[GitHub] [spark] HyukjinKwon commented on a change in pull request #30130: [SPARK-33408][SPARK-32354][K8S][R] Use R 3.6.3 in K8s R image and re-enable RTestsSuite
HyukjinKwon commented on a change in pull request #30130:
URL: https://github.com/apache/spark/pull/30130#discussion_r534859502
##
File path:
resource-managers/kubernetes/docker/src/main/dockerfiles/spark/bindings/R/Dockerfile
##
@@ -25,7 +25,14 @@ USER 0
RUN mkdir ${SPARK_HOME}/R
-RUN apt-get update && apt install -y r-base r-base-dev && rm -rf
/var/cache/apt/*
+# Install R 3.6.3 (http://cloud.r-project.org/bin/linux/debian/)
+RUN \
+ echo "deb http://cloud.r-project.org/bin/linux/debian buster-cran35/" >>
/etc/apt/sources.list && \
+ apt install -y gnupg && \
+ apt-key adv --keyserver keys.gnupg.net --recv-key
'E19F5F87128899B192B1A2C2AD5F960A256A04AF' && \
Review comment:
@dongjoon-hyun, I am very sorry to leave a comment late like this but
have you ever faced an error message such as:
```
Setting up gpgsm (2.2.12-1+deb10u1) ...
Setting up dirmngr (2.2.12-1+deb10u1) ...
Setting up gpg-wks-server (2.2.12-1+deb10u1) ...
Setting up gpg-wks-client (2.2.12-1+deb10u1) ...
Setting up gnupg (2.2.12-1+deb10u1) ...
Processing triggers for libc-bin (2.28-10) ...
Warning: apt-key output should not be parsed (stdout is not a terminal)
Executing: /tmp/apt-key-gpghome.XSaWDqGyN4/gpg.1.sh --keyserver
keys.gnupg.net --recv-key E19F5F87128899B192B1A2C2AD5F960A256A04AF
gpg: keyserver receive failed: No name
The command '/bin/sh -c echo "deb
http://cloud.r-project.org/bin/linux/debian buster-cran35/" >>
/etc/apt/sources.list && apt install -y gnupg && apt-key adv --keyserver
keys.gnupg.net --recv-key 'E19F5F87128899B192B1A2C2AD5F960A256A04AF' &&
apt-get update && apt install -y -t buster-cran35 r-base r-base-dev && rm
-rf /var/cache/apt/*' returned a non-zero code: 2
Failed to build SparkR Docker image, please refer to Docker build output for
details.
[ERROR] Command execution failed.
org.apache.commons.exec.ExecuteException: Process exited with an error: 1
(Exit value: 1)
at org.apache.commons.exec.DefaultExecutor.executeInternal
(DefaultExecutor.java:404)
at org.apache.commons.exec.DefaultExecutor.execute
(DefaultExecutor.java:166)
at org.codehaus.mojo.exec.ExecMojo.executeCommandLine (ExecMojo.java:804)
at org.codehaus.mojo.exec.ExecMojo.executeCommandLine (ExecMojo.java:751)
at org.codehaus.mojo.exec.ExecMojo.execute (ExecMojo.java:313)
at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo
(DefaultBuildPluginManager.java:137)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute
(MojoExecutor.java:210)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute
(MojoExecutor.java:156)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute
(MojoExecutor.java:148)
at
org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject
(LifecycleModuleBuilder.java:117)
at
org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject
(LifecycleModuleBuilder.java:81)
at
org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build
(SingleThreadedBuilder.java:56)
at org.apache.maven.lifecycle.internal.LifecycleStarter.execute
(LifecycleStarter.java:128)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:305)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:192)
at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:105)
at org.apache.maven.cli.MavenCli.execute (MavenCli.java:957)
at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:289)
at org.apache.maven.cli.MavenCli.main (MavenCli.java:193)
at sun.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke
(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke
(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke (Method.java:498)
at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced
(Launcher.java:282)
at org.codehaus.plexus.classworlds.launcher.Launcher.launch
(Launcher.java:225)
at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode
(Launcher.java:406)
at org.codehaus.plexus.classworlds.launcher.Launcher.main
(Launcher.java:347)
```
before when you run IT tests locally?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on a change in pull request #30312: [SPARK-32917][SHUFFLE][CORE] Adds support for executors to push shuffle blocks after successful map task completion
Ngone51 commented on a change in pull request #30312:
URL: https://github.com/apache/spark/pull/30312#discussion_r534644897
##
File path: core/src/main/scala/org/apache/spark/shuffle/ShuffleBlockPusher.scala
##
@@ -0,0 +1,458 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.shuffle
+
+import java.io.File
+import java.net.ConnectException
+import java.nio.ByteBuffer
+import java.util.concurrent.ExecutorService
+
+import scala.collection.mutable.{ArrayBuffer, HashMap, HashSet, Queue}
+
+import com.google.common.base.Throwables
+
+import org.apache.spark.{ShuffleDependency, SparkConf, SparkEnv}
+import org.apache.spark.annotation.Since
+import org.apache.spark.internal.Logging
+import org.apache.spark.internal.config._
+import org.apache.spark.launcher.SparkLauncher
+import org.apache.spark.network.buffer.{FileSegmentManagedBuffer,
ManagedBuffer, NioManagedBuffer}
+import org.apache.spark.network.netty.SparkTransportConf
+import org.apache.spark.network.shuffle.BlockFetchingListener
+import org.apache.spark.network.shuffle.ErrorHandler.BlockPushErrorHandler
+import org.apache.spark.network.util.TransportConf
+import org.apache.spark.shuffle.ShuffleBlockPusher._
+import org.apache.spark.storage.{BlockId, BlockManagerId, ShufflePushBlockId}
+import org.apache.spark.util.{ThreadUtils, Utils}
+
+/**
+ * Used for pushing shuffle blocks to remote shuffle services when push
shuffle is enabled.
+ * When push shuffle is enabled, it is created after the shuffle writer
finishes writing the shuffle
+ * file and initiates the block push process.
+ *
+ * @param conf spark configuration
+ */
+@Since("3.1.0")
+private[spark] class ShuffleBlockPusher(conf: SparkConf) extends Logging {
+ private[this] val maxBlockSizeToPush =
conf.get(SHUFFLE_MAX_BLOCK_SIZE_TO_PUSH) * 1024
+ private[this] val maxBlockBatchSize =
+conf.get(SHUFFLE_MAX_BLOCK_BATCH_SIZE_FOR_PUSH) * 1024 * 1024
+ private[this] val maxBytesInFlight =
+conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024
+ private[this] val maxReqsInFlight =
conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue)
+ private[this] val maxBlocksInFlightPerAddress =
conf.get(REDUCER_MAX_BLOCKS_IN_FLIGHT_PER_ADDRESS)
+ private[this] var bytesInFlight = 0L
+ private[this] var reqsInFlight = 0
+ private[this] val numBlocksInFlightPerAddress = new HashMap[BlockManagerId,
Int]()
+ private[this] val deferredPushRequests = new HashMap[BlockManagerId,
Queue[PushRequest]]()
+ private[this] val pushRequests = new Queue[PushRequest]
+ private[this] val errorHandler = createErrorHandler()
+ // VisibleForTesting
+ private[shuffle] val unreachableBlockMgrs = new HashSet[BlockManagerId]()
+ private[this] var stopPushing = false
+
+ // VisibleForTesting
+ private[shuffle] def createErrorHandler(): BlockPushErrorHandler = {
+new BlockPushErrorHandler() {
+ // For a connection exception against a particular host, we will stop
pushing any
+ // blocks to just that host and continue push blocks to other hosts. So,
here push of
+ // all blocks will only stop when it is "Too Late". Also see
updateStateAndCheckIfPushMore.
+ override def shouldRetryError(t: Throwable): Boolean = {
+// If the block is too late, there is no need to retry it
+
!Throwables.getStackTraceAsString(t).contains(BlockPushErrorHandler.TOO_LATE_MESSAGE_SUFFIX)
+ }
+}
+ }
+
+ /**
+ * Initiates the block push.
+ *
+ * @param dataFile mapper generated shuffle data file
+ * @param partitionLengths array of shuffle block size so we can tell
shuffle block
+ * @param dep shuffle dependency to get shuffle ID and the
location of remote shuffle
+ * services to push local shuffle blocks
+ * @param partitionId map index of the shuffle map task
+ */
+ private[shuffle] def initiateBlockPush(
+ dataFile: File,
+ partitionLengths: Array[Long],
+ dep: ShuffleDependency[_, _, _],
+ partitionId: Int): Unit = {
+val numPartitions = dep.partitioner.numPartitions
+val mergerLocs = dep.getMergerLocs.map(loc => BlockManagerId("", loc.host,
loc.port))
+va
[GitHub] [spark] HeartSaVioR commented on a change in pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
HeartSaVioR commented on a change in pull request #24173:
URL: https://github.com/apache/spark/pull/24173#discussion_r534807436
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/StateSchemaCompatibilityChecker.scala
##
@@ -0,0 +1,142 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.state
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.execution.streaming.CheckpointFileManager
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.types.{ArrayType, DataType, MapType, StructType}
+
+case class StateSchemaNotCompatible(message: String) extends Exception(message)
+
+class StateSchemaCompatibilityChecker(
+providerId: StateStoreProviderId,
+hadoopConf: Configuration) extends Logging {
+
+ private val storeCpLocation = providerId.storeId.storeCheckpointLocation()
+ private val fm = CheckpointFileManager.create(storeCpLocation, hadoopConf)
+ private val schemaFileLocation = schemaFile(storeCpLocation)
+
+ fm.mkdirs(schemaFileLocation.getParent)
+
+ def check(keySchema: StructType, valueSchema: StructType): Unit = {
+if (fm.exists(schemaFileLocation)) {
+ logDebug(s"Schema file for provider $providerId exists. Comparing with
provided schema.")
