[GitHub] [spark] Ngone51 commented on pull request #36162: [SPARK-32170][CORE] Improve the speculation through the stage task metrics.
Ngone51 commented on PR #36162: URL: https://github.com/apache/spark/pull/36162#issuecomment-1175852257 This's a good idea to me. @weixiuli Could you help do some initial investigation on it? We can continue to improve this if it benifits. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #36564: [SPARK-39195][SQL] Spark OutputCommitCoordinator should abort stage when committed file not consistent with task status
AngersZh commented on PR #36564: URL: https://github.com/apache/spark/pull/36564#issuecomment-1175851865 Yea -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #37075: [SparkConnect] Initial Protobuf Definitions
grundprinzip commented on code in PR #37075: URL: https://github.com/apache/spark/pull/37075#discussion_r914475557 ## pom.xml: ## @@ -116,7 +116,7 @@ 2.17.2 3.3.3 -2.5.0 +3.21.1 Review Comment: Absolutely, the shading an relocation rules haven't been updated yet. I'm still a bit unclear what the best way to progress is to avoid conflicts with third-party packages or Spark consumers. I've discussed some approaches and one way would be to produce a shaded spark connect artifact that is then consumed in it's shaded version by spark itself or to shade and relocate after the build. However, this PR is mostly for discussing the proto interface. ## pom.xml: ## @@ -116,7 +116,7 @@ 2.17.2 3.3.3 -2.5.0 +3.21.1 Review Comment: Absolutely, the shading and relocation rules haven't been updated yet. I'm still a bit unclear what the best way to progress is to avoid conflicts with third-party packages or Spark consumers. I've discussed some approaches and one way would be to produce a shaded spark connect artifact that is then consumed in it's shaded version by spark itself or to shade and relocate after the build. However, this PR is mostly for discussing the proto interface. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] allisonwang-db opened a new pull request, #37099: [SPARK-37287][SQL] Pull out dynamic partition and bucket sort from FileFormatWriter
allisonwang-db opened a new pull request, #37099: URL: https://github.com/apache/spark/pull/37099 ### What changes were proposed in this pull request? This PR develops on top of the original PR https://github.com/apache/spark/pull/34568. It - Adds a new trait `V1WriteCommand` that extends the `DataWritingCommand` with an abstract method `requiredOrdering`. - Changes each of the following commands to extend `V1WriteCommand` and implement `requiredOrdering`: - CreateDataSourceTableAsSelectCommand - InsertIntoHadoopFsRelationCommand - InsertIntoHiveTable - CreateHiveTableAsSelectBase - Adds a new rule `V1Writes` (similar to `V2Writes`) to decide whether we should add a logical `Sort` operator based on the required ordering of a V1 data writing command. - Adds a new config **spark.sql.plannedWrite.enabled** (default: true) to indicate if logical sorts have been added during the query optimization stage. ### Why are the changes needed? Simplify `FileFormatWriter` and unify the logic of V1 and V2 write commands. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? New unit tests. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #37087: [SPARK-39447][SQL][3.2] Avoid AssertionError in AdaptiveSparkPlanExec.doExecuteBroadcast
cloud-fan commented on PR #37087: URL: https://github.com/apache/spark/pull/37087#issuecomment-1175840358 > Shall we also backport https://github.com/apache/spark/pull/36953 into branch-3.2 ? +1 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37020: [SPARK-34927][INFRA] Support TPCDSQueryBenchmark in Benchmarks
LuciferYang commented on PR #37020: URL: https://github.com/apache/spark/pull/37020#issuecomment-1175830680 Sorry, there's a problem I didn't notice before. I found that `Generate an input dataset for TPCDSQueryBenchmark with SF=1`always be executed even if I didn't specify to run `TPCDSQueryBenchmark`, Is this what we want? For example https://github.com/LuciferYang/spark/runs/7207453029?check_suite_focus=true I just want to run `MapStatusesConvertBenchmark`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang closed pull request #37086: [SPARK-39680][CORE] Remove `hasSpaceForAnotherRecord` from `UnsafeExternalSorter`
LuciferYang closed pull request #37086: [SPARK-39680][CORE] Remove `hasSpaceForAnotherRecord` from `UnsafeExternalSorter` URL: https://github.com/apache/spark/pull/37086 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37086: [SPARK-39680][CORE] Remove `hasSpaceForAnotherRecord` from `UnsafeExternalSorter`
LuciferYang commented on PR #37086: URL: https://github.com/apache/spark/pull/37086#issuecomment-1175821690 thanks for your review @dongjoon-hyun -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37086: [SPARK-39680][CORE] Remove `hasSpaceForAnotherRecord` from `UnsafeExternalSorter`
LuciferYang commented on PR #37086: URL: https://github.com/apache/spark/pull/37086#issuecomment-1175821199 > May I ask if you are currently some other refactoring on this area? I'm wondering if you want to encapsulate back for some reasons or not. Not yet, just see this method is no longer used. I will close this pr -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mskapilks opened a new pull request, #37098: [SPARK-39690][SQL] Fixes Reuse exchange across subqueries with AQE if subquery side exchange materialized first
mskapilks opened a new pull request, #37098: URL: https://github.com/apache/spark/pull/37098 ### What changes were proposed in this pull request? When trying to reuse Exchange of a subquery in main plan, if the Exchange inside subquery materialize first then main ASPE node won't have that stage info (in [stageToReplace](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/AdaptiveSparkPlanExec.scala#L243)) to replace in current logical plan. This will cause AQE to produce new candidate physical plan without reusing the exchange present inside subquery. And depending on how complex the inner plan is (no. of exchanges) AQE could choose plan without ReusedExchange. We have seen this with multiple queries with our private build. This can happen in DPP also. ### Why are the changes needed? To reuse exchange from subqueries in AQE ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually verified in unit test `SPARK-34637: DPP side broadcast query stage is created firstly` [Code](https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/DynamicPartitionPruningSuite.scala#L1426). The last candidate physical plan created by AQE in this test does not have reuse exchange before this change. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #37086: [SPARK-39680][CORE] Remove `hasSpaceForAnotherRecord` from `UnsafeExternalSorter`
dongjoon-hyun commented on code in PR #37086:
URL: https://github.com/apache/spark/pull/37086#discussion_r914446291
##
core/src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeExternalSorter.java:
##
@@ -562,10 +562,6 @@ public UnsafeSorterIterator getSortedIterator() throws
IOException {
}
}
- @VisibleForTesting boolean hasSpaceForAnotherRecord() {
Review Comment:
Thank you for making a PR, but I'd not remove this. Although this is not
used currently, this was added once inevitably. I feel this removal might
become a too hasty decision because `UnsafeExternalSorter` is designed to be
based on `UnsafeInMemorySorter` and
`UnsafeInMemorySorter.hasSpaceForAnotherRecord()` is a useful public method. It
still looks okay to me to have this `VisibleForTesting` method to expose the
underlying structure.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #37086: [SPARK-39680][CORE] Remove `hasSpaceForAnotherRecord` from `UnsafeExternalSorter`
dongjoon-hyun commented on code in PR #37086:
URL: https://github.com/apache/spark/pull/37086#discussion_r914446291
##
core/src/main/java/org/apache/spark/util/collection/unsafe/sort/UnsafeExternalSorter.java:
##
@@ -562,10 +562,6 @@ public UnsafeSorterIterator getSortedIterator() throws
IOException {
}
}
- @VisibleForTesting boolean hasSpaceForAnotherRecord() {
Review Comment:
Thank you for making a PR, but I'd not remove this. Although this is not
used currently, this was added once inevitably. I feel this removal might be
too hasty decision because `UnsafeExternalSorter` is designed to be based on
`UnsafeInMemorySorter` and `UnsafeInMemorySorter.hasSpaceForAnotherRecord()` is
a useful public method. It still looks okay to me to have this
`VisibleForTesting` method to expose the underlying structure.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #37075: [SparkConnect] Initial Protobuf Definitions
LuciferYang commented on code in PR #37075: URL: https://github.com/apache/spark/pull/37075#discussion_r914442245 ## pom.xml: ## @@ -116,7 +116,7 @@ 2.17.2 3.3.3 -2.5.0 +3.21.1 Review Comment: Maybe we should shade and relocation `protobuf` in spark to avoid potential conflicts with other third-party libraries, such as hadoop -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #37075: [SparkConnect] Initial Protobuf Definitions
