[jira] [Updated] (FLINK-30005) Translate "Schema Migration Limitations for State Schema Evolution" into Chinese
[ https://issues.apache.org/jira/browse/FLINK-30005?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] hao wang updated FLINK-30005: - Component/s: Documentation > Translate "Schema Migration Limitations for State Schema Evolution" into > Chinese > > > Key: FLINK-30005 > URL: https://issues.apache.org/jira/browse/FLINK-30005 > Project: Flink > Issue Type: Sub-task > Components: Documentation >Affects Versions: 1.16.0 >Reporter: hao wang >Priority: Minor > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-30005) Translate "Schema Migration Limitations for State Schema Evolution" into Chinese
[ https://issues.apache.org/jira/browse/FLINK-30005?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] hao wang updated FLINK-30005: - Affects Version/s: 1.16.0 > Translate "Schema Migration Limitations for State Schema Evolution" into > Chinese > > > Key: FLINK-30005 > URL: https://issues.apache.org/jira/browse/FLINK-30005 > Project: Flink > Issue Type: Sub-task >Affects Versions: 1.16.0 >Reporter: hao wang >Priority: Minor > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Created] (FLINK-30006) Cannot remove columns that are incorrectly considered constants from an Aggregate In Streaming
lincoln lee created FLINK-30006:
---
Summary: Cannot remove columns that are incorrectly considered
constants from an Aggregate In Streaming
Key: FLINK-30006
URL: https://issues.apache.org/jira/browse/FLINK-30006
Project: Flink
Issue Type: Bug
Components: Table SQL / Planner
Affects Versions: 1.16.0
Reporter: lincoln lee
Fix For: 1.17.0
In Streaming, columns generated by dynamic functions are incorrectly considered
constants and removed from an Aggregate via optimization rule
`CoreRules.AGGREGATE_PROJECT_PULL_UP_CONSTANTS`
an example query:
{code}
SELECT
cat, gmt_date, SUM(cnt), count(*)
FROM t1
WHERE gmt_date = current_date
GROUP BY cat, gmt_date
{code}
the wrong plan:
{code}
Calc(select=[cat, CAST(CURRENT_DATE() AS DATE) AS gmt_date, EXPR$2, EXPR$3])
+- GroupAggregate(groupBy=[cat], select=[cat, SUM(cnt) AS EXPR$2, COUNT(*) AS
EXPR$3])
+- Exchange(distribution=[hash[cat]])
+- Calc(select=[cat, cnt], where=[=(gmt_date, CURRENT_DATE())])
+- TableSourceScan(table=[[default_catalog, default_database, t1,
filter=[], project=[cat, cnt, gmt_date], metadata=[]]], fields=[cat, cnt,
gmt_date])
{code}
In addition to this issue, we need to check all optimization rules in streaming
completely to avoid similar problems.
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Created] (FLINK-30005) Translate "Schema Migration Limitations for State Schema Evolution" into Chinese
hao wang created FLINK-30005: Summary: Translate "Schema Migration Limitations for State Schema Evolution" into Chinese Key: FLINK-30005 URL: https://issues.apache.org/jira/browse/FLINK-30005 Project: Flink Issue Type: Sub-task Reporter: hao wang -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] luoyuxia commented on pull request #21302: [FLINK-29992][hive] fix lookup join fail with Hive table as lookup table source
luoyuxia commented on PR #21302: URL: https://github.com/apache/flink/pull/21302#issuecomment-1312658536 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #21306: [FLINK-29650] Stop printing the contents of error lines when parsing …
flinkbot commented on PR #21306: URL: https://github.com/apache/flink/pull/21306#issuecomment-1312657083 ## CI report: * 8be1a39721ce7b6d6522627a76f3fb02b6ad5289 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-29650) Printing the contents of error lines when parsing yaml file may leak sensitive configuration values
[
https://issues.apache.org/jira/browse/FLINK-29650?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17633221#comment-17633221
]
luyuan commented on FLINK-29650:
I am sorry to miss this message.
This is the error message in flink-conf.yaml, and the password will be printed
when flink load this file.
