[GitHub] [spark] SparkQA commented on pull request #30025: [SPARK-33095][SQL] Support ALTER TABLE in JDBC v2 Table Catalog: add, update type and nullability of columns (MySQL dialect)
SparkQA commented on pull request #30025: URL: https://github.com/apache/spark/pull/30025#issuecomment-709859600 **[Test build #129880 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129880/testReport)** for PR 30025 at commit [`dfd6d4b`](https://github.com/apache/spark/commit/dfd6d4b5ee2bfad370ec57e264b1c18de038e8ae). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
SparkQA removed a comment on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709775887 **[Test build #129875 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129875/testReport)** for PR 30057 at commit [`199aa8f`](https://github.com/apache/spark/commit/199aa8f01673ba0b990567516771106dd15ff143). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
AmplabJenkins removed a comment on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709848373 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/129875/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30066: [SPARK-XXX][INFRA] Use pre-built image at GitHub Action SparkR job
SparkQA commented on pull request #30066: URL: https://github.com/apache/spark/pull/30066#issuecomment-709848582 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34483/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
AmplabJenkins removed a comment on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709848361 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
AmplabJenkins commented on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709848361 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
SparkQA commented on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709848218 **[Test build #129875 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129875/testReport)** for PR 30057 at commit [`199aa8f`](https://github.com/apache/spark/commit/199aa8f01673ba0b990567516771106dd15ff143). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30065: [SPARK-33165][SQL][TESTS][FOLLOW-UP] Use scala.Predef.assert instead
AmplabJenkins removed a comment on pull request #30065: URL: https://github.com/apache/spark/pull/30065#issuecomment-709847660 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30065: [SPARK-33165][SQL][TESTS][FOLLOW-UP] Use scala.Predef.assert instead
AmplabJenkins commented on pull request #30065: URL: https://github.com/apache/spark/pull/30065#issuecomment-709847660 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30046: [SPARK-33154][CORE][K8S] Handle cleaned shuffles during migration
AmplabJenkins removed a comment on pull request #30046: URL: https://github.com/apache/spark/pull/30046#issuecomment-709847313 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30065: [SPARK-33165][SQL][TESTS][FOLLOW-UP] Use scala.Predef.assert instead
SparkQA removed a comment on pull request #30065: URL: https://github.com/apache/spark/pull/30065#issuecomment-709699989 **[Test build #129870 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129870/testReport)** for PR 30065 at commit [`6971fdf`](https://github.com/apache/spark/commit/6971fdfd77553e01b69cd8cf866508a8ec923941). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30046: [SPARK-33154][CORE][K8S] Handle cleaned shuffles during migration
AmplabJenkins commented on pull request #30046: URL: https://github.com/apache/spark/pull/30046#issuecomment-709847313 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30065: [SPARK-33165][SQL][TESTS][FOLLOW-UP] Use scala.Predef.assert instead
SparkQA commented on pull request #30065: URL: https://github.com/apache/spark/pull/30065#issuecomment-709846092 **[Test build #129870 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129870/testReport)** for PR 30065 at commit [`6971fdf`](https://github.com/apache/spark/commit/6971fdfd77553e01b69cd8cf866508a8ec923941). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30046: [SPARK-33154][CORE][K8S] Handle cleaned shuffles during migration
SparkQA removed a comment on pull request #30046: URL: https://github.com/apache/spark/pull/30046#issuecomment-709700011 **[Test build #129871 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129871/testReport)** for PR 30046 at commit [`b50eea8`](https://github.com/apache/spark/commit/b50eea895a084c04784399faaf74f2b822405e84). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30046: [SPARK-33154][CORE][K8S] Handle cleaned shuffles during migration
SparkQA commented on pull request #30046: URL: https://github.com/apache/spark/pull/30046#issuecomment-709845677 **[Test build #129871 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129871/testReport)** for PR 30046 at commit [`b50eea8`](https://github.com/apache/spark/commit/b50eea895a084c04784399faaf74f2b822405e84). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
AmplabJenkins removed a comment on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709844264 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
AmplabJenkins commented on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709844264 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
SparkQA commented on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709844239 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34482/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #30042: [SPARK-33139][SQL] protect setActionSession and clearActiveSession
HyukjinKwon commented on a change in pull request #30042:
URL: https://github.com/apache/spark/pull/30042#discussion_r506087792
##
File path: python/pyspark/sql/session.py
