[GitHub] [spark] HyukjinKwon commented on pull request #39947: [SPARK-40453][SPARK-41715][CONNECT] Take super class into account when throwing an exception
HyukjinKwon commented on PR #39947: URL: https://github.com/apache/spark/pull/39947#issuecomment-1423774647 cc @xinrong-meng @grundprinzip @ueshin @zhengruifeng PTAL -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39947: [SPARK-40453][SPARK-41715][CONNECT] Take super class into account when throwing an exception
HyukjinKwon commented on code in PR #39947:
URL: https://github.com/apache/spark/pull/39947#discussion_r1101076905
##
python/pyspark/errors/exceptions/connect.py:
##
@@ -61,41 +97,34 @@ class AnalysisException(SparkConnectGrpcException,
BaseAnalysisException):
Failed to analyze a SQL query plan from Spark Connect server.
"""
-def __init__(
-self,
-message: Optional[str] = None,
-error_class: Optional[str] = None,
-message_parameters: Optional[Dict[str, str]] = None,
-plan: Optional[str] = None,
-reason: Optional[str] = None,
-) -> None:
-self.message = message # type: ignore[assignment]
-if plan is not None:
-self.message = f"{self.message}\nPlan: {plan}"
Review Comment:
Example:
```python
spark.range(1).select("a").show()
```
```
Traceback (most recent call last):
File "", line 1, in
File "/.../spark/python/pyspark/sql/connect/dataframe.py", line 776, in
show
print(self._show_string(n, truncate, vertical))
File "/.../spark/python/pyspark/sql/connect/dataframe.py", line 619, in
_show_string
pdf = DataFrame.withPlan(
File "/.../spark/python/pyspark/sql/connect/dataframe.py", line 1325, in
toPandas
return self._session.client.to_pandas(query)
File "/.../spark/python/pyspark/sql/connect/client.py", line 449, in
to_pandas
table, metrics = self._execute_and_fetch(req)
File "/.../spark/python/pyspark/sql/connect/client.py", line 636, in
_execute_and_fetch
self._handle_error(rpc_error)
File "/.../spark/python/pyspark/sql/connect/client.py", line 670, in
_handle_error
raise convert_exception(info, status.message) from None
pyspark.errors.exceptions.connect.AnalysisException:
[UNRESOLVED_COLUMN.WITH_SUGGESTION] A column or function parameter with name
`a` cannot be resolved. Did you mean one of the following? [`id`].;
'Project ['a]
+- Range (0, 1, step=1, splits=Some(16))
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39947: [SPARK-40453][SPARK-41715][CONNECT] Take super class into account when throwing an exception
HyukjinKwon commented on code in PR #39947:
URL: https://github.com/apache/spark/pull/39947#discussion_r1101075312
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectService.scala:
##
@@ -83,27 +107,19 @@ class SparkConnectService(debug: Boolean)
private def handleError[V](
opType: String,
observer: StreamObserver[V]): PartialFunction[Throwable, Unit] = {
-case ae: AnalysisException =>
- logError(s"Error during: $opType", ae)
- val status = RPCStatus
-.newBuilder()
-.setCode(RPCCode.INTERNAL_VALUE)
-.addDetails(
- ProtoAny.pack(
-ErrorInfo
- .newBuilder()
- .setReason(ae.getClass.getName)
- .setDomain("org.apache.spark")
- .putMetadata("message", ae.getSimpleMessage)
- .putMetadata("plan", Option(ae.plan).flatten.map(p =>
s"$p").getOrElse(""))
- .build()))
-.setMessage(ae.getLocalizedMessage)
-.build()
- observer.onError(StatusProto.toStatusRuntimeException(status))
+case se: SparkException
+if se.getCause != null && se.getCause
+ .isInstanceOf[PythonException] && se.getCause.getStackTrace
+
.exists(_.toString.contains("org.apache.spark.sql.execution.python")) =>
+ // Python UDF execution
+ logError(s"Error during: $opType", se)
+ observer.onError(
+
StatusProto.toStatusRuntimeException(buildStatusFromThrowable(se.getCause)))
Review Comment:
Example:
```python
from pyspark.sql.functions import udf
@udf
def aa(a):
1/0
spark.range(1).select(aa("id")).show()
```
```
Traceback (most recent call last):
File "", line 1, in
File "/.../spark/python/pyspark/sql/connect/dataframe.py", line 776, in
show
print(self._show_string(n, truncate, vertical))
File "/.../spark/python/pyspark/sql/connect/dataframe.py", line 619, in
_show_string
pdf = DataFrame.withPlan(
File "/.../spark/python/pyspark/sql/connect/dataframe.py", line 1325, in
toPandas
return self._session.client.to_pandas(query)
File "/.../spark/python/pyspark/sql/connect/client.py", line 449, in
to_pandas
table, metrics = self._execute_and_fetch(req)
File "/.../spark/python/pyspark/sql/connect/client.py", line 636, in
_execute_and_fetch
self._handle_error(rpc_error)
File "/.../spark/python/pyspark/sql/connect/client.py", line 670, in
_handle_error
raise convert_exception(info, status.message) from None
pyspark.errors.exceptions.connect.PythonException:
An exception was thrown from the Python worker. Please see the stack trace
below.
Traceback (most recent call last):
File "", line 3, in aa
ZeroDivisionError: division by zero
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39947: [SPARK-40453][SPARK-41715][CONNECT] Take super class into account when throwing an exception
HyukjinKwon commented on code in PR #39947:
URL: https://github.com/apache/spark/pull/39947#discussion_r1101075312
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectService.scala:
##
@@ -83,27 +107,19 @@ class SparkConnectService(debug: Boolean)
private def handleError[V](
opType: String,
observer: StreamObserver[V]): PartialFunction[Throwable, Unit] = {
-case ae: AnalysisException =>
- logError(s"Error during: $opType", ae)
- val status = RPCStatus
-.newBuilder()
-.setCode(RPCCode.INTERNAL_VALUE)
-.addDetails(
- ProtoAny.pack(
-ErrorInfo
- .newBuilder()
- .setReason(ae.getClass.getName)
- .setDomain("org.apache.spark")
- .putMetadata("message", ae.getSimpleMessage)
- .putMetadata("plan", Option(ae.plan).flatten.map(p =>
s"$p").getOrElse(""))
- .build()))
-.setMessage(ae.getLocalizedMessage)
-.build()
- observer.onError(StatusProto.toStatusRuntimeException(status))
+case se: SparkException
+if se.getCause != null && se.getCause
+ .isInstanceOf[PythonException] && se.getCause.getStackTrace
+
.exists(_.toString.contains("org.apache.spark.sql.execution.python")) =>
+ // Python UDF execution
+ logError(s"Error during: $opType", se)
+ observer.onError(
+
StatusProto.toStatusRuntimeException(buildStatusFromThrowable(se.getCause)))
Review Comment:
Example:
```
Traceback (most recent call last):
File "", line 1, in
File "/.../spark/python/pyspark/sql/connect/dataframe.py", line 776, in
show
print(self._show_string(n, truncate, vertical))
File "/.../spark/python/pyspark/sql/connect/dataframe.py", line 619, in
_show_string
pdf = DataFrame.withPlan(
File "/.../spark/python/pyspark/sql/connect/dataframe.py", line 1325, in
toPandas
return self._session.client.to_pandas(query)
File "/.../spark/python/pyspark/sql/connect/client.py", line 449, in
to_pandas
table, metrics = self._execute_and_fetch(req)
File "/.../spark/python/pyspark/sql/connect/client.py", line 636, in
_execute_and_fetch
self._handle_error(rpc_error)
File "/.../spark/python/pyspark/sql/connect/client.py", line 670, in
_handle_error
raise convert_exception(info, status.message) from None
pyspark.errors.exceptions.connect.PythonException:
An exception was thrown from the Python worker. Please see the stack trace
below.
