[GitHub] [spark] SparkQA removed a comment on pull request #31245: [SPARK-34157][SQL] Unify output of SHOW TABLES and pass output attributes properly
SparkQA removed a comment on pull request #31245: URL: https://github.com/apache/spark/pull/31245#issuecomment-772186623 **[Test build #134805 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134805/testReport)** for PR 31245 at commit [`350bf94`](https://github.com/apache/spark/commit/350bf94d60d0ba420a37af40099023b3f527d9b2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31245: [SPARK-34157][SQL] Unify output of SHOW TABLES and pass output attributes properly
SparkQA commented on pull request #31245: URL: https://github.com/apache/spark/pull/31245#issuecomment-772312717 **[Test build #134805 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134805/testReport)** for PR 31245 at commit [`350bf94`](https://github.com/apache/spark/commit/350bf94d60d0ba420a37af40099023b3f527d9b2). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31454: [WIP] Skip zinc start and shutdown in aarch64 os.
AmplabJenkins commented on pull request #31454: URL: https://github.com/apache/spark/pull/31454#issuecomment-772312572 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31378: [SPARK-34240][SQL] Unify output of SHOW TBLPROPERTIES pass output attribute properly
AmplabJenkins removed a comment on pull request #31378: URL: https://github.com/apache/spark/pull/31378#issuecomment-772311963 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134804/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31447: [SPARK-33726][SQL][FOLLOW-UP] Add assertion to FixedLengthRowBasedKeyValueBatch
AmplabJenkins removed a comment on pull request #31447: URL: https://github.com/apache/spark/pull/31447#issuecomment-772311973 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134803/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31451: [WIP][SPARK-34338][SQL] Report metrics from Datasource v2 scan
AmplabJenkins removed a comment on pull request #31451: URL: https://github.com/apache/spark/pull/31451#issuecomment-772311968 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39399/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31450: [WIP][SPARK-33763] Add metrics for better tracking of dynamic allocation
AmplabJenkins removed a comment on pull request #31450: URL: https://github.com/apache/spark/pull/31450#issuecomment-772311962 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39400/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31449: [SPARK-34326][CORE][SQL] Fix UTs added in SPARK-31793 depending on the length of temp path
AmplabJenkins removed a comment on pull request #31449: URL: https://github.com/apache/spark/pull/31449#issuecomment-772311967 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134807/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31451: [WIP][SPARK-34338][SQL] Report metrics from Datasource v2 scan
AmplabJenkins commented on pull request #31451: URL: https://github.com/apache/spark/pull/31451#issuecomment-772311968 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39399/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31449: [SPARK-34326][CORE][SQL] Fix UTs added in SPARK-31793 depending on the length of temp path
AmplabJenkins commented on pull request #31449: URL: https://github.com/apache/spark/pull/31449#issuecomment-772311967 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134807/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31447: [SPARK-33726][SQL][FOLLOW-UP] Add assertion to FixedLengthRowBasedKeyValueBatch
AmplabJenkins commented on pull request #31447: URL: https://github.com/apache/spark/pull/31447#issuecomment-772311973 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134803/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31450: [WIP][SPARK-33763] Add metrics for better tracking of dynamic allocation
AmplabJenkins commented on pull request #31450: URL: https://github.com/apache/spark/pull/31450#issuecomment-772311962 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39400/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31378: [SPARK-34240][SQL] Unify output of SHOW TBLPROPERTIES pass output attribute properly
AmplabJenkins commented on pull request #31378: URL: https://github.com/apache/spark/pull/31378#issuecomment-772311963 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134804/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #31453: [SPARK-34340][CORE] Support ZSTD JNI BufferPool
dongjoon-hyun commented on pull request #31453: URL: https://github.com/apache/spark/pull/31453#issuecomment-772311032 Thank you, @HyukjinKwon and @maropu . According to the review comment, I renamed it from `spark.io.compression.zstd.enableBufferPool` to `spark.io.compression.zstd.bufferPool.enabled`. Also, cc @cloud-fan for the conf naming. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31453: [SPARK-34340][CORE] Support ZSTD JNI BufferPool
HyukjinKwon commented on a change in pull request #31453:
URL: https://github.com/apache/spark/pull/31453#discussion_r569195872
##
File path: core/src/main/scala/org/apache/spark/internal/config/package.scala
##
@@ -1680,6 +1680,13 @@ package object config {
.bytesConf(ByteUnit.BYTE)
.createWithDefaultString("32k")
+ private[spark] val IO_COMPRESSION_ZSTD_ENABLE_BUFFERPOOL =
+ConfigBuilder("spark.io.compression.zstd.enableBufferPool")
Review comment:
Thanks @dongjoon-hyun.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #31453: [SPARK-34340][CORE] Support ZSTD JNI BufferPool
dongjoon-hyun commented on a change in pull request #31453:
URL: https://github.com/apache/spark/pull/31453#discussion_r569195640
##
File path: core/src/main/scala/org/apache/spark/internal/config/package.scala
##
@@ -1680,6 +1680,13 @@ package object config {
.bytesConf(ByteUnit.BYTE)
.createWithDefaultString("32k")
+ private[spark] val IO_COMPRESSION_ZSTD_ENABLE_BUFFERPOOL =
+ConfigBuilder("spark.io.compression.zstd.enableBufferPool")
Review comment:
So, `.enabled` can make a namespace? I'm fine to make it as `.enabled`.
I'll update the PR soon.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31378: [SPARK-34240][SQL] Unify output of SHOW TBLPROPERTIES pass output attribute properly
AngersZh commented on a change in pull request #31378: URL: https://github.com/apache/spark/pull/31378#discussion_r569193648 ## File path: docs/sql-migration-guide.md ## @@ -56,6 +56,8 @@ license: | In Spark 3.1 and earlier, table refreshing leaves dependents uncached. - In Spark 3.2, the usage of `count(tblName.*)` is blocked to avoid producing ambiguous results. Because `count(*)` and `count(tblName.*)` will output differently if there is any null values. To restore the behavior before Spark 3.2, you can set `spark.sql.legacy.allowStarWithSingleTableIdentifierInCount` to `true`. + + - In Spark 3.2, a `SHOW TBLPROPERTIES` clause's output shows `key` and `value` columns whether you specify the property key. In Spark 3.1 and earlier, a `SHOW TBLPROPERTIES` clause's output only show a `value` column when you specify the property key. Review comment: > nit: "whether you specify the property key." => "whether you specify the table property `key`." Done This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on pull request #31453: [SPARK-34340][CORE] Support ZSTD JNI BufferPool
maropu commented on pull request #31453: URL: https://github.com/apache/spark/pull/31453#issuecomment-772307357 Looks fine if the tests pass. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31453: [SPARK-34340][CORE] Support ZSTD JNI BufferPool
maropu commented on a change in pull request #31453:
URL: https://github.com/apache/spark/pull/31453#discussion_r569192651
##
File path: core/src/main/scala/org/apache/spark/internal/config/package.scala
##
@@ -1680,6 +1680,13 @@ package object config {
.bytesConf(ByteUnit.BYTE)
.createWithDefaultString("32k")
+ private[spark] val IO_COMPRESSION_ZSTD_ENABLE_BUFFERPOOL =
+ConfigBuilder("spark.io.compression.zstd.enableBufferPool")
Review comment:
I don't have a strong preference, but our policy below says naming
`featureName.enabled` is a best practice... as @HyukjinKwon suggested above.
So, I tend to follow it in most cases;
https://github.com/apache/spark/blob/89bf2afb3337a44f34009a36cae16dd0ff86b353/core/src/main/scala/org/apache/spark/internal/config/ConfigEntry.scala#L33-L40
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31449: [SPARK-34326][CORE][SQL] Fix UTs added in SPARK-31793 depending on the length of temp path
SparkQA removed a comment on pull request #31449: URL: https://github.com/apache/spark/pull/31449#issuecomment-772233390 **[Test build #134807 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134807/testReport)** for PR 31449 at commit [`5f37003`](https://github.com/apache/spark/commit/5f37003b94e68e1a7f22f9f13293e0aae6ae9563). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31449: [SPARK-34326][CORE][SQL] Fix UTs added in SPARK-31793 depending on the length of temp path
SparkQA commented on pull request #31449: URL: https://github.com/apache/spark/pull/31449#issuecomment-772306025 **[Test build #134807 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134807/testReport)** for PR 31449 at commit [`5f37003`](https://github.com/apache/spark/commit/5f37003b94e68e1a7f22f9f13293e0aae6ae9563). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31453: [SPARK-34340][CORE] Support ZSTD JNI BufferPool
HyukjinKwon commented on a change in pull request #31453:
URL: https://github.com/apache/spark/pull/31453#discussion_r569190239
##
File path: core/src/main/scala/org/apache/spark/internal/config/package.scala
##
@@ -1680,6 +1680,13 @@ package object config {
.bytesConf(ByteUnit.BYTE)
.createWithDefaultString("32k")
+ private[spark] val IO_COMPRESSION_ZSTD_ENABLE_BUFFERPOOL =
+ConfigBuilder("spark.io.compression.zstd.enableBufferPool")
Review comment:
.. but probably it's not a big deal since there's already inconsistency
there ..
