[jira] [Updated] (HDDS-3288) Update default RPC handler SCM/OM count to 100
[
https://issues.apache.org/jira/browse/HDDS-3288?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Mukul Kumar Singh updated HDDS-3288:
Fix Version/s: 0.6.0
Resolution: Fixed
Status: Resolved (was: Patch Available)
Thanks for the contribution [~rakeshr]. I have committed this.
> Update default RPC handler SCM/OM count to 100
> ---
>
> Key: HDDS-3288
> URL: https://issues.apache.org/jira/browse/HDDS-3288
> Project: Hadoop Distributed Data Store
> Issue Type: Improvement
> Components: om, SCM
>Reporter: Rakesh Radhakrishnan
>Assignee: Rakesh Radhakrishnan
>Priority: Minor
> Labels: pull-request-available
> Fix For: 0.6.0
>
> Time Spent: 20m
> Remaining Estimate: 0h
>
> Presently, default PC handler count of {{ozone.scm.handler.count.key=10}} and
> {{ozone.om.handler.count.key=20}} are too small values and its good to
> increase the default values to a realistic value.
> {code:java}
> ozone.om.handler.count.key=100
> ozone.scm.handler.count.key=100
> {code}
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] mukul1987 merged pull request #729: HDDS-3288: Update default RPC handler SCM/OM count to 100
mukul1987 merged pull request #729: HDDS-3288: Update default RPC handler SCM/OM count to 100 URL: https://github.com/apache/hadoop-ozone/pull/729 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Comment Edited] (HDDS-3241) Invalid container reported to SCM should be deleted
[
https://issues.apache.org/jira/browse/HDDS-3241?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17069198#comment-17069198
]
Yiqun Lin edited comment on HDDS-3241 at 3/28/20, 2:55 AM:
---
Thanks for the comments, [~elek] / [~msingh].
Actually current SCM safemode can also ensure this behavior is safe enough once
we startup SCM with wrong container/pipeline db files. And then leads large
containers deleted. This should not happen because SCM won't exit safemode
firstly since DN containers reported will not reach the safemode threshold
anyway.
Also I have mentioned another case that in large clusters, the node sent to
repair and come back to cluster again. SCM deletion behavior can help
automation cleanup Datanode stale container datas. This is also one common
cases.
I have updated the PR to make this configurable and disabled by default. Please
help have a look, thanks.
was (Author: linyiqun):
Thanks for the comments, [~elek] / [~msingh].
Actually current SCM safemode can also protect this behavior once we startup
SCM with wrong container/pipeline db files. And then leads large containers
deleted. This should not happen because SCM won't exit safemode firstly since
DN containers reported will not reach the safemode threshold anyway.
Also I have mentioned another case that in large clusters, the node sent to
repair and come back to cluster again. SCM deletion behavior can help
automation cleanup Datanode stale container datas. This is also one common
cases.
I have updated the PR to make this configurable and disabled by default. Please
help have a look, thanks.
> Invalid container reported to SCM should be deleted
> ---
>
> Key: HDDS-3241
> URL: https://issues.apache.org/jira/browse/HDDS-3241
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
>Affects Versions: 0.4.1
>Reporter: Yiqun Lin
>Assignee: Yiqun Lin
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> For the invalid or out-updated container reported by Datanode,
> ContainerReportHandler in SCM only prints error log and doesn't
> take any action.
> {noformat}
> 2020-03-15 05:19:41,072 ERROR
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler: Received
> container report for an unknown container 37 from datanode
> 0d98dfab-9d34-46c3-93fd-6b64b65ff543{ip: xx.xx.xx.xx, host: lyq-xx.xx.xx.xx,
> networkLocation: /dc2/rack1, certSerialId: null}.
> org.apache.hadoop.hdds.scm.container.ContainerNotFoundException: Container
> with id #37 not found.
> at
> org.apache.hadoop.hdds.scm.container.states.ContainerStateMap.checkIfContainerExist(ContainerStateMap.java:542)
> at
> org.apache.hadoop.hdds.scm.container.states.ContainerStateMap.getContainerInfo(ContainerStateMap.java:188)
> at
> org.apache.hadoop.hdds.scm.container.ContainerStateManager.getContainer(ContainerStateManager.java:484)
> at
> org.apache.hadoop.hdds.scm.container.SCMContainerManager.getContainer(SCMContainerManager.java:204)
> at
> org.apache.hadoop.hdds.scm.container.AbstractContainerReportHandler.processContainerReplica(AbstractContainerReportHandler.java:85)
> at
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler.processContainerReplicas(ContainerReportHandler.java:126)
> at
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler.onMessage(ContainerReportHandler.java:97)
> at
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler.onMessage(ContainerReportHandler.java:46)
> at
> org.apache.hadoop.hdds.server.events.SingleThreadExecutor.lambda$onMessage$1(SingleThreadExecutor.java:81)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
> at java.lang.Thread.run(Thread.java:745)
> 2020-03-15 05:19:41,073 ERROR
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler: Received
> container report for an unknown container 38 from datanode
> 0d98dfab-9d34-46c3-93fd-6b64b65ff543{ip: xx.xx.xx.xx, host: lyq-xx.xx.xx.xx,
> networkLocation: /dc2/rack1, certSerialId: null}.
> org.apache.hadoop.hdds.scm.container.ContainerNotFoundException: Container
> with id #38 not found.
> at
> org.apache.hadoop.hdds.scm.container.states.ContainerStateMap.checkIfContainerExist(ContainerStateMap.java:542)
> at
> org.apache.hadoop.hdds.scm.container.states.ContainerStateMap.getContainerInfo(ContainerStateMap.java:188)
> at
> org.apache.hadoop.hdds.scm.container.ContainerStateManager.getContainer(ContainerStateManager.java:484)
> at
> org.apache.hadoop.hdds.scm.cont
[jira] [Commented] (HDDS-3241) Invalid container reported to SCM should be deleted
[
https://issues.apache.org/jira/browse/HDDS-3241?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17069198#comment-17069198
]
Yiqun Lin commented on HDDS-3241:
-
Thanks for the comments, [~elek] / [~msingh].
Actually current SCM safemode can also protect this behavior once we startup
SCM with wrong container/pipeline db files. And then leads large containers
deleted. This should not happen because SCM won't exit safemode firstly since
DN containers reported will not reach the safemode threshold anyway.
Also I have mentioned another case that in large clusters, the node sent to
repair and come back to cluster again. SCM deletion behavior can help
automation cleanup Datanode stale container datas. This is also one common
cases.
I have updated the PR to make this configurable and disabled by default. Please
help have a look, thanks.
> Invalid container reported to SCM should be deleted
> ---
>
> Key: HDDS-3241
> URL: https://issues.apache.org/jira/browse/HDDS-3241
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
>Affects Versions: 0.4.1
>Reporter: Yiqun Lin
>Assignee: Yiqun Lin
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> For the invalid or out-updated container reported by Datanode,
> ContainerReportHandler in SCM only prints error log and doesn't
> take any action.
> {noformat}
> 2020-03-15 05:19:41,072 ERROR
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler: Received
> container report for an unknown container 37 from datanode
> 0d98dfab-9d34-46c3-93fd-6b64b65ff543{ip: xx.xx.xx.xx, host: lyq-xx.xx.xx.xx,
> networkLocation: /dc2/rack1, certSerialId: null}.
> org.apache.hadoop.hdds.scm.container.ContainerNotFoundException: Container
> with id #37 not found.
> at
> org.apache.hadoop.hdds.scm.container.states.ContainerStateMap.checkIfContainerExist(ContainerStateMap.java:542)
> at
> org.apache.hadoop.hdds.scm.container.states.ContainerStateMap.getContainerInfo(ContainerStateMap.java:188)
> at
> org.apache.hadoop.hdds.scm.container.ContainerStateManager.getContainer(ContainerStateManager.java:484)
> at
> org.apache.hadoop.hdds.scm.container.SCMContainerManager.getContainer(SCMContainerManager.java:204)
> at
> org.apache.hadoop.hdds.scm.container.AbstractContainerReportHandler.processContainerReplica(AbstractContainerReportHandler.java:85)
> at
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler.processContainerReplicas(ContainerReportHandler.java:126)
> at
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler.onMessage(ContainerReportHandler.java:97)
> at
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler.onMessage(ContainerReportHandler.java:46)
> at
> org.apache.hadoop.hdds.server.events.SingleThreadExecutor.lambda$onMessage$1(SingleThreadExecutor.java:81)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
> at java.lang.Thread.run(Thread.java:745)
> 2020-03-15 05:19:41,073 ERROR
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler: Received
> container report for an unknown container 38 from datanode
> 0d98dfab-9d34-46c3-93fd-6b64b65ff543{ip: xx.xx.xx.xx, host: lyq-xx.xx.xx.xx,
> networkLocation: /dc2/rack1, certSerialId: null}.
> org.apache.hadoop.hdds.scm.container.ContainerNotFoundException: Container
> with id #38 not found.
> at
> org.apache.hadoop.hdds.scm.container.states.ContainerStateMap.checkIfContainerExist(ContainerStateMap.java:542)
> at
> org.apache.hadoop.hdds.scm.container.states.ContainerStateMap.getContainerInfo(ContainerStateMap.java:188)
> at
> org.apache.hadoop.hdds.scm.container.ContainerStateManager.getContainer(ContainerStateManager.java:484)
> at
> org.apache.hadoop.hdds.scm.container.SCMContainerManager.getContainer(SCMContainerManager.java:204)
> at
> org.apache.hadoop.hdds.scm.container.AbstractContainerReportHandler.processContainerReplica(AbstractContainerReportHandler.java:85)
> at
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler.processContainerReplicas(ContainerReportHandler.java:126)
> at
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler.onMessage(ContainerReportHandler.java:97)
> at
> org.apache.hadoop.hdds.scm.container.ContainerReportHandler.onMessage(ContainerReportHandler.java:46)
> at
> org.apache.hadoop.hdds.server.events.SingleThreadExecutor.lambda$onMessage$1(SingleThreadExecutor.java:81)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadP
[jira] [Created] (HDDS-3296) Ozone admin should always have read/write ACL permission on ozone objects
Xiaoyu Yao created HDDS-3296: Summary: Ozone admin should always have read/write ACL permission on ozone objects Key: HDDS-3296 URL: https://issues.apache.org/jira/browse/HDDS-3296 Project: Hadoop Distributed Data Store Issue Type: Bug Affects Versions: 0.5.0 Reporter: Xiaoyu Yao Assignee: Xiaoyu Yao Ozone admin should always have read/write acl permission to ozone objects. This way, if owner incorrectly set the acls and lose access, admin can always help to get acces back. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3291) Write operation when both OM followers are shutdown
[
https://issues.apache.org/jira/browse/HDDS-3291?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HDDS-3291:
-
Labels: pull-request-available (was: )
> Write operation when both OM followers are shutdown
> ---
>
> Key: HDDS-3291
> URL: https://issues.apache.org/jira/browse/HDDS-3291
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
>Reporter: Nilotpal Nandi
>Assignee: Bharat Viswanadham
>Priority: Major
> Labels: pull-request-available
>
> steps taken :
> --
> 1. In OM HA environment, shutdown both OM followers.
> 2. Start PUT key operation.
> PUT key operation is hung.
> Cluster details :
> https://quasar-vwryte-1.quasar-vwryte.root.hwx.site:7183/cmf/home
> Snippet of OM log on LEADER:
> {code:java}
> 2020-03-24 04:16:46,249 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:46,249 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:46,250 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:46,250 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:46,750 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:46,750 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:46,750 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:46,750 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:47,250 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:47,251 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:47,251 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:47,251 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:47,751 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:47,751 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:47,752 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:47,752 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:48,252 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:48,252 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:48,252 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:48,252 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:48,752 WARN org.apache.rati
[GitHub] [hadoop-ozone] bharatviswa504 opened a new pull request #733: HDDS-3291. Write operation when both OM followers are shutdown.