Traceback (most recent call last):
File "", line 3, in aa
ZeroDivisionError: division by zero
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] panbingkun commented on pull request #39865: [SPARK-42052][SQL] Codegen Support for HiveSimpleUDF
panbingkun commented on PR #39865: URL: https://github.com/apache/spark/pull/39865#issuecomment-1423716592 > Hm, I think we should better go and figure out to resolve this by using `Invoke` so we don't have to manually implement the codegen logic. I was fine with #39555 as a one time thing but seems like there are some more to fix. As the first step, I have submitted a new Pr(https://github.com/apache/spark/pull/39949) to rewrite HiveGenericUDF with Invoke. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] panbingkun opened a new pull request, #39949: [SPARK-42386][SQL] Rewrite HiveGenericUDF with Invoke
panbingkun opened a new pull request, #39949: URL: https://github.com/apache/spark/pull/39949 ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #39941: [MINOR][DOCS] Add link to Hadoop docs
itholic commented on code in PR #39941: URL: https://github.com/apache/spark/pull/39941#discussion_r1101026968 ## docs/rdd-programming-guide.md: ## @@ -442,7 +442,7 @@ Apart from text files, Spark's Python API also supports several other data forma **Writable Support** -PySpark SequenceFile support loads an RDD of key-value pairs within Java, converts Writables to base Java types, and pickles the +PySpark SequenceFile support loads an RDD of key-value pairs within Java, converts [Writables](https://hadoop.apache.org/docs/current/api/org/apache/hadoop/io/Writable.html) to base Java types, and pickles the Review Comment: Sounds good! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] chaoqin-li1123 commented on pull request #39897: [WIP][SPARK-42353][SS] Cleanup orphan sst and log files in RocksDB checkpoint directory
chaoqin-li1123 commented on PR #39897: URL: https://github.com/apache/spark/pull/39897#issuecomment-1423698887 @rangadi -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] chaoqin-li1123 commented on a diff in pull request #39897: [WIP][SPARK-42353][SS] Cleanup orphan sst and log files in RocksDB checkpoint directory
chaoqin-li1123 commented on code in PR #39897:
URL: https://github.com/apache/spark/pull/39897#discussion_r1101025106
##
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/RocksDBFileManager.scala:
##
@@ -269,29 +306,46 @@ class RocksDBFileManager(
s"$numVersionsToRetain versions")
// Resolve RocksDB files for all the versions and find the max version
each file is used
-val fileToMaxUsedVersion = new mutable.HashMap[RocksDBImmutableFile, Long]
+val fileToMaxUsedVersion = new mutable.HashMap[String, Long]
sortedVersions.foreach { version =>
val files = Option(versionToRocksDBFiles.get(version)).getOrElse {
val newResolvedFiles = getImmutableFilesFromVersionZip(version)
versionToRocksDBFiles.put(version, newResolvedFiles)
newResolvedFiles
}
- files.foreach(f => fileToMaxUsedVersion(f) = version)
+ files.foreach(f => fileToMaxUsedVersion(f.dfsFileName) =
+math.max(version, fileToMaxUsedVersion.getOrElse(f.dfsFileName,
version)))
}
// Best effort attempt to delete SST files that were last used in
to-be-deleted versions
val filesToDelete = fileToMaxUsedVersion.filter { case (_, v) =>
versionsToDelete.contains(v) }
+
+val sstDir = new Path(dfsRootDir,
RocksDBImmutableFile.SST_FILES_DFS_SUBDIR)
+val logDir = new Path(dfsRootDir,
RocksDBImmutableFile.LOG_FILES_DFS_SUBDIR)
+val allSstFiles = if (fm.exists(sstDir)) fm.list(sstDir).toSeq else
Seq.empty
+val allLogFiles = if (fm.exists(logDir)) fm.list(logDir).toSeq else
Seq.empty
+filesToDelete ++= findOrphanFiles(fileToMaxUsedVersion.keys.toSeq,
allSstFiles ++ allLogFiles)
+ .map(_ -> -1L)
logInfo(s"Deleting ${filesToDelete.size} files not used in versions >=
$minVersionToRetain")
var failedToDelete = 0
-filesToDelete.foreach { case (file, maxUsedVersion) =>
+filesToDelete.foreach { case (dfsFileName, maxUsedVersion) =>
try {
-val dfsFile = dfsFilePath(file.dfsFileName)
+val dfsFile = dfsFilePath(dfsFileName)
fm.delete(dfsFile)
-logDebug(s"Deleted file $file that was last used in version
$maxUsedVersion")
+if (maxUsedVersion == -1) {
+ logDebug(s"Deleted orphan file $dfsFileName")
+} else {
+ logDebug(s"Deleted file $dfsFileName that was last used in version
$maxUsedVersion")
+}
+logDebug(s"Deleted file $dfsFileName that was last used in version
$maxUsedVersion")
Review Comment:
Thanks, fixed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39937: [SPARK-42309][SQL] Assign name to _LEGACY_ERROR_TEMP_1204
itholic commented on PR #39937: URL: https://github.com/apache/spark/pull/39937#issuecomment-1423666280 @MaxGekk Just updated the structure to apply sub-error classes per each `addError`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] db-scnakandala commented on a diff in pull request #39722: [SPARK-42162] Introduce MultiCommutativeOp expression as a memory optimization for canonicalizing large trees of commutative
db-scnakandala commented on code in PR #39722:
URL: https://github.com/apache/spark/pull/39722#discussion_r1101002739
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/arithmetic.scala:
##
@@ -632,7 +636,12 @@ case class Multiply(
override lazy val canonicalized: Expression = {
// TODO: do not reorder consecutive `Multiply`s with different `evalMode`
-orderCommutative({ case Multiply(l, r, _) => Seq(l, r)
}).reduce(Multiply(_, _, evalMode))
+val reorderResult = buildCanonicalizedPlan(
+ { case Multiply(l, r, _) => Seq(l, r) }
+ { case (l: Expression, r: Expression) => Multiply(l, r, evalMode)},
+ Some(evalMode)
+)
+reorderResult
Review Comment:
done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #39722: [SPARK-42162] Introduce MultiCommutativeOp expression as a memory optimization for canonicalizing large trees of commutative expr
cloud-fan commented on code in PR #39722:
URL: https://github.com/apache/spark/pull/39722#discussion_r1101001554
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/arithmetic.scala:
##
@@ -479,8 +480,11 @@ case class Add(
override lazy val canonicalized: Expression = {
// TODO: do not reorder consecutive `Add`s with different `evalMode`
-val reorderResult =
- orderCommutative({ case Add(l, r, _) => Seq(l, r) }).reduce(Add(_, _,
evalMode))
+val reorderResult = buildCanonicalizedPlan(
+ { case Add(l, r, _) => Seq(l, r) },
+ { case (l: Expression, r: Expression) => Add(l, r, evalMode)},
+ Some(evalMode)
+)
if (resolved && reorderResult.resolved && reorderResult.dataType ==
dataType) {
Review Comment:
not related to this PR, @gengliangwang do we have a followup to apply this
fix for multiply?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #39722: [SPARK-42162] Introduce MultiCommutativeOp expression as a memory optimization for canonicalizing large trees of commutative expr
cloud-fan commented on code in PR #39722:
URL: https://github.com/apache/spark/pull/39722#discussion_r1101000846
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/arithmetic.scala:
##
@@ -632,7 +636,12 @@ case class Multiply(
override lazy val canonicalized: Expression = {
// TODO: do not reorder consecutive `Multiply`s with different `evalMode`
-orderCommutative({ case Multiply(l, r, _) => Seq(l, r)
}).reduce(Multiply(_, _, evalMode))
+val reorderResult = buildCanonicalizedPlan(
+ { case Multiply(l, r, _) => Seq(l, r) }
+ { case (l: Expression, r: Expression) => Multiply(l, r, evalMode)},
+ Some(evalMode)
+)
+reorderResult
Review Comment:
```suggestion
buildCanonicalizedPlan(
{ case Multiply(l, r, _) => Seq(l, r) }
{ case (l: Expression, r: Expression) => Multiply(l, r, evalMode)},
Some(evalMode)
)
```
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/arithmetic.scala:
##
@@ -632,7 +636,12 @@ case class Multiply(
override lazy val canonicalized: Expression = {
// TODO: do not reorder consecutive `Multiply`s with different `evalMode`
-orderCommutative({ case Multiply(l, r, _) => Seq(l, r)
}).reduce(Multiply(_, _, evalMode))
+val reorderResult = buildCanonicalizedPlan(
+ { case Multiply(l, r, _) => Seq(l, r) }
+ { case (l: Expression, r: Expression) => Multiply(l, r, evalMode)},
+ Some(evalMode)
+)
+reorderResult
Review Comment:
same for other places.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang opened a new pull request, #39948: [SPARK-42385][BUILD] Upgrade RoaringBitmap to 0.9.39
LuciferYang opened a new pull request, #39948: URL: https://github.com/apache/spark/pull/39948 ### What changes were proposed in this pull request? This pr aims upgrade RoaringBitmap 0.9.39 ### Why are the changes needed? This version bring a bug fix: - https://github.com/RoaringBitmap/RoaringBitmap/pull/614 other changes as follows: https://github.com/RoaringBitmap/RoaringBitmap/compare/0.9.38...0.9.39 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GitHub Actions -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39947: [SPARK-40453][SPARK-41715][CONNECT] Take super class into account when throwing an exception
HyukjinKwon commented on code in PR #39947:
URL: https://github.com/apache/spark/pull/39947#discussion_r1100994819
##
python/pyspark/errors/exceptions/connect.py:
##
@@ -61,41 +97,34 @@ class AnalysisException(SparkConnectGrpcException,
BaseAnalysisException):
Failed to analyze a SQL query plan from Spark Connect server.
"""
-def __init__(
-self,
-message: Optional[str] = None,
-error_class: Optional[str] = None,
-message_parameters: Optional[Dict[str, str]] = None,
-plan: Optional[str] = None,
-reason: Optional[str] = None,
-) -> None:
-self.message = message # type: ignore[assignment]
-if plan is not None:
-self.message = f"{self.message}\nPlan: {plan}"
Review Comment:
The original `AnalysisException.getMessage` contains the string
representation of the underlying plan.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39947: [SPARK-40453][SPARK-41715][CONNECT] Take super class into account when throwing an exception
HyukjinKwon commented on code in PR #39947:
URL: https://github.com/apache/spark/pull/39947#discussion_r1100994134
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/service/SparkConnectService.scala:
##
@@ -53,19 +59,37 @@ class SparkConnectService(debug: Boolean)
extends SparkConnectServiceGrpc.SparkConnectServiceImplBase
with Logging {
- private def buildStatusFromThrowable[A <: Throwable with SparkThrowable](st:
A): RPCStatus = {
-val t = Option(st.getCause).getOrElse(st)
+ private def allClasses(cl: Class[_]): Seq[Class[_]] = {
+val classes = ArrayBuffer.empty[Class[_]]
+if (cl != null && cl != classOf[java.lang.Object]) {
+ classes.append(cl) // Includes itself.
+}
+
+@tailrec
+def appendSuperClasses(clazz: Class[_]): Unit = {
+ if (clazz == null || clazz == classOf[java.lang.Object]) return
+ classes.append(clazz.getSuperclass)
+ appendSuperClasses(clazz.getSuperclass)
+}
+
+appendSuperClasses(cl)
+classes
+ }
+
+ private def buildStatusFromThrowable(st: Throwable): RPCStatus = {
RPCStatus
.newBuilder()
.setCode(RPCCode.INTERNAL_VALUE)
.addDetails(
ProtoAny.pack(
ErrorInfo
.newBuilder()
-.setReason(t.getClass.getName)
+.setReason(st.getClass.getName)
.setDomain("org.apache.spark")
+.putMetadata("message", StringUtils.abbreviate(st.getMessage,
2048))
Review Comment:
Otherwise, it complains the header length (8KiB limit). It can be configured
below via `NettyChannelBuilder.maxInboundMessageSize` but I didn't change it
here, see also https://stackoverflow.com/a/686243
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #39897: [WIP][SPARK-42353][SS] Cleanup orphan sst and log files in RocksDB checkpoint directory
HeartSaVioR commented on code in PR #39897:
URL: https://github.com/apache/spark/pull/39897#discussion_r1100978171
##
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/state/RocksDBFileManager.scala:
##
@@ -269,29 +306,46 @@ class RocksDBFileManager(
s"$numVersionsToRetain versions")
// Resolve RocksDB files for all the versions and find the max version
each file is used
-val fileToMaxUsedVersion = new mutable.HashMap[RocksDBImmutableFile, Long]
+val fileToMaxUsedVersion = new mutable.HashMap[String, Long]
sortedVersions.foreach { version =>
val files = Option(versionToRocksDBFiles.get(version)).getOrElse {
val newResolvedFiles = getImmutableFilesFromVersionZip(version)
versionToRocksDBFiles.put(version, newResolvedFiles)
newResolvedFiles
}
- files.foreach(f => fileToMaxUsedVersion(f) = version)
+ files.foreach(f => fileToMaxUsedVersion(f.dfsFileName) =
+math.max(version, fileToMaxUsedVersion.getOrElse(f.dfsFileName,
version)))
}
// Best effort attempt to delete SST files that were last used in
to-be-deleted versions
val filesToDelete = fileToMaxUsedVersion.filter { case (_, v) =>
versionsToDelete.contains(v) }
+
+val sstDir = new Path(dfsRootDir,
RocksDBImmutableFile.SST_FILES_DFS_SUBDIR)
+val logDir = new Path(dfsRootDir,
RocksDBImmutableFile.LOG_FILES_DFS_SUBDIR)
+val allSstFiles = if (fm.exists(sstDir)) fm.list(sstDir).toSeq else
Seq.empty
+val allLogFiles = if (fm.exists(logDir)) fm.list(logDir).toSeq else
Seq.empty
+filesToDelete ++= findOrphanFiles(fileToMaxUsedVersion.keys.toSeq,
allSstFiles ++ allLogFiles)
+ .map(_ -> -1L)
logInfo(s"Deleting ${filesToDelete.size} files not used in versions >=
$minVersionToRetain")
var failedToDelete = 0
-filesToDelete.foreach { case (file, maxUsedVersion) =>
+filesToDelete.foreach { case (dfsFileName, maxUsedVersion) =>
try {
-val dfsFile = dfsFilePath(file.dfsFileName)
+val dfsFile = dfsFilePath(dfsFileName)
fm.delete(dfsFile)
-logDebug(s"Deleted file $file that was last used in version
$maxUsedVersion")
+if (maxUsedVersion == -1) {
+ logDebug(s"Deleted orphan file $dfsFileName")
+} else {
+ logDebug(s"Deleted file $dfsFileName that was last used in version
$maxUsedVersion")
+}
+logDebug(s"Deleted file $dfsFileName that was last used in version
$maxUsedVersion")
Review Comment:
nit: remove?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] db-scnakandala commented on a diff in pull request #39722: [SPARK-42162] Introduce MultiCommutativeOp expression as a memory optimization for canonicalizing large trees of commutative
db-scnakandala commented on code in PR #39722:
URL: https://github.com/apache/spark/pull/39722#discussion_r1100974436
##
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:
##
@@ -240,6 +240,15 @@ object SQLConf {
.intConf
.createWithDefault(100)
+ val MULTI_COMMUTATIVE_OP_OPT_THRESHOLD =
+
buildConf("spark.sql.analyzer.canonicalization.multiCommutativeOpMemoryOptThreshold")
+ .internal()
+ .doc("The minimum number of consecutive non-commutative operands to" +
Review Comment:
Changed it to `The minimum number of operands in a commutative expression
tree`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #39722: [SPARK-42162] Introduce MultiCommutativeOp expression as a memory optimization for canonicalizing large trees of commutative expr
cloud-fan commented on code in PR #39722:
URL: https://github.com/apache/spark/pull/39722#discussion_r1100956662
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Expression.scala:
##
@@ -1335,3 +1335,72 @@ trait CommutativeExpression extends Expression {
f: PartialFunction[CommutativeExpression, Seq[Expression]]):
Seq[Expression] =
gatherCommutative(this, f).sortBy(_.hashCode())
}
+
+/**
+ * A helper class used by the Commutative expressions during canonicalization.
