[GitHub] [spark] MaxGekk commented on pull request #31633: [SPARK-31891][SQL][DOCS][FOLLOWUP] Fix typo in the description of `MSCK REPAIR TABLE`
MaxGekk commented on pull request #31633: URL: https://github.com/apache/spark/pull/31633#issuecomment-784872986 @cloud-fan @dongjoon-hyun Please, review this PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #31499: [SPARK-31891][SQL] Support `MSCK REPAIR TABLE .. [{ADD|DROP|SYNC} PARTITIONS]`
MaxGekk commented on a change in pull request #31499:
URL: https://github.com/apache/spark/pull/31499#discussion_r581718451
##
File path: docs/sql-ref-syntax-ddl-repair-table.md
##
@@ -39,6 +39,13 @@ MSCK REPAIR TABLE table_identifier
**Syntax:** `[ database_name. ] table_name`
+* **`{ADD|DROP|SYNC} PARTITIONS`**
+
+* If specified, `MSCK REPAIR TABLE` only adds partitions to the session
catalog.
Review comment:
Here is the PR https://github.com/apache/spark/pull/31633
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk opened a new pull request #31633: [SPARK-31891][SQL][DOCS][FOLLOWUP] Fix typo in the description of `MSCK REPAIR TABLE`
MaxGekk opened a new pull request #31633: URL: https://github.com/apache/spark/pull/31633 ### What changes were proposed in this pull request? Fix typo and highlight that `ADD PARTITIONS` is the default. ### Why are the changes needed? Fix a typo which can mislead users. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? n/a This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31624: [SPARK-34392][SQL] Support ZoneOffset +h:mm in DateTimeUtils. getZoneId
SparkQA commented on pull request #31624: URL: https://github.com/apache/spark/pull/31624#issuecomment-784871537 **[Test build #135410 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135410/testReport)** for PR 31624 at commit [`f3972c9`](https://github.com/apache/spark/commit/f3972c99fe4405009c21dda50e1e75ca1f9a3e53). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31630: [SPARK-34514][SQL] Push down limit for LEFT SEMI and LEFT ANTI join
SparkQA commented on pull request #31630: URL: https://github.com/apache/spark/pull/31630#issuecomment-784869889 **[Test build #135409 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135409/testReport)** for PR 31630 at commit [`22bfd5e`](https://github.com/apache/spark/commit/22bfd5e13ffb5b51a6a29851161146a1af6a5666). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
SparkQA commented on pull request #31632: URL: https://github.com/apache/spark/pull/31632#issuecomment-784868045 **[Test build #135408 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135408/testReport)** for PR 31632 at commit [`38f798c`](https://github.com/apache/spark/commit/38f798c13414de9b0270caebfaf9c8781698246a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29542: [SPARK-32703][SQL] Replace deprecated API calls from SpecificParquetRecordReaderBase
LuciferYang commented on a change in pull request #29542:
URL: https://github.com/apache/spark/pull/29542#discussion_r581690994
##
File path:
sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##
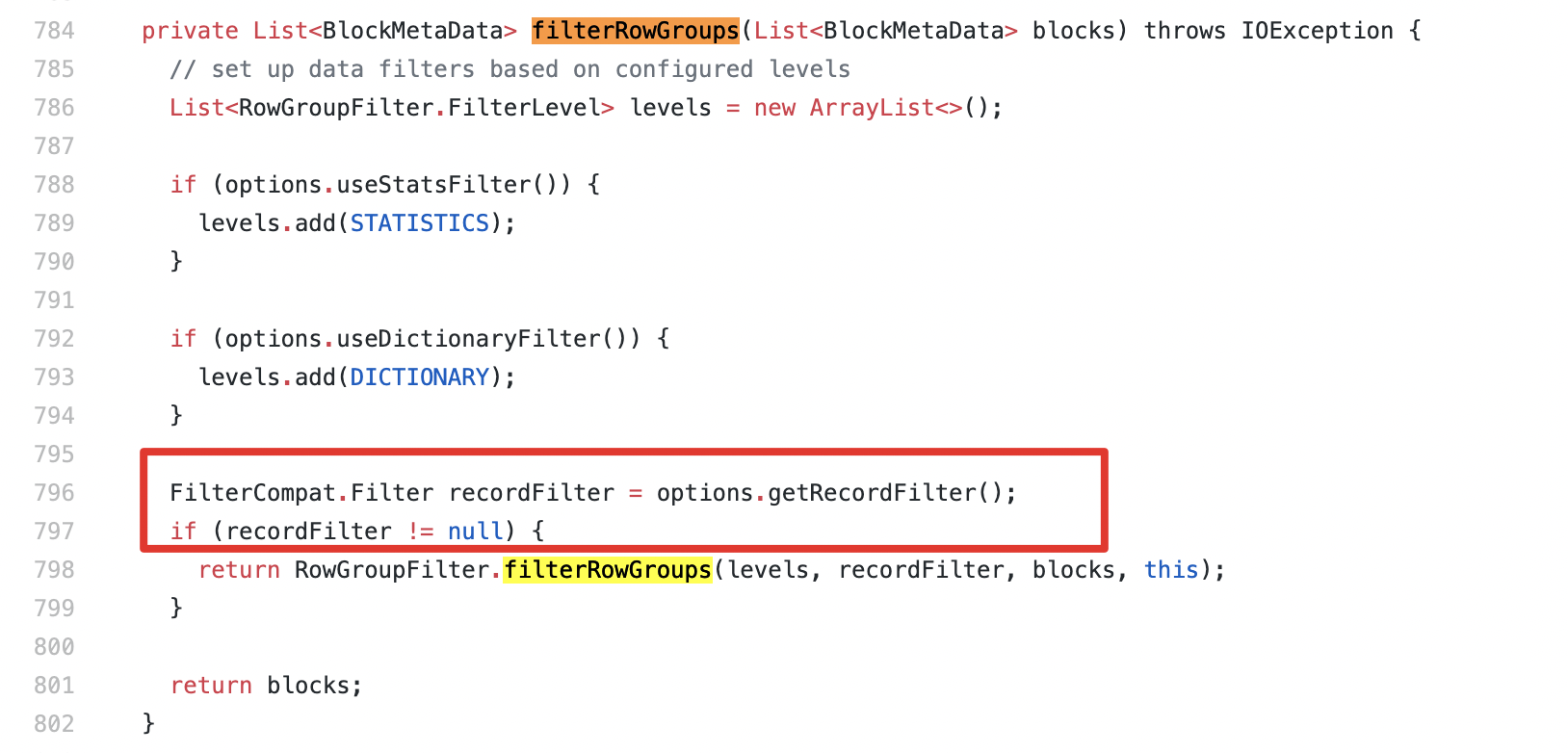
@@ -92,67 +88,23 @@
public void initialize(InputSplit inputSplit, TaskAttemptContext
taskAttemptContext)
throws IOException, InterruptedException {
Configuration configuration = taskAttemptContext.getConfiguration();
-ParquetInputSplit split = (ParquetInputSplit)inputSplit;
+FileSplit split = (FileSplit) inputSplit;
this.file = split.getPath();
-long[] rowGroupOffsets = split.getRowGroupOffsets();
-
-ParquetMetadata footer;
-List blocks;
-// if task.side.metadata is set, rowGroupOffsets is null
-if (rowGroupOffsets == null) {
- // then we need to apply the predicate push down filter
- footer = readFooter(configuration, file, range(split.getStart(),
split.getEnd()));
- MessageType fileSchema = footer.getFileMetaData().getSchema();
- FilterCompat.Filter filter = getFilter(configuration);
- blocks = filterRowGroups(filter, footer.getBlocks(), fileSchema);
-} else {
- // SPARK-33532: After SPARK-13883 and SPARK-13989, the parquet read
process will
- // no longer enter this branch because `ParquetInputSplit` only be
constructed in
- // `ParquetFileFormat.buildReaderWithPartitionValues` and
- // `ParquetPartitionReaderFactory.buildReaderBase` method,
- // and the `rowGroupOffsets` in `ParquetInputSplit` set to null
explicitly.
- // We didn't delete this branch because PARQUET-131 wanted to move this
to the
- // parquet-mr project.
- // otherwise we find the row groups that were selected on the client
- footer = readFooter(configuration, file, NO_FILTER);
- Set offsets = new HashSet<>();
- for (long offset : rowGroupOffsets) {
-offsets.add(offset);
- }
- blocks = new ArrayList<>();
- for (BlockMetaData block : footer.getBlocks()) {
-if (offsets.contains(block.getStartingPos())) {
- blocks.add(block);
-}
- }
- // verify we found them all
- if (blocks.size() != rowGroupOffsets.length) {
-long[] foundRowGroupOffsets = new long[footer.getBlocks().size()];
-for (int i = 0; i < foundRowGroupOffsets.length; i++) {
- foundRowGroupOffsets[i] = footer.getBlocks().get(i).getStartingPos();
-}
-// this should never happen.
-// provide a good error message in case there's a bug
-throw new IllegalStateException(
-"All the offsets listed in the split should be found in the file."
