[GitHub] [spark] SparkQA removed a comment on pull request #30212: [SPARK-33308][SQL] Refract current grouping analytics
SparkQA removed a comment on pull request #30212: URL: https://github.com/apache/spark/pull/30212#issuecomment-735354809 **[Test build #131924 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131924/testReport)** for PR 30212 at commit [`7e267b8`](https://github.com/apache/spark/commit/7e267b85538da120fd8265a91861b276b631febc). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30212: [SPARK-33308][SQL] Refract current grouping analytics
SparkQA commented on pull request #30212: URL: https://github.com/apache/spark/pull/30212#issuecomment-735357230 **[Test build #131924 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131924/testReport)** for PR 30212 at commit [`7e267b8`](https://github.com/apache/spark/commit/7e267b85538da120fd8265a91861b276b631febc). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30212: [SPARK-33308][SQL] Refract current grouping analytics
maropu commented on a change in pull request #30212: URL: https://github.com/apache/spark/pull/30212#discussion_r532169671 ## File path: sql/core/src/test/resources/sql-tests/inputs/group-analytics.sql ## @@ -18,12 +18,19 @@ AS courseSales(course, year, earnings); -- ROLLUP SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP(course, year) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP (course, year) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP(course, year, (course, year)) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP(course, year, (course, year), ()) ORDER BY course, year; -- CUBE SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE(course, year) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE (course, year) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE(course, year, (course, year)) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE(course, year, (course, year), ()) ORDER BY course, year; Review comment: Okay, thanks for the check. So, could you follow the PostgreSQL/Oracle behaviour? Let's revisit it if other reviewers leave comments about the behaviour. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30212: [SPARK-33308][SQL] Refract current grouping analytics
AngersZh commented on a change in pull request #30212: URL: https://github.com/apache/spark/pull/30212#discussion_r532169398 ## File path: sql/core/src/test/resources/sql-tests/inputs/group-analytics.sql ## @@ -18,12 +18,19 @@ AS courseSales(course, year, earnings); -- ROLLUP SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP(course, year) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP (course, year) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP(course, year, (course, year)) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP(course, year, (course, year), ()) ORDER BY course, year; -- CUBE SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE(course, year) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE (course, year) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE(course, year, (course, year)) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE(course, year, (course, year), ()) ORDER BY course, year; Review comment: And which place should we prevent this illegal case? 1. In AstBuilder throw a ParseException 2. In Analyzer throw a AnalysisException 3. in Cube/Rollup class with a assert ` assert(groupingSets.forall(_.nonEmpty))` IMO we should throw ParseExceptionin AstBuilder This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30529: [SPARK-33588][SQL] Respect the `spark.sql.caseSensitive` config while resolving partition spec in v1 `SHOW TABLE EXTENDED`
SparkQA commented on pull request #30529: URL: https://github.com/apache/spark/pull/30529#issuecomment-735356142 **[Test build #131925 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131925/testReport)** for PR 30529 at commit [`aeceb63`](https://github.com/apache/spark/commit/aeceb63ee1bcc2550f2ed31c9a3f97c4eaac8469). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30212: [SPARK-33308][SQL] Refract current grouping analytics
AngersZh commented on a change in pull request #30212: URL: https://github.com/apache/spark/pull/30212#discussion_r532169014 ## File path: sql/core/src/test/resources/sql-tests/inputs/group-analytics.sql ## @@ -18,12 +18,19 @@ AS courseSales(course, year, earnings); -- ROLLUP SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP(course, year) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP (course, year) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP(course, year, (course, year)) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY ROLLUP(course, year, (course, year), ()) ORDER BY course, year; -- CUBE SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE(course, year) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE (course, year) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE(course, year, (course, year)) ORDER BY course, year; +SELECT course, year, SUM(earnings) FROM courseSales GROUP BY CUBE(course, year, (course, year), ()) ORDER BY course, year; Review comment: > Could you check the behaviour of other systems (other than postgresql) when having an empty set in cube/rollup? Test in Oracle, it not support empty set in groupingset of cube/rollup too. 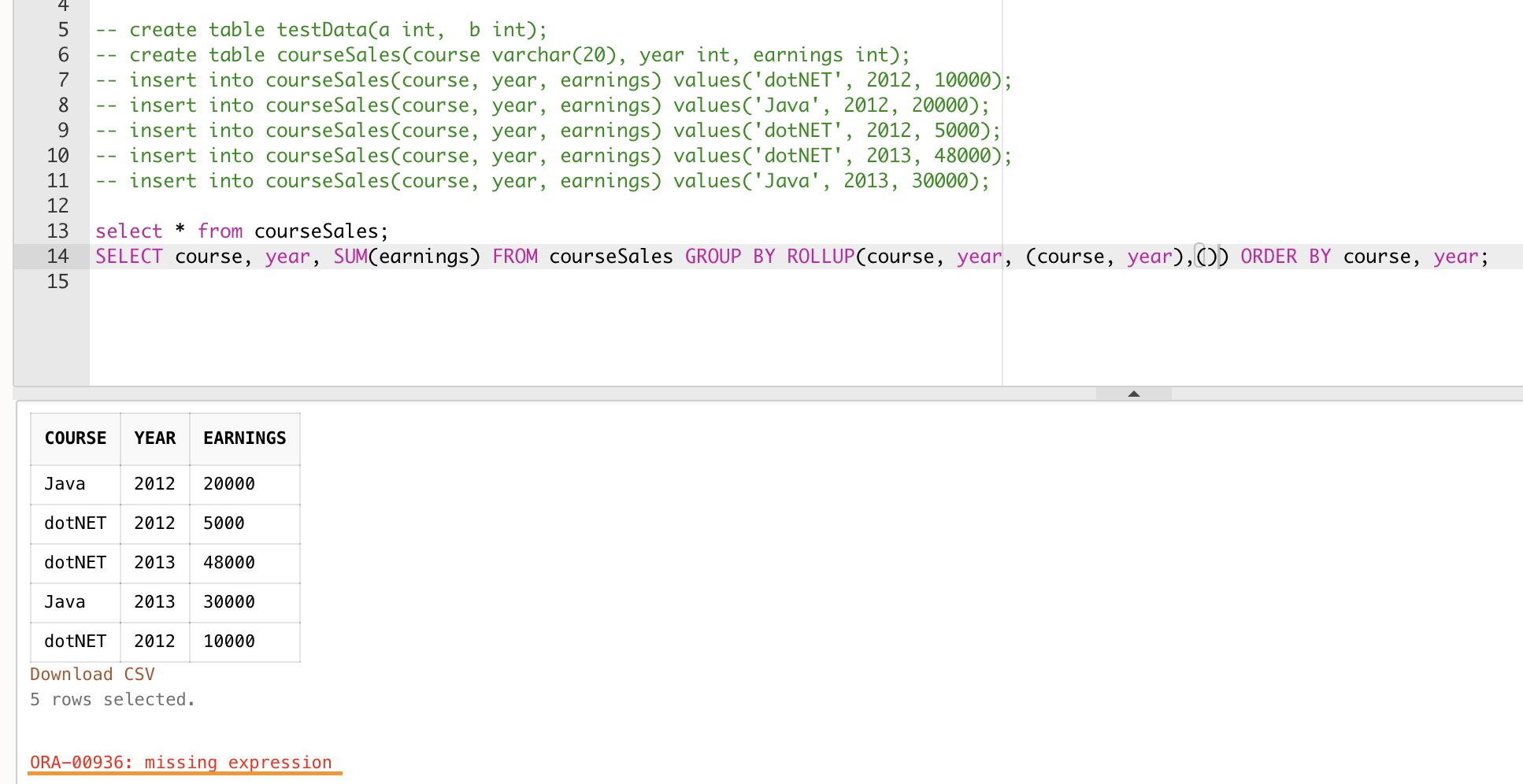 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30334: [SPARK-33411][SQL] Cardinality estimation of union, sort and range operator
maropu commented on a change in pull request #30334:
URL: https://github.com/apache/spark/pull/30334#discussion_r532168676
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/statsEstimation/UnionEstimation.scala
##
@@ -0,0 +1,97 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.plans.logical.statsEstimation
+
+import scala.collection.mutable.ArrayBuffer
+
+import org.apache.spark.sql.catalyst.expressions.{Attribute, AttributeMap}
+import org.apache.spark.sql.catalyst.plans.logical.{ColumnStat, Statistics,
Union}
+import org.apache.spark.sql.types.{ByteType, DataType, DateType, DecimalType,
DoubleType, FloatType, IntegerType, LongType, ShortType, TimestampType}
+
+/**
+ * Estimate the number of output rows by doing the sum of output rows for each
child of union,
+ * and estimate min and max stats for each column by finding the overall min
and max of that
+ * column coming from its children.
