[GitHub] [spark] SparkQA commented on issue #27260: [SPARK-30549][SQL] Fix the subquery shown issue in UI When enable AQE
SparkQA commented on issue #27260: [SPARK-30549][SQL] Fix the subquery shown issue in UI When enable AQE URL: https://github.com/apache/spark/pull/27260#issuecomment-575545121 **[Test build #116925 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/116925/testReport)** for PR 27260 at commit [`77747c5`](https://github.com/apache/spark/commit/77747c5fe56105fc03fe49965234894101192b36). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] JkSelf opened a new pull request #27260: [SPARK-30549][SQL] Fix the subquery shown issue in UI When enable AQE
JkSelf opened a new pull request #27260: [SPARK-30549][SQL] Fix the subquery shown issue in UI When enable AQE URL: https://github.com/apache/spark/pull/27260 ### What changes were proposed in this pull request? Currently the subquery metric can not be shown in UI. And this PR will fix the subquery shown issue. ### Why are the changes needed? Showing the subquery metric in UI when enable AQE ### Does this PR introduce any user-facing change? No ### How was this patch tested? Existing UT This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] fuwhu commented on a change in pull request #26805: [SPARK-15616][SQL] Add optimizer rule PruneHiveTablePartitions
fuwhu commented on a change in pull request #26805: [SPARK-15616][SQL] Add
optimizer rule PruneHiveTablePartitions
URL: https://github.com/apache/spark/pull/26805#discussion_r367836420
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/PruneHiveTablePartitions.scala
##
@@ -0,0 +1,109 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import org.apache.hadoop.hive.common.StatsSetupConst
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.catalyst.analysis.CastSupport
+import org.apache.spark.sql.catalyst.catalog.{CatalogStatistics, CatalogTable,
CatalogTablePartition, ExternalCatalogUtils, HiveTableRelation}
+import org.apache.spark.sql.catalyst.expressions.{And, AttributeSet,
Expression, ExpressionSet, SubqueryExpression}
+import org.apache.spark.sql.catalyst.planning.PhysicalOperation
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LogicalPlan,
Project}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.datasources.DataSourceStrategy
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * TODO: merge this with PruneFileSourcePartitions after we completely make
hive as a data source.
+ */
+private[sql] class PruneHiveTablePartitions(session: SparkSession)
+ extends Rule[LogicalPlan] with CastSupport {
+
+ override val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Extract the partition filters from the filters on the table.
+ */
+ private def getPartitionKeyFilters(
+ filters: Seq[Expression],
+ relation: HiveTableRelation): ExpressionSet = {
+val normalizedFilters = DataSourceStrategy.normalizeExprs(
+ filters.filter(f => f.deterministic &&
!SubqueryExpression.hasSubquery(f)), relation.output)
+val partitionColumnSet = AttributeSet(relation.partitionCols)
+ExpressionSet(normalizedFilters.filter { f =>
+ !f.references.isEmpty && f.references.subsetOf(partitionColumnSet)
+})
+ }
+
+ /**
+ * Prune the hive table using filters on the partitions of the table.
+ */
+ private def prunePartitions(
+ relation: HiveTableRelation,
+ partitionFilters: ExpressionSet): Seq[CatalogTablePartition] = {
+if (conf.metastorePartitionPruning) {
+ session.sessionState.catalog.listPartitionsByFilter(
+relation.tableMeta.identifier, partitionFilters.toSeq)
+} else {
+ ExternalCatalogUtils.prunePartitionsByFilter(relation.tableMeta,
Review comment:
so we don't need change here, right?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure
HeartSaVioR commented on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure URL: https://github.com/apache/spark/pull/27259#issuecomment-575543531 retest this, please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] fuwhu commented on a change in pull request #26805: [SPARK-15616][SQL] Add optimizer rule PruneHiveTablePartitions
fuwhu commented on a change in pull request #26805: [SPARK-15616][SQL] Add
optimizer rule PruneHiveTablePartitions
URL: https://github.com/apache/spark/pull/26805#discussion_r367836199
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/PruneHiveTablePartitions.scala
##
@@ -0,0 +1,109 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import org.apache.hadoop.hive.common.StatsSetupConst
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.catalyst.analysis.CastSupport
+import org.apache.spark.sql.catalyst.catalog.{CatalogStatistics, CatalogTable,
CatalogTablePartition, ExternalCatalogUtils, HiveTableRelation}
+import org.apache.spark.sql.catalyst.expressions.{And, AttributeSet,
Expression, ExpressionSet, SubqueryExpression}
+import org.apache.spark.sql.catalyst.planning.PhysicalOperation
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LogicalPlan,
Project}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.datasources.DataSourceStrategy
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * TODO: merge this with PruneFileSourcePartitions after we completely make
hive as a data source.
+ */
+private[sql] class PruneHiveTablePartitions(session: SparkSession)
+ extends Rule[LogicalPlan] with CastSupport {
+
+ override val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Extract the partition filters from the filters on the table.
+ */
+ private def getPartitionKeyFilters(
+ filters: Seq[Expression],
+ relation: HiveTableRelation): ExpressionSet = {
+val normalizedFilters = DataSourceStrategy.normalizeExprs(
+ filters.filter(f => f.deterministic &&
!SubqueryExpression.hasSubquery(f)), relation.output)
+val partitionColumnSet = AttributeSet(relation.partitionCols)
+ExpressionSet(normalizedFilters.filter { f =>
+ !f.references.isEmpty && f.references.subsetOf(partitionColumnSet)
+})
+ }
+
+ /**
+ * Prune the hive table using filters on the partitions of the table.
+ */
+ private def prunePartitions(
+ relation: HiveTableRelation,
+ partitionFilters: ExpressionSet): Seq[CatalogTablePartition] = {
+if (conf.metastorePartitionPruning) {
+ session.sessionState.catalog.listPartitionsByFilter(
+relation.tableMeta.identifier, partitionFilters.toSeq)
+} else {
+ ExternalCatalogUtils.prunePartitionsByFilter(relation.tableMeta,
+
session.sessionState.catalog.listPartitions(relation.tableMeta.identifier),
+partitionFilters.toSeq, conf.sessionLocalTimeZone)
+}
+ }
+
+ /**
+ * Update the statistics of the table.
