[GitHub] [spark] zzzzming95 commented on pull request #40688: [SPARK-43021][SQL] `CoalesceBucketsInJoin` not work when using AQE
ming95 commented on PR #40688: URL: https://github.com/apache/spark/pull/40688#issuecomment-153144 > We may need adding test case. yeah , i will add UT later -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a diff in pull request #40697: [SPARK-43061][SQL] Introduce TaskEvaluator for SQL operator execution
viirya commented on code in PR #40697:
URL: https://github.com/apache/spark/pull/40697#discussion_r1160484655
##
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala:
##
@@ -750,37 +750,29 @@ case class WholeStageCodegenExec(child: SparkPlan)(val
codegenStageId: Int)
// but the output must be rows.
val rdds = child.asInstanceOf[CodegenSupport].inputRDDs()
assert(rdds.size <= 2, "Up to two input RDDs can be supported")
+val evaluatorFactory = new WholeStageCodegenEvaluatorFactory(
+ cleanedSource, durationMs, references)
if (rdds.length == 1) {
- rdds.head.mapPartitionsWithIndex { (index, iter) =>
-val (clazz, _) = CodeGenerator.compile(cleanedSource)
-val buffer =
clazz.generate(references).asInstanceOf[BufferedRowIterator]
-buffer.init(index, Array(iter))
-new Iterator[InternalRow] {
- override def hasNext: Boolean = {
-val v = buffer.hasNext
-if (!v) durationMs += buffer.durationMs()
-v
- }
- override def next: InternalRow = buffer.next()
+ if (conf.getConf(SQLConf.USE_TASK_EVALUATOR)) {
+rdds.head.mapPartitionsWithEvaluator(evaluatorFactory)
+ } else {
+rdds.head.mapPartitionsWithIndex { (index, iter) =>
+ val evaluator = evaluatorFactory.createEvaluator()
+ evaluator.eval(index, iter)
}
}
} else {
// Right now, we support up to two input RDDs.
- rdds.head.zipPartitions(rdds(1)) { (leftIter, rightIter) =>
-Iterator((leftIter, rightIter))
-// a small hack to obtain the correct partition index
- }.mapPartitionsWithIndex { (index, zippedIter) =>
-val (leftIter, rightIter) = zippedIter.next()
-val (clazz, _) = CodeGenerator.compile(cleanedSource)
-val buffer =
clazz.generate(references).asInstanceOf[BufferedRowIterator]
-buffer.init(index, Array(leftIter, rightIter))
-new Iterator[InternalRow] {
- override def hasNext: Boolean = {
-val v = buffer.hasNext
-if (!v) durationMs += buffer.durationMs()
-v
- }
- override def next: InternalRow = buffer.next()
+ if (conf.getConf(SQLConf.USE_TASK_EVALUATOR)) {
+rdds.head.zipPartitionsWithEvaluator(rdds(1), evaluatorFactory)
+ } else {
+rdds.head.zipPartitions(rdds(1)) { (leftIter, rightIter) =>
+ Iterator((leftIter, rightIter))
+ // a small hack to obtain the correct partition index
+}.mapPartitionsWithIndex { (index, zippedIter) =>
+ val (leftIter, rightIter) = zippedIter.next()
+ val evaluator = evaluatorFactory.createEvaluator()
Review Comment:
Hm? If `USE_TASK_EVALUATOR` is disabled, seems it still uses evaluator
factory and evaluator? The difference is which RDD API is called
(`mapPartitionsWithEvaluator` or `mapPartitionsWithIndex`).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #40663: [SPARK-39696][CORE] Fix data race in access to TaskMetrics.externalAccums
LuciferYang commented on PR #40663: URL: https://github.com/apache/spark/pull/40663#issuecomment-155046 @dongjoon-hyun Scala 2.13.5 does not require this fix. I apologize for providing incorrect information earlier -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #40639: [SPARK-43007][BUILD] Upgrade rocksdbjni to 8.0.0
LuciferYang commented on PR #40639: URL: https://github.com/apache/spark/pull/40639#issuecomment-156415 > Thank you, @HeartSaVioR . To @LuciferYang , could you address the above comment? OK, Let me update the results of `StateStoreBasicOperationsBenchmark ` in a follow-up -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on pull request #40697: [SPARK-43061][SQL] Introduce TaskEvaluator for SQL operator execution
yaooqinn commented on PR #40697: URL: https://github.com/apache/spark/pull/40697#issuecomment-1500011078 I'm just curious about the prefix Task for Evaluator. Is it more specific to Partition, Split for SQL/DataFrame, or RDD? `Task` more likely belongs to the scheduler. Before reviewing the PR description and implementation, I thought it was to evaluate the cost of task execution or something. :) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikf commented on pull request #40437: [SPARK-41259][SQL] SparkSQLDriver Output schema and result string should be consistent
Yikf commented on PR #40437: URL: https://github.com/apache/spark/pull/40437#issuecomment-1500012982 > > Spark generates golden files for SQLQueryTestSuite; > > I think golden files there should match `df.show` instead of hive result. This may be a bit of a regression, maybe... first, golden generation and validation are done with `hiveResultString `, it won't have what problem, then, the output is more readable, finally, `ThriftServerQueryTestSuite` test case generation also uses the independent `hiveString`, this also needs to reconstruct. So what's the benefit of removal? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
HeartSaVioR commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160494146 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: I just had a discussion with @zsxwing offline. There was a confusion that we guarantee the same output between batch and streaming for new API which isn't true. To remove any confusion from users, we agreed to remove supporting batch query. I'll reflect the decision. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikf commented on pull request #40437: [SPARK-41259][SQL] SparkSQLDriver Output schema and result string should be consistent
Yikf commented on PR #40437: URL: https://github.com/apache/spark/pull/40437#issuecomment-1500014177 It would be best if we had a separate 'df.show' method to format the results. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
HeartSaVioR commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160494146 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: I just had a discussion with @zsxwing offline. There was a confusion that we guarantee the same output between batch and streaming for new API (like existing dropDuplicates) which isn't true. To remove any confusion from users, we agreed to remove supporting batch query. I'll reflect the decision. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
zsxwing commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160495501 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: @HeartSaVioR Thanks! We can wait for the user's feedback first before supporting batch queries. Changing from an error to no error is always easier. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikf commented on pull request #40437: [SPARK-41259][SQL] SparkSQLDriver Output schema and result string should be consistent
Yikf commented on PR #40437: URL: https://github.com/apache/spark/pull/40437#issuecomment-1500018627 Like following: https://user-images.githubusercontent.com/51110188/230561881-177790a2-3b0b-4081-ba95-7e902af6b05f.png";> And expression describes `ExpressionInfo`, it uses NULL instead of null -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #40697: [SPARK-43061][SQL] Introduce TaskEvaluator for SQL operator execution
cloud-fan commented on code in PR #40697:
URL: https://github.com/apache/spark/pull/40697#discussion_r1160503755
##
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala:
##
@@ -750,37 +750,29 @@ case class WholeStageCodegenExec(child: SparkPlan)(val
codegenStageId: Int)
// but the output must be rows.
val rdds = child.asInstanceOf[CodegenSupport].inputRDDs()
assert(rdds.size <= 2, "Up to two input RDDs can be supported")
+val evaluatorFactory = new WholeStageCodegenEvaluatorFactory(
+ cleanedSource, durationMs, references)
if (rdds.length == 1) {
- rdds.head.mapPartitionsWithIndex { (index, iter) =>
-val (clazz, _) = CodeGenerator.compile(cleanedSource)
-val buffer =
clazz.generate(references).asInstanceOf[BufferedRowIterator]
-buffer.init(index, Array(iter))
-new Iterator[InternalRow] {
- override def hasNext: Boolean = {
-val v = buffer.hasNext
-if (!v) durationMs += buffer.durationMs()
-v
- }
- override def next: InternalRow = buffer.next()
+ if (conf.getConf(SQLConf.USE_TASK_EVALUATOR)) {
+rdds.head.mapPartitionsWithEvaluator(evaluatorFactory)
+ } else {
+rdds.head.mapPartitionsWithIndex { (index, iter) =>
+ val evaluator = evaluatorFactory.createEvaluator()
+ evaluator.eval(index, iter)
}
}
} else {
// Right now, we support up to two input RDDs.
- rdds.head.zipPartitions(rdds(1)) { (leftIter, rightIter) =>
-Iterator((leftIter, rightIter))
-// a small hack to obtain the correct partition index
- }.mapPartitionsWithIndex { (index, zippedIter) =>
-val (leftIter, rightIter) = zippedIter.next()
-val (clazz, _) = CodeGenerator.compile(cleanedSource)
-val buffer =
clazz.generate(references).asInstanceOf[BufferedRowIterator]
-buffer.init(index, Array(leftIter, rightIter))
-new Iterator[InternalRow] {
- override def hasNext: Boolean = {
-val v = buffer.hasNext
-if (!v) durationMs += buffer.durationMs()
-v
- }
- override def next: InternalRow = buffer.next()
+ if (conf.getConf(SQLConf.USE_TASK_EVALUATOR)) {
+rdds.head.zipPartitionsWithEvaluator(rdds(1), evaluatorFactory)
+ } else {
+rdds.head.zipPartitions(rdds(1)) { (leftIter, rightIter) =>
+ Iterator((leftIter, rightIter))
+ // a small hack to obtain the correct partition index
+}.mapPartitionsWithIndex { (index, zippedIter) =>
+ val (leftIter, rightIter) = zippedIter.next()
+ val evaluator = evaluatorFactory.createEvaluator()
Review Comment:
using evaluator is just a factor (code move around), otherwise will have to
duplicate the code
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #40697: [SPARK-43061][SQL] Introduce TaskEvaluator for SQL operator execution
cloud-fan commented on code in PR #40697:
URL: https://github.com/apache/spark/pull/40697#discussion_r1160503755
##
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala:
##
@@ -750,37 +750,29 @@ case class WholeStageCodegenExec(child: SparkPlan)(val
codegenStageId: Int)
// but the output must be rows.
val rdds = child.asInstanceOf[CodegenSupport].inputRDDs()
assert(rdds.size <= 2, "Up to two input RDDs can be supported")
+val evaluatorFactory = new WholeStageCodegenEvaluatorFactory(
+ cleanedSource, durationMs, references)
if (rdds.length == 1) {
- rdds.head.mapPartitionsWithIndex { (index, iter) =>
-val (clazz, _) = CodeGenerator.compile(cleanedSource)
-val buffer =
clazz.generate(references).asInstanceOf[BufferedRowIterator]
-buffer.init(index, Array(iter))
-new Iterator[InternalRow] {
- override def hasNext: Boolean = {
-val v = buffer.hasNext
-if (!v) durationMs += buffer.durationMs()
-v
- }
- override def next: InternalRow = buffer.next()
+ if (conf.getConf(SQLConf.USE_TASK_EVALUATOR)) {
+rdds.head.mapPartitionsWithEvaluator(evaluatorFactory)
+ } else {
+rdds.head.mapPartitionsWithIndex { (index, iter) =>
+ val evaluator = evaluatorFactory.createEvaluator()
+ evaluator.eval(index, iter)
}
}
} else {
// Right now, we support up to two input RDDs.
