[GitHub] [spark] SparkQA commented on issue #23531: [SPARK-24497][SQL] Support recursive SQL query
SparkQA commented on issue #23531: [SPARK-24497][SQL] Support recursive SQL query URL: https://github.com/apache/spark/pull/23531#issuecomment-526573618 **[Test build #109944 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109944/testReport)** for PR 23531 at commit [`f35a784`](https://github.com/apache/spark/commit/f35a78495732d03baf671cb9465ed4b00c2d05a3). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #23531: [SPARK-24497][SQL] Support recursive SQL query
AmplabJenkins commented on issue #23531: [SPARK-24497][SQL] Support recursive SQL query URL: https://github.com/apache/spark/pull/23531#issuecomment-526575217 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #23531: [SPARK-24497][SQL] Support recursive SQL query
AmplabJenkins commented on issue #23531: [SPARK-24497][SQL] Support recursive SQL query URL: https://github.com/apache/spark/pull/23531#issuecomment-526575225 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14970/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #23531: [SPARK-24497][SQL] Support recursive SQL query
AmplabJenkins removed a comment on issue #23531: [SPARK-24497][SQL] Support recursive SQL query URL: https://github.com/apache/spark/pull/23531#issuecomment-526575217 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #23531: [SPARK-24497][SQL] Support recursive SQL query
AmplabJenkins removed a comment on issue #23531: [SPARK-24497][SQL] Support recursive SQL query URL: https://github.com/apache/spark/pull/23531#issuecomment-526575225 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14970/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25299: [SPARK-27651][Core] Avoid the network when shuffle blocks are fetched from the same host
cloud-fan commented on a change in pull request #25299: [SPARK-27651][Core] Avoid the network when shuffle blocks are fetched from the same host URL: https://github.com/apache/spark/pull/25299#discussion_r319474398 ## File path: core/src/main/scala/org/apache/spark/storage/BlockManager.scala ## @@ -206,6 +206,8 @@ private[spark] class BlockManager( new BlockManager.RemoteBlockDownloadFileManager(this) private val maxRemoteBlockToMem = conf.get(config.MAX_REMOTE_BLOCK_SIZE_FETCH_TO_MEM) + private val executorIdToLocalDirsCache = new mutable.HashMap[String, Array[String]]() Review comment: when do we update it? e.g. what if an executor is down. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25299: [SPARK-27651][Core] Avoid the network when shuffle blocks are fetched from the same host
cloud-fan commented on a change in pull request #25299: [SPARK-27651][Core]
Avoid the network when shuffle blocks are fetched from the same host
URL: https://github.com/apache/spark/pull/25299#discussion_r319469667
##
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##
@@ -2851,6 +2851,9 @@ object SparkContext extends Logging {
memoryPerSlaveInt, sc.executorMemory))
}
+// for local cluster mode the SHUFFLE_HOST_LOCAL_DISK_READING_ENABLED
defaults to false
+sc.conf.setIfMissing(config.SHUFFLE_HOST_LOCAL_DISK_READING_ENABLED,
false)
Review comment:
why is this necessary?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25299: [SPARK-27651][Core] Avoid the network when shuffle blocks are fetched from the same host
cloud-fan commented on a change in pull request #25299: [SPARK-27651][Core]
Avoid the network when shuffle blocks are fetched from the same host
URL: https://github.com/apache/spark/pull/25299#discussion_r319473468
##
File path: core/src/main/scala/org/apache/spark/network/BlockDataManager.scala
##
@@ -22,16 +22,22 @@ import scala.reflect.ClassTag
import org.apache.spark.TaskContext
import org.apache.spark.network.buffer.ManagedBuffer
import org.apache.spark.network.client.StreamCallbackWithID
-import org.apache.spark.storage.{BlockId, StorageLevel}
+import org.apache.spark.storage.{BlockId, ShuffleBlockId, StorageLevel}
private[spark]
trait BlockDataManager {
+ /**
+ * Interface to get host-local shuffle block data. Throws an exception if
the block cannot be
Review comment:
The block manager keeps RDD blocks as well, shall we support it? I think
it's better to have a `def getHostLocalBlockData(blockId: BlockId, dirs:
Array[String])`, to be consistent with `getLocalBlockData`. We can add an
assert in `getHostLocalBlockData` to make sure the `blockId` is
`ShuffleBlockId`, if we don't want to support RDD blocks now.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #23531: [SPARK-24497][SQL] Support recursive SQL query
SparkQA commented on issue #23531: [SPARK-24497][SQL] Support recursive SQL query URL: https://github.com/apache/spark/pull/23531#issuecomment-526575750 **[Test build #109945 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109945/testReport)** for PR 23531 at commit [`1def9fa`](https://github.com/apache/spark/commit/1def9fa7078948d50fa9ff4a80fe0321ce948ada). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25299: [SPARK-27651][Core] Avoid the network when shuffle blocks are fetched from the same host
cloud-fan commented on a change in pull request #25299: [SPARK-27651][Core] Avoid the network when shuffle blocks are fetched from the same host URL: https://github.com/apache/spark/pull/25299#discussion_r319477754 ## File path: core/src/main/scala/org/apache/spark/storage/BlockManagerMasterEndpoint.scala ## @@ -51,6 +53,13 @@ class BlockManagerMasterEndpoint( // Mapping from block manager id to the block manager's information. private val blockManagerInfo = new mutable.HashMap[BlockManagerId, BlockManagerInfo] + // Mapping from executor id to the block manager's local disk directories. + private val executorIdToLocalDirs = Review comment: shall we update it in `removeBlockManager`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gaborgsomogyi opened a new pull request #25631: [SPARK-28928][SS] Take over Kafka delegation token protocol on sources/sinks
gaborgsomogyi opened a new pull request #25631: [SPARK-28928][SS] Take over Kafka delegation token protocol on sources/sinks URL: https://github.com/apache/spark/pull/25631 ### What changes were proposed in this pull request? At the moment there are 3 places where communication protocol with Kafka cluster has to be set when delegation token used: * On delegation token * On source * On sink Most of the time users are using the same protocol on all these places (within one Kafka cluster). It would be better to declare it in one place (delegation token side) and Kafka sources/sinks can take this config over. In this PR I've I've modified the code in a way that Kafka sources/sinks are taking over delegation token side `security.protocol` configuration when the token and the source/sink matches in `bootstrap.servers` configuration. This default configuration can be overwritten on each source/sink independently by using `kafka.security.protocol` configuration. ### Why are the changes needed? The actual configuration's default behavior represents the minority of the use-cases and inconvenient. ### Does this PR introduce any user-facing change? Yes, with this change users need to provide less configuration parameters by default. ### How was this patch tested? Existing + additional unit tests. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #25628: [SPARK-28897][Core]'coalesce' error when executing dataframe.na.fill
HyukjinKwon commented on a change in pull request #25628:
[SPARK-28897][Core]'coalesce' error when executing dataframe.na.fill
URL: https://github.com/apache/spark/pull/25628#discussion_r319482514
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/DataFrameNaFunctions.scala
##
@@ -435,11 +435,10 @@ final class DataFrameNaFunctions private[sql](df:
DataFrame) {
* Returns a [[Column]] expression that replaces null value in `col` with
`replacement`.
