[GitHub] [kafka] socutes commented on pull request #10749: KAFKA-12773: Use UncheckedIOException when wrapping IOException
socutes commented on pull request #10749: URL: https://github.com/apache/kafka/pull/10749#issuecomment-855340683 @jsancio Can this PR be merged into the trunk? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dongjinleekr commented on a change in pull request #10428: KAFKA-12572: Add import ordering checkstyle rule and configure an automatic formatter
dongjinleekr commented on a change in pull request #10428:
URL: https://github.com/apache/kafka/pull/10428#discussion_r646056035
##
File path: core/src/test/java/kafka/test/MockController.java
##
@@ -250,20 +238,18 @@ private ApiError incrementalAlterResource(ConfigResource
resource,
}
@Override
-public CompletableFuture
-alterPartitionReassignments(AlterPartitionReassignmentsRequestData
request) {
+public CompletableFuture
alterPartitionReassignments(AlterPartitionReassignmentsRequestData request) {
throw new UnsupportedOperationException();
}
@Override
-public CompletableFuture
-listPartitionReassignments(ListPartitionReassignmentsRequestData
request) {
+public CompletableFuture
listPartitionReassignments(ListPartitionReassignmentsRequestData request) {
throw new UnsupportedOperationException();
}
@Override
public CompletableFuture> legacyAlterConfigs(
-Map> newConfigs, boolean
validateOnly) {
+
Map> newConfigs, boolean validateOnly) {
Review comment:
case 1. If you put the parameters of this method on the same line as the
method name and run formatter: remains one line.
case 2. If you put the parameters separated and run formatter: broken.
(below)

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] dongjinleekr commented on a change in pull request #10827: KAFKA-12899: Support --bootstrap-server in ReplicaVerificationTool
dongjinleekr commented on a change in pull request #10827:
URL: https://github.com/apache/kafka/pull/10827#discussion_r646053346
##
File path: core/src/main/scala/kafka/tools/ReplicaVerificationTool.scala
##
@@ -75,9 +75,14 @@ object ReplicaVerificationTool extends Logging {
def main(args: Array[String]): Unit = {
val parser = new OptionParser(false)
-val brokerListOpt = parser.accepts("broker-list", "REQUIRED: The list of
hostname and port of the server to connect to.")
+val brokerListOpt = parser.accepts("broker-list", "DEPRECATED, use
--bootstrap-server instead; ignored if --bootstrap-server is specified. The
list of hostname and port of the server to connect to.")
.withRequiredArg
- .describedAs("hostname:port,...,hostname:port")
+ .describedAs("HOST1:PORT1,...,HOST3:PORT3")
+ .ofType(classOf[String])
+val bootstrapServerOpt = parser.accepts("bootstrap-server", "REQUIRED. The
list of hostname and port of the server to connect to.")
Review comment:
I will. Stay tuned! :smile:
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] wenbingshen commented on a change in pull request #10827: KAFKA-12899: Support --bootstrap-server in ReplicaVerificationTool
wenbingshen commented on a change in pull request #10827:
URL: https://github.com/apache/kafka/pull/10827#discussion_r646052588
##
File path: core/src/main/scala/kafka/tools/ReplicaVerificationTool.scala
##
@@ -75,9 +75,14 @@ object ReplicaVerificationTool extends Logging {
def main(args: Array[String]): Unit = {
val parser = new OptionParser(false)
-val brokerListOpt = parser.accepts("broker-list", "REQUIRED: The list of
hostname and port of the server to connect to.")
+val brokerListOpt = parser.accepts("broker-list", "DEPRECATED, use
--bootstrap-server instead; ignored if --bootstrap-server is specified. The
list of hostname and port of the server to connect to.")
.withRequiredArg
- .describedAs("hostname:port,...,hostname:port")
+ .describedAs("HOST1:PORT1,...,HOST3:PORT3")
+ .ofType(classOf[String])
+val bootstrapServerOpt = parser.accepts("bootstrap-server", "REQUIRED. The
list of hostname and port of the server to connect to.")
