[GitHub] [spark] CaptionKid commented on a change in pull request #8404: [SPARK-10198][SQL] Turn off partition verification by default
CaptionKid commented on a change in pull request #8404: [SPARK-10198][SQL] Turn
off partition verification by default
URL: https://github.com/apache/spark/pull/8404#discussion_r298012727
##
File path: sql/core/src/main/scala/org/apache/spark/sql/SQLConf.scala
##
@@ -312,7 +312,7 @@ private[spark] object SQLConf {
doc = "When true, enable filter pushdown for ORC files.")
val HIVE_VERIFY_PARTITION_PATH =
booleanConf("spark.sql.hive.verifyPartitionPath",
-defaultValue = Some(true),
+defaultValue = Some(false),
Review comment:
Why this place use false as default value
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on issue #24918: [SPARK-28077][SQL] Support ANSI SQL OVERLAY function.
beliefer commented on issue #24918: [SPARK-28077][SQL] Support ANSI SQL OVERLAY function. URL: https://github.com/apache/spark/pull/24918#issuecomment-506190750 @ueshin Could you continue to review this PR? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu removed a comment on issue #24909: [SPARK-28106][SQL] When Spark SQL use "add jar" , before add to SparkContext, check jar path exist first.
AngersZh removed a comment on issue #24909: [SPARK-28106][SQL] When Spark SQL use "add jar" , before add to SparkContext, check jar path exist first. URL: https://github.com/apache/spark/pull/24909#issuecomment-505778340 @GregOwen @srowen How about my latest change, this way can avoid problem srowen mentioned and fix the problem of addJar This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu removed a comment on issue #24909: [SPARK-28106][SQL] When Spark SQL use "add jar" , before add to SparkContext, check jar path exist first.
AngersZh removed a comment on issue #24909: [SPARK-28106][SQL] When Spark SQL use "add jar" , before add to SparkContext, check jar path exist first. URL: https://github.com/apache/spark/pull/24909#issuecomment-505281996 @srowen About ' JAR might not yet exist at the time the driver is started', Do you have any conclusions. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu removed a comment on issue #24909: [SPARK-28106][SQL] When Spark SQL use "add jar" , before add to SparkContext, check jar path exist first.
AngersZh removed a comment on issue #24909: [SPARK-28106][SQL] When Spark SQL use "add jar" , before add to SparkContext, check jar path exist first. URL: https://github.com/apache/spark/pull/24909#issuecomment-505283141 @GregOwen How about add a condition in SparkContext#addJar, if it's start workflow, we don't check it, if not, we check it. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on issue #24909: [SPARK-28106][SQL] When Spark SQL use "add jar" , before add to SparkContext, check jar path exist first.
AngersZh commented on issue #24909: [SPARK-28106][SQL] When Spark SQL use "add jar" , before add to SparkContext, check jar path exist first. URL: https://github.com/apache/spark/pull/24909#issuecomment-506183262 @cloud-fan @gatorsmile @GregOwen @srowen Could you review again, I think current version can cover all you concerns . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #24973: [SPARK-28169] Fix Partition table partition PushDown failed by "OR" expression
AngersZh commented on a change in pull request #24973: [SPARK-28169] Fix
Partition table partition PushDown failed by "OR" expression
URL: https://github.com/apache/spark/pull/24973#discussion_r298003649
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveStrategies.scala
##
@@ -237,21 +237,75 @@ private[hive] trait HiveStrategies {
* applied.
*/
object HiveTableScans extends Strategy {
+
+def constructBinaryOperators(left:Expression, right: Expression, op_type:
String): Expression ={
+ (left == null, right == null) match {
+case (true, true) => null
+case (true, false) => right
+case (false, true) => left
+case (false, false) =>
+ if(op_type == "or")
+Or(left, right)
+ else if (op_type == "and")
+And(left, right)
+ else
+null
+ }
+}
+
+def resolveAndExpression(expr: Expression, partitionKeyIds: AttributeSet):
Expression = {
+ expr match {
+case and: And =>
+ constructBinaryOperators(resolveAndExpression(and.left,
partitionKeyIds), resolveAndExpression(and.right, partitionKeyIds), "and")
+case _ =>
+ resolvePredicatesExpression(expr, partitionKeyIds)
+ }
+}
+
+def resolveOrExpression(or: Or, partitionKeyIds: AttributeSet): Expression
= {
+ (or.left.isInstanceOf[Or],or.right.isInstanceOf[Or]) match {
+case (true, true) =>
constructBinaryOperators(resolveOrExpression(or.left.asInstanceOf[Or],
partitionKeyIds) , resolveOrExpression(or.right.asInstanceOf[Or],
partitionKeyIds), "or")
+case (true, false) =>
constructBinaryOperators(resolveOrExpression(or.left.asInstanceOf[Or],
partitionKeyIds) , resolveAndExpression(or.right, partitionKeyIds), "or")
+case (false, true) =>
constructBinaryOperators(resolveAndExpression(or.left, partitionKeyIds) ,
resolveOrExpression(or.right.asInstanceOf[Or], partitionKeyIds), "or")
+case (false, false) =>
constructBinaryOperators(resolveAndExpression(or.left, partitionKeyIds) ,
resolveAndExpression(or.right, partitionKeyIds), "or")
+ }
+}
+
+def resolvePredicatesExpression(expr: Expression, partitionKeyIds:
AttributeSet): Expression ={
+ if(!expr.references.isEmpty && expr.references.subsetOf(partitionKeyIds))
+expr
+ else
+null
+}
+
+def extractPushDownPredicate(predicates: Seq[Expression], partitionKeyIds:
AttributeSet): Seq[Expression] ={
+ predicates.map {
+case or: Or =>
+ resolveOrExpression(or, partitionKeyIds)
+case predicate =>
+ resolvePredicatesExpression(predicate, partitionKeyIds)
+ }
+}
+
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case PhysicalOperation(projectList, predicates, relation:
HiveTableRelation) =>
// Filter out all predicates that only deal with partition keys, these
are given to the
// hive table scan operator to be used for partition pruning.
val partitionKeyIds = AttributeSet(relation.partitionCols)
-val (pruningPredicates, otherPredicates) = predicates.partition {
predicate =>
+val (_, otherPredicates) = predicates.partition { predicate => {
!predicate.references.isEmpty &&
- predicate.references.subsetOf(partitionKeyIds)
+predicate.references.subsetOf(partitionKeyIds)
}
+}
+
+val extractedPruningPredicates = extractPushDownPredicate(predicates,
partitionKeyIds)
+ .filter(_ != null)
Review comment:
@HyukjinKwon I know that it's better to convert Hive table reading
operations into Spark's , but it can't fix all situation. In our production
env, we just change hive data's default storage type to orc. For partition
table, if different partition's serde is not the same, Convert will failed,
since during converting , it will check all partition's file by table level
serde.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #24973: [SPARK-28169] Fix Partition table partition PushDown failed by "OR" expression
AngersZh commented on a change in pull request #24973: [SPARK-28169] Fix
Partition table partition PushDown failed by "OR" expression
URL: https://github.com/apache/spark/pull/24973#discussion_r298003649
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveStrategies.scala
##
@@ -237,21 +237,75 @@ private[hive] trait HiveStrategies {
* applied.
