[GitHub] [flink] flinkbot commented on pull request #19494: [FLINK-27267][contrib] Migrate tests to JUnit5
flinkbot commented on PR #19494: URL: https://github.com/apache/flink/pull/19494#issuecomment-1100499721 ## CI report: * 4b20ff4a6cbbc48cc8ce3e1baa10befdee58840a UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27267) [JUnit5 Migration] Module: flink-contrib
[ https://issues.apache.org/jira/browse/FLINK-27267?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-27267: --- Labels: pull-request-available (was: ) > [JUnit5 Migration] Module: flink-contrib > > > Key: FLINK-27267 > URL: https://issues.apache.org/jira/browse/FLINK-27267 > Project: Flink > Issue Type: Sub-task > Components: Tests >Affects Versions: 1.16.0 >Reporter: RocMarshal >Priority: Major > Labels: pull-request-available > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] RocMarshal opened a new pull request, #19494: [FLINK-27267][contrib] Migrate tests to JUnit5
RocMarshal opened a new pull request, #19494: URL: https://github.com/apache/flink/pull/19494 ## What is the purpose of the change Migrate tests to JUnit5 ## Brief change log Migrate tests to JUnit5 ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / **no**) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / **no**) - The serializers: (yes / **no** / don't know) - The runtime per-record code paths (performance sensitive): (yes / **no** / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / **no** / don't know) - The S3 file system connector: (yes / **no** / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / **no**) - If yes, how is the feature documented? (**not applicable** / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-27267) [JUnit5 Migration] Module: flink-contrib
RocMarshal created FLINK-27267: -- Summary: [JUnit5 Migration] Module: flink-contrib Key: FLINK-27267 URL: https://issues.apache.org/jira/browse/FLINK-27267 Project: Flink Issue Type: Sub-task Components: Tests Affects Versions: 1.16.0 Reporter: RocMarshal -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-21501) Sync Chinese documentation with FLINK-21343
[ https://issues.apache.org/jira/browse/FLINK-21501?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-21501: --- Labels: auto-deprioritized-major auto-deprioritized-minor auto-unassigned pull-request-available (was: auto-deprioritized-major auto-unassigned pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Sync Chinese documentation with FLINK-21343 > --- > > Key: FLINK-21501 > URL: https://issues.apache.org/jira/browse/FLINK-21501 > Project: Flink > Issue Type: Bug > Components: Documentation >Affects Versions: 1.13.0 >Reporter: Dawid Wysakowicz >Priority: Not a Priority > Labels: auto-deprioritized-major, auto-deprioritized-minor, > auto-unassigned, pull-request-available > > We should update the Chinese documentation with changes introduced in > FLINK-21343 -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-20561) Add documentation for `records-lag-max` metric.
[ https://issues.apache.org/jira/browse/FLINK-20561?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-20561: --- Labels: auto-deprioritized-major auto-deprioritized-minor pull-request-available (was: auto-deprioritized-major pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Add documentation for `records-lag-max` metric. > > > Key: FLINK-20561 > URL: https://issues.apache.org/jira/browse/FLINK-20561 > Project: Flink > Issue Type: Improvement > Components: Documentation >Affects Versions: 1.11.0, 1.12.0 >Reporter: xiaozilong >Priority: Not a Priority > Labels: auto-deprioritized-major, auto-deprioritized-minor, > pull-request-available > > Currently, there are no metric description for kafka topic's lag in f[link > metrics > docs|https://ci.apache.org/projects/flink/flink-docs-release-1.11/monitoring/metrics.html#connectors]. > But this metric was reported in flink actually. So we should add some docs > to guide the users to use it. > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-20778) [FLINK-20778] the comment for the type of kafka consumer is wrong at KafkaPartitionSplit
[
https://issues.apache.org/jira/browse/FLINK-20778?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-20778:
---
Labels: auto-deprioritized-major auto-deprioritized-minor auto-unassigned
pull-request-available (was: auto-deprioritized-major auto-unassigned
pull-request-available stale-minor)
Priority: Not a Priority (was: Minor)
This issue was labeled "stale-minor" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Minor, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> [FLINK-20778] the comment for the type of kafka consumer is wrong at
> KafkaPartitionSplit
> -
>
> Key: FLINK-20778
> URL: https://issues.apache.org/jira/browse/FLINK-20778
> Project: Flink
> Issue Type: Improvement
> Components: Connectors / Kafka
>Reporter: Jeremy Mei
>Priority: Not a Priority
> Labels: auto-deprioritized-major, auto-deprioritized-minor,
> auto-unassigned, pull-request-available
> Attachments: Screen Capture_select-area_20201228011944.png
>
>
> the current code:
> {code:java}
> // Indicating the split should consume from the earliest.
> public static final long LATEST_OFFSET = -1;
> // Indicating the split should consume from the latest.
> public static final long EARLIEST_OFFSET = -2;
> {code}
> should be adjusted as blew
> {code:java}
> // Indicating the split should consume from the latest.
> public static final long LATEST_OFFSET = -1;
> // Indicating the split should consume from the earliest.
> public static final long EARLIEST_OFFSET = -2;
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-26104) KeyError: 'type_info' in PyFlink test
[
https://issues.apache.org/jira/browse/FLINK-26104?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-26104:
---
Labels: stale-major test-stability (was: test-stability)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as
Major but is unassigned and neither itself nor its Sub-Tasks have been updated
for 60 days. I have gone ahead and added a "stale-major" to the issue". If this
ticket is a Major, please either assign yourself or give an update. Afterwards,
please remove the label or in 7 days the issue will be deprioritized.
> KeyError: 'type_info' in PyFlink test
> -
>
> Key: FLINK-26104
> URL: https://issues.apache.org/jira/browse/FLINK-26104
> Project: Flink
> Issue Type: Bug
> Components: API / Python
>Affects Versions: 1.14.3
>Reporter: Huang Xingbo
>Priority: Major
> Labels: stale-major, test-stability
>
> {code:java}
> 2022-02-14T04:33:10.9891373Z Feb 14 04:33:10 E Caused by:
> java.lang.RuntimeException: Failed to create stage bundle factory!
> INFO:root:Initializing Python harness:
> /__w/1/s/flink-python/pyflink/fn_execution/beam/beam_boot.py --id=103-1
> --provision_endpoint=localhost:46669
> 2022-02-14T04:33:10.9892470Z Feb 14 04:33:10 E
> INFO:root:Starting up Python harness in a standalone process.
> 2022-02-14T04:33:10.9893079Z Feb 14 04:33:10 E Traceback
> (most recent call last):
> 2022-02-14T04:33:10.9894030Z Feb 14 04:33:10 E File
> "/__w/1/s/flink-python/dev/.conda/lib/python3.7/runpy.py", line 193, in
> _run_module_as_main
> 2022-02-14T04:33:10.9894791Z Feb 14 04:33:10 E
> "__main__", mod_spec)
> 2022-02-14T04:33:10.9895653Z Feb 14 04:33:10 E File
> "/__w/1/s/flink-python/dev/.conda/lib/python3.7/runpy.py", line 85, in
> _run_code
> 2022-02-14T04:33:10.9896395Z Feb 14 04:33:10 E
> exec(code, run_globals)
> 2022-02-14T04:33:10.9904913Z Feb 14 04:33:10 E File
> "/__w/1/s/flink-python/pyflink/fn_execution/beam/beam_boot.py", line 116, in
>
> 2022-02-14T04:33:10.9930244Z Feb 14 04:33:10 E from
> pyflink.fn_execution.beam import beam_sdk_worker_main
> 2022-02-14T04:33:10.9931563Z Feb 14 04:33:10 E File
> "/__w/1/s/flink-python/pyflink/fn_execution/beam/beam_sdk_worker_main.py",
> line 21, in
> 2022-02-14T04:33:10.9932630Z Feb 14 04:33:10 E import
> pyflink.fn_execution.beam.beam_operations # noqa # pylint:
> disable=unused-import
> 2022-02-14T04:33:10.9933754Z Feb 14 04:33:10 E File
> "/__w/1/s/flink-python/pyflink/fn_execution/beam/beam_operations.py", line
> 23, in
> 2022-02-14T04:33:10.9934415Z Feb 14 04:33:10 E from
> pyflink.fn_execution import flink_fn_execution_pb2
> 2022-02-14T04:33:10.9935335Z Feb 14 04:33:10 E File
> "/__w/1/s/flink-python/pyflink/fn_execution/flink_fn_execution_pb2.py", line
> 2581, in
> 2022-02-14T04:33:10.9936378Z Feb 14 04:33:10 E
> _SCHEMA_FIELDTYPE.fields_by_name['time_info'].containing_oneof =
> _SCHEMA_FIELDTYPE.oneofs_by_name['type_info']
> 2022-02-14T04:33:10.9946519Z Feb 14 04:33:10 E KeyError:
> 'type_info'
> 2022-02-14T04:33:10.9947110Z Feb 14 04:33:10 E
> 2022-02-14T04:33:10.9947911Z Feb 14 04:33:10 Eat
> org.apache.flink.streaming.api.runners.python.beam.BeamPythonFunctionRunner.createStageBundleFactory(BeamPythonFunctionRunner.java:566)
> 2022-02-14T04:33:10.9949048Z Feb 14 04:33:10 Eat
> org.apache.flink.streaming.api.runners.python.beam.BeamPythonFunctionRunner.open(BeamPythonFunctionRunner.java:255)
> 2022-02-14T04:33:10.9950162Z Feb 14 04:33:10 Eat
> org.apache.flink.streaming.api.operators.python.AbstractPythonFunctionOperator.open(AbstractPythonFunctionOperator.java:131)
> 2022-02-14T04:33:10.9951344Z Feb 14 04:33:10 Eat
> org.apache.flink.streaming.api.operators.python.AbstractOneInputPythonFunctionOperator.open(AbstractOneInputPythonFunctionOperator.java:116)
> 2022-02-14T04:33:10.9952487Z Feb 14 04:33:10 Eat
> org.apache.flink.streaming.api.operators.python.PythonKeyedProcessOperator.open(PythonKeyedProcessOperator.java:121)
> 2022-02-14T04:33:10.9953561Z Feb 14 04:33:10 Eat
> org.apache.flink.streaming.runtime.tasks.RegularOperatorChain.initializeStateAndOpenOperators(RegularOperatorChain.java:110)
> 2022-02-14T04:33:10.9954565Z Feb 14 04:33:10 Eat
>
[jira] [Updated] (FLINK-25442) HBaseConnectorITCase.testTableSink failed on azure
[
https://issues.apache.org/jira/browse/FLINK-25442?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-25442:
---
Labels: auto-deprioritized-critical test-stability (was: stale-critical
test-stability)
Priority: Major (was: Critical)
This issue was labeled "stale-critical" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Critical,
please raise the priority and ask a committer to assign you the issue or revive
the public discussion.
> HBaseConnectorITCase.testTableSink failed on azure
> --
>
> Key: FLINK-25442
> URL: https://issues.apache.org/jira/browse/FLINK-25442
> Project: Flink
> Issue Type: Bug
> Components: Connectors / HBase
>Affects Versions: 1.15.0, 1.14.2, 1.16.0
>Reporter: Yun Gao
>Priority: Major
> Labels: auto-deprioritized-critical, test-stability
>
> {code:java}
> Dec 24 00:48:54 Picked up JAVA_TOOL_OPTIONS: -XX:+HeapDumpOnOutOfMemoryError
> Dec 24 00:48:54 OpenJDK 64-Bit Server VM warning: ignoring option
> MaxPermSize=128m; support was removed in 8.0
> Dec 24 00:48:54 Running org.apache.flink.connector.hbase2.HBaseConnectorITCase
> Dec 24 00:48:59 Formatting using clusterid: testClusterID
> Dec 24 00:50:15 java.lang.ThreadGroup[name=PEWorkerGroup,maxpri=10]
> Dec 24 00:50:15 Thread[HFileArchiver-8,5,PEWorkerGroup]
> Dec 24 00:50:15 Thread[HFileArchiver-9,5,PEWorkerGroup]
> Dec 24 00:50:15 Thread[HFileArchiver-10,5,PEWorkerGroup]
> Dec 24 00:50:15 Thread[HFileArchiver-11,5,PEWorkerGroup]
> Dec 24 00:50:15 Thread[HFileArchiver-12,5,PEWorkerGroup]
> Dec 24 00:50:15 Thread[HFileArchiver-13,5,PEWorkerGroup]
> Dec 24 00:50:16 Tests run: 9, Failures: 1, Errors: 0, Skipped: 0, Time
> elapsed: 82.068 sec <<< FAILURE! - in
> org.apache.flink.connector.hbase2.HBaseConnectorITCase
> Dec 24 00:50:16
> testTableSink(org.apache.flink.connector.hbase2.HBaseConnectorITCase) Time
> elapsed: 8.534 sec <<< FAILURE!
> Dec 24 00:50:16 java.lang.AssertionError: expected:<8> but was:<5>
> Dec 24 00:50:16 at org.junit.Assert.fail(Assert.java:89)
> Dec 24 00:50:16 at org.junit.Assert.failNotEquals(Assert.java:835)
> Dec 24 00:50:16 at org.junit.Assert.assertEquals(Assert.java:120)
> Dec 24 00:50:16 at org.junit.Assert.assertEquals(Assert.java:146)
> Dec 24 00:50:16 at
> org.apache.flink.connector.hbase2.HBaseConnectorITCase.testTableSink(HBaseConnectorITCase.java:291)
> Dec 24 00:50:16 at sun.reflect.NativeMethodAccessorImpl.invoke0(Native
> Method)
> Dec 24 00:50:16 at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> Dec 24 00:50:16 at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> Dec 24 00:50:16 at java.lang.reflect.Method.invoke(Method.java:498)
> Dec 24 00:50:16 at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:59)
> Dec 24 00:50:16 at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> Dec 24 00:50:16 at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:56)
> Dec 24 00:50:16 at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> Dec 24 00:50:16 at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> Dec 24 00:50:16 at
> org.junit.runners.ParentRunner$3.evaluate(ParentRunner.java:306)
> Dec 24 00:50:16 at
> org.junit.runners.BlockJUnit4ClassRunner$1.evaluate(BlockJUnit4ClassRunner.java:100)
> Dec 24 00:50:16 at
> org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:366)
> Dec 24 00:50:16 at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:103)
> Dec 24 00:50:16 at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:63)
> Dec 24 00:50:16 at
> org.junit.runners.ParentRunner$4.run(ParentRunner.java:331)
> Dec 24 00:50:16 at
> org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:79)
> Dec 24 00:50:16 at
> org.junit.runners.ParentRunner.runChildren(ParentRunner.java:329)
> Dec 24 00:50:16 at
> org.junit.runners.ParentRunner.access$100(ParentRunner.java:66)
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-20918) Avoid excessive flush of Hadoop output stream
[ https://issues.apache.org/jira/browse/FLINK-20918?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-20918: --- Labels: auto-deprioritized-major auto-deprioritized-minor pull-request-available (was: auto-deprioritized-major pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Avoid excessive flush of Hadoop output stream > - > > Key: FLINK-20918 > URL: https://issues.apache.org/jira/browse/FLINK-20918 > Project: Flink > Issue Type: Bug > Components: Connectors / Hadoop Compatibility, FileSystems >Affects Versions: 1.11.3, 1.12.0 >Reporter: Paul Lin >Priority: Not a Priority > Labels: auto-deprioritized-major, auto-deprioritized-minor, > pull-request-available > > [HadoopRecoverableFsDataOutputStream#sync|https://github.com/apache/flink/blob/67d167ccd45046fc5ed222ac1f1e3ba5e6ec434b/flink-filesystems/flink-hadoop-fs/src/main/java/org/apache/flink/runtime/fs/hdfs/HadoopRecoverableFsDataOutputStream.java#L123] > calls both `hflush` and `hsync`, whereas `hsync` is an enhanced version of > `hflush`. We should remove the `hflush` call to avoid the excessive flush. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-20938) Implement Flink's own tencent COS filesystem
[ https://issues.apache.org/jira/browse/FLINK-20938?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-20938: --- Labels: auto-deprioritized-major auto-deprioritized-minor pull-request-available (was: auto-deprioritized-major pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Implement Flink's own tencent COS filesystem > > > Key: FLINK-20938 > URL: https://issues.apache.org/jira/browse/FLINK-20938 > Project: Flink > Issue Type: New Feature > Components: FileSystems >Affects Versions: 1.12.0 >Reporter: hayden zhou >Priority: Not a Priority > Labels: auto-deprioritized-major, auto-deprioritized-minor, > pull-request-available > > Tencent's COS is widely used among China's cloud users, and Hadoop supports > Tencent COS since 3.3.0. > Open this jira to wrap CosNFileSystem in FLINK(similar to oss support), so > that users can read from & write to COS more easily in FLINK. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-26110) AvroStreamingFileSinkITCase failed on azure
[
https://issues.apache.org/jira/browse/FLINK-26110?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-26110:
---
Labels: stale-major test-stability (was: test-stability)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as
Major but is unassigned and neither itself nor its Sub-Tasks have been updated
for 60 days. I have gone ahead and added a "stale-major" to the issue". If this
ticket is a Major, please either assign yourself or give an update. Afterwards,
please remove the label or in 7 days the issue will be deprioritized.
> AvroStreamingFileSinkITCase failed on azure
> ---
>
> Key: FLINK-26110
> URL: https://issues.apache.org/jira/browse/FLINK-26110
> Project: Flink
> Issue Type: Bug
> Components: Connectors / FileSystem
>Affects Versions: 1.13.5
>Reporter: Yun Gao
>Priority: Major
> Labels: stale-major, test-stability
>
> {code:java}
> Feb 12 01:00:00 [ERROR] Tests run: 3, Failures: 1, Errors: 0, Skipped: 0,
> Time elapsed: 2.433 s <<< FAILURE! - in
> org.apache.flink.formats.avro.AvroStreamingFileSinkITCase
> Feb 12 01:00:00 [ERROR]
> testWriteAvroGeneric(org.apache.flink.formats.avro.AvroStreamingFileSinkITCase)
> Time elapsed: 0.433 s <<< FAILURE!