##
@@ -230,7 +230,10 @@ def __init__(self, sparkContext, jsparkSession=None):
SparkSession._instantiatedSession = self
SparkSession._activeSession = self
self._jvm.SparkSession.setDefaultSession(self._jsparkSession)
-self._jvm.SparkSession.setActiveSession(self._jsparkSession)
+
self._jvm.java.lang.Class.forName("org.apache.spark.sql.SparkSession$")\
+.getDeclaredField("MODULE$")\
+.get(None)\
+.setActiveSessionInternal(self._jsparkSession)
Review comment:
Thanks, please go ahead for a followup.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
AmplabJenkins removed a comment on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709842833 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/129877/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
SparkQA removed a comment on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709798588 **[Test build #129877 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129877/testReport)** for PR 28938 at commit [`3fbfd5d`](https://github.com/apache/spark/commit/3fbfd5d5edc52519dea3e7958ee0b4d64ff930fa). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
AmplabJenkins removed a comment on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709842821 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
AmplabJenkins commented on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709842821 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
SparkQA commented on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709842475 **[Test build #129877 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129877/testReport)** for PR 28938 at commit [`3fbfd5d`](https://github.com/apache/spark/commit/3fbfd5d5edc52519dea3e7958ee0b4d64ff930fa). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #26312: [SPARK-29649][SQL] Stop task set if FileAlreadyExistsException was thrown when writing to output file
viirya commented on a change in pull request #26312:
URL: https://github.com/apache/spark/pull/26312#discussion_r506086784
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileFormatWriter.scala
##
@@ -281,6 +281,10 @@ object FileFormatWriter extends Logging {
} catch {
case e: FetchFailedException =>
throw e
+ case f: FileAlreadyExistsException =>
Review comment:
I see. Thanks for the details. We have different standpoints. For your
cases the first one option looks a better choice. The customers we had are
using HDFS and `FileAlreadyExistsException` isn't recoverable. So the pain
point comes from more time spent on a failed job.
I believe even SPARK-27194 is resolved, fast-fail of a failed job caused by
`FileAlreadyExistsException` or maybe other errors if we know they are
un-recoverable in advance, is still useful.
Seems to me there are options, one is to revert this completely, second is
to add a config for the fast-fail behavior and set it false by default. I
prefer the second one because the reason above, we can relieve the pain of
wasting time on failed job if users want.
WDYT?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #30042: [SPARK-33139][SQL] protect setActionSession and clearActiveSession
HyukjinKwon commented on a change in pull request #30042:
URL: https://github.com/apache/spark/pull/30042#discussion_r506086362
##
File path: python/pyspark/sql/session.py
##
@@ -230,7 +230,10 @@ def __init__(self, sparkContext, jsparkSession=None):
SparkSession._instantiatedSession = self
SparkSession._activeSession = self
self._jvm.SparkSession.setDefaultSession(self._jsparkSession)
-self._jvm.SparkSession.setActiveSession(self._jsparkSession)
+
self._jvm.java.lang.Class.forName("org.apache.spark.sql.SparkSession$")\
Review comment:
`Class.forName` should better not directly used. This is banned by Scala
style:
https://github.com/apache/spark/blob/e93b8f02cd706bedc47c9b55a73f632fe9e61ec3/scalastyle-config.xml#L197-L206
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] leanken commented on a change in pull request #30042: [SPARK-33139][SQL] protect setActionSession and clearActiveSession
leanken commented on a change in pull request #30042:
URL: https://github.com/apache/spark/pull/30042#discussion_r506086345
##
File path: python/pyspark/sql/session.py
##
@@ -230,7 +230,10 @@ def __init__(self, sparkContext, jsparkSession=None):
SparkSession._instantiatedSession = self
SparkSession._activeSession = self
self._jvm.SparkSession.setDefaultSession(self._jsparkSession)
-self._jvm.SparkSession.setActiveSession(self._jsparkSession)
+
self._jvm.java.lang.Class.forName("org.apache.spark.sql.SparkSession$")\
+.getDeclaredField("MODULE$")\
+.get(None)\
+.setActiveSessionInternal(self._jsparkSession)
Review comment:
OK, I will test and update in next PR, thanks @HyukjinKwon
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #30042: [SPARK-33139][SQL] protect setActionSession and clearActiveSession
HyukjinKwon commented on a change in pull request #30042:
URL: https://github.com/apache/spark/pull/30042#discussion_r506085277
##
File path: python/pyspark/sql/session.py
##
@@ -230,7 +230,10 @@ def __init__(self, sparkContext, jsparkSession=None):
SparkSession._instantiatedSession = self
SparkSession._activeSession = self
self._jvm.SparkSession.setDefaultSession(self._jsparkSession)
-self._jvm.SparkSession.setActiveSession(self._jsparkSession)
+
self._jvm.java.lang.Class.forName("org.apache.spark.sql.SparkSession$")\
+.getDeclaredField("MODULE$")\
+.get(None)\
+.setActiveSessionInternal(self._jsparkSession)
Review comment:
Hey, you don't need to manually reflect here. package level private
accessor is already accessible in Java as you did so you can just mimic it here
via `getattr(getattr(spark._jvm, "SparkSession$"),
"MODULE$").setActiveSessionInternal`(...).
