[GitHub] [spark] felixcheung commented on issue #24939: [SPARK-18569][ML][R] Support RFormula arithmetic, I() and spark functions
felixcheung commented on issue #24939: [SPARK-18569][ML][R] Support RFormula arithmetic, I() and spark functions URL: https://github.com/apache/spark/pull/24939#issuecomment-511281967 can we get more test coverage for this change? https://github.com/apache/spark/pull/24939/commits/88be1dcc67283c90922512477062805f63105703 seems a bit more involved This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25155: [SPARK-28392][SQL][TESTS] Add traits for UDF and PostgreSQL tests to share initialization
AmplabJenkins removed a comment on issue #25155: [SPARK-28392][SQL][TESTS] Add traits for UDF and PostgreSQL tests to share initialization URL: https://github.com/apache/spark/pull/25155#issuecomment-511280685 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/107655/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25155: [SPARK-28392][SQL][TESTS] Add traits for UDF and PostgreSQL tests to share initialization
AmplabJenkins removed a comment on issue #25155: [SPARK-28392][SQL][TESTS] Add traits for UDF and PostgreSQL tests to share initialization URL: https://github.com/apache/spark/pull/25155#issuecomment-511280682 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25155: [SPARK-28392][SQL][TESTS] Add traits for UDF and PostgreSQL tests to share initialization
AmplabJenkins commented on issue #25155: [SPARK-28392][SQL][TESTS] Add traits for UDF and PostgreSQL tests to share initialization URL: https://github.com/apache/spark/pull/25155#issuecomment-511280682 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25155: [SPARK-28392][SQL][TESTS] Add traits for UDF and PostgreSQL tests to share initialization
AmplabJenkins commented on issue #25155: [SPARK-28392][SQL][TESTS] Add traits for UDF and PostgreSQL tests to share initialization URL: https://github.com/apache/spark/pull/25155#issuecomment-511280685 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/107655/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25155: [SPARK-28392][SQL][TESTS] Add traits for UDF and PostgreSQL tests to share initialization
SparkQA commented on issue #25155: [SPARK-28392][SQL][TESTS] Add traits for UDF and PostgreSQL tests to share initialization URL: https://github.com/apache/spark/pull/25155#issuecomment-511280421 **[Test build #107655 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107655/testReport)** for PR 25155 at commit [`feea2d9`](https://github.com/apache/spark/commit/feea2d9b19f0948adaed8b9705cc28b366e3f1d5). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on issue #24991: [SPARK-28188] Materialize Dataframe API
felixcheung commented on issue #24991: [SPARK-28188] Materialize Dataframe API
URL: https://github.com/apache/spark/pull/24991#issuecomment-511280363
> @rxin, this runs the query up to the point where `materialize` is called.
The underlying RDD can then pick up from the last shuffle the next time it is
used. This works better than caching in most cases when using dynamic
allocation because executors are not sitting idle, but work can be resumed and
shared across queries. We could rename the method if that would be more clear.
>
> @srowen, I've seen this suggested on the dev list a few times and I think
it is a good idea to add it. There is not guarantee that `count` does the same
thing -- it could be optimized -- and it is a little tricky to get this to work
with the dataset API. This version creates a new DataFrame from the underlying
RDD so that the work is reused from the last shuffle, instead of allowing the
planner to re-optimize with later changes (usually projections) and discard the
intermediate result. We have found this really useful for better control over
the planner, as well as to cache data using the shuffle system.
I have to agree with this - I've seen `count()` or `cache()` mis-used too
many times and too many times people need to go back to clean up and remove all
calls to `count()`. So much so I'm planning to write a optimizer rule to remove
them. I'm only partly kidding.
Maybe this isn't the API for it, and that's ok, let's improve it then and
make good suggestion to the community/contributor etc.
I'm not sure `df.write.format("noop").save` is a good suggestion to general
spark user.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25155: [SPARK-28392][SQL][TESTS] Add traits for UDF and PostgreSQL tests to share initialization
SparkQA removed a comment on issue #25155: [SPARK-28392][SQL][TESTS] Add traits for UDF and PostgreSQL tests to share initialization URL: https://github.com/apache/spark/pull/25155#issuecomment-511259721 **[Test build #107655 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107655/testReport)** for PR 25155 at commit [`feea2d9`](https://github.com/apache/spark/commit/feea2d9b19f0948adaed8b9705cc28b366e3f1d5). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung edited a comment on issue #24991: [SPARK-28188] Materialize Dataframe API
felixcheung edited a comment on issue #24991: [SPARK-28188] Materialize
Dataframe API
URL: https://github.com/apache/spark/pull/24991#issuecomment-511280363
> @rxin, this runs the query up to the point where `materialize` is called.
The underlying RDD can then pick up from the last shuffle the next time it is
used. This works better than caching in most cases when using dynamic
allocation because executors are not sitting idle, but work can be resumed and
shared across queries. We could rename the method if that would be more clear.
>
> @srowen, I've seen this suggested on the dev list a few times and I think
it is a good idea to add it. There is not guarantee that `count` does the same
thing -- it could be optimized -- and it is a little tricky to get this to work
with the dataset API. This version creates a new DataFrame from the underlying
RDD so that the work is reused from the last shuffle, instead of allowing the
planner to re-optimize with later changes (usually projections) and discard the
intermediate result. We have found this really useful for better control over
the planner, as well as to cache data using the shuffle system.
I have to agree with this - I've seen `count()` or `cache()` mis-used too
many times and too many times people need to go back to clean up and remove all
calls to `count()`. So much so I'm planning to write an optimizer rule to
remove them. I'm only partly kidding.
Maybe this isn't the API for it, and that's ok, let's improve it then and
make good suggestion to the community/contributor etc.
