) WITH (
'connector' = 'values',
'changelog-mode' = 'UA,D'
);
SELECT a, b, c FROM src WHERE a > 1
{code}
{code}
Calc(select=[a, b, c], where=[>(a, 1)], changelogMode=[I,UB,UA,D])
+- ChangelogNormalize(key=[id], changelogMode=[I,UB,UA,D])
+- Exchange(distribution=[hash[id]], changelogMode=[UA,D])
+- WatermarkAssigner(rowtime=[ts], watermark=[-(ts, 1000:INTERVAL
SECOND)], changelogMode=[UA,D])
+- Calc(select=[id, a, +(a, 1) AS b, c, TO_TIMESTAMP(c) AS ts],
changelogMode=[UA,D])
+- TableSourceScan(table=[[default_catalog, default_database,
src]], fields=[id, a, c], changelogMode=[UA,D])
{code}
A better plan should be:
{code}
Calc(select=[a, +(a, 1) AS b, c], where=[>(a, 1)], changelogMode=[I,UB,UA,D])
+- ChangelogNormalize(key=[id], changelogMode=[I,UB,UA,D])
+- Exchange(distribution=[hash[id]], changelogMode=[UA,D])
+- WatermarkAssigner(rowtime=[ts], watermark=[-(ts, 1000:INTERVAL
SECOND)], changelogMode=[UA,D])
+- Calc(select=[id, a, c, TO_TIMESTAMP(c) AS ts], changelogMode=[UA,D])
+- TableSourceScan(table=[[default_catalog, default_database,
src]], fields=[id, a, c], changelogMode=[UA,D])
{code}
was:
In FLINK-19878, we improved that the ChangelogNormalize is applied after
WatermarkAssigner to make the watermark to be close to the source. This helps
the watermark to be more fine-grained.
However, in some cases, this may shuffle more data, because we may apply all
computed column expressions before ChangelogNormalize. As follows, {{a+1}} can
be applied after ChangelogNormalize to reduce the shuffles.
{code:sql}
CREATE TABLE src (
id STRING,
a INT,
b AS a + 1,
c STRING,
ts as to_timestamp(c),
PRIMARY KEY (id) NOT ENFORCED,
WATERMARK FOR ts AS ts - INTERVAL '1' SECOND
) WITH (
'connector' = 'values',
'changelog-mode' = 'UA,D'
);
SELECT a, b, c FROM src WHERE a > 1
{code}
{code}
Calc(select=[a, b, c], where=[>(a, 1)], changelogMode=[I,UB,UA,D])
+- ChangelogNormalize(key=[id], changelogMode=[I,UB,UA,D])
+- Exchange(distribution=[hash[id]], changelogMode=[UA,D])
+- WatermarkAssigner(rowtime=[ts], watermark=[-(ts, 1000:INTERVAL
SECOND)], changelogMode=[UA,D])
+- Calc(select=[id, a, +(a, 1) AS b, c, TO_TIMESTAMP(c) AS ts],
changelogMode=[UA,D])
+- TableSourceScan(table=[[default_catalog, default_database,
src]], fields=[id, a, c], changelogMode=[UA,D])
{code}
> Computed columns can be calculated after ChangelogNormalize to reduce shuffle
> -
>
> Key: FLINK-20289
> URL: https://issues.apache.org/jira/browse/FLINK-20289
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / Planner
>Reporter: Jark Wu
>Priority: Major
>
> In FLINK-19878, we improved that the ChangelogNormalize is applied after
> WatermarkAssigner to make the watermark to be close to the source. This helps
> the watermark to be more fine-grained.
> However, in some cases, this may shuffle more data, because we may apply all
> computed column expressions before ChangelogNormalize. As follows, {{a+1}}
> can be applied after ChangelogNormalize to reduce the shuffles.
> {code:sql}
> CREATE TABLE src (
> id STRING,
> a INT,
> b AS a + 1,
> c STRING,
> ts as to_timestamp(c),
> PRIMARY KEY (id) NOT ENFORCED,
> WATERMARK FOR ts AS ts - INTERVAL '1' SECOND
> ) WITH (
> 'connector' = 'values',
> 'changelog-mode' = 'UA,D'
> );
> SELECT a, b, c FROM src WHERE a > 1
> {code}
> {code}
> Calc(select=[a, b, c], where=[>(a, 1)], changelogMode=[I,UB,UA,D])
> +- ChangelogNormalize(key=[id], changelogMode=[I,UB,UA,D])
>+- Exchange(distribution=[hash[id]], changelogMode=[UA,D])
> +- WatermarkAssigner(rowtime=[ts], watermark=[-(ts, 1000:INTERVAL
> SECOND)], changelogMode=[UA,D])
> +- Calc(select=[id, a, +(a, 1) AS b, c, TO_TIMESTAMP(c) AS ts],
> changelogMode=[UA,D])
> +- TableSourceScan(table=[[default_catalog, default_database,
> src]], fields=[id, a, c], changelogMode=[UA,D])
> {code}
> A better plan should be:
> {co
[jira] [Commented] (FLINK-20289) Computed columns can be calculated after ChangelogNormalize to reduce shuffle
[
https://issues.apache.org/jira/browse/FLINK-20289?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239047#comment-17239047
]
Jark Wu commented on FLINK-20289:
-
It is an improvement that only rowtime expressions should be pushded down, all
other computed columns can be calcuted after ChangelogNormalize, to reduce the
shuffle data.