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #30363: [SPARK-33438][SQL] Eagerly init all SQLConf objects for command `set -v`
viirya commented on a change in pull request #30363:
URL: https://github.com/apache/spark/pull/30363#discussion_r569188211
##
File path:
core/src/main/scala/org/apache/spark/util/SparkConfRegisterLoader.scala
##
@@ -0,0 +1,61 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.util
+
+import java.net.URL
+
+import scala.collection.JavaConverters._
+import scala.io.Source
+import scala.reflect.runtime.{universe => ru}
+import scala.util.control.NonFatal
+
+import org.apache.spark.internal.Logging
+
+object SparkConfRegisterLoader extends Logging {
Review comment:
Fixing `SetCommand` first sounds good to me.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31378: [SPARK-34240][SQL] Unify output of SHOW TBLPROPERTIES pass output attribute properly
maropu commented on a change in pull request #31378: URL: https://github.com/apache/spark/pull/31378#discussion_r569188018 ## File path: docs/sql-migration-guide.md ## @@ -56,6 +56,8 @@ license: | In Spark 3.1 and earlier, table refreshing leaves dependents uncached. - In Spark 3.2, the usage of `count(tblName.*)` is blocked to avoid producing ambiguous results. Because `count(*)` and `count(tblName.*)` will output differently if there is any null values. To restore the behavior before Spark 3.2, you can set `spark.sql.legacy.allowStarWithSingleTableIdentifierInCount` to `true`. + + - In Spark 3.2, a `SHOW TBLPROPERTIES` clause's output shows `key` and `value` columns whether you specify the property key. In Spark 3.1 and earlier, a `SHOW TBLPROPERTIES` clause's output only show a `value` column when you specify the property key. Review comment: nit: "whether you specify the property key." => "whether you specify the table property \`key\`." This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31453: [SPARK-34340][CORE] Support ZSTD JNI BufferPool
HyukjinKwon commented on a change in pull request #31453:
URL: https://github.com/apache/spark/pull/31453#discussion_r569187049
##
File path: core/src/main/scala/org/apache/spark/internal/config/package.scala
##
@@ -1680,6 +1680,13 @@ package object config {
.bytesConf(ByteUnit.BYTE)
.createWithDefaultString("32k")
+ private[spark] val IO_COMPRESSION_ZSTD_ENABLE_BUFFERPOOL =
+ConfigBuilder("spark.io.compression.zstd.enableBufferPool")
Review comment:
Looks like postfix `.enabled` is more common in this file though.
```
ConfigBuilder("spark.driver.log.persistToDfs.enabled")
private[spark] val EVENT_LOG_ENABLED =
ConfigBuilder("spark.eventLog.enabled")
ConfigBuilder("spark.eventLog.logBlockUpdates.enabled")
ConfigBuilder("spark.eventLog.erasureCoding.enabled")
ConfigBuilder("spark.eventLog.longForm.enabled")
ConfigBuilder("spark.eventLog.rolling.enabled")
ConfigBuilder("spark.executor.processTreeMetrics.enabled")
private[spark] val MEMORY_OFFHEAP_ENABLED =
ConfigBuilder("spark.memory.offHeap.enabled")
"If off-heap memory use is enabled, then spark.memory.offHeap.size
must be positive.")
"accordingly. This must be set to a positive value when
spark.memory.offHeap.enabled=true.")
ConfigBuilder("spark.storage.decommission.enabled")
ConfigBuilder("spark.storage.decommission.shuffleBlocks.enabled")
ConfigBuilder("spark.storage.decommission.rddBlocks.enabled")
ConfigBuilder("spark.dynamicAllocation.enabled")
ConfigBuilder("spark.dynamicAllocation.shuffleTracking.enabled")
ConfigBuilder("spark.shuffle.service.enabled")
ConfigBuilder("spark.shuffle.service.db.enabled")
ConfigBuilder("spark.task.reaper.enabled")
ConfigBuilder("spark.excludeOnFailure.enabled")
.withAlternative("spark.blacklist.enabled")
ConfigBuilder("spark.excludeOnFailure.application.fetchFailure.enabled")
.withAlternative("spark.blacklist.application.fetchFailure.enabled")
ConfigBuilder("spark.metrics.executorMetricsSource.enabled")
ConfigBuilder("spark.metrics.staticSources.enabled")
private[spark] val IO_ENCRYPTION_ENABLED =
ConfigBuilder("spark.io.encryption.enabled")
ConfigBuilder("spark.authenticate.enableSaslEncryption")
ConfigBuilder("spark.shuffle.reduceLocality.enabled")
ConfigBuilder("spark.unsafe.sorter.spill.read.ahead.enabled")
ConfigBuilder("spark.executor.logs.rolling.enableCompression")
private[spark] val MASTER_REST_SERVER_ENABLED =
ConfigBuilder("spark.master.rest.enabled")
ConfigBuilder("spark.decommission.enabled")
ConfigBuilder("spark.shuffle.push.enabled")
```
I think we have used `.enabled` postfix to indicate a boolean
configuration, and setting it to `true` is enabling it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30902: [SPARK-33888][SQL] JDBC SQL TIME type represents incorrectly as TimestampType, it should be physical Int in millis
cloud-fan commented on a change in pull request #30902:
URL: https://github.com/apache/spark/pull/30902#discussion_r569186823
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JdbcUtils.scala
##
@@ -408,6 +421,23 @@ object JdbcUtils extends Logging {
(rs: ResultSet, row: InternalRow, pos: Int) =>
row.setFloat(pos, rs.getFloat(pos + 1))
+
+// SPARK-33888 - sql TIME type represents as physical int in millis
+// Represents a time of day, with no reference to a particular calendar,
+// time zone or date, with a precision of one millisecond.
Review comment:
It may confuse Spark users, as Spark timestamp is microsecond precision.
After more thought, it's probably better to return timestamp when reading
JDBC time, with a clear rule: we convert the time to timestamp by using "zero
epoch" as the date part. It's also more useful as users can call `hour`
function or similar ones to get some field values. What do you think?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30363: [SPARK-33438][SQL] Eagerly init all SQLConf objects for command `set -v`
maropu commented on a change in pull request #30363:
URL: https://github.com/apache/spark/pull/30363#discussion_r569184928
##
File path:
core/src/main/scala/org/apache/spark/util/SparkConfRegisterLoader.scala
##
@@ -0,0 +1,61 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.util
+
+import java.net.URL
+
+import scala.collection.JavaConverters._
+import scala.io.Source
+import scala.reflect.runtime.{universe => ru}
+import scala.util.control.NonFatal
+
+import org.apache.spark.internal.Logging
+
+object SparkConfRegisterLoader extends Logging {
Review comment:
> One PR to add the resource file loading, which allows people to define
SQL configs outside of Spark.
Ah, I see. Anyway, I also think It is better to separate the bug fix and the
feature improvement as @cloud-fan said above.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31378: [SPARK-34240][SQL] Unify output of SHOW TBLPROPERTIES pass output attribute properly
SparkQA removed a comment on pull request #31378: URL: https://github.com/apache/spark/pull/31378#issuecomment-772180730 **[Test build #134804 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134804/testReport)** for PR 31378 at commit [`348ab27`](https://github.com/apache/spark/commit/348ab27dc72d97138f17b8feb6c34e3451674434). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31378: [SPARK-34240][SQL] Unify output of SHOW TBLPROPERTIES pass output attribute properly
SparkQA commented on pull request #31378: URL: https://github.com/apache/spark/pull/31378#issuecomment-772298181 **[Test build #134804 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134804/testReport)** for PR 31378 at commit [`348ab27`](https://github.com/apache/spark/commit/348ab27dc72d97138f17b8feb6c34e3451674434). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun opened a new pull request #31454: Skip zinc start and shutdown in aarch64 os.