> Feb 12 01:00:00 java.lang.AssertionError: expected:<1> but was:<2>
> Feb 12 01:00:00 at org.junit.Assert.fail(Assert.java:88)
> Feb 12 01:00:00 at org.junit.Assert.failNotEquals(Assert.java:834)
> Feb 12 01:00:00 at org.junit.Assert.assertEquals(Assert.java:645)
> Feb 12 01:00:00 at org.junit.Assert.assertEquals(Assert.java:631)
> Feb 12 01:00:00 at
> org.apache.flink.formats.avro.AvroStreamingFileSinkITCase.validateResults(AvroStreamingFileSinkITCase.java:139)
> Feb 12 01:00:00 at
> org.apache.flink.formats.avro.AvroStreamingFileSinkITCase.testWriteAvroGeneric(AvroStreamingFileSinkITCase.java:109)
> Feb 12 01:00:00 at sun.reflect.NativeMethodAccessorImpl.invoke0(Native
> Method)
> Feb 12 01:00:00 at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> Feb 12 01:00:00 at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> Feb 12 01:00:00 at java.lang.reflect.Method.invoke(Method.java:498)
> Feb 12 01:00:00 at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50)
> Feb 12 01:00:00 at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> Feb 12 01:00:00 at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47)
> Feb 12 01:00:00 at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> Feb 12 01:00:00 at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> Feb 12 01:00:00 at
> org.junit.internal.runners.statements.FailOnTimeout$CallableStatement.call(FailOnTimeout.java:298)
> Feb 12 01:00:00 at
> org.junit.internal.runners.statements.FailOnTimeout$CallableStatement.call(FailOnTimeout.java:292)
> Feb 12 01:00:00 at
> java.util.concurrent.FutureTask.run(FutureTask.java:266)
> Feb 12 01:00:00 at java.lang.Thread.run(Thread.java:748)
> Feb 12 01:00:00
> {code}
> https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=31304=logs=c91190b6-40ae-57b2-5999-31b869b0a7c1=43529380-51b4-5e90-5af4-2dccec0ef402=13026
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-26047) Support usrlib in HDFS for YARN application mode
[
https://issues.apache.org/jira/browse/FLINK-26047?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-26047:
---
Labels: pull-request-available stale-assigned (was: pull-request-available)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issue is assigned but has not
received an update in 30 days, so it has been labeled "stale-assigned".
If you are still working on the issue, please remove the label and add a
comment updating the community on your progress. If this issue is waiting on
feedback, please consider this a reminder to the committer/reviewer. Flink is a
very active project, and so we appreciate your patience.
If you are no longer working on the issue, please unassign yourself so someone
else may work on it.
> Support usrlib in HDFS for YARN application mode
>
>
> Key: FLINK-26047
> URL: https://issues.apache.org/jira/browse/FLINK-26047
> Project: Flink
> Issue Type: Improvement
> Components: Deployment / YARN
>Reporter: Biao Geng
>Assignee: Biao Geng
>Priority: Major
> Labels: pull-request-available, stale-assigned
>
> In YARN Application mode, we currently support using user jar and lib jar
> from HDFS. For example, we can run commands like:
> {quote}./bin/flink run-application -t yarn-application \
> -Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" \
> hdfs://myhdfs/jars/my-application.jar{quote}
> For {{usrlib}}, we currently only support local directory. I propose to add
> HDFS support for {{usrlib}} to work with CLASSPATH_INCLUDE_USER_JAR better.
> It can also benefit cases like using notebook to submit flink job.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-21643) JDBC sink should be able to execute statements on multiple tables
[ https://issues.apache.org/jira/browse/FLINK-21643?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-21643: --- Labels: auto-deprioritized-major auto-deprioritized-minor pull-request-available (was: auto-deprioritized-major pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > JDBC sink should be able to execute statements on multiple tables > - > > Key: FLINK-21643 > URL: https://issues.apache.org/jira/browse/FLINK-21643 > Project: Flink > Issue Type: New Feature > Components: Connectors / JDBC >Reporter: Maciej Obuchowski >Priority: Not a Priority > Labels: auto-deprioritized-major, auto-deprioritized-minor, > pull-request-available > > Currently datastream JDBC sink supports outputting data only to one table - > by having to provide SQL template, from which SimpleBatchStatementExecutor > creates PreparedStatement. Creating multiple sinks, each of which writes data > to one table is impractical for moderate to large number of tables - > relational databases don't usually tolerate large number of connections. > I propose adding DynamicBatchStatementExecutor, which will additionally > require > 1) provided mechanism to create SQL statements based on given object > 2) cache for prepared statements > 3) mechanism for determining which statement should be used for given object -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-25529) java.lang.ClassNotFoundException: org.apache.orc.PhysicalWriter when write bulkly into hive-2.1.1 orc table
[
https://issues.apache.org/jira/browse/FLINK-25529?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-25529:
---
Labels: pull-request-available stale-major (was: pull-request-available)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as
Major but is unassigned and neither itself nor its Sub-Tasks have been updated
for 60 days. I have gone ahead and added a "stale-major" to the issue". If this
ticket is a Major, please either assign yourself or give an update. Afterwards,
please remove the label or in 7 days the issue will be deprioritized.
> java.lang.ClassNotFoundException: org.apache.orc.PhysicalWriter when write
> bulkly into hive-2.1.1 orc table
> ---
>
> Key: FLINK-25529
> URL: https://issues.apache.org/jira/browse/FLINK-25529
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Hive
> Environment: hive 2.1.1
> flink 1.12.4
>Reporter: Yuan Zhu
>Priority: Major
> Labels: pull-request-available, stale-major
> Attachments: lib.jpg
>
>
> I tried to write data bulkly into hive-2.1.1 with orc format, and encountered
> java.lang.ClassNotFoundException: org.apache.orc.PhysicalWriter
>
> Using bulk writer by setting table.exec.hive.fallback-mapred-writer = false;
>
> {code:java}
> SET 'table.sql-dialect'='hive';
> create table orders(
> order_id int,
> order_date timestamp,
> customer_name string,
> price decimal(10,3),
> product_id int,
> order_status boolean
> )partitioned by (dt string)
> stored as orc;
>
> SET 'table.sql-dialect'='default';
> create table datagen_source (
> order_id int,
> order_date timestamp(9),
> customer_name varchar,
> price decimal(10,3),
> product_id int,
> order_status boolean
> )with('connector' = 'datagen');
> create catalog myhive with ('type' = 'hive', 'hive-conf-dir' = '/mnt/conf');
> set table.exec.hive.fallback-mapred-writer = false;
> insert into myhive.`default`.orders
> /*+ OPTIONS(
> 'sink.partition-commit.trigger'='process-time',
> 'sink.partition-commit.policy.kind'='metastore,success-file',
> 'sink.rolling-policy.file-size'='128MB',
> 'sink.rolling-policy.rollover-interval'='10s',
> 'sink.rolling-policy.check-interval'='10s',
> 'auto-compaction'='true',
> 'compaction.file-size'='1MB' ) */
> select * , date_format(now(),'-MM-dd') as dt from datagen_source; {code}
> [ERROR] Could not execute SQL statement. Reason:
> java.lang.ClassNotFoundException: org.apache.orc.PhysicalWriter
>
> My jars in lib dir listed in attachment.
> In HiveTableSink#createStreamSink(line:270), createBulkWriterFactory if
> table.exec.hive.fallback-mapred-writer is false.
> If table is orc, HiveShimV200#createOrcBulkWriterFactory will be invoked.
> OrcBulkWriterFactory depends on org.apache.orc.PhysicalWriter in orc-core,
> but flink-connector-hive excludes orc-core for conflicting with hive-exec.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-20979) Wrong description of 'sink.bulk-flush.max-actions'
[
https://issues.apache.org/jira/browse/FLINK-20979?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-20979:
---
Labels: auto-deprioritized-major auto-deprioritized-minor
pull-request-available starter (was: auto-deprioritized-major
pull-request-available stale-minor starter)
Priority: Not a Priority (was: Minor)
This issue was labeled "stale-minor" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Minor, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> Wrong description of 'sink.bulk-flush.max-actions'
> --
>
> Key: FLINK-20979
> URL: https://issues.apache.org/jira/browse/FLINK-20979
> Project: Flink
> Issue Type: Bug
> Components: Connectors / ElasticSearch, Documentation, Table SQL /
> Ecosystem
>Affects Versions: 1.12.0
>Reporter: Dawid Wysakowicz
>Priority: Not a Priority
> Labels: auto-deprioritized-major, auto-deprioritized-minor,
> pull-request-available, starter
>
> The documentation claims the option can be disabled with '0', but it can
> actually be disable with '-1' whereas '0' is an illegal value.
> {{Maximum number of buffered actions per bulk request. Can be set to '0' to
> disable it. }}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-26109) Avro Confluent Schema Registry nightly end-to-end test failed on azure
[
https://issues.apache.org/jira/browse/FLINK-26109?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-26109:
---
Labels: stale-major test-stability (was: test-stability)
I am the [Flink Jira Bot|https://github.com/apache/flink-jira-bot/] and I help
the community manage its development. I see this issues has been marked as
Major but is unassigned and neither itself nor its Sub-Tasks have been updated
for 60 days. I have gone ahead and added a "stale-major" to the issue". If this
ticket is a Major, please either assign yourself or give an update. Afterwards,
please remove the label or in 7 days the issue will be deprioritized.
> Avro Confluent Schema Registry nightly end-to-end test failed on azure
> --
>
> Key: FLINK-26109
> URL: https://issues.apache.org/jira/browse/FLINK-26109
> Project: Flink
> Issue Type: Bug
> Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile)
>Affects Versions: 1.15.0
>Reporter: Yun Gao
>Priority: Major
> Labels: stale-major, test-stability
>
> {code:java}
> Feb 12 07:55:02 Stopping job timeout watchdog (with pid=130662)
> Feb 12 07:55:03 Checking for errors...
> Feb 12 07:55:03 Found error in log files; printing first 500 lines; see full
> logs for details:
> ...
> az209-567.vil1xujjdrkuxjp2ihtao45w0e.ax.internal.cloudapp.net
> (dataPort=41161).
> org.apache.flink.util.FlinkException: The TaskExecutor is shutting down.
> at
> org.apache.flink.runtime.taskexecutor.TaskExecutor.onStop(TaskExecutor.java:456)
> ~[flink-dist-1.15-SNAPSHOT.jar:1.15-SNAPSHOT]
> at
> org.apache.flink.runtime.rpc.RpcEndpoint.internalCallOnStop(RpcEndpoint.java:214)
> ~[flink-dist-1.15-SNAPSHOT.jar:1.15-SNAPSHOT]
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor$StartedState.lambda$terminate$0(AkkaRpcActor.java:568)
> ~[flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at
> org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:83)
> ~[flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor$StartedState.terminate(AkkaRpcActor.java:567)
> ~[flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at
> org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleControlMessage(AkkaRpcActor.java:191)
> ~[flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24)
> ~[flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:20)
> ~[flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at scala.PartialFunction.applyOrElse(PartialFunction.scala:123)
> ~[flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at scala.PartialFunction.applyOrElse$(PartialFunction.scala:122)
> ~[flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:20)
> ~[flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
> [flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
> [flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at akka.actor.Actor.aroundReceive(Actor.scala:537)
> [flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at akka.actor.Actor.aroundReceive$(Actor.scala:535)
> [flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:220)
> [flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at akka.actor.ActorCell.receiveMessage(ActorCell.scala:580)
> [flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at akka.actor.ActorCell.invoke(ActorCell.scala:548)
> [flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:270)
> [flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at akka.dispatch.Mailbox.run(Mailbox.scala:231)
> [flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at akka.dispatch.Mailbox.exec(Mailbox.scala:243)
> [flink-rpc-akka_7dcae025-2017-4b0f-828d-f89a7ceb9bf7.jar:1.15-SNAPSHOT]
> at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
> [?:1.8.0_312]
> at
> java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
>
[jira] [Updated] (FLINK-21440) Translate Real Time Reporting with the Table API doc and correct a spelling mistake
[ https://issues.apache.org/jira/browse/FLINK-21440?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-21440: --- Labels: auto-deprioritized-major auto-deprioritized-minor pull-request-available (was: auto-deprioritized-major pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Translate Real Time Reporting with the Table API doc and correct a spelling > mistake > --- > > Key: FLINK-21440 > URL: https://issues.apache.org/jira/browse/FLINK-21440 > Project: Flink > Issue Type: Improvement > Components: Documentation, Table SQL / Ecosystem >Reporter: GuotaoLi >Priority: Not a Priority > Labels: auto-deprioritized-major, auto-deprioritized-minor, > pull-request-available > > * Translate Real Time Reporting with the Table API doc to Chinese > * Correct Real Time Reporting with the Table API doc allong with spelling > mistake to along with -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-21444) Lookup joins should deal with intermediate table scans correctly
[
https://issues.apache.org/jira/browse/FLINK-21444?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-21444:
---
Labels: auto-deprioritized-major auto-deprioritized-minor auto-unassigned
(was: auto-deprioritized-major auto-unassigned stale-minor)
Priority: Not a Priority (was: Minor)
This issue was labeled "stale-minor" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Minor, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> Lookup joins should deal with intermediate table scans correctly
>
>
> Key: FLINK-21444
> URL: https://issues.apache.org/jira/browse/FLINK-21444
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.12.0, 1.13.0
>Reporter: Caizhi Weng
>Priority: Not a Priority
> Labels: auto-deprioritized-major, auto-deprioritized-minor,
> auto-unassigned
>
> Add the following test case to
> {{org.apache.flink.table.planner.runtime.stream.sql.LookupJoinITCase}}
> {code:scala}
> @Test
> def myTest(): Unit = {
>
> tEnv.getConfig.getConfiguration.setBoolean(OptimizerConfigOptions.TABLE_OPTIMIZER_REUSE_SOURCE_ENABLED,
> true)
>
> tEnv.getConfig.getConfiguration.setBoolean(RelNodeBlockPlanBuilder.TABLE_OPTIMIZER_REUSE_OPTIMIZE_BLOCK_WITH_DIGEST_ENABLED,
> true)
> val ddl1 =
> """
> |CREATE TABLE sink1 (
> | `id` BIGINT
> |) WITH (
> | 'connector' = 'blackhole'
> |)
> |""".stripMargin
> tEnv.executeSql(ddl1)
> val ddl2 =
> """
> |CREATE TABLE sink2 (
> | `id` BIGINT
> |) WITH (
> | 'connector' = 'blackhole'
> |)
> |""".stripMargin
> tEnv.executeSql(ddl2)
> val sql1 = "INSERT INTO sink1 SELECT T.id FROM src AS T JOIN user_table for
> system_time as of T.proctime AS D ON T.id = D.id"
> val sql2 = "INSERT INTO sink2 SELECT T.id FROM src AS T JOIN user_table for
> system_time as of T.proctime AS D ON T.id + 1 = D.id"
> val stmtSet = tEnv.createStatementSet()
> stmtSet.addInsertSql(sql1)
> stmtSet.addInsertSql(sql2)
> stmtSet.execute().await()
> }
> {code}
> The following exception will occur
> {code}
> org.apache.flink.table.api.ValidationException: Temporal Table Join requires
> primary key in versioned table, but no primary key can be found. The physical
> plan is:
> FlinkLogicalJoin(condition=[AND(=($0, $2),
> __INITIAL_TEMPORAL_JOIN_CONDITION($1, __TEMPORAL_JOIN_LEFT_KEY($0),
> __TEMPORAL_JOIN_RIGHT_KEY($2)))], joinType=[inner])
> FlinkLogicalCalc(select=[id, proctime])
> FlinkLogicalIntermediateTableScan(table=[[IntermediateRelTable_0]],
> fields=[id, len, content, proctime])
> FlinkLogicalSnapshot(period=[$cor0.proctime])
> FlinkLogicalCalc(select=[id])
> FlinkLogicalIntermediateTableScan(table=[[IntermediateRelTable_1]],
> fields=[age, id, name])
> at
> org.apache.flink.table.planner.plan.rules.logical.TemporalJoinRewriteWithUniqueKeyRule.org$apache$flink$table$planner$plan$rules$logical$TemporalJoinRewriteWithUniqueKeyRule$$validateRightPrimaryKey(TemporalJoinRewriteWithUniqueKeyRule.scala:124)
> at
> org.apache.flink.table.planner.plan.rules.logical.TemporalJoinRewriteWithUniqueKeyRule$$anon$1.visitCall(TemporalJoinRewriteWithUniqueKeyRule.scala:88)
> at
> org.apache.flink.table.planner.plan.rules.logical.TemporalJoinRewriteWithUniqueKeyRule$$anon$1.visitCall(TemporalJoinRewriteWithUniqueKeyRule.scala:70)
> at org.apache.calcite.rex.RexCall.accept(RexCall.java:174)
> at org.apache.calcite.rex.RexShuttle.visitList(RexShuttle.java:158)
> at org.apache.calcite.rex.RexShuttle.visitCall(RexShuttle.java:110)
> at
> org.apache.flink.table.planner.plan.rules.logical.TemporalJoinRewriteWithUniqueKeyRule$$anon$1.visitCall(TemporalJoinRewriteWithUniqueKeyRule.scala:109)
> at
> org.apache.flink.table.planner.plan.rules.logical.TemporalJoinRewriteWithUniqueKeyRule$$anon$1.visitCall(TemporalJoinRewriteWithUniqueKeyRule.scala:70)
> at org.apache.calcite.rex.RexCall.accept(RexCall.java:174)
> at
> org.apache.flink.table.planner.plan.rules.logical.TemporalJoinRewriteWithUniqueKeyRule.onMatch(TemporalJoinRewriteWithUniqueKeyRule.scala:70)
> at
> org.apache.calcite.plan.AbstractRelOptPlanner.fireRule(AbstractRelOptPlanner.java:333)
> at org.apache.calcite.plan.hep.HepPlanner.applyRule(HepPlanner.java:542)
> at
> org.apache.calcite.plan.hep.HepPlanner.applyRules(HepPlanner.java:407)
> at
> org.apache.calcite.plan.hep.HepPlanner.executeInstruction(HepPlanner.java:243)
> at
> org.apache.calcite.plan.hep.HepInstruction$RuleInstance.execute(HepInstruction.java:127)
> at
>
[jira] [Updated] (FLINK-21686) Duplicate code in hive parser file should be abstracted into functions
[ https://issues.apache.org/jira/browse/FLINK-21686?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-21686: --- Labels: auto-deprioritized-minor pull-request-available (was: pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Duplicate code in hive parser file should be abstracted into functions > -- > > Key: FLINK-21686 > URL: https://issues.apache.org/jira/browse/FLINK-21686 > Project: Flink > Issue Type: Improvement > Components: Connectors / Hive >Reporter: humengyu >Priority: Not a Priority > Labels: auto-deprioritized-minor, pull-request-available > > It would be better to use functions rather than duplicate code in hive parser > file: > # option should be abstracted into a function; > #option should be abstracted into a function. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-27255) Flink-avro does not support serialization and deserialization of avro schema longer than 65535 characters
[ https://issues.apache.org/jira/browse/FLINK-27255?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522943#comment-17522943 ] Steven Zhen Wu commented on FLINK-27255: [~jinyius] this issue existed for a while now. not sth new. > Flink-avro does not support serialization and deserialization of avro schema > longer than 65535 characters > - > > Key: FLINK-27255 > URL: https://issues.apache.org/jira/browse/FLINK-27255 > Project: Flink > Issue Type: Bug > Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile) >Affects Versions: 1.14.4 >Reporter: Haizhou Zhao >Assignee: Haizhou Zhao >Priority: Major > > The underlying serialization of avro schema uses string serialization method > of ObjectOutputStream.class, however, the default string serialization by > ObjectOutputStream.class does not support handling string of more than 66535 > characters (64kb). As a result, constructing flink operators that > input/output Avro Generic Record with huge schema is not possible. > > The purposed fix is two change the serialization and deserialization method > of these following classes so that huge string could also be handled. > > [GenericRecordAvroTypeInfo|https://github.com/apache/flink/blob/master/flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/typeutils/GenericRecordAvroTypeInfo.java#L107] > [SerializableAvroSchema|https://github.com/apache/flink/blob/master/flink-formats/flink-avro/src/main/java/org/apache/flink/formats/avro/typeutils/SerializableAvroSchema.java#L55] > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink-kubernetes-operator] gyfora commented on pull request #165: [FLINK-26140] Support rollback strategies
gyfora commented on PR #165: URL: https://github.com/apache/flink-kubernetes-operator/pull/165#issuecomment-1100367932 @wangyang0918 I think for the suspend to work, I need to fix 2 things basically: 1. If the user suspends a job, the spec should be automatically marked as `lastStableSpec` 2. If an upgrade after a suspend fails, we should roll back to the suspended state (simply stop the job) Will work on this over the weekend -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] metaswirl commented on a diff in pull request #17228: [FLINK-24236] Migrate tests to factory approach
metaswirl commented on code in PR #17228:
URL: https://github.com/apache/flink/pull/17228#discussion_r851495599
##
flink-runtime/src/test/java/org/apache/flink/runtime/metrics/ReporterSetupTest.java:
##
@@ -47,17 +50,30 @@
import static org.junit.Assert.assertTrue;
/** Tests for the {@link ReporterSetup}. */
-public class ReporterSetupTest extends TestLogger {
+@ExtendWith(TestLoggerExtension.class)
+class ReporterSetupTest {
+
+@RegisterExtension
+static final ContextClassLoaderExtension CONTEXT_CLASS_LOADER_EXTENSION =
+ContextClassLoaderExtension.builder()
+.withServiceEntry(
+MetricReporterFactory.class,
+TestReporter1.class.getName(),
+TestReporter2.class.getName(),
+TestReporter11.class.getName(),
+TestReporter12.class.getName(),
+TestReporter13.class.getName())
+.build();
Review Comment:
What is the benefit of using a custom class loader here?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #19493: [FLINK-27205][docs-zh] Translate "Concepts -> Glossary" page into Chinese.