I'm not sure `df.write.format("noop").save` is a good suggestion to general
spark user.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25111: [SPARK-28346][SQL] clone the query plan between analyzer, optimizer and planner
AmplabJenkins removed a comment on issue #25111: [SPARK-28346][SQL] clone the query plan between analyzer, optimizer and planner URL: https://github.com/apache/spark/pull/25111#issuecomment-511278971 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/107657/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25111: [SPARK-28346][SQL] clone the query plan between analyzer, optimizer and planner
AmplabJenkins commented on issue #25111: [SPARK-28346][SQL] clone the query plan between analyzer, optimizer and planner URL: https://github.com/apache/spark/pull/25111#issuecomment-511278971 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/107657/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25111: [SPARK-28346][SQL] clone the query plan between analyzer, optimizer and planner
SparkQA removed a comment on issue #25111: [SPARK-28346][SQL] clone the query plan between analyzer, optimizer and planner URL: https://github.com/apache/spark/pull/25111#issuecomment-511262826 **[Test build #107657 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107657/testReport)** for PR 25111 at commit [`f614cc6`](https://github.com/apache/spark/commit/f614cc6cd4fe16e493d912493884883f34a77f30). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25111: [SPARK-28346][SQL] clone the query plan between analyzer, optimizer and planner
AmplabJenkins removed a comment on issue #25111: [SPARK-28346][SQL] clone the query plan between analyzer, optimizer and planner URL: https://github.com/apache/spark/pull/25111#issuecomment-511278968 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25111: [SPARK-28346][SQL] clone the query plan between analyzer, optimizer and planner
AmplabJenkins commented on issue #25111: [SPARK-28346][SQL] clone the query plan between analyzer, optimizer and planner URL: https://github.com/apache/spark/pull/25111#issuecomment-511278968 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25111: [SPARK-28346][SQL] clone the query plan between analyzer, optimizer and planner
SparkQA commented on issue #25111: [SPARK-28346][SQL] clone the query plan between analyzer, optimizer and planner URL: https://github.com/apache/spark/pull/25111#issuecomment-511278862 **[Test build #107657 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107657/testReport)** for PR 25111 at commit [`f614cc6`](https://github.com/apache/spark/commit/f614cc6cd4fe16e493d912493884883f34a77f30). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM
AmplabJenkins removed a comment on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM URL: https://github.com/apache/spark/pull/25133#issuecomment-511278744 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM
AmplabJenkins commented on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM URL: https://github.com/apache/spark/pull/25133#issuecomment-511278746 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/107660/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM
AmplabJenkins removed a comment on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM URL: https://github.com/apache/spark/pull/25133#issuecomment-511278746 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/107660/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM
AmplabJenkins commented on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM URL: https://github.com/apache/spark/pull/25133#issuecomment-511278744 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM
SparkQA removed a comment on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM URL: https://github.com/apache/spark/pull/25133#issuecomment-511269919 **[Test build #107660 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107660/testReport)** for PR 25133 at commit [`f985eba`](https://github.com/apache/spark/commit/f985eba8c006327f934c254fedf91ff3987b7297). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM
SparkQA commented on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM URL: https://github.com/apache/spark/pull/25133#issuecomment-511278616 **[Test build #107660 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107660/testReport)** for PR 25133 at commit [`f985eba`](https://github.com/apache/spark/commit/f985eba8c006327f934c254fedf91ff3987b7297). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sujith71955 commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
sujith71955 commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-511277045 @dongjoon-hyun Gentle ping, Let me know for any inputs. thanks all for the valuable inputs. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25047: [WIP][SPARK-27371][CORE] Support GPU-aware resources scheduling in Standalone
AmplabJenkins removed a comment on issue #25047: [WIP][SPARK-27371][CORE] Support GPU-aware resources scheduling in Standalone URL: https://github.com/apache/spark/pull/25047#issuecomment-511276916 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/107659/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25047: [WIP][SPARK-27371][CORE] Support GPU-aware resources scheduling in Standalone
SparkQA removed a comment on issue #25047: [WIP][SPARK-27371][CORE] Support GPU-aware resources scheduling in Standalone URL: https://github.com/apache/spark/pull/25047#issuecomment-511265225 **[Test build #107659 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107659/testReport)** for PR 25047 at commit [`e19a9b6`](https://github.com/apache/spark/commit/e19a9b670b25ffc00f1a16eef89febfe244a4088). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25047: [WIP][SPARK-27371][CORE] Support GPU-aware resources scheduling in Standalone
AmplabJenkins removed a comment on issue #25047: [WIP][SPARK-27371][CORE] Support GPU-aware resources scheduling in Standalone URL: https://github.com/apache/spark/pull/25047#issuecomment-511276913 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25047: [WIP][SPARK-27371][CORE] Support GPU-aware resources scheduling in Standalone
AmplabJenkins commented on issue #25047: [WIP][SPARK-27371][CORE] Support GPU-aware resources scheduling in Standalone URL: https://github.com/apache/spark/pull/25047#issuecomment-511276913 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25047: [WIP][SPARK-27371][CORE] Support GPU-aware resources scheduling in Standalone
AmplabJenkins commented on issue #25047: [WIP][SPARK-27371][CORE] Support GPU-aware resources scheduling in Standalone URL: https://github.com/apache/spark/pull/25047#issuecomment-511276916 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/107659/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25047: [WIP][SPARK-27371][CORE] Support GPU-aware resources scheduling in Standalone
SparkQA commented on issue #25047: [WIP][SPARK-27371][CORE] Support GPU-aware resources scheduling in Standalone URL: https://github.com/apache/spark/pull/25047#issuecomment-511276873 **[Test build #107659 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107659/testReport)** for PR 25047 at commit [`e19a9b6`](https://github.com/apache/spark/commit/e19a9b670b25ffc00f1a16eef89febfe244a4088). * This patch **fails PySpark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #25092: [SPARK-28312][SQL][TEST] Port numeric.sql