Yikun opened a new pull request #31454: URL: https://github.com/apache/spark/pull/31454 ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31453: [SPARK-34340][CORE] Support ZSTD JNI BufferPool
SparkQA commented on pull request #31453: URL: https://github.com/apache/spark/pull/31453#issuecomment-772297148 **[Test build #134817 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134817/testReport)** for PR 31453 at commit [`6e88103`](https://github.com/apache/spark/commit/6e88103772692eddf482b00fda9923a79589a06f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #31453: [SPARK-34340][CORE] Support ZSTD JNI BufferPool
dongjoon-hyun commented on a change in pull request #31453:
URL: https://github.com/apache/spark/pull/31453#discussion_r569183105
##
File path: core/src/main/scala/org/apache/spark/internal/config/package.scala
##
@@ -1680,6 +1680,13 @@ package object config {
.bytesConf(ByteUnit.BYTE)
.createWithDefaultString("32k")
+ private[spark] val IO_COMPRESSION_ZSTD_ENABLE_BUFFERPOOL =
+ConfigBuilder("spark.io.compression.zstd.enableBufferPool")
Review comment:
Thank you for review. I cannot make `bufferPool` as a new namespace
because we have only one configuration here `enableBufferPool`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #31423: [SPARK-34314][SQL] Create new file index after partition schema inferring w/ the schema
MaxGekk commented on a change in pull request #31423: URL: https://github.com/apache/spark/pull/31423#discussion_r568362026 ## File path: sql/hive/src/test/scala/org/apache/spark/sql/hive/PartitionedTablePerfStatsSuite.scala ## @@ -370,7 +370,7 @@ class PartitionedTablePerfStatsSuite assert(HiveCatalogMetrics.METRIC_PARTITIONS_FETCHED.getCount() == 0) // reads and caches all the files initially - assert(HiveCatalogMetrics.METRIC_FILES_DISCOVERED.getCount() == 5) + assert(HiveCatalogMetrics.METRIC_FILES_DISCOVERED.getCount() == 10) Review comment: The second partition discovery should re-use file statuses from the cache if the cache is not the NoOp cache This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31453: [SPARK-34340][CORE] Support ZSTD JNI BufferPool
HyukjinKwon commented on a change in pull request #31453:
URL: https://github.com/apache/spark/pull/31453#discussion_r569182485
##
File path: core/src/main/scala/org/apache/spark/internal/config/package.scala
##
@@ -1680,6 +1680,13 @@ package object config {
.bytesConf(ByteUnit.BYTE)
.createWithDefaultString("32k")
+ private[spark] val IO_COMPRESSION_ZSTD_ENABLE_BUFFERPOOL =
+ConfigBuilder("spark.io.compression.zstd.enableBufferPool")
Review comment:
maybe `spark.io.compression.zstd.bufferPool.enabled` :-)?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31450: [WIP][SPARK-33763] Add metrics for better tracking of dynamic allocation
SparkQA commented on pull request #31450: URL: https://github.com/apache/spark/pull/31450#issuecomment-772295859 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39400/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #31405: [SPARK-34304][SQL] Remove view checks in v1 alter table commands
MaxGekk commented on a change in pull request #31405:
URL: https://github.com/apache/spark/pull/31405#discussion_r569180642
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/command/AlterTableDropPartitionSuiteBase.scala
##
@@ -222,7 +222,7 @@ trait AlterTableDropPartitionSuiteBase extends QueryTest
with DDLCommandTestUtil
}
val v2 = s"${spark.sharedState.globalTempViewManager.database}.v2"
- withGlobalTempView(v2) {
+ withGlobalTempView("v2") {
Review comment:
This is a bug fix. `withGlobalTempView()` doesn't remove global temp
view if it is called with full path: `withGlobalTempView("global_temp.v2")`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] saikocat commented on a change in pull request #30902: [SPARK-33888][SQL] JDBC SQL TIME type represents incorrectly as TimestampType, it should be physical Int in millis
saikocat commented on a change in pull request #30902:
URL: https://github.com/apache/spark/pull/30902#discussion_r569180539
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JdbcUtils.scala
##
@@ -408,6 +421,23 @@ object JdbcUtils extends Logging {
(rs: ResultSet, row: InternalRow, pos: Int) =>
row.setFloat(pos, rs.getFloat(pos + 1))
+
+// SPARK-33888 - sql TIME type represents as physical int in millis
+// Represents a time of day, with no reference to a particular calendar,
+// time zone or date, with a precision of one millisecond.
Review comment:
Since we are converting to/from java.sql.Time, and according to the
javadoc https://docs.oracle.com/javase/8/docs/api/java/sql/Time.html , it
supports till milliseconds for constructor.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31451: [WIP][SPARK-34338][SQL] Report metrics from Datasource v2 scan
SparkQA commented on pull request #31451: URL: https://github.com/apache/spark/pull/31451#issuecomment-772292807 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39399/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #30363: [SPARK-33438][SQL] Eagerly init all SQLConf objects for command `set -v`
HyukjinKwon commented on a change in pull request #30363:
URL: https://github.com/apache/spark/pull/30363#discussion_r569178700
##
File path:
core/src/main/scala/org/apache/spark/util/SparkConfRegisterLoader.scala
##
@@ -0,0 +1,61 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.util
+
+import java.net.URL
+
+import scala.collection.JavaConverters._
+import scala.io.Source
+import scala.reflect.runtime.{universe => ru}
+import scala.util.control.NonFatal
+
+import org.apache.spark.internal.Logging
+
+object SparkConfRegisterLoader extends Logging {
Review comment:
> One PR to add the resource file loading, which allows people to define
SQL configs outside of Spark.
We should probably make `SQLConf.buildConf` and `SQLConf.buildStaticConf` as
proper developer APIs first
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31452: [SPARK-34317][SQL][FOLLOW-UP] Use relationTypeMismatchHint when UnresolvedTable is resolved to a temp view
SparkQA commented on pull request #31452: URL: https://github.com/apache/spark/pull/31452#issuecomment-772291116 **[Test build #134813 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134813/testReport)** for PR 31452 at commit [`63ed2c3`](https://github.com/apache/spark/commit/63ed2c3eab8bbd8f58fba3bad9361f359a702a74). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30902: [SPARK-33888][SQL] JDBC SQL TIME type represents incorrectly as TimestampType, it should be physical Int in millis
cloud-fan commented on a change in pull request #30902:
URL: https://github.com/apache/spark/pull/30902#discussion_r569177848
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JdbcUtils.scala
##
@@ -408,6 +421,23 @@ object JdbcUtils extends Logging {
(rs: ResultSet, row: InternalRow, pos: Int) =>
row.setFloat(pos, rs.getFloat(pos + 1))
+
+// SPARK-33888 - sql TIME type represents as physical int in millis
+// Represents a time of day, with no reference to a particular calendar,
+// time zone or date, with a precision of one millisecond.
Review comment:
After a second thought, why do we pick millisecond precision? Why not
microsecond? Is there a standard for it?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31447: [SPARK-33726][SQL][FOLLOW-UP] Add assertion to FixedLengthRowBasedKeyValueBatch
SparkQA removed a comment on pull request #31447: URL: https://github.com/apache/spark/pull/31447#issuecomment-772180681 **[Test build #134803 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134803/testReport)** for PR 31447 at commit [`03cb772`](https://github.com/apache/spark/commit/03cb77224ae4c3279878d03b2873de0b30bfc5f0). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31447: [SPARK-33726][SQL][FOLLOW-UP] Add assertion to FixedLengthRowBasedKeyValueBatch
SparkQA commented on pull request #31447: URL: https://github.com/apache/spark/pull/31447#issuecomment-772289508 **[Test build #134803 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134803/testReport)** for PR 31447 at commit [`03cb772`](https://github.com/apache/spark/commit/03cb77224ae4c3279878d03b2873de0b30bfc5f0). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun opened a new pull request #31453: [SPARK-34340][CORE] Support ZSTD JNI BufferPool
dongjoon-hyun opened a new pull request #31453: URL: https://github.com/apache/spark/pull/31453 ### What changes were proposed in this pull request? This PR aims to support ZSTD JNI BufferPool feature by adding a new configuration, `spark.io.compression.zstd.enableBufferPool`. ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on pull request #31409: [SPARK-34307][SQL] TakeOrderedAndProjectExec avoid shuffle if input rdd has single partition
maropu commented on pull request #31409: URL: https://github.com/apache/spark/pull/31409#issuecomment-772287363 late lgtm This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30483: [SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
SparkQA commented on pull request #30483: URL: https://github.com/apache/spark/pull/30483#issuecomment-772284582 **[Test build #134816 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134816/testReport)** for PR 30483 at commit [`120678d`](https://github.com/apache/spark/commit/120678d8b4400cb67cd29787532f56d445acead4). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30841: [SPARK-28191][SS] New data source - state - reader part
SparkQA commented on pull request #30841: URL: https://github.com/apache/spark/pull/30841#issuecomment-772284355 **[Test build #134815 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134815/testReport)** for PR 30841 at commit [`47f12ac`](https://github.com/apache/spark/commit/47f12ac0f9b87c23280583a30e1f288d70f779a0). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
SparkQA commented on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-772284221 **[Test build #134814 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134814/testReport)** for PR 31179 at commit [`68e0256`](https://github.com/apache/spark/commit/68e025600fcea3a5ee65206c4f62c71effd5acdd). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] imback82 commented on a change in pull request #31452: [SPARK-34317][SQL][FOLLOW-UP] Use relationTypeMismatchHint when UnresolvedTable is resolved to a temp view
imback82 commented on a change in pull request #31452:
URL: https://github.com/apache/spark/pull/31452#discussion_r569171350
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala
##
@@ -192,11 +192,6 @@ private[spark] object QueryCompilationErrors {
s"$quoted as it's not a data source v2 relation.")
