[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21312 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21312 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90547/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21312 **[Test build #90547 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90547/testReport)** for PR 21312 at commit [`48ef560`](https://github.com/apache/spark/commit/48ef5604212d9bb1648ea15337604709b06b8a7b). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21213: [SPARK-24120] Show `Jobs` page when `jobId` is missing
Github user jongyoul commented on the issue: https://github.com/apache/spark/pull/21213 @gengliangwang Thanks. But changing URI format might make any incompatibility with other versions, thus we need to consider other aspects more. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21213: [SPARK-24120] Show `Jobs` page when `jobId` is missing
Github user gengliangwang commented on the issue: https://github.com/apache/spark/pull/21213 @jongyoul @ajbozarth Personally I prefer to the current way, showing the error message: 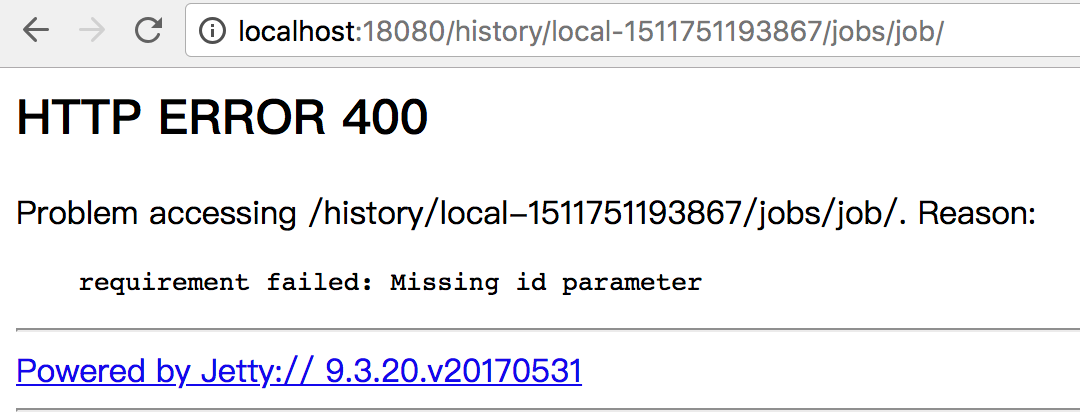 If the problem is `yarn filter couldn't pass query strings`, can we consider changing the url from ``` /jobs/job?id=1 ``` to ``` /jobs/1 ``` which is more restful. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21304: Fix typo in UDF type match error message
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21304 @wzhfy wanna try to merge this one? Seems safe to merge to both master and branch-2.3. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21106: [SPARK-23711][SQL][WIP] Add fallback logic for UnsafePro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21106 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90546/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21106: [SPARK-23711][SQL][WIP] Add fallback logic for UnsafePro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21106 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21106: [SPARK-23711][SQL][WIP] Add fallback logic for UnsafePro...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21106 **[Test build #90546 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90546/testReport)** for PR 21106 at commit [`67f8701`](https://github.com/apache/spark/commit/67f870133ab22a32e2af020a1b8893595dcef7cf). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21299 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21299 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3174/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21106: [SPARK-23711][SQL][WIP] Add fallback logic for UnsafePro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21106 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90545/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21304: Fix typo in UDF type match error message
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21304 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90548/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21106: [SPARK-23711][SQL][WIP] Add fallback logic for UnsafePro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21106 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21299 **[Test build #90549 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90549/testReport)** for PR 21299 at commit [`bf8b42d`](https://github.com/apache/spark/commit/bf8b42d494d4a8f21bd08b2fd6ed531e21e4eb49). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21304: Fix typo in UDF type match error message
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21304 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21304: Fix typo in UDF type match error message