+ */
+object UnionEstimation {
+ import EstimationUtils._
+
+ def compare(a: Any, b: Any, dataType: DataType): Boolean = {
+dataType match {
+ case dt: IntegerType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: LongType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: FloatType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: DoubleType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: ShortType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: ByteType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: DateType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: TimestampType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a,
b)
+ case dt: DecimalType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case _ => false
+}
+ }
+
+ def estimate(union: Union): Option[Statistics] = {
+val sizeInBytes = union.children.map(_.stats.sizeInBytes).sum
+val outputRows: Option[BigInt] = if (rowCountsExist(union.children: _*)) {
+ Some(union.children.map(_.stats.rowCount.get).sum)
+} else {
+ None
+}
+
+val output = union.output
+val outputAttrStats = new ArrayBuffer[(Attribute, ColumnStat)]()
+
+union.children.map(_.output).transpose.zipWithIndex.foreach {
+ case (attrs, outputIndex) =>
+val validStat = attrs.zipWithIndex.forall {
+ case (attr, childIndex) =>
+val attrStats = union.children(childIndex).stats.attributeStats
+attrStats.get(attr).isDefined && attrStats(attr).hasMinMaxStats
+}
+if (validStat) {
+ val dataType = output(outputIndex).dataType
+ val minStart: Option[Any] = None
Review comment:
How about removing the intermediate variables like this?
```
val minMaxValue = attrs.zipWithIndex.foldLeft[(Option[Any],
Option[Any])]((None, None)) {
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30334: [SPARK-33411][SQL] Cardinality estimation of union, sort and range operator
maropu commented on a change in pull request #30334:
URL: https://github.com/apache/spark/pull/30334#discussion_r532045253
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/statsEstimation/UnionEstimation.scala
##
@@ -0,0 +1,97 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.plans.logical.statsEstimation
+
+import scala.collection.mutable.ArrayBuffer
+
+import org.apache.spark.sql.catalyst.expressions.{Attribute, AttributeMap}
+import org.apache.spark.sql.catalyst.plans.logical.{ColumnStat, Statistics,
Union}
+import org.apache.spark.sql.types.{ByteType, DataType, DateType, DecimalType,
DoubleType, FloatType, IntegerType, LongType, ShortType, TimestampType}
Review comment:
nit: `import org.apache.spark.sql.types._` looks okay.
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/statsEstimation/UnionEstimation.scala
##
@@ -0,0 +1,97 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.plans.logical.statsEstimation
+
+import scala.collection.mutable.ArrayBuffer
+
+import org.apache.spark.sql.catalyst.expressions.{Attribute, AttributeMap}
+import org.apache.spark.sql.catalyst.plans.logical.{ColumnStat, Statistics,
Union}
+import org.apache.spark.sql.types.{ByteType, DataType, DateType, DecimalType,
DoubleType, FloatType, IntegerType, LongType, ShortType, TimestampType}
+
+/**
+ * Estimate the number of output rows by doing the sum of output rows for each
child of union,
+ * and estimate min and max stats for each column by finding the overall min
and max of that
+ * column coming from its children.
+ */
+object UnionEstimation {
+ import EstimationUtils._
+
+ def compare(a: Any, b: Any, dataType: DataType): Boolean = {
+dataType match {
+ case dt: IntegerType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: LongType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: FloatType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: DoubleType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: ShortType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: ByteType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: DateType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case dt: TimestampType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a,
b)
+ case dt: DecimalType => dt.ordering.asInstanceOf[Ordering[Any]].lt(a, b)
+ case _ => false
+}
+ }
+
+ def estimate(union: Union): Option[Statistics] = {
+val sizeInBytes = union.children.map(_.stats.sizeInBytes).sum
+val outputRows: Option[BigInt] = if (rowCountsExist(union.children: _*)) {
+ Some(union.children.map(_.stats.rowCount.get).sum)
+} else {
+ None
+}
+
+val output = union.output
+val outputAttrStats = new ArrayBuffer[(Attribute, ColumnStat)]()
+
+union.children.map(_.output).transpose.zipWithIndex.foreach {
+ case (attrs, outputIndex) =>
+val validStat = attrs.zipWithIndex.forall {
+ case (attr, childIndex) =>
+val attrStats = union.children(childIndex).stats.attributeStats
+attrStats.get(attr).isDefined && attrStats(attr).hasMinMaxStats
+}
+if (validStat) {
+ val dataType = output(outputIndex).dataType
+
[GitHub] [spark] gaborgsomogyi commented on pull request #29729: [SPARK-32032][SS] Avoid infinite wait in driver because of KafkaConsumer.poll(long) API
gaborgsomogyi commented on pull request #29729: URL: https://github.com/apache/spark/pull/29729#issuecomment-735355267 @HeartSaVioR Thanks for the new round of review, it's really a huge change and appreciate your effort! I agree on your suggestions and will apply them starting from Monday. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30212: [SPARK-33308][SQL] Refract current grouping analytics
SparkQA commented on pull request #30212: URL: https://github.com/apache/spark/pull/30212#issuecomment-735354809 **[Test build #131924 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131924/testReport)** for PR 30212 at commit [`7e267b8`](https://github.com/apache/spark/commit/7e267b85538da120fd8265a91861b276b631febc). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AmplabJenkins removed a comment on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735354560 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AmplabJenkins commented on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735354560 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30212: [SPARK-33308][SQL] Refract current grouping analytics
AngersZh commented on a change in pull request #30212:
URL: https://github.com/apache/spark/pull/30212#discussion_r532165123
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -1529,7 +1475,25 @@ class Analyzer(override val catalogManager:
CatalogManager)
}
val resolvedGroupingExprs = a.groupingExpressions
- .map(resolveExpressionTopDown(_, planForResolve, trimAlias = true))
+ .map {
+case c @ Cube(groupingSets) =>
+ c.copy(groupingSets =
+groupingSets.map(_.map(resolveExpressionTopDown(_, a,
trimAlias = true))
Review comment:
> Hm, I see. Since these extra entries for `GroupingSet` make the
analyzer more complicated, could you find another approach for removing them?
IIUC these entries are needed because `GroupingSet` holds `grpuingSets` as
non-children exprs. For example, it seems `groupingSets` exprs and its children
(`groupByExprs` exprs) looks duplicated, so is it possible to replace
`groupingSets` exprs with integer indices to `groupByExprs` ?
This complexed code make me confused too, and I have tried to find way to
solve this but failed, thanks for your suggestion about use `integer indices `.
I have change the code to convert to/from `groupingSets` and `children` to
remove such, and it works. How about current code?
> `groupingSets` exprs and its children (`groupByExprs` exprs) looks
duplicated, so is it possible to replace `groupingSets` exprs with integer
indices to `groupByExprs` ?