!image-2022-11-13-14-53-01-121.png!
> Printing the contents of error lines when parsing yaml file may leak
> sensitive configuration values
> ---
>
> Key: FLINK-29650
> URL: https://issues.apache.org/jira/browse/FLINK-29650
> Project: Flink
> Issue Type: Bug
> Components: API / Core
>Affects Versions: 1.16.0
>Reporter: luyuan
>Priority: Critical
> Labels: pull-request-available
> Attachments: image-2022-11-13-14-52-31-770.png,
> image-2022-11-13-14-53-01-121.png
>
>
> This following is error configuration item. Password is '123456' and is
> displayed.
> {code:java}
> password:123456
> #or
> password 123456{code}
> Could we just print file name and row number when parsing fails.
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-29650) Printing the contents of error lines when parsing yaml file may leak sensitive configuration values
[
https://issues.apache.org/jira/browse/FLINK-29650?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated FLINK-29650:
---
Labels: pull-request-available (was: )
> Printing the contents of error lines when parsing yaml file may leak
> sensitive configuration values
> ---
>
> Key: FLINK-29650
> URL: https://issues.apache.org/jira/browse/FLINK-29650
> Project: Flink
> Issue Type: Bug
> Components: API / Core
>Affects Versions: 1.16.0
>Reporter: luyuan
>Priority: Critical
> Labels: pull-request-available
> Attachments: image-2022-11-13-14-52-31-770.png,
> image-2022-11-13-14-53-01-121.png
>
>
> This following is error configuration item. Password is '123456' and is
> displayed.
> {code:java}
> password:123456
> #or
> password 123456{code}
> Could we just print file name and row number when parsing fails.
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] lyssg opened a new pull request, #21306: [FLINK-29650] Stop printing the contents of error lines when parsing …
lyssg opened a new pull request, #21306: URL: https://github.com/apache/flink/pull/21306 ## What is the purpose of the change Stop printing the contents of error lines when parsing yaml file ## Brief change log delete one line code in org.apache.flink.configuration.GlobalConfiguration#loadYAMLResource ## Verifying this change Please make sure both new and modified tests in this PR follows the conventions defined in our code quality guide: https://flink.apache.org/contributing/code-style-and-quality-common.html#testing *(Please pick either of the following options)* This change is a trivial rework / code cleanup without any test coverage. *(or)* This change is already covered by existing tests, such as *(please describe tests)*. *(or)* This change added tests and can be verified as follows: test by start a local cluster and view startup log. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes) - The serializers: (no) - The runtime per-record code paths (performance sensitive): (no) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (no) - The S3 file system connector: (no) ## Documentation - Does this pull request introduce a new feature? (no) - If yes, how is the feature documented? (not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-29650) Printing the contents of error lines when parsing yaml file may leak sensitive configuration values
[
https://issues.apache.org/jira/browse/FLINK-29650?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
luyuan updated FLINK-29650:
---
Attachment: image-2022-11-13-14-53-01-121.png
> Printing the contents of error lines when parsing yaml file may leak
> sensitive configuration values
> ---
>
> Key: FLINK-29650
> URL: https://issues.apache.org/jira/browse/FLINK-29650
> Project: Flink
> Issue Type: Bug
> Components: API / Core
>Affects Versions: 1.16.0
>Reporter: luyuan
>Priority: Critical
> Attachments: image-2022-11-13-14-52-31-770.png,
> image-2022-11-13-14-53-01-121.png
>
>
> This following is error configuration item. Password is '123456' and is
> displayed.
> {code:java}
> password:123456
> #or
> password 123456{code}
> Could we just print file name and row number when parsing fails.
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (FLINK-29650) Printing the contents of error lines when parsing yaml file may leak sensitive configuration values
[
https://issues.apache.org/jira/browse/FLINK-29650?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
luyuan updated FLINK-29650:
---
Attachment: image-2022-11-13-14-52-31-770.png
> Printing the contents of error lines when parsing yaml file may leak
> sensitive configuration values
> ---
>
> Key: FLINK-29650
> URL: https://issues.apache.org/jira/browse/FLINK-29650
> Project: Flink
> Issue Type: Bug
> Components: API / Core
>Affects Versions: 1.16.0
>Reporter: luyuan
>Priority: Critical
> Attachments: image-2022-11-13-14-52-31-770.png
>
>
> This following is error configuration item. Password is '123456' and is
> displayed.
