[GitHub] [spark] AngersZhuuuu commented on a change in pull request #28805: [SPARK-28169][SQL] Convert scan predicate condition to CNF
AngersZh commented on a change in pull request #28805:
URL: https://github.com/apache/spark/pull/28805#discussion_r446805961
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/PruneFileSourcePartitionsSuite.scala
##
@@ -108,4 +109,54 @@ class PruneFileSourcePartitionsSuite extends QueryTest
with SQLTestUtils with Te
}
}
}
+
+ test("SPARK-28169: Convert scan predicate condition to CNF") {
Review comment:
> at least this new test can be shared between the 2 test suites?
Updated
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28898: [SPARK-32059][SQL] Allow nested schema pruning thru window/sort/filter plans
SparkQA removed a comment on pull request #28898: URL: https://github.com/apache/spark/pull/28898#issuecomment-650853588 **[Test build #124616 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124616/testReport)** for PR 28898 at commit [`acce8c5`](https://github.com/apache/spark/commit/acce8c5d8d51bae5f981e56a8811f075cb07d214). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28898: [SPARK-32059][SQL] Allow nested schema pruning thru window/sort/filter plans
SparkQA commented on pull request #28898: URL: https://github.com/apache/spark/pull/28898#issuecomment-650965128 **[Test build #124616 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124616/testReport)** for PR 28898 at commit [`acce8c5`](https://github.com/apache/spark/commit/acce8c5d8d51bae5f981e56a8811f075cb07d214). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LantaoJin commented on a change in pull request #28935: [SPARK-20680][SQL] Adding HiveVoidType in Spark to be compatible with Hive
LantaoJin commented on a change in pull request #28935:
URL: https://github.com/apache/spark/pull/28935#discussion_r446804385
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
##
@@ -2212,6 +2212,7 @@ class AstBuilder(conf: SQLConf) extends
SqlBaseBaseVisitor[AnyRef] with Logging
case ("decimal" | "dec" | "numeric", precision :: scale :: Nil) =>
DecimalType(precision.getText.toInt, scale.getText.toInt)
case ("interval", Nil) => CalendarIntervalType
+ case ("void", Nil) => HiveVoidType
Review comment:
Em, yes. We don't need this line in this PR, right?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LantaoJin commented on a change in pull request #28935: [SPARK-20680][SQL] Adding HiveVoidType in Spark to be compatible with Hive
LantaoJin commented on a change in pull request #28935:
URL: https://github.com/apache/spark/pull/28935#discussion_r446799790
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/types/HiveStringType.scala
##
@@ -47,9 +47,7 @@ object HiveStringType {
case MapType(kt, vt, nullable) =>
MapType(replaceCharType(kt), replaceCharType(vt), nullable)
case StructType(fields) =>
- StructType(fields.map { field =>
-field.copy(dataType = replaceCharType(field.dataType))
- })
+ StructType(fields.map(f => f.copy(dataType =
replaceCharType(f.dataType
Review comment:
Ok, get the rule now. I will rollback this line
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #28616: [SPARK-31798][SHUFFLE][API] Shuffle Writer API changes to return custom map output metadata
HyukjinKwon commented on pull request #28616: URL: https://github.com/apache/spark/pull/28616#issuecomment-650950403 LGTM too This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28924: [SPARK-32091][CORE] Ignore timeout error when remove blocks on the lost executor
AmplabJenkins removed a comment on pull request #28924: URL: https://github.com/apache/spark/pull/28924#issuecomment-650949521 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28924: [SPARK-32091][CORE] Ignore timeout error when remove blocks on the lost executor
AmplabJenkins commented on pull request #28924: URL: https://github.com/apache/spark/pull/28924#issuecomment-650949521 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yairogen commented on a change in pull request #28629: [SPARK-31769][CORE] Add MDC support for driver threads
yairogen commented on a change in pull request #28629:
URL: https://github.com/apache/spark/pull/28629#discussion_r446798079
##
File path: core/src/test/scala/org/apache/spark/util/ThreadUtilsSuite.scala
##
@@ -25,11 +25,27 @@ import scala.concurrent.duration._
import scala.util.Random
import org.scalatest.concurrent.Eventually._
+import org.slf4j.MDC
import org.apache.spark.SparkFunSuite
class ThreadUtilsSuite extends SparkFunSuite {
+ test("newDaemonSingleThreadExecutor with MDC") {
+val appIdValue = s"appId-${System.currentTimeMillis()}"
+MDC.put("appId", appIdValue)
Review comment:
right. there is no way to make MDC put something in another process.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] igreenfield commented on a change in pull request #28629: [SPARK-31769][CORE] Add MDC support for driver threads
igreenfield commented on a change in pull request #28629:
URL: https://github.com/apache/spark/pull/28629#discussion_r446797352
##
File path: core/src/test/scala/org/apache/spark/util/ThreadUtilsSuite.scala
##
@@ -25,11 +25,27 @@ import scala.concurrent.duration._
import scala.util.Random
import org.scalatest.concurrent.Eventually._
+import org.slf4j.MDC
import org.apache.spark.SparkFunSuite
class ThreadUtilsSuite extends SparkFunSuite {
+ test("newDaemonSingleThreadExecutor with MDC") {
+val appIdValue = s"appId-${System.currentTimeMillis()}"
+MDC.put("appId", appIdValue)
Review comment:
For the driver is true. for the Executor as it is in another process it
should be called explicitly by the user.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28935: [SPARK-20680][SQL] Adding HiveVoidType in Spark to be compatible with Hive
SparkQA removed a comment on pull request #28935: URL: https://github.com/apache/spark/pull/28935#issuecomment-650844766 **[Test build #124614 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124614/testReport)** for PR 28935 at commit [`a3a1cef`](https://github.com/apache/spark/commit/a3a1cefa4823954858f6b996f852ad2495f60b00). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28935: [SPARK-20680][SQL] Adding HiveVoidType in Spark to be compatible with Hive
SparkQA commented on pull request #28935: URL: https://github.com/apache/spark/pull/28935#issuecomment-650947540 **[Test build #124614 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124614/testReport)** for PR 28935 at commit [`a3a1cef`](https://github.com/apache/spark/commit/a3a1cefa4823954858f6b996f852ad2495f60b00). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xianyinxin commented on pull request #28943: [SPARK-32127][SQL]: Check rules for MERGE INTO should use MergeAction.conditition other than MergeAction.children
xianyinxin commented on pull request #28943: URL: https://github.com/apache/spark/pull/28943#issuecomment-650947651 @cloud-fan @brkyvz , pls take a look. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xianyinxin commented on a change in pull request #28875: [SPARK-32030][SQL] Support unlimited MATCHED and NOT MATCHED clauses in MERGE INTO
xianyinxin commented on a change in pull request #28875:
URL: https://github.com/apache/spark/pull/28875#discussion_r446796512
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
##
@@ -468,13 +458,25 @@ class AstBuilder(conf: SQLConf) extends
SqlBaseBaseVisitor[AnyRef] with Logging
throw new ParseException("There must be at least one WHEN clause in a
MERGE statement", ctx)
}
// children being empty means that the condition is not set
-if (matchedActions.length == 2 && matchedActions.head.children.isEmpty) {
- throw new ParseException("When there are 2 MATCHED clauses in a MERGE
statement, " +
-"the first MATCHED clause must have a condition", ctx)
-}
-if (matchedActions.groupBy(_.getClass).mapValues(_.size).exists(_._2 > 1))
{
+val matchedActionSize = matchedActions.length
+if (matchedActionSize >= 2 &&
!matchedActions.init.forall(_.condition.nonEmpty)) {
Review comment:
Submitted a pr at https://github.com/apache/spark/pull/28943.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28629: [SPARK-31769][CORE] Add MDC support for driver threads
cloud-fan commented on a change in pull request #28629:
URL: https://github.com/apache/spark/pull/28629#discussion_r446795038
##
File path: core/src/test/scala/org/apache/spark/util/ThreadUtilsSuite.scala
##
@@ -25,11 +25,27 @@ import scala.concurrent.duration._
import scala.util.Random
import org.scalatest.concurrent.Eventually._
+import org.slf4j.MDC
import org.apache.spark.SparkFunSuite
class ThreadUtilsSuite extends SparkFunSuite {
+ test("newDaemonSingleThreadExecutor with MDC") {
+val appIdValue = s"appId-${System.currentTimeMillis()}"
+MDC.put("appId", appIdValue)
Review comment:
I mean user-facing APIs. Eventually, we have to call `MDC.put` as this
is how MDC works.
