[jira] [Updated] (KAFKA-7706) Spotbugs task fails with Gradle 5.0
[
https://issues.apache.org/jira/browse/KAFKA-7706?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
FuQiao Wang updated KAFKA-7706:
---
Description:
When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task occurred.
I'm running "gradle build --stacktrace".
An interesting part of the stacktrace is:
{quote}
{code:java}
Caused by: java.lang.NoClassDefFoundError:
org/gradle/api/internal/ClosureBackedAction at
com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136) at
com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55) at
org.gradle.api.reporting.Reporting$reports.call(Unknown Source) at
build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:18)
at org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70) at
org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154) at
org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130) at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:600) at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:92) at
org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:103) at
org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:161)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:190)
at
org.gradle.api.internal.tasks.DefaultRealizableTaskCollection.all(DefaultRealizableTaskCollection.java:229)
at
org.gradle.api.internal.DefaultDomainObjectCollection.withType(DefaultDomainObjectCollection.java:201)
at org.gradle.api.DomainObjectCollection$withType.call(Unknown Source) at
build_9sk7crqolfjf8m0yenkwy63v1.run(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:17)
at
org.gradle.groovy.scripts.internal.DefaultScriptRunnerFactory$ScriptRunnerImpl.run(DefaultScriptRunnerFactory.java:90)
... 102 more{code}
{quote}
was:
When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task occurred.
I'm running "gradle build --stacktrace".
An interesting part of the stacktrace is:
{quote}{{Caused by: java.lang.NoClassDefFoundError:
org/gradle/api/internal/ClosureBackedAction at
com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136) at
com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55) at
org.gradle.api.reporting.Reporting$reports.call(Unknown Source) at
build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:18)
at org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70) at
org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154) at
org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130) at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:600) at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:92) at
org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:103) at
org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:161)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:190)
at
org.gradle.api.internal.tasks.DefaultRealizableTaskCollection.all(DefaultRealizableTaskCollection.java:229)
at
org.gradle.api.internal.DefaultDomainObjectCollection.withType(DefaultDomainObjectCollection.java:201)
at org.gradle.api.DomainObjectCollection$withType.call(Unknown Source) at
build_9sk7crqolfjf8m0yenkwy63v1.run(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:17)
at
org.gradle.groovy.scripts.internal.DefaultScriptRunnerFactory$ScriptRunnerImpl.run(DefaultScriptRunnerFactory.java:90)
... 102 more}}
{quote}
> Spotbugs task fails with Gradle 5.0
> ---
>
> Key: KAFKA-7706
> URL: https://issues.apache.org/jira/browse/KAFKA-7706
> Project: Kafka
> Issue Type: Bug
> Components: build
> Environment: jdk1.8
> scala 2.12.7
> gradle 5.0
> Ubuntu/Windows
>Reporter: FuQiao Wang
>Priority: Major
> Labels: build
>
> When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task
> occurred.
> I'm running "gradle build --stacktrace".
> An interesting part of the stacktrace is:
> {quote}
> {code:java}
> Caused by: java.lang.NoClassDefFoundError:
> org/gradle/api/internal/ClosureBackedAction at
> com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136) at
> com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55) at
> org.gradle.api.reporting.Reporting$reports.call(Unknown Source) at
> build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/proj
[jira] [Updated] (KAFKA-7706) Spotbugs task fails with Gradle 5.0
[
https://issues.apache.org/jira/browse/KAFKA-7706?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
FuQiao Wang updated KAFKA-7706:
---
Description:
When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task occurred.
I'm running "gradle build --stacktrace".
An interesting part of the stacktrace is:
{quote}
{code:java}
Caused by: java.lang.NoClassDefFoundError:
org/gradle/api/internal/ClosureBackedAction at
com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136) at
com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55) at
org.gradle.api.reporting.Reporting$reports.call(Unknown Source) at
build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:18)
at org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70) at
org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154) at
org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130) at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:600) at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:92) at
org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:103) at
org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:161)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:190)
at
org.gradle.api.internal.tasks.DefaultRealizableTaskCollection.all(DefaultRealizableTaskCollection.java:229)
at
org.gradle.api.internal.DefaultDomainObjectCollection.withType(DefaultDomainObjectCollection.java:201)
at org.gradle.api.DomainObjectCollection$withType.call(Unknown Source) at
build_9sk7crqolfjf8m0yenkwy63v1.run(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:17)
at
org.gradle.groovy.scripts.internal.DefaultScriptRunnerFactory$ScriptRunnerImpl.run(DefaultScriptRunnerFactory.java:90)
... 102 more{code}
{quote}
was:
When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task occurred.
I'm running "gradle build --stacktrace".
An interesting part of the stacktrace is:
{quote}
{code:java}
Caused by: java.lang.NoClassDefFoundError:
org/gradle/api/internal/ClosureBackedAction at
com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136) at
com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55) at
org.gradle.api.reporting.Reporting$reports.call(Unknown Source) at
build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:18)
at org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70) at
org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154) at
org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130) at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:600) at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:92) at
org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:103) at
org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:161)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:190)
at
org.gradle.api.internal.tasks.DefaultRealizableTaskCollection.all(DefaultRealizableTaskCollection.java:229)
at
org.gradle.api.internal.DefaultDomainObjectCollection.withType(DefaultDomainObjectCollection.java:201)
at org.gradle.api.DomainObjectCollection$withType.call(Unknown Source) at
build_9sk7crqolfjf8m0yenkwy63v1.run(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:17)
at
org.gradle.groovy.scripts.internal.DefaultScriptRunnerFactory$ScriptRunnerImpl.run(DefaultScriptRunnerFactory.java:90)
... 102 more{code}
{quote}
> Spotbugs task fails with Gradle 5.0
> ---
>
> Key: KAFKA-7706
> URL: https://issues.apache.org/jira/browse/KAFKA-7706
> Project: Kafka
> Issue Type: Bug
> Components: build
> Environment: jdk1.8
> scala 2.12.7
> gradle 5.0
> Ubuntu/Windows
>Reporter: FuQiao Wang
>Priority: Major
> Labels: build
>
> When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task
> occurred.
> I'm running "gradle build --stacktrace".
> An interesting part of the stacktrace is:
> {quote}
> {code:java}
> Caused by: java.lang.NoClassDefFoundError:
> org/gradle/api/internal/ClosureBackedAction at
> com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136) at
> com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55) at
> org.gradle.api.reporting.Reporting$reports.call(Unknown Source) at
> build_9sk7crqolfjf8m0yenkwy63v1$_run_closu
[jira] [Updated] (KAFKA-7706) Spotbugs task fails with Gradle 5.0
[
https://issues.apache.org/jira/browse/KAFKA-7706?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
FuQiao Wang updated KAFKA-7706:
---
Description:
When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task occurred.
I'm running "gradle build --stacktrace".
An interesting part of the stacktrace is:
{quote}
{code:java}
Caused by: java.lang.NoClassDefFoundError:
org/gradle/api/internal/ClosureBackedAction
at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136)
at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55)
at org.gradle.api.reporting.Reporting$reports.call(Unknown Source)
at
build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:18)
at org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70)
at org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154)
at org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130)
at org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:600)
at org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:92)
at org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:103) at
org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:161)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:190)
at
org.gradle.api.internal.tasks.DefaultRealizableTaskCollection.all(DefaultRealizableTaskCollection.java:229)
at
org.gradle.api.internal.DefaultDomainObjectCollection.withType(DefaultDomainObjectCollection.java:201)
at org.gradle.api.DomainObjectCollection$withType.call(Unknown Source)
at
build_9sk7crqolfjf8m0yenkwy63v1.run(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:17)
at
org.gradle.groovy.scripts.internal.DefaultScriptRunnerFactory$ScriptRunnerImpl.run(DefaultScriptRunnerFactory.java:90)
... 102 more{code}
{quote}
was:
When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task occurred.
I'm running "gradle build --stacktrace".
An interesting part of the stacktrace is:
{quote}
{code:java}
Caused by: java.lang.NoClassDefFoundError:
org/gradle/api/internal/ClosureBackedAction at
com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136) at
com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55) at
org.gradle.api.reporting.Reporting$reports.call(Unknown Source) at
build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:18)
at org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70) at
org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154) at
org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130) at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:600) at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:92) at
org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:103) at
org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:161)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:190)
at
org.gradle.api.internal.tasks.DefaultRealizableTaskCollection.all(DefaultRealizableTaskCollection.java:229)
at
org.gradle.api.internal.DefaultDomainObjectCollection.withType(DefaultDomainObjectCollection.java:201)
at org.gradle.api.DomainObjectCollection$withType.call(Unknown Source) at
build_9sk7crqolfjf8m0yenkwy63v1.run(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:17)
at
org.gradle.groovy.scripts.internal.DefaultScriptRunnerFactory$ScriptRunnerImpl.run(DefaultScriptRunnerFactory.java:90)
... 102 more{code}
{quote}
> Spotbugs task fails with Gradle 5.0
> ---
>
> Key: KAFKA-7706
> URL: https://issues.apache.org/jira/browse/KAFKA-7706
> Project: Kafka
> Issue Type: Bug
> Components: build
> Environment: jdk1.8
> scala 2.12.7
> gradle 5.0
> Ubuntu/Windows
>Reporter: FuQiao Wang
>Priority: Major
> Labels: build
>
> When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task
> occurred.
> I'm running "gradle build --stacktrace".
> An interesting part of the stacktrace is:
> {quote}
> {code:java}
> Caused by: java.lang.NoClassDefFoundError:
> org/gradle/api/internal/ClosureBackedAction
> at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136)
> at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55)
> at org.gradle.api.reporting.Reporting$reports.call(Unknown Source)
> at
> build_9sk7crqolfjf8m0yenkwy63v1$_run_c
[jira] [Created] (KAFKA-7706) Spotbugs task fails with Gradle 5.0
FuQiao Wang created KAFKA-7706:
--
Summary: Spotbugs task fails with Gradle 5.0
Key: KAFKA-7706
URL: https://issues.apache.org/jira/browse/KAFKA-7706
Project: Kafka
Issue Type: Bug
Components: build
Environment: jdk1.8
scala 2.12.7
gradle 5.0
Ubuntu/Windows
Reporter: FuQiao Wang
When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task occurred.
I'm running "gradle build --stacktrace".
An interesting part of the stacktrace is:
{quote}{{Caused by: java.lang.NoClassDefFoundError:
org/gradle/api/internal/ClosureBackedAction at
com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136) at
com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55) at
org.gradle.api.reporting.Reporting$reports.call(Unknown Source) at
build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:18)
at org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70) at
org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154) at
org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130) at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:600) at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:92) at
org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:103) at
org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:161)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:190)
at
org.gradle.api.internal.tasks.DefaultRealizableTaskCollection.all(DefaultRealizableTaskCollection.java:229)
at
org.gradle.api.internal.DefaultDomainObjectCollection.withType(DefaultDomainObjectCollection.java:201)
at org.gradle.api.DomainObjectCollection$withType.call(Unknown Source) at
build_9sk7crqolfjf8m0yenkwy63v1.run(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:17)
at
org.gradle.groovy.scripts.internal.DefaultScriptRunnerFactory$ScriptRunnerImpl.run(DefaultScriptRunnerFactory.java:90)
... 102 more}}
{quote}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (KAFKA-7706) Spotbugs task fails with Gradle 5.0
[
https://issues.apache.org/jira/browse/KAFKA-7706?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
FuQiao Wang updated KAFKA-7706:
---
Description:
*1.* When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task
occurred.
I'm running "gradle build --stacktrace".
An interesting part of the stacktrace is:
{quote}
{code:java}
Caused by: java.lang.NoClassDefFoundError:
org/gradle/api/internal/ClosureBackedAction
at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136)
at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55)
at org.gradle.api.reporting.Reporting$reports.call(Unknown Source)
at
build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:18)
at
org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70)
at
org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154)
at org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130)
at
org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:600)
at org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:92)
at org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:103) at
org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:161)
at
org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:190)
at
org.gradle.api.internal.tasks.DefaultRealizableTaskCollection.all(DefaultRealizableTaskCollection.java:229)
at
org.gradle.api.internal.DefaultDomainObjectCollection.withType(DefaultDomainObjectCollection.java:201)
at org.gradle.api.DomainObjectCollection$withType.call(Unknown Source)
at
build_9sk7crqolfjf8m0yenkwy63v1.run(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:17)
at
org.gradle.groovy.scripts.internal.DefaultScriptRunnerFactory$ScriptRunnerImpl.run(DefaultScriptRunnerFactory.java:90)
... 102 more
{code}
{quote}
*2.* Similar to the previous one--- ---When I'm building Kafka with Gradle 5.0,
apply plugin[org.scoverage] fails
I'm running "gradle build --stacktrace".
An interesting part of the stacktrace is:
{quote}
{code:java}
Caused by: org.gradle.api.internal.plugins.PluginApplicationException: Failed
to apply plugin [id 'org.scoverage']
at
org.gradle.api.internal.plugins.DefaultPluginManager.doApply(DefaultPluginManager.java:160)
at
org.gradle.api.internal.plugins.DefaultPluginManager.apply(DefaultPluginManager.java:130)
... ...
Caused by: org.gradle.api.reflect.ObjectInstantiationException: Could not
create an instance of type org.scoverage.ScoverageExtension_Decorated.
at
org.gradle.internal.reflect.DirectInstantiator.newInstance(DirectInstantiator.java:53)
at
org.gradle.api.internal.ClassGeneratorBackedInstantiator.newInstance(ClassGeneratorBackedInstantiator.java:36)
at
org.gradle.api.internal.plugins.DefaultConvention.instantiate(DefaultConvention.java:242)
at
org.gradle.api.internal.plugins.DefaultConvention.create(DefaultConvention.java:142)
at org.scoverage.ScoveragePlugin.apply(ScoveragePlugin.groovy:18)
at org.scoverage.ScoveragePlugin.apply(ScoveragePlugin.groovy)
at
org.gradle.api.internal.plugins.ImperativeOnlyPluginTarget.applyImperative(ImperativeOnlyPluginTarget.java:42)
at
org.gradle.api.internal.plugins.RuleBasedPluginTarget.applyImperative(RuleBasedPluginTarget.java:50)
at
org.gradle.api.internal.plugins.DefaultPluginManager.addPlugin(DefaultPluginManager.java:174)
at
org.gradle.api.internal.plugins.DefaultPluginManager.access$300(DefaultPluginManager.java:50)
... 167 more
Caused by: org.gradle.api.InvalidUserDataException: You can't map a property
that does not exist: propertyName=testClassesDir
at
org.gradle.api.internal.ConventionAwareHelper.map(ConventionAwareHelper.java:56)
at
org.gradle.api.internal.ConventionAwareHelper.map(ConventionAwareHelper.java:80)
at org.gradle.api.internal.ConventionMapping$map.call(Unknown Source)
at
org.scoverage.ScoverageExtension$_closure6.doCall(ScoverageExtension.groovy:89)
at
org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70)
at org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154)
at org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130)
... 186 more
{code}
{quote}
was:
When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task occurred.
I'm running "gradle build --stacktrace".
An interesting part of the stacktrace is:
{quote}
{code:java}
Caused by: java.lang.NoClassD
[jira] [Updated] (KAFKA-7706) Spotbugs task fails with Gradle 5.0
[
https://issues.apache.org/jira/browse/KAFKA-7706?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
FuQiao Wang updated KAFKA-7706:
---
Attachment: 0001-fix-bug-build-fails-wiht-gradle-5.0.patch
> Spotbugs task fails with Gradle 5.0
> ---
>
> Key: KAFKA-7706
> URL: https://issues.apache.org/jira/browse/KAFKA-7706
> Project: Kafka
> Issue Type: Bug
> Components: build
> Environment: jdk1.8
> scala 2.12.7
> gradle 5.0
> Ubuntu/Windows
>Reporter: FuQiao Wang
>Priority: Major
> Labels: build
> Attachments: 0001-fix-bug-build-fails-wiht-gradle-5.0.patch
>
>
> *1.* When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task
> occurred.
> I'm running "gradle build --stacktrace".
> An interesting part of the stacktrace is:
> {quote}
> {code:java}
> Caused by: java.lang.NoClassDefFoundError:
> org/gradle/api/internal/ClosureBackedAction
> at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136)
> at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55)
> at org.gradle.api.reporting.Reporting$reports.call(Unknown Source)
> at
> build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:18)
>
> at
> org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70)
> at
> org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154)
> at
> org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130)
> at
> org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:600)
> at
> org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:92)
> at org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:103) at
> org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166)
>
> at
> org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:161)
>
> at
> org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:190)
>
> at
> org.gradle.api.internal.tasks.DefaultRealizableTaskCollection.all(DefaultRealizableTaskCollection.java:229)
>
> at
> org.gradle.api.internal.DefaultDomainObjectCollection.withType(DefaultDomainObjectCollection.java:201)
>
> at org.gradle.api.DomainObjectCollection$withType.call(Unknown
> Source)
> at
> build_9sk7crqolfjf8m0yenkwy63v1.run(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:17)
>
> at
> org.gradle.groovy.scripts.internal.DefaultScriptRunnerFactory$ScriptRunnerImpl.run(DefaultScriptRunnerFactory.java:90)
> ... 102 more
> {code}
> {quote}
> *2.* Similar to the previous one--- ---When I'm building Kafka with Gradle
> 5.0, apply plugin[org.scoverage] fails
> I'm running "gradle build --stacktrace".
> An interesting part of the stacktrace is:
> {quote}
> {code:java}
> Caused by: org.gradle.api.internal.plugins.PluginApplicationException: Failed
> to apply plugin [id 'org.scoverage']
> at
> org.gradle.api.internal.plugins.DefaultPluginManager.doApply(DefaultPluginManager.java:160)
> at
> org.gradle.api.internal.plugins.DefaultPluginManager.apply(DefaultPluginManager.java:130)
> ... ...
> Caused by: org.gradle.api.reflect.ObjectInstantiationException: Could not
> create an instance of type org.scoverage.ScoverageExtension_Decorated.
> at
> org.gradle.internal.reflect.DirectInstantiator.newInstance(DirectInstantiator.java:53)
> at
> org.gradle.api.internal.ClassGeneratorBackedInstantiator.newInstance(ClassGeneratorBackedInstantiator.java:36)
> at
> org.gradle.api.internal.plugins.DefaultConvention.instantiate(DefaultConvention.java:242)
> at
> org.gradle.api.internal.plugins.DefaultConvention.create(DefaultConvention.java:142)
> at org.scoverage.ScoveragePlugin.apply(ScoveragePlugin.groovy:18)
> at org.scoverage.ScoveragePlugin.apply(ScoveragePlugin.groovy)
> at
> org.gradle.api.internal.plugins.ImperativeOnlyPluginTarget.applyImperative(ImperativeOnlyPluginTarget.java:42)
> at
> org.gradle.api.internal.plugins.RuleBasedPluginTarget.applyImperative(RuleBasedPluginTarget.java:50)
> at
> org.gradle.api.internal.plugins.DefaultPluginManager.addPlugin(DefaultPluginManager.java:174)
> at
> org.gradle.api.internal.plugins.DefaultPluginManager.access$300(DefaultPluginManager.java:50)
> ... 167 more
> Caused by: org.gradle.api.InvalidUserDataException: You can't map a property
> that does not exist: propertyName=testClassesDir
> at
> org.gradle.api.internal.ConventionAwareHelper.map(ConventionAwareHelper.java:56)
> at
> org.gradle.api.internal
[jira] [Updated] (KAFKA-7706) Spotbugs task fails with Gradle 5.0
[
https://issues.apache.org/jira/browse/KAFKA-7706?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
FuQiao Wang updated KAFKA-7706:
---
Attachment: (was: 0001-fix-bug-build-fails-wiht-gradle-5.0.patch)
> Spotbugs task fails with Gradle 5.0
> ---
>
> Key: KAFKA-7706
> URL: https://issues.apache.org/jira/browse/KAFKA-7706
> Project: Kafka
> Issue Type: Bug
> Components: build
> Environment: jdk1.8
> scala 2.12.7
> gradle 5.0
> Ubuntu/Windows
>Reporter: FuQiao Wang
>Priority: Major
> Labels: build
> Attachments: 0001-fix-bug-build-fails-wiht-gradle-5.0.patch
>
>
> *1.* When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task
> occurred.