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21304 **[Test build #90548 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90548/testReport)** for PR 21304 at commit [`c1d79d2`](https://github.com/apache/spark/commit/c1d79d2258d79e19fc015a533a2026b026376961). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21106: [SPARK-23711][SQL][WIP] Add fallback logic for UnsafePro...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21106 **[Test build #90545 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90545/testReport)** for PR 21106 at commit [`129b6ac`](https://github.com/apache/spark/commit/129b6acc5a24c7ef48f94e407c91575645cd46b2). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21312 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21312 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90544/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21312 **[Test build #90544 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90544/testReport)** for PR 21312 at commit [`093728e`](https://github.com/apache/spark/commit/093728ef75f4cecbac5d5f4f82fcce0cc47759b5). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21304: Fix typo in UDF type match error message
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21304 **[Test build #90548 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90548/testReport)** for PR 21304 at commit [`c1d79d2`](https://github.com/apache/spark/commit/c1d79d2258d79e19fc015a533a2026b026376961). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21304: Fix typo in UDF type match error message
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21304 ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21304: Fix typo in UDF type match error message
Github user robinske commented on the issue: https://github.com/apache/spark/pull/21304 Looked through the other text/error messages and didn't see any other typos jump out. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21307: [SPARK-24186][R][SQL]change reverse and concat to...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/21307#discussion_r187788406
--- Diff: R/pkg/R/functions.R ---
@@ -2055,20 +2058,10 @@ setMethod("countDistinct",
#' @details
#' \code{concat}: Concatenates multiple input columns together into a
single column.
-#' If all inputs are binary, concat returns an output as binary.
Otherwise, it returns as string.
+#' The function works with strings, binary and compatible array columns.
--- End diff --
btw, what does "compatible array columns" mean?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user viirya commented on the issue: https://github.com/apache/spark/pull/21312 Thanks @HyukjinKwon --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21312 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21312 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3173/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21312 **[Test build #90547 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90547/testReport)** for PR 21312 at commit [`48ef560`](https://github.com/apache/spark/commit/48ef5604212d9bb1648ea15337604709b06b8a7b). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21312#discussion_r187787882
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/arrow/ArrowWriter.scala
---
@@ -311,6 +311,7 @@ private[arrow] class ArrayWriter(
override def reset(): Unit = {
super.reset()
elementWriter.reset()
+valueVector.clear()
--- End diff --
I've also noticed that @BryanCutler added `reset` to `ListVector`. But we
can only use `clear` for now.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21312#discussion_r187787511
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/arrow/ArrowWriter.scala
---
@@ -311,6 +311,7 @@ private[arrow] class ArrayWriter(
override def reset(): Unit = {
super.reset()
elementWriter.reset()
+valueVector.clear()
--- End diff --
Yeah, I think so.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/21312#discussion_r187787343
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/arrow/ArrowWriter.scala
---
@@ -311,6 +311,7 @@ private[arrow] class ArrayWriter(
override def reset(): Unit = {
super.reset()
elementWriter.reset()
+valueVector.clear()
--- End diff --
Looks @BryanCutler added `reset()` interface in 0.9.0 mentioned in:
https://github.com/apache/spark/blob/eb386be1ed383323da6e757f63f3b8a7ced38cc4/sql/core/src/main/scala/org/apache/spark/sql/execution/arrow/ArrowWriter.scala#L132
at
https://github.com/apache/arrow/commit/4dbce607d50031a405af39d36e08cd03c5ffc764
and https://issues.apache.org/jira/browse/ARROW-1962
but if we think about backporting, probably I guess we can go this way as a
bug fix as is? Roughly looks making sense.
