[jira] [Commented] (FLINK-21966) Support Kinesis connector in Python DataStream API.
[ https://issues.apache.org/jira/browse/FLINK-21966?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543794#comment-17543794 ] Dian Fu commented on FLINK-21966: - [~pemide] Thanks for the offering. I have assigned it to you~ > Support Kinesis connector in Python DataStream API. > --- > > Key: FLINK-21966 > URL: https://issues.apache.org/jira/browse/FLINK-21966 > Project: Flink > Issue Type: Sub-task > Components: API / Python >Reporter: Shuiqiang Chen >Assignee: pengmd >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Assigned] (FLINK-21966) Support Kinesis connector in Python DataStream API.
[ https://issues.apache.org/jira/browse/FLINK-21966?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Dian Fu reassigned FLINK-21966: --- Assignee: pengmd > Support Kinesis connector in Python DataStream API. > --- > > Key: FLINK-21966 > URL: https://issues.apache.org/jira/browse/FLINK-21966 > Project: Flink > Issue Type: Sub-task > Components: API / Python >Reporter: Shuiqiang Chen >Assignee: pengmd >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] chucheng92 commented on pull request #19827: [FLINK-27806][table] Support binary & varbinary types in datagen connector
chucheng92 commented on PR #19827: URL: https://github.com/apache/flink/pull/19827#issuecomment-1140769198 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] chucheng92 commented on pull request #19827: [FLINK-27806][table] Support binary & varbinary types in datagen connector
chucheng92 commented on PR #19827: URL: https://github.com/apache/flink/pull/19827#issuecomment-1140768985 @wuchong can u help me to review this pr? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] chucheng92 commented on pull request #19827: [FLINK-27806][table] Support binary & varbinary types in datagen connector
chucheng92 commented on PR #19827: URL: https://github.com/apache/flink/pull/19827#issuecomment-1140768703 @flinkbot attention @wuchong @lirui-apache -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-21966) Support Kinesis connector in Python DataStream API.
[ https://issues.apache.org/jira/browse/FLINK-21966?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543792#comment-17543792 ] pengmd commented on FLINK-21966: [~dianfu] I am very interested in this issue. Could you please assign this issue to me? > Support Kinesis connector in Python DataStream API. > --- > > Key: FLINK-21966 > URL: https://issues.apache.org/jira/browse/FLINK-21966 > Project: Flink > Issue Type: Sub-task > Components: API / Python >Reporter: Shuiqiang Chen >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink-table-store] LadyForest commented on a diff in pull request #138: [FLINK-27707] Implement ManagedTableFactory#onCompactTable
LadyForest commented on code in PR #138:
URL: https://github.com/apache/flink-table-store/pull/138#discussion_r884472377
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/TableStoreManagedFactory.java:
##
@@ -183,6 +204,84 @@ public void onDropTable(Context context, boolean
ignoreIfNotExists) {
@Override
public Map onCompactTable(
Context context, CatalogPartitionSpec catalogPartitionSpec) {
-throw new UnsupportedOperationException("Not implement yet");
+Map newOptions = new
HashMap<>(context.getCatalogTable().getOptions());
+FileStore fileStore = buildTableStore(context).buildFileStore();
+FileStoreScan.Plan plan =
+fileStore
+.newScan()
+.withPartitionFilter(
+PredicateConverter.CONVERTER.fromMap(
+
catalogPartitionSpec.getPartitionSpec(),
+fileStore.partitionType()))
+.plan();
+
+Preconditions.checkState(
+plan.snapshotId() != null && !plan.files().isEmpty(),
+"The specified %s to compact does not exist any snapshot",
+catalogPartitionSpec.getPartitionSpec().isEmpty()
+? "table"
+: String.format("partition %s",
catalogPartitionSpec.getPartitionSpec()));
+Map>> groupBy =
plan.groupByPartFiles();
+if
(!Boolean.parseBoolean(newOptions.get(COMPACTION_RESCALE_BUCKET.key( {
+groupBy =
+pickManifest(
+groupBy,
+new
FileStoreOptions(Configuration.fromMap(newOptions))
+.mergeTreeOptions(),
+new
KeyComparatorSupplier(fileStore.partitionType()).get());
+}
+try {
+newOptions.put(
+COMPACTION_SCANNED_MANIFEST.key(),
+Base64.getEncoder()
+.encodeToString(
+InstantiationUtil.serializeObject(
+new PartitionedManifestMeta(
+plan.snapshotId(),
groupBy;
+} catch (IOException e) {
+throw new RuntimeException(e);
+}
+return newOptions;
+}
+
+@VisibleForTesting
+Map>> pickManifest(
Review Comment:
> You have picked files here, but how to make sure that writer will compact
these files?
As offline discussed, the main purpose for `ALTER TABLE COMPACT` is to
squeeze those files which have key range overlapped or too small. It is not
exactly what universal compaction does. As a result, when after picking these
files at the planning phase, the runtime should not pick them again, because
they are already picked. So `FileStoreWriteImpl` should create different
compact strategies for ① the auto-compaction triggered by ordinary writes v.s.
② the manual triggered compaction. For the latter, the strategy should directly
return all the files it receives.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-table-store] LadyForest commented on a diff in pull request #138: [FLINK-27707] Implement ManagedTableFactory#onCompactTable
LadyForest commented on code in PR #138:
URL: https://github.com/apache/flink-table-store/pull/138#discussion_r884472377
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/TableStoreManagedFactory.java:
##
@@ -183,6 +204,84 @@ public void onDropTable(Context context, boolean
ignoreIfNotExists) {
@Override
public Map onCompactTable(
Context context, CatalogPartitionSpec catalogPartitionSpec) {
-throw new UnsupportedOperationException("Not implement yet");
+Map newOptions = new
HashMap<>(context.getCatalogTable().getOptions());
+FileStore fileStore = buildTableStore(context).buildFileStore();
+FileStoreScan.Plan plan =
+fileStore
+.newScan()
+.withPartitionFilter(
+PredicateConverter.CONVERTER.fromMap(
+
catalogPartitionSpec.getPartitionSpec(),
+fileStore.partitionType()))
+.plan();
+
+Preconditions.checkState(
+plan.snapshotId() != null && !plan.files().isEmpty(),
+"The specified %s to compact does not exist any snapshot",
+catalogPartitionSpec.getPartitionSpec().isEmpty()
+? "table"
+: String.format("partition %s",
catalogPartitionSpec.getPartitionSpec()));
+Map>> groupBy =
plan.groupByPartFiles();
+if
(!Boolean.parseBoolean(newOptions.get(COMPACTION_RESCALE_BUCKET.key( {
+groupBy =
+pickManifest(
+groupBy,
+new
FileStoreOptions(Configuration.fromMap(newOptions))
+.mergeTreeOptions(),
+new
KeyComparatorSupplier(fileStore.partitionType()).get());
+}
+try {
+newOptions.put(
+COMPACTION_SCANNED_MANIFEST.key(),
+Base64.getEncoder()
+.encodeToString(
+InstantiationUtil.serializeObject(
+new PartitionedManifestMeta(
+plan.snapshotId(),
groupBy;
+} catch (IOException e) {
+throw new RuntimeException(e);
+}
+return newOptions;
+}
+
+@VisibleForTesting
+Map>> pickManifest(
Review Comment:
> You have picked files here, but how to make sure that writer will compact
these files?
As offline discussed, the main purpose for `ALTER TABLE COMPACT` is to
squeeze those files which have key range overlapped or too small. It is not
exactly what universal compaction does. As a result, when after picking these
files at the planning phase, the runtime should not pick them again, because
they are already picked. So `FileStoreWriteImpl` should create different
compact strategies for the auto-compaction for normal write v.s. the manual
triggered compaction. For the latter, the strategy should directly return all
the files it receives.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-table-store] LadyForest commented on a diff in pull request #138: [FLINK-27707] Implement ManagedTableFactory#onCompactTable
LadyForest commented on code in PR #138:
URL: https://github.com/apache/flink-table-store/pull/138#discussion_r884456680
##
flink-table-store-connector/src/test/java/org/apache/flink/table/store/connector/TableStoreManagedFactoryTest.java:
##
@@ -256,9 +284,288 @@ public void testCreateAndCheckTableStore(
}
}
+@Test
+public void testOnCompactTableForNoSnapshot() {
+RowType partType = RowType.of();
+MockTableStoreManagedFactory mockTableStoreManagedFactory =
+new MockTableStoreManagedFactory(partType,
NON_PARTITIONED_ROW_TYPE);
+prepare(
+TABLE + "_" + UUID.randomUUID(),
+partType,
+NON_PARTITIONED_ROW_TYPE,
+NON_PARTITIONED,
+true);
+assertThatThrownBy(
+() ->
+mockTableStoreManagedFactory.onCompactTable(
+context, new
CatalogPartitionSpec(emptyMap(
+.isInstanceOf(IllegalStateException.class)
+.hasMessageContaining("The specified table to compact does not
exist any snapshot");
+}
+
+@ParameterizedTest
+@ValueSource(booleans = {true, false})
+public void testOnCompactTableForNonPartitioned(boolean rescaleBucket)
throws Exception {
+RowType partType = RowType.of();
+runTest(
+new MockTableStoreManagedFactory(partType,
NON_PARTITIONED_ROW_TYPE),
+TABLE + "_" + UUID.randomUUID(),
+partType,
+NON_PARTITIONED_ROW_TYPE,
+NON_PARTITIONED,
+rescaleBucket);
+}
+
+@ParameterizedTest
+@ValueSource(booleans = {true, false})
+public void testOnCompactTableForSinglePartitioned(boolean rescaleBucket)
throws Exception {
+runTest(
+new MockTableStoreManagedFactory(
+SINGLE_PARTITIONED_PART_TYPE,
SINGLE_PARTITIONED_ROW_TYPE),
+TABLE + "_" + UUID.randomUUID(),
+SINGLE_PARTITIONED_PART_TYPE,
+SINGLE_PARTITIONED_ROW_TYPE,
+SINGLE_PARTITIONED,
+rescaleBucket);
+}
+
+@ParameterizedTest
+@ValueSource(booleans = {true, false})
+public void testOnCompactTableForMultiPartitioned(boolean rescaleBucket)
throws Exception {
+runTest(
+new MockTableStoreManagedFactory(),
+TABLE + "_" + UUID.randomUUID(),
+DEFAULT_PART_TYPE,
+DEFAULT_ROW_TYPE,
+MULTI_PARTITIONED,
+rescaleBucket);
+}
+
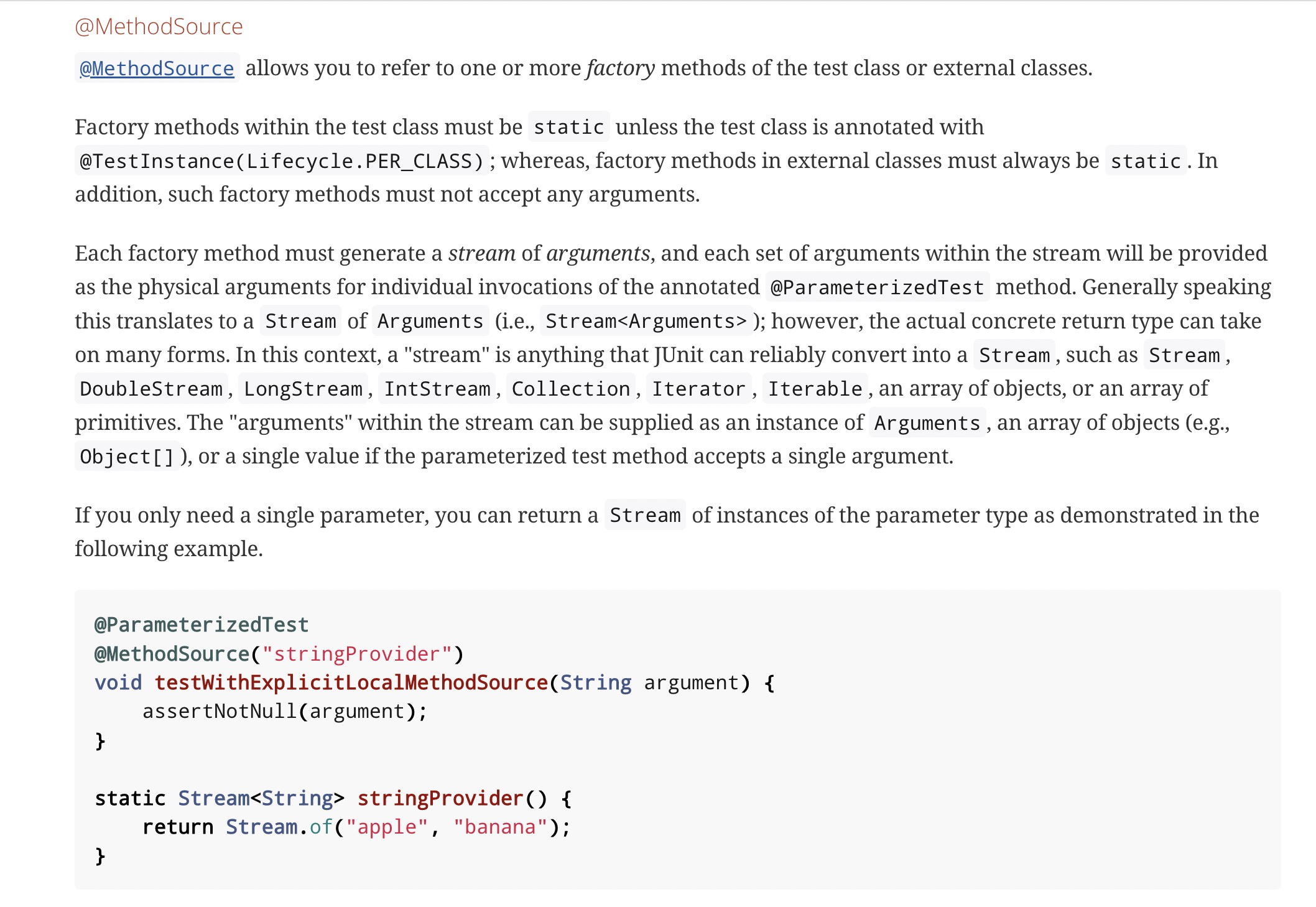
+@MethodSource("provideManifest")
+@ParameterizedTest
Review Comment:
> Can we have a name for each parameter? Very difficult to maintain without
a name.
I cannot understand well what you mean. Do you suggest not use Junit5
parameterized test? Method source doc illustrates the usage.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] morhidi commented on a diff in pull request #244: [FLINK-27520] Use admission-controller-framework in Webhook
morhidi commented on code in PR #244:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/244#discussion_r884442238
##
flink-kubernetes-webhook/pom.xml:
##
@@ -36,6 +36,19 @@ under the License.
org.apache.flink
flink-kubernetes-operator
${project.version}
+provided
+
+
+
+io.javaoperatorsdk
+operator-framework-framework-core
+${operator.sdk.admission-controller.version}
+
+
+*
Review Comment:
Had to keep the excludes in the dependency for the unit tests.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] wangyang0918 commented on pull request #237: [FLINK-27257] Flink kubernetes operator triggers savepoint failed because of not all tasks running
wangyang0918 commented on PR #237: URL: https://github.com/apache/flink-kubernetes-operator/pull/237#issuecomment-1140726331 For Flink batch jobs, we do not require all the tasks running to indicate that the Flink job is running. So it does not make sense when we want to use `getJobDetails` to verify whether the job is running. But I agree it could be used to check whether all the tasks are running before triggering a savepoint. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] morhidi commented on a diff in pull request #244: [FLINK-27520] Use admission-controller-framework in Webhook
morhidi commented on code in PR #244:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/244#discussion_r884434216
##
flink-kubernetes-webhook/pom.xml:
##
@@ -36,6 +36,19 @@ under the License.
org.apache.flink
flink-kubernetes-operator
${project.version}
+provided
+
+
+
+io.javaoperatorsdk
+operator-framework-framework-core
+${operator.sdk.admission-controller.version}
+
+
+*
Review Comment:
Thanks @gyfora for the suggestion, I like it better myself. Changed and
pushed it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] zou-can commented on pull request #19828: [FLINK-27762][connector/kafka] KafkaPartitionSplitReader#wakeup should only unblock KafkaConsumer#poll invocation
zou-can commented on PR #19828:
URL: https://github.com/apache/flink/pull/19828#issuecomment-1140717266
As i commented on https://issues.apache.org/jira/browse/FLINK-27762
The exception we met is in method
**KafkaPartitionSplitReader#removeEmptySplits**. But i can't find any action
for handling this exception in that method.
```
// KafkaPartitionSplitReader#removeEmptySplits
private void removeEmptySplits() {
List emptyPartitions = new ArrayList<>();
for (TopicPartition tp : consumer.assignment()) {
// WakeUpException is thrown here.
// since KafkaConsumer#wakeUp is called before, if execute
KafkaConsumer#postion in 'if statement' above, it will throw WakeUpException.
if (consumer.position(tp) >= getStoppingOffset(tp)) {
emptyPartitions.add(tp);
}
}
// ignore irrelevant code...
}
```
What I'm focus is **how to handle WakeUpException** after it was thrown.
As what is done in **KafkaPartitionSplitReader#fetch**
```
// KafkaPartitionSplitReader#fetch
public RecordsWithSplitIds> fetch() throws
IOException {
ConsumerRecords consumerRecords;
try {
consumerRecords = consumer.poll(Duration.ofMillis(POLL_TIMEOUT));
} catch (WakeupException we) {
// catch exception and return empty result.
return new KafkaPartitionSplitRecords(
ConsumerRecords.empty(), kafkaSourceReaderMetrics);
}
// ignore irrelevant code...
}
```
Maybe we should catch this exception in
**KafkaPartitionSplitReader#removeEmptySplits**, and retry
**KafkaConsumer#postion** again.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-27009) Support SQL job submission in flink kubernetes opeartor
[ https://issues.apache.org/jira/browse/FLINK-27009?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543770#comment-17543770 ] Márton Balassi commented on FLINK-27009: [~wangyang0918] I do not have well-formed thoughts yet, I was only thinking about SQLScript to this point, but I do see how that come become tedious and warrant a SQLScriptURI instead or as an option. For the sake of concise examples it would be nice to be able to drop the sql into a field, but I am not hell-bent on it. > Support SQL job submission in flink kubernetes opeartor > --- > > Key: FLINK-27009 > URL: https://issues.apache.org/jira/browse/FLINK-27009 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Reporter: Biao Geng >Assignee: Biao Geng >Priority: Major > > Currently, the flink kubernetes opeartor is for jar job using application or > session cluster. For SQL job, there is no out of box solution in the > operator. > One simple and short-term solution is to wrap the SQL script into a jar job > using table API with limitation. > The long-term solution may work with > [FLINK-26541|https://issues.apache.org/jira/browse/FLINK-26541] to achieve > the full support. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27831) Provide example of Beam on the k8s operator
[ https://issues.apache.org/jira/browse/FLINK-27831?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543769#comment-17543769 ] Márton Balassi commented on FLINK-27831: On second thought the example has heavy dependencies on the Beam side, might make more sense for it to live in Beam instead with only some of the docs in the flink-kubernetes-operator side. [~mxm] what do you think? > Provide example of Beam on the k8s operator > --- > > Key: FLINK-27831 > URL: https://issues.apache.org/jira/browse/FLINK-27831 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Márton Balassi >Assignee: Márton Balassi >Priority: Minor > Fix For: kubernetes-operator-1.1.0 > > > Multiple users have asked for whether the operator supports Beam jobs in > different shapes. I assume that running a Beam job ultimately with the > current operator ultimately comes down to having the right jars on the > classpath / packaged into the user's fatjar. > At this stage I suggest adding one such example, providing it might attract > new users. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Comment Edited] (FLINK-27834) Flink kubernetes operator dockerfile could not work with podman
[
https://issues.apache.org/jira/browse/FLINK-27834?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543768#comment-17543768
]
Zili Chen edited comment on FLINK-27834 at 5/30/22 3:42 AM:
Thanks for your notification [~wangyang0918]. I'll take a look today.
was (Author: tison):
Thanks for your notification [~wangyang0918]. I'll try a look today.
> Flink kubernetes operator dockerfile could not work with podman
> ---
>
> Key: FLINK-27834
> URL: https://issues.apache.org/jira/browse/FLINK-27834
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
>
> [1/2] STEP 16/19: COPY *.git ./.git
> Error: error building at STEP "COPY *.git ./.git": checking on sources under
> "/root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0": Rel: can't
> make relative to
> /root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0; copier: stat:
> ["/*.git"]: no such file or directory
>
> podman version
> Client: Podman Engine
> Version: 4.0.2
> API Version: 4.0.2
>
>
> I think the root cause is "*.git" is not respected by podman. Maybe we could
> simply copy the whole directory when building the image.
>
> {code:java}
> WORKDIR /app
> COPY . .
> RUN --mount=type=cache,target=/root/.m2 mvn -ntp clean install -pl
> !flink-kubernetes-docs -DskipTests=$SKIP_TESTS {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (FLINK-27834) Flink kubernetes operator dockerfile could not work with podman
[
https://issues.apache.org/jira/browse/FLINK-27834?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543768#comment-17543768
]
Zili Chen commented on FLINK-27834:
---
Thanks for your notification [~wangyang0918]. I'll try a look today.
> Flink kubernetes operator dockerfile could not work with podman
> ---
>
> Key: FLINK-27834
> URL: https://issues.apache.org/jira/browse/FLINK-27834
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
>
> [1/2] STEP 16/19: COPY *.git ./.git
> Error: error building at STEP "COPY *.git ./.git": checking on sources under
> "/root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0": Rel: can't
> make relative to
> /root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0; copier: stat:
> ["/*.git"]: no such file or directory
>
> podman version
> Client: Podman Engine
> Version: 4.0.2
> API Version: 4.0.2
>
>
> I think the root cause is "*.git" is not respected by podman. Maybe we could
> simply copy the whole directory when building the image.