> Computed columns can be calculated after ChangelogNormalize to reduce shuffle
> -
>
> Key: FLINK-20289
> URL: https://issues.apache.org/jira/browse/FLINK-20289
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / Planner
>Reporter: Jark Wu
>Priority: Major
>
> In FLINK-19878, we improved that the ChangelogNormalize is applied after
> WatermarkAssigner to make the watermark to be close to the source. This helps
> the watermark to be more fine-grained.
> However, in some cases, this may shuffle more data, because we may apply all
> computed column expressions before ChangelogNormalize. As follows, {{a+1}}
> can be applied after ChangelogNormalize to reduce the shuffles.
> {code:sql}
> CREATE TABLE src (
> id STRING,
> a INT,
> b AS a + 1,
> c STRING,
> ts as to_timestamp(c),
> PRIMARY KEY (id) NOT ENFORCED,
> WATERMARK FOR ts AS ts - INTERVAL '1' SECOND
> ) WITH (
> 'connector' = 'values',
> 'changelog-mode' = 'UA,D'
> );
> SELECT a, b, c FROM src WHERE a > 1
> {code}
> {code}
> Calc(select=[a, b, c], where=[>(a, 1)], changelogMode=[I,UB,UA,D])
> +- ChangelogNormalize(key=[id], changelogMode=[I,UB,UA,D])
>+- Exchange(distribution=[hash[id]], changelogMode=[UA,D])
> +- WatermarkAssigner(rowtime=[ts], watermark=[-(ts, 1000:INTERVAL
> SECOND)], changelogMode=[UA,D])
> +- Calc(select=[id, a, +(a, 1) AS b, c, TO_TIMESTAMP(c) AS ts],
> changelogMode=[UA,D])
> +- TableSourceScan(table=[[default_catalog, default_database,
> src]], fields=[id, a, c], changelogMode=[UA,D])
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (FLINK-20289) Computed columns can be calculated after ChangelogNormalize to reduce shuffle
[
https://issues.apache.org/jira/browse/FLINK-20289?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17238118#comment-17238118
]
Nicholas Jiang edited comment on FLINK-20289 at 11/26/20, 3:20 AM:
---
[~jark], is this improvement that all computed column expressions is pushed
down after ChangelogNormalize?
IMO, I could try to work for the calculation of computed columns after
ChangelogNormalize.
was (Author: nicholasjiang):
[~jark], is this improvement that all computed column expressions is pushed
down after ChangelogNormalize? IMO, I could try to work for the calculation of
computed columns after ChangelogNormalize.
> Computed columns can be calculated after ChangelogNormalize to reduce shuffle
> -
>
> Key: FLINK-20289
> URL: https://issues.apache.org/jira/browse/FLINK-20289
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / Planner
>Reporter: Jark Wu
>Priority: Major
>
> In FLINK-19878, we improved that the ChangelogNormalize is applied after
> WatermarkAssigner to make the watermark to be close to the source. This helps
> the watermark to be more fine-grained.
> However, in some cases, this may shuffle more data, because we may apply all
> computed column expressions before ChangelogNormalize. As follows, {{a+1}}
> can be applied after ChangelogNormalize to reduce the shuffles.
> {code:sql}
> CREATE TABLE src (
> id STRING,
> a INT,
> b AS a + 1,
> c STRING,
> ts as to_timestamp(c),
> PRIMARY KEY (id) NOT ENFORCED,
> WATERMARK FOR ts AS ts - INTERVAL '1' SECOND
> ) WITH (
> 'connector' = 'values',
> 'changelog-mode' = 'UA,D'
> );
> SELECT a, b, c FROM src WHERE a > 1
> {code}
> {code}
> Calc(select=[a, b, c], where=[>(a, 1)], changelogMode=[I,UB,UA,D])
> +- ChangelogNormalize(key=[id], changelogMode=[I,UB,UA,D])
>+- Exchange(distribution=[hash[id]], changelogMode=[UA,D])
> +- WatermarkAssigner(rowtime=[ts], watermark=[-(ts, 1000:INTERVAL
> SECOND)], changelogMode=[UA,D])
> +- Calc(select=[id, a, +(a, 1) AS b, c, TO_TIMESTAMP(c) AS ts],
> changelogMode=[UA,D])
> +- TableSourceScan(table=[[default_catalog, default_database,
> src]], fields=[id, a, c], changelogMode=[UA,D])
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] flinkbot edited a comment on pull request #14226: [FLINK-20362][doc] Fix broken link in sourceSinks.zh.md
flinkbot edited a comment on pull request #14226: URL: https://github.com/apache/flink/pull/14226#issuecomment-734044273 ## CI report: * e0e112b0a92a02a62de739fa37a98f2d132e5a46 Azure: [PENDING](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=10143) Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot edited a comment on pull request #14204: [FLINK-20325][build] Move docs_404_check to CI stage
flinkbot edited a comment on pull request #14204: URL: https://github.com/apache/flink/pull/14204#issuecomment-733048767 ## CI report: * 6550d3e1b01af94d4f652f993834b75272da1020 UNKNOWN * c460e22339284c6817e5aad3ea947e87743272e7 Azure: [SUCCESS](https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=10128) * 595ab82c651f8c225193eeeba90d6366fdff341d UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-13611) Introduce analyze statistic utility to generate table & column statistics
[
https://issues.apache.org/jira/browse/FLINK-13611?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239041#comment-17239041
