[GitHub] [flink] KarmaGYZ commented on pull request #19481: [FLINK-27256][runtime] Log the root exception in closing the task man…
KarmaGYZ commented on PR #19481: URL: https://github.com/apache/flink/pull/19481#issuecomment-1099873917 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #19484: [FLINK-27258] [Doc] fix chinese deploment doc malformed text
flinkbot commented on PR #19484: URL: https://github.com/apache/flink/pull/19484#issuecomment-1099832665 ## CI report: * 714c3dfc1eec638a1ec71330e31bb0dab6bbe8ed UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27258) Deployment Chinese document malformed text
[ https://issues.apache.org/jira/browse/FLINK-27258?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-27258: --- Labels: pull-request-available (was: ) > Deployment Chinese document malformed text > -- > > Key: FLINK-27258 > URL: https://issues.apache.org/jira/browse/FLINK-27258 > Project: Flink > Issue Type: Bug > Components: Documentation >Affects Versions: 1.12.7, 1.13.6, 1.14.4 >Reporter: FanJia >Priority: Minor > Labels: pull-request-available > Attachments: image-2022-04-15-11-35-19-712.png > > > !image-2022-04-15-11-35-19-712.png! > malformed text need to be fix. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] BenJFan opened a new pull request, #19484: [FLINK-27258] [Doc] fix chinese deploment doc malformed text
BenJFan opened a new pull request, #19484: URL: https://github.com/apache/flink/pull/19484 ## What is the purpose of the change  fix chinese deploment doc malformed text ## Brief change log - fix chinese deploment doc malformed text -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] mas-chen commented on a diff in pull request #19456: [FLINK-27041][connector/kafka] Catch IllegalStateException in KafkaPartitionSplitReader.fetch() to handle no valid partition case
mas-chen commented on code in PR #19456:
URL: https://github.com/apache/flink/pull/19456#discussion_r851041663
##
flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/connector/kafka/source/reader/KafkaPartitionSplitReader.java:
##
@@ -131,12 +138,7 @@ public RecordsWithSplitIds>
fetch() throws IOExce
kafkaSourceReaderMetrics.maybeAddRecordsLagMetric(consumer, tp);
}
-// Some splits are discovered as empty when handling split additions.
These splits should be
-// added to finished splits to clean up states in split fetcher and
source reader.
-if (!emptySplits.isEmpty()) {
-recordsBySplits.finishedSplits.addAll(emptySplits);
-emptySplits.clear();
-}
+markEmptySplitsAsFinished(recordsBySplits);
Review Comment:
Good catch!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] tweise commented on a diff in pull request #165: [FLINK-26140] Support rollback strategies
tweise commented on code in PR #165:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/165#discussion_r851041385
##
flink-kubernetes-operator/src/main/java/org/apache/flink/kubernetes/operator/reconciler/deployment/ApplicationReconciler.java:
##
@@ -102,36 +111,84 @@ public void reconcile(FlinkDeployment flinkApp, Context
context, Configuration e
}
if (currentJobState == JobState.SUSPENDED && desiredJobState ==
JobState.RUNNING) {
if (upgradeMode == UpgradeMode.STATELESS) {
-deployFlinkJob(flinkApp, effectiveConfig,
Optional.empty());
-} else if (upgradeMode == UpgradeMode.LAST_STATE
-|| upgradeMode == UpgradeMode.SAVEPOINT) {
-restoreFromLastSavepoint(flinkApp, effectiveConfig);
+deployFlinkJob(currentJobSpec, status, effectiveConfig,
Optional.empty());
+} else {
+restoreFromLastSavepoint(currentJobSpec, status,
effectiveConfig);
}
stateAfterReconcile = JobState.RUNNING;
}
-IngressUtils.updateIngressRules(flinkApp, effectiveConfig,
kubernetesClient);
+IngressUtils.updateIngressRules(
+deployMeta, currentDeploySpec, effectiveConfig,
kubernetesClient);
ReconciliationUtils.updateForSpecReconciliationSuccess(flinkApp,
stateAfterReconcile);
-} else if (SavepointUtils.shouldTriggerSavepoint(flinkApp) &&
isJobRunning(flinkApp)) {
+} else if (ReconciliationUtils.shouldRollBack(reconciliationStatus,
effectiveConfig)) {
+rollbackApplication(flinkApp);
+} else if (SavepointUtils.shouldTriggerSavepoint(currentJobSpec,
status)
+&& isJobRunning(status)) {
triggerSavepoint(flinkApp, effectiveConfig);
ReconciliationUtils.updateSavepointReconciliationSuccess(flinkApp);
+} else {
+LOG.info("Deployment is fully reconciled, nothing to do.");
}
}
+private void rollbackApplication(FlinkDeployment flinkApp) throws
Exception {
+ReconciliationStatus reconciliationStatus =
flinkApp.getStatus().getReconciliationStatus();
+
+if (reconciliationStatus.getState() !=
ReconciliationStatus.State.ROLLING_BACK) {
+LOG.warn("Preparing to roll back to last stable spec.");
+if (flinkApp.getStatus().getError() == null) {
+flinkApp.getStatus()
+.setError(
+"Deployment is not ready within the configured
timeout, rolling-back.");
+}
+
reconciliationStatus.setState(ReconciliationStatus.State.ROLLING_BACK);
+return;
+}
+
+LOG.warn("Executing roll-back operation");
+
+FlinkDeploymentSpec rollbackSpec =
reconciliationStatus.deserializeLastStableSpec();
+Configuration rollbackConfig =
+FlinkUtils.getEffectiveConfig(flinkApp.getMetadata(),
rollbackSpec, defaultConfig);
+
+UpgradeMode upgradeMode = flinkApp.getSpec().getJob().getUpgradeMode();
+
+suspendJob(
Review Comment:
Agreed that we should not change the spec, which in some case may also not
be possible due to access control. The reason not to change
`lastReconciledSpec` is more related to the implementation as it pertains to
the status, nevertheless I think the current approach makes sense.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] dianfu commented on a diff in pull request #19480: [FLINK-27213][API/Python]Add PurgingTrigger
dianfu commented on code in PR #19480: URL: https://github.com/apache/flink/pull/19480#discussion_r851034880 ## flink-python/pyflink/datastream/window.py: ## @@ -840,6 +841,65 @@ def register_next_fire_timestamp(self, ctx.register_processing_time_timer(next_fire_timestamp) +class PurgingTrigger(Trigger[T, TimeWindow]): Review Comment: Why it's always TimeWindow? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-27259) Observer should not clear savepoint errors even though deployment is healthy
Yang Wang created FLINK-27259:
-
Summary: Observer should not clear savepoint errors even though
deployment is healthy
Key: FLINK-27259
URL: https://issues.apache.org/jira/browse/FLINK-27259
Project: Flink
Issue Type: Bug
Components: Kubernetes Operator
Reporter: Yang Wang
Even though the deployment is healthy and job is running, triggering savepoint
still could fail with errors. See FLINK-27257 for more information. These
errors should not be cleared in {{{}AbstractDeploymentObserver{}}}.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Created] (FLINK-27258) Deployment Chinese document malformed text
FanJia created FLINK-27258: -- Summary: Deployment Chinese document malformed text Key: FLINK-27258 URL: https://issues.apache.org/jira/browse/FLINK-27258 Project: Flink Issue Type: Bug Components: Documentation Affects Versions: 1.14.4, 1.13.6, 1.12.7 Reporter: FanJia Attachments: image-2022-04-15-11-35-19-712.png !image-2022-04-15-11-35-19-712.png! malformed text need to be fix. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-27258) Deployment Chinese document malformed text
[ https://issues.apache.org/jira/browse/FLINK-27258?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522637#comment-17522637 ] FanJia commented on FLINK-27258: Let me fix it for my first issue. > Deployment Chinese document malformed text > -- > > Key: FLINK-27258 > URL: https://issues.apache.org/jira/browse/FLINK-27258 > Project: Flink > Issue Type: Bug > Components: Documentation >Affects Versions: 1.12.7, 1.13.6, 1.14.4 >Reporter: FanJia >Priority: Minor > Attachments: image-2022-04-15-11-35-19-712.png > > > !image-2022-04-15-11-35-19-712.png! > malformed text need to be fix. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-27218) Serializer in OperatorState has not been updated when new Serializers are NOT incompatible
[
https://issues.apache.org/jira/browse/FLINK-27218?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522634#comment-17522634
]
Yun Tang commented on FLINK-27218:
--
[~mayuehappy] I think you're right, this would affect the correctness when
executing copy during snapshot. Do you like to take this ticket to fix this bug?
> Serializer in OperatorState has not been updated when new Serializers are NOT
> incompatible
> --
>
> Key: FLINK-27218
> URL: https://issues.apache.org/jira/browse/FLINK-27218
> Project: Flink
> Issue Type: Bug
> Components: Runtime / State Backends
>Affects Versions: 1.15.1
>Reporter: Yue Ma
>Priority: Major
> Attachments: image-2022-04-13-14-50-10-921.png
>
>
> OperatorState such as *BroadcastState* or *PartitionableListState* can only
> be constructed via {*}DefaultOperatorStateBackend{*}. But when
> *BroadcastState* or *PartitionableListState* Serializer changes after we
> restart the job , it seems to have the following problems .
> As an example, we can see how PartitionableListState is initialized.
> First, RestoreOperation will construct a restored PartitionableListState
> based on the information in the snapshot.
> Then StateMetaInfo in partitionableListState will be updated as the
> following code
> {code:java}
> TypeSerializerSchemaCompatibility stateCompatibility =
>
> restoredPartitionableListStateMetaInfo.updatePartitionStateSerializer(newPartitionStateSerializer);
> partitionableListState.setStateMetaInfo(restoredPartitionableListStateMetaInfo);{code}
> The main problem is that there is also an *internalListCopySerializer* in
> *PartitionableListState* that is built using the previous Serializer and it
> has not been updated.
> Therefore, when we update the StateMetaInfo, the *internalListCopySerializer*
> also needs to be updated.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-27257) Flink kubernetes operator triggers savepoint failed because of not all tasks running
[
https://issues.apache.org/jira/browse/FLINK-27257?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522632#comment-17522632
]
Yang Wang commented on FLINK-27257:
---
The expected behavior is the subsequent reconciliation should trigger the
savepoint again.
> Flink kubernetes operator triggers savepoint failed because of not all tasks
> running
>
>
> Key: FLINK-27257
> URL: https://issues.apache.org/jira/browse/FLINK-27257
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
>
> {code:java}
> 2022-04-15 02:38:56,551 o.a.f.k.o.s.FlinkService [INFO
> ][default/flink-example-statemachine] Fetching savepoint result with
> triggerId: 182d7f176496856d7b33fe2f3767da18
> 2022-04-15 02:38:56,690 o.a.f.k.o.s.FlinkService
> [ERROR][default/flink-example-statemachine] Savepoint error
> org.apache.flink.runtime.checkpoint.CheckpointException: Checkpoint
> triggering task Source: Custom Source (1/2) of job
> is not being executed at the moment.
> Aborting checkpoint. Failure reason: Not all required tasks are currently
> running.
> at
> org.apache.flink.runtime.checkpoint.DefaultCheckpointPlanCalculator.checkTasksStarted(DefaultCheckpointPlanCalculator.java:143)
> at
> org.apache.flink.runtime.checkpoint.DefaultCheckpointPlanCalculator.lambda$calculateCheckpointPlan$1(DefaultCheckpointPlanCalculator.java:105)
> at
> java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1604)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.lambda$handleRunAsync$4(AkkaRpcActor.java:455)
> at
> org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:68)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:455)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:213)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:78)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:163)
> at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24)
> at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:20)
> at scala.PartialFunction.applyOrElse(PartialFunction.scala:123)
> at scala.PartialFunction.applyOrElse$(PartialFunction.scala:122)
> at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:20)
> at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
> at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
> at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
> at akka.actor.Actor.aroundReceive(Actor.scala:537)
> at akka.actor.Actor.aroundReceive$(Actor.scala:535)
> at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:220)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:580)
> at akka.actor.ActorCell.invoke(ActorCell.scala:548)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:270)
> at akka.dispatch.Mailbox.run(Mailbox.scala:231)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:243)
> at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
> at
> java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
> at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
> at
> java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:175)
> 2022-04-15 02:38:56,693 o.a.f.k.o.o.SavepointObserver
> [ERROR][default/flink-example-statemachine] Checkpoint triggering task
> Source: Custom Source (1/2) of job is not
> being executed at the moment. Aborting checkpoint. Failure reason: Not all
> required tasks are currently running. {code}
> How to reproduce?
> Update arbitrary fields(e.g. parallelism) along with
> {{{}savepointTriggerNonce{}}}.
>
> The root cause might be the running state return by
> {{ClusterClient#listJobs()}} does not mean all the tasks are running.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] (FLINK-27257) Flink kubernetes operator triggers savepoint failed because of not all tasks running
[ https://issues.apache.org/jira/browse/FLINK-27257 ]
Yang Wang deleted comment on FLINK-27257:
---
was (Author: fly_in_gis):
It is also strange that the subsequent reconciliation does not trigger the
savepoint again. Otherwise, this should not be a problem.
> Flink kubernetes operator triggers savepoint failed because of not all tasks
> running
>
>
> Key: FLINK-27257
> URL: https://issues.apache.org/jira/browse/FLINK-27257
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
>
> {code:java}
> 2022-04-15 02:38:56,551 o.a.f.k.o.s.FlinkService [INFO
> ][default/flink-example-statemachine] Fetching savepoint result with
> triggerId: 182d7f176496856d7b33fe2f3767da18
> 2022-04-15 02:38:56,690 o.a.f.k.o.s.FlinkService
> [ERROR][default/flink-example-statemachine] Savepoint error
> org.apache.flink.runtime.checkpoint.CheckpointException: Checkpoint
> triggering task Source: Custom Source (1/2) of job
> is not being executed at the moment.
> Aborting checkpoint. Failure reason: Not all required tasks are currently
> running.
> at
> org.apache.flink.runtime.checkpoint.DefaultCheckpointPlanCalculator.checkTasksStarted(DefaultCheckpointPlanCalculator.java:143)
> at
> org.apache.flink.runtime.checkpoint.DefaultCheckpointPlanCalculator.lambda$calculateCheckpointPlan$1(DefaultCheckpointPlanCalculator.java:105)
> at
> java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1604)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.lambda$handleRunAsync$4(AkkaRpcActor.java:455)
> at
> org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:68)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:455)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:213)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:78)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:163)
> at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24)
> at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:20)
> at scala.PartialFunction.applyOrElse(PartialFunction.scala:123)
> at scala.PartialFunction.applyOrElse$(PartialFunction.scala:122)
> at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:20)
> at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
> at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
> at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
> at akka.actor.Actor.aroundReceive(Actor.scala:537)
> at akka.actor.Actor.aroundReceive$(Actor.scala:535)
> at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:220)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:580)
> at akka.actor.ActorCell.invoke(ActorCell.scala:548)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:270)
> at akka.dispatch.Mailbox.run(Mailbox.scala:231)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:243)
> at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
> at
> java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
> at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
> at
> java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:175)
> 2022-04-15 02:38:56,693 o.a.f.k.o.o.SavepointObserver
> [ERROR][default/flink-example-statemachine] Checkpoint triggering task
> Source: Custom Source (1/2) of job is not
> being executed at the moment. Aborting checkpoint. Failure reason: Not all
> required tasks are currently running. {code}
> How to reproduce?
> Update arbitrary fields(e.g. parallelism) along with
> {{{}savepointTriggerNonce{}}}.
>
> The root cause might be the running state return by
> {{ClusterClient#listJobs()}} does not mean all the tasks are running.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] liuzhuang2017 commented on pull request #19483: [hotfix][docs-zh] Fix "Google Cloud PubSub" Chinese page under "DataStream Connectors"
liuzhuang2017 commented on PR #19483: URL: https://github.com/apache/flink/pull/19483#issuecomment-1099812887 @wuchong ,Thanks for your review. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-27236) No task slot allocated for job in larege-scale job
[
https://issues.apache.org/jira/browse/FLINK-27236?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522631#comment-17522631
]
Lijie Wang edited comment on FLINK-27236 at 4/15/22 3:15 AM:
-
[~freeke]
-> At least, the previous execution shouldn't be still allocated to the tm .
Honestly, I have no idea about how to implement it. I think it is inevitable
that the slot states in RM/TM and JM will be inconsistent for a short period of
time, because they are different akka actors and can only synchronize
information via RPC.
In a streaming job (only one pipeline region), all task deployments are
performed in the same RPC Call (but this RPC time may be very long due to slow
deployement, for example 30s). That is, during this period, if RM/TM wants to
notify JM of slot states via RPC, JM can only handle it after 30s.
Unfortunately, at that point the task deployments have completed(and
encountered the mentioned problem).
Do you have any idea about that?
was (Author: wanglijie95):
[~freeke]
-> At least, the previous execution shouldn't be still allocated to the tm .
Honestly, I have no idea about how to implement it. I think it is inevitable
that the slot states in RM/TM and JM will be inconsistent for a short period of
time, because they are different akka actors and can only synchronize
information via RPC.
In a streaming job (only one pipeline region), all task deployments are
performed in the same RPC Call (but this RPC time may be very long due to slow
deployement, for example 30s). That is, during this period, if RM/TM wants to
notify JM of slot states via RPC, JM can only handle it after 30s.
