[GitHub] [spark] SparkQA removed a comment on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion
SparkQA removed a comment on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion URL: https://github.com/apache/spark/pull/25453#issuecomment-523796599 **[Test build #109564 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109564/testReport)** for PR 25453 at commit [`aa7afdf`](https://github.com/apache/spark/commit/aa7afdf241d8f73d5d7d8cc052509e99a27b7bce). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion
SparkQA commented on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion URL: https://github.com/apache/spark/pull/25453#issuecomment-523874049 **[Test build #109564 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109564/testReport)** for PR 25453 at commit [`aa7afdf`](https://github.com/apache/spark/commit/aa7afdf241d8f73d5d7d8cc052509e99a27b7bce). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Udbhav30 commented on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory
Udbhav30 commented on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory URL: https://github.com/apache/spark/pull/25398#issuecomment-523871118 cc @HyukjinKwon This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amanomer commented on issue #25543: [SPARK-28795][DOC][SQL] Document CREATE VIEW statement in SQL Reference
amanomer commented on issue #25543: [SPARK-28795][DOC][SQL] Document CREATE VIEW statement in SQL Reference URL: https://github.com/apache/spark/pull/25543#issuecomment-523869660 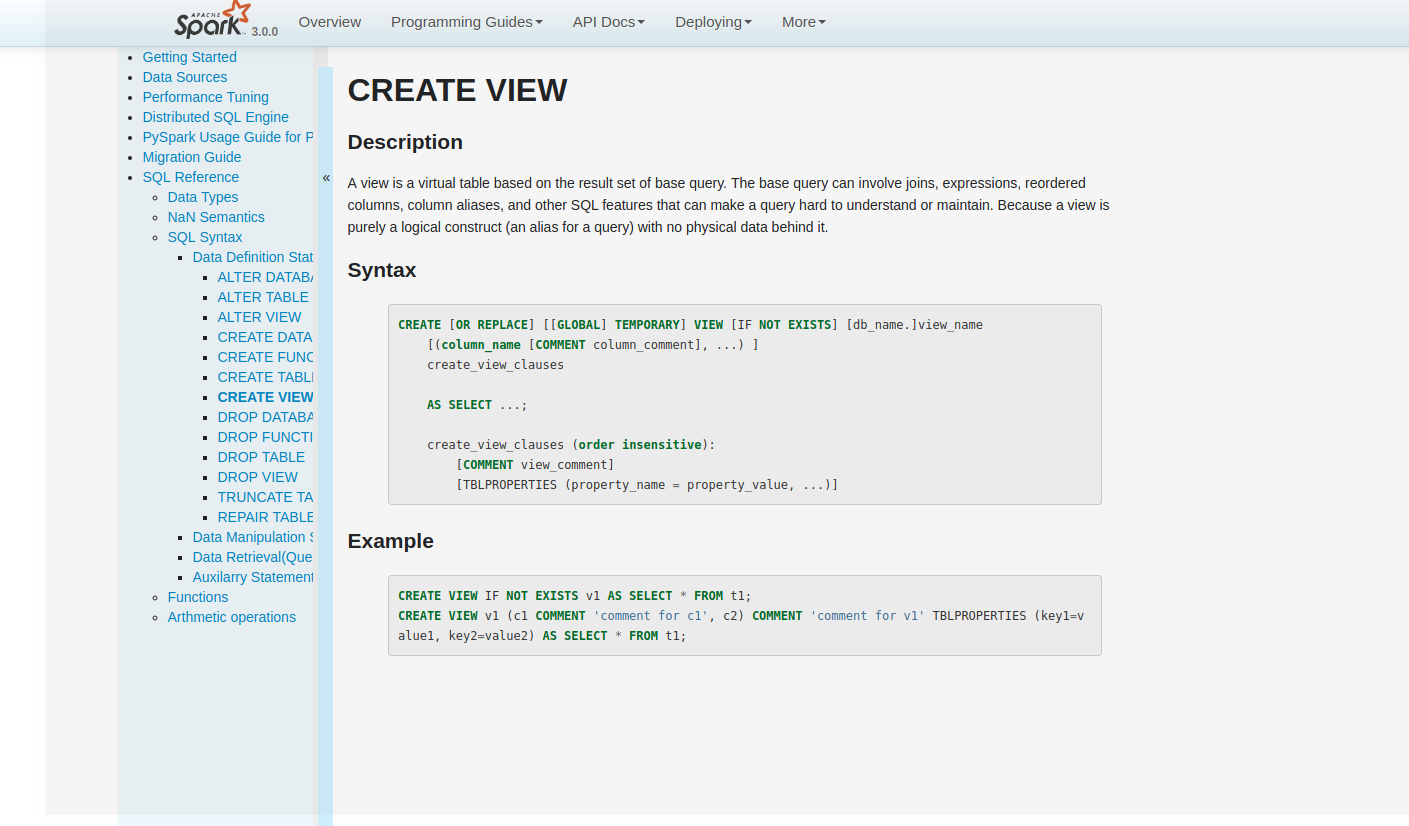 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming
SparkQA commented on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming URL: https://github.com/apache/spark/pull/22282#issuecomment-523865901 **[Test build #109572 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109572/testReport)** for PR 22282 at commit [`aa758ed`](https://github.com/apache/spark/commit/aa758ed8678db26da2c8656d1d693a093f1f0f49). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjinleekr commented on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming
dongjinleekr commented on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming URL: https://github.com/apache/spark/pull/22282#issuecomment-523864982 @HeartSaVioR You are right. Thanks for the reasoning. @zsxwing Reverted. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25554: [SPARK-28796][DOC]Document DROP DATABASE statement in SQL Reference
AmplabJenkins removed a comment on issue #25554: [SPARK-28796][DOC]Document DROP DATABASE statement in SQL Reference URL: https://github.com/apache/spark/pull/25554#issuecomment-523862668 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25554: [SPARK-28796][DOC]Document DROP DATABASE statement in SQL Reference
AmplabJenkins commented on issue #25554: [SPARK-28796][DOC]Document DROP DATABASE statement in SQL Reference URL: https://github.com/apache/spark/pull/25554#issuecomment-523863447 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24759: [SPARK-27395][SQL] Improve EXPLAIN command
AmplabJenkins commented on issue #24759: [SPARK-27395][SQL] Improve EXPLAIN command URL: https://github.com/apache/spark/pull/24759#issuecomment-523863249 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24759: [SPARK-27395][SQL] Improve EXPLAIN command
AmplabJenkins commented on issue #24759: [SPARK-27395][SQL] Improve EXPLAIN command URL: https://github.com/apache/spark/pull/24759#issuecomment-523863253 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109562/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24759: [SPARK-27395][SQL] Improve EXPLAIN command
AmplabJenkins removed a comment on issue #24759: [SPARK-27395][SQL] Improve EXPLAIN command URL: https://github.com/apache/spark/pull/24759#issuecomment-523863253 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109562/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24759: [SPARK-27395][SQL] Improve EXPLAIN command
AmplabJenkins removed a comment on issue #24759: [SPARK-27395][SQL] Improve EXPLAIN command URL: https://github.com/apache/spark/pull/24759#issuecomment-523863249 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25554: [SPARK-28796][DOC]Document DROP DATABASE statement in SQL Reference
AmplabJenkins commented on issue #25554: [SPARK-28796][DOC]Document DROP DATABASE statement in SQL Reference URL: https://github.com/apache/spark/pull/25554#issuecomment-523862668 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24759: [SPARK-27395][SQL] Improve EXPLAIN command
SparkQA removed a comment on issue #24759: [SPARK-27395][SQL] Improve EXPLAIN command URL: https://github.com/apache/spark/pull/24759#issuecomment-523781067 **[Test build #109562 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109562/testReport)** for PR 24759 at commit [`b846922`](https://github.com/apache/spark/commit/b846922bcd4172d554f688bd8f713c6837d9c2d0). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24759: [SPARK-27395][SQL] Improve EXPLAIN command
SparkQA commented on issue #24759: [SPARK-27395][SQL] Improve EXPLAIN command URL: https://github.com/apache/spark/pull/24759#issuecomment-523862622 **[Test build #109562 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109562/testReport)** for PR 24759 at commit [`b846922`](https://github.com/apache/spark/commit/b846922bcd4172d554f688bd8f713c6837d9c2d0). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25554: [SPARK-28796][DOC]Document DROP DATABASE statement in SQL Reference