bharatviswa504 opened a new pull request #733: HDDS-3291. Write operation when both OM followers are shutdown. URL: https://github.com/apache/hadoop-ozone/pull/733 ## What changes were proposed in this pull request? Add IPC client time out, so that the client will fail with socket time out exception in cases of 2 OM node failures. ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-3291 Please replace this section with the link to the Apache JIRA) ## How was this patch tested? Tested it in docker compose cluster with 1 minute, and see that it failed finally, instead of hanging. To repro this test, we need to change leader.election.time.out value also to large value, as we need this request to be submitted to ratis, and as ratis server keeps on retry then only we will see this issue. 2020-03-27 16:25:27,625 [main] INFO RetryInvocationHandler:411 - com.google.protobuf.ServiceException: java.net.SocketTimeoutException: Call From c5263a1df1ad/172.22.0.3 to om2:9862 failed on socket timeout exception: java.net.SocketTimeoutException: 6 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/172.22.0.3:56460 remote=om2/172.22.0.4:9862]; For more details see: http://wiki.apache.org/hadoop/SocketTimeout, while invoking $Proxy19.submitRequest over nodeId=om2,nodeAddress=om2:9862 after 15 failover attempts. Trying to failover immediately. 2020-03-27 16:25:27,626 [main] ERROR OMFailoverProxyProvider:285 - Failed to connect to OMs: [nodeId=om1,nodeAddress=om1:9862, nodeId=om3,nodeAddress=om3:9862, nodeId=om2,nodeAddress=om2:9862]. Attempted 15 failovers. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] vivekratnavel commented on issue #732: HDDS-3295. Ozone admins getting Permission Denied error while creating volume
vivekratnavel commented on issue #732: HDDS-3295. Ozone admins getting Permission Denied error while creating volume URL: https://github.com/apache/hadoop-ozone/pull/732#issuecomment-605341527 @bharatviswa504 @xiaoyuyao Please review This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3295) Ozone admins getting Permission Denied error while creating volume
[ https://issues.apache.org/jira/browse/HDDS-3295?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDDS-3295: - Labels: pull-request-available (was: ) > Ozone admins getting Permission Denied error while creating volume > --- > > Key: HDDS-3295 > URL: https://issues.apache.org/jira/browse/HDDS-3295 > Project: Hadoop Distributed Data Store > Issue Type: Bug > Components: Security >Affects Versions: 0.5.0 >Reporter: Vivek Ratnavel Subramanian >Assignee: Vivek Ratnavel Subramanian >Priority: Major > Labels: pull-request-available > > Even when a user is added to ozone.administrators, Permission Denied error > is thrown while creating a new volume. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] vivekratnavel opened a new pull request #732: HDDS-3295. Ozone admins getting Permission Denied error while creating volume
vivekratnavel opened a new pull request #732: HDDS-3295. Ozone admins getting Permission Denied error while creating volume URL: https://github.com/apache/hadoop-ozone/pull/732 ## What changes were proposed in this pull request? - get user information from om request instead of client ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-3295 ## How was this patch tested? Tested manually in a cluster by replacing the ozone-manager jar. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3295) Ozone admins getting Permission Denied error while creating volume
Vivek Ratnavel Subramanian created HDDS-3295: Summary: Ozone admins getting Permission Denied error while creating volume Key: HDDS-3295 URL: https://issues.apache.org/jira/browse/HDDS-3295 Project: Hadoop Distributed Data Store Issue Type: Bug Components: Security Affects Versions: 0.5.0 Reporter: Vivek Ratnavel Subramanian Assignee: Vivek Ratnavel Subramanian Even when a user is added to ozone.administrators, Permission Denied error is thrown while creating a new volume. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Commented] (HDDS-3266) Intermittent integration test failure due to DEADLINE_EXCEEDED
[
https://issues.apache.org/jira/browse/HDDS-3266?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17069067#comment-17069067
]
Attila Doroszlai commented on HDDS-3266:
{code:title=https://github.com/apache/hadoop-ozone/pull/582/checks?check_run_id=540143086}
ERROR freon.RandomKeyGenerator (RandomKeyGenerator.java:run(1064)) - Exception
while validating write.
...
Caused by: java.io.IOException: java.util.concurrent.ExecutionException:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED:
ClientCall started after deadline exceeded: -0.186633493s from now
{code}
> Intermittent integration test failure due to DEADLINE_EXCEEDED
> --
>
> Key: HDDS-3266
> URL: https://issues.apache.org/jira/browse/HDDS-3266
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
> Components: test
>Reporter: Attila Doroszlai
>Priority: Blocker
> Attachments:
> org.apache.hadoop.ozone.client.rpc.TestSecureOzoneRpcClient-output.txt,
> org.apache.hadoop.ozone.client.rpc.TestSecureOzoneRpcClient.txt,
> org.apache.hadoop.ozone.freon.TestRandomKeyGenerator-output.txt
>
>
> {code:title=https://github.com/apache/hadoop-ozone/runs/527778966}
> Tests run: 71, Failures: 0, Errors: 1, Skipped: 3, Time elapsed: 85.254 s <<<
> FAILURE! - in org.apache.hadoop.ozone.client.rpc.TestSecureOzoneRpcClient
> testReadKeyWithCorruptedDataWithMutiNodes(org.apache.hadoop.ozone.client.rpc.TestSecureOzoneRpcClient)
> Time elapsed: 2.577 s <<< ERROR!
> java.io.IOException: Unexpected OzoneException: java.io.IOException:
> java.util.concurrent.ExecutionException:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException:
> DEADLINE_EXCEEDED: ClientCall started after deadline exceeded: -0.611771733s
> from now
> at
> org.apache.hadoop.hdds.scm.storage.ChunkInputStream.readChunk(ChunkInputStream.java:341)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] hanishakoneru commented on a change in pull request #625: HDDS-2980. Delete replayed entry from OpenKeyTable during commit
hanishakoneru commented on a change in pull request #625: HDDS-2980. Delete
replayed entry from OpenKeyTable during commit
URL: https://github.com/apache/hadoop-ozone/pull/625#discussion_r399554295
##
File path:
hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/om/request/s3/multipart/S3MultipartUploadCommitPartRequest.java
##
@@ -147,11 +146,6 @@ public OMClientResponse
validateAndUpdateCache(OzoneManager ozoneManager,
throw new OMException("Failed to commit Multipart Upload key, as " +
openKey + "entry is not found in the openKey table",
KEY_NOT_FOUND);
- } else {
-// Check the OpenKeyTable if this transaction is a replay of ratis
logs.
Review comment:
This check was redundant. Irrespective of whether KeyCreate Request was
replayed or not, if key+clientID exits in the openKey table, then the
CommitPart request should also be executed (same as we do for KeyCommit
Request).
If the same Key part was created again, the clientID would be different.
Hence the openKey would also be different.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3266) Intermittent integration test failure due to DEADLINE_EXCEEDED
[
https://issues.apache.org/jira/browse/HDDS-3266?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Attila Doroszlai updated HDDS-3266:
---
Summary: Intermittent integration test failure due to DEADLINE_EXCEEDED
(was: Intermittent TestSecureOzoneRpcClient failure due to DEADLINE_EXCEEDED)
> Intermittent integration test failure due to DEADLINE_EXCEEDED
> --
>
> Key: HDDS-3266
> URL: https://issues.apache.org/jira/browse/HDDS-3266
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
> Components: test
>Reporter: Attila Doroszlai
>Priority: Blocker
> Attachments:
> org.apache.hadoop.ozone.client.rpc.TestSecureOzoneRpcClient-output.txt,
> org.apache.hadoop.ozone.client.rpc.TestSecureOzoneRpcClient.txt,
> org.apache.hadoop.ozone.freon.TestRandomKeyGenerator-output.txt
>
>
> {code:title=https://github.com/apache/hadoop-ozone/runs/527778966}
> Tests run: 71, Failures: 0, Errors: 1, Skipped: 3, Time elapsed: 85.254 s <<<
> FAILURE! - in org.apache.hadoop.ozone.client.rpc.TestSecureOzoneRpcClient
> testReadKeyWithCorruptedDataWithMutiNodes(org.apache.hadoop.ozone.client.rpc.TestSecureOzoneRpcClient)
> Time elapsed: 2.577 s <<< ERROR!
> java.io.IOException: Unexpected OzoneException: java.io.IOException:
> java.util.concurrent.ExecutionException:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException:
> DEADLINE_EXCEEDED: ClientCall started after deadline exceeded: -0.611771733s
> from now
> at
> org.apache.hadoop.hdds.scm.storage.ChunkInputStream.readChunk(ChunkInputStream.java:341)
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 edited a comment on issue #728: Master stable
bharatviswa504 edited a comment on issue #728: Master stable URL: https://github.com/apache/hadoop-ozone/pull/728#issuecomment-605312146 > @bharatviswa504 There are multiple problems. The space issue is fixed thanks to @adoroszlai (and I forget to merge it originally as he wrote). But the space issue is just one problem. > > HDDS-3234 + HDDS-3064 together can cause timeout problems visible both in integration and acceptance tests (at least this is my understanding) Because I see HDDS-3234 PR got committed after a clean run. Might be including both has caused the problem, but once it is affecting write time out and other is reads. But I am fine with reverting, but I just want to say it out here. https://github.com/apache/hadoop-ozone/runs/518369082 I will open a new PR to try out with HDDS-3234 again. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on issue #728: Master stable
bharatviswa504 commented on issue #728: Master stable URL: https://github.com/apache/hadoop-ozone/pull/728#issuecomment-605312146 > @bharatviswa504 There are multiple problems. The space issue is fixed thanks to @adoroszlai (and I forget to merge it originally as he wrote). But the space issue is just one problem. > > HDDS-3234 + HDDS-3064 together can cause timeout problems visible both in integration and acceptance tests (at least this is my understanding) Because I see HDDS-3234 PR got committed after a clean run. https://github.com/apache/hadoop-ozone/runs/518369082 Can we try with reverting that change or I can open a new PR to try out? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #728: Master stable
elek commented on issue #728: Master stable URL: https://github.com/apache/hadoop-ozone/pull/728#issuecomment-605301043 @bharatviswa504 There are multiple problems. The space issue is fixed thanks to @adoroszlai (and I forget to merge it originally as he wrote). But the space issue is just one problem. HDDS-3234 + HDDS-3064 together can cause timeout problems visible both in integration and acceptance tests (at least this is my understanding) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Commented] (HDDS-2011) TestRandomKeyGenerator fails due to timeout
[
https://issues.apache.org/jira/browse/HDDS-2011?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17069020#comment-17069020
]
Siyao Meng commented on HDDS-2011:
--
Also found in:
https://github.com/apache/hadoop-ozone/pull/696/checks?check_run_id=540098578
and
https://github.com/apache/hadoop-ozone/pull/582/checks?check_run_id=540143086
> TestRandomKeyGenerator fails due to timeout
> ---
>
> Key: HDDS-2011
> URL: https://issues.apache.org/jira/browse/HDDS-2011
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
> Components: test
>Reporter: Attila Doroszlai
>Priority: Major
>
> {{TestRandomKeyGenerator#bigFileThan2GB}} is failing intermittently due to
> timeout in Ratis {{appendEntries}}. Commit on pipeline fails, and new
> pipeline cannot be created with 2 nodes (there are 5 nodes total).
> Most recent one:
> https://github.com/elek/ozone-ci/tree/master/trunk/trunk-nightly-pz9vg/integration/hadoop-ozone/tools
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Assigned] (HDDS-3294) Flaky test TestContainerStateMachineFailureOnRead#testReadStateMachineFailureClosesPipeline
[
https://issues.apache.org/jira/browse/HDDS-3294?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Siyao Meng reassigned HDDS-3294:
Assignee: (was: Siyao Meng)
> Flaky test
> TestContainerStateMachineFailureOnRead#testReadStateMachineFailureClosesPipeline
> ---
>
> Key: HDDS-3294
> URL: https://issues.apache.org/jira/browse/HDDS-3294
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
>Reporter: Siyao Meng
>Priority: Major
>
> Shows up in a PR: https://github.com/apache/hadoop-ozone/runs/540133363
> {code:title=log}
> [INFO] Running
> org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead
> [ERROR] Tests run: 1, Failures: 0, Errors: 1, Skipped: 0, Time elapsed:
> 49.766 s <<< FAILURE! - in
> org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead
> [ERROR]
> testReadStateMachineFailureClosesPipeline(org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead)
> Time elapsed: 49.623 s <<< ERROR!
> java.lang.NullPointerException
> at
> org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead.testReadStateMachineFailureClosesPipeline(TestContainerStateMachineFailureOnRead.java:204)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
> at
> org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
> at
> org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
> at
> org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
> at
> org.junit.internal.runners.statements.FailOnTimeout$StatementThread.run(FailOnTimeout.java:74)
> {code}
> {code:title=Location of NPE at
> TestContainerStateMachineFailureOnRead.java:204}
> // delete the container dir from leader
> FileUtil.fullyDelete(new File(
> leaderDn.get().getDatanodeStateMachine()
> .getContainer().getContainerSet()
>
> .getContainer(omKeyLocationInfo.getContainerID()).getContainerData() <-- this
> line
> .getContainerPath()));
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3294) Flaky test TestContainerStateMachineFailureOnRead#testReadStateMachineFailureClosesPipeline
Siyao Meng created HDDS-3294:
Summary: Flaky test
TestContainerStateMachineFailureOnRead#testReadStateMachineFailureClosesPipeline
Key: HDDS-3294
URL: https://issues.apache.org/jira/browse/HDDS-3294
Project: Hadoop Distributed Data Store
Issue Type: Bug
Reporter: Siyao Meng
Assignee: Siyao Meng
Shows up in a PR: https://github.com/apache/hadoop-ozone/runs/540133363
{code:title=log}
[INFO] Running
org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead
[ERROR] Tests run: 1, Failures: 0, Errors: 1, Skipped: 0, Time elapsed: 49.766
s <<< FAILURE! - in
org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead
[ERROR]
testReadStateMachineFailureClosesPipeline(org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead)
Time elapsed: 49.623 s <<< ERROR!