wangyum commented on a change in pull request #25092: [SPARK-28312][SQL][TEST] Port numeric.sql URL: https://github.com/apache/spark/pull/25092#discussion_r303289190 ## File path: sql/core/src/test/resources/sql-tests/inputs/pgSQL/numeric.sql ## @@ -0,0 +1,1095 @@ +-- +-- Portions Copyright (c) 1996-2019, PostgreSQL Global Development Group +-- +-- +-- NUMERIC +-- https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/numeric.sql +-- + +CREATE TABLE num_data (id int, val decimal(38,10)) USING parquet; +CREATE TABLE num_exp_add (id1 int, id2 int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_sub (id1 int, id2 int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_div (id1 int, id2 int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_mul (id1 int, id2 int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_sqrt (id int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_ln (id int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_log10 (id int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_power_10_ln (id int, expected decimal(38,10)) USING parquet; + +CREATE TABLE num_result (id1 int, id2 int, result decimal(38,10)) USING parquet; + + +-- ** +-- * The following EXPECTED results are computed by bc(1) +-- * with a scale of 200 +-- ** + +-- BEGIN TRANSACTION; +INSERT INTO num_exp_add VALUES (0,0,'0'); +INSERT INTO num_exp_sub VALUES (0,0,'0'); +INSERT INTO num_exp_mul VALUES (0,0,'0'); +INSERT INTO num_exp_div VALUES (0,0,'NaN'); +INSERT INTO num_exp_add VALUES (0,1,'0'); +INSERT INTO num_exp_sub VALUES (0,1,'0'); +INSERT INTO num_exp_mul VALUES (0,1,'0'); +INSERT INTO num_exp_div VALUES (0,1,'NaN'); +INSERT INTO num_exp_add VALUES (0,2,'-34338492.215397047'); +INSERT INTO num_exp_sub VALUES (0,2,'34338492.215397047'); +INSERT INTO num_exp_mul VALUES (0,2,'0'); +INSERT INTO num_exp_div VALUES (0,2,'0'); +INSERT INTO num_exp_add VALUES (0,3,'4.31'); +INSERT INTO num_exp_sub VALUES (0,3,'-4.31'); +INSERT INTO num_exp_mul VALUES (0,3,'0'); +INSERT INTO num_exp_div VALUES (0,3,'0'); +INSERT INTO num_exp_add VALUES (0,4,'7799461.4119'); +INSERT INTO num_exp_sub VALUES (0,4,'-7799461.4119'); +INSERT INTO num_exp_mul VALUES (0,4,'0'); +INSERT INTO num_exp_div VALUES (0,4,'0'); +INSERT INTO num_exp_add VALUES (0,5,'16397.038491'); +INSERT INTO num_exp_sub VALUES (0,5,'-16397.038491'); +INSERT INTO num_exp_mul VALUES (0,5,'0'); +INSERT INTO num_exp_div VALUES (0,5,'0'); +INSERT INTO num_exp_add VALUES (0,6,'93901.57763026'); +INSERT INTO num_exp_sub VALUES (0,6,'-93901.57763026'); +INSERT INTO num_exp_mul VALUES (0,6,'0'); +INSERT INTO num_exp_div VALUES (0,6,'0'); +INSERT INTO num_exp_add VALUES (0,7,'-83028485'); +INSERT INTO num_exp_sub VALUES (0,7,'83028485'); +INSERT INTO num_exp_mul VALUES (0,7,'0'); +INSERT INTO num_exp_div VALUES (0,7,'0'); +INSERT INTO num_exp_add VALUES (0,8,'74881'); +INSERT INTO num_exp_sub VALUES (0,8,'-74881'); +INSERT INTO num_exp_mul VALUES (0,8,'0'); +INSERT INTO num_exp_div VALUES (0,8,'0'); +INSERT INTO num_exp_add VALUES (0,9,'-24926804.045047420'); +INSERT INTO num_exp_sub VALUES (0,9,'24926804.045047420'); +INSERT INTO num_exp_mul VALUES (0,9,'0'); +INSERT INTO num_exp_div VALUES (0,9,'0'); +INSERT INTO num_exp_add VALUES (1,0,'0'); +INSERT INTO num_exp_sub VALUES (1,0,'0'); +INSERT INTO num_exp_mul VALUES (1,0,'0'); +INSERT INTO num_exp_div VALUES (1,0,'NaN'); +INSERT INTO num_exp_add VALUES (1,1,'0'); +INSERT INTO num_exp_sub VALUES (1,1,'0'); +INSERT INTO num_exp_mul VALUES (1,1,'0'); +INSERT INTO num_exp_div VALUES (1,1,'NaN'); +INSERT INTO num_exp_add VALUES (1,2,'-34338492.215397047'); +INSERT INTO num_exp_sub VALUES (1,2,'34338492.215397047'); +INSERT INTO num_exp_mul VALUES (1,2,'0'); +INSERT INTO num_exp_div VALUES (1,2,'0'); +INSERT INTO num_exp_add VALUES (1,3,'4.31'); +INSERT INTO num_exp_sub VALUES (1,3,'-4.31'); +INSERT INTO num_exp_mul VALUES (1,3,'0'); +INSERT INTO num_exp_div VALUES (1,3,'0'); +INSERT INTO num_exp_add VALUES (1,4,'7799461.4119'); +INSERT INTO num_exp_sub VALUES (1,4,'-7799461.4119'); +INSERT INTO num_exp_mul VALUES (1,4,'0'); +INSERT INTO num_exp_div VALUES (1,4,'0'); +INSERT INTO num_exp_add VALUES (1,5,'16397.038491'); +INSERT INTO num_exp_sub VALUES (1,5,'-16397.038491'); +INSERT INTO num_exp_mul VALUES (1,5,'0'); +INSERT INTO num_exp_div VALUES (1,5,'0'); +INSERT INTO num_exp_add VALUES (1,6,'93901.57763026'); +INSERT INTO num_exp_sub VALUES (1,6,'-93901.57763026'); +INSERT INTO num_exp_mul VALUES (1,6,'0'); +INSERT INTO num_exp_div VALUES (1,6,'0'); +INSERT INTO num_exp_add VALUES (1,7,'-83028485'); +INSERT INTO num_exp_sub VALUES (1,7,'83028485'); +INSERT INTO num_exp_mul VALUES (1,7,'0'); +INSERT INTO num_exp_div VALUES (1,7,'0'); +INSERT INTO num_exp_add VALUES (1,8,'74881'); +INSERT INTO num_exp_sub VALUES (1,8,'-74881'); +INSERT INTO
[GitHub] [spark] AmplabJenkins removed a comment on issue #24793: [SPARK-27944][ML] Unify the behavior of checking empty output column names
AmplabJenkins removed a comment on issue #24793: [SPARK-27944][ML] Unify the behavior of checking empty output column names URL: https://github.com/apache/spark/pull/24793#issuecomment-511275368 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24793: [SPARK-27944][ML] Unify the behavior of checking empty output column names
AmplabJenkins removed a comment on issue #24793: [SPARK-27944][ML] Unify the behavior of checking empty output column names URL: https://github.com/apache/spark/pull/24793#issuecomment-511275374 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12793/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24793: [SPARK-27944][ML] Unify the behavior of checking empty output column names
AmplabJenkins commented on issue #24793: [SPARK-27944][ML] Unify the behavior of checking empty output column names URL: https://github.com/apache/spark/pull/24793#issuecomment-511275374 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12793/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24793: [SPARK-27944][ML] Unify the behavior of checking empty output column names
AmplabJenkins commented on issue #24793: [SPARK-27944][ML] Unify the behavior of checking empty output column names URL: https://github.com/apache/spark/pull/24793#issuecomment-511275368 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql
dongjoon-hyun closed pull request #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql URL: https://github.com/apache/spark/pull/25150 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25092: [SPARK-28312][SQL][TEST] Port numeric.sql
AmplabJenkins removed a comment on issue #25092: [SPARK-28312][SQL][TEST] Port numeric.sql URL: https://github.com/apache/spark/pull/25092#issuecomment-511273476 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12792/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25092: [SPARK-28312][SQL][TEST] Port numeric.sql
SparkQA commented on issue #25092: [SPARK-28312][SQL][TEST] Port numeric.sql URL: https://github.com/apache/spark/pull/25092#issuecomment-511273751 **[Test build #107664 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107664/testReport)** for PR 25092 at commit [`bc11e02`](https://github.com/apache/spark/commit/bc11e02fba3f0f9627e25048dbbd4d2daa7b). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql
AmplabJenkins removed a comment on issue #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql URL: https://github.com/apache/spark/pull/25150#issuecomment-511273458 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12790/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql
AmplabJenkins removed a comment on issue #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql URL: https://github.com/apache/spark/pull/25150#issuecomment-511273453 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25156: [SPARK-28394][SCHEDULER]: Performance Metrics for Driver
AmplabJenkins removed a comment on issue #25156: [SPARK-28394][SCHEDULER]: Performance Metrics for Driver URL: https://github.com/apache/spark/pull/25156#issuecomment-511273373 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25092: [SPARK-28312][SQL][TEST] Port numeric.sql
AmplabJenkins removed a comment on issue #25092: [SPARK-28312][SQL][TEST] Port numeric.sql URL: https://github.com/apache/spark/pull/25092#issuecomment-511273471 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op
AmplabJenkins removed a comment on issue #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op URL: https://github.com/apache/spark/pull/25130#issuecomment-511273444 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op
AmplabJenkins removed a comment on issue #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op URL: https://github.com/apache/spark/pull/25130#issuecomment-511273449 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12791/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op
SparkQA commented on issue #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op URL: https://github.com/apache/spark/pull/25130#issuecomment-511273759 **[Test build #107663 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107663/testReport)** for PR 25130 at commit [`1164ee9`](https://github.com/apache/spark/commit/1164ee940e507fc209e57933a5598ffd13e925fd). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25147: [SPARK-28333][SQL] NULLS FIRST for DESC and NULLS LAST for ASC
HyukjinKwon commented on a change in pull request #25147: [SPARK-28333][SQL]
NULLS FIRST for DESC and NULLS LAST for ASC
URL: https://github.com/apache/spark/pull/25147#discussion_r303287018
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/SortOrder.scala
##
@@ -36,12 +36,12 @@ abstract sealed class NullOrdering {
case object Ascending extends SortDirection {
override def sql: String = "ASC"
- override def defaultNullOrdering: NullOrdering = NullsFirst
+ override def defaultNullOrdering: NullOrdering = NullsLast
}
case object Descending extends SortDirection {
override def sql: String = "DESC"
- override def defaultNullOrdering: NullOrdering = NullsLast
+ override def defaultNullOrdering: NullOrdering = NullsFirst
Review comment:
I think the current behaviour already makes sense. I wouldn't fix it. cc
@dongjoon-hyun, @wangyum, @gatorsmile WDYT?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25156: [SPARK-28394][SCHEDULER]: Performance Metrics for Driver
AmplabJenkins commented on issue #25156: [SPARK-28394][SCHEDULER]: Performance Metrics for Driver URL: https://github.com/apache/spark/pull/25156#issuecomment-511273709 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25092: [SPARK-28312][SQL][TEST] Port numeric.sql
AmplabJenkins commented on issue #25092: [SPARK-28312][SQL][TEST] Port numeric.sql URL: https://github.com/apache/spark/pull/25092#issuecomment-511273471 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25156: [SPARK-28394][SCHEDULER]: Performance Metrics for Driver
AmplabJenkins commented on issue #25156: [SPARK-28394][SCHEDULER]: Performance Metrics for Driver URL: https://github.com/apache/spark/pull/25156#issuecomment-511273373 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25156: [SPARK-28394][SCHEDULER]: Performance Metrics for Driver
AmplabJenkins removed a comment on issue #25156: [SPARK-28394][SCHEDULER]: Performance Metrics for Driver URL: https://github.com/apache/spark/pull/25156#issuecomment-511273301 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op
AmplabJenkins commented on issue #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op URL: https://github.com/apache/spark/pull/25130#issuecomment-511273449 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12791/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql
AmplabJenkins commented on issue #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql URL: https://github.com/apache/spark/pull/25150#issuecomment-511273458 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12790/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql
AmplabJenkins commented on issue #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql URL: https://github.com/apache/spark/pull/25150#issuecomment-511273453 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #24931: [SPARK-28129][SQL][TEST] Port float8.sql
wangyum commented on issue #24931: [SPARK-28129][SQL][TEST] Port float8.sql URL: https://github.com/apache/spark/pull/24931#issuecomment-511273469 Thank you @dongjoon-hyun . I will update it later. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25092: [SPARK-28312][SQL][TEST] Port numeric.sql
AmplabJenkins commented on issue #25092: [SPARK-28312][SQL][TEST] Port numeric.sql URL: https://github.com/apache/spark/pull/25092#issuecomment-511273476 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12792/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op
AmplabJenkins commented on issue #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op URL: https://github.com/apache/spark/pull/25130#issuecomment-511273444 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25156: [SPARK-28394][SCHEDULER]: Performance Metrics for Driver
AmplabJenkins commented on issue #25156: [SPARK-28394][SCHEDULER]: Performance Metrics for Driver URL: https://github.com/apache/spark/pull/25156#issuecomment-511273301 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #25092: [SPARK-28312][SQL][TEST] Port numeric.sql
wangyum commented on a change in pull request #25092: [SPARK-28312][SQL][TEST] Port numeric.sql URL: https://github.com/apache/spark/pull/25092#discussion_r303286758 ## File path: sql/core/src/test/resources/sql-tests/inputs/pgSQL/numeric.sql ## @@ -0,0 +1,1095 @@ +-- +-- Portions Copyright (c) 1996-2019, PostgreSQL Global Development Group +-- +-- +-- NUMERIC +-- https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/numeric.sql +-- + +CREATE TABLE num_data (id int, val decimal(38,10)) USING parquet; Review comment: OK. Added it. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon removed a comment on issue #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op
HyukjinKwon removed a comment on issue #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op URL: https://github.com/apache/spark/pull/25130#issuecomment-511263305 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hthuynh2 opened a new pull request #25156: initial commit
