[GitHub] [spark] SparkQA commented on issue #26193: [SPARK-25065][k8s] Allow setting up correct logging configuration on driver and executor.
SparkQA commented on issue #26193: [SPARK-25065][k8s] Allow setting up correct logging configuration on driver and executor. URL: https://github.com/apache/spark/pull/26193#issuecomment-588084045 **[Test build #118665 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118665/testReport)** for PR 26193 at commit [`9372b62`](https://github.com/apache/spark/commit/9372b625ff0673c82f13e5405ef082a94ed9abd9). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization"
cloud-fan closed pull request #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization" URL: https://github.com/apache/spark/pull/27630 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization"
cloud-fan commented on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization" URL: https://github.com/apache/spark/pull/27630#issuecomment-588083598 thanks, merging to master/3.0! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured
AmplabJenkins removed a comment on issue #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured URL: https://github.com/apache/spark/pull/27633#issuecomment-588081768 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/23416/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured
AmplabJenkins removed a comment on issue #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured URL: https://github.com/apache/spark/pull/27633#issuecomment-588081759 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured
AmplabJenkins commented on issue #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured URL: https://github.com/apache/spark/pull/27633#issuecomment-588081768 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/23416/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured
AmplabJenkins commented on issue #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured URL: https://github.com/apache/spark/pull/27633#issuecomment-588081759 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured
SparkQA commented on issue #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured URL: https://github.com/apache/spark/pull/27633#issuecomment-588081239 **[Test build #118664 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118664/testReport)** for PR 27633 at commit [`936c5b3`](https://github.com/apache/spark/commit/936c5b313c4cbb39713ba6b738b877b38c28a930). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xuanyuanking commented on issue #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured
xuanyuanking commented on issue #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured URL: https://github.com/apache/spark/pull/27633#issuecomment-588081209 cc @cloud-fan @gatorsmile This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xuanyuanking opened a new pull request #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured
xuanyuanking opened a new pull request #27633: [SPARK-30556][SQL][BACKPORT-2.4] Reset the status changed in SQLExecution withThreadLocalCaptured URL: https://github.com/apache/spark/pull/27633 ### What changes were proposed in this pull request? Follow up for #27267, reset the status changed in SQLExecution.withThreadLocalCaptured. ### Why are the changes needed? For code safety. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Existing UT. (cherry picked from commit a6b91d2bf727e175d0e175295001db85647539b1) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on issue #27431: [MINOR][SQL] Improve readability for window execution
beliefer commented on issue #27431: [MINOR][SQL] Improve readability for window execution URL: https://github.com/apache/spark/pull/27431#issuecomment-588075144 @cloud-fan @hvanhovell @HyukjinKwon @dongjoon-hyun Thanks for all your help. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] prakharjain09 edited a comment on issue #27539: [SPARK-30786] [CORE] Fix Block replication failure propogation issue in BlockManager
prakharjain09 edited a comment on issue #27539: [SPARK-30786] [CORE] Fix Block replication failure propogation issue in BlockManager URL: https://github.com/apache/spark/pull/27539#issuecomment-588066491 @Ngone51 @cloud-fan Can you please approve and merge the changes if everything looks good. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #27538: [SPARK-30785][SQL] Create table like should keep tracksPartitionsInCatalog same with source table
cloud-fan commented on issue #27538: [SPARK-30785][SQL] Create table like should keep tracksPartitionsInCatalog same with source table URL: https://github.com/apache/spark/pull/27538#issuecomment-588067924 thanks, merging to master/3.0! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #27538: [SPARK-30785][SQL] Create table like should keep tracksPartitionsInCatalog same with source table
cloud-fan closed pull request #27538: [SPARK-30785][SQL] Create table like should keep tracksPartitionsInCatalog same with source table URL: https://github.com/apache/spark/pull/27538 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] prakharjain09 commented on issue #27539: [SPARK-30786] [CORE] Fix Block replication failure propogation issue in BlockManager
prakharjain09 commented on issue #27539: [SPARK-30786] [CORE] Fix Block replication failure propogation issue in BlockManager URL: https://github.com/apache/spark/pull/27539#issuecomment-588066491 @Ngone51 @cloud-fan Can you please review and merge the changes if everything looks good. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] prakharjain09 commented on issue #27539: [SPARK-30786] [CORE] Fix Block replication failure propogation issue in BlockManager
prakharjain09 commented on issue #27539: [SPARK-30786] [CORE] Fix Block replication failure propogation issue in BlockManager URL: https://github.com/apache/spark/pull/27539#issuecomment-588066239 > @prakharjain09 actually, you could also try "Jenkins, retest this please" when you want to re-trigger the test. As per https://spark.apache.org/contributing.html page, a Committer has to add me to whitelist using "Jenkins, add to whitelist" :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on issue #27398: [SPARK-30481][DOCS][FOLLOWUP] Document event log compaction into new section of monitoring.md
HeartSaVioR commented on issue #27398: [SPARK-30481][DOCS][FOLLOWUP] Document event log compaction into new section of monitoring.md URL: https://github.com/apache/spark/pull/27398#issuecomment-588065574 @dongjoon-hyun @tgravescs Kindly reminder. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27632: [WIP][SPARK-30872][SQL] Constraints inferred from inferred attributes
AmplabJenkins removed a comment on issue #27632: [WIP][SPARK-30872][SQL] Constraints inferred from inferred attributes URL: https://github.com/apache/spark/pull/27632#issuecomment-588059400 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/23415/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27632: [WIP][SPARK-30872][SQL] Constraints inferred from inferred attributes
AmplabJenkins removed a comment on issue #27632: [WIP][SPARK-30872][SQL] Constraints inferred from inferred attributes URL: https://github.com/apache/spark/pull/27632#issuecomment-588059392 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27632: [WIP][SPARK-30872][SQL] Constraints inferred from inferred attributes
AmplabJenkins commented on issue #27632: [WIP][SPARK-30872][SQL] Constraints inferred from inferred attributes URL: https://github.com/apache/spark/pull/27632#issuecomment-588059400 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/23415/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27632: [WIP][SPARK-30872][SQL] Constraints inferred from inferred attributes
AmplabJenkins commented on issue #27632: [WIP][SPARK-30872][SQL] Constraints inferred from inferred attributes URL: https://github.com/apache/spark/pull/27632#issuecomment-588059392 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27632: [WIP][SPARK-30872][SQL] Constraints inferred from inferred attributes
SparkQA commented on issue #27632: [WIP][SPARK-30872][SQL] Constraints inferred from inferred attributes URL: https://github.com/apache/spark/pull/27632#issuecomment-588058965 **[Test build #118663 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118663/testReport)** for PR 27632 at commit [`2fe8253`](https://github.com/apache/spark/commit/2fe825302bb6c9252ee135f9febfe339b9af74be). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum opened a new pull request #27632: [WIP][SPARK-30872][SQL] Constraints inferred from inferred attributes
wangyum opened a new pull request #27632: [WIP][SPARK-30872][SQL] Constraints
inferred from inferred attributes
URL: https://github.com/apache/spark/pull/27632
### What changes were proposed in this pull request?
This PR fix a special case about infer additional constraints. How to
reproduce this issue:
```scala
scala> spark.range(20).selectExpr("id as a", "id as b", "id as
c").write.saveAsTable("t1")
scala> spark.sql("select count(*) from t1 where a = b and b = c and (c = 3
or c = 13)").explain(false)
== Physical Plan ==
*(2) HashAggregate(keys=[], functions=[count(1)])
+- Exchange SinglePartition, true, [id=#76]
+- *(1) HashAggregate(keys=[], functions=[partial_count(1)])
+- *(1) Project
+- *(1) Filter (((isnotnull(c#36L) AND ((b#35L = 3) OR (b#35L =
13))) AND isnotnull(b#35L)) AND (a#34L = c#36L)) AND isnotnull(a#34L)) AND
(a#34L = b#35L)) AND (b#35L = c#36L)) AND ((c#36L = 3) OR (c#36L = 13)))
+- *(1) ColumnarToRow
+- FileScan parquet default.t1[a#34L,b#35L,c#36L] Batched:
true, DataFilters: [isnotnull(c#36L), ((b#35L = 3) OR (b#35L = 13)),
isnotnull(b#35L), (a#34L = c#36L), isnotnull(a#..., Format: Parquet, Location:
InMemoryFileIndex[file:/Users/yumwang/Downloads/spark-3.0.0-preview2-bin-hadoop2.7/spark-warehous...,
PartitionFilters: [], PushedFilters: [IsNotNull(c),
Or(EqualTo(b,3),EqualTo(b,13)), IsNotNull(b), IsNotNull(a),
Or(EqualTo(c,3),EqualT..., ReadSchema: struct
```
We can infer more constraints: `(a#34L = 3) OR (a#34L = 13)`.