Would it be also safe to do:
```
valueVector match {
case fixedWidthVector: BaseFixedWidthVector =>
fixedWidthVector.reset()
case variableWidthVector: BaseVariableWidthVector =>
variableWidthVector.reset()
case repeatedValueVector: BaseRepeatedValueVector =>
repeatedValueVector.clear()
case _ =>
}
```
? @icexelloss, @BryanCutler and @viirya?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21299: [SPARK-24250][SQL] support accessing SQLConf insi...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21299#discussion_r187787271
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
---
@@ -898,7 +898,6 @@ object SparkSession extends Logging {
* @since 2.0.0
*/
def getOrCreate(): SparkSession = synchronized {
- assertOnDriver()
--- End diff --
Is this meaning we can create SparkSession on driver?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21299: [SPARK-24250][SQL] support accessing SQLConf insi...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21299#discussion_r187787215
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/SQLExecution.scala ---
@@ -68,16 +68,27 @@ object SQLExecution {
// sparkContext.getCallSite() would first try to pick up any call
site that was previously
// set, then fall back to Utils.getCallSite(); call
Utils.getCallSite() directly on
// streaming queries would give us call site like "run at
:0"
- val callSite = sparkSession.sparkContext.getCallSite()
+ val callSite = sc.getCallSite()
-
sparkSession.sparkContext.listenerBus.post(SparkListenerSQLExecutionStart(
+ // Set all the specified SQL configs to local properties, so that
they can be available at
+ // the executor side.
+ val allConfigs = sparkSession.sessionState.conf.getAllConfs
+ allConfigs.foreach {
+// Excludes external configs defined by users.
+case (key, value) if key.startsWith("spark") =>
sc.setLocalProperty(key, value)
--- End diff --
Oh, I see. `getAllConfs` only returns set configs.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21299: [SPARK-24250][SQL] support accessing SQLConf insi...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21299#discussion_r187787208
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/SQLExecution.scala ---
@@ -68,16 +68,27 @@ object SQLExecution {
// sparkContext.getCallSite() would first try to pick up any call
site that was previously
// set, then fall back to Utils.getCallSite(); call
Utils.getCallSite() directly on
// streaming queries would give us call site like "run at
:0"
- val callSite = sparkSession.sparkContext.getCallSite()
+ val callSite = sc.getCallSite()
-
sparkSession.sparkContext.listenerBus.post(SparkListenerSQLExecutionStart(
+ // Set all the specified SQL configs to local properties, so that
they can be available at
+ // the executor side.
+ val allConfigs = sparkSession.sessionState.conf.getAllConfs
+ allConfigs.foreach {
+// Excludes external configs defined by users.
+case (key, value) if key.startsWith("spark") =>
sc.setLocalProperty(key, value)
--- End diff --
Only propagate config values that have been set other than default value?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21106: [SPARK-23711][SQL][WIP] Add fallback logic for UnsafePro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21106 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21299: [SPARK-24250][SQL] support accessing SQLConf insi...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21299#discussion_r187787083
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/CreateJacksonParser.scala
---
@@ -78,17 +78,4 @@ private[sql] object CreateJacksonParser extends
Serializable {
def inputStream(enc: String, jsonFactory: JsonFactory, is: InputStream):
JsonParser = {
jsonFactory.createParser(new InputStreamReader(is, enc))
}
-
- def internalRow(jsonFactory: JsonFactory, row: InternalRow): JsonParser
= {
-val ba = row.getBinary(0)
-
-jsonFactory.createParser(ba, 0, ba.length)
- }
-
- def internalRow(enc: String, jsonFactory: JsonFactory, row:
InternalRow): JsonParser = {
-val binary = row.getBinary(0)
-val sd = getStreamDecoder(enc, binary, binary.length)
-
-jsonFactory.createParser(sd)
- }
--- End diff --
Why these two removed? Looks like no SQLConf involved here?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21106: [SPARK-23711][SQL][WIP] Add fallback logic for UnsafePro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21106 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3172/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21106: [SPARK-23711][SQL][WIP] Add fallback logic for UnsafePro...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21106 **[Test build #90546 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90546/testReport)** for PR 21106 at commit [`67f8701`](https://github.com/apache/spark/commit/67f870133ab22a32e2af020a1b8893595dcef7cf). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21106: [SPARK-23711][SQL][WIP] Add fallback logic for UnsafePro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21106 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3171/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21106: [SPARK-23711][SQL][WIP] Add fallback logic for UnsafePro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21106 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21106: [SPARK-23711][SQL][WIP] Add fallback logic for UnsafePro...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21106 **[Test build #90545 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90545/testReport)** for PR 21106 at commit [`129b6ac`](https://github.com/apache/spark/commit/129b6acc5a24c7ef48f94e407c91575645cd46b2). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21106: [SPARK-23711][SQL][WIP] Add fallback logic for Un...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/21106#discussion_r187786817
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/CodegenObjectFactory.scala
---
@@ -0,0 +1,80 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.expressions
+
+import org.codehaus.commons.compiler.CompileException
+import org.codehaus.janino.InternalCompilerException
+
+import org.apache.spark.TaskContext
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.util.Utils
+
+/**
+ * Catches compile error during code generation.