]
Zou commented on FLINK-13611:
-
Big +1 for this feature, it is a very important feature for batch SQL, any
progress on this ticket? [~godfreyhe]
> Introduce analyze statistic utility to generate table & column statistics
> -
>
> Key: FLINK-13611
> URL: https://issues.apache.org/jira/browse/FLINK-13611
> Project: Flink
> Issue Type: New Feature
> Components: Table SQL / Planner
>Reporter: godfrey he
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> this issue aims to introduce a utility class to generate table & column
> statistics, the main steps include:
> 1. generate sql, like
> {code:sql}
> select approx_count_distinct(a) as ndv, count(1) - count(a) as nullCount,
> avg(char_length(a)) as avgLen, max(char_lenght(a)) as maxLen, max(a) as
> maxValue, min(a) as minValue, ... from MyTable
> {code}
> 2. execute the query
> 3. convert to the result to {{TableStats}} (maybe the source table is not a
> {{ConnectorCatalogTable}})
> 4. convert to {{TableStats}} to {{CatalogTableStatistics}} if needed
> This issue does not involve DDL(like {{ANALYZE TABLE XXX}}), however the DDL
> could use this utility class once it's supported.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-20348) Make "schema-registry.subject" optional for Kafka sink with avro-confluent format
[
https://issues.apache.org/jira/browse/FLINK-20348?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239040#comment-17239040
]
Jark Wu commented on FLINK-20348:
-
[~dwysakowicz] yes, you are right. Kafka connector will populate this option if
not set explicity when working with 'avro-confluent' format.
Because only Kafka connector knows it is used in key format or value format. So
I think (2) doesn't work.
> Make "schema-registry.subject" optional for Kafka sink with avro-confluent
> format
> -
>
> Key: FLINK-20348
> URL: https://issues.apache.org/jira/browse/FLINK-20348
> Project: Flink
> Issue Type: Improvement
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile), Table
> SQL / Ecosystem
>Reporter: Jark Wu
>Priority: Major
> Fix For: 1.12.0
>
>
> Currently, configuration "schema-registry.subject" in avro-confluent format
> is required by sink. However, this is quite verbose set it manually. By
> default, it can be to set to {{-key}} and {{-value}}
> if it works with kafka or upsert-kafka connector. This can also makes
> 'avro-confluent' format to be more handy and works better with
> Kafka/Confluent ecosystem.
> {code:sql}
> CREATE TABLE kafka_gmv (
> day_str STRING,
> gmv BIGINT,
> PRIMARY KEY (day_str) NOT ENFORCED
> ) WITH (
> 'connector' = 'upsert-kafka',
> 'topic' = 'kafka_gmv',
> 'properties.bootstrap.servers' = 'localhost:9092',
> -- 'key.format' = 'raw',
> 'key.format' = 'avro-confluent',
> 'key.avro-confluent.schema-registry.url' = 'http://localhost:8181',
> 'key.avro-confluent.schema-registry.subject' = 'kafka_gmv-key',
> 'value.format' = 'avro-confluent',
> 'value.avro-confluent.schema-registry.url' = 'http://localhost:8181',
> 'value.avro-confluent.schema-registry.subject' = 'kafka_gmv-value'
> );
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-20301) Flink sql 1.10 : Legacy Decimal and decimal for Array that is not Compatible
[
https://issues.apache.org/jira/browse/FLINK-20301?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
hehuiyuan updated FLINK-20301:
--
Affects Version/s: 1.10.0
> Flink sql 1.10 : Legacy Decimal and decimal for Array that is not Compatible
> --
>
> Key: FLINK-20301
> URL: https://issues.apache.org/jira/browse/FLINK-20301
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.10.0
>Reporter: hehuiyuan
>Priority: Minor
> Attachments: image-2020-11-23-23-48-02-102.png
>
>
> The error log:
>
> {code:java}
> Exception in thread "main" org.apache.flink.table.api.ValidationException:
> Type ARRAY of table field 'numbers' does not match with the
> physical type ARRAY of the 'numbers' field of
> the TableSource return type.Exception in thread "main"
> org.apache.flink.table.api.ValidationException: Type ARRAY
> of table field 'numbers' does not match with the physical type
> ARRAY of the 'numbers' field of the TableSource
> return type. at
> org.apache.flink.table.utils.TypeMappingUtils.lambda$checkPhysicalLogicalTypeCompatible$4(TypeMappingUtils.java:160)
> at
> org.apache.flink.table.utils.TypeMappingUtils.checkPhysicalLogicalTypeCompatible(TypeMappingUtils.java:185)
> at
> org.apache.flink.table.utils.TypeMappingUtils.lambda$computeInCompositeType$8(TypeMappingUtils.java:246)
> at java.util.stream.Collectors.lambda$toMap$58(Collectors.java:1321) at
> java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169) at
> java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1382)
> at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at
> java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
> at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
> at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at