Unfortunately, at that point the task deployments have completed(and
encountered the mentioned problem).
Do you have any idea about this?
> No task slot allocated for job in larege-scale job
> --
>
> Key: FLINK-27236
> URL: https://issues.apache.org/jira/browse/FLINK-27236
> Project: Flink
> Issue Type: Bug
>Affects Versions: 1.13.3
>Reporter: yanpengshi
>Priority: Major
> Attachments: jobmanager.log.26, taskmanager.log, topology.png
>
> Original Estimate: 444h
> Remaining Estimate: 444h
>
> Hey,
>
> We run a large-scale flink job containing six vertices with 3k parallelism.
> The Topology is shown below.
> !topology.png!
> We meets the following exception in jobmanager.log:[^jobmanager.log.26]
> {code:java}
> 2022-03-02 08:01:16,601 INFO [1998]
> [org.apache.flink.runtime.executiongraph.Execution.transitionState(Execution.java:1446)]
> - Source: tdbank_exposure_wx - Flat Map (772/3000)
> (6cd18d4ead1887a4e19fd3f337a6f4f8) switched from DEPLOYING to FAILED on
> container_e03_1639558254334_10048_01_004716 @ 11.104.77.40
> (dataPort=39313).java.util.concurrent.CompletionException:
> org.apache.flink.runtime.taskexecutor.exceptions.TaskSubmissionException: No
> task slot allocated for job ID ed780087 and
> allocation ID beb058d837c09e8d5a4a6aaf2426ca99. {code}
>
> In the taskmanager.log [^taskmanager.log], the slot is freed due to timeout
> and the taskmanager receives the new allocated request. By increasing the
> value of key: taskmanager.slot.timeout, we can avoid this exception
> temporarily.
> Here are some our guesses:
> # When the job is scheduled, the slot and execution have been bound, and
> then the task is deployed to the corresponding taskmanager.
> # The slot is released after the idle interval times out and notify the
> ResouceManager the slot free. Thus, the resourceManager will assign other
> request to the slot.
> # The task is deployed to taskmanager according the previous correspondence
>
> The key problems are :
> # When the slot is free, the execution is not unassigned from the slot;
> # The slot state is not consistent in JobMaster and ResourceManager
>
> Has anyone else encountered this problem? When the slot is freed, how can we
> unassign the previous bounded execution? Or we need to update the resource
> address of the execution. @[~zhuzh] @[~wanglijie95]
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-27236) No task slot allocated for job in larege-scale job
[
https://issues.apache.org/jira/browse/FLINK-27236?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522631#comment-17522631
]
Lijie Wang commented on FLINK-27236:
[~freeke]
-> At least, the previous execution shouldn't be still allocated to the tm .
Honestly, I have no idea about how to implement it. I think it is inevitable
that the slot states in RM/TM and JM will be inconsistent for a short period of
time, because they are different akka actors and can only synchronize
information via RPC.
In a streaming job (only one pipeline region), all task deployments are
performed in the same RPC Call (but this RPC time may be very long due to slow
deployement, for example 30s). That is, during this period, if RM/TM wants to
notify JM of slot states via RPC, JM can only handle it after 30s.
Unfortunately, at that point the task deployments have completed(and
encountered the mentioned problem).
Do you have any idea about this?
> No task slot allocated for job in larege-scale job
> --
>
> Key: FLINK-27236
> URL: https://issues.apache.org/jira/browse/FLINK-27236
> Project: Flink
> Issue Type: Bug
>Affects Versions: 1.13.3
>Reporter: yanpengshi
>Priority: Major
> Attachments: jobmanager.log.26, taskmanager.log, topology.png
>
> Original Estimate: 444h
> Remaining Estimate: 444h
>
> Hey,
>
> We run a large-scale flink job containing six vertices with 3k parallelism.
> The Topology is shown below.
> !topology.png!
> We meets the following exception in jobmanager.log:[^jobmanager.log.26]
> {code:java}
> 2022-03-02 08:01:16,601 INFO [1998]
> [org.apache.flink.runtime.executiongraph.Execution.transitionState(Execution.java:1446)]
> - Source: tdbank_exposure_wx - Flat Map (772/3000)
> (6cd18d4ead1887a4e19fd3f337a6f4f8) switched from DEPLOYING to FAILED on
> container_e03_1639558254334_10048_01_004716 @ 11.104.77.40
> (dataPort=39313).java.util.concurrent.CompletionException:
> org.apache.flink.runtime.taskexecutor.exceptions.TaskSubmissionException: No
> task slot allocated for job ID ed780087 and
> allocation ID beb058d837c09e8d5a4a6aaf2426ca99. {code}
>
> In the taskmanager.log [^taskmanager.log], the slot is freed due to timeout
> and the taskmanager receives the new allocated request. By increasing the
> value of key: taskmanager.slot.timeout, we can avoid this exception
> temporarily.
> Here are some our guesses:
> # When the job is scheduled, the slot and execution have been bound, and
> then the task is deployed to the corresponding taskmanager.
> # The slot is released after the idle interval times out and notify the
> ResouceManager the slot free. Thus, the resourceManager will assign other
> request to the slot.
> # The task is deployed to taskmanager according the previous correspondence
>
> The key problems are :
> # When the slot is free, the execution is not unassigned from the slot;
> # The slot state is not consistent in JobMaster and ResourceManager
>
> Has anyone else encountered this problem? When the slot is freed, how can we
> unassign the previous bounded execution? Or we need to update the resource
> address of the execution. @[~zhuzh] @[~wanglijie95]
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] flinkbot commented on pull request #19483: [hotfix][docs-zh] Fix "Google Cloud PubSub" Chinese page under "DataStream Connectors"
flinkbot commented on PR #19483: URL: https://github.com/apache/flink/pull/19483#issuecomment-1099811000 ## CI report: * deb4187089fc00f51f320a4983d00584e802d779 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wuchong commented on pull request #19483: [hotfix][docs-zh] Fix "Google Cloud PubSub" Chinese page under "DataStream Connectors"
wuchong commented on PR #19483: URL: https://github.com/apache/flink/pull/19483#issuecomment-1099810162 I will merge it when the CI passed. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] liuzhuang2017 opened a new pull request, #19483: [hotfix][docs-zh] Fix "Google Cloud PubSub" Chinese page under "DataStream Connectors"
liuzhuang2017 opened a new pull request, #19483: URL: https://github.com/apache/flink/pull/19483 ## What is the purpose of the change # **This is the English document:** 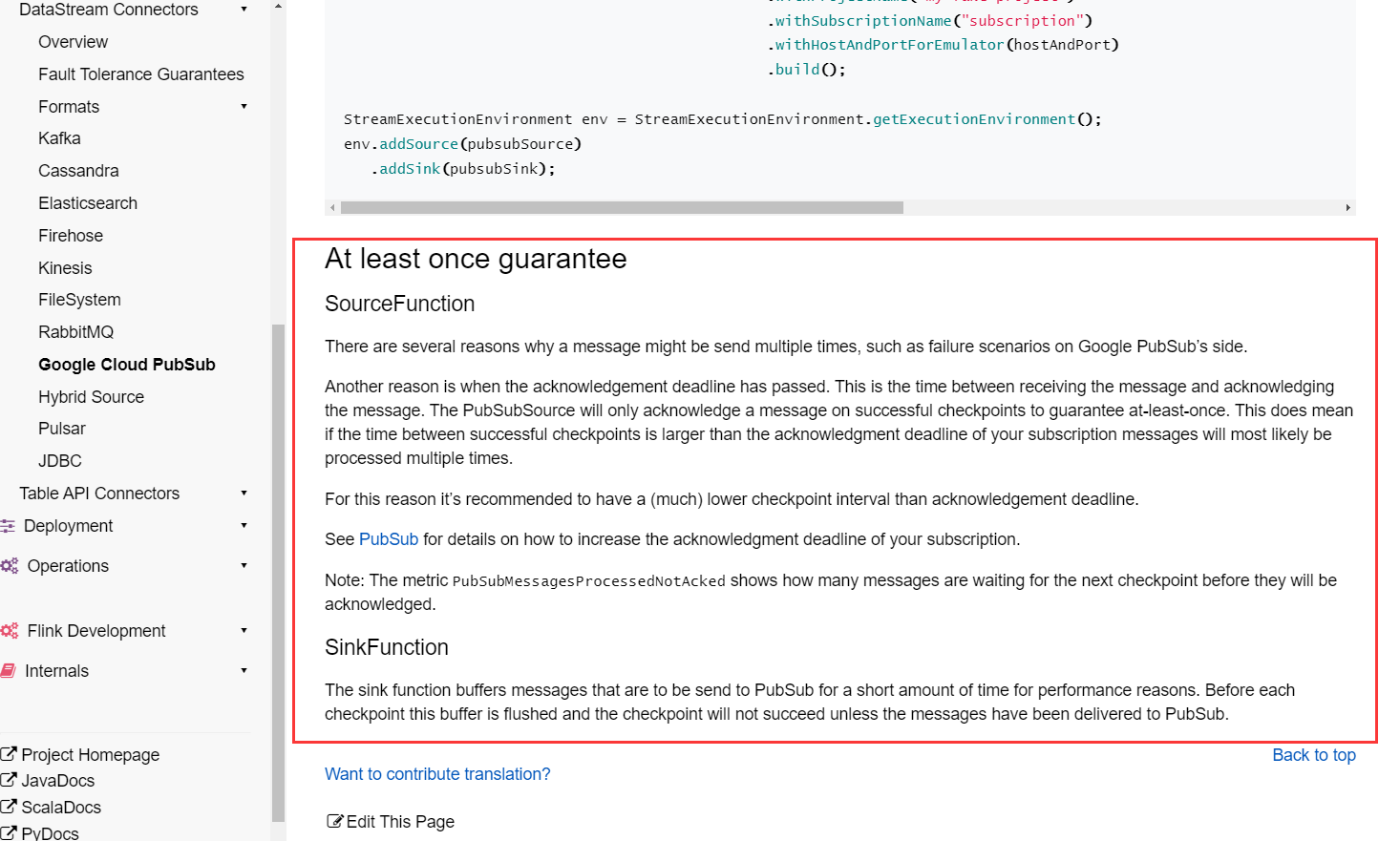 # **This is the Chinese document:** 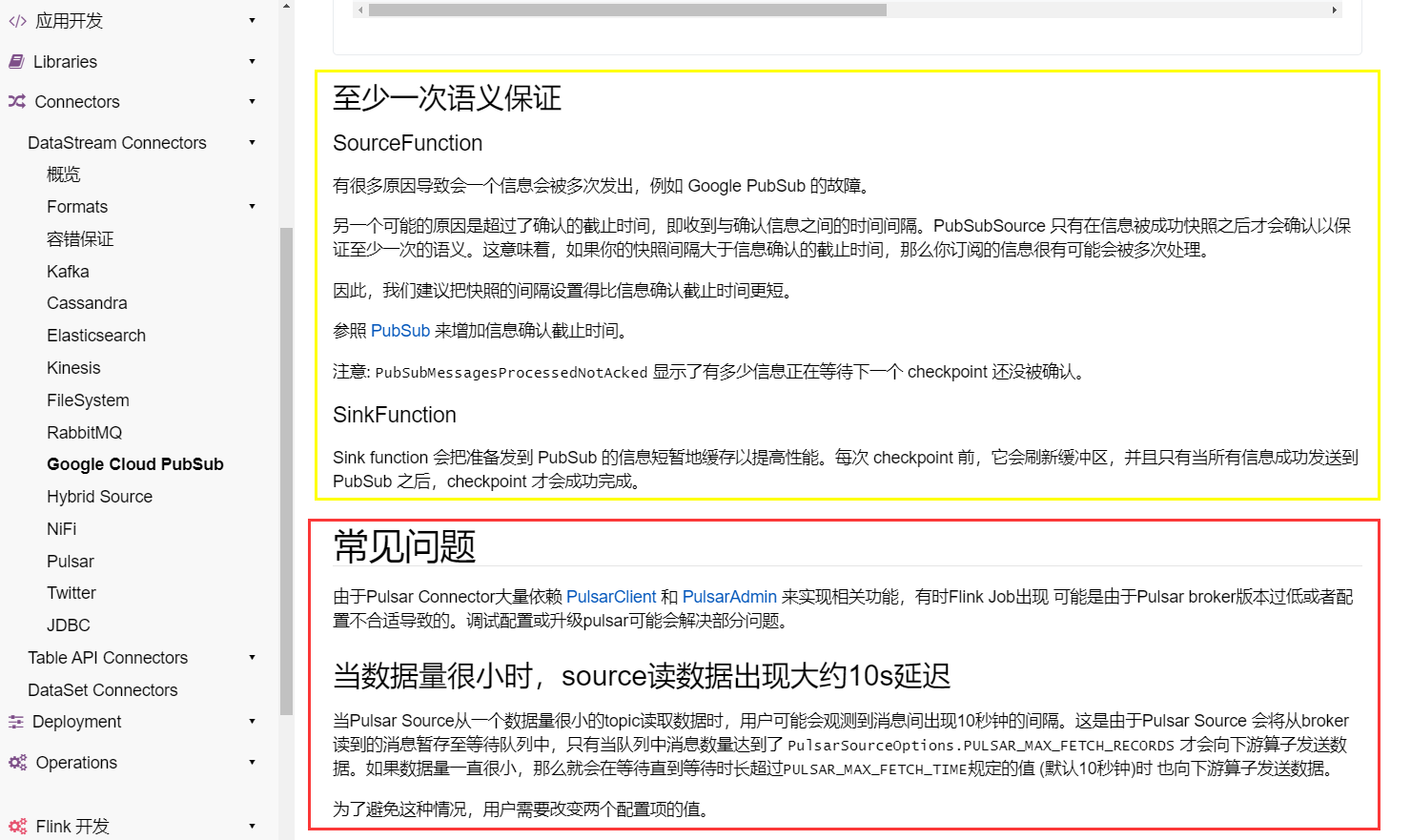 We can see from the above picture that compared with the English document, the Chinese document has a part that is irrelevant to the content. ## Brief change log Fix "Google Cloud PubSub" Chinese page under "DataStream Connectors" ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27055) java.lang.ArrayIndexOutOfBoundsException in BinarySegmentUtils
[
https://issues.apache.org/jira/browse/FLINK-27055?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522629#comment-17522629
]
Kenny Ma commented on FLINK-27055:
--
[~jark] do you have any suggestion? Upgrading to 1.14 would require major
refactoring in our application and it is not guaranteed that the issue doesn't
exist in the newer version.
> java.lang.ArrayIndexOutOfBoundsException in BinarySegmentUtils
> --
>
> Key: FLINK-27055
> URL: https://issues.apache.org/jira/browse/FLINK-27055
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Runtime
>Affects Versions: 1.12.0
>Reporter: Kenny Ma
>Priority: Major
>
> I am using SQL for my streaming job and the job keeps failing with the
> java.lang.ArrayIndexOutOfBoundsException thrown in BinarySegmentUtils.
> Stacktrace:
>
> {code:java}
> java.lang.ArrayIndexOutOfBoundsException: Index 1 out of bounds for length 1
> at
> org.apache.flink.table.data.binary.BinarySegmentUtils.getLongSlowly(BinarySegmentUtils.java:773)
> at
> org.apache.flink.table.data.binary.BinarySegmentUtils.getLongMultiSegments(BinarySegmentUtils.java:763)
> at
> org.apache.flink.table.data.binary.BinarySegmentUtils.getLong(BinarySegmentUtils.java:751)
> at
> org.apache.flink.table.data.binary.BinaryArrayData.getString(BinaryArrayData.java:210)
> at
> org.apache.flink.table.data.ArrayData.lambda$createElementGetter$95d74a6c$1(ArrayData.java:250)
> at
> org.apache.flink.table.data.conversion.MapMapConverter.toExternal(MapMapConverter.java:79)
> at StreamExecCalc$11860.processElement(Unknown Source)
> at
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.pushToOperator(ChainingOutput.java:112)
> at
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:93)
> at
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:39)
> at
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:52)
> at
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:30)
> at
> org.apache.flink.streaming.api.operators.TimestampedCollector.collect(TimestampedCollector.java:53)
> at
> org.apache.flink.table.runtime.operators.window.AggregateWindowOperator.collect(AggregateWindowOperator.java:183)
> at
> org.apache.flink.table.runtime.operators.window.AggregateWindowOperator.emitWindowResult(AggregateWindowOperator.java:176)
> at
> org.apache.flink.table.runtime.operators.window.WindowOperator.onEventTime(WindowOperator.java:384)
> at
> org.apache.flink.streaming.api.operators.InternalTimerServiceImpl.advanceWatermark(InternalTimerServiceImpl.java:276)
> at
> org.apache.flink.streaming.api.operators.InternalTimeServiceManagerImpl.advanceWatermark(InternalTimeServiceManagerImpl.java:183)
> at
> org.apache.flink.streaming.api.operators.AbstractStreamOperator.processWatermark(AbstractStreamOperator.java:600)
> at
> org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitWatermark(OneInputStreamTask.java:199)
> at
> org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.findAndOutputNewMinWatermarkAcrossAlignedChannels(StatusWatermarkValve.java:173)
> at
> org.apache.flink.streaming.runtime.streamstatus.StatusWatermarkValve.inputWatermark(StatusWatermarkValve.java:95)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:181)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:152)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:67)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:372)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:186)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:575)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:539)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:722)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:547)
> {code}
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-27257) Flink kubernetes operator triggers savepoint failed because of not all tasks running
[
https://issues.apache.org/jira/browse/FLINK-27257?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522628#comment-17522628
]
Yang Wang commented on FLINK-27257:
---
It is also strange that the subsequent reconciliation does not trigger the
savepoint again. Otherwise, this should not be a problem.