+ val (storedKeySchema, storedValueSchema) = readSchemaFile()
+
+ val errorMsg = "Provided schema doesn't match to the schema for existing
state! " +
+"Please note that Spark allow difference of field name: check count of
fields " +
+"and data type of each field.\n" +
+s"- provided schema: key $keySchema value $valueSchema\n" +
+s"- existing schema: key $storedKeySchema value $storedValueSchema\n" +
+s"If you want to force running query without schema validation, please
set " +
+s"${SQLConf.STATE_SCHEMA_CHECK_ENABLED.key} to false."
+
+ if (storedKeySchema.equals(keySchema) &&
storedValueSchema.equals(valueSchema)) {
+// schema is exactly same
+ } else if (!schemasCompatible(storedKeySchema, keySchema) ||
+!schemasCompatible(storedValueSchema, valueSchema)) {
+logError(errorMsg)
+throw StateSchemaNotCompatible(errorMsg)
+ } else {
+logInfo("Detected schema change which is compatible: will overwrite
schema file to new.")
+// It tries best-effort to overwrite current schema file.
+// the schema validation doesn't break even it fails, though it might
miss on detecting
+// change which is not a big deal.
+createSchemaFile(keySchema, valueSchema)
+ }
+} else {
+ // schema doesn't exist, create one now
+ logDebug(s"Schema file for provider $providerId doesn't exist. Creating
one.")
+ createSchemaFile(keySchema, valueSchema)
+}
+ }
+
+ private def schemasCompatible(storedSchema: StructType, schema: StructType):
Boolean =
+equalsIgnoreCompatibleNullability(storedSchema, schema)
+
+ private def equalsIgnoreCompatibleNullability(from: DataType, to: DataType):
Boolean = {
+// This implementations should be same with
DataType.equalsIgnoreCompatibleNullability, except
+// this shouldn't check the name equality.
+(from, to) match {
+ case (ArrayType(fromElement, fn), ArrayType(toElement, tn)) =>
+(tn || !fn) && equalsIgnoreCompatibleNullability(fromElement,
toElement)
+
+ case (MapType(fromKey, fromValue, fn), MapType(toKey, toValue, tn)) =>
+(tn || !fn) &&
+ equalsIgnoreCompatibleNullability(fromKey, toKey) &&
+ equalsIgnoreCompatibleNullability(fromValue, toValue)
+
+ case (StructType(fromFields), StructType(toFields)) =>
+fromFields.length == toFields.length &&
+ fromFields.zip(toFields).forall { case (fromField, toField) =>
+ (toField.nullable || !fromField.nullable) &&
+ equalsIgnoreCompatibleNullability(fromField.dataType,
toField.dataType)
+ }
+
+ case (fromDataType, toDataType) => fromDataType == toDataType
+}
+ }
+
+ private def readSchemaFile(): (StructType, S
[GitHub] [spark] HeartSaVioR commented on a change in pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
HeartSaVioR commented on a change in pull request #24173:
URL: https://github.com/apache/spark/pull/24173#discussion_r534842510
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/StateSchemaCompatibilityChecker.scala
##
@@ -0,0 +1,142 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.state
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.execution.streaming.CheckpointFileManager
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.types.{ArrayType, DataType, MapType, StructType}
+
+case class StateSchemaNotCompatible(message: String) extends Exception(message)
+
+class StateSchemaCompatibilityChecker(
+providerId: StateStoreProviderId,
+hadoopConf: Configuration) extends Logging {
+
+ private val storeCpLocation = providerId.storeId.storeCheckpointLocation()
+ private val fm = CheckpointFileManager.create(storeCpLocation, hadoopConf)
+ private val schemaFileLocation = schemaFile(storeCpLocation)
+
+ fm.mkdirs(schemaFileLocation.getParent)
+
+ def check(keySchema: StructType, valueSchema: StructType): Unit = {
+if (fm.exists(schemaFileLocation)) {
+ logDebug(s"Schema file for provider $providerId exists. Comparing with
provided schema.")
+ val (storedKeySchema, storedValueSchema) = readSchemaFile()
+
+ val errorMsg = "Provided schema doesn't match to the schema for existing
state! " +
+"Please note that Spark allow difference of field name: check count of
fields " +
+"and data type of each field.\n" +
+s"- provided schema: key $keySchema value $valueSchema\n" +
+s"- existing schema: key $storedKeySchema value $storedValueSchema\n" +
+s"If you want to force running query without schema validation, please
set " +
+s"${SQLConf.STATE_SCHEMA_CHECK_ENABLED.key} to false."
+
+ if (storedKeySchema.equals(keySchema) &&
storedValueSchema.equals(valueSchema)) {
+// schema is exactly same
+ } else if (!schemasCompatible(storedKeySchema, keySchema) ||
+!schemasCompatible(storedValueSchema, valueSchema)) {
+logError(errorMsg)
+throw StateSchemaNotCompatible(errorMsg)
+ } else {
+logInfo("Detected schema change which is compatible: will overwrite
schema file to new.")
+// It tries best-effort to overwrite current schema file.
+// the schema validation doesn't break even it fails, though it might
miss on detecting
+// change which is not a big deal.
+createSchemaFile(keySchema, valueSchema)
+ }
+} else {
+ // schema doesn't exist, create one now
+ logDebug(s"Schema file for provider $providerId doesn't exist. Creating
one.")
+ createSchemaFile(keySchema, valueSchema)
+}
+ }
+
+ private def schemasCompatible(storedSchema: StructType, schema: StructType):
Boolean =
+equalsIgnoreCompatibleNullability(storedSchema, schema)
+
+ private def equalsIgnoreCompatibleNullability(from: DataType, to: DataType):
Boolean = {
+// This implementations should be same with
DataType.equalsIgnoreCompatibleNullability, except
+// this shouldn't check the name equality.
+(from, to) match {
+ case (ArrayType(fromElement, fn), ArrayType(toElement, tn)) =>
+(tn || !fn) && equalsIgnoreCompatibleNullability(fromElement,
toElement)
+
+ case (MapType(fromKey, fromValue, fn), MapType(toKey, toValue, tn)) =>
+(tn || !fn) &&
+ equalsIgnoreCompatibleNullability(fromKey, toKey) &&
+ equalsIgnoreCompatibleNullability(fromValue, toValue)
+
+ case (StructType(fromFields), StructType(toFields)) =>
+fromFields.length == toFields.length &&
+ fromFields.zip(toFields).forall { case (fromField, toField) =>
+ (toField.nullable || !fromField.nullable) &&
+ equalsIgnoreCompatibleNullability(fromField.dataType,
toField.dataType)
+ }
+
+ case (fromDataType, toDataType) => fromDataType == toDataType
+}
+ }
+
+ private def readSchemaFile(): (StructType, S
[GitHub] [spark] yaooqinn opened a new pull request #30586: [SPARK-33641][SQL] Invalidate new char-like type in public APIs that produce incorrect results
yaooqinn opened a new pull request #30586:
URL: https://github.com/apache/spark/pull/30586
…
### What changes were proposed in this pull request?
In this PR, we suppose to narrow the use cases of the char-like data types,
of which are invalid now or later
### Why are the changes needed?
1. udf
```scala
scala> spark.udf.register("abcd", () => "12345",
org.apache.spark.sql.types.VarcharType(2))
scala> spark.sql("select abcd()").show
scala.MatchError: CharType(2) (of class
org.apache.spark.sql.types.VarcharType)
at
org.apache.spark.sql.catalyst.encoders.RowEncoder$.externalDataTypeFor(RowEncoder.scala:215)
at
org.apache.spark.sql.catalyst.encoders.RowEncoder$.externalDataTypeForInput(RowEncoder.scala:212)
at
org.apache.spark.sql.catalyst.expressions.objects.ValidateExternalType.(objects.scala:1741)
at
org.apache.spark.sql.catalyst.encoders.RowEncoder$.$anonfun$serializerFor$3(RowEncoder.scala:175)
at
scala.collection.TraversableLike.$anonfun$flatMap$1(TraversableLike.scala:245)
at
scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
at
scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198)
at scala.collection.TraversableLike.flatMap(TraversableLike.scala:245)
at scala.collection.TraversableLike.flatMap$(TraversableLike.scala:242)
at scala.collection.mutable.ArrayOps$ofRef.flatMap(ArrayOps.scala:198)
at
org.apache.spark.sql.catalyst.encoders.RowEncoder$.serializerFor(RowEncoder.scala:171)
at
org.apache.spark.sql.catalyst.encoders.RowEncoder$.apply(RowEncoder.scala:66)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:99)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:768)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:96)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:611)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:768)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:606)
... 47 elided
```
2. spark.createDataframe
```
scala> spark.createDataFrame(spark.read.text("README.md").rdd, new
org.apache.spark.sql.types.StructType().add("c", "char(1)")).show
++
| c|
++
| # Apache Spark|
||
|Spark is a unifie...|
|high-level APIs i...|
|supports general ...|
|rich set of highe...|
|MLlib for machine...|
|and Structured St...|
||
| spark.read.schema("a varchar(2)").text("./README.md").show(100)