+ */
+ private def updateTableMeta(
+ tableMeta: CatalogTable,
+ prunedPartitions: Seq[CatalogTablePartition]): CatalogTable = {
+val sizeOfPartitions = prunedPartitions.map { partition =>
+ val rawDataSize =
partition.parameters.get(StatsSetupConst.RAW_DATA_SIZE).map(_.toLong)
+ val totalSize =
partition.parameters.get(StatsSetupConst.TOTAL_SIZE).map(_.toLong)
+ if (rawDataSize.isDefined && rawDataSize.get > 0) {
+rawDataSize.get
+ } else if (totalSize.isDefined && totalSize.get > 0L) {
+totalSize.get
+ } else {
+0L
+ }
+}
+if (sizeOfPartitions.forall(s => s>0)) {
+ val sizeInBytes = sizeOfPartitions.sum
+ tableMeta.copy(stats = Some(CatalogStatistics(sizeInBytes =
BigInt(sizeInBytes
+} else {
+ tableMeta
+}
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperators {
+case op @ PhysicalOperation(projections, filters, relation:
HiveTableRelation)
+ if filters.nonEmpty && relation.isPartitioned &&
relation.prunedPartitions.isEmpty =>
+ val partitionKeyFilters = getPartitionKeyFilters(filters, relation)
+ if (partitionKeyFilters.nonEmpty) {
+val newPartitions = prunePartitions(relation, partitionKeyFilters)
+val newTableMeta = updateTableMeta(relation.tableMeta, newPartitions)
+val newRelation = relation.copy(
+ tableMeta = newTableMeta, prunedPartitions = Some(newPartitions))
+
[GitHub] [spark] HeartSaVioR commented on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure
HeartSaVioR commented on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure URL: https://github.com/apache/spark/pull/27259#issuecomment-575543475 Given it's flaky, I have to trigger some of builds concurrently to reduce the time. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure
AmplabJenkins removed a comment on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure URL: https://github.com/apache/spark/pull/27259#issuecomment-575542766 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure
AmplabJenkins removed a comment on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure URL: https://github.com/apache/spark/pull/27259#issuecomment-575542778 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21693/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure
AmplabJenkins commented on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure URL: https://github.com/apache/spark/pull/27259#issuecomment-575542778 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21693/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure
AmplabJenkins commented on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure URL: https://github.com/apache/spark/pull/27259#issuecomment-575542766 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] davidvrba commented on a change in pull request #27231: [SPARK-28478] [SQL] Remove redundant null checks
davidvrba commented on a change in pull request #27231: [SPARK-28478] [SQL]
Remove redundant null checks
URL: https://github.com/apache/spark/pull/27231#discussion_r367834785
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/expressions.scala
##
@@ -757,3 +757,45 @@ object CombineConcats extends Rule[LogicalPlan] {
flattenConcats(concat)
}
}
+
+/**
+ * Removes unnecessary null checks for If/CaseWhen conditions
+ * with NullIntolerant expressions.
+ */
+object RemoveRedundantNullChecks extends Rule[LogicalPlan] {
+ /**
+ * @param ifNullExpr expression that takes place if checkedExpr is null
+ * @param ifNotNullExpr expression that takes place if checkedExpr is not
null
+ * @param checkedExpr expression that is checked for null value
+ */
+ private def isRedundant(
+ ifNullExpr: Expression,
+ ifNotNullExpr: Expression,
+ checkedExpr: Expression): Boolean = {
+(ifNullExpr == checkedExpr || ifNullExpr == Literal.create(null,
checkedExpr.dataType)) &&
+ ifNotNullExpr.isInstanceOf[NullIntolerant] &&
+ ifNotNullExpr.children.contains(checkedExpr)
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = plan transformAllExpressions {
+case i @ If(predicate, trueValue, falseValue) => predicate match {
Review comment:
ok, it is moved
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure
SparkQA commented on issue #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure URL: https://github.com/apache/spark/pull/27259#issuecomment-575542131 **[Test build #116924 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/116924/testReport)** for PR 27259 at commit [`4aeb9ec`](https://github.com/apache/spark/commit/4aeb9ecf0388ebd94d64152a530af56c509fdd87). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR opened a new pull request #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure
HeartSaVioR opened a new pull request #27259: [DO-NOT-MERGE][WIP] Investigating SPARK-30541 flaky test failure URL: https://github.com/apache/spark/pull/27259 As title says, DO NOT MERGE. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint
AmplabJenkins removed a comment on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint URL: https://github.com/apache/spark/pull/27252#issuecomment-575539695 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint
AmplabJenkins removed a comment on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint URL: https://github.com/apache/spark/pull/27252#issuecomment-575539697 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21692/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint
AmplabJenkins commented on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint URL: https://github.com/apache/spark/pull/27252#issuecomment-575539695 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint
AmplabJenkins commented on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint URL: https://github.com/apache/spark/pull/27252#issuecomment-575539697 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21692/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27258: [SPARK-30547][SQL] Add unstable annotation to the CalendarInterval class
AmplabJenkins removed a comment on issue #27258: [SPARK-30547][SQL] Add unstable annotation to the CalendarInterval class URL: https://github.com/apache/spark/pull/27258#issuecomment-575537121 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27258: [SPARK-30547][SQL] Add unstable annotation to the CalendarInterval class
AmplabJenkins removed a comment on issue #27258: [SPARK-30547][SQL] Add unstable annotation to the CalendarInterval class URL: https://github.com/apache/spark/pull/27258#issuecomment-575537127 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21691/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27258: [SPARK-30547][SQL] Add unstable annotation to the CalendarInterval class
SparkQA commented on issue #27258: [SPARK-30547][SQL] Add unstable annotation to the CalendarInterval class URL: https://github.com/apache/spark/pull/27258#issuecomment-575539232 **[Test build #116922 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/116922/testReport)** for PR 27258 at commit [`1a90651`](https://github.com/apache/spark/commit/1a9065194e96e72038bf6bf52723acc11425199e). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint
SparkQA commented on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint URL: https://github.com/apache/spark/pull/27252#issuecomment-575539208 **[Test build #116923 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/116923/testReport)** for PR 27252 at commit [`048a0ec`](https://github.com/apache/spark/commit/048a0ecc65763c6feaa939938e2dec6f4040d939). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method
AmplabJenkins removed a comment on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method URL: https://github.com/apache/spark/pull/27254#issuecomment-575537937 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116917/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method
AmplabJenkins removed a comment on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method URL: https://github.com/apache/spark/pull/27254#issuecomment-575537928 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LucaCanali commented on a change in pull request #26675: [SPARK-30041][SQL][WEBUI] Add Codegen Stage Id to Stage DAG visualization in Web UI
LucaCanali commented on a change in pull request #26675:
[SPARK-30041][SQL][WEBUI] Add Codegen Stage Id to Stage DAG visualization in
Web UI
URL: https://github.com/apache/spark/pull/26675#discussion_r367829734
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkPlan.scala
##
@@ -206,7 +206,11 @@ abstract class SparkPlan extends QueryPlan[SparkPlan]
with Logging with Serializ
* for visualization.