*/
private def fillCol[T](col: StructField, replacement: T): Column = {
-val quotedColName = "`" + col.name + "`"
Review comment:
Does `.` work too?
```scala
scala> val df = spark.range(1).selectExpr("1 as `a.b`")
df: org.apache.spark.sql.DataFrame = [a.b: int]
scala> df.col("a.b")
org.apache.spark.sql.AnalysisException: Cannot resolve column name "a.b"
among (a.b);
at org.apache.spark.sql.Dataset.$anonfun$resolve$1(Dataset.scala:259)
at scala.Option.getOrElse(Option.scala:138)
at org.apache.spark.sql.Dataset.resolve(Dataset.scala:259)
at org.apache.spark.sql.Dataset.col(Dataset.scala:1340)
... 47 elided
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25631: [SPARK-28928][SS] Take over Kafka delegation token protocol on sources/sinks
AmplabJenkins commented on issue #25631: [SPARK-28928][SS] Take over Kafka delegation token protocol on sources/sinks URL: https://github.com/apache/spark/pull/25631#issuecomment-526577073 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25631: [SPARK-28928][SS] Take over Kafka delegation token protocol on sources/sinks
AmplabJenkins commented on issue #25631: [SPARK-28928][SS] Take over Kafka delegation token protocol on sources/sinks URL: https://github.com/apache/spark/pull/25631#issuecomment-526577253 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25631: [SPARK-28928][SS] Take over Kafka delegation token protocol on sources/sinks
AmplabJenkins removed a comment on issue #25631: [SPARK-28928][SS] Take over Kafka delegation token protocol on sources/sinks URL: https://github.com/apache/spark/pull/25631#issuecomment-526577073 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25631: [SPARK-28928][SS] Take over Kafka delegation token protocol on sources/sinks
SparkQA commented on issue #25631: [SPARK-28928][SS] Take over Kafka delegation token protocol on sources/sinks URL: https://github.com/apache/spark/pull/25631#issuecomment-526578034 **[Test build #109946 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109946/testReport)** for PR 25631 at commit [`a79d77f`](https://github.com/apache/spark/commit/a79d77fbf793a37752912a8d84d9caf5d906b187). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
SparkQA commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526578038 **[Test build #109947 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109947/testReport)** for PR 25497 at commit [`1068514`](https://github.com/apache/spark/commit/1068514162cc9f27e57d0342d3a953967aaf76e2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25631: [SPARK-28928][SS] Take over Kafka delegation token protocol on sources/sinks
AmplabJenkins removed a comment on issue #25631: [SPARK-28928][SS] Take over Kafka delegation token protocol on sources/sinks URL: https://github.com/apache/spark/pull/25631#issuecomment-526577253 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shivusondur opened a new pull request #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference
shivusondur opened a new pull request #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference URL: https://github.com/apache/spark/pull/25632 ### What changes were proposed in this pull request? Added the document reference for SHOW TABLE EXTENDED sql command ### Why are the changes needed? For User reference ### Does this PR introduce any user-facing change? yes, it provides document reference for SHOW TABLE EXTENDED sql command ### How was this patch tested? verified in snap Attached the Snap 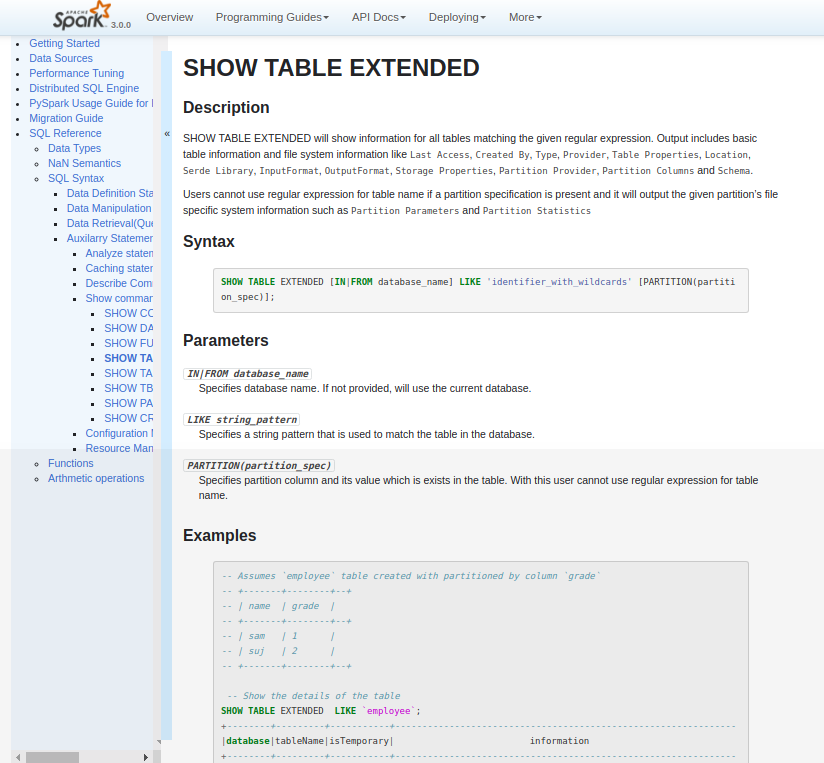   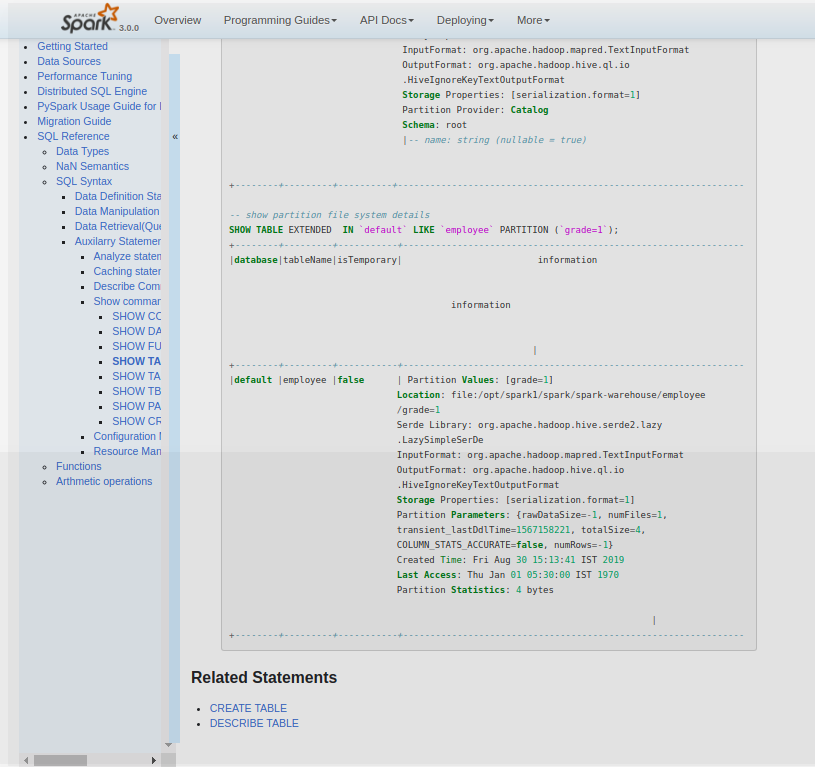 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shivusondur commented on issue #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference
shivusondur commented on issue #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference URL: https://github.com/apache/spark/pull/25632#issuecomment-526580336 @dilipbiswal @gatorsmile plz review This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference
AmplabJenkins commented on issue #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference URL: https://github.com/apache/spark/pull/25632#issuecomment-526580405 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25104: [SPARK-28341][SQL] create a public API for V2SessionCatalog
SparkQA commented on issue #25104: [SPARK-28341][SQL] create a public API for V2SessionCatalog URL: https://github.com/apache/spark/pull/25104#issuecomment-526580515 **[Test build #109948 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109948/testReport)** for PR 25104 at commit [`8cd5cde`](https://github.com/apache/spark/commit/8cd5cde53c12ba363e2ec556ce03ba4544d76cf2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference
AmplabJenkins commented on issue #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference URL: https://github.com/apache/spark/pull/25632#issuecomment-526582100 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference
AmplabJenkins removed a comment on issue #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference URL: https://github.com/apache/spark/pull/25632#issuecomment-526580405 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference
AmplabJenkins commented on issue #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference URL: https://github.com/apache/spark/pull/25632#issuecomment-526582292 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25104: [SPARK-28341][SQL] create a public API for V2SessionCatalog
AmplabJenkins commented on issue #25104: [SPARK-28341][SQL] create a public API for V2SessionCatalog URL: https://github.com/apache/spark/pull/25104#issuecomment-526582495 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14972/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
AmplabJenkins removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526582463 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
AmplabJenkins commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526582463 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
AmplabJenkins commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526582474 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14971/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