During
+ * canonicalization, when we have a long tree of commutative operations, we
use the MultiCommutative
+ * expression to represent that tree instead of creating new commutative
objects.
+ * This class is added as a memory optimization for processing large
commutative operation trees
+ * without creating a large number of new intermediate objects.
+ * The MultiCommutativeOp memory optimization is applied to the following
commutative
+ * expressions:
+ * Add, Multiply, And, Or, BitwiseAnd, BitwiseOr, BitwiseXor.
+ * @param operands A sequence of operands that produces a commutative
expression tree.
+ * @param opCls The class of the root operator of the expression tree.
+ * @param evalMode The optional expression evaluation mode.
+ * @param originalRoot Root operator of the commutative expression tree before
canonicalization.
+ * This object reference is used to deduce the return
dataType of Add and
+ * Multiply operations when the input datatype is decimal.
+ */
+case class MultiCommutativeOp(
+operands: Seq[Expression],
+opCls: Class[_],
+evalMode: Option[EvalMode.Value])(originalRoot: Expression) extends
Unevaluable {
+ // Helper method to deduce the data type of a single operation.
+ private def singleOpDataType(lType: DataType, rType: DataType): DataType = {
+originalRoot match {
+ case add: Add =>
+(lType, rType) match {
+ case (DecimalType.Fixed(p1, s1), DecimalType.Fixed(p2, s2)) =>
+add.resultDecimalType(p1, s1, p2, s2)
+ case _ => lType
+}
+ case multiply: Multiply =>
+(lType, rType) match {
+ case (DecimalType.Fixed(p1, s1), DecimalType.Fixed(p2, s2)) =>
+multiply.resultDecimalType(p1, s1, p2, s2)
+ case _ => lType
+}
+}
+ }
+
+ /**
+ * Returns the [[DataType]] of the result of evaluating this expression. It
is
+ * invalid to query the dataType of an unresolved expression (i.e., when
`resolved` == false).
+ */
+ override def dataType: DataType = {
+originalRoot match {
+ case _: Add | _: Multiply =>
+operands.map(_.dataType).reduce((l, r) => singleOpDataType(l, r))
+ case other => other.dataType
+}
+ }
+
+ /**
+ * Returns whether this node is nullable. This node is nullable if any of
its children is
+ * nullable.
+ */
+ override def nullable: Boolean = operands.exists(_.nullable)
+
+ /**
+ * Returns a Seq of the children of this node.
+ * Children should not change. Immutability required for containsChild
optimization
+ */
+ override def children: Seq[Expression] = operands
+
Review Comment:
how about providing a util function in this trait so that sub-classes is
easier to do canonicalization?
```
def buildCanonicalizedPlan(collectOperands: PartialFunction[Expression,
Seq[Expression]], buildBinaryOp: (Expression, Expression) => Expression) = ...
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #39722: [SPARK-42162] Introduce MultiCommutativeOp expression as a memory optimization for canonicalizing large trees of commutative expr
cloud-fan commented on code in PR #39722:
URL: https://github.com/apache/spark/pull/39722#discussion_r1100955001
##
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:
##
@@ -240,6 +240,15 @@ object SQLConf {
.intConf
.createWithDefault(100)
+ val MULTI_COMMUTATIVE_OP_OPT_THRESHOLD =
+
buildConf("spark.sql.analyzer.canonicalization.multiCommutativeOpMemoryOptThreshold")
+ .internal()
+ .doc("The minimum number of consecutive non-commutative operands to" +
Review Comment:
non-commutative?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #39722: [SPARK-42162] Introduce MultiCommutativeOp expression as a memory optimization for canonicalizing large trees of commutative expr
cloud-fan commented on code in PR #39722:
URL: https://github.com/apache/spark/pull/39722#discussion_r1100954235
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Expression.scala:
##
@@ -1335,3 +1335,72 @@ trait CommutativeExpression extends Expression {
f: PartialFunction[CommutativeExpression, Seq[Expression]]):
Seq[Expression] =
gatherCommutative(this, f).sortBy(_.hashCode())
}
+
+/**
+ * A helper class used by the Commutative expressions during canonicalization.
During
+ * canonicalization, when we have a long tree of commutative operations, we
use the MultiCommutative
+ * expression to represent that tree instead of creating new commutative
objects.
+ * This class is added as a memory optimization for processing large
commutative operation trees
+ * without creating a large number of new intermediate objects.
+ * The MultiCommutativeOp memory optimization is applied to the following
commutative
+ * expressions:
+ * Add, Multiply, And, Or, BitwiseAnd, BitwiseOr, BitwiseXor.
+ * @param operands A sequence of operands that produces a commutative
expression tree.
+ * @param opCls The class of the root operator of the expression tree.
+ * @param evalMode The optional expression evaluation mode.
+ * @param originalRoot Root operator of the commutative expression tree before
canonicalization.
+ * This object reference is used to deduce the return
dataType of Add and
+ * Multiply operations when the input datatype is decimal.
+ */
+case class MultiCommutativeOp(
+operands: Seq[Expression],
+opCls: Class[_],
+evalMode: Option[EvalMode.Value])(originalRoot: Expression) extends
Unevaluable {
+ // Helper method to deduce the data type of a single operation.
+ private def singleOpDataType(lType: DataType, rType: DataType): DataType = {
+originalRoot match {
+ case add: Add =>
+(lType, rType) match {
+ case (DecimalType.Fixed(p1, s1), DecimalType.Fixed(p2, s2)) =>
+add.resultDecimalType(p1, s1, p2, s2)
+ case _ => lType
+}
+ case multiply: Multiply =>
+(lType, rType) match {
+ case (DecimalType.Fixed(p1, s1), DecimalType.Fixed(p2, s2)) =>
+multiply.resultDecimalType(p1, s1, p2, s2)
+ case _ => lType
+}
+}
+ }
+
+ /**
+ * Returns the [[DataType]] of the result of evaluating this expression. It
is
+ * invalid to query the dataType of an unresolved expression (i.e., when
`resolved` == false).