+ */
+object CodegenError {
+ def unapply(throwable: Throwable): Option[Exception] = throwable match {
+case e: InternalCompilerException => Some(e)
+case e: CompileException => Some(e)
+case _ => None
+ }
+}
+
+/**
+ * Defines values for `SQLConf` config of fallback mode. Use for test only.
+ */
+object CodegenObjectFactoryMode extends Enumeration {
+ val AUTO, CODEGEN_ONLY, NO_CODEGEN = Value
+
+ def currentMode: CodegenObjectFactoryMode.Value = {
+// If we weren't on task execution, accesses that config.
+if (TaskContext.get == null) {
+ val config = SQLConf.get.getConf(SQLConf.CODEGEN_FACTORY_MODE)
+ CodegenObjectFactoryMode.withName(config)
+} else {
+ CodegenObjectFactoryMode.AUTO
+}
+ }
+}
+
+/**
+ * A factory which can be used to create objects that have both codegen
and interpreted
+ * implementations. This tries to create codegen object first, if any
compile error happens,
+ * it fallbacks to interpreted version.
+ */
+abstract class CodegenObjectFactory[IN, OUT] {
--- End diff --
Ok. Reamed.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21273: [SPARK-17916][SQL] Fix empty string being parsed as null...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21273 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21273: [SPARK-17916][SQL] Fix empty string being parsed as null...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21273 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90543/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21273: [SPARK-17916][SQL] Fix empty string being parsed as null...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21273 **[Test build #90543 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90543/testReport)** for PR 21273 at commit [`f3a0072`](https://github.com/apache/spark/commit/f3a0072b82c23566d4010d977172578f04f51bff). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user viirya commented on the issue: https://github.com/apache/spark/pull/21307 LGTM --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user viirya commented on the issue: https://github.com/apache/spark/pull/21312 cc @HyukjinKwon @BryanCutler --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21312 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3170/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21312 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21287: [SPARK-1849][Core]Add encoding customization supp...
Github user cqzlxl closed the pull request at: https://github.com/apache/spark/pull/21287 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21312 **[Test build #90544 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90544/testReport)** for PR 21312 at commit [`093728e`](https://github.com/apache/spark/commit/093728ef75f4cecbac5d5f4f82fcce0cc47759b5). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21312: [SPARK-24259][SQL] ArrayWriter for Arrow produces...
GitHub user viirya opened a pull request: https://github.com/apache/spark/pull/21312 [SPARK-24259][SQL] ArrayWriter for Arrow produces wrong output ## What changes were proposed in this pull request? Right now `ArrayWriter` used to output Arrow data for array type, doesn't do `clear` or `reset` after each batch. It produces wrong output. ## How was this patch tested? Added test. You can merge this pull request into a Git repository by running: $ git pull https://github.com/viirya/spark-1 SPARK-24259 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21312.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21312 commit 093728ef75f4cecbac5d5f4f82fcce0cc47759b5 Author: Liang-Chi Hsieh Date: 2018-05-13T00:29:09Z Call clear after each batch. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21273: [SPARK-17916][SQL] Fix empty string being parsed as null...