*/
object HiveTableScans extends Strategy {
+
+def constructBinaryOperators(left:Expression, right: Expression, op_type:
String): Expression ={
+ (left == null, right == null) match {
+case (true, true) => null
+case (true, false) => right
+case (false, true) => left
+case (false, false) =>
+ if(op_type == "or")
+Or(left, right)
+ else if (op_type == "and")
+And(left, right)
+ else
+null
+ }
+}
+
+def resolveAndExpression(expr: Expression, partitionKeyIds: AttributeSet):
Expression = {
+ expr match {
+case and: And =>
+ constructBinaryOperators(resolveAndExpression(and.left,
partitionKeyIds), resolveAndExpression(and.right, partitionKeyIds), "and")
+case _ =>
+ resolvePredicatesExpression(expr, partitionKeyIds)
+ }
+}
+
+def resolveOrExpression(or: Or, partitionKeyIds: AttributeSet): Expression
= {
+ (or.left.isInstanceOf[Or],or.right.isInstanceOf[Or]) match {
+case (true, true) =>
constructBinaryOperators(resolveOrExpression(or.left.asInstanceOf[Or],
partitionKeyIds) , resolveOrExpression(or.right.asInstanceOf[Or],
partitionKeyIds), "or")
+case (true, false) =>
constructBinaryOperators(resolveOrExpression(or.left.asInstanceOf[Or],
partitionKeyIds) , resolveAndExpression(or.right, partitionKeyIds), "or")
+case (false, true) =>
constructBinaryOperators(resolveAndExpression(or.left, partitionKeyIds) ,
resolveOrExpression(or.right.asInstanceOf[Or], partitionKeyIds), "or")
+case (false, false) =>
constructBinaryOperators(resolveAndExpression(or.left, partitionKeyIds) ,
resolveAndExpression(or.right, partitionKeyIds), "or")
+ }
+}
+
+def resolvePredicatesExpression(expr: Expression, partitionKeyIds:
AttributeSet): Expression ={
+ if(!expr.references.isEmpty && expr.references.subsetOf(partitionKeyIds))
+expr
+ else
+null
+}
+
+def extractPushDownPredicate(predicates: Seq[Expression], partitionKeyIds:
AttributeSet): Seq[Expression] ={
+ predicates.map {
+case or: Or =>
+ resolveOrExpression(or, partitionKeyIds)
+case predicate =>
+ resolvePredicatesExpression(predicate, partitionKeyIds)
+ }
+}
+
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case PhysicalOperation(projectList, predicates, relation:
HiveTableRelation) =>
// Filter out all predicates that only deal with partition keys, these
are given to the
// hive table scan operator to be used for partition pruning.
val partitionKeyIds = AttributeSet(relation.partitionCols)
-val (pruningPredicates, otherPredicates) = predicates.partition {
predicate =>
+val (_, otherPredicates) = predicates.partition { predicate => {
!predicate.references.isEmpty &&
- predicate.references.subsetOf(partitionKeyIds)
+predicate.references.subsetOf(partitionKeyIds)
}
+}
+
+val extractedPruningPredicates = extractPushDownPredicate(predicates,
partitionKeyIds)
+ .filter(_ != null)
Review comment:
@HyukjinKwon I know that it's better to us convert hive metastore to
DataSource API, but it can't fix all situation. In our production env, we just
change hive data's default storage type to orc. For partition table, if
different partition;s serde is not the same, Convert will failed thing using
convert, it will check all partition by table level serde.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #24973: [SPARK-28169] Fix Partition table partition PushDown failed by "OR" expression
HyukjinKwon commented on a change in pull request #24973: [SPARK-28169] Fix
Partition table partition PushDown failed by "OR" expression
URL: https://github.com/apache/spark/pull/24973#discussion_r297999646
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveStrategies.scala
##
@@ -237,21 +237,75 @@ private[hive] trait HiveStrategies {
* applied.
*/
object HiveTableScans extends Strategy {
+
+def constructBinaryOperators(left:Expression, right: Expression, op_type:
String): Expression ={
+ (left == null, right == null) match {
+case (true, true) => null
+case (true, false) => right
+case (false, true) => left
+case (false, false) =>
+ if(op_type == "or")
+Or(left, right)
+ else if (op_type == "and")
+And(left, right)
+ else
+null
+ }
+}
+
+def resolveAndExpression(expr: Expression, partitionKeyIds: AttributeSet):
Expression = {
+ expr match {
+case and: And =>
+ constructBinaryOperators(resolveAndExpression(and.left,
partitionKeyIds), resolveAndExpression(and.right, partitionKeyIds), "and")
+case _ =>
+ resolvePredicatesExpression(expr, partitionKeyIds)
+ }
+}
+
+def resolveOrExpression(or: Or, partitionKeyIds: AttributeSet): Expression
= {
+ (or.left.isInstanceOf[Or],or.right.isInstanceOf[Or]) match {
+case (true, true) =>
constructBinaryOperators(resolveOrExpression(or.left.asInstanceOf[Or],
partitionKeyIds) , resolveOrExpression(or.right.asInstanceOf[Or],
partitionKeyIds), "or")
+case (true, false) =>
constructBinaryOperators(resolveOrExpression(or.left.asInstanceOf[Or],
partitionKeyIds) , resolveAndExpression(or.right, partitionKeyIds), "or")
+case (false, true) =>
constructBinaryOperators(resolveAndExpression(or.left, partitionKeyIds) ,
resolveOrExpression(or.right.asInstanceOf[Or], partitionKeyIds), "or")
+case (false, false) =>
constructBinaryOperators(resolveAndExpression(or.left, partitionKeyIds) ,
resolveAndExpression(or.right, partitionKeyIds), "or")
+ }
+}
+
+def resolvePredicatesExpression(expr: Expression, partitionKeyIds:
AttributeSet): Expression ={
+ if(!expr.references.isEmpty && expr.references.subsetOf(partitionKeyIds))
+expr
+ else
+null
+}
+
+def extractPushDownPredicate(predicates: Seq[Expression], partitionKeyIds:
AttributeSet): Seq[Expression] ={
+ predicates.map {
+case or: Or =>
+ resolveOrExpression(or, partitionKeyIds)
+case predicate =>
+ resolvePredicatesExpression(predicate, partitionKeyIds)
+ }
+}
+
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case PhysicalOperation(projectList, predicates, relation:
HiveTableRelation) =>
// Filter out all predicates that only deal with partition keys, these
are given to the
// hive table scan operator to be used for partition pruning.