Maybe it's better to say that Spark can propagate the MDC properties to both
driver thread pools and executor tasks. So end-users only need to call
`MDC.put`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28875: [SPARK-32030][SQL] Support unlimited MATCHED and NOT MATCHED clauses in MERGE INTO
SparkQA commented on pull request #28875: URL: https://github.com/apache/spark/pull/28875#issuecomment-650944873 **[Test build #5047 has finished](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/5047/testReport)** for PR 28875 at commit [`d5edef3`](https://github.com/apache/spark/commit/d5edef3c2b950440614fc5c9ee1e770bcd0b9884). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `sealed abstract class MergeAction extends Expression with Unevaluable ` * `case class DeleteAction(condition: Option[Expression]) extends MergeAction` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xianyinxin opened a new pull request #28943: SPARK-32127: Check rules for MERGE INTO should use MergeAction.conditition other than MergeAction.children
xianyinxin opened a new pull request #28943: URL: https://github.com/apache/spark/pull/28943 ### What changes were proposed in this pull request? This pr fix a bug of check rules for MERGE INTO. ### Why are the changes needed? SPARK-30924 adds some check rules for MERGE INTO one of which ensures the first MATCHED clause must have a condition. However, it uses `MergeAction.children` in the checking which is not accurate for the case, and it lets the below case pass the check: ``` MERGE INTO testcat1.ns1.ns2.tbl AS target xxx WHEN MATCHED THEN UPDATE SET target.col2 = source.col2 WHEN MATCHED THEN DELETE xxx ``` We should use `MergeAction.condition` instead. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? An existed ut is modified. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28875: [SPARK-32030][SQL] Support unlimited MATCHED and NOT MATCHED clauses in MERGE INTO
SparkQA removed a comment on pull request #28875: URL: https://github.com/apache/spark/pull/28875#issuecomment-650882037 **[Test build #5047 has started](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/5047/testReport)** for PR 28875 at commit [`d5edef3`](https://github.com/apache/spark/commit/d5edef3c2b950440614fc5c9ee1e770bcd0b9884). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28916: [SPARK-32083][SQL] Coalesce to one partition when all partitions are empty in AQE
cloud-fan commented on pull request #28916: URL: https://github.com/apache/spark/pull/28916#issuecomment-650938932 I checked the related code and came up with the same conclusion as @viirya . Can you elaborate more about how this happens? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28930: [SPARK-29999][SS][FOLLOWUP] Fix test to check the actual metadata log directory
cloud-fan commented on pull request #28930: URL: https://github.com/apache/spark/pull/28930#issuecomment-650934435 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #27620: [SPARK-30866][SS] FileStreamSource: Cache fetched list of files beyond maxFilesPerTrigger as unread files
HeartSaVioR commented on pull request #27620: URL: https://github.com/apache/spark/pull/27620#issuecomment-650932618 After looking at a couple of more issues on file stream source, I'm feeling that we also need to have upper bound of the cache, as file stream source is already contributing memory usage on driver and this adds (possibly) unbounded amount of memory. I guess 10,000 entries are good enough, as it affects 100 batches when maxFilesPerTrigger is set to 100, and affects 10 batches when maxFilesPerTrigger is set to 1000. Once we find that higher value is OK for memory usage and pretty much helpful on majority of workloads, we can make it configurable with higher default value. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28647: [SPARK-31828][SQL] Retain table properties at CreateTableLikeCommand
cloud-fan commented on a change in pull request #28647:
URL: https://github.com/apache/spark/pull/28647#discussion_r446789203
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/ddl.scala
##
@@ -839,6 +839,19 @@ case class AlterTableSetLocationCommand(
object DDLUtils {
val HIVE_PROVIDER = "hive"
+ val METASTORE_GENERATED_PROPERTIES: Set[String] = Set(
Review comment:
I don't feel comfortable maintaining this list here. Is it possible to
remove Hive specific properties in `HiveClientImpl`? So that the hive related
stuff remains in hive related classes.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28647: [SPARK-31828][SQL] Retain table properties at CreateTableLikeCommand
cloud-fan commented on a change in pull request #28647: URL: https://github.com/apache/spark/pull/28647#discussion_r446788640 ## File path: docs/sql-ref-syntax-ddl-create-table-like.md ## @@ -57,6 +57,8 @@ CREATE TABLE [IF NOT EXISTS] table_identifier LIKE source_table_identifier * **TBLPROPERTIES** Table properties that have to be set are specified, such as `created.by.user`, `owner`, etc. +Note that a basic set of table properties defined in a source table is copied into a new table. Review comment: let's update the doc as well. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28647: [SPARK-31828][SQL] Retain table properties at CreateTableLikeCommand
cloud-fan commented on pull request #28647: URL: https://github.com/apache/spark/pull/28647#issuecomment-650925029 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] manuzhang commented on pull request #28916: [SPARK-32083][SQL] Coalesce to one partition when all partitions are empty in AQE
manuzhang commented on pull request #28916: URL: https://github.com/apache/spark/pull/28916#issuecomment-650925712 @cloud-fan here it is 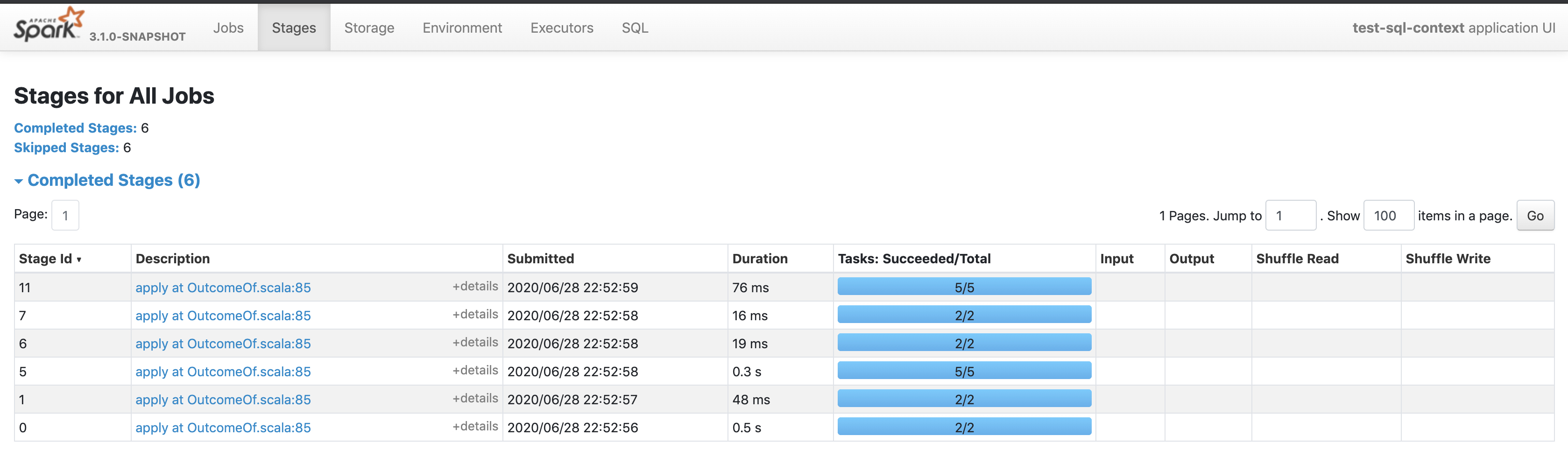 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #28788: [SPARK-31960][Yarn][Build] Only populate Hadoop classpath for no-hadoop build
HyukjinKwon commented on a change in pull request #28788:
URL: https://github.com/apache/spark/pull/28788#discussion_r446784525
##
File path:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/config.scala
##
@@ -74,10 +76,11 @@ package object config {
.doc("Whether to populate Hadoop classpath from
`yarn.application.classpath` and " +
"`mapreduce.application.classpath` Note that if this is set to `false`,
it requires " +
"a `with-Hadoop` Spark distribution that bundles Hadoop runtime or user
has to provide " +
- "a Hadoop installation separately.")
+ "a Hadoop installation separately. By default, for `with-hadoop` Spark
distribution, " +
+ "this is set to `false`; for `no-hadoop` distribution, this is set to
`true`.")