hthuynh2 opened a new pull request #25156: initial commit URL: https://github.com/apache/spark/pull/25156 ## What changes were proposed in this pull request? Description This PR added the framework for monitoring the schedulers and displaying performance metrics to the UI. More specifically, for each event type that is handled by the DAGScheduler, CoarsedGrainedSchedulerBackend, and TaskResultGetter, it keeps track of the following information: number of handled events of this type, number of pending events of this type, average time to handle an event of this type, total time spending on handling all events of this type. --- Design and implementation: General Idea: For each event type, every time we handle an event of this type, we collect the information (e.g. the time taken to handle this event, number of pending events,...), and having a background thread that periodically collects the information and display to the UI. UI Explanation https://user-images.githubusercontent.com/15680678/61195997-50592900-a691-11e9-8e8b-5a4faa5ecc05.png;> Explanation of columns: - Event Type: The type of event that the information in this row below to - Number of Handled Events: The number of events of this type that is handled - Number of Pending Events: The number of events of this type that is pending in the queue - Processing Speed: The average time that is used to handle an event of this type - Total time: The total time that is used to handled all events of this type - Timestamp: The time at the end of the interval that we collect the information displayed in this row. Driver Schedulers Summary Metrics table - This table contains information accumulatively collected since the application starts (e.g. the “Number of Handled Events” is the total number of events that are handled since the application starts) Driver Schedulers Busy Intervals Metrics table - This table contains the information for only some busy intervals. The purpose of this table is to pinpoint the time that the scheduler is busy. An interval is considered busy if the total time spending on handling all events of a type during this interval is greater than 70% of the interval length (This 70% is configurable). And the information displayed is the information collected during that interval only (e.g. the “Number of Handled Events” is the number of events that are handled during that interval). Note that we only keep track of top 5 busiest intervals sorted by the “total time” (This number 5 is configurable). An example of how to read the table and how it can be useful for monitoring and debugging the application: For an example shown in the figure below, let’s look at the first row of the “Driver Schedulers Busy Intervals Metrics” table. This row contains the information about the ReviveOffers event that is handled by the CoarseGrainedSchedulerBackend. There are 12 ReviveOffers events that is handled by the CoarseGrainedSchedulerBackend during the interval the ends at "2019/06/19 04:03:13". The number of ReviveOffers events that are pending is N/A (This is because getting the number of pending events that are waiting to be handled by the CoarseGrainedSchedulerBackend is difficult, so I leave it as N/A for now). The time for the CoarseGrainedSchedulerBackend to handle an ReviveOffers is 763ms. The total time spending on handling all 12 ReviveOffers events during this interval is 9s (For this example, the interval length is 10s). Finally, this interval ends at 2019/06/19 04:03:13. From the information above, we can easily see that it takes too long for the CoarseGrainedSchedulerBackend to handle the event ReviveOffers (for some interval, it takes up to 700ms to handle just one ReviveOffers event). This is actually an issue that is mentioned in [SPARK-26755](https://issues.apache.org/jira/browse/SPARK-26755). And this example is the application mentioned in [PR #23677](https://github.com/apache/spark/pull/23677). We can see that having these metrics can help to identify the bottleneck for the application. --- Implementation: Introduce 2 new classes: - SchedulerEventHandlingMetricTracker: This is used to keep track of the information for an event type - SchedulerMetricsManager: This is used to manage all the SchedulerEventHandlingMetricTracker for all event types - Configurations: spark.scheduler.metric.compute.enabled: Indicate if this feature is enable or not (default value is false) spark.scheduler.metric.compute.interval: This is the interval length (default value is 10s) spark.scheduler.metric.compute.numTopBusiestInterval: This is the number of busiest intervals that we will keep (default value is 5) spark.scheduler.metric.compute.busyIntervalThreshold: This is the threshold (in percent) for an interval to be considered busy
[GitHub] [spark] wangyum commented on a change in pull request #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql
wangyum commented on a change in pull request #25150: [SPARK-28384][SQL][TEST]
Port select_distinct.sql
URL: https://github.com/apache/spark/pull/25150#discussion_r303286587
##
File path:
sql/core/src/test/resources/sql-tests/inputs/pgSQL/select_distinct.sql
##
@@ -0,0 +1,83 @@
+--
+-- Portions Copyright (c) 1996-2019, PostgreSQL Global Development Group
+--
+--
+-- SELECT_DISTINCT
+--
https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/select_distinct.sql
+--
+
+CREATE OR REPLACE TEMPORARY VIEW tmp AS
+SELECT two, stringu1, ten, string4
+FROM onek;
+
+--
+-- awk '{print $3;}' onek.data | sort -n | uniq
+--
+SELECT DISTINCT two FROM tmp ORDER BY 1;
+
+--
+-- awk '{print $5;}' onek.data | sort -n | uniq
+--
+SELECT DISTINCT ten FROM tmp ORDER BY 1;
+
+--
+-- awk '{print $16;}' onek.data | sort -d | uniq
+--
+SELECT DISTINCT string4 FROM tmp ORDER BY 1;
+
+-- [SPARK-28010] Support ORDER BY ... USING syntax
+--
+-- awk '{print $3,$16,$5;}' onek.data | sort -d | uniq |
+-- sort +0n -1 +1d -2 +2n -3
+--
Review comment:
OK. Added it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25092: [SPARK-28312][SQL][TEST] Port numeric.sql
dongjoon-hyun commented on a change in pull request #25092: [SPARK-28312][SQL][TEST] Port numeric.sql URL: https://github.com/apache/spark/pull/25092#discussion_r303286519 ## File path: sql/core/src/test/resources/sql-tests/inputs/pgSQL/numeric.sql ## @@ -0,0 +1,1095 @@ +-- +-- Portions Copyright (c) 1996-2019, PostgreSQL Global Development Group +-- +-- +-- NUMERIC +-- https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/numeric.sql +-- + +CREATE TABLE num_data (id int, val decimal(38,10)) USING parquet; +CREATE TABLE num_exp_add (id1 int, id2 int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_sub (id1 int, id2 int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_div (id1 int, id2 int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_mul (id1 int, id2 int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_sqrt (id int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_ln (id int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_log10 (id int, expected decimal(38,10)) USING parquet; +CREATE TABLE num_exp_power_10_ln (id int, expected decimal(38,10)) USING parquet; + +CREATE TABLE num_result (id1 int, id2 int, result decimal(38,10)) USING parquet; + + +-- ** +-- * The following EXPECTED results are computed by bc(1) +-- * with a scale of 200 +-- ** + +-- BEGIN TRANSACTION; +INSERT INTO num_exp_add VALUES (0,0,'0'); +INSERT INTO num_exp_sub VALUES (0,0,'0'); +INSERT INTO num_exp_mul VALUES (0,0,'0'); +INSERT INTO num_exp_div VALUES (0,0,'NaN'); +INSERT INTO num_exp_add VALUES (0,1,'0'); +INSERT INTO num_exp_sub VALUES (0,1,'0'); +INSERT INTO num_exp_mul VALUES (0,1,'0'); +INSERT INTO num_exp_div VALUES (0,1,'NaN'); +INSERT INTO num_exp_add VALUES (0,2,'-34338492.215397047'); +INSERT INTO num_exp_sub