java.lang.NullPointerException
at
org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead.testReadStateMachineFailureClosesPipeline(TestContainerStateMachineFailureOnRead.java:204)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
at
org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at
org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
at
org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at
org.junit.internal.runners.statements.FailOnTimeout$StatementThread.run(FailOnTimeout.java:74)
{code}
{code:title=Location of NPE at TestContainerStateMachineFailureOnRead.java:204}
// delete the container dir from leader
FileUtil.fullyDelete(new File(
leaderDn.get().getDatanodeStateMachine()
.getContainer().getContainerSet()
.getContainer(omKeyLocationInfo.getContainerID()).getContainerData() <-- this
line
.getContainerPath()));
{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDDS-3281) Add timeouts to all robot tests
[ https://issues.apache.org/jira/browse/HDDS-3281?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Hanisha Koneru resolved HDDS-3281. -- Resolution: Fixed > Add timeouts to all robot tests > --- > > Key: HDDS-3281 > URL: https://issues.apache.org/jira/browse/HDDS-3281 > Project: Hadoop Distributed Data Store > Issue Type: Bug > Components: test >Reporter: Hanisha Koneru >Assignee: Hanisha Koneru >Priority: Major > Labels: pull-request-available > Time Spent: 20m > Remaining Estimate: 0h > > We have seen in some CI runs that the acceptance test suit is getting > cancelled as it runs for more than 6 hours. Because of this, the test results > and logs are also not saved. > This Jira aims to add a 5 minute timeout to all robot tests. In case some > tests require more time, we can update the timeout. This would help to > isolate the test which could be causing the whole acceptance test suit to > time out. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] hanishakoneru commented on issue #723: HDDS-3281. Add timeouts to all robot tests
hanishakoneru commented on issue #723: HDDS-3281. Add timeouts to all robot tests URL: https://github.com/apache/hadoop-ozone/pull/723#issuecomment-605255750 Thank you all for the reviews. Will merge this PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] hanishakoneru merged pull request #723: HDDS-3281. Add timeouts to all robot tests
hanishakoneru merged pull request #723: HDDS-3281. Add timeouts to all robot tests URL: https://github.com/apache/hadoop-ozone/pull/723 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] aryangupta1998 opened a new pull request #730: HDDS-3289. Add a freon generator to create nested directories.
aryangupta1998 opened a new pull request #730: HDDS-3289. Add a freon generator to create nested directories. URL: https://github.com/apache/hadoop-ozone/pull/730 ## What changes were proposed in this pull request? This Jira proposes to add a functionality to freon to create nested directories. Also, multiple child directories can be created inside the leaf directory and also multiple top level directories can be created. ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-3289 ## How was this patch tested? Tested manually by running Freon Directory Generator. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3047) ObjectStore#listVolumesByUser and CreateVolumeHandler#call should get principal name by default
[
https://issues.apache.org/jira/browse/HDDS-3047?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Siyao Meng updated HDDS-3047:
-
Summary: ObjectStore#listVolumesByUser and CreateVolumeHandler#call should
get principal name by default (was: ObjectStore#listVolumesByUser and
CreateVolumeHandler#call should get full principal name by default)
> ObjectStore#listVolumesByUser and CreateVolumeHandler#call should get
> principal name by default
> ---
>
> Key: HDDS-3047
> URL: https://issues.apache.org/jira/browse/HDDS-3047
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
> Components: Ozone Client
>Reporter: Siyao Meng
>Assignee: Siyao Meng
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> [{{ObjectStore#listVolumesByUser}}|https://github.com/apache/hadoop-ozone/blob/2fa37ef99b8fb4575169ba8326eeb677b3d2ed74/hadoop-ozone/client/src/main/java/org/apache/hadoop/ozone/client/ObjectStore.java#L249-L256]
> is using {{getShortUserName()}} by default (when user is empty or null):
> {code:java|title=ObjectStore#listVolumesByUser}
> public Iterator listVolumesByUser(String user,
> String volumePrefix, String prevVolume)
> throws IOException {
> if(Strings.isNullOrEmpty(user)) {
> user = UserGroupInformation.getCurrentUser().getShortUserName(); // <--
> }
> return new VolumeIterator(user, volumePrefix, prevVolume);
> }
> {code}
> It should use {{getUserName()}} instead.
> For a quick reference for the difference between {{getUserName()}} and
> {{getShortUserName()}}:
> {code:java|title=UserGroupInformation#getUserName}
> /**
>* Get the user's full principal name.
>* @return the user's full principal name.
>*/
> @InterfaceAudience.Public
> @InterfaceStability.Evolving
> public String getUserName() {
> return user.getName();
> }
> {code}
> {code:java|title=UserGroupInformation#getShortUserName}
> /**
>* Get the user's login name.
>* @return the user's name up to the first '/' or '@'.
>*/
> public String getShortUserName() {
> return user.getShortName();
> }
> {code}
> This won't cause issue if Kerberos is not in use. However, once Kerberos is
> enabled, {{getUserName()}} and {{getShortUserName()}} result differs and can
> cause some issues.
> When Kerberos is enabled, {{getUserName()}} returns full principal name e.g.
> {{om/o...@example.com}}, but {{getShortUserName()}} will return login name
> e.g. {{hadoop}}.
> If {{hadoop.security.auth_to_local}} is set, {{getShortUserName()}} result
> can become very different from full principal name.
> For example, when {{hadoop.security.auth_to_local =
> RULE:[2:$1@$0](.*)s/.*/root/}},
> {{getShortUserName()}} returns {{root}}, while {{getUserName()}} still gives
> {{om/o...@example.com}}.)
> This can lead to user experience issue (when Kerberos is enabled) where the
> user creates a volume with ozone shell ([uses
> {{getUserName()}}|https://github.com/apache/hadoop-ozone/blob/ecb5bf4df1d80723835a1500d595102f3f861708/hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/web/ozShell/volume/CreateVolumeHandler.java#L63-L65]
> internally) then try to list it with {{ObjectStore#listVolumesByUser(null,
> ...)}} ([uses {{getShortUserName()}} by
> default|https://github.com/apache/hadoop-ozone/blob/2fa37ef99b8fb4575169ba8326eeb677b3d2ed74/hadoop-ozone/client/src/main/java/org/apache/hadoop/ozone/client/ObjectStore.java#L238-L256]
> when user param is empty or null), the user won't see any volumes because of
> the mismatch.
> We should also double check *all* usages that uses {{getShortUserName()}}.
> *Update:*
> Xiaoyu and I checked that the usage of {{getShortUserName()}} on the server
> side shouldn't become a problem. Because server should've maintained it's own
> auth_to_local rules (admin should make sure they separate each user into
> different short names. just don't map multiple principal names into the same
> then it won't be a problem).
> The usage in {{BasicOzoneFileSystem}} itself also seems valid because that
> {{getShortUserName()}} is only used for client side purpose (to set
> {{workingDir}}, etc.).
> But the usage in {{ObjectStore#listVolumesByUser}} is confirmed problematic
> at the moment, which needs to be fixed. Same for
> [{{CreateVolumeHandler#call}}|https://github.com/apache/hadoop-ozone/blob/ecb5bf4df1d80723835a1500d595102f3f861708/hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/web/ozShell/volume/CreateVolumeHandler.java#L81-L83]:
> {code:java|title=CreateVolumeHandler#call}
> } else {
> rootName = UserGroupInformation.getCurrentUser().getShortUserName();
> }
> {code}
> It should pa
[GitHub] [hadoop-ozone] aryangupta1998 closed pull request #730: HDDS-3289. Add a freon generator to create nested directories.
aryangupta1998 closed pull request #730: HDDS-3289. Add a freon generator to create nested directories. URL: https://github.com/apache/hadoop-ozone/pull/730 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3047) ObjectStore#listVolumesByUser and CreateVolumeHandler#call should get full principal name by default
[
https://issues.apache.org/jira/browse/HDDS-3047?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Siyao Meng updated HDDS-3047:
-
Summary: ObjectStore#listVolumesByUser and CreateVolumeHandler#call should
get full principal name by default (was: ObjectStore#listVolumesByUser and
CreateVolumeHandler#call should get user's full principal name instead of login
name by default)
> ObjectStore#listVolumesByUser and CreateVolumeHandler#call should get full
> principal name by default
>
>
> Key: HDDS-3047
> URL: https://issues.apache.org/jira/browse/HDDS-3047
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
> Components: Ozone Client
>Reporter: Siyao Meng
>Assignee: Siyao Meng
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> [{{ObjectStore#listVolumesByUser}}|https://github.com/apache/hadoop-ozone/blob/2fa37ef99b8fb4575169ba8326eeb677b3d2ed74/hadoop-ozone/client/src/main/java/org/apache/hadoop/ozone/client/ObjectStore.java#L249-L256]
> is using {{getShortUserName()}} by default (when user is empty or null):
> {code:java|title=ObjectStore#listVolumesByUser}
> public Iterator listVolumesByUser(String user,
> String volumePrefix, String prevVolume)
> throws IOException {
> if(Strings.isNullOrEmpty(user)) {
> user = UserGroupInformation.getCurrentUser().getShortUserName(); // <--
> }
> return new VolumeIterator(user, volumePrefix, prevVolume);
> }
> {code}
> It should use {{getUserName()}} instead.
> For a quick reference for the difference between {{getUserName()}} and
> {{getShortUserName()}}:
> {code:java|title=UserGroupInformation#getUserName}
> /**
>* Get the user's full principal name.
>* @return the user's full principal name.
>*/
> @InterfaceAudience.Public
> @InterfaceStability.Evolving
> public String getUserName() {
> return user.getName();
> }
> {code}
> {code:java|title=UserGroupInformation#getShortUserName}
> /**
>* Get the user's login name.
>* @return the user's name up to the first '/' or '@'.
>*/
> public String getShortUserName() {
> return user.getShortName();
> }
> {code}
> This won't cause issue if Kerberos is not in use. However, once Kerberos is
> enabled, {{getUserName()}} and {{getShortUserName()}} result differs and can
> cause some issues.
> When Kerberos is enabled, {{getUserName()}} returns full principal name e.g.
> {{om/o...@example.com}}, but {{getShortUserName()}} will return login name
> e.g. {{hadoop}}.
> If {{hadoop.security.auth_to_local}} is set, {{getShortUserName()}} result
> can become very different from full principal name.
> For example, when {{hadoop.security.auth_to_local =
> RULE:[2:$1@$0](.*)s/.*/root/}},
> {{getShortUserName()}} returns {{root}}, while {{getUserName()}} still gives
> {{om/o...@example.com}}.)
> This can lead to user experience issue (when Kerberos is enabled) where the
> user creates a volume with ozone shell ([uses
> {{getUserName()}}|https://github.com/apache/hadoop-ozone/blob/ecb5bf4df1d80723835a1500d595102f3f861708/hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/web/ozShell/volume/CreateVolumeHandler.java#L63-L65]
> internally) then try to list it with {{ObjectStore#listVolumesByUser(null,
> ...)}} ([uses {{getShortUserName()}} by
> default|https://github.com/apache/hadoop-ozone/blob/2fa37ef99b8fb4575169ba8326eeb677b3d2ed74/hadoop-ozone/client/src/main/java/org/apache/hadoop/ozone/client/ObjectStore.java#L238-L256]
> when user param is empty or null), the user won't see any volumes because of
> the mismatch.
> We should also double check *all* usages that uses {{getShortUserName()}}.
> *Update:*
> Xiaoyu and I checked that the usage of {{getShortUserName()}} on the server
> side shouldn't become a problem. Because server should've maintained it's own
> auth_to_local rules (admin should make sure they separate each user into
> different short names. just don't map multiple principal names into the same
> then it won't be a problem).
> The usage in {{BasicOzoneFileSystem}} itself also seems valid because that
> {{getShortUserName()}} is only used for client side purpose (to set
> {{workingDir}}, etc.).
> But the usage in {{ObjectStore#listVolumesByUser}} is confirmed problematic
> at the moment, which needs to be fixed. Same for
> [{{CreateVolumeHandler#call}}|https://github.com/apache/hadoop-ozone/blob/ecb5bf4df1d80723835a1500d595102f3f861708/hadoop-ozone/ozone-manager/src/main/java/org/apache/hadoop/ozone/web/ozShell/volume/CreateVolumeHandler.java#L81-L83]:
> {code:java|title=CreateVolumeHandler#call}
> } else {
> rootName = UserGroupInformation.getCurrentUser().getShort
[GitHub] [hadoop-ozone] aryangupta1998 opened a new pull request #730: HDDS-3289. Add a freon generator to create nested directories.
aryangupta1998 opened a new pull request #730: HDDS-3289. Add a freon generator to create nested directories. URL: https://github.com/apache/hadoop-ozone/pull/730 ## What changes were proposed in this pull request? This Jira proposes to add a functionality to freon to create nested directories. Also, multiple child directories can be created inside the leaf directory and also multiple top level directories can be created. ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-3289 ## How was this patch tested? Tested manually by running Freon Directory Generator. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Assigned] (HDDS-2976) Recon throws error while trying to get snapshot in secure environment
[
https://issues.apache.org/jira/browse/HDDS-2976?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Siddharth Wagle reassigned HDDS-2976:
-
Assignee: Prashant Pogde (was: Siddharth Wagle)
> Recon throws error while trying to get snapshot in secure environment
> -
>
> Key: HDDS-2976
> URL: https://issues.apache.org/jira/browse/HDDS-2976
> Project: Hadoop Distributed Data Store
> Issue Type: Sub-task
> Components: Ozone Recon
>Reporter: Vivek Ratnavel Subramanian
>Assignee: Prashant Pogde
>Priority: Critical
>
> Recon throws the following exception while trying to get snapshot from OM in
> a secure env:
> {code:java}
> 10:19:24.743 PMINFO OzoneManagerServiceProviderImpl Obtaining full snapshot
> from Ozone Manager
> 10:19:24.754 PMERROR OzoneManagerServiceProviderImpl Unable to obtain Ozone
> Manager DB Snapshot.