AmplabJenkins removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526582474 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14971/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25104: [SPARK-28341][SQL] create a public API for V2SessionCatalog
AmplabJenkins removed a comment on issue #25104: [SPARK-28341][SQL] create a public API for V2SessionCatalog URL: https://github.com/apache/spark/pull/25104#issuecomment-526582495 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14972/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25104: [SPARK-28341][SQL] create a public API for V2SessionCatalog
AmplabJenkins removed a comment on issue #25104: [SPARK-28341][SQL] create a public API for V2SessionCatalog URL: https://github.com/apache/spark/pull/25104#issuecomment-526582490 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference
AmplabJenkins removed a comment on issue #25632: [SPARK-28809][DOC][SQL]Document SHOW TABLE in SQL Reference URL: https://github.com/apache/spark/pull/25632#issuecomment-526582100 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25104: [SPARK-28341][SQL] create a public API for V2SessionCatalog
AmplabJenkins commented on issue #25104: [SPARK-28341][SQL] create a public API for V2SessionCatalog URL: https://github.com/apache/spark/pull/25104#issuecomment-526582490 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
SparkQA commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526583180 **[Test build #109949 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109949/testReport)** for PR 25497 at commit [`806d443`](https://github.com/apache/spark/commit/806d443ab71dc34ed555b9d3fa7f894fe660eacc). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gaborgsomogyi commented on a change in pull request #25477: [SPARK-28760][SS][TESTS] Add Kafka delegation token end-to-end test with mini KDC
gaborgsomogyi commented on a change in pull request #25477:
[SPARK-28760][SS][TESTS] Add Kafka delegation token end-to-end test with mini
KDC
URL: https://github.com/apache/spark/pull/25477#discussion_r319491077
##
File path:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaDelegationTokenSuite.scala
##
@@ -0,0 +1,120 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.util.UUID
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.security.{Credentials, UserGroupInformation}
+import org.apache.kafka.common.security.auth.SecurityProtocol.SASL_PLAINTEXT
+
+import org.apache.spark.deploy.SparkHadoopUtil
+import org.apache.spark.deploy.security.HadoopDelegationTokenManager
+import org.apache.spark.internal.config.{KEYTAB, PRINCIPAL}
+import org.apache.spark.sql.execution.streaming.MemoryStream
+import org.apache.spark.sql.streaming.{OutputMode, StreamTest}
+import org.apache.spark.sql.test.SharedSQLContext
+
+class KafkaDelegationTokenSuite extends StreamTest with SharedSQLContext with
KafkaTest {
+
+ import testImplicits._
+
+ protected var testUtils: KafkaTestUtils = _
+
+ protected override def sparkConf = super.sparkConf
+.set("spark.security.credentials.hadoopfs.enabled", "false")
+.set("spark.security.credentials.hbase.enabled", "false")
+.set(KEYTAB, testUtils.clientKeytab)
+.set(PRINCIPAL, testUtils.clientPrincipal)
+.set("spark.kafka.clusters.cluster1.auth.bootstrap.servers",
testUtils.brokerAddress)
+.set("spark.kafka.clusters.cluster1.security.protocol",
SASL_PLAINTEXT.name)
+
+ override def beforeAll(): Unit = {
+testUtils = new KafkaTestUtils(Map.empty, true)
+testUtils.setup()
+super.beforeAll()
+ }
+
+ override def afterAll(): Unit = {
+try {
+ if (testUtils != null) {
+testUtils.teardown()
+testUtils = null
+ }
+ UserGroupInformation.reset()
+} finally {
+ super.afterAll()
+}
+ }
+
+ test("Roundtrip") {
+val hadoopConf = new Configuration()
+val manager = new HadoopDelegationTokenManager(spark.sparkContext.conf,
hadoopConf, null)
+val credentials = new Credentials()
+manager.obtainDelegationTokens(credentials)
+val serializedCredentials = SparkHadoopUtil.get.serialize(credentials)
+SparkHadoopUtil.get.addDelegationTokens(serializedCredentials,
spark.sparkContext.conf)
+
+val topic = "topic-" + UUID.randomUUID().toString
+testUtils.createTopic(topic, partitions = 5)
+
+withTempDir { checkpointDir =>
+ val input = MemoryStream[String]
+
+ val df = input.toDF()
+ val writer = df.writeStream
+.outputMode(OutputMode.Append)
+.format("kafka")
+.option("checkpointLocation", checkpointDir.getCanonicalPath)
+.option("kafka.bootstrap.servers", testUtils.brokerAddress)
+.option("kafka.security.protocol", SASL_PLAINTEXT.name)
Review comment:
For tracking purposes I've filed SPARK-28928.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gaborgsomogyi commented on a change in pull request #25477: [SPARK-28760][SS][TESTS] Add Kafka delegation token end-to-end test with mini KDC
gaborgsomogyi commented on a change in pull request #25477:
[SPARK-28760][SS][TESTS] Add Kafka delegation token end-to-end test with mini
KDC
URL: https://github.com/apache/spark/pull/25477#discussion_r319491077
##
File path:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaDelegationTokenSuite.scala
##
@@ -0,0 +1,120 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.util.UUID
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.security.{Credentials, UserGroupInformation}
+import org.apache.kafka.common.security.auth.SecurityProtocol.SASL_PLAINTEXT
+
+import org.apache.spark.deploy.SparkHadoopUtil
+import org.apache.spark.deploy.security.HadoopDelegationTokenManager
+import org.apache.spark.internal.config.{KEYTAB, PRINCIPAL}
+import org.apache.spark.sql.execution.streaming.MemoryStream
+import org.apache.spark.sql.streaming.{OutputMode, StreamTest}
+import org.apache.spark.sql.test.SharedSQLContext
+
+class KafkaDelegationTokenSuite extends StreamTest with SharedSQLContext with
KafkaTest {
+
+ import testImplicits._
+
+ protected var testUtils: KafkaTestUtils = _
+
+ protected override def sparkConf = super.sparkConf
+.set("spark.security.credentials.hadoopfs.enabled", "false")
+.set("spark.security.credentials.hbase.enabled", "false")
+.set(KEYTAB, testUtils.clientKeytab)
+.set(PRINCIPAL, testUtils.clientPrincipal)
+.set("spark.kafka.clusters.cluster1.auth.bootstrap.servers",
testUtils.brokerAddress)
+.set("spark.kafka.clusters.cluster1.security.protocol",