Review Comment:
nit: if you look at other sub-classes of `Expression`, we don't repeat the
api doc in the override methods.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon opened a new pull request, #39947: [SPARK-40453][SPARK-41715][CONNECT] Take super class into account when throwing an exception
HyukjinKwon opened a new pull request, #39947: URL: https://github.com/apache/spark/pull/39947 ### What changes were proposed in this pull request? This PR proposes to take the super classes into account when throwing an exception from the server to Python side by adding more metadata of classes, causes and traceback in JVM. In addition, this PR matches the exceptions being thrown to the regular PySpark exceptions defined: https://github.com/apache/spark/blob/04550edd49ee587656d215e59d6a072772d7d5ec/python/pyspark/errors/exceptions/captured.py#L108-L147 ### Why are the changes needed? Right now, many exceptions cannot be handled (e.g., `NoSuchDatabaseException` that inherits `AnalysisException`) in Python side. ### Does this PR introduce _any_ user-facing change? No to end users. Yes, it matches the exceptions to the regular PySpark exceptions. ### How was this patch tested? Unittests fixed. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
beliefer commented on PR #38799: URL: https://github.com/apache/spark/pull/38799#issuecomment-1423565384 > there are 3 tpc queries having plan change, what's their perf result? 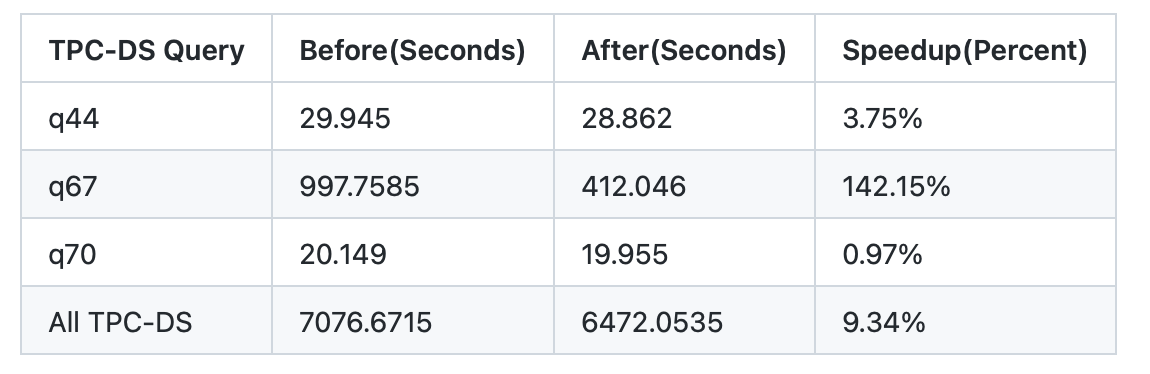 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39893: [SPARK-42350][SQL][K8S][SS] Replcace `get().getOrElse` with `getOrElse`
LuciferYang commented on PR #39893: URL: https://github.com/apache/spark/pull/39893#issuecomment-1423562100 Thanks @srowen -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39899: [SPARK-42355][BUILD] Upgrade some maven-plugins
LuciferYang commented on PR #39899: URL: https://github.com/apache/spark/pull/39899#issuecomment-1423561970 Thanks @srowen @HyukjinKwon -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #39946: [SPARK-42310][SQL] Assign name to _LEGACY_ERROR_TEMP_1289
itholic commented on code in PR #39946:
URL: https://github.com/apache/spark/pull/39946#discussion_r1100935378
##
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSourceUtils.scala:
##
@@ -73,7 +73,8 @@ object DataSourceUtils extends PredicateHelper {
def checkFieldNames(format: FileFormat, schema: StructType): Unit = {
schema.foreach { field =>
if (!format.supportFieldName(field.name)) {
-throw
QueryCompilationErrors.columnNameContainsInvalidCharactersError(field.name)
+throw QueryCompilationErrors.invalidColumnNameAsPathError(
+ format.getClass.getSimpleName, field.name)
Review Comment:
FYI: If we don't use `getSimpleName` here, it displays the format with full
package path something like:
`org.apache.spark.sql.hive.execution.HiveFileFormat`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39946: [SPARK-42310][SQL] Assign name to _LEGACY_ERROR_TEMP_1289
itholic commented on PR #39946: URL: https://github.com/apache/spark/pull/39946#issuecomment-1423557987 Thanks for the review, @MaxGekk ! Just adjusted the comments. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100921709
##
sql/core/src/main/scala/org/apache/spark/sql/execution/window/WindowGroupLimitExec.scala:
##
@@ -0,0 +1,245 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.window
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Ascending, Attribute,
DenseRank, Expression, Rank, RowNumber, SortOrder, UnsafeProjection, UnsafeRow}
+import org.apache.spark.sql.catalyst.expressions.codegen.GenerateOrdering
+import org.apache.spark.sql.catalyst.plans.physical.{AllTuples,
ClusteredDistribution, Distribution, Partitioning}
+import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
+
+sealed trait WindowGroupLimitMode
+
+case object Partial extends WindowGroupLimitMode
+
+case object Final extends WindowGroupLimitMode
+
+/**
+ * This operator is designed to filter out unnecessary rows before WindowExec
+ * for top-k computation.
+ * @param partitionSpec Should be the same as [[WindowExec#partitionSpec]].
+ * @param orderSpec Should be the same as [[WindowExec#orderSpec]].
+ * @param rankLikeFunction The function to compute row rank, should be
RowNumber/Rank/DenseRank.
+ * @param limit The limit for rank value.
+ * @param mode The mode describes [[WindowGroupLimitExec]] before or after
shuffle.
+ * @param child The child spark plan.
+ */
+case class WindowGroupLimitExec(
+partitionSpec: Seq[Expression],
+orderSpec: Seq[SortOrder],
+rankLikeFunction: Expression,
+limit: Int,
+mode: WindowGroupLimitMode,
+child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def requiredChildDistribution: Seq[Distribution] = mode match {
+case Partial => super.requiredChildDistribution
+case Final =>
+ if (partitionSpec.isEmpty) {
+AllTuples :: Nil
+ } else {
+ClusteredDistribution(partitionSpec) :: Nil
+ }
+ }
+
+ override def requiredChildOrdering: Seq[Seq[SortOrder]] =
+Seq(partitionSpec.map(SortOrder(_, Ascending)) ++ orderSpec)
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def outputPartitioning: Partitioning = child.outputPartitioning
+
+ protected override def doExecute(): RDD[InternalRow] = rankLikeFunction
match {
+case _: RowNumber =>
+ child.execute().mapPartitionsInternal(
+SimpleGroupLimitIterator(partitionSpec, output, _, limit))
+case _: Rank =>
+ child.execute().mapPartitionsInternal(
+RankGroupLimitIterator(partitionSpec, output, _, orderSpec, limit))
+case _: DenseRank =>
+ child.execute().mapPartitionsInternal(
+DenseRankGroupLimitIterator(partitionSpec, output, _, orderSpec,
limit))
+ }
+
+ override protected def withNewChildInternal(newChild: SparkPlan):
WindowGroupLimitExec =
+copy(child = newChild)
+}
+
+abstract class WindowIterator extends Iterator[InternalRow] {
+
+ def partitionSpec: Seq[Expression]
+
+ def output: Seq[Attribute]
+
+ def input: Iterator[InternalRow]
+
+ def limit: Int
+
+ val grouping = UnsafeProjection.create(partitionSpec, output)
Review Comment:
Yes. I have another PR do the work.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on a diff in pull request #39941: [MINOR][DOCS] Add link to Hadoop docs
srowen commented on code in PR #39941: URL: https://github.com/apache/spark/pull/39941#discussion_r1100921708 ## docs/rdd-programming-guide.md: ## @@ -442,7 +442,7 @@ Apart from text files, Spark's Python API also supports several other data forma **Writable Support** -PySpark SequenceFile support loads an RDD of key-value pairs within Java, converts Writables to base Java types, and pickles the +PySpark SequenceFile support loads an RDD of key-value pairs within Java, converts [Writables](https://hadoop.apache.org/docs/current/api/org/apache/hadoop/io/Writable.html) to base Java types, and pickles the Review Comment: Yeah I might write `[Writable](..)s` but that's awkward. `[Writable](...) objects`? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on pull request #39899: [SPARK-42355][BUILD] Upgrade some maven-plugins
srowen commented on PR #39899: URL: https://github.com/apache/spark/pull/39899#issuecomment-1423539058 Merged to master -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen closed pull request #39899: [SPARK-42355][BUILD] Upgrade some maven-plugins
srowen closed pull request #39899: [SPARK-42355][BUILD] Upgrade some maven-plugins URL: https://github.com/apache/spark/pull/39899 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen closed pull request #39893: [SPARK-42350][SQL][K8S][SS] Replcace `get().getOrElse` with `getOrElse`
srowen closed pull request #39893: [SPARK-42350][SQL][K8S][SS] Replcace `get().getOrElse` with `getOrElse` URL: https://github.com/apache/spark/pull/39893 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on pull request #39893: [SPARK-42350][SQL][K8S][SS] Replcace `get().getOrElse` with `getOrElse`
srowen commented on PR #39893: URL: https://github.com/apache/spark/pull/39893#issuecomment-1423538496 Merged to master -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100920458
##
sql/core/src/test/scala/org/apache/spark/sql/DataFrameWindowFunctionsSuite.scala:
##
@@ -1265,4 +1265,168 @@ class DataFrameWindowFunctionsSuite extends QueryTest
)
)
}
+
+ test("SPARK-37099: Insert window group limit node for top-k computation") {
+
+val nullStr: String = null
+val df = Seq(
+ ("a", 0, "c", 1.0),
+ ("a", 1, "x", 2.0),
+ ("a", 2, "y", 3.0),
+ ("a", 3, "z", -1.0),
+ ("a", 4, "", 2.0),
+ ("a", 4, "", 2.0),
+ ("b", 1, "h", Double.NaN),
+ ("b", 1, "n", Double.PositiveInfinity),
+ ("c", 1, "z", -2.0),
+ ("c", 1, "a", -4.0),
+ ("c", 2, nullStr, 5.0)).toDF("key", "value", "order", "value2")
+
+val window = Window.partitionBy($"key").orderBy($"order".asc_nulls_first)
+val window2 = Window.partitionBy($"key").orderBy($"order".desc_nulls_first)
+
+Seq(-1, 100).foreach { threshold =>
+ withSQLConf(SQLConf.WINDOW_GROUP_LIMIT_THRESHOLD.key ->
threshold.toString) {
+Seq($"rn" === 0, $"rn" < 1, $"rn" <= 0).foreach { condition =>
+ checkAnswer(df.withColumn("rn",
row_number().over(window)).where(condition),
+Seq.empty[Row]
+ )
+}
+
+Seq($"rn" === 1, $"rn" < 2, $"rn" <= 1).foreach { condition =>
+ checkAnswer(df.withColumn("rn",
row_number().over(window)).where(condition),
+Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("c", 2, null, 5.0, 1)
+)
+ )
+
+ checkAnswer(df.withColumn("rn",
rank().over(window)).where(condition),
+Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("c", 2, null, 5.0, 1)
+)
+ )
+
+ checkAnswer(df.withColumn("rn",
dense_rank().over(window)).where(condition),
+Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("c", 2, null, 5.0, 1)
+)
+ )
+}
+
+Seq($"rn" < 3, $"rn" <= 2).foreach { condition =>
+ checkAnswer(df.withColumn("rn",
row_number().over(window)).where(condition),
+Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 2),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("b", 1, "n", Double.PositiveInfinity, 2),
+ Row("c", 1, "a", -4.0, 2),
+ Row("c", 2, null, 5.0, 1)
+)
+ )
+
+ checkAnswer(df.withColumn("rn",
rank().over(window)).where(condition),
+Seq(
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("b", 1, "n", Double.PositiveInfinity, 2),
+ Row("c", 1, "a", -4.0, 2),
+ Row("c", 2, null, 5.0, 1)
+)
+ )
+
+ checkAnswer(df.withColumn("rn",
dense_rank().over(window)).where(condition),
+Seq(
+ Row("a", 0, "c", 1.0, 2),
+ Row("a", 4, "", 2.0, 1),
+ Row("a", 4, "", 2.0, 1),
+ Row("b", 1, "h", Double.NaN, 1),
+ Row("b", 1, "n", Double.PositiveInfinity, 2),
+ Row("c", 1, "a", -4.0, 2),
+ Row("c", 2, null, 5.0, 1)
+)
+ )
+}
+
+val condition = $"rn" === 2 && $"value2" > 0.5
+checkAnswer(df.withColumn("rn",
row_number().over(window)).where(condition),
+ Seq(
+Row("a", 4, "", 2.0, 2),
+Row("b", 1, "n", Double.PositiveInfinity, 2)
+ )
+)
+
+checkAnswer(df.withColumn("rn", rank().over(window)).where(condition),
+ Seq(
+Row("b", 1, "n", Double.PositiveInfinity, 2)
+ )
+)
+
+checkAnswer(df.withColumn("rn",
dense_rank().over(window)).where(condition),
+ Seq(
+Row("a", 0, "c", 1.0, 2),
+Row("b", 1, "n", Double.PositiveInfinity, 2)
+ )
+)
+
+val multipleRowNumbers = df
+ .withColumn("rn", row_number().over(window))
+ .withColumn("rn2", row_number().over(window))
+ .where('rn < 2 && 'rn2 < 3)
+checkAnswer(multipleRowNumbers,
+ Seq(
+Row("a", 4, "", 2.0, 1, 1),
+Row("b", 1, "h", Double.NaN, 1, 1),
+Row("c", 2, null, 5.0, 1, 1)
+ )
+)
+
+val multipleRanks = df
+ .withColumn("rn", rank().over(window))
+ .withColumn("rn2", rank().over(window))
+ .where('rn < 2 && 'rn2 < 3)
+checkAnswer(multipleRanks,
+ Seq(
+Row("a", 4, "", 2.0, 1, 1),
+Row("a", 4, "",
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100919419
##
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala:
##
@@ -2580,6 +2580,18 @@ object SQLConf {
.intConf
.createWithDefault(SHUFFLE_SPILL_NUM_ELEMENTS_FORCE_SPILL_THRESHOLD.defaultValue.get)
+ val WINDOW_GROUP_LIMIT_THRESHOLD =
+buildConf("spark.sql.optimizer.windowGroupLimitThreshold")
+ .internal()
+ .doc("Threshold for filter the dataset by the window group limit before"
+
Review Comment:
0 means the output results is empty.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39933: [SPARK-42377][CONNECT][TESTS] Test framework for Spark Connect Scala Client
LuciferYang commented on PR #39933: URL: https://github.com/apache/spark/pull/39933#issuecomment-1423533123 https://user-images.githubusercontent.com/1475305/217703128-b0cb8d3e-a103-4595-80b1-db3e4a9da72a.png";> license test failed, need add new rule to `.rat-excludes`? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39933: [SPARK-42377][CONNECT][TESTS] Test framework for Spark Connect Scala Client
LuciferYang commented on PR #39933: URL: https://github.com/apache/spark/pull/39933#issuecomment-1423528903 @hvanhovell checked, local maven test passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #38799: [SPARK-37099][SQL] Introduce the group limit of Window for rank-based filter to optimize top-k computation
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1100909992
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##
@@ -0,0 +1,96 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions.{Alias, Attribute,
CurrentRow, DenseRank, EqualTo, Expression, GreaterThan, GreaterThanOrEqual,
IntegerLiteral, LessThan, LessThanOrEqual, NamedExpression, PredicateHelper,
Rank, RowFrame, RowNumber, SpecifiedWindowFrame, UnboundedPreceding,
WindowExpression, WindowSpecDefinition}
+import org.apache.spark.sql.catalyst.plans.logical.{Filter, LocalRelation,
LogicalPlan, Window, WindowGroupLimit}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.catalyst.trees.TreePattern.{FILTER, WINDOW}
+
+/**
+ * Optimize the filter based on rank-like window function by reduce not
required rows.