LuciferYang commented on code in PR #37075: URL: https://github.com/apache/spark/pull/37075#discussion_r914442245 ## pom.xml: ## @@ -116,7 +116,7 @@ 2.17.2 3.3.3 -2.5.0 +3.21.1 Review Comment: Maybe we should shade and relocation `protobuf-java` in spark to avoid potential conflicts with other third-party libraries, such as hadoop -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #37087: [SPARK-39447][SQL][3.2] Avoid AssertionError in AdaptiveSparkPlanExec.doExecuteBroadcast
dongjoon-hyun commented on code in PR #37087:
URL: https://github.com/apache/spark/pull/37087#discussion_r914436645
##
sql/core/src/test/scala/org/apache/spark/sql/DynamicPartitionPruningSuite.scala:
##
@@ -1597,6 +1597,25 @@ class DynamicPartitionPruningV1SuiteAEOff extends
DynamicPartitionPruningV1Suite
class DynamicPartitionPruningV1SuiteAEOn extends DynamicPartitionPruningV1Suite
with EnableAdaptiveExecutionSuite {
+ test("SPARK-39447: Avoid AssertionError in
AdaptiveSparkPlanExec.doExecuteBroadcast") {
Review Comment:
Do you mean this test case doesn't fail currently in branch-3.2 because we
don't have SPARK-39551, @ulysses-you ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #37097: [SPARK-39616][BUILD][ML][FOLLOWUP] Fix flaky doctests
dongjoon-hyun commented on PR #37097: URL: https://github.com/apache/spark/pull/37097#issuecomment-1175804926 Thank you, @zhengruifeng , @HyukjinKwon , @Yikun . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #37097: [SPARK-39616][BUILD][ML][FOLLOWUP] Fix flaky doctests
dongjoon-hyun closed pull request #37097: [SPARK-39616][BUILD][ML][FOLLOWUP] Fix flaky doctests URL: https://github.com/apache/spark/pull/37097 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] singhpk234 commented on pull request #37083: [SPARK-39678][SQL] Improve stats estimation for v2 tables
singhpk234 commented on PR #37083: URL: https://github.com/apache/spark/pull/37083#issuecomment-1175798196 Thanks @wangyum ! > So enabling spark.sql.cbo.enabled is what you want? I believe then setting `spark.sql.cbo.enabled` to true by default could help, (what i wanted was to take this valuable stat of row count, bubbled up from v2 connector to be accounted for in default spark behaviour) but I think it requires some additional efforts, since our other defaults such as auto-bhj etc needs to adjusted accordingly. > I think it's by design for my knowledge, can you please point me to some jira's ,happy to learn more. Love to know your thoughts on the same, Happy to close this as well if we consider this is not a problem at all. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun commented on a diff in pull request #37005: [SPARK-39522][INFRA]Uses Docker image cache over a custom image in pyspark job
Yikun commented on code in PR #37005:
URL: https://github.com/apache/spark/pull/37005#discussion_r914420987
##
.github/workflows/build_and_test.yml:
##
@@ -805,3 +853,27 @@ jobs:
with:
name: unit-tests-log-docker-integration--8-${{ inputs.hadoop }}-hive2.3
path: "**/target/unit-tests.log"
+
+ # Note that: there are only GHCR creation permission for secrets.GITHUB_TOKEN
+ # If you want to clean up the CI images, you need to:
+ # - 1. Generate the token from https://github.com/settings/tokens with
`write:packages` and `delete:packages`
+ # - 2. Add the the token as secrets `GHCR_DEL` in
https://github.com/{username}}/spark/settings/secrets/actions
+ infra-image-post:
+# Always runs after pyspark/sparkr/lint have completed, regardless of
whether they were successful
+if: always()
+needs: [pyspark, sparkr, lint]
+runs-on: ubuntu-20.04
+env:
+ GHCR_DEL: ${{ secrets.GHCR_DEL }}
Review Comment:
https://docs.github.com/en/actions/using-workflows/reusing-workflows#using-inputs-and-secrets-in-a-reusable-workflow
need to define secrets in main workflow
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on pull request #37087: [SPARK-39447][SQL][3.2] Avoid AssertionError in AdaptiveSparkPlanExec.doExecuteBroadcast
ulysses-you commented on PR #37087: URL: https://github.com/apache/spark/pull/37087#issuecomment-1175757982 @cloud-fan oh, this patch is based on #36953 but it does not backport into branch-3.2. Shall we also backport #36953 into branch-3.2 ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #37097: [SPARK-39616][BUILD][ML][FOLLOWUP] Skip flaky doctests
zhengruifeng commented on code in PR #37097: URL: https://github.com/apache/spark/pull/37097#discussion_r914375796 ## python/pyspark/mllib/linalg/distributed.py: ## @@ -423,7 +423,7 @@ def computeSVD( [DenseVector([-0.7071, 0.7071]), DenseVector([-0.7071, -0.7071])] >>> svd_model.s DenseVector([3.4641, 3.1623]) ->>> svd_model.V # doctest: +ELLIPSIS +>>> svd_model.V # doctest: +SKIP DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, 0.0], 0) Review Comment: good idea -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37097: [SPARK-39616][BUILD][ML][FOLLOWUP] Skip flaky doctests
HyukjinKwon commented on code in PR #37097: URL: https://github.com/apache/spark/pull/37097#discussion_r914374186 ## python/pyspark/mllib/linalg/distributed.py: ## @@ -423,7 +423,7 @@ def computeSVD( [DenseVector([-0.7071, 0.7071]), DenseVector([-0.7071, -0.7071])] >>> svd_model.s DenseVector([3.4641, 3.1623]) ->>> svd_model.V # doctest: +ELLIPSIS +>>> svd_model.V # doctest: +SKIP DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, 0.0], 0) Review Comment: Or you can change like this too I believe. ```suggestion DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, ...0.0], 0) ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng opened a new pull request, #37097: [SPARK-39616][BUILD][ML][FOLLOWUP] Skip flaky doctests
zhengruifeng opened a new pull request, #37097: URL: https://github.com/apache/spark/pull/37097 ### What changes were proposed in this pull request? Skip flaky doctests ### Why are the changes needed? ``` File "/__w/spark/spark/python/pyspark/mllib/linalg/distributed.py", line 859, in __main__.IndexedRowMatrix.computeSVD Failed example: svd_model.V # doctest: +ELLIPSIS Expected: DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, 0.0], 0) Got: DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, -0.0], 0) ** File "/__w/spark/spark/python/pyspark/mllib/linalg/distributed.py", line 426, in __main__.RowMatrix.computeSVD Failed example: svd_model.V # doctest: +ELLIPSIS Expected: DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, 0.0], 0) Got: DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, -0.0], 0) ** 1 of 6 in __main__.IndexedRowMatrix.computeSVD 1 of 6 in __main__.RowMatrix.computeSVD ***Test Failed*** 2 failures. Had test failures in pyspark.mllib.linalg.distributed with python3.9; see logs. ``` https://github.com/apache/spark/pull/37002 occasionally cause above tests output `-0.0` instead of `0.0`, I think they are both acceptable. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? updated doctests -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xinrong-databricks commented on a diff in pull request #37038: [SPARK-39648][PYTHON][DOC] Fix type hints of `like`, `rlike`, `ilike` of Column
xinrong-databricks commented on code in PR #37038:
URL: https://github.com/apache/spark/pull/37038#discussion_r914357361
##
python/pyspark/sql/column.py:
##
@@ -656,9 +668,9 @@ def __iter__(self) -> None:
"""
contains = _bin_op("contains", _contains_doc)
-rlike = _bin_op("rlike", _rlike_doc)
-like = _bin_op("like", _like_doc)
-ilike = _bin_op("ilike", _ilike_doc)
+rlike = _bin_op("rlike", _rlike_doc, is_other_str=True)
Review Comment:
Sounds good! Defined `_bin_op_other_str`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xinrong-databricks commented on a diff in pull request #37038: [SPARK-39648][PYTHON][DOC] Fix type hints of `like`, `rlike`, `ilike` of Column
xinrong-databricks commented on code in PR #37038:
URL: https://github.com/apache/spark/pull/37038#discussion_r914357361
##
python/pyspark/sql/column.py:
##
@@ -656,9 +668,9 @@ def __iter__(self) -> None:
"""
contains = _bin_op("contains", _contains_doc)
-rlike = _bin_op("rlike", _rlike_doc)
-like = _bin_op("like", _like_doc)
-ilike = _bin_op("ilike", _ilike_doc)
+rlike = _bin_op("rlike", _rlike_doc, is_other_str=True)
Review Comment:
Sounds good! Defined `_bin_op_other_str`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] pan3793 commented on a diff in pull request #36991: [SPARK-39601][YARN] AllocationFailure should not be treated as exitCausedByApp when driver is shutting down
pan3793 commented on code in PR #36991:
URL: https://github.com/apache/spark/pull/36991#discussion_r914354354
##
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnAllocator.scala:
##
@@ -859,7 +859,8 @@ private[yarn] class YarnAllocator(
//
.com/apache/hadoop/blob/228156cfd1b474988bc4fedfbf7edddc87db41e3/had
//
oop-yarn-project/hadoop-yarn/hadoop-yarn-common/src/main/java/org/ap
// ache/hadoop/yarn/util/Apps.java#L273 for details)
-if
(NOT_APP_AND_SYSTEM_FAULT_EXIT_STATUS.contains(other_exit_status)) {
+if
(NOT_APP_AND_SYSTEM_FAULT_EXIT_STATUS.contains(other_exit_status) ||
+SparkContext.getActive.forall(_.isStopped)) {
Review Comment:
The SparkContext set `stopped` to false at the beginning of the stop
procedure, do you have other suggestions to check if spark context is stopped?