SASL_PLAINTEXT.name)
+
+ override def beforeAll(): Unit = {
+testUtils = new KafkaTestUtils(Map.empty, true)
+testUtils.setup()
+super.beforeAll()
+ }
+
+ override def afterAll(): Unit = {
+try {
+ if (testUtils != null) {
+testUtils.teardown()
+testUtils = null
+ }
+ UserGroupInformation.reset()
+} finally {
+ super.afterAll()
+}
+ }
+
+ test("Roundtrip") {
+val hadoopConf = new Configuration()
+val manager = new HadoopDelegationTokenManager(spark.sparkContext.conf,
hadoopConf, null)
+val credentials = new Credentials()
+manager.obtainDelegationTokens(credentials)
+val serializedCredentials = SparkHadoopUtil.get.serialize(credentials)
+SparkHadoopUtil.get.addDelegationTokens(serializedCredentials,
spark.sparkContext.conf)
+
+val topic = "topic-" + UUID.randomUUID().toString
+testUtils.createTopic(topic, partitions = 5)
+
+withTempDir { checkpointDir =>
+ val input = MemoryStream[String]
+
+ val df = input.toDF()
+ val writer = df.writeStream
+.outputMode(OutputMode.Append)
+.format("kafka")
+.option("checkpointLocation", checkpointDir.getCanonicalPath)
+.option("kafka.bootstrap.servers", testUtils.brokerAddress)
+.option("kafka.security.protocol", SASL_PLAINTEXT.name)
Review comment:
For tracking purposes I've filed
[SPARK-28928](https://issues.apache.org/jira/browse/SPARK-28928).
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cxzl25 commented on a change in pull request #23516: [SPARK-26598] Fix HiveThriftServer2 set hiveconf and hivevar in every sql
cxzl25 commented on a change in pull request #23516: [SPARK-26598] Fix
HiveThriftServer2 set hiveconf and hivevar in every sql
URL: https://github.com/apache/spark/pull/23516#discussion_r319491134
##
File path:
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/server/SparkSQLOperationManager.scala
##
@@ -51,9 +50,6 @@ private[thriftserver] class SparkSQLOperationManager()
require(sqlContext != null, s"Session handle:
${parentSession.getSessionHandle} has not been" +
s" initialized or had already closed.")
val conf = sqlContext.sessionState.conf
-val hiveSessionState = parentSession.getSessionState
-setConfMap(conf, hiveSessionState.getOverriddenConfigurations)
-setConfMap(conf, hiveSessionState.getHiveVariables)
Review comment:
```
cat < test.sql
select '\${a}', '\${b}';
set b=MOD_VALUE;
set b;
EOF
beeline -u jdbc:hive2://localhost:1 --hiveconf a=avalue --hivevar
b=bvalue -f test.sql
```
Result:
```
+-+-+--+
| key | value |
+-+-+--+
| b | bvalue |
+-+-+--+
1 row selected (0.022 seconds)
```
It is wrong to set the hivevar/hiveconf variable in every operation, which
prevents variable updates.
The intention is just an initialized value, so setting it once in
SparkSQLSessionManager#openSession is enough.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
AmplabJenkins commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526584963 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14973/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
AmplabJenkins commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526584956 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
AmplabJenkins removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526584963 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14973/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
AmplabJenkins removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526584956 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core] Support rolling back a shuffle map stage and re-generate the shuffle files
cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core]
Support rolling back a shuffle map stage and re-generate the shuffle files
URL: https://github.com/apache/spark/pull/25620#discussion_r319495883
##
File path:
common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/ExternalBlockHandler.java
##
@@ -106,7 +106,7 @@ protected void handleMessage(
numBlockIds += ids.length;
}
streamId = streamManager.registerStream(client.getClientId(),
-new ManagedBufferIterator(msg, numBlockIds), client.getChannel());
+new ShuffleManagedBufferIterator(msg), client.getChannel());
Review comment:
we can also remove
```
numBlockIds = 0;
for (int[] ids: msg.reduceIds) {
numBlockIds += ids.length;
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gaborgsomogyi commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
gaborgsomogyi commented on a change in pull request #22138: [SPARK-25151][SS]
Apply Apache Commons Pool to KafkaDataConsumer
URL: https://github.com/apache/spark/pull/22138#discussion_r319496507
##
File path:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/InternalKafkaConsumerPool.scala
##
@@ -0,0 +1,221 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.{util => ju}
+import java.util.concurrent.ConcurrentHashMap
+
+import org.apache.commons.pool2.{BaseKeyedPooledObjectFactory, PooledObject,
SwallowedExceptionListener}
+import org.apache.commons.pool2.impl.{DefaultEvictionPolicy,
DefaultPooledObject, GenericKeyedObjectPool, GenericKeyedObjectPoolConfig}
+
+import org.apache.spark.SparkConf
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.kafka010.InternalKafkaConsumerPool._
+import org.apache.spark.sql.kafka010.KafkaDataConsumer.CacheKey
+
+/**
+ * Provides object pool for [[InternalKafkaConsumer]] which is grouped by
[[CacheKey]].
+ *
+ * This class leverages [[GenericKeyedObjectPool]] internally, hence providing
methods based on
+ * the class, and same contract applies: after using the borrowed object, you
must either call
+ * returnObject() if the object is healthy to return to pool, or
invalidateObject() if the object
+ * should be destroyed.
+ *
+ * The soft capacity of pool is determined by
"spark.kafka.consumer.cache.capacity" config value,
+ * and the pool will have reasonable default value if the value is not
provided.
+ * (The instance will do its best effort to respect soft capacity but it can
exceed when there's
+ * a borrowing request and there's neither free space nor idle object to
clear.)
+ *
+ * This class guarantees that no caller will get pooled object once the object
is borrowed and
+ * not yet returned, hence provide thread-safety usage of non-thread-safe
[[InternalKafkaConsumer]]
+ * unless caller shares the object to multiple threads.
