[GitHub] [flink] twalthr opened a new pull request, #19677: [FLINK-27534][build] Apply scalafmt to 1.15 branch
twalthr opened a new pull request, #19677: URL: https://github.com/apache/flink/pull/19677 ## What is the purpose of the change This applies FLINK-27317, FLINK-27232, and FLINK-26553 to the 1.15 branch. ## Brief change log See commit messages. ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27534) Apply scalafmt to 1.15 branch
[ https://issues.apache.org/jira/browse/FLINK-27534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-27534: --- Labels: pull-request-available (was: ) > Apply scalafmt to 1.15 branch > - > > Key: FLINK-27534 > URL: https://issues.apache.org/jira/browse/FLINK-27534 > Project: Flink > Issue Type: Improvement > Components: Build System >Reporter: Timo Walther >Assignee: Timo Walther >Priority: Major > Labels: pull-request-available > > As discussed on the mailing list: > https://lists.apache.org/thread/9jznwjh73jhcncnx46531kzyr0q7pz90 > We backport scalafmt to 1.15 to ease merging of patches. > This includes FLINK-27317, FLINK-27232, and FLINK-26553. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] twalthr commented on pull request #19677: [FLINK-27534][build] Apply scalafmt to 1.15 branch
twalthr commented on PR #19677: URL: https://github.com/apache/flink/pull/19677#issuecomment-1120718478 @zentol please let me know if I forgot something? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] Tartarus0zm commented on a diff in pull request #19656: [FLINK-26371][hive] Support variable substitution for sql statement while using Hive dialect
Tartarus0zm commented on code in PR #19656:
URL: https://github.com/apache/flink/pull/19656#discussion_r867688723
##
flink-connectors/flink-connector-hive/src/test/java/org/apache/flink/connectors/hive/HiveDialectITCase.java:
##
@@ -807,6 +807,29 @@ public void testShowPartitions() throws Exception {
assertTrue(partitions.toString().contains("dt=2020-04-30
01:02:03/country=china"));
}
+@Test
+public void testStatementVariableSubstitution() {
+// test system variable for substitution
+System.setProperty("k1", "v1");
+List result =
+CollectionUtil.iteratorToList(
+tableEnv.executeSql("select
'${system:k1}'").collect());
+assertEquals("[+I[v1]]", result.toString());
+
+// test env variable for substitution
+String classPath = System.getenv("CLASSPATH");
Review Comment:
env `CLASSPATH ` maybe not exist, CI details [test
fail](https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=35446&view=logs&j=fc5181b0-e452-5c8f-68de-1097947f6483&t=995c650b-6573-581c-9ce6-7ad4cc038461)
We should test for an environment variable that exists and an environment
variable that does not exist.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #19677: [FLINK-27534][build] Apply scalafmt to 1.15 branch
flinkbot commented on PR #19677: URL: https://github.com/apache/flink/pull/19677#issuecomment-1120719526 ## CI report: * 45709473ee30c99afdf0c3fb9e370a37320a86c9 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-table-store] JingsongLi commented on a diff in pull request #114: [FLINK-27542] Refactor E2eTestBase with docker compose
JingsongLi commented on code in PR #114:
URL: https://github.com/apache/flink-table-store/pull/114#discussion_r867694545
##
flink-table-store-e2e-tests/src/test/java/org/apache/flink/table/store/tests/E2eTestBase.java:
##
@@ -55,95 +51,70 @@ public abstract class E2eTestBase {
private static final Logger LOG =
LoggerFactory.getLogger(E2eTestBase.class);
-//
--
-// Flink Variables
-//
--
-private static final String FLINK_IMAGE_TAG;
-
-static {
-Properties properties = new Properties();
-try {
-properties.load(
-
E2eTestBase.class.getClassLoader().getResourceAsStream("project.properties"));
-} catch (IOException e) {
-throw new RuntimeException(e);
-}
-// TODO change image tag to official flink image after 1.15 is released
-FLINK_IMAGE_TAG = "tsreaper/flink-test:" +
properties.getProperty("flink.version");
+private final boolean withKafka;
+
+protected E2eTestBase() {
+this(false);
+}
+
+protected E2eTestBase(boolean withKafka) {
+this.withKafka = withKafka;
}
-private static final String INTER_CONTAINER_JM_ALIAS = "jobmanager";
-private static final String INTER_CONTAINER_TM_ALIAS = "taskmanager";
-private static final int JOB_MANAGER_REST_PORT = 8081;
-private static final String FLINK_PROPERTIES =
-String.join(
-"\n",
-Arrays.asList(
-"jobmanager.rpc.address: jobmanager",
-"taskmanager.numberOfTaskSlots: 9",
-"parallelism.default: 3",
-"sql-client.execution.result-mode: TABLEAU"));
-
-//
--
-// Additional Jars
-//
--
private static final String TABLE_STORE_JAR_NAME = "flink-table-store.jar";
private static final String BUNDLED_HADOOP_JAR_NAME = "bundled-hadoop.jar";
-
-protected static final String TEST_DATA_DIR = "/opt/flink/test-data";
-
-@ClassRule public static final Network NETWORK = Network.newNetwork();
-private GenericContainer jobManager;
-protected GenericContainer taskManager;
+protected static final String TEST_DATA_DIR = "/test-data";
private static final String PRINT_SINK_IDENTIFIER =
"table-store-e2e-result";
private static final int CHECK_RESULT_INTERVAL_MS = 1000;
private static final int CHECK_RESULT_RETRIES = 60;
private final List currentResults = new ArrayList<>();
+private DockerComposeContainer environment;
+private static final Object environmentStartLock = new Object();
Review Comment:
I'm a little curious as to why checkstyle didn't fail, it looks like the
name `environmentStartLock` should be upper here.
Maybe we can just `synchronized(E2eTestBase.class)`
##
flink-table-store-e2e-tests/src/test/resources-filtered/docker-compose.yaml:
##
@@ -0,0 +1,99 @@
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+version: "3"
+
+services:
+
+ #
+ # Flink services
+ #
+
+ jobmanager:
+# TODO change image tag to official flink image after 1.15 is released
+image: tsreaper/flink-test:${flink.version}
Review Comment:
Can we use flink 1.15.0? I think it has been released.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.o
[jira] [Updated] (FLINK-27552) Prometheus metrics disappear after starting a job
[
https://issues.apache.org/jira/browse/FLINK-27552?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
João Boto updated FLINK-27552:
--
Summary: Prometheus metrics disappear after starting a job (was:
Prometheus metrics)
> Prometheus metrics disappear after starting a job
> -
>
> Key: FLINK-27552
> URL: https://issues.apache.org/jira/browse/FLINK-27552
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Metrics
>Affects Versions: 1.15.0
>Reporter: João Boto
>Priority: Major
>
> I have a Standalone cluster (with jobmanager and taskmanager on same machine)
> on 1.14.4 and I'm testing the migration to 1.15.0
> But I keep losing the taskmanager metrics when I start a job on the 1.15
> cluster
> I use the same configuration as in the previous cluster
> {{ }}
> {code:java}
> metrics.reporters: prom
> metrics.reporter.prom.factory.class:
> org.apache.flink.metrics.prometheus.PrometheusReporterFactory
> metrics.reporter.prom.port: 9250-9251{code}
> {{ }}
> If the cluster is running without jobs I can see the metrics on port 9250 for
> jobmanager and on port 9251 for taskmanager
> If I start a job, the metrics from taskmanager disappear and if I stop the
> job the metrics come live again
> What am I missing?
>
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (FLINK-27552) Prometheus metrics disappear after starting a job
[
https://issues.apache.org/jira/browse/FLINK-27552?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533647#comment-17533647
]
Peter Schrott commented on FLINK-27552:
---
If you are using Kafka source / sink you might not be doing something wrong.
There is a bug in Flink 1.15.0. Please find more infos here:
[https://lists.apache.org/thread/6bd9vmcroh7576d7h1kdcd8czf0b4l73]
You also can find a "workaround" in the thread.
There is already a Jira Ticket for Flink created:
[https://issues.apache.org/jira/projects/FLINK/issues/FLINK-27487?filter=allopenissues]
> Prometheus metrics disappear after starting a job
> -
>
> Key: FLINK-27552
> URL: https://issues.apache.org/jira/browse/FLINK-27552
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Metrics
>Affects Versions: 1.15.0
>Reporter: João Boto
>Priority: Major
>
> I have a Standalone cluster (with jobmanager and taskmanager on same machine)
> on 1.14.4 and I'm testing the migration to 1.15.0
> But I keep losing the taskmanager metrics when I start a job on the 1.15
> cluster
> I use the same configuration as in the previous cluster
> {{ }}
> {code:java}
> metrics.reporters: prom
> metrics.reporter.prom.factory.class:
> org.apache.flink.metrics.prometheus.PrometheusReporterFactory
> metrics.reporter.prom.port: 9250-9251{code}
> {{ }}
> If the cluster is running without jobs I can see the metrics on port 9250 for
> jobmanager and on port 9251 for taskmanager
> If I start a job, the metrics from taskmanager disappear and if I stop the
> job the metrics come live again
> What am I missing?
>
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (FLINK-27551) Consider implementing our own status update logic
[ https://issues.apache.org/jira/browse/FLINK-27551?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533656#comment-17533656 ] Matyas Orhidi commented on FLINK-27551: --- Just thinking out loud: Retrying status updates in case of a version conflict makes no sense, it'll never succeed. We should probably just let the current status update go and wait another reconcile loop to deal with it. > Consider implementing our own status update logic > - > > Key: FLINK-27551 > URL: https://issues.apache.org/jira/browse/FLINK-27551 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Gyula Fora >Priority: Critical > > If a custom resource version is applied while in the middle of a reconcile > loop (for the same resource but previous version) the status update will > throw an error and re-trigger reconciliation. > In our case this might be problematic as it would mean we would retry > operations that are not necessarily retriable and might require manual user > intervention. > Please see: > [https://github.com/java-operator-sdk/java-operator-sdk/issues/1198] > I think we should consider implementing our own status update logic that is > independent of the current resource version to make the flow more robust. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] twalthr commented on a diff in pull request #19262: [hotfix][table][tests] Improve code - use assertJ
twalthr commented on code in PR #19262:
URL: https://github.com/apache/flink/pull/19262#discussion_r867705630
##
flink-table/flink-table-runtime/src/test/java/org/apache/flink/table/data/DataStructureConvertersTest.java:
##
@@ -367,36 +365,40 @@ public static List testData() {
@Parameter public TestSpec testSpec;
-@Rule public ExpectedException thrown = ExpectedException.none();
-
@Test
public void testConversions() {
-if (testSpec.expectedErrorMessage != null) {
-thrown.expect(TableException.class);
-thrown.expectMessage(equalTo(testSpec.expectedErrorMessage));
-}
for (Map.Entry, Object> from :
testSpec.conversions.entrySet()) {
final DataType fromDataType =
testSpec.dataType.bridgedTo(from.getKey());
-final DataStructureConverter fromConverter =
-
simulateSerialization(DataStructureConverters.getConverter(fromDataType));
-
fromConverter.open(DataStructureConvertersTest.class.getClassLoader());
-
-final Object internalValue =
fromConverter.toInternalOrNull(from.getValue());
-
-final Object anotherValue =
testSpec.conversionsWithAnotherValue.get(from.getKey());
-if (anotherValue != null) {
-fromConverter.toInternalOrNull(anotherValue);
-}
-
-for (Map.Entry, Object> to :
testSpec.conversions.entrySet()) {
-final DataType toDataType =
testSpec.dataType.bridgedTo(to.getKey());
-
-final DataStructureConverter toConverter =
-
simulateSerialization(DataStructureConverters.getConverter(toDataType));
-
toConverter.open(DataStructureConvertersTest.class.getClassLoader());
-
-
assertThat(toConverter.toExternalOrNull(internalValue)).isEqualTo(to.getValue());
+if (testSpec.expectedErrorMessage != null) {
+assertThatThrownBy(
+() ->
+simulateSerialization(
Review Comment:
remove in the `simulateSerialization` in this case
##
flink-table/flink-table-runtime/src/test/java/org/apache/flink/table/runtime/typeutils/RowDataSerializerTest.java:
##
@@ -347,26 +345,24 @@ public void testCopy() {
@Test
public void testWrongCopy() {
-thrown.expect(IllegalArgumentException.class);
-serializer.copy(new GenericRowData(serializer.getArity() + 1));
+assertThatThrownBy(() -> serializer.copy(new
GenericRowData(serializer.getArity() + 1)))
+.isInstanceOf(IllegalArgumentException.class);
}
@Test
public void testWrongCopyReuse() {
-thrown.expect(IllegalArgumentException.class);
for (RowData row : testData) {
-checkDeepEquals(
-row, serializer.copy(row, new
GenericRowData(row.getArity() + 1)), false);
+assertThatThrownBy(
+() ->
+checkDeepEquals(
+row,
+serializer.copy(
+row, new
GenericRowData(row.getArity() + 1)),
+false))
+.isInstanceOf(IllegalArgumentException.class);
}
}
/** Class used for concurrent testing with KryoSerializer. */
-private static class WrappedString {
Review Comment:
I'm sure this had a deeper meaning. Let's keep it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-table-store] tsreaper commented on a diff in pull request #99: [FLINK-27307] Flink table store support append-only ingestion without primary keys.