https://github.com/apache/spark/blob/c1d1ec5f3bde0b46bc34a161935ebfc2c41ec153/core/src/main/scala/org/apache/spark/SparkContext.scala#L2056-L2065
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun commented on pull request #37003: [SPARK-39522][INFRA] Add Apache Spark infra GA image cache
Yikun commented on PR #37003: URL: https://github.com/apache/spark/pull/37003#issuecomment-1175683700 - Cache build works well: https://github.com/apache/spark/actions/workflows/build_infra_images_cache.yml - Image has been published in: https://github.com/apache/spark/pkgs/container/spark%2Fapache-spark-github-action-image-cache - Image build from cache works well: https://github.com/Yikun/spark/runs/7206936628?check_suite_focus=true#step:7:102 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #37092: [SPARK-39687][PYTHON][DOCS] Make sure new catalog methods listed in API reference
zhengruifeng commented on PR #37092: URL: https://github.com/apache/spark/pull/37092#issuecomment-1175681321 Thank you @HyukjinKwon for remindering me to check the doc and helping view -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #37090: [SPARK-37527][SQL][FOLLOWUP] Cannot compile COVAR_POP, COVAR_SAMP and CORR in `H2Dialect` if them with `DISTINCT`
beliefer commented on PR #37090: URL: https://github.com/apache/spark/pull/37090#issuecomment-1175679627 ping @huaxingao cc @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on pull request #36696: [SPARK-39312][SQL] Use parquet native In predicate for in filter push down
wangyum commented on PR #36696: URL: https://github.com/apache/spark/pull/36696#issuecomment-1175662846 Could you update the `FilterPushdownBenchmark` results? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on pull request #37083: [SPARK-39678][SQL] Improve stats estimation for v2 tables
wangyum commented on PR #37083: URL: https://github.com/apache/spark/pull/37083#issuecomment-1175649786 I think it's by design. So enabling `spark.sql.cbo.enabled` is what you want? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #37002: [SPARK-39616][BUILD][ML] Upgrade Breeze to 2.0
zhengruifeng commented on PR #37002: URL: https://github.com/apache/spark/pull/37002#issuecomment-1175640643 @HyukjinKwon @dongjoon-hyun let me take a look, thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #37002: [SPARK-39616][BUILD][ML] Upgrade Breeze to 2.0
dongjoon-hyun commented on PR #37002: URL: https://github.com/apache/spark/pull/37002#issuecomment-1175634920 Thank you for reporting that, @HyukjinKwon . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #37003: [SPARK-39522][INFRA] Add Apache Spark infra GA image cache
HyukjinKwon closed pull request #37003: [SPARK-39522][INFRA] Add Apache Spark infra GA image cache URL: https://github.com/apache/spark/pull/37003 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37003: [SPARK-39522][INFRA] Add Apache Spark infra GA image cache
HyukjinKwon commented on PR #37003: URL: https://github.com/apache/spark/pull/37003#issuecomment-1175633739 Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun commented on pull request #37003: [SPARK-39522][INFRA] Add Apache Spark infra GA image cache
Yikun commented on PR #37003: URL: https://github.com/apache/spark/pull/37003#issuecomment-1175633700 @HyukjinKwon Yes, I think it ok to go! Thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37075: [SparkConnect] Initial Protobuf Definitions
HyukjinKwon commented on PR #37075: URL: https://github.com/apache/spark/pull/37075#issuecomment-1175628073 Let me turn this to a draft since it's WIP -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37002: [SPARK-39616][BUILD][ML] Upgrade Breeze to 2.0
HyukjinKwon commented on PR #37002: URL: https://github.com/apache/spark/pull/37002#issuecomment-1175625302 @zhengruifeng seems like there's one test flaky presumably after this: ``` File "/__w/spark/spark/python/pyspark/mllib/linalg/distributed.py", line 859, in __main__.IndexedRowMatrix.computeSVD Failed example: svd_model.V # doctest: +ELLIPSIS Expected: DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, 0.0], 0) Got: DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, -0.0], 0) ** File "/__w/spark/spark/python/pyspark/mllib/linalg/distributed.py", line 426, in __main__.RowMatrix.computeSVD Failed example: svd_model.V # doctest: +ELLIPSIS Expected: DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, 0.0], 0) Got: DenseMatrix(3, 2, [-0.4082, -0.8165, -0.4082, 0.8944, -0.4472, -0.0], 0) ** 1 of 6 in __main__.IndexedRowMatrix.computeSVD 1 of 6 in __main__.RowMatrix.computeSVD ***Test Failed*** 2 failures. Had test failures in pyspark.mllib.linalg.distributed with python3.9; see logs. ``` Mind taking a look please? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kazuyukitanimura commented on a diff in pull request #37096: [SPARK-39584][SQL][TESTS] Fix TPCDSQueryBenchmark Measuring Performance of Wrong Query Results
kazuyukitanimura commented on code in PR #37096:
URL: https://github.com/apache/spark/pull/37096#discussion_r914297412
##
sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/TPCDSQueryBenchmark.scala:
##
@@ -65,23 +67,19 @@ object TPCDSQueryBenchmark extends SqlBasedBenchmark with
Logging {
"web_returns", "web_site", "reason", "call_center", "warehouse",
"ship_mode", "income_band",
"time_dim", "web_page")
- def setupTables(dataLocation: String, createTempView: Boolean): Map[String,
Long] = {
+ def setupTables(dataLocation: String, tableColumns: Map[String,
StructType]): Map[String, Long] =
tables.map { tableName =>
- if (createTempView) {
Review Comment:
It was initially introduced by #31011
My understanding is that the temp view was disabled for CBO because CBO runs
`spark.sql(s"ANALYZE TABLE $tableName COMPUTE STATISTICS FOR ALL COLUMNS")`
https://github.com/apache/spark/pull/31011/files#diff-f0ef9be2f138cb947253f07c4285a8cf6b054355cf53beb2ba70ce82a380356bR173
`ANALYZE TABLE` requires actual table rather than temp view. Otherwise, it
will throw `org.apache.spark.sql.AnalysisException: Temporary view is not
cached for analyzing columns.`
@maropu please chime in if I said anything wrong.
With this PR, all input data are creating table with the forced schema.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kazuyukitanimura commented on a diff in pull request #37096: [SPARK-39584][SQL][TESTS] Fix TPCDSQueryBenchmark Measuring Performance of Wrong Query Results
kazuyukitanimura commented on code in PR #37096:
URL: https://github.com/apache/spark/pull/37096#discussion_r914297412
##
sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/TPCDSQueryBenchmark.scala:
##
@@ -65,23 +67,19 @@ object TPCDSQueryBenchmark extends SqlBasedBenchmark with
Logging {
"web_returns", "web_site", "reason", "call_center", "warehouse",
"ship_mode", "income_band",
"time_dim", "web_page")
- def setupTables(dataLocation: String, createTempView: Boolean): Map[String,
Long] = {
+ def setupTables(dataLocation: String, tableColumns: Map[String,
StructType]): Map[String, Long] =
tables.map { tableName =>
- if (createTempView) {
Review Comment:
It was initially introduced by #31011
My understanding is that the temp view was disabled for CBO because CBO runs
`spark.sql(s"ANALYZE TABLE $tableName COMPUTE STATISTICS FOR ALL COLUMNS")`
https://github.com/apache/spark/pull/31011/files#diff-f0ef9be2f138cb947253f07c4285a8cf6b054355cf53beb2ba70ce82a380356bR173
`ANALYZE TABLE` requires actual table rather than temp view. Otherwise, it
will throw `org.apache.spark.sql.AnalysisException`
@maropu please chime in if I said anything wrong.