> Flink kubernetes operator triggers savepoint failed because of not all tasks
> running
>
>
> Key: FLINK-27257
> URL: https://issues.apache.org/jira/browse/FLINK-27257
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
>
> {code:java}
> 2022-04-15 02:38:56,551 o.a.f.k.o.s.FlinkService [INFO
> ][default/flink-example-statemachine] Fetching savepoint result with
> triggerId: 182d7f176496856d7b33fe2f3767da18
> 2022-04-15 02:38:56,690 o.a.f.k.o.s.FlinkService
> [ERROR][default/flink-example-statemachine] Savepoint error
> org.apache.flink.runtime.checkpoint.CheckpointException: Checkpoint
> triggering task Source: Custom Source (1/2) of job
> is not being executed at the moment.
> Aborting checkpoint. Failure reason: Not all required tasks are currently
> running.
> at
> org.apache.flink.runtime.checkpoint.DefaultCheckpointPlanCalculator.checkTasksStarted(DefaultCheckpointPlanCalculator.java:143)
> at
> org.apache.flink.runtime.checkpoint.DefaultCheckpointPlanCalculator.lambda$calculateCheckpointPlan$1(DefaultCheckpointPlanCalculator.java:105)
> at
> java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1604)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.lambda$handleRunAsync$4(AkkaRpcActor.java:455)
> at
> org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:68)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:455)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:213)
> at
> org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:78)
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:163)
> at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24)
> at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:20)
> at scala.PartialFunction.applyOrElse(PartialFunction.scala:123)
> at scala.PartialFunction.applyOrElse$(PartialFunction.scala:122)
> at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:20)
> at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
> at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
> at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
> at akka.actor.Actor.aroundReceive(Actor.scala:537)
> at akka.actor.Actor.aroundReceive$(Actor.scala:535)
> at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:220)
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:580)
> at akka.actor.ActorCell.invoke(ActorCell.scala:548)
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:270)
> at akka.dispatch.Mailbox.run(Mailbox.scala:231)
> at akka.dispatch.Mailbox.exec(Mailbox.scala:243)
> at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
> at
> java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
> at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
> at
> java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:175)
> 2022-04-15 02:38:56,693 o.a.f.k.o.o.SavepointObserver
> [ERROR][default/flink-example-statemachine] Checkpoint triggering task
> Source: Custom Source (1/2) of job is not
> being executed at the moment. Aborting checkpoint. Failure reason: Not all
> required tasks are currently running. {code}
> How to reproduce?
> Update arbitrary fields(e.g. parallelism) along with
> {{{}savepointTriggerNonce{}}}.
>
> The root cause might be the running state return by
> {{ClusterClient#listJobs()}} does not mean all the tasks are running.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-27247) ScalarOperatorGens.numericCasting is not compatible with legacy behavior
[
https://issues.apache.org/jira/browse/FLINK-27247?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522626#comment-17522626
]
xuyang commented on FLINK-27247:
Hi, [~matriv], I think currently this is not the problem with casting. Because
this part of code gen doesn't not care of the nullable with the type and other
part of code gen will avoid the nullable exists. For example, you can see the
following code generated:
{code:java}
// the result rand(...) will be null only if the arg in rand is nullable, like
"rand(cast (null as int))"
// so if the sql is "rand() + 1", the generated code is:
isNull$3 = false;
result$4 = random$2.nextDouble();
// and if the sql is "rand(cast(null as int))":
isNull$3 = true;
result$4 = -1.0d;
if (!isNull$3) {
result$4 = random$2.nextDouble();
}{code}
This part that i fixed is only about the code : "result$4 =
random$2.nextDouble();" and this should just ignore the nullable between
DOUBLE and DOUBLE NOT NULL. And actually the logic of the legacy code does this
by pre-checking the same type not necessary to cast before casting this
different types.
I strongly agree with you that the logic in casting should throw an exception
if it meets casting a type from nullable to not nullable. But the problem of
this issue is before casting logic.
By the way, I think converting casting logic to different rules is a good
improvement but should not affect the base logic when change the code. You can
see the code before and after rewriting casting rules:
before:
{code:java}
// no casting necessary
if (isInteroperable(operandType, resultType)) {
operandTerm => s"$operandTerm"
}
// decimal to decimal, may have different precision/scale
else if (isDecimal(resultType) && isDecimal(operandType)) {
val dt = resultType.asInstanceOf[DecimalType]
operandTerm =>
s"$DECIMAL_UTIL.castToDecimal($operandTerm, ${dt.getPrecision},
${dt.getScale})"
}
// non_decimal_numeric to decimal
else if ...{code}
after:
{code:java}
// All numeric rules are assumed to be instance of
AbstractExpressionCodeGeneratorCastRule
val rule = CastRuleProvider.resolve(operandType, resultType)
rule match {
case codeGeneratorCastRule: ExpressionCodeGeneratorCastRule[_, _] =>
operandTerm =>
codeGeneratorCastRule.generateExpression(
toCodegenCastContext(ctx),
operandTerm,
operandType,
resultType
)
case _ =>
throw new CodeGenException(s"Unsupported casting from $operandType to
$resultType.")
} {code}
Looking forward to your reply :)
> ScalarOperatorGens.numericCasting is not compatible with legacy behavior
>
>
> Key: FLINK-27247
> URL: https://issues.apache.org/jira/browse/FLINK-27247
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Reporter: xuyang
>Priority: Minor
> Labels: pull-request-available
>
> Add the following test cases in ScalarFunctionsTest:
> {code:java}
> // code placeholder
> @Test
> def test(): Unit ={
> testSqlApi("rand(1) + 1","")
> } {code}
> it will throw the following exception:
> {code:java}
> // code placeholder
> org.apache.flink.table.planner.codegen.CodeGenException: Unsupported casting
> from DOUBLE to DOUBLE NOT NULL.
> at
> org.apache.flink.table.planner.codegen.calls.ScalarOperatorGens$.numericCasting(ScalarOperatorGens.scala:1734)
> at
> org.apache.flink.table.planner.codegen.calls.ScalarOperatorGens$.generateBinaryArithmeticOperator(ScalarOperatorGens.scala:85)
> at
> org.apache.flink.table.planner.codegen.ExprCodeGenerator.generateCallExpression(ExprCodeGenerator.scala:507)
> at
> org.apache.flink.table.planner.codegen.ExprCodeGenerator.visitCall(ExprCodeGenerator.scala:481)
> at
> org.apache.flink.table.planner.codegen.ExprCodeGenerator.visitCall(ExprCodeGenerator.scala:57)
> at org.apache.calcite.rex.RexCall.accept(RexCall.java:174)
> at
> org.apache.flink.table.planner.codegen.ExprCodeGenerator.$anonfun$visitCall$1(ExprCodeGenerator.scala:478)
> at
> scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:233)
> at
> scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:58)
> at
> scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:51)
> at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
> at scala.collection.TraversableLike.map(TraversableLike.scala:233)
> at scala.collection.TraversableLike.map$(TraversableLike.scala:226)
> at scala.collection.AbstractTraversable.map(Traversable.scala:104)
> at
> org.apache.flink.table.planner.codegen.ExprCodeGenerator.visitCall(ExprCodeGenerator.scala:469)
> ... {code}
> This is because in ScalarOperatorGens#numericCasting, FLINK-24779
[jira] [Commented] (FLINK-27121) Translate "Configuration#overview" paragraph and the code example in "Application Development > Table API & SQL" to Chinese
[
https://issues.apache.org/jira/browse/FLINK-27121?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522625#comment-17522625
]
LEI ZHOU commented on FLINK-27121:
--
[~martijnvisser] ok,thanks very much!!!
> Translate "Configuration#overview" paragraph and the code example in
> "Application Development > Table API & SQL" to Chinese
> ---
>
> Key: FLINK-27121
> URL: https://issues.apache.org/jira/browse/FLINK-27121
> Project: Flink
> Issue Type: Improvement
> Components: Documentation
>Reporter: Marios Trivyzas
>Assignee: LEI ZHOU
>Priority: Major
> Labels: chinese-translation, pull-request-available
>
> After [https://github.com/apache/flink/pull/19387
> |https://github.com/apache/flink/pull/19387] is merged, we need to update the
> translation for
> [https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/table/config/#overview]
> The markdown file is located in
> {noformat}
> flink/docs/content.zh/docs/dev/table/config.md{noformat}
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] flinkbot commented on pull request #19482: [FLINK-27244][hive] Support read sub-directories in partition directory with Hive tables
flinkbot commented on PR #19482: URL: https://github.com/apache/flink/pull/19482#issuecomment-1099802626 ## CI report: * e9b2b761abf6aee6415b4daec7374340015c0426 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-24932) Frocksdb cannot run on Apple M1
[
https://issues.apache.org/jira/browse/FLINK-24932?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522624#comment-17522624
]
Yun Tang commented on FLINK-24932:
--
[~maver1ck] Thanks for your information. We actually always watch the progress.
However, since Flink community leverage FRocksDB which is based on the original
RocksDB, we need some time to bump the RocksDB version.
> Frocksdb cannot run on Apple M1
> ---
>
> Key: FLINK-24932
> URL: https://issues.apache.org/jira/browse/FLINK-24932
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / State Backends
>Reporter: Yun Tang
>Priority: Minor
>
> After we bump up RocksDB version to 6.20.3, we support to run RocksDB on
> linux arm cluster. However, according to the feedback from Robert, Apple M1
> machines cannot run FRocksDB yet:
> {code:java}
> java.lang.Exception: Exception while creating StreamOperatorStateContext.
> at
> org.apache.flink.streaming.api.operators.StreamTaskStateInitializerImpl.streamOperatorStateContext(StreamTaskStateInitializerImpl.java:255)
> ~[flink-streaming-java_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.streaming.api.operators.AbstractStreamOperator.initializeState(AbstractStreamOperator.java:268)
> ~[flink-streaming-java_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.streaming.runtime.tasks.RegularOperatorChain.initializeStateAndOpenOperators(RegularOperatorChain.java:109)
> ~[flink-streaming-java_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.restoreGates(StreamTask.java:711)
> ~[flink-streaming-java_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.call(StreamTaskActionExecutor.java:55)
> ~[flink-streaming-java_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.restoreInternal(StreamTask.java:687)
> ~[flink-streaming-java_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.restore(StreamTask.java:654)
> ~[flink-streaming-java_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)
> ~[flink-runtime-1.14.0.jar:1.14.0]
> at
> org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:927)
> ~[flink-runtime-1.14.0.jar:1.14.0]
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766)
> ~[flink-runtime-1.14.0.jar:1.14.0]
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)
> ~[flink-runtime-1.14.0.jar:1.14.0]
> at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_312]
> Caused by: org.apache.flink.util.FlinkException: Could not restore keyed
> state backend for StreamFlatMap_c21234bcbf1e8eb4c61f1927190efebd_(1/1) from
> any of the 1 provided restore options.
> at
> org.apache.flink.streaming.api.operators.BackendRestorerProcedure.createAndRestore(BackendRestorerProcedure.java:160)
> ~[flink-streaming-java_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.streaming.api.operators.StreamTaskStateInitializerImpl.keyedStatedBackend(StreamTaskStateInitializerImpl.java:346)
> ~[flink-streaming-java_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.streaming.api.operators.StreamTaskStateInitializerImpl.streamOperatorStateContext(StreamTaskStateInitializerImpl.java:164)
> ~[flink-streaming-java_2.11-1.14.0.jar:1.14.0]
> ... 11 more
> Caused by: java.io.IOException: Could not load the native RocksDB library
> at
> org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend.ensureRocksDBIsLoaded(EmbeddedRocksDBStateBackend.java:882)
> ~[flink-statebackend-rocksdb_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend.createKeyedStateBackend(EmbeddedRocksDBStateBackend.java:402)
> ~[flink-statebackend-rocksdb_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.contrib.streaming.state.RocksDBStateBackend.createKeyedStateBackend(RocksDBStateBackend.java:345)
> ~[flink-statebackend-rocksdb_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.contrib.streaming.state.RocksDBStateBackend.createKeyedStateBackend(RocksDBStateBackend.java:87)
> ~[flink-statebackend-rocksdb_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.streaming.api.operators.StreamTaskStateInitializerImpl.lambda$keyedStatedBackend$1(StreamTaskStateInitializerImpl.java:329)
> ~[flink-streaming-java_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.streaming.api.operators.BackendRestorerProcedure.attemptCreateAndRestore(BackendRestorerProcedure.java:168)
> ~[flink-streaming-java_2.11-1.14.0.jar:1.14.0]
> at
> org.apache.flink.streaming.api.operators.BackendRestorerProcedure.createAndRestore(BackendRestorerProcedure.java:135)
>
[jira] [Created] (FLINK-27257) Flink kubernetes operator triggers savepoint failed because of not all tasks running
Yang Wang created FLINK-27257:
-
Summary: Flink kubernetes operator triggers savepoint failed
because of not all tasks running
Key: FLINK-27257
URL: https://issues.apache.org/jira/browse/FLINK-27257
Project: Flink
Issue Type: Bug
Components: Kubernetes Operator
Reporter: Yang Wang
{code:java}
2022-04-15 02:38:56,551 o.a.f.k.o.s.FlinkService [INFO
][default/flink-example-statemachine] Fetching savepoint result with triggerId:
182d7f176496856d7b33fe2f3767da18
2022-04-15 02:38:56,690 o.a.f.k.o.s.FlinkService
[ERROR][default/flink-example-statemachine] Savepoint error
org.apache.flink.runtime.checkpoint.CheckpointException: Checkpoint triggering
task Source: Custom Source (1/2) of job is not
being executed at the moment. Aborting checkpoint. Failure reason: Not all
required tasks are currently running.
at
org.apache.flink.runtime.checkpoint.DefaultCheckpointPlanCalculator.checkTasksStarted(DefaultCheckpointPlanCalculator.java:143)
at
org.apache.flink.runtime.checkpoint.DefaultCheckpointPlanCalculator.lambda$calculateCheckpointPlan$1(DefaultCheckpointPlanCalculator.java:105)
at
java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1604)
at
org.apache.flink.runtime.rpc.akka.AkkaRpcActor.lambda$handleRunAsync$4(AkkaRpcActor.java:455)
at
org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:68)
at
org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:455)
at
org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:213)
at
org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:78)
at
org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:163)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:20)
at scala.PartialFunction.applyOrElse(PartialFunction.scala:123)
at scala.PartialFunction.applyOrElse$(PartialFunction.scala:122)
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:20)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
at akka.actor.Actor.aroundReceive(Actor.scala:537)
at akka.actor.Actor.aroundReceive$(Actor.scala:535)
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:220)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:580)
at akka.actor.ActorCell.invoke(ActorCell.scala:548)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:270)
at akka.dispatch.Mailbox.run(Mailbox.scala:231)
at akka.dispatch.Mailbox.exec(Mailbox.scala:243)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at
java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
at
java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:175)
2022-04-15 02:38:56,693 o.a.f.k.o.o.SavepointObserver
[ERROR][default/flink-example-statemachine] Checkpoint triggering task Source:
Custom Source (1/2) of job is not being
executed at the moment. Aborting checkpoint. Failure reason: Not all required
tasks are currently running. {code}
How to reproduce?
Update arbitrary fields(e.g. parallelism) along with
{{{}savepointTriggerNonce{}}}.
The root cause might be the running state return by
{{ClusterClient#listJobs()}} does not mean all the tasks are running.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink-kubernetes-operator] tweise commented on a diff in pull request #165: [FLINK-26140] Support rollback strategies
tweise commented on code in PR #165:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/165#discussion_r851023715
##
flink-kubernetes-operator/src/main/java/org/apache/flink/kubernetes/operator/observer/deployment/ApplicationObserver.java:
##
@@ -70,23 +70,28 @@ protected Optional updateJobStatus(
}
@Override
-public void observeIfClusterReady(
-FlinkDeployment flinkApp, Context context, Configuration
lastValidatedConfig) {
+protected boolean observeFlinkCluster(
+FlinkDeployment flinkApp, Context context, Configuration
deployedConfig) {
+
+JobStatus jobStatus = flinkApp.getStatus().getJobStatus();
+
boolean jobFound =
jobStatusObserver.observe(
-flinkApp.getStatus().getJobStatus(),
-lastValidatedConfig,
-new ApplicationObserverContext(flinkApp, context,
lastValidatedConfig));
+jobStatus,
+deployedConfig,
+new ApplicationObserverContext(flinkApp, context,
deployedConfig));
if (jobFound) {
savepointObserver
-.observe(
-
flinkApp.getStatus().getJobStatus().getSavepointInfo(),
-flinkApp.getStatus().getJobStatus().getJobId(),
-lastValidatedConfig)
+.observe(jobStatus.getSavepointInfo(),
jobStatus.getJobId(), deployedConfig)
.ifPresent(
error ->
ReconciliationUtils.updateForReconciliationError(
flinkApp, error));
}
+return isJobReady(jobStatus);
+}
+
+private boolean isJobReady(JobStatus jobStatus) {
+return
org.apache.flink.api.common.JobStatus.RUNNING.name().equals(jobStatus.getState());
Review Comment:
Can we add a TODO here? RUNNING doesn't mean that the job is executing as
expected, even a job that flip flops may intermittently have RUNNING status.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] snailHumming commented on pull request #19401: [FLINK-25716][docs-zh] Translate "Streaming Concepts" page of "Applic…
snailHumming commented on PR #19401: URL: https://github.com/apache/flink/pull/19401#issuecomment-1099800909 Should I create a new PR for applying these changes to master branch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27244) Support subdirectories with Hive tables
[
https://issues.apache.org/jira/browse/FLINK-27244?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-27244:
---
Labels: pull-request-available (was: )
> Support subdirectories with Hive tables
> ---
>
> Key: FLINK-27244
> URL: https://issues.apache.org/jira/browse/FLINK-27244
> Project: Flink
> Issue Type: Sub-task
> Components: Connectors / Hive
>Reporter: luoyuxia
>Priority: Major
> Labels: pull-request-available
>
> Hive support to read recursive directory by setting the property 'set
> mapred.input.dir.recursive=true', and Spark also support [such
> behavior|[https://stackoverflow.com/questions/42026043/how-to-recursively-read-hadoop-files-from-directory-using-spark]].