++
| a|
++
| # Apache Spark|
||
|Spark is a unifie...|
|high-level APIs i...|
|supports general ...|
```
4. etc
### Does this PR introduce _any_ user-facing change?
NO, we intend to avoid protentical breaking change
### How was this patch tested?
new tests
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30581: [WIP][SPARK-33615][K8S][TESTS] Add spark.archive tests in K8S
SparkQA commented on pull request #30581: URL: https://github.com/apache/spark/pull/30581#issuecomment-737727470 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36699/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30350: [SPARK-33428][SQL] Conv UDF use BigInt to avoid Long value overflow
SparkQA commented on pull request #30350: URL: https://github.com/apache/spark/pull/30350#issuecomment-737727021 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36700/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
HeartSaVioR commented on a change in pull request #24173:
URL: https://github.com/apache/spark/pull/24173#discussion_r534831091
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/StateSchemaCompatibilityChecker.scala
##
@@ -0,0 +1,142 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.state
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.execution.streaming.CheckpointFileManager
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.types.{ArrayType, DataType, MapType, StructType}
+
+case class StateSchemaNotCompatible(message: String) extends Exception(message)
+
+class StateSchemaCompatibilityChecker(
+providerId: StateStoreProviderId,
+hadoopConf: Configuration) extends Logging {
+
+ private val storeCpLocation = providerId.storeId.storeCheckpointLocation()
+ private val fm = CheckpointFileManager.create(storeCpLocation, hadoopConf)
+ private val schemaFileLocation = schemaFile(storeCpLocation)
+
+ fm.mkdirs(schemaFileLocation.getParent)
+
+ def check(keySchema: StructType, valueSchema: StructType): Unit = {
+if (fm.exists(schemaFileLocation)) {
+ logDebug(s"Schema file for provider $providerId exists. Comparing with
provided schema.")
+ val (storedKeySchema, storedValueSchema) = readSchemaFile()
+
+ val errorMsg = "Provided schema doesn't match to the schema for existing
state! " +
+"Please note that Spark allow difference of field name: check count of
fields " +
+"and data type of each field.\n" +
+s"- provided schema: key $keySchema value $valueSchema\n" +
+s"- existing schema: key $storedKeySchema value $storedValueSchema\n" +
+s"If you want to force running query without schema validation, please
set " +
+s"${SQLConf.STATE_SCHEMA_CHECK_ENABLED.key} to false."
+
+ if (storedKeySchema.equals(keySchema) &&
storedValueSchema.equals(valueSchema)) {
+// schema is exactly same
+ } else if (!schemasCompatible(storedKeySchema, keySchema) ||
+!schemasCompatible(storedValueSchema, valueSchema)) {
+logError(errorMsg)
+throw StateSchemaNotCompatible(errorMsg)
+ } else {
+logInfo("Detected schema change which is compatible: will overwrite
schema file to new.")
+// It tries best-effort to overwrite current schema file.
+// the schema validation doesn't break even it fails, though it might
miss on detecting
+// change which is not a big deal.
+createSchemaFile(keySchema, valueSchema)
+ }
+} else {
+ // schema doesn't exist, create one now
+ logDebug(s"Schema file for provider $providerId doesn't exist. Creating
one.")
+ createSchemaFile(keySchema, valueSchema)
+}
+ }
+
+ private def schemasCompatible(storedSchema: StructType, schema: StructType):
Boolean =
+equalsIgnoreCompatibleNullability(storedSchema, schema)
+
+ private def equalsIgnoreCompatibleNullability(from: DataType, to: DataType):
Boolean = {
Review comment:
I see DataType is already duplicating the code - please refer the
sibling of `DataType.equalsIgnoreXXX`.
It's OK we also move this to `DataType` and rename like
`equalsIgnoreNameAndCompatibleNullability`, but now I'm not sure deduplicating
is a must.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] WeichenXu123 commented on pull request #30471: [SPARK-33520][ML][PySpark] make CrossValidator/TrainValidateSplit/OneVsRest Reader/Writer support Python backend estimator/evaluator
WeichenXu123 commented on pull request #30471: URL: https://github.com/apache/spark/pull/30471#issuecomment-737725930 I would like to keep this PR open for one more day to see whether @srowen has some comment. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30583: [SPARK-33640][TESTS] Extend connection timeout to DB server for DB2IntegrationSuite and its variants
AmplabJenkins removed a comment on pull request #30583: URL: https://github.com/apache/spark/pull/30583#issuecomment-737724285 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30583: [SPARK-33640][TESTS] Extend connection timeout to DB server for DB2IntegrationSuite and its variants
AmplabJenkins commented on pull request #30583: URL: https://github.com/apache/spark/pull/30583#issuecomment-737724285 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30583: [SPARK-33640][TESTS] Extend connection timeout to DB server for DB2IntegrationSuite and its variants
SparkQA commented on pull request #30583: URL: https://github.com/apache/spark/pull/30583#issuecomment-737724269 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36694/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #30564: [SPARK-32670][SQL][FOLLOWUP] Group exception messages in Catalyst Analyzer in one file
beliefer commented on pull request #30564: URL: https://github.com/apache/spark/pull/30564#issuecomment-737722164 cc @cloud-fan @HyukjinKwon @maropu @dongjoon-hyun This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
HeartSaVioR commented on a change in pull request #24173:
URL: https://github.com/apache/spark/pull/24173#discussion_r534812004
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/StateSchemaCompatibilityChecker.scala
##
@@ -0,0 +1,142 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.state
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.execution.streaming.CheckpointFileManager
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.types.{ArrayType, DataType, MapType, StructType}
+
+case class StateSchemaNotCompatible(message: String) extends Exception(message)
+
+class StateSchemaCompatibilityChecker(
+providerId: StateStoreProviderId,
+hadoopConf: Configuration) extends Logging {
+
+ private val storeCpLocation = providerId.storeId.storeCheckpointLocation()
+ private val fm = CheckpointFileManager.create(storeCpLocation, hadoopConf)
+ private val schemaFileLocation = schemaFile(storeCpLocation)
+
+ fm.mkdirs(schemaFileLocation.getParent)
+
+ def check(keySchema: StructType, valueSchema: StructType): Unit = {
+if (fm.exists(schemaFileLocation)) {
+ logDebug(s"Schema file for provider $providerId exists. Comparing with
provided schema.")
+ val (storedKeySchema, storedValueSchema) = readSchemaFile()
+
+ val errorMsg = "Provided schema doesn't match to the schema for existing
state! " +
Review comment:
Nice finding. Thanks!
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30584: [SPARK-33472][SQL][FOLLOW-UP] Update RemoveRedundantSorts comment
AmplabJenkins removed a comment on pull request #30584: URL: https://github.com/apache/spark/pull/30584#issuecomment-737721415 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30433: [SPARK-32916][SHUFFLE][test-maven][test-hadoop2.7] Ensure the number of chunks in meta file and index file are equal
AmplabJenkins removed a comment on pull request #30433: URL: https://github.com/apache/spark/pull/30433#issuecomment-737721310 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30584: [SPARK-33472][SQL][FOLLOW-UP] Update RemoveRedundantSorts comment
AmplabJenkins commented on pull request #30584: URL: https://github.com/apache/spark/pull/30584#issuecomment-737721415 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30584: [SPARK-33472][SQL][FOLLOW-UP] Update RemoveRedundantSorts comment
SparkQA commented on pull request #30584: URL: https://github.com/apache/spark/pull/30584#issuecomment-737721398 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36693/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30433: [SPARK-32916][SHUFFLE][test-maven][test-hadoop2.7] Ensure the number of chunks in meta file and index file are equal
AmplabJenkins commented on pull request #30433: URL: https://github.com/apache/spark/pull/30433#issuecomment-737721310 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30433: [SPARK-32916][SHUFFLE][test-maven][test-hadoop2.7] Ensure the number of chunks in meta file and index file are equal
SparkQA commented on pull request #30433: URL: https://github.com/apache/spark/pull/30433#issuecomment-737721294 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36698/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30481: [SPARK-33526][SQL] Add config to control if cancel invoke interrupt task on thriftserver
AmplabJenkins removed a comment on pull request #30481: URL: https://github.com/apache/spark/pull/30481#issuecomment-737721173 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30481: [SPARK-33526][SQL] Add config to control if cancel invoke interrupt task on thriftserver
AmplabJenkins commented on pull request #30481: URL: https://github.com/apache/spark/pull/30481#issuecomment-737721173 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30481: [SPARK-33526][SQL] Add config to control if cancel invoke interrupt task on thriftserver
SparkQA commented on pull request #30481: URL: https://github.com/apache/spark/pull/30481#issuecomment-737721149 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36697/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
HeartSaVioR commented on a change in pull request #24173:
URL: https://github.com/apache/spark/pull/24173#discussion_r534807436
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/StateSchemaCompatibilityChecker.scala
##
@@ -0,0 +1,142 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.state
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.execution.streaming.CheckpointFileManager
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.types.{ArrayType, DataType, MapType, StructType}
+
+case class StateSchemaNotCompatible(message: String) extends Exception(message)
+
+class StateSchemaCompatibilityChecker(
+providerId: StateStoreProviderId,
+hadoopConf: Configuration) extends Logging {
+
+ private val storeCpLocation = providerId.storeId.storeCheckpointLocation()
+ private val fm = CheckpointFileManager.create(storeCpLocation, hadoopConf)
+ private val schemaFileLocation = schemaFile(storeCpLocation)
+
+ fm.mkdirs(schemaFileLocation.getParent)
+
+ def check(keySchema: StructType, valueSchema: StructType): Unit = {
+if (fm.exists(schemaFileLocation)) {
+ logDebug(s"Schema file for provider $providerId exists. Comparing with
provided schema.")
