[jira] [Updated] (KAFKA-12273) InterBrokerSendThread#pollOnce throws FatalExitError even though it is shutdown correctly
[ https://issues.apache.org/jira/browse/KAFKA-12273?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Chia-Ping Tsai updated KAFKA-12273: --- Fix Version/s: 2.8.0 > InterBrokerSendThread#pollOnce throws FatalExitError even though it is > shutdown correctly > - > > Key: KAFKA-12273 > URL: https://issues.apache.org/jira/browse/KAFKA-12273 > Project: Kafka > Issue Type: Test >Reporter: Chia-Ping Tsai >Assignee: Chia-Ping Tsai >Priority: Major > Fix For: 2.8.0 > > > kafka tests sometimes shutdown gradle with non-zero code. The (one of) root > cause is that InterBrokerSendThread#pollOnce encounters DisconnectException > when NetworkClient is closing. DisconnectException should be viewed as > "expected" error as we do close it. In other words, > InterBrokerSendThread#pollOnce should swallow it. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] chia7712 commented on pull request #10124: MINOR: apply Utils.isBlank to code base
chia7712 commented on pull request #10124: URL: https://github.com/apache/kafka/pull/10124#issuecomment-780347504 @tang7526 Thanks for your patch. Could you fix following code also? 1. https://github.com/apache/kafka/blob/trunk/connect/runtime/src/main/java/org/apache/kafka/connect/runtime/isolation/Plugins.java#L448 1. https://github.com/apache/kafka/blob/trunk/clients/src/test/java/org/apache/kafka/common/security/oauthbearer/internals/unsecured/OAuthBearerScopeUtilsTest.java#L31 1. https://github.com/apache/kafka/blob/trunk/connect/api/src/test/java/org/apache/kafka/connect/data/ValuesTest.java#L914 1. https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/network/SocketServer.scala#L642 1. https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/server/KafkaServer.scala#L473 1. https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/utils/Log4jController.scala#L74 1. https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/utils/Log4jController.scala#L83 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cadonna commented on a change in pull request #10052: KAFKA-12289: Adding test cases for prefix scan in InMemoryKeyValueStore
cadonna commented on a change in pull request #10052:
URL: https://github.com/apache/kafka/pull/10052#discussion_r577363631
##
File path:
streams/src/test/java/org/apache/kafka/streams/state/internals/InMemoryKeyValueStoreTest.java
##
@@ -60,4 +67,22 @@ public void shouldRemoveKeysWithNullValues() {
assertThat(store.get(0), nullValue());
}
+
+
+@Test
+public void shouldReturnKeysWithGivenPrefix(){
+store = createKeyValueStore(driver.context());
+final String value = "value";
+final List> entries = new ArrayList<>();
+entries.add(new KeyValue<>(1, value));
+entries.add(new KeyValue<>(2, value));
+entries.add(new KeyValue<>(11, value));
+entries.add(new KeyValue<>(13, value));
+
+store.putAll(entries);
+final KeyValueIterator keysWithPrefix =
store.prefixScan(1, new IntegerSerializer());
Review comment:
That sounds good!
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] vamossagar12 commented on a change in pull request #10052: KAFKA-12289: Adding test cases for prefix scan in InMemoryKeyValueStore
vamossagar12 commented on a change in pull request #10052:
URL: https://github.com/apache/kafka/pull/10052#discussion_r577363103
##
File path:
streams/src/test/java/org/apache/kafka/streams/state/internals/InMemoryKeyValueStoreTest.java
##
@@ -60,4 +67,22 @@ public void shouldRemoveKeysWithNullValues() {
assertThat(store.get(0), nullValue());
}
+
+
+@Test
+public void shouldReturnKeysWithGivenPrefix(){
+store = createKeyValueStore(driver.context());
+final String value = "value";
+final List> entries = new ArrayList<>();
+entries.add(new KeyValue<>(1, value));
+entries.add(new KeyValue<>(2, value));
+entries.add(new KeyValue<>(11, value));
+entries.add(new KeyValue<>(13, value));
+
+store.putAll(entries);
+final KeyValueIterator keysWithPrefix =
store.prefixScan(1, new IntegerSerializer());
Review comment:
> The reason, we get only `1` when we scan for prefix `1` is that the
integer serializer serializes `11` and `13` in the least significant byte
instead of serializing `1` in the byte before the least significant byte and
`1` and `3` in the least significant byte. With the former the **byte**
lexicographical order of `1 2 11 13` would be `1 2 11 13` which corresponds to
the natural order of integers. With the latter the **byte** lexicographical
order of `1 2 11 13` would be `1 11 13 2` which corresponds to the string
lexicographical order. So the serializer determines the order of the entries
and the store always returns the entries in byte lexicographical order.
>
> You will experience a similar when you call `range(-1, 2)` on the
in-memory state store in the unit test. You will get back an empty result since
`-1` is larger then `2` in byte lexicographical order
> when the `IntegerSerializer` is used. Also not the warning that is output,
especially this part `... or serdes that don't preserve ordering when
lexicographically comparing the serialized bytes ...`
>
> I think we should clearly state this limitation in the javadocs of the
`prefixScan()` as we have done for `range()`, maybe with an example.
>
> Currently, to get `prefixScan()` working for all types, we would need to
do a complete scan (i.e. `all()`) followed by a filter, right?
That is correct. That is the only way currently.
>
> Double checking: Is my understanding correct? @ableegoldman
I think adding a warning similar to the range() query would be good. I will
do that as part of the PR. However, in this test class, adding test cases for
the integer serializer won't make sense. Probably I will create another KVStore
and add tests for those. Is that ok, @cadonna ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] vamossagar12 commented on a change in pull request #10052: KAFKA-12289: Adding test cases for prefix scan in InMemoryKeyValueStore
vamossagar12 commented on a change in pull request #10052:
URL: https://github.com/apache/kafka/pull/10052#discussion_r577360887
##
File path:
streams/src/test/java/org/apache/kafka/streams/state/internals/InMemoryKeyValueStoreTest.java
##
@@ -60,4 +67,22 @@ public void shouldRemoveKeysWithNullValues() {
assertThat(store.get(0), nullValue());
}
+
+
+@Test
+public void shouldReturnKeysWithGivenPrefix(){
+store = createKeyValueStore(driver.context());
+final String value = "value";
+final List> entries = new ArrayList<>();
+entries.add(new KeyValue<>(1, value));
+entries.add(new KeyValue<>(2, value));
+entries.add(new KeyValue<>(11, value));
+entries.add(new KeyValue<>(13, value));
+
+store.putAll(entries);
+final KeyValueIterator keysWithPrefix =
store.prefixScan(1, new IntegerSerializer());
Review comment:
Thanks @cadonna , @ableegoldman for the detailed explanation. I
understood the behaviour now.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #10123: KAFKA-12327: Remove MethodHandle usage in CompressionType
ijuma commented on pull request #10123: URL: https://github.com/apache/kafka/pull/10123#issuecomment-780326554 I'm not sure it's worth it since the cost of compressing on the broker during fetches is significantly higher than compressing during produce (the data is already on the heap for the latter and there are usually multiple fetches per produce). That is not to say that it's never useful, just that the ROI seems a bit low. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] kamalcph opened a new pull request #10139: MINOR: Print the warning log before truncation.
kamalcph opened a new pull request #10139: URL: https://github.com/apache/kafka/pull/10139 - After truncation, hw can be moved to the truncation offset. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jsancio opened a new pull request #10138: KAFKA-12331: Use LEO for the base offset of LeaderChangeMessage batch
jsancio opened a new pull request #10138: URL: https://github.com/apache/kafka/pull/10138 WIP *More detailed description of your change, if necessary. The PR title and PR message become the squashed commit message, so use a separate comment to ping reviewers.* *Summary of testing strategy (including rationale) for the feature or bug fix. Unit and/or integration tests are expected for any behaviour change and system tests should be considered for larger changes.* ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9906: KAFKA-10885 Refactor MemoryRecordsBuilderTest/MemoryRecordsTest to avoid a lot of…
chia7712 commented on pull request #9906: URL: https://github.com/apache/kafka/pull/9906#issuecomment-780309024 @g1geordie Thanks for your updating. I will merge it tomorrow :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vvcephei commented on a change in pull request #10137: KAFKA-12268: Implement task idling semantics via currentLag API
vvcephei commented on a change in pull request #10137: URL: https://github.com/apache/kafka/pull/10137#discussion_r577333186 ## File path: clients/src/main/java/org/apache/kafka/clients/consumer/Consumer.java ## @@ -243,6 +244,11 @@ */ Map endOffsets(Collection partitions, Duration timeout); +/** + * @see KafkaConsumer#currentLag(TopicPartition) + */ +OptionalLong currentLag(TopicPartition topicPartition); Review comment: Woah, you are _fast_, @chia7712 ! I just sent a message to the vote thread. I wanted to submit this PR first so that the vote thread message can have the full context available. Do you mind reading over what I said there? If it sounds good to you, then I'll update the KIP, and we can maybe put this whole mess to bed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #10137: KAFKA-12268: Implement task idling semantics via currentLag API
chia7712 commented on a change in pull request #10137: URL: https://github.com/apache/kafka/pull/10137#discussion_r577332179 ## File path: clients/src/main/java/org/apache/kafka/clients/consumer/Consumer.java ## @@ -243,6 +244,11 @@ */ Map endOffsets(Collection partitions, Duration timeout); +/** + * @see KafkaConsumer#currentLag(TopicPartition) + */ +OptionalLong currentLag(TopicPartition topicPartition); Review comment: Pardon me, KIP-695 does not include this change. It seems KIP-695 is still based on `metadata`? Please correct me If I misunderstand anything :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #10123: KAFKA-12327: Remove MethodHandle usage in CompressionType
chia7712 commented on pull request #10123: URL: https://github.com/apache/kafka/pull/10123#issuecomment-780303685 > Today, the solution would be to either: Include the relevant native compression libraries Limit topic data to the compression algorithms supported on the relevant platform Both seem doable. @ijuma Thanks for the sharing. IIRC, kafka producer which does not support the compression can send uncompressed data to server. The data get compressed on server-side. It is a useful feature since the compression does not obstruct us from producing data on env which can't load native compression libraries. In contrast with producer, kafka consumer can't get data from compressed topic if it can't load native compression libraries. WDYT? Does it pay to support such scenario? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vvcephei opened a new pull request #10137: KAFKA-12268: Implement task idling semantics via currentLag API
vvcephei opened a new pull request #10137: URL: https://github.com/apache/kafka/pull/10137 Implements KIP-695 Reverts a previous behavior change to Consumer.poll and replaces it with a new Consumer.currentLag API, which returns the client's currently cached lag. Uses this new API to implement the desired task idling semantics improvement from KIP-695. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] abbccdda commented on a change in pull request #10135: KAFKA-10348: Share client channel between forwarding and auto creation manager
abbccdda commented on a change in pull request #10135: URL: https://github.com/apache/kafka/pull/10135#discussion_r577322703 ## File path: core/src/main/scala/kafka/server/KafkaServer.scala ## @@ -134,6 +134,8 @@ class KafkaServer( var autoTopicCreationManager: AutoTopicCreationManager = null + var clientToControllerChannelManager: Option[BrokerToControllerChannelManager] = None + var alterIsrManager: AlterIsrManager = null Review comment: We are planning to consolidate into two channels eventually: 1. broker to controller channel 2. client to controller channel here, auto topic creation and forwarding fall into the 2nd category, while AlterIsr would be the 1st category. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #10130: MINOR: Fix typo in MirrorMaker
chia7712 commented on pull request #10130: URL: https://github.com/apache/kafka/pull/10130#issuecomment-780286687 @runom Thanks for your patch :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 merged pull request #10130: MINOR: Fix typo in MirrorMaker
chia7712 merged pull request #10130: URL: https://github.com/apache/kafka/pull/10130 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #10130: MINOR: Fix typo in MirrorMaker
chia7712 commented on pull request #10130: URL: https://github.com/apache/kafka/pull/10130#issuecomment-780286136 the error is traced by #10024 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 merged pull request #10082: MINOR: use 'mapKey' to avoid unnecessary grouped data
chia7712 merged pull request #10082: URL: https://github.com/apache/kafka/pull/10082 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dengziming commented on a change in pull request #10135: KAFKA-10348: Share client channel between forwarding and auto creation manager
dengziming commented on a change in pull request #10135: URL: https://github.com/apache/kafka/pull/10135#discussion_r577312082 ## File path: core/src/main/scala/kafka/server/KafkaServer.scala ## @@ -134,6 +134,8 @@ class KafkaServer( var autoTopicCreationManager: AutoTopicCreationManager = null + var clientToControllerChannelManager: Option[BrokerToControllerChannelManager] = None + var alterIsrManager: AlterIsrManager = null Review comment: Hello, I have a question, should we also share the channel between alterIsrManager and autoCreationManager, furthermore, also share the same one with alterReplicaStateManager proposed in KIP-589. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #10082: MINOR: use 'mapKey' to avoid unnecessary grouped data
chia7712 commented on pull request #10082: URL: https://github.com/apache/kafka/pull/10082#issuecomment-780282255 the error is traced by #10024 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #10082: MINOR: use 'mapKey' to avoid unnecessary grouped data
chia7712 commented on pull request #10082: URL: https://github.com/apache/kafka/pull/10082#issuecomment-780282166 > Looks like ConsumerProtocolAssignment was also changed to have mapKey, so worth updating the PR to include that information. done This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dengziming opened a new pull request #10136: MONOR: Import classes that is used is docs to fix warnings.
dengziming opened a new pull request #10136: URL: https://github.com/apache/kafka/pull/10136 *More detailed description of your change* Fix this: 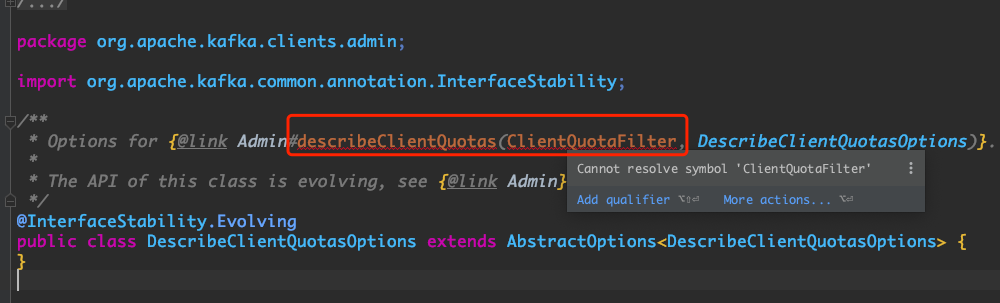 *Summary of testing strategy (including rationale)* None ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (KAFKA-12331) KafkaRaftClient should use the LEO when appending LeaderChangeMessage
[
https://issues.apache.org/jira/browse/KAFKA-12331?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jason Gustafson reassigned KAFKA-12331:
---
Assignee: Jose Armando Garcia Sancio
> KafkaRaftClient should use the LEO when appending LeaderChangeMessage
> -
>
> Key: KAFKA-12331
> URL: https://issues.apache.org/jira/browse/KAFKA-12331
> Project: Kafka
> Issue Type: Sub-task
> Components: replication
>Reporter: Jose Armando Garcia Sancio
>Assignee: Jose Armando Garcia Sancio
>Priority: Major
>
> KafkaMetadataLog's appendAsLeader expects the base offset to match the LEO.
> This is enforced when KafkaRaftClient uses the BatchAccumulator to create
> batches. When creating the control batch for the LeaderChangeMessage the
> KafkaRaftClient doesn't use the BatchAccumulator and instead creates the
> batch with the default base offset of 0.
> This causes the validation in KafkaMetadataLog to fail with the following
> exception:
> {code:java}
> kafka.common.UnexpectedAppendOffsetException: Unexpected offset in append to
> @metadata-0. First offset 0 is less than the next offset 5. First 10 offsets
> in append: ArrayBuffer(0), last offset in append: 0. Log start offset = 0
> at kafka.log.Log.append(Log.scala:1217)
> at kafka.log.Log.appendAsLeader(Log.scala:1092)
> at kafka.raft.KafkaMetadataLog.appendAsLeader(KafkaMetadataLog.scala:92)
> at
> org.apache.kafka.raft.KafkaRaftClient.appendAsLeader(KafkaRaftClient.java:1158)
> at
> org.apache.kafka.raft.KafkaRaftClient.appendLeaderChangeMessage(KafkaRaftClient.java:449)
> at
> org.apache.kafka.raft.KafkaRaftClient.onBecomeLeader(KafkaRaftClient.java:409)
> at
> org.apache.kafka.raft.KafkaRaftClient.maybeTransitionToLeader(KafkaRaftClient.java:463)
> at
> org.apache.kafka.raft.KafkaRaftClient.handleVoteResponse(KafkaRaftClient.java:663)
> at
> org.apache.kafka.raft.KafkaRaftClient.handleResponse(KafkaRaftClient.java:1530)
> at
> org.apache.kafka.raft.KafkaRaftClient.handleInboundMessage(KafkaRaftClient.java:1652)
> at org.apache.kafka.raft.KafkaRaftClient.poll(KafkaRaftClient.java:2183)
> at kafka.raft.KafkaRaftManager$RaftIoThread.doWork(RaftManager.scala:52)
> at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:96)
> {code}
> We should make the following changes:
> # Fix MockLog to perform similar validation as
> KafkaMetadataLog::appendAsLeader
> # Use the LEO when creating the control batch for the LeaderChangedMessage
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-12331) KafkaRaftClient should use the LEO when appending LeaderChangeMessage
[
https://issues.apache.org/jira/browse/KAFKA-12331?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jose Armando Garcia Sancio updated KAFKA-12331:
---
Description:
KafkaMetadataLog's appendAsLeader expects the base offset to match the LEO.
This is enforced when KafkaRaftClient uses the BatchAccumulator to create
batches. When creating the control batch for the LeaderChangeMessage the
KafkaRaftClient doesn't use the BatchAccumulator and instead creates the batch
with the default base offset of 0.
This causes the validation in KafkaMetadataLog to fail with the following
exception:
{code:java}
kafka.common.UnexpectedAppendOffsetException: Unexpected offset in append to
@metadata-0. First offset 0 is less than the next offset 5. First 10 offsets in
append: ArrayBuffer(0), last offset in append: 0. Log start offset = 0
at kafka.log.Log.append(Log.scala:1217)
at kafka.log.Log.appendAsLeader(Log.scala:1092)
at kafka.raft.KafkaMetadataLog.appendAsLeader(KafkaMetadataLog.scala:92)
at
org.apache.kafka.raft.KafkaRaftClient.appendAsLeader(KafkaRaftClient.java:1158)
at
org.apache.kafka.raft.KafkaRaftClient.appendLeaderChangeMessage(KafkaRaftClient.java:449)
at
org.apache.kafka.raft.KafkaRaftClient.onBecomeLeader(KafkaRaftClient.java:409)
at
org.apache.kafka.raft.KafkaRaftClient.maybeTransitionToLeader(KafkaRaftClient.java:463)
at
org.apache.kafka.raft.KafkaRaftClient.handleVoteResponse(KafkaRaftClient.java:663)
at
org.apache.kafka.raft.KafkaRaftClient.handleResponse(KafkaRaftClient.java:1530)
at
org.apache.kafka.raft.KafkaRaftClient.handleInboundMessage(KafkaRaftClient.java:1652)
at org.apache.kafka.raft.KafkaRaftClient.poll(KafkaRaftClient.java:2183)
at kafka.raft.KafkaRaftManager$RaftIoThread.doWork(RaftManager.scala:52)
at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:96)
{code}
We should make the following changes:
# Fix MockLog to perform similar validation as KafkaMetadataLog::appendAsLeader
# Use the LEO when creating the control batch for the LeaderChangedMessage
was:
KafkaMetadataLog's appendAsLeader expects the base offset to match the LEO.