With this PR, all input data are creating table with the forced schema.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #37096: [SPARK-39584][SQL][TESTS] Fix TPCDSQueryBenchmark Measuring Performance of Wrong Query Results
dongjoon-hyun commented on code in PR #37096:
URL: https://github.com/apache/spark/pull/37096#discussion_r914282181
##
sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/TPCDSQueryBenchmark.scala:
##
@@ -65,23 +67,19 @@ object TPCDSQueryBenchmark extends SqlBasedBenchmark with
Logging {
"web_returns", "web_site", "reason", "call_center", "warehouse",
"ship_mode", "income_band",
"time_dim", "web_page")
- def setupTables(dataLocation: String, createTempView: Boolean): Map[String,
Long] = {
+ def setupTables(dataLocation: String, tableColumns: Map[String,
StructType]): Map[String, Long] =
tables.map { tableName =>
- if (createTempView) {
Review Comment:
Do you know the reason why we use `createTempView =
!benchmarkArgs.cboEnabled` before?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37003: [SPARK-39522][INFRA] Add Apache Spark infra GA image cache
HyukjinKwon commented on PR #37003: URL: https://github.com/apache/spark/pull/37003#issuecomment-1175598372 @Yikun is it good to go? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #37092: [SPARK-39687][PYTHON][DOCS] Make sure new catalog methods listed in API reference
HyukjinKwon closed pull request #37092: [SPARK-39687][PYTHON][DOCS] Make sure new catalog methods listed in API reference URL: https://github.com/apache/spark/pull/37092 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37092: [SPARK-39687][PYTHON][DOCS] Make sure new catalog methods listed in API reference
HyukjinKwon commented on PR #37092: URL: https://github.com/apache/spark/pull/37092#issuecomment-1175597057 Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #37091: [SPARK-39686][INFRA] Disable scheduled builds that did not pass even once
HyukjinKwon closed pull request #37091: [SPARK-39686][INFRA] Disable scheduled builds that did not pass even once URL: https://github.com/apache/spark/pull/37091 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37091: [SPARK-39686][INFRA] Disable scheduled builds that did not pass even once
HyukjinKwon commented on PR #37091: URL: https://github.com/apache/spark/pull/37091#issuecomment-1175596012 Thanks all! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37091: [SPARK-39686][INFRA] Disable scheduled builds that did not pass even once
HyukjinKwon commented on PR #37091: URL: https://github.com/apache/spark/pull/37091#issuecomment-1175595952 Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Jonathancui123 commented on pull request #36871: [SPARK-39469][SQL] Infer date type for CSV schema inference
Jonathancui123 commented on PR #36871: URL: https://github.com/apache/spark/pull/36871#issuecomment-1175592703 > would appreciate it if you summarize any unaddressed comments or concerns. I am fine given that we disable this here by default. @HyukjinKwon I don't see any remaining unaddressed comments - I believe we are ready to merge this PR. Here are the resolutions to potential concerns: - No backwards compatibility concern: `Legacy` parser policy cannot be used with `inferDate`. We can open another ticket to add a `LegacyStrictSimpleDateFormatter` [as Bruce suggested](https://github.com/apache/spark/pull/36871#discussion_r905348742) if necessary. - Performance degradation: Benchmark results ([in the bottom of PR description](https://github.com/apache/spark/pull/36871#issue-1271523396)) show that date inference greatly slows down schema inference for CSVs with dates. This feature is guarded by the CSV Option `inferDate` and is off by default. - Logical errors for strict parsing and converting Date to TimestampNTZ have been fixed and have unit tests -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Jonathancui123 commented on a diff in pull request #36871: [SPARK-39469][SQL] Infer date type for CSV schema inference
Jonathancui123 commented on code in PR #36871:
URL: https://github.com/apache/spark/pull/36871#discussion_r909084899
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityParser.scala:
##
@@ -197,34 +198,46 @@ class UnivocityParser(
Decimal(decimalParser(datum), dt.precision, dt.scale)
}
-case _: TimestampType => (d: String) =>
+case _: DateType => (d: String) =>
nullSafeDatum(d, name, nullable, options) { datum =>
try {
- timestampFormatter.parse(datum)
+ dateFormatter.parse(datum)
} catch {
case NonFatal(e) =>
// If fails to parse, then tries the way used in 2.0 and 1.x for
backwards
// compatibility.
val str =
DateTimeUtils.cleanLegacyTimestampStr(UTF8String.fromString(datum))
-DateTimeUtils.stringToTimestamp(str,
options.zoneId).getOrElse(throw e)
+DateTimeUtils.stringToDate(str).getOrElse(throw e)
}
}
-case _: TimestampNTZType => (d: String) =>
- nullSafeDatum(d, name, nullable, options) { datum =>
-timestampNTZFormatter.parseWithoutTimeZone(datum, false)
- }
-
-case _: DateType => (d: String) =>
+case _: TimestampType => (d: String) =>
nullSafeDatum(d, name, nullable, options) { datum =>
try {
- dateFormatter.parse(datum)
+ timestampFormatter.parse(datum)
} catch {
case NonFatal(e) =>
// If fails to parse, then tries the way used in 2.0 and 1.x for
backwards
// compatibility.
val str =
DateTimeUtils.cleanLegacyTimestampStr(UTF8String.fromString(datum))
-DateTimeUtils.stringToDate(str).getOrElse(throw e)
+DateTimeUtils.stringToTimestamp(str, options.zoneId).getOrElse {
+ // There may be date type entries in timestamp column due to
schema inference
+ if (options.inferDate) {
+daysToMicros(dateFormatter.parse(datum), options.zoneId)
+ } else {
+throw(e)
+ }
+}
+}
+ }
+
+case _: TimestampNTZType => (d: String) =>
+ nullSafeDatum(d, name, nullable, options) { datum =>
+try {
+ timestampNTZFormatter.parseWithoutTimeZone(datum, false)
+} catch {
+ case NonFatal(e) if (options.inferDate) =>
+daysToMicros(dateFormatter.parse(datum), options.zoneId)
Review Comment:
Wow great catch! I hadn't fully considered the effect of user timeZone on
TimestampNTZ parsing.
I've fixed the error and I've modified this test to have a PST user and
check that the parsed date is converted to a timestamp in UTC.
https://github.com/Jonathancui123/spark/blob/8df7ebbd6c1c0d5bb875ce554026f9b9aeae148e/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/csv/UnivocityParserSuite.scala#L368-L374
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Jonathancui123 commented on a diff in pull request #36871: [SPARK-39469][SQL] Infer date type for CSV schema inference
Jonathancui123 commented on code in PR #36871:
URL: https://github.com/apache/spark/pull/36871#discussion_r909084899
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityParser.scala:
##
@@ -197,34 +198,46 @@ class UnivocityParser(
Decimal(decimalParser(datum), dt.precision, dt.scale)
}
-case _: TimestampType => (d: String) =>
+case _: DateType => (d: String) =>
nullSafeDatum(d, name, nullable, options) { datum =>
try {
- timestampFormatter.parse(datum)
+ dateFormatter.parse(datum)
} catch {
case NonFatal(e) =>
// If fails to parse, then tries the way used in 2.0 and 1.x for
backwards
// compatibility.
val str =
DateTimeUtils.cleanLegacyTimestampStr(UTF8String.fromString(datum))
-DateTimeUtils.stringToTimestamp(str,
options.zoneId).getOrElse(throw e)
+DateTimeUtils.stringToDate(str).getOrElse(throw e)
}
}
-case _: TimestampNTZType => (d: String) =>
- nullSafeDatum(d, name, nullable, options) { datum =>
-timestampNTZFormatter.parseWithoutTimeZone(datum, false)
- }
-
-case _: DateType => (d: String) =>
+case _: TimestampType => (d: String) =>
nullSafeDatum(d, name, nullable, options) { datum =>
try {
- dateFormatter.parse(datum)
+ timestampFormatter.parse(datum)
} catch {
case NonFatal(e) =>
// If fails to parse, then tries the way used in 2.0 and 1.x for
backwards
// compatibility.
val str =
DateTimeUtils.cleanLegacyTimestampStr(UTF8String.fromString(datum))
-DateTimeUtils.stringToDate(str).getOrElse(throw e)
+DateTimeUtils.stringToTimestamp(str, options.zoneId).getOrElse {
+ // There may be date type entries in timestamp column due to
schema inference
+ if (options.inferDate) {
+daysToMicros(dateFormatter.parse(datum), options.zoneId)
+ } else {
+throw(e)
+ }
+}
+}
+ }
+
+case _: TimestampNTZType => (d: String) =>
+ nullSafeDatum(d, name, nullable, options) { datum =>
+try {
+ timestampNTZFormatter.parseWithoutTimeZone(datum, false)
+} catch {
+ case NonFatal(e) if (options.inferDate) =>
+daysToMicros(dateFormatter.parse(datum), options.zoneId)
Review Comment:
Wow great catch! I hadn't fully considered the effect of user timeZone on
TimestampNTZ parsing.