- rdds.head.zipPartitions(rdds(1)) { (leftIter, rightIter) =>
-Iterator((leftIter, rightIter))
-// a small hack to obtain the correct partition index
- }.mapPartitionsWithIndex { (index, zippedIter) =>
-val (leftIter, rightIter) = zippedIter.next()
-val (clazz, _) = CodeGenerator.compile(cleanedSource)
-val buffer =
clazz.generate(references).asInstanceOf[BufferedRowIterator]
-buffer.init(index, Array(leftIter, rightIter))
-new Iterator[InternalRow] {
- override def hasNext: Boolean = {
-val v = buffer.hasNext
-if (!v) durationMs += buffer.durationMs()
-v
- }
- override def next: InternalRow = buffer.next()
+ if (conf.getConf(SQLConf.USE_TASK_EVALUATOR)) {
+rdds.head.zipPartitionsWithEvaluator(rdds(1), evaluatorFactory)
+ } else {
+rdds.head.zipPartitions(rdds(1)) { (leftIter, rightIter) =>
+ Iterator((leftIter, rightIter))
+ // a small hack to obtain the correct partition index
+}.mapPartitionsWithIndex { (index, zippedIter) =>
+ val (leftIter, rightIter) = zippedIter.next()
+ val evaluator = evaluatorFactory.createEvaluator()
Review Comment:
using evaluator is just a refactor (code move around), otherwise will have
to duplicate the code
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #40639: [SPARK-43007][BUILD] Upgrade rocksdbjni to 8.0.0
LuciferYang commented on PR #40639: URL: https://github.com/apache/spark/pull/40639#issuecomment-1500025387 Need to update later because https://user-images.githubusercontent.com/1475305/230563757-cf26102c-3f87-43a9-95f3-84f8a65b530c.png";> -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #40697: [SPARK-43061][SQL] Introduce TaskEvaluator for SQL operator execution
cloud-fan commented on PR #40697: URL: https://github.com/apache/spark/pull/40697#issuecomment-1500034764 @beliefer This is not a performance feature. It's just to avoid people making mistakes referencing extra objects in the closure, which can slow down task serialization and increase query latency. @yaooqinn I don't have a strong opinion. how about PartitionEvaluator? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikf opened a new pull request, #40699: [SPARK-43063][SQL] `df.show` handle null should print NULL instead of null
Yikf opened a new pull request, #40699:
URL: https://github.com/apache/spark/pull/40699
### What changes were proposed in this pull request?
`df.show` handle null should print NULL instead of null to consistent
behavior;
Like as the following behavior is currently inconsistent:
``` shell
scala> spark.sql("select decode(6, 1, 'Southlake', 2, 'San Francisco', 3,
'New Jersey', 4, 'Seattle') as result").show(false)
+--+
|result|
+--+
|null |
+--+
```
``` shell
spark-sql> DESC FUNCTION EXTENDED decode;
function_desc
Function: decode
Class: org.apache.spark.sql.catalyst.expressions.Decode
Usage:
decode(bin, charset) - Decodes the first argument using the second
argument character set.
decode(expr, search, result [, search, result ] ... [, default]) -
Compares expr
to each search value in order. If expr is equal to a search value,
decode returns
the corresponding result. If no match is found, then it returns
default. If default
is omitted, it returns null.
Extended Usage:
Examples:
> SELECT decode(encode('abc', 'utf-8'), 'utf-8');
abc
> SELECT decode(2, 1, 'Southlake', 2, 'San Francisco', 3, 'New
Jersey', 4, 'Seattle', 'Non domestic');
San Francisco
> SELECT decode(6, 1, 'Southlake', 2, 'San Francisco', 3, 'New
Jersey', 4, 'Seattle', 'Non domestic');
Non domestic
> SELECT decode(6, 1, 'Southlake', 2, 'San Francisco', 3, 'New
Jersey', 4, 'Seattle');
NULL
Since: 3.2.0
Time taken: 0.074 seconds, Fetched 4 row(s)
```
``` shell
spark-sql> select decode(6, 1, 'Southlake', 2, 'San Francisco', 3, 'New
Jersey', 4, 'Seattle');
NULL
```
### Why are the changes needed?
`df.show` keep consistent behavior when handle `null` with spark-sql CLI.
### Does this PR introduce _any_ user-facing change?
Yes, `null` will display NULL instead of null.
### How was this patch tested?
GA
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] caican00 opened a new pull request, #40700: [SPARK][SQL]Set job description for tpcds queries
caican00 opened a new pull request, #40700: URL: https://github.com/apache/spark/pull/40700 ### What changes were proposed in this pull request? Set job description for tpcds queries. Before optimization:  After optimization: 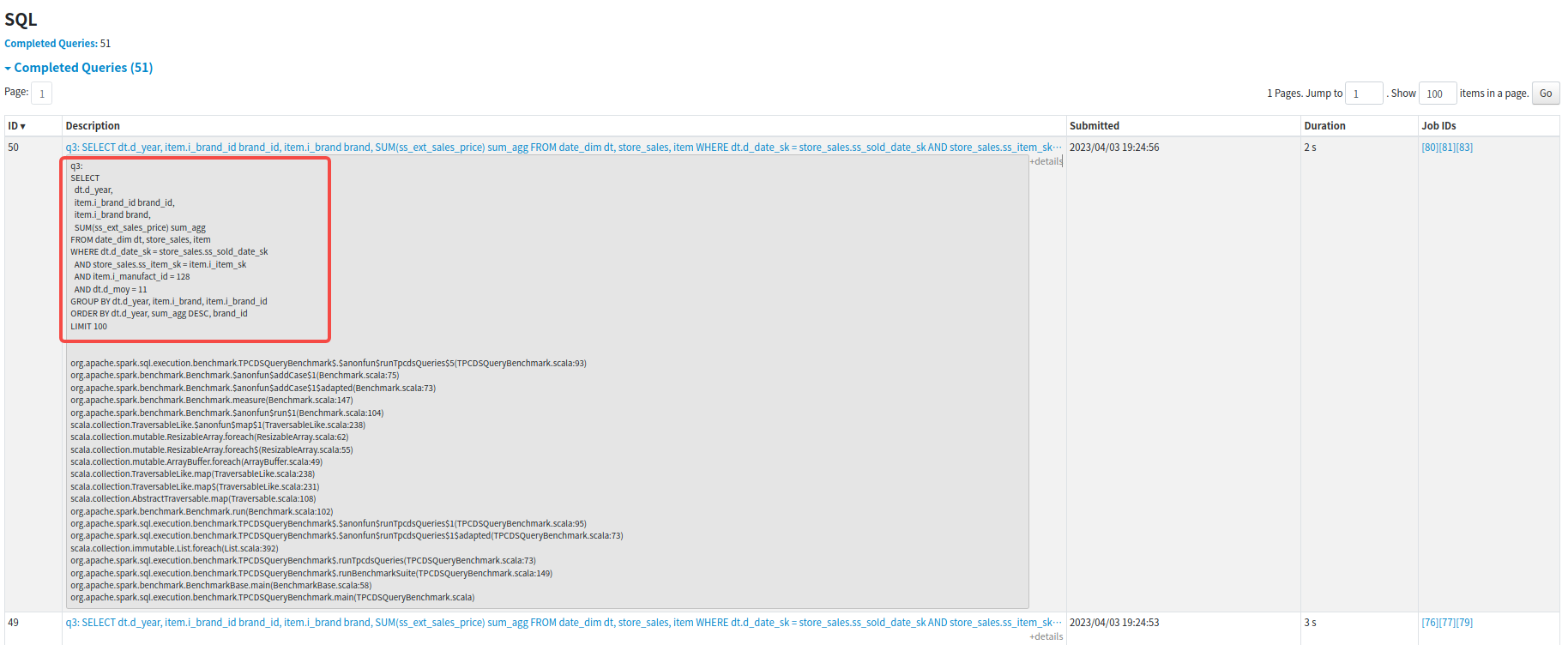 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
HeartSaVioR commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r116052 ## sql/core/src/test/java/test/org/apache/spark/sql/JavaDatasetSuite.java: ## @@ -562,79 +562,6 @@ private void assertEqualsUnorderly( ); } - @Test Review Comment: This was actually missing piece for dropDuplicates() as well. Since we remove the functionality for batch query in dropDuplicatesWithinWatermark(), it's probably better to have another PR to deal with this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
HeartSaVioR commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160522284 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: This commit addressed the rollback of supporting batch query. 0608889e4d1afc4bb5d1710eef45cf50d3c29a0f @zsxwing @rangadi Please have a quick look at the change. Thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] caican00 commented on pull request #40700: [SPARK][SQL]Set job description for tpcds queries
caican00 commented on PR #40700: URL: https://github.com/apache/spark/pull/40700#issuecomment-1500048705 @maropu Could you help to review this pr? Thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
HeartSaVioR commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160522284 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: This commit addressed the rollback of supporting batch query. Changes in test suites are rolled back because these test suites are for batch queries. 0608889e4d1afc4bb5d1710eef45cf50d3c29a0f @zsxwing @rangadi Please have a quick look at the change. Thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #40437: [SPARK-41259][SQL] SparkSQLDriver Output schema and result string should be consistent
cloud-fan commented on PR #40437: URL: https://github.com/apache/spark/pull/40437#issuecomment-1500054156 I'm looking for consistency. `df.show` is what users see, and `hiveResultString` is for golden files. Shouldn't the golden file match what users really see? Why do we test something that is almost invisible to users? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40654: [SPARK-43022][CONNECT] Support protobuf functions for Scala client
LuciferYang commented on code in PR #40654:
URL: https://github.com/apache/spark/pull/40654#discussion_r1160529800
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/ClientE2ETestSuite.scala:
##
@@ -863,6 +866,46 @@ class ClientE2ETestSuite extends RemoteSparkSession with
SQLHelper {
}.getMessage
assert(message.contains("PARSE_SYNTAX_ERROR"))
}
+
+ test("protobuf functions") {
+assert(IntegrationTestUtils.isSparkProtobufJarAvailable)
+// scalastyle:off line.size.limit
+// If `common.desc` needs to be updated, execute the following command to
regenerate it:
+// 1. cd connector/connect/common/src/main/protobuf/spark/connect
+// 2. protoc --include_imports
--descriptor_set_out=../../../../test/resources/protobuf-tests/common.desc
common.proto
+// scalastyle:on line.size.limit
+val descPath = {
Review Comment:
At first, I wrote the following case in `PlanGenerationTestSuite ` to test
`from_protobuf` with `descFilePath`:
```
test("from_protobuf messageClassName options descFilePath") {
binary.select(
pbFn.from_protobuf(
data = fn.col("bytes"),
messageName = "StorageLevel",
descFilePath = "file://fake.desc"))
}
```
but when I run `ProtoToParsedPlanTestSuite `, there is following errors:
```
[info] - from_protobuf_messageClassName_options_descFilePath *** FAILED ***
(11 milliseconds)
[info] org.apache.spark.sql.AnalysisException:
[PROTOBUF_DESCRIPTOR_FILE_NOT_FOUND] Error reading Protobuf descriptor file at
path: file://fake.desc.
[info] at
org.apache.spark.sql.errors.QueryCompilationErrors$.cannotFindDescriptorFileError(QueryCompilationErrors.scala:3375)
[info] at
org.apache.spark.sql.protobuf.utils.ProtobufUtils$.parseFileDescriptorSet(ProtobufUtils.scala:234)
[info] at
org.apache.spark.sql.protobuf.utils.ProtobufUtils$.buildDescriptor(ProtobufUtils.scala:212)
[info] at
org.apache.spark.sql.protobuf.utils.ProtobufUtils$.buildDescriptor(ProtobufUtils.scala:149)
[info] at
org.apache.spark.sql.protobuf.ProtobufDataToCatalyst.messageDescriptor$lzycompute(ProtobufDataToCatalyst.scala:57)
[info] at
org.apache.spark.sql.protobuf.ProtobufDataToCatalyst.messageDescriptor(ProtobufDataToCatalyst.scala:56)
[info] at
org.apache.spark.sql.protobuf.ProtobufDataToCatalyst.dataType$lzycompute(ProtobufDataToCatalyst.scala:42)
[info] at
org.apache.spark.sql.protobuf.ProtobufDataToCatalyst.dataType(ProtobufDataToCatalyst.scala:41)
...