> For normal case, it won't happed for reading recursive directory. But it may
> happen in the following case:
> I have a paritioned table `fact_tz` with partition day/hour
> {code:java}
> CREATE TABLE fact_tz(x int) PARTITIONED BY (ds STRING, hr STRING) {code}
> Then I want to create an external table `fact_daily` refering to `fact_tz`,
> but with a coarse-grained partition day.
> {code:java}
> create external table fact_daily(x int) PARTITIONED BY (ds STRING) location
> 'fact_tz_localtion' ;
> ALTER TABLE fact_daily ADD PARTITION (ds='1') location
> 'fact_tz_localtion/ds=1'{code}
> But it wll throw exception "Not a file: fact_tz_localtion/ds=1" when try to
> query this table `fact_daily` for it's the first level of the origin
> partition and is actually a directory .
>
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] luoyuxia opened a new pull request, #19482: [FLINK-27244][hive] Support read sub-directories in partition directory with Hive tables
luoyuxia opened a new pull request, #19482: URL: https://github.com/apache/flink/pull/19482 ## What is the purpose of the change Support read sub-directories in partition directory with Hive tables ## Brief change log Add an option to read partition directory recursively with Hive tables. ## Verifying this change Newly test [...link-connector-hive/src/test/java/org/apache/flink/connectors/hive/HiveDialectITCase.java](https://github.com/apache/flink/compare/master...luoyuxia:FLINK-27244?expand=1#diff-748a9fa63f15b3bd3ea5426a5b42179cadee77ecf3359c83f846aedb27d96871)#testTableWithSubDirsInPartitionDir ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? no -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #19481: [FLINK-27256][runtime] Log the root exception in closing the task man…
flinkbot commented on PR #19481: URL: https://github.com/apache/flink/pull/19481#issuecomment-1099795917 ## CI report: * fd30fc5691495b033a82c8289454d16fd9f6107f UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27256) Log the root exception in closing the task manager connection
[ https://issues.apache.org/jira/browse/FLINK-27256?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-27256: --- Labels: pull-request-available (was: ) > Log the root exception in closing the task manager connection > - > > Key: FLINK-27256 > URL: https://issues.apache.org/jira/browse/FLINK-27256 > Project: Flink > Issue Type: Improvement > Components: Runtime / Coordination >Reporter: Yangze Guo >Assignee: Yangze Guo >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > > When close the task manager connection, we'd better log the root cause of it > for debugging. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] KarmaGYZ opened a new pull request, #19481: [FLINK-27256][runtime] Log the root exception in closing the task man…
KarmaGYZ opened a new pull request, #19481: URL: https://github.com/apache/flink/pull/19481 …ager connection ## What is the purpose of the change Log the root exception in closing the task manager connection for ease of debugging. ## Brief change log Log the root exception in closing the task manager connection. ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? (not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27212) Failed to CAST('abcde', VARBINARY)
[
https://issues.apache.org/jira/browse/FLINK-27212?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522618#comment-17522618
]
Wenlong Lyu commented on FLINK-27212:
-
[~matriv] I think you may have some misunderstanding here. Regarding x'XXX', it
means a hexdecimal
literal(https://dev.mysql.com/doc/refman/8.0/en/hexadecimal-literals.html), it
requires even number of values, the error in calcite means that the literal is
illegal. it is irrelevant to the casting behavior I think.
BTW, we may need a FLIP for such kind of change to collect more feedbacks from
devs and users. I think it is better to keep it the same as former versions,
and make the decision later.
> Failed to CAST('abcde', VARBINARY)
> --
>
> Key: FLINK-27212
> URL: https://issues.apache.org/jira/browse/FLINK-27212
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Runtime
>Affects Versions: 1.16.0
>Reporter: Shengkai Fang
>Assignee: Marios Trivyzas
>Priority: Blocker
> Fix For: 1.16.0
>
>
> Please add test in the CalcITCase
> {code:scala}
> @Test
> def testCalc(): Unit = {
> val sql =
> """
> |SELECT CAST('abcde' AS VARBINARY(6))
> |""".stripMargin
> val result = tEnv.executeSql(sql)
> print(result.getResolvedSchema)
> result.print()
> }
> {code}
> The exception is
> {code:java}
> Caused by: org.apache.flink.table.api.TableException: Odd number of
> characters.
> at
> org.apache.flink.table.utils.EncodingUtils.decodeHex(EncodingUtils.java:203)
> at StreamExecCalc$33.processElement(Unknown Source)
> at
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.pushToOperator(ChainingOutput.java:99)
> at
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:80)
> at
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:39)
> at
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:56)
> at
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:29)
> at
> org.apache.flink.streaming.api.operators.StreamSourceContexts$ManualWatermarkContext.processAndCollect(StreamSourceContexts.java:418)
> at
> org.apache.flink.streaming.api.operators.StreamSourceContexts$WatermarkContext.collect(StreamSourceContexts.java:513)
> at
> org.apache.flink.streaming.api.operators.StreamSourceContexts$SwitchingOnClose.collect(StreamSourceContexts.java:103)
> at
> org.apache.flink.streaming.api.functions.source.InputFormatSourceFunction.run(InputFormatSourceFunction.java:92)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:67)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:332)
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] flinkbot commented on pull request #19480: [FLINK-27213][API/Python]Add PurgingTrigger
flinkbot commented on PR #19480: URL: https://github.com/apache/flink/pull/19480#issuecomment-1099791847 ## CI report: * 2bb742ac2836616e82401169eed3f24a8a608315 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-27256) Log the root exception in closing the task manager connection
Yangze Guo created FLINK-27256: -- Summary: Log the root exception in closing the task manager connection Key: FLINK-27256 URL: https://issues.apache.org/jira/browse/FLINK-27256 Project: Flink Issue Type: Improvement Components: Runtime / Coordination Reporter: Yangze Guo Assignee: Yangze Guo Fix For: 1.16.0 When close the task manager connection, we'd better log the root cause of it for debugging. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-27213) Add PurgingTrigger
[ https://issues.apache.org/jira/browse/FLINK-27213?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-27213: --- Labels: pull-request-available (was: ) > Add PurgingTrigger > --- > > Key: FLINK-27213 > URL: https://issues.apache.org/jira/browse/FLINK-27213 > Project: Flink > Issue Type: New Feature > Components: API / Python >Reporter: zhangjingcun >Priority: Major > Labels: pull-request-available > > Introduce PurgingTrigger which is already supported in the Java API -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] cun8cun8 opened a new pull request, #19480: [FLINK-27213][API/Python]Add PurgingTrigger
cun8cun8 opened a new pull request, #19480: URL: https://github.com/apache/flink/pull/19480 ## What is the purpose of the change *(For example: This pull request makes task deployment go through the blob server, rather than through RPC. That way we avoid re-transferring them on each deployment (during recovery).)* ## Brief change log *(for example:)* - *The TaskInfo is stored in the blob store on job creation time as a persistent artifact* - *Deployments RPC transmits only the blob storage reference* - *TaskManagers retrieve the TaskInfo from the blob cache* ## Verifying this change Please make sure both new and modified tests in this PR follows the conventions defined in our code quality guide: https://flink.apache.org/contributing/code-style-and-quality-common.html#testing *(Please pick either of the following options)* This change is a trivial rework / code cleanup without any test coverage. *(or)* This change is already covered by existing tests, such as *(please describe tests)*. *(or)* This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end deployment with large payloads (100MB)* - *Extended integration test for recovery after master (JobManager) failure* - *Added test that validates that TaskInfo is transferred only once across recoveries* - *Manually verified the change by running a 4 node cluster with 2 JobManagers and 4 TaskManagers, a stateful streaming program, and killing one JobManager and two TaskManagers during the execution, verifying that recovery happens correctly.* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] xuyangzhong commented on pull request #19465: [FLINK-27239][table-planner] rewrite PreValidateReWriter from scala to java
xuyangzhong commented on PR #19465: URL: https://github.com/apache/flink/pull/19465#issuecomment-1099790332 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] PatrickRen commented on a diff in pull request #19456: [FLINK-27041][connector/kafka] Catch IllegalStateException in KafkaPartitionSplitReader.fetch() to handle no valid partition cas
PatrickRen commented on code in PR #19456:
URL: https://github.com/apache/flink/pull/19456#discussion_r851005151
##
flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/connector/kafka/source/reader/KafkaPartitionSplitReader.java:
##
@@ -131,12 +138,7 @@ public RecordsWithSplitIds>
fetch() throws IOExce
kafkaSourceReaderMetrics.maybeAddRecordsLagMetric(consumer, tp);
}
-// Some splits are discovered as empty when handling split additions.
These splits should be
-// added to finished splits to clean up states in split fetcher and
source reader.
-if (!emptySplits.isEmpty()) {
-recordsBySplits.finishedSplits.addAll(emptySplits);
-emptySplits.clear();
-}
+markEmptySplitsAsFinished(recordsBySplits);
Review Comment:
The stopping offset of unbounded partitions is set to Long.MAX, so they
won't be treated as empty.
https://github.com/apache/flink/blob/release-1.14.4/flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/connector/kafka/source/reader/KafkaPartitionSplitReader.java#L311-L331
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Comment Edited] (FLINK-27236) No task slot allocated for job in larege-scale job
[
https://issues.apache.org/jira/browse/FLINK-27236?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522609#comment-17522609
]
yanpengshi edited comment on FLINK-27236 at 4/15/22 2:00 AM:
-
Hi. [~wanglijie95], thank you for your response, I have foucused on the feature
before.
However, when the slot is released by tm, it will report to the rm and may be
allocated other task. However, the according execution in the jm isn't released
and will also still be deployed to tm. Thus, it will cause the above problem.
It seems the problem will be always caused when the slot is free in tm.
Actually, the problem is caused due to slot state is not consistent in
JobMaster and ResourceManager.
Should we need to do something when the slot is freed? At least, the previous
execution shouldn't be still allocated to the tm .
was (Author: freeke):
Hi. [~wanglijie95], thank you for your response, I have ever foucused on the
feature.
However, when the slot is released by tm, it will report to the rm and may be
allocated other task. However, the according execution in the jm isn't released
and will also still be deployed to tm. Thus, it will cause the above problem.
It seems the problem will be always caused when the slot is free in tm.
Actually, the problem is caused due to slot state is not consistent in
JobMaster and ResourceManager.
Should we need to do something when the slot is freed? At least, the previous
execution shouldn't be still allocated to the tm .
> No task slot allocated for job in larege-scale job
> --
>
> Key: FLINK-27236
> URL: https://issues.apache.org/jira/browse/FLINK-27236
> Project: Flink
> Issue Type: Bug
>Affects Versions: 1.13.3
>Reporter: yanpengshi
>Priority: Major
> Attachments: jobmanager.log.26, taskmanager.log, topology.png
>
> Original Estimate: 444h
> Remaining Estimate: 444h
>
> Hey,
>
> We run a large-scale flink job containing six vertices with 3k parallelism.
> The Topology is shown below.
> !topology.png!
> We meets the following exception in jobmanager.log:[^jobmanager.log.26]
> {code:java}
> 2022-03-02 08:01:16,601 INFO [1998]
> [org.apache.flink.runtime.executiongraph.Execution.transitionState(Execution.java:1446)]
> - Source: tdbank_exposure_wx - Flat Map (772/3000)
> (6cd18d4ead1887a4e19fd3f337a6f4f8) switched from DEPLOYING to FAILED on
> container_e03_1639558254334_10048_01_004716 @ 11.104.77.40
> (dataPort=39313).java.util.concurrent.CompletionException:
> org.apache.flink.runtime.taskexecutor.exceptions.TaskSubmissionException: No
> task slot allocated for job ID ed780087 and
> allocation ID beb058d837c09e8d5a4a6aaf2426ca99. {code}
>
> In the taskmanager.log [^taskmanager.log], the slot is freed due to timeout
> and the taskmanager receives the new allocated request. By increasing the
> value of key: taskmanager.slot.timeout, we can avoid this exception
> temporarily.
> Here are some our guesses:
> # When the job is scheduled, the slot and execution have been bound, and
> then the task is deployed to the corresponding taskmanager.
> # The slot is released after the idle interval times out and notify the
> ResouceManager the slot free. Thus, the resourceManager will assign other
> request to the slot.
> # The task is deployed to taskmanager according the previous correspondence
>
> The key problems are :
> # When the slot is free, the execution is not unassigned from the slot;
> # The slot state is not consistent in JobMaster and ResourceManager
>
> Has anyone else encountered this problem? When the slot is freed, how can we
> unassign the previous bounded execution? Or we need to update the resource
> address of the execution. @[~zhuzh] @[~wanglijie95]
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-27236) No task slot allocated for job in larege-scale job
[
https://issues.apache.org/jira/browse/FLINK-27236?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522609#comment-17522609
]
yanpengshi commented on FLINK-27236:
Hi. [~wanglijie95], thank you for your response, I have ever foucused on the
feature.
However, when the slot is released by tm, it will report to the rm and may be
allocated other task. However, the according execution in the jm isn't released
and will also still be deployed to tm. Thus, it will cause the above problem.
It seems the problem will be always caused when the slot is free in tm.
Actually, the problem is caused due to slot state is not consistent in
JobMaster and ResourceManager.
Should we need to do something when the slot is freed? At least, the previous
execution shouldn't be still allocated to the tm .
> No task slot allocated for job in larege-scale job
> --
>
> Key: FLINK-27236
> URL: https://issues.apache.org/jira/browse/FLINK-27236
> Project: Flink
> Issue Type: Bug
>Affects Versions: 1.13.3
>Reporter: yanpengshi
>Priority: Major
> Attachments: jobmanager.log.26, taskmanager.log, topology.png
>
> Original Estimate: 444h
> Remaining Estimate: 444h
>
> Hey,
>
> We run a large-scale flink job containing six vertices with 3k parallelism.
> The Topology is shown below.
> !topology.png!
> We meets the following exception in jobmanager.log:[^jobmanager.log.26]
> {code:java}
> 2022-03-02 08:01:16,601 INFO [1998]
> [org.apache.flink.runtime.executiongraph.Execution.transitionState(Execution.java:1446)]
> - Source: tdbank_exposure_wx - Flat Map (772/3000)
> (6cd18d4ead1887a4e19fd3f337a6f4f8) switched from DEPLOYING to FAILED on
> container_e03_1639558254334_10048_01_004716 @ 11.104.77.40
> (dataPort=39313).java.util.concurrent.CompletionException:
> org.apache.flink.runtime.taskexecutor.exceptions.TaskSubmissionException: No
> task slot allocated for job ID ed780087 and
> allocation ID beb058d837c09e8d5a4a6aaf2426ca99. {code}
>
> In the taskmanager.log [^taskmanager.log], the slot is freed due to timeout
> and the taskmanager receives the new allocated request. By increasing the
> value of key: taskmanager.slot.timeout, we can avoid this exception
> temporarily.
> Here are some our guesses:
> # When the job is scheduled, the slot and execution have been bound, and
> then the task is deployed to the corresponding taskmanager.
> # The slot is released after the idle interval times out and notify the
> ResouceManager the slot free. Thus, the resourceManager will assign other
> request to the slot.
> # The task is deployed to taskmanager according the previous correspondence
>
> The key problems are :
> # When the slot is free, the execution is not unassigned from the slot;
> # The slot state is not consistent in JobMaster and ResourceManager
>
> Has anyone else encountered this problem? When the slot is freed, how can we
> unassign the previous bounded execution? Or we need to update the resource
> address of the execution. @[~zhuzh] @[~wanglijie95]
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-27235) Publish Flink k8s Operator Helm Charts via Github Actions
[
https://issues.apache.org/jira/browse/FLINK-27235?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522606#comment-17522606
]
Yang Wang commented on FLINK-27235:
---
Fot the main branch, I expect only when the {{helm/flink-kubernetes-operator}}
has some changes, then it will trigger the github actions to publish the latest
charts.
What should we do for the release branches? Do we host them both on the
"https://downloads.apache.org/flink/; and github packages?