+ */
+private[kafka010] class InternalKafkaConsumerPool(
+objectFactory: ObjectFactory,
+poolConfig: PoolConfig) extends Logging {
+
+ def this(conf: SparkConf) = {
+this(new ObjectFactory, new PoolConfig(conf))
+ }
+
+ // the class is intended to have only soft capacity
+ assert(poolConfig.getMaxTotal < 0)
+
+ private val pool = {
+val internalPool = new GenericKeyedObjectPool[CacheKey,
InternalKafkaConsumer](
+ objectFactory, poolConfig)
+
internalPool.setSwallowedExceptionListener(CustomSwallowedExceptionListener)
+internalPool
+ }
+
+ /**
+ * Borrows [[InternalKafkaConsumer]] object from the pool. If there's no
idle object for the key,
+ * the pool will create the [[InternalKafkaConsumer]] object.
+ *
+ * If the pool doesn't have idle object for the key and also exceeds the
soft capacity,
+ * pool will try to clear some of idle objects.
+ *
+ * Borrowed object must be returned by either calling returnObject or
invalidateObject, otherwise
+ * the object will be kept in pool as active object.
+ */
+ def borrowObject(key: CacheKey, kafkaParams: ju.Map[String, Object]):
InternalKafkaConsumer = {
+updateKafkaParamForKey(key, kafkaParams)
+
+if (size >= poolConfig.softMaxSize) {
+ logWarning("Pool exceeds its soft max size, cleaning up idle objects...")
+ pool.clearOldest()
+}
+
+pool.borrowObject(key)
+ }
+
+ /** Returns borrowed object to the pool. */
+ def returnObject(consumer: InternalKafkaConsumer): Unit = {
+pool.returnObject(extractCacheKey(consumer), consumer)
+ }
+
+ /** Invalidates (destroy) borrowed object to the pool. */
+ def invalidateObject(consumer: InternalKafkaConsumer): Unit = {
+pool.invalidateObject(extractCacheKey(consumer), consumer)
+ }
+
+ /** Invalidates all idle consumers for the key */
+ def invalidateKey(key: CacheKey): Unit = {
+pool.clear(key)
+ }
+
+ /**
+ * Closes the keyed object pool. Once the pool is closed,
+ * borrowObject will fail with [[IllegalStateException]], but returnObject
and invalidateObject
+ * will continue to work, with returned objects destroyed on return.
+ *
+ * Also destroys idle instances in
[GitHub] [spark] cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core] Support rolling back a shuffle map stage and re-generate the shuffle files
cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core] Support rolling back a shuffle map stage and re-generate the shuffle files URL: https://github.com/apache/spark/pull/25620#discussion_r319498094 ## File path: core/src/main/java/org/apache/spark/shuffle/api/ShuffleExecutorComponents.java ## @@ -39,17 +39,15 @@ /** * Called once per map task to create a writer that will be responsible for persisting all the * partitioned bytes written by that map task. - * @param shuffleId Unique identifier for the shuffle the map task is a part of - * @param mapId Within the shuffle, the identifier of the map task - * @param mapTaskAttemptId Identifier of the task attempt. Multiple attempts of the same map task - * with the same (shuffleId, mapId) pair can be distinguished by the - * different values of mapTaskAttemptId. + * @param shuffleId Unique identifier for the shuffle the map task is a part of + * @param mapId Identifier of the task attempt. Multiple attempts of the same map task with the Review comment: let's rephrase it. How about `An id of the map task which is unique within this Spark application.` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core] Support rolling back a shuffle map stage and re-generate the shuffle files
cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core] Support rolling back a shuffle map stage and re-generate the shuffle files URL: https://github.com/apache/spark/pull/25620#discussion_r319498094 ## File path: core/src/main/java/org/apache/spark/shuffle/api/ShuffleExecutorComponents.java ## @@ -39,17 +39,15 @@ /** * Called once per map task to create a writer that will be responsible for persisting all the * partitioned bytes written by that map task. - * @param shuffleId Unique identifier for the shuffle the map task is a part of - * @param mapId Within the shuffle, the identifier of the map task - * @param mapTaskAttemptId Identifier of the task attempt. Multiple attempts of the same map task - * with the same (shuffleId, mapId) pair can be distinguished by the - * different values of mapTaskAttemptId. + * @param shuffleId Unique identifier for the shuffle the map task is a part of + * @param mapId Identifier of the task attempt. Multiple attempts of the same map task with the Review comment: let's rephrase it. How about `An ID of the map task. The ID is unique within this Spark application.` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gaborgsomogyi commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
gaborgsomogyi commented on a change in pull request #22138: [SPARK-25151][SS]
Apply Apache Commons Pool to KafkaDataConsumer
URL: https://github.com/apache/spark/pull/22138#discussion_r319498159
##
File path:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaSparkConfSuite.scala
##
@@ -1,30 +0,0 @@
-/*
- * Licensed to the Apache Software Foundation (ASF) under one or more
- * contributor license agreements. See the NOTICE file distributed with
- * this work for additional information regarding copyright ownership.
- * The ASF licenses this file to You under the Apache License, Version 2.0
- * (the "License"); you may not use this file except in compliance with
- * the License. You may obtain a copy of the License at
- *
- *http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-package org.apache.spark.sql.kafka010
-
-import org.apache.spark.{LocalSparkContext, SparkConf, SparkFunSuite}
-import org.apache.spark.util.ResetSystemProperties
-
-class KafkaSparkConfSuite extends SparkFunSuite with LocalSparkContext with
ResetSystemProperties {
Review comment:
Hmm, what has happened with this test?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gaborgsomogyi commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
gaborgsomogyi commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#discussion_r319500037 ## File path: external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaDataConsumer.scala ## @@ -269,9 +300,12 @@ private[kafka010] case class InternalKafkaConsumer( // When there is some error thrown, it's better to use a new consumer to drop all cached // states in the old consumer. We don't need to worry about the performance because this // is not a common path. - resetConsumer() - reportDataLoss(failOnDataLoss, s"Cannot fetch offset $toFetchOffset", e) - toFetchOffset = getEarliestAvailableOffsetBetween(toFetchOffset, untilOffset) + releaseConsumer() + fetchedData.reset() Review comment: Don't we need `releaseFetchedData` here? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS]
Apply Apache Commons Pool to KafkaDataConsumer
URL: https://github.com/apache/spark/pull/22138#discussion_r319500084
##
File path:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaSparkConfSuite.scala
##
@@ -1,30 +0,0 @@
-/*
- * Licensed to the Apache Software Foundation (ASF) under one or more
- * contributor license agreements. See the NOTICE file distributed with
- * this work for additional information regarding copyright ownership.