flinkbot commented on PR #19493: URL: https://github.com/apache/flink/pull/19493#issuecomment-1100198258 ## CI report: * 42bb3147bb7ab02a51fdc0c0b9cca28c15289a91 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] liuzhuang2017 opened a new pull request, #19493: [FLINK-27205][docs-zh] Translate "Concepts -> Glossary" page into Chinese.
liuzhuang2017 opened a new pull request, #19493: URL: https://github.com/apache/flink/pull/19493 ## What is the purpose of the change  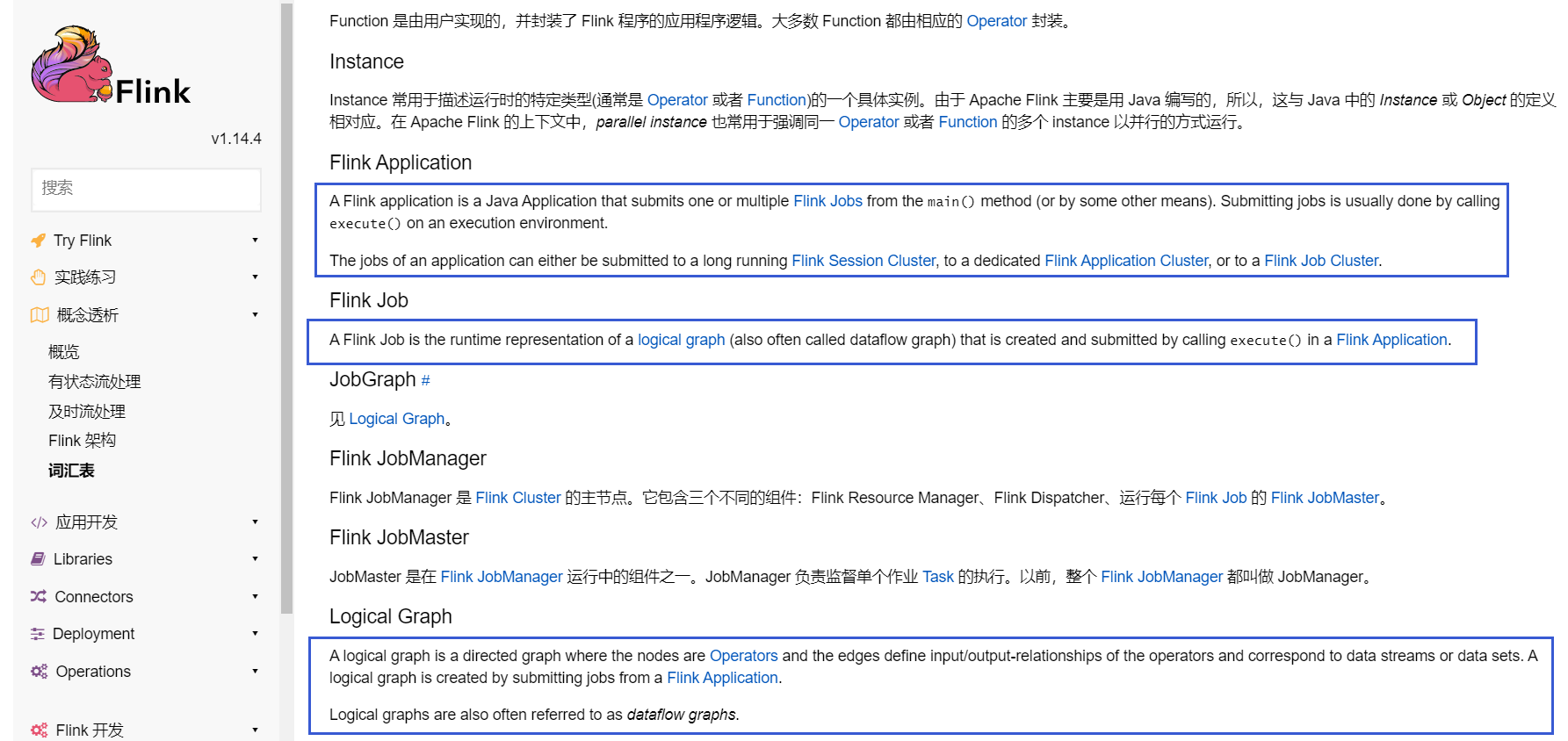 - **As can be seen from the above figure, there are still some untranslated content in the Chinese document, so this part is translated.** ## Brief change log Translate "Concepts -> Glossary" page into Chinese. ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27264) Add ITCase for concurrent batch overwrite and streaming insert
[ https://issues.apache.org/jira/browse/FLINK-27264?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-27264: --- Labels: pull-request-available (was: ) > Add ITCase for concurrent batch overwrite and streaming insert > -- > > Key: FLINK-27264 > URL: https://issues.apache.org/jira/browse/FLINK-27264 > Project: Flink > Issue Type: Sub-task > Components: Table Store >Affects Versions: table-store-0.1.0 >Reporter: Jane Chan >Assignee: Jane Chan >Priority: Major > Labels: pull-request-available > Fix For: table-store-0.1.0 > > Attachments: image-2022-04-15-19-26-09-649.png > > > !image-2022-04-15-19-26-09-649.png|width=609,height=241! > Add it case for user story -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink-table-store] LadyForest opened a new pull request, #91: [FLINK-27264] Add IT case for concurrent batch overwrite and streaming insert into
LadyForest opened a new pull request, #91: URL: https://github.com/apache/flink-table-store/pull/91 Add it case to cover the user story -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-web] liuzhuang2017 commented on pull request #521: [hotfix][docs] Fix link tags typo.
liuzhuang2017 commented on PR #521: URL: https://github.com/apache/flink-web/pull/521#issuecomment-1100116349 @wuchong ,Hi,please help me review this pr when you are free time, thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #19492: Update TimeWindow.java
flinkbot commented on PR #19492: URL: https://github.com/apache/flink/pull/19492#issuecomment-1100089900 ## CI report: * e5b4f082ff6f70ab1e93b3c6384e08424a71e97f UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-26793) Flink Cassandra connector performance issue
[
https://issues.apache.org/jira/browse/FLINK-26793?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522355#comment-17522355
]
Etienne Chauchot edited comment on FLINK-26793 at 4/15/22 12:58 PM:
[~bumblebee] I reproduced the behavior you observed: I ran [this streaming
infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited too long for an internal replication (raplication to another node in the
same casssandra "datacenter") and did not ack the write.
This led to a failure of the write task and to a restoration of the job from
the last checkpoint see job manager log:
{code:java}
2022-04-13 16:38:20,847 INFO
org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job Cassandra
Pojo Sink Streaming example (dc7522bc1855f6f98038ac2b4eed4095) switched from
state RESTARTING to RUNNING.
2022-04-13 16:38:20,850 INFO
org.apache.flink.runtime.checkpoint.CheckpointCoordinator[] - Restoring job
dc7522bc1855f6f98038ac2b4eed4095 from Checkpoint 136 @ 1649858983772 for
dc7522bc1855f6f98038ac2b4eed4095 located at
file:/tmp/flink-checkpoints/dc7522bc1855f6f98038ac2b4eed4095/chk-136.
{code}
This restoration led to the restoration of the _CassandraPojoSink_ and to the
call of _CassandraPojoSink#open_ which reconnects to cassandra cluster and
re-creates the related _MappingManager_
So in short, this is what I supposed in my previous comments. Restoring from
checkpoints slows down your writes (job restart time + cassandra driver state
re-creation - reconnection, prepared statements recreation in the
MappingManager etc... -)
The problem is that the timeout comes from Cassandra itself not from Flink and
it is normal that Flink restores the job in such circumstances.
What you can do is to increase the Cassandra write timeout to adapt to your
workload in your Cassandra cluster so that such timeout errors do not happen.
For that you need to raise _write_request_timeout_in_ms_ conf parameter in
your _cassandra.yml_.
I do not recommend that you lower the replication factor in your Cassandra
cluster (I did that only for local tests on Flink) because it is mandatory that
you do not loose data in case of your Cassandra cluster failure. Waiting for a
single replica for write acknowledge is the minimum level for this guarantee in
Cassandra.
Best
Etienne
[^Capture d’écran de 2022-04-14 16-34-59.png]
[^Capture d’écran de 2022-04-14 16-35-30.png]
[^Capture d’écran de 2022-04-14 16-35-07.png]
[^jobmanager_log.txt]
[^taskmanager_127.0.1.1_33251-af56fa_log]
was (Author: echauchot):
[~bumblebee] I reproduced the behavior you observed: I ran [this streaming
infinite
pipeline|https://github.com/echauchot/flink-samples/blob/master/src/main/java/org/example/CassandraPojoSinkStreamingExample.java]
for 3 days on a local flink 1.14.4 cluster + cassandra 3.0 docker (I did not
have rights to instanciate a cassandra cluster on Azure). The pipeline has
checkpointing configured every 10 min with exactly once semantics and no
watermark defined. It was run at parallelism 16 which corresponds to the number
of cores on my laptop. I created a source that gives pojos every 100 ms. The
source is mono-threaded so at parallelism 1. See all the screenshots
I ran the pipeline for more than 72 hours and indeed after little less than
72h, I got an exception from Cassandra cluster see task manager log:
{code:java}
2022-04-13 16:38:15,227 ERROR
org.apache.flink.streaming.connectors.cassandra.CassandraPojoSink [] - Error
while sending value.
com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout
during write query at consistency LOCAL_ONE (1 replica were required but only 0
acknowledged the write)
{code}
This exception means that Cassandra coordinator node (internal Cassandra)
waited
[jira] [Comment Edited] (FLINK-26824) Upgrade Flink's supported Cassandra versions to match with the Cassandra community supported versions
[ https://issues.apache.org/jira/browse/FLINK-26824?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17521203#comment-17521203 ] Etienne Chauchot edited comment on FLINK-26824 at 4/15/22 12:57 PM: and by the way, there was a complete refactoring of datastax cassandra driver and a relocation starting at 4.0 that impacts all our code base. But using latest 3.x driver works with both Cassandra 4.x and 3.x. So I suggest we keep the cassandra-driver 3.x versions was (Author: echauchot): and by the way, there was a complete refactoring of cassandra driver and a relocation starting at 4.0 that impacts all our code base. But using latest 3.x driver works with both Cassandra 4.x and 3.x. So I suggest we keep the cassandra-driver 3.x versions > Upgrade Flink's supported Cassandra versions to match with the Cassandra > community supported versions > - > > Key: FLINK-26824 > URL: https://issues.apache.org/jira/browse/FLINK-26824 > Project: Flink > Issue Type: Sub-task > Components: Connectors / Cassandra >Reporter: Martijn Visser >Assignee: Etienne Chauchot >Priority: Major > > Flink's Cassandra connector is currently only supporting > com.datastax.cassandra:cassandra-driver-core version 3.0.0. > The Cassandra community supports 3 versions. One GA (general availability, > the latest version), one stable and one older supported release per > https://cassandra.apache.org/_/download.html. > These are currently: > Cassandra 4.0 (GA) > Cassandra 3.11 (Stable) > Cassandra 3.0 (Older supported release). > We should support (and follow) the supported versions by the Cassandra > community -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] huacaicai commented on pull request #19492: Update TimeWindow.java
huacaicai commented on PR #19492: URL: https://github.com/apache/flink/pull/19492#issuecomment-1100087484 Based on the rolling window is a special window with a step size equal to the window size, so I modified the parameter to the window step size, which can better express the meaning of the method parameters. Please pass -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-6755) Allow triggering Checkpoints through command line client
[
https://issues.apache.org/jira/browse/FLINK-6755?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17458438#comment-17458438
]
Piotr Nowojski edited comment on FLINK-6755 at 4/15/22 12:52 PM:
-
The motivation behind this feature request will be covered by FLINK-25276.
As mentioned above by Aljoscha, there might be still a value of exposing manual
checkpoint triggering REST API hook, so I'm keeping this ticket open. However
it doesn't look like such feature is well motivated. Implementation of this
should be quite straightforward since Flink internally already supports this
(FLINK-24280). It's just not exposed in anyway to the user.
edit: Although this idea might be still valid, I strongly think we should not
expose checkpoint directory when triggering checkpoints as proposed in the
description:
{noformat}
./bin/flink checkpoint [checkpointDirectory]
{noformat}
Since checkpoints are owned fully by Flink, CLI/REST API call to trigger
checkpoints should not expose anything like that. If anything, it should be
just a simple trigger with optionally parameters like whether the checkpoint
should be full or incremental.
The same remark applies to:
{noformat}
./bin/flink cancel -c [targetDirectory]
{nofrmat}
and I don't see a point of supporting cancelling/stopping job with checkpoint.
was (Author: pnowojski):
The motivation behind this feature request will be covered by FLINK-25276.
As mentioned above by Aljoscha, there might be still a value of exposing manual
checkpoint triggering REST API hook, so I'm keeping this ticket open. However
it doesn't look like such feature is well motivated. Implementation of this
should be quite straightforward since Flink internally already supports this
(FLINK-24280). It's just not exposed in anyway to the user.
edit: Although this idea might be still valid, I strongly think we should not
expose checkpoint directory when triggering checkpoints as proposed in the
description:
{noformat}
./bin/flink checkpoint [checkpointDirectory]
{noformat}
Since checkpoints are owned fully by Flink, CLI/REST API call to trigger
checkpoints should not expose anything like that. If anything, it should be
just a simple trigger with optionally parameters like whether the checkpoint
should be full or incremental.
> Allow triggering Checkpoints through command line client
>
>
> Key: FLINK-6755
> URL: https://issues.apache.org/jira/browse/FLINK-6755
> Project: Flink
> Issue Type: New Feature
> Components: Command Line Client, Runtime / Checkpointing
>Affects Versions: 1.3.0
>Reporter: Gyula Fora
>Priority: Not a Priority
> Labels: auto-deprioritized-major, auto-unassigned
>
> The command line client currently only allows triggering (and canceling with)
> Savepoints.
> While this is good if we want to fork or modify the pipelines in a
> non-checkpoint compatible way, now with incremental checkpoints this becomes
> wasteful for simple job restarts/pipeline updates.
> I suggest we add a new command:
> ./bin/flink checkpoint [checkpointDirectory]
> and a new flag -c for the cancel command to indicate we want to trigger a
> checkpoint:
> ./bin/flink cancel -c [targetDirectory]
> Otherwise this can work similar to the current savepoint taking logic, we
> could probably even piggyback on the current messages by adding boolean flag
> indicating whether it should be a savepoint or a checkpoint.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Created] (FLINK-27266) in hive_read_write.md, there is an extra backtick in the description
陈磊 created FLINK-27266: -- Summary: in hive_read_write.md, there is an extra backtick in the description Key: FLINK-27266 URL: https://issues.apache.org/jira/browse/FLINK-27266 Project: Flink Issue Type: New Feature Components: Documentation Reporter: 陈磊 Attachments: image-2022-04-15-20-52-40-819.png in hive_read_write.md, there is an extra backtick in the description !image-2022-04-15-20-52-40-819.png! -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] huacaicai commented on pull request #19492: Update TimeWindow.java
huacaicai commented on PR #19492: URL: https://github.com/apache/flink/pull/19492#issuecomment-1100087060 The window size cannot accurately express the true meaning of the parameter, because the sliding window needs to pass in the step size, and the rolling window passes in the window size. Based on the rolling window is a special window with a step size equal to the window size, so I modified the parameter to the window step size, which can better express the meaning of the method parameters -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] huacaicai commented on pull request #19492: Update TimeWindow.java
huacaicai commented on PR #19492: URL: https://github.com/apache/flink/pull/19492#issuecomment-1100086913 The window size cannot accurately express the true meaning of the parameter, because the sliding window needs to pass in the step size, and the rolling window passes in the window size. Based on the rolling window is a special window with a step size equal to the window size, so I modified the parameter to the window step size, which can better express the meaning of the method parameters. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-6755) Allow triggering Checkpoints through command line client
[
https://issues.apache.org/jira/browse/FLINK-6755?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17458438#comment-17458438
]
Piotr Nowojski edited comment on FLINK-6755 at 4/15/22 12:51 PM:
-
The motivation behind this feature request will be covered by FLINK-25276.