>
> {code:java}
> WORKDIR /app
> COPY . .
> RUN --mount=type=cache,target=/root/.m2 mvn -ntp clean install -pl
> !flink-kubernetes-docs -DskipTests=$SKIP_TESTS {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [flink-table-store] LadyForest commented on a diff in pull request #138: [FLINK-27707] Implement ManagedTableFactory#onCompactTable
LadyForest commented on code in PR #138:
URL: https://github.com/apache/flink-table-store/pull/138#discussion_r884394501
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/TableStoreManagedFactory.java:
##
@@ -183,6 +204,84 @@ public void onDropTable(Context context, boolean
ignoreIfNotExists) {
@Override
public Map onCompactTable(
Context context, CatalogPartitionSpec catalogPartitionSpec) {
-throw new UnsupportedOperationException("Not implement yet");
+Map newOptions = new
HashMap<>(context.getCatalogTable().getOptions());
+FileStore fileStore = buildTableStore(context).buildFileStore();
+FileStoreScan.Plan plan =
+fileStore
+.newScan()
+.withPartitionFilter(
+PredicateConverter.CONVERTER.fromMap(
+
catalogPartitionSpec.getPartitionSpec(),
+fileStore.partitionType()))
+.plan();
+
+Preconditions.checkState(
+plan.snapshotId() != null && !plan.files().isEmpty(),
+"The specified %s to compact does not exist any snapshot",
+catalogPartitionSpec.getPartitionSpec().isEmpty()
+? "table"
+: String.format("partition %s",
catalogPartitionSpec.getPartitionSpec()));
+Map>> groupBy =
plan.groupByPartFiles();
+if
(!Boolean.parseBoolean(newOptions.get(COMPACTION_RESCALE_BUCKET.key( {
+groupBy =
+pickManifest(
+groupBy,
+new
FileStoreOptions(Configuration.fromMap(newOptions))
+.mergeTreeOptions(),
+new
KeyComparatorSupplier(fileStore.partitionType()).get());
+}
+try {
+newOptions.put(
+COMPACTION_SCANNED_MANIFEST.key(),
+Base64.getEncoder()
+.encodeToString(
+InstantiationUtil.serializeObject(
+new PartitionedManifestMeta(
+plan.snapshotId(),
groupBy;
+} catch (IOException e) {
+throw new RuntimeException(e);
+}
+return newOptions;
+}
+
+@VisibleForTesting
+Map>> pickManifest(
+Map>> groupBy,
+MergeTreeOptions options,
+Comparator keyComparator) {
+Map>> filtered = new
HashMap<>();
+
+for (Map.Entry>>
partEntry :
+groupBy.entrySet()) {
+Map> manifests = new HashMap<>();
+for (Map.Entry> bucketEntry :
+partEntry.getValue().entrySet()) {
+List smallFiles =
Review Comment:
> For example:
inputs: File1(0-10) File2(10-90) File3(90-100)
merged: File4(0-100) File2(10-90)
This can lead to results with overlapping.
I agree with you that "we cannot pick small files at random". But the
example you provide cannot prove this. These three files are all overlapped.
The small file threshold will pick File1(0-10) and File3(90-100), and the
interval partition will pick all of them. So after deduplication, they all get
compacted.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-27831) Provide example of Beam on the k8s operator
[ https://issues.apache.org/jira/browse/FLINK-27831?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543767#comment-17543767 ] Márton Balassi commented on FLINK-27831: I managed to get the Beam [WordCount|https://github.com/apache/beam/blob/master/examples/java/src/main/java/org/apache/beam/examples/WordCount.java] example based on the [quickstart|https://beam.apache.org/get-started/quickstart-java/#get-the-example-code] running with Flink 1.14 on the operator. It needs a bit of tweaking to make it pretty, will create a PR soonish. > Provide example of Beam on the k8s operator > --- > > Key: FLINK-27831 > URL: https://issues.apache.org/jira/browse/FLINK-27831 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Márton Balassi >Assignee: Márton Balassi >Priority: Minor > Fix For: kubernetes-operator-1.1.0 > > > Multiple users have asked for whether the operator supports Beam jobs in > different shapes. I assume that running a Beam job ultimately with the > current operator ultimately comes down to having the right jars on the > classpath / packaged into the user's fatjar. > At this stage I suggest adding one such example, providing it might attract > new users. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27762) Kafka WakeUpException during handling splits changes
[
https://issues.apache.org/jira/browse/FLINK-27762?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543766#comment-17543766
]
Qingsheng Ren commented on FLINK-27762:
---
Thanks a lot for the review [~zoucan] ! What about moving the discussion about
code and PRs to Github?
> Kafka WakeUpException during handling splits changes
>
>
> Key: FLINK-27762
> URL: https://issues.apache.org/jira/browse/FLINK-27762
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.3
>Reporter: zoucan
>Assignee: Qingsheng Ren
>Priority: Major
> Labels: pull-request-available
>
>
> We enable dynamic partition discovery in our flink job, but job failed when
> kafka partition is changed.
> Exception detail is shown as follows:
> {code:java}
> java.lang.RuntimeException: One or more fetchers have encountered exception
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:225)
> at
> org.apache.flink.connector.base.source.reader.SourceReaderBase.getNextFetch(SourceReaderBase.java:169)
> at
> org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:130)
> at
> org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:350)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:496)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:809)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:761)
> at
> org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)
> at
> org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:937)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)
> at java.lang.Thread.run(Thread.java:748)
> Caused by: java.lang.RuntimeException: SplitFetcher thread 0 received
> unexpected exception while polling the records
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:150)
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:105)
> at
> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
> at java.util.concurrent.FutureTask.run(FutureTask.java:266)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> ... 1 more
> Caused by: org.apache.kafka.common.errors.WakeupException
> at
> org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.maybeTriggerWakeup(ConsumerNetworkClient.java:511)
> at
> org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:275)
> at
> org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:233)
> at
> org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:224)
> at
> org.apache.kafka.clients.consumer.KafkaConsumer.position(KafkaConsumer.java:1726)
> at
> org.apache.kafka.clients.consumer.KafkaConsumer.position(KafkaConsumer.java:1684)
> at
> org.apache.flink.connector.kafka.source.reader.KafkaPartitionSplitReader.removeEmptySplits(KafkaPartitionSplitReader.java:315)
> at
> org.apache.flink.connector.kafka.source.reader.KafkaPartitionSplitReader.handleSplitsChanges(KafkaPartitionSplitReader.java:200)
> at
> org.apache.flink.connector.base.source.reader.fetcher.AddSplitsTask.run(AddSplitsTask.java:51)
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:142)
> ... 6 more {code}
>
> After preliminary investigation, according to source code of KafkaSource,
> At first:
> method *org.apache.kafka.clients.consumer.KafkaConsumer.wakeup()* will be
> called if consumer is polling data.
> Later:
> method *org.apache.kafka.clients.consumer.KafkaConsumer.position()* will be
> called during handle splits changes.
> Since consumer has been waken up, it will throw WakeUpException.
--
This message was sent
[GitHub] [flink-table-store] LadyForest commented on a diff in pull request #138: [FLINK-27707] Implement ManagedTableFactory#onCompactTable
LadyForest commented on code in PR #138: URL: https://github.com/apache/flink-table-store/pull/138#discussion_r884390344 ## flink-table-store-core/src/main/java/org/apache/flink/table/store/file/utils/FileStorePathFactory.java: ## @@ -61,20 +61,24 @@ public FileStorePathFactory(Path root, RowType partitionType, String defaultPart this.root = root; this.uuid = UUID.randomUUID().toString(); -String[] partitionColumns = partitionType.getFieldNames().toArray(new String[0]); -this.partitionComputer = -new RowDataPartitionComputer( -defaultPartValue, -partitionColumns, -partitionType.getFields().stream() -.map(f -> LogicalTypeDataTypeConverter.toDataType(f.getType())) -.toArray(DataType[]::new), -partitionColumns); +this.partitionComputer = getPartitionComputer(partitionType, defaultPartValue); this.manifestFileCount = new AtomicInteger(0); this.manifestListCount = new AtomicInteger(0); } +public static RowDataPartitionComputer getPartitionComputer( Review Comment: > Just for test? Maybe for logging too. Currently, the log does not reveal the readable partition -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-table-store] JingsongLi commented on a diff in pull request #138: [FLINK-27707] Implement ManagedTableFactory#onCompactTable
JingsongLi commented on code in PR #138:
URL: https://github.com/apache/flink-table-store/pull/138#discussion_r884388037
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/TableStoreManagedFactory.java:
##
@@ -183,6 +204,84 @@ public void onDropTable(Context context, boolean
ignoreIfNotExists) {
@Override
public Map onCompactTable(
Context context, CatalogPartitionSpec catalogPartitionSpec) {
-throw new UnsupportedOperationException("Not implement yet");
+Map newOptions = new
HashMap<>(context.getCatalogTable().getOptions());
+FileStore fileStore = buildTableStore(context).buildFileStore();
+FileStoreScan.Plan plan =
+fileStore
+.newScan()
+.withPartitionFilter(
+PredicateConverter.CONVERTER.fromMap(
+
catalogPartitionSpec.getPartitionSpec(),
+fileStore.partitionType()))
+.plan();
+
+Preconditions.checkState(
+plan.snapshotId() != null && !plan.files().isEmpty(),
+"The specified %s to compact does not exist any snapshot",
+catalogPartitionSpec.getPartitionSpec().isEmpty()
+? "table"
+: String.format("partition %s",
catalogPartitionSpec.getPartitionSpec()));
+Map>> groupBy =
plan.groupByPartFiles();
+if
(!Boolean.parseBoolean(newOptions.get(COMPACTION_RESCALE_BUCKET.key( {
+groupBy =
+pickManifest(
+groupBy,
+new
FileStoreOptions(Configuration.fromMap(newOptions))
+.mergeTreeOptions(),
+new
KeyComparatorSupplier(fileStore.partitionType()).get());
+}
+try {
+newOptions.put(
+COMPACTION_SCANNED_MANIFEST.key(),
+Base64.getEncoder()
+.encodeToString(
+InstantiationUtil.serializeObject(
+new PartitionedManifestMeta(
+plan.snapshotId(),
groupBy;
+} catch (IOException e) {
+throw new RuntimeException(e);
+}
+return newOptions;
+}
+
+@VisibleForTesting
+Map>> pickManifest(
+Map>> groupBy,
+MergeTreeOptions options,
+Comparator keyComparator) {
+Map>> filtered = new
HashMap<>();
+
+for (Map.Entry>>
partEntry :
+groupBy.entrySet()) {
+Map> manifests = new HashMap<>();
+for (Map.Entry> bucketEntry :
+partEntry.getValue().entrySet()) {
+List smallFiles =
Review Comment:
Here we cannot pick small files at random, which would cause the merged
files min and max to skip the middle data.
For example:
inputs: File1(0-10) File2(10-90) File3(90-100)
merged: File4(0-100) File2(10-90)
This can lead to results with overlapping.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-27834) Flink kubernetes operator dockerfile could not work with podman
[
https://issues.apache.org/jira/browse/FLINK-27834?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543762#comment-17543762
]
Yang Wang commented on FLINK-27834:
---
cc [~Tison] I remember you also have the same idea when fixing FLINK-27746.
> Flink kubernetes operator dockerfile could not work with podman
> ---
>
> Key: FLINK-27834
> URL: https://issues.apache.org/jira/browse/FLINK-27834
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
>
> [1/2] STEP 16/19: COPY *.git ./.git
> Error: error building at STEP "COPY *.git ./.git": checking on sources under
> "/root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0": Rel: can't
> make relative to
> /root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0; copier: stat:
> ["/*.git"]: no such file or directory
>
> podman version
> Client: Podman Engine
> Version: 4.0.2
> API Version: 4.0.2
>
>
> I think the root cause is "*.git" is not respected by podman. Maybe we could
> simply copy the whole directory when building the image.
>
> {code:java}
> WORKDIR /app
> COPY . .
> RUN --mount=type=cache,target=/root/.m2 mvn -ntp clean install -pl
> !flink-kubernetes-docs -DskipTests=$SKIP_TESTS {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (FLINK-27834) Flink kubernetes operator dockerfile could not work with podman
[
https://issues.apache.org/jira/browse/FLINK-27834?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543761#comment-17543761
]
Gyula Fora commented on FLINK-27834:
Maybe this is not a big concern, would love to hear what [~matyas] or
[~jbusche] think
> Flink kubernetes operator dockerfile could not work with podman
> ---
>
> Key: FLINK-27834
> URL: https://issues.apache.org/jira/browse/FLINK-27834
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
>
> [1/2] STEP 16/19: COPY *.git ./.git
> Error: error building at STEP "COPY *.git ./.git": checking on sources under
> "/root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0": Rel: can't
> make relative to
> /root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0; copier: stat:
> ["/*.git"]: no such file or directory
>
> podman version
> Client: Podman Engine
> Version: 4.0.2
> API Version: 4.0.2
>
>
> I think the root cause is "*.git" is not respected by podman. Maybe we could
> simply copy the whole directory when building the image.
>
> {code:java}
> WORKDIR /app
> COPY . .
> RUN --mount=type=cache,target=/root/.m2 mvn -ntp clean install -pl
> !flink-kubernetes-docs -DskipTests=$SKIP_TESTS {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (FLINK-27834) Flink kubernetes operator dockerfile could not work with podman
[
https://issues.apache.org/jira/browse/FLINK-27834?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543760#comment-17543760
]
Gyula Fora commented on FLINK-27834:
yes, the user can have anything in their local directory by accident
> Flink kubernetes operator dockerfile could not work with podman
> ---
>
> Key: FLINK-27834
> URL: https://issues.apache.org/jira/browse/FLINK-27834
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
>
> [1/2] STEP 16/19: COPY *.git ./.git
> Error: error building at STEP "COPY *.git ./.git": checking on sources under
> "/root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0": Rel: can't
> make relative to
> /root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0; copier: stat:
> ["/*.git"]: no such file or directory
>
> podman version
> Client: Podman Engine
> Version: 4.0.2
> API Version: 4.0.2
>
>
> I think the root cause is "*.git" is not respected by podman. Maybe we could
> simply copy the whole directory when building the image.
>
> {code:java}
> WORKDIR /app
> COPY . .
> RUN --mount=type=cache,target=/root/.m2 mvn -ntp clean install -pl
> !flink-kubernetes-docs -DskipTests=$SKIP_TESTS {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (FLINK-27834) Flink kubernetes operator dockerfile could not work with podman
[
https://issues.apache.org/jira/browse/FLINK-27834?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543759#comment-17543759
]
Yang Wang commented on FLINK-27834:
---
Do you mean we might accidentally bundle the credentials into the image?
> Flink kubernetes operator dockerfile could not work with podman
> ---
>
> Key: FLINK-27834
> URL: https://issues.apache.org/jira/browse/FLINK-27834
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
>
> [1/2] STEP 16/19: COPY *.git ./.git
> Error: error building at STEP "COPY *.git ./.git": checking on sources under
> "/root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0": Rel: can't
> make relative to
> /root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0; copier: stat:
> ["/*.git"]: no such file or directory
>
> podman version
> Client: Podman Engine
> Version: 4.0.2
> API Version: 4.0.2
>
>
> I think the root cause is "*.git" is not respected by podman. Maybe we could
> simply copy the whole directory when building the image.
>
> {code:java}
> WORKDIR /app
> COPY . .
> RUN --mount=type=cache,target=/root/.m2 mvn -ntp clean install -pl
> !flink-kubernetes-docs -DskipTests=$SKIP_TESTS {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Assigned] (FLINK-25865) Support to set restart policy of TaskManager pod for native K8s integration
[
https://issues.apache.org/jira/browse/FLINK-25865?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Yang Wang reassigned FLINK-25865:
-
Assignee: Aitozi
> Support to set restart policy of TaskManager pod for native K8s integration
> ---
>
> Key: FLINK-25865
> URL: https://issues.apache.org/jira/browse/FLINK-25865
> Project: Flink
> Issue Type: Improvement
> Components: Deployment / Kubernetes
>Reporter: Yang Wang
>Assignee: Aitozi
>Priority: Major
>
> After FLIP-201, Flink's TaskManagers will be able to be restarted without
> losing its local state. So it is reasonable to make the restart policy[1] of
> TaskManager pod could be configured.
> The current restart policy is {{{}Never{}}}. Flink will always delete the
> failed TaskManager pod directly and create a new one instead. This ticket
> could help to decrease the recovery time of TaskManager failure.
>
> Please note that the working directory needs to be located in the
> emptyDir[1], which is retained in different restarts.
>
> [1].
> https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#restart-policy
> [2]. https://kubernetes.io/docs/concepts/storage/volumes/#emptydir
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (FLINK-27834) Flink kubernetes operator dockerfile could not work with podman
[
https://issues.apache.org/jira/browse/FLINK-27834?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543758#comment-17543758
]
Gyula Fora commented on FLINK-27834:
I have bad feelings about this, it might lead to accidentally leaking
credentials from local working directories.
> Flink kubernetes operator dockerfile could not work with podman
> ---
>
> Key: FLINK-27834
> URL: https://issues.apache.org/jira/browse/FLINK-27834
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
>
> [1/2] STEP 16/19: COPY *.git ./.git
> Error: error building at STEP "COPY *.git ./.git": checking on sources under
> "/root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0": Rel: can't
> make relative to
> /root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0; copier: stat:
> ["/*.git"]: no such file or directory
>
> podman version
> Client: Podman Engine
> Version: 4.0.2
> API Version: 4.0.2
>
>
> I think the root cause is "*.git" is not respected by podman. Maybe we could
> simply copy the whole directory when building the image.
>
> {code:java}
> WORKDIR /app
> COPY . .
> RUN --mount=type=cache,target=/root/.m2 mvn -ntp clean install -pl
> !flink-kubernetes-docs -DskipTests=$SKIP_TESTS {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Comment Edited] (FLINK-27762) Kafka WakeUpException during handling splits changes
[
https://issues.apache.org/jira/browse/FLINK-27762?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543756#comment-17543756
]
zoucan edited comment on FLINK-27762 at 5/30/22 2:50 AM:
-
[~renqs]
Thanks for your effort for this issue.
I‘ve reviewed your pr and i have a question. The exception i met is in method
{*}KafkaPartitionSplitReader#removeEmptySplits{*}. But i can't find any action
for handling this exception in that method.
{code:java}
//
org.apache.flink.connector.kafka.source.reader.KafkaPartitionSplitReader#removeEmptySplits
private void removeEmptySplits() {
List emptyPartitions = new ArrayList<>();
for (TopicPartition tp : consumer.assignment()) {
// WakeUpException is thrown here.
// since KafkaConsumer#wakeUp is called before,if execute
KafkaConsumer#postion() in 'if statement' above, it will throw WakeUpException.
if (consumer.position(tp) >= getStoppingOffset(tp)) {
emptyPartitions.add(tp);
}
}
// ignore irrelevant code...
} {code}
Maybe we should check whether *KafkaConsumer#wakeUp* is called before, or catch
WakeUpException in *KafkaPartitionSplitReader#removeEmptySplits.*
was (Author: JIRAUSER289972):
[~renqs]
Thanks for your effort for this issue.
I‘ve reviewed your pr and i have a question. The exception i met is in method
{*}KafkaPartitionSplitReader#removeEmptySplits{*}. But i can't find any action
for handling this exception.
{code:java}
//
org.apache.flink.connector.kafka.source.reader.KafkaPartitionSplitReader#removeEmptySplits
private void removeEmptySplits() {
List emptyPartitions = new ArrayList<>();
for (TopicPartition tp : consumer.assignment()) {
// WakeUpException is thrown here.
// since KafkaConsumer#wakeUp is called before,if execute
KafkaConsumer#postion() in 'if statement' above, it will throw WakeUpException.
if (consumer.position(tp) >= getStoppingOffset(tp)) {
emptyPartitions.add(tp);
}
}
// ignore irrelevant code...
} {code}
Maybe we should check whether *KafkaConsumer#wakeUp* is called before, or catch
WakeUpException in *KafkaPartitionSplitReader#removeEmptySplits.*
> Kafka WakeUpException during handling splits changes
>
>
> Key: FLINK-27762
> URL: https://issues.apache.org/jira/browse/FLINK-27762
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.3
>Reporter: zoucan
>Assignee: Qingsheng Ren
>Priority: Major
> Labels: pull-request-available
>
>
> We enable dynamic partition discovery in our flink job, but job failed when
> kafka partition is changed.
> Exception detail is shown as follows:
> {code:java}
> java.lang.RuntimeException: One or more fetchers have encountered exception
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:225)
> at
> org.apache.flink.connector.base.source.reader.SourceReaderBase.getNextFetch(SourceReaderBase.java:169)
> at
> org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:130)
> at
> org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:350)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:496)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:809)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:761)
> at
> org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)
> at
> org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:937)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)
> at java.lang.Thread.run(Thread.java:748)
> Caused by: java.lang.RuntimeException: SplitFetcher thread 0 received
> unexpected exception while polling the records
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:150)
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:105)
> at
> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
> at jav
[GitHub] [flink] flinkbot commented on pull request #19843: [hotfix] Fix comment typo in TypeExtractor class
flinkbot commented on PR #19843: URL: https://github.com/apache/flink/pull/19843#issuecomment-1140628091 ## CI report: * 056a8e7e0028e39bd5428a8b40b22454e01a0560 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (FLINK-27762) Kafka WakeUpException during handling splits changes
[
https://issues.apache.org/jira/browse/FLINK-27762?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543756#comment-17543756
]
zoucan edited comment on FLINK-27762 at 5/30/22 2:46 AM:
-
[~renqs]
Thanks for your effort for this issue.