Github user MaxGekk commented on the issue: https://github.com/apache/spark/pull/21273 @gengliangwang @gatorsmile I added a benchmark for parsing of quoted values. Parsing time dropped by **28%** (look at the commit https://github.com/apache/spark/pull/21273/commits/f3a0072b82c23566d4010d977172578f04f51bff) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21273: [SPARK-17916][SQL] Fix empty string being parsed as null...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21273 **[Test build #90543 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90543/testReport)** for PR 21273 at commit [`f3a0072`](https://github.com/apache/spark/commit/f3a0072b82c23566d4010d977172578f04f51bff). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21045: [SPARK-23931][SQL] Adds zip function to sparksql
Github user mgaido91 commented on the issue: https://github.com/apache/spark/pull/21045 @DylanGuedes you can see an example of functions supporting a variable number of arguments in `Coalesce` for instance. Please refer to it. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20869: Improve implicitNotFound message for Encoder
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/20869 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20869: Improve implicitNotFound message for Encoder
Github user srowen commented on the issue: https://github.com/apache/spark/pull/20869 Merged to master --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21247: [SPARK-24190] Separating JSONOptions for read
Github user MaxGekk commented on a diff in the pull request:
https://github.com/apache/spark/pull/21247#discussion_r187780271
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JSONOptions.scala
---
@@ -138,3 +121,40 @@ private[sql] class JSONOptions(
factory.configure(JsonParser.Feature.ALLOW_UNQUOTED_CONTROL_CHARS,
allowUnquotedControlChars)
}
}
+
+private[sql] class JSONOptionsInRead(
+@transient override val parameters: CaseInsensitiveMap[String],
+defaultTimeZoneId: String,
+defaultColumnNameOfCorruptRecord: String)
+ extends JSONOptions(parameters, defaultTimeZoneId,
defaultColumnNameOfCorruptRecord) {
+
+ def this(
+parameters: Map[String, String],
+defaultTimeZoneId: String,
+defaultColumnNameOfCorruptRecord: String = "") = {
+this(
+ CaseInsensitiveMap(parameters),
+ defaultTimeZoneId,
+ defaultColumnNameOfCorruptRecord)
+ }
+
+ protected override def checkedEncoding(enc: String): String = {
+// The following encodings are not supported in per-line mode
(multiline is false)
+// because they cause some problems in reading files with BOM which is
supposed to
+// present in the files with such encodings. After splitting input
files by lines,
+// only the first lines will have the BOM which leads to impossibility
for reading
+// the rest lines. Besides of that, the lineSep option must have the
BOM in such
+// encodings which can never present between lines.
+val blacklist = Seq(Charset.forName("UTF-16"),
Charset.forName("UTF-32"))
+val isBlacklisted = blacklist.contains(Charset.forName(enc))
+require(multiLine || !isBlacklisted,
--- End diff --
There is no reasons to blacklist `UTF-16` and `UTF-32` in write. I have
checked the content of written JSON files on @gatorsmile 's
[test](https://github.com/apache/spark/pull/21247/commits/97c4af76addc78a85ceb503a5db16f3285f18a5f).