> I'm running "gradle build --stacktrace".
> An interesting part of the stacktrace is:
> {quote}
> {code:java}
> Caused by: java.lang.NoClassDefFoundError:
> org/gradle/api/internal/ClosureBackedAction
> at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136)
> at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55)
> at org.gradle.api.reporting.Reporting$reports.call(Unknown Source)
> at
> build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:18)
>
> at
> org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70)
> at
> org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154)
> at
> org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130)
> at
> org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:600)
> at
> org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:92)
> at org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:103) at
> org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166)
>
> at
> org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:161)
>
> at
> org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:190)
>
> at
> org.gradle.api.internal.tasks.DefaultRealizableTaskCollection.all(DefaultRealizableTaskCollection.java:229)
>
> at
> org.gradle.api.internal.DefaultDomainObjectCollection.withType(DefaultDomainObjectCollection.java:201)
>
> at org.gradle.api.DomainObjectCollection$withType.call(Unknown
> Source)
> at
> build_9sk7crqolfjf8m0yenkwy63v1.run(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:17)
>
> at
> org.gradle.groovy.scripts.internal.DefaultScriptRunnerFactory$ScriptRunnerImpl.run(DefaultScriptRunnerFactory.java:90)
> ... 102 more
> {code}
> {quote}
> *2.* Similar to the previous one--- ---When I'm building Kafka with Gradle
> 5.0, apply plugin[org.scoverage] fails
> I'm running "gradle build --stacktrace".
> An interesting part of the stacktrace is:
> {quote}
> {code:java}
> Caused by: org.gradle.api.internal.plugins.PluginApplicationException: Failed
> to apply plugin [id 'org.scoverage']
> at
> org.gradle.api.internal.plugins.DefaultPluginManager.doApply(DefaultPluginManager.java:160)
> at
> org.gradle.api.internal.plugins.DefaultPluginManager.apply(DefaultPluginManager.java:130)
> ... ...
> Caused by: org.gradle.api.reflect.ObjectInstantiationException: Could not
> create an instance of type org.scoverage.ScoverageExtension_Decorated.
> at
> org.gradle.internal.reflect.DirectInstantiator.newInstance(DirectInstantiator.java:53)
> at
> org.gradle.api.internal.ClassGeneratorBackedInstantiator.newInstance(ClassGeneratorBackedInstantiator.java:36)
> at
> org.gradle.api.internal.plugins.DefaultConvention.instantiate(DefaultConvention.java:242)
> at
> org.gradle.api.internal.plugins.DefaultConvention.create(DefaultConvention.java:142)
> at org.scoverage.ScoveragePlugin.apply(ScoveragePlugin.groovy:18)
> at org.scoverage.ScoveragePlugin.apply(ScoveragePlugin.groovy)
> at
> org.gradle.api.internal.plugins.ImperativeOnlyPluginTarget.applyImperative(ImperativeOnlyPluginTarget.java:42)
> at
> org.gradle.api.internal.plugins.RuleBasedPluginTarget.applyImperative(RuleBasedPluginTarget.java:50)
> at
> org.gradle.api.internal.plugins.DefaultPluginManager.addPlugin(DefaultPluginManager.java:174)
> at
> org.gradle.api.internal.plugins.DefaultPluginManager.access$300(DefaultPluginManager.java:50)
> ... 167 more
> Caused by: org.gradle.api.InvalidUserDataException: You can't map a property
> that does not exist: propertyName=testClassesDir
> at
> org.gradle.api.internal.ConventionAwareHelper.map(ConventionAwareHelper.java:56)
> at
> org.gradle.a
Re: [jira] [Updated] (KAFKA-7705) Update javadoc for the values of delivery.timeout.ms or linger.ms
should put delivery.timeout.ms a bit higher than 3 + 1? (default value of request.timeout.ms and specific value of linger.ms) > On Dec 5, 2018, at 04:43, John Roesler (JIRA) wrote: > > > [ > https://issues.apache.org/jira/browse/KAFKA-7705?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel > ] > > John Roesler updated KAFKA-7705: > >Component/s: producer > clients > >> Update javadoc for the values of delivery.timeout.ms or linger.ms >> - >> >>Key: KAFKA-7705 >>URL: https://issues.apache.org/jira/browse/KAFKA-7705 >>Project: Kafka >> Issue Type: Bug >> Components: clients, documentation, producer >> Affects Versions: 2.1.0 >> Reporter: huxihx >> Priority: Minor >> Labels: newbie >> >> In >> [https://kafka.apache.org/21/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html,] >> the sample producer code fails to run due to the ConfigException thrown: >> delivery.timeout.ms should be equal to or larger than linger.ms + >> request.timeout.ms >> The given value for delivery.timeout.ms or linger.ms on that page should be >> updated accordingly. > > > > -- > This message was sent by Atlassian JIRA > (v7.6.3#76005)
[jira] [Commented] (KAFKA-7697) Possible deadlock in kafka.cluster.Partition
[
https://issues.apache.org/jira/browse/KAFKA-7697?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16709777#comment-16709777
]
ASF GitHub Bot commented on KAFKA-7697:
---
rajinisivaram closed pull request #5999: KAFKA-7697: Process DelayedFetch
without holding leaderIsrUpdateLock
URL: https://github.com/apache/kafka/pull/5999
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/core/src/main/scala/kafka/cluster/Partition.scala
b/core/src/main/scala/kafka/cluster/Partition.scala
index 745c89a393b..1f52bd769cf 100755
--- a/core/src/main/scala/kafka/cluster/Partition.scala
+++ b/core/src/main/scala/kafka/cluster/Partition.scala
@@ -740,8 +740,6 @@ class Partition(val topicPartition: TopicPartition,
}
val info = log.appendAsLeader(records, leaderEpoch =
this.leaderEpoch, isFromClient)
- // probably unblock some follower fetch requests since log end
offset has been updated
-
replicaManager.tryCompleteDelayedFetch(TopicPartitionOperationKey(this.topic,
this.partitionId))
// we may need to increment high watermark since ISR could be down
to 1
(info, maybeIncrementLeaderHW(leaderReplica))
@@ -754,6 +752,10 @@ class Partition(val topicPartition: TopicPartition,
// some delayed operations may be unblocked after HW changed
if (leaderHWIncremented)
tryCompleteDelayedRequests()
+else {
+ // probably unblock some follower fetch requests since log end offset
has been updated
+ replicaManager.tryCompleteDelayedFetch(new
TopicPartitionOperationKey(topicPartition))
+}
info
}
diff --git a/core/src/test/scala/unit/kafka/cluster/PartitionTest.scala
b/core/src/test/scala/unit/kafka/cluster/PartitionTest.scala
index 6e38ca9575b..cfaa147f407 100644
--- a/core/src/test/scala/unit/kafka/cluster/PartitionTest.scala
+++ b/core/src/test/scala/unit/kafka/cluster/PartitionTest.scala
@@ -19,14 +19,14 @@ package kafka.cluster
import java.io.File
import java.nio.ByteBuffer
import java.util.{Optional, Properties}
-import java.util.concurrent.CountDownLatch
+import java.util.concurrent.{CountDownLatch, Executors, TimeUnit,
TimeoutException}
import java.util.concurrent.atomic.AtomicBoolean
import kafka.api.Request
import kafka.common.UnexpectedAppendOffsetException
import kafka.log.{Defaults => _, _}
import kafka.server._
-import kafka.utils.{MockScheduler, MockTime, TestUtils}
+import kafka.utils.{CoreUtils, MockScheduler, MockTime, TestUtils}
import kafka.zk.KafkaZkClient
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.errors.ReplicaNotAvailableException
@@ -39,7 +39,7 @@ import org.apache.kafka.common.requests.{IsolationLevel,
LeaderAndIsrRequest, Li
import org.junit.{After, Before, Test}
import org.junit.Assert._
import org.scalatest.Assertions.assertThrows
-import org.easymock.EasyMock
+import org.easymock.{Capture, EasyMock, IAnswer}
import scala.collection.JavaConverters._
@@ -671,7 +671,95 @@ class PartitionTest {
partition.updateReplicaLogReadResult(follower1Replica,
readResult(FetchDataInfo(LogOffsetMetadata(currentLeaderEpochStartOffset),
batch3), leaderReplica))
assertEquals("ISR", Set[Integer](leader, follower1, follower2),
partition.inSyncReplicas.map(_.brokerId))
- }
+ }
+
+ /**
+ * Verify that delayed fetch operations which are completed when records are
appended don't result in deadlocks.
+ * Delayed fetch operations acquire Partition leaderIsrUpdate read lock for
one or more partitions. So they
+ * need to be completed after releasing the lock acquired to append records.
Otherwise, waiting writers
+ * (e.g. to check if ISR needs to be shrinked) can trigger deadlock in
request handler threads waiting for
+ * read lock of one Partition while holding on to read lock of another
Partition.
+ */
+ @Test
+ def testDelayedFetchAfterAppendRecords(): Unit = {
+val replicaManager: ReplicaManager = EasyMock.mock(classOf[ReplicaManager])
+val zkClient: KafkaZkClient = EasyMock.mock(classOf[KafkaZkClient])
+val controllerId = 0
+val controllerEpoch = 0
+val leaderEpoch = 5
+val replicaIds = List[Integer](brokerId, brokerId + 1).asJava
+val isr = replicaIds
+val logConfig = LogConfig(new Properties)
+
+val topicPartitions = (0 until 5).map { i => new
TopicPartition("test-topic", i) }
+val logs = topicPartitions.map { tp => logManager.getOrCreateLog(tp,
logConfig) }
+val replicas = logs.map { log => new Replica(brokerId, log.topicPartition,
time, log = Some(log)) }
+val partitions = replicas.map { replica =>
+ val tp = repli
[jira] [Commented] (KAFKA-7705) Update javadoc for the values of delivery.timeout.ms or linger.ms
[ https://issues.apache.org/jira/browse/KAFKA-7705?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16709791#comment-16709791 ] ASF GitHub Bot commented on KAFKA-7705: --- hackerwin7 opened a new pull request #6000: MINOR KAFKA-7705 : update java doc for delivery.timeout.ms URL: https://github.com/apache/kafka/pull/6000 update KafkaProducer javadoc to put delivery.timeout.ms >= request.timeout.ms + linger.ms This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Update javadoc for the values of delivery.timeout.ms or linger.ms > - > > Key: KAFKA-7705 > URL: https://issues.apache.org/jira/browse/KAFKA-7705 > Project: Kafka > Issue Type: Bug > Components: clients, documentation, producer >Affects Versions: 2.1.0 >Reporter: huxihx >Priority: Minor > Labels: newbie > > In > [https://kafka.apache.org/21/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html,] > the sample producer code fails to run due to the ConfigException thrown: > delivery.timeout.ms should be equal to or larger than linger.ms + > request.timeout.ms > The given value for delivery.timeout.ms or linger.ms on that page should be > updated accordingly. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-7706) Spotbugs task fails with Gradle 5.0
[ https://issues.apache.org/jira/browse/KAFKA-7706?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16709800#comment-16709800 ] ASF GitHub Bot commented on KAFKA-7706: --- FuqiaoWang opened a new pull request #6001: KAFKA-7706: Spotbugs task fails with Gradle 5.0 URL: https://github.com/apache/kafka/pull/6001 1. When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task occurred. I'm running "gradle build --stacktrace". An interesting part of the stacktrace is: ``` Caused by: java.lang.NoClassDefFoundError: org/gradle/api/internal/ClosureBackedAction at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136) at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55) at org.gradle.api.reporting.Reporting$reports.call(Unknown Source) at build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:18) at org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70) at org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154) at org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130) at org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:600) at org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:92) at org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:103) at org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166) at org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:161) at org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:190) at org.gradle.api.internal.tasks.DefaultRealizableTaskCollection.all(DefaultRealizableTaskCollection.java:229) at org.gradle.api.internal.DefaultDomainObjectCollection.withType(DefaultDomainObjectCollection.java:201) at org.gradle.api.DomainObjectCollection$withType.call(Unknown Source) at build_9sk7crqolfjf8m0yenkwy63v1.run(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:17) at org.gradle.groovy.scripts.internal.DefaultScriptRunnerFactory$ScriptRunnerImpl.run(DefaultScriptRunnerFactory.java:90) ... 102 more ``` 2. Similar to the previous one--- ---When I'm building Kafka with Gradle 5.0, apply plugin[org.scoverage] fails I'm running "gradle build --stacktrace". An interesting part of the stacktrace is: ``` Caused by: org.gradle.api.internal.plugins.PluginApplicationException: Failed to apply plugin [id 'org.scoverage'] at org.gradle.api.internal.plugins.DefaultPluginManager.doApply(DefaultPluginManager.java:160) at org.gradle.api.internal.plugins.DefaultPluginManager.apply(DefaultPluginManager.java:130) ... ... Caused by: org.gradle.api.reflect.ObjectInstantiationException: Could not create an instance of type org.scoverage.ScoverageExtension_Decorated. at org.gradle.internal.reflect.DirectInstantiator.newInstance(DirectInstantiator.java:53) at org.gradle.api.internal.ClassGeneratorBackedInstantiator.newInstance(ClassGeneratorBackedInstantiator.java:36) at org.gradle.api.internal.plugins.DefaultConvention.instantiate(DefaultConvention.java:242) at org.gradle.api.internal.plugins.DefaultConvention.create(DefaultConvention.java:142) at org.scoverage.ScoveragePlugin.apply(ScoveragePlugin.groovy:18) at org.scoverage.ScoveragePlugin.apply(ScoveragePlugin.groovy) at org.gradle.api.internal.plugins.ImperativeOnlyPluginTarget.applyImperative(ImperativeOnlyPluginTarget.java:42) at org.gradle.api.internal.plugins.RuleBasedPluginTarget.applyImperative(RuleBasedPluginTarget.java:50) at org.gradle.api.internal.plugins.DefaultPluginManager.addPlugin(DefaultPluginManager.java:174) at org.gradle.api.internal.plugins.DefaultPluginManager.access$300(DefaultPluginManager.java:50) ... 167 more Caused by: org.gradle.api.InvalidUserDataException: You can't map a property that does not exist: propertyName=testClassesDir at org.gradle.api.internal.ConventionAwareHelper.map(ConventionAwareHelper.java:56) at org.gradle.api.internal.ConventionAwareHelper.map(ConventionAwareHelper.java:80) at org.gradle.api.internal.ConventionMapping$map.call(Unknown Source) at org.scoverage.ScoverageExtension$_closure6.doCall(ScoverageExtension.groovy:89) at org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70) at org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154) at org.gradle.util
[jira] [Commented] (KAFKA-7706) Spotbugs task fails with Gradle 5.0
[
https://issues.apache.org/jira/browse/KAFKA-7706?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16709811#comment-16709811
]
ASF GitHub Bot commented on KAFKA-7706:
---
FuqiaoWang closed pull request #6001: KAFKA-7706: Spotbugs task fails with
Gradle 5.0
URL: https://github.com/apache/kafka/pull/6001
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/build.gradle b/build.gradle
index d4a92a216c1..d1651f261d6 100644
--- a/build.gradle
+++ b/build.gradle
@@ -29,11 +29,11 @@ buildscript {
// For Apache Rat plugin to ignore non-Git files
classpath "org.ajoberstar:grgit:1.9.3"
classpath 'com.github.ben-manes:gradle-versions-plugin:0.17.0'
-classpath 'org.scoverage:gradle-scoverage:2.3.0'
+classpath 'org.scoverage:gradle-scoverage:2.5.0'
classpath 'com.github.jengelman.gradle.plugins:shadow:2.0.4'
classpath 'org.owasp:dependency-check-gradle:3.2.1'
classpath "com.diffplug.spotless:spotless-plugin-gradle:3.10.0"
-classpath "gradle.plugin.com.github.spotbugs:spotbugs-gradle-plugin:1.6.3"
+classpath "gradle.plugin.com.github.spotbugs:spotbugs-gradle-plugin:1.6.5"
}
}
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Spotbugs task fails with Gradle 5.0
> ---
>
> Key: KAFKA-7706
> URL: https://issues.apache.org/jira/browse/KAFKA-7706
> Project: Kafka
> Issue Type: Bug
> Components: build
> Environment: jdk1.8
> scala 2.12.7
> gradle 5.0
> Ubuntu/Windows
>Reporter: FuQiao Wang
>Priority: Major
> Labels: build
> Attachments: 0001-fix-bug-build-fails-wiht-gradle-5.0.patch
>
>
> *1.* When I'm building Kafka with Gradle 5.0, the failure of Spotbugs task
> occurred.
> I'm running "gradle build --stacktrace".
> An interesting part of the stacktrace is:
> {quote}
> {code:java}
> Caused by: java.lang.NoClassDefFoundError:
> org/gradle/api/internal/ClosureBackedAction
> at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:136)
> at com.github.spotbugs.SpotBugsTask.reports(SpotBugsTask.java:55)
> at org.gradle.api.reporting.Reporting$reports.call(Unknown Source)
> at
> build_9sk7crqolfjf8m0yenkwy63v1$_run_closure1.doCall(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:18)
>
> at
> org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:70)
> at
> org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154)
> at
> org.gradle.util.ConfigureUtil.configureSelf(ConfigureUtil.java:130)
> at
> org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:600)
> at
> org.gradle.api.internal.AbstractTask.configure(AbstractTask.java:92)
> at org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:103) at
> org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166)
>
> at
> org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:161)
>
> at
> org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:190)
>
> at
> org.gradle.api.internal.tasks.DefaultRealizableTaskCollection.all(DefaultRealizableTaskCollection.java:229)
>
> at
> org.gradle.api.internal.DefaultDomainObjectCollection.withType(DefaultDomainObjectCollection.java:201)
>
> at org.gradle.api.DomainObjectCollection$withType.call(Unknown
> Source)
> at
> build_9sk7crqolfjf8m0yenkwy63v1.run(/Users/mchalupa/projects/others/spotbugsFailExample/build.gradle:17)
>
> at
> org.gradle.groovy.scripts.internal.DefaultScriptRunnerFactory$ScriptRunnerImpl.run(DefaultScriptRunnerFactory.java:90)
> ... 102 more
> {code}
> {quote}
> *2.* Similar to the previous one--- ---When I'm building Kafka with Gradle
> 5.0, apply plugin[org.scoverage] fails
> I'm running "gradle build --stacktrace".