I‘ve reviewed your pr and i have a question. The exception i met is in method
{*}KafkaPartitionSplitReader#removeEmptySplits{*}. But i can't find any action
for handling this exception.
{code:java}
//
org.apache.flink.connector.kafka.source.reader.KafkaPartitionSplitReader#removeEmptySplits
private void removeEmptySplits() {
List emptyPartitions = new ArrayList<>();
for (TopicPartition tp : consumer.assignment()) {
// WakeUpException is thrown here.
// since KafkaConsumer#wakeUp is called before,if execute
KafkaConsumer#postion() in 'if statement' above, it will throw WakeUpException.
if (consumer.position(tp) >= getStoppingOffset(tp)) {
emptyPartitions.add(tp);
}
}
// ignore irrelevant code...
} {code}
Maybe we should check whether *KafkaConsumer#wakeUp* is called before, or catch
WakeUpException in *KafkaPartitionSplitReader#removeEmptySplits.*
was (Author: JIRAUSER289972):
[~renqs]
Thanks for your effort for this issue.
I‘ve reviewed your pr and i have a question. The exception i met is in method
{*}KafkaPartitionSplitReader#removeEmptySplits{*}. But i can't find any action
to handling this exception.
{code:java}
//
org.apache.flink.connector.kafka.source.reader.KafkaPartitionSplitReader#removeEmptySplits
private void removeEmptySplits() {
List emptyPartitions = new ArrayList<>();
for (TopicPartition tp : consumer.assignment()) {
// WakeUpException is thrown here.
// since KafkaConsumer#wakeUp is called before,if execute
KafkaConsumer#postion() in 'if statement' above, it will throw WakeUpException.
if (consumer.position(tp) >= getStoppingOffset(tp)) {
emptyPartitions.add(tp);
}
}
// ignore irrelevant code...
} {code}
Maybe we should check whether *KafkaConsumer#wakeUp* is called before, or catch
WakeUpException in *KafkaPartitionSplitReader#removeEmptySplits.*
> Kafka WakeUpException during handling splits changes
>
>
> Key: FLINK-27762
> URL: https://issues.apache.org/jira/browse/FLINK-27762
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.3
>Reporter: zoucan
>Assignee: Qingsheng Ren
>Priority: Major
> Labels: pull-request-available
>
>
> We enable dynamic partition discovery in our flink job, but job failed when
> kafka partition is changed.
> Exception detail is shown as follows:
> {code:java}
> java.lang.RuntimeException: One or more fetchers have encountered exception
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:225)
> at
> org.apache.flink.connector.base.source.reader.SourceReaderBase.getNextFetch(SourceReaderBase.java:169)
> at
> org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:130)
> at
> org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:350)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:496)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:809)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:761)
> at
> org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)
> at
> org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:937)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)
> at java.lang.Thread.run(Thread.java:748)
> Caused by: java.lang.RuntimeException: SplitFetcher thread 0 received
> unexpected exception while polling the records
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:150)
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:105)
> at
> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
> at java.util.concurren
[jira] [Comment Edited] (FLINK-27762) Kafka WakeUpException during handling splits changes
[
https://issues.apache.org/jira/browse/FLINK-27762?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543756#comment-17543756
]
zoucan edited comment on FLINK-27762 at 5/30/22 2:45 AM:
-
[~renqs]
Thanks for your effort for this issue.
I‘ve reviewed your pr and i have a question. The exception i met is in method
{*}KafkaPartitionSplitReader#removeEmptySplits{*}. But i can't find any action
to handling this exception.
{code:java}
//
org.apache.flink.connector.kafka.source.reader.KafkaPartitionSplitReader#removeEmptySplits
private void removeEmptySplits() {
List emptyPartitions = new ArrayList<>();
for (TopicPartition tp : consumer.assignment()) {
// WakeUpException is thrown here.
// since KafkaConsumer#wakeUp is called before,if execute
KafkaConsumer#postion() in 'if statement' above, it will throw WakeUpException.
if (consumer.position(tp) >= getStoppingOffset(tp)) {
emptyPartitions.add(tp);
}
}
// ignore irrelevant code...
} {code}
Maybe we should check whether *KafkaConsumer#wakeUp* is called before, or catch
WakeUpException in *KafkaPartitionSplitReader#removeEmptySplits.*
was (Author: JIRAUSER289972):
[~renqs]
Thanks for your effort for this issue.
I‘ve reviewed your pr and i have a question. The exception i met is in method
{*}KafkaPartitionSplitReader#removeEmptySplits{*}. But i can't find any action
to handling this exception.
{code:java}
//
org.apache.flink.connector.kafka.source.reader.KafkaPartitionSplitReader#removeEmptySplits
private void removeEmptySplits() {
List emptyPartitions = new ArrayList<>();
for (TopicPartition tp : consumer.assignment()) {
// WakeUpException is thrown here.
// since KafkaConsumer#wakeUp is called before,if execute
KafkaConsumer#postion() in 'if statement' above, it will throw WakeUpException.
if (consumer.position(tp) >= getStoppingOffset(tp)) {
emptyPartitions.add(tp);
}
}
// ignore irrelevant code...
} {code}
Maybe we should check whether *KafkaConsumer#wakeUp* is called before, or catch
WakeUpException in *KafkaPartitionSplitReader#removeEmptySplits.*
> Kafka WakeUpException during handling splits changes
>
>
> Key: FLINK-27762
> URL: https://issues.apache.org/jira/browse/FLINK-27762
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.3
>Reporter: zoucan
>Assignee: Qingsheng Ren
>Priority: Major
> Labels: pull-request-available
>
>
> We enable dynamic partition discovery in our flink job, but job failed when
> kafka partition is changed.
> Exception detail is shown as follows:
> {code:java}
> java.lang.RuntimeException: One or more fetchers have encountered exception
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:225)
> at
> org.apache.flink.connector.base.source.reader.SourceReaderBase.getNextFetch(SourceReaderBase.java:169)
> at
> org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:130)
> at
> org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:350)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:496)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:809)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:761)
> at
> org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)
> at
> org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:937)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)
> at java.lang.Thread.run(Thread.java:748)
> Caused by: java.lang.RuntimeException: SplitFetcher thread 0 received
> unexpected exception while polling the records
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:150)
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:105)
> at
> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
> at java.util.conc
[GitHub] [flink] deadwind4 opened a new pull request, #19843: [hotfix] Fix comment typo in TypeExtractor class
deadwind4 opened a new pull request, #19843: URL: https://github.com/apache/flink/pull/19843 Fix comment typo in TypeExtractor class. Add a `the` before `highest`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink-table-store] JingsongLi commented on a diff in pull request #138: [FLINK-27707] Implement ManagedTableFactory#onCompactTable
JingsongLi commented on code in PR #138:
URL: https://github.com/apache/flink-table-store/pull/138#discussion_r884378698
##
flink-table-store-connector/src/test/java/org/apache/flink/table/store/connector/TableStoreManagedFactoryTest.java:
##
@@ -256,9 +284,288 @@ public void testCreateAndCheckTableStore(
}
}
+@Test
+public void testOnCompactTableForNoSnapshot() {
+RowType partType = RowType.of();
+MockTableStoreManagedFactory mockTableStoreManagedFactory =
+new MockTableStoreManagedFactory(partType,
NON_PARTITIONED_ROW_TYPE);
+prepare(
+TABLE + "_" + UUID.randomUUID(),
+partType,
+NON_PARTITIONED_ROW_TYPE,
+NON_PARTITIONED,
+true);
+assertThatThrownBy(
+() ->
+mockTableStoreManagedFactory.onCompactTable(
+context, new
CatalogPartitionSpec(emptyMap(
+.isInstanceOf(IllegalStateException.class)
+.hasMessageContaining("The specified table to compact does not
exist any snapshot");
+}
+
+@ParameterizedTest
+@ValueSource(booleans = {true, false})
+public void testOnCompactTableForNonPartitioned(boolean rescaleBucket)
throws Exception {
+RowType partType = RowType.of();
+runTest(
+new MockTableStoreManagedFactory(partType,
NON_PARTITIONED_ROW_TYPE),
+TABLE + "_" + UUID.randomUUID(),
+partType,
+NON_PARTITIONED_ROW_TYPE,
+NON_PARTITIONED,
+rescaleBucket);
+}
+
+@ParameterizedTest
+@ValueSource(booleans = {true, false})
+public void testOnCompactTableForSinglePartitioned(boolean rescaleBucket)
throws Exception {
+runTest(
+new MockTableStoreManagedFactory(
+SINGLE_PARTITIONED_PART_TYPE,
SINGLE_PARTITIONED_ROW_TYPE),
+TABLE + "_" + UUID.randomUUID(),
+SINGLE_PARTITIONED_PART_TYPE,
+SINGLE_PARTITIONED_ROW_TYPE,
+SINGLE_PARTITIONED,
+rescaleBucket);
+}
+
+@ParameterizedTest
+@ValueSource(booleans = {true, false})
+public void testOnCompactTableForMultiPartitioned(boolean rescaleBucket)
throws Exception {
+runTest(
+new MockTableStoreManagedFactory(),
+TABLE + "_" + UUID.randomUUID(),
+DEFAULT_PART_TYPE,
+DEFAULT_ROW_TYPE,
+MULTI_PARTITIONED,
+rescaleBucket);
+}
+
+@MethodSource("provideManifest")
+@ParameterizedTest
Review Comment:
Can we have a name for each parameter?
Very difficult to maintain without a name.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-27762) Kafka WakeUpException during handling splits changes
[
https://issues.apache.org/jira/browse/FLINK-27762?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543756#comment-17543756
]
zoucan commented on FLINK-27762:
[~renqs]
Thanks for your effort for this issue.
I‘ve reviewed your pr and i have a question. The exception i met is in method
{*}KafkaPartitionSplitReader#removeEmptySplits{*}. But i can't find any action
to handling this exception.
{code:java}
//
org.apache.flink.connector.kafka.source.reader.KafkaPartitionSplitReader#removeEmptySplits
private void removeEmptySplits() {
List emptyPartitions = new ArrayList<>();
for (TopicPartition tp : consumer.assignment()) {
// WakeUpException is thrown here.
// since KafkaConsumer#wakeUp is called before,if execute
KafkaConsumer#postion() in 'if statement' above, it will throw WakeUpException.
if (consumer.position(tp) >= getStoppingOffset(tp)) {
emptyPartitions.add(tp);
}
}
// ignore irrelevant code...
} {code}
Maybe we should check whether *KafkaConsumer#wakeUp* is called before, or catch
WakeUpException in *KafkaPartitionSplitReader#removeEmptySplits.*
> Kafka WakeUpException during handling splits changes
>
>
> Key: FLINK-27762
> URL: https://issues.apache.org/jira/browse/FLINK-27762
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.3
>Reporter: zoucan
>Assignee: Qingsheng Ren
>Priority: Major
> Labels: pull-request-available
>
>
> We enable dynamic partition discovery in our flink job, but job failed when
> kafka partition is changed.
> Exception detail is shown as follows:
> {code:java}
> java.lang.RuntimeException: One or more fetchers have encountered exception
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:225)
> at
> org.apache.flink.connector.base.source.reader.SourceReaderBase.getNextFetch(SourceReaderBase.java:169)
> at
> org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:130)
> at
> org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:350)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:496)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:809)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:761)
> at
> org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)
> at
> org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:937)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)
> at java.lang.Thread.run(Thread.java:748)
> Caused by: java.lang.RuntimeException: SplitFetcher thread 0 received
> unexpected exception while polling the records
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:150)
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:105)
> at
> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
> at java.util.concurrent.FutureTask.run(FutureTask.java:266)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> ... 1 more
> Caused by: org.apache.kafka.common.errors.WakeupException
> at
> org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.maybeTriggerWakeup(ConsumerNetworkClient.java:511)
> at
> org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:275)
> at
> org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:233)
> at
> org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:224)
> at
> org.apache.kafka.clients.consumer.KafkaConsumer.position(KafkaConsumer.java:1726)
> at
> org.apache.kafka.clients.consumer.KafkaConsumer.position(KafkaConsumer.java:1684)
> at
> org.apache.flink.connector.kafka.source.reader.KafkaPartiti
[jira] [Comment Edited] (FLINK-27762) Kafka WakeUpException during handling splits changes
[
https://issues.apache.org/jira/browse/FLINK-27762?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543756#comment-17543756
]
zoucan edited comment on FLINK-27762 at 5/30/22 2:44 AM:
-
[~renqs]
Thanks for your effort for this issue.
I‘ve reviewed your pr and i have a question. The exception i met is in method
{*}KafkaPartitionSplitReader#removeEmptySplits{*}. But i can't find any action
to handling this exception.
{code:java}
//
org.apache.flink.connector.kafka.source.reader.KafkaPartitionSplitReader#removeEmptySplits
private void removeEmptySplits() {
List emptyPartitions = new ArrayList<>();
for (TopicPartition tp : consumer.assignment()) {
// WakeUpException is thrown here.
// since KafkaConsumer#wakeUp is called before,if execute
KafkaConsumer#postion() in 'if statement' above, it will throw WakeUpException.
if (consumer.position(tp) >= getStoppingOffset(tp)) {
emptyPartitions.add(tp);
}
}
// ignore irrelevant code...
} {code}
Maybe we should check whether *KafkaConsumer#wakeUp* is called before, or catch
WakeUpException in *KafkaPartitionSplitReader#removeEmptySplits.*
was (Author: JIRAUSER289972):
[~renqs]
Thanks for your effort for this issue.
I‘ve reviewed your pr and i have a question. The exception i met is in method
{*}KafkaPartitionSplitReader#removeEmptySplits{*}. But i can't find any action
to handling this exception.
{code:java}
//
org.apache.flink.connector.kafka.source.reader.KafkaPartitionSplitReader#removeEmptySplits
private void removeEmptySplits() {
List emptyPartitions = new ArrayList<>();
for (TopicPartition tp : consumer.assignment()) {
// WakeUpException is thrown here.
// since KafkaConsumer#wakeUp is called before,if execute
KafkaConsumer#postion() in 'if statement' above, it will throw WakeUpException.
if (consumer.position(tp) >= getStoppingOffset(tp)) {
emptyPartitions.add(tp);
}
}
// ignore irrelevant code...
} {code}
Maybe we should check whether *KafkaConsumer#wakeUp* is called before, or catch
WakeUpException in *KafkaPartitionSplitReader#removeEmptySplits.*
> Kafka WakeUpException during handling splits changes
>
>
> Key: FLINK-27762
> URL: https://issues.apache.org/jira/browse/FLINK-27762
> Project: Flink
> Issue Type: Bug
> Components: Connectors / Kafka
>Affects Versions: 1.14.3
>Reporter: zoucan
>Assignee: Qingsheng Ren
>Priority: Major
> Labels: pull-request-available
>
>
> We enable dynamic partition discovery in our flink job, but job failed when
> kafka partition is changed.
> Exception detail is shown as follows:
> {code:java}
> java.lang.RuntimeException: One or more fetchers have encountered exception
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:225)
> at
> org.apache.flink.connector.base.source.reader.SourceReaderBase.getNextFetch(SourceReaderBase.java:169)
> at
> org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:130)
> at
> org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:350)
> at
> org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68)
> at
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:496)
> at
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:809)
> at
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:761)
> at
> org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)
> at
> org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:937)
> at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)
> at java.lang.Thread.run(Thread.java:748)
> Caused by: java.lang.RuntimeException: SplitFetcher thread 0 received
> unexpected exception while polling the records
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:150)
> at
> org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:105)
> at
> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
>
[GitHub] [flink-table-store] JingsongLi commented on a diff in pull request #138: [FLINK-27707] Implement ManagedTableFactory#onCompactTable
JingsongLi commented on code in PR #138:
URL: https://github.com/apache/flink-table-store/pull/138#discussion_r884379183
##
flink-table-store-core/src/main/java/org/apache/flink/table/store/file/operation/FileStoreReadImpl.java:
##
@@ -55,14 +56,14 @@ public FileStoreReadImpl(
WriteMode writeMode,
RowType keyType,
RowType valueType,
-Comparator keyComparator,
+Supplier> keyComparatorSupplier,
Review Comment:
Why a util method will modify `Comparator` to `Supplier`?
We shouldn't create it repeatedly unless there is a thread safety issue here.
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/TableStoreManagedFactory.java:
##
@@ -183,6 +204,84 @@ public void onDropTable(Context context, boolean
ignoreIfNotExists) {
@Override
public Map onCompactTable(
Context context, CatalogPartitionSpec catalogPartitionSpec) {
-throw new UnsupportedOperationException("Not implement yet");
+Map newOptions = new
HashMap<>(context.getCatalogTable().getOptions());
+FileStore fileStore = buildTableStore(context).buildFileStore();
+FileStoreScan.Plan plan =
+fileStore
+.newScan()
+.withPartitionFilter(
+PredicateConverter.CONVERTER.fromMap(
+
catalogPartitionSpec.getPartitionSpec(),
+fileStore.partitionType()))
+.plan();
+
+Preconditions.checkState(
+plan.snapshotId() != null && !plan.files().isEmpty(),
+"The specified %s to compact does not exist any snapshot",
+catalogPartitionSpec.getPartitionSpec().isEmpty()
+? "table"
+: String.format("partition %s",
catalogPartitionSpec.getPartitionSpec()));
+Map>> groupBy =
plan.groupByPartFiles();
+if
(!Boolean.parseBoolean(newOptions.get(COMPACTION_RESCALE_BUCKET.key( {
+groupBy =
+pickManifest(
+groupBy,
+new
FileStoreOptions(Configuration.fromMap(newOptions))
+.mergeTreeOptions(),
+new
KeyComparatorSupplier(fileStore.partitionType()).get());
+}
+try {
+newOptions.put(
+COMPACTION_SCANNED_MANIFEST.key(),
+Base64.getEncoder()
+.encodeToString(
+InstantiationUtil.serializeObject(
+new PartitionedManifestMeta(
+plan.snapshotId(),
groupBy;
+} catch (IOException e) {
+throw new RuntimeException(e);
+}
+return newOptions;
+}
+
+@VisibleForTesting
+Map>> pickManifest(
+Map>> groupBy,
+MergeTreeOptions options,
+Comparator keyComparator) {
+Map>> filtered = new
HashMap<>();
+
+for (Map.Entry>>
partEntry :
+groupBy.entrySet()) {
+Map> manifests = new HashMap<>();
+for (Map.Entry> bucketEntry :
+partEntry.getValue().entrySet()) {
+List smallFiles =
+bucketEntry.getValue().stream()
+.filter(fileMeta -> fileMeta.fileSize() <
options.targetFileSize)
+.collect(Collectors.toList());
+List intersectedFiles =
+new IntervalPartition(bucketEntry.getValue(),
keyComparator)
+.partition().stream()
+.filter(section -> section.size() > 1)
+.flatMap(Collection::stream)
+.map(SortedRun::files)
+.flatMap(Collection::stream)
+.collect(Collectors.toList());
+
+List filteredFiles =
Review Comment:
`bucketFiles`?
##
flink-table-store-connector/src/test/java/org/apache/flink/table/store/connector/TableStoreManagedFactoryTest.java:
##
@@ -256,9 +284,288 @@ public void testCreateAndCheckTableStore(
}
}
+@Test
+public void testOnCompactTableForNoSnapshot() {
+RowType partType = RowType.of();
+MockTableStoreManagedFactory mockTableStoreManagedFactory =
+new MockTableStoreManagedFactory(partType,
NON_PARTITIONED_ROW_TYPE);
+prepare(
+TABLE + "_" + UUID.randomUUID(),
+partType,
+NON_PARTITIONED_ROW_TYPE,
+NON_PARTITIONED,
+
[jira] [Commented] (FLINK-27834) Flink kubernetes operator dockerfile could not work with podman
[
https://issues.apache.org/jira/browse/FLINK-27834?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543753#comment-17543753
]
Yang Wang commented on FLINK-27834:
---
[~gyfora] Given that the copied directory is only used for ephemeral maven
build, do you have any concern on this?
> Flink kubernetes operator dockerfile could not work with podman
> ---
>
> Key: FLINK-27834
> URL: https://issues.apache.org/jira/browse/FLINK-27834
> Project: Flink
> Issue Type: Bug
> Components: Kubernetes Operator
>Reporter: Yang Wang
>Priority: Major
>
> [1/2] STEP 16/19: COPY *.git ./.git
> Error: error building at STEP "COPY *.git ./.git": checking on sources under
> "/root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0": Rel: can't
> make relative to
> /root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0; copier: stat:
> ["/*.git"]: no such file or directory
>
> podman version
> Client: Podman Engine
> Version: 4.0.2
> API Version: 4.0.2
>
>
> I think the root cause is "*.git" is not respected by podman. Maybe we could
> simply copy the whole directory when building the image.
>
> {code:java}
> WORKDIR /app
> COPY . .
> RUN --mount=type=cache,target=/root/.m2 mvn -ntp clean install -pl
> !flink-kubernetes-docs -DskipTests=$SKIP_TESTS {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Created] (FLINK-27834) Flink kubernetes operator dockerfile could not work with podman
Yang Wang created FLINK-27834:
-
Summary: Flink kubernetes operator dockerfile could not work with
podman
Key: FLINK-27834
URL: https://issues.apache.org/jira/browse/FLINK-27834
Project: Flink
Issue Type: Bug
Components: Kubernetes Operator
Reporter: Yang Wang
[1/2] STEP 16/19: COPY *.git ./.git
Error: error building at STEP "COPY *.git ./.git": checking on sources under
"/root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0": Rel: can't make
relative to /root/FLINK/release-1.0-rc2/flink-kubernetes-operator-1.0.0;
copier: stat: ["/*.git"]: no such file or directory
podman version
Client: Podman Engine
Version: 4.0.2
API Version: 4.0.2
I think the root cause is "*.git" is not respected by podman. Maybe we could
simply copy the whole directory when building the image.