> javax.net.ssl.SSLHandshakeException: Received fatal alert: handshake_failure
> at sun.security.ssl.Alerts.getSSLException(Alerts.java:192)
> at sun.security.ssl.Alerts.getSSLException(Alerts.java:154)
> at sun.security.ssl.SSLSocketImpl.recvAlert(SSLSocketImpl.java:2020)
> at sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:1127)
> at
> sun.security.ssl.SSLSocketImpl.performInitialHandshake(SSLSocketImpl.java:1367)
> at
> sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1395)
> at
> sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1379)
> at
> org.apache.http.conn.ssl.SSLConnectionSocketFactory.createLayeredSocket(SSLConnectionSocketFactory.java:394)
> at
> org.apache.http.conn.ssl.SSLConnectionSocketFactory.connectSocket(SSLConnectionSocketFactory.java:353)
> at
> org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect(DefaultHttpClientConnectionOperator.java:141)
> at
> org.apache.http.impl.conn.PoolingHttpClientConnectionManager.connect(PoolingHttpClientConnectionManager.java:353)
> at
> org.apache.http.impl.execchain.MainClientExec.establishRoute(MainClientExec.java:380)
> at
> org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:236)
> at
> org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:184)
> at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:88)
> at
> org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:110)
> at
> org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:184)
> at
> org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:82)
> at
> org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:107)
> at
> org.apache.hadoop.ozone.recon.ReconUtils.makeHttpCall(ReconUtils.java:232)
> at
> org.apache.hadoop.ozone.recon.spi.impl.OzoneManagerServiceProviderImpl.getOzoneManagerDBSnapshot(OzoneManagerServiceProviderImpl.java:239)
> at
> org.apache.hadoop.ozone.recon.spi.impl.OzoneManagerServiceProviderImpl.updateReconOmDBWithNewSnapshot(OzoneManagerServiceProviderImpl.java:267)
> at
> org.apache.hadoop.ozone.recon.spi.impl.OzoneManagerServiceProviderImpl.syncDataFromOM(OzoneManagerServiceProviderImpl.java:358)
> at
> java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
> at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
> at
> java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
> at
> java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> 10:19:24.755 PMERROR OzoneManagerServiceProviderImpl Null snapshot location
> got from OM.
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] aryangupta1998 closed pull request #730: HDDS-3289. Add a freon generator to create nested directories.
aryangupta1998 closed pull request #730: HDDS-3289. Add a freon generator to create nested directories. URL: https://github.com/apache/hadoop-ozone/pull/730 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3293) read operation failing when two container replicas are corrupted
Nilotpal Nandi created HDDS-3293:
Summary: read operation failing when two container replicas are
corrupted
Key: HDDS-3293
URL: https://issues.apache.org/jira/browse/HDDS-3293
Project: Hadoop Distributed Data Store
Issue Type: Bug
Components: Ozone Datanode
Reporter: Nilotpal Nandi
steps taken :
1) Mounted noise injection FUSE on all datanodes.
2) Write a key ( multi blocks)
3) Select one of the container ids , inject error on 2 container replicas for
that container id.
4) Run GET key operation.
GET key operation fails intermittenly.
Error seen :
-
{noformat}
20/03/27 18:30:40 WARN impl.MetricsConfig: Cannot locate configuration: tried
hadoop-metrics2-xceiverclientmetrics.properties,hadoop-metrics2.properties
E 20/03/27 18:30:40 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot
period at 10 second(s).
E 20/03/27 18:30:40 INFO impl.MetricsSystemImpl: XceiverClientMetrics metrics
system started
E 20/03/27 18:31:12 ERROR scm.XceiverClientGrpc: Failed to execute command
cmdType: ReadChunk
E traceID: "f80a51eaec481a1c:cbb8e92869015a53:f80a51eaec481a1c:0"
E containerID: 67
E datanodeUuid: "96101390-2446-40e6-a54e-36e170497e57"
E readChunk {
E blockID {
E containerID: 67
E localID: 103896435892617248
E blockCommitSequenceId: 1010
E }
E chunkData {
E chunkName: "103896435892617248_chunk_28"
E offset: 113246208
E len: 4194304
E checksumData {
E type: CRC32
E bytesPerChecksum: 1048576
E checksums: "\034\376\313\031"
E checksums: ";U\225\037"
E checksums: "\327m\332."
E checksums: "|\307\004E"
E }
E }
E }
E on the pipeline Pipeline[ Id: bce6316c-9690-452b-80e3-0f3590533444, Nodes:
96101390-2446-40e6-a54e-36e170497e57{ip: 172.27.111.129, host:
quasar-olrywk-3.quasar-olrywk.root.hwx.site, networkLocation: /default-rack,
certSerialId: null}3e85204d-2399-43b5-952a-55b837eb4c1d{ip: 172.27.100.0, host:
quasar-olrywk-1.quasar-olrywk.root.hwx.site, networkLocation: /default-rack,
certSerialId: null}5af0340a-6fee-4ce8-9f68-37fa35566a5a{ip: 172.27.73.0, host:
quasar-olrywk-9.quasar-olrywk.root.hwx.site, networkLocation: /default-rack,
certSerialId: null}, Type:STAND_ALONE, Factor:THREE, State:OPEN,
leaderId:96101390-2446-40e6-a54e-36e170497e57,
CreationTimestamp2020-03-27T03:36:51.880Z].
E Unexpected OzoneException: java.io.IOException:
java.util.concurrent.ExecutionException:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED:
deadline exceeded after 84603913ns. [remote_addr=/172.27.73.0:9859]]{noformat}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] smengcl edited a comment on issue #731: HDDS-3279. Rebase OFS branch
smengcl edited a comment on issue #731: HDDS-3279. Rebase OFS branch URL: https://github.com/apache/hadoop-ozone/pull/731#issuecomment-605202481 Unrelated flaky test `org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead`. Will commit in a min. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] smengcl commented on issue #731: HDDS-3279. Rebase OFS branch
smengcl commented on issue #731: HDDS-3279. Rebase OFS branch URL: https://github.com/apache/hadoop-ozone/pull/731#issuecomment-605202481 Unrelated flaky test `org.apache.hadoop.ozone.client.rpc.TestContainerStateMachineFailureOnRead`. Will merge in a min. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] smengcl merged pull request #731: HDDS-3279. Rebase OFS branch
smengcl merged pull request #731: HDDS-3279. Rebase OFS branch URL: https://github.com/apache/hadoop-ozone/pull/731 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] xiaoyuyao commented on issue #665: HDDS-3160. Disable index and filter block cache for RocksDB.
xiaoyuyao commented on issue #665: HDDS-3160. Disable index and filter block cache for RocksDB. URL: https://github.com/apache/hadoop-ozone/pull/665#issuecomment-605189323 Note even we don't put the filter/index into the block cache after this change, they will still be put into off-heap memory by rocksdb. It is good to track the OM JVM heap usage w/wo this change during compaction to fully understand the impact of this change. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] adoroszlai commented on issue #723: HDDS-3281. Add timeouts to all robot tests
adoroszlai commented on issue #723: HDDS-3281. Add timeouts to all robot tests URL: https://github.com/apache/hadoop-ozone/pull/723#issuecomment-605153928 > @adoroszlai, @elek are we good to merge this patch? Yes, thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] adoroszlai commented on issue #728: Master stable
adoroszlai commented on issue #728: Master stable URL: https://github.com/apache/hadoop-ozone/pull/728#issuecomment-605148945 > Downloaded tarball and see that it failed due to no disk space. Disk space issue was fixed after `master-stable` branch had been created, so fix was brought into the branch with most recent merge from `master`: ``` * 947ca10a1 (origin/master-stable) retrigger build * f801e60e7 Merge remote-tracking branch 'origin/master' into master-stable |\ | * 7d132ce38 (origin/master) HDDS-3179. Pipeline placement based on Topology does not have fallback (#678) | * 3d2856869 HDDS-3074. Make the configuration of container scrub consistent. (#722) | * 07fcb79e8 HDDS-3284. ozonesecure-mr test fails due to lack of disk space (#725) | * 4682babb6 HDDS-3164. Add Recon endpoint to serve missing containers and its metadata. (#714) | * f6be7660a HDDS-3243. Recon should not have the ability to send Create/Close Container commands to Datanode. (#712) | * 824938534 HDDS-3250. Create a separate log file for Warnings and Errors in MiniOzoneChaosCluster. (#711) * | 58cdc36c2 Revert "HDDS-3234. Fix retry interval default in Ozone client. (#698)" * | 1d4227b5d Revert "HDDS-3064. Get Key is hung when READ delay is injected in chunk file path. (#673)" |/ * 512d607df Revert "HDDS-3142. Create isolated enviornment for OM to test it without SCM. (#656)" ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 edited a comment on issue #728: Master stable
bharatviswa504 edited a comment on issue #728: Master stable URL: https://github.com/apache/hadoop-ozone/pull/728#issuecomment-605143568 @elek Even for a revert of HDDS-3234 mr jobs failed. So, HDDS-3234 is not a real issue I think, our underlying CI has some issue. Downloaded tarball and see that it failed due to no disk space. https://user-images.githubusercontent.com/8586345/77783575-5708b000-7016-11ea-9233-c228e471be96.png";> This PR fixed this issue of disk space issue. https://github.com/apache/hadoop-ozone/commit/07fcb79e8253c19d9537772ab8f3d82c51a0220f This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 edited a comment on issue #728: Master stable
bharatviswa504 edited a comment on issue #728: Master stable URL: https://github.com/apache/hadoop-ozone/pull/728#issuecomment-605143568 @elek Even for a revert of HDDS-3234 mr jobs failed. So, HDDS-3234 is not a real issue I think, our underlying CI has some issue. Downloaded tarball and see that it failed due to no disk space. https://user-images.githubusercontent.com/8586345/77783575-5708b000-7016-11ea-9233-c228e471be96.png";> This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] bharatviswa504 commented on issue #728: Master stable
bharatviswa504 commented on issue #728: Master stable URL: https://github.com/apache/hadoop-ozone/pull/728#issuecomment-605143568 @elek Even for revert of HDDS-3234 mr jobs failed. Downloaded tarball and see that it failed due to no disk space. https://user-images.githubusercontent.com/8586345/77783575-5708b000-7016-11ea-9233-c228e471be96.png";> This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] smengcl opened a new pull request #731: HDDS-3279. Rebase OFS branch
smengcl opened a new pull request #731: HDDS-3279. Rebase OFS branch URL: https://github.com/apache/hadoop-ozone/pull/731 ## What changes were proposed in this pull request? Get the necessary changes in OFS dev branch after the rebase to master branch. See the description and comments in https://github.com/apache/hadoop-ozone/pull/721 ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-3279 ## How was this patch tested? Tested in https://github.com/apache/hadoop-ozone/pull/721 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] smengcl edited a comment on issue #721: HDDS-3279. Rebase OFS branch (Draft)
smengcl edited a comment on issue #721: HDDS-3279. Rebase OFS branch (Draft) URL: https://github.com/apache/hadoop-ozone/pull/721#issuecomment-605136056 Thanks @xiaoyuyao . I am going to do the following: 1. Close this PR; 2. Merge master commits to OFS dev branch manually; 3. Create a new PR https://github.com/apache/hadoop-ozone/pull/731 with only the 3 commits I posted in this PR already; 4. Merge that new PR https://github.com/apache/hadoop-ozone/pull/731. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Assigned] (HDDS-3285) MiniOzoneChaosCluster exits because of deadline exceeding
[
https://issues.apache.org/jira/browse/HDDS-3285?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Mukul Kumar Singh reassigned HDDS-3285:
---
Assignee: Shashikant Banerjee
> MiniOzoneChaosCluster exits because of deadline exceeding
> -
>
> Key: HDDS-3285
> URL: https://issues.apache.org/jira/browse/HDDS-3285
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
> Components: Ozone Datanode
>Reporter: Mukul Kumar Singh
>Assignee: Shashikant Banerjee
>Priority: Major
> Labels: MiniOzoneChaosCluster
> Attachments: complete.log.gz
>
>
> 2020-03-26 21:26:48,869 [pool-326-thread-2] INFO util.ExitUtil
> (ExitUtil.java:terminate(210)) - Exiting with status 1: java.io.IOException:
> java.util.concurrent.ExecutionException: org.apache.ratis.thirdparty.io.