+ * This rule optimizes the following cases:
+ * {{{
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1
WHERE rn = 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1
WHERE 5 = rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1
WHERE rn < 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1
WHERE 5 > rn
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1
WHERE rn <= 5
+ * SELECT *, ROW_NUMBER() OVER(PARTITION BY k ORDER BY a) AS rn FROM Tab1
WHERE 5 >= rn
+ * }}}
+ */
+object InsertWindowGroupLimit extends Rule[LogicalPlan] with PredicateHelper {
+
+ /**
+ * Extract all the limit values from predicates.
+ */
+ def extractLimits(condition: Expression, attr: Attribute): Option[Int] = {
+val limits = splitConjunctivePredicates(condition).collect {
+ case EqualTo(IntegerLiteral(limit), e) if e.semanticEquals(attr) => limit
+ case EqualTo(e, IntegerLiteral(limit)) if e.semanticEquals(attr) => limit
+ case LessThan(e, IntegerLiteral(limit)) if e.semanticEquals(attr) =>
limit - 1
+ case GreaterThan(IntegerLiteral(limit), e) if e.semanticEquals(attr) =>
limit - 1
+ case LessThanOrEqual(e, IntegerLiteral(limit)) if e.semanticEquals(attr)
=> limit
+ case GreaterThanOrEqual(IntegerLiteral(limit), e) if
e.semanticEquals(attr) => limit
+}
+
+if (limits.nonEmpty) Some(limits.min) else None
+ }
+
+ private def support(
+ windowExpression: NamedExpression): Boolean = windowExpression match {
+case Alias(WindowExpression(_: Rank | _: DenseRank | _: RowNumber,
WindowSpecDefinition(_, _,
+SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow))), _) =>
true
+case _ => false
+ }
+
+ def apply(plan: LogicalPlan): LogicalPlan = {
+if (conf.windowGroupLimitThreshold == -1) return plan
+
+plan.transformWithPruning(_.containsAllPatterns(FILTER, WINDOW), ruleId) {
+ case filter @ Filter(condition,
+window @ Window(windowExpressions, partitionSpec, orderSpec, child))
+if !child.isInstanceOf[WindowGroupLimit] &&
windowExpressions.exists(support) &&
+ orderSpec.nonEmpty =>
+val limits = windowExpressions.collect {
+ case alias @ Alias(WindowExpression(rankLikeFunction, _), _) if
support(alias) =>
+extractLimits(condition, alias.toAttribute).map((_,
rankLikeFunction))
+}.flatten
+
+// multiple different rank-like functions unsupported.
+if (limits.isEmpty) {
+ filter
+} else {
+ limits.minBy(_._1) match {
Review Comment:
Good idea.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.or
[GitHub] [spark] LuciferYang commented on pull request #39893: [SPARK-42350][SQL][K8S][SS] Replcace `get().getOrElse` with `getOrElse`
LuciferYang commented on PR #39893: URL: https://github.com/apache/spark/pull/39893#issuecomment-1423517707 should be no more -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #39925: [SPARK-41812][SPARK-41823][CONNECT][SQL][PYTHON] Resolve ambiguous columns issue in `Join`
zhengruifeng commented on code in PR #39925:
URL: https://github.com/apache/spark/pull/39925#discussion_r1100882974
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala:
##
@@ -123,6 +123,11 @@ class SparkConnectPlanner(val session: SparkSession) {
transformRelationPlugin(rel.getExtension)
case _ => throw InvalidPlanInput(s"${rel.getUnknown} not supported.")
}
+
+if (rel.hasCommon) {
+ plan.setTagValue(LogicalPlan.PLAN_ID_TAG, rel.getCommon.getPlanId)
Review Comment:
ok, let us make it optional.
~~the Commands and Catalogs like `CreateView` and `WriteOperation` will not
have a plan id~~
Let me also add plan_id for Commands, maybe useful in the future
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #39925: [SPARK-41812][SPARK-41823][CONNECT][SQL][PYTHON] Resolve ambiguous columns issue in `Join`
zhengruifeng commented on code in PR #39925: URL: https://github.com/apache/spark/pull/39925#discussion_r1100886574 ## python/pyspark/sql/connect/plan.py: ## @@ -259,6 +272,8 @@ def __init__( def plan(self, session: "SparkConnectClient") -> proto.Relation: plan = proto.Relation() Review Comment: nice, will add a helper method -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #39925: [SPARK-41812][SPARK-41823][CONNECT][SQL][PYTHON] Resolve ambiguous columns issue in `Join`
zhengruifeng commented on code in PR #39925:
URL: https://github.com/apache/spark/pull/39925#discussion_r1100882974
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala:
##
@@ -123,6 +123,11 @@ class SparkConnectPlanner(val session: SparkSession) {
transformRelationPlugin(rel.getExtension)
case _ => throw InvalidPlanInput(s"${rel.getUnknown} not supported.")
}
+
+if (rel.hasCommon) {
+ plan.setTagValue(LogicalPlan.PLAN_ID_TAG, rel.getCommon.getPlanId)
Review Comment:
ok, let us make it optional.
the Commands and Catalogs like `CreateView` and `WriteOperation` will not
have a plan id
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #39925: [SPARK-41812][SPARK-41823][CONNECT][SQL][PYTHON] Resolve ambiguous columns issue in `Join`
zhengruifeng commented on code in PR #39925:
URL: https://github.com/apache/spark/pull/39925#discussion_r1100881330
##
connector/connect/common/src/main/protobuf/spark/connect/relations.proto:
##
@@ -91,8 +91,11 @@ message Unknown {}
// Common metadata of all relations.
message RelationCommon {
+ // (Required) A globally unique id for a given connect plan.
+ int64 plan_id = 1;
+
// (Required) Shared relation metadata.
- string source_info = 1;
+ string source_info = 2;
Review Comment:
ok
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #39925: [SPARK-41812][SPARK-41823][CONNECT][SQL][PYTHON] Resolve ambiguous columns issue in `Join`
zhengruifeng commented on code in PR #39925:
URL: https://github.com/apache/spark/pull/39925#discussion_r1100881164
##
connector/connect/common/src/main/protobuf/spark/connect/relations.proto:
##
@@ -91,8 +91,11 @@ message Unknown {}
// Common metadata of all relations.
message RelationCommon {
+ // (Required) A globally unique id for a given connect plan.