.version("2.4.6")
.booleanConf
-.createWithDefault(true)
+.createWithDefault(isHadoopProvided())
Review comment:
@dbtsai, seems like it has not been added yet. Could we add it soon
before we forget :-)?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sarutak commented on pull request #28942: [SPARK-32125][UI] Support get taskList by status in Web UI and SHS Rest API
sarutak commented on pull request #28942: URL: https://github.com/apache/spark/pull/28942#issuecomment-650921592 Hi @warrenzhu25 , thank you for your contribution. This PR seems to add a new feature so could you add a testcase for it? You can find tests for the status API in `UISeleniumSuite` and `HistoryServerSuite`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28916: [SPARK-32083][SQL] Coalesce to one partition when all partitions are empty in AQE
cloud-fan commented on pull request #28916: URL: https://github.com/apache/spark/pull/28916#issuecomment-650920696 @manuzhang can you check the web UI as well? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28875: [SPARK-32030][SQL] Support unlimited MATCHED and NOT MATCHED clauses in MERGE INTO
SparkQA removed a comment on pull request #28875: URL: https://github.com/apache/spark/pull/28875#issuecomment-650882027 **[Test build #5046 has started](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/5046/testReport)** for PR 28875 at commit [`d5edef3`](https://github.com/apache/spark/commit/d5edef3c2b950440614fc5c9ee1e770bcd0b9884). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28875: [SPARK-32030][SQL] Support unlimited MATCHED and NOT MATCHED clauses in MERGE INTO
SparkQA commented on pull request #28875: URL: https://github.com/apache/spark/pull/28875#issuecomment-650919677 **[Test build #5046 has finished](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/5046/testReport)** for PR 28875 at commit [`d5edef3`](https://github.com/apache/spark/commit/d5edef3c2b950440614fc5c9ee1e770bcd0b9884). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `sealed abstract class MergeAction extends Expression with Unevaluable ` * `case class DeleteAction(condition: Option[Expression]) extends MergeAction` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] TJX2014 commented on a change in pull request #28882: [SPARK-31751][SQL]Serde property `path` overwrites hive table property location
TJX2014 commented on a change in pull request #28882:
URL: https://github.com/apache/spark/pull/28882#discussion_r446782110
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveExternalCatalog.scala
##
@@ -545,7 +545,11 @@ private[spark] class HiveExternalCatalog(conf: SparkConf,
hadoopConf: Configurat
}
private def getLocationFromStorageProps(table: CatalogTable): Option[String]
= {
-CaseInsensitiveMap(table.storage.properties).get("path")
+if (conf.get(HiveUtils.FOLLOW_TABLE_LOCATION)) {
Review comment:
@cloud-fan Thank you for your suggestion, I have corrected.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
SparkQA removed a comment on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-650870128 **[Test build #124619 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124619/testReport)** for PR 28938 at commit [`96dfd17`](https://github.com/apache/spark/commit/96dfd17c631e2d8ef2e330dbe2cbe63fd4e7a262). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28939: [SPARK-32119][CORE] ExecutorPlugin doesn't work with Standalone Cluster
AmplabJenkins removed a comment on pull request #28939: URL: https://github.com/apache/spark/pull/28939#issuecomment-650913498 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/124622/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28939: [SPARK-32119][CORE] ExecutorPlugin doesn't work with Standalone Cluster
AmplabJenkins commented on pull request #28939: URL: https://github.com/apache/spark/pull/28939#issuecomment-650913498 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/124622/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28939: [SPARK-32119][CORE] ExecutorPlugin doesn't work with Standalone Cluster
AmplabJenkins removed a comment on pull request #28939: URL: https://github.com/apache/spark/pull/28939#issuecomment-650913159 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
SparkQA commented on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-650913642 **[Test build #124619 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124619/testReport)** for PR 28938 at commit [`96dfd17`](https://github.com/apache/spark/commit/96dfd17c631e2d8ef2e330dbe2cbe63fd4e7a262). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28924: [SPARK-32091][CORE] Ignore timeout error when remove blocks on the lost executor
SparkQA removed a comment on pull request #28924: URL: https://github.com/apache/spark/pull/28924#issuecomment-650870142 **[Test build #124620 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124620/testReport)** for PR 28924 at commit [`a09990f`](https://github.com/apache/spark/commit/a09990f4c1f9b5672ffe1856641d051e1eb77e86). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28939: [SPARK-32119][CORE] ExecutorPlugin doesn't work with Standalone Cluster
SparkQA removed a comment on pull request #28939: URL: https://github.com/apache/spark/pull/28939#issuecomment-650912108 **[Test build #124622 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124622/testReport)** for PR 28939 at commit [`b571f4c`](https://github.com/apache/spark/commit/b571f4cd7c945e0c14b6d7aed7b179946eb8f4c2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28939: [SPARK-32119][CORE] ExecutorPlugin doesn't work with Standalone Cluster
AmplabJenkins commented on pull request #28939: URL: https://github.com/apache/spark/pull/28939#issuecomment-650913159 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28924: [SPARK-32091][CORE] Ignore timeout error when remove blocks on the lost executor
SparkQA commented on pull request #28924: URL: https://github.com/apache/spark/pull/28924#issuecomment-650912895 **[Test build #124620 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124620/testReport)** for PR 28924 at commit [`a09990f`](https://github.com/apache/spark/commit/a09990f4c1f9b5672ffe1856641d051e1eb77e86). * This patch passes all tests. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * ` case class IsExecutorAlive(executorId: String) extends CoarseGrainedClusterMessage` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28939: [SPARK-32119][CORE] ExecutorPlugin doesn't work with Standalone Cluster
SparkQA commented on pull request #28939: URL: https://github.com/apache/spark/pull/28939#issuecomment-650912866 **[Test build #124622 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124622/testReport)** for PR 28939 at commit [`b571f4c`](https://github.com/apache/spark/commit/b571f4cd7c945e0c14b6d7aed7b179946eb8f4c2). * This patch **fails build dependency tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28939: [SPARK-32119][CORE] ExecutorPlugin doesn't work with Standalone Cluster
SparkQA commented on pull request #28939: URL: https://github.com/apache/spark/pull/28939#issuecomment-650912108 **[Test build #124622 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124622/testReport)** for PR 28939 at commit [`b571f4c`](https://github.com/apache/spark/commit/b571f4cd7c945e0c14b6d7aed7b179946eb8f4c2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #28761: [SPARK-25557][SQL] Nested column predicate pushdown for ORC
viirya commented on a change in pull request #28761:
URL: https://github.com/apache/spark/pull/28761#discussion_r446778323
##
File path:
sql/core/v2.3/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilterSuite.scala
##
@@ -74,9 +75,9 @@ class OrcFilterSuite extends OrcTest with SharedSparkSession {
}
protected def checkFilterPredicate
Review comment:
Might be changed by IDE. Going to revert it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yairogen commented on a change in pull request #28629: [SPARK-31769][CORE] Add MDC support for driver threads
yairogen commented on a change in pull request #28629:
URL: https://github.com/apache/spark/pull/28629#discussion_r446777693
##
File path: core/src/test/scala/org/apache/spark/util/ThreadUtilsSuite.scala
##
@@ -25,11 +25,27 @@ import scala.concurrent.duration._
import scala.util.Random
import org.scalatest.concurrent.Eventually._
+import org.slf4j.MDC
import org.apache.spark.SparkFunSuite
class ThreadUtilsSuite extends SparkFunSuite {
+ test("newDaemonSingleThreadExecutor with MDC") {
+val appIdValue = s"appId-${System.currentTimeMillis()}"
+MDC.put("appId", appIdValue)
Review comment:
@cloud-fan I think he is using `MDC.put` in both cases. The only
difference is that for executor we also have to call `sc.setLocalProperties` in
order to pass the property into the executor JVM. Once the executor process has
knowledge of the appId or any other property, it is put into MDC the same way.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28895: [SPARK-32055][CORE][SQL] Unify getReader and getReaderForRange in ShuffleManager
SparkQA commented on pull request #28895: URL: https://github.com/apache/spark/pull/28895#issuecomment-650910831 **[Test build #5048 has started](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/5048/testReport)** for PR 28895 at commit [`4247fa3`](https://github.com/apache/spark/commit/4247fa323f264af65609f7285e82f86b8dd9be60). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] manuzhang commented on pull request #28916: [SPARK-32083][SQL] Coalesce to one partition when all partitions are empty in AQE