### Why are the changes needed?
Improve query performance.
### Does this PR introduce any user-facing change?
No.
### How was this patch tested?
Unit test.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #27431: [MINOR][SQL] Improve readability for window execution
cloud-fan commented on issue #27431: [MINOR][SQL] Improve readability for window execution URL: https://github.com/apache/spark/pull/27431#issuecomment-588057354 thanks, merging to master/3.0! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #27431: [MINOR][SQL] Improve readability for window execution
cloud-fan closed pull request #27431: [MINOR][SQL] Improve readability for window execution URL: https://github.com/apache/spark/pull/27431 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization"
AmplabJenkins removed a comment on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization" URL: https://github.com/apache/spark/pull/27630#issuecomment-588049830 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization"
AmplabJenkins removed a comment on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization" URL: https://github.com/apache/spark/pull/27630#issuecomment-588049843 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118660/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization"
AmplabJenkins commented on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization" URL: https://github.com/apache/spark/pull/27630#issuecomment-588049843 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118660/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization"
AmplabJenkins commented on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization" URL: https://github.com/apache/spark/pull/27630#issuecomment-588049830 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization"
SparkQA removed a comment on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization" URL: https://github.com/apache/spark/pull/27630#issuecomment-587991700 **[Test build #118660 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118660/testReport)** for PR 27630 at commit [`2734b24`](https://github.com/apache/spark/commit/2734b249a2e276cc0e8a5c7cfe278137b24686bf). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization"
SparkQA commented on issue #27630: [SPARK-30812] [SQL] update the skew join configs by adding the prefix "skewedJoinOptimization" URL: https://github.com/apache/spark/pull/27630#issuecomment-588049265 **[Test build #118660 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118660/testReport)** for PR 27630 at commit [`2734b24`](https://github.com/apache/spark/commit/2734b249a2e276cc0e8a5c7cfe278137b24686bf). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27628: [SPARK-30858][SQL] Make IntegralDivide's dataType independent from SQL config changes
cloud-fan commented on a change in pull request #27628: [SPARK-30858][SQL] Make
IntegralDivide's dataType independent from SQL config changes
URL: https://github.com/apache/spark/pull/27628#discussion_r381090086
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/arithmetic.scala
##
@@ -403,11 +403,18 @@ case class Divide(left: Expression, right: Expression)
extends DivModLike {
""",
since = "3.0.0")
// scalastyle:on line.size.limit
-case class IntegralDivide(left: Expression, right: Expression) extends
DivModLike {
+case class IntegralDivide(
+left: Expression,
+right: Expression,
+returnLong: Boolean) extends DivModLike {
Review comment:
can we just add a `private val returnLong =
SQLConf.get.integralDivideReturnLong` in the class body? Then the config value
is fixed when the expression is created. And it can be serialized to executors.
The spark Expression constructor is kind of exposed to end users when they
call functions in SQL. BTW `Cast` already use a `val` to store config values.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27580: [SPARK-27619][SQL]MapType should be prohibited in hash expressions
AmplabJenkins removed a comment on issue #27580: [SPARK-27619][SQL]MapType should be prohibited in hash expressions URL: https://github.com/apache/spark/pull/27580#issuecomment-588047727 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/23414/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract
AmplabJenkins removed a comment on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract URL: https://github.com/apache/spark/pull/27631#issuecomment-588047672 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/23413/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27580: [SPARK-27619][SQL]MapType should be prohibited in hash expressions
AmplabJenkins removed a comment on issue #27580: [SPARK-27619][SQL]MapType should be prohibited in hash expressions URL: https://github.com/apache/spark/pull/27580#issuecomment-588047720 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract
AmplabJenkins removed a comment on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract URL: https://github.com/apache/spark/pull/27631#issuecomment-588047668 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27580: [SPARK-27619][SQL]MapType should be prohibited in hash expressions
AmplabJenkins commented on issue #27580: [SPARK-27619][SQL]MapType should be prohibited in hash expressions URL: https://github.com/apache/spark/pull/27580#issuecomment-588047727 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/23414/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27580: [SPARK-27619][SQL]MapType should be prohibited in hash expressions
AmplabJenkins commented on issue #27580: [SPARK-27619][SQL]MapType should be prohibited in hash expressions URL: https://github.com/apache/spark/pull/27580#issuecomment-588047720 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract
AmplabJenkins commented on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract URL: https://github.com/apache/spark/pull/27631#issuecomment-588047672 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/23413/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract
AmplabJenkins commented on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract URL: https://github.com/apache/spark/pull/27631#issuecomment-588047668 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27622: [SPARK-27528][followup] improve migration guide
cloud-fan commented on a change in pull request #27622: [SPARK-27528][followup] improve migration guide URL: https://github.com/apache/spark/pull/27622#discussion_r381088243 ## File path: docs/sql-migration-guide.md ## @@ -87,7 +87,7 @@ license: | - In Spark version 2.4, when a spark session is created via `cloneSession()`, the newly created spark session inherits its configuration from its parent `SparkContext` even though the same configuration may exist with a different value in its parent spark session. Since Spark 3.0, the configurations of a parent `SparkSession` have a higher precedence over the parent `SparkContext`. The old behavior can be restored by setting `spark.sql.legacy.sessionInitWithConfigDefaults` to `true`. - - Since Spark 3.0, parquet logical type `TIMESTAMP_MICROS` is used by default while saving `TIMESTAMP` columns. In Spark version 2.4 and earlier, `TIMESTAMP` columns are saved as `INT96` in parquet files. To set `INT96` to `spark.sql.parquet.outputTimestampType` restores the previous behavior. + - Since Spark 3.0, parquet logical type `TIMESTAMP_MICROS` is used by default while saving `TIMESTAMP` columns. In Spark version 2.4 and earlier, `TIMESTAMP` columns are saved as `INT96` in parquet files. Note that, some SQL systems like Impala 2.x can only read `INT96` timestamps, you can set `spark.sql.parquet.outputTimestampType` as `INT96` to restore the previous behavior and keep interoperability. Review comment: Parquet is an open format and interoperability is important. I know Impala supports the logical timestamp since 3.2.0, that why I use "Impala 2.x" here. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27580: [SPARK-27619][SQL]MapType should be prohibited in hash expressions
SparkQA commented on issue #27580: [SPARK-27619][SQL]MapType should be prohibited in hash expressions URL: https://github.com/apache/spark/pull/27580#issuecomment-588047393 **[Test build #118662 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118662/testReport)** for PR 27580 at commit [`ab27a0f`](https://github.com/apache/spark/commit/ab27a0fc9b0f0599a7e1b92aa584b5a6e111a88e). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract
SparkQA commented on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract URL: https://github.com/apache/spark/pull/27631#issuecomment-588047374 **[Test build #118661 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118661/testReport)** for PR 27631 at commit [`6a62d2f`](https://github.com/apache/spark/commit/6a62d2fc0c68be94d50810c82b24dcd620b63cce). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] iRakson commented on a change in pull request #27580: [SPARK-27619][SQL]MapType should be prohibited in hash expressions
iRakson commented on a change in pull request #27580: [SPARK-27619][SQL]MapType
should be prohibited in hash expressions
URL: https://github.com/apache/spark/pull/27580#discussion_r381088173
##
File path: sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
##
@@ -2121,6 +2121,26 @@ class SQLQuerySuite extends QueryTest with
SharedSparkSession with AdaptiveSpark
}
}
+ test("SPARK-27619: Throw analysis exception when hash and xxhash64 is used
on MapType") {
+Seq("hash", "xxhash64").foreach {
+ case hashExpression =>
+intercept[AnalysisException] {
+ spark.createDataset(Map(1 -> 10, 2 -> 20) ::
Nil).selectExpr(s"$hashExpression(*)")
+}
+}
+ }
+
+ test("SPARK-27619: when spark.sql.legacy.useHashOnMapType is true, hash can
be used on Maptype") {
+Seq("hash", "xxhash64").foreach {
+ case hashExpression =>
Review comment:
I modified the code.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract
beliefer commented on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract URL: https://github.com/apache/spark/pull/27631#issuecomment-588047099 cc @cloud-fan This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer edited a comment on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract
beliefer edited a comment on issue #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract URL: https://github.com/apache/spark/pull/27631#issuecomment-588047099 cc @cloud-fan @maropu This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer opened a new pull request #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract
beliefer opened a new pull request #27631: [SPARK-30763][SQL][FOLLOWUP] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract URL: https://github.com/apache/spark/pull/27631 ### What changes were proposed in this pull request? This PR follows https://github.com/apache/spark/pull/27508 and used to spark2.4. ### Why are the changes needed? Fix a bug `java.lang.IndexOutOfBoundsException No group 1` ### Does this PR introduce any user-facing change? Yes ### How was this patch tested? New UT. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #27624: [SPARK-30814][SQL][3.0] ALTER TABLE ... ADD COLUMN position should be able to reference columns being added
cloud-fan commented on issue #27624: [SPARK-30814][SQL][3.0] ALTER TABLE ... ADD COLUMN position should be able to reference columns being added URL: https://github.com/apache/spark/pull/27624#issuecomment-588046095 thanks, merging to 3.0! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jiangxb1987 commented on a change in pull request #27072: [SPARK-30404][Core] Fix wrong log for FetchFailed task's successful speculation
jiangxb1987 commented on a change in pull request #27072: [SPARK-30404][Core]
Fix wrong log for FetchFailed task's successful speculation
URL: https://github.com/apache/spark/pull/27072#discussion_r381084318
##
File path: core/src/main/scala/org/apache/spark/scheduler/TaskSetManager.scala
##
@@ -879,11 +889,12 @@ private[spark] class TaskSetManager(
}
}
-if (successful(index)) {
- logInfo(s"Task ${info.id} in stage ${taskSet.id} (TID $tid) failed, but
the task will not" +
-s" be re-executed (either because the task failed with a shuffle data
fetch failure," +
-s" so the previous stage needs to be re-run, or because a different
copy of the task" +
-s" has already succeeded).")