val partitionKeyIds = AttributeSet(relation.partitionCols)
-val (pruningPredicates, otherPredicates) = predicates.partition {
predicate =>
+val (_, otherPredicates) = predicates.partition { predicate => {
!predicate.references.isEmpty &&
- predicate.references.subsetOf(partitionKeyIds)
+predicate.references.subsetOf(partitionKeyIds)
}
+}
+
+val extractedPruningPredicates = extractPushDownPredicate(predicates,
partitionKeyIds)
+ .filter(_ != null)
Review comment:
I think we convert Hive table reading operations into Spark's ones, via, for
instance, `spark.sql.hive.convertMetastoreParquet` conf. If the diff is small,
I might be fine but this does look like an overkill to me. I haven't taken a
close look but it virtually looks like we need a fix like
https://github.com/apache/spark/pull/24598
I won't object if some other committers are fine with that.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable
AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506146846 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106952/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable
AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506146844 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable
AmplabJenkins commented on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506146844 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable
AmplabJenkins commented on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506146846 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106952/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable
SparkQA removed a comment on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506096790 **[Test build #106952 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106952/testReport)** for PR 24832 at commit [`c9c9bc1`](https://github.com/apache/spark/commit/c9c9bc17e27ced3a15cd0923d289ce4fd3154c4e). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable
SparkQA commented on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506146555 **[Test build #106952 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106952/testReport)** for PR 24832 at commit [`c9c9bc1`](https://github.com/apache/spark/commit/c9c9bc17e27ced3a15cd0923d289ce4fd3154c4e). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24979: [SPARK-28179][SQL] Avoid hard-coded config: spark.sql.globalTempDatabase
SparkQA commented on issue #24979: [SPARK-28179][SQL] Avoid hard-coded config: spark.sql.globalTempDatabase URL: https://github.com/apache/spark/pull/24979#issuecomment-506142240 **[Test build #106953 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106953/testReport)** for PR 24979 at commit [`7ce8e39`](https://github.com/apache/spark/commit/7ce8e3967aaff5274c2e90d6abeb2171147a58ba). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24979: [SPARK-28179][SQL] Avoid hard-coded config: spark.sql.globalTempDatabase
AmplabJenkins removed a comment on issue #24979: [SPARK-28179][SQL] Avoid hard-coded config: spark.sql.globalTempDatabase URL: https://github.com/apache/spark/pull/24979#issuecomment-506141882 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12155/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24979: [SPARK-28179][SQL] Avoid hard-coded config: spark.sql.globalTempDatabase
AmplabJenkins removed a comment on issue #24979: [SPARK-28179][SQL] Avoid hard-coded config: spark.sql.globalTempDatabase URL: https://github.com/apache/spark/pull/24979#issuecomment-506141880 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24979: [SPARK-28179][SQL] Avoid hard-coded config: spark.sql.globalTempDatabase
AmplabJenkins commented on issue #24979: [SPARK-28179][SQL] Avoid hard-coded config: spark.sql.globalTempDatabase URL: https://github.com/apache/spark/pull/24979#issuecomment-506141880 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24979: [SPARK-28179][SQL] Avoid hard-coded config: spark.sql.globalTempDatabase
AmplabJenkins commented on issue #24979: [SPARK-28179][SQL] Avoid hard-coded config: spark.sql.globalTempDatabase URL: https://github.com/apache/spark/pull/24979#issuecomment-506141882 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12155/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum opened a new pull request #24979: [SPARK-28179][SQL] Avoid hard-coded config: spark.sql.globalTempDatabase
wangyum opened a new pull request #24979: [SPARK-28179][SQL] Avoid hard-coded config: spark.sql.globalTempDatabase URL: https://github.com/apache/spark/pull/24979 ## What changes were proposed in this pull request? Avoid hard-coded config: `spark.sql.globalTempDatabase`. ## How was this patch tested? N/A This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24970: [SPARK-23977][SQL] Support High Performance S3A committers [test-hadoop3.2][test-maven]
AmplabJenkins removed a comment on issue #24970: [SPARK-23977][SQL] Support High Performance S3A committers [test-hadoop3.2][test-maven] URL: https://github.com/apache/spark/pull/24970#issuecomment-506138282 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24970: [SPARK-23977][SQL] Support High Performance S3A committers [test-hadoop3.2][test-maven]
AmplabJenkins removed a comment on issue #24970: [SPARK-23977][SQL] Support High Performance S3A committers [test-hadoop3.2][test-maven] URL: https://github.com/apache/spark/pull/24970#issuecomment-506138287 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106947/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24970: [SPARK-23977][SQL] Support High Performance S3A committers [test-hadoop3.2][test-maven]
AmplabJenkins commented on issue #24970: [SPARK-23977][SQL] Support High Performance S3A committers [test-hadoop3.2][test-maven] URL: https://github.com/apache/spark/pull/24970#issuecomment-506138287 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106947/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24970: [SPARK-23977][SQL] Support High Performance S3A committers [test-hadoop3.2][test-maven]
AmplabJenkins commented on issue #24970: [SPARK-23977][SQL] Support High Performance S3A committers [test-hadoop3.2][test-maven] URL: https://github.com/apache/spark/pull/24970#issuecomment-506138282 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24970: [SPARK-23977][SQL] Support High Performance S3A committers [test-hadoop3.2][test-maven]
SparkQA removed a comment on issue #24970: [SPARK-23977][SQL] Support High Performance S3A committers [test-hadoop3.2][test-maven] URL: https://github.com/apache/spark/pull/24970#issuecomment-506064791 **[Test build #106947 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106947/testReport)** for PR 24970 at commit [`b8307f4`](https://github.com/apache/spark/commit/b8307f494543d2f12b436a86bf392faef3792214). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24970: [SPARK-23977][SQL] Support High Performance S3A committers [test-hadoop3.2][test-maven]
SparkQA commented on issue #24970: [SPARK-23977][SQL] Support High Performance S3A committers [test-hadoop3.2][test-maven] URL: https://github.com/apache/spark/pull/24970#issuecomment-506137808 **[Test build #106947 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106947/testReport)** for PR 24970 at commit [`b8307f4`](https://github.com/apache/spark/commit/b8307f494543d2f12b436a86bf392faef3792214). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on issue #24841: [SPARK-27369][CORE] Setup resources when Standalone Worker starts up
Ngone51 commented on issue #24841: [SPARK-27369][CORE] Setup resources when Standalone Worker starts up URL: https://github.com/apache/spark/pull/24841#issuecomment-506133728 Thank you @jiangxb1987 @tgravescs @viirya @WeichenXu123 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on a change in pull request #24817: [SPARK-27963][core] Allow dynamic allocation without a shuffle service.
Ngone51 commented on a change in pull request #24817: [SPARK-27963][core] Allow
dynamic allocation without a shuffle service.
URL: https://github.com/apache/spark/pull/24817#discussion_r297955925
##
File path:
core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
##
@@ -264,7 +426,18 @@ private[spark] class ExecutorMonitor(
def updateTimeout(): Unit = {
val oldDeadline = timeoutAt
val newDeadline = if (idleStart >= 0) {
-idleStart + (if (cachedBlocks.nonEmpty) storageTimeoutMs else
idleTimeoutMs)
+val timeout = if (cachedBlocks.nonEmpty || (shuffleIds != null &&
shuffleIds.nonEmpty)) {
+ val _cacheTimeout = if (cachedBlocks.nonEmpty) storageTimeoutMs else
Long.MaxValue
+ val _shuffleTimeout = if (shuffleIds != null && shuffleIds.nonEmpty)
{
Review comment:
Shall we add `hasActiveShuffle` in if condition or starts with `if (isIdle)`
rather than `if (idleStart >= 0)` ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #24973: [SPARK-28169] Fix Partition table partition PushDown failed by "OR" expression
AngersZh commented on a change in pull request #24973: [SPARK-28169] Fix
Partition table partition PushDown failed by "OR" expression
URL: https://github.com/apache/spark/pull/24973#discussion_r297953462
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveStrategies.scala
##
@@ -237,21 +237,75 @@ private[hive] trait HiveStrategies {
* applied.