> {code:java}
> password:123456
> #or
> password 123456{code}
> Could we just print file name and row number when parsing fails.
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[GitHub] [flink] gaborgsomogyi commented on pull request #21294: [FLINK-29704][runtime][security] E2E test for delegation token framework
gaborgsomogyi commented on PR #21294: URL: https://github.com/apache/flink/pull/21294#issuecomment-1312584460 cc @mbalassi -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-29939) Add metrics for Kubernetes Client Response 5xx count and rate
[ https://issues.apache.org/jira/browse/FLINK-29939?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17632733#comment-17632733 ] Zhou Jiang commented on FLINK-29939: Yes, I'd like to work on this > Add metrics for Kubernetes Client Response 5xx count and rate > - > > Key: FLINK-29939 > URL: https://issues.apache.org/jira/browse/FLINK-29939 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Affects Versions: kubernetes-operator-1.3.0 >Reporter: Zhou Jiang >Priority: Minor > > Operator now publishes k8s client response count by response code. In > addition to the accumulative count, adding rate for k8s client error > responses could help to setup alerts detect underlying cluster API server > status proactively. This is for enhancement of metrics when Flink Operator is > deployed to shared / multi-tenant k8s clusters. > > Why is rate needed for certain response codes? > To detect issues proactively by setting up alerts in certain cases. It could > not the total number but the rate indicates the start / end of unavailability > issue. > > Why do some 4xx matter in prod? > For example - noisy neighbor issue may happen at random time in shared > clusters, and operator may start to see increased number of 429 if cluster > does not have fairness in rate limiting. Another example is about churn: when > the cluster has namespaces quota defined and namespace is under pod churn, > there could be increasing number of 409. In these cases, metrics and alerting > on count / rate of certain 4xx is critical to understand start / end of prod > outage. > > Why is 5xx needed ? > For faster identify infrastructure issue. With 5xx response count + rate, > It's more straightforward than enumerating possible 5xx codes when setting up > prod alerts. > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Created] (FLINK-30004) Cannot resume deployment after suspend with savepoint due to leftover confgmaps
Thomas Weise created FLINK-30004: Summary: Cannot resume deployment after suspend with savepoint due to leftover confgmaps Key: FLINK-30004 URL: https://issues.apache.org/jira/browse/FLINK-30004 Project: Flink Issue Type: Bug Components: Kubernetes Operator Affects Versions: 1.2 Reporter: Thomas Weise Assignee: Thomas Weise Due to the possibility of incomplete cleanup of HA data in Flink 1.14, the deployment can get into a limbo state that requires manual intervention after suspend with savepoint. If the config maps are not cleaned up the resumed job will be considered finished and the operator recognize the JM deployment as missing. Due to check for HA data which are now cleaned up, the job fails to start and manual redeployment with initial savepoint is necessary. This can be avoided by removing any leftover HA config maps after the job has successfully stopped with savepoint (upgrade mode savepoint). -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] 1996fanrui commented on pull request #21304: [FLINK-30003][rpc] Wait the scheduler future is done before check