For example, for `UTF-16`
```
$ hexdump -C ...c000.json
fe ff 00 7b 00 22 00 5f 00 31 00 22 00 3a 00 22
|...{."._.1.".:."|
0010 00 61 00 22 00 2c 00 22 00 5f 00 32 00 22 00 3a
|.a.".,."._.2.".:|
0020 00 31 00 7d 00 0a 00 7b 00 22 00 5f 00 31 00 22
|.1.}...{."._.1."|
0030 00 3a 00 22 00 63 00 22 00 2c 00 22 00 5f 00 32
|.:.".c.".,."._.2|
0040 00 22 00 3a 00 33 00 7d 00 0a|.".:.3.}..|
004a
```
It contains BOM `fe ff` at the beginning as it is expected, and written
line separator doesn't contains BOM (look at the position 0x24-0x25) - `00 7d`
**00 0a** `00 7b`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21299 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90542/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21299 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21299 **[Test build #90542 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90542/testReport)** for PR 21299 at commit [`2ecabe4`](https://github.com/apache/spark/commit/2ecabe4fd984bb6a3f909364dcee27490c7a5d0a). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21295: [SPARK-24230][SQL] Fix SpecificParquetRecordReade...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/21295#discussion_r187778727
--- Diff:
sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
---
@@ -147,7 +147,8 @@ public void initialize(InputSplit inputSplit,
TaskAttemptContext taskAttemptCont
this.sparkSchema =
StructType$.MODULE$.fromString(sparkRequestedSchemaString);
this.reader = new ParquetFileReader(
configuration, footer.getFileMetaData(), file, blocks,
requestedSchema.getColumns());
-for (BlockMetaData block : blocks) {
+// use the blocks from the reader in case some do not match filters
and will not be read
--- End diff --
Could you be more specific by mentioning the corresponding Parquet JIRA
issue or versions (1.10.0)?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21295: [SPARK-24230][SQL] Fix SpecificParquetRecordReade...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/21295#discussion_r187778648
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetQuerySuite.scala
---
@@ -879,6 +879,18 @@ class ParquetQuerySuite extends QueryTest with
ParquetTest with SharedSQLContext
}
}
}
+
+ test("SPARK-24230: filter row group using dictionary") {
+withSQLConf(("parquet.filter.dictionary.enabled", "true")) {
--- End diff --
Is this a valid way to control this configuration? It seems to pass with
`false`, too.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20869: Improve implicitNotFound message for Encoder
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20869 **[Test build #4173 has finished](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/4173/testReport)** for PR 20869 at commit [`588dffc`](https://github.com/apache/spark/commit/588dffc51df53bcbb885305e8ecd5bf39aa2e465). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21307 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21307 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90541/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21307 **[Test build #90541 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90541/testReport)** for PR 21307 at commit [`4f1513b`](https://github.com/apache/spark/commit/4f1513baccd5d66a0c374c83499bf453a3f590bc). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21045: [SPARK-23931][SQL] Adds zip function to sparksql
Github user DylanGuedes commented on the issue: https://github.com/apache/spark/pull/21045 @mgaido91 Thank you for the suggestions and for being so patient. I updated the code with `zip` name, more tests in CollectionExpression (I'll add more after adding support to any number of arrays as input), the stripMargin syntax and a little refactor in the doGenCode (Is it the change that you was thinking of? I can make the code shorter but i'll be more complicated I think). I didn't find the proper way to add support to any number of arrays, since the number of inputs looks limited (unary, binary and ternary expressions, didn't find a "n-nary" or something similar). What you think? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21299 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3169/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21299 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21045: [SPARK-23931][SQL] Adds zip function to sparksql
Github user DylanGuedes commented on a diff in the pull request:
https://github.com/apache/spark/pull/21045#discussion_r187775631
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
---
@@ -90,6 +90,112 @@ case class MapKeys(child: Expression)
override def prettyName: String = "map_keys"
}
+@ExpressionDescription(
+ usage = """_FUNC_(a1, a2) - Returns a merged array matching N-th element
of first
+ array with the N-th element of second.""",
+ examples = """
+Examples:
+ > SELECT _FUNC_(array(1, 2, 3), array(2, 3, 4));