- * The ASF licenses this file to You under the Apache License, Version 2.0
- * (the "License"); you may not use this file except in compliance with
- * the License. You may obtain a copy of the License at
- *
- *http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-package org.apache.spark.sql.kafka010
-
-import org.apache.spark.{LocalSparkContext, SparkConf, SparkFunSuite}
-import org.apache.spark.util.ResetSystemProperties
-
-class KafkaSparkConfSuite extends SparkFunSuite with LocalSparkContext with
ResetSystemProperties {
Review comment:
I have renamed the config to old one per feedback, so no longer need this
test.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#discussion_r319500695 ## File path: external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaDataConsumer.scala ## @@ -269,9 +300,12 @@ private[kafka010] case class InternalKafkaConsumer( // When there is some error thrown, it's better to use a new consumer to drop all cached // states in the old consumer. We don't need to worry about the performance because this // is not a common path. - resetConsumer() - reportDataLoss(failOnDataLoss, s"Cannot fetch offset $toFetchOffset", e) - toFetchOffset = getEarliestAvailableOffsetBetween(toFetchOffset, untilOffset) + releaseConsumer() + fetchedData.reset() Review comment: Yes, as FetchedData is designed to be modified per task. Once you get the one for that task, you can just modify it, and also reset if necessary. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#discussion_r319500695 ## File path: external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaDataConsumer.scala ## @@ -269,9 +300,12 @@ private[kafka010] case class InternalKafkaConsumer( // When there is some error thrown, it's better to use a new consumer to drop all cached // states in the old consumer. We don't need to worry about the performance because this // is not a common path. - resetConsumer() - reportDataLoss(failOnDataLoss, s"Cannot fetch offset $toFetchOffset", e) - toFetchOffset = getEarliestAvailableOffsetBetween(toFetchOffset, untilOffset) + releaseConsumer() + fetchedData.reset() Review comment: Yes, as FetchedData is designed to be modified per task. (So based on the desired offset, in most cases pool will provide same FetchedData. Once you get the one for that task, you can just modify it, and also reset if necessary. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#discussion_r319500695 ## File path: external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaDataConsumer.scala ## @@ -269,9 +300,12 @@ private[kafka010] case class InternalKafkaConsumer( // When there is some error thrown, it's better to use a new consumer to drop all cached // states in the old consumer. We don't need to worry about the performance because this // is not a common path. - resetConsumer() - reportDataLoss(failOnDataLoss, s"Cannot fetch offset $toFetchOffset", e) - toFetchOffset = getEarliestAvailableOffsetBetween(toFetchOffset, untilOffset) + releaseConsumer() + fetchedData.reset() Review comment: Yes, as FetchedData is designed to be modified per task. So based on the desired offset, in most cases pool will provide same FetchedData. Once you get the one for that task, you can just modify it, and also reset if necessary. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
HeartSaVioR commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#discussion_r319500695 ## File path: external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaDataConsumer.scala ## @@ -269,9 +300,12 @@ private[kafka010] case class InternalKafkaConsumer( // When there is some error thrown, it's better to use a new consumer to drop all cached // states in the old consumer. We don't need to worry about the performance because this // is not a common path. - resetConsumer() - reportDataLoss(failOnDataLoss, s"Cannot fetch offset $toFetchOffset", e) - toFetchOffset = getEarliestAvailableOffsetBetween(toFetchOffset, untilOffset) + releaseConsumer() + fetchedData.reset() Review comment: No, as FetchedData is designed to be modified per task. So based on the desired offset, in most cases pool will provide same FetchedData. Once you get the one for that task, you can just modify it, and also reset if necessary. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming
HeartSaVioR commented on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming URL: https://github.com/apache/spark/pull/25618#issuecomment-526593592 Well, someone could say it as 2PC since the behavior is similar, but generally 2PC assumes coordinator and participants. In second phase, coordinator "ask" for commit/abort to participants, not committing/aborting things participants just did in first phase by itself. Based on that, driver should request tasks to commit their outputs, but Spark doesn't provide such flow. So that's pretty simplified version of 2PC and also pretty limited. I think the point is whether we are feeling OK to have exactly-once with some restrictions end users need to be aware of. Could you please initiate discussion on this in Spark dev mailing list? That would be good to hear others' voices. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core] Support rolling back a shuffle map stage and re-generate the shuffle files
cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core]
Support rolling back a shuffle map stage and re-generate the shuffle files
URL: https://github.com/apache/spark/pull/25620#discussion_r319502863
##
File path: core/src/main/scala/org/apache/spark/scheduler/MapStatus.scala
##
@@ -100,16 +108,19 @@ private[spark] object MapStatus {
*
* @param loc location where the task is being executed.
* @param compressedSizes size of the blocks, indexed by reduce partition id.
+ * @param mapTaskId unique task id for the task
Review comment:
let's call it `mapId`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core] Support rolling back a shuffle map stage and re-generate the shuffle files
cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core]
Support rolling back a shuffle map stage and re-generate the shuffle files
URL: https://github.com/apache/spark/pull/25620#discussion_r319502863
##
File path: core/src/main/scala/org/apache/spark/scheduler/MapStatus.scala
##
@@ -100,16 +108,19 @@ private[spark] object MapStatus {
*
* @param loc location where the task is being executed.
* @param compressedSizes size of the blocks, indexed by reduce partition id.
+ * @param mapTaskId unique task id for the task
Review comment:
let's call it `mapId`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
SparkQA commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526594832 **[Test build #109943 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109943/testReport)** for PR 25497 at commit [`99a2182`](https://github.com/apache/spark/commit/99a21824580349e9f0524573e1c7ce5a739360e9). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
SparkQA removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526556962 **[Test build #109943 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109943/testReport)** for PR 25497 at commit [`99a2182`](https://github.com/apache/spark/commit/99a21824580349e9f0524573e1c7ce5a739360e9). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon opened a new pull request #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor
HyukjinKwon opened a new pull request #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor URL: https://github.com/apache/spark/pull/25633 ### What changes were proposed in this pull request? This PR proposes to upgrade scala-maven-plugin from 3.4.4 to 4.2.0. Upgrade to 4.1.1 was reverted due to unexpected build failure on AppVeyor. The root cause seems to be an issue specific to AppVeyor - loading the system library 'kernel32.dll' seems being failed. ``` Suppressed: java.lang.NoClassDefFoundError: Could not initialize class com.sun.jna.platform.win32.Kernel32 at sbt.internal.io.WinMilli$.getHandle(Milli.scala:264) at sbt.internal.io.WinMilli$.getModifiedTimeNative(Milli.scala:289) at sbt.internal.io.WinMilli$.getModifiedTimeNative(Milli.scala:260) at sbt.internal.io.MilliNative.getModifiedTime(Milli.scala:61) at sbt.internal.io.Milli$.getModifiedTime(Milli.scala:360) at sbt.io.IO$.$anonfun$getModifiedTimeOrZero$1(IO.scala:1373) at scala.runtime.java8.JFunction0$mcJ$sp.apply(JFunction0$mcJ$sp.java:23) at sbt.internal.io.Retry$.liftedTree2$1(Retry.scala:38) at sbt.internal.io.Retry$.impl$1(Retry.scala:38) at sbt.internal.io.Retry$.apply(Retry.scala:52) at sbt.internal.io.Retry$.apply(Retry.scala:24) at sbt.io.IO$.getModifiedTimeOrZero(IO.scala:1373) at sbt.internal.inc.caching.ClasspathCache$.fromCacheOrHash$1(ClasspathCache.scala:44) at sbt.internal.inc.caching.ClasspathCache$.$anonfun$hashClasspath$1(ClasspathCache.scala:53) at scala.collection.parallel.mutable.ParArray$Map.leaf(ParArray.scala:659) at scala.collection.parallel.Task.$anonfun$tryLeaf$1(Tasks.scala:53) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at scala.util.control.Breaks$$anon$1.catchBreak(Breaks.scala:67) at scala.collection.parallel.Task.tryLeaf(Tasks.scala:56) at scala.collection.parallel.Task.tryLeaf$(Tasks.scala:50) at scala.collection.parallel.mutable.ParArray$Map.tryLeaf(ParArray.scala:650) at scala.collection.parallel.AdaptiveWorkStealingTasks$WrappedTask.internal(Tasks.scala:170) ... 25 more ``` By setting `-Djna.nosys=true`, it directly loads the library from the jar instead of system's. In this way, the build seems working fine. ### Why are the changes needed? It upgrades the plugin to fix bugs and fixes the CI build. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? It was tested at https://github.com/apache/spark/pull/25497 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor
HyukjinKwon commented on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor URL: https://github.com/apache/spark/pull/25633#issuecomment-526595448 cc @dongjoon-hyun, @srowen and @wangyum This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
AmplabJenkins commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526595458 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
AmplabJenkins commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526595460 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109943/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
AmplabJenkins removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526595458 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
AmplabJenkins removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526595460 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109943/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor
AmplabJenkins commented on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor URL: https://github.com/apache/spark/pull/25633#issuecomment-526595755 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
HyukjinKwon closed pull request #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor
AmplabJenkins commented on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor URL: https://github.com/apache/spark/pull/25633#issuecomment-526595766 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14974/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core] Support rolling back a shuffle map stage and re-generate the shuffle files
cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core]
Support rolling back a shuffle map stage and re-generate the shuffle files
URL: https://github.com/apache/spark/pull/25620#discussion_r319504661
##
File path:
core/src/main/scala/org/apache/spark/storage/ShuffleBlockFetcherIterator.scala
##
@@ -48,9 +48,10 @@ import org.apache.spark.util.{CompletionIterator,
TaskCompletionListener, Utils}
* @param shuffleClient [[BlockStoreClient]] for fetching remote blocks
* @param blockManager [[BlockManager]] for reading local blocks
* @param blocksByAddress list of blocks to fetch grouped by the
[[BlockManagerId]].