+ int64 plan_id = 1;
Review Comment:
will update
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on a diff in pull request #39925: [SPARK-41812][SPARK-41823][CONNECT][SQL][PYTHON] Resolve ambiguous columns issue in `Join`
zhengruifeng commented on code in PR #39925: URL: https://github.com/apache/spark/pull/39925#discussion_r1100881055 ## python/pyspark/sql/connect/plan.py: ## @@ -673,32 +716,34 @@ def plan(self, session: "SparkConnectClient") -> proto.Relation: from pyspark.sql.connect.functions import lit assert self._child is not None +plan = proto.Relation() +plan.common.plan_id = self._plan_id -agg = proto.Relation() - -agg.aggregate.input.CopyFrom(self._child.plan(session)) +plan.aggregate.input.CopyFrom(self._child.plan(session)) -agg.aggregate.grouping_expressions.extend([c.to_plan(session) for c in self._grouping_cols]) -agg.aggregate.aggregate_expressions.extend( +plan.aggregate.grouping_expressions.extend( +[c.to_plan(session) for c in self._grouping_cols] +) +plan.aggregate.aggregate_expressions.extend( [c.to_plan(session) for c in self._aggregate_cols] ) if self._group_type == "groupby": -agg.aggregate.group_type = proto.Aggregate.GroupType.GROUP_TYPE_GROUPBY +plan.aggregate.group_type = proto.Aggregate.GroupType.GROUP_TYPE_GROUPBY elif self._group_type == "rollup": -agg.aggregate.group_type = proto.Aggregate.GroupType.GROUP_TYPE_ROLLUP +plan.aggregate.group_type = proto.Aggregate.GroupType.GROUP_TYPE_ROLLUP elif self._group_type == "cube": -agg.aggregate.group_type = proto.Aggregate.GroupType.GROUP_TYPE_CUBE +plan.aggregate.group_type = proto.Aggregate.GroupType.GROUP_TYPE_CUBE elif self._group_type == "pivot": -agg.aggregate.group_type = proto.Aggregate.GroupType.GROUP_TYPE_PIVOT +plan.aggregate.group_type = proto.Aggregate.GroupType.GROUP_TYPE_PIVOT assert self._pivot_col is not None -agg.aggregate.pivot.col.CopyFrom(self._pivot_col.to_plan(session)) +plan.aggregate.pivot.col.CopyFrom(self._pivot_col.to_plan(session)) if self._pivot_values is not None and len(self._pivot_values) > 0: -agg.aggregate.pivot.values.extend( +plan.aggregate.pivot.values.extend( [lit(v).to_plan(session).literal for v in self._pivot_values] ) -return agg +return plan Review Comment: both `plan` and `rel` are fine to me, I just want to make the naming consistent. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xinrong-meng commented on pull request #39860: [SPARK-42210][CONNECT][PYTHON] Standardize registered pickled Python UDFs
xinrong-meng commented on PR #39860: URL: https://github.com/apache/spark/pull/39860#issuecomment-1423489976 Forced push to base on the latest master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #39667: [SPARK-42131][SQL] Extract the function that construct the select statement for JDBC dialect.
beliefer commented on PR #39667: URL: https://github.com/apache/spark/pull/39667#issuecomment-1423472035 @cloud-fan @sadikovi Thank you! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #38223: [SPARK-40770][PYTHON] Improved error messages for applyInPandas for schema mismatch
HyukjinKwon closed pull request #38223: [SPARK-40770][PYTHON] Improved error messages for applyInPandas for schema mismatch URL: https://github.com/apache/spark/pull/38223 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #38223: [SPARK-40770][PYTHON] Improved error messages for applyInPandas for schema mismatch
HyukjinKwon commented on PR #38223: URL: https://github.com/apache/spark/pull/38223#issuecomment-1423450435 Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] github-actions[bot] commented on pull request #37232: [SPARK-39821][PYTHON][PS] Fix error during using DatetimeIndex
github-actions[bot] commented on PR #37232: URL: https://github.com/apache/spark/pull/37232#issuecomment-1423412026 We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] github-actions[bot] commented on pull request #37369: [SPARK-39942][PYTHON][PS] Need to verify the input nums is integer in nsmallest func
github-actions[bot] commented on PR #37369: URL: https://github.com/apache/spark/pull/37369#issuecomment-1423411990 We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] github-actions[bot] commented on pull request #38070: [SPARK-38004][PYTHON] Mangle dupe cols documentation
github-actions[bot] commented on PR #38070: URL: https://github.com/apache/spark/pull/38070#issuecomment-1423411943 We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] github-actions[bot] closed pull request #38068: [SPARK-40409] spark-sql supports reading `ByteType` data of avro serde
github-actions[bot] closed pull request #38068: [SPARK-40409] spark-sql supports reading `ByteType` data of avro serde URL: https://github.com/apache/spark/pull/38068 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] github-actions[bot] closed pull request #38233: [SPARK-40781][CORE] Explain exit code 137 as killed due to OOM
github-actions[bot] closed pull request #38233: [SPARK-40781][CORE] Explain exit code 137 as killed due to OOM URL: https://github.com/apache/spark/pull/38233 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #39943: [SPARK-40819][SQL][FOLLOWUP] Update SqlConf version for nanosAsLong configuration
HyukjinKwon commented on PR #39943: URL: https://github.com/apache/spark/pull/39943#issuecomment-1423397038 Merged to master, branch-3.4, branch-3.3 and branch-3.2. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #39943: [SPARK-40819][SQL][FOLLOWUP] Update SqlConf version for nanosAsLong configuration
HyukjinKwon closed pull request #39943: [SPARK-40819][SQL][FOLLOWUP] Update SqlConf version for nanosAsLong configuration URL: https://github.com/apache/spark/pull/39943 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] holdenk commented on a diff in pull request #39825: [SPARK-42261][SPARK-42260][K8S] Log Allocation Stalls and Trigger Allocation event without blocking on snapshot
holdenk commented on code in PR #39825:
URL: https://github.com/apache/spark/pull/39825#discussion_r1100813043
##
resource-managers/kubernetes/core/src/test/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsAllocatorSuite.scala:
##
@@ -161,7 +161,7 @@ class ExecutorPodsAllocatorSuite extends SparkFunSuite with
BeforeAndAfter {
assert(ExecutorPodsAllocator.splitSlots(seq2, 4) === Seq(("a", 2), ("b",
1), ("c", 1)))
}
- test("SPARK-36052: pending pod limit with multiple resource profiles") {
+ test("SPARK-42261: Allow allocations without snapshot up to min of max
pending & alloc size.") {
Review Comment:
Sounds good, will refactor next week.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #39941: [MINOR][DOCS] Add link to Hadoop docs
itholic commented on code in PR #39941: URL: https://github.com/apache/spark/pull/39941#discussion_r1100795489 ## docs/rdd-programming-guide.md: ## @@ -442,7 +442,7 @@ Apart from text files, Spark's Python API also supports several other data forma **Writable Support** -PySpark SequenceFile support loads an RDD of key-value pairs within Java, converts Writables to base Java types, and pickles the +PySpark SequenceFile support loads an RDD of key-value pairs within Java, converts [Writables](https://hadoop.apache.org/docs/current/api/org/apache/hadoop/io/Writable.html) to base Java types, and pickles the Review Comment: nit: Maybe `Writables` -> `Writable` ?? Seems like `Writable` is an official naming. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #39941: [MINOR][DOCS] Add link to Hadoop docs
itholic commented on code in PR #39941: URL: https://github.com/apache/spark/pull/39941#discussion_r1100795489 ## docs/rdd-programming-guide.md: ## @@ -442,7 +442,7 @@ Apart from text files, Spark's Python API also supports several other data forma **Writable Support** -PySpark SequenceFile support loads an RDD of key-value pairs within Java, converts Writables to base Java types, and pickles the +PySpark SequenceFile support loads an RDD of key-value pairs within Java, converts [Writables](https://hadoop.apache.org/docs/current/api/org/apache/hadoop/io/Writable.html) to base Java types, and pickles the Review Comment: nit: Maybe `Writables` -> `Writable` ?? Seems like Writable is an official naming. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on pull request #39933: [SPARK-42377][CONNECT][TESTS] Test framework for Spark Connect Scala Client
hvanhovell commented on PR #39933: URL: https://github.com/apache/spark/pull/39933#issuecomment-1423312392 @LuciferYang can you check if maven works now? It should. There is an outstanding issue with one of the UDF tests, but that is for a different PR. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR closed pull request #39936: [SPARK-42379][SS] Use FileSystem.exists in FileSystemBasedCheckpointFileManager.exists
HeartSaVioR closed pull request #39936: [SPARK-42379][SS] Use FileSystem.exists in FileSystemBasedCheckpointFileManager.exists URL: https://github.com/apache/spark/pull/39936 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #39936: [SPARK-42379][SS] Use FileSystem.exists in FileSystemBasedCheckpointFileManager.exists
HeartSaVioR commented on PR #39936: URL: https://github.com/apache/spark/pull/39936#issuecomment-1423307538 Thanks, merging to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39906: [SPARK-41962][MINOR][SQL] Update the order of imports in class SpecificParquetRecordReaderBase
dongjoon-hyun commented on PR #39906: URL: https://github.com/apache/spark/pull/39906#issuecomment-1423293234 Thank you for the confirmation, @wayneguow . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wayneguow commented on pull request #39906: [SPARK-41962][MINOR][SQL] Update the order of imports in class SpecificParquetRecordReaderBase
wayneguow commented on PR #39906: URL: https://github.com/apache/spark/pull/39906#issuecomment-1423286391 > You can make a new backporting PR to branch-3.2 if needed, @wayneguow . https://user-images.githubusercontent.com/16032294/217658729-c709f636-1c3a-429b-b7e8-9929961eba49.png";> It seems that it is ok without those unordered imports in branch-3.2, so just reverting this for branch-3.2 is enough. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] hvanhovell commented on pull request #39933: [SPARK-42377][CONNECT][TESTS] Test framework for Spark Connect Scala Client
hvanhovell commented on PR #39933: URL: https://github.com/apache/spark/pull/39933#issuecomment-1423286123 Alright the golden files for the `ProtoToParsedPlanTestSuite` have been updated. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39906: [SPARK-41962][MINOR][SQL] Update the order of imports in class SpecificParquetRecordReaderBase
dongjoon-hyun commented on PR #39906: URL: https://github.com/apache/spark/pull/39906#issuecomment-1423275269 Also, cc @parthchandra for branch-3.2 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39906: [SPARK-41962][MINOR][SQL] Update the order of imports in class SpecificParquetRecordReaderBase
dongjoon-hyun commented on PR #39906: URL: https://github.com/apache/spark/pull/39906#issuecomment-1423274262 You can make a new backporting PR to branch-3.2 if needed, @wayneguow . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wayneguow commented on pull request #39906: [SPARK-41962][MINOR][SQL] Update the order of imports in class SpecificParquetRecordReaderBase
wayneguow commented on PR #39906: URL: https://github.com/apache/spark/pull/39906#issuecomment-1423272897 > I reverted the commit from `branch-3.2` because the `import` statement is unused. > > * [c8b47ec](https://github.com/apache/spark/commit/c8b47ec2d0a066f539a98488502fce99efe006f0) > >  @dongjoon-hyun Thank you for resolving it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39906: [SPARK-41962][MINOR][SQL] Update the order of imports in class SpecificParquetRecordReaderBase
dongjoon-hyun commented on PR #39906: URL: https://github.com/apache/spark/pull/39906#issuecomment-1423268335 I reverted the commit because the `import` statement is unused. - https://github.com/apache/spark/commit/c8b47ec2d0a066f539a98488502fce99efe006f0 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39906: [SPARK-41962][MINOR][SQL] Update the order of imports in class SpecificParquetRecordReaderBase
dongjoon-hyun commented on PR #39906: URL: https://github.com/apache/spark/pull/39906#issuecomment-1423266159 Hi, @wayneguow and @HyukjinKwon This broke branch-3.2. - https://github.com/apache/spark/commits/branch-3.2 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] db-scnakandala commented on pull request #39722: [SPARK-42162] Introduce MultiCommutativeOp expression as a memory optimization for canonicalizing large trees of commutative expressio
db-scnakandala commented on PR #39722: URL: https://github.com/apache/spark/pull/39722#issuecomment-1423248966 > > @peter-toth Can you elaborate more on the statement "shouldn't canonicalize a single expression to MultiCommutativeOp" > > From what I understand since the operator is a commutative expression, it should at least have two operands (?) > > I would keep the canonicalization of a single commutative expression like: `Add(x, y)` as it is: `Add(x, y)`, but when we have at least 2 nested: `Add(Add(x, y), z)` then as `MultiCommutativeOp(x, y, z, Add)` If I understand it correctly, setting the threshold to `3` should achieve this requirement, right? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #39946: [SPARK-42310][SQL] Assign name to _LEGACY_ERROR_TEMP_1289
MaxGekk commented on code in PR #39946:
URL: https://github.com/apache/spark/pull/39946#discussion_r1100686476
##
core/src/main/resources/error/error-classes.json:
##
@@ -774,6 +774,12 @@
"The expected format is ByteString, but was ()."