AmplabJenkins removed a comment on issue #25554: [SPARK-28796][DOC]Document DROP DATABASE statement in SQL Reference URL: https://github.com/apache/spark/pull/25554#issuecomment-523862515 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25554: [SPARK-28796][DOC]Document DROP DATABASE statement in SQL Reference
AmplabJenkins commented on issue #25554: [SPARK-28796][DOC]Document DROP DATABASE statement in SQL Reference URL: https://github.com/apache/spark/pull/25554#issuecomment-523862515 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sandeep-katta opened a new pull request #25554: [SPARK-28796][DOC]Document DROP DATABASE statement in SQL Reference
sandeep-katta opened a new pull request #25554: [SPARK-28796][DOC]Document DROP DATABASE statement in SQL Reference URL: https://github.com/apache/spark/pull/25554 ### What changes were proposed in this pull request? Document DROP DATABASE statement in SQL Reference ### Why are the changes needed? Currently from spark there is no complete sql guide is present, so it is better to document all the sql commands, this jira is sub part of this task. ### Does this PR introduce any user-facing change? Yes, Before there was no documentation about drop database syntax After Fix 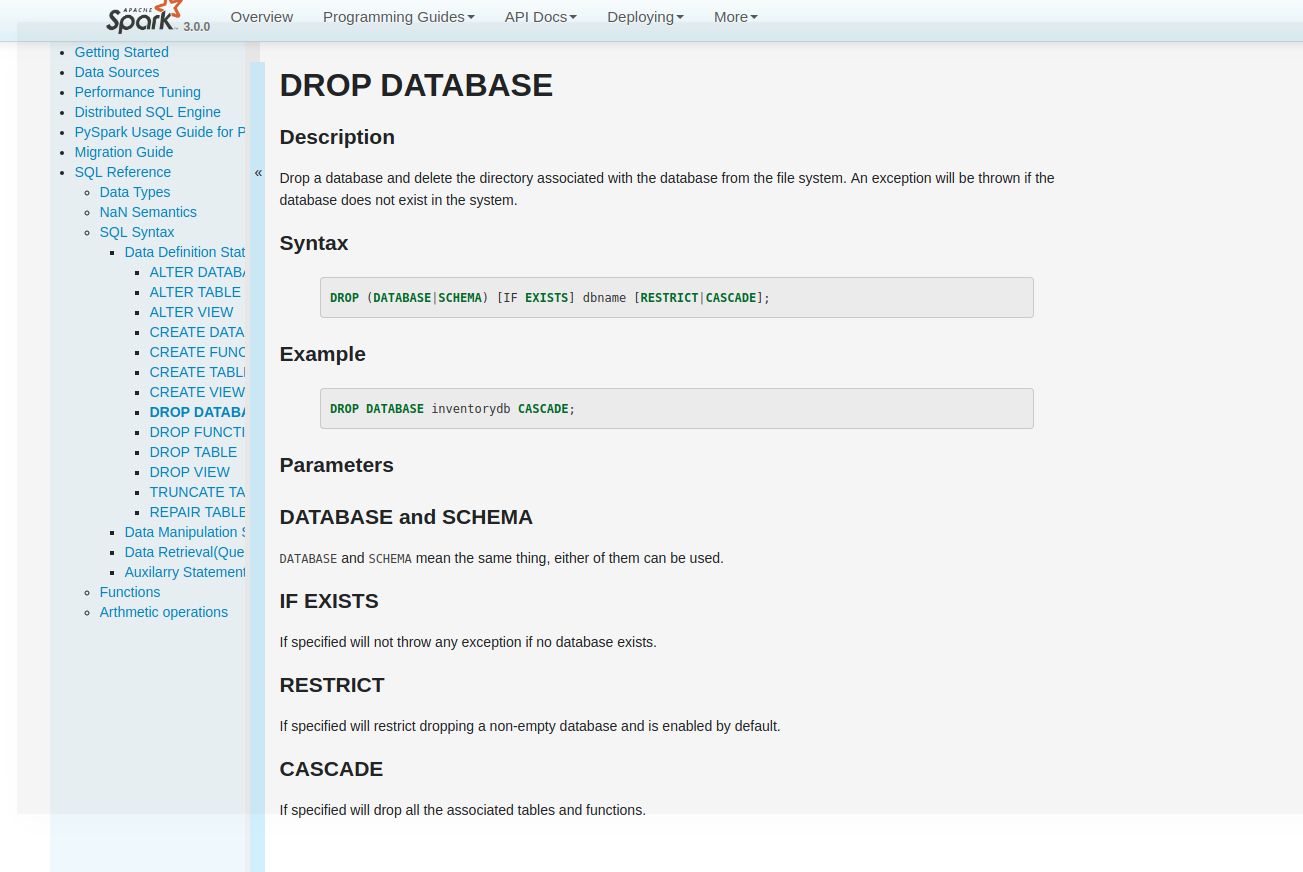 ### How was this patch tested? tested with jenkyll build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
SparkQA commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-523861108 **[Test build #109571 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109571/testReport)** for PR 24903 at commit [`e2f962d`](https://github.com/apache/spark/commit/e2f962dd61b7d243afe3427e88988310f0e2740c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
AmplabJenkins removed a comment on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-523860494 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14628/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
AmplabJenkins removed a comment on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-523860481 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
AmplabJenkins removed a comment on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on URL: https://github.com/apache/spark/pull/25551#issuecomment-523854838 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
AmplabJenkins commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-523860481 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
AmplabJenkins commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-523860494 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14628/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
SparkQA commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on URL: https://github.com/apache/spark/pull/25551#issuecomment-523855526 **[Test build #109570 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109570/testReport)** for PR 25551 at commit [`4363ef1`](https://github.com/apache/spark/commit/4363ef144a94176b50d883be531b69f165d3d955). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
AmplabJenkins removed a comment on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on URL: https://github.com/apache/spark/pull/25551#issuecomment-523854891 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14627/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs
SparkQA removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs URL: https://github.com/apache/spark/pull/25465#issuecomment-523778594 **[Test build #109560 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109560/testReport)** for PR 25465 at commit [`a807f43`](https://github.com/apache/spark/commit/a807f437bb52bef340890377425a5002492c3dac). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs
AmplabJenkins removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs URL: https://github.com/apache/spark/pull/25465#issuecomment-523839690 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109560/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs
AmplabJenkins removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs URL: https://github.com/apache/spark/pull/25465#issuecomment-523839681 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
HyukjinKwon commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on URL: https://github.com/apache/spark/pull/25551#issuecomment-523853640 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25553: [SPARK-28797][DOC] Document DROP FUNCTION statement in SQL Reference.
AmplabJenkins commented on issue #25553: [SPARK-28797][DOC] Document DROP FUNCTION statement in SQL Reference. URL: https://github.com/apache/spark/pull/25553#issuecomment-523852935 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum
AmplabJenkins commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum URL: https://github.com/apache/spark/pull/25347#issuecomment-523852351 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109565/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25553: [SPARK-28797][DOC] Document DROP FUNCTION statement in SQL Reference.