+if (fetchFailedIndex.contains(index)) {
Review comment:
This log info mainly inform the user that we won't re=execute the failed
task, it makes little sense to differentiate between FetchFailed tasks and
speculative tasks.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27550: [SPARK-30799][SQL] "spark_catalog.t" should not be resolved to temp view
cloud-fan commented on a change in pull request #27550: [SPARK-30799][SQL]
"spark_catalog.t" should not be resolved to temp view
URL: https://github.com/apache/spark/pull/27550#discussion_r381082389
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/connector/catalog/LookupCatalog.scala
##
@@ -94,6 +94,10 @@ private[sql] trait LookupCatalog extends Logging {
* Extract catalog and identifier from a multi-part name with the current
catalog if needed.
* Catalog name takes precedence over identifier, but for a single-part
name, identifier takes
* precedence over catalog name.
+ *
+ * Note that, this pattern is used to look up permanent catalog objects like
table, view,
+ * function, etc. If you need to look up temp objects like temp view, please
do it separately
+ * before calling this pattern, as temp objects don't belong to any catalog.
Review comment:
> our internal SessionCatalog also manages temp objects
We can move them out and put it in a temp view manager like the
`GlobalTempViewManager`. I'm talking more about the theory.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #27596: [SPARK-30843][SQL] Fix getting of time components before 1582 year
cloud-fan commented on a change in pull request #27596: [SPARK-30843][SQL] Fix getting of time components before 1582 year URL: https://github.com/apache/spark/pull/27596#discussion_r381081926 ## File path: sql/core/benchmarks/DateTimeBenchmark-results.txt ## @@ -2,428 +2,428 @@ Extract components -OpenJDK 64-Bit Server VM 1.8.0_232-8u232-b09-0ubuntu1~18.04.1-b09 on Linux 4.15.0-1044-aws +OpenJDK 64-Bit Server VM 1.8.0_242-8u242-b08-0ubuntu3~18.04-b08 on Linux 4.15.0-1044-aws Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz cast to timestamp:Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative -cast to timestamp wholestage off425447 30 23.5 42.5 1.0X -cast to timestamp wholestage on 368401 29 27.2 36.8 1.2X +cast to timestamp wholestage off447462 21 22.4 44.7 1.0X +cast to timestamp wholestage on 390426 54 25.7 39.0 1.1X -OpenJDK 64-Bit Server VM 1.8.0_232-8u232-b09-0ubuntu1~18.04.1-b09 on Linux 4.15.0-1044-aws +OpenJDK 64-Bit Server VM 1.8.0_242-8u242-b08-0ubuntu3~18.04-b08 on Linux 4.15.0-1044-aws Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz year of timestamp:Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative -year of timestamp wholestage off 1158 1215 80 8.6 115.8 1.0X -year of timestamp wholestage on1158 1179 31 8.6 115.8 1.0X +year of timestamp wholestage off 1189 1285 135 8.4 118.9 1.0X +year of timestamp wholestage on1146 1156 9 8.7 114.6 1.0X -OpenJDK 64-Bit Server VM 1.8.0_232-8u232-b09-0ubuntu1~18.04.1-b09 on Linux 4.15.0-1044-aws +OpenJDK 64-Bit Server VM 1.8.0_242-8u242-b08-0ubuntu3~18.04-b08 on Linux 4.15.0-1044-aws Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz quarter of timestamp: Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative -quarter of timestamp wholestage off1285 1295 15 7.8 128.5 1.0X -quarter of timestamp wholestage on 1243 1257 11 8.0 124.3 1.0X +quarter of timestamp wholestage off1290 1293 4 7.8 129.0 1.0X +quarter of timestamp wholestage on 1237 1251 13 8.1 123.7 1.0X -OpenJDK 64-Bit Server VM 1.8.0_232-8u232-b09-0ubuntu1~18.04.1-b09 on Linux 4.15.0-1044-aws +OpenJDK 64-Bit Server VM 1.8.0_242-8u242-b08-0ubuntu3~18.04-b08 on Linux 4.15.0-1044-aws Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz month of timestamp: Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative -month of timestamp wholestage off 1076 1082 8 9.3 107.6 1.0X -month of timestamp wholestage on 1088 1098 9 9.2 108.8 1.0X +month of timestamp wholestage off 1096 1101 7 9.1 109.6 1.0X +month of timestamp wholestage on 1088 1095 7 9.2 108.8 1.0X -OpenJDK 64-Bit Server VM 1.8.0_232-8u232-b09-0ubuntu1~18.04.1-b09 on Linux 4.15.0-1044-aws +OpenJDK 64-Bit Server VM 1.8.0_242-8u242-b08-0ubuntu3~18.04-b08 on Linux 4.15.0-1044-aws Intel(R) Xeon(R) CPU E5-2670 v2 @ 2.50GHz weekofyear of timestamp: Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative -weekofyear of timestamp wholestage off 1649 1659 14 6.1 164.9 1.0X -weekofyear of timestamp wholestage on 1648 1656 8 6.1
[GitHub] [spark] cloud-fan commented on a change in pull request #27619: revert SPARK-29663 and SPARK-29688
cloud-fan commented on a change in pull request #27619: revert SPARK-29663 and
SPARK-29688
URL: https://github.com/apache/spark/pull/27619#discussion_r381081689
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/DataFrameAggregateSuite.scala
##
@@ -957,17 +957,4 @@ class DataFrameAggregateSuite extends QueryTest
assert(error.message.contains("function count_if requires boolean type"))
}
}
-
- test("calendar interval agg support hash aggregate") {
Review comment:
support interval in `UnsafeRow` is fine. It has perf benefits, not just for
hash aggregate, so we shouldn't revert it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint
wangyum commented on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint URL: https://github.com/apache/spark/pull/27252#issuecomment-588039419 @gatorsmile Done This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer edited a comment on issue #27508: [SPARK-30763][SQL] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract
beliefer edited a comment on issue #27508: [SPARK-30763][SQL] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract URL: https://github.com/apache/spark/pull/27508#issuecomment-588030529 @gatorsmile OK. Let me take a look. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on issue #27508: [SPARK-30763][SQL] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract
beliefer commented on issue #27508: [SPARK-30763][SQL] Fix java.lang.IndexOutOfBoundsException No group 1 for regexp_extract URL: https://github.com/apache/spark/pull/27508#issuecomment-588030529 @gatorsmile OK This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27610: [SPARK-30856][SQL][PySpark] Fix SQLContext.getOrCreate() when SparkContext is restarted