> java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at
> org.apache.flink.table.utils.TypeMappingUtils.computeInCompositeType(TypeMappingUtils.java:228)
> at
> org.apache.flink.table.utils.TypeMappingUtils.computePhysicalIndices(TypeMappingUtils.java:206)
> at
> org.apache.flink.table.utils.TypeMappingUtils.computePhysicalIndicesOrTimeAttributeMarkers(TypeMappingUtils.java:110)
> at
> org.apache.flink.table.planner.plan.nodes.physical.stream.StreamExecTableSourceScan.computeIndexMapping(StreamExecTableSourceScan.scala:212)
> at
> org.apache.flink.table.planner.plan.nodes.physical.stream.StreamExecTableSourceScan.translateToPlanInternal(StreamExecTableSourceScan.scala:107)
> at
> org.apache.flink.table.planner.plan.nodes.physical.stream.StreamExecTableSourceScan.translateToPlanInternal(StreamExecTableSourceScan.scala:62)
> at
> org.apache.flink.table.planner.plan.nodes.exec.ExecNode$class.translateToPlan(ExecNode.scala:58)
> at
> org.apache.flink.table.planner.plan.nodes.physical.stream.StreamExecTableSourceScan.translateToPlan(StreamExecTableSourceScan.scala:62)
> at
> org.apache.flink.table.planner.plan.nodes.physical.stream.StreamExecSink.translateToTransformation(StreamExecSink.scala:184)
> at
> org.apache.flink.table.planner.plan.nodes.physical.stream.StreamExecSink.translateToPlanInternal(StreamExecSink.scala:118)
> at
> org.apache.flink.table.planner.plan.nodes.physical.stream.StreamExecSink.translateToPlanInternal(StreamExecSink.scala:48)
> at
> org.apache.flink.table.planner.plan.nodes.exec.ExecNode$class.translateToPlan(ExecNode.scala:58)
> at
> org.apache.flink.table.planner.plan.nodes.physical.stream.StreamExecSink.translateToPlan(StreamExecSink.scala:48)
> at
> org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$translateToPlan$1.apply(StreamPlanner.scala:60)
> at
> org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$translateToPlan$1.apply(StreamPlanner.scala:59)
> at
> scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
> at
> scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
> at scala.collection.Iterator$class.foreach(Iterator.scala:893) at
> scala.collection.AbstractIterator.foreach(Iterator.scala:1336) at
> scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at
> scala.collection.AbstractIterable.foreach(Iterable.scala:54) at
> scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at
> scala.collection.AbstractTraversable.map(Traversable.scala:104) at
> org.apache.flink.table.planner.delegation.StreamPlanner.translateToPlan(StreamPlanner.scala:59)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.translate(PlannerBase.scala:153)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.translate(TableEnvir
[jira] [Commented] (FLINK-20361) Using sliding window with duration of hours in Table API returns wrong time
[
https://issues.apache.org/jira/browse/FLINK-20361?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239036#comment-17239036
]
Jark Wu commented on FLINK-20361:
-
The result is as expected. You can see the sliding window definition here:
https://ci.apache.org/projects/flink/flink-docs-master/dev/stream/operators/windows.html#sliding-windows
Do you mean the result of SQL is different than Table API?
> Using sliding window with duration of hours in Table API returns wrong time
> ---
>
> Key: FLINK-20361
> URL: https://issues.apache.org/jira/browse/FLINK-20361
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / API
>Affects Versions: 1.11.0, 1.11.1, 1.11.2
> Environment: Java 11, test executed in IntelliJ IDE on mac OS.
>Reporter: Aleksandra Cz
>Priority: Blocker
> Fix For: 1.11.2
>
>
> If in [Table walkthrough|
> [https://github.com/apache/flink-playgrounds/blob/master/table-walkthrough/src/main/java/org/apache/flink/playgrounds/spendreport/SpendReport.java]]
>
> implemented *report* method would be as follows:
>
> {code:java}
> public static Table report(Table transactions) {
> return transactions
>
> .window(Slide.over(lit(1).hours()).every(lit(5).minute()).on($("transaction_time")).as("log_ts"))
> .groupBy($("log_ts"),$("account_id"))
> .select(
> $("log_ts").start().as("log_ts_start"),
> $("log_ts").end().as("log_ts_end"),
> $("account_id"),
> $("amount").sum().as("amount"));
> {code}
>
> Then the resulting sliding window start and sliding window end would be in
> year 1969/1970. Please see first 3 elements of resulting table:
> {code:java}
> [1969-12-31T23:05,1970-01-01T00:05,3,432,
> 1969-12-31T23:10,1970-01-01T00:10,3,432,
> 1969-12-31T23:15,1970-01-01T00:15,3,432]{code}
> This behaviour repeats if using SQL instead of Table API,
> it does not repeat for window duration of minutes, nor in Tumbling window.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Resolved] (FLINK-19998) Invalid Links in docs
[
https://issues.apache.org/jira/browse/FLINK-19998?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Yun Tang resolved FLINK-19998.