I think change code about about `groupByExprs` and `groupingSets` make it
hard to understand. So I change to use relation about `children` and
`groupjngSets`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30212: [SPARK-33308][SQL] Refract current grouping analytics
AngersZh commented on a change in pull request #30212:
URL: https://github.com/apache/spark/pull/30212#discussion_r532164002
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##
@@ -39,45 +41,64 @@ trait GroupingSet extends Expression with CodegenFallback {
override def eval(input: InternalRow): Any = throw new
UnsupportedOperationException
}
-// scalastyle:off line.size.limit line.contains.tab
-@ExpressionDescription(
- usage = """
-_FUNC_([col1[, col2 ..]]) - create a multi-dimensional cube using the
specified columns
- so that we can run aggregation on them.
- """,
- examples = """
-Examples:
- > SELECT name, age, count(*) FROM VALUES (2, 'Alice'), (5, 'Bob')
people(age, name) GROUP BY _FUNC_(name, age);
-Bob5 1
-Alice 2 1
-Alice NULL1
-NULL 2 1
-NULL NULL2
-BobNULL1
-NULL 5 1
- """,
- since = "2.0.0")
-// scalastyle:on line.size.limit line.contains.tab
-case class Cube(groupByExprs: Seq[Expression]) extends GroupingSet {}
+object GroupingSet {
+ /*
+ * GROUP BY a, b, c WITH ROLLUP
Review comment:
> (I know this is not your mistake though) could you remove the single
leading space?
Done
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##
@@ -39,45 +41,64 @@ trait GroupingSet extends Expression with CodegenFallback {
override def eval(input: InternalRow): Any = throw new
UnsupportedOperationException
}
-// scalastyle:off line.size.limit line.contains.tab
-@ExpressionDescription(
- usage = """
-_FUNC_([col1[, col2 ..]]) - create a multi-dimensional cube using the
specified columns
- so that we can run aggregation on them.
- """,
- examples = """
-Examples:
- > SELECT name, age, count(*) FROM VALUES (2, 'Alice'), (5, 'Bob')
people(age, name) GROUP BY _FUNC_(name, age);
-Bob5 1
-Alice 2 1
-Alice NULL1
-NULL 2 1
-NULL NULL2
-BobNULL1
-NULL 5 1
- """,
- since = "2.0.0")
-// scalastyle:on line.size.limit line.contains.tab
-case class Cube(groupByExprs: Seq[Expression]) extends GroupingSet {}
+object GroupingSet {
+ /*
+ * GROUP BY a, b, c WITH ROLLUP
+ * is equivalent to
+ * GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (a), ( ) ).
+ * Group Count: N + 1 (N is the number of group expressions)
+ *
+ * We need to get all of its subsets for the rule described above, the
subset is
+ * represented as sequence of expressions.
+ */
+ def rollupExprs(exprs: Seq[Seq[Expression]]): Seq[Seq[Expression]] =
+exprs.inits.map(_.flatten).toIndexedSeq
-// scalastyle:off line.size.limit line.contains.tab
-@ExpressionDescription(
- usage = """
-_FUNC_([col1[, col2 ..]]) - create a multi-dimensional rollup using the
specified columns
- so that we can run aggregation on them.
- """,
- examples = """
-Examples:
- > SELECT name, age, count(*) FROM VALUES (2, 'Alice'), (5, 'Bob')
people(age, name) GROUP BY _FUNC_(name, age);
-Bob5 1
-Alice 2 1
-Alice NULL1
-NULL NULL2
-BobNULL1
- """,
- since = "2.0.0")
-// scalastyle:on line.size.limit line.contains.tab
-case class Rollup(groupByExprs: Seq[Expression]) extends GroupingSet {}
+ /*
+ * GROUP BY a, b, c WITH CUBE
Review comment:
Done
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/grouping.scala
##
@@ -39,45 +41,64 @@ trait GroupingSet extends Expression with CodegenFallback {
override def eval(input: InternalRow): Any = throw new
UnsupportedOperationException
}
-// scalastyle:off line.size.limit line.contains.tab
-@ExpressionDescription(
- usage = """
-_FUNC_([col1[, col2 ..]]) - create a multi-dimensional cube using the
specified columns
- so that we can run aggregation on them.
- """,
- examples = """
-Examples:
- > SELECT name, age, count(*) FROM VALUES (2, 'Alice'), (5, 'Bob')
people(age, name) GROUP BY _FUNC_(name, age);
-Bob5 1
-Alice 2 1
-Alice NULL1
-NULL 2 1
-NULL NULL2
-BobNULL1
-NULL 5 1
- """,
- since = "2.0.0")
-// scalastyle:on line.size.limit line.contains.tab
-case class Cube(groupByExprs: Seq[Expression]) extends GroupingSet {}
+object GroupingSet {
+ /*
+ * GROUP BY a, b, c WITH ROLLUP
+ * is equivalent to
+ * GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (a), ( ) ).
+ * Group Count: N + 1 (N is the number of group expressions)
+ *
+ * We need to get all of its subsets for the rule described above, the
subset is
+ * represented as sequence of expressions.
+ */
+ de
[GitHub] [spark] SparkQA removed a comment on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
SparkQA removed a comment on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735340981 **[Test build #131922 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131922/testReport)** for PR 29966 at commit [`e921245`](https://github.com/apache/spark/commit/e92124581e76767929883d54e2eb6d97e0502aac). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
SparkQA commented on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735351504 **[Test build #131922 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131922/testReport)** for PR 29966 at commit [`e921245`](https://github.com/apache/spark/commit/e92124581e76767929883d54e2eb6d97e0502aac). * This patch **fails SparkR unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
AmplabJenkins removed a comment on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735350202 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
AmplabJenkins commented on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735350202 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
SparkQA removed a comment on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735341493 **[Test build #131923 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131923/testReport)** for PR 30535 at commit [`b363d0c`](https://github.com/apache/spark/commit/b363d0c5d4271fd070c4d6a4a2090bd032cbe009). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
SparkQA commented on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735349100 **[Test build #131923 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131923/testReport)** for PR 30535 at commit [`b363d0c`](https://github.com/apache/spark/commit/b363d0c5d4271fd070c4d6a4a2090bd032cbe009). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on a change in pull request #30521: [SPARK-33577][SS] Add support for V1Table in stream writer table API
zsxwing commented on a change in pull request #30521:
URL: https://github.com/apache/spark/pull/30521#discussion_r532158522
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/streaming/DataStreamWriter.scala
##
@@ -304,46 +308,68 @@ final class DataStreamWriter[T] private[sql](ds:
Dataset[T]) {
* @since 3.1.0
*/
@throws[TimeoutException]
- def saveAsTable(tableName: String): StreamingQuery = {
-this.source = SOURCE_NAME_TABLE
+ def table(tableName: String): StreamingQuery = {
Review comment:
`saveAsTable` sounds weird to me since `DataStreamWriter` doesn't have a
`save` method like `DataFrameWriter`.
I prefer `DataStreamWriter.table` as it's consistent with
`DataStreamReader.table`: `DataStreamReader.table` triggers `load` and
`DataStreamWrite.table` triggers `start`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AmplabJenkins removed a comment on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735346176 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AmplabJenkins commented on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735346176 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on a change in pull request #30492: [SPARK-33545][CORE] Support Fallback Storage during Worker decommission
zsxwing commented on a change in pull request #30492:
URL: https://github.com/apache/spark/pull/30492#discussion_r532157528
##
File path: core/src/main/scala/org/apache/spark/internal/config/package.scala
##
@@ -471,6 +471,15 @@ package object config {
"cache block replication should be positive.")