This is enforced when KafkaRaftClient uses the BatchAccumulator to create
batches. When creating the control batch for the LeaderChangeMessage the
KafkaRaftClient doesn't use the BatchAccumulator and instead creates the batch
with the default base offset of 0.
This causes the validation in KafkaMetadataLog to fail with the following
exception:
{code:java}
kafka.common.UnexpectedAppendOffsetException: Unexpected offset in append to
@metadata-0. First offset 0 is less than the next offset 5. First 10 offsets in
append: ArrayBuffer(0), last offset in append: 0. Log start offset = 0
at kafka.log.Log.append(Log.scala:1217)
at kafka.log.Log.appendAsLeader(Log.scala:1092)
at kafka.raft.KafkaMetadataLog.appendAsLeader(KafkaMetadataLog.scala:92)
at
org.apache.kafka.raft.KafkaRaftClient.appendAsLeader(KafkaRaftClient.java:1158)
at
org.apache.kafka.raft.KafkaRaftClient.appendLeaderChangeMessage(KafkaRaftClient.java:449)
at
org.apache.kafka.raft.KafkaRaftClient.onBecomeLeader(KafkaRaftClient.java:409)
at
org.apache.kafka.raft.KafkaRaftClient.maybeTransitionToLeader(KafkaRaftClient.java:463)
at
org.apache.kafka.raft.KafkaRaftClient.handleVoteResponse(KafkaRaftClient.java:663)
at
org.apache.kafka.raft.KafkaRaftClient.handleResponse(KafkaRaftClient.java:1530)
at
org.apache.kafka.raft.KafkaRaftClient.handleInboundMessage(KafkaRaftClient.java:1652)
at org.apache.kafka.raft.KafkaRaftClient.poll(KafkaRaftClient.java:2183)
at kafka.raft.KafkaRaftManager$RaftIoThread.doWork(RaftManager.scala:52)
at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:96)
{code}
> KafkaRaftClient should use the LEO when appending LeaderChangeMessage
> -
>
> Key: KAFKA-12331
> URL: https://issues.apache.org/jira/browse/KAFKA-12331
> Project: Kafka
> Issue Type: Sub-task
> Components: replication
>Reporter: Jose Armando Garcia Sancio
>Priority: Major
>
> KafkaMetadataLog's appendAsLeader expects the base offset to match the LEO.
> This is enforced when KafkaRaftClient uses the BatchAccumulator to create
> batches. When creating the control batch for the LeaderChangeMessage the
> KafkaRaftClient doesn't use the BatchAccumulator and instead creates the
> batch with the default base offset of 0.
> This causes the validation in KafkaMetadataLog to fail with the following
> exception:
> {code:java}
> kafka.common.UnexpectedAppendOffsetException: Unexpected offset in append to
> @metadata-0. First offset 0 is less than
[jira] [Created] (KAFKA-12331) KafkaRaftClient should use the LEO when appending LeaderChangeMessage
Jose Armando Garcia Sancio created KAFKA-12331:
--
Summary: KafkaRaftClient should use the LEO when appending
LeaderChangeMessage
Key: KAFKA-12331
URL: https://issues.apache.org/jira/browse/KAFKA-12331
Project: Kafka
Issue Type: Sub-task
Components: replication
Reporter: Jose Armando Garcia Sancio
KafkaMetadataLog's appendAsLeader expects the base offset to match the LEO.
This is enforced when KafkaRaftClient uses the BatchAccumulator to create
batches. When creating the control batch for the LeaderChangeMessage the
KafkaRaftClient doesn't use the BatchAccumulator and instead creates the batch
with the default base offset of 0.
This causes the validation in KafkaMetadataLog to fail with the following
exception:
{code:java}
kafka.common.UnexpectedAppendOffsetException: Unexpected offset in append to
@metadata-0. First offset 0 is less than the next offset 5. First 10 offsets in
append: ArrayBuffer(0), last offset in append: 0. Log start offset = 0
at kafka.log.Log.append(Log.scala:1217)
at kafka.log.Log.appendAsLeader(Log.scala:1092)
at kafka.raft.KafkaMetadataLog.appendAsLeader(KafkaMetadataLog.scala:92)
at
org.apache.kafka.raft.KafkaRaftClient.appendAsLeader(KafkaRaftClient.java:1158)
at
org.apache.kafka.raft.KafkaRaftClient.appendLeaderChangeMessage(KafkaRaftClient.java:449)
at
org.apache.kafka.raft.KafkaRaftClient.onBecomeLeader(KafkaRaftClient.java:409)
at
org.apache.kafka.raft.KafkaRaftClient.maybeTransitionToLeader(KafkaRaftClient.java:463)
at
org.apache.kafka.raft.KafkaRaftClient.handleVoteResponse(KafkaRaftClient.java:663)
at
org.apache.kafka.raft.KafkaRaftClient.handleResponse(KafkaRaftClient.java:1530)
at
org.apache.kafka.raft.KafkaRaftClient.handleInboundMessage(KafkaRaftClient.java:1652)
at org.apache.kafka.raft.KafkaRaftClient.poll(KafkaRaftClient.java:2183)
at kafka.raft.KafkaRaftManager$RaftIoThread.doWork(RaftManager.scala:52)
at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:96)
{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] abbccdda opened a new pull request #10135: KAFKA-10348: Share client channel between forwarding and auto creation manager
abbccdda opened a new pull request #10135: URL: https://github.com/apache/kafka/pull/10135 We want to consolidate forwarding and auto creation channel into one channel to reduce the unnecessary connections maintained between brokers and controller. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] junrao commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
junrao commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577278241
##
File path:
metadata/src/main/java/org/apache/kafka/controller/QuorumController.java
##
@@ -0,0 +1,920 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.config.ConfigDef;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.ApiException;
+import org.apache.kafka.common.errors.NotControllerException;
+import org.apache.kafka.common.errors.UnknownServerException;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.ConfigRecord;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.QuotaRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.quota.ClientQuotaAlteration;
+import org.apache.kafka.common.quota.ClientQuotaEntity;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.common.utils.Utils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.metalog.MetaLogLeader;
+import org.apache.kafka.metalog.MetaLogListener;
+import org.apache.kafka.metalog.MetaLogManager;
+import org.apache.kafka.queue.EventQueue.EarliestDeadlineFunction;
+import org.apache.kafka.queue.EventQueue;
+import org.apache.kafka.queue.KafkaEventQueue;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.List;
+import java.util.Map.Entry;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Random;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.RejectedExecutionException;
+import java.util.concurrent.TimeUnit;
+import java.util.function.Supplier;
+import java.util.stream.Collectors;
+
+
+public final class QuorumController implements Controller {
+/**
+ * A builder class which creates the QuorumController.
+ */
+static public class Builder {
+private final int nodeId;
+private Time time = Time.SYSTEM;
+private String threadNamePrefix = null;
+private LogContext logContext = null;
+private Map configDefs =
Collections.emptyMap();
+private MetaLogManager logManager = null;
+private Map supportedFeatures =
Collections.emptyMap();
+private short defaultReplicationFactor = 3;
+private int defaultNumPartitions = 1;
+private ReplicaPlacementPolicy replicaPlacementPolicy =
+new SimpleReplicaPlacementPolicy(new Random());
+private long sessionTimeoutNs = TimeUnit.NANOSECONDS.convert(18,
TimeUnit.SECONDS);
+
+public Builder(int nodeId) {
+this.nodeId = nodeId;
+}
+
+public
[GitHub] [kafka] junrao commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
junrao commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577268593
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ClusterControlManager.java
##
@@ -0,0 +1,456 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.common.Endpoint;
+import org.apache.kafka.common.errors.DuplicateBrokerRegistrationException;
+import org.apache.kafka.common.errors.StaleBrokerEpochException;
+import org.apache.kafka.common.errors.UnsupportedVersionException;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistration;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+
+
+public class ClusterControlManager {
+class ReadyBrokersFuture {
+private final CompletableFuture future;
+private final int minBrokers;
+
+ReadyBrokersFuture(CompletableFuture future, int minBrokers) {
+this.future = future;
+this.minBrokers = minBrokers;
+}
+
+boolean check() {
+int numUnfenced = 0;
+for (BrokerRegistration registration :
brokerRegistrations.values()) {
+if (!registration.fenced()) {
+numUnfenced++;
+}
+if (numUnfenced >= minBrokers) {
+return true;
+}
+}
+return false;
+}
+}
+
+/**
+ * The SLF4J log context.
+ */
+private final LogContext logContext;
+
+/**
+ * The SLF4J log object.
+ */
+private final Logger log;
+
+/**
+ * The Kafka clock object to use.
+ */
+private final Time time;
+
+/**
+ * How long sessions should last, in nanoseconds.
+ */
+private final long sessionTimeoutNs;
+
+/**
+ * The replica placement policy to use.
+ */
+private final ReplicaPlacementPolicy placementPolicy;
+
+/**
+ * Maps broker IDs to broker registrations.
+ */
+private final TimelineHashMap
brokerRegistrations;
+
+/**
+ * The broker heartbeat manager, or null if this controller is on standby.
+ */
+private BrokerHeartbeatManager heartbeatManager;
+
+/**
+ * A future which is completed as soon as we have the given number of
brokers
+ * ready.
+ */
+private Optional readyBrokersFuture;
+
+ClusterControlManager(LogContext logContext,
+ Time time,
+ SnapshotRegistry snapshotRegistry,
+ long sessionTimeoutNs,
+ ReplicaPlacementPolicy placementPolicy) {
+this.logContext = logContext;
+this.log = logContext.logger(ClusterControlManager.class);
+this.time = time;
+this.sessionTimeoutNs = sessionTimeoutNs;
+this.placementPolicy = placementPolicy;
+this.brokerRegistrations = new TimelineHashMap<>(snapshotRegistry, 0);
+this.heartbeatManager = null;
+this.readyBrokersFuture = Optional.empty();
+}
+
+/**
+ * Transition
[GitHub] [kafka] junrao commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
junrao commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577263866
##
File path:
metadata/src/main/java/org/apache/kafka/controller/QuorumController.java
##
@@ -0,0 +1,920 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.config.ConfigDef;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.ApiException;
+import org.apache.kafka.common.errors.NotControllerException;
+import org.apache.kafka.common.errors.UnknownServerException;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.ConfigRecord;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.QuotaRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.quota.ClientQuotaAlteration;
+import org.apache.kafka.common.quota.ClientQuotaEntity;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.common.utils.Utils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.metalog.MetaLogLeader;
+import org.apache.kafka.metalog.MetaLogListener;
+import org.apache.kafka.metalog.MetaLogManager;
+import org.apache.kafka.queue.EventQueue.EarliestDeadlineFunction;
+import org.apache.kafka.queue.EventQueue;
+import org.apache.kafka.queue.KafkaEventQueue;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.List;
+import java.util.Map.Entry;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Random;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.RejectedExecutionException;
+import java.util.concurrent.TimeUnit;
+import java.util.function.Supplier;
+import java.util.stream.Collectors;
+
+
+public final class QuorumController implements Controller {
+/**
+ * A builder class which creates the QuorumController.
+ */
+static public class Builder {
+private final int nodeId;
+private Time time = Time.SYSTEM;
+private String threadNamePrefix = null;
+private LogContext logContext = null;
+private Map configDefs =
Collections.emptyMap();
+private MetaLogManager logManager = null;
+private Map supportedFeatures =
Collections.emptyMap();
+private short defaultReplicationFactor = 3;
+private int defaultNumPartitions = 1;
+private ReplicaPlacementPolicy replicaPlacementPolicy =
+new SimpleReplicaPlacementPolicy(new Random());
+private long sessionTimeoutNs = TimeUnit.NANOSECONDS.convert(18,
TimeUnit.SECONDS);
+
+public Builder(int nodeId) {
+this.nodeId = nodeId;
+}
+
+public
[GitHub] [kafka] junrao commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
junrao commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577262652
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -0,0 +1,712 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.ElectionType;
+import org.apache.kafka.common.Uuid;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.InvalidReplicationFactorException;
+import org.apache.kafka.common.errors.InvalidRequestException;
+import org.apache.kafka.common.errors.InvalidTopicException;
+import org.apache.kafka.common.internals.Topic;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableReplicaAssignment;
+import org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopic;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopicCollection;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import
org.apache.kafka.common.message.CreateTopicsResponseData.CreatableTopicResult;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData.TopicPartitions;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.PartitionResult;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.ReplicaElectionResult;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.protocol.Errors;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.controller.BrokersToIsrs.TopicPartition;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.AbstractMap.SimpleImmutableEntry;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Objects;
+import java.util.Random;
+
+import static org.apache.kafka.clients.admin.AlterConfigOp.OpType.SET;
+import static org.apache.kafka.common.config.ConfigResource.Type.TOPIC;
+
+
+public class ReplicationControlManager {
+static class TopicControlInfo {
+private final Uuid id;
+private final TimelineHashMap parts;
+
+TopicControlInfo(SnapshotRegistry snapshotRegistry, Uuid id) {
+this.id = id;
+this.parts = new TimelineHashMap<>(snapshotRegistry, 0);
+}
+}
+
+static class PartitionControlInfo {
+private final int[] replicas;
+private final int[] isr;
+private final int[] removingReplicas;
+private final int[] addingReplicas;
+private final int leader;
+private final int leaderEpoch;
+private final int partitionEpoch;
+
+PartitionControlInfo(PartitionRecord record) {
+this(Replicas.toArray(record.replicas()),
+Replicas.toArray(record.isr()),
+Replicas.toArray(record.removingReplicas()),
+Replicas.toArray(record.addingReplicas()),
+record.leader(),
+record.leaderEpoch(),
+record.partitionEpoch());
+}
+
+PartitionControlInfo(int[] replicas, int[] isr, int[] removingReplicas,
+ int[] addingReplicas, int leader, int leaderEpoch,
+ int partitionEpoch) {
+this.replicas = replicas;
+this.isr = isr;
+
[GitHub] [kafka] junrao commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
junrao commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577259797
##
File path:
metadata/src/main/java/org/apache/kafka/controller/QuorumController.java
##
@@ -0,0 +1,920 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.config.ConfigDef;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.ApiException;
+import org.apache.kafka.common.errors.NotControllerException;
+import org.apache.kafka.common.errors.UnknownServerException;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.ConfigRecord;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.QuotaRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.quota.ClientQuotaAlteration;
+import org.apache.kafka.common.quota.ClientQuotaEntity;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.common.utils.Utils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.metalog.MetaLogLeader;
+import org.apache.kafka.metalog.MetaLogListener;
+import org.apache.kafka.metalog.MetaLogManager;
+import org.apache.kafka.queue.EventQueue.EarliestDeadlineFunction;
+import org.apache.kafka.queue.EventQueue;
+import org.apache.kafka.queue.KafkaEventQueue;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.List;
+import java.util.Map.Entry;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Random;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.RejectedExecutionException;
+import java.util.concurrent.TimeUnit;
+import java.util.function.Supplier;
+import java.util.stream.Collectors;
+
+
+public final class QuorumController implements Controller {
+/**
+ * A builder class which creates the QuorumController.
+ */
+static public class Builder {
+private final int nodeId;
+private Time time = Time.SYSTEM;
+private String threadNamePrefix = null;
+private LogContext logContext = null;
+private Map configDefs =
Collections.emptyMap();
+private MetaLogManager logManager = null;
+private Map supportedFeatures =
Collections.emptyMap();
+private short defaultReplicationFactor = 3;
+private int defaultNumPartitions = 1;
+private ReplicaPlacementPolicy replicaPlacementPolicy =
+new SimpleReplicaPlacementPolicy(new Random());
+private long sessionTimeoutNs = TimeUnit.NANOSECONDS.convert(18,
TimeUnit.SECONDS);
+
+public Builder(int nodeId) {
+this.nodeId = nodeId;
+}
+
+public
[GitHub] [kafka] mjsax commented on pull request #9670: MINOR: Clarify config names for EOS versions 1 and 2
mjsax commented on pull request #9670: URL: https://github.com/apache/kafka/pull/9670#issuecomment-780225430 Thanks @JimGalasyn! Merged to `trunk` and cherry-picked to `2.8`, `2.7`, and `2.6` branches. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] mjsax merged pull request #9670: MINOR: Clarify config names for EOS versions 1 and 2
mjsax merged pull request #9670: URL: https://github.com/apache/kafka/pull/9670 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-12328) Find out partition of a store iterator
[
https://issues.apache.org/jira/browse/KAFKA-12328?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285569#comment-17285569
]
Matthias J. Sax commented on KAFKA-12328:
-
You should be able to use `ProcessorContext.taskId()` – task-ids are encoded as
"_" so with some string parsing you should
be able to get the partition number.
Because no record is processed in a punctuation, there is not really a
partition number... (`ProcessorContext.partition()` returns the partition of
the currently processed record). – I guess, strictly speaking (given the
current design), the partition number is fixed (tied to the task) so we could
actually always return it independently if we have a record at hand or not.
> Find out partition of a store iterator
> --
>
> Key: KAFKA-12328
> URL: https://issues.apache.org/jira/browse/KAFKA-12328
> Project: Kafka
> Issue Type: Wish
> Components: streams
>Reporter: fml2
>Priority: Major
>
> This question was posted [on
> stakoverflow|https://stackoverflow.com/questions/66032099/kafka-streams-how-to-get-the-partition-an-iterartor-is-iterating-over]
> and got an answer but the solution is quite complicated hence this ticket.
>
> In my Kafka Streams application, I have a task that sets up a scheduled (by
> the wall time) punctuator. The punctuator iterates over the entries of a
> store and does something with them. Like this:
> {code:java}
> var store = context().getStateStore("MyStore");
> var iter = store.all();
> while (iter.hasNext()) {
>var entry = iter.next();
>// ... do something with the entry
> }
> // Print a summary (now): N entries processed
> // Print a summary (wish): N entries processed in partition P
> {code}
> Is it possible to find out which partition the punctuator operates on? The
> java docs for {{ProcessorContext.partition()}} states that this method
> returns {{-1}} within punctuators.
> I've read [Kafka Streams: Punctuate vs
> Process|https://stackoverflow.com/questions/50776987/kafka-streams-punctuate-vs-process]
> and the answers there. I can understand that a task is, in general, not tied
> to a particular partition. But an iterator should be tied IMO.
> How can I find out the partition?
> Or is my assumption that a particular instance of a store iterator is tied to
> a partion wrong?
> What I need it for: I'd like to include the partition number in some log
> messages. For now, I have several nearly identical log messages stating that
> the punctuator does this and that. In order to make those messages "unique"
> I'd like to include the partition number into them.
> Since I'm working with a single store here (which might be partitioned), I
> assume that every single execution of the punctuator is bound to a single
> partition of that store.
>
> It would be cool if there were a method {{iterator.partition}} (or similar)
> to get this information.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-12328) Find out partition of a store iterator
[
https://issues.apache.org/jira/browse/KAFKA-12328?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Matthias J. Sax updated KAFKA-12328:
Component/s: streams
> Find out partition of a store iterator
> --
>
> Key: KAFKA-12328
> URL: https://issues.apache.org/jira/browse/KAFKA-12328
> Project: Kafka
> Issue Type: Wish
> Components: streams
>Reporter: fml2
>Priority: Major
>
> This question was posted [on
> stakoverflow|https://stackoverflow.com/questions/66032099/kafka-streams-how-to-get-the-partition-an-iterartor-is-iterating-over]
> and got an answer but the solution is quite complicated hence this ticket.