*/
object HiveTableScans extends Strategy {
+
+def constructBinaryOperators(left:Expression, right: Expression, op_type:
String): Expression ={
+ (left == null, right == null) match {
+case (true, true) => null
+case (true, false) => right
+case (false, true) => left
+case (false, false) =>
+ if(op_type == "or")
+Or(left, right)
+ else if (op_type == "and")
+And(left, right)
+ else
+null
+ }
+}
+
+def resolveAndExpression(expr: Expression, partitionKeyIds: AttributeSet):
Expression = {
+ expr match {
+case and: And =>
+ constructBinaryOperators(resolveAndExpression(and.left,
partitionKeyIds), resolveAndExpression(and.right, partitionKeyIds), "and")
+case _ =>
+ resolvePredicatesExpression(expr, partitionKeyIds)
+ }
+}
+
+def resolveOrExpression(or: Or, partitionKeyIds: AttributeSet): Expression
= {
+ (or.left.isInstanceOf[Or],or.right.isInstanceOf[Or]) match {
+case (true, true) =>
constructBinaryOperators(resolveOrExpression(or.left.asInstanceOf[Or],
partitionKeyIds) , resolveOrExpression(or.right.asInstanceOf[Or],
partitionKeyIds), "or")
+case (true, false) =>
constructBinaryOperators(resolveOrExpression(or.left.asInstanceOf[Or],
partitionKeyIds) , resolveAndExpression(or.right, partitionKeyIds), "or")
+case (false, true) =>
constructBinaryOperators(resolveAndExpression(or.left, partitionKeyIds) ,
resolveOrExpression(or.right.asInstanceOf[Or], partitionKeyIds), "or")
+case (false, false) =>
constructBinaryOperators(resolveAndExpression(or.left, partitionKeyIds) ,
resolveAndExpression(or.right, partitionKeyIds), "or")
+ }
+}
+
+def resolvePredicatesExpression(expr: Expression, partitionKeyIds:
AttributeSet): Expression ={
+ if(!expr.references.isEmpty && expr.references.subsetOf(partitionKeyIds))
+expr
+ else
+null
+}
+
+def extractPushDownPredicate(predicates: Seq[Expression], partitionKeyIds:
AttributeSet): Seq[Expression] ={
+ predicates.map {
+case or: Or =>
+ resolveOrExpression(or, partitionKeyIds)
+case predicate =>
+ resolvePredicatesExpression(predicate, partitionKeyIds)
+ }
+}
+
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case PhysicalOperation(projectList, predicates, relation:
HiveTableRelation) =>
// Filter out all predicates that only deal with partition keys, these
are given to the
// hive table scan operator to be used for partition pruning.
val partitionKeyIds = AttributeSet(relation.partitionCols)
-val (pruningPredicates, otherPredicates) = predicates.partition {
predicate =>
+val (_, otherPredicates) = predicates.partition { predicate => {
!predicate.references.isEmpty &&
- predicate.references.subsetOf(partitionKeyIds)
+predicate.references.subsetOf(partitionKeyIds)
}
+}
+
+val extractedPruningPredicates = extractPushDownPredicate(predicates,
partitionKeyIds)
+ .filter(_ != null)
Review comment:
@HyukjinKwon What I do is to extract condition's about partition keys.For
the old code :
` val (pruningPredicates, otherPredicates) = predicates.partition {
predicate =>
!predicate.references.isEmpty &&
predicate.references.subsetOf(partitionKeyIds) }`
If in expression, there contains other key, it won't be a push to
HiveTableScanExec, So what I to it to fix this situation, just extract all
condition about partition keys, then push it to HiveTableScanExec,
HiveTableScanExec will handle complex combine expressions.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #24973: [SPARK-28169] Fix Partition table partition PushDown failed by "OR" expression
AngersZh commented on a change in pull request #24973: [SPARK-28169] Fix
Partition table partition PushDown failed by "OR" expression
URL: https://github.com/apache/spark/pull/24973#discussion_r297954382
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveStrategies.scala
##
@@ -237,21 +237,75 @@ private[hive] trait HiveStrategies {
* applied.
*/
object HiveTableScans extends Strategy {
+
+def constructBinaryOperators(left:Expression, right: Expression, op_type:
String): Expression ={
+ (left == null, right == null) match {
+case (true, true) => null
+case (true, false) => right
+case (false, true) => left
+case (false, false) =>
+ if(op_type == "or")
+Or(left, right)
+ else if (op_type == "and")
+And(left, right)
+ else
+null
+ }
+}
+
+def resolveAndExpression(expr: Expression, partitionKeyIds: AttributeSet):
Expression = {
+ expr match {
+case and: And =>
+ constructBinaryOperators(resolveAndExpression(and.left,
partitionKeyIds), resolveAndExpression(and.right, partitionKeyIds), "and")
+case _ =>
+ resolvePredicatesExpression(expr, partitionKeyIds)
+ }
+}
+
+def resolveOrExpression(or: Or, partitionKeyIds: AttributeSet): Expression
= {
+ (or.left.isInstanceOf[Or],or.right.isInstanceOf[Or]) match {
+case (true, true) =>
constructBinaryOperators(resolveOrExpression(or.left.asInstanceOf[Or],
partitionKeyIds) , resolveOrExpression(or.right.asInstanceOf[Or],
partitionKeyIds), "or")
+case (true, false) =>
constructBinaryOperators(resolveOrExpression(or.left.asInstanceOf[Or],
partitionKeyIds) , resolveAndExpression(or.right, partitionKeyIds), "or")
+case (false, true) =>
constructBinaryOperators(resolveAndExpression(or.left, partitionKeyIds) ,
resolveOrExpression(or.right.asInstanceOf[Or], partitionKeyIds), "or")
+case (false, false) =>
constructBinaryOperators(resolveAndExpression(or.left, partitionKeyIds) ,
resolveAndExpression(or.right, partitionKeyIds), "or")
+ }
+}
+
+def resolvePredicatesExpression(expr: Expression, partitionKeyIds:
AttributeSet): Expression ={
+ if(!expr.references.isEmpty && expr.references.subsetOf(partitionKeyIds))
+expr
+ else
+null
+}
+
+def extractPushDownPredicate(predicates: Seq[Expression], partitionKeyIds:
AttributeSet): Seq[Expression] ={
+ predicates.map {
+case or: Or =>
+ resolveOrExpression(or, partitionKeyIds)
+case predicate =>
+ resolvePredicatesExpression(predicate, partitionKeyIds)
+ }
+}
+
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case PhysicalOperation(projectList, predicates, relation:
HiveTableRelation) =>
// Filter out all predicates that only deal with partition keys, these
are given to the
// hive table scan operator to be used for partition pruning.