> grpc.StatusRuntimeException: DEADLINE_EXCEEDED: ClientCall started after
> deadline exceeded: -4.330590725s from now
> {code}
> 2020-03-26 21:26:48,866 [pool-326-thread-2] ERROR
> loadgenerators.LoadExecutors (LoadExecutors.java:load(64)) - FileSystem
> LOADGEN: null Exiting due to exception
> java.io.IOException: java.util.concurrent.ExecutionException:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException:
> DEADLINE_EXCEEDED: ClientCall started after deadline exceeded: -4.330590725s
> from now
> at
> org.apache.hadoop.hdds.scm.XceiverClientGrpc.sendCommandWithRetry(XceiverClientGrpc.java:359)
> at
> org.apache.hadoop.hdds.scm.XceiverClientGrpc.sendCommandWithTraceIDAndRetry(XceiverClientGrpc.java:281)
> at
> org.apache.hadoop.hdds.scm.XceiverClientGrpc.sendCommand(XceiverClientGrpc.java:259)
> at
> org.apache.hadoop.hdds.scm.storage.ContainerProtocolCalls.getBlock(ContainerProtocolCalls.java:119)
> at
> org.apache.hadoop.hdds.scm.storage.BlockInputStream.getChunkInfos(BlockInputStream.java:199)
> at
> org.apache.hadoop.hdds.scm.storage.BlockInputStream.initialize(BlockInputStream.java:133)
> at
> org.apache.hadoop.hdds.scm.storage.BlockInputStream.read(BlockInputStream.java:254)
> at
> org.apache.hadoop.ozone.client.io.KeyInputStream.read(KeyInputStream.java:197)
> at
> org.apache.hadoop.fs.ozone.OzoneFSInputStream.read(OzoneFSInputStream.java:63)
> at java.io.DataInputStream.read(DataInputStream.java:100)
> at
> org.apache.hadoop.ozone.utils.LoadBucket$ReadOp.doPostOp(LoadBucket.java:205)
> at
> org.apache.hadoop.ozone.utils.LoadBucket$Op.execute(LoadBucket.java:121)
> at
> org.apache.hadoop.ozone.utils.LoadBucket$ReadOp.execute(LoadBucket.java:180)
> at
> org.apache.hadoop.ozone.utils.LoadBucket.readKey(LoadBucket.java:82)
> at
> org.apache.hadoop.ozone.loadgenerators.FilesystemLoadGenerator.generateLoad(FilesystemLoadGenerator.java:54)
> at
> org.apache.hadoop.ozone.loadgenerators.LoadExecutors.load(LoadExecutors.java:62)
> at
> org.apache.hadoop.ozone.loadgenerators.LoadExecutors.lambda$startLoad$0(LoadExecutors.java:78)
> at
> java.util.concurrent.CompletableFuture$AsyncRun.run(CompletableFuture.java:1626)
> at
> java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
> at
> java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
> at java.lang.Thread.run(Thread.java:748)
> Caused by: java.util.concurrent.ExecutionException:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException:
> DEADLINE_EXCEEDED: ClientCall started after deadline exceeded: -4.330590725s
> from now
> at
> java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
> at
> java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1895)
> at
> org.apache.hadoop.hdds.scm.XceiverClientGrpc.sendCommandWithRetry(XceiverClientGrpc.java:336)
> ... 20 more
> Caused by: org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException:
> DEADLINE_EXCEEDED: ClientCall started after deadline exceeded: -4.330590725s
> from now
> at
> org.apache.ratis.thirdparty.io.grpc.Status.asRuntimeException(Status.java:533)
> at
> org.apache.ratis.thirdparty.io.grpc.stub.ClientCalls$StreamObserverToCallListenerAdapter.onClose(ClientCalls.java:442)
> at
> org.apache.ratis.thirdparty.io.grpc.PartialForwardingClientCallListener.onClose(PartialForwardingClientCallListener.java:39)
> at
> org.apache.ratis.thirdparty.io.grpc.ForwardingClientCallListener.onClose(ForwardingClientCallListener.java:23)
> at
> org.apache.ratis.thirdparty.io.grpc.ForwardingClientCallListener$SimpleForwardingClientCallListener.onClose(ForwardingClientCallListener.java:40)
>at
> org.apache.ratis.thirdparty.io.grpc.internal.CensusStat
[GitHub] [hadoop-ozone] smengcl commented on issue #721: HDDS-3279. Rebase OFS branch
smengcl commented on issue #721: HDDS-3279. Rebase OFS branch URL: https://github.com/apache/hadoop-ozone/pull/721#issuecomment-605136056 Thanks @xiaoyuyao . I am going to do the following: 1. Close this PR; 2. Merge master commits to OFS dev branch manually; 3. Create a new PR with only the 3 commits I posted in this PR already; 4. Merge that new PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3291) Write operation when both OM followers are shutdown
[
https://issues.apache.org/jira/browse/HDDS-3291?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Mukul Kumar Singh updated HDDS-3291:
Reporter: Nilotpal Nandi (was: Bharat Viswanadham)
> Write operation when both OM followers are shutdown
> ---
>
> Key: HDDS-3291
> URL: https://issues.apache.org/jira/browse/HDDS-3291
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
>Reporter: Nilotpal Nandi
>Assignee: Bharat Viswanadham
>Priority: Major
>
> steps taken :
> --
> 1. In OM HA environment, shutdown both OM followers.
> 2. Start PUT key operation.
> PUT key operation is hung.
> Cluster details :
> https://quasar-vwryte-1.quasar-vwryte.root.hwx.site:7183/cmf/home
> Snippet of OM log on LEADER:
> {code:java}
> 2020-03-24 04:16:46,249 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:46,249 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:46,250 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:46,250 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:46,750 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:46,750 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:46,750 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:46,750 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:47,250 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:47,251 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:47,251 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:47,251 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:47,751 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:47,751 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:47,752 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:47,752 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:48,252 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:48,252 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
> om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
> org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
> exception
> 2020-03-24 04:16:48,252 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:48,252 INFO org.apache.ratis.server.impl.FollowerInfo:
> om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
> 2020-03-24 04:16:48,752 WARN org.apache.ratis.grpc.server.GrpcLogAppende
[GitHub] [hadoop-ozone] smengcl closed pull request #721: HDDS-3279. Rebase OFS branch
smengcl closed pull request #721: HDDS-3279. Rebase OFS branch URL: https://github.com/apache/hadoop-ozone/pull/721 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-2964) Fix @Ignore-d integration tests
[
https://issues.apache.org/jira/browse/HDDS-2964?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Shashikant Banerjee updated HDDS-2964:
--
Status: Open (was: Patch Available)
> Fix @Ignore-d integration tests
> ---
>
> Key: HDDS-2964
> URL: https://issues.apache.org/jira/browse/HDDS-2964
> Project: Hadoop Distributed Data Store
> Issue Type: Improvement
> Components: test
>Reporter: Marton Elek
>Priority: Major
>
> We marked all the intermittent unit tests with @Ignore to get reliable
> feedback from CI builds.
> Before HDDS-2833 we had 21 @Ignore annotations, HDDS-2833 introduced 34 new
> one.
> We need to review all of these tests and either fix, or delete or convert
> them to real unit tests.
> The current list of ignore tests:
> {code:java}
> hadoop-hdds/server-scm
> org/apache/hadoop/hdds/scm/node/TestContainerPlacement.java: @Ignore
> hadoop-hdds/server-scm
> org/apache/hadoop/hdds/scm/node/TestDeadNodeHandler.java: @Ignore("Tracked
> by HDDS-2508.")
> hadoop-hdds/server-scm
> org/apache/hadoop/hdds/scm/node/TestSCMNodeManager.java: @Ignore
> hadoop-hdds/server-scm
> org/apache/hadoop/hdds/scm/node/TestSCMNodeManager.java: @Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/hdds/scm/container/TestContainerStateManagerIntegration.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/hdds/scm/container/TestContainerStateManagerIntegration.java:
> @Ignore("TODO:HDDS-1159")
> hadoop-ozone/integration-test
> org/apache/hadoop/hdds/scm/pipeline/TestNodeFailure.java: @Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/hdds/scm/pipeline/TestNodeFailure.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/hdds/scm/pipeline/TestRatisPipelineCreateAndDestroy.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/hdds/scm/safemode/TestSCMSafeModeWithPipelineRules.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/Test2WayCommitInRatis.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestBlockOutputStreamWithFailures.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestCloseContainerHandlingByClient.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestCloseContainerHandlingByClient.java:
> @Ignore // test needs to be fixed after close container is handled for
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestCommitWatcher.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestContainerReplicationEndToEnd.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestContainerStateMachineFailures.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestContainerStateMachine.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestDeleteWithSlowFollower.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestFailureHandlingByClient.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestMultiBlockWritesWithDnFailures.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestOzoneAtRestEncryption.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestOzoneClientRetriesOnException.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestOzoneRpcClientAbstract.java: @Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestOzoneRpcClientAbstract.java:
> @Ignore("Debug Jenkins Timeout")
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestOzoneRpcClientForAclAuditLog.java:@Ignore("Fix
> this after adding audit support for HA Acl code. This will be " +
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestOzoneRpcClientWithRatis.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestSecureOzoneRpcClient.java:
> @Ignore("Needs to be moved out of this class as client setup is static")
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/client/rpc/TestWatchForCommit.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/container/common/statemachine/commandhandler/TestBlockDeletion.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/container/common/statemachine/commandhandler/TestCloseContainerByPipeline.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/container/common/transport/server/ratis/TestCSMMetrics.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/ozone/container/ozoneimpl/TestOzoneContainer.java:@Ignore
> hadoop-ozone/integration-test
> org/apache/hadoop/o
[GitHub] [hadoop-ozone] smengcl commented on issue #582: HDDS-3047. ObjectStore#listVolumesByUser and CreateVolumeHandler#call should get user's full principal name instead of login name by default
smengcl commented on issue #582: HDDS-3047. ObjectStore#listVolumesByUser and CreateVolumeHandler#call should get user's full principal name instead of login name by default URL: https://github.com/apache/hadoop-ozone/pull/582#issuecomment-605130860 Rebased to latest master to include test failure fix HDDS-3284. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] smengcl edited a comment on issue #582: HDDS-3047. ObjectStore#listVolumesByUser and CreateVolumeHandler#call should get user's full principal name instead of login name by def
smengcl edited a comment on issue #582: HDDS-3047. ObjectStore#listVolumesByUser and CreateVolumeHandler#call should get user's full principal name instead of login name by default URL: https://github.com/apache/hadoop-ozone/pull/582#issuecomment-605130860 Rebased to latest master to include (unrelated) test failure fix HDDS-3284. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] smengcl commented on issue #696: HDDS-3056. Allow users to list volumes they have access to, and optionally allow all users to list all volumes
smengcl commented on issue #696: HDDS-3056. Allow users to list volumes they have access to, and optionally allow all users to list all volumes URL: https://github.com/apache/hadoop-ozone/pull/696#issuecomment-605129354 Rebased onto latest master to include the acceptance test failure fix HDDS-3284. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3292) Support Hadoop 3.3
Wei-Chiu Chuang created HDDS-3292: - Summary: Support Hadoop 3.3 Key: HDDS-3292 URL: https://issues.apache.org/jira/browse/HDDS-3292 Project: Hadoop Distributed Data Store Issue Type: Task Reporter: Wei-Chiu Chuang Hadoop 3.3.0 is coming out soon. We should start testing Ozone on Hadoop 3.3 -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3291) Write operation when both OM followers are shutdown
[
https://issues.apache.org/jira/browse/HDDS-3291?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Bharat Viswanadham updated HDDS-3291:
-
Description:
steps taken :
--
1. In OM HA environment, shutdown both OM followers.
2. Start PUT key operation.
PUT key operation is hung.
Cluster details :
https://quasar-vwryte-1.quasar-vwryte.root.hwx.site:7183/cmf/home
Snippet of OM log on LEADER:
{code:java}
2020-03-24 04:16:46,249 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:46,249 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:46,250 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:46,250 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:46,750 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:46,750 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:46,750 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:46,750 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:47,250 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:47,251 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:47,251 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:47,251 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:47,751 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:47,751 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:47,752 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:47,752 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:48,252 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:48,252 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:48,252 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:48,252 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:48,752 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:48,752 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:48,753 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:48,753
[jira] [Created] (HDDS-3291) Write operation when both OM followers are shutdown
Bharat Viswanadham created HDDS-3291:
Summary: Write operation when both OM followers are shutdown
Key: HDDS-3291
URL: https://issues.apache.org/jira/browse/HDDS-3291
Project: Hadoop Distributed Data Store
Issue Type: Bug
Reporter: Bharat Viswanadham
Assignee: Bharat Viswanadham
steps taken :
--
1. In OM HA environment, shutdown both OM followers.
2. Start PUT key operation.
PUT key operation is hung.
Cluster details :
https://quasar-vwryte-1.quasar-vwryte.root.hwx.site:7183/cmf/home
Snippet of OM log on LEADER:
{code:java}
2020-03-24 04:16:46,249 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:46,249 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:46,250 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:46,250 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:46,750 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:46,750 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:46,750 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:46,750 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:47,250 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:47,251 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:47,251 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:47,251 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:47,751 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:47,751 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:47,752 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:47,752 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:48,252 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:48,252 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:48,252 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om2: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:48,252 INFO org.apache.ratis.server.impl.FollowerInfo:
om1@group-9F198C4C3682->om3: nextIndex: updateUnconditionally 360 -> 359
2020-03-24 04:16:48,752 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om3-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: UNAVAILABLE: io
exception
2020-03-24 04:16:48,752 WARN org.apache.ratis.grpc.server.GrpcLogAppender:
om1@group-9F198C4C3682->om2-AppendLogResponseHandler: Failed appendEntries:
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException:
[GitHub] [hadoop-ozone] hanishakoneru commented on issue #723: HDDS-3281. Add timeouts to all robot tests
hanishakoneru commented on issue #723: HDDS-3281. Add timeouts to all robot tests URL: https://github.com/apache/hadoop-ozone/pull/723#issuecomment-605096549 > Note: originally I suggested to put the Timeout to the commonlib.robot to avoid code duplication, but I tested it and doesn't work. Yes. Learned that robot framework does not allow "global timeout" by design. @adoroszlai, @elek are we good to merge this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] hanishakoneru edited a comment on issue #723: HDDS-3281. Add timeouts to all robot tests
hanishakoneru edited a comment on issue #723: HDDS-3281. Add timeouts to all robot tests URL: https://github.com/apache/hadoop-ozone/pull/723#issuecomment-605096549 > Note: originally I suggested to put the Timeout to the commonlib.robot to avoid code duplication, but I tested it and doesn't work. Yes. Learned that robot framework does not allow "global timeout" by design. @adoroszlai, @elek are we good to merge this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3288) Update default RPC handler SCM/OM count to 100
[
https://issues.apache.org/jira/browse/HDDS-3288?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Rakesh Radhakrishnan updated HDDS-3288:
---
Status: Patch Available (was: Open)
> Update default RPC handler SCM/OM count to 100
> ---
>
> Key: HDDS-3288
> URL: https://issues.apache.org/jira/browse/HDDS-3288
> Project: Hadoop Distributed Data Store
> Issue Type: Improvement
> Components: om, SCM
>Reporter: Rakesh Radhakrishnan
>Assignee: Rakesh Radhakrishnan
>Priority: Minor
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> Presently, default PC handler count of {{ozone.scm.handler.count.key=10}} and
> {{ozone.om.handler.count.key=20}} are too small values and its good to
> increase the default values to a realistic value.