[info] Cause: java.io.FileNotFoundException: file:/fake.desc (No such file
or directory)
...
```
`ProtobufDataToCatalyst.dataType` need the `descFilePath` file to resolve
`dataType`, so I change the case as follows:
```
private lazy val descPath = {
getWorkspaceFilePath(
"connector",
"connect",
"common",
"src",
"test",
"resources",
"protobuf-tests",
"common.desc")
test("from_protobuf messageClassName options descFilePath") {
binary.select(
pbFn.from_protobuf(
data = fn.col("bytes"),
messageName = "StorageLevel",
descFilePath = descPath.toFile.getPath))
}
```
the test will success, but the contens of `.explain` as follows:
```Project [from_protobuf(bytes#0, StorageLevel,
Some(/Users/yangjie01/SourceCode/git/spark-mine-sbt/connector/connect/common/src/test/resources/protobuf-tests/common.desc))
AS from_protobuf(bytes)#0]
+- LocalRelation , [id#0L, bytes#0]
```
the `descFilePath` is a absolute path, any better suggestions? @hvanhovell
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40654: [SPARK-43022][CONNECT] Support protobuf functions for Scala client
LuciferYang commented on code in PR #40654:
URL: https://github.com/apache/spark/pull/40654#discussion_r1160529800
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/ClientE2ETestSuite.scala:
##
@@ -863,6 +866,46 @@ class ClientE2ETestSuite extends RemoteSparkSession with
SQLHelper {
}.getMessage
assert(message.contains("PARSE_SYNTAX_ERROR"))
}
+
+ test("protobuf functions") {
+assert(IntegrationTestUtils.isSparkProtobufJarAvailable)
+// scalastyle:off line.size.limit
+// If `common.desc` needs to be updated, execute the following command to
regenerate it:
+// 1. cd connector/connect/common/src/main/protobuf/spark/connect
+// 2. protoc --include_imports
--descriptor_set_out=../../../../test/resources/protobuf-tests/common.desc
common.proto
+// scalastyle:on line.size.limit
+val descPath = {
Review Comment:
At first, I wrote the following case in `PlanGenerationTestSuite ` to test
`from_protobuf` with `descFilePath`:
```
test("from_protobuf messageClassName options descFilePath") {
binary.select(
pbFn.from_protobuf(
data = fn.col("bytes"),
messageName = "StorageLevel",
descFilePath = "file://fake.desc"))
}
```
but when I run `ProtoToParsedPlanTestSuite `, there is following errors:
```
[info] - from_protobuf_messageClassName_options_descFilePath *** FAILED ***
(11 milliseconds)
[info] org.apache.spark.sql.AnalysisException:
[PROTOBUF_DESCRIPTOR_FILE_NOT_FOUND] Error reading Protobuf descriptor file at
path: file://fake.desc.
[info] at
org.apache.spark.sql.errors.QueryCompilationErrors$.cannotFindDescriptorFileError(QueryCompilationErrors.scala:3375)
[info] at
org.apache.spark.sql.protobuf.utils.ProtobufUtils$.parseFileDescriptorSet(ProtobufUtils.scala:234)
[info] at
org.apache.spark.sql.protobuf.utils.ProtobufUtils$.buildDescriptor(ProtobufUtils.scala:212)
[info] at
org.apache.spark.sql.protobuf.utils.ProtobufUtils$.buildDescriptor(ProtobufUtils.scala:149)
[info] at
org.apache.spark.sql.protobuf.ProtobufDataToCatalyst.messageDescriptor$lzycompute(ProtobufDataToCatalyst.scala:57)
[info] at
org.apache.spark.sql.protobuf.ProtobufDataToCatalyst.messageDescriptor(ProtobufDataToCatalyst.scala:56)
[info] at
org.apache.spark.sql.protobuf.ProtobufDataToCatalyst.dataType$lzycompute(ProtobufDataToCatalyst.scala:42)
[info] at
org.apache.spark.sql.protobuf.ProtobufDataToCatalyst.dataType(ProtobufDataToCatalyst.scala:41)
...
[info] Cause: java.io.FileNotFoundException: file:/fake.desc (No such file
or directory)
...
```
`ProtobufDataToCatalyst.dataType` need the `descFilePath` file to resolve
`dataType`, so I change the case as follows:
```
private lazy val descPath = {
getWorkspaceFilePath(
"connector",
"connect",
"common",
"src",
"test",
"resources",
"protobuf-tests",
"common.desc")
test("from_protobuf messageClassName options descFilePath") {
binary.select(
pbFn.from_protobuf(
data = fn.col("bytes"),
messageName = "StorageLevel",
descFilePath = descPath.toFile.getPath))
}
```
the test will success, but the contens of `.explain` as follows:
```
Project [from_protobuf(bytes#0, StorageLevel,
Some(/Users/yangjie01/SourceCode/git/spark-mine-sbt/connector/connect/common/src/test/resources/protobuf-tests/common.desc))
AS from_protobuf(bytes)#0]
+- LocalRelation , [id#0L, bytes#0]
```
the `descFilePath` is a absolute path, any better suggestions? @hvanhovell
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu opened a new pull request, #40701: [SPARK-43064][SQL] Spark SQL CLI SQL tab should only show once statement once
AngersZh opened a new pull request, #40701: URL: https://github.com/apache/spark/pull/40701 ### What changes were proposed in this pull request? Before https://user-images.githubusercontent.com/46485123/230573688-42acb9f2-6fa0-48d0-bfde-c7ceeb306aef.png";> After https://user-images.githubusercontent.com/46485123/230573720-2c2a7731-d776-439c-ba6f-0dad9dc87a42.png";> ### Why are the changes needed? Don't need show twice, too weird ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? MT -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #40701: [SPARK-43064][SQL] Spark SQL CLI SQL tab should only show once statement once
AngersZh commented on PR #40701: URL: https://github.com/apache/spark/pull/40701#issuecomment-1500071438 ping @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40605: [SPARK-42958][CONNECT] Refactor `connect-jvm-client-mima-check` to support mima check with avro module
LuciferYang commented on code in PR #40605: URL: https://github.com/apache/spark/pull/40605#discussion_r1160542658 ## dev/connect-jvm-client-mima-check: ## @@ -34,20 +34,18 @@ fi rm -f .connect-mima-check-result -echo "Build sql module, connect-client-jvm module and connect-client-jvm test jar..." -build/sbt "sql/package;connect-client-jvm/assembly;connect-client-jvm/Test/package" +echo "Build required modules..." +build/sbt "sql/package;connect-client-jvm/assembly;connect-client-jvm/Test/package;avro/package" CONNECT_TEST_CLASSPATH="$(build/sbt -DcopyDependencies=false "export connect-client-jvm/Test/fullClasspath" | grep jar | tail -n1)" -CONNECT_CLASSPATH="$(build/sbt -DcopyDependencies=false "export connect-client-jvm/fullClasspath" | grep jar | tail -n1)" SQL_CLASSPATH="$(build/sbt -DcopyDependencies=false "export sql/fullClasspath" | grep jar | tail -n1)" - echo "Do connect-client-jvm module mima check ..." $JAVA_CMD \ -Xmx2g \ -XX:+IgnoreUnrecognizedVMOptions --add-opens=java.base/java.util.jar=ALL-UNNAMED \ - -cp "$CONNECT_CLASSPATH:$CONNECT_TEST_CLASSPATH:$SQL_CLASSPATH" \ + -cp "$CONNECT_TEST_CLASSPATH:$SQL_CLASSPATH" \ Review Comment: @hvanhovell Yes, you are right. Only `checkDatasetApiCompatibility` needs `SQL_CLASSPATH ` because it is not a pure mima check. So we just need `CONNECT_TEST_CLASSPATH` for `CheckConnectJvmClientCompatibility ` and `SQL_CLASSPATH` for `checkDatasetApiCompatibility` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikf commented on pull request #40437: [SPARK-41259][SQL] SparkSQLDriver Output schema and result string should be consistent
Yikf commented on PR #40437: URL: https://github.com/apache/spark/pull/40437#issuecomment-1500073818 > I'm looking for consistency. `df.show` is what users see, and `hiveResultString` is for golden files. Shouldn't the golden file match what users really see? Why do we test something that is almost invisible to users? In fact, `SQLQueryTestSuite` does not test `df.show`, it is actually something under the `DataSet`, and `hiveResultString` only prints out the data of the `DataSet`, but I agree with you. It is better to print with spark's resultString -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #40314: [SPARK-42698][CORE] SparkSubmit should also stop SparkContext when exit program in yarn mode and pass exitCode to AM side
AngersZh commented on PR #40314: URL: https://github.com/apache/spark/pull/40314#issuecomment-1500073974 ping @dongjoon-hyun @HyukjinKwon @attilapiros @srowen -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #40701: [SPARK-43064][SQL] Spark SQL CLI SQL tab should only show once statement once
cloud-fan commented on code in PR #40701:
URL: https://github.com/apache/spark/pull/40701#discussion_r1160551276
##
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLDriver.scala:
##
@@ -65,8 +66,13 @@ private[hive] class SparkSQLDriver(val context: SQLContext =
SparkSQLEnv.sqlCont
}
context.sparkContext.setJobDescription(substitutorCommand)
val execution =
context.sessionState.executePlan(context.sql(command).logicalPlan)
- hiveResponse = SQLExecution.withNewExecutionId(execution, Some("cli")) {
-hiveResultString(execution.executedPlan)
+ execution.logical match {
+case CommandResult(_, _, _, _) =>
Review Comment:
can we add some comments to explain it?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #40701: [SPARK-43064][SQL] Spark SQL CLI SQL tab should only show once statement once
cloud-fan commented on code in PR #40701:
URL: https://github.com/apache/spark/pull/40701#discussion_r1160551428
##
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLDriver.scala:
##
@@ -65,8 +66,13 @@ private[hive] class SparkSQLDriver(val context: SQLContext =
SparkSQLEnv.sqlCont
}
context.sparkContext.setJobDescription(substitutorCommand)
val execution =
context.sessionState.executePlan(context.sql(command).logicalPlan)
- hiveResponse = SQLExecution.withNewExecutionId(execution, Some("cli")) {
-hiveResultString(execution.executedPlan)
+ execution.logical match {
+case CommandResult(_, _, _, _) =>
Review Comment:
```suggestion
case _: CommandResult =>
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #40437: [SPARK-41259][SQL] SparkSQLDriver Output schema and result string should be consistent
cloud-fan commented on PR #40437: URL: https://github.com/apache/spark/pull/40437#issuecomment-1500082745 also cc @AngersZh -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40605: [SPARK-42958][CONNECT] Refactor `connect-jvm-client-mima-check` to support mima check with avro module
LuciferYang commented on code in PR #40605:
URL: https://github.com/apache/spark/pull/40605#discussion_r1160556535
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/CheckConnectJvmClientCompatibility.scala:
##
@@ -62,15 +62,29 @@ object CheckConnectJvmClientCompatibility {
"spark-connect-client-jvm-assembly",
"spark-connect-client-jvm")
val sqlJar: File = findJar("sql/core", "spark-sql", "spark-sql")
- val problems = checkMiMaCompatibility(clientJar, sqlJar)
- if (problems.nonEmpty) {
+ val problemsWithSqlModule =
checkMiMaCompatibilityWithSqlModule(clientJar, sqlJar)
+ if (problemsWithSqlModule.nonEmpty) {
resultWriter.write(s"ERROR: Comparing client jar: $clientJar and and
sql jar: $sqlJar \n")
-resultWriter.write(s"problems: \n")
-resultWriter.write(s"${problems.map(p =>
p.description("client")).mkString("\n")}")
+resultWriter.write(s"problemsWithSqlModule: \n")
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40352: [SPARK-42664][CONNECT] Support `bloomFilter` function for `DataFrameStatFunctions`
LuciferYang commented on code in PR #40352:
URL: https://github.com/apache/spark/pull/40352#discussion_r1160557436
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala:
##
@@ -1073,6 +1074,91 @@ class SparkConnectPlanner(val session: SparkSession) {
}
Some(Lead(children.head, children(1), children(2), ignoreNulls))
+ case "bloom_filter_agg" if fun.getArgumentsCount == 5 =>
+// [col, catalogString: String, expectedNumItems: Long, numBits: Long,
fpp: Double]
+val children =
fun.getArgumentsList.asScala.toSeq.map(transformExpression)
+val dt = {
+ val ddl = children(1) match {
+case StringLiteral(s) => s
+case other =>
+ throw InvalidPlanInput(s"col dataType should be a literal
string, but got $other")
+ }
+ DataType.fromDDL(ddl)
+}
+val col = dt match {
+ case IntegerType | ShortType | ByteType => Cast(children.head,
LongType)
+ case LongType | StringType => children.head
+ case other =>
+throw InvalidPlanInput(
+ s"Bloom filter only supports integral types, " +
+s"and does not support type $other.")