.createWithDefaultString("30s")
+ private[spark] val STORAGE_DECOMMISSION_FALLBACK_STORAGE_PATH =
+ConfigBuilder("spark.storage.decommission.fallbackStorage.path")
+ .doc("The location for fallback storage during block manager
decommissioning." +
Review comment:
nit: it's better to remind the user to enable TTL in the doc since Spark
doesn't clean up the fallback storage.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30534: [SPARK-33582][SQL] Hive Metastore support filter by not-equals
AmplabJenkins removed a comment on pull request #30534: URL: https://github.com/apache/spark/pull/30534#issuecomment-735345323 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30534: [SPARK-33582][SQL] Hive Metastore support filter by not-equals
AmplabJenkins commented on pull request #30534: URL: https://github.com/apache/spark/pull/30534#issuecomment-735345323 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on a change in pull request #30492: [SPARK-33545][CORE] Support Fallback Storage during Worker decommission
zsxwing commented on a change in pull request #30492:
URL: https://github.com/apache/spark/pull/30492#discussion_r532157411
##
File path: core/src/main/scala/org/apache/spark/storage/FallbackStorage.scala
##
@@ -0,0 +1,171 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.storage
+
+import java.io.DataInputStream
+import java.nio.ByteBuffer
+
+import scala.concurrent.Future
+import scala.reflect.ClassTag
+
+import org.apache.hadoop.fs.{FileSystem, Path}
+
+import org.apache.spark.SparkConf
+import org.apache.spark.deploy.SparkHadoopUtil
+import org.apache.spark.internal.Logging
+import
org.apache.spark.internal.config.STORAGE_DECOMMISSION_FALLBACK_STORAGE_PATH
+import org.apache.spark.network.buffer.{ManagedBuffer, NioManagedBuffer}
+import org.apache.spark.rpc.{RpcAddress, RpcEndpointRef, RpcTimeout}
+import org.apache.spark.shuffle.{IndexShuffleBlockResolver, ShuffleBlockInfo}
+import org.apache.spark.shuffle.IndexShuffleBlockResolver.NOOP_REDUCE_ID
+import org.apache.spark.util.Utils
+
+/**
+ * A fallback storage used by storage decommissioners.
+ */
+private[storage] class FallbackStorage(conf: SparkConf) extends Logging {
+ require(conf.get(STORAGE_DECOMMISSION_FALLBACK_STORAGE_PATH).isDefined)
+
+ private val fallbackPath = new
Path(conf.get(STORAGE_DECOMMISSION_FALLBACK_STORAGE_PATH).get)
+ private val hadoopConf = SparkHadoopUtil.get.newConfiguration(conf)
+ private val fallbackFileSystem = FileSystem.get(fallbackPath.toUri,
hadoopConf)
+
+ // Visible for testing
+ def copy(
+ shuffleBlockInfo: ShuffleBlockInfo,
+ bm: BlockManager): Unit = {
+val shuffleId = shuffleBlockInfo.shuffleId
+val mapId = shuffleBlockInfo.mapId
+
+bm.migratableResolver match {
+ case r: IndexShuffleBlockResolver =>
+val indexFile = r.getIndexFile(shuffleId, mapId)
+
+if (indexFile.exists()) {
+ fallbackFileSystem.copyFromLocalFile(
+new Path(indexFile.getAbsolutePath),
+new Path(fallbackPath, s"$shuffleId/${indexFile.getName}"))
+
+ val dataFile = r.getDataFile(shuffleId, mapId)
+ if (dataFile.exists()) {
+fallbackFileSystem.copyFromLocalFile(
+ new Path(dataFile.getAbsolutePath),
+ new Path(fallbackPath, s"$shuffleId/${dataFile.getName}"))
Review comment:
Should we add the application id to the path? For example, a user may
just run the same codes multiple times. It would be more convenient if the user
doesn't need to use a different configuration value for each run.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30534: [SPARK-33582][SQL] Hive Metastore support filter by not-equals
SparkQA removed a comment on pull request #30534: URL: https://github.com/apache/spark/pull/30534#issuecomment-735320260 **[Test build #131920 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131920/testReport)** for PR 30534 at commit [`22e149d`](https://github.com/apache/spark/commit/22e149d43729bb6efcc15391dba2ac1c9b9f223e). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30534: [SPARK-33582][SQL] Hive Metastore support filter by not-equals
SparkQA commented on pull request #30534: URL: https://github.com/apache/spark/pull/30534#issuecomment-735342825 **[Test build #131920 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131920/testReport)** for PR 30534 at commit [`22e149d`](https://github.com/apache/spark/commit/22e149d43729bb6efcc15391dba2ac1c9b9f223e). * This patch passes all tests. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `case class UnixTimestamp(` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AmplabJenkins removed a comment on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735341535 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AmplabJenkins commented on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735341535 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
SparkQA commented on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735341493 **[Test build #131923 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131923/testReport)** for PR 30535 at commit [`b363d0c`](https://github.com/apache/spark/commit/b363d0c5d4271fd070c4d6a4a2090bd032cbe009). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
wangyum commented on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735341289 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
AmplabJenkins removed a comment on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735340971 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
AmplabJenkins commented on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735340971 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
SparkQA commented on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735340981 **[Test build #131922 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131922/testReport)** for PR 29966 at commit [`e921245`](https://github.com/apache/spark/commit/e92124581e76767929883d54e2eb6d97e0502aac). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
SparkQA removed a comment on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735320251 **[Test build #131919 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131919/testReport)** for PR 30535 at commit [`b363d0c`](https://github.com/apache/spark/commit/b363d0c5d4271fd070c4d6a4a2090bd032cbe009). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30534: [SPARK-33582][SQL] Hive Metastore support filter by not-equals
AmplabJenkins removed a comment on pull request #30534: URL: https://github.com/apache/spark/pull/30534#issuecomment-735340836 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
AmplabJenkins removed a comment on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735340837 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
SparkQA commented on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735340885 **[Test build #131919 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131919/testReport)** for PR 30535 at commit [`b363d0c`](https://github.com/apache/spark/commit/b363d0c5d4271fd070c4d6a4a2090bd032cbe009). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30534: [SPARK-33582][SQL] Hive Metastore support filter by not-equals
AmplabJenkins commented on pull request #30534: URL: https://github.com/apache/spark/pull/30534#issuecomment-735340836 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
AmplabJenkins commented on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735340837 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
AmplabJenkins commented on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735338418 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
SparkQA removed a comment on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735314423 **[Test build #131918 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131918/testReport)** for PR 30528 at commit [`312f042`](https://github.com/apache/spark/commit/312f0422f7c6379747762c0b2eaf523e76c96a9b). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
SparkQA removed a comment on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735337456 **[Test build #131921 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131921/testReport)** for PR 29966 at commit [`875d8a7`](https://github.com/apache/spark/commit/875d8a7b640b8112d280e49d827677215e3fb1b8). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AmplabJenkins removed a comment on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735337600 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
SparkQA commented on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735338285 **[Test build #131918 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131918/testReport)** for PR 30528 at commit [`312f042`](https://github.com/apache/spark/commit/312f0422f7c6379747762c0b2eaf523e76c96a9b). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AmplabJenkins commented on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735337600 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
SparkQA commented on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735337596 **[Test build #131921 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131921/testReport)** for PR 29966 at commit [`875d8a7`](https://github.com/apache/spark/commit/875d8a7b640b8112d280e49d827677215e3fb1b8). * This patch **fails Scala style tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
SparkQA commented on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-735337456 **[Test build #131921 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131921/testReport)** for PR 29966 at commit [`875d8a7`](https://github.com/apache/spark/commit/875d8a7b640b8112d280e49d827677215e3fb1b8). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #28036: [SPARK-26341][CORE]Expose executor memory metrics at the stage level, in the Stages tab
AngersZh commented on pull request #28036: URL: https://github.com/apache/spark/pull/28036#issuecomment-735322071 > cc @AngersZh I will be happy to help. My work email is [r...@linkedin.com](mailto:r...@linkedin.com). What is your email? Can you show this problem with some unit test? Or I have to deploy the software on Hadoop in order to show the problem? Please advise. can't show with UT, just build with this par and start spark application, run some sql, do as https://github.com/apache/spark/pull/28036#issuecomment-624502374 said, and you will found that the page keep loading and open developer tool, to see the web output you will see the error. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r532135394
##
File path: core/src/main/scala/org/apache/spark/util/DependencyUtils.scala
##
@@ -25,12 +25,95 @@ import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
+import org.apache.spark.deploy.SparkSubmitUtils
import org.apache.spark.internal.Logging
-import org.apache.spark.util.{MutableURLClassLoader, Utils}
-private[deploy] object DependencyUtils extends Logging {
+private[spark] object DependencyUtils extends Logging {
+
+ def getIvyProperties(): Seq[String] = {
+Seq(
+ "spark.jars.excludes",
+ "spark.jars.packages",
+ "spark.jars.repositories",
+ "spark.jars.ivy",
+ "spark.jars.ivySettings"
+).map(sys.props.get(_).orNull)
+ }
+
+
+ private def parseURLQueryParameter(queryString: String, queryTag: String):
Array[String] = {
+if (queryString == null || queryString.isEmpty) {
+ Array.empty[String]
+} else {
+ val mapTokens = queryString.split("&")
+ assert(mapTokens.forall(_.split("=").length == 2)
+, "Invalid URI query string: [ " + queryString + " ]")
+ mapTokens.map(_.split("=")).map(kv => (kv(0), kv(1))).filter(_._1 ==
queryTag).map(_._2)
+}
+ }
+
+ /**
+ * Parse excluded list in ivy URL. When download ivy URL jar, Spark won't
download transitive jar
+ * in excluded list.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of exclude.