-+ " expected: " + Arrays.toString(rowGroupOffsets)
-+ " found: " + blocks
-+ " out of: " + Arrays.toString(foundRowGroupOffsets)
-+ " in range " + split.getStart() + ", " + split.getEnd());
- }
-}
-this.fileSchema = footer.getFileMetaData().getSchema();
-Map fileMetadata =
footer.getFileMetaData().getKeyValueMetaData();
+ParquetReadOptions options = HadoopReadOptions
+ .builder(configuration)
+ .withRange(split.getStart(), split.getStart() + split.getLength())
Review comment:
@sunchao @HyukjinKwon I think build `ParquetReadOptions` should add
`.withRecordFilter(ParquetInputFormat.getFilter(configuration))` to ensure that
the filter is pushed down because `recordFilter` is obtained from
`ParquetReadOptions` in `ParquetFileReader#filterRowGroups` method in Parquet
1.11.
```
ParquetReadOptions options = HadoopReadOptions
.builder(configuration)
.withRecordFilter(ParquetInputFormat.getFilter(configuration))
.withRange(split.getStart(), split.getStart() + split.getLength())
.build();
```
1.11.1:
https://github.com/apache/parquet-mr/blob/765bd5cd7fdef2af1cecd0755000694b992bfadd/parquet-hadoop/src/main/java/org/apache/parquet/hadoop/ParquetFileReader.java#L784-L802
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29542: [SPARK-32703][SQL] Replace deprecated API calls from SpecificParquetRecordReaderBase
LuciferYang commented on a change in pull request #29542:
URL: https://github.com/apache/spark/pull/29542#discussion_r581690994
##
File path:
sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##
@@ -92,67 +88,23 @@
public void initialize(InputSplit inputSplit, TaskAttemptContext
taskAttemptContext)
throws IOException, InterruptedException {
Configuration configuration = taskAttemptContext.getConfiguration();
-ParquetInputSplit split = (ParquetInputSplit)inputSplit;
+FileSplit split = (FileSplit) inputSplit;
this.file = split.getPath();
-long[] rowGroupOffsets = split.getRowGroupOffsets();
-
-ParquetMetadata footer;
-List blocks;
-// if task.side.metadata is set, rowGroupOffsets is null
-if (rowGroupOffsets == null) {
- // then we need to apply the predicate push down filter
- footer = readFooter(configuration, file, range(split.getStart(),
split.getEnd()));
- MessageType fileSchema = footer.getFileMetaData().getSchema();
- FilterCompat.Filter filter = getFilter(configuration);
- blocks = filterRowGroups(filter, footer.getBlocks(), fileSchema);
-} else {
- // SPARK-33532: After SPARK-13883 and SPARK-13989, the parquet read
process will
- // no longer enter this branch because `ParquetInputSplit` only be
constructed in
- // `ParquetFileFormat.buildReaderWithPartitionValues` and
- // `ParquetPartitionReaderFactory.buildReaderBase` method,
- // and the `rowGroupOffsets` in `ParquetInputSplit` set to null
explicitly.
- // We didn't delete this branch because PARQUET-131 wanted to move this
to the
- // parquet-mr project.
- // otherwise we find the row groups that were selected on the client
- footer = readFooter(configuration, file, NO_FILTER);
- Set offsets = new HashSet<>();
- for (long offset : rowGroupOffsets) {
-offsets.add(offset);
- }
- blocks = new ArrayList<>();
- for (BlockMetaData block : footer.getBlocks()) {
-if (offsets.contains(block.getStartingPos())) {
- blocks.add(block);
-}
- }
- // verify we found them all
- if (blocks.size() != rowGroupOffsets.length) {
-long[] foundRowGroupOffsets = new long[footer.getBlocks().size()];
-for (int i = 0; i < foundRowGroupOffsets.length; i++) {
- foundRowGroupOffsets[i] = footer.getBlocks().get(i).getStartingPos();
-}
-// this should never happen.
-// provide a good error message in case there's a bug
-throw new IllegalStateException(
-"All the offsets listed in the split should be found in the file."
-+ " expected: " + Arrays.toString(rowGroupOffsets)
-+ " found: " + blocks
-+ " out of: " + Arrays.toString(foundRowGroupOffsets)
-+ " in range " + split.getStart() + ", " + split.getEnd());
- }
-}
-this.fileSchema = footer.getFileMetaData().getSchema();
-Map fileMetadata =
footer.getFileMetaData().getKeyValueMetaData();
+ParquetReadOptions options = HadoopReadOptions
+ .builder(configuration)
+ .withRange(split.getStart(), split.getStart() + split.getLength())
Review comment:
@sunchao @HyukjinKwon I think build `ParquetReadOptions` should add
`.withRecordFilter(ParquetInputFormat.getFilter(configuration))` to ensure that
the filter is pushed down because `recordFilter` is obtained from
`ParquetReadOptions` in `ParquetFileReader#filterRowGroups` method in Parquet
1.11.
```
ParquetReadOptions options = HadoopReadOptions
.builder(configuration)
.withRecordFilter(ParquetInputFormat.getFilter(configuration))
.withRange(split.getStart(), split.getStart() + split.getLength())
.build();
```
1.11.1:
https://github.com/apache/parquet-mr/blob/765bd5cd7fdef2af1cecd0755000694b992bfadd/parquet-hadoop/src/main/java/org/apache/parquet/hadoop/ParquetFileReader.java#L784-L802

This logic is different from the master code of Apache Parquet:
https://github.com/apache/parquet-mr/blob/ab402f84e956d17ab67b63f91d01c63a92e7ae1e/parquet-hadoop/src/main/java/org/apache/parquet/hadoop/ParquetFileReader.java#L853-L871
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsub
[GitHub] [spark] LuciferYang commented on a change in pull request #29542: [SPARK-32703][SQL] Replace deprecated API calls from SpecificParquetRecordReaderBase
LuciferYang commented on a change in pull request #29542:
URL: https://github.com/apache/spark/pull/29542#discussion_r581690994
##
File path:
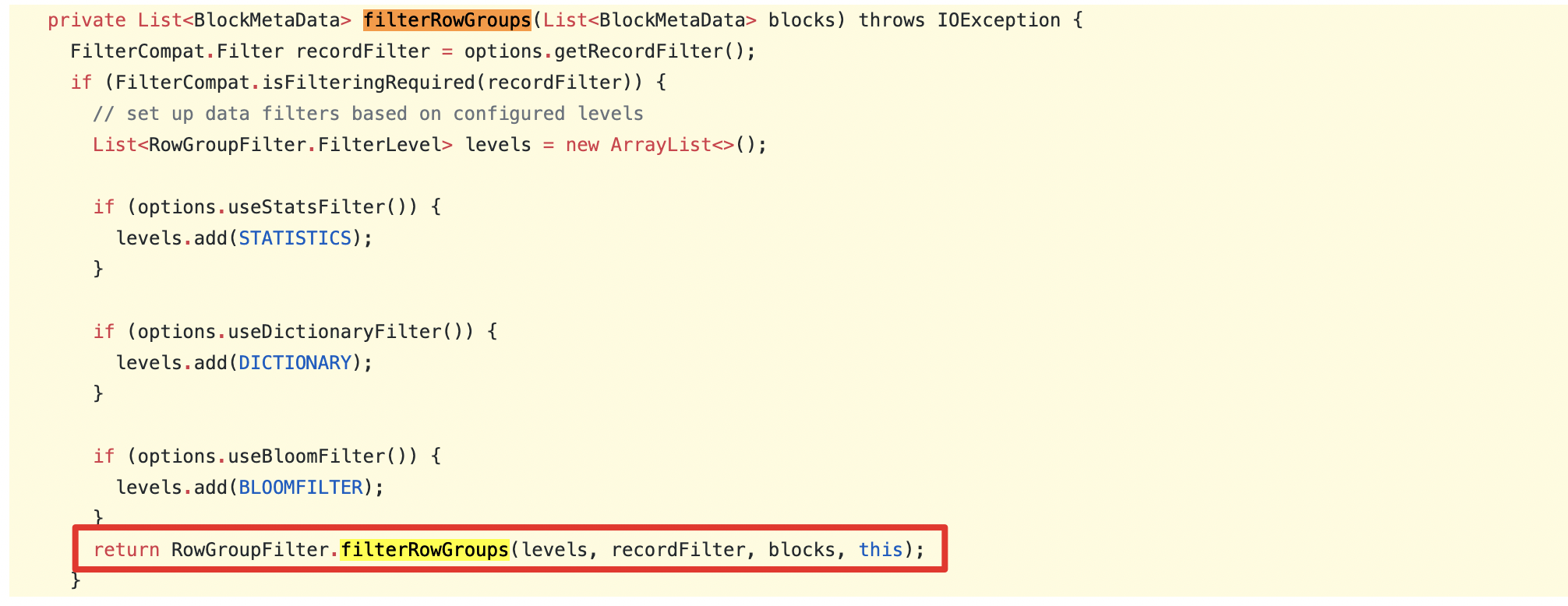
sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##
@@ -92,67 +88,23 @@
public void initialize(InputSplit inputSplit, TaskAttemptContext
taskAttemptContext)
throws IOException, InterruptedException {
Configuration configuration = taskAttemptContext.getConfiguration();
-ParquetInputSplit split = (ParquetInputSplit)inputSplit;
+FileSplit split = (FileSplit) inputSplit;
this.file = split.getPath();
-long[] rowGroupOffsets = split.getRowGroupOffsets();
-
-ParquetMetadata footer;
-List blocks;
-// if task.side.metadata is set, rowGroupOffsets is null
-if (rowGroupOffsets == null) {
- // then we need to apply the predicate push down filter
- footer = readFooter(configuration, file, range(split.getStart(),
split.getEnd()));
- MessageType fileSchema = footer.getFileMetaData().getSchema();
- FilterCompat.Filter filter = getFilter(configuration);
- blocks = filterRowGroups(filter, footer.getBlocks(), fileSchema);
-} else {
- // SPARK-33532: After SPARK-13883 and SPARK-13989, the parquet read
process will
- // no longer enter this branch because `ParquetInputSplit` only be
constructed in
- // `ParquetFileFormat.buildReaderWithPartitionValues` and
- // `ParquetPartitionReaderFactory.buildReaderBase` method,
- // and the `rowGroupOffsets` in `ParquetInputSplit` set to null
explicitly.