+}
+
+val fpp = children(4) match {
+ case DoubleLiteral(d) => d
+ case _ =>
+throw InvalidPlanInput("False positive must be double literal.")
+}
+
+if (fpp.isNaN) {
+ // Use expectedNumItems and numBits when `fpp.isNaN` if true.
+ // Check expectedNumItems > 0L
+ val expectedNumItemsExpr = children(2)
+ val expectedNumItems = expectedNumItemsExpr match {
+case Literal(l: Long, LongType) => l
+case _ =>
+ throw InvalidPlanInput("Expected insertions must be long
literal.")
+ }
+ if (expectedNumItems <= 0L) {
+throw InvalidPlanInput("Expected insertions must be positive.")
+ }
+ // Check numBits > 0L
+ val numBitsExpr = children(3)
+ val numBits = numBitsExpr match {
+case Literal(l: Long, LongType) => l
+case _ =>
+ throw InvalidPlanInput("Number of bits must be long literal.")
+ }
+ if (numBits <= 0L) {
+throw InvalidPlanInput("Number of bits must be positive.")
+ }
+ // Create BloomFilterAggregate with expectedNumItemsExpr and
numBitsExpr.
+ Some(
+new BloomFilterAggregate(col, expectedNumItemsExpr, numBitsExpr)
+ .toAggregateExpression())
+
+} else {
+ def optimalNumOfBits(n: Long, p: Double): Long =
Review Comment:
this is a java file, no `private[spark]`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a diff in pull request #39937: [SPARK-42309][SQL] Introduce `INCOMPATIBLE_DATA_TO_TABLE` and sub classes.
MaxGekk commented on code in PR #39937:
URL: https://github.com/apache/spark/pull/39937#discussion_r1160535300
##
sql/core/src/test/scala/org/apache/spark/sql/sources/InsertSuite.scala:
##
@@ -776,38 +808,62 @@ class InsertSuite extends DataSourceTest with
SharedSparkSession {
SQLConf.STORE_ASSIGNMENT_POLICY.key ->
SQLConf.StoreAssignmentPolicy.ANSI.toString) {
withTable("t") {
sql("CREATE TABLE t(i int, t timestamp) USING parquet")
-val msg = intercept[AnalysisException] {
- sql("INSERT INTO t VALUES (TIMESTAMP('2010-09-02 14:10:10'), 1)")
-}.getMessage
-assert(msg.contains("Cannot safely cast 'i': timestamp to int"))
-assert(msg.contains("Cannot safely cast 't': int to timestamp"))
+checkError(
+ exception = intercept[AnalysisException] {
+sql("INSERT INTO t VALUES (TIMESTAMP('2010-09-02 14:10:10'), 1)")
+ },
+ errorClass = "INCOMPATIBLE_DATA_FOR_TABLE.CANNOT_SAFELY_CAST",
+ parameters = Map(
+"tableName" -> "`spark_catalog`.`default`.`t`",
+"colPath" -> "`i`",
+"from" -> "\"TIMESTAMP\"",
+"to" -> "\"INT\"")
+)
}
withTable("t") {
sql("CREATE TABLE t(i int, d date) USING parquet")
-val msg = intercept[AnalysisException] {
- sql("INSERT INTO t VALUES (date('2010-09-02'), 1)")
-}.getMessage
-assert(msg.contains("Cannot safely cast 'i': date to int"))
-assert(msg.contains("Cannot safely cast 'd': int to date"))
+checkError(
+ exception = intercept[AnalysisException] {
+sql("INSERT INTO t VALUES (date('2010-09-02'), 1)")
+ },
+ errorClass = "INCOMPATIBLE_DATA_FOR_TABLE.CANNOT_SAFELY_CAST",
+ parameters = Map(
+"tableName" -> "`spark_catalog`.`default`.`t`",
+"colPath" -> "`i`",
+"from" -> "\"DATE\"",
+"to" -> "\"INT\"")
+)
}
withTable("t") {
sql("CREATE TABLE t(b boolean, t timestamp) USING parquet")
-val msg = intercept[AnalysisException] {
- sql("INSERT INTO t VALUES (TIMESTAMP('2010-09-02 14:10:10'), true)")
-}.getMessage
-assert(msg.contains("Cannot safely cast 'b': timestamp to boolean"))
-assert(msg.contains("Cannot safely cast 't': boolean to timestamp"))
+checkError(
+ exception = intercept[AnalysisException] {
+sql("INSERT INTO t VALUES (TIMESTAMP('2010-09-02 14:10:10'),
true)")
+ },
+errorClass = "INCOMPATIBLE_DATA_FOR_TABLE.CANNOT_SAFELY_CAST",
+parameters = Map(
+"tableName" -> "`spark_catalog`.`default`.`t`",
+"colPath" -> "`b`",
+"from" -> "\"TIMESTAMP\"",
+"to" -> "\"BOOLEAN\"")
Review Comment:
Please, fix indentation.
##
sql/core/src/test/scala/org/apache/spark/sql/sources/InsertSuite.scala:
##
@@ -776,38 +808,62 @@ class InsertSuite extends DataSourceTest with
SharedSparkSession {
SQLConf.STORE_ASSIGNMENT_POLICY.key ->
SQLConf.StoreAssignmentPolicy.ANSI.toString) {
withTable("t") {
sql("CREATE TABLE t(i int, t timestamp) USING parquet")
-val msg = intercept[AnalysisException] {
- sql("INSERT INTO t VALUES (TIMESTAMP('2010-09-02 14:10:10'), 1)")
-}.getMessage
-assert(msg.contains("Cannot safely cast 'i': timestamp to int"))
-assert(msg.contains("Cannot safely cast 't': int to timestamp"))
+checkError(
+ exception = intercept[AnalysisException] {
+sql("INSERT INTO t VALUES (TIMESTAMP('2010-09-02 14:10:10'), 1)")
+ },
+ errorClass = "INCOMPATIBLE_DATA_FOR_TABLE.CANNOT_SAFELY_CAST",
+ parameters = Map(
+"tableName" -> "`spark_catalog`.`default`.`t`",
+"colPath" -> "`i`",
+"from" -> "\"TIMESTAMP\"",
+"to" -> "\"INT\"")
+)
}
withTable("t") {
sql("CREATE TABLE t(i int, d date) USING parquet")
-val msg = intercept[AnalysisException] {
- sql("INSERT INTO t VALUES (date('2010-09-02'), 1)")
-}.getMessage
-assert(msg.contains("Cannot safely cast 'i': date to int"))
-assert(msg.contains("Cannot safely cast 'd': int to date"))
+checkError(
+ exception = intercept[AnalysisException] {
+sql("INSERT INTO t VALUES (date('2010-09-02'), 1)")
+ },
+ errorClass = "INCOMPATIBLE_DATA_FOR_TABLE.CANNOT_SAFELY_CAST",
+ parameters = Map(
+"tableName" -> "`spark_catalog`.`default`.`t`",
+"colPath" -> "`i`",
+"from" -> "\"DATE\"",
+"to" -> "\"INT\"")
+)
}
withTable("t") {
sql("CREATE TABLE t(b boolean, t timestamp) USING parquet")
-val msg = intercept[AnalysisException] {
- sql("INS
[GitHub] [spark] AngersZhuuuu commented on a diff in pull request #40701: [SPARK-43064][SQL] Spark SQL CLI SQL tab should only show once statement once
AngersZh commented on code in PR #40701:
URL: https://github.com/apache/spark/pull/40701#discussion_r1160561169
##
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLDriver.scala:
##
@@ -65,8 +66,13 @@ private[hive] class SparkSQLDriver(val context: SQLContext =
SparkSQLEnv.sqlCont
}
context.sparkContext.setJobDescription(substitutorCommand)
val execution =
context.sessionState.executePlan(context.sql(command).logicalPlan)
- hiveResponse = SQLExecution.withNewExecutionId(execution, Some("cli")) {
-hiveResultString(execution.executedPlan)
+ execution.logical match {
+case CommandResult(_, _, _, _) =>
Review Comment:
DOne
##
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLDriver.scala:
##
@@ -65,8 +66,13 @@ private[hive] class SparkSQLDriver(val context: SQLContext =
SparkSQLEnv.sqlCont
}
context.sparkContext.setJobDescription(substitutorCommand)
val execution =
context.sessionState.executePlan(context.sql(command).logicalPlan)
- hiveResponse = SQLExecution.withNewExecutionId(execution, Some("cli")) {
-hiveResultString(execution.executedPlan)
+ execution.logical match {
+case CommandResult(_, _, _, _) =>
Review Comment:
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Hisoka-X commented on a diff in pull request #40632: [SPARK-42298][SQL] Assign name to _LEGACY_ERROR_TEMP_2132
Hisoka-X commented on code in PR #40632:
URL: https://github.com/apache/spark/pull/40632#discussion_r1160562342
##
sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala:
##
@@ -1404,8 +1404,8 @@ private[sql] object QueryExecutionErrors extends
QueryErrorsBase {
def cannotParseJsonArraysAsStructsError(): SparkRuntimeException = {
new SparkRuntimeException(
- errorClass = "_LEGACY_ERROR_TEMP_2132",
- messageParameters = Map.empty)
+ errorClass = "CANNOT_PARSE_JSON_ARRAYS_AS_STRUCTS",
Review Comment:
Hi, @MaxGekk , any update? What change should I do?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40352: [SPARK-42664][CONNECT] Support `bloomFilter` function for `DataFrameStatFunctions`
LuciferYang commented on code in PR #40352:
URL: https://github.com/apache/spark/pull/40352#discussion_r1160563946
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala:
##
@@ -1154,6 +1155,91 @@ class SparkConnectPlanner(val session: SparkSession) {
}
Some(Lead(children.head, children(1), children(2), ignoreNulls))
+ case "bloom_filter_agg" if fun.getArgumentsCount == 5 =>
Review Comment:
`bloom_filter_agg ` is an internal function that does not allow users to
directly use it, `fold it back into the FunctionRegistry.` may require some
additional work
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40352: [SPARK-42664][CONNECT] Support `bloomFilter` function for `DataFrameStatFunctions`
LuciferYang commented on code in PR #40352: URL: https://github.com/apache/spark/pull/40352#discussion_r1160566049 ## sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/aggregate/BloomFilterAggregate.scala: ## @@ -78,7 +79,7 @@ case class BloomFilterAggregate( "exprName" -> "estimatedNumItems or numBits" ) ) - case (LongType, LongType, LongType) => + case (LongType, LongType, LongType) | (StringType, LongType, LongType) => Review Comment: Thanks, fixed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #40315: [SPARK-42699][CONNECT] SparkConnectServer should make client and AM same exit code
AngersZh commented on PR #40315: URL: https://github.com/apache/spark/pull/40315#issuecomment-1500104571 @amaliujia Like current? also ping @HyukjinKwon -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on pull request #40114: [SPARK-42513][SQL] Push down topK through join
wangyum commented on PR #40114: URL: https://github.com/apache/spark/pull/40114#issuecomment-1500110950 Date | No. of queries optimized by this patch | No. of total queries -- | -- | -- 2023/4/5 | 62 | 167608 2023/4/4 | 139 | 203393 2023/4/3 | 62 | 191147 2023/4/2 | 14 | 133519 2023/4/1 | 10 | 175728 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on pull request #40437: [SPARK-41259][SQL] SparkSQLDriver Output schema and result string should be consistent
yaooqinn commented on PR #40437: URL: https://github.com/apache/spark/pull/40437#issuecomment-1500113298 Adjusting `df.show` may need to change the output of `show` first. Some data values do not have a nice string representation yet -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on pull request #40697: [SPARK-43061][SQL] Introduce TaskEvaluator for SQL operator execution