1996fanrui commented on PR #21304: URL: https://github.com/apache/flink/pull/21304#issuecomment-1312537889 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] zhougit86 commented on pull request #21080: [FLINK-29545][runtime] add netty idle state handler
zhougit86 commented on PR #21080: URL: https://github.com/apache/flink/pull/21080#issuecomment-1312507297 Looks like some discussion has taken place before. I think my case is a little similar to the issue I attached. And we got the root cause in our company is our cloud provider has some HW issue my cause the network packet consistent loss. Anyway , I understand this is a rare case. maybe someday in the future we want to work on this situation, let me take the ticket -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] yanghua commented on pull request #6375: [FLINK-9609] [connectors] Add bucket ready mechanism for BucketingSin…
yanghua commented on PR #6375: URL: https://github.com/apache/flink/pull/6375#issuecomment-1312495146 > The BucketingSink has been removed. The lazy review of the community wastes the huge enthusiasm and energy of early contributors. This is the reason for the decline or the homogenization of the community. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] flinkbot commented on pull request #21305: [FLINK][docs] fix rescaling operator description error
flinkbot commented on PR #21305: URL: https://github.com/apache/flink/pull/21305#issuecomment-1312491223 ## CI report: * ab87f4f802200a744ca6b7d65d609b60d02f3e81 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] sandiegoe opened a new pull request, #21305: [FLINK][docs] fix rescaling operator description error
sandiegoe opened a new pull request, #21305: URL: https://github.com/apache/flink/pull/21305 ## What is the purpose of the change *(For example: This pull request makes task deployment go through the blob server, rather than through RPC. That way we avoid re-transferring them on each deployment (during recovery).)* ## Brief change log *(for example:)* - *The TaskInfo is stored in the blob store on job creation time as a persistent artifact* - *Deployments RPC transmits only the blob storage reference* - *TaskManagers retrieve the TaskInfo from the blob cache* ## Verifying this change Please make sure both new and modified tests in this PR follows the conventions defined in our code quality guide: https://flink.apache.org/contributing/code-style-and-quality-common.html#testing *(Please pick either of the following options)* This change is a trivial rework / code cleanup without any test coverage. *(or)* This change is already covered by existing tests, such as *(please describe tests)*. *(or)* This change added tests and can be verified as follows: *(example:)* - *Added integration tests for end-to-end deployment with large payloads (100MB)* - *Extended integration test for recovery after master (JobManager) failure* - *Added test that validates that TaskInfo is transferred only once across recoveries* - *Manually verified the change by running a 4 node cluster with 2 JobManagers and 4 TaskManagers, a stateful streaming program, and killing one JobManager and two TaskManagers during the execution, verifying that recovery happens correctly.* ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? (yes / no) - If yes, how is the feature documented? (not applicable / docs / JavaDocs / not documented) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] 1996fanrui commented on pull request #21281: [FLINK-29969][checkpoint] Show the root cause when exceeded checkpoint tolerable failure threshold
1996fanrui commented on PR #21281: URL: https://github.com/apache/flink/pull/21281#issuecomment-1312487773 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-29798) Rename K8s operator client code module