Review comment:
Do we need to add a unit test for this new option?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] wenbingshen commented on pull request #10815: KAFKA-12885: Add the --timeout property to kafka-leader-election.sh
wenbingshen commented on pull request #10815: URL: https://github.com/apache/kafka/pull/10815#issuecomment-855314268 @socutes Thanks for your reply. We need a KIP for adding a new flag to a command line tool as it is considered as part of the public API. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Issue Comment Deleted] (KAFKA-5560) LogManager should be able to create new logs based on free disk space
[ https://issues.apache.org/jira/browse/KAFKA-5560?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Georgy updated KAFKA-5560: -- Comment: was deleted (was: [~huxi_2b] [~junrao] Will this task be in progress someday or maybe there is some alternative how to automatically distribute partitions on disks according to partition size and not only count when multiple data log dirs are used?) > LogManager should be able to create new logs based on free disk space > - > > Key: KAFKA-5560 > URL: https://issues.apache.org/jira/browse/KAFKA-5560 > Project: Kafka > Issue Type: Improvement > Components: log >Affects Versions: 0.11.0.0 >Reporter: huxihx >Priority: Major > Labels: needs-kip > > Currently, log manager chooses a directory configured in `log.dirs` by > calculating the number partitions in each directory and then choosing the one > with the fewest partitions. But in some real production scenarios where data > volumes of partitions are not even, some disks nearly become full whereas the > others have a lot of spaces which lead to a poor data distribution. > We should offer a new strategy to users to have log manager honor the real > disk free spaces and choose the directory with the most disk space. Maybe a > new broker configuration parameter is needed, `log.directory.strategy` for > instance. A new KIP is created to track this issue: > https://cwiki.apache.org/confluence/display/KAFKA/KIP-178%3A+Size-based+log+directory+selection+strategy > Does it make sense? -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-188) Support multiple data directories
[ https://issues.apache.org/jira/browse/KAFKA-188?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17358002#comment-17358002 ] Georgy commented on KAFKA-188: -- [~jkreps] please look at KAFKA-12900 It seems that we do not have fair data/IO spread now. > Support multiple data directories > - > > Key: KAFKA-188 > URL: https://issues.apache.org/jira/browse/KAFKA-188 > Project: Kafka > Issue Type: New Feature >Reporter: Jay Kreps >Assignee: Jay Kreps >Priority: Major > Fix For: 0.8.0 > > Attachments: KAFKA-188-v2.patch, KAFKA-188-v3.patch, > KAFKA-188-v4.patch, KAFKA-188-v5.patch, KAFKA-188-v6.patch, > KAFKA-188-v7.patch, KAFKA-188-v8.patch, KAFKA-188.patch > > > Currently we allow only a single data directory. This means that a multi-disk > configuration needs to be a RAID array or LVM volume or something like that > to be mounted as a single directory. > For a high-throughput low-reliability configuration this would mean RAID0 > striping. Common wisdom in Hadoop land has it that a JBOD setup that just > mounts each disk as a separate directory and does application-level balancing > over these results in about 30% write-improvement. For example see this claim > here: > http://old.nabble.com/Re%3A-RAID-vs.-JBOD-p21466110.html > It is not clear to me why this would be the case--it seems the RAID > controller should be able to balance writes as well as the application so it > may depend on the details of the setup. > Nonetheless this would be really easy to implement, all you need to do is add > multiple data directories and balance partition creation over these disks. > One problem this might cause is if a particular topic is much larger than the > others it might unbalance the load across the disks. The partition->disk > assignment policy should probably attempt to evenly spread each topic to > avoid this, rather than just trying keep the number of partitions balanced > between disks. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-12900) JBOD: Partitions count calculation does not take into account topic name
[ https://issues.apache.org/jira/browse/KAFKA-12900?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Georgy updated KAFKA-12900: --- Description: In KAFKA-188 multiple data directories support was implemented. New partitions are spread to multiple log dirs based on partitions count calculation, log dir with least partitions count is selected as next dir. The problem exists because we do not take into account topic names when we do such calculations. As a result some "fat" partitions can be located on fewer disks than they should be. Example: Fat topic "F" with partitions: F1, F2, ... , F6 Thin topic "t" with partitions: t1, t2, ... , t6 Log dirs on broker: dir1, dir2, dir3 What we have now in some cases: dir1: t1 t2 t4 t6 dir2: F1 F3 F4 F5 dir3: F2 t3 t5 F6 There is a skew but in terms of partition calculation it is "balanced" because all of the log dirs have the same partition count. It would be better if we count partitions in all log dirs _for the current topic_ which partition is going to be written. And then log dir with least partitions