val partitionKeyIds = AttributeSet(relation.partitionCols)
-val (pruningPredicates, otherPredicates) = predicates.partition {
predicate =>
+val (_, otherPredicates) = predicates.partition { predicate => {
!predicate.references.isEmpty &&
- predicate.references.subsetOf(partitionKeyIds)
+predicate.references.subsetOf(partitionKeyIds)
}
+}
+
+val extractedPruningPredicates = extractPushDownPredicate(predicates,
partitionKeyIds)
+ .filter(_ != null)
Review comment:
@HyukjinKwon
Spark's Parquet or ORC is perfect, and it can push down filter condition,
but it can't resolve the problem that when we read a Hive table, our first
behavior is scan, What this pr want to do is to reduce the time of resolve
file info and partition metadata, and the file we scan. Then the file num or
partition num is big, it takes too long.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jiangxb1987 closed pull request #24841: [SPARK-27369][CORE] Setup resources when Standalone Worker starts up
jiangxb1987 closed pull request #24841: [SPARK-27369][CORE] Setup resources when Standalone Worker starts up URL: https://github.com/apache/spark/pull/24841 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jiangxb1987 commented on issue #24841: [SPARK-27369][CORE] Setup resources when Standalone Worker starts up
jiangxb1987 commented on issue #24841: [SPARK-27369][CORE] Setup resources when Standalone Worker starts up URL: https://github.com/apache/spark/pull/24841#issuecomment-506128206 Thanks, merged to master! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #24973: [SPARK-28169] Fix Partition table partition PushDown failed by "OR" expression
HyukjinKwon commented on a change in pull request #24973: [SPARK-28169] Fix
Partition table partition PushDown failed by "OR" expression
URL: https://github.com/apache/spark/pull/24973#discussion_r297951185
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveStrategies.scala
##
@@ -237,21 +237,75 @@ private[hive] trait HiveStrategies {
* applied.
*/
object HiveTableScans extends Strategy {
+
+def constructBinaryOperators(left:Expression, right: Expression, op_type:
String): Expression ={
+ (left == null, right == null) match {
+case (true, true) => null
+case (true, false) => right
+case (false, true) => left
+case (false, false) =>
+ if(op_type == "or")
+Or(left, right)
+ else if (op_type == "and")
+And(left, right)
+ else
+null
+ }
+}
+
+def resolveAndExpression(expr: Expression, partitionKeyIds: AttributeSet):
Expression = {
+ expr match {
+case and: And =>
+ constructBinaryOperators(resolveAndExpression(and.left,
partitionKeyIds), resolveAndExpression(and.right, partitionKeyIds), "and")
+case _ =>
+ resolvePredicatesExpression(expr, partitionKeyIds)
+ }
+}
+
+def resolveOrExpression(or: Or, partitionKeyIds: AttributeSet): Expression
= {
+ (or.left.isInstanceOf[Or],or.right.isInstanceOf[Or]) match {
+case (true, true) =>
constructBinaryOperators(resolveOrExpression(or.left.asInstanceOf[Or],
partitionKeyIds) , resolveOrExpression(or.right.asInstanceOf[Or],
partitionKeyIds), "or")
+case (true, false) =>
constructBinaryOperators(resolveOrExpression(or.left.asInstanceOf[Or],
partitionKeyIds) , resolveAndExpression(or.right, partitionKeyIds), "or")
+case (false, true) =>
constructBinaryOperators(resolveAndExpression(or.left, partitionKeyIds) ,
resolveOrExpression(or.right.asInstanceOf[Or], partitionKeyIds), "or")
+case (false, false) =>
constructBinaryOperators(resolveAndExpression(or.left, partitionKeyIds) ,
resolveAndExpression(or.right, partitionKeyIds), "or")
+ }
+}
+
+def resolvePredicatesExpression(expr: Expression, partitionKeyIds:
AttributeSet): Expression ={
+ if(!expr.references.isEmpty && expr.references.subsetOf(partitionKeyIds))
+expr
+ else
+null
+}
+
+def extractPushDownPredicate(predicates: Seq[Expression], partitionKeyIds:
AttributeSet): Seq[Expression] ={
+ predicates.map {
+case or: Or =>
+ resolveOrExpression(or, partitionKeyIds)
+case predicate =>
+ resolvePredicatesExpression(predicate, partitionKeyIds)
+ }
+}
+
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case PhysicalOperation(projectList, predicates, relation:
HiveTableRelation) =>
// Filter out all predicates that only deal with partition keys, these
are given to the
// hive table scan operator to be used for partition pruning.
val partitionKeyIds = AttributeSet(relation.partitionCols)
-val (pruningPredicates, otherPredicates) = predicates.partition {
predicate =>
+val (_, otherPredicates) = predicates.partition { predicate => {
!predicate.references.isEmpty &&
- predicate.references.subsetOf(partitionKeyIds)
+predicate.references.subsetOf(partitionKeyIds)
}
+}
+
+val extractedPruningPredicates = extractPushDownPredicate(predicates,
partitionKeyIds)
+ .filter(_ != null)
Review comment:
@AngersZh, just for clarification, this code path does support OR
expression but you want to do a partial pushdown right? Considering it needs a
lot of codes as @wangyum pointed out, I think we should better try to promote
to use (or convert) Spark's Parquet or ORC. It looks like an overkill to me.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on issue #24973: [SPARK-28169] Fix Partition table partition PushDown failed by "OR" expression
AngersZh commented on issue #24973: [SPARK-28169] Fix Partition table partition PushDown failed by "OR" expression URL: https://github.com/apache/spark/pull/24973#issuecomment-506108176 @dongjoon-hyun @cloud-fan @HyukjinKwon This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24978: [SPARK-28177][SQL] Adjust post shuffle partition number in adaptive execution
AmplabJenkins removed a comment on issue #24978: [SPARK-28177][SQL] Adjust post shuffle partition number in adaptive execution URL: https://github.com/apache/spark/pull/24978#issuecomment-506105795 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24978: [SPARK-28177][SQL] Adjust post shuffle partition number in adaptive execution
AmplabJenkins removed a comment on issue #24978: [SPARK-28177][SQL] Adjust post shuffle partition number in adaptive execution URL: https://github.com/apache/spark/pull/24978#issuecomment-506105801 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106949/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24978: [SPARK-28177][SQL] Adjust post shuffle partition number in adaptive execution
AmplabJenkins commented on issue #24978: [SPARK-28177][SQL] Adjust post shuffle partition number in adaptive execution URL: https://github.com/apache/spark/pull/24978#issuecomment-506105801 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106949/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24978: [SPARK-28177][SQL] Adjust post shuffle partition number in adaptive execution
AmplabJenkins commented on issue #24978: [SPARK-28177][SQL] Adjust post shuffle partition number in adaptive execution URL: https://github.com/apache/spark/pull/24978#issuecomment-506105795 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24978: [SPARK-28177][SQL] Adjust post shuffle partition number in adaptive execution