VALUES (0,2,'34338492.215397047'); +INSERT INTO num_exp_mul VALUES (0,2,'0'); +INSERT INTO num_exp_div VALUES (0,2,'0'); +INSERT INTO num_exp_add VALUES (0,3,'4.31'); +INSERT INTO num_exp_sub VALUES (0,3,'-4.31'); +INSERT INTO num_exp_mul VALUES (0,3,'0'); +INSERT INTO num_exp_div VALUES (0,3,'0'); +INSERT INTO num_exp_add VALUES (0,4,'7799461.4119'); +INSERT INTO num_exp_sub VALUES (0,4,'-7799461.4119'); +INSERT INTO num_exp_mul VALUES (0,4,'0'); +INSERT INTO num_exp_div VALUES (0,4,'0'); +INSERT INTO num_exp_add VALUES (0,5,'16397.038491'); +INSERT INTO num_exp_sub VALUES (0,5,'-16397.038491'); +INSERT INTO num_exp_mul VALUES (0,5,'0'); +INSERT INTO num_exp_div VALUES (0,5,'0'); +INSERT INTO num_exp_add VALUES (0,6,'93901.57763026'); +INSERT INTO num_exp_sub VALUES (0,6,'-93901.57763026'); +INSERT INTO num_exp_mul VALUES (0,6,'0'); +INSERT INTO num_exp_div VALUES (0,6,'0'); +INSERT INTO num_exp_add VALUES (0,7,'-83028485'); +INSERT INTO num_exp_sub VALUES (0,7,'83028485'); +INSERT INTO num_exp_mul VALUES (0,7,'0'); +INSERT INTO num_exp_div VALUES (0,7,'0'); +INSERT INTO num_exp_add VALUES (0,8,'74881'); +INSERT INTO num_exp_sub VALUES (0,8,'-74881'); +INSERT INTO num_exp_mul VALUES (0,8,'0'); +INSERT INTO num_exp_div VALUES (0,8,'0'); +INSERT INTO num_exp_add VALUES (0,9,'-24926804.045047420'); +INSERT INTO num_exp_sub VALUES (0,9,'24926804.045047420'); +INSERT INTO num_exp_mul VALUES (0,9,'0'); +INSERT INTO num_exp_div VALUES (0,9,'0'); +INSERT INTO num_exp_add VALUES (1,0,'0'); +INSERT INTO num_exp_sub VALUES (1,0,'0'); +INSERT INTO num_exp_mul VALUES (1,0,'0'); +INSERT INTO num_exp_div VALUES (1,0,'NaN'); +INSERT INTO num_exp_add VALUES (1,1,'0'); +INSERT INTO num_exp_sub VALUES (1,1,'0'); +INSERT INTO num_exp_mul VALUES (1,1,'0'); +INSERT INTO num_exp_div VALUES (1,1,'NaN'); +INSERT INTO num_exp_add VALUES (1,2,'-34338492.215397047'); +INSERT INTO num_exp_sub VALUES (1,2,'34338492.215397047'); +INSERT INTO num_exp_mul VALUES (1,2,'0'); +INSERT INTO num_exp_div VALUES (1,2,'0'); +INSERT INTO num_exp_add VALUES (1,3,'4.31'); +INSERT INTO num_exp_sub VALUES (1,3,'-4.31'); +INSERT INTO num_exp_mul VALUES (1,3,'0'); +INSERT INTO num_exp_div VALUES (1,3,'0'); +INSERT INTO num_exp_add VALUES (1,4,'7799461.4119'); +INSERT INTO num_exp_sub VALUES (1,4,'-7799461.4119'); +INSERT INTO num_exp_mul VALUES (1,4,'0'); +INSERT INTO num_exp_div VALUES (1,4,'0'); +INSERT INTO num_exp_add VALUES (1,5,'16397.038491'); +INSERT INTO num_exp_sub VALUES (1,5,'-16397.038491'); +INSERT INTO num_exp_mul VALUES (1,5,'0'); +INSERT INTO num_exp_div VALUES (1,5,'0'); +INSERT INTO num_exp_add VALUES (1,6,'93901.57763026'); +INSERT INTO num_exp_sub VALUES (1,6,'-93901.57763026'); +INSERT INTO num_exp_mul VALUES (1,6,'0'); +INSERT INTO num_exp_div VALUES (1,6,'0'); +INSERT INTO num_exp_add VALUES (1,7,'-83028485'); +INSERT INTO num_exp_sub VALUES (1,7,'83028485'); +INSERT INTO num_exp_mul VALUES (1,7,'0'); +INSERT INTO num_exp_div VALUES (1,7,'0'); +INSERT INTO num_exp_add VALUES (1,8,'74881'); +INSERT INTO num_exp_sub VALUES (1,8,'-74881'); +INSERT
[GitHub] [spark] SparkQA commented on issue #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql
SparkQA commented on issue #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql URL: https://github.com/apache/spark/pull/25150#issuecomment-511272636 **[Test build #107662 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107662/testReport)** for PR 25150 at commit [`e06f467`](https://github.com/apache/spark/commit/e06f4677606f2029f66f2264fa4d293f4ac56e52). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #25035: [SPARK-28235][SQL] Sum of decimals should return a decimal with MAX_PRECISION
cloud-fan commented on issue #25035: [SPARK-28235][SQL] Sum of decimals should return a decimal with MAX_PRECISION URL: https://github.com/apache/spark/pull/25035#issuecomment-511272440 I do feel it's just a heuristic. Even if you set the precision to 38 it can still overflow. I don't think this is a better solution compared to `p + 10`, as it's already hard to hit overflow according to https://github.com/apache/spark/pull/25035#discussion_r300271855 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #24232: [SPARK-27297] [SQL] Add higher order functions to scala API
HyukjinKwon commented on issue #24232: [SPARK-27297] [SQL] Add higher order functions to scala API URL: https://github.com/apache/spark/pull/24232#issuecomment-511272125 ping @nvander1 are you able to compile locally? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shivusondur commented on a change in pull request #25147: [SPARK-28333][SQL] NULLS FIRST for DESC and NULLS LAST for ASC
shivusondur commented on a change in pull request #25147: [SPARK-28333][SQL]
NULLS FIRST for DESC and NULLS LAST for ASC
URL: https://github.com/apache/spark/pull/25147#discussion_r303286142
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/SortOrder.scala
##
@@ -36,12 +36,12 @@ abstract sealed class NullOrdering {
case object Ascending extends SortDirection {
override def sql: String = "ASC"
- override def defaultNullOrdering: NullOrdering = NullsFirst
+ override def defaultNullOrdering: NullOrdering = NullsLast
}
case object Descending extends SortDirection {
override def sql: String = "DESC"
- override def defaultNullOrdering: NullOrdering = NullsLast
+ override def defaultNullOrdering: NullOrdering = NullsFirst
Review comment:
@HyukjinKwon
From the below link, spark is consistent with **mysql, sqlserver**
But inconsitent with **DB2, Oracle, Postgresql**
https://docs.mendix.com/refguide/null-ordering-behavior#3-overview-of-default-nulls-sort-order
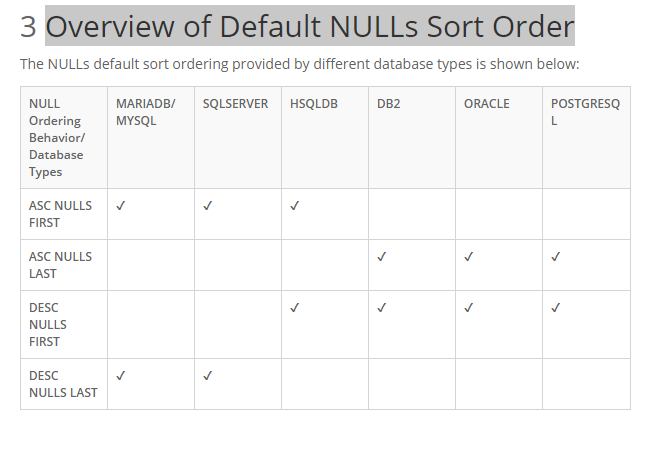
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25117: [Python] Validate LongType in _make_type_verifier
AmplabJenkins removed a comment on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511271629 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/107661/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25117: [Python] Validate LongType in _make_type_verifier
AmplabJenkins commented on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511271628 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25117: [Python] Validate LongType in _make_type_verifier
SparkQA removed a comment on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511269920 **[Test build #107661 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107661/testReport)** for PR 25117 at commit [`1d8761a`](https://github.com/apache/spark/commit/1d8761ae3d426d3fb2a6a577e6f245154b35a59d). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25117: [Python] Validate LongType in _make_type_verifier
SparkQA commented on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511271594 **[Test build #107661 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107661/testReport)** for PR 25117 at commit [`1d8761a`](https://github.com/apache/spark/commit/1d8761ae3d426d3fb2a6a577e6f245154b35a59d). * This patch **fails PySpark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25117: [Python] Validate LongType in _make_type_verifier
AmplabJenkins removed a comment on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511271628 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25117: [Python] Validate LongType in _make_type_verifier