count for that topic should be the next one. As a result partitions from example above could be spread like this: dir1: t1 F1 t6 F6 dir2: F2 t2 t4 F4 dir3: F3 t3 t5 F5 In my case there will be no skew because the producer's partitioner is "round robin" by default and partition sizes are the same. I've prepared a patch, please check it. was: In [KAFKA-188|https://issues.apache.org/jira/browse/KAFKA-188] multiple data directories support was implemented. New partitions are spread to multiple log dirs based on partitions count calculation, log dir with least partitions count is selected as next dir. The problem exists because we do not take into account topic names when we do such calculations. As a result some "fat" partitions can be located on fewer disks than they should be. Example: Fat topic "F" with partitions: F1, F2, ... , F6 Thin topic "t" with partitions: t1, t2, ... , t6 Log dirs on broker: dir1, dir2, dir3 What we have now in some cases: dir1: t1 t2 t4 t6 dir2: F1 F3 F4 F5 dir3: F2 t3 t5 F6 There is a skew but in terms of partition calculation it is "balanced" because all of the log dirs have the same partition count. It would be better if we count partitions in all log dirs for the current topic which partition is going to be written. And then log dir with least partitions count for that topic should be the next one. As a result partitions from example above could be spread like this: dir1: t1 F1 t6 F6 dir2: F2 t2 t4 F4 dir3: F3 t3 t5 F5 In my case there will be no skew because the producer's partitioner is "round robin" by default and partition sizes are the same. I've prepared a patch, please check it. > JBOD: Partitions count calculation does not take into account topic name > > > Key: KAFKA-12900 > URL: https://issues.apache.org/jira/browse/KAFKA-12900 > Project: Kafka > Issue Type: Bug > Components: core, jbod >Affects Versions: 2.8.0 >Reporter: Georgy >Priority: Major > Attachments: KAFKA-12900.patch > > > In KAFKA-188 multiple data directories support was implemented. New > partitions are spread to multiple log dirs based on partitions count > calculation, log dir with least partitions count is selected as next dir. > The problem exists because we do not take into account topic names when we > do such calculations. As a result some "fat" partitions can be located on > fewer disks than they should be. > Example: > Fat topic "F" with partitions: F1, F2, ... , F6 > Thin topic "t" with partitions: t1, t2, ... , t6 > Log dirs on broker: dir1, dir2, dir3 > What we have now in some cases: > dir1: t1 t2 t4 t6 > dir2: F1 F3 F4 F5 > dir3: F2 t3 t5 F6 > There is a skew but in terms of partition calculation it is "balanced" > because all of the log dirs have the same partition count. > It would be better if we count partitions in all log dirs _for the current > topic_ which partition is going to be written. And then log dir with least > partitions count for that topic should be the next one. As a result > partitions from example above could be spread like this: > dir1: t1 F1 t6 F6 > dir2: F2 t2 t4 F4 > dir3: F3 t3 t5 F5 > In my case there will be no skew because the producer's partitioner is "round > robin" by default and partition sizes are the same. > I've prepared a patch, please check it. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Updated] (KAFKA-12900) JBOD: Partitions count calculation does not take into account topic name
[ https://issues.apache.org/jira/browse/KAFKA-12900?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Georgy updated KAFKA-12900: --- Attachment: KAFKA-12900.patch > JBOD: Partitions count calculation does not take into account topic name > > > Key: KAFKA-12900 > URL: https://issues.apache.org/jira/browse/KAFKA-12900 > Project: Kafka > Issue Type: Bug > Components: core, jbod >Affects Versions: 2.8.0 >Reporter: Georgy >Priority: Major > Attachments: KAFKA-12900.patch > > > In [KAFKA-188|https://issues.apache.org/jira/browse/KAFKA-188] multiple data > directories support was implemented. New partitions are spread to multiple > log dirs based on partitions count calculation, log dir with least partitions > count is selected as next dir. > The problem exists because we do not take into account topic names when we do > such calculations. As a result some "fat" partitions can be located on fewer > disks than they should be. > Example: > Fat topic "F" with partitions: F1, F2, ... , F6 > Thin topic "t" with partitions: t1, t2, ... , t6 > Log dirs on broker: dir1, dir2, dir3 > What we have now in some cases: > dir1: t1 t2 t4 t6 > dir2: F1 F3 F4 F5 > dir3: F2 t3 t5 F6 > There is a skew but in terms of partition calculation it is "balanced" > because all of the log dirs have the same partition count. > It would be better if we count partitions in all log dirs for the current > topic which partition is going to be written. And then log dir with least > partitions count for that topic should be the next one. As a result > partitions from example above could be spread like this: > dir1: t1 F1 t6 F6 > dir2: F2 t2 t4 F4 > dir3: F3 t3 t5 F5 > In my case there will be no skew because the producer's partitioner is "round > robin" by default and partition sizes are the same. > I've prepared a patch, please check it. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-12900) JBOD: Partitions count calculation does not take into account topic name