HyukjinKwon commented on a change in pull request #27610: [SPARK-30856][SQL][PySpark] Fix SQLContext.getOrCreate() when SparkContext is restarted URL: https://github.com/apache/spark/pull/27610#discussion_r381072105 ## File path: python/pyspark/sql/session.py ## @@ -699,12 +699,14 @@ def streams(self): def stop(self): """Stop the underlying :class:`SparkContext`. """ +from pyspark.sql.context import SQLContext self._sc.stop() # We should clean the default session up. See SPARK-23228. self._jvm.SparkSession.clearDefaultSession() self._jvm.SparkSession.clearActiveSession() SparkSession._instantiatedSession = None SparkSession._activeSession = None +SQLContext._instantiatedContext = None Review comment: @afavaro can you remove [this line](https://github.com/apache/spark/pull/27614/files#diff-fadcca87874ab0f0c00d3c4a08d56a77R273) too after syncing to the master? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] liupc commented on a change in pull request #26016: [SPARK-24914][SQL] New statistic to improve data size estimate for columnar storage formats
liupc commented on a change in pull request #26016: [SPARK-24914][SQL] New
statistic to improve data size estimate for columnar storage formats
URL: https://github.com/apache/spark/pull/26016#discussion_r381071658
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/CommandUtils.scala
##
@@ -56,39 +64,94 @@ object CommandUtils extends Logging {
}
}
- def calculateTotalSize(spark: SparkSession, catalogTable: CatalogTable):
BigInt = {
+ def calculateTotalSize(
+ spark: SparkSession,
+ catalogTable: CatalogTable): SizeInBytesWithDeserFactor = {
val sessionState = spark.sessionState
val startTime = System.nanoTime()
val totalSize = if (catalogTable.partitionColumnNames.isEmpty) {
- calculateLocationSize(sessionState, catalogTable.identifier,
catalogTable.storage.locationUri)
+ calculateLocationSize(
+sessionState,
+catalogTable.identifier,
+catalogTable.storage.locationUri,
+catalogTable.storage.serde)
} else {
// Calculate table size as a sum of the visible partitions. See
SPARK-21079
val partitions =
sessionState.catalog.listPartitions(catalogTable.identifier)
logInfo(s"Starting to calculate sizes for ${partitions.length}
partitions.")
- if (spark.sessionState.conf.parallelFileListingInStatsComputation) {
-val paths = partitions.map(x => new Path(x.storage.locationUri.get))
-val stagingDir =
sessionState.conf.getConfString("hive.exec.stagingdir", ".hive-staging")
-val pathFilter = new PathFilter with Serializable {
- override def accept(path: Path): Boolean = isDataPath(path,
stagingDir)
+ val sizeWithDeserFactorsForPartitions =
+if (sessionState.conf.parallelFileListingInStatsComputation) {
+ val paths = partitions.map(x => new Path(x.storage.locationUri.get))
+ val stagingDir =
sessionState.conf.getConfString("hive.exec.stagingdir", ".hive-staging")
+ val pathFilter = new PathFilter with Serializable {
+override def accept(path: Path): Boolean = isDataPath(path,
stagingDir)
+ }
+ val deserFactCalcEnabled =
sessionState.conf.deserFactorStatCalcEnabled
+ val hadoopConf = sessionState.newHadoopConf()
+ val fileStatusSeq = InMemoryFileIndex.bulkListLeafFiles(
+paths, hadoopConf, pathFilter, spark, areRootPaths = true)
+ fileStatusSeq.flatMap { case (_, fileStatuses) =>
+fileStatuses.map { fileStatus =>
+ sizeInBytesWithDeserFactor(
+deserFactCalcEnabled,
+hadoopConf,
+fileStatus,
+catalogTable.storage.serde)
+}
+ }
+} else {
+ partitions.map { p =>
+calculateLocationSize(
+ sessionState,
+ catalogTable.identifier,
+ p.storage.locationUri,
+ p.storage.serde)
+ }
}
-val fileStatusSeq = InMemoryFileIndex.bulkListLeafFiles(
- paths, sessionState.newHadoopConf(), pathFilter, spark, areRootPaths
= true)
-fileStatusSeq.flatMap(_._2.map(_.getLen)).sum
- } else {
-partitions.map { p =>
- calculateLocationSize(sessionState, catalogTable.identifier,
p.storage.locationUri)
-}.sum
- }
+ sumSizeWithMaxDeserializationFactor(sizeWithDeserFactorsForPartitions)
}
logInfo(s"It took ${(System.nanoTime() - startTime) / (1000 * 1000)} ms to
calculate" +
s" the total size for table ${catalogTable.identifier}.")
totalSize
}
+ def sumSizeWithMaxDeserializationFactor(
+ sizesWithFactors: Seq[SizeInBytesWithDeserFactor]):
SizeInBytesWithDeserFactor = {
+val definedFactors =
sizesWithFactors.filter(_.deserFactor.isDefined).map(_.deserFactor.get)
+SizeInBytesWithDeserFactor(
+ sizesWithFactors.map(_.sizeInBytes).sum,
+ if (definedFactors.isEmpty) None else Some(definedFactors.max))
+ }
+
+ def sizeInBytesWithDeserFactor(
+ calcDeserFact: Boolean,
+ hadoopConf: Configuration,
+ fStatus: FileStatus,
+ serde: Option[String]): SizeInBytesWithDeserFactor = {
+assert(fStatus.isFile)
+val factor = if (calcDeserFact) {
+ val isOrc = serde.contains(orcSerDeCanonicalClass) ||
fStatus.getPath.getName.endsWith(".orc")
Review comment:
Are there any plan to support datasource table to calculate this stats on
demand? Maybe we can also add an option to enable this for on demand
calculation?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [spark] liupc commented on a change in pull request #26016: [SPARK-24914][SQL] New statistic to improve data size estimate for columnar storage formats
liupc commented on a change in pull request #26016: [SPARK-24914][SQL] New
statistic to improve data size estimate for columnar storage formats
URL: https://github.com/apache/spark/pull/26016#discussion_r381070895
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/CommandUtils.scala
##
@@ -56,39 +64,94 @@ object CommandUtils extends Logging {
}
}
- def calculateTotalSize(spark: SparkSession, catalogTable: CatalogTable):
BigInt = {
+ def calculateTotalSize(
+ spark: SparkSession,
+ catalogTable: CatalogTable): SizeInBytesWithDeserFactor = {
val sessionState = spark.sessionState
val startTime = System.nanoTime()
val totalSize = if (catalogTable.partitionColumnNames.isEmpty) {
- calculateLocationSize(sessionState, catalogTable.identifier,
catalogTable.storage.locationUri)
+ calculateLocationSize(
+sessionState,
+catalogTable.identifier,
+catalogTable.storage.locationUri,
+catalogTable.storage.serde)
} else {
// Calculate table size as a sum of the visible partitions. See
SPARK-21079
val partitions =
sessionState.catalog.listPartitions(catalogTable.identifier)
logInfo(s"Starting to calculate sizes for ${partitions.length}
partitions.")