yaooqinn commented on PR #40697: URL: https://github.com/apache/spark/pull/40697#issuecomment-1500115645 `PartitionEvaluator` looks better to me, altho I don't have a strong option either. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikf commented on pull request #40437: [SPARK-41259][SQL] SparkSQLDriver Output schema and result string should be consistent
Yikf commented on PR #40437: URL: https://github.com/apache/spark/pull/40437#issuecomment-150019 After code validation, ThriftServerQueryTestSuite and SQLQueryTestSuite depend on goldgen files; If goldgen file follows the format of df.show (the format of df.show depends on the DF rowEncoder); For SQLQueryTestSuite, you can easily generate df.show format; For ThriftServerQueryTestSuite, as a result of this suite ThriftServer, based on the client side output as the Object, not the DataSet, It is difficult to match the format of df.show (unless you copy the logic of a DataSet encoder); In addition to ThriftServerQueryTestSuite, it seems that it does not have to follow the df. The format of the show? In both of these kits, which are internal tests, is the format of output based on the DataSet only required to be consistent, rather than having to use the format of df.show? Because it's not testing at df.show -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR opened a new pull request, #40702: [SPARK-43066][SQL] Add test for dropDuplicates in JavaDatasetSuite
HeartSaVioR opened a new pull request, #40702: URL: https://github.com/apache/spark/pull/40702 ### What changes were proposed in this pull request? This PR proposes to add test for dropDuplicates in JavaDatasetSuite. ### Why are the changes needed? The API dropDuplicates wasn't tested by Java test suite. It'd be better to have a sanity check to verify inter-op between Scala and Java works well. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? CI will verify. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #40352: [SPARK-42664][CONNECT] Support `bloomFilter` function for `DataFrameStatFunctions`
LuciferYang commented on PR #40352: URL: https://github.com/apache/spark/pull/40352#issuecomment-1500146157 In the last commit, make `BloomFilterAggregate` explicitly supported `IntegerType/ShortType/ByteType` and added corresponding updaters, then removed pass `dataType` and `adding cast nodes` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #40352: [SPARK-42664][CONNECT] Support `bloomFilter` function for `DataFrameStatFunctions`
LuciferYang commented on PR #40352: URL: https://github.com/apache/spark/pull/40352#issuecomment-1500147099 GA failure is not related to the current PR -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #40697: [SPARK-43061][SQL] Introduce TaskEvaluator for SQL operator execution
beliefer commented on PR #40697: URL: https://github.com/apache/spark/pull/40697#issuecomment-1500156450 > @beliefer This is not a performance feature. It's just to avoid people making mistakes referencing extra objects in the closure, which can slow down task serialization and increase query latency. Got it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40352: [SPARK-42664][CONNECT] Support `bloomFilter` function for `DataFrameStatFunctions`
LuciferYang commented on code in PR #40352:
URL: https://github.com/apache/spark/pull/40352#discussion_r1160620933
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/DataFrameStatFunctions.scala:
##
@@ -584,6 +585,86 @@ final class DataFrameStatFunctions private[sql]
(sparkSession: SparkSession, roo
}
CountMinSketch.readFrom(ds.head())
}
+
+ /**
+ * Builds a Bloom filter over a specified column.
+ *
+ * @param colName
+ * name of the column over which the filter is built
+ * @param expectedNumItems
+ * expected number of items which will be put into the filter.
+ * @param fpp
+ * expected false positive probability of the filter.
+ * @since 3.5.0
+ */
+ def bloomFilter(colName: String, expectedNumItems: Long, fpp: Double):
BloomFilter = {
+buildBloomFilter(Column(colName), expectedNumItems, -1L, fpp)
+ }
+
+ /**
+ * Builds a Bloom filter over a specified column.
+ *
+ * @param col
+ * the column over which the filter is built
+ * @param expectedNumItems
+ * expected number of items which will be put into the filter.
+ * @param fpp
+ * expected false positive probability of the filter.
+ * @since 3.5.0
+ */
+ def bloomFilter(col: Column, expectedNumItems: Long, fpp: Double):
BloomFilter = {
+buildBloomFilter(col, expectedNumItems, -1L, fpp)
+ }
+
+ /**
+ * Builds a Bloom filter over a specified column.
+ *
+ * @param colName
+ * name of the column over which the filter is built
+ * @param expectedNumItems
+ * expected number of items which will be put into the filter.
+ * @param numBits
+ * expected number of bits of the filter.
+ * @since 3.5.0
+ */
+ def bloomFilter(colName: String, expectedNumItems: Long, numBits: Long):
BloomFilter = {
+buildBloomFilter(Column(colName), expectedNumItems, numBits, Double.NaN)
+ }
+
+ /**
+ * Builds a Bloom filter over a specified column.
+ *
+ * @param col
+ * the column over which the filter is built
+ * @param expectedNumItems
+ * expected number of items which will be put into the filter.
+ * @param numBits
+ * expected number of bits of the filter.
+ * @since 3.5.0
+ */
+ def bloomFilter(col: Column, expectedNumItems: Long, numBits: Long):
BloomFilter = {
+buildBloomFilter(col, expectedNumItems, numBits, Double.NaN)
+ }
+
+ private def buildBloomFilter(
+ col: Column,
+ expectedNumItems: Long,
+ numBits: Long,
+ fpp: Double): BloomFilter = {
+
+val agg = if (!fpp.isNaN) {
Review Comment:
Before [chanage to always pass 3
parameters](https://github.com/apache/spark/pull/40352/commits/5bd616954aaef21b88b161e20e0f49bc067cae0c),
always pass all 4 parameters.
Now change to pass (`col`, expectedNumItems, fpp) if `!fpp. isNaN `,
otherwise pass (`col`, expectedNumItems, numBits).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40352: [SPARK-42664][CONNECT] Support `bloomFilter` function for `DataFrameStatFunctions`
LuciferYang commented on code in PR #40352:
URL: https://github.com/apache/spark/pull/40352#discussion_r1160620933
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/DataFrameStatFunctions.scala:
##
@@ -584,6 +585,86 @@ final class DataFrameStatFunctions private[sql]
(sparkSession: SparkSession, roo
}
CountMinSketch.readFrom(ds.head())
}
+
+ /**
+ * Builds a Bloom filter over a specified column.
+ *
+ * @param colName
+ * name of the column over which the filter is built
+ * @param expectedNumItems
+ * expected number of items which will be put into the filter.
+ * @param fpp
+ * expected false positive probability of the filter.
+ * @since 3.5.0
+ */
+ def bloomFilter(colName: String, expectedNumItems: Long, fpp: Double):
BloomFilter = {
+buildBloomFilter(Column(colName), expectedNumItems, -1L, fpp)
+ }
+
+ /**
+ * Builds a Bloom filter over a specified column.
+ *
+ * @param col
+ * the column over which the filter is built
+ * @param expectedNumItems
+ * expected number of items which will be put into the filter.
+ * @param fpp
+ * expected false positive probability of the filter.
+ * @since 3.5.0
+ */
+ def bloomFilter(col: Column, expectedNumItems: Long, fpp: Double):
BloomFilter = {
+buildBloomFilter(col, expectedNumItems, -1L, fpp)
+ }
+
+ /**
+ * Builds a Bloom filter over a specified column.
+ *
+ * @param colName
+ * name of the column over which the filter is built
+ * @param expectedNumItems
+ * expected number of items which will be put into the filter.
+ * @param numBits
+ * expected number of bits of the filter.
+ * @since 3.5.0
+ */
+ def bloomFilter(colName: String, expectedNumItems: Long, numBits: Long):
BloomFilter = {
+buildBloomFilter(Column(colName), expectedNumItems, numBits, Double.NaN)
+ }
+
+ /**
+ * Builds a Bloom filter over a specified column.
+ *
+ * @param col
+ * the column over which the filter is built
+ * @param expectedNumItems
+ * expected number of items which will be put into the filter.
+ * @param numBits
+ * expected number of bits of the filter.
+ * @since 3.5.0
+ */
+ def bloomFilter(col: Column, expectedNumItems: Long, numBits: Long):
BloomFilter = {
+buildBloomFilter(col, expectedNumItems, numBits, Double.NaN)
+ }
+
+ private def buildBloomFilter(
+ col: Column,
+ expectedNumItems: Long,
+ numBits: Long,
+ fpp: Double): BloomFilter = {
+
+val agg = if (!fpp.isNaN) {
Review Comment:
Before [chanage to always pass 3
parameters](https://github.com/apache/spark/pull/40352/commits/5bd616954aaef21b88b161e20e0f49bc067cae0c),
always pass all 4 parameters.
Now change to pass (`col`, `expectedNumItems`, `fpp`) if `!fpp. isNaN `,
otherwise pass (`col`, `expectedNumItems`, `numBits`).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #40352: [SPARK-42664][CONNECT] Support `bloomFilter` function for `DataFrameStatFunctions`
LuciferYang commented on code in PR #40352:
URL: https://github.com/apache/spark/pull/40352#discussion_r1160631080
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala:
##
@@ -1073,6 +1074,91 @@ class SparkConnectPlanner(val session: SparkSession) {
}
Some(Lead(children.head, children(1), children(2), ignoreNulls))
+ case "bloom_filter_agg" if fun.getArgumentsCount == 5 =>
+// [col, catalogString: String, expectedNumItems: Long, numBits: Long,
fpp: Double]
+val children =
fun.getArgumentsList.asScala.toSeq.map(transformExpression)
+val dt = {
+ val ddl = children(1) match {
+case StringLiteral(s) => s
+case other =>
+ throw InvalidPlanInput(s"col dataType should be a literal
string, but got $other")
+ }
+ DataType.fromDDL(ddl)
+}
+val col = dt match {
+ case IntegerType | ShortType | ByteType => Cast(children.head,
LongType)
+ case LongType | StringType => children.head
+ case other =>
+throw InvalidPlanInput(
+ s"Bloom filter only supports integral types, " +
+s"and does not support type $other.")