manuzhang commented on pull request #28916: URL: https://github.com/apache/spark/pull/28916#issuecomment-650909946 @cloud-fan Yes, also from the UT log before this change (I enabled the lineage log) ``` = TEST OUTPUT FOR o.a.s.sql.execution.adaptive.AdaptiveQueryExecSuite: 'Empty stage coalesced to 0-partition RDD' = ... 22:06:00.535 ScalaTest-run-running-AdaptiveQueryExecSuite INFO ShufflePartitionsUtil: For shuffle(0, 1), advisory target size: 67108864, actual target size 16. 22:06:00.683 ScalaTest-run-running-AdaptiveQueryExecSuite INFO CodeGenerator: Code generated in 88.071331 ms 22:06:00.700 ScalaTest-run-running-AdaptiveQueryExecSuite INFO CodeGenerator: Code generated in 11.13 ms 22:06:00.752 ScalaTest-run-running-AdaptiveQueryExecSuite INFO CodeGenerator: Code generated in 9.213245 ms 22:06:00.801 ScalaTest-run-running-AdaptiveQueryExecSuite INFO CodeGenerator: Code generated in 12.257591 ms 22:06:00.855 ScalaTest-run-running-AdaptiveQueryExecSuite INFO SparkContext: Starting job: apply at OutcomeOf.scala:85 22:06:00.858 ScalaTest-run-running-AdaptiveQueryExecSuite INFO SparkContext: RDD's recursive dependencies: (5) MapPartitionsRDD[43] at apply at OutcomeOf.scala:85 [] | SQLExecutionRDD[42] at apply at OutcomeOf.scala:85 [] | MapPartitionsRDD[41] at apply at OutcomeOf.scala:85 [] | MapPartitionsRDD[40] at apply at OutcomeOf.scala:85 [] | ShuffledRowRDD[39] at apply at OutcomeOf.scala:85 [] +-(0) MapPartitionsRDD[38] at apply at OutcomeOf.scala:85 [] | MapPartitionsRDD[37] at apply at OutcomeOf.scala:85 [] | ZippedPartitionsRDD2[36] at apply at OutcomeOf.scala:85 [] | MapPartitionsRDD[33] at apply at OutcomeOf.scala:85 [] | ShuffledRowRDD[32] at apply at OutcomeOf.scala:85 [] +-(2) MapPartitionsRDD[27] at apply at OutcomeOf.scala:85 [] | MapPartitionsRDD[26] at apply at OutcomeOf.scala:85 [] | MapPartitionsRDD[25] at apply at OutcomeOf.scala:85 [] | ParallelCollectionRDD[24] at apply at OutcomeOf.scala:85 [] | MapPartitionsRDD[35] at apply at OutcomeOf.scala:85 [] | ShuffledRowRDD[34] at apply at OutcomeOf.scala:85 [] +-(2) MapPartitionsRDD[31] at apply at OutcomeOf.scala:85 [] | MapPartitionsRDD[30] at apply at OutcomeOf.scala:85 [] | MapPartitionsRDD[29] at apply at OutcomeOf.scala:85 [] | ParallelCollectionRDD[28] at apply at OutcomeOf.scala:85 [] 22:06:00.860 dag-scheduler-event-loop INFO DAGScheduler: Registering RDD 38 (apply at OutcomeOf.scala:85) as input to shuffle 2 22:06:00.861 dag-scheduler-event-loop INFO DAGScheduler: Got job 2 (apply at OutcomeOf.scala:85) with 5 output partitions 22:06:00.861 dag-scheduler-event-loop INFO DAGScheduler: Final stage: ResultStage 5 (apply at OutcomeOf.scala:85) 22:06:00.861 dag-scheduler-event-loop INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 4) 22:06:00.862 dag-scheduler-event-loop INFO DAGScheduler: Missing parents: List() 22:06:00.863 dag-scheduler-event-loop INFO DAGScheduler: Submitting ResultStage 5 (MapPartitionsRDD[43] at apply at OutcomeOf.scala:85), which has no missing parents ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28805: [SPARK-28169][SQL] Convert scan predicate condition to CNF
cloud-fan commented on a change in pull request #28805:
URL: https://github.com/apache/spark/pull/28805#discussion_r446776081
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/PruneFileSourcePartitionsSuite.scala
##
@@ -108,4 +109,54 @@ class PruneFileSourcePartitionsSuite extends QueryTest
with SQLTestUtils with Te
}
}
}
+
+ test("SPARK-28169: Convert scan predicate condition to CNF") {
Review comment:
at least this new test can be shared between the 2 test suites?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #28930: [SPARK-29999][SS][FOLLOWUP] Fix test to check the actual metadata log directory
HeartSaVioR commented on a change in pull request #28930:
URL: https://github.com/apache/spark/pull/28930#discussion_r446775390
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -55,6 +54,13 @@ object FileStreamSink extends Logging {
}
}
+ def getMetadataLogPath(path: Path, hadoopConf: Configuration, sqlConf:
SQLConf): Path = {
+val metadataDir = new Path(path, FileStreamSink.metadataDir)
+val fs = metadataDir.getFileSystem(hadoopConf)
+FileStreamSink.checkEscapedMetadataPath(fs, metadataDir, sqlConf)
Review comment:
Oh sorry I should have explained before. That's to avoid test to copy
same code (logic) what FileStreamSink does, so that we don't break the test
when we somehow change it. So that's a refactor and doesn't mean there's a bug
in FileStreamSink.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #28930: [SPARK-29999][SS][FOLLOWUP] Fix test to check the actual metadata log directory
HeartSaVioR commented on a change in pull request #28930:
URL: https://github.com/apache/spark/pull/28930#discussion_r446775390
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -55,6 +54,13 @@ object FileStreamSink extends Logging {
}
}
+ def getMetadataLogPath(path: Path, hadoopConf: Configuration, sqlConf:
SQLConf): Path = {
+val metadataDir = new Path(path, FileStreamSink.metadataDir)
+val fs = metadataDir.getFileSystem(hadoopConf)
+FileStreamSink.checkEscapedMetadataPath(fs, metadataDir, sqlConf)
Review comment:
Oh sorry I should have explained before. That's to avoid test to copy
same code (logic) what FileStreamSink does, so that we don't break the test
when we somehow change it. Doesn't mean there's a bug in FileStreamSink.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #28930: [SPARK-29999][SS][FOLLOWUP] Fix test to check the actual metadata log directory
HeartSaVioR commented on a change in pull request #28930:
URL: https://github.com/apache/spark/pull/28930#discussion_r446775390
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -55,6 +54,13 @@ object FileStreamSink extends Logging {
}
}
+ def getMetadataLogPath(path: Path, hadoopConf: Configuration, sqlConf:
SQLConf): Path = {
+val metadataDir = new Path(path, FileStreamSink.metadataDir)
+val fs = metadataDir.getFileSystem(hadoopConf)
+FileStreamSink.checkEscapedMetadataPath(fs, metadataDir, sqlConf)
Review comment:
Oh sorry I should have explained before. That's to avoid test to copy
same code (logic) what FileStreamSink does, so that we don't break the test
when we somehow change it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #28930: [SPARK-29999][SS][FOLLOWUP] Fix test to check the actual metadata log directory
HeartSaVioR commented on a change in pull request #28930:
URL: https://github.com/apache/spark/pull/28930#discussion_r446775390
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -55,6 +54,13 @@ object FileStreamSink extends Logging {
}
}
+ def getMetadataLogPath(path: Path, hadoopConf: Configuration, sqlConf:
SQLConf): Path = {
+val metadataDir = new Path(path, FileStreamSink.metadataDir)
+val fs = metadataDir.getFileSystem(hadoopConf)
+FileStreamSink.checkEscapedMetadataPath(fs, metadataDir, sqlConf)
Review comment:
Oh sorry I should have explained before. That's to avoid test to have
same code what FileStreamSink does, so that we don't break the test when we
somehow change it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28930: [SPARK-29999][SS][FOLLOWUP] Fix test to check the actual metadata log directory
cloud-fan commented on a change in pull request #28930:
URL: https://github.com/apache/spark/pull/28930#discussion_r446774988
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -55,6 +54,13 @@ object FileStreamSink extends Logging {
}
}
+ def getMetadataLogPath(path: Path, hadoopConf: Configuration, sqlConf:
SQLConf): Path = {
+val metadataDir = new Path(path, FileStreamSink.metadataDir)
+val fs = metadataDir.getFileSystem(hadoopConf)
+FileStreamSink.checkEscapedMetadataPath(fs, metadataDir, sqlConf)
Review comment:
this is new code. So this PR fixes a bug instead of just fixing a test?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28930: [SPARK-29999][SS][FOLLOWUP] Fix test to check the actual metadata log directory
cloud-fan commented on a change in pull request #28930:
URL: https://github.com/apache/spark/pull/28930#discussion_r446774699
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -55,6 +54,13 @@ object FileStreamSink extends Logging {
}
}
+ def getMetadataLogPath(path: Path, hadoopConf: Configuration, sqlConf:
SQLConf): Path = {
+val metadataDir = new Path(path, FileStreamSink.metadataDir)
+val fs = metadataDir.getFileSystem(hadoopConf)
Review comment:
shall we pass the `fs` as a parameter as well?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sarutak commented on a change in pull request #28939: [SPARK-32119][CORE] ExecutorPlugin doesn't work with Standalone Cluster
sarutak commented on a change in pull request #28939:
URL: https://github.com/apache/spark/pull/28939#discussion_r446774168
##
File path: core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala
##
@@ -1254,7 +1255,7 @@ class SparkSubmitSuite
|public void init(PluginContext ctx, Map extraConf) {
| String str = null;
| try (BufferedReader reader =
-|new BufferedReader(new InputStreamReader(new
FileInputStream($tempFileName {
+|new BufferedReader(new InputStreamReader(new
FileInputStream("$tempFileName" {
Review comment:
Actually, I replaced `"test.txt"` with `$tempFileName` just before the
first push so, it's a miss-replacement.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sarutak commented on a change in pull request #28939: [SPARK-32119][CORE] ExecutorPlugin doesn't work with Standalone Cluster
sarutak commented on a change in pull request #28939:
URL: https://github.com/apache/spark/pull/28939#discussion_r446774168
##
File path: core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala
##
@@ -1254,7 +1255,7 @@ class SparkSubmitSuite