I've fixed the error and I've modified this test to have a PST user and
check that the parsed date is converted to a timestamp in UTC.
https://github.com/Jonathancui123/spark/blob/8df7ebbd6c1c0d5bb875ce554026f9b9aeae148e/sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/csv/UnivocityParserSuite.scala#L368-L374
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kazuyukitanimura commented on pull request #37096: [SPARK-39584][SQL][TESTS] Fix TPCDSQueryBenchmark Measuring Performance of Wrong Query Results
kazuyukitanimura commented on PR #37096: URL: https://github.com/apache/spark/pull/37096#issuecomment-1175537588 cc @dongjoon-hyun @sunchao @viirya @wangyum @LuciferYang @HyukjinKwon @peter-toth @maropu Appreciate your feedback! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kazuyukitanimura opened a new pull request, #37096: [SPARK-39584][SQL][TESTS] Fix TPCDSQueryBenchmark Measuring Performance of Wrong Query Results
kazuyukitanimura opened a new pull request, #37096: URL: https://github.com/apache/spark/pull/37096 ### What changes were proposed in this pull request? `GenTPCDSData` uses the schema defined in `TPCDSSchema` that contains `char(N)`. When `GenTPCDSData` generates parquet files, that pads spaces for strings whose lengths are `< N`. When `TPCDSQueryBenchmark` reads data from parquet generated by `GenTPCDSData`, it uses schema from the parquet file and keeps the paddings. Due to the extra spaces, string filter queries of TPC-DS fail to match. For example, `q13` query results are all nulls and returns too fast because string filter does not meet any rows. This PR proposes to pass the schema definition to the table creation before reading in order to fix the issue. This is similar to what the Spark TPC-DS unit tests do. In particular, this PR uses `createTable(tableName, source, schema, options)` interface. History related to the `char` issue https://lists.apache.org/thread/rg7pgwyto3616hb15q78n0sykls9j7rn ### Why are the changes needed? Currently, `TPCDSQueryBenchmark` is benchmarking with wrong query results and that is showing inaccurate performance results. Therefore, the `Per Row(ns)` column of `TPCDSQueryBenchmark-results.txt` is `Infinity`. With this PR, the column now shows real numbers. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Tested on Github Actions. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #37074: [SPARK-39672][SQL][3.1] Don't remove project before filter for IN or correlated EXISTS subquery
dongjoon-hyun commented on PR #37074: URL: https://github.com/apache/spark/pull/37074#issuecomment-1175515574 FYI, cc @viirya and @huaxingao -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #37042: [SPARK-39564][SQL][FOLLOWUP] Consider the case of serde available in CatalogTable on explain string for LogicalRelation
HeartSaVioR commented on PR #37042: URL: https://github.com/apache/spark/pull/37042#issuecomment-1175475311 Thanks all for reviewing and merging! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #37095: [SPARK-39688][K8S] `getReusablePVCs` should handle accounts with no PVC permission
dongjoon-hyun closed pull request #37095: [SPARK-39688][K8S] `getReusablePVCs` should handle accounts with no PVC permission URL: https://github.com/apache/spark/pull/37095 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #37095: [SPARK-39688][K8S] `getReusablePVCs` should handle accounts with no PVC permission
dongjoon-hyun commented on PR #37095: URL: https://github.com/apache/spark/pull/37095#issuecomment-1175466973 Thank you, @viirya . K8s test passed. Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] huaxingao closed pull request #37071: [SPARK-39656][SQL][3.3] Fix wrong namespace in DescribeNamespaceExec
huaxingao closed pull request #37071: [SPARK-39656][SQL][3.3] Fix wrong namespace in DescribeNamespaceExec URL: https://github.com/apache/spark/pull/37071 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] huaxingao closed pull request #37072: [SPARK-39656][SQL][3.2] Fix wrong namespace in DescribeNamespaceExec
huaxingao closed pull request #37072: [SPARK-39656][SQL][3.2] Fix wrong namespace in DescribeNamespaceExec URL: https://github.com/apache/spark/pull/37072 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kazuyukitanimura commented on pull request #37020: [SPARK-34927][INFRA] Support TPCDSQueryBenchmark in Benchmarks
kazuyukitanimura commented on PR #37020: URL: https://github.com/apache/spark/pull/37020#issuecomment-1175433010 Thank you Dongjoon! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #37020: [SPARK-34927][INFRA] Support TPCDSQueryBenchmark in Benchmarks
dongjoon-hyun closed pull request #37020: [SPARK-34927][INFRA] Support TPCDSQueryBenchmark in Benchmarks URL: https://github.com/apache/spark/pull/37020 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] huaxingao commented on pull request #37071: [SPARK-39656][SQL][3.3] Fix wrong namespace in DescribeNamespaceExec
huaxingao commented on PR #37071: URL: https://github.com/apache/spark/pull/37071#issuecomment-1175431435 Merged to 3.3. Thanks @ulysses-you -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] huaxingao commented on pull request #37072: [SPARK-39656][SQL][3.2] Fix wrong namespace in DescribeNamespaceExec
huaxingao commented on PR #37072: URL: https://github.com/apache/spark/pull/37072#issuecomment-1175429363 Merged to 3.2. Thanks @ulysses-you -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #37002: [SPARK-39616][BUILD][ML] Upgrade Breeze to 2.0
dongjoon-hyun closed pull request #37002: [SPARK-39616][BUILD][ML] Upgrade Breeze to 2.0 URL: https://github.com/apache/spark/pull/37002 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #37002: [SPARK-39616][BUILD][ML] Upgrade Breeze to 2.0
dongjoon-hyun commented on PR #37002: URL: https://github.com/apache/spark/pull/37002#issuecomment-1175426740 Thank you, @zhengruifeng , @srowen , @HyukjinKwon . Merged to master for Apache Spark 3.4. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #37095: [SPARK-39688][K8S] `getReusablePVCs` should handle accounts with no PVC permission
dongjoon-hyun commented on PR #37095: URL: https://github.com/apache/spark/pull/37095#issuecomment-1175425035 Could you review this when you have some time, @viirya ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun opened a new pull request, #37095: [SPARK-39688][K8S] getReusablePVCs should handle accounts with no PVC permission
dongjoon-hyun opened a new pull request, #37095: URL: https://github.com/apache/spark/pull/37095 ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] attilapiros commented on a diff in pull request #37052: [SPARK-39647][CORE] Register the executor with ESS before registering the BlockManager
attilapiros commented on code in PR #37052:
URL: https://github.com/apache/spark/pull/37052#discussion_r914058583
##
core/src/test/scala/org/apache/spark/storage/BlockManagerSuite.scala:
##
@@ -2177,6 +2177,43 @@ class BlockManagerSuite extends SparkFunSuite with
Matchers with BeforeAndAfterE
assert(kryoException.getMessage === "java.io.IOException: Input/output
error")
}
+ test("SPARK-39647: Failure to register with ESS should prevent registering
the BM") {
+val timeoutExec = "timeoutExec"
Review Comment:
nit: this val is not needed anymore.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] attilapiros commented on a diff in pull request #37052: [SPARK-39647][CORE] Register the executor with ESS before registering the BlockManager
attilapiros commented on code in PR #37052:
URL: https://github.com/apache/spark/pull/37052#discussion_r914027452
##
core/src/test/scala/org/apache/spark/storage/BlockManagerSuite.scala:
##
@@ -2177,6 +2177,46 @@ class BlockManagerSuite extends SparkFunSuite with
Matchers with BeforeAndAfterE
assert(kryoException.getMessage === "java.io.IOException: Input/output
error")
}
+ test("SPARK-39647: Failure to register with ESS should prevent registering
the BM") {
+val timeoutExec = "timeoutExec"
+val handler = new NoOpRpcHandler {
+ override def receive(
+ client: TransportClient,
+ message: ByteBuffer,
+ callback: RpcResponseCallback): Unit = {
+val msgObj = BlockTransferMessage.Decoder.fromByteBuffer(message)
+msgObj match {
+
+ case exec: RegisterExecutor if exec.execId == timeoutExec =>
Review Comment:
As you are using this handler for only one executor ("timeoutExec") you can
remove the if part.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] attilapiros commented on a diff in pull request #37052: [SPARK-39647][CORE] Register the executor with ESS before registering the BlockManager
attilapiros commented on code in PR #37052:
URL: https://github.com/apache/spark/pull/37052#discussion_r914025635
##
core/src/test/scala/org/apache/spark/storage/BlockManagerSuite.scala:
##
@@ -2177,6 +2177,46 @@ class BlockManagerSuite extends SparkFunSuite with
Matchers with BeforeAndAfterE
assert(kryoException.getMessage === "java.io.IOException: Input/output
error")
}
+ test("SPARK-39647: Failure to register with ESS should prevent registering
the BM") {
+val timeoutExec = "timeoutExec"
+val handler = new NoOpRpcHandler {
+ override def receive(
+ client: TransportClient,
+ message: ByteBuffer,
+ callback: RpcResponseCallback): Unit = {
+val msgObj = BlockTransferMessage.Decoder.fromByteBuffer(message)
+msgObj match {
+
+ case exec: RegisterExecutor if exec.execId == timeoutExec =>
+() // No reply to generate client-side timeout
+}
+ }
+}
+val transConf = SparkTransportConf.fromSparkConf(conf, "shuffle",
numUsableCores = 0)
+Utils.tryWithResource(new TransportContext(transConf, handler, true)) {
transCtx =>
+ // a server which delays response 50ms and must try twice for success.