+ * Example: Input:
exclude=org.mortbay.jetty:jetty,org.eclipse.jetty:jetty-http
+ * Output: [org.mortbay.jetty:jetty, org.eclipse.jetty:jetty-http]
+ */
+ private def parseExcludeList(queryString: String): String = {
+parseURLQueryParameter(queryString, "exclude")
+ .flatMap { excludeString =>
+val excludes: Array[String] = excludeString.split(",")
+assert(excludes.forall(_.split(":").length == 2),
+ "Invalid exclude string: expected 'org:module,org:module,..'," +
+" found [ " + excludeString + " ]")
+excludes
+ }.mkString(":")
+ }
+
+ /**
+ * Parse transitive parameter in ivy URL, default value is false.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of transitive.
+ * Example: Input: exclude=org.mortbay.jetty:jetty&transitive=true
+ * Output: true
+ */
+ private def parseTransitive(queryString: String): Boolean = {
+val transitive = parseURLQueryParameter(queryString, "transitive")
+if (transitive.isEmpty) {
+ false
+} else {
+ if (transitive.length > 1) {
+logWarning("It's best to specify `transitive` parameter in ivy URL
query only once." +
+ " If there are multiple `transitive` parameter, we will select the
last one")
+ }
+ transitive.last.toBoolean
+}
+ }
+
+ /**
+ * Download Ivy URIs dependent jars.
Review comment:
Done
##
File path: core/src/main/scala/org/apache/spark/util/DependencyUtils.scala
##
@@ -25,12 +25,95 @@ import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
+import org.apache.spark.deploy.SparkSubmitUtils
import org.apache.spark.internal.Logging
-import org.apache.spark.util.{MutableURLClassLoader, Utils}
-private[deploy] object DependencyUtils extends Logging {
+private[spark] object DependencyUtils extends Logging {
+
+ def getIvyProperties(): Seq[String] = {
+Seq(
+ "spark.jars.excludes",
+ "spark.jars.packages",
+ "spark.jars.repositories",
+ "spark.jars.ivy",
+ "spark.jars.ivySettings"
+).map(sys.props.get(_).orNull)
+ }
+
+
+ private def parseURLQueryParameter(queryString: String, queryTag: String):
Array[String] = {
+if (queryString == null || queryString.isEmpty) {
+ Array.empty[String]
+} else {
+ val mapTokens = queryString.split("&")
+ assert(mapTokens.forall(_.split("=").length == 2)
+, "Invalid URI query string: [ " + queryString + " ]")
+ mapTokens.map(_.split("=")).map(kv => (kv(0), kv(1))).filter(_._1 ==
queryTag).map(_._2)
+}
+ }
+
+ /**
+ * Parse excluded list in ivy URL. When download ivy URL jar, Spark won't
download transitive jar
+ * in excluded list.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of exclude.
+ * Example: Input:
exclude=org.mortbay.jetty:jetty,org.eclipse.jetty:jetty-http
+ * Output: [org.mortbay.jetty:jetty, org.eclipse.jetty:jetty-http]
+ */
+ private def parseExcludeList(queryString: String): String = {
+parseURLQueryParameter(queryString, "exclude")
+
[GitHub] [spark] SparkQA commented on pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
SparkQA commented on pull request #30535: URL: https://github.com/apache/spark/pull/30535#issuecomment-735320251 **[Test build #131919 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131919/testReport)** for PR 30535 at commit [`b363d0c`](https://github.com/apache/spark/commit/b363d0c5d4271fd070c4d6a4a2090bd032cbe009). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30534: [SPARK-33582][SQL] Hive Metastore support filter by not-equals
SparkQA commented on pull request #30534: URL: https://github.com/apache/spark/pull/30534#issuecomment-735320260 **[Test build #131920 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131920/testReport)** for PR 30534 at commit [`22e149d`](https://github.com/apache/spark/commit/22e149d43729bb6efcc15391dba2ac1c9b9f223e). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum opened a new pull request #30535: [SPARK-33584][SQL] Hive Metastore support filter by string type with date values
wangyum opened a new pull request #30535:
URL: https://github.com/apache/spark/pull/30535
### What changes were proposed in this pull request?
This pr make Hive Metastore support filter by string type with date values,
a common case is:
```scala
spark.sql("create table t1(id string) partitioned by (part string) stored as
parquet")
spark.sql("insert into t1 values('1', '2019-01-01')")
spark.sql("insert into t1 values('2', '2019-01-02')")
spark.sql("select * from t1 where part = date '2019-01-01' ").show
```
By
[default](https://github.com/apache/spark/blob/6d31daeb6a2c5607ffe3b23ffb381626ad57f576/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TypeCoercion.scala#L126-L129),
we use `DateType` to compare `StringType` and `DateType`.