|public void init(PluginContext ctx, Map extraConf) {
| String str = null;
| try (BufferedReader reader =
-|new BufferedReader(new InputStreamReader(new
FileInputStream($tempFileName {
+|new BufferedReader(new InputStreamReader(new
FileInputStream("$tempFileName" {
Review comment:
Actually, I replaced `"test.txt"` with `$tempFileName` just before first
push so, it's a miss-replacement.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya edited a comment on pull request #28916: [SPARK-32083][SQL] Coalesce to one partition when all partitions are empty in AQE
viirya edited a comment on pull request #28916: URL: https://github.com/apache/spark/pull/28916#issuecomment-650899063 > It's because `ShuffleRowedRDD` is created with default number of shuffle partitions here https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/ShuffleExchangeExec.scala#L98 When `partitionSpecs` is empty, `CustomShuffleReaderExec` creates `ShuffledRowRDD` with empty `partitionSpecs`. https://github.com/apache/spark/blob/079b3623c85192ff61a35cc99a4dae7ba6c599f0/sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/CustomShuffleReaderExec.scala#L183-L184 https://github.com/apache/spark/blob/34c7ec8e0cb395da50e5cbeee67463414dacd776/sql/core/src/main/scala/org/apache/spark/sql/execution/ShuffledRowRDD.scala#L156-L160 The shuffle is changed by AQE and `CustomShuffleReaderExec` will replace original `ShuffleExchangeExec`, I think the code you pointed is replaced by above code path. So it should be empty partitions. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on pull request #28919: [SPARK-32038][SQL][FOLLOWUP] Make the alias name pretty after float/double normalization
dongjoon-hyun edited a comment on pull request #28919: URL: https://github.com/apache/spark/pull/28919#issuecomment-650903736 Thank you all. Merged to master/3.0. (The last commit is adding only two comments) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #28919: [SPARK-32038][SQL][FOLLOWUP] Make the alias name pretty after float/double normalization
dongjoon-hyun closed pull request #28919: URL: https://github.com/apache/spark/pull/28919 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #28919: [SPARK-32038][SQL][FOLLOWUP] Make the alias name pretty after float/double normalization
dongjoon-hyun commented on pull request #28919: URL: https://github.com/apache/spark/pull/28919#issuecomment-650903736 Thank you all. Merged to master/3.0. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28935: [SPARK-20680][SQL] Adding HiveVoidType in Spark to be compatible with Hive
cloud-fan commented on a change in pull request #28935:
URL: https://github.com/apache/spark/pull/28935#discussion_r446771337
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
##
@@ -2212,6 +2212,7 @@ class AstBuilder(conf: SQLConf) extends
SqlBaseBaseVisitor[AnyRef] with Logging
case ("decimal" | "dec" | "numeric", precision :: scale :: Nil) =>
DecimalType(precision.getText.toInt, scale.getText.toInt)
case ("interval", Nil) => CalendarIntervalType
+ case ("void", Nil) => HiveVoidType
Review comment:
We can just reuse `NullType`. We should forbid creating table with null
type completely, including `spark.catalog.createTable`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28916: [SPARK-32083][SQL] Coalesce to one partition when all partitions are empty in AQE
cloud-fan commented on pull request #28916: URL: https://github.com/apache/spark/pull/28916#issuecomment-650902976 @manuzhang can you check the Spark web UI and make sure AQE does launch tasks for empty partitions? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28754: [SPARK-10520][SQL] Allow average out of DateType
AmplabJenkins removed a comment on pull request #28754: URL: https://github.com/apache/spark/pull/28754#issuecomment-650902644 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/124611/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28754: [SPARK-10520][SQL] Allow average out of DateType
AmplabJenkins commented on pull request #28754: URL: https://github.com/apache/spark/pull/28754#issuecomment-650902644 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/124611/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #28923: [SPARK-32090][SQL] Improve UserDefinedType.equal() to make it be symmetrical
dongjoon-hyun closed pull request #28923: URL: https://github.com/apache/spark/pull/28923 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #28941: [SPARK-32124][CORE][SHS] Fix taskEndReasonFromJson to handle event logs from old Spark versions
HeartSaVioR commented on pull request #28941: URL: https://github.com/apache/spark/pull/28941#issuecomment-650902412 Late LGTM. Thanks for taking care of! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28754: [SPARK-10520][SQL] Allow average out of DateType
AmplabJenkins removed a comment on pull request #28754: URL: https://github.com/apache/spark/pull/28754#issuecomment-650902400 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28754: [SPARK-10520][SQL] Allow average out of DateType
AmplabJenkins commented on pull request #28754: URL: https://github.com/apache/spark/pull/28754#issuecomment-650902400 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #28923: [SPARK-32090][SQL] Improve UserDefinedType.equal() to make it be symmetrical
dongjoon-hyun commented on pull request #28923: URL: https://github.com/apache/spark/pull/28923#issuecomment-650902382 Thank you, @Ngone51 and all. Today's 3 commits are only test case changes and I tested locally. The main body is already tested. Merged to master for Apache Spark 3.1.0. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #28761: [SPARK-25557][SQL] Nested column predicate pushdown for ORC
viirya commented on a change in pull request #28761: URL: https://github.com/apache/spark/pull/28761#discussion_r446769137 ## File path: sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcTest.scala ## @@ -78,12 +78,16 @@ abstract class OrcTest extends QueryTest with FileBasedDataSourceTest with Befor (f: String => Unit): Unit = withDataSourceFile(data)(f) /** - * Writes `data` to a Orc file and reads it back as a `DataFrame`, + * Writes `df` dataframe to a Orc file and reads it back as a `DataFrame`, * which is then passed to `f`. The Orc file will be deleted after `f` returns. */ - protected def withOrcDataFrame[T <: Product: ClassTag: TypeTag] - (data: Seq[T], testVectorized: Boolean = true) - (f: DataFrame => Unit): Unit = withDataSourceDataFrame(data, testVectorized)(f) + protected def withOrcDataFrame(df: DataFrame, testVectorized: Boolean = true) Review comment: I remember adding overridden version causes compilation error. Scala compiler complains ambiguity of overridden methods. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28629: [SPARK-31769][CORE] Add MDC support for driver threads
cloud-fan commented on a change in pull request #28629:
URL: https://github.com/apache/spark/pull/28629#discussion_r446768786
##
File path: core/src/test/scala/org/apache/spark/util/ThreadUtilsSuite.scala
##
@@ -25,11 +25,27 @@ import scala.concurrent.duration._
import scala.util.Random
import org.scalatest.concurrent.Eventually._
+import org.slf4j.MDC
import org.apache.spark.SparkFunSuite
class ThreadUtilsSuite extends SparkFunSuite {
+ test("newDaemonSingleThreadExecutor with MDC") {
+val appIdValue = s"appId-${System.currentTimeMillis()}"
+MDC.put("appId", appIdValue)
Review comment:
I'm still worried about API inconsistency. We should use either
`sc.setLocalProperties` or `MDC.put` for both driver and executor side MDC
properties.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cchighman commented on pull request #28841: [SPARK-31962][SQL][SS] Provide option to load files after a specified date when reading from a folder path
cchighman commented on pull request #28841: URL: https://github.com/apache/spark/pull/28841#issuecomment-650900831 > > I wonder though if structured streaming always implied an event source, particularly when streaming from a file source? > > Ideally it should be. It's not 100% really for file stream source (as it doesn't store offset and allows reading late files), but it's partially considered as file stream source "sorts" the files by its timestamp, in both directions, forward and backward. Probably you're thinking about "offset" as a file offset, while I mean "offset" to mark where we read so far. In this case, modified time, with some processed files as there could be new files having same modified time (some of files may not be picked up due to max number of files per trigger). > > > For example, modifiedDateFilter applies specifically to a point in time when you begin structured streaming on a file data source. You would not have an offset yet in commitedOffsets. The offset use case would imply you are restarting an existing, checkpointed stream or attempting to read from a checkpointed location, right? > > Yes, but you'll want to consider the case where end users "changes" modifiedDataFilter before restaring the query from the checkpoint. Every options can be changed during restart, which makes things very complicated. You'll need to consider combinations of `modifiedDataFilter`, `latestFirst`, `maxFilesAge`. And also make sure the behavior is intuitive to the end users. Please refer #28422 for what I proposed and which review comments it got. > > > When using an offset with a Kafka data source, some write has occurred by which a written checkpoint exists. With the file data source for files that have not yet been read or written, I'm curious how I would apply offset bounds in this way. I was thinking I would have