- if (spark.sessionState.conf.parallelFileListingInStatsComputation) {
-val paths = partitions.map(x => new Path(x.storage.locationUri.get))
-val stagingDir =
sessionState.conf.getConfString("hive.exec.stagingdir", ".hive-staging")
-val pathFilter = new PathFilter with Serializable {
- override def accept(path: Path): Boolean = isDataPath(path,
stagingDir)
+ val sizeWithDeserFactorsForPartitions =
+if (sessionState.conf.parallelFileListingInStatsComputation) {
+ val paths = partitions.map(x => new Path(x.storage.locationUri.get))
+ val stagingDir =
sessionState.conf.getConfString("hive.exec.stagingdir", ".hive-staging")
+ val pathFilter = new PathFilter with Serializable {
+override def accept(path: Path): Boolean = isDataPath(path,
stagingDir)
+ }
+ val deserFactCalcEnabled =
sessionState.conf.deserFactorStatCalcEnabled
+ val hadoopConf = sessionState.newHadoopConf()
+ val fileStatusSeq = InMemoryFileIndex.bulkListLeafFiles(
Review comment:
Can we submit a job to calculate this `SizeInBytesWithDeserFactor` directly?
I think in some cases too many fileStatuses may introduce unnecessary memory
pressure.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] liupc commented on a change in pull request #26016: [SPARK-24914][SQL] New statistic to improve data size estimate for columnar storage formats
liupc commented on a change in pull request #26016: [SPARK-24914][SQL] New
statistic to improve data size estimate for columnar storage formats
URL: https://github.com/apache/spark/pull/26016#discussion_r381069711
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/CommandUtils.scala
##
@@ -56,39 +64,94 @@ object CommandUtils extends Logging {
}
}
- def calculateTotalSize(spark: SparkSession, catalogTable: CatalogTable):
BigInt = {
+ def calculateTotalSize(
+ spark: SparkSession,
+ catalogTable: CatalogTable): SizeInBytesWithDeserFactor = {
val sessionState = spark.sessionState
val startTime = System.nanoTime()
val totalSize = if (catalogTable.partitionColumnNames.isEmpty) {
- calculateLocationSize(sessionState, catalogTable.identifier,
catalogTable.storage.locationUri)
+ calculateLocationSize(
+sessionState,
+catalogTable.identifier,
+catalogTable.storage.locationUri,
+catalogTable.storage.serde)
} else {
// Calculate table size as a sum of the visible partitions. See
SPARK-21079
val partitions =
sessionState.catalog.listPartitions(catalogTable.identifier)
logInfo(s"Starting to calculate sizes for ${partitions.length}
partitions.")
- if (spark.sessionState.conf.parallelFileListingInStatsComputation) {
-val paths = partitions.map(x => new Path(x.storage.locationUri.get))
-val stagingDir =
sessionState.conf.getConfString("hive.exec.stagingdir", ".hive-staging")
-val pathFilter = new PathFilter with Serializable {
- override def accept(path: Path): Boolean = isDataPath(path,
stagingDir)
+ val sizeWithDeserFactorsForPartitions =
+if (sessionState.conf.parallelFileListingInStatsComputation) {
+ val paths = partitions.map(x => new Path(x.storage.locationUri.get))
+ val stagingDir =
sessionState.conf.getConfString("hive.exec.stagingdir", ".hive-staging")
+ val pathFilter = new PathFilter with Serializable {
+override def accept(path: Path): Boolean = isDataPath(path,
stagingDir)
+ }
+ val deserFactCalcEnabled =
sessionState.conf.deserFactorStatCalcEnabled
+ val hadoopConf = sessionState.newHadoopConf()
+ val fileStatusSeq = InMemoryFileIndex.bulkListLeafFiles(
+paths, hadoopConf, pathFilter, spark, areRootPaths = true)
+ fileStatusSeq.flatMap { case (_, fileStatuses) =>
+fileStatuses.map { fileStatus =>
+ sizeInBytesWithDeserFactor(
+deserFactCalcEnabled,
+hadoopConf,
+fileStatus,
+catalogTable.storage.serde)
+}
+ }
+} else {
+ partitions.map { p =>
+calculateLocationSize(
+ sessionState,
+ catalogTable.identifier,
+ p.storage.locationUri,
+ p.storage.serde)
+ }
}
-val fileStatusSeq = InMemoryFileIndex.bulkListLeafFiles(
- paths, sessionState.newHadoopConf(), pathFilter, spark, areRootPaths
= true)
-fileStatusSeq.flatMap(_._2.map(_.getLen)).sum
- } else {
-partitions.map { p =>
- calculateLocationSize(sessionState, catalogTable.identifier,
p.storage.locationUri)
-}.sum
- }
+ sumSizeWithMaxDeserializationFactor(sizeWithDeserFactorsForPartitions)
}
logInfo(s"It took ${(System.nanoTime() - startTime) / (1000 * 1000)} ms to
calculate" +
s" the total size for table ${catalogTable.identifier}.")
totalSize
}
+ def sumSizeWithMaxDeserializationFactor(
+ sizesWithFactors: Seq[SizeInBytesWithDeserFactor]):
SizeInBytesWithDeserFactor = {
+val definedFactors =
sizesWithFactors.filter(_.deserFactor.isDefined).map(_.deserFactor.get)
Review comment:
`flatMap(_.deserFactor)`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gatorsmile commented on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint
gatorsmile commented on issue #27252: [SPARK-29231][SQL] Constraints should be inferred from cast equality constraint URL: https://github.com/apache/spark/pull/27252#issuecomment-588026713 @wangyum Could you update the PR description with the perf measurement? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27623: [SPARK-30867][ML] Add FValueRegressionTest
zhengruifeng commented on a change in pull request #27623: [SPARK-30867][ML]
Add FValueRegressionTest
URL: https://github.com/apache/spark/pull/27623#discussion_r381063994
##
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##
@@ -0,0 +1,100 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.{avg, col, stddev}
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector`
(`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature
against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol:
String):
+Array[SelectionTestResult] = {
+
+val spark = dataset.sparkSession
+import spark.implicits._
+
+SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+val Row(xMeans: Vector, xStd: Vector, yMean: Double, yStd: Double, count:
Long) = dataset
+ .select(Summarizer.metrics("mean", "std",
"count").summary(col(featuresCol)).as("summary"),
+avg(col(labelCol)).as("yMean"),
+stddev(col(labelCol)).as("yStd"))
+ .select("summary.mean", "summary.std", "yMean", "yStd", "summary.count")
+ .first()
+
+val labeledPointRdd = dataset.select(col("label").cast("double"),
col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+val numFeatures = labeledPointRdd.first().features.size
Review comment:
using `val numFeatures = xMeans.size` instead to avoid this `first` job
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27623: [SPARK-30867][ML] Add FValueRegressionTest
zhengruifeng commented on a change in pull request #27623: [SPARK-30867][ML]
Add FValueRegressionTest
URL: https://github.com/apache/spark/pull/27623#discussion_r381068169
##
File path:
mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTestResult.scala
##
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.spark.annotation.Since
+
+/**
+ * Trait for selection test results.