> An interesting part of the stacktrace is:
> {quote}
> {code:java}
> Caused by: org.gradle.api.internal.plugins.PluginApplicationException: Failed
> to apply plugin [id 'org.scoverage']
> at
> org.gradle.api.internal.plugins.DefaultPluginManager.doApply(DefaultPluginManager.java:160)
> at
> org.gradle.api.internal.plugins.DefaultPluginManager.apply(DefaultPluginManage
[jira] [Created] (KAFKA-7707) Some code is not necessary
huangyiming created KAFKA-7707:
--
Summary: Some code is not necessary
Key: KAFKA-7707
URL: https://issues.apache.org/jira/browse/KAFKA-7707
Project: Kafka
Issue Type: Improvement
Reporter: huangyiming
Attachments: image-2018-12-05-18-01-46-886.png
!image-2018-12-05-18-01-46-886.png!
in the trunk branch,i think the code can clean,is not necessary,it will never
execute
{code:java}
if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) &&
!this.waiters.isEmpty())
this.waiters.peekFirst().signal();
{code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (KAFKA-7707) Some code is not necessary
[
https://issues.apache.org/jira/browse/KAFKA-7707?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Sönke Liebau updated KAFKA-7707:
Description:
In the trunk branch in
[BufferPool.java|https://github.com/apache/kafka/blob/578205cadd0bf64d671c6c162229c4975081a9d6/clients/src/main/java/org/apache/kafka/clients/producer/internals/BufferPool.java#L174],
i think the code can clean,is not necessary,it will never execute
{code:java}
if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) &&
!this.waiters.isEmpty())
this.waiters.peekFirst().signal();
{code}
was:
!image-2018-12-05-18-01-46-886.png!
in the trunk branch,i think the code can clean,is not necessary,it will never
execute
{code:java}
if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) &&
!this.waiters.isEmpty())
this.waiters.peekFirst().signal();
{code}
> Some code is not necessary
> --
>
> Key: KAFKA-7707
> URL: https://issues.apache.org/jira/browse/KAFKA-7707
> Project: Kafka
> Issue Type: Improvement
>Reporter: huangyiming
>Priority: Minor
> Attachments: image-2018-12-05-18-01-46-886.png
>
>
> In the trunk branch in
> [BufferPool.java|https://github.com/apache/kafka/blob/578205cadd0bf64d671c6c162229c4975081a9d6/clients/src/main/java/org/apache/kafka/clients/producer/internals/BufferPool.java#L174],
> i think the code can clean,is not necessary,it will never execute
> {code:java}
> if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) &&
> !this.waiters.isEmpty())
> this.waiters.peekFirst().signal();
> {code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (KAFKA-5286) Producer should await transaction completion in close
[ https://issues.apache.org/jira/browse/KAFKA-5286?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16709877#comment-16709877 ] Viktor Somogyi commented on KAFKA-5286: --- [~apurva], [~ijuma], [~hachikuji] Is this the same as KAFKA-6635? I have a wip solution on that but I'd be happy to receive some feedback if I'm going towards the right direction. > Producer should await transaction completion in close > - > > Key: KAFKA-5286 > URL: https://issues.apache.org/jira/browse/KAFKA-5286 > Project: Kafka > Issue Type: Sub-task > Components: clients, core, producer >Affects Versions: 0.11.0.0 >Reporter: Jason Gustafson >Priority: Major > Fix For: 2.2.0 > > > We should wait at least as long as the timeout for a transaction which has > begun completion (commit or abort) to be finished. Tricky thing is whether we > should abort a transaction which is in progress. It seems reasonable since > that's the coordinator will either timeout and abort the transaction or the > next producer using the same transactionalId will fence the producer and > abort the transaction. In any case, the transaction will be aborted, so > perhaps we should do it proactively. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-7707) Some code is not necessary
[
https://issues.apache.org/jira/browse/KAFKA-7707?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16709878#comment-16709878
]
ASF GitHub Bot commented on KAFKA-7707:
---
huangyiminghappy opened a new pull request #6002: KAFKA-7707: clean the code
never execute
URL: https://github.com/apache/kafka/pull/6002
in the BufferPool,the waiters is locked by ReentrantLock,and the waiters add
Condition all within the lock,and the waiters remove also within the lock.in
the waiters there is only one Condition instance.
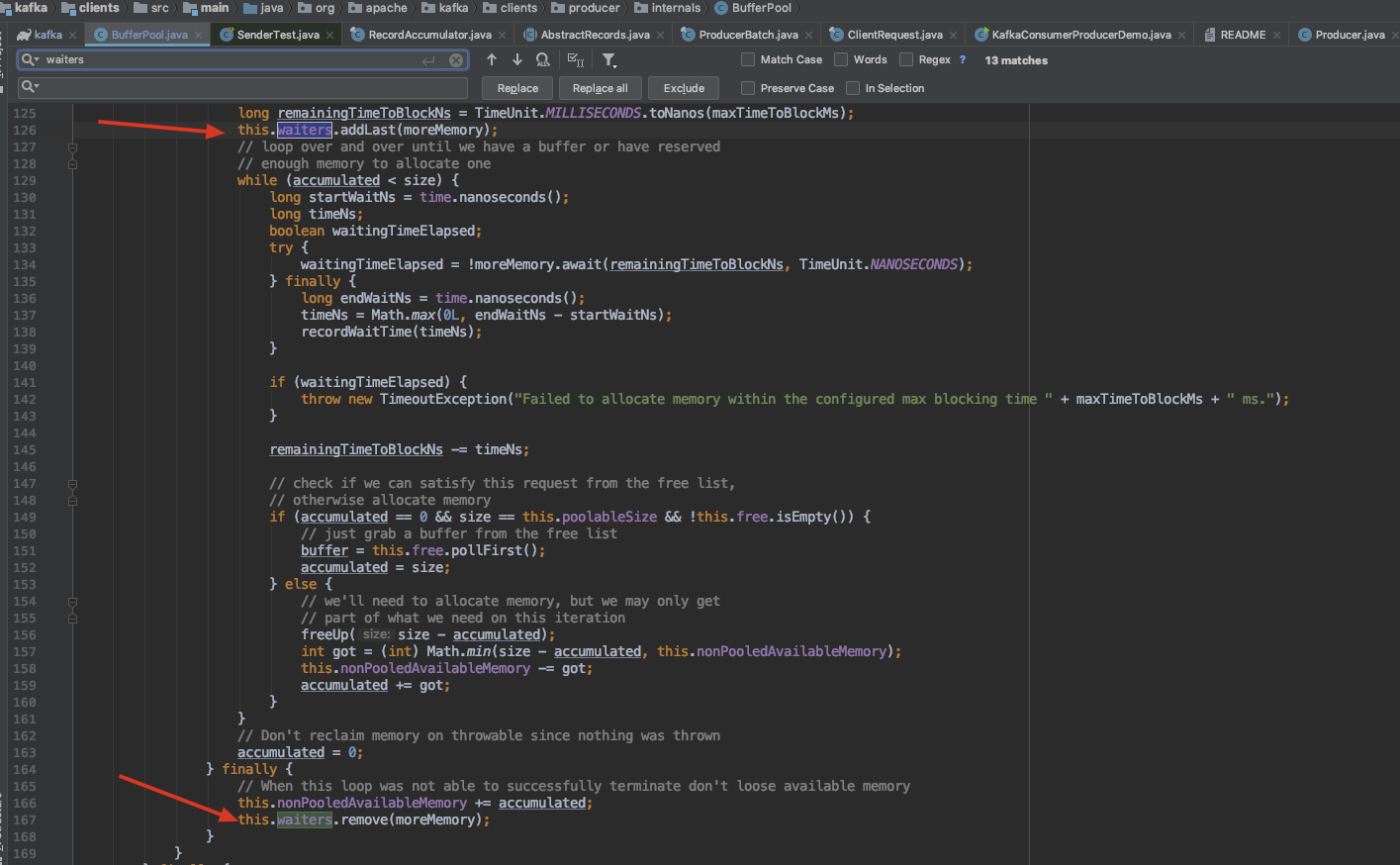
and in the finally we have remove the waiters's condition,so in the last we
use the
``` java
finally {
// signal any additional waiters if there is more memory left
// over for them
try {
if (!(this.nonPooledAvailableMemory == 0 &&
this.free.isEmpty()) && !this.waiters.isEmpty())
this.waiters.peekFirst().signal();
} finally {
// Another finally... otherwise find bugs complains
lock.unlock();
}
}
```
can modify like
``` java
finally {
lock.unlock();
}
```
### Committer Checklist (excluded from commit message)
- [ ] Verify design and implementation
- [ ] Verify test coverage and CI build status
- [ ] Verify documentation (including upgrade notes)
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Some code is not necessary
> --
>
> Key: KAFKA-7707
> URL: https://issues.apache.org/jira/browse/KAFKA-7707
> Project: Kafka
> Issue Type: Improvement
>Reporter: huangyiming
>Priority: Minor
> Attachments: image-2018-12-05-18-01-46-886.png
>
>
> In the trunk branch in
> [BufferPool.java|https://github.com/apache/kafka/blob/578205cadd0bf64d671c6c162229c4975081a9d6/clients/src/main/java/org/apache/kafka/clients/producer/internals/BufferPool.java#L174],
> i think the code can clean,is not necessary,it will never execute
> {code:java}
> if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) &&
> !this.waiters.isEmpty())
> this.waiters.peekFirst().signal();
> {code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Assigned] (KAFKA-5209) Transient failure: kafka.server.MetadataRequestTest.testControllerId
[
https://issues.apache.org/jira/browse/KAFKA-5209?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Viktor Somogyi reassigned KAFKA-5209:
-
Assignee: Umesh Chaudhary
> Transient failure: kafka.server.MetadataRequestTest.testControllerId
>
>
> Key: KAFKA-5209
> URL: https://issues.apache.org/jira/browse/KAFKA-5209
> Project: Kafka
> Issue Type: Sub-task
> Components: unit tests
>Reporter: Guozhang Wang
>Assignee: Umesh Chaudhary
>Priority: Major
>
> {code}
> Stacktrace
> java.lang.NullPointerException
> at
> kafka.server.MetadataRequestTest.testControllerId(MetadataRequestTest.scala:57)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:78)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:57)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:363)
> at
> org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecuter.runTestClass(JUnitTestClassExecuter.java:114)
> at
> org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecuter.execute(JUnitTestClassExecuter.java:57)
> at
> org.gradle.api.internal.tasks.testing.junit.JUnitTestClassProcessor.processTestClass(JUnitTestClassProcessor.java:66)
> at
> org.gradle.api.internal.tasks.testing.SuiteTestClassProcessor.processTestClass(SuiteTestClassProcessor.java:51)
> at sun.reflect.GeneratedMethodAccessor50.invoke(Unknown Source)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:35)
> at
> org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:24)
> at
> org.gradle.internal.dispatch.ContextClassLoaderDispatch.dispatch(ContextClassLoaderDispatch.java:32)
> at
> org.gradle.internal.dispatch.ProxyDispatchAdapter$DispatchingInvocationHandler.invoke(ProxyDispatchAdapter.java:93)
> at com.sun.proxy.$Proxy2.processTestClass(Unknown Source)
> at
> org.gradle.api.internal.tasks.testing.worker.TestWorker.processTestClass(TestWorker.java:109)
> at sun.reflect.GeneratedMethodAccessor49.invoke(Unknown Source)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:35)
> at
> org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:24)
> at
> org.gradle.internal.remote.internal.hub.MessageHubBackedObjectConnection$DispatchWrapper.dispatch(MessageHubBackedObjectConnection.java:147)
> at
> org.gradle.internal.remote.internal.hub.MessageHubBackedObjectConnection$DispatchWrapper.dispatch(MessageHubBackedObjectConnection.java:129)
> at
> org.gradle.internal.remote.internal.hub.MessageHub$Handler.run(MessageHub.java:404)
> at
> org.gradle.internal.concurrent.ExecutorPolicy$CatchAndRecordFailures.onExecute(ExecutorPolicy.java:63)
> at
> org.gradle.internal.concurrent.StoppableExecutorImpl$1.run(StoppableExecutorImpl.java:46)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
> at
> java.util.concurrent.ThreadPoolExecu
[jira] [Commented] (KAFKA-5209) Transient failure: kafka.server.MetadataRequestTest.testControllerId
[
https://issues.apache.org/jira/browse/KAFKA-5209?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16709880#comment-16709880
]
Viktor Somogyi commented on KAFKA-5209:
---
[~umesh9...@gmail.com] are you planning to continue this? I've assigned it to
you but if you think you won't continue, I'm happy to take over.
> Transient failure: kafka.server.MetadataRequestTest.testControllerId
>
>
> Key: KAFKA-5209
> URL: https://issues.apache.org/jira/browse/KAFKA-5209
> Project: Kafka
> Issue Type: Sub-task
> Components: unit tests
>Reporter: Guozhang Wang
>Assignee: Umesh Chaudhary
>Priority: Major
>
> {code}
> Stacktrace
> java.lang.NullPointerException
> at
> kafka.server.MetadataRequestTest.testControllerId(MetadataRequestTest.scala:57)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
> at
> org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
> at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:78)
> at
> org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:57)
> at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290)
> at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71)
> at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288)
> at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58)
> at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268)
> at org.junit.runners.ParentRunner.run(ParentRunner.java:363)
> at
> org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecuter.runTestClass(JUnitTestClassExecuter.java:114)
> at
> org.gradle.api.internal.tasks.testing.junit.JUnitTestClassExecuter.execute(JUnitTestClassExecuter.java:57)
> at
> org.gradle.api.internal.tasks.testing.junit.JUnitTestClassProcessor.processTestClass(JUnitTestClassProcessor.java:66)
> at
> org.gradle.api.internal.tasks.testing.SuiteTestClassProcessor.processTestClass(SuiteTestClassProcessor.java:51)
> at sun.reflect.GeneratedMethodAccessor50.invoke(Unknown Source)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:35)
> at
> org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:24)
> at
> org.gradle.internal.dispatch.ContextClassLoaderDispatch.dispatch(ContextClassLoaderDispatch.java:32)
> at
> org.gradle.internal.dispatch.ProxyDispatchAdapter$DispatchingInvocationHandler.invoke(ProxyDispatchAdapter.java:93)
> at com.sun.proxy.$Proxy2.processTestClass(Unknown Source)
> at
> org.gradle.api.internal.tasks.testing.worker.TestWorker.processTestClass(TestWorker.java:109)
> at sun.reflect.GeneratedMethodAccessor49.invoke(Unknown Source)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:35)
> at
> org.gradle.internal.dispatch.ReflectionDispatch.dispatch(ReflectionDispatch.java:24)
> at
> org.gradle.internal.remote.internal.hub.MessageHubBackedObjectConnection$DispatchWrapper.dispatch(MessageHubBackedObjectConnection.java:147)
> at
> org.gradle.internal.remote.internal.hub.MessageHubBackedObjectConnection$DispatchWrapper.dispatch(MessageHubBackedObjectConnection.java:129)
> at
> org.gradle.internal.remote.internal.hub.MessageHub$Handler.run(MessageHub.java:404)
> at
> org.gradle.internal.concurrent.ExecutorPolicy$CatchAndRecordFailures.onExecute(ExecutorPolicy.java:63)
> at
> org.gradle.internal.concurrent.StoppableExecutorImpl$1.run(StoppableE
[jira] [Commented] (KAFKA-7707) Some code is not necessary
[
https://issues.apache.org/jira/browse/KAFKA-7707?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16709870#comment-16709870
]
Sönke Liebau commented on KAFKA-7707:
-
Hi [~huangyimingha...@163.com],
thanks for looking into this and opening a ticket!
I've taken the liberty of replacing your Intellij screenshot by a link to the
relevant code on github, I hope that is ok with you.
Also, could you please explain why it is that you think this code will never be
executed?
> Some code is not necessary
> --
>
> Key: KAFKA-7707
> URL: https://issues.apache.org/jira/browse/KAFKA-7707
> Project: Kafka
> Issue Type: Improvement
>Reporter: huangyiming
>Priority: Minor
> Attachments: image-2018-12-05-18-01-46-886.png
>
>
> In the trunk branch in
> [BufferPool.java|https://github.com/apache/kafka/blob/578205cadd0bf64d671c6c162229c4975081a9d6/clients/src/main/java/org/apache/kafka/clients/producer/internals/BufferPool.java#L174],
> i think the code can clean,is not necessary,it will never execute
> {code:java}
> if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) &&
> !this.waiters.isEmpty())
> this.waiters.peekFirst().signal();
> {code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (KAFKA-5383) Additional Test Cases for ReplicaManager
[ https://issues.apache.org/jira/browse/KAFKA-5383?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16709926#comment-16709926 ] Viktor Somogyi commented on KAFKA-5383: --- [~hachikuji] do you mind if I pick this up? Since I've been working on the incremental partition reassignment, I think this is a good candidate for me. > Additional Test Cases for ReplicaManager > > > Key: KAFKA-5383 > URL: https://issues.apache.org/jira/browse/KAFKA-5383 > Project: Kafka > Issue Type: Sub-task > Components: clients, core, producer >Reporter: Jason Gustafson >Priority: Major > Fix For: 2.2.0 > > > KAFKA-5355 and KAFKA-5376 have shown that current testing of ReplicaManager > is inadequate. This is definitely the case when it comes to KIP-98 and is > likely true in general. We should improve this. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-5453) Controller may miss requests sent to the broker when zk session timeout happens.
[
https://issues.apache.org/jira/browse/KAFKA-5453?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16709927#comment-16709927
]
Viktor Somogyi commented on KAFKA-5453:
---
[~becket_qin] I'd pick this up if you don't mind, I'm interested in this issue.
> Controller may miss requests sent to the broker when zk session timeout
> happens.
>
>
> Key: KAFKA-5453
> URL: https://issues.apache.org/jira/browse/KAFKA-5453
> Project: Kafka
> Issue Type: Bug
> Components: core
>Affects Versions: 0.11.0.0
>Reporter: Jiangjie Qin
>Priority: Major
> Fix For: 2.2.0
>
>
> The issue I encountered was the following:
> 1. Partition reassignment was in progress, one replica of a partition is
> being reassigned from broker 1 to broker 2.
> 2. Controller received an ISR change notification which indicates broker 2
> has caught up.
> 3. Controller was sending StopReplicaRequest to broker 1.
> 4. Broker 1 zk session timeout occurs. Controller removed broker 1 from the
> cluster and cleaned up the queue. i.e. the StopReplicaRequest was removed
> from the ControllerChannelManager.
> 5. Broker 1 reconnected to zk and act as if it is still a follower replica of
> the partition.
> 6. Broker 1 will always receive exception from the leader because it is not
> in the replica list.
> Not sure what is the correct fix here. It seems that broke 1 in this case
> should ask the controller for the latest replica assignment.
> There are two related bugs:
> 1. when a {{NotAssignedReplicaException}} is thrown from
> {{Partition.updateReplicaLogReadResult()}}, the other partitions in the same
> request will failed to update the fetch timestamp and offset and thus also
> drop out of the ISR.