+}
+
+val fpp = children(4) match {
+ case DoubleLiteral(d) => d
+ case _ =>
+throw InvalidPlanInput("False positive must be double literal.")
+}
+
+if (fpp.isNaN) {
+ // Use expectedNumItems and numBits when `fpp.isNaN` if true.
+ // Check expectedNumItems > 0L
+ val expectedNumItemsExpr = children(2)
+ val expectedNumItems = expectedNumItemsExpr match {
+case Literal(l: Long, LongType) => l
+case _ =>
+ throw InvalidPlanInput("Expected insertions must be long
literal.")
+ }
+ if (expectedNumItems <= 0L) {
+throw InvalidPlanInput("Expected insertions must be positive.")
+ }
+ // Check numBits > 0L
+ val numBitsExpr = children(3)
+ val numBits = numBitsExpr match {
+case Literal(l: Long, LongType) => l
+case _ =>
+ throw InvalidPlanInput("Number of bits must be long literal.")
+ }
+ if (numBits <= 0L) {
+throw InvalidPlanInput("Number of bits must be positive.")
+ }
+ // Create BloomFilterAggregate with expectedNumItemsExpr and
numBitsExpr.
+ Some(
+new BloomFilterAggregate(col, expectedNumItemsExpr, numBitsExpr)
+ .toAggregateExpression())
+
+} else {
+ def optimalNumOfBits(n: Long, p: Double): Long =
Review Comment:
make this as Java `package` access scope and introduce `BloomFilterHelper`
in connect-server module to make it can access in `spark ` package
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala:
##
@@ -1073,6 +1074,91 @@ class SparkConnectPlanner(val session: SparkSession) {
}
Some(Lead(children.head, children(1), children(2), ignoreNulls))
+ case "bloom_filter_agg" if fun.getArgumentsCount == 5 =>
+// [col, catalogString: String, expectedNumItems: Long, numBits: Long,
fpp: Double]
+val children =
fun.getArgumentsList.asScala.toSeq.map(transformExpression)
+val dt = {
+ val ddl = children(1) match {
+case StringLiteral(s) => s
+case other =>
+ throw InvalidPlanInput(s"col dataType should be a literal
string, but got $other")
+ }
+ DataType.fromDDL(ddl)
+}
+val col = dt match {
+ case IntegerType | ShortType | ByteType => Cast(children.head,
LongType)
+ case LongType | StringType => children.head
+ case other =>
+throw InvalidPlanInput(
+ s"Bloom filter only supports integral types, " +
+s"and does not support type $other.")
+}
+
+val fpp = children(4) match {
+ case DoubleLiteral(d) => d
+ case _ =>
+throw InvalidPlanInput("False positive must be double literal.")
+}
+
+if (fpp.isNaN) {
+ // Use expectedNumItems and numBits when `fpp.isNaN` if true.
+ // Check expectedNumItems > 0L
+ val expectedNumItemsExpr = children(2)
+ val expectedNumItems = expectedNumItemsExpr match {
+case Literal(l: Long, LongType) => l
+case _ =>
+ throw InvalidPlanInput("Expected insertions must be long
literal.")
+ }
+ if (expectedNumItems <= 0L) {
+throw InvalidPlanInput("Expected insertions must be positive.")
+ }
+ // Check numBits > 0L
+ val numBitsExpr = children(3)
+ val numBits = numBitsExpr match {
+case Literal(l: Long, LongTy
[GitHub] [spark] clownxc opened a new pull request, #40703: [SPARK-43033][SQL] Avoid task retries due to AssertNotNull checks
clownxc opened a new pull request, #40703: URL: https://github.com/apache/spark/pull/40703 ## What changes were proposed in this pull request? This PR update the task retry logic to not retry if the exception has an error class which means a user error. ## Why are the changes needed? As discussed [here](https://github.com/apache/spark/pull/40655#discussion_r1156693696), tasks that failed because of exceptions generated by AssertNotNull should not be retried. ## Does this PR introduce any user-facing change? No ## How was this patch tested? This PR comes with tests. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk opened a new pull request, #40704: [WIP][SPARK-43038][SQL] Support the CBC mode by `aes_encrypt()`/`aes_decrypt()`
MaxGekk opened a new pull request, #40704: URL: https://github.com/apache/spark/pull/40704 ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR opened a new pull request, #40705: [SPARK-43067][SS] Correct the location of error class resource file in Kafka connector
HeartSaVioR opened a new pull request, #40705: URL: https://github.com/apache/spark/pull/40705 ### What changes were proposed in this pull request? This PR moves the error class resource file in Kafka connector from test to src, so that error class works without test artifacts. ### Why are the changes needed? Refer to the `How was this patch tested?`. ### Does this PR introduce _any_ user-facing change? Yes, but the possibility of encountering this is small enough. ### How was this patch tested? Ran spark-shell with Kafka connector artifacts (without test artifacts) and triggered KafkaExceptions to confirm that exception is properly raised. ``` scala> import org.apache.spark.sql.kafka010.KafkaExceptions import org.apache.spark.sql.kafka010.KafkaExceptions scala> import org.apache.kafka.common.TopicPartition import org.apache.kafka.common.TopicPartition scala> KafkaExceptions.mismatchedTopicPartitionsBetweenEndOffsetAndPrefetched(Set[TopicPartition](), Set[TopicPartition]()) res1: org.apache.spark.SparkException = org.apache.spark.SparkException: Kafka data source in Trigger.AvailableNow should provide the same topic partitions in pre-fetched offset to end offset for each microbatch. The error could be transient - restart your query, and report if you still see the same issue. topic-partitions for pre-fetched offset: Set(), topic-partitions for end offset: Set(). ``` Without the fix, triggering KafkaExceptions failed to load error class resource file and led unexpected exception. ``` scala> KafkaExceptions.mismatchedTopicPartitionsBetweenEndOffsetAndPrefetched(Set[TopicPartition](), Set[TopicPartition]()) java.lang.IllegalArgumentException: argument "src" is null at com.fasterxml.jackson.databind.ObjectMapper._assertNotNull(ObjectMapper.java:4885) at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:3618) at org.apache.spark.ErrorClassesJsonReader$.org$apache$spark$ErrorClassesJsonReader$$readAsMap(ErrorClassesJSONReader.scala:95) at org.apache.spark.ErrorClassesJsonReader.$anonfun$errorInfoMap$1(ErrorClassesJSONReader.scala:44) at scala.collection.immutable.List.map(List.scala:293) at org.apache.spark.ErrorClassesJsonReader.(ErrorClassesJSONReader.scala:44) at org.apache.spark.sql.kafka010.KafkaExceptions$.(KafkaExceptions.scala:27) at org.apache.spark.sql.kafka010.KafkaExceptions$.(KafkaExceptions.scala) ... 47 elided ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #40705: [SPARK-43067][SS] Correct the location of error class resource file in Kafka connector
HeartSaVioR commented on PR #40705: URL: https://github.com/apache/spark/pull/40705#issuecomment-1500261827 This is introduced from 3.4 hence ideal to land the fix to 3.4, but the possibility to trigger the bug is relatively very low, hence probably not urgent. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a diff in pull request #40697: [SPARK-43061][SQL] Introduce TaskEvaluator for SQL operator execution
cloud-fan commented on code in PR #40697:
URL: https://github.com/apache/spark/pull/40697#discussion_r1160503755
##
sql/core/src/main/scala/org/apache/spark/sql/execution/WholeStageCodegenExec.scala:
##
@@ -750,37 +750,29 @@ case class WholeStageCodegenExec(child: SparkPlan)(val
codegenStageId: Int)
// but the output must be rows.
val rdds = child.asInstanceOf[CodegenSupport].inputRDDs()
assert(rdds.size <= 2, "Up to two input RDDs can be supported")
+val evaluatorFactory = new WholeStageCodegenEvaluatorFactory(
+ cleanedSource, durationMs, references)
if (rdds.length == 1) {
- rdds.head.mapPartitionsWithIndex { (index, iter) =>
-val (clazz, _) = CodeGenerator.compile(cleanedSource)
-val buffer =
clazz.generate(references).asInstanceOf[BufferedRowIterator]
-buffer.init(index, Array(iter))
-new Iterator[InternalRow] {
- override def hasNext: Boolean = {
-val v = buffer.hasNext
-if (!v) durationMs += buffer.durationMs()
-v
- }
- override def next: InternalRow = buffer.next()
+ if (conf.getConf(SQLConf.USE_TASK_EVALUATOR)) {
+rdds.head.mapPartitionsWithEvaluator(evaluatorFactory)
+ } else {
+rdds.head.mapPartitionsWithIndex { (index, iter) =>
+ val evaluator = evaluatorFactory.createEvaluator()
+ evaluator.eval(index, iter)
}
}
} else {
// Right now, we support up to two input RDDs.