+[[1, 2], [2, 3], [3, 4]]
+ """,
+ since = "2.4.0")
+case class ZipLists(left: Expression, right: Expression)
+ extends BinaryExpression with ExpectsInputTypes {
+
+ override def inputTypes: Seq[AbstractDataType] = Seq(ArrayType,
ArrayType)
+
+ override def dataType: DataType = ArrayType(StructType(
+StructField("_1", left.dataType.asInstanceOf[ArrayType].elementType,
true) ::
+StructField("_2", right.dataType.asInstanceOf[ArrayType].elementType,
true) ::
+ Nil))
+
+ override def prettyName: String = "zip_lists"
+
+ override def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = {
+nullSafeCodeGen(ctx, ev, (arr1, arr2) => {
+ val genericArrayData = classOf[GenericArrayData].getName
+ val genericInternalRow = classOf[GenericInternalRow].getName
+
+ val i = ctx.freshName("i")
+ val values = ctx.freshName("values")
+ val len1 = ctx.freshName("len1")
+ val len2 = ctx.freshName("len2")
+ val pair = ctx.freshName("pair")
+ val getValue1 = CodeGenerator.getValue(
+arr1, left.dataType.asInstanceOf[ArrayType].elementType, i)
+ val getValue2 = CodeGenerator.getValue(
+arr2, right.dataType.asInstanceOf[ArrayType].elementType, i)
+
+ s"""
--- End diff --
Done! I am currently using sbt and an editor, actually.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21299: [SPARK-24250][SQL] support accessing SQLConf insi...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/21299#discussion_r187775593
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/SQLExecution.scala ---
@@ -68,16 +68,27 @@ object SQLExecution {
// sparkContext.getCallSite() would first try to pick up any call
site that was previously
// set, then fall back to Utils.getCallSite(); call
Utils.getCallSite() directly on
// streaming queries would give us call site like "run at
:0"
- val callSite = sparkSession.sparkContext.getCallSite()
+ val callSite = sc.getCallSite()
-
sparkSession.sparkContext.listenerBus.post(SparkListenerSQLExecutionStart(
+ // Set all the specified SQL configs to local properties, so that
they can be available at
+ // the executor side.
+ val allConfigs = sparkSession.sessionState.conf.getAllConfs
+ allConfigs.foreach {
+// Excludes external configs defined by users.
+case (key, value) if key.startsWith("spark") =>
sc.setLocalProperty(key, value)
--- End diff --
This causes `scala.MatchError`. We need to cover the other case, too.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21307 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3168/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21307 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21307 **[Test build #90541 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90541/testReport)** for PR 21307 at commit [`4f1513b`](https://github.com/apache/spark/commit/4f1513baccd5d66a0c374c83499bf453a3f590bc). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21299 **[Test build #90542 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90542/testReport)** for PR 21299 at commit [`2ecabe4`](https://github.com/apache/spark/commit/2ecabe4fd984bb6a3f909364dcee27490c7a5d0a). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21299: [SPARK-24250][SQL] support accessing SQLConf inside task...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/21299 Retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user huaxingao commented on the issue: https://github.com/apache/spark/pull/21307 @HyukjinKwon I think I resolved the problem. Thanks! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21301: [SPARK-24228][SQL] Fix Java lint errors
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/21301 @kiszk . Could you update your PR description like this? ``` ~/PR-21301:PR-21301$ dev/lint-java exec: curl --progress-bar -L https://downloads.typesafe.com/zinc/0.3.15/zinc-0.3.15.tgz 100.0% exec: curl --progress-bar -L https://downloads.typesafe.com/scala/2.11.8/scala-2.11.8.tgz 100.0% exec: curl --progress-bar -L https://www.apache.org/dyn/closer.lua?action=download&filename=/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz 100.0% Using `mvn` from path: /home/dongjoon/PR-21301/build/apache-maven-3.3.9/bin/mvn Checkstyle checks passed. ``` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21307 @huaxingao. feel free to reopen a PR if you get any problem. It's fine. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21114: [SPARK-22371][CORE] Return None instead of throwi...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21114#discussion_r187763308
--- Diff: core/src/test/scala/org/apache/spark/AccumulatorSuite.scala ---
@@ -237,6 +236,65 @@ class AccumulatorSuite extends SparkFunSuite with
Matchers with LocalSparkContex
acc.merge("kindness")
assert(acc.value === "kindness")
}
+
+ test("updating garbage collected accumulators") {
+// Simulate FetchFailedException in the first attempt to force a retry.