> 2. The {{NotAssignedReplicaException}} was not properly returned to the
> replicas, instead, a UnknownServerException is returned.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Assigned] (KAFKA-7703) KafkaConsumer.position may return a wrong offset after "seekToEnd" is called
[ https://issues.apache.org/jira/browse/KAFKA-7703?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Viktor Somogyi reassigned KAFKA-7703: - Assignee: Viktor Somogyi > KafkaConsumer.position may return a wrong offset after "seekToEnd" is called > > > Key: KAFKA-7703 > URL: https://issues.apache.org/jira/browse/KAFKA-7703 > Project: Kafka > Issue Type: Bug > Components: clients >Affects Versions: 1.1.0, 1.1.1, 2.0.0, 2.0.1, 2.1.0 >Reporter: Shixiong Zhu >Assignee: Viktor Somogyi >Priority: Major > > After "seekToEnd" is called, "KafkaConsumer.position" may return a wrong > offset set by another reset request. > Here is a reproducer: > https://github.com/zsxwing/kafka/commit/4e1aa11bfa99a38ac1e2cb0872c055db56b33246 > In this reproducer, "poll(0)" will send an "earliest" request in background. > However, after "seekToEnd" is called, due to a race condition in > "Fetcher.resetOffsetIfNeeded" (It's not atomic, "seekToEnd" could happen > between the check > https://github.com/zsxwing/kafka/commit/4e1aa11bfa99a38ac1e2cb0872c055db56b33246#diff-b45245913eaae46aa847d2615d62cde0R585 > and the seek > https://github.com/zsxwing/kafka/commit/4e1aa11bfa99a38ac1e2cb0872c055db56b33246#diff-b45245913eaae46aa847d2615d62cde0R605), > "KafkaConsumer.position" may return an "earliest" offset. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-7703) KafkaConsumer.position may return a wrong offset after "seekToEnd" is called
[ https://issues.apache.org/jira/browse/KAFKA-7703?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710012#comment-16710012 ] Viktor Somogyi commented on KAFKA-7703: --- [~zsxwing] I'll pick this up if you don't mind and look into it. > KafkaConsumer.position may return a wrong offset after "seekToEnd" is called > > > Key: KAFKA-7703 > URL: https://issues.apache.org/jira/browse/KAFKA-7703 > Project: Kafka > Issue Type: Bug > Components: clients >Affects Versions: 1.1.0, 1.1.1, 2.0.0, 2.0.1, 2.1.0 >Reporter: Shixiong Zhu >Assignee: Viktor Somogyi >Priority: Major > > After "seekToEnd" is called, "KafkaConsumer.position" may return a wrong > offset set by another reset request. > Here is a reproducer: > https://github.com/zsxwing/kafka/commit/4e1aa11bfa99a38ac1e2cb0872c055db56b33246 > In this reproducer, "poll(0)" will send an "earliest" request in background. > However, after "seekToEnd" is called, due to a race condition in > "Fetcher.resetOffsetIfNeeded" (It's not atomic, "seekToEnd" could happen > between the check > https://github.com/zsxwing/kafka/commit/4e1aa11bfa99a38ac1e2cb0872c055db56b33246#diff-b45245913eaae46aa847d2615d62cde0R585 > and the seek > https://github.com/zsxwing/kafka/commit/4e1aa11bfa99a38ac1e2cb0872c055db56b33246#diff-b45245913eaae46aa847d2615d62cde0R605), > "KafkaConsumer.position" may return an "earliest" offset. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Resolved] (KAFKA-7697) Possible deadlock in kafka.cluster.Partition
[ https://issues.apache.org/jira/browse/KAFKA-7697?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Rajini Sivaram resolved KAFKA-7697. --- Resolution: Fixed Reviewer: Jason Gustafson > Possible deadlock in kafka.cluster.Partition > > > Key: KAFKA-7697 > URL: https://issues.apache.org/jira/browse/KAFKA-7697 > Project: Kafka > Issue Type: Bug >Affects Versions: 2.1.0 >Reporter: Gian Merlino >Assignee: Rajini Sivaram >Priority: Blocker > Fix For: 2.2.0, 2.1.1 > > Attachments: threaddump.txt > > > After upgrading a fairly busy broker from 0.10.2.0 to 2.1.0, it locked up > within a few minutes (by "locked up" I mean that all request handler threads > were busy, and other brokers reported that they couldn't communicate with > it). I restarted it a few times and it did the same thing each time. After > downgrading to 0.10.2.0, the broker was stable. I attached a thread dump from > the last attempt on 2.1.0 that shows lots of kafka-request-handler- threads > trying to acquire the leaderIsrUpdateLock lock in kafka.cluster.Partition. > It jumps out that there are two threads that already have some read lock > (can't tell which one) and are trying to acquire a second one (on two > different read locks: 0x000708184b88 and 0x00070821f188): > kafka-request-handler-1 and kafka-request-handler-4. Both are handling a > produce request, and in the process of doing so, are calling > Partition.fetchOffsetSnapshot while trying to complete a DelayedFetch. At the > same time, both of those locks have writers from other threads waiting on > them (kafka-request-handler-2 and kafka-scheduler-6). Neither of those locks > appear to have writers that hold them (if only because no threads in the dump > are deep enough in inWriteLock to indicate that). > ReentrantReadWriteLock in nonfair mode prioritizes waiting writers over > readers. Is it possible that kafka-request-handler-1 and > kafka-request-handler-4 are each trying to read-lock the partition that is > currently locked by the other one, and they're both parked waiting for > kafka-request-handler-2 and kafka-scheduler-6 to get write locks, which they > never will, because the former two threads own read locks and aren't giving > them up? -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Assigned] (KAFKA-5453) Controller may miss requests sent to the broker when zk session timeout happens.
[
https://issues.apache.org/jira/browse/KAFKA-5453?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jiangjie Qin reassigned KAFKA-5453:
---
Assignee: Viktor Somogyi
> Controller may miss requests sent to the broker when zk session timeout
> happens.
>
>
> Key: KAFKA-5453
> URL: https://issues.apache.org/jira/browse/KAFKA-5453
> Project: Kafka
> Issue Type: Bug
> Components: core
>Affects Versions: 0.11.0.0
>Reporter: Jiangjie Qin
>Assignee: Viktor Somogyi
>Priority: Major
> Fix For: 2.2.0
>
>
> The issue I encountered was the following:
> 1. Partition reassignment was in progress, one replica of a partition is
> being reassigned from broker 1 to broker 2.
> 2. Controller received an ISR change notification which indicates broker 2
> has caught up.
> 3. Controller was sending StopReplicaRequest to broker 1.
> 4. Broker 1 zk session timeout occurs. Controller removed broker 1 from the
> cluster and cleaned up the queue. i.e. the StopReplicaRequest was removed
> from the ControllerChannelManager.
> 5. Broker 1 reconnected to zk and act as if it is still a follower replica of
> the partition.
> 6. Broker 1 will always receive exception from the leader because it is not
> in the replica list.
> Not sure what is the correct fix here. It seems that broke 1 in this case
> should ask the controller for the latest replica assignment.
> There are two related bugs:
> 1. when a {{NotAssignedReplicaException}} is thrown from
> {{Partition.updateReplicaLogReadResult()}}, the other partitions in the same
> request will failed to update the fetch timestamp and offset and thus also
> drop out of the ISR.
> 2. The {{NotAssignedReplicaException}} was not properly returned to the
> replicas, instead, a UnknownServerException is returned.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (KAFKA-5453) Controller may miss requests sent to the broker when zk session timeout happens.
[
https://issues.apache.org/jira/browse/KAFKA-5453?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710023#comment-16710023
]
Jiangjie Qin commented on KAFKA-5453:
-
[~viktorsomogyi] Sure. Go ahead. Thanks for being interested in contributing :)
> Controller may miss requests sent to the broker when zk session timeout
> happens.
>
>
> Key: KAFKA-5453
> URL: https://issues.apache.org/jira/browse/KAFKA-5453
> Project: Kafka
> Issue Type: Bug
> Components: core
>Affects Versions: 0.11.0.0
>Reporter: Jiangjie Qin
>Priority: Major
> Fix For: 2.2.0
>
>
> The issue I encountered was the following:
> 1. Partition reassignment was in progress, one replica of a partition is
> being reassigned from broker 1 to broker 2.
> 2. Controller received an ISR change notification which indicates broker 2
> has caught up.
> 3. Controller was sending StopReplicaRequest to broker 1.
> 4. Broker 1 zk session timeout occurs. Controller removed broker 1 from the
> cluster and cleaned up the queue. i.e. the StopReplicaRequest was removed
> from the ControllerChannelManager.
> 5. Broker 1 reconnected to zk and act as if it is still a follower replica of
> the partition.
> 6. Broker 1 will always receive exception from the leader because it is not
> in the replica list.
> Not sure what is the correct fix here. It seems that broke 1 in this case
> should ask the controller for the latest replica assignment.
> There are two related bugs:
> 1. when a {{NotAssignedReplicaException}} is thrown from
> {{Partition.updateReplicaLogReadResult()}}, the other partitions in the same
> request will failed to update the fetch timestamp and offset and thus also
> drop out of the ISR.
> 2. The {{NotAssignedReplicaException}} was not properly returned to the
> replicas, instead, a UnknownServerException is returned.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (KAFKA-5214) Re-add KafkaAdminClient#apiVersions
[ https://issues.apache.org/jira/browse/KAFKA-5214?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710105#comment-16710105 ] Viktor Somogyi commented on KAFKA-5214: --- +1 for this, it is a requirement for KAFKA-5723 too. > Re-add KafkaAdminClient#apiVersions > --- > > Key: KAFKA-5214 > URL: https://issues.apache.org/jira/browse/KAFKA-5214 > Project: Kafka > Issue Type: Improvement >Reporter: Colin P. McCabe >Assignee: Colin P. McCabe >Priority: Minor > Fix For: 2.2.0 > > > We removed KafkaAdminClient#apiVersions just before 0.11.0.0 to give us a bit > more time to iterate on it before it's included in a release. We should add > the relevant methods back. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-7708) [kafka-streams-scala] Invalid signature for KTable join in 2.12
[ https://issues.apache.org/jira/browse/KAFKA-7708?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710252#comment-16710252 ] Edmondo Porcu commented on KAFKA-7708: -- By the way we have verified there are no real tests, the KTable test is a copy paste of the KStream test and it's joining the Kstream not the Ktables [https://github.com/apache/kafka/blob/trunk/streams/streams-scala/src/test/scala/org/apache/kafka/streams/scala/kstream/KTableTest.scala] line 104 / line 127 > [kafka-streams-scala] Invalid signature for KTable join in 2.12 > --- > > Key: KAFKA-7708 > URL: https://issues.apache.org/jira/browse/KAFKA-7708 > Project: Kafka > Issue Type: Bug >Reporter: Edmondo Porcu >Priority: Major > > The signature in Scala 2.12 for the join in the > org.kafka.streams.scala.streams.KTable cannot be resolved by the compiler, > probably due to the way parameters lists are handled by the compiler . > See: > > [https://github.com/scala/bug/issues/11288] > [https://stackoverflow.com/questions/53615950/scalac-2-12-fails-to-resolve-overloaded-methods-with-multiple-argument-lists-whe] > > We are wondering how this is not captured by the current build of Kafka, we > are building on 2.12.7 as well -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (KAFKA-7708) [kafka-streams-scala] Invalid signature for KTable join in 2.12
Edmondo Porcu created KAFKA-7708: Summary: [kafka-streams-scala] Invalid signature for KTable join in 2.12 Key: KAFKA-7708 URL: https://issues.apache.org/jira/browse/KAFKA-7708 Project: Kafka Issue Type: Bug Reporter: Edmondo Porcu The signature in Scala 2.12 for the join in the org.kafka.streams.scala.streams.KTable cannot be resolved by the compiler, probably due to the way parameters lists are handled by the compiler . See: [https://github.com/scala/bug/issues/11288] [https://stackoverflow.com/questions/53615950/scalac-2-12-fails-to-resolve-overloaded-methods-with-multiple-argument-lists-whe] We are wondering how this is not captured by the current build of Kafka, we are building on 2.12.7 as well -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-6144) Allow state stores to serve stale reads during rebalance
[
https://issues.apache.org/jira/browse/KAFKA-6144?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710330#comment-16710330
]
Nikolay Izhikov commented on KAFKA-6144:
[~NaviBrar] I think you should discuss your patch on the dev-list.
Seems, this ticket requires KIP.
So, prior to the patch review, you should make and discuss KIP.
> Allow state stores to serve stale reads during rebalance
>
>
> Key: KAFKA-6144
> URL: https://issues.apache.org/jira/browse/KAFKA-6144
> Project: Kafka
> Issue Type: New Feature
> Components: streams
>Reporter: Antony Stubbs
>Assignee: Nikolay Izhikov
>Priority: Major
> Labels: needs-kip
>
> Currently when expanding the KS cluster, the new node's partitions will be
> unavailable during the rebalance, which for large states can take a very long
> time, or for small state stores even more than a few ms can be a deal breaker
> for micro service use cases.
> One workaround is to allow stale data to be read from the state stores when
> use case allows.
> Relates to KAFKA-6145 - Warm up new KS instances before migrating tasks -
> potentially a two phase rebalance
> This is the description from KAFKA-6031 (keeping this JIRA as the title is
> more descriptive):
> {quote}
> Currently reads for a key are served by single replica, which has 2 drawbacks:
> - if replica is down there is a down time in serving reads for keys it was
> responsible for until a standby replica takes over
> - in case of semantic partitioning some replicas might become hot and there
> is no easy way to scale the read load
> If standby replicas would have endpoints that are exposed in StreamsMetadata
> it would enable serving reads from several replicas, which would mitigate the
> above drawbacks.
> Due to the lag between replicas reading from multiple replicas simultaneously
> would have weaker (eventual) consistency comparing to reads from single
> replica. This however should be acceptable tradeoff in many cases.
> {quote}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (KAFKA-7708) [kafka-streams-scala] Invalid signature for KTable join in 2.12
[ https://issues.apache.org/jira/browse/KAFKA-7708?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Matthias J. Sax updated KAFKA-7708: --- Component/s: streams > [kafka-streams-scala] Invalid signature for KTable join in 2.12 > --- > > Key: KAFKA-7708 > URL: https://issues.apache.org/jira/browse/KAFKA-7708 > Project: Kafka > Issue Type: Bug > Components: streams >Reporter: Edmondo Porcu >Priority: Major > Labels: scala > > The signature in Scala 2.12 for the join in the > org.kafka.streams.scala.streams.KTable cannot be resolved by the compiler, > probably due to the way parameters lists are handled by the compiler . > See: > > [https://github.com/scala/bug/issues/11288] > [https://stackoverflow.com/questions/53615950/scalac-2-12-fails-to-resolve-overloaded-methods-with-multiple-argument-lists-whe] > > We are wondering how this is not captured by the current build of Kafka, we > are building on 2.12.7 as well -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (KAFKA-7708) [kafka-streams-scala] Invalid signature for KTable join in 2.12
[ https://issues.apache.org/jira/browse/KAFKA-7708?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Matthias J. Sax updated KAFKA-7708: --- Labels: scala (was: ) > [kafka-streams-scala] Invalid signature for KTable join in 2.12 > --- > > Key: KAFKA-7708 > URL: https://issues.apache.org/jira/browse/KAFKA-7708 > Project: Kafka > Issue Type: Bug > Components: streams >Reporter: Edmondo Porcu >Priority: Major > Labels: scala > > The signature in Scala 2.12 for the join in the > org.kafka.streams.scala.streams.KTable cannot be resolved by the compiler, > probably due to the way parameters lists are handled by the compiler . > See: > > [https://github.com/scala/bug/issues/11288] > [https://stackoverflow.com/questions/53615950/scalac-2-12-fails-to-resolve-overloaded-methods-with-multiple-argument-lists-whe] > > We are wondering how this is not captured by the current build of Kafka, we > are building on 2.12.7 as well -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-6970) Kafka streams lets the user call init() and close() on a state store, when inside Processors
[ https://issues.apache.org/jira/browse/KAFKA-6970?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710463#comment-16710463 ] Nikolay Izhikov commented on KAFKA-6970: [~mjsax] Seems, all cases from this ticket will be covered in KAFKA-7420. So, when KAFKA-7420 will be resolved we can close this ticket as duplicate. Am I miss something? > Kafka streams lets the user call init() and close() on a state store, when > inside Processors > > > Key: KAFKA-6970 > URL: https://issues.apache.org/jira/browse/KAFKA-6970 > Project: Kafka > Issue Type: Bug > Components: streams >Reporter: James Cheng >Assignee: Nikolay Izhikov >Priority: Major > > When using a state store within Transform (and Processor and > TransformValues), the user is able to call init() and close() on the state > stores. Those APIs should only be called by kafka streams itself. > If possible, it would be good to guard those APIs so that the user cannot > call them. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-6970) Kafka streams lets the user call init() and close() on a state store, when inside Processors
[ https://issues.apache.org/jira/browse/KAFKA-6970?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710492#comment-16710492 ] Matthias J. Sax commented on KAFKA-6970: It's different. For this ticket, it's about _all_ stores – not just global stores. > Kafka streams lets the user call init() and close() on a state store, when > inside Processors > > > Key: KAFKA-6970 > URL: https://issues.apache.org/jira/browse/KAFKA-6970 > Project: Kafka > Issue Type: Bug > Components: streams >Reporter: James Cheng >Assignee: Nikolay Izhikov >Priority: Major > > When using a state store within Transform (and Processor and > TransformValues), the user is able to call init() and close() on the state > stores. Those APIs should only be called by kafka streams itself. > If possible, it would be good to guard those APIs so that the user cannot > call them. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-7420) Global stores should be guarded as read-only for regular tasks
[
https://issues.apache.org/jira/browse/KAFKA-7420?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710530#comment-16710530
]
ASF GitHub Bot commented on KAFKA-7420:
---
mjsax closed pull request #5865: KAFKA-7420: Global store surrounded by read
only implementation
URL: https://github.com/apache/kafka/pull/5865
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/streams/src/main/java/org/apache/kafka/streams/processor/internals/ProcessorContextImpl.java
b/streams/src/main/java/org/apache/kafka/streams/processor/internals/ProcessorContextImpl.java
index 7c181173c43..570c2b1d82a 100644
---
a/streams/src/main/java/org/apache/kafka/streams/processor/internals/ProcessorContextImpl.java
+++
b/streams/src/main/java/org/apache/kafka/streams/processor/internals/ProcessorContextImpl.java
@@ -19,13 +19,20 @@
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.errors.StreamsException;
import org.apache.kafka.streams.internals.ApiUtils;
+import org.apache.kafka.streams.kstream.Windowed;
import org.apache.kafka.streams.processor.Cancellable;
+import org.apache.kafka.streams.processor.ProcessorContext;
import org.apache.kafka.streams.processor.PunctuationType;
import org.apache.kafka.streams.processor.Punctuator;
import org.apache.kafka.streams.processor.StateStore;
import org.apache.kafka.streams.processor.TaskId;
import org.apache.kafka.streams.processor.To;
import org.apache.kafka.streams.processor.internals.metrics.StreamsMetricsImpl;
+import org.apache.kafka.streams.state.KeyValueIterator;
+import org.apache.kafka.streams.state.KeyValueStore;
+import org.apache.kafka.streams.state.SessionStore;
+import org.apache.kafka.streams.state.WindowStore;
+import org.apache.kafka.streams.state.WindowStoreIterator;
import org.apache.kafka.streams.state.internals.ThreadCache;
import java.time.Duration;
@@ -63,6 +70,7 @@ public RecordCollector recordCollector() {
/**
* @throws StreamsException if an attempt is made to access this state
store from an unknown node
*/
+@SuppressWarnings("unchecked")
@Override
public StateStore getStateStore(final String name) {
if (currentNode() == null) {
@@ -71,6 +79,14 @@ public StateStore getStateStore(final String name) {
final StateStore global = stateManager.getGlobalStore(name);
if (global != null) {
+if (global instanceof KeyValueStore) {
+return new KeyValueStoreReadOnlyDecorator((KeyValueStore)
global);
+} else if (global instanceof WindowStore) {
+return new WindowStoreReadOnlyDecorator((WindowStore) global);
+} else if (global instanceof SessionStore) {
+return new SessionStoreReadOnlyDecorator((SessionStore)
global);
+}
+
return global;
}
@@ -177,4 +193,169 @@ public long streamTime() {
return streamTimeSupplier.get();
}
+private abstract static class StateStoreReadOnlyDecorator implements StateStore {
+static final String ERROR_MESSAGE = "Global store is read only";
+
+final T underlying;
+
+StateStoreReadOnlyDecorator(final T underlying) {
+this.underlying = underlying;
+}
+
+@Override
+public String name() {
+return underlying.name();
+}
+
+@Override
+public void init(final ProcessorContext context, final StateStore
root) {
+underlying.init(context, root);
+}
+
+@Override
+public void flush() {
+throw new UnsupportedOperationException(ERROR_MESSAGE);
+}
+
+@Override
+public void close() {
+underlying.close();
+}
+
+@Override
+public boolean persistent() {
+return underlying.persistent();
+}
+
+@Override
+public boolean isOpen() {
+return underlying.isOpen();
+}
+}
+
+private static class KeyValueStoreReadOnlyDecorator extends
StateStoreReadOnlyDecorator> implements KeyValueStore
{
+KeyValueStoreReadOnlyDecorator(final KeyValueStore underlying) {
+super(underlying);
+}
+
+@Override
+public V get(final K key) {
+return underlying.get(key);
+}
+
+@Override
+public KeyValueIterator range(final K from, final K to) {
+return underlying.range(from, to);
+}
+
+@Override
+public KeyValueIterator all() {
+return underlying.all();
+}
+
+@Override
+public long approximateNumEntries() {
+return underlyi
[jira] [Commented] (KAFKA-7709) ConcurrentModificationException occurs when iterating through multiple partitions in Sender.getExpiredInflightBatches
[ https://issues.apache.org/jira/browse/KAFKA-7709?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710529#comment-16710529 ] ASF GitHub Bot commented on KAFKA-7709: --- markcho opened a new pull request #6005: KAFKA-7709: Fix ConcurrentModificationException when retrieving expired inflight batches on multiple partitions. URL: https://github.com/apache/kafka/pull/6005 *Summary of testing strategy (including rationale) for the feature or bug fix. Unit and/or integration tests are expected for any behaviour change and system tests should be considered for larger changes.* - Unit test - Integration test ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > ConcurrentModificationException occurs when iterating through multiple > partitions in Sender.getExpiredInflightBatches > - > > Key: KAFKA-7709 > URL: https://issues.apache.org/jira/browse/KAFKA-7709 > Project: Kafka > Issue Type: Bug > Components: core >Affects Versions: 2.1.0 >Reporter: Mark Cho >Priority: Major > > In Sender.getExpiredInflightBatches method, delivery.timeout on multiple > partitions causes ConcurrentModificationException due to the underlying Java > collection being mutated while being iterated on. > In Java HashMap, you cannot mutate the underlying map while iterating through > it, as this will cause ConcurrentModificationException. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (KAFKA-7709) ConcurrentModificationException occurs when iterating through multiple partitions in Sender.getExpiredInflightBatches
Mark Cho created KAFKA-7709: --- Summary: ConcurrentModificationException occurs when iterating through multiple partitions in Sender.getExpiredInflightBatches Key: KAFKA-7709 URL: https://issues.apache.org/jira/browse/KAFKA-7709 Project: Kafka Issue Type: Bug Components: core Affects Versions: 2.1.0 Reporter: Mark Cho In Sender.getExpiredInflightBatches method, delivery.timeout on multiple partitions causes ConcurrentModificationException due to the underlying Java collection being mutated while being iterated on. In Java HashMap, you cannot mutate the underlying map while iterating through it, as this will cause ConcurrentModificationException. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-7678) Failed to close producer due to java.lang.NullPointerException
[
https://issues.apache.org/jira/browse/KAFKA-7678?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710556#comment-16710556
]
ASF GitHub Bot commented on KAFKA-7678:
---
mjsax closed pull request #5993: KAFKA-7678: Avoid NPE when closing the
RecordCollector
URL: https://github.com/apache/kafka/pull/5993
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/streams/src/main/java/org/apache/kafka/streams/processor/internals/RecordCollectorImpl.java
b/streams/src/main/java/org/apache/kafka/streams/processor/internals/RecordCollectorImpl.java
index 5df14ee2815..d3a00301d7a 100644
---
a/streams/src/main/java/org/apache/kafka/streams/processor/internals/RecordCollectorImpl.java
+++
b/streams/src/main/java/org/apache/kafka/streams/processor/internals/RecordCollectorImpl.java
@@ -249,8 +249,10 @@ public void flush() {
@Override
public void close() {
log.debug("Closing producer");
-producer.close();
-producer = null;
+if (producer != null) {
+producer.close();
+producer = null;
+}
checkForException();
}
diff --git
a/streams/src/test/java/org/apache/kafka/streams/processor/internals/RecordCollectorTest.java
b/streams/src/test/java/org/apache/kafka/streams/processor/internals/RecordCollectorTest.java
index e63751899f2..0bc65ccbe10 100644
---
a/streams/src/test/java/org/apache/kafka/streams/processor/internals/RecordCollectorTest.java
+++
b/streams/src/test/java/org/apache/kafka/streams/processor/internals/RecordCollectorTest.java
@@ -387,6 +387,18 @@ public void testRecordHeaderPassThroughSerializer() {
}
}
+@Test
+public void testShouldNotThrowNPEOnCloseIfProducerIsNotInitialized() {
+final RecordCollectorImpl collector = new RecordCollectorImpl(
+"NoNPE",
+logContext,
+new DefaultProductionExceptionHandler(),
+new Metrics().sensor("skipped-records")
+);
+
+collector.close();
+}
+
private static class CustomStringSerializer extends StringSerializer {
private boolean isKey;
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Failed to close producer due to java.lang.NullPointerException
> --
>
> Key: KAFKA-7678
> URL: https://issues.apache.org/jira/browse/KAFKA-7678
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Reporter: Jonathan Santilli
>Assignee: Jonathan Santilli
>Priority: Minor
> Labels: bug
>
> This occurs when the group is rebalancing in a Kafka Stream application and
> the process (the Kafka Stream application) receives a *SIGTERM* to stop it
> gracefully.