tsreaper commented on code in PR #99:
URL: https://github.com/apache/flink-table-store/pull/99#discussion_r867696446
##
flink-table-store-core/src/main/java/org/apache/flink/table/store/file/writer/AppendOnlyWriter.java:
##
@@ -0,0 +1,176 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.store.file.writer;
+
+import org.apache.flink.api.common.serialization.BulkWriter;
+import org.apache.flink.core.fs.Path;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.store.file.ValueKind;
+import org.apache.flink.table.store.file.data.DataFileMeta;
+import org.apache.flink.table.store.file.data.DataFilePathFactory;
+import org.apache.flink.table.store.file.format.FileFormat;
+import org.apache.flink.table.store.file.mergetree.Increment;
+import org.apache.flink.table.store.file.stats.FieldStats;
+import org.apache.flink.table.store.file.stats.FieldStatsCollector;
+import org.apache.flink.table.store.file.stats.FileStatsExtractor;
+import org.apache.flink.table.store.file.utils.FileUtils;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.util.Preconditions;
+
+import org.apache.flink.shaded.guava30.com.google.common.collect.Lists;
+
+import java.io.IOException;
+import java.util.List;
+import java.util.concurrent.atomic.AtomicLong;
+import java.util.function.Supplier;
+
+/** A {@link RecordWriter} implementation that only accepts append-only
records. */
+public class AppendOnlyWriter implements RecordWriter {
+private final BulkWriter.Factory writerFactory;
+private final RowType writeSchema;
+private final long targetFileSize;
+private final List existingFiles;
+private final DataFilePathFactory pathFactory;
+private final FileStatsExtractor fileStatsExtractor;
+
+private final AtomicLong nextSeqNum;
+
+private RowRollingWriter writer;
+
+public AppendOnlyWriter(
+FileFormat fileFormat,
+long targetFileSize,
+RowType writeSchema,
+List existingFiles,
+DataFilePathFactory pathFactory,
+FileStatsExtractor fileStatsExtractor) {
+
+this.writerFactory = fileFormat.createWriterFactory(writeSchema);
+this.writeSchema = writeSchema;
+this.targetFileSize = targetFileSize;
+
+this.existingFiles = existingFiles;
+this.pathFactory = pathFactory;
+this.fileStatsExtractor = fileStatsExtractor;
+
+this.nextSeqNum = new AtomicLong(maxSequenceNumber() + 1);
+
+this.writer = createRollingRowWriter();
+}
+
+private long maxSequenceNumber() {
+return existingFiles.stream()
+.map(DataFileMeta::maxSequenceNumber)
+.max(Long::compare)
+.orElse(-1L);
+}
+
+@Override
+public void write(ValueKind valueKind, RowData key, RowData value) throws
Exception {
+Preconditions.checkArgument(
+valueKind == ValueKind.ADD,
+"Append-only writer cannot accept ValueKind: " + valueKind);
+
+writer.write(value);
+}
+
+@Override
+public Increment prepareCommit() throws Exception {
+List newFiles = Lists.newArrayList();
+
+if (writer != null) {
+writer.close();
+
+// Reopen the writer to accept further records.
+newFiles.addAll(writer.result());
+writer = createRollingRowWriter();
+}
+
+return new Increment(Lists.newArrayList(newFiles));
+}
+
+@Override
+public void sync() throws Exception {
+// TODO add the flush method for FileWriter.
Review Comment:
Is this a must? Before each checkpoint and before the end of input
`prepareCommit` will be called and in that method `writer.close()` is called.
`writer.close()` will flush the writer.
##
flink-table-store-core/src/main/java/org/apache/flink/table/store/file/writer/AppendOnlyWriter.java:
##
@@ -0,0 +1,176 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright
[GitHub] [flink-table-store] openinx opened a new pull request, #115: [FLINK-27546] Add append only writer which implements the RecordWriter interface
openinx opened a new pull request, #115: URL: https://github.com/apache/flink-table-store/pull/115 It's a sub PR for https://github.com/apache/flink-table-store/pull/99, which is trying to add an AppendOnlyWriter and unit test to accept records without any key or sort order. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27546) Add append only writer which implements the RecordWriter interface.
[ https://issues.apache.org/jira/browse/FLINK-27546?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-27546: --- Labels: pull-request-available (was: ) > Add append only writer which implements the RecordWriter interface. > --- > > Key: FLINK-27546 > URL: https://issues.apache.org/jira/browse/FLINK-27546 > Project: Flink > Issue Type: Sub-task >Reporter: Zheng Hu >Assignee: Zheng Hu >Priority: Major > Labels: pull-request-available > Fix For: table-store-0.2.0 > > > We already has a DataFileWriter in our current flink table store, but this > DataFileWriter was designed to flush the records which were sorted by their > keys. > For the append-only table, the records to write will not have any keys or > sort orders. So let's introduce an append-only writer to ingest the > append-only records. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] MartijnVisser merged pull request #19509: [hotfix][docs-zh] Delete redundant lines in pulsar.md
MartijnVisser merged PR #19509: URL: https://github.com/apache/flink/pull/19509 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-table-store] openinx commented on a diff in pull request #115: [FLINK-27546] Add append only writer which implements the RecordWriter interface
openinx commented on code in PR #115:
URL: https://github.com/apache/flink-table-store/pull/115#discussion_r867721699
##
flink-table-store-core/src/main/java/org/apache/flink/table/store/file/writer/AppendOnlyWriter.java:
##
@@ -0,0 +1,173 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.flink.table.store.file.writer;
+
+import org.apache.flink.api.common.serialization.BulkWriter;
+import org.apache.flink.core.fs.Path;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.store.file.ValueKind;
+import org.apache.flink.table.store.file.data.DataFileMeta;
+import org.apache.flink.table.store.file.data.DataFilePathFactory;
+import org.apache.flink.table.store.file.format.FileFormat;
+import org.apache.flink.table.store.file.mergetree.Increment;
+import org.apache.flink.table.store.file.stats.FieldStats;
+import org.apache.flink.table.store.file.stats.FieldStatsCollector;
+import org.apache.flink.table.store.file.stats.FileStatsExtractor;
+import org.apache.flink.table.store.file.utils.FileUtils;
+import org.apache.flink.table.types.logical.RowType;
+import org.apache.flink.util.Preconditions;
+
+import org.apache.flink.shaded.guava30.com.google.common.collect.Lists;
+
+import java.io.IOException;
+import java.util.List;
+import java.util.concurrent.atomic.AtomicLong;
+import java.util.function.Supplier;
+
+/**
+ * A {@link RecordWriter} implementation that only accepts records which are
always insert
+ * operations and don't have any unique keys or sort keys.
+ */
+public class AppendOnlyWriter implements RecordWriter {
+private final BulkWriter.Factory writerFactory;
+private final RowType writeSchema;
+private final long targetFileSize;
+private final DataFilePathFactory pathFactory;
+private final FileStatsExtractor fileStatsExtractor;
+
+private final AtomicLong nextSeqNum;
+
+private RowRollingWriter writer;
+
+public AppendOnlyWriter(
+FileFormat fileFormat,
+long targetFileSize,
+RowType writeSchema,
+long maxWroteSeqNumber,
+DataFilePathFactory pathFactory) {
+
+this.writerFactory = fileFormat.createWriterFactory(writeSchema);
+this.writeSchema = writeSchema;
+this.targetFileSize = targetFileSize;
+
+this.pathFactory = pathFactory;
+this.fileStatsExtractor =
fileFormat.createStatsExtractor(writeSchema).orElse(null);
+
+this.nextSeqNum = new AtomicLong(maxWroteSeqNumber + 1);
+
+this.writer = createRollingRowWriter();
+}
+
+@Override
+public void write(ValueKind valueKind, RowData key, RowData value) throws
Exception {
+Preconditions.checkArgument(
+valueKind == ValueKind.ADD,
+"Append-only writer cannot accept ValueKind: " + valueKind);
+
+writer.write(value);
+}
+
+@Override
+public Increment prepareCommit() throws Exception {
+List newFiles = Lists.newArrayList();
+
+if (writer != null) {
+writer.close();
+
+// Reopen the writer to accept further records.
+newFiles.addAll(writer.result());
+writer = createRollingRowWriter();
+}
+
+return new Increment(Lists.newArrayList(newFiles));
+}
+
+@Override
+public void sync() throws Exception {
+// Do nothing here, as this writer don't introduce any async
compaction thread currently.
+}
+
+@Override
+public List close() throws Exception {
+sync();
+
+List result = Lists.newArrayList();
+if (writer != null) {
+// Abort this writer to clear uncommitted files.
+writer.abort();
Review Comment:
I'm just curious that the `RecordWriter#close` will close the writer and
**delete the uncommitted files** automatically, which is a bit mismatching the
normal `close` semantic of writer. [1]
Actually, the behavior is more matching the `abort` semantic. So I filed a
separate issue to address this issue. I mean we can define separate `abort()`
and `close()` methods in this interface, and the `close()` will just close the
opening writer, and the `abort(
[GitHub] [flink] MartijnVisser merged pull request #19522: [hotfix] [docs] Add missing translation in datastream.md
MartijnVisser merged PR #19522: URL: https://github.com/apache/flink/pull/19522 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] chucheng92 commented on pull request #19654: [FLINK-27529][connector/common] Replace HybridSourceSplitEnumerator readerSourceIndex to safely Integer check
chucheng92 commented on PR #19654: URL: https://github.com/apache/flink/pull/19654#issuecomment-1120757526 @tweise Thanks for reviewing. And sorry i haven’t illustrate details clearly. Question-1: actual problem is == with Integer for readerIndex comparison. ``` Integer i1 = 128; Integer i2 = 128; System.out.println(i1 == i2); int i3 = 128; int i4 = 128; System.out.println((Integer) i3 == (Integer) i4); ``` It will show false, false. As hybrid source definition, it can concat with more than 2 child sources. so currently works just because Integer cache(only works <=127), if we have more sources will fail on error. In a word, we can't use == to compare Integer index unless we limit hybrid sources only works <=127. Question-2, the `e.getKey()` above will be null when we run any of cases in `HybridSourceSplitEnumeratorTest`. 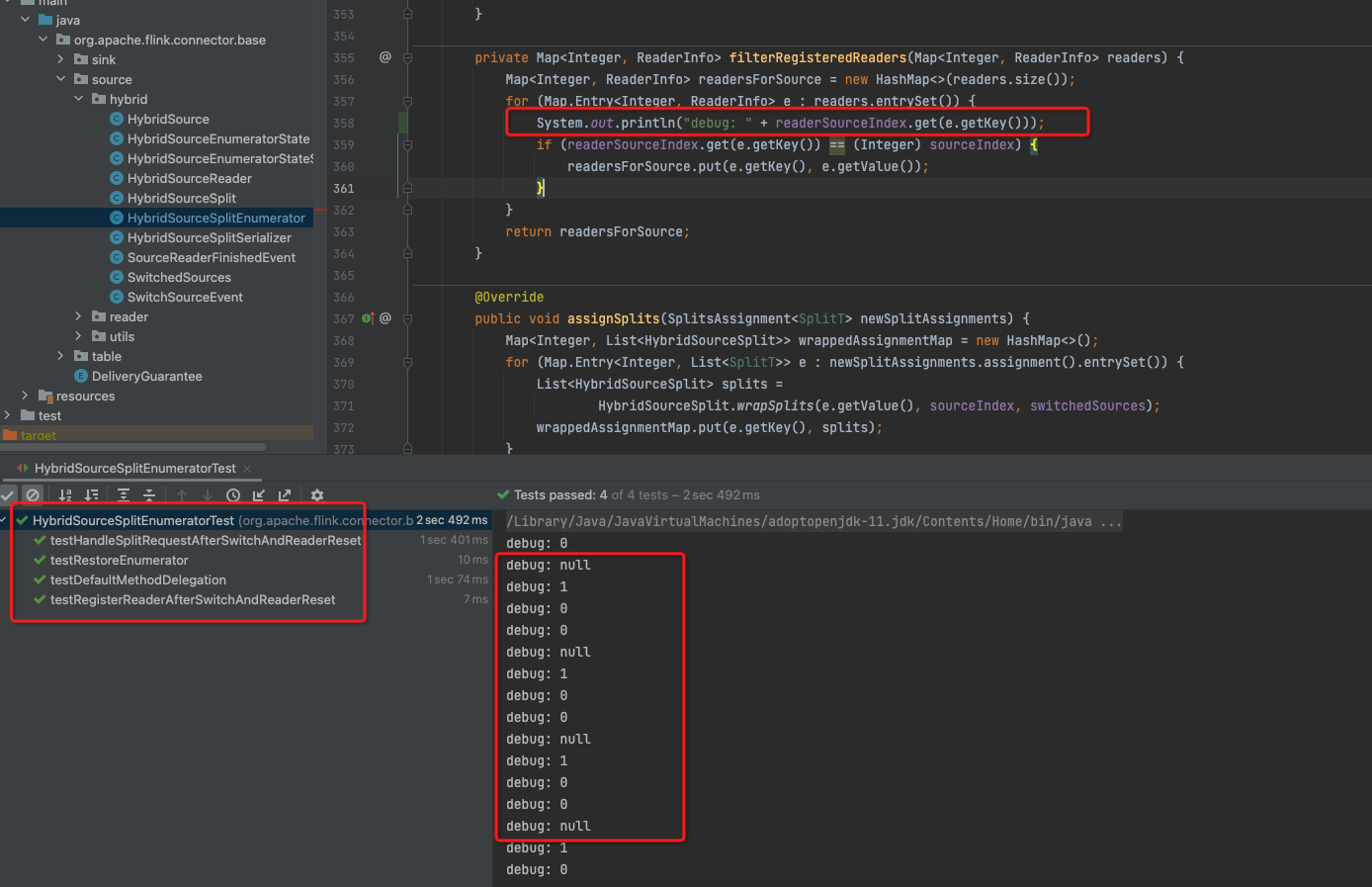 currently works because here we cast sourceIndex to Integer. but if we want to solve the Question-1, then here may deal with this null. Thanks. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27543) Introduce StatsProducer to refactor code in DataFileWriter
[ https://issues.apache.org/jira/browse/FLINK-27543?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533666#comment-17533666 ] Zheng Hu commented on FLINK-27543: -- I think a better approach is hiding the `fileStatsExtractor` or `StatsExtractor` inside the writer which was created by the file format's writer factory. Let me publish a PR for this. > Introduce StatsProducer to refactor code in DataFileWriter > --- > > Key: FLINK-27543 > URL: https://issues.apache.org/jira/browse/FLINK-27543 > Project: Flink > Issue Type: Improvement > Components: Table Store >Reporter: Jingsong Lee >Priority: Major > Fix For: table-store-0.2.0 > > > Lots of `fileStatsExtractor == null` looks bad. > I think we can have a `StatsProducer` to unify `StatsExtractor` and > `StatsCollector`. To reduce caller complexity. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] fapaul commented on pull request #19661: [FLINK-27487][kafka] Only forward measurable Kafka metrics and ignore others
fapaul commented on PR #19661: URL: https://github.com/apache/flink/pull/19661#issuecomment-1120766178 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] fapaul commented on pull request #19649: [FLINK-27487][kafka] Only forward measurable Kafka metrics and ignore others
fapaul commented on PR #19649: URL: https://github.com/apache/flink/pull/19649#issuecomment-1120766757 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27551) Consider implementing our own status update logic
[ https://issues.apache.org/jira/browse/FLINK-27551?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533671#comment-17533671 ] Yang Wang commented on FLINK-27551: --- I am trying to understand this issue. Do you mean the resource version conflicts will happen when the CR is updated externally in the middle of a reconcile loop? This is due to java-operator-sdk is doing the "lock resource version and then update". Right? > Consider implementing our own status update logic > - > > Key: FLINK-27551 > URL: https://issues.apache.org/jira/browse/FLINK-27551 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Gyula Fora >Priority: Critical > > If a custom resource version is applied while in the middle of a reconcile > loop (for the same resource but previous version) the status update will > throw an error and re-trigger reconciliation. > In our case this might be problematic as it would mean we would retry > operations that are not necessarily retriable and might require manual user > intervention. > Please see: > [https://github.com/java-operator-sdk/java-operator-sdk/issues/1198] > I think we should consider implementing our own status update logic that is > independent of the current resource version to make the flow more robust. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Updated] (FLINK-27554) The asf-site does not build on Apple Silicon
[
https://issues.apache.org/jira/browse/FLINK-27554?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Martijn Visser updated FLINK-27554:
---
Parent: FLINK-26981
Issue Type: Sub-task (was: Improvement)
> The asf-site does not build on Apple Silicon
>
>
> Key: FLINK-27554
> URL: https://issues.apache.org/jira/browse/FLINK-27554
> Project: Flink
> Issue Type: Sub-task
> Components: Project Website
>Affects Versions: 1.15.0
>Reporter: Jiangjie Qin
>Priority: Major
>
> It looks that the ASF website does not build on my laptop with Apple silicon.