> Publish Flink k8s Operator Helm Charts via Github Actions
> -
>
> Key: FLINK-27235
> URL: https://issues.apache.org/jira/browse/FLINK-27235
> Project: Flink
> Issue Type: New Feature
> Components: Kubernetes Operator
>Reporter: Gezim Sejdiu
>Assignee: Gezim Sejdiu
>Priority: Minor
>
> Hi team,
>
> thanks a lot for providing k8s-operator for Flink and glad to see the
> community around it.
>
> Recently I did some experiments with the possibility to release Helm Charts
> via Github-Actions: [https://github.com/GezimSejdiu/helm-chart-releaser-demo]
> and was thinking if that would also be great if we can also integrate the
> same for Flink Kubernetes Operator so that the release doesn't need to be
> done manually, but triggered whenever anything does change on the Helm Chart
> folder.
>
> If you think this will add any value to having all those processed present on
> Github Actions, I would be more than happy to contribute it.
>
> Best regards,
> Gezim
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Assigned] (FLINK-27235) Publish Flink k8s Operator Helm Charts via Github Actions
[ https://issues.apache.org/jira/browse/FLINK-27235?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Yang Wang reassigned FLINK-27235: - Assignee: Gezim Sejdiu > Publish Flink k8s Operator Helm Charts via Github Actions > - > > Key: FLINK-27235 > URL: https://issues.apache.org/jira/browse/FLINK-27235 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Reporter: Gezim Sejdiu >Assignee: Gezim Sejdiu >Priority: Minor > > Hi team, > > thanks a lot for providing k8s-operator for Flink and glad to see the > community around it. > > Recently I did some experiments with the possibility to release Helm Charts > via Github-Actions: [https://github.com/GezimSejdiu/helm-chart-releaser-demo] > and was thinking if that would also be great if we can also integrate the > same for Flink Kubernetes Operator so that the release doesn't need to be > done manually, but triggered whenever anything does change on the Helm Chart > folder. > > If you think this will add any value to having all those processed present on > Github Actions, I would be more than happy to contribute it. > > Best regards, > Gezim -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-27245) Flink job on Yarn cannot revover when zookeeper in Exception
[
https://issues.apache.org/jira/browse/FLINK-27245?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
hjw updated FLINK-27245:
Description:
Flink job cannot revover when zookeeper in Exception.
I noticed that the data in high-availability.storageDir deleled when Job
failed , resulting in failure when pulling up again.
Ps: The Job restart is done automatically by yarn, not manually
{code:java}
(SmarterLeaderLatch.java:570)
2022-04-07 19:54:29,002 | INFO | [Suspend state waiting handler] | Connection
to Zookeeper is SUSPENDED. Wait it to be back. Already waited 10 seconds. |
org.apache.flink.runtime.leaderelection.SmarterLeaderLatch
(SmarterLeaderLatch.java:570)
2022-04-07 19:54:29,004 | INFO | [Suspend state waiting handler] | Connection
to Zookeeper is SUSPENDED. Wait it to be back. Already waited 10 seconds. |
org.apache.flink.runtime.leaderelection.SmarterLeaderLatch
(SmarterLeaderLatch.java:570)
2022-04-07 19:54:29,004 | INFO | [Suspend state waiting handler] | Connection
to Zookeeper is SUSPENDED. Wait it to be back. Already waited 10 seconds. |
org.apache.flink.runtime.leaderelection.SmarterLeaderLatch
(SmarterLeaderLatch.java:570)
2022-04-07 19:54:30,002 | INFO | [Suspend state waiting handler] | Connection
to Zookeeper is SUSPENDED. Wait it to be back. Already waited 11 seconds. |
org.apache.flink.runtime.leaderelection.SmarterLeaderLatch
(SmarterLeaderLatch.java:570)
2022-04-07 19:54:30,002 | INFO | [Suspend state waiting handler] | Connection
to Zookeeper is SUSPENDED. Wait it to be back. Already waited 11 seconds. |
org.apache.flink.runtime.leaderelection.SmarterLeaderLatch
(SmarterLeaderLatch.java:570)
2022-04-07 19:54:30,004 | INFO | [Suspend state waiting handler] | Connection
to Zookeeper is SUSPENDED. Wait it to be back. Already waited 11 seconds. |
org.apache.flink.runtime.leaderelection.SmarterLeaderLatch
(SmarterLeaderLatch.java:570)
2022-04-07 19:54:30,004 | INFO | [Suspend state waiting handler] | Connection
to Zookeeper is SUSPENDED. Wait it to be back. Already waited 11 seconds. |
org.apache.flink.runtime.leaderelection.SmarterLeaderLatch
(SmarterLeaderLatch.java:570)
2022-04-07 19:54:30,769 | INFO | [BlobServer shutdown hook] |
FileSystemBlobStore cleaning up
hdfs:/flink/recovery/application_1625720467511_45233. |
org.apache.flink.runtime.blob.FileSystemBlobStor
{code}
{code:java}
2022-04-07 19:55:29,452 | INFO | [flink-akka.actor.default-dispatcher-4] |
Recovered SubmittedJobGraph(1898637f2d11429bd5f5767ea1daaf79, null). |
org.apache.flink.runtime.jobmanager.ZooKeeperSubmittedJobGraphStore
(ZooKeeperSubmittedJobGraphStore.java:215)
2022-04-07 19:55:29,467 | ERROR | [flink-akka.actor.default-dispatcher-17] |
Fatal error occurred in the cluster entrypoint. |
org.apache.flink.runtime.entrypoint.ClusterEntrypoint
(ClusterEntrypoint.java:408)
java.lang.RuntimeException:
org.apache.flink.runtime.client.JobExecutionException: Could not set up
JobManager
at
org.apache.flink.util.function.CheckedSupplier.lambda$unchecked$0(CheckedSupplier.java:36)
at
java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1590)
at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:39)
at
akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:415)
at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at
scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at
scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at
scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
Caused by: org.apache.flink.runtime.client.JobExecutionException: Could not set
up JobManager
at
org.apache.flink.runtime.jobmaster.JobManagerRunner.(JobManagerRunner.java:176)
at
org.apache.flink.runtime.dispatcher.Dispatcher$DefaultJobManagerRunnerFactory.createJobManagerRunner(Dispatcher.java:1058)
at
org.apache.flink.runtime.dispatcher.Dispatcher.lambda$createJobManagerRunner$5(Dispatcher.java:308)
at
org.apache.flink.util.function.CheckedSupplier.lambda$unchecked$0(CheckedSupplier.java:34)
... 7 common frames omitted
Caused by: java.lang.Exception: Cannot set up the user code libraries: File
does not exist:
/flink/recovery/application_1625720467511_45233/blob/job_1898637f2d11429bd5f5767ea1daaf79/blob_p-7128d0ae4a06a277e3b1182c99eb616ffd45b590-c90586d4a5d4641fcc0c9e4cab31c131
at
org.apache.hadoop.hdfs.server.namenode.INodeFile.valueOf(INodeFile.java:86)
at
org.apache.hadoop.hdfs.server.namenode.INodeFile.valueOf(INodeFile.java:76)
at
org.apache.hadoop.hdfs.server.namenode.FSDirStatAndListingOp.getBlockLocations(FSDirStatAndListingOp.java:153)
at
[jira] [Commented] (FLINK-27255) Flink-avro does not support serialization and deserialization of avro schema longer than 65535 characters
[ https://issues.apache.org/jira/browse/FLINK-27255?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522595#comment-17522595 ] J Y commented on FLINK-27255: - has this issue existed for awhile now (1.11+)? or, is it just constrained to 1.14.4? > Flink-avro does not support serialization and deserialization of avro schema > longer than 65535 characters > - > > Key: FLINK-27255 > URL: https://issues.apache.org/jira/browse/FLINK-27255 > Project: Flink > Issue Type: Bug > Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile) >Affects Versions: 1.14.4 >Reporter: Haizhou Zhao >Assignee: Haizhou Zhao >Priority: Blocker > > The underlying serialization of avro schema uses string serialization method > of ObjectOutputStream.class, however, the default string serialization by > ObjectOutputStream.class does not support handling string of more than 66535 > characters (64kb). As a result, constructing flink operators that > input/output Avro Generic Record with huge schema is not possible. > > The purposed fix is two change the serialization and deserialization method > of these following classes so that huge string could also be handled. > > [GenericRecordAvroTypeInfo|https://github.com/apache/flink/blob/master/flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/typeutils/GenericRecordAvroTypeInfo.java#L107] > [SerializableAvroSchema|https://github.com/apache/flink/blob/master/flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/typeutils/SerializableAvroSchema.java#L55] > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Assigned] (FLINK-27255) Flink-avro does not support serialization and deserialization of avro schema longer than 65535 characters
[ https://issues.apache.org/jira/browse/FLINK-27255?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Thomas Weise reassigned FLINK-27255: Assignee: Haizhou Zhao > Flink-avro does not support serialization and deserialization of avro schema > longer than 65535 characters > - > > Key: FLINK-27255 > URL: https://issues.apache.org/jira/browse/FLINK-27255 > Project: Flink > Issue Type: Bug > Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile) >Affects Versions: 1.14.4 >Reporter: Haizhou Zhao >Assignee: Haizhou Zhao >Priority: Blocker > > The underlying serialization of avro schema uses string serialization method > of ObjectOutputStream.class, however, the default string serialization by > ObjectOutputStream.class does not support handling string of more than 66535 > characters (64kb). As a result, constructing flink operators that > input/output Avro Generic Record with huge schema is not possible. > > The purposed fix is two change the serialization and deserialization method > of these following classes so that huge string could also be handled. > > [GenericRecordAvroTypeInfo|https://github.com/apache/flink/blob/master/flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/typeutils/GenericRecordAvroTypeInfo.java#L107] > [SerializableAvroSchema|https://github.com/apache/flink/blob/master/flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/typeutils/SerializableAvroSchema.java#L55] > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-27101) Periodically break the chain of incremental checkpoint
[ https://issues.apache.org/jira/browse/FLINK-27101?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522594#comment-17522594 ] Feifan Wang commented on FLINK-27101: - Hi [~yunta], [~pnowojski] , I think solution 3 can support more flexible triggering of checkpoint in addition to solving the problem of this issue. For example, users can suspend triggering checkpoints when processing delayed data. However, if the checkpoint trigger is exposed to the user, how to define the ownership of the checkpoint and the relationship between the checkpoint and the savepoint need to be carefully considered. > Periodically break the chain of incremental checkpoint > -- > > Key: FLINK-27101 > URL: https://issues.apache.org/jira/browse/FLINK-27101 > Project: Flink > Issue Type: New Feature > Components: Runtime / Checkpointing >Reporter: Steven Zhen Wu >Priority: Major > > Incremental checkpoint is almost a must for large-state jobs. It greatly > reduces the bytes uploaded to DFS per checkpoint. However, there are a few > implications from incremental checkpoint that are problematic for production > operations. Will use S3 as an example DFS for the rest of description. > 1. Because there is no way to deterministically know how far back the > incremental checkpoint can refer to files uploaded to S3, it is very > difficult to set S3 bucket/object TTL. In one application, we have observed > Flink checkpoint referring to files uploaded over 6 months ago. S3 TTL can > corrupt the Flink checkpoints. > S3 TTL is important for a few reasons > - purge orphaned files (like external checkpoints from previous deployments) > to keep the storage cost in check. This problem can be addressed by > implementing proper garbage collection (similar to JVM) by traversing the > retained checkpoints from all jobs and traverse the file references. But that > is an expensive solution from engineering cost perspective. > - Security and privacy. E.g., there may be requirement that Flink state can't > keep the data for more than some duration threshold (hours/days/weeks). > Application is expected to purge keys to satisfy the requirement. However, > with incremental checkpoint and how deletion works in RocksDB, it is hard to > set S3 TTL to purge S3 files. Even though those old S3 files don't contain > live keys, they may still be referrenced by retained Flink checkpoints. > 2. Occasionally, corrupted checkpoint files (on S3) are observed. As a > result, restoring from checkpoint failed. With incremental checkpoint, it > usually doesn't help to try other older checkpoints, because they may refer > to the same corrupted file. It is unclear whether the corruption happened > before or during S3 upload. This risk can be mitigated with periodical > savepoints. > It all boils down to periodical full snapshot (checkpoint or savepoint) to > deterministically break the chain of incremental checkpoints. Search the jira > history, the behavior that FLINK-23949 [1] trying to fix is actually close to > what we would need here. > There are a few options > 1. Periodically trigger savepoints (via control plane). This is actually not > a bad practice and might be appealing to some people. The problem is that it > requires a job deployment to break the chain of incremental checkpoint. > periodical job deployment may sound hacky. If we make the behavior of full > checkpoint after a savepoint (fixed in FLINK-23949) configurable, it might be > an acceptable compromise. The benefit is that no job deployment is required > after savepoints. > 2. Build the feature in Flink incremental checkpoint. Periodically (with some > cron style config) trigger a full checkpoint to break the incremental chain. > If the full checkpoint failed (due to whatever reason), the following > checkpoints should attempt full checkpoint as well until one successful full > checkpoint is completed. > 3. For the security/privacy requirement, the main thing is to apply > compaction on the deleted keys. That could probably avoid references to the > old files. Is there any RocksDB compation can achieve full compaction of > removing old delete markers. Recent delete markers are fine > [1] https://issues.apache.org/jira/browse/FLINK-23949 -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Created] (FLINK-27255) Flink-avro does not support serialization and deserialization of avro schema longer than 65535 characters
Haizhou Zhao created FLINK-27255: Summary: Flink-avro does not support serialization and deserialization of avro schema longer than 65535 characters Key: FLINK-27255 URL: https://issues.apache.org/jira/browse/FLINK-27255 Project: Flink Issue Type: Bug Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile) Affects Versions: 1.14.4 Reporter: Haizhou Zhao The underlying serialization of avro schema uses string serialization method of ObjectOutputStream.class, however, the default string serialization by ObjectOutputStream.class does not support handling string of more than 66535 characters (64kb). As a result, constructing flink operators that input/output Avro Generic Record with huge schema is not possible. The purposed fix is two change the serialization and deserialization method of these following classes so that huge string could also be handled. [GenericRecordAvroTypeInfo|https://github.com/apache/flink/blob/master/flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/typeutils/GenericRecordAvroTypeInfo.java#L107] [SerializableAvroSchema|https://github.com/apache/flink/blob/master/flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/typeutils/SerializableAvroSchema.java#L55] -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-27101) Periodically break the chain of incremental checkpoint
[ https://issues.apache.org/jira/browse/FLINK-27101?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522586#comment-17522586 ] Steven Zhen Wu commented on FLINK-27101: [~pnowojski] Option 3 (externally triggered checkpoint) should work well. Thanks! > Periodically break the chain of incremental checkpoint > -- > > Key: FLINK-27101 > URL: https://issues.apache.org/jira/browse/FLINK-27101 > Project: Flink > Issue Type: New Feature > Components: Runtime / Checkpointing >Reporter: Steven Zhen Wu >Priority: Major > > Incremental checkpoint is almost a must for large-state jobs. It greatly > reduces the bytes uploaded to DFS per checkpoint. However, there are a few > implications from incremental checkpoint that are problematic for production > operations. Will use S3 as an example DFS for the rest of description. > 1. Because there is no way to deterministically know how far back the > incremental checkpoint can refer to files uploaded to S3, it is very > difficult to set S3 bucket/object TTL. In one application, we have observed > Flink checkpoint referring to files uploaded over 6 months ago. S3 TTL can > corrupt the Flink checkpoints. > S3 TTL is important for a few reasons > - purge orphaned files (like external checkpoints from previous deployments) > to keep the storage cost in check. This problem can be addressed by > implementing proper garbage collection (similar to JVM) by traversing the > retained checkpoints from all jobs and traverse the file references. But that > is an expensive solution from engineering cost perspective. > - Security and privacy. E.g., there may be requirement that Flink state can't > keep the data for more than some duration threshold (hours/days/weeks). > Application is expected to purge keys to satisfy the requirement. However, > with incremental checkpoint and how deletion works in RocksDB, it is hard to > set S3 TTL to purge S3 files. Even though those old S3 files don't contain > live keys, they may still be referrenced by retained Flink checkpoints. > 2. Occasionally, corrupted checkpoint files (on S3) are observed. As a > result, restoring from checkpoint failed. With incremental checkpoint, it > usually doesn't help to try other older checkpoints, because they may refer > to the same corrupted file. It is unclear whether the corruption happened > before or during S3 upload. This risk can be mitigated with periodical > savepoints. > It all boils down to periodical full snapshot (checkpoint or savepoint) to > deterministically break the chain of incremental checkpoints. Search the jira > history, the behavior that FLINK-23949 [1] trying to fix is actually close to > what we would need here. > There are a few options > 1. Periodically trigger savepoints (via control plane). This is actually not > a bad practice and might be appealing to some people. The problem is that it > requires a job deployment to break the chain of incremental checkpoint. > periodical job deployment may sound hacky. If we make the behavior of full > checkpoint after a savepoint (fixed in FLINK-23949) configurable, it might be > an acceptable compromise. The benefit is that no job deployment is required > after savepoints. > 2. Build the feature in Flink incremental checkpoint. Periodically (with some > cron style config) trigger a full checkpoint to break the incremental chain. > If the full checkpoint failed (due to whatever reason), the following > checkpoints should attempt full checkpoint as well until one successful full > checkpoint is completed. > 3. For the security/privacy requirement, the main thing is to apply > compaction on the deleted keys. That could probably avoid references to the > old files. Is there any RocksDB compation can achieve full compaction of > removing old delete markers. Recent delete markers are fine > [1] https://issues.apache.org/jira/browse/FLINK-23949 -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-24066) Provides a new stop entry for Kubernetes session mode
[
https://issues.apache.org/jira/browse/FLINK-24066?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-24066:
---
Labels: auto-deprioritized-minor pull-request-available (was:
pull-request-available stale-minor)
Priority: Not a Priority (was: Minor)
This issue was labeled "stale-minor" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Minor, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> Provides a new stop entry for Kubernetes session mode
> -
>
> Key: FLINK-24066
> URL: https://issues.apache.org/jira/browse/FLINK-24066
> Project: Flink
> Issue Type: Improvement
> Components: Deployment / Kubernetes
>Reporter: liuzhuo
>Priority: Not a Priority
> Labels: auto-deprioritized-minor, pull-request-available
>
> For the current Native Kubernetes session mode, the way to stop a session is:
> {code:java}
> # (3) Stop Kubernetes session by deleting cluster deployment
> $ kubectl delete deployment/my-first-flink-cluster
> {code}
> or
> {code:java}
> $ echo 'stop' | ./bin/kubernetes-session.sh \
> -Dkubernetes.cluster-id=my-first-flink-cluster \
> -Dexecution.attached=true
> {code}
> I think a more friendly interface should be added to stop the session mode,
> such as:
> {code:java}
> $ ./bin/kubernetes-session.sh stop
> -Dkubernetes.cluster-id=my-first-flink-cluster
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-26177) PulsarSourceITCase.testScaleDown fails with timeout
[
https://issues.apache.org/jira/browse/FLINK-26177?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-26177:
---
Labels: pull-request-available stale-blocker stale-critical test-stability
(was: pull-request-available stale-blocker test-stability)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as
Critical but is unassigned and neither itself nor its Sub-Tasks have been
updated for 14 days. I have gone ahead and marked it "stale-critical". If this
ticket is critical, please either assign yourself or give an update.