{code:java}
WORKDIR /app
COPY . .
RUN --mount=type=cache,target=/root/.m2 mvn -ntp clean install -pl
!flink-kubernetes-docs -DskipTests=$SKIP_TESTS {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [flink-table-store] tsreaper commented on a diff in pull request #121: [FLINK-27626] Introduce AggregatuibMergeFunction
tsreaper commented on code in PR #121:
URL: https://github.com/apache/flink-table-store/pull/121#discussion_r884370488
##
flink-table-store-connector/src/test/java/org/apache/flink/table/store/connector/AggregationITCase.java:
##
@@ -0,0 +1,206 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.table.store.connector;
+
+import org.apache.flink.types.Row;
+
+import org.junit.Test;
+
+import java.util.ArrayList;
+import java.util.List;
+import java.util.concurrent.ExecutionException;
+
+import static org.apache.flink.util.CollectionUtil.iteratorToList;
+import static org.assertj.core.api.Assertions.assertThat;
+
+/** ITCase for partial update. */
+public class AggregationITCase extends FileStoreTableITCase {
+
+@Override
+protected List ddl() {
+
+String ddl1 =
+"CREATE TABLE IF NOT EXISTS T3 ( "
++ " a STRING, "
++ " b BIGINT, "
++ " c INT, "
++ " PRIMARY KEY (a) NOT ENFORCED )"
++ " WITH ("
++ " 'merge-engine'='aggregation' ,"
++ " 'b.aggregate-function'='sum' ,"
++ " 'c.aggregate-function'='sum' "
++ " );";
+String ddl2 =
+"CREATE TABLE IF NOT EXISTS T4 ( "
++ " a STRING,"
++ " b INT,"
++ " c DOUBLE,"
++ " PRIMARY KEY (a, b) NOT ENFORCED )"
++ " WITH ("
++ " 'merge-engine'='aggregation',"
++ " 'c.aggregate-function' = 'sum'"
++ " );";
+String ddl3 =
+"CREATE TABLE IF NOT EXISTS T5 ( "
++ " a STRING,"
++ " b INT,"
++ " c DOUBLE,"
++ " PRIMARY KEY (a) NOT ENFORCED )"
++ " WITH ("
++ " 'merge-engine'='aggregation',"
++ " 'b.aggregate-function' = 'sum'"
++ " );";
+List lists = new ArrayList<>();
+lists.add(ddl1);
+lists.add(ddl2);
+lists.add(ddl3);
+return lists;
+}
+
+@Test
+public void testCreateAggregateFunction() throws ExecutionException,
InterruptedException {
+List result;
+
+// T5
+try {
+bEnv.executeSql("INSERT INTO T5 VALUES " + "('pk1',1, 2.0), " +
"('pk1',1, 2.0)")
+.await();
+throw new AssertionError("create table T5 should failed");
+} catch (IllegalArgumentException e) {
+assert ("should set aggregate function for every column not part
of primary key"
+.equals(e.getLocalizedMessage()));
+}
+}
+
+@Test
+public void testMergeInMemory() throws ExecutionException,
InterruptedException {
+List result;
+// T3
+bEnv.executeSql("INSERT INTO T3 VALUES " + "('pk1',1, 2), " +
"('pk1',1, 2)").await();
+result = iteratorToList(bEnv.from("T3").execute().collect());
+assertThat(result).containsExactlyInAnyOrder(Row.of("pk1", 2L, 4));
+
+// T4
+bEnv.executeSql("INSERT INTO T4 VALUES " + "('pk1',1, 2.0), " +
"('pk1',1, 2.0)").await();
+result = iteratorToList(bEnv.from("T4").execute().collect());
+assertThat(result).containsExactlyInAnyOrder(Row.of("pk1", 1, 4.0));
+}
+
+@Test
+public void testMergeRead() throws ExecutionException,
InterruptedException {
+List result;
+// T3
+bEnv.executeSql("INSERT INTO T3 VALUES ('pk1',1, 2)").await();
+bEnv.executeSql("INSERT INTO T3 VALUES ('pk1',1, 4)").await();
+bEnv.executeSql("INSERT INTO T3 VALUES ('pk1',2, 0)").await();
+result = iteratorToList(bEnv.from("T3").execute().collect());
+assertThat(result).containsExactlyInAnyOrder(Row.of("pk1", 4L, 6));
+
+// T4
+bEnv.executeSql("INSERT INTO T4 VALUES ('pk1',1, 2.0)").await();
+bEnv.executeSql("INSERT I
[GitHub] [flink-table-store] JingsongLi commented on a diff in pull request #138: [FLINK-27707] Implement ManagedTableFactory#onCompactTable
JingsongLi commented on code in PR #138:
URL: https://github.com/apache/flink-table-store/pull/138#discussion_r884375368
##
flink-table-store-connector/src/main/java/org/apache/flink/table/store/connector/AbstractTableStoreFactory.java:
##
@@ -155,7 +155,7 @@ static Map
filterLogStoreOptions(Map options) {
Map.Entry::getValue));
}
-static TableStore buildTableStore(DynamicTableFactory.Context context) {
Review Comment:
Add document
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] Aitozi commented on a diff in pull request #19840: [FLINK-24713][Runtime/Coordination] Support the initial delay for SlotManager to wait fo…
Aitozi commented on code in PR #19840:
URL: https://github.com/apache/flink/pull/19840#discussion_r884374610
##
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/DeclarativeSlotManager.java:
##
@@ -79,8 +81,19 @@ public class DeclarativeSlotManager implements SlotManager {
private final Map jobMasterTargetAddresses = new
HashMap<>();
private final Map pendingSlotAllocations;
+/** Delay of the requirement change check in the slot manager. */
+private final Duration requirementsCheckDelay;
Review Comment:
Get it, will do it
##
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/DeclarativeSlotManager.java:
##
@@ -79,8 +81,19 @@ public class DeclarativeSlotManager implements SlotManager {
private final Map jobMasterTargetAddresses = new
HashMap<>();
private final Map pendingSlotAllocations;
+/** Delay of the requirement change check in the slot manager. */
+private final Duration requirementsCheckDelay;
Review Comment:
do you mean create another ticket for this ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (FLINK-26179) Support periodic savepointing in the operator
[ https://issues.apache.org/jira/browse/FLINK-26179?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543748#comment-17543748 ] Gyula Fora commented on FLINK-26179: I think the question of configurable native/canonical savepoint format is not specific to this feature. It also applies to upgrades and manual triggering. Users should naturally not configure small periodic savepoint interval, but otherwise it's completely up to them. > Support periodic savepointing in the operator > - > > Key: FLINK-26179 > URL: https://issues.apache.org/jira/browse/FLINK-26179 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Reporter: Gyula Fora >Assignee: Gyula Fora >Priority: Major > Fix For: kubernetes-operator-1.1.0 > > > Automatic triggering of savepoints is a commonly requested feature. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-26179) Support periodic savepointing in the operator
[ https://issues.apache.org/jira/browse/FLINK-26179?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543744#comment-17543744 ] Yang Wang commented on FLINK-26179: --- It is harmless to introduce such a new feature. Do we need to support the NATIVE savepoint format type? If not, we should notice the users taking savepoint with CANONICAL is expensive. It should not be configured as small as checkpoint interval. > Support periodic savepointing in the operator > - > > Key: FLINK-26179 > URL: https://issues.apache.org/jira/browse/FLINK-26179 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Reporter: Gyula Fora >Assignee: Gyula Fora >Priority: Major > Fix For: kubernetes-operator-1.1.0 > > > Automatic triggering of savepoints is a commonly requested feature. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Created] (FLINK-27833) PulsarSourceITCase.testTaskManagerFailure failed with AssertionError
Huang Xingbo created FLINK-27833:
Summary: PulsarSourceITCase.testTaskManagerFailure failed with
AssertionError
Key: FLINK-27833
URL: https://issues.apache.org/jira/browse/FLINK-27833
Project: Flink
Issue Type: Bug
Components: Connectors / Pulsar
Affects Versions: 1.14.4
Reporter: Huang Xingbo
{code:java}
2022-05-28T02:40:24.3137097Z May 28 02:40:24 [ERROR] Tests run: 8, Failures: 1,
Errors: 0, Skipped: 0, Time elapsed: 123.914 s <<< FAILURE! - in
org.apache.flink.connector.pulsar.source.PulsarSourceITCase
2022-05-28T02:40:24.3139274Z May 28 02:40:24 [ERROR]
testTaskManagerFailure{TestEnvironment, ExternalContext,
ClusterControllable}[2] Time elapsed: 25.823 s <<< FAILURE!
2022-05-28T02:40:24.3140450Z May 28 02:40:24 java.lang.AssertionError:
2022-05-28T02:40:24.3141062Z May 28 02:40:24
2022-05-28T02:40:24.3141875Z May 28 02:40:24 Expected: Records consumed by
Flink should be identical to test data and preserve the order in split
2022-05-28T02:40:24.3143710Z May 28 02:40:24 but: Mismatched record at
position 18: Expected '0-iuKyiUwhhuO3NoDPvpLxIUw3' but was '0-98Y'
2022-05-28T02:40:24.3145019Z May 28 02:40:24at
org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:20)
2022-05-28T02:40:24.3146064Z May 28 02:40:24at
org.hamcrest.MatcherAssert.assertThat(MatcherAssert.java:8)
2022-05-28T02:40:24.3147334Z May 28 02:40:24at
org.apache.flink.connectors.test.common.testsuites.SourceTestSuiteBase.testTaskManagerFailure(SourceTestSuiteBase.java:289)
2022-05-28T02:40:24.3148548Z May 28 02:40:24at
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
2022-05-28T02:40:24.3149690Z May 28 02:40:24at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
2022-05-28T02:40:24.3150910Z May 28 02:40:24at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
2022-05-28T02:40:24.3158249Z May 28 02:40:24at
java.lang.reflect.Method.invoke(Method.java:498)
2022-05-28T02:40:24.3159819Z May 28 02:40:24at
org.junit.platform.commons.util.ReflectionUtils.invokeMethod(ReflectionUtils.java:688)
2022-05-28T02:40:24.3161222Z May 28 02:40:24at
org.junit.jupiter.engine.execution.MethodInvocation.proceed(MethodInvocation.java:60)
2022-05-28T02:40:24.3162609Z May 28 02:40:24at
org.junit.jupiter.engine.execution.InvocationInterceptorChain$ValidatingInvocation.proceed(InvocationInterceptorChain.java:131)
2022-05-28T02:40:24.3164030Z May 28 02:40:24at
org.junit.jupiter.engine.extension.TimeoutExtension.intercept(TimeoutExtension.java:149)
2022-05-28T02:40:24.3165548Z May 28 02:40:24at
org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestableMethod(TimeoutExtension.java:140)
2022-05-28T02:40:24.3167224Z May 28 02:40:24at
org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestTemplateMethod(TimeoutExtension.java:92)
2022-05-28T02:40:24.3169087Z May 28 02:40:24at
org.junit.jupiter.engine.execution.ExecutableInvoker$ReflectiveInterceptorCall.lambda$ofVoidMethod$0(ExecutableInvoker.java:115)
2022-05-28T02:40:24.3170540Z May 28 02:40:24at
org.junit.jupiter.engine.execution.ExecutableInvoker.lambda$invoke$0(ExecutableInvoker.java:105)
2022-05-28T02:40:24.3171970Z May 28 02:40:24at
org.junit.jupiter.engine.execution.InvocationInterceptorChain$InterceptedInvocation.proceed(InvocationInterceptorChain.java:106)
2022-05-28T02:40:24.3173499Z May 28 02:40:24at
org.junit.jupiter.engine.execution.InvocationInterceptorChain.proceed(InvocationInterceptorChain.java:64)
2022-05-28T02:40:24.3175023Z May 28 02:40:24at
org.junit.jupiter.engine.execution.InvocationInterceptorChain.chainAndInvoke(InvocationInterceptorChain.java:45)
2022-05-28T02:40:24.3176435Z May 28 02:40:24at
org.junit.jupiter.engine.execution.InvocationInterceptorChain.invoke(InvocationInterceptorChain.java:37)
2022-05-28T02:40:24.3177715Z May 28 02:40:24at
org.junit.jupiter.engine.execution.ExecutableInvoker.invoke(ExecutableInvoker.java:104)
2022-05-28T02:40:24.3178985Z May 28 02:40:24at
org.junit.jupiter.engine.execution.ExecutableInvoker.invoke(ExecutableInvoker.java:98)
2022-05-28T02:40:24.3180563Z May 28 02:40:24at
org.junit.jupiter.engine.descriptor.TestMethodTestDescriptor.lambda$invokeTestMethod$6(TestMethodTestDescriptor.java:210)
2022-05-28T02:40:24.3182004Z May 28 02:40:24at
org.junit.platform.engine.support.hierarchical.ThrowableCollector.execute(ThrowableCollector.java:73)
2022-05-28T02:40:24.3183400Z May 28 02:40:24at
org.junit.jupiter.engine.descriptor.TestMethodTestDescriptor.invokeTestMethod(TestMethodTestDescriptor.java:206)
2022-05-28T02:40:24.3184865Z May 28 02:40:24at
org.junit.jupiter.engine.descriptor.TestMethodTestDescriptor.execute(TestMethodTestDescriptor.java:131)
2022-05-28T02:40:24.3185720Z May 28 02:40:24at
[jira] [Commented] (FLINK-27009) Support SQL job submission in flink kubernetes opeartor
[
https://issues.apache.org/jira/browse/FLINK-27009?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543743#comment-17543743
]
Yang Wang commented on FLINK-27009:
---
[~mbalassi] Maybe you could also share some use cases from your internal users.
For example, how would you they like to submit a SQL job?
By introducing a new field named with {{SQLScriptURI}} or they prefer a pure
raw field {{{}SQLScript{}}}. After then we could integrate them into the
proposal.
> Support SQL job submission in flink kubernetes opeartor
> ---
>
> Key: FLINK-27009
> URL: https://issues.apache.org/jira/browse/FLINK-27009
> Project: Flink
> Issue Type: New Feature
> Components: Kubernetes Operator
>Reporter: Biao Geng
>Assignee: Biao Geng
>Priority: Major
>
> Currently, the flink kubernetes opeartor is for jar job using application or
> session cluster. For SQL job, there is no out of box solution in the
> operator.
> One simple and short-term solution is to wrap the SQL script into a jar job
> using table API with limitation.
> The long-term solution may work with
> [FLINK-26541|https://issues.apache.org/jira/browse/FLINK-26541] to achieve
> the full support.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[GitHub] [flink-table-store] JingsongLi commented on pull request #133: [FLINK-27502] Add file Suffix to data files
JingsongLi commented on PR #133: URL: https://github.com/apache/flink-table-store/pull/133#issuecomment-1140603513 ``` Error: Failures: Error:DataFilePathFactoryTest.testNoPartition:46 expected: /tmp/junit13044672734532131/bucket-123/data-de33b78b-2802-49a0-8ec7-cbeeed7af049-0 but was: /tmp/junit13044672734532131/bucket-123/data-de33b78b-2802-49a0-8ec7-cbeeed7af049-0.orc Error:DataFilePathFactoryTest.testWithPartition:64 expected: /tmp/junit3939205851475787579/dt=20211224/bucket-123/data-8a204f50-ad09-4e55-a41f-39c94da0863c-0 but was: /tmp/junit3939205851475787579/dt=20211224/bucket-123/data-8a204f50-ad09-4e55-a41f-39c94da0863c-0.orc [INFO] ``` Test failure, you need to adjust some testing codes too. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-27832) SplitAggregateITCase tests failed with Could not acquire the minimum required resources
Huang Xingbo created FLINK-27832:
Summary: SplitAggregateITCase tests failed with Could not acquire
the minimum required resources
Key: FLINK-27832
URL: https://issues.apache.org/jira/browse/FLINK-27832
Project: Flink
Issue Type: Bug
Components: Table SQL / Planner
Affects Versions: 1.16.0
Reporter: Huang Xingbo
{code:java}
2022-05-27T17:42:59.4814999Z May 27 17:42:59 [ERROR] Tests run: 64, Failures:
23, Errors: 1, Skipped: 0, Time elapsed: 305.5 s <<< FAILURE! - in
org.apache.flink.table.planner.runtime.stream.sql.SplitAggregateITCase
2022-05-27T17:42:59.4815983Z May 27 17:42:59 [ERROR]
SplitAggregateITCase.testAggWithJoin Time elapsed: 278.742 s <<< ERROR!
2022-05-27T17:42:59.4816608Z May 27 17:42:59
org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
2022-05-27T17:42:59.4819182Z May 27 17:42:59at
org.apache.flink.runtime.jobmaster.JobResult.toJobExecutionResult(JobResult.java:144)
2022-05-27T17:42:59.4820363Z May 27 17:42:59at
org.apache.flink.runtime.minicluster.MiniClusterJobClient.lambda$getJobExecutionResult$3(MiniClusterJobClient.java:141)
2022-05-27T17:42:59.4821463Z May 27 17:42:59at
java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:616)
2022-05-27T17:42:59.4822292Z May 27 17:42:59at
java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591)
2022-05-27T17:42:59.4823317Z May 27 17:42:59at
java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
2022-05-27T17:42:59.4824210Z May 27 17:42:59at
java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975)
2022-05-27T17:42:59.4825081Z May 27 17:42:59at
org.apache.flink.runtime.rpc.akka.AkkaInvocationHandler.lambda$invokeRpc$1(AkkaInvocationHandler.java:268)
2022-05-27T17:42:59.4825927Z May 27 17:42:59at
java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774)
2022-05-27T17:42:59.4826748Z May 27 17:42:59at
java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750)
2022-05-27T17:42:59.4827596Z May 27 17:42:59at
java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
2022-05-27T17:42:59.4828416Z May 27 17:42:59at
java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975)
2022-05-27T17:42:59.4829284Z May 27 17:42:59at
org.apache.flink.util.concurrent.FutureUtils.doForward(FutureUtils.java:1277)
2022-05-27T17:42:59.4830111Z May 27 17:42:59at
org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.lambda$null$1(ClassLoadingUtils.java:93)
2022-05-27T17:42:59.4831015Z May 27 17:42:59at
org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:68)
2022-05-27T17:42:59.483Z May 27 17:42:59at
org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.lambda$guardCompletionWithContextClassLoader$2(ClassLoadingUtils.java:92)
2022-05-27T17:42:59.4833162Z May 27 17:42:59at
java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774)
2022-05-27T17:42:59.4834250Z May 27 17:42:59at
java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750)
2022-05-27T17:42:59.4835236Z May 27 17:42:59at
java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
2022-05-27T17:42:59.4836035Z May 27 17:42:59at
java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975)
2022-05-27T17:42:59.4836872Z May 27 17:42:59at
org.apache.flink.runtime.concurrent.akka.AkkaFutureUtils$1.onComplete(AkkaFutureUtils.java:47)
2022-05-27T17:42:59.4837630Z May 27 17:42:59at
akka.dispatch.OnComplete.internal(Future.scala:300)
2022-05-27T17:42:59.4838394Z May 27 17:42:59at
akka.dispatch.OnComplete.internal(Future.scala:297)
2022-05-27T17:42:59.4839044Z May 27 17:42:59at
akka.dispatch.japi$CallbackBridge.apply(Future.scala:224)
2022-05-27T17:42:59.4839748Z May 27 17:42:59at
akka.dispatch.japi$CallbackBridge.apply(Future.scala:221)
2022-05-27T17:42:59.4840463Z May 27 17:42:59at
scala.concurrent.impl.CallbackRunnable.run(Promise.scala:60)
2022-05-27T17:42:59.4841313Z May 27 17:42:59at
org.apache.flink.runtime.concurrent.akka.AkkaFutureUtils$DirectExecutionContext.execute(AkkaFutureUtils.java:65)
2022-05-27T17:42:59.4842335Z May 27 17:42:59at
scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:68)
2022-05-27T17:42:59.4843300Z May 27 17:42:59at
scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1(Promise.scala:284)
2022-05-27T17:42:59.4844146Z May 27 17:42:59at
scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1$adapted(Promise.scala:284)
2022-05-27T17:42:59.4844882Z May 27 17:42:59at
scala.concurrent.impl.Promise$DefaultPromise.t
[jira] [Updated] (FLINK-27625) Add query hint for async lookup join
[
https://issues.apache.org/jira/browse/FLINK-27625?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
lincoln lee updated FLINK-27625:
Description:
The hint name discuss thread:
https://lists.apache.org/thread/jm9kg33wk9z2bvo2b0g5bp3n5kfj6qv8
FLINK-27623 adds a global parameter 'table.exec.async-lookup.output-mode' for
table users so that all three control parameters related to async I/O can be
configured at the same job level.
As planned in the issue, we‘d like to go a step further to offer more precise
control for async join operation more than job level config, to introduce a new
join hint: ‘ASYNC_LOOKUP’.
For the hint option, for intuitive and user-friendly reasons, we want to
support both simple and kv forms, with all options except table name being
optional (use job level configuration if not set)
# 1. simple form: (ordered hint option list)
```
ASYNC_LOOKUP('tableName'[, 'output-mode', 'buffer-capacity', 'timeout'])
optional:
output-mode
buffer-capacity
timeout
```
Note: since Calcite currently does not support the mixed type hint options,
the table name here needs to be a string instead of an identifier. (For
`SqlHint`: The option format can not be mixed in, they should either be all
simple identifiers or all literals or all key value pairs.) We can improve
this after Calcite support.