> It errors out when installing libv8 via the following command:
> {noformat}
> gem install libv8 -v '3.16.14.19' --source 'https://rubygems.org/'
> {noformat}
> The error logs are following:
> {noformat}
> current directory: /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/ext/libv8
> /System/Library/Frameworks/Ruby.framework/Versions/2.6/usr/bin/ruby -I
> /System/Library/Frameworks/Ruby.framework/Versions/2.6/usr/lib/ruby/2.6.0 -r
> ./siteconf20220509-16154-19vsxkp.rb extconf.rb
> creating Makefile
> Applying
> /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/patches/disable-building-tests.patch
> Applying
> /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/patches/disable-werror-on-osx.patch
> Applying
> /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/patches/disable-xcode-debugging.patch
> Applying
> /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/patches/do-not-imply-vfp3-and-armv7.patch
> Applying
> /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/patches/do-not-use-MAP_NORESERVE-on-freebsd.patch
> Applying
> /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/patches/do-not-use-vfp2.patch
> Applying
> /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/patches/fPIC-for-static.patch
> Compiling v8 for x64
> Using python 2.7.18
> Using compiler: c++ (clang version 13.1.6)
> Unable to find a compiler officially supported by v8.
> It is recommended to use GCC v4.4 or higher
> Beginning compilation. This will take some time.
> Building v8 with env CXX=c++ LINK=c++ /usr/bin/make x64.release vfp2=off
> vfp3=on hardfp=on ARFLAGS.target=crs werror=no
> GYP_GENERATORS=make \
> build/gyp/gyp --generator-output="out" build/all.gyp \
> -Ibuild/standalone.gypi --depth=. \
> -Dv8_target_arch=x64 \
> -S.x64 -Dv8_enable_backtrace=1
> -Dv8_can_use_vfp2_instructions=false -Dv8_can_use_vfp3_instructions=true
> -Darm_fpu=vfpv3 -Dwerror='' -Dv8_use_arm_eabi_hardfloat=true
> CXX(target)
> /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/vendor/v8/out/x64.release/obj.target/preparser_lib/src/allocation.o
> clang: warning: include path for libstdc++ headers not found; pass
> '-stdlib=libc++' on the command line to use the libc++ standard library
> instead [-Wstdlibcxx-not-found]
> In file included from ../src/allocation.cc:33:
> ../src/utils.h:33:10: fatal error: 'climits' file not found
> #include
> ^
> 1 error generated.
> make[1]: ***
> [/Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/vendor/v8/out/x64.release/obj.target/preparser_lib/src/allocation.o]
> Error 1
> make: *** [x64.release] Error 2
> /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/ext/libv8/location.rb:36:in
> `block in verify_installation!': libv8 did not install properly, expected
> binary v8 archive
> '/Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/vendor/v8/out/x64.release/obj.target/tools/gyp/libv8_base.a'to
> exist, but it was not found (Libv8::Location::Vendor::ArchiveNotFound)
> from
> /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/ext/libv8/location.rb:35:in
> `each'
> from
> /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/ext/libv8/location.rb:35:in
> `verify_installation!'
> from
> /Library/Ruby/Gems/2.6.0/gems/libv8-3.16.14.19/ext/libv8/location.rb:26:in
> `install!'
> from extconf.rb:7:in `'
>
> extconf failed, exit code 1
> {noformat}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (FLINK-27438) SQL validation failed when constructing a map array
[
https://issues.apache.org/jira/browse/FLINK-27438?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533672#comment-17533672
]
Marios Trivyzas commented on FLINK-27438:
-
I'm not a committer myself, so we'd need to wait for Martijn or Timo.
> SQL validation failed when constructing a map array
> ---
>
> Key: FLINK-27438
> URL: https://issues.apache.org/jira/browse/FLINK-27438
> Project: Flink
> Issue Type: Bug
> Components: Table SQL / Planner
>Affects Versions: 1.15.0, 1.14.4
>Reporter: Wei Zhong
>Assignee: Roman Boyko
>Priority: Major
> Labels: pull-request-available
>
> Exception:
> {code:java}
> Exception in thread "main" org.apache.flink.table.api.ValidationException:
> SQL validation failed. Unsupported type when convertTypeToSpec: MAP
> at
> org.apache.flink.table.planner.calcite.FlinkPlannerImpl.org$apache$flink$table$planner$calcite$FlinkPlannerImpl$$validate(FlinkPlannerImpl.scala:185)
> at
> org.apache.flink.table.planner.calcite.FlinkPlannerImpl.validate(FlinkPlannerImpl.scala:110)
> at
> org.apache.flink.table.planner.operations.SqlToOperationConverter.convert(SqlToOperationConverter.java:237)
> at
> org.apache.flink.table.planner.delegation.ParserImpl.parse(ParserImpl.java:105)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeSql(TableEnvironmentImpl.java:695)
> at
> org.apache.flink.table.planner.plan.stream.sql.LegacyTableFactoryTest.(LegacyTableFactoryTest.java:35)
> at
> org.apache.flink.table.planner.plan.stream.sql.LegacyTableFactoryTest.main(LegacyTableFactoryTest.java:49)
> Caused by: java.lang.UnsupportedOperationException: Unsupported type when
> convertTypeToSpec: MAP
> at
> org.apache.calcite.sql.type.SqlTypeUtil.convertTypeToSpec(SqlTypeUtil.java:1059)
> at
> org.apache.calcite.sql.type.SqlTypeUtil.convertTypeToSpec(SqlTypeUtil.java:1081)
> at
> org.apache.flink.table.planner.functions.utils.SqlValidatorUtils.castTo(SqlValidatorUtils.java:82)
> at
> org.apache.flink.table.planner.functions.utils.SqlValidatorUtils.adjustTypeForMultisetConstructor(SqlValidatorUtils.java:74)
> at
> org.apache.flink.table.planner.functions.utils.SqlValidatorUtils.adjustTypeForArrayConstructor(SqlValidatorUtils.java:39)
> at
> org.apache.flink.table.planner.functions.sql.SqlArrayConstructor.inferReturnType(SqlArrayConstructor.java:44)
> at
> org.apache.calcite.sql.SqlOperator.validateOperands(SqlOperator.java:449)
> at org.apache.calcite.sql.SqlOperator.deriveType(SqlOperator.java:531)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl$DeriveTypeVisitor.visit(SqlValidatorImpl.java:5716)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl$DeriveTypeVisitor.visit(SqlValidatorImpl.java:5703)
> at org.apache.calcite.sql.SqlCall.accept(SqlCall.java:139)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.deriveTypeImpl(SqlValidatorImpl.java:1736)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.deriveType(SqlValidatorImpl.java:1727)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.expandSelectItem(SqlValidatorImpl.java:421)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.validateSelectList(SqlValidatorImpl.java:4061)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.validateSelect(SqlValidatorImpl.java:3347)
> at
> org.apache.calcite.sql.validate.SelectNamespace.validateImpl(SelectNamespace.java:60)
> at
> org.apache.calcite.sql.validate.AbstractNamespace.validate(AbstractNamespace.java:84)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.validateNamespace(SqlValidatorImpl.java:997)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.validateQuery(SqlValidatorImpl.java:975)
> at org.apache.calcite.sql.SqlSelect.validate(SqlSelect.java:232)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.validateScopedExpression(SqlValidatorImpl.java:952)
> at
> org.apache.calcite.sql.validate.SqlValidatorImpl.validate(SqlValidatorImpl.java:704)
> at
> org.apache.flink.table.planner.calcite.FlinkPlannerImpl.org$apache$flink$table$planner$calcite$FlinkPlannerImpl$$validate(FlinkPlannerImpl.scala:180)
> ... 6 more {code}
> How to reproduce:
> {code:java}
> tableEnv.executeSql("select array[map['A', 'AA'], map['B', 'BB'], map['C',
> CAST(NULL AS STRING)]] from (VALUES ('a'))").print(); {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (FLINK-27544) Example code in 'Structure of Table API and SQL Programs' is out of date and cannot run
[
https://issues.apache.org/jira/browse/FLINK-27544?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533674#comment-17533674
]
Martijn Visser commented on FLINK-27544:
[~yckkcy] Could you work on fixing the issues?
> Example code in 'Structure of Table API and SQL Programs' is out of date and
> cannot run
> ---
>
> Key: FLINK-27544
> URL: https://issues.apache.org/jira/browse/FLINK-27544
> Project: Flink
> Issue Type: Improvement
> Components: Documentation
>Affects Versions: 1.15.0, 1.14.4
>Reporter: Chengkai Yang
>Priority: Major
>
> The example code in [Structure of Table API and SQL
> Programs|https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/common/#structure-of-table-api-and-sql-programs]
> of ['Concepts & Common
> API'|https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/common/]
> is out of date and when user run this piece of code, they will get the
> following result:
> {code:java}
> Exception in thread "main" org.apache.flink.table.api.ValidationException:
> Unable to create a sink for writing table
> 'default_catalog.default_database.SinkTable'.
> Table options are:
> 'connector'='blackhole'
> 'rows-per-second'='1'
> at
> org.apache.flink.table.factories.FactoryUtil.createDynamicTableSink(FactoryUtil.java:262)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.getTableSink(PlannerBase.scala:421)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.translateToRel(PlannerBase.scala:222)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.$anonfun$translate$1(PlannerBase.scala:178)
> at
> scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:233)
> at scala.collection.Iterator.foreach(Iterator.scala:937)
> at scala.collection.Iterator.foreach$(Iterator.scala:937)
> at scala.collection.AbstractIterator.foreach(Iterator.scala:1425)
> at scala.collection.IterableLike.foreach(IterableLike.scala:70)
> at scala.collection.IterableLike.foreach$(IterableLike.scala:69)
> at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
> at scala.collection.TraversableLike.map(TraversableLike.scala:233)
> at scala.collection.TraversableLike.map$(TraversableLike.scala:226)
> at scala.collection.AbstractTraversable.map(Traversable.scala:104)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.translate(PlannerBase.scala:178)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.translate(TableEnvironmentImpl.java:1656)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:782)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:861)
> at
> org.apache.flink.table.api.internal.TablePipelineImpl.execute(TablePipelineImpl.java:56)
> at com.yck.TestTableAPI.main(TestTableAPI.java:43)
> Caused by: org.apache.flink.table.api.ValidationException: Unsupported
> options found for 'blackhole'.
> Unsupported options:
> rows-per-second
> Supported options:
> connector
> property-version
> at
> org.apache.flink.table.factories.FactoryUtil.validateUnconsumedKeys(FactoryUtil.java:624)
> at
> org.apache.flink.table.factories.FactoryUtil$FactoryHelper.validate(FactoryUtil.java:914)
> at
> org.apache.flink.table.factories.FactoryUtil$TableFactoryHelper.validate(FactoryUtil.java:978)
> at
> org.apache.flink.connector.blackhole.table.BlackHoleTableSinkFactory.createDynamicTableSink(BlackHoleTableSinkFactory.java:64)
> at
> org.apache.flink.table.factories.FactoryUtil.createDynamicTableSink(FactoryUtil.java:259)
> ... 19 more
> {code}
> I think this mistake would drive users crazy when they first fry Table API &
> Flink SQL since this is the very first code they see.