As mentioned above by Aljoscha, there might be still a value of exposing manual
checkpoint triggering REST API hook, so I'm keeping this ticket open. However
it doesn't look like such feature is well motivated. Implementation of this
should be quite straightforward since Flink internally already supports this
(FLINK-24280). It's just not exposed in anyway to the user.
edit: Although this idea might be still valid, I strongly think we should not
expose checkpoint directory when triggering checkpoints as proposed in the
description:
{noformat}
./bin/flink checkpoint [checkpointDirectory]
{noformat}
Since checkpoints are owned fully by Flink, CLI/REST API call to trigger
checkpoints should not expose anything like that. If anything, it should be
just a simple trigger with optionally parameters like whether the checkpoint
should be full or incremental.
was (Author: pnowojski):
The motivation behind this feature request will be covered by FLINK-25276.
As mentioned above by Aljoscha, there might be still a value of exposing manual
checkpoint triggering REST API hook, so I'm keeping this ticket open. However
it doesn't look like such feature is well motivated. Implementation of this
should be quite straightforward since Flink internally already supports this
(FLINK-24280). It's just not exposed in anyway to the user.
> Allow triggering Checkpoints through command line client
>
>
> Key: FLINK-6755
> URL: https://issues.apache.org/jira/browse/FLINK-6755
> Project: Flink
> Issue Type: New Feature
> Components: Command Line Client, Runtime / Checkpointing
>Affects Versions: 1.3.0
>Reporter: Gyula Fora
>Priority: Not a Priority
> Labels: auto-deprioritized-major, auto-unassigned
>
> The command line client currently only allows triggering (and canceling with)
> Savepoints.
> While this is good if we want to fork or modify the pipelines in a
> non-checkpoint compatible way, now with incremental checkpoints this becomes
> wasteful for simple job restarts/pipeline updates.
> I suggest we add a new command:
> ./bin/flink checkpoint [checkpointDirectory]
> and a new flag -c for the cancel command to indicate we want to trigger a
> checkpoint:
> ./bin/flink cancel -c [targetDirectory]
> Otherwise this can work similar to the current savepoint taking logic, we
> could probably even piggyback on the current messages by adding boolean flag
> indicating whether it should be a savepoint or a checkpoint.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] huacaicai opened a new pull request, #19492: Update TimeWindow.java
huacaicai opened a new pull request, #19492: URL: https://github.com/apache/flink/pull/19492 The window size cannot accurately express the true meaning of the parameter, because the sliding window needs to pass in the step size, and the rolling window passes in the window size. Based on the rolling window is a special window with a step size equal to the window size, so I modified the parameter to the window step size, which can better express the meaning of the method parameters. ## What is the purpose of the change *(For example: This pull request makes task deployment go through the blob server, rather than through RPC. That way we avoid re-transferring them on each deployment (during recovery).)* ## Brief change log *(for example:)* - *The TaskInfo is stored in the blob store on job creation time as a persistent artifact* - *Deployments RPC transmits only the blob storage reference* - *TaskManagers retrieve the TaskInfo from the blob cache* ## Verifying this change Please make sure both new and modified tests in this PR follows the conventions defined in our code quality guide: https://flink.apache.org/contributing/code-style-and-quality-common.html#testing *(Please pick either of the following options)* This change is a trivial rework / code cleanup without any test coverage. *(or)* This change is already covered by existing tests, such as *(please describe tests)*. *(or)* This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end deployment with large payloads (100MB)* - *Extended integration test for recovery after master (JobManager) failure* - *Added test that validates that TaskInfo is transferred only once across recoveries* - *Manually verified the change by running a 4 node cluster with 2 JobManagers and 4 TaskManagers, a stateful streaming program, and killing one JobManager and two TaskManagers during the execution, verifying that recovery happens correctly.* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-27101) Periodically break the chain of incremental checkpoint
[ https://issues.apache.org/jira/browse/FLINK-27101?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522815#comment-17522815 ] Piotr Nowojski edited comment on FLINK-27101 at 4/15/22 12:48 PM: -- Checkpoint would be still owned by the Flink itself. Only triggering mechanism would be exposed. In principle it's not far of from externally induced checkpoints like [1] or [2]. Does it matter if checkpoints are triggered via some internal timer or a REST API call? So all in all I don't see any problems here, but please correct me if I'm wrong. [1] https://nightlies.apache.org/flink/flink-docs-release-1.15/api/java/org/apache/flink/streaming/api/checkpoint/ExternallyInducedSource.CheckpointTrigger.html [2] https://nightlies.apache.org/flink/flink-docs-release-1.15/api/java/org/apache/flink/api/connector/source/ExternallyInducedSourceReader.html edit: just note that the API as initially proposed in FLINK-6755 is clearly incompatible with the checkpoint ownership model. FLINK-6755 is pretty old, and in the description it was proposed to pass "checkpoint directory" parameter, which we definitely should not do. was (Author: pnowojski): Checkpoint would be still owned by the Flink itself. Only triggering mechanism would be exposed. In principle it's not far of from externally induced checkpoints like [1] or [2]. Does it matter if checkpoints are triggered via some internal timer or a REST API call? So all in all I don't see any problems here, but please correct me if I'm wrong. [1] https://nightlies.apache.org/flink/flink-docs-release-1.15/api/java/org/apache/flink/streaming/api/checkpoint/ExternallyInducedSource.CheckpointTrigger.html [2] https://nightlies.apache.org/flink/flink-docs-release-1.15/api/java/org/apache/flink/api/connector/source/ExternallyInducedSourceReader.html > Periodically break the chain of incremental checkpoint > -- > > Key: FLINK-27101 > URL: https://issues.apache.org/jira/browse/FLINK-27101 > Project: Flink > Issue Type: New Feature > Components: Runtime / Checkpointing >Reporter: Steven Zhen Wu >Priority: Major > > Incremental checkpoint is almost a must for large-state jobs. It greatly > reduces the bytes uploaded to DFS per checkpoint. However, there are a few > implications from incremental checkpoint that are problematic for production > operations. Will use S3 as an example DFS for the rest of description. > 1. Because there is no way to deterministically know how far back the > incremental checkpoint can refer to files uploaded to S3, it is very > difficult to set S3 bucket/object TTL. In one application, we have observed > Flink checkpoint referring to files uploaded over 6 months ago. S3 TTL can > corrupt the Flink checkpoints. > S3 TTL is important for a few reasons > - purge orphaned files (like external checkpoints from previous deployments) > to keep the storage cost in check. This problem can be addressed by > implementing proper garbage collection (similar to JVM) by traversing the > retained checkpoints from all jobs and traverse the file references. But that > is an expensive solution from engineering cost perspective. > - Security and privacy. E.g., there may be requirement that Flink state can't > keep the data for more than some duration threshold (hours/days/weeks). > Application is expected to purge keys to satisfy the requirement. However, > with incremental checkpoint and how deletion works in RocksDB, it is hard to > set S3 TTL to purge S3 files. Even though those old S3 files don't contain > live keys, they may still be referrenced by retained Flink checkpoints. > 2. Occasionally, corrupted checkpoint files (on S3) are observed. As a > result, restoring from checkpoint failed. With incremental checkpoint, it > usually doesn't help to try other older checkpoints, because they may refer > to the same corrupted file. It is unclear whether the corruption happened > before or during S3 upload. This risk can be mitigated with periodical > savepoints. > It all boils down to periodical full snapshot (checkpoint or savepoint) to > deterministically break the chain of incremental checkpoints. Search the jira > history, the behavior that FLINK-23949 [1] trying to fix is actually close to > what we would need here. > There are a few options > 1. Periodically trigger savepoints (via control plane). This is actually not > a bad practice and might be appealing to some people. The problem is that it > requires a job deployment to break the chain of incremental checkpoint. > periodical job deployment may sound hacky. If we make the behavior of full > checkpoint after a savepoint (fixed in FLINK-23949) configurable, it might be > an acceptable compromise. The benefit is that no job deployment is
[jira] [Comment Edited] (FLINK-6755) Allow triggering Checkpoints through command line client
[ https://issues.apache.org/jira/browse/FLINK-6755?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17458438#comment-17458438 ] Piotr Nowojski edited comment on FLINK-6755 at 4/15/22 12:48 PM: - The motivation behind this feature request will be covered by FLINK-25276. As mentioned above by Aljoscha, there might be still a value of exposing manual checkpoint triggering REST API hook, so I'm keeping this ticket open. However it doesn't look like such feature is well motivated. Implementation of this should be quite straightforward since Flink internally already supports this (FLINK-24280). It's just not exposed in anyway to the user. was (Author: pnowojski): The motivation behind this feature request will be covered by FLINK-25276. As mentioned above by Aljoscha, there might be still a value of exposing manual checkpoint triggering REST API hook, so I'm keeping this ticket open. However it doesn't look like such feature is well motivated. Implementation of this should be quite straightforward since Flink internally already supports this (FLINK-24280). It's just not exposed in anyway to the user. > Allow triggering Checkpoints through command line client > > > Key: FLINK-6755 > URL: https://issues.apache.org/jira/browse/FLINK-6755 > Project: Flink > Issue Type: New Feature > Components: Command Line Client, Runtime / Checkpointing >Affects Versions: 1.3.0 >Reporter: Gyula Fora >Priority: Not a Priority > Labels: auto-deprioritized-major, auto-unassigned > > The command line client currently only allows triggering (and canceling with) > Savepoints. > While this is good if we want to fork or modify the pipelines in a > non-checkpoint compatible way, now with incremental checkpoints this becomes > wasteful for simple job restarts/pipeline updates. > I suggest we add a new command: > ./bin/flink checkpoint [checkpointDirectory] > and a new flag -c for the cancel command to indicate we want to trigger a > checkpoint: > ./bin/flink cancel -c [targetDirectory] > Otherwise this can work similar to the current savepoint taking logic, we > could probably even piggyback on the current messages by adding boolean flag > indicating whether it should be a savepoint or a checkpoint. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Comment Edited] (FLINK-27101) Periodically break the chain of incremental checkpoint
[ https://issues.apache.org/jira/browse/FLINK-27101?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522815#comment-17522815 ] Piotr Nowojski edited comment on FLINK-27101 at 4/15/22 12:47 PM: -- Checkpoint would be still owned by the Flink itself. Only triggering mechanism would be exposed. In principle it's not far of from externally induced checkpoints like [1] or [2]. Does it matter if checkpoints are triggered via some internal timer or a REST API call? So all in all I don't see any problems here, but please correct me if I'm wrong. [1] https://nightlies.apache.org/flink/flink-docs-release-1.15/api/java/org/apache/flink/streaming/api/checkpoint/ExternallyInducedSource.CheckpointTrigger.html [2] https://nightlies.apache.org/flink/flink-docs-release-1.15/api/java/org/apache/flink/api/connector/source/ExternallyInducedSourceReader.html was (Author: pnowojski): Checkpoint would be still owned by the Flink itself. Only triggering mechanism would be exposed. In principle it's not far of from externally induced checkpoints like [1] or [2]. Does it matter if checkpoints are triggered via some internal timer or a REST API call? So all in all I don't see any problems here, but please correct me if I'm wrong. [1] https://nightlies.apache.org/flink/flink-docs-release-1.15/api/java/org/apache/flink/streaming/api/checkpoint/ExternallyInducedSource.CheckpointTrigger.html [2] https://nightlies.apache.org/flink/flink-docs-release-1.15/api/java/org/apache/flink/api/connector/source/ExternallyInducedSourceReader.html > Periodically break the chain of incremental checkpoint > -- > > Key: FLINK-27101 > URL: https://issues.apache.org/jira/browse/FLINK-27101 > Project: Flink > Issue Type: New Feature > Components: Runtime / Checkpointing >Reporter: Steven Zhen Wu >Priority: Major > > Incremental checkpoint is almost a must for large-state jobs. It greatly > reduces the bytes uploaded to DFS per checkpoint. However, there are a few > implications from incremental checkpoint that are problematic for production > operations. Will use S3 as an example DFS for the rest of description. > 1. Because there is no way to deterministically know how far back the > incremental checkpoint can refer to files uploaded to S3, it is very > difficult to set S3 bucket/object TTL. In one application, we have observed > Flink checkpoint referring to files uploaded over 6 months ago. S3 TTL can > corrupt the Flink checkpoints. > S3 TTL is important for a few reasons > - purge orphaned files (like external checkpoints from previous deployments) > to keep the storage cost in check. This problem can be addressed by > implementing proper garbage collection (similar to JVM) by traversing the > retained checkpoints from all jobs and traverse the file references. But that > is an expensive solution from engineering cost perspective. > - Security and privacy. E.g., there may be requirement that Flink state can't > keep the data for more than some duration threshold (hours/days/weeks). > Application is expected to purge keys to satisfy the requirement. However, > with incremental checkpoint and how deletion works in RocksDB, it is hard to > set S3 TTL to purge S3 files. Even though those old S3 files don't contain > live keys, they may still be referrenced by retained Flink checkpoints. > 2. Occasionally, corrupted checkpoint files (on S3) are observed. As a > result, restoring from checkpoint failed. With incremental checkpoint, it > usually doesn't help to try other older checkpoints, because they may refer > to the same corrupted file. It is unclear whether the corruption happened > before or during S3 upload. This risk can be mitigated with periodical > savepoints. > It all boils down to periodical full snapshot (checkpoint or savepoint) to > deterministically break the chain of incremental checkpoints. Search the jira > history, the behavior that FLINK-23949 [1] trying to fix is actually close to > what we would need here. > There are a few options > 1. Periodically trigger savepoints (via control plane). This is actually not > a bad practice and might be appealing to some people. The problem is that it > requires a job deployment to break the chain of incremental checkpoint. > periodical job deployment may sound hacky. If we make the behavior of full > checkpoint after a savepoint (fixed in FLINK-23949) configurable, it might be > an acceptable compromise. The benefit is that no job deployment is required > after savepoints. > 2. Build the feature in Flink incremental checkpoint. Periodically (with some > cron style config) trigger a full checkpoint to break the incremental chain. > If the full checkpoint failed (due to whatever reason), the following > checkpoints
[GitHub] [flink] flinkbot commented on pull request #19491: [hotfix][docs-zh] Delete the "mongodb.md" file under "Formats" under "DataStream Connectors".
flinkbot commented on PR #19491: URL: https://github.com/apache/flink/pull/19491#issuecomment-1100083966 ## CI report: * 4523dd09c135ef477ff1698f8a4bae96ab3e4c20 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] liuzhuang2017 commented on pull request #19491: [hotfix][docs-zh] Delete the "mongodb.md" file under "Formats" under "DataStream Connectors".
liuzhuang2017 commented on PR #19491: URL: https://github.com/apache/flink/pull/19491#issuecomment-1100083881 @wuchong ,Hi,please help me review this pr when you are free time, thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27101) Periodically break the chain of incremental checkpoint
[ https://issues.apache.org/jira/browse/FLINK-27101?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522815#comment-17522815 ] Piotr Nowojski commented on FLINK-27101: Checkpoint would be still owned by the Flink itself. Only triggering mechanism would be exposed. In principle it's not far of from externally induced checkpoints like [1] or [2]. Does it matter if checkpoints are triggered via some internal timer or a REST API call? So all in all I don't see any problems here, but please correct me if I'm wrong. [1] https://nightlies.apache.org/flink/flink-docs-release-1.15/api/java/org/apache/flink/streaming/api/checkpoint/ExternallyInducedSource.CheckpointTrigger.html [2] https://nightlies.apache.org/flink/flink-docs-release-1.15/api/java/org/apache/flink/api/connector/source/ExternallyInducedSourceReader.html > Periodically break the chain of incremental checkpoint > -- > > Key: FLINK-27101 > URL: https://issues.apache.org/jira/browse/FLINK-27101 > Project: Flink > Issue Type: New Feature > Components: Runtime / Checkpointing >Reporter: Steven Zhen Wu >Priority: Major > > Incremental checkpoint is almost a must for large-state jobs. It greatly > reduces the bytes uploaded to DFS per checkpoint. However, there are a few > implications from incremental checkpoint that are problematic for production > operations. Will use S3 as an example DFS for the rest of description. > 1. Because there is no way to deterministically know how far back the > incremental checkpoint can refer to files uploaded to S3, it is very > difficult to set S3 bucket/object TTL. In one application, we have observed > Flink checkpoint referring to files uploaded over 6 months ago. S3 TTL can > corrupt the Flink checkpoints. > S3 TTL is important for a few reasons > - purge orphaned files (like external checkpoints from previous deployments) > to keep the storage cost in check. This problem can be addressed by > implementing proper garbage collection (similar to JVM) by traversing the > retained checkpoints from all jobs and traverse the file references. But that > is an expensive solution from engineering cost perspective. > - Security and privacy. E.g., there may be requirement that Flink state can't > keep the data for more than some duration threshold (hours/days/weeks). > Application is expected to purge keys to satisfy the requirement. However, > with incremental checkpoint and how deletion works in RocksDB, it is hard to > set S3 TTL to purge S3 files. Even though those old S3 files don't contain > live keys, they may still be referrenced by retained Flink checkpoints. > 2. Occasionally, corrupted checkpoint files (on S3) are observed. As a > result, restoring from checkpoint failed. With incremental checkpoint, it > usually doesn't help to try other older checkpoints, because they may refer > to the same corrupted file. It is unclear whether the corruption happened > before or during S3 upload. This risk can be mitigated with periodical > savepoints. > It all boils down to periodical full snapshot (checkpoint or savepoint) to > deterministically break the chain of incremental checkpoints. Search the jira > history, the behavior that FLINK-23949 [1] trying to fix is actually close to > what we would need here. > There are a few options > 1. Periodically trigger savepoints (via control plane). This is actually not > a bad practice and might be appealing to some people. The problem is that it > requires a job deployment to break the chain of incremental checkpoint. > periodical job deployment may sound hacky. If we make the behavior of full > checkpoint after a savepoint (fixed in FLINK-23949) configurable, it might be > an acceptable compromise. The benefit is that no job deployment is required > after savepoints. > 2. Build the feature in Flink incremental checkpoint. Periodically (with some > cron style config) trigger a full checkpoint to break the incremental chain. > If the full checkpoint failed (due to whatever reason), the following > checkpoints should attempt full checkpoint as well until one successful full > checkpoint is completed. > 3. For the security/privacy requirement, the main thing is to apply > compaction on the deleted keys. That could probably avoid references to the > old files. Is there any RocksDB compation can achieve full compaction of > removing old delete markers. Recent delete markers are fine > [1] https://issues.apache.org/jira/browse/FLINK-23949 -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-27265) The problem described by the filesystem.md documentation
[ https://issues.apache.org/jira/browse/FLINK-27265?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522814#comment-17522814 ] 陈磊 commented on FLINK-27265: [https://github.com/apache/flink/pull/19489] [~MartijnVisser] Hi, Could you merge this PR? Thanks. > The problem described by the filesystem.md documentation > > > Key: FLINK-27265 > URL: https://issues.apache.org/jira/browse/FLINK-27265 > Project: Flink > Issue Type: Bug > Components: Documentation >Reporter: 陈磊 >Priority: Minor > Attachments: image-2022-04-15-20-25-26-150.png > > > in filesystem.md, flink comes with four built-in BulkWriter factories, in > fact, the list has five. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] liuzhuang2017 opened a new pull request, #19491: [hotfix][docs-zh] Delete the "mongodb.md" file under "Formats" under "DataStream Connectors".