- // We didn't delete this branch because PARQUET-131 wanted to move this
to the
- // parquet-mr project.
- // otherwise we find the row groups that were selected on the client
- footer = readFooter(configuration, file, NO_FILTER);
- Set offsets = new HashSet<>();
- for (long offset : rowGroupOffsets) {
-offsets.add(offset);
- }
- blocks = new ArrayList<>();
- for (BlockMetaData block : footer.getBlocks()) {
-if (offsets.contains(block.getStartingPos())) {
- blocks.add(block);
-}
- }
- // verify we found them all
- if (blocks.size() != rowGroupOffsets.length) {
-long[] foundRowGroupOffsets = new long[footer.getBlocks().size()];
-for (int i = 0; i < foundRowGroupOffsets.length; i++) {
- foundRowGroupOffsets[i] = footer.getBlocks().get(i).getStartingPos();
-}
-// this should never happen.
-// provide a good error message in case there's a bug
-throw new IllegalStateException(
-"All the offsets listed in the split should be found in the file."
-+ " expected: " + Arrays.toString(rowGroupOffsets)
-+ " found: " + blocks
-+ " out of: " + Arrays.toString(foundRowGroupOffsets)
-+ " in range " + split.getStart() + ", " + split.getEnd());
- }
-}
-this.fileSchema = footer.getFileMetaData().getSchema();
-Map fileMetadata =
footer.getFileMetaData().getKeyValueMetaData();
+ParquetReadOptions options = HadoopReadOptions
+ .builder(configuration)
+ .withRange(split.getStart(), split.getStart() + split.getLength())
Review comment:
@sunchao I think build `ParquetReadOptions` should add
`.withRecordFilter(ParquetInputFormat.getFilter(configuration))` to ensure that
the filter is pushed down because `recordFilter` is obtained from
`ParquetReadOptions` in `ParquetFileReader#filterRowGroups` method in Parquet
1.11.
1.11.1:
https://github.com/apache/parquet-mr/blob/765bd5cd7fdef2af1cecd0755000694b992bfadd/parquet-hadoop/src/main/java/org/apache/parquet/hadoop/ParquetFileReader.java#L784-L802

This logic is different from the master code of Apache Parquet:
https://github.com/apache/parquet-mr/blob/ab402f84e956d17ab67b63f91d01c63a92e7ae1e/parquet-hadoop/src/main/java/org/apache/parquet/hadoop/ParquetFileReader.java#L853-L871

This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29542: [SPARK-32703][SQL] Replace deprecated API calls from SpecificParquetRecordReaderBase
LuciferYang commented on a change in pull request #29542:
URL: https://github.com/apache/spark/pull/29542#discussion_r581690994
##
File path:
sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java
##
@@ -92,67 +88,23 @@
public void initialize(InputSplit inputSplit, TaskAttemptContext
taskAttemptContext)
throws IOException, InterruptedException {
Configuration configuration = taskAttemptContext.getConfiguration();
-ParquetInputSplit split = (ParquetInputSplit)inputSplit;
+FileSplit split = (FileSplit) inputSplit;
this.file = split.getPath();
-long[] rowGroupOffsets = split.getRowGroupOffsets();
-
-ParquetMetadata footer;
-List blocks;
-// if task.side.metadata is set, rowGroupOffsets is null
-if (rowGroupOffsets == null) {
- // then we need to apply the predicate push down filter
- footer = readFooter(configuration, file, range(split.getStart(),
split.getEnd()));
- MessageType fileSchema = footer.getFileMetaData().getSchema();
- FilterCompat.Filter filter = getFilter(configuration);
- blocks = filterRowGroups(filter, footer.getBlocks(), fileSchema);
-} else {
- // SPARK-33532: After SPARK-13883 and SPARK-13989, the parquet read
process will
- // no longer enter this branch because `ParquetInputSplit` only be
constructed in
- // `ParquetFileFormat.buildReaderWithPartitionValues` and
- // `ParquetPartitionReaderFactory.buildReaderBase` method,
- // and the `rowGroupOffsets` in `ParquetInputSplit` set to null
explicitly.
- // We didn't delete this branch because PARQUET-131 wanted to move this
to the
- // parquet-mr project.
- // otherwise we find the row groups that were selected on the client
- footer = readFooter(configuration, file, NO_FILTER);
- Set offsets = new HashSet<>();
- for (long offset : rowGroupOffsets) {
-offsets.add(offset);
- }
- blocks = new ArrayList<>();
- for (BlockMetaData block : footer.getBlocks()) {
-if (offsets.contains(block.getStartingPos())) {
- blocks.add(block);
-}
- }
- // verify we found them all
- if (blocks.size() != rowGroupOffsets.length) {
-long[] foundRowGroupOffsets = new long[footer.getBlocks().size()];
-for (int i = 0; i < foundRowGroupOffsets.length; i++) {
- foundRowGroupOffsets[i] = footer.getBlocks().get(i).getStartingPos();
-}
-// this should never happen.
-// provide a good error message in case there's a bug
-throw new IllegalStateException(
-"All the offsets listed in the split should be found in the file."
-+ " expected: " + Arrays.toString(rowGroupOffsets)
-+ " found: " + blocks
-+ " out of: " + Arrays.toString(foundRowGroupOffsets)
-+ " in range " + split.getStart() + ", " + split.getEnd());
- }
-}
-this.fileSchema = footer.getFileMetaData().getSchema();
-Map fileMetadata =
footer.getFileMetaData().getKeyValueMetaData();
+ParquetReadOptions options = HadoopReadOptions
+ .builder(configuration)
+ .withRange(split.getStart(), split.getStart() + split.getLength())
Review comment:
I think build `ParquetReadOptions` should add
`.withRecordFilter(ParquetInputFormat.getFilter(configuration))` to ensure that
the filter is pushed down because `recordFilter` is obtained from
`ParquetReadOptions` in `ParquetFileReader#filterRowGroups` method in Parquet
1.11.
1.11.1:
https://github.com/apache/parquet-mr/blob/765bd5cd7fdef2af1cecd0755000694b992bfadd/parquet-hadoop/src/main/java/org/apache/parquet/hadoop/ParquetFileReader.java#L784-L802
This logic is different from the master code of Apache Parquet:
https://github.com/apache/parquet-mr/blob/ab402f84e956d17ab67b63f91d01c63a92e7ae1e/parquet-hadoop/src/main/java/org/apache/parquet/hadoop/ParquetFileReader.java#L853-L871
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
AngersZh commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r581689593
##
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+// These configurations related to driver when deploy like `spark.master`,
+// `spark.driver.memory`, this kind of properties may not be affected when
+// setting programmatically through SparkConf in runtime, or the behavior
is
+// depending on which cluster manager and deploy mode you choose, so it
would
+// be suggested to set through configuration file or spark-submit command
line options.
Review comment:
> @AngersZh, I would first document this explicitly and what happen
for each configuration before taking an action to show a warning. Also,
shouldn't we do this in `SparkContext` too?
How about we add a new section in
https://spark.apache.org/docs/latest/configuration.html to collect and show
configuration's usage scope.
Also we can add a `scope` tag in ConfigBuilder for these special
configuration.