>
> In my Kafka Streams application, I have a task that sets up a scheduled (by
> the wall time) punctuator. The punctuator iterates over the entries of a
> store and does something with them. Like this:
> {code:java}
> var store = context().getStateStore("MyStore");
> var iter = store.all();
> while (iter.hasNext()) {
>var entry = iter.next();
>// ... do something with the entry
> }
> // Print a summary (now): N entries processed
> // Print a summary (wish): N entries processed in partition P
> {code}
> Is it possible to find out which partition the punctuator operates on? The
> java docs for {{ProcessorContext.partition()}} states that this method
> returns {{-1}} within punctuators.
> I've read [Kafka Streams: Punctuate vs
> Process|https://stackoverflow.com/questions/50776987/kafka-streams-punctuate-vs-process]
> and the answers there. I can understand that a task is, in general, not tied
> to a particular partition. But an iterator should be tied IMO.
> How can I find out the partition?
> Or is my assumption that a particular instance of a store iterator is tied to
> a partion wrong?
> What I need it for: I'd like to include the partition number in some log
> messages. For now, I have several nearly identical log messages stating that
> the punctuator does this and that. In order to make those messages "unique"
> I'd like to include the partition number into them.
> Since I'm working with a single store here (which might be partitioned), I
> assume that every single execution of the punctuator is bound to a single
> partition of that store.
>
> It would be cool if there were a method {{iterator.partition}} (or similar)
> to get this information.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] mjsax opened a new pull request #10134: TRIVIAL: fix JavaDocs formatting
mjsax opened a new pull request #10134: URL: https://github.com/apache/kafka/pull/10134 Should be cherry-picked to `2.8` branch. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on a change in pull request #10063: KAFKA-12258: Add support for splitting appending records
hachikuji commented on a change in pull request #10063:
URL: https://github.com/apache/kafka/pull/10063#discussion_r577225891
##
File path:
raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java
##
@@ -79,67 +80,110 @@ public BatchAccumulator(
}
/**
- * Append a list of records into an atomic batch. We guarantee all records
- * are included in the same underlying record batch so that either all of
- * the records become committed or none of them do.
+ * Append a list of records into as many batches as necessary.
*
- * @param epoch the expected leader epoch. If this does not match, then
- * {@link Long#MAX_VALUE} will be returned as an offset which
- * cannot become committed.
- * @param records the list of records to include in a batch
- * @return the expected offset of the last record (which will be
- * {@link Long#MAX_VALUE} if the epoch does not match), or null if
- * no memory could be allocated for the batch at this time
+ * The order of the elements in the records argument will match the order
in the batches.
+ * This method will use as many batches as necessary to serialize all of
the records. Since
+ * this method can split the records into multiple batches it is possible
that some of the
+ * recors will get committed while other will not when the leader fails.
+ *
+ * @param epoch the expected leader epoch. If this does not match, then
{@link Long#MAX_VALUE}
+ * will be returned as an offset which cannot become committed
+ * @param records the list of records to include in the batches
+ * @return the expected offset of the last record; {@link Long#MAX_VALUE}
if the epoch does not
+ * match; null if no memory could be allocated for the batch at
this time
+ * @throws RecordBatchTooLargeException if the size of one record T is
greater than the maximum
+ * batch size; if this exception is throw some of the elements in
records may have
+ * been committed
*/
public Long append(int epoch, List records) {
+return append(epoch, records, false);
+}
+
+/**
+ * Append a list of records into an atomic batch. We guarantee all records
are included in the
+ * same underlying record batch so that either all of the records become
committed or none of
+ * them do.
+ *
+ * @param epoch the expected leader epoch. If this does not match, then
{@link Long#MAX_VALUE}
+ * will be returned as an offset which cannot become committed
+ * @param records the list of records to include in a batch
+ * @return the expected offset of the last record; {@link Long#MAX_VALUE}
if the epoch does not
+ * match; null if no memory could be allocated for the batch at
this time
+ * @throws RecordBatchTooLargeException if the size of the records is
greater than the maximum
+ * batch size; if this exception is throw none of the elements in
records were
+ * committed
+ */
+public Long appendAtomic(int epoch, List records) {
+return append(epoch, records, true);
+}
+
+private Long append(int epoch, List records, boolean isAtomic) {
if (epoch != this.epoch) {
-// If the epoch does not match, then the state machine probably
-// has not gotten the notification about the latest epoch change.
-// In this case, ignore the append and return a large offset value
-// which will never be committed.
return Long.MAX_VALUE;
}
ObjectSerializationCache serializationCache = new
ObjectSerializationCache();
-int batchSize = 0;
-for (T record : records) {
-batchSize += serde.recordSize(record, serializationCache);
-}
-
-if (batchSize > maxBatchSize) {
-throw new IllegalArgumentException("The total size of " + records
+ " is " + batchSize +
-", which exceeds the maximum allowed batch size of " +
maxBatchSize);
-}
+int[] recordSizes = records
+.stream()
+.mapToInt(record -> serde.recordSize(record, serializationCache))
+.toArray();
appendLock.lock();
try {
maybeCompleteDrain();
-BatchBuilder batch = maybeAllocateBatch(batchSize);
-if (batch == null) {
-return null;
-}
-
-// Restart the linger timer if necessary
-if (!lingerTimer.isRunning()) {
-lingerTimer.reset(time.milliseconds() + lingerMs);
+BatchBuilder batch = null;
+if (isAtomic) {
+batch = maybeAllocateBatch(recordSizes);
}
for (T record : records) {
+if (!isAtomic) {
+batch =
[GitHub] [kafka] hachikuji commented on a change in pull request #10063: KAFKA-12258: Add support for splitting appending records
hachikuji commented on a change in pull request #10063:
URL: https://github.com/apache/kafka/pull/10063#discussion_r577216920
##
File path: raft/src/main/java/org/apache/kafka/raft/RaftClient.java
##
@@ -77,6 +79,29 @@ default void handleResign() {}
*/
void register(Listener listener);
+/**
+ * Append a list of records to the log. The write will be scheduled for
some time
+ * in the future. There is no guarantee that appended records will be
written to
+ * the log and eventually committed. While the order of the records is
preserve, they can
+ * be appended to the log using one or more batches. This means that each
record could
+ * be committed independently.
Review comment:
It might already be clear enough given the previous sentence, but maybe
we could emphasize that if any record becomes committed, then all records
ordered before it are guaranteed to be committed as well.
##
File path:
raft/src/main/java/org/apache/kafka/raft/internals/BatchAccumulator.java
##
@@ -79,67 +80,110 @@ public BatchAccumulator(
}
/**
- * Append a list of records into an atomic batch. We guarantee all records
- * are included in the same underlying record batch so that either all of
- * the records become committed or none of them do.
+ * Append a list of records into as many batches as necessary.
*
- * @param epoch the expected leader epoch. If this does not match, then
- * {@link Long#MAX_VALUE} will be returned as an offset which
- * cannot become committed.
- * @param records the list of records to include in a batch
- * @return the expected offset of the last record (which will be
- * {@link Long#MAX_VALUE} if the epoch does not match), or null if
- * no memory could be allocated for the batch at this time
+ * The order of the elements in the records argument will match the order
in the batches.
+ * This method will use as many batches as necessary to serialize all of
the records. Since
+ * this method can split the records into multiple batches it is possible
that some of the
+ * recors will get committed while other will not when the leader fails.
+ *
+ * @param epoch the expected leader epoch. If this does not match, then
{@link Long#MAX_VALUE}
+ * will be returned as an offset which cannot become committed
+ * @param records the list of records to include in the batches
+ * @return the expected offset of the last record; {@link Long#MAX_VALUE}
if the epoch does not
+ * match; null if no memory could be allocated for the batch at
this time
+ * @throws RecordBatchTooLargeException if the size of one record T is
greater than the maximum
+ * batch size; if this exception is throw some of the elements in
records may have
+ * been committed
*/
public Long append(int epoch, List records) {
+return append(epoch, records, false);
+}
+
+/**
+ * Append a list of records into an atomic batch. We guarantee all records
are included in the
+ * same underlying record batch so that either all of the records become
committed or none of
+ * them do.
+ *
+ * @param epoch the expected leader epoch. If this does not match, then
{@link Long#MAX_VALUE}
+ * will be returned as an offset which cannot become committed
+ * @param records the list of records to include in a batch
+ * @return the expected offset of the last record; {@link Long#MAX_VALUE}
if the epoch does not
+ * match; null if no memory could be allocated for the batch at
this time
+ * @throws RecordBatchTooLargeException if the size of the records is
greater than the maximum
+ * batch size; if this exception is throw none of the elements in
records were
+ * committed
+ */
+public Long appendAtomic(int epoch, List records) {
+return append(epoch, records, true);
+}
+
+private Long append(int epoch, List records, boolean isAtomic) {
if (epoch != this.epoch) {
-// If the epoch does not match, then the state machine probably
-// has not gotten the notification about the latest epoch change.
-// In this case, ignore the append and return a large offset value
-// which will never be committed.
return Long.MAX_VALUE;
}
ObjectSerializationCache serializationCache = new
ObjectSerializationCache();
-int batchSize = 0;
-for (T record : records) {
-batchSize += serde.recordSize(record, serializationCache);
-}
-
-if (batchSize > maxBatchSize) {
-throw new IllegalArgumentException("The total size of " + records
+ " is " + batchSize +
-", which exceeds the maximum allowed batch size of " +
maxBatchSize);
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577217605
##
File path:
metadata/src/main/java/org/apache/kafka/controller/QuorumController.java
##
@@ -0,0 +1,920 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.config.ConfigDef;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.ApiException;
+import org.apache.kafka.common.errors.NotControllerException;
+import org.apache.kafka.common.errors.UnknownServerException;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.ConfigRecord;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.QuotaRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.quota.ClientQuotaAlteration;
+import org.apache.kafka.common.quota.ClientQuotaEntity;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.common.utils.Utils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.metalog.MetaLogLeader;
+import org.apache.kafka.metalog.MetaLogListener;
+import org.apache.kafka.metalog.MetaLogManager;
+import org.apache.kafka.queue.EventQueue.EarliestDeadlineFunction;
+import org.apache.kafka.queue.EventQueue;
+import org.apache.kafka.queue.KafkaEventQueue;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.List;
+import java.util.Map.Entry;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Random;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.RejectedExecutionException;
+import java.util.concurrent.TimeUnit;
+import java.util.function.Supplier;
+import java.util.stream.Collectors;
+
+
+public final class QuorumController implements Controller {
+/**
+ * A builder class which creates the QuorumController.
+ */
+static public class Builder {
+private final int nodeId;
+private Time time = Time.SYSTEM;
+private String threadNamePrefix = null;
+private LogContext logContext = null;
+private Map configDefs =
Collections.emptyMap();
+private MetaLogManager logManager = null;
+private Map supportedFeatures =
Collections.emptyMap();
+private short defaultReplicationFactor = 3;
+private int defaultNumPartitions = 1;
+private ReplicaPlacementPolicy replicaPlacementPolicy =
+new SimpleReplicaPlacementPolicy(new Random());
+private long sessionTimeoutNs = TimeUnit.NANOSECONDS.convert(18,
TimeUnit.SECONDS);
+
+public Builder(int nodeId) {
+this.nodeId = nodeId;
+}
+
+public
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577214559
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ClusterControlManager.java
##
@@ -0,0 +1,456 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.common.Endpoint;
+import org.apache.kafka.common.errors.DuplicateBrokerRegistrationException;
+import org.apache.kafka.common.errors.StaleBrokerEpochException;
+import org.apache.kafka.common.errors.UnsupportedVersionException;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistration;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+
+
+public class ClusterControlManager {
+class ReadyBrokersFuture {
+private final CompletableFuture future;
+private final int minBrokers;
+
+ReadyBrokersFuture(CompletableFuture future, int minBrokers) {
+this.future = future;
+this.minBrokers = minBrokers;
+}
+
+boolean check() {
+int numUnfenced = 0;
+for (BrokerRegistration registration :
brokerRegistrations.values()) {
+if (!registration.fenced()) {
+numUnfenced++;
+}
+if (numUnfenced >= minBrokers) {
+return true;
+}
+}
+return false;
+}
+}
+
+/**
+ * The SLF4J log context.
+ */
+private final LogContext logContext;
+
+/**
+ * The SLF4J log object.
+ */
+private final Logger log;
+
+/**
+ * The Kafka clock object to use.
+ */
+private final Time time;
+
+/**
+ * How long sessions should last, in nanoseconds.
+ */
+private final long sessionTimeoutNs;
+
+/**
+ * The replica placement policy to use.
+ */
+private final ReplicaPlacementPolicy placementPolicy;
+
+/**
+ * Maps broker IDs to broker registrations.
+ */
+private final TimelineHashMap
brokerRegistrations;
+
+/**
+ * The broker heartbeat manager, or null if this controller is on standby.
+ */
+private BrokerHeartbeatManager heartbeatManager;
+
+/**
+ * A future which is completed as soon as we have the given number of
brokers
+ * ready.
+ */
+private Optional readyBrokersFuture;
+
+ClusterControlManager(LogContext logContext,
+ Time time,
+ SnapshotRegistry snapshotRegistry,
+ long sessionTimeoutNs,
+ ReplicaPlacementPolicy placementPolicy) {
+this.logContext = logContext;
+this.log = logContext.logger(ClusterControlManager.class);
+this.time = time;
+this.sessionTimeoutNs = sessionTimeoutNs;
+this.placementPolicy = placementPolicy;
+this.brokerRegistrations = new TimelineHashMap<>(snapshotRegistry, 0);
+this.heartbeatManager = null;
+this.readyBrokersFuture = Optional.empty();
+}
+
+/**
+ * Transition
[GitHub] [kafka] hachikuji merged pull request #10133: MINOR: Update raft README and add a more specific error message.
hachikuji merged pull request #10133: URL: https://github.com/apache/kafka/pull/10133 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-12241) Partition offline when ISR shrinks to leader and LogDir goes offline
[
https://issues.apache.org/jira/browse/KAFKA-12241?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285537#comment-17285537
]
Ajay Patel commented on KAFKA-12241:
We have a different trigger for the ISR shrinkage, but the same symptoms. We
also prefer not to enable unclean leader election, as it carries the risk of
electing a broker which has not yet met the highWatermark for that partition.
Electing a broker that was removed from the ISR at the highWatermark without
having to enable unclean leader election would be a great way to allow both a
seamless failover and no loss of data.
> Partition offline when ISR shrinks to leader and LogDir goes offline
>
>
> Key: KAFKA-12241
> URL: https://issues.apache.org/jira/browse/KAFKA-12241
> Project: Kafka
> Issue Type: Bug
> Components: core
>Affects Versions: 2.4.2
>Reporter: Noa Resare
>Priority: Major
>
> This is a long standing issue that we haven't previously tracked in a JIRA.
> We experience this maybe once per month on average and we see the following
> sequence of events:
> # A broker shrinks ISR to just itself for a partition. However, the
> followers are at highWatermark:{{ [Partition PARTITION broker=601] Shrinking
> ISR from 1501,601,1201,1801 to 601. Leader: (highWatermark: 432385279,
> endOffset: 432385280). Out of sync replicas: (brokerId: 1501, endOffset:
> 432385279) (brokerId: 1201, endOffset: 432385279) (brokerId: 1801, endOffset:
> 432385279).}}
> # Around this time (in the case I have in front of me, 20ms earlier
> according to the logging subsystem) LogDirFailureChannel captures an Error
> while appending records to PARTITION due to a readonly filesystem.
> # ~20 ms after the ISR shrink, LogDirFailureHandler offlines the partition:
> Logs for partitions LIST_OF_PARTITIONS are offline and logs for future
> partitions are offline due to failure on log directory /kafka/d6/data
> # ~50ms later the controller marks the replicas as offline from 601:
> message: [Controller id=901] Mark replicas LIST_OF_PARTITIONS on broker 601
> as offline
> # ~2ms later the controller offlines the partition: [Controller id=901
> epoch=4] Changed partition PARTITION state from OnlinePartition to
> OfflinePartition
> To resolve this someone needs to manually enable unclean leader election,
> which is obviously not ideal. Since the leader knows that all the followers
> that are removed from ISR is at highWatermark, maybe it could convey that to
> the controller in the LeaderAndIsr response so that the controller could pick
> a new leader without having to resort to unclean leader election.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577188202
##
File path:
metadata/src/main/java/org/apache/kafka/controller/QuorumController.java
##
@@ -0,0 +1,920 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.config.ConfigDef;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.ApiException;
+import org.apache.kafka.common.errors.NotControllerException;
+import org.apache.kafka.common.errors.UnknownServerException;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.ConfigRecord;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.QuotaRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.quota.ClientQuotaAlteration;
+import org.apache.kafka.common.quota.ClientQuotaEntity;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.common.utils.Utils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.metalog.MetaLogLeader;
+import org.apache.kafka.metalog.MetaLogListener;
+import org.apache.kafka.metalog.MetaLogManager;
+import org.apache.kafka.queue.EventQueue.EarliestDeadlineFunction;
+import org.apache.kafka.queue.EventQueue;
+import org.apache.kafka.queue.KafkaEventQueue;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.List;
+import java.util.Map.Entry;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Random;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.RejectedExecutionException;
+import java.util.concurrent.TimeUnit;
+import java.util.function.Supplier;
+import java.util.stream.Collectors;
+
+
+public final class QuorumController implements Controller {
+/**
+ * A builder class which creates the QuorumController.
+ */
+static public class Builder {
+private final int nodeId;
+private Time time = Time.SYSTEM;
+private String threadNamePrefix = null;
+private LogContext logContext = null;
+private Map configDefs =
Collections.emptyMap();
+private MetaLogManager logManager = null;
+private Map supportedFeatures =
Collections.emptyMap();
+private short defaultReplicationFactor = 3;
+private int defaultNumPartitions = 1;
+private ReplicaPlacementPolicy replicaPlacementPolicy =
+new SimpleReplicaPlacementPolicy(new Random());
+private long sessionTimeoutNs = TimeUnit.NANOSECONDS.convert(18,
TimeUnit.SECONDS);
+
+public Builder(int nodeId) {
+this.nodeId = nodeId;
+}
+
+public
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577187004
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ClusterControlManager.java
##
@@ -0,0 +1,456 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.common.Endpoint;
+import org.apache.kafka.common.errors.DuplicateBrokerRegistrationException;
+import org.apache.kafka.common.errors.StaleBrokerEpochException;
+import org.apache.kafka.common.errors.UnsupportedVersionException;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistration;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+
+
+public class ClusterControlManager {
+class ReadyBrokersFuture {
+private final CompletableFuture future;
+private final int minBrokers;
+
+ReadyBrokersFuture(CompletableFuture future, int minBrokers) {
+this.future = future;
+this.minBrokers = minBrokers;
+}
+
+boolean check() {
+int numUnfenced = 0;
+for (BrokerRegistration registration :
brokerRegistrations.values()) {
+if (!registration.fenced()) {
+numUnfenced++;
+}
+if (numUnfenced >= minBrokers) {
+return true;
+}
+}
+return false;
+}
+}
+
+/**
+ * The SLF4J log context.
+ */
+private final LogContext logContext;
+
+/**
+ * The SLF4J log object.
+ */
+private final Logger log;
+
+/**
+ * The Kafka clock object to use.