### Why are the changes needed?
Improve query performance.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Unit test.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
AmplabJenkins removed a comment on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735318912 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
AmplabJenkins commented on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735318912 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum opened a new pull request #30534: [SPARK-33582][SQL] Hive Metastore support filter by not-equals
wangyum opened a new pull request #30534: URL: https://github.com/apache/spark/pull/30534 ### What changes were proposed in this pull request? This pr make partition predicate pushdown into Hive metastore support not-equals operator. Hive related changes: https://github.com/apache/hive/blob/b8bd4594bef718b1eeac9fceb437d7df7b480ed1/itests/hive-unit/src/test/java/org/apache/hadoop/hive/metastore/TestHiveMetaStore.java#L2194-L2207 https://issues.apache.org/jira/browse/HIVE-2702 ### Why are the changes needed? Improve query performance. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Unit test. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
SparkQA removed a comment on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735305414 **[Test build #131916 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131916/testReport)** for PR 30528 at commit [`1ec1c1d`](https://github.com/apache/spark/commit/1ec1c1dc4baea6235d8a1e0e6d2b72790c950f51). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
SparkQA commented on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735316930 **[Test build #131916 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131916/testReport)** for PR 30528 at commit [`1ec1c1d`](https://github.com/apache/spark/commit/1ec1c1dc4baea6235d8a1e0e6d2b72790c950f51). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on pull request #30525: [SPARK-33581][SQL][TEST] Refactor HivePartitionFilteringSuite
wangyum commented on pull request #30525: URL: https://github.com/apache/spark/pull/30525#issuecomment-735315745 Merged to master. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum closed pull request #30525: [SPARK-33581][SQL][TEST] Refactor HivePartitionFilteringSuite
wangyum closed pull request #30525: URL: https://github.com/apache/spark/pull/30525 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ron8hu commented on pull request #28036: [SPARK-26341][CORE]Expose executor memory metrics at the stage level, in the Stages tab
ron8hu commented on pull request #28036: URL: https://github.com/apache/spark/pull/28036#issuecomment-735314812 cc @AngersZh I will be happy to help. My work email is r...@linkedin.com. What is your email? Can you show this problem with some unit test? Or I have to deploy the software on Hadoop in order to show the problem? Please advise. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
AmplabJenkins removed a comment on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735314485 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
AmplabJenkins commented on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735314485 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
SparkQA commented on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735314423 **[Test build #131918 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131918/testReport)** for PR 30528 at commit [`312f042`](https://github.com/apache/spark/commit/312f0422f7c6379747762c0b2eaf523e76c96a9b). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
AmplabJenkins removed a comment on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735314155 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
AmplabJenkins commented on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735314155 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30533: [SPARK-33380] [EXAMPLES] New python example (series-pi.py) to calculate pi via series
AmplabJenkins commented on pull request #30533: URL: https://github.com/apache/spark/pull/30533#issuecomment-735313995 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
SparkQA removed a comment on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735305036 **[Test build #131915 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131915/testReport)** for PR 30528 at commit [`2720b60`](https://github.com/apache/spark/commit/2720b602e1b263d7c0115eab4ecc0b23d18962fc). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29994: [DONOTMERGE][WHITESPACE] workflow exercise
AmplabJenkins removed a comment on pull request #29994: URL: https://github.com/apache/spark/pull/29994#issuecomment-735313906 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
SparkQA commented on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735313956 **[Test build #131915 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131915/testReport)** for PR 30528 at commit [`2720b60`](https://github.com/apache/spark/commit/2720b602e1b263d7c0115eab4ecc0b23d18962fc). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29994: [DONOTMERGE][WHITESPACE] workflow exercise
AmplabJenkins commented on pull request #29994: URL: https://github.com/apache/spark/pull/29994#issuecomment-735313906 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jsoref commented on pull request #30323: Spelling
jsoref commented on pull request #30323: URL: https://github.com/apache/spark/pull/30323#issuecomment-735313703 Things I know will remain: * `create` (it spans multiple directories) -- we can address this after the current open PRs resolve (probably using this PR) * `enabled` (`legacy_setops_precedence_enbled` appears to be a public API -- addressing it would be done as its own distinct PR if at all -- one approach is to add a correct spelling making that the preferred and adding a deprecated annotation to the current spelling -- another approach is to just add a comment acknowledging the API botch) I think that's everything, but we'll see. Note to self: I changed one `E.g.` to `For example` (which actually fit w/ a second one that I did the same to earlier), so I'm going to have a merge conflict: resolver=drop. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29994: [DONOTMERGE][WHITESPACE] workflow exercise
SparkQA removed a comment on pull request #29994: URL: https://github.com/apache/spark/pull/29994#issuecomment-735309349 **[Test build #131917 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131917/testReport)** for PR 29994 at commit [`995d434`](https://github.com/apache/spark/commit/995d434531efc727d19538341a08dd9fa15f8c86). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29994: [DONOTMERGE][WHITESPACE] workflow exercise
SparkQA commented on pull request #29994: URL: https://github.com/apache/spark/pull/29994#issuecomment-735313444 **[Test build #131917 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131917/testReport)** for PR 29994 at commit [`995d434`](https://github.com/apache/spark/commit/995d434531efc727d19538341a08dd9fa15f8c86). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] milindvdamle opened a new pull request #30533: [SPARK-33380] [EXAMPLES] New python example (series-pi.py) to calculate pi via series
milindvdamle opened a new pull request #30533: URL: https://github.com/apache/spark/pull/30533 ### What changes were proposed in this pull request? ### Why are the changes needed? The current example script (pi.py) produces an approximate value for pi based on randomly-chosen points and is neither deterministic nor accurate. A new example is needed to fix this issue. https://en.wikipedia.org/wiki/Approximations_of_%CF%80 http://oeis.org/wiki/Pi#Decimal_expansion_of_.CF.80.E2.80.8A2 https://mathworld.wolfram.com/PiFormulas.html  This new example calculates pi using a partial sum of series that implements the formula shown in the attached image. ### Does this PR introduce _any_ user-facing change? Yes, it provides an additional example python script (series-pi.py) to calculate pi. ### How was this patch tested? The script accepts two optional command-line parameters. The first parameter specifies the number of terms to use to approximate pi. The second parameter specifies the number of Spark partitions to use to calculate the result. The script was run multiple times with 10 million terms, 100 million terms, 500 million terms and 1 billion terms each as the value of the first parameter. The resulting approximate value for pi was verified against the published/known approximation (https://oeis.org/A000796). Two things were noted and verified: 1. For the same number of terms provided, it was verified that each run of the script produced a deterministic value for pi. 2. Increasing the number of terms (first parameter) produced a more accurate approximation. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jsoref commented on a change in pull request #30532: [MINOR] Spelling sql not core
jsoref commented on a change in pull request #30532: URL: https://github.com/apache/spark/pull/30532#discussion_r532126432 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -21,7 +21,7 @@ grammar SqlBase; * When false, INTERSECT is given the greater precedence over the other set * operations (UNION, EXCEPT and MINUS) as per the SQL standard. */ - public boolean legacy_setops_precedence_enbled = false; + public boolean legacy_setops_precedence_enabled = false; Review comment: GitHub says maybe: https://github.com/search?q=legacy_setops_precedence_enbled&type=code I'm going to drop this for now, we can revisit it separately. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
dongjoon-hyun commented on a change in pull request #30528:
URL: https://github.com/apache/spark/pull/30528#discussion_r532125888
##
File path: core/src/main/scala/org/apache/spark/internal/config/package.scala
##
@@ -1946,6 +1946,16 @@ package object config {
.booleanConf
.createWithDefault(false)
+ private[spark] val EXECUTOR_KILL_ON_FATAL_ERROR_DEPTH =
+ConfigBuilder("spark.executor.killOnFatalError.depth")
+ .doc("The max depth of the exception chain in a failed task Spark will
search for a fatal " +
+"error to check whether it should kill an executor. 0 means not
checking any fatal " +
+"error, 1 means checking only the exception but not the cause, and so
on.")
Review comment:
Thanks!
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on a change in pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
zsxwing commented on a change in pull request #30528:
URL: https://github.com/apache/spark/pull/30528#discussion_r532125783
##
File path: core/src/main/scala/org/apache/spark/internal/config/package.scala
##
@@ -1946,6 +1946,16 @@ package object config {
.booleanConf
.createWithDefault(false)
+ private[spark] val EXECUTOR_KILL_ON_FATAL_ERROR_DEPTH =
+ConfigBuilder("spark.executor.killOnFatalError.depth")
+ .doc("The max depth of the exception chain in a failed task Spark will
search for a fatal " +
+"error to check whether it should kill an executor. 0 means not
checking any fatal " +
+"error, 1 means checking only the exception but not the cause, and so
on.")