# 2. kv form: (support unordered hint option list)
```
ASYNC_LOOKUP('table'='tableName'[, 'output-mode'='ordered|allow-unordered',
'capacity'='int', 'timeout'='duration'])
optional kvs:
'output-mode'='ordered|allow-unordered'
'capacity'='int'
'timeout'='duration'
```
e.g., if the job level configuration is:
```
table.exec.async-lookup.output-mode: ORDERED
table.exec.async-lookup.buffer-capacity: 100
table.exec.async-lookup.timeout: 180s
```
then the following hints:
```
1. ASYNC_LOOKUP('dim1', 'allow-unordered', '200', '300s')
2. ASYNC_LOOKUP('dim1', 'allow-unordered', '200')
3. ASYNC_LOOKUP('table'='dim1', 'output-mode'='allow-unordered')
4. ASYNC_LOOKUP('table'='dim1', 'timeout'='300s')
5. ASYNC_LOOKUP('table'='dim1', 'capacity'='300')
```
are equivalent to:
```
1. ASYNC_LOOKUP('dim1', 'allow-unordered', '200', '300s')
2. ASYNC_LOOKUP('dim1', 'allow-unordered', '200', '180s')
3. ASYNC_LOOKUP('table'='dim1', 'output-mode'='allow-unordered',
'capacity'='100', 'timeout'='180s')
4. ASYNC_LOOKUP('table'='dim1', 'output-mode'='ordered', 'capacity'='100',
'timeout'='300s')
5. ASYNC_LOOKUP('table'='dim1', 'output-mode'='ordered', 'capacity'='300',
'timeout'='180s')
```
In addition, if the lookup source implements both sync and async table
function, the planner prefers to choose the async function when the
'ASYNC_LOOKUP' hint is specified.
was:
Add query hint for async lookup join for join level control:
e.g.,
{code}
// ordered mode
ASYNC_LOOKUP(dim1, 'ordered', '100', '180s')
// unordered mode
ASYNC_LOOKUP(dim1, 'allow-unordered', '100', '180s')
{code}
TODO: The hint name should be discussed in ML.
> Add query hint for async lookup join
>
>
> Key: FLINK-27625
> URL: https://issues.apache.org/jira/browse/FLINK-27625
> Project: Flink
> Issue Type: Sub-task
> Components: Table SQL / API
>Reporter: lincoln lee
>Assignee: lincoln lee
>Priority: Major
> Fix For: 1.16.0
>
>
> The hint name discuss thread:
> https://lists.apache.org/thread/jm9kg33wk9z2bvo2b0g5bp3n5kfj6qv8
> FLINK-27623 adds a global parameter 'table.exec.async-lookup.output-mode' for
> table users so that all three control parameters related to async I/O can be
> configured at the same job level.
> As planned in the issue, we‘d like to go a step further to offer more precise
> control for async join operation more than job level config, to introduce a
> new join hint: ‘ASYNC_LOOKUP’.
> For the hint option, for intuitive and user-friendly reasons, we want to
> support both simple and kv forms, with all options except table name being
> optional (use job level configuration if not set)
> # 1. simple form: (ordered hint option list)
> ```
> ASYNC_LOOKUP('tableName'[, 'output-mode', 'buffer-capacity', 'timeout'])
> optional:
> output-mode
> buffer-capacity
> timeout
> ```
> Note: since Calcite currently does not support the mixed type hint options,
> the table name here needs to be a string instead of an identifier. (For
> `SqlHint`: The option format can not be mixed in, they should either be all
> simple identifiers or all literals or all key value pairs.) We can improve
> this after Calcite support.
> # 2. kv form: (support unordered hint option list)
> ```
> ASYNC_LOOKUP('table'='tableName'[, 'output-mode'='ordered|allow-unordered',
> 'capacity'='int', 'timeout'='duration'])
> optional kvs:
> 'output-mode'='ordered|allow-unordered'
> 'capacity'='int'
> 'timeout'='duration'
> ```
> e.g., if the job level configuration is:
>
[jira] [Updated] (FLINK-27625) Add query hint for async lookup join
[
https://issues.apache.org/jira/browse/FLINK-27625?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
lincoln lee updated FLINK-27625:
Description:
The hint name discuss thread:
https://lists.apache.org/thread/jm9kg33wk9z2bvo2b0g5bp3n5kfj6qv8
FLINK-27623 adds a global parameter 'table.exec.async-lookup.output-mode' for
table users so that all three control parameters related to async I/O can be
configured at the same job level.
As planned in the issue, we‘d like to go a step further to offer more precise
control for async join operation more than job level config, to introduce a new
join hint: ‘ASYNC_LOOKUP’.
For the hint option, for intuitive and user-friendly reasons, we want to
support both simple and kv forms, with all options except table name being
optional (use job level configuration if not set)
1. simple form: (ordered hint option list)
```
ASYNC_LOOKUP('tableName'[, 'output-mode', 'buffer-capacity', 'timeout'])
optional:
output-mode
buffer-capacity
timeout
```
Note: since Calcite currently does not support the mixed type hint options,
the table name here needs to be a string instead of an identifier. (For
`SqlHint`: The option format can not be mixed in, they should either be all
simple identifiers or all literals or all key value pairs.) We can improve
this after Calcite support.
2. kv form: (support unordered hint option list)
```
ASYNC_LOOKUP('table'='tableName'[, 'output-mode'='ordered|allow-unordered',
'capacity'='int', 'timeout'='duration'])
optional kvs:
'output-mode'='ordered|allow-unordered'
'capacity'='int'
'timeout'='duration'
```
e.g., if the job level configuration is:
```
table.exec.async-lookup.output-mode: ORDERED
table.exec.async-lookup.buffer-capacity: 100
table.exec.async-lookup.timeout: 180s
```
then the following hints:
```
1. ASYNC_LOOKUP('dim1', 'allow-unordered', '200', '300s')
2. ASYNC_LOOKUP('dim1', 'allow-unordered', '200')
3. ASYNC_LOOKUP('table'='dim1', 'output-mode'='allow-unordered')
4. ASYNC_LOOKUP('table'='dim1', 'timeout'='300s')
5. ASYNC_LOOKUP('table'='dim1', 'capacity'='300')
```
are equivalent to:
```
1. ASYNC_LOOKUP('dim1', 'allow-unordered', '200', '300s')
2. ASYNC_LOOKUP('dim1', 'allow-unordered', '200', '180s')
3. ASYNC_LOOKUP('table'='dim1', 'output-mode'='allow-unordered',
'capacity'='100', 'timeout'='180s')
4. ASYNC_LOOKUP('table'='dim1', 'output-mode'='ordered', 'capacity'='100',
'timeout'='300s')
5. ASYNC_LOOKUP('table'='dim1', 'output-mode'='ordered', 'capacity'='300',
'timeout'='180s')
```
In addition, if the lookup source implements both sync and async table
function, the planner prefers to choose the async function when the
'ASYNC_LOOKUP' hint is specified.
was:
The hint name discuss thread:
https://lists.apache.org/thread/jm9kg33wk9z2bvo2b0g5bp3n5kfj6qv8
FLINK-27623 adds a global parameter 'table.exec.async-lookup.output-mode' for
table users so that all three control parameters related to async I/O can be
configured at the same job level.
As planned in the issue, we‘d like to go a step further to offer more precise
control for async join operation more than job level config, to introduce a new
join hint: ‘ASYNC_LOOKUP’.
For the hint option, for intuitive and user-friendly reasons, we want to
support both simple and kv forms, with all options except table name being
optional (use job level configuration if not set)
# 1. simple form: (ordered hint option list)
```
ASYNC_LOOKUP('tableName'[, 'output-mode', 'buffer-capacity', 'timeout'])
optional:
output-mode
buffer-capacity
timeout
```
Note: since Calcite currently does not support the mixed type hint options,
the table name here needs to be a string instead of an identifier. (For
`SqlHint`: The option format can not be mixed in, they should either be all
simple identifiers or all literals or all key value pairs.) We can improve
this after Calcite support.
# 2. kv form: (support unordered hint option list)
```
ASYNC_LOOKUP('table'='tableName'[, 'output-mode'='ordered|allow-unordered',
'capacity'='int', 'timeout'='duration'])
optional kvs:
'output-mode'='ordered|allow-unordered'
'capacity'='int'
'timeout'='duration'
```
e.g., if the job level configuration is:
```
table.exec.async-lookup.output-mode: ORDERED
table.exec.async-lookup.buffer-capacity: 100
table.exec.async-lookup.timeout: 180s
```
then the following hints:
```
1. ASYNC_LOOKUP('dim1', 'allow-unordered', '200', '300s')
2. ASYNC_LOOKUP('dim1', 'allow-unordered', '200')
3. ASYNC_LOOKUP('table'='dim1', 'output-mode'='allow-unordered')
4. ASYNC_LOOKUP('table'='dim1', 'timeout'='300s')
5. ASYNC_LOOKUP('table'='dim1', 'capacity'='300')
```
are equivalent to:
```
1. ASYNC_LOOKUP('dim1', 'allow-unordered', '200', '300s')
2. ASYNC_LOOKUP('dim1', 'allow-unordered', '200', '180s')
3. ASYNC_LOOKUP('table'='dim1', 'output-mode'='allow-unordered',
'capacity'='100', 'timeout'='180s')
4. ASYNC_LOOKUP('table'='dim1', 'output-mode'='ordered', 'capacity
[GitHub] [flink] flinkbot commented on pull request #19842: [FLINK-27522][network] Ignore max buffers per channel when allocate buffer
flinkbot commented on PR #19842: URL: https://github.com/apache/flink/pull/19842#issuecomment-1140596253 ## CI report: * aa380f29ca66553b6f168a177dcedb4563efb05a UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27826) Support machine learning training for very high dimesional models
[ https://issues.apache.org/jira/browse/FLINK-27826?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Zhipeng Zhang updated FLINK-27826: -- Description: There is limited support for training high dimensional machine learning models in FlinkML though it is often useful, especially in industrial cases. When the size of the model parameter can not be hold in the memory of a single machine, FlinkML crashes now. So it would be nice if we support high dimensional model training in FlinkML. To achieve this, we probably need to do the following things: # Do a survey on how to training large machine learning models of existing machine learning systems (e.g. data paralllel, model parallel). # Define/Implement the infra of supporting large model training in FlinkML. # Implement a machine learning model (e.g., logisitic regression, factorzation machine, etc) that can train models with more than ten billion parameters. # Benchmark the implementation and further improve it. was: There is limited support for training high dimensional machine learning models in FlinkML though it is often useful, especially in industrial cases. When the size of the model parameter can not be hold in the memory of a single machine, FlinkML crashes now. So it would be nice if we support high dimensional model training in FlinkML. To achieve this, we probably need to do the following things: # Do a survey on how to training large machine learning models of existing machine learning systems (e.g. data paralllel, model parallel). # Define/Implement the infra of supporting large model training in FlinkML. # Implement a logistic regression model that can train models with more than ten billion parameters. # Benchmark the implementation and further improve it. > Support machine learning training for very high dimesional models > - > > Key: FLINK-27826 > URL: https://issues.apache.org/jira/browse/FLINK-27826 > Project: Flink > Issue Type: New Feature > Components: Library / Machine Learning >Reporter: Zhipeng Zhang >Assignee: Zhipeng Zhang >Priority: Major > > There is limited support for training high dimensional machine learning > models in FlinkML though it is often useful, especially in industrial cases. > When the size of the model parameter can not be hold in the memory of a > single machine, FlinkML crashes now. > So it would be nice if we support high dimensional model training in FlinkML. > To achieve this, we probably need to do the following things: > # Do a survey on how to training large machine learning models of existing > machine learning systems (e.g. data paralllel, model parallel). > # Define/Implement the infra of supporting large model training in FlinkML. > # Implement a machine learning model (e.g., logisitic regression, > factorzation machine, etc) that can train models with more than ten billion > parameters. > # Benchmark the implementation and further improve it. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Updated] (FLINK-27522) Ignore max buffers per channel when allocate buffer
[ https://issues.apache.org/jira/browse/FLINK-27522?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-27522: --- Labels: pull-request-available (was: ) > Ignore max buffers per channel when allocate buffer > --- > > Key: FLINK-27522 > URL: https://issues.apache.org/jira/browse/FLINK-27522 > Project: Flink > Issue Type: Sub-task > Components: Runtime / Checkpointing, Runtime / Network >Affects Versions: 1.14.0, 1.15.0 >Reporter: fanrui >Priority: Major > Labels: pull-request-available > Fix For: 1.16.0 > > > This is first task of > [FLIP-227|https://cwiki.apache.org/confluence/display/FLINK/FLIP-227%3A+Support+overdraft+buffer] > The LocalBufferPool will be unavailable when the maxBuffersPerChannel is > reached for this channel or availableMemorySegments.isEmpty. > If we request a memory segment from LocalBufferPool and the > maxBuffersPerChannel is reached for this channel, we just ignore that and > continue to allocate buffer while availableMemorySegments isn't empty in > LocalBufferPool. > -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] 1996fanrui opened a new pull request, #19842: [FLINK-27522][network] Ignore max buffers per channel when allocate buffer
1996fanrui opened a new pull request, #19842: URL: https://github.com/apache/flink/pull/19842 ## What is the purpose of the change Ignore max buffers per channel when allocate buffer ## Brief change log Ignore max buffers per channel when allocate buffer ## Verifying this change This change is already covered by existing tests, such as `LocalBufferPoolTest#testMaxBuffersPerChannelAndAvailability`. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not documented -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-27831) Provide example of Beam on the k8s operator
Márton Balassi created FLINK-27831: -- Summary: Provide example of Beam on the k8s operator Key: FLINK-27831 URL: https://issues.apache.org/jira/browse/FLINK-27831 Project: Flink Issue Type: Improvement Components: Kubernetes Operator Reporter: Márton Balassi Assignee: Márton Balassi Fix For: kubernetes-operator-1.1.0 Multiple users have asked for whether the operator supports Beam jobs in different shapes. I assume that running a Beam job ultimately with the current operator ultimately comes down to having the right jars on the classpath / packaged into the user's fatjar. At this stage I suggest adding one such example, providing it might attract new users. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] KarmaGYZ commented on a diff in pull request #19840: [FLINK-24713][Runtime/Coordination] Support the initial delay for SlotManager to wait fo…
KarmaGYZ commented on code in PR #19840:
URL: https://github.com/apache/flink/pull/19840#discussion_r884357127
##
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/DeclarativeSlotManager.java:
##
@@ -79,8 +81,19 @@ public class DeclarativeSlotManager implements SlotManager {
private final Map jobMasterTargetAddresses = new
HashMap<>();
private final Map pendingSlotAllocations;
+/** Delay of the requirement change check in the slot manager. */
+private final Duration requirementsCheckDelay;
Review Comment:
Yes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (FLINK-27827) StreamExecutionEnvironment method supporting explicit Boundedness
[
https://issues.apache.org/jira/browse/FLINK-27827?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Andreas Hailu updated FLINK-27827:
--
Description:
When creating a {{{}DataStreamSource{}}}, an explicitly bounded input is only
returned if the {{InputFormat}} provided implements {{{}FileInputFormat{}}}.
This is results in runtime exceptions when trying to run applications in Batch
execution mode while using non {{{}FileInputFormat{}}}s e.g. Apache Iceberg
[1], Flink's Hadoop MapReduce compatibility API's [2] inputs, etc...
I understand there is a {{DataSource}} API [3] that supports the specification
of the boundedness of an input, but that would require all connectors to revise
their APIs to leverage it which would take some time.
My organization is in the middle of migrating from the {{DataSet}} API to the
{{{}DataStream API{}}}, and we've found this to be a challenge as nearly all of
our inputs have been determined to be unbounded as we use {{InputFormats}} that
are not {{{}FileInputFormat{}}}s.
Our work-around was to provide a local patch in {{StreamExecutionEnvironment}}
with a method supporting explicitly bounded inputs.
As this helped us implement a Batch {{DataStream}} solution, perhaps this is
something that may be helpful for others?
[1] [https://iceberg.apache.org/docs/latest/flink/#reading-with-datastream]
[2]
[https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/dataset/hadoop_map_reduce/]
[3]
[https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/sources/#the-data-source-api]
was:
When creating a {{{}DataStreamSource{}}}, an explicitly bounded input is only
returned if the {{InputFormat}} provided implements {{{}FileInputFormat{}}}.
This is results in runtime exceptions when trying to run applications in Batch
execution mode while using non {{{}FileInputFormat{}}}s e.g. Apache Iceberg
[1], Flink's Hadoop MapReduce compatibility API's [2] inputs, etc...
I understand there is a {{DataSource}} API [3] that supports the specification
of the boundedness of an input, but that would require all connectors to revise
their APIs to leverage it which would take some time.
My organization is in the middle of migrating from the {{DataSet}} API to the
{{{}DataStream API{}}}, and we've found this to be a challenge as nearly all of
our inputs have been determined to be unbounded as we use{{ InputFormats}} that
are not {{{}FileInputFormat{}}}s.
Our work-around was to provide a local patch in {{StreamExecutionEnvironment}}
with a method supporting explicitly bounded inputs.
As this helped us implement a Batch {{DataStream}} solution, perhaps this is
something that may be helpful for others?
[1] [https://iceberg.apache.org/docs/latest/flink/#reading-with-datastream]
[2]
[https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/dataset/hadoop_map_reduce/]
[3]
[https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/sources/#the-data-source-api]
> StreamExecutionEnvironment method supporting explicit Boundedness
> -
>
> Key: FLINK-27827
> URL: https://issues.apache.org/jira/browse/FLINK-27827
> Project: Flink
> Issue Type: Improvement
> Components: API / DataStream
>Reporter: Andreas Hailu
>Priority: Minor
>
> When creating a {{{}DataStreamSource{}}}, an explicitly bounded input is only
> returned if the {{InputFormat}} provided implements {{{}FileInputFormat{}}}.
> This is results in runtime exceptions when trying to run applications in
> Batch execution mode while using non {{{}FileInputFormat{}}}s e.g. Apache
> Iceberg [1], Flink's Hadoop MapReduce compatibility API's [2] inputs, etc...
> I understand there is a {{DataSource}} API [3] that supports the
> specification of the boundedness of an input, but that would require all
> connectors to revise their APIs to leverage it which would take some time.
> My organization is in the middle of migrating from the {{DataSet}} API to the
> {{{}DataStream API{}}}, and we've found this to be a challenge as nearly all
> of our inputs have been determined to be unbounded as we use {{InputFormats}}
> that are not {{{}FileInputFormat{}}}s.
> Our work-around was to provide a local patch in
> {{StreamExecutionEnvironment}} with a method supporting explicitly bounded
> inputs.
> As this helped us implement a Batch {{DataStream}} solution, perhaps this is
> something that may be helpful for others?
>
> [1] [https://iceberg.apache.org/docs/latest/flink/#reading-with-datastream]
> [2]
> [https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/dataset/hadoop_map_reduce/]
>
> [3]
> [https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/sources/#the-data-source-api]
>
--
This mes
[jira] [Updated] (FLINK-27827) StreamExecutionEnvironment method supporting explicit Boundedness
[
https://issues.apache.org/jira/browse/FLINK-27827?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Andreas Hailu updated FLINK-27827:
--
Description:
When creating a {{{}DataStreamSource{}}}, an explicitly bounded input is only
returned if the {{InputFormat}} provided implements {{{}FileInputFormat{}}}.
This is results in runtime exceptions when trying to run applications in Batch
execution mode while using non {{{}FileInputFormat{}}}s e.g. Apache Iceberg
[1], Flink's Hadoop MapReduce compatibility API's [2] inputs, etc...
I understand there is a {{DataSource}} API [3] that supports the specification
of the boundedness of an input, but that would require all connectors to revise
their APIs to leverage it which would take some time.
My organization is in the middle of migrating from the {{DataSet}} API to the
{{{}DataStream API{}}}, and we've found this to be a challenge as nearly all of
our inputs have been determined to be unbounded as we use{{ InputFormats}} that
are not {{{}FileInputFormat{}}}s.
Our work-around was to provide a local patch in {{StreamExecutionEnvironment}}
with a method supporting explicitly bounded inputs.
As this helped us implement a Batch {{DataStream}} solution, perhaps this is
something that may be helpful for others?
[1] [https://iceberg.apache.org/docs/latest/flink/#reading-with-datastream]
[2]
[https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/dataset/hadoop_map_reduce/]
[3]
[https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/sources/#the-data-source-api]
was:
When creating a {{{}DataStreamSource{}}}, an explicitly bounded input is only
returned if the {{InputFormat}} provided implements {{{}FileInputFormat{}}}.
This is results in runtime exceptions when trying to run applications in Batch
execution mode while using non {{{}FileInputFormat{}}}s e.g. Apache Iceberg
[1], Flink's Hadoop MapReduce compatibility API's [2] inputs, etc...
I understand there is a {{DataSource}} API [3] that supports the specification
of the boundedness of an input, but that would require all connectors to revise
their APIs to leverage it which would take some time.
My organization is in the middle of migrating from the {{DataSet}} API to the
{{DataStream API, and we've found this to be a challenge as nearly all of our
inputs have been determines to be unbounded as we use InputFormats}} that are
not {{{}FileInputFormat{}}}s. Our work-around was to provide a local patch in
{{StreamExecutionEnvironment}} with a method supporting explicitly bounded
inputs.
As this helped us implement a Batch {{DataStream}} solution, perhaps this is
something that may be helpful for others?
[1] [https://iceberg.apache.org/docs/latest/flink/#reading-with-datastream]
[2]
[https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/dataset/hadoop_map_reduce/]
[3]
[https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/sources/#the-data-source-api]
> StreamExecutionEnvironment method supporting explicit Boundedness
> -
>
> Key: FLINK-27827
> URL: https://issues.apache.org/jira/browse/FLINK-27827
> Project: Flink
> Issue Type: Improvement
> Components: API / DataStream
>Reporter: Andreas Hailu
>Priority: Minor
>
> When creating a {{{}DataStreamSource{}}}, an explicitly bounded input is only
> returned if the {{InputFormat}} provided implements {{{}FileInputFormat{}}}.