Georgy created KAFKA-12900: -- Summary: JBOD: Partitions count calculation does not take into account topic name Key: KAFKA-12900 URL: https://issues.apache.org/jira/browse/KAFKA-12900 Project: Kafka Issue Type: Bug Components: core, jbod Affects Versions: 2.8.0 Reporter: Georgy In [KAFKA-188|https://issues.apache.org/jira/browse/KAFKA-188] multiple data directories support was implemented. New partitions are spread to multiple log dirs based on partitions count calculation, log dir with least partitions count is selected as next dir. The problem exists because we do not take into account topic names when we do such calculations. As a result some "fat" partitions can be located on fewer disks than they should be. Example: Fat topic "F" with partitions: F1, F2, ... , F6 Thin topic "t" with partitions: t1, t2, ... , t6 Log dirs on broker: dir1, dir2, dir3 What we have now in some cases: dir1: t1 t2 t4 t6 dir2: F1 F3 F4 F5 dir3: F2 t3 t5 F6 There is a skew but in terms of partition calculation it is "balanced" because all of the log dirs have the same partition count. It would be better if we count partitions in all log dirs for the current topic which partition is going to be written. And then log dir with least partitions count for that topic should be the next one. As a result partitions from example above could be spread like this: dir1: t1 F1 t6 F6 dir2: F2 t2 t4 F4 dir3: F3 t3 t5 F5 In my case there will be no skew because the producer's partitioner is "round robin" by default and partition sizes are the same. I've prepared a patch, please check it. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] ijuma commented on pull request #10828: MINOR: Only log overridden topic configs during topic creation
ijuma commented on pull request #10828: URL: https://github.com/apache/kafka/pull/10828#issuecomment-855297271 @rondagostino Can you double check if what I stated regarding the kraft work is true? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma opened a new pull request #10828: MINOR: Only log overridden topic configs during topic creation
ijuma opened a new pull request #10828: URL: https://github.com/apache/kafka/pull/10828 I think this behavior changed unintentionally as part of the kraft work. Also make sure to redact sensitive and unknown config values. Unit test included. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-12899) Support --bootstrap-server in ReplicaVerificationTool
[ https://issues.apache.org/jira/browse/KAFKA-12899?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17357947#comment-17357947 ] Dongjin Lee commented on KAFKA-12899: - Hi [~guozhang], Please don't leave this issue. I checked all the remaining tools, and this is the last piece of KIP-499 with kafka-streams-application-reset. (linked) I just filed a small KIP on this. > Support --bootstrap-server in ReplicaVerificationTool > - > > Key: KAFKA-12899 > URL: https://issues.apache.org/jira/browse/KAFKA-12899 > Project: Kafka > Issue Type: Improvement > Components: tools >Reporter: Dongjin Lee >Assignee: Dongjin Lee >Priority: Minor > Labels: needs-kip > Fix For: 3.0.0 > > > kafka.tools.ReplicaVerificationTool still uses --broker-list, breaking > consistency with other (already migrated) tools. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] dongjinleekr opened a new pull request #10827: KAFKA-12899: Support --bootstrap-server in ReplicaVerificationTool
dongjinleekr opened a new pull request #10827: URL: https://github.com/apache/kafka/pull/10827 ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (KAFKA-12899) Support --bootstrap-server in ReplicaVerificationTool
Dongjin Lee created KAFKA-12899: --- Summary: Support --bootstrap-server in ReplicaVerificationTool Key: KAFKA-12899 URL: https://issues.apache.org/jira/browse/KAFKA-12899 Project: Kafka Issue Type: Improvement Components: tools Reporter: Dongjin Lee Assignee: Dongjin Lee Fix For: 3.0.0 kafka.tools.ReplicaVerificationTool still uses --broker-list, breaking consistency with other (already migrated) tools. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-10269) AdminClient ListOffsetsResultInfo/timestamp is always -1
[
https://issues.apache.org/jira/browse/KAFKA-10269?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17357938#comment-17357938
]
Dongjin Lee commented on KAFKA-10269:
-
[~huxi_2b] It seems like this is not a bug. Reviewing the code, I found the
following:
1. AdminClient#listOffsets can take OffsetSpec parameter per TopicPartition,
which can be one of EarliestSpec, LatestSpec, TimestampSpec.
2. For EarliestSpec and LatestSpec, a timestamp is not returned. see:
https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/log/Log.scala#L1310
Instead, -1 is returned.
3. For TimestampSpec, the designated timestamp is returned:
https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/cluster/Partition.scala#L1152
I think this issue is rather a lack of documentation.
> AdminClient ListOffsetsResultInfo/timestamp is always -1
>
>
> Key: KAFKA-10269
> URL: https://issues.apache.org/jira/browse/KAFKA-10269
> Project: Kafka
> Issue Type: Bug
> Components: admin
>Affects Versions: 2.5.0
>Reporter: Derek Troy-West
>Priority: Minor
>
> When using AdminClient/listOffsets the resulting ListOffsetResultInfos appear
> to always have a timestamp of -1.