Review comment:
done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jsoref commented on a change in pull request #30531: [MINOR] Spelling sql/core
jsoref commented on a change in pull request #30531: URL: https://github.com/apache/spark/pull/30531#discussion_r532125721 ## File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetRowConverter.scala ## @@ -188,13 +188,13 @@ private[parquet] class ParquetRowConverter( */ def currentRecord: InternalRow = currentRow - private val dateRebaseFunc = DataSourceUtils.creteDateRebaseFuncInRead( + private val dateRebaseFunc = DataSourceUtils.createDateRebaseFuncInRead( Review comment: Sigh, yeah, this'll definitely fail. I've hit this repeatedly while dropping things. Lemme drop it from here. It can merge in the root PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #30527: [MINOR][SQL] Remove `getTables()` from `r.SQLUtils`
dongjoon-hyun closed pull request #30527: URL: https://github.com/apache/spark/pull/30527 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on a change in pull request #30532: Spelling sql not core
srowen commented on a change in pull request #30532: URL: https://github.com/apache/spark/pull/30532#discussion_r532124633 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -21,7 +21,7 @@ grammar SqlBase; * When false, INTERSECT is given the greater precedence over the other set * operations (UNION, EXCEPT and MINUS) as per the SQL standard. */ - public boolean legacy_setops_precedence_enbled = false; + public boolean legacy_setops_precedence_enabled = false; Review comment: Oh hm I wonder if this has any implications elsewhere, like does this affect any non-private generated code? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] github-actions[bot] commented on pull request #29442: [SPARK-32627][SQL][WEBUI] Add showSessionLink parameter to SqlStatsPagedTable class in ThriftServerPage
github-actions[bot] commented on pull request #29442: URL: https://github.com/apache/spark/pull/29442#issuecomment-735311304 We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on a change in pull request #30531: Spelling sql/core
srowen commented on a change in pull request #30531:
URL: https://github.com/apache/spark/pull/30531#discussion_r532124529
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetRowConverter.scala
##
@@ -188,13 +188,13 @@ private[parquet] class ParquetRowConverter(
*/
def currentRecord: InternalRow = currentRow
- private val dateRebaseFunc = DataSourceUtils.creteDateRebaseFuncInRead(
+ private val dateRebaseFunc = DataSourceUtils.createDateRebaseFuncInRead(
Review comment:
Oh which of the PRs has the method rename? I wonder if others will fail
if they don't have that change as well.
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/DatasetPrimitiveSuite.scala
##
@@ -170,23 +170,23 @@ class DatasetPrimitiveSuite extends QueryTest with
SharedSparkSession {
test("groupBy function, map") {
val ds = Seq(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11).toDS()
val grouped = ds.groupByKey(_ % 2)
-val agged = grouped.mapGroups { (g, iter) =>
+val aggregated = grouped.mapGroups { (g, iter) =>
Review comment:
I don't feel strongly either way, but these don't necessarily need to be
renamed. They're intentionally shorthand it seems. It might just reduce the
number of lines touched.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
dongjoon-hyun commented on a change in pull request #30528:
URL: https://github.com/apache/spark/pull/30528#discussion_r532124495
##
File path: core/src/main/scala/org/apache/spark/internal/config/package.scala
##
@@ -1946,6 +1946,16 @@ package object config {
.booleanConf
.createWithDefault(false)
+ private[spark] val EXECUTOR_KILL_ON_FATAL_ERROR_DEPTH =
+ConfigBuilder("spark.executor.killOnFatalError.depth")
+ .doc("The max depth of the exception chain in a failed task Spark will
search for a fatal " +
+"error to check whether it should kill an executor. 0 means not
checking any fatal " +
+"error, 1 means checking only the exception but not the cause, and so
on.")
Review comment:
Although this is `internal`, shall we add Spark version, @zsxwing ?
Since SPARK-33587 is filed as `Improvement`, `3.1.0`?
```scala
.version("3.1.0")
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
dongjoon-hyun commented on a change in pull request #30528:
URL: https://github.com/apache/spark/pull/30528#discussion_r532124495
##
File path: core/src/main/scala/org/apache/spark/internal/config/package.scala
##
@@ -1946,6 +1946,16 @@ package object config {
.booleanConf
.createWithDefault(false)
+ private[spark] val EXECUTOR_KILL_ON_FATAL_ERROR_DEPTH =
+ConfigBuilder("spark.executor.killOnFatalError.depth")
+ .doc("The max depth of the exception chain in a failed task Spark will
search for a fatal " +
+"error to check whether it should kill an executor. 0 means not
checking any fatal " +
+"error, 1 means checking only the exception but not the cause, and so
on.")
Review comment:
Could you add Spark version, @zsxwing ? Since SPARK-33587 is filed as
`Improvement`, `3.1.0`?
```scala
.version("3.1.0")
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on a change in pull request #30530: Spelling bin core docs external mllib repl
srowen commented on a change in pull request #30530: URL: https://github.com/apache/spark/pull/30530#discussion_r532124096 ## File path: docs/sql-migration-guide.md ## @@ -333,7 +333,7 @@ license: | - - Since Spark 2.4, when there is a struct field in front of the IN operator before a subquery, the inner query must contain a struct field as well. In previous versions, instead, the fields of the struct were compared to the output of the inner query. Eg. if `a` is a `struct(a string, b int)`, in Spark 2.4 `a in (select (1 as a, 'a' as b) from range(1))` is a valid query, while `a in (select 1, 'a' from range(1))` is not. In previous version it was the opposite. + - Since Spark 2.4, when there is a struct field in front of the IN operator before a subquery, the inner query must contain a struct field as well. In previous versions, instead, the fields of the struct were compared to the output of the inner query. E.g. if `a` is a `struct(a string, b int)`, in Spark 2.4 `a in (select (1 as a, 'a' as b) from range(1))` is a valid query, while `a in (select 1, 'a' from range(1))` is not. In previous version it was the opposite. Review comment: Nit, for if we need to fix anything else: "E.g." probably should not begin a sentence. "For example," is better ## File path: docs/sql-migration-guide.md ## @@ -532,11 +532,11 @@ license: | - Since Spark 2.3, by default arithmetic operations between decimals return a rounded value if an exact representation is not possible (instead of returning NULL). This is compliant with SQL ANSI 2011 specification and Hive's new behavior introduced in Hive 2.2 (HIVE-15331). This involves the following changes -- The rules to determine the result type of an arithmetic operation have been updated. In particular, if the precision / scale needed are out of the range of available values, the scale is reduced up to 6, in order to prevent the truncation of the integer part of the decimals. All the arithmetic operations are affected by the change, ie. addition (`+`), subtraction (`-`), multiplication (`*`), division (`/`), remainder (`%`) and positive module (`pmod`). +- The rules to determine the result type of an arithmetic operation have been updated. In particular, if the precision / scale needed are out of the range of available values, the scale is reduced up to 6, in order to prevent the truncation of the integer part of the decimals. All the arithmetic operations are affected by the change, i.e. addition (`+`), subtraction (`-`), multiplication (`*`), division (`/`), remainder (`%`) and positive module (`pmod`). Review comment: Also let's fix "positive module" to "positive modulus" This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30510: [SPARK-33565][INFRA][FOLLOW-UP] Keep the test coverage with Python 3.8 in GitHub Actions
dongjoon-hyun commented on pull request #30510: URL: https://github.com/apache/spark/pull/30510#issuecomment-735309363 +1, late LGTM. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on a change in pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
zsxwing commented on a change in pull request #28363:
URL: https://github.com/apache/spark/pull/28363#discussion_r532122900
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -136,8 +136,9 @@ class FileStreamSink(
private val basePath = new Path(path)
private val logPath = getMetadataLogPath(basePath.getFileSystem(hadoopConf),
basePath,
sparkSession.sessionState.conf)
- private val fileLog =
-new FileStreamSinkLog(FileStreamSinkLog.VERSION, sparkSession,
logPath.toString)
+ private val outputTimeToLive = options.get("outputRetentionMs").map(_.toLong)
Review comment:
Nit: it would be great to output an info log for this value if it's set.