}
- def expectTableNotTempViewError(quoted: String, cmd: String, t:
TreeNode[_]): Throwable = {
Review comment:
We can just reuse `expectTableNotViewError` if we pass `ResolvedView`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31258: [SPARK-34168] [SQL] Support DPP in AQE when the join is Broadcast hash join at the beginning
AmplabJenkins removed a comment on pull request #31258: URL: https://github.com/apache/spark/pull/31258#issuecomment-772281833 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39398/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31349: [SPARK-34246][SQL] New type coercion syntax rules in ANSI mode
AmplabJenkins removed a comment on pull request #31349: URL: https://github.com/apache/spark/pull/31349#issuecomment-772281832 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39397/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31448: [SPARK-28137][SQL] Data Type Formatting Functions: `to_number`.
AmplabJenkins removed a comment on pull request #31448: URL: https://github.com/apache/spark/pull/31448#issuecomment-772281830 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
AmplabJenkins removed a comment on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-772281834 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39394/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] imback82 opened a new pull request #31452: [SPARK-34317][SQL][FOLLOW-UP] Use relationTypeMismatchHint when UnresolvedTable is resolved to a temp view
imback82 opened a new pull request #31452:
URL: https://github.com/apache/spark/pull/31452
### What changes were proposed in this pull request?
This is a follow up to #31424, and proposes to use
`UnresolvedTable.relationTypeMismatchHint` when `UnresolvedTable` is resolved
to a temp view.
### Why are the changes needed?
This change utilizes the type mismatch hint when a relation is resolved to a
temp view when a table is expected.
For example, `ALTER TABLE tmpView SET TBLPROPERTIES ('p' = 'an')` will now
include `Please use ALTER VIEW instead.` in the exception message: `tmpView is
a temp view. 'ALTER TABLE ... SET TBLPROPERTIES' expects a table. Please use
ALTER VIEW instead.`
### Does this PR introduce _any_ user-facing change?
Yes, adds the hint in the exception message.
### How was this patch tested?
Update existing tests to include the hint.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