- rdds.head.zipPartitions(rdds(1)) { (leftIter, rightIter) =>
-Iterator((leftIter, rightIter))
-// a small hack to obtain the correct partition index
- }.mapPartitionsWithIndex { (index, zippedIter) =>
-val (leftIter, rightIter) = zippedIter.next()
-val (clazz, _) = CodeGenerator.compile(cleanedSource)
-val buffer =
clazz.generate(references).asInstanceOf[BufferedRowIterator]
-buffer.init(index, Array(leftIter, rightIter))
-new Iterator[InternalRow] {
- override def hasNext: Boolean = {
-val v = buffer.hasNext
-if (!v) durationMs += buffer.durationMs()
-v
- }
- override def next: InternalRow = buffer.next()
+ if (conf.getConf(SQLConf.USE_TASK_EVALUATOR)) {
+rdds.head.zipPartitionsWithEvaluator(rdds(1), evaluatorFactory)
+ } else {
+rdds.head.zipPartitions(rdds(1)) { (leftIter, rightIter) =>
+ Iterator((leftIter, rightIter))
+ // a small hack to obtain the correct partition index
+}.mapPartitionsWithIndex { (index, zippedIter) =>
+ val (leftIter, rightIter) = zippedIter.next()
+ val evaluator = evaluatorFactory.createEvaluator()
Review Comment:
using evaluator is just a refactor (code move around), otherwise we will
have to duplicate the code
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic opened a new pull request, #40706: [SPARK-43059][CONNECT][PYTHON] Migrate TypeError from DataFrame(Reader|Writer) into error class
itholic opened a new pull request, #40706: URL: https://github.com/apache/spark/pull/40706 ### What changes were proposed in this pull request? This PR proposes to migrate TypeError from DataFrame(Reader|Writer) into error class ### Why are the changes needed? Improve user experience for PySpark error messages. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? This existing CI should padd -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #40701: [SPARK-43064][SQL] Spark SQL CLI SQL tab should only show once statement once
cloud-fan commented on PR #40701: URL: https://github.com/apache/spark/pull/40701#issuecomment-1500331931 https://github.com/apache/spark/pull/40437 might be related. We want to remove `hiveResultString` from CLI and only use it in hive compatibility tests. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] warrenzhu25 commented on a diff in pull request #39280: [SPARK-41766][CORE] Handle decommission request sent before executor registration
warrenzhu25 commented on code in PR #39280: URL: https://github.com/apache/spark/pull/39280#discussion_r1160765918 ## core/src/main/scala/org/apache/spark/scheduler/cluster/CoarseGrainedSchedulerBackend.scala: ## @@ -102,6 +103,15 @@ class CoarseGrainedSchedulerBackend(scheduler: TaskSchedulerImpl, val rpcEnv: Rp // Executors which are being decommissioned. Maps from executorId to ExecutorDecommissionInfo. protected val executorsPendingDecommission = new HashMap[String, ExecutorDecommissionInfo] + // Unknown Executors which are being decommissioned. This could be caused by unregistered executor + // This executor should be decommissioned after registration. + // Maps from executorId to (ExecutorDecommissionInfo, adjustTargetNumExecutors, + // triggeredByExecutor). + protected val unknownExecutorsPendingDecommission = +CacheBuilder.newBuilder() + .maximumSize(1000) Review Comment: Done -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] warrenzhu25 commented on pull request #38852: [SPARK-41341][CORE] Wait shuffle fetch to finish when decommission executor
warrenzhu25 commented on PR #38852: URL: https://github.com/apache/spark/pull/38852#issuecomment-1500375839 @holdenk @dongjoon-hyun @Ngone51 Help take a look? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rangadi commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
rangadi commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160800555 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: dropDuplicates does not support exact same output between batch and streaming either. No stateful operation guarantees in the precense of late records. What is the difference here? Better to support batch in the same manner as dropDuplicates(). I don't think it is a good UX for customer to get errors then we fix it by relaxing. But I will leave the decision to you. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rangadi closed pull request #40373: [Draft] Streaming Spark Connect POC
rangadi closed pull request #40373: [Draft] Streaming Spark Connect POC URL: https://github.com/apache/spark/pull/40373 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] aokolnychyi commented on pull request #40308: [SPARK-42151][SQL] Align UPDATE assignments with table attributes
aokolnychyi commented on PR #40308: URL: https://github.com/apache/spark/pull/40308#issuecomment-1500441091 Failures don't seem to be related. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] anishshri-db commented on pull request #40696: [SPARK-43056][SS] RocksDB state store commit should continue b/ground work only if its paused
anishshri-db commented on PR #40696: URL: https://github.com/apache/spark/pull/40696#issuecomment-1500446559 > Could you please rebase so that CI is retriggered? If the new trial fails again, maybe good to post to dev@ and see whether someone encountered this before, and/or someone is willing to volunteer to fix if that's not a transient issue. Seems like a known issue someone already posted to dev channel - https://github.com/sbt/sbt/issues/7202 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zzzzming95 commented on a diff in pull request #40688: [SPARK-43021][SQL] `CoalesceBucketsInJoin` not work when using AQE
ming95 commented on code in PR #40688: URL: https://github.com/apache/spark/pull/40688#discussion_r1160843998 ## sql/core/src/main/scala/org/apache/spark/sql/execution/adaptive/InsertAdaptiveSparkPlan.scala: ## @@ -60,6 +61,7 @@ case class InsertAdaptiveSparkPlan( val subqueryMap = buildSubqueryMap(plan) val planSubqueriesRule = PlanAdaptiveSubqueries(subqueryMap) val preprocessingRules = Seq( +CoalesceBucketsInJoin, planSubqueriesRule) Review Comment: I agree with your and move to `queryStagePreparationRules`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zzzzming95 commented on pull request #40688: [SPARK-43021][SQL] `CoalesceBucketsInJoin` not work when using AQE
ming95 commented on PR #40688: URL: https://github.com/apache/spark/pull/40688#issuecomment-1500479527 One more question , it time to make the default value of `SQLConf.COALESCE_BUCKETS_IN_JOIN_ENABLED` as true ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] clownxc opened a new pull request, #40707: [SPARK-43033][SQL] Avoid task retries due to AssertNotNull checks
clownxc opened a new pull request, #40707: URL: https://github.com/apache/spark/pull/40707 ## What changes were proposed in this pull request? This PR update the task retry logic to not retry if the exception has an error class which means a user error. ## Why are the changes needed? As discussed https://github.com/apache/spark/pull/40655#discussion_r1156693696, tasks that failed because of exceptions generated by AssertNotNull should not be retried. ## Does this PR introduce any user-facing change? No ## How was this patch tested? This PR comes with tests. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] clownxc closed pull request #40703: [SPARK-43033][SQL] Avoid task retries due to AssertNotNull checks
clownxc closed pull request #40703: [SPARK-43033][SQL] Avoid task retries due to AssertNotNull checks URL: https://github.com/apache/spark/pull/40703 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #40688: [SPARK-43021][SQL] `CoalesceBucketsInJoin` not work when using AQE
dongjoon-hyun commented on PR #40688: URL: https://github.com/apache/spark/pull/40688#issuecomment-1500503549 Maybe, no? If this is not working properly before, we cannot enable this configuration at Apache Spark 3.5.0. Since we need to wait for one release cycle, we may be able to do that at Apache Spark 3.6.0 if we want. > One more question , it time to make the default value of `SQLConf.COALESCE_BUCKETS_IN_JOIN_ENABLED` as true ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on pull request #40656: [SPARK-43023][CONNECT][TESTS] Add switch catalog testing scenario for `CatalogSuite`
amaliujia commented on PR #40656: URL: https://github.com/apache/spark/pull/40656#issuecomment-1500518103 late LGTM! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] RyanBerti commented on pull request #40615: [WIP][SPARK-16484][SQL] Add support for Datasketches HllSketch
RyanBerti commented on PR #40615: URL: https://github.com/apache/spark/pull/40615#issuecomment-1500518140 @dtenedor FYI, I updated the tests and am just missing one for empty input table, and one for merging sparse/dense sketches. Once I get the build to be green, I'm going to remove the WIP tag from the PR and send an e-mail back on that initial spark-dev thread (or maybe start a new thread) letting everyone know that the implementation is open for review. I think renaming functions is still do-able at this point, so let me know if you'd like to setup another sync to discuss updated function names? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on pull request #40315: [SPARK-42699][CONNECT] SparkConnectServer should make client and AM same exit code
amaliujia commented on PR #40315: URL: https://github.com/apache/spark/pull/40315#issuecomment-1500531162 LGTM -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun opened a new pull request, #40708: [SPARK-43069][BUILD] Use `sbt-eclipse` instead of `sbteclipse-plugin`
dongjoon-hyun opened a new pull request, #40708: URL: https://github.com/apache/spark/pull/40708 ### What changes were proposed in this pull request? This PR aims to use `set-eclipse` instead of `sbteclipse-plugin`. ### Why are the changes needed? Thanks to SPARK-34959, Apache Spark 3.2+ uses SBT 1.5.0 and we can use `set-eclipse` instead of old `sbteclipse-plugin`. - https://github.com/sbt/sbt-eclipse/releases ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] anishshri-db commented on pull request #40696: [SPARK-43056][SS] RocksDB state store commit should continue b/ground work only if its paused
anishshri-db commented on PR #40696: URL: https://github.com/apache/spark/pull/40696#issuecomment-150022 @HeartSaVioR - all tests passed. Please merge when you get a chance. Thx -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #40708: [SPARK-43069][BUILD] Use `sbt-eclipse` instead of `sbteclipse-plugin`
dongjoon-hyun commented on PR #40708:
URL: https://github.com/apache/spark/pull/40708#issuecomment-1500561170
Could you review this, @viirya ?
Although the build system seems to be recovering now, I want to reduce the
chance of failures in the future by switching the repo.
- https://github.com/apache/spark/commits/master
```
- addSbtPlugin("com.typesafe.sbteclipse" % "sbteclipse-plugin" % "5.2.4")
+ addSbtPlugin("com.github.sbt" % "sbt-eclipse" % "6.0.0")
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ueshin commented on a diff in pull request #40015: [SPARK-42437][PYTHON][CONNECT] PySpark catalog.cacheTable will allow to specify storage level
ueshin commented on code in PR #40015: URL: https://github.com/apache/spark/pull/40015#discussion_r1160908837 ## python/pyspark/sql/connect/plan.py: ## @@ -1830,14 +1831,24 @@ def plan(self, session: "SparkConnectClient") -> proto.Relation: class CacheTable(LogicalPlan): -def __init__(self, table_name: str) -> None: +def __init__(self, table_name: str, storage_level: Optional[StorageLevel] = None) -> None: super().__init__(None) self._table_name = table_name - -def plan(self, session: "SparkConnectClient") -> proto.Relation: -plan = proto.Relation( - catalog=proto.Catalog(cache_table=proto.CacheTable(table_name=self._table_name)) -) +self._storage_level = storage_level + +def plan(self, session: "SparkConnectClient") -> proto.Relation: +_cache_table = proto.CacheTable(table_name=self._table_name) +if self._storage_level: +_cache_table.storage_level.CopyFrom( +proto.StorageLevel( +use_disk=self._storage_level.useDisk, +use_memory=self._storage_level.useMemory, +use_off_heap=self._storage_level.useOffHeap, +deserialized=self._storage_level.deserialized, +replication=self._storage_level.replication, +) Review Comment: Shall we extract functions to convert to/from `proto.StorageLevel` and reuse them in `client.py` as well? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on pull request #40708: [SPARK-43069][BUILD] Use `sbt-eclipse` instead of `sbteclipse-plugin`
viirya commented on PR #40708: URL: https://github.com/apache/spark/pull/40708#issuecomment-1500583121 > This PR aims to use set-eclipse instead of sbteclipse-plugin. One typo `set-eclipse` in the description. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #40708: [SPARK-43069][BUILD] Use `sbt-eclipse` instead of `sbteclipse-plugin`
dongjoon-hyun commented on PR #40708: URL: https://github.com/apache/spark/pull/40708#issuecomment-1500587401 Thank you, @viirya . The description is fixed now. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #40708: [SPARK-43069][BUILD] Use `sbt-eclipse` instead of `sbteclipse-plugin`
dongjoon-hyun closed pull request #40708: [SPARK-43069][BUILD] Use `sbt-eclipse` instead of `sbteclipse-plugin` URL: https://github.com/apache/spark/pull/40708 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #40708: [SPARK-43069][BUILD] Use `sbt-eclipse` instead of `sbteclipse-plugin`
dongjoon-hyun commented on PR #40708: URL: https://github.com/apache/spark/pull/40708#issuecomment-1500594750 I tested this manually. Merged to master/3.4/3.3/3.2. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun opened a new pull request, #40709: [SPARK-43070][BUILD] Upgrade sbt-unidoc to 0.5.0
dongjoon-hyun opened a new pull request, #40709: URL: https://github.com/apache/spark/pull/40709 ### What changes were proposed in this pull request? This PR aims to upgrade `sbt-unidoc` to 0.5.0. ### Why are the changes needed? Since v0.5.0, organization has moved from `com.eed3si9n` to `com.github.sbt` - https://github.com/sbt/sbt-unidoc/releases/tag/v0.5.0 ### Does this PR introduce _any_ user-facing change? No, this is a dev-only change. ### How was this patch tested? Pass the CIs. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39280: [SPARK-41766][CORE] Handle decommission request sent before executor registration
dongjoon-hyun commented on code in PR #39280:
URL: https://github.com/apache/spark/pull/39280#discussion_r1160945224
##
core/src/main/scala/org/apache/spark/internal/config/package.scala:
##
@@ -2242,6 +2242,16 @@ package object config {
.checkValue(_ >= 0, "needs to be a non-negative value")
.createWithDefault(0)
+ private[spark] val SCHEDULER_MAX_RETAINED_UNKNOWN_EXECUTORS =
+ConfigBuilder("spark.scheduler.maxRetainedUnknownDecommissionExecutors")
+ .internal()
+ .doc("Max number of unknown executors by decommission to retain. This
affects " +
+"whether executor could receive decommission request sent before its
registration.")