It might be useful when debugging data issues caused by the retention.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #30511: [SPARK-33565][INFRA][FOLLOW-UP][3.0] Keep the test coverage with Python 3.8 in GitHub Actions
dongjoon-hyun commented on pull request #30511: URL: https://github.com/apache/spark/pull/30511#issuecomment-735309344 +1, late LGTM. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29994: [DONOTMERGE][WHITESPACE] workflow exercise
SparkQA commented on pull request #29994: URL: https://github.com/apache/spark/pull/29994#issuecomment-735309349 **[Test build #131917 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131917/testReport)** for PR 29994 at commit [`995d434`](https://github.com/apache/spark/commit/995d434531efc727d19538341a08dd9fa15f8c86). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30529: [SPARK-33588][SQL] Respect the `spark.sql.caseSensitive` config while resolving partition spec in v1 `SHOW TABLE EXTENDED`
AmplabJenkins removed a comment on pull request #30529: URL: https://github.com/apache/spark/pull/30529#issuecomment-735308969 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30528: [SPARK-33587][Core]Kill the executor on nested fatal errors
AmplabJenkins removed a comment on pull request #30528: URL: https://github.com/apache/spark/pull/30528#issuecomment-735308970 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30523: [SPARK-33579][CORE] Fix executor blank pages behind proxy
AmplabJenkins removed a comment on pull request #30523: URL: https://github.com/apache/spark/pull/30523#issuecomment-735308971 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30492: [SPARK-33545][CORE] Support Fallback Storage during Worker decommission
dongjoon-hyun commented on a change in pull request #30492:
URL: https://github.com/apache/spark/pull/30492#discussion_r532122517
##
File path: core/src/main/scala/org/apache/spark/storage/BlockManager.scala
##
@@ -627,7 +627,16 @@ private[spark] class BlockManager(
override def getLocalBlockData(blockId: BlockId): ManagedBuffer = {
if (blockId.isShuffle) {
logDebug(s"Getting local shuffle block ${blockId}")
- shuffleManager.shuffleBlockResolver.getBlockData(blockId)
+ try {
+shuffleManager.shuffleBlockResolver.getBlockData(blockId)
+ } catch {
+case e: IOException =>
+ if
(conf.get(config.STORAGE_DECOMMISSION_FALLBACK_STORAGE_PATH).isDefined) {
+FallbackStorage.read(conf, blockId)
+ } else {
+throw e
+ }
Review comment:
It's already `IOException` and `FallbackStorage.read` throws
`IOException` for non-exist files and it's fine and legitimate in the
`WorkerDecomission` context, @viirya . Please note the following.
- The whole Worker decommission (including `shuffle and rdd storage
decommission`) is designed as a best-effort approach.
- It's because the main use case is K8s graceful shutdown with the default
period (`30s`). We can increase the period, but we cannot set it to the
infinite value technically. It means executor hangs in case of disk full
situation.
- What we are aiming is to rescue data as much as possible, but `100%` is
not guaranteed always.
- Lastly, data block selection(shuffle or rdd) was a random-order from the
beginning. It became worse when there are multiple shuffle across multiple
executors.
Due to the above reasons, we introduced `SPARK-33387 Support ordered shuffle
block migration` to rescue as complete as possible. However, we can still
easily imagine that multiple shuffles coexist on an executor in a skewed
manner. While the other executor succeeds to complete the migration, the skewed
executor may fail to complete the migration in the given grace period.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30531: Spelling sql/core
AmplabJenkins commented on pull request #30531: URL: https://github.com/apache/spark/pull/30531#issuecomment-735309023 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30532: Spelling sql not core
AmplabJenkins commented on pull request #30532: URL: https://github.com/apache/spark/pull/30532#issuecomment-735309019 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on a change in pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
zsxwing commented on a change in pull request #28363:
URL: https://github.com/apache/spark/pull/28363#discussion_r532122181
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSinkLog.scala
##
@@ -96,6 +97,19 @@ class FileStreamSinkLog(
require(defaultCompactInterval > 0,
s"Please set ${SQLConf.FILE_SINK_LOG_COMPACT_INTERVAL.key} (was
$defaultCompactInterval) " +
"to a positive value.")
+
+ private val ttlMs = outputTimeToLiveMs.getOrElse(Long.MaxValue)
+
+ override def shouldRetain(log: SinkFileStatus): Boolean = {
+val curTime = System.currentTimeMillis()
Review comment:
It would be great to avoid calling `System.currentTimeMillis()` if the
option is not set, considering we need to call this method once (a JNI call)
for each log entry.
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -136,8 +136,9 @@ class FileStreamSink(
private val basePath = new Path(path)
private val logPath = getMetadataLogPath(basePath.getFileSystem(hadoopConf),
basePath,
sparkSession.sessionState.conf)
- private val fileLog =
-new FileStreamSinkLog(FileStreamSinkLog.VERSION, sparkSession,
logPath.toString)
+ private val outputTimeToLive = options.get("outputRetentionMs").map(_.toLong)
Review comment:
Can we use `Utils.timeStringAsMs` to parse this? Users likely set this
to multiple days and asking them to calculate milliseconds is not user friendly.
Nit: regarding the option name, can we call it `retention`? It's obvious
that the query is outputting files, so `output` sounds redundant to me.
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -136,8 +136,9 @@ class FileStreamSink(
private val basePath = new Path(path)
private val logPath = getMetadataLogPath(basePath.getFileSystem(hadoopConf),
basePath,
sparkSession.sessionState.conf)
- private val fileLog =
-new FileStreamSinkLog(FileStreamSinkLog.VERSION, sparkSession,
logPath.toString)
+ private val outputTimeToLive = options.get("outputRetentionMs").map(_.toLong)
Review comment:
Nit: any reason to use a different name `outputTimeToLive`? Using the
same name as the option would help other people read codes.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #30492: [SPARK-33545][CORE] Support Fallback Storage during Worker decommission
dongjoon-hyun commented on a change in pull request #30492:
URL: https://github.com/apache/spark/pull/30492#discussion_r532122517
##
File path: core/src/main/scala/org/apache/spark/storage/BlockManager.scala
##
@@ -627,7 +627,16 @@ private[spark] class BlockManager(
override def getLocalBlockData(blockId: BlockId): ManagedBuffer = {
if (blockId.isShuffle) {
logDebug(s"Getting local shuffle block ${blockId}")
- shuffleManager.shuffleBlockResolver.getBlockData(blockId)
+ try {
+shuffleManager.shuffleBlockResolver.getBlockData(blockId)
+ } catch {
+case e: IOException =>
+ if
(conf.get(config.STORAGE_DECOMMISSION_FALLBACK_STORAGE_PATH).isDefined) {
+FallbackStorage.read(conf, blockId)
+ } else {
+throw e
+ }
Review comment:
It's already `IOException` and `FallbackStorage.read` throws
`IOException` for non-exist files and it's fine and legitimate in the
`WorkerDecomission` context, @viirya . Please note the following.
- The whole Worker decommission (including `shuffle and rdd storage
decommission`) is designed as a best-effort approach.
- It's because the main use case is K8s graceful shutdown with the default
period (`30s`). We can increase it, but we cannot set it infinite value
technically. It means executor hangs in case of disk full situation.
- What we are aiming is to rescue data as much as possible, but `100%` is
not guaranteed always.
- Lastly, data block selection(shuffle or rdd) was a random-order from the
beginning. It became worse when there are multiple shuffle across multiple
executors.
Due to the above reasons, we introduced `SPARK-33387 Support ordered shuffle
block migration` to rescue as complete as possible. However, we can still
easily imagine that multiple shuffles coexist on an executor in a skewed
manner. While the other executor succeeds to complete the migration, the skewed
executor may fail to complete the migration in the given grace period.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org