> I've run listOffsets against live clusters with multiple Kafka versions (from
> 1.0 to 2.5) with both CreateTIme and LogAppendTime for
> message.timestamp.type, every result has -1 timestamp.
> e.g.
> {{org.apache.kafka.clients.admin.ListOffsetsResult$ListOffsetsResultInfo#}}{{0x5c3a771}}
> ListOffsetsResultInfo(} offset=23016, timestamp=-1,
> {{leaderEpoch=Optional[0])}}
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] dongjinleekr commented on pull request #10826: KAFKA-7632: Support Compression Level
dongjinleekr commented on pull request #10826: URL: https://github.com/apache/kafka/pull/10826#issuecomment-855263796 @ijuma @guozhangwang Could you have a look when you are free? I refined the original work with a benchmark with a real-world dataset. As you can see in the updated KIP, this option can improve the producer's performance significantly. :pray: -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dongjinleekr edited a comment on pull request #5927: KAFKA-7632: Allow fine-grained configuration for compression
dongjinleekr edited a comment on pull request #5927: URL: https://github.com/apache/kafka/pull/5927#issuecomment-855263224 Closes this PR in preference of a [new one](https://github.com/apache/kafka/pull/10826). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dongjinleekr opened a new pull request #10826: KAFKA-7632: Support Compression Level
dongjinleekr opened a new pull request #10826: URL: https://github.com/apache/kafka/pull/10826 Since I reworked [KIP-390](https://cwiki.apache.org/confluence/display/KAFKA/KIP-390%3A+Support+Compression+Level) from scratch, here I open a new PR. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dongjinleekr commented on pull request #5927: KAFKA-7632: Allow fine-grained configuration for compression
dongjinleekr commented on pull request #5927: URL: https://github.com/apache/kafka/pull/5927#issuecomment-855263224 Closes this PR in preference of a new one. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dongjinleekr closed pull request #5927: KAFKA-7632: Allow fine-grained configuration for compression
dongjinleekr closed pull request #5927: URL: https://github.com/apache/kafka/pull/5927 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-7632) Support Compression Level
[ https://issues.apache.org/jira/browse/KAFKA-7632?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Dongjin Lee updated KAFKA-7632: --- Summary: Support Compression Level (was: Allow fine-grained configuration for compression) > Support Compression Level > - > > Key: KAFKA-7632 > URL: https://issues.apache.org/jira/browse/KAFKA-7632 > Project: Kafka > Issue Type: Improvement > Components: clients >Affects Versions: 2.1.0 > Environment: all >Reporter: Dave Waters >Assignee: Dongjin Lee >Priority: Major > Labels: needs-kip > > The compression level for ZSTD is currently set to use the default level (3), > which is a conservative setting that in some use cases eliminates the value > that ZSTD provides with improved compression. Each use case will vary, so > exposing the level as a broker configuration setting will allow the user to > adjust the level. > Since it applies to the other compression codecs, we should add the same > functionalities to them. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-12370) Refactor KafkaStreams exposed metadata hierarchy
[
https://issues.apache.org/jira/browse/KAFKA-12370?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17357869#comment-17357869
]
Josep Prat commented on KAFKA-12370:
As I'm already half familiar with these changes, I'd might give it a go and
write the KIP. However, due to the timeline, it won't be possible to squeeze
this one for 3.0.0.
Unless [~guozhang] wants to work on this of course.
> Refactor KafkaStreams exposed metadata hierarchy
>
>
> Key: KAFKA-12370
> URL: https://issues.apache.org/jira/browse/KAFKA-12370
> Project: Kafka
> Issue Type: Improvement
> Components: streams
>Reporter: Guozhang Wang
>Priority: Major
> Labels: needs-kip
>
> Currently in KafkaStreams we have two groups of metadata getter:
> 1.
> {code}
> allMetadata
> allMetadataForStore
> {code}
> Return collection of {{StreamsMetadata}}, which only contains the partitions
> as active/standby, plus the hostInfo, but not exposing any task info.
> 2.
> {code}
> queryMetadataForKey
> {code}
> Returns {{KeyQueryMetadata}} that includes the hostInfos of active and
> standbys, plus the partition id.
> 3.
> {code}
> localThreadsMetadata
> {code}
> Returns {{ThreadMetadata}}, that includes a collection of {{TaskMetadata}}
> for active and standby tasks.
> All the above functions are used for interactive queries, but their exposed
> metadata are very different, and some use cases would need to have all
> client, thread, and task metadata to fulfill the feature development. At the
> same time, we may have a more dynamic "task -> thread" mapping in the future
> and also the embedded clients like consumers would not be per thread, but per
> client.