+ */
+private final Time time;
+
+/**
+ * How long sessions should last, in nanoseconds.
+ */
+private final long sessionTimeoutNs;
+
+/**
+ * The replica placement policy to use.
+ */
+private final ReplicaPlacementPolicy placementPolicy;
+
+/**
+ * Maps broker IDs to broker registrations.
+ */
+private final TimelineHashMap
brokerRegistrations;
+
+/**
+ * The broker heartbeat manager, or null if this controller is on standby.
+ */
+private BrokerHeartbeatManager heartbeatManager;
+
+/**
+ * A future which is completed as soon as we have the given number of
brokers
+ * ready.
+ */
+private Optional readyBrokersFuture;
+
+ClusterControlManager(LogContext logContext,
+ Time time,
+ SnapshotRegistry snapshotRegistry,
+ long sessionTimeoutNs,
+ ReplicaPlacementPolicy placementPolicy) {
+this.logContext = logContext;
+this.log = logContext.logger(ClusterControlManager.class);
+this.time = time;
+this.sessionTimeoutNs = sessionTimeoutNs;
+this.placementPolicy = placementPolicy;
+this.brokerRegistrations = new TimelineHashMap<>(snapshotRegistry, 0);
+this.heartbeatManager = null;
+this.readyBrokersFuture = Optional.empty();
+}
+
+/**
+ * Transition
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577187004
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ClusterControlManager.java
##
@@ -0,0 +1,456 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.common.Endpoint;
+import org.apache.kafka.common.errors.DuplicateBrokerRegistrationException;
+import org.apache.kafka.common.errors.StaleBrokerEpochException;
+import org.apache.kafka.common.errors.UnsupportedVersionException;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistration;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+
+
+public class ClusterControlManager {
+class ReadyBrokersFuture {
+private final CompletableFuture future;
+private final int minBrokers;
+
+ReadyBrokersFuture(CompletableFuture future, int minBrokers) {
+this.future = future;
+this.minBrokers = minBrokers;
+}
+
+boolean check() {
+int numUnfenced = 0;
+for (BrokerRegistration registration :
brokerRegistrations.values()) {
+if (!registration.fenced()) {
+numUnfenced++;
+}
+if (numUnfenced >= minBrokers) {
+return true;
+}
+}
+return false;
+}
+}
+
+/**
+ * The SLF4J log context.
+ */
+private final LogContext logContext;
+
+/**
+ * The SLF4J log object.
+ */
+private final Logger log;
+
+/**
+ * The Kafka clock object to use.
+ */
+private final Time time;
+
+/**
+ * How long sessions should last, in nanoseconds.
+ */
+private final long sessionTimeoutNs;
+
+/**
+ * The replica placement policy to use.
+ */
+private final ReplicaPlacementPolicy placementPolicy;
+
+/**
+ * Maps broker IDs to broker registrations.
+ */
+private final TimelineHashMap
brokerRegistrations;
+
+/**
+ * The broker heartbeat manager, or null if this controller is on standby.
+ */
+private BrokerHeartbeatManager heartbeatManager;
+
+/**
+ * A future which is completed as soon as we have the given number of
brokers
+ * ready.
+ */
+private Optional readyBrokersFuture;
+
+ClusterControlManager(LogContext logContext,
+ Time time,
+ SnapshotRegistry snapshotRegistry,
+ long sessionTimeoutNs,
+ ReplicaPlacementPolicy placementPolicy) {
+this.logContext = logContext;
+this.log = logContext.logger(ClusterControlManager.class);
+this.time = time;
+this.sessionTimeoutNs = sessionTimeoutNs;
+this.placementPolicy = placementPolicy;
+this.brokerRegistrations = new TimelineHashMap<>(snapshotRegistry, 0);
+this.heartbeatManager = null;
+this.readyBrokersFuture = Optional.empty();
+}
+
+/**
+ * Transition
[jira] [Updated] (KAFKA-12330) FetchSessionCache may cause starvation for partitions when FetchResponse is full
[
https://issues.apache.org/jira/browse/KAFKA-12330?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Lucas Bradstreet updated KAFKA-12330:
-
Description:
The incremental FetchSessionCache sessions deprioritizes partitions where a
response is returned. This may happen if log metadata such as log start offset,
hwm, etc is returned, or if data for that partition is returned.
When a fetch response fills to maxBytes, data may not be returned for
partitions even if the fetch offset is lower than the fetch upper bound.
However, the fetch response will still contain updates to metadata such as hwm
if that metadata has changed. This can lead to degenerate behavior where a
partition's hwm or log start offset is updated resulting in the next fetch
being unnecessarily skipped for that partition. At first this appeared to be
worse, as hwm updates occur frequently, but starvation should result in hwm
movement becoming blocked, allowing a fetch to go through and then becoming
unstuck. However, it'll still require one more fetch request than necessary to
do so. Consumers may be affected more than replica fetchers, however they often
remove partitions with fetched data from the next fetch request and this may be
helping prevent starvation.
I believe we should only reorder the partition fetch priority if data is
actually returned for a partition.
{noformat}
private class PartitionIterator(val iter: FetchSession.RESP_MAP_ITER,
val updateFetchContextAndRemoveUnselected:
Boolean)
extends FetchSession.RESP_MAP_ITER {
var nextElement: util.Map.Entry[TopicPartition,
FetchResponse.PartitionData[Records]] = null
override def hasNext: Boolean = {
while ((nextElement == null) && iter.hasNext) {
val element = iter.next()
val topicPart = element.getKey
val respData = element.getValue
val cachedPart = session.partitionMap.find(new CachedPartition(topicPart))
val mustRespond = cachedPart.maybeUpdateResponseData(respData,
updateFetchContextAndRemoveUnselected)
if (mustRespond) {
nextElement = element
// Example POC change:
// Don't move partition to end of queue if we didn't actually fetch data
// This should help avoid starvation even when we are filling the fetch
response fully while returning metadata for these partitions
if (updateFetchContextAndRemoveUnselected && respData.records != null
&& respData.records.sizeInBytes > 0) {
session.partitionMap.remove(cachedPart)
session.partitionMap.mustAdd(cachedPart)
}
} else {
if (updateFetchContextAndRemoveUnselected) {
iter.remove()
}
}
}
nextElement != null
}{noformat}
was:
The incremental FetchSessionCache sessions deprioritizes partitions where a
response is returned. This may happen if log metadata such as log start offset,
hwm, etc is returned, or if data for that partition is returned.
When a fetch response fills to maxBytes, data may not be returned for
partitions even if the fetch offset is lower than the fetch upper bound.
However, the fetch response will still contain updates to metadata such as hwm
if that metadata has changed. This can lead to degenerate behavior where a
partition's hwm or log start offset is updated resulting in the next fetch
being unnecessarily skipped for that partition. At first this appeared to be
worse, as hwm updates occur frequently, but starvation should result in hwm
movement becoming blocked, allowing a fetch to go through and then becoming
unstuck. However, it'll still require one more fetch request than necessary to
do so. Consumers may be affected more than replica fetchers, however they often
remove partitions with fetched data from the next fetch request and this may be
helping prevent starvation.
I believe we should only reorder the partition fetch priority if data is
actually returned for a partition.
{noformat}
private class PartitionIterator(val iter: FetchSession.RESP_MAP_ITER,
val updateFetchContextAndRemoveUnselected:
Boolean)
extends FetchSession.RESP_MAP_ITER {
var nextElement: util.Map.Entry[TopicPartition,
FetchResponse.PartitionData[Records]] = null
override def hasNext: Boolean = {
while ((nextElement == null) && iter.hasNext) {
val element = iter.next()
val topicPart = element.getKey
val respData = element.getValue
val cachedPart = session.partitionMap.find(new CachedPartition(topicPart))
val mustRespond = cachedPart.maybeUpdateResponseData(respData,
updateFetchContextAndRemoveUnselected)
if (mustRespond) {
nextElement = element
// Don't move partition to end of queue if we didn't actually fetch data
// This should help avoid starvation even when we are filling the fetch
response fully while returning metadata for these
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577178197
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ClusterControlManager.java
##
@@ -0,0 +1,456 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.common.Endpoint;
+import org.apache.kafka.common.errors.DuplicateBrokerRegistrationException;
+import org.apache.kafka.common.errors.StaleBrokerEpochException;
+import org.apache.kafka.common.errors.UnsupportedVersionException;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistration;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+
+
+public class ClusterControlManager {
+class ReadyBrokersFuture {
+private final CompletableFuture future;
+private final int minBrokers;
+
+ReadyBrokersFuture(CompletableFuture future, int minBrokers) {
+this.future = future;
+this.minBrokers = minBrokers;
+}
+
+boolean check() {
+int numUnfenced = 0;
+for (BrokerRegistration registration :
brokerRegistrations.values()) {
+if (!registration.fenced()) {
+numUnfenced++;
+}
+if (numUnfenced >= minBrokers) {
+return true;
+}
+}
+return false;
+}
+}
+
+/**
+ * The SLF4J log context.
+ */
+private final LogContext logContext;
+
+/**
+ * The SLF4J log object.
+ */
+private final Logger log;
+
+/**
+ * The Kafka clock object to use.
+ */
+private final Time time;
+
+/**
+ * How long sessions should last, in nanoseconds.
+ */
+private final long sessionTimeoutNs;
+
+/**
+ * The replica placement policy to use.
+ */
+private final ReplicaPlacementPolicy placementPolicy;
+
+/**
+ * Maps broker IDs to broker registrations.
+ */
+private final TimelineHashMap
brokerRegistrations;
+
+/**
+ * The broker heartbeat manager, or null if this controller is on standby.
+ */
+private BrokerHeartbeatManager heartbeatManager;
+
+/**
+ * A future which is completed as soon as we have the given number of
brokers
+ * ready.
+ */
+private Optional readyBrokersFuture;
+
+ClusterControlManager(LogContext logContext,
+ Time time,
+ SnapshotRegistry snapshotRegistry,
+ long sessionTimeoutNs,
+ ReplicaPlacementPolicy placementPolicy) {
+this.logContext = logContext;
+this.log = logContext.logger(ClusterControlManager.class);
+this.time = time;
+this.sessionTimeoutNs = sessionTimeoutNs;
+this.placementPolicy = placementPolicy;
+this.brokerRegistrations = new TimelineHashMap<>(snapshotRegistry, 0);
+this.heartbeatManager = null;
+this.readyBrokersFuture = Optional.empty();
+}
+
+/**
+ * Transition
[jira] [Updated] (KAFKA-12330) FetchSessionCache may cause starvation for partitions when FetchResponse is full
[
https://issues.apache.org/jira/browse/KAFKA-12330?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Lucas Bradstreet updated KAFKA-12330:
-
Description:
The incremental FetchSessionCache sessions deprioritizes partitions where a
response is returned. This may happen if log metadata such as log start offset,
hwm, etc is returned, or if data for that partition is returned.
When a fetch response fills to maxBytes, data may not be returned for
partitions even if the fetch offset is lower than the fetch upper bound.
However, the fetch response will still contain updates to metadata such as hwm
if that metadata has changed. This can lead to degenerate behavior where a
partition's hwm or log start offset is updated resulting in the next fetch
being unnecessarily skipped for that partition. At first this appeared to be
worse, as hwm updates occur frequently, but starvation should result in hwm
movement becoming blocked, allowing a fetch to go through and then becoming
unstuck. However, it'll still require one more fetch request than necessary to
do so. Consumers may be affected more than replica fetchers, however they often
remove partitions with fetched data from the next fetch request and this may be
helping prevent starvation.
I believe we should only reorder the partition fetch priority if data is
actually returned for a partition.
{noformat}
private class PartitionIterator(val iter: FetchSession.RESP_MAP_ITER,
val updateFetchContextAndRemoveUnselected:
Boolean)
extends FetchSession.RESP_MAP_ITER {
var nextElement: util.Map.Entry[TopicPartition,
FetchResponse.PartitionData[Records]] = null
override def hasNext: Boolean = {
while ((nextElement == null) && iter.hasNext) {
val element = iter.next()
val topicPart = element.getKey
val respData = element.getValue
val cachedPart = session.partitionMap.find(new CachedPartition(topicPart))
val mustRespond = cachedPart.maybeUpdateResponseData(respData,
updateFetchContextAndRemoveUnselected)
if (mustRespond) {
nextElement = element
// Don't move partition to end of queue if we didn't actually fetch data
// This should help avoid starvation even when we are filling the fetch
response fully while returning metadata for these partitions
if (updateFetchContextAndRemoveUnselected && respData.records != null
&& respData.records.sizeInBytes > 0) {
session.partitionMap.remove(cachedPart)
session.partitionMap.mustAdd(cachedPart)
}
} else {
if (updateFetchContextAndRemoveUnselected) {
iter.remove()
}
}
}
nextElement != null
}{noformat}
was:
The incremental FetchSessionCache sessions deprioritizes partitions where a
response is returned. This may happen if log metadata such as log start offset,
hwm, etc is returned, or if data for that partition is returned.
When a fetch response fills to maxBytes, data may not be returned for
partitions where it's available. However, the fetch response will still contain
updates to metadata such as hwm if that metadata has changed. This can lead to
degenerate behavior where a partition's hwm or log start offset is updated
resulting in the next fetch being unnecessarily skipped for that partition. At
first this appeared to be worse, as hwm updates occur frequently, but
starvation should result in hwm movement becoming blocked, allowing a fetch to
go through and then becoming unstuck. However, it'll still require one more
fetch request than necessary to do so. Consumers may be affected more than
replica fetchers, however they often remove partitions with fetched data from
the next fetch request and this may be helping prevent starvation.
I believe we should only reorder the partition fetch priority if data is
actually returned for a partition.
{noformat}
private class PartitionIterator(val iter: FetchSession.RESP_MAP_ITER,
val updateFetchContextAndRemoveUnselected:
Boolean)
extends FetchSession.RESP_MAP_ITER {
var nextElement: util.Map.Entry[TopicPartition,
FetchResponse.PartitionData[Records]] = null
override def hasNext: Boolean = {
while ((nextElement == null) && iter.hasNext) {
val element = iter.next()
val topicPart = element.getKey
val respData = element.getValue
val cachedPart = session.partitionMap.find(new CachedPartition(topicPart))
val mustRespond = cachedPart.maybeUpdateResponseData(respData,
updateFetchContextAndRemoveUnselected)
if (mustRespond) {
nextElement = element
// Don't move partition to end of queue if we didn't actually fetch data
// This should help avoid starvation even when we are filling the fetch
response fully while returning metadata for these partitions
if (updateFetchContextAndRemoveUnselected &&
[jira] [Updated] (KAFKA-12330) FetchSessionCache may cause starvation for partitions when FetchResponse is full
[
https://issues.apache.org/jira/browse/KAFKA-12330?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Lucas Bradstreet updated KAFKA-12330:
-
Description:
The incremental FetchSessionCache sessions deprioritizes partitions where a
response is returned. This may happen if log metadata such as log start offset,
hwm, etc is returned, or if data for that partition is returned.
When a fetch response fills to maxBytes, data may not be returned for
partitions where it's available. However, the fetch response will still contain
updates to metadata such as hwm if that metadata has changed. This can lead to
degenerate behavior where a partition's hwm or log start offset is updated
resulting in the next fetch being unnecessarily skipped for that partition. At
first this appeared to be worse, as hwm updates occur frequently, but
starvation should result in hwm movement becoming blocked, allowing a fetch to
go through and then becoming unstuck. However, it'll still require one more
fetch request than necessary to do so. Consumers may be affected more than
replica fetchers, however they often remove partitions with fetched data from
the next fetch request and this may be helping prevent starvation.
I believe we should only reorder the partition fetch priority if data is
actually returned for a partition.
{noformat}
private class PartitionIterator(val iter: FetchSession.RESP_MAP_ITER,
val updateFetchContextAndRemoveUnselected:
Boolean)
extends FetchSession.RESP_MAP_ITER {
var nextElement: util.Map.Entry[TopicPartition,
FetchResponse.PartitionData[Records]] = null
override def hasNext: Boolean = {
while ((nextElement == null) && iter.hasNext) {
val element = iter.next()
val topicPart = element.getKey
val respData = element.getValue
val cachedPart = session.partitionMap.find(new CachedPartition(topicPart))
val mustRespond = cachedPart.maybeUpdateResponseData(respData,
updateFetchContextAndRemoveUnselected)
if (mustRespond) {
nextElement = element
// Don't move partition to end of queue if we didn't actually fetch data
// This should help avoid starvation even when we are filling the fetch
response fully while returning metadata for these partitions
if (updateFetchContextAndRemoveUnselected && respData.records != null
&& respData.records.sizeInBytes > 0) {
session.partitionMap.remove(cachedPart)
session.partitionMap.mustAdd(cachedPart)
}
} else {
if (updateFetchContextAndRemoveUnselected) {
iter.remove()
}
}
}
nextElement != null
}{noformat}
was:
The incremental FetchSessionCache sessions deprioritizes partitions where a
response is returned. This may happen if log metadata such as log start offset,
hwm, etc is returned, or if data for that partition is returned.
When a fetch response fills to maxBytes, data may not be returned for
partitions where it's available. However, the fetch response will still contain
updates to metadata such as hwm if that metadata has changed. This can lead to
degenerate behavior where a partition's hwm or log start offset is updated
resulting in the next fetch being unnecessarily skipped for that partition. At
first this appeared to be worse, as hwm updates occur frequently, but
starvation should result in hwm movement becoming blocked, allowing a fetch to
go through and then becoming unstuck. However, it'll still require one more
fetch request than necessary to do so.
I believe we should only reorder the partition fetch priority if data is
actually returned for a partition.