Then in this pr, we can just check the config type and warn message.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #31316: [SPARK-33599][SQL][FOLLOWUP] Group exception messages in catalyst/analysis
cloud-fan closed pull request #31316: URL: https://github.com/apache/spark/pull/31316 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #31316: [SPARK-33599][SQL][FOLLOWUP] Group exception messages in catalyst/analysis
cloud-fan commented on pull request #31316: URL: https://github.com/apache/spark/pull/31316#issuecomment-784858388 thanks, merging to master! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31316: [SPARK-33599][SQL][FOLLOWUP] Group exception messages in catalyst/analysis
AmplabJenkins removed a comment on pull request #31316: URL: https://github.com/apache/spark/pull/31316#issuecomment-784857291 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135397/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31316: [SPARK-33599][SQL][FOLLOWUP] Group exception messages in catalyst/analysis
AmplabJenkins commented on pull request #31316: URL: https://github.com/apache/spark/pull/31316#issuecomment-784857291 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135397/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31316: [SPARK-33599][SQL][FOLLOWUP] Group exception messages in catalyst/analysis
SparkQA removed a comment on pull request #31316: URL: https://github.com/apache/spark/pull/31316#issuecomment-784710544 **[Test build #135397 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135397/testReport)** for PR 31316 at commit [`bf3e931`](https://github.com/apache/spark/commit/bf3e931ffd88badad402d16a876f70fa09b64b32). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31316: [SPARK-33599][SQL][FOLLOWUP] Group exception messages in catalyst/analysis
SparkQA commented on pull request #31316: URL: https://github.com/apache/spark/pull/31316#issuecomment-784856047 **[Test build #135397 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135397/testReport)** for PR 31316 at commit [`bf3e931`](https://github.com/apache/spark/commit/bf3e931ffd88badad402d16a876f70fa09b64b32). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31595: [SPARK-34474][SQL] Remove unnecessary Union under Distinct/Deduplicate
AmplabJenkins removed a comment on pull request #31595: URL: https://github.com/apache/spark/pull/31595#issuecomment-784855083 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135404/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31624: [SPARK-34392][SQL] Support ZoneOffset +h:mm in DateTimeUtils. getZoneId
AmplabJenkins removed a comment on pull request #31624: URL: https://github.com/apache/spark/pull/31624#issuecomment-784854517 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135399/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
AmplabJenkins removed a comment on pull request #31632: URL: https://github.com/apache/spark/pull/31632#issuecomment-784854520 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39987/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31595: [SPARK-34474][SQL] Remove unnecessary Union under Distinct/Deduplicate
SparkQA removed a comment on pull request #31595: URL: https://github.com/apache/spark/pull/31595#issuecomment-784758841 **[Test build #135404 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135404/testReport)** for PR 31595 at commit [`9cf1f2b`](https://github.com/apache/spark/commit/9cf1f2b25828dfef12bdcfd5721675ac97928379). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31595: [SPARK-34474][SQL] Remove unnecessary Union under Distinct/Deduplicate
AmplabJenkins commented on pull request #31595: URL: https://github.com/apache/spark/pull/31595#issuecomment-784855083 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135404/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
AmplabJenkins commented on pull request #31632: URL: https://github.com/apache/spark/pull/31632#issuecomment-784854520 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39987/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31624: [SPARK-34392][SQL] Support ZoneOffset +h:mm in DateTimeUtils. getZoneId
AmplabJenkins commented on pull request #31624: URL: https://github.com/apache/spark/pull/31624#issuecomment-784854517 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135399/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31595: [SPARK-34474][SQL] Remove unnecessary Union under Distinct/Deduplicate
SparkQA commented on pull request #31595: URL: https://github.com/apache/spark/pull/31595#issuecomment-784854249 **[Test build #135404 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135404/testReport)** for PR 31595 at commit [`9cf1f2b`](https://github.com/apache/spark/commit/9cf1f2b25828dfef12bdcfd5721675ac97928379). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on a change in pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
ulysses-you commented on a change in pull request #31632:
URL: https://github.com/apache/spark/pull/31632#discussion_r581682495
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##
@@ -769,7 +769,8 @@ private[client] class Shim_v0_13 extends Shim_v0_12 {
case InSet(child, values) if useAdvanced && values.size > inSetThreshold
=>
val dataType = child.dataType
-val sortedValues =
values.toSeq.sorted(TypeUtils.getInterpretedOrdering(dataType))
+val sortedValues = values.filter(_ != null).toSeq
Review comment:
looks better
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on a change in pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
ulysses-you commented on a change in pull request #31632:
URL: https://github.com/apache/spark/pull/31632#discussion_r581682271
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##
@@ -769,7 +769,8 @@ private[client] class Shim_v0_13 extends Shim_v0_12 {
case InSet(child, values) if useAdvanced && values.size > inSetThreshold
=>
val dataType = child.dataType
-val sortedValues =
values.toSeq.sorted(TypeUtils.getInterpretedOrdering(dataType))
+val sortedValues = values.filter(_ != null).toSeq
+ .sorted(TypeUtils.getInterpretedOrdering(dataType))
Review comment:
It's safe, since `In` has already do this.
https://github.com/apache/spark/blob/714ff73d4aec317fddf32720d5a7a1c283921983/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala#L666-L684
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] c21 commented on a change in pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
c21 commented on a change in pull request #31632:
URL: https://github.com/apache/spark/pull/31632#discussion_r581682146
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##
@@ -769,7 +769,8 @@ private[client] class Shim_v0_13 extends Shim_v0_12 {
case InSet(child, values) if useAdvanced && values.size > inSetThreshold
=>
val dataType = child.dataType
-val sortedValues =
values.toSeq.sorted(TypeUtils.getInterpretedOrdering(dataType))
+val sortedValues = values.filter(_ != null).toSeq
Review comment:
Shall we add a similar comment for why this is safe, similar to `IN` -
https://github.com/apache/spark/pull/21832 ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31624: [SPARK-34392][SQL] Support ZoneOffset +h:mm in DateTimeUtils. getZoneId
SparkQA removed a comment on pull request #31624: URL: https://github.com/apache/spark/pull/31624#issuecomment-784730124 **[Test build #135399 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135399/testReport)** for PR 31624 at commit [`8b167b3`](https://github.com/apache/spark/commit/8b167b3aa4a762a5833ac0d4d37c5e508ff5815a). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
cloud-fan commented on a change in pull request #31632:
URL: https://github.com/apache/spark/pull/31632#discussion_r581681224
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##
@@ -769,7 +769,8 @@ private[client] class Shim_v0_13 extends Shim_v0_12 {
case InSet(child, values) if useAdvanced && values.size > inSetThreshold
=>
val dataType = child.dataType
-val sortedValues =
values.toSeq.sorted(TypeUtils.getInterpretedOrdering(dataType))
+val sortedValues = values.filter(_ != null).toSeq
+ .sorted(TypeUtils.getInterpretedOrdering(dataType))
Review comment:
same question here. The null sematic of IN is pretty tricky.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31624: [SPARK-34392][SQL] Support ZoneOffset +h:mm in DateTimeUtils. getZoneId
SparkQA commented on pull request #31624: URL: https://github.com/apache/spark/pull/31624#issuecomment-784847726 **[Test build #135399 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135399/testReport)** for PR 31624 at commit [`8b167b3`](https://github.com/apache/spark/commit/8b167b3aa4a762a5833ac0d4d37c5e508ff5815a). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
viirya commented on a change in pull request #31632:
URL: https://github.com/apache/spark/pull/31632#discussion_r581679091
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##
@@ -769,7 +769,8 @@ private[client] class Shim_v0_13 extends Shim_v0_12 {
case InSet(child, values) if useAdvanced && values.size > inSetThreshold
=>
val dataType = child.dataType
-val sortedValues =
values.toSeq.sorted(TypeUtils.getInterpretedOrdering(dataType))
+val sortedValues = values.filter(_ != null).toSeq
+ .sorted(TypeUtils.getInterpretedOrdering(dataType))
Review comment:
Will this change the result of `InSet` which contains null?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31499: [SPARK-31891][SQL] Support `MSCK REPAIR TABLE .. [{ADD|DROP|SYNC} PARTITIONS]`
cloud-fan commented on a change in pull request #31499:
URL: https://github.com/apache/spark/pull/31499#discussion_r581672432
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/MsckRepairTableSuite.scala
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.command.v1
+
+import java.io.File
+
+import org.apache.commons.io.FileUtils
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.execution.command
+
+/**