> {code:java}
> ozone.om.handler.count.key=100
> ozone.scm.handler.count.key=100
> {code}
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #687: HDDS-2184. Rename ozone scmcli to ozone admin
elek commented on issue #687: HDDS-2184. Rename ozone scmcli to ozone admin URL: https://github.com/apache/hadoop-ozone/pull/687#issuecomment-605047108 Base branch is changed. Please merge it manually instead of using github UI button. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3290) Remove deprecated RandomKeyGenerator
Marton Elek created HDDS-3290: - Summary: Remove deprecated RandomKeyGenerator Key: HDDS-3290 URL: https://issues.apache.org/jira/browse/HDDS-3290 Project: Hadoop Distributed Data Store Issue Type: Improvement Reporter: Marton Elek Assignee: Marton Elek Our first Freon test (RandomKeyGenerator) is depracated as we have all the functionalities with a simplified architecture (BaseFreonGenerator). We can remove it (especially as it's flaky...) -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #710: HDDS-3173. Provide better default JVM options
elek commented on issue #710: HDDS-3173. Provide better default JVM options URL: https://github.com/apache/hadoop-ozone/pull/710#issuecomment-605005247 > What do you think? I think it's a very good idea to print out the flags when we touch them, but not sure what is your suggestion exactly: 1. Print out the JVM settings (and/or a warning) when we set the defaults (which can be unexpected) 2. Print JVM settings always? 3. Print out a notification when we don't add the defaults? (any other -XX options are used). What is your preference? I am thinking about printing out all the JVM options *always* (similar to the classpath) + a warning that we defined the default GC parameters (2nd option) ``` NOTE: default JVM parameters are applied. Use any -XX: JVM parameter to use your own instead of the defaults. CLASSPATH: . HADOOP_OPTS: ... ``` Is it possible that somebody adds any secret information to the `HADOOP_OPTS` which should be hidden? (Do we need to use 1st option?) > and if someone sets something we would like to let him/her know what would have been set, so he/she can review and preserve what is still needed. As a main rule we don't set anything when any of the `-XX` flags are present. But I agree that it's more clear if it's somehow printed out. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3289) Add a freon generator to create nested directories
[ https://issues.apache.org/jira/browse/HDDS-3289?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDDS-3289: - Labels: pull-request-available (was: ) > Add a freon generator to create nested directories > -- > > Key: HDDS-3289 > URL: https://issues.apache.org/jira/browse/HDDS-3289 > Project: Hadoop Distributed Data Store > Issue Type: Bug > Components: Tools >Reporter: Aryan Gupta >Assignee: Aryan Gupta >Priority: Major > Labels: pull-request-available > > This Jira proposes to add a functionality to freon to create nested > directories. Also, multiple child directories can be created inside the leaf > directory and also multiple top level directories can be created. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #713: HDDS-3251. Bump version to 0.6.0-SNAPSHOT
elek commented on issue #713: HDDS-3251. Bump version to 0.6.0-SNAPSHOT URL: https://github.com/apache/hadoop-ozone/pull/713#issuecomment-604995537 BTW, I changed the base branch to master-stable, please don't merge it with Github UI, just manually... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] aryangupta1998 opened a new pull request #730: HDDS-3289. Add a freon generator to create nested directories.
aryangupta1998 opened a new pull request #730: HDDS-3289. Add a freon generator to create nested directories. URL: https://github.com/apache/hadoop-ozone/pull/730 ## What changes were proposed in this pull request? This Jira proposes to add a functionality to freon to create nested directories. Also, multiple child directories can be created inside the leaf directory and also multiple top level directories can be created. ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-3289 ## How was this patch tested? Tested manually by running Freon Directory Generator. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #713: HDDS-3251. Bump version to 0.6.0-SNAPSHOT
elek commented on issue #713: HDDS-3251. Bump version to 0.6.0-SNAPSHOT URL: https://github.com/apache/hadoop-ozone/pull/713#issuecomment-604995129 Thanks the review @dineshchitlangia > @elek the failures are unrelated to your proposed change. I am -1 to merge anything without clean build even if they are unrelated ;-) It's very easy to miss something when one unrelated test hides a related problem. Working on cleaning up master first, and will merge it after a green build. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #665: HDDS-3160. Disable index and filter block cache for RocksDB.
elek commented on issue #665: HDDS-3160. Disable index and filter block cache for RocksDB. URL: https://github.com/apache/hadoop-ozone/pull/665#issuecomment-604992384 Base branch is changed. Please don't merge it from github ui, only manually. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #714: HDDS-3164. Add Recon endpoint to serve missing containers and its metadata.
elek commented on issue #714: HDDS-3164. Add Recon endpoint to serve missing containers and its metadata. URL: https://github.com/apache/hadoop-ozone/pull/714#issuecomment-604987204 If you see a flaky test, please disable it (without and issue) + create a new open issue and repeat the build. There is some risk that one flakiness hides a other. Merging patches without green build makes harder to debug flaky tests. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #722: HDDS-3074. Make the configuration of container scrub consistent.
elek commented on issue #722: HDDS-3074. Make the configuration of container scrub consistent. URL: https://github.com/apache/hadoop-ozone/pull/722#issuecomment-604986683 If you see a flaky test, please disable it (without and issue) + create a new open issue and repeat the build. There is some risk that one flakiness hides a other. Merging patches without green build makes harder to debug flaky tests. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #678: HDDS-3179 Pipeline placement based on Topology does not have fallback
elek commented on issue #678: HDDS-3179 Pipeline placement based on Topology does not have fallback URL: https://github.com/apache/hadoop-ozone/pull/678#issuecomment-604986545 If you see a flaky test, please disable it (without and issue) + create a new open issue and repeat the build. There is some risk that one flakiness hides a other. Merging patches without green build makes harder to debug flaky tests. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #665: HDDS-3160. Disable index and filter block cache for RocksDB.
elek commented on issue #665: HDDS-3160. Disable index and filter block cache for RocksDB. URL: https://github.com/apache/hadoop-ozone/pull/665#issuecomment-604982534 > Given this does not happen during the key creation earlier. This seems very likely from a RocksDB compaction, which updates the filters/indices of the SSTs. Yes, this is after a compaction: 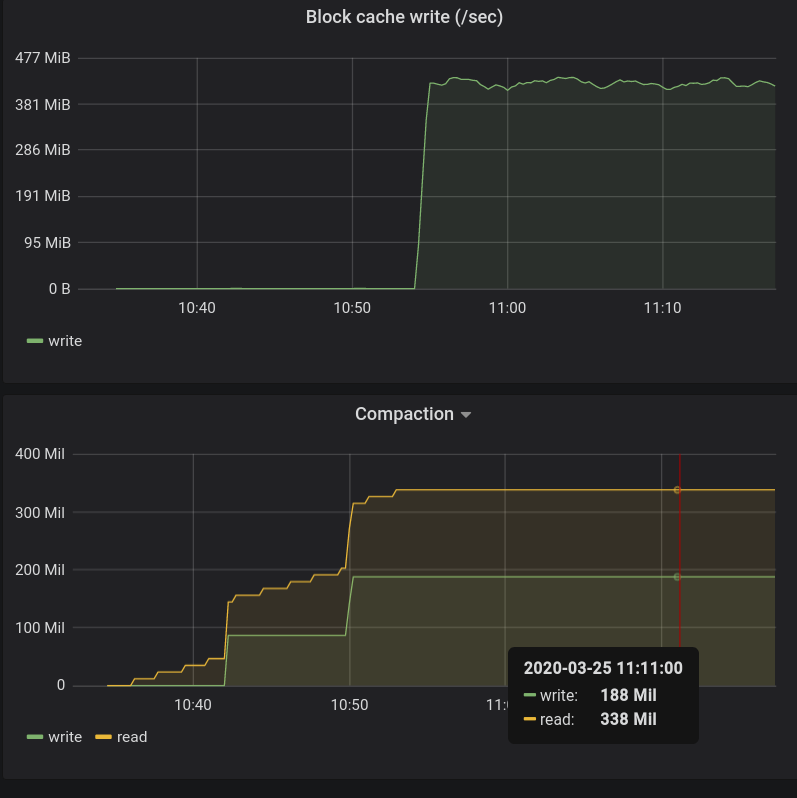 I think after the compaction both the size of index/filter and block numbers are increased and the fixed amount of cache is not enough. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #708: HDDS-3239. Provide message-level metrics from the generic protocol dispatch.
elek commented on issue #708: HDDS-3239. Provide message-level metrics from the generic protocol dispatch. URL: https://github.com/apache/hadoop-ozone/pull/708#issuecomment-604981594 Base branch is changed. Please don't merge it from the github web ui, only manually. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3289) Add a freon generator to create nested directories
Aryan Gupta created HDDS-3289: - Summary: Add a freon generator to create nested directories Key: HDDS-3289 URL: https://issues.apache.org/jira/browse/HDDS-3289 Project: Hadoop Distributed Data Store Issue Type: Bug Components: Tools Reporter: Aryan Gupta Assignee: Aryan Gupta This Jira proposes to add a functionality to freon to create nested directories. Also, multiple child directories can be created inside the leaf directory and also multiple top level directories can be created. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3288) Update default RPC handler SCM/OM count to 100
[
https://issues.apache.org/jira/browse/HDDS-3288?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HDDS-3288:
-
Labels: pull-request-available (was: )
> Update default RPC handler SCM/OM count to 100
> ---
>
> Key: HDDS-3288
> URL: https://issues.apache.org/jira/browse/HDDS-3288
> Project: Hadoop Distributed Data Store
> Issue Type: Improvement
> Components: om, SCM
>Reporter: Rakesh Radhakrishnan
>Assignee: Rakesh Radhakrishnan
>Priority: Minor
> Labels: pull-request-available
>
> Presently, default PC handler count of {{ozone.scm.handler.count.key=10}} and
> {{ozone.om.handler.count.key=20}} are too small values and its good to
> increase the default values to a realistic value.