AmplabJenkins commented on issue #25553: [SPARK-28797][DOC] Document DROP FUNCTION statement in SQL Reference. URL: https://github.com/apache/spark/pull/25553#issuecomment-523852265 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum
SparkQA commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum URL: https://github.com/apache/spark/pull/25347#issuecomment-523852034 **[Test build #109565 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109565/testReport)** for PR 25347 at commit [`aae4642`](https://github.com/apache/spark/commit/aae4642670126fdadaf593c24ea14c2bf66ebae0). * This patch **fails Spark unit tests**. * This patch **does not merge cleanly**. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sandeep-katta opened a new pull request #25553: [SPARK-28797][DOC] Document DROP FUNCTION statement in SQL Reference.
sandeep-katta opened a new pull request #25553: [SPARK-28797][DOC] Document DROP FUNCTION statement in SQL Reference. URL: https://github.com/apache/spark/pull/25553 ### What changes were proposed in this pull request? Add DROP FUNCTION sql description in SQL reference ### Why are the changes needed? Currently from spark there is no complete sql guide is present, so it is better to document all the sql commands, this jira is sub part of this task. ### Does this PR introduce any user-facing change? Yes before user cannot find any reference for drop function command in the spark docs. After Fix: 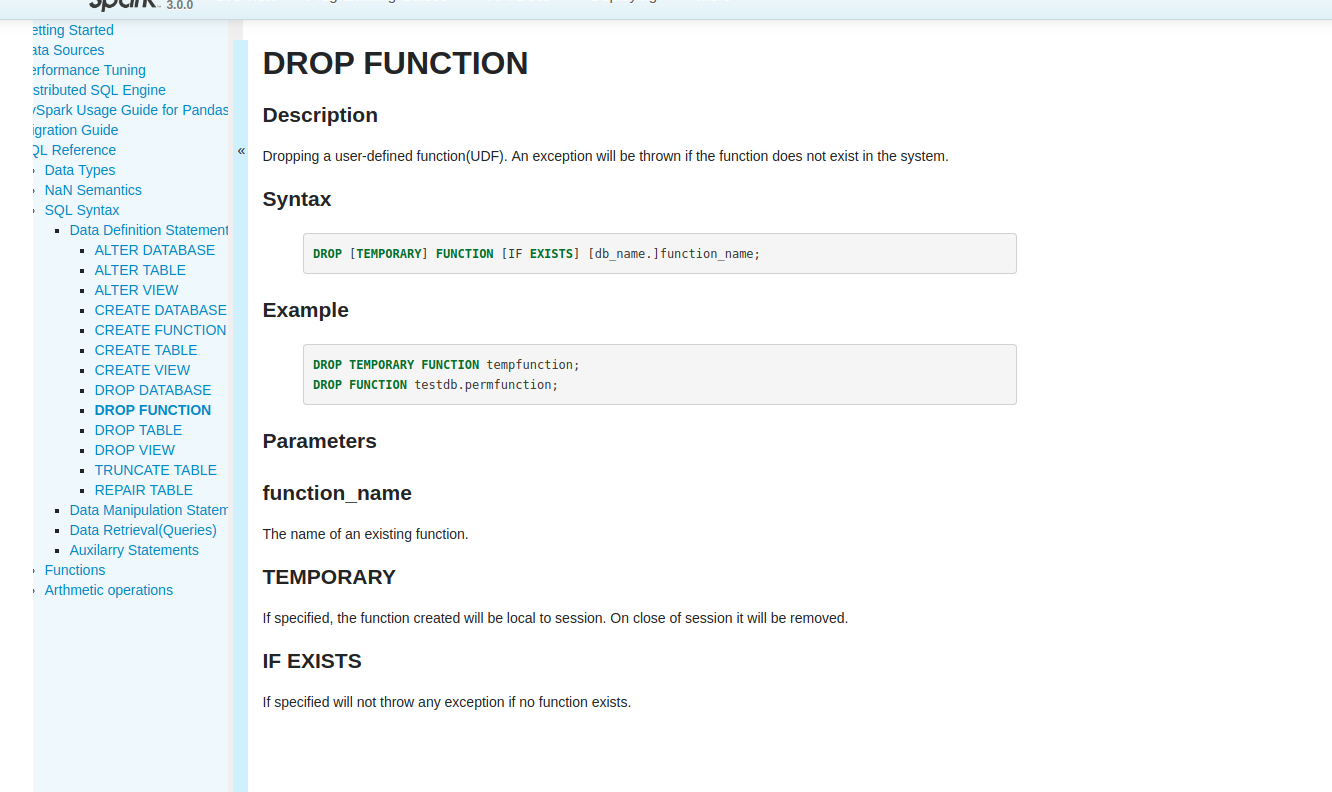 ### How was this patch tested? tested with jekyll build This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
SparkQA commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on URL: https://github.com/apache/spark/pull/25551#issuecomment-523851257 **[Test build #109568 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109568/testReport)** for PR 25551 at commit [`4363ef1`](https://github.com/apache/spark/commit/4363ef144a94176b50d883be531b69f165d3d955). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs
AmplabJenkins removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs URL: https://github.com/apache/spark/pull/25465#issuecomment-523839690 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109560/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs
AmplabJenkins removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs URL: https://github.com/apache/spark/pull/25465#issuecomment-523839681 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs
SparkQA removed a comment on issue #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs URL: https://github.com/apache/spark/pull/25465#issuecomment-523778594 **[Test build #109560 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109560/testReport)** for PR 25465 at commit [`a807f43`](https://github.com/apache/spark/commit/a807f437bb52bef340890377425a5002492c3dac). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
AmplabJenkins commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-523847477 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109567/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
AmplabJenkins commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-523847457 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
SparkQA commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-523847234 **[Test build #109567 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109567/testReport)** for PR 24903 at commit [`f11e815`](https://github.com/apache/spark/commit/f11e8157b78fe86ec24520673320807a9c337ffc). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] juliuszsompolski commented on issue #25277: [WIP] Thriftserver support interval type
juliuszsompolski commented on issue #25277: [WIP] Thriftserver support interval type URL: https://github.com/apache/spark/pull/25277#issuecomment-523846918 This has been filed as SPARK-28637. Could you update the PR description? If we want to return intervals as string, since Spark does not support actual Interval Year Month and Interval Day Second, then I think this PR is good to go. But then, I think maybe we should actually override GetTypeInfoOperation. Currently `!typeinfo` returns INTERVAL_YEAR_MONTH, INTERVAL_DAY_TIME, ARRAY, MAP, STRUCT, UNIONTYPE and USER_DEFINED, all of which Spark turns into string. Maybe we should make SparkGetTypeInfoOperation, to exclude types which we don't support? Then we would be missing only SparkGetCatalogsOperation, which we may add for completeness - e.g. for it to use the `HiveThriftServer2.listener` and show up in the UI. WDYT @wangyum ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25552: [SPARK-28849][CORE] Add a number to control transferTo calls to avoid infinite loop in some occasional cases
AmplabJenkins removed a comment on issue #25552: [SPARK-28849][CORE] Add a number to control transferTo calls to avoid infinite loop in some occasional cases URL: https://github.com/apache/spark/pull/25552#issuecomment-523829575 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14626/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25552: [SPARK-28849][CORE] Add a number to control transferTo calls to avoid infinite loop in some occasional cases
AmplabJenkins removed a comment on issue #25552: [SPARK-28849][CORE] Add a number to control transferTo calls to avoid infinite loop in some occasional cases URL: https://github.com/apache/spark/pull/25552#issuecomment-523829565 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25550: [SPARK-28847][TEST] Annotate HiveExternalCatalogVersionsSuite with ExtendedHiveTest
AmplabJenkins removed a comment on issue #25550: [SPARK-28847][TEST] Annotate HiveExternalCatalogVersionsSuite with ExtendedHiveTest URL: https://github.com/apache/spark/pull/25550#issuecomment-523821900 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25550: [SPARK-28847][TEST] Annotate HiveExternalCatalogVersionsSuite with ExtendedHiveTest
AmplabJenkins removed a comment on issue #25550: [SPARK-28847][TEST] Annotate HiveExternalCatalogVersionsSuite with ExtendedHiveTest URL: https://github.com/apache/spark/pull/25550#issuecomment-523821914 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109561/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25550: [SPARK-28847][TEST] Annotate HiveExternalCatalogVersionsSuite with ExtendedHiveTest
SparkQA removed a comment on issue #25550: [SPARK-28847][TEST] Annotate HiveExternalCatalogVersionsSuite with ExtendedHiveTest URL: https://github.com/apache/spark/pull/25550#issuecomment-523781042 **[Test build #109561 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109561/testReport)** for PR 25550 at commit [`39e7ece`](https://github.com/apache/spark/commit/39e7ecec7c03b2cae97b3564952a2dfde4b6a712). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shivusondur commented on issue #25503: [SPARK-28702][SQL] Display useful error message (instead of NPE) for invalid Dataset operations
shivusondur commented on issue #25503: [SPARK-28702][SQL] Display useful error message (instead of NPE) for invalid Dataset operations URL: https://github.com/apache/spark/pull/25503#issuecomment-523844298 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
AmplabJenkins removed a comment on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on URL: https://github.com/apache/spark/pull/25551#issuecomment-523815569 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
AmplabJenkins removed a comment on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on URL: https://github.com/apache/spark/pull/25551#issuecomment-523815578 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14624/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #25542: [SPARK-28840][SQL][test-hadoop3.2]conf.getClassLoader in SparkSQLCLIDriver should be avoided as it returns the UDFClassLoader whi
wangyum commented on a change in pull request #25542:
[SPARK-28840][SQL][test-hadoop3.2]conf.getClassLoader in SparkSQLCLIDriver
should be avoided as it returns the UDFClassLoader which is created by Hive
URL: https://github.com/apache/spark/pull/25542#discussion_r316600772
##
File path:
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLCLIDriver.scala
##
@@ -140,7 +141,7 @@ private[hive] object SparkSQLCLIDriver extends Logging {
// Hadoop-20 and above - we need to augment classpath using hiveconf
// components.