{code:java}
{code}
{noformat}
private class PartitionIterator(val iter: FetchSession.RESP_MAP_ITER,
val updateFetchContextAndRemoveUnselected:
Boolean)
extends FetchSession.RESP_MAP_ITER {
var nextElement: util.Map.Entry[TopicPartition,
FetchResponse.PartitionData[Records]] = null
override def hasNext: Boolean = {
while ((nextElement == null) && iter.hasNext) {
val element = iter.next()
val topicPart = element.getKey
val respData = element.getValue
val cachedPart = session.partitionMap.find(new CachedPartition(topicPart))
val mustRespond = cachedPart.maybeUpdateResponseData(respData,
updateFetchContextAndRemoveUnselected)
if (mustRespond) {
nextElement = element
// Don't move partition to end of queue if we didn't actually fetch data
// This should help avoid starvation even when we are filling the fetch
response fully while returning metadata for these partitions
if (updateFetchContextAndRemoveUnselected && respData.records != null
&& respData.records.sizeInBytes > 0) {
session.partitionMap.remove(cachedPart)
session.partitionMap.mustAdd(cachedPart)
}
} else {
if
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577176042
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -0,0 +1,712 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.ElectionType;
+import org.apache.kafka.common.Uuid;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.InvalidReplicationFactorException;
+import org.apache.kafka.common.errors.InvalidRequestException;
+import org.apache.kafka.common.errors.InvalidTopicException;
+import org.apache.kafka.common.internals.Topic;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableReplicaAssignment;
+import org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopic;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopicCollection;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import
org.apache.kafka.common.message.CreateTopicsResponseData.CreatableTopicResult;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData.TopicPartitions;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.PartitionResult;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.ReplicaElectionResult;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.protocol.Errors;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.controller.BrokersToIsrs.TopicPartition;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.AbstractMap.SimpleImmutableEntry;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Objects;
+import java.util.Random;
+
+import static org.apache.kafka.clients.admin.AlterConfigOp.OpType.SET;
+import static org.apache.kafka.common.config.ConfigResource.Type.TOPIC;
+
+
+public class ReplicationControlManager {
+static class TopicControlInfo {
+private final Uuid id;
+private final TimelineHashMap parts;
+
+TopicControlInfo(SnapshotRegistry snapshotRegistry, Uuid id) {
+this.id = id;
+this.parts = new TimelineHashMap<>(snapshotRegistry, 0);
+}
+}
+
+static class PartitionControlInfo {
+private final int[] replicas;
+private final int[] isr;
+private final int[] removingReplicas;
+private final int[] addingReplicas;
+private final int leader;
+private final int leaderEpoch;
+private final int partitionEpoch;
+
+PartitionControlInfo(PartitionRecord record) {
+this(Replicas.toArray(record.replicas()),
+Replicas.toArray(record.isr()),
+Replicas.toArray(record.removingReplicas()),
+Replicas.toArray(record.addingReplicas()),
+record.leader(),
+record.leaderEpoch(),
+record.partitionEpoch());
+}
+
+PartitionControlInfo(int[] replicas, int[] isr, int[] removingReplicas,
+ int[] addingReplicas, int leader, int leaderEpoch,
+ int partitionEpoch) {
+this.replicas = replicas;
+this.isr = isr;
+
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577176042
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -0,0 +1,712 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.ElectionType;
+import org.apache.kafka.common.Uuid;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.InvalidReplicationFactorException;
+import org.apache.kafka.common.errors.InvalidRequestException;
+import org.apache.kafka.common.errors.InvalidTopicException;
+import org.apache.kafka.common.internals.Topic;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableReplicaAssignment;
+import org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopic;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopicCollection;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import
org.apache.kafka.common.message.CreateTopicsResponseData.CreatableTopicResult;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData.TopicPartitions;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.PartitionResult;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.ReplicaElectionResult;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.protocol.Errors;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.controller.BrokersToIsrs.TopicPartition;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.AbstractMap.SimpleImmutableEntry;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Objects;
+import java.util.Random;
+
+import static org.apache.kafka.clients.admin.AlterConfigOp.OpType.SET;
+import static org.apache.kafka.common.config.ConfigResource.Type.TOPIC;
+
+
+public class ReplicationControlManager {
+static class TopicControlInfo {
+private final Uuid id;
+private final TimelineHashMap parts;
+
+TopicControlInfo(SnapshotRegistry snapshotRegistry, Uuid id) {
+this.id = id;
+this.parts = new TimelineHashMap<>(snapshotRegistry, 0);
+}
+}
+
+static class PartitionControlInfo {
+private final int[] replicas;
+private final int[] isr;
+private final int[] removingReplicas;
+private final int[] addingReplicas;
+private final int leader;
+private final int leaderEpoch;
+private final int partitionEpoch;
+
+PartitionControlInfo(PartitionRecord record) {
+this(Replicas.toArray(record.replicas()),
+Replicas.toArray(record.isr()),
+Replicas.toArray(record.removingReplicas()),
+Replicas.toArray(record.addingReplicas()),
+record.leader(),
+record.leaderEpoch(),
+record.partitionEpoch());
+}
+
+PartitionControlInfo(int[] replicas, int[] isr, int[] removingReplicas,
+ int[] addingReplicas, int leader, int leaderEpoch,
+ int partitionEpoch) {
+this.replicas = replicas;
+this.isr = isr;
+
[jira] [Created] (KAFKA-12330) FetchSessionCache may cause starvation for partitions when FetchResponse is full
Lucas Bradstreet created KAFKA-12330:
Summary: FetchSessionCache may cause starvation for partitions
when FetchResponse is full
Key: KAFKA-12330
URL: https://issues.apache.org/jira/browse/KAFKA-12330
Project: Kafka
Issue Type: Bug
Reporter: Lucas Bradstreet
The incremental FetchSessionCache sessions deprioritizes partitions where a
response is returned. This may happen if log metadata such as log start offset,
hwm, etc is returned, or if data for that partition is returned.
When a fetch response fills to maxBytes, data may not be returned for
partitions where it's available. However, the fetch response will still contain
updates to metadata such as hwm if that metadata has changed. This can lead to
degenerate behavior where a partition's hwm or log start offset is updated
resulting in the next fetch being unnecessarily skipped for that partition. At
first this appeared to be worse, as hwm updates occur frequently, but
starvation should result in hwm movement becoming blocked, allowing a fetch to
go through and then becoming unstuck. However, it'll still require one more
fetch request than necessary to do so.
I believe we should only reorder the partition fetch priority if data is
actually returned for a partition.
{code:java}
{code}
{noformat}
private class PartitionIterator(val iter: FetchSession.RESP_MAP_ITER,
val updateFetchContextAndRemoveUnselected:
Boolean)
extends FetchSession.RESP_MAP_ITER {
var nextElement: util.Map.Entry[TopicPartition,
FetchResponse.PartitionData[Records]] = null
override def hasNext: Boolean = {
while ((nextElement == null) && iter.hasNext) {
val element = iter.next()
val topicPart = element.getKey
val respData = element.getValue
val cachedPart = session.partitionMap.find(new CachedPartition(topicPart))
val mustRespond = cachedPart.maybeUpdateResponseData(respData,
updateFetchContextAndRemoveUnselected)
if (mustRespond) {
nextElement = element
// Don't move partition to end of queue if we didn't actually fetch data
// This should help avoid starvation even when we are filling the fetch
response fully while returning metadata for these partitions
if (updateFetchContextAndRemoveUnselected && respData.records != null
&& respData.records.sizeInBytes > 0) {
session.partitionMap.remove(cachedPart)
session.partitionMap.mustAdd(cachedPart)
}
} else {
if (updateFetchContextAndRemoveUnselected) {
iter.remove()
}
}
}
nextElement != null
}{noformat}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577167941
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ConfigurationControlManager.java
##
@@ -0,0 +1,367 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.config.ConfigDef.ConfigKey;
+import org.apache.kafka.common.config.ConfigDef;
+import org.apache.kafka.common.config.ConfigResource.Type;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.internals.Topic;
+import org.apache.kafka.common.metadata.ConfigRecord;
+import org.apache.kafka.common.protocol.Errors;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.HashMap;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Objects;
+
+import static org.apache.kafka.clients.admin.AlterConfigOp.OpType.APPEND;
+
+public class ConfigurationControlManager {
+private final Logger log;
+private final SnapshotRegistry snapshotRegistry;
+private final Map configDefs;
+private final TimelineHashMap> configData;
+
+ConfigurationControlManager(LogContext logContext,
+SnapshotRegistry snapshotRegistry,
+Map
configDefs) {
+this.log = logContext.logger(ConfigurationControlManager.class);
+this.snapshotRegistry = snapshotRegistry;
+this.configDefs = configDefs;
+this.configData = new TimelineHashMap<>(snapshotRegistry, 0);
+}
+
+/**
+ * Determine the result of applying a batch of incremental configuration
changes. Note
+ * that this method does not change the contents of memory. It just
generates a
+ * result, that you can replay later if you wish using replay().
+ *
+ * Note that there can only be one result per ConfigResource. So if you
try to modify
+ * several keys and one modification fails, the whole ConfigKey fails and
nothing gets
+ * changed.
+ *
+ * @param configChanges Maps each resource to a map from config keys to
+ * operation data.
+ * @return The result.
+ */
+ControllerResult> incrementalAlterConfigs(
+Map>>
configChanges) {
+List outputRecords = new ArrayList<>();
+Map outputResults = new HashMap<>();
+for (Entry>>
resourceEntry :
+configChanges.entrySet()) {
+incrementalAlterConfigResource(resourceEntry.getKey(),
+resourceEntry.getValue(),
+outputRecords,
+outputResults);
+}
+return new ControllerResult<>(outputRecords, outputResults);
+}
+
+private void incrementalAlterConfigResource(ConfigResource configResource,
+Map> keysToOps,
+List
outputRecords,
+Map
outputResults) {
+ApiError error = checkConfigResource(configResource);
+if (error.isFailure()) {
+outputResults.put(configResource, error);
+return;
+}
+List newRecords = new ArrayList<>();
+for (Entry> keysToOpsEntry :
keysToOps.entrySet()) {
+String key = keysToOpsEntry.getKey();
+String currentValue = null;
+TimelineHashMap currentConfigs =
configData.get(configResource);
+if (currentConfigs != null) {
+currentValue = currentConfigs.get(key);
+}
+String newValue = currentValue;
+Entry opTypeAndNewValue =
keysToOpsEntry.getValue();
+
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577167409
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -0,0 +1,712 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.ElectionType;
+import org.apache.kafka.common.Uuid;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.InvalidReplicationFactorException;
+import org.apache.kafka.common.errors.InvalidRequestException;
+import org.apache.kafka.common.errors.InvalidTopicException;
+import org.apache.kafka.common.internals.Topic;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableReplicaAssignment;
+import org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopic;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopicCollection;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import
org.apache.kafka.common.message.CreateTopicsResponseData.CreatableTopicResult;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData.TopicPartitions;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.PartitionResult;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.ReplicaElectionResult;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.protocol.Errors;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.controller.BrokersToIsrs.TopicPartition;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.AbstractMap.SimpleImmutableEntry;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Objects;
+import java.util.Random;
+
+import static org.apache.kafka.clients.admin.AlterConfigOp.OpType.SET;
+import static org.apache.kafka.common.config.ConfigResource.Type.TOPIC;
+
+
+public class ReplicationControlManager {
+static class TopicControlInfo {
+private final Uuid id;
+private final TimelineHashMap parts;
+
+TopicControlInfo(SnapshotRegistry snapshotRegistry, Uuid id) {
+this.id = id;
+this.parts = new TimelineHashMap<>(snapshotRegistry, 0);
+}
+}
+
+static class PartitionControlInfo {
+private final int[] replicas;
+private final int[] isr;
+private final int[] removingReplicas;
+private final int[] addingReplicas;
+private final int leader;
+private final int leaderEpoch;
+private final int partitionEpoch;
+
+PartitionControlInfo(PartitionRecord record) {
+this(Replicas.toArray(record.replicas()),
+Replicas.toArray(record.isr()),
+Replicas.toArray(record.removingReplicas()),
+Replicas.toArray(record.addingReplicas()),
+record.leader(),
+record.leaderEpoch(),
+record.partitionEpoch());
+}
+
+PartitionControlInfo(int[] replicas, int[] isr, int[] removingReplicas,
+ int[] addingReplicas, int leader, int leaderEpoch,
+ int partitionEpoch) {
+this.replicas = replicas;
+this.isr = isr;
+
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577163457
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -0,0 +1,712 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.ElectionType;
+import org.apache.kafka.common.Uuid;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.InvalidReplicationFactorException;
+import org.apache.kafka.common.errors.InvalidRequestException;
+import org.apache.kafka.common.errors.InvalidTopicException;
+import org.apache.kafka.common.internals.Topic;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableReplicaAssignment;
+import org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopic;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopicCollection;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import
org.apache.kafka.common.message.CreateTopicsResponseData.CreatableTopicResult;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData.TopicPartitions;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.PartitionResult;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.ReplicaElectionResult;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.protocol.Errors;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.controller.BrokersToIsrs.TopicPartition;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.AbstractMap.SimpleImmutableEntry;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Objects;
+import java.util.Random;
+
+import static org.apache.kafka.clients.admin.AlterConfigOp.OpType.SET;
+import static org.apache.kafka.common.config.ConfigResource.Type.TOPIC;
+
+
+public class ReplicationControlManager {
+static class TopicControlInfo {
+private final Uuid id;
+private final TimelineHashMap parts;
+
+TopicControlInfo(SnapshotRegistry snapshotRegistry, Uuid id) {
+this.id = id;
+this.parts = new TimelineHashMap<>(snapshotRegistry, 0);
+}
+}
+
+static class PartitionControlInfo {
+private final int[] replicas;
+private final int[] isr;
+private final int[] removingReplicas;
+private final int[] addingReplicas;
+private final int leader;
+private final int leaderEpoch;
+private final int partitionEpoch;
+
+PartitionControlInfo(PartitionRecord record) {
+this(Replicas.toArray(record.replicas()),
+Replicas.toArray(record.isr()),
+Replicas.toArray(record.removingReplicas()),
+Replicas.toArray(record.addingReplicas()),
+record.leader(),
+record.leaderEpoch(),
+record.partitionEpoch());
+}
+
+PartitionControlInfo(int[] replicas, int[] isr, int[] removingReplicas,
+ int[] addingReplicas, int leader, int leaderEpoch,
+ int partitionEpoch) {
+this.replicas = replicas;
+this.isr = isr;
+
[GitHub] [kafka] rondagostino commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
rondagostino commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577148212
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -0,0 +1,712 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.ElectionType;
+import org.apache.kafka.common.Uuid;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.InvalidReplicationFactorException;
+import org.apache.kafka.common.errors.InvalidRequestException;
+import org.apache.kafka.common.errors.InvalidTopicException;
+import org.apache.kafka.common.internals.Topic;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableReplicaAssignment;
+import org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopic;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopicCollection;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import
org.apache.kafka.common.message.CreateTopicsResponseData.CreatableTopicResult;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData.TopicPartitions;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.PartitionResult;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.ReplicaElectionResult;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.protocol.Errors;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.controller.BrokersToIsrs.TopicPartition;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.AbstractMap.SimpleImmutableEntry;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Objects;
+import java.util.Random;
+
+import static org.apache.kafka.clients.admin.AlterConfigOp.OpType.SET;
+import static org.apache.kafka.common.config.ConfigResource.Type.TOPIC;
+
+
+public class ReplicationControlManager {
+static class TopicControlInfo {
+private final Uuid id;
+private final TimelineHashMap parts;
+
+TopicControlInfo(SnapshotRegistry snapshotRegistry, Uuid id) {
+this.id = id;
+this.parts = new TimelineHashMap<>(snapshotRegistry, 0);
+}
+}
+
+static class PartitionControlInfo {
+private final int[] replicas;
+private final int[] isr;
+private final int[] removingReplicas;
+private final int[] addingReplicas;
+private final int leader;
+private final int leaderEpoch;
+private final int partitionEpoch;
+
+PartitionControlInfo(PartitionRecord record) {
+this(Replicas.toArray(record.replicas()),
+Replicas.toArray(record.isr()),
+Replicas.toArray(record.removingReplicas()),
+Replicas.toArray(record.addingReplicas()),
+record.leader(),
+record.leaderEpoch(),
+record.partitionEpoch());
+}
+
+PartitionControlInfo(int[] replicas, int[] isr, int[] removingReplicas,
+ int[] addingReplicas, int leader, int leaderEpoch,
+ int partitionEpoch) {
+this.replicas = replicas;
+this.isr = isr;
+
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070: URL: https://github.com/apache/kafka/pull/10070#discussion_r577117523 ## File path: metadata/src/main/java/org/apache/kafka/metalog/LocalLogManager.java ## @@ -0,0 +1,379 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.kafka.metalog; + +import org.apache.kafka.common.protocol.ApiMessage; +import org.apache.kafka.common.utils.LogContext; +import org.apache.kafka.common.utils.Time; +import org.apache.kafka.metadata.ApiMessageAndVersion; +import org.apache.kafka.queue.EventQueue; +import org.apache.kafka.queue.KafkaEventQueue; +import org.slf4j.Logger; +import org.slf4j.LoggerFactory; + +import java.util.AbstractMap.SimpleImmutableEntry; +import java.util.ArrayList; +import java.util.HashMap; +import java.util.Iterator; +import java.util.List; +import java.util.Map.Entry; +import java.util.Objects; +import java.util.TreeMap; +import java.util.concurrent.CompletableFuture; +import java.util.concurrent.ExecutionException; +import java.util.concurrent.ThreadLocalRandom; +import java.util.stream.Collectors; + + +/** + * The LocalLogManager is a test implementation that relies on the contents of memory. Review comment: Yes, it is. I will move it to the test directory. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070: URL: https://github.com/apache/kafka/pull/10070#discussion_r577117523 ## File path: metadata/src/main/java/org/apache/kafka/metalog/LocalLogManager.java ## @@ -0,0 +1,379 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.kafka.metalog; + +import org.apache.kafka.common.protocol.ApiMessage; +import org.apache.kafka.common.utils.LogContext; +import org.apache.kafka.common.utils.Time; +import org.apache.kafka.metadata.ApiMessageAndVersion; +import org.apache.kafka.queue.EventQueue; +import org.apache.kafka.queue.KafkaEventQueue; +import org.slf4j.Logger; +import org.slf4j.LoggerFactory; + +import java.util.AbstractMap.SimpleImmutableEntry; +import java.util.ArrayList; +import java.util.HashMap; +import java.util.Iterator; +import java.util.List; +import java.util.Map.Entry; +import java.util.Objects; +import java.util.TreeMap; +import java.util.concurrent.CompletableFuture; +import java.util.concurrent.ExecutionException; +import java.util.concurrent.ThreadLocalRandom; +import java.util.stream.Collectors; + + +/** + * The LocalLogManager is a test implementation that relies on the contents of memory. Review comment: Yes, it is is. I will move it to the test directory. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577148107
##
File path:
metadata/src/main/java/org/apache/kafka/controller/QuorumController.java
##
@@ -0,0 +1,920 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.config.ConfigDef;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.ApiException;
+import org.apache.kafka.common.errors.NotControllerException;
+import org.apache.kafka.common.errors.UnknownServerException;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.ConfigRecord;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.QuotaRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.quota.ClientQuotaAlteration;
+import org.apache.kafka.common.quota.ClientQuotaEntity;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.common.utils.Utils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.metalog.MetaLogLeader;
+import org.apache.kafka.metalog.MetaLogListener;
+import org.apache.kafka.metalog.MetaLogManager;
+import org.apache.kafka.queue.EventQueue.EarliestDeadlineFunction;
+import org.apache.kafka.queue.EventQueue;
+import org.apache.kafka.queue.KafkaEventQueue;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.List;
+import java.util.Map.Entry;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Random;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.RejectedExecutionException;
+import java.util.concurrent.TimeUnit;
+import java.util.function.Supplier;
+import java.util.stream.Collectors;
+
+
+public final class QuorumController implements Controller {
+/**
+ * A builder class which creates the QuorumController.