> {code:java}
> ozone.om.handler.count.key=100
> ozone.scm.handler.count.key=100
> {code}
>
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] rakeshadr opened a new pull request #729: HDDS-3288: Update default RPC handler SCM/OM count to 100
rakeshadr opened a new pull request #729: HDDS-3288: Update default RPC handler SCM/OM count to 100 URL: https://github.com/apache/hadoop-ozone/pull/729 ## What changes were proposed in this pull request? Presently, default PC handler count of ozone.scm.handler.count.key=10 and ozone.om.handler.count.key=20 are too small values and its good to increase the default values to a realistic value. ``` ozone.om.handler.count.key=100 ozone.scm.handler.count.key=100 ``` ## What is the link to the Apache JIRA https://issues.apache.org/jira/browse/HDDS-3288 ## How was this patch tested? Config changes and no UTs added. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] runzhiwang closed pull request #709: HDDS-3244. Improve write efficiency by opening RocksDB only once
runzhiwang closed pull request #709: HDDS-3244. Improve write efficiency by opening RocksDB only once URL: https://github.com/apache/hadoop-ozone/pull/709 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] runzhiwang opened a new pull request #709: HDDS-3244. Improve write efficiency by opening RocksDB only once
runzhiwang opened a new pull request #709: HDDS-3244. Improve write efficiency by opening RocksDB only once URL: https://github.com/apache/hadoop-ozone/pull/709 ## What changes were proposed in this pull request? What's the problem ? 1. This happens when datanode create container. I split the `HddsDispatcher.WriteChunk` into `HddsDispatcher.WriteData` and `HddsDispatcher.CommitData` as the code shows, to show the cost of them in jaeger UI.  2. when datanode create each container, a new RocksDB instance will be [created](https://github.com/apache/hadoop-ozone/blob/master/hadoop-hdds/container-service/src/main/java/org/apache/hadoop/ozone/container/keyvalue/helpers/KeyValueContainerUtil.java#L76) in `HddsDispatcher.WriteData` , but then the created RocksDB was [closed](https://github.com/apache/hadoop-ozone/blob/master/hadoop-hdds/container-service/src/main/java/org/apache/hadoop/ozone/container/keyvalue/helpers/KeyValueContainerUtil.java#L83), until `HddsDispatcher.PutBlock` the RocsDB will be [opend](https://github.com/apache/hadoop-ozone/blob/master/hadoop-hdds/container-service/src/main/java/org/apache/hadoop/ozone/container/common/utils/ContainerCache.java#L123) again, so the RocksDB was open twice in each datanode. And the RocksDB was not used until `HddsDispatcher.PutBlock`. 3. Besides, as the image shows, when leader datanode open RocksDB in `HddsDispatcher.WriteData` , 2 follower datanodes can not open RocksDB until the leader finish it. So the whole write cost 3 * cost(RocksDB.open) = 600ms to open RocksDB.  4. When upload a 3KB file five times, the average cost is 912ms.  How to fix it ? 1. Open RocksDB in `HddsDispatcher.CommitData` rather than `HddsDispatcher.WriteData`, because leader datanode and 2 follower datanodes can open RocksDB in parallel in `HddsDispatcher.CommitData`. 2. Put the RocksDB handler into cache after open it in `HddsDispatcher.CommitData`, to avoid open it again when `HddsDispatcher.PutBlock`. 3. So the whole write cost 1 * cost(RocksDB.open) = 200ms to open RocksDB. 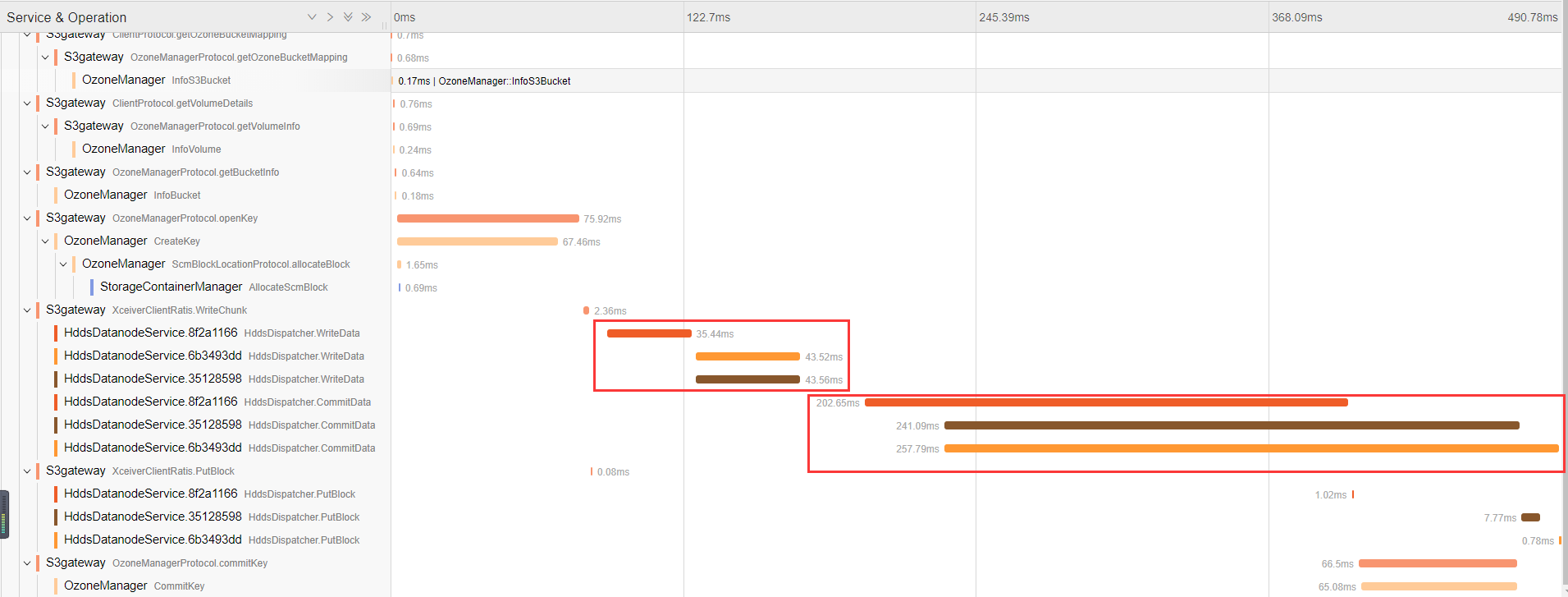 4. When upload a 3KB file five times, the average cost is 516ms, improve about 44%. 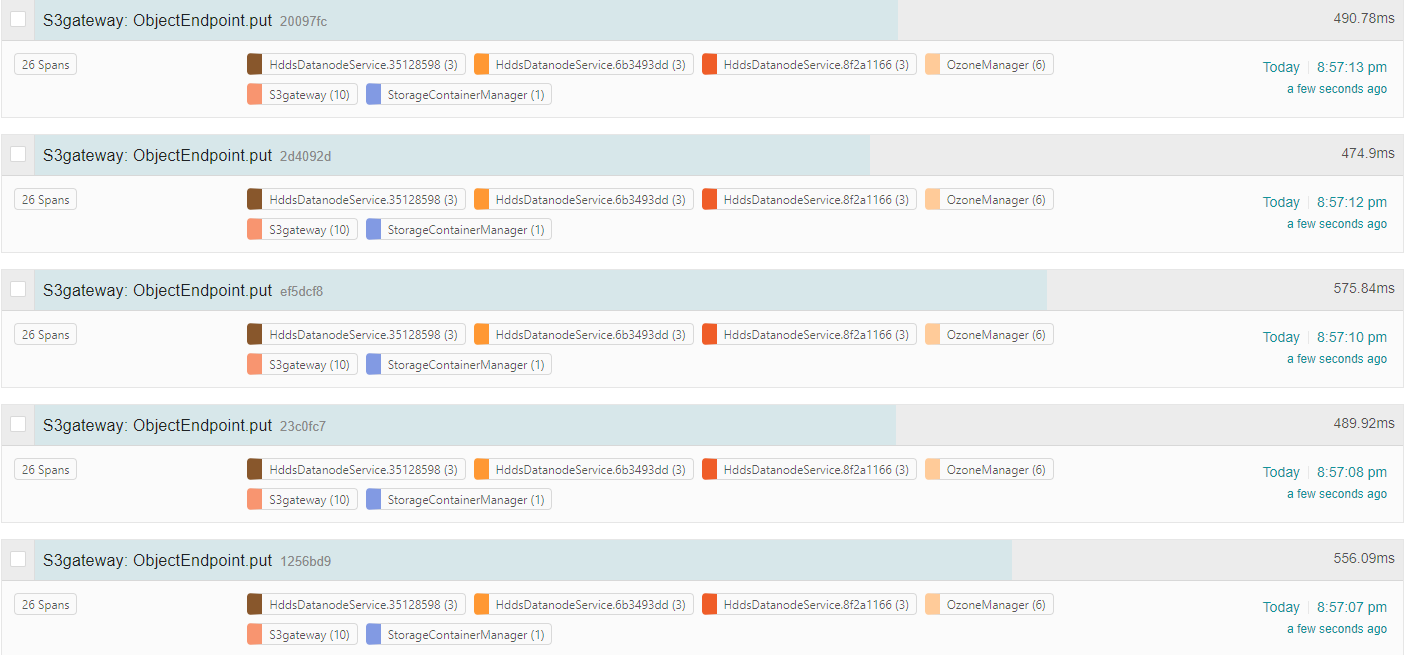 ## What is the link to the Apache JIRA https://issues.apache.org/jira/projects/HDDS/issues/HDDS-3244 ## How was this patch tested? I will change the UTs to pass the CI. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3288) Update default RPC handler SCM/OM count to 100
Rakesh Radhakrishnan created HDDS-3288:
--
Summary: Update default RPC handler SCM/OM count to 100
Key: HDDS-3288
URL: https://issues.apache.org/jira/browse/HDDS-3288
Project: Hadoop Distributed Data Store
Issue Type: Improvement
Components: om, SCM
Reporter: Rakesh Radhakrishnan
Assignee: Rakesh Radhakrishnan
Presently, default PC handler count of {{ozone.scm.handler.count.key=10}} and
{{ozone.om.handler.count.key=20}} are too small values and its good to increase
the default values to a realistic value.
{code:java}
ozone.om.handler.count.key=100
ozone.scm.handler.count.key=100
{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on a change in pull request #700: HDDS-3172 Use DBStore instead of MetadataStore in SCM
elek commented on a change in pull request #700: HDDS-3172 Use DBStore instead of MetadataStore in SCM URL: https://github.com/apache/hadoop-ozone/pull/700#discussion_r399153032 ## File path: hadoop-ozone/recon/src/main/java/org/apache/hadoop/ozone/recon/scm/ReconStorageContainerManagerFacade.java ## @@ -92,14 +95,22 @@ public ReconStorageContainerManagerFacade(OzoneConfiguration conf, this.ozoneConfiguration = getReconScmConfiguration(conf); this.scmStorageConfig = new ReconStorageConfig(conf); this.clusterMap = new NetworkTopologyImpl(conf); +DBStore dbStore = new SCMDBDefinition().createDBStore(conf); Review comment: Good catch, thanks. Fixed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on a change in pull request #700: HDDS-3172 Use DBStore instead of MetadataStore in SCM
elek commented on a change in pull request #700: HDDS-3172 Use DBStore instead of MetadataStore in SCM URL: https://github.com/apache/hadoop-ozone/pull/700#discussion_r399152379 ## File path: hadoop-ozone/recon/src/main/java/org/apache/hadoop/ozone/recon/scm/ReconNodeManager.java ## @@ -44,6 +40,10 @@ import org.apache.hadoop.ozone.protocol.commands.SCMCommand; import org.apache.hadoop.ozone.recon.ReconUtils; import org.apache.hadoop.util.Time; + +import static org.apache.hadoop.hdds.scm.ScmConfigKeys.OZONE_SCM_DB_CACHE_SIZE_DEFAULT; +import static org.apache.hadoop.hdds.scm.ScmConfigKeys.OZONE_SCM_DB_CACHE_SIZE_MB; +import static org.apache.hadoop.ozone.recon.ReconConstants.RECON_SCM_NODE_DB; import org.slf4j.Logger; import org.slf4j.LoggerFactory; Review comment: Not particular reason, just reducing the size the patch. I renamed my original Jira to fix SCM only. Recon and Datanode can be fixed in next two jira. (But thanks to point it to me, I was not aware of this. But it also can be moved to SCM. AFAK @Nanda had a plan to persist it on the SCM side, too...) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #723: HDDS-3281. Add timeouts to all robot tests
elek commented on issue #723: HDDS-3281. Add timeouts to all robot tests
URL: https://github.com/apache/hadoop-ozone/pull/723#issuecomment-604911971
> @adoroszlai, I think even with that limitation the timeout will help us
isolate the problem. Let's say the acceptance suit is cancelled, we could still
get to know which test contributed to the time out.
There are two timeouts:
1. timeout of the test (measured between two steps)
2. timeout of one step test steps
As far as I understood @adoroszlai warned us that even if we have a test
level timeout it doesn't help at all, if 2nd is not in place. If one `curl`
based command is hanging (and robot test doesn't do a `kill`) it won't be
stopped (and we won't have any logs / results).
But I agree even without 2nd, it's good to have this patch.
On the other hand, I tested it with sleep, and it seems to be working for
me...
```
*** Settings ***
Documentation Timeout test
Library OperatingSystem
Test Timeout20 seconds
#Resourcecommonlib.robot
*** Test cases ***
Execute PI calculation
${output} = Run sleep 60
Should Contain ${output} completed
successfully
```
```
time robot test.robot
==
Test :: Timeout test
==
Execute PI calculation| FAIL
|
Test timeout 20 seconds exceeded.
--
Test :: Timeout test | FAIL
|
1 critical test, 0 passed, 1 failed
1 test total, 0 passed, 1 failed
==
Output:
/home/elek/projects/ozone/hadoop-ozone/dist/target/ozone-0.5.0-SNAPSHOT/smoketest/output.xml
Log:
/home/elek/projects/ozone/hadoop-ozone/dist/target/ozone-0.5.0-SNAPSHOT/smoketest/log.html
Report:
/home/elek/projects/ozone/hadoop-ozone/dist/target/ozone-0.5.0-SNAPSHOT/smoketest/report.html
robot test.robot 0.25s user 0.03s system 1% cpu 20.285 total
```
As you see my sleep command was killed after 20 seconds.
Note: originally I suggested to put the `Timeout` to the `commonlib.robot`
to avoid code duplication, but I tested it and doesn't work.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #720: HDDS-3185 Construct a standalone ratis server for SCM.
elek commented on issue #720: HDDS-3185 Construct a standalone ratis server for SCM. URL: https://github.com/apache/hadoop-ozone/pull/720#issuecomment-604904324 Speaking about the code in the patch: I would suggest to use the new config based annotation model for new code: https://cwiki.apache.org/confluence/display/HADOOP/Java-based+configuration+API (I know it's not used everywhere, therefore it's hard to notice this movement, and some features can be still missing, but new code seems to be a good opportunity to switch to the new API) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #720: HDDS-3185 Construct a standalone ratis server for SCM.
elek commented on issue #720: HDDS-3185 Construct a standalone ratis server for SCM. URL: https://github.com/apache/hadoop-ozone/pull/720#issuecomment-604901383 @timmylicheng Thanks the explain it. I will add your explanation to the next Community Meeting minutes. ``` SCM-HA: First draft is already available and will be updated soon based on the existing feedback. Prototype implementation has been started at HDDS-2823 branch. ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] ChenSammi commented on issue #720: HDDS-3185 Construct a standalone ratis server for SCM.
ChenSammi commented on issue #720: HDDS-3185 Construct a standalone ratis server for SCM. URL: https://github.com/apache/hadoop-ozone/pull/720#issuecomment-604899459 +1 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] ChenSammi merged pull request #720: HDDS-3185 Construct a standalone ratis server for SCM.