// See also: code in ExecDriver.java
- var loader = conf.getClassLoader
+ var loader = orginalClassLoader
val auxJars = HiveConf.getVar(conf, HiveConf.ConfVars.HIVEAUXJARS)
if (StringUtils.isNotBlank(auxJars)) {
Review comment:
Please add another test case to cover `Utilities.addToClassPath(loader,
StringUtils.split(auxJars, ","))`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #25542: [SPARK-28840][SQL][test-hadoop3.2]conf.getClassLoader in SparkSQLCLIDriver should be avoided as it returns the UDFClassLoader whi
wangyum commented on a change in pull request #25542:
[SPARK-28840][SQL][test-hadoop3.2]conf.getClassLoader in SparkSQLCLIDriver
should be avoided as it returns the UDFClassLoader which is created by Hive
URL: https://github.com/apache/spark/pull/25542#discussion_r316600471
##
File path:
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLCLIDriver.scala
##
@@ -140,7 +141,7 @@ private[hive] object SparkSQLCLIDriver extends Logging {
// Hadoop-20 and above - we need to augment classpath using hiveconf
// components.
// See also: code in ExecDriver.java
- var loader = conf.getClassLoader
+ var loader = orginalClassLoader
Review comment:
I think this is a correct fix. Another approach is add the Spark jars to
`Utilities.addToClassPath` to make `UDFClassLoader` work:
```scala
val sparkJars = sparkConf.get(org.apache.spark.internal.config.JARS)
if (sparkJars.nonEmpty || StringUtils.isNotBlank(auxJars)) {
loader = Utilities.addToClassPath(loader, sparkJars.toArray ++
StringUtils.split(auxJars, ","))
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25552: [SPARK-28849][CORE] Add a number to control transferTo calls to avoid infinite loop in some occasional cases
SparkQA commented on issue #25552: [SPARK-28849][CORE] Add a number to control transferTo calls to avoid infinite loop in some occasional cases URL: https://github.com/apache/spark/pull/25552#issuecomment-523830201 **[Test build #109569 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109569/testReport)** for PR 25552 at commit [`50bb20d`](https://github.com/apache/spark/commit/50bb20df1371d2ca33a4910acd147ac43e1d0284). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR edited a comment on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming
HeartSaVioR edited a comment on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming URL: https://github.com/apache/spark/pull/22282#issuecomment-523827720 The fix wouldn't work since KafkaOffsetReader will be shared across tasks in same JVM (since it's a singleton `object`) and `UnsafeProjection` instances being created via `UnsafeProjection.create` are not thread-safe. That's the reason why UTs fail. You may either make them `ThreadLocal` (though it may grow incrementally so don't recommend), or just follow the previous approach of `KafkaRecordToUnsafeRowConverter` and initialize per caller (would be each task). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR edited a comment on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming
HeartSaVioR edited a comment on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming URL: https://github.com/apache/spark/pull/22282#issuecomment-523827720 The fix wouldn't work since KafkaOffsetReader will be shared across tasks in same JVM (since it's a singleton `object`) and `UnsafeProjection` instances being created via `UnsafeProjection.create` are not thread-safe. That's the reason why UTs fail. You may either make them `ThreadLocal` (though it may grow incrementally so don't recommend), or just follow the previous approach of `KafkaRecordToUnsafeRowConverter` and initialize per caller (would be each task). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25552: [SPARK-28849][CORE] Add a number to control transferTo calls to avoid infinite loop in some occasional cases
AmplabJenkins commented on issue #25552: [SPARK-28849][CORE] Add a number to control transferTo calls to avoid infinite loop in some occasional cases URL: https://github.com/apache/spark/pull/25552#issuecomment-523829565 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25552: [SPARK-28849][CORE] Add a number to control transferTo calls to avoid infinite loop in some occasional cases
AmplabJenkins commented on issue #25552: [SPARK-28849][CORE] Add a number to control transferTo calls to avoid infinite loop in some occasional cases URL: https://github.com/apache/spark/pull/25552#issuecomment-523829575 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14626/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR edited a comment on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming
HeartSaVioR edited a comment on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming URL: https://github.com/apache/spark/pull/22282#issuecomment-523827720 The fix wouldn't work since KafkaOffsetReader will be shared across tasks (since it's a singleton `object`) and `UnsafeProjection` instances being created via `UnsafeProjection.create` are not thread-safe. That's the reason why UTs fail. You may either make them `ThreadLocal` (though it may grow incrementally so don't recommend), or just follow the previous approach of `KafkaRecordToUnsafeRowConverter` and initialize per caller (task). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jerryshao opened a new pull request #25552: [SPARK-28849][CORE] Add number of transferTo calls to avoid infinite loop in some occasional cases
jerryshao opened a new pull request #25552: [SPARK-28849][CORE] Add number of transferTo calls to avoid infinite loop in some occasional cases URL: https://github.com/apache/spark/pull/25552 This patch propose a way to detect the infinite loop issue in `transferTo` and make it fail fast. The detailed issue is shown in https://issues.apache.org/jira/browse/SPARK-28849. Here propose a new undocumented configuration and a way to track the number of `transferTo` calls, if the number is larger than the specified value, it will jump out of the loop and throw an exception. Typically this will not be happened, and user don't need to set this configuration explicitly, in our environment it happens occasionally and cause the task hung infinitely. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables
cloud-fan commented on issue #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables URL: https://github.com/apache/spark/pull/25247#issuecomment-523828834 LGTM except for several minor comments, thanks for working on it! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR edited a comment on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming
HeartSaVioR edited a comment on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming URL: https://github.com/apache/spark/pull/22282#issuecomment-523827720 The fix wouldn't work since KafkaOffsetReader will be shared across tasks (since it's a singleton `object`) and created `UnsafeProjection` instance is not thread-safe. That's the reason why UTs fail. You may either make them `ThreadLocal` (though it may grow incrementally so don't recommend), or just follow the previous approach of `KafkaRecordToUnsafeRowConverter` and initialize per caller (task). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming
HeartSaVioR commented on issue #22282: [SPARK-23539][SS] Add support for Kafka headers in Structured Streaming URL: https://github.com/apache/spark/pull/22282#issuecomment-523827720 The fix wouldn't work since KafkaOffsetReader will be shared across tasks (since it's a singleton `object`) and created `UnsafeProjection` instance is not thread-safe. That's the reason why UTs fail. You may either make them `ThreadLocal` (though it may grow incrementally so don't recommend), or just follow the previous approach of `KafkaRecordToUnsafeRowConverter` and initialize per caller (task). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables
cloud-fan commented on a change in pull request #25247: [SPARK-28319][SQL]
Implement SHOW TABLES for Data Source V2 Tables
URL: https://github.com/apache/spark/pull/25247#discussion_r316580880
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/sources/v2/DataSourceV2SQLSuite.scala
##
@@ -482,6 +482,8 @@ class DataSourceV2SQLSuite extends QueryTest with
SharedSparkSession with Before
val rdd = sparkContext.parallelize(table.asInstanceOf[InMemoryTable].rows)
checkAnswer(spark.internalCreateDataFrame(rdd, table.schema),
spark.table("source"))
+
+spark.sql("DROP TABLE table_name")
Review comment:
why is this need? This test suite always clear all the tables after each
test case.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables
cloud-fan commented on a change in pull request #25247: [SPARK-28319][SQL]
Implement SHOW TABLES for Data Source V2 Tables
URL: https://github.com/apache/spark/pull/25247#discussion_r316580937
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/sources/v2/DataSourceV2SQLSuite.scala
##
@@ -498,6 +500,8 @@ class DataSourceV2SQLSuite extends QueryTest with
SharedSparkSession with Before
val t = catalog("session").asTableCatalog
.loadTable(Identifier.of(Array.empty, "table_name"))
assert(t.isInstanceOf[UnresolvedTable], "V1 table wasn't returned as an
unresolved table")
+
+spark.sql("DROP TABLE table_name")
Review comment:
ditto
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables
cloud-fan commented on a change in pull request #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables URL: https://github.com/apache/spark/pull/25247#discussion_r316579615 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala ## @@ -616,6 +616,14 @@ case class AlterTable( } } +/** + * Show tables. Review comment: `The logical plan of the SHOW TABLE command that works for v2 catalogs.` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25247: [SPARK-28319][SQL] Implement SHOW TABLES for Data Source V2 Tables
cloud-fan commented on a change in pull request #25247: [SPARK-28319][SQL]
Implement SHOW TABLES for Data Source V2 Tables
URL: https://github.com/apache/spark/pull/25247#discussion_r316578880
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/sql/ShowTablesStatement.scala
##
@@ -0,0 +1,31 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.plans.logical.sql
+
+import org.apache.spark.sql.catalyst.expressions.{Attribute,
AttributeReference}
+import org.apache.spark.sql.types.StringType
+
+/**
+ * A SHOW TABLES statement, as parsed from SQL.