Afterwards, please remove the label or in 7 days the issue will be
deprioritized.
> PulsarSourceITCase.testScaleDown fails with timeout
> ---
>
> Key: FLINK-26177
> URL: https://issues.apache.org/jira/browse/FLINK-26177
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Pulsar
>Affects Versions: 1.15.0, 1.16.0
>Reporter: Matthias Pohl
>Priority: Critical
> Labels: pull-request-available, stale-blocker, stale-critical,
> test-stability
>
> We observed a [build
> failure|https://dev.azure.com/mapohl/flink/_build/results?buildId=742=logs=f3dc9b18-b77a-55c1-591e-264c46fe44d1=2d3cd81e-1c37-5c31-0ee4-f5d5cdb9324d=26553]
> caused by {{PulsarSourceITCase.testScaleDown}}:
> {code}
> Feb 15 20:56:02 [ERROR] Tests run: 16, Failures: 1, Errors: 0, Skipped: 0,
> Time elapsed: 431.023 s <<< FAILURE! - in
> org.apache.flink.connector.pulsar.source.PulsarSourceITCase
> Feb 15 20:56:02 [ERROR]
> org.apache.flink.connector.pulsar.source.PulsarSourceITCase.testScaleDown(TestEnvironment,
> DataStreamSourceExternalContext, CheckpointingMode)[2] Time elapsed:
> 138.444 s <<< FAILURE!
> Feb 15 20:56:02 java.lang.AssertionError:
> Feb 15 20:56:02
> Feb 15 20:56:02 Expecting
> Feb 15 20:56:02
> Feb 15 20:56:02 to be completed within 2M.
> Feb 15 20:56:02
> Feb 15 20:56:02 exception caught while trying to get the future result:
> java.util.concurrent.TimeoutException
> Feb 15 20:56:02 at
> java.util.concurrent.CompletableFuture.timedGet(CompletableFuture.java:1784)
> [...]
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-23847) [Kafka] Error msg are obscure when KafkaConsumer init, valueDeserializer is null
[ https://issues.apache.org/jira/browse/FLINK-23847?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-23847: --- Labels: auto-deprioritized-minor pull-request-available (was: pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > [Kafka] Error msg are obscure when KafkaConsumer init, valueDeserializer is > null > > > Key: FLINK-23847 > URL: https://issues.apache.org/jira/browse/FLINK-23847 > Project: Flink > Issue Type: Bug > Components: Connectors / Kafka >Reporter: camilesing >Priority: Not a Priority > Labels: auto-deprioritized-minor, pull-request-available > > As the title, i think the msg can be clearer. > > _this.deserializer = checkNotNull(deserializer, "valueDeserializer");_ > _->_ > _this.deserializer = checkNotNull(deserializer, "valueDeserializer cannot be > null");_ -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-23187) [Documentation] PubSubSink should use "withTopicName" rather than "withSubscriptionName"
[ https://issues.apache.org/jira/browse/FLINK-23187?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-23187: --- Labels: auto-deprioritized-minor pull-request-available (was: pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > [Documentation] PubSubSink should use "withTopicName" rather than > "withSubscriptionName" > > > Key: FLINK-23187 > URL: https://issues.apache.org/jira/browse/FLINK-23187 > Project: Flink > Issue Type: Bug >Reporter: Jared Wasserman >Priority: Not a Priority > Labels: auto-deprioritized-minor, pull-request-available > > There are two PubSubSink code examples in the documentation: > [https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/connectors/datastream/pubsub/#pubsub-sink] > [https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/connectors/datastream/pubsub/#integration-testing] > These examples should use "withTopicName" rather than "withSubscriptionName" > in the builders. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-23861) flink sql client support dynamic params
[ https://issues.apache.org/jira/browse/FLINK-23861?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-23861: --- Labels: auto-deprioritized-minor pull-request-available (was: pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > flink sql client support dynamic params > --- > > Key: FLINK-23861 > URL: https://issues.apache.org/jira/browse/FLINK-23861 > Project: Flink > Issue Type: Improvement > Components: Table SQL / Client >Affects Versions: 1.13.2 >Reporter: zhangbin >Priority: Not a Priority > Labels: auto-deprioritized-minor, pull-request-available > Attachments: image-2021-08-18-23-41-13-629.png, > image-2021-08-18-23-42-04-257.png, image-2021-08-18-23-43-04-323.png > > > 1 Every time the set command is executed, the method call process is very > long and a new createTableEnvironment object is created > 2 As a result of the previous discussion in FLINK-22770, I don't think it's a > good habit for users to put quotes around keys and values. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-23397) [DOCS] task_failure_recovery page return 404
[ https://issues.apache.org/jira/browse/FLINK-23397?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-23397: --- Labels: auto-deprioritized-major auto-deprioritized-minor pull-request-available (was: auto-deprioritized-major pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > [DOCS] task_failure_recovery page return 404 > > > Key: FLINK-23397 > URL: https://issues.apache.org/jira/browse/FLINK-23397 > Project: Flink > Issue Type: Bug > Components: Documentation >Reporter: Dino Zhang >Priority: Not a Priority > Labels: auto-deprioritized-major, auto-deprioritized-minor, > pull-request-available > Attachments: image-2021-07-15-17-32-39-423.png > > > > [https://ci.apache.org/projects/flink/flink-docs-master/docs/ops/state/task_failure_recovery/] > > [https://ci.apache.org/projects/flink/flink-docs-master/docs/deployment/config/#advanced-fault-tolerance-options] > https://ci.apache.org/projects/flink/flink-docs-master/docs/deployment/config/#full-jobmanager-options > > > In the above page, clicking here will return a 404 > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-24398) KafkaSourceFetcherManager should re-use an existing SplitFetcher to commit offset if possible
[ https://issues.apache.org/jira/browse/FLINK-24398?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-24398: --- Labels: auto-deprioritized-minor pull-request-available (was: pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > KafkaSourceFetcherManager should re-use an existing SplitFetcher to commit > offset if possible > - > > Key: FLINK-24398 > URL: https://issues.apache.org/jira/browse/FLINK-24398 > Project: Flink > Issue Type: Improvement >Reporter: Dong Lin >Priority: Not a Priority > Labels: auto-deprioritized-minor, pull-request-available > > Currently KafkaSourceFetcherManager::commitOffset() will create a new > SplitFetcher if the fetchers.get(0) == null. As a result, if the first > fetcher has already been closed and removed, N fetchers will be created for N > commitOffset() invocations. > A more efficient approach is to re-use an existing fetcher to commit the > offset if there is any running fetchers in this KafkaSourceFetcherManager. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-25747) UdfStreamOperatorCheckpointingITCase hangs on AZP
[
https://issues.apache.org/jira/browse/FLINK-25747?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-25747:
---
Labels: auto-deprioritized-critical stale-major test-stability (was:
auto-deprioritized-critical test-stability)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as
Major but is unassigned and neither itself nor its Sub-Tasks have been updated
for 60 days. I have gone ahead and added a "stale-major" to the issue". If this
ticket is a Major, please either assign yourself or give an update. Afterwards,
please remove the label or in 7 days the issue will be deprioritized.
> UdfStreamOperatorCheckpointingITCase hangs on AZP
> -
>
> Key: FLINK-25747
> URL: https://issues.apache.org/jira/browse/FLINK-25747
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Checkpointing
>Affects Versions: 1.15.0
>Reporter: Till Rohrmann
>Priority: Major
> Labels: auto-deprioritized-critical, stale-major, test-stability
>
> The test {{UdfStreamOperatorCheckpointingITCase}} hangs on AZP.
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=29840=logs=b0a398c0-685b-599c-eb57-c8c2a771138e=d13f554f-d4b9-50f8-30ee-d49c6fb0b3cc=15424
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-24142) Fix Document DataStream Connectors File Sink ORC Format Scala example
[ https://issues.apache.org/jira/browse/FLINK-24142?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-24142: --- Labels: auto-deprioritized-minor pull-request-available (was: pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Fix Document DataStream Connectors File Sink ORC Format Scala example > - > > Key: FLINK-24142 > URL: https://issues.apache.org/jira/browse/FLINK-24142 > Project: Flink > Issue Type: Bug > Components: Documentation >Reporter: MasonMa >Priority: Not a Priority > Labels: auto-deprioritized-minor, pull-request-available > > Compared with the Java sample, batch.size in the implementation of vectorizer > in scala cannot be increased. As a result, the generated Orc file has no data -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-24009) Upgrade to Apache pom parent 24
[ https://issues.apache.org/jira/browse/FLINK-24009?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-24009: --- Labels: auto-deprioritized-minor pull-request-available (was: pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Upgrade to Apache pom parent 24 > --- > > Key: FLINK-24009 > URL: https://issues.apache.org/jira/browse/FLINK-24009 > Project: Flink > Issue Type: Improvement > Components: Build System >Affects Versions: 1.13.2 >Reporter: Kevin Ratnasekera >Priority: Not a Priority > Labels: auto-deprioritized-minor, pull-request-available > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-24093) Supports setting the percentage of kubernetes Request resources
[
https://issues.apache.org/jira/browse/FLINK-24093?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-24093:
---
Labels: auto-deprioritized-minor pull-request-available (was:
pull-request-available stale-minor)
Priority: Not a Priority (was: Minor)
This issue was labeled "stale-minor" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Minor, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> Supports setting the percentage of kubernetes Request resources
> ---
>
> Key: FLINK-24093
> URL: https://issues.apache.org/jira/browse/FLINK-24093
> Project: Flink
> Issue Type: Improvement
> Components: Deployment / Kubernetes
>Reporter: liuzhuo
>Priority: Not a Priority
> Labels: auto-deprioritized-minor, pull-request-available
>
> For the current native Kubernetes, we start the job to apply for resources
> (CPU,Memory) of the same *limit* and *request*, so as to achieve the best
> performance. However, in general, when the kubernetes cluster resources are
> used up by request allocation, In fact, there are still some physical
> resources left. If there is a way to reduce the number of requests per job,
> more jobs can be run and the resource utilization of the cluster can be
> improved.
> Here are some simple configurations to scale down the value of request:
>
> {code:java}
> kubernetes.cpu.request.percent
> kubernetes.mem.request.percent
> {code}
>
> *kubernetes.mem.request.percent*: the default value is 1.0, the effective
> range of 0.0 to 1.0, the meaning of this value is: If the value is 0.5 and
> the total memory of taskmanager/jobmanager is 2048MB, the value of request is
> 2048MB*0.5=1024MB. That is, if the remaining memory of nodes is larger than
> 1024MB, pods can be allocated to run
> *kubernetes.cpu.request.percent:*the default value is 1.0, the effective
> range of 0.0 to 1.0, the meaning of this value is: If the value is 0.5 and
> the number of cpus requested by TaskManager/JobManager is 1, the value of
> request is 1 x 0.5=0.5, that is, the remaining CPU usage of Nodes is greater
> than 0.5 to allocate pods to run
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-24251) Make default constructor of BinaryStringData construct empty binary string again
[
https://issues.apache.org/jira/browse/FLINK-24251?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-24251:
---
Labels: auto-deprioritized-minor pull-request-available (was:
pull-request-available stale-minor)
Priority: Not a Priority (was: Minor)
This issue was labeled "stale-minor" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Minor, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> Make default constructor of BinaryStringData construct empty binary string
> again
>
>
> Key: FLINK-24251
> URL: https://issues.apache.org/jira/browse/FLINK-24251
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / Runtime
>Reporter: Caizhi Weng
>Priority: Not a Priority
> Labels: auto-deprioritized-minor, pull-request-available
>
> In FLINK-23289 we add a not null checking for {{BinarySection}}. After the
> change the default constructor of {{BinaryStringData}} will now construct a
> {{BinaryStringData}} with {{null}} Java object and {{null}}
> {{BinarySection}}. This is different from the behavior before where the
> default constructor constructs an empty binary string.
> Although {{BinaryStringData}} is an internal class, it might confuse some
> developers (actually I myself have been confused) if they build their
> programs around this class. So we should make the default constructor
> construct an empty binary string again without breaking the not null checking.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] mas-chen commented on a diff in pull request #19456: [FLINK-27041][connector/kafka] Catch IllegalStateException in KafkaPartitionSplitReader.fetch() to handle no valid partition case
mas-chen commented on code in PR #19456:
URL: https://github.com/apache/flink/pull/19456#discussion_r850797500
##
flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/connector/kafka/source/reader/KafkaPartitionSplitReader.java:
##
@@ -131,12 +138,7 @@ public RecordsWithSplitIds>
fetch() throws IOExce
kafkaSourceReaderMetrics.maybeAddRecordsLagMetric(consumer, tp);
}
-// Some splits are discovered as empty when handling split additions.
These splits should be
-// added to finished splits to clean up states in split fetcher and
source reader.
-if (!emptySplits.isEmpty()) {
-recordsBySplits.finishedSplits.addAll(emptySplits);
-emptySplits.clear();
-}
+markEmptySplitsAsFinished(recordsBySplits);
Review Comment:
We should only finish empty splits in bounded mode, right? Empty partitions
may eventually contain data in streaming mode.
##
flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/connector/kafka/source/reader/KafkaPartitionSplitReader.java:
##
@@ -98,9 +98,16 @@ public RecordsWithSplitIds>
fetch() throws IOExce
ConsumerRecords consumerRecords;
try {
consumerRecords = consumer.poll(Duration.ofMillis(POLL_TIMEOUT));
-} catch (WakeupException we) {
-return new KafkaPartitionSplitRecords(
-ConsumerRecords.empty(), kafkaSourceReaderMetrics);
+} catch (WakeupException | IllegalStateException e) {
+// IllegalStateException will be thrown if the consumer is not
assigned any partitions.