]
},
+ "INVALID_COLUMN_NAME" : {
Review Comment:
How about to make it more specific:
```suggestion
"INVALID_COLUMN_NAME_AS_PATH" : {
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen closed pull request #39878: [SPARK-42335][SQL] Pass the comment option through to univocity if users set it explicitly in CSV dataSource
srowen closed pull request #39878: [SPARK-42335][SQL] Pass the comment option through to univocity if users set it explicitly in CSV dataSource URL: https://github.com/apache/spark/pull/39878 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on pull request #39878: [SPARK-42335][SQL] Pass the comment option through to univocity if users set it explicitly in CSV dataSource
srowen commented on PR #39878: URL: https://github.com/apache/spark/pull/39878#issuecomment-1423245678 Merged to master -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #39946: [SPARK-42310][SQL] Assign name to _LEGACY_ERROR_TEMP_1289
MaxGekk commented on code in PR #39946:
URL: https://github.com/apache/spark/pull/39946#discussion_r1100680165
##
core/src/main/resources/error/error-classes.json:
##
@@ -774,6 +774,12 @@
"The expected format is ByteString, but was ()."
]
},
+ "INVALID_COLUMN_NAME" : {
+"message" : [
+ "Column name contains invalid character(s). Please use
alias to rename it."
Review Comment:
The message is slightly generic, and doesn't give a clear picture. From the
source code, the error is a datasource specific, and raised when the datasource
doesn't support a file name that is the same as a column name. Can we rephrase
it:
```suggestion
"The datasource cannot save the column
because its name contains some characters that are not allowed in file paths.
Please, use an alias to rename it."
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] peter-toth commented on pull request #39722: [SPARK-42162] Introduce MultiCommutativeOp expression as a memory optimization for canonicalizing large trees of commutative expressions
peter-toth commented on PR #39722: URL: https://github.com/apache/spark/pull/39722#issuecomment-1423185628 > @peter-toth Can you elaborate more on the statement "shouldn't canonicalize a single expression to MultiCommutativeOp" > > From what I understand since the operator is a commutative expression, it should at least have two operands (?) I would keep the canonicalization of a single commutative expression like: `Add(x, y)` as it is: `Add(x, y)`, but when we have at least 2 nested: `Add(Add(x, y), z)` then as `MultiCommutativeOp(x, y, z, Add)` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk closed pull request #39891: [SPARK-42318][SPARK-42319][SQL] Assign name to _LEGACY_ERROR_TEMP_(2123|2125)
MaxGekk closed pull request #39891: [SPARK-42318][SPARK-42319][SQL] Assign name to _LEGACY_ERROR_TEMP_(2123|2125) URL: https://github.com/apache/spark/pull/39891 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #39891: [SPARK-42318][SPARK-42319][SQL] Assign name to _LEGACY_ERROR_TEMP_(2123|2125)
MaxGekk commented on PR #39891: URL: https://github.com/apache/spark/pull/39891#issuecomment-1423117120 +1, LGTM. Merging to master/3.4. Thank you, @itholic and @srielau for review. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] db-scnakandala commented on pull request #39722: [SPARK-42162] Introduce MultiCommutativeOp expression as a memory optimization for canonicalizing large trees of commutative expressio
db-scnakandala commented on PR #39722: URL: https://github.com/apache/spark/pull/39722#issuecomment-1423094159 > > Maybe we can change the default value to 2. WDYT? > > Now the description of the config says the `The minimum number of consecutive commutative expressions`, but seemingly the logic uses the number of non-commutative operads below those commutative expressions (`operands.length < SQLConf.get.getConf(MULTI_COMMUTATIVE_OP_OPT_THRESHOLD)`). So I would argue that the default value 2 sounds good, but the logic should follow that description and we should optimize only when there are at least 2 nested expressions and shouldn't canonicalize a single expression to `MultiCommutativeOp`. @peter-toth Can you elaborate more on the statement "shouldn't canonicalize a single expression to `MultiCommutativeOp`" From what I understand since the operator is a commutative expression, it should at least have two operands (?) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] bersprockets commented on a diff in pull request #39945: [SPARK-42384][SQL] Check for null input in generated code for mask function
bersprockets commented on code in PR #39945:
URL: https://github.com/apache/spark/pull/39945#discussion_r1100528061
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/maskExpressions.scala:
##
@@ -223,16 +223,32 @@ case class Mask(
val fifthGen = children(4).genCode(ctx)
val resultCode =
f(firstGen.value, secondGen.value, thirdGen.value, fourthGen.value,
fifthGen.value)
-ev.copy(
- code = code"""
+if (nullable) {
+ // this function is somewhat like a `UnaryExpression`, in that only the
first child
+ // determines whether the result is null
+ val nullSafeEval = ctx.nullSafeExec(children(0).nullable,
firstGen.isNull)(resultCode)
+ ev.copy(code = code"""
+${firstGen.code}
+${secondGen.code}
+${thirdGen.code}
+${fourthGen.code}
+${fifthGen.code}
+boolean ${ev.isNull} = ${firstGen.isNull};
+${CodeGenerator.javaType(dataType)} ${ev.value} =
${CodeGenerator.defaultValue(dataType)};
+$nullSafeEval
+ """)
+} else {
Review Comment:
Btw, the new generated code will look like this (if the first child is null,
then the result is null):
```
/* 031 */ boolean isNull_1 = i.isNullAt(0);
/* 032 */ UTF8String value_1 = isNull_1 ?
/* 033 */ null : (i.getUTF8String(0));
/* 034 */
/* 035 */
/* 036 */
/* 037 */
/* 038 */ boolean isNull_0 = isNull_1;
/* 039 */ UTF8String value_0 = null;
/* 040 */
/* 041 */ if (!isNull_1) {
/* 042 */ value_0 =
org.apache.spark.sql.catalyst.expressions.Mask.transformInput(value_1,
((UTF8String) references[0] /* literal */), ((UTF8String) references[1] /*
literal */), ((UTF8String) references[2] /* literal */), ((UTF8String)
references[3] /* literal */));;
/* 043 */ }
/* 044 */ if (isNull_0) {
/* 045 */ mutableStateArray_0[0].setNullAt(0);
/* 046 */ } else {
/* 047 */ mutableStateArray_0[0].write(0, value_0);
/* 048 */ }
/* 049 */ return (mutableStateArray_0[0].getRow());
```
Versus the old generated code, which looks like this (call
`Mask.transformInput` even when input is null, and call `UnsafeWriter.write(0,
value_0)` even if `value_0` is null):
```
/* 031 */ boolean isNull_1 = i.isNullAt(0);
/* 032 */ UTF8String value_1 = isNull_1 ?
/* 033 */ null : (i.getUTF8String(0));
/* 034 */
/* 035 */
/* 036 */
/* 037 */
/* 038 */ UTF8String value_0 = null;
/* 039 */ value_0 =
org.apache.spark.sql.catalyst.expressions.Mask.transformInput(value_1,
((UTF8String) references[0] /* literal */), ((UTF8String) references[1] /*
literal */), ((UTF8String) references[2] /* literal */), ((UTF8String)
references[3] /* literal */));;
/* 040 */ if (false) {
/* 041 */ mutableStateArray_0[0].setNullAt(0);
/* 042 */ } else {
/* 043 */ mutableStateArray_0[0].write(0, value_0);
/* 044 */ }
/* 045 */ return (mutableStateArray_0[0].getRow());
/* 046 */ }
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on pull request #39893: [SPARK-42350][SQL][K8S][SS] Replcace `get().getOrElse` with `getOrElse`
srowen commented on PR #39893: URL: https://github.com/apache/spark/pull/39893#issuecomment-1423047291 Can you look for more instances across the code base? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on pull request #39880: typo: StogeLevel -> StorageLevel
srowen commented on PR #39880: URL: https://github.com/apache/spark/pull/39880#issuecomment-1423046235 Just for completeness can you try rerunning tests? I'm sure it doesn't affect functionality -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic opened a new pull request, #39946: [SPARK-42310][SQL] Assign name to _LEGACY_ERROR_TEMP_1289
itholic opened a new pull request, #39946: URL: https://github.com/apache/spark/pull/39946 ### What changes were proposed in this pull request? This PR proposes to assign name to _LEGACY_ERROR_TEMP_1289, "INVALID_COLUMN_NAME". ### Why are the changes needed? We should assign proper name to _LEGACY_ERROR_TEMP_* ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? `./build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite*` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #39937: [SPARK-42309][SQL] Assign name to _LEGACY_ERROR_TEMP_1204
itholic commented on code in PR #39937:
URL: https://github.com/apache/spark/pull/39937#discussion_r1100501971
##
core/src/main/resources/error/error-classes.json:
##
@@ -116,6 +116,12 @@
""
]
},
+ "CANNOT_WRITE_INCOMPATIBLE_DATA_TO_TABLE" : {
+"message" : [
+ "Cannot write incompatible data to table :",
+ "- ."
Review Comment:
Sounds good!
Will separate into sub-error classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #39937: [SPARK-42309][SQL] Assign name to _LEGACY_ERROR_TEMP_1204
MaxGekk commented on code in PR #39937:
URL: https://github.com/apache/spark/pull/39937#discussion_r1100495181
##
core/src/main/resources/error/error-classes.json:
##
@@ -116,6 +116,12 @@
""
]
},
+ "CANNOT_WRITE_INCOMPATIBLE_DATA_TO_TABLE" : {
+"message" : [
+ "Cannot write incompatible data to table :",
+ "- ."