+ */
+case class ShowTablesStatement(namespace: Option[Seq[String]], pattern:
Option[String])
+extends ParsedStatement {
Review comment:
nit: a `Statement` is an unresolved plan and we don't need to define the
output here. Let's define the output in `ShowTables`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25550: [SPARK-28847][TEST] Annotate HiveExternalCatalogVersionsSuite with ExtendedHiveTest
AmplabJenkins commented on issue #25550: [SPARK-28847][TEST] Annotate HiveExternalCatalogVersionsSuite with ExtendedHiveTest URL: https://github.com/apache/spark/pull/25550#issuecomment-523821914 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109561/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25550: [SPARK-28847][TEST] Annotate HiveExternalCatalogVersionsSuite with ExtendedHiveTest
AmplabJenkins commented on issue #25550: [SPARK-28847][TEST] Annotate HiveExternalCatalogVersionsSuite with ExtendedHiveTest URL: https://github.com/apache/spark/pull/25550#issuecomment-523821900 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25550: [SPARK-28847][TEST] Annotate HiveExternalCatalogVersionsSuite with ExtendedHiveTest
SparkQA commented on issue #25550: [SPARK-28847][TEST] Annotate HiveExternalCatalogVersionsSuite with ExtendedHiveTest URL: https://github.com/apache/spark/pull/25550#issuecomment-523821356 **[Test build #109561 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109561/testReport)** for PR 25550 at commit [`39e7ece`](https://github.com/apache/spark/commit/39e7ecec7c03b2cae97b3564952a2dfde4b6a712). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #24715: [SPARK-25474][SQL] Data source tables support fallback to HDFS for size estimation
wangyum commented on a change in pull request #24715: [SPARK-25474][SQL] Data
source tables support fallback to HDFS for size estimation
URL: https://github.com/apache/spark/pull/24715#discussion_r316570564
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/StatisticsCollectionSuite.scala
##
@@ -650,4 +652,129 @@ class StatisticsCollectionSuite extends
StatisticsCollectionTestBase with Shared
}
}
}
+
+ test("Non-partitioned data source table support fallback to HDFS for size
estimation") {
+withTempDir { dir =>
+ Seq(false, true).foreach { fallBackToHDFS =>
+withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHDFS") {
+ withTable("spark_25474") {
+sql(s"CREATE TABLE spark_25474 (c1 BIGINT) USING PARQUET LOCATION
'${dir.toURI}'")
+
spark.range(5).write.mode(SaveMode.Overwrite).parquet(dir.getCanonicalPath)
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+// Table statistics are always recalculated by FileIndex
+assert(relation.stats.sizeInBytes === getDataSize(dir))
+ }
+}
+ }
+}
+ }
+
+ test("Partitioned data source table support fallback to HDFS for size
estimation") {
+Seq(false, true).foreach { fallBackToHDFS =>
+ withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHDFS") {
+withTempDir { dir =>
+ withTable("spark_25474") {
+sql("CREATE TABLE spark_25474(a int, b int) USING parquet " +
+s"PARTITIONED BY(a) LOCATION '${dir.toURI}'")
+sql("INSERT INTO TABLE spark_25474 PARTITION(a=1) SELECT 2")
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+if (fallBackToHDFS) {
+ assert(relation.stats.sizeInBytes ===
+CommandUtils.getSizeInBytesFallBackToHdfs(spark,
getCatalogTable("spark_25474")))
+} else {
+ assert(relation.stats.sizeInBytes === conf.defaultSizeInBytes)
+}
+ }
+}
+ }
+}
+ }
+
+ test("Partitioned data source table support fallback to HDFS for size
estimation" +
+"with defaultSizeInBytes") {
+val defaultSizeInBytes = 10 * 1024 * 1024
+Seq(false, true).foreach { fallBackToHDFS =>
+ withSQLConf(
+SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key -> s"$fallBackToHDFS",
+SQLConf.DEFAULT_SIZE_IN_BYTES.key -> s"$defaultSizeInBytes") {
+withTempDir { dir =>
+ withTable("spark_25474") {
+sql("CREATE TABLE spark_25474(a int, b int) USING parquet " +
+ s"PARTITIONED BY(a) LOCATION '${dir.toURI}'")
+sql("INSERT INTO TABLE spark_25474 PARTITION(a=1) SELECT 2")
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+if (fallBackToHDFS) {
+ assert(relation.stats.sizeInBytes ===
+CommandUtils.getSizeInBytesFallBackToHdfs(spark,
getCatalogTable("spark_25474")))
+} else {
+ assert(relation.stats.sizeInBytes === defaultSizeInBytes)
+}
+ }
+}
+ }
+}
+ }
+
+ test("Partitioned data source table stats should be cached") {
+Seq(false, true).foreach { fallBackToHDFS =>
+ withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHDFS") {
+withTempDir { dir =>
+ withTable("spark_25474") {
+sql("CREATE TABLE spark_25474(a int, b int) USING parquet " +
+ s"PARTITIONED BY(a) LOCATION '${dir.toURI}'")
+sql("INSERT INTO TABLE spark_25474 PARTITION(a=1) SELECT 2")
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+if (fallBackToHDFS) {
+ val dataSize =
+CommandUtils.getSizeInBytesFallBackToHdfs(spark,
getCatalogTable("spark_25474"))
+ assert(relation.stats.sizeInBytes === dataSize)
+
+ val qualifiedTableName =
+
QualifiedTableName(spark.sessionState.catalog.getCurrentDatabase, "spark_25474")
+ val logicalRelation =
spark.sessionState.catalog.getCachedTable(qualifiedTableName)
+.asInstanceOf[LogicalRelation]
+ assert(logicalRelation.catalogTable.get.stats.get.sizeInBytes
=== dataSize)
+} else {
+ assert(relation.stats.sizeInBytes === conf.defaultSizeInBytes)
+}
+ }
+}
+ }
+}
+ }
+
+ test("External partitioned data source table does not support fallback to
HDFS " +
+
[GitHub] [spark] AmplabJenkins removed a comment on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
AmplabJenkins removed a comment on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-523815620 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
AmplabJenkins removed a comment on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-523815633 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14625/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
HyukjinKwon commented on a change in pull request #25551: [SPARK-28839][CORE]
Avoids NPE in context cleaner when shuffle service is on
URL: https://github.com/apache/spark/pull/25551#discussion_r316568998
##
File path:
core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
##
@@ -476,7 +476,7 @@ private[spark] class ExecutorMonitor(
}
def removeShuffle(id: Int): Unit = {
- if (shuffleIds.remove(id) && shuffleIds.isEmpty) {
+ if (shuffleIds != null && shuffleIds.remove(id) && shuffleIds.isEmpty) {
Review comment:
Yup, I think so.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25465: [SPARK-28747][SQL] merge the two data source v2 fallback configs
cloud-fan commented on a change in pull request #25465: [SPARK-28747][SQL]
merge the two data source v2 fallback configs
URL: https://github.com/apache/spark/pull/25465#discussion_r316568505
##
File path: sql/core/src/main/scala/org/apache/spark/sql/DataFrameWriter.scala
##
@@ -251,37 +251,17 @@ final class DataFrameWriter[T] private[sql](ds:
Dataset[T]) {
assertNotBucketed("save")
-val session = df.sparkSession
-val cls = DataSource.lookupDataSource(source, session.sessionState.conf)
-val canUseV2 = canUseV2Source(session, cls) && partitioningColumns.isEmpty
-
-// In Data Source V2 project, partitioning is still under development.