+ val (storedKeySchema, storedValueSchema) = readSchemaFile()
+
+ val errorMsg = "Provided schema doesn't match to the schema for existing
state! " +
+"Please note that Spark allow difference of field name: check count of
fields " +
+"and data type of each field.\n" +
+s"- provided schema: key $keySchema value $valueSchema\n" +
+s"- existing schema: key $storedKeySchema value $storedValueSchema\n" +
+s"If you want to force running query without schema validation, please
set " +
+s"${SQLConf.STATE_SCHEMA_CHECK_ENABLED.key} to false."
+
+ if (storedKeySchema.equals(keySchema) &&
storedValueSchema.equals(valueSchema)) {
+// schema is exactly same
+ } else if (!schemasCompatible(storedKeySchema, keySchema) ||
+!schemasCompatible(storedValueSchema, valueSchema)) {
+logError(errorMsg)
+throw StateSchemaNotCompatible(errorMsg)
+ } else {
+logInfo("Detected schema change which is compatible: will overwrite
schema file to new.")
+// It tries best-effort to overwrite current schema file.
+// the schema validation doesn't break even it fails, though it might
miss on detecting
+// change which is not a big deal.
+createSchemaFile(keySchema, valueSchema)
+ }
+} else {
+ // schema doesn't exist, create one now
+ logDebug(s"Schema file for provider $providerId doesn't exist. Creating
one.")
+ createSchemaFile(keySchema, valueSchema)
+}
+ }
+
+ private def schemasCompatible(storedSchema: StructType, schema: StructType):
Boolean =
+equalsIgnoreCompatibleNullability(storedSchema, schema)
+
+ private def equalsIgnoreCompatibleNullability(from: DataType, to: DataType):
Boolean = {
+// This implementations should be same with
DataType.equalsIgnoreCompatibleNullability, except
+// this shouldn't check the name equality.
+(from, to) match {
+ case (ArrayType(fromElement, fn), ArrayType(toElement, tn)) =>
+(tn || !fn) && equalsIgnoreCompatibleNullability(fromElement,
toElement)
+
+ case (MapType(fromKey, fromValue, fn), MapType(toKey, toValue, tn)) =>
+(tn || !fn) &&
+ equalsIgnoreCompatibleNullability(fromKey, toKey) &&
+ equalsIgnoreCompatibleNullability(fromValue, toValue)
+
+ case (StructType(fromFields), StructType(toFields)) =>
+fromFields.length == toFields.length &&
+ fromFields.zip(toFields).forall { case (fromField, toField) =>
+ (toField.nullable || !fromField.nullable) &&
+ equalsIgnoreCompatibleNullability(fromField.dataType,
toField.dataType)
+ }
+
+ case (fromDataType, toDataType) => fromDataType == toDataType
+}
+ }
+
+ private def readSchemaFile(): (StructType, S
[GitHub] [spark] SparkQA commented on pull request #30581: [WIP][SPARK-33615][K8S][TESTS] Add spark.archive tests in K8S
SparkQA commented on pull request #30581: URL: https://github.com/apache/spark/pull/30581#issuecomment-737718059 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36699/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30243: [SPARK-33335][SQL] Support `has_all` func
SparkQA commented on pull request #30243: URL: https://github.com/apache/spark/pull/30243#issuecomment-737717879 **[Test build #132102 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132102/testReport)** for PR 30243 at commit [`daa8da3`](https://github.com/apache/spark/commit/daa8da3fbac0dc4be839521bd3a67b6b23c6a49a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30585: [SPARK-26218][SQL][FOLLOW UP] Fix the corner case of codegen when casting float to Integer
SparkQA commented on pull request #30585: URL: https://github.com/apache/spark/pull/30585#issuecomment-737717527 **[Test build #132101 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132101/testReport)** for PR 30585 at commit [`5697260`](https://github.com/apache/spark/commit/5697260543b13592fecaf5488c4bdea41b5a09ff). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30543: [SPARK-33597][SQL] Support REGEXP_LIKE for consistent with mainstream databases
AmplabJenkins removed a comment on pull request #30543: URL: https://github.com/apache/spark/pull/30543#issuecomment-737717106 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30543: [SPARK-33597][SQL] Support REGEXP_LIKE for consistent with mainstream databases
AmplabJenkins commented on pull request #30543: URL: https://github.com/apache/spark/pull/30543#issuecomment-737717106 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30350: [SPARK-33428][SQL] Conv UDF use BigInt to avoid Long value overflow
SparkQA commented on pull request #30350: URL: https://github.com/apache/spark/pull/30350#issuecomment-737716383 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36700/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30582: [SPARK-33636][PYTHON][ML][FOLLOWUP] Update since tag of labelsArray in StringIndexer
AmplabJenkins removed a comment on pull request #30582: URL: https://github.com/apache/spark/pull/30582#issuecomment-737715490 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
AmplabJenkins removed a comment on pull request #24173: URL: https://github.com/apache/spark/pull/24173#issuecomment-737715489 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30581: [WIP][SPARK-33615][K8S][TESTS] Add spark.archive tests in K8S
AmplabJenkins removed a comment on pull request #30581: URL: https://github.com/apache/spark/pull/30581#issuecomment-737715488 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30350: [SPARK-33428][SQL] Conv UDF use BigInt to avoid Long value overflow
SparkQA commented on pull request #30350: URL: https://github.com/apache/spark/pull/30350#issuecomment-737715812 **[Test build #132100 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132100/testReport)** for PR 30350 at commit [`0e7221a`](https://github.com/apache/spark/commit/0e7221afa678064b55c813d9fe74360349abe907). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30581: [WIP][SPARK-33615][K8S][TESTS] Add spark.archive tests in K8S
AmplabJenkins commented on pull request #30581: URL: https://github.com/apache/spark/pull/30581#issuecomment-737715488 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
AmplabJenkins commented on pull request #24173: URL: https://github.com/apache/spark/pull/24173#issuecomment-737715489 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30582: [SPARK-33636][PYTHON][ML][FOLLOWUP] Update since tag of labelsArray in StringIndexer
AmplabJenkins commented on pull request #30582: URL: https://github.com/apache/spark/pull/30582#issuecomment-737715490 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
SparkQA removed a comment on pull request #24173: URL: https://github.com/apache/spark/pull/24173#issuecomment-737672331 **[Test build #132092 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132092/testReport)** for PR 24173 at commit [`2e2134c`](https://github.com/apache/spark/commit/2e2134cf14cdf83ff3ed310647b1e1229ef1341f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
SparkQA commented on pull request #24173: URL: https://github.com/apache/spark/pull/24173#issuecomment-737713538 **[Test build #132092 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132092/testReport)** for PR 24173 at commit [`2e2134c`](https://github.com/apache/spark/commit/2e2134cf14cdf83ff3ed310647b1e1229ef1341f). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
HeartSaVioR commented on a change in pull request #24173:
URL: https://github.com/apache/spark/pull/24173#discussion_r534778233
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/StateSchemaCompatibilityChecker.scala
##
@@ -0,0 +1,142 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.state
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.execution.streaming.CheckpointFileManager
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.types.{ArrayType, DataType, MapType, StructType}
+
+case class StateSchemaNotCompatible(message: String) extends Exception(message)
+
+class StateSchemaCompatibilityChecker(
+providerId: StateStoreProviderId,
+hadoopConf: Configuration) extends Logging {
+
+ private val storeCpLocation = providerId.storeId.storeCheckpointLocation()
+ private val fm = CheckpointFileManager.create(storeCpLocation, hadoopConf)
+ private val schemaFileLocation = schemaFile(storeCpLocation)
+
+ fm.mkdirs(schemaFileLocation.getParent)
+
+ def check(keySchema: StructType, valueSchema: StructType): Unit = {
+if (fm.exists(schemaFileLocation)) {
+ logDebug(s"Schema file for provider $providerId exists. Comparing with
provided schema.")
+ val (storedKeySchema, storedValueSchema) = readSchemaFile()
+
+ val errorMsg = "Provided schema doesn't match to the schema for existing
state! " +
+"Please note that Spark allow difference of field name: check count of
fields " +
+"and data type of each field.\n" +
+s"- provided schema: key $keySchema value $valueSchema\n" +
+s"- existing schema: key $storedKeySchema value $storedValueSchema\n" +
+s"If you want to force running query without schema validation, please
set " +
+s"${SQLConf.STATE_SCHEMA_CHECK_ENABLED.key} to false."
+
+ if (storedKeySchema.equals(keySchema) &&
storedValueSchema.equals(valueSchema)) {
+// schema is exactly same
+ } else if (!schemasCompatible(storedKeySchema, keySchema) ||
+!schemasCompatible(storedValueSchema, valueSchema)) {
+logError(errorMsg)
+throw StateSchemaNotCompatible(errorMsg)
+ } else {
+logInfo("Detected schema change which is compatible: will overwrite
schema file to new.")
+// It tries best-effort to overwrite current schema file.
+// the schema validation doesn't break even it fails, though it might
miss on detecting
+// change which is not a big deal.
+createSchemaFile(keySchema, valueSchema)
+ }
+} else {
+ // schema doesn't exist, create one now
+ logDebug(s"Schema file for provider $providerId doesn't exist. Creating
one.")