>
>
> {noformat}
> ERROR org.apache.kafka.streams.processor.internals.StreamTask - task [1_46]
> Failed to close producer due to the following error:
> java.lang.NullPointerException
> at
> org.apache.kafka.streams.processor.internals.RecordCollectorImpl.close(RecordCollectorImpl.java:252)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.maybeAbortTransactionAndCloseRecordCollector(StreamTask.java:607)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.suspend(StreamTask.java:584)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.close(StreamTask.java:691)
> at
> org.apache.kafka.streams.processor.internals.AssignedTasks.closeUnclean(AssignedTasks.java:428)
> at
> org.apache.kafka.streams.processor.internals.AssignedTasks.close(AssignedTasks.java:408)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.shutdown(TaskManager.java:260)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.completeShutdown(StreamThread.java:1181)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:758){noformat}
>
>
> Although I have checked the code and the method
> `*maybeAbortTransactionAndCloseRecordCollector*` in the `*StreamTask*.*java*`
> class is expecting any kind of error to happen since is catching
> `*Throwable*`.
>
>
>
> {noformat}
> try {
> recordCollector.close();
> } catch (final Throwable e) {
> log.error("Failed to close producer due to the following error:", e);
> } finally {
> producer = null;
> }{noformat}
>
> Should we consid
[jira] [Commented] (KAFKA-7657) Invalid reporting of stream state in Kafka streams application
[
https://issues.apache.org/jira/browse/KAFKA-7657?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710573#comment-16710573
]
Patrik Kleindl commented on KAFKA-7657:
---
[~guozhang]
I have tried to grab the relevant part of the log and remove all client
references, not much to be seen.
{code:java}
2018-11-30 08:50:06,885 INFO
[org.apache.kafka.clients.consumer.internals.AbstractCoordinator]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ... [Consumer
clientId=client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16-consumer,
groupId=client-appname] Group coordinator broker:9092 (id: 2147483644 rack:
null) is unavailable or invalid, will attempt rediscovery
2018-11-30 08:50:06,986 INFO
[org.apache.kafka.clients.consumer.internals.AbstractCoordinator]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ... [Consumer
clientId=client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16-consumer,
groupId=client-appname] Discovered group coordinator broker:9092 (id:
2147483644 rack: null)
2018-11-30 08:50:06,986 INFO
[org.apache.kafka.clients.consumer.internals.AbstractCoordinator]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ... [Consumer
clientId=client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16-consumer,
groupId=client-appname] Group coordinator broker:9092 (id: 2147483644 rack:
null) is unavailable or invalid, will attempt rediscovery
2018-11-30 08:50:07,087 INFO
[org.apache.kafka.clients.consumer.internals.AbstractCoordinator]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ... [Consumer
clientId=client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16-consumer,
groupId=client-appname] Discovered group coordinator broker:9092 (id:
2147483644 rack: null)
2018-11-30 09:08:45,717 INFO
[org.apache.kafka.clients.consumer.internals.AbstractCoordinator]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ... [Consumer
clientId=client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16-consumer,
groupId=client-appname] Attempt to heartbeat failed since group is rebalancing
2018-11-30 09:08:45,749 INFO
[org.apache.kafka.clients.consumer.internals.ConsumerCoordinator]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ... [Consumer
clientId=client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16-consumer,
groupId=client-appname] Revoking previously assigned partitions [...]
2018-11-30 09:08:45,750 INFO
[org.apache.kafka.streams.processor.internals.StreamThread]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ...
stream-thread [client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16]
State transition from RUNNING to PARTITIONS_REVOKED
2018-11-30 09:08:45,750 INFO [org.apache.kafka.streams.KafkaStreams]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ...
stream-client [client-610151c7-8769-4cc5-9254-969a831e4a4d] State transition
from RUNNING to REBALANCING
2018-11-30 09:08:45,865 INFO
[org.apache.kafka.streams.processor.internals.StreamThread]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ...
stream-thread [client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16]
partition revocation took 115 ms.
2018-11-30 09:08:45,865 INFO
[org.apache.kafka.clients.consumer.internals.AbstractCoordinator]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ... [Consumer
clientId=client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16-consumer,
groupId=client-appname] (Re-)joining group
2018-11-30 09:08:47,544 INFO
[org.apache.kafka.clients.consumer.internals.AbstractCoordinator]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ... [Consumer
clientId=client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16-consumer,
groupId=client-appname] Successfully joined group with generation 3374
2018-11-30 09:08:47,547 INFO
[org.apache.kafka.clients.consumer.internals.ConsumerCoordinator]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ... [Consumer
clientId=client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16-consumer,
groupId=client-appname] Setting newly assigned partitions [...]
2018-11-30 09:08:47,547 INFO
[org.apache.kafka.streams.processor.internals.StreamThread]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ...
stream-thread [client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16]
State transition from PARTITIONS_REVOKED to PARTITIONS_ASSIGNED
2018-11-30 09:08:47,574 INFO
[org.apache.kafka.streams.processor.internals.StreamThread]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16) - ...
stream-thread [client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16]
partition assignment took 27 ms.
2018-11-30 09:08:47,874 INFO
[org.apache.kafka.streams.processor.internals.StreamThread]
(client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThre
[jira] [Commented] (KAFKA-6970) Kafka streams lets the user call init() and close() on a state store, when inside Processors
[ https://issues.apache.org/jira/browse/KAFKA-6970?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710580#comment-16710580 ] Nikolay Izhikov commented on KAFKA-6970: [~mjsax] Got it. Thanks for an answer. > Kafka streams lets the user call init() and close() on a state store, when > inside Processors > > > Key: KAFKA-6970 > URL: https://issues.apache.org/jira/browse/KAFKA-6970 > Project: Kafka > Issue Type: Bug > Components: streams >Reporter: James Cheng >Assignee: Nikolay Izhikov >Priority: Major > > When using a state store within Transform (and Processor and > TransformValues), the user is able to call init() and close() on the state > stores. Those APIs should only be called by kafka streams itself. > If possible, it would be good to guard those APIs so that the user cannot > call them. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-6388) Error while trying to roll a segment that already exists
[
https://issues.apache.org/jira/browse/KAFKA-6388?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710713#comment-16710713
]
ASF GitHub Bot commented on KAFKA-6388:
---
hachikuji closed pull request #5986: KAFKA-6388: Recover from rolling an empty
segment that already exists
URL: https://github.com/apache/kafka/pull/5986
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/core/src/main/scala/kafka/log/Log.scala
b/core/src/main/scala/kafka/log/Log.scala
index 688736c7d66..c448805e0e6 100644
--- a/core/src/main/scala/kafka/log/Log.scala
+++ b/core/src/main/scala/kafka/log/Log.scala
@@ -1548,8 +1548,8 @@ class Log(@volatile var dir: File,
in the header.
*/
appendInfo.firstOffset match {
-case Some(firstOffset) => roll(firstOffset)
-case None => roll(maxOffsetInMessages - Integer.MAX_VALUE)
+case Some(firstOffset) => roll(Some(firstOffset))
+case None => roll(Some(maxOffsetInMessages - Integer.MAX_VALUE))
}
} else {
segment
@@ -1562,22 +1562,45 @@ class Log(@volatile var dir: File,
*
* @return The newly rolled segment
*/
- def roll(expectedNextOffset: Long = 0): LogSegment = {
+ def roll(expectedNextOffset: Option[Long] = None): LogSegment = {
maybeHandleIOException(s"Error while rolling log segment for
$topicPartition in dir ${dir.getParent}") {
val start = time.hiResClockMs()
lock synchronized {
checkIfMemoryMappedBufferClosed()
-val newOffset = math.max(expectedNextOffset, logEndOffset)
+val newOffset = math.max(expectedNextOffset.getOrElse(0L),
logEndOffset)
val logFile = Log.logFile(dir, newOffset)
-val offsetIdxFile = offsetIndexFile(dir, newOffset)
-val timeIdxFile = timeIndexFile(dir, newOffset)
-val txnIdxFile = transactionIndexFile(dir, newOffset)
-for (file <- List(logFile, offsetIdxFile, timeIdxFile, txnIdxFile) if
file.exists) {
- warn(s"Newly rolled segment file ${file.getAbsolutePath} already
exists; deleting it first")
- Files.delete(file.toPath)
-}
-
Option(segments.lastEntry).foreach(_.getValue.onBecomeInactiveSegment())
+if (segments.containsKey(newOffset)) {
+ // segment with the same base offset already exists and loaded
+ if (activeSegment.baseOffset == newOffset && activeSegment.size ==
0) {
+// We have seen this happen (see KAFKA-6388) after shouldRoll()
returns true for an
+// active segment of size zero because of one of the indexes is
"full" (due to _maxEntries == 0).
+warn(s"Trying to roll a new log segment with start offset
$newOffset " +
+ s"=max(provided offset = $expectedNextOffset, LEO =
$logEndOffset) while it already " +
+ s"exists and is active with size 0. Size of time index:
${activeSegment.timeIndex.entries}," +
+ s" size of offset index:
${activeSegment.offsetIndex.entries}.")
+deleteSegment(activeSegment)
+ } else {
+throw new KafkaException(s"Trying to roll a new log segment for
topic partition $topicPartition with start offset $newOffset" +
+ s" =max(provided offset =
$expectedNextOffset, LEO = $logEndOffset) while it already exists. Existing " +
+ s"segment is ${segments.get(newOffset)}.")
+ }
+} else if (!segments.isEmpty && newOffset < activeSegment.baseOffset) {
+ throw new KafkaException(
+s"Trying to roll a new log segment for topic partition
$topicPartition with " +
+s"start offset $newOffset =max(provided offset =
$expectedNextOffset, LEO = $logEndOffset) lower than start offset of the active
segment $activeSegment")
+} else {
+ val offsetIdxFile = offsetIndexFile(dir, newOffset)
+ val timeIdxFile = timeIndexFile(dir, newOffset)
+ val txnIdxFile = transactionIndexFile(dir, newOffset)
+
+ for (file <- List(logFile, offsetIdxFile, timeIdxFile, txnIdxFile)
if file.exists) {
+warn(s"Newly rolled segment file ${file.getAbsolutePath} already
exists; deleting it first")
+Files.delete(file.toPath)
+ }
+
+
Option(segments.lastEntry).foreach(_.getValue.onBecomeInactiveSegment())
+}
// take a snapshot of the producer state to facilitate recovery. It is
useful to have the snapshot
// offset align with the new segment offset since this ensures we can
recover the segment by beginning
@@ -1594,10 +1617,7 @@ class Log(@volatile var dir: File,
fil
[jira] [Updated] (KAFKA-7678) Failed to close producer due to java.lang.NullPointerException
[
https://issues.apache.org/jira/browse/KAFKA-7678?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Matthias J. Sax updated KAFKA-7678:
---
Fix Version/s: 2.0.2
2.1.1
2.2.0
1.1.2
> Failed to close producer due to java.lang.NullPointerException
> --
>
> Key: KAFKA-7678
> URL: https://issues.apache.org/jira/browse/KAFKA-7678
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 1.1.1, 2.0.1, 2.1.0
>Reporter: Jonathan Santilli
>Assignee: Jonathan Santilli
>Priority: Minor
> Fix For: 1.1.2, 2.2.0, 2.1.1, 2.0.2
>
>
> This occurs when the group is rebalancing in a Kafka Stream application and
> the process (the Kafka Stream application) receives a *SIGTERM* to stop it
> gracefully.
>
>
> {noformat}
> ERROR org.apache.kafka.streams.processor.internals.StreamTask - task [1_46]
> Failed to close producer due to the following error:
> java.lang.NullPointerException
> at
> org.apache.kafka.streams.processor.internals.RecordCollectorImpl.close(RecordCollectorImpl.java:252)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.maybeAbortTransactionAndCloseRecordCollector(StreamTask.java:607)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.suspend(StreamTask.java:584)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.close(StreamTask.java:691)
> at
> org.apache.kafka.streams.processor.internals.AssignedTasks.closeUnclean(AssignedTasks.java:428)
> at
> org.apache.kafka.streams.processor.internals.AssignedTasks.close(AssignedTasks.java:408)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.shutdown(TaskManager.java:260)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.completeShutdown(StreamThread.java:1181)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:758){noformat}
>
>
> Although I have checked the code and the method
> `*maybeAbortTransactionAndCloseRecordCollector*` in the `*StreamTask*.*java*`
> class is expecting any kind of error to happen since is catching
> `*Throwable*`.
>
>
>
> {noformat}
> try {
> recordCollector.close();
> } catch (final Throwable e) {
> log.error("Failed to close producer due to the following error:", e);
> } finally {
> producer = null;
> }{noformat}
>
> Should we consider this a bug?
> In my opinion, we could check for the `*null*` possibility at
> `*RecordCollectorImpl*.*java*` class:
> {noformat}
> @Override
> public void close() {
> log.debug("Closing producer");
> producer.close();
> producer = null;
> checkForException();
> }{noformat}
>
> Change it for:
>
> {noformat}
> @Override
> public void close() {
> log.debug("Closing producer");
> if ( Objects.nonNull(producer) ) {
> producer.close();
> producer = null;
> }
> checkForException();
> }{noformat}
>
> How does that sound?
>
> Kafka Brokers running 2.0.0
> Kafka Stream and client 2.1.0
> OpenJDK 8
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (KAFKA-7678) Failed to close producer due to java.lang.NullPointerException
[
https://issues.apache.org/jira/browse/KAFKA-7678?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Matthias J. Sax updated KAFKA-7678:
---
Labels: (was: bug)
> Failed to close producer due to java.lang.NullPointerException
> --
>
> Key: KAFKA-7678
> URL: https://issues.apache.org/jira/browse/KAFKA-7678
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 1.1.1, 2.0.1, 2.1.0
>Reporter: Jonathan Santilli
>Assignee: Jonathan Santilli
>Priority: Minor
> Fix For: 1.1.2, 2.2.0, 2.1.1, 2.0.2
>
>
> This occurs when the group is rebalancing in a Kafka Stream application and
> the process (the Kafka Stream application) receives a *SIGTERM* to stop it
> gracefully.