> Overall this code is outdated in two places:
> 1. The Query creating temporary table should be
> {code:sql}
> CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'blackhole') LIKE
> SourceTable (EXCLUDING OPTIONS)
> {code}
> instead of
> {code:sql}
> CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'blackhole') LIKE
> SourceTable
> {code} which missed {code:sql}
> (EXCLUDING OPTIONS)
> {code} sql_like_pattern
> 2. The part creating a source table should be
> {code:java}
> tableEnv.createTemporaryTable("SourceTable",
> TableDescriptor.forConnector("datagen")
> .schema(Schema.newBuilder()
> .column("f0", DataTypes.STRING())
> .build())
> .option(DataGenConnectorOptions.ROWS_PER_SECOND, 1L)
> .build());
>
[jira] [Commented] (FLINK-27544) Example code in 'Structure of Table API and SQL Programs' is out of date and cannot run
[
https://issues.apache.org/jira/browse/FLINK-27544?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533679#comment-17533679
]
Chengkai Yang commented on FLINK-27544:
---
[~martijnvisser] sure!
> Example code in 'Structure of Table API and SQL Programs' is out of date and
> cannot run
> ---
>
> Key: FLINK-27544
> URL: https://issues.apache.org/jira/browse/FLINK-27544
> Project: Flink
> Issue Type: Improvement
> Components: Documentation
>Affects Versions: 1.15.0, 1.14.4
>Reporter: Chengkai Yang
>Priority: Major
>
> The example code in [Structure of Table API and SQL
> Programs|https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/common/#structure-of-table-api-and-sql-programs]
> of ['Concepts & Common
> API'|https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/common/]
> is out of date and when user run this piece of code, they will get the
> following result:
> {code:java}
> Exception in thread "main" org.apache.flink.table.api.ValidationException:
> Unable to create a sink for writing table
> 'default_catalog.default_database.SinkTable'.
> Table options are:
> 'connector'='blackhole'
> 'rows-per-second'='1'
> at
> org.apache.flink.table.factories.FactoryUtil.createDynamicTableSink(FactoryUtil.java:262)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.getTableSink(PlannerBase.scala:421)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.translateToRel(PlannerBase.scala:222)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.$anonfun$translate$1(PlannerBase.scala:178)
> at
> scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:233)
> at scala.collection.Iterator.foreach(Iterator.scala:937)
> at scala.collection.Iterator.foreach$(Iterator.scala:937)
> at scala.collection.AbstractIterator.foreach(Iterator.scala:1425)
> at scala.collection.IterableLike.foreach(IterableLike.scala:70)
> at scala.collection.IterableLike.foreach$(IterableLike.scala:69)
> at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
> at scala.collection.TraversableLike.map(TraversableLike.scala:233)
> at scala.collection.TraversableLike.map$(TraversableLike.scala:226)
> at scala.collection.AbstractTraversable.map(Traversable.scala:104)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.translate(PlannerBase.scala:178)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.translate(TableEnvironmentImpl.java:1656)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:782)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:861)
> at
> org.apache.flink.table.api.internal.TablePipelineImpl.execute(TablePipelineImpl.java:56)
> at com.yck.TestTableAPI.main(TestTableAPI.java:43)
> Caused by: org.apache.flink.table.api.ValidationException: Unsupported
> options found for 'blackhole'.
> Unsupported options:
> rows-per-second
> Supported options:
> connector
> property-version
> at
> org.apache.flink.table.factories.FactoryUtil.validateUnconsumedKeys(FactoryUtil.java:624)
> at
> org.apache.flink.table.factories.FactoryUtil$FactoryHelper.validate(FactoryUtil.java:914)
> at
> org.apache.flink.table.factories.FactoryUtil$TableFactoryHelper.validate(FactoryUtil.java:978)
> at
> org.apache.flink.connector.blackhole.table.BlackHoleTableSinkFactory.createDynamicTableSink(BlackHoleTableSinkFactory.java:64)
> at
> org.apache.flink.table.factories.FactoryUtil.createDynamicTableSink(FactoryUtil.java:259)
> ... 19 more
> {code}
> I think this mistake would drive users crazy when they first fry Table API &
> Flink SQL since this is the very first code they see.
> Overall this code is outdated in two places:
> 1. The Query creating temporary table should be
> {code:sql}
> CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'blackhole') LIKE
> SourceTable (EXCLUDING OPTIONS)
> {code}
> instead of
> {code:sql}
> CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'blackhole') LIKE
> SourceTable
> {code} which missed {code:sql}
> (EXCLUDING OPTIONS)
> {code} sql_like_pattern
> 2. The part creating a source table should be
> {code:java}
> tableEnv.createTemporaryTable("SourceTable",
> TableDescriptor.forConnector("datagen")
> .schema(Schema.newBuilder()
> .column("f0", DataTypes.STRING())
> .build())
> .option(DataGenConnectorOptions.ROWS_PER_SECOND, 1L)
> .build());
> {code}
> instead of
> {
[jira] [Commented] (FLINK-27552) Prometheus metrics disappear after starting a job
[
https://issues.apache.org/jira/browse/FLINK-27552?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533680#comment-17533680
]
João Boto commented on FLINK-27552:
---
Hi [~peter.schrott] , thanks for the links..
Yes I have a KafkaSource..
I try to disable de KafaMetrics
{code:java}
kafkaSourceBuilder.setProperty(KafkaSourceOptions.REGISTER_KAFKA_CONSUMER_METRICS.key(),
"false");
{code}
But I continue without taskmanager metrics
> Prometheus metrics disappear after starting a job
> -
>
> Key: FLINK-27552
> URL: https://issues.apache.org/jira/browse/FLINK-27552
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Metrics
>Affects Versions: 1.15.0
>Reporter: João Boto
>Priority: Major
>
> I have a Standalone cluster (with jobmanager and taskmanager on same machine)
> on 1.14.4 and I'm testing the migration to 1.15.0
> But I keep losing the taskmanager metrics when I start a job on the 1.15
> cluster
> I use the same configuration as in the previous cluster
> {{ }}
> {code:java}
> metrics.reporters: prom
> metrics.reporter.prom.factory.class:
> org.apache.flink.metrics.prometheus.PrometheusReporterFactory
> metrics.reporter.prom.port: 9250-9251{code}
> {{ }}
> If the cluster is running without jobs I can see the metrics on port 9250 for
> jobmanager and on port 9251 for taskmanager
> If I start a job, the metrics from taskmanager disappear and if I stop the
> job the metrics come live again
> What am I missing?
>
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Updated] (FLINK-27543) Introduce StatsProducer to refactor code in DataFileWriter
[ https://issues.apache.org/jira/browse/FLINK-27543?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Zheng Hu updated FLINK-27543: - Parent: FLINK-27307 Issue Type: Sub-task (was: Improvement) > Introduce StatsProducer to refactor code in DataFileWriter > --- > > Key: FLINK-27543 > URL: https://issues.apache.org/jira/browse/FLINK-27543 > Project: Flink > Issue Type: Sub-task > Components: Table Store >Reporter: Jingsong Lee >Priority: Major > Fix For: table-store-0.2.0 > > > Lots of `fileStatsExtractor == null` looks bad. > I think we can have a `StatsProducer` to unify `StatsExtractor` and > `StatsCollector`. To reduce caller complexity. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Created] (FLINK-27555) Performance regression in schedulingDownstreamTasks on 02.05.2022
Roman Khachatryan created FLINK-27555: - Summary: Performance regression in schedulingDownstreamTasks on 02.05.2022 Key: FLINK-27555 URL: https://issues.apache.org/jira/browse/FLINK-27555 Project: Flink Issue Type: Bug Components: Benchmarks, Runtime / Coordination Affects Versions: 1.16.0 Reporter: Roman Khachatryan http://codespeed.dak8s.net:8000/timeline/#/?exe=5&ben=schedulingDownstreamTasks.BATCH&extr=on&quarts=on&equid=off&env=2&revs=200 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Updated] (FLINK-27555) Performance regression in schedulingDownstreamTasks on 02.05.2022
[ https://issues.apache.org/jira/browse/FLINK-27555?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Roman Khachatryan updated FLINK-27555: -- Attachment: Screenshot_2022-05-09_10-33-11.png > Performance regression in schedulingDownstreamTasks on 02.05.2022 > - > > Key: FLINK-27555 > URL: https://issues.apache.org/jira/browse/FLINK-27555 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Runtime / Coordination >Affects Versions: 1.16.0 >Reporter: Roman Khachatryan >Priority: Major > Attachments: Screenshot_2022-05-09_10-33-11.png > > > http://codespeed.dak8s.net:8000/timeline/#/?exe=5&ben=schedulingDownstreamTasks.BATCH&extr=on&quarts=on&equid=off&env=2&revs=200 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Created] (FLINK-27556) Performance regression in checkpointSingleInput.UNALIGNED on 29.04.2022
Roman Khachatryan created FLINK-27556: - Summary: Performance regression in checkpointSingleInput.UNALIGNED on 29.04.2022 Key: FLINK-27556 URL: https://issues.apache.org/jira/browse/FLINK-27556 Project: Flink Issue Type: Bug Components: Benchmarks, Runtime / Checkpointing Affects Versions: 1.16.0 Reporter: Roman Khachatryan http://codespeed.dak8s.net:8000/timeline/#/?exe=1&ben=checkpointSingleInput.UNALIGNED&extr=on&quarts=on&equid=off&env=2&revs=200 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27551) Consider implementing our own status update logic
[ https://issues.apache.org/jira/browse/FLINK-27551?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533688#comment-17533688 ] Matyas Orhidi commented on FLINK-27551: --- Yes, and according to [https://github.com/java-operator-sdk/java-operator-sdk/issues/1198] the retries are supposed to deal with this scenario. I was wondering why is not the casein the operator? > Consider implementing our own status update logic > - > > Key: FLINK-27551 > URL: https://issues.apache.org/jira/browse/FLINK-27551 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Gyula Fora >Priority: Critical > > If a custom resource version is applied while in the middle of a reconcile > loop (for the same resource but previous version) the status update will > throw an error and re-trigger reconciliation. > In our case this might be problematic as it would mean we would retry > operations that are not necessarily retriable and might require manual user > intervention. > Please see: > [https://github.com/java-operator-sdk/java-operator-sdk/issues/1198] > I think we should consider implementing our own status update logic that is > independent of the current resource version to make the flow more robust. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Updated] (FLINK-27556) Performance regression in checkpointSingleInput.UNALIGNED on 29.04.2022
[ https://issues.apache.org/jira/browse/FLINK-27556?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Roman Khachatryan updated FLINK-27556: -- Attachment: Screenshot_2022-05-09_10-35-57.png > Performance regression in checkpointSingleInput.UNALIGNED on 29.04.2022 > --- > > Key: FLINK-27556 > URL: https://issues.apache.org/jira/browse/FLINK-27556 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Runtime / Checkpointing >Affects Versions: 1.16.0 >Reporter: Roman Khachatryan >Priority: Major > Attachments: Screenshot_2022-05-09_10-35-57.png > > > http://codespeed.dak8s.net:8000/timeline/#/?exe=1&ben=checkpointSingleInput.UNALIGNED&extr=on&quarts=on&equid=off&env=2&revs=200 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] twalthr commented on a diff in pull request #19409: [FLINK-24577][table-planner] Implement Cast from BINARY to RAW
twalthr commented on code in PR #19409:
URL: https://github.com/apache/flink/pull/19409#discussion_r867767879
##
flink-table/flink-table-planner/src/main/java/org/apache/calcite/rex/RexSimplify.java:
##
@@ -2024,7 +2029,9 @@ private RexNode simplifySearch(RexCall call, RexUnknownAs
unknownAs) {
private RexNode simplifyCast(RexCall e) {
RexNode operand = e.getOperands().get(0);
operand = simplify(operand, UNKNOWN);
-if (sameTypeOrNarrowsNullability(e.getType(), operand.getType())) {
+if (sameTypeOrNarrowsNullability(e.getType(), operand.getType())
Review Comment:
The change in this line and in `RexLiteral` is a blocker for this PR in my
opinion. We should fix these things in Calcite first and only port the changes
to the Flink code base, once merged in Calcite.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] liuzhuang2017 opened a new pull request, #19678: Zh docs examples
liuzhuang2017 opened a new pull request, #19678: URL: https://github.com/apache/flink/pull/19678 ## What is the purpose of the change - Fix two inaccessible links in the Chinese documentation. ## Brief change log - Fix two inaccessible links in the Chinese documentation. ## Verifying this change - This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (**no**) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (**no**) - The serializers: (**no**) - The runtime per-record code paths (performance sensitive): (**no**) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (**no**) - The S3 file system connector: (**no**) ## Documentation - Does this pull request introduce a new feature? (**no**) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27555) Performance regression in schedulingDownstreamTasks on 02.05.2022
[ https://issues.apache.org/jira/browse/FLINK-27555?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533691#comment-17533691 ] Roman Khachatryan commented on FLINK-27555: --- [~mapohl] could you please take a look at this? cc: [~maguowei], [~chesnay] > Performance regression in schedulingDownstreamTasks on 02.05.2022 > - > > Key: FLINK-27555 > URL: https://issues.apache.org/jira/browse/FLINK-27555 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Runtime / Coordination >Affects Versions: 1.16.0 >Reporter: Roman Khachatryan >Priority: Major > Attachments: Screenshot_2022-05-09_10-33-11.png > > > http://codespeed.dak8s.net:8000/timeline/#/?exe=5&ben=schedulingDownstreamTasks.BATCH&extr=on&quarts=on&equid=off&env=2&revs=200 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] flinkbot commented on pull request #19678: Zh docs examples
flinkbot commented on PR #19678: URL: https://github.com/apache/flink/pull/19678#issuecomment-1120817816 ## CI report: * e0c614a9d035fea3ac36b38ec8d40fc92a6cbf9c UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] liuzhuang2017 commented on pull request #19678: Zh docs examples
liuzhuang2017 commented on PR #19678: URL: https://github.com/apache/flink/pull/19678#issuecomment-1120817838 @MartijnVisser , Sorry to bother you, can you help me review this pr? Thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27556) Performance regression in checkpointSingleInput.UNALIGNED on 29.04.2022
[ https://issues.apache.org/jira/browse/FLINK-27556?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533695#comment-17533695 ] Roman Khachatryan commented on FLINK-27556: --- [~akalashnikov] , [~dwysakowicz] could you please take a look at this? > Performance regression in checkpointSingleInput.UNALIGNED on 29.04.2022 > --- > > Key: FLINK-27556 > URL: https://issues.apache.org/jira/browse/FLINK-27556 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Runtime / Checkpointing >Affects Versions: 1.16.0 >Reporter: Roman Khachatryan >Priority: Major > Attachments: Screenshot_2022-05-09_10-35-57.png > > > http://codespeed.dak8s.net:8000/timeline/#/?exe=1&ben=checkpointSingleInput.UNALIGNED&extr=on&quarts=on&equid=off&env=2&revs=200 -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] ChengkaiYang2022 commented on pull request #19498: [FLINK-26588][docs]Translate the new CAST documentation to Chinese
ChengkaiYang2022 commented on PR #19498: URL: https://github.com/apache/flink/pull/19498#issuecomment-1120818878 The CI test faild because of some 'Test - finegrained_resource_management'? Not sure what that means. Should I rebase from master again? ![Uploading 屏幕截图 2022-05-09 164352.png…]() -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27552) Prometheus metrics disappear after starting a job
[
https://issues.apache.org/jira/browse/FLINK-27552?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533697#comment-17533697
]
Peter Schrott commented on FLINK-27552:
---
[~eskabetxe] if you have a KafkaSink, you need to disable the metrics for it
too.