AmplabJenkins commented on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-772281834 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39394/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31258: [SPARK-34168] [SQL] Support DPP in AQE when the join is Broadcast hash join at the beginning
AmplabJenkins commented on pull request #31258: URL: https://github.com/apache/spark/pull/31258#issuecomment-772281833 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39398/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31448: [SPARK-28137][SQL] Data Type Formatting Functions: `to_number`.
AmplabJenkins commented on pull request #31448: URL: https://github.com/apache/spark/pull/31448#issuecomment-772281830 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31349: [SPARK-34246][SQL] New type coercion syntax rules in ANSI mode
AmplabJenkins commented on pull request #31349: URL: https://github.com/apache/spark/pull/31349#issuecomment-772281832 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39397/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] allisonwang-db commented on pull request #31444: [SPARK-34335][SQL] Support referencing subquery with column aliases by table alias
allisonwang-db commented on pull request #31444: URL: https://github.com/apache/spark/pull/31444#issuecomment-772280943 cc @maropu This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31450: [WIP][SPARK-33763] Add metrics for better tracking of dynamic allocation
SparkQA commented on pull request #31450: URL: https://github.com/apache/spark/pull/31450#issuecomment-772279654 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39400/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31451: [WIP][SPARK-34338][SQL] Report metrics from Datasource v2 scan
SparkQA commented on pull request #31451: URL: https://github.com/apache/spark/pull/31451#issuecomment-772277403 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39399/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31448: [SPARK-28137][SQL] Data Type Formatting Functions: `to_number`.
SparkQA removed a comment on pull request #31448: URL: https://github.com/apache/spark/pull/31448#issuecomment-772232798 **[Test build #134808 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134808/testReport)** for PR 31448 at commit [`2eac9ec`](https://github.com/apache/spark/commit/2eac9ec67a652bc184143c1788d7ba7393a75ae8). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31448: [SPARK-28137][SQL] Data Type Formatting Functions: `to_number`.