*/
protected final def executeQuery[T](query: => T): T = {
-RDDOperationScope.withScope(sparkContext, nodeName, false, true) {
+val nodeNameScope = this match {
Review comment:
+1
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint
wangyum commented on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint URL: https://github.com/apache/spark/pull/27252#issuecomment-575537844 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method
SparkQA removed a comment on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method URL: https://github.com/apache/spark/pull/27254#issuecomment-575524224 **[Test build #116917 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/116917/testReport)** for PR 27254 at commit [`e58ceae`](https://github.com/apache/spark/commit/e58ceaecb9722b800fd26c3478edf0ad10c5f738). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method
AmplabJenkins commented on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method URL: https://github.com/apache/spark/pull/27254#issuecomment-575537937 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116917/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method
AmplabJenkins commented on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method URL: https://github.com/apache/spark/pull/27254#issuecomment-575537928 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method
SparkQA commented on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method URL: https://github.com/apache/spark/pull/27254#issuecomment-575537709 **[Test build #116917 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/116917/testReport)** for PR 27254 at commit [`e58ceae`](https://github.com/apache/spark/commit/e58ceaecb9722b800fd26c3478edf0ad10c5f738). * This patch **fails PySpark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27258: [SPARK-30547][SQL] Add unstable annotation to the CalendarInterval class
AmplabJenkins commented on issue #27258: [SPARK-30547][SQL] Add unstable annotation to the CalendarInterval class URL: https://github.com/apache/spark/pull/27258#issuecomment-575537121 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27258: [SPARK-30547][SQL] Add unstable annotation to the CalendarInterval class
AmplabJenkins commented on issue #27258: [SPARK-30547][SQL] Add unstable annotation to the CalendarInterval class URL: https://github.com/apache/spark/pull/27258#issuecomment-575537127 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21691/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn opened a new pull request #27258: [SPARK-30547][SQL] Add unstable annotation to the CalendarInterval class
yaooqinn opened a new pull request #27258: [SPARK-30547][SQL] Add unstable
annotation to the CalendarInterval class
URL: https://github.com/apache/spark/pull/27258
### What changes were proposed in this pull request?
`CalendarInterval` is maintained as a private class but might be used in a
public way by users
e.g.
```scala
scala> spark.udf.register("getIntervalMonth",
(_:org.apache.spark.unsafe.types.CalendarInterval).months)
scala> sql("select interval 2 month 1 day
a").selectExpr("getIntervalMonth(a)").show
+---+
|getIntervalMonth(a)|
+---+
| 2|
+---+
```
And it exists since 1.5.0, now we go to the 3.x era,may be it's time to make
it public
### Why are the changes needed?
make the interval more future-proofing
### Does this PR introduce any user-facing change?
doc change
### How was this patch tested?
add ut.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26805: [SPARK-15616][SQL] Add optimizer rule PruneHiveTablePartitions
cloud-fan commented on a change in pull request #26805: [SPARK-15616][SQL] Add
optimizer rule PruneHiveTablePartitions
URL: https://github.com/apache/spark/pull/26805#discussion_r367826109
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/PruneHiveTablePartitions.scala
##
@@ -0,0 +1,109 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import org.apache.hadoop.hive.common.StatsSetupConst
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.catalyst.analysis.CastSupport
+import org.apache.spark.sql.catalyst.catalog.{CatalogStatistics, CatalogTable,
CatalogTablePartition, ExternalCatalogUtils, HiveTableRelation}
+import org.apache.spark.sql.catalyst.expressions.{And, AttributeSet,
Expression, ExpressionSet, SubqueryExpression}
+import org.apache.spark.sql.catalyst.planning.PhysicalOperation
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LogicalPlan,
Project}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.datasources.DataSourceStrategy
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * TODO: merge this with PruneFileSourcePartitions after we completely make
hive as a data source.
+ */
+private[sql] class PruneHiveTablePartitions(session: SparkSession)
+ extends Rule[LogicalPlan] with CastSupport {
+
+ override val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Extract the partition filters from the filters on the table.
+ */
+ private def getPartitionKeyFilters(
+ filters: Seq[Expression],
+ relation: HiveTableRelation): ExpressionSet = {
+val normalizedFilters = DataSourceStrategy.normalizeExprs(
+ filters.filter(f => f.deterministic &&
!SubqueryExpression.hasSubquery(f)), relation.output)
+val partitionColumnSet = AttributeSet(relation.partitionCols)
+ExpressionSet(normalizedFilters.filter { f =>
+ !f.references.isEmpty && f.references.subsetOf(partitionColumnSet)
+})
+ }
+
+ /**
+ * Prune the hive table using filters on the partitions of the table.
+ */
+ private def prunePartitions(
+ relation: HiveTableRelation,
+ partitionFilters: ExpressionSet): Seq[CatalogTablePartition] = {
+if (conf.metastorePartitionPruning) {
+ session.sessionState.catalog.listPartitionsByFilter(
+relation.tableMeta.identifier, partitionFilters.toSeq)
+} else {
+ ExternalCatalogUtils.prunePartitionsByFilter(relation.tableMeta,
+
session.sessionState.catalog.listPartitions(relation.tableMeta.identifier),
+partitionFilters.toSeq, conf.sessionLocalTimeZone)
+}
+ }
+
+ /**
+ * Update the statistics of the table.
+ */
+ private def updateTableMeta(
+ tableMeta: CatalogTable,
+ prunedPartitions: Seq[CatalogTablePartition]): CatalogTable = {
+val sizeOfPartitions = prunedPartitions.map { partition =>
+ val rawDataSize =
partition.parameters.get(StatsSetupConst.RAW_DATA_SIZE).map(_.toLong)
+ val totalSize =
partition.parameters.get(StatsSetupConst.TOTAL_SIZE).map(_.toLong)
+ if (rawDataSize.isDefined && rawDataSize.get > 0) {
+rawDataSize.get
+ } else if (totalSize.isDefined && totalSize.get > 0L) {
+totalSize.get
+ } else {
+0L
+ }
+}
+if (sizeOfPartitions.forall(s => s>0)) {
+ val sizeInBytes = sizeOfPartitions.sum
+ tableMeta.copy(stats = Some(CatalogStatistics(sizeInBytes =
BigInt(sizeInBytes
+} else {
+ tableMeta
+}
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperators {
+case op @ PhysicalOperation(projections, filters, relation:
HiveTableRelation)
+ if filters.nonEmpty && relation.isPartitioned &&
relation.prunedPartitions.isEmpty =>
+ val partitionKeyFilters = getPartitionKeyFilters(filters, relation)
+ if (partitionKeyFilters.nonEmpty) {
+val newPartitions = prunePartitions(relation, partitionKeyFilters)
+val newTableMeta = updateTableMeta(relation.tableMeta, newPartitions)
+val newRelation = relation.copy(
+ tableMeta = newTableMeta, prunedPartitions = Some(newPartitions))
+
[GitHub] [spark] cloud-fan commented on a change in pull request #26805: [SPARK-15616][SQL] Add optimizer rule PruneHiveTablePartitions
cloud-fan commented on a change in pull request #26805: [SPARK-15616][SQL] Add
optimizer rule PruneHiveTablePartitions
URL: https://github.com/apache/spark/pull/26805#discussion_r367826109
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/PruneHiveTablePartitions.scala
##
@@ -0,0 +1,109 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import org.apache.hadoop.hive.common.StatsSetupConst
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.catalyst.analysis.CastSupport
+import org.apache.spark.sql.catalyst.catalog.{CatalogStatistics, CatalogTable,
CatalogTablePartition, ExternalCatalogUtils, HiveTableRelation}
+import org.apache.spark.sql.catalyst.expressions.{And, AttributeSet,
Expression, ExpressionSet, SubqueryExpression}
+import org.apache.spark.sql.catalyst.planning.PhysicalOperation
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LogicalPlan,
Project}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.datasources.DataSourceStrategy
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * TODO: merge this with PruneFileSourcePartitions after we completely make
hive as a data source.