-// Here we fallback to V1 if partitioning columns are specified.
-// TODO(SPARK-26778): use V2 implementations when partitioning feature is
supported.
-if (canUseV2) {
- val provider =
cls.getConstructor().newInstance().asInstanceOf[TableProvider]
+val maybeV2Provider = lookupV2Provider()
+// TODO(SPARK-26778): use V2 implementations when partition columns are
specified
+if (maybeV2Provider.isDefined && partitioningColumns.isEmpty) {
Review comment:
makes sense. Since it's minor let me just finish this TODO in this PR.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sekikn commented on issue #24651: [SPARK-27420][DSTREAMS][Kinesis] KinesisInputDStream should expose a way to configure CloudWatch metrics
sekikn commented on issue #24651: [SPARK-27420][DSTREAMS][Kinesis] KinesisInputDStream should expose a way to configure CloudWatch metrics URL: https://github.com/apache/spark/pull/24651#issuecomment-523816081 Hmm, I'm not sure why the CI failed on PySpark, because it succeeds with the same options on my local environment. ``` $ git checkout master $ curl -sLO https://github.com/apache/spark/pull/24651.patch $ git apply 24651.patch $ build/mvn clean install -Pkinesis-asl -DskipTests (snip) [INFO] Spark Project Kinesis Assembly . SUCCESS [ 5.044 s] [INFO] [INFO] BUILD SUCCESS [INFO] [INFO] Total time: 20:39 min [INFO] Finished at: 2019-08-22T15:20:42+09:00 [INFO] $ ENABLE_KINESIS_TESTS=1 python/run-tests --modules=pyspark-streaming,pyspark-mllib,pyspark-ml Running PySpark tests. Output is in /home/sekikn/repos/spark/python/unit-tests.log Will test against the following Python executables: ['python2.7', 'python3.6', 'pypy'] Will test the following Python modules: ['pyspark-streaming', 'pyspark-mllib', 'pyspark-ml'] Starting test(pypy): pyspark.streaming.tests.test_dstream Starting test(pypy): pyspark.streaming.tests.test_listener Starting test(pypy): pyspark.streaming.tests.test_context Starting test(pypy): pyspark.streaming.tests.test_kinesis (snip) Finished test(pypy): pyspark.streaming.tests.test_kinesis (178s) (snip) Tests passed in 1140 seconds Skipped tests in pyspark.ml.tests.test_image with python2.7: test_read_images_multiple_times (pyspark.ml.tests.test_image.ImageFileFormatOnHiveContextTest) ... skipped 'Hive is not available.' Skipped tests in pyspark.ml.tests.test_image with python3.6: test_read_images_multiple_times (pyspark.ml.tests.test_image.ImageFileFormatOnHiveContextTest) ... skipped 'Hive is not available.' $ echo $? 0 ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
SparkQA commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on URL: https://github.com/apache/spark/pull/25551#issuecomment-523816385 **[Test build #109568 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109568/testReport)** for PR 25551 at commit [`4363ef1`](https://github.com/apache/spark/commit/4363ef144a94176b50d883be531b69f165d3d955). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
dongjoon-hyun commented on a change in pull request #25551: [SPARK-28839][CORE]
Avoids NPE in context cleaner when shuffle service is on
URL: https://github.com/apache/spark/pull/25551#discussion_r316568410
##
File path:
core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala
##
@@ -476,7 +476,7 @@ private[spark] class ExecutorMonitor(
}
def removeShuffle(id: Int): Unit = {
- if (shuffleIds.remove(id) && shuffleIds.isEmpty) {
+ if (shuffleIds != null && shuffleIds.remove(id) && shuffleIds.isEmpty) {
Review comment:
So, is this only for `3.0`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
AmplabJenkins commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on URL: https://github.com/apache/spark/pull/25551#issuecomment-523815578 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14624/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
AmplabJenkins commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on URL: https://github.com/apache/spark/pull/25551#issuecomment-523815569 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
SparkQA commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-523813378 **[Test build #109567 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109567/testReport)** for PR 24903 at commit [`f11e815`](https://github.com/apache/spark/commit/f11e8157b78fe86ec24520673320807a9c337ffc). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon opened a new pull request #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
HyukjinKwon opened a new pull request #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on URL: https://github.com/apache/spark/pull/25551 ### What changes were proposed in this pull request? This PR proposes to avoid to thrown NPE at context cleaner when shuffle service is on - it is kind of a small followup in https://github.com/apache/spark/pull/24817 Seems like it sets `null` for `shuffleIds` to track when the service is on. Later, `removeShuffle` tries to remove an element at `shuffleIds` which leads to NPE. See the code path below: https://github.com/apache/spark/blob/cbad616d4cb0c58993a88df14b5e30778c7f7e85/core/src/main/scala/org/apache/spark/SparkContext.scala#L584 https://github.com/apache/spark/blob/cbad616d4cb0c58993a88df14b5e30778c7f7e85/core/src/main/scala/org/apache/spark/ContextCleaner.scala#L125 https://github.com/apache/spark/blob/cbad616d4cb0c58993a88df14b5e30778c7f7e85/core/src/main/scala/org/apache/spark/ContextCleaner.scala#L190 https://github.com/apache/spark/blob/cbad616d4cb0c58993a88df14b5e30778c7f7e85/core/src/main/scala/org/apache/spark/ContextCleaner.scala#L220-L230 https://github.com/apache/spark/blob/cbad616d4cb0c58993a88df14b5e30778c7f7e85/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala#L353-L357 https://github.com/apache/spark/blob/cbad616d4cb0c58993a88df14b5e30778c7f7e85/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala#L347 https://github.com/apache/spark/blob/cbad616d4cb0c58993a88df14b5e30778c7f7e85/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala#L400-L406 https://github.com/apache/spark/blob/cbad616d4cb0c58993a88df14b5e30778c7f7e85/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala#L475 https://github.com/apache/spark/blob/cbad616d4cb0c58993a88df14b5e30778c7f7e85/core/src/main/scala/org/apache/spark/scheduler/dynalloc/ExecutorMonitor.scala#L427 ### Why are the changes needed? This is a bug fix. ### Does this PR introduce any user-facing change? It prevents the exception: ``` 19/08/21 06:44:01 ERROR AsyncEventQueue: Listener ExecutorMonitor threw an exception java.lang.NullPointerException at org.apache.spark.scheduler.dynalloc.ExecutorMonitor$Tracker.removeShuffle(ExecutorMonitor.scala:479) at org.apache.spark.scheduler.dynalloc.ExecutorMonitor.$anonfun$cleanupShuffle$2(ExecutorMonitor.scala:408) at org.apache.spark.scheduler.dynalloc.ExecutorMonitor.$anonfun$cleanupShuffle$2$adapted(ExecutorMonitor.scala:407) at scala.collection.Iterator.foreach(Iterator.scala:941) at scala.collection.Iterator.foreach$(Iterator.scala:941) at scala.collection.AbstractIterator.foreach(Iterator.scala:1429) at scala.collection.IterableLike.foreach(IterableLike.scala:74) at scala.collection.IterableLike.foreach$(IterableLike.scala:73) at scala.collection.AbstractIterable.foreach(Iterable.scala:56) at org.apache.spark.scheduler.dynalloc.ExecutorMonitor.cleanupShuffle(ExecutorMonitor.scala:407) at org.apache.spark.scheduler.dynalloc.ExecutorMonitor.onOtherEvent(ExecutorMonitor.sc ``` ### How was this patch test Unittest was added. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on
HyukjinKwon commented on issue #25551: [SPARK-28839][CORE] Avoids NPE in context cleaner when shuffle service is on URL: https://github.com/apache/spark/pull/25551#issuecomment-523813395 @vanzin do you mind if I ask to take a look and see if it makes sense? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion
SparkQA commented on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion URL: https://github.com/apache/spark/pull/25453#issuecomment-523807621 **[Test build #109566 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109566/testReport)** for PR 25453 at commit [`eb9442c`](https://github.com/apache/spark/commit/eb9442cdeadd2ab2232c82a3dfb65055489e4e06). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion
AmplabJenkins removed a comment on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion URL: https://github.com/apache/spark/pull/25453#issuecomment-523806996 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14622/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum
AmplabJenkins removed a comment on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum URL: https://github.com/apache/spark/pull/25347#issuecomment-523806968 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14623/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum
AmplabJenkins removed a comment on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum URL: https://github.com/apache/spark/pull/25347#issuecomment-523806959 Build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion
AmplabJenkins removed a comment on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion URL: https://github.com/apache/spark/pull/25453#issuecomment-523806985 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion
AmplabJenkins commented on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion URL: https://github.com/apache/spark/pull/25453#issuecomment-523806996 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14622/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum
AmplabJenkins commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum URL: https://github.com/apache/spark/pull/25347#issuecomment-523806968 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14623/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion
AmplabJenkins commented on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion URL: https://github.com/apache/spark/pull/25453#issuecomment-523806985 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum
AmplabJenkins commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum URL: https://github.com/apache/spark/pull/25347#issuecomment-523806959 Build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum
SparkQA commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum URL: https://github.com/apache/spark/pull/25347#issuecomment-523804876 **[Test build #109565 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109565/testReport)** for PR 25347 at commit [`aae4642`](https://github.com/apache/spark/commit/aae4642670126fdadaf593c24ea14c2bf66ebae0). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24715: [SPARK-25474][SQL] Data source tables support fallback to HDFS for size estimation
dongjoon-hyun commented on a change in pull request #24715: [SPARK-25474][SQL]
Data source tables support fallback to HDFS for size estimation
URL: https://github.com/apache/spark/pull/24715#discussion_r316554164
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/StatisticsCollectionSuite.scala
##
@@ -650,4 +652,129 @@ class StatisticsCollectionSuite extends
StatisticsCollectionTestBase with Shared
}
}
}
+
+ test("Non-partitioned data source table support fallback to HDFS for size
estimation") {
+withTempDir { dir =>
+ Seq(false, true).foreach { fallBackToHDFS =>
+withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHDFS") {
+ withTable("spark_25474") {
+sql(s"CREATE TABLE spark_25474 (c1 BIGINT) USING PARQUET LOCATION
'${dir.toURI}'")
+
spark.range(5).write.mode(SaveMode.Overwrite).parquet(dir.getCanonicalPath)
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+// Table statistics are always recalculated by FileIndex
+assert(relation.stats.sizeInBytes === getDataSize(dir))
+ }
+}
+ }
+}
+ }
+
+ test("Partitioned data source table support fallback to HDFS for size
estimation") {
+Seq(false, true).foreach { fallBackToHDFS =>
+ withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHDFS") {
+withTempDir { dir =>
+ withTable("spark_25474") {
+sql("CREATE TABLE spark_25474(a int, b int) USING parquet " +
+s"PARTITIONED BY(a) LOCATION '${dir.toURI}'")
+sql("INSERT INTO TABLE spark_25474 PARTITION(a=1) SELECT 2")
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+if (fallBackToHDFS) {
+ assert(relation.stats.sizeInBytes ===
+CommandUtils.getSizeInBytesFallBackToHdfs(spark,
getCatalogTable("spark_25474")))
+} else {
+ assert(relation.stats.sizeInBytes === conf.defaultSizeInBytes)
+}
+ }
+}
+ }
+}
+ }
+
+ test("Partitioned data source table support fallback to HDFS for size
estimation" +
+"with defaultSizeInBytes") {
+val defaultSizeInBytes = 10 * 1024 * 1024
+Seq(false, true).foreach { fallBackToHDFS =>
+ withSQLConf(
+SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key -> s"$fallBackToHDFS",
+SQLConf.DEFAULT_SIZE_IN_BYTES.key -> s"$defaultSizeInBytes") {
+withTempDir { dir =>
+ withTable("spark_25474") {
+sql("CREATE TABLE spark_25474(a int, b int) USING parquet " +
+ s"PARTITIONED BY(a) LOCATION '${dir.toURI}'")
+sql("INSERT INTO TABLE spark_25474 PARTITION(a=1) SELECT 2")
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+if (fallBackToHDFS) {
+ assert(relation.stats.sizeInBytes ===
+CommandUtils.getSizeInBytesFallBackToHdfs(spark,
getCatalogTable("spark_25474")))
+} else {
+ assert(relation.stats.sizeInBytes === defaultSizeInBytes)
+}
+ }
+}
+ }
+}
+ }
+
+ test("Partitioned data source table stats should be cached") {
+Seq(false, true).foreach { fallBackToHDFS =>
+ withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHDFS") {
+withTempDir { dir =>
+ withTable("spark_25474") {
+sql("CREATE TABLE spark_25474(a int, b int) USING parquet " +
+ s"PARTITIONED BY(a) LOCATION '${dir.toURI}'")
+sql("INSERT INTO TABLE spark_25474 PARTITION(a=1) SELECT 2")
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+if (fallBackToHDFS) {
+ val dataSize =
+CommandUtils.getSizeInBytesFallBackToHdfs(spark,
getCatalogTable("spark_25474"))
+ assert(relation.stats.sizeInBytes === dataSize)
+
+ val qualifiedTableName =
+
QualifiedTableName(spark.sessionState.catalog.getCurrentDatabase, "spark_25474")
+ val logicalRelation =
spark.sessionState.catalog.getCachedTable(qualifiedTableName)
+.asInstanceOf[LogicalRelation]
+ assert(logicalRelation.catalogTable.get.stats.get.sizeInBytes
=== dataSize)
+} else {
+ assert(relation.stats.sizeInBytes === conf.defaultSizeInBytes)
+}
+ }
+}
+ }
+}
+ }
+
+ test("External partitioned data source table does not support fallback to
HDFS "
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24715: [SPARK-25474][SQL] Data source tables support fallback to HDFS for size estimation
dongjoon-hyun commented on a change in pull request #24715: [SPARK-25474][SQL]
Data source tables support fallback to HDFS for size estimation
URL: https://github.com/apache/spark/pull/24715#discussion_r316553636
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/StatisticsCollectionSuite.scala
##
@@ -650,4 +652,129 @@ class StatisticsCollectionSuite extends
StatisticsCollectionTestBase with Shared
}
}
}
+
+ test("Non-partitioned data source table support fallback to HDFS for size
estimation") {
+withTempDir { dir =>
+ Seq(false, true).foreach { fallBackToHDFS =>
+withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHDFS") {
+ withTable("spark_25474") {
+sql(s"CREATE TABLE spark_25474 (c1 BIGINT) USING PARQUET LOCATION
'${dir.toURI}'")
+
spark.range(5).write.mode(SaveMode.Overwrite).parquet(dir.getCanonicalPath)
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+// Table statistics are always recalculated by FileIndex
+assert(relation.stats.sizeInBytes === getDataSize(dir))
+ }
+}
+ }
+}
+ }
+
+ test("Partitioned data source table support fallback to HDFS for size
estimation") {
+Seq(false, true).foreach { fallBackToHDFS =>
+ withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHDFS") {