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] moomindani commented on pull request #28953: [SPARK-32013][SQL] Support query execution before reading DataFrame and before/after writing DataFrame over JDBC
moomindani commented on pull request #28953: URL: https://github.com/apache/spark/pull/28953#issuecomment-709838989 @gatorsmile Just a reminder.. Can you take a look? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30001: [SPARK-33112][SQL] Avoid executeBatch when JDBC does not support batch updates
AmplabJenkins removed a comment on pull request #30001: URL: https://github.com/apache/spark/pull/30001#issuecomment-70983 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30001: [SPARK-33112][SQL] Avoid executeBatch when JDBC does not support batch updates
AmplabJenkins commented on pull request #30001: URL: https://github.com/apache/spark/pull/30001#issuecomment-70983 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30001: [SPARK-33112][SQL] Avoid executeBatch when JDBC does not support batch updates
SparkQA removed a comment on pull request #30001: URL: https://github.com/apache/spark/pull/30001#issuecomment-709656628 **[Test build #129862 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129862/testReport)** for PR 30001 at commit [`0ebceb0`](https://github.com/apache/spark/commit/0ebceb01d1bbd30345f4d0a3662f34a51bc965d7). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30001: [SPARK-33112][SQL] Avoid executeBatch when JDBC does not support batch updates
SparkQA commented on pull request #30001: URL: https://github.com/apache/spark/pull/30001#issuecomment-709834570 **[Test build #129862 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129862/testReport)** for PR 30001 at commit [`0ebceb0`](https://github.com/apache/spark/commit/0ebceb01d1bbd30345f4d0a3662f34a51bc965d7). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
SparkQA commented on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709831123 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34482/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30066: [SPARK-XXX][INFRA] Use pre-built image at GitHub Action SparkR job
SparkQA commented on pull request #30066: URL: https://github.com/apache/spark/pull/30066#issuecomment-709826033 **[Test build #129879 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129879/testReport)** for PR 30066 at commit [`32ec11a`](https://github.com/apache/spark/commit/32ec11ac3866a88ee6628b22c4379e27ec9b212b). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
AmplabJenkins removed a comment on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709820783 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
SparkQA commented on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709820708 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34480/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
AmplabJenkins commented on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709820783 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30053: [SPARK-32816][SQL][3.0] Fix analyzer bug when aggregating multiple distinct DECIMAL columns
AmplabJenkins removed a comment on pull request #30053: URL: https://github.com/apache/spark/pull/30053#issuecomment-709817363 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/34481/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #30042: [SPARK-33139][SQL] protect setActionSession and clearActiveSession
cloud-fan closed pull request #30042: URL: https://github.com/apache/spark/pull/30042 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30053: [SPARK-32816][SQL][3.0] Fix analyzer bug when aggregating multiple distinct DECIMAL columns
SparkQA commented on pull request #30053: URL: https://github.com/apache/spark/pull/30053#issuecomment-709817336 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34481/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] planga82 edited a comment on pull request #29837: [SPARK-32463][SQL][DOCS] Add "Type Conversion" section in "Supported Data Types" of SQL docs