+ * This base suite contains unified tests for the `MSCK REPAIR TABLE` command
that
+ * check V1 table catalogs. The tests that cannot run for all V1 catalogs are
located in more
+ * specific test suites:
+ *
+ * - V1 In-Memory catalog:
+ * `org.apache.spark.sql.execution.command.v1.MsckRepairTableSuite`
+ * - V1 Hive External catalog:
+ * `org.apache.spark.sql.hive.execution.command.MsckRepairTableSuite`
+ */
+trait MsckRepairTableSuiteBase extends command.MsckRepairTableSuiteBase {
+ def deletePartitionDir(tableName: String, part: String): Unit = {
+val partLoc = getPartitionLocation(tableName, part)
+FileUtils.deleteDirectory(new File(partLoc))
+ }
+
+ test("drop partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(spark.table(t), Seq(Row(0, 0), Row(1, 1)))
+ deletePartitionDir(t, "part=1")
+ sql(s"MSCK REPAIR TABLE $t DROP PARTITIONS")
+ checkPartitions(t, Map("part" -> "0"))
+ checkAnswer(spark.table(t), Seq(Row(0, 0)))
+}
+ }
+
+ test("sync partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(0, 0), Row(1, 1)))
+ copyPartition(t, "part=0", "part=2")
+ deletePartitionDir(t, "part=0")
+ sql(s"MSCK REPAIR TABLE $t SYNC PARTITIONS")
+ checkPartitions(t, Map("part" -> "1"), Map("part" -> "2"))
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(1, 1), Row(0, 2)))
+}
+ }
Review comment:
no need to
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #31273: [SPARK-34152][SQL] Make CreateViewStatement.child to be LogicalPlan's children so that it's resolved in analyze phase
cloud-fan closed pull request #31273: URL: https://github.com/apache/spark/pull/31273 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #31273: [SPARK-34152][SQL] Make CreateViewStatement.child to be LogicalPlan's children so that it's resolved in analyze phase
cloud-fan commented on pull request #31273: URL: https://github.com/apache/spark/pull/31273#issuecomment-784835942 thanks, merging to master! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #31499: [SPARK-31891][SQL] Support `MSCK REPAIR TABLE .. [{ADD|DROP|SYNC} PARTITIONS]`
MaxGekk commented on a change in pull request #31499:
URL: https://github.com/apache/spark/pull/31499#discussion_r581671180
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/MsckRepairTableSuite.scala
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.command.v1
+
+import java.io.File
+
+import org.apache.commons.io.FileUtils
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.execution.command
+
+/**
+ * This base suite contains unified tests for the `MSCK REPAIR TABLE` command
that
+ * check V1 table catalogs. The tests that cannot run for all V1 catalogs are
located in more
+ * specific test suites:
+ *
+ * - V1 In-Memory catalog:
+ * `org.apache.spark.sql.execution.command.v1.MsckRepairTableSuite`
+ * - V1 Hive External catalog:
+ * `org.apache.spark.sql.hive.execution.command.MsckRepairTableSuite`
+ */
+trait MsckRepairTableSuiteBase extends command.MsckRepairTableSuiteBase {
+ def deletePartitionDir(tableName: String, part: String): Unit = {
+val partLoc = getPartitionLocation(tableName, part)
+FileUtils.deleteDirectory(new File(partLoc))
+ }
+
+ test("drop partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(spark.table(t), Seq(Row(0, 0), Row(1, 1)))
+ deletePartitionDir(t, "part=1")
+ sql(s"MSCK REPAIR TABLE $t DROP PARTITIONS")
+ checkPartitions(t, Map("part" -> "0"))
+ checkAnswer(spark.table(t), Seq(Row(0, 0)))
+}
+ }
+
+ test("sync partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(0, 0), Row(1, 1)))
+ copyPartition(t, "part=0", "part=2")
+ deletePartitionDir(t, "part=0")
+ sql(s"MSCK REPAIR TABLE $t SYNC PARTITIONS")
+ checkPartitions(t, Map("part" -> "1"), Map("part" -> "2"))
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(1, 1), Row(0, 2)))
+}
+ }
Review comment:
@cloud-fan If you would like to test `MSCK REPAIR TABLE .. ADD
PARTITIONS` explicitly, we could mix the
`v1.AlterTableRecoverPartitionsSuiteBase` to `MsckRepairTableSuiteBase` to run
the existing tests automatically.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #31499: [SPARK-31891][SQL] Support `MSCK REPAIR TABLE .. [{ADD|DROP|SYNC} PARTITIONS]`
MaxGekk commented on a change in pull request #31499:
URL: https://github.com/apache/spark/pull/31499#discussion_r581671180
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/MsckRepairTableSuite.scala
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.command.v1
+
+import java.io.File
+
+import org.apache.commons.io.FileUtils
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.execution.command
+
+/**
+ * This base suite contains unified tests for the `MSCK REPAIR TABLE` command
that
+ * check V1 table catalogs. The tests that cannot run for all V1 catalogs are
located in more
+ * specific test suites:
+ *
+ * - V1 In-Memory catalog:
+ * `org.apache.spark.sql.execution.command.v1.MsckRepairTableSuite`
+ * - V1 Hive External catalog:
+ * `org.apache.spark.sql.hive.execution.command.MsckRepairTableSuite`
+ */
+trait MsckRepairTableSuiteBase extends command.MsckRepairTableSuiteBase {
+ def deletePartitionDir(tableName: String, part: String): Unit = {
+val partLoc = getPartitionLocation(tableName, part)
+FileUtils.deleteDirectory(new File(partLoc))
+ }
+
+ test("drop partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(spark.table(t), Seq(Row(0, 0), Row(1, 1)))
+ deletePartitionDir(t, "part=1")
+ sql(s"MSCK REPAIR TABLE $t DROP PARTITIONS")
+ checkPartitions(t, Map("part" -> "0"))
+ checkAnswer(spark.table(t), Seq(Row(0, 0)))
+}
+ }
+
+ test("sync partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(0, 0), Row(1, 1)))
+ copyPartition(t, "part=0", "part=2")
+ deletePartitionDir(t, "part=0")
+ sql(s"MSCK REPAIR TABLE $t SYNC PARTITIONS")
+ checkPartitions(t, Map("part" -> "1"), Map("part" -> "2"))
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(1, 1), Row(0, 2)))
+}
+ }
Review comment:
@cloud-fan If you would like to `MSCK REPAIR TABLE .. ADD PARTITIONS`,
we could mix the `v1.AlterTableRecoverPartitionsSuiteBase` to
`MsckRepairTableSuiteBase` to run the existing tests automatically.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
ulysses-you commented on pull request #31632: URL: https://github.com/apache/spark/pull/31632#issuecomment-784834915 @maropu yes, it affects the branch-3.1, since the feature `spark.sql.hive.metastorePartitionPruningInSetThreshold` lands at Spark 3.1.0. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31499: [SPARK-31891][SQL] Support `MSCK REPAIR TABLE .. [{ADD|DROP|SYNC} PARTITIONS]`
cloud-fan commented on a change in pull request #31499:
URL: https://github.com/apache/spark/pull/31499#discussion_r581670571
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/MsckRepairTableSuite.scala
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.command.v1
+
+import java.io.File
+
+import org.apache.commons.io.FileUtils
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.execution.command
+
+/**
+ * This base suite contains unified tests for the `MSCK REPAIR TABLE` command
that
+ * check V1 table catalogs. The tests that cannot run for all V1 catalogs are
located in more
+ * specific test suites:
+ *
+ * - V1 In-Memory catalog:
+ * `org.apache.spark.sql.execution.command.v1.MsckRepairTableSuite`
+ * - V1 Hive External catalog:
+ * `org.apache.spark.sql.hive.execution.command.MsckRepairTableSuite`
+ */
+trait MsckRepairTableSuiteBase extends command.MsckRepairTableSuiteBase {
+ def deletePartitionDir(tableName: String, part: String): Unit = {
+val partLoc = getPartitionLocation(tableName, part)
+FileUtils.deleteDirectory(new File(partLoc))
+ }
+
+ test("drop partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(spark.table(t), Seq(Row(0, 0), Row(1, 1)))
+ deletePartitionDir(t, "part=1")
+ sql(s"MSCK REPAIR TABLE $t DROP PARTITIONS")
+ checkPartitions(t, Map("part" -> "0"))
+ checkAnswer(spark.table(t), Seq(Row(0, 0)))
+}
+ }
+
+ test("sync partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(0, 0), Row(1, 1)))
+ copyPartition(t, "part=0", "part=2")
+ deletePartitionDir(t, "part=0")
+ sql(s"MSCK REPAIR TABLE $t SYNC PARTITIONS")
+ checkPartitions(t, Map("part" -> "1"), Map("part" -> "2"))
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(1, 1), Row(0, 2)))
+}
+ }
Review comment:
I see
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
SparkQA commented on pull request #31632: URL: https://github.com/apache/spark/pull/31632#issuecomment-784833117 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39987/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] c21 commented on a change in pull request #31630: [SPARK-34514][SQL] Push down limit for LEFT SEMI and LEFT ANTI join
c21 commented on a change in pull request #31630:
URL: https://github.com/apache/spark/pull/31630#discussion_r581668995
##
File path: sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
##
@@ -4034,6 +4034,36 @@ class SQLQuerySuite extends QueryTest with
SharedSparkSession with AdaptiveSpark
checkAnswer(df, Row(0, 0) :: Row(0, 1) :: Row(0, 2) :: Nil)
}
}
+
+ test("SPARK-34514: Push down limit through LEFT SEMI and LEFT ANTI join") {
+withTable("left_table", "nonempty_right_table", "empty_right_table") {
+ spark.range(5).toDF().repartition(1).write.saveAsTable("left_table")
+ spark.range(3).write.saveAsTable("nonempty_right_table")
+ spark.range(0).write.saveAsTable("empty_right_table")
+ Seq("LEFT SEMI").foreach { joinType =>
Review comment:
@cloud-fan - good catch, I was accidentally removing it during
debugging, fixed.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31631: [SPARK-33504][CORE][3.0] The application log in the Spark history server contains sensitive attributes should be redacted
AmplabJenkins removed a comment on pull request #31631: URL: https://github.com/apache/spark/pull/31631#issuecomment-784830019 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39986/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31631: [SPARK-33504][CORE][3.0] The application log in the Spark history server contains sensitive attributes should be redacted