> This is results in runtime exceptions when trying to run applications in
> Batch execution mode while using non {{{}FileInputFormat{}}}s e.g. Apache
> Iceberg [1], Flink's Hadoop MapReduce compatibility API's [2] inputs, etc...
> I understand there is a {{DataSource}} API [3] that supports the
> specification of the boundedness of an input, but that would require all
> connectors to revise their APIs to leverage it which would take some time.
> My organization is in the middle of migrating from the {{DataSet}} API to the
> {{{}DataStream API{}}}, and we've found this to be a challenge as nearly all
> of our inputs have been determined to be unbounded as we use{{ InputFormats}}
> that are not {{{}FileInputFormat{}}}s.
> Our work-around was to provide a local patch in
> {{StreamExecutionEnvironment}} with a method supporting explicitly bounded
> inputs.
> As this helped us implement a Batch {{DataStream}} solution, perhaps this is
> something that may be helpful for others?
>
> [1] [https://iceberg.apache.org/docs/latest/flink/#reading-with-datastream]
> [2]
> [https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/dataset/hadoop_map_reduce/]
>
> [3]
> [https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/sources/#the-data-source-api]
>
--
This message was
[jira] [Updated] (FLINK-27827) StreamExecutionEnvironment method supporting explicit Boundedness
[
https://issues.apache.org/jira/browse/FLINK-27827?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Andreas Hailu updated FLINK-27827:
--
Description:
When creating a {{{}DataStreamSource{}}}, an explicitly bounded input is only
returned if the {{InputFormat}} provided implements {{{}FileInputFormat{}}}.
This is results in runtime exceptions when trying to run applications in Batch
execution mode while using non {{{}FileInputFormat{}}}s e.g. Apache Iceberg
[1], Flink's Hadoop MapReduce compatibility API's [2] inputs, etc...
I understand there is a {{DataSource}} API [3] that supports the specification
of the boundedness of an input, but that would require all connectors to revise
their APIs to leverage it which would take some time.
My organization is in the middle of migrating from the {{DataSet}} API to the
{{DataStream API, and we've found this to be a challenge as nearly all of our
inputs have been determines to be unbounded as we use InputFormats}} that are
not {{{}FileInputFormat{}}}s. Our work-around was to provide a local patch in
{{StreamExecutionEnvironment}} with a method supporting explicitly bounded
inputs.
As this helped us implement a Batch {{DataStream}} solution, perhaps this is
something that may be helpful for others?
[1] [https://iceberg.apache.org/docs/latest/flink/#reading-with-datastream]
[2]
[https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/dataset/hadoop_map_reduce/]
[3]
[https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/sources/#the-data-source-api]
was:
When creating a {{{}DataStreamSource{}}}, an explicitly bounded input is only
returned if the {{InputFormat}} provided implements {{{}FileInputFormat{}}}.
This is results in runtime exceptions when trying to run applications in Batch
execution mode while using non {{{}FileInputFormat{}}}s e.g. Apache Iceberg
[1], Flink's Hadoop MapReduce compatibility API's [2] inputs, etc...
I understand there is a {{DataSource}} API [3] that supports the specification
of the boundedness of an input, but that would require all connectors to revise
their APIs to leverage it which would take some time.
My organization is in the middle of migrating from the {{DataSet}} API to the
{{DataStream }}API, and we've found this to be a challenge as nearly all of our
inputs have been determines to be unbounded as we use {{InputFormats}} that are
not {{{}FileInputFormat{}}}s. Our work-around was to provide a local patch in
{{StreamExecutionEnvironment}} with a method supporting explicitly bounded
inputs.
As this helped us implement a Batch {{DataStream}} solution, perhaps this is
something that may be helpful for others?
[1] [https://iceberg.apache.org/docs/latest/flink/#reading-with-datastream]
[2]
[https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/dataset/hadoop_map_reduce/]
[3]
[https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/sources/#the-data-source-api]
> StreamExecutionEnvironment method supporting explicit Boundedness
> -
>
> Key: FLINK-27827
> URL: https://issues.apache.org/jira/browse/FLINK-27827
> Project: Flink
> Issue Type: Improvement
> Components: API / DataStream
>Reporter: Andreas Hailu
>Priority: Minor
>
> When creating a {{{}DataStreamSource{}}}, an explicitly bounded input is only
> returned if the {{InputFormat}} provided implements {{{}FileInputFormat{}}}.
> This is results in runtime exceptions when trying to run applications in
> Batch execution mode while using non {{{}FileInputFormat{}}}s e.g. Apache
> Iceberg [1], Flink's Hadoop MapReduce compatibility API's [2] inputs, etc...
> I understand there is a {{DataSource}} API [3] that supports the
> specification of the boundedness of an input, but that would require all
> connectors to revise their APIs to leverage it which would take some time.
> My organization is in the middle of migrating from the {{DataSet}} API to the
> {{DataStream API, and we've found this to be a challenge as nearly all of our
> inputs have been determines to be unbounded as we use InputFormats}} that are
> not {{{}FileInputFormat{}}}s. Our work-around was to provide a local patch in
> {{StreamExecutionEnvironment}} with a method supporting explicitly bounded
> inputs.
> As this helped us implement a Batch {{DataStream}} solution, perhaps this is
> something that may be helpful for others?
>
> [1] [https://iceberg.apache.org/docs/latest/flink/#reading-with-datastream]
> [2]
> [https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/dataset/hadoop_map_reduce/]
>
> [3]
> [https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/sources/#the-data-source-api]
>
--
This message was sent by Atlas
[jira] [Comment Edited] (FLINK-27593) Parquet/Orc format reader optimization
[ https://issues.apache.org/jira/browse/FLINK-27593?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543551#comment-17543551 ] Jing Ge edited comment on FLINK-27593 at 5/29/22 9:13 PM: -- [~lsy] would you please describe what the issues are and what should be exactly done for this task? was (Author: jingge): [~lsy] would you please describe what are the issues and what should be exactly done for this task? > Parquet/Orc format reader optimization > -- > > Key: FLINK-27593 > URL: https://issues.apache.org/jira/browse/FLINK-27593 > Project: Flink > Issue Type: Improvement > Components: Formats (JSON, Avro, Parquet, ORC, SequenceFile), Table > SQL / Runtime >Reporter: dalongliu >Priority: Major > Fix For: 1.16.0 > > -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink] NicoK closed pull request #10607: [FLINK-15298][docs] Fix dependences in the DataStream API Tutorial doc
NicoK closed pull request #10607: [FLINK-15298][docs] Fix dependences in the DataStream API Tutorial doc URL: https://github.com/apache/flink/pull/10607 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] NicoK commented on pull request #10607: [FLINK-15298][docs] Fix dependences in the DataStream API Tutorial doc
NicoK commented on PR #10607: URL: https://github.com/apache/flink/pull/10607#issuecomment-1140516269 sorry for not re-reviewing it earlier - since 1.9 is a bit too old now, let me close this PR -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27830) My Pyflink job could not submit to Flink cluster
[
https://issues.apache.org/jira/browse/FLINK-27830?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
TongMeng updated FLINK-27830:
-
Environment:
python 3.6.9
Flink 1.13.0
PyFlink 1.13.0
zookeeper 3.4.14
hadoop 2.10.1
> My Pyflink job could not submit to Flink cluster
>
>
> Key: FLINK-27830
> URL: https://issues.apache.org/jira/browse/FLINK-27830
> Project: Flink
> Issue Type: Bug
> Components: API / Python
>Affects Versions: 1.13.0
> Environment: python 3.6.9
> Flink 1.13.0
> PyFlink 1.13.0
> zookeeper 3.4.14
> hadoop 2.10.1
>Reporter: TongMeng
>Priority: Major
> Attachments: error.txt
>
>
> I use commd
> {code:java}
> ./flink run --python /home/ubuntu/pyflink/main.py
> /home/ubuntu/pyflink/xmltest.xml /home/ubuntu/pyflink/task.xml --pyFliles
> /home/ubuntu/pyflink/logtest.py /home/ubuntu/pyflink/KafkaSource.py
> /home/ubuntu/pyflink/KafkaSink.py /home/ubuntu/pyflink/pyFlinkState.py
> /home/ubuntu/pyflink/projectInit.py /home/ubuntu/pyflink/taskInit.py
> /home/ubuntu/pyflink/UDF1.py {code}
> to submit my pyflink job.
> The error happened on:
> {code:java}
> st_env.create_statement_set().add_insert_sql(f"insert into algorithmsink
> select {taskInfo}(line, calculationStatusMap, gathertime, storetime, rawData,
> terminal, deviceID, recievetime, car, sendtime, baseInfoMap, workStatusMap,
> `timestamp`) from mysource").execute().wait()
> {code}
> My appendix error.txt contains the exceptions. It seems like there is
> something wrong with Apache Beam.
> When I use python command to run my job (in standalone mode instead of
> submitting to Flink cluster), it works well.
>
>
>
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Updated] (FLINK-27830) My Pyflink job could not submit to Flink cluster
[
https://issues.apache.org/jira/browse/FLINK-27830?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
TongMeng updated FLINK-27830:
-
Description:
I use commd
{code:java}
./flink run --python /home/ubuntu/pyflink/main.py
/home/ubuntu/pyflink/xmltest.xml /home/ubuntu/pyflink/task.xml --pyFliles
/home/ubuntu/pyflink/logtest.py /home/ubuntu/pyflink/KafkaSource.py
/home/ubuntu/pyflink/KafkaSink.py /home/ubuntu/pyflink/pyFlinkState.py
/home/ubuntu/pyflink/projectInit.py /home/ubuntu/pyflink/taskInit.py
/home/ubuntu/pyflink/UDF1.py {code}
to submit my pyflink job.
The error happened on:
{code:java}
st_env.create_statement_set().add_insert_sql(f"insert into algorithmsink select
{taskInfo}(line, calculationStatusMap, gathertime, storetime, rawData,
terminal, deviceID, recievetime, car, sendtime, baseInfoMap, workStatusMap,
`timestamp`) from mysource").execute().wait()
{code}
My appendix error.txt contains the exceptions. It seems like there is something
wrong with Apache Beam.
When I use python command to run my job (in standalone mode instead of
submitting to Flink cluster), it works well.
was:
I use commd
{code:java}
./flink run --python /home/ubuntu/pyflink/main.py
/home/ubuntu/pyflink/xmltest.xml /home/ubuntu/pyflink/task.xml --pyFliles
/home/ubuntu/pyflink/logtest.py /home/ubuntu/pyflink/KafkaSource.py
/home/ubuntu/pyflink/KafkaSink.py /home/ubuntu/pyflink/pyFlinkState.py
/home/ubuntu/pyflink/projectInit.py /home/ubuntu/pyflink/taskInit.py
/home/ubuntu/pyflink/UDF1.py {code}
to submit my pyflink job.
The error happened on:
{code:java}
st_env.create_statement_set().add_insert_sql(f"insert into algorithmsink select
{taskInfo}(line, calculationStatusMap, gathertime, storetime, rawData,
terminal, deviceID, recievetime, car, sendtime, baseInfoMap, workStatusMap,
`timestamp`) from mysource").execute().wait()
{code}
My appendix error.txt contains the exceptions. It seems like there is something
wrong with Apache Beam.
When I use python command to run my job (in standalone mode instead of
submitting to Flink cluster), it works well.
> My Pyflink job could not submit to Flink cluster
>
>
> Key: FLINK-27830
> URL: https://issues.apache.org/jira/browse/FLINK-27830
> Project: Flink
> Issue Type: Bug
> Components: API / Python
>Affects Versions: 1.13.0
>Reporter: TongMeng
>Priority: Major
> Attachments: error.txt
>
>
> I use commd
> {code:java}
> ./flink run --python /home/ubuntu/pyflink/main.py
> /home/ubuntu/pyflink/xmltest.xml /home/ubuntu/pyflink/task.xml --pyFliles
> /home/ubuntu/pyflink/logtest.py /home/ubuntu/pyflink/KafkaSource.py
> /home/ubuntu/pyflink/KafkaSink.py /home/ubuntu/pyflink/pyFlinkState.py
> /home/ubuntu/pyflink/projectInit.py /home/ubuntu/pyflink/taskInit.py
> /home/ubuntu/pyflink/UDF1.py {code}
> to submit my pyflink job.
> The error happened on:
> {code:java}
> st_env.create_statement_set().add_insert_sql(f"insert into algorithmsink
> select {taskInfo}(line, calculationStatusMap, gathertime, storetime, rawData,
> terminal, deviceID, recievetime, car, sendtime, baseInfoMap, workStatusMap,
> `timestamp`) from mysource").execute().wait()
> {code}
> My appendix error.txt contains the exceptions. It seems like there is
> something wrong with Apache Beam.
> When I use python command to run my job (in standalone mode instead of
> submitting to Flink cluster), it works well.
>
>
>
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Updated] (FLINK-27830) My Pyflink job could not submit to Flink cluster
[
https://issues.apache.org/jira/browse/FLINK-27830?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
TongMeng updated FLINK-27830:
-
Description:
I use commd
{code:java}
./flink run --python /home/ubuntu/pyflink/main.py
/home/ubuntu/pyflink/xmltest.xml /home/ubuntu/pyflink/task.xml --pyFliles
/home/ubuntu/pyflink/logtest.py /home/ubuntu/pyflink/KafkaSource.py
/home/ubuntu/pyflink/KafkaSink.py /home/ubuntu/pyflink/pyFlinkState.py
/home/ubuntu/pyflink/projectInit.py /home/ubuntu/pyflink/taskInit.py
/home/ubuntu/pyflink/UDF1.py {code}
to submit my pyflink job.
The error happened on:
{code:java}
st_env.create_statement_set().add_insert_sql(f"insert into algorithmsink select
{taskInfo}(line, calculationStatusMap, gathertime, storetime, rawData,
terminal, deviceID, recievetime, car, sendtime, baseInfoMap, workStatusMap,
`timestamp`) from mysource").execute().wait()
{code}
My appendix error.txt contains the exceptions. It seems like there is something
wrong with Apache Beam.
When I use python command to run my job (in standalone mode instead of
submitting to Flink cluster), it works well.
was:
I use commd
{code:java}
//代码占位符
./flink run --python /home/ubuntu/pyflink/main.py
/home/ubuntu/pyflink/xmltest.xml /home/ubuntu/pyflink/task.xml --pyFliles
/home/ubuntu/pyflink/logtest.py /home/ubuntu/pyflink/KafkaSource.py
/home/ubuntu/pyflink/KafkaSink.py /home/ubuntu/pyflink/pyFlinkState.py
/home/ubuntu/pyflink/projectInit.py /home/ubuntu/pyflink/taskInit.py
/home/ubuntu/pyflink/UDF1.py {code}
to submit my pyflink job.
The error happened on:
{code:java}
//代码占位符
st_env.create_statement_set().add_insert_sql(f"insert into algorithmsink select
{taskInfo}(line, calculationStatusMap, gathertime, storetime, rawData,
terminal, deviceID, recievetime, car, sendtime, baseInfoMap, workStatusMap,
`timestamp`) from mysource").execute().wait()
{code}
My appendix error.txt contains the exceptions. It seems like there is something
wrong with Apache Beam.
When I use python command to run my job (in standalone mode instead of
submitting to Flink cluster), it works well.
> My Pyflink job could not submit to Flink cluster
>
>
> Key: FLINK-27830
> URL: https://issues.apache.org/jira/browse/FLINK-27830
> Project: Flink
> Issue Type: Bug
> Components: API / Python
>Affects Versions: 1.13.0
>Reporter: TongMeng
>Priority: Major
> Attachments: error.txt
>
>
> I use commd
> {code:java}
> ./flink run --python /home/ubuntu/pyflink/main.py
> /home/ubuntu/pyflink/xmltest.xml /home/ubuntu/pyflink/task.xml --pyFliles
> /home/ubuntu/pyflink/logtest.py /home/ubuntu/pyflink/KafkaSource.py
> /home/ubuntu/pyflink/KafkaSink.py /home/ubuntu/pyflink/pyFlinkState.py
> /home/ubuntu/pyflink/projectInit.py /home/ubuntu/pyflink/taskInit.py
> /home/ubuntu/pyflink/UDF1.py {code}
>
> to submit my pyflink job.
> The error happened on:
> {code:java}
> st_env.create_statement_set().add_insert_sql(f"insert into algorithmsink
> select {taskInfo}(line, calculationStatusMap, gathertime, storetime, rawData,
> terminal, deviceID, recievetime, car, sendtime, baseInfoMap, workStatusMap,
> `timestamp`) from mysource").execute().wait()
> {code}
> My appendix error.txt contains the exceptions. It seems like there is
> something wrong with Apache Beam.
> When I use python command to run my job (in standalone mode instead of
> submitting to Flink cluster), it works well.
>
>
>
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Created] (FLINK-27830) My Pyflink job could not submit to Flink cluster
TongMeng created FLINK-27830:
Summary: My Pyflink job could not submit to Flink cluster
Key: FLINK-27830
URL: https://issues.apache.org/jira/browse/FLINK-27830
Project: Flink
Issue Type: Bug
Components: API / Python
Affects Versions: 1.13.0
Reporter: TongMeng
Attachments: error.txt
I use commd
{code:java}
//代码占位符
./flink run --python /home/ubuntu/pyflink/main.py
/home/ubuntu/pyflink/xmltest.xml /home/ubuntu/pyflink/task.xml --pyFliles
/home/ubuntu/pyflink/logtest.py /home/ubuntu/pyflink/KafkaSource.py
/home/ubuntu/pyflink/KafkaSink.py /home/ubuntu/pyflink/pyFlinkState.py
/home/ubuntu/pyflink/projectInit.py /home/ubuntu/pyflink/taskInit.py
/home/ubuntu/pyflink/UDF1.py {code}
to submit my pyflink job.
The error happened on:
{code:java}
//代码占位符
st_env.create_statement_set().add_insert_sql(f"insert into algorithmsink select
{taskInfo}(line, calculationStatusMap, gathertime, storetime, rawData,
terminal, deviceID, recievetime, car, sendtime, baseInfoMap, workStatusMap,
`timestamp`) from mysource").execute().wait()
{code}
My appendix error.txt contains the exceptions. It seems like there is something
wrong with Apache Beam.
When I use python command to run my job (in standalone mode instead of
submitting to Flink cluster), it works well.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Commented] (FLINK-26179) Support periodic savepointing in the operator
[ https://issues.apache.org/jira/browse/FLINK-26179?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543656#comment-17543656 ] Márton Balassi commented on FLINK-26179: Agreed, based on recent discussion with multiple users this comes up too frequently to ignore. The point that made it obvious for me is that I user rightfully expects that they can keep the last submitted custom resource in git and if we ask them to cron a savepointTriggerNonce update regularly that will result in regular unwanted commits. We should just add a config for this instead. Gyula's solution to not add a new timer callback to the system, but only check once per reconcile loop is the adequate compromise for this (the tradeoff is that the reconciliation interval is effectively the lower bound of the savepoint trigger interval). Please proceed. > Support periodic savepointing in the operator > - > > Key: FLINK-26179 > URL: https://issues.apache.org/jira/browse/FLINK-26179 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Reporter: Gyula Fora >Assignee: Gyula Fora >Priority: Major > Fix For: kubernetes-operator-1.1.0 > > > Automatic triggering of savepoints is a commonly requested feature. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Commented] (FLINK-27009) Support SQL job submission in flink kubernetes opeartor
[ https://issues.apache.org/jira/browse/FLINK-27009?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543655#comment-17543655 ] Márton Balassi commented on FLINK-27009: [~bgeng777] cool, I assigned the ticket to you then. Looking forward to the FLIP. :) > Support SQL job submission in flink kubernetes opeartor > --- > > Key: FLINK-27009 > URL: https://issues.apache.org/jira/browse/FLINK-27009 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Reporter: Biao Geng >Assignee: Biao Geng >Priority: Major > > Currently, the flink kubernetes opeartor is for jar job using application or > session cluster. For SQL job, there is no out of box solution in the > operator. > One simple and short-term solution is to wrap the SQL script into a jar job > using table API with limitation. > The long-term solution may work with > [FLINK-26541|https://issues.apache.org/jira/browse/FLINK-26541] to achieve > the full support. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[jira] [Assigned] (FLINK-27009) Support SQL job submission in flink kubernetes opeartor
[ https://issues.apache.org/jira/browse/FLINK-27009?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Márton Balassi reassigned FLINK-27009: -- Assignee: Biao Geng > Support SQL job submission in flink kubernetes opeartor > --- > > Key: FLINK-27009 > URL: https://issues.apache.org/jira/browse/FLINK-27009 > Project: Flink > Issue Type: New Feature > Components: Kubernetes Operator >Reporter: Biao Geng >Assignee: Biao Geng >Priority: Major > > Currently, the flink kubernetes opeartor is for jar job using application or > session cluster. For SQL job, there is no out of box solution in the > operator. > One simple and short-term solution is to wrap the SQL script into a jar job > using table API with limitation. > The long-term solution may work with > [FLINK-26541|https://issues.apache.org/jira/browse/FLINK-26541] to achieve > the full support. -- This message was sent by Atlassian Jira (v8.20.7#820007)
[GitHub] [flink-ml] weibozhao commented on a diff in pull request #83: [FLINK-27170] Add Transformer and Estimator for OnlineLogisticRegression
weibozhao commented on code in PR #83:
URL: https://github.com/apache/flink-ml/pull/83#discussion_r884283585
##
flink-ml-lib/src/main/java/org/apache/flink/ml/classification/logisticregression/OnlineLogisticRegressionParams.java:
##
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.ml.classification.logisticregression;
+
+import org.apache.flink.ml.common.param.HasBatchStrategy;
+import org.apache.flink.ml.common.param.HasElasticNet;
+import org.apache.flink.ml.common.param.HasGlobalBatchSize;
+import org.apache.flink.ml.common.param.HasLabelCol;
+import org.apache.flink.ml.common.param.HasReg;
+import org.apache.flink.ml.common.param.HasWeightCol;
+import org.apache.flink.ml.param.DoubleParam;
+import org.apache.flink.ml.param.Param;
+import org.apache.flink.ml.param.ParamValidators;
+
+/**
+ * Params of {@link OnlineLogisticRegression}.