planga82 edited a comment on pull request #29837: URL: https://github.com/apache/spark/pull/29837#issuecomment-709815971 > This is **not true**. The type conversion rules are more complex than that. > > ``` > spark-sql> explain select 1 in (2, 'a'); > *(1) Project [false AS (CAST(1 AS STRING) IN (CAST(2 AS STRING), CAST(a AS STRING)))#19] > > spark-sql> explain select 1 = '2'; > *(1) Project [false AS (1 = CAST(2 AS INT))#11] > > spark-sql> explain select 1 + '2'; > *(1) Project [3.0 AS (CAST(1 AS DOUBLE) + CAST(2 AS DOUBLE))#17] > ``` Ok, I see, do you think it's better to drop StringType from this matrix? Do we have other differences in other types? Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30053: [SPARK-32816][SQL][3.0] Fix analyzer bug when aggregating multiple distinct DECIMAL columns
AmplabJenkins commented on pull request #30053: URL: https://github.com/apache/spark/pull/30053#issuecomment-709817355 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #30042: [SPARK-33139][SQL] protect setActionSession and clearActiveSession
cloud-fan commented on pull request #30042: URL: https://github.com/apache/spark/pull/30042#issuecomment-709817334 thanks, merging to master! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on pull request #29837: [SPARK-32463][SQL][DOCS] Add "Type Conversion" section in "Supported Data Types" of SQL docs
gengliangwang commented on pull request #29837: URL: https://github.com/apache/spark/pull/29837#issuecomment-709818254 > Ok, I see, do you think it's better to drop StringType from this matrix? Do we have other differences in other types? Yes, but still we need to describe the behavior of type conversion between string type and numeric/date/timestamp type. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30053: [SPARK-32816][SQL][3.0] Fix analyzer bug when aggregating multiple distinct DECIMAL columns
AmplabJenkins removed a comment on pull request #30053: URL: https://github.com/apache/spark/pull/30053#issuecomment-709817355 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30066: [SPARK-XXX][INFRA] Use pre-built image at GitHub Action SparkR job
AmplabJenkins removed a comment on pull request #30066: URL: https://github.com/apache/spark/pull/30066#issuecomment-709816796 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/129878/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30066: [SPARK-XXX][INFRA] Use pre-built image at GitHub Action SparkR job
dongjoon-hyun commented on pull request #30066: URL: https://github.com/apache/spark/pull/30066#issuecomment-709816875 BTW, this is still WIP because I want to handle one R test failure. Also, after testings, CRAN check seems to fail for unknown reason . I'll share the progress in this PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30066: [SPARK-XXX][INFRA] Use pre-built image at GitHub Action SparkR job
AmplabJenkins removed a comment on pull request #30066: URL: https://github.com/apache/spark/pull/30066#issuecomment-709816786 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30066: [SPARK-XXX][INFRA] Use pre-built image at GitHub Action SparkR job
AmplabJenkins commented on pull request #30066: URL: https://github.com/apache/spark/pull/30066#issuecomment-709816786 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30066: [SPARK-XXX][INFRA] Use pre-built image at GitHub Action SparkR job
SparkQA commented on pull request #30066: URL: https://github.com/apache/spark/pull/30066#issuecomment-709816770 **[Test build #129878 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129878/testReport)** for PR 30066 at commit [`7969f72`](https://github.com/apache/spark/commit/7969f72ccb9ad189822b3b549baf4841f38037f3). * This patch **fails R style tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30066: [SPARK-XXX][INFRA] Use pre-built image at GitHub Action SparkR job