- *For each block we also require the size (in bytes as
a long field) in
- *order to throttle the memory usage. Note that
zero-sized blocks are
- *already excluded, which happened in
+ *For each block we also require two info: 1. the size
(in bytes as a long
+ *field) in order to throttle the memory usage; 2. the
mapId for this
Review comment:
`mapId` -> `mapIndex`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25630: [WIP][SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results
SparkQA commented on issue #25630: [WIP][SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results URL: https://github.com/apache/spark/pull/25630#issuecomment-526596051 **[Test build #109942 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109942/testReport)** for PR 25630 at commit [`28e7f2f`](https://github.com/apache/spark/commit/28e7f2fc326270b63e9d15c1f366f96742f7e282). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25630: [WIP][SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results
AmplabJenkins commented on issue #25630: [WIP][SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results URL: https://github.com/apache/spark/pull/25630#issuecomment-526596275 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25630: [WIP][SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results
AmplabJenkins commented on issue #25630: [WIP][SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results URL: https://github.com/apache/spark/pull/25630#issuecomment-526596279 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109942/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gaborgsomogyi commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
gaborgsomogyi commented on a change in pull request #22138: [SPARK-25151][SS]
Apply Apache Commons Pool to KafkaDataConsumer
URL: https://github.com/apache/spark/pull/22138#discussion_r319505166
##
File path:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaSparkConfSuite.scala
##
@@ -1,30 +0,0 @@
-/*
- * Licensed to the Apache Software Foundation (ASF) under one or more
- * contributor license agreements. See the NOTICE file distributed with
- * this work for additional information regarding copyright ownership.
- * The ASF licenses this file to You under the Apache License, Version 2.0
- * (the "License"); you may not use this file except in compliance with
- * the License. You may obtain a copy of the License at
- *
- *http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-package org.apache.spark.sql.kafka010
-
-import org.apache.spark.{LocalSparkContext, SparkConf, SparkFunSuite}
-import org.apache.spark.util.ResetSystemProperties
-
-class KafkaSparkConfSuite extends SparkFunSuite with LocalSparkContext with
ResetSystemProperties {
Review comment:
Which comment are you referring to? Looking for it but maybe closed.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core] Support rolling back a shuffle map stage and re-generate the shuffle files
cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core] Support rolling back a shuffle map stage and re-generate the shuffle files URL: https://github.com/apache/spark/pull/25620#discussion_r319505049 ## File path: core/src/main/scala/org/apache/spark/storage/ShuffleBlockFetcherIterator.scala ## @@ -591,6 +596,7 @@ private class BufferReleasingInputStream( private[storage] val delegate: InputStream, private val iterator: ShuffleBlockFetcherIterator, private val blockId: BlockId, +private val mapId: Int, Review comment: `mapIndex`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25630: [WIP][SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results
SparkQA removed a comment on issue #25630: [WIP][SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results URL: https://github.com/apache/spark/pull/25630#issuecomment-526552539 **[Test build #109942 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109942/testReport)** for PR 25630 at commit [`28e7f2f`](https://github.com/apache/spark/commit/28e7f2fc326270b63e9d15c1f366f96742f7e282). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core] Support rolling back a shuffle map stage and re-generate the shuffle files
cloud-fan commented on a change in pull request #25620: [SPARK-25341][Core]
Support rolling back a shuffle map stage and re-generate the shuffle files
URL: https://github.com/apache/spark/pull/25620#discussion_r319505384
##
File path:
core/src/main/scala/org/apache/spark/storage/ShuffleBlockFetcherIterator.scala
##
@@ -706,6 +714,7 @@ object ShuffleBlockFetcherIterator {
*/
private[storage] case class SuccessFetchResult(
blockId: BlockId,
+ mapId: Int,
Review comment:
why we need the map index here?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor
AmplabJenkins removed a comment on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor URL: https://github.com/apache/spark/pull/25633#issuecomment-526595766 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14974/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor
AmplabJenkins removed a comment on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor URL: https://github.com/apache/spark/pull/25633#issuecomment-526595755 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor
SparkQA commented on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor URL: https://github.com/apache/spark/pull/25633#issuecomment-526596416 **[Test build #109950 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109950/testReport)** for PR 25633 at commit [`0fd34b3`](https://github.com/apache/spark/commit/0fd34b30ab9f07d6c6f9ccfad0541a59db31405e). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25630: [WIP][SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results
AmplabJenkins removed a comment on issue #25630: [WIP][SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results URL: https://github.com/apache/spark/pull/25630#issuecomment-526596275 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor
HyukjinKwon commented on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor URL: https://github.com/apache/spark/pull/25633#issuecomment-526596865 4.2.0 has https://github.com/davidB/scala-maven-plugin/pull/358 fix too FWIW. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25630: [WIP][SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results
AmplabJenkins removed a comment on issue #25630: [WIP][SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results URL: https://github.com/apache/spark/pull/25630#issuecomment-526596279 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/109942/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] iRakson opened a new pull request #25634: [SPARK-28929][CORE] Spark Logging level should be INFO instead of DEBUG in Executor Plugin API
iRakson opened a new pull request #25634: [SPARK-28929][CORE] Spark Logging level should be INFO instead of DEBUG in Executor Plugin API URL: https://github.com/apache/spark/pull/25634 ### What changes were proposed in this pull request? Log levels in Executor.scala are changed from DEBUG to INFO. ### Does this PR introduce any user-facing change? No ### How was this patch tested? Manually tested. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25634: [SPARK-28929][CORE] Spark Logging level should be INFO instead of DEBUG in Executor Plugin API
AmplabJenkins commented on issue #25634: [SPARK-28929][CORE] Spark Logging level should be INFO instead of DEBUG in Executor Plugin API URL: https://github.com/apache/spark/pull/25634#issuecomment-526598072 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25634: [SPARK-28929][CORE] Spark Logging level should be INFO instead of DEBUG in Executor Plugin API