SparkQA commented on pull request #31631: URL: https://github.com/apache/spark/pull/31631#issuecomment-784829995 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39986/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31631: [SPARK-33504][CORE][3.0] The application log in the Spark history server contains sensitive attributes should be redacted
AmplabJenkins commented on pull request #31631: URL: https://github.com/apache/spark/pull/31631#issuecomment-784830019 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39986/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #31499: [SPARK-31891][SQL] Support `MSCK REPAIR TABLE .. [{ADD|DROP|SYNC} PARTITIONS]`
MaxGekk commented on a change in pull request #31499:
URL: https://github.com/apache/spark/pull/31499#discussion_r58189
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/MsckRepairTableSuite.scala
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.command.v1
+
+import java.io.File
+
+import org.apache.commons.io.FileUtils
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.execution.command
+
+/**
+ * This base suite contains unified tests for the `MSCK REPAIR TABLE` command
that
+ * check V1 table catalogs. The tests that cannot run for all V1 catalogs are
located in more
+ * specific test suites:
+ *
+ * - V1 In-Memory catalog:
+ * `org.apache.spark.sql.execution.command.v1.MsckRepairTableSuite`
+ * - V1 Hive External catalog:
+ * `org.apache.spark.sql.hive.execution.command.MsckRepairTableSuite`
+ */
+trait MsckRepairTableSuiteBase extends command.MsckRepairTableSuiteBase {
+ def deletePartitionDir(tableName: String, part: String): Unit = {
+val partLoc = getPartitionLocation(tableName, part)
+FileUtils.deleteDirectory(new File(partLoc))
+ }
+
+ test("drop partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(spark.table(t), Seq(Row(0, 0), Row(1, 1)))
+ deletePartitionDir(t, "part=1")
+ sql(s"MSCK REPAIR TABLE $t DROP PARTITIONS")
+ checkPartitions(t, Map("part" -> "0"))
+ checkAnswer(spark.table(t), Seq(Row(0, 0)))
+}
+ }
+
+ test("sync partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(0, 0), Row(1, 1)))
+ copyPartition(t, "part=0", "part=2")
+ deletePartitionDir(t, "part=0")
+ sql(s"MSCK REPAIR TABLE $t SYNC PARTITIONS")
+ checkPartitions(t, Map("part" -> "1"), Map("part" -> "2"))
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(1, 1), Row(0, 2)))
+}
+ }
Review comment:
We already have many tests for ADD in `AlterTableRecoverPartitionsSuite`
since `ALTER TABLE .. RECOVER PARTITIONS` is equal to `MSCK REPAIR TABLE .. ADD
PARTITIONS` semantically.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yeshengm closed pull request #31542: [SPARK-34414][SQL] OptimizeMetadataOnlyQuery should only apply for deterministic filters
yeshengm closed pull request #31542: URL: https://github.com/apache/spark/pull/31542 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #31499: [SPARK-31891][SQL] Support `MSCK REPAIR TABLE .. [{ADD|DROP|SYNC} PARTITIONS]`
MaxGekk commented on a change in pull request #31499:
URL: https://github.com/apache/spark/pull/31499#discussion_r58189
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/MsckRepairTableSuite.scala
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.command.v1
+
+import java.io.File
+
+import org.apache.commons.io.FileUtils
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.execution.command
+
+/**
+ * This base suite contains unified tests for the `MSCK REPAIR TABLE` command
that
+ * check V1 table catalogs. The tests that cannot run for all V1 catalogs are
located in more
+ * specific test suites:
+ *
+ * - V1 In-Memory catalog:
+ * `org.apache.spark.sql.execution.command.v1.MsckRepairTableSuite`
+ * - V1 Hive External catalog:
+ * `org.apache.spark.sql.hive.execution.command.MsckRepairTableSuite`
+ */
+trait MsckRepairTableSuiteBase extends command.MsckRepairTableSuiteBase {
+ def deletePartitionDir(tableName: String, part: String): Unit = {
+val partLoc = getPartitionLocation(tableName, part)
+FileUtils.deleteDirectory(new File(partLoc))
+ }
+
+ test("drop partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(spark.table(t), Seq(Row(0, 0), Row(1, 1)))
+ deletePartitionDir(t, "part=1")
+ sql(s"MSCK REPAIR TABLE $t DROP PARTITIONS")
+ checkPartitions(t, Map("part" -> "0"))
+ checkAnswer(spark.table(t), Seq(Row(0, 0)))
+}
+ }
+
+ test("sync partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(0, 0), Row(1, 1)))
+ copyPartition(t, "part=0", "part=2")
+ deletePartitionDir(t, "part=0")
+ sql(s"MSCK REPAIR TABLE $t SYNC PARTITIONS")
+ checkPartitions(t, Map("part" -> "1"), Map("part" -> "2"))
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(1, 1), Row(0, 2)))
+}
+ }
Review comment:
We already have many tests for ADD in `AlterTableRecoverPartitionsSuite`
since `ALTER TABLE .. RECOVER PARTITIONS` maps to `MSCK REPAIR TABLE .. ADD
PARTITIONS`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31273: [SPARK-34152][SQL] Make CreateViewStatement.child to be LogicalPlan's children so that it's resolved in analyze phase
AmplabJenkins removed a comment on pull request #31273: URL: https://github.com/apache/spark/pull/31273#issuecomment-784823052 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135392/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31273: [SPARK-34152][SQL] Make CreateViewStatement.child to be LogicalPlan's children so that it's resolved in analyze phase
AmplabJenkins commented on pull request #31273: URL: https://github.com/apache/spark/pull/31273#issuecomment-784823052 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135392/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31273: [SPARK-34152][SQL] Make CreateViewStatement.child to be LogicalPlan's children so that it's resolved in analyze phase
SparkQA removed a comment on pull request #31273: URL: https://github.com/apache/spark/pull/31273#issuecomment-784671202 **[Test build #135392 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135392/testReport)** for PR 31273 at commit [`84d817c`](https://github.com/apache/spark/commit/84d817cdd11a33798bd1f4088b9e7e016b4ec74b). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31273: [SPARK-34152][SQL] Make CreateViewStatement.child to be LogicalPlan's children so that it's resolved in analyze phase
SparkQA commented on pull request #31273: URL: https://github.com/apache/spark/pull/31273#issuecomment-784821826 **[Test build #135392 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135392/testReport)** for PR 31273 at commit [`84d817c`](https://github.com/apache/spark/commit/84d817cdd11a33798bd1f4088b9e7e016b4ec74b). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31595: [SPARK-34474][SQL] Remove unnecessary Union under Distinct/Deduplicate
AmplabJenkins removed a comment on pull request #31595: URL: https://github.com/apache/spark/pull/31595#issuecomment-784821271 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39984/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31623: [SPARK-34506][CORE] ADD JAR with ivy coordinates should be compatible with Hive transitive behavior
AmplabJenkins removed a comment on pull request #31623: URL: https://github.com/apache/spark/pull/31623#issuecomment-784821269 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135400/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31630: [SPARK-34514][SQL] Push down limit for LEFT SEMI and LEFT ANTI join
AmplabJenkins removed a comment on pull request #31630: URL: https://github.com/apache/spark/pull/31630#issuecomment-784821268 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39982/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31273: [SPARK-34152][SQL] Make CreateViewStatement.child to be LogicalPlan's children so that it's resolved in analyze phase
AmplabJenkins removed a comment on pull request #31273: URL: https://github.com/apache/spark/pull/31273#issuecomment-784821270 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39985/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31349: [SPARK-34246][SQL] New type coercion syntax rules in ANSI mode
AmplabJenkins removed a comment on pull request #31349: URL: https://github.com/apache/spark/pull/31349#issuecomment-784821265 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39983/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31349: [SPARK-34246][SQL] New type coercion syntax rules in ANSI mode
AmplabJenkins commented on pull request #31349: URL: https://github.com/apache/spark/pull/31349#issuecomment-784821265 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39983/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31595: [SPARK-34474][SQL] Remove unnecessary Union under Distinct/Deduplicate
AmplabJenkins commented on pull request #31595: URL: https://github.com/apache/spark/pull/31595#issuecomment-784821271 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39984/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31623: [SPARK-34506][CORE] ADD JAR with ivy coordinates should be compatible with Hive transitive behavior
AmplabJenkins commented on pull request #31623: URL: https://github.com/apache/spark/pull/31623#issuecomment-784821269 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135400/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31630: [SPARK-34514][SQL] Push down limit for LEFT SEMI and LEFT ANTI join
AmplabJenkins commented on pull request #31630: URL: https://github.com/apache/spark/pull/31630#issuecomment-784821268 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39982/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31273: [SPARK-34152][SQL] Make CreateViewStatement.child to be LogicalPlan's children so that it's resolved in analyze phase