+ */
+static public class Builder {
+private final int nodeId;
+private Time time = Time.SYSTEM;
+private String threadNamePrefix = null;
+private LogContext logContext = null;
+private Map configDefs =
Collections.emptyMap();
+private MetaLogManager logManager = null;
+private Map supportedFeatures =
Collections.emptyMap();
+private short defaultReplicationFactor = 3;
+private int defaultNumPartitions = 1;
+private ReplicaPlacementPolicy replicaPlacementPolicy =
+new SimpleReplicaPlacementPolicy(new Random());
+private long sessionTimeoutNs = TimeUnit.NANOSECONDS.convert(18,
TimeUnit.SECONDS);
+
+public Builder(int nodeId) {
+this.nodeId = nodeId;
+}
+
+public
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577143791
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -0,0 +1,712 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.ElectionType;
+import org.apache.kafka.common.Uuid;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.InvalidReplicationFactorException;
+import org.apache.kafka.common.errors.InvalidRequestException;
+import org.apache.kafka.common.errors.InvalidTopicException;
+import org.apache.kafka.common.internals.Topic;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableReplicaAssignment;
+import org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopic;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopicCollection;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import
org.apache.kafka.common.message.CreateTopicsResponseData.CreatableTopicResult;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData.TopicPartitions;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.PartitionResult;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.ReplicaElectionResult;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.protocol.Errors;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.controller.BrokersToIsrs.TopicPartition;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.AbstractMap.SimpleImmutableEntry;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Objects;
+import java.util.Random;
+
+import static org.apache.kafka.clients.admin.AlterConfigOp.OpType.SET;
+import static org.apache.kafka.common.config.ConfigResource.Type.TOPIC;
+
+
+public class ReplicationControlManager {
+static class TopicControlInfo {
+private final Uuid id;
+private final TimelineHashMap parts;
+
+TopicControlInfo(SnapshotRegistry snapshotRegistry, Uuid id) {
+this.id = id;
+this.parts = new TimelineHashMap<>(snapshotRegistry, 0);
+}
+}
+
+static class PartitionControlInfo {
+private final int[] replicas;
+private final int[] isr;
+private final int[] removingReplicas;
+private final int[] addingReplicas;
+private final int leader;
+private final int leaderEpoch;
+private final int partitionEpoch;
+
+PartitionControlInfo(PartitionRecord record) {
+this(Replicas.toArray(record.replicas()),
+Replicas.toArray(record.isr()),
+Replicas.toArray(record.removingReplicas()),
+Replicas.toArray(record.addingReplicas()),
+record.leader(),
+record.leaderEpoch(),
+record.partitionEpoch());
+}
+
+PartitionControlInfo(int[] replicas, int[] isr, int[] removingReplicas,
+ int[] addingReplicas, int leader, int leaderEpoch,
+ int partitionEpoch) {
+this.replicas = replicas;
+this.isr = isr;
+
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577146421
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ClusterControlManager.java
##
@@ -0,0 +1,456 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.common.Endpoint;
+import org.apache.kafka.common.errors.DuplicateBrokerRegistrationException;
+import org.apache.kafka.common.errors.StaleBrokerEpochException;
+import org.apache.kafka.common.errors.UnsupportedVersionException;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.security.auth.SecurityProtocol;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistration;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+
+
+public class ClusterControlManager {
+class ReadyBrokersFuture {
+private final CompletableFuture future;
+private final int minBrokers;
+
+ReadyBrokersFuture(CompletableFuture future, int minBrokers) {
+this.future = future;
+this.minBrokers = minBrokers;
+}
+
+boolean check() {
+int numUnfenced = 0;
+for (BrokerRegistration registration :
brokerRegistrations.values()) {
+if (!registration.fenced()) {
+numUnfenced++;
+}
+if (numUnfenced >= minBrokers) {
+return true;
+}
+}
+return false;
+}
+}
+
+/**
+ * The SLF4J log context.
+ */
+private final LogContext logContext;
+
+/**
+ * The SLF4J log object.
+ */
+private final Logger log;
+
+/**
+ * The Kafka clock object to use.
+ */
+private final Time time;
+
+/**
+ * How long sessions should last, in nanoseconds.
+ */
+private final long sessionTimeoutNs;
+
+/**
+ * The replica placement policy to use.
+ */
+private final ReplicaPlacementPolicy placementPolicy;
+
+/**
+ * Maps broker IDs to broker registrations.
+ */
+private final TimelineHashMap
brokerRegistrations;
+
+/**
+ * The broker heartbeat manager, or null if this controller is on standby.
+ */
+private BrokerHeartbeatManager heartbeatManager;
+
+/**
+ * A future which is completed as soon as we have the given number of
brokers
+ * ready.
+ */
+private Optional readyBrokersFuture;
+
+ClusterControlManager(LogContext logContext,
+ Time time,
+ SnapshotRegistry snapshotRegistry,
+ long sessionTimeoutNs,
+ ReplicaPlacementPolicy placementPolicy) {
+this.logContext = logContext;
+this.log = logContext.logger(ClusterControlManager.class);
+this.time = time;
+this.sessionTimeoutNs = sessionTimeoutNs;
+this.placementPolicy = placementPolicy;
+this.brokerRegistrations = new TimelineHashMap<>(snapshotRegistry, 0);
+this.heartbeatManager = null;
+this.readyBrokersFuture = Optional.empty();
+}
+
+/**
+ * Transition
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577143791
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -0,0 +1,712 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.ElectionType;
+import org.apache.kafka.common.Uuid;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.InvalidReplicationFactorException;
+import org.apache.kafka.common.errors.InvalidRequestException;
+import org.apache.kafka.common.errors.InvalidTopicException;
+import org.apache.kafka.common.internals.Topic;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableReplicaAssignment;
+import org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopic;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopicCollection;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import
org.apache.kafka.common.message.CreateTopicsResponseData.CreatableTopicResult;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData.TopicPartitions;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.PartitionResult;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.ReplicaElectionResult;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.protocol.Errors;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.controller.BrokersToIsrs.TopicPartition;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.AbstractMap.SimpleImmutableEntry;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Objects;
+import java.util.Random;
+
+import static org.apache.kafka.clients.admin.AlterConfigOp.OpType.SET;
+import static org.apache.kafka.common.config.ConfigResource.Type.TOPIC;
+
+
+public class ReplicationControlManager {
+static class TopicControlInfo {
+private final Uuid id;
+private final TimelineHashMap parts;
+
+TopicControlInfo(SnapshotRegistry snapshotRegistry, Uuid id) {
+this.id = id;
+this.parts = new TimelineHashMap<>(snapshotRegistry, 0);
+}
+}
+
+static class PartitionControlInfo {
+private final int[] replicas;
+private final int[] isr;
+private final int[] removingReplicas;
+private final int[] addingReplicas;
+private final int leader;
+private final int leaderEpoch;
+private final int partitionEpoch;
+
+PartitionControlInfo(PartitionRecord record) {
+this(Replicas.toArray(record.replicas()),
+Replicas.toArray(record.isr()),
+Replicas.toArray(record.removingReplicas()),
+Replicas.toArray(record.addingReplicas()),
+record.leader(),
+record.leaderEpoch(),
+record.partitionEpoch());
+}
+
+PartitionControlInfo(int[] replicas, int[] isr, int[] removingReplicas,
+ int[] addingReplicas, int leader, int leaderEpoch,
+ int partitionEpoch) {
+this.replicas = replicas;
+this.isr = isr;
+
[GitHub] [kafka] jolshan opened a new pull request #10133: MINOR: Update raft README and add a more specific error message.
jolshan opened a new pull request #10133: URL: https://github.com/apache/kafka/pull/10133 `test-raft-server-start.sh` requires the config to be specified with `--config`. I've included this in the README and added an error message for this specific case. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #10052: KAFKA-12289: Adding test cases for prefix scan in InMemoryKeyValueStore
ableegoldman commented on a change in pull request #10052:
URL: https://github.com/apache/kafka/pull/10052#discussion_r577140223
##
File path:
streams/src/test/java/org/apache/kafka/streams/state/internals/InMemoryKeyValueStoreTest.java
##
@@ -60,4 +67,22 @@ public void shouldRemoveKeysWithNullValues() {
assertThat(store.get(0), nullValue());
}
+
+
+@Test
+public void shouldReturnKeysWithGivenPrefix(){
+store = createKeyValueStore(driver.context());
+final String value = "value";
+final List> entries = new ArrayList<>();
+entries.add(new KeyValue<>(1, value));
+entries.add(new KeyValue<>(2, value));
+entries.add(new KeyValue<>(11, value));
+entries.add(new KeyValue<>(13, value));
+
+store.putAll(entries);
+final KeyValueIterator keysWithPrefix =
store.prefixScan(1, new IntegerSerializer());
Review comment:
Yeah, the underlying store compares the serializer bytes
lexicographically, it doesn't have any concept of "Integer" or any other type.
And the really tricky thing is that it scans lexicographically, which means
from left to right, whereas when we serialize things we usually do so from
right to left. eg `2` in binary is `10` whereas 11 in binary is `1011` and 13
is `1101`.
The problem here is that the serialized version of 2 is a different number
of bytes than the serialized form of 11/13, so the lexicographical comparator
is effectively comparing digits of a different magnitude.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577136289
##
File path:
metadata/src/main/java/org/apache/kafka/controller/QuorumController.java
##
@@ -0,0 +1,920 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.config.ConfigDef;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.ApiException;
+import org.apache.kafka.common.errors.NotControllerException;
+import org.apache.kafka.common.errors.UnknownServerException;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.ConfigRecord;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.QuotaRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.quota.ClientQuotaAlteration;
+import org.apache.kafka.common.quota.ClientQuotaEntity;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.common.utils.Utils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.metalog.MetaLogLeader;
+import org.apache.kafka.metalog.MetaLogListener;
+import org.apache.kafka.metalog.MetaLogManager;
+import org.apache.kafka.queue.EventQueue.EarliestDeadlineFunction;
+import org.apache.kafka.queue.EventQueue;
+import org.apache.kafka.queue.KafkaEventQueue;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.List;
+import java.util.Map.Entry;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Random;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.RejectedExecutionException;
+import java.util.concurrent.TimeUnit;
+import java.util.function.Supplier;
+import java.util.stream.Collectors;
+
+
+public final class QuorumController implements Controller {
+/**
+ * A builder class which creates the QuorumController.
+ */
+static public class Builder {
+private final int nodeId;
+private Time time = Time.SYSTEM;
+private String threadNamePrefix = null;
+private LogContext logContext = null;
+private Map configDefs =
Collections.emptyMap();
+private MetaLogManager logManager = null;
+private Map supportedFeatures =
Collections.emptyMap();
+private short defaultReplicationFactor = 3;
+private int defaultNumPartitions = 1;
+private ReplicaPlacementPolicy replicaPlacementPolicy =
+new SimpleReplicaPlacementPolicy(new Random());
+private long sessionTimeoutNs = TimeUnit.NANOSECONDS.convert(18,
TimeUnit.SECONDS);
+
+public Builder(int nodeId) {
+this.nodeId = nodeId;
+}
+
+public
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577135430
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -0,0 +1,712 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.ElectionType;
+import org.apache.kafka.common.Uuid;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.InvalidReplicationFactorException;
+import org.apache.kafka.common.errors.InvalidRequestException;
+import org.apache.kafka.common.errors.InvalidTopicException;
+import org.apache.kafka.common.internals.Topic;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableReplicaAssignment;
+import org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopic;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopicCollection;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import
org.apache.kafka.common.message.CreateTopicsResponseData.CreatableTopicResult;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData.TopicPartitions;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.PartitionResult;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.ReplicaElectionResult;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.protocol.Errors;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.controller.BrokersToIsrs.TopicPartition;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.AbstractMap.SimpleImmutableEntry;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Objects;
+import java.util.Random;
+
+import static org.apache.kafka.clients.admin.AlterConfigOp.OpType.SET;
+import static org.apache.kafka.common.config.ConfigResource.Type.TOPIC;
+
+
+public class ReplicationControlManager {
+static class TopicControlInfo {
+private final Uuid id;
+private final TimelineHashMap parts;
+
+TopicControlInfo(SnapshotRegistry snapshotRegistry, Uuid id) {
+this.id = id;
+this.parts = new TimelineHashMap<>(snapshotRegistry, 0);
+}
+}
+
+static class PartitionControlInfo {
+private final int[] replicas;
+private final int[] isr;
+private final int[] removingReplicas;
+private final int[] addingReplicas;
+private final int leader;
+private final int leaderEpoch;
+private final int partitionEpoch;
+
+PartitionControlInfo(PartitionRecord record) {
+this(Replicas.toArray(record.replicas()),
+Replicas.toArray(record.isr()),
+Replicas.toArray(record.removingReplicas()),
+Replicas.toArray(record.addingReplicas()),
+record.leader(),
+record.leaderEpoch(),
+record.partitionEpoch());
+}
+
+PartitionControlInfo(int[] replicas, int[] isr, int[] removingReplicas,
+ int[] addingReplicas, int leader, int leaderEpoch,
+ int partitionEpoch) {
+this.replicas = replicas;
+this.isr = isr;
+
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577127231
##
File path:
metadata/src/main/java/org/apache/kafka/controller/ReplicationControlManager.java
##
@@ -0,0 +1,712 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.ElectionType;
+import org.apache.kafka.common.Uuid;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.InvalidReplicationFactorException;
+import org.apache.kafka.common.errors.InvalidRequestException;
+import org.apache.kafka.common.errors.InvalidTopicException;
+import org.apache.kafka.common.internals.Topic;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableReplicaAssignment;
+import org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopic;
+import
org.apache.kafka.common.message.CreateTopicsRequestData.CreatableTopicCollection;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import
org.apache.kafka.common.message.CreateTopicsResponseData.CreatableTopicResult;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData.TopicPartitions;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.PartitionResult;
+import
org.apache.kafka.common.message.ElectLeadersResponseData.ReplicaElectionResult;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.protocol.Errors;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.controller.BrokersToIsrs.TopicPartition;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.apache.kafka.timeline.TimelineHashMap;
+import org.slf4j.Logger;
+
+import java.util.AbstractMap.SimpleImmutableEntry;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.HashMap;
+import java.util.HashSet;
+import java.util.Iterator;
+import java.util.List;
+import java.util.Map;
+import java.util.Map.Entry;
+import java.util.Objects;
+import java.util.Random;
+
+import static org.apache.kafka.clients.admin.AlterConfigOp.OpType.SET;
+import static org.apache.kafka.common.config.ConfigResource.Type.TOPIC;
+
+
+public class ReplicationControlManager {
+static class TopicControlInfo {
+private final Uuid id;
+private final TimelineHashMap parts;
+
+TopicControlInfo(SnapshotRegistry snapshotRegistry, Uuid id) {
+this.id = id;
+this.parts = new TimelineHashMap<>(snapshotRegistry, 0);
+}
+}
+
+static class PartitionControlInfo {
+private final int[] replicas;
+private final int[] isr;
+private final int[] removingReplicas;
+private final int[] addingReplicas;
+private final int leader;
+private final int leaderEpoch;
+private final int partitionEpoch;
+
+PartitionControlInfo(PartitionRecord record) {
+this(Replicas.toArray(record.replicas()),
+Replicas.toArray(record.isr()),
+Replicas.toArray(record.removingReplicas()),
+Replicas.toArray(record.addingReplicas()),
+record.leader(),
+record.leaderEpoch(),
+record.partitionEpoch());
+}
+
+PartitionControlInfo(int[] replicas, int[] isr, int[] removingReplicas,
+ int[] addingReplicas, int leader, int leaderEpoch,
+ int partitionEpoch) {
+this.replicas = replicas;
+this.isr = isr;
+
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070:
URL: https://github.com/apache/kafka/pull/10070#discussion_r577125115
##
File path:
metadata/src/main/java/org/apache/kafka/controller/QuorumController.java
##
@@ -0,0 +1,920 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.kafka.controller;
+
+import org.apache.kafka.clients.admin.AlterConfigOp.OpType;
+import org.apache.kafka.common.config.ConfigDef;
+import org.apache.kafka.common.config.ConfigResource;
+import org.apache.kafka.common.errors.ApiException;
+import org.apache.kafka.common.errors.NotControllerException;
+import org.apache.kafka.common.errors.UnknownServerException;
+import org.apache.kafka.common.message.AlterIsrRequestData;
+import org.apache.kafka.common.message.AlterIsrResponseData;
+import org.apache.kafka.common.message.BrokerHeartbeatRequestData;
+import org.apache.kafka.common.message.BrokerRegistrationRequestData;
+import org.apache.kafka.common.message.CreateTopicsRequestData;
+import org.apache.kafka.common.message.CreateTopicsResponseData;
+import org.apache.kafka.common.message.ElectLeadersRequestData;
+import org.apache.kafka.common.message.ElectLeadersResponseData;
+import org.apache.kafka.common.metadata.ConfigRecord;
+import org.apache.kafka.common.metadata.FenceBrokerRecord;
+import org.apache.kafka.common.metadata.IsrChangeRecord;
+import org.apache.kafka.common.metadata.MetadataRecordType;
+import org.apache.kafka.common.metadata.PartitionRecord;
+import org.apache.kafka.common.metadata.QuotaRecord;
+import org.apache.kafka.common.metadata.RegisterBrokerRecord;
+import org.apache.kafka.common.metadata.TopicRecord;
+import org.apache.kafka.common.metadata.UnfenceBrokerRecord;
+import org.apache.kafka.common.metadata.UnregisterBrokerRecord;
+import org.apache.kafka.common.protocol.ApiMessage;
+import org.apache.kafka.common.quota.ClientQuotaAlteration;
+import org.apache.kafka.common.quota.ClientQuotaEntity;
+import org.apache.kafka.common.requests.ApiError;
+import org.apache.kafka.common.utils.LogContext;
+import org.apache.kafka.common.utils.Time;
+import org.apache.kafka.common.utils.Utils;
+import org.apache.kafka.metadata.ApiMessageAndVersion;
+import org.apache.kafka.metadata.BrokerHeartbeatReply;
+import org.apache.kafka.metadata.BrokerRegistrationReply;
+import org.apache.kafka.metadata.FeatureManager;
+import org.apache.kafka.metadata.VersionRange;
+import org.apache.kafka.metalog.MetaLogLeader;
+import org.apache.kafka.metalog.MetaLogListener;
+import org.apache.kafka.metalog.MetaLogManager;
+import org.apache.kafka.queue.EventQueue.EarliestDeadlineFunction;
+import org.apache.kafka.queue.EventQueue;
+import org.apache.kafka.queue.KafkaEventQueue;
+import org.apache.kafka.timeline.SnapshotRegistry;
+import org.slf4j.Logger;
+
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.Collections;
+import java.util.List;
+import java.util.Map.Entry;
+import java.util.Map;
+import java.util.Optional;
+import java.util.Random;
+import java.util.Set;
+import java.util.concurrent.CompletableFuture;
+import java.util.concurrent.RejectedExecutionException;
+import java.util.concurrent.TimeUnit;
+import java.util.function.Supplier;
+import java.util.stream.Collectors;
+
+
+public final class QuorumController implements Controller {
+/**
+ * A builder class which creates the QuorumController.
+ */
+static public class Builder {
+private final int nodeId;
+private Time time = Time.SYSTEM;
+private String threadNamePrefix = null;
+private LogContext logContext = null;
+private Map configDefs =
Collections.emptyMap();
+private MetaLogManager logManager = null;
+private Map supportedFeatures =
Collections.emptyMap();
+private short defaultReplicationFactor = 3;
+private int defaultNumPartitions = 1;
+private ReplicaPlacementPolicy replicaPlacementPolicy =
+new SimpleReplicaPlacementPolicy(new Random());
+private long sessionTimeoutNs = TimeUnit.NANOSECONDS.convert(18,
TimeUnit.SECONDS);
+
+public Builder(int nodeId) {
+this.nodeId = nodeId;
+}
+
+public
[GitHub] [kafka] cmccabe commented on a change in pull request #10070: KAFKA-12276: Add the quorum controller code
cmccabe commented on a change in pull request #10070: URL: https://github.com/apache/kafka/pull/10070#discussion_r577117523 ## File path: metadata/src/main/java/org/apache/kafka/metalog/LocalLogManager.java ## @@ -0,0 +1,379 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.kafka.metalog; + +import org.apache.kafka.common.protocol.ApiMessage; +import org.apache.kafka.common.utils.LogContext; +import org.apache.kafka.common.utils.Time; +import org.apache.kafka.metadata.ApiMessageAndVersion; +import org.apache.kafka.queue.EventQueue; +import org.apache.kafka.queue.KafkaEventQueue; +import org.slf4j.Logger; +import org.slf4j.LoggerFactory; + +import java.util.AbstractMap.SimpleImmutableEntry; +import java.util.ArrayList; +import java.util.HashMap; +import java.util.Iterator; +import java.util.List; +import java.util.Map.Entry; +import java.util.Objects; +import java.util.TreeMap; +import java.util.concurrent.CompletableFuture; +import java.util.concurrent.ExecutionException; +import java.util.concurrent.ThreadLocalRandom; +import java.util.stream.Collectors; + + +/** + * The LocalLogManager is a test implementation that relies on the contents of memory. Review comment: Yes. I have moved it to the test directory. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] JimGalasyn commented on pull request #9670: DOCS-6076: Clarify config names for EOS versions 1 and 2
JimGalasyn commented on pull request #9670: URL: https://github.com/apache/kafka/pull/9670#issuecomment-780061593 @abbccdda @mjsax Is this ready to merge? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Comment Edited] (KAFKA-10888) Sticky partition leads to uneven product msg, resulting in abnormal delays in some partations
[
https://issues.apache.org/jira/browse/KAFKA-10888?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285383#comment-17285383
]
Jason Gustafson edited comment on KAFKA-10888 at 2/16/21, 6:09 PM:
---
We have found one cause of imbalance when the sticky partitioner is used.