liuzhuang2017 opened a new pull request, #19491: URL: https://github.com/apache/flink/pull/19491 ## What is the purpose of the change # This is the English document:  # This is the Chinese document:  **As we can see from the above figure, the "mongdb.md" file in the Chinese document is redundant compared to the English document.** ## Brief change log Delete the "mongodb.md" file under "Formats" under "DataStream Connectors". ## Verifying this change Delete the "mongodb.md" file under "Formats" under "DataStream Connectors". -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] luoyuxia commented on pull request #19435: [FLINK-27121][docs-zh]Translate "Configuration#overview" paragraph and the code example in "Application Development > Table API & SQL" to Ch
luoyuxia commented on PR #19435: URL: https://github.com/apache/flink/pull/19435#issuecomment-1100081624 @leizhou666 Thanks for you contribution. LGTM @MartijnVisser Could you please help merge? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27265) The problem described by the filesystem.md documentation
[ https://issues.apache.org/jira/browse/FLINK-27265?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] 陈磊 updated FLINK-27265: --- Description: in filesystem.md, flink comes with four built-in BulkWriter factories, in fact, the list has five. (was: 1) in hive_read_write.md, there is an extra backtick in the description 2) in filesystem.md, the format parameter described is incomplete. 3) in filesystem.md, flink comes with four built-in BulkWriter factories, in fact, the list has five.) Summary: The problem described by the filesystem.md documentation (was: The problem described by the filesystem.md and hive_write_read.mddocumentation) > The problem described by the filesystem.md documentation > > > Key: FLINK-27265 > URL: https://issues.apache.org/jira/browse/FLINK-27265 > Project: Flink > Issue Type: Bug > Components: Documentation >Reporter: 陈磊 >Priority: Minor > Attachments: image-2022-04-15-20-25-26-150.png > > > in filesystem.md, flink comes with four built-in BulkWriter factories, in > fact, the list has five. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-27265) The problem described by the filesystem.md documentation
[ https://issues.apache.org/jira/browse/FLINK-27265?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] 陈磊 updated FLINK-27265: --- Attachment: (was: image-2022-04-15-20-26-09-895.png) > The problem described by the filesystem.md documentation > > > Key: FLINK-27265 > URL: https://issues.apache.org/jira/browse/FLINK-27265 > Project: Flink > Issue Type: Bug > Components: Documentation >Reporter: 陈磊 >Priority: Minor > Attachments: image-2022-04-15-20-25-26-150.png > > > in filesystem.md, flink comes with four built-in BulkWriter factories, in > fact, the list has five. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-27265) The problem described by the filesystem.md documentation
[ https://issues.apache.org/jira/browse/FLINK-27265?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] 陈磊 updated FLINK-27265: --- Attachment: (was: image-2022-04-15-20-20-00-116.png) > The problem described by the filesystem.md documentation > > > Key: FLINK-27265 > URL: https://issues.apache.org/jira/browse/FLINK-27265 > Project: Flink > Issue Type: Bug > Components: Documentation >Reporter: 陈磊 >Priority: Minor > Attachments: image-2022-04-15-20-25-26-150.png > > > in filesystem.md, flink comes with four built-in BulkWriter factories, in > fact, the list has five. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-27155) Reduce multiple reads to the same Changelog file in the same taskmanager during restore
[
https://issues.apache.org/jira/browse/FLINK-27155?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522810#comment-17522810
]
Feifan Wang commented on FLINK-27155:
-
Hi [~roman] , I think we can achieve this by :
* Chang{color:#172b4d}e _StateChangeFormat#read(StreamStateHandle, long)_ to
_StateChangeFormat#read(DataInputStream)_{color}
* Add new class _StateChangeIteratorWithLocalCache_ implements
{_}StateChangelogHandleStreamHandleReader.StateChangeIterator{_}. It downloads
the file referenced by _StreamStateHandle_ from DFS, uncompress it and save in
a local temporary file. Then, open a _FileInputStream_ on the local temporary
file and seek to the offset before pass it to
{_}StateChangeFormat#read(DataInputStream){_}. The local file is kept for a
few minutes (maybe should expose an option to user), during which time all
requests to the same _StreamStateHandle_ are carried by the local file.
How do you think about ?
> Reduce multiple reads to the same Changelog file in the same taskmanager
> during restore
> ---
>
> Key: FLINK-27155
> URL: https://issues.apache.org/jira/browse/FLINK-27155
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / State Backends
>Reporter: Feifan Wang
>Assignee: Feifan Wang
>Priority: Major
> Fix For: 1.16.0
>
>
> h3. Background
> In the current implementation, State changes of different operators in the
> same taskmanager may be written to the same changelog file, which effectively
> reduces the number of files and requests to DFS.
> But on the other hand, the current implementation also reads the same
> changelog file multiple times on recovery. More specifically, the number of
> times the same changelog file is accessed is related to the number of
> ChangeSets contained in it. And since each read needs to skip the preceding
> bytes, this network traffic is also wasted.
> The result is a lot of unnecessary request to DFS when there are multiple
> slots and keyed state in the same taskmanager.
> h3. Proposal
> We can reduce multiple reads to the same changelog file in the same
> taskmanager during restore.
> One possible approach is to read the changelog file all at once and cache it
> in memory or local file for a period of time when reading the changelog file.
> I think this could be a subtask of [v2 FLIP-158: Generalized incremental
> checkpoints|https://issues.apache.org/jira/browse/FLINK-25842] .
> Hi [~ym] , [~roman] how do you think about ?
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Created] (FLINK-27265) The problem described by the filesystem.md and hive_write_read.mddocumentation
陈磊 created FLINK-27265: -- Summary: The problem described by the filesystem.md and hive_write_read.mddocumentation Key: FLINK-27265 URL: https://issues.apache.org/jira/browse/FLINK-27265 Project: Flink Issue Type: Bug Components: Documentation Reporter: 陈磊 Attachments: image-2022-04-15-20-20-00-116.png, image-2022-04-15-20-25-26-150.png, image-2022-04-15-20-26-09-895.png 1) in hive_read_write.md, there is an extra backtick in the description 2) in filesystem.md, the format parameter described is incomplete. 3) in filesystem.md, flink comes with four built-in BulkWriter factories, in fact, the list has five. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Assigned] (FLINK-27264) Add ITCase for concurrent batch overwrite and streaming insert
[ https://issues.apache.org/jira/browse/FLINK-27264?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee reassigned FLINK-27264: Assignee: Jane Chan > Add ITCase for concurrent batch overwrite and streaming insert > -- > > Key: FLINK-27264 > URL: https://issues.apache.org/jira/browse/FLINK-27264 > Project: Flink > Issue Type: Sub-task > Components: Table Store >Affects Versions: table-store-0.1.0 >Reporter: Jane Chan >Assignee: Jane Chan >Priority: Major > Fix For: table-store-0.1.0 > > Attachments: image-2022-04-15-19-26-09-649.png > > > !image-2022-04-15-19-26-09-649.png|width=609,height=241! > Add it case for user story -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Commented] (FLINK-27212) Failed to CAST('abcde', VARBINARY)
[
https://issues.apache.org/jira/browse/FLINK-27212?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522807#comment-17522807
]
Jark Wu commented on FLINK-27212:
-
Hi [~matriv], {{x'45F0AB'}} is a {{BINARY}} not {{CHAR/VARCHAR}} type. So,
{{CAST(x'45F0AB' AS VARBINARY(6))}} is a CAST BINARY to BINRY, conversion (the
hex string of course should be in hex digits). Therefore, what we are missing
is CAST CHAR to BINARY, and this is supported in previous versions and other
database systems.
I would still vote this to be a blocker issue.
cc [~twalthr]
> Failed to CAST('abcde', VARBINARY)
> --
>
> Key: FLINK-27212
> URL: https://issues.apache.org/jira/browse/FLINK-27212
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Runtime
>Affects Versions: 1.16.0
>Reporter: Shengkai Fang
>Assignee: Marios Trivyzas
>Priority: Blocker
> Fix For: 1.16.0
>
>
> Please add test in the CalcITCase
> {code:scala}
> @Test
> def testCalc(): Unit = {
> val sql =
> """
> |SELECT CAST('abcde' AS VARBINARY(6))
> |""".stripMargin
> val result = tEnv.executeSql(sql)
> print(result.getResolvedSchema)
> result.print()
> }
> {code}
> The exception is
> {code:java}
> Caused by: org.apache.flink.table.api.TableException: Odd number of
> characters.
> at
> org.apache.flink.table.utils.EncodingUtils.decodeHex(EncodingUtils.java:203)
> at StreamExecCalc$33.processElement(Unknown Source)
> at
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.pushToOperator(ChainingOutput.java:99)
> at
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:80)
> at
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:39)
> at
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:56)
> at
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:29)
> at
> org.apache.flink.streaming.api.operators.StreamSourceContexts$ManualWatermarkContext.processAndCollect(StreamSourceContexts.java:418)
> at
> org.apache.flink.streaming.api.operators.StreamSourceContexts$WatermarkContext.collect(StreamSourceContexts.java:513)
> at
> org.apache.flink.streaming.api.operators.StreamSourceContexts$SwitchingOnClose.collect(StreamSourceContexts.java:103)
> at
> org.apache.flink.streaming.api.functions.source.InputFormatSourceFunction.run(InputFormatSourceFunction.java:92)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:67)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:332)
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Comment Edited] (FLINK-27212) Failed to CAST('abcde', VARBINARY)
[
https://issues.apache.org/jira/browse/FLINK-27212?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522807#comment-17522807
]
Jark Wu edited comment on FLINK-27212 at 4/15/22 12:13 PM:
---
Hi [~matriv], {{x'45F0AB'}} is a {{BINARY}} not {{CHAR/VARCHAR}} type [1]. So,
{{CAST(x'45F0AB' AS VARBINARY(6))}} is a CAST BINARY to BINRY, conversion (the
hex string of course should be in hex digits). Therefore, what we are missing
is CAST CHAR to BINARY, and this is supported in previous versions and other
database systems.
I would still vote this to be a blocker issue.
cc [~twalthr]
[1]: https://calcite.apache.org/docs/reference.html#scalar-types
was (Author: jark):
Hi [~matriv], {{x'45F0AB'}} is a {{BINARY}} not {{CHAR/VARCHAR}} type. So,
{{CAST(x'45F0AB' AS VARBINARY(6))}} is a CAST BINARY to BINRY, conversion (the
hex string of course should be in hex digits). Therefore, what we are missing
is CAST CHAR to BINARY, and this is supported in previous versions and other
database systems.
I would still vote this to be a blocker issue.
cc [~twalthr]
> Failed to CAST('abcde', VARBINARY)
> --
>
> Key: FLINK-27212
> URL: https://issues.apache.org/jira/browse/FLINK-27212
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Runtime
>Affects Versions: 1.16.0
>Reporter: Shengkai Fang
>Assignee: Marios Trivyzas
>Priority: Blocker
> Fix For: 1.16.0
>
>
> Please add test in the CalcITCase
> {code:scala}
> @Test
> def testCalc(): Unit = {
> val sql =
> """
> |SELECT CAST('abcde' AS VARBINARY(6))
> |""".stripMargin
> val result = tEnv.executeSql(sql)
> print(result.getResolvedSchema)
> result.print()
> }
> {code}
> The exception is
> {code:java}
> Caused by: org.apache.flink.table.api.TableException: Odd number of
> characters.
> at
> org.apache.flink.table.utils.EncodingUtils.decodeHex(EncodingUtils.java:203)
> at StreamExecCalc$33.processElement(Unknown Source)
> at
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.pushToOperator(ChainingOutput.java:99)
> at
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:80)
> at
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:39)
> at
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:56)
> at
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:29)
> at
> org.apache.flink.streaming.api.operators.StreamSourceContexts$ManualWatermarkContext.processAndCollect(StreamSourceContexts.java:418)
> at
> org.apache.flink.streaming.api.operators.StreamSourceContexts$WatermarkContext.collect(StreamSourceContexts.java:513)
> at
> org.apache.flink.streaming.api.operators.StreamSourceContexts$SwitchingOnClose.collect(StreamSourceContexts.java:103)
> at
> org.apache.flink.streaming.api.functions.source.InputFormatSourceFunction.run(InputFormatSourceFunction.java:92)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:110)
> at
> org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:67)
> at
> org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:332)
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] luoyuxia commented on a diff in pull request #19419: [FLINK-22317][table] Support DROP column/constraint/watermark for ALTER TABLE statement
luoyuxia commented on code in PR #19419:
URL: https://github.com/apache/flink/pull/19419#discussion_r848239830
##
flink-table/flink-table-planner/src/main/java/org/apache/flink/table/planner/utils/OperationConverterUtils.java:
##
@@ -117,6 +128,193 @@ public static Operation convertAddReplaceColumns(
catalogTable.getComment()));
}
+public static Operation convertAlterTableDropConstraint(
+ObjectIdentifier tableIdentifier,
+CatalogTable catalogTable,
+SqlAlterTableDropConstraint alterTableDropConstraint) {
+boolean isPrimaryKey = alterTableDropConstraint.isPrimaryKey();
+Optional oriPrimaryKey =
+catalogTable.getUnresolvedSchema().getPrimaryKey();
+// validate primary key is exists in table
+if (!oriPrimaryKey.isPresent()) {
+throw new ValidationException(
+String.format("Table %s does not exist primary key.",
tableIdentifier));
+}
+
+String constraintName = null;
+if (alterTableDropConstraint.getConstraintName().isPresent()) {
+constraintName =
alterTableDropConstraint.getConstraintName().get().getSimple();
+}
+if (!StringUtils.isNullOrWhitespaceOnly(constraintName)
+&&
!oriPrimaryKey.get().getConstraintName().equals(constraintName)) {
Review Comment:
Some confuses about the code. Seems the constraints will always be
primarykey?
##
flink-table/flink-table-api-java/src/main/java/org/apache/flink/table/operations/ddl/AlterTableDropConstraintOperation.java:
##
@@ -20,24 +20,42 @@
import org.apache.flink.table.catalog.ObjectIdentifier;
+import javax.annotation.Nullable;
+
+import java.util.Optional;
+
/** Operation of "ALTER TABLE ADD [CONSTRAINT constraintName] ..." clause. * */
public class AlterTableDropConstraintOperation extends AlterTableOperation {
-private final String constraintName;
+
+private final boolean isPrimaryKey;
+private final @Nullable String constraintName;
public AlterTableDropConstraintOperation(
-ObjectIdentifier tableIdentifier, String constraintName) {
+ObjectIdentifier tableIdentifier,
+boolean isPrimaryKey,
Review Comment:
Will it better to wrap `isPrimaryKey` and `constraintName` to a class may
called `Constraint`?
##
flink-table/flink-table-planner/src/main/java/org/apache/flink/table/planner/utils/OperationConverterUtils.java:
##
@@ -117,6 +128,193 @@ public static Operation convertAddReplaceColumns(
catalogTable.getComment()));
}
+public static Operation convertAlterTableDropConstraint(
+ObjectIdentifier tableIdentifier,
+CatalogTable catalogTable,
+SqlAlterTableDropConstraint alterTableDropConstraint) {
+boolean isPrimaryKey = alterTableDropConstraint.isPrimaryKey();
+Optional oriPrimaryKey =
+catalogTable.getUnresolvedSchema().getPrimaryKey();
+// validate primary key is exists in table
Review Comment:
nit:
```suggestion
// validate primary key exists in table
```
##
flink-table/flink-table-planner/src/main/java/org/apache/flink/table/planner/utils/OperationConverterUtils.java:
##
@@ -117,6 +128,193 @@ public static Operation convertAddReplaceColumns(
catalogTable.getComment()));
}
+public static Operation convertAlterTableDropConstraint(
+ObjectIdentifier tableIdentifier,
+CatalogTable catalogTable,
+SqlAlterTableDropConstraint alterTableDropConstraint) {
+boolean isPrimaryKey = alterTableDropConstraint.isPrimaryKey();
+Optional oriPrimaryKey =
+catalogTable.getUnresolvedSchema().getPrimaryKey();
+// validate primary key is exists in table
+if (!oriPrimaryKey.isPresent()) {
+throw new ValidationException(
+String.format("Table %s does not exist primary key.",
tableIdentifier));
+}
+
+String constraintName = null;
+if (alterTableDropConstraint.getConstraintName().isPresent()) {
+constraintName =
alterTableDropConstraint.getConstraintName().get().getSimple();
+}
+if (!StringUtils.isNullOrWhitespaceOnly(constraintName)
+&&
!oriPrimaryKey.get().getConstraintName().equals(constraintName)) {
+throw new ValidationException(
+String.format(
+"CONSTRAINT [%s] does not exist in table %s",
+constraintName, tableIdentifier));
+}
+
+return new AlterTableDropConstraintOperation(tableIdentifier,
isPrimaryKey, constraintName);
+}
+
+public static Operation convertDropWatermark(
+ObjectIdentifier tableIdentifier, CatalogTable catalogTable) {
+
[jira] [Commented] (FLINK-27261) Disable web.cancel.enable for session jobs
[
https://issues.apache.org/jira/browse/FLINK-27261?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522797#comment-17522797
]
Gyula Fora commented on FLINK-27261:
But isn’t this something only the session cluster could disable?