>
>
> {noformat}
> ERROR org.apache.kafka.streams.processor.internals.StreamTask - task [1_46]
> Failed to close producer due to the following error:
> java.lang.NullPointerException
> at
> org.apache.kafka.streams.processor.internals.RecordCollectorImpl.close(RecordCollectorImpl.java:252)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.maybeAbortTransactionAndCloseRecordCollector(StreamTask.java:607)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.suspend(StreamTask.java:584)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.close(StreamTask.java:691)
> at
> org.apache.kafka.streams.processor.internals.AssignedTasks.closeUnclean(AssignedTasks.java:428)
> at
> org.apache.kafka.streams.processor.internals.AssignedTasks.close(AssignedTasks.java:408)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.shutdown(TaskManager.java:260)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.completeShutdown(StreamThread.java:1181)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:758){noformat}
>
>
> Although I have checked the code and the method
> `*maybeAbortTransactionAndCloseRecordCollector*` in the `*StreamTask*.*java*`
> class is expecting any kind of error to happen since is catching
> `*Throwable*`.
>
>
>
> {noformat}
> try {
> recordCollector.close();
> } catch (final Throwable e) {
> log.error("Failed to close producer due to the following error:", e);
> } finally {
> producer = null;
> }{noformat}
>
> Should we consider this a bug?
> In my opinion, we could check for the `*null*` possibility at
> `*RecordCollectorImpl*.*java*` class:
> {noformat}
> @Override
> public void close() {
> log.debug("Closing producer");
> producer.close();
> producer = null;
> checkForException();
> }{noformat}
>
> Change it for:
>
> {noformat}
> @Override
> public void close() {
> log.debug("Closing producer");
> if ( Objects.nonNull(producer) ) {
> producer.close();
> producer = null;
> }
> checkForException();
> }{noformat}
>
> How does that sound?
>
> Kafka Brokers running 2.0.0
> Kafka Stream and client 2.1.0
> OpenJDK 8
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (KAFKA-7678) Failed to close producer due to java.lang.NullPointerException
[
https://issues.apache.org/jira/browse/KAFKA-7678?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Matthias J. Sax updated KAFKA-7678:
---
Affects Version/s: 1.1.1
2.0.1
2.1.0
> Failed to close producer due to java.lang.NullPointerException
> --
>
> Key: KAFKA-7678
> URL: https://issues.apache.org/jira/browse/KAFKA-7678
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 1.1.1, 2.0.1, 2.1.0
>Reporter: Jonathan Santilli
>Assignee: Jonathan Santilli
>Priority: Minor
> Fix For: 1.1.2, 2.2.0, 2.1.1, 2.0.2
>
>
> This occurs when the group is rebalancing in a Kafka Stream application and
> the process (the Kafka Stream application) receives a *SIGTERM* to stop it
> gracefully.
>
>
> {noformat}
> ERROR org.apache.kafka.streams.processor.internals.StreamTask - task [1_46]
> Failed to close producer due to the following error:
> java.lang.NullPointerException
> at
> org.apache.kafka.streams.processor.internals.RecordCollectorImpl.close(RecordCollectorImpl.java:252)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.maybeAbortTransactionAndCloseRecordCollector(StreamTask.java:607)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.suspend(StreamTask.java:584)
> at
> org.apache.kafka.streams.processor.internals.StreamTask.close(StreamTask.java:691)
> at
> org.apache.kafka.streams.processor.internals.AssignedTasks.closeUnclean(AssignedTasks.java:428)
> at
> org.apache.kafka.streams.processor.internals.AssignedTasks.close(AssignedTasks.java:408)
> at
> org.apache.kafka.streams.processor.internals.TaskManager.shutdown(TaskManager.java:260)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.completeShutdown(StreamThread.java:1181)
> at
> org.apache.kafka.streams.processor.internals.StreamThread.run(StreamThread.java:758){noformat}
>
>
> Although I have checked the code and the method
> `*maybeAbortTransactionAndCloseRecordCollector*` in the `*StreamTask*.*java*`
> class is expecting any kind of error to happen since is catching
> `*Throwable*`.
>
>
>
> {noformat}
> try {
> recordCollector.close();
> } catch (final Throwable e) {
> log.error("Failed to close producer due to the following error:", e);
> } finally {
> producer = null;
> }{noformat}
>
> Should we consider this a bug?
> In my opinion, we could check for the `*null*` possibility at
> `*RecordCollectorImpl*.*java*` class:
> {noformat}
> @Override
> public void close() {
> log.debug("Closing producer");
> producer.close();
> producer = null;
> checkForException();
> }{noformat}
>
> Change it for:
>
> {noformat}
> @Override
> public void close() {
> log.debug("Closing producer");
> if ( Objects.nonNull(producer) ) {
> producer.close();
> producer = null;
> }
> checkForException();
> }{noformat}
>
> How does that sound?
>
> Kafka Brokers running 2.0.0
> Kafka Stream and client 2.1.0
> OpenJDK 8
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Resolved] (KAFKA-6388) Error while trying to roll a segment that already exists
[
https://issues.apache.org/jira/browse/KAFKA-6388?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jason Gustafson resolved KAFKA-6388.
Resolution: Fixed
Fix Version/s: 2.0.2
2.1.1
> Error while trying to roll a segment that already exists
>
>
> Key: KAFKA-6388
> URL: https://issues.apache.org/jira/browse/KAFKA-6388
> Project: Kafka
> Issue Type: Bug
> Components: log
>Affects Versions: 1.0.0
>Reporter: David Hay
>Priority: Blocker
> Fix For: 2.1.1, 2.0.2
>
>
> Recreating this issue from KAFKA-654 as we've been hitting it repeatedly in
> our attempts to get a stable 1.0 cluster running (upgrading from 0.8.2.2).
> After spending 30 min or more spewing log messages like this:
> {noformat}
> [2017-12-19 16:44:28,998] INFO Replica loaded for partition
> screening.save.results.screening.save.results.processor.error-43 with initial
> high watermark 0 (kafka.cluster.Replica)
> {noformat}
> Eventually, the replica thread throws the error below (also referenced in the
> original issue). If I remove that partition from the data directory and
> bounce the broker, it eventually rebalances (assuming it doesn't hit a
> different partition with the same error).
> {noformat}
> 2017-12-19 15:16:24,227] WARN Newly rolled segment file
> 0002.log already exists; deleting it first (kafka.log.Log)
> [2017-12-19 15:16:24,227] WARN Newly rolled segment file
> 0002.index already exists; deleting it first (kafka.log.Log)
> [2017-12-19 15:16:24,227] WARN Newly rolled segment file
> 0002.timeindex already exists; deleting it first
> (kafka.log.Log)
> [2017-12-19 15:16:24,232] INFO [ReplicaFetcherManager on broker 2] Removed
> fetcher for partitions __consumer_offsets-20
> (kafka.server.ReplicaFetcherManager)
> [2017-12-19 15:16:24,297] ERROR [ReplicaFetcher replicaId=2, leaderId=1,
> fetcherId=0] Error due to (kafka.server.ReplicaFetcherThread)
> kafka.common.KafkaException: Error processing data for partition
> sr.new.sr.new.processor.error-38 offset 2
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2$$anonfun$apply$mcV$sp$1$$anonfun$apply$2.apply(AbstractFetcherThread.scala:204)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2$$anonfun$apply$mcV$sp$1$$anonfun$apply$2.apply(AbstractFetcherThread.scala:172)
> at scala.Option.foreach(Option.scala:257)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2$$anonfun$apply$mcV$sp$1.apply(AbstractFetcherThread.scala:172)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2$$anonfun$apply$mcV$sp$1.apply(AbstractFetcherThread.scala:169)
> at
> scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
> at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2.apply$mcV$sp(AbstractFetcherThread.scala:169)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2.apply(AbstractFetcherThread.scala:169)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2.apply(AbstractFetcherThread.scala:169)
> at kafka.utils.CoreUtils$.inLock(CoreUtils.scala:217)
> at
> kafka.server.AbstractFetcherThread.processFetchRequest(AbstractFetcherThread.scala:167)
> at
> kafka.server.AbstractFetcherThread.doWork(AbstractFetcherThread.scala:113)
> at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:64)
> Caused by: kafka.common.KafkaException: Trying to roll a new log segment for
> topic partition sr.new.sr.new.processor.error-38 with start offset 2 while it
> already exists.
> at kafka.log.Log$$anonfun$roll$2.apply(Log.scala:1338)
> at kafka.log.Log$$anonfun$roll$2.apply(Log.scala:1297)
> at kafka.log.Log.maybeHandleIOException(Log.scala:1669)
> at kafka.log.Log.roll(Log.scala:1297)
> at kafka.log.Log.kafka$log$Log$$maybeRoll(Log.scala:1284)
> at kafka.log.Log$$anonfun$append$2.apply(Log.scala:710)
> at kafka.log.Log$$anonfun$append$2.apply(Log.scala:624)
> at kafka.log.Log.maybeHandleIOException(Log.scala:1669)
> at kafka.log.Log.append(Log.scala:624)
> at kafka.log.Log.appendAsFollower(Log.scala:607)
> at
> kafka.server.ReplicaFetcherThread.processPartitionData(ReplicaFetcherThread.scala:102)
> at
> kafka.server.ReplicaFetcherThread.processPartitionData(ReplicaFetcherThread.scala:41)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2$$anonfun$apply$mcV$sp$1$$anonfun$apply$2.apply(AbstractFetcherThread.scala:184)
>
[jira] [Commented] (KAFKA-6388) Error while trying to roll a segment that already exists
[
https://issues.apache.org/jira/browse/KAFKA-6388?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710789#comment-16710789
]
ASF GitHub Bot commented on KAFKA-6388:
---
apovzner opened a new pull request #6006: KAFKA-6388: Recover from rolling an
empty segment that already exists (branch 1.1)
URL: https://github.com/apache/kafka/pull/6006
Same as https://github.com/apache/kafka/pull/5986 but for AK 1.1.
### Committer Checklist (excluded from commit message)
- [ ] Verify design and implementation
- [ ] Verify test coverage and CI build status
- [ ] Verify documentation (including upgrade notes)
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
> Error while trying to roll a segment that already exists
>
>
> Key: KAFKA-6388
> URL: https://issues.apache.org/jira/browse/KAFKA-6388
> Project: Kafka
> Issue Type: Bug
> Components: log
>Affects Versions: 1.0.0
>Reporter: David Hay
>Priority: Blocker
> Fix For: 2.1.1, 2.0.2
>
>
> Recreating this issue from KAFKA-654 as we've been hitting it repeatedly in
> our attempts to get a stable 1.0 cluster running (upgrading from 0.8.2.2).
> After spending 30 min or more spewing log messages like this:
> {noformat}
> [2017-12-19 16:44:28,998] INFO Replica loaded for partition
> screening.save.results.screening.save.results.processor.error-43 with initial
> high watermark 0 (kafka.cluster.Replica)
> {noformat}
> Eventually, the replica thread throws the error below (also referenced in the
> original issue). If I remove that partition from the data directory and
> bounce the broker, it eventually rebalances (assuming it doesn't hit a
> different partition with the same error).
> {noformat}
> 2017-12-19 15:16:24,227] WARN Newly rolled segment file
> 0002.log already exists; deleting it first (kafka.log.Log)
> [2017-12-19 15:16:24,227] WARN Newly rolled segment file
> 0002.index already exists; deleting it first (kafka.log.Log)
> [2017-12-19 15:16:24,227] WARN Newly rolled segment file
> 0002.timeindex already exists; deleting it first
> (kafka.log.Log)
> [2017-12-19 15:16:24,232] INFO [ReplicaFetcherManager on broker 2] Removed
> fetcher for partitions __consumer_offsets-20
> (kafka.server.ReplicaFetcherManager)
> [2017-12-19 15:16:24,297] ERROR [ReplicaFetcher replicaId=2, leaderId=1,
> fetcherId=0] Error due to (kafka.server.ReplicaFetcherThread)
> kafka.common.KafkaException: Error processing data for partition
> sr.new.sr.new.processor.error-38 offset 2
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2$$anonfun$apply$mcV$sp$1$$anonfun$apply$2.apply(AbstractFetcherThread.scala:204)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2$$anonfun$apply$mcV$sp$1$$anonfun$apply$2.apply(AbstractFetcherThread.scala:172)
> at scala.Option.foreach(Option.scala:257)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2$$anonfun$apply$mcV$sp$1.apply(AbstractFetcherThread.scala:172)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2$$anonfun$apply$mcV$sp$1.apply(AbstractFetcherThread.scala:169)
> at
> scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
> at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2.apply$mcV$sp(AbstractFetcherThread.scala:169)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2.apply(AbstractFetcherThread.scala:169)
> at
> kafka.server.AbstractFetcherThread$$anonfun$processFetchRequest$2.apply(AbstractFetcherThread.scala:169)
> at kafka.utils.CoreUtils$.inLock(CoreUtils.scala:217)
> at
> kafka.server.AbstractFetcherThread.processFetchRequest(AbstractFetcherThread.scala:167)
> at
> kafka.server.AbstractFetcherThread.doWork(AbstractFetcherThread.scala:113)
> at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:64)
> Caused by: kafka.common.KafkaException: Trying to roll a new log segment for
> topic partition sr.new.sr.new.processor.error-38 with start offset 2 while it
> already exists.
> at kafka.log.Log$$anonfun$roll$2.apply(Log.scala:1338)
> at kafka.log.Log$$anonfun$roll$2.apply(Log.scala:1297)
> at kafka.log.Log.maybeHandleIOException(Log.scala:1669)
> at kafka.log.Log.roll(Log.sca
[jira] [Commented] (KAFKA-7660) Stream Metrics - Memory Analysis
[
https://issues.apache.org/jira/browse/KAFKA-7660?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710810#comment-16710810
]
ASF GitHub Bot commented on KAFKA-7660:
---
mjsax closed pull request #5981: KAFKA-7660: fix streams and Metrics memory
leaks
URL: https://github.com/apache/kafka/pull/5981
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
b/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
index e83085e7132..803fd7c9cca 100644
--- a/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
+++ b/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
@@ -446,6 +446,12 @@ public void removeSensor(String name) {
removeMetric(metric.metricName());
log.debug("Removed sensor with name {}", name);
childSensors = childrenSensors.remove(sensor);
+for (final Sensor parent : sensor.parents()) {
+final List peers =
childrenSensors.get(parent);
+if (peers != null) {
+peers.remove(sensor);
+}
+}
}
}
}
diff --git a/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
b/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
index 7ee23d31f47..16f33c2d095 100644
--- a/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
+++ b/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
@@ -22,13 +22,15 @@
import org.apache.kafka.common.utils.Utils;
import java.util.ArrayList;
-import java.util.Collections;
import java.util.HashSet;
import java.util.List;
import java.util.Locale;
import java.util.Set;
import java.util.concurrent.TimeUnit;
+import static java.util.Arrays.asList;
+import static java.util.Collections.unmodifiableList;
+
/**
* A sensor applies a continuous sequence of numerical values to a set of
associated metrics. For example a sensor on
* message size would record a sequence of message sizes using the {@link
#record(double)} api and would maintain a set
@@ -134,6 +136,10 @@ public String name() {
return this.name;
}
+List parents() {
+return unmodifiableList(asList(parents));
+}
+
/**
* Record an occurrence, this is just short-hand for {@link
#record(double) record(1.0)}
*/
@@ -271,7 +277,7 @@ public boolean hasExpired() {
}
synchronized List metrics() {
-return Collections.unmodifiableList(this.metrics);
+return unmodifiableList(this.metrics);
}
/**
diff --git
a/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
b/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
index 7a973daf043..7dd780d4497 100644
--- a/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
+++ b/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
@@ -16,6 +16,8 @@
*/
package org.apache.kafka.common.metrics;
+import static java.util.Collections.emptyList;
+import static java.util.Collections.singletonList;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertFalse;
import static org.junit.Assert.assertNotNull;
@@ -197,6 +199,20 @@ public void testBadSensorHierarchy() {
metrics.sensor("gc", c1, c2); // should fail
}
+@Test
+public void testRemoveChildSensor() {
+final Metrics metrics = new Metrics();
+
+final Sensor parent = metrics.sensor("parent");
+final Sensor child = metrics.sensor("child", parent);
+
+assertEquals(singletonList(child),
metrics.childrenSensors().get(parent));
+
+metrics.removeSensor("child");
+
+assertEquals(emptyList(), metrics.childrenSensors().get(parent));
+}
+
@Test
public void testRemoveSensor() {
int size = metrics.metrics().size();
diff --git
a/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
b/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
index 464beca5c5c..59a9d4f249f 100644
---
a/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
+++
b/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
@@ -222,10 +222,9 @@ public void removeSensor(Sensor sensor) {
Objects.requireNonNull(sensor, "Sensor is null");
metrics.removeSensor(sensor.name());
-
[jira] [Commented] (KAFKA-7660) Stream Metrics - Memory Analysis
[
https://issues.apache.org/jira/browse/KAFKA-7660?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710811#comment-16710811
]
ASF GitHub Bot commented on KAFKA-7660:
---
mjsax closed pull request #5982: KAFKA-7660: fix streams and Metrics memory
leaks
URL: https://github.com/apache/kafka/pull/5982
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
b/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
index a9d80f1dde3..ac1ffaf9418 100644
--- a/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
+++ b/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
@@ -446,6 +446,12 @@ public void removeSensor(String name) {
removeMetric(metric.metricName());
log.debug("Removed sensor with name {}", name);
childSensors = childrenSensors.remove(sensor);
+for (final Sensor parent : sensor.parents()) {
+final List peers =
childrenSensors.get(parent);
+if (peers != null) {
+peers.remove(sensor);
+}
+}
}
}
}
diff --git a/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
b/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
index 321fab661cd..c845ff80895 100644
--- a/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
+++ b/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
@@ -22,13 +22,15 @@
import org.apache.kafka.common.utils.Utils;
import java.util.ArrayList;
-import java.util.Collections;
import java.util.HashSet;
import java.util.List;
import java.util.Locale;
import java.util.Set;
import java.util.concurrent.TimeUnit;
+import static java.util.Arrays.asList;
+import static java.util.Collections.unmodifiableList;
+
/**
* A sensor applies a continuous sequence of numerical values to a set of
associated metrics. For example a sensor on
* message size would record a sequence of message sizes using the {@link
#record(double)} api and would maintain a set
@@ -132,6 +134,10 @@ public String name() {
return this.name;
}
+List parents() {
+return unmodifiableList(asList(parents));
+}
+
/**
* Record an occurrence, this is just short-hand for {@link
#record(double) record(1.0)}
*/
@@ -267,6 +273,6 @@ public boolean hasExpired() {
}
synchronized List metrics() {
-return Collections.unmodifiableList(this.metrics);
+return unmodifiableList(this.metrics);
}
}
diff --git
a/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
b/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
index 216493f84a6..3db46e2fb72 100644
--- a/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
+++ b/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
@@ -16,6 +16,8 @@
*/
package org.apache.kafka.common.metrics;
+import static java.util.Collections.emptyList;
+import static java.util.Collections.singletonList;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertFalse;
import static org.junit.Assert.assertNotNull;
@@ -177,6 +179,20 @@ public void testBadSensorHierarchy() {
metrics.sensor("gc", c1, c2); // should fail
}
+@Test
+public void testRemoveChildSensor() {
+final Metrics metrics = new Metrics();
+
+final Sensor parent = metrics.sensor("parent");
+final Sensor child = metrics.sensor("child", parent);
+
+assertEquals(singletonList(child),
metrics.childrenSensors().get(parent));
+
+metrics.removeSensor("child");
+
+assertEquals(emptyList(), metrics.childrenSensors().get(parent));
+}
+
@Test
public void testRemoveSensor() {
int size = metrics.metrics().size();
diff --git
a/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
b/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
index cf25dd10fda..7b50feeaf8d 100644
---
a/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
+++
b/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
@@ -222,10 +222,9 @@ public void removeSensor(Sensor sensor) {
Objects.requireNonNull(sensor, "Sensor is null");
metrics.removeSensor(sensor.name());
-final
[jira] [Commented] (KAFKA-7673) Upgrade RocksDB to include fix for WinEnvIO::GetSectorSize
[ https://issues.apache.org/jira/browse/KAFKA-7673?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710814#comment-16710814 ] ASF GitHub Bot commented on KAFKA-7673: --- guozhangwang closed pull request #5985: KAFKA-7673: Upgrade rocksdb to 5.15.10 URL: https://github.com/apache/kafka/pull/5985 This is a PR merged from a forked repository. As GitHub hides the original diff on merge, it is displayed below for the sake of provenance: As this is a foreign pull request (from a fork), the diff is supplied below (as it won't show otherwise due to GitHub magic): diff --git a/gradle/dependencies.gradle b/gradle/dependencies.gradle index 59f56fcd4ab..1621be946ee 100644 --- a/gradle/dependencies.gradle +++ b/gradle/dependencies.gradle @@ -78,7 +78,7 @@ versions += [ mockito: "2.23.0", powermock: "2.0.0-RC.3", reflections: "0.9.11", - rocksDB: "5.14.2", + rocksDB: "5.15.10", scalatest: "3.0.5", scoverage: "1.3.1", slf4j: "1.7.25", This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org > Upgrade RocksDB to include fix for WinEnvIO::GetSectorSize > -- > > Key: KAFKA-7673 > URL: https://issues.apache.org/jira/browse/KAFKA-7673 > Project: Kafka > Issue Type: Improvement > Components: streams >Affects Versions: 2.1.0 >Reporter: Yanick Salzmann >Priority: Major > Fix For: 2.2.0 > > > The following fix would help making it possible to work with kafka streams in > Windows 7 (right now it is not possible to start an application using Kafka > Streams): > [https://github.com/facebook/rocksdb/commit/9c7da963bc8b3df8f3ed3865f00dd7c483267ac0] > According to the tags it would require an upgrade to one of the below > versions: > * [v5.17.2|https://github.com/facebook/rocksdb/releases/tag/v5.17.2] > * [v5.16.6|https://github.com/facebook/rocksdb/releases/tag/v5.16.6] > * [v5.15.10|https://github.com/facebook/rocksdb/releases/tag/v5.15.10] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Resolved] (KAFKA-7673) Upgrade RocksDB to include fix for WinEnvIO::GetSectorSize
[ https://issues.apache.org/jira/browse/KAFKA-7673?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Guozhang Wang resolved KAFKA-7673. -- Resolution: Fixed Assignee: Guozhang Wang [~yanicks] we've merged https://github.com/apache/kafka/pull/5985 to trunk, it would be included in the next release (2.2.0). > Upgrade RocksDB to include fix for WinEnvIO::GetSectorSize > -- > > Key: KAFKA-7673 > URL: https://issues.apache.org/jira/browse/KAFKA-7673 > Project: Kafka > Issue Type: Improvement > Components: streams >Affects Versions: 2.1.0 >Reporter: Yanick Salzmann >Assignee: Guozhang Wang >Priority: Major > Fix For: 2.2.0 > > > The following fix would help making it possible to work with kafka streams in > Windows 7 (right now it is not possible to start an application using Kafka > Streams): > [https://github.com/facebook/rocksdb/commit/9c7da963bc8b3df8f3ed3865f00dd7c483267ac0] > According to the tags it would require an upgrade to one of the below > versions: > * [v5.17.2|https://github.com/facebook/rocksdb/releases/tag/v5.17.2] > * [v5.16.6|https://github.com/facebook/rocksdb/releases/tag/v5.16.6] > * [v5.15.10|https://github.com/facebook/rocksdb/releases/tag/v5.15.10] > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-7657) Invalid reporting of stream state in Kafka streams application
[
https://issues.apache.org/jira/browse/KAFKA-7657?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710842#comment-16710842
]
Guozhang Wang commented on KAFKA-7657:
--
[~pkleindl] Seems you have at least 16 because
"client-610151c7-8769-4cc5-9254-969a831e4a4d-StreamThread-16", could you grab
for the keywords of
{code}
State transition from
{code}
which should include both thread-level state transition as well as application
instance-level state transition. Note that the latter is what we observed the
issue, i.e. it never transits back to RUNNING, but it should be as long as ALL
of its threads have transited to RUNNING. So I'd like to verify if:
1) all threads have indeed transit back to RUNNING after rebalance.