+ */
+@Since("3.1.0")
+trait SelectionTestResult {
Review comment:
`Selector` should be in `.feature` like `ChiSqSelector`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27623: [SPARK-30867][ML] Add FValueRegressionTest
zhengruifeng commented on a change in pull request #27623: [SPARK-30867][ML]
Add FValueRegressionTest
URL: https://github.com/apache/spark/pull/27623#discussion_r381064590
##
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##
@@ -0,0 +1,100 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.{avg, col, stddev}
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector`
(`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature
against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol:
String):
+Array[SelectionTestResult] = {
+
+val spark = dataset.sparkSession
+import spark.implicits._
+
+SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+val Row(xMeans: Vector, xStd: Vector, yMean: Double, yStd: Double, count:
Long) = dataset
+ .select(Summarizer.metrics("mean", "std",
"count").summary(col(featuresCol)).as("summary"),
+avg(col(labelCol)).as("yMean"),
+stddev(col(labelCol)).as("yStd"))
+ .select("summary.mean", "summary.std", "yMean", "yStd", "summary.count")
+ .first()
+
+val labeledPointRdd = dataset.select(col("label").cast("double"),
col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+val numFeatures = labeledPointRdd.first().features.size
+val numSamples = count
+val degreeOfFreedom = numSamples.toInt - 2
+var fTestResultArray = new Array[SelectionTestResult](numFeatures)
+
+// Use two pass equation Cov[X,Y] = E[(X - E[X]) * (Y - E[Y])] to compute
covariance because
+// one pass equation Cov[X,Y] = E[XY] - E[X]E[Y] is susceptible to
catastrophic cancellation
+//
Review comment:
nit: remove this line?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27623: [SPARK-30867][ML] Add FValueRegressionTest
zhengruifeng commented on a change in pull request #27623: [SPARK-30867][ML]
Add FValueRegressionTest
URL: https://github.com/apache/spark/pull/27623#discussion_r381065990
##
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##
@@ -0,0 +1,100 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.{avg, col, stddev}
+
+@Since("3.1.0")
+object SelectionTest {
Review comment:
Why adding such a class and file? It seems that current `XXXTest` are in
spearate files. Like `ChiSquareTest`, `KolmogorovSmirnovTest`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27623: [SPARK-30867][ML] Add FValueRegressionTest
zhengruifeng commented on a change in pull request #27623: [SPARK-30867][ML]
Add FValueRegressionTest
URL: https://github.com/apache/spark/pull/27623#discussion_r381067119
##
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##
@@ -0,0 +1,100 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.{avg, col, stddev}
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector`
(`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature
against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol:
String):
+Array[SelectionTestResult] = {
+
+val spark = dataset.sparkSession
+import spark.implicits._
+
+SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+val Row(xMeans: Vector, xStd: Vector, yMean: Double, yStd: Double, count:
Long) = dataset
+ .select(Summarizer.metrics("mean", "std",
"count").summary(col(featuresCol)).as("summary"),
+avg(col(labelCol)).as("yMean"),
+stddev(col(labelCol)).as("yStd"))
+ .select("summary.mean", "summary.std", "yMean", "yStd", "summary.count")
+ .first()
+
+val labeledPointRdd = dataset.select(col("label").cast("double"),
col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
+
+val numFeatures = labeledPointRdd.first().features.size
+val numSamples = count
+val degreeOfFreedom = numSamples.toInt - 2
+var fTestResultArray = new Array[SelectionTestResult](numFeatures)
+
+// Use two pass equation Cov[X,Y] = E[(X - E[X]) * (Y - E[Y])] to compute
covariance because
+// one pass equation Cov[X,Y] = E[XY] - E[X]E[Y] is susceptible to
catastrophic cancellation
+//
+// sumForCov = Sum(((Xi - Avg(X)) * ((Yi-Avg(Y)))
+val sumForCov = labeledPointRdd.mapPartitions { iter =>
+ if (iter.hasNext) {
+val array = Array.ofDim[Double](numFeatures)
+while(iter.hasNext) {
+ val LabeledPoint(label, features) = iter.next
+ val yDiff = label - yMean
+ if (yDiff != 0) {
+features.iterator.zip(xMeans.iterator)
+ .foreach { case ((col, x), (_, xMean)) => array(col) += yDiff *
(x - xMean) }
+ }
+}
+Iterator.single(array)
+ } else Iterator.empty
+}.treeReduce { case (array1, array2) =>
+ var i = 0
+ while (i < numFeatures) {
+array1(i) += array2(i)
+i += 1
+ }
+ array1
+}
+
+for(i <- 0 until numFeatures) {
+ // Cov(X,Y) = Sum(((Xi - Avg(X)) * ((Yi-Avg(Y))) / (N-1)
+ val covariance = sumForCov (i) / (numSamples - 1)
+ val corr = covariance / (yStd * xStd(i))
+ val fValue = corr * corr / (1 - corr * corr) * degreeOfFreedom
+ val pValue = 1.0 - new FDistribution(1,
degreeOfFreedom).cumulativeProbability(fValue)
Review comment:
What about reusing `new FDistribution(1, degreeOfFreedom)` as a variable:
```
val fd = new FDistribution(1, degreeOfFreedom)
for(...){
...
val pValue = 1.0 - fd.cumulativeProbability(fValue)
...
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [spark] zhengruifeng commented on a change in pull request #27623: [SPARK-30867][ML] Add FValueRegressionTest
zhengruifeng commented on a change in pull request #27623: [SPARK-30867][ML]
Add FValueRegressionTest
URL: https://github.com/apache/spark/pull/27623#discussion_r381066633
##
File path: mllib/src/main/scala/org/apache/spark/ml/stat/SelectionTest.scala
##
@@ -0,0 +1,100 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.ml.stat
+
+import org.apache.commons.math3.distribution.FDistribution
+
+import org.apache.spark.annotation.Since
+import org.apache.spark.ml.feature.LabeledPoint
+import org.apache.spark.ml.linalg.{Vector, VectorUDT}
+import org.apache.spark.ml.util.SchemaUtils
+import org.apache.spark.sql.{Dataset, Row}
+import org.apache.spark.sql.functions.{avg, col, stddev}
+
+@Since("3.1.0")
+object SelectionTest {
+
+ /**
+ * @param dataset DataFrame of continuous labels and continuous features.
+ * @param featuresCol Name of features column in dataset, of type `Vector`
(`VectorUDT`)
+ * @param labelCol Name of label column in dataset, of any numerical type
+ * @return Array containing the SelectionTestResult for every feature
against the label.
+ */
+ @Since("3.1.0")
+ def fValueRegressionTest(dataset: Dataset[_], featuresCol: String, labelCol:
String):
+Array[SelectionTestResult] = {
+
+val spark = dataset.sparkSession
+import spark.implicits._
+
+SchemaUtils.checkColumnType(dataset.schema, featuresCol, new VectorUDT)
+SchemaUtils.checkNumericType(dataset.schema, labelCol)
+
+val Row(xMeans: Vector, xStd: Vector, yMean: Double, yStd: Double, count:
Long) = dataset
+ .select(Summarizer.metrics("mean", "std",
"count").summary(col(featuresCol)).as("summary"),
+avg(col(labelCol)).as("yMean"),
+stddev(col(labelCol)).as("yStd"))
+ .select("summary.mean", "summary.std", "yMean", "yStd", "summary.count")
+ .first()
+
+val labeledPointRdd = dataset.select(col("label").cast("double"),
col("features"))
+ .as[(Double, Vector)]
+ .rdd.map { case (label, features) => LabeledPoint(label, features) }
Review comment:
it seems we do not need to convert `(label, features)` to `LabeledPoint`,
since this algorithm is not implemented in the `.mllib` side like other
`ChiSquareTest`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a change in pull request #27600: [MINOR][ML] ML cleanup