+withTempDir { dir =>
+ withTable("spark_25474") {
+sql("CREATE TABLE spark_25474(a int, b int) USING parquet " +
+s"PARTITIONED BY(a) LOCATION '${dir.toURI}'")
+sql("INSERT INTO TABLE spark_25474 PARTITION(a=1) SELECT 2")
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+if (fallBackToHDFS) {
+ assert(relation.stats.sizeInBytes ===
+CommandUtils.getSizeInBytesFallBackToHdfs(spark,
getCatalogTable("spark_25474")))
+} else {
+ assert(relation.stats.sizeInBytes === conf.defaultSizeInBytes)
+}
+ }
+}
+ }
+}
+ }
+
+ test("Partitioned data source table support fallback to HDFS for size
estimation" +
+"with defaultSizeInBytes") {
+val defaultSizeInBytes = 10 * 1024 * 1024
+Seq(false, true).foreach { fallBackToHDFS =>
+ withSQLConf(
+SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key -> s"$fallBackToHDFS",
+SQLConf.DEFAULT_SIZE_IN_BYTES.key -> s"$defaultSizeInBytes") {
+withTempDir { dir =>
+ withTable("spark_25474") {
+sql("CREATE TABLE spark_25474(a int, b int) USING parquet " +
+ s"PARTITIONED BY(a) LOCATION '${dir.toURI}'")
+sql("INSERT INTO TABLE spark_25474 PARTITION(a=1) SELECT 2")
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+if (fallBackToHDFS) {
+ assert(relation.stats.sizeInBytes ===
+CommandUtils.getSizeInBytesFallBackToHdfs(spark,
getCatalogTable("spark_25474")))
+} else {
+ assert(relation.stats.sizeInBytes === defaultSizeInBytes)
+}
+ }
+}
+ }
+}
+ }
+
+ test("Partitioned data source table stats should be cached") {
+Seq(false, true).foreach { fallBackToHDFS =>
+ withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHDFS") {
+withTempDir { dir =>
+ withTable("spark_25474") {
+sql("CREATE TABLE spark_25474(a int, b int) USING parquet " +
+ s"PARTITIONED BY(a) LOCATION '${dir.toURI}'")
+sql("INSERT INTO TABLE spark_25474 PARTITION(a=1) SELECT 2")
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+if (fallBackToHDFS) {
+ val dataSize =
+CommandUtils.getSizeInBytesFallBackToHdfs(spark,
getCatalogTable("spark_25474"))
+ assert(relation.stats.sizeInBytes === dataSize)
+
+ val qualifiedTableName =
+
QualifiedTableName(spark.sessionState.catalog.getCurrentDatabase, "spark_25474")
+ val logicalRelation =
spark.sessionState.catalog.getCachedTable(qualifiedTableName)
+.asInstanceOf[LogicalRelation]
+ assert(logicalRelation.catalogTable.get.stats.get.sizeInBytes
=== dataSize)
+} else {
+ assert(relation.stats.sizeInBytes === conf.defaultSizeInBytes)
+}
+ }
+}
+ }
+}
+ }
+
+ test("External partitioned data source table does not support fallback to
HDFS "
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24715: [SPARK-25474][SQL] Data source tables support fallback to HDFS for size estimation
dongjoon-hyun commented on a change in pull request #24715: [SPARK-25474][SQL]
Data source tables support fallback to HDFS for size estimation
URL: https://github.com/apache/spark/pull/24715#discussion_r316552743
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/StatisticsCollectionSuite.scala
##
@@ -650,4 +652,129 @@ class StatisticsCollectionSuite extends
StatisticsCollectionTestBase with Shared
}
}
}
+
+ test("Non-partitioned data source table support fallback to HDFS for size
estimation") {
+withTempDir { dir =>
+ Seq(false, true).foreach { fallBackToHDFS =>
+withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHDFS") {
+ withTable("spark_25474") {
+sql(s"CREATE TABLE spark_25474 (c1 BIGINT) USING PARQUET LOCATION
'${dir.toURI}'")
+
spark.range(5).write.mode(SaveMode.Overwrite).parquet(dir.getCanonicalPath)
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+// Table statistics are always recalculated by FileIndex
+assert(relation.stats.sizeInBytes === getDataSize(dir))
+ }
+}
+ }
+}
+ }
+
+ test("Partitioned data source table support fallback to HDFS for size
estimation") {
+Seq(false, true).foreach { fallBackToHDFS =>
+ withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHDFS") {
+withTempDir { dir =>
+ withTable("spark_25474") {
+sql("CREATE TABLE spark_25474(a int, b int) USING parquet " +
+s"PARTITIONED BY(a) LOCATION '${dir.toURI}'")
+sql("INSERT INTO TABLE spark_25474 PARTITION(a=1) SELECT 2")
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+if (fallBackToHDFS) {
+ assert(relation.stats.sizeInBytes ===
+CommandUtils.getSizeInBytesFallBackToHdfs(spark,
getCatalogTable("spark_25474")))
+} else {
+ assert(relation.stats.sizeInBytes === conf.defaultSizeInBytes)
+}
+ }
+}
+ }
+}
+ }
+
+ test("Partitioned data source table support fallback to HDFS for size
estimation" +
+"with defaultSizeInBytes") {
+val defaultSizeInBytes = 10 * 1024 * 1024
+Seq(false, true).foreach { fallBackToHDFS =>
+ withSQLConf(
+SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key -> s"$fallBackToHDFS",
+SQLConf.DEFAULT_SIZE_IN_BYTES.key -> s"$defaultSizeInBytes") {
+withTempDir { dir =>
+ withTable("spark_25474") {
+sql("CREATE TABLE spark_25474(a int, b int) USING parquet " +
+ s"PARTITIONED BY(a) LOCATION '${dir.toURI}'")
+sql("INSERT INTO TABLE spark_25474 PARTITION(a=1) SELECT 2")
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+if (fallBackToHDFS) {
+ assert(relation.stats.sizeInBytes ===
+CommandUtils.getSizeInBytesFallBackToHdfs(spark,
getCatalogTable("spark_25474")))
+} else {
+ assert(relation.stats.sizeInBytes === defaultSizeInBytes)
+}
+ }
+}
+ }
+}
+ }
+
+ test("Partitioned data source table stats should be cached") {
+Seq(false, true).foreach { fallBackToHDFS =>
+ withSQLConf(SQLConf.ENABLE_FALL_BACK_TO_HDFS_FOR_STATS.key ->
s"$fallBackToHDFS") {
+withTempDir { dir =>
+ withTable("spark_25474") {
+sql("CREATE TABLE spark_25474(a int, b int) USING parquet " +
+ s"PARTITIONED BY(a) LOCATION '${dir.toURI}'")
+sql("INSERT INTO TABLE spark_25474 PARTITION(a=1) SELECT 2")
+
+assert(getCatalogTable("spark_25474").stats.isEmpty)
+val relation =
spark.table("spark_25474").queryExecution.analyzed.children.head
+if (fallBackToHDFS) {
+ val dataSize =
+CommandUtils.getSizeInBytesFallBackToHdfs(spark,
getCatalogTable("spark_25474"))
+ assert(relation.stats.sizeInBytes === dataSize)
+
+ val qualifiedTableName =
+
QualifiedTableName(spark.sessionState.catalog.getCurrentDatabase, "spark_25474")
+ val logicalRelation =
spark.sessionState.catalog.getCachedTable(qualifiedTableName)
+.asInstanceOf[LogicalRelation]
+ assert(logicalRelation.catalogTable.get.stats.get.sizeInBytes
=== dataSize)
+} else {
+ assert(relation.stats.sizeInBytes === conf.defaultSizeInBytes)
+}
+ }
+}
+ }
+}
+ }
+
+ test("External partitioned data source table does not support fallback to
HDFS "
[GitHub] [spark] mgaido91 commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum
mgaido91 commented on issue #25347: [SPARK-28610][SQL] Allow having a decimal buffer for long sum URL: https://github.com/apache/spark/pull/25347#issuecomment-523800999 > The change to support decimal sum buffer itself looks nice to me, but I think we'd like a coarser flag for that. @maropu @cloud-fan any suggestion on what this flag should be/look like? Meanwhile I'll update the PR to limit the scope only to the buffer, thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion
AmplabJenkins removed a comment on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion URL: https://github.com/apache/spark/pull/25453#issuecomment-523798554 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14621/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion
AmplabJenkins removed a comment on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion URL: https://github.com/apache/spark/pull/25453#issuecomment-523798546 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion
AmplabJenkins commented on issue #25453: [SPARK-28730][SQL] Configurable type coercion policy for table insertion URL: https://github.com/apache/spark/pull/25453#issuecomment-523798554 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14621/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org