[ https://issues.apache.org/jira/browse/FLINK-29798?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17632666#comment-17632666 ] Márton Balassi commented on FLINK-29798: After more consideration I decided to exclude these modules from the maven deployment without renaming. > Rename K8s operator client code module > -- > > Key: FLINK-29798 > URL: https://issues.apache.org/jira/browse/FLINK-29798 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Affects Versions: kubernetes-operator-1.2.0 >Reporter: Márton Balassi >Assignee: Márton Balassi >Priority: Major > Fix For: kubernetes-operator-1.3.0 > > > The example code module in the k8s operator is named simply > kubernetes-client-examples, and thus is published like so: > [https://repo1.maven.org/maven2/org/apache/flink/kubernetes-client-examples/1.2.0/] > We should make this more specific. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] flinkbot commented on pull request #21304: [FLINK-30003][rpc] Wait the scheduler future is done before check
flinkbot commented on PR #21304: URL: https://github.com/apache/flink/pull/21304#issuecomment-1312465970 ## CI report: * dce74d13ea2cf339d66505b7ba9d95592a3b7131 UNKNOWN Bot commands The @flinkbot bot supports the following commands: - `@flinkbot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (FLINK-30003) The ConcurrentModificationException occurred at ContextClassLoadingSettingTest
[ https://issues.apache.org/jira/browse/FLINK-30003?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Rui Fan updated FLINK-30003: Description: CI fails due to main thread didn't wait the future is done. The contextClassLoaders may be empty when checking. [https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=43092=logs=0da23115-68bb-5dcd-192c-bd4c8adebde1=24c3384f-1bcb-57b3-224f-51bf973bbee8=ae4f8708-9994-57d3-c2d7-b892156e7812] !image-2022-11-12-19-53-53-963.png! was: CI fails: [https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=43092=logs=0da23115-68bb-5dcd-192c-bd4c8adebde1=24c3384f-1bcb-57b3-224f-51bf973bbee8=ae4f8708-9994-57d3-c2d7-b892156e7812] !image-2022-11-12-19-53-53-963.png! The contextClassLoaders is always empty when checking due to main thread didn't wait the future is done. > The ConcurrentModificationException occurred at ContextClassLoadingSettingTest > -- > > Key: FLINK-30003 > URL: https://issues.apache.org/jira/browse/FLINK-30003 > Project: Flink > Issue Type: Bug > Components: Runtime / RPC >Affects Versions: 1.17.0 >Reporter: Rui Fan >Priority: Major > Labels: pull-request-available > Fix For: 1.17.0 > > Attachments: image-2022-11-12-19-53-53-963.png > > > > > CI fails due to main thread didn't wait the future is done. The > contextClassLoaders may be empty when checking. > [https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=43092=logs=0da23115-68bb-5dcd-192c-bd4c8adebde1=24c3384f-1bcb-57b3-224f-51bf973bbee8=ae4f8708-9994-57d3-c2d7-b892156e7812] > > !image-2022-11-12-19-53-53-963.png! -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Updated] (FLINK-30003) The ConcurrentModificationException occurred at ContextClassLoadingSettingTest