SparkQA commented on pull request #31448: URL: https://github.com/apache/spark/pull/31448#issuecomment-772275970 **[Test build #134808 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134808/testReport)** for PR 31448 at commit [`2eac9ec`](https://github.com/apache/spark/commit/2eac9ec67a652bc184143c1788d7ba7393a75ae8). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `case class ToNumber(left: Expression, right: Expression)` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang edited a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772273452
Simple test:
```
val df = spark.read.parquet(or orc)("file:/home/work/xxx/data")
df.createOrReplaceTempView("test_table")
spark.sql("select sum(a), sum(b), sum(c) from test_table where id =
1381339").show
spark.sql("select sum(a), sum(b), sum(c) from test_table where id =
28643411").show
```
Data Source V1:
1. parquet with `spark.sql.fileMetaCache.parquet.enabled =false`
**Each footer was read 4 times, both queries read 6.9m data.**
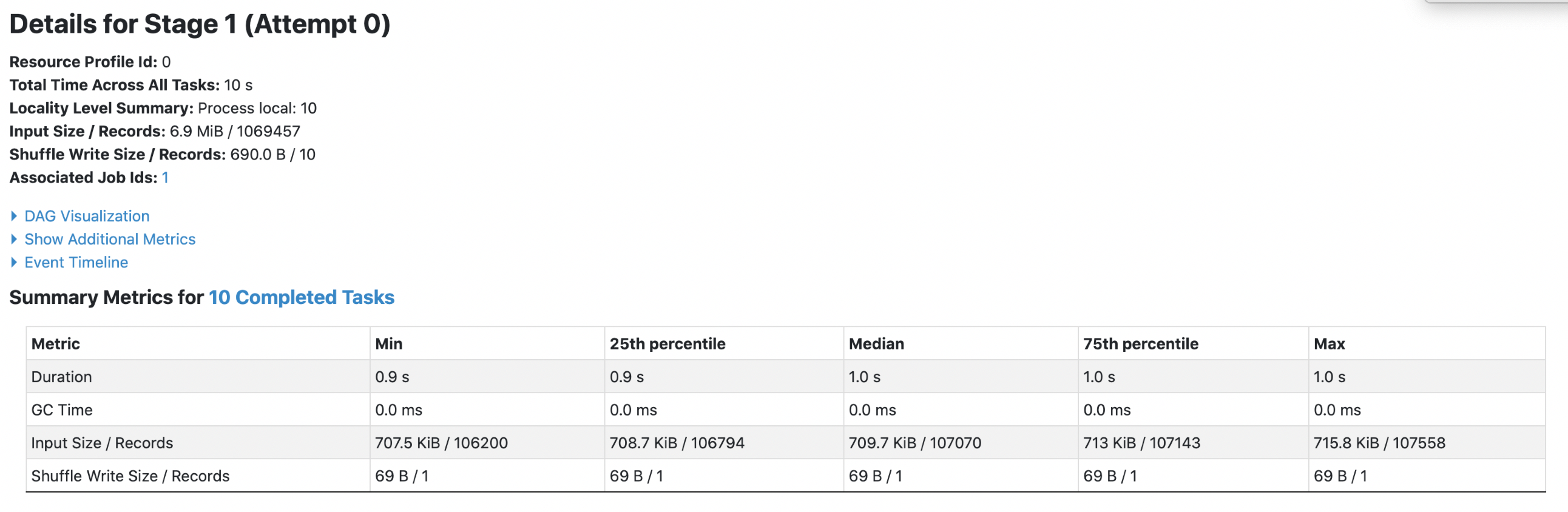
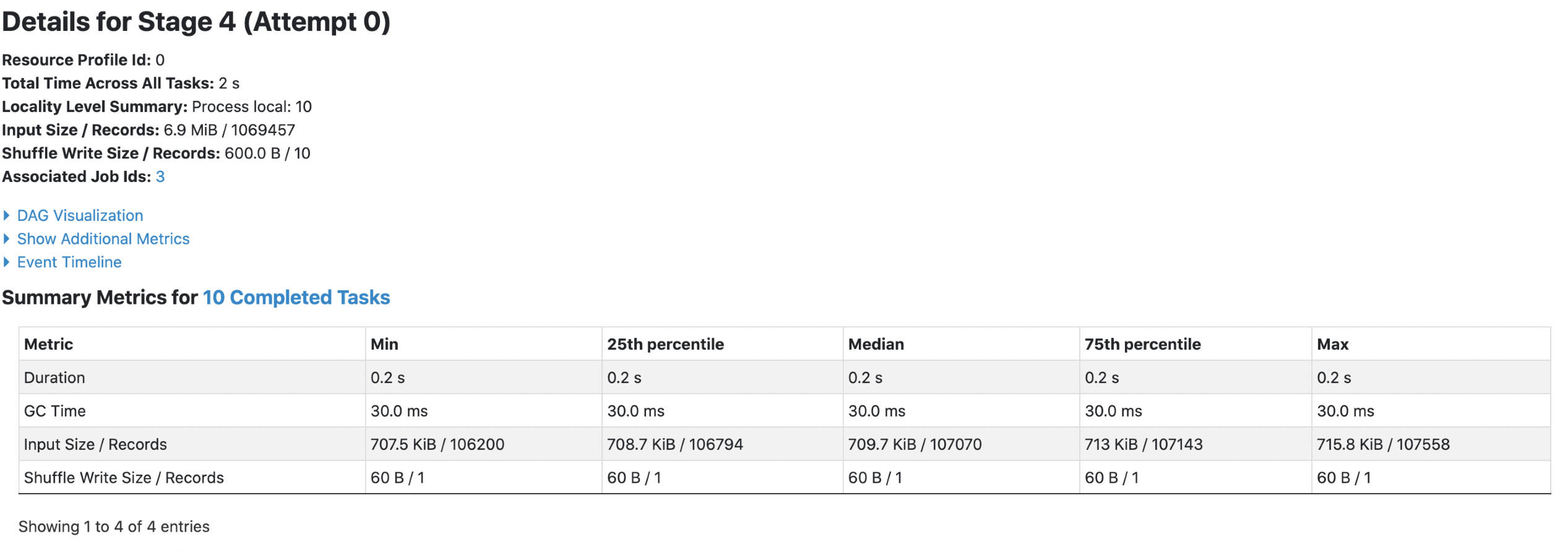
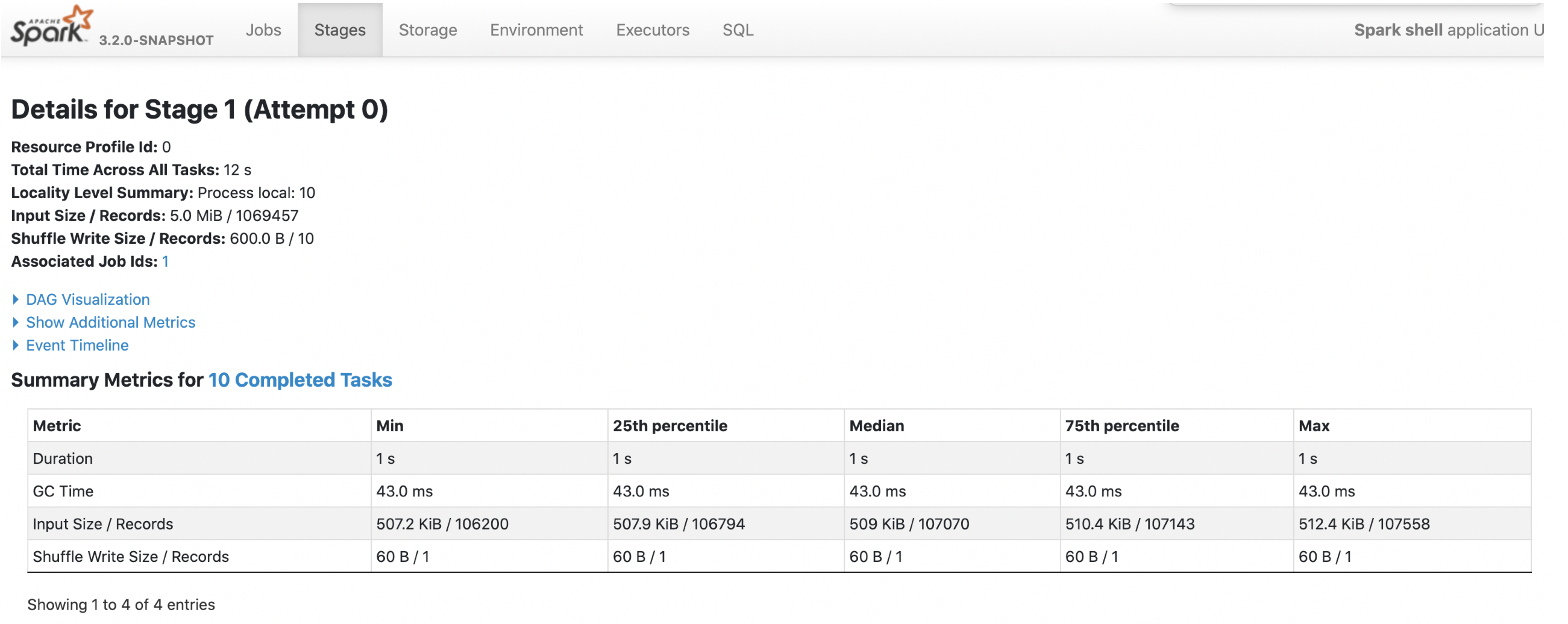
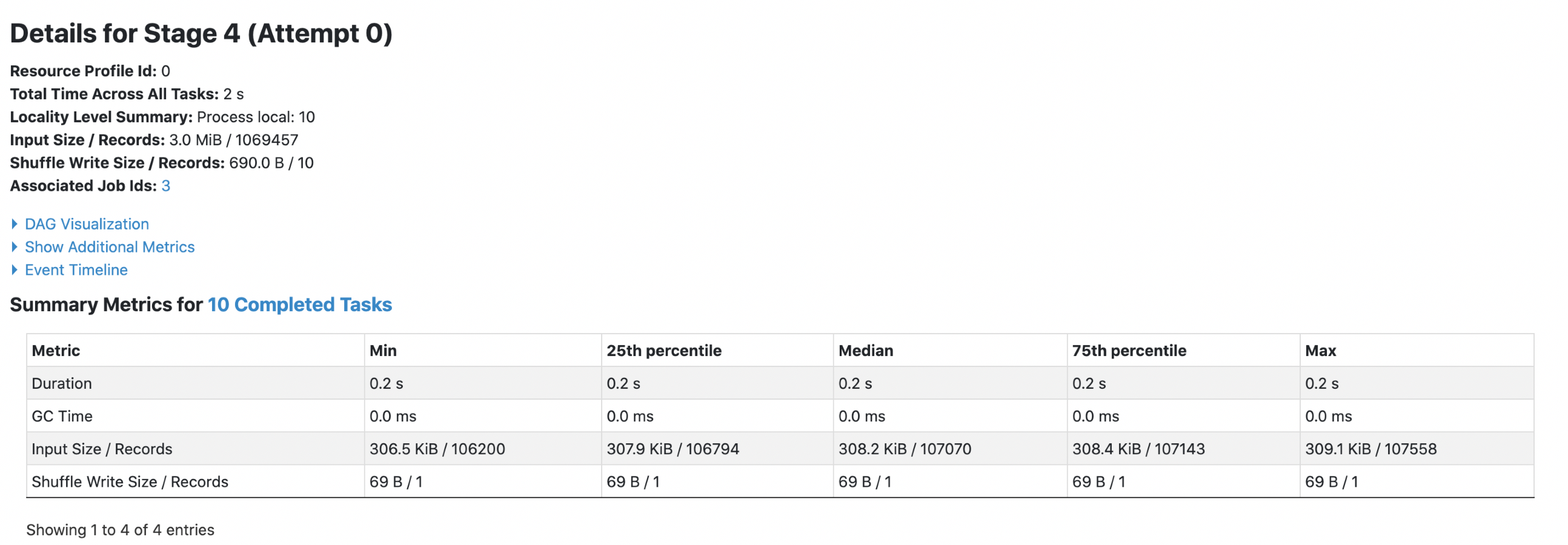
2. parquet with `spark.sql.fileMetaCache.parquet.enabled =true`
**Each footer was read 1 times, 1st query read 5m data and 2nd query read 3m
data.**
3. orc with `spark.sql.fileMetaCache.orc.enabled =false`
**Each footer was read 4 times, both queries read 52.3m data.**
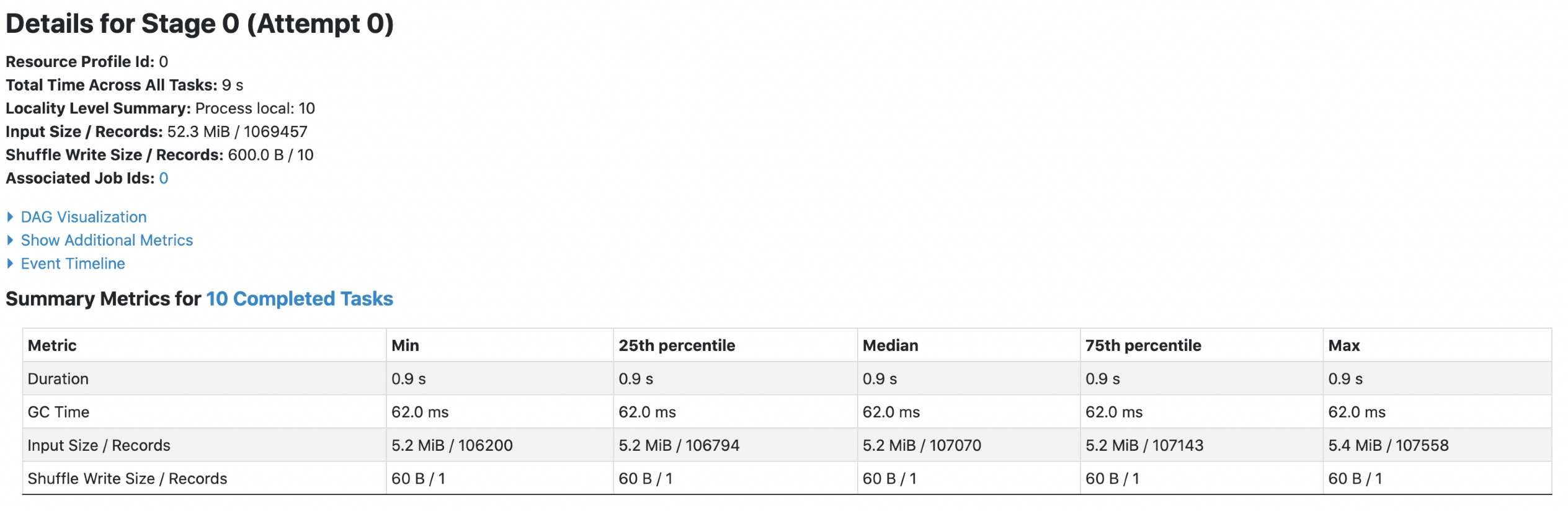
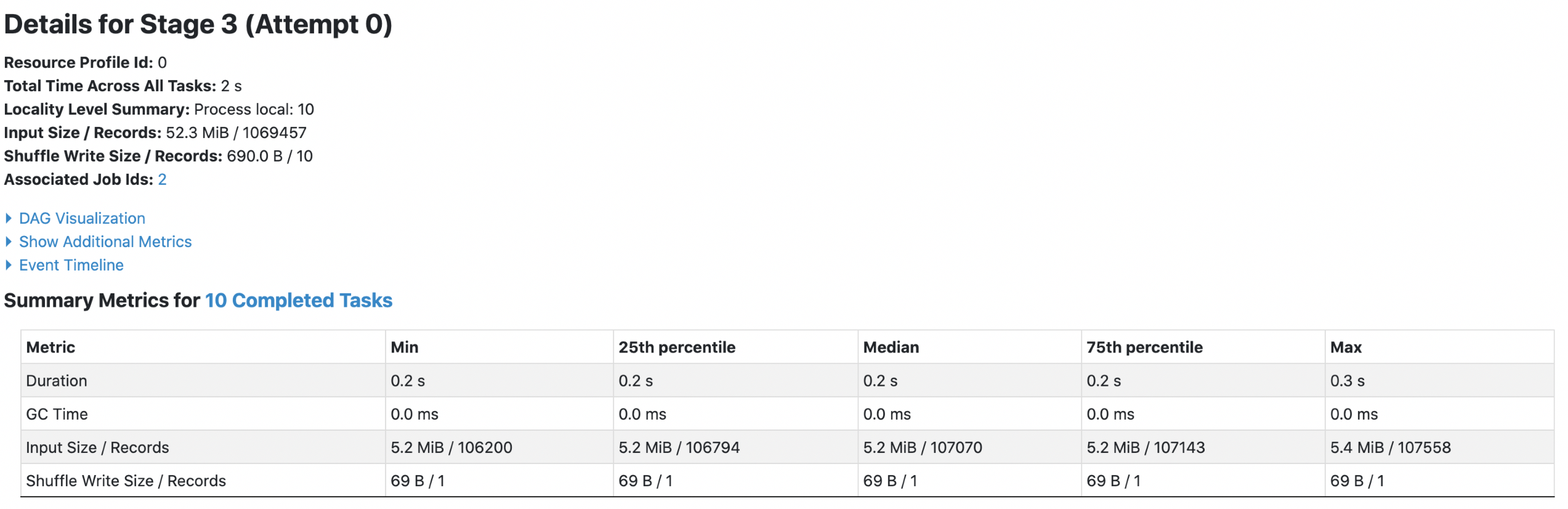
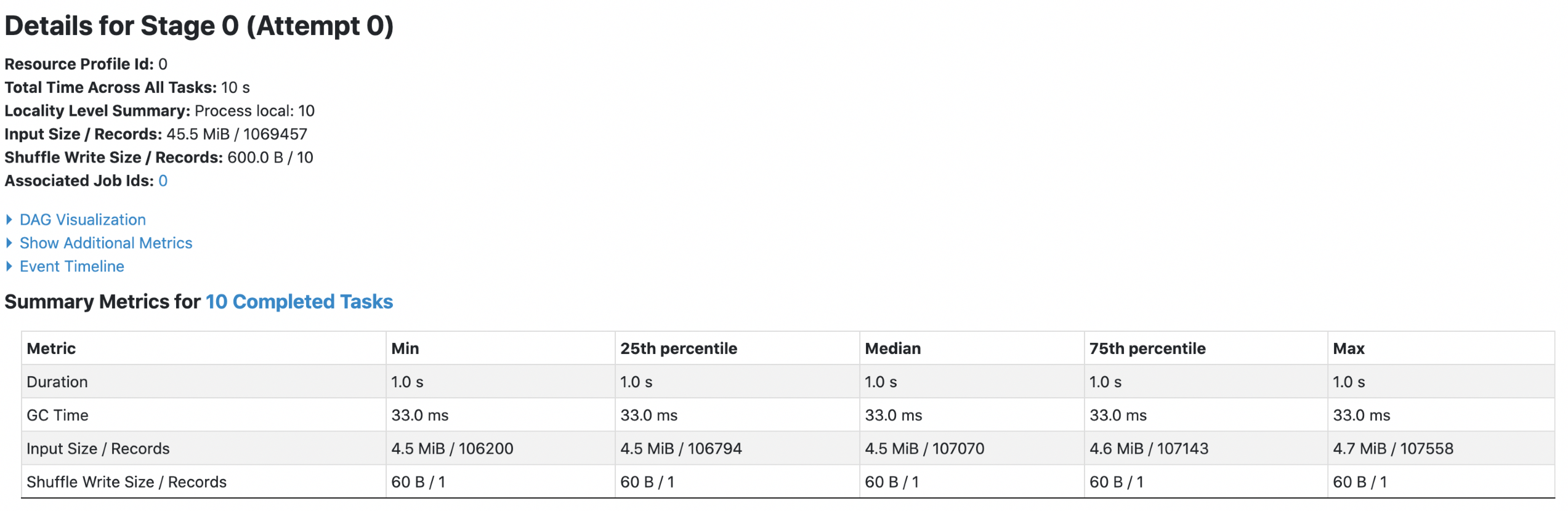
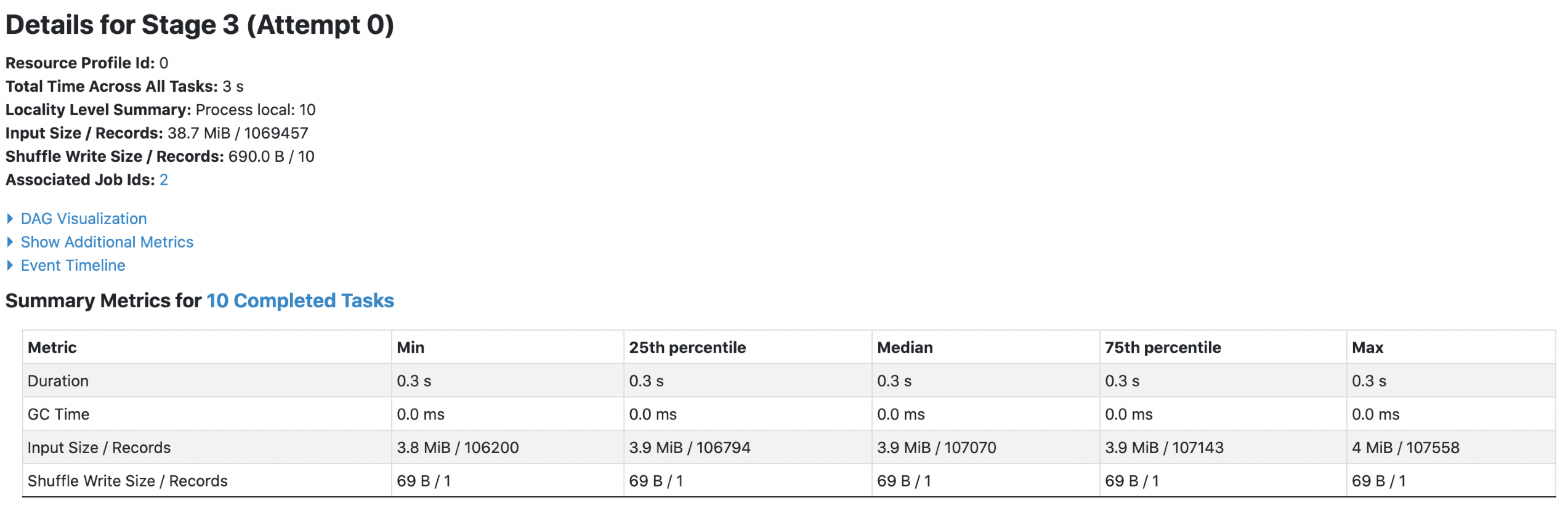
4. orc with `spark.sql.fileMetaCache.orc.enabled =true`
**Each footer was read 1 times, 1st query read 45.5m data and 2nd query read
38.7m data.**
DataSource V2 API has similar results.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang edited a comment on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
LuciferYang edited a comment on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772273452
Simple test:
```
val df = spark.read.parquet(or orc)("file:/home/work/xxx/data")
df.createOrReplaceTempView("test_table")
spark.sql("select sum(a), sum(b), sum(c) from test_table where id =
1381339").show
spark.sql("select sum(a), sum(b), sum(c) from test_table where id =
28643411").show
```
Data Source V1:
1. parquet with `spark.sql.fileMetaCache.parquet.enabled =false`
Each footer was read 4 times, both queries read 6.9m data.