SparkQA removed a comment on pull request #30066: URL: https://github.com/apache/spark/pull/30066#issuecomment-709813105 **[Test build #129878 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129878/testReport)** for PR 30066 at commit [`7969f72`](https://github.com/apache/spark/commit/7969f72ccb9ad189822b3b549baf4841f38037f3). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] planga82 commented on pull request #29837: [SPARK-32463][SQL][DOCS] Add "Type Conversion" section in "Supported Data Types" of SQL docs
planga82 commented on pull request #29837: URL: https://github.com/apache/spark/pull/29837#issuecomment-709815971 > This is **not true**. The type conversion rules are more complex than that. > > ``` > spark-sql> explain select 1 in (2, 'a'); > *(1) Project [false AS (CAST(1 AS STRING) IN (CAST(2 AS STRING), CAST(a AS STRING)))#19] > > spark-sql> explain select 1 = '2'; > *(1) Project [false AS (1 = CAST(2 AS INT))#11] > > spark-sql> explain select 1 + '2'; > *(1) Project [3.0 AS (CAST(1 AS DOUBLE) + CAST(2 AS DOUBLE))#17] > ``` Ok, I see, do you think it's better to drop StringType from this matrix? Do we have other differences in other types? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30066: [SPARK-XXX][INFRA] Use pre-built image at GitHub Action SparkR job
HyukjinKwon commented on pull request #30066: URL: https://github.com/apache/spark/pull/30066#issuecomment-709815506 Nice This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30066: [SPARK-XXX][INFRA] Use pre-built image at GitHub Action SparkR job
SparkQA commented on pull request #30066: URL: https://github.com/apache/spark/pull/30066#issuecomment-709813105 **[Test build #129878 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129878/testReport)** for PR 30066 at commit [`7969f72`](https://github.com/apache/spark/commit/7969f72ccb9ad189822b3b549baf4841f38037f3). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30062: [SPARK-32916][SHUFFLE] Implementation of shuffle service that leverages push-based shuffle in YARN deployment mode
AmplabJenkins removed a comment on pull request #30062: URL: https://github.com/apache/spark/pull/30062#issuecomment-709810752 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30065: [SPARK-33165][SQL][TESTS][FOLLOW-UP] Use scala.Predef.assert instead
dongjoon-hyun commented on pull request #30065: URL: https://github.com/apache/spark/pull/30065#issuecomment-709810309 For SparkR setup flakiness, I made a draft PR first. - https://github.com/apache/spark/pull/30066 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30062: [SPARK-32916][SHUFFLE] Implementation of shuffle service that leverages push-based shuffle in YARN deployment mode
AmplabJenkins commented on pull request #30062: URL: https://github.com/apache/spark/pull/30062#issuecomment-709810752 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on pull request #30065: [SPARK-33165][SQL][TESTS][FOLLOW-UP] Use scala.Predef.assert instead
dongjoon-hyun edited a comment on pull request #30065: URL: https://github.com/apache/spark/pull/30065#issuecomment-709810309 For SparkR setup flakiness, I converted my personal draft to this repository first. - https://github.com/apache/spark/pull/30066 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30062: [SPARK-32916][SHUFFLE] Implementation of shuffle service that leverages push-based shuffle in YARN deployment mode
SparkQA removed a comment on pull request #30062: URL: https://github.com/apache/spark/pull/30062#issuecomment-709692748 **[Test build #129869 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129869/testReport)** for PR 30062 at commit [`dceae72`](https://github.com/apache/spark/commit/dceae72f4a1719972cda23c8ea9f2309c129c4dd). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
SparkQA commented on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709809596 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34480/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on pull request #29837: [SPARK-32463][SQL][DOCS] Add "Type Conversion" section in "Supported Data Types" of SQL docs