> Prometheus metrics disappear after starting a job
> -
>
> Key: FLINK-27552
> URL: https://issues.apache.org/jira/browse/FLINK-27552
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Metrics
>Affects Versions: 1.15.0
>Reporter: João Boto
>Priority: Major
>
> I have a Standalone cluster (with jobmanager and taskmanager on same machine)
> on 1.14.4 and I'm testing the migration to 1.15.0
> But I keep losing the taskmanager metrics when I start a job on the 1.15
> cluster
> I use the same configuration as in the previous cluster
> {{ }}
> {code:java}
> metrics.reporters: prom
> metrics.reporter.prom.factory.class:
> org.apache.flink.metrics.prometheus.PrometheusReporterFactory
> metrics.reporter.prom.port: 9250-9251{code}
> {{ }}
> If the cluster is running without jobs I can see the metrics on port 9250 for
> jobmanager and on port 9251 for taskmanager
> If I start a job, the metrics from taskmanager disappear and if I stop the
> job the metrics come live again
> What am I missing?
>
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [flink] masteryhx commented on a diff in pull request #19598: [FLINK-25470][changelog] Expose more metrics of materialization
masteryhx commented on code in PR #19598: URL: https://github.com/apache/flink/pull/19598#discussion_r867776186 ## docs/content.zh/docs/ops/metrics.md: ## @@ -1277,7 +1277,7 @@ Note that the metrics are only available via reporters. - Job (only available on TaskManager) + Job (only available on TaskManager) Review Comment: Which you pointed out is just chinese version ? We are in content.zh currently ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-table-store] JingsongLi merged pull request #114: [FLINK-27542] Refactor E2eTestBase with docker compose
JingsongLi merged PR #114: URL: https://github.com/apache/flink-table-store/pull/114 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] liuzhuang2017 commented on pull request #19668: [hotfix][docs] Fix the formatting errors of some Chinese documents.
liuzhuang2017 commented on PR #19668: URL: https://github.com/apache/flink/pull/19668#issuecomment-1120821232 @MartijnVisser , Sorry to bother you, can you help me review this pr? Thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (FLINK-27542) Add end to end tests for Hive to read external table store files
[ https://issues.apache.org/jira/browse/FLINK-27542?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee closed FLINK-27542. Assignee: Caizhi Weng Resolution: Fixed master: ad9e09dbd9621ff2935f193c53a35b355c76fac6 > Add end to end tests for Hive to read external table store files > > > Key: FLINK-27542 > URL: https://issues.apache.org/jira/browse/FLINK-27542 > Project: Flink > Issue Type: Sub-task > Components: Table Store >Affects Versions: table-store-0.2.0 >Reporter: Caizhi Weng >Assignee: Caizhi Weng >Priority: Major > Labels: pull-request-available > Fix For: table-store-0.2.0 > > > To ensure that jar produced by flink-table-store-hive module can actually > work in real Hive system we need to add end to end tests. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Assigned] (FLINK-27346) [umbrella] Introduce Hive reader for table store
[ https://issues.apache.org/jira/browse/FLINK-27346?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee reassigned FLINK-27346: Assignee: Caizhi Weng > [umbrella] Introduce Hive reader for table store > > > Key: FLINK-27346 > URL: https://issues.apache.org/jira/browse/FLINK-27346 > Project: Flink > Issue Type: Improvement > Components: Table Store >Reporter: Jingsong Lee >Assignee: Caizhi Weng >Priority: Major > Fix For: table-store-0.2.0 > > > Add the ability of Hive engine to read table of Flink Table Store. > Currently the typical query engine is still the Hive engine. For storage, the > ecology of queries is very important. > We currently write an InputFormat for Hive, which requires us to: > - Organize code dependencies to avoid creating dependency conflicts with Hive > - some necessary refactoring to make the programming interface more generic > - Write the Hive InputFormat and implement some pushdown -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27552) Prometheus metrics disappear after starting a job
[
https://issues.apache.org/jira/browse/FLINK-27552?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533701#comment-17533701
]
João Boto commented on FLINK-27552:
---
nop, only a KafkaSource
the sink is a custom Jdbc implemented with sink2
> Prometheus metrics disappear after starting a job
> -
>
> Key: FLINK-27552
> URL: https://issues.apache.org/jira/browse/FLINK-27552
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Metrics
>Affects Versions: 1.15.0
>Reporter: João Boto
>Priority: Major
>
> I have a Standalone cluster (with jobmanager and taskmanager on same machine)
> on 1.14.4 and I'm testing the migration to 1.15.0
> But I keep losing the taskmanager metrics when I start a job on the 1.15
> cluster
> I use the same configuration as in the previous cluster
> {{ }}
> {code:java}
> metrics.reporters: prom
> metrics.reporter.prom.factory.class:
> org.apache.flink.metrics.prometheus.PrometheusReporterFactory
> metrics.reporter.prom.port: 9250-9251{code}
> {{ }}
> If the cluster is running without jobs I can see the metrics on port 9250 for
> jobmanager and on port 9251 for taskmanager
> If I start a job, the metrics from taskmanager disappear and if I stop the
> job the metrics come live again
> What am I missing?
>
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [flink] rkhachatryan commented on a diff in pull request #19598: [FLINK-25470][changelog] Expose more metrics of materialization
rkhachatryan commented on code in PR #19598: URL: https://github.com/apache/flink/pull/19598#discussion_r867784366 ## docs/content.zh/docs/ops/metrics.md: ## @@ -1277,7 +1277,7 @@ Note that the metrics are only available via reporters. - Job (only available on TaskManager) + Job (only available on TaskManager) Review Comment: Sorry, I meant to synchronize the both versions (in regard to this edit). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] fapaul merged pull request #19629: [FLINK-27480][kafka] Explain possible metrics InstanceAlreadyExistsException in docs
fapaul merged PR #19629: URL: https://github.com/apache/flink/pull/19629 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] fapaul merged pull request #19659: [FLINK-27480][kafka] Explain possible metrics InstanceAlreadyExistsException in docs
fapaul merged PR #19659: URL: https://github.com/apache/flink/pull/19659 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] fapaul merged pull request #19658: [FLINK-27480][kafka] Explain possible metrics InstanceAlreadyExistsException in docs
fapaul merged PR #19658: URL: https://github.com/apache/flink/pull/19658 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Resolved] (FLINK-27480) KafkaSources sharing the groupId might lead to InstanceAlreadyExistException warning
[ https://issues.apache.org/jira/browse/FLINK-27480?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Fabian Paul resolved FLINK-27480. - Fix Version/s: 1.16.0 1.14.5 1.15.1 Resolution: Fixed > KafkaSources sharing the groupId might lead to InstanceAlreadyExistException > warning > > > Key: FLINK-27480 > URL: https://issues.apache.org/jira/browse/FLINK-27480 > Project: Flink > Issue Type: Improvement > Components: Connectors / Kafka >Affects Versions: 1.15.0, 1.14.4, 1.16.0 >Reporter: Fabian Paul >Assignee: Fabian Paul >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0, 1.14.5, 1.15.1 > > > More and more frequently, users ran into an issue by not correctly > configuring the KafkaSource > ([https://stackoverflow.com/questions/72026997/flink-instancealreadyexistsexception-while-migrating-to-the-kafkasource)] > and setting non-distinguishable groupIds for the source. Internally the used > KafkaConsumer tries to register with the metric system and incorporates the > groupId as part of the metric, leading to name collision. > We should update the documentation to explain the situation properly. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27480) KafkaSources sharing the groupId might lead to InstanceAlreadyExistException warning
[ https://issues.apache.org/jira/browse/FLINK-27480?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533706#comment-17533706 ] Fabian Paul commented on FLINK-27480: - Merged in * master: f723242e2249b90da22867fde7f8fa99b3c9de98 * release-1.15: f92da27b486ee555ac70b923fad9ca8784914397 * release-1.14: df7206589f755d90950a3c6d1a986453faae6017 > KafkaSources sharing the groupId might lead to InstanceAlreadyExistException > warning > > > Key: FLINK-27480 > URL: https://issues.apache.org/jira/browse/FLINK-27480 > Project: Flink > Issue Type: Improvement > Components: Connectors / Kafka >Affects Versions: 1.15.0, 1.14.4, 1.16.0 >Reporter: Fabian Paul >Assignee: Fabian Paul >Priority: Major > Labels: pull-request-available > > More and more frequently, users ran into an issue by not correctly > configuring the KafkaSource > ([https://stackoverflow.com/questions/72026997/flink-instancealreadyexistsexception-while-migrating-to-the-kafkasource)] > and setting non-distinguishable groupIds for the source. Internally the used > KafkaConsumer tries to register with the metric system and incorporates the > groupId as part of the metric, leading to name collision. > We should update the documentation to explain the situation properly. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Closed] (FLINK-27480) KafkaSources sharing the groupId might lead to InstanceAlreadyExistException warning
[ https://issues.apache.org/jira/browse/FLINK-27480?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Fabian Paul closed FLINK-27480. --- > KafkaSources sharing the groupId might lead to InstanceAlreadyExistException > warning > > > Key: FLINK-27480 > URL: https://issues.apache.org/jira/browse/FLINK-27480 > Project: Flink > Issue Type: Improvement > Components: Connectors / Kafka >Affects Versions: 1.15.0, 1.14.4, 1.16.0 >Reporter: Fabian Paul >Assignee: Fabian Paul >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0, 1.14.5, 1.15.1 > > > More and more frequently, users ran into an issue by not correctly > configuring the KafkaSource > ([https://stackoverflow.com/questions/72026997/flink-instancealreadyexistsexception-while-migrating-to-the-kafkasource)] > and setting non-distinguishable groupIds for the source. Internally the used > KafkaConsumer tries to register with the metric system and incorporates the > groupId as part of the metric, leading to name collision. > We should update the documentation to explain the situation properly. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] matriv commented on a diff in pull request #19409: [FLINK-24577][table-planner] Implement Cast from BINARY to RAW
matriv commented on code in PR #19409:
URL: https://github.com/apache/flink/pull/19409#discussion_r867806761
##
flink-table/flink-table-planner/src/main/java/org/apache/calcite/rex/RexSimplify.java:
##
@@ -2024,7 +2029,9 @@ private RexNode simplifySearch(RexCall call, RexUnknownAs
unknownAs) {
private RexNode simplifyCast(RexCall e) {
RexNode operand = e.getOperands().get(0);
operand = simplify(operand, UNKNOWN);
-if (sameTypeOrNarrowsNullability(e.getType(), operand.getType())) {
+if (sameTypeOrNarrowsNullability(e.getType(), operand.getType())
Review Comment:
I've spent quite some time here, and couldn't find a workaround.
I could modify the PR and only allow it for TableAPI for the moment, and try
to fix this in Calcite first.
If it's accepted, have a follow up PR to enable this for SQL in flink.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] matriv commented on pull request #19262: [hotfix][table][tests] Improve code - use assertJ
matriv commented on PR #19262: URL: https://github.com/apache/flink/pull/19262#issuecomment-1120860830 thank you @twalthr! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-27543) Introduce StatsProducer to refactor code in DataFileWriter
[ https://issues.apache.org/jira/browse/FLINK-27543?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jingsong Lee reassigned FLINK-27543: Assignee: Zheng Hu > Introduce StatsProducer to refactor code in DataFileWriter > --- > > Key: FLINK-27543 > URL: https://issues.apache.org/jira/browse/FLINK-27543 > Project: Flink > Issue Type: Sub-task > Components: Table Store >Reporter: Jingsong Lee >Assignee: Zheng Hu >Priority: Major > Fix For: table-store-0.2.0 > > > Lots of `fileStatsExtractor == null` looks bad. > I think we can have a `StatsProducer` to unify `StatsExtractor` and > `StatsCollector`. To reduce caller complexity. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] MartijnVisser merged pull request #19668: [hotfix][docs] Fix the formatting errors of some Chinese documents.
MartijnVisser merged PR #19668: URL: https://github.com/apache/flink/pull/19668 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-ml] yunfengzhou-hub commented on a diff in pull request #86: [FLINK-27294] Add Transformer for BinaryClassificationEvaluator
yunfengzhou-hub commented on code in PR #86:
URL: https://github.com/apache/flink-ml/pull/86#discussion_r867784038
##
flink-ml-lib/src/main/java/org/apache/flink/ml/evaluation/binaryclassificationevaluator/BinaryClassificationEvaluatorParams.java:
##
@@ -0,0 +1,67 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.evaluation.binaryclassificationevaluator;
+
+import org.apache.flink.ml.common.param.HasLabelCol;
+import org.apache.flink.ml.common.param.HasRawPredictionCol;
+import org.apache.flink.ml.common.param.HasWeightCol;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.param.ParamValidators;
+import org.apache.flink.ml.param.StringArrayParam;
+
+/**
+ * Params of BinaryClassificationEvaluator.