+ createSchemaFile(keySchema, valueSchema)
+}
+ }
+
+ private def schemasCompatible(storedSchema: StructType, schema: StructType):
Boolean =
+equalsIgnoreCompatibleNullability(storedSchema, schema)
+
+ private def equalsIgnoreCompatibleNullability(from: DataType, to: DataType):
Boolean = {
+// This implementations should be same with
DataType.equalsIgnoreCompatibleNullability, except
+// this shouldn't check the name equality.
+(from, to) match {
+ case (ArrayType(fromElement, fn), ArrayType(toElement, tn)) =>
+(tn || !fn) && equalsIgnoreCompatibleNullability(fromElement,
toElement)
+
+ case (MapType(fromKey, fromValue, fn), MapType(toKey, toValue, tn)) =>
+(tn || !fn) &&
+ equalsIgnoreCompatibleNullability(fromKey, toKey) &&
+ equalsIgnoreCompatibleNullability(fromValue, toValue)
+
+ case (StructType(fromFields), StructType(toFields)) =>
+fromFields.length == toFields.length &&
+ fromFields.zip(toFields).forall { case (fromField, toField) =>
+ (toField.nullable || !fromField.nullable) &&
+ equalsIgnoreCompatibleNullability(fromField.dataType,
toField.dataType)
+ }
+
+ case (fromDataType, toDataType) => fromDataType == toDataType
+}
+ }
+
+ private def readSchemaFile(): (StructType, S
[GitHub] [spark] HeartSaVioR commented on a change in pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
HeartSaVioR commented on a change in pull request #24173:
URL: https://github.com/apache/spark/pull/24173#discussion_r534776507
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/StateStoreCoordinator.scala
##
@@ -150,6 +172,25 @@ private class StateStoreCoordinator(override val rpcEnv:
RpcEnv)
storeIdsToRemove.mkString(", "))
context.reply(true)
+case ValidateSchema(providerId, keySchema, valueSchema, checkEnabled) =>
+ // normalize partition ID to validate only once for one state operator
+ val newProviderId =
StateStoreProviderId.withNoPartitionInformation(providerId)
+
+ val result = schemaValidated.getOrElseUpdate(newProviderId, {
+val checker = new StateSchemaCompatibilityChecker(newProviderId,
hadoopConf)
+
+// regardless of configuration, we check compatibility to at least
write schema file
+// if necessary
+val ret = Try(checker.check(keySchema,
valueSchema)).toEither.fold(Some(_), _ => None)
Review comment:
https://github.com/apache/spark/pull/24173/files#r534772017
Let's just check it without sending RPC. We'll need some trick - hope that's
acceptable.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30243: [SPARK-33335][SQL] Support `has_all` func
AngersZh commented on pull request #30243: URL: https://github.com/apache/spark/pull/30243#issuecomment-737712017 ping @kiszk @cloud-fan @zero323 @viirya @HyukjinKwon Now update function name to `has_all` for disambiguation. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
HeartSaVioR commented on a change in pull request #24173:
URL: https://github.com/apache/spark/pull/24173#discussion_r534772017
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/StateStore.scala
##
@@ -391,10 +399,18 @@ object StateStore extends Logging {
require(version >= 0)
val storeProvider = loadedProviders.synchronized {
startMaintenanceIfNeeded()
+
+ val newProvIdSchemaCheck =
StateStoreProviderId.withNoPartitionInformation(storeProviderId)
+ if (!schemaValidated.contains(newProvIdSchemaCheck)) {
Review comment:
It will be really odd if they're flipping the config during multiple
runs and schema somehow changes in compatible way. It won't break compatibility
check as the compatibility check is transitive (if I'm not mistaken), but once
the compatibility is broken we may show legacy schema instead of the one for
previous batch.
Probably I should just apply the trick to check this in reserved partition
only (0) and don't trigger RPC. I don't think it should hurt, but please let me
know if we still want to disable at all at the risk of odd result.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30583: [SPARK-33640][TESTS] Extend connection timeout to DB server for DB2IntegrationSuite and its variants
SparkQA commented on pull request #30583: URL: https://github.com/apache/spark/pull/30583#issuecomment-737711285 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36694/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
HeartSaVioR commented on a change in pull request #24173:
URL: https://github.com/apache/spark/pull/24173#discussion_r534772017
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/StateStore.scala
##
@@ -391,10 +399,18 @@ object StateStore extends Logging {
require(version >= 0)
val storeProvider = loadedProviders.synchronized {
startMaintenanceIfNeeded()
+
+ val newProvIdSchemaCheck =
StateStoreProviderId.withNoPartitionInformation(storeProviderId)
+ if (!schemaValidated.contains(newProvIdSchemaCheck)) {
Review comment:
It will be really odd if they're flipping the config during multiple
runs and schema somehow changes in compatible way. It won't break compatibility
check as the compatibility check is transitive (if I'm not mistaken), but once
the compatibility is broken we may show legacy schema instead of the one for
previous batch.
Probably I should just apply the trick to check this in reserved partition
only (0) and don't trigger RPC.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #30585: [SPARK-26218][SQL][FOLLOW UP] Fix the corner case of codegen when casting float to Integer
cloud-fan commented on pull request #30585: URL: https://github.com/apache/spark/pull/30585#issuecomment-737710751 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30584: [SPARK-33472][SQL][FOLLOW-UP] Update RemoveRedundantSorts comment
SparkQA commented on pull request #30584: URL: https://github.com/apache/spark/pull/30584#issuecomment-737709894 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36693/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30481: [SPARK-33526][SQL] Add config to control if cancel invoke interrupt task on thriftserver
SparkQA commented on pull request #30481: URL: https://github.com/apache/spark/pull/30481#issuecomment-737709945 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36697/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30433: [SPARK-32916][SHUFFLE][test-maven][test-hadoop2.7] Ensure the number of chunks in meta file and index file are equal
SparkQA commented on pull request #30433: URL: https://github.com/apache/spark/pull/30433#issuecomment-737709304 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36698/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
HeartSaVioR commented on a change in pull request #24173:
URL: https://github.com/apache/spark/pull/24173#discussion_r534759253
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/StateSchemaCompatibilityChecker.scala
##
@@ -0,0 +1,142 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.state
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.execution.streaming.CheckpointFileManager
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.types.{ArrayType, DataType, MapType, StructType}
+
+case class StateSchemaNotCompatible(message: String) extends Exception(message)
+
+class StateSchemaCompatibilityChecker(
+providerId: StateStoreProviderId,
+hadoopConf: Configuration) extends Logging {
+
+ private val storeCpLocation = providerId.storeId.storeCheckpointLocation()
+ private val fm = CheckpointFileManager.create(storeCpLocation, hadoopConf)
+ private val schemaFileLocation = schemaFile(storeCpLocation)
+
+ fm.mkdirs(schemaFileLocation.getParent)
+
+ def check(keySchema: StructType, valueSchema: StructType): Unit = {
+if (fm.exists(schemaFileLocation)) {
+ logDebug(s"Schema file for provider $providerId exists. Comparing with
provided schema.")
+ val (storedKeySchema, storedValueSchema) = readSchemaFile()
+
+ val errorMsg = "Provided schema doesn't match to the schema for existing
state! " +
+"Please note that Spark allow difference of field name: check count of
fields " +
+"and data type of each field.\n" +
+s"- provided schema: key $keySchema value $valueSchema\n" +
+s"- existing schema: key $storedKeySchema value $storedValueSchema\n" +
+s"If you want to force running query without schema validation, please
set " +
+s"${SQLConf.STATE_SCHEMA_CHECK_ENABLED.key} to false."
+
+ if (storedKeySchema.equals(keySchema) &&
storedValueSchema.equals(valueSchema)) {
+// schema is exactly same
+ } else if (!schemasCompatible(storedKeySchema, keySchema) ||
+!schemasCompatible(storedValueSchema, valueSchema)) {
+logError(errorMsg)
+throw StateSchemaNotCompatible(errorMsg)
+ } else {
+logInfo("Detected schema change which is compatible: will overwrite
schema file to new.")
+// It tries best-effort to overwrite current schema file.
+// the schema validation doesn't break even it fails, though it might
miss on detecting
+// change which is not a big deal.
+createSchemaFile(keySchema, valueSchema)
+ }
+} else {
+ // schema doesn't exist, create one now
+ logDebug(s"Schema file for provider $providerId doesn't exist. Creating
one.")