Review Comment:
This comment is copy-pasted from "SPARK-20640: Shuffle registration timeout
and maxAttempts conf are working" but here it is not a valid statement.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kazuyukitanimura commented on pull request #37020: [SPARK-34927][INFRA] Support TPCDSQueryBenchmark in Benchmarks
kazuyukitanimura commented on PR #37020: URL: https://github.com/apache/spark/pull/37020#issuecomment-1175285111 Thank you @dongjoon-hyun @wangyum @LuciferYang @HyukjinKwon for the review. Could you please help me with merging this if there are no more feedbacks? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maryannxue commented on pull request #37014: [SPARK-39624][SQL] Support coalesce partition through CartesianProduct
maryannxue commented on PR #37014: URL: https://github.com/apache/spark/pull/37014#issuecomment-1175224895 Can you please rework your PR description, by stating what's the behavior before and after your change? That screenshot doesn't say anything here. You can remove it. Maybe use some before/after examples instead. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maryannxue commented on a diff in pull request #37014: [SPARK-39624][SQL] Support coalesce partition through CartesianProduct
maryannxue commented on code in PR #37014: URL: https://github.com/apache/spark/pull/37014#discussion_r913956638 ## sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/CoalesceShufflePartitions.scala: ## @@ -132,6 +133,7 @@ case class CoalesceShufflePartitions(session: SparkSession) extends AQEShuffleRe Seq(collectShuffleStageInfos(r)) case unary: UnaryExecNode => collectCoalesceGroups(unary.child) case union: UnionExec => union.children.flatMap(collectCoalesceGroups) +case cartesian: CartesianProductExec => cartesian.children.flatMap(collectCoalesceGroups) Review Comment: update the javadoc for this method. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maryannxue commented on a diff in pull request #37014: [SPARK-39624][SQL] Support coalesce partition through CartesianProduct
maryannxue commented on code in PR #37014:
URL: https://github.com/apache/spark/pull/37014#discussion_r913956001
##
sql/core/src/test/scala/org/apache/spark/sql/execution/adaptive/AdaptiveQueryExecSuite.scala:
##
@@ -2602,6 +2602,59 @@ class AdaptiveQueryExecSuite
assert(findTopLevelBroadcastNestedLoopJoin(adaptivePlan).size == 1)
}
}
+
+ test("SPARK-39624 Support coalesce partition through CartesianProduct") {
+def checkResultPartition(
+ df: Dataset[Row],
+ numShuffleReader: Int,
+ numPartition: Int): Unit = {
+ df.collect()
+ assert(collect(df.queryExecution.executedPlan) {
+case r: AQEShuffleReadExec => r
+ }.size === numShuffleReader)
+ assert(df.rdd.partitions.length === numPartition)
+}
+withSQLConf(SQLConf.ADAPTIVE_EXECUTION_ENABLED.key -> "true",
+ SQLConf.COALESCE_PARTITIONS_ENABLED.key -> "true",
+ SQLConf.ADVISORY_PARTITION_SIZE_IN_BYTES.key -> "1048576",
+ SQLConf.COALESCE_PARTITIONS_MIN_PARTITION_NUM.key -> "1",
+ SQLConf.SHUFFLE_PARTITIONS.key -> "10") {
+ withTempView("t1", "t2", "t3") {
+spark.sparkContext.parallelize((1 to 10).map(i => TestData(i,
i.toString)), 2)
+ .toDF().createOrReplaceTempView("t1")
+spark.sparkContext.parallelize((1 to 10).map(i => TestData(i,
i.toString)), 4)
+ .toDF().createOrReplaceTempView("t2")
+spark.sparkContext.parallelize((1 to 10).map(i => TestData(i,
i.toString)), 4)
+ .toDF().createOrReplaceTempView("t3")
+// positive test that could be coalesced
Review Comment:
can you explain a little more in the code comment why a query `can` (not
could) be coalesced or why it can't?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk closed pull request #37093: [SPARK-39677][SQL][DOCS][3.2] Fix args formatting of the regexp and like functions
MaxGekk closed pull request #37093: [SPARK-39677][SQL][DOCS][3.2] Fix args formatting of the regexp and like functions URL: https://github.com/apache/spark/pull/37093 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #37093: [SPARK-39677][SQL][DOCS][3.2] Fix args formatting of the regexp and like functions
MaxGekk commented on PR #37093: URL: https://github.com/apache/spark/pull/37093#issuecomment-1175193736 Merging to 3.2 since all tests passed, and the fixes have been merged to master already. https://user-images.githubusercontent.com/1580697/177363428-ec1d021b-91a0-4b2a-a70f-25784101c061.png";> -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk closed pull request #37094: [SPARK-39677][SQL][DOCS][3.1] Fix args formatting of the regexp and like functions
MaxGekk closed pull request #37094: [SPARK-39677][SQL][DOCS][3.1] Fix args formatting of the regexp and like functions URL: https://github.com/apache/spark/pull/37094 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #37094: [SPARK-39677][SQL][DOCS][3.1] Fix args formatting of the regexp and like functions
MaxGekk commented on PR #37094: URL: https://github.com/apache/spark/pull/37094#issuecomment-1175184867 Merging this to 3.1 since the original PR was approved and has been merged to master already. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun commented on a diff in pull request #37091: [SPARK-39686][INFRA] Disable scheduled builds that did not pass even once
Yikun commented on code in PR #37091:
URL: https://github.com/apache/spark/pull/37091#discussion_r913892631
##
.github/workflows/build_branch32.yml:
##
@@ -36,12 +36,12 @@ jobs:
{
"SCALA_PROFILE": "scala2.13"
}
+ # TODO(SPARK-39681): Reenable "lint": "true"
+ # TODO(SPARK-39685): Reenable "pyspark": "true"
Review Comment:
```suggestion
# TODO(SPARK-39685): Reenable "lint": "true"
# TODO(SPARK-39681): Reenable "pyspark": "true"
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs commented on a diff in pull request #36991: [SPARK-39601][YARN] AllocationFailure should not be treated as exitCausedByApp when driver is shutting down
tgravescs commented on code in PR #36991:
URL: https://github.com/apache/spark/pull/36991#discussion_r913871806