zhengruifeng commented on a change in pull request #27600: [MINOR][ML] ML
cleanup
URL: https://github.com/apache/spark/pull/27600#discussion_r381063088
##
File path: mllib/src/main/scala/org/apache/spark/ml/recommendation/ALS.scala
##
@@ -1049,7 +1049,7 @@ object ALS extends DefaultParamsReadable[ALS] with
Logging {
.join(userFactors)
.mapPartitions({ items =>
items.flatMap { case (_, (ids, factors)) =>
- ids.view.zip(factors)
+ ids.iterator.zip(factors.iterator)
Review comment:
I guess `.view` was used to avoid creating a new Array
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on issue #27600: [MINOR][ML] ML cleanup
zhengruifeng commented on issue #27600: [MINOR][ML] ML cleanup URL: https://github.com/apache/spark/pull/27600#issuecomment-588020643 This should be a bug in scala-plugin of IDEA, it can not correctly infer the types if `.view` is used. 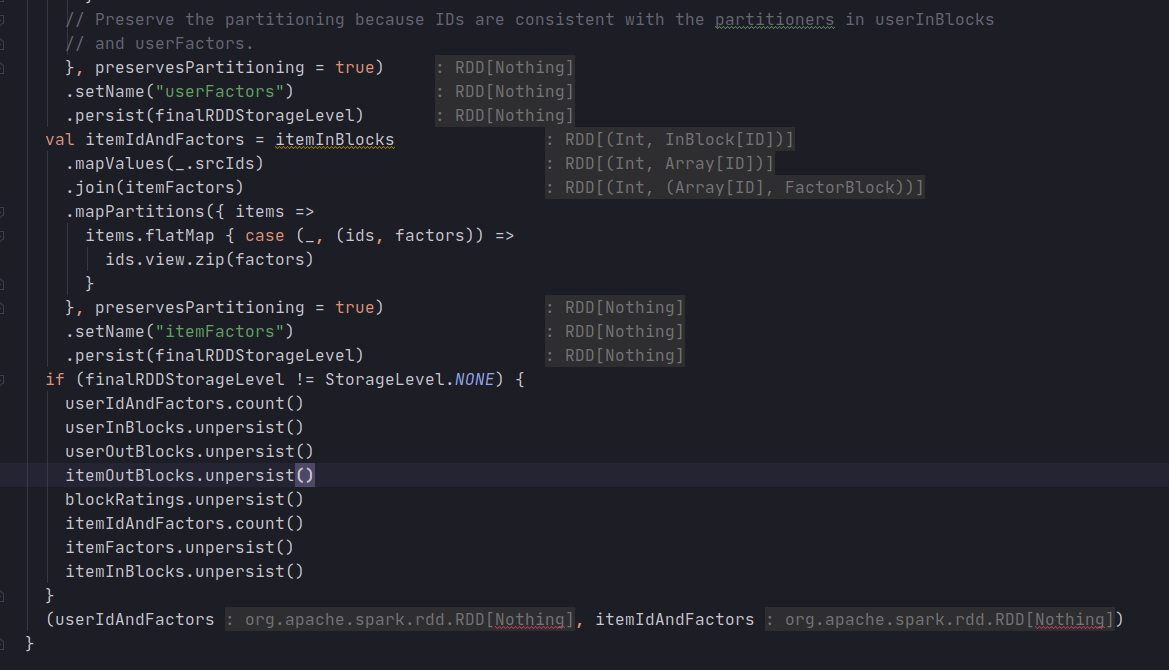 After change `.view` to `.iterator`: 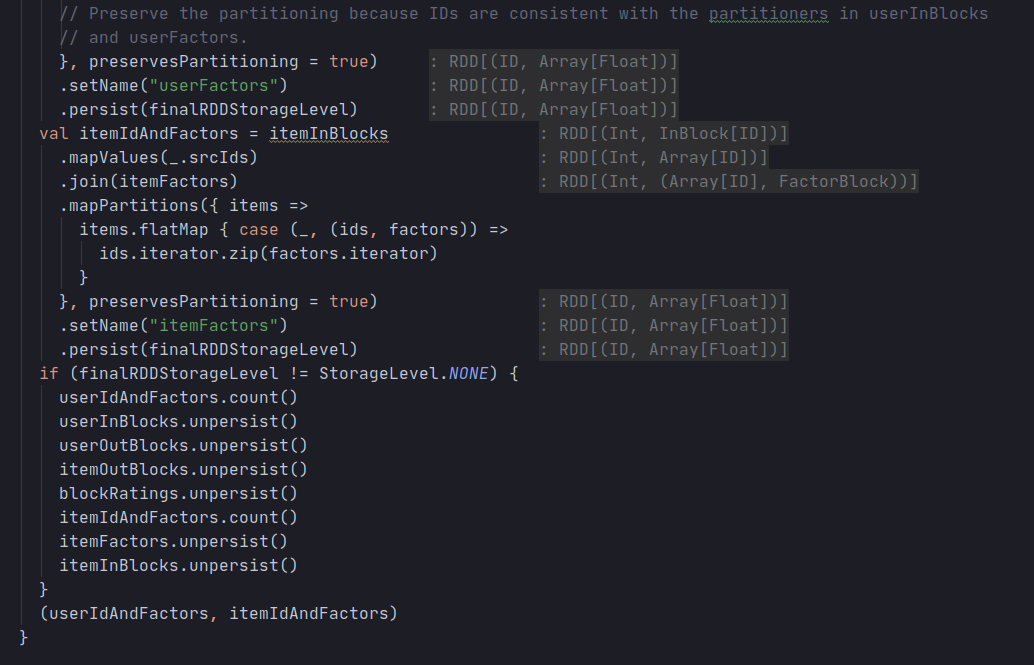 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext
AmplabJenkins removed a comment on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext URL: https://github.com/apache/spark/pull/27395#issuecomment-588018833 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118658/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext
AmplabJenkins removed a comment on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext URL: https://github.com/apache/spark/pull/27395#issuecomment-588018827 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext
AmplabJenkins commented on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext URL: https://github.com/apache/spark/pull/27395#issuecomment-588018827 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext
AmplabJenkins commented on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext URL: https://github.com/apache/spark/pull/27395#issuecomment-588018833 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118658/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext
SparkQA removed a comment on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext URL: https://github.com/apache/spark/pull/27395#issuecomment-587987972 **[Test build #118658 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118658/testReport)** for PR 27395 at commit [`24adef3`](https://github.com/apache/spark/commit/24adef3c8abb4b7c5d6c148782a50aa8ca63c283). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext
SparkQA commented on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext URL: https://github.com/apache/spark/pull/27395#issuecomment-588018592 **[Test build #118658 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118658/testReport)** for PR 27395 at commit [`24adef3`](https://github.com/apache/spark/commit/24adef3c8abb4b7c5d6c148782a50aa8ca63c283). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27592: [SPARK-30840][CORE][SQL] Add version property for ConfigEntry and ConfigBuilder
AmplabJenkins removed a comment on issue #27592: [SPARK-30840][CORE][SQL] Add version property for ConfigEntry and ConfigBuilder URL: https://github.com/apache/spark/pull/27592#issuecomment-588016520 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27592: [SPARK-30840][CORE][SQL] Add version property for ConfigEntry and ConfigBuilder
AmplabJenkins removed a comment on issue #27592: [SPARK-30840][CORE][SQL] Add version property for ConfigEntry and ConfigBuilder URL: https://github.com/apache/spark/pull/27592#issuecomment-588016525 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118657/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27592: [SPARK-30840][CORE][SQL] Add version property for ConfigEntry and ConfigBuilder
AmplabJenkins commented on issue #27592: [SPARK-30840][CORE][SQL] Add version property for ConfigEntry and ConfigBuilder URL: https://github.com/apache/spark/pull/27592#issuecomment-588016520 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext
AmplabJenkins removed a comment on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext URL: https://github.com/apache/spark/pull/27395#issuecomment-588016060 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118659/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27592: [SPARK-30840][CORE][SQL] Add version property for ConfigEntry and ConfigBuilder
AmplabJenkins commented on issue #27592: [SPARK-30840][CORE][SQL] Add version property for ConfigEntry and ConfigBuilder URL: https://github.com/apache/spark/pull/27592#issuecomment-588016525 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118657/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27592: [SPARK-30840][CORE][SQL] Add version property for ConfigEntry and ConfigBuilder
SparkQA removed a comment on issue #27592: [SPARK-30840][CORE][SQL] Add version property for ConfigEntry and ConfigBuilder URL: https://github.com/apache/spark/pull/27592#issuecomment-58798 **[Test build #118657 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118657/testReport)** for PR 27592 at commit [`6d8eb75`](https://github.com/apache/spark/commit/6d8eb75f0c29962962f994d8f212fafae8577cfc). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext
AmplabJenkins removed a comment on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext URL: https://github.com/apache/spark/pull/27395#issuecomment-588016051 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext
SparkQA removed a comment on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext URL: https://github.com/apache/spark/pull/27395#issuecomment-587989886 **[Test build #118659 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118659/testReport)** for PR 27395 at commit [`d2fffe1`](https://github.com/apache/spark/commit/d2fffe1df73973962302c898bf90c67bb6714cd1). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27592: [SPARK-30840][CORE][SQL] Add version property for ConfigEntry and ConfigBuilder
SparkQA commented on issue #27592: [SPARK-30840][CORE][SQL] Add version property for ConfigEntry and ConfigBuilder URL: https://github.com/apache/spark/pull/27592#issuecomment-588016046 **[Test build #118657 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118657/testReport)** for PR 27592 at commit [`6d8eb75`](https://github.com/apache/spark/commit/6d8eb75f0c29962962f994d8f212fafae8577cfc). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext
AmplabJenkins commented on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext URL: https://github.com/apache/spark/pull/27395#issuecomment-588016060 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118659/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext
AmplabJenkins commented on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext URL: https://github.com/apache/spark/pull/27395#issuecomment-588016051 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext
SparkQA commented on issue #27395: [SPARK-30667][CORE] Add allGather method to BarrierTaskContext URL: https://github.com/apache/spark/pull/27395#issuecomment-588015784 **[Test build #118659 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118659/testReport)** for PR 27395 at commit [`d2fffe1`](https://github.com/apache/spark/commit/d2fffe1df73973962302c898bf90c67bb6714cd1). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #27002: [SPARK-30346][CORE]Improve logging when events dropped