SparkQA removed a comment on issue #24978: [SPARK-28177][SQL] Adjust post shuffle partition number in adaptive execution URL: https://github.com/apache/spark/pull/24978#issuecomment-506072255 **[Test build #106949 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106949/testReport)** for PR 24978 at commit [`6f6bdaf`](https://github.com/apache/spark/commit/6f6bdaf99339ccacf4c30aa9af3c2566730f320b). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24978: [SPARK-28177][SQL] Adjust post shuffle partition number in adaptive execution
SparkQA commented on issue #24978: [SPARK-28177][SQL] Adjust post shuffle partition number in adaptive execution URL: https://github.com/apache/spark/pull/24978#issuecomment-506105473 **[Test build #106949 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106949/testReport)** for PR 24978 at commit [`6f6bdaf`](https://github.com/apache/spark/commit/6f6bdaf99339ccacf4c30aa9af3c2566730f320b). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on issue #24841: [SPARK-27369][CORE] Setup resources when Standalone Worker starts up
Ngone51 commented on issue #24841: [SPARK-27369][CORE] Setup resources when Standalone Worker starts up URL: https://github.com/apache/spark/pull/24841#issuecomment-506104521 > Where's the code to detect this case and then raise error ? This part is planning to be done in the following PR :) @WeichenXu123 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24956: [SPARK-27815][SQL] Predicate pushdown in one pass for cascading joins
AmplabJenkins commented on issue #24956: [SPARK-27815][SQL] Predicate pushdown in one pass for cascading joins URL: https://github.com/apache/spark/pull/24956#issuecomment-506104218 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106948/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24956: [SPARK-27815][SQL] Predicate pushdown in one pass for cascading joins
AmplabJenkins commented on issue #24956: [SPARK-27815][SQL] Predicate pushdown in one pass for cascading joins URL: https://github.com/apache/spark/pull/24956#issuecomment-506104212 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24956: [SPARK-27815][SQL] Predicate pushdown in one pass for cascading joins
AmplabJenkins removed a comment on issue #24956: [SPARK-27815][SQL] Predicate pushdown in one pass for cascading joins URL: https://github.com/apache/spark/pull/24956#issuecomment-506104212 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24956: [SPARK-27815][SQL] Predicate pushdown in one pass for cascading joins
AmplabJenkins removed a comment on issue #24956: [SPARK-27815][SQL] Predicate pushdown in one pass for cascading joins URL: https://github.com/apache/spark/pull/24956#issuecomment-506104218 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106948/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24956: [SPARK-27815][SQL] Predicate pushdown in one pass for cascading joins
SparkQA removed a comment on issue #24956: [SPARK-27815][SQL] Predicate pushdown in one pass for cascading joins URL: https://github.com/apache/spark/pull/24956#issuecomment-506070485 **[Test build #106948 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106948/testReport)** for PR 24956 at commit [`f46c5c6`](https://github.com/apache/spark/commit/f46c5c69fce6121d2bf3e8658fa6510494edad77). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24956: [SPARK-27815][SQL] Predicate pushdown in one pass for cascading joins
SparkQA commented on issue #24956: [SPARK-27815][SQL] Predicate pushdown in one pass for cascading joins URL: https://github.com/apache/spark/pull/24956#issuecomment-506103884 **[Test build #106948 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106948/testReport)** for PR 24956 at commit [`f46c5c6`](https://github.com/apache/spark/commit/f46c5c69fce6121d2bf3e8658fa6510494edad77). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu edited a comment on issue #24973: [WIP][SPARK-28169] Fix Partition table partition PushDown failed by "OR" expression
AngersZh edited a comment on issue #24973: [WIP][SPARK-28169] Fix Partition table partition PushDown failed by "OR" expression URL: https://github.com/apache/spark/pull/24973#issuecomment-506101843 @wangyum I looked about #24598 , we are not same , what I want to do is to fix the problem of hive partition table's partition push down. That pr is for ORC & Parquet filter condition push down. By the way, we are in the Kyuubi wechat group This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on issue #24973: [WIP][SPARK-28169] Fix PushDown failed by "OR" expression
AngersZh commented on issue #24973: [WIP][SPARK-28169] Fix PushDown failed by "OR" expression URL: https://github.com/apache/spark/pull/24973#issuecomment-506101843 @wangyum I looked about #24598 , we are not same , what I want to do is to fix the problem of hive partition table's partition push down. That pr is for ORC & Parquet filter condition push down. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu removed a comment on issue #24909: [SPARK-28106][SQL] When Spark SQL use "add jar" , before add to SparkContext, check jar path exist first.
AngersZh removed a comment on issue #24909: [SPARK-28106][SQL] When Spark SQL use "add jar" , before add to SparkContext, check jar path exist first. URL: https://github.com/apache/spark/pull/24909#issuecomment-505789472 ok to test This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jzhuge commented on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable
jzhuge commented on issue #24832: [SPARK-27845][SQL] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506099696 Will look into supporting `IfPartitionNotExists` flag with DSv2 tables in follow-up PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jzhuge commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
jzhuge commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506098472 Will do DataFrameWriter.insertInto in a separate PR, so this PR is no longer WIP. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #24972: [WIP][SPARK-28167][SQL] Show global temporary view in database tool
wangyum commented on a change in pull request #24972: [WIP][SPARK-28167][SQL]
Show global temporary view in database tool
URL: https://github.com/apache/spark/pull/24972#discussion_r297922140
##
File path:
sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/SparkMetadataOperationSuite.scala
##
@@ -150,10 +154,13 @@ class SparkMetadataOperationSuite extends
HiveThriftJdbcTest {
Seq(
"CREATE TABLE table1(key INT, val STRING)",
"CREATE TABLE table2(key INT, val STRING)",
-"CREATE VIEW view1 AS SELECT * FROM table2").foreach(statement.execute)
+"CREATE VIEW view1 AS SELECT * FROM table2",
+"CREATE OR REPLACE TEMPORARY VIEW view_temp_1 AS SELECT 1 as col1",
Review comment:
How about temp view also showed in `global_temp`?