> ---
> Rethinking about the metadata, I feel we can have a more consistent hierarchy
> as the following:
> * {{StreamsMetadata}} represent the metadata for the client, which includes
> the set of {{ThreadMetadata}} for its existing thread and the set of
> {{TaskMetadata}} for active and standby tasks assigned to this client, plus
> client metadata including hostInfo, embedded client ids.
> * {{ThreadMetadata}} includes name, state, the set of {{TaskMetadata}} for
> currently assigned tasks.
> * {{TaskMetadata}} includes the name (including the sub-topology id and the
> partition id), the state, the corresponding sub-topology description
> (including the state store names, source topic names).
> * {{allMetadata}}, {{allMetadataForStore}}, {{allMetadataForKey}} (renamed
> from queryMetadataForKey) returns the set of {{StreamsMetadata}}, and
> {{localMetadata}} (renamed from localThreadMetadata) returns a single
> {{StreamsMetadata}}.
> * {{KeyQueryMetadata}} Class would be deprecated and replaced by
> {{TaskMetadata}}.
> To illustrate as an example, to find out who are the current active host /
> standby hosts of a specific store, we would call {{allMetadataForStore}}, and
> for each returned {{StreamsMetadata}} we loop over their contained
> {{TaskMetadata}} for active / standby, and filter by its corresponding
> sub-topology's description's contained store name.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-12847) Dockerfile needed for kafka system tests needs changes
[
https://issues.apache.org/jira/browse/KAFKA-12847?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17357861#comment-17357861
]
Abhijit Mane commented on KAFKA-12847:
--
Thanks [~chia7712]. I understand what you have noted wherein UID=1000 ensures
ducker uid is 1000 inside container and the "logs" & "results" dirs it creates
are also owned by the same uid (1000) outside the container i.e. on the host as
we map kafka root dir on the host to "/opt/kafka-dev" inside the container. No
confusion there.
However, if I run sysTests as per README, it fails during image build at the
'useradd' step in Dockerfile. Hence tests cannot start. It doesn't matter if
you run as root or non-root or what Linux flavor or arch.
---
server:/kafka> *bash tests/docker/run_tests.sh*
ARG *UID*="1000"
RUN useradd -u $*UID* ducker
// {color:#de350b}*Error during docker build*{color} => useradd: UID 0 is not
unique, root user id is 0
---
I don't want to override anything and stick to defaults. Only after modifying
to a non-conflicting name like UID_DUCKER, does the image build & subsequent
steps succeed triggering the sysTests. Hope I am clear now.
Just curious to know if you did not face this issue and what I maybe missing.
> Dockerfile needed for kafka system tests needs changes
> --
>
> Key: KAFKA-12847
> URL: https://issues.apache.org/jira/browse/KAFKA-12847
> Project: Kafka
> Issue Type: Bug
> Components: system tests
>Affects Versions: 2.8.0, 2.7.1
> Environment: Issue tested in environments below but is independent of
> h/w arch. or Linux flavor: -
> 1.) RHEL-8.3 on x86_64
> 2.) RHEL-8.3 on IBM Power (ppc64le)
> 3.) apache/kafka branch tested: trunk (master)
>Reporter: Abhijit Mane
>Assignee: Abhijit Mane
>Priority: Major
> Labels: easyfix
> Attachments: Dockerfile.upstream, 截圖 2021-06-05 上午1.53.17.png
>
>
> Hello,
> I tried apache/kafka system tests as per documentation: -
> ([https://github.com/apache/kafka/tree/trunk/tests#readme|https://github.com/apache/kafka/tree/trunk/tests#readme_])
> =
> PROBLEM
> ~~
> 1.) As root user, clone kafka github repo and start "kafka system tests"
> # git clone [https://github.com/apache/kafka.git]
> # cd kafka
> # ./gradlew clean systemTestLibs
> # bash tests/docker/run_tests.sh
> 2.) Dockerfile issue -
> [https://github.com/apache/kafka/blob/trunk/tests/docker/Dockerfile]
> This file has an *UID* entry as shown below: -
> ---
> ARG *UID*="1000"
> RUN useradd -u $*UID* ducker
> // {color:#de350b}*Error during docker build*{color} => useradd: UID 0 is not
> unique, root user id is 0
> ---
> I ran everything as root which means the built-in bash environment variable
> 'UID' always
> resolves to 0 and can't be changed. Hence, the docker build fails. The issue
> should be seen even if run as non-root.