[ https://issues.apache.org/jira/browse/FLINK-30003?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated FLINK-30003: --- Labels: pull-request-available (was: ) > The ConcurrentModificationException occurred at ContextClassLoadingSettingTest > -- > > Key: FLINK-30003 > URL: https://issues.apache.org/jira/browse/FLINK-30003 > Project: Flink > Issue Type: Bug > Components: Runtime / RPC >Affects Versions: 1.17.0 >Reporter: Rui Fan >Priority: Major > Labels: pull-request-available > Fix For: 1.17.0 > > Attachments: image-2022-11-12-19-53-53-963.png > > > CI fails: > [https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=43092=logs=0da23115-68bb-5dcd-192c-bd4c8adebde1=24c3384f-1bcb-57b3-224f-51bf973bbee8=ae4f8708-9994-57d3-c2d7-b892156e7812] > > !image-2022-11-12-19-53-53-963.png! > > The contextClassLoaders is always empty when checking due to main thread > didn't wait the future is done. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] 1996fanrui opened a new pull request, #21304: [FLINK-30003][rpc] Wait the scheduler future is done before check
1996fanrui opened a new pull request, #21304: URL: https://github.com/apache/flink/pull/21304 ## What is the purpose of the change CI fails due to main thread didn't wait the future is done. The contextClassLoaders may be empty when checking. https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=43092=logs=0da23115-68bb-5dcd-192c-bd4c8adebde1=24c3384f-1bcb-57b3-224f-51bf973bbee8=ae4f8708-9994-57d3-c2d7-b892156e7812 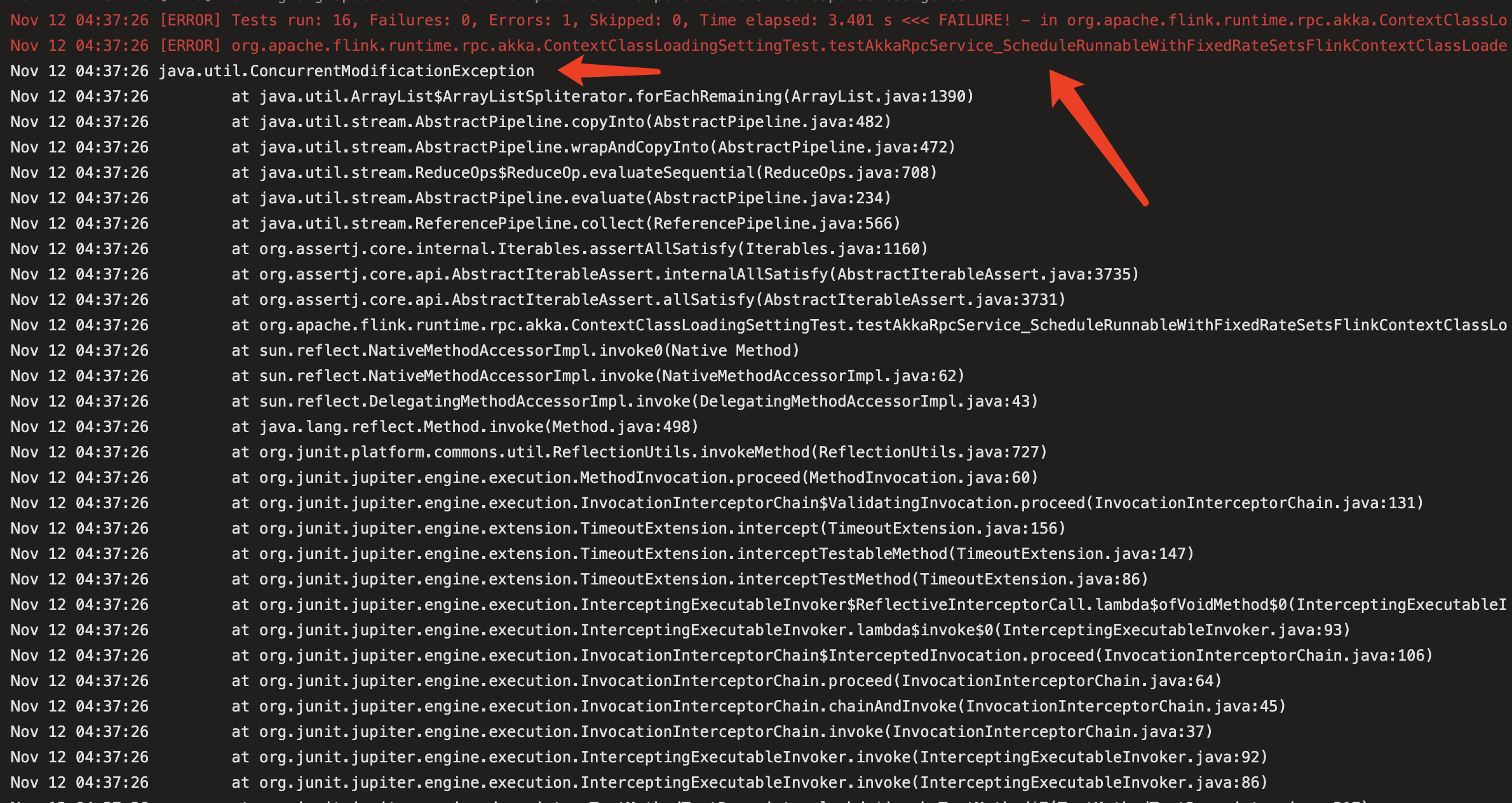 ## Brief change log Wait the scheduler future is done before check ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): no - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: no - The serializers: no - The runtime per-record code paths (performance sensitive): no - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Kubernetes/Yarn, ZooKeeper: no - The S3 file system connector: no ## Documentation - Does this pull request introduce a new feature? no - If yes, how is the feature documented? not documented -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (FLINK-30003) The ConcurrentModificationException occurred at ContextClassLoadingSettingTest
Rui Fan created FLINK-30003: --- Summary: The ConcurrentModificationException occurred at ContextClassLoadingSettingTest Key: FLINK-30003 URL: https://issues.apache.org/jira/browse/FLINK-30003 Project: Flink Issue Type: Bug Components: Runtime / RPC Affects Versions: 1.17.0 Reporter: Rui Fan Fix For: 1.17.0 Attachments: image-2022-11-12-19-53-53-963.png CI fails: [https://dev.azure.com/apache-flink/apache-flink/_build/results?buildId=43092=logs=0da23115-68bb-5dcd-192c-bd4c8adebde1=24c3384f-1bcb-57b3-224f-51bf973bbee8=ae4f8708-9994-57d3-c2d7-b892156e7812] !image-2022-11-12-19-53-53-963.png! The contextClassLoaders is always empty when checking due to main thread didn't wait the future is done. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] 1996fanrui commented on pull request #21281: [FLINK-29969][checkpoint] Show the root cause when exceeded checkpoint tolerable failure threshold
1996fanrui commented on PR #21281: URL: https://github.com/apache/flink/pull/21281#issuecomment-1312459114 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-29939) Add metrics for Kubernetes Client Response 5xx count and rate
[ https://issues.apache.org/jira/browse/FLINK-29939?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17632658#comment-17632658 ] Márton Balassi commented on FLINK-29939: [~ZhouJIANG] thanks. Would you like me to assign the ticket to you? > Add metrics for Kubernetes Client Response 5xx count and rate > - > > Key: FLINK-29939 > URL: https://issues.apache.org/jira/browse/FLINK-29939 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Affects Versions: kubernetes-operator-1.3.0 >Reporter: Zhou Jiang >Priority: Minor > > Operator now publishes k8s client response count by response code. In > addition to the accumulative count, adding rate for k8s client error > responses could help to setup alerts detect underlying cluster API server > status proactively. This is