+ */
+private[sql] class PruneHiveTablePartitions(session: SparkSession)
+ extends Rule[LogicalPlan] with CastSupport {
+
+ override val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Extract the partition filters from the filters on the table.
+ */
+ private def getPartitionKeyFilters(
+ filters: Seq[Expression],
+ relation: HiveTableRelation): ExpressionSet = {
+val normalizedFilters = DataSourceStrategy.normalizeExprs(
+ filters.filter(f => f.deterministic &&
!SubqueryExpression.hasSubquery(f)), relation.output)
+val partitionColumnSet = AttributeSet(relation.partitionCols)
+ExpressionSet(normalizedFilters.filter { f =>
+ !f.references.isEmpty && f.references.subsetOf(partitionColumnSet)
+})
+ }
+
+ /**
+ * Prune the hive table using filters on the partitions of the table.
+ */
+ private def prunePartitions(
+ relation: HiveTableRelation,
+ partitionFilters: ExpressionSet): Seq[CatalogTablePartition] = {
+if (conf.metastorePartitionPruning) {
+ session.sessionState.catalog.listPartitionsByFilter(
+relation.tableMeta.identifier, partitionFilters.toSeq)
+} else {
+ ExternalCatalogUtils.prunePartitionsByFilter(relation.tableMeta,
+
session.sessionState.catalog.listPartitions(relation.tableMeta.identifier),
+partitionFilters.toSeq, conf.sessionLocalTimeZone)
+}
+ }
+
+ /**
+ * Update the statistics of the table.
+ */
+ private def updateTableMeta(
+ tableMeta: CatalogTable,
+ prunedPartitions: Seq[CatalogTablePartition]): CatalogTable = {
+val sizeOfPartitions = prunedPartitions.map { partition =>
+ val rawDataSize =
partition.parameters.get(StatsSetupConst.RAW_DATA_SIZE).map(_.toLong)
+ val totalSize =
partition.parameters.get(StatsSetupConst.TOTAL_SIZE).map(_.toLong)
+ if (rawDataSize.isDefined && rawDataSize.get > 0) {
+rawDataSize.get
+ } else if (totalSize.isDefined && totalSize.get > 0L) {
+totalSize.get
+ } else {
+0L
+ }
+}
+if (sizeOfPartitions.forall(s => s>0)) {
+ val sizeInBytes = sizeOfPartitions.sum
+ tableMeta.copy(stats = Some(CatalogStatistics(sizeInBytes =
BigInt(sizeInBytes
+} else {
+ tableMeta
+}
+ }
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperators {
+case op @ PhysicalOperation(projections, filters, relation:
HiveTableRelation)
+ if filters.nonEmpty && relation.isPartitioned &&
relation.prunedPartitions.isEmpty =>
+ val partitionKeyFilters = getPartitionKeyFilters(filters, relation)
+ if (partitionKeyFilters.nonEmpty) {
+val newPartitions = prunePartitions(relation, partitionKeyFilters)
+val newTableMeta = updateTableMeta(relation.tableMeta, newPartitions)
+val newRelation = relation.copy(
+ tableMeta = newTableMeta, prunedPartitions = Some(newPartitions))
+
[GitHub] [spark] cloud-fan closed pull request #26921: [SPARK-30282][SQL] Migrate SHOW TBLPROPERTIES to new framework
cloud-fan closed pull request #26921: [SPARK-30282][SQL] Migrate SHOW TBLPROPERTIES to new framework URL: https://github.com/apache/spark/pull/26921 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #27233: [WIP][SPARK-29701][SQL] Correct behaviours of group analytical queries when empty input given
cloud-fan commented on issue #27233: [WIP][SPARK-29701][SQL] Correct behaviours of group analytical queries when empty input given URL: https://github.com/apache/spark/pull/27233#issuecomment-575533810 what problems do you hit when dealing with sort/filter? I took a quick look and have no clue. If it's difficult, I'm ok to do it in optimizer too. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #26921: [SPARK-30282][SQL] Migrate SHOW TBLPROPERTIES to new framework
cloud-fan commented on issue #26921: [SPARK-30282][SQL] Migrate SHOW TBLPROPERTIES to new framework URL: https://github.com/apache/spark/pull/26921#issuecomment-575532449 the last commit is just adding migration guide, and the previous commit passes all tests. I'm merging it to master, thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26805: [SPARK-15616][SQL] Add optimizer rule PruneHiveTablePartitions
cloud-fan commented on a change in pull request #26805: [SPARK-15616][SQL] Add
optimizer rule PruneHiveTablePartitions
URL: https://github.com/apache/spark/pull/26805#discussion_r367822954
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/PruneHiveTablePartitions.scala
##
@@ -0,0 +1,109 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import org.apache.hadoop.hive.common.StatsSetupConst
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.catalyst.analysis.CastSupport
+import org.apache.spark.sql.catalyst.catalog.{CatalogStatistics, CatalogTable,
CatalogTablePartition, ExternalCatalogUtils, HiveTableRelation}
+import org.apache.spark.sql.catalyst.expressions.{And, AttributeSet,
Expression, ExpressionSet, SubqueryExpression}
+import org.apache.spark.sql.catalyst.planning.PhysicalOperation
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LogicalPlan,
Project}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.datasources.DataSourceStrategy
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * TODO: merge this with PruneFileSourcePartitions after we completely make
hive as a data source.
+ */
+private[sql] class PruneHiveTablePartitions(session: SparkSession)
+ extends Rule[LogicalPlan] with CastSupport {
+
+ override val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Extract the partition filters from the filters on the table.
+ */
+ private def getPartitionKeyFilters(
+ filters: Seq[Expression],
+ relation: HiveTableRelation): ExpressionSet = {
+val normalizedFilters = DataSourceStrategy.normalizeExprs(
+ filters.filter(f => f.deterministic &&
!SubqueryExpression.hasSubquery(f)), relation.output)
+val partitionColumnSet = AttributeSet(relation.partitionCols)
+ExpressionSet(normalizedFilters.filter { f =>
+ !f.references.isEmpty && f.references.subsetOf(partitionColumnSet)
+})
+ }
+
+ /**
+ * Prune the hive table using filters on the partitions of the table.
+ */
+ private def prunePartitions(
+ relation: HiveTableRelation,
+ partitionFilters: ExpressionSet): Seq[CatalogTablePartition] = {
+if (conf.metastorePartitionPruning) {
+ session.sessionState.catalog.listPartitionsByFilter(
+relation.tableMeta.identifier, partitionFilters.toSeq)
+} else {
+ ExternalCatalogUtils.prunePartitionsByFilter(relation.tableMeta,
Review comment:
sorry I misread the code. so there are 2 optimizations:
1. pushdown predicates to hive metastore
2. pushdown predicates earlier to get precise data size info.