--
Resolution: Fixed
> Invalid Links in docs
> -
>
> Key: FLINK-19998
> URL: https://issues.apache.org/jira/browse/FLINK-19998
> Project: Flink
> Issue Type: Bug
> Components: Documentation
>Affects Versions: 1.11.2
>Reporter: Aditya Agarwal
>Assignee: Aditya Agarwal
>Priority: Minor
> Labels: documentation, pull-request-available
>
> Multiple broken links matching pattern: *site.baseurl }}{% link*
> All these need to be replaced. Eg:
> In the *docs/concepts/stateful-stream-processing.md* file, under the first
> section (What is State), the following two links are broken:
> # Checkpoints: *[checkpoints](\{{ site.baseurl}}\{% link
> dev/stream/state/checkpointing.md %})*
> # Savepoints: *[savepoints](\{{ site.baseurl }}\{%link
> ops/state/savepoints.md %})*
> This results in the target link as follows:
> # For Checkpoints:
> [https://ci.apache.org/projects/flink/flink-docs-master//ci.apache.org/projects/flink/flink-docs-master/dev/stream/state/checkpointing.html]
> #
> [https://ci.apache.org/projects/flink/flink-docs-master//ci.apache.org/projects/flink/flink-docs-master/ops/state/savepoints.html]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (FLINK-19998) Invalid Links in docs
[
https://issues.apache.org/jira/browse/FLINK-19998?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239033#comment-17239033
]
Yun Tang commented on FLINK-19998:
--
merged in master c008907d2a629449c8d0ad9725d13b0604fc2141
> Invalid Links in docs
> -
>
> Key: FLINK-19998
> URL: https://issues.apache.org/jira/browse/FLINK-19998
> Project: Flink
> Issue Type: Bug
> Components: Documentation
>Affects Versions: 1.11.2
>Reporter: Aditya Agarwal
>Assignee: Aditya Agarwal
>Priority: Minor
> Labels: documentation, pull-request-available
>
> Multiple broken links matching pattern: *site.baseurl }}{% link*
> All these need to be replaced. Eg:
> In the *docs/concepts/stateful-stream-processing.md* file, under the first
> section (What is State), the following two links are broken:
> # Checkpoints: *[checkpoints](\{{ site.baseurl}}\{% link
> dev/stream/state/checkpointing.md %})*
> # Savepoints: *[savepoints](\{{ site.baseurl }}\{%link
> ops/state/savepoints.md %})*
> This results in the target link as follows:
> # For Checkpoints:
> [https://ci.apache.org/projects/flink/flink-docs-master//ci.apache.org/projects/flink/flink-docs-master/dev/stream/state/checkpointing.html]
> #
> [https://ci.apache.org/projects/flink/flink-docs-master//ci.apache.org/projects/flink/flink-docs-master/ops/state/savepoints.html]
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-20225) Broken link in the document
[ https://issues.apache.org/jira/browse/FLINK-20225?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu updated FLINK-20225: Summary: Broken link in the document (was: broken link in the document) > Broken link in the document > --- > > Key: FLINK-20225 > URL: https://issues.apache.org/jira/browse/FLINK-20225 > Project: Flink > Issue Type: Improvement > Components: Deployment / Kubernetes, Documentation >Affects Versions: 1.11.0 >Reporter: Guowei Ma >Priority: Critical > > In the > [doc|https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/kubernetes.html#start-a-job-cluster] > there is a broken link: > A _Flink Job cluster_ is a dedicated cluster which runs a single job. You can > find more details > [here|https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/kubernetes.html#start-a-job-cluster]. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-20225) broken link in the document
[ https://issues.apache.org/jira/browse/FLINK-20225?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jark Wu updated FLINK-20225: Summary: broken link in the document (was: Break link in the document) > broken link in the document > --- > > Key: FLINK-20225 > URL: https://issues.apache.org/jira/browse/FLINK-20225 > Project: Flink > Issue Type: Improvement > Components: Deployment / Kubernetes, Documentation >Affects Versions: 1.11.0 >Reporter: Guowei Ma >Priority: Critical > > In the > [doc|https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/kubernetes.html#start-a-job-cluster] > there is a broken link: > A _Flink Job cluster_ is a dedicated cluster which runs a single job. You can > find more details > [here|https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/kubernetes.html#start-a-job-cluster]. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [flink] flinkbot commented on pull request #14226: [FLINK-20362][doc] Fix broken link in sourceSinks.zh.md
flinkbot commented on pull request #14226: URL: https://github.com/apache/flink/pull/14226#issuecomment-734044273 ## CI report: * e0e112b0a92a02a62de739fa37a98f2d132e5a46 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run travis` re-run the last Travis build - `@flinkbot run azure` re-run the last Azure build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-20362) Broken Link in dev/table/sourceSinks.zh.md
[
https://issues.apache.org/jira/browse/FLINK-20362?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jark Wu reassigned FLINK-20362:
---
Assignee: Shengkai Fang
> Broken Link in dev/table/sourceSinks.zh.md
> --
>
> Key: FLINK-20362
> URL: https://issues.apache.org/jira/browse/FLINK-20362
> Project: Flink
> Issue Type: Bug
> Components: Documentation, Table SQL / API
>Affects Versions: 1.12.0
>Reporter: Huang Xingbo
>Assignee: Shengkai Fang
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.12.0
>
>
> When executing the script build_docs.sh, it will throw the following
> exception:
> {code:java}
> Liquid Exception: Could not find document 'dev/table/legacySourceSinks.md' in
> tag 'link'. Make sure the document exists and the path is correct. in
> dev/table/sourceSinks.zh.md Could not find document
> 'dev/table/legacySourceSinks.md' in tag 'link'.