2) if 1) is true, is there any transition happened for the application
instance-level state.
> Invalid reporting of stream state in Kafka streams application
> --
>
> Key: KAFKA-7657
> URL: https://issues.apache.org/jira/browse/KAFKA-7657
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.0.1
>Reporter: Thomas Crowley
>Priority: Major
> Labels: bug
>
> We have a streams application with 3 instances running, two of which are
> reporting the state of REBALANCING even after they have been running for
> days. Restarting the application has no effect on the stream state.
> This seems suspect because each instance appears to be processing messages,
> and the kafka-consumer-groups CLI tool reports hardly any offset lag in any
> of the partitions assigned to the REBALANCING consumers. Each partition seems
> to be processing an equal amount of records too.
> Inspecting the state.dir on disk, it looks like the RocksDB state has been
> built and hovers at the expected size on disk.
> This problem has persisted for us after we rebuilt our Kafka cluster and
> reset topics + consumer groups in our dev environment.
> There is nothing in the logs (with level set to DEBUG) in both the broker or
> the application that suggests something exceptional has happened causing the
> application to be stuck REBALANCING.
> We are also running multiple streaming applications where this problem does
> not exist.
> Two differences between this application and our other streaming applications
> are:
> * We have processing.guarantee set to exactly_once
> * We are using a ValueTransformer which fetches from and puts data on a
> windowed state store
> The REBALANCING state is returned from both polling the state method of our
> KafkaStreams instance, and our custom metric which is derived from some logic
> in a KafkaStreams.StateListener class attached via the setStateListener
> method.
>
> While I have provided a bit of context, before I reply with some reproducible
> code - is there a simple way in which I can determine that my streams
> application is in a RUNNING state without relying on the same mechanisms as
> used above?
> Further, given that it seems like my application is actually running - could
> this perhaps be a bug to do with how the stream state is being reported (in
> the context of a transactional stream using the processor API)?
>
>
>
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (KAFKA-7660) Stream Metrics - Memory Analysis
[
https://issues.apache.org/jira/browse/KAFKA-7660?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710843#comment-16710843
]
ASF GitHub Bot commented on KAFKA-7660:
---
mjsax closed pull request #5984: KAFKA-7660: fix streams and Metrics memory
leaks
URL: https://github.com/apache/kafka/pull/5984
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
b/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
index 512c18e74ac..874c172acf5 100644
--- a/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
+++ b/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
@@ -367,6 +367,12 @@ public void removeSensor(String name) {
removeMetric(metric.metricName());
log.debug("Removed sensor with name {}", name);
childSensors = childrenSensors.remove(sensor);
+for (final Sensor parent : sensor.parents()) {
+final List peers =
childrenSensors.get(parent);
+if (peers != null) {
+peers.remove(sensor);
+}
+}
}
}
}
diff --git a/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
b/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
index 4a9b488d1c5..33829f9f5a0 100644
--- a/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
+++ b/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
@@ -18,13 +18,15 @@
import org.apache.kafka.common.utils.Utils;
import java.util.ArrayList;
-import java.util.Collections;
import java.util.HashSet;
import java.util.List;
import java.util.Locale;
import java.util.Set;
import java.util.concurrent.TimeUnit;
+import static java.util.Arrays.asList;
+import static java.util.Collections.unmodifiableList;
+
/**
* A sensor applies a continuous sequence of numerical values to a set of
associated metrics. For example a sensor on
* message size would record a sequence of message sizes using the {@link
#record(double)} api and would maintain a set
@@ -128,6 +130,10 @@ public String name() {
return this.name;
}
+List parents() {
+return unmodifiableList(asList(parents));
+}
+
/**
* Record an occurrence, this is just short-hand for {@link
#record(double) record(1.0)}
*/
@@ -260,6 +266,6 @@ public boolean hasExpired() {
}
synchronized List metrics() {
-return Collections.unmodifiableList(this.metrics);
+return unmodifiableList(this.metrics);
}
}
diff --git
a/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
b/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
index 5797b369758..5ee79de81f2 100644
--- a/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
+++ b/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
@@ -12,6 +12,8 @@
*/
package org.apache.kafka.common.metrics;
+import static java.util.Collections.emptyList;
+import static java.util.Collections.singletonList;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertFalse;
import static org.junit.Assert.assertNotNull;
@@ -169,6 +171,20 @@ public void testBadSensorHierarchy() {
metrics.sensor("gc", c1, c2); // should fail
}
+@Test
+public void testRemoveChildSensor() {
+final Metrics metrics = new Metrics();
+
+final Sensor parent = metrics.sensor("parent");
+final Sensor child = metrics.sensor("child", parent);
+
+assertEquals(singletonList(child),
metrics.childrenSensors().get(parent));
+
+metrics.removeSensor("child");
+
+assertEquals(emptyList(), metrics.childrenSensors().get(parent));
+}
+
@Test
public void testRemoveSensor() {
int size = metrics.metrics().size();
diff --git
a/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
b/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
index bccf736d0a8..93748826720 100644
---
a/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
+++
b/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
@@ -196,11 +196,11 @@ public void measureLatencyNs(final Time time, final
Runnable action, final Senso
*/
@Override
public void removeSensor(Sensor sensor) {
-S
[jira] [Updated] (KAFKA-7660) Stream Metrics - Memory Analysis
[ https://issues.apache.org/jira/browse/KAFKA-7660?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Matthias J. Sax updated KAFKA-7660: --- Fix Version/s: 2.0.2 2.1.1 1.1.2 1.0.3 0.11.0.4 0.10.0.2 > Stream Metrics - Memory Analysis > > > Key: KAFKA-7660 > URL: https://issues.apache.org/jira/browse/KAFKA-7660 > Project: Kafka > Issue Type: Bug > Components: metrics, streams >Affects Versions: 2.0.0 >Reporter: Patrik Kleindl >Assignee: John Roesler >Priority: Minor > Fix For: 0.10.0.2, 0.11.0.4, 1.0.3, 1.1.2, 2.2.0, 2.1.1, 2.0.2 > > Attachments: Mem_Collections.jpeg, Mem_DuplicateStrings.jpeg, > Mem_DuplicateStrings2.jpeg, Mem_Hotspots.jpeg, Mem_KeepAliveSet.jpeg, > Mem_References.jpeg, heapdump-1543441898901.hprof > > > During the analysis of JVM memory two possible issues were shown which I > would like to bring to your attention: > 1) Duplicate strings > Top findings: > string_content="stream-processor-node-metrics" count="534,277" > string_content="processor-node-id" count="148,437" > string_content="stream-rocksdb-state-metrics" count="41,832" > string_content="punctuate-latency-avg" count="29,681" > > "stream-processor-node-metrics" seems to be used in Sensors.java as a > literal and not interned. > > 2) The HashMap parentSensors from > org.apache.kafka.streams.processor.internals.StreamThread$StreamsMetricsThreadImpl > was reported multiple times as suspicious for potentially keeping alive a > lot of objects. In our case the reported size was 40-50MB each. > I haven't looked too deep in the code but noticed that the class Sensor.java > which is used as a key in the HashMap does not implement equals or hashCode > method. Not sure this is a problem though. > > The analysis was done with Dynatrace 7.0 > We are running Confluent 5.0/Kafka2.0-cp1 (Brokers as well as Clients) > > Screenshots are attached. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-7657) Invalid reporting of stream state in Kafka streams application
[ https://issues.apache.org/jira/browse/KAFKA-7657?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710864#comment-16710864 ] Guozhang Wang commented on KAFKA-7657: -- Another question for [~pkleindl] [~tscrowley]: in your topology, do you have any global stores / GlobalKTable? > Invalid reporting of stream state in Kafka streams application > -- > > Key: KAFKA-7657 > URL: https://issues.apache.org/jira/browse/KAFKA-7657 > Project: Kafka > Issue Type: Bug > Components: streams >Affects Versions: 2.0.1 >Reporter: Thomas Crowley >Priority: Major > Labels: bug > > We have a streams application with 3 instances running, two of which are > reporting the state of REBALANCING even after they have been running for > days. Restarting the application has no effect on the stream state. > This seems suspect because each instance appears to be processing messages, > and the kafka-consumer-groups CLI tool reports hardly any offset lag in any > of the partitions assigned to the REBALANCING consumers. Each partition seems > to be processing an equal amount of records too. > Inspecting the state.dir on disk, it looks like the RocksDB state has been > built and hovers at the expected size on disk. > This problem has persisted for us after we rebuilt our Kafka cluster and > reset topics + consumer groups in our dev environment. > There is nothing in the logs (with level set to DEBUG) in both the broker or > the application that suggests something exceptional has happened causing the > application to be stuck REBALANCING. > We are also running multiple streaming applications where this problem does > not exist. > Two differences between this application and our other streaming applications > are: > * We have processing.guarantee set to exactly_once > * We are using a ValueTransformer which fetches from and puts data on a > windowed state store > The REBALANCING state is returned from both polling the state method of our > KafkaStreams instance, and our custom metric which is derived from some logic > in a KafkaStreams.StateListener class attached via the setStateListener > method. > > While I have provided a bit of context, before I reply with some reproducible > code - is there a simple way in which I can determine that my streams > application is in a RUNNING state without relying on the same mechanisms as > used above? > Further, given that it seems like my application is actually running - could > this perhaps be a bug to do with how the stream state is being reported (in > the context of a transactional stream using the processor API)? > > > > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (KAFKA-7660) Stream Metrics - Memory Analysis
[
https://issues.apache.org/jira/browse/KAFKA-7660?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16710841#comment-16710841
]
ASF GitHub Bot commented on KAFKA-7660:
---
mjsax closed pull request #5983: KAFKA-7660: fix streams and Metrics memory
leaks
URL: https://github.com/apache/kafka/pull/5983
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
b/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
index c4cd6765263..f6b6a4faf1a 100644
--- a/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
+++ b/clients/src/main/java/org/apache/kafka/common/metrics/Metrics.java
@@ -435,6 +435,12 @@ public void removeSensor(String name) {
removeMetric(metric.metricName());
log.debug("Removed sensor with name {}", name);
childSensors = childrenSensors.remove(sensor);
+for (final Sensor parent : sensor.parents()) {
+final List peers =
childrenSensors.get(parent);
+if (peers != null) {
+peers.remove(sensor);
+}
+}
}
}
}
diff --git a/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
b/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
index ae331e7b40e..47f3fbaa019 100644
--- a/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
+++ b/clients/src/main/java/org/apache/kafka/common/metrics/Sensor.java
@@ -22,13 +22,15 @@
import org.apache.kafka.common.utils.Utils;
import java.util.ArrayList;
-import java.util.Collections;
import java.util.HashSet;
import java.util.List;
import java.util.Locale;
import java.util.Set;
import java.util.concurrent.TimeUnit;
+import static java.util.Arrays.asList;
+import static java.util.Collections.unmodifiableList;
+
/**
* A sensor applies a continuous sequence of numerical values to a set of
associated metrics. For example a sensor on
* message size would record a sequence of message sizes using the {@link
#record(double)} api and would maintain a set
@@ -132,6 +134,10 @@ public String name() {
return this.name;
}
+List parents() {
+return unmodifiableList(asList(parents));
+}
+
/**
* Record an occurrence, this is just short-hand for {@link
#record(double) record(1.0)}
*/
@@ -266,6 +272,6 @@ public boolean hasExpired() {
}
synchronized List metrics() {
-return Collections.unmodifiableList(this.metrics);
+return unmodifiableList(this.metrics);
}
}
diff --git
a/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
b/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
index 0904a414dbe..1a0efa396bf 100644
--- a/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
+++ b/clients/src/test/java/org/apache/kafka/common/metrics/MetricsTest.java
@@ -16,6 +16,8 @@
*/
package org.apache.kafka.common.metrics;
+import static java.util.Collections.emptyList;
+import static java.util.Collections.singletonList;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertFalse;
import static org.junit.Assert.assertNotNull;
@@ -173,6 +175,20 @@ public void testBadSensorHierarchy() {
metrics.sensor("gc", c1, c2); // should fail
}
+@Test
+public void testRemoveChildSensor() {
+final Metrics metrics = new Metrics();
+
+final Sensor parent = metrics.sensor("parent");
+final Sensor child = metrics.sensor("child", parent);
+
+assertEquals(singletonList(child),
metrics.childrenSensors().get(parent));
+
+metrics.removeSensor("child");
+
+assertEquals(emptyList(), metrics.childrenSensors().get(parent));
+}
+
@Test
public void testRemoveSensor() {
int size = metrics.metrics().size();
diff --git
a/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
b/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
index 7f269e04c4c..7871ec4b3a8 100644
---
a/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
+++
b/streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsMetricsImpl.java
@@ -209,14 +209,13 @@ public void measureLatencyNs(final Time time, final
Runnable action, final Senso
*/
@Override
public void removeSensor(Sensor sensor) {
-S
[jira] [Created] (KAFKA-7710) Poor Zookeeper ACL management with Kerberos
Mr Kafka created KAFKA-7710:
---
Summary: Poor Zookeeper ACL management with Kerberos
Key: KAFKA-7710
URL: https://issues.apache.org/jira/browse/KAFKA-7710
Project: Kafka
Issue Type: Bug
Reporter: Mr Kafka
I have seen many organizations run many Kafka clusters. The simplest scenario
is you may have a *kafka.dev.example.com* cluster and a
*kafka.prod.example.com* cluster. The more extreme examples is teams with in an
organization may run their own individual clusters.
When you enable Zookeeper ACLs in Kafka the ACL looks to be set to the
principal (SPN) that is used to authenticate against Zookeeper.
For example I have brokers:
* *01.kafka.dev.example.com*
* *02.kafka.dev.example.com***
* *03.kafka.dev.example.com***
On *01.kafka.dev.example.com* **I run the below the security-migration tool:
{code:java}
KAFKA_OPTS="-Djava.security.auth.login.config=/etc/kafka/kafka_server_jaas.conf
-Dzookeeper.sasl.clientconfig=ZkClient" zookeeper-security-migration
--zookeeper.acl=secure --zookeeper.connect=a01.zookeeper.dev.example.com:2181
{code}
I end up with ACL's in Zookeeper as below:
{code:java}
# [zk: localhost:2181(CONNECTED) 2] getAcl /cluster
# 'sasl,'kafka/01.kafka.dev.example.com@EXAMPLE
# : cdrwa
{code}
This ACL means no other broker in the cluster can access the znode in Zookeeper
except broker 01.
To resolve the issue you need to set the below properties in Zookeeper's config:
{code:java}
kerberos.removeHostFromPrincipal = true
kerberos.removeRealmFromPrincipal = true
{code}
Now when Kafka set ACL's they are stored as:
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (KAFKA-7710) Poor Zookeeper ACL management with Kerberos
[
https://issues.apache.org/jira/browse/KAFKA-7710?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Mr Kafka updated KAFKA-7710:
Description:
I have seen many organizations run many Kafka clusters. The simplest scenario
is you may have a *kafka.dev.example.com* cluster and a
*kafka.prod.example.com* cluster. The more extreme examples is teams with in an
organization may run their own individual clusters.