> Disable web.cancel.enable for session jobs
> --
>
> Key: FLINK-27261
> URL: https://issues.apache.org/jira/browse/FLINK-27261
> Project: Flink
> Issue Type: Sub-task
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
> Labels: starter
>
> In FLINK-27154, we disable {{web.cancel.enable}} for application cluster. We
> should also do this for session jobs.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-27264) Add ITCase for concurrent batch overwrite and streaming insert
[ https://issues.apache.org/jira/browse/FLINK-27264?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jane Chan updated FLINK-27264: -- Description: !image-2022-04-15-19-26-09-649.png|width=609,height=241! Add it case for user story > Add ITCase for concurrent batch overwrite and streaming insert > -- > > Key: FLINK-27264 > URL: https://issues.apache.org/jira/browse/FLINK-27264 > Project: Flink > Issue Type: Sub-task > Components: Table Store >Affects Versions: table-store-0.1.0 >Reporter: Jane Chan >Priority: Major > Fix For: table-store-0.1.0 > > Attachments: image-2022-04-15-19-26-09-649.png > > > !image-2022-04-15-19-26-09-649.png|width=609,height=241! > Add it case for user story -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-27264) Add ITCase for concurrent batch overwrite and streaming insert
[ https://issues.apache.org/jira/browse/FLINK-27264?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jane Chan updated FLINK-27264: -- Attachment: image-2022-04-15-19-26-09-649.png > Add ITCase for concurrent batch overwrite and streaming insert > -- > > Key: FLINK-27264 > URL: https://issues.apache.org/jira/browse/FLINK-27264 > Project: Flink > Issue Type: Sub-task > Components: Table Store >Affects Versions: table-store-0.1.0 >Reporter: Jane Chan >Priority: Major > Fix For: table-store-0.1.0 > > Attachments: image-2022-04-15-19-26-09-649.png > > -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Created] (FLINK-27264) Add ITCase for concurrent batch overwrite and streaming insert
Jane Chan created FLINK-27264: - Summary: Add ITCase for concurrent batch overwrite and streaming insert Key: FLINK-27264 URL: https://issues.apache.org/jira/browse/FLINK-27264 Project: Flink Issue Type: Sub-task Components: Table Store Affects Versions: table-store-0.1.0 Reporter: Jane Chan Fix For: table-store-0.1.0 -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-27237) Partitioned table statement enhancement
[
https://issues.apache.org/jira/browse/FLINK-27237?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
dalongliu updated FLINK-27237:
--
Description:
This is an umbrella issue which is used to track the syntax enhancement about
partitioned table in FLIP [1]. These new syntaxes are very useful for
partitioned tables, especially for batch job.
The supported statement about partitioned table as follows:
{code:sql}
-- add partition
ALTER TABLE table_name ADD [IF NOT EXISTS] { PARTITION
[PARTITION ...] }
-- drop partition
ALTER TABLE table_name DROP [ IF EXISTS ] { PARTITION
[PARTITION ...] } [PURGE]
-- rename partition
ALTER TABLE table_name PARTITION RENAME TO PARTITION
;
-- show partitions
SHOW PARTITIONS table_name [PARTITION ]
::
(partition_col_name=partition_col_val, ...)
{code}
Reference:
[1]:
[https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support]
[[2]
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition|https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition]
[3]:
[https://spark.apache.org/docs/3.2.1/sql-ref-syntax-ddl-alter-table.html#add-partition|https://spark.apache.org/docs/3.0.0/sql-ref-syntax-ddl-alter-table.html#add-partition]
[4]:
[https://spark.apache.org/docs/3.2.1/sql-ref-syntax-aux-show-partitions.html]
was:
This is an umbrella issue which is used to track the syntax enhancement about
partitioned table. These new syntaxes are very useful for partitioned tables,
especially for batch job.
The supported statement about partitioned table as follows:
{code:sql}
-- add partition
ALTER TABLE table_name ADD [IF NOT EXISTS] { PARTITION
[PARTITION ...] }
-- drop partition
ALTER TABLE table_name DROP [ IF EXISTS ] { PARTITION
[PARTITION ...] } [PURGE]
-- rename partition
ALTER TABLE table_name PARTITION RENAME TO PARTITION
;
-- show partitions
SHOW PARTITIONS table_name [PARTITION ]
::
(partition_col_name=partition_col_val, ...)
{code}
Reference:
[1]:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support
[[2]
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition|https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition]
[3]:
[https://spark.apache.org/docs/3.2.1/sql-ref-syntax-ddl-alter-table.html#add-partition|https://spark.apache.org/docs/3.0.0/sql-ref-syntax-ddl-alter-table.html#add-partition]
[4]:
[https://spark.apache.org/docs/3.2.1/sql-ref-syntax-aux-show-partitions.html]
> Partitioned table statement enhancement
> ---
>
> Key: FLINK-27237
> URL: https://issues.apache.org/jira/browse/FLINK-27237
> Project: Flink
> Issue Type: New Feature
> Components: Table SQL / API
>Reporter: dalongliu
>Priority: Major
> Fix For: 1.16.0
>
>
> This is an umbrella issue which is used to track the syntax enhancement about
> partitioned table in FLIP [1]. These new syntaxes are very useful for
> partitioned tables, especially for batch job.
> The supported statement about partitioned table as follows:
> {code:sql}
> -- add partition
> ALTER TABLE table_name ADD [IF NOT EXISTS] { PARTITION
> [PARTITION ...] }
> -- drop partition
> ALTER TABLE table_name DROP [ IF EXISTS ] { PARTITION
> [PARTITION ...] } [PURGE]
> -- rename partition
> ALTER TABLE table_name PARTITION RENAME TO PARTITION
> ;
> -- show partitions
> SHOW PARTITIONS table_name [PARTITION ]
> ::
> (partition_col_name=partition_col_val, ...)
> {code}
>
> Reference:
> [1]:
> [https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support]
> [[2]
> https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition|https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition]
> [3]:
> [https://spark.apache.org/docs/3.2.1/sql-ref-syntax-ddl-alter-table.html#add-partition|https://spark.apache.org/docs/3.0.0/sql-ref-syntax-ddl-alter-table.html#add-partition]
> [4]:
> [https://spark.apache.org/docs/3.2.1/sql-ref-syntax-aux-show-partitions.html]
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] zoltar9264 commented on pull request #19252: [FLINK-25867][docs] translate ChangelogBackend documentation to chinese
zoltar9264 commented on PR #19252: URL: https://github.com/apache/flink/pull/19252#issuecomment-1100046811 Thank you very much @Myasuka , your suggestion does look better, learn a lot ! I hive committed those change and squash them into first commit in this pr. (Last three commits are hotfix for other issue.) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #19490: [FLINK-27263][table] Rename the metadata column to the user specified…
flinkbot commented on PR #19490: URL: https://github.com/apache/flink/pull/19490#issuecomment-1100045930 ## CI report: * b98759b38d05a732ef3c9ceabfc844dfaf4bd2e8 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27018) timestamp missing end zero when outputing to kafka
[
https://issues.apache.org/jira/browse/FLINK-27018?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522793#comment-17522793
]
jeff-zou commented on FLINK-27018:
--
I think it's better to be consistent in converting, because many scenarios
require equals, For example, After I sinked the result to ES, I need to use
the original value to find out if the result exsits.
> timestamp missing end zero when outputing to kafka
> ---
>
> Key: FLINK-27018
> URL: https://issues.apache.org/jira/browse/FLINK-27018
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.13.5
>Reporter: jeff-zou
>Priority: Major
> Attachments: kafka.png
>
>
> the bug is described as follows:
>
> {code:java}
> data in source:
> 2022-04-02 03:34:21.260
> but after sink by sql, data in kafka:
> 2022-04-02 03:34:21.26
> {code}
>
> data miss end zero in kafka.
>
> sql:
> {code:java}
> create kafka_table(stime stimestamp) with ('connector'='kafka','format' =
> 'json');
> insert into kafka_table select stime from (values(timestamp '2022-04-02
> 03:34:21.260')){code}
> the value in kafka is : \{"stime":"2022-04-02 03:34:21.26"}, missed end zero.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-27263) Rename the metadata column to the user specified name in DDL
[ https://issues.apache.org/jira/browse/FLINK-27263?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-27263: --- Labels: pull-request-available (was: ) > Rename the metadata column to the user specified name in DDL > > > Key: FLINK-27263 > URL: https://issues.apache.org/jira/browse/FLINK-27263 > Project: Flink > Issue Type: Improvement >Reporter: Shengkai Fang >Priority: Major > Labels: pull-request-available > > Currently the source output the metadata column with the "$metadata"+ > metadata key as the column name. It's better that keep the name align with > the user name specified in the DDL,e.g. use event_time as the name if the > user specifies`event_time` TIMESTAMP(3) FROM 'timestamp'. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] fsk119 opened a new pull request, #19490: [FLINK-27263][table] Rename the metadata column to the user specified…
fsk119 opened a new pull request, #19490: URL: https://github.com/apache/flink/pull/19490 … name in DDL ## What is the purpose of the change *Currently the source output the metadata column with the `"$metadata"+ metadata key` as the column name. It's better that keep the name align with the user name specified in the DDL,e.g. use `event_time` as the name if the user specifies `event_time TIMESTAMP(3) FROM 'timestamp'`.* ## Brief change log - *Make call in the projection to do the rename* ## Verifying this change This change is already covered by existing tests in the `PushProjectIntoTableSourceScanRuleTest`. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / **no**) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / **no**) - The serializers: (yes / **no** / don't know) - The runtime per-record code paths (performance sensitive): (yes / **no** / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / **no** / don't know) - The S3 file system connector: (yes / **no** / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / **no**) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / **not documented**) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-27263) Rename the metadata column to the user specified name in DDL
Shengkai Fang created FLINK-27263: - Summary: Rename the metadata column to the user specified name in DDL Key: FLINK-27263 URL: https://issues.apache.org/jira/browse/FLINK-27263 Project: Flink Issue Type: Improvement Reporter: Shengkai Fang Currently the source output the metadata column with the "$metadata"+ metadata key as the column name. It's better that keep the name align with the user name specified in the DDL,e.g. use event_time as the name if the user specifies`event_time` TIMESTAMP(3) FROM 'timestamp'. -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] MartijnVisser merged pull request #19401: [FLINK-25716][docs-zh] Translate "Streaming Concepts" page of "Applic…
MartijnVisser merged PR #19401: URL: https://github.com/apache/flink/pull/19401 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] MartijnVisser commented on pull request #19401: [FLINK-25716][docs-zh] Translate "Streaming Concepts" page of "Applic…
MartijnVisser commented on PR #19401: URL: https://github.com/apache/flink/pull/19401#issuecomment-1100038830 @snailHumming Thanks for the PR. I've squashed and rebased commits. The successful CI run was in https://dev.azure.com/apache-flink/98463496-1af2-4620-8eab-a2ecc1a2e6fe/_build/results?buildId=34715. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] MartijnVisser commented on pull request #19489: in filesystem.md, flink comes with four built-in BulkWriter factories…
MartijnVisser commented on PR #19489: URL: https://github.com/apache/flink/pull/19489#issuecomment-1100037906 @chenlei677 Thanks for the PR. Please check and follow the code contribution guide at https://flink.apache.org/contributing/contribute-code.html and update your PR, else it can't get merged. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] MartijnVisser commented on pull request #19487: in filesystem.md, the format parameter described is incomplete.
MartijnVisser commented on PR #19487: URL: https://github.com/apache/flink/pull/19487#issuecomment-1100037548 @chenlei677 Thanks for the PR. However, the list of formats in the documentation is not an extensive list of all formats. I don't think adding one adds a lot of value in this case. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] MartijnVisser closed pull request #19485: Mssql branch
MartijnVisser closed pull request #19485: Mssql branch URL: https://github.com/apache/flink/pull/19485 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] MartijnVisser commented on pull request #19485: Mssql branch
MartijnVisser commented on PR #19485: URL: https://github.com/apache/flink/pull/19485#issuecomment-1100036893 @yinweiwen Please check and follow the code contribution guide at https://flink.apache.org/contributing/contribute-code.html - This PR is incorrect, therefore I'm closing it -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-22246) when use HiveCatalog create table , can't set Table owner property correctly
[
https://issues.apache.org/jira/browse/FLINK-22246?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-22246:
---
Labels: auto-deprioritized-major auto-deprioritized-minor
pull-request-available (was: auto-deprioritized-major pull-request-available
stale-minor)
Priority: Not a Priority (was: Minor)
This issue was labeled "stale-minor" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Minor, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> when use HiveCatalog create table , can't set Table owner property correctly
> -
>
> Key: FLINK-22246
> URL: https://issues.apache.org/jira/browse/FLINK-22246
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Hive
>Affects Versions: 1.11.1, 1.12.0
>Reporter: xiangtao
>Priority: Not a Priority
> Labels: auto-deprioritized-major, auto-deprioritized-minor,
> pull-request-available
>
> when i use HiveCatalog create table in sql-client , i found it can't set
> Hive Table `owner` property correctly. i debug code , i found in
> `HiveCatalog.createTable` method
> {code:java}
> Table hiveTable =
> org.apache.hadoop.hive.ql.metadata.Table.getEmptyTable(
> tablePath.getDatabaseName(), tablePath.getObjectName());
> {code}
>
> this get hiveTable obj , owner field is null . beacuse it set owner through
> {code:java}
> t.setOwner(SessionState.getUserFromAuthenticator());
> {code}
>
> but SessionState is null .
> Fix this bug , we can add one code in HiveCatalog.open method .
> {code:java}
> SessionState.setCurrentSessionState(new SessionState(hiveConf));
> {code}
>
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-21699) SecurityUtils JaasModule make JVM dirty
[ https://issues.apache.org/jira/browse/FLINK-21699?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-21699: --- Labels: auto-deprioritized-major auto-deprioritized-minor pull-request-available (was: auto-deprioritized-major pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > SecurityUtils JaasModule make JVM dirty > --- > > Key: FLINK-21699 > URL: https://issues.apache.org/jira/browse/FLINK-21699 > Project: Flink > Issue Type: Bug > Components: Runtime / Configuration >Affects Versions: 1.12.2 >Reporter: tonychan >Priority: Not a Priority > Labels: auto-deprioritized-major, auto-deprioritized-minor, > pull-request-available > Attachments: image-2021-03-10-13-19-04-251.png > > > System.setProperty(JAVA_SECURITY_AUTH_LOGIN_CONFIG, > configFile.getAbsolutePath()); > "java.security.auth.login.config": "/tmp/jaas-4611020726588581730.conf", > "zookeeper.sasl.client": "true", > > !image-2021-03-10-13-19-04-251.png! -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-22644) Translate "Native Kubernetes" page into Chinese
[ https://issues.apache.org/jira/browse/FLINK-22644?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-22644: --- Labels: auto-deprioritized-major auto-deprioritized-minor auto-unassigned pull-request-available (was: auto-deprioritized-major auto-unassigned pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Translate "Native Kubernetes" page into Chinese > --- > > Key: FLINK-22644 > URL: https://issues.apache.org/jira/browse/FLINK-22644 > Project: Flink > Issue Type: Improvement > Components: Documentation >Reporter: Yuchen Cheng >Priority: Not a Priority > Labels: auto-deprioritized-major, auto-deprioritized-minor, > auto-unassigned, pull-request-available > > The page url is > https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/deployment/resource-providers/native_kubernetes/ -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-22663) Release YARN resource very slow when cancel the job after some NodeManagers shutdown
[
https://issues.apache.org/jira/browse/FLINK-22663?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-22663:
---
Labels: YARN auto-deprioritized-major auto-deprioritized-minor
pull-request-available (was: YARN auto-deprioritized-major
pull-request-available stale-minor)
Priority: Not a Priority (was: Minor)
This issue was labeled "stale-minor" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Minor, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> Release YARN resource very slow when cancel the job after some NodeManagers
> shutdown
>
>
> Key: FLINK-22663
> URL: https://issues.apache.org/jira/browse/FLINK-22663
> Project: Flink
> Issue Type: Bug
> Components: Deployment / YARN
>Affects Versions: 1.12.2
>Reporter: Jinhong Liu
>Priority: Not a Priority
> Labels: YARN, auto-deprioritized-major,
> auto-deprioritized-minor, pull-request-available
>
> When I test flink on YARN, there is a case that may cause some problems.
> Hadoop Version: 2.7.3
> Flink Version: 1.12.2
> I deploy a flink job on YARN, when the job is running I stop one NodeManager,
> after one or two minutes, the job is auto recovered. But in this situation,
> if I cancel the job, the containers cannot be released immediately, there are
> still some containers that are running include the app master. About 5
> minutes later, these containers exit, and about 10 minutes later the app
> master exit.
> I check the log of app master, seems it try to stop the containers on the
> NodeManger which I have already stopped.
> {code:java}
> 2021-05-14 06:15:17,389 INFO
> org.apache.flink.runtime.executiongraph.ExecutionGraph [] - Job class
> tv.freewheel.reporting.fastlane.Fastlane$ (da883ab39a7a82e4d45a3803bc77dd6f)
> switched from state CANCELLING to CANCELED.
> 2021-05-14 06:15:17,389 INFO
> org.apache.flink.runtime.checkpoint.CheckpointCoordinator[] - Stopping
> checkpoint coordinator for job da883ab39a7a82e4d45a3803bc77dd6f.
> 2021-05-14 06:15:17,390 INFO
> org.apache.flink.runtime.checkpoint.StandaloneCompletedCheckpointStore [] -
> Shutting down
> 2021-05-14 06:15:17,408 INFO
> org.apache.flink.runtime.dispatcher.MiniDispatcher [] - Job
> da883ab39a7a82e4d45a3803bc77dd6f reached globally terminal state CANCELED.
> 2021-05-14 06:15:17,409 INFO
> org.apache.flink.runtime.dispatcher.MiniDispatcher [] - Shutting
> down cluster with state CANCELED, jobCancelled: true, executionMode: DETACHED
> 2021-05-14 06:15:17,409 INFO
> org.apache.flink.runtime.entrypoint.ClusterEntrypoint[] - Shutting
> YarnJobClusterEntrypoint down with application status CANCELED. Diagnostics
> null.
> 2021-05-14 06:15:17,409 INFO
> org.apache.flink.runtime.jobmaster.MiniDispatcherRestEndpoint [] - Shutting
> down rest endpoint.