> 3.) Next, as root, as per README, I ran: -
> server:/kafka> *bash tests/docker/run_tests.sh*
> The ducker tool builds the container images & switches to user '*ducker*'
> inside the container
> & maps kafka root dir ('kafka') from host to '/opt/kafka-dev' in the
> container.
> Ref:
> [https://github.com/apache/kafka/blob/trunk/tests/docker/ducker-ak|https://github.com/apache/kafka/blob/trunk/tests/docker/ducker-ak]
> Ex: docker run -d *-v "${kafka_dir}:/opt/kafka-dev"*
> This fails as the 'ducker' user has *no write permissions* to create files
> under 'kafka' root dir. Hence, it needs to be made writeable.
> // *chmod -R a+w kafka*
> – needed as container is run as 'ducker' and needs write access since kafka
> root volume from host is mapped to container as "/opt/kafka-dev" where the
> 'ducker' user writes logs
> =
> =
> *FIXES needed*
> ~
> 1.) Dockerfile -
> [https://github.com/apache/kafka/blob/trunk/tests/docker/Dockerfile]
> Change 'UID' to '*UID_DUCKER*'.
> This won't conflict with built in bash env. var UID and the docker image
> build should succeed.
> ---
> ARG *UID_DUCKER*="1000"
> RUN useradd -u $*UID_DUCKER* ducker
> // *{color:#57d9a3}No Error{color}* => No conflict with built-in UID
> ---
> 2.) README needs an update where we must ensure the kafka root dir from where
> the tests
> are launched is writeable to allow the 'ducker' user to create results/logs.
> # chmod -R a+w kafka
> With this, I was able to get the docker images built and system tests started
>
[GitHub] [kafka] tang7526 commented on pull request #10588: KAFKA-12662: add unit test for ProducerPerformance
tang7526 commented on pull request #10588: URL: https://github.com/apache/kafka/pull/10588#issuecomment-855235007 > @tang7526 thanks for your patch. Could you run `benchmark_test.py` to make sure this refactor does not make performance regression? @chia7712 Thank you for your opinion. I have run `benchmark_test.py`. The patch's result is almost the same as trunk. **Before** average run time is 147.171 seconds. average records per sec is 26.8866. average mb_per_sec is 2.564. **After** average run time is 146.313 seconds. average records per sec is 27.1467. average mb_per_sec is 2.589. 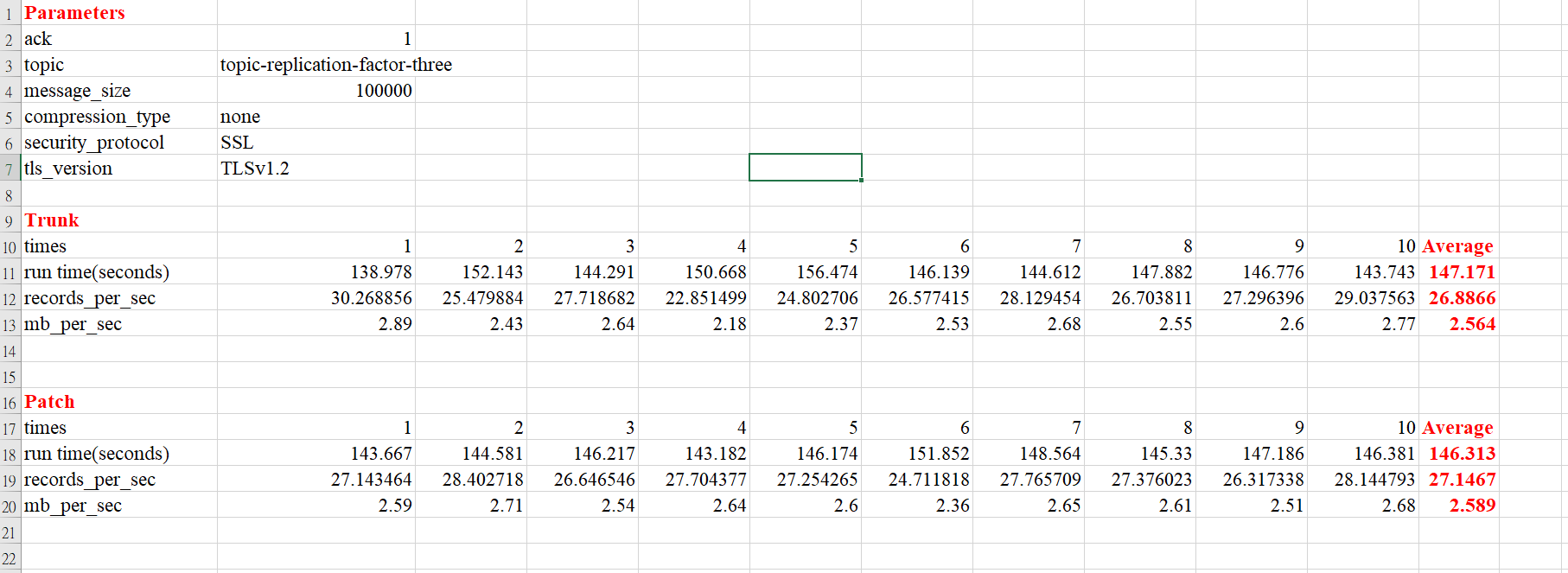 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #10820: KAFKA-12892: disable testChrootExistsAndRootIsLocked
showuon commented on pull request #10820: URL: https://github.com/apache/kafka/pull/10820#issuecomment-855233257 @omkreddy , sure. Hope it fixes the build. Thank you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] omkreddy commented on pull request #10820: KAFKA-12892: disable testChrootExistsAndRootIsLocked
omkreddy commented on pull request #10820: URL: https://github.com/apache/kafka/pull/10820#issuecomment-855231676 @showuon I have merged the PR https://github.com/apache/kafka/pull/10821. Let us monitor any build failures. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] omkreddy merged pull request #10821: KAFKA-12892: Use dedicated root in ZK ACL test
omkreddy merged pull request #10821: URL: https://github.com/apache/kafka/pull/10821 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vitojeng commented on pull request #10825: KAFKA-5876: Add `streams()` method to StateStoreProvider
vitojeng commented on pull request #10825: URL: https://github.com/apache/kafka/pull/10825#issuecomment-855223713 @ableegoldman Please take a look :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] vitojeng opened a new pull request #10825: KAFKA-5876: Add `streams()` method to StateStoreProvider