This rule is for the second optimization, and this branch is for skip the
first optimization.
makes sense to me
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts
dongjoon-hyun commented on issue #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts URL: https://github.com/apache/spark/pull/27257#issuecomment-575530580 I meant the following section in the `PR description`. > ### Does this PR introduce any user-facing change? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #26881: [SPARK-30252][SQL] Disallow negative scale of Decimal
AmplabJenkins removed a comment on issue #26881: [SPARK-30252][SQL] Disallow negative scale of Decimal URL: https://github.com/apache/spark/pull/26881#issuecomment-575529629 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21690/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #26881: [SPARK-30252][SQL] Disallow negative scale of Decimal
AmplabJenkins removed a comment on issue #26881: [SPARK-30252][SQL] Disallow negative scale of Decimal URL: https://github.com/apache/spark/pull/26881#issuecomment-575529622 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #26881: [SPARK-30252][SQL] Disallow negative scale of Decimal
AmplabJenkins commented on issue #26881: [SPARK-30252][SQL] Disallow negative scale of Decimal URL: https://github.com/apache/spark/pull/26881#issuecomment-575529622 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #26986: [SPARK-30333][CORE][BUILD][BRANCH-2.4] Upgrade jackson-databind to 2.6.7.3
dongjoon-hyun edited a comment on issue #26986: [SPARK-30333][CORE][BUILD][BRANCH-2.4] Upgrade jackson-databind to 2.6.7.3 URL: https://github.com/apache/spark/pull/26986#issuecomment-575524685 Hi, All. It seems that we missed `sbt` build. It's added at #26417 before this PR. I'll make a follow-up. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #26881: [SPARK-30252][SQL] Disallow negative scale of Decimal
AmplabJenkins commented on issue #26881: [SPARK-30252][SQL] Disallow negative scale of Decimal URL: https://github.com/apache/spark/pull/26881#issuecomment-575529629 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21690/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #26881: [SPARK-30252][SQL] Disallow negative scale of Decimal
SparkQA commented on issue #26881: [SPARK-30252][SQL] Disallow negative scale of Decimal URL: https://github.com/apache/spark/pull/26881#issuecomment-575529233 **[Test build #116921 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/116921/testReport)** for PR 26881 at commit [`603aed0`](https://github.com/apache/spark/commit/603aed0231d5df345748319af08ba45547b844ac). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27249: [SPARK-30019][SQL] Add ALTER TABLE SET OWNER syntax
cloud-fan commented on a change in pull request #27249: [SPARK-30019][SQL] Add
ALTER TABLE SET OWNER syntax
URL: https://github.com/apache/spark/pull/27249#discussion_r367819717
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/WriteToDataSourceV2Exec.scala
##
@@ -227,13 +228,14 @@ case class AtomicReplaceTableAsSelectExec(
override protected def doExecute(): RDD[InternalRow] = {
val schema = query.schema.asNullable
+val propertiesWithOwner = withDefaultOwnership(properties).asJava
Review comment:
that also works
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts
AmplabJenkins commented on issue #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts URL: https://github.com/apache/spark/pull/27257#issuecomment-575529111 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts
AmplabJenkins removed a comment on issue #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts URL: https://github.com/apache/spark/pull/27257#issuecomment-575527113 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark
SparkQA commented on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark URL: https://github.com/apache/spark/pull/27251#issuecomment-575529229 **[Test build #116920 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/116920/testReport)** for PR 27251 at commit [`438c8c9`](https://github.com/apache/spark/commit/438c8c9e7513e1ac0af491129fa68f857e83aec0). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zuston commented on issue #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts
zuston commented on issue #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts URL: https://github.com/apache/spark/pull/27257#issuecomment-575528487 > Hi, @zuston . Thank you for making a PR. > Could you attach the screenshot of before and after into the PR description? Of course, as follows. 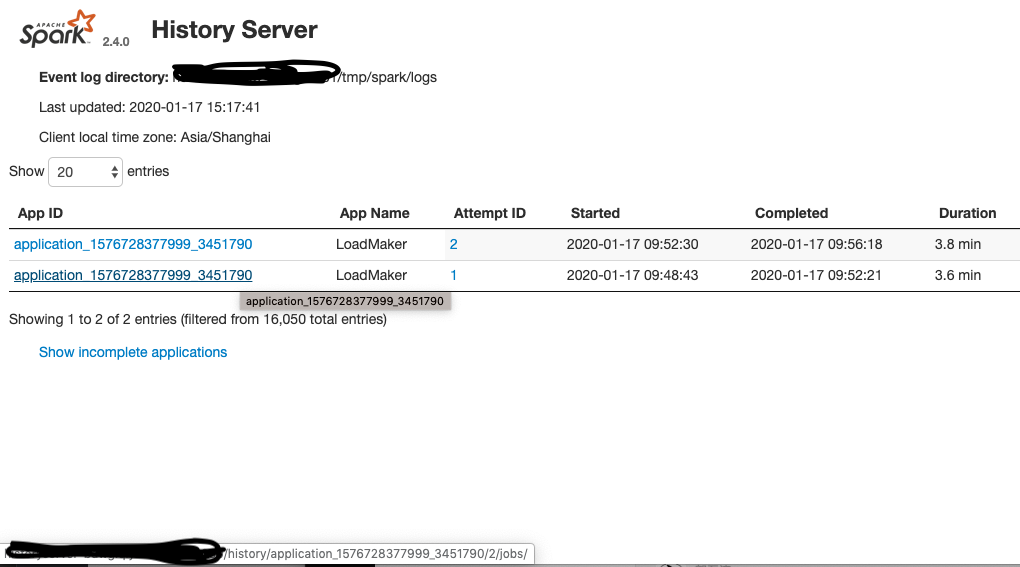 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource
AmplabJenkins removed a comment on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource URL: https://github.com/apache/spark/pull/27199#issuecomment-575527299 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27256: [SPARK-30333][CORE][BUILD][FOLLOWUP][2.4] Update sbt build together
AmplabJenkins removed a comment on issue #27256: [SPARK-30333][CORE][BUILD][FOLLOWUP][2.4] Update sbt build together URL: https://github.com/apache/spark/pull/27256#issuecomment-575527239 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark
AmplabJenkins removed a comment on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark URL: https://github.com/apache/spark/pull/27251#issuecomment-575527251 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark
AmplabJenkins removed a comment on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark URL: https://github.com/apache/spark/pull/27251#issuecomment-575527269 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21688/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27256: [SPARK-30333][CORE][BUILD][FOLLOWUP][2.4] Update sbt build together
AmplabJenkins removed a comment on issue #27256: [SPARK-30333][CORE][BUILD][FOLLOWUP][2.4] Update sbt build together URL: https://github.com/apache/spark/pull/27256#issuecomment-575527245 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21687/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource
AmplabJenkins removed a comment on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource URL: https://github.com/apache/spark/pull/27199#issuecomment-575527308 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21689/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27256: [SPARK-30333][CORE][BUILD][FOLLOWUP][2.4] Update sbt build together
AmplabJenkins commented on issue #27256: [SPARK-30333][CORE][BUILD][FOLLOWUP][2.4] Update sbt build together URL: https://github.com/apache/spark/pull/27256#issuecomment-575527245 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21687/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark
AmplabJenkins commented on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark URL: https://github.com/apache/spark/pull/27251#issuecomment-575527269 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21688/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark
AmplabJenkins commented on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark URL: https://github.com/apache/spark/pull/27251#issuecomment-575527251 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource
AmplabJenkins commented on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource URL: https://github.com/apache/spark/pull/27199#issuecomment-575527308 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21689/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts
dongjoon-hyun commented on issue #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts URL: https://github.com/apache/spark/pull/27257#issuecomment-575527365 Hi, @zuston . Thank you for making a PR. Could you attach the screenshot of before and after into the PR description? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource
AmplabJenkins commented on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource URL: https://github.com/apache/spark/pull/27199#issuecomment-575527299 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27256: [SPARK-30333][CORE][BUILD][FOLLOWUP][2.4] Update sbt build together
AmplabJenkins commented on issue #27256: [SPARK-30333][CORE][BUILD][FOLLOWUP][2.4] Update sbt build together URL: https://github.com/apache/spark/pull/27256#issuecomment-575527239 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts
AmplabJenkins commented on issue #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts URL: https://github.com/apache/spark/pull/27257#issuecomment-575527113 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zuston opened a new pull request #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts
zuston opened a new pull request #27257: [SPARK-30540][Web UI] HistoryServer application link is incorrect when one application having multiple attempts URL: https://github.com/apache/spark/pull/27257 ### What changes were proposed in this pull request? ### Why are the changes needed? When having multiple attempts, the applicaiton link is incorrect. No matter which attempt is clicked, the link still points to the largest attemptId. ### Does this PR introduce any user-facing change? No ### How was this patch tested? Webui involved, may not require testing This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark
dongjoon-hyun commented on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark URL: https://github.com/apache/spark/pull/27251#issuecomment-575527006 Retest this please. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27256: [SPARK-30333][CORE][BUILD][FOLLOWUP][2.4] Update sbt build together
SparkQA commented on issue #27256: [SPARK-30333][CORE][BUILD][FOLLOWUP][2.4] Update sbt build together URL: https://github.com/apache/spark/pull/27256#issuecomment-575526794 **[Test build #116918 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/116918/testReport)** for PR 27256 at commit [`3324def`](https://github.com/apache/spark/commit/3324def0dcac6efc4d2b989a50be26b653563fc0). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource
SparkQA commented on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource URL: https://github.com/apache/spark/pull/27199#issuecomment-575526796 **[Test build #116919 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/116919/testReport)** for PR 27199 at commit [`48e5a26`](https://github.com/apache/spark/commit/48e5a269da8ae2bd3902e160db2a4f0d82ba0c27). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method
AmplabJenkins removed a comment on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method URL: https://github.com/apache/spark/pull/27254#issuecomment-575524675 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun opened a new pull request #27256: [SPARK-30333][CORE][BUILD][FOLLOWUP][2.4] Update sbt build together
dongjoon-hyun opened a new pull request #27256: [SPARK-30333][CORE][BUILD][FOLLOWUP][2.4] Update sbt build together URL: https://github.com/apache/spark/pull/27256 ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce any user-facing change? ### How was this patch tested? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method
AmplabJenkins removed a comment on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method URL: https://github.com/apache/spark/pull/27254#issuecomment-575524679 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21686/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method
AmplabJenkins commented on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method URL: https://github.com/apache/spark/pull/27254#issuecomment-575524675 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method
AmplabJenkins commented on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method URL: https://github.com/apache/spark/pull/27254#issuecomment-575524679 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21686/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource
Ngone51 commented on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource URL: https://github.com/apache/spark/pull/27199#issuecomment-575524733 Jenkins, retest this please. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #26986: [SPARK-30333][CORE][BUILD][BRANCH-2.4] Upgrade jackson-databind to 2.6.7.3
dongjoon-hyun commented on issue #26986: [SPARK-30333][CORE][BUILD][BRANCH-2.4] Upgrade jackson-databind to 2.6.7.3 URL: https://github.com/apache/spark/pull/26986#issuecomment-575524685 Hi, All. It seems that we missed `sbt` build. It's added at #26417 . I'll make a follow-up. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on a change in pull request #27249: [SPARK-30019][SQL] Add ALTER TABLE SET OWNER syntax
yaooqinn commented on a change in pull request #27249: [SPARK-30019][SQL] Add
ALTER TABLE SET OWNER syntax
URL: https://github.com/apache/spark/pull/27249#discussion_r367814229
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/WriteToDataSourceV2Exec.scala
##
@@ -227,13 +228,14 @@ case class AtomicReplaceTableAsSelectExec(
override protected def doExecute(): RDD[InternalRow] = {
val schema = query.schema.asNullable
+val propertiesWithOwner = withDefaultOwnership(properties).asJava
Review comment:
maybe we can add them in DataSourceV2Strategy? then we don't need extra
analyzer rules to copy themselves
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method
SparkQA commented on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method URL: https://github.com/apache/spark/pull/27254#issuecomment-575524224 **[Test build #116917 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/116917/testReport)** for PR 27254 at commit [`e58ceae`](https://github.com/apache/spark/commit/e58ceaecb9722b800fd26c3478edf0ad10c5f738). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27255: [SPARK-30544][BUILD] Upgrade the version of Genjavadoc to 0.15
AmplabJenkins removed a comment on issue #27255: [SPARK-30544][BUILD] Upgrade the version of Genjavadoc to 0.15 URL: https://github.com/apache/spark/pull/27255#issuecomment-575522021 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21685/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27255: [SPARK-30544][BUILD] Upgrade the version of Genjavadoc to 0.15
AmplabJenkins removed a comment on issue #27255: [SPARK-30544][BUILD] Upgrade the version of Genjavadoc to 0.15 URL: https://github.com/apache/spark/pull/27255#issuecomment-575522014 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27255: [SPARK-30544][BUILD] Upgrade the version of Genjavadoc to 0.15
AmplabJenkins commented on issue #27255: [SPARK-30544][BUILD] Upgrade the version of Genjavadoc to 0.15 URL: https://github.com/apache/spark/pull/27255#issuecomment-575522014 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27255: [SPARK-30544][BUILD] Upgrade the version of Genjavadoc to 0.15
AmplabJenkins commented on issue #27255: [SPARK-30544][BUILD] Upgrade the version of Genjavadoc to 0.15 URL: https://github.com/apache/spark/pull/27255#issuecomment-575522021 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/21685/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27255: [SPARK-30544][BUILD] Upgrade the version of Genjavadoc to 0.15
SparkQA commented on issue #27255: [SPARK-30544][BUILD] Upgrade the version of Genjavadoc to 0.15 URL: https://github.com/apache/spark/pull/27255#issuecomment-575521527 **[Test build #116916 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/116916/testReport)** for PR 27255 at commit [`6de473e`](https://github.com/apache/spark/commit/6de473ed19e33050e57cc4875fb4cdcddef9c005). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] fuwhu commented on a change in pull request #26805: [SPARK-15616][SQL] Add optimizer rule PruneHiveTablePartitions
fuwhu commented on a change in pull request #26805: [SPARK-15616][SQL] Add
optimizer rule PruneHiveTablePartitions
URL: https://github.com/apache/spark/pull/26805#discussion_r367810100
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/PruneHiveTablePartitions.scala
##
@@ -0,0 +1,109 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import org.apache.hadoop.hive.common.StatsSetupConst
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.catalyst.analysis.CastSupport
+import org.apache.spark.sql.catalyst.catalog.{CatalogStatistics, CatalogTable,
CatalogTablePartition, ExternalCatalogUtils, HiveTableRelation}
+import org.apache.spark.sql.catalyst.expressions.{And, AttributeSet,
Expression, ExpressionSet, SubqueryExpression}
+import org.apache.spark.sql.catalyst.planning.PhysicalOperation
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LogicalPlan,
Project}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.datasources.DataSourceStrategy
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * TODO: merge this with PruneFileSourcePartitions after we completely make
hive as a data source.