+ createSchemaFile(keySchema, valueSchema)
+}
+ }
+
+ private def schemasCompatible(storedSchema: StructType, schema: StructType):
Boolean =
+equalsIgnoreCompatibleNullability(storedSchema, schema)
+
+ private def equalsIgnoreCompatibleNullability(from: DataType, to: DataType):
Boolean = {
Review comment:
If we're OK to have something like
`DataType.equalsIgnoreNameAndCompatibleNullability` then yes. I'll go with this
one, and roll back anyone concerns.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30582: [SPARK-33636][PYTHON][ML][FOLLOWUP] Update since tag of labelsArray in StringIndexer
SparkQA commented on pull request #30582: URL: https://github.com/apache/spark/pull/30582#issuecomment-737706776 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36692/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] luluorta commented on pull request #30585: [SPARK-26218][SQL][FOLLOW UP] Fix the corner case of codegen when casting float to Integer
luluorta commented on pull request #30585: URL: https://github.com/apache/spark/pull/30585#issuecomment-737702651 cc @turboFei @cloud-fan This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] luluorta opened a new pull request #30585: [SPARK-26218][SQL][FOLLOW UP] Fix the corner case of codegen when casting float to Integer
luluorta opened a new pull request #30585: URL: https://github.com/apache/spark/pull/30585 ### What changes were proposed in this pull request? This is a followup of [#27151](https://github.com/apache/spark/pull/27151). It fixes the same issue for the codegen path. ### Why are the changes needed? Result corrupt. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added Unit test. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30581: [WIP][SPARK-33615][K8S][TESTS] Add spark.archive tests in K8S
SparkQA removed a comment on pull request #30581: URL: https://github.com/apache/spark/pull/30581#issuecomment-737695740 **[Test build #132099 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132099/testReport)** for PR 30581 at commit [`b87e1c7`](https://github.com/apache/spark/commit/b87e1c78ebb8fc98b481980adbc0052e19560397). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30581: [WIP][SPARK-33615][K8S][TESTS] Add spark.archive tests in K8S
SparkQA commented on pull request #30581: URL: https://github.com/apache/spark/pull/30581#issuecomment-737701167 **[Test build #132099 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132099/testReport)** for PR 30581 at commit [`b87e1c7`](https://github.com/apache/spark/commit/b87e1c78ebb8fc98b481980adbc0052e19560397). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30573: [SPARK-26341][CORE]Expose executor memory metrics at the stage level, in the Stages tab
AmplabJenkins commented on pull request #30573: URL: https://github.com/apache/spark/pull/30573#issuecomment-737700164 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] manbuyun edited a comment on pull request #30572: [SPARK-33628][SQL] Use the Hive.getPartitionsByNames method instead of Hive.getPartitions in the HiveClientImpl
manbuyun edited a comment on pull request #30572: URL: https://github.com/apache/spark/pull/30572#issuecomment-737652179 And, Hive.getPartitions will cause MetaStoreClient close connection. Similar issue: https://issues.apache.org/jira/browse/SPARK-29409 The chain of method calls is as follows: Hive.getPartitions -> Hive.getUserName -> SessionState.getUserFromAuthenticator -> SessionState.get().getAuthenticator -> SessionState.setupAuth -> SessionState.setAuthorizerV2Config -> Hive.get -> Hive.getInternal -> Hive.create -> Hive.close -> metaStoreClient.close 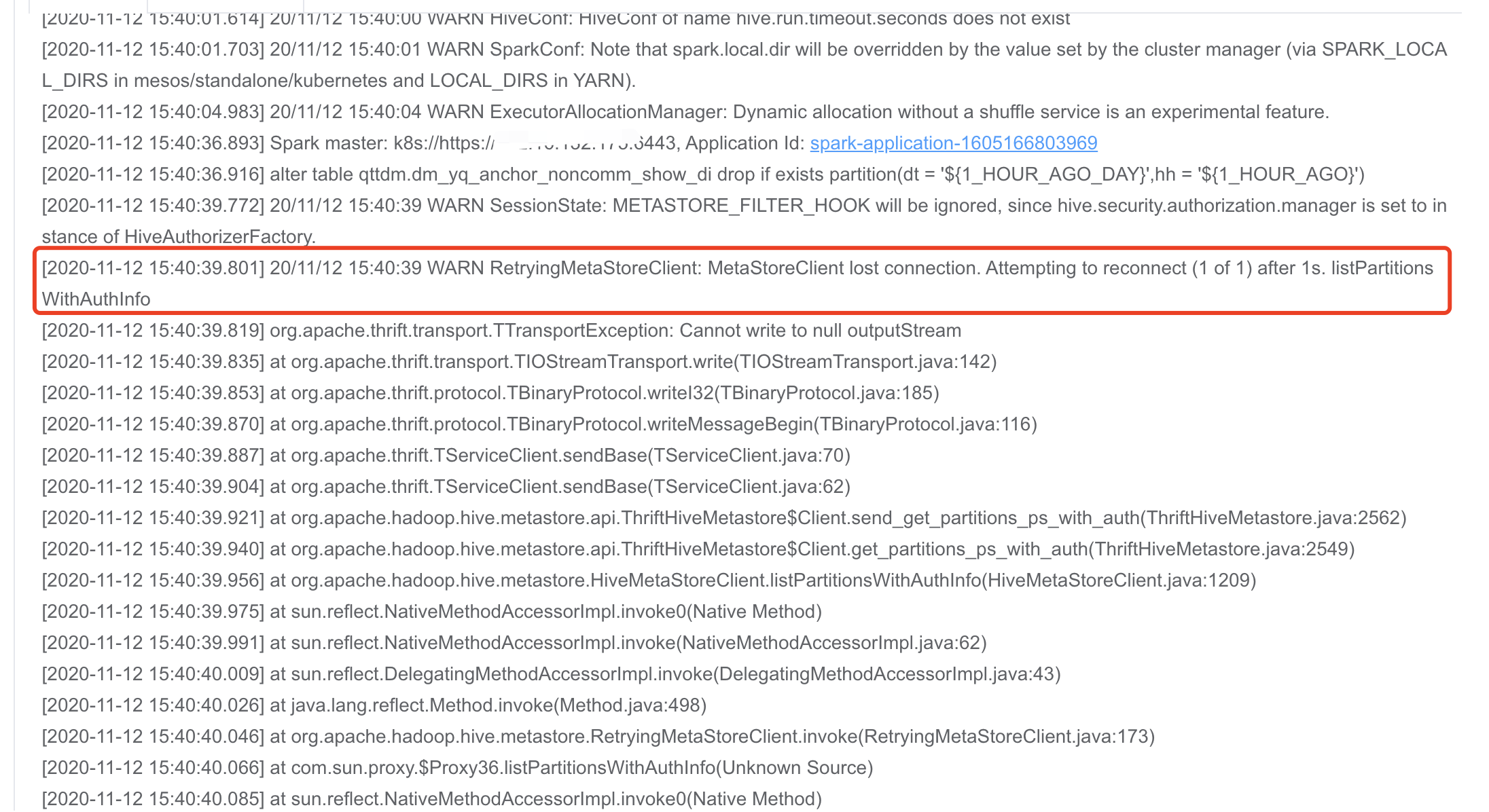 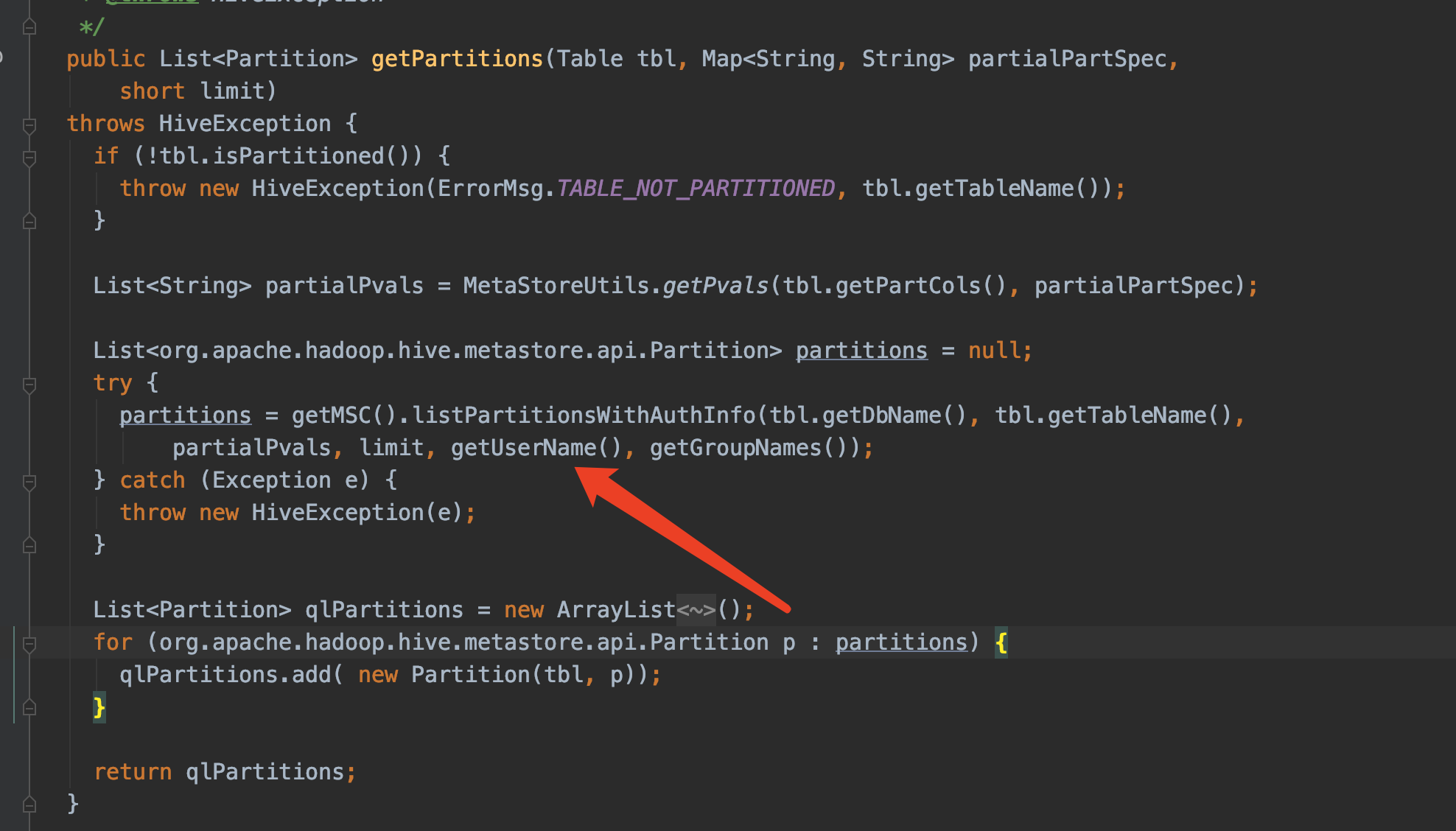 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30573: [SPARK-26341][CORE]Expose executor memory metrics at the stage level, in the Stages tab
SparkQA removed a comment on pull request #30573: URL: https://github.com/apache/spark/pull/30573#issuecomment-737654876 **[Test build #132085 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132085/testReport)** for PR 30573 at commit [`91a1f8e`](https://github.com/apache/spark/commit/91a1f8e09881a886a834e5133b90451b2b653133). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30573: [SPARK-26341][CORE]Expose executor memory metrics at the stage level, in the Stages tab
SparkQA commented on pull request #30573: URL: https://github.com/apache/spark/pull/30573#issuecomment-737699385 **[Test build #132085 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132085/testReport)** for PR 30573 at commit [`91a1f8e`](https://github.com/apache/spark/commit/91a1f8e09881a886a834e5133b90451b2b653133). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30433: [SPARK-32916][SHUFFLE][test-maven][test-hadoop2.7] Ensure the number of chunks in meta file and index file are equal
AmplabJenkins removed a comment on pull request #30433: URL: https://github.com/apache/spark/pull/30433#issuecomment-737698947 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30350: [SPARK-33428][SQL] Conv UDF use BigInt to avoid Long value overflow
AngersZh commented on pull request #30350: URL: https://github.com/apache/spark/pull/30350#issuecomment-737699065 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30433: [SPARK-32916][SHUFFLE][test-maven][test-hadoop2.7] Ensure the number of chunks in meta file and index file are equal
AmplabJenkins commented on pull request #30433: URL: https://github.com/apache/spark/pull/30433#issuecomment-737698947 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30433: [SPARK-32916][SHUFFLE][test-maven][test-hadoop2.7] Ensure the number of chunks in meta file and index file are equal
SparkQA commented on pull request #30433: URL: https://github.com/apache/spark/pull/30433#issuecomment-737698932 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36690/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30581: [WIP][SPARK-33615][K8S][TESTS] Add spark.archive tests in K8S
AmplabJenkins removed a comment on pull request #30581: URL: https://github.com/apache/spark/pull/30581#issuecomment-737698182 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30581: [WIP][SPARK-33615][K8S][TESTS] Add spark.archive tests in K8S
AmplabJenkins commented on pull request #30581: URL: https://github.com/apache/spark/pull/30581#issuecomment-737698182 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30581: [WIP][SPARK-33615][K8S][TESTS] Add spark.archive tests in K8S
SparkQA commented on pull request #30581: URL: https://github.com/apache/spark/pull/30581#issuecomment-737698159 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36689/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] manbuyun edited a comment on pull request #30572: [SPARK-33628][SQL] Use the Hive.getPartitionsByNames method instead of Hive.getPartitions in the HiveClientImpl
manbuyun edited a comment on pull request #30572: URL: https://github.com/apache/spark/pull/30572#issuecomment-737652179 And, Hive.getPartitions will cause MetaStoreClient close connection. Similar issue: https://issues.apache.org/jira/browse/SPARK-29409 The chain of method calls is as follows: Hive.getPartitions -> Hive.getUserName -> SessionState.getUserFromAuthenticator -> SessionState.get().getAuthenticator -> SessionState.setupAuth -> SessionState.setAuthorizerV2Config -> Hive.get -> Hive.getInternal -> Hive.create -> Hive.close -> metaStoreClient.close   This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30581: [WIP][SPARK-33615][K8S][TESTS] Add spark.archive tests in K8S
SparkQA commented on pull request #30581: URL: https://github.com/apache/spark/pull/30581#issuecomment-737695740 **[Test build #132099 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132099/testReport)** for PR 30581 at commit [`b87e1c7`](https://github.com/apache/spark/commit/b87e1c78ebb8fc98b481980adbc0052e19560397). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
AmplabJenkins removed a comment on pull request #24173: URL: https://github.com/apache/spark/pull/24173#issuecomment-737695354 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
SparkQA commented on pull request #24173: URL: https://github.com/apache/spark/pull/24173#issuecomment-737695345 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36691/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