gengliangwang commented on pull request #29837: URL: https://github.com/apache/spark/pull/29837#issuecomment-709809437 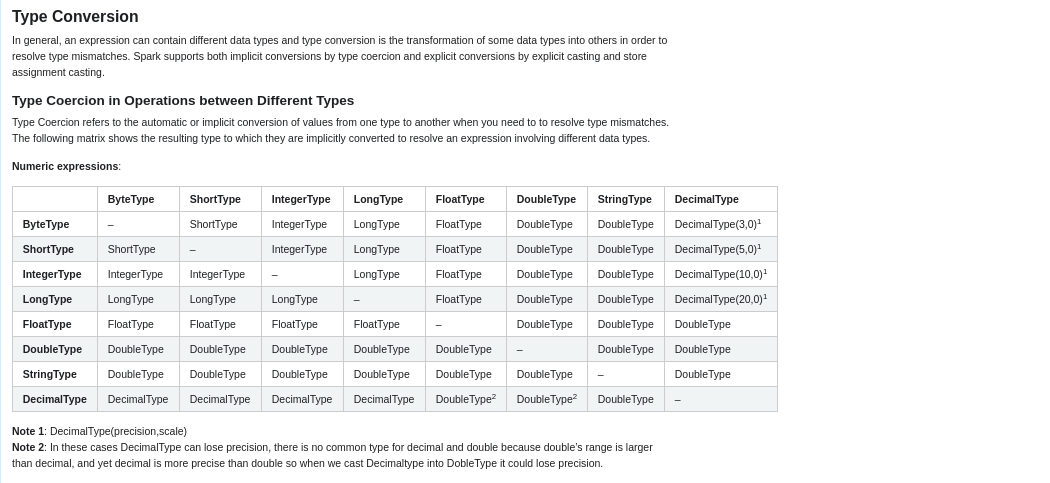 This is not true. The type conversion rules are more complex than that. ``` spark-sql> explain select 1 in (2, 'a'); *(1) Project [false AS (CAST(1 AS STRING) IN (CAST(2 AS STRING), CAST(a AS STRING)))#19] spark-sql> explain select 1 = '2'; *(1) Project [false AS (1 = CAST(2 AS INT))#11] spark-sql> explain select 1 + '2'; *(1) Project [3.0 AS (CAST(1 AS DOUBLE) + CAST(2 AS DOUBLE))#17] ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30062: [SPARK-32916][SHUFFLE] Implementation of shuffle service that leverages push-based shuffle in YARN deployment mode
SparkQA commented on pull request #30062: URL: https://github.com/apache/spark/pull/30062#issuecomment-709809399 **[Test build #129869 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129869/testReport)** for PR 30062 at commit [`dceae72`](https://github.com/apache/spark/commit/dceae72f4a1719972cda23c8ea9f2309c129c4dd). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang edited a comment on pull request #29837: [SPARK-32463][SQL][DOCS] Add "Type Conversion" section in "Supported Data Types" of SQL docs
gengliangwang edited a comment on pull request #29837: URL: https://github.com/apache/spark/pull/29837#issuecomment-709809437  This is **not true**. The type conversion rules are more complex than that. ``` spark-sql> explain select 1 in (2, 'a'); *(1) Project [false AS (CAST(1 AS STRING) IN (CAST(2 AS STRING), CAST(a AS STRING)))#19] spark-sql> explain select 1 = '2'; *(1) Project [false AS (1 = CAST(2 AS INT))#11] spark-sql> explain select 1 + '2'; *(1) Project [3.0 AS (CAST(1 AS DOUBLE) + CAST(2 AS DOUBLE))#17] ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun opened a new pull request #30066: [SPARK-XXX][INFRA] Use pre-built image at GitHub Action SparkR job
dongjoon-hyun opened a new pull request #30066: URL: https://github.com/apache/spark/pull/30066 ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30053: [SPARK-32816][SQL][3.0] Fix analyzer bug when aggregating multiple distinct DECIMAL columns
SparkQA commented on pull request #30053: URL: https://github.com/apache/spark/pull/30053#issuecomment-709807827 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/34481/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30065: [SPARK-33165][SQL][TESTS][FOLLOW-UP] Use scala.Predef.assert instead
dongjoon-hyun commented on pull request #30065: URL: https://github.com/apache/spark/pull/30065#issuecomment-709803937 +1, late LGTM. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29843: [SPARK-29250][BUILD] Upgrade to Hadoop 3.2.1 and move to shaded client
AmplabJenkins removed a comment on pull request #29843: URL: https://github.com/apache/spark/pull/29843#issuecomment-709800958 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/129858/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29843: [SPARK-29250][BUILD] Upgrade to Hadoop 3.2.1 and move to shaded client
AmplabJenkins removed a comment on pull request #29843: URL: https://github.com/apache/spark/pull/29843#issuecomment-709800953 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29843: [SPARK-29250][BUILD] Upgrade to Hadoop 3.2.1 and move to shaded client
AmplabJenkins commented on pull request #29843: URL: https://github.com/apache/spark/pull/29843#issuecomment-709800953 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
SparkQA commented on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709798588 **[Test build #129877 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129877/testReport)** for PR 28938 at commit [`3fbfd5d`](https://github.com/apache/spark/commit/3fbfd5d5edc52519dea3e7958ee0b4d64ff930fa). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] akiyamaneko commented on pull request #30035: [SPARK-33145] [WEBUI] Fix when `Succeeded Jobs` has many child url elements,they will extend over the edge of the page.