AmplabJenkins commented on pull request #31273: URL: https://github.com/apache/spark/pull/31273#issuecomment-784821270 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39985/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31631: [SPARK-33504][CORE][3.0] The application log in the Spark history server contains sensitive attributes should be redacted
SparkQA commented on pull request #31631: URL: https://github.com/apache/spark/pull/31631#issuecomment-784820379 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39986/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
maropu commented on pull request #31632: URL: https://github.com/apache/spark/pull/31632#issuecomment-784818918 Can this issue happen in branch-3.1, too? I saw `Affects Version/s: 3.2.0` in the jira though. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #29542: [SPARK-32703][SQL] Replace deprecated API calls from SpecificParquetRecordReaderBase
dongjoon-hyun commented on pull request #29542: URL: https://github.com/apache/spark/pull/29542#issuecomment-784816521 Thank you for reporting and reverting, @maropu and @HyukjinKwon . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
SparkQA commented on pull request #31632: URL: https://github.com/apache/spark/pull/31632#issuecomment-784816395 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39987/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31623: [SPARK-34506][CORE] ADD JAR with ivy coordinates should be compatible with Hive transitive behavior
SparkQA removed a comment on pull request #31623: URL: https://github.com/apache/spark/pull/31623#issuecomment-784723103 **[Test build #135400 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135400/testReport)** for PR 31623 at commit [`c63b605`](https://github.com/apache/spark/commit/c63b605ac65bd74c6647bf59b261e6412982e1e2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31623: [SPARK-34506][CORE] ADD JAR with ivy coordinates should be compatible with Hive transitive behavior
SparkQA commented on pull request #31623: URL: https://github.com/apache/spark/pull/31623#issuecomment-784814542 **[Test build #135400 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135400/testReport)** for PR 31623 at commit [`c63b605`](https://github.com/apache/spark/commit/c63b605ac65bd74c6647bf59b261e6412982e1e2). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31622: [SPARK-34497][SQL] Fix built-in JDBC connection providers to restore JVM security context changes
maropu commented on a change in pull request #31622:
URL: https://github.com/apache/spark/pull/31622#discussion_r581657146
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/connection/DB2ConnectionProvider.scala
##
@@ -34,15 +35,22 @@ private[sql] class DB2ConnectionProvider extends
SecureConnectionProvider {
override def getConnection(driver: Driver, options: Map[String, String]):
Connection = {
val jdbcOptions = new JDBCOptions(options)
-setAuthenticationConfigIfNeeded(driver, jdbcOptions)
-
UserGroupInformation.loginUserFromKeytabAndReturnUGI(jdbcOptions.principal,
jdbcOptions.keytab)
- .doAs(
-new PrivilegedExceptionAction[Connection]() {
- override def run(): Connection = {
-DB2ConnectionProvider.super.getConnection(driver, options)
+val parent = Configuration.getConfiguration
+try {
+ setAuthenticationConfig(parent, driver, jdbcOptions)
+
UserGroupInformation.loginUserFromKeytabAndReturnUGI(jdbcOptions.principal,
+jdbcOptions.keytab)
+.doAs(
+ new PrivilegedExceptionAction[Connection]() {
+override def run(): Connection = {
+ DB2ConnectionProvider.super.getConnection(driver, options)
+}
}
-}
- )
+)
+} finally {
+ logDebug("Restoring original security configuration")
+ Configuration.setConfiguration(parent)
+}
Review comment:
It looks like this is a boilerplate code, so could we handle this
outside `getConnection`? IIUC, in the current approach, 3rd-party developers
need to write the same code in a user-defined provider overriding
`ConnectionProvider. getConnection`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31273: [SPARK-34152][SQL] Make CreateViewStatement.child to be LogicalPlan's children so that it's resolved in analyze phase
SparkQA commented on pull request #31273: URL: https://github.com/apache/spark/pull/31273#issuecomment-784809732 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39985/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31630: [SPARK-34514][SQL] Push down limit for LEFT SEMI and LEFT ANTI join
SparkQA commented on pull request #31630: URL: https://github.com/apache/spark/pull/31630#issuecomment-784807029 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39982/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31595: [SPARK-34474][SQL] Remove unnecessary Union under Distinct/Deduplicate
SparkQA commented on pull request #31595: URL: https://github.com/apache/spark/pull/31595#issuecomment-784806758 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39984/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #31499: [SPARK-31891][SQL] Support `MSCK REPAIR TABLE .. [{ADD|DROP|SYNC} PARTITIONS]`
cloud-fan commented on pull request #31499: URL: https://github.com/apache/spark/pull/31499#issuecomment-784805608 late LGTM This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31499: [SPARK-31891][SQL] Support `MSCK REPAIR TABLE .. [{ADD|DROP|SYNC} PARTITIONS]`
cloud-fan commented on a change in pull request #31499:
URL: https://github.com/apache/spark/pull/31499#discussion_r581647130
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/command/v1/MsckRepairTableSuite.scala
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.command.v1
+
+import java.io.File
+
+import org.apache.commons.io.FileUtils
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.execution.command
+
+/**
+ * This base suite contains unified tests for the `MSCK REPAIR TABLE` command
that
+ * check V1 table catalogs. The tests that cannot run for all V1 catalogs are
located in more
+ * specific test suites:
+ *
+ * - V1 In-Memory catalog:
+ * `org.apache.spark.sql.execution.command.v1.MsckRepairTableSuite`
+ * - V1 Hive External catalog:
+ * `org.apache.spark.sql.hive.execution.command.MsckRepairTableSuite`
+ */
+trait MsckRepairTableSuiteBase extends command.MsckRepairTableSuiteBase {
+ def deletePartitionDir(tableName: String, part: String): Unit = {
+val partLoc = getPartitionLocation(tableName, part)
+FileUtils.deleteDirectory(new File(partLoc))
+ }
+
+ test("drop partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(spark.table(t), Seq(Row(0, 0), Row(1, 1)))
+ deletePartitionDir(t, "part=1")
+ sql(s"MSCK REPAIR TABLE $t DROP PARTITIONS")
+ checkPartitions(t, Map("part" -> "0"))
+ checkAnswer(spark.table(t), Seq(Row(0, 0)))
+}
+ }
+
+ test("sync partitions") {
+withNamespaceAndTable("ns", "tbl") { t =>
+ sql(s"CREATE TABLE $t (col INT, part INT) $defaultUsing PARTITIONED BY
(part)")
+ sql(s"INSERT INTO $t PARTITION (part=0) SELECT 0")
+ sql(s"INSERT INTO $t PARTITION (part=1) SELECT 1")
+
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(0, 0), Row(1, 1)))
+ copyPartition(t, "part=0", "part=2")
+ deletePartitionDir(t, "part=0")
+ sql(s"MSCK REPAIR TABLE $t SYNC PARTITIONS")
+ checkPartitions(t, Map("part" -> "1"), Map("part" -> "2"))
+ checkAnswer(sql(s"SELECT col, part FROM $t"), Seq(Row(1, 1), Row(0, 2)))
+}
+ }
Review comment:
shall we test ADD?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31499: [SPARK-31891][SQL] Support `MSCK REPAIR TABLE .. [{ADD|DROP|SYNC} PARTITIONS]`
cloud-fan commented on a change in pull request #31499:
URL: https://github.com/apache/spark/pull/31499#discussion_r581644177
##
File path: docs/sql-ref-syntax-ddl-repair-table.md
##
@@ -39,6 +39,13 @@ MSCK REPAIR TABLE table_identifier
**Syntax:** `[ database_name. ] table_name`
+* **`{ADD|DROP|SYNC} PARTITIONS`**
+
+* If specified, `MSCK REPAIR TABLE` only adds partitions to the session
catalog.
Review comment:
I think it's better to put it in the end, and say `If not specified, ADD
is the default.`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31499: [SPARK-31891][SQL] Support `MSCK REPAIR TABLE .. [{ADD|DROP|SYNC} PARTITIONS]`
cloud-fan commented on a change in pull request #31499:
URL: https://github.com/apache/spark/pull/31499#discussion_r581644015
##
File path: docs/sql-ref-syntax-ddl-repair-table.md
##
@@ -39,6 +39,13 @@ MSCK REPAIR TABLE table_identifier
**Syntax:** `[ database_name. ] table_name`
+* **`{ADD|DROP|SYNC} PARTITIONS`**
+
+* If specified, `MSCK REPAIR TABLE` only adds partitions to the session
catalog.
Review comment:
typo: should be `If not specified`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
SparkQA commented on pull request #31632: URL: https://github.com/apache/spark/pull/31632#issuecomment-784799757 **[Test build #135407 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135407/testReport)** for PR 31632 at commit [`662714b`](https://github.com/apache/spark/commit/662714b83f3cefab08d9d5ad7e65a41943a70197). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r581643234
##
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+// These configurations related to driver when deploy like `spark.master`,
+// `spark.driver.memory`, this kind of properties may not be affected when
+// setting programmatically through SparkConf in runtime, or the behavior
is
+// depending on which cluster manager and deploy mode you choose, so it
would
+// be suggested to set through configuration file or spark-submit command
line options.
Review comment:
We can document first, and then link the documentation URL in the
warning message.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r581642779
##
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+// These configurations related to driver when deploy like `spark.master`,
+// `spark.driver.memory`, this kind of properties may not be affected when
+// setting programmatically through SparkConf in runtime, or the behavior
is
+// depending on which cluster manager and deploy mode you choose, so it
would
+// be suggested to set through configuration file or spark-submit command
line options.