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] wuchong commented on a change in pull request #14103: [FLINK-18545] Introduce `pipeline.name` to allow users to specify job name by configuration
wuchong commented on a change in pull request #14103:
URL: https://github.com/apache/flink/pull/14103#discussion_r530745246
##
File path:
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/environment/StreamExecutionEnvironment.java
##
@@ -2330,4 +2330,8 @@ public void registerCachedFile(String filePath, String
name, boolean executable)
}
return (T) resolvedTypeInfo;
}
+
+ private String getJobName() {
+ return configuration.getString(PipelineOptions.NAME,
DEFAULT_JOB_NAME);
Review comment:
`TableEnvironment` also uses a different default name for the SQL query,
e.g. `insert-into_`. So I think no default value makes more sense,
that the default value is defined by different environment.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] wuchong commented on a change in pull request #14103: [FLINK-18545] Introduce `pipeline.name` to allow users to specify job name by configuration
wuchong commented on a change in pull request #14103:
URL: https://github.com/apache/flink/pull/14103#discussion_r530745246
##
File path:
flink-streaming-java/src/main/java/org/apache/flink/streaming/api/environment/StreamExecutionEnvironment.java
##
@@ -2330,4 +2330,8 @@ public void registerCachedFile(String filePath, String
name, boolean executable)
}
return (T) resolvedTypeInfo;
}
+
+ private String getJobName() {
+ return configuration.getString(PipelineOptions.NAME,
DEFAULT_JOB_NAME);
Review comment:
`TableEnvironment` also uses a different default name for the SQL query,
e.g. "insert-into_". So I think no default value makes more sense,
that the default value is defined by different environment.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] wuchong commented on pull request #14204: [FLINK-20325][build] Move docs_404_check to CI stage
wuchong commented on pull request #14204: URL: https://github.com/apache/flink/pull/14204#issuecomment-734042205 Hi @rmetzger , the build should fail because there are some 404 pages, however it is passed. I looked into the log, it did report an unfounded page by the web server process ``` [2020-11-25 16:48:48] ERROR `/zh/dev/datastream_execution_mode.html' not found. ``` , but the `check_links.sh` returns success and no broken links are found. I'm wondering maybe it is related to the `grep` command or the language of the `spider.log`. Do you know how to download the `spider.log`? Logs: ``` Auto-regeneration: enabled for '/home/vsts/work/1/s/docs' Server address: http://0.0.0.0:4000/ Server running... press ctrl-c to stop. Waiting for server... HTTP/1.1 200 OK Etag: 8f45f-8418-5fbe8ae3 Content-Type: text/html; charset=utf-8 Content-Length: 33816 Last-Modified: Wed, 25 Nov 2020 16:48:35 GMT Cache-Control: private, max-age=0, proxy-revalidate, no-store, no-cache, must-revalidate Server: WEBrick/1.3.1 (Ruby/2.4.10/2020-03-31) Date: Wed, 25 Nov 2020 16:48:40 GMT Connection: Keep-Alive [2020-11-25 16:48:48] ERROR `/zh/dev/datastream_execution_mode.html' not found. All links in docs are valid! ``` https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=10128&view=logs&j=c5d67f7d-375d-5407-4743-f9d0c4436a81&t=38411795-40c9-51fa-10b0-bd083cf9f5a5 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-20284) Error happens in TaskExecutor when closing JobMaster connection if there was a python UDF
[
https://issues.apache.org/jira/browse/FLINK-20284?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239030#comment-17239030
]
Zhu Zhu commented on FLINK-20284:
-
Thanks for the investigation and fixing this problem! [~hxbks2ks]
> Error happens in TaskExecutor when closing JobMaster connection if there was
> a python UDF
> -
>
> Key: FLINK-20284
> URL: https://issues.apache.org/jira/browse/FLINK-20284
> Project: Flink
> Issue Type: Bug
> Components: API / Python
>Affects Versions: 1.11.0, 1.12.0
>Reporter: Zhu Zhu
>Assignee: Huang Xingbo
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.12.0, 1.11.3
>
>
> When a TaskExecutor successfully finished running a python UDF task and
> disconnecting from JobMaster, errors below will happen. This error, however,
> seems not affect job execution at the moment.
> {code:java}
> 2020-11-20 17:05:21,932 INFO
> org.apache.beam.runners.fnexecution.logging.GrpcLoggingService [] - 1 Beam Fn
> Logging clients still connected during shutdown.
> 2020-11-20 17:05:21,938 WARN
> org.apache.beam.sdk.fn.data.BeamFnDataGrpcMultiplexer[] - Hanged up
> for unknown endpoint.