> 2021-05-14 06:15:17,420 INFO org.apache.flink.runtime.jobmaster.JobMaster
> [] - Stopping the JobMaster for job class
> tv.freewheel.reporting.fastlane.Fastlane$(da883ab39a7a82e4d45a3803bc77dd6f).
> 2021-05-14 06:15:17,422 INFO
> org.apache.flink.runtime.jobmaster.MiniDispatcherRestEndpoint [] - Removing
> cache directory
> /tmp/flink-web-af72a00c-0ddd-4e5e-a62c-8244d6caa552/flink-web-ui
> 2021-05-14 06:15:17,432 INFO
> org.apache.flink.runtime.jobmaster.MiniDispatcherRestEndpoint [] -
> http://ip-10-23-19-197.ec2.internal:43811 lost leadership
> 2021-05-14 06:15:17,432 INFO
> org.apache.flink.runtime.jobmaster.MiniDispatcherRestEndpoint [] - Shut down
> complete.
> 2021-05-14 06:15:17,436 INFO
> org.apache.flink.runtime.resourcemanager.active.ActiveResourceManager [] -
> Shut down cluster because application is in CANCELED, diagnostics null.
> 2021-05-14 06:15:17,436 INFO org.apache.flink.yarn.YarnResourceManagerDriver
> [] - Unregister application from the YARN Resource Manager with
> final status KILLED.
> 2021-05-14 06:15:17,458 INFO
> org.apache.flink.runtime.jobmaster.slotpool.SlotPoolImpl [] - Suspending
> SlotPool.
> 2021-05-14 06:15:17,458 INFO org.apache.flink.runtime.jobmaster.JobMaster
> [] - Close ResourceManager connection
> 493862ba148679a4f16f7de5ffaef665: Stopping JobMaster for job class
> tv.freewheel.reporting.fastlane.Fastlane$(da883ab39a7a82e4d45a3803bc77dd6f)..
> 2021-05-14 06:15:17,458 INFO
> org.apache.flink.runtime.jobmaster.slotpool.SlotPoolImpl [] - Stopping
> SlotPool.
> 2021-05-14 06:15:17,482 INFO
> org.apache.hadoop.yarn.client.api.impl.AMRMClientImpl[] - Waiting for
> application to be successfully unregistered.
> 2021-05-14 06:15:17,566 INFO
[jira] [Updated] (FLINK-22437) Miss adding parallesim for filter operator in batch mode
[
https://issues.apache.org/jira/browse/FLINK-22437?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-22437:
---
Labels: auto-deprioritized-major auto-deprioritized-minor auto-unassigned
pull-request-available (was: auto-deprioritized-major auto-unassigned
pull-request-available stale-minor)
Priority: Not a Priority (was: Minor)
This issue was labeled "stale-minor" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Minor, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> Miss adding parallesim for filter operator in batch mode
>
>
> Key: FLINK-22437
> URL: https://issues.apache.org/jira/browse/FLINK-22437
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.12.2
>Reporter: zoucao
>Priority: Not a Priority
> Labels: auto-deprioritized-major, auto-deprioritized-minor,
> auto-unassigned, pull-request-available
>
> when I execute batch sql as follow in flink-1.12.2, I found lots of small
> files in hdfs. In filesystem connector, `GroupedPartitionWriter` will be
> used, and it close the last partiton if a new record does not belong to the
> existing partition. The phenomenon occurred if there are more than one
> partiton's records are sent to filesystem sink at the same time. Hive source
> can determine parallesim by the number of file and partition, and the
> parallesim will extended by sort operator, but in
> `CommonPhysicalSink#createSinkTransformation`,a filter operator will be add
> to support `SinkNotNullEnforcer`, there is no parallesim set for it, so
> filesystem sink operator can not get the correct parallesim from inputstream.
> {code:java}
> CREATE CATALOG myHive with (
> 'type'='hive',
> 'property-version'='1',
> 'default-database' = 'flink_sql_online_test'
> );
> -- SET table.sql-dialect=hive;
> -- CREATE TABLE IF NOT EXISTS myHive.flink_sql_online_test.hive_sink (
> --`timestamp` BIGINT,
> --`time` STRING,
> --id BIGINT,
> --product STRING,
> --price DOUBLE,
> --canSell STRING,
> --selledNum BIGINT
> -- ) PARTITIONED BY (
> --dt STRING,
> --`hour` STRING,
> -- `min` STRING
> -- ) TBLPROPERTIES (
> --'partition.time-extractor.timestamp-pattern'='$dt $hr:$min:00',
> --'sink.partition-commit.trigger'='partition-time',
> --'sink.partition-commit.delay'='1 min',
> --'sink.partition-commit.policy.kind'='metastore,success-file'
> -- );
> create table fs_sink (
> `timestamp` BIGINT,
> `time` STRING,
> id BIGINT,
> product STRING,
> price DOUBLE,
> canSell STRING,
> selledNum BIGINT,
> dt STRING,
> `hour` STRING,
> `min` STRING
> ) PARTITIONED BY (dt, `hour`, `min`) with (
> 'connector'='filesystem',
> 'path'='hdfs://',
> 'format'='csv'
> );
> insert into fs_sink
> select * from myHive.flink_sql_online_test.hive_sink;
> {code}
> I think this problem can be fixed by adding a parallesim for it just like
> {code:java}
> val dataStream = new DataStream(env, inputTransformation).filter(enforcer)
> .setParallelism(inputTransformation.getParallelism)
> {code}
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-22679) code optimization:Transformation.equals
[
https://issues.apache.org/jira/browse/FLINK-22679?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-22679:
---
Labels: auto-deprioritized-minor pull-request-available (was:
pull-request-available stale-minor)
Priority: Not a Priority (was: Minor)
This issue was labeled "stale-minor" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Minor, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> code optimization:Transformation.equals
>
>
> Key: FLINK-22679
> URL: https://issues.apache.org/jira/browse/FLINK-22679
> Project: Flink
> Issue Type: Improvement
> Components: API / DataStream
>Affects Versions: 1.13.0
>Reporter: huzeming
>Priority: Not a Priority
> Labels: auto-deprioritized-minor, pull-request-available
>
> code optimization:Transformation.equals , line : 550
> {code:java}
> // old
> return outputType != null ? outputType.equals(that.outputType) :
> that.outputType == null;
> // new
> return Objects.equals(outputType, that.outputType);{code}
> I think after change it will be more readable
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-22798) Exception handling of transactional producer
[
https://issues.apache.org/jira/browse/FLINK-22798?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-22798:
---
Labels: auto-deprioritized-major auto-deprioritized-minor
pull-request-available (was: auto-deprioritized-major pull-request-available
stale-minor)
Priority: Not a Priority (was: Minor)
This issue was labeled "stale-minor" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Minor, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> Exception handling of transactional producer
>
>
> Key: FLINK-22798
> URL: https://issues.apache.org/jira/browse/FLINK-22798
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Reporter: Jin Xu
>Priority: Not a Priority
> Labels: auto-deprioritized-major, auto-deprioritized-minor,
> pull-request-available
>
> [https://github.com/apache/flink/blob/8e90425462f287b94e867ba778d75abb193763bd/flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/streaming/connectors/kafka/FlinkKafkaProducer.java#L1013]
>
> [https://github.com/apache/flink/blob/8e90425462f287b94e867ba778d75abb193763bd/flink-connectors/flink-connector-kafka/src/main/java/org/apache/flink/streaming/connectors/kafka/FlinkKafkaProducer.java#L1047]
>
> current implementation of commit and abort do not handle critical exception
> and try to recycle/reuse the producer.
>
> Kafka doc
> [https://kafka.apache.org/11/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html]
> recommends catch critical exceptions and should not recycle the producer.
> {code:java}
> catch (ProducerFencedException | OutOfOrderSequenceException |
> AuthorizationException e)
> {code}
>
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-22526) Rename TopicId to topic in Kafka related code
[ https://issues.apache.org/jira/browse/FLINK-22526?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-22526: --- Labels: auto-deprioritized-major auto-deprioritized-minor pull-request-available (was: auto-deprioritized-major pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Rename TopicId to topic in Kafka related code > - > > Key: FLINK-22526 > URL: https://issues.apache.org/jira/browse/FLINK-22526 > Project: Flink > Issue Type: Improvement > Components: Connectors / Kafka >Reporter: dengziming >Priority: Not a Priority > Labels: auto-deprioritized-major, auto-deprioritized-minor, > pull-request-available > > TopicId is a new concept introduced in Kafka 2.8.0, we can use it to > produce/consume in future Kafka version, so we should avoid use topicId when > referring to a topic. > for more details: > https://cwiki.apache.org/confluence/display/KAFKA/KIP-516:+Topic+Identifiers -- This message was sent by Atlassian Jira (v8.20.1#820001)
[jira] [Updated] (FLINK-23158) Source transformation is not added to the StreamExecutionEnvironment explicitly
[
https://issues.apache.org/jira/browse/FLINK-23158?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Flink Jira Bot updated FLINK-23158:
---
Labels: auto-deprioritized-major auto-deprioritized-minor
pull-request-available (was: auto-deprioritized-major pull-request-available
stale-minor)
Priority: Not a Priority (was: Minor)
This issue was labeled "stale-minor" 7 days ago and has not received any
updates so it is being deprioritized. If this ticket is actually Minor, please
raise the priority and ask a committer to assign you the issue or revive the
public discussion.
> Source transformation is not added to the StreamExecutionEnvironment
> explicitly
> ---
>
> Key: FLINK-23158
> URL: https://issues.apache.org/jira/browse/FLINK-23158
> Project: Flink
> Issue Type: Bug
> Components: API / DataStream
>Affects Versions: 1.14.0
>Reporter: Yun Gao
>Priority: Not a Priority
> Labels: auto-deprioritized-major, auto-deprioritized-minor,
> pull-request-available
>
> Currently for the implementation of `StreamExecutionEnvironment#fromSource()`
> and `StreamExecutionEnvironment#addSource()`, the SourceTransformation is not
> added to the transformation list explicitly, this make the job with a single
> source could not run directly. For example,
> {code:java}
> StreamExecutionEnvironment env =
> StreamExecutionEnvironment.getExecutionEnvironment();
> env.addSource(new SourceFunction() {
> @Override
> public void run(SourceContext sourceContext)
> throws Exception {
> }
> @Override
> public void cancel() {
> }
> });
> env.execute();
> {code}
> would throws the exception:
> {code:java}
> Exception in thread "main" java.lang.IllegalStateException: No operators
> defined in streaming topology. Cannot execute.
> at
> org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.getStreamGraphGenerator(StreamExecutionEnvironment.java:2019)
> at
> org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.getStreamGraph(StreamExecutionEnvironment.java:2010)
> at
> org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.getStreamGraph(StreamExecutionEnvironment.java:1995)
> at
> org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1834)
> at
> org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1817)
> at test.SingleSourceTest.main(SingleSourceTest.java:41)
> {code}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Updated] (FLINK-23163) Add debug ability for kubernetes client
[ https://issues.apache.org/jira/browse/FLINK-23163?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Flink Jira Bot updated FLINK-23163: --- Labels: auto-deprioritized-minor pull-request-available (was: pull-request-available stale-minor) Priority: Not a Priority (was: Minor) This issue was labeled "stale-minor" 7 days ago and has not received any updates so it is being deprioritized. If this ticket is actually Minor, please raise the priority and ask a committer to assign you the issue or revive the public discussion. > Add debug ability for kubernetes client > > > Key: FLINK-23163 > URL: https://issues.apache.org/jira/browse/FLINK-23163 > Project: Flink > Issue Type: Improvement > Components: Deployment / Kubernetes >Affects Versions: 1.13.0 >Reporter: Aitozi >Priority: Not a Priority > Labels: auto-deprioritized-minor, pull-request-available > > add option to enable http client debug log -- This message was sent by Atlassian Jira (v8.20.1#820001)
[GitHub] [flink] flinkbot commented on pull request #19489: in filesystem.md, flink comes with four built-in BulkWriter factories…
flinkbot commented on PR #19489: URL: https://github.com/apache/flink/pull/19489#issuecomment-1100028822 ## CI report: * ab93146354ccd9d981e5fb854dcdfb9ce33047e1 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27218) Serializer in OperatorState has not been updated when new Serializers are NOT incompatible
[
https://issues.apache.org/jira/browse/FLINK-27218?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522779#comment-17522779
]
Yue Ma commented on FLINK-27218:
[~yunta] ok i'm glad to do this fix, i'll submit a pr soon
> Serializer in OperatorState has not been updated when new Serializers are NOT
> incompatible
> --
>
> Key: FLINK-27218
> URL: https://issues.apache.org/jira/browse/FLINK-27218
> Project: Flink
> Issue Type: Bug
> Components: Runtime / State Backends
>Affects Versions: 1.15.1
>Reporter: Yue Ma
>Priority: Major
> Attachments: image-2022-04-13-14-50-10-921.png
>
>
> OperatorState such as *BroadcastState* or *PartitionableListState* can only
> be constructed via {*}DefaultOperatorStateBackend{*}. But when
> *BroadcastState* or *PartitionableListState* Serializer changes after we
> restart the job , it seems to have the following problems .
> As an example, we can see how PartitionableListState is initialized.
> First, RestoreOperation will construct a restored PartitionableListState
> based on the information in the snapshot.
> Then StateMetaInfo in partitionableListState will be updated as the
> following code
> {code:java}
> TypeSerializerSchemaCompatibility stateCompatibility =
>
> restoredPartitionableListStateMetaInfo.updatePartitionStateSerializer(newPartitionStateSerializer);
> partitionableListState.setStateMetaInfo(restoredPartitionableListStateMetaInfo);{code}
> The main problem is that there is also an *internalListCopySerializer* in
> *PartitionableListState* that is built using the previous Serializer and it
> has not been updated.
> Therefore, when we update the StateMetaInfo, the *internalListCopySerializer*
> also needs to be updated.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] chenlei677 opened a new pull request, #19489: in filesystem.md, flink comes with four built-in BulkWriter factories…
chenlei677 opened a new pull request, #19489: URL: https://github.com/apache/flink/pull/19489 ## What is the purpose of the change in filesystem.md, flink comes with four built-in BulkWriter factories, in fact, the list has five. ## Brief change log in filesystem.md, flink comes with four built-in BulkWriter factories, in fact, the list has five. ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. yes ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] Myasuka commented on a diff in pull request #19252: [FLINK-25867][docs] translate ChangelogBackend documentation to chinese
Myasuka commented on code in PR #19252:
URL: https://github.com/apache/flink/pull/19252#discussion_r851163050
##
docs/content.zh/docs/ops/state/state_backends.md:
##
@@ -306,77 +329,75 @@ public class MyOptionsFactory implements
ConfigurableRocksDBOptionsFactory {
{{< top >}}
-## Enabling Changelog
+
-{{< hint warning >}} This feature is in experimental status. {{< /hint >}}
+## 开启 Changelog
-{{< hint warning >}} Enabling Changelog may have a negative performance impact
on your application (see below). {{< /hint >}}
+{{< hint warning >}} 该功能处于实验状态。 {{< /hint >}}
-### Introduction
+{{< hint warning >}} 开启 Changelog 可能会给您的应用带来性能损失。(见下文) {{< /hint >}}
-Changelog is a feature that aims to decrease checkpointing time and,
therefore, end-to-end latency in exactly-once mode.
+
-Most commonly, checkpoint duration is affected by:
+### 介绍
-1. Barrier travel time and alignment, addressed by
- [Unaligned checkpoints]({{< ref
"docs/ops/state/checkpointing_under_backpressure#unaligned-checkpoints" >}})
- and [Buffer debloating]({{< ref
"docs/ops/state/checkpointing_under_backpressure#buffer-debloating" >}})
-2. Snapshot creation time (so-called synchronous phase), addressed by
asynchronous snapshots (mentioned [above]({{<
- ref "#the-embeddedrocksdbstatebackend">}}))
-4. Snapshot upload time (asynchronous phase)
+Changelog 是一项旨在减少 checkpointing 时间的功能,因此也可以减少 exactly-once 模式下的端到端延迟。
-Upload time can be decreased by [incremental checkpoints]({{< ref
"#incremental-checkpoints" >}}).
-However, most incremental state backends perform some form of compaction
periodically, which results in re-uploading the
-old state in addition to the new changes. In large deployments, the
probability of at least one task uploading lots of
-data tends to be very high in every checkpoint.
+一般情况下 checkpoint 持续时间受如下因素影响:
Review Comment:
```suggestion
一般情况下 checkpoint 的持续时间受如下因素影响:
```
##
docs/content.zh/docs/ops/state/state_backends.md:
##
@@ -306,77 +329,75 @@ public class MyOptionsFactory implements
ConfigurableRocksDBOptionsFactory {
{{< top >}}
-## Enabling Changelog
+
-{{< hint warning >}} This feature is in experimental status. {{< /hint >}}
+## 开启 Changelog
-{{< hint warning >}} Enabling Changelog may have a negative performance impact
on your application (see below). {{< /hint >}}
+{{< hint warning >}} 该功能处于实验状态。 {{< /hint >}}
-### Introduction
+{{< hint warning >}} 开启 Changelog 可能会给您的应用带来性能损失。(见下文) {{< /hint >}}
-Changelog is a feature that aims to decrease checkpointing time and,
therefore, end-to-end latency in exactly-once mode.
+
-Most commonly, checkpoint duration is affected by:
+### 介绍
-1. Barrier travel time and alignment, addressed by
- [Unaligned checkpoints]({{< ref
"docs/ops/state/checkpointing_under_backpressure#unaligned-checkpoints" >}})
- and [Buffer debloating]({{< ref
"docs/ops/state/checkpointing_under_backpressure#buffer-debloating" >}})
-2. Snapshot creation time (so-called synchronous phase), addressed by
asynchronous snapshots (mentioned [above]({{<
- ref "#the-embeddedrocksdbstatebackend">}}))
-4. Snapshot upload time (asynchronous phase)
+Changelog 是一项旨在减少 checkpointing 时间的功能,因此也可以减少 exactly-once 模式下的端到端延迟。
-Upload time can be decreased by [incremental checkpoints]({{< ref
"#incremental-checkpoints" >}}).
-However, most incremental state backends perform some form of compaction
periodically, which results in re-uploading the
-old state in addition to the new changes. In large deployments, the
probability of at least one task uploading lots of
-data tends to be very high in every checkpoint.
+一般情况下 checkpoint 持续时间受如下因素影响:
-With Changelog enabled, Flink uploads state changes continuously and forms a
changelog. On checkpoint, only the relevant
-part of this changelog needs to be uploaded. The configured state backend is
snapshotted in the
-background periodically. Upon successful upload, the changelog is truncated.