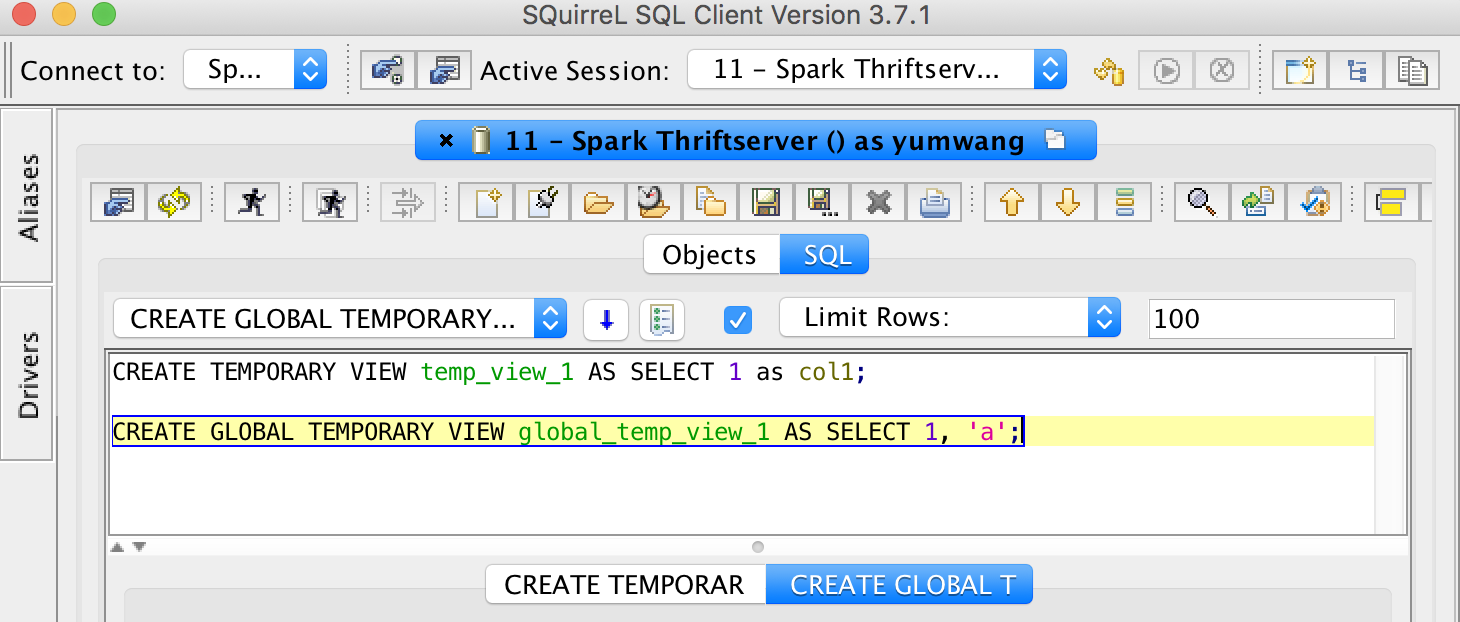
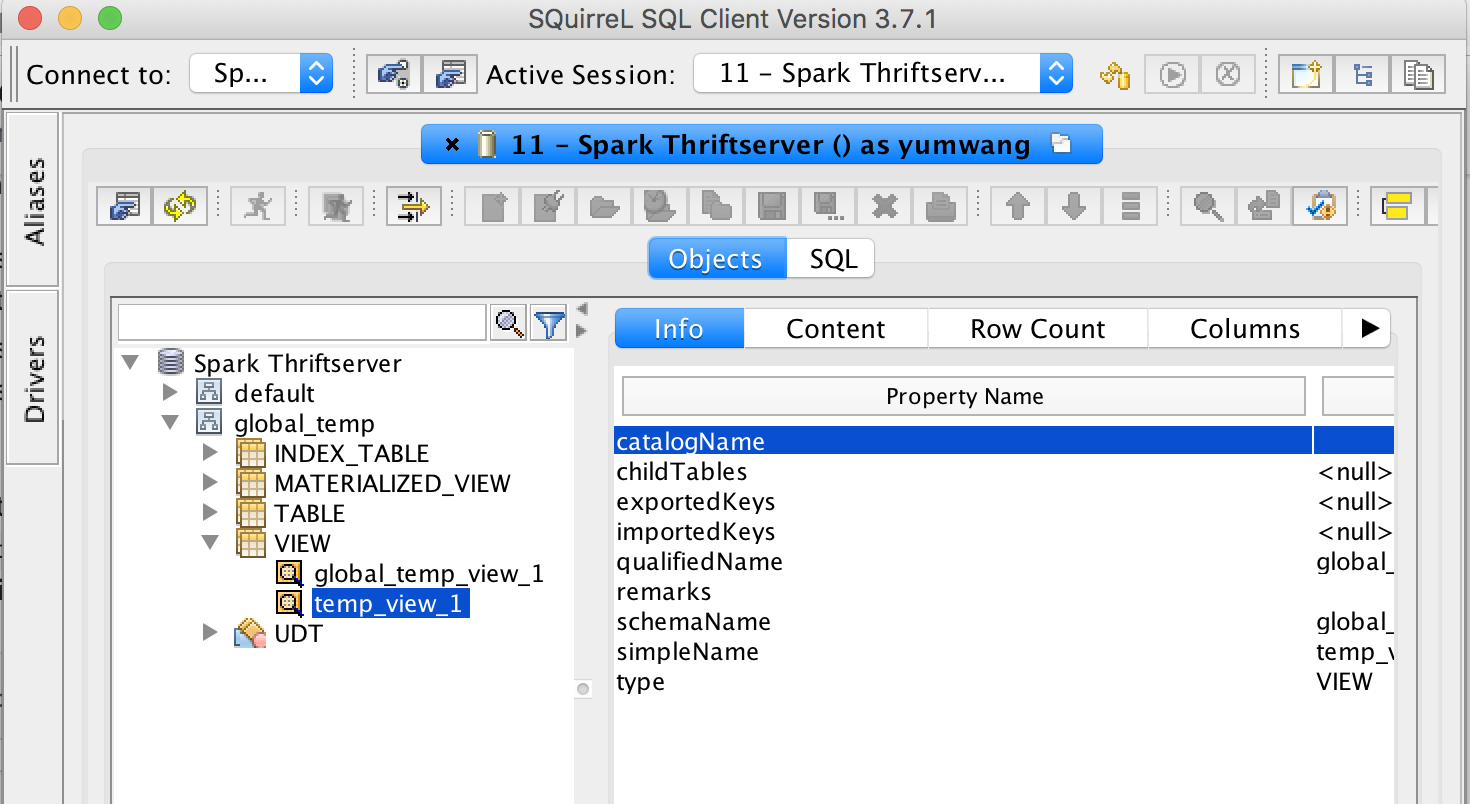
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
SparkQA commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506096790 **[Test build #106952 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106952/testReport)** for PR 24832 at commit [`c9c9bc1`](https://github.com/apache/spark/commit/c9c9bc17e27ced3a15cd0923d289ce4fd3154c4e). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506096478 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12154/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506096473 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506096473 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506096478 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12154/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24976: [SPARK-28174][BUILD][SS] Upgrade to Kafka 2.3.0
dongjoon-hyun commented on issue #24976: [SPARK-28174][BUILD][SS] Upgrade to Kafka 2.3.0 URL: https://github.com/apache/spark/pull/24976#issuecomment-506096250 Could you review this, @dbtsai ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
dongjoon-hyun commented on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24977#issuecomment-506096184 Could you review and merge this for `branch-2.3`, @dbtsai ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
dongjoon-hyun commented on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24975#issuecomment-506096109 Could you review and merge this, @dbtsai ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
dongjoon-hyun edited a comment on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24975#issuecomment-506096109 Could you review and merge this for `branch-2.4`, @dbtsai ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506094464 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106951/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
SparkQA removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506094240 **[Test build #106951 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106951/testReport)** for PR 24832 at commit [`fe4b24e`](https://github.com/apache/spark/commit/fe4b24e6bff38a74c6d65eb302738e7973adf591). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506094459 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506094459 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
SparkQA commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506094455 **[Test build #106951 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106951/testReport)** for PR 24832 at commit [`fe4b24e`](https://github.com/apache/spark/commit/fe4b24e6bff38a74c6d65eb302738e7973adf591). * This patch **fails Scala style tests**. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `case class InsertTableStatement(` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506094464 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106951/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
SparkQA commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506094240 **[Test build #106951 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106951/testReport)** for PR 24832 at commit [`fe4b24e`](https://github.com/apache/spark/commit/fe4b24e6bff38a74c6d65eb302738e7973adf591). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506093909 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506093909 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506093912 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12153/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506093912 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12153/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rdblue commented on a change in pull request #24937: [SPARK-28139][SQL] Add v2 ALTER TABLE implementation.
rdblue commented on a change in pull request #24937: [SPARK-28139][SQL] Add v2
ALTER TABLE implementation.