AmplabJenkins commented on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511271629 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/107661/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #24798: [SPARK-27724][SQL] Implement REPLACE TABLE and REPLACE TABLE AS SELECT with V2
cloud-fan commented on issue #24798: [SPARK-27724][SQL] Implement REPLACE TABLE and REPLACE TABLE AS SELECT with V2 URL: https://github.com/apache/spark/pull/24798#issuecomment-511271344 I was not saying that REPLACE TABLE isn't important, I just want to emphasize that, it's better to have smaller Spark PRs when possible. Many people try to enforce it when reviewing PRs, and I don't want to break the rule here. It not only easy the review, but also make the commit history clearer. This PR does 2 things: 1. introduce `StagingTableCatalog` API 2. implement REPLACE TABLE (depends on 1) We can create a new PR for `StagingTableCatalog`, and keep this PR for review/discussion. After the new PR is merged, rebase this PR. This is also what I do for individual stuff in big PRs: https://github.com/apache/spark/pull/25107 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25092: [SPARK-28312][SQL][TEST] Port numeric.sql
dongjoon-hyun commented on a change in pull request #25092: [SPARK-28312][SQL][TEST] Port numeric.sql URL: https://github.com/apache/spark/pull/25092#discussion_r303285429 ## File path: sql/core/src/test/resources/sql-tests/inputs/pgSQL/numeric.sql ## @@ -0,0 +1,1095 @@ +-- +-- Portions Copyright (c) 1996-2019, PostgreSQL Global Development Group +-- +-- +-- NUMERIC +-- https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/numeric.sql +-- + +CREATE TABLE num_data (id int, val decimal(38,10)) USING parquet; Review comment: `decimal(38,10)` vs `numeric(210,10)`? Is this difference covered by SPARK-28318? Could you add a JIRA ID before this line? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #25151: [SPARK-28387][SQL][TEST] Port select_having.sql
dongjoon-hyun closed pull request #25151: [SPARK-28387][SQL][TEST] Port select_having.sql URL: https://github.com/apache/spark/pull/25151 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25150: [SPARK-28384][SQL][TEST] Port select_distinct.sql
dongjoon-hyun commented on a change in pull request #25150:
[SPARK-28384][SQL][TEST] Port select_distinct.sql
URL: https://github.com/apache/spark/pull/25150#discussion_r303284929
##
File path:
sql/core/src/test/resources/sql-tests/inputs/pgSQL/select_distinct.sql
##
@@ -0,0 +1,83 @@
+--
+-- Portions Copyright (c) 1996-2019, PostgreSQL Global Development Group
+--
+--
+-- SELECT_DISTINCT
+--
https://github.com/postgres/postgres/blob/REL_12_BETA2/src/test/regress/sql/select_distinct.sql
+--
+
+CREATE OR REPLACE TEMPORARY VIEW tmp AS
+SELECT two, stringu1, ten, string4
+FROM onek;
+
+--
+-- awk '{print $3;}' onek.data | sort -n | uniq
+--
+SELECT DISTINCT two FROM tmp ORDER BY 1;
+
+--
+-- awk '{print $5;}' onek.data | sort -n | uniq
+--
+SELECT DISTINCT ten FROM tmp ORDER BY 1;
+
+--
+-- awk '{print $16;}' onek.data | sort -d | uniq
+--
+SELECT DISTINCT string4 FROM tmp ORDER BY 1;
+
+-- [SPARK-28010] Support ORDER BY ... USING syntax
+--
+-- awk '{print $3,$16,$5;}' onek.data | sort -d | uniq |
+-- sort +0n -1 +1d -2 +2n -3
+--
Review comment:
Could you put the original query?
```
SELECT DISTINCT two, string4, ten
FROM tmp
ORDER BY two using <, string4 using <, ten using <;
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25115: [SPARK-28351][SQL] Support DELETE in DataSource V2
HyukjinKwon commented on a change in pull request #25115: [SPARK-28351][SQL]
Support DELETE in DataSource V2
URL: https://github.com/apache/spark/pull/25115#discussion_r303284920
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/sources/filters.scala
##
@@ -163,6 +187,7 @@ case class IsNotNull(attribute: String) extends Filter {
*/
@Stable
case class And(left: Filter, right: Filter) extends Filter {
+ override def sql: String = s"${left.sql} AND ${right.sql}"
Review comment:
> for simple case like DELETE by filters in this pr, just pass the filter to
datasource is more suitable, a 'spark job' is not needed.
BTW, I don't know why this is needed but it won't work with the combinations
of `AND` and `OR`. `a OR b AND C`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #24991: [SPARK-28188] Materialize Dataframe API
cloud-fan commented on issue #24991: [SPARK-28188] Materialize Dataframe API
URL: https://github.com/apache/spark/pull/24991#issuecomment-511269953
It's simple to write to noop sink: `df.write.format("noop").save`, why do we
need this extra public API?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM
SparkQA commented on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM URL: https://github.com/apache/spark/pull/25133#issuecomment-511269919 **[Test build #107660 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107660/testReport)** for PR 25133 at commit [`f985eba`](https://github.com/apache/spark/commit/f985eba8c006327f934c254fedf91ff3987b7297). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25117: [Python] Validate LongType in _make_type_verifier
SparkQA commented on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511269920 **[Test build #107661 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/107661/testReport)** for PR 25117 at commit [`1d8761a`](https://github.com/apache/spark/commit/1d8761ae3d426d3fb2a6a577e6f245154b35a59d). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25117: [Python] Validate LongType in _make_type_verifier
AmplabJenkins removed a comment on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511269682 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25117: [Python] Validate LongType in _make_type_verifier
AmplabJenkins removed a comment on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511269683 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12789/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM
AmplabJenkins removed a comment on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM URL: https://github.com/apache/spark/pull/25133#issuecomment-511269672 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM
AmplabJenkins commented on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM URL: https://github.com/apache/spark/pull/25133#issuecomment-511269672 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM
AmplabJenkins commented on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM URL: https://github.com/apache/spark/pull/25133#issuecomment-511269675 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12788/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25117: [Python] Validate LongType in _make_type_verifier
AmplabJenkins commented on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511269683 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12789/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM
AmplabJenkins removed a comment on issue #25133: [SPARK-28365][ML] Fallback locale to en_US in StopWordsRemover if system default locale isn't in available locales in JVM URL: https://github.com/apache/spark/pull/25133#issuecomment-511269675 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/12788/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25117: [Python] Validate LongType in _make_type_verifier
AmplabJenkins commented on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511269682 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #25117: [Python] Validate LongType in _make_type_verifier