When you enable Zookeeper ACLs in Kafka the ACL looks to be set to the
principal (SPN) that is used to authenticate against Zookeeper.
For example I have brokers:
* *01.kafka.dev.example.com*
* *02.kafka.dev.example.com***
* *03.kafka.dev.example.com***
On *01.kafka.dev.example.com* **I run the below the security-migration tool:
{code:java}
KAFKA_OPTS="-Djava.security.auth.login.config=/etc/kafka/kafka_server_jaas.conf
-Dzookeeper.sasl.clientconfig=ZkClient" zookeeper-security-migration
--zookeeper.acl=secure --zookeeper.connect=a01.zookeeper.dev.example.com:2181
{code}
I end up with ACL's in Zookeeper as below:
{code:java}
# [zk: localhost:2181(CONNECTED) 2] getAcl /cluster
# 'sasl,'kafka/01.kafka.dev.example.com@EXAMPLE
# : cdrwa
{code}
This ACL means no other broker in the cluster can access the znode in Zookeeper
except broker 01.
To resolve the issue you need to set the below properties in Zookeeper's config:
{code:java}
kerberos.removeHostFromPrincipal = true
kerberos.removeRealmFromPrincipal = true
{code}
Now when Kafka set ACL's they are stored as:
{code:java}
# [zk: localhost:2181(CONNECTED) 2] getAcl /cluster
# 'sasl,'kafka
#: cdrwa
{code}
This now means any broker in the cluster can access the ZK node.This means if I
have a dev Kafka broker it can right to a "prod.zookeeper.example.com"
zookeeper host as when it auth's based on a SPN
"kafka/01.kafka.dev.example.com" the host is dropped and we auth against the
service principal kafka.
If your organization is flexible you may be able to create different Kerberos
Realms per cluster and use:
{code:java}
kerberos.removeHostFromPrincipal = true
kerberos.removeRealmFromPrincipal = false{code}
That means acl's will be in the format "kafka/REALM" which means only brokers
in the same realm can connect. The difficulty here is your average large
organization security team willing to create adhoc realms.
*Proposal*
Kafka support setting ACLs for all known brokers in the cluster i.e ACLs on a
Znode have
{code:java}
kafka/01.kafka.dev.example.com@EXAMPLE
kafka/02.kafka.dev.example.com@EXAMPLE
kafka/03.kafka.dev.example.com@EXAMPLE{code}
With this though some kind of support will need to be added so if a new broker
joins the cluster the host ACL gets added to existing ZNodes.
was:
I have seen many organizations run many Kafka clusters. The simplest scenario
is you may have a *kafka.dev.example.com* cluster and a
*kafka.prod.example.com* cluster. The more extreme examples is teams with in an
organization may run their own individual clusters.
When you enable Zookeeper ACLs in Kafka the ACL looks to be set to the
principal (SPN) that is used to authenticate against Zookeeper.
For example I have brokers:
* *01.kafka.dev.example.com*
* *02.kafka.dev.example.com***
* *03.kafka.dev.example.com***
On *01.kafka.dev.example.com* **I run the below the security-migration tool:
{code:java}
KAFKA_OPTS="-Djava.security.auth.login.config=/etc/kafka/kafka_server_jaas.conf
-Dzookeeper.sasl.clientconfig=ZkClient" zookeeper-security-migration
--zookeeper.acl=secure --zookeeper.connect=a01.zookeeper.dev.example.com:2181
{code}
I end up with ACL's in Zookeeper as below:
{code:java}
# [zk: localhost:2181(CONNECTED) 2] getAcl /cluster
# 'sasl,'kafka/01.kafka.dev.example.com@EXAMPLE
# : cdrwa
{code}
This ACL means no other broker in the cluster can access the znode in Zookeeper
except broker 01.
To resolve the issue you need to set the below properties in Zookeeper's config:
{code:java}
kerberos.removeHostFromPrincipal = true
kerberos.removeRealmFromPrincipal = true
{code}
Now when Kafka set ACL's they are stored as:
{code:java}
# [zk: localhost:2181(CONNECTED) 2] getAcl /cluster
# 'sasl,'kafka
#: cdrwa
{code}
This now means any broker in the cluster can access the ZK node.This means if I
have a dev Kafka broker it can right to a "prod.zookeeper.example.com"
zookeeper host as when it auth's based on a SPN
"kafka/01.kafka.dev.example.com" the host is dropped and we auth against the
service principal kafka.
If your organization is flexible you may be able to create different Kerberos
Realms per cluster and use:
{code:java}
kerberos.removeHostFromPrincipal = true
kerberos.removeRealmFromPrincipal = false{code}
That means acl's will be in the format "kafka/REALM" which means only brokers
in the same realm can connect. The difficulty here is your average large
organization security team willing to create adhoc realms.
*Proposal*
Kafka support setting ACLs for all known broker
[jira] [Updated] (KAFKA-7710) Poor Zookeeper ACL management with Kerberos
[
https://issues.apache.org/jira/browse/KAFKA-7710?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Mr Kafka updated KAFKA-7710:
Description:
I have seen many organizations run many Kafka clusters. The simplest scenario
is you may have a *kafka.dev.example.com* cluster and a
*kafka.prod.example.com* cluster. The more extreme examples is teams within an
organization may run their own individual clusters and want isolation.
When you enable Zookeeper ACLs in Kafka the ACL looks to be set to the
principal (SPN) that is used to authenticate against Zookeeper.
For example I have brokers:
* *01.kafka.dev.example.com*
* *02.kafka.dev.example.com***
* *03.kafka.dev.example.com***
On *01.kafka.dev.example.com* **I run the below the security-migration tool:
{code:java}
KAFKA_OPTS="-Djava.security.auth.login.config=/etc/kafka/kafka_server_jaas.conf
-Dzookeeper.sasl.clientconfig=ZkClient" zookeeper-security-migration
--zookeeper.acl=secure --zookeeper.connect=a01.zookeeper.dev.example.com:2181
{code}
I end up with ACL's in Zookeeper as below:
{code:java}
# [zk: localhost:2181(CONNECTED) 2] getAcl /cluster
# 'sasl,'kafka/01.kafka.dev.example.com@EXAMPLE
# : cdrwa
{code}
This ACL means no other broker in the cluster can access the znode in Zookeeper
except broker 01.
To resolve the issue you need to set the below properties in Zookeeper's config:
{code:java}
kerberos.removeHostFromPrincipal = true
kerberos.removeRealmFromPrincipal = true
{code}
Now when Kafka set ACL's they are stored as:
{code:java}
# [zk: localhost:2181(CONNECTED) 2] getAcl /cluster
# 'sasl,'kafka
#: cdrwa
{code}
This now means any broker in the cluster can access the ZK node.This means if I
have a dev Kafka broker it can right to a "prod.zookeeper.example.com"
zookeeper host as when it auth's based on a SPN
"kafka/01.kafka.dev.example.com" the host is dropped and we auth against the
service principal kafka.
If your organization is flexible you may be able to create different Kerberos
Realms per cluster and use:
{code:java}
kerberos.removeHostFromPrincipal = true
kerberos.removeRealmFromPrincipal = false{code}
That means acl's will be in the format "kafka/REALM" which means only brokers
in the same realm can connect. The difficulty here is your average large
organization security team willing to create adhoc realms.
*Proposal*
Kafka support setting ACLs for all known brokers in the cluster i.e ACLs on a
Znode have
{code:java}
kafka/01.kafka.dev.example.com@EXAMPLE
kafka/02.kafka.dev.example.com@EXAMPLE
kafka/03.kafka.dev.example.com@EXAMPLE{code}
With this though some kind of support will need to be added so if a new broker
joins the cluster the host ACL gets added to existing ZNodes.
was:
I have seen many organizations run many Kafka clusters. The simplest scenario
is you may have a *kafka.dev.example.com* cluster and a
*kafka.prod.example.com* cluster. The more extreme examples is teams with in an
organization may run their own individual clusters.
When you enable Zookeeper ACLs in Kafka the ACL looks to be set to the
principal (SPN) that is used to authenticate against Zookeeper.
For example I have brokers:
* *01.kafka.dev.example.com*
* *02.kafka.dev.example.com***
* *03.kafka.dev.example.com***
On *01.kafka.dev.example.com* **I run the below the security-migration tool:
{code:java}
KAFKA_OPTS="-Djava.security.auth.login.config=/etc/kafka/kafka_server_jaas.conf
-Dzookeeper.sasl.clientconfig=ZkClient" zookeeper-security-migration
--zookeeper.acl=secure --zookeeper.connect=a01.zookeeper.dev.example.com:2181
{code}
I end up with ACL's in Zookeeper as below:
{code:java}
# [zk: localhost:2181(CONNECTED) 2] getAcl /cluster
# 'sasl,'kafka/01.kafka.dev.example.com@EXAMPLE
# : cdrwa
{code}
This ACL means no other broker in the cluster can access the znode in Zookeeper
except broker 01.
To resolve the issue you need to set the below properties in Zookeeper's config:
{code:java}
kerberos.removeHostFromPrincipal = true
kerberos.removeRealmFromPrincipal = true
{code}
Now when Kafka set ACL's they are stored as:
{code:java}
# [zk: localhost:2181(CONNECTED) 2] getAcl /cluster
# 'sasl,'kafka
#: cdrwa
{code}
This now means any broker in the cluster can access the ZK node.This means if I
have a dev Kafka broker it can right to a "prod.zookeeper.example.com"
zookeeper host as when it auth's based on a SPN
"kafka/01.kafka.dev.example.com" the host is dropped and we auth against the
service principal kafka.
If your organization is flexible you may be able to create different Kerberos
Realms per cluster and use:
{code:java}
kerberos.removeHostFromPrincipal = true
kerberos.removeRealmFromPrincipal = false{code}
That means acl's will be in the format "kafka/REALM" which means only brokers
in the same realm can connect. The difficulty here is your average large
organization security team willing to create adhoc realms.
*Proposal*
Kafka support setting ACLs fo
[jira] [Updated] (KAFKA-7710) Poor Zookeeper ACL management with Kerberos
[
https://issues.apache.org/jira/browse/KAFKA-7710?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Mr Kafka updated KAFKA-7710:
Description:
I have seen many organizations run many Kafka clusters. The simplest scenario
is you may have a *kafka.dev.example.com* cluster and a
*kafka.prod.example.com* cluster. The more extreme examples is teams with in an
organization may run their own individual clusters.
When you enable Zookeeper ACLs in Kafka the ACL looks to be set to the
principal (SPN) that is used to authenticate against Zookeeper.
For example I have brokers:
* *01.kafka.dev.example.com*
* *02.kafka.dev.example.com***
* *03.kafka.dev.example.com***
On *01.kafka.dev.example.com* **I run the below the security-migration tool:
{code:java}
KAFKA_OPTS="-Djava.security.auth.login.config=/etc/kafka/kafka_server_jaas.conf
-Dzookeeper.sasl.clientconfig=ZkClient" zookeeper-security-migration
--zookeeper.acl=secure --zookeeper.connect=a01.zookeeper.dev.example.com:2181
{code}
I end up with ACL's in Zookeeper as below:
{code:java}
# [zk: localhost:2181(CONNECTED) 2] getAcl /cluster
# 'sasl,'kafka/01.kafka.dev.example.com@EXAMPLE
# : cdrwa
{code}
This ACL means no other broker in the cluster can access the znode in Zookeeper
except broker 01.
To resolve the issue you need to set the below properties in Zookeeper's config:
{code:java}
kerberos.removeHostFromPrincipal = true
kerberos.removeRealmFromPrincipal = true
{code}
Now when Kafka set ACL's they are stored as:
{code:java}
# [zk: localhost:2181(CONNECTED) 2] getAcl /cluster
# 'sasl,'kafka
#: cdrwa
{code}
This now means any broker in the cluster can access the ZK node.This means if I
have a dev Kafka broker it can right to a "prod.zookeeper.example.com"
zookeeper host as when it auth's based on a SPN
"kafka/01.kafka.dev.example.com" the host is dropped and we auth against the
service principal kafka.
If your organization is flexible you may be able to create different Kerberos
Realms per cluster and use:
{code:java}
kerberos.removeHostFromPrincipal = true
kerberos.removeRealmFromPrincipal = false{code}
That means acl's will be in the format "kafka/REALM" which means only brokers
in the same realm can connect. The difficulty here is your average large
organization security team willing to create adhoc realms.
*Proposal*
Kafka support setting ACLs for all known brokers in the cluster i.e ACLs on a
Znode have
{code:java}
kafka/01.kafka.dev.example.com@EXAMPLE
kafka/02.kafka.dev.example.com@EXAMPLE
kafka/03.kafka.dev.example.com@EXAMPLE{code}
With this though some kind of support will need to be added so if a new broker
is added to a cluster the host ACL gets added to existing ZNodes.
was:
I have seen many organizations run many Kafka clusters. The simplest scenario
is you may have a *kafka.dev.example.com* cluster and a
*kafka.prod.example.com* cluster. The more extreme examples is teams with in an
organization may run their own individual clusters.
When you enable Zookeeper ACLs in Kafka the ACL looks to be set to the
principal (SPN) that is used to authenticate against Zookeeper.
For example I have brokers:
* *01.kafka.dev.example.com*
* *02.kafka.dev.example.com***
* *03.kafka.dev.example.com***
On *01.kafka.dev.example.com* **I run the below the security-migration tool:
{code:java}
KAFKA_OPTS="-Djava.security.auth.login.config=/etc/kafka/kafka_server_jaas.conf
-Dzookeeper.sasl.clientconfig=ZkClient" zookeeper-security-migration
--zookeeper.acl=secure --zookeeper.connect=a01.zookeeper.dev.example.com:2181
{code}
I end up with ACL's in Zookeeper as below:
{code:java}
# [zk: localhost:2181(CONNECTED) 2] getAcl /cluster
# 'sasl,'kafka/01.kafka.dev.example.com@EXAMPLE
# : cdrwa
{code}
This ACL means no other broker in the cluster can access the znode in Zookeeper
except broker 01.
To resolve the issue you need to set the below properties in Zookeeper's config:
{code:java}
kerberos.removeHostFromPrincipal = true
kerberos.removeRealmFromPrincipal = true
{code}
Now when Kafka set ACL's they are stored as:
> Poor Zookeeper ACL management with Kerberos
> ---
>
> Key: KAFKA-7710
> URL: https://issues.apache.org/jira/browse/KAFKA-7710
> Project: Kafka
> Issue Type: Bug
>Reporter: Mr Kafka
>Priority: Major
>
> I have seen many organizations run many Kafka clusters. The simplest scenario
> is you may have a *kafka.dev.example.com* cluster and a
> *kafka.prod.example.com* cluster. The more extreme examples is teams with in
> an organization may run their own individual clusters.
> When you enable Zookeeper ACLs in Kafka the ACL looks to be set to the
> principal (SPN) that is used to authenticate against Zookeeper.
> For example I have brokers:
> * *01.kafka.dev.example.com*
> * *02.kafka.dev.example.com***
> * *03.kafka.dev.example.com***
>
[jira] [Updated] (KAFKA-7704) kafka.server.ReplicaFetechManager.MaxLag.Replica metric is reported incorrectly
[
https://issues.apache.org/jira/browse/KAFKA-7704?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Yu Yang updated KAFKA-7704:
---
Attachment: Screen Shot 2018-12-05 at 10.13.09 PM.png
> kafka.server.ReplicaFetechManager.MaxLag.Replica metric is reported
> incorrectly
> ---
>
> Key: KAFKA-7704
> URL: https://issues.apache.org/jira/browse/KAFKA-7704
> Project: Kafka
> Issue Type: Bug
> Components: metrics
>Affects Versions: 2.1.0
>Reporter: Yu Yang
>Assignee: huxihx
>Priority: Major
> Attachments: Screen Shot 2018-12-03 at 4.33.35 PM.png, Screen Shot
> 2018-12-05 at 10.13.09 PM.png
>
>
> We recently deployed kafka 2.1, and noticed a jump in
> kafka.server.ReplicaFetcherManager.MaxLag.Replica metric. At the same time,
> there is no under-replicated partitions for the cluster.
> The initial analysis shows that kafka 2.1.0 does not report metric correctly
> for topics that have no incoming traffic right now, but had traffic earlier.
> For those topics, ReplicaFetcherManager will consider the maxLag be the
> latest offset.
> For instance, we have a topic named `test_topic`:
> {code}
> [root@kafkabroker03002:/mnt/kafka/test_topic-0]# ls -l
> total 8
> -rw-rw-r-- 1 kafka kafka 10485760 Dec 4 00:13 099043947579.index
> -rw-rw-r-- 1 kafka kafka0 Sep 23 03:01 099043947579.log
> -rw-rw-r-- 1 kafka kafka 10 Dec 4 00:13 099043947579.snapshot
> -rw-rw-r-- 1 kafka kafka 10485756 Dec 4 00:13 099043947579.timeindex
> -rw-rw-r-- 1 kafka kafka4 Dec 4 00:13 leader-epoch-checkpoint
> {code}
> kafka reports ReplicaFetcherManager.MaxLag.Replica be 99043947579
> !Screen Shot 2018-12-03 at 4.33.35 PM.png|width=720px!
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (KAFKA-7704) kafka.server.ReplicaFetechManager.MaxLag.Replica metric is reported incorrectly
[
https://issues.apache.org/jira/browse/KAFKA-7704?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16711009#comment-16711009
]
Yu Yang commented on KAFKA-7704:
[~huxi_2b], [~junrao] I verified that
https://github.com/apache/kafka/pull/5998 does fix the maxlag metric issue.
Thanks for the quick fix!
> kafka.server.ReplicaFetechManager.MaxLag.Replica metric is reported
> incorrectly
> ---
>
> Key: KAFKA-7704
> URL: https://issues.apache.org/jira/browse/KAFKA-7704
> Project: Kafka
> Issue Type: Bug
> Components: metrics
>Affects Versions: 2.1.0
>Reporter: Yu Yang
>Assignee: huxihx
>Priority: Major
> Attachments: Screen Shot 2018-12-03 at 4.33.35 PM.png
>
>
> We recently deployed kafka 2.1, and noticed a jump in
> kafka.server.ReplicaFetcherManager.MaxLag.Replica metric. At the same time,
> there is no under-replicated partitions for the cluster.
> The initial analysis shows that kafka 2.1.0 does not report metric correctly
> for topics that have no incoming traffic right now, but had traffic earlier.
> For those topics, ReplicaFetcherManager will consider the maxLag be the
> latest offset.
> For instance, we have a topic named `test_topic`:
> {code}
> [root@kafkabroker03002:/mnt/kafka/test_topic-0]# ls -l
> total 8
> -rw-rw-r-- 1 kafka kafka 10485760 Dec 4 00:13 099043947579.index
> -rw-rw-r-- 1 kafka kafka0 Sep 23 03:01 099043947579.log
> -rw-rw-r-- 1 kafka kafka 10 Dec 4 00:13 099043947579.snapshot
> -rw-rw-r-- 1 kafka kafka 10485756 Dec 4 00:13 099043947579.timeindex
> -rw-rw-r-- 1 kafka kafka4 Dec 4 00:13 leader-epoch-checkpoint
> {code}
> kafka reports ReplicaFetcherManager.MaxLag.Replica be 99043947579
> !Screen Shot 2018-12-03 at 4.33.35 PM.png|width=720px!
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)