> 2020-11-20 17:05:22,126 INFO org.apache.flink.runtime.taskmanager.Task
> [] - Source: Custom Source -> select: (f0) -> select:
> (add_one(f0) AS a) -> to: Tuple2 -> Sink: Streaming select table sink (1/1)#0
> (b0c2104dd8f87bb1caf0c83586c22a51) switched from RUNNING to FINISHED.
> 2020-11-20 17:05:22,126 INFO org.apache.flink.runtime.taskmanager.Task
> [] - Freeing task resources for Source: Custom Source -> select:
> (f0) -> select: (add_one(f0) AS a) -> to: Tuple2 -> Sink: Streaming select
> table sink (1/1)#0 (b0c2104dd8f87bb1caf0c83586c22a51).
> 2020-11-20 17:05:22,128 INFO
> org.apache.flink.runtime.taskexecutor.TaskExecutor [] -
> Un-registering task and sending final execution state FINISHED to JobManager
> for task Source: Custom Source -> select: (f0) -> select: (add_one(f0) AS a)
> -> to: Tuple2 -> Sink: Streaming select table sink (1/1)#0
> b0c2104dd8f87bb1caf0c83586c22a51.
> 2020-11-20 17:05:22,156 INFO
> org.apache.flink.runtime.taskexecutor.slot.TaskSlotTableImpl [] - Free slot
> TaskSlot(index:0, state:ACTIVE, resource profile:
> ResourceProfile{cpuCores=1., taskHeapMemory=384.000mb
> (402653174 bytes), taskOffHeapMemory=0 bytes, managedMemory=512.000mb
> (536870920 bytes), networkMemory=128.000mb (134217730 bytes)}, allocationId:
> b67c3307dcf93757adfb4f0f9f7b8c7b, jobId: d05f32162f38ec3ec813c4621bc106d9).
> 2020-11-20 17:05:22,157 INFO
> org.apache.flink.runtime.taskexecutor.DefaultJobLeaderService [] - Remove job
> d05f32162f38ec3ec813c4621bc106d9 from job leader monitoring.
> 2020-11-20 17:05:22,157 INFO
> org.apache.flink.runtime.taskexecutor.TaskExecutor [] - Close
> JobManager connection for job d05f32162f38ec3ec813c4621bc106d9.
> 2020-11-20 17:05:23,064 ERROR
> org.apache.beam.vendor.grpc.v1p26p0.io.netty.util.concurrent.DefaultPromise.rejectedExecution
> [] - Failed to submit a listener notification task. Event loop shut down?
> java.lang.NoClassDefFoundError:
> org/apache/beam/vendor/grpc/v1p26p0/io/netty/util/concurrent/GlobalEventExecutor$2
> at
> org.apache.beam.vendor.grpc.v1p26p0.io.netty.util.concurrent.GlobalEventExecutor.startThread(GlobalEventExecutor.java:227)
>
> ~[blob_p-bd7a5d615512eb8a2e856e7c1630a0c22fca7cf3-ff27946fda7e2b8cb24ea56d505b689e:1.12-SNAPSHOT]
> at
> org.apache.beam.vendor.grpc.v1p26p0.io.netty.util.concurrent.GlobalEventExecutor.execute(GlobalEventExecutor.java:215)
>
> ~[blob_p-bd7a5d615512eb8a2e856e7c1630a0c22fca7cf3-ff27946fda7e2b8cb24ea56d505b689e:1.12-SNAPSHOT]
> at
> org.apache.beam.vendor.grpc.v1p26p0.io.netty.util.concurrent.DefaultPromise.safeExecute(DefaultPromise.java:841)
>
> [blob_p-bd7a5d615512eb8a2e856e7c1630a0c22fca7cf3-ff27946fda7e2b8cb24ea56d505b689e:1.12-SNAPSHOT]
> at
> org.apache.beam.vendor.grpc.v1p26p0.io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:498)
>
> [blob_p-bd7a5d615512eb8a2e856e7c1630a0c22fca7cf3-ff27946fda7e2b8cb24ea56d505b689e:1.12-SNAPSHOT]
> at
> org.apache.beam.vendor.grpc.v1p26p0.io.netty.util.concurrent.DefaultPromise.setValue0(DefaultPromise.java:615)
>
> [blob_p-bd7a5d615512eb8a2e856e7c1630a0c22fca7cf3-ff27946fda7e2b8cb24ea56d505b689e:1.12-SNAPSHOT]
> at
> org.apache.beam.vendor.grpc.v1p26p0.io.netty.util.concurrent.DefaultPromise.setSuccess0(DefaultPromise.java:604)
>
> [blob_p-bd7a5d615512eb8a2e856e7c1630a0c22fca7cf3-ff27946fda7e2b8cb24ea56d505b689e:1.12-SNAPSHOT]
> at
> org.apache.beam.vendor
[GitHub] [flink] flinkbot commented on pull request #14226: [FLINK-20362][doc] Fix broken link in sourceSinks.zh.md
flinkbot commented on pull request #14226: URL: https://github.com/apache/flink/pull/14226#issuecomment-734041759 Thanks a lot for your contribution to the Apache Flink project. I'm the @flinkbot. I help the community to review your pull request. We will use this comment to track the progress of the review. ## Automated Checks Last check on commit e0e112b0a92a02a62de739fa37a98f2d132e5a46 (Thu Nov 26 02:48:31 UTC 2020) **Warnings:** * **This pull request references an unassigned [Jira ticket](https://issues.apache.org/jira/browse/FLINK-20362).** According to the [code contribution guide](https://flink.apache.org/contributing/contribute-code.html), tickets need to be assigned before starting with the implementation work. Mention the bot in a comment to re-run the automated checks. ## Review Progress * ❓ 1. The [description] looks good. * ❓ 2. There is [consensus] that the contribution should go into to Flink. * ❓ 3. Needs [attention] from. * ❓ 4. The change fits into the overall [architecture]. * ❓ 5. Overall code [quality] is good. Please see the [Pull Request Review Guide](https://flink.apache.org/contributing/reviewing-prs.html) for a full explanation of the review process. The Bot is tracking the review progress through labels. Labels are applied according to the order of the review items. For consensus, approval by a Flink committer of PMC member is required Bot commands The @flinkbot bot supports the following commands: - `@flinkbot approve description` to approve one or more aspects (aspects: `description`, `consensus`, `architecture` and `quality`) - `@flinkbot approve all` to approve all aspects - `@flinkbot approve-until architecture` to approve everything until `architecture` - `@flinkbot attention @username1 [@username2 ..]