+ .version("3.4.0")
Review Comment:
`3.5.0`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39280: [SPARK-41766][CORE] Handle decommission request sent before executor registration
dongjoon-hyun commented on PR #39280: URL: https://github.com/apache/spark/pull/39280#issuecomment-1500617216 Gentle ping @Ngone51 once more. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] warrenzhu25 commented on a diff in pull request #39280: [SPARK-41766][CORE] Handle decommission request sent before executor registration
warrenzhu25 commented on code in PR #39280:
URL: https://github.com/apache/spark/pull/39280#discussion_r1160949314
##
core/src/main/scala/org/apache/spark/internal/config/package.scala:
##
@@ -2242,6 +2242,16 @@ package object config {
.checkValue(_ >= 0, "needs to be a non-negative value")
.createWithDefault(0)
+ private[spark] val SCHEDULER_MAX_RETAINED_UNKNOWN_EXECUTORS =
+ConfigBuilder("spark.scheduler.maxRetainedUnknownDecommissionExecutors")
+ .internal()
+ .doc("Max number of unknown executors by decommission to retain. This
affects " +
+"whether executor could receive decommission request sent before its
registration.")
+ .version("3.4.0")
Review Comment:
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] WweiL commented on pull request #40691: [SPARK-43031] [SS] [Connect] Enable unit test and doctest for streaming
WweiL commented on PR #40691: URL: https://github.com/apache/spark/pull/40691#issuecomment-1500623778 CC @rangadi @pengzhon-db -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #40709: [SPARK-43070][BUILD] Upgrade `sbt-unidoc` to 0.5.0
dongjoon-hyun commented on PR #40709: URL: https://github.com/apache/spark/pull/40709#issuecomment-1500625015 Yes, correctly. Apache Spark 3.2.0+ uses SBT 1.5.0+ via SPARK-34959. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on a diff in pull request #40692: [SPARK-43055][CONNECT][PYTHON] Support duplicated nested field names
amaliujia commented on code in PR #40692:
URL: https://github.com/apache/spark/pull/40692#discussion_r1160953776
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/connect/client/SparkResult.scala:
##
@@ -60,13 +61,19 @@ private[sql] class SparkResult[T](
private def processResponses(stopOnFirstNonEmptyResponse: Boolean): Boolean
= {
while (responses.hasNext) {
val response = responses.next()
+ if (response.hasSchema) {
+structType =
Review Comment:
This logic actual becomes more confusing now about the structType assingment.
I am wondering if it should becomes something like
```
if (response.hasSchema)
else if (response.hasArrowBatch)
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on a diff in pull request #40692: [SPARK-43055][CONNECT][PYTHON] Support duplicated nested field names
amaliujia commented on code in PR #40692:
URL: https://github.com/apache/spark/pull/40692#discussion_r1160953776
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/connect/client/SparkResult.scala:
##
@@ -60,13 +61,19 @@ private[sql] class SparkResult[T](
private def processResponses(stopOnFirstNonEmptyResponse: Boolean): Boolean
= {
while (responses.hasNext) {
val response = responses.next()
+ if (response.hasSchema) {
+structType =
Review Comment:
This logic actual becomes more confusing now about the structType assingment.
I am wondering if it should becomes something like
```
if (response.hasSchema)
else if (response.hasArrowBatch)
```
I am becoming now sure as the code is
1. if response gives a schema, use it
2. if response didn't give then try arrow's schema
then how to handle when both `response has a schema` and `arrow has schema`
is not clear, or which one should be used first, etc.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on a diff in pull request #40692: [SPARK-43055][CONNECT][PYTHON] Support duplicated nested field names
amaliujia commented on code in PR #40692:
URL: https://github.com/apache/spark/pull/40692#discussion_r1160953776
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/connect/client/SparkResult.scala:
##
@@ -60,13 +61,19 @@ private[sql] class SparkResult[T](
private def processResponses(stopOnFirstNonEmptyResponse: Boolean): Boolean
= {
while (responses.hasNext) {
val response = responses.next()
+ if (response.hasSchema) {
+structType =
Review Comment:
This logic actual becomes more confusing now about the structType assingment.
I am wondering if it should becomes something like
```
if (response.hasSchema)
else if (response.hasArrowBatch)
```
I am becoming not sure as the code is
1. if response gives a schema, use it
2. if response didn't give then try arrow's schema
then how to handle when both `response has a schema` and `arrow has schema`
is not clear, or which one should be used first, etc.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] amaliujia commented on a diff in pull request #40692: [SPARK-43055][CONNECT][PYTHON] Support duplicated nested field names
amaliujia commented on code in PR #40692:
URL: https://github.com/apache/spark/pull/40692#discussion_r1160953776
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/connect/client/SparkResult.scala:
##
@@ -60,13 +61,19 @@ private[sql] class SparkResult[T](
private def processResponses(stopOnFirstNonEmptyResponse: Boolean): Boolean
= {
while (responses.hasNext) {
val response = responses.next()
+ if (response.hasSchema) {
+structType =
Review Comment:
This logic actual becomes more confusing now about the structType assingment.
I am wondering if it should becomes something like
```
if (response.hasSchema)
else if (response.hasArrowBatch)
```
I am becoming not sure as the code is
1. if response gives a schema, use it
2. if response didn't give then try arrow's schema
then how to handle when both `response has a schema` and `arrow has schema`
is not clear, or which one should be used first, etc. Per my read the response
schema and arrow schema could be even not consistent?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
HeartSaVioR commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160964896 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: If you don't have any late record then dropDuplicates() guarantees the same result. That enables users to test their code with batch query first, and then migrate to streaming query later. dropDuplicatesWithinWatermark doesn't guarantee such thing so it's making no sense to test with batch query and migrate to streaming. That was why I had a offline discussion with @zsxwing . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
HeartSaVioR commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160964896 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: If you don't have any late record then dropDuplicates() guarantees the same result. That enables users to test their code with batch query first, and then migrate to streaming query later. dropDuplicatesWithinWatermark doesn't guarantee such thing so it's making no sense to test with batch query and migrate to streaming. That was why I had an offline discussion with @zsxwing . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jiangxb1987 commented on pull request #40690: [SPARK-43043][CORE] Improve the performance of MapOutputTracker.updateMapOutput
jiangxb1987 commented on PR #40690: URL: https://github.com/apache/spark/pull/40690#issuecomment-1500652566 This happens on a benchmark job generating a large number of very tiny blocks. When the job is finished, the cluster tries to shutdown the idle executors and migrate all the blocks to other active executors, the driver acts like hanging, then resumed after a while. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
HeartSaVioR commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160967676 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: If we want to support this API in batch query, I think we have to implement the same behavior, not forwarding to dropDuplicates(). But that's also very odd because we are telling users that watermark is no-op in batch query and now we have to get delay threshold from withWatermark. I'd say it conflicts with base concept. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
HeartSaVioR commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160967676 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: If we want to support this API in batch query, I think we have to implement the same behavior, not just forwarding to dropDuplicates(). But that's also very odd because we are telling users that watermark is no-op in batch query and now we have to get delay threshold from withWatermark. I'd say it conflicts with base concept. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
HeartSaVioR commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160970094 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: (If we want to implement the same behavior to batch query, we will have to kick the part of "best effort" out as well in streaming. e.g. We deduplicate the event whenever there is an existing state, which does not say they're within delay threshold. We evict the state at the end of processing, hence we are accepting slightly more events to be deduplicated. That might be better behavior for streaming, but if we want to match the behavior between batch and streaming, the behavior must be deterministic.) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
HeartSaVioR commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160970094 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: (If we want to implement the same behavior to batch query, we will have to kick the part of "best effort" out as well in streaming. e.g. We deduplicate the event whenever there is an existing state, which does not strictly say they're within delay threshold. We evict the state at the end of processing, hence we are accepting slightly more events to be deduplicated. That might be better behavior for streaming, but if we want to match the behavior between batch and streaming, the behavior must be deterministic.) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a diff in pull request #40561: [SPARK-42931][SS] Introduce dropDuplicatesWithinWatermark
HeartSaVioR commented on code in PR #40561: URL: https://github.com/apache/spark/pull/40561#discussion_r1160970094 ## python/pyspark/sql/dataframe.py: ## @@ -3928,6 +3928,71 @@ def dropDuplicates(self, subset: Optional[List[str]] = None) -> "DataFrame": jdf = self._jdf.dropDuplicates(self._jseq(subset)) return DataFrame(jdf, self.sparkSession) +def dropDuplicatesWithinWatermark(self, subset: Optional[List[str]] = None) -> "DataFrame": +"""Return a new :class:`DataFrame` with duplicate rows removed, + optionally only considering certain columns, within watermark. + +For a static batch :class:`DataFrame`, it just drops duplicate rows. For a streaming +:class:`DataFrame`, this will keep all data across triggers as intermediate state to drop +duplicated rows. The state will be kept to guarantee the semantic, "Events are deduplicated +as long as the time distance of earliest and latest events are smaller than the delay +threshold of watermark." The watermark for the input :class:`DataFrame` must be set via +:func:`withWatermark`. Users are encouraged to set the delay threshold of watermark longer Review Comment: (If we want to implement the same behavior to batch query, we will have to kick the part of "best effort" out as well in streaming. e.g. We deduplicate the event whenever there is an existing state, which does not strictly say they're within delay threshold. We evict the state at the end of processing, hence we are accepting slightly more events to be deduplicated. That might be better behavior for streaming, but if we want to guarantee the same result between batch and streaming, the behavior must be deterministic.) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jiangxb1987 commented on a diff in pull request #40690: [SPARK-43043][CORE] Improve the performance of MapOutputTracker.updateMapOutput
jiangxb1987 commented on code in PR #40690:
URL: https://github.com/apache/spark/pull/40690#discussion_r1160971328
##
core/src/main/scala/org/apache/spark/MapOutputTracker.scala:
##
@@ -157,22 +164,29 @@ private class ShuffleStatus(
invalidateSerializedMapOutputStatusCache()
}
mapStatuses(mapIndex) = status
+mapIdToMapIndex(status.mapId) = mapIndex
}
/**
* Update the map output location (e.g. during migration).
*/
def updateMapOutput(mapId: Long, bmAddress: BlockManagerId): Unit =
withWriteLock {
try {
- val mapStatusOpt = mapStatuses.find(x => x != null && x.mapId == mapId)
+ // OpenHashMap would return 0 if the key doesn't exist.
+ val mapIndex = if (mapIdToMapIndex.contains(mapId)) {
+Some(mapIdToMapIndex(mapId))
+ } else {
+None
+ }
Review Comment:
The problem is OpenHashMap casts null value to the declared type internally.
Thus if the key doesn't exist, it would cast `null` to Int, and the output
would be 0. It is not possible for us tell whether the key doesn't exist or the
value is really 0, without calling the `contains` function.
I'll try to follow the first option to add a `get(key): Option[V]`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhenlineo closed pull request #40274: [SPARK-42215][CONNECT] Simplify Scala Client IT tests
zhenlineo closed pull request #40274: [SPARK-42215][CONNECT] Simplify Scala Client IT tests URL: https://github.com/apache/spark/pull/40274 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org