to be reading from a data source that had used structured streaming with checkpointing in order for the offset to exist (committed). > > > > Does this make sense? It seems like once you've written a checkpoint while writing to a stream from the readStream dataframe that's loading files, you would have clear context to apply offset-based semantics. > > Yeah, that should be ideally an "offset" instead of file stream source's own metadata, but I'm not sure how far we want to go. Probably I've been thinking too far, but there's a real issue on file stream source metadata growing, and I support the way it also clearly fixes the issue. I'm worried that once we introduce a relevent option without enough consideration, that would bug us via respecting backward compatiblity. > > > With_startingOffsetByTimestamp_, you have the ability to indicate start/end offsets per topic such as TopicA or TopicB. If this concept were applied to a file data source with the underlying intent that each file name represented a topic, problems begin to emerge. For example, if there are multiple files, they would have different file names, different file names may imply a new topic. > > `underlying intent that each file name represented a topic` - I don't think so (If you thought I proposed it then I didn't mean that). Do you remember a file is an unit of processing on file source? Spark doesn't process the file partially, in other words, Spark never splits the file across micro-batches. If you reflect the file source as Kafka data source, an record in Kafka data source = a file in File data source. > > So the timestamp can represent the offset how Spark has been read so far - though there're some issues below: > > 1) We allowed to read late files - there's new updated file but modified time being set to "previous time". I don't think it should be, but current File data source allows to do so, so that's arguable topic. > > 2) There can be lots of files in same timestamp, and Spark has max files to process in a batch. That means there's a case only partial files get processed. That's why only storing timestamp doesn't work here and we still need to store some processed files as well to mitigate. > > 3) That's technically really odd, but considering eventual consistency like S3... Listing operation may not show some of available files. This may be a blocker to use timestamp as an offset, but even with eventual consistency we don't expect it shows after days. (Do I understand correctly on expectation for eventual consistency on S3?) That said, (ts for (timestamp - some margin) + processed files within margin) could be used for timestamp instead. We can leverage purge timestamp in SeenFileMap, though I think 7 days are too long. And latestFirst should be replaced with something else, because it just simply defeats maxFilesAge and unable to apply offset-like approach. > > Does it make sense? We were writing responses at the same time. Just saw this and will read thr
[GitHub] [spark] cloud-fan commented on a change in pull request #28882: [SPARK-31751][SQL]Serde property `path` overwrites hive table property location
cloud-fan commented on a change in pull request #28882:
URL: https://github.com/apache/spark/pull/28882#discussion_r446768236
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveExternalCatalog.scala
##
@@ -545,7 +545,11 @@ private[spark] class HiveExternalCatalog(conf: SparkConf,
hadoopConf: Configurat
}
private def getLocationFromStorageProps(table: CatalogTable): Option[String]
= {
-CaseInsensitiveMap(table.storage.properties).get("path")
+if (conf.get(HiveUtils.FOLLOW_TABLE_LOCATION)) {
Review comment:
It looks tricky to have a config for such a subtle behavior. I think it
makes more sense to fail when the path serde property doesn't match the table
location, and ask users to either correct the path property or the table
location.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #28936: [SPARK-32126][SS] Scope Session.active in IncrementalExecution
dongjoon-hyun closed pull request #28936: URL: https://github.com/apache/spark/pull/28936 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #28936: [SPARK-32126][SS] Scope Session.active in IncrementalExecution
dongjoon-hyun commented on pull request #28936: URL: https://github.com/apache/spark/pull/28936#issuecomment-650899447 Thanks, @xuanyuanking and @cloud-fan . I created SPARK-32126 and update the title. Merged to master/3.0. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cchighman edited a comment on pull request #28841: [SPARK-31962][SQL][SS] Provide option to load files after a specified date when reading from a folder path
cchighman edited a comment on pull request #28841: URL: https://github.com/apache/spark/pull/28841#issuecomment-650899177 @HeartSaVioR It's in effect no different than a path globular filter except that instead of my wildcard specifying a file extension, it's a wildcard on other metadata, the modified date. `pathGlobFilter` doesn't use offset-based semantics. What it sounds like, though, is the ability to use a timestamp so that you can replay some segment of an event sourced stream that's acting as an append-only transaction log. This would allow much better control of playing back streaming data from files. I believe that would be an awesome feature but not what this is trying to achieve. Here's a clear example of the difference: suppose I'm reading from a folder path having files from 2008. If I were using offset by timestamp, the timestamp may refer to a point in time when I had consumed a particular file with no context to when the file itself was modified last. So, this would mean if my goal was to only begin streaming with files in the path that began after 2019, I'd still be consuming older files. Let me know if my train of thought here is off, I appreciate your patience. @gengliangwang for comment as the current implementation followed guidance for `pathGlobFilter`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR edited a comment on pull request #28841: [SPARK-31962][SQL][SS] Provide option to load files after a specified date when reading from a folder path
HeartSaVioR edited a comment on pull request #28841: URL: https://github.com/apache/spark/pull/28841#issuecomment-650898695 > I wonder though if structured streaming always implied an event source, particularly when streaming from a file source? Ideally it should be. It's not 100% really for file stream source (as it doesn't store offset and allows reading late files), but it's partially considered as file stream source "sorts" the files by its timestamp, in both directions, forward and backward. Probably you're thinking about "offset" as a file offset, while I mean "offset" to mark where we read so far. In this case, modified time, with some processed files as there could be new files having same modified time (some of files may not be picked up due to max number of files per trigger). > For example, modifiedDateFilter applies specifically to a point in time when you begin structured streaming on a file data source. You would not have an offset yet in commitedOffsets. The offset use case would imply you are restarting an existing, checkpointed stream or attempting to read from a checkpointed location, right? Yes, but you'll want to consider the case where end users "changes" modifiedDataFilter before restaring the query from the checkpoint. Every options can be changed during restart, which makes things very complicated. You'll need to consider combinations of `modifiedDataFilter`, `latestFirst`, `maxFilesAge`. And also make sure the behavior is intuitive to the end users. Please refer #28422 for what I proposed and which review comments it got. > When using an offset with a Kafka data source, some write has occurred by which a written checkpoint exists. With the file data source for files that have not yet been read or written, I'm curious how I would apply offset bounds in this way. I was thinking I would have to be reading from a data source that had used structured streaming with checkpointing in order for the offset to exist (committed). > > Does this make sense? It seems like once you've written a checkpoint while writing to a stream from the readStream dataframe that's loading files, you would have clear context to apply offset-based semantics. Yeah, that should be ideally an "offset" instead of file stream source's own metadata, but I'm not sure how far we want to go. Probably I've been thinking too far, but there's a real issue on file stream source metadata growing, and I support the way it also clearly fixes the issue. I'm worried that once we introduce a relevent option without enough consideration, that would bug us via respecting backward compatiblity. > With_startingOffsetByTimestamp_, you have the ability to indicate start/end offsets per topic such as TopicA or TopicB. If this concept were applied to a file data source with the underlying intent that each file name represented a topic, problems begin to emerge. For example, if there are multiple files, they would have different file names, different file names may imply a new topic. `underlying intent that each file name represented a topic` - I don't think so (If you thought I proposed it then I didn't mean that). Do you remember a file is an unit of processing on file source? Spark doesn't process the file partially, in other words, Spark never splits the file across micro-batches. If you reflect the file source as Kafka data source, an record in Kafka data source = a file in File data source. So the timestamp can represent the offset how Spark has been read so far - though there're some issues below: 1) We allowed to read late files - there's new updated file but modified time being set to "previous time". I don't think it should be, but current File data source allows to do so, so that's arguable topic. 2) There can be lots of files in same timestamp, and Spark has max files to process in a batch. That means there's a case only partial files get processed. That's why only storing timestamp doesn't work here and we still need to store some processed files as well to mitigate. 3) That's technically really odd, but considering eventual consistency like S3... Listing operation may not show some of available files. This may be a blocker to use timestamp as an offset, but even with eventual consistency we don't expect it shows after days. (Do I understand correctly on expectation for eventual consistency on S3?) That said, (ts for (timestamp - some margin) + processed files within margin) could be used for timestamp instead. We can leverage purge timestamp in SeenFileMap, though I think 7 days are too long. And latestFirst should be replaced with something else, because it just simply defeats maxFilesAge and unable to apply offset-like approach. Does it make sense? This is an automated message from the Apache Git Service. To r