+ *
+ * @param The class type of this instance.
+ */
+public interface OnlineLogisticRegressionParams
+extends HasLabelCol,
+HasWeightCol,
+HasBatchStrategy,
+HasGlobalBatchSize,
+HasReg,
+HasElasticNet,
+OnlineLogisticRegressionModelParams {
+
+Param ALPHA =
+new DoubleParam("alpha", "The parameter alpha of ftrl.", 0.1,
ParamValidators.gt(0.0));
+
+default Double getAlpha() {
+return get(ALPHA);
+}
+
+default T setAlpha(Double value) {
+return set(ALPHA, value);
+}
+
+Param BETA =
+new DoubleParam("alpha", "The parameter beta of ftrl.", 0.1,
ParamValidators.gt(0.0));
Review Comment:
I have add ftrl doc in the doc of Online logistic regression.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] itaykat commented on pull request #7598: [FLINK-11333][protobuf] First-class serializer support for Protobuf types
itaykat commented on PR #7598: URL: https://github.com/apache/flink/pull/7598#issuecomment-1140457071 Any updates regarding this one? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-27652) CompactManager.Rewriter cannot handle different partition keys invoked compaction
[
https://issues.apache.org/jira/browse/FLINK-27652?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jane Chan updated FLINK-27652:
--
Description:
h3. Issue Description
When enabling {{commit.force-compact}} for the partitioned managed table, there
had a chance that the successive synchronized
writes got failure. {{rewrite}} method messing up with the wrong data file
with the {{partition}} and {{{}bucket{}}}.
{code:java}
Caused by: java.io.IOException: java.util.concurrent.ExecutionException:
java.lang.RuntimeException: java.io.FileNotFoundException: File
file:/var/folders/xd/9dp1y4vd3h56kjkvdk426l50gn/T/junit5920507275110651781/junit4163667468681653619/default_catalog.catalog/default_database.db/T1/f1=Autumn/bucket-0/data-59826283-c5d1-4344-96ae-2203d4e60a57-0
does not exist or the user running Flink ('jane.cjm') has insufficient
permissions to access it. at
org.apache.flink.table.store.connector.sink.StoreSinkWriter.prepareCommit(StoreSinkWriter.java:172)
{code}
However, data-59826283-c5d1-4344-96ae-2203d4e60a57-0 does not belong to
partition Autumn. It seems like the rewriter found the wrong partition/bucket
with the wrong file.
h3. How to Reproduce
{code:java}
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.table.store.connector;
import org.junit.Test;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.ExecutionException;
/** A reproducible case. */
public class ForceCompactionITCase extends FileStoreTableITCase {
@Override
protected List ddl() {
return Collections.singletonList(
"CREATE TABLE IF NOT EXISTS T1 ("
+ "f0 INT, f1 STRING, f2 STRING) PARTITIONED BY (f1)");
}
@Test
public void test() throws ExecutionException, InterruptedException {
bEnv.executeSql("ALTER TABLE T1 SET ('num-levels' = '3')");
bEnv.executeSql("ALTER TABLE T1 SET ('commit.force-compact' = 'true')");
bEnv.executeSql(
"INSERT INTO T1 VALUES(1, 'Winter', 'Winter is Coming')"
+ ",(2, 'Winter', 'The First Snowflake'), "
+ "(2, 'Spring', 'The First Rose in Spring'), "
+ "(7, 'Summer', 'Summertime Sadness')")
.await();
bEnv.executeSql("INSERT INTO T1 VALUES(12, 'Winter', 'Last
Christmas')").await();
bEnv.executeSql("INSERT INTO T1 VALUES(11, 'Winter', 'Winter is
Coming')").await();
bEnv.executeSql("INSERT INTO T1 VALUES(10, 'Autumn',
'Refrain')").await();
bEnv.executeSql(
"INSERT INTO T1 VALUES(6, 'Summer', 'Watermelon
Sugar'), "
+ "(4, 'Spring', 'Spring Water')")
.await();
bEnv.executeSql(
"INSERT INTO T1 VALUES(66, 'Summer', 'Summer Vibe'),"
+ " (9, 'Autumn', 'Wake Me Up When September
Ends')")
.await();
bEnv.executeSql(
"INSERT INTO T1 VALUES(666, 'Summer', 'Summer Vibe'),"
+ " (9, 'Autumn', 'Wake Me Up When September
Ends')")
.await();
bEnv.executeSql(
"INSERT INTO T1 VALUES(, 'Summer', 'Summer Vibe'),"
+ " (9, 'Autumn', 'Wake Me Up When September
Ends')")
.await();
bEnv.executeSql(
"INSERT INTO T1 VALUES(6, 'Summer', 'Summer Vibe'),"
+ " (9, 'Autumn', 'Wake Me Up When September
Ends')")
.await();
bEnv.executeSql(
"INSERT INTO T1 VALUES(66, 'Summer', 'Summer
Vibe'),"
+ " (9, 'Autumn', 'Wake Me Up When September
Ends')")
.await();
bEnv.executeSql(
"INSERT INTO T1 VALUES(666, 'Summer', 'Summer
Vibe'),"
+ " (9, 'Autumn', 'Wake Me Up When September
Ends')")
.await();
}
}
{code}
was:
h3. Issue Description
When enabling {{com
[jira] [Commented] (FLINK-27813) java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
[
https://issues.apache.org/jira/browse/FLINK-27813?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543637#comment-17543637
]
Galen Warren commented on FLINK-27813:
--
Cool! Glad it was something simple.
> java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
> -
>
> Key: FLINK-27813
> URL: https://issues.apache.org/jira/browse/FLINK-27813
> Project: Flink
> Issue Type: Bug
> Components: API / State Processor
>Affects Versions: statefun-3.2.0
>Reporter: Oleksandr Kazimirov
>Priority: Blocker
> Attachments: screenshot-1.png
>
>
> Issue was met after migration from
> flink-statefun:3.1.1-java11
> to
> flink-statefun:3.2.0-java11
>
> {code:java}
> ts.execution-paymentManualValidationRequestEgress-egress, Sink:
> ua.aval.payments.execution-norkomExecutionRequested-egress, Sink:
> ua.aval.payments.execution-shareStatusToManualValidation-egress) (1/1)#15863
> (98a1f6bef9a435ef9d0292fefeb64022) switched from RUNNING to FAILED with
> failure cause: java.lang.IllegalStateException: Unable to parse Netty
> transport spec.\n\tat
> org.apache.flink.statefun.flink.core.nettyclient.NettyRequestReplyClientFactory.parseTransportSpec(NettyRequestReplyClientFactory.java:56)\n\tat
>
> org.apache.flink.statefun.flink.core.nettyclient.NettyRequestReplyClientFactory.createTransportClient(NettyRequestReplyClientFactory.java:39)\n\tat
>
> org.apache.flink.statefun.flink.core.httpfn.HttpFunctionProvider.functionOfType(HttpFunctionProvider.java:49)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.PredefinedFunctionLoader.load(PredefinedFunctionLoader.java:70)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.PredefinedFunctionLoader.load(PredefinedFunctionLoader.java:47)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.StatefulFunctionRepository.load(StatefulFunctionRepository.java:71)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.StatefulFunctionRepository.get(StatefulFunctionRepository.java:59)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.LocalFunctionGroup.enqueue(LocalFunctionGroup.java:48)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.Reductions.enqueue(Reductions.java:153)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.Reductions.apply(Reductions.java:148)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.FunctionGroupOperator.processElement(FunctionGroupOperator.java:90)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.pushToOperator(ChainingOutput.java:99)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:80)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:39)\n\tat
>
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:56)\n\tat
>
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:29)\n\tat
>
> org.apache.flink.statefun.flink.core.feedback.FeedbackUnionOperator.sendDownstream(FeedbackUnionOperator.java:180)\n\tat
>
> org.apache.flink.statefun.flink.core.feedback.FeedbackUnionOperator.processElement(FeedbackUnionOperator.java:86)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:233)\n\tat
>
> org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134)\n\tat
>
> org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105)\n\tat
>
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:496)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:809)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:761)\n\tat
>
> org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)\n\tat
>
> org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:937)\n\tat
> org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766)\n\tat
> org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)\n\tat
> java.base/java.lang.Thread.run(Unknown Source)\nCaused by:
> org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.JsonMappingException:
> Time interval unit label 'm' does not match any of the recognized units:
> DAYS: (d | day | days), HOURS: (h | hour | hours), MINUTES: (
[jira] [Closed] (FLINK-27813) java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
[
https://issues.apache.org/jira/browse/FLINK-27813?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Oleksandr closed FLINK-27813.
-
Resolution: Won't Fix
> java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
> -
>
> Key: FLINK-27813
> URL: https://issues.apache.org/jira/browse/FLINK-27813
> Project: Flink
> Issue Type: Bug
> Components: API / State Processor
>Affects Versions: statefun-3.2.0
>Reporter: Oleksandr
>Priority: Blocker
> Attachments: screenshot-1.png
>
>
> Issue was met after migration from
> flink-statefun:3.1.1-java11
> to
> flink-statefun:3.2.0-java11
>
> {code:java}
> ts.execution-paymentManualValidationRequestEgress-egress, Sink:
> ua.aval.payments.execution-norkomExecutionRequested-egress, Sink:
> ua.aval.payments.execution-shareStatusToManualValidation-egress) (1/1)#15863
> (98a1f6bef9a435ef9d0292fefeb64022) switched from RUNNING to FAILED with
> failure cause: java.lang.IllegalStateException: Unable to parse Netty
> transport spec.\n\tat
> org.apache.flink.statefun.flink.core.nettyclient.NettyRequestReplyClientFactory.parseTransportSpec(NettyRequestReplyClientFactory.java:56)\n\tat
>
> org.apache.flink.statefun.flink.core.nettyclient.NettyRequestReplyClientFactory.createTransportClient(NettyRequestReplyClientFactory.java:39)\n\tat
>
> org.apache.flink.statefun.flink.core.httpfn.HttpFunctionProvider.functionOfType(HttpFunctionProvider.java:49)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.PredefinedFunctionLoader.load(PredefinedFunctionLoader.java:70)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.PredefinedFunctionLoader.load(PredefinedFunctionLoader.java:47)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.StatefulFunctionRepository.load(StatefulFunctionRepository.java:71)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.StatefulFunctionRepository.get(StatefulFunctionRepository.java:59)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.LocalFunctionGroup.enqueue(LocalFunctionGroup.java:48)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.Reductions.enqueue(Reductions.java:153)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.Reductions.apply(Reductions.java:148)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.FunctionGroupOperator.processElement(FunctionGroupOperator.java:90)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.pushToOperator(ChainingOutput.java:99)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:80)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:39)\n\tat
>
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:56)\n\tat
>
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:29)\n\tat
>
> org.apache.flink.statefun.flink.core.feedback.FeedbackUnionOperator.sendDownstream(FeedbackUnionOperator.java:180)\n\tat
>
> org.apache.flink.statefun.flink.core.feedback.FeedbackUnionOperator.processElement(FeedbackUnionOperator.java:86)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:233)\n\tat
>
> org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134)\n\tat
>
> org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105)\n\tat
>
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:496)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:809)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:761)\n\tat
>
> org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)\n\tat
>
> org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:937)\n\tat
> org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766)\n\tat
> org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)\n\tat
> java.base/java.lang.Thread.run(Unknown Source)\nCaused by:
> org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.JsonMappingException:
> Time interval unit label 'm' does not match any of the recognized units:
> DAYS: (d | day | days), HOURS: (h | hour | hours), MINUTES: (min | minute |
> minutes), SECONDS: (s | sec | secs | second | seconds), MILLISECONDS
[jira] [Commented] (FLINK-27813) java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
[
https://issues.apache.org/jira/browse/FLINK-27813?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543624#comment-17543624
]
Oleksandr commented on FLINK-27813:
---
[~galenwarren] I found the issue in the configuration in module.yaml
we used such a config in 3.1.0:
{code:java}
kind: io.statefun.endpoints.v2/http
spec:
functions: ua.test.execution/*
urlPathTemplate: http://test-{{ $.Values.global.platformEnvironment
}}.svc.cluster.local:8080/v1/functions
transport:
type: io.statefun.transports.v1/async
timeouts:
call: 6m{code}
now in 3.2.0 - *6m* should be *6min*
> java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
> -
>
> Key: FLINK-27813
> URL: https://issues.apache.org/jira/browse/FLINK-27813
> Project: Flink
> Issue Type: Bug
> Components: API / State Processor
>Affects Versions: statefun-3.2.0
>Reporter: Oleksandr
>Priority: Blocker
> Attachments: screenshot-1.png
>
>
> Issue was met after migration from
> flink-statefun:3.1.1-java11
> to
> flink-statefun:3.2.0-java11
>
> {code:java}
> ts.execution-paymentManualValidationRequestEgress-egress, Sink:
> ua.aval.payments.execution-norkomExecutionRequested-egress, Sink:
> ua.aval.payments.execution-shareStatusToManualValidation-egress) (1/1)#15863
> (98a1f6bef9a435ef9d0292fefeb64022) switched from RUNNING to FAILED with
> failure cause: java.lang.IllegalStateException: Unable to parse Netty
> transport spec.\n\tat
> org.apache.flink.statefun.flink.core.nettyclient.NettyRequestReplyClientFactory.parseTransportSpec(NettyRequestReplyClientFactory.java:56)\n\tat
>
> org.apache.flink.statefun.flink.core.nettyclient.NettyRequestReplyClientFactory.createTransportClient(NettyRequestReplyClientFactory.java:39)\n\tat
>
> org.apache.flink.statefun.flink.core.httpfn.HttpFunctionProvider.functionOfType(HttpFunctionProvider.java:49)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.PredefinedFunctionLoader.load(PredefinedFunctionLoader.java:70)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.PredefinedFunctionLoader.load(PredefinedFunctionLoader.java:47)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.StatefulFunctionRepository.load(StatefulFunctionRepository.java:71)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.StatefulFunctionRepository.get(StatefulFunctionRepository.java:59)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.LocalFunctionGroup.enqueue(LocalFunctionGroup.java:48)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.Reductions.enqueue(Reductions.java:153)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.Reductions.apply(Reductions.java:148)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.FunctionGroupOperator.processElement(FunctionGroupOperator.java:90)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.pushToOperator(ChainingOutput.java:99)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:80)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:39)\n\tat
>
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:56)\n\tat
>
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:29)\n\tat
>
> org.apache.flink.statefun.flink.core.feedback.FeedbackUnionOperator.sendDownstream(FeedbackUnionOperator.java:180)\n\tat
>
> org.apache.flink.statefun.flink.core.feedback.FeedbackUnionOperator.processElement(FeedbackUnionOperator.java:86)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:233)\n\tat
>
> org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134)\n\tat
>
> org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105)\n\tat
>
> org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:496)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:809)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:761)\n\tat
>
> org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)\n\tat
>
> org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:937)\n\tat
> org.apache.flink.runtime.taskmanager.Task.doRun(Task.j
[jira] (FLINK-27813) java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
[ https://issues.apache.org/jira/browse/FLINK-27813 ]
Oleksandr deleted comment on FLINK-27813:
---
was (Author: JIRAUSER290114):
We have job manager running that is configured via module.yaml(egress and
ingress for kafka topics).
Our stateful functions are on a separate remote service built on top of Spring
boot with controller:
{code:java}
@RequestMapping("/v1/functions")
@RequiredArgsConstructor
public class FunctionRouteController {
private final RequestReplyHandler handler;
@PostMapping(consumes = MediaType.APPLICATION_OCTET_STREAM_VALUE)
public CompletableFuture onRequest(@RequestBody byte[] request) {
return handler
.handle(Slices.wrap(request))
.thenApply(Slice::toByteArray);
}
} {code}
where actually used
'org.apache.flink.statefun.sdk.java.handlerConcurrentRequestReplyHandler' and
we just define beans:
{code:java}
@Bean
public StatefulFunctions statefulFunctions(StatefulFunctions
autoRegisteredStatefulFunctions) {
// obtain a request-reply handler based on the spec above
StatefulFunctions statefulFunctions = new StatefulFunctions()
.withStatefulFunction(fallbackFn())
.withStatefulFunction(transactionFn());
autoRegisteredStatefulFunctions.functionSpecs().values().forEach(statefulFunctions::withStatefulFunction);
return statefulFunctions;
}
@Bean
public RequestReplyHandler requestReplyHandler(StatefulFunctions
statefulFunctions) {
return statefulFunctions.requestReplyHandler();
} {code}
statefulFunctions.requestReplyHandler() is :
{code:java}
public RequestReplyHandler requestReplyHandler() {
return new ConcurrentRequestReplyHandler(this.specs);
}
{code}
flink-conf.yaml
{code:java}
{
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
taskmanager.numberOfTaskSlots: 2
execution.checkpointing.interval: 1min
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.min-pause: 6
execution.checkpointing.timeout: 120
execution.checkpointing.externalized-checkpoint-retention:RETAIN_ON_CANCELLATION
state.backend: rocksdb
state.backend.async: true
state.checkpoints.num-retained: 3
state.savepoints.dir: s3://savepoints-dev/savepoints
state.checkpoints.dir: s3://checkpoints-dev/checkpoints
s3.endpoint: https://minio.test
s3.path.style.access: true
s3.access-key: ***
s3.secret-key: ***
state.backend.incremental: true
jobmanager.memory.process.size: 1g
taskmanager.memory.process.size: 4g
}{code}
> java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
> -
>
> Key: FLINK-27813
> URL: https://issues.apache.org/jira/browse/FLINK-27813
> Project: Flink
> Issue Type: Bug
> Components: API / State Processor
>Affects Versions: statefun-3.2.0
>Reporter: Oleksandr
>Priority: Blocker
> Attachments: screenshot-1.png
>
>
> Issue was met after migration from
> flink-statefun:3.1.1-java11
> to
> flink-statefun:3.2.0-java11
>
> {code:java}
> ts.execution-paymentManualValidationRequestEgress-egress, Sink:
> ua.aval.payments.execution-norkomExecutionRequested-egress, Sink:
> ua.aval.payments.execution-shareStatusToManualValidation-egress) (1/1)#15863
> (98a1f6bef9a435ef9d0292fefeb64022) switched from RUNNING to FAILED with
> failure cause: java.lang.IllegalStateException: Unable to parse Netty
> transport spec.\n\tat
> org.apache.flink.statefun.flink.core.nettyclient.NettyRequestReplyClientFactory.parseTransportSpec(NettyRequestReplyClientFactory.java:56)\n\tat
>
> org.apache.flink.statefun.flink.core.nettyclient.NettyRequestReplyClientFactory.createTransportClient(NettyRequestReplyClientFactory.java:39)\n\tat
>
> org.apache.flink.statefun.flink.core.httpfn.HttpFunctionProvider.functionOfType(HttpFunctionProvider.java:49)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.PredefinedFunctionLoader.load(PredefinedFunctionLoader.java:70)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.PredefinedFunctionLoader.load(PredefinedFunctionLoader.java:47)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.StatefulFunctionRepository.load(StatefulFunctionRepository.java:71)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.StatefulFunctionRepository.get(StatefulFunctionRepository.java:59)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.LocalFunctionGroup.enqueue(LocalFunctionGroup.java:48)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.Reductions.enqueue(Reductions.java:153)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.Reductions.apply(Reductions.java:148)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.FunctionGroupOperator.processElement(FunctionGroupOperator.java:90)\n\tat
>
> or
[jira] [Comment Edited] (FLINK-27813) java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
[
https://issues.apache.org/jira/browse/FLINK-27813?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543616#comment-17543616
]
Oleksandr edited comment on FLINK-27813 at 5/29/22 11:13 AM:
-
We have job manager running that is configured via module.yaml(egress and
ingress for kafka topics).
Our stateful functions are on a separate remote service built on top of Spring
boot with controller:
{code:java}
@RequestMapping("/v1/functions")
@RequiredArgsConstructor
public class FunctionRouteController {
private final RequestReplyHandler handler;
@PostMapping(consumes = MediaType.APPLICATION_OCTET_STREAM_VALUE)
public CompletableFuture onRequest(@RequestBody byte[] request) {
return handler
.handle(Slices.wrap(request))
.thenApply(Slice::toByteArray);
}
} {code}
where actually used
'org.apache.flink.statefun.sdk.java.handlerConcurrentRequestReplyHandler' and
we just define beans:
{code:java}
@Bean
public StatefulFunctions statefulFunctions(StatefulFunctions
autoRegisteredStatefulFunctions) {
// obtain a request-reply handler based on the spec above
StatefulFunctions statefulFunctions = new StatefulFunctions()
.withStatefulFunction(fallbackFn())
.withStatefulFunction(transactionFn());
autoRegisteredStatefulFunctions.functionSpecs().values().forEach(statefulFunctions::withStatefulFunction);
return statefulFunctions;
}
@Bean
public RequestReplyHandler requestReplyHandler(StatefulFunctions
statefulFunctions) {
return statefulFunctions.requestReplyHandler();
} {code}
statefulFunctions.requestReplyHandler() is :
{code:java}
public RequestReplyHandler requestReplyHandler() {
return new ConcurrentRequestReplyHandler(this.specs);
}
{code}
flink-conf.yaml
{code:java}
{
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
taskmanager.numberOfTaskSlots: 2
execution.checkpointing.interval: 1min
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.min-pause: 6
execution.checkpointing.timeout: 120
execution.checkpointing.externalized-checkpoint-retention:RETAIN_ON_CANCELLATION
state.backend: rocksdb
state.backend.async: true
state.checkpoints.num-retained: 3
state.savepoints.dir: s3://savepoints-dev/savepoints
state.checkpoints.dir: s3://checkpoints-dev/checkpoints
s3.endpoint: https://minio.test
s3.path.style.access: true
s3.access-key: ***
s3.secret-key: ***
state.backend.incremental: true
jobmanager.memory.process.size: 1g
taskmanager.memory.process.size: 4g
}{code}
was (Author: JIRAUSER290114):
[~galenwarren]
We have job manager running that is configured via module.yaml(egress and
ingress for kafka topics).