akiyamaneko commented on pull request #30035: URL: https://github.com/apache/spark/pull/30035#issuecomment-709797200 cc: @sarutak @gengliangwang This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LantaoJin commented on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
LantaoJin commented on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709796207 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30063: [SPARK-32402][SQL][FOLLOW-UP] Add case sensitivity tests for column resolution in ALTER TABLE
AmplabJenkins removed a comment on pull request #30063: URL: https://github.com/apache/spark/pull/30063#issuecomment-709792902 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30063: [SPARK-32402][SQL][FOLLOW-UP] Add case sensitivity tests for column resolution in ALTER TABLE
AmplabJenkins commented on pull request #30063: URL: https://github.com/apache/spark/pull/30063#issuecomment-709792902 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29843: [SPARK-29250][BUILD] Upgrade to Hadoop 3.2.1 and move to shaded client
AmplabJenkins removed a comment on pull request #29843: URL: https://github.com/apache/spark/pull/29843#issuecomment-709790846 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/129857/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29843: [SPARK-29250][BUILD] Upgrade to Hadoop 3.2.1 and move to shaded client
AmplabJenkins removed a comment on pull request #29843: URL: https://github.com/apache/spark/pull/29843#issuecomment-709790822 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30063: [SPARK-32402][SQL][FOLLOW-UP] Add case sensitivity tests for column resolution in ALTER TABLE
SparkQA removed a comment on pull request #30063: URL: https://github.com/apache/spark/pull/30063#issuecomment-709653848 **[Test build #129861 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129861/testReport)** for PR 30063 at commit [`aee4d88`](https://github.com/apache/spark/commit/aee4d88443874236350c87f7cea86d2ee2191c16). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30063: [SPARK-32402][SQL][FOLLOW-UP] Add case sensitivity tests for column resolution in ALTER TABLE
SparkQA commented on pull request #30063: URL: https://github.com/apache/spark/pull/30063#issuecomment-709791516 **[Test build #129861 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129861/testReport)** for PR 30063 at commit [`aee4d88`](https://github.com/apache/spark/commit/aee4d88443874236350c87f7cea86d2ee2191c16). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29843: [SPARK-29250][BUILD] Upgrade to Hadoop 3.2.1 and move to shaded client
AmplabJenkins commented on pull request #29843: URL: https://github.com/apache/spark/pull/29843#issuecomment-709790822 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
AmplabJenkins removed a comment on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709782124 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/34479/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
AmplabJenkins removed a comment on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709782115 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
AmplabJenkins commented on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709782115 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30053: [SPARK-32816][SQL][3.0] Fix analyzer bug when aggregating multiple distinct DECIMAL columns
SparkQA commented on pull request #30053: URL: https://github.com/apache/spark/pull/30053#issuecomment-709781462 **[Test build #129876 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129876/testReport)** for PR 30053 at commit [`2634588`](https://github.com/apache/spark/commit/2634588874042dd20c3293e4c67a7ae0199fe5b9). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
AmplabJenkins removed a comment on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709776746 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/129874/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #29992: [SPARK-32881][CORE] Catch some race condition errors and log them more clearly
HyukjinKwon commented on pull request #29992: URL: https://github.com/apache/spark/pull/29992#issuecomment-709777531 gentle ping. This PR introduces the very first place that catches and suppresses `NullPointerException` in the codebase - the second place that catches `NullPointerException` (`mllib/src/main/scala/org/apache/spark/ml/feature/VectorAssembler.scala`) rethrows NPE. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
SparkQA removed a comment on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709729676 **[Test build #129874 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129874/testReport)** for PR 28938 at commit [`3fbfd5d`](https://github.com/apache/spark/commit/3fbfd5d5edc52519dea3e7958ee0b4d64ff930fa). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on a change in pull request #26312: [SPARK-29649][SQL] Stop task set if FileAlreadyExistsException was thrown when writing to output file
zsxwing commented on a change in pull request #26312:
URL: https://github.com/apache/spark/pull/26312#discussion_r506051720
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileFormatWriter.scala
##
@@ -281,6 +281,10 @@ object FileFormatWriter extends Logging {
} catch {
case e: FetchFailedException =>
throw e
+ case f: FileAlreadyExistsException =>
Review comment:
If SPARK-27194 is not rare, it sounds a serious bug. Can we focus on
fixing SPARK-27194 instead? Maybe speed up the review for #29000? If
SPARK-27194 is resolved, we won't need this hack. Right? In addition, it's
weird that FileFormatWriter needs to understand the behavior of
`SQLHadoopMapReduceCommitProtocol`. It would be great if we can avoid leaking
the implementation details of a commit protocol to `FileFormatWriter`.
Regarding user cases, I have seen multiple customers hitting recoverable
`FileAlreadyExistsException` caused by
https://issues.apache.org/jira/browse/HADOOP-17015 . But they could not upgrade
the their Hadoop version. It's much harder to upgrade Hadoop than Spark. This
change makes their jobs fail occasionally after upgrading to Spark 3.0 because
Spark doesn't retry `FileAlreadyExistsException`. And like what you said, the
user cannot change Spark's behavior to retry `FileAlreadyExistsException`.