+// Then complete remaining task from the first attempt after the second
+// attempt started, but before it completes. Completion event for the
first
+// attempt will try to update garbage collected accumulators.
+val numPartitions = 2
+sc = new SparkContext("local[2]", "test")
+
+val attempt0Latch = new TestLatch("attempt0")
+val attempt1Latch = new TestLatch("attempt1")
+
+val x = sc.parallelize(1 to 100, numPartitions).groupBy(identity)
+val sid = x.dependencies.head.asInstanceOf[ShuffleDependency[_, _,
_]].shuffleHandle.shuffleId
+val rdd = x.mapPartitionsWithIndex { case (i, iter) =>
+ val taskContext = TaskContext.get()
+ if (taskContext.stageAttemptNumber() == 0) {
+if (i == 0) {
+ // Fail the first task in the first stage attempt to force retry.
+ throw new FetchFailedException(
+SparkEnv.get.blockManager.blockManagerId,
+sid,
+taskContext.partitionId(),
+taskContext.partitionId(),
+"simulated fetch failure")
+} else {
+ // Wait till the second attempt starts.
+ attempt0Latch.await()
+ iter
+}
+ } else {
+if (i == 0) {
+ // Wait till the first attempt completes.
+ attempt1Latch.await()
+}
+iter
+ }
+}
+
+sc.addSparkListener(new SparkListener {
+ override def onTaskStart(taskStart: SparkListenerTaskStart): Unit = {
+if (taskStart.stageId == 1 && taskStart.stageAttemptId == 1) {
--- End diff --
Should we add 'taskStart.taskInfo.index == 0' here to make sure it's the
partition 0?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21114: [SPARK-22371][CORE] Return None instead of throwi...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21114#discussion_r187763285
--- Diff: core/src/test/scala/org/apache/spark/AccumulatorSuite.scala ---
@@ -209,10 +209,8 @@ class AccumulatorSuite extends SparkFunSuite with
Matchers with LocalSparkContex
System.gc()
assert(ref.get.isEmpty)
-// Getting a garbage collected accum should throw error
-intercept[IllegalStateException] {
- AccumulatorContext.get(accId)
-}
+// Getting a garbage collected accum should return None.
+assert(AccumulatorContext.get(accId).isEmpty)
--- End diff --
Cool!
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21307 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21307 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3167/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21307 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/90540/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21307 **[Test build #90540 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90540/testReport)** for PR 21307 at commit [`132af85`](https://github.com/apache/spark/commit/132af853bba50561926a0be3bb9b585305b4c8b5). * This patch **fails RAT tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21307 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21307: [SPARK-24186][R][SQL]change reverse and concat to collec...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21307 **[Test build #90540 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/90540/testReport)** for PR 21307 at commit [`132af85`](https://github.com/apache/spark/commit/132af853bba50561926a0be3bb9b585305b4c8b5). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19680: [SPARK-22461][ML] Refactor Spark ML model summaries
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/19680 Build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19680: [SPARK-22461][ML] Refactor Spark ML model summaries
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/19680 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/3166/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21300: [SPARK-24067][BACKPORT-2.3][STREAMING][KAFKA] All...
Github user koeninger closed the pull request at: https://github.com/apache/spark/pull/21300 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19951: [SPARK-22760][CORE][YARN] When sc.stop() is calle...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/19951 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21281: Branch 1.6
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/21281 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20635: [SPARK-23053][CORE][BRANCH-2.1] taskBinarySeriali...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/20635 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20530: [SPARK-23349][SQL]ShuffleExchangeExec: Duplicate ...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/20530 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21303: [BUILD] Close stale PRs
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/21303 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20557: [SPARK-23364][SQL]'desc table' command in spark-s...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/20557 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20683: [SPARK-8605] Exclude files in StreamingContext. t...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/20683 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19694: [SPARK-22470][DOC][SQL] functions.hash is also us...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/19694 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org