[GitHub] [spark] viirya commented on pull request #28916: [SPARK-32083][SQL] Coalesce to one partition when all partitions are empty in AQE
viirya commented on pull request #28916: URL: https://github.com/apache/spark/pull/28916#issuecomment-650899063 > It's because `ShuffleRowedRDD` is created with default number of shuffle partitions here https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/ShuffleExchangeExec.scala#L98 When `partitionSpecs` is empty, `CustomShuffleReaderExec` creates `ShuffledRowRDD` with empty `partitionSpecs`. https://github.com/apache/spark/blob/079b3623c85192ff61a35cc99a4dae7ba6c599f0/sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/CustomShuffleReaderExec.scala#L183-L184 https://github.com/apache/spark/blob/34c7ec8e0cb395da50e5cbeee67463414dacd776/sql/core/src/main/scala/org/apache/spark/sql/execution/ShuffledRowRDD.scala#L156-L160 The shuffle is changed by AQE and `CustomShuffleReaderExec` will replace original `ShuffleExchangeExec`, I think the code you pointed is replaced by above code path. So it should be empty partition. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cchighman commented on pull request #28841: [SPARK-31962][SQL][SS] Provide option to load files after a specified date when reading from a folder path
cchighman commented on pull request #28841: URL: https://github.com/apache/spark/pull/28841#issuecomment-650899177 @HeartSaVioR It's in effect no different than a path globular filter except that instead instead of my wildcard specifying a file extension, it's a wildcard on other metadata, the modified date. `pathGlobFilter` doesn't use offset-based semantics. What it sounds like, though, is the ability to use a timestamp so that you can replay some segment of an event sourced stream that's acting as an append-only transaction log. This would allow much better control of playing back streaming data from files. I believe that would be an awesome feature but not what this is trying to achieve. Here's a clear example of the difference: suppose I'm reading from a folder path having files from 2008. If I were using offset by timestamp, the timestamp may refer to a point in time when I had consumed a particular file with no context to when the file itself was modified last. So, this would mean if my goal was to only begin streaming with files in the path that began after 2019, I'd still be consuming older files. Let me know if my train of thought here is off, I appreciate your patience. @gengliangwang for comment as the current implementation followed guidance for `pathGlobFilter`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #28841: [SPARK-31962][SQL][SS] Provide option to load files after a specified date when reading from a folder path
HeartSaVioR commented on pull request #28841: URL: https://github.com/apache/spark/pull/28841#issuecomment-650898695 > I wonder though if structured streaming always implied an event source, particularly when streaming from a file source? Ideally it should be. It's not 100% really for file stream source (as it doesn't store offset and allows reading late files), but it's partially considered as file stream source "sorts" the files by its timestamp, in both directions, forward and backward. Probably you're thinking about "offset" as a file offset, while I mean "offset" to mark where we read so far. In this case, modified time, with some processed files as there could be new files having same modified time (some of files may not be picked up due to max number of files per trigger). > For example, modifiedDateFilter applies specifically to a point in time when you begin structured streaming on a file data source. You would not have an offset yet in commitedOffsets. The offset use case would imply you are restarting an existing, checkpointed stream or attempting to read from a checkpointed location, right? Yes, but you'll want to consider the case where end users "changes" modifiedDataFilter before restaring the query from the checkpoint. Every options can be changed during restart, which makes things very complicated. You'll need to consider combinations of `modifiedDataFilter`, `latestFirst`, `maxFilesAge`. And also make sure the behavior is intuitive to the end users. Please refer #28422 for what I proposed and which review comments it got. > When using an offset with a Kafka data source, some write has occurred by which a written checkpoint exists. With the file data source for files that have not yet been read or written, I'm curious how I would apply offset bounds in this way. I was thinking I would have to be reading from a data source that had used structured streaming with checkpointing in order for the offset to exist (committed). > > Does this make sense? It seems like once you've written a checkpoint while writing to a stream from the readStream dataframe that's loading files, you would have clear context to apply offset-based semantics. Yeah, that should be ideally an "offset" instead of file stream source's own metadata, but I'm not sure how far we want to go. Probably I've been thinking too far, but there's a real issue on file stream source metadata growing, and I support the way it also clearly fixes the issue. I'm worried that once we introduce a relevent option without enough consideration, that would bug us via respecting backward compatiblity. > With_startingOffsetByTimestamp_, you have the ability to indicate start/end offsets per topic such as TopicA or TopicB. If this concept were applied to a file data source with the underlying intent that each file name represented a topic, problems begin to emerge. For example, if there are multiple files, they would have different file names, different file names may imply a new topic. `underlying intent that each file name represented a topic` I don't think so. Do you remember a file is an unit of processing on file source? Spark doesn't process the file partially, in other words, Spark never splits the file across micro-batches. If you reflect the file source as Kafka data source, an record in Kafka data source = a file in File data source. So the timestamp can represent the offset how Spark has been read so far - though there're some issues below: 1) We allowed to read late files - there's new updated file but modified time being set to "previous time". I don't think it should be, but current File data source allows to do so, so that's arguable topic. 2) There can be lots of files in same timestamp, and Spark has max files to process in a batch. That means there's a case only partial files get processed. That's why only storing timestamp doesn't work here and we still need to store some processed files as well to mitigate. 3) That's technically really odd, but considering eventual consistency like S3... Listing operation may not show some of available files. This may be a blocker to use timestamp as an offset, but even with eventual consistency we don't expect it shows after days. (Do I understand correctly on expectation for eventual consistency on S3?) That said, (ts for (timestamp - some margin) + processed files within margin) could be used for timestamp instead. We can leverage purge timestamp in SeenFileMap, though I think 7 days are too long. And latestFirst should be replaced with something else, because it just simply defeats maxFilesAge and unable to apply offset-like approach. Does it make sense? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL ab
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #28939: [SPARK-32119][CORE] ExecutorPlugin doesn't work with Standalone Cluster
dongjoon-hyun commented on a change in pull request #28939:
URL: https://github.com/apache/spark/pull/28939#discussion_r446766094
##
File path: core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala
##
@@ -1254,7 +1255,7 @@ class SparkSubmitSuite
|public void init(PluginContext ctx, Map extraConf) {
| String str = null;
| try (BufferedReader reader =
-|new BufferedReader(new InputStreamReader(new
FileInputStream($tempFileName {
+|new BufferedReader(new InputStreamReader(new
FileInputStream("$tempFileName" {
Review comment:
Oh, interesting. Previously, this test case succeeds with `"`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] pan3793 commented on a change in pull request #28940: [SPARK-32121][SHUFFLE][TEST] Fix ExternalShuffleBlockResolverSuite failed on Windows