+ */
+private[sql] class PruneHiveTablePartitions(session: SparkSession)
+ extends Rule[LogicalPlan] with CastSupport {
+
+ override val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Extract the partition filters from the filters on the table.
+ */
+ private def getPartitionKeyFilters(
+ filters: Seq[Expression],
+ relation: HiveTableRelation): ExpressionSet = {
+val normalizedFilters = DataSourceStrategy.normalizeExprs(
+ filters.filter(f => f.deterministic &&
!SubqueryExpression.hasSubquery(f)), relation.output)
+val partitionColumnSet = AttributeSet(relation.partitionCols)
+ExpressionSet(normalizedFilters.filter { f =>
+ !f.references.isEmpty && f.references.subsetOf(partitionColumnSet)
+})
+ }
+
+ /**
+ * Prune the hive table using filters on the partitions of the table.
+ */
+ private def prunePartitions(
+ relation: HiveTableRelation,
+ partitionFilters: ExpressionSet): Seq[CatalogTablePartition] = {
+if (conf.metastorePartitionPruning) {
+ session.sessionState.catalog.listPartitionsByFilter(
+relation.tableMeta.identifier, partitionFilters.toSeq)
+} else {
+ ExternalCatalogUtils.prunePartitionsByFilter(relation.tableMeta,
Review comment:
you mean totally remove this if clause and always call
"session.sessionState.catalog.listPartitionsByFilter" ?
it means always pushing down to hive metadata for pruning and also make sure
returned partitions are exactly what we want. is that expected ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sarutak opened a new pull request #27255: [SPARK-30544][BUILD] Upgrade the version of Genjavadoc to 0.15
sarutak opened a new pull request #27255: [SPARK-30544][BUILD] Upgrade the version of Genjavadoc to 0.15 URL: https://github.com/apache/spark/pull/27255 ### What changes were proposed in this pull request? Upgrade the version of Genjavadoc from 0.14 to 0.15. ### Why are the changes needed? To enable to build for Scala 2.13. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? I confirmed there is no dependency error related to genjavadoc by manual build. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] fuwhu commented on a change in pull request #26805: [SPARK-15616][SQL] Add optimizer rule PruneHiveTablePartitions
fuwhu commented on a change in pull request #26805: [SPARK-15616][SQL] Add
optimizer rule PruneHiveTablePartitions
URL: https://github.com/apache/spark/pull/26805#discussion_r367810100
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/PruneHiveTablePartitions.scala
##
@@ -0,0 +1,109 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import org.apache.hadoop.hive.common.StatsSetupConst
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.catalyst.analysis.CastSupport
+import org.apache.spark.sql.catalyst.catalog.{CatalogStatistics, CatalogTable,
CatalogTablePartition, ExternalCatalogUtils, HiveTableRelation}
+import org.apache.spark.sql.catalyst.expressions.{And, AttributeSet,
Expression, ExpressionSet, SubqueryExpression}
+import org.apache.spark.sql.catalyst.planning.PhysicalOperation
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LogicalPlan,
Project}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.datasources.DataSourceStrategy
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * TODO: merge this with PruneFileSourcePartitions after we completely make
hive as a data source.
+ */
+private[sql] class PruneHiveTablePartitions(session: SparkSession)
+ extends Rule[LogicalPlan] with CastSupport {
+
+ override val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Extract the partition filters from the filters on the table.
+ */
+ private def getPartitionKeyFilters(
+ filters: Seq[Expression],
+ relation: HiveTableRelation): ExpressionSet = {
+val normalizedFilters = DataSourceStrategy.normalizeExprs(
+ filters.filter(f => f.deterministic &&
!SubqueryExpression.hasSubquery(f)), relation.output)
+val partitionColumnSet = AttributeSet(relation.partitionCols)
+ExpressionSet(normalizedFilters.filter { f =>
+ !f.references.isEmpty && f.references.subsetOf(partitionColumnSet)
+})
+ }
+
+ /**
+ * Prune the hive table using filters on the partitions of the table.
+ */
+ private def prunePartitions(
+ relation: HiveTableRelation,
+ partitionFilters: ExpressionSet): Seq[CatalogTablePartition] = {
+if (conf.metastorePartitionPruning) {
+ session.sessionState.catalog.listPartitionsByFilter(
+relation.tableMeta.identifier, partitionFilters.toSeq)
+} else {
+ ExternalCatalogUtils.prunePartitionsByFilter(relation.tableMeta,
Review comment:
you mean totally remove this if clause and always call
"session.sessionState.catalog.listPartitionsByFilter" ?
it means already pushing down to hive metadata for pruning and also make
sure returned partitions are exactly what we want. is that expected ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #26201: [SPARK-29543][SS][UI] Init structured streaming ui
AmplabJenkins removed a comment on issue #26201: [SPARK-29543][SS][UI] Init structured streaming ui URL: https://github.com/apache/spark/pull/26201#issuecomment-575520306 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116899/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource
AmplabJenkins removed a comment on issue #27199: [SPARK-30508][SQL] Add SparkSession.executeCommand API for external datasource URL: https://github.com/apache/spark/pull/27199#issuecomment-575520108 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116904/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #26921: [SPARK-30282][SQL] Migrate SHOW TBLPROPERTIES to new framework
AmplabJenkins removed a comment on issue #26921: [SPARK-30282][SQL] Migrate SHOW TBLPROPERTIES to new framework URL: https://github.com/apache/spark/pull/26921#issuecomment-575520137 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116905/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark
AmplabJenkins removed a comment on issue #27251: [SPARK-30539][PYTHON][SQL] Add DataFrame.tail in PySpark URL: https://github.com/apache/spark/pull/27251#issuecomment-575520145 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116900/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27249: [SPARK-30019][SQL] Add ALTER TABLE SET OWNER syntax
AmplabJenkins removed a comment on issue #27249: [SPARK-30019][SQL] Add ALTER TABLE SET OWNER syntax URL: https://github.com/apache/spark/pull/27249#issuecomment-575520013 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116914/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27058: [SPARK-30276][SQL] Support Filter expression allows simultaneous use of DISTINCT
AmplabJenkins removed a comment on issue #27058: [SPARK-30276][SQL] Support Filter expression allows simultaneous use of DISTINCT URL: https://github.com/apache/spark/pull/27058#issuecomment-575520172 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116895/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] fuwhu commented on a change in pull request #26805: [SPARK-15616][SQL] Add optimizer rule PruneHiveTablePartitions
fuwhu commented on a change in pull request #26805: [SPARK-15616][SQL] Add
optimizer rule PruneHiveTablePartitions
URL: https://github.com/apache/spark/pull/26805#discussion_r367810100
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/PruneHiveTablePartitions.scala
##
@@ -0,0 +1,109 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import org.apache.hadoop.hive.common.StatsSetupConst
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.catalyst.analysis.CastSupport
+import org.apache.spark.sql.catalyst.catalog.{CatalogStatistics, CatalogTable,
CatalogTablePartition, ExternalCatalogUtils, HiveTableRelation}
+import org.apache.spark.sql.catalyst.expressions.{And, AttributeSet,
Expression, ExpressionSet, SubqueryExpression}
+import org.apache.spark.sql.catalyst.planning.PhysicalOperation
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LogicalPlan,
Project}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.datasources.DataSourceStrategy
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * TODO: merge this with PruneFileSourcePartitions after we completely make
hive as a data source.