##
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnAllocator.scala:
##
@@ -859,7 +859,8 @@ private[yarn] class YarnAllocator(
//
.com/apache/hadoop/blob/228156cfd1b474988bc4fedfbf7edddc87db41e3/had
//
oop-yarn-project/hadoop-yarn/hadoop-yarn-common/src/main/java/org/ap
// ache/hadoop/yarn/util/Apps.java#L273 for details)
-if
(NOT_APP_AND_SYSTEM_FAULT_EXIT_STATUS.contains(other_exit_status)) {
+if
(NOT_APP_AND_SYSTEM_FAULT_EXIT_STATUS.contains(other_exit_status) ||
+SparkContext.getActive.forall(_.isStopped)) {
Review Comment:
I'd prefer to know we are in shutdown vs checking the spark context active
level but I need to refresh my memory on that shutdown sequence
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #37060: [SPARK-39663][SQL][TESTS] Add UT for MysqlDialect listIndexes method
LuciferYang commented on code in PR #37060:
URL: https://github.com/apache/spark/pull/37060#discussion_r913829758
##
connector/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/v2/V2JDBCTest.scala:
##
@@ -219,11 +221,21 @@ private[v2] trait V2JDBCTest extends SharedSparkSession
with DockerIntegrationFu
s" The supported Index Types are:"))
sql(s"CREATE index i1 ON $catalogName.new_table USING BTREE (col1)")
+assert(jdbcTable.indexExists("i1"))
+if (supportListIndexes) {
+ val indexes = jdbcTable.listIndexes()
+ assert(indexes.size == 1)
+ assert(indexes(0).indexName() == "i1")
Review Comment:
Yes, `.head` is always recommended
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] panbingkun commented on pull request #37058: [SPARK-39661][SQL] Avoid creating unnecessary SLF4J Logger
panbingkun commented on PR #37058: URL: https://github.com/apache/spark/pull/37058#issuecomment-1175082503 > Hm, tests timed out. Can you retrigger? I'm sure it's not related, but good to see tests pass to be sure. okay -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on a diff in pull request #37060: [SPARK-39663][SQL][TESTS] Add UT for MysqlDialect listIndexes method
srowen commented on code in PR #37060:
URL: https://github.com/apache/spark/pull/37060#discussion_r913808190
##
connector/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/v2/V2JDBCTest.scala:
##
@@ -219,11 +221,21 @@ private[v2] trait V2JDBCTest extends SharedSparkSession
with DockerIntegrationFu
s" The supported Index Types are:"))
sql(s"CREATE index i1 ON $catalogName.new_table USING BTREE (col1)")
+assert(jdbcTable.indexExists("i1"))
+if (supportListIndexes) {
+ val indexes = jdbcTable.listIndexes()
+ assert(indexes.size == 1)
+ assert(indexes(0).indexName() == "i1")
Review Comment:
While we're nit-picking, `indexes.head`? doesn't matter
##
connector/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/v2/V2JDBCTest.scala:
##
@@ -219,11 +221,21 @@ private[v2] trait V2JDBCTest extends SharedSparkSession
with DockerIntegrationFu
s" The supported Index Types are:"))
sql(s"CREATE index i1 ON $catalogName.new_table USING BTREE (col1)")
+assert(jdbcTable.indexExists("i1"))
+if (supportListIndexes) {
+ val indexes = jdbcTable.listIndexes()
+ assert(indexes.size == 1)
+ assert(indexes(0).indexName() == "i1")
+}
+
sql(s"CREATE index i2 ON $catalogName.new_table (col2, col3, col5)" +
s" OPTIONS ($indexOptions)")
-
-assert(jdbcTable.indexExists("i1") == true)
-assert(jdbcTable.indexExists("i2") == true)
+assert(jdbcTable.indexExists("i2"))
+if (supportListIndexes) {
+ val indexes = jdbcTable.listIndexes()
+ assert(indexes.size == 2)
+ assert(indexes.map(index => index.indexName()).sorted ===
Array("i1", "i2"))
Review Comment:
`.map(_.indexName())`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #37075: [SparkConnect] Initial Protobuf Definitions
grundprinzip commented on code in PR #37075: URL: https://github.com/apache/spark/pull/37075#discussion_r913806860 ## sql/core/pom.xml: ## @@ -145,6 +145,30 @@ org.apache.xbean xbean-asm9-shaded + + io.grpc + grpc-netty-shaded + runtime + + + io.grpc + grpc-protobuf + + + io.grpc + grpc-stub + + + org.apache.tomcat + annotations-api + provided + + + + com.thesamet.scalapb + scalapb-runtime-grpc_2.12 Review Comment: Thanks, fixed it. ## sql/core/pom.xml: ## @@ -265,6 +297,36 @@ + Review Comment: Yeah, I had to find a colleague with M1 to test, I pushed a new version that actually works. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on pull request #37075: [SparkConnect] Initial Protobuf Definitions
grundprinzip commented on PR #37075: URL: https://github.com/apache/spark/pull/37075#issuecomment-1175070660 Added the missing licence headers, fixed the M1 build. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #37011: [SPARK-39625][SPARK-38904][SQL] Add Dataset.as(StructType)
cloud-fan commented on PR #37011: URL: https://github.com/apache/spark/pull/37011#issuecomment-1175058395 @ravwojdyla I'm fine to support this use case. We can use the `AssertNotNull` expression to do this. What I was against is the opposite: the dataframe infers some columns as non-nullable, but users want to forcibly mark these columns as nullable, to degrade performance. @dilipbiswal what do you think of this use case? When the column is nullable but the specified schema requires it to be non-nullabl, shall we add runtime null check to make it work? At least this can be under a config. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #36994: [SPARK-39606][SQL] Use child stats to estimate order operator
cloud-fan commented on PR #36994: URL: https://github.com/apache/spark/pull/36994#issuecomment-1175051179 late LGTM -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on pull request #37058: [SPARK-39661][SQL] Avoid creating unnecessary SLF4J Logger
srowen commented on PR #37058: URL: https://github.com/apache/spark/pull/37058#issuecomment-1175050327 Hm, tests timed out. Can you retrigger? I'm sure it's not related, but good to see tests pass to be sure. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #37082: [SPARK-39677][SQL][DOCS] Fix args formatting of the regexp and like functions