+ *
+ * @param The class type of this instance.
+ */
+public interface BinaryClassificationEvaluatorParams
+extends HasLabelCol, HasRawPredictionCol, HasWeightCol {
+String AREA_UNDER_ROC = "areaUnderROC";
+String AREA_UNDER_PR = "areaUnderPR";
+String AREA_UNDER_LORENZ = "areaUnderLorenz";
+String KS = "ks";
+
+/**
+ * param for metric names in evaluation (supports 'areaUnderROC',
'areaUnderPR', 'KS' and
+ * 'areaUnderLorenz').
+ *
+ *
+ * areaUnderROC: the area under the receiver operating
characteristic (ROC) curve.
+ * areaUnderPR: the area under the precision-recall curve.
+ * ks: Kolmogorov-Smirnov, measures the ability of the model to
separate positive and
+ * negative samples.
+ * areaUnderLorenz: the area under the lorenz curve.
+ *
+ */
+Param METRICS_NAMES =
+new StringArrayParam(
+"metricsNames",
+"Names of output metrics. The array element must be
'areaUnderROC', 'areaUnderPR', 'ks' and 'areaUnderLorenz'",
Review Comment:
nit: it might be better to remove "The array element ...", since other
array-typed parameters, like `HasHandleInvalid` or `HasBatchStrategy` does not
contain this sentence.
##
flink-ml-lib/src/main/java/org/apache/flink/ml/evaluation/binaryclassificationevaluator/BinaryClassificationEvaluatorParams.java:
##
@@ -0,0 +1,67 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.evaluation.binaryclassificationevaluator;
Review Comment:
nit: Maybe `binaryclassification` makes a better package name, unless we
have something like `binaryclassificationregressor` or
`binaryclassificationscaler`.
##
flink-ml-lib/src/main/java/org/apache/flink/ml/evaluation/binaryclassificationevaluator/BinaryClassificationEvaluatorParams.java:
##
@@ -0,0 +1,67 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific l
[GitHub] [flink-kubernetes-operator] wangyang0918 commented on a diff in pull request #197: [FLINK-27412] Allow flinkVersion v1_13 in flink-kubernetes-operator
wangyang0918 commented on code in PR #197: URL: https://github.com/apache/flink-kubernetes-operator/pull/197#discussion_r867833143 ## e2e-tests/data/sessionjob-cr.yaml: ## @@ -76,7 +76,7 @@ metadata: spec: deploymentName: session-cluster-1 job: -jarURI: https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming_2.12/1.14.3/flink-examples-streaming_2.12-1.14.3.jar +jarURI: https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming_2.12/1.13.6/flink-examples-streaming_2.12-1.13.6.jar Review Comment: I prefer to still use the 1.14 by default in the e2e tests. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-26793) Flink Cassandra connector performance issue
[ https://issues.apache.org/jira/browse/FLINK-26793?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533731#comment-17533731 ] Etienne Chauchot commented on FLINK-26793: -- [~arvid] just to let you know, I have not forgotten the last task on this ticket to check if we can improve the code, I'm just waiting for the [cassandra upgrade PR|https://github.com/apache/flink/pull/19586] to be merged before testing the perf again and see if something can be improved > Flink Cassandra connector performance issue > > > Key: FLINK-26793 > URL: https://issues.apache.org/jira/browse/FLINK-26793 > Project: Flink > Issue Type: Improvement > Components: Connectors / Cassandra >Affects Versions: 1.14.4 >Reporter: Jay Ghiya >Assignee: Etienne Chauchot >Priority: Major > Attachments: Capture d’écran de 2022-04-14 16-34-59.png, Capture > d’écran de 2022-04-14 16-35-07.png, Capture d’écran de 2022-04-14 > 16-35-30.png, jobmanager_log.txt, taskmanager_127.0.1.1_33251-af56fa_log > > > A warning is observed during long runs of flink job stating “Insertions into > scylla might be suffering. Expect performance problems unless this is > resolved.” > Upon initial analysis - “flink cassandra connector is not keeping instance of > mapping manager that is used to convert a pojo to cassandra row. Ideally the > mapping manager should have the same life time as cluster and session objects > which are also created once when the driver is initialized” > Reference: > https://stackoverflow.com/questions/59203418/cassandra-java-driver-warning -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink-kubernetes-operator] wangyang0918 commented on a diff in pull request #197: [FLINK-27412] Allow flinkVersion v1_13 in flink-kubernetes-operator
wangyang0918 commented on code in PR #197:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/197#discussion_r867839436
##
.github/workflows/ci.yml:
##
@@ -143,10 +150,13 @@ jobs:
kubectl get pods
- name: Run Flink e2e tests
run: |
+ sed -i "s/image: flink:.*/image: ${{ matrix.versions.image }}/"
e2e-tests/data/*.yaml
+ sed -i "s/flinkVersion: .*/flinkVersion: ${{
matrix.versions.flinkVersion }}/" e2e-tests/data/*.yaml
ls e2e-tests/test_*.sh | while read script_test;do \
Review Comment:
I would like to add a `git diff HEAD` here to verify that the `sed` is
executed successfully.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] wangyang0918 commented on pull request #19675: [FLINK-27550] Remove checking yarn queues before submitting job to Yarn
wangyang0918 commented on PR #19675: URL: https://github.com/apache/flink/pull/19675#issuecomment-1120905406 I am not fully understand your problem. When using capacity scheduler, how do you specify the yarn queue when submitting a Flink job? `-Dyarn.application.queue=default` or `-Dyarn.application.queue=root.default`, I think both of them could work. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27552) Prometheus metrics disappear after starting a job
[
https://issues.apache.org/jira/browse/FLINK-27552?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533738#comment-17533738
]
Peter Schrott commented on FLINK-27552:
---
[~eskabetxe] oke! In the mailing list thread Cheasney also gave a way to
forward j.u.l. loggings to slf4j, so you could maybe investigate further.
> Prometheus metrics disappear after starting a job
> -
>
> Key: FLINK-27552
> URL: https://issues.apache.org/jira/browse/FLINK-27552
> Project: Flink
> Issue Type: Bug
> Components: Runtime / Metrics
>Affects Versions: 1.15.0
>Reporter: João Boto
>Priority: Major
>
> I have a Standalone cluster (with jobmanager and taskmanager on same machine)
> on 1.14.4 and I'm testing the migration to 1.15.0
> But I keep losing the taskmanager metrics when I start a job on the 1.15
> cluster
> I use the same configuration as in the previous cluster
> {{ }}
> {code:java}
> metrics.reporters: prom
> metrics.reporter.prom.factory.class:
> org.apache.flink.metrics.prometheus.PrometheusReporterFactory
> metrics.reporter.prom.port: 9250-9251{code}
> {{ }}
> If the cluster is running without jobs I can see the metrics on port 9250 for
> jobmanager and on port 9251 for taskmanager
> If I start a job, the metrics from taskmanager disappear and if I stop the
> job the metrics come live again
> What am I missing?
>
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (FLINK-27551) Consider implementing our own status update logic
[ https://issues.apache.org/jira/browse/FLINK-27551?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533740#comment-17533740 ] Yang Wang commented on FLINK-27551: --- It seems they would like to use "patch" instead of "lock-and-update" in the java-operator-sdk. After then, we will avoid the conflicts. Right? > Consider implementing our own status update logic > - > > Key: FLINK-27551 > URL: https://issues.apache.org/jira/browse/FLINK-27551 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Gyula Fora >Priority: Critical > > If a custom resource version is applied while in the middle of a reconcile > loop (for the same resource but previous version) the status update will > throw an error and re-trigger reconciliation. > In our case this might be problematic as it would mean we would retry > operations that are not necessarily retriable and might require manual user > intervention. > Please see: > [https://github.com/java-operator-sdk/java-operator-sdk/issues/1198] > I think we should consider implementing our own status update logic that is > independent of the current resource version to make the flow more robust. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] fsk119 commented on pull request #19498: [FLINK-26588][docs]Translate the new CAST documentation to Chinese
fsk119 commented on PR #19498: URL: https://github.com/apache/flink/pull/19498#issuecomment-1120930024 @ChengkaiYang2022 I think we should make a try. Seems the CI is not stable.. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] ChengkaiYang2022 commented on pull request #19498: [FLINK-26588][docs]Translate the new CAST documentation to Chinese
ChengkaiYang2022 commented on PR #19498: URL: https://github.com/apache/flink/pull/19498#issuecomment-1120936375 > @ChengkaiYang2022 I think we should make a try. Seems the CI is not stable.. Okay I will rebase again ASAP -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] ChengkaiYang2022 commented on pull request #19498: [FLINK-26588][docs]Translate the new CAST documentation to Chinese
ChengkaiYang2022 commented on PR #19498: URL: https://github.com/apache/flink/pull/19498#issuecomment-1120942976  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] ChengkaiYang2022 commented on pull request #19498: [FLINK-26588][docs]Translate the new CAST documentation to Chinese
ChengkaiYang2022 commented on PR #19498: URL: https://github.com/apache/flink/pull/19498#issuecomment-1120943147 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] xintongsong closed pull request #19676: [hotfix][docs] Mention changes of "RuntimeContext#getMetricGroup" in 1.14 release notes.
xintongsong closed pull request #19676: [hotfix][docs] Mention changes of "RuntimeContext#getMetricGroup" in 1.14 release notes. URL: https://github.com/apache/flink/pull/19676 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] twalthr closed pull request #19262: [hotfix][table][tests] Improve code - use assertJ
twalthr closed pull request #19262: [hotfix][table][tests] Improve code - use assertJ URL: https://github.com/apache/flink/pull/19262 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] liuzhuang2017 commented on pull request #19668: [hotfix][docs] Fix the formatting errors of some Chinese documents.
liuzhuang2017 commented on PR #19668: URL: https://github.com/apache/flink/pull/19668#issuecomment-1120962235 @MartijnVisser ,Thank you very much for your review. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] masteryhx opened a new pull request, #19679: [FLINK-23143][state/changelog] Support state migration for ChangelogS…
masteryhx opened a new pull request, #19679: URL: https://github.com/apache/flink/pull/19679 ## What is the purpose of the change This pull request makes Changelog support state migration. ## Brief change log - added `getOrCreateKeyedState(RegisteredKeyValueStateBackendMetaInfo metaInfo, StateDescriptor stateDesc)` in `KeyedStateBackend` - added `create(RegisteredPriorityQueueStateBackendMetaInfo metaInfo)` in `PriorityQueueSetFactory` ## Verifying this change - added `ChangelogStateBackendMigrationTest` ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? no -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-23143) Support state migration
[ https://issues.apache.org/jira/browse/FLINK-23143?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-23143: --- Labels: pull-request-available (was: ) > Support state migration > --- > > Key: FLINK-23143 > URL: https://issues.apache.org/jira/browse/FLINK-23143 > Project: Flink > Issue Type: Sub-task > Components: Runtime / State Backends >Reporter: Roman Khachatryan >Priority: Minor > Labels: pull-request-available > Fix For: 1.16.0 > > > ChangelogKeyedStateBackend.getOrCreateKeyedState is currently used during > recovery; on 1st user access, it doesn't update metadata nor migrate state > (as opposed to other backends). > > The proposed solution is to > # wrap serializers (and maybe other objects) in getOrCreateKeyedState > # store wrapping objects in a new map keyed by state name > # pass wrapped objects to delegatedBackend.createInternalState > # on 1st user access, lookup wrapper and upgrade its wrapped serializer > This should be done for both KV/PQ states. > > See also [https://github.com/apache/flink/pull/15420#discussion_r656934791] > > cc: [~yunta] -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] flinkbot commented on pull request #19679: [FLINK-23143][state/changelog] Support state migration for ChangelogS…
flinkbot commented on PR #19679: URL: https://github.com/apache/flink/pull/19679#issuecomment-1120967080 ## CI report: * eab98cfce9e1c18c41cc94256d0e670661b04237 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-23143) Support state migration
[
https://issues.apache.org/jira/browse/FLINK-23143?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533756#comment-17533756
]
Hangxiang Yu commented on FLINK-23143:
--
[~roman]
Sure, I just pushed my draft as you could see.
Another problem is the key serializer:
# If the materialization part is empty, the key serializer will not be
updated/check-compatibility. But the key serializer will be used to deserialize
state in non-materialization part which will cause exception if the key
serializer have changed.
# For the non-materialization part, we may need to store its key serializer
when snapshot and read the key serializer before build the delegated keyed
state backend and changelog keyed state backend. But in the solution, we may
need to change the process of {{ChangelogBackendRestoreOperation#restore}} .
Do you have any other better ideas about it ? Thanks a lot!
> Support state migration
> ---
>
> Key: FLINK-23143
> URL: https://issues.apache.org/jira/browse/FLINK-23143
> Project: Flink
> Issue Type: Sub-task
> Components: Runtime / State Backends
>Reporter: Roman Khachatryan
>Priority: Minor
> Labels: pull-request-available
> Fix For: 1.16.0
>
>
> ChangelogKeyedStateBackend.getOrCreateKeyedState is currently used during
> recovery; on 1st user access, it doesn't update metadata nor migrate state
> (as opposed to other backends).
>
> The proposed solution is to
> # wrap serializers (and maybe other objects) in getOrCreateKeyedState
> # store wrapping objects in a new map keyed by state name
> # pass wrapped objects to delegatedBackend.createInternalState
> # on 1st user access, lookup wrapper and upgrade its wrapped serializer
> This should be done for both KV/PQ states.