for enhancement of metrics when Flink Operator is > deployed to shared / multi-tenant k8s clusters. > > Why is rate needed for certain response codes? > To detect issues proactively by setting up alerts in certain cases. It could > not the total number but the rate indicates the start / end of unavailability > issue. > > Why do some 4xx matter in prod? > For example - noisy neighbor issue may happen at random time in shared > clusters, and operator may start to see increased number of 429 if cluster > does not have fairness in rate limiting. Another example is about churn: when > the cluster has namespaces quota defined and namespace is under pod churn, > there could be increasing number of 409. In these cases, metrics and alerting > on count / rate of certain 4xx is critical to understand start / end of prod > outage. > > Why is 5xx needed ? > For faster identify infrastructure issue. With 5xx response count + rate, > It's more straightforward than enumerating possible 5xx codes when setting up > prod alerts. > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Commented] (FLINK-27448) Enable standalone mode for old Flink versions
[ https://issues.apache.org/jira/browse/FLINK-27448?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17632656#comment-17632656 ] Márton Balassi commented on FLINK-27448: [~usamj] could you please specify the range of version you are shooting for here? > Enable standalone mode for old Flink versions > - > > Key: FLINK-27448 > URL: https://issues.apache.org/jira/browse/FLINK-27448 > Project: Flink > Issue Type: Improvement > Components: Kubernetes Operator >Reporter: Usamah Jassat >Priority: Major > Fix For: kubernetes-operator-1.3.0 > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [flink] 1996fanrui commented on pull request #21193: [hotfix] Add the final and fix typo
1996fanrui commented on PR #21193: URL: https://github.com/apache/flink/pull/21193#issuecomment-1312452502 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [flink] 1996fanrui commented on pull request #21281: [FLINK-29969][checkpoint] Show the root cause when exceeded checkpoint tolerable failure threshold
1996fanrui commented on PR #21281: URL: https://github.com/apache/flink/pull/21281#issuecomment-1312451228 @flinkbot run azure -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: issues-unsubscr...@flink.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (FLINK-29387) IntervalJoinITCase.testIntervalJoinSideOutputRightLateData failed with AssertionError
[
https://issues.apache.org/jira/browse/FLINK-29387?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17632623#comment-17632623
]
chenyuzhi commented on FLINK-29387:
---
[~mapohl]
[~hxbks2ks]
I think the problem may be the watermark in the stream instead of parallel
execution. For example , let's see the two sources in method
_testIntervalJoinSideOutputRightLateData_ :
{code:java}
DataStream> streamOne =
buildSourceStream(
env,
(ctx) -> {
ctx.collectWithTimestamp(Tuple2.of("key", 2), 2L);
ctx.collectWithTimestamp(Tuple2.of("key", 3), 3L);
ctx.emitWatermark(new Watermark(3));
ctx.collectWithTimestamp(Tuple2.of("key", 4), 4L);
});
DataStream> streamTwo =
buildSourceStream(
env,
(ctx) -> {
ctx.collectWithTimestamp(Tuple2.of("key", 1), 1L);
ctx.collectWithTimestamp(Tuple2.of("key", 3), 3L);
ctx.emitWatermark(new Watermark(3));
ctx.collectWithTimestamp(Tuple2.of("key", 2), 2L); // late
data
}); {code}
If _streamTwo_ emit late data with timestamp=2L *before* _streamOne emit_
_Watermark(3), the_ _Watemark_ in IntervalJoin Operator is still the
Long.MIN_VALUE. Thus when IntervalJoin Operator handle the late data, it won't
sideout.