ChenSammi merged pull request #720: HDDS-3185 Construct a standalone ratis server for SCM. URL: https://github.com/apache/hadoop-ozone/pull/720 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek opened a new pull request #728: Master stable
elek opened a new pull request #728: Master stable URL: https://github.com/apache/hadoop-ozone/pull/728 ## What changes were proposed in this pull request? Recently we have seen a lot of timeout errors in integrations tests and acceptance tests. My theory is that it caused by the combination of (HDDS-3234. Fix retry interval default in Ozone client) and (HDDS-3064. Get Key is hung when READ delay is injected in chunk file path.) (HDDS-3285, HDDS-3257, ...) ## What is the link to the Apache JIRA We have the original JIRAs. ## How was this patch tested? Full CI + I will use this branch as target branch of my PRs. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] elek commented on issue #690: HDDS-3221. Refactor SafeModeHandler to use a Notification Interface
elek commented on issue #690: HDDS-3221. Refactor SafeModeHandler to use a Notification Interface URL: https://github.com/apache/hadoop-ozone/pull/690#issuecomment-604894837 I am not full happy that my suggestion is ignored. I think it would be better to switch to the EventQueue unless we have a strong arguments against it (what I would accept happily, but I haven't see it yet). I don't think it's a good idea to develop more complexity on top of a structure what we would like to replace very soon... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3257) Intermittent timeout in integration tests
[ https://issues.apache.org/jira/browse/HDDS-3257?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Attila Doroszlai updated HDDS-3257: --- Attachment: org.apache.hadoop.fs.ozone.contract.ITestOzoneContractMkdir-output.txt > Intermittent timeout in integration tests > - > > Key: HDDS-3257 > URL: https://issues.apache.org/jira/browse/HDDS-3257 > Project: Hadoop Distributed Data Store > Issue Type: Bug >Reporter: Attila Doroszlai >Assignee: Shashikant Banerjee >Priority: Critical > Attachments: > org.apache.hadoop.fs.ozone.contract.ITestOzoneContractMkdir-output.txt, > org.apache.hadoop.ozone.client.rpc.TestBlockOutputStreamWithFailures-output.txt, > org.apache.hadoop.ozone.freon.TestOzoneClientKeyGenerator-output.txt, > org.apache.hadoop.ozone.freon.TestRandomKeyGenerator-output.txt > > > Even after the changes done in HDDS-3086, some integration tests (especially > in it-freon) are intermittently timing out. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Commented] (HDDS-3257) Intermittent timeout in integration tests
[
https://issues.apache.org/jira/browse/HDDS-3257?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17068434#comment-17068434
]
Attila Doroszlai commented on HDDS-3257:
{code:title=https://github.com/apache/hadoop-ozone/runs/538728907}
---
Test set: org.apache.hadoop.fs.ozone.contract.ITestOzoneContractMkdir
---
Tests run: 8, Failures: 0, Errors: 2, Skipped: 0, Time elapsed: 396.407 s <<<
FAILURE! - in org.apache.hadoop.fs.ozone.contract.ITestOzoneContractMkdir
testMkdirOverParentFile(org.apache.hadoop.fs.ozone.contract.ITestOzoneContractMkdir)
Time elapsed: 180.022 s <<< ERROR!
java.lang.Exception: test timed out after 18 milliseconds
...
at
java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908)
at
org.apache.hadoop.hdds.scm.storage.BlockOutputStream.waitOnFlushFutures(BlockOutputStream.java:525)
at
org.apache.hadoop.hdds.scm.storage.BlockOutputStream.handleFlush(BlockOutputStream.java:488)
at
org.apache.hadoop.hdds.scm.storage.BlockOutputStream.close(BlockOutputStream.java:503)
at
org.apache.hadoop.ozone.client.io.BlockOutputStreamEntry.close(BlockOutputStreamEntry.java:144)
at
org.apache.hadoop.ozone.client.io.KeyOutputStream.handleStreamAction(KeyOutputStream.java:482)
at
org.apache.hadoop.ozone.client.io.KeyOutputStream.handleFlushOrClose(KeyOutputStream.java:456)
at
org.apache.hadoop.ozone.client.io.KeyOutputStream.close(KeyOutputStream.java:509)
at
org.apache.hadoop.fs.ozone.OzoneFSOutputStream.close(OzoneFSOutputStream.java:56)
at
org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72)
at
org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:101)
at
org.apache.hadoop.fs.contract.ContractTestUtils.createFile(ContractTestUtils.java:638)
at
org.apache.hadoop.fs.contract.AbstractContractMkdirTest.testMkdirOverParentFile(AbstractContractMkdirTest.java:92)
testNoMkdirOverFile(org.apache.hadoop.fs.ozone.contract.ITestOzoneContractMkdir)
Time elapsed: 180.006 s <<< ERROR!
java.lang.Exception: test timed out after 18 milliseconds
...
at
java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908)
at
org.apache.hadoop.hdds.scm.storage.BlockOutputStream.waitOnFlushFutures(BlockOutputStream.java:525)
at
org.apache.hadoop.hdds.scm.storage.BlockOutputStream.handleFlush(BlockOutputStream.java:488)
at
org.apache.hadoop.hdds.scm.storage.BlockOutputStream.close(BlockOutputStream.java:503)
at
org.apache.hadoop.ozone.client.io.BlockOutputStreamEntry.close(BlockOutputStreamEntry.java:144)
at
org.apache.hadoop.ozone.client.io.KeyOutputStream.handleStreamAction(KeyOutputStream.java:482)
at
org.apache.hadoop.ozone.client.io.KeyOutputStream.handleFlushOrClose(KeyOutputStream.java:456)
at
org.apache.hadoop.ozone.client.io.KeyOutputStream.close(KeyOutputStream.java:509)
at
org.apache.hadoop.fs.ozone.OzoneFSOutputStream.close(OzoneFSOutputStream.java:56)
at
org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72)
at
org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:101)
at
org.apache.hadoop.fs.contract.ContractTestUtils.createFile(ContractTestUtils.java:638)
at
org.apache.hadoop.fs.contract.AbstractContractMkdirTest.testNoMkdirOverFile(AbstractContractMkdirTest.java:66)
{code}
> Intermittent timeout in integration tests
> -
>
> Key: HDDS-3257
> URL: https://issues.apache.org/jira/browse/HDDS-3257
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
>Reporter: Attila Doroszlai
>Assignee: Shashikant Banerjee
>Priority: Critical
> Attachments:
> org.apache.hadoop.ozone.client.rpc.TestBlockOutputStreamWithFailures-output.txt,
> org.apache.hadoop.ozone.freon.TestOzoneClientKeyGenerator-output.txt,
> org.apache.hadoop.ozone.freon.TestRandomKeyGenerator-output.txt
>
>
> Even after the changes done in HDDS-3086, some integration tests (especially
> in it-freon) are intermittently timing out.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3284) ozonesecure-mr test fails due to lack of disk space
[
https://issues.apache.org/jira/browse/HDDS-3284?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Attila Doroszlai updated HDDS-3284:
---
Fix Version/s: 0.6.0
Resolution: Fixed
Status: Resolved (was: Patch Available)
> ozonesecure-mr test fails due to lack of disk space
> ---
>
> Key: HDDS-3284
> URL: https://issues.apache.org/jira/browse/HDDS-3284
> Project: Hadoop Distributed Data Store
> Issue Type: Bug
> Components: test
>Reporter: Attila Doroszlai
>Assignee: Attila Doroszlai
>Priority: Major
> Labels: pull-request-available
> Fix For: 0.6.0
>
> Time Spent: 20m
> Remaining Estimate: 0h
>
> {{ozonesecure-mr}} acceptance test is failing with {{No space available in
> any of the local directories.}}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
-
To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3287) keyLocationVersions become bigger and bigger when upload the same file many times.
[ https://issues.apache.org/jira/browse/HDDS-3287?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] runzhiwang updated HDDS-3287: - Summary: keyLocationVersions become bigger and bigger when upload the same file many times. (was: OmKeyInfo become bigger and bigger when upload the same file many times.) > keyLocationVersions become bigger and bigger when upload the same file many > times. > -- > > Key: HDDS-3287 > URL: https://issues.apache.org/jira/browse/HDDS-3287 > Project: Hadoop Distributed Data Store > Issue Type: Improvement >Reporter: runzhiwang >Assignee: runzhiwang >Priority: Major > > Because keyLocationVersions get biger and gi -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3287) keyLocationVersions become bigger and bigger when upload the same file many times.
[ https://issues.apache.org/jira/browse/HDDS-3287?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] runzhiwang updated HDDS-3287: - Description: Add a config to define keep how many versions. (was: Because keyLocationVersions get biger and gi) > keyLocationVersions become bigger and bigger when upload the same file many > times. > -- > > Key: HDDS-3287 > URL: https://issues.apache.org/jira/browse/HDDS-3287 > Project: Hadoop Distributed Data Store > Issue Type: Improvement >Reporter: runzhiwang >Assignee: runzhiwang >Priority: Major > > Add a config to define keep how many versions. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3287) OmKeyInfo become bigger and bigger when upload the same file many times.
[ https://issues.apache.org/jira/browse/HDDS-3287?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] runzhiwang updated HDDS-3287: - Description: Because keyLocationVersions get biger and gi > OmKeyInfo become bigger and bigger when upload the same file many times. > > > Key: HDDS-3287 > URL: https://issues.apache.org/jira/browse/HDDS-3287 > Project: Hadoop Distributed Data Store > Issue Type: Improvement >Reporter: runzhiwang >Assignee: runzhiwang >Priority: Major > > Because keyLocationVersions get biger and gi -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Commented] (HDDS-3287) OmKeyInfo become bigger and bigger when upload the same file many times.
[ https://issues.apache.org/jira/browse/HDDS-3287?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17068422#comment-17068422 ] runzhiwang commented on HDDS-3287: -- I'm working on it > OmKeyInfo become bigger and bigger when upload the same file many times. > > > Key: HDDS-3287 > URL: https://issues.apache.org/jira/browse/HDDS-3287 > Project: Hadoop Distributed Data Store > Issue Type: Bug >Reporter: runzhiwang >Assignee: runzhiwang >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Updated] (HDDS-3287) OmKeyInfo become bigger and bigger when upload the same file many times.
[ https://issues.apache.org/jira/browse/HDDS-3287?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] runzhiwang updated HDDS-3287: - Issue Type: Improvement (was: Bug) > OmKeyInfo become bigger and bigger when upload the same file many times. > > > Key: HDDS-3287 > URL: https://issues.apache.org/jira/browse/HDDS-3287 > Project: Hadoop Distributed Data Store > Issue Type: Improvement >Reporter: runzhiwang >Assignee: runzhiwang >Priority: Major > -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Created] (HDDS-3287) OmKeyInfo become bigger and bigger when upload the same file many times.
runzhiwang created HDDS-3287: Summary: OmKeyInfo become bigger and bigger when upload the same file many times. Key: HDDS-3287 URL: https://issues.apache.org/jira/browse/HDDS-3287 Project: Hadoop Distributed Data Store Issue Type: Bug Reporter: runzhiwang Assignee: runzhiwang -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDDS-3179) Pipeline placement based on Topology does not have fall back protection
[ https://issues.apache.org/jira/browse/HDDS-3179?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Stephen O'Donnell resolved HDDS-3179. - Resolution: Fixed > Pipeline placement based on Topology does not have fall back protection > --- > > Key: HDDS-3179 > URL: https://issues.apache.org/jira/browse/HDDS-3179 > Project: Hadoop Distributed Data Store > Issue Type: Bug > Components: SCM >Affects Versions: 0.4.1 >Reporter: Li Cheng >Assignee: Li Cheng >Priority: Major > Labels: pull-request-available > Fix For: 0.6.0 > > Time Spent: 20m > Remaining Estimate: 0h > > When rack awareness and topology is enabled, pipeline placement can fail when > there is only one node on the rack. > > Should add fall back logic to search for nodes from other racks. -- This message was sent by Atlassian Jira (v8.3.4#803005) - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] sodonnel merged pull request #678: HDDS-3179 Pipeline placement based on Topology does not have fallback
sodonnel merged pull request #678: HDDS-3179 Pipeline placement based on Topology does not have fallback URL: https://github.com/apache/hadoop-ozone/pull/678 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org
[GitHub] [hadoop-ozone] sodonnel commented on issue #678: HDDS-3179 Pipeline placement based on Topology does not have fallback
sodonnel commented on issue #678: HDDS-3179 Pipeline placement based on Topology does not have fallback URL: https://github.com/apache/hadoop-ozone/pull/678#issuecomment-604854734 All tests are green except this one, which I have seen fail in several other PRs, so it is flaky: ``` [INFO] Tests run: 2, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 52.235 s - in org.apache.hadoop.ozone.freon.TestDataValidateWithUnsafeByteOperations [INFO] Running org.apache.hadoop.ozone.freon.TestRandomKeyGenerator [ERROR] Tests run: 6, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 338.009 s <<< FAILURE! - in org.apache.hadoop.ozone.freon.TestRandomKeyGenerator [ERROR] bigFileThan2GB(org.apache.hadoop.ozone.freon.TestRandomKeyGenerator) Time elapsed: 276.915 s <<< FAILURE! java.lang.AssertionError: expected:<1> but was:<0> at org.junit.Assert.fail(Assert.java:88) at org.junit.Assert.failNotEquals(Assert.java:743) at org.junit.Assert.assertEquals(Assert.java:118) ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: ozone-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: ozone-issues-h...@hadoop.apache.org