>
> See also [https://github.com/apache/flink/pull/15420#discussion_r656934791]
>
> cc: [~yunta]
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Updated] (FLINK-27544) Example code in 'Structure of Table API and SQL Programs' is out of date and cannot run
[
https://issues.apache.org/jira/browse/FLINK-27544?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Chengkai Yang updated FLINK-27544:
--
Affects Version/s: 1.14.3
1.14.2
1.14.0
> Example code in 'Structure of Table API and SQL Programs' is out of date and
> cannot run
> ---
>
> Key: FLINK-27544
> URL: https://issues.apache.org/jira/browse/FLINK-27544
> Project: Flink
> Issue Type: Improvement
> Components: Documentation
>Affects Versions: 1.14.0, 1.15.0, 1.14.2, 1.14.3, 1.14.4
>Reporter: Chengkai Yang
>Priority: Major
>
> The example code in [Structure of Table API and SQL
> Programs|https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/common/#structure-of-table-api-and-sql-programs]
> of ['Concepts & Common
> API'|https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/common/]
> is out of date and when user run this piece of code, they will get the
> following result:
> {code:java}
> Exception in thread "main" org.apache.flink.table.api.ValidationException:
> Unable to create a sink for writing table
> 'default_catalog.default_database.SinkTable'.
> Table options are:
> 'connector'='blackhole'
> 'rows-per-second'='1'
> at
> org.apache.flink.table.factories.FactoryUtil.createDynamicTableSink(FactoryUtil.java:262)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.getTableSink(PlannerBase.scala:421)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.translateToRel(PlannerBase.scala:222)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.$anonfun$translate$1(PlannerBase.scala:178)
> at
> scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:233)
> at scala.collection.Iterator.foreach(Iterator.scala:937)
> at scala.collection.Iterator.foreach$(Iterator.scala:937)
> at scala.collection.AbstractIterator.foreach(Iterator.scala:1425)
> at scala.collection.IterableLike.foreach(IterableLike.scala:70)
> at scala.collection.IterableLike.foreach$(IterableLike.scala:69)
> at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
> at scala.collection.TraversableLike.map(TraversableLike.scala:233)
> at scala.collection.TraversableLike.map$(TraversableLike.scala:226)
> at scala.collection.AbstractTraversable.map(Traversable.scala:104)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.translate(PlannerBase.scala:178)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.translate(TableEnvironmentImpl.java:1656)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:782)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:861)
> at
> org.apache.flink.table.api.internal.TablePipelineImpl.execute(TablePipelineImpl.java:56)
> at com.yck.TestTableAPI.main(TestTableAPI.java:43)
> Caused by: org.apache.flink.table.api.ValidationException: Unsupported
> options found for 'blackhole'.
> Unsupported options:
> rows-per-second
> Supported options:
> connector
> property-version
> at
> org.apache.flink.table.factories.FactoryUtil.validateUnconsumedKeys(FactoryUtil.java:624)
> at
> org.apache.flink.table.factories.FactoryUtil$FactoryHelper.validate(FactoryUtil.java:914)
> at
> org.apache.flink.table.factories.FactoryUtil$TableFactoryHelper.validate(FactoryUtil.java:978)
> at
> org.apache.flink.connector.blackhole.table.BlackHoleTableSinkFactory.createDynamicTableSink(BlackHoleTableSinkFactory.java:64)
> at
> org.apache.flink.table.factories.FactoryUtil.createDynamicTableSink(FactoryUtil.java:259)
> ... 19 more
> {code}
> I think this mistake would drive users crazy when they first fry Table API &
> Flink SQL since this is the very first code they see.
> Overall this code is outdated in two places:
> 1. The Query creating temporary table should be
> {code:sql}
> CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'blackhole') LIKE
> SourceTable (EXCLUDING OPTIONS)
> {code}
> instead of
> {code:sql}
> CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'blackhole') LIKE
> SourceTable
> {code} which missed {code:sql}
> (EXCLUDING OPTIONS)
> {code} sql_like_pattern
> 2. The part creating a source table should be
> {code:java}
> tableEnv.createTemporaryTable("SourceTable",
> TableDescriptor.forConnector("datagen")
> .schema(Schema.newBuilder()
> .column("f0", DataTypes.STRING())
> .build())
> .option(DataGenConnectorOptions.ROWS_PER_SECOND, 1L)
> .build
[jira] [Updated] (FLINK-27261) Disable web.cancel.enable for session cluster
[
https://issues.apache.org/jira/browse/FLINK-27261?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-27261:
---
Labels: pull-request-available starter (was: starter)
> Disable web.cancel.enable for session cluster
> -
>
> Key: FLINK-27261
> URL: https://issues.apache.org/jira/browse/FLINK-27261
> Project: Flink
> Issue Type: Improvement
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Assignee: Nicholas Jiang
>Priority: Major
> Labels: pull-request-available, starter
>
> In FLINK-27154, we disable {{web.cancel.enable}} for application cluster. We
> should also do this for session cluster.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [flink-kubernetes-operator] SteNicholas opened a new pull request, #198: [FLINK-27261] Disable web.cancel.enable for session cluster
SteNicholas opened a new pull request, #198: URL: https://github.com/apache/flink-kubernetes-operator/pull/198 In [FLINK-27154](https://issues.apache.org/jira/browse/FLINK-27154), we disable `web.cancel.enable` for application cluster. We should also do this for session cluster. **The brief change log** - Sets `web.cancel.enable` to false at default in `FlinkConfigBuilder` to avoid users accidentally cancelling jobs. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27551) Consider implementing our own status update logic
[ https://issues.apache.org/jira/browse/FLINK-27551?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533761#comment-17533761 ] Gyula Fora commented on FLINK-27551: [~wangyang0918] Yes you are right this is due to the locking behaviour, this might be fixed in the josdk 2.1.3, I will test. But still I think we should consider making FlinkDeployment status updates manually also. There are cases where we need to persist information into the status before we can proceed. For this we would now need to retrigger reconciliation with an intermediate state persisted (such as storing last savepoint info before shutting down a failed cluster). In these cases we should simply make the status update ourself. This would simplify the logic and eliminate some corner cases . > Consider implementing our own status update logic > - > > Key: FLINK-27551 > URL: https://issues.apache.org/jira/browse/FLINK-27551 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Gyula Fora >Priority: Critical > > If a custom resource version is applied while in the middle of a reconcile > loop (for the same resource but previous version) the status update will > throw an error and re-trigger reconciliation. > In our case this might be problematic as it would mean we would retry > operations that are not necessarily retriable and might require manual user > intervention. > Please see: > [https://github.com/java-operator-sdk/java-operator-sdk/issues/1198] > I think we should consider implementing our own status update logic that is > independent of the current resource version to make the flow more robust. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Updated] (FLINK-27457) CassandraOutputFormats should support flush
[ https://issues.apache.org/jira/browse/FLINK-27457?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-27457: --- Labels: pull-request-available (was: ) > CassandraOutputFormats should support flush > --- > > Key: FLINK-27457 > URL: https://issues.apache.org/jira/browse/FLINK-27457 > Project: Flink > Issue Type: Improvement > Components: Connectors / Cassandra >Reporter: Etienne Chauchot >Assignee: Etienne Chauchot >Priority: Major > Labels: pull-request-available > > When migrating to Cassandra 4.x in [this > PR|https://github.com/apache/flink/pull/19586] a race condition in the tests > between the asynchronous writes and the junit assertions was uncovered. So it > was decided to introduce the flush mechanism to asynchronous writes in the > Cassandra output formats similarly to what was done in Cassandra sinks. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] echauchot opened a new pull request, #19680: [FLINK-27457] Implement flush() logic in Cassandra output formats
echauchot opened a new pull request, #19680: URL: https://github.com/apache/flink/pull/19680 ## What is the purpose of the change When migrating to Cassandra 4.x in [this PR](https://github.com/apache/flink/pull/19586) a race condition in the tests between the asynchronous writes and the junit assertions was uncovered. So it was decided to introduce the flush mechanism to asynchronous writes in the Cassandra output formats similarly to what was done in Cassandra sinks. ## Brief change log The existing class `CassandraOutputFormatBase` that was previously used as a base class only for Tuple and Row outputFormats is now used as a base class for the 3 output formats including Pojo. the base class for column based output formats (tuple and row) is now a new class called CassandraColumnarOutputFormatBase. Regarding configuration of the flush I preferred using simple setters to a configuration object as there was no builders for the output formats. Regarding other modules: I extracted a utility method for semaphore management (SinkUtils) because it is used by both sinks and output formats now. And I also had to change the exceptions thrown in OutputFormat as some methods can now throw TimeoutException and InterruptedException because of the flush mechanism. I think it is ok as this interface is not user facing. ## Verifying this change This change is already covered by existing ITCAse tests This change added UTests for the flush mechanism and can be verified as follows: CassandraOutputFormatBaseTest ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): adding semaphore permit management + flush on close - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? yes - If yes, how is the feature documented? javadocs -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #19680: [FLINK-27457] Implement flush() logic in Cassandra output formats
flinkbot commented on PR #19680: URL: https://github.com/apache/flink/pull/19680#issuecomment-1120982216 ## CI report: * 6485a7ae38abe5421eab32e008ad3f7abf971394 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] fapaul commented on a diff in pull request #19655: [FLINK-27527] Create a file-based upsert sink for testing internal components
fapaul commented on code in PR #19655:
URL: https://github.com/apache/flink/pull/19655#discussion_r867894179
##
flink-connectors/flink-connector-upsert-test/pom.xml:
##
@@ -0,0 +1,151 @@
+
+
+http://maven.apache.org/POM/4.0.0";
+xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance";
+xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd";>
+
+ flink-connectors
+ org.apache.flink
+ 1.16-SNAPSHOT
+
+ 4.0.0
+
+ flink-connector-upsert-test
+ Flink : Connectors : Upsert Test
+
+ jar
+
+
+
+
+
+
+ org.apache.flink
+ flink-connector-base
+ ${project.version}
+
+
+
+ org.apache.flink
+ flink-streaming-java
+ ${project.version}
+ provided
+
+
+
+ org.apache.flink
+ flink-table-api-java-bridge
+ ${project.version}
+ provided
+ true
+
+
+
+
+
+ org.apache.flink
+ flink-test-utils
+ ${project.version}
+ test
+
+
+
+ org.apache.flink
+ flink-connector-test-utils
+ ${project.version}
+ test
+
+
+
+ org.apache.flink
+ flink-streaming-java
+ ${project.version}
+ test-jar
+ test
+
+
+
+ org.apache.flink
+ flink-table-common
+ ${project.version}
+ test-jar
+ test
+
+
+
+ org.apache.flink
+
flink-table-planner_${scala.binary.version}
+ ${project.version}
+ test
+
+
+
+ org.apache.flink
+ flink-json
+ ${project.version}
+ test
+
+
+
+
+
+ org.apache.flink
+ flink-architecture-tests-test
+ test
+
+
+
+
+
+
+
+ org.apache.maven.plugins
+ maven-jar-plugin
+
+
+
+ test-jar
Review Comment:
Why do you need to build a test-jar?
##
flink-connectors/flink-connector-upsert-test/src/main/java/org/apache/flink/connector/upserttest/table/UpsertTestDynamicTableSink.java:
##
@@ -0,0 +1,119 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.connector.upserttest.table;
+
+import org.apache.flink.annotation.Internal;
+import org.apache.flink.api.common.serialization.SerializationSchema;
+import org.apache.flink.connector.upserttest.sink.UpsertTestSink;
+import org.apache.flink.table.connector.ChangelogMode;
+import org.apache.flink.table.connector.format.EncodingFormat;
+import org.apache.flink.table.connector.sink.DynamicTableSink;
+import org.apache.flink.table.connector.sink.SinkV2Provider;
+import org.apache.flink.table.data.RowData;
+import org.apache.flink.table.types.DataType;
+import org.apache.flink.types.RowKind;
+
+import java.io.File;
+import java.util.Objects;
+
+import static org.apache.flink.util.Preconditions.checkNotNull;
+
+/**
+ * A {@link DynamicTableSink} that describes how to create a {@link
UpsertTestSink} from a logical
+ * des
[jira] [Assigned] (FLINK-26981) [Umbrella] Make Flink work on Apple M1 ARM chipset
[ https://issues.apache.org/jira/browse/FLINK-26981?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Martijn Visser reassigned FLINK-26981: -- Assignee: Martijn Visser > [Umbrella] Make Flink work on Apple M1 ARM chipset > -- > > Key: FLINK-26981 > URL: https://issues.apache.org/jira/browse/FLINK-26981 > Project: Flink > Issue Type: Technical Debt > Components: Build System >Reporter: Martijn Visser >Assignee: Martijn Visser >Priority: Major > > There are currently multiple reported issues reported when compiling/using > Flink on Apple M1 ARM chipsets. This ticket serves as an umbrella ticket to > keep track of all of them. Help from the community on identifying and > resolving these issues are much appreciated. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] ChengkaiYang2022 opened a new pull request, #19681: [FLINK-27544][docs]Example code in 'Structure of Table API and SQL Programs' is out of date and cannot run.
ChengkaiYang2022 opened a new pull request, #19681: URL: https://github.com/apache/flink/pull/19681 ## What is the purpose of the change Update outdated code in the example, for more details please [FLINK-27544 on jira](https://issues.apache.org/jira/browse/FLINK-27544?page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel&focusedCommentId=17533584#comment-17533584) ## Brief change log Edit example code in common.md in content\docs\dev\table and content.zh\docs\dev\table ## Verifying this change Please make sure both new and modified tests in this PR follows the conventions defined in our code quality guide: https://flink.apache.org/contributing/code-style-and-quality-common.html#testing This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) no - The serializers: (yes / no / don't know) no - The runtime per-record code paths (performance sensitive): (yes / no / don't know) no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / no / don't know) no - The S3 file system connector: (yes / no / don't know) no ## Documentation - Does this pull request introduce a new feature? (yes / no) no - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27544) Example code in 'Structure of Table API and SQL Programs' is out of date and cannot run
[
https://issues.apache.org/jira/browse/FLINK-27544?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-27544:
---
Labels: pull-request-available (was: )
> Example code in 'Structure of Table API and SQL Programs' is out of date and
> cannot run
> ---
>
> Key: FLINK-27544
> URL: https://issues.apache.org/jira/browse/FLINK-27544
> Project: Flink
> Issue Type: Improvement
> Components: Documentation
>Affects Versions: 1.14.0, 1.15.0, 1.14.2, 1.14.3, 1.14.4
>Reporter: Chengkai Yang
>Priority: Major
> Labels: pull-request-available
>
> The example code in [Structure of Table API and SQL
> Programs|https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/common/#structure-of-table-api-and-sql-programs]
> of ['Concepts & Common
> API'|https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/common/]
> is out of date and when user run this piece of code, they will get the
> following result:
> {code:java}
> Exception in thread "main" org.apache.flink.table.api.ValidationException:
> Unable to create a sink for writing table
> 'default_catalog.default_database.SinkTable'.