Review Comment:
Regarding to the general field ``. I would prefer to see separate
errors classes (sub-classes) per every `addError()`:
-
https://github.com/apache/spark/blob/df36124636c600937644734f439670cbd35dbdf6/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TableOutputResolver.scala#L80
-
https://github.com/apache/spark/blob/df36124636c600937644734f439670cbd35dbdf6/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TableOutputResolver.scala#L83
-
https://github.com/apache/spark/blob/df36124636c600937644734f439670cbd35dbdf6/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TableOutputResolver.scala#L117
-
https://github.com/apache/spark/blob/df36124636c600937644734f439670cbd35dbdf6/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/TableOutputResolver.scala#L135
##
core/src/main/resources/error/error-classes.json:
##
@@ -116,6 +116,12 @@
""
]
},
+ "CANNOT_WRITE_INCOMPATIBLE_DATA_TO_TABLE" : {
Review Comment:
Can you make it shorter like `INCOMPATIBLE_DATA ...`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39945: [SPARK-42384][SQL] Check for null input in generated code for mask function
LuciferYang commented on PR #39945: URL: https://github.com/apache/spark/pull/39945#issuecomment-1423021598 cc @gengliangwang FYI -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk closed pull request #39890: [SPARK-42314][SQL] Assign name to _LEGACY_ERROR_TEMP_2127
MaxGekk closed pull request #39890: [SPARK-42314][SQL] Assign name to _LEGACY_ERROR_TEMP_2127 URL: https://github.com/apache/spark/pull/39890 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on pull request #39890: [SPARK-42314][SQL] Assign name to _LEGACY_ERROR_TEMP_2127
MaxGekk commented on PR #39890: URL: https://github.com/apache/spark/pull/39890#issuecomment-1423008240 +1, LGTM. Merging to master/3.4. Thank you, @itholic and @srielau for review. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] awdavidson commented on pull request #39943: [SPARK-40819][SQL][FOLLOWUP] Update SqlConf version for nanosAsLong configuration
awdavidson commented on PR #39943: URL: https://github.com/apache/spark/pull/39943#issuecomment-1423004010 > PR title should be `[SPARK-40819][SQL][FOLLOWUP]...` > > And the pr title and description a little difficult to understand for me if I didn't look at the changes ... No problem - updated both title and description. Hoping the clarifies the change -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #39866: [SPARK-42287][CONNECT][BUILD] Fix the client dependency jars
LuciferYang commented on code in PR #39866:
URL: https://github.com/apache/spark/pull/39866#discussion_r1100468326
##
connector/connect/client/jvm/pom.xml:
##
@@ -112,40 +124,57 @@
false
+ com.google.android:*
+ com.google.api.grpc:*
+ com.google.code.findbugs:*
+ com.google.code.gson:*
+ com.google.errorprone:*
com.google.guava:*
- io.grpc:*
+ com.google.j2objc:*
com.google.protobuf:*
+ io.grpc:*
+ io.netty:*
+ io.perfmark:*
+ org.codehaus.mojo:*
+ org.checkerframework:*
org.apache.spark:spark-connect-common_${scala.binary.version}
io.grpc
-
${spark.shade.packageName}.connect.client.grpc
+
${spark.shade.packageName}.connect.client.io.grpc
io.grpc.**
- com.google.protobuf
-
${spark.shade.packageName}.connect.protobuf
-
-com.google.protobuf.**
-
+ com.google
+
${spark.shade.packageName}.connect.client.com.google
- com.google.common
-
${spark.shade.packageName}.connect.client.guava
-
-com.google.common.**
-
+ io.netty
Review Comment:
Yes, you are right.
To clarify, I mean we need to ensure that the `native-image.properties`
files in `META-INF/native-image/io.netty/netty-xxx/` are rewritten correctly if
we need to shade netty
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] steveloughran commented on pull request #39124: [DON'T MERGE] Test build and test with hadoop 3.3.5-RC0
steveloughran commented on PR #39124: URL: https://github.com/apache/spark/pull/39124#issuecomment-1422989141 bTW, I've been testing #39185 on 3.3.5, switching to the new manifest committer added for abfs/gcs commit performance; works well. That change doesn't depend on this PR, it just chooses the new committer if found on the classpath -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #39866: [SPARK-42287][CONNECT][BUILD] Fix the client dependency jars
LuciferYang commented on code in PR #39866:
URL: https://github.com/apache/spark/pull/39866#discussion_r1100468326
##
connector/connect/client/jvm/pom.xml:
##
@@ -112,40 +124,57 @@
false
+ com.google.android:*
+ com.google.api.grpc:*
+ com.google.code.findbugs:*
+ com.google.code.gson:*
+ com.google.errorprone:*
com.google.guava:*
- io.grpc:*
+ com.google.j2objc:*
com.google.protobuf:*
+ io.grpc:*
+ io.netty:*
+ io.perfmark:*
+ org.codehaus.mojo:*
+ org.checkerframework:*
org.apache.spark:spark-connect-common_${scala.binary.version}
io.grpc
-
${spark.shade.packageName}.connect.client.grpc
+
${spark.shade.packageName}.connect.client.io.grpc
io.grpc.**
- com.google.protobuf
-
${spark.shade.packageName}.connect.protobuf
-
-com.google.protobuf.**
-
+ com.google
+
${spark.shade.packageName}.connect.client.com.google
- com.google.common
-
${spark.shade.packageName}.connect.client.guava
-
-com.google.common.**
-
+ io.netty
Review Comment:
Yes, you are right.
To clarify, I mean we need to ensure that the `native-image.properties`
files in `META-INF/native-image/io.netty/netty-codec-xxx/` are rewritten
correctly if we need to shade netty
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhenlineo commented on a diff in pull request #39866: [SPARK-42287][CONNECT][BUILD] Fix the client dependency jars
zhenlineo commented on code in PR #39866:
URL: https://github.com/apache/spark/pull/39866#discussion_r1100451807
##
connector/connect/client/jvm/pom.xml:
##
@@ -112,40 +124,57 @@
false
+ com.google.android:*
+ com.google.api.grpc:*
+ com.google.code.findbugs:*
+ com.google.code.gson:*
+ com.google.errorprone:*
com.google.guava:*
- io.grpc:*
+ com.google.j2objc:*
com.google.protobuf:*
+ io.grpc:*
+ io.netty:*
+ io.perfmark:*
+ org.codehaus.mojo:*
+ org.checkerframework:*
org.apache.spark:spark-connect-common_${scala.binary.version}
io.grpc
-
${spark.shade.packageName}.connect.client.grpc
+
${spark.shade.packageName}.connect.client.io.grpc
io.grpc.**
- com.google.protobuf
-
${spark.shade.packageName}.connect.protobuf
-
-com.google.protobuf.**
-
+ com.google
+
${spark.shade.packageName}.connect.client.com.google
- com.google.common
-
${spark.shade.packageName}.connect.client.guava
-
-com.google.common.**
-
+ io.netty
Review Comment:
Let me come back to you. grpc has this grpc with shaded netty and the one
without. We used the one without netty.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39941: [DOCS] Add link to Hadoop docs
itholic commented on PR #39941: URL: https://github.com/apache/spark/pull/39941#issuecomment-1422967169 Anyway, seems fine to me when the test passed. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39941: [DOCS] Add link to Hadoop docs
itholic commented on PR #39941: URL: https://github.com/apache/spark/pull/39941#issuecomment-1422965975 Also please check https://github.com/apache/spark/pull/39941/checks?check_run_id=11190702189 out to enable GitHub Actions in your forked repository -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39941: [DOCS] Add link to Hadoop docs
itholic commented on PR #39941: URL: https://github.com/apache/spark/pull/39941#issuecomment-1422965066 Can we create corresponding JIRA ticket [here](https://issues.apache.org/jira/projects/SPARK/issues/SPARK-34827?filter=allopenissues), and add a JIRA number to the title?? e.g. `[SPARK-12345][DOCS] Add link to Hadoop docs` or we can just add `[MINOR]` tag without creating ticket to JIRA, when the change is small enough. e.g. `[MINOR][DOCS] Add link to Hadoop docs` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] bersprockets opened a new pull request, #39945: [SPARK-42384][SQL] Check for null input in generated code for mask function
bersprockets opened a new pull request, #39945:
URL: https://github.com/apache/spark/pull/39945
### What changes were proposed in this pull request?
When generating code for the mask function, call `ctx.nullSafeExec` to
produce null safe code.
This change assumes that the mask function returns null only when the input
is null (which appears to be the case, from reading the code of
`Mask.transformInput`).
### Why are the changes needed?
The following query fails with a `NullPointerException`:
```
create or replace temp view v1 as
select * from values
(null),
('AbCD123-@$#')
as data(col1);
cache table v1;
select mask(col1) from v1;
23/02/07 16:36:06 ERROR Executor: Exception in task 0.0 in stage 3.0 (TID 3)
java.lang.NullPointerException
at
org.apache.spark.sql.catalyst.expressions.codegen.UnsafeWriter.write(UnsafeWriter.java:110)
at
org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown
Source)
at
org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at
org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:760)
```
The generated code calls `UnsafeWriter.write(0, value_0)` regardless of
whether `Mask.transformInput` returns null or not. The `UnsafeWriter.write`
method for `UTF8String` does not expect a null pointer.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
New unit tests.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39937: [SPARK-42309][SQL] Assign name to _LEGACY_ERROR_TEMP_1204
itholic commented on PR #39937: URL: https://github.com/apache/spark/pull/39937#issuecomment-1422948702 cc @srielau @MaxGekk @cloud-fan Could you review this error class when you find some time? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on pull request #39936: [SPARK-42379][SS] Use FileSystem.exists in FileSystemBasedCheckpointFileManager.exists
viirya commented on PR #39936: URL: https://github.com/apache/spark/pull/39936#issuecomment-1422929142 Sounds reasonable to remove it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ivoson commented on a diff in pull request #39459: [SPARK-41497][CORE] Fixing accumulator undercount in the case of the retry task with rdd cache
ivoson commented on code in PR #39459: URL: https://github.com/apache/spark/pull/39459#discussion_r1100333545 ## core/src/main/scala/org/apache/spark/storage/BlockManagerMasterEndpoint.scala: ## @@ -77,6 +77,11 @@ class BlockManagerMasterEndpoint( // Mapping from block id to the set of block managers that have the block. private val blockLocations = new JHashMap[BlockId, mutable.HashSet[BlockManagerId]] + // Mapping from task id to the set of rdd blocks which are generated from the task. + private val tidToRddBlockIds = new mutable.HashMap[Long, mutable.HashSet[RDDBlockId]] + // Record the visible RDD blocks which have been generated at least from one successful task. + private val visibleRDDBlocks = new mutable.HashSet[RDDBlockId] Review Comment: Let me explain this further. If we track visible blocks, it's clear that we always know which blocks are visible. If we track invisible blocks, the way we consider a block as visible is that at least one block exists and it's not in invisible lists. So if the existing blocks got lost, we will lose the information. Next time the cache is re-computed, we will do this again(firstly put it into invisible lists, then promote it to visible by removing it from invisible list once task finished successfully). And after doing the process again, the cache would be visible then. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org