vitojeng opened a new pull request #10825: URL: https://github.com/apache/kafka/pull/10825 follow-up #8200 KAFKA-5876's PR break into multiple parts, this PR is part 5. In KIP-216, the following exceptions is currently not completed: StreamsRebalancingException, StreamsRebalancingException, StateStoreNotAvailableException. In the CompositeReadOnlyStore class, we need using streams state to decide which exception should be throw. This PR add a new method `streams()` to StateStoreProvider interface, so that we can get streams state in the CompositeReadOnlyStore class to decide which exception should be throw. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] omkreddy commented on pull request #10821: KAFKA-12892: Use dedicated root in ZK ACL test
omkreddy commented on pull request #10821: URL: https://github.com/apache/kafka/pull/10821#issuecomment-855205284 Changes LGTM. let us re-run the tests. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #10821: KAFKA-12892: Use dedicated root in ZK ACL test
showuon commented on pull request #10821: URL: https://github.com/apache/kafka/pull/10821#issuecomment-85519 @soarez , thanks for the quick fix. But unfortunately, the PR build still failed for "JDK 15 and Scala 2.13" build. I don't see the AclException in the log, but still failed the build. FYI. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #10820: KAFKA-12892: disable testChrootExistsAndRootIsLocked
showuon commented on pull request #10820: URL: https://github.com/apache/kafka/pull/10820#issuecomment-855197435 2 PR builds have no build failure. This PR can fix the trunk build failure issue. Thanks. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] predatorray commented on pull request #10525: KAFKA-7572: Producer should not send requests with negative partition id
predatorray commented on pull request #10525: URL: https://github.com/apache/kafka/pull/10525#issuecomment-855196926 @jjkoshy Could you help me review this pr and share some thoughts about the exception with us? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] wenbingshen commented on a change in pull request #10794: KAFKA-12677: parse envelope response to check if not_controller error existed
wenbingshen commented on a change in pull request #10794:
URL: https://github.com/apache/kafka/pull/10794#discussion_r645948173
##
File path:
core/src/main/scala/kafka/server/BrokerToControllerChannelManager.scala
##
@@ -350,7 +372,8 @@ class BrokerToControllerRequestThread(
} else if (response.wasDisconnected()) {
updateControllerAddress(null)
requestQueue.putFirst(queueItem)
-} else if
(response.responseBody().errorCounts().containsKey(Errors.NOT_CONTROLLER)) {
+} else if
(response.responseBody().errorCounts().containsKey(Errors.NOT_CONTROLLER) ||
+
maybeCheckNotControllerErrorInsideEnvelopeResponse(queueItem.requestHeader,
response.responseBody())) {
Review comment:
@showuon Because it's all checking for Not Controller error, can we put
the logic for check NotControllerError into the same method? So the else if
argument is a little bit cleaner. But this is only a small tip, and it's up to
you to decide if you need to do it. This is a great discovery. You have solved
my confusion when I met UNKNOWN_SERVER_ERROR. Thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org