HyukjinKwon commented on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511269586 ok to test This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25117: [Python] Validate LongType in _make_type_verifier
AmplabJenkins removed a comment on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-510499121 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #25117: [Python] Validate LongType in _make_type_verifier
HyukjinKwon commented on issue #25117: [Python] Validate LongType in _make_type_verifier URL: https://github.com/apache/spark/pull/25117#issuecomment-511269564 Can you show the output before / after? Also, please file a JIRA. See https://spark.apache.org/contributing.html This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op
cloud-fan commented on a change in pull request #25130: [SPARK-28359][SQL][PYTHON][TESTS] Make integrated UDF tests robust by making UDFs (virtually) no-op URL: https://github.com/apache/spark/pull/25130#discussion_r303283620 ## File path: sql/core/src/test/scala/org/apache/spark/sql/IntegratedUDFTestUtils.scala ## @@ -35,8 +36,12 @@ import org.apache.spark.sql.types.StringType * This object targets to integrate various UDF test cases so that Scalar UDF, Python UDF and * Scalar Pandas UDFs can be tested in SBT & Maven tests. * - * The available UDFs cast input to strings, which take one column as input and return a string - * type column as output. + * The available UDFs are special. It defines an UDF wrapped by cast. So, Input column is casted + * into string, UDF returns strings as are, and then output column is casted back to the input + * column. In this way, UDF is virtually no-op. + * + * Note that, due to this implementation limitation, complex types such as map, array and struct + * types do not work this this UDF because they cannot be same after the cast roundtrip. Review comment: double `this`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24931: [SPARK-28129][SQL][TEST] Port float8.sql
dongjoon-hyun commented on issue #24931: [SPARK-28129][SQL][TEST] Port float8.sql URL: https://github.com/apache/spark/pull/24931#issuecomment-511268877 Hi, @wangyum . Since #25041 is merged, could you update this PR once more? Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #25146: [SPARK-28152][SQL] Mapped ShortType to SMALLINT and FloatType to REAL for MsSqlServerDialect
dongjoon-hyun edited a comment on issue #25146: [SPARK-28152][SQL] Mapped ShortType to SMALLINT and FloatType to REAL for MsSqlServerDialect URL: https://github.com/apache/spark/pull/25146#issuecomment-511268693 Could you elaborate your PR description a little bit more, @shivsood ? Please refer the other commit logs. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25146: [SPARK-28152][SQL] Mapped ShortType to SMALLINT and FloatType to REAL for MsSqlServerDialect
dongjoon-hyun commented on issue #25146: [SPARK-28152][SQL] Mapped ShortType to SMALLINT and FloatType to REAL for MsSqlServerDialect URL: https://github.com/apache/spark/pull/25146#issuecomment-511268693 Could you elaborate your PR description a little bit more, @shivsood ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25146: [SPARK-28152][SQL] Mapped ShortType to SMALLINT and FloatType to REAL for MsSqlServerDialect
dongjoon-hyun commented on a change in pull request #25146: [SPARK-28152][SQL]
Mapped ShortType to SMALLINT and FloatType to REAL for MsSqlServerDialect
URL: https://github.com/apache/spark/pull/25146#discussion_r303283367
##
File path: sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala
##
@@ -895,8 +895,20 @@ class JDBCSuite extends QueryTest
"BIT")
assert(msSqlServerDialect.getJDBCType(BinaryType).map(_.databaseTypeDefinition).get
==
"VARBINARY(MAX)")
+
assert(msSqlServerDialect.getJDBCType(ShortType).map(_.databaseTypeDefinition).get
==
+ "SMALLINT")
}
+ test("SPARK-28152 MsSqlServerDialect catalyst type mapping") {
+val msSqlServerDialect = JdbcDialects.get("jdbc:sqlserver")
+val metadata = new MetadataBuilder().putLong("scale", 1)
+assert(msSqlServerDialect.getCatalystType(java.sql.Types.SMALLINT,
"SMALLINT", 1,
+ metadata).get == ShortType)
+assert(msSqlServerDialect.getCatalystType(java.sql.Types.REAL, "REAL", 1,
+ metadata).get == FloatType)
+ }
+
+
Review comment:
nit. Let's remove this redundant empty line.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25147: [SPARK-28333][SQL] NULLS FIRST for DESC and NULLS LAST for ASC
HyukjinKwon commented on a change in pull request #25147: [SPARK-28333][SQL]
NULLS FIRST for DESC and NULLS LAST for ASC
URL: https://github.com/apache/spark/pull/25147#discussion_r303283180
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/SortOrder.scala
##
@@ -36,12 +36,12 @@ abstract sealed class NullOrdering {
case object Ascending extends SortDirection {
override def sql: String = "ASC"
- override def defaultNullOrdering: NullOrdering = NullsFirst
+ override def defaultNullOrdering: NullOrdering = NullsLast
}
case object Descending extends SortDirection {
override def sql: String = "DESC"
- override def defaultNullOrdering: NullOrdering = NullsLast
+ override def defaultNullOrdering: NullOrdering = NullsFirst
Review comment:
I think this is a breaking change and workaround looks pretty easy. Can you
check what other DBMSs do? If it's consistent with some other DBMSs, I think we
shouldn't fix it and resolve the ticket as `Won't Do`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24128: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
AmplabJenkins commented on issue #24128: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files URL: https://github.com/apache/spark/pull/24128#issuecomment-511267376 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #25041: [SPARK-28133][SQL] Add acosh/asinh/atanh functions to SQL
HyukjinKwon commented on issue #25041: [SPARK-28133][SQL] Add acosh/asinh/atanh functions to SQL URL: https://github.com/apache/spark/pull/25041#issuecomment-511266861 +1 looks fine to me too. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Tonix517 commented on issue #25041: [SPARK-28133][SQL] Add acosh/asinh/atanh functions to SQL
Tonix517 commented on issue #25041: [SPARK-28133][SQL] Add acosh/asinh/atanh functions to SQL URL: https://github.com/apache/spark/pull/25041#issuecomment-511266819 @dongjoon-hyun @mgaido91 Thank you very much for all your guidance and patience. Learned a lot :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #25041: [SPARK-28133][SQL] Add acosh/asinh/atanh functions to SQL
dongjoon-hyun closed pull request #25041: [SPARK-28133][SQL] Add acosh/asinh/atanh functions to SQL URL: https://github.com/apache/spark/pull/25041 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25041: [SPARK-28133][SQL] Add acosh/asinh/atanh functions to SQL
dongjoon-hyun commented on issue #25041: [SPARK-28133][SQL] Add acosh/asinh/atanh functions to SQL URL: https://github.com/apache/spark/pull/25041#issuecomment-511265725 Thank you, @mgaido91 . Yes, I tried in several use cases including `CAST/CTAS/INSERT/WHERE` for the second case. The argument of that function is stored into `double` primitive variables like `double project_value_1` or `double filter_value_2` already. It turns out pure `double` operations. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org