+ */
+private[sql] class PruneHiveTablePartitions(session: SparkSession)
+ extends Rule[LogicalPlan] with CastSupport {
+
+ override val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Extract the partition filters from the filters on the table.
+ */
+ private def getPartitionKeyFilters(
+ filters: Seq[Expression],
+ relation: HiveTableRelation): ExpressionSet = {
+val normalizedFilters = DataSourceStrategy.normalizeExprs(
+ filters.filter(f => f.deterministic &&
!SubqueryExpression.hasSubquery(f)), relation.output)
+val partitionColumnSet = AttributeSet(relation.partitionCols)
+ExpressionSet(normalizedFilters.filter { f =>
+ !f.references.isEmpty && f.references.subsetOf(partitionColumnSet)
+})
+ }
+
+ /**
+ * Prune the hive table using filters on the partitions of the table.
+ */
+ private def prunePartitions(
+ relation: HiveTableRelation,
+ partitionFilters: ExpressionSet): Seq[CatalogTablePartition] = {
+if (conf.metastorePartitionPruning) {
+ session.sessionState.catalog.listPartitionsByFilter(
+relation.tableMeta.identifier, partitionFilters.toSeq)
+} else {
+ ExternalCatalogUtils.prunePartitionsByFilter(relation.tableMeta,
Review comment:
you mean totally remove this if statement and always call
"session.sessionState.catalog.listPartitionsByFilter" ?
it means already pushing down to hive metadata for pruning and also make
sure returned partitions are exactly what we want. is that expected ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] fuwhu commented on a change in pull request #26805: [SPARK-15616][SQL] Add optimizer rule PruneHiveTablePartitions
fuwhu commented on a change in pull request #26805: [SPARK-15616][SQL] Add
optimizer rule PruneHiveTablePartitions
URL: https://github.com/apache/spark/pull/26805#discussion_r367810100
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/PruneHiveTablePartitions.scala
##
@@ -0,0 +1,109 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import org.apache.hadoop.hive.common.StatsSetupConst
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.catalyst.analysis.CastSupport
+import org.apache.spark.sql.catalyst.catalog.{CatalogStatistics, CatalogTable,
CatalogTablePartition, ExternalCatalogUtils, HiveTableRelation}
+import org.apache.spark.sql.catalyst.expressions.{And, AttributeSet,
Expression, ExpressionSet, SubqueryExpression}
+import org.apache.spark.sql.catalyst.planning.PhysicalOperation
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LogicalPlan,
Project}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.execution.datasources.DataSourceStrategy
+import org.apache.spark.sql.internal.SQLConf
+
+/**
+ * TODO: merge this with PruneFileSourcePartitions after we completely make
hive as a data source.
+ */
+private[sql] class PruneHiveTablePartitions(session: SparkSession)
+ extends Rule[LogicalPlan] with CastSupport {
+
+ override val conf: SQLConf = session.sessionState.conf
+
+ /**
+ * Extract the partition filters from the filters on the table.
+ */
+ private def getPartitionKeyFilters(
+ filters: Seq[Expression],
+ relation: HiveTableRelation): ExpressionSet = {
+val normalizedFilters = DataSourceStrategy.normalizeExprs(
+ filters.filter(f => f.deterministic &&
!SubqueryExpression.hasSubquery(f)), relation.output)
+val partitionColumnSet = AttributeSet(relation.partitionCols)
+ExpressionSet(normalizedFilters.filter { f =>
+ !f.references.isEmpty && f.references.subsetOf(partitionColumnSet)
+})
+ }
+
+ /**
+ * Prune the hive table using filters on the partitions of the table.
+ */
+ private def prunePartitions(
+ relation: HiveTableRelation,
+ partitionFilters: ExpressionSet): Seq[CatalogTablePartition] = {
+if (conf.metastorePartitionPruning) {
+ session.sessionState.catalog.listPartitionsByFilter(
+relation.tableMeta.identifier, partitionFilters.toSeq)
+} else {
+ ExternalCatalogUtils.prunePartitionsByFilter(relation.tableMeta,
Review comment:
you mean totally remove this if clause and always call
"session.sessionState.catalog.listPartitionsByFilter" ?
it means already pushing down to hive metadata for pruning and also make
sure returned partitions are exactly what we want. is that expected ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27253: [SPARK-30524] [SQL] follow up SPARK-30524 to resolve comments
AmplabJenkins removed a comment on issue #27253: [SPARK-30524] [SQL] follow up SPARK-30524 to resolve comments URL: https://github.com/apache/spark/pull/27253#issuecomment-575520027 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116910/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method
AmplabJenkins removed a comment on issue #27254: [SPARK-30543][ML][PYSPARK] RandomForest add Param bootstrap to control sampling method URL: https://github.com/apache/spark/pull/27254#issuecomment-575519996 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116913/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #26675: [SPARK-30041][SQL][WEBUI] Add Codegen Stage Id to Stage DAG visualization in Web UI
AmplabJenkins removed a comment on issue #26675: [SPARK-30041][SQL][WEBUI] Add Codegen Stage Id to Stage DAG visualization in Web UI URL: https://github.com/apache/spark/pull/26675#issuecomment-575520125 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116902/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #26201: [SPARK-29543][SS][UI] Init structured streaming ui
AmplabJenkins removed a comment on issue #26201: [SPARK-29543][SS][UI] Init structured streaming ui URL: https://github.com/apache/spark/pull/26201#issuecomment-575520300 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint
AmplabJenkins removed a comment on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint URL: https://github.com/apache/spark/pull/27252#issuecomment-575520034 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116909/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #26675: [SPARK-30041][SQL][WEBUI] Add Codegen Stage Id to Stage DAG visualization in Web UI
AmplabJenkins removed a comment on issue #26675: [SPARK-30041][SQL][WEBUI] Add Codegen Stage Id to Stage DAG visualization in Web UI URL: https://github.com/apache/spark/pull/26675#issuecomment-575520112 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27058: [SPARK-30276][SQL] Support Filter expression allows simultaneous use of DISTINCT
AmplabJenkins removed a comment on issue #27058: [SPARK-30276][SQL] Support Filter expression allows simultaneous use of DISTINCT URL: https://github.com/apache/spark/pull/27058#issuecomment-575519997 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/116915/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org