Basically the intuition behind the sticky partitioner breaks down a little bit
when a small `linger.ms` is in use (sadly this is the default). The user is
opting out of batching with this setting which means there is often little
opportunity to fill batches before they get drained and sent. That leaves the
door open to sustained imbalance in some cases.
To see why, suppose that we have a producer writing to 3 partitions with
linger.ms=0 and one partition slows down a little bit for some reason. It could
be a leader change or some transient network issue. The producer will have to
hold onto the batches for that partition until it becomes available. While it
is holding onto those batches, additional batches will begin piling up. Each of
these batches is likely to get filled because the producer is not ready to send
to this partition yet.
Consider this from the perspective of the sticky partitioner. Every time the
slow partition gets selected, the producer will fill the batches completely. On
the other hand, the remaining "fast" partitions will likely not get their
batches filled because of the `linger.ms=0` setting. As soon as a single record
is available, it might get sent. So more data ends up getting written to the
partition that has already started to build a backlog. And even after the cause
of the original slowness (e.g. leader change) gets resolved, it might take some
time for this imbalance to recover. We believe this can even create a runaway
effect if the partition cannot catch up with the handicap of the additional
load.
We analyzed one case where we thought this might be going on. Below I've
summarized the writes over a period of one hour to 3 partitions. Partition 0
here is the "slow" partition. All partitions get roughly the same number of
batches, but the slow partition has much bigger batch sizes.
{code}
Partition TotalBatches TotalBytes TotalRecords BytesPerBatch RecordsPerBatch
0 1683 25953200 2522815420.80 14.99
1 1713 78368784622 4574.94 2.70
2 1711 75462124381 4410.41 2.56
{code}
After restarting the application, the producer was healthy again. It just was
not able to recover with the imbalanced workload.
was (Author: hachikuji):
We have found one cause of imbalance when the sticky partitioner is used.
Basically the intuition behind the sticky partitioner breaks down a little bit
when a small `linger.ms` is in use (sadly this is the default). The user is
sort of opting out of batching with this setting which means there is little
opportunity to fill batches before they get drained and sent. That leaves the
door open for a kind of imbalanced write problem.
To see why, suppose that we have a producer writing to 3 partitions with
linger.ms=0 and one partition slows down a little bit for some reason. It could
be a leader change or some transient network issue. The producer will have to
hold onto the batches for that partition until it becomes available. While it
is holding onto those batches, additional batches will begin piling up. Each of
these batches is likely to get filled because the producer is not ready to send
to this partition yet.
Consider this from the perspective of the sticky partitioner. Every time the
slow partition gets selected, the producer will fill the batches completely. On
the other hand, the remaining "fast" partitions will likely not get their
batches filled because of the `linger.ms=0` setting. As soon as a single record
is available, it might get sent. So more data ends up getting written to the
partition that has already started to build a backlog. And even after the cause
of the original slowness (e.g. leader change) gets resolved, it might take some
time for this imbalance to recover. We believe this can even create a runaway
effect if the partition cannot catch up with the handicap of the additional
load.
We analyzed one case where we thought this might be going on. Below I've
summarized the writes over a period of one hour to 3 partitions. Partition 0
here is the "slow" partition. All partitions get roughly the same number of
batches, but the slow partition has much bigger batch sizes.
{code}
Partition TotalBatches TotalBytes TotalRecords BytesPerBatch RecordsPerBatch
0 1683 25953200 2522815420.80 14.99
1 1713 78368784622 4574.94 2.70
2 1711 75462124381 4410.41 2.56
{code}
After restarting the application, the producer was
[jira] [Commented] (KAFKA-10888) Sticky partition leads to uneven product msg, resulting in abnormal delays in some partations
[
https://issues.apache.org/jira/browse/KAFKA-10888?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285383#comment-17285383
]
Jason Gustafson commented on KAFKA-10888:
-
We have found one cause of imbalance when the sticky partitioner is used.
Basically the intuition behind the sticky partitioner breaks down a little bit
when a small `linger.ms` is in use (sadly this is the default). The user is
sort of opting out of batching with this setting which means there is little
opportunity to fill batches before they get drained and sent. That leaves the
door open for a kind of imbalanced write problem.
To see why, suppose that we have a producer writing to 3 partitions with
linger.ms=0 and one partition slows down a little bit for some reason. It could
be a leader change or some transient network issue. The producer will have to
hold onto the batches for that partition until it becomes available. While it
is holding onto those batches, additional batches will begin piling up. Each of
these batches is likely to get filled because the producer is not ready to send
to this partition yet.
Consider this from the perspective of the sticky partitioner. Every time the
slow partition gets selected, the producer will fill the batches completely. On
the other hand, the remaining "fast" partitions will likely not get their
batches filled because of the `linger.ms=0` setting. As soon as a single record
is available, it might get sent. So more data ends up getting written to the
partition that has already started to build a backlog. And even after the cause
of the original slowness (e.g. leader change) gets resolved, it might take some
time for this imbalance to recover. We believe this can even create a runaway
effect if the partition cannot catch up with the handicap of the additional
load.
We analyzed one case where we thought this might be going on. Below I've
summarized the writes over a period of one hour to 3 partitions. Partition 0
here is the "slow" partition. All partitions get roughly the same number of
batches, but the slow partition has much bigger batch sizes.
{code}
Partition TotalBatches TotalBytes TotalRecords BytesPerBatch RecordsPerBatch
0 1683 25953200 2522815420.80 14.99
1 1713 78368784622 4574.94 2.70
2 1711 75462124381 4410.41 2.56
{code}
After restarting the application, the producer was healthy again. It just was
not able to recover with the imbalanced workload.
> Sticky partition leads to uneven product msg, resulting in abnormal delays
> in some partations
> --
>
> Key: KAFKA-10888
> URL: https://issues.apache.org/jira/browse/KAFKA-10888
> Project: Kafka
> Issue Type: Bug
> Components: clients, producer
>Affects Versions: 2.4.1
>Reporter: jr
>Priority: Major
> Attachments: image-2020-12-24-21-05-02-800.png,
> image-2020-12-24-21-09-47-692.png, image-2020-12-24-21-10-24-407.png
>
>
> 110 producers ,550 partitions ,550 consumers , 5 nodes Kafka cluster
> The producer uses the nullkey+stick partitioner, the total production rate
> is about 100w tps
> Observed partition delay is abnormal and message distribution is uneven,
> which leads to the maximum production and consumption delay of the partition
> with more messages
> abnormal.
> I cannot find reason that stick will make the message distribution uneven
> at this production rate.
> I can't switch to the round-robin partitioner, which will increase the
> delay and cpu cost. Is thathe stick partationer design cause uneven message
> distribution, or this is abnormal. How to solve it?
> !image-2020-12-24-21-09-47-692.png!
> As shown in the picture, the uneven distribution is concentrated on some
> partitions and some brokers, there seems to be some rules.
> This problem does not only occur in one cluster, but in many high tps
> clusters,
> The problem is more obvious on the test cluster we built.
> !image-2020-12-24-21-10-24-407.png!
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-12313) Consider deprecating the default.windowed.serde.inner.class configs
[ https://issues.apache.org/jira/browse/KAFKA-12313?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Guozhang Wang updated KAFKA-12313: -- Fix Version/s: 3.0.0 > Consider deprecating the default.windowed.serde.inner.class configs > --- > > Key: KAFKA-12313 > URL: https://issues.apache.org/jira/browse/KAFKA-12313 > Project: Kafka > Issue Type: Improvement > Components: streams >Reporter: A. Sophie Blee-Goldman >Priority: Major > Labels: needs-kip > Fix For: 3.0.0 > > > During the discussion of KIP-659 we discussed whether it made sense to have a > "default" class for the serdes of windowed inner classes across Streams. > Using these configs instead of specifying an actual Serde object can lead to > subtle bugs, since the WindowedDeserializer requires a windowSize in addition > to the inner class. If the default constructor is invoked, as it will be when > falling back on the config, this windowSize defaults to MAX_VALUE. > If the downstream program doesn't care about the window end time in the > output, then this can go unnoticed and technically there is no problem. But > if anything does depend on the end time, or the user just wants to manually > read the output for testing purposes, then the MAX_VALUE will result in a > garbage timestamp. > We should consider whether the convenience of specifying a config instead of > instantiating a Serde in each operator is really worth the risk of a user > accidentally failing to specify a windowSize -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] purplefox opened a new pull request #10132: Fix ssl close
purplefox opened a new pull request #10132: URL: https://github.com/apache/kafka/pull/10132 *More detailed description of your change, if necessary. The PR title and PR message become the squashed commit message, so use a separate comment to ping reviewers.* *Summary of testing strategy (including rationale) for the feature or bug fix. Unit and/or integration tests are expected for any behaviour change and system tests should be considered for larger changes.* ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (KAFKA-12329) kafka-reassign-partitions command should give a better error message when a topic does not exist
David Jacot created KAFKA-12329:
---
Summary: kafka-reassign-partitions command should give a better
error message when a topic does not exist
Key: KAFKA-12329
URL: https://issues.apache.org/jira/browse/KAFKA-12329
Project: Kafka
Issue Type: Improvement
Reporter: David Jacot
Assignee: David Jacot
The `kafka-reassign-partitions` command spits out a generic when the
reassignment contains a topic which does not exist:
{noformat}
$ ./bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092
--execute --reassignment-json-file reassignment.json
Error: org.apache.kafka.common.errors.UnknownTopicOrPartitionException: This
server does not host this topic-partition.
{noformat}
When the reassignment contains multiple topic-partitions, this is quite
annoying. It would be better if it could at least give the concerned
topic-partition.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] chia7712 merged pull request #10128: MINOR: remove duplicate code of serializing auto-generated data
chia7712 merged pull request #10128: URL: https://github.com/apache/kafka/pull/10128 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on a change in pull request #10024: KAFKA-12273 InterBrokerSendThread#pollOnce throws FatalExitError even…
chia7712 commented on a change in pull request #10024:
URL: https://github.com/apache/kafka/pull/10024#discussion_r576927931
##
File path: core/src/main/scala/kafka/common/InterBrokerSendThread.scala
##
@@ -78,6 +77,9 @@ abstract class InterBrokerSendThread(
failExpiredRequests(now)
unsentRequests.clean()
} catch {
+ case _: DisconnectException if isShutdownInitiated =>
+// DisconnectException is caused by NetworkClient#ensureActive
+// this thread is closing so this error is acceptable
Review comment:
@dajac Could you take a look at above comment? thanks.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] C0urante commented on pull request #10074: KAFKA-12305: Fix Flatten SMT for array types
C0urante commented on pull request #10074: URL: https://github.com/apache/kafka/pull/10074#issuecomment-779866655 @gharris1727 @ncliang @tombentley anyone got time to take a look? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] C0urante commented on pull request #10073: KAFKA-12303: Fix handling of null values by Flatten SMT
C0urante commented on pull request #10073: URL: https://github.com/apache/kafka/pull/10073#issuecomment-779866596 @gharris1727 @ncliang @tombentley anyone got time to take a look? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10383) KTable Join on Foreign key is opinionated
[ https://issues.apache.org/jira/browse/KAFKA-10383?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285225#comment-17285225 ] Marco Lotz commented on KAFKA-10383: [~vvcephei] I have sent the email to Kafka's dev list requesting privileges to create KIP last Thursday. It is still not granted yet. Was there the right place to request the access to create the KIP? > KTable Join on Foreign key is opinionated > -- > > Key: KAFKA-10383 > URL: https://issues.apache.org/jira/browse/KAFKA-10383 > Project: Kafka > Issue Type: Improvement > Components: streams >Affects Versions: 2.4.1 >Reporter: Marco Lotz >Assignee: Marco Lotz >Priority: Major > Labels: needs-kip > > *Status Quo:* > The current implementation of [KIP-213 > |[https://cwiki.apache.org/confluence/display/KAFKA/KIP-213+Support+non-key+joining+in+KTable]] > of Foreign Key Join between two KTables is _opinionated_ in terms of storage > layer. > Independently of the Materialization method provided in the method argument, > it generates an intermediary RocksDB state store. Thus, even when the > Materialization method provided is "in memory", it will use RocksDB > under-the-hood for this internal state-store. > > *Related problems:* > * IT Tests: Having an implicit materialization method for state-store > affects tests using foreign key state-stores. [On windows based systems > |[https://stackoverflow.com/questions/50602512/failed-to-delete-the-state-directory-in-ide-for-kafka-stream-application]], > that are affected by the RocksDB filesystem removal problem, an approach to > avoid the bug is to use in-memory state-stores (rather than exception > swallowing). Having the intermediate RocksDB storage being created > disregarding materialization method forces any IT test to necessarily use the > manual FS deletion with exception swallowing hack. > * Short lived Streams: Ktables can be short lived in a way that neither > persistent storage nor change-logs creation are desired. The current > implementation prevents this. > *Suggestion:* > One possible solution is to use a similar materialization method (to the one > provided in the argument) when creating the intermediary Foreign Key > state-store. If the Materialization is in memory and without changelog, the > same happens in the intermediate state-sore. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-3702) SslTransportLayer.close() does not shutdown gracefully
[ https://issues.apache.org/jira/browse/KAFKA-3702?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285220#comment-17285220 ] Ismael Juma commented on KAFKA-3702: [~purplefox] it may be simplest if you submit a PR with the changes you think are required. :) > SslTransportLayer.close() does not shutdown gracefully > -- > > Key: KAFKA-3702 > URL: https://issues.apache.org/jira/browse/KAFKA-3702 > Project: Kafka > Issue Type: Bug >Affects Versions: 0.10.0.0 >Reporter: Rajini Sivaram >Assignee: Rajini Sivaram >Priority: Major > > The warning "Failed to send SSL Close message" occurs very frequently when > SSL connections are closed. Close should write outbound data and shutdown > gracefully. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-3702) SslTransportLayer.close() does not shutdown gracefully
[
https://issues.apache.org/jira/browse/KAFKA-3702?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285218#comment-17285218
]
Ismael Juma commented on KAFKA-3702:
Also `isOutboundDone` says:
{quote}Returns whether wrap(ByteBuffer, ByteBuffer) will produce any more
outbound data messages.
Note that during the closure phase, a SSLEngine may generate handshake closure
data that must be sent to the peer. wrap() must be called to generate this
data. When this method returns true, no more outbound data will be created.
{quote}
> SslTransportLayer.close() does not shutdown gracefully
> --
>
> Key: KAFKA-3702
> URL: https://issues.apache.org/jira/browse/KAFKA-3702
> Project: Kafka
> Issue Type: Bug
>Affects Versions: 0.10.0.0
>Reporter: Rajini Sivaram
>Assignee: Rajini Sivaram
>Priority: Major
>
> The warning "Failed to send SSL Close message" occurs very frequently when
> SSL connections are closed. Close should write outbound data and shutdown
> gracefully.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-3702) SslTransportLayer.close() does not shutdown gracefully
[ https://issues.apache.org/jira/browse/KAFKA-3702?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285216#comment-17285216 ] Tim Fox commented on KAFKA-3702: >> A possible issue (identified by [~david.mao]) is that we don't check if >>`isOutboundDone` is true in the `close` method. Yes, I think this is also an issue (perhaps a separate one). According to the SSLEngine javadoc, wrap() or isOutboundDone() should be called _repeatedly_ until it returns CLOSED/true. Currently we only call it once and assume it will immediately return with CLOSED/true. > SslTransportLayer.close() does not shutdown gracefully > -- > > Key: KAFKA-3702 > URL: https://issues.apache.org/jira/browse/KAFKA-3702 > Project: Kafka > Issue Type: Bug >Affects Versions: 0.10.0.0 >Reporter: Rajini Sivaram >Assignee: Rajini Sivaram >Priority: Major > > The warning "Failed to send SSL Close message" occurs very frequently when > SSL connections are closed. Close should write outbound data and shutdown > gracefully. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-3702) SslTransportLayer.close() does not shutdown gracefully
[
https://issues.apache.org/jira/browse/KAFKA-3702?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285215#comment-17285215
]
Ismael Juma commented on KAFKA-3702:
[~purplefox] The documentation for `closeOutbound` says you must still call
`wrap` after:
{quote}wrap(ByteBuffer, ByteBuffer) should be called to flush any remaining
handshake data.
{quote}
> SslTransportLayer.close() does not shutdown gracefully
> --
>
> Key: KAFKA-3702
> URL: https://issues.apache.org/jira/browse/KAFKA-3702
> Project: Kafka
> Issue Type: Bug
>Affects Versions: 0.10.0.0
>Reporter: Rajini Sivaram
>Assignee: Rajini Sivaram
>Priority: Major
>
> The warning "Failed to send SSL Close message" occurs very frequently when
> SSL connections are closed. Close should write outbound data and shutdown
> gracefully.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-3702) SslTransportLayer.close() does not shutdown gracefully
[ https://issues.apache.org/jira/browse/KAFKA-3702?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285212#comment-17285212 ] Tim Fox commented on KAFKA-3702: Maybe I am missing something but writing to the connection (via flush) after closeOutbound has been called seems wrong to me. closeOutBound cause close_notify to be sent to the peer. AIUI, you shouldn't wrote more data on a connection after close_notify has been sent. When the peer receives the close_notify it might close the connection. If we then continue to send more data it's likely that we might receive "connection reset by peer" or similar as the connection will already have been closed (I believe this is what we see). > SslTransportLayer.close() does not shutdown gracefully > -- > > Key: KAFKA-3702 > URL: https://issues.apache.org/jira/browse/KAFKA-3702 > Project: Kafka > Issue Type: Bug >Affects Versions: 0.10.0.0 >Reporter: Rajini Sivaram >Assignee: Rajini Sivaram >Priority: Major > > The warning "Failed to send SSL Close message" occurs very frequently when > SSL connections are closed. Close should write outbound data and shutdown > gracefully. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] MarcoLotz opened a new pull request #10131: KAFKA-5146 / move kafka-streams example to a new module
MarcoLotz opened a new pull request #10131: URL: https://github.com/apache/kafka/pull/10131 Moved "streams-examples" to its own module outside kafka-streams module. Because of org.apache.kafka.streams.processor.internals.StateDirectory in kafka-streams module, I had to add the jackson binder dependency. Before the change, It was probably being retrieved as a transitive dependency through "connect-json" dependency. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-3702) SslTransportLayer.close() does not shutdown gracefully
[ https://issues.apache.org/jira/browse/KAFKA-3702?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285199#comment-17285199 ] Ismael Juma commented on KAFKA-3702: A possible issue (identified by [~david.mao]) is that we don't check if `isOutboundDone` is true in the `close` method. > SslTransportLayer.close() does not shutdown gracefully > -- > > Key: KAFKA-3702 > URL: https://issues.apache.org/jira/browse/KAFKA-3702 > Project: Kafka > Issue Type: Bug >Affects Versions: 0.10.0.0 >Reporter: Rajini Sivaram >Assignee: Rajini Sivaram >Priority: Major > > The warning "Failed to send SSL Close message" occurs very frequently when > SSL connections are closed. Close should write outbound data and shutdown > gracefully. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Comment Edited] (KAFKA-5649) Producer is being closed generating ssl exception
[
https://issues.apache.org/jira/browse/KAFKA-5649?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285170#comment-17285170
]
Julian edited comment on KAFKA-5649 at 2/16/21, 12:45 PM:
--
We have now moved to HDP 3.1.5 having spark 2.3.2 and Kafka 2+ but we are
forced to use kafka 0.10 libraries as no structured streaming build for these
combined versions. On this new cluster, the issue is still happening in spark
streaming from kafka. See https://issues.apache.org/jira/browse/SPARK-21453
which I also updated and linked back to this case. I also see
https://issues.apache.org/jira/browse/KAFKA-3702 and
https://issues.apache.org/jira/browse/KAFKA-5649 maybe related here.