AmplabJenkins commented on pull request #24173: URL: https://github.com/apache/spark/pull/24173#issuecomment-737695354 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] manbuyun edited a comment on pull request #30572: [SPARK-33628][SQL] Use the Hive.getPartitionsByNames method instead of Hive.getPartitions in the HiveClientImpl
manbuyun edited a comment on pull request #30572: URL: https://github.com/apache/spark/pull/30572#issuecomment-737652179 And, Hive.getPartitions will cause MetaStoreClient close connection The chain of method calls is as follows: Hive.getPartitions -> Hive.getUserName -> SessionState.getUserFromAuthenticator -> SessionState.get().getAuthenticator -> SessionState.setupAuth -> SessionState.setAuthorizerV2Config -> Hive.get -> Hive.getInternal -> Hive.create -> Hive.close -> metaStoreClient.close   This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu edited a comment on pull request #30350: [SPARK-33428][SQL] Conv UDF use BigInt to avoid Long value overflow
AngersZh edited a comment on pull request #30350: URL: https://github.com/apache/spark/pull/30350#issuecomment-737690572 > Fixing overflow should be good. It's not very intuitive to read the results of this function. Is there any database we can use as a reference? Mysql: https://dev.mysql.com/doc/refman/8.0/en/mathematical-functions.html#function_conv But still only support 64-bit presicion. Hive: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF https://github.com/apache/hive/blob/9cc3dc4830466ae9a744ea3442872f9289b917d1/ql/src/java/org/apache/hadoop/hive/ql/udf/UDFConv.java#L94-L109  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30582: [SPARK-33636][PYTHON][ML][FOLLOWUP] Update since tag of labelsArray in StringIndexer
SparkQA commented on pull request #30582: URL: https://github.com/apache/spark/pull/30582#issuecomment-737694018 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36692/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu edited a comment on pull request #30350: [SPARK-33428][SQL] Conv UDF use BigInt to avoid Long value overflow
AngersZh edited a comment on pull request #30350: URL: https://github.com/apache/spark/pull/30350#issuecomment-737690572 > Fixing overflow should be good. It's not very intuitive to read the results of this function. Is there any database we can use as a reference? Mysql: https://dev.mysql.com/doc/refman/8.0/en/mathematical-functions.html#function_conv But still only support 64-bit presicion. Hive: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF Latest version support BigInt now but internal logic still use `long`.. https://github.com/apache/hive/blob/9cc3dc4830466ae9a744ea3442872f9289b917d1/ql/src/java/org/apache/hadoop/hive/ql/udf/UDFConv.java#L94-L109  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu edited a comment on pull request #30350: [SPARK-33428][SQL] Conv UDF use BigInt to avoid Long value overflow
AngersZh edited a comment on pull request #30350: URL: https://github.com/apache/spark/pull/30350#issuecomment-737690572 > Fixing overflow should be good. It's not very intuitive to read the results of this function. Is there any database we can use as a reference? Mysql: https://dev.mysql.com/doc/refman/8.0/en/mathematical-functions.html#function_conv But still only support 64-bit presicion. Hive: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF Latest version support BigInt now but internal logic still use `long`..  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30433: [SPARK-32916][SHUFFLE][test-maven][test-hadoop2.7] Ensure the number of chunks in meta file and index file are equal
SparkQA commented on pull request #30433: URL: https://github.com/apache/spark/pull/30433#issuecomment-737692908 **[Test build #132098 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132098/testReport)** for PR 30433 at commit [`f5783a9`](https://github.com/apache/spark/commit/f5783a9e3f83d91308572230a7d050e000c49fa7). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30567: [SPARK-33142][SQL] Store SQL text for SQL temp view
SparkQA commented on pull request #30567: URL: https://github.com/apache/spark/pull/30567#issuecomment-737692863 **[Test build #132096 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132096/testReport)** for PR 30567 at commit [`979daa6`](https://github.com/apache/spark/commit/979daa654d10d9dd391cba67da05aa4b427021cf). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30584: [SPARK-33472][SQL][FOLLOW-UP] Update RemoveRedundantSorts comment
SparkQA commented on pull request #30584: URL: https://github.com/apache/spark/pull/30584#issuecomment-737692698 **[Test build #132094 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132094/testReport)** for PR 30584 at commit [`4f16499`](https://github.com/apache/spark/commit/4f16499efa6563c372944b35b7497f21e0b79725). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30543: [SPARK-33597][SQL] Support REGEXP_LIKE for consistent with mainstream databases
SparkQA commented on pull request #30543: URL: https://github.com/apache/spark/pull/30543#issuecomment-737692642 **[Test build #132097 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132097/testReport)** for PR 30543 at commit [`280d4c9`](https://github.com/apache/spark/commit/280d4c99fe95b572018b42dc889e9156a154a029). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30583: [SPARK-33640][TESTS] Extend connection timeout to DB server for DB2IntegrationSuite and its variants
SparkQA commented on pull request #30583: URL: https://github.com/apache/spark/pull/30583#issuecomment-737692603 **[Test build #132095 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132095/testReport)** for PR 30583 at commit [`7444a08`](https://github.com/apache/spark/commit/7444a0871e2d0f0f51490fdfc30b9050d1256b3f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30577: [SPARK-33621][SQL] Add a way to inject data source rewrite rules
LuciferYang commented on a change in pull request #30577:
URL: https://github.com/apache/spark/pull/30577#discussion_r534718894
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/SparkSessionExtensions.scala
##
@@ -199,6 +199,21 @@ class SparkSessionExtensions {
optimizerRules += builder
}
+ private[this] val dataSourceRewriteRules = mutable.Buffer.empty[RuleBuilder]
+
+ private[sql] def buildDataSourceRewriteRules(session: SparkSession):
Seq[Rule[LogicalPlan]] = {
+dataSourceRewriteRules.map(_.apply(session))
Review comment:
`dataSourceRewriteRules.map(_.apply(session))` need to call 'toSeq' to
compatible with Scala 2.13
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30582: [SPARK-33636][PYTHON][ML][FOLLOWUP] Update since tag of labelsArray in StringIndexer
AmplabJenkins removed a comment on pull request #30582: URL: https://github.com/apache/spark/pull/30582#issuecomment-737691321 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30543: [SPARK-33597][SQL] Support REGEXP_LIKE for consistent with mainstream databases
AmplabJenkins removed a comment on pull request #30543: URL: https://github.com/apache/spark/pull/30543#issuecomment-737691325 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30567: [SPARK-33142][SQL] Store SQL text for SQL temp view
AmplabJenkins removed a comment on pull request #30567: URL: https://github.com/apache/spark/pull/30567#issuecomment-737691328 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30582: [SPARK-33636][PYTHON][ML][FOLLOWUP] Update since tag of labelsArray in StringIndexer
AmplabJenkins commented on pull request #30582: URL: https://github.com/apache/spark/pull/30582#issuecomment-737691321 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30517: [DO-NOT-MERGE][test-maven] Test compatibility for Parquet 1.11.1, Avro 1.10.0 and Hive 2.3.8
AmplabJenkins removed a comment on pull request #30517: URL: https://github.com/apache/spark/pull/30517#issuecomment-737641867 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30543: [SPARK-33597][SQL] Support REGEXP_LIKE for consistent with mainstream databases