Our stateful functions are on a separate remote service built on top of Spring
boot with controller:
{code:java}
@RequestMapping("/v1/functions")
@RequiredArgsConstructor
public class FunctionRouteController {
private final RequestReplyHandler handler;
@PostMapping(consumes = MediaType.APPLICATION_OCTET_STREAM_VALUE)
public CompletableFuture onRequest(@RequestBody byte[] request) {
return handler
.handle(Slices.wrap(request))
.thenApply(Slice::toByteArray);
}
} {code}
where actually used
'org.apache.flink.statefun.sdk.java.handlerConcurrentRequestReplyHandler' and
we just define beans:
{code:java}
@Bean
public StatefulFunctions statefulFunctions(StatefulFunctions
autoRegisteredStatefulFunctions) {
// obtain a request-reply handler based on the spec above
StatefulFunctions statefulFunctions = new StatefulFunctions()
.withStatefulFunction(fallbackFn())
.withStatefulFunction(transactionFn());
autoRegisteredStatefulFunctions.functionSpecs().values().forEach(statefulFunctions::withStatefulFunction);
return statefulFunctions;
}
@Bean
public RequestReplyHandler requestReplyHandler(StatefulFunctions
statefulFunctions) {
return statefulFunctions.requestReplyHandler();
} {code}
statefulFunctions.requestReplyHandler() is :
{code:java}
public RequestReplyHandler requestReplyHandler() {
return new ConcurrentRequestReplyHandler(this.specs);
}
{code}
flink-conf.yaml
{code:java}
{
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
taskmanager.numberOfTaskSlots: 2
execution.checkpointing.interval: 1min
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.min-pause: 6
execution.checkpointing.timeout: 120
execution.checkpointing.externalized-checkpoint-retention:RETAIN_ON_CANCELLATION
state.backend: rocksdb
state.backend.async: true
state.checkpoints.num-retained: 3
state.savepoints.dir: s3://savepoints-dev/savepoints
state.checkpoints.dir: s3://checkpoints-dev/checkpoints
s3.endpoi
[jira] [Comment Edited] (FLINK-27813) java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
[
https://issues.apache.org/jira/browse/FLINK-27813?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543616#comment-17543616
]
Oleksandr edited comment on FLINK-27813 at 5/29/22 11:06 AM:
-
[~galenwarren]
We have job manager running that is configured via module.yaml(egress and
ingress for kafka topics).
Our stateful functions are on a separate remote service built on top of Spring
boot with controller:
{code:java}
@RequestMapping("/v1/functions")
@RequiredArgsConstructor
public class FunctionRouteController {
private final RequestReplyHandler handler;
@PostMapping(consumes = MediaType.APPLICATION_OCTET_STREAM_VALUE)
public CompletableFuture onRequest(@RequestBody byte[] request) {
return handler
.handle(Slices.wrap(request))
.thenApply(Slice::toByteArray);
}
} {code}
where actually used
'org.apache.flink.statefun.sdk.java.handlerConcurrentRequestReplyHandler' and
we just define beans:
{code:java}
@Bean
public StatefulFunctions statefulFunctions(StatefulFunctions
autoRegisteredStatefulFunctions) {
// obtain a request-reply handler based on the spec above
StatefulFunctions statefulFunctions = new StatefulFunctions()
.withStatefulFunction(fallbackFn())
.withStatefulFunction(transactionFn());
autoRegisteredStatefulFunctions.functionSpecs().values().forEach(statefulFunctions::withStatefulFunction);
return statefulFunctions;
}
@Bean
public RequestReplyHandler requestReplyHandler(StatefulFunctions
statefulFunctions) {
return statefulFunctions.requestReplyHandler();
} {code}
statefulFunctions.requestReplyHandler() is :
{code:java}
public RequestReplyHandler requestReplyHandler() {
return new ConcurrentRequestReplyHandler(this.specs);
}
{code}
flink-conf.yaml
{code:java}
{
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
taskmanager.numberOfTaskSlots: 2
execution.checkpointing.interval: 1min
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.min-pause: 6
execution.checkpointing.timeout: 120
execution.checkpointing.externalized-checkpoint-retention:RETAIN_ON_CANCELLATION
state.backend: rocksdb
state.backend.async: true
state.checkpoints.num-retained: 3
state.savepoints.dir: s3://savepoints-dev/savepoints
state.checkpoints.dir: s3://checkpoints-dev/checkpoints
s3.endpoint: https://minio.test
s3.path.style.access: true
s3.access-key: ***
s3.secret-key: ***
state.backend.incremental: true
jobmanager.memory.process.size: 1g
taskmanager.memory.process.size: 4g
}{code}
was (Author: JIRAUSER290114):
We have job manager running that is configured via module.yaml(egress and
ingress for kafka topics).
Our stateful functions are on a separate remote service built on top of Spring
boot with controller:
{code:java}
@RequestMapping("/v1/functions")
@RequiredArgsConstructor
public class FunctionRouteController {
private final RequestReplyHandler handler;
@PostMapping(consumes = MediaType.APPLICATION_OCTET_STREAM_VALUE)
public CompletableFuture onRequest(@RequestBody byte[] request) {
return handler
.handle(Slices.wrap(request))
.thenApply(Slice::toByteArray);
}
} {code}
where actually used
'org.apache.flink.statefun.sdk.java.handlerConcurrentRequestReplyHandler' and
we just define beans:
{code:java}
@Bean
public StatefulFunctions statefulFunctions(StatefulFunctions
autoRegisteredStatefulFunctions) {
// obtain a request-reply handler based on the spec above
StatefulFunctions statefulFunctions = new StatefulFunctions()
.withStatefulFunction(fallbackFn())
.withStatefulFunction(transactionFn());
autoRegisteredStatefulFunctions.functionSpecs().values().forEach(statefulFunctions::withStatefulFunction);
return statefulFunctions;
}
@Bean
public RequestReplyHandler requestReplyHandler(StatefulFunctions
statefulFunctions) {
return statefulFunctions.requestReplyHandler();
} {code}
statefulFunctions.requestReplyHandler() is :
{code:java}
public RequestReplyHandler requestReplyHandler() {
return new ConcurrentRequestReplyHandler(this.specs);
}
{code}
flink-conf.yaml
{code:java}
{
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
taskmanager.numberOfTaskSlots: 2
execution.checkpointing.interval: 1min
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.min-pause: 6
execution.checkpointing.timeout: 120
execution.checkpointing.externalized-checkpoint-retention:RETAIN_ON_CANCELLATION
state.backend: rocksdb
state.backend.async: true
state.checkpoints.num-retained: 3
state.savepoints.dir: s3://savepoints-dev/savepoints
state.checkpoints.dir: s3://checkpoints-dev/checkpoints
s3.endpoi
[jira] [Comment Edited] (FLINK-27813) java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
[
https://issues.apache.org/jira/browse/FLINK-27813?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543616#comment-17543616
]
Oleksandr edited comment on FLINK-27813 at 5/29/22 11:06 AM:
-
We have job manager running that is configured via module.yaml(egress and
ingress for kafka topics).
Our stateful functions are on a separate remote service built on top of Spring
boot with controller:
{code:java}
@RequestMapping("/v1/functions")
@RequiredArgsConstructor
public class FunctionRouteController {
private final RequestReplyHandler handler;
@PostMapping(consumes = MediaType.APPLICATION_OCTET_STREAM_VALUE)
public CompletableFuture onRequest(@RequestBody byte[] request) {
return handler
.handle(Slices.wrap(request))
.thenApply(Slice::toByteArray);
}
} {code}
where actually used
'org.apache.flink.statefun.sdk.java.handlerConcurrentRequestReplyHandler' and
we just define beans:
{code:java}
@Bean
public StatefulFunctions statefulFunctions(StatefulFunctions
autoRegisteredStatefulFunctions) {
// obtain a request-reply handler based on the spec above
StatefulFunctions statefulFunctions = new StatefulFunctions()
.withStatefulFunction(fallbackFn())
.withStatefulFunction(transactionFn());
autoRegisteredStatefulFunctions.functionSpecs().values().forEach(statefulFunctions::withStatefulFunction);
return statefulFunctions;
}
@Bean
public RequestReplyHandler requestReplyHandler(StatefulFunctions
statefulFunctions) {
return statefulFunctions.requestReplyHandler();
} {code}
statefulFunctions.requestReplyHandler() is :
{code:java}
public RequestReplyHandler requestReplyHandler() {
return new ConcurrentRequestReplyHandler(this.specs);
}
{code}
flink-conf.yaml
{code:java}
{
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
taskmanager.numberOfTaskSlots: 2
execution.checkpointing.interval: 1min
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.min-pause: 6
execution.checkpointing.timeout: 120
execution.checkpointing.externalized-checkpoint-retention:RETAIN_ON_CANCELLATION
state.backend: rocksdb
state.backend.async: true
state.checkpoints.num-retained: 3
state.savepoints.dir: s3://savepoints-dev/savepoints
state.checkpoints.dir: s3://checkpoints-dev/checkpoints
s3.endpoint: https://minio.test
s3.path.style.access: true
s3.access-key: ***
s3.secret-key: ***
state.backend.incremental: true
jobmanager.memory.process.size: 1g
taskmanager.memory.process.size: 4g
}{code}
was (Author: JIRAUSER290114):
We have job manager running that is configured via module.yaml(egress and
ingress for kafka topics).
Our stateful functions are on a separate remote service built on top of Spring
boot with controller:
{code:java}
@RequestMapping("/v1/functions")
@RequiredArgsConstructor
public class FunctionRouteController {
private final RequestReplyHandler handler;
@PostMapping(consumes = MediaType.APPLICATION_OCTET_STREAM_VALUE)
public CompletableFuture onRequest(@RequestBody byte[] request) {
return handler
.handle(Slices.wrap(request))
.thenApply(Slice::toByteArray);
}
} {code}
where actually used
'org.apache.flink.statefun.sdk.java.handlerConcurrentRequestReplyHandler' and
we just define beans:
{code:java}
@Bean
public StatefulFunctions statefulFunctions(StatefulFunctions
autoRegisteredStatefulFunctions) {
// obtain a request-reply handler based on the spec above
StatefulFunctions statefulFunctions = new StatefulFunctions()
.withStatefulFunction(fallbackFn())
.withStatefulFunction(transactionFn());
autoRegisteredStatefulFunctions.functionSpecs().values().forEach(statefulFunctions::withStatefulFunction);
return statefulFunctions;
}
@Bean
public RequestReplyHandler requestReplyHandler(StatefulFunctions
statefulFunctions) {
return statefulFunctions.requestReplyHandler();
} {code}
statefulFunctions.requestReplyHandler() is :
{code:java}
public RequestReplyHandler requestReplyHandler() {
return new ConcurrentRequestReplyHandler(this.specs);
} {code}
> java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
> -
>
> Key: FLINK-27813
> URL: https://issues.apache.org/jira/browse/FLINK-27813
> Project: Flink
> Issue Type: Bug
> Components: API / State Processor
>Affects Versions: statefun-3.2.0
>Reporter: Oleksandr
>Priority: Blocker
> Attachments: screenshot-1.png
>
>
> Issue was met after migration from
> flink-statefun:3.1.1-java11
> to
> flink-statefun:3.2.0-java11
>
> {code:java}
> ts.execution-paymentMan
[GitHub] [flink-kubernetes-operator] gyfora commented on a diff in pull request #244: [FLINK-27520] Use admission-controller-framework in Webhook
gyfora commented on code in PR #244:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/244#discussion_r884251881
##
flink-kubernetes-webhook/pom.xml:
##
@@ -36,6 +36,19 @@ under the License.
org.apache.flink
flink-kubernetes-operator
${project.version}
+provided
+
+
+
+io.javaoperatorsdk
+operator-framework-framework-core
+${operator.sdk.admission-controller.version}
+
+
+*
Review Comment:
I think the slightly cleaner approach here would be to remove the exclude
all and explicitly include artifacts in the shade plugin:
```
io.javaoperatorsdk:operator-framework-framework-core
org.apache.flink.kubernetes.operator.admission.FlinkOperatorWebhook
```
This will be more flexible in the future when we need to add 1-2 extra
packages here
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink-kubernetes-operator] gyfora commented on pull request #239: [FLINK-27714] Migrate to java-operator-sdk v3
gyfora commented on PR #239: URL: https://github.com/apache/flink-kubernetes-operator/pull/239#issuecomment-1140423713 +1 for waiting 1-2 days for the JOSDK fixes before merging -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-27813) java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
[
https://issues.apache.org/jira/browse/FLINK-27813?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17543616#comment-17543616
]
Oleksandr commented on FLINK-27813:
---
We have job manager running that is configured via module.yaml(egress and
ingress for kafka topics).
Our stateful functions are on a separate remote service built on top of Spring
boot with controller:
{code:java}
@RequestMapping("/v1/functions")
@RequiredArgsConstructor
public class FunctionRouteController {
private final RequestReplyHandler handler;
@PostMapping(consumes = MediaType.APPLICATION_OCTET_STREAM_VALUE)
public CompletableFuture onRequest(@RequestBody byte[] request) {
return handler
.handle(Slices.wrap(request))
.thenApply(Slice::toByteArray);
}
} {code}
where actually used
'org.apache.flink.statefun.sdk.java.handlerConcurrentRequestReplyHandler' and
we just define beans:
{code:java}
@Bean
public StatefulFunctions statefulFunctions(StatefulFunctions
autoRegisteredStatefulFunctions) {
// obtain a request-reply handler based on the spec above
StatefulFunctions statefulFunctions = new StatefulFunctions()
.withStatefulFunction(fallbackFn())
.withStatefulFunction(transactionFn());
autoRegisteredStatefulFunctions.functionSpecs().values().forEach(statefulFunctions::withStatefulFunction);
return statefulFunctions;
}
@Bean
public RequestReplyHandler requestReplyHandler(StatefulFunctions
statefulFunctions) {
return statefulFunctions.requestReplyHandler();
} {code}
statefulFunctions.requestReplyHandler() is :
{code:java}
public RequestReplyHandler requestReplyHandler() {
return new ConcurrentRequestReplyHandler(this.specs);
} {code}
> java.lang.IllegalStateException: after migration from statefun-3.1.1 to 3.2.0
> -
>
> Key: FLINK-27813
> URL: https://issues.apache.org/jira/browse/FLINK-27813
> Project: Flink
> Issue Type: Bug
> Components: API / State Processor
>Affects Versions: statefun-3.2.0
>Reporter: Oleksandr
>Priority: Blocker
> Attachments: screenshot-1.png
>
>
> Issue was met after migration from
> flink-statefun:3.1.1-java11
> to
> flink-statefun:3.2.0-java11
>
> {code:java}
> ts.execution-paymentManualValidationRequestEgress-egress, Sink:
> ua.aval.payments.execution-norkomExecutionRequested-egress, Sink:
> ua.aval.payments.execution-shareStatusToManualValidation-egress) (1/1)#15863
> (98a1f6bef9a435ef9d0292fefeb64022) switched from RUNNING to FAILED with
> failure cause: java.lang.IllegalStateException: Unable to parse Netty
> transport spec.\n\tat
> org.apache.flink.statefun.flink.core.nettyclient.NettyRequestReplyClientFactory.parseTransportSpec(NettyRequestReplyClientFactory.java:56)\n\tat
>
> org.apache.flink.statefun.flink.core.nettyclient.NettyRequestReplyClientFactory.createTransportClient(NettyRequestReplyClientFactory.java:39)\n\tat
>
> org.apache.flink.statefun.flink.core.httpfn.HttpFunctionProvider.functionOfType(HttpFunctionProvider.java:49)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.PredefinedFunctionLoader.load(PredefinedFunctionLoader.java:70)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.PredefinedFunctionLoader.load(PredefinedFunctionLoader.java:47)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.StatefulFunctionRepository.load(StatefulFunctionRepository.java:71)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.StatefulFunctionRepository.get(StatefulFunctionRepository.java:59)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.LocalFunctionGroup.enqueue(LocalFunctionGroup.java:48)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.Reductions.enqueue(Reductions.java:153)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.Reductions.apply(Reductions.java:148)\n\tat
>
> org.apache.flink.statefun.flink.core.functions.FunctionGroupOperator.processElement(FunctionGroupOperator.java:90)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.pushToOperator(ChainingOutput.java:99)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:80)\n\tat
>
> org.apache.flink.streaming.runtime.tasks.ChainingOutput.collect(ChainingOutput.java:39)\n\tat
>
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:56)\n\tat
>
> org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:29)\n\tat
>
> org.apache.flink.statefun.flink.core.feedback.FeedbackUnionOperator.sendDownstream(FeedbackUnionOperator.java:180)\n\tat
>
> org.apache.flink.statefun.flink.core.feedback.FeedbackUnionOperator.processElement(FeedbackUnionOperator.java:86)\n\tat
>
> org.apache.flink.st
[GitHub] [flink-kubernetes-operator] gyfora commented on a diff in pull request #247: [FLINK-27668] Document dynamic operator configuration
gyfora commented on code in PR #247:
URL:
https://github.com/apache/flink-kubernetes-operator/pull/247#discussion_r884250202
##
docs/content/docs/operations/configuration.md:
##
@@ -50,11 +50,50 @@ defaultConfiguration:
To learn more about metrics and logging configuration please refer to the
dedicated [docs page]({{< ref "docs/operations/metrics-logging" >}}).
+## Dynamic Operator Configuration
+
+The Kubernetes operator supports dynamic config changes through the operator
ConfigMaps. Dynamic operator configuration can be enabled by setting
`kubernetes.operator.dynamic.config.enabled` to true. Time interval for
checking dynamic config changes is specified by
`kubernetes.operator.dynamic.config.check.interval` of which default value is 5
minutes.
+
+Verify whether dynamic operator configuration updates is enabled via the
`deploy/flink-kubernetes-operator` log has:
+
+```
+2022-05-28 13:08:29,222 o.a.f.k.o.c.FlinkConfigManager [INFO ] Enabled dynamic
config updates, checking config changes every PT5M
+```
+
+For example, the default configuration of `flink-conf.yaml` in the
`defaultConfiguration` section of the Helm `values.yaml` file is as follows:
+
+```
+defaultConfiguration:
+ create: true
+ append: false
+ flink-conf.yaml: |+
+# Flink Config Overrides
+kubernetes.operator.reconciler.reschedule.interval: 60 s
+```
+
+When the interval for the controller to reschedule the reconcile process need
to change with 30 seconds, `kubernetes.operator.reconciler.reschedule.interval`
in the `defaultConfiguration` section can directly change to 30s:
+
+```
+defaultConfiguration:
+ create: true
+ append: false
+ flink-conf.yaml: |+
+# Flink Config Overrides
+kubernetes.operator.reconciler.reschedule.interval: 30 s
+```
Review Comment:
I think this is not a good example because if you try to update the
configmap through the Helm chart (using helm-upgrade) nothing will happen
because helm only checks if the configmap is present. It will not update it.
We should simply show an example of editing the configmap directly.
##
docs/content/docs/operations/configuration.md:
##
@@ -50,11 +50,50 @@ defaultConfiguration:
To learn more about metrics and logging configuration please refer to the
dedicated [docs page]({{< ref "docs/operations/metrics-logging" >}}).
+## Dynamic Operator Configuration
+
+The Kubernetes operator supports dynamic config changes through the operator
ConfigMaps. Dynamic operator configuration can be enabled by setting
`kubernetes.operator.dynamic.config.enabled` to true. Time interval for
checking dynamic config changes is specified by
`kubernetes.operator.dynamic.config.check.interval` of which default value is 5
minutes.
Review Comment:
We should say that it is enabled by default, and can be **disabled** with
the config.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] Aitozi commented on a diff in pull request #19840: [FLINK-24713][Runtime/Coordination] Support the initial delay for SlotManager to wait fo…
Aitozi commented on code in PR #19840:
URL: https://github.com/apache/flink/pull/19840#discussion_r884246309
##
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/DeclarativeSlotManager.java:
##
@@ -79,8 +81,19 @@ public class DeclarativeSlotManager implements SlotManager {
private final Map jobMasterTargetAddresses = new
HashMap<>();
private final Map pendingSlotAllocations;
+/** Delay of the requirement change check in the slot manager. */
+private final Duration requirementsCheckDelay;
Review Comment:
do you mean create another ticker for this ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] KarmaGYZ commented on a diff in pull request #19840: [FLINK-24713][Runtime/Coordination] Support the initial delay for SlotManager to wait fo…
KarmaGYZ commented on code in PR #19840:
URL: https://github.com/apache/flink/pull/19840#discussion_r884242067
##
flink-runtime/src/main/java/org/apache/flink/runtime/resourcemanager/slotmanager/DeclarativeSlotManager.java:
##
@@ -79,8 +81,19 @@ public class DeclarativeSlotManager implements SlotManager {
private final Map jobMasterTargetAddresses = new
HashMap<>();
private final Map pendingSlotAllocations;
+/** Delay of the requirement change check in the slot manager. */
+private final Duration requirementsCheckDelay;
Review Comment:
I tend to move this to a preceding issue.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [flink] ChengkaiYang2022 commented on pull request #19681: [FLINK-27544][docs]Example code in 'Structure of Table API and SQL Programs' is out of date and cannot run.
ChengkaiYang2022 commented on PR #19681: URL: https://github.com/apache/flink/pull/19681#issuecomment-1140390388 Hi,Could you @MartijnVisser help to check it ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org