> Table options are:
> 'connector'='blackhole'
> 'rows-per-second'='1'
> at
> org.apache.flink.table.factories.FactoryUtil.createDynamicTableSink(FactoryUtil.java:262)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.getTableSink(PlannerBase.scala:421)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.translateToRel(PlannerBase.scala:222)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.$anonfun$translate$1(PlannerBase.scala:178)
> at
> scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:233)
> at scala.collection.Iterator.foreach(Iterator.scala:937)
> at scala.collection.Iterator.foreach$(Iterator.scala:937)
> at scala.collection.AbstractIterator.foreach(Iterator.scala:1425)
> at scala.collection.IterableLike.foreach(IterableLike.scala:70)
> at scala.collection.IterableLike.foreach$(IterableLike.scala:69)
> at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
> at scala.collection.TraversableLike.map(TraversableLike.scala:233)
> at scala.collection.TraversableLike.map$(TraversableLike.scala:226)
> at scala.collection.AbstractTraversable.map(Traversable.scala:104)
> at
> org.apache.flink.table.planner.delegation.PlannerBase.translate(PlannerBase.scala:178)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.translate(TableEnvironmentImpl.java:1656)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:782)
> at
> org.apache.flink.table.api.internal.TableEnvironmentImpl.executeInternal(TableEnvironmentImpl.java:861)
> at
> org.apache.flink.table.api.internal.TablePipelineImpl.execute(TablePipelineImpl.java:56)
> at com.yck.TestTableAPI.main(TestTableAPI.java:43)
> Caused by: org.apache.flink.table.api.ValidationException: Unsupported
> options found for 'blackhole'.
> Unsupported options:
> rows-per-second
> Supported options:
> connector
> property-version
> at
> org.apache.flink.table.factories.FactoryUtil.validateUnconsumedKeys(FactoryUtil.java:624)
> at
> org.apache.flink.table.factories.FactoryUtil$FactoryHelper.validate(FactoryUtil.java:914)
> at
> org.apache.flink.table.factories.FactoryUtil$TableFactoryHelper.validate(FactoryUtil.java:978)
> at
> org.apache.flink.connector.blackhole.table.BlackHoleTableSinkFactory.createDynamicTableSink(BlackHoleTableSinkFactory.java:64)
> at
> org.apache.flink.table.factories.FactoryUtil.createDynamicTableSink(FactoryUtil.java:259)
> ... 19 more
> {code}
> I think this mistake would drive users crazy when they first fry Table API &
> Flink SQL since this is the very first code they see.
> Overall this code is outdated in two places:
> 1. The Query creating temporary table should be
> {code:sql}
> CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'blackhole') LIKE
> SourceTable (EXCLUDING OPTIONS)
> {code}
> instead of
> {code:sql}
> CREATE TEMPORARY TABLE SinkTable WITH ('connector' = 'blackhole') LIKE
> SourceTable
> {code} which missed {code:sql}
> (EXCLUDING OPTIONS)
> {code} sql_like_pattern
> 2. The part creating a source table should be
> {code:java}
> tableEnv.createTemporaryTable("SourceTable",
> TableDescriptor.forConnector("datagen")
> .schema(Schema.newBuilder()
> .column("f0", DataTypes.STRING())
> .build())
> .option(DataGenConnectorOptions.ROWS_PER_SECOND, 1L)
> .bui
[GitHub] [flink] ChengkaiYang2022 commented on pull request #19681: [FLINK-27544][docs]Example code in 'Structure of Table API and SQL Programs' is out of date and cannot run.
ChengkaiYang2022 commented on PR #19681: URL: https://github.com/apache/flink/pull/19681#issuecomment-1121008061 The test code is in my [github Repository(version 1.15)](https://github.com/ChengkaiYang2022/flink-test/blob/main/flink115/src/main/java/com/yck/TestTableAPI.java#L22) and [version 1.14](https://github.com/ChengkaiYang2022/flink-test/blob/main/flink114/src/main/java/com/yck/TestTableAPI.java) which are also mentioned in JIRA. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #19681: [FLINK-27544][docs]Example code in 'Structure of Table API and SQL Programs' is out of date and cannot run.
flinkbot commented on PR #19681: URL: https://github.com/apache/flink/pull/19681#issuecomment-1121007346 ## CI report: * e53da2a6dc1a9de7caebf1219305cfd198cd6386 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] ChengkaiYang2022 commented on pull request #19681: [FLINK-27544][docs]Example code in 'Structure of Table API and SQL Programs' is out of date and cannot run.
ChengkaiYang2022 commented on PR #19681: URL: https://github.com/apache/flink/pull/19681#issuecomment-1121010697 Hi, @RocMarshal I found some outdated code in the document, would you mind take a look at this?For more details you can check the jira page -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] JingGe commented on pull request #19664: [hotfix][doc] add content for using numRecordsSend and deprecating numRecordsOutErrors
JingGe commented on PR #19664: URL: https://github.com/apache/flink/pull/19664#issuecomment-1121011528 Thanks for your feedback @fapaul , I addressed your comments, please let me know your thoughts. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (FLINK-27551) Consider implementing our own status update logic
[ https://issues.apache.org/jira/browse/FLINK-27551?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gyula Fora reassigned FLINK-27551: -- Assignee: Gyula Fora > Consider implementing our own status update logic > - > > Key: FLINK-27551 > URL: https://issues.apache.org/jira/browse/FLINK-27551 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Gyula Fora >Assignee: Gyula Fora >Priority: Critical > > If a custom resource version is applied while in the middle of a reconcile > loop (for the same resource but previous version) the status update will > throw an error and re-trigger reconciliation. > In our case this might be problematic as it would mean we would retry > operations that are not necessarily retriable and might require manual user > intervention. > Please see: > [https://github.com/java-operator-sdk/java-operator-sdk/issues/1198] > I think we should consider implementing our own status update logic that is > independent of the current resource version to make the flow more robust. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27539) support consuming update and delete changes In Windowing TVFs
[
https://issues.apache.org/jira/browse/FLINK-27539?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533783#comment-17533783
]
Martijn Visser commented on FLINK-27539:
[~hjw] Could you explain your use case for this? I don't see how you could want
to change the outcome of a previous window result. It would mean that any given
result could be changed at any moment in time. I'm curious what [~jingzhang]
thinks on this.
> support consuming update and delete changes In Windowing TVFs
> -
>
> Key: FLINK-27539
> URL: https://issues.apache.org/jira/browse/FLINK-27539
> Project: Flink
> Issue Type: Improvement
> Components: Table SQL / API
>Affects Versions: 1.15.0
>Reporter: hjw
>Priority: Major
>
> custom_kafka is a cdc table
> sql:
> {code:java}
> select DATE_FORMAT(window_end,'-MM-dd') as date_str,sum(money) as
> total,name
> from TABLE(CUMULATE(TABLE custom_kafka,descriptor(createtime),interval '1'
> MINUTES,interval '1' DAY ))
> where status='1'
> group by name,window_start,window_end;
> {code}
> Error
> {code:java}
> Exception in thread "main" org.apache.flink.table.api.TableException:
> StreamPhysicalWindowAggregate doesn't support consuming update and delete
> changes which is produced by node TableSourceScan(table=[[default_catalog,
> default_database, custom_kafka, watermark=[-(createtime, 5000:INTERVAL
> SECOND)]]], fields=[name, money, status, createtime, operation_ts])
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTraitVisitor.createNewNode(FlinkChangelogModeInferenceProgram.scala:396)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTraitVisitor.visit(FlinkChangelogModeInferenceProgram.scala:315)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTraitVisitor.visitChild(FlinkChangelogModeInferenceProgram.scala:353)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTraitVisitor.$anonfun$visitChildren$1(FlinkChangelogModeInferenceProgram.scala:342)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTraitVisitor.$anonfun$visitChildren$1$adapted(FlinkChangelogModeInferenceProgram.scala:341)
> at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:233)
> at scala.collection.immutable.Range.foreach(Range.scala:155)
> at scala.collection.TraversableLike.map(TraversableLike.scala:233)
> at scala.collection.TraversableLike.map$(TraversableLike.scala:226)
> at scala.collection.AbstractTraversable.map(Traversable.scala:104)
> at
> org.apache.flink.table.planner.plan.optimize.program.FlinkChangelogModeInferenceProgram$SatisfyModifyKindSetTraitVisitor.visitChildren(FlinkChangelogModeInferenceProgram.scala:341)
> {code}
> But I found Group Window Aggregation is works when use cdc table
> {code:java}
> select DATE_FORMAT(TUMBLE_END(createtime,interval '10' MINUTES),'-MM-dd')
> as date_str,sum(money) as total,name
> from custom_kafka
> where status='1'
> group by name,TUMBLE(createtime,interval '10' MINUTES)
> {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [flink] deadwind4 opened a new pull request, #19682: [FLINK-25795][python][connector/pulsar] Add pulsar sink DataStream API
deadwind4 opened a new pull request, #19682: URL: https://github.com/apache/flink/pull/19682 ## What is the purpose of the change There is no python pulsar sink API. ## Brief change log Add python pulsar sink. ## Verifying this change This change added tests and can be verified as follows: *(example:)* - *Added test that validates sink configuration* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (no) - The S3 file system connector: (n ) ## Documentation - Does this pull request introduce a new feature? (yes) - If yes, how is the feature documented? (PyDocs) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-25795) Support Pulsar sink connector in Python DataStream API.
[ https://issues.apache.org/jira/browse/FLINK-25795?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-25795: --- Labels: pull-request-available (was: ) > Support Pulsar sink connector in Python DataStream API. > --- > > Key: FLINK-25795 > URL: https://issues.apache.org/jira/browse/FLINK-25795 > Project: Flink > Issue Type: New Feature > Components: API / Python, Connectors / Pulsar >Affects Versions: 1.14.3 >Reporter: LuNng Wang >Assignee: LuNng Wang >Priority: Major > Labels: pull-request-available > > https://issues.apache.org/jira/browse/FLINK-20732 the PR of this ticket is > reviewd, we could develop Python Pulsar sink. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] flinkbot commented on pull request #19682: [FLINK-25795][python][connector/pulsar] Add pulsar sink DataStream API
flinkbot commented on PR #19682: URL: https://github.com/apache/flink/pull/19682#issuecomment-1121038475 ## CI report: * 98e1d5b3da03a11416e7247cc7360900d494efff UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] echauchot commented on pull request #19586: [FLINK-26824] [FLINK-27457] Upgrade Flink's supported Cassandra versions to match all Apache Cassandra supported versions and support flush
echauchot commented on PR #19586: URL: https://github.com/apache/flink/pull/19586#issuecomment-1121050292 > Please note that the existing class `CassandraOutputFormatBase` that was previously used as a base class only for Tuple and Row outputFormats is now used as a base class for the 3 output formats including Pojo. the base class for column based output formats (tuple and row) is now a new class called `CassandraColumnarOutputFormatBase`. > Regarding configuration of the flush I preferred using simple setters to a configuration object as there was no builders for the output formats. > Regarding other modules: I extracted a utility method for semaphore management (SinkUtils) because it is used by both sinks and output formats now. And I also had to change the exceptions thrown in `OutputFormat` as some methods can now throw `TimeoutException` and `InterruptedException` because of the flush mechanism. I think it is ok as this interface is not user facing. I just opened: https://github.com/apache/flink/pull/19680 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] echauchot commented on pull request #19680: [FLINK-27457] Implement flush() logic in Cassandra output formats
echauchot commented on PR #19680: URL: https://github.com/apache/flink/pull/19680#issuecomment-1121050723 R @zentol -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] echauchot commented on pull request #19586: [FLINK-26824] [FLINK-27457] Upgrade Flink's supported Cassandra versions to match all Apache Cassandra supported versions and support flush
echauchot commented on PR #19586: URL: https://github.com/apache/flink/pull/19586#issuecomment-1121051329 > > I could be in that case the uncovered race condition won't be fixed. So the output formats tests would fail on cassandra 4.0 between the two PR merges. I guess if we merge the two PRs almost at the same time, it won't be a problem > > We would naturally first merge the flushing changes, and then rebase this PR on top of that. I just opened: https://github.com/apache/flink/pull/19680 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] echauchot commented on pull request #19586: [FLINK-26824] Upgrade Flink's supported Cassandra versions to match all Apache Cassandra supported versions
echauchot commented on PR #19586: URL: https://github.com/apache/flink/pull/19586#issuecomment-1121062218 @zentol I dropped the flush commits. So, race condition is back. Waiting for the other PR merge to rebase this one. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27556) Performance regression in checkpointSingleInput.UNALIGNED on 29.04.2022
[ https://issues.apache.org/jira/browse/FLINK-27556?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17533795#comment-17533795 ] Anton Kalashnikov commented on FLINK-27556: --- I will take a look > Performance regression in checkpointSingleInput.UNALIGNED on 29.04.2022 > --- > > Key: FLINK-27556 > URL: https://issues.apache.org/jira/browse/FLINK-27556 > Project: Flink > Issue Type: Bug > Components: Benchmarks, Runtime / Checkpointing >Affects Versions: 1.16.0 >Reporter: Roman Khachatryan >Priority: Major > Attachments: Screenshot_2022-05-09_10-35-57.png > > > http://codespeed.dak8s.net:8000/timeline/#/?exe=1&ben=checkpointSingleInput.UNALIGNED&extr=on&quarts=on&equid=off&env=2&revs=200 -- This message was sent by Atlassian Jira (v8.20.7#820007)