Their jobs should have been finished but because Spark didn't retry, they
wasted hours of work.
Throwing spark specific exception for commit protocol errors cannot resolve
this because the issue is in the underlying FileSystem implementation called by
Spark directly.
IMO, we need to make the tradeoff between:
- Make a job successful if we retry `FileAlreadyExistsException`, but a
failed job may take more time to fail.
- Make a job fail when it should have been successful if we retried
`FileAlreadyExistsException`, but make a failed job fail fast.
I prefer the first one as we can make more jobs successful and the behavior
is the same as before.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
AmplabJenkins removed a comment on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709776736 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
AmplabJenkins commented on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709776736 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
SparkQA commented on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709775887 **[Test build #129875 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129875/testReport)** for PR 30057 at commit [`199aa8f`](https://github.com/apache/spark/commit/199aa8f01673ba0b990567516771106dd15ff143). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28938: [SPARK-32118][SQL] Use fine-grained read write lock for each database in HiveExternalCatalog
SparkQA commented on pull request #28938: URL: https://github.com/apache/spark/pull/28938#issuecomment-709776321 **[Test build #129874 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129874/testReport)** for PR 28938 at commit [`3fbfd5d`](https://github.com/apache/spark/commit/3fbfd5d5edc52519dea3e7958ee0b4d64ff930fa). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on a change in pull request #26312: [SPARK-29649][SQL] Stop task set if FileAlreadyExistsException was thrown when writing to output file
zsxwing commented on a change in pull request #26312:
URL: https://github.com/apache/spark/pull/26312#discussion_r506051720
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileFormatWriter.scala
##
@@ -281,6 +281,10 @@ object FileFormatWriter extends Logging {
} catch {
case e: FetchFailedException =>
throw e
+ case f: FileAlreadyExistsException =>
Review comment:
If SPARK-27194 is not rare, it sounds a serious bug. Can we focus on
fixing SPARK-27194 instead? Maybe speed up the review for #29000? If
SPARK-27194 is resolved, we won't need this hack. Right? In addition, it's
weird that FileFormatWriter needs to understand the behavior of
`SQLHadoopMapReduceCommitProtocol`. It would be great if we can avoid leaking
the implementation details of a commit protocol to `FileFormatWriter`.
Regarding user cases, I have seen multiple customers hitting recoverable
`FileAlreadyExistsException` caused by
https://issues.apache.org/jira/browse/HADOOP-17015 . But they could not upgrade
the their Hadoop version. It's much harder to upgrade Hadoop than Spark. This
change makes their jobs fail occasionally after upgrading to Spark 3.0 because
Spark doesn't retry `FileAlreadyExistsException`. And like what you said, the
user cannot change Spark's behavior to retry `FileAlreadyExistsException`.
Their jobs should have been finished but because Spark didn't retry, they
wasted hours of work.
Throwing spark specific exception for commit protocol errors cannot resolve
this because the issue is in the underlying FileSystem implementation called by
Spark directly.
IMO, we need to make the tradeoff between:
- Make a job successful if we retry `FileAlreadyExistsException`, but a
failed job may take more time to fail.
- Make a job fail when it should have been successful if we retry
`FileAlreadyExistsException`, but make a failed job fail fast.
I prefer the first one as we can make more jobs successful and the behavior
is the same as before.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30065: [SPARK-33165][SQL][TESTS][FOLLOW-UP] Use scala.Predef.assert instead
HyukjinKwon commented on pull request #30065: URL: https://github.com/apache/spark/pull/30065#issuecomment-709772049 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #30065: [SPARK-33165][SQL][TESTS][FOLLOW-UP] Use scala.Predef.assert instead
HyukjinKwon closed pull request #30065: URL: https://github.com/apache/spark/pull/30065 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
AmplabJenkins removed a comment on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709766928 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/129873/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
SparkQA removed a comment on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709709708 **[Test build #129873 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/129873/testReport)** for PR 30057 at commit [`620956d`](https://github.com/apache/spark/commit/620956d5f9a0b15cbd1a5ad8cf41a8efe4d382e9). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
AmplabJenkins removed a comment on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709766905 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
AmplabJenkins commented on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709766905 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30057: [SPARK-32838][SQL]Check DataSource insert command path with actual path
AmplabJenkins removed a comment on pull request #30057: URL: https://github.com/apache/spark/pull/30057#issuecomment-709765683 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org