` to require somebody's attention - `@flinkbot disapprove architecture` to remove an approval you gave earlier This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-20123) Test native support of PyFlink on Kubernetes
[ https://issues.apache.org/jira/browse/FLINK-20123?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17239029#comment-17239029 ] Yang Wang commented on FLINK-20123: --- I am afraid [~csq] has found a issue about canceling the job in Application attach mode. It could not deregister the Flink cluster from K8s even though the only existing Flink job is canceled. > Test native support of PyFlink on Kubernetes > > > Key: FLINK-20123 > URL: https://issues.apache.org/jira/browse/FLINK-20123 > Project: Flink > Issue Type: Sub-task > Components: API / Python >Affects Versions: 1.12.0 >Reporter: Robert Metzger >Assignee: Shuiqiang Chen >Priority: Critical > Fix For: 1.12.0 > > > > [General Information about the Flink 1.12 release > testing|https://cwiki.apache.org/confluence/display/FLINK/1.12+Release+-+Community+Testing] > When testing a feature, consider the following aspects: > - Is the documentation easy to understand > - Are the error messages, log messages, APIs etc. easy to understand > - Is the feature working as expected under normal conditions > - Is the feature working / failing as expected with invalid input, induced > errors etc. > If you find a problem during testing, please file a ticket > (Priority=Critical; Fix Version = 1.12.0), and link it in this testing ticket. > During the testing keep us updated on tests conducted, or please write a > short summary of all things you have tested in the end. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (FLINK-20349) Query fails with "A conflict is detected. This is unexpected."
[
https://issues.apache.org/jira/browse/FLINK-20349?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
godfrey he updated FLINK-20349:
---
Affects Version/s: 1.12.0
> Query fails with "A conflict is detected. This is unexpected."
> --
>
> Key: FLINK-20349
> URL: https://issues.apache.org/jira/browse/FLINK-20349
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.12.0
>Reporter: Rui Li
>Assignee: Caizhi Weng
>Priority: Major
> Fix For: 1.12.0
>
>
> The test case to reproduce:
> {code}
> @Test
> public void test() throws Exception {
> tableEnv.executeSql("create table src(key string,val string)");
> tableEnv.executeSql("SELECT sum(char_length(src5.src1_value))
> FROM " +
> "(SELECT src3.*, src4.val as src4_value,
> src4.key as src4_key FROM src src4 JOIN " +
> "(SELECT src2.*, src1.key as src1_key, src1.val
> as src1_value FROM src src1 JOIN src src2 ON src1.key = src2.key) src3 " +
> "ON src3.src1_key = src4.key) src5").collect();
> }
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (FLINK-20362) Broken Link in dev/table/sourceSinks.zh.md
[
https://issues.apache.org/jira/browse/FLINK-20362?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-20362:
---
Labels: pull-request-available (was: )
> Broken Link in dev/table/sourceSinks.zh.md
> --
>
> Key: FLINK-20362
> URL: https://issues.apache.org/jira/browse/FLINK-20362
> Project: Flink
> Issue Type: Bug
> Components: Documentation, Table SQL / API
>Affects Versions: 1.12.0
>Reporter: Huang Xingbo
>Priority: Major
> Labels: pull-request-available
> Fix For: 1.12.0
>
>
> When executing the script build_docs.sh, it will throw the following
> exception:
> {code:java}
> Liquid Exception: Could not find document 'dev/table/legacySourceSinks.md' in
> tag 'link'. Make sure the document exists and the path is correct. in
> dev/table/sourceSinks.zh.md Could not find document
> 'dev/table/legacySourceSinks.md' in tag 'link'.
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [flink] fsk119 opened a new pull request #14226: [FLINK-20362][doc] Fix broken link in sourceSinks.zh.md
fsk119 opened a new pull request #14226:
URL: https://github.com/apache/flink/pull/14226
## What is the purpose of the change
*Fix broken link `{% link dev/table/legacySourceSinks.md %} ->({% link
dev/table/legacySourceSinks.zh.md %})`*
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org