Review comment:
@AngersZh, I would first document this explicitly and what happen
for each configuration before taking an action to show a warning. Also,
shouldn't we do this in `SparkContext` too?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r581642779
##
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+// These configurations related to driver when deploy like `spark.master`,
+// `spark.driver.memory`, this kind of properties may not be affected when
+// setting programmatically through SparkConf in runtime, or the behavior
is
+// depending on which cluster manager and deploy mode you choose, so it
would
+// be suggested to set through configuration file or spark-submit command
line options.
Review comment:
@AngersZh, I would first document this explicitly and what happen
for each configuration before taking an action to show a warning. Also,
shouldn't we do this in `SparkContext`?
##
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+// These configurations related to driver when deploy like `spark.master`,
Review comment:
`spark.master` seems not here?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31273: [SPARK-34152][SQL] Make CreateViewStatement.child to be LogicalPlan's children so that it's resolved in analyze phase
SparkQA commented on pull request #31273: URL: https://github.com/apache/spark/pull/31273#issuecomment-784798564 **[Test build #135406 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135406/testReport)** for PR 31273 at commit [`82d58ba`](https://github.com/apache/spark/commit/82d58baa98235f912141b2b40cdcd3bf0bdbe744). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31631: [SPARK-33504][CORE][3.0] The application log in the Spark history server contains sensitive attributes should be redacted
SparkQA commented on pull request #31631: URL: https://github.com/apache/spark/pull/31631#issuecomment-784797818 **[Test build #135405 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135405/testReport)** for PR 31631 at commit [`23bf3fe`](https://github.com/apache/spark/commit/23bf3fec5b9d2329d017661029381f73ffe6). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang closed pull request #31349: [SPARK-34246][SQL] New type coercion syntax rules in ANSI mode
gengliangwang closed pull request #31349: URL: https://github.com/apache/spark/pull/31349 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31623: [SPARK-34506][CORE] ADD JAR with ivy coordinates should be compatible with Hive transitive behavior
AmplabJenkins removed a comment on pull request #31623: URL: https://github.com/apache/spark/pull/31623#issuecomment-784794538 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39980/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on pull request #31349: [SPARK-34246][SQL] New type coercion syntax rules in ANSI mode
gengliangwang commented on pull request #31349: URL: https://github.com/apache/spark/pull/31349#issuecomment-784794922 GA passes. Merging to master. @maropu @cloud-fan thank you so much for the review! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31623: [SPARK-34506][CORE] ADD JAR with ivy coordinates should be compatible with Hive transitive behavior
AmplabJenkins commented on pull request #31623: URL: https://github.com/apache/spark/pull/31623#issuecomment-784794538 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39980/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31623: [SPARK-34506][CORE] ADD JAR with ivy coordinates should be compatible with Hive transitive behavior
SparkQA commented on pull request #31623: URL: https://github.com/apache/spark/pull/31623#issuecomment-784794518 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39980/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31273: [SPARK-34152][SQL] Make CreateViewStatement.child to be LogicalPlan's children so that it's resolved in analyze phase
SparkQA commented on pull request #31273: URL: https://github.com/apache/spark/pull/31273#issuecomment-784793000 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39985/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31630: [SPARK-34514][SQL] Push down limit for LEFT SEMI and LEFT ANTI join
AmplabJenkins removed a comment on pull request #31630: URL: https://github.com/apache/spark/pull/31630#issuecomment-784746638 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31630: [SPARK-34514][SQL] Push down limit for LEFT SEMI and LEFT ANTI join
SparkQA commented on pull request #31630: URL: https://github.com/apache/spark/pull/31630#issuecomment-784792491 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39982/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31595: [SPARK-34474][SQL] Remove unnecessary Union under Distinct/Deduplicate
SparkQA commented on pull request #31595: URL: https://github.com/apache/spark/pull/31595#issuecomment-784789271 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39984/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31563: [SPARK-34436][SQL] DPP support LIKE ANY/ALL expression
maropu commented on a change in pull request #31563:
URL: https://github.com/apache/spark/pull/31563#discussion_r581635353
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/DynamicPartitionPruningSuite.scala
##
@@ -1388,6 +1388,26 @@ abstract class DynamicPartitionPruningSuiteBase
checkAnswer(df, Nil)
}
}
+
+ test("SPARK-34436: DPP support LIKE ANY/ALL expression") {
+withSQLConf(SQLConf.DYNAMIC_PARTITION_PRUNING_ENABLED.key -> "true") {
+ val df = sql(
+"""
+ |SELECT date_id, product_id FROM fact_sk f
+ |JOIN dim_store s
+ |ON f.store_id = s.store_id WHERE s.country LIKE ANY ('%D%E%',
'%A%B%')
Review comment:
How about adding more tests for `LIKE ALL`, `NOT LIKE ANY`, and `NOT
LIKE ALL`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you opened a new pull request #31632: [SPARK-34515][SQL] Fix NPE if InSet contains null value during getPartitionsByFilter
ulysses-you opened a new pull request #31632: URL: https://github.com/apache/spark/pull/31632 ### What changes were proposed in this pull request? Skip null value during rewrite `InSet` to `>= and <=` at getPartitionsByFilter. ### Why are the changes needed? Spark will convert `InSet` to `>= and <=` if it's values size over `spark.sql.hive.metastorePartitionPruningInSetThreshold` during pruning partition . At this case, if values contain a null, we will get such exception ``` java.lang.NullPointerException at org.apache.spark.unsafe.types.UTF8String.compareTo(UTF8String.java:1389) at org.apache.spark.unsafe.types.UTF8String.compareTo(UTF8String.java:50) at scala.math.LowPriorityOrderingImplicits$$anon$3.compare(Ordering.scala:153) at java.util.TimSort.countRunAndMakeAscending(TimSort.java:355) at java.util.TimSort.sort(TimSort.java:220) at java.util.Arrays.sort(Arrays.java:1438) at scala.collection.SeqLike.sorted(SeqLike.scala:659) at scala.collection.SeqLike.sorted$(SeqLike.scala:647) at scala.collection.AbstractSeq.sorted(Seq.scala:45) at org.apache.spark.sql.hive.client.Shim_v0_13.convert$1(HiveShim.scala:772) at org.apache.spark.sql.hive.client.Shim_v0_13.$anonfun$convertFilters$4(HiveShim.scala:826) at scala.collection.immutable.Stream.flatMap(Stream.scala:489) at org.apache.spark.sql.hive.client.Shim_v0_13.convertFilters(HiveShim.scala:826) at org.apache.spark.sql.hive.client.Shim_v0_13.getPartitionsByFilter(HiveShim.scala:848) at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$getPartitionsByFilter$1(HiveClientImpl.scala:750) ``` ### Does this PR introduce _any_ user-facing change? Yes, bug fix. ### How was this patch tested? Add test. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31611: [SPARK-34488][CORE] Support task Metrics Distributions and executor Metrics Distributions in the REST API call for a specified
AmplabJenkins removed a comment on pull request #31611: URL: https://github.com/apache/spark/pull/31611#issuecomment-784781928 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135396/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31624: [SPARK-34392][SQL] Support ZoneOffset +h:mm in DateTimeUtils. getZoneId
AmplabJenkins removed a comment on pull request #31624: URL: https://github.com/apache/spark/pull/31624#issuecomment-784781933 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39979/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31611: [SPARK-34488][CORE] Support task Metrics Distributions and executor Metrics Distributions in the REST API call for a specified stage
AmplabJenkins commented on pull request #31611: URL: https://github.com/apache/spark/pull/31611#issuecomment-784781928 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135396/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31624: [SPARK-34392][SQL] Support ZoneOffset +h:mm in DateTimeUtils. getZoneId
AmplabJenkins commented on pull request #31624: URL: https://github.com/apache/spark/pull/31624#issuecomment-784781933 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39979/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #31605: [SPARK-34290][SQL] Support v2 `TRUNCATE TABLE`
cloud-fan closed pull request #31605: URL: https://github.com/apache/spark/pull/31605 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #31605: [SPARK-34290][SQL] Support v2 `TRUNCATE TABLE`
cloud-fan commented on pull request #31605: URL: https://github.com/apache/spark/pull/31605#issuecomment-784779429 thanks, merging to master! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31613: [SPARK-34476][SQL] Duplicate referenceNames are given for ambiguousReferences
cloud-fan commented on a change in pull request #31613: URL: https://github.com/apache/spark/pull/31613#discussion_r581633880 ## File path: sql/core/src/test/resources/sql-tests/results/postgreSQL/join.sql.out ## @@ -3225,7 +3225,7 @@ select * from struct<> -- !query output org.apache.spark.sql.AnalysisException -Reference 'f1' is ambiguous, could be: j.f1, j.f1.; line 2 pos 63 +Reference 'f1' is ambiguous, could be: j.f1#x, j.f1#x.; line 2 pos 63 Review comment: It doesn't help because end-users can't specify attr id when referring to the column. If a table/relation has duplicated column names, I think the only way out is to get the column by position, e.g. `df.select(Column(df.logicalPlan.output(2)))`, and attr id doesn't matter. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #31628: [MINOR][DOCS][K8S] Use hadoop-aws 3.2.2 in K8s example
dongjoon-hyun commented on pull request #31628: URL: https://github.com/apache/spark/pull/31628#issuecomment-784773673 Thank you, @HyukjinKwon ! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org