Maybe kafka 2 is solving this, but unfortunately we have a long way to go until
we get to spark 2.4, kafka 2+ and the relevant structured streaming builds
supporting these two.
was (Author: julescs0):
We have now moved to HDP 3.1.5 having spark 2.3.2 and Kafka 2+ but we are
forced to use kafka 0.10 libraries as no structured streaming build for these
combined versions. On this new cluster, the issue is still happening in spark
streaming from kafka. See https://issues.apache.org/jira/browse/SPARK-21453
which I also updated and linked back to this case. I also see
https://issues.apache.org/jira/browse/KAFKA-3702 maybe related here.
Maybe kafka 2 is solving this, but unfortunately we have a long way to go until
we get to spark 2.4, kafka 2+ and the relevant structured streaming builds
supporting these two.
> Producer is being closed generating ssl exception
> -
>
> Key: KAFKA-5649
> URL: https://issues.apache.org/jira/browse/KAFKA-5649
> Project: Kafka
> Issue Type: Bug
> Components: producer
>Affects Versions: 0.10.2.1
> Environment: Spark 2.2.0 and kafka 0.10.2.0
>Reporter: Pablo Panero
>Priority: Major
>
> On a streaming job using built-in kafka source and sink (over SSL), with I am
> getting the following exception:
> On a streaming job using built-in kafka source and sink (over SSL), with I
> am getting the following exception:
> Config of the source:
> {code:java}
> val df = spark.readStream
> .format("kafka")
> .option("kafka.bootstrap.servers", config.bootstrapServers)
> .option("failOnDataLoss", value = false)
> .option("kafka.connections.max.idle.ms", 360)
> //SSL: this only applies to communication between Spark and Kafka
> brokers; you are still responsible for separately securing Spark inter-node
> communication.
> .option("kafka.security.protocol", "SASL_SSL")
> .option("kafka.sasl.mechanism", "GSSAPI")
> .option("kafka.sasl.kerberos.service.name", "kafka")
> .option("kafka.ssl.truststore.location", "/etc/pki/java/cacerts")
> .option("kafka.ssl.truststore.password", "changeit")
> .option("subscribe", config.topicConfigList.keys.mkString(","))
> .load()
> {code}
> Config of the sink:
> {code:java}
> .writeStream
> .option("checkpointLocation",
> s"${config.checkpointDir}/${topicConfig._1}/")
> .format("kafka")
> .option("kafka.bootstrap.servers", config.bootstrapServers)
> .option("kafka.connections.max.idle.ms", 360)
> //SSL: this only applies to communication between Spark and Kafka
> brokers; you are still responsible for separately securing Spark inter-node
> communication.
> .option("kafka.security.protocol", "SASL_SSL")
> .option("kafka.sasl.mechanism", "GSSAPI")
> .option("kafka.sasl.kerberos.service.name", "kafka")
> .option("kafka.ssl.truststore.location", "/etc/pki/java/cacerts")
> .option("kafka.ssl.truststore.password", "changeit")
> .start()
> {code}
> And in some cases it throws the exception making the spark job stuck in that
> step. Exception stack trace is the following:
> {code:java}
> 17/07/18 10:11:58 WARN SslTransportLayer: Failed to send SSL Close message
> java.io.IOException: Broken pipe
> at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
> at sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:47)
> at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
> at sun.nio.ch.IOUtil.write(IOUtil.java:65)
> at sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:471)
> at
> org.apache.kafka.common.network.SslTransportLayer.flush(SslTransportLayer.java:195)
> at
> org.apache.kafka.common.network.SslTransportLayer.close(SslTransportLayer.java:163)
> at org.apache.kafka.common.utils.Utils.closeAll(Utils.java:731)
> at
> org.apache.kafka.common.network.KafkaChannel.close(KafkaChannel.java:54)
> at org.apache.kafka.common.network.Selector.doClose(Selector.java:540)
> at
[jira] [Comment Edited] (KAFKA-5649) Producer is being closed generating ssl exception
[
https://issues.apache.org/jira/browse/KAFKA-5649?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285170#comment-17285170
]
Julian edited comment on KAFKA-5649 at 2/16/21, 12:45 PM:
--
We have now moved to HDP 3.1.5 having spark 2.3.2 and Kafka 2+ but we are
forced to use kafka 0.10 libraries as no structured streaming build for these
combined versions. On this new cluster, the issue is still happening in spark
streaming from kafka. See https://issues.apache.org/jira/browse/SPARK-21453
which I also updated and linked back to this case. I also see
https://issues.apache.org/jira/browse/KAFKA-3702 maybe related here.
Maybe kafka 2 is solving this, but unfortunately we have a long way to go until
we get to spark 2.4, kafka 2+ and the relevant structured streaming builds
supporting these two.
was (Author: julescs0):
We have now moved to HDP 3.1.5 having spark 2.3.2 and Kafka 2+ but we are
forced to use kafka 0.10 libraries as no structured streaming build for these
combined versions. On this new cluster, the issue is still happening in spark
streaming from kafka. See https://issues.apache.org/jira/browse/SPARK-21453
which I also updated and linked back to this case. I also see
https://issues.apache.org/jira/browse/KAFKA-3702 and
https://issues.apache.org/jira/browse/KAFKA-5649 maybe related here.
Maybe kafka 2 is solving this, but unfortunately we have a long way to go until
we get to spark 2.4, kafka 2+ and the relevant structured streaming builds
supporting these two.
> Producer is being closed generating ssl exception
> -
>
> Key: KAFKA-5649
> URL: https://issues.apache.org/jira/browse/KAFKA-5649
> Project: Kafka
> Issue Type: Bug
> Components: producer
>Affects Versions: 0.10.2.1
> Environment: Spark 2.2.0 and kafka 0.10.2.0
>Reporter: Pablo Panero
>Priority: Major
>
> On a streaming job using built-in kafka source and sink (over SSL), with I am
> getting the following exception:
> On a streaming job using built-in kafka source and sink (over SSL), with I
> am getting the following exception:
> Config of the source:
> {code:java}
> val df = spark.readStream
> .format("kafka")
> .option("kafka.bootstrap.servers", config.bootstrapServers)
> .option("failOnDataLoss", value = false)
> .option("kafka.connections.max.idle.ms", 360)
> //SSL: this only applies to communication between Spark and Kafka
> brokers; you are still responsible for separately securing Spark inter-node
> communication.
> .option("kafka.security.protocol", "SASL_SSL")
> .option("kafka.sasl.mechanism", "GSSAPI")
> .option("kafka.sasl.kerberos.service.name", "kafka")
> .option("kafka.ssl.truststore.location", "/etc/pki/java/cacerts")
> .option("kafka.ssl.truststore.password", "changeit")
> .option("subscribe", config.topicConfigList.keys.mkString(","))
> .load()
> {code}
> Config of the sink:
> {code:java}
> .writeStream
> .option("checkpointLocation",
> s"${config.checkpointDir}/${topicConfig._1}/")
> .format("kafka")
> .option("kafka.bootstrap.servers", config.bootstrapServers)
> .option("kafka.connections.max.idle.ms", 360)
> //SSL: this only applies to communication between Spark and Kafka
> brokers; you are still responsible for separately securing Spark inter-node
> communication.
> .option("kafka.security.protocol", "SASL_SSL")
> .option("kafka.sasl.mechanism", "GSSAPI")
> .option("kafka.sasl.kerberos.service.name", "kafka")
> .option("kafka.ssl.truststore.location", "/etc/pki/java/cacerts")
> .option("kafka.ssl.truststore.password", "changeit")
> .start()
> {code}
> And in some cases it throws the exception making the spark job stuck in that
> step. Exception stack trace is the following:
> {code:java}
> 17/07/18 10:11:58 WARN SslTransportLayer: Failed to send SSL Close message
> java.io.IOException: Broken pipe
> at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
> at sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:47)
> at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
> at sun.nio.ch.IOUtil.write(IOUtil.java:65)
> at sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:471)
> at
> org.apache.kafka.common.network.SslTransportLayer.flush(SslTransportLayer.java:195)
> at
> org.apache.kafka.common.network.SslTransportLayer.close(SslTransportLayer.java:163)
> at org.apache.kafka.common.utils.Utils.closeAll(Utils.java:731)
> at
> org.apache.kafka.common.network.KafkaChannel.close(KafkaChannel.java:54)
> at org.apache.kafka.common.network.Selector.doClose(Selector.java:540)
> at
[GitHub] [kafka] cadonna commented on a change in pull request #10052: KAFKA-12289: Adding test cases for prefix scan in InMemoryKeyValueStore
cadonna commented on a change in pull request #10052:
URL: https://github.com/apache/kafka/pull/10052#discussion_r576789945
##
File path:
streams/src/test/java/org/apache/kafka/streams/state/internals/InMemoryKeyValueStoreTest.java
##
@@ -60,4 +67,22 @@ public void shouldRemoveKeysWithNullValues() {
assertThat(store.get(0), nullValue());
}
+
+
+@Test
+public void shouldReturnKeysWithGivenPrefix(){
+store = createKeyValueStore(driver.context());
+final String value = "value";
+final List> entries = new ArrayList<>();
+entries.add(new KeyValue<>(1, value));
+entries.add(new KeyValue<>(2, value));
+entries.add(new KeyValue<>(11, value));
+entries.add(new KeyValue<>(13, value));
+
+store.putAll(entries);
+final KeyValueIterator keysWithPrefix =
store.prefixScan(1, new IntegerSerializer());
Review comment:
The reason, we get only `1` when we scan for prefix `1` is that the
integer serializer serializes `11` and `13` in the least significant byte
instead of serializing `1` in the byte before the least significant byte and
`1` and `3` in the least significant byte. With the former the **byte**
lexicographical order of `1 2 11 13` would be `1 2 11 13` which corresponds to
the natural order of integers. With the latter the **byte** lexicographical
order of `1 2 11 13` would be `1 11 13 2` which corresponds to the string
lexicographical order. So the serializer determines the order of the entries
and the store always returns the entries in byte lexicographical order.
You will experience a similar when you call `range(-1, 2)` on the in-memory
state store in the unit test. You will get back an empty result since `-1` is
larger then `2` in byte lexicographical order
when the `IntegerSerializer` is used. Also not the warning that is output,
especially this part `... or serdes that don't preserve ordering when
lexicographically comparing the serialized bytes ...`
I think we should clearly state this limitation in the javadocs of the
`prefixScan()` as we have done for `range()`, maybe with an example.
Currently, to get `prefixScan()` working for all types, we would need to do
a complete scan (i.e. `all()`) followed by a filter, right?
Double checking: Is my understanding correct? @ableegoldman
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-3702) SslTransportLayer.close() does not shutdown gracefully
[ https://issues.apache.org/jira/browse/KAFKA-3702?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285172#comment-17285172 ] Julian commented on KAFKA-3702: --- Hi, I came across this issue while searching in relation to the other two jiras I have been commenting for which this same error is also cropping up. I think these may all be related... Regardless, it all points to kafka 0.10 versions.. this issue has been in our clusters for near 2 years now... https://issues.apache.org/jira/browse/KAFKA-5649 https://issues.apache.org/jira/browse/SPARK-21453 > SslTransportLayer.close() does not shutdown gracefully > -- > > Key: KAFKA-3702 > URL: https://issues.apache.org/jira/browse/KAFKA-3702 > Project: Kafka > Issue Type: Bug >Affects Versions: 0.10.0.0 >Reporter: Rajini Sivaram >Assignee: Rajini Sivaram >Priority: Major > > The warning "Failed to send SSL Close message" occurs very frequently when > SSL connections are closed. Close should write outbound data and shutdown > gracefully. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-12328) Find out partition of a store iterator
fml2 created KAFKA-12328:
Summary: Find out partition of a store iterator
Key: KAFKA-12328
URL: https://issues.apache.org/jira/browse/KAFKA-12328
Project: Kafka
Issue Type: Wish
Reporter: fml2
This question was posted [on
stakoverflow|https://stackoverflow.com/questions/66032099/kafka-streams-how-to-get-the-partition-an-iterartor-is-iterating-over]
and got an answer but the solution is quite complicated hence this ticket.
In my Kafka Streams application, I have a task that sets up a scheduled (by the
wall time) punctuator. The punctuator iterates over the entries of a store and
does something with them. Like this:
{code:java}
var store = context().getStateStore("MyStore");
var iter = store.all();
while (iter.hasNext()) {
var entry = iter.next();
// ... do something with the entry
}
// Print a summary (now): N entries processed
// Print a summary (wish): N entries processed in partition P
{code}
Is it possible to find out which partition the punctuator operates on? The java
docs for {{ProcessorContext.partition()}} states that this method returns
{{-1}} within punctuators.
I've read [Kafka Streams: Punctuate vs
Process|https://stackoverflow.com/questions/50776987/kafka-streams-punctuate-vs-process]
and the answers there. I can understand that a task is, in general, not tied
to a particular partition. But an iterator should be tied IMO.
How can I find out the partition?
Or is my assumption that a particular instance of a store iterator is tied to a
partion wrong?
What I need it for: I'd like to include the partition number in some log
messages. For now, I have several nearly identical log messages stating that
the punctuator does this and that. In order to make those messages "unique" I'd
like to include the partition number into them.
Since I'm working with a single store here (which might be partitioned), I
assume that every single execution of the punctuator is bound to a single
partition of that store.
It would be cool if there were a method {{iterator.partition}} (or similar) to
get this information.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-5649) Producer is being closed generating ssl exception
[
https://issues.apache.org/jira/browse/KAFKA-5649?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17285170#comment-17285170
]
Julian commented on KAFKA-5649:
---
We have now moved to HDP 3.1.5 having spark 2.3.2 and Kafka 2+ but we are
forced to use kafka 0.10 libraries as no structured streaming build for these
combined versions. On this new cluster, the issue is still happening in spark
streaming from kafka. See https://issues.apache.org/jira/browse/SPARK-21453
which I also updated and linked back to this case. I also see
https://issues.apache.org/jira/browse/KAFKA-3702 maybe related here.
Maybe kafka 2 is solving this, but unfortunately we have a long way to go until
we get to spark 2.4, kafka 2+ and the relevant structured streaming builds
supporting these two.
> Producer is being closed generating ssl exception
> -
>
> Key: KAFKA-5649
> URL: https://issues.apache.org/jira/browse/KAFKA-5649
> Project: Kafka
> Issue Type: Bug
> Components: producer
>Affects Versions: 0.10.2.1
> Environment: Spark 2.2.0 and kafka 0.10.2.0
>Reporter: Pablo Panero
>Priority: Major
>
> On a streaming job using built-in kafka source and sink (over SSL), with I am
> getting the following exception:
> On a streaming job using built-in kafka source and sink (over SSL), with I
> am getting the following exception:
> Config of the source:
> {code:java}
> val df = spark.readStream
> .format("kafka")
> .option("kafka.bootstrap.servers", config.bootstrapServers)
> .option("failOnDataLoss", value = false)
> .option("kafka.connections.max.idle.ms", 360)
> //SSL: this only applies to communication between Spark and Kafka
> brokers; you are still responsible for separately securing Spark inter-node
> communication.
> .option("kafka.security.protocol", "SASL_SSL")
> .option("kafka.sasl.mechanism", "GSSAPI")
> .option("kafka.sasl.kerberos.service.name", "kafka")
> .option("kafka.ssl.truststore.location", "/etc/pki/java/cacerts")
> .option("kafka.ssl.truststore.password", "changeit")
> .option("subscribe", config.topicConfigList.keys.mkString(","))
> .load()
> {code}
> Config of the sink:
> {code:java}
> .writeStream
> .option("checkpointLocation",
> s"${config.checkpointDir}/${topicConfig._1}/")
> .format("kafka")
> .option("kafka.bootstrap.servers", config.bootstrapServers)
> .option("kafka.connections.max.idle.ms", 360)
> //SSL: this only applies to communication between Spark and Kafka
> brokers; you are still responsible for separately securing Spark inter-node
> communication.
> .option("kafka.security.protocol", "SASL_SSL")
> .option("kafka.sasl.mechanism", "GSSAPI")
> .option("kafka.sasl.kerberos.service.name", "kafka")
> .option("kafka.ssl.truststore.location", "/etc/pki/java/cacerts")
> .option("kafka.ssl.truststore.password", "changeit")
> .start()
> {code}
> And in some cases it throws the exception making the spark job stuck in that
> step. Exception stack trace is the following:
> {code:java}
> 17/07/18 10:11:58 WARN SslTransportLayer: Failed to send SSL Close message
> java.io.IOException: Broken pipe
> at sun.nio.ch.FileDispatcherImpl.write0(Native Method)
> at sun.nio.ch.SocketDispatcher.write(SocketDispatcher.java:47)
> at sun.nio.ch.IOUtil.writeFromNativeBuffer(IOUtil.java:93)
> at sun.nio.ch.IOUtil.write(IOUtil.java:65)
> at sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:471)
> at
> org.apache.kafka.common.network.SslTransportLayer.flush(SslTransportLayer.java:195)
> at
> org.apache.kafka.common.network.SslTransportLayer.close(SslTransportLayer.java:163)
> at org.apache.kafka.common.utils.Utils.closeAll(Utils.java:731)
> at
> org.apache.kafka.common.network.KafkaChannel.close(KafkaChannel.java:54)
> at org.apache.kafka.common.network.Selector.doClose(Selector.java:540)
> at org.apache.kafka.common.network.Selector.close(Selector.java:531)
> at
> org.apache.kafka.common.network.Selector.pollSelectionKeys(Selector.java:378)
> at org.apache.kafka.common.network.Selector.poll(Selector.java:303)
> at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:349)
> at
> org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:226)
> at
> org.apache.kafka.clients.consumer.KafkaConsumer.pollOnce(KafkaConsumer.java:1047)
> at
> org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:995)
> at
> org.apache.spark.sql.kafka010.CachedKafkaConsumer.poll(CachedKafkaConsumer.scala:298)
> at
>
[GitHub] [kafka] runom opened a new pull request #10130: MINOR: Fix typo in MirrorMaker
runom opened a new pull request #10130: URL: https://github.com/apache/kafka/pull/10130 This PR fixes a typo. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dajac opened a new pull request #10129: KAFKA-10817; Add clusterId validation to Fetch handling
dajac opened a new pull request #10129: URL: https://github.com/apache/kafka/pull/10129 ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org