2. parquet with `spark.sql.fileMetaCache.parquet.enabled =true`
Each footer was read 1 times, 1st query read 5m data and 2nd query read 3m
data.


3. orc with `spark.sql.fileMetaCache.orc.enabled =false`
Each footer was read 4 times, both queries read 52.3m data.


4. orc with `spark.sql.fileMetaCache.orc.enabled =true`
Each footer was read 1 times, 1st query read 45.5m data and 2nd query read
38.7m data.


DataSource V2 API has similar results.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #30483: [WIP][SPARK-33449][SQL] Add File Metadata cache support for Parquet and Orc
LuciferYang commented on pull request #30483:
URL: https://github.com/apache/spark/pull/30483#issuecomment-772273452
Simple test:
```
val df = spark.read.parquet(or orc)("file:/home/work/xxx/data")
df.createOrReplaceTempView("test_table")
spark.sql("select sum(a), sum(b), sum(c) from test_table where id =
1381339").show
spark.sql("select sum(a), sum(b), sum(c) from test_table where id =
28643411").show
```
Data Source V1:
1. parquet with `spark.sql.fileMetaCache.parquet.enabled =false`


2. parquet with `spark.sql.fileMetaCache.parquet.enabled =true`


3. orc with `spark.sql.fileMetaCache.orc.enabled =false`


4. orc with `spark.sql.fileMetaCache.orc.enabled =true`


This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
SparkQA commented on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-772270200 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39394/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #30841: [SPARK-28191][SS] New data source - state - reader part
HeartSaVioR commented on pull request #30841: URL: https://github.com/apache/spark/pull/30841#issuecomment-772269114 retest this, please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
AngersZh commented on a change in pull request #31179:
URL: https://github.com/apache/spark/pull/31179#discussion_r569161195
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/SQLQuerySuite.scala
##
@@ -2581,6 +2581,59 @@ abstract class SQLQuerySuiteBase extends QueryTest with
SQLTestUtils with TestHi
}
}
}
+
+ test("xxx") {
Review comment:
> Looks like we should have a proper test name btw
H, updated ==
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31258: [SPARK-34168] [SQL] Support DPP in AQE when the join is Broadcast hash join at the beginning
SparkQA commented on pull request #31258: URL: https://github.com/apache/spark/pull/31258#issuecomment-772262379 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39398/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31349: [SPARK-34246][SQL] New type coercion syntax rules in ANSI mode
SparkQA commented on pull request #31349: URL: https://github.com/apache/spark/pull/31349#issuecomment-772261696 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39397/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #31409: [SPARK-34307][SQL] TakeOrderedAndProjectExec avoid shuffle if input rdd has single partition
zhengruifeng commented on pull request #31409: URL: https://github.com/apache/spark/pull/31409#issuecomment-772261328 thanks all for reviewing! > We may have more operators that adding shuffle in the doExecute method instead of the planner I will look for other similar operators that may skip shuffle like this PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
HyukjinKwon commented on a change in pull request #31179:
URL: https://github.com/apache/spark/pull/31179#discussion_r569154926
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/SQLQuerySuite.scala
##
@@ -2581,6 +2581,59 @@ abstract class SQLQuerySuiteBase extends QueryTest with
SQLTestUtils with TestHi
}
}
}
+
+ test("xxx") {
Review comment:
Looks like we should have a proper test name btw
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31448: [SPARK-28137][SQL] Data Type Formatting Functions: `to_number`.
SparkQA commented on pull request #31448: URL: https://github.com/apache/spark/pull/31448#issuecomment-772260591 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39396/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31451: [WIP][SPARK-34338][SQL] Report metrics from Datasource v2 scan
SparkQA commented on pull request #31451: URL: https://github.com/apache/spark/pull/31451#issuecomment-772259785 **[Test build #134811 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134811/testReport)** for PR 31451 at commit [`4d941c7`](https://github.com/apache/spark/commit/4d941c7bb606ebf7d8a76b7b3e3d6fd6a3a00b95). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] imback82 commented on a change in pull request #31424: [SPARK-34317][SQL] Introduce relationTypeMismatchHint to UnresolvedTable for a better error message
imback82 commented on a change in pull request #31424:
URL: https://github.com/apache/spark/pull/31424#discussion_r569152899
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -1144,18 +1144,20 @@ class Analyzer(override val catalogManager:
CatalogManager)
lookupRelation(u.multipartIdentifier, u.options, u.isStreaming)
.map(resolveViews).getOrElse(u)
- case u @ UnresolvedTable(identifier, cmd) =>
+ case u @ UnresolvedTable(identifier, cmd, relationTypeMismatchHint) =>
lookupTableOrView(identifier).map {
- case v: ResolvedView => throw
QueryCompilationErrors.expectTableNotViewError(v, cmd, u)
+ case v: ResolvedView =>
Review comment:
@cloud-fan looks like I missed handling this in `ResolveTempViews`. I
will create a follow up PR. Sorry about that.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31436: [SPARK-34327][BUILD] Strip passwords from inlining into build information while releasing.
HyukjinKwon commented on pull request #31436: URL: https://github.com/apache/spark/pull/31436#issuecomment-772256896 Merged to master, branch-3.1, branch-3.0 and branch-2.4. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #31436: [SPARK-34327][BUILD] Strip passwords from inlining into build information while releasing.