AmplabJenkins commented on pull request #30543: URL: https://github.com/apache/spark/pull/30543#issuecomment-737691325 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30517: [DO-NOT-MERGE][test-maven] Test compatibility for Parquet 1.11.1, Avro 1.10.0 and Hive 2.3.8
AmplabJenkins commented on pull request #30517: URL: https://github.com/apache/spark/pull/30517#issuecomment-737691336 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30567: [SPARK-33142][SQL] Store SQL text for SQL temp view
AmplabJenkins commented on pull request #30567: URL: https://github.com/apache/spark/pull/30567#issuecomment-737691328 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30350: [SPARK-33428][SQL] Conv UDF use BigInt to avoid Long value overflow
AngersZh commented on pull request #30350: URL: https://github.com/apache/spark/pull/30350#issuecomment-737690572 > Fixing overflow should be good. It's not very intuitive to read the results of this function. Is there any database we can use as a reference? Mysql: https://dev.mysql.com/doc/refman/8.0/en/mathematical-functions.html#function_conv But still only support 64-bit presicion. Hive: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF Latest version support BigInt now  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] allisonwang-db opened a new pull request #30584: [SPARK-33472][SQL][FOLLOW-UP] Update RemoveRedundantSorts comment
allisonwang-db opened a new pull request #30584: URL: https://github.com/apache/spark/pull/30584 ### What changes were proposed in this pull request? This PR is a follow-up for #30373 that updates the comment for RemoveRedundantSorts in QueryExecution. ### Why are the changes needed? To update an incorrect comment. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? N/A This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] manbuyun edited a comment on pull request #30572: [SPARK-33628][SQL] Use the Hive.getPartitionsByNames method instead of Hive.getPartitions in the HiveClientImpl
manbuyun edited a comment on pull request #30572: URL: https://github.com/apache/spark/pull/30572#issuecomment-737652179 And, Hive.getPartitions will cause MetaStoreClient close connection   This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30433: [SPARK-32916][SHUFFLE][test-maven][test-hadoop2.7] Ensure the number of chunks in meta file and index file are equal
SparkQA commented on pull request #30433: URL: https://github.com/apache/spark/pull/30433#issuecomment-737687656 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36690/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sarutak opened a new pull request #30583: [SPARK-33640][TESTS] Extend connection timeout to DB server for DB2IntegrationSuite and its variants
sarutak opened a new pull request #30583: URL: https://github.com/apache/spark/pull/30583 ### What changes were proposed in this pull request? This PR extends the connection timeout to the DB server for DB2IntegrationSuite and its variants. The container image ibmcom/db2 creates a database when it starts up. The database creation can take over 2 minutes. DB2IntegrationSuite and its variants use the container image but the connection timeout is set to 2 minutes so these suites almost always fail. ### Why are the changes needed? To pass those suites. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I confirmed the suites pass with the following commands. ``` $ build/sbt -Pdocker-integration-tests -Phive -Phive-thriftserver package "testOnly org.apache.spark.sql.jdbc.DB2IntegrationSuite" $ build/sbt -Pdocker-integration-tests -Phive -Phive-thriftserver package "testOnly org.apache.spark.sql.jdbc.v2.DB2IntegrationSuite" $ build/sbt -Pdocker-integration-tests -Phive -Phive-thriftserver package "testOnly org.apache.spark.sql.jdbc.DB2KrbIntegrationSuite" This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
SparkQA commented on pull request #24173: URL: https://github.com/apache/spark/pull/24173#issuecomment-737686530 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36691/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30581: [WIP][SPARK-33615][K8S][TESTS] Add spark.archive tests in K8S
SparkQA commented on pull request #30581: URL: https://github.com/apache/spark/pull/30581#issuecomment-737685942 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36689/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30567: [SPARK-33142][SQL] Store SQL text for SQL temp view
SparkQA removed a comment on pull request #30567: URL: https://github.com/apache/spark/pull/30567#issuecomment-737654886 **[Test build #132086 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132086/testReport)** for PR 30567 at commit [`f049fa1`](https://github.com/apache/spark/commit/f049fa1c59d42641bb404081bd7e805efeb1089a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30567: [SPARK-33142][SQL] Store SQL text for SQL temp view
SparkQA commented on pull request #30567: URL: https://github.com/apache/spark/pull/30567#issuecomment-737685247 **[Test build #132086 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/132086/testReport)** for PR 30567 at commit [`f049fa1`](https://github.com/apache/spark/commit/f049fa1c59d42641bb404081bd7e805efeb1089a). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on a change in pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
zsxwing commented on a change in pull request #24173:
URL: https://github.com/apache/spark/pull/24173#discussion_r534679600
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/StateSchemaCompatibilityChecker.scala
##
@@ -0,0 +1,142 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.state
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.execution.streaming.CheckpointFileManager
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.types.{ArrayType, DataType, MapType, StructType}
+
+case class StateSchemaNotCompatible(message: String) extends Exception(message)
+
+class StateSchemaCompatibilityChecker(
+providerId: StateStoreProviderId,
+hadoopConf: Configuration) extends Logging {
+
+ private val storeCpLocation = providerId.storeId.storeCheckpointLocation()
+ private val fm = CheckpointFileManager.create(storeCpLocation, hadoopConf)
+ private val schemaFileLocation = schemaFile(storeCpLocation)
+
+ fm.mkdirs(schemaFileLocation.getParent)
+
+ def check(keySchema: StructType, valueSchema: StructType): Unit = {
+if (fm.exists(schemaFileLocation)) {
+ logDebug(s"Schema file for provider $providerId exists. Comparing with
provided schema.")
+ val (storedKeySchema, storedValueSchema) = readSchemaFile()
+
+ val errorMsg = "Provided schema doesn't match to the schema for existing
state! " +
Review comment:
We should not create the error message if the schema matches. The schema
may be large and it may take time to create the string.
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/StateSchemaCompatibilityChecker.scala
##
@@ -0,0 +1,142 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.streaming.state
+
+import org.apache.hadoop.conf.Configuration
+import org.apache.hadoop.fs.Path
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.execution.streaming.CheckpointFileManager
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.types.{ArrayType, DataType, MapType, StructType}
+
+case class StateSchemaNotCompatible(message: String) extends Exception(message)
+
+class StateSchemaCompatibilityChecker(
+providerId: StateStoreProviderId,
+hadoopConf: Configuration) extends Logging {
+
+ private val storeCpLocation = providerId.storeId.storeCheckpointLocation()
+ private val fm = CheckpointFileManager.create(storeCpLocation, hadoopConf)
+ private val schemaFileLocation = schemaFile(storeCpLocation)
+
+ fm.mkdirs(schemaFileLocation.getParent)
+
+ def check(keySchema: StructType, valueSchema: StructType): Unit = {
+if (fm.exists(schemaFileLocation)) {
+ logDebug(s"Schema file for provider $providerId exists. Comparing with
provided schema.")
+ val (storedKeySchema, storedValueSchema) = readSchemaFile()
+
+ val errorMsg = "Provided schema doesn't match to the schema for existing
state! " +
+"Please note that Spark allow difference of field name: check count of
fields " +
+"and data type of each field.\n" +
+s"- provided schema: key $keySchema value $valueSchema\n" +
+s"- existing schema: key $storedKeySchema value $storedValueSchema\n" +
+