HyukjinKwon commented on issue #27002: [SPARK-30346][CORE]Improve logging when events dropped URL: https://github.com/apache/spark/pull/27002#issuecomment-588013199 also merged to branch-3.0. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #27495: [SPARK-28880][SQL] Support ANSI nested bracketed comments
gengliangwang commented on a change in pull request #27495: [SPARK-28880][SQL] Support ANSI nested bracketed comments URL: https://github.com/apache/spark/pull/27495#discussion_r381050531 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -1797,11 +1797,11 @@ SIMPLE_COMMENT ; BRACKETED_EMPTY_COMMENT -: '/**/' -> channel(HIDDEN) +: '/*' BRACKETED_EMPTY_COMMENT* '*/' -> channel(HIDDEN) ; BRACKETED_COMMENT -: '/*' ~[+] .*? '*/' -> channel(HIDDEN) +: '/*' (BRACKETED_COMMENT .*? | ~[+] (BRACKETED_COMMENT|.)*?)*? '*/' -> channel(HIDDEN) Review comment: Ah, I see. I am not sure about the latest code now. I think it is more reasonable to follow @cloud-fan 's advice. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #27614: [SPARK-30861][PYTHON][SQL] Deprecate constructor of SQLContext and getOrCreate in SQLContext at PySpark
HyukjinKwon closed pull request #27614: [SPARK-30861][PYTHON][SQL] Deprecate constructor of SQLContext and getOrCreate in SQLContext at PySpark URL: https://github.com/apache/spark/pull/27614 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #27614: [SPARK-30861][PYTHON][SQL] Deprecate constructor of SQLContext and getOrCreate in SQLContext at PySpark
HyukjinKwon commented on issue #27614: [SPARK-30861][PYTHON][SQL] Deprecate constructor of SQLContext and getOrCreate in SQLContext at PySpark URL: https://github.com/apache/spark/pull/27614#issuecomment-588000534 Let me merge this one first - seems #27610 needs some more reviews. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #27614: [SPARK-30861][PYTHON][SQL] Deprecate constructor of SQLContext and getOrCreate in SQLContext at PySpark
HyukjinKwon commented on issue #27614: [SPARK-30861][PYTHON][SQL] Deprecate constructor of SQLContext and getOrCreate in SQLContext at PySpark URL: https://github.com/apache/spark/pull/27614#issuecomment-588000593 Merged to master and branch-3.0. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a change in pull request #27495: [SPARK-28880][SQL] Support ANSI nested bracketed comments
beliefer commented on a change in pull request #27495: [SPARK-28880][SQL] Support ANSI nested bracketed comments URL: https://github.com/apache/spark/pull/27495#discussion_r381040836 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -1797,11 +1797,11 @@ SIMPLE_COMMENT ; BRACKETED_EMPTY_COMMENT -: '/**/' -> channel(HIDDEN) +: '/*' BRACKETED_EMPTY_COMMENT* '*/' -> channel(HIDDEN) ; BRACKETED_COMMENT -: '/*' ~[+] .*? '*/' -> channel(HIDDEN) +: '/*' (BRACKETED_COMMENT .*? | ~[+] (BRACKETED_COMMENT|.)*?)*? '*/' -> channel(HIDDEN) Review comment: It can't pass `PlanParserSuite`. ``` - SPARK-20854: multiple hints *** FAILED *** (6 milliseconds) [info] == FAIL: Plans do not match === [info] !'Project [*] 'UnresolvedHint HINT1, ['a, 1] [info] !+- 'UnresolvedRelation [t] +- 'UnresolvedHint hint2, ['b, 2] [info] !+- 'Project [*] [info] ! +- 'UnresolvedRelation [t] (PlanTest.scala:147) ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a change in pull request #27495: [SPARK-28880][SQL] Support ANSI nested bracketed comments
beliefer commented on a change in pull request #27495: [SPARK-28880][SQL] Support ANSI nested bracketed comments URL: https://github.com/apache/spark/pull/27495#discussion_r381040836 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -1797,11 +1797,11 @@ SIMPLE_COMMENT ; BRACKETED_EMPTY_COMMENT -: '/**/' -> channel(HIDDEN) +: '/*' BRACKETED_EMPTY_COMMENT* '*/' -> channel(HIDDEN) ; BRACKETED_COMMENT -: '/*' ~[+] .*? '*/' -> channel(HIDDEN) +: '/*' (BRACKETED_COMMENT .*? | ~[+] (BRACKETED_COMMENT|.)*?)*? '*/' -> channel(HIDDEN) Review comment: It can't pass `PlanParserSuite`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a change in pull request #27495: [SPARK-28880][SQL] Support ANSI nested bracketed comments
beliefer commented on a change in pull request #27495: [SPARK-28880][SQL] Support ANSI nested bracketed comments URL: https://github.com/apache/spark/pull/27495#discussion_r381040836 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -1797,11 +1797,11 @@ SIMPLE_COMMENT ; BRACKETED_EMPTY_COMMENT -: '/**/' -> channel(HIDDEN) +: '/*' BRACKETED_EMPTY_COMMENT* '*/' -> channel(HIDDEN) ; BRACKETED_COMMENT -: '/*' ~[+] .*? '*/' -> channel(HIDDEN) +: '/*' (BRACKETED_COMMENT .*? | ~[+] (BRACKETED_COMMENT|.)*?)*? '*/' -> channel(HIDDEN) Review comment: It can't pass `SQLQueryTestSuite`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27628: [SPARK-30858][SQL] Make IntegralDivide's dataType independent from SQL config changes
AmplabJenkins removed a comment on issue #27628: [SPARK-30858][SQL] Make IntegralDivide's dataType independent from SQL config changes URL: https://github.com/apache/spark/pull/27628#issuecomment-587995183 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118654/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #27628: [SPARK-30858][SQL] Make IntegralDivide's dataType independent from SQL config changes
AmplabJenkins removed a comment on issue #27628: [SPARK-30858][SQL] Make IntegralDivide's dataType independent from SQL config changes URL: https://github.com/apache/spark/pull/27628#issuecomment-587995180 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #27495: [SPARK-28880][SQL] Support ANSI nested bracketed comments
gengliangwang commented on a change in pull request #27495: [SPARK-28880][SQL] Support ANSI nested bracketed comments URL: https://github.com/apache/spark/pull/27495#discussion_r381038067 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -1797,11 +1797,11 @@ SIMPLE_COMMENT ; BRACKETED_EMPTY_COMMENT -: '/**/' -> channel(HIDDEN) +: '/*' BRACKETED_EMPTY_COMMENT* '*/' -> channel(HIDDEN) ; BRACKETED_COMMENT -: '/*' ~[+] .*? '*/' -> channel(HIDDEN) +: '/*' (BRACKETED_COMMENT .*? | ~[+] (BRACKETED_COMMENT|.)*?)*? '*/' -> channel(HIDDEN) Review comment: I tried and it works This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27628: [SPARK-30858][SQL] Make IntegralDivide's dataType independent from SQL config changes
AmplabJenkins commented on issue #27628: [SPARK-30858][SQL] Make IntegralDivide's dataType independent from SQL config changes URL: https://github.com/apache/spark/pull/27628#issuecomment-587995183 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/118654/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #27628: [SPARK-30858][SQL] Make IntegralDivide's dataType independent from SQL config changes
AmplabJenkins commented on issue #27628: [SPARK-30858][SQL] Make IntegralDivide's dataType independent from SQL config changes URL: https://github.com/apache/spark/pull/27628#issuecomment-587995180 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #27628: [SPARK-30858][SQL] Make IntegralDivide's dataType independent from SQL config changes
SparkQA commented on issue #27628: [SPARK-30858][SQL] Make IntegralDivide's dataType independent from SQL config changes URL: https://github.com/apache/spark/pull/27628#issuecomment-587994723 **[Test build #118654 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/118654/testReport)** for PR 27628 at commit [`ebeec38`](https://github.com/apache/spark/commit/ebeec388f5b6f2a1b3b3cb5e972a7262ee463aef). * This patch passes all tests. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `case class IntegralDivide(` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org