+// This happens if all assigned partitions are invalid or empty
(starting offset >=
Review Comment:
The design makes sense, but I was thinking in terms of the specified offsets
initializer. Looks like it is handled properly by the enumerator in that case
though.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #19479: [FLINK-25694][FileSystems][S3] Upgrade Presto to resolve GSON/Alluxio Vulnerability
flinkbot commented on PR #19479: URL: https://github.com/apache/flink/pull/19479#issuecomment-1099563224 ## CI report: * 309ce3cb15d98a31d4307c7b6322d44469bc8a73 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-25694) Upgrade Presto to resolve GSON/Alluxio Vulnerability
[ https://issues.apache.org/jira/browse/FLINK-25694?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522513#comment-17522513 ] David Perkins commented on FLINK-25694: --- Created PRs for 1.14 and 1.15 * release-1.14: [https://github.com/apache/flink/pull/19478] * release-1.15: https://github.com/apache/flink/pull/19479 > Upgrade Presto to resolve GSON/Alluxio Vulnerability > > > Key: FLINK-25694 > URL: https://issues.apache.org/jira/browse/FLINK-25694 > Project: Flink > Issue Type: Technical Debt > Components: Connectors / FileSystem, FileSystems >Affects Versions: 1.14.2 >Reporter: David Perkins >Assignee: David Perkins >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > > GSON has a bug, which was fixed in 2.8.9, see > [https://github.com/google/gson/pull/1991|https://github.com/google/gson/pull/1991]. > This results in the possibility for DOS attacks. > GSON is included in the `flink-s3-fs-presto` plugin, because Alluxio includes > it in their shaded client. I've opened an issue in Alluxio: > [https://github.com/Alluxio/alluxio/issues/14868]. When that is fixed, the > plugin also needs to be updated. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] David-N-Perkins opened a new pull request, #19479: [FLINK-25694][FileSystems][S3] Upgrade Presto to resolve GSON/Alluxio Vulnerability
David-N-Perkins opened a new pull request, #19479: URL: https://github.com/apache/flink/pull/19479 ## What is the purpose of the change * Updated presto to the latest version due to GSON bug ## Brief change log - Updated prosto library to `.272` ## Verifying this change This change is already covered by existing tests. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): yes - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: yes ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #19478: [FLINK-25694][FileSystems][S3] Upgrade Presto to resolve GSON/Alluxio Vulnerability
flinkbot commented on PR #19478: URL: https://github.com/apache/flink/pull/19478#issuecomment-1099553046 ## CI report: * 2a1fd978334d3712397ab1b35da3fddc883c933f UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] David-N-Perkins opened a new pull request, #19478: [FLINK-25694][FileSystems][S3] Upgrade Presto to resolve GSON/Alluxio Vulnerability
David-N-Perkins opened a new pull request, #19478: URL: https://github.com/apache/flink/pull/19478 ## What is the purpose of the change * Updated presto to the latest version due to GSON bug ## Brief change log - Updated prosto library to `.272` ## Verifying this change This change is already covered by existing tests. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): yes - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: yes ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] MartijnVisser commented on pull request #19428: [FLINK-25694][FileSystems][S3] Upgrade Presto to resolve GSON/Alluxio Vulnerability
MartijnVisser commented on PR #19428: URL: https://github.com/apache/flink/pull/19428#issuecomment-1099530607 @David-N-Perkins I think we could consider backports to both `release-1.15` and `release-1.14`, being the last 2 releases that are being supported. I'm not 100% sure if we could merge this before Flink 1.15 is released (since the release candidate has just been created and the release is really close), but let's first at least have those backports available :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] MartijnVisser commented on pull request #19473: [FLINK-27231][Connector/Pulsar] Bump pulsar to 2.10.0
MartijnVisser commented on PR #19473: URL: https://github.com/apache/flink/pull/19473#issuecomment-1099526008 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] David-N-Perkins commented on pull request #19428: [FLINK-25694][FileSystems][S3] Upgrade Presto to resolve GSON/Alluxio Vulnerability
David-N-Perkins commented on PR #19428: URL: https://github.com/apache/flink/pull/19428#issuecomment-1099523678 @MartijnVisser Does this need to get merged into any other support branches? And is there a time frame on when this would get released? My company is tracking this vulnerability in our Flink deployments. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-27120) Translate "Gradle" tab of "Application Development > Project Configuration > Overview" to Chinese
[
https://issues.apache.org/jira/browse/FLINK-27120?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Martijn Visser closed FLINK-27120.
--
Fix Version/s: 1.16.0
Resolution: Fixed
Fixed in master: 93567633aa3aee20e456146b74318bdb4a5e9980
> Translate "Gradle" tab of "Application Development > Project Configuration >
> Overview" to Chinese
> -
>
> Key: FLINK-27120
> URL: https://issues.apache.org/jira/browse/FLINK-27120
> Project: Flink
> Issue Type: Improvement
> Components: Documentation
>Affects Versions: 1.15.0
>Reporter: Marios Trivyzas
>Assignee: Feifan Wang
>Priority: Major
> Labels: chinese-translation, pull-request-available
> Fix For: 1.16.0
>
>
> Translate the changes of
> [https://github.com/apache/flink/pull/18609,|https://github.com/apache/flink/pull/18609]
> we need to update the translation for
> [https://nightlies.apache.org/flink/flink-docs-master/zh/docs/dev/configuration/overview/]
> The markdown file is located in
> {noformat}
> flink/docs/content.zh/docs/dev/configuration/overview.md{noformat}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] MartijnVisser merged pull request #19403: [FLINK-27120][docs-zh] Translate "Gradle" tab of development > conf > overview
MartijnVisser merged PR #19403: URL: https://github.com/apache/flink/pull/19403 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-25694) Upgrade Presto to resolve GSON/Alluxio Vulnerability
[ https://issues.apache.org/jira/browse/FLINK-25694?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Martijn Visser closed FLINK-25694. -- Fix Version/s: 1.16.0 Resolution: Fixed Fixed in master: fa4410a313de385e9e9af2591c15e40c298f05d6 > Upgrade Presto to resolve GSON/Alluxio Vulnerability > > > Key: FLINK-25694 > URL: https://issues.apache.org/jira/browse/FLINK-25694 > Project: Flink > Issue Type: Technical Debt > Components: Connectors / FileSystem, FileSystems >Affects Versions: 1.14.2 >Reporter: David Perkins >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > > GSON has a bug, which was fixed in 2.8.9, see > [https://github.com/google/gson/pull/1991|https://github.com/google/gson/pull/1991]. > This results in the possibility for DOS attacks. > GSON is included in the `flink-s3-fs-presto` plugin, because Alluxio includes > it in their shaded client. I've opened an issue in Alluxio: > [https://github.com/Alluxio/alluxio/issues/14868]. When that is fixed, the > plugin also needs to be updated. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Assigned] (FLINK-25694) Upgrade Presto to resolve GSON/Alluxio Vulnerability
[ https://issues.apache.org/jira/browse/FLINK-25694?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Martijn Visser reassigned FLINK-25694: -- Assignee: David Perkins > Upgrade Presto to resolve GSON/Alluxio Vulnerability > > > Key: FLINK-25694 > URL: https://issues.apache.org/jira/browse/FLINK-25694 > Project: Flink > Issue Type: Technical Debt > Components: Connectors / FileSystem, FileSystems >Affects Versions: 1.14.2 >Reporter: David Perkins >Assignee: David Perkins >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > > GSON has a bug, which was fixed in 2.8.9, see > [https://github.com/google/gson/pull/1991|https://github.com/google/gson/pull/1991]. > This results in the possibility for DOS attacks. > GSON is included in the `flink-s3-fs-presto` plugin, because Alluxio includes > it in their shaded client. I've opened an issue in Alluxio: > [https://github.com/Alluxio/alluxio/issues/14868]. When that is fixed, the > plugin also needs to be updated. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] MartijnVisser merged pull request #19428: [FLINK-25694][FileSystems][S3] Upgrade Presto to resolve GSON/Alluxio Vulnerability
MartijnVisser merged PR #19428: URL: https://github.com/apache/flink/pull/19428 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] MartijnVisser commented on pull request #19428: [FLINK-25694][FileSystems][S3] Upgrade Presto to resolve GSON/Alluxio Vulnerability
MartijnVisser commented on PR #19428: URL: https://github.com/apache/flink/pull/19428#issuecomment-1099521175 Verified that S3 is working as expected in https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=34682=results. Merging this now. Thanks again @David-N-Perkins ! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-27254) Add Volume and VolumeMount supports for FlinkSessionJob
Xin Hao created FLINK-27254:
---
Summary: Add Volume and VolumeMount supports for FlinkSessionJob
Key: FLINK-27254
URL: https://issues.apache.org/jira/browse/FLINK-27254
Project: Flink
Issue Type: Improvement
Components: Kubernetes Operator
Reporter: Xin Hao
We should add Volume and VolumeMount supports for the FlinkSessionJob CRD
The reasons why not do this by PodTemplate are:
1. If I only want to mount a volume for the session job, PodTemplate is a bit
complex
2. The volume and mount are dynamic for different session jobs in my scenarios
The draft CRD will look like
{code:java}
apiVersion: flink.apache.org/v1beta1
kind: FlinkSessionJob
...
spec:
...
job:
...
volumes:
...
volumeMounts:
...{code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] XComp commented on pull request #19475: [FLINK-27250][sql][build] Remove custom surefire config
XComp commented on PR #19475: URL: https://github.com/apache/flink/pull/19475#issuecomment-1099402041 Out of curiosity: How did you test this change? Just running CI with this change and verifying that no error occurs? Or do we have other means to check that everything's working as expected? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] gaoyunhaii closed pull request #19466: (1.15) [FLINK-27231][FLINK-27230][FLINK-27233] Fix the remaining licence issues on 1.15
gaoyunhaii closed pull request #19466: (1.15) [FLINK-27231][FLINK-27230][FLINK-27233] Fix the remaining licence issues on 1.15 URL: https://github.com/apache/flink/pull/19466 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] gaoyunhaii commented on pull request #19466: (1.15) [FLINK-27231][FLINK-27230][FLINK-27233] Fix the remaining licence issues on 1.15
gaoyunhaii commented on PR #19466: URL: https://github.com/apache/flink/pull/19466#issuecomment-1099369913 Very thanks @dawidwys @zentol for the review! Will merge~ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] gyfora commented on pull request #165: [FLINK-26140] Support rollback strategies
gyfora commented on PR #165: URL: https://github.com/apache/flink-kubernetes-operator/pull/165#issuecomment-1099324926 @wangyang0918 I just pushed a commit before your comment :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] wangyang0918 commented on pull request #165: [FLINK-26140] Support rollback strategies
wangyang0918 commented on PR #165: URL: https://github.com/apache/flink-kubernetes-operator/pull/165#issuecomment-1099317348 One more comment, I forgot to note that the session job rollback has not been supported. I assume it will be done in a separate ticket. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27253) Remove custom surefire config from connector-cassandra
[ https://issues.apache.org/jira/browse/FLINK-27253?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-27253: --- Labels: pull-request-available (was: ) > Remove custom surefire config from connector-cassandra > -- > > Key: FLINK-27253 > URL: https://issues.apache.org/jira/browse/FLINK-27253 > Project: Flink > Issue Type: Technical Debt > Components: Build System, Connectors / Cassandra >Reporter: Chesnay Schepler >Assignee: Chesnay Schepler >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > > With the recent improvements around the cassandra test stability we can clean > up some technical debt. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] flinkbot commented on pull request #19477: [FLINK-27253][cassandra][build] Remove custom surefire config
flinkbot commented on PR #19477: URL: https://github.com/apache/flink/pull/19477#issuecomment-1099288245 ## CI report: * 92e8bcb226fc5d467ff8c3d18725c065687fedfa UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27252) Remove surefire fork options from connector-hive
[ https://issues.apache.org/jira/browse/FLINK-27252?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-27252: --- Labels: pull-request-available (was: ) > Remove surefire fork options from connector-hive > > > Key: FLINK-27252 > URL: https://issues.apache.org/jira/browse/FLINK-27252 > Project: Flink > Issue Type: Technical Debt > Components: Connectors / Hive >Reporter: Chesnay Schepler >Assignee: Chesnay Schepler >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > > Cleanup of unnecessary settings, that will also slightly speed up testing. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] flinkbot commented on pull request #19476: [FLINK-27252][hive][build] Remove surefire fork settings
flinkbot commented on PR #19476: URL: https://github.com/apache/flink/pull/19476#issuecomment-1099288080 ## CI report: * 8598760b2ff4e76da87afa2b929ad9b6d1292069 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-26793) Flink Cassandra connector performance issue
[
https://issues.apache.org/jira/browse/FLINK-26793?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522355#comment-17522355
]
Etienne Chauchot edited comment on FLINK-26793 at 4/14/22 3:10 PM:
---
[~bumblebee] I reproduced the behavior you observed: I ran [this streaming
infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited too long for an internal replication (raplication to another node in the
same casssandra "datacenter") and did not ack the write.
This led to a failure of the write task and to a restoration of the job from
the last checkpoint see job manager log:
{code:java}
2022-04-13 16:38:20,847 INFO
org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job Cassandra
Pojo Sink Streaming example (dc7522bc1855f6f98038ac2b4eed4095) switched from
state RESTARTING to RUNNING.
2022-04-13 16:38:20,850 INFO
org.apache.flink.runtime.checkpoint.CheckpointCoordinator[] - Restoring job
dc7522bc1855f6f98038ac2b4eed4095 from Checkpoint 136 @ 1649858983772 for
dc7522bc1855f6f98038ac2b4eed4095 located at
file:/tmp/flink-checkpoints/dc7522bc1855f6f98038ac2b4eed4095/chk-136.
{code}
This restoration led to the restoration of the _CassandraPojoSink_ and to the
call of _CassandraPojoSink#open_ which reconnects to cassandra cluster and
re-creates the related _MappingManager_
So in short, this is exactly what I supposed in my previous comments. Restoring
from checkpoints slows down your writes (job restart time + cassandra driver
state re-creation - reconnection, prepared statements recreation in the
MappingManager etc... -)
The problem is that the timeout comes from Cassandra itself not from Flink and
it is normal that Flink restores the job in such circumstances.
What you can do is to increase the Cassandra write timeout to adapt to your
workload in your Cassandra cluster so that such timeout errors do not happen.
For that you need to raise _write_request_timeout_in_ms_ conf parameter in
your _cassandra.yml_.
I do not recommend that you lower the replication factor in your Cassandra
cluster (I did that only for local tests on Flink) because it is mandatory that
you do not loose data in case of your Cassandra cluster failure. Waiting for a
single replica for write acknowledge is the minimum level for this guarantee in
Cassandra.
Best
Etienne
[^Capture d’écran de 2022-04-14 16-34-59.png]
[^Capture d’écran de 2022-04-14 16-35-30.png]
[^Capture d’écran de 2022-04-14 16-35-07.png]
[^jobmanager_log.txt]
[^taskmanager_127.0.1.1_33251-af56fa_log]
was (Author: echauchot):
[~bumblebee] I reproduced the behavior you observed: I ran [this streaming
infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
[jira] [Comment Edited] (FLINK-26793) Flink Cassandra connector performance issue
[
https://issues.apache.org/jira/browse/FLINK-26793?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522355#comment-17522355
]
Etienne Chauchot edited comment on FLINK-26793 at 4/14/22 3:08 PM:
---
[~bumblebee] I reproduced the behavior you observed: I ran [this streaming
infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited too long for an internal replication (raplication to another node in the
same casssandra "datacenter") and did not ack the write.
This led to a failure of the write task and to a restoration of the job from
the last checkpoint see job manager log:
{code:java}
2022-04-13 16:38:20,847 INFO
org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job Cassandra
Pojo Sink Streaming example (dc7522bc1855f6f98038ac2b4eed4095) switched from
state RESTARTING to RUNNING.
2022-04-13 16:38:20,850 INFO
org.apache.flink.runtime.checkpoint.CheckpointCoordinator[] - Restoring job
dc7522bc1855f6f98038ac2b4eed4095 from Checkpoint 136 @ 1649858983772 for
dc7522bc1855f6f98038ac2b4eed4095 located at
file:/tmp/flink-checkpoints/dc7522bc1855f6f98038ac2b4eed4095/chk-136.
{code}
This restoration led to the restoration of the _CassandraPojoSink_ and to the
call of _CassandraPojoSink#open_ which reconnects to cassandra cluster and
re-creates the related _MappingManager_
So in short, this is exactly what I supposed in my previous comments. Restoring
from checkpoints slows down your writes (job restart time + cassandra driver
state re-creation - reconnection, prepared statements recreation in the
MappingManager etc... -)
The problem is that the timeout comes from Cassandra itself not from Flink and
it is normal that Flink restores the job in such circumstances.
What you can do is to increase the Cassandra write timeout to adapt to your
workload in your Cassandra cluster so that such timeout errors do not happen.
For that you need to raise _write_request_timeout_in_ms_ conf parameter in
your _cassandra.yml_.
I do not recommend that you lower the replication factor in your Cassandra
cluster (I did that only from local tests on Flink) because it is mandatory
that you do not loose data in case of your Cassandra cluster failure. Waiting
for a single replica for write acknowledge is the minimum level for this
guarantee.
Best
Etienne
[^Capture d’écran de 2022-04-14 16-34-59.png]
[^Capture d’écran de 2022-04-14 16-35-30.png]
[^Capture d’écran de 2022-04-14 16-35-07.png]
[^jobmanager_log.txt]
[^taskmanager_127.0.1.1_33251-af56fa_log]
was (Author: echauchot):
[~bumblebee] I reproduced the behavior you observed: I ran [this streaming
infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited too
[jira] [Created] (FLINK-27253) Remove custom surefire config from connector-cassandra
Chesnay Schepler created FLINK-27253: Summary: Remove custom surefire config from connector-cassandra Key: FLINK-27253 URL: https://issues.apache.org/jira/browse/FLINK-27253 Project: Flink Issue Type: Technical Debt Components: Build System, Connectors / Cassandra Reporter: Chesnay Schepler Assignee: Chesnay Schepler Fix For: 1.16.0 With the recent improvements around the cassandra test stability we can clean up some technical debt. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-27232) .scalafmt.conf cant be located when running in sub-directory
[ https://issues.apache.org/jira/browse/FLINK-27232?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522372#comment-17522372 ] Marios Trivyzas commented on FLINK-27232: - I get your points, not insisting, we can leave it as is. > .scalafmt.conf cant be located when running in sub-directory > > > Key: FLINK-27232 > URL: https://issues.apache.org/jira/browse/FLINK-27232 > Project: Flink > Issue Type: Technical Debt > Components: Build System >Affects Versions: 1.16.0 >Reporter: Chesnay Schepler >Assignee: Chesnay Schepler >Priority: Major > Labels: pull-request-available > > cd flink-scala > mvn validate > Error: Failed to execute goal > com.diffplug.spotless:spotless-maven-plugin:2.13.0:check (spotless-check) on > project flink-scala_2.12: Execution spotless-check of goal > com.diffplug.spotless:spotless-maven-plugin:2.13.0:check failed: Unable to > locate file with path: .scalafmt.conf: Could not find resource > '.scalafmt.conf'. -> [Help 1] > Currently breaks the docs build. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Created] (FLINK-27252) Remove surefire fork options from connector-hive
Chesnay Schepler created FLINK-27252: Summary: Remove surefire fork options from connector-hive Key: FLINK-27252 URL: https://issues.apache.org/jira/browse/FLINK-27252 Project: Flink Issue Type: Technical Debt Components: Connectors / Hive Reporter: Chesnay Schepler Assignee: Chesnay Schepler Fix For: 1.16.0 Cleanup of unnecessary settings, that will also slightly speed up testing. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-27247) ScalarOperatorGens.numericCasting is not compatible with legacy behavior
[
https://issues.apache.org/jira/browse/FLINK-27247?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522367#comment-17522367
]
Marios Trivyzas commented on FLINK-27247:
-
Commented on the PR as well, I think we need to fix the root of the issue which
is the implicit cast introduced to cast from a nullable to a not nullable type,
and not just allow this in the code gen.