+1. Barrier 到达和对齐时间,可以通过 [Unaligned checkpoints]({{< ref
"docs/ops/state/checkpointing_under_backpressure#unaligned-checkpoints" >}}) 和
[Buffer debloating]({{< ref
"docs/ops/state/checkpointing_under_backpressure#buffer-debloating" >}}) 解决。
-As a result, asynchronous phase duration is reduced, as well as synchronous
phase - because no data needs to be flushed
-to disk. In particular, long-tail latency is improved.
+2. 快照制作时间(所谓同步阶段), 可以通过异步快照解决(如[上文]({{<
+ ref "#the-embeddedrocksdbstatebackend">}})所述)。
-However, resource usage is higher:
+3. 快照上传时间(异步阶段)。
-- more files are created on DFS
-- more files can be left undeleted DFS (this will be addressed in the future
versions in FLINK-25511 and FLINK-25512)
-- more IO bandwidth is used to upload state changes
-- more CPU used to serialize state changes
-- more memory used by Task Managers to buffer state changes
+可以用[增量 checkpoints]({{< ref "#incremental-checkpoints" >}})
[GitHub] [flink-kubernetes-operator] wangyang0918 commented on pull request #165: [FLINK-26140] Support rollback strategies
wangyang0918 commented on PR #165: URL: https://github.com/apache/flink-kubernetes-operator/pull/165#issuecomment-1100014552 @gyfora No hurry, take your time. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27215) JDBC sink transiently deleted a record because of -u message of that record
[
https://issues.apache.org/jira/browse/FLINK-27215?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522764#comment-17522764
]
Shengkai Fang commented on FLINK-27215:
---
Hi, [~yulei0824].
It's up to the planner to determine whether the upstream operator sends the -U.
The logic just about how the jdbc sink processes the -U messages. If you are
interested about the ChangelogMode inference, you can take a look at the
FlinkChangelogModeInferenceProgram. I think we have already made the
optimizaiton.
> JDBC sink transiently deleted a record because of -u message of that record
> ---
>
> Key: FLINK-27215
> URL: https://issues.apache.org/jira/browse/FLINK-27215
> Project: Flink
> Issue Type: Bug
> Components: Connectors / JDBC
>Affects Versions: 1.12.7, 1.13.5, 1.14.3
>Reporter: tim yu
>Priority: Major
>
> A record is deleted transiently when using JDBC sink in upsert mode.
> The -U message is processed as delete operation in class
> TableBufferReducedStatementExecutor.
> The following codes show how to process -U message:
> {code:java}
> /**
> * Returns true if the row kind is INSERT or UPDATE_AFTER, returns false
> if the row kind is
> * DELETE or UPDATE_BEFORE.
> */
> private boolean changeFlag(RowKind rowKind) {
> switch (rowKind) {
> case INSERT:
> case UPDATE_AFTER:
> return true;
> case DELETE:
> case UPDATE_BEFORE:
> return false;
> default:
> throw new UnsupportedOperationException(
> String.format(
> "Unknown row kind, the supported row kinds
> is: INSERT, UPDATE_BEFORE, UPDATE_AFTER,"
> + " DELETE, but get: %s.",
> rowKind));
> }
> }
> @Override
> public void executeBatch() throws SQLException {
> for (Map.Entry> entry :
> reduceBuffer.entrySet()) {
> if (entry.getValue().f0) {
> upsertExecutor.addToBatch(entry.getValue().f1);
> } else {
> // delete by key
> deleteExecutor.addToBatch(entry.getKey());
> }
> }
> upsertExecutor.executeBatch();
> deleteExecutor.executeBatch();
> reduceBuffer.clear();
> }
> {code}
> If -U and +U messages of one record are executed separately in different JDBC
> batches, that record will be deleted transiently in external database and
> then insert a new updated record to it. In fact, this record should be merely
> updated once in the external database.
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] luoyuxia commented on a diff in pull request #19424: [FLINK-22732][table] Restrict ALTER TABLE from setting empty table op…
luoyuxia commented on code in PR #19424:
URL: https://github.com/apache/flink/pull/19424#discussion_r851182447
##
flink-table/flink-table-planner/src/main/java/org/apache/flink/table/planner/operations/SqlToOperationConverter.java:
##
@@ -547,6 +547,12 @@ private Operation convertAlterTableOptions(
ObjectIdentifier tableIdentifier,
CatalogTable oldTable,
SqlAlterTableOptions alterTableOptions) {
+Map setOptions =
Review Comment:
Will it be better to do the validation when parse `alter table set` in
`parserImpls.ftl`
For me, it looks like a restriction in sql synax level. From my sense,
`alter table cat1.db1.tb1 set ()` is like a illegal sql.
Anyway, looks good to me for either way .
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-27237) Partitioned table statement enhancement
[
https://issues.apache.org/jira/browse/FLINK-27237?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
dalongliu updated FLINK-27237:
--
Description:
This is an umbrella issue which is used to track the syntax enhancement about
partitioned table. These new syntaxes are very useful for partitioned tables,
especially for batch job.
The supported statement about partitioned table as follows:
{code:sql}
-- add partition
ALTER TABLE table_name ADD [IF NOT EXISTS] { PARTITION
[PARTITION ...] }
-- drop partition
ALTER TABLE table_name DROP [ IF EXISTS ] { PARTITION
[PARTITION ...] } [PURGE]
-- rename partition
ALTER TABLE table_name PARTITION RENAME TO PARTITION
;
-- show partitions
SHOW PARTITIONS table_name [PARTITION ]
::
(partition_col_name=partition_col_val, ...)
{code}
Reference:
[1]:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support
[[2]
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition|https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition]
[3]:
[https://spark.apache.org/docs/3.2.1/sql-ref-syntax-ddl-alter-table.html#add-partition|https://spark.apache.org/docs/3.0.0/sql-ref-syntax-ddl-alter-table.html#add-partition]
[4]:
[https://spark.apache.org/docs/3.2.1/sql-ref-syntax-aux-show-partitions.html]
was:
This is an umbrella issue which is used to discuss the syntax enhancement about
partitioned table. These new syntaxes are very useful for partitioned tables,
especially for batch job.
Therefore, I propose to support the following statement about partitioned table:
{code:sql}
-- add partition
ALTER TABLE table_name ADD [IF NOT EXISTS] { PARTITION
[PARTITION ...] }
-- drop partition
ALTER TABLE table_name DROP [ IF EXISTS ] { PARTITION
[PARTITION ...] } [PURGE]
-- rename partition
ALTER TABLE table_name PARTITION RENAME TO PARTITION
;
-- show partitions
SHOW PARTITIONS table_name [PARTITION ]
::
(partition_col_name=partition_col_val, ...)
{code}
Reference:
[1]:
[https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition]
[2]:
[https://spark.apache.org/docs/3.2.1/sql-ref-syntax-ddl-alter-table.html#add-partition|https://spark.apache.org/docs/3.0.0/sql-ref-syntax-ddl-alter-table.html#add-partition]
[3]:
[https://spark.apache.org/docs/3.2.1/sql-ref-syntax-aux-show-partitions.html]
> Partitioned table statement enhancement
> ---
>
> Key: FLINK-27237
> URL: https://issues.apache.org/jira/browse/FLINK-27237
> Project: Flink
> Issue Type: New Feature
> Components: Table SQL / API
>Reporter: dalongliu
>Priority: Major
> Fix For: 1.16.0
>
>
> This is an umbrella issue which is used to track the syntax enhancement about
> partitioned table. These new syntaxes are very useful for partitioned tables,
> especially for batch job.
> The supported statement about partitioned table as follows:
> {code:sql}
> -- add partition
> ALTER TABLE table_name ADD [IF NOT EXISTS] { PARTITION
> [PARTITION ...] }
> -- drop partition
> ALTER TABLE table_name DROP [ IF EXISTS ] { PARTITION
> [PARTITION ...] } [PURGE]
> -- rename partition
> ALTER TABLE table_name PARTITION RENAME TO PARTITION
> ;
> -- show partitions
> SHOW PARTITIONS table_name [PARTITION ]
> ::
> (partition_col_name=partition_col_val, ...)
> {code}
>
> Reference:
> [1]:
> https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support
> [[2]
> https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition|https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition]
> [3]:
> [https://spark.apache.org/docs/3.2.1/sql-ref-syntax-ddl-alter-table.html#add-partition|https://spark.apache.org/docs/3.0.0/sql-ref-syntax-ddl-alter-table.html#add-partition]
> [4]:
> [https://spark.apache.org/docs/3.2.1/sql-ref-syntax-aux-show-partitions.html]
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Comment Edited] (FLINK-27237) Partitioned table statement enhancement
[
https://issues.apache.org/jira/browse/FLINK-27237?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522755#comment-17522755
]
dalongliu edited comment on FLINK-27237 at 4/15/22 9:31 AM:
We have discussed and voted this ticket in FLIP-63
[https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support],so
it is the continuation of FLIP-63.
was (Author: lsy):
We have discussed and voted this ticket in
[FLIP-63|[https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support]]
,so it is the continuation of FLIP-63.
> Partitioned table statement enhancement
> ---
>
> Key: FLINK-27237
> URL: https://issues.apache.org/jira/browse/FLINK-27237
> Project: Flink
> Issue Type: New Feature
> Components: Table SQL / API
>Reporter: dalongliu
>Priority: Major
> Fix For: 1.16.0
>
>
> This is an umbrella issue which is used to discuss the syntax enhancement
> about partitioned table. These new syntaxes are very useful for partitioned
> tables, especially for batch job.
> Therefore, I propose to support the following statement about partitioned
> table:
> {code:sql}
> -- add partition
> ALTER TABLE table_name ADD [IF NOT EXISTS] { PARTITION
> [PARTITION ...] }
> -- drop partition
> ALTER TABLE table_name DROP [ IF EXISTS ] { PARTITION
> [PARTITION ...] } [PURGE]
> -- rename partition
> ALTER TABLE table_name PARTITION RENAME TO PARTITION
> ;
> -- show partitions
> SHOW PARTITIONS table_name [PARTITION ]
> ::
> (partition_col_name=partition_col_val, ...)
> {code}
>
> Reference:
> [1]:
> [https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition]
> [2]:
> [https://spark.apache.org/docs/3.2.1/sql-ref-syntax-ddl-alter-table.html#add-partition|https://spark.apache.org/docs/3.0.0/sql-ref-syntax-ddl-alter-table.html#add-partition]
> [3]:
> [https://spark.apache.org/docs/3.2.1/sql-ref-syntax-aux-show-partitions.html]
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Comment Edited] (FLINK-27237) Partitioned table statement enhancement
[
https://issues.apache.org/jira/browse/FLINK-27237?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522755#comment-17522755
]
dalongliu edited comment on FLINK-27237 at 4/15/22 9:30 AM:
We have discussed and voted this ticket in
[FLIP-63|[https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support]]
,so it is the continuation of FLIP-63.
was (Author: lsy):
We have discussed and voted this ticket in
[FLIP-63|[https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support]]
So it is the continuation of FLIP-63.
> Partitioned table statement enhancement
> ---
>
> Key: FLINK-27237
> URL: https://issues.apache.org/jira/browse/FLINK-27237
> Project: Flink
> Issue Type: New Feature
> Components: Table SQL / API
>Reporter: dalongliu
>Priority: Major
> Fix For: 1.16.0
>
>
> This is an umbrella issue which is used to discuss the syntax enhancement
> about partitioned table. These new syntaxes are very useful for partitioned
> tables, especially for batch job.
> Therefore, I propose to support the following statement about partitioned
> table:
> {code:sql}
> -- add partition
> ALTER TABLE table_name ADD [IF NOT EXISTS] { PARTITION
> [PARTITION ...] }
> -- drop partition
> ALTER TABLE table_name DROP [ IF EXISTS ] { PARTITION
> [PARTITION ...] } [PURGE]
> -- rename partition
> ALTER TABLE table_name PARTITION RENAME TO PARTITION
> ;
> -- show partitions
> SHOW PARTITIONS table_name [PARTITION ]
> ::
> (partition_col_name=partition_col_val, ...)
> {code}
>
> Reference:
> [1]:
> [https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition]
> [2]:
> [https://spark.apache.org/docs/3.2.1/sql-ref-syntax-ddl-alter-table.html#add-partition|https://spark.apache.org/docs/3.0.0/sql-ref-syntax-ddl-alter-table.html#add-partition]
> [3]:
> [https://spark.apache.org/docs/3.2.1/sql-ref-syntax-aux-show-partitions.html]
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-27261) Disable web.cancel.enable for session jobs
[
https://issues.apache.org/jira/browse/FLINK-27261?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522757#comment-17522757
]
Yang Wang commented on FLINK-27261:
---
Hmm. I mean to disable for all the session jobs, not a per job level.
> Disable web.cancel.enable for session jobs
> --
>
> Key: FLINK-27261
> URL: https://issues.apache.org/jira/browse/FLINK-27261
> Project: Flink
> Issue Type: Sub-task
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
> Labels: starter
>
> In FLINK-27154, we disable {{web.cancel.enable}} for application cluster. We
> should also do this for session jobs.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Commented] (FLINK-27237) Partitioned table statement enhancement
[
https://issues.apache.org/jira/browse/FLINK-27237?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522755#comment-17522755
]
dalongliu commented on FLINK-27237:
---
We have discussed and voted this ticket in
[FLIP-63|[https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support].]
So it is the continuation of FLIP-63.
> Partitioned table statement enhancement
> ---
>
> Key: FLINK-27237
> URL: https://issues.apache.org/jira/browse/FLINK-27237
> Project: Flink
> Issue Type: New Feature
> Components: Table SQL / API
>Reporter: dalongliu
>Priority: Major
> Fix For: 1.16.0
>
>
> This is an umbrella issue which is used to discuss the syntax enhancement
> about partitioned table. These new syntaxes are very useful for partitioned
> tables, especially for batch job.
> Therefore, I propose to support the following statement about partitioned
> table:
> {code:sql}
> -- add partition
> ALTER TABLE table_name ADD [IF NOT EXISTS] { PARTITION
> [PARTITION ...] }
> -- drop partition
> ALTER TABLE table_name DROP [ IF EXISTS ] { PARTITION
> [PARTITION ...] } [PURGE]
> -- rename partition
> ALTER TABLE table_name PARTITION RENAME TO PARTITION
> ;
> -- show partitions
> SHOW PARTITIONS table_name [PARTITION ]
> ::
> (partition_col_name=partition_col_val, ...)
> {code}
>
> Reference:
> [1]:
> [https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition]
> [2]:
> [https://spark.apache.org/docs/3.2.1/sql-ref-syntax-ddl-alter-table.html#add-partition|https://spark.apache.org/docs/3.0.0/sql-ref-syntax-ddl-alter-table.html#add-partition]
> [3]:
> [https://spark.apache.org/docs/3.2.1/sql-ref-syntax-aux-show-partitions.html]
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[jira] [Comment Edited] (FLINK-27237) Partitioned table statement enhancement
[
https://issues.apache.org/jira/browse/FLINK-27237?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522755#comment-17522755
]
dalongliu edited comment on FLINK-27237 at 4/15/22 9:29 AM:
We have discussed and voted this ticket in
[FLIP-63|[https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support]]
So it is the continuation of FLIP-63.
was (Author: lsy):
We have discussed and voted this ticket in
[FLIP-63|[https://cwiki.apache.org/confluence/display/FLINK/FLIP-63%3A+Rework+table+partition+support].]
So it is the continuation of FLIP-63.
> Partitioned table statement enhancement
> ---
>
> Key: FLINK-27237
> URL: https://issues.apache.org/jira/browse/FLINK-27237
> Project: Flink
> Issue Type: New Feature
> Components: Table SQL / API
>Reporter: dalongliu
>Priority: Major
> Fix For: 1.16.0
>
>
> This is an umbrella issue which is used to discuss the syntax enhancement
> about partitioned table. These new syntaxes are very useful for partitioned
> tables, especially for batch job.
> Therefore, I propose to support the following statement about partitioned
> table:
> {code:sql}
> -- add partition
> ALTER TABLE table_name ADD [IF NOT EXISTS] { PARTITION
> [PARTITION ...] }
> -- drop partition
> ALTER TABLE table_name DROP [ IF EXISTS ] { PARTITION
> [PARTITION ...] } [PURGE]
> -- rename partition
> ALTER TABLE table_name PARTITION RENAME TO PARTITION
> ;
> -- show partitions
> SHOW PARTITIONS table_name [PARTITION ]
> ::
> (partition_col_name=partition_col_val, ...)
> {code}
>
> Reference:
> [1]:
> [https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-AlterPartition]
> [2]:
> [https://spark.apache.org/docs/3.2.1/sql-ref-syntax-ddl-alter-table.html#add-partition|https://spark.apache.org/docs/3.0.0/sql-ref-syntax-ddl-alter-table.html#add-partition]
> [3]:
> [https://spark.apache.org/docs/3.2.1/sql-ref-syntax-aux-show-partitions.html]
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink-kubernetes-operator] gyfora commented on pull request #165: [FLINK-26140] Support rollback strategies
gyfora commented on PR #165: URL: https://github.com/apache/flink-kubernetes-operator/pull/165#issuecomment-102022 @wangyang0918 thanks, I will work on fixing this and covering with tests. Also I have a few follow up Jiras in mind including the sessionjob support I am traveling today so I might need a day or so -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] wuchong merged pull request #19483: [hotfix][docs-zh] Fix "Google Cloud PubSub" Chinese page under "DataStream Connectors"
wuchong merged PR #19483: URL: https://github.com/apache/flink/pull/19483 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27261) Disable web.cancel.enable for session jobs
[
https://issues.apache.org/jira/browse/FLINK-27261?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17522753#comment-17522753
]
Gyula Fora commented on FLINK-27261:
I don’t think we can do this on a per job level and session clusters can have
non-managed jobs as well
> Disable web.cancel.enable for session jobs
> --
>
> Key: FLINK-27261
> URL: https://issues.apache.org/jira/browse/FLINK-27261
> Project: Flink
> Issue Type: Sub-task
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
> Labels: starter
>
> In FLINK-27154, we disable {{web.cancel.enable}} for application cluster. We
> should also do this for session jobs.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
[GitHub] [flink] snailHumming commented on pull request #19488: [FLINK-25716][docs-zh] Apply CR changes
snailHumming commented on PR #19488: URL: https://github.com/apache/flink/pull/19488#issuecomment-1099983403 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org