AmplabJenkins removed a comment on issue #25634: [SPARK-28929][CORE] Spark Logging level should be INFO instead of DEBUG in Executor Plugin API URL: https://github.com/apache/spark/pull/25634#issuecomment-526598072 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25634: [SPARK-28929][CORE] Spark Logging level should be INFO instead of DEBUG in Executor Plugin API
AmplabJenkins commented on issue #25634: [SPARK-28929][CORE] Spark Logging level should be INFO instead of DEBUG in Executor Plugin API URL: https://github.com/apache/spark/pull/25634#issuecomment-526598284 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25634: [SPARK-28929][CORE] Spark Logging level should be INFO instead of DEBUG in Executor Plugin API
AmplabJenkins commented on issue #25634: [SPARK-28929][CORE] Spark Logging level should be INFO instead of DEBUG in Executor Plugin API URL: https://github.com/apache/spark/pull/25634#issuecomment-526599082 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25630: [SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results
SparkQA commented on issue #25630: [SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results URL: https://github.com/apache/spark/pull/25630#issuecomment-526599196 **[Test build #109951 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109951/testReport)** for PR 25630 at commit [`a3c73c8`](https://github.com/apache/spark/commit/a3c73c86bba940054b3434e876411ded24b6c2b3). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gaborgsomogyi commented on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming
gaborgsomogyi commented on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming URL: https://github.com/apache/spark/pull/25618#issuecomment-526599116 +1 having discussion on that. My perspective is clear. Having such limitation is a bit too much in such scenario so I'm not feeling comfortable with it. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25634: [SPARK-28929][CORE] Spark Logging level should be INFO instead of DEBUG in Executor Plugin API
AmplabJenkins removed a comment on issue #25634: [SPARK-28929][CORE] Spark Logging level should be INFO instead of DEBUG in Executor Plugin API URL: https://github.com/apache/spark/pull/25634#issuecomment-526598284 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gaborgsomogyi commented on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming
gaborgsomogyi commented on issue #25618: [SPARK-28908][SS]Implement Kafka EOS sink for Structured Streaming URL: https://github.com/apache/spark/pull/25618#issuecomment-526599976 In the meantime I'm speaking with Gyula from Flink side to understand things deeper... This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25630: [SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results
AmplabJenkins commented on issue #25630: [SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results URL: https://github.com/apache/spark/pull/25630#issuecomment-526601210 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14975/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25630: [SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results
AmplabJenkins commented on issue #25630: [SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results URL: https://github.com/apache/spark/pull/25630#issuecomment-526601202 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25630: [SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results
AmplabJenkins removed a comment on issue #25630: [SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results URL: https://github.com/apache/spark/pull/25630#issuecomment-526601202 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25630: [SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results
AmplabJenkins removed a comment on issue #25630: [SPARK-28894][SQL][TESTS] Add a clue to make it easier to debug via Jenkins's test results URL: https://github.com/apache/spark/pull/25630#issuecomment-526601210 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/14975/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor
srowen commented on issue #25633: [SPARK-28759][BUILD] Upgrade scala-maven-plugin to 4.2.0 and fix build profile on AppVeyor URL: https://github.com/apache/spark/pull/25633#issuecomment-526602411 Oh nice, so this possibly enables cross-compilation from JDK 11 to JDK 8 now? great This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gaborgsomogyi commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
gaborgsomogyi commented on a change in pull request #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#discussion_r319517484 ## File path: external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaDataConsumer.scala ## @@ -269,9 +300,12 @@ private[kafka010] case class InternalKafkaConsumer( // When there is some error thrown, it's better to use a new consumer to drop all cached // states in the old consumer. We don't need to worry about the performance because this // is not a common path. - resetConsumer() - reportDataLoss(failOnDataLoss, s"Cannot fetch offset $toFetchOffset", e) - toFetchOffset = getEarliestAvailableOffsetBetween(toFetchOffset, untilOffset) + releaseConsumer() + fetchedData.reset() Review comment: Had a refreshing look and see the concept, looks OK. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gaborgsomogyi commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer
gaborgsomogyi commented on issue #22138: [SPARK-25151][SS] Apply Apache Commons Pool to KafkaDataConsumer URL: https://github.com/apache/spark/pull/22138#issuecomment-526608400 As a general comment since the consumer caching is described in the doc it would be good to adopt. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on a change in pull request #25612: [SPARK-3137][Core]Replace the global TorrentBroadcast lock with fine grained KeyLock
Ngone51 commented on a change in pull request #25612: [SPARK-3137][Core]Replace
the global TorrentBroadcast lock with fine grained KeyLock
URL: https://github.com/apache/spark/pull/25612#discussion_r319525047
##
File path: core/src/main/scala/org/apache/spark/util/KeyLock.scala
##
@@ -0,0 +1,71 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.util
+
+import java.util.concurrent.ConcurrentHashMap
+
+/**
+ * A special locking mechanism to provide locking with a given key. By
providing the same key
+ * (identity is tested using the `equals` method), we ensure there is only one
`func` running at
+ * the same time.
+ *
+ * @tparam K the type of key to identify a lock. This type must implement
`equals` and `hashCode`
+ * correctly as it will be the key type of an internal Map.
+ */
+private[spark] class KeyLock[K] {
+
+ private val lockMap = new ConcurrentHashMap[K, AnyRef]()
+
+ private def acquireLock(key: K): Unit = {
+while (true) {
+ val lock = lockMap.putIfAbsent(key, new Object)
+ if (lock == null) return
+ lock.synchronized {
+while (lockMap.get(key) eq lock) {
Review comment:
After releasing keylock, if a new thread for the same broadcastId enters to
put a new object before another queueing thread to check `lockMap.get(key) eq
lock`, both threads could get the keylock finally ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
SparkQA commented on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526624198 **[Test build #109947 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109947/testReport)** for PR 25497 at commit [`1068514`](https://github.com/apache/spark/commit/1068514162cc9f27e57d0342d3a953967aaf76e2). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0
SparkQA removed a comment on issue #25497: [BUILD][DO-NOT-MERGE] Investigate the detla in scala-maven-plugin 3.4.6 <> 4.0.0 URL: https://github.com/apache/spark/pull/25497#issuecomment-526578038 **[Test build #109947 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/109947/testReport)** for PR 25497 at commit [`1068514`](https://github.com/apache/spark/commit/1068514162cc9f27e57d0342d3a953967aaf76e2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org