> ScalarOperatorGens.numericCasting is not compatible with legacy behavior
>
>
> Key: FLINK-27247
> URL: https://issues.apache.org/jira/browse/FLINK-27247
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Reporter: xuyang
>Priority: Minor
> Labels: pull-request-available
>
> Add the following test cases in ScalarFunctionsTest:
> {code:java}
> // code placeholder
> @Test
> def test(): Unit ={
> testSqlApi("rand(1) + 1","")
> } {code}
> it will throw the following exception:
> {code:java}
> // code placeholder
> org.apache.flink.table.planner.codegen.CodeGenException: Unsupported casting
> from DOUBLE to DOUBLE NOT NULL.
> at
> org.apache.flink.table.planner.codegen.calls.ScalarOperatorGens$.numericCasting(ScalarOperatorGens.scala:1734)
> at
> org.apache.flink.table.planner.codegen.calls.ScalarOperatorGens$.generateBinaryArithmeticOperator(ScalarOperatorGens.scala:85)
> at
> org.apache.flink.table.planner.codegen.ExprCodeGenerator.generateCallExpression(ExprCodeGenerator.scala:507)
> at
> org.apache.flink.table.planner.codegen.ExprCodeGenerator.visitCall(ExprCodeGenerator.scala:481)
> at
> org.apache.flink.table.planner.codegen.ExprCodeGenerator.visitCall(ExprCodeGenerator.scala:57)
> at org.apache.calcite.rex.RexCall.accept(RexCall.java:174)
> at
> org.apache.flink.table.planner.codegen.ExprCodeGenerator.$anonfun$visitCall$1(ExprCodeGenerator.scala:478)
> at
> scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:233)
> at
> scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:58)
> at
> scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:51)
> at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
> at scala.collection.TraversableLike.map(TraversableLike.scala:233)
> at scala.collection.TraversableLike.map$(TraversableLike.scala:226)
> at scala.collection.AbstractTraversable.map(Traversable.scala:104)
> at
> org.apache.flink.table.planner.codegen.ExprCodeGenerator.visitCall(ExprCodeGenerator.scala:469)
> ... {code}
> This is because in ScalarOperatorGens#numericCasting, FLINK-24779 lost the
> logic that in some cases there is no need to casting the left and right type.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-26803) Merge small ChannelState file for Unaligned Checkpoint
[ https://issues.apache.org/jira/browse/FLINK-26803?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522363#comment-17522363 ] fanrui commented on FLINK-26803: Hi [~akalashnikov] , thanks for your quick feedback. For some flink jobs with a small number of tasks and relatively small parallelism, UC will not generate many files, we can ignore them. Actually, the main purpose of file merging is to optimize flink jobs with high parallelism and a large number of tasks. > Merge small ChannelState file for Unaligned Checkpoint > -- > > Key: FLINK-26803 > URL: https://issues.apache.org/jira/browse/FLINK-26803 > Project: Flink > Issue Type: Improvement > Components: Runtime / Checkpointing, Runtime / Network >Reporter: fanrui >Priority: Major > > When making an unaligned checkpoint, the number of ChannelState files is > TaskNumber * subtaskNumber. For high parallelism job, it writes too many > small files. It causes high load for hdfs NN. > > In our production, a job writes more than 50K small files for each Unaligned > Checkpoint. Could we merge these files before write FileSystem? We can > configure the maximum number of files each TM can write in a single Unaligned > Checkpoint. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Comment Edited] (FLINK-26793) Flink Cassandra connector performance issue
[
https://issues.apache.org/jira/browse/FLINK-26793?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522355#comment-17522355
]
Etienne Chauchot edited comment on FLINK-26793 at 4/14/22 2:59 PM:
---
[~bumblebee] I reproduced the behavior you observed: I ran [this streaming
infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited too long for an internal replication (raplication to another node in the
same casssandra "datacenter") and did not ack the write.
This led to a failure of the write task and to a restoration of the job from
the last checkpoint see job manager log:
{code:java}
2022-04-13 16:38:20,847 INFO
org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job Cassandra
Pojo Sink Streaming example (dc7522bc1855f6f98038ac2b4eed4095) switched from
state RESTARTING to RUNNING.
2022-04-13 16:38:20,850 INFO
org.apache.flink.runtime.checkpoint.CheckpointCoordinator[] - Restoring job
dc7522bc1855f6f98038ac2b4eed4095 from Checkpoint 136 @ 1649858983772 for
dc7522bc1855f6f98038ac2b4eed4095 located at
file:/tmp/flink-checkpoints/dc7522bc1855f6f98038ac2b4eed4095/chk-136.
{code}
This restoration led to the re-creation of the _CassandraPojoSink_ and to the
re-creation of the related _MappingManager_
So in short, this is exactly what I supposed in my previous comments. Restoring
from checkpoints slow down you writes (job restart time + cassandra driver
state re-creation - connection, prepared statements etc... -)
The problem is that the timeout comes from Cassandra itself not from Flink and
it is normal that Flink restores the job in such circumstances.
What you can do is to increase the Cassandra write timeout to your workload in
your Cassandra cluster so that such errors do not happen. For that you need to
raise _write_request_timeout_in_ms_ conf parameter in your _cassandra.yml_.
I do not recommend that you lower the replication factor in your Cassandra
cluster (I did that only from local tests on Flink) because it is mandatory
that you do not loose data in case of your Cassandra cluster failure. Waiting
for a single replica for write acknowledge is the minimum level for this
guarantee.
Best
Etienne
[^Capture d’écran de 2022-04-14 16-34-59.png]
[^Capture d’écran de 2022-04-14 16-35-30.png]
[^Capture d’écran de 2022-04-14 16-35-07.png]
[^jobmanager_log.txt]
[^taskmanager_127.0.1.1_33251-af56fa_log]
was (Author: echauchot):
[~bumblebee] I reproduced the behavior you observed: I ran [this streaming
infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited too long for an internal replication (raplication to another node in the
same casssandra "datacenter") and did not ack the write.
[jira] [Comment Edited] (FLINK-26793) Flink Cassandra connector performance issue
[
https://issues.apache.org/jira/browse/FLINK-26793?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522355#comment-17522355
]
Etienne Chauchot edited comment on FLINK-26793 at 4/14/22 2:56 PM:
---
[~bumblebee] I reproduced the behavior you observed: I ran [this streaming
infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited too long for an internal replication (raplication to another node in the
same casssandra "datacenter") and did not ack the write.
This led to a failure of the write task and to a restoration of the job from
the last checkpoint see job manager log:
{code:java}
2022-04-13 16:38:20,847 INFO
org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job Cassandra
Pojo Sink Streaming example (dc7522bc1855f6f98038ac2b4eed4095) switched from
state RESTARTING to RUNNING.
2022-04-13 16:38:20,850 INFO
org.apache.flink.runtime.checkpoint.CheckpointCoordinator[] - Restoring job
dc7522bc1855f6f98038ac2b4eed4095 from Checkpoint 136 @ 1649858983772 for
dc7522bc1855f6f98038ac2b4eed4095 located at
file:/tmp/flink-checkpoints/dc7522bc1855f6f98038ac2b4eed4095/chk-136.
{code}
Obviously, this restoration led to the re-creation of the _CassandraPojoSink_
and to the re-creation of the related _MappingManager_
So in short, this is exactly what I supposed in my previous comments. Restoring
from checkpoints slow down you writes (job restart time + cassandra driver
state re-creation - connection, prepared statements etc... -)
The problem is that the timeout comes from Cassandra itself not from Flink and
it is normal that Flink restores the job in such circumstances.
What you can do is to increase the Cassandra write timeout to your workload in
your Cassandra cluster so that such errors do not happen. For that you need to
raise _write_request_timeout_in_ms_ conf parameter in your _cassandra.yml_.
I do not recommend that you lower the replication factor in your Cassandra
cluster (I did that only from local tests on Flink) because it is mandatory
that you do not loose data in case of your Cassandra cluster failure. Waiting
for a single replica for write acknowledge is the minimum level for this
guarantee.
Best
Etienne
[^Capture d’écran de 2022-04-14 16-34-59.png]
[^Capture d’écran de 2022-04-14 16-35-30.png]
[^Capture d’écran de 2022-04-14 16-35-07.png]
[^jobmanager_log.txt]
[^taskmanager_127.0.1.1_33251-af56fa_log]
was (Author: echauchot):
[~bumblebee] I reproduced the behavior you observed: I ran [this streaming
infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited too long for an internal replication (raplication to another node in the
same casssandra "datacenter") and did not ack the
[jira] [Comment Edited] (FLINK-26793) Flink Cassandra connector performance issue
[
https://issues.apache.org/jira/browse/FLINK-26793?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522355#comment-17522355
]
Etienne Chauchot edited comment on FLINK-26793 at 4/14/22 2:55 PM:
---
!Capture d’écran de 2022-04-14 16-35-07.png! [~bumblebee] I reproduced the
behavior you observed: I ran [this streaming infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited too long for an internal replication (raplication to another node in the
same casssandra "datacenter") and did not ack the write.
This led to a failure of the write task and to a restoration of the job from
the last checkpoint see job manager log:
{code:java}
2022-04-13 16:38:20,847 INFO
org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job Cassandra
Pojo Sink Streaming example (dc7522bc1855f6f98038ac2b4eed4095) switched from
state RESTARTING to RUNNING.
2022-04-13 16:38:20,850 INFO
org.apache.flink.runtime.checkpoint.CheckpointCoordinator[] - Restoring job
dc7522bc1855f6f98038ac2b4eed4095 from Checkpoint 136 @ 1649858983772 for
dc7522bc1855f6f98038ac2b4eed4095 located at
file:/tmp/flink-checkpoints/dc7522bc1855f6f98038ac2b4eed4095/chk-136.
{code}
Obviously, this restoration led to the re-creation of the _CassandraPojoSink_
and to the re-creation of the related _MappingManager_
So in short, this is exactly what I supposed in my previous comments. Restoring
from checkpoints slow down you writes (job restart time + cassandra driver
state re-creation - connection, prepared statements etc... -)
The problem is that the timeout comes from Cassandra itself not from Flink and
it is normal that Flink restores the job in such circumstances.
What you can do is to increase the Cassandra write timeout to your workload in
your Cassandra cluster so that such errors do not happen. For that you need to
raise _write_request_timeout_in_ms_ conf parameter in your _cassandra.yml_.
I do not recommend that you lower the replication factor in your Cassandra
cluster (I did that only from local tests on Flink) because it is mandatory
that you do not loose data in case of your Cassandra cluster failure. Waiting
for a single replica for write acknowledge is the minimum level for this
guarantee.
Best
Etienne
!Capture d’écran de 2022-04-14 16-34-59.png!
!Capture d’écran de 2022-04-14 16-35-30.png!
!Capture d’écran de 2022-04-14 16-35-07.png!
[^jobmanager_log.txt]
[^taskmanager_127.0.1.1_33251-af56fa_log]
was (Author: echauchot):
[~bumblebee] I reproduced the behavior you observed: I ran [this streaming
infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited too long for an internal replication (raplication to another node in the
same
[jira] [Comment Edited] (FLINK-26793) Flink Cassandra connector performance issue
[
https://issues.apache.org/jira/browse/FLINK-26793?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522355#comment-17522355
]
Etienne Chauchot edited comment on FLINK-26793 at 4/14/22 2:55 PM:
---
[~bumblebee] I reproduced the behavior you observed: I ran [this streaming
infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited too long for an internal replication (raplication to another node in the
same casssandra "datacenter") and did not ack the write.
This led to a failure of the write task and to a restoration of the job from
the last checkpoint see job manager log:
{code:java}
2022-04-13 16:38:20,847 INFO
org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job Cassandra
Pojo Sink Streaming example (dc7522bc1855f6f98038ac2b4eed4095) switched from
state RESTARTING to RUNNING.
2022-04-13 16:38:20,850 INFO
org.apache.flink.runtime.checkpoint.CheckpointCoordinator[] - Restoring job
dc7522bc1855f6f98038ac2b4eed4095 from Checkpoint 136 @ 1649858983772 for
dc7522bc1855f6f98038ac2b4eed4095 located at
file:/tmp/flink-checkpoints/dc7522bc1855f6f98038ac2b4eed4095/chk-136.
{code}
Obviously, this restoration led to the re-creation of the _CassandraPojoSink_
and to the re-creation of the related _MappingManager_
So in short, this is exactly what I supposed in my previous comments. Restoring
from checkpoints slow down you writes (job restart time + cassandra driver
state re-creation - connection, prepared statements etc... -)
The problem is that the timeout comes from Cassandra itself not from Flink and
it is normal that Flink restores the job in such circumstances.
What you can do is to increase the Cassandra write timeout to your workload in
your Cassandra cluster so that such errors do not happen. For that you need to
raise _write_request_timeout_in_ms_ conf parameter in your _cassandra.yml_.
I do not recommend that you lower the replication factor in your Cassandra
cluster (I did that only from local tests on Flink) because it is mandatory
that you do not loose data in case of your Cassandra cluster failure. Waiting
for a single replica for write acknowledge is the minimum level for this
guarantee.
Best
Etienne
!Capture d’écran de 2022-04-14 16-34-59.png!
!Capture d’écran de 2022-04-14 16-35-30.png!
!Capture d’écran de 2022-04-14 16-35-07.png!
[^jobmanager_log.txt]
[^taskmanager_127.0.1.1_33251-af56fa_log]
was (Author: echauchot):
!Capture d’écran de 2022-04-14 16-35-07.png! [~bumblebee] I reproduced the
behavior you observed: I ran [this streaming infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited too long for an internal replication (raplication to another node in the
same
[jira] [Updated] (FLINK-26793) Flink Cassandra connector performance issue
[ https://issues.apache.org/jira/browse/FLINK-26793?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Etienne Chauchot updated FLINK-26793: - Attachment: taskmanager_127.0.1.1_33251-af56fa_log > Flink Cassandra connector performance issue > > > Key: FLINK-26793 > URL: https://issues.apache.org/jira/browse/FLINK-26793 > Project: Flink > Issue Type: Improvement > Components: Connectors / Cassandra >Affects Versions: 1.14.4 >Reporter: Jay Ghiya >Assignee: Etienne Chauchot >Priority: Major > Attachments: Capture d’écran de 2022-04-14 16-34-59.png, Capture > d’écran de 2022-04-14 16-35-07.png, Capture d’écran de 2022-04-14 > 16-35-30.png, jobmanager_log.txt, taskmanager_127.0.1.1_33251-af56fa_log > > > A warning is observed during long runs of flink job stating “Insertions into > scylla might be suffering. Expect performance problems unless this is > resolved.” > Upon initial analysis - “flink cassandra connector is not keeping instance of > mapping manager that is used to convert a pojo to cassandra row. Ideally the > mapping manager should have the same life time as cluster and session objects > which are also created once when the driver is initialized” > Reference: > https://stackoverflow.com/questions/59203418/cassandra-java-driver-warning -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-26793) Flink Cassandra connector performance issue
[ https://issues.apache.org/jira/browse/FLINK-26793?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Etienne Chauchot updated FLINK-26793: - Attachment: jobmanager_log.txt > Flink Cassandra connector performance issue > > > Key: FLINK-26793 > URL: https://issues.apache.org/jira/browse/FLINK-26793 > Project: Flink > Issue Type: Improvement > Components: Connectors / Cassandra >Affects Versions: 1.14.4 >Reporter: Jay Ghiya >Assignee: Etienne Chauchot >Priority: Major > Attachments: Capture d’écran de 2022-04-14 16-34-59.png, Capture > d’écran de 2022-04-14 16-35-07.png, Capture d’écran de 2022-04-14 > 16-35-30.png, jobmanager_log.txt, taskmanager_127.0.1.1_33251-af56fa_log > > > A warning is observed during long runs of flink job stating “Insertions into > scylla might be suffering. Expect performance problems unless this is > resolved.” > Upon initial analysis - “flink cassandra connector is not keeping instance of > mapping manager that is used to convert a pojo to cassandra row. Ideally the > mapping manager should have the same life time as cluster and session objects > which are also created once when the driver is initialized” > Reference: > https://stackoverflow.com/questions/59203418/cassandra-java-driver-warning -- This message was sent by Atlassian Jira (v8.20.1#820001)