cloud-fan commented on PR #37082: URL: https://github.com/apache/spark/pull/37082#issuecomment-1175050026 late LGTM -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #37082: [SPARK-39677][SQL][DOCS] Fix args formatting of the regexp and like functions
MaxGekk commented on PR #37082: URL: https://github.com/apache/spark/pull/37082#issuecomment-1175007274 Here are backports: - 3.2: https://github.com/apache/spark/pull/37093 - 3.1: https://github.com/apache/spark/pull/37094 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk opened a new pull request, #37094: [SPARK-39677][SQL][DOCS][3.1] Fix args formatting of the regexp and like functions
MaxGekk opened a new pull request, #37094: URL: https://github.com/apache/spark/pull/37094 ### What changes were proposed in this pull request? In the PR, I propose to fix args formatting of some regexp functions by adding explicit new lines. That fixes the following items in arg lists. Before: https://user-images.githubusercontent.com/1580697/177274234-04209d43-a542-4c71-b5ca-6f3239208015.png";> After: https://user-images.githubusercontent.com/1580697/177280718-cb05184c-8559-4461-b94d-dfaaafda7dd2.png";> ### Why are the changes needed? To improve readability of Spark SQL docs. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By building docs and checking manually: ``` $ SKIP_SCALADOC=1 SKIP_PYTHONDOC=1 SKIP_RDOC=1 bundle exec jekyll build ``` Authored-by: Max Gekk Signed-off-by: Max Gekk (cherry picked from commit 4e42f8b12e8dc57a15998f22d508a19cf3c856aa) Signed-off-by: Max Gekk -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk opened a new pull request, #37093: [SPARK-39677][SQL][DOCS][3.2] Fix args formatting of the regexp and like functions
MaxGekk opened a new pull request, #37093: URL: https://github.com/apache/spark/pull/37093 ### What changes were proposed in this pull request? In the PR, I propose to fix args formatting of some regexp functions by adding explicit new lines. That fixes the following items in arg lists. Before: https://user-images.githubusercontent.com/1580697/177274234-04209d43-a542-4c71-b5ca-6f3239208015.png";> After: https://user-images.githubusercontent.com/1580697/177280718-cb05184c-8559-4461-b94d-dfaaafda7dd2.png";> ### Why are the changes needed? To improve readability of Spark SQL docs. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By building docs and checking manually: ``` $ SKIP_SCALADOC=1 SKIP_PYTHONDOC=1 SKIP_RDOC=1 bundle exec jekyll build ``` Authored-by: Max Gekk Signed-off-by: Max Gekk (cherry picked from commit 4e42f8b12e8dc57a15998f22d508a19cf3c856aa) Signed-off-by: Max Gekk -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun commented on pull request #37091: [SPARK-39686][INFRA] Disable scheduled builds that did not pass even once
Yikun commented on PR #37091: URL: https://github.com/apache/spark/pull/37091#issuecomment-1174989349 Looks like all failures are container-based job (maybe just a coincidence), is our strategy always let all tests pass with latest images (or to say latest deps)? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #37092: [SPARK-39687][PYTHON][DOCS] Make sure new catalog methods listed in API reference
zhengruifeng commented on PR #37092: URL: https://github.com/apache/spark/pull/37092#issuecomment-1174987095 cc @HyukjinKwon @itholic -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng opened a new pull request, #37092: [SPARK-39687][PYTHON][DOCS] Make sure new catalog methods listed in API reference
zhengruifeng opened a new pull request, #37092: URL: https://github.com/apache/spark/pull/37092 ### What changes were proposed in this pull request? 1, add new methods to `catalog.rst`; 2, follow sphinx synctax `AnalysisException` -> ``:class:`AnalysisException`` ### Why are the changes needed? Make sure new catalog methods listed in API reference ### Does this PR introduce _any_ user-facing change? No, docs only ### How was this patch tested? manually doc build and check, such as 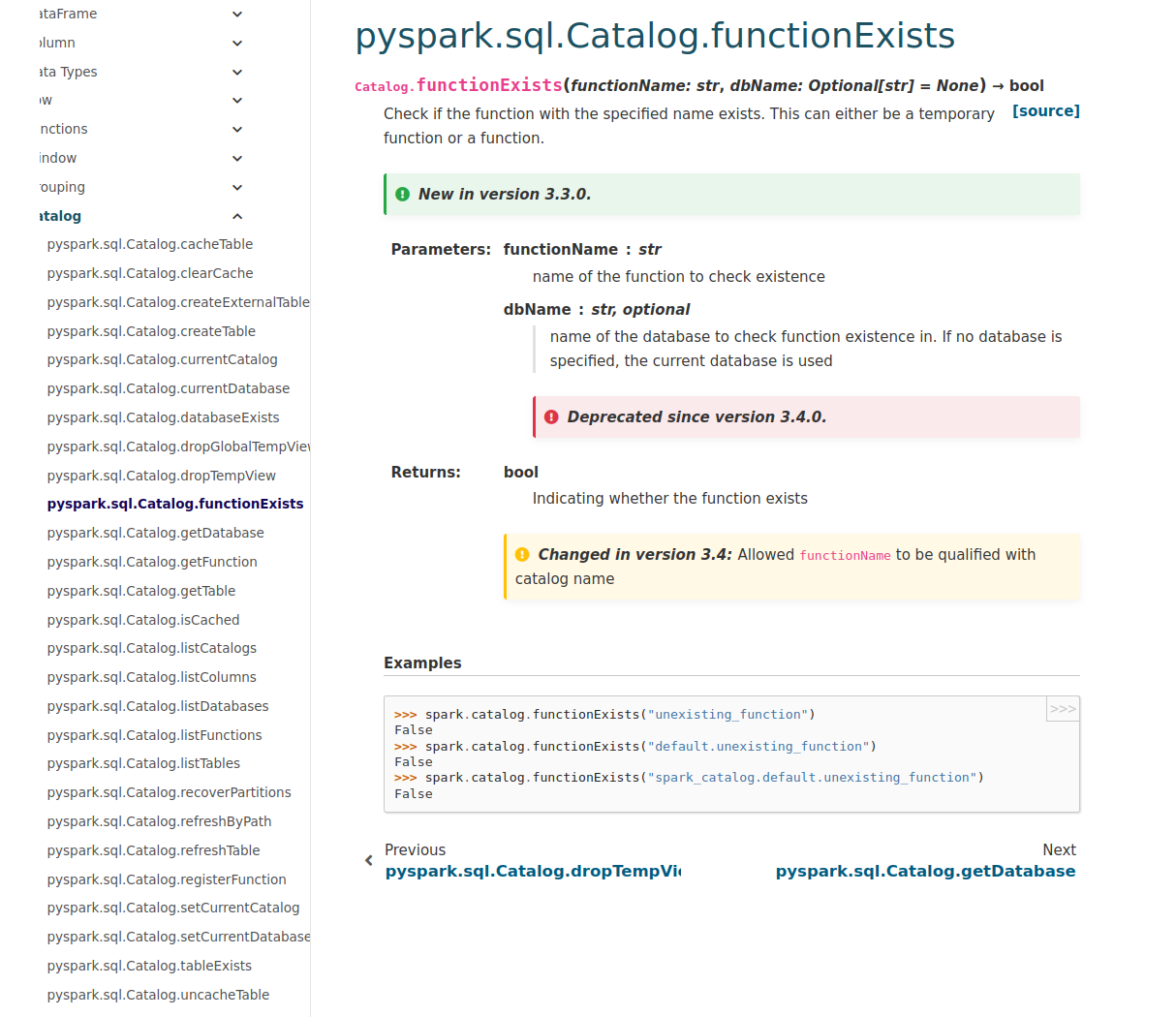 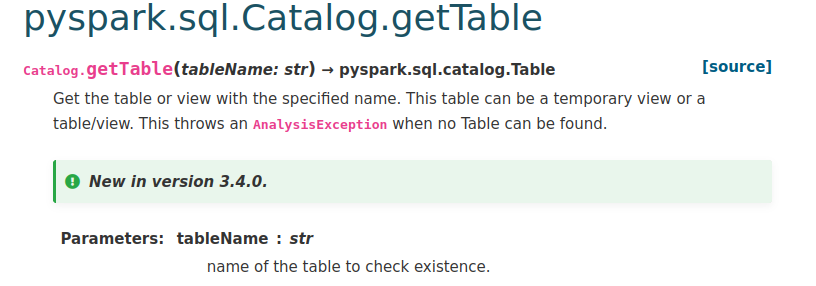 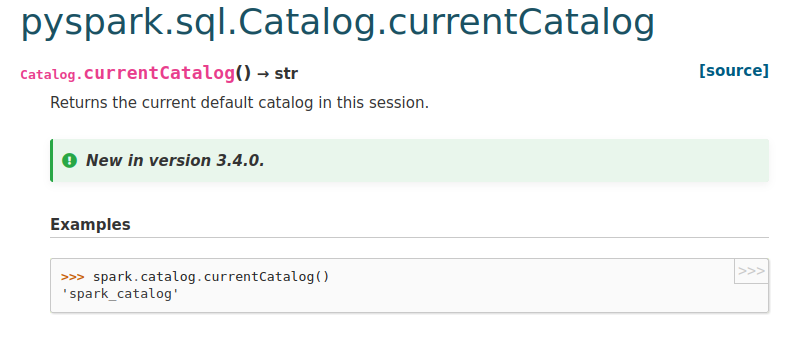 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #37088: [SPARK-39579][PYTHON][FOLLOWUP] fix functionExists(functionName, dbName) when dbName is not None
zhengruifeng commented on PR #37088: URL: https://github.com/apache/spark/pull/37088#issuecomment-1174972340 merged to master -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #37079: [SPARK-39610][INFRA] Add GITHUB_WORKSPACE to git trust safe.directory for container based job
HyukjinKwon closed pull request #37079: [SPARK-39610][INFRA] Add GITHUB_WORKSPACE to git trust safe.directory for container based job URL: https://github.com/apache/spark/pull/37079 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37079: [SPARK-39610][INFRA] Add GITHUB_WORKSPACE to git trust safe.directory for container based job
HyukjinKwon commented on PR #37079: URL: https://github.com/apache/spark/pull/37079#issuecomment-1174972063 Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng closed pull request #37088: [SPARK-39579][PYTHON][FOLLOWUP] fix functionExists(functionName, dbName) when dbName is not None
zhengruifeng closed pull request #37088: [SPARK-39579][PYTHON][FOLLOWUP] fix functionExists(functionName, dbName) when dbName is not None URL: https://github.com/apache/spark/pull/37088 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #37078: [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__
HyukjinKwon closed pull request #37078: [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__ URL: https://github.com/apache/spark/pull/37078 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37078: [SPARK-39611][PYTHON][PS] Fix wrong aliases in __array_ufunc__
HyukjinKwon commented on PR #37078: URL: https://github.com/apache/spark/pull/37078#issuecomment-1174970899 Merged to master, branch-3.3 and branch-3.2. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org