pan3793 commented on a change in pull request #28940:
URL: https://github.com/apache/spark/pull/28940#discussion_r446766066
##
File path:
common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/ExecutorDiskUtils.java
##
@@ -27,7 +27,7 @@
public class ExecutorDiskUtils {
- private static final Pattern MULTIPLE_SEPARATORS =
Pattern.compile(File.separator + "{2,}");
+ private static final Pattern MULTIPLE_SEPARATORS =
Pattern.compile("[/]+");
Review comment:
You are right, `\\` is legal char in filename on Unix-like OS, but not
on Windows, use different pattern is a better choice.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
dongjoon-hyun commented on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-650898036 Please put that on the PR description. That will be a commit log permanantly. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #28935: [SPARK-20680][SQL] Adding HiveVoidType in Spark to be compatible with Hive
dongjoon-hyun commented on a change in pull request #28935:
URL: https://github.com/apache/spark/pull/28935#discussion_r446765171
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/types/HiveStringType.scala
##
@@ -47,9 +47,7 @@ object HiveStringType {
case MapType(kt, vt, nullable) =>
MapType(replaceCharType(kt), replaceCharType(vt), nullable)
case StructType(fields) =>
- StructType(fields.map { field =>
-field.copy(dataType = replaceCharType(field.dataType))
- })
+ StructType(fields.map(f => f.copy(dataType =
replaceCharType(f.dataType
Review comment:
@LantaoJin . I understand that you want to match the style, but a PR
should be minimal and should not touch irrelevant parts.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #28935: [SPARK-20680][SQL] Adding HiveVoidType in Spark to be compatible with Hive
dongjoon-hyun commented on a change in pull request #28935:
URL: https://github.com/apache/spark/pull/28935#discussion_r44676
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/types/HiveStringType.scala
##
@@ -47,9 +47,7 @@ object HiveStringType {
case MapType(kt, vt, nullable) =>
MapType(replaceCharType(kt), replaceCharType(vt), nullable)
case StructType(fields) =>
- StructType(fields.map { field =>
-field.copy(dataType = replaceCharType(field.dataType))
- })
+ StructType(fields.map(f => f.copy(dataType =
replaceCharType(f.dataType
Review comment:
Ur, is this relevant to this `HiveVoidType` PR?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #28941: [SPARK-32124][CORE][SHS] Fix taskEndReasonFromJson to handle event logs from old Spark versions
dongjoon-hyun commented on pull request #28941: URL: https://github.com/apache/spark/pull/28941#issuecomment-650893785 SPARK-32124 is assigned to you, @warrenzhu25 . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #28761: [SPARK-25557][SQL] Nested column predicate pushdown for ORC
HyukjinKwon commented on a change in pull request #28761: URL: https://github.com/apache/spark/pull/28761#discussion_r446761037 ## File path: sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcTest.scala ## @@ -78,12 +78,16 @@ abstract class OrcTest extends QueryTest with FileBasedDataSourceTest with Befor (f: String => Unit): Unit = withDataSourceFile(data)(f) /** - * Writes `data` to a Orc file and reads it back as a `DataFrame`, + * Writes `df` dataframe to a Orc file and reads it back as a `DataFrame`, * which is then passed to `f`. The Orc file will be deleted after `f` returns. */ - protected def withOrcDataFrame[T <: Product: ClassTag: TypeTag] - (data: Seq[T], testVectorized: Boolean = true) - (f: DataFrame => Unit): Unit = withDataSourceDataFrame(data, testVectorized)(f) + protected def withOrcDataFrame(df: DataFrame, testVectorized: Boolean = true) Review comment: @viirya why do we need to change this? Looks we can just add the overridden version to test nested DataFrame without touching other tests. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #28941: [SPARK-32124][CORE][SHS] Fix taskEndReasonFromJson to handle event logs from old Spark versions
dongjoon-hyun closed pull request #28941: URL: https://github.com/apache/spark/pull/28941 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28895: [SPARK-32055][CORE][SQL] Unify getReader and getReaderForRange in ShuffleManager
cloud-fan commented on pull request #28895: URL: https://github.com/apache/spark/pull/28895#issuecomment-650892863 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28916: [SPARK-32083][SQL] Coalesce to one partition when all partitions are empty in AQE
cloud-fan commented on pull request #28916: URL: https://github.com/apache/spark/pull/28916#issuecomment-650892593 Ideally we should launch no task for empty partitions. Launching one task is still not the best solution. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #28761: [SPARK-25557][SQL] Nested column predicate pushdown for ORC
HyukjinKwon commented on a change in pull request #28761:
URL: https://github.com/apache/spark/pull/28761#discussion_r446759277
##
File path:
sql/core/v2.3/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilterSuite.scala
##
@@ -74,9 +75,9 @@ class OrcFilterSuite extends OrcTest with SharedSparkSession {
}
protected def checkFilterPredicate
Review comment:
Seems we don't need to change here
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #28904: [SPARK-30462][SS] Streamline the logic on file stream source and sink to avoid memory issue
HeartSaVioR commented on pull request #28904: URL: https://github.com/apache/spark/pull/28904#issuecomment-650889370 UPDATE: SPARK-30946 + SPARK-30462 with lower down driver memory to 1.5G now writes batch 9039 which RES is around 1.3g. I guess the process uses up available memory if possible, but not leads to OOME. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] manuzhang edited a comment on pull request #28916: [SPARK-32083][SQL] Coalesce to one partition when all partitions are empty in AQE
manuzhang edited a comment on pull request #28916: URL: https://github.com/apache/spark/pull/28916#issuecomment-650888636 @viirya It's because `ShuffleRowedRDD` is created with default number of shuffle partitions here https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/ShuffleExchangeExec.scala#L98 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] manuzhang commented on pull request #28916: [SPARK-32083][SQL] Coalesce to one partition when all partitions are empty in AQE
manuzhang commented on pull request #28916: URL: https://github.com/apache/spark/pull/28916#issuecomment-650888636 @viirya It's because of `ShuffleRowedRDD` is created with default number of shuffle partitions here https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/ShuffleExchangeExec.scala#L98 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #27983: [SPARK-32105][SQL]Implement ScriptTransformation in sql/core
HyukjinKwon commented on pull request #27983: URL: https://github.com/apache/spark/pull/27983#issuecomment-650886614 Let's keep the PR description and title up-to-date. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27983: [SPARK-32105][SQL]Implement ScriptTransformation in sql/core
HyukjinKwon commented on a change in pull request #27983:
URL: https://github.com/apache/spark/pull/27983#discussion_r446754091
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveStrategies.scala
##
@@ -22,7 +22,7 @@ import java.util.Locale
import org.apache.hadoop.fs.{FileSystem, Path}
-import org.apache.spark.sql._
+import org.apache.spark.sql.{Strategy, _}
Review comment:
This change seems not needed.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #27983: [SPARK-32105][SQL]Implement ScriptTransformation in sql/core
HyukjinKwon commented on a change in pull request #27983: URL: https://github.com/apache/spark/pull/27983#discussion_r446753971 ## File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/HiveScriptTransformationExec.scala ## @@ -0,0 +1,400 @@ +/* Review comment: @AngersZh, let's rename this file later when you actually add `ScriptTransformationExec`. If we do the renaming first in this PR and merge, I think that will keep file renaming. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28882: [SPARK-31751][SQL]Serde property `path` overwrites hive table property location
AmplabJenkins removed a comment on pull request #28882: URL: https://github.com/apache/spark/pull/28882#issuecomment-650885129 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28882: [SPARK-31751][SQL]Serde property `path` overwrites hive table property location
AmplabJenkins commented on pull request #28882: URL: https://github.com/apache/spark/pull/28882#issuecomment-650885129 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28754: [SPARK-10520][SQL] Allow average out of DateType
SparkQA removed a comment on pull request #28754: URL: https://github.com/apache/spark/pull/28754#issuecomment-650828437 **[Test build #124611 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124611/testReport)** for PR 28754 at commit [`bbf72c4`](https://github.com/apache/spark/commit/bbf72c4a271d56c1a92770aba0a573179b57b765). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28754: [SPARK-10520][SQL] Allow average out of DateType
SparkQA commented on pull request #28754: URL: https://github.com/apache/spark/pull/28754#issuecomment-650882399 **[Test build #124611 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124611/testReport)** for PR 28754 at commit [`bbf72c4`](https://github.com/apache/spark/commit/bbf72c4a271d56c1a92770aba0a573179b57b765). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org