I try to fix it, but I found it diffcult to control the data order between two
streams. Could you do me a favor?
Finally, I'd like to take this ticket .
> IntervalJoinITCase.testIntervalJoinSideOutputRightLateData failed with
> AssertionError
> -
>
> Key: FLINK-29387
> URL: https://issues.apache.org/jira/browse/FLINK-29387
> Project: Flink
> Issue Type: Bug
> Components: API / DataStream
>Affects Versions: 1.17.0
>Reporter: Huang Xingbo
>Priority: Blocker
> Labels: test-stability
>
> {code:java}
> 2022-09-22T04:40:21.9296331Z Sep 22 04:40:21 [ERROR]
> org.apache.flink.test.streaming.runtime.IntervalJoinITCase.testIntervalJoinSideOutputRightLateData
> Time elapsed: 2.46 s <<< FAILURE!
> 2022-09-22T04:40:21.9297487Z Sep 22 04:40:21 java.lang.AssertionError:
> expected:<[(key,2)]> but was:<[]>
> 2022-09-22T04:40:21.9298208Z Sep 22 04:40:21 at
> org.junit.Assert.fail(Assert.java:89)
> 2022-09-22T04:40:21.9298927Z Sep 22 04:40:21 at
> org.junit.Assert.failNotEquals(Assert.java:835)
> 2022-09-22T04:40:21.9299655Z Sep 22 04:40:21 at
> org.junit.Assert.assertEquals(Assert.java:120)
> 2022-09-22T04:40:21.9300403Z Sep 22 04:40:21 at
> org.junit.Assert.assertEquals(Assert.java:146)
> 2022-09-22T04:40:21.9301538Z Sep 22 04:40:21 at
> org.apache.flink.test.streaming.runtime.IntervalJoinITCase.expectInAnyOrder(IntervalJoinITCase.java:521)
> 2022-09-22T04:40:21.9302578Z Sep 22 04:40:21 at
> org.apache.flink.test.streaming.runtime.IntervalJoinITCase.testIntervalJoinSideOutputRightLateData(IntervalJoinITCase.java:280)
> 2022-09-22T04:40:21.9303641Z Sep 22 04:40:21 at
> sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> 2022-09-22T04:40:21.9304472Z Sep 22 04:40:21 at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> 2022-09-22T04:40:21.9305371Z Sep 22 04:40:21 at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> 2022-09-22T04:40:21.9306195Z Sep 22 04:40:21 at
> java.lang.reflect.Method.invoke(Method.java:498)
> 2022-09-22T04:40:21.9307011Z Sep 22 04:40:21 at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:59)
> 2022-09-22T04:40:21.9308077Z Sep 22 04:40:21 at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> 2022-09-22T04:40:21.9308968Z Sep 22 04:40:21 at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:56)
> 2022-09-22T04:40:21.9309849Z Sep 22 04:40:21 at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> 2022-09-22T04:40:21.9310704Z Sep 22 04:40:21 at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> 2022-09-22T04:40:21.9311533Z Sep 22 04:40:21 at
> org.junit.runners.ParentRunner$3.evaluate(ParentRunner.java:306)
> 2022-09-22T04:40:21.9312386Z Sep 22 04:40:21 at
> org.junit.runners.BlockJUnit4ClassRunner$1.evaluate(BlockJUnit4ClassRunner.java:100)
> 2022-09-22T04:40:21.9313231Z Sep 22 04:40:21 at
> org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:366)
> 2022-09-22T04:40:21.9314985Z Sep 22 04:40:21 at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:103)
> 2022-09-22T04:40:21.9315857Z Sep 22 04:40:21 at
>