URL: https://github.com/apache/spark/pull/24937#discussion_r297917661
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/CheckAnalysis.scala
##
@@ -313,6 +314,42 @@ trait CheckAnalysis extends PredicateHelper {
failAnalysis(s"Invalid partitioning: ${badReferences.mkString(",
")}")
}
+ case alter: AlterTable if alter.childrenResolved =>
+val table = alter.table
+def findField(operation: String, fieldName: Array[String]):
StructField = {
+ // include collections because structs nested in maps and arrays
may be altered
+ val field = table.schema.findNestedField(fieldName,
includeCollections = true)
+ if (field.isEmpty) {
+throw new AnalysisException(
+ s"Cannot $operation missing field in ${table.name} schema:
${fieldName.quoted}")
+ }
+ field.get
+}
+
+alter.changes.foreach {
+ case add: AddColumn =>
+val parent = add.fieldNames.init
+if (parent.nonEmpty) {
+ findField("add to", parent)
+}
+ case update: UpdateColumnType =>
+val field = findField("update", update.fieldNames)
+if (!Cast.canUpCast(field.dataType, update.newDataType)) {
Review comment:
Okay, I agree that you should not be able to alter complex types with
another complex type
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506090391 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106950/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
SparkQA commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506090379 **[Test build #106950 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106950/testReport)** for PR 24832 at commit [`2f8ada2`](https://github.com/apache/spark/commit/2f8ada2b96bf452e03714d9e2fc31a36cc01977d). * This patch **fails Scala style tests**. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `case class InsertTableStatement(` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
SparkQA removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506090137 **[Test build #106950 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106950/testReport)** for PR 24832 at commit [`2f8ada2`](https://github.com/apache/spark/commit/2f8ada2b96bf452e03714d9e2fc31a36cc01977d). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506090387 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506090387 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506090391 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106950/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
SparkQA commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506090137 **[Test build #106950 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106950/testReport)** for PR 24832 at commit [`2f8ada2`](https://github.com/apache/spark/commit/2f8ada2b96bf452e03714d9e2fc31a36cc01977d). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506089786 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12152/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins commented on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506089780 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506089786 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12152/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable
AmplabJenkins removed a comment on issue #24832: [SPARK-27845][SQL][WIP] DataSourceV2: InsertTable URL: https://github.com/apache/spark/pull/24832#issuecomment-506089780 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
AmplabJenkins removed a comment on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24977#issuecomment-506087210 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106945/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
AmplabJenkins removed a comment on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24977#issuecomment-506087204 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
AmplabJenkins commented on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24977#issuecomment-506087204 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
AmplabJenkins commented on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24977#issuecomment-506087210 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106945/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
SparkQA removed a comment on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24977#issuecomment-506023921 **[Test build #106945 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106945/testReport)** for PR 24977 at commit [`09092fa`](https://github.com/apache/spark/commit/09092fab1e28e794c17355ffb51fa86455f6f3cd). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
SparkQA commented on issue #24977: [SPARK-28157][CORE][2.3] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24977#issuecomment-506086964 **[Test build #106945 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106945/testReport)** for PR 24977 at commit [`09092fa`](https://github.com/apache/spark/commit/09092fab1e28e794c17355ffb51fa86455f6f3cd). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
AmplabJenkins removed a comment on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24975#issuecomment-506086621 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
AmplabJenkins removed a comment on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24975#issuecomment-506086626 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106943/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
AmplabJenkins commented on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24975#issuecomment-506086621 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
SparkQA removed a comment on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24975#issuecomment-506011225 **[Test build #106943 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106943/testReport)** for PR 24975 at commit [`c64b8e1`](https://github.com/apache/spark/commit/c64b8e1513970df1c1ce818330ecfa1757d0da23). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
AmplabJenkins commented on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24975#issuecomment-506086626 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/106943/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries
SparkQA commented on issue #24975: [SPARK-28157][CORE][2.4] Make SHS clear KVStore `LogInfo`s for the blacklisted entries URL: https://github.com/apache/spark/pull/24975#issuecomment-506086357 **[Test build #106943 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/106943/testReport)** for PR 24975 at commit [`c64b8e1`](https://github.com/apache/spark/commit/c64b8e1513970df1c1ce818330ecfa1757d0da23). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rdblue commented on a change in pull request #24937: [SPARK-28139][SQL] Add v2 ALTER TABLE implementation.
rdblue commented on a change in pull request #24937: [SPARK-28139][SQL] Add v2
ALTER TABLE implementation.
URL: https://github.com/apache/spark/pull/24937#discussion_r297908457
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -34,6 +34,7 @@ import org.apache.spark.sql.catalyst.expressions.aggregate._
import org.apache.spark.sql.catalyst.expressions.objects._
import org.apache.spark.sql.catalyst.plans._
import org.apache.spark.sql.catalyst.plans.logical._
+import
org.apache.spark.sql.catalyst.plans.logical.sql.{AlterTableAddColumnsStatement,
AlterTableAlterColumnStatement, AlterTableDropColumnsStatement,
AlterTableRenameColumnStatement, AlterTableSetLocationStatement,
AlterTableSetPropertiesStatement, AlterTableUnsetPropertiesStatement}
Review comment:
No, I've noted in several places that this is a bad practice because it
causes namespace problems (duplicate names accidentally imported) and commit
conflicts.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rdblue commented on a change in pull request #24937: [SPARK-28139][SQL] Add v2 ALTER TABLE implementation.
rdblue commented on a change in pull request #24937: [SPARK-28139][SQL] Add v2
ALTER TABLE implementation.
URL: https://github.com/apache/spark/pull/24937#discussion_r297908184
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/CheckAnalysis.scala
##
@@ -313,6 +314,42 @@ trait CheckAnalysis extends PredicateHelper {
failAnalysis(s"Invalid partitioning: ${badReferences.mkString(",
")}")
}
+ case alter: AlterTable if alter.childrenResolved =>
+val table = alter.table
+def findField(operation: String, fieldName: Array[String]):
StructField = {
+ // include collections because structs nested in maps and arrays
may be altered
+ val field = table.schema.findNestedField(fieldName,
includeCollections = true)
+ if (field.isEmpty) {
+throw new AnalysisException(
+ s"Cannot $operation missing field in ${table.name} schema:
${fieldName.quoted}")
+ }
+ field.get
+}
+
+alter.changes.foreach {
+ case add: AddColumn =>
+val parent = add.fieldNames.init
+if (parent.nonEmpty) {
+ findField("add to", parent)
+}
+ case update: UpdateColumnType =>
+val field = findField("update", update.fieldNames)
+if (!Cast.canUpCast(field.dataType, update.newDataType)) {
Review comment:
There is a test for upcast failure. See "AlterTable: update column type must
be compatible".
Why should altering a nested column fail? As long as the new column is
optional, there is no problem.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org