HyukjinKwon closed pull request #31436: URL: https://github.com/apache/spark/pull/31436 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31450: [WIP][SPARK-33763] Add metrics for better tracking of dynamic allocation
AmplabJenkins removed a comment on pull request #31450: URL: https://github.com/apache/spark/pull/31450#issuecomment-772255241 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134812/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31450: [WIP][SPARK-33763] Add metrics for better tracking of dynamic allocation
SparkQA removed a comment on pull request #31450: URL: https://github.com/apache/spark/pull/31450#issuecomment-772254067 **[Test build #134812 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134812/testReport)** for PR 31450 at commit [`5560ec6`](https://github.com/apache/spark/commit/5560ec6b32f329ed6f9ad614df8f8d5c06ab33a7). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31450: [WIP][SPARK-33763] Add metrics for better tracking of dynamic allocation
SparkQA commented on pull request #31450: URL: https://github.com/apache/spark/pull/31450#issuecomment-772255230 **[Test build #134812 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134812/testReport)** for PR 31450 at commit [`5560ec6`](https://github.com/apache/spark/commit/5560ec6b32f329ed6f9ad614df8f8d5c06ab33a7). * This patch **fails Scala style tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31450: [WIP][SPARK-33763] Add metrics for better tracking of dynamic allocation
AmplabJenkins commented on pull request #31450: URL: https://github.com/apache/spark/pull/31450#issuecomment-772255241 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/134812/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31450: [WIP][SPARK-33763] Add metrics for better tracking of dynamic allocation
SparkQA commented on pull request #31450: URL: https://github.com/apache/spark/pull/31450#issuecomment-772254067 **[Test build #134812 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134812/testReport)** for PR 31450 at commit [`5560ec6`](https://github.com/apache/spark/commit/5560ec6b32f329ed6f9ad614df8f8d5c06ab33a7). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31449: [SPARK-34326][CORE][SQL] Fix UTs added in SPARK-31793 depending on the length of temp path
AmplabJenkins removed a comment on pull request #31449: URL: https://github.com/apache/spark/pull/31449#issuecomment-772253544 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39395/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31449: [SPARK-34326][CORE][SQL] Fix UTs added in SPARK-31793 depending on the length of temp path
AmplabJenkins commented on pull request #31449: URL: https://github.com/apache/spark/pull/31449#issuecomment-772253544 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39395/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31349: [SPARK-34246][SQL] New type coercion syntax rules in ANSI mode
SparkQA commented on pull request #31349: URL: https://github.com/apache/spark/pull/31349#issuecomment-772253263 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39397/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31449: [SPARK-34326][CORE][SQL] Fix UTs added in SPARK-31793 depending on the length of temp path
SparkQA commented on pull request #31449: URL: https://github.com/apache/spark/pull/31449#issuecomment-772252809 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39395/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya edited a comment on pull request #31398: [SPARK-34297][SQL][SS] Add metrics for data loss and offset out range for KafkaMicroBatchStream
viirya edited a comment on pull request #31398: URL: https://github.com/apache/spark/pull/31398#issuecomment-772250575 > For continuous execution, it's like an endless batch execution, so we can only use heartbeat events to update metrics. And we update the metrics in the UI in every epoch. Because I only test micro-batch case, I'm not sure if SQLMetrics metrics work for continuous streaming or not. But I also don't see special handling of common metrics (number of rows) in continuous streaming. If current number of rows metric works, then I think the newly added metrics should also work. I will check if SQLMetrics work with continuous streaming. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31449: [SPARK-34326][CORE][SQL] Fix UTs added in SPARK-31793 depending on the length of temp path
SparkQA commented on pull request #31449: URL: https://github.com/apache/spark/pull/31449#issuecomment-772250583 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39395/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on pull request #31398: [SPARK-34297][SQL][SS] Add metrics for data loss and offset out range for KafkaMicroBatchStream
viirya commented on pull request #31398: URL: https://github.com/apache/spark/pull/31398#issuecomment-772250575 > For continuous execution, it's like an endless batch execution, so we can only use heartbeat events to update metrics. And we update the metrics in the UI in every epoch. Because I only test micro-batch case, I'm not sure if SQLMetrics metrics work for continuous streaming or not. But I also don't see special handling of common metrics (number of rows) in continuous streaming. I will check if SQLMetrics work with continuous streaming. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31258: [SPARK-34168] [SQL] Support DPP in AQE when the join is Broadcast hash join at the beginning
SparkQA commented on pull request #31258: URL: https://github.com/apache/spark/pull/31258#issuecomment-772250089 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39398/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on pull request #31398: [SPARK-34297][SQL][SS] Add metrics for data loss and offset out range for KafkaMicroBatchStream
viirya commented on pull request #31398: URL: https://github.com/apache/spark/pull/31398#issuecomment-772248993 I extract generalized DS v2 change to #31451. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #31422: [SPARK-34313][SQL] Migrate ALTER TABLE SET/UNSET TBLPROPERTIES commands to use UnresolvedTable to resolve the identifier
cloud-fan closed pull request #31422: URL: https://github.com/apache/spark/pull/31422 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya opened a new pull request #31451: [WIP][SPARK-34338][SQL] Report metrics from Datasource v2 scan
viirya opened a new pull request #31451: URL: https://github.com/apache/spark/pull/31451 ### What changes were proposed in this pull request? This patch proposes to add a few public API change to DS v2, to make DS v2 scan can report metrics to Spark. One public interface `CustomMetric` is added. The interface simply can return metric name, description and value. There are two public methods added to existing public interfaces. * `PartitionReader.getCustomMetrics()`: returns an array of CustomMetric. Here is where the actual metrics values are collected. Empty array by default. * `Scan.supportedCustomMetrics()`: returns an array of supported custom metrics with name and description. Empty array by default. The metric collection happens as following. * `BatchScanExec`, `MicroBatchScanExec`, `ContinuousScanExec` call its scan's `supportedCustomMetrics` method to know what custom SQL metrics should be added. * `BatchScanExec`, `MicroBatchScanExec`, `ContinuousScanExec` pass a callback function for updating metrics to the underlying RDD. When it completes data consumption, calling the callback function to update metrics from `PartitionReader`. ### Why are the changes needed? This is related to #31398. In SPARK-34297, we want to add a couple of metrics when reading from Kafka in SS. We need some public API change in DS v2 to make it possible. This extracts only DS v2 change and make it general for DS v2 instead of micro-batch DS v2 API. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Test with SS-specific metrics in #31398. Unit test WIP This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #31422: [SPARK-34313][SQL] Migrate ALTER TABLE SET/UNSET TBLPROPERTIES commands to use UnresolvedTable to resolve the identifier
cloud-fan commented on pull request #31422: URL: https://github.com/apache/spark/pull/31422#issuecomment-772248371 thanks, merging to master! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31422: [SPARK-34313][SQL] Migrate ALTER TABLE SET/UNSET TBLPROPERTIES commands to use UnresolvedTable to resolve the identifier
cloud-fan commented on a change in pull request #31422:
URL: https://github.com/apache/spark/pull/31422#discussion_r569145719
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/SQLViewSuite.scala
##
@@ -167,6 +167,12 @@ abstract class SQLViewSuite extends QueryTest with
SQLTestUtils {
assertAnalysisError(
s"ALTER TABLE $viewName DROP PARTITION (a='4', b='8')",
s"$viewName is a temp view. 'ALTER TABLE ... DROP PARTITION ...'
expects a table")
+ assertAnalysisError(
+s"ALTER TABLE $viewName SET TBLPROPERTIES ('p' = 'an')",
+s"$viewName is a temp view. 'ALTER TABLE ... SET TBLPROPERTIES'
expects a table")
+ assertAnalysisError(
Review comment:
I don't think so. It's UT and we know how the code works. The catalog
implementation doesn't matter. Testing it once with whatever catalog is good
enough.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31448: [SPARK-28137][SQL] Data Type Formatting Functions: `to_number`.
SparkQA commented on pull request #31448: URL: https://github.com/apache/spark/pull/31448#issuecomment-772247585 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39396/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #31398: [SPARK-34297][SQL][SS] Add metrics for data loss and offset out range for KafkaMicroBatchStream
cloud-fan commented on pull request #31398: URL: https://github.com/apache/spark/pull/31398#issuecomment-772246886 Yea creating a separate PR SGTM. Let's have a high-level discussion first (I haven't read this PR yet). From my understanding, metrics in batch execution can be done as: 1. data source returns custom metrics in each read/write task (via task completion event or heartbeat event) 2. data source aggregates custom metrics from all tasks For microbatch execution, we just repeat the batch execution steps for each microbatch. And we update the metrics in the UI in every microbatch. For continuous execution, it's like an endless batch execution, so we can only use heartbeat events to update metrics. And we update the metrics in the UI in every epoch. The problem here is how to integrate this with Spark SQL. One idea is to use `AccumulatorV2`, which is a public API already and is very flexible. But we need to figure out how to make it work with the SQL UI. The other idea is to use `SQLMetrics`, which is private and we need some API design to map public API to `SQLMetrics`. It also limits the way of aggregating metrics. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] attilapiros opened a new pull request #31450: [WIP][SPARK-33763] Add metrics for better tracking of dynamic allocation
attilapiros opened a new pull request #31450: URL: https://github.com/apache/spark/pull/31450 ### What changes were proposed in this pull request? This PR adds the following metrics to track executor remove reasons during dynamic allocation: - `numberExecutorsGracefullyDecommissioned`: number of executors which reached the finished decommissioning state and shut itself down cleanly - `numberExecutorsDecommissionUnfinished`: executors which requested to decommission but they stopped without reaching the finished decommissioning state - `numberExecutorsKilledByDriver`: executors killed by the driver (requested to stop) - `numberExecutorsExitedUnexpectedly`: executors exited without driver request ### Why are the changes needed? For supporting monitoring of dynamic allocation better with these metrics. ### Does this PR introduce _any_ user-facing change? Yes. The new metrics will be available for monitoring. ### How was this patch tested? With unit and integration tests. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31349: [SPARK-34246][SQL] New type coercion syntax rules in ANSI mode
SparkQA commented on pull request #31349: URL: https://github.com/apache/spark/pull/31349#issuecomment-772234464 **[Test build #134809 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/134809/testReport)** for PR 31349 at commit [`462eea1`](https://github.com/apache/spark/commit/462eea155e4a5ca65e7ed2887e8f11ef368425a2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org